|
ąŁčäč乥ą║čéąĖą▓ąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čĆąĄčüčāčĆčüąŠą▓ čüąĖčüč鹥ą╝čŗ čÅą▓ą╗čÅąĄčéčüčÅ ą║čĆąĖčéąĖč湥čüą║ąĖą╝ ą┤ą╗čÅ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣, ą║ąŠč鹊čĆčŗąĄ ąĘą░ą┐čĆą░čłąĖą▓ą░čÄčé čłąĖčĆąŠą║čāčÄ ą┐ąŠą╗ąŠčüčā ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ ą┐čĆąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĄ ą┤ą░ąĮąĮčŗčģ. ąĪąĖčüč鹥ą╝čŗ čćą░čüč鹊 čĆą░ą▒ąŠčéą░čÄčé ą▓ čāčüą╗ąŠą▓ąĖčÅčģ ąĮąĄčģą▓ą░čéą║ąĖ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖčÅ, ą┤ą░ąČąĄ ąĄčüą╗ąĖ čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅ ą║ ą┐ąŠą╗ąŠčüąĄ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ ąĮą░čģąŠą┤čÅčéčüčÅ ą▓ ą┐čĆąĄą┤ąĄą╗ą░čģ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ čüąĖčüč鹥ą╝čŗ. ąÜčĆąĖčéąĖč湥čüą║ąĖą╝ąĖ čäą░ą║č鹊čĆą░ą╝ąĖ, čćą░čüč鹊 ąĖą╗ąĖ ąĮąĄ čćą░čüč鹊 ą▓ą╗ąĖčÅčÄčēąĖą╝ąĖ ąĮą░ čüąĮąĖąČąĄąĮąĖąĄ ąŠąČąĖą┤ą░ąĄą╝ąŠą╣ čüą║ąŠčĆąŠčüčéąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ, čÅą▓ą╗čÅčÄčéčüčÅ ąĘą░ą┤ąĄčƹȹ║ąĖ ą┤ąŠčüčéčāą┐ą░ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ (external memory access latencies) ąĖ ąĮąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüąĖčüč鹥ą╝ąĮčŗčģ čĆąĄčüčāčĆčüąŠą▓. ą¦č鹊ą▒čŗ ą┐ąŠą╗ąĮąŠčüčéčīčÄ čĆą░čüą║čĆčŗčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ą╝ąĖą║čĆąŠą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ (ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą┤ą╗čÅ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣), ą▓ą░ąČąĮąŠ ą┐ąŠąĮąĖą╝ą░čéčī ąĄą│ąŠ čüąĖčüč鹥ą╝ąĮčāčÄ ą░čĆčģąĖč鹥ą║čéčāčĆčā ąĖ ą┤ąŠčüčéčāą┐ąĮčŗąĄ ą┤ą╗čÅ ąĮąĄčæ č鹥čģąĮąĖą║ąĖ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ. ąŁč鹊čé EE-Note ą┤ą░ąĄčé ą▒čŗčüčéčĆčŗą╣ ąŠą▒ąĘąŠčĆ ąĖąĄčĆą░čĆčģąĖč湥čüą║ąŠą╣ čüčéčĆčāą║čéčāčĆčŗ ą┐ą░ą╝čÅčéąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin┬« ąĖ ąĄą│ąŠ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ čüąĖčüč鹥ą╝čŗ. ąöąŠą║čāą╝ąĄąĮčé čéą░ą║ąČąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┐čĆą░ą║čéąĖč湥čüą║ąĖąĄ čāą║ą░ąĘą░ąĮąĖčÅ ą┐ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÄ č鹥čģąĮąĖą║ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ ą┤ą╗čÅ čŹčäč乥ą║čéąĖą▓ąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┤ąŠčüčéčāą┐ąĮčŗčģ čüąĖčüč鹥ą╝ąĮčŗčģ čĆąĄčüčāčĆčüąŠą▓, ąĖ ąŠą▒čüčāąČą┤ą░ąĄčé ą▓ąŠą┐čĆąŠčüčŗ ąĖčüčüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖčÅ (benchmark), čćč鹊ą▒čŗ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ąŠčåąĄąĮąĖčéčī, ąĮą░čüą║ąŠą╗čīą║ąŠ čŹčäč乥ą║čéąĖą▓ąĮąŠ ą▒čŗą╗ą░ ą┐čĆąĖą╝ąĄąĮąĄąĮą░ č鹥čģąĮąĖą║ą░ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ. ąÆ čŹč鹊ą╣ čüčéą░čéčīąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮ ą┐ąĄčĆąĄą▓ąŠą┤ ą┤ąŠą║čāą╝ąĄąĮčéą░ EE-324 ą║ąŠą╝ą┐ą░ąĮąĖąĖ Analog Devices [1]. ąÆčüąĄ ąĮąĄą┐ąŠąĮčÅčéąĮčŗąĄ čüąŠą║čĆą░čēąĄąĮąĖčÅ ąĖ č鹥čĆą╝ąĖąĮčŗ ąĖčēąĖč鹥 ą▓ čĆą░ąĘą┤ąĄą╗ąĄ ąĪą╗ąŠą▓ą░čĆąĖą║ čüčéą░č鹥ą╣ [2, 3].
[ąÉčĆčģąĖč鹥ą║čéčāčĆą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin]
ąÆ čŹč鹊ą╣ čüąĄą║čåąĖąĖ ąŠą▒čüčāąČą┤ą░ąĄčéčüčÅ ąĖąĄčĆą░čĆčģąĖčÅ ą┐ą░ą╝čÅčéąĖ ąĖ ą░čĆčģąĖč鹥ą║čéčāčĆą░ čüąĖčüč鹥ą╝čŗ. ąÜą░ąČą┤ą░čÅ čüąĄą║čåąĖčÅ ąĮą░čćąĖąĮą░ąĄčéčüčÅ čü ąŠą┐ąĖčüą░ąĮąĖčÅ čĆąĄčüčāčĆčüą░ (ą┐ą░ą╝čÅčéčī, čüąĖčüč鹥ą╝ąĮą░čÅ čłąĖąĮą░, ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆčŗ DMA ąĖ čé. ą┤.), ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ąĖą┤čāčé čĆąĄą║ąŠą╝ąĄąĮą┤ą░čåąĖąĖ ą┐ąŠ ą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠą╝čā ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÄ čŹč鹊ą│ąŠ čĆąĄčüčāčĆčüą░. ąÉčĆčģąĖč鹥ą║čéčāčĆą░ ąŠą┐ąĖčüą░ąĮą░ ą▒ąŠą╗čīčłąĄ čü č鹊čćą║ąĖ ąĘčĆąĄąĮąĖčÅ ą┐ąĄčĆčüą┐ąĄą║čéąĖą▓ čāčüą║ąŠčĆąĄąĮąĖčÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ, čü ąĖą│ąĮąŠčĆąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ą┤čĆčāą│ąĖčģ ą┐ąŠą┤čĆąŠą▒ąĮąŠčüč鹥ą╣. ąŚą░ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĄą╣ ąŠą▒čĆą░čēą░ą╣č鹥čüčī ą║ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ Hardware Reference ąÆą░čłąĄą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░, čüą╝. ą▓čĆąĄąĘą║čā "ąĪą┐ąĖčüąŠą║ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ą╗ąĖč鹥čĆą░čéčāčĆčŗ" ą▓ ą║ąŠąĮčåąĄ čüčéą░čéčīąĖ (čéą░ą║ąČąĄ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin ADSP-BF538 čüą╝. [2, 3]).
ąśąĄčĆą░čĆčģąĖčÅ ą┐ą░ą╝čÅčéąĖ. ąÆ čŹč鹊ą╣ čüąĄą║čåąĖąĖ ąŠą▒čüčāąČą┤ą░ąĄčéčüčÅ ąĖąĄčĆą░čĆčģąĖčÅ ą┐ą░ą╝čÅčéąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin (čĆąĖčü. 1) ąĖ ą║ąŠą╝ą┐čĆąŠą╝ąĖčüčü ą┐čĆąĖ ą▓čŗą▒ąŠčĆąĄ ą╝ąĄąČą┤čā ą▓čüčéčĆąŠąĄąĮąĮąŠą╣ ą┐ą░ą╝čÅčéčīčÄ (L1 ąĖ L2) ąĖ ą▓ąĮąĄčłąĮąĄą╣ (external) ą┐ą░ą╝čÅčéčīčÄ. ą¤čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčéčüčÅ čéą░ą║ąČąĄ čüąŠą▓ąĄčéčŗ ą┐ąŠ čŹčäč乥ą║čéąĖą▓ąĮąŠą╣ ą┐čĆąĖą▓čÅąĘą║ąĄ ą║ąŠą┤ą░ ąĖ ą┤ą░ąĮąĮčŗčģ ą║ ąĖąĄčĆą░čĆčģąĖąĖ ą┐ą░ą╝čÅčéąĖ, čćč鹊ą▒čŗ ą┤ąŠčüčéąĖčćčī ą╝ąĖąĮąĖą╝ą░ą╗čīąĮčŗčģ ąĘą░ą┤ąĄčƹȹĄą║ ąĮą░ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ (memory access latencies).
ą×ą┐ąĖčüą░ąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ L1. ą¤čĆąŠčåąĄčüčüąŠčĆčŗ Blackfin ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ąŠčéą┤ąĄą╗čīąĮčŗąĄ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ ąĖ ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ ą┐ą░ą╝čÅčéąĖ L1. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ą┐ą░ą╝čÅčéčī ą┤ą░ąĮąĮčŗčģ L1 čéą░ą║ąČąĄ čĆą░ąĘą┤ąĄą╗ąĄąĮčŗ ąĮą░ ą▒ą░ąĮą║ąĖ: data bank A ąĖ data bank B. ąöą╗čÅ ą┐ąŠą▓čŗčłąĄąĮąĖčÅ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖčÅ ą┐ą░ą╝čÅčéčī L1 čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮą░ ą║ą░ą║ ąŠą┤ąĮąŠą┐ąŠčĆč鹊ą▓čŗąĄ ą┐ąŠą┤ą▒ą░ąĮą║ąĖ, čćč鹊ą▒čŗ ąŠą▒ąĄčüą┐ąĄčćąĖčéčī ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗą╣ ą┤ąŠčüčéčāą┐ čüąŠ čüč鹊čĆąŠąĮčŗ ąĘą░ą┐čĆą░čłąĖą▓ą░čÄčēąĖčģ ą┐ą░ą╝čÅčéčī 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ (čÅą┤čĆąŠ, DMA, ąĖ čé. ą┐.). ą¤ą░ą╝čÅčéčī L1 čéą░ą║ąČąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé SRAM ąĖ ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄą╝čāčÄ ą┐ą░ą╝čÅčéčī ą║čŹčłą░, čćč鹊ą▒čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓ čüą▓ąŠąĖčģ ąĖąĮč鹥čĆąĄčüą░čģ čüą┐ąĄčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗąĄ, ą┐čĆąĖą▓čÅąĘą░ąĮąĮčŗąĄ ą║ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÄ čģą░čĆą░ą║č鹥čĆąĖčüčéąĖą║ąĖ čĆą░ą▒ąŠč湥ą╣ ąĮą░ą│čĆčāąĘą║ąĖ.
ą¤ąŠą┤ą▒ą░ąĮą║ąĖ ą┐ą░ą╝čÅčéąĖ L1 ą┤ą╗čÅ ą║ąŠą┤ą░ ąĖ ą┤ą░ąĮąĮčŗčģ. ą¤ą░ą╝čÅčéčī ą║ąŠą┤ą░ L1 čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮą░ ą║ą░ą║ ąŠą┤ąĮąŠą┐ąŠčĆč鹊ą▓čŗąĄ ą┐ąŠą┤ą▒ą░ąĮą║ąĖ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠąČąĮąŠ čŹčäč乥ą║čéąĖą▓ąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą║ą░ą║ ą┤ą▓čāčģą┐ąŠčĆč鹊ą▓čŗąĄ. ąĪ čŹč鹊ą╣ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčīčÄ čÅą┤čĆąŠ ąĖ DMA, ąĖą╗ąĖ čüąĖčüč鹥ą╝ąĮčŗąĄ čłąĖąĮčŗ ą╝ąŠą│čāčé ą┐ąŠą╗čāčćąĖčéčī ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ ą║ąŠą┤ą░ L1, ą┐ąŠą║ą░ čŹčéąĖ ą┤ąŠčüčéčāą┐čŗ ą┐čĆąĖčģąŠą┤čÅčéčüčÅ ąĮąĄ ą▓ ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ ą┐ąŠ ą┐ąŠą┤ą▒ą░ąĮą║. ą¤ąŠą┤ąŠą▒ąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝ ą┐ą░ą╝čÅčéčī ą┤ą░ąĮąĮčŗčģ L1 č乊čĆą╝ąĖčĆčāąĄčé ą╝ąĮąŠą│ąŠą┐ąŠčĆč鹊ą▓čŗąĄ ą┐ąŠą┤ą▒ą░ąĮą║ąĖ, čćč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą▓ ąŠą┤ąĮąŠą╝ čåąĖą║ą╗ąĄ čÅą┤čĆą░ čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ:
ŌĆó ąöą▓ąĄ ąĘą░ą│čĆčāąĘą║ąĖ 32-ą▒ąĖčéąĮąŠą│ąŠ ą│ąĄąĮąĄčĆą░č鹊čĆą░ ą░ą┤čĆąĄčüą░ ą┤ą░ąĮąĮčŗčģ (data address generator, DAG).
ŌĆó ą×ą┤ąĮąŠ ą║ąŠąĮą▓ąĄą╣ąĄčĆąĖąĘąĖčĆąŠą▓ą░ąĮąĮąŠąĄ čüąŠčģčĆą░ąĮąĄąĮąĖąĄ čü ą┐ąŠą╝ąŠčēčīčÄ DAG.
ŌĆó ą×ą┤ąĖąĮ 64-ą▒ąĖčéąĮčŗą╣ DMA I/O.
ŌĆó ą×ą┤ąĖąĮ ą┐ąŠą╗ąĮčŗą╣ (fill/victim) 64-ą▒ąĖčéąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą║čŹčłčā.
ąÜąŠąĮčäąĖą│čāčĆą░čåąĖčÅ L1 SRAM/ą║čŹčł. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą▓čüčÅ ą┐ą░ą╝čÅčéčī L1 čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮą░ ą║ą░ą║ SRAM, ąĖ ą║ ąĮąĄą╣ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮ ą┐ąŠą╗ąĮčŗą╣ ą┤ąŠčüčéčāą┐ čüąŠ čüč鹊čĆąŠąĮčŗ čÅą┤čĆą░. ą¤ą░ą╝čÅčéčī SRAM ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé ą┤ąŠčüčéčāą┐ ą║ čüą▓ąŠąĖą╝ čÅč湥ą╣ą║ą░ą╝ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖą╗ąĖ ą┤ą░ąĮąĮčŗčģ ąĘą░ 1 čåąĖą║ą╗, ąĖ ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ąŠčéčüčāčéčüčéą▓čāąĄčé čéą░ą║ąŠąĄ ą┐ąŠąĮčÅčéąĖąĄ, ą║ą░ą║ ą┐čĆąŠą╝ą░čģ ą║čŹčłą░. ą×ą┤ąĮą░ą║ąŠ ąĄčüčéčī ąŠą│čĆą░ąĮąĖč湥ąĮąĖąĄ ąĮą░ čĆą░ąĘą╝ąĄčĆ ą┤ąŠčüčéčāą┐ąĮąŠą╣ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ. ąöą╗čÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣, čā ą║ąŠč鹊čĆčŗčģ ą║ąŠą┤ ąĖ ą┤ą░ąĮąĮčŗąĄ ą┐čĆąĄą▓čŗčłą░čÄčé ą┐ąŠ čĆą░ąĘą╝ąĄčĆčā ąŠą▒ą╗ą░čüčéčī ą┐ą░ą╝čÅčéąĖ L1, čćą░čüčéčī ą┐ą░ą╝čÅčéąĖ L1 ą╝ąŠąČąĄčé ą▒čŗčéčī čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮą░ ą║ą░ą║ ą║čŹčł, čćč鹊ą▒čŗ čüąĮąĖąĘąĖčéčī ąĘą░čéčĆą░čéčŗ ą▓čĆąĄą╝ąĄąĮąĖ ąĮą░ ąŠą▒čĆą░čēąĄąĮąĖčÅ ą║ ą▒ąŠą╗ąĄąĄ ą╝ąĄą┤ą╗ąĄąĮąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ.
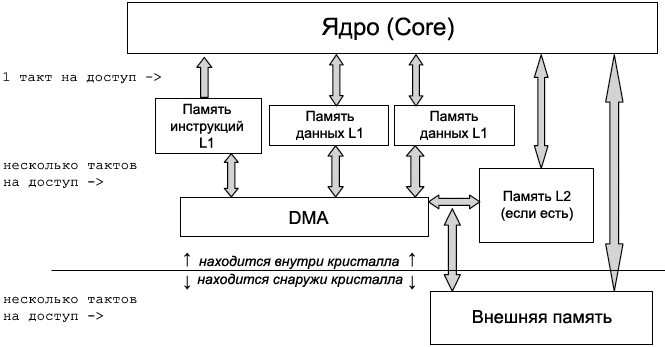
ąĀąĖčü. 1. ąśąĄčĆą░čĆčģąĖčÅ ą┐ą░ą╝čÅčéąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin.
ąÜčŹčłąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą┐ą░ą╝čÅčéčī ą╝ąŠąČąĄčé ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī ąĘąĮą░čćąĖč鹥ą╗čīąĮčŗą╣ ą▓čŗąĖą│čĆčŗčł ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░ ąĖ ą┤ąŠčüčéčāą┐ą░ ą║ ą┤ą░ąĮąĮčŗčģ, ą║ąŠą│ą┤ą░ ą║čŹčł ą┐čĆąĖą▓čÅąĘą░ąĮą░ ą║ L2 ąĖą╗ąĖ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ. ąæčŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ ą║čŹčłą░ ąĘą░ą▓ąĖčüąĖčé ąŠčé čģą░čĆą░ą║č鹥čĆąĖčüčéąĖą║ ą▓čĆąĄą╝ąĄąĮąĖ ąĖ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. ąØąĄą┤ąŠčüčéą░č鹊ą║ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ ą║čŹčłą░ ą▓ č鹊ą╝, čćč鹊 čüą║ąŠčĆąŠčüčéčī ą┤ąŠčüčéčāą┐ą░ čüčéčĆą░ą┤ą░ąĄčé ą▓ čüą╗čāčćą░ąĄ ą┐čĆąŠą╝ą░čģąŠą▓ ą║čŹčłą░ (ą║ąŠą│ą┤ą░ ąĮčāąČąĮą░čÅ ąĖąĮč乊čĆą╝ą░čåąĖčÅ ąĮąĄ čüąŠą┤ąĄčƹȹĖčéčüčÅ ą▓ ą║čŹčłąĄ), čćč鹊 čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčé čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅ ą║ ą┐čĆąŠą┐čāčüą║ąĮąŠą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ ą┤ąŠčüčéčāą┐ą░ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ. ąóą░ą║ąČąĄ ą┤ą╗čÅ čüčéčĆąĖą╝ąĖąĮą│ą░ ą┤ą░ąĮąĮčŗčģ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čüą┤ąĄą╗ą░ąĮčŗ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝ąĖ, ą║ąŠą│ą┤ą░ ąĮąŠą▓čŗąĄ ą┤ą░ąĮąĮčŗąĄ ą┐ąĄčĆąĄą┤ą░čÄčéčüčÅ ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī. ą¤ąĄčĆąĄą▓ąŠą┤ čüčéčĆąŠą║ ą║čŹčłą░ ą▓ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ ą┤ąŠčĆąŠą│ ą┐ąŠ ąĘą░ą┤ąĄčƹȹ║ą░ą╝ ąĖ ą╝ąŠąČąĄčé ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠ čüąĮąĖąĘąĖčéčī ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ. ąØąĖąČąĄ ą▒čāą┤čāčé čĆą░čüčüą╝ąŠčéčĆąĄąĮčŗ čāą║ą░ąĘą░ąĮąĖčÅ ą┐ąŠ čāą╗čāčćčłąĄąĮąĖčÄ čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ L1.
ąÜą░ą║ čāčüą║ąŠčĆąĖčéčī ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ čü ą┐ąŠą╝ąŠčēčīčÄ ą┐ąŠą┤ą▒ą░ąĮą║ąŠą▓. ąÜą░ą║ čāąČąĄ čāą┐ąŠą╝ąĖąĮą░ą╗ąŠčüčī, ą║ąŠąĮą║čāčĆąĄąĮčåąĖčÅ ą┐ąŠ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠą╝čā ą┤ąŠčüčéčāą┐čā ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ č鹊ą╗čīą║ąŠ ąĄčüą╗ąĖ čÅą┤čĆąŠ ąĖ DMA ą┐čŗčéą░čÄčéčüčÅ ąŠą▒čĆą░čéąĖčéčīčüčÅ ą║ ąŠą┤ąĮąŠą╝čā ąĖ č鹊ą╝čā ąČąĄ ą┐ąŠą┤ą▒ą░ąĮą║čā ą┐ą░ą╝čÅčéąĖ. ąØą░ čĆąĖčü. 2 ą┐ąŠą║ą░ąĘą░ąĮ čüčåąĄąĮą░čĆąĖą╣, ą▓ ą║ąŠč鹊čĆąŠą╝ ą╝ąŠąČąĮąŠ ąĖąĘą▒ąĄąČą░čéčī ą║ąŠąĮą║čāčĆąĄąĮčéąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░, ąĄčüą╗ąĖ ą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĖčéčī ąŠą▒čŖąĄą║čéčŗ ą┤ą░ąĮąĮčŗčģ ą▓ ą┐ą░ą╝čÅčéąĖ L1.
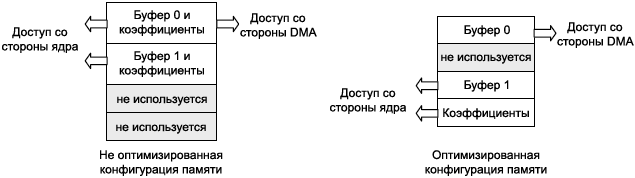
ąĀąĖčü. 2. ąŁčäč乥ą║čéąĖą▓ąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ ą╝ąĮąŠą│ąŠą┐ąŠčĆč鹊ą▓ąŠą╣ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ ą┐ąŠą┤ą▒ą░ąĮą║ąŠą▓.
ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ L1 č鹊ą╗čīą║ąŠ ą║ą░ą║ SRAM. ąĢčüą╗ąĖ čāą┤ą░čüčéčüčÅ ą▓čéąĖčüąĮčāčéčī ąĖ ą║ąŠą┤, ąĖ ą┤ą░ąĮąĮčŗąĄ ą▓ L1 SRAM, č鹊 čŹč鹊 ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčé čüą░ą╝čŗąĄ ąĮąĖąĘą║ąĖąĄ ąĘą░ą┤ąĄčƹȹ║ąĖ ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ ą┐ą░ą╝čÅčéąĖ. ąĢčüą╗ąĖ ąŠą▒čēąĖąĄ čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅ ą░ čĆą░ąĘą╝ąĄčĆčā ą║ąŠą┤ą░ ąĖ ą┤ą░ąĮąĮčŗčģ ą┐čĆąĄą▓čŗčłą░čÄčé ąĖą╝ąĄčÄčēąĖą╣čüčÅ ą▓ ąĮą░ą╗ąĖčćąĖąĖ čĆą░ąĘą╝ąĄčĆ L1 SRAM, č鹊 ą║ ą┐ą░ą╝čÅčéąĖ L1 čüą╗ąĄą┤čāąĄčé ą┐čĆąĖą▓čÅąĘą░čéčī č鹊čé ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ąĮą░ąĖą▒ąŠą╗ąĄąĄ čćą░čüč鹊, ąĖ č鹥 ą┤ą░ąĮąĮčŗąĄ, ą║ ą║ąŠč鹊čĆčŗą╝ čćą░čēąĄ ą▓čüąĄą│ąŠ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąŠą▒čĆą░čēąĄąĮąĖąĄ. ą¦č鹊ą▒čŗ čŹčäč乥ą║čéąĖą▓ąĮąŠ ą┐čĆąĖą▓čÅąĘą░čéčī ą║ąŠą┤ ą║ L1 SRAM, ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ą░ą▓č鹊ą╝ą░čéąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ąĖąĮčüčéčĆčāą╝ąĄąĮčé PGO linker tool, ąŠą┐ąĖčüą░ąĮąĮčŗą╣ ą▓ EE-306 [4]. ąĀą░ąĘą╝ąĄčēąĄąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ ą▓čüąĄ ąĄčēąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čüą┤ąĄą╗ą░ąĮąŠ ą▓čĆčāčćąĮčāčÄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüč鹊ą╝, čģąŠčéčÅ ąĮąĄą║ąŠč鹊čĆčŗąĄ č鹥čģąĮąĖą║ąĖ ą▒čāą┤čāčé čéą░ą║ąČąĄ ą┐čĆąĄą┤ą╗ąŠąČąĄąĮčŗ ą▓ čüą╗ąĄą┤čāčÄčēąĖčģ čüąĄą║čåąĖčÅčģ.
ą¤ą░ą╝čÅčéčī L1 SRAM ą╝ąŠąČąĄčé ą▒čŗčéčī čéą░ą║ąČąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮą░ ą┤ą╗čÅ ą┐čĆąĖą▓čÅąĘą║ąĖ ą║ąŠą┤ą░ ąĖ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗąĄ ą║čĆąĖčéąĖčćąĮčŗ ą║ čĆąĄą░ą╗čīąĮąŠą╝čā ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ, ą┐ąŠčüą║ąŠą╗čīą║čā ą┐ą░ą╝čÅčéčī SRAM ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą┤ąŠčüčéčāą┐ ąĘą░ 1 čåąĖą║ą╗ ą┤ą╗čÅ ą▓čüąĄčģ ąĘą░ą┐čĆąŠčüąŠą▓ ą║ ą┐ą░ą╝čÅčéąĖ. ąÜčŹčłąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą┐ą░ą╝čÅčéčī čüčéčĆą░ą┤ą░ąĄčé ąŠčé ą┐čĆąŠą╝ą░čģąŠą▓, čéą░ą║ čćč鹊 ąĮąĄčé ą┐čĆąĄą┤čüą║ą░ąĘčāąĄą╝ąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą┤ąŠčüčéčāą┐ą░ ą║ ąĘą░ą┐čĆą░čłąĖą▓ą░ąĄą╝ąŠą╝čā ą║ąŠą┤čā ąĖą╗ąĖ 菹╗ąĄą╝ąĄąĮčéčā ą┤ą░ąĮąĮčŗčģ. ąŁč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī ą║čĆąĖčéąĖčćąĮčŗą╝ ą┤ą╗čÅ čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆąĄąĮąĖčÅ čéčĆąĄą▒ąŠą▓ą░ąĮąĖą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ čüąĖčüč鹥ą╝čŗ, ą┐čĆąĖą▓čÅąĘą░ąĮąĮąŠą╣ ą║ čĆąĄą░ą╗čīąĮąŠą╝čā ą▓čĆąĄą╝ąĄąĮąĖ.
ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ L1 ą║ą░ą║ SRAM ąĖ ą║ą░ą║ ą║čŹčł. ąĢčüą╗ąĖ čĆą░ąĘą╝ąĄčĆ ą║ąŠą┤ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą▒ąŠą╗čīčłąĄ, č湥ą╝ ąŠą▒ą╗ą░čüčéčī L1 SRAM ąĖąĮčüčéčĆčāą║čåąĖą╣, č鹊 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą╝ąŠąČąĄčé čāą╝ąĄąĮčīčłąĖčéčī ą╗ą░č鹥ąĮčéąĮąŠčüčéčī ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ. ąÆ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░čĆąĖąĖ VisualDSP++ 4.5 ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓ą║ą╗čÄč湥ąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą║čŹčłą░ ą▓ ą┤ąĖą░ą╗ąŠą│ąĄ ąĮą░čüčéčĆąŠąĄą║ čüą▓ąŠą╣čüčéą▓ ą┐čĆąŠąĄą║čéą░ (Project Options), ą╗ąĖą▒ąŠ ą┐čāč鹥ą╝ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠą│ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą║ąŠąĮčüčéą░ąĮčéčŗ _cplb_ctrl ą▓ ąĖčüčģąŠą┤ąĮąŠą╝ čäą░ą╣ą╗ąĄ ą┐čĆąŠąĄą║čéą░.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą║čŹčłą░ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin čüą╝. čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąŠ EE-271 [5]. ą¤čĆąŠąĄą║čé, ą│ą┤ąĄ ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąĖą╝ąĄčĆ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą║čŹčłą░, ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą║ą░čéą░ą╗ąŠą│ąĄ čāčüčéą░ąĮąŠą▓ą║ąĖ VisualDSP++ (VisualDSP++ 4.5/Blackfin/Examples/ADSP-BF533 EZ-Kit Lite/Cache/).
ą¤čĆąŠčåąĄčüčüąŠčĆčŗ Blackfin čéą░ą║ąČąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅčÄčé ą░ą╗čīč鹥čĆąĮą░čéąĖą▓ąĮčŗąĄ čüą┐ąŠčüąŠą▒čŗ ą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠą│ąŠ čĆą░ąĘą╝ąĄčēąĄąĮąĖčÅ ą║ąŠą┤ą░ ąĖ ą┤ą░ąĮąĮčŗčģ ą▓ ąĖąĄčĆą░čĆčģąĖąĖ ą┐ą░ą╝čÅčéąĖ. ąĪąĖčüč鹥ą╝ą░ DMA ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮą░ ą┤ą╗čÅ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÅ ą║ąŠą┤ą░ ąĖ ą┤ą░ąĮąĮčŗčģ ą▓ą╝ąĄčüč鹊 ą╝ąĄčģą░ąĮąĖąĘą╝ą░ ą║čŹčłą░. ą¤čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ DMA ą║ąŠą┤ ąĖ ą┤ą░ąĮąĮčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ąĘą░ą│čĆčāąČąĄąĮčŗ ąĘą░čĆą░ąĮąĄąĄ ą┐ąĄčĆąĄą┤ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝, čćč鹊 čüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ ą╝ąŠąČąĄčé ą┐ąŠąĘą▓ąŠą╗ąĖčéčī ąĖąĘą▒ąĄąČą░čéčī ą┐čĆąŠą╝ą░čģąŠą▓ ą║čŹčłą░ ąĖ ą┐ąŠč鹥čĆąĖ čåąĖą║ą╗ąŠą▓ ą┐čĆąĖ ą┐ąĄčĆąĄą▓ąŠą┤ąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ą▓ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ. DMA čéą░ą║ąČąĄ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąŠčüčāčēąĄčüčéą▓ą╗čÅčéčī č乊ąĮąŠą▓čŗąĄ ą┐ąĄčĆąĄčüčŗą╗ą║ąĖ ą┤ą░ąĮąĮčŗčģ ą┐ąŠ ą┐ą░ą╝čÅčéąĖ ą▒ąĄąĘ čāčćą░čüčéąĖčÅ čÅą┤čĆą░, čćč鹊 čüąŠčģčĆą░ąĮčÅąĄčé čéą░ą║čéčŗ čÅą┤čĆą░ ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐ąŠą╗ąĄąĘąĮčŗčģ ą┤ąĄą╣čüčéą▓ąĖą╣. ą×ą┤ąĮą░ą║ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ DMA čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčé ą▓čĆąĄą╝čÅ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī čüą╗ąŠąČąĮčŗą╝ ą┤ą╗čÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣, ą║ąŠč鹊čĆčŗąĄ ąŠčüčāčēąĄčüčéą▓ą╗čÅčÄčé ąĮąĄčĆąĄą│čāą╗čÅčĆąĮčŗą╣ ąĖą╗ąĖ čüą╗čāčćą░ą╣ąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą┤ą░ąĮąĮčŗą╝ ąĖ ą║ąŠą┤čā.
ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ DMA ą┤ą╗čÅ čāą╝ąĄąĮčīčłąĄąĮąĖčÅ ą┐čĆąŠą╝ą░čģąŠą▓ ą║čŹčłą░. ą¦č鹊ą▒čŗ čŹčäč乥ą║čéąĖą▓ąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī DMA, ą▓ą░ąČąĮąŠ ąĘąĮą░čéčī ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ čłą░ą▒ą╗ąŠąĮčŗ ą┤ąŠčüčéčāą┐ą░ ą║ ą┤ą░ąĮąĮčŗą╝. ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą║ąŠą┤ąŠą╝ ąĖ ą┤ą░ąĮąĮčŗčģ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą┐ąŠą┐ą░ą┤ą░ąĄčé ą▓ ąĘąŠąĮčā ąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠčüčéąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčéą░; čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą▓ąŠąĘčĆą░čüčéą░ąĄčé ąŠąČąĖą┤ą░ąĄą╝ąŠąĄ ą▓čĆąĄą╝čÅ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. ą¦č鹊ą▒čŗ ą┐ąŠąĮčÅčéčī ą▓čŗą┐ąŠą╗ąĮąĖą╝ąŠčüčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ DMA ą┤ą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąŠą▒čŖąĄą║čéą░ą╝ąĖ ą┤ą░ąĮąĮčŗčģ ąĖ ą┐ąŠą╗čāčćąĖčéčī ą▒ąŠą╗ąĄąĄ ą┐ąŠą┤čĆąŠą▒ąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ą┐čĆąĄąĖą╝čāčēąĄčüčéą▓ DMA ą┐ąĄčĆąĄą┤ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą║čŹčłą░, ąŠą▒čĆą░čéąĖč鹥čüčī ą║ čĆčāą║ąŠą▓ąŠą┤čüčéą▓čā EE-301 [6]. ąóą░ą║ąČąĄ ą┐ąŠ ą┤ąŠčüč鹊ąĖąĮčüčéą▓ą░ą╝ ąĖ ąĮąĄą┤ąŠčüčéą░čéą║ą░ą╝ ą▓ą░čĆąĖą░ąĮč鹊ą▓ ą┐čĆąĖ ą▓čŗą▒ąŠčĆąĄ ą║ąŠą╝ą┐čĆąŠą╝ąĖčüčüą░ "ą║čŹčł ąĖą╗ąĖ DMA" čüą╝. čüčéą░čéčīčÄ [7].
[ą×ą┐ąĖčüą░ąĮąĖąĄ L2 SRAM]
ą¤ą░ą╝čÅčéčī čāčĆąŠą▓ąĮčÅ L2 ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī č鹊ą╗čīą║ąŠ ą║ą░ą║ ą┐ą░ą╝čÅčéčī SRAM. ąÆčĆąĄą╝čÅ ą┤ąŠčüčéčāą┐ą░ ą║ L2 ą▒ąŠą╗čīčłąĄ, č湥ą╝ ą║ L1, ąĮąŠ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčéčüčÅ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ ą╗čāčćčłąĄ, č湥ą╝ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ SDRAM, ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĮąŠą╣ ą║ ą║čĆąĖčüčéą░ą╗ą╗čā ą┐čĆąŠčåąĄčüčüąŠčĆą░ čüąĮą░čĆčāąČąĖ. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą┐ą░ą╝čÅčéčī L2 ąĖą╝ąĄąĄčéčüčÅ ą▓ ąĮą░ą╗ąĖčćąĖąĖ č鹊ą╗čīą║ąŠ ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ ADSP-BF561 ąĖ ADSP-BF54x Blackfin. ąóą░ą▒ą╗ąĖčåą░ 1 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ ą┐ą░ą╝čÅčéąĖ L2 ą▓ ąĄą┤ąĖąĮąĖčåą░čģ čéą░ą║č鹊ą▓ čÅą┤čĆą░ (core clock cycles, CCLK) ąĖ/ąĖą╗ąĖ čéą░ą║č鹊ą▓ čüąĖčüč鹥ą╝čŗ (system clock cycles, SCLK).
ąóą░ą▒ą╗ąĖčåą░ 1. ąæčŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ ą┐ą░ą╝čÅčéąĖ L2.
| ąóąĖą┐ ą┤ąŠčüčéčāą┐ą░ |
ąÜąŠą╗ąĖč湥čüčéą▓ąŠ čåąĖą║ą╗ąŠą▓ |
ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖąĖ |
| ą¤čĆčÅą╝ąŠą╣ ą┤ąŠčüčéčāą┐ čüąŠ čüč鹊čĆąŠąĮčŗ čÅą┤čĆą░ ą┤ą╗čÅ ą▓čŗą▒ąŠčĆą║ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ (64 ą▒ąĖčéą░) |
9 CCLK |
|
| ą¤čĆčÅą╝ąŠą╣ ą┤ąŠčüčéčāą┐ čüąŠ čüč鹊čĆąŠąĮčŗ čÅą┤čĆą░ ą┤ą╗čÅ ą▓čŗą▒ąŠčĆą║ąĖ ą┤ą░ąĮąĮčŗčģ |
9 CCLK (1-čÅ 32-ą▒ąĖčéąĮą░čÅ ą▓čŗą▒ąŠčĆą║ą░)
2 CCLK (2-čÅ 32-ą▒ąĖčéąĮą░čÅ ą▓čŗą▒ąŠčĆą║ą░) |
ąÆąŠąĘą╝ąŠąČąĄąĮ 8-, 16- ąĖ 32-ą▒ąĖčéąĮčŗą╣ ą┤ąŠčüčéčāą┐. |
| ąŚą░ą┐čĆąŠčü ąĮą░ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ą┤ą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖ ą┤ą░ąĮąĮčŗčģ (32 ą▒ąĖčéą░) |
15 CCLK |
ą¤ąĄčĆą▓čŗąĄ 8 ą▒ą░ą╣čé čüčéą░ąĮąŠą▓čÅčéčüčÅ ą┤ąŠčüčéčāą┐ąĮčŗ ą┐ąŠčüą╗ąĄ 9 CCLK, ąĖ ą┐ąŠ 2 čåąĖą║ą╗ą░ čéčĆą░čéčÅčéčüčÅ ąĮą░ ą║ą░ąČą┤čŗąĄ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖąĄ 8 ą▒ą░ą╣čé. |
| DMA-ą┐ąĄčĆąĄą┤ą░čćąĖ (8-ą▒ąĖčéąĮčŗąĄ) ą┤ą╗čÅ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ ą╝ąĄąČą┤čā ą┐ą░ą╝čÅčéčīčÄ L2 ąĖ L1 |
2 CCLK |
|
| ą¦č鹥ąĮąĖąĄ čüąĖčüč鹥ą╝ąŠą╣ L2 (čé. ąĄ. ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ ąĖąĘ L2 ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī) |
1 SCLK + 2 CCLK |
|
| ąŚą░ą┐ąĖčüčī čüąĖčüč鹥ą╝ąŠą╣ L2 (čé. ąĄ. ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ą▓ L2) |
1 SCLK |
|
ąÜą░ą║ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī L2 SRAM. L2 SRAM ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ ą┐čĆąĖą▓čÅąĘą║ąĖ ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗąĄ ąĮąĄ čāą╝ąĄčēą░čÄčéčüčÅ ą▓ ą┐ą░ą╝čÅčéčī L1 SRAM. ąĢčüą╗ąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą▓čāčģčÅą┤ąĄčĆąĮčŗą╣ ą┐čĆąŠčåąĄčüčüąŠčĆ ADSP-BF561, č鹊 ąŠą▒ą╗ą░čüčéčī ą┐ą░ą╝čÅčéąĖ L2 ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą║ą░ą║ ąŠą▒čēą░čÅ ą┤ą╗čÅ ąŠą▒ą╝ąĄąĮą░ ąŠą▒čŖąĄą║čéą░ą╝ąĖ ą┤ą░ąĮąĮčŗčģ ą╝ąĄąČą┤čā čÅą┤čĆą░ą╝ąĖ. ą¤ą░ą╝čÅčéčī L2 čéą░ą║ąČąĄ ąŠčĆą│ą░ąĮąĖąĘąŠą▓ą░ąĮą░ ą║ą░ą║ ą╝ąĮąŠą│ąŠą┐ąŠčĆč鹊ą▓čŗąĄ ą┐ąŠą┤ą▒ą░ąĮą║ąĖ. ąóą░ą║ą░čÅ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖčÅ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ L2 čüąŠ čüč鹊čĆąŠąĮčŗ čÅą┤čĆą░ ąĖ DMA, ąĄčüą╗ąĖ ąŠąĮąĖ ąŠčüčāčēąĄčüčéą▓ą╗čÅčÄčé ą┤ąŠčüčéčāą┐ ą║ čĆą░ąĘąĮčŗą╝ ą┐ąŠą┤ą▒ą░ąĮą║ą░ą╝.
[ą×ą┐ąĖčüą░ąĮąĖąĄ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ SDRAM]
ąöą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF561 Blackfin ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ SDRAM (SDC) ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą▒ą░ąĮą║ ą┐ą░ą╝čÅčéąĖ SDRAM čłąĖčĆąĖąĮąŠą╣ čłąĖąĮčŗ ą┤ą░ąĮąĮčŗčģ 16 ąĖą╗ąĖ 32 ą▒ąĖčéą░. ąöą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF53x ąĖ ADSP-BF52x, ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ SDC ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą▒ą░ąĮą║ąĖ SDRAM čłąĖčĆąĖąĮąŠą╣ 16 ą▒ąĖčé. ą¤ą░ą╝čÅčéčī SDRAM ą╝ąŠąČąĄčé ą┐ąĄčĆąĄą╝ąĄčēą░čéčī čüą▓ąŠąĖ ą┤ą░ąĮąĮčŗąĄ čü ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ čćą░čüč鹊č鹊ą╣ čłąĖąĮčŗ SCLK 133 ą£ąōčå. ąÜąŠąĮčéčĆąŠą╗ą╗ąĄčĆ SDC ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┐čĆąŠąĘčĆą░čćąĮčŗą╣ ąĖąĮč鹥čĆč乥ą╣čü ą║ čüčéą░ąĮą┤ą░čĆčéąĮčŗą╝ ą╝ąĖą║čĆąŠčüčģąĄą╝ą░ą╝ ą┐ą░ą╝čÅčéąĖ SDRAM čü 4 ą▓ąĮčāčéčĆąĄąĮąĮąĖą╝ąĖ ą▒ą░ąĮą║ą░ą╝ąĖ ą┐ą░ą╝čÅčéąĖ, ąĖ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┤ąŠčüčéčāą┐ ą║ ą▒ą░ąĮą║ą░ą╝ čü č湥čĆąĄą┤ąŠą▓ą░ąĮąĖąĄą╝ (interleaved bank memory access). ąóčĆąĄą▒čāąĄčéčüčÅ ą╗ąŠą│ąĖą║ą░ ą░čĆą▒ąĖčéčĆą░ąČą░ ą┤ą╗čÅ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ čüąŠ čüč鹊čĆąŠąĮčŗ čÅą┤čĆą░ ąĖ DMA. ąÆ čŹč鹊ą╣ čüąĄą║čåąĖąĖ ą┐ąŠą┤čĆąŠą▒ąĮąŠ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ąĄčéčüčÅ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ SDRAM ąĖ ąĄčæ ą┤ąĄą╗ąĄąĮąĖąĄ ąĮą░ ą▒ą░ąĮą║ąĖ.
ąöąĄą╗ąĄąĮąĖąĄ SDRAM ąĮą░ ą▒ą░ąĮą║ąĖ. ąŻ čüčéą░ąĮą┤ą░čĆčéąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ą┐ą░ą╝čÅčéąĖ SDRAM ąĄčüčéčī ą▓ąĮčāčéčĆąĄąĮąĮąĖąĄ ą▒ą░ąĮą║ąĖ ą┐ą░ą╝čÅčéąĖ. ą¦č鹊ą▒čŗ ą▓ąŠčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ąŠčüč鹊ąĖąĮčüčéą▓ą░ą╝ąĖ ą┤ąĄą╗ąĄąĮąĖčÅ ąĮą░ ą▒ą░ąĮą║ąĖ SDRAM, ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ SDC ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą┤ąŠčüčéčāą┐čŗ ą║ ą▒ą░ąĮą║ą░ą╝ ą┐ą░ą╝čÅčéąĖ čü č湥čĆąĄą┤ąŠą▓ą░ąĮąĖąĄą╝ (interleaved memory bank access). ąśąĮč鹥čĆč乥ą╣čü SDC ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą┤ąŠ 4 ą▓ąĮčāčéčĆąĄąĮąĮąĖčģ ą▒ą░ąĮą║ą░ ą┐ą░ą╝čÅčéąĖ.
ąÆąĮčāčéčĆąĄąĮąĮąĖą╣ ą░ą┤čĆąĄčü ą▒ą░ąĮą║ą░ SDRAM čüąŠčüč鹊ąĖčé ąĖąĘ ą░ą┤čĆąĄčüąŠą▓ čüčéčĆąŠą║ąĖ. ąÆąĮčāčéčĆąĄąĮąĮąĖąĄ ą▒ą░ąĮą║ąĖ ą┐ąŠą┤ąĄą╗ąĄąĮčŗ ąĮą░ ąĮą░ą▒ąŠčĆ čüčéčĆą░ąĮąĖčå ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗąĄ ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāčÄčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ čĆąĄą│ąĖčüčéčĆąŠą▓ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ SDC. ąÜąŠą╗ąĖč湥čüčéą▓ąŠ čüčéčĆą░ąĮąĖčå ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ čāčüčéą░ąĮąŠą▓ą║ą░ą╝ąĖ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ SDRAM ąĖ čĆą░ąĘą╝ąĄčĆąŠą╝ ą▓ąĮčāčéčĆąĄąĮąĮąĄą│ąŠ ą▒ą░ąĮą║ą░. ąÜąŠąĮčéčĆąŠą╗ą╗ąĄčĆ SDC ą▓ ą╗čÄą▒ąŠą╣ ą╝ąŠą╝ąĄąĮčé ą▓čĆąĄą╝ąĄąĮąĖ ą╝ąŠąČąĄčé ą┤ąĄčƹȹ░čéčī ąŠčéą║čĆčŗč鹊ą╣ č鹊ą╗čīą║ąŠ ąŠą┤ąĮčā čüčéčĆą░ąĮąĖčåčā ą▓ ą┐čĆąĄą┤ąĄą╗ą░čģ ą║ą░ąČą┤ąŠą│ąŠ ą▓ąĮčāčéčĆąĄąĮąĮąĄą│ąŠ ą▒ą░ąĮą║ą░. ą×čéą║čĆčŗčéąĖąĄ ąĘą░ą║čĆčŗč鹊ą╣ čüčéčĆą░ąĮąĖčåčŗ ą▓ąŠ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╝ ą▒ą░ąĮą║ąĄ čéčĆąĄą▒čāąĄčé ą▓čŗą┤ą░čćąĖ ą║ąŠą╝ą░ąĮą┤ pre-charge ąĖ activation. ąŁč鹊 SDC ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą┤ąĄą╗ą░ąĄčé ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ, ą▒ąĄąĘ čāčćą░čüčéąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčéą░, ąĮąŠ ąĮą░ ą▓čŗą┤ą░čćčā ą║ąŠą╝ą░ąĮą┤ čéčĆą░čéčÅčéčüčÅ čéą░ą║čéčŗ SCLK.
ąöąŠčüčéčāą┐ ą║ ąŠčéą║čĆčŗč鹊ą╣ čüčéčĆą░ąĮąĖčåąĄ ą┐ą░ą╝čÅčéąĖ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ ą┤ąŠčüčéčāą┐ąŠą╝ ą▓ ą┐čĆąĄą┤ąĄą╗ą░čģ ąŠą┤ąĮąŠą╣ čüčéčĆą░ąĮąĖčåčŗ (on-page access). ąŁč鹊čé ą┤ąŠčüčéčāą┐ čüą░ą╝čŗą╣ ą▒čŗčüčéčĆčŗą╣, ą┐ąŠč鹊ą╝čā čćč鹊 ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ ą▓čŗą┤ą░čćą░ ą║ąŠą╝ą░ąĮą┤ pre-charge ąĖą╗ąĖ activation. ąĢčüą╗ąĖ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ ą║ ąĘą░ą║čĆčŗč鹊ą╣ čüčéčĆą░ąĮąĖčåąĄ, č鹊 čéą░ą║ąŠą╣ ą┤ąŠčüčéčāą┐ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ ą┤ąŠčüčéčāą┐ąŠą╝ čü ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄą╝ čüčéčĆą░ąĮąĖčå (off-page access), ąĖ ąŠąĮ ą┐ąŠą╗čāčćą░ąĄčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčāčÄ ąĘą░ą┤ąĄčƹȹ║čā ąĮą░ čåąĖą║ą╗čŗ, čéčĆąĄą▒čāąĄą╝čŗąĄ ą┤ą╗čÅ ą▓čŗą┤ą░čćąĖ ą║ąŠą╝ą░ąĮą┤ pre-charge ąĖ activation. ą¦č鹊ą▒čŗ čāą▓ąĄą╗ąĖčćąĖčéčī čüą║ąŠčĆąŠčüčéčī ą┤ąŠčüčéčāą┐ą░ ą║ SDRAM, ą▓ą░ąČąĮąŠ ą╝ąĖąĮąĖą╝ąĖąĘąĖčĆąŠą▓ą░čéčī ą┤ąŠčüčéčāą┐čŗ čü ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄą╝ čüčéčĆą░ąĮąĖčå.
ąæčŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ SDRAM. ąÆ čéą░ą▒ą╗ąĖčåąĄ 2 ą┐čĆąĖą▓ąĄą┤ąĄąĮąŠ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ SDRAM ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą▓ ą┐čĆąĄą┤ąĄą╗ą░čģ ąŠą┤ąĮąŠą╣ čüčéčĆą░ąĮąĖčåčŗ (on-page access).
ąóą░ą▒ą╗ąĖčåą░ 2. ąĪą║ąŠčĆąŠčüčéčī ą┤ąŠčüčéčāą┐ą░ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ ąŠą▒čĆą░čēąĄąĮąĖčÅ ą║ čüą╗ąŠą▓čā ąĮą░ čüčéčĆą░ąĮąĖčåąĄ (* 32-ą▒ąĖčéą░ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF56x, 16-ą▒ąĖčé ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF53x ąĖ ADSP-BF52x).
| ąóąĖą┐ ą┤ąŠčüčéčāą┐ą░ |
ąÜąŠą╗ąĖč湥čüčéą▓ąŠ čåąĖą║ą╗ąŠą▓ SCLK ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ čüą╗ąŠą▓čā* |
| ąŚą░ą┐čĆąŠčü ąĮą░ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣/ą┤ą░ąĮąĮčŗčģ |
1.1 |
| ą¤čĆčÅą╝ą░čÅ ą▓čŗą▒ąŠčĆą║ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ čÅą┤čĆąŠą╝ |
1.1 |
| ąöąŠčüčéčāą┐ ąĮą░ čćč鹥ąĮąĖąĄ čüąŠ čüč鹊čĆąŠąĮčŗ DAG |
8 |
| ąöąŠčüčéčāą┐ ąĮą░ ąĘą░ą┐ąĖčüčī čüąŠ čüč鹊čĆąŠąĮčŗ DAG |
1 |
| ąöąŠčüčéčāą┐ ąĮą░ ąĘą░ą┐ąĖčüčī čüąŠ čüč鹊čĆąŠąĮčŗ MDMA (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ ąĖąĘ L1 ą▓ SDRAM) |
1 |
| ąöąŠčüčéčāą┐ ąĮą░ čćč鹥ąĮąĖąĄ čüąŠ čüč鹊čĆąŠąĮčŗ MDMA (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ ąĖąĘ SDRAM ą▓ L1) |
1.1 |
ąÆ čéą░ą▒ą╗ąĖčåąĄ 3 ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ SDRAM ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ čü ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄą╝ čüčéčĆą░ąĮąĖčå (off-page access).
ąóą░ą▒ą╗ąĖčåą░ 3. ąĪą║ąŠčĆąŠčüčéčī ą┤ąŠčüčéčāą┐ą░ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ ąŠą▒čĆą░čēąĄąĮąĖčÅ ą║ čüą╗ąŠą▓čā ą▓ąĮąĄ č鹥ą║čāčēąĄą╣ čüčéčĆą░ąĮąĖčåčŗ (* 32-ą▒ąĖčéą░ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF56x, 16-ą▒ąĖčé ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF53x ąĖ ADSP-BF52x).
| ąóąĖą┐ ą┤ąŠčüčéčāą┐ą░ |
ąÜąŠą╗ąĖč湥čüčéą▓ąŠ čåąĖą║ą╗ąŠą▓ SCLK ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ čüą╗ąŠą▓čā* |
| ą¦č鹥ąĮąĖąĄ |
tRP + tRCD +CL |
| ąŚą░ą┐ąĖčüčī |
tWR + tRP + tRCD |
ą×ą▒ąŠąĘąĮą░č湥ąĮąĖčÅ ą▓ čéą░ą▒ą╗ąĖčåąĄ 3:
tRP ąĘą░ą┤ąĄčƹȹ║ą░ ą╝ąĄąČą┤čā ą║ąŠą╝ą░ąĮą┤ąŠą╣ ą┐čĆąĄą┤ąĘą░čĆčÅą┤ą░ (pre-charge) ąĖ ą║ąŠą╝ą░ąĮą┤ąŠą╣ ą░ą║čéąĖą▓ą░čåąĖąĖ (1-7 čéą░ą║čéą░ SCLK).
tRCD ąĘą░ą┤ąĄčƹȹ║ą░ ą╝ąĄąČą┤čā ą║ąŠą╝ą░ąĮą┤ąŠą╣ ą░ą║čéąĖą▓ą░čåąĖąĖ ąĖ ą┐ąĄčĆą▓ąŠą╣ ą║ąŠą╝ą░ąĮą┤ąŠą╣ čćč鹥ąĮąĖčÅ / ąĘą░ą┐ąĖčüąĖ (1-7 čéą░ą║čéą░ SCLK).
tWR ąĘą░ą┤ąĄčƹȹ║ą░ ą╝ąĄąČą┤čā ą║ąŠą╝ą░ąĮą┤ąŠą╣ ąĘą░ą┐ąĖčüąĖ ąĖ ą║ąŠą╝ą░ąĮą┤ąŠą╣ ą┐čĆąĄą┤ąĘą░čĆčÅą┤ą░ (1-2 čéą░ą║čéą░ SCLK).
CL (CAS latency) ąĘą░ą┤ąĄčƹȹ║ą░ ą╝ąĄąČą┤čā ą║ąŠą╝ą░ąĮą┤ąŠą╣ čćč鹥ąĮąĖčÅ ąĖ ą┤ąŠčüčéčāą┐ąĮąŠčüčéčīčÄ ą┤ą░ąĮąĮčŗčģ ą▓ąĮąĄ čćąĖą┐ą░ (2-3 čéą░ą║čéą░ SCLK).
[ąÜą░ą║ čŹčäč乥ą║čéąĖą▓ąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī SDRAM]
ąøą░č鹥ąĮčéąĮąŠčüčéčī ą┤ąŠčüčéčāą┐ą░ ą┐čĆąĖ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĖ ą╝ąĄąČą┤čā čüčéčĆą░ąĮąĖčåą░ą╝ąĖ ą▓čŗčłąĄ, ą║ąŠą│ą┤ą░ ą║ąŠą┤ ąĖ ą┤ą░ąĮąĮčŗąĄ čĆą░ąĘą╝ąĄčēąĄąĮčŗ čüą╗čāčćą░ą╣ąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝, čü ą┐ąĄčĆąĄčüąĄč湥ąĮąĖąĄą╝ č湥čĆąĄąĘ ą│čĆą░ąĮąĖčåčŗ čüčéčĆą░ąĮąĖčå ą▓ąĮčāčéčĆąĄąĮąĮąĄą│ąŠ ą▒ą░ąĮą║ą░ ą┐ą░ą╝čÅčéąĖ. ą¦č鹊ą▒čŗ ą╝ąĖąĮąĖą╝ąĖąĘąĖčĆąŠą▓ą░čéčī ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ čüčéčĆą░ąĮąĖčå, ą┐čĆąĖą▓čÅąČąĖč鹥 ą▒ą╗ąŠą║ąĖ čü čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╝ ą║ąŠą┤ąŠą╝ ąĖ ą┤ą░ąĮąĮčŗą╝ąĖ ą║ ąŠą┤ąĮąŠą╣ ąĖ č鹊ą╣ ąČąĄ čüčéčĆą░ąĮąĖčåąĄ ą▓ąĮčāčéčĆąĄąĮąĮąĄą│ąŠ ą▒ą░ąĮą║ą░ ą┐ą░ą╝čÅčéąĖ. ą¦č鹊ą▒čŗ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ą▓čŗąĖą│čĆčŗčł ąŠčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠą│ąŠ ąŠčéą║čĆčŗčéąĖčÅ 4 čüčéčĆą░ąĮąĖčå ąĮą░ čĆą░ąĘąĮčŗčģ ą▒ą░ąĮą║ą░čģ ą┐ą░ą╝čÅčéąĖ SDRAM, ą╗čāčćčłąĄ ą▓čüąĄą│ąŠ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĖčéčī čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą║ąŠą┤ ąĮą░ 4 čüčéčĆą░ąĮąĖčåčŗ ą┐ą░ą╝čÅčéąĖ, ąĖ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĖčéčī čŹčéąĖ čüčéčĆą░ąĮąĖčåčŗ ą║ą░ąČą┤čāčÄ ą▓ ąŠčéą┤ąĄą╗čīąĮčŗą╣ ą▓ąĮčāčéčĆąĄąĮąĮąĖą╣ ą▒ą░ąĮą║.
ąĢčüą╗ąĖ čéčĆčāą┤ąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī čćą░čüč鹊čéčā ąŠą▒čĆą░čēąĄąĮąĖą╣ ą║ ąŠą▒ą╗ą░čüčéčÅą╝ ą║ąŠą┤ą░ ąĖ ą┤ą░ąĮąĮčŗčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ (ąŠą▒čŗčćąĮąŠ čŹč鹊 ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ), č鹊 čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą╝ąŠąČąĄčé ąŠčåąĄąĮąĖčéčī čüą╗ąĄą┤čāčÄčēąĖąĄ ą║ąŠą╝ą┐čĆąŠą╝ąĖčüčüąĮčŗąĄ čĆąĄčłąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓ ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąĖąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ.
1. ąĢčēąĄ čéčĆčāą┤ąĮąĄąĄ ąĖąĘą╝ąĄčĆąĖčéčī ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąĄąĮąĮčŗąĄ čģą░čĆą░ą║č鹥čĆąĖčüčéąĖą║ąĖ ą┤ą╗čÅ čüą╝ąĄčüąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ ą┤ą░ąĮąĮčŗčģ. ą¦č鹊ą▒čŗ čāą╝ąĄąĮčīčłąĖčéčī čāčüąĖą╗ąĖčÅ ąĮą░ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ, ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ čüą╗čāčćą░čÅčģ ą┐ą░ą╝čÅčéčī L2 ąĖ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ čĆą░ąĘą┤ąĄą╗ąĄąĮąĖčÅ ą╝ąĄąČą┤čā čüąŠą▒ąŠą╣ ąŠą▒ą╗ą░čüčéąĖ ą║ąŠą┤ą░ ąĖ ąŠą▒ą╗ą░čüčéąĖ ą┤ą░ąĮąĮčŗčģ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą║ąŠą┤ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ (ąĖą╗ąĖ ąĮą░ąĖą▒ąŠą╗ąĄąĄ čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą║ąŠą┤) ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą┐čĆąĖą▓čÅąĘą░ąĮ ą║ ą┐ą░ą╝čÅčéąĖ L1 ąĖą╗ąĖ L2, č鹊 ą▓čüčÅ ą▓ąĮąĄčłąĮčÅčÅ ą┐ą░ą╝čÅčéčī ą┐ąŠą╗čāčćą░ąĄčéčüčÅ ą┤ąŠčüčéčāą┐ąĮąŠą╣ ą┤ą╗čÅ ą┐čĆąĖą▓čÅąĘą║ąĖ ą║ ąĮąĄą╣ č鹊ą╗čīą║ąŠ ąŠą▒čŖąĄą║č鹊ą▓ ą┤ą░ąĮąĮčŗčģ. ą¤čĆąĖą▓čÅąĘą║ą░ ą┤ą░ąĮąĮčŗčģ č鹊ą╗čīą║ąŠ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čāą╗čāčćčłąĄąĮąĖąĄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąĖ ą┐čĆąĄą┤čüą║ą░ąĘčāąĄą╝ąŠčüčéąĖ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ. ą×ą┤ąĮą░ą║ąŠ čüą╗ąĄą┤čāąĄčé ąŠą▒čĆą░čéąĖčéčī ą▓ąĮąĖą╝ą░ąĮąĖąĄ ąĮą░ č鹊, čćč鹊 ą║ąŠą╝ą┐čĆąŠą╝ąĖčüčü ąĘą┤ąĄčüčī čüą┤ąĄą╗ą░ąĮ ą▓ čüč鹊čĆąŠąĮčā čāą▓ąĄą╗ąĖč湥ąĮąĖčÅ ą▓čĆąĄą╝ąĄąĮąĖ ą┤ąŠčüčéčāą┐ą░ ą║ ą┤ą░ąĮąĮčŗą╝. ąØą░ čĆąĖčü. 3 ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąĖą╝ąĄčĆ čéą░ą║ąŠą│ąŠ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ.
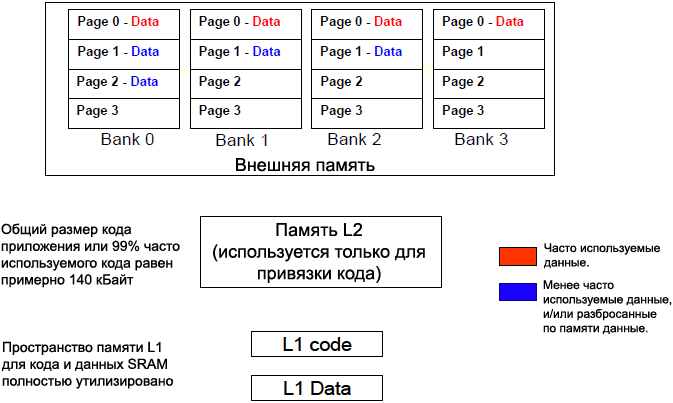
ąĀąĖčü. 3. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą┤ą░ąĮąĮčŗčģ.
2. ąÆąĮąĄčłąĮčÅčÅ ą┐ą░ą╝čÅčéčī ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠą┤ąĄą╗ąĄąĮą░ čéą░ą║, čćč鹊 ą║ąŠą┤ ąĖ ą┤ą░ąĮąĮčŗąĄ ą┐ąŠą┐ą░ą┤čāčé ą▓ čĆą░ąĘąĮčŗąĄ ą▓ąĮčāčéčĆąĄąĮąĮąĖąĄ ą▒ą░ąĮą║ąĖ ą┐ą░ą╝čÅčéąĖ. ąŁč鹊 ą┐ąŠą╗ąĄąĘąĮąŠ, ąĄčüą╗ąĖ ą┐ąĄčĆąĄč鹥ą║ą░ąĮąĖąĄ ą║ąŠą┤ą░ ąĖąĘ ą┐ą░ą╝čÅčéąĖ L1 ąĖ L2 ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĖą▓čÅąĘą░ąĮąŠ ą║ čéą░ą║ąĖą╝ čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╝ ąŠą▒ą╗ą░čüčéčÅą╝ ą║ąŠą┤ą░, ą║ąŠč鹊čĆčŗąĄ ąĮąĄ ą┐ąĄčĆąĄčüąĄą║ą░čÄčé ą│čĆą░ąĮąĖčåčŗ čüčéčĆą░ąĮąĖčåčŗ ą▓ąĮčāčéčĆąĄąĮąĮąĄą│ąŠ ą▒ą░ąĮą║ą░. ąØą░ čĆąĖčü. 4 ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąĖą╝ąĄčĆ čéą░ą║ąŠą│ąŠ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ.
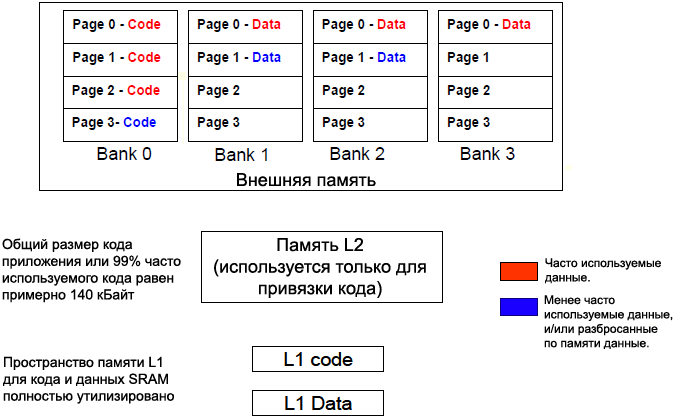
ąĀąĖčü. 4. ąĀą░ąĘą╝ąĄčēąĄąĮąĖąĄ ą║ąŠą┤ą░ ą▓ ą┐čĆąĄą┤ąĄą╗ą░čģ č鹊ą╗čīą║ąŠ ąŠą┤ąĮąŠą╣ čüčéčĆą░ąĮąĖčåčŗ ą▓ąĮčāčéčĆąĄąĮąĮąĄą│ąŠ ą▒ą░ąĮą║ą░ SDRAM.
3. ą×ą▒čŗčćąĮąŠ ą┤ą╗čÅ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▒čāč乥čĆąŠą▓ ą┤ą░ąĮąĮčŗčģ. ąŁčéąĖ ą▒čāč乥čĆčŗ ą╝ąŠąČąĮąŠ ą┐čĆąĖą▓čÅąĘą░čéčī ą║ ąŠčéą┤ąĄą╗čīąĮčŗą╝ ą▓ąĮčāčéčĆąĄąĮąĮąĖą╝ ą▒ą░ąĮą║ą░ą╝. ąØą░ čĆąĖčü. 5 ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąĖą╝ąĄčĆ čéą░ą║ąŠą│ąŠ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ. ąĪą╝. čéą░ą║ąČąĄ ą┤ą░čéą░čłąĖčé EE-301 [6] ą┤ą╗čÅ ą┐ąŠąĖčüą║ą░ ą░ą╗čīč鹥čĆąĮą░čéąĖą▓ąĮčŗčģ ą┐čāč鹥ą╣ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ ą▒čāč乥čĆą░ą╝ąĖ ą┤ą░ąĮąĮčŗčģ.
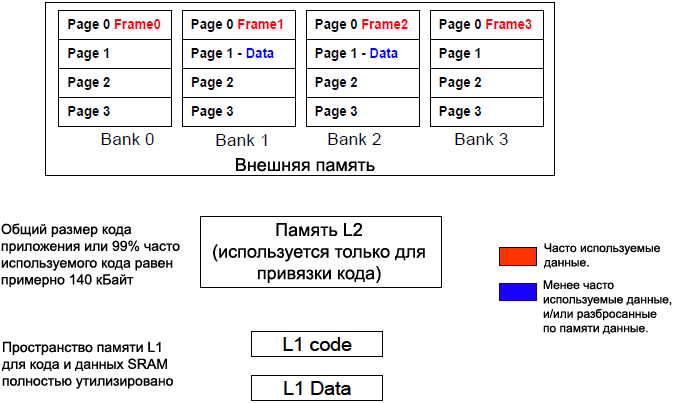
ąĀąĖčü. 5. ąĀą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą▒čāč乥čĆąŠą▓ čäčĆąĄą╣ą╝ą░ ą┐ąŠ 4 čĆą░ąĘąĮčŗą╝ ą▓ąĮčāčéčĆąĄąĮąĮąĖą╝ ą▒ą░ąĮą║ą░ą╝ SDRAM.
ąöčĆčāą│ąĖąĄ čüąŠą▓ąĄčéčŗ. ą×ą▒čŗčćąĮąŠ čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą║ąŠą┤ ąĖ ą┤ą░ąĮąĮčŗąĄ čĆą░ąĘą▒čĆąŠčüą░ąĮčŗ ą┐ąŠ ą▒ąŠą╗čīčłąŠą╝čā ąĖąĮč鹥čĆą▓ą░ą╗čā ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ą╝ąŠąČąĮąŠ čüč乊čĆą╝ąĖčĆąŠą▓ą░čéčī čüąĄą║čåąĖąĖ ą║ąŠą┤ą░ ąĖ ą┤ą░ąĮąĮčŗčģ, ą║ ą║ąŠč鹊čĆčŗą╝ čćą░čüč鹊 ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐, čĆą░ąĘą┤ąĄą╗ąĖčéčī ąĄą│ąŠ ąĮą░ 4 čćą░čüčéąĖ ą║ą░ąČą┤čāčÄ ą┐ąŠ čĆą░ąĘą╝ąĄčĆčā čüčéčĆą░ąĮąĖčåčŗ, ąĖ ąŠč鹊ą▒čĆą░ąĘąĖčéčī ą║ą░ąČą┤čāčÄ ąĖąĘ čŹčéąĖčģ čćą░čüč鹥ą╣ ąĮą░ ąŠčéą┤ąĄą╗čīąĮčāčÄ čüčéčĆą░ąĮąĖčåčā ą▓ ą║ą░ąČą┤ąŠą╝ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╝ ą▒ą░ąĮą║ąĄ.
ąöčĆčāą│ą░čÅ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī čāčüą║ąŠčĆąĖčéčī ą┤ąŠčüčéčāą┐ čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, čćč鹊ą▒čŗ ą┐ąŠą┐čŗčéą░čéčīčüčÅ ąĖąĘą▒ąĄąČą░čéčī ą┐čĆčÅą╝ąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ čüąŠ čüč鹊čĆąŠąĮčŗ čÅą┤čĆą░. ąöąŠčüčéčāą┐ ąĮą░ čćč鹥ąĮąĖąĄ čüąŠ čüč鹊čĆąŠąĮčŗ DAG, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ čéą░ą▒ą╗ąĖčåąĄ 2, ąĘą░ąĮąĖą╝ą░ąĄčé 8 čéą░ą║č鹊ą▓ SCLK, čćč鹊 ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą▓čŗčüąŠą║ąĖą╝ ąĘą░čéčĆą░čéą░ą╝ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ ą┤ą░ąČąĄ ą┐čĆąĖ ąŠą▒čĆą░čēąĄąĮąĖąĖ ą║ ą╝ą░ą╗čŗą╝ ą┐ąŠčĆčåąĖčÅą╝ ą┤ą░ąĮąĮčŗčģ ą▓ąŠ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ą║čŹčł ąĖą╗ąĖ DMA ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ąŠą▒čŖąĄą║čéą░ą╝, ą┐čĆąĖą▓čÅąĘą░ąĮąĮčŗą╝ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ.
[ąÉčĆčģąĖč鹥ą║čéčāčĆą░ čüąĖčüč鹥ą╝čŗ]
ąÆ čŹč鹊ą╣ čüąĄą║čåąĖąĖ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ąĄčéčüčÅ ą░čĆčģąĖč鹥ą║čéčāčĆą░ čüąĖčüč鹥ą╝čŗ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin, ą║ąŠč鹊čĆą░čÅ ą▓ą║ą╗čÄčćą░ąĄčé čüąĖčüč鹥ą╝ąĮčŗąĄ čłąĖąĮčŗ, ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆčŗ DMA, ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ ąĖ ą░čĆą▒ąĖčéčĆ ą▓ąĮąĄčłąĮąĄą╣ čłąĖąĮčŗ, ąĖ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčéčüčÅ čāą║ą░ąĘą░ąĮąĖčÅ ą┐ąŠ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ ąĖčģ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąŠą▒čüčāąČą┤ąĄąĮąĖąĄ ą┤ąĄą╗ą░ąĄčéčüčÅ č鹊ą╗čīą║ąŠ čü č鹊čćą║ąĖ ąĘčĆąĄąĮąĖčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ, ąĖ ąĖą│ąĮąŠčĆąĖčĆčāąĄčé ą┤čĆčāą│ąĖąĄ ą┐ąŠą┤čĆąŠą▒ąĮąŠčüčéąĖ. ąØąĖąČąĄ čĆą░čüčüą╝ąŠčéčĆąĄąĮčŗ čüąĖčüč鹥ą╝ąĮčŗąĄ čłąĖąĮčŗ, ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĮčŗąĄ ą║ ą║ą░ąĮą░ą╗ą░ą╝ DMA, ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗą╝ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ ąĖ čÅą┤čĆčā.
ą©ąĖąĮą░ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗą╝ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ (Peripheral Access Bus, PAB). ą©ąĖąĮą░ PAB čüąŠąĄą┤ąĖąĮčÅąĄčé ą▓čüąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░, ąĮą░čģąŠą┤čÅčēąĖąĄčüčÅ ą▓ąĮąĄ čÅą┤čĆą░, čü čüąĖčüč鹥ą╝ąĮčŗą╝ąĖ čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ MMR. ąöąŠčüčéčāą┐čŗ ąĮą░ čćč鹥ąĮąĖąĄ ąĖ ąĘą░ą┐ąĖčüčī čĆąĄą│ąĖčüčéčĆąŠą▓ ą┐ąŠ čłąĖąĮąĄ PAB ą┤ą░čÄčé ąĘą░ą┤ąĄčƹȹ║ąĖ ąĮą░ 3 ąĖ 2 čéą░ą║čéą░ SCLK čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ.
ą©ąĖąĮčŗ DMA. ąöą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ADSP-BF561 čüą╗ąĄą┤čāčÄčēąĖąĄ čłąĖąĮčŗ DMA čüąŠąĄą┤ąĖąĮčÅčÄčé ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ ąĖ ąĖąĄčĆą░čĆčģąĖčÄ ą┐ą░ą╝čÅčéąĖ.
ŌĆó ą©ąĖąĮčŗ ą┤ąŠčüčéčāą┐ą░ DMA (32-ą▒ąĖčéąĮą░čÅ DAB1 ąĖ 16-ą▒ąĖčéąĮą░čÅ DAB2, ą░ą▒ą▒čĆąĄą▓ąĖą░čéčāčĆą░ DAB čĆą░čüčłąĖčäčĆąŠą▓čŗą▓ą░ąĄčéčüčÅ ą║ą░ą║ DMA Access Bus) ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┐ąĄčĆąĄą┤ą░čćąĖ ą┤ą░ąĮąĮčŗčģ DMA ą▓ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ ąĖ ąĖąĘ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓.
ŌĆó ą©ąĖąĮčŗ DMA čÅą┤čĆą░ (32-ą▒ąĖčéąĮčŗąĄ DCB1, DCB2, DCB3 ąĖ DCB4, ą░ą▒ą▒čĆąĄą▓ąĖą░čéčāčĆą░ DCB čĆą░čüčłąĖčäčĆąŠą▓čŗą▓ą░ąĄčéčüčÅ ą║ą░ą║ DMA Core Bus) ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┐ąĄčĆąĄą┤ą░čćčā ą┤ą░ąĮąĮčŗčģ DMA ą╝ąĄąČą┤čā čÅą┤čĆąŠą╝ (A ąĖ B) ąĖ ą┐ą░ą╝čÅčéčīčÄ L1, ąĖą╗ąĖ ą┐ąĄčĆąĄą┤ą░čćąĖ ą┤ą░ąĮąĮčŗčģ DMA ą╝ąĄąČą┤čā čāčĆąŠą▓ąĮčÅą╝ąĖ ą┐ą░ą╝čÅčéąĖ L1 ąĖ L2.
ŌĆó ąÆąĮąĄčłąĮčÅčÅ čłąĖąĮą░ DMA (DMA External Bus, DEB) ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┐ąĄčĆąĄą┤ą░čćąĖ ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ ąŠą▒ą╝ąĄąĮą░ čü ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéčīčÄ (ąŠą▒čŗčćąĮąŠ čŹč鹊 SDRAM).
ąŚą░ą┤ąĄčƹȹ║ąĖ ą▓ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĖ ą┤ą░ąĮąĮčŗčģ ą╝ąĄąČą┤čā ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗą╝ąĖ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ąĖ ąĖ ą┐ą░ą╝čÅčéčīčÄ čüąŠčüčéą░ą▓ą╗čÅčÄčé 2 čéą░ą║čéą░ SCLK ą┤ą╗čÅ ą▓čŗą▒ąŠčĆąŠą║ ą┤ąŠčüčéčāą┐ą░ ą┤ąŠ 32 ą▒ąĖčé, čģąŠčéčÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ą╝ąŠąČąĄčé ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ čłąĖąĮąĄ ą║ą░ąČą┤čŗą╣ čéą░ą║čé SCLK ą┤ą╗čÅ čāčéąĖą╗ąĖąĘą░čåąĖąĖ ą┐ąŠą╗ąĮąŠą╣ ą┤ąŠčüčéčāą┐ąĮąŠą╣ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ. ą¤ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ ą╝ąĄąČą┤čā čĆą░ąĘąĮčŗą╝ąĖ čāčĆąŠą▓ąĮčÅą╝ąĖ ą┐ą░ą╝čÅčéąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ąŠčüčāčēąĄčüčéą▓ą╗ąĄąĮčŗ čü ąĘą░ą┤ąĄčƹȹ║ąŠą╣ ą▓ ąŠą┤ąĖąĮ čéą░ą║čé SCLK ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ 32-ą▒ąĖčéąĮąŠą│ąŠ čüą╗ąŠą▓ą░. ąöą╗čÅ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖą╣ ą╝ąĄąČą┤čā čāčĆąŠą▓ąĮčÅą╝ąĖ ą┐ą░ą╝čÅčéąĖ L1 ąĖ L2 čüą╗ąŠą▓ą░ čłąĖčĆąĖąĮąŠą╣ 32 ą▒ąĖčéą░ ą╝ąŠą│čāčé ą▒čŗčéčī ą┐ąĄčĆąĄą┤ą░ąĮčŗ ą▓ ą║ą░ąČą┤ąŠą╝ čéą░ą║č鹥 CCLK. ąÆ čéą░ą▒ą╗ąĖčåąĄ 4 ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąŠ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ ą┤ą╗čÅ ą┐ąĄčĆąĄą┤ą░čć DMA čéąĖą┐ą░ ą┐ą░ą╝čÅčéčī-ą┐ą░ą╝čÅčéčī ą╝ąĄąČą┤čā čĆą░ąĘąĮčŗą╝ąĖ čāčĆąŠą▓ąĮčÅą╝ąĖ ąĖąĄčĆą░čĆčģąĖąĖ ą┐ą░ą╝čÅčéąĖ.
ąóą░ą▒ą╗ąĖčåą░ 4. ą¤čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī čłąĖąĮ DMA ą┤ą╗čÅ ą┐ąĄčĆąĄą┤ą░čć čéąĖą┐ą░ ą┐ą░ą╝čÅčéčī-ą┐ą░ą╝čÅčéčī.
| ąśčüč鹊čćąĮąĖą║ |
ą£ąĄčüč鹊 ąĮą░ąĘąĮą░č湥ąĮąĖčÅ |
ą¤čĆąĖą╝ąĄčĆąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ SCLK ą┤ą╗čÅ n čüą╗ąŠą▓ (ąŠčé ąĮą░čćą░ą╗ą░ DMA ą┤ąŠ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ą┐ąŠ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÄ DMA) |
| 32-ą▒ąĖčéą░ SDRAM |
ą¤ą░ą╝čÅčéčī ą┤ą░ąĮąĮčŗčģ L1 |
n+14 |
| ą¤ą░ą╝čÅčéčī ą┤ą░ąĮąĮčŗčģ L1 |
32-ą▒ąĖčéą░ SDRAM |
n+11 |
| 32-ą▒ąĖčéąĮą░čÅ ą░čüąĖąĮčģčĆąŠąĮąĮą░čÅ ą┐ą░ą╝čÅčéčī |
ą¤ą░ą╝čÅčéčī ą┤ą░ąĮąĮčŗčģ L1 |
xn+12, ąĘą┤ąĄčüčī x čŹč鹊 ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čåąĖą║ą╗ąŠą▓ ąŠąČąĖą┤ą░ąĮąĖčÅ + čåąĖą║ą╗čŗ SCLK ąĮą░ čāčüčéą░ąĮąŠą▓ą║čā/čāą┤ąĄčƹȹ░ąĮąĖčÅ (ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ x čĆą░ą▓ąĮąŠ 2) |
| ą¤ą░ą╝čÅčéčī ą┤ą░ąĮąĮčŗčģ L1 |
32-ą▒ąĖčéąĮą░čÅ ą░čüąĖąĮčģčĆąŠąĮąĮą░čÅ ą┐ą░ą╝čÅčéčī |
xn+9, ąĘą┤ąĄčüčī x čŹč鹊 ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čåąĖą║ą╗ąŠą▓ ąŠąČąĖą┤ą░ąĮąĖčÅ + čåąĖą║ą╗čŗ SCLK ąĮą░ čāčüčéą░ąĮąŠą▓ą║čā/čāą┤ąĄčƹȹ░ąĮąĖčÅ (ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ x čĆą░ą▓ąĮąŠ 2) |
| 32-ą▒ąĖčéąĮą░čÅ SDRAM |
32-ą▒ąĖčéąĮą░čÅ SDRAM |
10+(17n/7) |
| 32-ą▒ąĖčéąĮą░čÅ ą░čüąĖąĮčģčĆąŠąĮąĮą░čÅ ą┐ą░ą╝čÅčéčī |
32-ą▒ąĖčéąĮą░čÅ ą░čüąĖąĮčģčĆąŠąĮąĮą░čÅ ą┐ą░ą╝čÅčéčī |
10+2xn, ąĘą┤ąĄčüčī x čŹč鹊 ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čåąĖą║ą╗ąŠą▓ ąŠąČąĖą┤ą░ąĮąĖčÅ + čåąĖą║ą╗čŗ SCLK ąĮą░ čāčüčéą░ąĮąŠą▓ą║čā/čāą┤ąĄčƹȹ░ąĮąĖčÅ (ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ x čĆą░ą▓ąĮąŠ 2) |
| ą¤ą░ą╝čÅčéčī ą┤ą░ąĮąĮčŗčģ L1 |
ą¤ą░ą╝čÅčéčī ą┤ą░ąĮąĮčŗčģ L1 |
2n+12 |
ąöą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF53x ąĖ ADSP-BF52x čüą╗ąĄą┤čāčÄčēąĖąĄ čłąĖąĮčŗ DMA čüąŠąĄą┤ąĖąĮčÅčÄčé ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ ąĖ ąĖąĄčĆą░čĆčģąĖąĖ čāčĆąŠą▓ąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ:
ŌĆó ą©ąĖąĮčŗ ą┤ąŠčüčéčāą┐ą░ DMA (16-ą▒ąĖčéąĮčŗą╣ DAB, ą░ą▒ą▒čĆąĄą▓ąĖą░čéčāčĆą░ DAB čĆą░čüčłąĖčäčĆąŠą▓čŗą▓ą░ąĄčéčüčÅ ą║ą░ą║ DMA Access Bus) ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ą┐ąĄčĆąĄą┤ą░čćąĖ DMA ą╝ąĄąČą┤čā ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗą╝ąĖ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ąĖ ąĖ ą┐ą░ą╝čÅčéčīčÄ.
ŌĆó ą©ąĖąĮčŗ DMA čÅą┤čĆą░ (16-ą▒ąĖčéąĮčŗą╣ DCB, ą░ą▒ą▒čĆąĄą▓ąĖą░čéčāčĆą░ DCB čĆą░čüčłąĖčäčĆąŠą▓čŗą▓ą░ąĄčéčüčÅ ą║ą░ą║ DMA Core Bus) ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┐ąĄčĆąĄą┤ą░čćąĖ ą┤ą░ąĮąĮčŗčģ DMA ą┤ą╗čÅ ąŠą▒ą╝ąĄąĮą░ ą┤ą░ąĮąĮčŗą╝ąĖ čü ą┐ą░ą╝čÅčéčīčÄ L1, ąĖą╗ąĖ ą┐ąĄčĆąĄą┤ą░čćčā ą┤ą░ąĮąĮčŗčģ DMA ą╝ąĄąČą┤čā L1 ąĖ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéčīčÄ.
ŌĆó ąÆąĮąĄčłąĮčÅčÅ čłąĖąĮą░ DMA (DMA External Bus, DEB) ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┐ąĄčĆąĄą┤ą░čćąĖ ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ ąŠą▒ą╝ąĄąĮą░ čü ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéčīčÄ (ąŠą▒čŗčćąĮąŠ čŹč鹊 SDRAM).
ąæčŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ ąĖ ą╗ą░č鹥ąĮčéąĮąŠčüčéčī ą┐ąĄčĆąĄą┤ą░čć ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF53x ąŠčüčéą░ą╗ąĖčüčī čéą░ą║ąĖą╝ąĖ ąČąĄ, ą║ą░ą║ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ADSP-BF561, ąĮąŠ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ čüą╗ąŠą▓ą░ čüąŠčüčéą░ą▓ą╗čÅąĄčé 16 ą▒ąĖčé ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ čéą░ą║čéą░ SCLK.
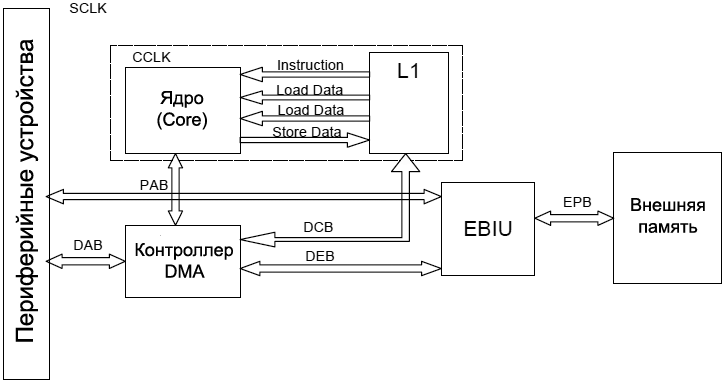
ąĀąĖčü. 6. ąÆąĮčāčéčĆąĄąĮąĮčÅčÅ čüčéčĆčāą║čéčāčĆą░ čłąĖąĮčŗ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF53x/ADSP-BF52x Blackfin. ąöą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF561 ąĘą┤ąĄčüčī ąĖą╝ąĄąĄčéčüčÅ 2 čÅą┤čĆą░, 2 ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ DMA, ąĖ ą▒ą╗ąŠą║ ą┐ą░ą╝čÅčéąĖ L2.
[ą©ąĖąĮą░ ą┤ąŠčüčéčāą┐ą░ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ EAB]
ą©ąĖąĮą░ ą┤ąŠčüčéčāą┐ą░ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ (External Access Bus, EAB) ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čÅą┤čĆčā ą┐ąŠą╗čāčćąĖčéčī ą┐čĆčÅą╝ąŠą╣ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ, ąĮą░čģąŠą┤čÅčēąĄą╣čüčÅ ą▓ąĮąĄ čćąĖą┐ą░. ąöą╗čÅ ą┤ą▓čāčģčÅą┤ąĄčĆąĮčŗčģ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF561 ą╝ąŠąČąĮąŠ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą┐ąĄčĆąĄą┤ą░čćąĖ 8-, 16- ąĖą╗ąĖ 32-ą▒ąĖčéąĮčŗčģ čüą╗ąŠą▓ ąĮą░ ą║ą░ąČą┤čŗą╣ čéą░ą║čé SCLK. ąöą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF53x ą╝ąŠąČąĮąŠ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą┐ąĄčĆąĄą┤ą░čćąĖ 8- ąĖą╗ąĖ 16-ą▒ąĖčéąĮčŗčģ čüą╗ąŠą▓ ąĮą░ ą║ą░ąČą┤čŗą╣ čéą░ą║čé SCLK. EAB čĆą░ą▒ąŠčéą░ąĄčé čü ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ čćą░čüč鹊č鹊ą╣ 133 ą£ąōčå.
[ąÜą░ą║ čŹčäč乥ą║čéąĖą▓ąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī EAB]
ąŻčéąĖą╗ąĖąĘą░čåąĖčÅ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ čłąĖąĮčŗ ąĖ čāą┐ą░ą║ąŠą▓ą║ą░ ąĮą░ čüč鹊čĆąŠąĮąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░. ą¤čĆąŠą┐čāčüą║ąĮčāčÄ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī čüąĖčüč鹥ą╝čŗ ą╝ąŠąČąĮąŠ ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠ čāą▓ąĄą╗ąĖčćąĖčéčī ą┐čāč鹥ą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą╝ą░ą║čüąĖą╝čāą╝ą░ ą┐ąŠą╗ąŠčüčŗ čłąĖąĮčŗ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ą┐ąĄčĆąĄą┤ą░čćąĖ. ąĢčüą╗ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī 32-ą▒ąĖčéąĮčŗą╣ ą┤ąŠčüčéčāą┐ DMA ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ADSP-BF561, ąĖ 16-ą▒ąĖčéąĮčŗą╣ ą┤ąŠčüčéčāą┐ DMA ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF53x/ADSP-BF52x ą▓ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ čü čāą┐ą░ą║ąŠą▓ą║ąŠą╣ ą┤ą░ąĮąĮčŗčģ (ąĄčüą╗ąĖ čéą░ą║ą░čÅ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ąĄčüčéčī čā ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░), č鹊 čŹč鹊 ą╝ąŠąČąĄčé ąŠčüą▓ąŠą▒ąŠą┤ąĖčéčī čüąĖčüč鹥ą╝ąĮčŗąĄ čłąĖąĮčŗ ą┤ą╗čÅ ą┤čĆčāą│ąĖčģ ą░ą║čéąĖą▓ąĮąŠčüč鹥ą╣, čćč鹊 čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠ čāą▓ąĄą╗ąĖčćąĖčé ą┐čĆąŠą┐čāčüą║ąĮčāčÄ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī čüąĖčüč鹥ą╝čŗ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą┐ąŠčĆčé PPI ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé 32-ą▒ąĖčéąĮčāčÄ čāą┐ą░ą║ąŠą▓ą║čā ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF561 ąĖ 16-ą▒ąĖčéąĮčāčÄ čāą┐ą░ą║ąŠą▓ą║čā ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF53x/ADSP-BF52x.
ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čéčĆą░čäąĖą║ąŠą╝ DMA. ą¤čĆąŠčåąĄčüčüąŠčĆčŗ Blackfin ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čéčĆą░čäąĖą║ąŠą╝ ą┤ą╗čÅ ą▓čüąĄčģ čüąĖčüč鹥ą╝ąĮčŗčģ čłąĖąĮ. ąĢčüą╗ąĖ čéčĆą░čäąĖą║ ąĮą░ čłąĖąĮąĄ čüą╗ąĖčłą║ąŠą╝ čćą░čüč鹊 ą╝ąĄąĮčÅąĄčé čüą▓ąŠąĄ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ, č鹊 čŹč鹊 ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ čāą▓ąĄą╗ąĖč湥ąĮąĖčÄ ąĘą░ą┤ąĄčƹȹĄą║ ąĖąĘ-ąĘą░ ą▓čĆąĄą╝ąĄąĮąĖ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ ą▒ą░ąĮą║ą░. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čĆąĄą│ąĖčüčéčĆąŠą▓ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čéčĆą░čäąĖą║ąŠą╝ čÅą▓ą╗čÅąĄčéčüčÅ ąŠą┤ąĮąĖą╝ ąĖąĘ ą╗čāčćčłąĖčģ čüą┐ąŠčüąŠą▒ąŠą▓ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ čéčĆą░čäąĖą║ą░ ąĮą░ čłąĖąĮąĄ, ą▓čüą╗ąĄą┤čüčéą▓ąĖąĄ č湥ą│ąŠ čāą╗čāčćčłąĖčéčüčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ čłąĖąĮčŗ. ą¤ąĄčĆąĖąŠą┤ čéčĆą░čäąĖą║ą░ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ čłąĖąĮčŗ DMA ą╝ąŠąČąĮąŠ čāą║ą░ąĘą░čéčī ą┤ą╗čÅ ą│čĆčāą┐ą┐čŗ ą┐ąĄčĆąĄą┤ą░čć ą▓ ąŠą┤ąĮąŠą╝ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĖ, č湥ą╝ čāą╝ąĄąĮčīčłą░čÄčéčüčÅ ą▓čĆąĄą╝ąĄąĮą░ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ ą▒ą░ąĮą║ą░. ąØą░ čĆąĖčü. 7 ą┐ąŠą║ą░ąĘą░ąĮ ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗą╣ čéčĆą░čäąĖą║ č湥čĆąĄąĘ čłąĖąĮčā DAB.
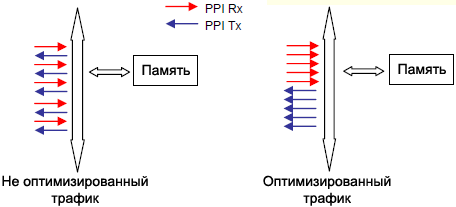
ąĀąĖčü. 7. ą×ą┐čéąĖą╝ąĖąĘą░čåąĖčÅ čéčĆą░čäąĖą║ą░ DMA ą╝ąĄąČą┤čā čüąĖčüč鹥ą╝ąĮčŗą╝ąĖ čłąĖąĮą░ą╝ąĖ.
ąĀąĖčüčāąĮąŠą║ 8 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čĆąĄą│ąĖčüčéčĆ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čéčĆą░čäąĖą║ąŠą╝ DMA (DMA traffic control register). ąÜą░ąČą┤ą░čÅ ąĖąĘ čłąĖąĮ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮą░ ą┤ą╗čÅ ą│čĆčāą┐ą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ąŠ 16 ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖą╣ ą┤ą░ąĮąĮčŗčģ ą▓ ąŠą┤ąĮąŠą╝ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĖ. ąóą░ą║ąČąĄ ą║ą░ąĮą░ą╗čŗ DMA ą┤ą╗čÅ ą┐ą░ą╝čÅčéąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ąĘą░ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮčŗ ą┤ą╗čÅ ą┐čĆąĖąŠčĆąĖč鹥ąĘą░čåąĖąĖ čéąĖą┐ą░ round-robin (ą║ą░čĆčāčüąĄą╗čīąĮą░čÅ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ą░čÅ ą┐čĆąĖąŠčĆąĖč鹥ąĘą░čåąĖčÅ) čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ čĆąĄą│ąĖčüčéčĆą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čéčĆą░čäąĖą║ąŠą╝.
ąŚąĮą░č湥ąĮąĖčÅ ą┤ą╗čÅ ą┐ąĄčĆąĖąŠą┤ą░ čéčĆą░čäąĖą║ą░ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąŠčåąĄąĮąĄąĮčŗ ąĮą░ ą▒ą░ąĘąĄ ąĖą╝ąĄčÄčēąĄą│ąŠčüčÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ąĖ ą║ąŠą╗ąĖč湥čüčéą▓ą░ čéčĆą░čäąĖą║ą░ čłąĖąĮčŗ ą▓ čüąĖčüč鹥ą╝ąĄ. ąÜą░ą║ ąŠčüąĮąŠą▓ąĮąŠąĄ ą┐čĆą░ą▓ąĖą╗ąŠ: ąĘąĮą░č湥ąĮąĖąĄ ą┐ąĄčĆąĖąŠą┤ą░ čéčĆą░čäąĖą║ą░, ą▒ą╗ąĖąĘą║ąŠąĄ ą║ 3, čÅą▓ą╗čÅąĄčéčüčÅ ąŠą┐čéąĖą╝ą░ą╗čīąĮčŗą╝, ą║ąŠą│ą┤ą░ 4 ąĖą╗ąĖ ą▒ąŠą╗čīčłąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ čĆą░ą▒ąŠčéą░čÄčé čü ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą╝ DMA, ąĖ ąĘąĮą░č湥ąĮąĖąĄ ą▒ą╗ąĖąĘą║ąŠąĄ ą║ 7 ą▒čāą┤ąĄčé ąŠą┐čéąĖą╝ą░ą╗čīąĮčŗą╝ ą▓ čüą╗čāčćą░ąĄ, ą│ą┤ąĄ 3 ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ą░ ąĖą╗ąĖ ą╝ąĄąĮčīčłąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ čü ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą╝ DMA. ąóą░ą║ąČąĄ ąŠą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĘąĮą░č湥ąĮąĖąĄ ą┐ąĄčĆąĖąŠą┤ą░ čéčĆą░čäąĖą║ą░ ą┤ą╗čÅ DEB čüąĖą╗čīąĮąĄąĄ ą▓čüąĄą│ąŠ ą▓ą╗ąĖčÅąĄčé ąĮą░ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ čüąĖčüč鹥ą╝čŗ; čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čŹč鹊 ąĘąĮą░č湥ąĮąĖąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą┐ąŠą┤ąŠą▒čĆą░ąĮąŠ ąĮą░ąĖą▒ąŠą╗ąĄąĄ čéčēą░č鹥ą╗čīąĮąŠ.
ąĢčēąĄ čüą╗ąĄą┤čāąĄčé ąĖą╝ąĄčéčī ą▓ ą▓ąĖą┤čā, čćč鹊 č湥ą╝ ą╝ąĄąĮčīčłąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┤ą╗čÅ round-robin ą┐ąĄčĆąĖąŠą┤ą░ ą┤ą╗čÅ memory DMA, č鹥ą╝ ą╝ąĄąĮčīčłąĄ ą┐čĆąŠą┐čāčüą║ąĮą░čÅ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī ą┐ąĄčĆąĄą┤ą░čć DMA, čéą░ą║ ą║ą░ą║ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą┐ąĄčĆąĄą║ą╗čÄčćą░ąĄčéčüčÅ ą╝ąĄąČą┤čā ą║ą░ąĮą░ą╗ą░ą╝ąĖ DMA č湥čĆąĄąĘ ą║ą░ąČą┤čŗąĄ ąĮąĄčüą║ąŠą╗čīą║ąŠ čüą╗ąŠą▓. ą×ą▒čŗčćąĮąŠ ą┤ą╗čÅ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ ą▒ąŠą╗čīčłąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ ą▒ą░ą╗ą░ąĮčüąĖčĆčāčÄčé ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī čü 菹║ą▓ąĖą▓ą░ą╗ąĄąĮčéąĮčŗą╝ čüąŠą▓ą╝ąĄčüčéąĮčŗą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ąŠą▒čēąĖčģ čĆąĄčüčāčĆčüąŠą▓.

ąĀąĖčü. 8. DMA traffic control register.
MDMA_ROUND_ROBIN_PERIOD[4:0]. ąŁč鹊 ą▒ąĖč鹊ą▓ąŠąĄ ą┐ąŠą╗ąĄ ąĘą░ą┤ą░ąĄčé ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčāčÄ ą┤ą╗ąĖąĮčā ą┐ąĄčĆąĄą┤ą░čć MDMA round robin. ąĢčüą╗ąĖ ąĮąĄ 0, ą╗čÄą▒ąŠą╣ ą┐ąŠč鹊ą║ MDMA, ą║ąŠč鹊čĆąŠą╝čā ą┤ą░ąĮ ą┤ąŠčüčéčāą┐, ą▒čāą┤ąĄčé čĆą░ąĘčĆąĄčłąĄąĮąŠ ą┐čĆąŠąĖąĘą▓ąĄčüčéąĖ čāą║ą░ąĘą░ąĮąĮąŠąĄ ą▓ čŹč鹊ą╝ ą┐ąŠą╗ąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąĄčĆąĄą┤ą░čć DMA, ą┐čĆąĖąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čÅ ąŠčüčéą░ą╗čīąĮčŗąĄ ą┐ąŠč鹊ą║ąĖ MDMA.
DAB_TRAFFIC_PERIOD[2:0]. 000 - ąĮąĄ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ
ąÆčŗą▒ąŠčĆ čüąŠąŠčéąĮąŠčłąĄąĮąĖčÅ čćą░čüč鹊čé CCLK/SCLK. ąØą░ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ čłąĖąĮ ą▓ą╗ąĖčÅąĄčé čüąŠąŠčéąĮąŠčłąĄąĮąĖąĄ ą╝ąĄąČą┤čā čćą░čüč鹊čéą░ą╝ąĖ čÅą┤čĆą░ ąĖ čüąĖčüč鹥ą╝čŗ. ąØą░ čüąŠąŠčéąĮąŠčłąĄąĮąĖčÅčģ ą┐ąŠčĆčÅą┤ą║ą░ 2.5:1 ąĘą░ą┤ąĄčƹȹ║ąĖ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ ąĖ ą┐čĆąŠčåąĄčüčüą░ ą║ąŠąĮą▓ąĄą╣ąĄčĆąĖąĘą░čåąĖąĖ ą┐čĆąĖą▓ąĄą┤čāčé ą║ čüąĮąĖąČąĄąĮąĖčÄ čāčéąĖą╗ąĖąĘą░čåąĖąĖ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ čłąĖąĮčŗ ą▓ ą┤ąŠą╝ąĄąĮąĄ čéą░ą║č鹊ą▓ąŠą╣ čćą░čüč鹊čéčŗ čüąĖčüč鹥ą╝čŗ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą┐čĆąĖ čüąŠąŠčéąĮąŠčłąĄąĮąĖąĖ čćą░čüč鹊čé čéą░ą║č鹊ą▓ 2:1 ąŠą▒čŗčćąĮąŠ DMA čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ čćą░čüč鹊č鹥 2/3 ąŠčé čćą░čüč鹊čéčŗ čéą░ą║č鹊ą▓ čüąĖčüč鹥ą╝ąĮąŠą╣ čłąĖąĮčŗ. ą¤ąŠą╗ąĮą░čÅ ą┐ąŠą╗ąŠčüą░ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┤ąŠčüčéąĖą│ąĮčāčéą░ ą┐čĆąĖ ą┐ąŠą▓čŗčłąĄąĮąĖąĖ čüąŠąŠčéąĮąŠčłąĄąĮąĖčÅ čćą░čüč鹊čé čÅą┤čĆąŠ/čüąĖčüč鹥ą╝ą░.
[ąÉčĆčģąĖč鹥ą║čéčāčĆą░ DMA]
ąÜąŠąĮčéčĆąŠą╗ą╗ąĄčĆ DMA čĆą░čüą┐čĆąĄą┤ąĄą╗čÅąĄčé ą░ą║čéąĖą▓ąĮąŠčüčéčī DMA ą╝ąĄąČą┤čā ąĖąĮč鹥čĆč乥ą╣čüąŠą╝ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ąĖ ą┐ą░ą╝čÅčéčīčÄ, ąĮą░čģąŠą┤čÅčēąĄą╣čüčÅ ą║ą░ą║ ą▓ąĮčāčéčĆąĖ čćąĖą┐ą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░, čéą░ą║ ąĖ čüąĮą░čĆčāąČąĖ. ąØąĄčüą║ąŠą╗čīą║ąŠ ą║ą░ąĮą░ą╗ąŠą▓ DMA ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ąĖ ą║ą░ąĮą░ą╗ąŠą▓ DMA ą┤ą╗čÅ ą┐ą░ą╝čÅčéąĖ ą║ąŠąĮą║čāčĆąĖčĆčāčÄčé ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝ ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ čĆąĄčüčāčĆčüą░ą╝ ą┐ą░ą╝čÅčéąĖ. ąŚą░ą┤ąĄčƹȹ║ąĖ ą┤ąŠčüčéčāą┐ą░ čāą╝ąĄąĮčīčłą░čÄčéčüčÅ ą┐čĆąĖ čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĖ čłąĖąĮ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ąĮą░ ą║ą░ąĮą░ą╗ąĄ DMA ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ (čłąĖąĮą░ DAB) ąĖ ą┤ąŠčüčéčāą┐ą░ ą┐ą░ą╝čÅčéčī-čÅą┤čĆąŠ (čłąĖąĮą░ DCB). ąóą░ą║ąČąĄ ą║ą░ąČą┤ąŠąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ čüąĮą░ą▒ąČąĄąĮąŠ čüąŠą▒čüčéą▓ąĄąĮąĮčŗą╝ ą▒čāč乥čĆąŠą╝ FIFO, ą║ąŠč鹊čĆčŗą╣ ąĄčēąĄ čāą╝ąĄąĮčīčłą░ąĄčé ą╗ą░č鹥ąĮčéąĮąŠčüčéčī ą┐ąŠ čüčĆą░ą▓ąĮąĄąĮąĖąĖ čü ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą║ąŠąĮą▓ąĄą╣ąĄčĆąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗą╝ ą┤ąŠčüčéčāą┐ąŠą╝ ą┐ąĄčĆąĖč乥čĆąĖčÅ-ą┐ą░ą╝čÅčéčī ą┐ąĄčĆąĄą┤ą░čć DMA.
ą¤ąĄčĆąĄą┤ą░čćą░ DMA ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖąĮąĖčåąĖąĖčĆąŠą▓ą░ąĮą░ ą▓ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čĆąĄąČąĖą╝ą░čģ: stop, auto-buffer, descriptor, ąĖ čé. ą┐. ąöą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ąŠą▒čĆą░čéąĖč鹥čüčī ą║ čĆą░ąĘą┤ąĄą╗čā DMA ą▓ ą░ą┐ą┐ą░čĆą░čéąĮąŠą╝ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąĄ ą┐ąŠ ąÆą░čłąĄą╝čā ą┐čĆąŠčåąĄčüčüąŠčĆčā (Hardware Reference manual). ąÆ čĆąĄąČąĖą╝ąĄ DMA čü ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ą╝ąĖ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ DMA ą▓čŗčćąĖčéčŗą▓ą░ąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ ąĖąĘ ąŠą▒čŖąĄą║č鹊ą▓ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ ąĖ ąĘą░ą│čĆčāąČą░ąĄčé ąĖčģ ą▓ čĆąĄą│ąĖčüčéčĆčŗ ą║ą░ąĮą░ą╗ą░ DMA. ąöąĄčüą║čĆąĖą┐č鹊čĆ ąĖą╗ąĖ ą╝ą░čüčüąĖą▓ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ ą╝ąŠą│čāčé čüą║čĆčŗčéčī ą┐čĆąĖčćąĖąĮčā ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĘą░ą┤ąĄčƹȹ║ąĖ, ąĄčüą╗ąĖ ąĘą░ą▒čŗčéčī ą┐čĆąŠ č鹊, čćč鹊 ąŠą▒čŖąĄą║čéčŗ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ čéą░ą║ąČąĄ ąĮą░čģąŠą┤čÅčéčüčÅ ą▓ ą┐ą░ą╝čÅčéąĖ, ąĖ ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗ ąĘą░ą┤ąĄčƹȹ║ąĖ ąĮą░ ą┤ąŠčüčéčāą┐ ą║ čŹč鹊ą╣ ą┐ą░ą╝čÅčéąĖ ą┐čĆąĖ MMR-ąĘą░ą┐ąĖčüčÅčģ ą▓ čĆąĄą│ąĖčüčéčĆčŗ DMA.
ąŻ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF561 ąĖą╝ąĄąĄčéčüčÅ 2 ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ DMA, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ čā ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF53x ąĄčüčéčī č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ. ąöą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓, čā ą║ąŠč鹊čĆčŗčģ ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą│ąŠ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ DMA, ą║ą░ąČą┤čŗą╣ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ DMA ą┐ąŠą┤ą║ą╗čÄč湥ąĮ ą║ ą┤ą▓čāą╝ čĆą░ąĘą┤ąĄą╗čīąĮčŗą╝ čłąĖąĮą░ą╝; čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą┐ąĄčĆąĄčüčŗą╗ą║ąĖ ą╝ąŠąČąĮąŠ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĖčéčī ą╝ąĄąČą┤čā ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ą╝ąĖ DMA, čćč鹊ą▒čŗ ą┐ąŠą▓čŗčüąĖčéčī ą┐čĆąŠą┐čāčüą║ąĮčāčÄ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī.
ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊ą▒čŗ ą┐ąŠą▓čŗčüąĖčéčī čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ DMA, čüčéą░čĆą░ą╣č鹥čüčī ą┐čĆąĖą┤ąĄčƹȹĖą▓ą░čéčīčüčÅ čüą╗ąĄą┤čāčÄčēąĖčģ čüąŠą▓ąĄč鹊ą▓:
1. ą¤čĆąĖąŠčĆąĖč鹥ąĘą░čåąĖčÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ čü ą▓čŗčüąŠą║ąĖą╝ąĖ čüą║ąŠčĆąŠčüčéčÅą╝ąĖ ą┐ąĄčĆąĄąĮąŠčüą░ ą┤ą░ąĮąĮčŗčģ čāą╗čāčćčłą░ąĄčé ą┐čĆąŠą┐čāčüą║ąĮčāčÄ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī. ąśąĘą╝ąĄąĮąĖč鹥 ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą╗čÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓, ą┐čĆąĖčüą▓ąŠąĄąĮąĮčŗąĄ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ą╝ DMA, ąĖčüą┐ąŠą╗čīąĘčāčÅ čĆąĄą│ąĖčüčéčĆ ą┐čĆąĖą▓čÅąĘą║ąĖ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ DMA (DMA peripheral map register).
2. ąĢčüą╗ąĖ ąĖą╝ąĄąĄčéčüčÅ ą▓ ąĮą░ą╗ąĖčćąĖąĖ ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą│ąŠ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ DMA, čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą┐ąĄčĆąĄą┤ą░čć ą╝ąĄąČą┤čā ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ą╝ąĖ DMA ą╝ąŠąČąĄčé čāą╝ąĄąĮčīčłąĖčéčī čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅ ą║ ą┐ąŠą╗ąŠčüąĄ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ čüąĖčüč鹥ą╝čŗ.
3. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą░ą▓č鹊ą▒čāč乥čĆą░ ąĖą╗ąĖ čĆąĄąČąĖą╝ą░ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ ą╝ąŠąČąĄčé čüąŠčģčĆą░ąĮąĖčéčī čéą░ą║čéčŗ čüąĖčüč鹥ą╝ąĮąŠą╣ čćą░čüč鹊čéčŗ.
[ąÉčĆą▒ąĖčéčĆ čłąĖąĮčŗ]
EBIU ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčé ą░čĆą▒ąĖčéčĆą░ąČ ą╝ąĄąČą┤čā čÅą┤čĆąŠą╝ ąĖ DMA ą┐čĆąĖ ąĖčģ ą┤ąŠčüčéčāą┐ąĄ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ. ą¤ąĄčĆąĄą┤ ą░čĆą▒ąĖčéčĆą░ąČąĄą╝ ą┐ąŠą╗ąĖčéąĖą║ąĖ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ čü ą░ą┤čĆąĄčüą░čåąĖąĄą╣ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, ą▓ą░ąČąĮąŠ ąĘą░ą╝ąĄčéąĖčéčī, ą║ąŠą│ą┤ą░ ąĘą░ą┐čĆąŠčü DMA ą║ą╗ą░čüčüąĖčäąĖčåąĖčĆčāąĄčéčüčÅ čüąĖčüč鹥ą╝ąŠą╣ ą║ą░ą║ čüčĆąŠčćąĮčŗą╣ (urgent DMA).
Urgent DMA. ąĀą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗ąĄą┤čāčÄčēąĖą╣ čüčåąĄąĮą░čĆąĖą╣, ą│ą┤ąĄ ą║ą░ąĮą░ą╗ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ą┐čĆąĖąĮąĖą╝ą░ąĄčé ą┤ą░ąĮąĮčŗąĄ ąĖąĘ ą▓ąĮąĄčłąĮąĄą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░. ąÜąŠą│ą┤ą░ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ą┐čĆąĖąĮąĖą╝ą░ąĄčé ą┤ą░ąĮąĮčŗąĄ (ąĖ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ąĘą░ą┐ąĖčüčī čŹčéąĖčģ ą┤ą░ąĮąĮčŗčģ ą▓ ą┐ą░ą╝čÅčéčī), ąĄčüą╗ąĖ FIFO ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ąĘą░ą┐ąŠą╗ąĮąĄąĮ, ąĖ DMA ąĮąĄ ą╝ąŠąČąĄčé ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ čłąĖąĮąĄ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ FIFO ą▓ ą┐ą░ą╝čÅčéčī, čüą║ąŠčĆąĄąĄ ą▓čüąĄą│ąŠ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ ą▒čāč乥čĆą░ ąĖ ą║ą░ą║ čüą╗ąĄą┤čüčéą▓ąĖąĄ ą┐ąŠč鹥čĆčÅ ą┐čĆąĖąĮąĖą╝ą░ąĄą╝čŗčģ ą┤ą░ąĮąĮčŗčģ. ąÆ čŹč鹊ą╣ čüąĖčéčāą░čåąĖąĖ ą▓čŗą┤ą░ąĄčéčüčÅ ąĘą░ą┐čĆąŠčü urgent DMA.
ą×ą▒čŗčćąĮąŠ, čćč鹊ą▒čŗ ąĘą░čēąĖčéąĖčéčīčüčÅ ąŠčé ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ ą▒čāč乥čĆą░, ąĘą░ą┐čĆąŠčüčŗ urgent DMA ą▒čāą┤čāčé ą▓čŗą┤ą░ą▓ą░čéčīčüčÅ ą┐čĆąĖ ą┐ąĄčĆąĄą┤ą░č湥 ąĖąĘ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ (čćč鹊 čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé čćč鹥ąĮąĖčÄ ą┐ą░ą╝čÅčéąĖ), ąĄčüą╗ąĖ čüč鹥ą║ FIFO ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ą┐čāčüčé, ąĖ DMA ąĮąĄ ą╝ąŠąČąĄčé ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ čłąĖąĮąĄ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ ąĖąĘ ą┐ą░ą╝čÅčéąĖ, čćč鹊ą▒čŗ ąĘą░ą┐ąŠą╗ąĮąĖčéčī FIFO.
ąöą╗čÅ ąŠą▒ąŠąĖčģ ą▓čŗčłąĄąŠą┐ąĖčüą░ąĮąĮčŗčģ čüąĖčéčāą░čåąĖą╣ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą╝ DMA ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą▓čŗą┤ą░ąĄčéčüčÅ ąĘą░ą┐čĆąŠčü urgent DMA, čéą░ą║ čćč鹊 ą▓ą╝ąĄčłą░č鹥ą╗čīčüčéą▓ąŠ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ. ąØą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ ADSP-BF534 / BF536 / BF537, ąĄčüą╗ąĖ ąĘą░ą┐čĆąŠčü DMA čüčéą░ąĮąŠą▓ąĖčéčüčÅ urgent, ą▓čüąĄ ąŠąČąĖą┤ą░čÄčēąĖąĄ ąĘą░ą┐čĆąŠčüčŗ DMA ą▓ čüąĖčüč鹥ą╝ąĄ ą┐ąŠą╝ąĄčćą░čÄčéčüčÅ ą║ą░ą║. ąöą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF531 / BF532 / BF533 ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF561 ąŠąČąĖą┤ą░čÄčēąĖąĄ ąĘą░ą┐čĆąŠčüčŗ ąĮąĄ ą┐ąĄčĆąĄą║ą╗čÄčćą░čÄčéčüčÅ ą▓ čüąŠčüč鹊čÅąĮąĖąĄ urgent, ą║ąŠą│ą┤ą░ ą┐ąŠčĆąŠąČą┤ą░ąĄčéčüčÅ urgent-ąĘą░ą┐čĆąŠčü. ą¦č鹊ą▒čŗ ąĮą░ čŹčéąĖčģ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ ą┐ąĄčĆąĄą▓ąĄčüčéąĖ ą▓čüąĄ ąŠąČąĖą┤ą░čÄčēąĖąĄ ąĘą░ą┐čĆąŠčüčŗ ą▓ čüąŠčüč鹊čÅąĮąĖąĄ urgent, ą╝ąŠąČąĄčé ą▒čŗčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą▒ąĖčé CDPRIO ą▓ čĆąĄą│ąĖčüčéčĆąĄ EBIU_AMGCTL, ą║ąŠč鹊čĆčŗą╣ ą▒ąŠą╗ąĄąĄ ą┐ąŠą┤čĆąŠą▒ąĮąŠ ąŠą┐ąĖčüą░ąĮ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╣ čüąĄą║čåąĖąĖ.
ąĪčģąĄą╝ą░ ą░čĆą▒ąĖčéčĆą░ąČą░. ąöą╗čÅ ą┤ąŠčüčéčāą┐ąŠą▓ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĘą░ą┐čĆąŠčüčŗ urgent DMA ąĖą╝ąĄčÄčé ąĮą░ąĖą▓čŗčüčłąĖą╣ ą┐čĆąĖąŠčĆąĖč鹥čé, ąĘą░č鹥ą╝ čüą╗ąĄą┤čāčÄčé ąĘą░ą┐čĆąŠčüčŗ čÅą┤čĆą░ ąĖ ąĘą░č鹥ą╝ ąĘą░ą┐čĆąŠčüčŗ DMA. ąŁčéą░ čüčģąĄą╝ą░ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆčāąĄčéčüčÅ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ąŠą▓ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, čćč鹊 ą▒čāą┤ąĄ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░čéčīčüčÅ ą▓ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ą░čģ čüą╗ąĄą┤čāčÄčēąĄą╣ čüąĄą║čåąĖąĖ.
ąöą╗čÅ ą┐ą░ą╝čÅčéąĖ L1 ąĖ L2 ąĘą░ą┐čĆąŠčüčŗ DMA ąĖ čÅą┤čĆą░ čüą╗ąĄą┤čāčÄčé čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą╝čā ą░čĆą▒ąĖčéčĆą░ąČčā. ąöą╗čÅ ą┤ąŠčüčéčāą┐ąŠą▓ ą║ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ą░čĆą▒ąĖčéčĆą░ąČ čéčĆąĄą▒čāąĄčéčüčÅ, č鹊ą╗čīą║ąŠ ąĄčüą╗ąĖ ą┤ąŠčüčéčāą┐čŗ DMA ąĖ čÅą┤čĆą░ ąŠčüčāčēąĄčüčéą▓ą╗čÅčÄčéčüčÅ ą▓ č鹊čé ąČąĄ čüą░ą╝čŗą╣ ą┐ąŠą┤ą▒ą░ąĮą║ ą┐ą░ą╝čÅčéąĖ. ąĢčüą╗ąĖ ą┤ąŠčüčéčāą┐ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓ ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ ą┐ąŠą┤ą▒ą░ąĮą║, č鹊 ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ DMA ą▓čŗąĖą│čĆčŗą▓ą░ąĄčé ą┐ąĄčĆąĄą┤ čÅą┤čĆąŠą╝. ąöą╗čÅ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĮčŗčģ ą┤ąŠčüčéčāą┐ąŠą▓ čÅą┤čĆą░ DMA ą▒čāą┤ąĄčé ąŠąČąĖą┤ą░čéčī, ą┐ąŠą║ą░ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą┤ąŠčüčéčāą┐ ąĮąĄ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ.
ąÜą░ą║ ą╗čāčćčłąĄ ą▓čüąĄą│ąŠ ą┐čĆąŠą▓ąŠą┤ąĖčéčī čĆą░ąĘčĆą░ą▒ąŠčéą║čā: ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ąŠą▓ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ąĘą░ą┐čĆąŠčüčŗ čÅą┤čĆą░ ąĖą╝ąĄčÄčé ą┐čĆąĖąŠčĆąĖč鹥čé ą▓čŗčłąĄ, č湥ą╝ ąĘą░ą┐čĆąŠčüčŗ DMA. ąŁč鹊 ą╝ąŠąČąĄčé ąĮąĄčüą║ąŠą╗čīą║ąŠ čāčģčāą┤čłąĖčéčī ą┐čĆąŠą┐čāčüą║ąĮčāčÄ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī, ąĄčüą╗ąĖ ąĖą╝ąĄąĄčéčüčÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĘą░ą┐čĆąŠčüąŠą▓ čÅą┤čĆą░ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ. ąŁč鹊ą│ąŠ ą╝ąŠąČąĮąŠ ąĖąĘą▒ąĄąČą░čéčī, ą┐čāč鹥ą╝ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅ ą▓čüąĄčģ ą┤ąŠčüčéčāą┐ąŠą▓ DMA ą▓ ą┤ąŠčüčéčāą┐čŗ urgent DMA, čŹčéąĖą╝ ą▓čüąĄ ą┤ąŠčüčéčāą┐čŗ DMA ą┐ąŠą╗čāčćą░čÄčé ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąĖą╣ ą┐čĆąĖąŠčĆąĖč鹥čé, č湥ą╝ ą┤ąŠčüčéčāą┐čŗ čÅą┤čĆą░. ąŁč鹊 ą╝ąŠąČąĮąŠ ąŠčüčāčēąĄčüčéą▓ąĖčéčī čāčüčéą░ąĮąŠą▓ą║ąŠą╣ ą▒ąĖčéą░ CDPRIO ąĖą╗ąĖ ą▒ąĖčéą░ DMAPRIO ą▓ čĆąĄą│ąĖčüčéčĆąĄ EBIU_AMGCTL.
[ąöčĆčāą│ąĖąĄ ąŠą▒čēąĖąĄ čüąŠą▓ąĄčéčŗ ą┐ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÄ]
ąóąĄąŠčĆąĄčéąĖč湥čüą║ą░čÅ ąŠčåąĄąĮą║ą░ ąŠą▒čēąĄą╣ ą┐ąŠą╗ąŠčüčŗ, čéčĆąĄą▒čāąĄą╝ąŠą╣ ą┤ą╗čÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, ą╝ąŠąČąĄčé ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī čģąŠčĆąŠčłčāčÄ ąĮą░čćą░ą╗čīąĮčāčÄ č鹊čćą║čā ą┤ą╗čÅ ąĖąĘčāč湥ąĮąĖčÅ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čüąĖčüč鹥ą╝čŗ čü č鹊čćą║ąĖ ąĘčĆąĄąĮąĖčÅ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ. ąÆ čüą╗čāčćą░čÅčģ, ą║ąŠą│ą┤ą░ čĆąĄčüčāčĆčüčŗ čüąĖčüč鹥ą╝čŗ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ąĮąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠ, ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ ąĮąĄą┤ąŠą│čĆčāąĘą║ą░ (underflow) ąĖą╗ąĖ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ (overflow) ą▒čāč乥čĆą░, ą┤ą░ąČąĄ ąĄčüą╗ąĖ čāčéąĖą╗ąĖąĘąĖčĆąŠą▓ą░ąĮąŠ ą╝ąĄąĮčīčłąĄ 20% ąŠčé ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ č鹥ąŠčĆąĄčéąĖč湥čüą║ąŠą╣ ą┐ąŠą╗ąŠčüčŗ čüąĖčüč鹥ą╝čŗ.
ą¦ą░čüč鹊 ąŠčłąĖą▒ą║ąĖ ąĮąĄą┤ąŠą│čĆčāąĘą║ąĖ/ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ ą▒čāč乥čĆą░ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ čüčéą░ąĮąŠą▓čÅčéčüčÅ ąĮąĄ ą▓čŗčÅą▓ą╗čÅąĄą╝čŗą╝ąĖ ą┤ą░ąČąĄ ą┐čĆąĖ ąĘąĮą░čćąĖč鹥ą╗čīąĮčŗčģ čāčüąĖą╗ąĖčÅčģ, ą┐čĆąĖą╗ą░ą│ą░ąĄą╝čŗčģ ą▓ ąŠčéą╗ą░ą┤ą║ąĄ. ą¤čāč鹥ą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ ąŠčłąĖą▒ą║ąĖ, ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄą╝čŗčģ ą┐čĆąŠčåąĄčüčüąŠčĆą░ą╝ąĖ Blackfin, ą╝ąŠąČąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, čĆą░ą▒ąŠčéą░ąĄčé ą╗ąĖ čüąĖčüč鹥ą╝ą░ ą▓ąĮąĄ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ. ąÆ čĆąĄą│ąĖčüčéčĆą░čģ čüčéą░čéčāčüą░ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ąĄčüčéčī ąĖąĮč乊čĆą╝ą░čåąĖčÅ ąŠą▒ ąŠčłąĖą▒ą║ą░čģ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĖą╗ąĖ ąĮąĄą┤ąŠą│čĆčāąĘą║ąĖ. ąśą╝ąĄą╣č鹥 ą▓ ą▓ąĖą┤čā, čćč鹊 ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąŠčłąĖą▒ą║ąĖ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĮąĄ ą▓ą║ą╗čÄč湥ąĮčŗ. ąØą░ ą▓čüąĄčģ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ Blackfin ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąŠčłąĖą▒ą║ąĖ ą┐čĆąĖą▓čÅąĘą░ąĮčŗ ą║ IVG7. ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ąŠčéą▓ąĄčćą░ąĄčé ąĘą░ č鹊, čćč鹊ą▒čŗ ą▓ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąŠčłąĖą▒ą║ąĖ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, ą║ą░ą║ąŠąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ą▓čŗąĘą▓ą░ą╗ąŠ ąŠčłąĖą▒ą║čā.
ą¤čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąŠčłąĖą▒ą║ąĖ ą╝ąŠą│čāčé ą▒čŗčéčī čĆą░ąĘčĆąĄčłąĄąĮčŗ ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ ą░ąĮą░ą╗ąŠą│ąĖčćąĮąŠ čĆą░ąĘčĆąĄčłąĄąĮąĖčÄ ą┤čĆčāą│ąĖčģ ą▓ąĄą║č鹊čĆąŠą▓ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ. ą×ą▒čĆą░ą▒ąŠčéčćąĖą║ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ą┤ąŠą╗ąČąĄąĮ čüą┐ąĄčåąĖą░ą╗čīąĮąŠ ą┐čĆąŠą▓ąĄčĆąĖčéčī čĆąĄą│ąĖčüčéčĆčŗ čüčéą░čéčāčüą░ ą▓čüąĄčģ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ čüąĖčüč鹥ą╝čŗ, čćč鹊ą▒čŗ č鹊čćąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ąĖčüč鹊čćąĮąĖą║ ąŠčłąĖą▒ą║ąĖ.
[ąóąĄčģąĮąĖą║ąĖ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ čüąĖčüč鹥ą╝čŗ]
ą£ąŠąČąĮąŠ ąŠą▒ąŠą▒čēąĖčéčī čĆą░ąĮąĄąĄ čāą┐ąŠą╝čÅąĮčāčéčŗąĄ č鹥čģąĮąĖą║ąĖ:
1. ąóąĄčģąĮąĖą║ąĖ ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠą│ąŠ čĆą░ąĘą╝ąĄčēąĄąĮąĖčÅ ą║ąŠą┤ą░ ąĖ ą┤ą░ąĮąĮčŗčģ
2. ąŻą┐ą░ą║ąŠą▓ą║ą░ ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą┐ąŠą╗ąĮąŠą╣ čłąĖčĆąĖąĮčŗ čłąĖąĮčŗ
3. ąŁčäč乥ą║čéąĖą▓ąĮąŠąĄ čĆą░ąĘą╝ąĄčēąĄąĮąĖąĄ ą▒ą░ąĮą║ą░
4. ą×ą┐čéąĖą╝ąĖąĘą░čåąĖčÅ čéčĆą░čäąĖą║ą░ čłąĖąĮčŗ, ąĖčüą┐ąŠą╗čīąĘčāčÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čéčĆą░čäąĖą║ąŠą╝ DMA (DMA traffic control)
5. ąĪąŠčģčĆą░ąĮąĄąĮąĖąĄ ą▓čŗčüąŠą║ąĖčģ čüąŠąŠčéąĮąŠčłąĄąĮąĖą╣ čćą░čüč鹊čé CCLK/SCLK
6. ąĀą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą┐ąĄčĆąĄą┤ą░čć ą┤ą░ąĮąĮčŗčģ ą┐ąŠ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ą╝ DMA, ą║ąŠą│ą┤ą░ čŹč鹊 ą▓ąŠąĘą╝ąŠąČąĮąŠ
7. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆčāąĄą╝čŗčģ čüčģąĄą╝ ą┐čĆąĖąŠčĆąĖč鹥čéą░ čłąĖąĮčŗ
ąŚą┤ąĄčüčī ą▒čāą┤čāčé čĆą░čüčüą╝ąŠčéčĆąĄąĮčŗ čŹčéąĖ č鹥čģąĮąĖą║ąĖ, ąĖ ą║ą░ąČą┤ą░čÅ ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ čāčüą╗ąŠą▓ąĖčÅčģ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ. ąóąĄčģąĮąĖą║ąĖ ą┐čĆąŠą│čĆąĄčüčüąĖą▓ąĮąŠ ą┤ąŠą▒ą░ą▓ą╗čÅčÄčéčüčÅ ą║ čüąĖčéčāą░čåąĖąĖ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ, ąĖ ąĮą░ ą║ą░ąČą┤ąŠą╝ čłą░ą│ąĄ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ ąŠčåąĄąĮąĖą▓ą░ąĄčéčüčÅ ą┐ąŠą╗ąŠčüą░ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ čüąĖčüč鹥ą╝čŗ. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 č鹥čģąĮąĖą║ą░ ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠą│ąŠ čĆą░ąĘą╝ąĄčēąĄąĮąĖčÅ ą║ąŠą┤ą░ ąĖ ą┤ą░ąĮąĮčŗčģ ąŠą┐ąĖčüą░ąĮą░ ą▓ EE-306 [4] ąĖ EE-301 [6] čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ, ą┐ąŠčŹč鹊ą╝čā ą▓ čŹč鹊ą╝ ą┤ąŠą║čāą╝ąĄąĮč鹥 čŹč鹊 ąĮąĄ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ąĄčéčüčÅ.
[ą£ąĄč鹊ą┤ąŠą╗ąŠą│ąĖčÅ ąŠčåąĄąĮą║ąĖ čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéąĖ]
ą¦č鹊ą▒čŗ ąŠčåąĄąĮąĖčéčī ą┐ąŠą╗ąŠčüčā ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ čüąĖčüč鹥ą╝čŗ, čüąĖąĮč鹥ąĘąĖčĆąŠą▓ą░ąĮčŗ 2 č鹥čüčéą░ ąĮą░ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ (benchmark). ą¤ąĄčĆą▓čŗą╣ benchmark - ą┐čĆąŠčüčéą░čÅ ą┐čĆąŠą│čĆą░ą╝ą╝ą░, ą║ąŠč鹊čĆą░čÅ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé č鹊ą╗čīą║ąŠ čćč鹥ąĮąĖčÅ ąĖ ąĘą░ą┐ąĖčüąĖ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ čü ą┐ąŠą╝ąŠčēčīčÄ DMA; ą┤ą╗čÅ čŹč鹊ą│ąŠ benchmark ąĮąĄ čĆą░ąĘčĆąĄčłąĄąĮą░ ąĮąĖą║ą░ą║ą░čÅ ą┤čĆčāą│ą░čÅ ą░ą║čéąĖą▓ąĮąŠčüčéčī ąĮą░ čüąĖčüč鹥ą╝ąĮąŠą╣ čłąĖąĮąĄ. ąÆč鹊čĆąŠą╣ benchmark - ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮą░čÅ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ čü ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ ą║ą░ąĮą░ą╗ą░ą╝ąĖ DMA ą┤ą╗čÅ ą┐ą░ą╝čÅčéąĖ, ą║ą░ąĮą░ą╗ą░ą╝ąĖ DMA ą┤ą╗čÅ ą┐ąĄčĆąĖč乥čĆąĖąĖ, ąĖ ą░ą║čéąĖą▓ąĮąŠčüčéčīčÄ čÅą┤čĆą░ ą▓ čüąĖčüč鹥ą╝ąĄ; čŹč鹊čé benchmark ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąĖ ą▓čŗąĖą│čĆčŗčłąĄą╣ ąŠą▒čüčāąČą┤ą░ąĄą╝čŗčģ č鹥čģąĮąĖą║ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ. ąÆ čüą╗ąĄą┤čāčÄčēąĄą╣ čćą░čüčéąĖ čŹč鹊ą│ąŠ ą░ąĮą░ą╗ąĖąĘą░, ąŠčéą┤ąĄą╗čīąĮąŠ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░čÄčéčüčÅ čŹčäč乥ą║čéčŗ čāčüčéą░ąĮąŠą▓ą║ąĖ čĆąĄą│ąĖčüčéčĆą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čéčĆą░čäąĖą║ąŠą╝ ąĖ ą▓čŗą▒ąŠčĆą░ čüąŠąŠčéąĮąŠčłąĄąĮąĖčÅ CCLK/SCLK ą┐čĆąĖ čāčéąĖą╗ąĖąĘą░čåąĖąĖ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ.
ą”ąĄą╗čī čŹč鹊ą│ąŠ ą░ąĮą░ą╗ąĖąĘą░ - ą┐ąŠą║ą░ąĘą░čéčī, ą║ą░ą║ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠą│čĆąĄčüčüąĖą▓ąĮąŠ čāą╗čāčćčłąĄąĮą░ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī čüąĖčüč鹥ą╝čŗ ą┐čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ čĆą░ąĘą╗ąĖčćąĮčŗčģ č鹥čģąĮąĖą║ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ. ą¦č鹊ą▒čŗ ą║ą▓ą░ą╗ąĖčäąĖčåąĖčĆąŠą▓ą░čéčī čŹčäč乥ą║čéčŗ, ą▒čŗą╗ą░ ą▓čŗą▒čĆą░ąĮą░ čüčĆąĄą┤ąĮčÅčÅ ą┐čĆąŠą┐čāčüą║ąĮą░čÅ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī ą▓ ą║ą░č湥čüčéą▓ąĄ ą╝ąĄčéčĆąĖą║ąĖ ąŠčåąĄąĮą║ąĖ č鹥čģąĮąĖą║ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ. ąĪčĆąĄą┤ąĮčÅčÅ ą┐čĆąŠą┐čāčüą║ąĮą░čÅ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī čüąĖčüč鹥ą╝čŗ (average system throughput, ASR) ą▓čŗčćąĖčüą╗čÅą╗ą░čüčī ą║ą░ą║ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čćč鹥ąĮąĖą╣ ąĖą╗ąĖ ąĘą░ą┐ąĖčüąĄą╣ ą┤ą░ąĮąĮčŗčģ ą▓ čüąĄą║čāąĮą┤čā (NRW) ą┐ąŠ č乊čĆą╝čāą╗ąĄ:
ASR = (NRW)/sec
ąśąĮč鹥čĆą▓ą░ą╗ ą▓čĆąĄą╝ąĄąĮąĖ ą┤ą╗čÅ ą░ą║čéąĖą▓ąĮąŠčüčéąĖ čüąĖčüč鹥ą╝ąĮąŠą╣ čłąĖąĮčŗ ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄčéčüčÅ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą▓ąĮčāčéčĆąĄąĮąĮąĄą│ąŠ čéą░ą╣ą╝ąĄčĆą░ čÅą┤čĆą░ (core timer). ąóą░ą╣ą╝ąĄčĆ ąĮą░čüčéčĆąŠąĄąĮ čéą░ą║, čćč鹊 ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ ą║ą░ąČą┤čāčÄ čüąĄą║čāąĮą┤čā. ąóą░ą╣ą╝ąĄčĆ ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ čüčĆą░ąĘčā ą┐ąĄčĆąĄą┤ čĆą░ąĘčĆąĄčłąĄąĮąĖąĄą╝ ą║ą░ąĮą░ą╗ąŠą▓ ą┐ąĄčĆąĖč乥čĆąĖąĖ/MDMA, ąĖ ąĘą░č鹥ą╝ ą║ą░ąĮą░ą╗čŗ ą┐ąĄčĆąĖč乥čĆąĖąĖ/MDMA ąĘą░ą┐čĆąĄčēą░čÄčéčüčÅ ą▓ąĮčāčéčĆąĖ ISR čéą░ą╣ą╝ąĄčĆą░ čÅą┤čĆą░. ąÜąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąĄčĆąĄą┤ą░ąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ąĖąĘą╝ąĄčĆčÅąĄčéčüčÅ ą┐ąŠ ąĘąĮą░č湥ąĮąĖčÄ čüč湥čéčćąĖą║ąŠą▓ ą▓ ISR ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓. ą¤čĆąĄčĆčŗą▓ą░ąĮąĖąĄ ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ąĮą░ ą║ą░ąČą┤ąŠą╣ ą┐ąĄčĆąĄą┤ą░č湥 ą▒čāč乥čĆą░, ąĖ čüč湥čéčćąĖą║ ąĖąĮą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄčéčüčÅ ą║ą░ąČą┤čŗą╣ čĆą░ąĘ, ą║ąŠą┤ą░ ą▓čŗąĘčŗą▓ą░ąĄčéčüčÅ ISR ą┐ąĄčĆąĖč乥čĆąĖąĖ /MDMA. ą¤ąŠčüą║ąŠą╗čīą║čā ą▓čüąĄ ą║ą░ąĮą░ą╗čŗ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ąĖ ą║ą░ąĮą░ą╗čŗ MDMA čĆą░ą▒ąŠčéą░čÄčé ą▓ čĆąĄąČąĖą╝ąĄ ą░ą▓č鹊ą▒čāč乥čĆą░, ą┤ą╗čÅ ą║ąŠąĮąĄčćąĮčŗčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ ą┐čĆąŠą┐čāčüą║ąĮąŠą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ ąĮąĄ ąĮčāąČąĮąŠ čāčćąĖčéčŗą▓ą░čéčī ąĘą░ą┤ąĄčƹȹ║čā, ą▓ąĮąŠčüąĖą╝čāčÄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄą╝ ąŠčé ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░.
ąæąĄąĮčćą╝ą░čĆą║ąĖ č鹥čüčéąĖčĆąŠą▓ą░ą╗ąĖčüčī ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆąĄ ADSP-BF561, ąĮąŠ ą┐ąŠą╗čāč湥ąĮąĮčŗąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ čéą░ą║ąČąĄ ą▒čāą┤čāčé ą┐čĆąĖą╝ąĄąĮąĖą╝čŗ ąĖ ą┤ą╗čÅ ą▓čüąĄčģ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin, ąĄčüą╗ąĖ ąĮąĄ ą▒čŗą╗ąŠ čüą┐ąĄčåąĖą░ą╗čīąĮąŠ ąĘą░ą╝ąĄč湥ąĮąŠ ąĮąĄčćč鹊 ą┤čĆčāą│ąŠąĄ.
[ąÉąĮą░ą╗ąĖąĘ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ čüąĖčüč鹥ą╝čŗ]
ąÆ čŹč鹊ą╣ čüąĄą║čåąĖąĖ ąŠą▒čüčāąČą┤ą░čÄčéčüčÅ 2 ą▒ąĄąĮčćą╝ą░čĆą║ą░: ą┐čĆąŠčüč鹊ą╣ ą┐čĆąĖą╝ąĄčĆ memory DMA (ą┐ąĄčĆąĄčüčŗą╗ą║ą░ ą▓ ą┐ą░ą╝čÅčéąĖ, MDMA), ąĖ čĆąĄą░ą╗ąĖčüčéąĖčćąĮčŗą╣ č鹥čüčé, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╣ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝ąŠą╝čā ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÄ, čĆąĄą░ą╗ąĖąĘčāčÄčēąĄą╝čā ą▓ą▓ąŠą┤/ą▓čŗą▓ąŠą┤ ą▓ąĖą┤ąĄąŠ ąĖ ą░čāą┤ąĖąŠ ąĖ čüąŠą▓ą╝ąĄčüčéąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čäą░ą╣ą╗ąŠą▓ąŠą╣ čüąĖčüč鹥ą╝čŗ.
ą¤čĆąĖą╝ąĄčĆ 1 - Memory DMA. ąÆ čŹč鹊ą╝ benchmark ą▒čāč乥čĆčŗ ą┐ąĄčĆąĄą╝ąĄčēą░čÄčéčüčÅ ą╝ąĄąČą┤čā ą┐ą░ą╝čÅčéčīčÄ L1 ąĖ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéčīčÄ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ąŠą┤ąĮąŠą╣ ą┐ą░čĆčŗ ą║ą░ąĮą░ą╗ąŠą▓ memory DMA. ąĀą░ąĘą╝ąĄčĆ ą▒čāč乥čĆą░ DMA čüąŠčüčéą░ą▓ą╗čÅąĄčé 8 ą║ąĖą╗ąŠą▒ą░ą╣čé, ąĖ čćą░čüč鹊čéčŗ CCLK ąĖ SCLK čāčüčéą░ąĮąŠą▓ą╗ąĄąĮčŗ ąĮą░ ąĘąĮą░č湥ąĮąĖčÅ 600 ąĖ 120 ą£ąōčå čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ. ąóą░ą▒ą╗ąĖčåą░ 5 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą░ąĮą░ą╗ąĖąĘ ą┐čĆąŠą┐čāčüą║ąĮąŠą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ąŠą▓ ą║ SDRAM. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĘą┤ąĄčüčī ą▓ čüąĖčüč鹥ą╝ąĄ čĆą░ą▒ąŠčéą░ąĄčé č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ ą║ą░ąĮą░ą╗ memory DMA, ąĖ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ąĮąĄ ą┤ąĄą╗ą░ąĄčéčüčÅ ąŠą▒čĆą░čēąĄąĮąĖą╣ čüąŠ čüč鹊čĆąŠąĮčŗ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ąĖą╗ąĖ čÅą┤čĆą░.
ąóą░ą▒ą╗ąĖčåą░ 5. ą¤čĆąŠą┐čāčüą║ąĮą░čÅ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ąŠą▓ ąĮą░ čćč鹥ąĮąĖąĄ ąĖ ąĘą░ą┐ąĖčüčī čüąŠ čüč鹊čĆąŠąĮčŗ DMA ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ.
| ą×ą┐ąĄčĆą░čåąĖčÅ DMA |
ąĀą░ąĘą╝ąĄčĆ ą┐ą░ą║ąĄčéą░ |
ąÜąŠą╗ąĖč湥čüčéą▓ąŠ ą▒čāč乥čĆąŠą▓, ą┐ąĄčĆąĄą┤ą░ąĮąĮčŗčģ ąĘą░ čüąĄą║čāąĮą┤čā |
ąĪčĆąĄą┤ąĮčÅčÅ ą┐čĆąŠą┐čāčüą║ąĮą░čÅ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī (MB/čüąĄą║) |
% ąŠčé č鹥ąŠčĆąĄčéąĖč湥čüą║ąŠą│ąŠ ą╝ą░ą║čüąĖą╝čāą╝ą░ ą┐čĆąŠą┐čāčüą║ąĮąŠą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ (480 MB/čüąĄą║) |
| ąöąŠčüčéčāą┐ ąĮą░ ąĘą░ą┐ąĖčüčī, ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ L1 ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī |
8 ą║ąĖą╗ąŠą▒ą░ą╣čé |
57303 |
469 |
98% |
| ąöąŠčüčéčāą┐ ąĮą░ čćč鹥ąĮąĖąĄ, ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ą▓ L1 |
8 ą║ąĖą╗ąŠą▒ą░ą╣čé |
51165 |
419 |
87% |
ąÜą░ąĮą░ą╗ memory DMA ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą▓ čĆąĄąČąĖą╝ąĄ ą░ą▓č鹊ą▒čāč乥čĆą░, ąĖ čĆą░ą▒ąŠčéą░ąĄčé ą▒ąĄąĘ ą┐ąĄčĆąĄčĆčŗą▓ą░ ą▓ čŹč鹊ą╝ čĆąĄąČąĖą╝ąĄ, ą┐ąŠą║ą░ ąĮąĄ ąĖčüč鹥č湥čé čéą░ą╣ą╝ąĄčĆ čÅą┤čĆą░. ąÆ čŹč鹊ą╝ benchmark ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ č鹥čģąĮąĖą║ąĖ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ čüąĖčüč鹥ą╝čŗ. ą×ą┤ąĮą░ą║ąŠ, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ čéą░ą▒ą╗ąĖčåąĄ 5, ą┐čĆąŠą┐čāčüą║ąĮą░čÅ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī ą▒ą╗ąĖąĘą║ą░ ą║ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ č鹥ąŠčĆąĄčéąĖč湥čüą║ąŠą╣. ą¤čĆąĖčćąĖąĮą░ ą▓ č鹊ą╝, čćč鹊 ąĮąĄčé ąĮąĖą║ą░ą║ąŠą╣ ą┤čĆčāą│ąŠą╣ ą░ą║čéąĖą▓ąĮąŠčüčéąĖ ąĮą░ ą▓ąĮąĄčłąĮąĄą╣ čłąĖąĮąĄ, ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ ą┤ąŠčüčéčāą┐ąŠą▓ ąĮą░ čćč鹥ąĮąĖąĄ/ąĘą░ą┐ąĖčüčī memory DMA channel 1. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ą┤ąŠčüčéčāą┐čŗ ąŠčüčāčēąĄčüčéą▓ą╗čÅčÄčéčüčÅ ą║ą░ąČą┤čŗą╣ čĆą░ąĘ ą║ č鹊ą╣ ąČąĄ čüą░ą╝ąŠą╣ čüčéčĆą░ąĮąĖčåąĄ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, čćč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĖąĘą▒ąĄąČą░čéčī čłčéčĆą░čäčŗ ąĘą░ą┤ąĄčƹȹĄą║ ąĮą░ ą┐čĆąŠą╝ą░čģąĖ ą╝ąĖą╝ąŠ č鹥ą║čāčēąĄą╣ čüčéčĆą░ąĮąĖčåčŗ. ąØą░ čćč鹥ąĮąĖąĄ ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ą▓ą╗ąĖčÅčÄčé ąĘą░ą┤ąĄčƹȹ║ąĖ CAS ąĮą░ ą║ą░ąČą┤ąŠą╝ čåąĖą║ą╗ąĄ čćč鹥ąĮąĖčÅ. ąöą╗čÅ ąĘą░ą┤ąĄčƹȹĄą║ ą┤ąŠčüčéčāą┐ą░ ąĮą░ čćč鹥ąĮąĖąĄ ąĖ ąĘą░ą┐ąĖčüčī DMA ą┐čĆąĖ ąŠą▒čĆą░čēąĄąĮąĖąĖ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ čüą╝. čéą░ą▒ą╗ąĖčåčā 2.
ą¤čĆąĖą╝ąĄčĆ 2 - ą░čāą┤ąĖąŠ/ą▓ąĖą┤ąĄąŠ čü ąŠą▒čēąĖą╝ ą┤ąŠčüčéčāą┐ąŠą╝ ą║ čäą░ą╣ą╗ą░ą╝. ąÆąŠ ą▓č鹊čĆąŠą╝ benchmark ą░ąĮą░ą╗ąĖąĘąĖčĆčāąĄčéčüčÅ čüčåąĄąĮą░čĆąĖą╣, ą▒ąŠą╗čīčłąĄ ą┐ąŠčģąŠąČąĖą╣ ąĮą░ čĆąĄą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ, ą▓ ą║ąŠč鹊čĆąŠą╝ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗą╣ ąĖąĮč鹥čĆč乥ą╣čü ą┤ą╗čÅ ą▓ą▓ąŠą┤ą░/ą▓čŗą▓ąŠą┤ą░ ą▓ąĖą┤ąĄąŠ, ą▓ą▓ąŠą┤ą░/ą▓čŗą▓ąŠą┤ą░ ą░čāą┤ąĖąŠ, ąĖ ąĮąĄą║ąŠč鹊čĆčŗą╣ ąŠą▒čēąĖą╣ ą┤ąŠčüčéčāą┐ ą║ čäą░ą╣ą╗čā č湥čĆąĄąĘ čüąĄč鹥ą▓ąŠą╣ ąĖąĮč鹥čĆč乥ą╣čü ąĖą╗ąĖ USB. ąŁč鹊čé benchmark ą▓ ąŠčüąĮąŠą▓ąĮąŠą╝ čüąŠčüč鹊ąĖčé ąĖąĘ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ąĖąĮč鹥čĆč乥ą╣čüąŠą▓ ą▓ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ čāąČąĄ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮąŠą╝čā ąŠą┤ąĖąĮąŠčćąĮąŠą╝čā ą▒ąĄąĮčćą╝ą░čĆą║čā memory DMA. ąśčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĄąĄ ąĮą░ąĘąĮą░č湥ąĮąĖąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ą┤ą╗čÅ ąĖąĮč鹥čĆč乥ą╣čüą░ čü ą▓ąĮąĄčłąĮąĖą╝ąĖ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ąĖ.
ąóą░ą▒ą╗ąĖčåą░ 6. ą¤čĆąĖą▓čÅąĘą║ą░ ą┐ąĄčĆąĖč乥čĆąĖąĖ/DMA ą┤ą╗čÅ ąĖąĮč鹥čĆč乥ą╣čüą░ čü ą▓ąĮąĄčłąĮąĖą╝ąĖ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ąĖ, ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĮčŗą╝ąĖ ą║ čüąĖčüč鹥ą╝ąĄ.
| ąÆąĮąĄčłąĮąĄąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ |
ąØą░ąĘąĮą░č湥ąĮąĮąŠąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ |
ąÜąŠąĮčéčĆąŠą╗ą╗ąĄčĆ DMA (DMAC) |
ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖąĖ |
| ąÜąŠą┤ąĄčĆ ą▓ąĖą┤ąĄąŠ |
PPI0 |
DMAC1 |
ążąŠčĆą╝ą░čé ą▓ąĖą┤ąĄąŠ ITU-656 |
| ąöąĄą║ąŠą┤ąĄčĆ ą▓ąĖą┤ąĄąŠ |
PPI1 |
DMAC1 |
|
| ąÆą▓ąŠą┤ ą░čāą┤ąĖąŠ |
SPORT0 RX |
DMAC2 |
|
| ąÆčŗą▓ąŠą┤ ą░čāą┤ąĖąŠ |
SPORT0 TX |
DMAC2 |
|
| ąŚą░ą┐ąĖčüčī čäą░ą╣ą╗ą░ ą▓ PC (ą┐ąĄčĆąĄą┤ą░čćą░ ąĖąĘ USB ą▓ ą░čüąĖąĮčģčĆąŠąĮąĮčāčÄ ą┐ą░ą╝čÅčéčī) |
MDMA1_1 |
DMAC1 |
ąŚą░ą┐ąĖčüčī ą▓ ą░čüąĖąĮčģčĆąŠąĮąĮčāčÄ ą┐ą░ą╝čÅčéčī |
| ą¤ąĄčĆąĄčüčŗą╗ą║ąĖ DMA ą┐ąŠ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ |
MDMA1_0 |
DMAC1 |
ąöą╗čÅ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ ąĖčģ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ą▓ ą┐ą░ą╝čÅčéčī L1 |
ą¦č鹊ą▒čŗ ąŠčåąĄąĮąĖčéčī č鹥čģąĮąĖą║ąĖ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ ą▓čŗčłąĄčāą║ą░ąĘą░ąĮąĮčŗąĄ čüąŠą▓ąĄčéčŗ, ą▒čŗą╗ąĖ čĆą░čüčüą╝ąŠčéčĆąĄąĮčŗ čüą╗ąĄą┤čāčÄčēąĖąĄ 4 čüčåąĄąĮą░čĆąĖčÅ ą┤ą╗čÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ:
ąĪčåąĄąĮą░čĆąĖą╣ 1: ąŠąĮ ąĮą░čüčéčĆąŠąĄąĮ čéą░ą║, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮą░ čĆąĖčü. 9. ąŁč鹊 ą▒ą░ąĘąŠą▓ą░čÅ ą╝ąŠą┤ąĄą╗čī čüčåąĄąĮą░čĆąĖčÅ, ą│ą┤ąĄ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ąĮąĖą║ą░ą║ąĖąĄ č鹥čģąĮąĖą║ąĖ ą┤ą╗čÅ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ.
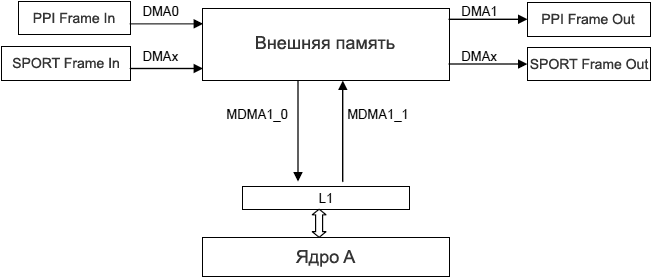
ąĀąĖčü. 9. ą¤čĆąĖą╝ąĄčĆ čüčåąĄąĮą░čĆąĖčÅ 1 (ą┐ą░ą╝čÅčéčī L2 ąĮąĄ ą┐ąŠą║ą░ąĘą░ąĮą░).
ąóą░ą▒ą╗ąĖčåą░ 7. ąÆčŗčćąĖčüą╗ąĄąĮąĖąĄ ą┐čĆąŠą┐čāčüą║ąĮąŠą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ ą┤ą╗čÅ ą▒ą░ąĘąŠą▓ąŠą│ąŠ čüčåąĄąĮą░čĆąĖčÅ 1.
| ą¤ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ |
ąĀą░ąĘą╝ąĄčĆ ą┐ą░ą║ąĄčéą░ |
ąÜąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ą░ą║ąĄč鹊ą▓, ą┐ąĄčĆąĄą┤ą░ąĮąĮčŗčģ ąĘą░ čüąĄą║čāąĮą┤čā |
MB/čüąĄą║ |
| PPI ąĮą░ ą▓ą▓ąŠą┤ (ą▓ąĖą┤ąĄąŠ NTSC, 30 ą£ąōčå) |
1716*525 = 900900 |
16 |
14 |
| PPI ąĮą░ ą▓čŗą▓ąŠą┤ (ą▓ąĖą┤ąĄąŠ NTSC, 30 ą£ąōčå) |
1716*525 = 900900 |
9 |
8 |
| MDMA |
8192 |
14 |
1 |
| SPORT0 RX/TX (4 ą£ąōčå) |
32 |
14649 |
0.1 |
| ąÆčüąĄą│ąŠ |
23 |
ąĪčåąĄąĮą░čĆąĖą╣ 2: ą┐ąĄčĆąĄą┤ą░čćąĖ Memory DMA (MDMA1_0, MDMA1_1) ą┐ąĄčĆąĄąĮąĄčüąĄąĮčŗ ąĮą░ ą▓č鹊čĆąŠą╣ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ DMA (MDMA2_0 MDMA2_1).
ąĪčåąĄąĮą░čĆąĖą╣ 3: ąŠą▒ą░ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ DMA ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ ą┐ąĄčĆąĄą┤ą░čć memory DMA.
ąĪčåąĄąĮą░čĆąĖą╣ 4: ą┤ąŠą▒ą░ą▓ą╗ąĄąĮ ąČąĄčüčéą║ąĖą╣ čåąĖą║ą╗ ą┤ąŠčüčéčāą┐ą░ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ čüąŠ čüč鹊čĆąŠąĮčŗ čÅą┤čĆą░.
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą║ą░ąĮą░ą╗čŗ MDMA ą╝ąŠą│čāčé ą┐ąĄčĆąĄąĮąŠčüąĖčéčī 32-ą▒ąĖčéąĮčŗąĄ čüą╗ąŠą▓ą░ ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī ąĮą░ ą║ą░ąČą┤ąŠą╝ čéą░ą║č鹥 SCLK, čćč鹊 ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą┤ą░ąĄčé ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčāčÄ čāčéąĖą╗ąĖąĘą░čåąĖčÄ čłąĖąĮčŗ. ąÜą░ąĮą░ą╗čŗ MDMA čĆą░ą▒ąŠčéą░čÄčé ąĮąĄą┐čĆąĄčĆčŗą▓ąĮąŠ ą▓ čĆąĄąČąĖą╝ąĄ ą░ą▓č鹊ą▒čāč乥čĆą░, čéą░ą║ čćč鹊 čāčéąĖą╗ąĖąĘąĖčĆčāčÄčé ą▓čüčÄ čüą▓ąŠą▒ąŠą┤ąĮčāčÄ ą┐ąŠą╗ąŠčüčā ą╝ąĄąČą┤čā ą┐ąĄčĆąĄą┤ą░čćą░ą╝ąĖ ą║ą░ąĮą░ą╗ąŠą▓ DMA ą┐ąĄčĆąĖč乥čĆąĖąĖ.
ąóą░ą▒ą╗ąĖčåą░ 8. ąŻą╗čāčćčłąĄąĮąĖčÅ ą┐čĆąŠą┐čāčüą║ąĮąŠą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ čü ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄą╝ čĆą░ąĘą╗ąĖčćąĮčŗčģ č鹥čģąĮąĖą║ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ ą┤ą╗čÅ čéčĆąĄčģ čĆą░ąĘą╗ąĖčćąĮčŗčģ čüčåąĄąĮą░čĆąĖąĄą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ.
ąóąĄčģąĮąĖą║ą░ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ
|
ąĪčåąĄąĮą░čĆąĖą╣ 1
|
ąĪčåąĄąĮą░čĆąĖą╣ 2
|
ąĪčåąĄąĮą░čĆąĖą╣ 3
|
| MB/čüąĄą║ |
ąŻą╗čāčćčłąĄąĮąĖąĄ |
MB/čüąĄą║ |
ąŻą╗čāčćčłąĄąĮąĖąĄ |
MB/čüąĄą║ |
ąŻą╗čāčćčłąĄąĮąĖąĄ |
| ąæą░ąĘąŠą▓ąŠąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ |
23 |
1x |
23 |
1x |
23 |
1x |
| ą©ąĖčĆąĖąĮą░ čłąĖąĮčŗ ąĖ čāą┐ą░ą║ąŠą▓ą║ą░ ą┤ą░ąĮąĮčŗčģ ąĮą░ PPI |
54 |
2.3x |
148 |
6.4x |
148 |
6.4x |
| ąŁčäč乥ą║čéąĖą▓ąĮąŠąĄ čĆą░ąĘą╝ąĄčēąĄąĮąĖąĄ ą▒ą░ąĮą║ą░ |
96 |
4.2x |
348 |
15.2x |
351 |
15.3x |
| ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čéčĆą░čäąĖą║ąŠą╝ DMA |
230 |
10x |
330 |
15x |
342 |
15.5x |
ąÜą░ą║ ą╝ąŠąČąĮąŠ čāą▓ąĖą┤ąĄčéčī ąĖąĘ čéą░ą▒ą╗ąĖčåčŗ 8, ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą┐ąŠą╗ąĮąŠą╣ ą┐ąŠą╗ąŠčüčŗ čłąĖąĮčŗ ąĖ čĆą░ąĘčĆąĄčłąĄąĮąĖąĄ čāą┐ą░ą║ąŠą▓ą║ąĖ ą╝ąŠąČąĄčé čāą╗čāčćčłąĖčéčī ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ą▓ 2.3 čĆą░ąĘą░ ą┤ą╗čÅ ą┐ąĄčĆą▓ąŠą│ąŠ čüčåąĄąĮą░čĆąĖčÅ ą▓ 6.4 čĆą░ąĘą░ ą┤ą╗čÅ ą▓č鹊čĆąŠą│ąŠ ąĖ čéčĆąĄčéčīąĄą│ąŠ čüčåąĄąĮą░čĆąĖąĄą▓. ąŁčäč乥ą║čéąĖą▓ąĮąŠąĄ čĆą░ąĘą╝ąĄčēąĄąĮąĖąĄ ą▒ą░ąĮą║ą░ ą╝ąŠąČąĄčé ą┤ą░čéčī ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ čāą╗čāčćčłąĄąĮąĖąĄ ą▓ 8 čĆą░ąĘ (15.2 - 6.4). ą¤čāč鹥ą╝ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą┐ąĄčĆąĄą┤ą░čć ą┤ą░ąĮąĮčŗčģ ą┐ąŠ ą┤ą▓čāą╝ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ą╝ DMA ą┐čĆąŠą┐čāčüą║ąĮą░čÅ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī čāą▓ąĄą╗ąĖčćąĖą╗ą░čüčī ą▓ 5 čĆą░ąĘ ą┐ąŠ čüčĆą░ą▓ąĮąĄąĮąĖčÄ čü ą▒ą░ąĘąŠą▓čŗą╝ čüčåąĄąĮą░čĆąĖąĄą╝. ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čéčĆą░čäąĖą║ąŠą╝ DMA čāą╗čāčćčłą░ąĄčé ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī, ą║ąŠą│ą┤ą░ čéčĆą░čäąĖą║ čĆą░čüą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ ąĮą░ ąŠą┤ąĮąŠą╝ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąĄ DMA (ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄčéčüčÅ ą▓ ą┐ąĄčĆą▓ąŠą╝ čüčåąĄąĮą░čĆąĖąĖ). ą¤čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ą┤ą▓čāčģ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą▓ DMA čāčéąĖą╗ąĖąĘą░čåąĖčÅ ą┐ąŠą╗ąŠčüčŗ čüčéą░ąĮąŠą▓ąĖčéčüčÅ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ č鹊ą╗čīą║ąŠ čü čāą┐ą░ą║ąŠą▓ą║ąŠą╣ čłąĖčĆąĖąĮčŗ čłąĖąĮčŗ ąĖ čŹčäč乥ą║čéąĖą▓ąĮčŗą╝ čĆą░ąĘą╝ąĄčēąĄąĮąĖąĄą╝ ą▒ą░ąĮą║ą░; čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čéčĆą░čäąĖą║ąŠą╝ ąĮąĄ ą┤ą░ąĄčé čéą░ą║ąŠąĄ ąČąĄ čāą▓ąĄą╗ąĖč湥ąĮąĖąĄ ą┐čĆąŠą┐čāčüą║ąĮąŠą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ (čüčåąĄąĮą░čĆąĖąĖ 2 ąĖ 3).
ąĀą░čüčüą╝ąŠčéčĆąĄąĮ čéą░ą║ąČąĄ 4-ą╣ čüčåąĄąĮą░čĆąĖą╣, ą│ą┤ąĄ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮ ąČąĄčüčéą║ąĖą╣ ą┤ąŠčüčéčāą┐ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ čüąŠ čüč鹊čĆąŠąĮčŗ čÅą┤čĆą░, čćč鹊 ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ čéą░ą▒ą╗ąĖčåąĄ 9.
ąóą░ą▒ą╗ąĖčåą░ 9. ąŻą╗čāčćčłąĄąĮąĖąĄ ą┐čĆąŠą┐čāčüą║ąĮąŠą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ ą┐čāč鹥ą╝ čāčüčéą░ąĮąŠą▓ą║ąĖ ą▒ąĖčéą░ CDPRIO, ą║ąŠą│ą┤ą░ čÅą┤čĆąŠ ąŠą▒čĆą░čēą░ąĄčéčüčÅ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ.
ąóąĄčģąĮąĖą║ą░ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ
|
ąĪčåąĄąĮą░čĆąĖą╣ 1
|
ąĪčåąĄąĮą░čĆąĖą╣ 4
|
| MB/čüąĄą║ |
ąŻą╗čāčćčłąĄąĮąĖąĄ |
MB/čüąĄą║ |
ąŻą╗čāčćčłąĄąĮąĖąĄ |
| ąæą░ąĘąŠą▓ąŠąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ |
23 |
1x |
21 |
1x |
| ą©ąĖčĆąĖąĮą░ čłąĖąĮčŗ ąĖ čāą┐ą░ą║ąŠą▓ą║ą░ ą┤ą░ąĮąĮčŗčģ ąĮą░ PPI |
54 |
2.3x |
52 |
2.5x |
| ąŁčäč乥ą║čéąĖą▓ąĮąŠąĄ čĆą░ąĘą╝ąĄčēąĄąĮąĖąĄ ą▒ą░ąĮą║ą░ |
96 |
4.2x |
54 |
2.6x |
| ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čéčĆą░čäąĖą║ąŠą╝ DMA |
230 |
10x |
55 |
2.6x |
| ąŻčüčéą░ąĮąŠą▓ą║ą░ CDPRIO |
230 |
10x |
195 |
9.3x |
ąÜą░ą║ ą╝ąŠąČąĮąŠ čāą▓ąĖą┤ąĄčéčī ąĖąĘ čéą░ą▒ą╗ąĖčåčŗ 9, ąČąĄčüčéą║ąĖą╣ ą┤ąŠčüčéčāą┐ čüąŠ čüč鹊čĆąŠąĮčŗ čÅą┤čĆą░ ą╝ąŠąČąĄčé ą▓ąĖčĆčéčāą░ą╗čīąĮąŠ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░čéčī čüąĖčüč鹥ą╝ąĮčāčÄ čłąĖąĮčā, čéą░ą║ čćč鹊 ą║ą░ąĮą░ą╗čŗ DMA ąĮąĄ čüą╝ąŠą│čāčé ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ čłąĖąĮąĄ. ąØąĖ ąŠą┤ąĮą░ ąĖąĘ č鹥čģąĮąĖą║ ąĮąĄ ą▒čāą┤ąĄčé čŹčäč乥ą║čéąĖą▓ąĮąŠą╣, ąĄčüą╗ąĖ DMA ąĮąĄ ą┐ąŠą╗čāčćąĖčé ą┤ąŠčüčéčāą┐ ą║ čłąĖąĮąĄ. ą¤čāč鹥ą╝ čāčüčéą░ąĮąŠą▓ą║ąĖ ą▒ąĖčéą░ CDPRIO ą┐čĆąŠą┐čāčüą║ąĮą░čÅ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī čāą▓ąĄą╗ąĖčćąĖčéčüčÅ.
[ą×čåąĄąĮą║ą░ Traffic Control Register]
ąÜą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓čŗčłąĄ, ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čéčĆą░čäąĖą║ąŠą╝ DMA (DMA traffic control) ą╝ąŠąČąĄčé ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠ čāą╗čāčćčłąĖčéčī ą┐čĆąŠą┐čāčüą║ąĮčāčÄ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī čüąĖčüč鹥ą╝čŗ, ąĮąŠ ąĄčüą╗ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▒ąŠą╗čīčłąĄ ąĘąĮą░č湥ąĮąĖčÅ ą┐ąĄčĆąĖąŠą┤ą░, č鹊 čŹč鹊 ą╝ąŠąČąĄčé ąĘą░čüčéą░ą▓ąĖčéčī ą┤čĆčāą│ąĖąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ ąČą┤ą░čéčī ą┤ą╗čÅ čüąĄą▒čÅ ą┤ą░ąĮąĮčŗąĄ ą▒ąŠą╗ąĄąĄ ą┐čĆąŠą┤ąŠą╗ąČąĖč鹥ą╗čīąĮčŗąĄ ą┐ąĄčĆąĖąŠą┤čŗ ą▓čĆąĄą╝ąĄąĮąĖ. ąØą░ą┐čĆąĖą╝ąĄčĆ ą┐čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ąĖąĮč鹥čĆč乥ą╣čüčŗ PPI0 ąĖ PPI1 ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ, čü PPI1 ą▓ čĆąĄąČąĖą╝ąĄ ą┐čĆąĖąĄą╝ą░ ąĖ PPI1 ą▓ čĆąĄąČąĖą╝ąĄ ą┐ąĄčĆąĄą┤ą░čćąĖ. ąĢčüą╗ąĖ ą┐ąĄčĆąĖąŠą┤ čéčĆą░čäąĖą║ą░ DEB ąĘą░ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮ ąĮą░ 16, č鹊 ą╗čÄą▒ąŠą╝čā ąĖąĘ PPI ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĖą┤ąĄčéčüčÅ ąŠąČąĖą┤ą░čéčī 16 ą┐ąĄčĆąĄą┤ą░čć ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ąŠąĮ ą╝ąŠąČąĄčé čüąĮąŠą▓ą░ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ čłąĖąĮąĄ. ąŁč鹊 ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ čüąĖčéčāą░čåąĖąĖ, ą║ąŠą│ą┤ą░ FIFO ąŠąČąĖą┤ą░čÄčēąĄą│ąŠ PPI ą┐ąŠą╗čāčćąĖčé ąĮąĄą┤ąŠą│čĆčāąĘą║čā ą┤ą░ąĮąĮčŗčģ (underflow) ąĖą╗ąĖ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ (overflow).
ą¦č鹊ą▒čŗ ą┐čĆąŠą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆąŠą▓ą░čéčī čŹč鹊, ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ č鹥čüč鹊ą▓čŗą╣ čüą╗čāčćą░ą╣ ą▓ čüą▓čÅąĘą░ąĮąĮąŠą╝ ZIP-čäą░ą╣ą╗ąĄ [8]. ąÆ ą┐čĆąŠąĄą║č鹥 ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą▓ą░ ą║ą░ąĮą░ą╗ą░ PPI ąĖ ą┤ą▓ą░ ą║ą░ąĮą░ą╗ą░ MDMA ąĮą░ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąĄ 1 DMA. ąÆ č鹥čüč鹊ą▓ąŠą╝ čüą╗čāčćą░ąĄ, ą║ąŠą│ą┤ą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čéčĆą░čäąĖą║ąŠą╝ ą▓čŗą║ą╗čÄč湥ąĮąŠ, čĆąĄą│ąĖčüčéčĆ čüąŠčüč鹊čÅąĮąĖčÅ PPI1 ą┐ąŠą║ą░ąČąĄčé ąŠčłąĖą▒ą║čā ąĮąĄą┤ąŠą│čĆčāąĘą║ąĖ ą┤ą░ąĮąĮčŗčģ (underflow error). ą¤čāč鹥ą╝ čāčüčéą░ąĮąŠą▓ą║ąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čéčĆą░čäąĖą║ąŠą╝ ą▓ 0x0777, ąŠčłąĖą▒ą║ą░ ąĮąĄą┤ąŠą│čĆčāąĘą║ąĖ ąĮą░ PPI1 ą▒čāą┤ąĄčé čāčüčéčĆą░ąĮąĄąĮą░, ą┐ąŠč鹊ą╝čā čćč鹊 čāą╝ąĄąĮčīčłą░čéčüčÅ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą▒ą░ąĮą║ą░. ą¦č鹊ą▒čŗ ąĄčēąĄ čāą▓ąĄą╗ąĖčćąĖčéčī ą┐čĆąŠą┐čāčüą║ąĮčāčÄ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī, čāčüčéą░ąĮąŠą▓ą║ą░ ą▒ąŠą╗ąĄąĄ ą░ą│čĆąĄčüčüąĖą▓ąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ 0x07ff čüąĮąŠą▓ą░ ą┤ą░čüčé ąŠčłąĖą▒ą║čā ąĮąĄą┤ąŠą│čĆčāąĘą║ąĖ ąĮą░ PPI1. ąŁč鹊 ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą┐ąŠč鹊ą╝čā, čćč鹊 čāą┤ąĄčƹȹ░ąĮąĖąĄ PPI1 ąĮą░ ą▒ąŠą╗čīčłąĄąĄ ą▓čĆąĄą╝čÅ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąŠąČąĖą┤ą░ąĮąĖčÄ ą┤ą░ąĮąĮčŗčģ ą▓ ąĄą│ąŠ FIFO, čćč鹊 čüą╗čāčćą░ą╣ąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝ ą▒čāą┤ąĄčé ą┤ą░ą▓ą░čéčī ąĮąĄą┤ąŠą│čĆčāąĘą║čā.
ąÜą░ą║ ąŠą▒čüčāąČą┤ą░ą╗ąŠčüčī ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ čüąĄą║čåąĖąĖ, ąŠčüąĮąŠą▓ąĮčŗą╝ ą┐čĆą░ą▓ąĖą╗ąŠą╝ ą▒čāą┤ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ ą┐ąĄčĆąĖąŠą┤ą░ čéčĆą░čäąĖą║ą░ 0x7 ą┤ą╗čÅ ą╝ąĄąĮąĄąĄ č湥ą╝ 3 ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ąĮą░ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąĄ DMA, ąĖ ą┐ąĄčĆąĖąŠą┤ čéčĆą░čäąĖą║ą░ 0x3, ą║ąŠą│ą┤ą░ 4 ąĖą╗ąĖ ą▒ąŠą╗čīčłąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ čĆą░ą▒ąŠčéą░čÄčé ąĮą░ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąĄ DMA. ąóą░ą║ąČąĄ ąĖąĮč鹥čĆąĄčüąĄąĮ č鹊čé čäą░ą║čé, čćč鹊 ą┐ąĄčĆąĖąŠą┤ čéčĆą░čäąĖą║ą░ DEB ąĖą╝ąĄąĄčé ą▒ąŠą╗čīčłąĄ ąĘąĮą░čćąĖą╝ąŠčüčéąĖ ą┤ą╗čÅ ą┐čĆąŠą┐čāčüą║ąĮąŠą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ, č湥ą╝ ą┐ąĄčĆąĖąŠą┤ čéčĆą░čäąĖą║ą░ čłąĖąĮčŗ DCB ąĖą╗ąĖ DAB, ą┐ąŠčüą║ąŠą╗čīą║čā ą▓čĆąĄą╝ąĄąĮą░ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą▒ą░ąĮą║ą░ ąĮą░ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ą┤ą░čÄčé ą▒ąŠą╗čīčłąĄ ą┐ąŠč鹥čĆčī, č湥ą╝ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ ąĮą░ ą┐ą░ą╝čÅčéąĖ L1 SRAM.
ą¤čÅčéčŗą╣ ąĖąĘ čüčéą░čĆčłąĖčģ ą▒ąĖč鹊ą▓ čĆąĄą│ąĖčüčéčĆą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čéčĆą░čäąĖą║ąŠą╝ čāą┐čĆą░ą▓ą╗čÅąĄčé ą┐ąĄčĆąĖąŠą┤ąŠą╝ round-robin MDMA. ąÉą╗ą│ąŠčĆąĖčéą╝ round-robin čāčĆą░ą▓ąĮčÅčéčī čüąŠą▓ą╝ąĄčüčéąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüčĆąĄą┤ąĖ ą║ą░ąĮą░ą╗ąŠą▓ MDMA, čéą░ą║ čćč鹊 ą║ą░ąĮą░ą╗ MDMA čü ą▒ąŠą╗čīčłąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ ąĮąĄ ąĘą░ą▒ą╗ąŠą║ąĖčĆčāąĄčé ą║ą░ąĮą░ą╗, čā ą║ąŠč鹊čĆąŠą│ąŠ ą┐čĆąĖąŠčĆąĖč鹥čé ą╝ąĄąĮčīčłąĄ. ą×ą┤ąĮą░ą║ąŠ ą▓ą▓ąĄą┤ąĄąĮąĖąĄ round-robin čüąĮąĖąČą░ąĄčé ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī DMA ąĖąĘ-ąĘą░ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĘą░ą┤ąĄčƹȹ║ąĖ ąĮą░ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą╝ąĄąČą┤čā ą║ą░ąĮą░ą╗ą░ą╝ąĖ. ąĀąĖčü. 10 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┐čĆąŠą┐čāčüą║ąĮčāčÄ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čüč湥čéčćąĖą║ą░ round-robin MDMA ą┤ą╗čÅ ą┤ą▓čāčģ ą║ą░ąĮą░ą╗ąŠą▓ MDMA, čĆą░ą▒ąŠčéą░čÄčēąĖčģ ąĮą░ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąĄ 1 DMA. ą¤čĆąŠą┐čāčüą║ąĮą░čÅ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī ąĖąĘą╝ąĄčĆčÅąĄčéčüčÅ čéą░ą║ąĖą╝ ąČąĄ čüą┐ąŠčüąŠą▒ąŠą╝, čćč鹊 ąĖ ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĖčģ 菹║čüą┐ąĄčĆąĖą╝ąĄąĮčéą░čģ.
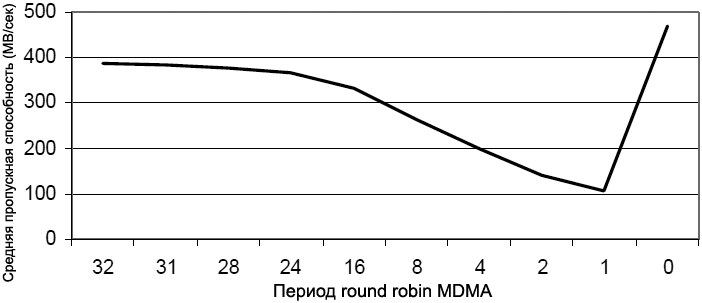
ąĀąĖčü. 10. ąŚą░ą▓ąĖčüąĖą╝ąŠčüčéčī ą┐ąĄčĆąĖąŠą┤ą░ round-robin MDMA ąĖ ą┐čĆąŠą┐čāčüą║ąĮąŠą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ.
ąÜą░ą║ ą╝ąŠąČąĮąŠ čāą▓ąĖą┤ąĄčéčī, čü čāą╝ąĄąĮčīčłąĄąĮąĖąĄą╝ čüč湥čéčćąĖą║ą░ round-robin, ą┤ąŠčüčéąĖąČąĖą╝ą░čÅ ą┐čĆąŠą┐čāčüą║ąĮą░čÅ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī čüąĖčüč鹥ą╝čŗ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ čāą╝ąĄąĮčīčłą░ąĄčéčüčÅ. ą¤čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐ąĄčĆąĖąŠą┤ą░ round-robin ąĮą░ 0 ą╝ą░ą║čüąĖą╝ąĖąĘąĖčĆčāąĄčé čāčéąĖą╗ąĖąĘą░čåąĖčÄ čüąĖčüč鹥ą╝ąĮąŠą╣ čłąĖąĮčŗ; ąŠą┤ąĮą░ą║ąŠ ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą║ą░ąĮą░ą╗ čü ą▓čŗčüąŠą║ąĖą╝ čāčĆąŠą▓ąĮąĄą╝ ą┐čĆąĖąŠčĆąĖč鹥čéą░ (MDMA1) ąĮąĄ ą┐ąŠąĘą▓ąŠą╗ąĖčé ą║ą░ąĮą░ą╗e čü čāčĆąŠą▓ąĮąĄą╝ ą┐čĆąĖąŠčĆąĖč鹥čéą░ ąĮąĖąČąĄ (MDMA2) ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ čłąĖąĮąĄ, ą┐ąŠą║ą░ ąĮąĄ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ č鹥ą║čāčēą░čÅ čéčĆą░ąĮąĘą░ą║čåąĖčÅ.
[ą×čåąĄąĮą║ą░ čüąŠąŠčéąĮąŠčłąĄąĮąĖčÅ CCLK/SCLK]
ąĪąŠąŠčéąĮąŠčłąĄąĮąĖąĄ CCLK ą║ SCLK čéą░ą║ąČąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ ą┐čĆąŠą┐čāčüą║ąĮčāčÄ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī čüąĖčüč鹥ą╝čŗ. ą¤čĆąĖčćąĖąĮą░ ą▓ č鹊ą╝, čćč鹊 č湥ą╝ ą╝ąĄąĮčīčłąĄ čéą░ą║č鹊ą▓ą░čÅ čćą░čüč鹊čéą░ čÅą┤čĆą░, č鹥ą╝ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÅ ąĖ čāą▓ąĄą╗ąĖč湥ąĮąĮčŗąĄ ąĘą░ą┤ąĄčƹȹ║ąĖ ąĮą░ čłąĖąĮą░čģ čÅą┤čĆą░ ą┐čĆąĖą▓ąĄą┤čāčé ą║ čāą╝ąĄąĮčīčłąĄąĮąĖčÄ čāčéąĖą╗ąĖąĘą░čåąĖąĖ čüąĖčüč鹥ą╝ąĮąŠą╣ čłąĖąĮčŗ. ąóą░ą▒ą╗ąĖčåą░ 10 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čŹčäč乥ą║čéčŗ ą▓ą╗ąĖčÅąĮąĖčÅ čüąŠąŠčéąĮąŠčłąĄąĮąĖčÅ CCLK/SCLK ąĮą░ ą┐čĆąŠą┐čāčüą║ąĮčāčÄ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī čüąĖčüč鹥ą╝čŗ. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗čüčÅ č鹥čüč鹊ą▓čŗą╣ čüą╗čāčćą░ą╣, ą┐ąŠą┤ąŠą▒ąĮčŗą╣ ąŠą┤ąĖąĮąŠčćąĮąŠą╝čā ą║ą░ąĮą░ą╗čā MDMA ą┤ą╗čÅ ą┐ąĄčĆąĄą┤ą░čćąĖ 8-ą║ąĖą╗ąŠą▒ą░ą╣čéąĮąŠą│ąŠ ą▒čāč乥čĆą░ DMA ą╝ąĄąČą┤čā L1 ąĖ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéčīčÄ, ąĖ 菹║čüą┐ąĄčĆąĖą╝ąĄąĮčé ą▒čŗą╗ ą┐ąŠą▓č鹊čĆąĄąĮ ą┤ą╗čÅ čĆą░ąĘąĮčŗčģ čüąŠąŠčéąĮąŠčłąĄąĮąĖą╣ CCLK/SCLK, ą┤ą╗čÅ čćč鹥ąĮąĖčÅ ąĖ ąĘą░ą┐ąĖčüąĖ ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ.
ąóą░ą▒ą╗ąĖčåą░ 10. ąÜą░ą║ ą▓ą╗ąĖčÅąĄčé čüąŠąŠčéąĮąŠčłąĄąĮąĖąĄ CCLK/SCLK ąĮą░ ą┐čĆąŠą┐čāčüą║ąĮčāčÄ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī čüąĖčüč鹥ą╝čŗ.
| ąöąŠčüčéčāą┐ DMA |
ąĪąŠąŠčéąĮąŠčłąĄąĮąĖąĄ CCLK/SCLK |
ąÜąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąĄčĆąĄą┤ą░čć ą▓ čüąĄą║čāąĮą┤čā |
ąĪčĆąĄą┤ąĮčÅčÅ ą┐čĆąŠą┐čāčüą║ąĮą░čÅ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī (ą┐ąĄčĆąĄą┤ą░čć ąĘą░ čüąĄą║čāąĮą┤čā * čĆą░ąĘą╝ąĄčĆ ą▒čāč乥čĆą░) |
% ąŠčé č鹥ąŠčĆąĄčéąĖč湥čüą║ąŠą│ąŠ ą╝ą░ą║čüąĖą╝čāą╝ą░ ą┐čĆąŠą┐čāčüą║ąĮąŠą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ (480 MB/čüąĄą║) |
| ąŚą░ą┐ąĖčüčī |
5 |
57303 |
469 |
97.71 |
| 4 |
46265 |
379 |
78.96 |
| 3 |
46265 |
379 |
78.96 |
| 2 |
33301 |
272 |
56.67 |
| 1 |
23378 |
191 |
39.79 |
| ą¦č鹥ąĮąĖąĄ |
5 |
51165 |
419 |
87.29 |
| 4 |
51165 |
419 |
87.29 |
| 3 |
51165 |
419 |
87.29 |
| 2 |
38757 |
317 |
66.04 |
| 1 |
29196 |
239 |
49.79 |
ąÜą░ą║ ą╝ąŠąČąĮąŠ čāą▓ąĖą┤ąĄčéčī, ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ąĘą░ą╝ąĄčéąĮąŠ ą┐ą░ą┤ą░ąĄčé ą┐čĆąĖ čüąŠąŠčéąĮąŠčłąĄąĮąĖąĖ CCLK/SCLK ąĮąĖąČąĄ 2:1. ą¦č鹥ąĮąĖąĄ ą╝ąĄąĮčīčłąĄ ą┐ąŠą┤ą▓ąĄčƹȹĄąĮąŠ ą┐ą░ą┤ąĄąĮąĖčÄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 ąĘą░ą┤ąĄčƹȹ║ąĖ čłąĖąĮčŗ čÅą┤čĆą░ čüą║čĆčŗą▓ą░čÄčéčüčÅ ąĖąĘ-ąĘą░ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĘą░ą┤ąĄčƹȹ║ąĖ CAS, ą║ąŠč鹊čĆą░čÅ ąĖą╝ąĄąĄčé ą╝ąĄčüč鹊 ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ąĮą░ čćč鹥ąĮąĖąĄ ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ. ąŻą╝ąĄąĮčīčłąĄąĮąĖąĄ čāčéąĖą╗ąĖąĘą░čåąĖąĖ čłąĖąĮčŗ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĖąĘ-ąĘą░ ąĘą░ą┤ąĄčƹȹĄą║ DCB, ąĮąŠ čŹč鹊 ą▒čāą┤ąĄčé čüą║čĆčŗč鹊, ąĄčüą╗ąĖ ąĄčüčéčī ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮą░čÅ ą░ą║čéąĖą▓ąĮąŠčüčéčī ąĮą░ čüąĖčüč鹥ą╝ąĮąŠą╣ čłąĖąĮąĄ, čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, DCB ąĮąĄ čÅą▓ą╗čÅąĄčéčüčÅ čāąĘą║ąĖą╝ ą╝ąĄčüč鹊ą╝.
[1] ADSP-BF533 Blackfin Processor Hardware Reference. Rev 3.2, July 2006. Analog Devices, Inc.
[2] ADSP-BF561 Blackfin Processor Hardware Reference. Rev 1.0, July 2005. Analog Devices, Inc.
[3] ADSP-BF537 Blackfin Processor Hardware Reference. Rev 2.0, December 2005. Analog Devices, Inc.
[4] Embedded Media Processing. David Katz and Rick Gentile. Newnes Publishers., Burlington, MA, USA, 2005.
[5] Video Framework Considerations for Image Processing on Blackfin Processors (EE-276). Rev 1, September 2005. Analog Devices Inc.
[6] VisualDSP++ 4.5 Device Drivers and System Services Manual for Blackfin Processors. Rev 2.0, March 2006. Analog Devices, Inc.
[ąĪčüčŗą╗ą║ąĖ]
1. System Optimization Techniques for Blackfin® Processors (EE-324) site:analog.com.
2. Blackfin ADSP-BF538.
3. ADSP-BF538: ą▒ą╗ąŠą║ ąĖąĮč鹥čĆč乥ą╣čüą░ ą▓ąĮąĄčłąĮąĄą╣ čłąĖąĮčŗ.
4. PGO Linker: ąĖąĮčüčéčĆčāą╝ąĄąĮčé čĆą░ąĘą╝ąĄčēąĄąĮąĖčÅ ą║ąŠą┤ą░ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin.
5. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą║čŹčłą░ ą▓ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ Blackfin.
6. Video Templates for Developing Multimedia Applications on Blackfin Processors (EE-301) site:analog.com.
7. The Best way to move multimedia data site:embedded.com.
8. 160118EE-324.zip - ąĖčüčģąŠą┤ąĮčŗą╣ ą║ąŠą┤ č鹥čüčéąĖčĆčāąĄą╝čŗčģ ą┐čĆąĖą╝ąĄčĆąŠą▓ ąĖ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖčÅ. |



