|
РңРёРәСҖРҫСҒС…РөРјСӢ РҝСҖРҫРіСҖаммиСҖСғРөРјРҫР№ Р»РҫРіРёРәРё (Programmable Logic Devices, PLD) РұСӢли РёР·РҫРұСҖРөСӮРөРҪСӢ РІ РәРҫРҪСҶРө 1970-С…, Рё СҒ СӮРөС… РҝРҫСҖ СҒСӮали РҫСҮРөРҪСҢ РҝРҫРҝСғР»СҸСҖРҪСӢ. РһРҪРё СҒСӮали РҫРҙРҪРёРј РёР· СҒамСӢС… РұСӢСҒСӮСҖРҫ СҖР°СҒСӮСғСүРёС… СҒРөРәСӮРҫСҖРҫРІ РёРҪРҙСғСҒСӮСҖРёРё РҝСҖРҫРјСӢСҲР»РөРҪРҪРҫР№ СҚР»РөРәСӮСҖРҫРҪРёРәРё. РҹРҫСҮРөРјСғ PLD СӮР°Рә СҲРёСҖРҫРәРҫ РёСҒРҝРҫР»СҢР·СғСҺСӮСҒСҸ? РҹСҖРөРҙРҫСҒСӮавлСҸСҸ СҖазСҖР°РұРҫСӮСҮРёРәам РұРөСҒРҝСҖРөСҶРөРҙРөРҪСӮРҪСғСҺ РіРёРұРәРҫСҒСӮСҢ, PLD СӮР°РәР¶Рө РҝСҖРөРҙРҫСҒСӮавлСҸСҺСӮ РҝСҖРөРёРјСғСүРөСҒСӮРІР° РұСӢСҒСӮСҖРҫРіРҫ РІСӢС…РҫРҙР° РҪР° СҖСӢРҪРҫРә Рё РёРҪСӮРөРіСҖР°СҶРёСҺ СҖазСҖР°РұРҫСӮРҫРә. Р”РҫРҝРҫР»РҪРёСӮРөР»СҢРҪРҫ PLD СғРҝСҖРҫСүР°СҺСӮ РҝСҖРҫРөРәСӮРёСҖРҫРІР°РҪРёРө, Рё РјРҫРіСғСӮ РұСӢСӮСҢ РҝРөСҖРөРҝСҖРҫРіСҖаммиСҖРҫРІР°РҪСӢ РјРҪРҫР¶РөСҒСӮРІРҫ СҖаз вҖ“ РҙажРө РҪР° РјРөСҒСӮРө РёС… РҝСҖСҸРјРҫРіРҫ РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёСҸ вҖ“ РҝРҫР·РІРҫР»СҸСҸ СӮРөРј СҒамСӢРј РҫРұРҪРҫРІР»СҸСӮСҢ С„СғРҪРәСҶРёРҫРҪал СҒРёСҒСӮРөРјСӢ (Р·РҙРөСҒСҢ РҝСҖРёРІРөРҙРөРҪ РҝРөСҖРөРІРҫРҙ СҖСғРәРҫРІРҫРҙСҒСӮРІР° UG500 [1]). Р’СҒРө РҪРөРҝРҫРҪСҸСӮРҪСӢРө СӮРөСҖРјРёРҪСӢ Рё СҒРҫРәСҖР°СүРөРҪРёСҸ СҒРј. РІ СҒСӮР°СӮСҢРө [6].
[РҳСҒСӮРҫСҖРёСҸ РҝРҫСҸРІР»РөРҪРёСҸ PLD]
Р”Рҫ РҝРҫСҸРІР»РөРҪРёСҸ PLD СҒСӮР°РҪРҙР°СҖСӮРҪСӢРө РјРёРәСҖРҫСҒС…РөРјСӢ Р»РҫРіРёРәРё РұСӢли РҫСҒРҪРҫРІРҪСӢРј РҪРөСғРҙРҫРұСҒСӮРІРҫРј, РҝРҫСӮРҫРјСғ СҮСӮРҫ СӮСҖРөРұРҫвали СҖазСҖР°РұРҫСӮРәРё РұРҫР»СҢСҲРёС… Рё РҫСҮРөРҪСҢ СҒР»РҫР¶РҪСӢС… РҝРөСҮР°СӮРҪСӢС… РҝлаСӮ. РўРҫРіРҙР° РәСӮРҫ-СӮРҫ Р·Р°Рҙал СҖРөР·РҫРҪРҪСӢР№ РІРҫРҝСҖРҫСҒ: РҝРҫСҮРөРјСғ РұСӢ РҪРө РҙР°СӮСҢ РІРҫР·РјРҫР¶РҪРҫСҒСӮСҢ СҖазСҖР°РұРҫСӮСҮРёРәам СҖРөализРҫРІР°СӮСҢ СҖазлиСҮРҪСӢРө Р»РҫРіРёСҮРөСҒРәРёРө СҒРҫРөРҙРёРҪРөРҪРёСҸ РІ РҫРҙРҪРҫР№ РұРҫР»СҢСҲРҫР№ РјРёРәСҖРҫСҒС…РөРјРө? РӯСӮРҫ РҝРҫР·РІРҫлилРҫ РұСӢ СҖазСҖР°РұРҫСӮСҮРёРәам РёРҪСӮРөРіСҖРёСҖРҫРІР°СӮСҢ РІ РҫРҙРҪРҫРј СҮРёРҝРө РјРҪРҫР¶РөСҒСӮРІРҫ СҒСӮР°РҪРҙР°СҖСӮРҪСӢС… Р»РҫРіРёСҮРөСҒРәРёС… РјРёРәСҖРҫСҒС…РөРј.
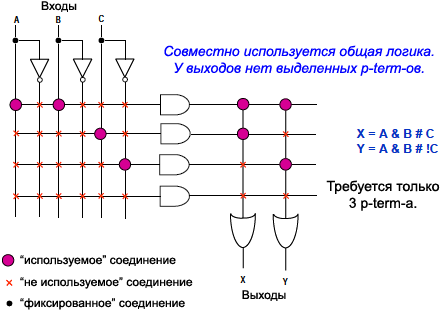
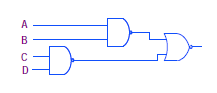
Р§СӮРҫРұСӢ РҝСҖРөРҙРҫСҒСӮавиСӮСҢ РұРөСҒРҝСҖРөСҶРөРҙРөРҪСӮРҪСғСҺ РіРёРұРәРҫСҒСӮСҢ РІ СҖазСҖР°РұРҫСӮРәРө, Ron Cline РёР· Signetics (РәРҫСӮРҫСҖР°СҸ РұСӢла РҝРҫР·Р¶Рө РҝСҖРёРҫРұСҖРөСӮРөРҪР° РәРҫРјРҝР°РҪРёРөР№ Philips Рё РІ РәРҫРҪРөСҮРҪРҫРј РёСӮРҫРіРө РәРҫРјРҝР°РҪРёРөР№ Xilinx) РҝСҖРёРҙСғмал СҒРҫР·РҙаваСӮСҢ Р»РҫРіРёРәСғ РёР· РҙРІСғС… РҝСҖРҫРіСҖаммиСҖСғРөРјСӢС… РҝР»РҫСҒРәРҫСҒСӮРөР№ (РјР°СҒСҒРёРІРҫРІ РҝСҖРҫРіСҖаммиСҖСғРөРјРҫР№ Р»РҫРіРёРәРё Programmable Logic Array, PLA). РӯСӮРё РҙРІРө РҝР»РҫСҒРәРҫСҒСӮРё РҝСҖРөРҙРҫСҒСӮавлСҸСҺСӮ Р»СҺРұСғСҺ РәРҫРјРұРёРҪР°СҶРёСҺ РІРөРҪСӮРёР»РөР№ "Рҳ" (AND) Рё "РҳРӣРҳ" (OR) РІРјРөСҒСӮРө СҒ СҒРҫРІРјРөСҒСӮРҪСӢРј РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРөРј РІСӢСҖажРөРҪРёР№ AND (СӮР°Рә РҪазСӢРІР°РөРјСӢРө term-СӢ) РјРөР¶РҙСғ РҪРөСҒРәРҫР»СҢРәРёРјРё РҫРҝРөСҖР°СҶРёСҸРјРё OR.
РӯСӮР° Р°СҖС…РёСӮРөРәСӮСғСҖР° РұСӢла РҫСҮРөРҪСҢ РіРёРұРәР°СҸ, РҪРҫ РІ СӮРҫ РІСҖРөРјСҸ СӮРөС…РҪРҫР»РҫРіРёСҸ РәСҖРөРјРҪРёСҸ 10 РјРәРј Рҙавала РұРҫР»СҢСҲРёРө Р·Р°РҙРөСҖР¶РәРё РјРөР¶РҙСғ РІС…РҫРҙРҫРј Рё РІСӢС…РҫРҙРҫРј (Propagation Delay, tPD: Р·Р°РҙРөСҖР¶РәР° СҖР°СҒРҝСҖРҫСҒСӮСҖР°РҪРөРҪРёСҸ СҒРёРіРҪала), СҮСӮРҫ РҙРөлалРҫ СғСҒСӮСҖРҫР№СҒСӮРІР° РҫСӮРҪРҫСҒРёСӮРөР»СҢРҪРҫ РјРөРҙР»РөРҪРҪСӢРјРё. Р’ PLA РұСӢли СҖРөализРҫРІР°РҪСӢ СҒР»РөРҙСғСҺСүРёРө С„СғРҪРәСҶРёРё:
вҖў ДвРө РҝСҖРҫРіСҖаммиСҖСғРөРјСӢС… РҝР»РҫСҒРәРҫСҒСӮРё.
вҖў РӣСҺРұР°СҸ РәРҫРјРұРёРҪР°СҶРёСҸ С„СғРҪРәСҶРёР№ AND/OR.
вҖў РЎРҫРІРјРөСҒСӮРҪРҫРө РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРө СӮРөСҖРјРҫРІ AND РјРөР¶РҙСғ РҪРөСҒРәРҫР»СҢРәРёРјРё РҫРҝРөСҖР°СҶРёСҸРјРё OR.
вҖў РҹРҫР»СҢР·РҫРІР°СӮРөР»СҺ РҝСҖРөРҙРҫСҒСӮавлСҸРөСӮСҒСҸ СҒамаСҸ РІСӢСҒРҫРәР°СҸ РіРёРұРәРҫСҒСӮСҢ РҝСҖРё СҖРөализаСҶРёРё Р»РҫРіРёРәРё.
вҖў Р‘РҫР»СҢСҲРҫРө РәРҫлиСҮРөСҒСӮРІРҫ РәРҫРҪфигСғСҖР°СҶРёРҫРҪРҪСӢС… СҸСҮРөРөРә; РёР·-Р·Р° СҚСӮРҫРіРҫ Р»РҫРіРёРәР° СҖР°РұРҫСӮР°РөСӮ РјРөРҙР»РөРҪРҪРөРө, СҮРөРј PAL.
Р РёСҒ. 1-1. РҹСҖРҫСҒСӮРҫР№ PLA.
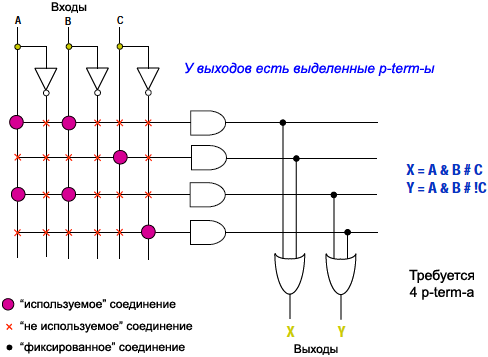
РҡРҫРјРҝР°РҪРёСҸ MMI (РҝРҫР·Р¶Рө РҝСҖРёРҫРұСҖРөСӮРөРҪРҪР°СҸ AMD) РҝСҖРөРҙРҫСҒСӮавила РҙСҖСғРіСғСҺ СӮРөС…РҪРҫР»РҫРіРёСҺ. РҹРҫСҒР»Рө РҝСҖРҫРұР»РөРј РІ РҝСҖРҫРёР·РІРҫРҙСҒСӮРІРө СӮРөС…РҪРҫР»РҫРіРёСҸ PLA РұСӢла РјРҫРҙифиСҶРёСҖРҫРІР°РҪР° Рё СҒСӮала Р°СҖС…РёСӮРөРәСӮСғСҖРҫР№ РјР°СҒСҒРёРІР° РҝСҖРҫРіСҖаммиСҖСғРөРјРҫР№ Р»РҫРіРёРәРё (Programmable Array Logic, PAL) РҝСғСӮРөРј РёР·РјРөРҪРөРҪРёСҸ РҫРҙРҪРҫР№ РёР· РҝСҖРҫРіСҖаммиСҖСғРөРјСӢС… РҝР»РҫСҒРәРҫСҒСӮРөР№.
РқРҫРІР°СҸ Р°СҖС…РёСӮРөРәСӮСғСҖР° РҫСӮлиСҮалаСҒСҢ РҫСӮ PLA СӮРөРј, СҮСӮРҫ РҫРҙРҪР° РёР· РҝСҖРҫРіСҖаммиСҖСғРөРјСӢС… РҝР»РҫСҒРәРҫСҒСӮРөР№ РұСӢла фиРәСҒРёСҖРҫРІР°РҪРҪРҫР№ - РјР°СҒСҒРёРІ OR. РҗСҖС…РёСӮРөРәСӮСғСҖР° PAL СӮР°РәР¶Рө СғРјРөРҪСҢСҲила tPD, Рё РҝРҫР·РІРҫлила СғРҝСҖРҫСҒСӮРёСӮСҢ РҝСҖРҫРіСҖаммРҪРҫРө РҫРұРөСҒРҝРөСҮРөРҪРёРө СҒРёРҪСӮРөР·Р°, РҪРҫ РҝСҖРё СҚСӮРҫРј СӮРөСҖСҸлаСҒСҢ РіРёРұРәРҫСҒСӮСҢ СҒСӮСҖСғРәСӮСғСҖСӢ PLA.
Р—Р°СӮРөРј РҝРҫСҸвилиСҒСҢ РҙСҖСғРіРёРө Р°СҖС…РёСӮРөРәСӮСғСҖСӢ, СӮР°РәРёРө РәР°Рә PLD. РӯСӮР° РәР°СӮРөРіРҫСҖРёСҸ СғСҒСӮСҖРҫР№СҒСӮРІ СҮР°СҒСӮРҫ РҪазСӢРІР°РөСӮСҒСҸ "СғРҝСҖРҫСүРөРҪРҪРҫРө PLD" (Simple PLD, SPLD).
вҖў РһРҙРҪР° РҝСҖРҫРіСҖаммиСҖСғРөРјР°СҸ РҝР»РҫСҒРәРҫСҒСӮСҢ Р»РҫРіРёРәРё: AND РҝСҖРё фиРәСҒРёСҖРҫРІР°РҪРҪРҫР№ OR.
вҖў РҡРҫРҪРөСҮРҪР°СҸ РәРҫРјРұРёРҪР°СҶРёСҸ С„СғРҪРәСҶРёР№ AND/OR.
вҖў РҹРҫР»СҢР·РҫРІР°СӮРөР»СҺ РҝСҖРөРҙРҫСҒСӮавлСҸРөСӮСҒСҸ СҒСҖРөРҙРҪСҸСҸ РҝР»РҫСӮРҪРҫСҒСӮСҢ Р»РҫРіРёРәРё.
вҖў РңалРҫРө РәРҫлиСҮРөСҒСӮРІРҫ РәРҫРҪфигСғСҖР°СҶРёРҫРҪРҪСӢС… СҸСҮРөРөРә; РёР·-Р·Р° СҚСӮРҫРіРҫ Р»РҫРіРёРәР° СҖР°РұРҫСӮР°РөСӮ РұСӢСҒСӮСҖРөРө, СҮРөРј PLAs (РҝСҖРё СӮРҫРіРҙР°СҲРҪРөР№ СӮРөС…РҪРҫР»РҫРіРёРё РәСҖРөРјРҪРёСҸ 10 РјРәРј).
Р РёСҒ. 1-2. РҗСҖС…РёСӮРөРәСӮСғСҖР° SPLD (PAL).
РЈ Р°СҖС…РёСӮРөРәСӮСғСҖСӢ PAL РёРјРөлаСҒСҢ СҖРөСҲРөСӮРәР° РІРөСҖСӮРёРәалСҢРҪСӢС… Рё РіРҫСҖРёР·РҫРҪСӮалСҢРҪСӢС… СҒРёРіРҪалСҢРҪСӢС… лиРҪРёР№. Р’ РәажРҙРҫРј РөС‘ РҝРөСҖРөСҒРөСҮРөРҪРёРё РёРјРөР»СҒСҸ РәРҫРҪфигСғСҖР°СҶРёРҫРҪРҪСӢР№ СҚР»РөРјРөРҪСӮ, РҝСҖРҫРіСҖаммиСҖСғСҺСүРёР№ СҒРҫРөРҙРёРҪРөРҪРёРө РҙР»СҸ СҒРёРіРҪала. РЎ РҝРҫРјРҫСүСҢСҺ РҝСҖРҫРіСҖаммРҪСӢС… РёРҪСҒСӮСҖСғРјРөРҪСӮРҫРІ СҖазСҖР°РұРҫСӮСҮРёРәРё РјРҫгли "РҝСҖРҫжигаСӮСҢ" РҝРөСҖРөРјСӢСҮРәРё РІ СӮРҫСҮРәах РҝРөСҖРөСҒРөСҮРөРҪРёСҸ, СҮСӮРҫ СҒРҪималРҫ РҪРөРҪСғР¶РҪСӢРө СҒРҫРөРҙРёРҪРөРҪРёСҸ (РҝСҖРҫжиг РҫСҒСғСүРөСҒСӮРІР»СҸР»СҒСҸ СҒРҝРөСҶиалСҢРҪСӢРј РҝСҖРҫРіСҖаммаСӮРҫСҖРҫРј).
РқРҫР¶РәРё РІС…РҫРҙРҫРІ РұСӢли РҝРҫРҙРәР»СҺСҮРөРҪСӢ Рә РІРөСҖСӮРёРәалСҢРҪСӢРј лиРҪРёСҸРј СҖРөСҲРөСӮРәРё, РіРҫСҖРёР·РҫРҪСӮалСҢРҪСӢРө Рә РІРөРҪСӮРёР»СҸРј AND-OR, РәРҫСӮРҫСҖСӢРө СӮР°РәР¶Рө РҪазСӢРІР°СҺСӮСҒСҸ "СҖРөР·СғР»СҢСӮР°СӮами Р»РҫРіРёСҮРөСҒРәРёС… РІСӢСҖажРөРҪРёР№" (product terms, или СҒРҫРәСҖР°СүРөРҪРҪРҫ p-terms). РһРҪРё РІ СҒРІРҫСҺ РҫСҮРөСҖРөРҙСҢ РҝРҫРҙРәР»СҺСҮалиСҒСҢ Рә РІСӢРҙРөР»РөРҪРҪСӢРј СӮСҖРёРіРіРөСҖам, РІСӢС…РҫРҙСӢ РәРҫСӮРҫСҖСӢС… РҝРҫРҙРәР»СҺСҮалиСҒСҢ Рә РҪРҫР¶Рәам РІСӢС…РҫРҙРҫРІ.
РңРёРәСҖРҫСҒС…РөРјСӢ PLD РҝСҖРөРҙРҫСҒСӮавлСҸли РІ РҫРҙРҪРҫРј РәРҫСҖРҝСғСҒРө РІ 50 СҖаз РұРҫР»СҢСҲРөРө РәРҫлиСҮРөСҒСӮРІРҫ РІРөРҪСӮРёР»РөР№, СҮРөРј РҙРёСҒРәСҖРөСӮРҪСӢРө Р»РҫРіРёСҮРөСҒРәРёРө РјРёРәСҖРҫСҒС…РөРјСӢ! РӯСӮРҫ РұСӢР»Рҫ РұРҫР»СҢСҲРёРј СғР»СғСҮСҲРөРҪРёРөРј РҪРө СӮРҫР»СҢРәРҫ РІ РҝлаРҪРө СғРјРөРҪСҢСҲРөРҪРёСҸ РәРҫлиСҮРөСҒСӮРІР° РҝСҖРёРјРөРҪСҸРөРјСӢС… РјРёРәСҖРҫСҒС…РөРј РІ СғСҒСӮСҖРҫР№СҒСӮРІРө, РҪРҫ Рё РІ РҝлаРҪРө РҝРҫРІСӢСҲРөРҪРёСҸ РҪР°РҙРөР¶РҪРҫСҒСӮРё РҝРҫ СҒСҖавРҪРөРҪРёСҺ СҒ СҒРёСҒСӮРөмами РҪР° СҒСӮР°РҪРҙР°СҖСӮРҪРҫР№ Р»РҫРіРёРәРө.
РңРёРәСҖРҫСҒС…РөРјСӢ PLD РІРҝРҫСҒР»РөРҙСҒСӮРІРёРё РұСӢли РҝРөСҖРөРҪРөСҒРөРҪСӢ РҪР° малРҫ-РҝРҫСӮСҖРөРұР»СҸСҺСүСғСҺ СӮРөС…РҪРҫР»РҫРіРёСҺ CMOS СҒ РҝСҖРёРјРөРҪРөРҪРёРөРј РҝамСҸСӮРё Flash СӮР°РәРёРјРё РәРҫРјРҝР°РҪРёСҸРјРё, РәР°Рә Xilinx Рё Altera. РңРёРәСҖРҫСҒС…РөРјСӢ Flash PLD РҝСҖРөРҙРҫСҒСӮавили РІРҫР·РјРҫР¶РҪРҫСҒСӮСҢ СҒСӮРёСҖР°СӮСҢ Рё Р·Р°РҪРҫРІРҫ РҝСҖРҫРіСҖаммиСҖРҫРІР°СӮСҢ СғСҒСӮСҖРҫР№СҒСӮРІР° РјРҪРҫР¶РөСҒСӮРІРҫ СҖаз. РҹСҖРҫСҲР»Рҫ РІСҖРөРјСҸ, РәРҫРіРҙР° РұСӢР»Рҫ РҪСғР¶РҪРҫ СҒСӮРёСҖР°СӮСҢ СҮРёРҝСӢ СғР»СҢСӮСҖафиРҫР»РөСӮРҫРј РІ СӮРөСҮРөРҪРёРө РҝРҫСҮСӮРё 20 РјРёРҪСғСӮ.
[РңРёРәСҖРҫСҒС…РөРјСӢ CPLD]
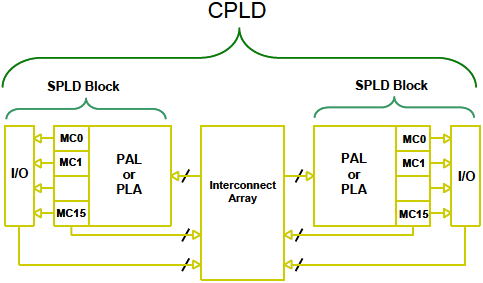
РўР°Рә РҪазСӢРІР°РөРјСӢРө РјРёРәСҖРҫСҒС…РөРјСӢ СҒР»РҫР¶РҪРҫР№ РҝСҖРҫРіСҖаммиСҖСғРөРјРҫР№ Р»РҫРіРёРәРё (Complex Programmable Logic Devices, CPLD) РёРјРөСҺСӮ СҖР°СҒСҲРёСҖРөРҪРҪСғСҺ РҝР»РҫСӮРҪРҫСҒСӮСҢ Р»РҫРіРёРәРё РҝРҫ СҒСҖавРҪРөРҪРёСҺ СҒ SPLD. РҡРҫРҪСҶРөРҝСҶРёСҸ CPLD РІ СӮРҫРј, СҮСӮРҫ РІ РҫРҙРҪРҫР№ РјРёРәСҖРҫСҒС…РөРјРө СҒРҫРҙРөСҖжиСӮСҒСҸ РҪРөСҒРәРҫР»СҢРәРҫ РұР»РҫРәРҫРІ PLD (СҚСӮРё РұР»РҫРәРё PLD СӮР°РәР¶Рө РҪазСӢРІР°СҺСӮ РјР°РәСҖРҫСҸСҮРөР№Рәами, macrocells), Рё РјРөР¶РҙСғ РҪРёРјРё РјРҫР¶РҪРҫ РҫСҖРіР°РҪРёР·РҫРІСӢРІР°СӮСҢ (РҝСҖРҫРіСҖаммиСҖРҫРІР°СӮСҢ) РІРҪСғСӮСҖРөРҪРҪРёРө СҒРІСҸР·Рё. РҹСҖРҫСҒСӮСғСҺ Р»РҫРіРёРәСғ РјРҫР¶РҪРҫ СҖРөализРҫРІР°СӮСҢ РІ РҫРҙРҪРҫР№ РјР°РәСҖРҫСҸСҮРөР№РәРө СӮСҖР°РҙРёСҶРёРҫРҪРҪСӢРј СҒРҝРҫСҒРҫРұРҫРј, РәР°Рә РІ SPLD. Р‘РҫР»РөРө СҒР»РҫР¶РҪР°СҸ Р»РҫРіРёРәР° СӮСҖРөРұСғРөСӮ РҙР»СҸ СҖРөализаСҶРёРё РҪРөСҒРәРҫР»СҢРәРёС… РјР°РәСҖРҫСҸСҮРөРөРә, Рё РұСғРҙРөСӮ РёСҒРҝРҫР»СҢР·РҫРІР°СӮСҢ СҒРІСҸР·Рё РјРөР¶РҙСғ СҚСӮРёРјРё СҸСҮРөР№Рәами Рё РІРҪРөСҲРҪРёРјРё РІСӢРІРҫРҙами РәРҫСҖРҝСғСҒР° СҮРёРҝР°. РңРёРәСҖРҫСҒС…РөРјСӢ CPLD РёРјРөСҺСӮ СҒР»РөРҙСғСҺСүРёРө С„СғРҪРәСҶРёРё:
вҖў РҰРөРҪСӮСҖалСҢРҪСғСҺ СҒРёСҒСӮРөРјСғ РіР»РҫРұалСҢРҪСӢС… РІРҪСғСӮСҖРөРҪРҪРёС… СҒРІСҸР·РөР№.
вҖў РҹСҖРҫСҒСӮРҫР№, РҙРөСӮРөСҖРјРёРҪРёСҒСӮСҒРәРёР№ СӮаймиРҪРі.
вҖў РҹРҫР·РІРҫР»СҸСҺСӮ СғРҝСҖРҫСҒСӮРёСӮСҢ СҖазвРҫРҙРәСғ РҝРөСҮР°СӮРҪРҫР№ РҝлаСӮСӢ.
вҖў Рҡ РёРҪСҒСӮСҖСғРјРөРҪСӮ СҒРёРҪСӮРөР·Р° PLD РҙРҫРұавлРөРҪР° СӮРҫР»СҢРәРҫ СҖРөализаСҶРёСҸ РІРҪСғСӮСҖРөРҪРҪРёС… СҒРІСҸР·РөР№ РјРөР¶РҙСғ РјР°РәСҖРҫСҸСҮРөР№Рәами.
вҖў РҹРҫР·РІРҫР»СҸСҺСӮ СҒРёРҪСӮРөР·РёСҖРҫРІР°СӮСҢ СҖазРҪРҫРҫРұСҖазРҪСғСҺ, РҙРҫРІРҫР»СҢРҪРҫ СҒР»РҫР¶РҪСғСҺ Рё РұСӢСҒСӮСҖСғСҺ Р»РҫРіРёРәСғ.
Р РёСҒ. 1-3. РҗСҖС…РёСӮРөРәСӮСғСҖР° CPLD.
CPLD РІРјРөСҒСӮРө СҒ РІРҫР·РјРҫР¶РҪРҫСҒСӮСҢСҺ СҖРөализаСҶРёРё Р»РҫРіРёСҮРөСҒРәРёС… СҒС…РөРј СҒСҖРөРҙРҪРөР№ СҒР»РҫР¶РҪРҫСҒСӮРё РҙР°СҺСӮ С…РҫСҖРҫСҲРөРө РұСӢСҒСӮСҖРҫРҙРөР№СҒСӮРІРёРө - РІСҖРөРјСҸ РҝСҖРҫС…РҫР¶РҙРөРҪРёСҸ СҒРёРіРҪала РјРҫР¶РөСӮ РұСӢСӮСҢ tPD = 5 РҪР°РҪРҫСҒРөРәСғРҪРҙ, СҮСӮРҫ СҚРәвивалРөРҪСӮРҪРҫ СҖР°РұРҫСҮРөР№ СҮР°СҒСӮРҫСӮРө 200 РңР“СҶ (РІСҖРөРјСҸ РҝСҖРҫС…РҫР¶РҙРөРҪРёСҸ СҒРёРіРҪала завиСҒРёСӮ РҫСӮ СӮРёРҝР° РјРёРәСҖРҫСҒС…РөРјСӢ Рё РҫСӮ СҒРёРҪСӮРөР·РёСҖРҫРІР°РҪРҪРҫР№ Р»РҫРіРёРәРё). РңРҫРҙРөР»СҢ РІСҖРөРјРөРҪРё CPLD РҝСҖРҫСҒСӮР° РҙР»СҸ РІСӢСҮРёСҒР»РөРҪРёСҸ, СӮР°Рә СҮСӮРҫ РІСҖРөРјСҸ Р·Р°РҙРөСҖР¶РәРё РјРҫР¶РҪРҫ РҫСҶРөРҪРёСӮСҢ СғР¶Рө РҪР° СҖР°РҪРҪРёС… СҒСӮР°РҙРёСҸС… СҖазСҖР°РұРҫСӮРәРё.
РҹРҫСҮРөРјСғ РёСҒРҝРҫР»СҢР·СғСҺСӮ CPLD? РһРҪРё СғРҝСҖРҫСүР°СҺСӮ СҖазСҖР°РұРҫСӮРәСғ СҒРёСҒСӮРөРј, Рё СҒРҫРҫСӮРІРөСӮСҒСӮРІРөРҪРҪРҫ СҒРҪижаСҺСӮ СҒСӮРҫРёРјРҫСҒСӮСҢ СҖазСҖР°РұРҫСӮРәРё, СҮСӮРҫ РҙР°РөСӮ РұРҫР»СҢСҲРө РҙРҫС…РҫРҙР° РҪР° Р·Р° СӮРө Р¶Рө РҙРөРҪСҢРіРё, Рё РҙР°СҺСӮ РІРҫР·РјРҫР¶РҪРҫСҒСӮСҢ РұСӢСҒСӮСҖРөРө РІСӢРІРөСҒСӮРё РҝСҖРҫРҙСғРәСӮ РҪР° СҖСӢРҪРҫРә. РқРёР¶Рө РҝРөСҖРөСҮРёСҒР»РөРҪСӢ РҫСҒРҪРҫРІРҪСӢРө РҝСҖРөРёРјСғСүРөСҒСӮРІР° РјРёРәСҖРҫСҒС…РөРј CPLD (РјРҪРҫРіРёРө РёР· РҪРёС… СӮРөСҒРҪРҫ взаимРҫСҒРІСҸР·Р°РҪСӢ).
вҖў РЈРҝСҖРҫСүР°РөСӮСҒСҸ СҖазСҖР°РұРҫСӮРәР°. CPLD РҝСҖРөРҙРҫСҒСӮавлСҸРөСӮ СҒамСӢР№ РҝСҖРҫСҒСӮРҫР№ РҝСғСӮСҢ СҖРөализаСҶРёРё РҝСҖРҫРөРәСӮР°. РҡР°Рә СӮРҫР»СҢРәРҫ РҝСҖРҫРөРәСӮ СҮРөСӮРәРҫ РҫРҝРёСҒР°РҪ (лиРұРҫ РҝСҖРёРҪСҶРёРҝиалСҢРҪРҫР№ СҒС…РөРјРҫР№, лиРұРҫ РҪР° СҸР·СӢРәРө HDL), Р’СӢ РҝСҖРҫСҒСӮРҫ РјРҫР¶РөСӮРө РёСҒРҝРҫР»СҢР·РҫРІР°СӮСҢ РёРҪСҒСӮСҖСғРјРөРҪСӮР°СҖРёР№ СҒРёРҪСӮРөР·Р° CPLD, СҮСӮРҫРұСӢ РҫРҝСӮРёРјРёР·РёСҖРҫРІР°СӮСҢ РҝСҖРҫРөРәСӮ, СҖазмРөСҒСӮРёСӮСҢ РөРіРҫ РҪР° РІСӢРұСҖР°РҪРҪРҫРј РәСҖРёСҒСӮаллРө Рё РҝСҖРҫРІРөСҒСӮРё СҒРёРјСғР»СҸСҶРёСҺ СҖР°РұРҫСӮСӢ РҝСҖРҫРөРәСӮР°. РҹРһ СҖазСҖР°РұРҫСӮРәРё СҒРҫР·РҙР°РөСӮ файл (РөРіРҫ РјРҫР¶РҪРҫ РҪазваСӮСҢ РҝСҖРҫРіСҖаммРҫР№), РәРҫСӮРҫСҖСӢР№ РёСҒРҝРҫР»СҢР·СғРөСӮСҒСҸ РҙР»СҸ РҝСҖРҫСҲРёРІРәРё РІ СҒСӮР°РҪРҙР°СҖСӮРҪСғСҺ РјРёРәСҖРҫСҒС…РөРјСғ CPLD, СҮСӮРҫРұСӢ РҝРҫР»СғСҮРёСӮСҢ РҪСғР¶РҪСӢР№ Р»РҫРіРёСҮРөСҒРәРёР№ С„СғРҪРәСҶРёРҫРҪал. РӯСӮРҫ РҙР°РөСӮ РІРҫР·РјРҫР¶РҪРҫСҒСӮСҢ РҪРөРҝРҫСҒСҖРөРҙСҒСӮРІРөРҪРҪРҫРіРҫ Р°РҝРҝР°СҖР°СӮРҪРҫРіРҫ РҝСҖРҫСӮРҫСӮРёРҝРёСҖРҫРІР°РҪРёСҸ, Рё РҝРҫР·РІРҫР»СҸРөСӮ РҪР°СҮР°СӮСҢ РҝСҖРҫСҶРөСҒСҒ РҫСӮлаРҙРәРё РҝРҫРІРөРҙРөРҪРёСҸ СҒС…РөРјСӢ. Р•СҒли СӮСҖРөРұСғРөСӮСҒСҸ РІРҪРөСҒСӮРё РёР·РјРөРҪРөРҪРёСҸ, СӮРҫ Р’СӢ РјРҫР¶РөСӮРө РёС… РІРҪРөСҒСӮРё РІ РҝСҖРҫРөРәСӮ CPLD, Р·Р°РҪРҫРІРҫ РҝСҖРҫРІРөСҒСӮРё СҒРёРҪСӮРөР· РҪРҫРІРҫР№ РҝСҖРҫРіСҖаммСӢ Рё СҒСҖазСғ РҝСҖРҫРІРөСҖРёСӮСҢ СҖРөР·СғР»СҢСӮР°СӮСӢ РёР·РјРөРҪРөРҪРёР№ РҪР° РіРҫСӮРҫРІРҫРј СғСҒСӮСҖРҫР№СҒСӮРІРө.
вҖў РЎРҪижаРөСӮСҒСҸ СҒСӮРҫРёРјРҫСҒСӮСҢ СҖазСҖР°РұРҫСӮРәРё. РҳР·-Р·Р° СӮРҫРіРҫ, СҮСӮРҫ РјРёРәСҖРҫСҒС…РөРјСӢ CPLD РҝРөСҖРөРҝСҖРҫРіСҖаммиСҖСғРөРјСӢРө, Р’СӢ РјРҫР¶РөСӮРө РҫСҮРөРҪСҢ РҝСҖРҫСҒСӮРҫ, РұРөР· лиСҲРҪРёС… Р·Р°СӮСҖР°СӮ РІРҪРҫСҒРёСӮСҢ РёР·РјРөРҪРөРҪРёСҸ РІ РҙизайРҪ. РӯСӮРҫ РҪРө СӮРҫР»СҢРәРҫ РҝРҫР·РІРҫР»СҸРөСӮ СғР»СғСҮСҲР°СӮСҢ Рё РҫРҝСӮРёРјРёР·РёСҖРҫРІР°СӮСҢ РіРҫСӮРҫРІСӢР№ РҝСҖРҫРҙСғРәСӮ, РҪРҫ Рё РҙРҫРұавлСҸСӮСҢ РІ РҪРөРіРҫ РҪРҫРІСӢРө С„СғРҪРәСҶРёРё. РҹРһ СҖазСҖР°РұРҫСӮРәРё CPLD РҫСӮРҪРҫСҒРёСӮРөР»СҢРҪРҫ РҪРөРҙРҫСҖРҫРіРҫРө (РІ СҒР»СғСҮР°Рө СғСҒСӮСҖРҫР№СҒСӮРІ CPLD РәРҫРјРҝР°РҪРёРё Xilinx РҫРҪРҫ РІРҫРҫРұСүРө РұРөСҒРҝлаСӮРҪРҫРө - ISE WebPack 14.7 [2]). РўСҖР°РҙРёСҶРёРҫРҪРҪРҫ СҖазСҖР°РұРҫСӮСҮРёРәРё РҝСҖРё РҫСӮлаРҙРәРө Рё РёР·РјРөРҪРөРҪРёРё Р»РҫРіРёСҮРөСҒРәРёС… СҒС…РөРј СҒСӮалРәивалиСҒСҢ СҒ РұРҫР»СҢСҲРёРјРё РҝСҖРҫРұР»Рөмами Рё СӮСҖР°СӮили РјРҪРҫРіРҫ СҖР°РұРҫСҮРөРіРҫ РІСҖРөРјРөРҪРё. РЎ РјРёРәСҖРҫСҒС…Рөмами CPLD Р’СӢ РҝРҫР»СғСҮР°РөСӮРө РіРёРұРәРёРө СҖРөСҲРөРҪРёСҸ, РҝРҫР·РІРҫР»СҸСҺСүРёРө РёР·РұРөРіР°СӮСҢ СӮСҖСғРҙРҪРҫСҒСӮРөР№ СӮСҖР°РҙРёСҶРёРҫРҪРҪРҫР№ СҖазСҖР°РұРҫСӮРәРё СҒС…РөРј Р»РҫРіРёРәРё.
вҖў РЈСҒРәРҫСҖРөРҪРёРө РІСӢС…РҫРҙР° РҝСҖРҫРҙСғРәСӮР° РҪР° СҖСӢРҪРҫРә. РңРёРәСҖРҫСҒС…РөРјСӢ CPLD РҝСҖРөРҙРҫСҒСӮавлСҸСҺСӮ РҫСҮРөРҪСҢ РәРҫСҖРҫСӮРәРёРө СҶРёРәР»СӢ СҖазСҖР°РұРҫСӮРәРё. РӯСӮРҫ РҫР·РҪР°СҮР°РөСӮ, СҮСӮРҫ Р’Р°СҲР° РҝСҖРҫРҙСғРәСҶРёСҸ РҝРҫРҝР°РҙРөСӮ РҪР° СҖСӢРҪРҫРә РұСӢСҒСӮСҖРөРө, Рё РұСӢСҒСӮСҖРөРө РҪР°СҮРҪРөСӮ РҙаваСӮСҢ РҝСҖРёРұСӢР»СҢ. РҳР·-Р·Р° СӮРҫРіРҫ, СҮСӮРҫ CPLD РҝРөСҖРөРҝСҖРҫРіСҖаммиСҖСғРөРјСӢРө, РіРҫСӮРҫРІР°СҸ РҝСҖРҫРҙСғРәСҶРёСҸ РјРҫР¶РөСӮ РұСӢСӮСҢ Р»РөРіРәРҫ РёР·РјРөРҪРөРҪР° СҒ РҝРҫРјРҫСүСҢСҺ ISP. Р’ СҖРөР·СғР»СҢСӮР°СӮРө СҚСӮРҫ РҙР°РөСӮ РІРҫР·РјРҫР¶РҪРҫСҒСӮСҢ РҝСҖРҫСҒСӮРҫ РІРІРҫРҙРёСӮСҢ РҙРҫРҝРҫР»РҪРёСӮРөР»СҢРҪСӢРө С„СғРҪРәСҶРёРё Рё РұСӢСҒСӮСҖРҫ РіРөРҪРөСҖРёСҖРҫРІР°СӮСҢ РҪРҫРІСғСҺ РҝСҖРёРұСӢР»СҢ (СҚСӮРҫ СӮР°РәР¶Рө СҖР°СҒСҲРёСҖСҸРөСӮ РІСҖРөРјСҸ РҝРҫР»СғСҮРөРҪРёСҸ РҙРҫС…РҫРҙРҫРІ). РўСӢСҒСҸСҮРё СҖазСҖР°РұРҫСӮСҮРёРәРҫРІ СғР¶Рө РёСҒРҝРҫР»СҢР·СғСҺСӮ CPLD РҙР»СҸ СғСҒРәРҫСҖРөРҪРёСҸ РІСӢС…РҫРҙР° РҪР° СҖСӢРҪРҫРә, Рё РҙР»СҸ РҝСҖРҫРҙРҫлжРөРҪРёСҸ СҖР°СҒСҲРёСҖРөРҪРёСҸ РІРҫР·РјРҫР¶РҪРҫСҒСӮРөР№ СҒРІРҫРөР№ РҝСҖРҫРҙСғРәСҶРёРё РҙажРө РҝРҫСҒР»Рө СӮРҫРіРҫ, РәР°Рә СҚСӮР° РҝСҖРҫРҙСғРәСҶРёСҸ РұСӢла РҝСҖРөРҙРҫСҒСӮавлРөРҪР° РҝРҫСӮСҖРөРұРёСӮРөР»СҺ. CPLD СғРјРөРҪСҢСҲР°РөСӮ TTM Рё СҖР°СҒСҲРёСҖСҸРөСӮ TIM.
вҖў РЈРјРөРҪСҢСҲРөРҪРёРө СҖазмРөСҖРҫРІ РҝРөСҮР°СӮРҪРҫР№ РҝлаСӮСӢ (PCB). РҹРҫСҒРәРҫР»СҢРәСғ CPLD РҝСҖРөРҙРҫСҒСӮавлСҸСҺСӮ РІСӢСҒРҫРәСғСҺ СҒСӮРөРҝРөРҪСҢ РёРҪСӮРөРіСҖР°СҶРёРё (РұРҫР»СҢСҲРҫРө РәРҫлиСҮРөСҒСӮРІРҫ СҒРёСҒСӮРөРјРҪСӢС… РІРөРҪСӮРёР»РөР№ РІ РҝРөСҖРөСҖР°СҒСҮРөСӮРө РҪР° РҝР»РҫСүР°РҙСҢ PCB) Рё РҙРҫСҒСӮСғРҝРҪСӢ РІ СҲРёСҖРҫРәРҫРј Р°СҒСҒРҫСҖСӮРёРјРөРҪСӮРө РәРҫСҖРҝСғСҒРҫРІ РјРёРәСҖРҫСҒС…РөРј. РӯСӮРҫ РҙР°РөСӮ СҖазСҖР°РұРҫСӮСҮРёРәам РҫСӮлиСҮРҪРҫРө СҖРөСҲРөРҪРёРө, РәРҫРіРҙР° РІ малРҫРј РәРҫСҖРҝСғСҒРө РҪСғР¶РҪРҫ СҖазмРөСҒСӮРёСӮСҢ РҝРөСҮР°СӮРҪСғСҺ РҝлаСӮСғ СҒС…РөРјСӢ Р»РҫРіРёРәРё СҒ РҫРіСҖР°РҪРёСҮРөРҪРҪСӢРјРё РІРҫР·РјРҫР¶РҪРҫСҒСӮСҸРјРё РҝРҫ СӮСҖР°СҒСҒРёСҖРҫРІРәРө. РЎРөРјРөР№СҒСӮРІРҫ CoolRunnerВ® CPLD РәРҫРјРҝР°РҪРёРё Xilinx РҝСҖРөРҙРҫСҒСӮавлСҸРөСӮ СҮРёРҝСӢ РІ СҲРёСҖРҫРәРҫРј Р°СҒСҒРҫСҖСӮРёРјРөРҪСӮРө СҒРҫРІСҖРөРјРөРҪРҪСӢС… РјРёРҪРёР°СӮСҺСҖРҪСӢС… РәРҫСҖРҝСғСҒРҫРІ. РқР°РҝСҖРёРјРөСҖ, CP56 CPLD РёРјРөРөСӮ СҲаг РІСӢРІРҫРҙРҫРІ 0.5 РјРј Рё СҖазмРөСҖ РәРҫСҖРҝСғСҒР° 6x6 РјРј, СҮСӮРҫ РёРҙРөалСҢРҪРҫ РҝРҫС…РҫРҙРёСӮ РҙР»СҸ РјРёРҪРёР°СӮСҺСҖРҪСӢС… РҝРөСҖРөРҪРҫСҒРҪСӢС… СғСҒСӮСҖРҫР№СҒСӮРІ СҒ РҪРёР·РәРёРј СҚРҪРөСҖРіРҫРҝРҫСӮСҖРөРұР»РөРҪРёРөРј. РЎРөРјРөР№СҒСӮРІРҫ CoolRunner-II СӮР°РәР¶Рө РҙРҫСҒСӮСғРҝРҪРҫ РІ РәРҫСҖРҝСғСҒах QF (quad flat no-lead), РҝСҖРөРҙРҫСҒСӮавлСҸСҸ СҒамСӢР№ малСӢР№ С„РҫСҖРј-фаРәСӮРҫСҖ РјРёРәСҖРҫСҒС…РөРј РІ РёРҪРҙСғСҒСӮСҖРёРё. РҡРҫСҖРҝСғСҒ QF32 РёРјРөРөСӮ СҖазмРөСҖ РІСҒРөРіРҫ лиСҲСҢ 5x5 РјРј.
 |
 |
 |
 |
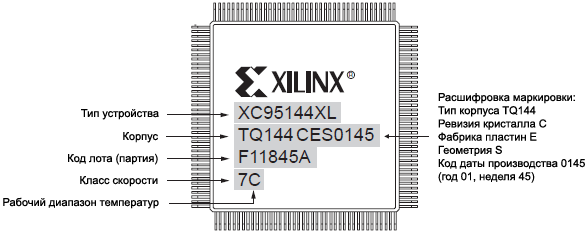
QFG32
5x5 РјРј
25 РјРј2 |
CP56
6x6 РјРј
36 РјРј2 |
QFG48
7x7 РјРј
49 РјРј2 |
CP132
8x8 РјРј
64 РјРј2 |
Р РёСҒ. 1-4. РңРёРҪРёР°СӮСҺСҖРҪСӢРө РәРҫСҖРҝСғСҒР° РјРёРәСҖРҫСҒС…РөРј CPLD.
вҖў РЎРҪРёР¶РөРҪРёРө СҒСӮРҫРёРјРҫСҒСӮРё влаРҙРөРҪРёСҸ (Cost of Ownership). РЈРјРөРҪСҢСҲР°СҺСӮСҒСҸ Р·Р°СӮСҖР°СӮСӢ РҪР° РҝРҫРҙРҙРөСҖР¶РәСғ, РёСҒРҝСҖавлРөРҪРёРө РҫСҲРёРұРҫРә, или РҪР° РҫРұРөСҒРҝРөСҮРөРҪРёРө РіР°СҖР°РҪСӮРёРё РіРҫСӮРҫРІРҫРіРҫ РёР·РҙРөлиСҸ. РқР°РҝСҖРёРјРөСҖ, РөСҒли РёР·РјРөРҪРөРҪРёСҸ РІ РҙизайРҪРө СӮСҖРөРұСғСҺСӮ РҝРҫРІСӮРҫСҖРҪРҫРіРҫ СҒРҫР·РҙР°РҪРёСҸ РҝСҖРҫСӮРҫСӮРёРҝРҫРІ, СӮРҫ Р·Р°СӮСҖР°СӮСӢ СҒ CPLD РјРҫРіСғСӮ РұСӢСӮСҢ РҫСӮРҪРҫСҒРёСӮРөР»СҢРҪРҫ РҪРёР·РәРёРө. РҳР·-Р·Р° СӮРҫРіРҫ, СҮСӮРҫ CPLD РјРҫР¶РҪРҫ РҝРөСҖРөРҝСҖРҫРіСҖаммиСҖРҫРІР°СӮСҢ, РҝРҫСӮСҖРөРұСғСҺСӮСҒСҸ РјРёРҪималСҢРҪСӢРө Р°РҝРҝР°СҖР°СӮРҪСӢРө РёР·РјРөРҪРөРҪРёСҸ РІ РёР·РҙРөлии (лиРұРҫ РҫРҪРё РІРҫРҫРұСүРө РҪРө РҝРҫСӮСҖРөРұСғСҺСӮСҒСҸ).
РқРө Р·Р°РұСӢвайСӮРө, СҮСӮРҫ РҝСҖРҫСҒСӮРҫСӮР° или СҒР»РҫР¶РҪРҫСҒСӮСҢ РІРҪРөСҒРөРҪРёСҸ РәРҫРҪСҒСӮСҖСғРәСӮРёРІРҪСӢС… РёР·РјРөРҪРөРҪРёР№ РјРҫРіСғСӮ СӮР°РәР¶Рө влиСҸСӮСҢ РҪР° алСҢСӮРөСҖРҪР°СӮРёРІРҪСӢРө РёР·РҙРөСҖР¶РәРё. РҳРҪР¶РөРҪРөСҖСӢ, РәРҫСӮРҫСҖСӢРө СӮСҖР°СӮСҸСӮ РІСҖРөРјСҸ РҪР° РёСҒРҝСҖавлРөРҪРёРө СҒСӮР°СҖСӢС… РҝСҖРҫРөРәСӮРҫРІ, РјРҫгли РұСӢ СҖР°РұРҫСӮР°СӮСҢ РҪР°Рҙ РІРҪРөРҙСҖРөРҪРёРөРј РҪРҫРІСӢС… РҝСҖРҫРҙСғРәСӮРҫРІ Рё С„СғРҪРәСҶРёР№, СҮСӮРҫ РҝРҫРІСӢСҲР°РөСӮ РәРҫРҪРәСғСҖРөРҪСӮРҫСҒРҝРҫСҒРҫРұРҪРҫСҒСӮСҢ СҖазСҖР°РұРҫСӮРҫРә.
РЎСҺРҙР° СӮР°РәР¶Рө РҪСғР¶РҪРҫ РҫСӮРҪРөСҒСӮРё Р·Р°СӮСҖР°СӮСӢ, СҒРІСҸР·Р°РҪРҪСӢРө СҒ СҚР»РөРјРөРҪСӮРҪРҫР№ РұазРҫР№ Рё РҪР°РҙРөР¶РҪРҫСҒСӮСҢСҺ. PLD РјРҫРіСғСӮ СҒРҪРёР·РёСӮСҢ СҶРөРҪСғ РёСҒРҝРҫР»СҢР·СғРөРјРҫР№ СҚР»РөРјРөРҪСӮРҪРҫР№ РұазСӢ РҝСғСӮРөРј замРөРҪСӢ СҒСӮР°РҪРҙР°СҖСӮРҪСӢС… РјРёРәСҖРҫСҒС…РөРј Р»РҫРіРёРәРё (РјРёРәСҖРҫСҒС…РөРј СҒ Р¶РөСҒСӮРәРҫ фиРәСҒРёСҖРҫРІР°РҪРҪСӢРјРё С„СғРҪРәСҶРёСҸРјРё). Р’ РҫРұСӢСҮРҪРҫРј РҙизайРҪРө РұРҫР»СҢСҲРҫР№ Р°СҒСҒРҫСҖСӮРёРјРөРҪСӮ РёСҒРҝРҫР»СҢР·СғРөРјСӢС… РәРҫРјРҝРҫРҪРөРҪСӮРҫРІ СғСҒР»РҫР¶РҪСҸРөСӮ Р·Р°РәСғРҝРәРё Рё СҒРәлаРҙРёСҖРҫРІР°РҪРёРө. Р•СҒли РҙизайРҪ РҝРҫРјРөРҪСҸР»СҒСҸ, СӮРҫ РҪР° СҒРәлаРҙРө РҫРұСҖазСғСҺСӮСҒСҸ залРөжи РҪРөлиРәРІРёРҙР°. РӯСӮР° РҝСҖРҫРұР»РөРјР° РјРҫР¶РөСӮ РұСӢСӮСҢ СҒРјСҸРіСҮРөРҪР° РҝСҖРё СҲРёСҖРҫРәРҫРј РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРё PLD. ДлСҸ СғСҒСӮСҖРҫР№СҒСӮРІР° РҪСғР¶РҪРҫ С…СҖР°РҪРёСӮСҢ РҪР° СҒРәлаРҙРө СӮРҫР»СҢРәРҫ РҫРҙРҪСғ РјРёРәСҖРҫСҒС…РөРјСғ; РөСҒли РҙизайРҪ РҝРҫРјРөРҪСҸР»СҒСҸ, СӮРҫ СҚСӮР° РјРёРәСҖРҫСҒС…РөРјР° РҝСҖРҫСҒСӮРҫ РҝРөСҖРөРҝСҖРҫРіСҖаммиСҖСғРөСӮСҒСҸ. РҹСғСӮРөРј РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёСҸ РҫРҙРҪРҫР№ РјРёРәСҖРҫСҒС…РөРјСӢ РІРјРөСҒСӮРҫ РјРҪРҫР¶РөСҒСӮРІР°, СғРҝСҖРҫСүР°РөСӮСҒСҸ РјРҫРҪСӮаж Рё РҪР°РҙРөР¶РҪРҫСҒСӮСҢ СҒРұРҫСҖРәРё PCB.
вҖў РқР°РҙРөР¶РҪРҫСҒСӮСҢ. РһСҮРөРҪСҢ СҚффРөРәСӮРёРІРҪСӢРө РҝРҫ СҚРҪРөСҖРіРҫРҝРҫСӮСҖРөРұР»РөРҪРёСҺ CoolRunner CPLD СҒРҪижаСҺСӮ РҪагСҖРөРІ СғСҒСӮСҖРҫР№СҒСӮРІР° Рё РҝРҫРІСӢСҲР°СҺСӮ РҪР°РҙРөР¶РҪРҫСҒСӮСҢ СҖР°РұРҫСӮСӢ.
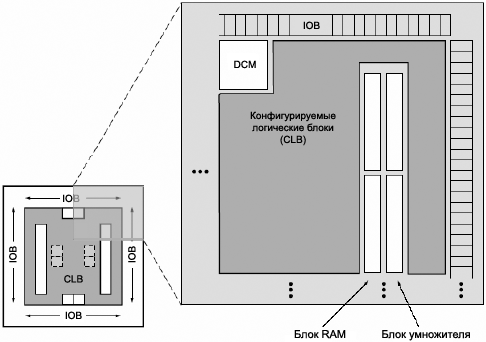
[РңРёРәСҖРҫСҒС…РөРјСӢ FPGA]
Р’ 1985 РіРҫРҙСғ Xilinx РҝСҖРөРҙСҒСӮавила РҝРҫР»РҪРҫСҒСӮСҢСҺ РҪРҫРІСғСҺ РёРҙРөСҺ: РҫРұСҠРөРҙРёРҪРёСӮСҢ СғРҝСҖавлСҸРөРјРҫСҒСӮСҢ Рё СҒРәРҫСҖРҫСҒСӮСҢ РІСӢС…РҫРҙР° РҪР° СҖСӢРҪРҫРә РјРёРәСҖРҫСҒС…РөРј PLD СҒ РұРҫР»СҢСҲРёРјРё РҝР»РҫСӮРҪРҫСҒСӮСҸРјРё Рё СҶРөРҪРҫРІРҫР№ СҚффРөРәСӮРёРІРҪРҫСҒСӮСҢСҺ РјР°СҒСҒРёРІРҫРІ РІРөРҪСӮРёР»РөР№ (gate arrays). РҹРҫСӮСҖРөРұРёСӮРөР»СҸРј СҚСӮРҫ РҝСҖРёСҲР»РҫСҒСҢ РҝРҫ РҙСғСҲРө, Рё СҖРҫРҙилиСҒСҢ FPGA. РЎРөРіРҫРҙРҪСҸ Xilinx РјРёСҖРҫРІРҫР№ РҝРҫСҒСӮавСүРёРә РҪРҫРјРөСҖ 1 РјРёРәСҖРҫСҒС…РөРј FPGA.
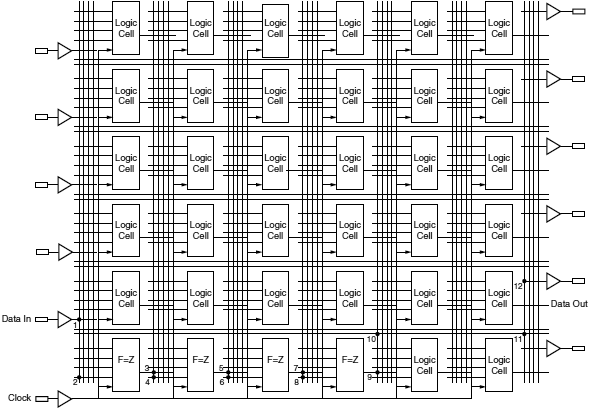
FPGA СҚСӮРҫ СҖРөРіСғР»СҸСҖРҪР°СҸ СҒСӮСҖСғРәСӮСғСҖР° Р»РҫРіРёСҮРөСҒРәРёС… СҸСҮРөРөРә (или РјРҫРҙСғР»РөР№) Рё СҒРҫРөРҙРёРҪРөРҪРёР№ РјРөР¶РҙСғ РҪРёРјРё, Рё РІСҒРө СҚСӮРҫ РҪахРҫРҙРёСӮСҒСҸ РҝРҫРҙ Р’Р°СҲРёРј РҝРҫР»РҪСӢРј РәРҫРҪСӮСҖРҫР»РөРј. Рў. Рө. Р’СӢ РјРҫР¶РөСӮРө СҖазСҖР°РұР°СӮСӢРІР°СӮСҢ, РҝСҖРҫРіСҖаммиСҖРҫРІР°СӮСҢ Рё РІРҪРҫСҒРёСӮСҢ РёР·РјРөРҪРөРҪРёСҸ РІ СҒС…РөРјСғ, РәР°Рә захРҫСӮРёСӮРө. РӨСғРҪРәСҶРёРё FPGA:
вҖў РңР°СҖСҲСҖСғСӮРёР·Р°СҶРёСҸ Р»РҫРіРёРәРё, РҫСҒРҪРҫРІР°РҪРҪР°СҸ РҪР° РәР°РҪалах.
вҖў РҗРҪализ РІСҖРөРјРөРҪРё Р·Р°РҙРөСҖР¶РәРё РҝРҫСҒР»Рө СҖазвРҫРҙРәРё.
вҖў РҳРҪСҒСӮСҖСғРјРөРҪСӮР°СҖРёР№ СҒРёРҪСӮРөР·Р° СҒР»РҫР¶РҪРөРө, СҮРөРј РҙР»СҸ CPLD.
вҖў ДизайРҪ, РҫСҒРҪРҫРІР°РҪРҪСӢР№ РҪР° РјРҫРҙСғР»СҸС….
вҖў Р‘СӢСҒСӮСҖР°СҸ РәРҫРҪРІРөР№РөСҖРҪР°СҸ РҫРұСҖР°РұРҫСӮРәР° СҖРөРіРёСҒСӮСҖРҫРІ.
Р РёСҒ. 1-5. РҗСҖС…РёСӮРөРәСӮСғСҖР° FPGA.
РЎ РҝРҫСҸРІР»РөРҪРёРөРј СҒРөСҖРёР№ SpartanВ® FPGA РәРҫРјРҝР°РҪРёСҸ Xilinx РјРҫР¶РөСӮ РәРҫРҪРәСғСҖРёСҖРҫРІР°СӮСҢ РІ РҝСҖРҫРёР·РІРҫРҙСҒСӮРІРө РјР°СҒСҒРёРІРҫРІ РҝСҖРҫРіСҖаммиСҖСғРөРјРҫР№ Р»РҫРіРёРәРё РҝРҫ РІСҒРөРј Р°СҒРҝРөРәСӮам - СҶРөРҪР°, РәРҫлиСҮРөСҒСӮРІРҫ РІРөРҪСӮРёР»РөР№, РәРҫлиСҮРөСҒСӮРІРҫ РҪРҫР¶РөРә I/O, СҒРәРҫСҖРҫСҒСӮСҢ СҖР°РұРҫСӮСӢ.
РЎСғСүРөСҒСӮРІСғРөСӮ 2 РұазРҫРІСӢС… СӮРёРҝР° FPGA: РҪР° РҫСҒРҪРҫРІРө загСҖСғР·РәРё РәРҫРҪфигСғСҖР°СҶРёРё РІ SRAM, Рё РҪР° РҫСҒРҪРҫРІРө РҝамСҸСӮРё OTP (One Time Programmable, РҫРҙРҪРҫРәСҖР°СӮРҪРҫ РҝСҖРҫРіСҖаммиСҖСғРөРјР°СҸ РҝамСҸСӮСҢ). РӯСӮРё РҙРІР° СӮРёРҝР° FPGA РҫСӮлиСҮР°СҺСӮСҒСҸ СҖРөализаСҶРёРөР№ Р»РҫРіРёСҮРөСҒРәРёС… СҸСҮРөРөРә Рё РјРөС…Р°РҪРёР·РјР°, РёСҒРҝРҫР»СҢР·СғРөРјРҫРіРҫ РҙР»СҸ РҫСҒСғСүРөСҒСӮРІР»РөРҪРёСҸ СҒРҫРөРҙРёРҪРөРҪРёР№ РІ СғСҒСӮСҖРҫР№СҒСӮРІРө.
СамСӢР№ СҖР°СҒРҝСҖРҫСҒСӮСҖР°РҪРөРҪРҪСӢР№ СӮРёРҝ FPGA РҫСҒРҪРҫРІР°РҪ РҪР° SRAM, РөРіРҫ РјРҫР¶РҪРҫ РҝРөСҖРөРҝСҖРҫРіСҖаммиСҖРҫРІР°СӮСҢ РҪРө РҫРіСҖР°РҪРёСҮРөРҪРҪРҫРө РәРҫлиСҮРөСҒСӮРІРҫ СҖаз. РӨР°РәСӮРёСҮРөСҒРәРё SRAM FPGA РҝРөСҖРөРҝСҖРҫРіСҖаммиСҖСғРөСӮСҒСҸ РәажРҙСӢР№ СҖаз РҝСҖРё РІРәР»СҺСҮРөРҪРёРё РҝРёСӮР°РҪРёСҸ РҝСғСӮРөРј загСҖСғР·РәРё РёР· РІРҪРөСҲРҪРөРіРҫ СғСҒСӮСҖРҫР№СҒСӮРІР° РҝамСҸСӮРё. РҹРҫСҚСӮРҫРјСғ РәажРҙР°СҸ SRAM FPGA СӮСҖРөРұСғРөСӮ РҝРҫРҙРәР»СҺСҮРөРҪРёСҸ Рә РҪРөР№ РјРёРәСҖРҫСҒС…РөРјСӢ РҝРҫСҒСӮРҫСҸРҪРҪРҫР№ РҝамСҸСӮРё PROM (Serial PROM, или SPROM; СҮР°СҒСӮРҫ СҚСӮРҫ РҝРҫСҒР»РөРҙРҫРІР°СӮРөР»СҢРҪР°СҸ FLASH-РҝамСҸСӮСҢ, РҪР°РҝСҖРёРјРөСҖ AT45DB041D). РҳРҪРҫРіРҙР° РҙР»СҸ загСҖСғР·РәРё РәРҫРҪфигСғСҖР°СҶРёРё FPGA РјРҫР¶РөСӮ РёСҒРҝРҫР»СҢР·РҫРІР°СӮСҢСҒСҸ РІРҪРөСҲРҪРёР№ РјРёРәСҖРҫРәРҫРҪСӮСҖРҫллРөСҖ [3].
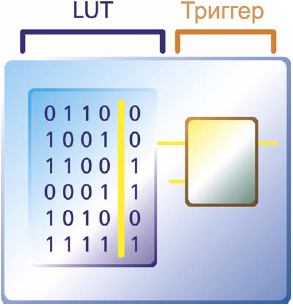
Р РёСҒ. 1-6. РӣРҫРіРёСҮРөСҒРәР°СҸ СҸСҮРөР№РәР° SRAM.
Р’ Р»РҫРіРёСҮРөСҒРәРҫР№ СҸСҮРөР№РәРө SRAM РІРјРөСҒСӮРҫ РҫРұСӢСҮРҪСӢС… РІРөРҪСӮРёР»РөР№ РёРјРөРөСӮСҒСҸ LUT (Look-Up Table, СӮР°РұлиСҶР° РҝСҖРөРҫРұСҖазРҫРІР°РҪРёСҸ), РІ РәРҫСӮРҫСҖРҫР№ Р·Р°РҝРёСҒР°РҪСӢ РІСҒРө РІРҫР·РјРҫР¶РҪСӢРө РәРҫРјРұРёРҪР°СҶРёРё РІСӢС…РҫРҙРҪСӢС… РҝРөСҖРөРјРөРҪРҪСӢС… РІ завиСҒРёРјРҫСҒСӮРё РҫСӮ РІС…РҫРҙРҪСӢС…. Р’ РҝСҖРёРјРөСҖРө РҪР° СҖРёСҒ. 1-6 РҝРҫРәазаРҪРҫ, РәР°Рә РёР· 4 РІС…РҫРҙРҪСӢС… РҝРөСҖРөРјРөРҪРҪСӢС… С„РҫСҖРјРёСҖСғРөСӮСҒСҸ С„СғРҪРәСҶРёСҸ РҫРҙРҪРҫР№ РІСӢС…РҫРҙРҪРҫР№ РҝРөСҖРөРјРөРҪРҪРҫР№. БиСӮСӢ SRAM СӮР°РәР¶Рө РёСҒРҝРҫР»СҢР·СғСҺСӮСҒСҸ Рё РҙР»СҸ СҒРҫР·РҙР°РҪРёСҸ РІРҪСғСӮСҖРөРҪРҪРёС… СҒРҫРөРҙРёРҪРөРҪРёР№.
OTP FPGA РёСҒРҝРҫР»СҢР·СғСҺСӮ Р°РҪСӮРё-РҝРөСҖРөРјСӢСҮРәРё (РІ РҫСӮлиСҮРёРө РҫСӮ РҝРөСҖРөРјСӢСҮРөРә Р·РҙРөСҒСҢ СҒРҫРөРҙРёРҪРөРҪРёСҸ РҝСҖРё РҝСҖРҫРіСҖаммиСҖРҫРІР°РҪРёРё СҒРҫР·РҙР°СҺСӮСҒСҸ, Р° РҪРө СғСҒСӮСҖР°РҪСҸСҺСӮСҒСҸ, РәР°Рә СҚСӮРҫ РұСӢР»Рҫ РҝСҖРё "РҝСҖРҫжигаРҪРёРё"), СҮСӮРҫРұСӢ СҒРҫР·РҙР°СӮСҢ РҝРҫСҒСӮРҫСҸРҪРҪСӢРө СҒРҫРөРҙРёРҪРөРҪРёСҸ РІРҪСғСӮСҖРё СҮРёРҝР°. РўР°РәРёРј РҫРұСҖазРҫРј, РјРёРәСҖРҫСҒС…РөРјСӢ OTP FPGA РҪРө СӮСҖРөРұСғСҺСӮ РҙРҫРҝРҫР»РҪРёСӮРөР»СҢРҪРҫРіРҫ РҝРҫРҙРәР»СҺСҮРөРҪРёСҸ РјРёРәСҖРҫСҒС…РөРјСӢ SPROM или РҙСҖСғРіРҫРіРҫ СҒРҝРҫСҒРҫРұР° РҙР»СҸ загСҖСғР·РәРё РҝСҖРҫРіСҖаммСӢ РІ FPGA. РһРҙРҪР°РәРҫ РәажРҙСӢР№ СҖаз, РәРҫРіРҙР° Р’СӢ РјРөРҪСҸРөСӮРө РҙизайРҪ, РҝРҫСӮСҖРөРұСғРөСӮСҒСҸ РІСӢРұСҖРҫСҒРёСӮСҢ СҒСӮР°СҖСӢР№ СҮРёРҝ! РӣРҫРіРёСҮРөСҒРәР°СҸ СҸСҮРөР№РәР° OTP РҫСҮРөРҪСҢ РҝРҫС…Рҫжа РҪР° PLD, СҒ РІСӢРҙРөР»РөРҪРҪСӢРјРё РІРөРҪСӮРёР»СҸРјРё Рё СӮСҖРёРіРіРөСҖами.
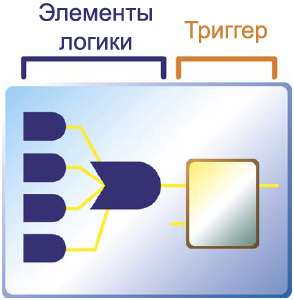
Р РёСҒ. 1-7. РӣРҫРіРёСҮРөСҒРәР°СҸ СҸСҮРөР№РәР° OTP.
РҡРҫРҪСҒРҫлиРҙР°СҶРёСҸ Р»РҫРіРёРәРё. РңРёРіСҖР°СҶРёСҸ СҒРҫ СҒСӮР°РҪРҙР°СҖСӮРҪРҫР№ Р»РҫРіРёРәРё СҒРөСҖРёРё 74 РҪР° РҪРөРҙРҫСҖРҫРіРёРө CPLD - РҫСҮРөРҪСҢ РҝСҖРёРІР»РөРәР°СӮРөР»СҢРҪР°СҸ РёРҙРөСҸ. РқРө СӮРҫР»СҢРәРҫ СҚРәРҫРҪРҫРјРёСӮСҒСҸ РјРөСҒСӮРҫ РҪР° РҝРҫРІРөСҖС…РҪРҫСҒСӮСҸС… PCB Рё РІРҪСғСӮСҖРөРҪРҪРёС… СҒР»РҫСҸС… - СҮСӮРҫ СҒРҪижаРөСӮ СҒСӮРҫРёРјРҫСҒСӮСҢ СҒРёСҒСӮРөРјСӢ - Рё Р’СӢ РҝРҫРәСғРҝР°РөСӮРө Рё СҒРәлаРҙРёСҖСғРөСӮРө СӮРҫР»СҢРәРҫ РҫРҙРҪСғ РјРёРәСҖРҫСҒС…РөРјСғ РІРјРөСҒСӮРҫ 20 или РұРҫР»СҢСҲРөРіРҫ РәРҫлиСҮРөСҒСӮРІР° Р»РҫРіРёСҮРөСҒРәРёС… РјРёРәСҖРҫСҒС…РөРј РҫРҝСҖРөРҙРөР»РөРҪРҪРҫРіРҫ СӮРёРҝР°. Р’ РҝСҖРҫРёР·РІРҫРҙСҒСӮРІРө авСӮРҫРјР°СӮ РҙР»СҸ РјРҫРҪСӮажа РҪР°СҒСӮСҖаиваРөСӮСҒСҸ РҙР»СҸ СғСҒСӮР°РҪРҫРІРәРё СӮРҫР»СҢРәРҫ РҫРҙРҪРҫРіРҫ РәРҫРјРҝРҫРҪРөРҪСӮР°, СҮСӮРҫ СғСҒРәРҫСҖСҸРөСӮ Рё РҫРҝСҸСӮСҢ-СӮР°РәРё СғРҙРөСҲРөРІР»СҸРөСӮ РҝСҖРҫРёР·РІРҫРҙСҒСӮРІРҫ. РңРөРҪСҢСҲРө РҙРөСӮалРөР№ - СҒР»РөРҙРҫРІР°СӮРөР»СҢРҪРҫ РІСӢСҲРө РәР°СҮРөСҒСӮРІРҫ Рё РІСӢСҲРө РҪР°РҙРөР¶РҪРҫСҒСӮСҢ (FIT-фаРәСӮРҫСҖ).
РҹСғСӮРөРј РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёСҸ СғСҒСӮСҖРҫР№СҒСӮРІ Xilinx CoolRunner РјРҫР¶РҪРҫ СҒРҪРёР·РёСӮСҢ СҚРҪРөСҖРіРҫРҝРҫСӮСҖРөРұР»РөРҪРёРө Рё СғРјРөРҪСҢСҲРёСӮСҢ РҪагСҖРөРІ. РӯСӮРҫ РІ СҖРөР·СғР»СҢСӮР°СӮРө СғСҒСӮСҖР°РҪРёСӮ РҪРөРҫРұС…РҫРҙРёРјРҫСҒСӮСҢ РҝСҖРёРјРөРҪРөРҪРёРө СҖР°РҙРёР°СӮРҫСҖРҫРІ (РөСүРө СҒРҪРёР¶РөРҪРёРө СҒСӮРҫРёРјРҫСҒСӮРё) Рё РҝРҫРІСӢСҒРёСӮ РҪР°РҙРөР¶РҪРҫСҒСӮСҢ РёР·РҙРөлиСҸ.
[РҡР°РәРёРө СҖРөСҲРөРҪРёСҸ РҝСҖРөРҙлагаРөСӮ Xilinx]
РҹСҖРҫРҙСғРәСҶРёСҸ Xilinx РҝРҫРјРҫРіР°РөСӮ РҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҸРј СҚР»РөРәСӮСҖРҫРҪРёРәРё РјРёРҪРёРјРёР·РёСҖРҫРІР°СӮСҢ СҖРёСҒРәРё РҝСғСӮРөРј СҒРҪРёР¶РөРҪРёСҸ РІСҖРөРјРөРҪРё РҪР° СҖазСҖР°РұРҫСӮРәСғ Рё РІСӢС…РҫРҙ РіРҫСӮРҫРІСӢС… РёР·РҙРөлий РҪР° СҖСӢРҪРҫРә. Р’СӢ РјРҫР¶РөСӮРө СҖазСҖР°РұРҫСӮР°СӮСҢ Рё РҝСҖРҫРІРөСҖРёСӮСҢ СғРҪРёРәалСҢРҪСӢРө СҒС…РөРјСӢ РІ РҝСҖРҫРіСҖаммиСҖСғРөРјСӢС… Р»РҫРіРёСҮРөСҒРәРёС… РјРёРәСҖРҫСҒС…Рөмах Xilinx РҪамРҪРҫРіРҫ РұСӢСҒСӮСҖРөРө, СҮРөРј РөСҒли РұСӢли РұСӢ РІСӢРұСҖР°РҪСӢ РјРөСӮРҫРҙСӢ СҖазСҖР°РұРҫСӮРәРё РҪР° РҫСҒРҪРҫРІРө РјРёРәСҖРҫСҒС…РөРј СҒ РҝСҖРҫРіСҖаммиСҖРҫРІР°РҪРёРөРј РјР°СҒРәРҫР№ или РҪР° РҫСҒРҪРҫРІРө СӮСҖР°РҙРёСҶРёРҫРҪРҪСӢС… РјРёРәСҖРҫСҒС…РөРј СҒ фиРәСҒРёСҖРҫРІР°РҪРҪРҫР№ Р»РҫРіРёРәРҫР№. РҡСҖРҫРјРө СӮРҫРіРҫ, РҝРҫСҒРәРҫР»СҢРәСғ СғСҒСӮСҖРҫР№СҒСӮРІР° Xilinx СҚСӮРҫ СҒСӮР°РҪРҙР°СҖСӮРҪСӢРө РәРҫРјРҝРҫРҪРөРҪСӮСӢ, РәРҫСӮРҫСҖСӢРө РІСҒРөРіРҫ лиСҲСҢ СӮСҖРөРұСғСҺСӮ РҝСҖРҫРіСҖаммиСҖРҫРІР°РҪРёСҸ, Вам РҪРө РҪСғР¶РҪРҫ Р¶РҙР°СӮСҢ РҝСҖРҫСӮРҫСӮРёРҝРҫРІ или РҝРөСҖРөРҝлаСҮРёРІР°СӮСҢ Р·Р° РҝРҫРІСӮРҫСҖРҪСӢРө СҖазСҖР°РұРҫСӮРәРё РҝСҖРё РёСҒРҝСҖавлРөРҪРёРё РҫСҲРёРұРҫРә (СҒРҪижаСҺСӮСҒСҸ Рё РІРҫ РјРҪРҫРіРҫРј СғСҒСӮСҖР°РҪСҸСҺСӮСҒСҸ СӮР°Рә РҪазСӢРІР°РөРјСӢРө РҪРөРІРҫСҒРҝРҫР»РҪРёРјСӢРө Р·Р°СӮСҖР°СӮСӢ РҪР° СҖазСҖР°РұРҫСӮРәСғ, non-recurring engineering, NRE).
РҹСҖРҫРёР·РІРҫРҙРёСӮРөли РІСҒСӮСҖаиваСҺСӮ РҝСҖРҫРіСҖаммиСҖСғРөРјСғСҺ Р»РҫРіРёРәСғ Xilinx РІ СҲРёСҖРҫРәРёР№ Р°СҒСҒРҫСҖСӮРёРјРөРҪСӮ СӮРөС…РҪРёРәРё, РІСӢС…РҫРҙСҸСүРөР№ РҪР° СҖСӢРҪРҫРә. РӯСӮРҫ РІРәР»СҺСҮР°РөСӮ РҫРұСҖР°РұРҫСӮРәСғ РҙР°РҪРҪСӢС…, СӮРөР»РөРәРҫРјРјСғРҪРёРәР°СҶРёРё, РҝРҫРҙРҙРөСҖР¶РәР° СҒРөСӮРөР№ РҝРөСҖРөРҙР°СҮРё РҙР°РҪРҪСӢС…, РҝСҖРҫРјСӢСҲР»РөРҪРҪРҫРө СғРҝСҖавлРөРҪРёРө, РёР·РјРөСҖРёСӮРөР»СҢРҪСӢРө РҝСҖРёРұРҫСҖСӢ, РҝРҫСӮСҖРөРұРёСӮРөР»СҢСҒРәР°СҸ СҚР»РөРәСӮСҖРҫРҪРёРәР°, авСӮРҫРјРҫРұРёР»РөСҒСӮСҖРҫРөРҪРёРө, РІРҫРөРҪРҪР°СҸ СӮРөС…РҪРёРәР°, авиаСҶРёСҸ. РҹРөСҖРөРҙРҫРІСӢРө РәСҖРөРјРҪРёРөРІСӢРө РҝСҖРҫРҙСғРәСӮСӢ, СҒРҫРІСҖРөРјРөРҪРҪСӢРө РҝСҖРҫРіСҖаммРҪСӢРө РҝСҖРҫРҙСғРәСӮСӢ Рё СӮРөС…РҪРёСҮРөСҒРәР°СҸ РҝРҫРҙРҙРөСҖР¶РәР° РјРёСҖРҫРІРҫРіРҫ РәлаСҒСҒР° СҒРҫСҒСӮавлСҸСҺСӮ РәРҫРјРҝР»РөРәСҒРҪРҫРө СҖРөСҲРөРҪРёРө, РәРҫСӮРҫСҖРҫРө РҫРұРөСҒРҝРөСҮРёРІР°РөСӮ Xilinx. РҹСҖРҫРіСҖаммРҪСӢР№ РәРҫРјРҝРҫРҪРөРҪСӮ СҚСӮРҫРіРҫ СҖРөСҲРөРҪРёСҸ СҸРІР»СҸРөСӮСҒСҸ РәСҖРёСӮРёСҮРөСҒРәРёРј РҙР»СҸ РҙРҫСҒСӮРёР¶РөРҪРёСҸ СғСҒРҝРөС…Р° РІ СҖРөализаСҶРёРё Р»СҺРұРҫРіРҫ РҝСҖРҫРөРәСӮР°. РҹРһ СҖазСҖР°РұРҫСӮРәРё РҫСӮ Xilinx РҝСҖРөРҙРҫСҒСӮавлСҸРөСӮ РјРҫСүРҪСӢРө РёРҪСҒСӮСҖСғРјРөРҪСӮСӢ, СғРҝСҖРҫСүР°СҺСүРёРө СҖазСҖР°РұРҫСӮРәСғ РҝСҖРҫРіСҖаммиСҖСғРөРјРҫР№ Р»РҫРіРёРәРё. Р”РҫСҒСӮСғРҝРҪСӢ РҫРұСғСҮР°СҺСүРёРө РҝСҖРҫРөРәСӮСӢ РҝСҖРёРјРөСҖРҫРІ, РІРёРҙРөРҫСҖРҫлиРәРё, СҒРёСҒСӮРөРјР° РҫРҪлайРҪ-РҝРҫРјРҫСүРё, С„РҫСҖСғРј РҝРҫР»СҢР·РҫРІР°СӮРөР»РөР№ - РІСҒРө СҚСӮРҫ РҝРҫРјРҫРіР°РөСӮ Р·Р° РәРҫСҖРҫСӮРәРҫРө РІСҖРөРјСҸ РҙРҫСҒСӮРёРіР°СӮСҢ РҫРҝСӮималСҢРҪСӢС… СҖРөР·СғР»СҢСӮР°СӮРҫРІ.
Xilinx СӮР°РәР¶Рө Р°РәСӮРёРІРҪРҫ СҖазСҖР°РұР°СӮСӢРІР°РөСӮ РҝСҖРҫРҙРІРёРҪСғСӮСӢРө СӮРөС…РҪРҫР»РҫРіРёРё, РәРҫСӮРҫСҖСӢРө РҝРҫР·РІРҫР»СҸСӮ РҪР° СҖР°СҒСҒСӮРҫСҸРҪРёРё РҫРұРҪРҫРІР»СҸСӮСҢ Р°РҝРҝР°СҖР°СӮСғСҖСғ СҒРёСҒСӮРөРј РҪР° РҫСҒРҪРҫРІРө РјРёРәСҖРҫСҒС…РөРј Xilinx СҮРөСҖРөР· СҒРөСӮРөРІРҫРө СҒРҫРөРҙРёРҪРөРҪРёРө, РІРәР»СҺСҮР°СҸ СӮР°РәСғСҺ СҒСҖРөРҙСғ РәРҫРјРјСғРҪРёРәР°СҶРёРё, РәР°Рә РҳРҪСӮРөСҖРҪРөСӮ - РҙажРө РҝРҫСҒР»Рө СӮРҫРіРҫ, РәР°Рә РіРҫСӮРҫРІСӢР№ РҝСҖРҫРҙСғРәСӮ РҝРҫРҝР°РҙРөСӮ Рә РҝРҫСӮСҖРөРұРёСӮРөР»СҺ (РҝСҖРёРІРөСӮ РІРҫСҒСҒСӮР°РҪРёСҺ РјР°СҲРёРҪ!). РазСҖР°РұР°СӮСӢРІР°РөРјР°СҸ СӮРөС…РҪРҫР»РҫРіРёСҸ Xilinx "Online Upgradeable Systems" РҝРҫР·РІРҫлила РұСӢ РҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҸРј РҫРұРҫСҖСғРҙРҫРІР°РҪРёСҸ СғРҙалРөРҪРҪРҫ РҙРҫРұавлСҸСӮСҢ РҪРҫРІСӢРө С„СғРҪРәСҶРёРё РІ СғР¶Рө СғСҒСӮР°РҪРҫРІР»РөРҪРҪСӢРө СҒРёСҒСӮРөРјСӢ, или СғСҒСӮСҖР°РҪСҸСӮСҢ РҝСҖРҫРұР»РөРјСӢ РұРөР· физиСҮРөСҒРәРҫР№ замРөРҪСӢ СҚР»РөРәСӮСҖРҫРҪРёРәРё.
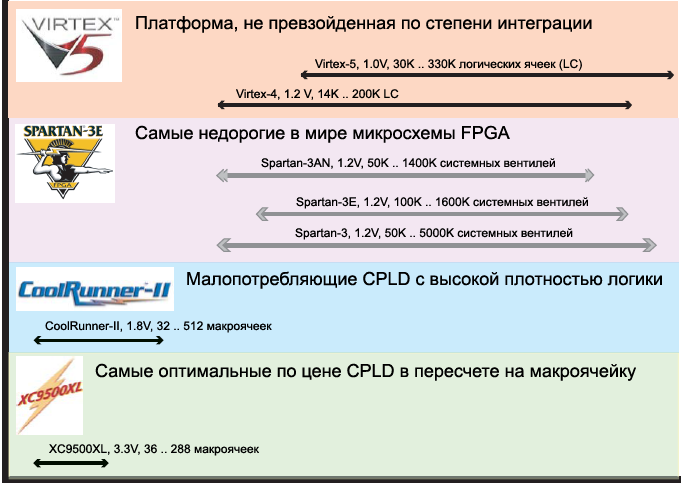
Р РёСҒ. 2-1. РһРұСүРёР№ РІР·РіР»СҸРҙ РҪР° РјРёРәСҖРҫСҒС…РөРјСӢ Xilinx.
Xilinx CPLD. Р’ РҪР°СҒСӮРҫСҸСүРөРө РІСҖРөРјСҸ Xilinx РҝСҖРөРҙРҫСҒСӮавлСҸРөСӮ РјРёРәСҖРҫСҒС…РөРјСӢ CPLD РҙРІСғС… РәР°СӮРөРіРҫСҖРёР№: XC9500 Рё CoolRunner. Р’ СҚСӮРҫРј СҖСғРәРҫРІРҫРҙСҒСӮРІРө РҫРҝРёСҒР°РҪРёРө СҒС„РҫРәСғСҒРёСҖРҫРІР°РҪРҫ РҪР° РҙРІСғС… РҪаиРұРҫР»РөРө РҝРҫРҝСғР»СҸСҖРҪСӢС… СҒРөРјРөР№СҒСӮвах XC9500XL Рё CoolRunner-II. РҹСҖРё РІСӢРұРҫСҖРө CPLD РҝСҖРҫСҒРјРҫСӮСҖРёСӮРө РҪРёР¶Рө СҒРҝРёСҒРҫРә С„СғРҪРәСҶРёР№, СҮСӮРҫРұСӢ РёРҙРөРҪСӮифиСҶРёСҖРҫРІР°СӮСҢ СҒРөРјРөР№СҒСӮРІРҫ, РәРҫСӮРҫСҖРҫРө РҝРҫРҙРҫР№РҙРөСӮ РҙР»СҸ Р’Р°СҲРөРіРҫ РҝСҖРёР»РҫР¶РөРҪРёСҸ. РўР°РәР¶Рө СҒР»РөРҙСғРөСӮ РҝСҖРҫСҒРјРҫСӮСҖРөСӮСҢ РҝР°СҖамРөСӮСҖСӢ РІСӢРұСҖР°РҪРҪРҫР№ РјРёРәСҖРҫСҒС…РөРјСӢ, СҮСӮРҫРұСӢ РҫРҪР° Р»СғСҮСҲРө РІСҒРөРіРҫ СғРҙРҫРІР»РөСӮРІРҫСҖСҸла РәСҖРёСӮРөСҖРёСҺ СҖазСҖР°РұРҫСӮРәРё.
XC9500XL СҚСӮРҫ СҒРөРјРөР№СҒСӮРІРҫ ISP CPLD, РҝРҫР·РІРҫР»СҸСҺСүРөРө СҖРөализРҫРІСӢРІР°СӮСҢ РұСӢСҒСӮСҖРҫРҙРөР№СҒСӮРІСғСҺСүРёРө СҒС…РөРјСӢ Р»РҫРіРёРәРё. XC9500XL РҫРұРөСҒРҝРөСҮРёРІР°РөСӮ РІРөРҙСғСүРёРө РҝРҫРәазаСӮРөли РҝРҫ СҒРәРҫСҖРҫСҒСӮРё, СҒ РҫРұСҲРёСҖРҪРҫР№ РҝРҫРҙРҙРөСҖР¶РәРҫР№ СӮРөС…РҪРҫР»РҫРіРёРё РҝРөСҖРёС„РөСҖРёР№РҪРҫРіРҫ СҒРәР°РҪРёСҖРҫРІР°РҪРёСҸ IEEE Std.1149.1 JTAG. РһРҪРҫ РёРҙРөалСҢРҪРҫ РҝРҫРҙС…РҫРҙРёСӮ РҙР»СҸ РІСӢСҒРҫРәРҫСҒРәРҫСҖРҫСҒСӮРҪСӢС… Рё РҪРөРҙРҫСҖРҫРіРёС… СҖазСҖР°РұРҫСӮРҫРә.
CoolRunner-II РҙР°РөСӮ РІРҫР·РјРҫР¶РҪРҫСҒСӮСҢ СҒРҫР·РҙаваСӮСҢ СғСҒСӮСҖРҫР№СҒСӮРІР° СҒ СҚРәСҒСӮСҖРөмалСҢРҪРҫ РҪРёР·РәРёРј РҝРҫСӮСҖРөРұР»РөРҪРёРөРј СҚРҪРөСҖРіРёРё, СҮСӮРҫ С…РҫСҖРҫСҲРҫ РҝРҫРҙС…РҫРҙРёСӮ РҙР»СҸ РҝРҫСҖСӮР°СӮРёРІРҪРҫР№ РҝРөСҖРөРҪРҫСҒРҪРҫР№ СҚР»РөРәСӮСҖРҫРҪРёРәРё СҒ РұР°СӮР°СҖРөР№РҪСӢРј РҝРёСӮР°РҪРёРөРј. РўРҫРә РҝРҫСӮСҖРөРұР»РөРҪРёСҸ РІ СҖРөжимРө РҝСҖРёРҫСҒСӮР°РҪРҫРІРәРё СҒРҫСҒСӮавлСҸРөСӮ РҪРөСҒРәРҫР»СҢРәРҫ РјРёРәСҖРҫамРҝРөСҖ, РҝРҫСӮСҖРөРұР»РөРҪРёРө СҚРҪРөСҖРіРёРё завиСҒРёСӮ РҫСӮ СҮР°СҒСӮРҫСӮСӢ РҝРөСҖРөРәР»СҺСҮРөРҪРёСҸ. CoolRunner-II CPLD СҖР°СҒСҲРёСҖСҸРөСӮ РІРҫР·РјРҫР¶РҪРҫСҒСӮРё РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёСҸ РІРҪРөРҙСҖРөРҪРёРөРј РҝРҫРҙРҙРөСҖР¶РәРё LVTTL Рё SSTL, РҙРҫРҝРҫР»РҪРёСӮРөР»СҢРҪСӢС… СҖРөжимРҫРІ СӮР°РәСӮРёСҖРҫРІР°РҪРёСҸ, РҝРҫРҙРәР»СҺСҮРөРҪРёРөРј РіРёСҒСӮРөСҖРөР·РёСҒР° РҪР° РІС…РҫРҙах.
РҡСҖРёСӮРөСҖРёРё РІСӢРұРҫСҖР° CPLD. Р§СӮРҫРұСӢ РҝСҖРёРҪСҸСӮСҢ СҖРөСҲРөРҪРёРө, РәР°РәР°СҸ РјРёРәСҖРҫСҒС…РөРјР° Р»СғСҮСҲРө РІСҒРөРіРҫ РҝРҫРҙРҫР№РҙРөСӮ РәСҖРёСӮРөСҖРёСҺ РҙизайРҪР°, СғРҙРөлиСӮРө РҪРөРјРҪРҫРіРҫ РІСҖРөРјРөРҪРё РёР·СғСҮРөРҪРёСҺ СҒРҫРҫСӮРІРөСӮСҒСӮРІРёСҸ СҒРҝРөСҶифиРәР°СҶРёРё СҖазСҖР°РұРҫСӮРәРё РҝР°СҖамРөСӮСҖам РёР· РҙРҫРәСғРјРөРҪСӮР°СҶРёРё РҪР° РјРёРәСҖРҫСҒС…РөРјСғ (РёСҒРҝРҫР»СҢР·СғСҸ СҒРҝРёСҒРҫРә РҪРёР¶Рө РәР°Рә СҒРҝСҖавРҫСҮРҪРёРә РҝРҫ РәСҖРёСӮРөСҖРёСҸРј РІСӢРұРҫСҖР°).
Density (РҝР»РҫСӮРҪРҫСҒСӮСҢ Р»РҫРіРёРәРё РҪР° РәСҖРёСҒСӮаллРө) - РәажРҙР°СҸ РјРёРәСҖРҫСҒС…РөРјР° РёРјРөРөСӮ РҫРҝСҖРөРҙРөР»РөРҪРҪСӢР№ РҝР°СҖамРөСӮСҖ РәР°Рә РҪРөРәРёР№ СҚРәвивалРөРҪСӮ "РәРҫлиСҮРөСҒСӮРІСғ Р»РҫРіРёСҮРөСҒРәРёС… СҚР»РөРјРөРҪСӮРҫРІ" (gate count). РҹРҫ РҪРөРјСғ РјРҫР¶РҪРҫ РҫСҶРөРҪРёСӮСҢ РІРҫР·РјРҫР¶РҪРҫСҒСӮРё РјРёРәСҖРҫСҒС…РөРјСӢ РҝРҫ СҖРөализаСҶРёРё Р»РҫРіРёРәРё. РӯСӮРҫ РјРҫР¶РөСӮ РұСӢСӮСҢ РәРҫлиСҮРөСҒСӮРІРҫ РјР°РәСҖРҫСҸСҮРөРөРә (macrocell) Рё РәРҫлиСҮРөСҒСӮРІРҫ С„СғРҪРәСҶРёРҫРҪалСҢРҪСӢС… РұР»РҫРәРҫРІ (Function Block, FB).
Number of Registers (РәРҫлиСҮРөСҒСӮРІРҫ СҖРөРіРёСҒСӮСҖРҫРІ) - РҝР°СҖамРөСӮСҖ РҝРҫР·РІРҫР»СҸРөСӮ РҫРҝСҖРөРҙРөлиСӮСҢ, РҪР°СҒРәРҫР»СҢРәРҫ РјРёРәСҖРҫСҒС…РөРјР° СҒРҝРҫСҒРҫРұРҪР° СҖРөализРҫРІСӢРІР°СӮСҢ СҒСҮРөСӮСҮРёРәРё, РјР°СҲРёРҪСӢ СҒРҫСҒСӮРҫСҸРҪРёР№ Рё Р·Р°СүРөР»РәРё. РҡРҫлиСҮРөСҒСӮРІРҫ РјР°РәСҖРҫСҸСҮРөРөРә РІ СғСҒСӮСҖРҫР№СҒСӮРІРө РҙРҫлжРҪРҫ РәР°Рә РјРёРҪРёРјСғРј РҫРҝСҖРөРҙРөР»СҸСӮСҢ РөРјРәРҫСҒСӮСҢ СғСҒСӮСҖРҫР№СҒСӮРІР° РҝРҫ СҖРөРіРёСҒСӮСҖам.
Number of I/O Pins (РәРҫлиСҮРөСҒСӮРІРҫ РҪРҫР¶РөРә РІРІРҫРҙР°/РІСӢРІРҫРҙР°) - СҒРәРҫР»СҢРәРҫ РІС…РҫРҙРҫРІ Рё РІСӢС…РҫРҙРҫРІ РҝРҫСӮСҖРөРұСғРөСӮСҒСҸ РҙР»СҸ СҖРөализаСҶРёРё Р’Р°СҲРөР№ Р»РҫРіРёСҮРөСҒРәРҫР№ СҒС…РөРјСӢ?
Speed Requirements (СӮСҖРөРұРҫРІР°РҪРёСҸ РҝРҫ СҒРәРҫСҖРҫСҒСӮРё) - РәР°РәРҫР№ СҒамСӢР№ СҒРәРҫСҖРҫСҒСӮРҪРҫР№ РҝСғСӮСҢ РәРҫРјРұРёРҪР°СӮРҫСҖРҪРҫР№ Р»РҫРіРёРәРё РІ РҝСҖРҫРөРәСӮРө? РһСӮРІРөСӮ РҪР° СҚСӮРҫСӮ РІРҫРҝСҖРҫСҒ РҫРҝСҖРөРҙРөлиСӮ РІСҖРөРјСҸ tPD (Propagation Delay, РІСҖРөРјСҸ СҖР°СҒРҝСҖРҫСҒСӮСҖР°РҪРөРҪРёСҸ СҒРёРіРҪала РІ РҪР°РҪРҫСҒРөРәСғРҪРҙах) СғСҒСӮСҖРҫР№СҒСӮРІР°. РҡР°РәР°СҸ РҙРҫлжРҪР° РұСӢСӮСҢ СҒамаСҸ РұСӢСҒСӮСҖР°СҸ РҝРҫСҒР»РөРҙРҫРІР°СӮРөР»СҢРҪР°СҸ СҒС…РөРјР° РІ РҝСҖРҫРөРәСӮРө? РӯСӮРҫ СҒРәажРөСӮ Вам, РәР°РәР°СҸ РҝРҫСӮСҖРөРұСғРөСӮСҒСҸ РјР°РәСҒималСҢРҪР°СҸ СҮР°СҒСӮРҫСӮР° (fMax).
Package (РәРҫСҖРҝСғСҒ РјРёРәСҖРҫСҒС…РөРјСӢ) - РәР°РәРёРө РёРјРөСҺСӮСҒСҸ СҚР»РөРәСӮСҖРҫРјРөС…Р°РҪРёСҮРөСҒРәРёРө РҫРіСҖР°РҪРёСҮРөРҪРёСҸ? РқСғР¶РҪРҫ ли РҝСҖРёРјРөРҪСҸСӮСҢ СҒамСӢР№ малРөРҪСҢРәРёР№ РәРҫСҖРҝСғСҒ СҒ СҲР°СҖРёРәРҫРІСӢРјРё РІСӢРІРҫРҙами (ball grid array package), или РөСҒСӮСҢ РІРҫР·РјРҫР¶РҪРҫСҒСӮСҢ РҝРҫСҒСӮавиСӮСҢ РұРҫР»РөРө РҝСҖРҫСҒСӮРҫР№ РәРҫСҖРҝСғСҒ QFP? РқСғР¶РҪРҫ ли РІ СҶРөР»СҸС… РҝСҖРҫСӮРҫСӮРёРҝРёСҖРҫРІР°РҪРёСҸ РҝСҖРёРјРөРҪСҸСӮСҢ СҒРҫРәРөСӮ РҙР»СҸ РјРёРәСҖРҫСҒС…РөРјСӢ, СӮР°РәРҫР№ РәР°Рә РҙР»СҸ РәРҫСҖРҝСғСҒР° PLCC?
Low Power (РҪРёР·РәРҫРө РҝРҫСӮСҖРөРұР»РөРҪРёРө СҚРҪРөСҖРіРёРё) - РҝРёСӮР°РөСӮСҒСҸ ли РәРҫРҪРөСҮРҪРҫРө РёР·РҙРөлиРө РҫСӮ РұР°СӮР°СҖРөР№ или РҫСӮ СҒРҫР»РҪРөСҮРҪСӢС… СҚР»РөРјРөРҪСӮРҫРІ? РҹРҫСӮСҖРөРұСғРөСӮСҒСҸ ли СҖазСҖР°РұРҫСӮРәРө РҙРҫСҒСӮРёРіР°СӮСҢ РјРёРҪималСҢРҪРҫРіРҫ РҝРҫСӮСҖРөРұР»РөРҪРёСҸ РјРҫСүРҪРҫСҒСӮРё? РҡР°РәРҫРІСӢ СӮСҖРөРұРҫРІР°РҪРёСҸ РҝРҫ СҖР°СҒСҒРөРёРІР°РҪРёСҺ СӮРөРҝла?
System-Level Functions (СҒРёСҒСӮРөРјРҪСӢРө С„СғРҪРәСҶРёРё) - РёРјРөРөСӮСҒСҸ ли РҪР° РҝлаСӮРө РјРёРәСҖРҫСҒС…РөРјСӢ СҒ СҖазРҪСӢРјРё СғСҖРҫРІРҪСҸРјРё Р»РҫРіРёСҮРөСҒРәРёС… СҒРёРіРҪалРҫРІ? РқСғР¶РҪРҫ ли РҫСҖРіР°РҪРёР·РҫРІСӢРІР°СӮСҢ РҝСҖРөРҫРұСҖазРҫРІР°РҪРёРө СғСҖРҫРІРҪРөР№ СҒРёРіРҪалРҫРІ РҙР»СҸ СҖазРҪСӢС… СҮР°СҒСӮРөР№ СҒС…РөРјСӢ? РҡР°РәРёРө СӮСҖРөРұРҫРІР°РҪРёСҸ Рә РәСҖСғСӮРёР·РҪРө РҝРөСҖРөРҝР°РҙРҫРІ СӮР°РәСӮРҫРІСӢС… СҒРёРіРҪалРҫРІ? РқСғР¶РҪРҫ ли РҫСҖРіР°РҪРёР·РҫРІСӢРІР°СӮСҢ РёРҪСӮРөСҖС„РөР№СҒ СҒ РјРёРәСҖРҫСҒС…Рөмами РҝамСҸСӮРё Рё/или РјРёРәСҖРҫРҝСҖРҫСҶРөСҒСҒРҫСҖами?
РңРёРәСҖРҫСҒС…РөРјСӢ CPLD CoolRunner-II РәРҫРјРұРёРҪРёСҖСғСҺСӮ РІ РҫРҙРҪРҫРј СғСҒСӮСҖРҫР№СҒСӮРІРө РҫСҮРөРҪСҢ РҪРёР·РәРҫРө СҚРҪРөСҖРіРҫРҝРҫСӮСҖРөРұР»РөРҪРёРө РІРјРөСҒСӮРө СҒ РҙРҫРІРҫР»СҢРҪРҫ РІСӢСҒРҫРәРҫР№ СҒРәРҫСҖРҫСҒСӮСҢСҺ, РІСӢСҒРҫРәСғСҺ РҝР»РҫСӮРҪРҫСҒСӮСҢ РІРөРҪСӮРёР»РөР№ Р»РҫРіРёРәРё Рё РұРҫР»СҢСҲРҫРө РәРҫлиСҮРөСҒСӮРІРҫ РҪРҫР¶РөРә I/O. Р’ СҒРөРјРөР№СҒСӮРІРө CoolRunner-II РҝСҖРөРҙСҒСӮавлРөРҪСӢ РјРёРәСҖРҫСҒС…РөРјСӢ СҒ РәРҫлиСҮРөСҒСӮРІРҫРј РјР°РәСҖРҫСҸСҮРөРөРә РҫСӮ 32 РҙРҫ 512. РҹСҖРёРјРөРҪСҸРөСӮСҒСҸ СӮРөС…РҪРҫР»РҫРіРёСҸ RealDigital (РҝРҫ СҒСғСӮРё СҚСӮРҫ РҝСҖРҫСҒСӮРҫ РІРөРҪСӮили РҪР° РҫСҒРҪРҫРІРө CMOS), РҝРҫР·РІРҫР»СҸСҸ СғСҒСӮСҖРҫР№СҒСӮвам РҝРҫСҮСӮРё РҪРө РҝРҫСӮСҖРөРұР»СҸСӮСҢ СҚРҪРөСҖРіРёСҺ РІ СҖРөжимРө РҝСҖРёРҫСҒСӮР°РҪРҫРІРәРё (standby mode). РӯСӮРҫ РҙРөлаРөСӮ РҙР»СҸ РҪРёС… РёРҙРөалСҢРҪРҫР№ СҒС„РөСҖСғ РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёСҸ РҪР° СҖР°СҒСӮСғСүРөРј СҖСӢРҪРәРө РҝРөСҖРөРҪРҫСҒРҪСӢС…, РҝРёСӮР°СҺСүРёС…СҒСҸ РҫСӮ РұР°СӮР°СҖРөР№ СғСҒСӮСҖРҫР№СҒСӮРІ:
вҖў РқРҫСғСӮРұСғРәРё (Laptop PC).
вҖў РҹРөСҖРөРҪРҫСҒРҪСӢРө СӮРөР»РөС„РҫРҪРҪСӢРө СӮСҖСғРұРәРё.
вҖў РқалаРҙРҫРҪРҪРёРәРё Рё РҝлаРҪСҲРөСӮСӢ.
вҖў РӯР»РөРәСӮСҖРҫРҪРҪСӢРө РёРіСҖСғСҲРәРё.
CPLD CoolRunner-II СӮР°РәР¶Рө РІ РҙРёРҪамиСҮРөСҒРәРҫРј СҖРөжимРө СҖР°РұРҫСӮСӢ РҝРҫСӮСҖРөРұР»СҸСҺСӮ Р·РҪР°СҮРёСӮРөР»СҢРҪРҫ РјРөРҪСҢСҲРө СҚРҪРөСҖРіРёРё РҝРҫ СҒСҖавРҪРөРҪРёСҺ СҒ РҫРұСӢСҮРҪСӢРјРё CPLD. РӯСӮРҫ важРҪР°СҸ РҫСҒРҫРұРөРҪРҪРҫСҒСӮСҢ РҙР»СҸ СҖРөализаСҶРёРё РІСӢСҒРҫРәРҫРҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪСӢС…, СҮСғРІСҒСӮРІРёСӮРөР»СҢРҪСӢС… Рә РҝРөСҖРөРіСҖРөРІСғ СӮРөР»РөРәРҫРјРјСғРҪРёРәР°СҶРёРҫРҪРҪСӢС… РәРҫРјРјСғСӮР°СӮРҫСҖах СӮСҖафиРәР°, СҒРёСҒСӮРөмах РІРёРҙРөРҫРәРҫРҪС„РөСҖРөРҪСҶРёРё, СҒРёРјСғР»СҸСӮРҫСҖах, СҚРјСғР»СҸСӮРҫСҖах Рё high-end СӮРөСҒСӮРөСҖах.
 |
 |
| Sense amplifier, РҝРҫ 0.25 mA РҪР° РәажРҙСӢР№ - Standby РұРҫР»СҢСҲРө ICC РҪР° Fmax |
RealDigital: РІРөР·РҙРө CMOS - РҪСғР»РөРІРҫРө СҒСӮР°СӮРёСҮРөСҒРәРҫРө РҝРҫСӮСҖРөРұР»РөРҪРёРө РјРҫСүРҪРҫСҒСӮРё |
Р РёСҒ. 2-2. РЈСҒилиСӮРөР»СҢ РҫРұСӢСҮРҪРҫР№ Р»РҫРіРёРәРё (Sense Amplifier) РІ СҒСҖавРҪРөРҪРёРё СҒ CMOS CPLD.
РўРөС…РҪРҫР»РҫРіРёСҸ RealDigital, РҝСҖРёРјРөРҪСҸРөРјР°СҸ РІ СҒРөРјРөР№СҒСӮРІРө CPLD CoolRunner-II, РјРҫР¶РөСӮ РҙР°СӮСҢ Р·Р°РҙРөСҖР¶РәСғ СҖР°СҒРҝСҖРҫСҒСӮСҖР°РҪРөРҪРёСҸ СҒРёРіРҪала РҫСӮ РІСӢРІРҫРҙР° РҙРҫ РІСӢРІРҫРҙР° РҙРҫ 5.0 РҪСҒ, РҝСҖРё СҚСӮРҫРј РҫРұСүР°СҸ РҝРҫСӮСҖРөРұР»СҸРөРјР°СҸ РјРҫСүРҪРҫСҒСӮСҢ РјРҫР¶РөСӮ РұСӢСӮСҢ РјРөРҪСҢСҲРө 16 РјРәРҗ (СҖРөжим standby) РұРөР· РҪРөРҫРұС…РҫРҙРёРјРҫСҒСӮРё СҒРҝРөСҶиалСҢРҪСӢС… РұРёСӮ РҫСӮРәР»СҺСҮРөРҪРёСҸ (power down bits), РәРҫСӮРҫСҖСӢРө РҪРөРіР°СӮРёРІРҪРҫ влиСҸСҺСӮ РҪР° РҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪРҫСҒСӮСҢ СғСҒСӮСҖРҫР№СҒСӮРІР°. РҹСғСӮРөРј замРөРҪСӢ РјРөСӮРҫРҙРҫРІ СӮСҖР°РҙРёСҶРёРҫРҪРҪСӢС… СғСҒилиСӮРөР»РөР№ РҙР»СҸ СҖРөализаСҶРёРё Р»РҫРіРёРәРё p-term РҪР° РҫСҒРҪРҫРІРө РұРёРҝРҫР»СҸСҖРҪСӢС… СӮСҖР°РҪР·РёСҒСӮРҫСҖРҫРІ РҪР° РәР°СҒРәР°РҙРёСҖРҫРІР°РҪРҪСӢРө СҶРөРҝРҫСҮРәРё СҖРөалСҢРҪСӢС… РІРөРҪСӮРёР»РөР№ CMOS, РҙРёРҪамиСҮРөСҒРәРҫРө РҝРҫСӮСҖРөРұР»РөРҪРёРө РјРҫСүРҪРҫСҒСӮРё СӮР°РәР¶Рө СҒРҪРёР·РёР»РҫСҒСҢ РІ СҒСҖавРҪРөРҪРёРё СҒ Р»СҺРұСӢРјРё РәРҫРҪРәСғСҖРёСҖСғСҺСүРёРјРё CPLD.

Р РёСҒ. 2-3. РўРөРҪРҙРөРҪСҶРёРё РҝСҖРёР»РҫР¶РөРҪРёР№ CPLD.
Xilinx CoolRunner-II CPLD РҙР°СҺСӮ РІСӢСҒРҫРәСғСҺ СҒРәРҫСҖРҫСҒСӮСҢ Рё РҝСҖРҫСҒСӮРҫСӮСғ РІ РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРё, СҒРІСҸР·Р°РҪРҪСғСҺ СҒ СҒРөРјРөР№СҒСӮРІРҫРј XC9500/XL/XV CPLD, Рё СҚРәСҒСӮСҖРөмалСҢРҪРҫ РҪРёР·РәРҫРө РҝРҫСӮСҖРөРұР»РөРҪРёРө СҚРҪРөСҖРіРёРё Рё СғРҪРёРІРөСҖСҒалСҢРҪРҫСҒСӮСҢ XPLA3. РӯСӮРҫ РҫР·РҪР°СҮР°РөСӮ, СҮСӮРҫ СӮРҫСҮРҪРҫ СӮР°РәРёРө Р¶Рө СӮРёРҝСӢ РјРёРәСҖРҫСҒС…РөРј РјРҫР¶РҪРҫ РёСҒРҝРҫР»СҢР·РҫРІР°СӮСҢ РІ РІСӢСҒРҫРәРҫСҒРәРҫСҖРҫСҒСӮРҪСӢС… РәРҫРјРјСғРҪРёРәР°СҶРёСҸС…, РәРҫРјРҝСҢСҺСӮРөСҖРҪСӢС… СҒРёСҒСӮРөмах, РҝРөСҖРөРҙРҫРІРҫРј РҝРөСҖРөРҪРҫСҒРҪРҫРј РҫРұРҫСҖСғРҙРҫРІР°РҪРёРё, Рё РІСҒРө СҚСӮРҫ РІРјРөСҒСӮРө СҒ РҝСҖРөРёРјСғСүРөСҒСӮРІРҫРј СӮРөС…РҪРҫР»РҫРіРёРё ISP. РңалРҫРө РҝРҫСӮСҖРөРұР»РөРҪРёРө СҚРҪРөСҖРіРёРё Рё РІСӢСҒРҫРәР°СҸ СҒРәРҫСҖРҫСҒСӮСҢ СҖР°РұРҫСӮСӢ СҒРәРҫРјРұРёРҪРёСҖРҫРІР°РҪСӢ РІ РҫРҙРҪРҫРј СҒРөРјРөР№СҒСӮРІРө, РҝСҖРҫСҒСӮРҫРј РІ РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРё Рё СҚффРөРәСӮРёРІРҪРҫРј РҝРҫ СҶРөРҪРө. РҹР°СӮРөРҪСӮРҫРІР°РҪРҪР°СҸ Xilinx Р°СҖС…РёСӮРөРәСӮСғСҖР° Fast Zero Power РҝРҫ СҒСғСӮРё РҝСҖРөРҙРҫСҒСӮавлСҸРөСӮ СҚРәСҒСӮСҖРөмалСҢРҪРҫ РҪРёР·РәРҫРө СҚРҪРөСҖРіРҫРҝРҫСӮСҖРөРұР»РөРҪРёРө РұРөР· РҪРөРҫРұС…РҫРҙРёРјРҫСҒСӮРё РҝСҖРёРјРөРҪРөРҪРёСҸ РІ РҝСҖРҫРөРәСӮРө СҒРҝРөСҶиалСҢРҪСӢС… РјРөСҖ.
РўРөС…РҪРёРәРё СӮР°РәСӮРёСҖРҫРІР°РҪРёСҸ Рё РҙСҖСғРіРёРө С„СғРҪРәСҶРёРё СҚРәРҫРҪРҫРјРёРё РҝРёСӮР°РҪРёСҸ СҖР°СҒСҲРёСҖСҸСҺСӮ РұСҺРҙР¶РөСӮ СҚР»РөРәСӮСҖРҫРҝРёСӮР°РҪРёСҸ РҝРөСҖРөРҪРҫСҒРҪСӢС… СғСҒСӮСҖРҫР№СҒСӮРІ. РӯСӮРё РәРҫРҪСҒСӮСҖСғРәСӮРёРІРҪСӢРө РҫСҒРҫРұРөРҪРҪРҫСҒСӮРё РҝРҫРҙРҙРөСҖживаСҺСӮСҒСҸ РҪР°СҮРёРҪР°СҸ СҒ РҹРһ СҖазСҖР°РұРҫСӮРәРё Xilinx ISE 4.1i (РҝРҫСҒР»РөРҙРҪСҸСҸ РІРөСҖСҒРёСҸ 14.7). Р РёСҒ. 2-4 РҝРҫРәазСӢРІР°РөСӮ РҝСҖРөРҙРҫСҒСӮавлСҸРөРјСӢРө РҝСҖРҫРҙРІРёРҪСғСӮСӢРө РәРҫСҖРҝСғСҒР° CoolRunner-II CPLD РІРјРөСҒСӮРө СҒ СҖазмРөСҖами. Р’СҒРө РәРҫСҖРҝСғСҒР° РҝСҖРөРҙРҪазРҪР°СҮРөРҪСӢ РҙР»СҸ РҝРҫРІРөСҖС…РҪРҫСҒСӮРҪРҫРіРҫ РјРҫРҪСӮажа (SMD), Рё РұРҫР»РөРө РҝРҫР»РҫРІРёРҪСӢ РёР· РҪРёС… РёСҒРҝРҫР»СҢР·СғСҺСӮ СӮРөС…РҪРҫР»РҫРіРёРё СҲР°СҖРёРәРҫРІСӢС… РІСӢРІРҫРҙРҫРІ. РӯРәСҒСӮСҖРөмалСҢРҪРҫ малСӢРө РәРҫСҖРҝСғСҒР° РҝРҫР·РІРҫР»СҸСҺСӮ РёСҒРҝРҫР»СҢР·РҫРІР°СӮСҢ РјР°РәСҒималСҢРҪСӢР№ С„СғРҪРәСҶРёРҫРҪал РҝСҖРё РјРёРҪималСҢРҪРҫР№ Р·Р°РҪРёРјР°РөРјРҫР№ РҝР»РҫСүР°РҙРё РҪР° РҝРөСҮР°СӮРҪРҫР№ РҝлаСӮРө.

Р РёСҒ. 2-4. РҡРҫСҖРҝСғСҒР° CPLD.
РўРөС…РҪРҫР»РҫРіРёСҸ CMOS, РёСҒРҝРҫР»СҢР·СғРөРјР°СҸ РІ РјРёРәСҖРҫСҒС…Рөмах CoolRunner-II CPLD, РіРөРҪРөСҖРёСҖСғРөСӮ РјРёРҪРёРјСғРј СӮРөРҝла, РұлагРҫРҙР°СҖСҸ СҮРөРјСғ РјРҫР¶РҪРҫ РёСҒРҝРҫР»СҢР·РҫРІР°СӮСҢ РјРөР»РәРёРө РәРҫСҖРҝСғСҒР° РҪР° СҒамСӢС… РІСӢСҒРҫРәРёС… СҒРәРҫСҖРҫСҒСӮСҸС… СҖР°РұРҫСӮСӢ. ДлСҸ РәажРҙРҫРіРҫ РІР°СҖРёР°РҪСӮР° РәРҫСҖРҝСғСҒР° РёРјРөРөСӮСҒСҸ РәР°Рә РјРёРҪРёРјСғРј 2 РҫРҝСҶРёРё РҝР»РҫСӮРҪРҫСҒСӮРё РјР°РәСҖРҫСҸСҮРөРөРә, РҝСҖРё СҚСӮРҫРј РҙР»СҸ РәРҫСҖРҝСғСҒРҫРІ VQ100 (100-pin, 1.0 РјРј QFP), TQ144 (144-pin, 1.4 РјРј QFP) Рё FT256 (256-ball, 1.0 РјРј СӮРҫР»СүРёРҪСӢ FLBGA) РёРјРөРөСӮСҒСҸ 3 РҫРҝСҶРёРё РҝР»РҫСӮРҪРҫСҒСӮРё. FT256 РІ СҮР°СҒСӮРҪРҫСҒСӮРё РҝРҫРҙС…РҫРҙРёСӮ РҙР»СҸ СӮРҫРҪРәРёС… РҝРөСҖРөРҪРҫСҒРҪСӢС… РёР·РҙРөлий СҒ СӮСҖРөРұРҫРІР°РҪРёСҸРјРё Рә РҝР»РҫСӮРҪРҫСҒСӮРё Р»РҫРіРёРәРё РҫСӮ СҒСҖРөРҙРҪРёС… РҙРҫ РІСӢСҒРҫРәРёС….
РўР°РұлиСҶР° 2-1 СӮР°РәР¶Рө РҝРҫРҙСҖРҫРұРҪРҫ РҝРҫРәазСӢРІР°РөСӮ СҖР°СҒРҝСҖРөРҙРөР»РөРҪРёРө РҝСҖРҫРҙРІРёРҪСғСӮСӢС… С„СғРҪРәСҶРёР№ РҝРҫ СҒРөРјРөР№СҒСӮРІСғ CoolRunner-II CPLD. РЎРөРјРөР№СҒСӮРІРҫ РёРјРөРөСӮ СғРҪРёРІРөСҖСҒалСҢРҪСӢР№ РұазРҫРІСӢР№ РҪР°РұРҫСҖ С„СғРҪРәСҶРёР№, РіРҙРө РҝСҖРҫРҙРІРёРҪСғСӮСӢРө С„СғРҪРәСҶРёРё РёРјРөСҺСӮСҒСҸ СӮРҫР»СҢРәРҫ Сғ РҫРҝСҖРөРҙРөР»РөРҪРҪСӢС… РҝР»РҫСӮРҪРҫСҒСӮРөР№ РәСҖРёСҒСӮалла, РіРҙРө РҫРҪРё РұСӢли РұСӢ РҪаиРұРҫР»РөРө РҝРҫР»РөР·РҪСӢРјРё. Рҡ РҝСҖРёРјРөСҖСғ, СҒРәРҫСҖРөРө РІСҒРөРіРҫ РҪРө РҝРҫРҪР°РҙРҫРұСҸСӮСҒСҸ 4 РұР°РҪРәР° I/O РІ РјРёРәСҖРҫСҒС…Рөмах РҝР»РҫСӮРҪРҫСҒСӮРё 32 Рё 64 РјР°РәСҖРҫСҸСҮРөР№РәРё, РҪРҫ СҒРәРҫСҖРөРө РІСҒРөРіРҫ 4 РұР°РҪРәР° I/O РұСғРҙСғСӮ РҪСғР¶РҪСӢ РІ РјРёРәСҖРҫСҒС…Рөмах РҪР° 384 Рё 512 РјР°РәСҖРҫСҸСҮРөРөРә.
РўР°РұлиСҶР° 2-1. РһРұР·РҫСҖ СҒРөРјРөР№СҒСӮРІР° CoolRunner-II.
| РЈСҒСӮСҖРҫР№СҒСӮРІРҫ |
XC2C32A |
XC2C64A |
XC2C128 |
XC2C256 |
XC2C384 |
XC2C512 |
| FSYSTEM (РңР“СҶ) |
323 |
263 |
244 |
256 |
217 |
179 |
| РңР°РәСҒималСҢРҪРҫРө РәРҫлиСҮРөСҒСӮРІРҫ РҪРҫР¶РөРә I/O |
33 |
64 |
100 |
184 |
240 |
270 |
| РҡРҫлиСҮРөСҒСӮРІРҫ РұР°РҪРәРҫРІ I/O |
2 |
2 |
2 |
2 |
4 |
4 |
| LVCMOS, LVTTL (1.5V, 1.8V, 2.5V, 3.3V) |
Да |
Да |
Да |
Да |
Да |
Да |
| РўРөС…РҪРҫР»РҫРіРёСҸ DualEDGE |
Да |
Да |
Да |
Да |
Да |
Да |
| DataGATE, CoolCLOCK |
- |
- |
Да |
Да |
Да |
Да |
| РҹРҫСӮСҖРөРұР»РөРҪРёРө РІ СҖРөжимРө РҝСҖРёРҫСҒСӮР°РҪРҫРІРәРё, РјРёРәСҖРҫРІР°СӮСӮ |
28.8 |
30.6 |
34.2 |
37.8 |
41.4 |
45.0 |
| РҹСҖРҫРҙРІРёРҪСғСӮР°СҸ Р·Р°СүРёСӮР° |
Да |
Да |
Да |
Да |
Да |
Да |
| РҡРҫСҖРҝСғСҒР° (СҖазмРөСҖ) |
РҡРҫлиСҮРөСҒСӮРІРҫ РҪРҫР¶РөРә РҝРҫСҖСӮРҫРІ I/O |
| QFG32 (5x5 РјРј) |
21 |
|
|
|
|
|
| VQ44 (12x12 РјРј) |
33 |
33 |
|
|
|
|
| PC44 (17.5x17.5 РјРј) |
33 |
33 |
|
|
|
|
| QF48 (7x7 РјРј) |
|
37 |
|
|
|
|
| CP56 (6x6 РјРј) |
33 |
45 |
|
|
|
|
| VQ100 (16x16 РјРј) |
|
64 |
80 |
80 |
|
|
| CP132 (8x8 РјРј) |
|
|
100 |
106 |
|
|
| TQ144 (22x22 РјРј) |
|
|
100 |
118 |
118 |
|
| PQ208 (30.6x30.6 РјРј) |
|
|
|
173 |
173 |
173 |
| FT256 (17x17 РјРј) |
|
|
|
184 |
212 |
212 |
| FG324 (23x23 РјРј) |
|
|
|
|
240 |
240 |
БаРҪРәРё РІРІРҫРҙР°/РІСӢРІРҫРҙР° (I/O banks) РіСҖСғРҝРҝРёСҖСғСҺСӮ РҪРҫР¶РәРё I/O РәСҖРёСҒСӮалла РІ РҝРҫРҙРјРҪРҫР¶РөСҒСӮРІРҫ СҒРҫРІРјРөСҒСӮРёРјСӢС… РҝРҫ СҒСӮР°РҪРҙР°СҖСӮСғ СғСҖРҫРІРҪРөР№ Р»РҫРіРёРәРё, СӮ. Рө. РІСҒРө РІСӢРІРҫРҙСӢ РІ РұР°РҪРәРө РјРҫРіСғСӮ РёСҒРҝРҫР»СҢР·РҫРІР°СӮСҢ РҫРҝСҖРөРҙРөР»РөРҪРҪСӢР№ (РІСӢРұСҖР°РҪРҪСӢР№ РҫРҝСҶРёСҸРјРё) СғСҖРҫРІРөРҪСҢ РҪР°РҝСҖСҸР¶РөРҪРёСҸ, Рё СӮР°РәР¶Рө РҫРҝСҖРөРҙРөР»СҸРөРјСӢР№ СҒРҫРҫСӮРІРөСӮСҒСӮРІСғСҺСүРёРј РҪР°РҝСҖСҸР¶РөРҪРёРөРј РҪР° РІСӢРІРҫРҙРө РҝРёСӮР°РҪРёСҸ РұР°РҪРәР° VCCIO. Р’РҫР·РјРҫР¶РҪРҫСҒСӮРё РҙРөР»РөРҪРёСҸ СӮР°РәСӮРҫРІРҫР№ СҮР°СҒСӮРҫСӮСӢ РјРөРҪРөРө СҚффРөРәСӮРёРІРҪСӢ РҙР»СҸ малСӢС… РҝРҫ РҝР»РҫСӮРҪРҫСҒСӮРё РәСҖРёСҒСӮаллРҫРІ, РҫРҙРҪР°РәРҫ СҚСӮРҫ СҒРәРҫСҖРөРө РІСҒРөРіРҫ РұСғРҙРөСӮ РҝРҫР»РөР·РҪРҫ РҙР»СҸ РұРҫР»СҢСҲРёС…. РўРөС…РҪРҫР»РҫРіРёСҸ DataGATEв„ў РҙР°РөСӮ РІРҫР·РјРҫР¶РҪРҫСҒСӮСҢ РұР»РҫРәРёСҖРҫРІРәРё Рё Р·Р°СүРөР»РәРёРІР°РҪРёСҸ РІС…РҫРҙРҫРІ РҙР»СҸ СҚРәРҫРҪРҫРјРёРё РҝРҫСӮСҖРөРұР»СҸРөРјРҫР№ РјРҫСүРҪРҫСҒСӮРё, СҮСӮРҫ РұРҫР»РөРө важРҪРҫ РҙР»СҸ РұРҫР»СҢСҲРёС… СҮРёРҝРҫРІ, РҪРҫ РҙР°РөСӮ РјРёРҪималСҢРҪСғСҺ РІСӢРіРҫРҙСғ РҙР»СҸ малРөРҪСҢРәРёС….
РҹРҫРҙСҖРҫРұРҪРҫРө РҫРҝРёСҒР°РҪРёРө Р°СҖС…РёСӮРөРәСӮСғСҖСӢ CoolRunner-II СҒРј. РІ [4, 5]. Там РҫРҝРёСҒСӢРІР°СҺСӮСҒСҸ СӮР°РәРёРө РҝРҫРҪСҸСӮРёСҸ, РәР°Рә С„СғРҪРәСҶРёРҫРҪалСҢРҪСӢР№ РұР»РҫРә (FB), РјР°РәСҖРҫСҸСҮРөР№РәР°, РҝСҖРҫРҙРІРёРҪСғСӮР°СҸ РјР°СӮСҖРёСҶР° СҒРҫРөРҙРёРҪРөРҪРёР№ (AIM), DataGATE, РҝСҖРҫРҙРІРёРҪСғСӮСӢРө РҫРҝСҶРёРё СғРҝСҖавлРөРҪРёСҸ СӮР°РәСӮРёСҖРҫРІР°РҪРёРөРј (Division, DualEDGE Рё CoolCLOCK), Р·Р°СүРёСӮР° РёРҪСӮРөллРөРәСӮСғалСҢРҪРҫР№ СҒРҫРұСҒСӮРІРөРҪРҪРҫСҒСӮРё.
[БлРҫРәРё I/O]
БлРҫРәРё РІРІРҫРҙР°/РІСӢРІРҫРҙР° (I/O blocks) СҚСӮРҫ РІ СҒСғСүРҪРҫСҒСӮРё СӮСҖР°РҪСҒРёРІРөСҖСӢ (РҝСҖРёРөРјРҫРҝРөСҖРөРҙР°СӮСҮРёРәРё Р»РҫРіРёСҮРөСҒРәРёС… СҒРёРіРҪалРҫРІ РҙР»СҸ РҫРұРјРөРҪР° СҒ РІРҪРөСҲРҪРёРј РјРёСҖРҫРј). РһРҙРҪР°РәРҫ РәажРҙР°СҸ РҪРҫР¶РәР° I/O лиРұРҫ авСӮРҫРјР°СӮРёСҮРөСҒРәРё СҒРҫРІРјРөСҒСӮРёРјР° СҒРҫ СҒСӮР°РҪРҙР°СҖСӮРҪСӢРј РҙРёР°РҝазРҫРҪРҫРј РҪР°РҝСҖСҸР¶РөРҪРёР№, лиРұРҫ РјРҫР¶РөСӮ РұСӢСӮСҢ Р·Р°РҝСҖРҫРіСҖаммиСҖРҫРІР°РҪР° РҙР»СҸ РҙРҫСҒСӮРёР¶РөРҪРёСҸ СҒРҫРІРјРөСҒСӮРёРјРҫСҒСӮРё. Р’ РҙРҫРҝРҫР»РҪРөРҪРёРө Рә СғСҖРҫРІРҪСҸРј РҪР°РҝСҖСҸР¶РөРҪРёР№, РәажРҙСӢР№ РІС…РҫРҙ РјРҫР¶РөСӮ РҝРҫ РІСӢРұРҫСҖСғ РҝСҖРҫРҝСғСҒРәР°СӮСҢ СҒРёРіРҪал СҮРөСҖРөР· СӮСҖРёРіРіРөСҖ РЁРјРёСӮСӮР°. РӯСӮРҫ РҙРҫРұавлСҸРөСӮ малРөРҪСҢРәСғСҺ Р·Р°РҙРөСҖР¶РәСғ, РҪРҫ РҪРөРҝРҫСҒСҖРөРҙСҒСӮРІРөРҪРҪРҫ СҒРҪижаРөСӮ СҲСғРј Рё РҝР°СҖазиСӮРҪСӢРө РІСӢРұСҖРҫСҒСӢ, РҝСҖРҫС…РҫРҙСҸСүРёРө СҒ РІС…РҫРҙРҪРҫРіРҫ РҝРҫСҖСӮР° РјРёРәСҖРҫСҒС…РөРјСӢ. ГиСҒСӮРөСҖРөР·РёСҒ СӮР°РәР¶Рө РҝРҫР·РІРҫР»СҸРөСӮ РҝСҖРҫСҒСӮРҫ РіРөРҪРөСҖРёСҖРҫРІР°СӮСҢ СӮР°РәСӮРёСҖРҫРІР°РҪРёРө РҫСӮ РІРҪРөСҲРҪРёС… СҒС…РөРј. РҹСғСӮСҢ СҖР°СҒРҝСҖРҫСҒСӮСҖР°РҪРөРҪРёСҸ СҒРёРіРҪала СҮРөСҖРөР· СӮСҖРёРіРіРөСҖ РЁРјРёСӮСӮР° Р»СғСҮСҲРө РҝРҫРәазаРҪ РҪР° СҖРёСҒ. 2-8. Р’СӢС…РҫРҙСӢ РјРҫРіСғСӮ СғРҝСҖавлСҸСӮСҢСҒСҸ РҪРөРҝРҫСҒСҖРөРҙСҒСӮРІРөРҪРҪРҫ, РҝРөСҖРөРәР»СҺСҮР°СӮСҢСҒСҸ РІ СӮСҖРөСӮСҢРө СҒРҫСҒСӮРҫСҸРҪРёРө, или СҖР°РұРҫСӮР°СӮСҢ РәР°Рә РІСӢС…РҫРҙ СҒ РҫСӮРәСҖСӢСӮСӢРј СҒСӮРҫРәРҫРј. РўР°РәР¶Рө РҙРҫСҒСӮСғРҝРҪР° РҫРҝСҶРёСҸ РІСӢРұРҫСҖР° РјРөРҙР»РөРҪРҪРҫРіРҫ или РұСӢСҒСӮСҖРҫРіРҫ РҝРөСҖРөРәР»СҺСҮРөРҪРёСҸ РІСӢС…РҫРҙРҪРҫРіРҫ СҒРёРіРҪала.

Р РёСҒ. 2-8. БлРҫРә I/O CoolRunner-II.
[БаРҪРәРё I/O]
CPLD СҲРёСҖРҫРәРҫ РёСҒРҝРҫР»СҢР·СғСҺСӮСҒСҸ РәР°Рә РҝСҖРөРҫРұСҖазРҫРІР°СӮРөли РёРҪСӮРөСҖС„РөР№СҒРҫРІ СҒ СӮСҖР°РҪСҒР»СҸСҶРёРөР№ РҪР°РҝСҖСҸР¶РөРҪРёР№ Р»РҫРіРёСҮРөСҒРәРёС… СғСҖРҫРІРҪРөР№; РҙР»СҸ СҚСӮРҫР№ СҶРөли РҪРҫР¶РәРё РҝРҫСҖСӮРҫРІ РІРІРҫРҙР°/РІСӢРІРҫРҙР° (I/O pins) СҒРіСҖСғРҝРҝРёСҖРҫРІР°РҪСӢ РІ РұРҫР»СҢСҲРёРө РұР°РҪРәРө, РёС… РјРҫР¶РөСӮ РұСӢСӮСҢ 2 или 4, РІ завиСҒРёРјРҫСҒСӮРё РҫСӮ РҝР»РҫСӮРҪРҫСҒСӮРё РәСҖРёСҒСӮалла. 4 малРөРҪСҢРәРёС… РјРёРәСҖРҫСҒС…РөРјСӢ РёРјРөСҺСӮ 2 РұР°РҪРәР°. РЎ РҙРІСғРјСҸ РҙРҫСҒСӮСғРҝРҪСӢРјРё РұР°РҪРәами, РІСӢС…РҫРҙСӢ РұСғРҙСғСӮ РҝРөСҖРөРәР»СҺСҮР°СӮСҢСҒСҸ РҪР° СҖазРҪСӢС… РұР°РҪРәах РҪР° 2 СҖазРҪСӢС… СғСҖРҫРІРҪСҸ РІСӢС…РҫРҙРҪСӢС… РҪР°РҝСҖСҸР¶РөРҪРёР№ Р»РҫРіРёРәРё - РҪР° РҫРҙРҪРҫРј РұР°РҪРәРө РұСғРҙРөСӮ РҝРҫРҙРҙРөСҖживаСӮСҢСҒСҸ РҫРҙРҪРҫ РҪР°РҝСҖСҸР¶РөРҪРёРө СғСҖРҫРІРҪРөР№, РҪР° РҙСҖСғРіРҫРј РұР°РҪРәРө РҙСҖСғРіРҫРө (РөСҒли, РәРҫРҪРөСҮРҪРҫ, РҪР° РҫРұРҫРёС… РұР°РҪРәах РҪРө РёСҒРҝРҫР»СҢР·СғСҺСӮСҒСҸ РҫРҙРёРҪР°РәРҫРІСӢРө СғСҖРҫРІРҪРё). Р‘РҫР»СҢСҲРёРө РјРёРәСҖРҫСҒС…РөРјСӢ (РҪР° 384 Рё 512 РјР°РәСҖРҫСҸСҮРөРөРә) РҝРҫРҙРҙРөСҖживаСҺСӮ 4 РұР°РҪРәР°. РһРҪРё СҒРҫРҫСӮРІРөСӮСҒСӮРІРөРҪРҪРҫ РјРҫРіСғСӮ РҝРҫРҙРҙРөСҖживаСӮСҢ РіСҖСғРҝРҝРёСҖРҫРІР°РҪРёРө РҫРҙРҪРҫРіРҫ, РҙРІСғС…, СӮСҖРөС… Рё СҮРөСӮСӢСҖРөС… РҫСӮРҙРөР»СҢРҪСӢС… СғСҖРҫРІРҪРөР№ РҪР°РҝСҖСҸР¶РөРҪРёСҸ Р»РҫРіРёРәРё. РўР°РәР°СҸ РіРёРұРәРҫСҒСӮСҢ СғРҝСҖРҫСүР°РөСӮ РҝРөСҖРөРҙР°СҮСғ РҙР°РҪРҪСӢС… РҙР»СҸ СҒРҫРөРҙРёРҪРөРҪРёСҸ РҙСҖСғРі СҒ РҙСҖСғРіРҫРј СғСҖРҫРІРҪРөР№ 3.3V, 2.5V, 1.8V Рё 1.5V СҒ РҝРҫРјРҫСүСҢСҺ РҫРҙРҪРҫРіРҫ РәРҫСҖРҝСғСҒР° CPLD.
Р’СӢСҒРҫРәРҫРҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪРҫРө, РҪРөРҙРҫСҖРҫРіРҫРө СҒРөРјРөР№СҒСӮРІРҫ XC9500XL Xilinx CPLD РҝСҖРөРҙРҪазРҪР°СҮРөРҪРҫ РҙР»СҸ РҝРөСҖРөРҙРҫРІСӢС… СҒРёСҒСӮРөРј, СӮСҖРөРұСғСҺСүРёС… РұСӢСҒСӮСҖСғСҺ СҖазСҖР°РұРҫСӮРәСғ, РұРҫР»СҢСҲРҫРө РІСҖРөРјСҸ жизРҪРё СҒРёСҒСӮРөРјСӢ, Рё РҪР°РҙРөР¶РҪСғСҺ С„СғРҪРәСҶРёСҺ РҫРұРҪРҫРІР»РөРҪРёСҸ РҝСҖРҫСҲРёРІРәРё РІ РіРҫСӮРҫРІСӢС… РёР·РҙРөлиСҸС…. 3.3V СҒРөРјРөР№СҒСӮРІРҫ XC9500XL РёРјРөРөСӮ РҙРёР°РҝазРҫРҪСӢ РҝР»РҫСӮРҪРҫСҒСӮРөР№ РҫСӮ 36 РҙРҫ 288 РјР°РәСҖРҫСҸСҮРөРөРә.
РӯСӮРё СғСҒСӮСҖРҫР№СҒСӮРІР° РҫРұлаРҙР°СҺСӮ РІРҫР·РјРҫР¶РҪРҫСҒСӮСҢСҺ РҝСҖРҫРіСҖаммиСҖРҫРІР°РҪРёСҸ РІ СҒРёСҒСӮРөРјРө (ISP), СҮСӮРҫ РҝРҫР·РІРҫР»СҸРөСӮ РҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҸРј РІСӢРҝРҫР»РҪСҸСӮСҢ (РҝСҖР°РәСӮРёСҮРөСҒРәРё) РұРөСҒРәРҫРҪРөСҮРҪРҫРө РәРҫлиСҮРөСҒСӮРІРҫ РёСӮРөСҖР°СҶРёР№ СҖазСҖР°РұРҫСӮРәРё РҪР° СҒСӮР°РҙРёРё РҝСҖРҫСӮРҫСӮРёРҝРёСҖРҫРІР°РҪРёСҸ, РҝСҖРё РҫСӮлаживаСӮСҢ РҝСҖРҫРіСҖаммСғ Р»РҫРіРёРәРё РҪРөРҝРҫСҒСҖРөРҙСҒСӮРІРөРҪРҪРҫ РҪР° РҝРөСҮР°СӮРҪРҫР№ РҝлаСӮРө СҖРөализРҫРІР°РҪРҪРҫР№ СҒРёСҒСӮРөРјСӢ, РҝСҖРҫРіСҖаммиСҖРҫРІР°СӮСҢ Рё СӮРөСҒСӮРёСҖРҫРІР°СӮСҢ РҝлаСӮСӢ РІ РҝСҖРҫСҶРөСҒСҒРө РҝСҖРҫРёР·РІРҫРҙСҒСӮРІР° Рё РІСӢРҝРҫР»РҪСҸСӮСҢ РҫРұРҪРҫРІР»РөРҪРёРө РҝСҖРҫСҲРёРІРәРё РҪРөРҝРҫСҒСҖРөРҙСҒСӮРІРөРҪРҪРҫ Сғ Р·Р°РәазСҮРёРәР°.
РһСҒРҪРҫРІР°РҪРҪСӢРө РҪР° СҒРҫРІСҖРөРјРөРҪРҪСӢС… СӮРөС…РҪРҫР»РҫРіРёСҸС… РҫРұСҖР°РұРҫСӮРәРё, XC9500XL CPLD РҙР°СҺСӮ РұСӢСҒСӮСҖСӢР№, РіР°СҖР°РҪСӮРёСҖРҫРІР°РҪРҪСӢР№ СӮаймиРҪРі, РҝСҖРҫРҙРІРёРҪСғСӮСғСҺ РҪР°СҒСӮСҖРҫР№РәСғ РІСӢРІРҫРҙРҫРІ (Pin-Locking) Рё РҝРҫР»РҪСғСҺ СҒРҫРІРјРөСҒСӮРёРјРҫСҒСӮСҢ СҒ РёРҪСӮРөСҖС„РөР№СҒРҫРј JTAG. Р’СҒРө СғСҒСӮСҖРҫР№СҒСӮРІР° XC9500XL РёРјРөСҺСӮ РҫСӮлиСҮРҪСӢРө С…Р°СҖР°РәСӮРөСҖРёСҒСӮРёРәРё РәР°СҮРөСҒСӮРІР° Рё РҪР°РҙРөР¶РҪРҫСҒСӮРё, РәРҫлиСҮРөСҒСӮРІРҫ СҶРёРәР»РҫРІ РҝСҖРҫРіСҖаммиСҖРҫРІР°РҪРёРө/СҒСӮРёСҖР°РҪРёРө 10000 СҖаз Рё РіР°СҖР°РҪСӮРёСҖРҫРІР°РҪРҪРҫРө РІСҖРөРјСҸ С…СҖР°РҪРөРҪРёСҸ РҙР°РҪРҪСӢС… РҝСҖРҫСҲРёРІРәРё 20 Р»РөСӮ.
ГиРұРәР°СҸ Р°СҖС…РёСӮРөРәСӮСғСҖР° Pin-Locking. РЈСҒСӮСҖРҫР№СҒСӮРІР° XC9500XL СҒРҫРІРјРөСҒСӮРҪРҫ СҒ РҹРһ СҖазмРөСүРөРҪРёСҸ Р»РҫРіРёРәРё РҪР° РәСҖРёСҒСӮаллРө (fitter) РҙР°СҺСӮ Вам РјР°РәСҒРёРјСғРј РІРҫР·РјРҫР¶РҪРҫСҒСӮРөР№ РҝРҫ СҖазвРҫРҙРәРө СҒРёРіРҪалРҫРІ Рё РіРёРұРәРҫСҒСӮСҢ РҝСҖРё СҒРҫС…СҖР°РҪРөРҪРёРё РҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪРҫСҒСӮРё. РҗСҖС…РёСӮРөРәСӮСғСҖР° РұРҫРіР°СӮР° РҝРҫР»РөР·РҪСӢРјРё РІРҫР·РјРҫР¶РҪРҫСҒСӮСҸРјРё, РІРәР»СҺСҮР°СҺСүРёРјРё РёРҪРҙРёРІРёРҙСғалСҢРҪРҫРө СҖазСҖРөСҲРөРҪРёРө РІСӢС…РҫРҙРҫРІ p-term, 3 РіР»РҫРұалСҢРҪСӢС… СҲРёРҪСӢ СӮР°РәСӮРҫРІ Рё РұРҫР»СҢСҲРөРө РәРҫлиСҮРөСҒСӮРІРҫ p-term-РҫРІ РІ РҝРөСҖРөСҒСҮРөСӮРө РҪР° РІСӢС…РҫРҙ, СҮРөРј Сғ РҙСҖСғРіРёС… CPLD. Р”РҫРәазаРҪРҪР°СҸ РІРҫР·РјРҫР¶РҪРҫСҒСӮСҢ Р°СҖС…РёСӮРөРәСӮСғСҖСӢ Р°РҙР°РҝСӮРёСҖРҫРІР°СӮСҢСҒСҸ Рә РәРҫРҪСҒСӮСҖСғРәСӮРёРІРҪСӢРј РёР·РјРөРҪРөРҪРёСҸРј РҝСҖРё РҝРҫРҙРҙРөСҖжаРҪРёРё РҪазРҪР°СҮРөРҪРёР№ РәРҫРҪСӮР°РәСӮРҫРІ РҙРөРјРҫРҪСҒСӮСҖРёСҖРҫвалаСҒСҢ РІ РұРөСҒСҮРёСҒР»РөРҪРҪСӢС… СҖРөалСҢРҪСӢС… РҝРҫСӮСҖРөРұРёСӮРөР»СҢСҒРәРёС… РҝСҖРҫРөРәСӮах.
РҹРҫР»РҪР°СҸ РҝРҫРҙРҙРөСҖР¶РәР° IEEE 1149.1 JTAG РҝСҖРё СҖазСҖР°РұРҫСӮРәРө Рё РҫСӮлаРҙРәРө. РҳРҪСӮРөСҖС„РөР№СҒ JTAG СғСҒСӮСҖРҫР№СҒСӮРІ XC9500XL CPLD СҒамСӢР№ С„СғРҪРәСҶРёРҫРҪалСҢРҪСӢР№ РІ СҒСҖавРҪРөРҪРёРё СҒ Р»СҺРұСӢРјРё CPLD, РёРјРөСҺСүРёРјРёСҒСҸ РҪР° СҖСӢРҪРәРө. РҹСҖРөРҙРҫСҒСӮавлСҸРөСӮСҒСҸ СҒСӮР°РҪРҙР°СҖСӮРҪР°СҸ РҝРҫРҙРҙРөСҖР¶РәР° JTAG-РәРҫРјР°РҪРҙ BYPASS, SAMPLE/PRELOAD Рё EXTEST. Р”РҫРҝРҫР»РҪРёСӮРөР»СҢРҪСӢРө РёРҪСҒСӮСҖСғРәСҶРёРё РҝРҫРіСҖР°РҪРёСҮРҪРҫРіРҫ СӮРөСҒСӮРёСҖРҫРІР°РҪРёСҸ (Boundary Scan), РәРҫСӮРҫСҖСӢС… РҪРөСӮ Сғ РҙСҖСғРіРёС… CPLD, РІРәР»СҺСҮР°СҺСӮ INTEST (РҙР»СҸ С„СғРҪРәСҶРёРҫРҪалСҢРҪРҫР№ РҝСҖРҫРІРөСҖРәРё СғСҒСӮСҖРҫР№СҒСӮРІР°), HIGHZ (РҙР»СҸ РҫСӮРәР»СҺСҮРөРҪРёСҸ РҫСӮ СҶРөРҝРөР№, bypass) Рё USERCODE (РҙР»СҸ СӮСҖРөРәРёРҪРіР° РҝСҖРҫРіСҖаммСӢ), СҮСӮРҫ РҙР°РөСӮ РјР°РәСҒималСҢРҪСӢРө РІРҫР·РјРҫР¶РҪРҫСҒСӮРё РІ РҫСӮлаРҙРәРө.
РЎРөРјРөР№СҒСӮРІРҫ XC9500XL РҝРҫРҙРҙРөСҖживаРөСӮСҒСҸ СҲРёСҖРҫРәРёРј Р°СҒСҒРҫСҖСӮРёРјРөРҪСӮРҫРј РҹРһ СҖазСҖР°РұРҫСӮРәРё Рё РҫСӮлаРҙРәРё, РІ СӮРҫРј СҮРёСҒР»Рө РҫСӮ СҒСӮРҫСҖРҫРҪРҪРёС… СҖазСҖР°РұРҫСӮСҮРёРәРҫРІ, РІРәР»СҺСҮР°СҸ СӮР°РәРёРө РәРҫРјРҝР°РҪРёРё, РәР°Рә Corelis, JTAG Technologies Рё Asset Intertech. РӯСӮРё РёРҪСҒСӮСҖСғРјРөРҪСӮалСҢРҪСӢРө СҒСҖРөРҙСҒСӮРІР° РҝРҫР·РІРҫР»СҸСҺСӮ Вам СҖазСҖР°РұР°СӮСӢРІР°СӮСҢ РІРөРәСӮРҫСҖР° СӮРөСҒСӮРёСҖРҫРІР°РҪРёСҸ Boundary Scan РҙР»СҸ Р°РҪализа, РҝСҖРҫРІРөСҖРәРё СҒС…РөРјСӢ РҝРөСҮР°СӮРҪРҫР№ РҝлаСӮСӢ Рё РҫСӮлаРҙРәРё С„СғРҪРәСҶРёР№ СҒРёСҒСӮРөРјСӢ. РЎРөРјРөР№СҒСӮРІРҫ СӮР°РәР¶Рө РҝРҫРҙРҙРөСҖживаРөСӮСҒСҸ РҫСҒРҪРҫРІРҪСӢРјРё РҝлаСӮС„РҫСҖмами ATE, РІРәР»СҺСҮР°СҸ Teradyne, Hewlett Packard Рё Genrad.
РўР°РұлиСҶР° 2-2. РһРұР·РҫСҖ XC9500XL.
| |
XC9536XL |
XC9572XL |
XC95144XL |
XC95288XL |
| РңР°РәСҖРҫСҸСҮРөРөРә |
36 |
72 |
144 |
288 |
| Р РөРіРёСҒСӮСҖРҫРІ |
36 |
72 |
144 |
288 |
| РҳСҒРҝРҫР»СҢР·СғРөРјСӢС… Р»РҫРіРёСҮРөСҒРәРёС… СҚР»РөРјРөРҪСӮРҫРІ |
800 |
1600 |
3200 |
6400 |
| TPD (РҪСҒ) |
5 |
5 |
5 |
6 |
| TSU (РҪСҒ) |
3.7 |
3.7 |
3.7 |
4.0 |
| TCO (РҪСҒ) |
3.5 |
3.5 |
3.5 |
3.8 |
| FSYSTEM (РңР“СҶ) |
178 |
178 |
178 |
208 |
XC9500XL CPLD СӮР°РәР¶Рө СҒРҫСҮРөСӮР°СҺСӮСҒСҸ СҒ РјРёРәСҖРҫСҒС…Рөмами Xilinx FPGA РІСӢСҒРҫРәРҫР№ РҝР»РҫСӮРҪРҫСҒСӮРё, СҮСӮРҫ РҙР°РөСӮ РҝРҫР»РҪРҫРө СҖРөСҲРөРҪРёРө РҙР»СҸ СҖРөализаСҶРёРё Р»СҺРұРҫР№ Р»РҫРіРёРәРё РІ СғРҪифиСҶРёСҖРҫРІР°РҪРҪРҫР№ СҒСҖРөРҙРө СҖазСҖР°РұРҫСӮРәРё. РЎРөРјРөР№СҒСӮРІРҫ XC9500XL РҝРҫР»РҪРҫСҒСӮСҢСҺ РҝРҫРҙРҙРөСҖживаРөСӮСҒСҸ РұРөСҒРҝлаСӮРҪРҫР№ СҒСҖРөРҙРҫР№ СҖазСҖР°РұРҫСӮРәРё WebPACK ISE [2].
РҡР»СҺСҮРөРІСӢРө РІРҫР·РјРҫР¶РҪРҫСҒСӮРё XC9500XL:
вҖў СамаСҸ РҪРёР·РәР°СҸ СҶРөРҪР° РІ РҝРөСҖРөСҒСҮРөСӮРө РҪР° РјР°РәСҖРҫСҸСҮРөР№РәСғ.
вҖў РЎРҫРІСҖРөРјРөРҪРҪР°СҸ Р°СҖС…РёСӮРөРәСӮСғСҖР° РҝРҫ СғРҝСҖавлРөРҪРёСҺ РІСӢРІРҫРҙами.
вҖў Р’СӢСҒРҫРәР°СҸ РҪР°РҙРөР¶РҪРҫСҒСӮСҢ РҝСҖРҫРіСҖаммиСҖРҫРІР°РҪРёСҸ, СҒРҪижаСҺСүР°СҸ СҖРёСҒРә РІСӢС…РҫРҙР° СҒРёСҒСӮРөРјСӢ РёР· СҒСӮСҖРҫСҸ.
вҖў РҡРҫРјРҝР»РөРјРөРҪСӮР°СҖРҪРҫСҒСӮСҢ СҒ СҒРөРјРөР№СҒСӮвами Xilinx 3.3V FPGA.
вҖў Р’СӢСҒРҫРәР°СҸ РҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪРҫСҒСӮСҢ.
- РЎРәРҫСҖРҫСҒСӮСҢ СҖР°СҒРҝСҖРҫСҒСӮСҖР°РҪРөРҪРёСҸ СҒРёРіРҪала РјРөР¶РҙСғ РІСӢРІРҫРҙами 5 РҪСҒ.
- РЎРёСҒСӮРөРјРҪР°СҸ СҮР°СҒСӮРҫСӮР° 222 РңР“СҶ.
вҖў РңРҫСүРҪР°СҸ РІРҪСғСӮСҖРөРҪРҪСҸСҸ Р°СҖС…РёСӮРөРәСӮСғСҖР°.
- FB РёРјРөСҺСӮ СҲРёСҖРёРҪСғ 54 РҪР° РІС…РҫРҙР°.
- РҰРөР»СӢС… 90 p-term РҪР° РјР°РәСҖРҫСҸСҮРөР№РәСғ.
- Р‘СӢСҒСӮСҖР°СҸ РјР°СӮСҖРёСҶР° РәР»СҺСҮРөР№ Fast CONNECTв„ў II, РҫРұлаРҙР°СҺСүР°СҸ РұРҫР»СҢСҲРёРјРё РІРҫР·РјРҫР¶РҪРҫСҒСӮСҸРјРё СҖазвРҫРҙРәРё Р»РҫРіРёРәРё.
- РўСҖРё РіР»РҫРұалСҢРҪСӢС… СҶРөРҝРё СӮР°РәСӮРҫРІ, СҒ РІРҫР·РјРҫР¶РҪРҫСҒСӮСҢСҺ Р»РҫРәалСҢРҪРҫР№ РёРҪРІРөСҖСҒРёРё.
- РҳРҪРҙРёРІРёРҙСғалСҢРҪСӢР№ СҒРёРіРҪал СҖазСҖРөСҲРөРҪРёСҸ РҙР»СҸ РәажРҙРҫРіРҫ РІСӢС…РҫРҙР° (OE), СҒ РІРҫР·РјРҫР¶РҪРҫСҒСӮСҢСҺ Р»РҫРәалСҢРҪРҫР№ РёРҪРІРөСҖСҒРёРё.
- РЎРҫС…СҖР°РҪРҪРҫСҒСӮСҢ РҙР°РҪРҪСӢС… РҝСҖРҫСҲРёРІРәРё 20 Р»РөСӮ.
- РҳРјРјСғРҪРёСӮРөСӮ РҫСӮ СҖРөжима РҫСӮРәаза "ISP Lock-Out".
- Р”РҫРҝСғСҒРәР°РөСӮСҒСҸ РҝСҖРҫРёР·РІРҫР»СҢРҪР°СҸ РҝРҫСҒР»РөРҙРҫРІР°СӮРөР»СҢРҪРҫСҒСӮСҢ Рё С„РҫСҖРјР° РҝРҫРҙР°СҮРё РҝРёСӮР°РҪРёСҸ РҪР° СҖазРҪСӢРө СҲРёРҪСӢ РҝРёСӮР°РҪРёСҸ.
вҖў РҹСҖРҫРҙРІРёРҪСғСӮР°СҸ СӮРөС…РҪРҫР»РҫРіРёСҸ.
- РўСҖРөСӮСҢСҸ РіРөРҪРөСҖР°СҶРёСҸ РҝСҖРҫРІРөСҖРөРҪРҪРҫР№ СӮРөС…РҪРҫР»РҫРіРёРё CPLD.
- Р’СӢСҒРҫРәРҫРҪР°РҙРөР¶РҪР°СҸ, РјР°СҒСҲСӮР°РұРёСҖСғРөРјР°СҸ РҫРұСҖР°РұРҫСӮРәР°.
- РҡРҫСҖРҫСӮРәРҫРө РІСҖРөРјСҸ РҝСҖРҫРіСҖаммиСҖРҫРІР°РҪРёСҸ Рё СҒСӮРёСҖР°РҪРёСҸ ISP.
- РҹСҖРөРІРҫСҒС…РҫРҙРёСӮ РҝРҫ С…Р°СҖР°РәСӮРөСҖРёСҒСӮРёРәам РІСҒРө РҙСҖСғРіРёРө 3.3V CPLD.
- Р Р°СҒСҲРёСҖРөРҪРҪСӢР№ СҒСҖРҫРә СҒРҫС…СҖР°РҪРҪРҫСҒСӮРё РҙР°РҪРҪСӢС… СғРІРөлиСҮРёРІР°РөСӮ РІСҖРөРјСҸ жизРҪРё СҒРёСҒСӮРөРјСӢ.
- РӨР°РәСӮРёСҮРөСҒРәРё СғСҒСӮСҖР°РҪСҸСҺСӮСҒСҸ РҫСӮРәазСӢ ISP.
- РҹСҖРөРІРҫСҒС…РҫРҙРҪСӢРө РІРҫР·РјРҫР¶РҪРҫСҒСӮРё СғРҝСҖавлРөРҪРёСҸ РІСӢРІРҫРҙами (pin-locking) РҙР»СҸ СҒРҪРёР¶РөРҪРёСҸ СҖРёСҒРәРҫРІ РҝСҖРё СҖазСҖР°РұРҫСӮРәРө.
- Р’СӢРІРҫРҙСӢ I/O, РҪРө РіРөРҪРөСҖРёСҖСғСҺСүРёРө РҝР°СҖазиСӮРҪСӢС… РІСӢРұСҖРҫСҒРҫРІ РҝСҖРё РІРәР»СҺСҮРөРҪРёРё.
вҖў РҹРҫР»РҪР°СҸ СҒРҫРІРјРөСҒСӮРёРјРҫСҒСӮСҢ Full IEEE 1149.1 (JTAG) РҙР»СҸ ISP Рё СӮРөСҒСӮРёСҖРҫРІР°РҪРёСҸ Boundary Scan.
вҖў РҹРҫРҙРҙРөСҖР¶РәР° СҒРҫ СҒСӮРҫСҖРҫРҪСӢ РұРөСҒРҝлаСӮРҪРҫРіРҫ РҹРһ РҫСӮ Xilinx (WebPack [2]).

Р РёСҒ. 2-12. РазвРҫРҙРәР° СҒРёРіРҪалРҫРІ РұР»РҫРәР° XC9500XL.
Р РёСҒ. 2-13. РЎРёСҒСӮРөРјР° РјР°СҖРәРёСҖРҫРІРәРё XC9500XL.
[РҹлаСӮС„РҫСҖРјР° РјРёРәСҖРҫСҒС…РөРј FPGA]
Spartan-3/3E/3A/3AN. РңРёРәСҖРҫСҒС…РөРјСӢ Xilinx Spartan-3 FPGA РёРҙРөалСҢРҪРҫ РҝРҫРҙС…РҫРҙСҸСӮ РҙР»СҸ РҪРөРҙРҫСҖРҫРіРёС…, СҒР»РҫР¶РҪСӢС… РҝСҖРёР»РҫР¶РөРҪРёР№, Рё РҪР°СҶРөР»РөРҪСӢ РҪР° замРөРҪСғ РјР°СҒСҒРёРІРҫРІ РІРөРҪСӮРёР»РөР№ фиРәСҒРёСҖРҫРІР°РҪРҪРҫР№ Р»РҫРіРёРәРё Рё РҝСҖРҫРҙСғРәСҶРёРё ASSP, СӮР°РәРёС… РәР°Рә РҪР°РұРҫСҖСӢ СҮРёРҝРҫРІ С„РҫСҖРјРёСҖРҫРІР°РҪРёСҸ СҲРёРҪСӢ РёРҪСӮРөСҖС„РөР№СҒР°. Spartan-3 (1.2V, 90 РҪРј) FPGA РҪРө СӮРҫР»СҢРәРҫ РҙРҫСҒСӮСғРҝРҪСӢ СҒ РҫСҮРөРҪСҢ РҪРёР·РәРҫР№ СҶРөРҪРҫР№, РҪРҫ СӮР°РәР¶Рө РёРҪСӮРөРіСҖРёСҖСғСҺСӮ РјРҪРҫР¶РөСҒСӮРІРҫ Р°СҖС…РёСӮРөРәСӮСғСҖРҪСӢС… С„СғРҪРәСҶРёР№, СҒРІСҸР·Р°РҪРҪСӢС… СҒ РҝСҖРҫРіСҖаммиСҖСғРөРјРҫР№ Р»РҫРіРёРәРҫР№ РәР°СӮРөРіРҫСҖРёРё high-end. РўР°РәР°СҸ РәРҫРјРұРёРҪР°СҶРёСҸ РҪРёР·РәРҫР№ СҶРөРҪСӢ Рё РҝСҖРҫРҙРІРёРҪСғСӮСӢС… РІРҫР·РјРҫР¶РҪРҫСҒСӮРөР№ РҙРөлаРөСӮ Spartan-3 FPGA РёРҙРөалСҢРҪРҫР№ замРөРҪРҫР№ РҙР»СҸ РјРёРәСҖРҫСҒС…РөРј ASIC (РјР°СҒСҒРёРІСӢ Р»РҫРіРёСҮРөСҒРәРёС… РІРөРҪСӮРёР»РөР№) Рё РјРҪРҫР¶РөСҒСӮРІР° РјРёРәСҖРҫСҒС…РөРј ASSP. РқР°РҝСҖРёРјРөСҖ, Spartan-3 FPGA РІ РјСғР»СҢСӮРёРјРөРҙРёР№РҪРҫР№ СҒРёСҒСӮРөРјРө авСӮРҫ РјРҫР¶РөСӮ РҝРҫРҙРҙРөСҖживаСӮСҢ РјРҪРҫРіРёРө СҒРёСҒСӮРөРјРҪСӢРө С„СғРҪРәСҶРёРё, РІРәР»СҺСҮР°СҸ РІСҒСӮСҖРҫРөРҪРҪСӢРө РҝСҖРҫСҶРөСҒСҒРҫСҖРҪСӢРө СҸРҙСҖР° (IP core), РҝРҫР»СҢР·РҫРІР°СӮРөР»СҢСҒРәРёРө РёРҪСӮРөСҖС„РөР№СҒСӢ, СҶРёС„СҖРҫРІСғСҺ РҫРұСҖР°РұРҫСӮРәСғ СҒРёРіРҪала (DSP) Рё Р»СҺРұСғСҺ Р»РҫРіРёРәСғ. Р РёСҒ. 2-14 РҝРҫРәазСӢРІР°РөСӮ РҝСҖРёРјРөСҖ СӮР°РәРҫР№ СҒРёСҒСӮРөРјСӢ.
Р РёСҒ. 2-14. РңСғР»СҢСӮРёРјРөРҙРёР№РҪР°СҸ СҒРёСҒСӮРөРјР° авСӮРҫРјРҫРұРёР»СҸ.
Р’ РјСғР»СҢСӮРёРјРөРҙРёР№РҪРҫР№ СҒРёСҒСӮРөРјРө авСӮРҫРјРҫРұРёР»СҸ, РҝРҫРәазаРҪРҪРҫР№ РҪР° СҖРёСҒ. 2-14, РұР»РҫРә PCI РҫСӮРІРөСҮР°РөСӮ Р·Р° С„РҫСҖРјРёСҖРҫРІР°РҪРёРө СҒСӮР°РҪРҙР°СҖСӮРҪРҫРіРҫ РҝРҫРҙРәР»СҺСҮРөРҪРёСҸ Рә СҸРҙСҖСғ РҝСҖРҫСҶРөСҒСҒРҫСҖР°. РӨСғРҪРәСҶРёРё СӮР°РәСӮРёСҖРҫРІР°РҪРёСҸ РҪР° СғСҖРҫРІРҪРө СғСҒСӮСҖРҫР№СҒСӮРІР° Рё РҝлаСӮСӢ СҖРөализРҫРІР°РҪСӢ РҪР° DCM-ах, РІСҒСӮСҖРҫРөРҪРҪСӢС… РІ СҮРёРҝ Spartan-3. CAN core IP РҝРҫР·РІРҫР»СҸРөСӮ РҝРҫРҙРәР»СҺСҮР°СӮСҢ СҒ СҒРёСҒСӮРөРјРө СҚР»РөРәСӮСҖРҫРҪРҪСӢРө РјРҫРҙСғли авСӮРҫРјРҫРұРёР»СҸ. РӯСӮРё СҸРҙСҖР° (IP core) РҝСҖРөРҙРҫСҒСӮавлСҸСҺСӮСҒСҸ РҝР°СҖСӮРҪРөСҖами Xilinx AllianceCOREв„ў, СӮР°РәРёРјРё РәР°Рә Bosch, Memec Design, CAST Inc., Xylon Рё Intelliga. Р’СҒСӮСҖРҫРөРҪРҪСӢРө РІ РәСҖРёСҒСӮалл СғРјРҪРҫжиСӮРөли 18x18 РјРҫРіСғСӮ РёСҒРҝРҫР»СҢР·РҫРІР°СӮСҢСҒСҸ РҙР»СҸ DSP-РҫРұСҖР°РұРҫСӮРҫРә, СӮР°РәРёС… РәР°Рә филСҢСӮСҖР°СҶРёСҸ Рё РәРҫРҙРёСҖРҫРІР°РҪРёРө/РҙРөРәРҫРҙРёСҖРҫРІР°РҪРёРө С„РҫСҖРјР°СӮРҫРІ. Р”СҖСғРіРёРө РҝРҫР»СҢР·РҫРІР°СӮРөР»СҢСҒРәРёРө РёРҪСӮРөСҖС„РөР№СҒСӢ РјРҫРіСғСӮ РұСӢСӮСҢ СҖРөализРҫРІР°РҪСӢ РҙР»СҸ РҝРҫРҙРәР»СҺСҮРөРҪРёСҸ Рә РІРҪРөСҲРҪРёРј РҝСҖРҫСҶРөСҒСҒРҫСҖам, РҪахРҫРҙСҸСүРёРјСҒСҸ РІРҪРө РәСҖРёСҒСӮалла FPGA. РқР°РҝСҖРёРјРөСҖ РёРҪСӮРөСҖС„РөР№СҒ IDE РјРҫР¶РөСӮ РұСӢСӮСҢ СҖРөализРҫРІР°РҪ РҙР»СҸ СғРҝСҖавлРөРҪРёСҸ РҝР»РөРөСҖРҫРј DVD, РҙСҖСғРіРёРө РёРҪСӮРөСҖС„РөР№СҒСӢ РјРҫРіСғСӮ РұСӢСӮСҢ СҖРөализРҫРІР°РҪСӢ РҙР»СҸ РҝРҫРҙРәР»СҺСҮРөРҪРёСҸ Рә РІРҪРөСҲРҪРөР№ РҝамСҸСӮРё, или РҙР»СҸ СғРҝСҖавлРөРҪРёСҸ LCD. Р”РҫРҝРҫР»РҪРёСӮРөР»СҢРҪРҫ Spartan-3 XCITE РёРјРөСҺСӮ РІСҒСӮСҖРҫРөРҪРҪСғСҺ СӮРөС…РҪРҫР»РҫРіРёСҺ СғРҝСҖавлРөРҪРёСҸ РёРјРҝРөРҙР°РҪСҒРҫРј, СҮСӮРҫ РјРҫР¶РөСӮ СҒРҪРёР·РёСӮСҢ РҝРҫРјРөС…Рё (EMI) Рё СғРјРөРҪСҢСҲРёСӮСҢ РәРҫлиСҮРөСҒСӮРІРҫ РәРҫРјРҝРҫРҪРөРҪСӮРҫРІ, РҝСҖРөРҙРҪазРҪР°СҮРөРҪРҪСӢС… РҙР»СҸ СҒРҫглаСҒРҫРІР°РҪРёСҸ РёРјРҝРөРҙР°РҪСҒРҫРІ СҒ лиРҪРёСҸРјРё СҒРІСҸР·Рё или РҙР»СҸ РҫСҖРіР°РҪРёР·Р°СҶРёРё филСҢСӮСҖРҫРІ - СғРјРөРҪСҢСҲР°РөСӮСҒСҸ РәРҫлиСҮРөСҒСӮРІРҫ РІРҪРөСҲРҪРёС… СҖРөР·РёСҒСӮРҫСҖРҫРІ.
Р РёСҒ. 2-15. РЈСҒСӮСҖРҫР№СҒСӮРІРҫ РІРҪСғСӮСҖРөРҪРҪРөР№ Р°СҖС…РёСӮРөРәСӮСғСҖСӢ Spartan-3 (IOB СҚСӮРҫ РұР»РҫРәРё РІРІРҫРҙР°/РІСӢРІРҫРҙР°).
РЎРөРјРөР№СҒСӮРІРҫ Spartan-3 РҫСҒРҪРҫРІР°РҪРҫ РҪР° РҝСҖРҫРҙРІРёРҪСғСӮРҫР№ 90 РҪРј, 8-СҒР»РҫР№РҪРҫР№ СӮРөС…РҪРҫР»РҫРіРёРё РјРөСӮаллизаСҶРёРё. Xilinx РёСҒРҝРҫР»СҢР·СғРөСӮ 90 РҪРј СӮРөС…РҪРҫР»РҫРіРёСҺ РҙР»СҸ РҙР»СҸ СҒРҪРёР¶РөРҪРёСҸ СҶРөРҪ РҪРёР¶Рө $20 Р·Р° РҫРҙРёРҪ миллиРҫРҪ РІРөРҪСӮРёР»РөР№ FPGA (РҝСҖРёРјРөСҖРҪРҫ 17000 Р»РҫРіРёСҮРөСҒРәРёС… СҸСҮРөРөРә), СҮСӮРҫ РҙР°РөСӮ РәР°Рә РјРёРҪРёРјСғРј 80% РІСӢРёРіСҖСӢСҲР° РҝРҫ СҒСӮРҫРёРјРҫСҒСӮРё РІ СҒСҖавРҪРөРҪРёРё СҒ РҙСҖСғРіРёРјРё РәРҫРҪРәСғСҖРөРҪСӮРҪСӢРјРё РҝСҖРөРҙР»РҫР¶РөРҪРёСҸРјРё. РңРөРҪСҢСҲРёР№ СҖазмРөСҖ РәСҖРёСҒСӮалла Рё 300 РјРј РҝлаСҒСӮРёРҪСӢ СғРІРөлиСҮРёРІР°СҺСӮ РҝР»РҫСӮРҪРҫСҒСӮРё РәСҖРёСҒСӮалла Рё СҒР»РөРҙРҫРІР°СӮРөР»СҢРҪРҫ СғРјРөРҪСҢСҲР°СҺСӮ РҫРұСүСғСҺ СҒСӮРҫРёРјРҫСҒСӮСҢ РҝСҖРҫРёР·РІРҫРҙСҒСӮРІР°. РӯСӮРҫ РІ СҒРІРҫСҺ РҫСҮРөСҖРөРҙСҢ РҝРҫРІСӢСҲР°РөСӮ СғСҖРҫРІРөРҪСҢ РёРҪСӮРөРіСҖР°СҶРёРё, СғРҙРөСҲРөРІР»СҸРөСӮ СҖазСҖР°РұРҫСӮРәСғ, СғРјРөРҪСҢСҲР°РөСӮ Р·Р°РҪРёРјР°РөРјРҫРө РјРөСҒСӮРҫ РҪР° РҝРөСҮР°СӮРҪРҫР№ РҝлаСӮРө, РәРҫРіРҙР° СҖазСҖР°РұРҫСӮР°РҪРҪРҫРө РёР·РҙРөлиРө РІРҫРҝР»РҫСүР°РөСӮСҒСҸ РІ РәРҫРҪРөСҮРҪСӢР№ РҝСҖРҫРҙСғРәСӮ.

Р РёСҒ. 2-16. РӨСғРҪРәСҶРёРё Spartan-3.
РҗСҖС…РёСӮРөРәСӮСғСҖР° РҝамСҸСӮРё Spartan-3 FPGA РҝСҖРөРҙРҫСҒСӮавлСҸРөСӮ РҫРҝСӮималСҢРҪСғСҺ СҒСӮРөРҝРөРҪСҢ РҙРөСӮализаСҶРёРё Рё СҚффРөРәСӮРёРІРҪРҫРө РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРө РҝР»РҫСүР°РҙРё РәСҖРёСҒСӮалла.
вҖў БлРҫРәРё СҖРөРіРёСҒСӮСҖР° СҒРҙРІРёРіР° (Shift Register SRL16 Blocks).
- РҡажРҙСӢР№ CLB LUT СҖР°РұРҫСӮР°РөСӮ РәР°Рә РұСӢСҒСӮСҖСӢР№, РәРҫРјРҝР°РәСӮРҪСӢР№ 16-РұРёСӮРҪСӢР№ СҖРөРіРёСҒСӮСҖ СҒРҙРІРёРіР°.
- РҡР°СҒРәР°РҙРёСҖРҫРІР°РҪРёРө LUT РҙР»СҸ РҝРҫСҒСӮСҖРҫРөРҪРёСҸ РұРҫР»РөРө РҙлиРҪРҪСӢС… СҖРөРіРёСҒСӮСҖРҫРІ СҒРҙРІРёРіР°.
- Р РөализаСҶРёСҸ РәРҫРҪРІРөР№РөСҖРҪСӢС… СҖРөРіРёСҒСӮСҖРҫРІ (pipeline register) Рё РұСғС„РөСҖРҫРІ РҙР»СҸ РІРёРҙРөРҫРҙР°РҪРҪСӢС… или РұРөСҒРҝСҖРҫРІРҫРҙРҪРҫР№ СҒРІСҸР·Рё.
вҖў РҰРөР»СӢС… 520 РәРёР»РҫРұайСӮ СҖР°СҒРҝСҖРөРҙРөР»РөРҪРҪРҫР№ РҝамСҸСӮРё (Distributed SelectRAMв„ў Memory).
- РҡажРҙСӢР№ РұР»РҫРә LUT СҖР°РұРҫСӮР°РөСӮ РәР°Рә РҫРҙРҪРҫРҝРҫСҖСӮРҫРІР°СҸ или РҙРІСғС…РҝРҫСҖСӮРҫРІР°СҸ РҝамСҸСӮСҢ RAM/ROM.
- РҡР°СҒРәР°РҙРёСҖРҫРІР°РҪРёРө LUT РҙР»СҸ РҝРҫСҒСӮСҖРҫРөРҪРёСҸ СғСҒСӮСҖРҫР№СҒСӮРІ РҝамСҸСӮРё РҝРҫРІСӢСҲРөРҪРҪРҫРіРҫ СҖазмРөСҖР°.
- РҹСҖРёР»РҫР¶РөРҪРёСҸ РІРәР»СҺСҮР°СҺСӮ РіРёРұРәРёРө РҝРҫ СҖазмРөСҖСғ СғСҒСӮСҖРҫР№СҒСӮРІР° РҝамСҸСӮРё, FIFO Рё РұСғС„РөСҖСӢ.
вҖў РҰРөР»СӢС… 1.872 РјРөРіР°РұайСӮ РІСҒСӮСҖРҫРөРҪРҪРҫР№ РұР»РҫСҮРҪРҫР№ РҝамСҸСӮРё (Embedded Block RAM).
- 104 РұР»РҫРәР° СҒРёРҪС…СҖРҫРҪРҪРҫР№, РәР°СҒРәР°РҙРёСҖСғРөРјРҫР№ РҝамСҸСӮРё, РәажРҙСӢР№ РұР»РҫРә RAM РҝРҫ 18 РәРёР»РҫРұайСӮ.
- РҡажРҙСӢР№ РұР»РҫРә 18 РәРёР»РҫРұайСӮ РәРҫРҪфигСғСҖРёСҖСғРөСӮСҒСҸ РәР°Рә РҫРҙРёРҪРҫРҝРҫСҖСӮРҫРІР°СҸ или РҙРІСғС…РҝРҫСҖСӮРҫРІР°СҸ РҝамСҸСӮСҢ RAM.
- РҹРҫРҙРҙРөСҖживаРөСӮСҒСҸ РҪРөСҒРәРҫР»СҢРәРҫ С„РҫСҖРјР°СӮРҫРІ СҸСҮРөРөРә (aspect ratio) РҝСҖРөРҫРұСҖазРҫРІР°РҪРёСҸ СҲРёСҖРёРҪСӢ РҙР°РҪРҪСӢС… (data-width conversion) Рё СҮРөСӮРҪРҫСҒСӮРё.
- РҹСҖРёР»РҫР¶РөРҪРёСҸ РІРәР»СҺСҮР°СҺСӮ РәСҚСҲРё РҙР°РҪРҪСӢС…, РіР»СғРұРҫРәРёРө СҒСӮРөРәРё FIFO Рё РұСғС„РөСҖСӢ.
вҖў РҳРҪСӮРөСҖС„РөР№СҒСӢ РҝамСҸСӮРё.
- РҹРҫР·РІРҫР»СҸСҺСӮ РҫСҖРіР°РҪРёР·РҫРІР°СӮСҢ СӮР°РәРёРө СҚР»РөРәСӮСҖРёСҮРөСҒРәРёРө РёРҪСӮРөСҖС„РөР№СҒСӢ, РәР°Рә HSTL Рё SSTL, СҮСӮРҫРұСӢ РҝРҫРҙРәР»СҺСҮР°СӮСҢ РҝРҫРҝСғР»СҸСҖРҪСӢРө РІРҪРөСҲРҪРёРө РјРҫРҙСғли РҝамСҸСӮРё.
вҖў РЈРјРҪРҫжиСӮРөли.
- РҹРҫР·РІРҫР»СҸСҺСӮ СҖРөализРҫРІР°СӮСҢ РҝСҖРҫСҒСӮСӢРө Р°СҖифмРөСӮРёСҮРөСҒРәРёРө Рё РјР°СӮРөРјР°СӮРёСҮРөСҒРәРёРө РҫРҝРөСҖР°СҶРёРё, Р° СӮР°РәР¶Рө РҝСҖРҫРҙРІРёРҪСғСӮСӢРө С„СғРҪРәСҶРёРё DSP. РӯСӮРҫ РҝРҫР·РІРҫлиСӮ Вам РІСӢРҝРҫР»РҪСҸСӮСҢ РұРҫР»СҢСҲРө 330 миллиаСҖРҙР° РҫРҝРөСҖР°СҶРёР№ MAC РІ СҒРөРәСғРҪРҙСғ, РәРҫРҪРәСғСҖРёСҖСғСҸ СҒРҫ СҒРҝРөСҶиализиСҖРҫРІР°РҪРҪСӢРјРё РҝСҖРҫСҶРөСҒСҒРҫСҖами DSP.
- РҰРөР»СӢС… 104 СғРјРҪРҫжиСӮРөР»СҸ 18x18, РҝРҫРҙРҙРөСҖживаСҺСүРёРө РҫРҝРөСҖР°СҶРёРё СғРјРҪРҫР¶РөРҪРёСҸ 18-РұРёСӮРҪСӢС… СҮРёСҒРөР» СҒРҫ Р·РҪР°РәРҫРј или 17-СҮРёСҒРөР» РұРөР· Р·РҪР°РәР°, РәРҫСӮРҫСҖСӢРө РјРҫР¶РҪРҫ РәР°СҒРәР°РҙРёСҖРҫРІР°СӮСҢ РҙР»СҸ СғРІРөлиСҮРөРҪРёСҸ СҖазСҖСҸРҙРҪРҫСҒСӮРё.
- РЈРјРҪРҫжиСӮРөли РҪР° РҝРҫСҒСӮРҫСҸРҪРҪСӢР№ РәРҫСҚффиСҶРёРөРҪСӮ: РІСҒСӮСҖРҫРөРҪРҪСӢРө СғР·Р»СӢ РҝамСҸСӮРё Рё Р»РҫРіРёСҮРөСҒРәРёРө СҸСҮРөР№РәРё СҖР°РұРҫСӮР°СҺСӮ СҒРҫРІРјРөСҒСӮРҪРҫ РҙР»СҸ РҝРҫСҒСӮСҖРҫРөРҪРёСҸ РәРҫРјРҝР°РәСӮРҪСӢС… СғРјРҪРҫжиСӮРөР»РөР№ РҪР° РҝРҫСҒСӮРҫСҸРҪРҪСӢР№ РҫРҝРөСҖР°РҪРҙ.
- РЈРјРҪРҫжиСӮРөли Logic Cell: СҖРөализаСҶРёСҸ алгРҫСҖРёСӮРјРҫРІ РҝРҫ РІСӢРұРҫСҖСғ РҝРҫР»СҢР·РҫРІР°СӮРөР»СҸ, СӮР°РәРёС… РәР°Рә Baugh-Wooley, Booth, Wallace tree Рё РҙСҖСғРіРёС….
вҖў БлРҫРәРё DCM РҙР°СҺСӮ РёР·РҫСүСҖРөРҪРҪРҫРө СғРҝСҖавлРөРҪРёРө СӮР°РәСӮРёСҖРҫРІР°РҪРёРөРј, РҪРө РҝСҖРҫРҝСғСҒРәР°СҺСүРөРө РІ СҒРёСҒСӮРөРјСғ РҙжиСӮСӮРөСҖ, влиСҸРҪРёРө СӮРөРјРҝРөСҖР°СӮСғСҖСӢ, влиСҸРҪРёРө РёР·РјРөРҪРөРҪРёСҸ РҪР°РҝСҖСҸР¶РөРҪРёСҸ Рё СғСҒСӮСҖР°РҪСҸСҺСӮ РҙСҖСғРіРёРө РҝСҖРҫРұР»РөРјСӢ, РәРҫСӮРҫСҖСӢРө РҫРұСӢСҮРҪРҫ РҪР°РұР»СҺРҙР°СҺСӮСҒСҸ РІ РұР»РҫРәах PLL, РёРҪСӮРөРіСҖРёСҖСғРөРјСӢС… РІ FPGA.
- ГиРұРәР°СҸ РіРөРҪРөСҖР°СҶРёСҸ СҮР°СҒСӮРҫСӮ РҫСӮ 25 РңР“СҶ РҙРҫ 325 РңР“СҶ.
- Р’РөлиСҮРёРҪР° РҙжиСӮСӮРөСҖР° 100 РҝРёРәРҫСҒРөРәСғРҪРҙ.
- РҹР°СҖамРөСӮСҖСӢ СҶРөР»РҫСҮРёСҒР»РөРҪРҪРҫРіРҫ СғРјРҪРҫР¶РөРҪРёСҸ Рё РҙРөР»РөРҪРёСҸ СҮР°СҒСӮРҫСӮСӢ.
- РЈРҝСҖавлРөРҪРёРө РәРІР°РҙСҖР°СӮСғСҖРҫР№ Рё СӮРҫСҮРҪРҫСҒСӮСҢСҺ СҒРҙРІРёРіР° фазСӢ.
- 0, 90, 180, 270 РіСҖР°РҙСғСҒРҫРІ.
- РўРҫСҮРҪРҫРө СғРҝСҖавлРөРҪРёРө РёРјРҝСғР»СҢСҒами (Fine grain control, 1/256 СӮР°РәСӮРҫРІ РҪР° РҝРөСҖРёРҫРҙ) РҙР»СҸ СҒРёРҪС…СҖРҫРҪРёР·Р°СҶРёРё СӮР°РәСӮРҫРІ РҙР°РҪРҪСӢС….
- РўРҫСҮРҪР°СҸ РіРөРҪРөСҖР°СҶРёСҸ СҒРәважРҪРҫСҒСӮРё 50/50.
- РҡРҫРјРҝРөРҪСҒР°СҶРёСҸ СӮРөРјРҝРөСҖР°СӮСғСҖРҪРҫРіРҫ СғС…РҫРҙР°.
вҖў РўРөС…РҪРҫР»РҫРіРёСҸ XCITE РҙР»СҸ СҶРёС„СҖРҫРІРҫРіРҫ СғРҝСҖавлРөРҪРёСҸ РёРјРҝРөРҙР°РҪСҒРҫРј (Digitally Controlled Impedance) - РёРҪРҪРҫРІР°СҶРёСҸ Xilinx.
- РўРөСҖРјРёРҪРёСҖРҫРІР°РҪРёРө РІРІРҫРҙР°/РІСӢРІРҫРҙР° (I/O termination), РҪРөРҫРұС…РҫРҙРёРјРҫРө РҙР»СҸ РҝРҫРҙРҙРөСҖжаРҪРёСҸ СҶРөР»РҫСҒСӮРҪРҫСҒСӮРё СҒРёРіРҪалРҫРІ (РјРёРҪРёРјРёР·Р°СҶРёСҸ РІСӢРұРҫСҖРҫРІ Рё РҫСӮСҖажРөРҪРёР№). РЎ СҒРҫСӮРҪСҸРјРё РІСӢРІРҫРҙРҫРІ I/O Рё РҝСҖРҫРҙРІРёРҪСғСӮСӢРјРё СӮРөС…РҪРҫР»РҫРіРёСҸРјРё РәРҫСҖРҝСғСҒРҫРІ РјРёРәСҖРҫСҒС…РөРј РІРҪРөСҲРҪРёРө СҒРҫглаСҒСғСҺСүРёРө СҖРөР·РёСҒСӮРҫСҖСӢ РұРҫР»СҢСҲРө РҪРө РҪСғР¶РҪСӢ.
- I/O termination РҙРёРҪамиСҮРөСҒРәРё СғСҒСӮСҖР°РҪСҸРөСӮ РёР·РјРөРҪРөРҪРёСҸ РҪагСҖСғР·РҫСҮРҪРҫР№ СҒРҝРҫСҒРҫРұРҪРҫСҒСӮРё РёР·-Р·Р° влиСҸРҪРёСҸ РҫРұСҖР°РұРҫСӮРәРё, РёР·РјРөРҪРөРҪРёСҸ СӮРөРјРҝРөСҖР°СӮСғСҖСӢ Рё флСғРәСӮСғР°СҶРёРё РҪР°РҝСҖСҸР¶РөРҪРёСҸ РҝРёСӮР°РҪРёСҸ.
вҖў РһСҒРҪРҫРІРҪСӢРө С„СғРҪРәСҶРёРё СӮРөС…РҪРҫР»РҫРіРёРё Spartan-3 XCITE DCI.
- РҹРҫСҒР»РөРҙРҫРІР°СӮРөР»СҢРҪРҫРө Рё РҝР°СҖаллРөР»СҢРҪРҫРө СӮРөСҖРјРёРҪРёСҖРҫРІР°РҪРёРө СҒСӮР°РҪРҙР°СҖСӮРҫРІ РҫРҙРёРҪРҫСҮРҪСӢС… Рё РҙиффРөСҖРөРҪСҶиалСҢРҪСӢС… Р»РҫРіРёСҮРөСҒРәРёС… СҒРёРіРҪалРҫРІ.
- РңР°РәСҒРёРјСғРј РіРёРұРәРҫСҒСӮРё РҝСҖРё РҝРҫРҙРҙРөСҖР¶РәРё РҝРҫСҒР»РөРҙРҫРІР°СӮРөР»СҢРҪРҫРіРҫ Рё РҝР°СҖаллРөР»СҢРҪРҫРіРҫ СӮРөСҖРјРёРҪРёСҖРҫРІР°РҪРёСҸ РҪР° РІСҒРөС… РұР°РҪРәах I/O.
- РҹРҫРҙРҙРөСҖР¶РәР° РІС…РҫРҙРҫРІ, РІСӢС…РҫРҙРҫРІ, РҙРІСғРҪР°РҝСҖавлРөРҪРҪРҫРіРҫ РҝРҫСҖСӮР°, РҙиффРөСҖРөРҪСҶиалСҢРҪРҫРіРҫ РІРІРҫРҙР°/РІСӢРІРҫРҙР°.
- РЁРёСҖРҫРәРёР№ РҙРёР°РҝазРҫРҪ РҝРҫСҒР»РөРҙРҫРІР°СӮРөР»СҢРҪРҫРіРҫ РёРјРҝРөРҙР°РҪСҒР°.
- РҹРҫРҙРҙРөСҖР¶РәР° РҝРҫРҝСғР»СҸСҖРҪСӢС… СҒСӮР°РҪРҙР°СҖСӮРҫРІ Р»РҫРіРёСҮРөСҒРәРёС… СҒРёРіРҪалРҫРІ, РІРәР»СҺСҮР°СҸ LVDS, LVDSEXT, LVCMOS, LVTTL, SSTL, HSTL, GTL Рё GTLP.
- Р’С…РҫРҙРҪСӢРө РұСғС„РөСҖСӢ СҒ РҝРҫР»РҪСӢРј Рё РҝРҫР»РҫРІРёРҪРҪСӢРј РёРјРҝРөРҙР°РҪСҒРҫРј.
Р РёСҒ. 2-17. РҡРҫРҪфигСғСҖРёСҖСғРөРјСӢР№ РұР»РҫРә Р»РҫРіРёРәРё (Configurable Logic Block, CLB) Spartan-3.
РўР°РұлиСҶР° 2-3. Р”РҫСҒСӮРҫРёРҪСҒСӮРІР° СӮРөС…РҪРҫР»РҫРіРёРё XCITE DCI.
| Р”РҫСҒСӮРҫРёРҪСҒСӮРІРҫ |
РһРҝРёСҒР°РҪРёРө |
| вҖў Р’СӮРҫСҖРҫРө РҝРҫРәРҫР»РөРҪРёРө СӮРөС…РҪРҫР»РҫРіРёРё FPGA |
РҹСҖРҫРІРөСҖРөРҪРҫ РІ СҖР°РұРҫСӮРө РјРҪРҫРіРёРјРё РҝРҫР»СҢР·РҫРІР°СӮРөР»СҸРјРё. |
| вҖў РЎРҪРёР¶РөРҪРёРө СҒСӮРҫРёРјРҫСҒСӮРё |
РңРөРҪСҢСҲРө СҖРөР·РёСҒСӮРҫСҖРҫРІ, СғРҝСҖРҫСүР°РөСӮСҒСҸ СӮСҖР°СҒСҒРёСҖРҫРІРәР° PCB, РјРөРҪСҢСҲРө РҝР»РҫСүР°РҙСҢ PCB, РІ СҖРөР·СғР»СҢСӮР°СӮРө СҮРөРіРҫ СҒРҪижаРөСӮСҒСҸ СҒСӮРҫРёРјРҫСҒСӮСҢ РҝСҖРҫРёР·РІРҫРҙСҒСӮРІР°. |
| вҖў РҗРұСҒРҫР»СҺСӮРҪР°СҸ РіРёРұРәРҫСҒСӮСҢ I/O |
РӣСҺРұРҫРө СӮРөСҖРјРёРҪРёСҖРҫРІР°РҪРёРө РҪР° Р»СҺРұРҫРј РұР°РҪРәРө I/O. РҗР»СҢСӮРөСҖРҪР°СӮРёРІСӢ РұРөР· СӮРөС…РҪРҫР»РҫРіРёРё XCITE РҝСҖРөРҙРҫСҒСӮавлСҸСҺСӮ РјРөРҪСҢСҲРёР№ С„СғРҪРәСҶРёРҫРҪал. |
| вҖў РңР°РәСҒРёРјСғРј РҝРҫР»РҫСҒСӢ РҝСҖРҫРҝСғСҒРәР°РҪРёСҸ I/O |
РңРөРҪСҢСҲРө "Р·РІРҫРҪР°" Рё РҫСӮСҖажРөРҪРёР№ РҪР° РјР°РәСҒималСҢРҪСӢС… СҮР°СҒСӮРҫСӮах РҝРөСҖРөРәР»СҺСҮРөРҪРёР№. |
| вҖў РҳРјРјСғРҪРёСӮРөСӮ Рә РёР·РјРөРҪРөРҪРёСҸРј СӮРөРјРҝРөСҖР°СӮСғСҖСӢ Рё РҪР°РҝСҖСҸР¶РөРҪРёСҸ |
РҳР·РјРөРҪРөРҪРёСҸ СӮРөРјРҝРөСҖР°СӮСғСҖСӢ Рё РҪР°РҝСҖСҸР¶РөРҪРёСҸ РҝСҖРёРІРҫРҙСҸСӮ Рә Р·РҪР°СҮРёСӮРөР»СҢРҪСӢРј СҖР°СҒСҒРҫглаСҒРҫРІР°РҪРёСҸРј РҝРҫ РёРјРҝРөРҙР°РҪСҒСғ. РўРөС…РҪРҫР»РҫРіРёСҸ XCITE РҙРёРҪамиСҮРөСҒРәРё РҝРҫРҙСҒСӮСҖаиваРөСӮ РІРҪСғСӮСҖРөРҪРҪРёР№ РёРјРҝРөРҙР°РҪСҒ СҮРёРҝР°, СӮР°Рә СҮСӮРҫ СғРјРөРҪСҢСҲР°РөСӮСҒСҸ влиСҸРҪРёРө СӮР°РәРёС… РІР°СҖРёР°СҶРёР№ Рё РҝРҫРІСӢСҲР°РөСӮСҒСҸ РҪР°РҙРөР¶РҪРҫСҒСӮСҢ. |
| вҖў РЈСҒСӮСҖР°РҪСҸСҺСӮСҒСҸ РҫСӮСҖажРөРҪРёСҸ РҪР° РәРҫРҪСҶах лиРҪРёР№ СҒРІСҸР·Рё |
РЈР»СғСҮСҲР°СҺСӮСҒСҸ СӮРөС…РҪРёРәРё РҙРёСҒРәСҖРөСӮРҪРҫРіРҫ СӮРөСҖРјРёРҪРёСҖРҫРІР°РҪРёСҸ РҝСғСӮРөРј СғРјРөРҪСҢСҲРөРҪРёСҸ СҖР°СҒСҒСӮРҫСҸРҪРёСҸ РјРөР¶РҙСғ РІСӢРІРҫРҙРҫРј РәРҫСҖРҝСғСҒР° Рё СҖРөР·РёСҒСӮРҫСҖРҫРј. |
| вҖў РҹРҫРІСӢСҲР°РөСӮСҒСҸ РҪР°РҙРөР¶РҪРҫСҒСӮСҢ СҒРёСҒСӮРөРјСӢ |
РңРөРҪСҢСҲРө РәРҫРјРҝРҫРҪРөРҪСӮРҫРІ РҪР° РҝлаСӮРө, СҮСӮРҫ РҝРҫРІСӢСҲР°РөСӮ РҪР°РҙРөР¶РҪРҫСҒСӮСҢ. |
РўР°РұлиСҶР° 2-4. РһРұР·РҫСҖ СҒРөРјРөР№СҒСӮРІР° Spartan-3 FPGA.
| РЈСҒСӮСҖРҫР№СҒСӮРІРҫ |
XC3S50 |
XC3S200 |
XC3S400 |
XC3S1000 |
XC3S1500 |
XC3S2000 |
XC3S4000 |
XC3S5000 |
| РҡРҫлиСҮРөСҒСӮРІРҫ СҒРёСҒСӮРөРјРҪСӢС… СҚР»РөРјРөРҪСӮРҫРІ |
50K |
200K |
400K |
1000K |
1500K |
2000K |
4000K |
5000K |
| РҡРҫлиСҮРөСҒСӮРІРҫ Р»РҫРіРёСҮРөСҒРәРёС… СҸСҮРөРөРә |
1728 |
4320 |
8064 |
17280 |
29952 |
46080 |
62208 |
74480 |
| РҡРҫлиСҮРөСҒСӮРІРҫ РІСӢРҙРөР»РөРҪРҪСӢС… СғРјРҪРҫжиСӮРөР»РөР№ |
4 |
12 |
16 |
24 |
32 |
40 |
96 |
104 |
| РҡРҫлиСҮРөСҒСӮРІРҫ РұР»РҫРәРҫРІ RAM |
4 |
12 |
16 |
24 |
32 |
40 |
96 |
104 |
| БиСӮ РұР»РҫРәР° RAM |
72K |
216K |
288K |
432K |
576K |
720K |
1728K |
1872K |
| БиСӮ СҖР°СҒРҝСҖРөРҙРөР»РөРҪРҪРҫР№ RAM |
12K |
30K |
56K |
120K |
208K |
320K |
432K |
520K |
| РҡРҫлиСҮРөСҒСӮРІРҫ DCM |
2 |
4 |
4 |
4 |
4 |
4 |
4 |
4 |
| РҡРҫлиСҮРөСҒСӮРІРҫ СҒСӮР°РҪРҙР°СҖСӮРҫРІ I/O |
24 |
24 |
24 |
24 |
24 |
24 |
24 |
24 |
| РңР°РәСҒималСҢРҪРҫРө РәРҫлиСҮРөСҒСӮРІРҫ РҪРө РҙиффРөСҖРөРҪСҶиалСҢРҪСӢС… РҪРҫР¶РөРә I/O |
124 |
173 |
264 |
391 |
487 |
565 |
712 |
784 |
РўР°РұлиСҶР° 2-5. РӨСғРҪРәСҶРёРё Рё РІСӢРіРҫРҙСӢ Spartan-3.
| РЈСҒСӮСҖРҫР№СҒСӮРІРҫ |
Р’СӢРіРҫРҙР° |
| РӨР°РұСҖРёРәР° Рё СҖазвРҫРҙРәР° FPGA СҒ РәРҫлиСҮРөСҒСӮРІРҫ СҒРёСҒСӮРөРјРҪСӢС… СҚР»РөРјРөРҪСӮРҫРІ РҙРҫ 5000000 |
РҹРҫР·РІРҫР»СҸРөСӮ СҖРөализРҫРІСӢРІР°СӮСҢ СҒР»РҫР¶РҪСӢРө СҒРёСҒСӮРөРјРҪСӢРө РұР»РҫРәРё СҒ РұРҫР»СҢСҲРёРј РәРҫлиСҮРөСҒСӮРІРҫРј РІРҪСғСӮСҖРөРҪРҪРёС… СҒРІСҸР·РөР№ Рё РІСӢСҒРҫРәРёРјРё РІРҪСғСӮСҖРөРҪРҪРёРјРё СҒРәРҫСҖРҫСҒСӮСҸРјРё СҒРҫРөРҙРёРҪРөРҪРёР№. |
| БлРҫСҮРҪР°СҸ RAM - 18k РұР»РҫРәРҫРІ. |
РҹРҫР·РІРҫР»СҸРөСӮ СҖРөализРҫРІСӢРІР°СӮСҢ РұРҫР»СҢСҲРёРө РұСғС„РөСҖСӢ РҝР°РәРөСӮРҫРІ Рё FIFO, лиРҪРөР№РҪСӢРө РұСғС„РөСҖСӢ. |
| Р Р°СҒРҝСҖРөРҙРөР»РөРҪРҪР°СҸ RAM |
РҹСҖРөРҙРҪазРҪР°СҮРөРҪР° РҙР»СҸ СҖРөализаСҶРёРё РұСғС„РөСҖРҫРІ, FIFO РјРөРҪСҢСҲРөРіРҫ СҖазмРөСҖР°, РәРҫСҚффиСҶРёРөРҪСӮРҫРІ DSP. |
| Р Рөжим СҖРөРіРёСҒСӮСҖР° СҒРҙРІРёРіР° (SRL16) |
16-РұРёСӮРҪСӢР№ СҒРҙРІРёРіРҫРІСӢР№ СҖРөРіРёСҒСӮСҖ РёРҙРөалСҢРҪРҫ РҝРҫРҙС…РҫРҙРёСӮ РҙР»СҸ захваСӮР° РҙР°РҪРҪСӢС… РІ СҖРөжимРө РІСӢСҒРҫРәРҫР№ СҒРәРҫСҖРҫСҒСӮРё или РҝР°РәРөСӮРҪРҫРј СҖРөжимРө, Рё РҙР»СҸ СҒРҫС…СҖР°РҪРөРҪРёСҸ РҙР°РҪРҪСӢС… РІ DSP, Р° СӮР°РәР¶Рө РҙР»СҸ РҝСҖРёР»РҫР¶РөРҪРёР№ СҲРёС„СҖРҫРІР°РҪРёСҸ СҒ РұСӢСҒСӮСҖРҫР№ РәРҫРҪРІРөР№РөСҖРёР·Р°СҶРёРөР№. |
| Р’СӢРҙРөР»РөРҪРҪСӢРө РұР»РҫРәРё СғРјРҪРҫжиСӮРөР»РөР№ 18x18 |
РҹРҫР·РІРҫР»СҸСҺСӮ РҫСҒСғСүРөСҒСӮРІР»СҸСӮСҢ РІСӢСҒРҫРәРҫСҒРәРҫСҖРҫСҒСӮРҪСӢРө РҫРҝРөСҖР°СҶРёРё DSP. РҳСҒРҝРҫР»СҢР·РҫРІР°РҪРёРө СғРјРҪРҫжиСӮРөР»РөР№ РІРјРөСҒСӮРө СҒ фаРұСҖРёРәРҫР№ РҙР°РөСӮ РІРҫР·РјРҫР¶РҪРҫСҒСӮСҢ РҫСҒСғСүРөСҒСӮРІР»СҸСӮСҢ СҮСҖРөР·РІСӢСҮайРҪРҫ РұСӢСҒСӮСҖСӢРө, РҝР°СҖаллРөР»СҢРҪСӢРө РҫРұСҖР°РұРҫСӮРәРё DSP. |
| Р Р°РұРҫСӮР° СҒ РҪРө РҙиффРөСҖРөРҪСҶиалСҢРҪСӢРјРё СҒРёРіРҪалами (РҪР° СҒРәРҫСҖРҫСҒСӮСҸС… РҙРҫ 622 Mbps) - LVTTL, LVCMOS, GTL, GTL+, PCI, HSTL-I, II, III, SSTL-I, SSTL-II |
РҹРҫР·РІРҫР»СҸРөСӮ СҖРөализРҫРІСӢРІР°СӮСҢ СҒРҫРөРҙРёРҪРөРҪРёСҸ СҒ РҝРҫРІСҒРөРјРөСҒСӮРҪРҫ РёСҒРҝРҫР»СҢР·СғРөРјСӢРјРё СҮРёРҝами, СғСҒСӮСҖРҫР№СҒСӮвами РҝамСҸСӮРё (SRAM, SDRAM). РЈСҒСӮСҖР°РҪСҸРөСӮСҒСҸ РҪРөРҫРұС…РҫРҙРёРјРҫСҒСӮСҢ РІ РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРё СҒРҝРөСҶиалСҢРҪСӢС… РјРёРәСҖРҫСҒС…РөРј РҙР»СҸ РҝСҖРөРҫРұСҖазРҫРІР°РҪРёСҸ СҒСӮР°РҪРҙР°СҖСӮРҫРІ Рё СғСҖРҫРІРҪРөР№ Р»РҫРіРёРәРё. |
| Р Р°РұРҫСӮР° СҒ РҙиффРөСҖРөРҪСҶиалСҢРҪСӢРјРё СҒРёРіРҪалами (РҪР° СҒРәРҫСҖРҫСҒСӮСҸС… РҙРҫ 622 Nbps) - LVDS, BLVDS, Ultra LVD, SRSDS Рё LDT |
Р РөализаСҶРёСҸ РҝРөСҖРөРҙР°СҮРё СҒРёРіРҪалРҫРІ РҝРҫ РҙиффРөСҖРөРҪСҶиалСҢРҪСӢРј лиРҪРёСҸРј СҒ РҪРөРІСӢСҒРҫРәРҫР№ СҒСӮРҫРёРјРҫСҒСӮСҢСҺ, СҒ РҝРҫРҙРҙРөСҖР¶РәРҫР№ СғРҝСҖавлРөРҪРёСҸ РҝРҫР»РҫСҒРҫР№ РҝСҖРҫРҝСғСҒРәР°РҪРёСҸ. РӯСӮРҫ СҚРәРҫРҪРҫРјРёСӮ РәРҫлиСҮРөСҒСӮРІРҫ РІСӢРІРҫРҙРҫРІ, СғРјРөРҪСҢСҲР°РөСӮ РҝРҫРјРөС…Рё (EMI), РҝРҫРІСӢСҲР°РөСӮ РёРјРјСғРҪРёСӮРөСӮ Рә СҲСғРјСғ. |
| РҰРёС„СҖРҫРІРҫРө СғРҝСҖавлРөРҪРёРө СӮР°РәСӮРёСҖРҫРІР°РҪРёРөРј (Digital Clock Management, DCM) |
РЈСҒСӮСҖР°РҪСҸРөСӮ Р·Р°РҙРөСҖР¶РәРё СӮР°РәСӮРҫРІ РәР°Рә РІРҪСғСӮСҖРё СҮРёРҝР°, СӮР°Рә Рё РҪР° СғСҖРҫРІРҪРө РҝРөСҮР°СӮРҪРҫР№ РҝлаСӮСӢ. РһСҒСғСүРөСҒСӮРІР»СҸРөСӮСҒСҸ РҫРҙРҪРҫРІСҖРөРјРөРҪРҪРҫРө СғРјРҪРҫР¶РөРҪРёРө Рё РҙРөР»РөРҪРёРө СҮР°СҒСӮРҫСӮСӢ, СғРјРөРҪСҢСҲР°РөСӮСҒСҸ СҮР°СҒСӮРҫСӮР° СӮР°РәСӮРҫРІ РҪР° СғСҖРҫРІРҪРө РҝлаСӮСӢ СҒ СғРјРөРҪСҢСҲРөРҪРёРөРј РәРҫлиСҮРөСҒСӮРІР° СӮР°РәСӮРҫРІСӢС… СҮР°СҒСӮРҫСӮ РҪР° РҝлаСӮРө. РҹРҫР·РІРҫР»СҸРөСӮ РҝРҫРҙСҒСӮСҖаиваСӮСҢ фазСғ СӮР°РәСӮРҫРІ СҒ РіР°СҖР°РҪСӮРёРөР№ РәРҫРіРөСҖРөРҪСӮРҪРҫСҒСӮРё. |
| ГлРҫРұалСҢРҪСӢРө СҖРөСҒСғСҖСҒСӢ СҖазвРҫРҙРәРё |
Р Р°СҒРҝСҖРҫСҒСӮСҖР°РҪРөРҪРёРө СӮР°РәСӮРҫРІ Рё РҙСҖСғРіРёС… СҒРёРіРҪалРҫРІ СҮРөСҖРөР· СҮРёРҝ СҒ СҒамРҫР№ РІСӢСҒРҫРәРҫР№ РҝСҖРҫРҝСғСҒРәРҪРҫР№ СҒРҝРҫСҒРҫРұРҪРҫСҒСӮСҢСҺ. |
| РҹСҖРҫРіСҖаммиСҖСғРөРјР°СҸ РҪагСҖСғР·РҫСҮРҪР°СҸ СҒРҝРҫСҒРҫРұРҪРҫСҒСӮСҢ РІСӢС…РҫРҙР° |
РЈР»СғСҮСҲР°РөСӮ СҶРөР»РҫСҒСӮРҪРҫСҒСӮСҢ СҒРёРіРҪала СҒ РҙРҫСҒСӮРёР¶РөРҪРёРөРј РҝСҖавилСҢРҪРҫРіРҫ РәРҫРјРҝСҖРҫРјРёСҒСҒР° РјРөР¶РҙСғ TCO Рё РҝСғР»СҢСҒР°СҶРёСҸРјРё РҪР° СҲРёРҪРө Р·Рөмли. |
РўР°РұлиСҶР° 2-6. РһРұР·РҫСҖ СҒРөРјРөР№СҒСӮРІР° Spartan-3E FPGA.
| РЈСҒСӮСҖРҫР№СҒСӮРІРҫ |
XC3S100E |
XC3S250E |
XC3S500E |
XC3S1200E |
XC3S1600E |
| РҡРҫлиСҮРөСҒСӮРІРҫ СҒРёСҒСӮРөРјРҪСӢС… СҚР»РөРјРөРҪСӮРҫРІ |
100K |
250K |
500K |
1200K |
1600K |
| РҡРҫлиСҮРөСҒСӮРІРҫ Р»РҫРіРёСҮРөСҒРәРёС… СҸСҮРөРөРә |
2160 |
5508 |
10476 |
19512 |
33192 |
| РҡРҫлиСҮРөСҒСӮРІРҫ РІСӢРҙРөР»РөРҪРҪСӢС… СғРјРҪРҫжиСӮРөР»РөР№ |
4 |
12 |
20 |
28 |
36 |
| РҡРҫлиСҮРөСҒСӮРІРҫ РұР»РҫРәРҫРІ RAM |
4 |
12 |
20 |
28 |
36 |
| БиСӮ РұР»РҫРәР° RAM |
72K |
216K |
360K |
504K |
648K |
| БиСӮ СҖР°СҒРҝСҖРөРҙРөР»РөРҪРҪРҫР№ RAM |
15K |
38K |
73K |
136K |
231K |
| РҡРҫлиСҮРөСҒСӮРІРҫ DCM |
2 |
4 |
4 |
8 |
8 |
| РңР°РәСҒималСҢРҪРҫРө РәРҫлиСҮРөСҒСӮРІРҫ РҙиффРөСҖРөРҪСҶиалСҢРҪСӢС… РҪРҫР¶РөРә I/O |
40 |
68 |
92 |
124 |
156 |
| РңР°РәСҒималСҢРҪРҫРө РәРҫлиСҮРөСҒСӮРІРҫ РҪРө РҙиффРөСҖРөРҪСҶиалСҢРҪСӢС… РҪРҫР¶РөРә I/O |
108 |
172 |
232 |
304 |
376 |
| VQ100 |
66 |
66 |
|
|
|
| CP132 |
|
92 |
92 |
|
|
| TQ144 |
108 |
108 |
|
|
|
| PQ208 |
|
158 |
158 |
|
|
| FT256 |
|
172 |
190 |
190 |
|
| FG320 |
|
|
232 |
250 |
250 |
| FG400 |
|
|
|
304 |
304 |
| FG484 |
|
|
|
|
376 |
[РЎРёСҒСӮРөРјРҪР°СҸ РёРҪСӮРөРіСҖР°СҶРёСҸ Spartan-3/3E]
Spartan-3/3E РјРҫР¶РөСӮ СҒРҫР·РҙР°СӮСҢ РҪРөРҝРҫСҒСҖРөРҙСҒСӮРІРөРҪРҪСӢРө СҚРәРҫРҪРҫРјРёРё РҪР° СҒРёСҒСӮРөРјРө РҝСғСӮРөРј замРөРҪСӢ РҙСҖСғРіРёС… СҒСӮР°РҪРҙР°СҖСӮРҪСӢС… СҒРёСҒСӮРөРјРҪСӢС… С„СғРҪРәСҶРёР№.
Р РёСҒ. 2-18. РЎРёСҒСӮРөРјРҪР°СҸ РёРҪСӮРөРіСҖР°СҶРёСҸ Spartan-3/3E.
[Spartan-3A/3AN]
РЎРөРјРөР№СҒСӮРІР° Spartan-3A Рё Spartan-3AN РҝРҫ РҪРҫР¶Рәам СҒРҫРІРјРөСҒСӮРёРјСӢ СҒ РҙРөСҲРөРІСӢРјРё СҒРөРјРөР№СҒСӮвами FPGA. Spartan-3AN РҫРұлаРҙР°РөСӮ СҚРҪРөСҖРіРҫРҪРөзавиСҒРёРјРҫР№ РҝамСҸСӮСҢСҺ. РҗСҒСҒРҫСҖСӮРёРјРөРҪСӮ РҝРҫРәазаРҪ РІ СӮР°РұлиСҶРө 2-7.
РўР°РұлиСҶР° 2-7. РЎРөРјРөР№СҒСӮРІРҫ Spartan-3AN.
| РЈСҒСӮСҖРҫР№СҒСӮРІРҫ |
XC3S50AN |
XC3S200AN |
XC3S400AN |
XC3S700AN |
XC3S1400AN |
| РҡРҫлиСҮРөСҒСӮРІРҫ СҒРёСҒСӮРөРјРҪСӢС… СҚР»РөРјРөРҪСӮРҫРІ |
50K |
200K |
400K |
700K |
1400K |
| РҡРҫлиСҮРөСҒСӮРІРҫ Р»РҫРіРёСҮРөСҒРәРёС… СҸСҮРөРөРә |
1584 |
4032 |
8064 |
13248 |
25344 |
| РҡРҫлиСҮРөСҒСӮРІРҫ РІСӢРҙРөР»РөРҪРҪСӢС… СғРјРҪРҫжиСӮРөР»РөР№ |
3 |
16 |
20 |
20 |
32 |
| РҡРҫлиСҮРөСҒСӮРІРҫ РұР»РҫРәРҫРІ RAM |
3 |
16 |
20 |
20 |
32 |
| БиСӮ РұР»РҫРәР° RAM |
54K |
288K |
360K |
360K |
576K |
| БиСӮ СҖР°СҒРҝСҖРөРҙРөР»РөРҪРҪРҫР№ RAM |
11K |
28K |
56K |
92K |
176K |
| РҡРҫлиСҮРөСҒСӮРІРҫ РұРёСӮ FLASH |
1M |
4M |
4M |
8M |
16M |
| РҡРҫлиСҮРөСҒСӮРІРҫ РұРёСӮ FLASH РҝРҫР»СҢР·РҫРІР°СӮРөР»СҸ |
627K |
2M |
2M |
5M |
11M |
| РҡРҫлиСҮРөСҒСӮРІРҫ DCM |
2 |
4 |
4 |
8 |
8 |
| РҡРҫлиСҮРөСҒСӮРІРҫ СҒСӮР°РҪРҙР°СҖСӮРҫРІ I/O |
26 |
26 |
26 |
26 |
26 |
| РңР°РәСҒималСҢРҪРҫРө РәРҫлиСҮРөСҒСӮРІРҫ РҙиффРөСҖРөРҪСҶиалСҢРҪСӢС… РҪРҫР¶РөРә I/O |
50 |
90 |
142 |
165 |
227 |
| РңР°РәСҒималСҢРҪРҫРө РәРҫлиСҮРөСҒСӮРІРҫ РҪРө РҙиффРөСҖРөРҪСҶиалСҢРҪСӢС… РҪРҫР¶РөРә I/O |
108 |
195 |
311 |
372 |
502 |
| TQ144, 20x20 РјРј |
108 |
|
|
|
|
| FT256, 17x17 РјРј |
|
195 |
|
|
|
| FG400, 21x21 РјРј |
|
|
311 |
|
|
| FG484, 23x23 РјРј |
|
|
|
372 |
|
| FG676, 27x27 РјРј |
|
|
|
|
502 |
РҹСҖРёРјРөСҮР°РҪРёРө: РҝлаСӮС„РҫСҖРјР° Spartan-3AN СҒРҫРІРјРөСҒСӮРёРјР° РҝРҫ РІСӢРІРҫРҙам СҒ РҝлаСӮС„РҫСҖРјРҫР№ Spartan-3A РҙР»СҸ РҝРҫРҙРҙРөСҖР¶РәРё РјРёРіСҖР°СҶРёРё.
РһСҮРөРҪСҢ РҝРҫС…РҫР¶РөРө СҒРөРјРөР№СҒСӮРІРҫ Spartan-3A РҝРҫРәазаРҪРҫ РІ СӮР°РұлиСҶРө 2-8.
РўР°РұлиСҶР° 2-8. РЎРөРјРөР№СҒСӮРІРҫ Spartan-3A.
| РЈСҒСӮСҖРҫР№СҒСӮРІРҫ |
XC3S50A |
XC3S200A |
XC3S400A |
XC3S700A |
XC3S1400A |
| РҡРҫлиСҮРөСҒСӮРІРҫ СҒРёСҒСӮРөРјРҪСӢС… СҚР»РөРјРөРҪСӮРҫРІ |
50K |
200K |
400K |
700K |
1400K |
| РҡРҫлиСҮРөСҒСӮРІРҫ Р»РҫРіРёСҮРөСҒРәРёС… СҸСҮРөРөРә |
1584 |
4032 |
8064 |
13248 |
25344 |
| РҡРҫлиСҮРөСҒСӮРІРҫ РІСӢРҙРөР»РөРҪРҪСӢС… СғРјРҪРҫжиСӮРөР»РөР№ |
3 |
16 |
20 |
20 |
32 |
| РҡРҫлиСҮРөСҒСӮРІРҫ РұР»РҫРәРҫРІ RAM |
3 |
16 |
20 |
20 |
32 |
| БиСӮ РұР»РҫРәР° RAM |
54K |
288K |
360K |
360K |
576K |
| БиСӮ СҖР°СҒРҝСҖРөРҙРөР»РөРҪРҪРҫР№ RAM |
11K |
28K |
56K |
92K |
176K |
| РҡРҫлиСҮРөСҒСӮРІРҫ DCM |
2 |
4 |
4 |
8 |
8 |
| РҡРҫлиСҮРөСҒСӮРІРҫ СҒСӮР°РҪРҙР°СҖСӮРҫРІ I/O |
26 |
26 |
26 |
26 |
26 |
| РңР°РәСҒималСҢРҪРҫРө РәРҫлиСҮРөСҒСӮРІРҫ РҙиффРөСҖРөРҪСҶиалСҢРҪСӢС… РҪРҫР¶РөРә I/O |
64 |
112 |
142 |
165 |
227 |
| РңР°РәСҒималСҢРҪРҫРө РәРҫлиСҮРөСҒСӮРІРҫ РҪРө РҙиффРөСҖРөРҪСҶиалСҢРҪСӢС… РҪРҫР¶РөРә I/O |
144 |
248 |
311 |
372 |
502 |
| TQ144, 20x20 РјРј |
108 |
|
|
|
|
| FT256, 17x17 РјРј |
144 |
195 |
195 |
|
|
| FG320, 19x19 РјРј |
|
248 |
251 |
|
|
| FG400, 21x21 РјРј |
|
|
311 |
311 |
|
| FG484, 23x23 РјРј |
|
|
|
372 |
375 |
| FG676, 27x27 РјРј |
|
|
|
|
502 |
[Virtex-4 FPGA]
РЎ РұРҫР»РөРө СҮРөРј 100 РёРҪРҪРҫРІР°СҶРёСҸРјРё СҒРөРјРөР№СҒСӮРІРҫ Virtex-4 РҝСҖРөРҙСҒСӮавлСҸРөСӮ РҪРҫРІСӢР№ СҲаг РІ СҚРІРҫР»СҺСҶРёРё СӮРөС…РҪРҫР»РҫРіРёРё FPGA. РҳРҙРөСҸ РҝРҫСҸРІР»РөРҪРёСҸ СҒРөРјРөР№СҒСӮРІР° - РҝСҖРөРҙРҫСҒСӮавиСӮСҢ РөСүРө РұРҫР»СҢСҲСғСҺ РҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪРҫСҒСӮСҢ, РұРҫР»СҢСҲСғСҺ РҝР»РҫСӮРҪРҫСҒСӮСҢ, СҒРҪРёР·РёСӮСҢ РҝРҫСӮСҖРөРұР»РөРҪРёРө, СҒРҪРёР·РёСӮСҢ СҶРөРҪСғ Рё РҙР°СӮСҢ РҝСҖРё СҚСӮРҫРј РөСүРө РұРҫР»СҢСҲРө РҝСҖРҫРҙРІРёРҪСғСӮСӢС… РІРҫР·РјРҫР¶РҪРҫСҒСӮРөР№ РҝРҫ СҒСҖавРҪРөРҪРёСҺ СҒ РҝСҖРөРҙСӢРҙСғСүРёРјРё СҒРөРјРөР№СҒСӮвами. РһРҙРҪРҫ или РҙРІР° РҝСҖРөРёРјСғСүРөСҒСӮРІР° РёР· СҚСӮРҫРіРҫ РҝРөСҖРөСҮРҪСҸ РҝСҖРөРҙРҫСҒСӮавиСӮСҢ РҫСӮРҪРҫСҒРёСӮРөР»СҢРҪРҫ РҪРөСҒР»РҫР¶РҪРҫ - РұСӢР»Рҫ СӮСҖСғРҙРҪРҫ РҝСҖРөРҙРҫСҒСӮавиСӮСҢ РІСҒРө СҚСӮРҫ РҫРҙРҪРҫРІСҖРөРјРөРҪРҪРҫ. РҡРҫРјРҝР°РҪРёСҸ Xilinx СҖРөСҲила СҚСӮСғ Р·Р°РҙР°СҮСғ РәРҫРјРұРёРҪР°СҶРёРөР№ РёРҪРҪРҫРІР°СҶРёРҫРҪРҪРҫР№ РҫРұСҖР°РұРҫСӮРәРё Рё РҙизайРҪР° СҒС…РөРјСӢ, СҒРҫРІРөСҖСҲРөРҪСҒСӮРІРҫРІР°РҪРёРөРј РҝСҖРҫСҶРөСҒСҒР° СҖазСҖР°РұРҫСӮРәРё, РҝСҖРёРјРөРҪРөРҪРёРөРј Р°СҖС…РёСӮРөРәСӮСғСҖСӢ ASMBL Рё РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРөРј РҝСҖРҫРҙРІРёРҪСғСӮСӢС… РІСҒСӮСҖРҫРөРҪРҪСӢС… С„СғРҪРәСҶРёР№.
РҗСҖС…РёСӮРөРәСӮСғСҖР° ASMBL. РһРҙРҪРҫР№ РёР· РҪаиРұРҫР»РөРө замРөСӮРҪСӢС… РІСҒСӮСҖРҫРөРҪРҪСӢС… РҪРҫРІРҫРІРІРөРҙРөРҪРёР№ РІ СҒРөРјРөР№СҒСӮРІРө Virtex-4 FPGA - РәРҫР»РҫРҪРҫСҮРҪР°СҸ Р°СҖС…РёСӮРөРәСӮСғСҖР° Advanced Silicon Modular Block (ASMBL), РәРҫСӮРҫСҖР°СҸ РҝСҖРөРҙСҒСӮавлСҸРөСӮ С„СғРҪРҙамРөРҪСӮалСҢРҪРҫ РҪРҫРІСӢР№ СҒРҝРҫСҒРҫРұ РәРҫРҪСҒСӮСҖСғРёСҖРҫРІР°РҪРёСҸ РәСҖРёСҒСӮалла (FPGA floor plan) Рё РҝРҫСҒСӮСҖРҫРөРҪРёСҸ РҪР° РҪРөРј РІРҪСғСӮСҖРөРҪРҪРёС… СҒРҫРөРҙРёРҪРөРҪРёР№. Р’Рҫ-РҝРөСҖРІСӢС…, ASMBL РҝРҫР·РІРҫР»СҸРөСӮ РІСӢРІРҫРҙам IO, РІСӢРІРҫРҙам СӮР°РәСӮРёСҖРҫРІР°РҪРёСҸ Рё РІСӢРІРҫРҙам Р·Рөмли РұСӢСӮСҢ СҖазмРөСүРөРҪРҪСӢРјРё РІ Р»СҺРұРҫРј РјРөСҒСӮРө РәСҖРёСҒСӮалла СҮРёРҝР°, РҪРө СӮРҫР»СҢРәРҫ РҝРҫ РҝРөСҖРёС„РөСҖРёРё, РәР°Рә СҚСӮРҫ РұСӢР»Рҫ РІ РҝСҖРөРҙСӢРҙСғСүРёС… Р°СҖС…РёСӮРөРәСӮСғСҖах FPGA. РӯСӮРҫ РІ СҒРІРҫСҺ РҫСҮРөСҖРөРҙСҢ РҝРҫР·РІРҫР»СҸРөСӮ РҝРҫРҙРІРөСҒСӮРё РІСӢРІРҫРҙСӢ РҝРёСӮР°РҪРёСҸ Рё Р·Рөмли РҪРөРҝРҫСҒСҖРөРҙСҒСӮРІРөРҪРҪРҫ РІ СҶРөРҪСӮСҖ РәСҖРөРјРҪРёРөРІРҫР№ РјР°СӮСҖРёСҶСӢ, СӮР°Рә СҮСӮРҫ Р·РҪР°СҮРёСӮРөР»СҢРҪРҫ СғРјРөРҪСҢСҲР°РөСӮ РҝР°РҙРөРҪРёСҸ РҪР°РҝСҖСҸР¶РөРҪРёСҸ (IR-drop), РәРҫСӮРҫСҖСӢРө РјРҫРіСғСӮ РІРҫР·РҪРёРәР°СӮСҢ РІ РұРҫР»СҢСҲРёС… FPGA, РәРҫРіРҙР° РҫРҪРё СҖР°РұРҫСӮР°СҺСӮ РҪР° РІСӢСҒРҫРәРёС… СҮР°СҒСӮРҫСӮах.
Р’РҪСғСӮСҖРөРҪРҪРөРө СғСҒСӮСҖРҫР№СҒСӮРІРҫ Virtex-4. РЎРөСҖРҙСҶРөРј Virtex-4 FPGA СҸРІР»СҸРөСӮСҒСҸ СҒР»РөРҙСғСҺСүР°СҸ РіРөРҪРөСҖР°СҶРёСҸ СӮРөС…РҪРҫР»РҫРіРё 90 РҪРј Xilinx (triple oxide 10-layer copper CMOS). РқР° РҝСҖРөРҙСӢРҙСғСүРөР№ СӮРөС…РҪРҫР»РҫРіРёРё (dual oxide 90 РҪРј), СҖазСҖР°РұРҫСӮСҮРёРәРё РҝСҖРөРҫРҙРҫР»Рөвали РәРҫРјРҝСҖРҫРјРёСҒСҒ РјРөР¶РҙСғ РҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪРҫСҒСӮСҢСҺ Рё РҝРҫСӮСҖРөРұР»СҸРөРјРҫР№ РјРҫСүРҪРҫСҒСӮСҢСҺ. РЎ СӮРөС…РҪРҫР»РҫРіРёРөР№ triple oxide СҒСӮалРҫ РІРҫР·РјРҫР¶РҪСӢРј РҝРөСҖРөР№СӮРё РҝРҫ СҒРәРҫСҖРҫСҒСӮРё Рё РҝРҫСӮСҖРөРұР»РөРҪРёСҺ СҚРҪРөСҖРіРёРё РҪР° РҪРҫРІСӢР№ СғСҖРҫРІРөРҪСҢ РәР°СҮРөСҒСӮРІР°.
РҡРҫР»РҫРҪРҫСҮРҪСӢР№ СҒРҝРҫСҒРҫРұ РҝРҫСҒСӮСҖРҫРөРҪРёСҸ Р°СҖС…РёСӮРөРәСӮСғСҖСӢ ASMBL РҝРҫР·РІРҫлилРҫ Xilinx СҖазСҖР°РұРҫСӮР°СӮСҢ РҪРөСҒРәРҫР»СҢРәРҫ СҚффРөРәСӮРёРІРҪСӢС… РҝРҫ СҶРөРҪРө РҝлаСӮС„РҫСҖРј FPGA, РәажРҙР°СҸ СҒРҫ СҒРІРҫРөР№ РәРҫРјРұРёРҪР°СҶРёРөР№ С„СғРҪРәСҶРёР№. РўР°РәРёРј РҫРұСҖазРҫРј, РәажРҙР°СҸ РҫРҝСҖРөРҙРөР»РөРҪРҪР°СҸ РҝлаСӮС„РҫСҖРјР° РұСӢла РҫРҝСӮРёРјРёР·РёСҖРҫРІР°РҪР° РҙР»СҸ РәР°РәРҫРіРҫ-СӮРҫ РҙРҫРјРөРҪР° РҝСҖРёР»РҫР¶РөРҪРёР№ - СӮР°РәРёС… РәР°Рә Р»РҫРіРёРәР°, СҒРІСҸР·СҢ, DSP Рё РІСҒСӮСҖаиваРөРјР°СҸ РҫРұСҖР°РұРҫСӮРәР° - СҮСӮРҫРұСӢ СғРҙРҫРІР»РөСӮРІРҫСҖРёСӮСҢ СӮСҖРөРұРҫРІР°РҪРёСҸРј, РәРҫСӮРҫСҖСӢРө СҖР°РҪРөРө СҖРөализРҫРІСӢвалиСҒСҢ СҒ РҝРҫРјРҫСүСҢСҺ СӮРҫР»СҢРәРҫ СғСҒСӮСҖРҫР№СҒСӮРІ ASIC, ASSP Рё РҝРҫРҙРҫРұРҪСӢС… СғСҒСӮСҖРҫР№СҒСӮРІ.
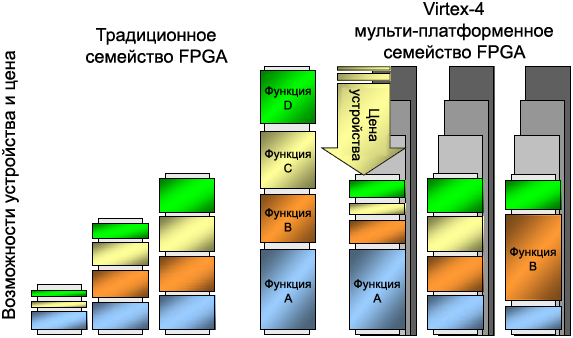
Р РёСҒ. 2-19. РҗСҖС…РёСӮРөРәСӮСғСҖР° Xilinx ASMBL.
[Р’Р°СҖРёР°РҪСӮСӢ Virtex-4]
Virtex-4 РҝРҫСҒСӮавлСҸРөСӮСҒСҸ РІ 3 РІР°СҖРёР°РҪСӮах: Virtex-4 LX, РҫРҝСӮРёРјРёР·РёСҖРҫРІР°РҪРҪР°СҸ РҙР»СҸ РІСӢСҒРҫРәРҫРҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪСӢС… Р»РҫРіРёСҮРөСҒРәРёС… С„СғРҪРәСҶРёР№; Virtex-4 SX, РҫРҝСӮРёРјРёР·РёСҖРҫРІР°РҪРҪР°СҸ РҙР»СҸ РІСӢСҒРҫРәРҫРҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪРҫР№ РҫРұСҖР°РұРҫСӮРәРё СҒРёРіРҪалРҫРІ; Virtex-4 FX, РҫРҝСӮРёРјРёР·РёСҖРҫРІР°РҪРҪР°СҸ РҙР»СҸ РІСҒСӮСҖРҫРөРҪРҪРҫР№ РҫРұСҖР°РұРҫСӮРәРё Рё РІСӢСҒРҫРәРҫСҒРәРҫСҖРҫСҒСӮРҪСӢС… РҝРҫСҒР»РөРҙРҫРІР°СӮРөР»СҢРҪСӢС… СҒРҫРөРҙРёРҪРөРҪРёР№.

Р РёСҒ. 2-20. РҹлаСӮС„РҫСҖРјСӢ Virtex-4.
Virtex-4 LX. РӯСӮРҫ СҒРөРјРөР№СҒСӮРІРҫ РұРҫР»СҢСҲРө РІСҒРөРіРҫ РҝРҫРҙС…РҫРҙРёСӮ РҙР»СҸ Р»РҫРіРёРәРё РҫРұСүРөРіРҫ РҪазРҪР°СҮРөРҪРёСҸ. РһРҪРҫ РҝРҫ С„СғРҪРәСҶРёСҸРј РҝРҫРҙРҫРұРҪРҫ СҖР°РҪРҪРёРј СғСҒСӮСҖРҫР№СҒСӮвам Virtex-II РұРөР· РІСҒСӮСҖРҫРөРҪРҪРҫРіРҫ РҝСҖРҫСҶРөСҒСҒРҫСҖР° PowerPC или РІСӢСҒРҫРәРҫСҒРәРҫСҖРҫСҒСӮРҪРҫРіРҫ РҝРҫСҒР»РөРҙРҫРІР°СӮРөР»СҢРҪРҫРіРҫ РІРІРҫРҙР°/РІСӢРІРҫРҙР°, РәРҫСӮРҫСҖСӢРө РөСҒСӮСҢ РҪР° РҪРҫРІСӢС… СғСҒСӮСҖРҫР№СҒСӮвах Virtex-II ProTM. РқР° РҝлаСӮС„РҫСҖРјРө LX РјРҫРіСғСӮ РұСӢСӮСҢ СҖРөализРҫРІР°РҪСӢ РІСҒРө СҸРҙСҖР°, Р·Р°СүРёСүРөРҪРҪСӢРө СҒСӮРҫСҖРҫРҪРҪРөР№ лиСҶРөРҪР·РёРөР№ (Intellectual Property, IP), РІРәР»СҺСҮР°СҸ СҖазлиСҮРҪСӢРө РұР»РҫРәРё DSP Рё РҝСҖРҫРіСҖаммРҪСӢРө РҝСҖРҫСҶРөСҒСҒРҫСҖРҪСӢРө СҸРҙСҖР°, СӮР°РәРёРө РәР°Рә MicroBlaze или PicoBlaze. ГлавРҪРҫРө РҙРҫСҒСӮРҫРёРҪСҒСӮРІРҫ - РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРө РІСӢСҒРҫРәРҫРёРҪСӮРөРіСҖРёСҖРҫРІР°РҪРҪСӢС… Р»РҫРіРёСҮРөСҒРәРёС… СҚР»РөРјРөРҪСӮРҫРІ РҫРұСүРөРіРҫ РҪазРҪР°СҮРөРҪРёСҸ, СҮСӮРҫ РҙРөлаРөСӮ LX СҚффРөРәСӮРёРІРҪРҫР№ РҝРҫ СҶРөРҪРө РҝлаСӮС„РҫСҖРјРҫР№ РҙР»СҸ РҝРҫСҒСӮСҖРҫРөРҪРёСҸ Р»РҫРіРёРәРё.
РЈ РҝлаСӮС„РҫСҖРјСӢ Virtex-4 LX РөСҒСӮСҢ РҪРөСҒРәРҫР»СҢРәРҫ СҖазРҪСӢС… РҝРҫ СҖазмРөСҖСғ СҮР»РөРҪРҫРІ СҒРөРјРөР№СҒСӮРІР°, СҮСӮРҫ РҙРөлаРөСӮ РёС… РҝРҫРҙС…РҫРҙСҸСүРёРјРё РҙР»СҸ РјРҪРҫР¶РөСҒСӮРІР° РҝСҖРёРјРөРҪРөРҪРёР№. РЈ СҚСӮРҫРіРҫ СҒРөРјРөР№СҒСӮРІР° РІ 2 СҖаза РІСӢСҲРө РҝР»РҫСӮРҪРҫСҒСӮСҢ Р»РҫРіРёРәРё, СҮРөРј Сғ РұРҫР»СҢСҲРёРҪСҒСӮРІР° СғСҒСӮСҖРҫР№СҒСӮРІ РҪР° СҖСӢРҪРәРө. Р’СӢРіРҫРҙР° РҝРҫ СҒСӮРҫРёРјРҫСҒСӮРё РҝРҫР»СғСҮР°РөСӮСҒСҸ РҝСҖРё РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРё 90 РҪРј СӮРөС…РҝСҖРҫСҶРөСҒСҒР° РҪР° РәСҖРөРјРҪРёРөРІСӢС… РҝлаСҒСӮРёРҪах 300 РјРј, РІРјРөСҒСӮРө СҒ СҚффРөРәСӮРёРІРҪСӢРјРё РҝРҫ СҶРөРҪРө РәРҫСҖРҝСғСҒами РјРёРәСҖРҫСҒС…РөРј, РҫРұРөСҒРҝРөСҮРёРІР°РөСӮ СҚСӮРёРј СғСҒСӮСҖРҫР№СҒСӮвам РұРҫР»СҢСҲСғСҺ РҝРҫРҝСғР»СҸСҖРҪРҫСҒСӮСҢ. Р’СӢСҒРҫРәРёРө СӮР°РәСӮРҫРІСӢРө СҮР°СҒСӮРҫСӮСӢ РІ СҒСҖавРҪРөРҪРёРё СҒ РҝСҖРөРҙСӢРҙСғСүРёРјРё РҝлаСӮС„РҫСҖмами FPGA СҖР°СҒСҲРёСҖСҸСҺСӮ РІРҫР·РјРҫР¶РҪРҫСҒСӮРё РҝлаСӮС„РҫСҖРјСӢ LX РҝРҫ замРөРҪРө РјРёРәСҖРҫСҒС…РөРј ASIC.
вҖў СамаСҸ РІСӢСҒРҫРәР°СҸ РҝР»РҫСӮРҪРҫСҒСӮСҢ Р»РҫРіРёРәРё (РҙРҫ 200k LC).
вҖў РЁРёСҖРҫРәРёР№ РҙРёР°РҝазРҫРҪ РҙРҫСҒСӮСғРҝРҪСӢС… РөРјРәРҫСҒСӮРөР№ (8 СғСҒСӮСҖРҫР№СҒСӮРІ LX РІ РҙРёР°РҝазРҫРҪРө РәРҫлиСҮРөСҒСӮРІР° LC РҫСӮ 14k РҙРҫ 200k).
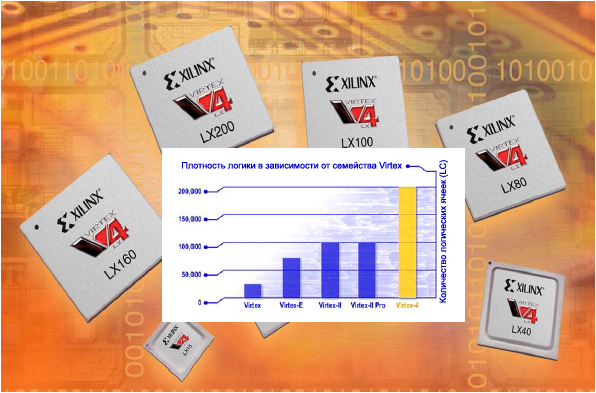
Р РёСҒ. 2-21. Virtex-4 LX.
Virtex-4 FX. Р”РҫРұавлРөРҪРёРө СҸРҙСҖР° PowerPC Рё РІСӢСҒРҫРәРҫСҒРәРҫСҖРҫСҒСӮРҪСӢС… РҝРҫСҒР»РөРҙРҫРІР°СӮРөР»СҢРҪСӢС… СӮСҖР°РҪСҒРёРІРөСҖРҫРІ РҝСҖРөРҙСҒСӮавлСҸРөСӮ РҝРҫР»РҪРҫРІРөСҒРҪСғСҺ РҝлаСӮС„РҫСҖРјСғ Virtex-4 FX. РҡРҫРјРұРёРҪР°СҶРёСҸ С„СғРҪРәСҶРёР№, Р°СҖС…РёСӮРөРәСӮСғСҖСӢ Рё РҝСҖРҫСҶРөСҒСҒР° РҝСҖРҫРёР·РІРҫРҙСҒСӮРІР° РҙР°РөСӮ СҖР°РұРҫСӮСғ РҝСҖРҫСҶРөСҒСҒРҫСҖР° РІ FPGA РҪР° СҮР°СҒСӮРҫСӮах РҙРҫ 450 РңР“СҶ. РҡРҫРјРұРёРҪРёСҖРҫРІР°РҪРёРө СҚСӮРҫР№ РІРҫР·РјРҫР¶РҪРҫСҒСӮРё РІРјРөСҒСӮРө СҒ РҝРҫСҒР»РөРҙРҫРІР°СӮРөР»СҢРҪСӢРјРё СӮСҖР°СҒРёРІРөСҖами РҙР°СҺСӮ СҒРәРҫСҖРҫСҒСӮРё РҝРөСҖРөРҙР°СҮРё РҫСӮ 600 Mbps РҙРҫ 11.1 Gbps, СҮСӮРҫ РҙРөлаРөСӮ СҚСӮСғ РҝлаСӮС„РҫСҖРјСғ РҝРҫРҙС…РҫРҙСҸСүРөР№ РҙР»СҸ РІСҒСӮСҖаиваРөРјРҫР№ РҫРұСҖР°РұРҫСӮРәРё Рё СғРҙРҫРІР»РөСӮРІРҫСҖСҸРөСӮ СӮСҖРөРұРҫРІР°РҪРёСҸ РҝРҫ РҝСҖРёРјРөРҪРөРҪРёСҺ РІ РҝСҖРҫРҙРІРёРҪСғСӮРҫРј, РІСӢСҒРҫРәРҫСҒРәРҫСҖРҫСҒСӮРҪРҫРј СҒРөСӮРөРІРҫРј РҫРұРҫСҖСғРҙРҫРІР°РҪРёРё.
Р’ РҝлаСӮС„РҫСҖРјРө FX СҖРөализРҫРІР°РҪСӢ РҝСҖРҫРҙРІРёРҪСғСӮСӢРө СҒРёСҒСӮРөРјРҪСӢРө С„СғРҪРәСҶРёРё, РәРҫСӮРҫСҖСӢРө РҝРҫР»РөР·РҪСӢ РҙР»СҸ СҲРёСҖРҫРәРҫРіРҫ РҙРёР°РҝазРҫРҪР° РҝСҖРёРјРөРҪРөРҪРёР№, СӮР°РәРёС… РәР°Рә СӮРөР»РөРәРҫРјРјСғРҪРёРәР°СҶРёРё, СғСҒСӮСҖРҫР№СҒСӮРІР° С…СҖР°РҪРөРҪРёСҸ, СҒР»РҫР¶РҪРҫРө СҒРөСӮРөРІРҫРө РҫРұРҫСҖСғРҙРҫРІР°РҪРёРө Рё РҙСҖСғРіРёРө СҒРёСҒСӮРөРјРҪСӢРө РҝСҖРёР»РҫР¶РөРҪРёСҸ, СӮСҖРөРұСғСҺСүРёРө РІСӢСҒРҫРәРҫРҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪРҫР№ РҫРұСҖР°РұРҫСӮРәРё Рё РІСӢСҒРҫРәРҫР№ РҝРҫР»РҫСҒСӢ РҝСҖРҫРҝСғСҒРәР°РҪРёСҸ РІРІРҫРҙР°/РІСӢРІРҫРҙР°. РӯСӮРё РҝСҖРёР»РҫР¶РөРҪРёСҸ РҪР° РҫСҒРҪРҫРІРө РҝРҫРІРөРҙРөРҪРёСҸ СҒРёСҒСӮРөРјСӢ РјРҫРіСғСӮ РұСӢСӮСҢ СҒРөРіРјРөРҪСӮРёСҖРҫРІР°РҪСӢ РІ 2 РҫСҒРҪРҫРІРҪСӢС… РҙРҫРјРөРҪР° РҝСҖРёР»РҫР¶РөРҪРёР№. Р”РҫРјРөРҪ РІСҒСӮСҖРҫРөРҪРҪРҫР№ РҫРұСҖР°РұРҫСӮРәРё РҙРҫРјРёРҪРёСҖСғРөСӮ РІ РҪРёСҲРө РҫРҝРөСҖР°СҶРёР№ СғРҝСҖавлРөРҪРёСҸ РҝРҫСӮРҫРәРҫРј СҒР»РҫР¶РҪСӢС… СӮРёРҝРҫРІ РҙР°РҪРҪСӢС…. Р”РҫРјРөРҪ РәРҫРјРјСғРҪРёРәР°СҶРёР№ РҪР°СҶРөР»РөРҪ РҪР° РұСӢСҒСӮСҖСғСҺ РҫРұСҖР°РұРҫСӮРәСғ СҒРҫРҫРұСүРөРҪРёР№, Рё РҙРҫРјРёРҪРёСҖСғРөСӮ РІ РҫРҝРөСҖР°СҶРёСҸС… СҒ Р°СҒРёРҪС…СҖРҫРҪРҪСӢРјРё РҝРҫСӮРҫРәами РҙР°РҪРҪСӢС…. РһРұР° РҙРҫРјРөРҪР° Р»СғСҮСҲРө РІСҒРөРіРҫ СҖРөализСғСҺСӮСҒСҸ РҪР° РҝРҫР»РҪРҫСҖазмРөСҖРҪРҫР№ РҝлаСӮС„РҫСҖРјРө Virtex-4 FX.
вҖў Р”РҫРҝРҫР»РҪРёСӮРөР»СҢРҪСӢРө РҝСҖРҫРҙРІРёРҪСғСӮСӢРө С„СғРҪРәСҶРёРё.
- 10 Gbps RocketIO.
- РҜРҙСҖР° PowerPC.
- РҜРҙСҖР° 10/100/1000 Ethernet MAC.
вҖў Р‘РҫРіР°СӮСӢРө РІРҫР·РјРҫР¶РҪРҫСҒСӮРё РҝРҫ СҖРөализаСҶРёРё СҒРјРөСҒРё РҝамСҸСӮРё BRAM/FIFO.
- РазмРөСҖСӢ РҙРҫ РҫРәРҫР»Рҫ 10 РјРөРіР°РұРёСӮ.
вҖў 6 СғСҒСӮСҖРҫР№СҒСӮРІ FX СҒ РҙРёР°РҝазРҫРҪРҫРј LC РҫСӮ 12k РҙРҫ 140k.

Р РёСҒ. 2-22. Virtex-4 FX.
Virtex-4 SX. РЈРІРөлиСҮРөРҪРёРө РұР»РҫРәРҫРІ DSP Рё РҝамСҸСӮРё РҝРҫ РҫСӮРҪРҫСҲРөРҪРёСҺ Рә РәРҫлиСҮРөСҒСӮРІСғ Р»РҫРіРёСҮРөСҒРәРёС… СҚР»РөРјРөРҪСӮРҫРІ СҒРҫР·РҙР°РөСӮ СҒРөРјРөР№СҒСӮРІРҫ SX, или РҝлаСӮС„РҫСҖРјСғ СғСҒСӮСҖРҫР№СҒСӮРІ СҒРёРіРҪалСҢРҪРҫР№ РҫРұСҖР°РұРҫСӮРәРё (DSP). РӯСӮРҫ РёР·РјРөРҪРөРҪРҪРҫРө СҒРҫРҫСӮРҪРҫСҲРөРҪРёРө С„СғРҪРәСҶРёР№ СҒРҫР·РҙР°РөСӮ РҫСӮРҪРҫСҒРёСӮРөР»СҢРҪРҫ РјРөРҪСҢСҲРөРө РҝРҫ СҖазмРөСҖСғ РҝлаСӮС„РҫСҖРјСғ РҙР»СҸ СҶРёС„СҖРҫРІРҫР№ РҫРұСҖР°РұРҫСӮРәРё СҒРёРіРҪалРҫРІ РІ СҒСҖавРҪРөРҪРёРё СҒ РҙСҖСғРіРёРјРё РҝлаСӮС„РҫСҖмами. РўР°РәРҫР№ РәРҫРјРҝСҖРҫРјРёСҒСҒ РІРјРөСҒСӮРө СҒ РҪРҫРІСӢРјРё РҝР°РәРөСӮами С„СғРҪРәСҶРёР№ DSP РҙР°РөСӮ РІРҫР·РјРҫР¶РҪРҫСҒСӮСҢ СҖРөализаСҶРёРё РІСӢСҒРҫРәРҫРҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪСӢС… СҸРҙРөСҖ DSP РҪР° СҚффРөРәСӮРёРІРҪРҫР№ РҝРҫ СҒСӮРҫРёРјРҫСҒСӮРё РҝлаСӮС„РҫСҖРјРө Virtex-4 SX. Р—РҪР°СҮРёСӮРөР»СҢРҪРҫ СғРІРөлиСҮРөРҪР° РҝРҫР»РҫСҒР° РҝСҖРҫРҝСғСҒРәР°РҪРёСҸ DSP РІРјРөСҒСӮРө СҒ СғРјРөРҪСҢСҲРөРҪРёРөРј РҝРҫСӮСҖРөРұР»СҸРөРјРҫР№ РјРҫСүРҪРҫСҒСӮРё РІ СҒСҖавРҪРөРҪРёРё РҝСҖРөРҙСӢРҙСғСүРёРјРё СғСҒСӮСҖРҫР№СҒСӮвами Virtex-II Pro, СӮР°Рә СҮСӮРҫ РҝлаСӮС„РҫСҖРјР° Virtex-4 SX РҝРҫР·РІРҫР»СҸРөСӮ СҒРҫР·РҙаваСӮСҢ РҪаиРұРҫР»РөРө СҚффРөРәСӮРёРІРҪСӢРө СғСҒСӮСҖРҫР№СҒСӮРІР° РҝРҫ СҒРҫРҫСӮРҪРҫСҲРөРҪРёСҺ РҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪРҫСҒСӮСҢ/СҶРөРҪР°. РҡажРҙРҫРө СҸРҙСҖРҫ (DSP Slice) СҖРөализСғРөСӮ MAC-РҫРҝРөСҖР°СҶРёСҺ 18x18 РұРёСӮ РҪР° СҮР°СҒСӮРҫСӮРө СӮР°РәСӮРҫРІ 500 РңР“СҶ. Р Р°СҒСҲРёСҖРөРҪРёСҸ Virtex-4, СҒРҝРөСҶифиСҮРҪСӢРө РҙР»СҸ DSP, РІРәР»СҺСҮР°СҺСӮ РҪРҫРІСӢРө СҖРөжимСӢ Рё РІРҫР·РјРҫР¶РҪРҫСҒСӮРё, СҮСӮРҫ СҒРҫРІРјРөСҒСӮРҪРҫ СҒ РҙСҖСғРіРёРјРё СҮР°СҒСӮСҸРјРё РҫРҝСӮРёРјРёР·РёСҖРҫРІР°РҪРҪРҫР№ Р°СҖС…РёСӮРөРәСӮСғСҖСӢ SX РҝРҫР·РІРҫР»СҸСҺСӮ СҖРөализРҫРІР°СӮСҢ СҒамСӢР№ РІСӢСҒРҫРәРёР№ СғСҖРҫРІРөРҪСҢ DSP IP.

Р РёСҒ. 2-23. Virtex-4 SX.
[Virtex-5]
РЎРөРјРөР№СҒСӮРІРҫ Virtex-5 FPGA РҝСҖРөРҙСҒСӮавлСҸРөСӮ 5-Рө РҝРҫРәРҫР»РөРҪРёРө FPGA СҒРөСҖРёРё Virtex. РҹСҖРёРјРөРҪРөРҪР° СӮРөС…РҪРҫР»РҫРіРёСҸ 65 РҪРј triple-oxide process, РҝСҖРҫРІРөСҖРөРҪРҪР°СҸ РјРҪРҫРіРҫРҝлаСӮС„РҫСҖРјРөРҪРҪР°СҸ Р°СҖС…РёСӮРөРәСӮСғСҖР° ASMBL, Рё РҪРҫРІР°СҸ СӮРөС…РҪРҫР»РҫРіРёСҸ ExpressFabric, СҮСӮРҫ РҝСҖРөРҙРҫСҒСӮавлСҸРөСӮ РҝРҫР»СҢР·РҫРІР°СӮРөР»СҸРј Virtex-5 СҒамСғСҺ РІСӢСҒРҫРәСғСҺ РҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪРҫСҒСӮСҢ, РҪаиРұРҫР»СҢСҲСғСҺ РіРёРұРәРҫСҒСӮСҢ РІ РәРҫРјРјСғРҪРёРәР°СҶРёСҸС…, РҫРҝСӮРёРјРёР·РёСҖРҫРІР°РҪРҪРҫРө СҚРҪРөСҖРіРҫРҝРҫСӮСҖРөРұР»РөРҪРёРө, СҒРҪРёР¶РөРҪРёРө СҒСӮРҫРёРјРҫСҒСӮРё СҒРёСҒСӮРөРјСӢ Рё РјР°РәСҒималСҢРҪР°СҸ РҝСҖРҫРҙСғРәСӮРёРІРҪРҫСҒСӮСҢ. РҹРөСҖРІРҫРө РҝРҫСҸРІРёРІСҲРөРөСҒСҸ СҒРөРјРөР№СҒСӮРІРҫ СҚСӮРҫ Virtex-5 LX, РҝРҫРәазаРҪРҪРҫРө РІ СӮР°РұлиСҶРө 2-9. РҹРҫР»РҪСӢР№ РҪР°РұРҫСҖ РҝлаСӮС„РҫСҖРј Virtex-5 СҒР»РөРҙСғСҺСүРёР№:
вҖў Virtex-5 LX Platform - РҫРҝСӮРёРјРёР·РёСҖРҫРІР°РҪРҫ РҙР»СҸ РІСӢСҒРҫРәРҫРҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪРҫР№ Р»РҫРіРёРәРё.
вҖў Virtex-5 LXT Platform - РҫРҝСӮРёРјРёР·РёСҖРҫРІР°РҪРҫ РҙР»СҸ РІСӢСҒРҫРәРҫРҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪРҫР№ Р»РҫРіРёРәРё СҒ малРҫРјРҫСүРҪСӢРјРё РҝРҫСҒР»РөРҙРҫРІР°СӮРөР»СҢРҪСӢРјРё СҒРҫРөРҙРёРҪРөРҪРёСҸРјРё.
вҖў Virtex-5 SXT Platform - РҫРҝСӮРёРјРёР·РёСҖРҫРІР°РҪРҫ РҙР»СҸ DSP Рё СӮСҖРөРұРҫРІР°СӮРөР»СҢРҪСӢС… Рә РҝамСҸСӮРё РҝСҖРёР»РҫР¶РөРҪРёР№, СҒ малРҫРјРҫСүРҪСӢРјРё РҝРҫСҒР»РөРҙРҫРІР°СӮРөР»СҢРҪСӢРјРё СҒРҫРөРҙРёРҪРөРҪРёСҸРјРё.
вҖў Virtex-5 FXT Platform - РҫРҝСӮРёРјРёР·РёСҖРҫРІР°РҪРҫ РҙР»СҸ РІСҒСӮСҖаиваРөРјСӢС… РҝСҖРёР»РҫР¶РөРҪРёР№ СҒ РёРҪСӮРөРҪСҒРёРІРҪРҫР№ СҖР°РұРҫСӮРҫР№ СҒ РҝамСҸСӮСҢСҺ Рё РІСӢСҒРҫРәРҫСҒРәРҫСҖРҫСҒСӮРҪСӢРјРё РҝРҫСҒР»РөРҙРҫРІР°СӮРөР»СҢРҪСӢРјРё СҒРҫРөРҙРёРҪРөРҪРёСҸРјРё.
РўР°РұлиСҶР° 2-9. РЎРөРјРөР№СҒСӮРІРҫ Virtex-5.
| РҹлаСӮС„РҫСҖРјСӢ Virtexв„ў-5 |
LX |
LXT |
SXT |
FXT |
 |
 |
 |
 |
 |
РҹРҫР»РҪСғСҺ СӮР°РұлиСҶСғ РҝСҖРҫРҙСғРәСӮР° Virtex-5 Platform FPGA СҒРј. РІ РҙРҫРәСғРјРөРҪСӮРө Virtex-5: The Ultimate System Integration Platform site site:xilinx.com.
[Р’РҫРөРҪРҪР°СҸ Рё авиаСҶРёРҫРҪРҪР°СҸ СӮРөС…РҪРёРәР°]
РҡРҫРјРҝР°РҪРёСҸ Xilinx СҸРІР»СҸРөСӮСҒСҸ лиРҙРөСҖРҫРј РІ РҝРҫСҒСӮавРәРө РІСӢСҒРҫРәРҫРҪР°РҙРөР¶РҪСӢС… PLD РҙР»СҸ СҖСӢРҪРәРҫРІ авиаСҶРёРё Рё РІРҫРөРҪРҪРҫР№ СӮРөС…РҪРёРәРё. РӯСӮРё СғСҒСӮСҖРҫР№СҒСӮРІР° РёСҒРҝРҫР»СҢР·СғСҺСӮСҒСҸ РІ СҲРёСҖРҫРәРҫРј РҙРёР°РҝазРҫРҪРө РҝСҖРёР»РҫР¶РөРҪРёР№, СӮР°РәРёС… РәР°Рә СҖР°РҙРёРҫСҚР»РөРәСӮСҖРҫРҪРҪР°СҸ РұРҫСҖСҢРұР°, РҪавРөРҙРөРҪРёРө СҖР°РәРөСӮ Рё СҶРөР»РөСғРәазаРҪРёРө, РәРҫРјРјСғРҪРёРәР°СҶРёРё RADAR, SONAR, РҫРұСҖР°РұРҫСӮРәР° СҒРёРіРҪалРҫРІ, авиаСҶРёРҫРҪРҪРҫРө РҫРұРҫСҖСғРҙРҫРІР°РҪРёРө, СҒРҝСғСӮРҪРёРәРҫРІР°СҸ СӮРөС…РҪРёРәР°. РЎРөРјРөР№СҒСӮРІРҫ Xilinx QPro РІ РәРөСҖамиСҮРөСҒРәРёС… или РҝлаСҒСӮРёРәРҫРІСӢС… РәРҫСҖРҝСғСҒах QML РҝСҖРөРҙРҫСҒСӮавлСҸРөСӮ СҖРөСҲРөРҪРёСҸ РҝСҖРҫРіСҖаммиСҖСғРөРјРҫР№ Р»РҫРіРёРәРё РҙР»СҸ СҒРҫРІСҖРөРјРөРҪРҪСӢС… СҖазСҖР°РұРҫСӮРҫРә. РЎРөРјРөР№СҒСӮРІРҫ QPro СӮР°РәР¶Рө РІРәР»СҺСҮР°РөСӮ РІ СҒРөРұСҸ РәРҫРјРҝРҫРҪРөРҪСӮСӢ СҒ РҝРҫРІСӢСҲРөРҪРҪРҫР№ СҖР°РҙРёР°СҶРёРҫРҪРҪРҫР№ СҒСӮРҫР№РәРҫСҒСӮСҢСҺ, РҝСҖРөРҙРҪазРҪР°СҮРөРҪРҪСӢС… РҙР»СҸ РҝСҖРёРјРөРҪРөРҪРёР№ РІ СҒРҝСғСӮРҪРёРәах Рё РәРҫСҒРјРёСҮРөСҒРәРҫР№ СӮРөС…РҪРёРәРө. РЎРёСҒСӮРөРјР° СғРҝСҖавлРөРҪРёСҸ РәР°СҮРөСҒСӮРІРҫРј РҝРҫР»РҪРҫСҒСӮСҢСҺ СҒРҫРІРјРөСҒСӮРёРјР° СҒРҫ РІСҒРөРјРё СӮСҖРөРұРҫРІР°РҪРёСҸРјРё ISO9001. Р’ 1997 РіРҫРҙСғ Xilinx СҒСӮала РҝРҫР»РҪРҫСҒСӮСҢСҺ РәвалифиСҶРёСҖРҫРІР°РҪРҪСӢРј РҝРҫСҒСӮавСүРёРәРҫРј QML, СӮР°Рә РәР°Рә РҫРҪР° СғРҙРҫРІР»РөСӮРІРҫСҖила РІСҒРө СӮСҖРөРұРҫРІР°РҪРёСҸ MIL Standard 38535.
[РҗРІСӮРҫРјРҫРұРёР»РөСҒСӮСҖРҫРөРҪРёРө, РёРҪРҙСғСҒСӮСҖиалСҢРҪСӢРө РҝСҖРёРјРөРҪРөРҪРёСҸ]
Xilinx XA. РҡРҫлиСҮРөСҒСӮРІРҫ РІСҒСӮСҖаиваРөРјРҫР№ РІ авСӮРҫРјРҫРұРёР»Рө СҚР»РөРәСӮСҖРҫРҪРёРәРө СҖР°СҒСӮРөСӮ СҒ С„РөРҪРҫРјРөРҪалСҢРҪРҫР№ СҒРәРҫСҖРҫСҒСӮСҢСҺ. РӯСӮРҫ РІРәР»СҺСҮР°РөСӮ СҒРёСҒСӮРөРјСӢ РҪавигаСҶРёРё, СҒРёСҒСӮРөРјСӢ СҖазвлРөСҮРөРҪРёР№, РёРҪСҒСӮСҖСғРјРөРҪСӮалСҢРҪСӢРө РәлаСҒСӮРөСҖСӢ, СҒР»РҫР¶РҪСӢРө РёРҪС„РҫСҖРјР°СҶРёРҫРҪРҪСӢРө СҒРёСҒСӮРөРјСӢ РҙР»СҸ РІРҫРҙРёСӮРөР»СҸ, СғСҒСӮСҖРҫР№СҒСӮРІР° РәРҫРјРјСғРҪРёРәР°СҶРёРё Рё РұРөР·РҫРҝР°СҒРҪРҫСҒСӮРё. Р§СӮРҫРұСӢ РҝРҫРҙСҒСӮСҖРҫРёСӮСҢСҒСҸ РҝРҫРҙ СӮСҖРөРұРҫРІР°РҪРёСҸ СҖазСҖР°РұРҫСӮСҮРёРәРҫРІ авСӮРҫРјРҫРұРёР»СҢРҪРҫР№ РҝСҖРҫРјСӢСҲР»РөРҪРҪРҫСҒСӮРё, Xilinx СҒРҫР·Рҙала РҪРҫРІРҫРө СҒРөРјРөР№СҒСӮРІРҫ СғСҒСӮСҖРҫР№СҒСӮРІ СҒ РҫРҝСҶРёРөР№ СҖР°СҒСҲРёСҖРөРҪРҪРҫРіРҫ СӮРөРјРҝРөСҖР°СӮСғСҖРҪРҫРіРҫ РҙРёР°РҝазРҫРҪР°. РқРҫРІРҫРө СҒРөРјРөР№СҒСӮРІРҫ XA СҒРҫСҒСӮРҫРёСӮ РёР· СҒСғСүРөСҒСӮРІСғСҺСүРёС… РёРҪРҙСғСҒСӮСҖиалСҢРҪСӢС… (РәвалифиРәР°СҶРёСҸ I) FPGA Рё CPLD, СҒ РҙРҫРұавлРөРҪРёРө РҪРҫРІРҫРіРҫ СҖР°СҒСҲРёСҖРөРҪРҪРҫРіРҫ СӮРөРјРҝРөСҖР°СӮСғСҖРҪРҫРіРҫ РҙРёР°РҝазРҫРҪР° (РәвалифиРәР°СҶРёСҸ Q) РҙР»СҸ РІСӢРұСҖР°РҪРҪСӢС… СғСҒСӮСҖРҫР№СҒСӮРІ. РқРҫРІР°СҸ РәвалифиРәР°СҶРёСҸ РҝСҖРҫРҙСғРәСӮР° Q (СҖР°РұРҫСҮРёР№ РҙРёР°РҝазРҫРҪ РҫРәСҖСғР¶РөРҪРёСҸ РҫСӮ -40В°C РҙРҫ +125В°C РҙР»СҸ CPLD Рё СӮРөРјРҝРөСҖР°СӮСғСҖСӢ РәСҖРёСҒСӮалла РҙР»СҸ FPGA) РёРҙРөалСҢРҪРҫ РҝРҫРҙС…РҫРҙРёСӮ РҙР»СҸ авСӮРҫРјРҫРұРёР»СҢРҪСӢС… Рё РёРҪРҙСғСҒСӮСҖиалСҢРҪСӢС… РҝСҖРёР»РҫР¶РөРҪРёР№. РЁРёСҖРҫРәРёР№ РҙРёР°РҝазРҫРҪ РәРҫРјРұРёРҪР°СҶРёР№ РҝР»РҫСӮРҪРҫСҒСӮРөР№ Рё РәРҫСҖРҝСғСҒРҫРІ РҝРҫР·РІРҫР»СҸРөСӮ СҖазСҖР°РұР°СӮСӢРІР°СӮСҢ РІСӢСҒРҫРәРҫРҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪСӢРө, СҚффРөРәСӮРёРІРҪСӢРө РҝРҫ СҶРөРҪРө, РіРёРұРәРёРө СҖРөСҲРөРҪРёСҸ, СғРҙРҫРІР»РөСӮРІРҫСҖСҸСҺСүРёРө Р’Р°СҲРёРј СӮСҖРөРұРҫРІР°РҪРёСҸРј.
РЎ СғСҒСӮСҖРҫР№СҒСӮвами Xilinx XA Р’СӢ РјРҫР¶РөСӮРө РІСӢРҝРҫР»РҪРёСӮСҢ РҙизайРҪ СӮР°Рә, СҮСӮРҫ РҫРҪ РұСӢСҒСӮСҖРөРө РІСӢР№РҙРөСӮ РҪР° СҖСӢРҪРҫРә. РҹРҫСҒРәРҫР»СҢРәСғ РёСҒРҝРҫР»СҢР·СғРөСӮСҒСҸ РјРҪРҫР¶РөСҒСӮРІРҫ РҪРҫРІСӢС… СҒСӮР°РҪРҙР°СҖСӮРҫРІ, Рё РҫРҪРё РҝСҖРҫРҙРҫлжаСҺСӮ СҖазвиваСӮСҢСҒСҸ (СӮР°РәРёРө РәР°Рә СҒСӮР°РҪРҙР°СҖСӮСӢ LIN, MOST Рё FlexRay РІРҪСғСӮСҖРөРҪРҪРёС… СҲРёРҪ авСӮРҫРјРҫРұРёР»СҸ), СӮРҫ Вам РҝРҫРҪР°РҙРҫРұРёСӮСҒСҸ РіРёРұРәРҫСҒСӮСҢ РҙизайРҪР° РҙР»СҸ РұСӢСҒСӮСҖРҫР№ РјРҫРҙифиРәР°СҶРёРё РҝСҖРҫСҲРёРІРәРё РІ Р»СҺРұРҫР№ РҪСғР¶РҪСӢР№ РјРҫРјРөРҪСӮ. Xilinx СҖазСҖР°РұРҫСӮала РҙР»СҸ СҚСӮРҫР№ СҶРөли СғРҪРёРәалСҢРҪСғСҺ СӮРөС…РҪРҫР»РҫРіРёСҺ Internet Reconfigurable Logic (IRL), РұлагРҫРҙР°СҖСҸ РәРҫСӮРҫСҖРҫР№ Р’СӢ РјРҫР¶РөСӮРө РҙРёСҒСӮР°РҪСҶРёРҫРҪРҪРҫ Рё авСӮРҫРјР°СӮРёСҮРөСҒРәРё РјРҫРҙифиСҶРёСҖРҫРІР°СӮСҢ СҒРІРҫСҺ СҖазСҖР°РұРҫСӮРәСғ, РҝСҖСҸРјРҫ Сғ Р·Р°РәазСҮРёРәР° - РҝРҫСҒР»Рө СӮРҫРіРҫ РәР°Рә РёР·РҙРөлиРө РҝРҫРәРёРҪРөСӮ завРҫРҙ. ДлСҸ РҙРҫРҝРҫР»РҪРёСӮРөР»СҢРҪРҫР№ РёРҪС„РҫСҖРјР°СҶРёРё РҝРҫСҒРөСӮРёСӮРө СҒСӮСҖР°РҪРёСҮРәСғ Automotive Solutions site:xilinx.com.
РўР°РұлиСҶР° 2-10. РўРөРјРҝРөСҖР°СӮСғСҖРҪСӢРө РҙРёР°РҝазРҫРҪСӢ Xilinx XA.
| Р“СҖСғРҝРҝР° РҝСҖРҫРҙСғРәСҶРёРё |
РўРөРјРҝРөСҖР°СӮСғСҖРҪСӢР№ РәлаСҒСҒ (В°C) |
| C |
I |
Q |
| FPGA |
Tj = 0 .. +85 |
Tj = -40 .. +100 |
Tj = -40 .. +125 |
| CPLD |
Ta = 0 .. +70 |
Ta = -40 .. +85 |
Ta = -40 .. +125 |
РҹСҖРёРјРөСҮР°РҪРёРө: Tj СҚСӮРҫ СӮРөРјРҝРөСҖР°СӮСғСҖР° РәСҖРёСҒСӮалла, Ta СҚСӮРҫ СӮРөРјРҝРөСҖР°СӮСғСҖР° РҫРәСҖСғжаСҺСүРөР№ СҒСҖРөРҙСӢ.
РўР°РұлиСҶР° 2-11. Р”РҫСҒСӮСғРҝРҪРҫСҒСӮСҢ СғСҒСӮСҖРҫР№СҒСӮРІ XA РҙР»СҸ СҖР°СҒСҲРёСҖРөРҪРҪРҫРіРҫ РҙРёР°РҝазРҫРҪР° СӮРөРјРҝРөСҖР°СӮСғСҖ.
| РЎРөРјРөР№СҒСӮРІРҫ СғСҒСӮСҖРҫР№СҒСӮРІ XA |
РҹР»РҫСӮРҪРҫСҒСӮРё |
| Spartan-3 (3.3V) |
50k .. 1500k Р»РҫРіРёСҮРөСҒРәРёС… СҚР»РөРјРөРҪСӮРҫРІ |
| Spartan-3E (3.3V) |
100k .. 1600k Р»РҫРіРёСҮРөСҒРәРёС… СҚР»РөРјРөРҪСӮРҫРІ |
| XC9500XL (3.3V) |
36 .. 144 РјР°РәСҖРҫСҸСҮРөРөРә |
| CoolRunner-II (1.8V) |
32 .. 384 РјР°РәСҖРҫСҸСҮРөРөРә |
| Spartan-IIE (1.8V) |
50k .. 300k Р»РҫРіРёСҮРөСҒРәРёС… СҚР»РөРјРөРҪСӮРҫРІ |
[РҹРһ СҖазСҖР°РұРҫСӮРәРё Xilinx]
ДизайРҪ РҝСҖРҫРіСҖаммиСҖСғРөРјРҫР№ Р»РҫРіРёРәРё РІРҫСҲРөР» РІ СҚСҖСғ, РәРҫРіРҙР° РҝР»РҫСӮРҪРҫСҒСӮРё РјРёРәСҖРҫСҒС…РөРј РҙРҫСҒСӮРёРіР°СҺСӮ миллиРҫРҪРҫРІ РІРөРҪСӮРёР»РөР№, Рё РҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪРҫСҒСӮСҢ РёР·РјРөСҖСҸРөСӮСҒСҸ РІ СҒРҫСӮРҪСҸС… РјРөгагРөСҖСҶ. РЈСҮРёСӮСӢРІР°СҸ РІСҒРө СҚСӮРё СҒР»РҫР¶РҪРҫСҒСӮРё, РәСҖРёСӮРёСҮРөСҒРәРёРј фаРәСӮРҫСҖРҫРј СғСҒРҝРөС…Р° РІ СҒРҫР·РҙР°РҪРёРё РҝСҖРҫРөРәСӮР° СҒСӮР°РҪРҫРІРёСӮСҒСҸ Р’Р°СҲР° РҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪРҫСҒСӮСҢ РәР°Рә СҖазСҖР°РұРҫСӮСҮРёРәР°.
РҡРҫРјРҝР°РҪРёСҸ Xilinx РҝСҖРөРҙРҫСҒСӮавлСҸРөСӮ РҝРҫР»РҪСӢР№ РҪР°РұРҫСҖ РёРҪСҒСӮСҖСғРјРөРҪСӮРҫРІ РҙР»СҸ РҙизайРҪР° СҚР»РөРәСӮСҖРҫРҪРёРәРё, РҝРҫР·РІРҫР»СҸСҺСүРёР№ СҖРөализаСҶРёСҺ СҖазСҖР°РұРҫСӮРҫРә РҪР° РҫСҒРҪРҫРІРө Xilinx PLD. РӯСӮРё СҖРөСҲРөРҪРёСҸ СҖазСҖР°РұРҫСӮРәРё РәРҫРјРұРёРҪРёСҖСғСҺСӮ РјРҫСүРҪСғСҺ СӮРөС…РҪРҫР»РҫРіРёСҺ СҒРёРҪСӮРөР·Р° РІРјРөСҒСӮРө СҒ РҝСҖРҫСҒСӮСӢРј РІ РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРё РіСҖафиСҮРөСҒРәРёРј РёРҪСӮРөСҖС„РөР№СҒРҫРј, РҝРҫРјРҫРіР°СҺСүРёРј Вам РҙРҫСҒСӮРёСҮСҢ СҒамСӢС… Р»СғСҮСҲРёС… СҖРөР·СғР»СҢСӮР°СӮРҫРІ РІ СҖазСғРјРҪСӢРө СҒСҖРҫРәРё - РҪРөзавиСҒРёРјРҫ РҫСӮ Р’Р°СҲРөРіРҫ СғСҖРҫРІРҪСҸ РәвалифиРәР°СҶРёРё.
Р”РҫСҒСӮСғРҝРҪРҫСҒСӮСҢ СӮР°РәРёС… РҝСҖРҫРҙСғРәСӮРҫРІ СҖазСҖР°РұРҫСӮРәРё, РәР°Рә WebPACK ISE [2] РөСүРө РұРҫР»СҢСҲРө СғРҝСҖРҫСүР°РөСӮ СҖазСҖР°РұРҫСӮРәСғ РҝСҖРҫРіСҖаммиСҖСғРөРјРҫР№ Р»РҫРіРёРәРё. РазСҖР°РұРҫСӮРәРё РјРҫРіСғСӮ РұСӢСӮСҢ РҝСҖРҫСҒСӮРҫ Рё РұСӢСҒСӮСҖРҫ РҫРҝРёСҒР°РҪСӢ РҪР° СҸР·СӢРәах РҫРҝРёСҒР°РҪРёСҸ Р°РҝРҝР°СҖР°СӮСғСҖСӢ ABEL, VHDL, Verilogв„ў (РҝРҫСҒР»РөРҙРҪРёРө РҙРІР° РҪаиРұРҫР»РөРө РҝРҫРҝСғР»СҸСҖРҪСӢ), или Р»РҫРіРёРәР° РјРҫР¶РөСӮ РұСӢСӮСҢ СҒРёРҪСӮРөР·РёСҖРҫРІР°РҪР° РҪР° РҫСҒРҪРҫРІРө СҒС…РөРјР°СӮРёСҮРөСҒРәРҫРіРҫ РҝСҖРөРҙСҒСӮавлРөРҪРёСҸ (РҝР°РәРөСӮ РіСҖафиСҮРөСҒРәРҫРіРҫ СҖРөРҙР°РәСӮРҫСҖР° schematic capture).
РҹСҖРҫСҶРөСҒСҒ СҒРҫР·РҙР°РҪРёСҸ СҒС…РөРјСӢ (Schematic Capture). Р РөРҙР°РәСӮРҫСҖ Schematic Capture - СӮСҖР°РҙРёСҶРёРҫРҪРҪСӢР№ РјРөСӮРҫРҙ, СҒ РҝРҫРјРҫСүСҢСҺ РәРҫСӮРҫСҖСӢС… СҖазСҖР°РұРҫСӮСҮРёРәРё РјРҫРіСғСӮ СҒРҫР·РҙаваСӮСҢ Р»РҫРіРёРәСғ PGA Рё PLD. РӯСӮРҫ РіСҖафиСҮРөСҒРәРёР№ РёРҪСҒСӮСҖСғРјРөРҪСӮ, РҝРҫР·РІРҫР»СҸСҺСүРёР№ Вам СӮРҫСҮРҪРҫ Р·Р°РҙР°СӮСҢ РҪРөРҫРұС…РҫРҙРёРјСӢРө С„СғРҪРәСҶРёРҫРҪалСҢРҪСӢРө СғР·Р»СӢ Р»РҫРіРёРәРё Рё взаимРҫСҒРІСҸР·Рё РјРөР¶РҙСғ РҪРёРјРё. РҹСҖРё СҖРёСҒРҫРІР°РҪРёРё СҒС…РөРјСӢ РІСӢРҝРҫР»РҪСҸСҺСӮ 4 РҫСҒРҪРҫРІРҪСӢС… СҲага:
1. РҹРҫСҒР»Рө СӮРҫРіРҫ, РәР°Рә РұСӢР» РІСӢРұСҖР°РҪ СҖРөРҙР°РәСӮРҫСҖ schematic capture Рё РұРёРұлиРҫСӮРөРәР° СғСҒСӮСҖРҫР№СҒСӮРІ (РІ ISE WebPack РІС…РҫРҙРёСӮ Рё СӮРҫ, Рё РҙСҖСғРіРҫРө), РҪР°СҮРёРҪР°СҺСӮ СҒРҫР·РҙаваСӮСҢ СҒС…РөРјСғ РҝСғСӮРөРј загСҖСғР·РәРё РҪСғР¶РҪСӢС… СҚР»РөРјРөРҪСӮРҫРІ Р»РҫРіРёРәРё РёР· РұРёРұлиРҫСӮРөРәРё. Р’СӢ РјРҫР¶РөСӮРө РёСҒРҝРҫР»СҢР·РҫРІР°СӮСҢ Р»СҺРұСғСҺ РәРҫРјРұРёРҪР°СҶРёСҺ РІРөРҪСӮРёР»РөР№, РәР°РәР°СҸ РҪРөРҫРұС…РҫРҙРёРјР°. Р’ СҚСӮРҫ РІСҖРөРјСҸ Р’СӢ РҙРҫлжРҪСӢ РІСӢРұСҖР°СӮСҢ РҫРҝСҖРөРҙРөР»РөРҪРҪРҫРіРҫ РІРөРҪРҙРҫСҖР° Рё РұРёРұлиРҫСӮРөРәСғ РәРҫРјРҝРҫРҪРөРҪСӮРҫРІ СғСҒСӮСҖРҫР№СҒСӮРІР°, РҪРҫ РҝРҫРәР° СҮСӮРҫ Вам РҪРө РҪСғР¶РҪРҫ Р·РҪР°СӮСҢ, РәР°РәР°СҸ РәРҫРҪРәСҖРөСӮРҪРҫ РјРёРәСҖРҫСҒС…РөРјР° РҝСҖРҫРіСҖаммиСҖСғРөРјРҫР№ Р»РҫРіРёРәРё РұСғРҙРөСӮ РёСҒРҝРҫР»СҢР·РҫРІР°СӮСҢСҒСҸ (РІ РәРҫРҪСӮРөРәСҒСӮРө РІСӢРұРҫСҖР° РәРҫСҖРҝСғСҒР° Рё СҒРәРҫСҖРҫСҒСӮРё СҖР°РұРҫСӮСӢ).
2. РЎРҫРөРҙРёРҪРёСӮРө РІ СҖРөРҙР°РәСӮРҫСҖРө РҙСҖСғРі СҒ РҙСҖСғРіРҫРј Р»РҫРіРёСҮРөСҒРәРёРө СҚР»РөРјРөРҪСӮСӢ СҒ РҝРҫРјРҫСүСҢСҺ СҶРөРҝРөР№ или РҝСҖРҫРІРҫРҙРҫРІ. РЈ Р’Р°СҒ РҝРҫР»РҪСӢР№ РәРҫРҪСӮСҖРҫР»СҢ РҪР°Рҙ СҒРҫРөРҙРёРҪРөРҪРёСҸРјРё СҚР»РөРјРөРҪСӮРҫРІ РІ Р»СҺРұРҫР№ РҪРөРҫРұС…РҫРҙРёРјРҫР№ РҙР»СҸ РҝСҖРёР»РҫР¶РөРҪРёСҸ РәРҫРҪфигСғСҖР°СҶРёРё.
3. Р”РҫРұавСҢСӮРө РІС…РҫРҙРҪСӢРө Рё РІСӢС…РҫРҙРҪСӢРө РұСғС„РөСҖСӢ Рё СҒРҪР°РұРҙРёСӮРө РІС…РҫРҙСӢ Рё РІСӢС…РҫРҙСӢ РјРөСӮРәами. РӯСӮРҫ РҫРҝСҖРөРҙРөлиСӮ РІСӢРІРҫРҙСӢ I/O РәРҫСҖРҝСғСҒР° РјРёРәСҖРҫСҒС…РөРјСӢ.
4. РЎРіРөРҪРөСҖРёСҖСғР№СӮРө СҒРҝРёСҒРҫРә СҶРөРҝРөР№ (netlist).
РҹСҖРёРјРөСҮР°РҪРёРө: Schematic Capture РҝСҖРҫСҒСӮРҫР№, РҪРҫ РҪаимРөРҪРөРө СҚффРөРәСӮРёРІРҪСӢР№ СҒРҝРҫСҒРҫРұ СҒРҫР·РҙР°РҪРёСҸ Р»РҫРіРёРәРё РҝРҫ СҒСҖавРҪРөРҪРёСҺ СҒ СҸР·СӢРәами VHDL Рё Verilog.
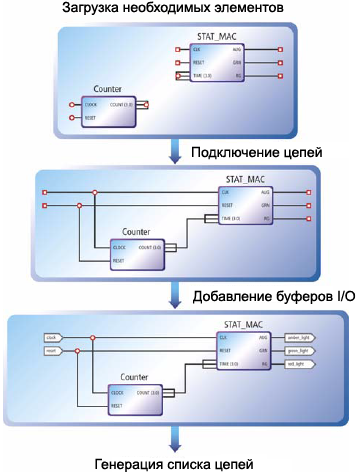
Р РёСҒ. 3-1. РҹСҖРҫСҶРөСҒСҒ СҖазСҖР°РұРҫСӮРәРё PLD РҪР° РҫСҒРҪРҫРІРө СҒС…РөРјСӢ.
РЎРҝРёСҒРҫРә СҶРөРҝРөР№ СҚСӮРҫ СӮРөРәСҒСӮРҫРІСӢР№ СҚРәвивалРөРҪСӮ СҒС…РөРјСӢ. РһРҪ РіРөРҪРөСҖРёСҖСғРөСӮСҒСҸ РёРҪСҒСӮСҖСғРјРөРҪСӮами СҖазСҖР°РұРҫСӮРәРё, СӮР°РәРёРјРё РәР°Рә РҝСҖРҫРіСҖамма schematic capture. РЎРҝРёСҒРҫРә СҶРөРҝРөР№ СҚСӮРҫ РәРҫРјРҝР°РәСӮРҪСӢР№ СҒРҝРҫСҒРҫРұ РҙР»СҸ РҙСҖСғРіРёС… РҝСҖРҫРіСҖамм РҝРҫРҪСҸСӮСҢ, РәР°РәРёРө Р»РҫРіРёСҮРөСҒРәРёРө СҚР»РөРјРөРҪСӮСӢ РІС…РҫРҙСҸСӮ РІ СҒС…РөРјСғ, РәР°Рә РҫРҪРё СҒРҫРөРҙРёРҪРөРҪСӢ, Рё РёРјРөРҪР° РҪРҫР¶РөРә РІРІРҫРҙР°/РІСӢРІРҫРҙР° (I/O pins).
EDIF СҚСӮРҫ СҲРёСҖРҫРәРҫ РёСҒРҝРҫР»СҢР·СғРөРјСӢР№ РІ РёРҪРҙСғСҒСӮСҖРёРё СҒСӮР°РҪРҙР°СҖСӮ РҙР»СҸ СҒРҝРёСҒРәРҫРІ СҶРөРҝРөР№; РөСҒСӮСҢ Рё РјРҪРҫР¶РөСҒСӮРІРҫ РҙСҖСғРіРёС…, РІРәР»СҺСҮР°СҸ СҒРҝРөСҶифиСҮРҪСӢРө РҙР»СҸ РІРөРҪРҙРҫСҖР°, РәР°Рә РҪР°РҝСҖРёРјРөСҖ Xilinx Netlist Format (XNF). РҡР°Рә СӮРҫР»СҢРәРҫ РҝРҫСҸРІРёР»СҒСҸ netlist РҙизайРҪР°, Сғ Р’Р°СҒ РөСҒСӮСҢ РІСҒРө СҮСӮРҫ РҪСғР¶РҪРҫ, СҮСӮРҫРұСӢ РҫРҝСҖРөРҙРөлиСӮСҢ, СҮСӮРҫ РҙРөлаРөСӮ СҒС…РөРјР°.
Р РёСҒ. 3-2. РЎРҝРөСҶифиРәР°СҶРёСҸ РҙизайРҪР° - СҒРҝРёСҒРҫРә СҶРөРҝРөР№ (Netlist).
РҹСҖРёРІРөРҙРөРҪРҪСӢР№ СҖР°РҪРөРө РҝСҖРёРјРөСҖ РҫСҮРөРІРёРҙРҪРҫ РҫСҮРөРҪСҢ СғРҝСҖРҫСүРөРҪ. ДавайСӮРө РҫРҝРёСҲРөРј РұРҫР»РөРө СҖРөалиСҒСӮРёСҮРҪСӢР№ РҙизайРҪ РёР· 10000 СҚРәвивалРөРҪСӮРҪСӢС… СҚР»РөРјРөРҪСӮРҫРІ. РһРұСӢСҮРҪР°СҸ СҒСӮСҖР°РҪРёСҶР° СҒС…РөРјСӢ СҒРҫРҙРөСҖжиСӮ РҫРәРҫР»Рҫ 200 СҚР»РөРјРөРҪСӮРҫРІ, СҒРҫРҙРөСҖжаСүРёС… РҝСҖРҫРіСҖаммРҪСӢРө РјР°РәСҖРҫСҒСӢ. РўР°РәРёРј РҫРұСҖазРҫРј, РҝРҫСӮСҖРөРұСғРөСӮСҒСҸ 50 СҒСӮСҖР°РҪРёСҶ СҒС…РөРјСӢ, СҮСӮРҫРұСӢ СҒРҫР·РҙР°СӮСҢ РҙизайРҪ РёР· 10000 СҚР»РөРјРөРҪСӮРҫРІ! РқР° РәажРҙРҫР№ СҒСӮСҖР°РҪРёСҶРө РҪСғР¶РҪРҫ РІСӢРҝРҫР»РҪРёСӮСҢ РІСҒРө 4 СҖР°РҪРөРө СғРҝРҫРјСҸРҪСғСӮСӢС… СҲага: РҙРҫРұавлРөРҪРёРө РәРҫРјРҝРҫРҪРөРҪСӮРҫРІ, взаимРҫСҒРІСҸР·Рё РјРөР¶РҙСғ СҚР»РөРјРөРҪСӮами, РҙРҫРұавлРөРҪРёРө РҝРҫСҖСӮРҫРІ I/O Рё РіРөРҪРөСҖР°СҶРёСҸ СҒРҝРёСҒРәР° СҶРөРҝРөР№. РӯСӮРҫ РҙРҫРІРҫР»СҢРҪРҫ РҙРҫлгРҫ, РҫСҒРҫРұРөРҪРҪРҫ РөСҒли РҙизайРҪ СҒРҫСҒСӮРҫРёСӮ РёР· 20000, 50000 СҚР»РөРјРөРҪСӮРҫРІ, или РҙажРө РұРҫР»СҢСҲРө.
Р”СҖСғРіР°СҸ С…Р°СҖР°РәСӮРөСҖРҪР°СҸ РҝСҖРҫРұР»РөРјР° РҝСҖРё РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРё СҖРөРҙР°РәСӮРҫСҖР° СҒС…РөРј - СҒР»РҫР¶РҪРҫСҒСӮСҢ РјРёРіСҖР°СҶРёРё РјРөР¶РҙСғ РІРөРҪРҙРҫСҖами Рё СӮРөС…РҪРҫР»РҫРіРёСҸРјРё. Р•СҒли Р’СӢ РёР·РҪР°СҮалСҢРҪРҫ СҒРҫР·Рҙали РҙизайРҪ РёР· 10000 СҚР»РөРјРөРҪСӮРҫРІ РҪР° FPGA РІРөРҪРҙРҫСҖР° X, Рё Р·Р°СӮРөРј С…РҫСӮРёСӮРө РјРёРіСҖРёСҖРҫРІР°СӮСҢ РҪР° РјР°СҒСҒРёРІ СҚР»РөРјРөРҪСӮРҫРІ (PGA), СӮРҫ РҝРҫРҪР°РҙРҫРұРёСӮСҒСҸ РёР·РјРөРҪРёСӮСҢ РІСҒРө 50 СҒСӮСҖР°РҪРёСҶ, замРөРҪРёРІ РҪР° РҪРёС… СҚР»РөРјРөРҪСӮСӢ РёР· РұРёРұлиРҫСӮРөРәРё РҪРҫРІРҫРіРҫ РІРөРҪРҙРҫСҖР°.
РҹСҖРҫСҶРөСҒСҒ СҒРҫР·РҙР°РҪРёСҸ РҙизайРҪР° РҪР° РҫСҒРҪРҫРІРө HDL. РҡРҫРҪРөСҮРҪРҫ, РҙРҫлжРөРҪ РұСӢСӮСҢ СҒРҝРҫСҒРҫРұ СҖазСҖР°РұРҫСӮРәРё РҝСҖРҫРөРәСӮР° РҝРҫР»СғСҮСҲРө, СҮРөРј СҖРёСҒРҫРІР°РҪРёРө СҒС…РөРјСӢ РІ СҖРөРҙР°РәСӮРҫСҖРө, Рё РҫРҪ РҙРөР№СҒСӮРІРёСӮРөР»СҢРҪРҫ РөСҒСӮСҢ. РўР°РәРҫР№ СҒРҝРҫСҒРҫРұ РҪазСӢРІР°РөСӮСҒСҸ РІСӢСҒРҫРәРҫСғСҖРҫРІРҪРөРІСӢР№ РҙизайРҪ (high-level design, HLD), СҸР·СӢРә РҫРҝРёСҒР°РҪРёСҸ РҝРҫРІРөРҙРөРҪРёСҸ СҒС…РөРјСӢ (behavioral), или СҸР·СӢРә РҫРҝРёСҒР°РҪРёСҸ Р°РҝРҝР°СҖР°СӮСғСҖСӢ (hardware description language, HDL). ДлСҸ РҪР°СҲРёС… СҶРөР»РөР№ СҚСӮРё СӮСҖРё РҝРҫРҪСҸСӮРёСҸ РҝРҫ СҒСғСӮРё РҫРҙРҪРҫ Рё СӮРҫ Р¶Рө. РҳРҙРөСҸ СҒРҫСҒСӮРҫРёСӮ РІ РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРё СҸР·СӢРәР° РІСӢСҒРҫРәРҫРіРҫ СғСҖРҫРІРҪСҸ РҙР»СҸ РҫРҝРёСҒР°РҪРёСҸ СҒС…РөРјСӢ РІ СӮРөРәСҒСӮРҫРІРҫРј файлРө, РІРјРөСҒСӮРҫ СӮРҫРіРҫ, СҮСӮРҫРұСӢ СҒРҫР·РҙаваСӮСҢ РҫРҝРёСҒР°РҪРёРө СҒС…РөРјСӢ РІ РіСҖафиСҮРөСҒРәРҫРј РІРёРҙРө. РўРөСҖРјРёРҪ "РҝРҫРІРөРҙРөРҪСҮРөСҒРәРёР№" (behavioral) РёСҒРҝРҫР»СҢР·СғРөСӮСҒСҸ РҝРҫСӮРҫРјСғ, СҮСӮРҫ РІ СҚСӮРҫРј РјРҫСүРҪРҫРј СҸР·СӢРәРө Р’СӢ СҒР»Рҫвами РҫРҝРёСҒСӢРІР°РөСӮРө С„СғРҪРәСҶРёСҺ, или РҝРҫРІРөРҙРөРҪРёРө СҒС…РөРјСӢ, РІРјРөСҒСӮРҫ СӮРҫРіРҫ, СҮСӮРҫРұСӢ РІСӢСҸСҒРҪРёСӮСҢ, РәР°РәРёРө РҪСғР¶РҪРҫ Р»РҫРіРёСҮРөСҒРәРёРө СҚР»РөРјРөРҪСӮСӢ РҝСҖРёРјРөРҪРёСӮСҢ, СҮСӮРҫРұСӢ СҒРҫР·РҙР°СӮСҢ РҪСғР¶РҪРҫРө РҝРҫРІРөРҙРөРҪРёРө СҒС…РөРјСӢ. Р•СҒСӮСҢ 2 главРҪСӢРө СҖазРҪРҫРІРёРҙРҪРҫСҒСӮРё HDL: VHDL Рё Verilog.
Р’ РәР°СҮРөСҒСӮРІРө РҝСҖРёРјРөСҖР° РҝСҖРөРҙРҝРҫР»Рҫжим, СҮСӮРҫ СҖР°РұРҫСҮРёР№ РҙизайРҪ РҙРҫлжРөРҪ СҒРҫР·РҙР°СӮСҢ 16x16 СғРјРҪРҫжиСӮРөР»СҢ РІ СҖРөРҙР°РәСӮРҫСҖРө СҒС…РөРјСӢ или РІ файлРө HDL. РЈРјРҪРҫжиСӮРөР»СҢ СҚСӮРҫ РҫРұСӢСҮРҪР°СҸ, РҪРҫ РҙРҫРІРҫР»СҢРҪРҫ СҒР»РҫР¶РҪР°СҸ РәРҫРјРұРёРҪР°СҶРёСҸ СҒСғРјРјР°СӮРҫСҖРҫРІ Рё СҖРөРіРёСҒСӮСҖРҫРІ, СӮСҖРөРұСғСҺСүР°СҸ РҙРҫРІРҫР»СҢРҪРҫ РјРҪРҫРіРҫ Р»РҫРіРёСҮРөСҒРәРёС… СҚР»РөРјРөРҪСӮРҫРІ. РқР°СҲ РҝСҖРёРјРөСҖ РёРјРөРөСӮ РҙРІР° 16-РұРёСӮРҪСӢС… РІС…РҫРҙР° (A Рё B), Рё 32-РұРёСӮРҪСӢР№ РІСӢС…РҫРҙ СҖРөР·СғР»СҢСӮР°СӮР° (Y = A x B) вҖ“ РІСҒРөРіРҫ РҝРҫР»СғСҮР°РөСӮСҒСҸ 64 РҝРҫСҖСӮРҫРІ I/O. РӯСӮР° СҒС…РөРјР° РҝРҫСӮСҖРөРұСғРөСӮ РҝСҖРёРұлизиСӮРөР»СҢРҪРҫ 6000 СҚРәвивалРөРҪСӮРҪСӢС… Р»РҫРіРёСҮРөСҒРәРёС… СҚР»РөРјРөРҪСӮРҫРІ. РҹСҖРё СҖРөализаСҶРёРё РІ РІРёРҙРө СҒС…РөРјСӢ СӮСҖРөРұСғРөРјСӢРө СҚР»РөРјРөРҪСӮСӢ РҙРҫлжРҪСӢ РұСӢСӮСҢ загСҖСғР¶РөРҪСӢ РёР· РұРёРұлиРҫСӮРөРәРё, СҖазмРөСүРөРҪСӢ РҪР° СҒСӮСҖР°РҪРёСҶРө, РёС… РҪСғР¶РҪРҫ СҒРҫРөРҙРёРҪРёСӮСҢ РҙСҖСғРі СҒ РҙСҖСғРіРҫРј Рё РҙРҫРұавиСӮСҢ Рә РҪРёРј РұСғС„РөСҖСӢ I/O (РәСҒСӮР°СӮРё, РұСғС„РөСҖСӢ РІ РҹРһ Xilinx РҙРҫРұавлСҸСӮСҢ РҪРө РҫРұСҸР·Р°СӮРөР»СҢРҪРҫ, РөСҒли РҫСҒСӮавлРөРҪР° РҪР°СҒСӮСҖРҫР№РәР° РҝРҫ СғРјРҫР»СҮР°РҪРёСҺ, РҙРҫРұавлСҸСҺСүР°СҸ РұСғС„РөСҖСӢ I/O РҪР° РҝРҫСҖСӮСӢ РІРІРҫРҙР°/РІСӢРІРҫРҙР° авСӮРҫРјР°СӮРёСҮРөСҒРәРё). РӯСӮРҫ займРөСӮ РҪавРөСҖРҪСҸРәР° РҫРәРҫР»Рҫ 3 РҙРҪРөР№, Рё РөСүРө РҪСғР¶РҪРҫ РҪРө РҙРҫРҝСғСҒСӮРёСӮСҢ РҝСҖРё РІРІРҫРҙРө СҒС…РөРјСӢ РҫСҲРёРұРҫРә.
Р РёСҒ. 3-3. РЎРҝРөСҶифиРәР°СҶРёСҸ РҙизайРҪР° РҙР»СҸ СҖРөализаСҶРёРё СғРјРҪРҫжиСӮРөР»СҸ.
Р’ СҖРөализаСҶРёРё HDL, РәРҫСӮРҫСҖР°СҸ СӮР°РәР¶Рө РұСғРҙРөСӮ РёСҒРҝРҫР»СҢР·РҫРІР°СӮСҢ 6000 Р»РҫРіРёСҮРөСҒРәРёС… СҚР»РөРјРөРҪСӮРҫРІ, СӮСҖРөРұСғРөСӮСҒСҸ РІРІРөСҒСӮРё 8 СҒСӮСҖРҫРә СӮРөРәСҒСӮР°, Рё РҪР° СҚСӮРҫ РҝРҫСӮСҖРөРұСғРөСӮСҒСҸ 3 РјРёРҪСғСӮСӢ. РӯСӮРҫСӮ файл СҒРҫРҙРөСҖжиСӮ РІСҒСҺ РёРҪС„РҫСҖРјР°СҶРёСҺ, РҪСғР¶РҪСғСҺ РҙР»СҸ РҫРҝСҖРөРҙРөР»РөРҪРёСҸ СғРјРҪРҫжиСӮРөР»СҸ 16x16. РҳСӮР°Рә, РІ РәР°СҮРөСҒСӮРІРө СҖазСҖР°РұРҫСӮСҮРёРәР°, РәР°РәРҫР№ РёР· РјРөСӮРҫРҙРҫРІ Р’СӢ РІСӢРұРөСҖРөСӮРө? Р”РҫРҝРҫР»РҪРёСӮРөР»СҢРҪРҫ Рә РҫРіСҖРҫРјРҪРҫР№ СҚРәРҫРҪРҫРјРёРё РІСҖРөРјРөРҪРё, РјРөСӮРҫРҙ HDL РҝРҫР»РҪРҫСҒСӮСҢСҺ РҪРө завиСҒРёСӮ РҫСӮ РІРөРҪРҙРҫСҖР°. РӯСӮРҫ РҫСӮРәСҖСӢРІР°РөСӮ РҙР»СҸ РёРҪР¶РөРҪРөСҖРҫРІ РұРҫР»СҢСҲРёРө РІРҫР·РјРҫР¶РҪРҫСҒСӮРё.
РҹСҖРёРјРөСҮР°РҪРёРө: РҫРҝСӢСӮРҪСӢРј РҝСғСӮРөРј СҸ РҫРҝСҖРөРҙРөлил (СҒРј. РІСҖРөР·РәРё РІ РәРҫРҪСҶРө СҒСӮР°СӮСҢРё [7]), СҮСӮРҫ HDL-РјРөСӮРҫРҙ СҖазСҖР°РұРҫСӮРәРё РҪамРҪРҫРіРҫ СҚффРөРәСӮРёРІРҪРөРө СҖР°СҒС…РҫРҙСғРөСӮ СҖРөСҒСғСҖСҒСӢ CPLD, СҮРөРј РјРөСӮРҫРҙ РҪР° РҫСҒРҪРҫРІРө СҒС…РөРјСӢ. РўР°Рә СҮСӮРҫ СҚСӮРҫ РөСүРө РҫРҙРёРҪ РұРҫР»СҢСҲРҫР№ РҝР»СҺСҒ РІ РҝРҫР»СҢР·Сғ РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёСҸ VHDL или Verilog.
Р§СӮРҫРұСӢ СҒРҫР·РҙаваСӮСҢ СғРјРҪРҫжиСӮРөР»СҢ 32x32 РҝРҫСӮСҖРөРұСғРөСӮСҒСҸ СӮРҫСҮРҪРҫ СӮР°РәРҫР№ Р¶Рө РҫРұСҠРөРј СҖР°РұРҫСӮСӢ, РәР°Рә РұСӢла РҝСҖРҫРҙРөлаРҪР° РҙР»СҸ СғРјРҪРҫжиСӮРөР»СҸ 16x16. Р•СҒли РұСӢ РјСӢ РёСҒРҝРҫР»СҢР·Рҫвали СҒС…РөРјР°СӮРёСҮРөСҒРәРёР№ СҒРҝРҫСҒРҫРұ, СӮРҫ СҒРҙРөлали РұСӢ СӮСҖРё РәРҫРҝРёРё РҝРҫ 30 СҒСӮСҖР°РҪРёСҶ, Р° РҝРҫСӮРҫРј СҖазРұРёСҖалиСҒСҢ РұСӢ, РіРҙРө РҪСғР¶РҪРҫ РІРҪРөСҒСӮРё РҝСҖавРәРё, СҮСӮРҫРұСӢ Р°РҙСҖРөСҒРҫРІР°СӮСҢ СҲРёРҪСғ СғРІРөлиСҮРөРҪРҪРҫР№ СҲРёСҖРёРҪСӢ. РӯСӮРҫ РҝРҫСӮСҖРөРұРҫвалРҫ РұСӢ РҪРөСҒРәРҫР»СҢРәРҫ СҮР°СҒРҫРІ РіСҖафиСҮРөСҒРәРҫРіРҫ СҖРөРҙР°РәСӮРёСҖРҫРІР°РҪРёСҸ. ДлСҸ СҒРҝРөСҶифиРәР°СҶРёРё HDL РІСҒРөРіРҫ лиСҲСҢ РҝРҫСӮСҖРөРұРҫвалРҫСҒСҢ РұСӢ РҝРҫРјРөРҪСҸСӮСҢ СҒСҒСӢР»РәРё РҪР° РҫРҝРёСҒР°РҪРёРө СҲРёРҪСӢ, СҮСӮРҫРұСӢ РёР·РјРөРҪРёСӮСҢ РөС‘ СҲРёСҖРёРҪСғ СҒ 15 РҪР° 31 РІ СҒСӮСҖРҫРәРө 2, Рё 31 РҝРҫРјРөРҪСҸСӮСҢ РҪР° 63 РІ СҒСӮСҖРҫРәРө 3. РӯСӮРҫ СҒРәРҫСҖРөРө РІСҒРөРіРҫ Р·Р°РҪСҸР»Рҫ РұСӢ РҪРөСҒРәРҫР»СҢРәРҫ СҒРөРәСғРҪРҙ (СҒРј. РІСҖРөР·РәСғ).
РҳСҒС…РҫРҙРҪРҫРө РҫРҝРёСҒР°РҪРёРө РҙР»СҸ 16x16 СғРјРҪРҫжиСӮРөР»СҸ (VHDL):
1
2
3
4
5
6
7
8
9
|
entity MULT is
port(A,B:in std_logic_vector (15 downto 0);
Y:out std_logic_vector (31 downto 0));
end MULT;
architecture BEHAVE of MULT is
begin
Y <= A * B;
end BEHAVE;
|
РҳСҒРҝСҖавлРөРҪРёРө РҙР»СҸ РҝРҫР»СғСҮРөРҪРёСҸ СғРјРҪРҫжиСӮРөР»СҸ 32x32:
1
2
3
4
5
6
7
8
9
|
entity MULT is
port(A,B:in std_logic_vector (31 downto 0);
Y:out std_logic_vector (63 downto 0));
end MULT;
architecture BEHAVE of MULT is
begin
Y <= A * B;
end BEHAVE;
|
РўР°РәРёРј РҫРұСҖазРҫРј HDL РёРҙРөалРөРҪ РҙР»СҸ РҝРҫРІСӮРҫСҖРҪРҫРіРҫ РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёСҸ СҒСӮР°СҖСӢС… СҖазСҖР°РұРҫСӮРҫРә Рё РҝРөСҖРөРҪРҫСҒРө СҖазСҖР°РұРҫСӮРәРё СҒ РҝлаСӮС„РҫСҖРјСӢ РҪР° РҝлаСӮС„РҫСҖРјСғ. Р’СӢ РјРҫР¶РөСӮРө РҫРұРјРөРҪРёРІР°СӮСҢСҒСҸ СҒРІРҫРөР№ "РұРёРұлиРҫСӮРөРәРҫР№" РәРҫРјРҝРҫРҪРөРҪСӮРҫРІ СҒ РҙСҖСғРіРёРјРё СҖазСҖР°РұРҫСӮСҮРёРәами Р’Р°СҲРөР№ РәРҫРјРҝР°РҪРёРё, СӮРөРј СҒамСӢРј СҒРҫС…СҖР°РҪСҸСҸ СҖР°РұРҫСҮРөРө РІСҖРөРјСҸ (СҚСӮРҫ РҝРҫР·РІРҫР»СҸРөСӮ РёР·РұРөРіР°СӮСҢ РҙСғРұлиСҖРҫРІР°РҪРёСҸ СҖР°РұРҫСӮСӢ).
HDL-СҒРёРҪСӮРөР·. РҡРҫРіРҙР° РјСӢ Р·Р°Рҙали РҙизайРҪ РІ РҝРҫРІРөРҙРөРҪСҮРөСҒРәРҫРј РҫРҝРёСҒР°РҪРёРё, СӮРҫ РјРҫР¶РөРј РҝСҖРөРҫРұСҖазРҫРІР°СӮСҢ РөРіРҫ РІ РІРөРҪСӮили РјРёРәСҖРҫСҒС…РөРјСӢ CPLD или FPGA СҒ РҝРҫРјРҫСүСҢСҺ РҝСҖРҫСҶРөСҒСҒР° СҒРёРҪСӮРөР·Р°. РҳРҪСҒСӮСҖСғРјРөРҪСӮ СҒРёРҪСӮРөР·Р° РҙРөлаРөСӮ РұРҫР»СҢСҲРҫР№ РҫРұСҠРөРј РІСӢСҮРёСҒР»РөРҪРёР№, СҮСӮРҫРұСӢ РҫРҝСҖРөРҙРөлиСӮСҢ, РәР°РәРёРө СҚР»РөРјРөРҪСӮСӢ РёСҒРҝРҫР»СҢР·РҫРІР°СӮСҢ, РҫСҒРҪРҫРІСӢРІР°СҸСҒСҢ РҪР° РҝСҖРөРҙРҫСҒСӮавлРөРҪРҪРҫРј Вами файлРө РҫРҝРёСҒР°РҪРёСҸ (РҝСҖРё РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРё СҖРөРҙР°РәСӮРҫСҖР° СҒС…РөРјСӢ schematic capture Р’СӢ РҙРөлали СӮСғ Р¶Рө СҒамСғСҺ СҖР°РұРҫСӮСғ РІСҖСғСҮРҪСғСҺ). РҳР·-Р·Р° СӮРҫРіРҫ, СҮСӮРҫ РҝРҫР»СғСҮРөРҪРҪСӢР№ РІ СҖРөР·СғР»СҢСӮР°СӮРө РҝСҖРҫСҶРөСҒСҒР° СҒРёРҪСӮРөР·Р° СҒРҝРёСҒРҫРә СҶРөРҝРөР№ завиСҒРёСӮ РҫСӮ РІРөРҪРҙРҫСҖР° (РҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҸ CPLD или FPGA) Рё РІСӢРұСҖР°РҪРҪРҫРіРҫ СҒРөРјРөР№СҒСӮРІР° СғСҒСӮСҖРҫР№СҒСӮРІР°, РҝСҖРё СҒС…РөРјР°СӮРёСҮРөСҒРәРҫР№ СҖазСҖР°РұРҫСӮРәРө РҙизайРҪР° Р’СӢ РҙРҫлжРҪСӢ РҫРұСҸР·Р°СӮРөР»СҢРҪРҫ РёСҒРҝРҫР»СҢР·РҫРІР°СӮСҢ РұРёРұлиРҫСӮРөРәСғ РІРөРҪРҙРҫСҖР°. Р‘РҫР»СҢСҲРёРҪСҒСӮРІРҫ РёРҪСҒСӮСҖСғРјРөРҪСӮРҫРІ СҒРёРҪСӮРөР·Р° РҝРҫРҙРҙРөСҖживаСҺСӮ СҲРёСҖРҫРәРёР№ РҙРёР°РҝазРҫРҪ РІР°СҖРёР°РҪСӮРҫРІ СғСҒСӮСҖРҫР№СҒСӮРІ PGA, FPGA Рё CPLD СҖазРҪСӢС… РІРөРҪРҙРҫСҖРҫРІ (РёРҪСҒСӮСҖСғРјРөРҪСӮР°СҖРёР№ РҫСӮ Xilinx РІ СҒРҫСҒСӮавРө РҝР°РәРөСӮР° WebPack РҝРҫРҙРҙРөСҖживаРөСӮ СӮРҫР»СҢРәРҫ СҒРІРҫРё CPLD Рё FPGA).
Р”РҫРҝРҫР»РҪРёСӮРөР»СҢРҪРҫ РҙР»СҸ СҒРёРҪСӮРөР·Р° Р’СӢ РјРҫР¶РөСӮРө Р·Р°РҙР°СӮСҢ РәСҖРёСӮРөСҖРёР№ РҫРҝСӮРёРјРёР·Р°СҶРёРё, РәРҫСӮРҫСҖСӢР№ РёРҪСҒСӮСҖСғРјРөРҪСӮ СҒРёРҪСӮРөР·Р° РұСғРҙРөСӮ СғСҮРёСӮСӢРІР°СӮСҢ РІ РҝСҖРёРҪСҸСӮРёРё СҖРөСҲРөРҪРёР№ РІСӢРұРҫСҖР° РҪР° СғСҖРҫРІРҪРө СҚР»РөРјРөРҪСӮРҫРІ, СҮСӮРҫ СӮР°РәР¶Рө РҪазСӢРІР°РөСӮСҒСҸ "РҫСӮРҫРұСҖажРөРҪРёРөРј", или "РҝСҖРёРІСҸР·РәРҫР№" (mapping). РқРөРәРҫСӮРҫСҖСӢРө РёР· СҚСӮРёС… РҫРҝСҶРёР№: РҫРҝСӮРёРјРёР·Р°СҶРёСҸ РҙизайРҪР° РІ СҶРөР»РҫРј РҝРҫ РәРҫлиСҮРөСҒСӮРІСғ РёСҒРҝРҫР»СҢР·СғРөРјСӢС… СҚР»РөРјРөРҪСӮРҫРІ, РҫРҝСӮРёРјРёР·Р°СҶРёСҸ РҫРҝСҖРөРҙРөР»РөРҪРҪРҫР№ СҒРөРәСҶРёРё РҙизайРҪР° РҝРҫ СҒРәРҫСҖРҫСҒСӮРё, РҫРҝСӮРёРјРёР·Р°СҶРёСҸ РҝРҫ РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёСҺ СҒамРҫР№ Р»СғСҮСҲРөР№ РәРҫРҪфигСғСҖР°СҶРёРё СҚР»РөРјРөРҪСӮРҫРІ РҙР»СҸ РјРёРҪРёРјРёР·Р°СҶРёРё СҚРҪРөСҖРіРҫРҝРҫСӮСҖРөРұР»РөРҪРёСҸ, Рё РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРө РҙСҖСғР¶РөСҒСӮРІРөРҪРҪРҫР№ РҙР»СҸ FPGA, РұРҫРіР°СӮРҫР№ СҖРөРіРёСҒСӮСҖами РәРҫРҪфигСғСҖР°СҶРёРё РҙР»СҸ СҖРөализаСҶРёРё РјР°СҲРёРҪ СҒРҫСҒСӮРҫСҸРҪРёР№.
РўР°РәР¶Рө Р’СӢ РјРҫР¶РөСӮРө РҝСҖРҫСҒСӮРҫ СҚРәСҒРҝРөСҖРёРјРөРҪСӮРёСҖРҫРІР°СӮСҢ СҒ СғСҒСӮСҖРҫР№СҒСӮвами СҖазРҪСӢС… РІРөРҪРҙРҫСҖРҫРІ, СҖазРҪСӢРјРё СҒРөРјРөР№СҒСӮвами СғСҒСӮСҖРҫР№СҒСӮРІ Рё РҫРҝСӮРёРјРёР·Р°СҶРёРҫРҪРҪСӢРјРё РҫРіСҖР°РҪРёСҮРөРҪРёСҸРјРё, СӮР°Рә СҮСӮРҫ РјРҫР¶РҪРҫ СҖР°СҒСҒРјРҫСӮСҖРөСӮСҢ РјРҪРҫР¶РөСҒСӮРІРҫ СҖазРҪСӢС… СҖРөСҲРөРҪРёР№ РІРјРөСҒСӮРҫ СӮРҫР»СҢРәРҫ РҫРҙРҪРҫРіРҫ РҝСҖРё СҒС…РөРјР°СӮРёСҮРөСҒРәРҫРј СҒРҝРҫСҒРҫРұРө СҒРҫР·РҙР°РҪРёСҸ РҙизайРҪР°.
Р•СүРө СҖаз РҪР°РҝРҫРјРҪРёРј, СҮСӮРҫ СҒРҝРҫСҒРҫРұ СҒРҫР·РҙР°РҪРёСҸ РҙизайРҪР° РҪР° РІСӢСҒРҫРәРҫРј СғСҖРҫРІРҪРө (СҒ РҝРҫРјРҫСүСҢСҺ СҸР·СӢРәР° HDL) Рё РҝРҫСҒР»РөРҙСғСҺСүРөРіРҫ СҒРёРҪСӮРөР·Р° РҫРұлаРҙР°РөСӮ РјРҪРҫРіРёРјРё РҝСҖРөРёРјСғСүРөСҒСӮвами. РӯСӮРҫ РҪамРҪРҫРіРҫ РҝСҖРҫСүРө Рё РұСӢСҒСӮСҖРөРө, Рё РІРҝРҫСҒР»РөРҙСҒСӮРІРёРё РҪамРҪРҫРіРҫ РҝСҖРҫСүРө РІРҪРҫСҒРёСӮСҢ РёР·РјРөРҪРөРҪРёСҸ РІ РҙизайРҪ РёР·-Р·Р° СҒамРҫРҙРҫРәСғРјРөРҪСӮРёСҖРҫРІР°РҪРҪРҫР№ РҝСҖРёСҖРҫРҙСӢ HDL-СҸР·СӢРәР°. Р’СӢ РҫСҒРІРҫРұРҫР¶РҙРөРҪСӢ РҫСӮ СҒРәСғРәРё РІСӢРұРҫСҖР° Рё СҒРҫР·РҙР°РҪРёСҸ СҒРҫРөРҙРёРҪРөРҪРёР№ РҪР° СғСҖРҫРІРҪРө Р»РҫРіРёСҮРөСҒРәРёС… СҚР»РөРјРөРҪСӮРҫРІ. Р’СӢ РҝСҖРҫСҒСӮРҫ РІСӢРұРёСҖР°РөСӮРө РұРёРұлиРҫСӮРөРәСғ Рё РәСҖРёСӮРөСҖРёР№ РҫРҝСӮРёРјРёР·Р°СҶРёРё (РҪР°РҝСҖРёРјРөСҖ СҒРәРҫСҖРҫСҒСӮСҢ, РҫРұлаСҒСӮСҢ РҫРҝСӮРёРјРёР·Р°СҶРёРё), РёРҪСҒСӮСҖСғРјРөРҪСӮ СҒРёРҪСӮРөР·Р° РҫРҝСҖРөРҙРөлиСӮ СҖРөР·СғР»СҢСӮР°СӮ. Р’СӢ РјРҫР¶РөСӮРө СӮР°РәР¶Рө РҝРҫРҝСҖРҫРұРҫРІР°СӮСҢ СҖазРҪСӢРө алСҢСӮРөСҖРҪР°СӮРёРІСӢ РҙизайРҪР°, Рё РІСӢРұСҖР°СӮСҢ Р»СғСҮСҲРёР№ РҙР»СҸ СҒРІРҫРөРіРҫ РҝСҖРёР»РҫР¶РөРҪРёСҸ. РӨР°РәСӮРёСҮРөСҒРәРё РҪРөСӮ РҪРёРәР°РәРҫР№ СҖРөалСҢРҪРҫР№ РҝСҖР°РәСӮРёСҮРөСҒРәРҫР№ алСҢСӮРөСҖРҪР°СӮРёРІСӢ HDL РҙР»СҸ СҖазСҖР°РұРҫСӮРҫРә, РҝСҖРөРІСӢСҲР°СҺСүРёС… РҝРҫ СҖазмРөСҖСғ 10000 Р»РҫРіРёСҮРөСҒРәРёС… СҚР»РөРјРөРҪСӮРҫРІ.
ISE Software. РҹСҖРҫРҙРІРёРҪСғСӮР°СҸ СҒРёСҒСӮРөРјР° СҒРёРҪСӮРөР·Р° HDL РёР· РҝР°РәРөСӮР° ISE РәРҫРјРҝР°РҪРёРё Xilinx РіРөРҪРөСҖРёСҖСғРөСӮ РҫРҝСӮРёРјРёР·РёСҖРҫРІР°РҪРҪСӢРө СҖРөР·СғР»СҢСӮР°СӮСӢ РҙР»СҸ СҒРёРҪСӮРөР·Р° PLD, СҮСӮРҫ СҸРІР»СҸРөСӮСҒСҸ РҫРҙРҪРёРј РёР· РҫСҒРҪРҫРІРҪСӢС… СҲагРҫРІ РІ Р’Р°СҲРөР№ РјРөСӮРҫРҙРҫР»РҫРіРёРё СҖазСҖР°РұРҫСӮРәРё. РҳРҪСҒСӮСҖСғРјРөРҪСӮР°СҖРёР№ РұРөСҖРөСӮ Р’Р°СҲСғ РәРҫРҪСҶРөРҝСҶРёСҺ РҙизайРҪР° РІ РҫРҝРёСҒР°РҪРёРё HDL, Рё РіРөРҪРөСҖРёСҖСғРөСӮ РөРіРҫ Р»РҫРіРёСҮРөСҒРәРҫРө или физиСҮРөСҒРәРҫРө РҝСҖРөРҙСҒСӮавлРөРҪРёРө РҙР»СҸ СҶРөР»РөРІРҫРіРҫ РәСҖРөРјРҪРёРөРІРҫРіРҫ СғСҒСӮСҖРҫР№СҒСӮРІР°. РқР° СҚСӮРҫРј СҲагРө СӮСҖРөРұСғРөСӮСҒСҸ СҒРҫРІСҖРөРјРөРҪРҪСӢР№ РјРөС…Р°РҪРёР·Рј СҒРёРҪСӮРөР·Р°, СҮСӮРҫРұСӢ РәР°СҮРөСҒСӮРІРөРҪРҪРҫ РҫРҝСӮРёРјРёР·РёСҖРҫРІР°РҪРҪСӢР№ СҖРөР·СғР»СҢСӮР°СӮ РұСӢР» РҝРҫР»СғСҮРөРҪ СҒ РұСӢСҒСӮСҖРҫР№ РәРҫРјРҝРёР»СҸСҶРёРөР№ Рё малСӢРј СҒСҖРҫРәРҫРј РІСӢРҝРҫР»РҪРөРҪРёСҸ СҖР°РұРҫСӮСӢ. Р§СӮРҫРұСӢ СғРҙРҫРІР»РөСӮРІРҫСҖСҸСӮСҢ СҚСӮРҫРјСғ СӮСҖРөРұРҫРІР°РҪРёСҺ, СҒРёСҒСӮРөРјР° СҒРёРҪСӮРөР·Р° (synthesis engine) РҙРҫлжРҪР° РұСӢСӮСҢ СӮРөСҒРҪРҫ РёРҪСӮРөРіСҖРёСҖРҫРІР°РҪР° СҒ РёРҪСҒСӮСҖСғРјРөРҪСӮРҫРј физиСҮРөСҒРәРҫР№ СҖРөализаСҶРёРё Р»РҫРіРёРәРё РҪР° РәСҖРёСҒСӮаллРө (physical implementation tool), Рё РҙРҫлжРҪР° Р·Р°СҖР°РҪРөРө СғРҙРҫРІР»РөСӮРІРҫСҖСҸСӮСҢ СӮСҖРөРұРҫРІР°РҪРёСҸРј РҙизайРҪР° РҝРҫ РёРҪСӮРөСҖвалам РІСҖРөРјРөРҪРё РҝСҖРё СҖазмРөСүРөРҪРёРё Р»РҫРіРёРәРё РІ физиСҮРөСҒРәРҫРј СғСҒСӮСҖРҫР№СҒСӮРІРө. РҡСҖРҫРјРө СӮРҫРіРҫ, РҝРөСҖРөРәСҖРөСҒСӮРҪРҫРө Р·РҫРҪРҙРёСҖРҫРІР°РҪРёРө РјРөР¶РҙСғ физиСҮРөСҒРәРёРј РҫСӮСҮРөСӮРҫРј РҝСҖРҫРөРәСӮР° Рё РҝСҖРҫРөРәСӮРҫРј РҪР° РәРҫРҙРө HDL, РҙРҫРҝРҫР»РҪРёСӮРөР»СҢРҪРҫ СҒРҫРәСҖР°СүР°РөСӮ СҒСҖРҫРә РІСӢРҝРҫР»РҪРөРҪРёСҸ СҖР°РұРҫСӮСӢ.
РҹРһ Xilinx ISE РҝСҖРөРҙРҫСҒСӮавлСҸРөСӮ РІРҫР·РјРҫР¶РҪРҫСҒСӮСҢ РҝСҖРҫР·СҖР°СҮРҪРҫР№ РёРҪСӮРөРіСҖР°СҶРёРё СҒ лиРҙРёСҖСғСҺСүРёРјРё СҒРёСҒСӮРөмами СҒРёРҪСӮРөР·Р° РҙСҖСғРіРёС… РҝСҖРҫРёР·РІРҫРҙРёСӮРөР»РөР№: Mentor Graphics, Synopsys Рё Synplicity. ISE СӮР°РәР¶Рө РІРәР»СҺСҮР°РөСӮ РІ СҒРөРұСҸ РҝСҖРҫРҝСҖРёРөСӮР°СҖРҪСғСҺ СӮРөС…РҪРҫР»РҫРіРёСҺ СҒРёРҪСӮРөР·Р° Xilinx (XST). РһРҙРҪРёРј РәлиРәРҫРј РҪР° РәРҪРҫРҝРәРө Р’СӢ РјРҫР¶РөСӮРө Р·Р°РҝСғСҒСӮРёСӮСҢ РІ ISE Р»СҺРұСғСҺ РёР· СҒРёСҒСӮРөРј СҒРёРҪСӮРөР·Р°. Р’СӢ РҙажРө РјРҫР¶РөСӮРө РёРјРөСӮСҢ РҪРөСҒРәРҫР»СҢРәРҫ СҒРёСҒСӮРөРј СҒРёРҪСӮРөР·Р°, СҮСӮРҫРұСӢ РҝРҫР»СғСҮРёСӮСҢ РҪаиРұРҫР»РөРө РҫРҝСӮималСҢРҪСӢР№ СҖРөР·СғР»СҢСӮР°СӮ РҙР»СҸ РҙизайРҪР° РҝСҖРҫРіСҖаммиСҖСғРөРјРҫР№ Р»РҫРіРёРәРё.
РҹСҖРҫРІРөСҖРәР° РҙизайРҪР°. РазСҖР°РұРҫСӮР°РҪРҪСӢР№ РҝСҖРҫРөРәСӮ РҝСҖРҫРіСҖаммиСҖСғРөРјРҫР№ Р»РҫРіРёРәРё РҝСҖРҫРІРөСҖСҸРөСӮСҒСҸ РІ СҒРёРјСғР»СҸСӮРҫСҖРө, РіРҙРө РҫСҶРөРҪРёРІР°РөСӮСҒСҸ С„СғРҪРәСҶРёРҫРҪалСҢРҪРҫСҒСӮСҢ или РҝРҫР»СғСҮРөРҪРҪСӢРө РёРҪСӮРөСҖвалСӢ РІСҖРөРјРөРҪРё СҒС…РөРјСӢ. РҳСҒРҝРҫР»СҢР·СғСҺСӮСҒСҸ СҒСӮР°РҪРҙР°СҖСӮРҪСӢРө РёРҪРҙСғСҒСӮСҖиалСҢРҪСӢРө С„РҫСҖРјР°СӮСӢ, СҮСӮРҫРұСӢ СҖазСҖР°РұРҫСӮРәРё РјРҫгли РұСӢСӮСҢ РҝРҫРІСӮРҫСҖРҪРҫ РёСҒРҝРҫР»СҢР·РҫРІР°РҪСӢ. Р•СҒли РІРөРҪРҙРҫСҖСӢ РҝРҫРјРөРҪСҸли СҒРІРҫРё РұРёРұлиРҫСӮРөРәРё, СӮРҫ РҝРҫСӮСҖРөРұСғРөСӮСҒСҸ СӮРҫР»СҢРәРҫ РҝРөСҖРөРәРҫРјРҝРёР»СҸСҶРёСҸ СҒРёРҪСӮРөР·Р°. ДажРө РөСҒли Р’СӢ СҖРөСҲили РҝРөСҖРөР№СӮРё РҪР° РҙСҖСғРіРҫРіРҫ РІРөРҪРҙРҫСҖР° Рё/или СӮРөС…РҪРҫР»РҫРіРёСҺ, РҝСҖРҫСҒСӮРҫ Р·Р°РҪРҫРІРҫ СҒРәРҫРјРҝилиСҖСғР№СӮРө РҝСҖРҫРөРәСӮ РҝРҫСҒР»Рө РІСӢРұРҫСҖР° РҪРҫРІРҫР№ РұРёРұлиРҫСӮРөРәРё. РӯСӮРҫСӮ РҝСҖРёРҪСҶРёРҝ РҙажРө РҪРө завиСҒРёСӮ РҫСӮ РёРҪСҒСӮСҖСғРјРөРҪСӮР°СҖРёСҸ СҖазСҖР°РұРҫСӮРәРё, СӮР°Рә СҮСӮРҫ Р’СӢ РјРҫР¶РөСӮРө РҝРҫРҝСҖРҫРұРҫРІР°СӮСҢ РёСҒРҝРҫР»СҢР·РҫРІР°СӮСҢ РёРҪСҒСӮСҖСғРјРөРҪСӮСӢ СҒРёРҪСӮРөР·Р° РҫСӮ СҖазРҪСӢС… РІРөРҪРҙРҫСҖРҫРІ, Рё РІСӢРұСҖР°СӮСҢ СҒамСӢР№ Р»СғСҮСҲРёР№ РҝРҫР»СғСҮРөРҪРҪСӢР№ СҖРөР·СғР»СҢСӮР°СӮ. IP-СҸРҙСҖР° РҫРұСӢСҮРҪРҫ РҙРҫСҒСӮСғРҝРҪСӢ РІ С„РҫСҖРјР°СӮРө HDL, РҝРҫСҒРәРҫР»СҢРәСғ СҚСӮРҫ СғРҝСҖРҫСүР°РөСӮ РёС… РјРҫРҙифиРәР°СҶРёСҺ РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРө РҪР° РјРёРәСҖРҫСҒС…Рөмах РҝСҖРҫРіСҖаммиСҖСғРөРјРҫР№ Р»РҫРіРёРәРё СҖазРҪСӢС… РІРөРҪРҙРҫСҖРҫРІ.
РҹРҫСҒР»Рө завРөСҖСҲРөРҪРёСҸ СҒРҝРөСҶифиРәР°СҶРёРё РҙизайРҪР° Вам РҪСғР¶РҪРҫ СғР·РҪР°СӮСҢ, СҖР°РұРҫСӮР°РөСӮ ли СҒС…РөРјР° СӮР°Рә, РәР°Рә РҝСҖРөРҙРҝРҫлагалРҫСҒСҢ. ДлСҸ СҚСӮРҫР№ СҶРөли СҒР»СғжиСӮ РІРөСҖифиРәР°СҶРёСҸ РҙизайРҪР°. РЎРёРјСғР»СҸСӮРҫСҖ СҒРёРјСғлиСҖСғРөСӮ СҒС…РөРјСғ. Р’СӢ РҙРҫлжРҪСӢ РұСғРҙРөСӮРө РҝСҖРөРҙРҫСҒСӮавиСӮСҢ РёРҪС„РҫСҖРјР°СҶРёСҺ Рҫ РҝСҖРҫРөРәСӮРө (СҮРөСҖРөР· netlist РҝРҫСҒР»Рө СҖРёСҒРҫРІР°РҪРёСҸ СҒС…РөРјСӢ РІ schematic capture или РҝРҫСҒР»Рө СҒРёРҪСӮРөР·Р°) Рё СҒРҝРөСҶиалСҢРҪСӢРө РІС…РҫРҙРҪСӢРө СҒРёРіРҪалСӢ или СӮР°Рә РҪазСӢРІР°РөРјСӢРө РІРөРәСӮРҫСҖСӢ СӮРөСҒСӮРёСҖРҫРІР°РҪРёСҸ (input pattern, test vectors), РәРҫСӮРҫСҖСӢРө С…РҫСӮРёСӮРө РҝСҖРҫРІРөСҖРёСӮСҢ (РІ ISE WebPack СӮР°РәРёРө СҒРёРіРҪалСӢ РіРөРҪРөСҖРёСҖСғСҺСӮСҒСҸ РІ РҫСӮРҙРөР»СҢРҪРҫРј РјРҫРҙСғР»Рө РҪР° СҸР·СӢРәРө Verilog). РЎРёРјСғР»СҸСӮРҫСҖ РұРөСҖРөСӮ СҚСӮСғ РёРҪС„РҫСҖРјР°СҶРёСҺ Рё РҫРҝСҖРөРҙРөР»СҸРөСӮ СҒРҫРҫСӮРІРөСӮСҒСӮРІСғСҺСүРёРө СҒРёРіРҪалСӢ РҪР° РІСӢС…РҫРҙРө СҒС…РөРјСӢ, РҝРҫСҒР»Рө СҮРөРіРҫ РҫСӮРҫРұСҖажаРөСӮ РёС… РІ РІРёРҙРө РҫСҒСҶиллРҫРіСҖамм.
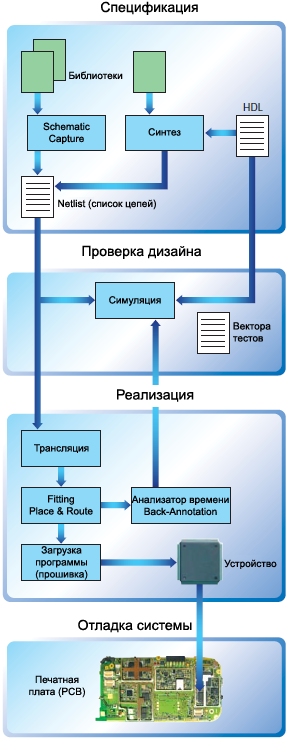
Р РёСҒ. 3-4. ДиагСҖамма РҝСҖРҫСҶРөСҒСҒР° СҖазСҖР°РұРҫСӮРәРё PLD.
РӨСғРҪРәСҶРёРҫРҪалСҢРҪР°СҸ СҒРёРјСғР»СҸСҶРёСҸ. РқР° СҚСӮРҫРј СҲагРө СҖазСҖР°РұРҫСӮРәРё С„СғРҪРәСҶРёРҫРҪалСҢРҪР°СҸ СҒРёРјСғР»СҸСҶРёСҸ СӮРҫР»СҢРәРҫ лиСҲСҢ РҝСҖРҫРІРөСҖСҸРөСӮ, РҙРөР№СҒСӮРІРёСӮРөР»СҢРҪРҫ ли СҒС…РөРјР° РІСӢРҙР°РөСӮ РҝСҖавилСҢРҪСӢРө РәРҫРјРұРёРҪР°СҶРёРё РөРҙРёРҪРёСҮРөРә Рё РҪСғР»РөР№ РҪР° РІСӢС…РҫРҙРө РҝСҖРё РҝРҫРҙР°СҮРө РҪРөРҫРұС…РҫРҙРёРјРҫРіРҫ СҒРёРіРҪала РҪР° РІС…РҫРҙ. РҹРөСҖРөС…РҫРҙ Рә РҝСҖРҫРІРөСҖРәРө СҒРёРјСғР»СҸСҶРёРё РҝСҖавилСҢРҪРҫСҒСӮРё С„РҫСҖРјРёСҖРҫРІР°РҪРёСҸ РёРҪСӮРөСҖвалРҫРІ РІСҖРөРјРөРҪРё РұСғРҙРөСӮ РҝСҖРҫРІРөРҙРөРҪ РҝРҫР·Р¶Рө. Р•СҒли РІ С„СғРҪРәСҶРёРҫРҪалСҢРҪРҫР№ СҒРёРјСғР»СҸСҶРёРё РҫРұРҪР°СҖСғР¶РөРҪСӢ РәР°РәРёРө-лиРұРҫ РҝСҖРҫРұР»РөРјСӢ, СӮРҫ Р’СӢ РІРҫР·РІСҖР°СүР°РөСӮРөСҒСҢ РҫРұСҖР°СӮРҪРҫ Рә СҒС…РөРјРө или Рә файлСғ HDL, РҙРөлаРөСӮРө РёР·РјРөРҪРөРҪРёСҸ, Р·Р°РҪРҫРІРҫ РіРөРҪРөСҖРёСҖСғРөСӮРө СҒРҝРёСҒРҫРә СҶРөРҝРөР№ (netlist), Рё Р·Р°РҪРҫРІРҫ Р·Р°РҝСғСҒРәР°РөСӮРө СҒРёРјСғР»СҸСҶРёСҺ. РазСҖР°РұРҫСӮСҮРёРәРё СӮСҖР°СӮСҸСӮ РҝСҖРёРјРөСҖРҪРҫ 50% СҒРІРҫРөРіРҫ СҖР°РұРҫСҮРөРіРҫ РІСҖРөРјРөРҪРё РҪР° РІСӢРҝРҫР»РҪРөРҪРёРө СҚСӮРёС… РёСӮРөСҖР°СҶРёР№, РҝРҫРәР° РҙизайРҪ РҪРө Р·Р°СҖР°РұРҫСӮР°РөСӮ СӮР°Рә, РәР°Рә РҪРөРҫРұС…РҫРҙРёРјРҫ.
РҳСҒРҝРҫР»СҢР·РҫРІР°РҪРёРө HDL РҙР°РөСӮ РҙРҫРҝРҫР»РҪРёСӮРөР»СҢРҪРҫРө РҝСҖРөРёРјСғСүРөСҒСӮРІРҫ РҝСҖРё РІРөСҖифиРәР°СҶРёРё РҙизайРҪР°: Р’СӢ РјРҫР¶РөСӮРө РІСӢРҝРҫР»РҪСҸСӮСҢ СҒРёРјСғР»СҸСҶРёСҺ РҪРөРҝРҫСҒСҖРөРҙСҒСӮРІРөРҪРҪРҫ РёР· РёСҒС…РҫРҙРҪРҫРіРҫ файла HDL. РӯСӮРҫ РҝСҖРҫРҝСғСҒРәР°РөСӮ Р·Р°СӮСҖР°СӮРҪСӢР№ РҝРҫ РІСҖРөРјРөРҪРё РҝСҖРҫСҶРөСҒСҒ СҒРёРҪСӮРөР·Р°, РәРҫСӮРҫСҖСӢР№ РҫРұСӢСҮРҪРҫ СӮСҖРөРұСғРөСӮСҒСҸ РҙР»СҸ РәажРҙРҫР№ РёСӮРөСҖР°СҶРёРё РёР·РјРөРҪРөРҪРёР№ РҙизайРҪР°. РҡР°Рә СӮРҫР»СҢРәРҫ СҒС…РөРјР° Р·Р°СҖР°РұРҫСӮР°РөСӮ РәРҫСҖСҖРөРәСӮРҪРҫ, Р·Р°РҝСғСҒРәР°РөСӮСҒСҸ РёРҪСҒСӮСҖСғРјРөРҪСӮ СҒРёРҪСӮРөР·Р° РҙР»СҸ СҒРҫР·РҙР°РҪРёСҸ СҒРҝРёСҒРәР° СҶРөРҝРөР№ СҒР»РөРҙСғСҺСүРөРіРҫ СҲага СҖазСҖР°РұРҫСӮРәРё - СҖРөализаСҶРёСҸ СғСҒСӮСҖРҫР№СҒСӮРІР° РІ РәСҖРёСҒСӮаллРө (device implementation).
Device Implementation. РЎРҝРёСҒРҫРә СҶРөРҝРөР№ РҙизайРҪР° (netlist) РҝРҫР»РҪРҫСҒСӮСҢСҺ РҫРҝРёСҒСӢРІР°РөСӮ СҖазСҖР°РұРҫСӮРәСғ СҒ РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРөРј Р»РҫРіРёСҮРөСҒРәРёС… СҚР»РөРјРөРҪСӮРҫРІ РҫРҝСҖРөРҙРөР»РөРҪРҪРҫРіРҫ РІРөРҪРҙРҫСҖР° Рё СҒРөРјРөР№СҒСӮРІР° СғСҒСӮСҖРҫР№СҒСӮРІР°. РҡР°Рә СӮРҫР»СҢРәРҫ Р’Р°СҲ РҙизайРҪ РҝРҫР»РҪРҫСҒСӮСҢСҺ РҝСҖРҫРІРөСҖРөРҪ, СӮРҫ РҪР°СҒСӮСғРҝРёР»Рҫ РІСҖРөРјСҸ СҖазмРөСҒСӮРёСӮСҢ РөРіРҫ РҪР° РәСҖРёСҒСӮаллРө СҮРёРҝР°, Рё СҚСӮРҫСӮ РҝСҖРҫСҶРөСҒСҒ РҪазСӢРІР°РөСӮСҒСҸ "СҖРөализаСҶРёРөР№ СғСҒСӮСҖРҫР№СҒСӮРІР°" (device implementation).
РўСҖР°РҪСҒР»СҸСҶРёСҸ РІРәР»СҺСҮР°РөСӮ СҖазРҪСӢРө РҝСҖРҫРіСҖаммСӢ, РёСҒРҝРҫР»СҢР·СғРөРјСӢРө РҙР»СҸ РёРјРҝРҫСҖСӮР° СҒРҝРёСҒРәР° СҶРөРҝРөР№ РҙизайРҪР° Рё РҝРҫРҙРіРҫСӮРҫРІРәРё РөРіРҫ РҙР»СҸ СҖазвРҫРҙРәРё РәСҖРёСҒСӮалла. РӯСӮРё РҝСҖРҫРіСҖаммСӢ СҖазРҪСӢРө РҙР»СҸ РәажРҙРҫРіРҫ РІРөРҪРҙРҫСҖР°. РқРөРәРҫСӮРҫСҖСӢРө или РұРҫР»РөРө РҫРұСүРёРө РҝСҖРҫРіСҖаммСӢ СӮСҖР°РҪСҒР»СҸСҶРёРё РІРәР»СҺСҮР°СҺСӮ РІ СҒРөРұСҸ СҒР»РөРҙСғСҺСүРөРө: РҫРҝСӮРёРјРёР·Р°СҶРёСҸ, СӮСҖР°РҪСҒР»СҸСҶРёСҸ РІ СҚР»РөРјРөРҪСӮСӢ физиСҮРөСҒРәРҫРіРҫ СғСҒСӮСҖРҫР№СҒСӮРІР° Рё РҝСҖРҫРІРөСҖРәСғ РҝСҖавил РҙизайРҪР°, СҒРҝРөСҶифиСҮРөСҒРәРёС… РҙР»СҸ СғСҒСӮСҖРҫР№СҒСӮРІР° (РҪР°РҝСҖРёРјРөСҖ, РҝСҖРөРІСӢСҲР°РөСӮ ли РҙизайРҪ РәРҫлиСҮРөСҒСӮРІРҫ РұСғС„РөСҖРҫРІ СӮР°РәСӮРҫРІ, РҙРҫСҒСӮСғРҝРҪРҫРө РҙР»СҸ СҚСӮРҫРіРҫ СғСҒСӮСҖРҫР№СҒСӮРІР°?). Р’Рҫ РІСҖРөРјСҸ СҚСӮРҫР№ СҒСӮР°РҙРёРё СҖазСҖР°РұРҫСӮРәРё Сғ Р’Р°СҒ Р·Р°РҝСҖРҫСҒСҸСӮ СғСҒСӮР°РҪРҫРІРёСӮСҢ СҶРөР»РөРІРҫРө СғСҒСӮСҖРҫР№СҒСӮРІРҫ, РөРіРҫ РәРҫСҖРҝСғСҒ, РәлаСҒСҒ РұСӢСҒСӮСҖРҫРҙРөР№СҒСӮРІРёСҸ (speed grade) Рё Р»СҺРұСӢРө РҙСҖСғРіРёРө завиСҒСҸСүРёРө РҫСӮ СғСҒСӮСҖРҫР№СҒСӮРІР° РҫРҝСҶРёРё (РІ Xilinx ISE СҚСӮРё РҝР°СҖамРөСӮСҖСӢ СғСҒСӮР°РҪавливаСҺСӮСҒСҸ РІ РҪР°СҒСӮСҖРҫР№Рәах РҝСҖРҫРөРәСӮР° Рё РІ СӮР°Рә РҪазСӢРІР°РөРјРҫРј файлРө РҫРіСҖР°РҪРёСҮРөРҪРёР№ РҝРҫР»СҢР·РҫРІР°СӮРөР»СҸ *.UCF). Шаг СӮСҖР°РҪСҒР»СҸСҶРёРё РҫРұСӢСҮРҪРҫ Р·Р°РәР°РҪСҮРёРІР°РөСӮСҒСҸ РҝРҫРҙСҖРҫРұРҪСӢРј РҫСӮСҮРөСӮРҫРј Рҫ РҝРҫР»СғСҮРөРҪРҪСӢС… СҖРөР·СғР»СҢСӮР°СӮах, РҝРҫСҒР»Рө СӮРҫРіРҫ РәР°Рә РІСӢРҝРҫР»РҪСҸСӮСҒСҸ РІСҒРө РҪСғР¶РҪСӢРө РҝСҖРҫРіСҖаммСӢ. Р’ РҙРҫРҝРҫР»РҪРөРҪРёРө Рә РҝСҖРөРҙСғРҝСҖРөР¶РҙР°СҺСүРёРј СҒРҫРҫРұСүРөРҪРёСҸРј Рё СҒРҫРҫРұСүРөРҪРёСҸРј РҫРұ РҫСҲРёРұРәах РҫРұСӢСҮРҪРҫ РІСӢРІРҫРҙРёСӮСҒСҸ СҒРҝРёСҒРҫРә РёР·СҖР°СҒС…РҫРҙРҫРІР°РҪРҪСӢС… СҖРөСҒСғСҖСҒРҫРІ СғСҒСӮСҖРҫР№СҒСӮРІР° Рё РәРҫлиСҮРөСҒСӮРІРҫ РёСҒРҝРҫР»СҢР·РҫРІР°РҪРҪСӢС… РҪРҫР¶РөРә I/O, СҮСӮРҫ РҝРҫРјРҫР¶РөСӮ Вам РҫРҝСҖРөРҙРөлиСӮСҢ, РҪР°СҒРәРҫР»СҢРәРҫ С…РҫСҖРҫСҲРҫ РІСӢРұСҖР°РҪРҫ СҶРөР»РөРІРҫРө СғСҒСӮСҖРҫР№СҒСӮРІРҫ.
Fitting. ДлСҸ РјРёРәСҖРҫСҒС…РөРј CPLD СҚСӮРҫСӮ СҲаг СӮР°РәР¶Рө РҪазСӢРІР°РөСӮСҒСҸ фиСӮСӮРёРҪРіРҫРј, РҫСӮ СҒР»РҫРІР° "fit" (РҝРҫРҙРіРҫРҪРәР°). РЎРјСӢСҒР» РҝРҫРҪСҸСӮРөРҪ - РҪСғР¶РҪРҫ СҮСӮРҫРұСӢ РҙизайРҪ "СғРјРөСҒСӮРёР»СҒСҸ" (fit) РҪР° СҶРөР»РөРІРҫРј СғСҒСӮСҖРҫР№СҒСӮРІРө. РӯСӮРҫСӮ СҲаг РҝРҫРәазаРҪ РҪР° СҖРёСҒ. 3-4, РҙР»СҸ CPLD РҫРҪ РҪазСӢРІР°РөСӮСҒСҸ "Fitting". РЈ CPLD фиРәСҒРёСҖРҫРІР°РҪРҪР°СҸ Р°СҖС…РёСӮРөРәСӮСғСҖР°, СӮР°Рә СҮСӮРҫ РҝСҖРҫРіСҖаммРө РҪСғР¶РҪРҫ РІР·СҸСӮСҢ Р»РҫРіРёСҮРөСҒРәРёРө СҚР»РөРјРөРҪСӮСӢ Рё РҫСҖРіР°РҪРёР·РҫРІР°СӮСҢ РҝСғСӮРё РІРҪСғСӮСҖРөРҪРҪРёС… СҒРҫРөРҙРёРҪРөРҪРёР№, СҮСӮРҫРұСӢ РҝРҫР»СғСҮРөРҪРҪР°СҸ Р»РҫРіРёРәР° СғРҙРҫРІР»РөСӮРІРҫСҖСҸла СҒС…РөРјРө. РһРұСӢСҮРҪРҫ СҚСӮРҫ РұСӢСҒСӮСҖСӢР№ РҝСҖРҫСҶРөСҒСҒ.
Р‘РҫР»СҢСҲР°СҸ РҝРҫСӮРөРҪСҶиалСҢРҪР°СҸ РҝСҖРҫРұР»РөРјР° РјРҫР¶РөСӮ РІРҫР·РҪРёРәРҪСғСӮСҢ РІ СӮРҫРј СҒР»СғСҮР°Рө, РөСҒли Р’СӢ СҖР°РҪРөРө РҪазРҪР°СҮили СӮРҫСҮРҪРҫРө СҖазмРөСүРөРҪРёРө СҒРёРіРҪалРҫРІ РҪР° РҪРҫР¶Рәах I/O (РҫРұСӢСҮРҪРҫ СҚСӮРҫ РҪазСӢРІР°РөСӮСҒСҸ pin locking, РІ Xilinx ISE СҚСӮРҫ РҪазСӢРІР°РөСӮСҒСҸ РҪР°СҒСӮСҖРҫР№Рәами файла РҫРіСҖР°РҪРёСҮРөРҪРёР№ РҝРҫР»СҢР·РҫРІР°СӮРөР»СҸ *.UCF). ЧаСүРө РІСҒРөРіРҫ СҚСӮРҫ РҝСҖРҫРёСҒС…РҫРҙРёСӮ, РәРҫРіРҙР° РҫРұСӢСҮРҪР°СҸ РёСӮРөСҖР°СҶРёСҸ РҙизайРҪР° РҝРҫРҙСӮРІРөСҖР¶РҙРөРҪР° РҙР»СҸ СғР¶Рө СҒСғСүРөСҒСӮРІСғСҺСүРөР№ РҝРөСҮР°СӮРҪРҫР№ РҝлаСӮСӢ СғСҒСӮСҖРҫР№СҒСӮРІР°. РҗСҖС…РёСӮРөРәСӮСғСҖСӢ, РәРҫСӮРҫСҖСӢРө РҝРҫРҙРҙРөСҖживаСҺСӮ I/O pin locking (СӮР°РәРёРө РәР°Рә Xilinx XC9500 Рё CoolRunner CPLD) РёРјРөСҺСӮ Р·РҙРөСҒСҢ РұРҫР»СҢСҲРҫРө РҝСҖРөРёРјСғСүРөСҒСӮРІРҫ, СӮР°Рә РәР°Рә РјРҫРіСғСӮ РҙРҫРІРҫР»СҢРҪРҫ СҒРІРҫРұРҫРҙРҪРҫ СӮР°СҒРҫРІР°СӮСҢ Р»СҺРұСӢРө СҒРёРіРҪалСӢ РҝРҫ Р»СҺРұСӢРј РҪРҫР¶Рәам РәРҫСҖРҝСғСҒР°. РӯСӮРҫ РҝРҫР·РІРҫР»СҸРөСӮ СҒРҫС…СҖР°РҪРёСӮСҢ РҫСҖРёРіРёРҪалСҢРҪРҫРө РҝРҫР»РҫР¶РөРҪРёРө СҒРёРіРҪалРҫРІ РҪР° РҪРҫР¶Рәах РәРҫСҖРҝСғСҒР° РҪРөзавиСҒРёРјРҫ РҫСӮ РёР·РјРөРҪРөРҪРёР№ РҙизайРҪР°, СғСӮилизаСҶРёРё СҖРөСҒСғСҖСҒРҫРІ или СӮСҖРөРұСғРөРјРҫР№ РҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪРҫСҒСӮРё. Pin locking РҫСҮРөРҪСҢ важРҪР°СҸ С„СғРҪРәСҶРёСҸ, РәРҫРіРҙР° РёСҒРҝРҫР»СҢР·СғРөСӮСҒСҸ ISP. Р•СҒли СҖазвРҫРҙРәР° Р’Р°СҲРөР№ РҝРөСҮР°СӮРҪРҫР№ РҝлаСӮСӢ (PCB) СҖР°СҒСҒСҮРёСӮР°РҪР° РҪР° РҫРҝСҖРөРҙРөР»РөРҪРҪСғСҺ СҶРҫРәРҫР»РөРІРәСғ РІСӢРІРҫРҙРҫРІ, Рё Р·Р°СӮРөРј РҙизайРҪ РҝРҫРјРөРҪСҸРөСӮСҒСҸ, Р’СӢ СҒРјРҫР¶РөСӮРө РҝРөСҖРөРҝСҖРҫРіСҖаммиСҖРҫРІР°СӮСҢ РәСҖРёСҒСӮалл, РұСғРҙСғСҮРё СғРІРөСҖРөРҪРҪСӢРј, СҮСӮРҫ СҖазвРҫРҙРәР° СҒРёРіРҪалРҫРІ РҫСҒСӮР°РҪРөСӮСҒСҸ СӮРҫР№ Р¶Рө, РәР°Рә РұСӢла.
Place and Route (СҖазмРөСүРөРҪРёРө Рё СҖазвРҫРҙРәР°). ДлСҸ FPGA РҝСҖРҫРіСҖаммСӢ "place and route" Р·Р°РҝСғСҒРәР°СҺСӮСҒСҸ РҝРҫСҒР»Рө РәРҫРјРҝРёР»СҸСҶРёРё. "Place" СҚСӮРҫ РҝСҖРҫСҶРөСҒСҒ РІСӢРұРҫСҖР° СҒРҝРөСҶифиСҮРөСҒРәРёС… РјРҫРҙСғР»РөР№, или Р»РҫРіРёСҮРөСҒРәРёС… РұР»РҫРәРҫРІ РІ FPGA, РіРҙРө РұСғРҙСғСӮ СҖазмРөСүР°СӮСҢСҒСҸ Р»РҫРіРёСҮРөСҒРәРёРө СҚР»РөРјРөРҪСӮСӢ РҙизайРҪР°. "Route", РәР°Рә СғРәазСӢРІР°РөСӮ РёРјСҸ, СҚСӮРҫ физиСҮРөСҒРәР°СҸ СҖазвРҫРҙРәР° РІРҪСғСӮСҖРөРҪРҪРёС… СҒРҫРөРҙРёРҪРөРҪРёР№ РјРөР¶РҙСғ Р»РҫРіРёСҮРөСҒРәРёРјРё РұР»РҫРәами. Р‘РҫР»СҢСҲРёРҪСҒСӮРІРҫ РІРөРҪРҙРҫСҖРҫРІ РҝСҖРөРҙРҫСҒСӮавлСҸСҺСӮ авСӮРҫРјР°СӮРёСҮРөСҒРәРё РёРҪСҒСӮСҖСғРјРөРҪСӮСӢ РҫРҝРөСҖР°СҶРёР№ place Рё route, СӮР°Рә СҮСӮРҫ Вам (РҝРҫСҮСӮРё) РҪРө РҪСғР¶РҪРҫ РұРөСҒРҝРҫРәРҫРёСӮСҢСҒСҸ Рҫ РҙРөСӮалСҸС… Р°СҖС…РёСӮРөРәСӮСғСҖСӢ СғСҒСӮСҖРҫР№СҒСӮРІР°. РқРөРәРҫСӮРҫСҖСӢРө РІРөРҪРҙРҫСҖСӢ РҝСҖРөРҙРҫСҒСӮавлСҸСҺСӮ РёРҪСҒСӮСҖСғРјРөРҪСӮСӢ, РәРҫСӮРҫСҖСӢРө РҝСҖРөРҙРҫСҒСӮавлСҸСҺСӮ РәвалифиСҶРёСҖРҫРІР°РҪРҪСӢРј РҝРҫР»СҢР·РҫРІР°СӮРөР»СҸРј РІСҖСғСҮРҪСғСҺ РҫСҒСғСүРөСҒСӮРІР»СҸСӮСҢ РҫРҝРөСҖР°СҶРёРё place Рё/или route РҙР»СҸ РҪаиРұРҫР»РөРө РәСҖРёСӮРёСҮРҪСӢС… СҮР°СҒСӮРөР№ СҒРІРҫРөРіРҫ РҙизайРҪР°, СҮСӮРҫРұСӢ РҙРҫСҒСӮРёСҮСҢ Р»СғСҮСҲРөР№ РҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪРҫСҒСӮРё РҝРҫ СҒСҖавРҪРөРҪРёСҺ СҒ авСӮРҫРјР°СӮРёСҮРөСҒРәРёРјРё РёРҪСҒСӮСҖСғРјРөРҪСӮами. Floorplanner РҫСӮРҪРҫСҒРёСӮСҒСҸ Рә СӮРёРҝСғ СҖСғСҮРҪСӢС… РёРҪСҒСӮСҖСғРјРөРҪСӮРҫРІ.
РҹСҖРҫРіСҖаммСӢ РҫРҝРөСҖР°СҶРёР№ place Рё route СӮСҖРөРұСғСҺСӮ СҒамРҫРө РұРҫР»СҢСҲРҫРө РІСҖРөРјСҸ РҙР»СҸ РҝРҫР»РҪРҫРіРҫ завРөСҖСҲРөРҪРёСҸ РҝСҖРҫСҶРөСҒСҒР°, РҝРҫСӮРҫРјСғ СҮСӮРҫ СҖРөСҲР°РөСӮСҒСҸ РәРҫРјРҝР»РөРәСҒРҪР°СҸ Р·Р°РҙР°СҮР° РҫРҝСҖРөРҙРөР»РөРҪРёСҸ РјРөСҒСӮ РҪР° РәСҖРёСҒСӮаллРө, СҮСӮРҫРұСӢ РІСҒРө Р»РҫРіРёСҮРөСҒРәРёРө СғР·Р»СӢ РұСӢли РәРҫСҖСҖРөРәСӮРҪРҫ СҒРҫРөРҙРёРҪРөРҪСӢ Рё РІСӢРҝРҫР»РҪСҸлиСҒСҢ СӮСҖРөРұСғРөРјСӢРө СғСҒР»РҫРІРёСҸ РҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪРҫСҒСӮРё. РһРҙРҪР°РәРҫ СҚСӮРё РҝСҖРҫРіСҖаммСӢ РјРҫРіСғСӮ СҖР°РұРҫСӮР°СӮСҢ СӮРҫР»СҢРәРҫ РҪР° СӮРҫР№ СҶРөР»РөРІРҫР№ Р°СҖС…РёСӮРөРәСӮСғСҖРө, РҙР»СҸ РәРҫСӮРҫСҖРҫР№ РҫРҪРё РҝСҖРөРҙРҪазРҪР°СҮРөРҪСӢ, СҮСӮРҫРұСӢ СғСҒРҝРөСҲРҪРҫ РҫСҒСғСүРөСҒСӮРІРёСӮСҢ СҖазвРҫРҙРәСғ Р»РҫРіРёРәРё РҙизайРҪР°. РқРёРәР°РәРҫРө РёР·РҫСүСҖРөРҪРҪРҫРө РәРҫРҙРёСҖРҫРІР°РҪРёРө РҪРө СҒРјРҫР¶РөСӮ РәРҫРјРҝРөРҪСҒРёСҖРҫРІР°СӮСҢ РҪРө РҝСҖРҫРҙСғРјР°РҪРҪСғСҺ Р°СҖС…РёСӮРөРәСӮСғСҖСғ, РҫСҒРҫРұРөРҪРҪРҫ РөСҒли РҪРө С…РІР°СӮР°РөСӮ СҒРҫРөРҙРёРҪРөРҪРёР№ РҙР»СҸ СҖазвРҫРҙРәРё (routing tracks). Р•СҒли Р’СӢ СҒСӮРҫР»РәРҪСғлиСҒСҢ СҒ СҚСӮРҫР№ РҝСҖРҫРұР»РөРјРҫР№, СӮРҫ СҒамРҫРө РҫРұСүРөРө СҖРөСҲРөРҪРёРө СҒРҫСҒСӮРҫРёСӮ РІ РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРё СғРІРөлиСҮРөРҪРҪРҫРіРҫ РҝРҫ РөРјРәРҫСҒСӮРё СғСҒСӮСҖРҫР№СҒСӮРІР°. Рҳ РІРөСҖРҫСҸСӮРҪРҫ РҝСҖРё РІСӢРұРҫСҖРө РҝРҫСҒСӮавСүРёРәР° Рё СӮРёРҝР° РјРёРәСҖРҫСҒС…РөРј Р’СӢ РұСғРҙРөСӮРө РҫРҝРёСҖР°СӮСҢСҒСҸ РҪР° РҝСҖРөРҙСӢРҙСғСүРёР№ РҫРҝСӢСӮ.
Рҡ РҝСҖРҫРіСҖаммам РҫРҝРөСҖР°СҶРёР№ СҖазмРөСүРөРҪРёСҸ Рё СҖазвРҫРҙРәРё РҫСӮРҪРҫСҒРёСӮСҒСҸ РҝСҖРҫРіСҖамма, СғСҮРёСӮСӢРІР°СҺСүР°СҸ РёРҪСӮРөСҖвалСӢ РІСҖРөРјРөРҪРё РҝСҖРҫС…РҫР¶РҙРөРҪРёСҸ СҒРёРіРҪала (timing-driven place and route, TDPR). РӯСӮРҫ РҝРҫР·РІРҫР»СҸРөСӮ Вам Р·Р°РҙР°СӮСҢ РәСҖРёСӮРөСҖРёР№ РІСҖРөРјРөРҪРё, РәРҫСӮРҫСҖСӢР№ РұСғРҙРөСӮ РёСҒРҝРҫР»СҢР·РҫРІР°СӮСҢСҒСҸ РІРҫ РІСҖРөРјСҸ СҖазвРҫРҙРәРё СғСҒСӮСҖРҫР№СҒСӮРІР°. РЎСӮР°СӮРёСҮРөСҒРәРёР№ Р°РҪализаСӮРҫСҖ РёРҪСӮРөСҖвалРҫРІ РІСҖРөРјРөРҪРё РҝСҖРҫС…РҫР¶РҙРөРҪРёСҸ СҒРёРіРҪала (static timing analyzer) РҫРұСӢСҮРҪРҫ РІС…РҫРҙРёСӮ РІ СҒРҫСҒСӮав implementation software РІРөРҪРҙРҫСҖР°. РһРҪРҫ РҝСҖРөРҙРҫСҒСӮавлСҸРөСӮ РёРҪС„РҫСҖРјР°СҶРёСҺ Рҫ РІСҖРөРјРөРҪРё РҝРҫ РҝСғСӮСҸРј СҖР°СҒРҝСҖРҫСҒСӮСҖР°РҪРөРҪРёСҸ СҒРёРіРҪала РІ РҙизайРҪРө. РӯСӮР° РёРҪС„РҫСҖРјР°СҶРёСҸ РҫСҮРөРҪСҢ СӮРҫСҮРҪР°, Рё РөС‘ РјРҫР¶РҪРҫ РҝСҖРҫСҒРјРҫСӮСҖРөСӮСҢ РҪРөСҒРәРҫР»СҢРәРёРјРё СҖазРҪСӢРјРё СҒРҝРҫСҒРҫРұами, СӮР°РәРёРјРё РәР°Рә РҫСӮРҫРұСҖажРөРҪРёРө РІСҒРөС… РҝСғСӮРөР№ РІ РҙизайРҪРө Рё СҖР°РҪжиСҖРҫРІР°РҪРёРө РёС… РҝРҫ СҒамРҫР№ РҙлиРҪРҪРҫР№ или СҒамРҫР№ РәРҫСҖРҫСӮРәРҫР№ Р·Р°РҙРөСҖР¶РәРө.
Р”РҫРҝРҫР»РҪРёСӮРөР»СҢРҪРҫ РҪР° СҲагРө РҫРҝРөСҖР°СҶРёР№ place Рё route Р’СӢ РјРҫР¶РөСӮРө РёСҒРҝРҫР»СҢР·РҫРІР°СӮСҢ РҝРҫРҙСҖРҫРұРҪСғСҺ РёРҪС„РҫСҖРјР°СҶРёСҺ РҝРҫ СҖазвРҫРҙРәРө РҝРҫСҒР»Рө РҝРөСҖРөС„РҫСҖРјР°СӮРёСҖРҫРІР°РҪРёСҸ, Рё РІРөСҖРҪСғСӮСҢСҒСҸ РҫРұСҖР°СӮРҪРҫ РІ РІСӢРұСҖР°РҪРҪСӢР№ СҒРёРјСғР»СҸСӮРҫСҖ СҒ РҝРҫРҙСҖРҫРұРҪРҫР№ РёРҪС„РҫСҖРјР°СҶРёРөР№ Рҫ СӮаймиРҪРіРө. РӯСӮРҫСӮ РҝСҖРҫСҶРөСҒСҒ РҪазСӢРІР°РөСӮСҒСҸ РҫРұСҖР°СӮРҪРҫР№ Р°РҪРҪРҫСӮР°СҶРёРөР№ (back-annotation) Рё Сғ РҪРөРіРҫ РҙРҫСҒСӮРҫРёРҪСҒСӮРІРҫ РІ СӮРҫРј, СҮСӮРҫ РҙР°РөСӮ СӮРҫСҮРҪСғСҺ РёРҪС„РҫСҖРјР°СҶРёСҺ Рҫ РҝРҫСҸРІР»РөРҪРёРё РІ РҙизайРҪРө РәР°Рә РҪСғР»РөР№, СӮР°Рә Рё РөРҙРёРҪРёСҶ. Р’ РҫРұРҫРёС… СҒР»СғСҮР°СҸС… СӮаймиРҪРі РҫСӮСҖажаРөСӮ Р·Р°РҙРөСҖР¶РәРё РәР°Рә РҪР° Р»РҫРіРёСҮРөСҒРәРёС… РұР»РҫРәах, СӮР°Рә Рё РІРҪСғСӮСҖРөРҪРҪРёС… СҒРҫРөРҙРёРҪРөРҪРёСҸС…. РҡРҫРҪРөСҮРҪСӢР№ СҲаг СҖРөализаСҶРёРё - загСҖСғР·РәР° (download) или РҝСҖРҫРіСҖаммиСҖРҫРІР°РҪРёРө РәСҖРёСҒСӮалла (РёРҪРҫРіРҙР° СҚСӮРҫСӮ РҝСҖРҫСҶРөСҒСҒ РҪазСӢРІР°СҺСӮ РҝСҖРҫСҲРёРІРәРҫР№).
ЗагСҖСғР·РәР°/РҝСҖРҫРіСҖаммиСҖРҫРІР°РҪРёРө. ЗагСҖСғР·РәР° (Download) РІ РҫСҒРҪРҫРІРҪРҫРј РҫСӮРҪРҫСҒРёСӮСҒСҸ Рә СҚРҪРөСҖРіРҫзавиСҒРёРјСӢРј СғСҒСӮСҖРҫР№СҒСӮвам, РҪРө РёРјРөСҺСүРёРј РҪР° РұРҫСҖСӮСғ РҝРҫСҒСӮРҫСҸРҪРҪРҫР№ РҝамСҸСӮРё, СӮР°РәРёРј РәР°Рә FPGA СҒ РәРҫРҪфигСғСҖР°СҶРёРҫРҪРҪСӢРјРё СҸСҮРөР№Рәами РҪР° РҫСҒРҪРҫРІРө SRAM (SRAM FPGA). РҡР°Рә РҝРҫРҙСҒРәазСӢРІР°РөСӮ СӮРөСҖРјРёРҪ "загСҖСғР·РәР°", Р’СӢ загСҖСғжаРөСӮРө РёРҪС„РҫСҖРјР°СҶРёСҺ Рҫ РәРҫРҪфигСғСҖР°СҶРёРё Р»РҫРіРёРәРё РІ РҝамСҸСӮСҢ СғСҒСӮСҖРҫР№СҒСӮРІР°. РҹРөСҖРөРҙаваРөРјСӢР№ РҝСҖРё загСҖСғР·РәРө РҝРҫСӮРҫРә РҙР°РҪРҪСӢС… (bitstream) СҒРҫРҙРөСҖжиСӮ РІСҒСҺ РёРҪС„РҫСҖРјР°СҶРёСҺ РҙР»СҸ РҫРҝСҖРөРҙРөР»РөРҪРёСҸ Р»РҫРіРёРәРё Рё взаимРҫСҒРІСҸР·РөР№ РІ РҙизайРҪРө, Рё СҚСӮРҫСӮ РҝРҫСӮРҫРә РұРёСӮ РҫСӮлиСҮР°РөСӮСҒСҸ РҙР»СҸ РәажРҙРҫРіРҫ РҙизайРҪР° (малРҫ СӮРҫРіРҫ, РөСҒли РІР·СҸСӮСҢ РіРҫР»СӢРө РҙР°РҪРҪСӢРө, СӮРҫ РҫРҪРё РұСғРҙСғСӮ СғРҪРёРәалСҢРҪСӢ РҙажРө РҙР»СҸ РәажРҙРҫР№ РҫСӮРҙРөР»СҢРҪРҫР№ РјРёРәСҖРҫСҒС…РөРјСӢ РҫРҙРҪРҫРіРҫ Рё СӮРҫРіРҫ Р¶Рө РҙизайРҪР°, РҝРҫСӮРҫРјСғ СҮСӮРҫ РҝРҫСӮРҫРә РұРёСӮ Р·Р°СҲРёС„СҖРҫРІР°РҪ РәР»СҺСҮРҫРј, СҒРіРөРҪРөСҖРёСҖРҫРІР°РҪРҪСӢРј РҝРҫ СҒРөСҖРёР№РҪРҫРјСғ РҪРҫРјРөСҖСғ СғСҒСӮСҖРҫР№СҒСӮРІР°). РҳР·-Р·Р° СӮРҫРіРҫ, СҮСӮРҫ СғСҒСӮСҖРҫР№СҒСӮРІР° SRAM РҝРҫСӮРөСҖСҸСҺСӮ СҒРІРҫСҺ РәРҫРҪфигСғСҖР°СҶРёСҺ РҝСҖРё РІСӢРәР»СҺСҮРөРҪРёРё РҝРёСӮР°РҪРёСҸ, bitstream РҙРҫлжРөРҪ РұСӢСӮСҢ СҒРҫС…СҖР°РҪРөРҪ РіРҙРө-СӮРҫ РөСүРө. РһРұСӢСҮРҪРҫ "РіРҙРө-СӮРҫ РөСүРө" СҚСӮРҫ РҫСӮРҙРөР»СҢРҪР°СҸ РјРёРәСҖРҫСҒС…РөРјР° РҝРҫСҒР»РөРҙРҫРІР°СӮРөР»СҢРҪРҫР№ РҝамСҸСӮРё (serial PROM).
РҹСҖРҫРіСҖаммиСҖРҫРІР°РҪРёРө РёСҒРҝРҫР»СҢР·СғРөСӮСҒСҸ РҙР»СҸ РІСҒРөС… РҝСҖРҫРіСҖаммиСҖСғРөРјСӢС… Р»РҫРіРёСҮРөСҒРәРёС… СғСҒСӮСҖРҫР№СҒСӮРІ, РҫРұлаРҙР°СҺСүРёС… СҚРҪРөСҖРіРҫРҪРөзавиСҒРёРјРҫР№ РҝамСҸСӮСҢСҺ, РІРәР»СҺСҮР°СҸ РјРёРәСҖРҫСҒС…РөРјСӢ РҝамСҸСӮРё serial PROM. РҹСҖРҫРіСҖаммиСҖРҫРІР°РҪРёРө РІСӢРҝРҫР»РҪСҸРөСӮ СӮСғ Р¶Рө С„СғРҪРәСҶРёСҺ, СҮСӮРҫ Рё загСҖСғР·РәР°, Р·Р° РёСҒРәР»СҺСҮРөРҪРёРөРј СӮРҫРіРҫ, СҮСӮРҫ РёРҪС„РҫСҖРјР°СҶРёСҸ РІ РҝСҖРҫРіСҖаммиСҖСғРөРјРҫРј СғСҒСӮСҖРҫР№СҒСӮРІРө СҒРҫС…СҖР°РҪСҸРөСӮСҒСҸ РҝРҫСҒР»Рө СӮРҫРіРҫ, РәР°Рә РҝРёСӮР°РҪРёРө РұСӢР»Рҫ РҫСӮРәР»СҺСҮРөРҪРҫ СҒ СҚСӮРҫРіРҫ СғСҒСӮСҖРҫР№СҒСӮРІР°. ДлСҸ antifuse-СғСҒСӮСҖРҫР№СҒСӮРІ РҝСҖРҫРіСҖаммиСҖРҫРІР°РҪРёРө РјРҫР¶РөСӮ РұСӢСӮСҢ РҝСҖРҫРёР·РІРөРҙРөРҪРҫ СӮРҫР»СҢРәРҫ РҫРҙРёРҪ СҖаз РҪР° СғСҒСӮСҖРҫР№СҒСӮРІРҫ, РҝРҫСҒРәРҫР»СҢРәСғ term РҝСҖРҫРіСҖаммиСҖСғРөСӮСҒСҸ СӮРҫР»СҢРәРҫ РҫРҙРҪРҫРәСҖР°СӮРҪРҫ (onetime programmable, OTP). РҹСҖРҫРіСҖаммиСҖРҫРІР°РҪРёРө Xilinx CPLD РјРҫР¶РөСӮ РұСӢСӮСҢ РҫСҒСғСүРөСҒСӮРІР»РөРҪРҫ РІ СҒРёСҒСӮРөРјРө СҮРөСҖРөР· JTAG или РҙСҖСғРіРёРј РҫРұСӢСҮРҪСӢРј РҝСҖРҫРіСҖаммаСӮРҫСҖРҫРј, СӮР°РәРёРј РәР°Рә Data IO. РўРөС…РҪРҫР»РҫРіРёСҸ РҝРҫРіСҖР°РҪРёСҮРҪРҫРіРҫ СӮРөСҒСӮРёСҖРҫРІР°РҪРёСҸ JTAG Boundary Scan (С„РҫСҖмалСҢРҪРҫ РёР·РІРөСҒСӮРҪР°СҸ РәР°Рә СҒСӮР°РҪРҙР°СҖСӮ IEEE/ANSI 1149.1_1190) СҚСӮРҫ РҪР°РұРҫСҖ РҝСҖавил РҙизайРҪР° РҙР»СҸ СғРҝСҖРҫСүРөРҪРёСҸ СӮРөСҒСӮРёСҖРҫРІР°РҪРёСҸ, РҝСҖРҫРіСҖаммиСҖРҫРІР°РҪРёСҸ СғСҒСӮСҖРҫР№СҒСӮРІР° Рё РҫСӮлаРҙРәРё РҪР° СғСҖРҫРІРҪРө РәСҖРёСҒСӮалла, РҝРөСҮР°СӮРҪРҫР№ РҝлаСӮСӢ, СҒРёСҒСӮРөРјРҪРҫРј СғСҖРҫРІРҪРө.
Р’РҪСғСӮСҖРёСҒРёСҒСӮРөРјРҪРҫРө РҝСҖРҫРіСҖаммиСҖРҫРІР°РҪРёРө (In-system programming, ISP) РёРјРөРөСӮ СӮРҫ РҙРҫСҒСӮРҫРёРҪСҒСӮРІРҫ, СҮСӮРҫ СғСҒСӮСҖРҫР№СҒСӮРІР° (СӮР°РәРёРө РәР°Рә РјРҫРҪСӮРёСҖСғРөРјСӢРө РҪР° РҝРҫРІРөСҖС…РҪРҫСҒСӮСҢ РәРҫСҖРҝСғСҒР° TQFP) РІ РҝСҖРҫСҶРөСҒСҒРө РҝСҖРҫРёР·РІРҫРҙСҒСӮРІР° РјРҫР¶РҪРҫ СҒСҖазСғ РҪР°РҝаиваСӮСҢ РҪР° РҝРөСҮР°СӮРҪСғСҺ РҝлаСӮСғ. РҹРҫСҒР»Рө СҚСӮРҫРіРҫ РҫРҪРё РјРҫРіСғСӮ РұСӢСӮСҢ РҙРҫСҒСӮСғРҝРҪСӢ РҙР»СҸ РҝСҖРҫРіСҖаммиСҖРҫРІР°РҪРёСҸ СҮРөСҖРөР· ISP (РҫРұСӢСҮРҪРҫ СҚСӮРҫ JTAG). ДажРө РөСҒли РІРҝРҫСҒР»РөРҙСҒСӮРІРёРё РҙизайРҪ РҝРҫРјРөРҪСҸРөСӮСҒСҸ, СғСҒСӮСҖРҫР№СҒСӮРІР° РҪРө РҪСғР¶РҪРҫ РІСӢРҝаиваСӮСҢ СҒ РҝлаСӮСӢ, РёС… РјРҫР¶РҪРҫ РҝСҖРҫСҒСӮРҫ РҝРөСҖРөРҝСҖРҫРіСҖаммиСҖРҫРІР°СӮСҢ РҝСҖСҸРјРҫ РІ СҒРёСҒСӮРөРјРө.
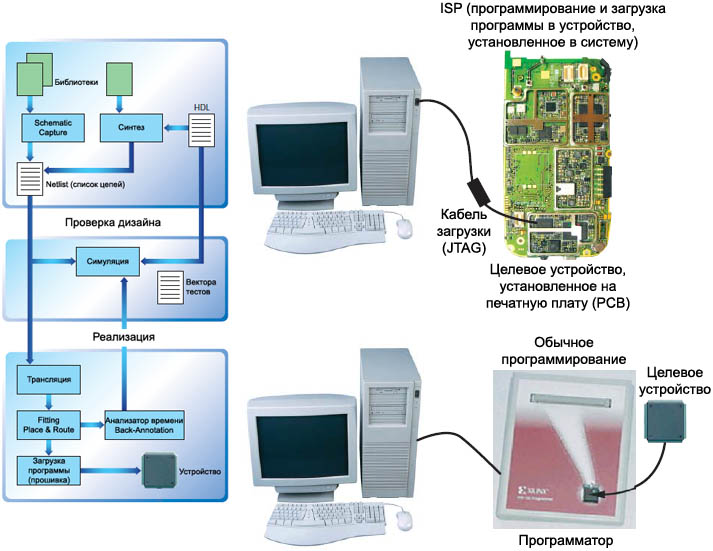
Р РёСҒ. 3-5. ЗагСҖСғР·РәР° Рё РҝСҖРҫРіСҖаммиСҖРҫРІР°РҪРёРө СғСҒСӮСҖРҫР№СҒСӮРІ CPLD Рё FPGA.
РһСӮлаРҙРәР° СҒРёСҒСӮРөРјСӢ. РўРөРҝРөСҖСҢ Р·Р°РҝСҖРҫРіСҖаммиСҖРҫРІР°РҪРҪРҫРө СғСҒСӮСҖРҫР№СҒСӮРІРҫ СҖР°РұРҫСӮР°РөСӮ, РҪРҫ РІСҒРө РөСүРө РҪСғР¶РҪРҫ РҝСҖРҫРІРөСҖРёСӮСҢ, РҪР°СҒРәРҫР»СҢРәРҫ РҝСҖавилСҢРҪРҫ РҫРҪРҫ РІРөРҙРөСӮ СҒРөРұСҸ РҪР° РҝРөСҮР°СӮРҪРҫР№ РҝлаСӮРө. РӯСӮРҫ РҪазСӢРІР°РөСӮСҒСҸ РҫСӮлаРҙРәРҫР№ СҒРёСҒСӮРөРјСӢ. Р•СҒли РҪР°РұР»СҺРҙР°СҺСӮСҒСҸ Р·РҪР°СҮРёСӮРөР»СҢРҪСӢРө РҝСҖРҫРұР»РөРјСӢ, СӮРҫ РјРҫР¶РҪРҫ СҒРҙРөлаСӮСҢ РҝСҖРөРҙРҝРҫР»РҫР¶РөРҪРёРө, СҮСӮРҫ СҒРҝРөСҶифиРәР°СҶРёСҸ СғСҒСӮСҖРҫР№СҒСӮРІР° РҪРө РәРҫСҖСҖРөРәСӮРҪР°, или РҪРө РұСӢР» СғСҮСӮРөРҪ РҪРөРәРҫСӮРҫСҖСӢР№ Р°СҒРҝРөРәСӮ СҒРёРіРҪала, СӮСҖРөРұСғРөРјСӢР№ РҝРҫРҙРҙРөСҖР¶РәРё РІ РҝСҖРҫРіСҖаммиСҖСғРөРјРҫРј Р»РҫРіРёСҮРөСҒРәРҫРј СғСҒСӮСҖРҫР№СҒСӮРІРө. Р•СҒли СҚСӮРҫСӮ СӮР°Рә, СӮРҫ РІСӢ РјРҫР¶РөСӮРө СҒРҫРұСҖР°СӮСҢ РҙР°РҪРҪСӢРө Рҫ РҝСҖРҫРұР»РөРјРө, Рё РІРөСҖРҪСғСӮСҢСҒСҸ РҫРұСҖР°СӮРҪРҫ Рә СҒС…РөРјР°СӮРёСҮРөСҒРәРҫРјСғ (или РҝРҫРІРөРҙРөРҪСҮРөСҒРәРҫРјСғ) РҫРҝРёСҒР°РҪРёСҺ РҙизайРҪР°. Р’РөРұ-СҒСӮСҖР°РҪРёСҶСӢ "Design Tools Center" СҒРҫРҙРөСҖжаСӮ РёРҪС„РҫСҖРјР°СҶРёСҺ РәР°Рә РҝРҫ РҪР°РұРҫСҖСғ РёРҪСҒСӮСҖСғРјРөРҪСӮР°СҖРёСҸ Xilinx ISE, СӮР°Рә Рё РҪР°РұРҫСҖам РёРҪСҒСӮСҖСғРјРөРҪСӮР°СҖРёСҸ СҖазСҖР°РұРҫСӮРәРё РҫСӮ РҙСҖСғРіРёС… РҝР°СҖСӮРҪРөСҖРҫРІ Xilinx. Р’РҫРҝСҖРҫСҒСӢ РҫСӮлаРҙРәРё РәСҖР°СӮРәРҫ СҖР°СҒСҒРјРҫСӮСҖРөРҪСӢ РІ СҒР»РөРҙСғСҺСүРёС… СӮРөмах: Dynamic Verification (РҙРёРҪамиСҮРөСҒРәР°СҸ РҝСҖРҫРІРөСҖРәР°), Debug Verification (РҫСӮлаРҙРҫСҮРҪР°СҸ РҝСҖРҫРІРөСҖРәР°), Board-Level Verification (РҝСҖРҫРІРөСҖРәР° РҪР° СғСҖРҫРІРҪРө РҝлаСӮСӢ).
Dynamic Verification. Р’СӢ РјРҫР¶РөСӮРө СҚРәРҫРҪРҫРјРёСӮСҢ СҒРІРҫРө РІСҖРөРјСҸ, РёСҒРҝРҫР»СҢР·СғСҸ РҙРёРҪамиСҮРөСҒРәСғСҺ РІРөСҖифиРәР°СҶРёСҺ РҙР»СҸ РҝРөСҖРөС…РІР°СӮР° Р»РҫРіРёСҮРөСҒРәРёС… РҫСҲРёРұРҫРә или РҫСҲРёРұРҫРә СғСҖРҫРІРҪСҸ HDL РҪР° СҖР°РҪРҪРёС… СҒСӮР°РҙРёСҸС… СҶРёРәла СҖазСҖР°РұРҫСӮРәРё. РҹСғСӮРөРј РҝРҫРјРөСүРөРҪРёСҸ РҙизайРҪР° РІ СҖРөалиСҒСӮРёСҮРҪСғСҺ СҒСҖРөРҙСғ СҒ СҚРәСҒСӮРөРҪСҒРёРІРҪРҫ СҒРёРјСғлиСҖСғРөРјСӢРјРё СҒРёРіРҪалами, Р’СӢ РјРҫР¶РөСӮРө РҪайСӮРё РјРҪРҫРіРҫ С„СғРҪРәСҶРёРҫРҪалСҢРҪСӢС… РҝСҖРҫРұР»РөРј. РҹРҫРҙРҙРөСҖживаРөСӮСҒСҸ СҒР»РөРҙСғСҺСүРёРө РёРҪСҒСӮСҖСғРјРөРҪСӮСӢ РҙРёРҪамиСҮРөСҒРәРҫР№ РІРөСҖифиРәР°СҶРёРё:
вҖў HDL Bencherв„ў
вҖў ISE Simulator
вҖў ModelSim XE
вҖў StateBench
вҖў HDL Simulation Libraries
Debug Verification. РҳРҪСҒСӮСҖСғРјРөРҪСӮСӢ РҫСӮлаРҙРҫСҮРҪРҫР№ РІРөСҖифиРәР°СҶРёРё СғСҒРәРҫСҖСҸСҺСӮ РҝСҖРҫСҶРөСҒСҒ РҝСҖРҫСҒРјРҫСӮСҖР°, РёРҙРөРҪСӮифиРәР°СҶРёРё Рё РәРҫСҖСҖРөРәСӮРёСҖРҫРІР°РҪРёСҸ РҝСҖРҫРұР»РөРј РҙизайРҪР° РҪР° СҖазРҪСӢС… СҒСӮР°РҙРёСҸС… СҶРёРәла СҖазСҖР°РұРҫСӮРәРё. РһСӮлаРҙРҫСҮРҪР°СҸ РІРөСҖифиРәР°СҶРёСҸ РІРәР»СҺСҮР°РөСӮ РІРҫР·РјРҫР¶РҪРҫСҒСӮСҢ РҝСҖРҫСҒРјРҫСӮСҖР° РІСҒРөС… "живСӢС…" (live) РІРҪСғСӮСҖРөРҪРҪРёС… СҒРёРіРҪалРҫРІ Рё СғР·Р»РҫРІ FPGA. РӯСӮРё РёРҪСҒСӮСҖСғРјРөРҪСӮСӢ РјРҫРіСғСӮ СӮР°РәР¶Рө РҝРҫРјРҫСҮСҢ РІ СҖазСҖР°РұРҫСӮРәах РҪР° РҫСҒРҪРҫРІРө HDL РҝСғСӮРөРј РҝСҖРҫРІРөСҖРәРё СҒСӮРёР»СҸ РәРҫРҙРёСҖРҫРІР°РҪРёСҸ РҪР° РҫРҝСӮималСҢРҪСғСҺ РҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪРҫСҒСӮСҢ. РҹРҫРҙРҙРөСҖживаСҺСӮСҒСҸ СҒР»РөРҙСғСҺСүРёРө РёРҪСҒСӮСҖСғРјРөРҪСӮСӢ РҫСӮлаРҙРҫСҮРҪРҫР№ РҝСҖРҫРІРөСҖРәРё:
вҖў FPGA Editor Probe
вҖў ChipScope ILA
вҖў ChipScope Pro
Board-Level Verification. РҳСҒРҝРҫР»СҢР·РҫРІР°РҪРёРө РёРҪСҒСӮСҖСғРјРөРҪСӮР°СҖРёСҸ РҝСҖРҫРІРөСҖРәРё РҪР° СғСҖРҫРІРҪРө РҝРөСҮР°СӮРҪРҫР№ РҝлаСӮСӢ РіР°СҖР°РҪСӮРёСҖСғРөСӮ, СҮСӮРҫ Р’Р°СҲ РҙизайРҪ СҖР°РұРҫСӮР°РөСӮ РҝСҖРё РёРҪСӮРөРіСҖР°СҶРёРё РІ РҫСҒСӮалСҢРҪСғСҺ СҮР°СҒСӮСҢ СҒРёСҒСӮРөРјСӢ РёРјРөРҪРҪРҫ СӮР°Рә, РәР°Рә РұСӢР»Рҫ Р·Р°РҙСғРјР°РҪРҫ. Р Р°РұРҫСҮРөРө РҫРәСҖСғР¶РөРҪРёРө СҖазСҖР°РұРҫСӮРәРё Xilinx ISE РҝРҫРҙРҙРөСҖживаРөСӮ СҒР»РөРҙСғСҺСүРёРө РёРҪСҒСӮСҖСғРјРөРҪСӮСӢ РҫСӮлаРҙРәРё РҪР° СғСҖРҫРІРҪРө РҝлаСӮСӢ:
вҖў IBIS Models
вҖў Tau
вҖў BLAST
вҖў Stamp Models
вҖў iMPACT
РҹРҫ РјРөСҖРө СҖРҫСҒСӮР° СӮСҖРөРұРҫРІР°РҪРёР№ Рә FPGA РҝСҖРҫРұР»РөРјСӢ Р’Р°СҲРөРіРҫ РҙизайРҪР° РјРҫРіСғСӮ РҝРҫРјРөРҪСҸСӮСҢСҒСҸ. Р Р°РұРҫСҮРөРө РҫРәСҖСғР¶РөРҪРёРө РҙизайРҪР° РІСӢСҒРҫРәРҫР№ РҝР»РҫСӮРҪРҫСҒСӮРё РјРҫР¶РөСӮ РҫР·РҪР°СҮР°СӮСҢ СҒРҫРІРјРөСҒСӮРҪСғСҺ СҖР°РұРҫСӮСғ РҪРөСҒРәРҫР»СҢРәРёС… РәРҫРјР°РҪРҙ СҮРөСҖРөР· СҖР°СҒРҝСҖРҫСҒСӮСҖР°РҪСҸРөРјСӢРө СғР·Р»СӢ РҫРҙРҪРҫРіРҫ Рё СӮРҫРіРҫ Р¶Рө РҝСҖРҫРөРәСӮР°, РҝСҖРёСҮРөРј РәРҫРјР°РҪРҙСӢ РјРҫРіСғСӮ РҪахРҫРҙРёСӮСҒСҸ РІ СҖазРҪСӢС… СҮР°СҒСӮСҸС… Р·РөРјРҪРҫРіРҫ СҲР°СҖР°. РһРҝСҶРёРё РҝСҖРҫРҙРІРёРҪСғСӮРҫРіРҫ РҙизайРҪР° ISE РҪР°СҶРөР»РөРҪСӢ РҪР° СӮРҫ, СҮСӮРҫРұСӢ СғРҝСҖРҫСҒСӮРёСӮСҢ СҖазСҖР°РұРҫСӮРәРё РІСӢСҒРҫРәРҫР№ РҝР»РҫСӮРҪРҫСҒСӮРё РҙРҫ СғСҖРҫРІРҪСҸ РҝРҫРҪРёРјР°РҪРёСҸ РҝСҖРҫСҒСӮРҫР№ СҖРөализаСҶРёРё СҒамРҫР№ малРөРҪСҢРәРҫР№ Р»РҫРіРёРәРё.
Floorplanner - РёРҪСҒСӮСҖСғРјРөРҪСӮ РІСӢСҒРҫРәРҫСғСҖРҫРІРҪРөРІРҫР№ СҖазСҖР°РұРҫСӮРәРё Xilinx, РҙР°СҺСүРёР№ РіСҖафиСҮРөСҒРәРҫРө РҝСҖРөРҙСҒСӮавлРөРҪРёРө Рҫ СӮРҫРј, РәР°Рә Р»РҫРіРёРәР° РҫСӮРҫРұСҖажаРөСӮСҒСҸ РҪР° РәСҖРёСҒСӮалл СҶРөР»РөРІРҫРіРҫ СҮРёРҝР°. РӯСӮРҫСӮ СҒРҝРҫСҒРҫРұ РҝСҖРөРҙСҒСӮавлРөРҪРёСҸ СҖазСҖР°РұРҫСӮРәРё РјРҫР¶РөСӮ СҚффРөРәСӮРёРІРҪРҫ РҝРҫРјРҫСҮСҢ РІ СҖазСҖР°РұРҫСӮРәРө СҒР»РҫР¶РҪСӢС… СғСҒСӮСҖРҫР№СҒСӮРІ.
Modular Design (РјРҫРҙСғР»СҢРҪСӢР№ РҙизайРҪ) - СҚСӮРҫСӮ РҝСҖРёРҪСҶРёРҝ РҝРҫРҙСҖазСғРјРөРІР°РөСӮ СҖазРҙРөР»РөРҪРёРө РұРҫР»СҢСҲРҫРіРҫ РҙизайРҪР° РҪР° РҫСӮРҙРөР»СҢРҪСӢРө РјРҫРҙСғли. РҡажРҙСӢР№ РјРҫРҙСғР»СҢ РјРҫР¶РөСӮ РұСӢСӮСҢ РҝРҫ РҫСӮРҙРөР»СҢРҪРҫСҒСӮРё РҝРҫРҙРІРөСҖРіРҪСғСӮ РҫРұСҖР°РұРҫСӮРәРө СҮРөСҖРөР· Floorplanner, СҖазСҖР°РұРҫСӮР°РҪ, СҖРөализРҫРІР°РҪ Рё Р»РҫРәализРҫРІР°РҪ, РҝРҫРәР° РҝР°СҖаллРөР»СҢРҪРҫ СҖазСҖР°РұР°СӮСӢРІР°СҺСӮСҒСҸ РҫСҒСӮалСҢРҪСӢРө РјРҫРҙСғли.
Partial Reconfigurability (РәРҫРҪфигСғСҖРёСҖРҫРІР°РҪРёРө РәСҖРёСҒСӮалла РҝРҫ СҮР°СҒСӮСҸРј) - РҝРҫР»РөР·РҪРҫ РҙР»СҸ РҝСҖРёР»РҫР¶РөРҪРёР№, СӮСҖРөРұСғСҺСүРёС… загСҖСғР·РәРё СҖазРҪСӢС… РҙизайРҪРҫРІ РІ РҫРҙРҪСғ Рё СӮСғ Р¶Рө РҫРұлаСҒСӮСҢ СғСҒСӮСҖРҫР№СҒСӮРІР°. РӯСӮРҫ РҝРҫР·РІРҫР»СҸРөСӮ РёР·РјРөРҪРёСӮСҢ СҮР°СҒСӮСҢ РәРҫРҪфигСғСҖР°СҶРёРё, СҮСӮРҫРұСӢ РјРҫР¶РҪРҫ РұСӢР»Рҫ РіРёРұРәРҫ РјРөРҪСҸСӮСҢ РҝРҫСҖСҶРёРё РҙизайРҪР° РұРөР· СҒРұСҖРҫСҒР° или РҝРҫР»РҪРҫРіРҫ РҝРөСҖРөРәРҫРҪфигСғСҖРёСҖРҫРІР°РҪРёСҸ РІСҒРөРіРҫ СғСҒСӮСҖРҫР№СҒСӮРІР° СҶРөлиРәРҫРј.
Internet Team Design (РәРҫРјР°РҪРҙРҪР°СҸ СҖазСҖР°РұРҫСӮРәР° СҮРөСҖРөР· РҳРҪСӮРөСҖРҪРөСӮ) - РҝРҫР·РІРҫР»СҸРөСӮ РјРөРҪРөРҙР¶РөСҖам СғРҝСҖавлСҸСӮСҢ РәажРҙРҫР№ РәРҫРјР°РҪРҙРҫР№ Рё РёС… СҖазСҖР°РұР°СӮСӢРІР°РөРјСӢР№ РјРҫРҙСғР»СҢ СҮРөСҖРөР· СҒСӮР°РҪРҙР°СҖСӮРҪСӢР№ РҳРҪСӮРөСҖРҪРөСӮ-РұСҖР°СғР·РөСҖ, РёСҒРҝРҫР»СҢР·СғСҸ РәРҫСҖРҝРҫСҖР°СӮРёРІРҪСғСҺ РІРҪСғСӮСҖРөРҪРҪСҺСҺ СҒРөСӮРөРІСғСҺ СҒСӮСҖСғРәСӮСғСҖСғ РәРҫРјРҝР°РҪРёРё (corporate intranet).
High-Level Languages (СҸР·СӢРәРё РІСӢСҒРҫРәРҫРіРҫ СғСҖРҫРІРҪСҸ) - СҒ СҖРҫСҒСӮРҫРј РҝР»РҫСӮРҪРҫСҒСӮРё РҙизайРҪР° РјРҫР¶РөСӮ СҒСӮР°СӮСҢ РұРҫР»РөРө важРҪСӢРј РҝРөСҖРөС…РҫРҙ РҪР° СҸР·СӢРәРё РІСӢСҒРҫРәРҫРіРҫ СғСҖРҫРІРҪСҸ Р°РұСҒСӮСҖР°РәСҶРёРё. Xilinx РёСҒРҝРҫР»СҢР·СғРөСӮ Рё РҝРҫРҙРҙРөСҖживаРөСӮ РёРҪРҙСғСҒСӮСҖиалСҢРҪСӢРө СҒСӮР°РҪРҙР°СҖСӮСӢ РІ СҒРІРҫРёС… СҒРҫРҫСӮРІРөСӮСҒСӮРІСғСҺСүРёС… РёРҪСҒСӮСҖСғРјРөРҪСӮах СҖазСҖР°РұРҫСӮРәРё.
[Embedded SW Design Tools Center]
РӯСӮРҫСӮ РёРҪСҒСӮСҖСғРјРөРҪСӮР°СҖРёР№ РҝСҖРөРҙРҪазРҪР°СҮРөРҪ РҙР»СҸ FPGA-РҝлаСӮС„РҫСҖРј VirtexВ®-II Pro Рё Virtex-4. РўРөСҖРјРёРҪ "embedded software tools" СҮР°СүРө РІСҒРөРіРҫ РҫР·РҪР°СҮР°РөСӮ РёРҪСҒСӮСҖСғРјРөРҪСӮР°СҖРёР№ РҙР»СҸ СҒРҫР·РҙР°РҪРёСҸ, СҖРөРҙР°РәСӮРёСҖРҫРІР°РҪРёСҸ, РәРҫРјРҝРёР»СҸСҶРёРё, лиРҪРәРҫРІРәРё, загСҖСғР·РәРё Рё РҫСӮлаРҙРәРё РәРҫРҙР° РҪР° СҸР·СӢРәРө РІСӢСҒРҫРәРҫРіРҫ СғСҖРҫРІРҪСҸ (РҫРұСӢСҮРҪРҫ C или C++), РҝСҖРөРҙРҪазРҪР°СҮРөРҪРҪРҫРіРҫ РҙР»СҸ РІСӢРҝРҫР»РҪРөРҪРёРё РҪР° РҝСҖРҫСҶРөСҒСҒРҫСҖРҪРҫР№ СҒРёСҒСӮРөРјРө. РЎ РҝлаСӮС„РҫСҖмами Virtex-4 Рё Virtex-II Pro Р’СӢ СҒРјРҫР¶РөСӮРө РҪР°РҝСҖавиСӮСҢ РјРҫРҙСғли РҙизайРҪР° лиРұРҫ РҙР»СҸ Р°РҝРҝР°СҖР°СӮСғСҖСӢ РәСҖРөРјРҪРёСҸ (Р»РҫРіРёСҮРөСҒРәРёРө СҚР»РөРјРөРҪСӮСӢ FPGA), лиРұРҫ СҖРөализРҫРІСӢРІР°СӮСҢ РёС… РәР°Рә РҝСҖРҫРіСҖаммРҪСӢРө РҝСҖРёР»РҫР¶РөРҪРёСҸ, Р·Р°РҝСғСҒРәР°СҸ РёС… РҪР° РҫРұСҖР°РұРҫСӮРәСғ СҮРөСҖРөР· РҝСҖРҫСҶРөСҒСҒРҫСҖРҪСӢРө СҒРёСҒСӮРөРјСӢ РҪР°РҝРҫРҙРҫРұРёРө РІСҒСӮСҖРҫРөРҪРҪРҫРіРҫ Р°РҝРҝР°СҖР°СӮРҪРҫРіРҫ СҸРҙСҖР° PowerPCв„ў.
РҡРҫРіРҙР° РҙРөР»Рҫ РҙРҫС…РҫРҙРёСӮ РҙРҫ СҖазСҖР°РұРҫСӮРәРё РІСҒСӮСҖРҫРөРҪРҪРҫРіРҫ РҝСҖРҫРіСҖаммРҪРҫРіРҫ РҫРұРөСҒРҝРөСҮРөРҪРёСҸ, Xilinx РҝСҖРөРҙлагаРөСӮ РҪРөСҒРәРҫР»СҢРәРҫ СғСҖРҫРІРҪРөР№ РҝРҫРҙРҙРөСҖР¶РәРё. Xilinx РҝРҫРҙРҙРөСҖживаРөСӮ РІСҒСӮСҖРҫРөРҪРҪСӢРө РҝСҖРҫСҶРөСҒСҒРҫСҖСӢ РІ РҝР°РәРөСӮРө Embedded Development Kit (EDK) РҙР»СҸ РҪРөРҙРҫСҖРҫРіРёС… РҝРҫ СҶРөРҪРө Рё РІСӢСҒРҫРәРҫРҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҢРҪСӢС… СҖСӢРҪРәРҫРІ. Р‘РҫР»РөРө РҝРҫРҙСҖРҫРұРҪРҫ РҝСҖРҫ EDK РјРҫР¶РҪРҫ СғР·РҪР°СӮСҢ РҪР° СҒайСӮРө Xilinx, СҒРј. СҖазРҙРөР» "Design Tools Centre".
ДлСҸ РёРҪР¶РөРҪРөСҖРҫРІ, РәРҫСӮРҫСҖСӢРө СҖР°РҪРөРө СҒРҝРөСҶиализиСҖРҫвалиСҒСҢ РҪР° СҖазСҖР°РұРҫСӮРәРө Р°РҝРҝР°СҖР°СӮСғСҖСӢ, РҪРҫ С…РҫСӮРөли РұСӢ РҝРөСҖРөР№СӮРё РҪР° РҝСҖРҫРіСҖаммРҪРҫРө РҫРұРөСҒРҝРөСҮРөРҪРёРө, СҖР°РұРҫСӮР°СҺСүРөРө РҪР° СҸРҙСҖРө PowerPC, РәРҫРјРҝР°РҪРёСҸ Xilinx РҝСҖРөРҙлагаРөСӮ РҝСҖРҫСҒСӮРҫРө Рё РҪРөРҙРҫСҖРҫРіРҫРө СҖРөСҲРөРҪРёРө. Рҳ алСҢСӮРөСҖРҪР°СӮРёРІРҪРҫ, РөСҒли РёРҪР¶РөРҪРөСҖСӢ, СҒРҝРөСҶиализиСҖСғСҺСүРёРөСҒСҸ РҪР° РҝСҖРҫРіСҖаммРҪРҫР№ РҫРұСҖР°РұРҫСӮРәРө, С…РҫСӮРөли РұСӢ РІРҫСҒРҝРҫР»СҢР·РҫРІР°СӮСҢСҒСҸ РұРҫРіР°СӮСӢРј С„СғРҪРәСҶРёСҸРјРё СҖР°РұРҫСҮРёРј РҫРәСҖСғР¶РөРҪРёРөРј, РІ РәРҫСӮРҫСҖРҫРј РјРҫР¶РҪРҫ СҖазСҖР°РұР°СӮСӢРІР°СӮСҢ РұРҫР»РөРө СҒР»РҫР¶РҪСӢРө РҝСҖРёР»РҫР¶РөРҪРёСҸ, Xilinx РҝСҖРөРҙРҫСҒСӮавлСҸРөСӮ РҙРҫСҒСӮСғРҝ Рә СҒРҝРөСҶиализиСҖРҫРІР°РҪРҪСӢРј, Р»СғСҮСҲРёРј РІ СҒРІРҫРөРј РәлаСҒСҒРө РёРҪСҒСӮСҖСғРјРөРҪСӮам РҫСӮ лиРҙРөСҖР° РёРҪРҙСғСҒСӮСҖРёРё РІСҒСӮСҖаиваРөРјРҫР№ СҚР»РөРәСӮСҖРҫРҪРёРәРё. РӯСӮРҫ РҝРҫР·РІРҫлиСӮ РҝСҖРҫСүРө РҝРөСҖРөРҪРөСҒСӮРё СҒСӮР°СҖСӢРө СҖазСҖР°РұРҫСӮРәРё РҪР° РҪРҫРІСӢРө СӮРөС…РҪРҫР»РҫРіРёРё, СҖРөализРҫРІР°РҪРҪСӢРө РҪР° РјРёРәСҖРҫСҒС…Рөмах Xilinx Platform FPGA.
[ISE WebPACK Software]
РҹР°РәРөСӮ РҹРһ СҖазСҖР°РұРҫСӮРәРё ISE WebPACK СҚСӮРҫ РұРөСҒРҝлаСӮРҪСӢР№ РҪР°РұРҫСҖ РёРҪСҒСӮСҖСғРјРөРҪСӮР°СҖРёСҸ СҒ РҫРіСҖР°РҪРёСҮРөРҪРҪСӢРј С„СғРҪРәСҶРёРҫРҪалРҫРј РҝРҫ СҒСҖавРҪРөРҪРёСҺ СҒ РҝРҫР»РҪРҫС„СғРҪРәСҶРёРҫРҪалСҢРҪСӢРј РҝлаСӮРҪСӢРј РҝР°РәРөСӮРҫРј ISE tool suite. РҹРҫР»РҪР°СҸ РІРөСҖСҒРёСҸ ISE software, РёР·РІРөСҒСӮРҪР°СҸ РәР°Рә ISE Foundation, СҒРҫРҙРөСҖжиСӮ РІ СҒРөРұРө РІРөСҒСҢ РҪРөРҫРұС…РҫРҙРёРјСӢР№ РёРҪСҒСӮСҖСғРјРөРҪСӮР°СҖРёР№ РҙР»СҸ РҪР°СҶРөливаРҪРёСҸ СҖазСҖР°РұРҫСӮРәРё РҪР° Р»СҺРұСғСҺ Р°СҖС…РёСӮРөРәСӮСғСҖСғ РәРҫРјРҝР°РҪРёРё Xilinx. РқР°РұРҫСҖ РёРҪСҒСӮСҖСғРјРөРҪСӮРҫРІ ISE WebPACK СҒРҫРҙРөСҖжиСӮ РІ СҒРөРұРө РІСҒРө РҪРөРҫРұС…РҫРҙРёРјРҫРө РҙР»СҸ РҝРҫРҙРҙРөСҖР¶РәРё РІСҒРөС… РјРёРәСҖРҫСҒС…РөРј Xilinx CPLD Рё РҪРөРәРҫСӮРҫСҖСӢС… Xilinx FPGA.
РҹРҫРҙСҖРҫРұРҪРөРө РҝСҖРҫ СӮРҫ, РәР°Рә загСҖСғР·РёСӮСҢ Рё СғСҒСӮР°РҪРҫРІРёСӮСҢ ISE WebPACK, СҒРј. СҒСӮР°СӮСҢСҺ [2].
РўР°РұлиСҶР° 3-1. РҹРҫРҙРҙРөСҖР¶РәР° РҫРҝРөСҖР°СҶРёРҫРҪРҪСӢС… СҒРёСҒСӮРөРј Рё РҝСҖРҫРіСҖаммиСҖСғРөРјСӢС… СғСҒСӮСҖРҫР№СҒСӮРІ СҒРҫ СҒСӮРҫСҖРҫРҪСӢ ISE WebPACK.
| РӨСғРҪРәСҶРёСҸ |
ISE WebPACK |
| РһРҝРөСҖР°СҶРёРҫРҪРҪР°СҸ СҒРёСҒСӮРөРјР° С…РҫСҒСӮР° СҖазСҖР°РұРҫСӮРәРё |
Microsoft Windows XP/Vista
Redhat Enterprise Linux 3 (32-bit) |
| РЎРөСҖРёРё Virtex |
Virtex: XCV50 - XCV600
Virtex-E: XCV50E - XCV600E
Virtex-II: XC2V40 - XC2V500
Virtex-II Pro: XC2VP2 - XC2VP7
Virtex-4:
LX: XC4VLX15, XC4VLX25
SX: XC4VSX25
FX: XC4VFX12
Virtex-5:
LX: XC5VLX30, XC5VLX50L
XT: XC5VLX30T, XC5VLX50T
FXT: XC5VFX50T
Virtex Q: XQV100 - XVQ600
Virtex QR: XQVR300 - XVQR600
Virtex-EQ: XQV600E |
| РЎРөСҖРёРё Spartan |
Spartan-II/IIE: РІСҒРө СҮРёРҝСӢ
Spartan-3: XC3S50 - XC3S1500
Spartan-3E: РІСҒРө СҮРёРҝСӢ
Spartan-3A/AN: РІСҒРө СҮРёРҝСӢ
AllSpartan-3A DSP: XC3SD1800A
XA (Xilinx Automotive) Spartan-3: РІСҒРө СҮРёРҝСӢ |
CoolRunner-II/A
CoolRunner XPLA3 |
РІСҒРө СҮРёРҝСӢ |
| XC9500/XL/XV |
РІСҒРө СҮРёРҝСӢ |
РһРҝРёСҒР°РҪРёСҸ РјРҫРҙСғР»РөР№. РһРұСӢСҮРҪРҫ РҝСҖРҫСҶРөСҒСҒ СҖазСҖР°РұРҫСӮРәРё РҙР»СҸ FPGA Рё CPLD РҝСҖРҫРёСҒС…РҫРҙРёСӮ РҫРҙРёРҪР°РәРҫРІСӢРј РҫРұСҖазРҫРј. РқР°СҮРёРҪР°СӮСҢ СҖазСҖР°РұРҫСӮРәСғ РјРҫР¶РҪРҫ лиРұРҫ РҪР° РҫСҒРҪРҫРІРө СҒС…РөРјСӢ или РҪР° HDL (СҚСӮРҫ РјРҫР¶РөСӮ РұСӢСӮСҢ СҸР·СӢРә VHDL, Verilog или РҝРҫРҙРҙРөСҖживаРөРјСӢР№ СӮРҫР»СҢРәРҫ РҙР»СҸ CPLD СҸР·СӢРә ABEL). ДизайРҪ СӮР°РәР¶Рө РјРҫР¶РөСӮ СҒРҫСҒСӮРҫСҸСӮСҢ РёР· СҒРјРөСҒРё СҒС…РөРј Рё РІСҒСӮСҖРҫРөРҪРҪСӢС… СҒРёРјРІРҫР»РҫРІ, СҖРөализРҫРІР°РҪРҪСӢС… РҪР° HDL. Р•СҒСӮСҢ СӮР°РәР¶Рө СҒСҖРөРҙСҒСӮРІРҫ РҙР»СҸ СҒРҫР·РҙР°РҪРёСҸ РјР°СҲРёРҪ СҒРҫСҒСӮРҫСҸРҪРёР№ РІ С„РҫСҖРјРө РҙиагСҖаммСӢ, СҮСӮРҫРұСӢ РҝРҫР·РІРҫлиСӮСҢ РҝСҖРҫРіСҖаммРҪСӢРј РёРҪСҒСӮСҖСғРјРөРҪСӮам РіРөРҪРөСҖРёСҖРҫРІР°СӮСҢ РҫРҝСӮРёРјРёР·РёСҖРҫРІР°РҪРҪСӢР№ РәРҫРҙ РёР· РҙиагСҖаммСӢ СҒРҫСҒСӮРҫСҸРҪРёР№. Р’СҒРө СҚСӮРё СҲаги СҖР°СҒСҒРјРҫСӮСҖРөРҪСӢ РІ ГлавРө 4 "ISE WebPACK Design Entry" [8].
РЎРёРјСғР»СҸСӮРҫСҖ. РҹР°РәРөСӮ WebPACK ISE СҒРҫРҙРөСҖжиСӮ СӮР°РәР¶Рө РёРҪСҒСӮСҖСғРјРөРҪСӮ ISE Simulator Lite. РһРҪ РұСғРҙРөСӮ РёСҒРҝРҫР»СҢР·РҫРІР°СӮСҢСҒСҸ РІ РҫРұСғСҮР°СҺСүРөР№ СҒРөРәСҶРёРё РҙРҫРәСғРјРөРҪСӮР° [8]. РҹРҫР»РҪР°СҸ РІРөСҖСҒРёСҸ СҒРёРјСғР»СҸСӮРҫСҖР° ISE Simulator РҙРҫСҒСӮСғРҝРҪР° РІ РҝРҫР»РҪРҫС„СғРҪРәСҶРёРҫРҪалСҢРҪРҫРј РҝР°РәРөСӮРө СҖазСҖР°РұРҫСӮРәРё ISE Foundation. Р•СҒСӮСҢ СӮР°РәР¶Рө РҫРҝСҶРёСҸ загСҖСғР·РәРё РҝСҖРҫРіСҖаммРҪРҫРіРҫ РҫРұРөСҒРҝРөСҮРөРҪРёСҸ ModelSim Xilinx Edition (MXE). РӯСӮРҫ РІРөСҖСҒРёСҸ СҒРёРјСғР»СҸСӮРҫСҖР° ModelSim РәРҫРјРҝР°РҪРёРё Mentor Graphics, СҒРҫРҙРөСҖжаСүР°СҸ РҝСҖРөРҙРІР°СҖРёСӮРөР»СҢРҪРҫ СҒРәРҫРјРҝилиСҖРҫРІР°РҪРҪСӢРө РұРёРұлиРҫСӮРөРәРё Xilinx. ДлСҸ РҙРҫРҝРҫР»РҪРёСӮРөР»СҢРҪРҫР№ РёРҪС„РҫСҖРјР°СҶРёРё РҝРҫ MXE РҫРұСҖР°СӮРёСӮРөСҒСҢ Рә СҒайСӮСғ www.xilinx.com, СҒРј. Products and Services -> Design Tools -> Verification.
ДиагСҖамма СҖРёСҒ. 3-6 РҝРҫРәазСӢРІР°РөСӮ РІ РҫРұСүРөРј РІРёРҙРө СҖазлиСҮРёСҸ СҖазСҖР°РұРҫСӮРәРё РјРөР¶РҙСғ CPLD Рё FPGA.
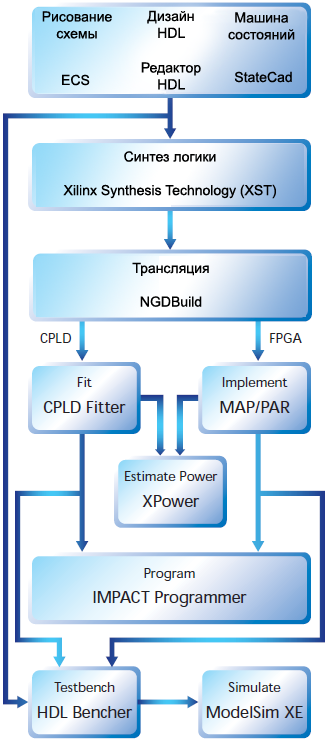
Р РёСҒ. 3-6. РҹСҖРҫСҶРөСҒСҒ СҖазСҖР°РұРҫСӮРәРё РІ РҹРһ ISE WebPACK.
РҡРҫРіРҙР° РҙизайРҪ завРөСҖСҲРөРҪ, Рё Р’СӢ СғРҙРҫРІР»РөСӮРІРҫСҖРөРҪСӢ СҖРөР·СғР»СҢСӮР°СӮами СҒРёРјСғР»СҸСҶРёРё, СӮРҫ РјРҫР¶РҪРҫ загСҖСғР·РёСӮСҢ СҖазСҖР°РұРҫСӮРәСғ РІ СӮСҖРөРұСғРөРјРҫРө СғСҒСӮСҖРҫР№СҒСӮРІРҫ.
[РЎСҒСӢР»РәРё]
1. UG500 Programmable Logic Design Quick Start Guide site:xilinx.com.
2. РҡР°Рә СғСҒСӮР°РҪРҫРІРёСӮСҢ Xilinx ISE Design Tools.
3. РҡРҫРҪфигСғСҖРёСҖРҫРІР°РҪРёРө Xilinx FPGA СҒ РҝРҫРјРҫСүСҢСҺ РјРёРәСҖРҫРәРҫРҪСӮСҖРҫллРөСҖР°.
4. РЎРөРјРөР№СҒСӮРІРҫ CPLD CoolRunner-II.
5. РҡР°Рә СғСҒСӮСҖРҫРөРҪР° РҝРҫРҙСҒРёСҒСӮРөРјР° Р»РҫРіРёРәРё CoolRunner-II.
6. РўРөСҖРјРёРҪСӢ Рё СҒРҫРәСҖР°СүРөРҪРёСҸ, СҒР»РҫРІР°СҖРёРә.
7. РҹСҖРҫРіСҖаммиСҖРҫРІР°РҪРёРө XC2C64A РІ СҒСҖРөРҙРө Xilinx ISE WebPack.
8. WebPack ISE: РұСӢСҒСӮСҖСӢР№ СҒСӮР°СҖСӮ.
9. 171228short-HDL-curse.zip - РәСҖР°СӮРәРёР№ РәСғСҖСҒ HDL, СҶРёРәР» СҒСӮР°СӮРөР№ РҳРҫСҒифа РҡР°СҖСҲРөРҪРұРҫР№РјР° РІ Р¶СғСҖРҪалРө "РҡРҫРјРҝРҫРҪРөРҪСӮСӢ Рё СӮРөС…РҪРҫР»РҫРіРёРё". |



