| Оптимизация системы на процессоре Blackfin |
|
| Добавил(а) microsin | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
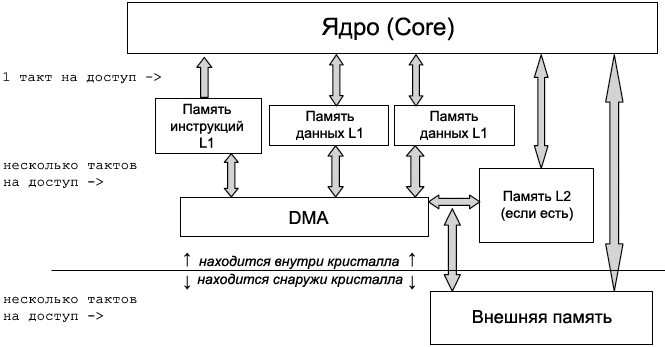
Эффективное использование ресурсов системы является критическим для разработки встраиваемых приложений, которые запрашивают широкую полосу пропускания при обработке данных. Системы часто работают в условиях нехватки быстродействия, даже если требования к полосе пропускания находятся в пределах возможности системы. Критическими факторами, часто или не часто влияющими на снижение ожидаемой скорости обработки, являются задержки доступа к внешней памяти (external memory access latencies) и не эффективное использование системных ресурсов. Чтобы полностью раскрыть возможности микроконтроллера (процессора для встраиваемых приложений), важно понимать его системную архитектуру и доступные для неё техники оптимизации. Этот EE-Note дает быстрый обзор иерархической структуры памяти процессора Blackfin® и его архитектуры системы. Документ также предоставляет практические указания по использованию техник оптимизации для эффективного использования доступных системных ресурсов, и обсуждает вопросы исследования быстродействия (benchmark), чтобы можно было оценить, насколько эффективно была применена техника оптимизации. В этой статье приведен перевод документа EE-324 компании Analog Devices [1]. Все непонятные сокращения и термины ищите в разделе Словарик статей [2, 3]. [Архитектура процессора Blackfin] В этой секции обсуждается иерархия памяти и архитектура системы. Каждая секция начинается с описания ресурса (память, системная шина, контроллеры DMA и т. д.), после чего идут рекомендации по более эффективному использованию этого ресурса. Архитектура описана больше с точки зрения перспектив ускорения обработки, с игнорированием других подробностей. За дополнительной информацией обращайтесь к документации Hardware Reference Вашего процессора, см. врезку "Список дополнительной литературы" в конце статьи (также для процессора Blackfin ADSP-BF538 см. [2, 3]). Иерархия памяти. В этой секции обсуждается иерархия памяти процессора Blackfin (рис. 1) и компромисс при выборе между встроенной памятью (L1 и L2) и внешней (external) памятью. Предоставляются также советы по эффективной привязке кода и данных к иерархии памяти, чтобы достичь минимальных задержек на доступ к памяти (memory access latencies). Описание памяти L1. Процессоры Blackfin предоставляют отдельные области памяти и данных для памяти L1. Кроме того, память данных L1 также разделены на банки: data bank A и data bank B. Для повышения быстродействия память L1 реализована как однопортовые подбанки, чтобы обеспечить одновременный доступ со стороны запрашивающих память элементов архитектуры (ядро, DMA, и т. п.). Память L1 также предоставляет SRAM и конфигурируемую память кэша, чтобы использовать в своих интересах специализированные, привязанные к приложению характеристики рабочей нагрузки. Подбанки памяти L1 для кода и данных. Память кода L1 реализована как однопортовые подбанки, которые можно эффективно использовать как двухпортовые. С этой возможностью ядро и DMA, или системные шины могут получить одновременный доступ к памяти кода L1, пока эти доступы приходятся не в один и тот же по подбанк. Подобным образом память данных L1 формирует многопортовые подбанки, что позволяет выполнить в одном цикле ядра следующие операции: • Две загрузки 32-битного генератора адреса данных (data address generator, DAG). Конфигурация L1 SRAM/кэш. По умолчанию вся память L1 сконфигурирована как SRAM, и к ней предоставлен полный доступ со стороны ядра. Память SRAM гарантирует доступ к своим ячейкам инструкции или данных за 1 цикл, и в этом случае отсутствует такое понятие, как промах кэша. Однако есть ограничение на размер доступной области памяти. Для приложений, у которых код и данные превышают по размеру область памяти L1, часть памяти L1 может быть сконфигурирована как кэш, чтобы снизить затраты времени на обращения к более медленной памяти.
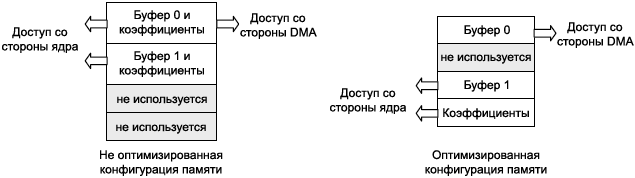
Рис. 1. Иерархия памяти процессора Blackfin. Кэшированная память может предоставить значительный выигрыш для выполнения кода и доступа к данных, когда кэш привязана к L2 или внешней памяти. Быстродействие кэша зависит от характеристик времени и пространства приложения. Недостаток использования памяти для кэша в том, что скорость доступа страдает в случае промахов кэша (когда нужная информация не содержится в кэше), что увеличивает требования к пропускной способности доступа к внешней памяти. Также для стриминга данных строки кэша должны быть сделаны недостоверными, когда новые данные передаются во внешнюю память. Перевод строк кэша в недостоверное состояние дорог по задержкам и может значительно снизить быстродействие. Ниже будут рассмотрены указания по улучшению эффективности использования памяти L1. Как ускорить быстродействие с помощью подбанков. Как уже упоминалось, конкуренция по одновременному доступу может произойти только если ядро и DMA пытаются обратиться к одному и тому же подбанку памяти. На рис. 2 показан сценарий, в котором можно избежать конкурентного доступа, если более эффективно распределить объекты данных в памяти L1.
Рис. 2. Эффективное использование внутренней многопортовой архитектуры подбанков. Использование L1 только как SRAM. Если удастся втиснуть и код, и данные в L1 SRAM, то это предоставит самые низкие задержки при доступе к памяти. Если общие требования а размеру кода и данных превышают имеющийся в наличии размер L1 SRAM, то к памяти L1 следует привязать тот код, который выполняется наиболее часто, и те данные, к которым чаще всего происходит обращение. Чтобы эффективно привязать код к L1 SRAM, используйте автоматизированный инструмент PGO linker tool, описанный в EE-306 [4]. Размещение данных все еще должно быть сделано вручную программистом, хотя некоторые техники будут также предложены в следующих секциях. Память L1 SRAM может быть также использована для привязки кода и элементов данных, которые критичны к реальному времени выполнения, поскольку память SRAM предоставляет гарантированный доступ за 1 цикл для всех запросов к памяти. Кэшированная память страдает от промахов, так что нет предсказуемого времени доступа к запрашиваемому коду или элементу данных. Это может быть критичным для удовлетворения требований программы системы, привязанной к реальному времени. Использование L1 как SRAM и как кэш. Если размер кода приложения больше, чем область L1 SRAM инструкций, то использование кэша инструкций может уменьшить латентность доступа к памяти более высокого уровня. В инструментарии VisualDSP++ 4.5 может быть включено использование кэша в диалоге настроек свойств проекта (Project Options), либо путем соответственного определения константы _cplb_ctrl в исходном файле проекта. Подробнее про использование кэша процессоров Blackfin см. руководство EE-271 [5]. Проект, где показан пример использования кэша, находится в каталоге установки VisualDSP++ (VisualDSP++ 4.5/Blackfin/Examples/ADSP-BF533 EZ-Kit Lite/Cache/). Процессоры Blackfin также представляют альтернативные способы более эффективного размещения кода и данных в иерархии памяти. Система DMA может быть использована для обслуживания кода и данных вместо механизма кэша. При использовании DMA код и данные могут быть загружены заранее перед использованием, что следовательно может позволить избежать промахов кэша и потери циклов при переводе строки кэша в недостоверное состояние. DMA также позволяет осуществлять фоновые пересылки данных по памяти без участия ядра, что сохраняет такты ядра для выполнения полезных действий. Однако использование DMA увеличивает время разработки и может быть сложным для приложений, которые осуществляют нерегулярный или случайный доступ к данным и коду. Использование DMA для уменьшения промахов кэша. Чтобы эффективно использовать DMA, важно знать поведение программы и используемые шаблоны доступа к данным. Управление кодом и данных полностью попадает в зону ответственности программиста; таким образом, возрастает ожидаемое время разработки приложения. Чтобы понять выполнимость использования DMA для управления объектами данных и получить более подробное описание преимуществ DMA перед использованием кэша, обратитесь к руководству EE-301 [6]. Также по достоинствам и недостаткам вариантов при выборе компромисса "кэш или DMA" см. статью [7]. [Описание L2 SRAM] Память уровня L2 процессора Blackfin можно использовать только как память SRAM. Время доступа к L2 больше, чем к L1, но предоставляется быстродействие лучше, чем для доступа к памяти SDRAM, подключенной к кристаллу процессора снаружи. Обратите внимание, что память L2 имеется в наличии только на процессорах ADSP-BF561 и ADSP-BF54x Blackfin. Таблица 1 показывает быстродействие памяти L2 в единицах тактов ядра (core clock cycles, CCLK) и/или тактов системы (system clock cycles, SCLK). Таблица 1. Быстродействие памяти L2.
Как использовать L2 SRAM. L2 SRAM можно использовать для привязки данных, которые не умещаются в память L1 SRAM. Если используется двухядерный процессор ADSP-BF561, то область памяти L2 может использоваться как общая для обмена объектами данных между ядрами. Память L2 также организована как многопортовые подбанки. Такая организация позволяет одновременный доступ к памяти L2 со стороны ядра и DMA, если они осуществляют доступ к разным подбанкам. [Описание внешней памяти SDRAM] Для процессоров ADSP-BF561 Blackfin контроллер SDRAM (SDC) поддерживает банк памяти SDRAM шириной шины данных 16 или 32 бита. Для процессоров ADSP-BF53x и ADSP-BF52x, контроллер SDC поддерживает банки SDRAM шириной 16 бит. Память SDRAM может перемещать свои данные с максимальной частотой шины SCLK 133 МГц. Контроллер SDC предоставляет прозрачный интерфейс к стандартным микросхемам памяти SDRAM с 4 внутренними банками памяти, и позволяет доступ к банкам с чередованием (interleaved bank memory access). Требуется логика арбитража для одновременного доступа к внешней памяти со стороны ядра и DMA. В этой секции подробно рассматривается быстродействие SDRAM и её деление на банки. Деление SDRAM на банки. У стандартных устройств памяти SDRAM есть внутренние банки памяти. Чтобы воспользоваться достоинствами деления на банки SDRAM, контроллер SDC поддерживает доступы к банкам памяти с чередованием (interleaved memory bank access). Интерфейс SDC поддерживает до 4 внутренних банка памяти. Внутренний адрес банка SDRAM состоит из адресов строки. Внутренние банки поделены на набор страниц памяти, которые конфигурируются с помощью регистров управления SDC. Количество страниц определяется установками конфигурации SDRAM и размером внутреннего банка. Контроллер SDC в любой момент времени может держать открытой только одну страницу в пределах каждого внутреннего банка. Открытие закрытой страницы во внутреннем банке требует выдачи команд pre-charge и activation. Это SDC контроллер делает автоматически, без участия программиста, но на выдачу команд тратятся такты SCLK. Доступ к открытой странице памяти называется доступом в пределах одной страницы (on-page access). Этот доступ самый быстрый, потому что не требуется выдача команд pre-charge или activation. Если осуществляется доступ к закрытой странице, то такой доступ называется доступом с переключением страниц (off-page access), и он получает дополнительную задержку на циклы, требуемые для выдачи команд pre-charge и activation. Чтобы увеличить скорость доступа к SDRAM, важно минимизировать доступы с переключением страниц. Быстродействие SDRAM. В таблице 2 приведено быстродействие SDRAM при доступе в пределах одной страницы (on-page access). Таблица 2. Скорость доступа к внешней памяти для обращения к слову на странице (* 32-бита для процессоров ADSP-BF56x, 16-бит для процессоров ADSP-BF53x и ADSP-BF52x).
В таблице 3 показано быстродействие SDRAM при доступе с переключением страниц (off-page access). Таблица 3. Скорость доступа к внешней памяти для обращения к слову вне текущей страницы (* 32-бита для процессоров ADSP-BF56x, 16-бит для процессоров ADSP-BF53x и ADSP-BF52x).
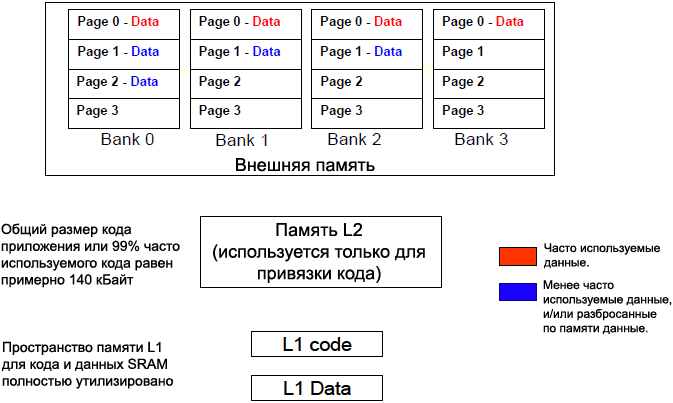
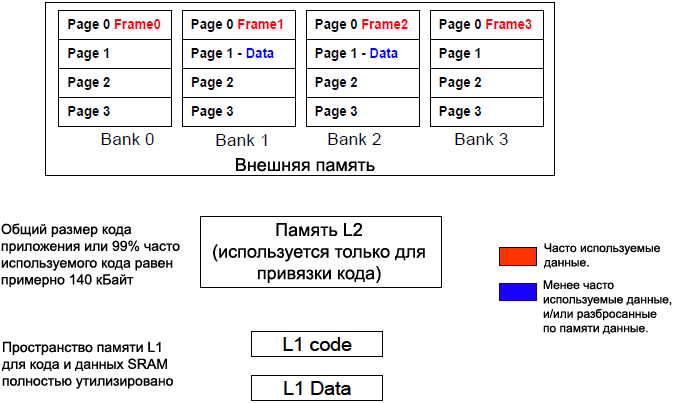
Обозначения в таблице 3: tRP задержка между командой предзаряда (pre-charge) и командой активации (1-7 такта SCLK). [Как эффективно использовать SDRAM] Латентность доступа при переключении между страницами выше, когда код и данные размещены случайным образом, с пересечением через границы страниц внутреннего банка памяти. Чтобы минимизировать переключение страниц, привяжите блоки с часто используемым кодом и данными к одной и той же странице внутреннего банка памяти. Чтобы дополнительно получить выигрыш от возможности одновременного открытия 4 страниц на разных банках памяти SDRAM, лучше всего распределить часто используемый код на 4 страницы памяти, и распределить эти страницы каждую в отдельный внутренний банк. Если трудно определить частоту обращений к областям кода и данных приложения (обычно это осуществляется с помощью профайлинга приложения), то разработчик приложения может оценить следующие компромиссные решения, которые можно использовать в планировании приложения. 1. Еще труднее измерить и использовать пространственные характеристики для смеси инструкций и данных. Чтобы уменьшить усилия на программирование, в определенных случаях память L2 и внешнюю память можно использовать для разделения между собой области кода и области данных. Например, если код приложения (или наиболее часто используемый код) может быть полностью привязан к памяти L1 или L2, то вся внешняя память получается доступной для привязки к ней только объектов данных. Привязка данных только к внешней памяти предоставляет улучшение управления и предсказуемости для доступа к внешней памяти. Однако следует обратить внимание на то, что компромисс здесь сделан в сторону увеличения времени доступа к данным. На рис. 3 показан пример такого распределения памяти.
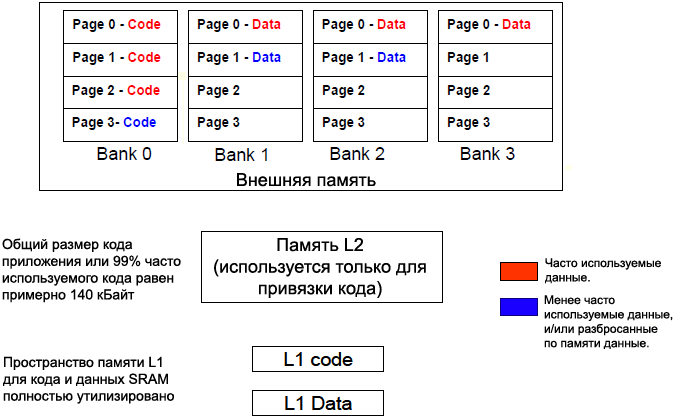
Рис. 3. Использование внешней памяти только для данных. 2. Внешняя память может быть поделена так, что код и данные попадут в разные внутренние банки памяти. Это полезно, если перетекание кода из памяти L1 и L2 может быть привязано к таким часто используемым областям кода, которые не пересекают границы страницы внутреннего банка. На рис. 4 показан пример такого распределения памяти.
Рис. 4. Размещение кода в пределах только одной страницы внутреннего банка SDRAM. 3. Обычно для обслуживания периферийных устройств поддерживается несколько буферов данных. Эти буферы можно привязать к отдельным внутренним банкам. На рис. 5 показан пример такого распределения памяти. См. также даташит EE-301 [6] для поиска альтернативных путей управления несколькими буферами данных.
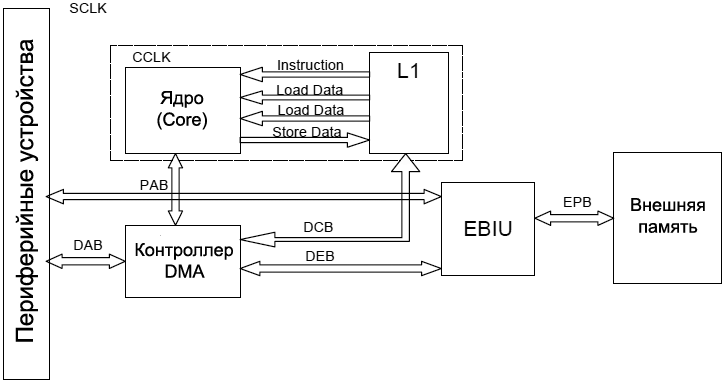
Рис. 5. Распределение буферов фрейма по 4 разным внутренним банкам SDRAM. Другие советы. Обычно часто используемый код и данные разбросаны по большому интервалу области памяти. Таким образом можно сформировать секции кода и данных, к которым часто осуществляется доступ, разделить его на 4 части каждую по размеру страницы, и отобразить каждую из этих частей на отдельную страницу в каждом внутреннем банке. Другая возможность ускорить доступ состоит в том, чтобы попытаться избежать прямого доступа к внешней памяти со стороны ядра. Доступ на чтение со стороны DAG, как показано в таблице 2, занимает 8 тактов SCLK, что может привести к высоким затратам полосы пропускания даже при обращении к малым порциям данных во внешней памяти. Таким образом, используйте кэш или DMA для доступа к объектам, привязанным к внешней памяти. [Архитектура системы] В этой секции рассматривается архитектура системы процессора Blackfin, которая включает системные шины, контроллеры DMA, периферийные устройства и арбитр внешней шины, и предоставляются указания по оптимизации их использования. Обратите внимание, что обсуждение делается только с точки зрения производительности, и игнорирует другие подробности. Ниже рассмотрены системные шины, подключенные к каналам DMA, периферийным устройствам и ядру. Шина доступа к периферийным устройствам (Peripheral Access Bus, PAB). Шина PAB соединяет все периферийные устройства, находящиеся вне ядра, с системными регистрами MMR. Доступы на чтение и запись регистров по шине PAB дают задержки на 3 и 2 такта SCLK соответственно. Шины DMA. Для процессора ADSP-BF561 следующие шины DMA соединяют периферийные устройства и иерархию памяти. • Шины доступа DMA (32-битная DAB1 и 16-битная DAB2, аббревиатура DAB расшифровывается как DMA Access Bus) предоставляет передачи данных DMA в периферийные устройства и из периферийных устройств. • Шины DMA ядра (32-битные DCB1, DCB2, DCB3 и DCB4, аббревиатура DCB расшифровывается как DMA Core Bus) предоставляет передачу данных DMA между ядром (A и B) и памятью L1, или передачи данных DMA между уровнями памяти L1 и L2. • Внешняя шина DMA (DMA External Bus, DEB) предоставляет передачи данных для обмена с внешней памятью (обычно это SDRAM). Задержки в перемещении данных между периферийными устройствами и памятью составляют 2 такта SCLK для выборок доступа до 32 бит, хотя периферийное устройство может получить доступ к шине каждый такт SCLK для утилизации полной доступной полосы пропускания. Перемещения между разными уровнями памяти могут быть осуществлены с задержкой в один такт SCLK для каждого 32-битного слова. Для перемещений между уровнями памяти L1 и L2 слова шириной 32 бита могут быть переданы в каждом такте CCLK. В таблице 4 перечислено быстродействие для передач DMA типа память-память между разными уровнями иерархии памяти. Таблица 4. Производительность шин DMA для передач типа память-память.
Для процессоров ADSP-BF53x и ADSP-BF52x следующие шины DMA соединяют периферийные устройства и иерархии уровней памяти: • Шины доступа DMA (16-битный DAB, аббревиатура DAB расшифровывается как DMA Access Bus) предоставляют передачи DMA между периферийными устройствами и памятью. Быстродействие и латентность передач для процессоров ADSP-BF53x остались такими же, как для процессора ADSP-BF561, но максимальный размер слова составляет 16 бит для каждого такта SCLK.
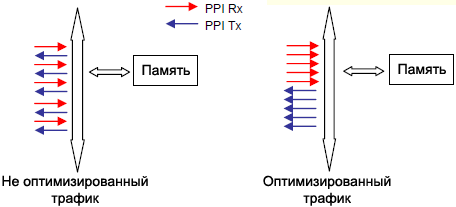
Рис. 6. Внутренняя структура шины для процессоров ADSP-BF53x/ADSP-BF52x Blackfin. Для процессоров ADSP-BF561 здесь имеется 2 ядра, 2 контроллера DMA, и блок памяти L2. [Шина доступа к внешней памяти EAB] Шина доступа к внешней памяти (External Access Bus, EAB) позволяет ядру получить прямой доступ к памяти, находящейся вне чипа. Для двухядерных процессоров ADSP-BF561 можно выполнить передачи 8-, 16- или 32-битных слов на каждый такт SCLK. Для процессоров ADSP-BF53x можно выполнить передачи 8- или 16-битных слов на каждый такт SCLK. EAB работает с максимальной частотой 133 МГц. [Как эффективно использовать EAB] Утилизация максимальной полосы пропускания шины и упаковка на стороне периферийного устройства. Пропускную способность системы можно значительно увеличить путем использования максимума полосы шины для каждой передачи. Если использовать 32-битный доступ DMA для процессора ADSP-BF561, и 16-битный доступ DMA для процессоров ADSP-BF53x/ADSP-BF52x в комбинации с упаковкой данных (если такая возможность есть у периферийного устройства), то это может освободить системные шины для других активностей, что таким образом значительно увеличит пропускную способность системы. Например, порт PPI предоставляет 32-битную упаковку для процессоров ADSP-BF561 и 16-битную упаковку для процессоров ADSP-BF53x/ADSP-BF52x. Управление трафиком DMA. Процессоры Blackfin предоставляют управление трафиком для всех системных шин. Если трафик на шине слишком часто меняет свое направление, то это приведет к увеличению задержек из-за времени переключения банка. Использование регистров управления трафиком является одним из лучших способов оптимизации трафика на шине, вследствие чего улучшится использование полосы пропускания шины. Период трафика для каждой шины DMA можно указать для группы передач в одном направлении, чем уменьшаются времена переключения банка. На рис. 7 показан оптимизированный трафик через шину DAB.
Рис. 7. Оптимизация трафика DMA между системными шинами. Рисунок 8 показывает регистр управления трафиком DMA (DMA traffic control register). Каждая из шин может быть запрограммирована для группирования до 16 перемещений данных в одном направлении. Также каналы DMA для памяти могут быть запрограммированы для приоритезации типа round-robin (карусельная динамическая приоритезация) с использованием регистра управления трафиком. Значения для периода трафика должны быть оценены на базе имеющегося приложения, в зависимости от количества периферийных устройств и количества трафика шины в системе. Как основное правило: значение периода трафика, близкое к 3, является оптимальным, когда 4 или большее количество периферийных устройств работают с контроллером DMA, и значение близкое к 7 будет оптимальным в случае, где 3 периферийных устройства или меньше используются с контроллером DMA. Также обратите внимание, что значение периода трафика для DEB сильнее всего влияет на быстродействие системы; таким образом, это значение должно быть подобрано наиболее тщательно. Еще следует иметь в виду, что чем меньше значение для round-robin периода для memory DMA, тем меньше пропускная способность передач DMA, так как контроллер переключается между каналами DMA через каждые несколько слов. Обычно для большинства приложений большие значения балансируют производительность с эквивалентным совместным использованием общих ресурсов.
Рис. 8. DMA traffic control register. MDMA_ROUND_ROBIN_PERIOD[4:0]. Это битовое поле задает максимальную длину передач MDMA round robin. Если не 0, любой поток MDMA, которому дан доступ, будет разрешено произвести указанное в этом поле количество передач DMA, приостанавливая остальные потоки MDMA. DAB_TRAFFIC_PERIOD[2:0]. 000 - не выполняется Выбор соотношения частот CCLK/SCLK. На быстродействие шин влияет соотношение между частотами ядра и системы. На соотношениях порядка 2.5:1 задержки синхронизации и процесса конвейеризации приведут к снижению утилизации полосы пропускания шины в домене тактовой частоты системы. Например, при соотношении частот тактов 2:1 обычно DMA работает на частоте 2/3 от частоты тактов системной шины. Полная полоса пропускания может быть достигнута при повышении соотношения частот ядро/система. [Архитектура DMA] Контроллер DMA распределяет активность DMA между интерфейсом периферийных устройств и памятью, находящейся как внутри чипа процессора, так и снаружи. Несколько каналов DMA периферийных устройств и каналов DMA для памяти конкурируют друг с другом при доступе к ресурсам памяти. Задержки доступа уменьшаются при разделении шин для доступа на канале DMA периферийных устройств (шина DAB) и доступа память-ядро (шина DCB). Также каждое периферийное устройство снабжено собственным буфером FIFO, который еще уменьшает латентность по сравнении с полностью конвейеризированным доступом периферия-память передач DMA. Передача DMA может быть инициирована в нескольких режимах: stop, auto-buffer, descriptor, и т. п. Для получения дополнительной информации обратитесь к разделу DMA в аппаратном руководстве по Вашему процессору (Hardware Reference manual). В режиме DMA с дескрипторами контроллер DMA вычитывает содержимое дескрипторов из объектов дескриптора и загружает их в регистры канала DMA. Дескриптор или массив дескрипторов могут скрыть причину дополнительной задержки, если забыть про то, что объекты дескриптора также находятся в памяти, и необходимы задержки на доступ к этой памяти при MMR-записях в регистры DMA. У процессоров ADSP-BF561 имеется 2 контроллера DMA, в то время как у процессоров ADSP-BF53x есть только один. Для процессоров, у которых больше одного контроллера DMA, каждый контроллер DMA подключен к двум раздельным шинам; таким образом, пересылки можно распределить между контроллерами DMA, чтобы повысить пропускную способность. Таким образом, чтобы повысить эффективность использования DMA, старайтесь придерживаться следующих советов: 1. Приоритезация периферийных устройств с высокими скоростями переноса данных улучшает пропускную способность. Измените назначения по умолчанию для периферийных устройств, присвоенные контроллерам DMA, используя регистр привязки периферийных устройств DMA (DMA peripheral map register). 2. Если имеется в наличии больше одного контроллера DMA, распределение передач между контроллерами DMA может уменьшить требования к полосе пропускания системы. 3. Использование автобуфера или режима дескриптора может сохранить такты системной частоты. [Арбитр шины] EBIU производит арбитраж между ядром и DMA при их доступе к внешней памяти. Перед арбитражем политики для доступа с адресацией внешней памяти, важно заметить, когда запрос DMA классифицируется системой как срочный (urgent DMA). Urgent DMA. Рассмотрим следующий сценарий, где канал периферийного устройства принимает данные из внешнего устройства. Когда периферийное устройство принимает данные (и осуществляется запись этих данных в память), если FIFO периферийного устройства заполнен, и DMA не может получить доступ к шине для записи содержимого FIFO в память, скорее всего произойдет переполнение буфера и как следствие потеря принимаемых данных. В этой ситуации выдается запрос urgent DMA. Обычно, чтобы защититься от переполнения буфера, запросы urgent DMA будут выдаваться при передаче из периферийного устройства (что соответствует чтению памяти), если стек FIFO периферийного устройства пуст, и DMA не может получить доступ к шине для чтения из памяти, чтобы заполнить FIFO. Для обоих вышеописанных ситуаций контроллером DMA автоматически выдается запрос urgent DMA, так что вмешательство пользователя не требуется. На процессорах ADSP-BF534 / BF536 / BF537, если запрос DMA становится urgent, все ожидающие запросы DMA в системе помечаются как. Для процессоров ADSP-BF531 / BF532 / BF533 и процессоров ADSP-BF561 ожидающие запросы не переключаются в состояние urgent, когда порождается urgent-запрос. Чтобы на этих процессорах перевести все ожидающие запросы в состояние urgent, может быть установлен бит CDPRIO в регистре EBIU_AMGCTL, который более подробно описан в следующей секции. Схема арбитража. Для доступов к внешней памяти по умолчанию запросы urgent DMA имеют наивысший приоритет, затем следуют запросы ядра и затем запросы DMA. Эта схема приоритетов программируется для доступов к внешней памяти, что буде рассматриваться в руководствах следующей секции. Для памяти L1 и L2 запросы DMA и ядра следуют фиксированному арбитражу. Для доступов к внутренней памяти арбитраж требуется, только если доступы DMA и ядра осуществляются в тот же самый подбанк памяти. Если доступ происходит в один и тот же подбанк, то по умолчанию DMA выигрывает перед ядром. Для заблокированных доступов ядра DMA будет ожидать, пока заблокированный доступ не завершится. Как лучше всего проводить разработку: для доступов к внешней памяти запросы ядра имеют приоритет выше, чем запросы DMA. Это может несколько ухудшить пропускную способность, если имеется несколько запросов ядра к внешней памяти. Этого можно избежать, путем преобразования всех доступов DMA в доступы urgent DMA, этим все доступы DMA получают более высокий приоритет, чем доступы ядра. Это можно осуществить установкой бита CDPRIO или бита DMAPRIO в регистре EBIU_AMGCTL. [Другие общие советы по программированию] Теоретическая оценка общей полосы, требуемой для приложения, может предоставить хорошую начальную точку для изучения возможности реализации системы с точки зрения полосы пропускания. В случаях, когда ресурсы системы используются не эффективно, может произойти недогрузка (underflow) или переполнение (overflow) буфера, даже если утилизировано меньше 20% от максимальной теоретической полосы системы. Часто ошибки недогрузки/переполнения буфера периферийного устройства становятся не выявляемыми даже при значительных усилиях, прилагаемых в отладке. Путем использования прерываний ошибки, поддерживаемых процессорами Blackfin, можно определить, работает ли система вне полосы пропускания. В регистрах статуса периферийных устройств есть информация об ошибках переполнения или недогрузки. Имейте в виду, что прерывания ошибки по умолчанию не включены. На всех процессорах Blackfin по умолчанию прерывания ошибки привязаны к IVG7. Пользователь отвечает за то, чтобы в обработчике прерывания ошибки определить, какое периферийное устройство вызвало ошибку. Прерывания ошибки могут быть разрешены в приложении аналогично разрешению других векторов прерывания. Обработчик прерывания должен специально проверить регистры статуса всех периферийных устройств системы, чтобы точно определить источник ошибки. [Техники оптимизации системы] Можно обобщить ранее упомянутые техники: 1. Техники оптимального размещения кода и данных Здесь будут рассмотрены эти техники, и каждая в определенных условиях тестирования. Техники прогрессивно добавляются к ситуации тестирования, и на каждом шаге добавления оценивается полоса пропускания системы. Обратите внимание, что техника оптимального размещения кода и данных описана в EE-306 [4] и EE-301 [6] соответственно, поэтому в этом документе это не рассматривается. [Методология оценки эффективности] Чтобы оценить полосу пропускания системы, синтезированы 2 теста на быстродействие (benchmark). Первый benchmark - простая программа, которая выполняет только чтения и записи внешней памяти с помощью DMA; для этого benchmark не разрешена никакая другая активность на системной шине. Второй benchmark - более сложная программа с несколькими каналами DMA для памяти, каналами DMA для периферии, и активностью ядра в системе; этот benchmark используется для демонстрации выигрышей обсуждаемых техник оптимизации. В следующей части этого анализа, отдельно рассматриваются эффекты установки регистра управления трафиком и выбора соотношения CCLK/SCLK при утилизации полосы пропускания. Цель этого анализа - показать, как может быть прогрессивно улучшена производительность системы при использовании различных техник оптимизации. Чтобы квалифицировать эффекты, была выбрана средняя пропускная способность в качестве метрики оценки техник оптимизации. Средняя пропускная способность системы (average system throughput, ASR) вычислялась как количество чтений или записей данных в секунду (NRW) по формуле: ASR = (NRW)/sec Интервал времени для активности системной шины конфигурируется с использованием внутреннего таймера ядра (core timer). Таймер настроен так, что генерирует прерывание каждую секунду. Таймер запускается сразу перед разрешением каналов периферии/MDMA, и затем каналы периферии/MDMA запрещаются внутри ISR таймера ядра. Количество переданных данных измеряется по значению счетчиков в ISR периферийных устройств. Прерывание генерируется на каждой передаче буфера, и счетчик инкрементируется каждый раз, кода вызывается ISR периферии /MDMA. Поскольку все каналы периферийных устройств и каналы MDMA работают в режиме автобуфера, для конечных вычислений пропускной способности не нужно учитывать задержку, вносимую прерыванием от периферийного устройства. Бенчмарки тестировались на процессоре ADSP-BF561, но полученные результаты также будут применимы и для всех процессоров Blackfin, если не было специально замечено нечто другое. [Анализ полосы пропускания системы] В этой секции обсуждаются 2 бенчмарка: простой пример memory DMA (пересылка в памяти, MDMA), и реалистичный тест, соответствующий встраиваемому приложению, реализующему ввод/вывод видео и аудио и совместное использование файловой системы. Пример 1 - Memory DMA. В этом benchmark буферы перемещаются между памятью L1 и внешней памятью с использованием одной пары каналов memory DMA. Размер буфера DMA составляет 8 килобайт, и частоты CCLK и SCLK установлены на значения 600 и 120 МГц соответственно. Таблица 5 показывает анализ пропускной способности для доступов к SDRAM. Обратите внимание, что здесь в системе работает только один канал memory DMA, и к внешней памяти не делается обращений со стороны периферийных устройств или ядра. Таблица 5. Пропускная способность для доступов на чтение и запись со стороны DMA к внешней памяти.
Канал memory DMA используется в режиме автобуфера, и работает без перерыва в этом режиме, пока не истечет таймер ядра. В этом benchmark не используются техники оптимизации системы. Однако, как показано в таблице 5, пропускная способность близка к максимальной теоретической. Причина в том, что нет никакой другой активности на внешней шине, за исключением доступов на чтение/запись memory DMA channel 1. Кроме того, доступы осуществляются каждый раз к той же самой странице внешней памяти, что позволяет избежать штрафы задержек на промахи мимо текущей страницы. На чтение из внешней памяти влияют задержки CAS на каждом цикле чтения. Для задержек доступа на чтение и запись DMA при обращении к внешней памяти см. таблицу 2. Пример 2 - аудио/видео с общим доступом к файлам. Во втором benchmark анализируется сценарий, больше похожий на реальное приложение, в котором используется периферийный интерфейс для ввода/вывода видео, ввода/вывода аудио, и некоторый общий доступ к файлу через сетевой интерфейс или USB. Этот benchmark в основном состоит из дополнительных интерфейсов в дополнение к уже установленному одиночному бенчмарку memory DMA. Используется следующее назначение периферийных устройств для интерфейса с внешними устройствами. Таблица 6. Привязка периферии/DMA для интерфейса с внешними устройствами, подключенными к системе.
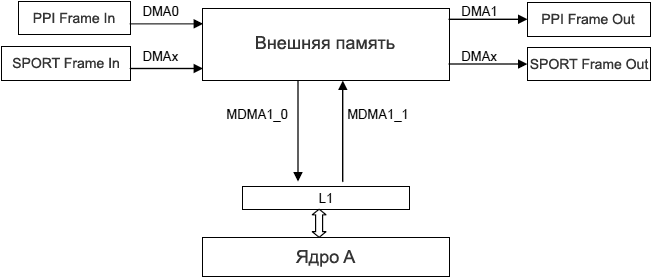
Чтобы оценить техники оптимизации вышеуказанные советы, были рассмотрены следующие 4 сценария для приложения: Сценарий 1: он настроен так, как показано на рис. 9. Это базовая модель сценария, где не используются никакие техники для оптимизации.
Рис. 9. Пример сценария 1 (память L2 не показана). Таблица 7. Вычисление пропускной способности для базового сценария 1.
Сценарий 2: передачи Memory DMA (MDMA1_0, MDMA1_1) перенесены на второй контроллер DMA (MDMA2_0 MDMA2_1). Сценарий 3: оба контроллера DMA используются для передач memory DMA. Сценарий 4: добавлен жесткий цикл доступа к внешней памяти со стороны ядра. Обратите внимание, что каналы MDMA могут переносить 32-битные слова во внешнюю память на каждом такте SCLK, что в результате дает максимальную утилизацию шины. Каналы MDMA работают непрерывно в режиме автобуфера, так что утилизируют всю свободную полосу между передачами каналов DMA периферии. Таблица 8. Улучшения пропускной способности с применением различных техник оптимизации для трех различных сценариев приложения.
Как можно увидеть из таблицы 8, использование полной полосы шины и разрешение упаковки может улучшить производительность в 2.3 раза для первого сценария в 6.4 раза для второго и третьего сценариев. Эффективное размещение банка может дать дополнительно улучшение в 8 раз (15.2 - 6.4). Путем распределения передач данных по двум контроллерам DMA пропускная способность увеличилась в 5 раз по сравнению с базовым сценарием. Управление трафиком DMA улучшает производительность, когда трафик распределяется на одном контроллере DMA (демонстрируется в первом сценарии). При использовании двух контроллеров DMA утилизация полосы становится максимальной только с упаковкой ширины шины и эффективным размещением банка; таким образом, добавление управления трафиком не дает такое же увеличение пропускной способности (сценарии 2 и 3). Рассмотрен также 4-й сценарий, где добавлен жесткий доступ к внешней памяти со стороны ядра, что показано в таблице 9. Таблица 9. Улучшение пропускной способности путем установки бита CDPRIO, когда ядро обращается к внешней памяти.
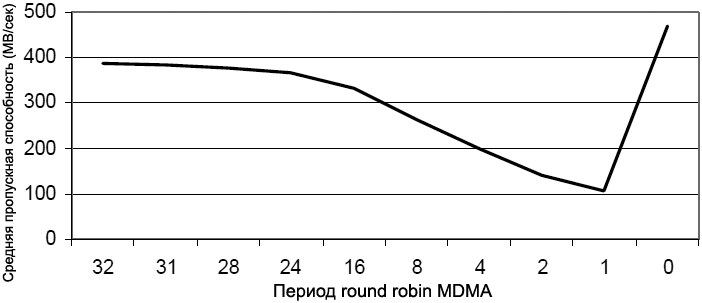
Как можно увидеть из таблицы 9, жесткий доступ со стороны ядра может виртуально заблокировать системную шину, так что каналы DMA не смогут получить доступ к шине. Ни одна из техник не будет эффективной, если DMA не получит доступ к шине. Путем установки бита CDPRIO пропускная способность увеличится. [Оценка Traffic Control Register] Как показано выше, использование управления трафиком DMA (DMA traffic control) может значительно улучшить пропускную способность системы, но если использовать больше значения периода, то это может заставить другие периферийные устройства ждать для себя данные более продолжительные периоды времени. Например предположим, что интерфейсы PPI0 и PPI1 используются в приложении, с PPI1 в режиме приема и PPI1 в режиме передачи. Если период трафика DEB запрограммирован на 16, то любому из PPI может быть придется ожидать 16 передач перед тем, как он может снова получить доступ к шине. Это может привести к ситуации, когда FIFO ожидающего PPI получит недогрузку данных (underflow) или переполнение (overflow). Чтобы продемонстрировать это, используется тестовый случай в связанном ZIP-файле [8]. В проекте используются два канала PPI и два канала MDMA на контроллере 1 DMA. В тестовом случае, когда управление трафиком выключено, регистр состояния PPI1 покажет ошибку недогрузки данных (underflow error). Путем установки управления трафиком в 0x0777, ошибка недогрузки на PPI1 будет устранена, потому что уменьшатся переключения направления банка. Чтобы еще увеличить пропускную способность, установка более агрессивного значения 0x07ff снова даст ошибку недогрузки на PPI1. Это произойдет потому, что удержание PPI1 на большее время приведет к ожиданию данных в его FIFO, что случайным образом будет давать недогрузку. Как обсуждалось в предыдущей секции, основным правилом будет использование значения периода трафика 0x7 для менее чем 3 периферийных устройств на контроллере DMA, и период трафика 0x3, когда 4 или большее количество периферийных устройств работают на контроллере DMA. Также интересен тот факт, что период трафика DEB имеет больше значимости для пропускной способности, чем период трафика шины DCB или DAB, поскольку времена переключения направления банка на внешней памяти дают больше потерь, чем переключения на памяти L1 SRAM. Пятый из старших битов регистра управления трафиком управляет периодом round-robin MDMA. Алгоритм round-robin уравнять совместное использование среди каналов MDMA, так что канал MDMA с большим приоритетом не заблокирует канал, у которого приоритет меньше. Однако введение round-robin снижает производительность DMA из-за дополнительной задержки на переключение между каналами. Рис. 10 показывает пропускную способность в зависимости от счетчика round-robin MDMA для двух каналов MDMA, работающих на контроллере 1 DMA. Пропускная способность измеряется таким же способом, что и в предыдущих экспериментах.
Рис. 10. Зависимость периода round-robin MDMA и пропускной способности. Как можно увидеть, с уменьшением счетчика round-robin, достижимая пропускная способность системы соответственно уменьшается. Программирование периода round-robin на 0 максимизирует утилизацию системной шины; однако в этом случае канал с высоким уровнем приоритета (MDMA1) не позволит каналe с уровнем приоритета ниже (MDMA2) получить доступ к шине, пока не завершится текущая транзакция. [Оценка соотношения CCLK/SCLK] Соотношение CCLK к SCLK также влияет на пропускную способность системы. Причина в том, что чем меньше тактовая частота ядра, тем синхронизация и увеличенные задержки на шинах ядра приведут к уменьшению утилизации системной шины. Таблица 10 показывает эффекты влияния соотношения CCLK/SCLK на пропускную способность системы. Использовался тестовый случай, подобный одиночному каналу MDMA для передачи 8-килобайтного буфера DMA между L1 и внешней памятью, и эксперимент был повторен для разных соотношений CCLK/SCLK, для чтения и записи при доступе к внешней памяти. Таблица 10. Как влияет соотношение CCLK/SCLK на пропускную способность системы.
Как можно увидеть, производительность заметно падает при соотношении CCLK/SCLK ниже 2:1. Чтение меньше подвержено падению производительности, потому что задержки шины ядра скрываются из-за дополнительной задержки CAS, которая имеет место при доступе на чтение из внешней памяти. Уменьшение утилизации шины происходит из-за задержек DCB, но это будет скрыто, если есть дополнительная активность на системной шине, таким образом, DCB не является узким местом. [1] ADSP-BF533 Blackfin Processor Hardware Reference. Rev 3.2, July 2006. Analog Devices, Inc. [2] ADSP-BF561 Blackfin Processor Hardware Reference. Rev 1.0, July 2005. Analog Devices, Inc. [3] ADSP-BF537 Blackfin Processor Hardware Reference. Rev 2.0, December 2005. Analog Devices, Inc. [4] Embedded Media Processing. David Katz and Rick Gentile. Newnes Publishers., Burlington, MA, USA, 2005. [5] Video Framework Considerations for Image Processing on Blackfin Processors (EE-276). Rev 1, September 2005. Analog Devices Inc. [6] VisualDSP++ 4.5 Device Drivers and System Services Manual for Blackfin Processors. Rev 2.0, March 2006. Analog Devices, Inc. [Ссылки] 1. System Optimization Techniques for Blackfin® Processors (EE-324) site:analog.com. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||