ąÆ čŹč鹊ą╣ čćą░čüčéąĖ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ č鹊 ąĮąŠą▓ąŠąĄ ą▓ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠą╝ API ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čü ą╝ąĮąŠą│ąŠčÅą┤ąĄčĆąĮčŗą╝ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ą╝ąĖ, ą║ąŠč鹊čĆąŠąĄ ą┐ąŠčÅą▓ąĖą╗ąŠčüčī ą▓ ą▓ąĄčĆčüąĖąĖ Framework 4.0:
ŌĆó Parallel LINQ ąĖą╗ąĖ PLINQ.
ąŁč鹊 API čéą░ą║ąČąĄ ąĖąĘą▓ąĄčüčéąĮąŠ ą║ą░ą║ PFX (Parallel Framework, ą░ą▒ą▒čĆąĄą▓ąĖą░čéčāčĆą░ ąśą£ąźą× ąĮąĄčüą║ąŠą╗čīą║ąŠ ąŠčłąĖą▒ąŠčćąĮą░čÅ). ąÜą╗ą░čüčü Parallel ą▓ą╝ąĄčüč鹥 čü ą║ąŠąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ą░ ąĘą░ą┤ą░čć ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąŠą╣ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗčģ ąĘą░ą┤ą░čć, ąĖą╗ąĖ TPL (Task Parallel Library).
Framework 4.0 čéą░ą║ąČąĄ ą┤ąŠą▒ą░ą▓ąĖą╗ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĮąĖąĘą║ąŠčāčĆąŠą▓ąĮąĄą▓čŗčģ ą║ąŠąĮčüčéčĆčāą║čåąĖą╣ ą┤ą╗čÅ ą┐ąŠč鹊ą║ąŠą▓, ą║ąŠč鹊čĆčŗąĄ ą▓čŗą┐ąŠą╗ąĮčÅčÄčé čéčĆą░ą┤ąĖčåąĖąŠąĮąĮčŗąĄ ą┤ą╗čÅ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠčüčéąĖ ąĘą░ą┤ą░čćąĖ. ą£čŗ ąĖčģ čāąČąĄ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ą╗ąĖ čĆą░ąĮąĄąĄ [5]:
ŌĆó ąÜąŠąĮčüčéčĆčāą║čåąĖąĖ čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖąĖ čü ą╝ą░ą╗čŗą╝ąĖ ąĘą░ą┤ąĄčƹȹ║ą░ą╝ąĖ (low-latency signaling constructs) SemaphoreSlim, ManualResetEventSlim, CountdownEvent ąĖ Barrier.
ąöą╗čÅ ą║ąŠą╝č乊čĆčéąĮąŠą│ąŠ ą┐ąŠąĮąĖą╝ą░ąĮąĖčÅ ą┐ąĄčĆąĄą┤ ą┤ą░ą╗čīąĮąĄą╣čłąĖą╝ čćč鹥ąĮąĖąĄą╝ ąČąĄą╗ą░č鹥ą╗čīąĮąŠ ąŠąĘąĮą░ą║ąŠą╝ąĖčéčīčüčÅ čü čćą░čüčéčÅą╝ąĖ 1..4 ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ [2, 3, 4, 5] - ą▓ čćą░čüčéąĮąŠčüčéąĖ ą┤ą╗čÅ ąĖąĘčāč湥ąĮąĖčÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║ (locking) ąĖ ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéąĖ čüąŠą▓ą╝ąĄčüčéąĮąŠą╣ čĆą░ą▒ąŠčéčŗ ą┐ąŠč鹊ą║ąŠą▓ (thread safety).
ąÆčüąĄ ą╗ąĖčüčéąĖąĮą│ąĖ ą║ąŠą┤ą░ čüąĄą║čåąĖą╣ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą│ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ąŠčüčéčāą┐ąĮčŗ ą║ą░ą║ ąĖąĮč鹥čĆą░ą║čéąĖą▓ąĮčŗąĄ ą┐čĆąĖą╝ąĄčĆčŗ ą▓ LINQPad [6]. LINQPad čŹč鹊 菹╗ąĄą║čéčĆąŠąĮąĮčŗą╣ ą▒ą╗ąŠą║ąĮąŠčé, ąĖą┤ąĄą░ą╗čīąĮąŠ ą┐ąŠą┤čģąŠą┤čÅčēąĖą╣ ą┤ą╗čÅ ą┐čĆąŠą▓ąĄčĆą║ąĖ ą▒ą╗ąŠą║ąŠą▓ ą║ąŠą┤ą░ C# ą▒ąĄąĘ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ čüąŠąĘą┤ą░ąĮąĖčÅ ąŠą║čĆčāąČą░čÄčēąĄą│ąŠ ą║ą╗ą░čüčüą░, ą┐čĆąŠąĄą║čéą░ ąĖą╗ąĖ čĆąĄčłąĄąĮąĖčÅ (ąĖą╝ąĄąĄčéčüčÅ ą▓ ą▓ąĖą┤čā čüčĆąĄą┤ą░ Microsoft Visual Studio). ąöą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐čĆąĖą╝ąĄčĆą░ą╝ ą║ą╗ąĖą║ąĮąĖč鹥 ąĮą░ "Download More Samples" ąĘą░ą║ą╗ą░ą┤ą║ąĖ " ąĮą░ ąĘą░ą║ą╗ą░ą┤ą║ąĄ" ą▓ LINQPad, ąĮą░čģąŠą┤čÅčēąĄą╣čüčÅ čüą╗ąĄą▓ą░ ą▓ąĮąĖąĘčā, ąĖ ą▓čŗą▒ąĄčĆąĖč鹥 "C# 4.0 in a Nutshell: More Chapters".
[ą¤ąŠč湥ą╝čā PFX? ]
ąÆ ą┐ąŠčüą╗ąĄą┤ąĮąĄąĄ ą▓čĆąĄą╝čÅ čéą░ą║č鹊ą▓čŗąĄ čćą░čüč鹊čéčŗ CPU ą┐ąĄčĆąĄčüčéą░ą╗ąĖ čĆą░čüčéąĖ, ąĖ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗ąĖ ą┐ąĄčĆąĄą║ą╗čÄčćąĖą╗ąĖčüčī čāą▓ąĄą╗ąĖč湥ąĮąĖąĄ ą┐čĆąŠčåąĄčüčüąŠčĆąĮčŗčģ čÅą┤ąĄčĆ. ąŁč鹊 čüąŠąĘą┤ą░ą╗ąŠ ąĮąĄą║ąŠč鹊čĆčāčÄ ą┐čĆąŠą▒ą╗ąĄą╝čā ą┤ą╗čÅ ąĮą░čü ą║ą░ą║ ą┤ą╗čÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüč鹊ą▓, ą┐ąŠč鹊ą╝čā čćč鹊 čüčéą░ąĮą┤ą░čĆčéąĮčŗą╣ ąŠą┤ąĮąŠą┐ąŠč鹊čćąĮčŗą╣ ą║ąŠą┤ ąĮąĄ ą▒čāą┤ąĄčé ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ čĆą░ą▒ąŠčéą░čéčī ą▒čŗčüčéčĆąĄąĄ ąĖąĘ-ąĘą░ čāą▓ąĄą╗ąĖč湥ąĮąĖčÅ čćąĖčüą╗ą░ čÅą┤ąĄčĆ.
ąŚą░ą┤ąĄą╣čüčéą▓ąŠą▓ą░ąĮąĖąĄ ą╝ąĮąŠą│ąĖčģ čÅą┤ąĄčĆ ą┐čĆąŠčēąĄ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ą▓ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ čüąĄčĆą▓ąĄčĆąĮčŗčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣, ą│ą┤ąĄ ą║ą░ąČą┤čŗą╣ ą┐ąŠč鹊ą║ ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ ąŠčé ą┤čĆčāą│ąĖčģ ą┐ąŠč鹊ą║ąŠą▓ čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ą┤ ąŠą▒čĆą░ą▒ąŠčéą║ąŠą╣ ąŠčéą┤ąĄą╗čīąĮąŠą│ąŠ ąĘą░ą┐čĆąŠčüą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ, ąĮąŠ čüą╗ąŠąČąĮąĄąĄ č鹊 ąČąĄ čüą░ą╝ąŠąĄ čüą┤ąĄą╗ą░čéčī ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ ą┤ąĄą║čüč鹊ą┐ą░ - ą┐ąŠč鹊ą╝čā čćč鹊 čŹč鹊 ąŠą▒čŗčćąĮąŠ čéčĆąĄą▒čāąĄčé ąŠčé ąĮą░ą│čĆčāąČąĄąĮąĮąŠą│ąŠ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅą╝ąĖ ą║ąŠą┤ą░ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čüą╗ąĄą┤čāčÄčēąĖčģ čäčāąĮą║čåąĖą╣:
1 . ąĀą░ąĘą▒ąĖąĄąĮąĖąĄ ą▓čüąĄą╣ ą▓čŗčćąĖčüą╗ąĖč鹥ą╗čīąĮąŠą╣ ąĘą░ą┤ą░čćąĖ ąĮą░ ą╝ą░ą╗čŗąĄ čćą░čüčéąĖ.2 . ąŚą░ą┐čāčüą║ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą╣ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čŹčéąĖčģ čćą░čüč鹥ą╣ čü ą┐ąŠą╝ąŠčēčīčÄ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠčüčéąĖ.3 . ąĪąŠą▒čĆą░čéčī ą▓čüąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ čĆą░ą▒ąŠčéčŗ ą▓ą╝ąĄčüč鹥, ą║ąŠą│ą┤ą░ ąŠąĮąĖ čüčéą░ąĮčāčé ą┤ąŠčüčéčāą┐ąĮčŗ.
ą¤ąŠčüą╗ąĄą┤ąĮąĄąĄ ąĮčāąČąĮąŠ čüą┤ąĄą╗ą░čéčī čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊ą▒čŗ ąĮąĄ ą┐ąŠą▓čĆąĄą┤ąĖčéčī čüąŠą▓ą╝ąĄčüčéąĮąŠą╣ čĆą░ą▒ąŠč鹥 ą┐ąŠč鹊ą║ąŠą▓ ąĮąĖ čü č鹊čćą║ąĖ ąĘčĆąĄąĮąĖčÅ ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéąĖ ąĖ čāčüč鹊ą╣čćąĖą▓ąŠčüčéąĖ (thread-safe), ąĮąĖ čü č鹊čćą║ąĖ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ. ąźąŠčéčÅ ąÆčŗ ą╝ąŠąČąĄč鹥 čüą┤ąĄą╗ą░čéčī ą▓čüąĄ čŹč鹊 ą║ą╗ą░čüčüąĖč湥čüą║ąĖą╝ąĖ ą║ąŠąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠčüčéąĖ, čŹč鹊 ą▒čāą┤ąĄčé ą│čĆčāą▒čŗą╝ ą┐ąŠą┤čģąŠą┤ąŠą╝ - ą▓ čćą░čüčéąĮąŠčüčéąĖ ąĮą░ čłą░ą│ą░čģ čĆą░ąĘą┤ąĄą╗ąĄąĮąĖčÅ ąŠą▒čēąĄą╣ ąĘą░ą┤ą░čćąĖ ąĮą░ čćą░čüčéąĖ ąĖ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĄą╣ čüą▒ąŠčĆą║ąĖ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ čĆą░ą▒ąŠčéčŗ ą┐ąŠč鹊ą║ąŠą▓. ąöčĆčāą│ą░čÅ ą┐čĆąŠą▒ą╗ąĄą╝ą░ ą▓ č鹊ą╝, čćč鹊 ąŠą▒čŗčćąĮą░čÅ čüčéčĆą░č鹥ą│ąĖčÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą┤ą╗čÅ ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéąĖ ą┐ąŠč鹊ą║ąŠą▓ ą▓čŗąĘčŗą▓ą░ąĄčé ą▒ąŠą╗čīčłčāčÄ ą║ąŠąĮą║čāčĆąĄąĮčåąĖčÄ ą┐ąŠč鹊ą║ąŠą▓, ą║ąŠą│ą┤ą░ ą╝ąĮąŠą│ąŠ ą┐ąŠč鹊ą║ąŠą▓ čĆą░ą▒ąŠčéą░čÄčé ąĮą░ą┤ ąŠą┤ąĮąĖą╝ąĖ ąĖ č鹥ą╝ąĖ ąČąĄ ą┤ą░ąĮąĮčŗą╝ąĖ čüčĆą░ąĘčā.
ąæąĖą▒ą╗ąĖąŠč鹥ą║ąĖ PFX čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮčŗ čüą┐ąĄčåąĖą░ą╗čīąĮąŠ ą┤ą╗čÅ č鹊ą│ąŠ, čćč鹊ą▒čŗ ą┐ąŠą╝ąŠčćčī ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░čéčī ą▓ čŹčéąĖčģ čüčåąĄąĮą░čĆąĖčÅčģ.
ą¤čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ čü čåąĄą╗čīčÄ ąĘą░ą┤ąĄą╣čüčéą▓ąŠą▓ą░ąĮąĖčÅ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čÅą┤ąĄčĆ ąĖą╗ąĖ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄą╝. ąŁč鹊 ą┐ąŠą┤ą╝ąĮąŠąČąĄčüčéą▓ąŠ ą▒ąŠą╗ąĄąĄ čłąĖčĆąŠą║ąŠą╣ ą║ąŠąĮčåąĄą┐čåąĖąĖ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠčüčéąĖ.
ąÜąŠąĮčåąĄą┐čåąĖąĖ PFX . ąĪčāčēąĄčüčéą▓čāąĄčé 2 čüčéčĆą░č鹥ą│ąĖąĖ ą┤ą╗čÅ čĆą░ąĘą┤ąĄą╗ąĄąĮąĖčÅ ąŠą▒čēąĄą╣ čĆą░ą▒ąŠčéčŗ ą╝ąĄąČą┤čā ą┐ąŠč鹊ą║ą░ą╝ąĖ: ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ ą┤ą░ąĮąĮčŗčģ (data parallelism) ąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ ąĘą░ą┤ą░čć (task parallelism).
ąÜąŠą│ą┤ą░ ąĮą░ą▒ąŠčĆ ąĘą░ą┤ą░čć ąĮčāąČąĮąŠ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąĮą░ ą╝ąĮąŠą│ąĖčģ ąĘąĮą░č湥ąĮąĖčÅčģ ą┤ą░ąĮąĮčŗčģ, ą╝čŗ ą╝ąŠąČąĄą╝ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖčéčī ą▓čüčÄ ąĘą░ą┤ą░čćčā čéą░ą║, čćč鹊ą▒čŗ ą║ą░ąČą┤čŗą╣ ą┐ąŠč鹊ą║ ą▓čŗą┐ąŠą╗ąĮčÅą╗ (ąŠą┤ąĖąĮą░ą║ąŠą▓čŗą╣) ąĮą░ą▒ąŠčĆ ą┤ąĄą╣čüčéą▓ąĖą╣ ąĮą░ą┤ ą┐ąŠą┤ą╝ąĮąŠąČąĄčüčéą▓ąŠą╝ ąĘąĮą░č湥ąĮąĖą╣. ąóą░ą║ąŠą╣ ą┐ąŠą┤čģąŠą┤ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ data parallelism, ą┐ąŠč鹊ą╝čā čćč鹊 ą╝čŗ čĆą░čüą┐čĆąĄą┤ąĄą╗čÅąĄą╝ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄą╝čŗąĄ ą┤ą░ąĮąĮčŗąĄ ą╝ąĄąČą┤čā ą┐ąŠč鹊ą║ą░ą╝ąĖ. ąÆ ąŠčéą╗ąĖčćąĖąĄ ąŠčé čŹč鹊ą│ąŠ task parallelism ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ čĆą░ąĘąĮčŗą╝ąĖ ą┐ąŠč鹊ą║ą░ą╝ąĖ čĆą░ąĘąĮčŗčģ ąĘą░ą┤ą░čć; ą┤čĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ą║ą░ąČą┤čŗą╣ ą┐ąŠč鹊ą║ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ąŠčéą╗ąĖčćą░čÄčēąĖą╣ ąŠčé ą┤čĆčāą│ąĖčģ ą┐ąŠč鹊ą║ąŠą▓ ą░ą╗ą│ąŠčĆąĖčéą╝ ą┤ąĄą╣čüčéą▓ąĖą╣.
ąÆ ąŠą▒čēąĄą╝ čüą╗čāčćą░ąĄ data parallelism ą┐čĆąŠčēąĄ čĆąĄą░ą╗ąĖąĘčāąĄčéčüčÅ ąĖ ą╗čāčćčłąĄ ą╝ą░čüčłčéą░ą▒ąĖčĆčāąĄčéčüčÅ ą┤ą╗čÅ ą┐ąŠą▓čŗčłąĄąĮąĖčÅ ą║ąŠą╗ąĖč湥čüčéą▓ą░ čÅą┤ąĄčĆ, ą┐ąŠč鹊ą╝čā čćč鹊 čéą░ą║ąŠą╣ ą┐ąŠą┤čģąŠą┤ čüąĮąĖąČą░ąĄčé ąĖą╗ąĖ ą▓ąŠą▓čüąĄ čāą▒ąĖčĆą░ąĄčé čĆą░ą▒ąŠčéčā ą┐ąŠč鹊ą║ąŠą▓ ąĮą░ą┤ ąŠą▒čēąĖą╝ąĖ ą┤ą░ąĮąĮčŗą╝ąĖ (ą▒ą╗ą░ą│ąŠą┤ą░čĆčÅ č湥ą╝čā čüąĮąĖąČą░ąĄčéčüčÅ ą║ąŠąĮą║čāčĆąĄąĮčåąĖčÅ ą┐ąŠč鹊ą║ąŠą▓ ąĖ ą╗ąĄą│č湥 čĆąĄčłą░čéčī ą┐čĆąŠą▒ą╗ąĄą╝čŗ thread-safety). ąóą░ą║ąČąĄ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ ą┤ą░ąĮąĮčŗčģ čāčüąĖą╗ąĖą▓ą░ąĄčé č鹊čé čäą░ą║čé, čćč鹊 čćą░čēąĄ ąĄčüčéčī ą▒ąŠą╗čīčłąĄ ąĘąĮą░č湥ąĮąĖą╣ ą┤ą░ąĮąĮčŗčģ, č湥ą╝ ą║ą░ą║ąĖčģ-č鹊 ą┤ąĖčüą║čĆąĄčéąĮčŗčģ ąĘą░ą┤ą░čć, čćč鹊 čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčé ą┐ąŠč鹥ąĮčåąĖą░ą╗ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ą░.
ą¤ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ ą┤ą░ąĮąĮčŗčģ čéą░ą║ąČąĄ čüą┐ąŠčüąŠą▒čüčéą▓čāąĄčé čüčéčĆčāą║čéčāčĆąĖčĆąŠą▓ą░ąĮąĮąŠą╝čā ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝čā, čćč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗąĄ ąĄą┤ąĖąĮąĖčåčŗ ąŠą▒čēąĄą╣ čĆą░ą▒ąŠčéčŗ ąĘą░ą┐čāčüą║ą░čÄčéčüčÅ ąĖ ąĘą░ą▓ąĄčĆčłą░čÄčéčüčÅ ą▓ ąŠą┤ąĮąŠą╝ ąĖ č鹊ą╝ ąČąĄ ą╝ąĄčüč鹥 ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ąÆ ąŠčéą╗ąĖčćąĖąĄ ąŠčé čŹč鹊ą│ąŠ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ ąĘą░ą┤ą░čć ąĖą╝ąĄąĄčé č鹥ąĮą┤ąĄąĮčåąĖčÄ ą▒čŗčéčī ąĮąĄ čüčéčĆčāą║čéčāčĆąĖčĆąŠą▓ą░ąĮąĮčŗą╝, čŹč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 菹╗ąĄą╝ąĄąĮčéčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą╣ čĆą░ą▒ąŠčéčŗ ą╝ąŠą│čāčé ąĮą░čćą░čéčīčüčÅ ąĖ ąĘą░ą▓ąĄčĆčłąĖčéčīčüčÅ ą▓ ą╝ąĄčüčéą░čģ, čĆą░čüčüąĄčÅąĮąĮčŗčģ ą┐ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ. ąĪčéčĆčāą║čéčāčĆąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ ą┐čĆąŠčēąĄ, ą╝ąĄąĮčīčłąĄ ą┐ąŠą┤ą▓ąĄčƹȹĄąĮ ąŠčłąĖą▒ą║ą░ą╝, ąĖ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąÆą░ą╝ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī čéčĆčāą┤ąĮąŠąĄ ąĘą░ą┤ą░ąĮąĖąĄ čĆą░ąĘą┤ąĄą╗ąĄąĮąĖčÅ ąĖ ą║ąŠąŠčĆą┤ąĖąĮą░čåąĖčÄ ą┐ąŠč鹊ą║ąŠą▓ (ąĖ ą┤ą░ąČąĄ čäąĖąĮą░ą╗čīąĮąŠąĄ čüąŠą┐ąŠčüčéą░ą▓ą╗ąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░č鹊ą▓) ąĖąĘ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║.
ąÜąŠą╝ą┐ąŠąĮąĄąĮčéčŗ PFX . PFX ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé ą┤ą▓ą░ čüą╗ąŠčÅ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéąĖ. ąÆąĄčĆčģąĮąĖą╣ čüą╗ąŠą╣ čüąŠčüč鹊ąĖčé ąĖąĘ ą┤ą▓čāčģ ą▓ąĖą┤ąŠą▓ data parallelism API: ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░ PLINQ ąĖ ą║ą╗ą░čüčü Parallel. ąØąĖąČąĮąĖą╣ čüą╗ąŠą╣ čüąŠą┤ąĄčƹȹĖčé ą║ą╗ą░čüčüčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ą░ ąĘą░ą┤ą░čć, ą┐ą╗čÄčü ąĮą░ą▒ąŠčĆ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ą║ąŠąĮčüčéčĆčāą║čåąĖą╣, čćč鹊ą▒čŗ ą┐ąŠą╝ąŠčćčī čü ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄą╝.
PLINQ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čüą░ą╝čŗą╣ ą▒ąŠą│ą░čéčŗą╣ čäčāąĮą║čåąĖąŠąĮą░ą╗: ą░ą▓č鹊ą╝ą░čéąĖąĘą░čåąĖčÅ ą▓čüąĄčģ čłą░ą│ąŠą▓ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖąĖ, ą▓ą║ą╗čÄčćą░čÅ čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ čĆą░ą▒ąŠčéčŗ ąĮą░ ąĘą░ą┤ą░čćąĖ, ąĘą░ą┐čāčüą║ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ čŹčéąĖčģ ąĘą░ą┤ą░čć ą▓ ą┐ąŠč鹊ą║ą░čģ ąĖ ą║ąŠąĮąĄčćąĮąŠąĄ čüąŠą┐ąŠčüčéą░ą▓ą╗ąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ą▓ ąŠą┤ąĮčā ą▓čŗčģąŠą┤ąĮčāčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī. ą×ąĮą░ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ ą┤ąĄą║ą╗ą░čĆą░čéąĖą▓ąĮąŠą╣ - ą┐ąŠč鹊ą╝čā čćč鹊 ąÆčŗ ą┐čĆąŠčüč鹊 ą┤ąĄą║ą╗ą░čĆąĖčĆčāąĄč鹥, čćč鹊 čģąŠčéąĖč鹥 čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖčéčī čüą▓ąŠčÄ čĆą░ą▒ąŠčéčā (čćč鹊 čüčéčĆčāą║čéčāčĆąĖčĆčāąĄč鹥 ą║ą░ą║ ąĘą░ą┐čĆąŠčü LINQ), ąĖ ą┐ąŠąĘą▓ąŠą╗čÅąĄč鹥 ą┐ą╗ą░čéč乊čĆą╝ąĄ ą┐ąŠąĘą░ą▒ąŠčéąĖčéčīčüčÅ ąŠ ą┤ąĄčéą░ą╗čÅčģ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ. ąÆ ąŠčéą╗ąĖčćąĖąĄ ąŠčé čéą░ą║ąŠą│ąŠ ą┐ąŠą┤čģąŠą┤ą░ ą┤čĆčāą│ąŠą╣ ą▓ą░čĆąĖą░ąĮčé čĆą░ą▒ąŠčéčŗ ąĖą╝ą┐ąĄčĆą░čéąĖą▓ąĮčŗą╣, ąĘą┤ąĄčüčī ąÆą░ą╝ ąĮčāąČąĮąŠ čüą┐ąĄčåąĖą░ą╗čīąĮąŠ ąĮą░ą┐ąĖčüą░čéčī ą║ąŠą┤ ą┤ą╗čÅ čĆą░ąĘą┤ąĄą╗ąĄąĮąĖčÅ ąĘą░ą┤ą░čćąĖ ąĮą░ čćą░čüčéąĖ ąĖ čüąŠą┐ąŠčüčéą░ą▓ą╗ąĄąĮąĖčÅ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ. ąÆ čüą╗čāčćą░ąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą║ą╗ą░čüčüą░ Parallel ąÆčŗ ą┤ąŠą╗ąČąĮčŗ čüąŠą▒čĆą░čéčī čĆąĄąĘčāą╗čīčéą░čéčŗ čĆą░ą▒ąŠčéčŗ ą┐ąŠč鹊ą║ąŠą▓ čüą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮąŠ; čü ą║ąŠąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ą░ ąĘą░ą┤ą░čć ąÆčŗ ą┤ąŠą╗ąČąĮčŗ čéą░ą║ąČąĄ čüą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮąŠ čĆą░ąĘą┤ąĄą╗ąĖčéčī čĆą░ą▒ąŠčéčā ąĮą░ čćą░čüčéąĖ:
ąĀąĄčłąĄąĮąĖąĄ ą┤ą╗čÅ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖąĖ ąĀą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ ąŠą▒čēąĄą╣ ąĪą▓ąĄą┤ąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░č鹊ą▓
PLINQ
ąöąÉ
ąöąÉ
ąÜą╗ą░čüčü Parallel
ąöąÉ
ąĮąĄčé
ą¤ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ ąĘą░ą┤ą░čć PFX
ąĮąĄčé
ąĮąĄčé
ąÜąŠą╗ą╗ąĄą║čåąĖąĖ ą║ąŠąĮą║čāčĆąĄąĮčåąĖąĖ (concurrent collections) ąĖ ą┐čĆąĖą╝ąĖčéąĖą▓čŗ čåąĖą║ą╗ąŠą▓ ąŠą┐čĆąŠčüą░ (spinning primitives) ą┐ąŠą╝ąŠą│čāčé ąÆą░ą╝ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ąĮą░ ąĮąĖąĘą║ąŠą╝ čāčĆąŠą▓ąĮąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ ą┐ąŠ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą╝čā ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÄ ąŁč鹊 ą▓ą░ąČąĮąŠ, ą┐ąŠč鹊ą╝čā čćč鹊 PFX ą▒čŗą╗ą░ čüą┐čĆąŠąĄą║čéąĖčĆąŠą▓ą░ąĮą░ ą┤ą╗čÅ čĆą░ą▒ąŠčéčŗ č鹊ą╗čīą║ąŠ ąĮą░ čüąĄą│ąŠą┤ąĮčÅčłąĮąĄą╣ ą░ą┐ą┐ą░čĆą░čéčāčĆąĄ, ąĮąŠ čéą░ą║ąČąĄ ą╝ąŠąČąĄčé ą┐ąŠčéčĆąĄą▒ąŠą▓ą░čéčīčüčÅ čĆą░ą▒ąŠčéą░čéčī čü ą▒čāą┤čāčēąĖą╝ąĖ ą╝ąŠą┤ąĄą╗čÅą╝ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓, ą│ą┤ąĄ ąĄčüčéčī ąĮą░ą╝ąĮąŠą│ąŠ ą▒ąŠą╗čīčłąĄ čÅą┤ąĄčĆ. ąĢčüą╗ąĖ ąÆčŗ čģąŠčéąĖč鹥 ą┐ąĄčĆąĄą╝ąĄčüčéąĖčéčī ą║čāčćčā ąĮą░ą┐ąĖą╗ąĄąĮąĮąŠą╣ ą┤čĆąĄą▓ąĄčüąĖąĮčŗ, ąĖą╝ąĄčÅ 32 čĆą░ą▒ąŠčćąĖčģ, č鹊 čüą░ą╝ą░čÅ ą▒ąŠą╗čīčłą░čÅ čéčĆčāą┤ąĮąŠčüčéčī ą┐čĆąĖ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĖ ą┤čĆąĄą▓ąĄčüąĖąĮčŗ čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, čćč鹊ą▒čŗ čŹčéąĖ čĆą░ą▒ąŠčćąĖąĄ ąĮąĄ ą╝ąĄčłą░ą╗ąĖ ą┤čĆčāą│ ą┤čĆčāą│čā. ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ čü ą┤ąĄą╗ąĄąĮąĖąĄą╝ ą░ą╗ą│ąŠčĆąĖčéą╝ą░ ą╝ąĄąČą┤čā 32 čÅą┤čĆą░ą╝ąĖ: ąŠą▒čŗčćąĮčŗąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ ąĘą░čēąĖčéčŗ ą┤ąŠčüčéčāą┐ą░ ą║ ąŠą▒čēąĖą╝ čĆąĄčüčāčĆčüą░ą╝, čĆąĄąĘčāą╗čīčéąĖčĆčāčÄčēą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą╝ąŠąČąĄčé ąŠąĘąĮą░čćą░čéčī, čćč鹊 č鹊ą╗čīą║ąŠ čćą░čüčéčī čŹčéąĖčģ čÅą┤ąĄčĆ ą║ąŠą│ą┤ą░-ą╗ąĖą▒ąŠ ą▒čāą┤čāčé ąĮą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ čĆą░ą▒ąŠčéą░čéčī ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ. ąÜąŠą╗ą╗ąĄą║čåąĖąĖ ą║ąŠąĮą║čāčĆąĄąĮčåąĖąĖ čüą┐ąĄčåąĖą░ą╗čīąĮąŠ ąĮą░čüčéčĆąŠąĄąĮčŗ ą┤ą╗čÅ ą▓čŗčüąŠą║ąŠ ą║ąŠąĮą║čāčĆąĄąĮčéąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░, čü č乊ą║čāčüąŠą╝ ąĮą░ ą╝ąĖąĮąĖą╝ąĖąĘą░čåąĖąĖ ąĖą╗ąĖ čāčüčéčĆą░ąĮąĄąĮąĖčÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║. PLINQ ąĖ ą║ą╗ą░čüčü Parallel čüą░ą╝ąĖ ą┐ąŠ čüąĄą▒ąĄ ą┐ąŠą╗ą░ą│ą░čÄčéčüčÅ ąĮą░ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ ą║ąŠąĮą║čāčĆąĄąĮčåąĖąĖ ąĖ ą┐čĆąĖą╝ąĖčéąĖą▓čŗ čåąĖą║ą╗ąŠą▓ ąŠą┐čĆąŠčüą░ ą┤ą╗čÅ čŹčäč乥ą║čéąĖą▓ąĮąŠą│ąŠ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čĆą░ą▒ąŠč鹊ą╣.
ąóčĆą░ą┤ąĖčåąĖąŠąĮąĮą░čÅ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠčüčéčī čŹč鹊 ąŠą┤ąĖąĮ ąĖąĘ čüčåąĄąĮą░čĆąĖąĄą▓, ą║ąŠą│ą┤ą░ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠčüčéčī ą┤ą░ąĄčé ą▓čŗąĖą│čĆčŗčł ą┤ą░ąČąĄ ąĮą░ ąŠą┤ąĮąŠčÅą┤ąĄčĆąĮąŠą╣ ą╝ą░čłąĖąĮąĄ, ą║ąŠą│ą┤ą░ ąĮą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ ąĮąĄčé ąĮą░čüč鹊čÅčēąĄą│ąŠ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ą░. ą£čŗ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ą╗ąĖ ą▓čüąĄ čŹč鹊 čĆą░ąĮąĄąĄ: ąĘą░ą┤ą░čćąĖ čéą░ą║ąŠą│ąŠ ą║ą╗ą░čüčüą░ ą┐čĆąĖąĘą▓ą░ąĮčŗ čüąŠčģčĆą░ąĮąĖčéčī ąŠčéąĘčŗą▓čćąĖą▓ąŠčüčéčī ąĖąĮč鹥čĆč乥ą╣čüą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ čü ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗą╝ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ą┤čĆčāą│ąĖčģ ąĘą░ą┤ą░čć ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ ąĘą░ą│čĆčāąĘą║ąĖ ą▓ąĄą▒-čüčéčĆą░ąĮąĖčå.
ąØąĄą║ąŠč鹊čĆčŗąĄ ą║ąŠąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ą▓ čüąĄą║čåąĖčÅčģ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą│ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ, čéą░ą║ąČąĄ ąĖąĮąŠą│ą┤ą░ ą┐ąŠą╗ąĄąĘąĮčŗ ąĖ ą┤ą╗čÅ čéčĆą░ą┤ąĖčåąĖąŠąĮąĮąŠą╣ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠčüčéąĖ. ąÆ čćą░čüčéąĮąŠčüčéąĖ:
ŌĆó PLINQ ąĖ ą║ą╗ą░čüčü Parallel ą┐ąŠą╗ąĄąĘąĮčŗ, ą║ąŠą│ą┤ą░ ąÆčŗ čģąŠčéąĖč鹥 ą▓čŗą┐ąŠą╗ąĮčÅčéčī ąŠą┐ąĄčĆą░čåąĖąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ ąĖ ąĘą░č鹥ą╝ ąČą┤ą░čéčī ąĖčģ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ (čüčéčĆčāą║čéčāčĆąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝). ąŁč鹊 ą▓ą║ą╗čÄčćą░ąĄčé ąĮąĄąĘąĮą░čćąĖč鹥ą╗čīąĮąŠ ąĮą░ą│čĆčāąČą░čÄčēąĖąĄ CPU ąĘą░ą┤ą░čćąĖ, čéą░ą║ąĖąĄ ą║ą░ą║ ą▓čŗąĘąŠą▓ ą▓ąĄą▒-čüą╗čāąČą▒čŗ.
ąÜąŠą│ą┤ą░ čüą╗ąĄą┤čāąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī PFX. ąśąĘąĮą░čćą░ą╗čīąĮąŠ PFX ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮ ą┤ą╗čÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą│ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ: ąĘą░ą┤ąĄą╣čüčéą▓ąŠą▓ą░ąĮąĖąĄ čÅą┤ąĄčĆ ą╝ąĮąŠą│ąŠčÅą┤ąĄčĆąĮčŗčģ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ą┤ą╗čÅ čāčüą║ąŠčĆąĄąĮąĖčÅ čĆą░ą▒ąŠčéčŗ ą║ąŠą┤ą░ čü ąĖąĮč鹥ąĮčüąĖą▓ąĮčŗą╝ąĖ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅą╝ąĖ.
ąĪą╗ąŠąČąĮąŠčüčéčī ą▓ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĖ ą╝ąĮąŠą│ąĖčģ čÅą┤ąĄčĆ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĘą░ą║ąŠąĮ ąÉą╝ą┤ą░ą╗ą░, ą║ąŠč鹊čĆčŗą╣ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé, čćč鹊 ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ čāą╗čāčćčłąĄąĮąĖąĄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ ąŠą│čĆą░ąĮąĖčćąĖą▓ą░ąĄčéčüčÅ ą┐ąŠčĆčåąĖąĄą╣ ą║ąŠą┤ą░, ą║ąŠč鹊čĆą░čÅ ąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ ą┤ąŠą╗ąČąĮą░ ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą┤ą▓ąĄ čéčĆąĄčéąĖ ą▓čĆąĄą╝ąĄąĮąĖ ą░ą╗ą│ąŠčĆąĖčéą╝ą░ ą╝ąŠąČąĮąŠ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖčéčī, ąÆčŗ ąĮąĄ čüą╝ąŠąČąĄč鹥 ą┐čĆąĄą▓čŗčüąĖčéčī ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╣ ą┐ąŠčĆąŠą│ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ, ą┤ą░ąČąĄ ąĄčüą╗ąĖ ą▒čāą┤ąĄč鹥 ąĖą╝ąĄčéčī ą▓ ąĮą░ą╗ąĖčćąĖąĖ ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čÅą┤ąĄčĆ [7].
ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ čüąĮą░čćą░ą╗ą░ ąĮčāąČąĮąŠ ąŠčåąĄąĮąĖčéčī čāąĘą║ąŠąĄ ą╝ąĄčüč鹊, ąŠą│čĆą░ąĮąĖčćąĖą▓ą░čÄčēąĄąĄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ą║ąŠą┤ą░. ąóą░ą║ąČąĄ čüč鹊ąĖčé ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčīčüčÅ, ąĮą░čüą║ąŠą╗čīą║ąŠ ąĮčāąČąĮčŗ ą▓ ą║ąŠą┤ąĄ ą║ąŠąĮą║čĆąĄčéąĮčŗąĄ ąĖąĮč鹥ąĮčüąĖą▓ąĮčŗąĄ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ - čćą░čüč鹊 ą░ą╗ą│ąŠčĆąĖčéą╝ąĖč湥čüą║ą░čÅ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖčÅ ą┤ą░ąĄčé čüą░ą╝čŗą╣ ą▒ąŠą╗čīčłąŠą╣ ą▓čŗąĖą│čĆčŗčł ą▓ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ. ą×ą┤ąĮą░ą║ąŠ ąĮąĄą┤ąŠčüčéą░č鹊ą║ čéą░ą║ąŠą│ąŠ ą┐ąŠą┤čģąŠą┤ą░ ą▓ č鹊ą╝, čćč鹊 ąĮąĄą║ąŠč鹊čĆčŗąĄ č鹥čģąĮąĖą║ąĖ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ čāčüą╗ąŠąČąĮčÅčÄčé čĆąĄą░ą╗ąĖąĘą░čåąĖčÄ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ą░ ą║ąŠą┤ą░.
ąĪą░ą╝čŗą╣ ą▒ąŠą╗čīčłąŠą╣ ą▓čŗąĖą│čĆčŗčł ą┤ą░ąĄčé ą┐čĆą░ą▓ąĖą╗čīąĮą░čÅ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖčÅ ą┐ąŠąČą░ą╗čāą╣ čüą░ą╝ąŠą│ąŠ čüą╗ąŠąČąĮąŠą│ąŠ ą╝ąŠą╝ąĄąĮčéą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ą░ - ą│ą┤ąĄ ąŠą▒čēą░čÅ čĆą░ą▒ąŠčéą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠčüč鹊 čĆą░ąĘą┤ąĄą╗ąĄąĮą░ ąĮą░ čćą░čüčéąĖ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠąČąĮąŠ čŹčäč乥ą║čéąĖą▓ąĮąŠ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą║ą░ą║ąĖą╝-č鹊 ą░ą╗ą│ąŠčĆąĖčéą╝ąŠą╝ (čüčéčĆčāą║čéčāčĆąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ ą╗čāčćčłąĄ ą▓čüąĄą│ąŠ ą┐ąŠą┤čģąŠą┤ąĖčé ą┤ą╗čÅ čéą░ą║ąĖčģ ą┐čĆąŠą▒ą╗ąĄą╝). ą¤čĆąĖą╝ąĄčĆą░ą╝ąĖ ą╝ąŠą│čāčé čüą╗čāąČąĖčéčī ąĘą░ą┤ą░čćąĖ ą┐ąŠ ąŠą▒čĆą░ą▒ąŠčéą║ąĄ ąĖąĘąŠą▒čĆą░ąČąĄąĮąĖą╣, ray tracing, ą░čéą░ą║ąĖ ą┐ąŠ ą┐ąŠą┤ą▒ąŠčĆčā ą▓ ą┐čĆąĖą║ą╗ą░ą┤ąĮąŠą╣ ą╝ą░č鹥ą╝ą░čéąĖą║ąĄ ąĖą╗ąĖ ą║čĆąĖą┐č鹊ą│čĆą░čäąĖąĖ. ąöčĆčāą│ąŠą╣ ą┐čĆąĖą╝ąĄčĆ ą┐čĆąŠą▒ą╗ąĄą╝čŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠčüčéąĖ - čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░ąĮąĮąŠą╣ ą▓ąĄčĆčüąĖąĖ ą░ą╗ą│ąŠčĆąĖčéą╝ą░ ą▒čŗčüčéčĆąŠą╣ čüąŠčĆčéąĖčĆąŠą▓ą║ąĖ - ą┤ąŠčüčéąĖąČąĄąĮąĖąĄ čģąŠčĆąŠčłąĄą│ąŠ čĆąĄąĘčāą╗čīčéą░čéą░ ąĮąĄ čéčĆąĖą▓ąĖą░ą╗čīąĮąŠ, ąĖ ą╝ąŠąČąĄčé ą┐ąŠčéčĆąĄą▒ąŠą▓ą░čéčī ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ ąĮąĄ čüčéčĆčāą║čéčāčĆąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ą░.
PLINQ ]
PLINQ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖą▓ą░ąĄčé ą╗ąŠą║ą░ą╗čīąĮčŗąĄ ąĘą░ą┐čĆąŠčüčŗ (LINQ queries). ąöąŠčüč鹊ąĖąĮčüčéą▓ąŠ PLINQ ą▓ č鹊ą╝, čćč鹊 ąĄčæ ą╗ąĄą│ą║ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī - ą┐ą╗ą░čéč乊čĆą╝ą░ ą▒ąĄčĆąĄčé ąĮą░ čüąĄą▒čÅ ąĘą░ą▒ąŠčéčā čĆą░ąĘą┤ąĄą╗ąĄąĮąĖčÅ ąŠą▒čēąĄą╣ čĆą░ą▒ąŠčéčŗ ąĖ ą║ąŠąĮąĄčćąĮąŠą│ąŠ čüą▓ąĄą┤ąĄąĮąĖčÅ ą▓ą╝ąĄčüč鹥 čĆąĄąĘčāą╗čīčéą░č鹊ą▓.
ą¦č鹊ą▒čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī PLINQ ą┐čĆąŠčüč鹊 ą▓čŗąĘąŠą▓ąĖč鹥 AsParallel() ąĮą░ ą▓čģąŠą┤ąĮąŠą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ, ąĖ ąĘą░č鹥ą╝ ą┐čĆąŠą┤ąŠą╗ąČąĖč鹥 ąĘą░ą┐čĆąŠčü LINQ, ą║ą░ą║ ąŠą▒čŗčćąĮąŠ. ąĪą╗ąĄą┤čāčÄčēąĖą╣ ąĘą░ą┐čĆąŠčü ą▓čŗčćąĖčüą╗čÅąĄčé ą┐čĆąŠčüčéčŗąĄ čćąĖčüą╗ą░ ą╝ąĄąČą┤čā 3 ąĖ 100000 - ą┐čĆąĖ ą┐ąŠą╗ąĮąŠą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ą▓čüąĄčģ čÅą┤ąĄčĆ čåąĄą╗ąĄą▓ąŠą╣ ą╝ą░čłąĖąĮčŗ:
// ąÆčŗčćąĖčüą╗ąĄąĮąĖąĄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ ą┐čĆąŠčüčéčŗčģ čćąĖčüąĄą╗ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ 菹╗ąĄą╝ąĄąĮčéą░čĆąĮąŠą│ąŠ // (ąĮąĄ ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ) ą░ą╗ą│ąŠčĆąĖčéą╝ą░. // // ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą▓čüąĄ ą║ąŠą┤čŗ ą╗ąĖčüčéąĖąĮą│ą░ ą▓ čŹč鹊ą╣ ą│ą╗ą░ą▓ąĄ ą┤ąŠčüčéčāą┐ąĮčŗ ą▓ LINQPad ą║ą░ą║ // ąĖąĮč鹥čĆą░ą║čéąĖą▓ąĮčŗąĄ ą║čāčüą║ąĖ ą║ąŠą┤ą░. ąöą╗čÅ ą░ą║čéąĖą▓ą░čåąĖąĖ čŹčéąĖčģ ą┐čĆąĖą╝ąĄčĆąŠą▓ ą║ą╗ąĖą║ąĮąĖč鹥 // "Download More Samples" ąĮą░ ąĘą░ą║ą╗ą░ą┤ą║ąĄ Samples čāčéąĖą╗ąĖčéčŗ LINQPad, // ąĮą░čģąŠą┤čÅčēąĄą╣čüčÅ čüą╗ąĄą▓ą░ ą▓ąĮąĖąĘčā, ąĖ ą▓čŗą▒ąĄčĆąĖč鹥 "C# 4.0 in a Nutshell: More Chapters".
IEnumerable< int > numbers = Enumerable.Range (3 , 100000 -3 );
var parallelQuery =
from n in numbers.AsParallel()
where Enumerable.Range (2 , (int ) Math.Sqrt (n)).All (i => n % i > 0 )
select n;
int [] primes = parallelQuery.ToArray();
AsParallel čŹč鹊 ą╝ąĄč鹊ą┤ čĆą░čüčłąĖčĆąĄąĮąĖčÅ ą▓ System.Linq.ParallelEnumerable. ą×ąĮ ąŠą▒ąŠčĆą░čćąĖą▓ą░ąĄčé ą▓ą▓ąŠą┤ ą▓ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ąĮą░ ą▒ą░ąĘąĄ ParallelQuery< TSource>, ą║ąŠč鹊čĆčŗą╣ ąĘą░ą┐čāčüą║ą░ąĄčé ąŠą┐ąĄčĆą░č鹊čĆčŗ ąĘą░ą┐čĆąŠčüą░ LINQ, ą║ąŠč鹊čĆčŗąĄ ąÆčŗ ą▓ą┐ąŠčüą╗ąĄą┤čüčéą▓ąĖąĖ ą▓čŗąĘčŗą▓ą░ąĄč鹥, čćč鹊ą▒čŗ čüą▓čÅąĘą░čéčī čü ą░ą╗čīč鹥čĆąĮą░čéąĖą▓ąĮčŗą╝ ąĮą░ą▒ąŠčĆąŠą╝ ą╝ąĄč鹊ą┤ąŠą▓ čĆą░čüčłąĖčĆąĄąĮąĖčÅ, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ ą▓ ParallelEnumerable. ąŁč鹊 ą┤ą░ąĄčé ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗąĄ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą║ą░ąČą┤ąŠą│ąŠ ąĖąĘ čüčéą░ąĮą┤ą░čĆčéąĮčŗčģ ąŠą┐ąĄčĆą░č鹊čĆąŠą▓ ąĘą░ą┐čĆąŠčüą░. ąÆ čüčāčēąĮąŠčüčéąĖ čŹč鹊 čĆą░ą▒ąŠčéą░ąĄčé ą┐ąŠ ą┐čĆąĖąĮčåąĖą┐čā čĆą░ąĘą┤ąĄą╗ąĄąĮąĖčÅ ą▓čģąŠą┤ąĮąŠą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ ąĮą░ ą║čāčüą║ąĖ, ą▓čŗą┐ąŠą╗ąĮčÅąĄą╝čŗąĄ ą▓ čĆą░ąĘąĮčŗčģ ą┐ąŠč鹊ą║ą░čģ, ą║ąŠč鹊čĆčŗąĄ čüąŠąĄą┤ąĖąĮčÅčÄčéčüčÅ ą▓ą╝ąĄčüč鹥 ąŠą▒čĆą░čéąĮąŠ ą▓ ąŠą┤ąĮčā ą▓čŗčģąŠą┤ąĮčāčÄ ą┐ąŠčéčĆąĄą▒ą╗čÅąĄą╝čāčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī.
ąØą░ ą║ą░čĆčéąĖąĮą║ąĄ ąĮąĖąČąĄ ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąĖčåąĖą┐ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖą▓ą░ąĮąĖčÅ ą▓čŗčĆą░ąČąĄąĮąĖčÅ:
"abcdef" .AsParallel().Select(c => char .ToUpper(c)).ToArray()
ąÆčŗąĘąŠą▓ AsSequential() čĆą░ąĘą▓ąŠčĆą░čćąĖą▓ą░ąĄčé ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ParallelQuery čéą░ą║, čćč鹊ą▒čŗ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐ąĄčĆą░č鹊čĆčŗ ąĘą░ą┐čĆąŠčüą░ čüą▓čÅąĘą░ą╗ąĖ čüą▓čÅąĘą░ą╗ąĖčüčī čüąŠ čüčéą░ąĮą┤ą░čĆčéąĮčŗą╝ąĖ ąŠą┐ąĄčĆą░č鹊čĆą░ą╝ąĖ ąĘą░ą┐čĆąŠčüą░ ąĖ ą▓čŗą┐ąŠą╗ąĮąĖą╗ąĖčüčī ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ. ąŁč鹊 ąĮčāąČąĮąŠ ą┐ąĄčĆąĄą┤ ą▓čŗąĘąŠą▓ąŠą╝ ą╝ąĄč鹊ą┤ąŠą▓, ą║ąŠč鹊čĆčŗąĄ ąĖą╝ąĄčÄčé ą┐ąŠą▒ąŠčćąĮčŗąĄ čŹčäč乥ą║čéčŗ ąĖą╗ąĖ ąĮąĄ ą▒ąĄąĘąŠą┐ą░čüąĮčŗ ą▓ čāčüą╗ąŠą▓ąĖčÅčģ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠčüčéąĖ.
ąöą╗čÅ ąŠą┐ąĄčĆą░č鹊čĆąŠą▓ ąĘą░ą┐čĆąŠčüą░, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąĖąĮąĖą╝ą░čÄčé ą┤ą▓ąĄ ą▓čģąŠą┤ąĮčŗąĄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ (Join, GroupJoin, Concat, Union, Intersect, Except ąĖ Zip), ąÆčŗ ą┤ąŠą╗ąČąĮčŗ ą┐čĆąĖą╝ąĄąĮąĖčéčī AsParallel() ą║ ąŠą▒ąŠąĖą╝ ą▓čģąŠą┤ąĮčŗą╝ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčÅą╝ (ąĖąĮą░č湥 ą▒čāą┤ąĄčé ą▓čŗą▒čĆąŠčłąĄąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ). ą×ą┤ąĮą░ą║ąŠ ąÆą░ą╝ ąĮąĄ ąĮčāąČąĮąŠ ą┐čĆąŠą┤ąŠą╗ąČą░čéčī ą┐čĆąĖą╝ąĄąĮčÅčéčī AsParallel ą║ ąĘą░ą┐čĆąŠčüčā ą▓ąŠ ą▓čĆąĄą╝čÅ ąĄą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠą┐ąĄčĆą░č鹊čĆčŗ ąĘą░ą┐čĆąŠčüą░ PLINQ ą▓čŗą▓ąŠą┤čÅčé ą┤čĆčāą│čāčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ParallelQuery. ążą░ą║čéąĖč湥čüą║ąĖ ą┐ąŠą▓č鹊čĆąĮčŗą╣ ą▓čŗąĘąŠą▓ AsParallel ą▒čāą┤ąĄčé ąĮąĄ čŹčäč乥ą║čéąĖą▓ąĮčŗą╝, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓čŗąĘąŠą▓ąĄčé čüą╗ąĖčÅąĮąĖąĄ ąĖ ą┐ąŠą▓č鹊čĆąĮąŠąĄ čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ ąĘą░ą┐čĆąŠčüą░:
mySequence.AsParallel() // ą×ą▒ąŠčĆą░čćąĖą▓ą░ąĄčé ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ą▓ ParallelQuery< int>
.Where (n => n > 100 ) // ąÆčŗą▓ąŠą┤ąĖčé ą┤čĆčāą│ąŠą╣ ParallelQuery< int>
.AsParallel() // ąØąĄ čéčĆąĄą▒čāąĄčéčüčÅ, ąĖ ąĮąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠ!
.Select (n => n * n)
ąØąĄ ą▓čüąĄ ąŠą┐ąĄčĆą░č鹊čĆčŗ ąĘą░ą┐čĆąŠčüą░ ą╝ąŠąČąĮąŠ čŹčäč乥ą║čéąĖą▓ąĮąŠ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖčéčī. ąöą╗čÅ č鹥čģ, ą║ąŠč鹊čĆčŗąĄ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖčéčī ąĮąĄą╗čīąĘčÅ, PLINQ ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ čĆąĄą░ą╗ąĖąĘčāąĄčé ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗą╣ ąŠą┐ąĄčĆą░č鹊čĆ. PLINQ ą╝ąŠąČąĄčé čéą░ą║ąČąĄ čĆą░ą▒ąŠčéą░čéčī ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ, ąĄčüą╗ąĖ ą┐ąŠą┤ąŠąĘčĆąĄą▓ą░ąĄčé, čćč鹊 ąĖąĘą┤ąĄčƹȹ║ąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖąĖ ąĮą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ ąĘą░ą╝ąĄą┤ą╗čÅčé ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╣ ąĘą░ą┐čĆąŠčü.
PLINQ ą┐ąŠą┤čģąŠą┤ąĖčé č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą╗ąŠą║ą░ą╗čīąĮčŗčģ ą║ąŠą╗ą╗ąĄą║čåąĖą╣: ąŠąĮ ąĮąĄ čĆą░ą▒ąŠčéą░ąĄčé čü LINQ ą║ SQL ąĖą╗ąĖ Entity Framework, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓ čŹčéąĖčģ čüą╗čāčćą░čÅčģ LINQ čéčĆą░ąĮčüą╗ąĖčĆčāąĄčéčüčÅ ą▓ SQL, ą║ąŠč鹊čĆčŗą╣ ąĘą░č鹥ą╝ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ąĮą░ čüąĄčĆą▓ąĄčĆąĄ ą▒ą░ąĘ ą┤ą░ąĮąĮčŗčģ. ą×ą┤ąĮą░ą║ąŠ ąÆčŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī PLINQ ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ą╗ąŠą║ą░ą╗čīąĮčŗčģ ąĘą░ą┐čĆąŠčüąŠą▓ ąĮą░ čĆąĄąĘčāą╗čīčéą░čéą░čģ, ą┐ąŠą╗čāč湥ąĮąĮčŗčģ ąĖąĘ ąĘą░ą┐čĆąŠčüąŠą▓ ą║ ą▒ą░ąĘąĄ ą┤ą░ąĮąĮčŗčģ.
ąĢčüą╗ąĖ ąĘą░ą┐čĆąŠčü PLINQ ą▓čŗą▒čĆą░čüčŗą▓ą░ąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ, č鹊 ąŠąĮąŠ ą┐ąĄčĆąĄą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ ą║ą░ą║ AggregateException, čā ą║ąŠč鹊čĆąŠą│ąŠ čüą▓ąŠą╣čüčéą▓ąŠ InnerExceptions čüąŠą┤ąĄčƹȹĖčé čĆąĄą░ą╗čīąĮąŠąĄ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ (ąĖą╗ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ). ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. "ąĀą░ą▒ąŠčéą░ čü AggregateException".
ąóą░ą║ ą║ą░ą║ AsParallel ą┐čĆąŠąĘčĆą░čćąĮąŠ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖą▓ą░ąĄčé ąĘą░ą┐čĆąŠčüčŗ LINQ, ą▓ąŠąĘąĮąĖą║ą░ąĄčé ą▓ąŠą┐čĆąŠčü: ą┐ąŠč湥ą╝čā Microsoft ąĮąĄ ą┤ąĄą╗ą░ąĄčé ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┐čĆąŠčüčéčāčÄ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖčÄ čüčéą░ąĮą┤ą░čĆčéąĮčŗčģ ąŠą┐ąĄčĆą░č鹊čĆąŠą▓ ąĘą░ą┐čĆąŠčüą░, čé. ąĄ. ąĮąĄ ą┐čĆąĖą╝ąĄąĮčÅąĄčé PLINQ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ?
ąóčāčé ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐čĆąĖčćąĖąĮ. ąÆąŠ-ą┐ąĄčĆą▓čŗčģ, ą┤ą╗čÅ č鹊ą│ąŠ, čćč鹊ą▒čŗ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ PLINQ ą▒čŗą╗ąŠ ą┐ąŠą╗ąĄąĘąĮčŗą╝, ą┤ąŠą╗ąČąĮąŠ ą┐čĆąĖčüčāčéčüčéą▓ąŠą▓ą░čéčī čĆą░ąĘčāą╝ąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĖąĮč鹥ąĮčüąĖą▓ąĮąŠą╣ ą▓čŗčćąĖčüą╗ąĖč鹥ą╗čīąĮąŠą╣ čĆą░ą▒ąŠčéčŗ, čćč鹊ą▒čŗ ą┐ąĄčĆąĄą┤ą░čéčī ąĄčæ ąĮą░ ąŠą▒čĆą░ą▒ąŠčéą║čā čĆą░ą▒ąŠčćąĖą╝ ą┐ąŠč鹊ą║ą░ą╝. ąæąŠą╗čīčłąĖąĮčüčéą▓ąŠ ąĘą░ą┐čĆąŠčüąŠą▓ LINQ ą║ ąŠą▒čŖąĄą║čéą░ą╝ ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ąŠč湥ąĮčī ą▒čŗčüčéčĆąŠ, ąĖ ą║ ąĮąĖą╝ ąĮąĄ č鹊ą╗čīą║ąŠ ąĮąĄ ąĮčāąČąĮąŠ ą┐čĆąĖą╝ąĄąĮčÅčéčī ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝, ąĮąŠ čŹč鹊 čéą░ą║ąČąĄ ą▒čāą┤ąĄčé ą▓ąŠą▓ą╗ąĄą║ą░čéčī ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ąĮąĄąĮčāąČąĮčŗąĄ ą▓čŗčćąĖčüą╗ąĖč鹥ą╗čīąĮčŗąĄ čĆą░čüčģąŠą┤čŗ ąĮą░ čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ ąĘą░ą┤ą░čćąĖ, čüą▒ąŠčĆ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ą▓ą╝ąĄčüč鹥, ą║ąŠąŠčĆą┤ąĖąĮą░čåąĖčÄ čĆą░ą▒ąŠčéčŗ ą┐ąŠč鹊ą║ąŠą▓, ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą▓čüąĄ č鹊ą╗čīą║ąŠ ąĘą░ą╝ąĄą┤ą╗ąĖčéčüčÅ.
ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ:
ŌĆó ąÆčŗčģąŠą┤ ąĘą░ą┐čĆąŠčüą░ PLINQ query (ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ) ą╝ąŠąČąĄčé ąŠčéą╗ąĖčćą░čéčīčüčÅ ąŠčé ąĘą░ą┐čĆąŠčüą░ LINQ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 čāą┐ąŠčĆčÅą┤ąŠčćąĖą▓ą░ąĮąĖčÅ čŹą╗ąĄą╝ąĄąĮč鹊ą▓.
ąś ąĮą░ą║ąŠąĮąĄčå, PLINQ ą┐čĆąĄą┤ą╗ą░ą│ą░ąĄčé ą┤ąŠą▓ąŠą╗čīąĮąŠ ą╝ąĮąŠą│ąŠ ą▓ą░čĆąĖą░ąĮč鹊ą▓ ąĮą░čüčéčĆąŠą╣ą║ąĖ. ą×ą▒čĆąĄą╝ąĄąĮąĄąĮąĖąĄ čüčéą░ąĮą┤ą░čĆčéąĮčŗčģ ąĘą░ą┐čĆąŠčüąŠą▓ LINQ ą║ Objects API čéą░ą║ąĖą╝ąĖ ąĮčÄą░ąĮčüą░ą╝ąĖ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ ąŠčéą▓ą╗ąĄą║ą░ą╗ąŠ ą▒čŗ ąŠčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąŠą▒čēąĄą╣ ąĘą░ą┤ą░čćąĖ.
ąæą░ą╗ą╗ąĖčüčéąĖą║ą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ . ąÜą░ą║ ąĖ ąŠą▒čŗčćąĮčŗąĄ ąĘą░ą┐čĆąŠčüčŗ LINQ, ąĘą░ą┐čĆąŠčüčŗ PLINQ ą▓čŗčćąĖčüą╗čÅčÄčéčüčÅ "ą╗ąĄąĮąĖą▓čŗą╝" čüą┐ąŠčüąŠą▒ąŠą╝. ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ čüčĆą░ą▒ą░čéčŗą▓ą░ąĄčé č鹊ą╗čīą║ąŠ ą║ąŠą│ą┤ą░ ąÆčŗ ąĮą░čćąĖąĮą░ąĄč鹥 ą┐ąŠčéčĆąĄą▒ą╗čÅčéčī čĆąĄąĘčāą╗čīčéą░čéčŗ ąĘą░ą┐čĆąŠčüą░ - ąŠą▒čŗčćąĮąŠ ą▓ čåąĖą║ą╗ąĄ foreach (čģąŠčéčÅ čŹč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī čüą┤ąĄą╗ą░ąĮąŠ ąĖ č湥čĆąĄąĘ ąŠą┐ąĄčĆą░č鹊čĆ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅ, čéą░ą║ąŠą╣ ą║ą░ą║ ToArray, ąĖą╗ąĖ ąŠą┐ąĄčĆą░č鹊čĆ, ą║ąŠč鹊čĆčŗą╣ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ąŠą┤ąĖąĮ 菹╗ąĄą╝ąĄąĮčé ąĖą╗ąĖ ąĘąĮą░č湥ąĮąĖąĄ).
ą×ą┤ąĮą░ą║ąŠ ą┐ąŠ ą╝ąĄčĆąĄ ą┐ąŠčéčĆąĄą▒ą╗ąĄąĮąĖčÅ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĖąĮą░č湥 ą┐ąŠ čüčĆą░ą▓ąĮąĄąĮąĖčÄ čü ąŠą▒čŗčćąĮčŗą╝ąĖ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗą╝ąĖ ąĘą░ą┐čĆąŠčüą░ą╝ąĖ. ą¤ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗą╣ ąĘą░ą┐čĆąŠčü ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗ąĄą╝ ą▓ čüčéąĖą╗ąĄ "ą▓čŗčéą░ą╗ą║ąĖą▓ą░ąĮąĖčÅ" (pull): ą║ą░ąČą┤čŗą╣ 菹╗ąĄą╝ąĄąĮčé ąĖąĘ ą▓čģąŠą┤ąĮąŠą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ č鹊čćąĮąŠ č鹊ą│ą┤ą░, ą║ąŠą│ą┤ą░ čŹč鹊ą│ąŠ čéčĆąĄą▒čāąĄčé ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗čī. ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗą╣ ąĘą░ą┐čĆąŠčü ąŠą▒čŗčćąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗąĄ ą┐ąŠč鹊ą║ąĖ ą┤ą╗čÅ ą▓čŗą▒ąŠčĆą║ąĖ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ąĖąĘ ą▓čģąŠą┤ąĮąŠą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ ąĮąĄą╝ąĮąŠą│ąŠ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ čŹč鹊 ą┐ąŠąĮą░ą┤ąŠą▒ąĖą╗ąŠčüčī ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗čÄ (ąĮąĄčćč鹊 ą┐ąŠčģąŠąČąĄąĄ ąĮą░ č鹥ą╗ąĄą▓ąĖąĘąĖąŠąĮąĮčŗą╣ čüčāčäą╗ąĄčĆ ą┤ą╗čÅ ą┤ąĖą║č鹊čĆąŠą▓ ąĖą╗ąĖ ą░ąĮčéąĖčłąŠą║ąŠą▓čŗą╣ ą▒čāč乥čĆ ą┤ą░ąĮąĮčŗčģ ą▓ CD-ą┐ą╗ąĄąĄčĆą░čģ). ąŚą░č鹥ą╝ ąŠąĮ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé 菹╗ąĄą╝ąĄąĮčéčŗ ą▓ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą╝ ąĘą░ą┐čĆąŠčüąĄ č湥čĆąĄąĘ čåąĄą┐ąŠčćą║čā ąĘą░ą┐čĆąŠčüą░, čüąŠčģčĆą░ąĮčÅčÅ čĆąĄąĘčāą╗čīčéą░čéčŗ ą▓ ą╝ą░ą╗ąĄąĮčīą║ąŠą╝ ą▒čāč乥čĆąĄ, ąŠčéą║čāą┤ą░ ąŠąĮąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓ąĘčÅčéčŗ ą┐ąŠ ąĘą░ą┐čĆąŠčüčā ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗čÅ. ąĢčüą╗ąĖ ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗čī ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ąĖą╗ ą┐ąŠčéčĆąĄą▒ą╗ąĄąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ ąĖą╗ąĖ čüčĆą░ąĘčā ą┐čĆąĄą║čĆą░čéąĖą╗ ąĖčģ ąŠą▒čĆą░ą▒ąŠčéą║čā, č鹊 ą┐čĆąŠčåąĄčüčüąŠčĆ ąĘą░ą┐čĆąŠčüą░ čéą░ą║ąČąĄ čüčéą░ą▓ąĖčé ąĮą░ ą┐ą░čāąĘčā ąĖą╗ąĖ ąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé čĆą░ą▒ąŠčéčā, čćč鹊ą▒čŗ ąĘčĆčÅ ąĮąĄ čĆą░čüčģąŠą┤ąŠą▓ą░čéčī ą▓čĆąĄą╝čÅ CPU ąĖą╗ąĖ ą┐ą░ą╝čÅčéčī.
ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐ąŠą┤čüčéčĆąŠąĖčéčī ą▒čāč乥čĆąĖąĘą░čåąĖčÄ PLINQ ą▓čŗąĘąŠą▓ąŠą╝ WithMergeOptions ą┐ąŠčüą╗ąĄ AsParallel. ąŚąĮą░č湥ąĮąĖąĄ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ AutoBuffered ąŠą▒čŗčćąĮąŠ ą┤ą░ąĄčé čüą░ą╝čŗąĄ ą╗čāčćčłąĖąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ. NotBuffered ąĘą░ą┐čĆąĄčēą░ąĄčé ą▒čāč乥čĆąĖąĘą░čåąĖčÄ, čćč鹊 ą┐ąŠą╗ąĄąĘąĮąŠ, ąĄčüą╗ąĖ ąÆčŗ čģąŠčéąĖč鹥 čāą▓ąĖą┤ąĄčéčī čĆąĄąĘčāą╗čīčéą░čéčŗ ąĮą░čüč鹊ą╗čīą║ąŠ ą▒čŗčüčéčĆąŠ, ąĮą░čüą║ąŠą╗čīą║ąŠ čŹč鹊 ą▓ąŠąĘą╝ąŠąČąĮąŠ; FullyBuffered ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą║čŹčłąĖčĆčāąĄčé ą▓ąĄčüčī ąĮą░ą▒ąŠčĆ čĆąĄąĘčāą╗čīčéą░čéą░ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ąŠąĮ ą▒čāą┤ąĄčé ą┤ąŠčüčéčāą┐ąĄąĮ ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗čÄ (ąŠą┐ąĄčĆą░č鹊čĆčŗ OrderBy ąĖ Reverse ą▓ čüčāčēąĮąŠčüčéąĖ čĆą░ą▒ąŠčéą░čÄčé ą┐ąŠ čéą░ą║ąŠą╝čā ą╝ąĄč鹊ą┤čā, ą║ą░ą║ ą║ą░ą║ ąĖ ąŠą┐ąĄčĆą░č鹊čĆčŗ 菹╗ąĄą╝ąĄąĮčéą░, ą░ą│čĆąĄą│ą░čåąĖąĖ ąĖ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅ).
PLINQ ąĖ ą┐ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ. ą¤ąŠą▒ąŠčćąĮčŗą╣ čŹčäč乥ą║čé ąŠčé ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖąĖ ąŠą┐ąĄčĆą░č鹊čĆąŠą▓ ąĘą░ą┐čĆąŠčüą░ čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, čćč鹊 ą║ąŠą│ą┤ą░ čĆąĄąĘčāą╗čīčéą░čéčŗ čüąŠąĄą┤ąĖąĮčÅčÄčéčüčÅ ą▓ą╝ąĄčüč鹥, č鹊 ąĮąĄ ąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ ąŠąĮąĖ ą▒čāą┤čāčé ą▓ č鹊ą╝ ąČąĄ ą┐ąŠčĆčÅą┤ą║ąĄ, ą▓ ą║ą░ą║ąŠą╝ ą▒čŗą╗ąĖ ąĮą░ ą▓čģąŠą┤ąĄ, čćč鹊 ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ ą┤ąĖą░ą│čĆą░ą╝ą╝ąĄ. ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ą▒ąŠą╗čīčłąĄ ąĮąĄ čüąŠą▒ą╗čÄą┤ą░ąĄčéčüčÅ ąĮąŠčĆą╝ą░ą╗čīąĮąŠąĄ čüąŠčģčĆą░ąĮąĄąĮąĖąĄ ą┐ąŠčĆčÅą┤ą║ą░ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ ąĘą░ą┐čĆąŠčüąŠą▓ LINQ.
ąĢčüą╗ąĖ ąÆą░ą╝ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ čüąŠčģčĆą░ąĮąĖčéčī ą┐ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ, č鹊 čŹč鹊 ą╝ąŠąČąĮąŠ ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ ą░ą║čéąĖą▓ąĖčĆąŠą▓ą░čéčī ą▓čŗąĘąŠą▓ąŠą╝ AsOrdered() ą┐ąŠčüą╗ąĄ AsParallel():
myCollection.AsParallel().AsOrdered()...
ąÆčŗąĘąŠą▓ AsOrdered čāčģčāą┤čłą░ąĄčé ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī čü ą▒ąŠą╗čīčłąĖą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąŠą╝ 菹╗ąĄą╝ąĄąĮč鹊ą▓, ą┐ąŠč鹊ą╝čā čćč鹊 PLINQ ą┤ąŠą╗ąČąĮą░ ąŠčéčüą╗ąĄąČąĖą▓ą░čéčī ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮčāčÄ ą┐ąŠąĘąĖčåąĖčÄ ą║ą░ąČą┤ąŠą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░.
ąÆčŗ ą╝ąŠąČąĄč鹥 ąŠčéą╝ąĄąĮąĖčéčī ą▓ ąĘą░ą┐čĆąŠčüąĄ ą┤ąĄą╣čüčéą▓ąĖąĄ AsOrdered ą┐ąŠąĘąČąĄ ą▓čŗąĘąŠą▓ąŠą╝ AsUnordered: čŹč鹊 ą▓ą▓ąŠą┤ąĖčé "č鹊čćą║čā čüą╗čāčćą░ą╣ąĮąŠą╣ ą┐ąĄčĆąĄčéą░čüąŠą▓ą║ąĖ" čćč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĘą░ą┐čĆąŠčüčā čü čŹč鹊ą│ąŠ ą╝ąŠą╝ąĄąĮčéą░ ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ ą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠ. ąĢčüą╗ąĖ ąÆą░ą╝ ąĮčāąČąĮąŠ čüąŠčģčĆą░ąĮąĖčéčī ą▓čģąŠą┤ąĮčāčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą┤ą▓čāčģ ą┐ąĄčĆą▓čŗčģ ąŠą┐ąĄčĆą░č鹊čĆąŠą▓ ąĘą░ą┐čĆąŠčüą░, č鹊 čüą┤ąĄą╗ą░ą╣č鹥 čéą░ą║:
inputSequence.AsParallel().AsOrdered()
.QueryOperator1()
.QueryOperator2()
.AsUnordered() // ąĪ čŹč鹊ą│ąŠ ą╝ąĄčüčéą░ ąŠč湥čĆąĄą┤ąĮąŠčüčéčī ą┤ą░ąĮąĮčŗčģ ąĮąĄ čüąŠą▒ą╗čÄą┤ą░ąĄčéčüčÅ.
.QueryOperator3()
...
ą¤ąŠą▓ąĄą┤ąĄąĮąĖąĄ AsOrdered ąĮąĄ ą░ą║čéąĖą▓ąĖčĆąŠą▓ą░ąĮąŠ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ, ą┐ąŠč鹊ą╝čā čćč鹊 ą┤ą╗čÅ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ą░ ąĘą░ą┐čĆąŠčüąŠą▓ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮčŗą╣ ą┐ąŠčĆčÅą┤ąŠą║ ą▓čģąŠą┤ąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ąĮąĄ ąĖą╝ąĄąĄčé ąĘąĮą░č湥ąĮąĖčÅ. ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ąĄčüą╗ąĖ ą▒čŗ AsOrdered ą┤ąĄą╣čüčéą▓ąŠą▓ą░ą╗ąŠ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ, č鹊 ąÆčŗ ą┐čĆąĖą╝ąĄąĮčÅą╗ąĖ ą▒čŗ AsUnordered ą┤ą╗čÅ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ą░ čüą▓ąŠąĖčģ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗčģ ąĘą░ą┐čĆąŠčüąŠą▓ ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ čüą░ą╝ąŠą╣ ą╗čāčćčłąĄą╣ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ (ąĖąĮą░č湥 ąĘą░č湥ą╝ ąĮą░ą╝ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝), čćč鹊 ą▒čŗą╗ąŠ ą▒čŗ ąŠą▒čĆąĄą╝ąĄąĮąĖč鹥ą╗čīąĮąŠ.
ą×ą│čĆą░ąĮąĖč湥ąĮąĖčÅ PLINQ . ąĢčüčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐čĆą░ą║čéąĖč湥čüą║ąĖčģ ąŠą│čĆą░ąĮąĖč湥ąĮąĖą╣ ąĮą░ č鹊, čćč鹊 PLINQ ą╝ąŠą│ ą▒čŗ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖčéčī. ąŁčéąĖ ąŠą│čĆą░ąĮąĖč湥ąĮąĖčÅ ą╝ąŠą│čāčé ą▓ą┐ąŠčüą╗ąĄą┤čüčéą▓ąĖąĖ ą▒čŗčéčī čāčüčéčĆą░ąĮąĄąĮčŗ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖą╝ąĖ čüąĄčĆą▓ąĖčü-ą┐ą░ą║ą░ą╝ąĖ ąĖ ą▒ąŠą╗ąĄąĄ ąĮąŠą▓čŗą╝ąĖ ą▓ąĄčĆčüąĖčÅą╝ąĖ Framework.
ąĪą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐ąĄčĆą░č鹊čĆčŗ ąĘą░ą┐čĆąŠčüą░ ąĮąĄ ą┐ąŠą┤ą┤ą░čÄčéčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖąĖ, ąĄčüą╗ąĖ ąĖčģ ąĖčüčģąŠą┤ąĮčŗąĄ 菹╗ąĄą╝ąĄąĮčéčŗ ąĮąĄ ąĮą░čģąŠą┤čÅčéčüčÅ ą▓ čüą▓ąŠąĄą╣ ąĖčüčģąŠą┤ąĮąŠą╣ ą┐ąŠąĘąĖčåąĖąĖ ąĖąĮą┤ąĄą║čüą░čåąĖąĖ:
ŌĆó Take, TakeWhile, Skip ąĖ SkipWhile.
ŌĆó ąśąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ Select, SelectMany ąĖ ElementAt.
ąæąŠą╗čīčłąĖąĮčüčéą▓ąŠ ąŠą┐ąĄčĆą░č鹊čĆąŠą▓ ąĘą░ą┐čĆąŠčüą░ ą╝ąĄąĮčÅčÄčé ą┐ąŠąĘąĖčåąĖčÄ ąĖąĮą┤ąĄą║čüą░čåąĖąĖ 菹╗ąĄą╝ąĄąĮč鹊ą▓ (ą▓ą║ą╗čÄčćą░čÅ č鹥, ą║ąŠč鹊čĆčŗąĄ čāą┤ą░ą╗čÅčÄčé 菹╗ąĄą╝ąĄąĮčéčŗ, čéą░ą║ąĖąĄ ą║ą░ą║ Where). ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ąĄčüą╗ąĖ ąÆčŗ čģąŠčéąĖč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čéą░ą║ąĖąĄ ą┐čĆąĄą┤čłąĄčüčéą▓čāčÄčēąĖąĄ ąŠą┐ąĄčĆą░č鹊čĆčŗ, č鹊 ąŠąĮąĖ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą┐ąĄčĆąĄą┤ ąĘą░ą┐čĆąŠčüąŠą╝.
ąĪą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐ąĄčĆą░č鹊čĆčŗ ąĘą░ą┐čĆąŠčüą░ ą╝ąŠą│čāčé ą▒čŗčéčī čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĄąĮčŗ, ąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ąĘą░čéčĆą░čéąĮčāčÄ čüčéčĆą░č鹥ą│ąĖčÄ čĆą░ąĘą┤ąĄą╗ąĄąĮąĖčÅ, ą║ąŠč鹊čĆą░čÅ ąĖąĮąŠą│ą┤ą░ ą╝ąŠąČąĄčé čĆą░ą▒ąŠčéą░čéčī ą╝ąĄą┤ą╗ąĄąĮąĮąĄąĄ, č湥ą╝ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░:
ŌĆó Join, GroupBy, GroupJoin, Distinct, Union, Intersect ąĖ Except.
ą×č鹊ą▒čĆą░ąĮąĮčŗąĄ ą┐ąĄčĆąĄą│čĆčāąĘą║ąĖ ąŠą┐ąĄčĆą░č鹊čĆą░ Aggregate ą▓ čüą▓ąŠąĖčģ čüčéą░ąĮą┤ą░čĆčéąĮčŗčģ ąĖąĮą║ą░čĆąĮą░čåąĖčÅčģ ąĮąĄ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘčāčÄčéčüčÅ - PLINQ ą┤ą╗čÅ ąĮąĖčģ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čüą┐ąĄčåąĖą░ą╗čīąĮčŗąĄ ą┐ąĄčĆąĄą│čĆčāąĘą║ąĖ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ ąŠą┐ąĄčĆą░č鹊čĆčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘčāčÄčéčüčÅ, čģąŠčéčÅ ąĖčģ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąĮąĄ ą┤ą░ąĄčé ą│ą░čĆą░ąĮčéąĖąĖ, čćč鹊 ąÆą░čł ąĘą░ą┐čĆąŠčü ą▒čāą┤ąĄčé čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĄąĮ. PLINQ ą╝ąŠąČąĄčé ąĘą░ą┐čāčüčéąĖčéčī ąÆą░čł ąĘą░ą┐čĆąŠčü ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ, ąĄčüą╗ąĖ ąĘą░ą┐ąŠą┤ąŠąĘčĆąĖčé, čćč鹊 ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ąĘą░čéčĆą░čéčŗ ąĮą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖčÄ ą┤ą░ą┤čāčé čŹčäč乥ą║čé ąĘą░ą╝ąĄą┤ą╗ąĄąĮąĖčÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ąĘą░ą┐čĆąŠčüą░. ąÆčŗ ą╝ąŠąČąĄč鹥 ąŠčéą╝ąĄąĮąĖčéčī čéą░ą║ąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĖ ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ ąĘą░čüčéą░ą▓ąĖčéčī ą┐čĆąĖą╝ąĄąĮčÅčéčī ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčāčÄ ąŠą▒čĆą░ą▒ąŠčéą║čā ą┐čāč鹥ą╝ ą▓čŗąĘąŠą▓ą░ čüą╗ąĄą┤čāčÄčēąĄą│ąŠ ąŠą┐ąĄčĆą░č鹊čĆą░ ą┐ąŠčüą╗ąĄ AsParallel():
.WithExecutionMode (ParallelExecutionMode.ForceParallelism)
ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ąĮą░ą╝ ąĮčāąČąĮąŠ ąĮą░ą┐ąĖčüą░čéčī čüą┐ąĄą╗ą╗č湥ą║ąĄčĆ, ą║ąŠč鹊čĆčŗą╣ ą▒čŗčüčéčĆąŠ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé ą▒ąŠą╗čīčłąĖąĄ ą┤ąŠą║čāą╝ąĄąĮčéčŗ, ąĮą░ą┐čĆčÅą│ą░čÅ ą▓čüąĄ ą┤ąŠčüčéčāą┐ąĮčŗąĄ čÅą┤čĆą░. ą¤čāč鹥ą╝ č乊čĆą╝čāą╗ąĖčĆąŠą▓ą░ąĮąĖčÅ ąĮą░čłąĄą│ąŠ ą░ą╗ą│ąŠčĆąĖčéą╝ą░ ą▓ ą▓ąĖą┤ąĄ ąĘą░ą┐čĆąŠčüą░ LINQ ą╝čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ ąŠč湥ąĮčī ą┐čĆąŠčüč鹊 čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖčéčī ąĄą│ąŠ.
ą¤ąĄčĆą▓čŗą╣ čłą░ą│ čüąŠčüč鹊ąĖčé ą▓ ąĘą░ą│čĆčāąĘą║ąĄ čüą╗ąŠą▓ą░čĆčÅ ą░ąĮą│ą╗ąĖą╣čüą║ąĖčģ čüą╗ąŠą▓ ą▓ HashSet ą┤ą╗čÅ čŹčäč乥ą║čéąĖą▓ąĮąŠą│ąŠ ąŠą▒čĆą░čēąĄąĮąĖčÅ ą║ ąĮąĄą╝čā:
if (!File.Exists ("WordLookup.txt" )) // ąóčāčé čüąŠą┤ąĄčƹȹĖčéčüčÅ ąŠą║ąŠą╗ąŠ 150000 čüą╗ąŠą▓
new WebClient ().DownloadFile (
"http://www.albahari.com/ispell/allwords.txt" , "WordLookup.txt" );
var wordLookup = new HashSet< string > (
File.ReadAllLines ("WordLookup.txt" ),
StringComparer.InvariantCultureIgnoreCase);
ą×ąÜ, č鹥ą┐ąĄčĆčī čüąŠąĘą┤ą░ą┤ąĖą╝ ąĖąĘ ąĮą░čłąĄą╣ čüą╗ąŠą▓ą░čĆąĮąŠą╣ čéą░ą▒ą╗ąĖčåčŗ č鹥čüč鹊ą▓čŗą╣ "ą┤ąŠą║čāą╝ąĄąĮčé", ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅčÄčēąĖą╣ ą╝ą░čüčüąĖą▓ ąĖąĘ ą╝ąĖą╗ą╗ąĖąŠąĮą░ čüą╗čāčćą░ą╣ąĮčŗčģ čüą╗ąŠą▓. ą¤ąŠčüą╗ąĄ čüą▒ąŠčĆą║ąĖ čŹč鹊ą│ąŠ ą╝ą░čüčüąĖą▓ą░ ą▓ą▓ąĄą┤ąĄą╝ ą▓ ąĮąĄą│ąŠ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąŠčĆč乊ą│čĆą░čäąĖč湥čüą║ąĖčģ ąŠčłąĖą▒ąŠą║:
var random = new Random();string [] wordList = wordLookup.ToArray();
string [] wordsToTest = Enumerable.Range (0 , 1000000 )
.Select (i => wordList [random.Next (0 , wordList.Length)])
.ToArray();
wordsToTest [12345 ] = "woozsh" ; // ąŁč鹊 ą▓ą▓ąĄą┤ąĄčé ą┐ą░čĆčā ąŠčłąĖą▒ąŠą║
wordsToTest [23456 ] = "wubsie" ; // ąŠčĆč乊ą│čĆą░čäąĖąĖ.
ąóąĄą┐ąĄčĆčī ą╝čŗ ą╝ąŠąČąĄą╝ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąĮą░čłčā ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčāčÄ ą┐čĆąŠą▓ąĄčĆą║čā ąŠčĆč乊ą│čĆą░čäąĖąĖ ą┐čāč鹥ą╝ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ wordsToTest ąĮą░ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĄ čüą╗ąŠą▓ą░čĆčÄ wordLookup. PLINQ ą┤ąĄą╗ą░ąĄčé čŹč鹊 ąŠč湥ąĮčī ą┐čĆąŠčüč鹊:
var query = wordsToTest
.AsParallel()
.Select ((word, index) => new IndexedWord { Word=word, Index=index })
.Where (iword => !wordLookup.Contains (iword.Word))
.OrderBy (iword => iword.Index);
query.Dump(); // ą×č鹊ą▒čĆą░ąČąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░ ą▓ LINQPad
ąÆąŠčé čĆąĄąĘčāą╗čīčéą░čé, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠą║ą░ąČąĄčé LINQPad:
OrderedParallelQuery< IndexedWord> (2 菹╗ąĄą╝ąĄąĮčéą░)
ąĪą╗ąŠą▓ąŠ ąśąĮą┤ąĄą║čü
woozsh
12345
wubsie
23456
IndexedWord čŹč鹊 ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ą░čÅ čüčéčĆčāą║čéčāčĆą░, ą║ąŠč鹊čĆčāčÄ ą╝čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖą╗ąĖ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
struct IndexedWord { public string Word; public int Index; }
ą£ąĄč鹊ą┤ wordLookup.Contains ą▓ ą┐čĆąĄą┤ąĖą║ą░č鹥 ą┤ą░ąĄčé ąĘą░ą┐čĆąŠčüčā ąĮąĄą║čāčÄ "čüčāčéčī" ąĖ ą┤ąĄą╗ą░ąĄčé ąĄą│ąŠ ą┤ąŠčüč鹊ą╣ąĮčŗą╝ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖąĖ.
ą£čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ ąĮąĄą╝ąĮąŠą│ąŠ čāą┐čĆąŠčüčéąĖčéčī ąĘą░ą┐čĆąŠčü čü ą┐ąŠą╝ąŠčēčīčÄ ą░ąĮąŠąĮąĖą╝ąĮąŠą│ąŠ čéąĖą┐ą░ ą▓ą╝ąĄčüč鹊 čüčéčĆčāą║čéčāčĆčŗ IndexedWord. ą×ą┤ąĮą░ą║ąŠ čŹč鹊 čüąĮąĖąĘąĖą╗ąŠ ą▒čŗ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī, ą┐ąŠč鹊ą╝čā čćč鹊 ą░ąĮąŠąĮąĖą╝ąĮčŗąĄ čéąĖą┐čŗ (ą║ąŠč鹊čĆčŗąĄ čÅą▓ą╗čÅčÄčéčüčÅ ą║ą╗ą░čüčüą░ą╝ąĖ, ąĖ ą┐ąŠčŹč鹊ą╝čā čüčüčŗą╗ąŠčćąĮčŗą╝ąĖ čéąĖą┐ą░ą╝ąĖ) ą┐čĆąĖą▓ąĄą╗ąĖ ą▒čŗ ą║ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÄ ą┐ą░ą╝čÅčéąĖ ą▓ ą║čāč湥 ąĖ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖą╣ ąĘą░ čŹčéąĖą╝ čüą▒ąŠčĆ ą╝čāčüąŠčĆą░.
ąĀą░ąĘąĮąĖčåą░ ą▓ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą╝ąĄąČą┤čā ą║čŹčłąĄą╝ ąĖ čüč鹥ą║ąŠą╝ ą╝ąŠą│ą╗ą░ ą▒čŗ ą▒čŗčéčī ąĮąĄąĘąĮą░čćąĖč鹥ą╗čīąĮąŠą╣ čü ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗą╝ąĖ ąĘą░ą┐čĆąŠčüą░ą╝ąĖ, ąĮąŠ čü ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗą╝ąĖ ąĘą░ą┐čĆąŠčüą░ą╝ąĖ čüč鹥ą║ąŠą▓ąŠąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┤ąŠą▓ąŠą╗čīąĮąŠ ą▓čŗą│ąŠą┤ąĮąĄąĄ. ą¤čĆąĖčćąĖąĮą░ ą▓ č鹊ą╝, čćč鹊 čüč鹥ą║ąŠą▓ąŠąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ąŠč湥ąĮčī čģąŠčĆąŠčłąŠ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘčāąĄčéčüčÅ (čā ą║ą░ąČą┤ąŠą│ąŠ ą┐ąŠč鹊ą║ą░ čüą▓ąŠą╣ čüąŠą▒čüčéą▓ąĄąĮąĮčŗą╣ čüč鹥ą║), ą▓ č鹊 ąČąĄ ą▓čĆąĄą╝čÅ ą▓čüąĄ ą┐ąŠč鹊ą║ąĖ ą┤ąŠą╗ąČąĮčŗ ą║ąŠąĮą║čāčĆąĖčĆąŠą▓ą░čéčī ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝ ąĮą░ ą║čāč湥, čćč鹊 čāą┐čĆą░ą▓ą╗čÅąĄčéčüčÅ ąŠą┤ąĮąĖą╝ ą╝ąĄąĮąĄą┤ąČąĄčĆąŠą╝ ą┐ą░ą╝čÅčéąĖ ąĖ čüą▒ąŠčĆčēąĖą║ąŠą╝ ą╝čāčüąŠčĆą░.
ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ThreadLocal< T>. ąöą░ą▓ą░ą╣č鹥 čĆą░čüčłąĖčĆąĖą╝ ąĮą░čł ą┐čĆąĖą╝ąĄčĆ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖąĄą╣ čüąŠąĘą┤ą░ąĮąĖčÅ čüą░ą╝ąŠą│ąŠ ą╝ą░čüčüąĖą▓ą░ č鹥čüč鹊ą▓čŗčģ čüą╗ąŠą▓. ąĪčéčĆčāą║čéčāčĆąĖčĆčāąĄą╝ ąĄą│ąŠ ą░ą╗ą│ąŠčĆąĖčéą╝ ą▓ ąĘą░ą┐čĆąŠčü LINQ, čćč鹊 ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą┐čĆąŠčüč鹊. ąÆąŠčé čéą░ą║ ą▓čŗą│ą╗čÅą┤ąĖčé ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮą░čÅ ą▓ąĄčĆčüąĖčÅ:
string [] wordsToTest = Enumerable.Range (0 , 1000000 )
.Select (i => wordList [random.Next (0 , wordList.Length)])
.ToArray();
ąÜ čüąŠąČą░ą╗ąĄąĮąĖčÄ, ą▓čŗąĘąŠą▓ random.Next ąĮąĄ ą┐ąŠč鹊ą║ąŠą▒ąĄąĘąŠą┐ą░čüąĄąĮ, čéą░ą║ čćč鹊 ąĮąĄ čéą░ą║ ą┐čĆąŠčüč鹊 ą▓čüčéą░ą▓ąĖčéčī AsParallel() ą▓ čŹč鹊čé ąĘą░ą┐čĆąŠčü. ą¤ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠąĄ čĆąĄčłąĄąĮąĖąĄ ą┐čĆąŠą▒ą╗ąĄą╝čŗ - ąĮą░ą┐ąĖčüą░čéčī čäčāąĮą║čåąĖčÄ, ą║ąŠč鹊čĆą░čÅ ą▒čāą┤ąĄčé ą┤ąĄą╗ą░čéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ą▓ąŠą║čĆčāą│ ą▓čŗąĘą▓ą░ąĮ random.Next; ąŠą┤ąĮą░ą║ąŠ čŹč鹊 čüąĮąĖąĘąĖą╗ąŠ ą▒čŗ čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéčī ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠčüčéąĖ. ąøčāčćčłąĄ ą▓čüąĄą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ThreadLocal< Random>, čćč鹊ą▒čŗ čüąŠąĘą┤ą░čéčī ąŠčéą┤ąĄą╗čīąĮčŗą╣ ąŠą▒čŖąĄą║čé Random ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą┐ąŠč鹊ą║ą░. ąóąŠą│ą┤ą░ ą╝čŗ čüą╝ąŠąČąĄą╝ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖčéčī ąĘą░ą┐čĆąŠčü čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
var localRandom = new ThreadLocal< Random>
( () => new Random (Guid.NewGuid().GetHashCode()) );
string [] wordsToTest = Enumerable.Range (0 , 1000000 ).AsParallel()
.Select (i => wordList [localRandom.Value.Next (0 , wordList.Length)])
.ToArray();
ąØą░čłą░ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮą░čÅ čäčāąĮą║čåąĖčÅ ąĮčāąČąĮą░ ą┤ą╗čÅ ąĖąĮčüčéą░ąĮčåąĖą░čåąĖąĖ ąŠą▒čŖąĄą║čéą░ Random. ąÆ ąĮąĄčæ ą╝čŗ ą┐ąĄčĆąĄą┤ą░ąĄą╝ čģąĄčł-ą║ąŠą┤ Guid, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ąĄčüą╗ąĖ ą┤ą▓ą░ ąŠą▒čŖąĄą║čéą░ Random ą▒čāą┤čāčé čüąŠąĘą┤ą░ąĮčŗ ą▓ ą║ąŠčĆąŠčéą║ąĖą╣ ą┐čĆąŠą╝ąĄąČčāč鹊ą║ ą▓čĆąĄą╝ąĄąĮąĖ, č鹊 ąŠąĮąĖ ą┐čĆąĖą▓ąĄą┤čāčé ą║ čĆą░ąĘą╗ąĖčćąĮčŗą╝ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčÅą╝ čüą╗čāčćą░ą╣ąĮąŠą│ąŠ čćąĖčüą╗ą░.
ąŚą░ą╝ą░ąĮčćąĖą▓ąŠ ą▒čŗą╗ąŠ ą▒čŗ ą┐ąĄčĆąĄą▒čĆą░čéčī ąÆą░čłąĖ ą│ąŠč鹊ą▓čŗąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą▓ ą┐ąŠąĖčüą║ąĄ ąĘą░ą┐čĆąŠčüąŠą▓ LINQ, ąĖ ą┐ąŠčŹą║čüą┐ąĄčĆąĖą╝ąĄąĮčéąĖčĆąŠą▓ą░čéčī čü ąĮąĖą╝ąĖ ąĮą░ ą┐čĆąĄą┤ą╝ąĄčé ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖąĖ. ąŁč鹊 ąŠą▒čŗčćąĮąŠ ąĮąĄ ą▒čāą┤ąĄčé ą┐čĆąŠą┤čāą║čéąĖą▓ąĮčŗą╝, ą┐ąŠč鹊ą╝čā čćč鹊 ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąŠ ą┐čĆąŠą▒ą╗ąĄą╝, ą┤ą╗čÅ čĆąĄčłąĄąĮąĖąĄ ą║ąŠč鹊čĆčŗčģ LINQ ą╗čāčćčłąĄ ą▓čüąĄą│ąŠ ą┐ąŠą┤čģąŠą┤ąĖčé, ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ąŠč湥ąĮčī ą▒čŗčüčéčĆąŠ, ąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖčÅ ąĮąĄ ą┤ą░čüčé ą▓čŗą│ąŠą┤čŗ. ąøčāčćčłąĄ ą▓čüąĄą│ąŠ ąĮą░ą╣čéąĖ č鹥 ą╝ąĄčüčéą░, ą│ą┤ąĄ ąĖąĮč鹥ąĮčüąĖą▓ąĮčŗąĄ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ CPU čüąŠčüčéą░ą▓ą╗čÅčÄčé čāąĘą║ąŠąĄ ą╝ąĄčüč鹊 ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ąĘą░ą┤ą░čéčī čüąĄą▒ąĄ ą▓ąŠą┐čĆąŠčü: "ą╝ąŠąČąĮąŠ ą╗ąĖ ą║ą░ą║-č鹊 ą┐čĆąĄą┤čüčéą░ą▓ąĖčéčī čŹčéąĖ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ ą▓ ą▓ąĖą┤ąĄ ąĘą░ą┐čĆąŠčüą░ LINQ?" (ą┤ąŠą▒čĆąŠ ą┐ąŠąČą░ą╗ąŠą▓ą░čéčī ą▓ ą┐ąŠą▒ąŠčćąĮčŗąĄ čŹčäč乥ą║čéčŗ čĆąĄčüčéčĆčāą║čéčāčĆąĖąĘą░čåąĖąĖ ą║ąŠą┤ą░, ą║ąŠą│ą┤ą░ LINQ ąŠą▒čŗčćąĮąŠ čāą╝ąĄąĮčīčłą░ąĄčé ą║ąŠą┤ ąĖ ą┤ąĄą╗ą░ąĄčé ąĄą│ąŠ ą▒ąŠą╗ąĄąĄ čćąĖčéą░ąĄą╝čŗą╝).
PLINQ čéą░ą║ąČąĄ čģąŠčĆąŠčłąŠ ą┐ąŠą┤čģąŠą┤ąĖčé ą┤ą╗čÅ čüą╗čāčćą░ąĄą▓, ą║ąŠą│ą┤ą░ ąĄčüčéčī čüą╗ąŠąČąĮąŠčüčéąĖ čü čĆčāčćąĮčŗą╝ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖą▓ą░ąĮąĖąĄą╝ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣. ąŁč鹊 čéą░ą║ąČąĄ ą┐ąŠą┤čģąŠą┤ąĖčé ą┤ą╗čÅ čüčéčĆčāą║čéčāčĆąĖčĆąŠą▓ą░ąĮąĮčŗčģ ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĖčģčüčÅ ąĘą░ą┤ą░čć, čéą░ą║ąĖčģ ą║ą░ą║ ą▓čŗąĘąŠą▓ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą▓ąĄą▒-čüąĄčĆą▓ąĖčüąŠą▓ čüčĆą░ąĘčā (čüą╝. "ąÆčŗąĘąŠą▓ ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĖčģ ąĖ ąĖąĮč鹥ąĮčüąĖą▓ąĮčŗčģ ą┐ąŠ ą▓ą▓ąŠą┤čā/ą▓čŗą▓ąŠą┤čā čäčāąĮą║čåąĖą╣").
PLINQ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ą╗ąŠčģąĖą╝ ą▓čŗą▒ąŠčĆąŠą╝ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĖąĘąŠą▒čĆą░ąČąĄąĮąĖą╣, ą┐ąŠč鹊ą╝čā čćč鹊 čüą▒ąŠčĆą║ą░ ą▓ą╝ąĄčüč鹥 ą╝ąĖą╗ą╗ąĖąŠąĮąŠą▓ č鹊č湥ą║ ą▓ ą▓čŗčģąŠą┤ąĮčāčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī čüčéą░ąĮąĄčé čāąĘą║ąĖą╝ ą╝ąĄčüč鹊ą╝ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą╗čāčćčłąĄ ą▓čüąĄą│ąŠ ąĘą░ą┐ąĖčüčŗą▓ą░čéčī č鹊čćą║ąĖ ą┐čĆčÅą╝ąŠ ą╝ą░čüčüąĖą▓ ąĮąĄ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ ą▒ą╗ąŠą║ą░ ą┐ą░ą╝čÅčéąĖ, ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą║ą╗ą░čüčü Parallel ąĖą╗ąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ ąĘą░ą┤ą░čć ą┤ą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠčüčéčīčÄ (ąŠą┤ąĮą░ą║ąŠ ąĄčüčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą┐ąŠą▒ąĄą┤ąĖčéčī ą║ąŠąĮąĄčćąĮčŗą╣ čüą▒ąŠčĆ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ForAll. ąóą░ą║ ą┤ąĄą╗ą░čéčī čüč鹊ąĖčé, ąĄčüą╗ąĖ ą░ą╗ą│ąŠčĆąĖčéą╝ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĖąĘąŠą▒čĆą░ąČąĄąĮąĖčÅ ąĄčüč鹥čüčéą▓ąĄąĮąĮąŠ čāą║ą╗ą░ą┤čŗą▓ą░ąĄčéčüčÅ ą▓ LINQ).
ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮą░čÅ čćąĖčüč鹊čéą░ . ą¤ąŠčüą║ąŠą╗čīą║čā PLINQ ąĘą░ą┐čāčüą║ą░ąĄčé ąÆą░čł ąĘą░ą┐čĆąŠčü ą▓ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗčģ ą┐ąŠč鹊ą║ą░čģ, ąÆčŗ ą┤ąŠą╗ąČąĮčŗ ąŠčüč鹥čĆąĄą│ą░čéčīčüčÅ ą▓čŗą┐ąŠą╗ąĮčÅčéčī ąĮąĄ ą▒ąĄąĘąŠą┐ą░čüąĮčŗąĄ ą┤ą╗čÅ ą┐ąŠč鹊ą║ąŠą▓ ąŠą┐ąĄčĆą░čåąĖąĖ. ąÆ čćą░čüčéąĮąŠčüčéąĖ, ąĘą░ą┐ąĖčüčī ą▓ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ ą┤ą░čüčé ą┐ąŠą▒ąŠčćąĮčŗąĄ čŹčäč乥ą║čéčŗ, ąĖ ą┐ąŠčŹč鹊ą╝čā ąĮąĄ ą▒čāą┤ąĄčé ą┐ąŠč鹊ą║ąŠą▒ąĄąĘąŠą┐ą░čüąĮąŠą╣:
// ąĪą╗ąĄą┤čāčÄčēąĖą╣ ąĘą░ą┐čĆąŠčü čāą╝ąĮąŠąČą░ąĄčé ą║ą░ąČą┤čŗą╣ 菹╗ąĄą╝ąĄąĮčé ąĮą░ ąĄą│ąŠ ą┐ąŠąĘąĖčåąĖčÄ. // ąĢčüą╗ąĖ ąĮą░ ą▓čģąŠą┤ąĄ Enumerable.Range(0,999), č鹊 čŹč鹊 ą┤ąŠą╗ąČąĮąŠ ą┤ą░čéčī ąĮą░ ą▓čŗčģąŠą┤ąĄ // ą║ą▓ą░ą┤čĆą░čéčŗ čćąĖčüąĄą╗. int i = 0 ;var query = from n in Enumerable.Range(0 ,999 ).AsParallel() select n * i++;
ą£čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ čüą┤ąĄą╗ą░čéčī ąĖąĮą║čĆąĄą╝ąĄąĮčé i ą┐ąŠč鹊ą║ąŠą▒ąĄąĘąŠą┐ą░čüąĮčŗą╝ ą┐čāč鹥ą╝ ą▓ą▓ąŠą┤ą░ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║ ąĖą╗ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą║ą╗ą░čüčüą░ Interlocked [5], ąĮąŠ ą┐čĆąŠą▒ą╗ąĄą╝ą░ ą▓čüąĄ ąĄčēąĄ ąŠčüčéą░ąĮąĄčéčüčÅ, ą┐ąŠčüą║ąŠą╗čīą║čā i ąĮąĄ ąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ ą▒čāą┤ąĄčé čüąŠąŠčéą▓ąĄčéčüčéą▓ąŠą▓ą░čéčī ą┐ąŠąĘąĖčåąĖąĖ ą▓čģąŠą┤ąĮąŠą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░. ąś ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ AsOrdered ą▓ ąĘą░ą┐čĆąŠčü ąĮąĄ čĆąĄčłąĖą╗ąŠ ą▒čŗ čŹčéčā ą┐čĆąŠą▒ą╗ąĄą╝čā, ą┐ąŠč鹊ą╝čā čćč鹊 AsOrdered ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé č鹊ą╗čīą║ąŠ č鹊, čćč鹊 菹╗ąĄą╝ąĄąĮčéčŗ ą┐ąŠčÅą▓čÅčéčüčÅ ąĮą░ ą▓čŗčģąŠą┤ąĄ ą▓ č鹊ą╝ ąČąĄ ą┐ąŠčĆčÅą┤ą║ąĄ, ą▓ ą║ą░ą║ąŠą╝ ąŠąĮąĖ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ą╗ąĖčüčī ą▒čŗ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ - ąĮąŠ čŹč鹊 ąĮąĄ ą┤ą░čüčé ąĖčģ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮčāčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčāčÄ ąŠą▒čĆą░ą▒ąŠčéą║čā.
ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ąĘą░ą┐čĆąŠčü ąĮčāąČąĮąŠ ą┐ąĄčĆąĄą┐ąĖčüą░čéčī čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą╣ ą▓ąĄčĆčüąĖąĖ Select:
var query = Enumerable.Range(0 ,999 ).AsParallel().Select ((n, i) => n * i);
ąöą╗čÅ ą╗čāčćčłąĄą╣ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą╗čÄą▒čŗąĄ ą╝ąĄč鹊ą┤čŗ, ą▓čŗąĘčŗą▓ą░ąĄą╝čŗąĄ ąĖąĘ ąŠą┐ąĄčĆą░č鹊čĆąŠą▓ ąĘą░ą┐čĆąŠčüą░, ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą┐ąŠč鹊ą║ąŠą▒ąĄąĘąŠą┐ą░čüąĮčŗą╝ąĖ, ą┤ą╗čÅ č湥ą│ąŠ ąŠąĮąĖ ąĮąĄ ą┤ąŠą╗ąČąĮčŗ ąĘą░ą┐ąĖčüčŗą▓ą░čéčī čćč鹊-č鹊 ą▓ ą┐ąŠą╗čÅ ąĖą╗ąĖ čüą▓ąŠą╣čüčéą▓ą░ (ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą▒ąĄąĘ ą┐ąŠą▒ąŠčćąĮčŗčģ čŹčäč乥ą║č鹊ą▓, ąĖą╗ąĖ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠ čćąĖčüčéčŗą╝ąĖ). ąĢčüą╗ąĖ ą┐ąŠč鹊ą║ąŠą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéčī ą┤ąŠčüčéąĖą│ą░ąĄčéčüčÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąŠą╣, č鹊 ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ ąĘą░ą┐čĆąŠčüą░ ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ ą▒čāą┤ąĄčé ąŠą│čĆą░ąĮąĖč湥ąĮ - ąĮą░ ą║ąŠčŹčäčäąĖčåąĖąĄąĮčé, čĆą░ą▓ąĮčŗą╣ ą┤ą╗ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ, ą┐ąŠą┤ąĄą╗ąĄąĮąĮąŠą╣ ąĮą░ ąŠą▒čēąĄąĄ ą▓čĆąĄą╝čÅ, ą┐ąŠčéčĆą░č湥ąĮąĮąŠąĄ ą▓ čŹč鹊ą╣ čäčāąĮą║čåąĖąĖ.
ąÆčŗąĘąŠą▓ ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĖčģ ąĖ ąĖąĮč鹥ąĮčüąĖą▓ąĮčŗčģ ą┐ąŠ ą▓ą▓ąŠą┤čā/ą▓čŗą▓ąŠą┤čā čäčāąĮą║čåąĖą╣. ąśąĮąŠą│ą┤ą░ ąĘą░ą┐čĆąŠčü ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą┤ąŠą╗ą│ąŠ ąĮąĄ ąĖąĘ-ąĘą░ ąĘą░ą│čĆčāąĘą║ąĖ CPU, ą░ ąĖąĘ-ąĘą░ ąŠąČąĖą┤ą░ąĮąĖčÅ č湥ą│ąŠ-ąĮąĖą▒čāą┤čī - čéą░ą║ąŠą│ąŠ ą║ą░ą║ ąŠąČąĖą┤ą░ąĮąĖąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ ą▓ąĄą▒-čüčéčĆą░ąĮąĖčåčŗ ąĖą╗ąĖ ąŠčéą▓ąĄčéą░ ą░ą┐ą┐ą░čĆą░čéčāčĆčŗ. PLINQ ą╝ąŠąČąĄčé čŹčäč乥ą║čéąĖą▓ąĮąŠ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖčéčī čéą░ą║ąĖąĄ ąĘą░ą┐čĆąŠčüčŗ, ąĄčüą╗ąĖ ąÆčŗ ą┤ą░ą┤ąĖč鹥 ąĄą╝čā ą┐ąŠą┤čüą║ą░ąĘą║čā, ą▓čŗąĘą▓ą░ą▓ WithDegreeOfParallelism ą┐ąŠčüą╗ąĄ AsParallel. ąØą░ą┐čĆąĖą╝ąĄčĆ ą┐čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ą╝čŗ čģąŠčéąĖą╝ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą┐ąĖąĮą│ čłąĄčüčéąĖ web-čüą░ą╣č鹊ą▓ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ. ąÆą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĮąĄčāą║ą╗čĹȹĖčģ ą░čüąĖąĮčģčĆąŠąĮąĮčŗčģ ą┤ąĄą╗ąĄą│ą░č鹊ą▓ ąĖą╗ąĖ ą▓čĆčāčćąĮčāčÄ ąĘą░ą┐čāčüą║ą░čéčī 6 ą┐ąŠč鹊ą║ąŠą▓, čŹč鹊 ą╝ąŠąČąĮąŠ čŹčäč乥ą║čéąĖą▓ąĮąŠ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąĘą░ą┐čĆąŠčüąŠą╝ PLINQ:
from site in new []
{
"www.albahari.com" ,
"www.linqpad.net" ,
"www.oreilly.com" ,
"www.takeonit.com" ,
"stackoverflow.com" ,
"www.rebeccarey.com"
}
.AsParallel().WithDegreeOfParallelism(6 )
let p = new Ping().Send (site)select new
{
site,
Result = p.Status,
Time = p.RoundtripTime
}
WithDegreeOfParallelism ą┐čĆąĖąĮčāąČą┤ą░ąĄčé PLINQ ąĘą░ą┐čāčüčéąĖčéčī čāą║ą░ąĘą░ąĮąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠč鹊ą║ąŠą▓ (ą▓ ą┤ą░ąĮąĮąŠą╝ ą┐čĆąĖą╝ąĄčĆąĄ 6) ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ. ąŁč鹊 ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ, ą║ąŠą│ą┤ą░ ą▓čŗąĘčŗą▓ą░čÄčéčüčÅ čéą░ą║ąĖąĄ ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĖąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐ąŠč鹊ą║ą░ čäčāąĮą║čåąĖąĖ, ą║ą░ą║ Ping.Send, ą┐ąŠč鹊ą╝čā čćč鹊 PLINQ ąĖąĮą░č湥 ą┐čĆąĄą┤ą┐ąŠą╗ą░ą│ą░ąĄčé, čćč鹊 ąĘą░ą┐čĆąŠčü ąĖąĮč鹥ąĮčüąĖą▓ąĮąŠ ąĘą░ą│čĆčāąČą░ąĄčé CPU, ąĖ ą▓čŗą┤ąĄą╗čÅąĄčé ąĘą░ą┤ą░čćąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĮą░ ą┤ą▓čāčģčÅą┤ąĄčĆąĮąŠą╣ ą╝ą░čłąĖąĮąĄ PLINQ ą╝ąŠąČąĄčé ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĘą░ą┐čāčüčéąĖčéčī ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ č鹊ą╗čīą║ąŠ 2 ąĘą░ą┤ą░čćąĖ, čćč鹊 ą▓ ą┤ą░ąĮąĮąŠą╣ čüąĖčéčāą░čåąĖąĖ ąŠč湥ąĮčī ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮąŠ.
PLINQ ąŠą▒čŗčćąĮąŠ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄčé ą║ą░ąČą┤čāčÄ ąĘą░ą┤ą░čćčā ą▓ ą┐ąŠč鹊ą║ąĄ čüąŠą│ą╗ą░čüąĮąŠ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÄ ą▓ ą┐čāą╗ąĄ ą┐ąŠč鹊ą║ąŠą▓. ąÆčŗ ą╝ąŠąČąĄč鹥 čāčüą║ąŠčĆąĖčéčī ąĮą░čćą░ą╗čīąĮčŗą╣ ąĘą░ą┐čāčüą║ ą┐ąŠč鹊ą║ąŠą▓ ą▓čŗąĘąŠą▓ąŠą╝ ThreadPool.SetMinThreads.
ąöą╗čÅ ą┤čĆčāą│ąŠą│ąŠ ą┐čĆąĖą╝ąĄčĆą░ ą┐čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ą╝čŗ ą┐ąĖčłąĄą╝ čüąĖčüč鹥ą╝čā ąĮą░ą▒ą╗čÄą┤ąĄąĮąĖčÅ, ąĖ čģąŠčéąĖą╝ čü ą┐ąŠą▓č鹊čĆą░ą╝ąĖ ą║ąŠą╝ą▒ąĖąĮąĖčĆąŠą▓ą░čéčī ąĖąĘąŠą▒čĆą░ąČąĄąĮąĖčÅ ąĖąĘ 4 ą║ą░ą╝ąĄčĆ ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéąĖ ą▓ ąŠą┤ąĮąŠ ąŠą▒čēąĄąĄ ąĖąĘąŠą▒čĆą░ąČąĄąĮąĖąĄ ą┤ą╗čÅ ąŠč鹊ą▒čĆą░ąČąĄąĮąĖčÅ ąĮą░ ą╝ąŠąĮąĖč鹊čĆąĄ ąĮą░ą▒ą╗čÄą┤ąĄąĮąĖčÅ. ą¤čĆąĄą┤čüčéą░ą▓ąĖą╝ ą║ą░ą╝ąĄčĆčā čüą╗ąĄą┤čāčÄčēąĖą╝ ą║ą╗ą░čüčüąŠą╝:
class Camera
{
public readonly int CameraID;
public Camera (int cameraID) { CameraID = cameraID; }
// ą¤ąŠą╗čāč湥ąĮąĖąĄ ąĖąĘąŠą▒čĆą░ąČąĄąĮąĖčÅ čü ą║ą░ą╝ąĄčĆčŗ: ą▓ąĄčĆąĮąĄčé ą┐čĆąŠčüčéčāčÄ čüčéčĆąŠą║čā ą▓ą╝ąĄčüč鹊 ą║ą░čĆčéąĖąĮą║ąĖ.
public string GetNextFrame ()
{
Thread.Sleep (123 ); // ąĪąĖą╝čāą╗čÅčåąĖčÅ ą▓čĆąĄą╝ąĄąĮąĖ ą┐ąŠą╗čāč湥ąĮąĖčÅ čüąĮąĖą╝ą║ą░.
return "ąÜą░ą┤čĆ ąĖąĘ ą║ą░ą╝ąĄčĆčŗ " + CameraID;
}
}
ą¦č鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī čüąŠčüčéą░ą▓ąĮčāčÄ ą║ą░čĆčéąĖąĮą║čā, ą╝čŗ ą┤ąŠą╗ąČąĮčŗ ą▓čŗąĘą▓ą░čéčī GetNextFrame ąĮą░ ą║ą░ąČą┤ąŠą╝ ąŠą▒čŖąĄą║č鹥 ą║ą░ą╝ąĄčĆčŗ. ąĢčüą╗ąĖ ąĘą░čĆą░ąĮąĄąĄ ąĘąĮą░čéčī, čćč鹊 čŹčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ ą┐čĆąĖą▓čÅąĘą░ąĮą░ ą║ ąĖąĮč鹥ąĮčüąĖą▓ąĮąŠą╝čā ą▓ą▓ąŠą┤čā/ą▓čŗą▓ąŠą┤čā, č鹊 ą╝ąŠąČąĮąŠ čāčüą║ąŠčĆąĖčéčī ą▓ 4 čĆą░ąĘą░ čüą║ąŠčĆąŠčüčéčī čüą╝ąĄąĮčŗ ą║ą░ą┤čĆąŠą▓ ąĮą░ ą╝ąŠąĮąĖč鹊čĆąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄą╝ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖąĖ - ą┤ą░ąČąĄ ąĮą░ ąŠą┤ąĮąŠčÅą┤ąĄčĆąĮąŠą╣ ą╝ą░čłąĖąĮąĄ. PLINQ ą┤ąĄą╗ą░ąĄčé čŹč鹊 ą▓ąŠąĘą╝ąŠąČąĮčŗą╝ čü ą╝ąĖąĮąĖą╝ą░ą╗čīąĮčŗą╝ąĖ čāčüąĖą╗ąĖčÅą╝ąĖ:
Camera[] cameras = Enumerable.Range (0 , 4 ) // ąĪąŠąĘą┤ą░ąĮąĖąĄ 4 ąŠą▒čŖąĄą║č鹊ą▓ ą║ą░ą╝ąĄčĆ.
.Select (i => new Camera (i))
.ToArray();
while (true )
{
string [] data = cameras
.AsParallel().AsOrdered().WithDegreeOfParallelism (4 )
.Select (c => c.GetNextFrame()).ToArray();
Console.WriteLine (string .Join (", " , data)); // ą×č鹊ą▒čĆą░ąČąĄąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ...
}
GetNextFrame čÅą▓ą╗čÅąĄčéčüčÅ ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĖą╝čüčÅ ą╝ąĄč鹊ą┤ąŠą╝, ą┐ąŠčŹč鹊ą╝čā ą╝čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ WithDegreeOfParallelism, čćč鹊ą▒čŗ ą┤ąŠčüčéąĖčćčī ąĮčāąČąĮąŠą╣ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠčüčéąĖ. ąÆ ąĮą░čłąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé, ą║ąŠą│ą┤ą░ ą╝čŗ ą▓čŗąĘčŗą▓ą░ąĄą╝ Sleep; ą▓ čĆąĄą░ą╗čīąĮąŠą╣ ąČąĖąĘąĮąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą▒čāą┤ąĄčé ą┐čĆąŠąĖčüčģąŠą┤ąĖčéčī ąĖąĘ-ąĘą░ ą┐ąŠą╗čāč湥ąĮąĖčÅ ąĖąĘąŠą▒čĆą░ąČąĄąĮąĖčÅ ąĖąĘ ą║ą░ą╝ąĄčĆčŗ, ą┐ąŠč鹊ą╝čā čćč鹊 ą┐ąŠč鹊ą║ ą▓ą▓ąŠą┤ą░/ą▓čŗą▓ąŠą┤ą░ ą┤ą░ąĮąĮčŗčģ čü ą║ą░ą╝ąĄčĆčŗ čéčĆąĄą▒čāąĄčé ą┐čĆąŠčüč鹊 ąŠąČąĖą┤ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ ąĖ ąĮąĄ ą▓ąŠą▓ą╗ąĄą║ą░ąĄčé ąĖąĮč鹥ąĮčüąĖą▓ąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ CPU.
ąÆčŗąĘąŠą▓ AsOrdered ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ą║ą░čĆčéąĖąĮą║ąĖ ą▒čāą┤čāčé ąŠč鹊ą▒čĆą░ąČą░ąĄčéčüčÅ ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╝ ą┐ąŠčĆčÅą┤ą║ąĄ. ą¤ąŠčüą║ąŠą╗čīą║čā ąĘą┤ąĄčüčī č鹊ą╗čīą║ąŠ 4 菹╗ąĄą╝ąĄąĮčéą░ ą▓ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ, čŹč鹊 ą┤ą░čüčé ąĮąĄąĘąĮą░čćąĖč鹥ą╗čīąĮčŗą╣ čŹčäč乥ą║čé ąĮą░ čüąĮąĖąČąĄąĮąĖąĄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ.
ąśąĘą╝ąĄąĮąĄąĮąĖąĄ čüč鹥ą┐ąĄąĮąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ą░ . ąÆčŗ ą╝ąŠąČąĄč鹥 č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ čĆą░ąĘ ą▓čŗąĘą▓ą░čéčī WithDegreeOfParallelism ą▓ ąĘą░ą┐čĆąŠčüąĄ PLINQ. ąĢčüą╗ąĖ ąĮčāąČąĮąŠ ą▓čŗąĘą▓ą░čéčī ąĄą│ąŠ čüąĮąŠą▓ą░, č鹊 čüą╗ąĄą┤čāąĄčé ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ čüą╗ąĖčéčī ą┤ą░ąĮąĮčŗąĄ ąĘą░ą┐čĆąŠčüą░ ąĖ ąĘą░ąĮąŠą▓ąŠ ąĄą│ąŠ čĆą░ąĘą┤ąĄą╗ąĖčéčī ą┐ąŠą▓č鹊čĆąĮčŗą╝ ą▓čŗąĘąŠą▓ąŠą╝ AsParallel() ą▓ ąĘą░ą┐čĆąŠčüąĄ:
"The Quick Brown Fox"
.AsParallel().WithDegreeOfParallelism (2 )
.Where (c => !char .IsWhiteSpace (c))
.AsParallel().WithDegreeOfParallelism (3 ) // ą¤čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠąĄ čüą╗ąĖčÅąĮąĖąĄ + čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ
.Select (c => char .ToUpper (c))
ą×čéą╝ąĄąĮą░ ąĘą░ą┐čĆąŠčüą░ (Cancellation). ą×čéą╝ąĄąĮą░ ąĘą░ą┐čĆąŠčüą░ PLINQ, ą║ąŠą│ą┤ą░ ąÆčŗ ą┐ąŠčéčĆąĄą▒ą╗čÅąĄč鹥 ąĄą│ąŠ čĆąĄąĘčāą╗čīčéą░čéčŗ ą▓ čåąĖą║ą╗ąĄ foreach, ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┐čĆąŠčüč鹊: ąŠą▒čŗčćąĮčŗą╣ break ą▓ čåąĖą║ą╗ąĄ foreach ąĘą░ą▓ąĄčĆčłąĖčé ą┐čĆąŠą║čĆčāčéą║čā čåąĖą║ą╗ą░, ąĖ ąĘą░ą┐čĆąŠčü ą▒čāą┤ąĄčé ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ąŠčéą╝ąĄąĮąĄąĮ ą┐ąŠčüą║ąŠą╗čīą║čā ą┐ąĄčĆąĄčćąĖčüą╗ąĖč鹥ą╗čī ą▒čŗą╗ ąĮąĄčÅą▓ąĮąŠ čāąĮąĖčćč鹊ąČąĄąĮ.
ąöą╗čÅ ąĘą░ą┐čĆąŠčüą░, ą║ąŠč鹊čĆčŗą╣ ąĘą░ą▓ąĄčĆčłą░ąĄčéčüčÅ ąĮą░ ąŠą┐ąĄčĆą░č鹊čĆ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅ, 菹╗ąĄą╝ąĄąĮčéą░ ąĖą╗ąĖ ą░ą│čĆąĄą│ą░čåąĖąĖ, ąĄą│ąŠ ą╝ąŠąČąĮąŠ ąŠčéą╝ąĄąĮąĖčéčī ąĖąĘ ą┤čĆčāą│ąŠą│ąŠ ą┐ąŠč鹊ą║ą░ č湥čĆąĄąĘ ą╝ą░čĆą║ąĄčĆ ąŠčéą╝ąĄąĮčŗ (cancellation token). ą¦č鹊ą▒čŗ ą▓čüčéą░ą▓ąĖčéčī ą╝ą░čĆą║ąĄčĆ (token), ą▓čŗąĘąŠą▓ąĖč鹥 WithCancellation ą┐ąŠčüą╗ąĄ ą▓čŗąĘąŠą▓ą░ AsParallel, ą┐ąĄčĆąĄą┤ą░ą▓ ą▓ čüą▓ąŠą╣čüčéą▓ąĄ Token ąŠą▒čŖąĄą║čé CancellationTokenSource. ą¤ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ą┤čĆčāą│ąŠą╣ ąŠą▒čŖąĄą║čé ą╝ąŠąČąĄčé ą▓čŗąĘą▓ą░čéčī Cancel ąĮą░ ąĖčüč鹊čćąĮąĖą║ąĄ ą╝ą░čĆą║ąĄčĆą░, čćč鹊 ą▓čŗą▒čĆąŠčüąĖčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ OperationCanceledException ą▓ ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗ąĄ ąĘą░ą┐čĆąŠčüą░:
IEnumerable< int > million = Enumerable.Range (3 , 1000000 );
var cancelSource = new CancellationTokenSource(); var primeNumberQuery =
from n in million.AsParallel().WithCancellation (cancelSource.Token)
where Enumerable.Range (2 , (int ) Math.Sqrt (n)).All (i => n % i > 0 )
select n;
new Thread (() => {
Thread.Sleep (100 ); // ą×čéą╝ąĄąĮą░ ąĘą░ą┐čĆąŠčüą░ č湥čĆąĄąĘ
cancelSource.Cancel(); // 100 ą╝ąĖą╗ą╗ąĖčüąĄą║čāąĮą┤.
}
).Start();try
{
// ąŚą░ą┐čāčüą║ ąĘą░ą┐čĆąŠčüą░ ą▓ čĆą░ą▒ąŠčéčā:
int [] primes = primeNumberQuery.ToArray();
// ąĪčÄą┤ą░ ą╝čŗ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą┐ąŠą┐ą░ą┤ąĄą╝, ą┐ąŠč鹊ą╝čā čćč鹊 ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║ ąŠčéą╝ąĄąĮąĖčé čĆą░ą▒ąŠčéčā čŹč鹊ą│ąŠ ą║ąŠą┤ą░.
}catch (OperationCanceledException)
{
Console.WriteLine ("ąŚą░ą┐čĆąŠčü ąŠčéą╝ąĄąĮąĄąĮ" );
}
PLINQ ąĮąĄ ą┤ąĄą╗ą░ąĄčé ą▓čŗč鹥čüąĮčÅčÄčēąĖą╣ ąŠą▒čĆčŗą▓ čĆą░ą▒ąŠčéčŗ ą┐ąŠč鹊ą║ą░, ą┐ąŠč鹊ą╝čā čćč鹊 čŹč鹊 ąŠą┐ą░čüąĮąŠ (čüą╝. "ą¤čĆąĄą║čĆą░čēąĄąĮąĖąĄ čĆą░ą▒ąŠčéčŗ ą┐ąŠč鹊ą║ą░" [5]). ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą┐čĆąĖ ąŠčéą╝ąĄąĮąĄ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąŠąČąĖą┤ą░ąĮąĖąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ č鹥ą║čāčēąĄą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░ čā ą║ą░ąČą┤ąŠą│ąŠ čĆą░ą▒ąŠč湥ą│ąŠ ą┐ąŠč鹊ą║ą░ ą┐ąĄčĆąĄą┤ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄą╝ ąĘą░ą┐čĆąŠčüą░. ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą╗čÄą▒čŗąĄ ą▓ąĮąĄčłąĮąĖąĄ ą╝ąĄč鹊ą┤čŗ, ą║ąŠč鹊čĆčŗąĄ ą▓čŗąĘčŗą▓ą░ąĄčé ąĘą░ą┐čĆąŠčü, ąŠčéčĆą░ą▒ąŠčéą░čÄčé ą┤ąŠ čüą▓ąŠąĄą│ąŠ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ.
ą×ą┐čéąĖą╝ąĖąĘą░čåąĖčÅ ą┐ąŠ ą▓čŗčģąŠą┤čā . ą×ą┤ąĮąŠ ąĖąĘ ą┤ąŠčüč鹊ąĖąĮčüčéą▓ PLINQ - čāą┤ąŠą▒ąĮąŠ čüąŠąĄą┤ąĖąĮčÅčÄčéčüčÅ čĆąĄąĘčāą╗čīčéą░čéčŗ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĄąĮąĮąŠą╣ čĆą░ą▒ąŠčéčŗ ą▓ ąŠą┤ąĮčā ą▓čŗčģąŠą┤ąĮčāčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī. ąźąŠčéčÅ ąĖąĮąŠą│ą┤ą░ ą▓čüąĄ, čćč鹊 čéčĆąĄą▒čāąĄčéčüčÅ - ąĘą░ą┐čāčüčéąĖčéčī ąĮąĄą║čāčÄ čäčāąĮą║čåąĖčÄ ą┐ąŠ ąŠą┤ąĮąŠą╝čā čĆą░ąĘčā ąĮą░ ą║ą░ąČą┤čŗą╣ 菹╗ąĄą╝ąĄąĮčé:
foreach (int n in parallelQuery)
DoSomething (n);
ąĢčüą╗ąĖ ąĖą╝ąĄąĄčé ą╝ąĄčüč鹊 čŹč鹊čé čüą╗čāčćą░ą╣, ąĖ ąĮąĄ ąĖą╝ąĄąĄčé ąĘąĮą░č湥ąĮąĖčÅ, ą▓ ą║ą░ą║ąŠą╝ ą┐ąŠčĆčÅą┤ą║ąĄ ą▒čāą┤čāčé ąŠą▒čĆą░ą▒ąŠčéą░ąĮčŗ 菹╗ąĄą╝ąĄąĮčéčŗ, č鹊 ą╝ąŠąČąĮąŠ čāą╗čāčćčłąĖčéčī čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéčī PLINQ ą╝ąĄč鹊ą┤ąŠą╝ ForAll.
ą£ąĄč鹊ą┤ ForAll ąĘą░ą┐čāčüą║ą░ąĄčé ą┤ąĄą╗ąĄą│ą░čéą░ ąĮą░ ą║ą░ąČą┤čŗą╣ ą▓čŗčģąŠą┤ąĮąŠą╣ 菹╗ąĄą╝ąĄąĮčé ParallelQuery. ąŁč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĮą░ą┐čĆčÅą╝čāčÄ ą▓ PLINQ, ą┐čĆąŠą┐čāčüą║ą░čÅ čłą░ą│ąĖ čüą╗ąĖčÅąĮąĖčÅ ąĖ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖčÅ čĆąĄąĘčāą╗čīčéą░č鹊ą▓. ą¤čĆąŠčüč鹥ą╣čłąĖą╣ ą┐čĆąĖą╝ąĄčĆ:
"abcdef" .AsParallel().Select (c => char .ToUpper(c)).ForAll (Console.Write);
ąĪą▒ąŠčĆ ą▓ą╝ąĄčüč鹥 ąĖ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ąĮąĄ ą╝ą░čüčüąĖą▓ąĮąŠ ą┤ąŠčĆąŠą│ą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ, čéą░ą║ čćč鹊 ąŠą┐čéąĖą╝ąĖąĘą░čåąĖčÅ ForAll čāčüčéčāą┐ą░ąĄčé ą▒ąŠą╗čīčłąĖą╝ ą▓čŗą│ąŠą┤ą░ą╝, ą║ąŠą│ą┤ą░ ą▒ąŠą╗čīčłąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒čŗčüčéčĆąŠ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄą╝čŗčģ ą▓čģąŠą┤ąĮčŗčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓.
ą×ą┐čéąĖą╝ąĖąĘą░čåąĖčÅ ą┐ąŠ ą▓čģąŠą┤čā . ąŻ PLINQ ąĄčüčéčī 3 čüčéčĆą░č鹥ą│ąĖąĖ čĆą░ąĘą┤ąĄą╗ąĄąĮąĖčÅ ąĘą░ą┤ą░čćąĖ ą┤ą╗čÅ ą┐ąĄčĆąĄą┤ą░čćąĖ ą▓čģąŠą┤ąĮčŗčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą┐ąŠč鹊ą║ą░ą╝:
ąĪčéčĆą░č鹥ą│ąĖčÅ ąÆčŗą┤ąĄą╗ąĄąĮąĖąĄ 菹╗ąĄą╝ąĄąĮčéą░ ą×čéąĮąŠčüąĖč鹥ą╗čīąĮąŠąĄ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ
Chunk partitioning
ąöąĖąĮą░ą╝ąĖč湥čüą║ąŠąĄ
ąĪčĆąĄą┤ąĮąĄąĄ
Range partitioning
ąĪčéą░čéąĖč湥čüą║ąŠąĄ
ą¤ą╗ąŠčģąŠąĄ ąĖą╗ąĖ ąŠčéą╗ąĖčćąĮąŠąĄ
Hash partitioning
ąĪčéą░čéąĖč湥čüą║ąŠąĄ
ą¤ą╗ąŠčģąŠąĄ
ąöą╗čÅ ąŠą┐ąĄčĆą░č鹊čĆąŠą▓ ąĘą░ą┐čĆąŠčüą░, ą║ąŠč鹊čĆčŗąĄ čéčĆąĄą▒čāčÄčé čüčĆą░ą▓ąĮąĄąĮąĖčÅ čŹą╗ąĄą╝ąĄąĮč鹊ą▓ (GroupBy, Join, GroupJoin, Intersect, Except, Union ąĖ Distinct), čā ąÆą░čü ąĮąĄčé ą▓čŗą▒ąŠčĆą░: PLINQ ą▓čüąĄą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčé hash-čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ. Hash-čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ ąĮąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 ą┤ąŠą╗ąČąĮąŠ ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮąŠ čĆą░čüčüčćąĖčéą░čéčī čģąĄčł-ą║ąŠą┤ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░ (čéą░ą║ čćč鹊 菹╗ąĄą╝ąĄąĮčéčŗ čü ąŠą┤ąĖąĮą░ą║ąŠą▓čŗą╝ąĖ čģąĄčł-ą║ąŠą┤ą░ą╝ąĖ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ąŠą▒čĆą░ą▒ąŠčéą░čéčī ą▓ ąŠą┤ąĮąŠą╝ ą┐ąŠč鹊ą║ąĄ). ąĢčüą╗ąĖ ąÆčŗ čĆąĄčłąĖą╗ąĖ, čćč鹊 čŹč鹊 čüą╗ąĖčłą║ąŠą╝ ą╝ąĄą┤ą╗ąĄąĮąĮąŠ, č鹊 ą╝ąŠąČąĄč鹥 č鹊ą╗čīą║ąŠ ą▓čŗąĘą▓ą░čéčī AsSequential ą┤ą╗čÅ ąĘą░ą┐čĆąĄčéą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ą░.
ąöą╗čÅ ą▓čüąĄčģ ą┤čĆčāą│ąĖčģ ąŠą┐ąĄčĆą░č鹊čĆąŠą▓ ąĘą░ą┐čĆąŠčüą░ čā ąÆą░čü ąĄčüčéčī ą▓čŗą▒ąŠčĆ - ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ ą┐ąŠ ą┤ąĖą░ą┐ą░ąĘąŠąĮčā (range) ąĖą╗ąĖ ą┐ąŠ ą║čāčüą║čā (chunk). ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ:
ŌĆó ąĢčüą╗ąĖ ą▓čģąŠą┤ąĮą░čÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮą░ (ąĄčüą╗ąĖ čŹč鹊 ą╝ą░čüčüąĖą▓, ąĖą╗ąĖ čĆąĄą░ą╗ąĖąĘčāąĄčéčüčÅ IList< T>), č鹊 PLINQ ąĖčüą┐ąŠą╗čīąĘčāąĄčé range-čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ.
ąÆ čüčāčēąĮąŠčüčéąĖ range-čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ ą▒čŗčüčéčĆąĄąĄ ąĮą░ ą┤ą╗ąĖąĮąĮčŗčģ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčÅčģ, ą│ą┤ąĄ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ą║ą░ąČą┤ąŠą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░ ąĘą░ąĮąĖą╝ą░ąĄčé ą┐čĆąĖą╝ąĄčĆąĮąŠ ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠąĄ ą▓čĆąĄą╝čÅ CPU. ąśąĮą░č湥 chunk-čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ ąŠą▒čŗčćąĮąŠ čĆą░ą▒ąŠčéą░ąĄčé ą▒čŗčüčéčĆąĄąĄ.
ą¦č鹊ą▒čŗ ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ ą▓ą║ą╗čÄčćąĖčéčī range-čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ:
ŌĆó ąĢčüą╗ąĖ ąĘą░ą┐čĆąŠčü ąĮą░čćąĖąĮą░ąĄčéčüčÅ ąĮą░ Enumerable.Range, ąĘą░ą╝ąĄąĮąĖč鹥 ąĄą│ąŠ ąĮą░ ParallelEnumerable.Range.
ParallelEnumerable.Range čŹč鹊 ąĮąĄ ą┐čĆąŠčüč鹊 čÅčĆą╗čŗč湊ą║ ą┤ą╗čÅ ą▓čŗąĘąŠą▓ą░ Enumerable.Range(...).AsParallel(). ąŁč鹊 ą╝ąĄąĮčÅąĄčé ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ąĘą░ą┐čĆąŠčüą░ ą┐čāč鹥ą╝ ą░ą║čéąĖą▓ą░čåąĖąĖ range-čĆą░ąĘą┤ąĄą╗ąĄąĮąĖčÅ.
ą¦č鹊ą▒čŗ ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ ą▓ą║ą╗čÄčćąĖčéčī chunk-čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ, ąŠą▒ąĄčĆąĮąĖč鹥 ą▓čģąŠą┤ąĮčāčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ą▓ ą▓čŗąĘąŠą▓ Partitioner.Create (ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ System.Collection.Concurrent) čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
int [] numbers = { 3 , 4 , 5 , 6 , 7 , 8 , 9 };var parallelQuery =
Partitioner.Create (numbers, true ).AsParallel()
.Where (...)
ąÆč鹊čĆąŠą╣ ą░čĆą│čāą╝ąĄąĮčé Partitioner.Create ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ąÆčŗ čģąŠčéąĖč鹥 čüą▒ą░ą╗ą░ąĮčüąĖčĆąŠą▓ą░čéčī ąĘą░ą┐čĆąŠčü ą┐ąŠ ąĮą░ą│čĆčāąĘą║ąĄ, čćč鹊 čÅą▓ą╗čÅąĄčéčüčÅ ą┤čĆčāą│ąĖą╝ čüą┐ąŠčüąŠą▒ąŠą╝ čāą║ą░ąĘą░čéčī, čćč鹊 ąĮčāąČąĮąŠ ą┐čĆąĖą╝ąĄąĮąĖčéčī chunk-čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ.
Chunk-čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ čĆą░ą▒ąŠčéą░ąĄčé čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊 ą║ą░ąČą┤čŗą╣ čĆą░ą▒ąŠčćąĖą╣ ą┐ąŠč鹊ą║ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║ąĖ ą▒ąĄčĆąĄčé ą╝ą░ą╗čŗąĄ ą┐ąŠčĆčåąĖąĖ 菹╗ąĄą╝ąĄąĮč鹊ą▓ (chunks) ąĖąĘ ą▓čģąŠą┤ąĮąŠą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ. PLINQ ąĮą░čćąĖąĮą░ąĄčé čü ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ąŠč湥ąĮčī ą╝ą░ą╗ąĄąĮčīą║ąĖčģ ą║čāčüą║ąŠą▓ (ąĖąĘ ąŠą┤ąĮąŠą│ąŠ ąĖą╗ąĖ ą┤ą▓čāčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ąĘą░ ąŠą┤ąĖąĮ čĆą░ąĘ), ąĘą░č鹥ą╝ čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčé čĆą░ąĘą╝ąĄčĆ ą║čāčüą║ą░ ą┐ąŠ ą╝ąĄčĆąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĘą░ą┐čĆąŠčüą░: čŹč鹊 ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ą╝ą░ą╗čŗąĄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ ą▒čāą┤čāčé čŹčäč乥ą║čéąĖą▓ąĮąŠ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĄąĮčŗ, ąĖ ą▒ąŠą╗čīčłąĖąĄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ ąĮąĄ ą┐čĆąĖą▓ąĄą┤čāčé ą║ čćčĆąĄąĘą╝ąĄčĆąĮčŗą╝ čĆą░čüčēąĄą┐ą╗ąĄąĮąĖčÅą╝ ą▓čģąŠą┤ąĮčŗčģ ą┤ą░ąĮąĮčŗčģ. ąĢčüą╗ąĖ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé čéą░ą║, čćč鹊 čĆą░ą▒ąŠčćąĖą╣ ą┐ąŠč鹊ą║ ą┐ąŠą╗čāčćą░ąĄčé "ą┐čĆąŠčüčéčŗąĄ" 菹╗ąĄą╝ąĄąĮčéčŗ (ą║ąŠč鹊čĆčŗąĄ ąŠą▒čĆą░ą▒ąŠčéą░čÄčéčüčÅ ą▒čŗčüčéčĆąŠ), č鹊 čŹč鹊 ąĘą░ą║ąŠąĮčćąĖčéčüčÅ č鹥ą╝, čćč鹊 ąŠąĮ ą┐ąŠą╗čāčćąĖčé ą▒ąŠą╗čīčłąĄ ą║čāčüą║ąŠą▓. ąóą░ą║ą░čÅ čüąĖčüč鹥ą╝ą░ čāą┤ąĄčƹȹĖą▓ą░ąĄčé ą║ą░ąČą┤čŗą╣ ą┐ąŠč鹊ą║ ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠ ąĮą░ą│čĆčāąČąĄąĮąĮčŗą╝ (čÅą┤čĆą░ ą┐ąŠą╗čāčćą░čÄčéčüčÅ "čüą▒ą░ą╗ą░ąĮčüąĖčĆąŠą▓ą░ąĮąĮčŗą╝ąĖ" ą┐ąŠ ąĮą░ą│čĆčāąĘą║ąĄ); ąĮąĄą┤ąŠčüčéą░č鹊ą║ ą▓ č鹊ą╝, čćč鹊 ą▓čŗą▒ąŠčĆą║ą░ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ąĖąĘ ąŠą▒čēąĄą╣ ą▓čģąŠą┤ąĮąŠą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ čéčĆąĄą▒čāąĄčé čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ (ąŠą▒čŗčćąĮąŠ ąĖčüą║ą╗čÄčćąĖč鹥ą╗čīąĮąŠą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ), čćč鹊 ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ąĮąĄą║ąŠč鹊čĆčŗą╝ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗą╝ čéčĆą░čéą░ą╝ ą┐ąŠ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅą╝ ąĖ ą║ąŠąĮą║čāčĆąĄąĮčåąĖąĖ ą┐ąŠč鹊ą║ąŠą▓.
Range-čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ ą┐čĆąŠą┐čāčüą║ą░ąĄčé ąŠą▒čŗčćąĮąŠąĄ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖąĄ ą┐ąŠ ą▓čģąŠą┤čā, ąĖ ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮąŠ ą▓čŗą┤ąĄą╗čÅąĄčé ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą┐ąŠč鹊ą║ą░, ąĖąĘą▒ąĄą│ą░čÅ čüąŠčüčéčÅąĘą░ąĮąĖčÅ ąĮą░ ą▓čģąŠą┤ąĮąŠą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ. ąØąŠ ąĄčüą╗ąĖ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé čéą░ą║, čćč鹊 ąĮąĄą║ąŠč鹊čĆčŗąĄ ą┐ąŠč鹊ą║ąĖ ą┐ąŠą╗čāčćą░čé ą┐čĆąŠčüčéčŗąĄ 菹╗ąĄą╝ąĄąĮčéčŗ, ąĖ ą▓čŗą┐ąŠą╗ąĮčÅčé čüą▓ąŠčÄ ąŠą▒čĆą░ą▒ąŠčéą║čā ą▒čŗčüčéčĆąĄąĄ, č鹊 ąŠąĮąĖ ąŠčüčéą░ąĮčāčéčüčÅ ą▓ ąŠąČąĖą┤ą░ąĮąĖąĖ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą▓ ąŠčüčéą░ą╗čīąĮčŗčģ ą┐ąŠč鹊ą║ą░čģ. ąØą░čł ą┐čĆąĄą┤čŗą┤čāčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ čü čćąĖčüą╗ąŠą▓čŗą╝ąĖ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅą╝ąĖ ą╝ąŠąČąĄčé ą┐ąŠą║ą░ąĘą░čéčī ą┐ą╗ąŠčģčāčÄ čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéčī ą┐čĆąĖ range-čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĖ. ą¤čĆąĖą╝ąĄčĆąŠą╝, ą║ąŠą│ą┤ą░ range-čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ čĆą░ą▒ąŠčéą░ąĄčé čģąŠčĆąŠčłąŠ, ą▒čāą┤ąĄčé ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ čüčāą╝ą╝čŗ ą║ą▓ą░ą┤čĆą░čéąĮčŗčģ ą║ąŠčĆąĮąĄą╣ ą┐ąĄčĆą▓čŗčģ 10 ą╝ąĖą╗ą╗ąĖąŠąĮąŠą▓ čåąĄą╗čŗčģ čćąĖčüąĄą╗:
ParallelEnumerable.Range (1 , 10000000 ).Sum (i => Math.Sqrt (i))
ParallelEnumerable.Range ą▓ąĄčĆąĮąĄčé ParallelQuery< T>, čéą░ą║ čćč鹊 ąÆą░ą╝ ąĮąĄ ąĮčāąČąĮąŠ ą▓ą┐ąŠčüą╗ąĄą┤čüčéą▓ąĖąĖ ą▓čŗąĘčŗą▓ą░čéčī AsParallel.
Range-čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ ąĮąĄ ąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ ą▒čāą┤ąĄčé ą▓čŗą┤ąĄą╗čÅčéčī ą┤ąĖą░ą┐ą░ąĘąŠąĮčŗ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą▓ ąĮąĄą┐čĆąĄčĆčŗą▓ąĮčŗčģ ą▒ą╗ąŠą║ą░čģ - ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą▒čĆą░ąĮą░ čüčéčĆą░č鹥ą│ąĖčÅ č湥čĆąĄą┤ąŠą▓ą░ąĮąĖčÅ (striping). ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ąĄčüčéčī ą┤ą▓ą░ čĆą░ą▒ąŠčćąĖčģ ą┐ąŠč鹊ą║ą░, č鹊 ąŠą┤ąĖąĮ ą╝ąŠąČąĄčé ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī 菹╗ąĄą╝ąĄąĮčéčŗ čü č湥čéąĮčŗą╝ąĖ ąĮąŠą╝ąĄčĆą░ą╝ąĖ, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ą┤čĆčāą│ąŠą╣ ą┐čĆąŠčåąĄčüčü čü ąĮąĄč湥čéąĮčŗą╝ąĖ. ą×ą┐ąĄčĆą░č鹊čĆ TakeWhile ą┐ąŠčćčéąĖ ąĮą░ą▓ąĄčĆąĮčÅą║ą░ ąĖąĮąĖčåąĖąĖčĆčāąĄčé striping-čüčéčĆą░č鹥ą│ąĖčÄ, čćč鹊ą▒čŗ ąĖąĘą▒ąĄąČą░čéčī ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮąŠą╣ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą▓ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ.
ą¤ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖčÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖčģ ą░ą│čĆąĄą│ą░čåąĖą╣ . PLINQ čŹčäč乥ą║čéąĖą▓ąĮąŠ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖą▓ą░ąĄčé ąŠą┐ąĄčĆą░č鹊čĆčŗ Sum, Average, Min ąĖ Max ą▒ąĄąĘ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą│ąŠ ą▓ą╝ąĄčłą░č鹥ą╗čīčüčéą▓ą░. ą×ą┤ąĮą░ą║ąŠ ąŠą┐ąĄčĆą░č鹊čĆ Aggregate ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé ą┤ą╗čÅ PLINQ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ čüą╗ąŠąČąĮąŠčüčéąĖ.
ąĢčüą╗ąĖ ąÆčŗ ąĮąĄ ąĘąĮą░ą║ąŠą╝čŗ čü čŹčéąĖą╝ ąŠą┐ąĄčĆą░č鹊čĆąŠą╝, č鹊 ą╝ąŠąČąĄč鹥 ą┤čāą╝ą░čéčī ąŠą▒ Aggregate ą║ą░ą║ ą┐čĆąŠ ąŠą▒ąŠą▒čēąĄąĮąĮčāčÄ ą▓ąĄčĆčüąĖčÄ Sum, Average, Min ąĖ Max - ą┤čĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, čŹč鹊 ąŠą┐ąĄčĆą░č鹊čĆ, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠąĘą▓ąŠą╗čÅčé ąÆą░ą╝ ą┐ąŠą┤ą║ą╗čÄčćąĖčéčī ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖą╣ ą░ą╗ą│ąŠčĆąĖčéą╝ ąĮą░ą║ąŠą┐ą╗ąĄąĮąĖčÅ ą┤ą╗čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ąĮąĄąŠą▒čŗčćąĮčŗčģ ą░ą│čĆąĄą│ą░čåąĖą╣. ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤ ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄčé, ą║ą░ą║ Aggregate ą╝ąŠąČąĄčé ą▓čŗą┐ąŠą╗ąĮąĖčéčī čĆą░ą▒ąŠčéčā Sum:
int [] numbers = { 2 , 3 , 4 };int sum = numbers.Aggregate (0 , (total, n) => total + n); // 9
ą¤ąĄčĆą▓čŗą╣ ą░čĆą│čāą╝ąĄąĮčé ą┤ą╗čÅ Aggregate čŹč鹊 ąĮą░čćą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ (seed), čü ą║ąŠč鹊čĆąŠą│ąŠ ąĮą░čćąĖąĮą░ąĄčéčüčÅ ąĮą░ą║ąŠą┐ą╗ąĄąĮąĖąĄ. ąÆč鹊čĆąŠą╣ ą░čĆą│čāą╝ąĄąĮčé čŹč鹊 ą▓čŗčĆą░ąČąĄąĮąĖąĄ ą┤ą╗čÅ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ ąĮą░ą║ą░ą┐ą╗ąĖą▓ą░ąĄą╝ąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ čü čāč湥č鹊ą╝ ąĮąŠą▓ąŠą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░. ą×ą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī čéčĆąĄčéąĖą╣ ą░čĆą│čāą╝ąĄąĮčé ą┤ą╗čÅ ą┐čĆąŠąĄą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ ą║ąŠąĮąĄčćąĮąŠą│ąŠ čĆąĄąĘčāą╗čīčéą░čéą░ ąĖąĘ ąĮą░ą║ąŠą┐ą╗ąĄąĮąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ.
ąæąŠą╗čīčłąĖąĮčüčéą▓ąŠ ą┐čĆąŠą▒ą╗ąĄą╝, ą┤ą╗čÅ ą║ąŠč鹊čĆčŗčģ ą▒čŗą╗ čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮ Aggregate, ą╝ąŠąČąĮąŠ čĆąĄčłąĖčéčī ą┐čĆąŠčēąĄ čü čåąĖą║ą╗ąŠą╝ foreach, čü ą▒ąŠą╗ąĄąĄ ąĘąĮą░ą║ąŠą╝čŗą╝ čüąĖąĮčéą░ą║čüąĖčüąŠą╝. ąöąŠčüč鹊ąĖąĮčüčéą▓ąŠ Aggregate ą▓ č鹊ą╝, čćč鹊 ą▒ąŠą╗čīčłąĖąĄ ąĖ čüą╗ąŠąČąĮčŗąĄ ą░ą│čĆąĄą│ą░čåąĖąĖ ą╝ąŠąČąĮąŠ ą┤ąĄą║ą╗ą░čĆą░čéąĖą▓ąĮąŠ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖčéčī čü ą┐ąŠą╝ąŠčēčīčÄ PLINQ.
ąÉą│čĆąĄą│ą░čåąĖąĖ ą▒ąĄąĘ ąĮą░čćą░ą╗čīąĮąŠą╣ č鹊čćą║ąĖ ąŠčéčüč湥čéą░ (unseeded). ąÆčŗ ą╝ąŠąČąĄčé ąŠą┐čāčüčéąĖčéčī ąĘąĮą░č湥ąĮąĖąĄ seed ą┐čĆąĖ ą▓čŗąĘąŠą▓ąĄ Aggregate, ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą┐ąĄčĆą▓čŗą╣ 菹╗ąĄą╝ąĄąĮčé čüčéą░ąĮąĄčé ąĮąĄčÅą▓ąĮčŗą╝ seed, ąĖ ą░ą│čĆąĄą│ą░čåąĖčÅ ąĮą░čćąĮąĄčéčüčÅ čüąŠ ą▓č鹊čĆąŠą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░. ąÆąŠčé ą┐čĆąĄą┤čŗą┤čāčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ, ą┐ąĄčĆąĄą┤ąĄą╗ą░ąĮąĮčŗą╣ ąĮą░ unseeded:
int [] numbers = { 1 , 2 , 3 };int sum = numbers.Aggregate ((total, n) => total + n); // 6
ąŁč鹊 ą┤ą░čüčé č鹊čé ąČąĄ čĆąĄąĘčāą╗čīčéą░čé, čćč鹊 ąĖ čĆą░ąĮąĄąĄ, ąĮąŠ čĆąĄą░ą╗čīąĮąŠ ą╝čŗ ą┤ąĄą╗ą░ąĄą╝ ą┤čĆčāą│ąŠąĄ ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ. ąĀą░ąĮčīčłąĄ ą╝čŗ ą▓čŗą┐ąŠą╗ąĮąĖą╗ąĖ ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ 0+1+2+3; č鹥ą┐ąĄčĆčī ąČąĄ 1+2+3. ą£čŗ ą╝ąŠąČąĄą╝ ą╗čāčćčłąĄ ą┐čĆąŠąĖą╗ą╗čÄčüčéčĆąĖčĆąŠą▓ą░čéčī čĆą░ąĘąĮąĖčåčā ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄą╝ čāą╝ąĮąŠąČąĄąĮąĖčÅ ą▓ą╝ąĄčüč鹊 čüą╗ąŠąČąĄąĮąĖčÅ:
int [] numbers = { 1 , 2 , 3 };int x = numbers.Aggregate (0 , (prod, n) => prod * n); // 0*1*2*3 = 0 int y = numbers.Aggregate ( (prod, n) => prod * n); // 1*2*3 = 6
ąÜą░ą║ ą╝čŗ čüą║ąŠčĆąŠ čāą▓ąĖą┤ąĖą╝, unseeded-ą░ą│čĆąĄą│ą░čåąĖąĖ ąĖą╝ąĄčÄčé ą┐čĆąĄąĖą╝čāčēąĄčüčéą▓ąŠ ą┤ą╗čÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖąĖ, čéą░ą║ ą║ą░ą║ ąĮąĄ čéčĆąĄą▒čāčÄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüą┐ąĄčåąĖą░ą╗čīąĮčŗčģ ą┐ąĄčĆąĄą│čĆčāąĘąŠą║. ąØąŠ čü unseeded-ą░ą│čĆąĄą│ą░čåąĖčÅą╝ąĖ ą╝ąŠąČąĮąŠ ą┐ąŠą┐ą░čüčéčī ą▓ ą╗ąŠą▓čāčłą║čā: ąĖčģ ą╝ąĄč鹊ą┤čŗ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮčŗ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čü ą┤ąĄą╗ąĄą│ą░čéą░ą╝ąĖ, ą║ąŠč鹊čĆčŗąĄ čÅą▓ą╗čÅčÄčéčüčÅ ą║ąŠą╝ą╝čāčéą░čéąĖą▓ąĮčŗą╝ąĖ ąĖ ą░čüčüąŠčåąĖą░čéąĖą▓ąĮčŗą╝ąĖ. ą¤čĆąĖ ą┤čĆčāą│ąŠą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ą╗čÄą▒ąŠą╣ čĆąĄąĘčāą╗čīčéą░čé ą▒čāą┤ąĄčé ąĮąĄ ąĖąĮčéčāąĖčéąĖą▓ąĮčŗą╝ (čü ąŠą▒čŗčćąĮčŗą╝ąĖ ąĘą░ą┐čĆąŠčüą░ą╝ąĖ) ąĖą╗ąĖ ąĮąĄ ą┤ąĄč鹥čĆą╝ąĖąĮąĖčĆąŠą▓ą░ąĮąĮčŗą╝ (ą▓ čüą╗čāčćą░ąĄ, ą║ąŠą│ą┤ą░ ąÆčŗ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖą╗ąĖ ąĘą░ą┐čĆąŠčü čü ą┐ąŠą╝ąŠčēčīčÄ PLINQ). ąöą╗čÅ ą┐čĆąĖą╝ąĄčĆą░ čĆą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗ąĄą┤čāčÄčēčāčÄ čäčāąĮą║čåąĖčÄ:
(total, n) => total + n * n
ą×ąĮą░ ąĮąĖ ą║ąŠą╝ą╝čāčéą░čéąĖą▓ąĮą░, ąĮąĖ ą░čüčüąŠčåąĖą░čéąĖą▓ąĮą░ (čé. ąĄ. 1+2*2 != 2+1*1). ą¤ąŠčüą╝ąŠčéčĆąĖą╝, čćč鹊 ą┐ąŠą╗čāčćąĖčéčüčÅ, ą║ąŠą│ą┤ą░ ą╝čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ ąĄčæ ą┤ą╗čÅ čüą╗ąŠąČąĄąĮąĖčÅ ą║ą▓ą░ą┤čĆą░č鹊ą▓ čćąĖčüąĄą╗ 2, 3 ąĖ 4:
int [] numbers = { 2 , 3 , 4 };int sum = numbers.Aggregate ((total, n) => total + n * n); // 27
ąÆą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī 29 ą║ą░ą║ čĆąĄąĘčāą╗čīčéą░čé 2*2 + 3*3 + 4*4, ą┐ąŠą╗čāčćąĖčéčüčÅ 27 ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ 2 + 3*3 + 4*4. ą£čŗ ą╝ąŠąČąĄą╝ ąĖčüą┐čĆą░ą▓ąĖčéčī čŹč鹊 ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ. ą¤ąĄčĆą▓čŗą╣ čüą┐ąŠčüąŠą▒ - ą┤ąŠą▒ą░ą▓ąĖčéčī 0 ą▓ ą║ą░č湥čüčéą▓ąĄ ą┐ąĄčĆą▓ąŠą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░:
int [] numbers = { 0 , 2 , 3 , 4 };
ą×ą┤ąĮą░ą║ąŠ čŹč鹊 ąĮąĄ č鹊ą╗čīą║ąŠ ąĮąĄ 菹╗ąĄą│ą░ąĮčéąĮąŠ, ąĮąŠ ą▓čüąĄ ąĄčēąĄ ą┤ą░čüčé ąĮąĄą║ąŠčĆčĆąĄą║čéąĮčŗąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ ą┐čĆąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 PLINQ čāčüąĖą╗ąĖą▓ą░ąĄčé ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄą╝čāčÄ ą░čüčüąŠčåąĖą░čéąĖą▓ąĮąŠčüčéčī čäčāąĮą║čåąĖąĖ, ą▓čŗą▒ąĖčĆą░čÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą║ą░ą║ seed-ąĘąĮą░č湥ąĮąĖčÅ. ąöą╗čÅ ąĖą╗ą╗čÄčüčéčĆą░čåąĖąĖ ą╝čŗ ąŠą▒ąŠąĘąĮą░čćąĖą╝ ąĮą░čłčā čäčāąĮą║čåąĖčÄ ą░ą│čĆąĄą│ą░čåąĖąĖ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
f(total, n) => total + n * n
č鹊ą│ą┤ą░ ąĘą░ą┐čĆąŠčü LINQ ą║ ąŠą▒čŖąĄą║čéą░ą╝ ą▓čŗčćąĖčüą╗ąĖą╗ ą▒čŗ f(f(f(0, 2),3),4), ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ PLINQ ą╝ąŠą│ ą▒čŗ čüą┤ąĄą╗ą░čéčī f(f(0,2),f(3,4)) čüąŠ čüą╗ąĄą┤čāčÄčēąĖą╝ čĆąĄąĘčāą╗čīčéą░č鹊ą╝:
ą¤ąĄčĆą▓ą░čÅ čćą░čüčéčī čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖą▓ą░ąĮąĖčÅ: a = 0 + 2*2 (= 4)
ąĢčüčéčī 2 čģąŠčĆąŠčłąĖčģ čĆąĄčłąĄąĮąĖčÅ. ą¤ąĄčĆą▓ąŠąĄ - ą┐čĆąĄą▓čĆą░čéąĖčéčī čŹč鹊 ą▓ seeded-ą░ą│čĆąĄą│ą░čåąĖčÄ čü ąĮčāą╗ąĄą╝ ą┤ą╗čÅ seed. ąĢą┤ąĖąĮčüčéą▓ąĄąĮąĮą░čÅ čüą╗ąŠąČąĮąŠčüčéčī ą▓ č鹊ą╝, čćč鹊 čü PLINQ ąĮą░ą╝ ąĮčāąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čüą┐ąĄčåąĖą░ą╗čīąĮčāčÄ ą┐ąĄčĆąĄą│čĆčāąĘą║čā, čćč鹊ą▒čŗ ąĘą░ą┐čĆąŠčü ąĮąĄ ą▓čŗą┐ąŠą╗ąĮčÅčéčüčÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ (čüą║ąŠčĆąŠ ą╝čŗ čŹč鹊 čāą▓ąĖą┤ąĖą╝).
ąÆč鹊čĆąŠąĄ čĆąĄčłąĄąĮąĖąĄ čĆąĄčüčéčĆčāą║čéčāčĆąĖčĆąŠą▓ą░čéčī ąĘą░ą┐čĆąŠčü čéą░ą║, čćč鹊ą▒čŗ čäčāąĮą║čåąĖčÅ ą░ą│čĆąĄą│ą░čåąĖąĖ čüčéą░ą╗ą░ ą║ąŠą╝ą╝čāčéą░čéąĖą▓ąĮąŠą╣ ąĖ ą░čüčüąŠčåąĖą░čéąĖą▓ąĮąŠą╣:
int sum = numbers.Select (n => n * n).Aggregate ((total, n) => total + n);
ąÜąŠąĮąĄčćąĮąŠ, ą▓ čéą░ą║ąŠą╝ ą┐čĆąŠčüč鹊ą╝ čüčåąĄąĮą░čĆąĖąĖ ąÆčŗ ą╝ąŠąČąĄč鹥 (ąĖ ą┤ąŠą╗ąČąĮčŗ) ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąŠą┐ąĄčĆą░č鹊čĆ Sum ą▓ą╝ąĄčüč鹊 Aggregate:
int sum = numbers.Sum (n => n * n);
ąÆčŗ ą╝ąŠąČąĄč鹥 ąĮą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ ą┐ąŠą╣čéąĖ ą┤ąŠą▓ąŠą╗čīąĮąŠ ą┤ą░ą╗ąĄą║ąŠ ą┐čĆąŠčüč鹊 čü Sum ąĖ Average. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī Average ą┤ą╗čÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ čüčĆąĄą┤ąĮąĄą│ąŠ ą║ą▓ą░ą┤čĆą░čéąĖč湥čüą║ąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ (root-mean-square, RMS):
Math.Sqrt (numbers.Average (n => n * n))
ąĖ ą┤ą░ąČąĄ čüčéą░ąĮą┤ą░čĆčéąĮčāčÄ ą┤ąĄą▓ąĖą░čåąĖčÄ:
double mean = numbers.Average();double sdev = Math.Sqrt (numbers.Average (n =>
{
double dif = n - mean;
return dif * dif;
}));
ą×ą▒ą░ ą▓ą░čĆąĖą░ąĮčéą░ ą▒ąĄąĘąŠą┐ą░čüąĮčŗ, čŹčäč乥ą║čéąĖą▓ąĮčŗą╝ ąĖ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘčāčÄčéčüčÅ.
ą¤ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖčÅ Aggregate . ą£čŗ č鹊ą╗čīą║ąŠ čćč鹊 ą│ąŠą▓ąŠčĆąĖą╗ąĖ, čćč鹊 ą┤ą╗čÅ unseeded-ą░ą│čĆąĄą│ą░čåąĖą╣ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗą╣ ą┤ąĄą╗ąĄą│ą░čé ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą░čüčüąŠčåąĖą░čéąĖą▓ąĮčŗą╝ ąĖ ą║ąŠą╝ą╝čāčéą░čéąĖą▓ąĮčŗą╝. PLINQ ą┤ą░čüčé ąĮąĄą║ąŠčĆčĆąĄą║čéąĮčŗąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ, ąĄčüą╗ąĖ čŹč鹊 ą┐čĆą░ą▓ąĖą╗ąŠ ąĮą░čĆčāčłą░ąĄčéčüčÅ, ą┐ąŠč鹊ą╝čā čćč鹊 čŹč鹊 ą▓ąŠą▓ą╗ąĄč湥čé ąĮąĄčüą║ąŠą╗čīą║ąŠ seed-ąĘąĮą░č湥ąĮąĖą╣ ąĖąĘ ą▓čģąŠą┤ąĮąŠą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ, čćč鹊ą▒čŗ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą░ą│čĆąĄą│ąĖčĆąŠą▓ą░čéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ čćą░čüč鹥ą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ.
ą»ą▓ąĮčŗąĄ seed-ą░ą│čĆąĄą│ą░čåąĖąĖ ą╝ąŠą│ą╗ąĖ ą▒čŗ ą▓čŗą│ą╗čÅą┤ąĄčéčī ą║ą░ą║ ą▒ąĄąĘąŠą┐ą░čüąĮą░čÅ ąŠą┐čåąĖčÅ čü PLINQ, ąĮąŠ ą║ čüąŠąČą░ą╗ąĄąĮąĖčÄ ąŠą▒čŗčćąĮąŠ ąŠąĮąĖ ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ, ą┐ąŠč鹊ą╝čā čćč鹊 ą┐ąŠą╗ą░ą│ą░čÄčéčüčÅ ąĮą░ ąŠą┤ąĮąŠ ąĘąĮą░č湥ąĮąĖąĄ seed. ą¦č鹊ą▒čŗ čüą╝čÅą│čćąĖčéčī čŹč鹊, PLINQ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┤čĆčāą│čāčÄ ą┐ąĄčĆąĄą│čĆčāąĘą║čā Aggregate, ą║ąŠč鹊čĆą░čÅ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čāą║ą░ąĘą░čéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĘąĮą░č湥ąĮąĖą╣ seed - ąĖą╗ąĖ čüą║ąŠčĆąĄąĄ čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮąĮčāčÄ čäčāąĮą║čåąĖčÄ ą┤ą╗čÅ seed. ąöą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą┐ąŠč鹊ą║ą░ čŹčéą░ čäčāąĮą║čåąĖčÅ ą▓čŗą┐ąŠą╗ąĮąĖčéčüčÅ, čćč鹊ą▒čŗ ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ąŠčéą┤ąĄą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ seed, ą║ąŠč鹊čĆąŠąĄ čüčéą░ąĮąŠą▓ąĖčéčüčÅ ą╗ąŠą║ą░ą╗čīąĮčŗą╝ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą╝ ą┤ą╗čÅ ą┐ąŠč鹊ą║ą░, ą▓ ą║ąŠč鹊čĆčŗą╣ ą▒čāą┤ąĄčé ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ ą░ą│čĆąĄą│ą░čåąĖčÅ čŹą╗ąĄą╝ąĄąĮč鹊ą▓.
ą£čŗ čéą░ą║ąČąĄ ą┤ąŠą╗ąČąĮčŗ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī čäčāąĮą║čåąĖčÄ ą┤ą╗čÅ ąĖąĮą┤ąĖą║ą░čåąĖąĖ, ą║ą░ą║ ą║ąŠą╝ą▒ąĖąĮąĖčĆąŠą▓ą░čéčī ą╗ąŠą║ą░ą╗čīąĮčŗą╣ ąĖ ą│ą╗ą░ą▓ąĮčŗą╣ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆčŗ. ąś ąĮą░ą║ąŠąĮąĄčå, čŹčéą░ ą┐ąĄčĆąĄą│čĆčāąĘą║ą░ Aggregate (ąĮąĄą╝ąĮąŠą│ąŠ ąĮąĄąŠą▒ąŠčüąĮąŠą▓ą░ąĮąĮąŠ) ąŠąČąĖą┤ą░ąĄčé ą┤ąĄą╗ąĄą│ą░čéą░ ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą╗čÄą▒ąŠą│ąŠ ą║ąŠąĮąĄčćąĮąŠą│ąŠ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅ ą┤ą╗čÅ čĆąĄąĘčāą╗čīčéą░čéą░ (č鹊ą│ąŠ ąČąĄ čüą░ą╝ąŠą│ąŠ čĆąĄąĘčāą╗čīčéą░čéą░ ąÆčŗ ą╝ąŠąČąĄč鹥 ą┤ąŠčüčéąĖčćčī, čüą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮąŠ ą▓čŗąĘą▓ą░ą▓ ą║ą░ą║čāčÄ-ąĮąĖą▒čāą┤čī čäčāąĮą║čåąĖčÄ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅ ą┐ąŠąĘąČąĄ). ąśčéą░ą║, ąĖą╝ąĄąĄčéčüčÅ 4 ą┤ąĄą╗ąĄą│ą░čéą░, ą┐ąĄčĆąĄą┤ą░ą▓ą░ąĄą╝čŗčģ ą▓ čéą░ą║ąŠą╝ ą┐ąŠčĆčÅą┤ą║ąĄ:
seedFactory. ąÆąĄčĆąĮąĄčé ąĮąŠą▓čŗą╣ ą╗ąŠą║ą░ą╗čīąĮčŗą╣ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ.
ąÆ ą┐čĆąŠčüčéčŗčģ čüčåąĄąĮą░čĆąĖčÅčģ ąÆčŗ ą╝ąŠąČąĄč鹥 čāą║ą░ąĘą░čéčī ąĘąĮą░č湥ąĮąĖąĄ seed ą▓ą╝ąĄčüč鹊 čäčāąĮą║čåąĖąĖ seed (ą▓ą╝ąĄčüč鹊 seedFactory). ąŁčéą░ čéą░ą║čéąĖą║ą░ ąĮąĄ čüčĆą░ą▒ąŠčéą░ąĄčé, ą║ąŠą│ą┤ą░ seed čÅą▓ą╗čÅąĄčéčüčÅ čüčüčŗą╗ąŠčćąĮčŗą╝ čéąĖą┐ąŠą╝, ą║ąŠč鹊čĆčŗą╣ ąÆčŗ čģąŠčéąĖč鹥 ą╝čāčéąĖčĆąŠą▓ą░čéčī, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ č鹊ą│ą┤ą░ ą▒čāą┤ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą║ą░ąČą┤čŗą╝ ą┐ąŠč鹊ą║ąŠą╝.
ąÆ ą║ą░č湥čüčéą▓ąĄ ąŠč湥ąĮčī ą┐čĆąŠčüč鹊ą│ąŠ ą┐čĆąĖą╝ąĄčĆą░ čĆą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗ąĄą┤čāčÄčēąĖąĄ čüčāą╝ą╝čŗ ąĘąĮą░č湥ąĮąĖą╣ ą▓ ą╝ą░čüčüąĖą▓ąĄ čćąĖčüąĄą╗:
numbers.AsParallel().Aggregate (
() => 0 , // seedFactory
(localTotal, n) => localTotal + n, // updateAccumulatorFunc
(mainTot, localTot) => mainTot + localTot, // combineAccumulatorFunc
finalResult => finalResult) // resultSelector
ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą╝čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī č鹊čé ąČąĄ ąŠčéą▓ąĄčé, ąĖčüą┐ąŠą╗čīąĘčāčÅ ą▒ąŠą╗ąĄąĄ ą┐čĆąŠčüčéčŗąĄ čüą┐ąŠčüąŠą▒čŗ (čéą░ą║ąĖąĄ ą║ą░ą║ ą░ą│čĆąĄą│ą░čåąĖčÅ unseeded, ąĖą╗ąĖ čćč鹊 ąĄčēąĄ ą╗čāčćčłąĄ, ąŠą┐ąĄčĆą░č鹊čĆ Sum). ą¦č鹊ą▒čŗ ą┤ą░čéčī ą▒ąŠą╗ąĄąĄ čĆąĄą░ą╗ąĖčüčéąĖčćąĮčŗą╣ ą┐čĆąĖą╝ąĄčĆ, ą┐čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ą╝čŗ čģąŠčéąĖą╝ ą▓čŗčćąĖčüą╗ąĖčéčī čćą░čüč鹊čéčā ą┐ąŠčÅą▓ą╗ąĄąĮąĖčÅ ą║ą░ąČą┤ąŠą╣ ą▒čāą║ą▓čŗ ą░ąĮą│ą╗ąĖą╣čüą║ąŠą│ąŠ ą░ą╗čäą░ą▓ąĖčéą░ ą▓ čāą║ą░ąĘą░ąĮąĮąŠą╣ čüčéčĆąŠą║ąĄ. ą¤čĆąŠčüč鹊ąĄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠąĄ čĆąĄčłąĄąĮąĖąĄ ą╝ąŠąČąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī ą▓ąŠčé čéą░ą║:
string text = "LetŌĆÖs suppose this is a really long string" ;var letterFrequencies = new int [26 ];foreach (char c in text)
{
int index = char .ToUpper (c) - 'A' ;
if (index >= 0 && index <= 26 ) letterFrequencies [index]++;
};
ą¤čĆąĖą╝ąĄčĆ, ą║ąŠą│ą┤ą░ čüčéčĆąŠą║ą░ ą▒čāą┤ąĄčé ąŠč湥ąĮčī ą▒ąŠą╗čīčłąŠą╣ - ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ ą│ąĄąĮąŠą╝ą░. ąóąŠą│ą┤ą░ "ą░ą╗čäą░ą▓ąĖčé" ą┤ąŠą╗ąČąĄąĮ čüąŠčüč鹊čÅčéčī ąĖąĘ ą▒čāą║ą▓ a, c, g ąĖ t.
ą¦č鹊ą▒čŗ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖčéčī čŹč鹊, ą╝čŗ ą┤ąŠą╗ąČąĮčŗ ąĘą░ą╝ąĄąĮąĖčéčī ąŠą┐ąĄčĆą░č鹊čĆ foreach ąĮą░ ą▓čŗąĘąŠą▓ Parallel.ForEach (čćč鹊 ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╣ čüąĄą║čåąĖąĖ), ąĮąŠ čéčāčé ą╝čŗ čüč鹊ą╗ą║ąĮąĄą╝čüčÅ čü ą┐čĆąŠą▒ą╗ąĄą╝ąŠą╣ ą║ąŠąĮą║čāčĆąĄąĮčéąĮąŠą╣ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąŠą▒čēąĄą│ąŠ ą╝ą░čüčüąĖą▓ą░. ąś ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą▓ąŠą║čĆčāą│ ą┤ąŠčüčéčāą┐ą░ ą║ čŹč鹊ą╝čā ą╝ą░čüčüąĖą▓ ą┤ą░ą╗ą░ ą▒čŗ ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéčī ą┤ą╗čÅ ą┐ąŠč鹊ą║ąŠą▓, ąĮąŠ čāą▒ąĖą╗ą░ ą▒čŗ ą▓ąĄčüčī ą┐ąŠč鹥ąĮčåąĖą░ą╗ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖąĖ.
ąÉą│čĆąĄą│ą░čé ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ąŠą┐čĆčÅčéąĮąŠąĄ čĆąĄčłąĄąĮąĖąĄ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ čŹč鹊 ą╝ą░čüčüąĖą▓, čéą░ą║ąŠą╣ ąČąĄ ą║ą░ą║ letterFrequencies ąĖąĘ ą┐čĆąĄą┤čŗą┤čāčēąĄą│ąŠ ą┐čĆąĖą╝ąĄčĆą░. ąÆąŠčé ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮą░čÅ ą▓ąĄčĆčüąĖčÅ, ąĖčüą┐ąŠą╗čīąĘčāčÄčēą░čÅ Aggregate:
int [] result =
text.Aggregate (
new int [26 ], // ąĪąŠąĘą┤ą░ąĮąĖąĄ "ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░"
(letterFrequencies, c) => // ąÉą│čĆąĄą│ąĖčĆąŠą▓ą░ąĮąĖąĄ ą▒čāą║ą▓čŗ ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ
{
int index = char .ToUpper (c) - 'A' ;
if (index >= 0 && index <= 26 ) letterFrequencies [index]++;
return letterFrequencies;
});
ąś č鹥ą┐ąĄčĆčī ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ą▓ąĄčĆčüąĖčÅ, ąĖčüą┐ąŠą╗čīąĘčāčÄčēą░čÅ čüą┐ąĄčåąĖą░ą╗čīąĮčāčÄ ą┐ąĄčĆąĄą│čĆčāąĘą║čā PLINQ:
int [] result =
text.AsParallel().Aggregate (
() => new int [26 ], // ąĪąŠąĘą┤ą░ąĮąĖąĄ ąĮąŠą▓ąŠą│ąŠ ą╗ąŠą║ą░ą╗čīąĮąŠą│ąŠ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░
(localFrequencies, c) => // ąÉą│čĆąĄą│ą░čåąĖčÅ ą▓ ą╗ąŠą║ą░ą╗čīąĮčŗą╣ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ
{
int index = char .ToUpper (c) - 'A' ;
if (index >= 0 && index <= 26 ) localFrequencies [index]++;
return localFrequencies;
},
// ąÉą│čĆąĄą│ą░čåąĖčÅ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ local->main
(mainFreq, localFreq) =>
mainFreq.Zip (localFreq, (f1, f2) => f1 + f2).ToArray(),
finalResult => finalResult // ąÆčŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐ąŠčüą╗ąĄą┤ąĮąĄą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ
); // ąĮą░ą┤ ą║ąŠąĮąĄčćąĮčŗą╝ čĆąĄąĘčāą╗čīčéą░č鹊ą╝.
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čäčāąĮą║čåąĖčÅ ą╗ąŠą║ą░ą╗čīąĮąŠą│ąŠ ąĮą░ą║ąŠą┐ą╗ąĄąĮąĖčÅ ą╝čāčéąĖčĆčāąĄčé ą╝ą░čüčüąĖą▓ localFrequencies. ąŁč鹊 ą▓ą░ąČąĮą░čÅ ąĖ ąĘą░ą║ąŠąĮąĮą░čÅ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 localFrequencies ą╗ąŠą║ą░ą╗ąĄąĮ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą┐ąŠč鹊ą║ą░.
ąÜą╗ą░čüčü Parallel ]
PFX ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą▒ą░ąĘąŠą▓čāčÄ č乊čĆą╝čā čüčéčĆčāą║čéčāčĆąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ą░ č湥čĆąĄąĘ čéčĆąĖ čüčéą░čéąĖč湥čüą║ąĖąĄ ą╝ąĄč鹊ą┤ą░ ą▓ ą║ą╗ą░čüčüąĄ Parallel:
Parallel.Invoke . ąŚą░ą┐čāčüą║ą░ąĄčé ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ ą┤ąĄą╗ąĄą│ą░č鹊ą▓ ąĖąĘ ą╝ą░čüčüąĖą▓ą░.Parallel.For . ąÆčŗą┐ąŠą╗ąĮčÅąĄčé ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗą╣ 菹║ą▓ąĖą▓ą░ą╗ąĄąĮčé čåąĖą║ą╗ą░ for čÅąĘčŗą║ą░ C#.Parallel.ForEach . ąÆčŗą┐ąŠą╗ąĮčÅąĄčé ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗą╣ 菹║ą▓ąĖą▓ą░ą╗ąĄąĮčé čåąĖą║ą╗ą░ foreach čÅąĘčŗą║ą░ C#.
ąÆčüąĄ čéčĆąĖ ą╝ąĄč鹊ą┤ą░ ą▒ą╗ąŠą║ąĖčĆčāčÄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┤ąŠ ą╝ąŠą╝ąĄąĮčéą░ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ čĆą░ą▒ąŠčéčŗ. ąÜą░ą║ čü PLINQ, ą┐ąŠčüą╗ąĄ ąĮąĄ ąŠą▒čĆą░ą▒ąŠčéą░ąĮąĮąŠą│ąŠ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąŠčüčéą░ą▓čłąĖąĄčüčÅ čĆą░ą▒ąŠčćąĖąĄ ą┐ąŠč鹊ą║ąĖ ąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čÄčéčüčÅ ą┐ąŠčüą╗ąĄ čüą▓ąŠąĄą╣ č鹥ą║čāčēąĄą╣ ąĖč鹥čĆą░čåąĖąĖ ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ (ąĖą╗ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ) ą▓čŗą▒čĆą░čüčŗą▓ą░čÄčéčüčÅ ąŠą▒čĆą░čéąĮąŠ ą▓ ą▓čŗąĘčŗą▓ą░čÄčēąĖą╣ ą║ąŠą┤ - ąŠą▒ąĄčĆąĮčāč鹊ąĄ ą▓ AggregateException.
Parallel.Invoke
public static void Invoke (params Action[] actions);
ąÆąŠčé čéą░ą║ ą╝čŗ ą╝ąŠąČąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī Parallel.Invoke, čćč鹊ą▒čŗ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ąĘą░ą│čĆčāąĘąĖčéčī ą┤ą▓ąĄ ą▓ąĄą▒-čüčéčĆą░ąĮąĖčćą║ąĖ:
Parallel.Invoke (
() => new WebClient().DownloadFile ("http://www.linqpad.net" , "lp.html" ),
() => new WebClient().DownloadFile ("http://www.jaoo.dk" , "jaoo.html" ));
ąÆąĮąĄčłąĮąĄ čŹč鹊 ą▓čŗą│ą╗čÅą┤ąĖčé ą║ą░ą║ čāą┤ąŠą▒ąĮčŗą╣ čÅčĆą╗čŗč湊ą║ ą┤ą╗čÅ čüąŠąĘą┤ą░ąĮąĖčÅ ąĖ ąŠąČąĖą┤ą░ąĮąĖčÅ ą┤ą▓čāčģ ąŠą▒čŖąĄą║č鹊ą▓ Task (ąĖą╗ąĖ ą░čüąĖąĮčģčĆąŠąĮąĮčŗčģ ą┤ąĄą╗ąĄą│ą░č鹊ą▓). ąØąŠ ąĘą┤ąĄčüčī ąĄčüčéčī ą▓ą░ąČąĮąŠąĄ ąŠčéą╗ąĖčćąĖąĄ: Parallel.Invoke ą▓čüąĄ ąĄčēąĄ čĆą░ą▒ąŠčéą░ąĄčé čŹčäč乥ą║čéąĖą▓ąĮąŠ, ąĄčüą╗ąĖ ąÆčŗ ą┐ąĄčĆąĄą┤ą░ą┤ąĖč鹥 ą▓ ą╝ą░čüčüąĖą▓ąĄ ą╝ąĖą╗ą╗ąĖąŠąĮ ą┤ąĄą╗ąĄą│ą░č鹊ą▓. ąŁč鹊 ą┐ąŠč鹊ą╝čā, čćč鹊 Parallel.Invoke ą┤ąĄą╗ąĖčé ą▒ąŠą╗čīčłąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ąĮą░ ą┐ą░ą║ąĄčéčŗ, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĄčé ąĮąĖąČąĄą╗ąĄąČą░čēąĖą╝ ąĘą░ą┤ą░čćą░ą╝ Task - ą▓ą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ čüąŠąĘą┤ą░ą▓ą░čéčī ąŠčéą┤ąĄą╗čīąĮčāčÄ Task ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą┤ąĄą╗ąĄą│ą░čéą░.
ąÜą░ą║ ąĖ čüąŠ ą▓čüąĄą╝ąĖ ą╝ąĄč鹊ą┤ą░ą╝ąĖ Parallel, ąÆčŗ ą┤ąĄą╣čüčéą▓čāąĄč鹥 čüą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮąŠ ą┐čĆąĖ čüą▓ąĄą┤ąĄąĮąĖąĖ ą▓ą╝ąĄčüč鹥 čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ. ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ąÆą░ą╝ ąĮčāąČąĮąŠ čāčćąĖčéčŗą▓ą░čéčī čüąŠčģčĆą░ąĮąĄąĮąĖąĄ ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéąĖ ą┐ąŠč鹊ą║ąŠą▓. ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤, ą║ ą┐čĆąĖą╝ąĄčĆčā, ąĮąĄ ą┐ąŠč鹊ą║ąŠą▒ąĄąĘąŠą┐ą░čüąĮčŗą╣:
var data = new List< string >();
Parallel.Invoke (
() => data.Add (new WebClient().DownloadString ("http://www.foo.com" )),
() => data.Add (new WebClient().DownloadString ("http://www.far.com" )));
ąæą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą▓ąŠą║čĆčāą│ čŹč鹊ą│ąŠ čüą┐ąĖčüą║ą░ List ąĖčüą┐čĆą░ą▓ąĖčé ą┐čĆąŠą▒ą╗ąĄą╝čā, čģąŠčéčÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ čüąŠąĘą┤ą░čüčé čāąĘą║ąŠąĄ ą╝ąĄčüč鹊, ąĄčüą╗ąĖ čā ąÆą░čü ąŠč湥ąĮčī ą▒ąŠą╗čīčłąŠą╣ ą╝ą░čüčüąĖą▓ ą▒čŗčüčéčĆąŠ ąĖčüą┐ąŠą╗ąĮčÅąĄą╝čŗčģ ą┤ąĄą╗ąĄą│ą░č鹊ą▓. ąĢčüčéčī čĆąĄčłąĄąĮąĖąĄ ą╗čāčćčłąĄ - ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī thread-safe collection, čéą░ą║čāčÄ ą║ą░ą║ ConcurrentBag, čćč鹊 ąĖą┤ąĄą░ą╗čīąĮąŠ ą┤ą╗čÅ čŹč鹊ą│ąŠ čüą╗čāčćą░čÅ.
Parallel.Invoke čéą░ą║ąČąĄ ą┐ąĄčĆąĄą│čĆčāąČą░ąĄčéčüčÅ ą┤ą╗čÅ č鹊ą│ąŠ, čćč鹊ą▒čŗ ą┐čĆąĖąĮčÅčéčī ąŠą▒čŖąĄą║čé ParallelOptions:
public static void Invoke (ParallelOptions options,
params Action[] actions);
ąÆą╝ąĄčüč鹥 čü ParallelOptions ąÆčŗ ą╝ąŠąČąĄč鹥 ą▓čüčéą░ą▓ąĖčéčī ą╝ą░čĆą║ąĄčĆ ąŠčéą╝ąĄąĮčŗ (cancellation token), ąŠą│čĆą░ąĮąĖčćąĖčéčī ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčāčÄ ą║ąŠąĮą║čāčĆąĄąĮčåąĖčÄ ąĖ čāą║ą░ąĘą░čéčī ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖą╣ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ ąĘą░ą┤ą░čć (custom task scheduler). ą£ą░čĆą║ąĄčĆ ąŠčéą╝ąĄąĮčŗ čāą╝ąĄčüč鹥ąĮ, ą║ąŠą│ą┤ą░ ąÆčŗ ą▓čŗą┐ąŠą╗ąĮčÅąĄč鹥 (ą│čĆčāą▒ąŠ) ą▒ąŠą╗čīčłąĄ ąĘą░ą┤ą░čć, č湥ą╝ ąĖą╝ąĄąĄčéčüčÅ ą▓ ąĮą░ą╗ąĖčćąĖąĖ čÅą┤ąĄčĆ: ą┐čĆąĖ ąŠčéą╝ąĄąĮąĄ ą╗čÄą▒čŗąĄ ąĮąĄ ąĘą░ą┐čāčēąĄąĮąĮčŗąĄ ą┤ąĄą╗ąĄą│ą░čéčŗ ą▒čāą┤čāčé ąĘą░ą▒čĆąŠčłąĄąĮčŗ. ą×ą┤ąĮą░ą║ąŠ ą╗čÄą▒čŗąĄ čāąČąĄ ą▓čŗą┐ąŠą╗ąĮčÅčÄčēąĖąĄčüčÅ ą┤ąĄą╗ąĄą│ą░čéčŗ ą▒čāą┤čāčé ą┐čĆąŠą┤ąŠą╗ąČą░čéčī čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┤ąŠ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ. ąĪą╝. "ą×čéą╝ąĄąĮą░ ąĘą░ą┐čĆąŠčüą░ (Cancellation)" ą▓ [4] ą┤ą╗čÅ ą┐čĆąĖą╝ąĄčĆą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą╝ą░čĆą║ąĄčĆąŠą▓ ąŠčéą╝ąĄąĮčŗ.
Parallel.For ąĖ Parallel.ForEach
public static ParallelLoopResult For (int fromInclusive,
int toExclusive,
Action< int > body)
public static ParallelLoopResult ForEach< TSource> (IEnumerable< TSource> source,
Action< TSource> body)
ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗą╣ čåąĖą║ą╗ for:
for (int i = 0 ; i < 100 ; i++)
Foo (i);
ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘčāąĄčéčüčÅ ą┐čĆąĖą╝ąĄčĆąĮąŠ čéą░ą║:
Parallel.For (0 , 100 , i => Foo (i));
ąĖą╗ąĖ ąĄčēąĄ ą┐čĆąŠčēąĄ:
Parallel.For (0 , 100 , Foo);
ąś čüą╗ąĄą┤čāčÄčēąĖą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗą╣ čåąĖą║ą╗ foreach:
foreach (char c in "Hello, world" )
Foo (c);
ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘčāąĄčéčüčÅ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ:
Parallel.ForEach ("Hello, world" , Foo);
ą¤čĆą░ą║čéąĖč湥čüą║ąĖą╣ ą┐čĆąĖą╝ąĄčĆ: ąĄčüą╗ąĖ ą╝čŗ ąĖą╝ą┐ąŠčĆčéąĖčĆčāąĄą╝ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ąĖą╝ąĄąĮ System.Security.Cryptography namespace, č鹊 ą╝ąŠąČąĄą╝ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī 6 ą┐ą░čĆ public/private čüčéčĆąŠą║ ą║ą╗čÄč湥ą╣:
var keyPairs = new string [6 ];
Parallel.For (0 , keyPairs.Length,
i => keyPairs[i] = RSA.Create().ToXmlString (true ));
ąÜą░ą║ čü Parallel.Invoke, ą╝čŗ ą╝ąŠąČąĄą╝ ą┐ąĄčĆąĄą┤ą░čéčī ą┤ą╗čÅ Parallel.For ąĖ Parallel.ForEach ą▒ąŠą╗čīčłąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄą╝čŗčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓, ąĖ ąŠąĮąĖ ą▒čāą┤čāčé čŹčäč乥ą║čéąĖą▓ąĮąŠ čĆą░ąĘą▒ąĖčéčŗ ąĮą░ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĘą░ą┤ą░čć.
ą¤ąŠčüą╗ąĄą┤ąĮąĖą╣ ąĘą░ą┐čĆąŠčü čéą░ą║ąČąĄ ą╝ąŠąČąĮąŠ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī čü ą┐ąŠą╝ąŠčēčīčÄ PLINQ:
string [] keyPairs =
ParallelEnumerable.Range (0 , 6 )
.Select (i => RSA.Create().ToXmlString (true ))
.ToArray();
ąĪčĆą░ą▓ąĮąĄąĮąĖąĄ ą▓ąĮąĄčłąĮąĖčģ ąĖ ą▓ąĮčāčéčĆąĄąĮąĮąĖčģ čåąĖą║ą╗ąŠą▓ . Parallel.For ąĖ Parallel.ForEach ąŠą▒čŗčćąĮąŠ čĆą░ą▒ąŠčéą░čÄčé ą╗čāčćčłąĄ ąĮą░ ą▓ąĮąĄčłąĮąĖčģ čåąĖą║ą╗ą░čģ (outer loop) č湥ą╝ ąĮą░ ą▓ąĮčāčéčĆąĄąĮąĮąĖčģ (inner loop). ąŁč鹊 ą▓čŗąĘą▓ą░ąĮąŠ č鹥ą╝, čćč鹊 čü ą▓ąĮąĄčłąĮąĖą╝ čåąĖą║ą╗ąŠą╝ ąÆčŗ ą┐čĆąĄą┤ą╗ą░ą│ą░ąĄč鹥 ą▒ąŠą╗čīčłąĖąĄ ą▒ą╗ąŠą║ąĖ čĆą░ą▒ąŠčéčŗ ą┤ą╗čÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖąĖ, čüąĮąĖąČą░čÅ ąĘą░čéčĆą░čéčŗ ąĮą░ ą▓ąĮąĄčłąĮąĄąĄ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖąĄ. ą¤ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖčÅ ąĖ ą▓ąĮčāčéčĆąĄąĮąĮąĖčģ, ąĖ ą▓ąĮąĄčłąĮąĖčģ čåąĖą║ą╗ąŠą▓ ąŠą▒čŗčćąĮąŠ ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ. ąÆ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ ąĮą░ą╝ ą┐ąŠąĮą░ą┤ąŠą▒ąĖą╗ąŠčüčī ą▒čŗ ą▒ąŠą╗čīčłąĄ 100 čÅą┤ąĄčĆ, čćč鹊ą▒čŗ ąĖąĘą▓ą╗ąĄčćčī ą▓čŗą│ąŠą┤čā ąŠčé ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖąĖ:
Parallel.For (0 , 100 , i =>
{
Parallel.For (0 , 50 , j => Foo (i, j)); // ąÆ čŹč鹊ą╝ ą╝ąĄčüč鹥 ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ
}); // čåąĖą║ą╗ą░ ą▒čŗą╗ąŠ ą▒čŗ ą╗čāčćčłąĄ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą│ąŠ.
ąśąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮčŗą╣ Parallel.ForEach . ąśąĮąŠą│ą┤ą░ ą┐ąŠą╗ąĄąĘąĮąŠ ąĘąĮą░čéčī ąĖąĮą┤ąĄą║čü ąĖč鹥čĆą░čåąĖąĖ čåąĖą║ą╗ą░. ąĪ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗą╝ foreach čŹč鹊 ą┐čĆąŠčüč鹊:
int i = 0 ;foreach (char c in "Hello, world" )
Console.WriteLine (c.ToString() + i++);
ąśąĮą║čĆąĄą╝ąĄąĮčé ąŠą▒čēąĄą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣, ąŠą┤ąĮą░ą║ąŠ, ąĮąĄ ą▒ąĄąĘąŠą┐ą░čüąĮąŠ ą┤ą╗čÅ ą┐ąŠč鹊ą║ąŠą▓ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ. ąÆčŗ ą┤ąŠą╗ąČąĮčŗ ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čüą╗ąĄą┤čāčÄčēčāčÄ ą▓ąĄčĆčüąĖčÄ ForEach:
public static ParallelLoopResult ForEach< TSource> (IEnumerable< TSource> source,
Action< TSource, ParallelLoopState, long > body)
ą£čŗ ą┐čĆąŠąĖą│ąĮąŠčĆąĖčĆčāąĄą╝ ParallelLoopState (čćč鹊 ą▒čāą┤ąĄčé čĆą░čüčüą╝ąŠčéčĆąĄąĮąŠ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╣ čüąĄą║čåąĖąĖ). ąĪąĄą╣čćą░čü ąĮą░ą╝ ąĖąĮč鹥čĆąĄčüąĄąĮ čéčĆąĄčéąĖą╣ ą┐ą░čĆą░ą╝ąĄčéčĆ čéąĖą┐ą░ long ą┤ąĄą╗ąĄą│ą░čéą░ Action, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĖąĮą┤ąĄą║čü čåąĖą║ą╗ą░:
Parallel.ForEach ("Hello, world" , (c, state, i) =>
{
Console.WriteLine (c.ToString() + i);
});
ą¦č鹊ą▒čŗ ą┐ąĄčĆąĄą▓ąĄčüčéąĖ čŹč鹊 ą▓ ą┐čĆą░ą║čéąĖč湥čüą║ąĖą╣ ą║ąŠąĮč鹥ą║čüčé, ą▓ąĄčĆąĮąĄą╝čüčÅ ą║ ą┐čĆąŠąĄą║čéčā čüą┐ąĄą╗ą╗č湥ą║ąĄčĆą░, ą║ąŠč鹊čĆčŗą╣ ą╝čŗ ą┐ąĖčüą░ą╗ąĖ ąĮą░ ąŠčüąĮąŠą▓ąĄ PLINQ. ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤ ąĘą░ą│čĆčāąČą░ąĄčé čüą╗ąŠą▓ą░čĆčī ą┤ą╗čÅ ą┐čĆąŠą▓ąĄčĆą║ąĖ ą╝ąĖą╗ą╗ąĖąŠąĮą░ čüą╗ąŠą▓:
if (!File.Exists ("WordLookup.txt" )) // ąĪąŠą┤ąĄčƹȹĖčé ąŠą║ąŠą╗ąŠ 150000 čüą╗ąŠą▓
new WebClient ().DownloadFile (
"http://www.albahari.com/ispell/allwords.txt" , "WordLookup.txt" );
var wordLookup = new HashSet< string > (
File.ReadAllLines ("WordLookup.txt" ),
StringComparer.InvariantCultureIgnoreCase);
var random = new Random();string [] wordList = wordLookup.ToArray();
string [] wordsToTest = Enumerable.Range (0 , 1000000 )
.Select (i => wordList [random.Next (0 , wordList.Length)])
.ToArray();
wordsToTest [12345 ] = "woozsh" ; // ąÆą▓ąŠą┤ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ąŠčłąĖą▒ąŠą║
wordsToTest [23456 ] = "wubsie" ; // ąŠčĆč乊ą│čĆą░čäąĖąĖ.
ą£čŗ ą╝ąŠąČąĄą╝ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą┐čĆąŠą▓ąĄčĆą║čā ąŠčĆč乊ą│čĆą░čäąĖąĖ ąĮą░čłąĄą│ąŠ ą╝ą░čüčüąĖą▓ą░ wordsToTest čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą╣ ą▓ąĄčĆčüąĖąĖ Parallel.ForEach čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
var misspellings = new ConcurrentBag< Tuple< int ,string >>();
Parallel.ForEach (wordsToTest, (word, state, i) =>
{
if (!wordLookup.Contains (word))
misspellings.Add (Tuple.Create ((int ) i, word));
});
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą╝čŗ ą┤ąŠą╗ąČąĮčŗ ą▒čŗą╗ąĖ čüąŠą┐ąŠčüčéą░ą▓ąĖčéčī čĆąĄąĘčāą╗čīčéą░čéčŗ ą▓ thread-safe ą║ąŠą╗ą╗ąĄą║čåąĖąĖ: ąĖąĘ-ąĘą░ čŹč鹊ą╣ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ čŹč鹊čé ą║ąŠą┤ ąĖą╝ąĄąĄčé ąĮąĄą┤ąŠčüčéą░č鹊ą║ ą┐ąŠ čüčĆą░ą▓ąĮąĄąĮąĖčÄ čü ą║ąŠą┤ąŠą╝ ąĮą░ PLINQ. ąöąŠčüč鹊ąĖąĮčüčéą▓ąŠ PLINQ ą▓ č鹊ą╝, čćč鹊 ą╝čŗ ąĖąĘą▒ąĄą│ą░ąĄą╝ čåąĄąĮčŗ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ ąŠą┐ąĄčĆą░č鹊čĆą░ ąĘą░ą┐čĆąŠčüą░ Select - ą║ąŠč鹊čĆčŗą╣ ą╝ąĄąĮąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮčŗą╣, č湥ą╝ ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ForEach.
ParallelLoopState: čĆą░ąĮąĮąĖą╣ ą▓čŗčģąŠą┤ ąĖąĘ čåąĖą║ą╗ąŠą▓ . ąśąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 č鹥ą╗ąŠ čåąĖą║ą╗ą░ ą▓ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą╝ For ąĖą╗ąĖ ForEach čŹč鹊 ą┤ąĄą╗ąĄą│ą░čé, ąÆčŗ ąĮąĄ ą╝ąŠąČąĄč鹥 ą▓čŗą┐ąŠą╗ąĮąĖčéčī čĆą░ąĮąĮąĖą╣ ą▓čŗčģąŠą┤ ąĖąĘ čåąĖą║ą╗ą░ čü ą┐ąŠą╝ąŠčēčīčÄ ąŠą┐ąĄčĆą░č鹊čĆą░ break. ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ąÆčŗ ą┤ąŠą╗ąČąĮčŗ ą▓čŗąĘą▓ą░čéčī Break ąĖą╗ąĖ Stop ąĮą░ ąŠą▒čŖąĄą║č鹥 ParallelLoopState:
public class ParallelLoopState
{
public void Break ();
public void Stop ();
public bool IsExceptional { get ; }
public bool IsStopped { get ; }
public long? LowestBreakIteration { get ; }
public bool ShouldExitCurrentIteration { get ; }
}
ą¤ąŠą╗čāčćąĖčéčī ParallelLoopState ą┐čĆąŠčüč鹊: ą▓čüąĄ ą▓ąĄčĆčüąĖąĖ For ąĖ ForEach ą┐ąĄčĆąĄą│čĆčāąČąĄąĮčŗ čćč鹊ą▒čŗ ą┐čĆąĖąĮčÅčéčī č鹥ą╗ą░ čåąĖą║ą╗ą░ čéąĖą┐ą░ Action< TSource, ParallelLoopState>. ąĀą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖą╝ ą▓ąŠčé čŹč鹊:
foreach (char c in "Hello, world" )
if (c == ',' )
break ;
else
Console.Write (c);
čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
Parallel.ForEach ("Hello, world" , (c, loopState) =>
{
if (c == ',' )
loopState.Break();
else
Console.Write (c);
});
ąÆčŗą▓ąĄą┤ąĄąĮąĮčŗą╣ čĆąĄąĘčāą╗čīčéą░čé:
ą£ąŠąČąĮąŠ čāą▓ąĖą┤ąĄčéčī ąĖąĘ ą▓čŗą▓ąĄą┤ąĄąĮąĮąŠą│ąŠ čĆąĄąĘčāą╗čīčéą░čéą░ "Hlloe", čćč鹊 č鹥ą╗ą░ čåąĖą║ą╗ą░ ą╝ąŠą│čāčé ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ ą▓ čüą╗čāčćą░ą╣ąĮąŠą╝ ą┐ąŠčĆčÅą┤ą║ąĄ. ąÜčĆąŠą╝ąĄ čŹč鹊ą│ąŠ ąŠčéą╗ąĖčćąĖčÅ, ą▓čŗąĘąŠą▓ Break ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ č鹊ą╝čā, čćč鹊 ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝ ąŠą┤ąĖąĮą░ą║ąŠą▓čŗąĄ 菹╗ąĄą╝ąĄąĮčéčŗ ą▓ čåąĖą║ą╗ąĄ ą▒čāą┤čāčé ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ: čŹč鹊čé ą┐čĆąĖą╝ąĄčĆ ą▓čüąĄą│ą┤ą░ ą▓čŗą▓ąĄą┤ąĄčé ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝ ą▒čāą║ą▓čŗ H, e, l, l ąĖ o ą▓ ąĮąĄą║ąŠč鹊čĆąŠą╝ ą┐ąŠčĆčÅą┤ą║ąĄ. ąÆčŗąĘąŠą▓ Stop ąŠčéą╗ąĖčćą░ąĄčéčüčÅ ąŠčé ą▓čŗąĘąŠą▓ą░ Break č鹥ą╝, čćč鹊 ą┐čĆąĖąĮčāąČą┤ą░ąĄčé ą▓čüąĄ ą┐ąŠč鹊ą║ąĖ ąĘą░ą▓ąĄčĆčłąĖčéčīčüčÅ čüčĆą░ąĘčā ą┐ąŠčüą╗ąĄ ąĖčģ č鹥ą║čāčēąĄą╣ ąĖč鹥čĆą░čåąĖąĖ. ąÆ ąĮą░čłąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą▓čŗąĘąŠą▓ Stop ą┤ą░ą╗ ą▒čŗ ąĮą░ą╝ ą┐ąŠą┤ą╝ąĮąŠąČąĄčüčéą▓ąŠ ą▒čāą║ą▓ H, e, l, l ąĖ o, ąĄčüą╗ąĖ ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║ ąŠčéčüčéą░ąĄčé. ąÆčŗąĘąŠą▓ Stop ą┐ąŠą╗ąĄąĘąĮąŠ čüą┤ąĄą╗ą░čéčī, ą║ąŠą│ą┤ą░ ąÆčŗ ąŠą▒ąĮą░čĆčāąČąĖą╗ąĖ č鹊, čćč鹊 ąĖčēąĄč鹥, ąĖą╗ąĖ ą║ąŠą│ą┤ą░ čćč鹊-č鹊 ą┐ąŠčłą╗ąŠ ąĮąĄ čéą░ą║, ąĖ ą╝čŗ ąĮąĄ čģąŠčéąĖą╝ čüą╝ąŠčéčĆąĄčéčī ąĮą░ čĆąĄąĘčāą╗čīčéą░čéčŗ.
ą£ąĄč鹊ą┤čŗ Parallel.For ąĖ Parallel.ForEach ą▓ąŠąĘą▓čĆą░čéčÅčé ąŠą▒čŖąĄą║čé ParallelLoopResult, ą║ąŠč鹊čĆčŗą╣ ą┐čāą▒ą╗ąĖą║čāąĄčé čüą▓ąŠą╣čüčéą▓ą░ IsCompleted ąĖ LowestBreakIteration. ą×ąĮąĖ čüą║ą░ąČčāčé ąÆą░ą╝, ą┤ąŠčĆą░ą▒ąŠčéą░ą╗ ą╗ąĖ čåąĖą║ą╗ ą┤ąŠ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ, ąĖ ąĄčüą╗ąĖ ąĮąĄčé, č鹊 ąĮą░ ą║ą░ą║ąŠą╣ ąĖč鹥čĆą░čåąĖąĖ čåąĖą║ą╗ ą▒čŗą╗ ąŠą▒ąŠčĆą▓ą░ąĮ.
ąĢčüą╗ąĖ LowestBreakIteration ą▓ąĄčĆąĮąĄčé null, č鹊 čŹč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ąÆčŗ ą▓čŗąĘą▓ą░ą╗ąĖ ąĮą░ čåąĖą║ą╗ąĄ Stop (ą▓ą╝ąĄčüč鹊 Break).
ąĢčüą╗ąĖ č鹥ą╗ąŠ ąÆą░čłąĄą│ąŠ čåąĖą║ą╗ą░ ą┤ą╗ąĖąĮąĮąŠąĄ, č鹊 ąÆčŗ ą╝ąŠąČąĄč鹥 ąĘą░čģąŠč鹥čéčī, čćč鹊ą▒čŗ ą┤čĆčāą│ąĖąĄ ą┐ąŠč鹊ą║ąĖ ąŠčüčéą░ąĮąŠą▓ąĖą╗ąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą▓ąĮčāčéčĆąĖ čüą▓ąŠąĄą│ąŠ č鹥ą╗ą░ ą▓ čüą╗čāčćą░ąĄ čĆą░ąĮąĮąĄą│ąŠ ą▓čŗąĘąŠą▓ą░ Break ąĖą╗ąĖ Stop. ąÆčŗ ą╝ąŠąČąĄč鹥 ą▓čŗą┐ąŠą╗ąĮąĖčéčī čŹč鹊 ąŠą┐čĆąŠčüąŠą╝ čüą▓ąŠą╣čüčéą▓ą░ ShouldExitCurrentIteration ą▓ čĆą░ąĘą╗ąĖčćąĮčŗčģ ą╝ąĄčüčéą░čģ čüą▓ąŠąĄą│ąŠ ą║ąŠą┤ą░; ąŠąĮąŠ čüčéą░ąĮąĄčé true čüčĆą░ąĘčā ą┐ąŠčüą╗ąĄ Stop - ąĖą╗ąĖ ą┐ąŠčćčéąĖ čüčĆą░ąĘčā ą┐ąŠčüą╗ąĄ Break.
ShouldExitCurrentIteration čéą░ą║ąČąĄ čüčéą░ąĮąĄčé true ą┐ąŠčüą╗ąĄ ąĘą░ą┐čĆąŠčüą░ ąŠčéą╝ąĄąĮčŗ (cancellation request) - ąĖą╗ąĖ ąĄčüą╗ąĖ ą▓ čåąĖą║ą╗ąĄ ą▓čŗą▒čĆąŠčłąĄąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ.
IsExceptional ą┐ąŠąĘą▓ąŠą╗ąĖčé ąÆą░ą╝ čāąĘąĮą░čéčī, ą┐čĆąŠąĖąĘąŠčłą╗ąŠ ą╗ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ą▓ ą┤čĆčāą│ąŠą╝ ą┐ąŠč鹊ą║ąĄ. ąøčÄą▒ąŠąĄ ąĮąĄ ąŠą▒čĆą░ą▒ąŠčéą░ąĮąĮąŠąĄ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąŠčüčéą░ąĮąŠą▓ą║ąĄ čåąĖą║ą╗ą░ ą┐ąŠčüą╗ąĄ ą║ą░ąČą┤ąŠą╣ č鹥ą║čāčēąĄą╣ ąĖč鹥čĆą░čåąĖąĖ ą┐ąŠč鹊ą║ą░: čćč鹊ą▒čŗ ąĖąĘą▒ąĄąČą░čéčī čŹč鹊ą│ąŠ, ąÆčŗ ą┤ąŠą╗ąČąĮčŗ čÅą▓ąĮąŠ ąŠą▒čĆą░ą▒ąŠčéą░čéčī ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą▓ čüą▓ąŠąĄą╝ ą║ąŠą┤ąĄ.
ą×ą┐čéąĖą╝ąĖąĘą░čåąĖčÅ čü ą╗ąŠą║ą░ą╗čīąĮčŗą╝ąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝ąĖ . Parallel.For ąĖ Parallel.ForEach ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ąĮą░ą▒ąŠčĆ ą┐ąĄčĆąĄą│čĆčāąĘąŠą║, čĆąĄą░ą╗ąĖąĘčāčÄčēąĖčģ ą░čĆą│čāą╝ąĄąĮčé ąŠą▒čŗčćąĮąŠą│ąŠ čéąĖą┐ą░ čü ąĖą╝ąĄąĮąĄą╝ TLocal. ąŁčéąĖ ą┐ąĄčĆąĄą│čĆčāąĘą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮčŗ, čćč鹊ą▒čŗ ą┐ąŠą╝ąŠčćčī ąÆą░ą╝ ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░čéčī čüą╗ąĖčÅąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ ą▓ čåąĖą║ą╗ą░čģ čü ąĖąĮč鹥ąĮčüąĖą▓ąĮčŗą╝ąĖ ąĖč鹥čĆą░čåąĖčÅą╝ąĖ. ąĪą░ą╝čŗą╣ ą┐čĆąŠčüč鹊ą╣ ą┐čĆąĖą╝ąĄčĆ:
public static ParallelLoopResult For < TLocal> (
int fromInclusive,
int toExclusive,
Func < TLocal> localInit, Func < int , ParallelLoopState, TLocal, TLocal> body,
Action < TLocal> localFinally);
ąŁčéąĖ ą╝ąĄč鹊ą┤čŗ čĆąĄą┤ą║ąŠ ąĮčāąČąĮčŗ ąĮą░ ą┐čĆą░ą║čéąĖą║ąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 ąĖčģ čåąĄą╗ąĄą▓čŗąĄ čüčåąĄąĮą░čĆąĖąĖ ąŠą▒čŗčćąĮąŠ ąŠą▒čüą╗čāąČąĖą▓ą░čÄčéčüčÅ PLINQ (čćč鹊 čāą┤ą░čćąĮąĄąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 čüąĖąĮčéą░ą║čüąĖčü čŹčéąĖčģ ą┐ąĄčĆąĄą│čĆčāąĘąŠą║ ą┐čāą│ą░ąĄčé).
ąÆ čüčāčēąĮąŠčüčéąĖ, ą┐čĆąŠą▒ą╗ąĄą╝ą░ ąĘą░ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╝: ą┐čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ą╝čŗ čģąŠčéąĖą╝ čüą╗ąŠąČąĖčéčī ą║ą▓ą░ą┤čĆą░čéąĮčŗąĄ ą║ąŠčĆąĮąĖ čćąĖčüąĄą╗ ąŠčé 1 ą┤ąŠ 10000000. ąÆčŗčćąĖčüą╗ąĄąĮąĖąĄ 10 ą╝ąĖą╗ą╗ąĖąŠąĮąŠą▓ ą║ą▓ą░ą┤čĆą░čéąĮčŗčģ ą║ąŠčĆąĮąĄą╣ ą┐čĆąŠčüč鹊 ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘčāąĄčéčüčÅ, ąĮąŠ čüčāą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖčģ ąĘąĮą░č湥ąĮąĖą╣ ą┐čĆąŠą▒ą╗ąĄą╝ą░čéąĖčćąĮąŠ, ą┐ąŠč鹊ą╝čā čćč鹊 ą╝čŗ ą┤ąŠą╗ąČąĮčŗ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ą▓ąŠą║čĆčāą│ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ čĆąĄąĘčāą╗čīčéą░čéą░:
object locker = new object ();double total = 0 ;
Parallel.For (1 , 10000000 ,
i => { lock (locker) total += Math.Sqrt (i); });
ąÆčŗąĖą│čĆčŗčł ąŠčé ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖąĖ ąĮąĖą▓ąĄą╗ąĖčĆčāąĄčéčüčÅ čåąĄąĮąŠą╣ ą┐ąŠą╗čāč湥ąĮąĖčÅ 10 ą╝ąĖą╗ą╗ąĖąŠąĮąŠą▓ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║ ą┐ą╗čÄčü čĆąĄąĘčāą╗čīčéąĖčĆčāčÄčēą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░.
ą×ą┤ąĮą░ą║ąŠ čĆąĄą░ą╗čīąĮąŠ ąĮą░ą╝ ąĮąĄ ąĮčāąČąĮčŗ čŹčéąĖ 10 ą╝ąĖą╗ą╗ąĖąŠąĮąŠą▓ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║. ąÆąŠąŠą▒čĆą░ąĘąĖč鹥 ą║ąŠą╝ą░ąĮą┤čā ą▓ąŠą╗ąŠąĮč鹥čĆąŠą▓, čüąŠą▒ąĖčĆą░čÄčēąĖčģ ą▒ąŠą╗čīčłąŠą╣ ąŠą▒čŖąĄą╝ ą╝čāčüąŠčĆą░. ąĢčüą╗ąĖ ą▒čŗ ą▓čüąĄ čĆą░ą▒ąŠčćąĖąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ąĖ ą▒čŗ ąŠą┤ąĮčā ą╝čāčüąŠčĆąĮčāčÄ ą║ąŠčƹʹĖąĮčā, č鹊 ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ čĆą░ą▒ąŠčćąĖčģ ąĖ ąĖčģ ą║ąŠąĮą║čāčĆąĄąĮčåąĖčÅ ąĘą░ ą║ąŠčƹʹĖąĮčā čüą┤ąĄą╗ą░ą╗ąĖ ą▒čŗ ąŠą▒čēąĖą╣ ą┐čĆąŠčåąĄčüčü čüą▒ąŠčĆą░ ą╝čāčüąŠčĆą░ 菹║čüčéčĆąĄą╝ą░ą╗čīąĮąŠ ąĮąĄ čŹčäč乥ą║čéąĖą▓ąĮčŗą╝. ą×č湥ą▓ąĖą┤ąĮąŠąĄ čĆąĄčłąĄąĮąĖąĄ - ą┤ą░čéčī ą║ą░ąČą┤ąŠą╝čā čĆą░ą▒ąŠč湥ą╝čā ą┐ąŠ "ą╗ąŠą║ą░ą╗čīąĮąŠą╝čā" ą╝čāčüąŠčĆąĮąŠą╝čā ą▓ąĄą┤čĆčā, ą║ąŠč鹊čĆąŠąĄ ąŠąĮ ą╝ąŠąČąĄčé ą┐ąŠ čüą╗čāčćą░čÄ ąŠą┐ąŠčĆąŠąČąĮčÅčéčī ą▓ ąŠą▒čēčāčÄ ą║ąŠčƹʹĖąĮčā.
TLocal-ą▓ąĄčĆčüąĖąĖ ą┤ą╗čÅ For ąĖ ForEach čĆą░ą▒ąŠčéą░čÄčé č鹊čćąĮąŠ ą┐ąŠ čéą░ą║ąŠą╝čā ą┐čĆąĖąĮčåąĖą┐čā. ąÆąŠą╗ąŠąĮč鹥čĆą░ą╝ąĖ čéčāčé čüą╗čāąČą░čé ą▓ąĮčāčéčĆąĄąĮąĮąĖąĄ čĆą░ą▒ąŠčćąĖąĄ ą┐ąŠč鹊ą║ąĖ, ąĖ ą╗ąŠą║ą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé ą╝ąĄčüčéąĮąŠąĄ ą▓ąĄą┤ąĄčĆą║ąŠ ą╝čāčüąŠčĆą░. ąÆ čüą╗čāčćą░ąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ Parallel ą┤ą╗čÅ čéą░ą║ąŠą╣ čĆą░ą▒ąŠčéčŗ ąÆčŗ ą┤ąŠą╗ąČąĮčŗ ą┐ąĄčĆąĄą┤ą░čéčī ąĄą╝čā ą┤ą▓čāčģ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ą┤ąĄą╗ąĄą│ą░č鹊ą▓, čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī:
1 . ąÜą░ą║ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī ąĮąŠą▓ąŠąĄ ą╗ąŠą║ą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.2 . ąÜą░ą║ ą║ąŠą╝ą▒ąĖąĮąĖčĆąŠą▓ą░čéčī ą╗ąŠą║ą░ą╗čīąĮčāčÄ ą░ą│čĆąĄą│ą░čåąĖčÄ čü ą│ą╗ą░ą▓ąĮčŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝.
ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ ą▓ą╝ąĄčüč鹊 č鹥ą╗ą░ ą┤ąĄą╗ąĄą│ą░čéą░, ą▓ąŠąĘą▓čĆą░čēą░čÄčēąĄą│ąŠ void, ąŠąĮ ą┤ąŠą╗ąČąĄąĮ ą▓ąŠąĘą▓čĆą░čēą░čéčī ąĮąŠą▓čŗą╣ ą░ą│čĆąĄą│ą░čé ą┤ą╗čÅ čŹč鹊ą│ąŠ ą╗ąŠą║ą░ą╗čīąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ. ąÆąŠčé ąĮą░čł ą┐ąĄčĆąĄčĆą░ą▒ąŠčéą░ąĮąĮčŗą╣ ą┐čĆąĖą╝ąĄčĆ:
object locker = new object ();double grandTotal = 0 ;
Parallel.For (1 , 10000000 ,
() => 0.0 , // ąśąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ ą╗ąŠą║ą░ą╗čīąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ.
(i, state, localTotal) => // ąöąĄą╗ąĄą│ą░čé č鹥ą╗ą░ čåąĖą║ą╗ą░. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąŠąĮ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé
localTotal + Math.Sqrt (i), // ąĮąŠą▓ąŠąĄ ąŠą▒čēąĄąĄ ą╗ąŠą║ą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ localTotal.
localTotal => // ąöąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ ą╗ąŠą║ą░ą╗čīąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ
{ lock (locker) grandTotal += localTotal; } // ą║ ąŠą▒čēąĄą╝čā ąĘąĮą░č湥ąĮąĖčÄ (čü ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąŠą╣).
);
ą£čŗ ą▓čüąĄ ąĄčēąĄ ą┤ąŠą╗ąČąĮčŗ ą┐čĆąĖą╝ąĄąĮąĖčéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā, č鹊 č鹥ą┐ąĄčĆčī č鹊ą╗čīą║ąŠ ą▓ąŠą║čĆčāą│ ą░ą│čĆąĄą│ą░čåąĖąĖ ą╗ąŠą║ą░ą╗čīąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ ą║ ąŠą▒čēąĄą╝čā. ąŁč鹊 ą┤ąĄą╗ą░ąĄčé ą▓ąĄčüčī ą┐čĆąŠčåąĄčüčü ą║ą░čĆą┤ąĖąĮą░ą╗čīąĮąŠ čŹčäč乥ą║čéąĖą▓ąĮąĄąĄ.
ąÜą░ą║ ą▒čŗą╗ąŠ ąĘą░ą╝ąĄč湥ąĮąŠ čĆą░ąĮąĄąĄ, PLINQ čćą░čüč鹊 čģąŠčĆąŠčłąŠ ą┐ąŠą┤čģąŠą┤ąĖčé ą┤ą╗čÅ ą┐ąŠą┤ąŠą▒ąĮčŗčģ ąĘą░ą┤ą░čć. ąØą░čł ą┐čĆąĖą╝ąĄčĆ ą╝ąŠą│ ą▒čŗ ąŠč湥ąĮčī ą┐čĆąŠčüč鹊 ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ PLINQ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ParallelEnumerable.Range(1 , 10000000 )
.Sum (i => Math.Sqrt (i))
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĘą┤ąĄčüčī ą╝čŗ ą┐čĆąĖą╝ąĄąĮąĖą╗ąĖ ParallelEnumerable, čćč鹊ą▒čŗ ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ ąĘą░ą┤ą░čéčī čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ ą┐ąŠ ą┤ąĖą░ą┐ą░ąĘąŠąĮčā (range partitioning): ą┤ą╗čÅ ąĮą░čłąĄą│ąŠ ą┐čĆąĖą╝ąĄčĆą░ čŹč鹊 čāą╗čāčćčłą░ąĄčé ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓čüąĄ čćąĖčüą╗ą░ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ą┐ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą┐čĆąĖą╝ąĄčĆąĮąŠ ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠ.
ąÆ ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮčŗčģ čüčåąĄąĮą░čĆąĖčÅčģ ąÆčŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąŠą┐ąĄčĆą░č鹊čĆ Aggregate ąĘą░ą┐čĆąŠčüą░ LINQ ą▓ą╝ąĄčüč鹊 Sum. ąĢčüą╗ąĖ ąÆčŗ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖą╗ąĖ čäčāąĮą║čåąĖčÄ ą╗ąŠą║ą░ą╗čīąĮąŠą│ąŠ ąĮą░čćą░ą╗čīąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ (local seed factory), č鹊 čüąĖčéčāą░čåąĖčÅ ą▒čŗą╗ą░ ą▒čŗ ą┐ąŠčģąŠąČąĄą╣ ąĮą░ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĖąĄ ą╗ąŠą║ą░ą╗čīąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ čäčāąĮą║čåąĖąĖ čü čåąĖą║ą╗ąŠą╝ Parallel.For.
ą¤ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ ąĘą░ą┤ą░čć ]
Task Parallelism (ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ ąĘą░ą┤ą░čć) čŹč鹊 ą╝ąĄč鹊ą┤ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą░čåąĖąĖ čüą░ą╝ąŠą│ąŠ ąĮąĖąĘą║ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ čü ą┐ąŠą╝ąŠčēčīčÄ PFX. ąÆ System.Threading.Tasks namespace ą┤ą╗čÅ čŹč鹊ą│ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮčŗ ą║ą╗ą░čüčüčŗ:
ąÜą╗ą░čüčü ąØą░ąĘąĮą░č湥ąĮąĖąĄ
Task
ąöą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąĄą┤ąĖąĮąĖčåąĄą╣ čĆą░ą▒ąŠčéčŗ.
Task< TResult>
ąöą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąĄą┤ąĖąĮąĖčåąĄą╣ čĆą░ą▒ąŠčéčŗ čü ą▓ąŠąĘą▓čĆą░č鹊ą╝ ąĘąĮą░č湥ąĮąĖčÅ.
TaskFactory
ąöą╗čÅ čüąŠąĘą┤ą░ąĮąĖčÅ ąĘą░ą┤ą░čć.
TaskFactory< TResult>
ąöą╗čÅ čüąŠąĘą┤ą░ąĮąĖčÅ ąĘą░ą┤ą░čć ąĖ ąĘą░ą┤ą░čć-ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖą╣ čü č鹥ą╝ ąČąĄ čüą░ą╝čŗą╝ ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝čŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝.
TaskScheduler
ąöą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ąĘą░ą┐čāčüą║ą░ ąĘą░ą┤ą░čć.
TaskCompletionSource
ąöą╗čÅ čĆčāčćąĮąŠą│ąŠ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čĆą░ą▒ąŠčćąĖą╝ ą┐čĆąŠčåąĄčüčüąŠą╝ ąĘą░ą┤ą░čć.
ąÆ čüčāčēąĮąŠčüčéąĖ ąĘą░ą┤ą░čćą░ (task) čŹč鹊 ąŠą▒ą╗ąĄą│č湥ąĮąĮčŗą╣ ąŠą▒čŖąĄą║čé ą┤ą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĄąĮąĮąŠą╣ ąĄą┤ąĖąĮąĖčåąĄą╣ čĆą░ą▒ąŠčéčŗ. Task ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĖąĘą▒ąĄąČą░čéčī ąĮą░ą║ą╗ą░ą┤ąĮčŗčģ čĆą░čüčģąŠą┤ąŠą▓ ąĮą░ ąĘą░ą┐čāčüą║ ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ą┐ąŠč鹊ą║ą░ čü ą┐ąŠą╝ąŠčēčīčÄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┐čāą╗ą░ ą┐ąŠč鹊ą║ąŠą▓ (CLR thread pool): čŹč鹊 č鹊čé ąČąĄ čüą░ą╝čŗą╣ ą┐čāą╗ ą┐ąŠč鹊ą║ąŠą▓, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ThreadPool.QueueUserWorkItem, čćč鹊 ą┐ąŠčÅą▓ąĖą╗ąŠčüčī ą▓ CLR 4.0, čćč鹊ą▒čŗ čŹčäč乥ą║čéąĖą▓ąĮąŠ čĆą░ą▒ąŠčéą░čéčī čü Tasks (ąĖ ąŠą▒čŗčćąĮąŠ ą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠ).
Tasks ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓čüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ąÆčŗ čģąŠčéąĖč鹥 čćč鹊-č鹊 ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ. ą×ą┤ąĮą░ą║ąŠ čŹč鹊 ąĘą░č鹊č湥ąĮąŠ ą┤ą╗čÅ ąĘą░ą┤ąĄą╣čüčéą▓ąŠą▓ą░ąĮąĖčÅ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čÅą┤ąĄčĆ: čäą░ą║čéąĖč湥čüą║ąĖ ą║ą╗ą░čüčü Parallel ąĖ ąĘą░ą┐čĆąŠčüčŗ PLINQ ą▓ąĮčāčéčĆąĄąĮąĮąĄ ą┐ąŠčüčéčĆąŠąĄąĮčŗ ąĮą░ ą║ąŠąĮčüčéčĆčāą║čåąĖčÅčģ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ą░ ąĘą░ą┤ą░čć.
Tasks ą┤ąĄą╗ą░čÄčé ą▒ąŠą╗čīčłąĄ, č湥ą╝ ą┐čĆąŠčüč鹊 ą┤ą░čÄčé ą┐čĆąŠčüč鹊ą╣ ąĖ čŹčäč乥ą║čéąĖą▓ąĮčŗą╣ čüą┐ąŠčüąŠą▒ čĆą░ą▒ąŠčéčŗ č湥čĆąĄąĘ ą┐čāą╗ ą┐ąŠč鹊ą║ąŠą▓. ą×ąĮąĖ čéą░ą║ąČąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ąĮąĄą║ąŠč鹊čĆčŗąĄ ą╝ąŠčēąĮčŗąĄ čäčāąĮą║čåąĖąĖ ą┤ą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąĄą┤ąĖąĮąĖčåą░ą╝ąĖ čĆą░ą▒ąŠčéčŗ, ą▓ą║ą╗čÄčćą░čÅ čüą╗ąĄą┤čāčÄčēąĄąĄ:
ŌĆó ąØą░čüčéčĆąŠą╣ą║ą░ ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąĖčÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĘą░ą┤ą░čć (task scheduling).
ąŚą░ą┤ą░čćąĖ čéą░ą║ąČąĄ čĆąĄą░ą╗ąĖąĘčāčÄčé ą╗ąŠą║ą░ą╗čīąĮčŗąĄ čĆą░ą▒ąŠčćąĖąĄ ąĘą░ą┐čĆąŠčüčŗ (local work queues). ąŁč鹊 ąŠą┐čéąĖą╝ąĖąĘą░čåąĖčÅ, ą║ąŠč鹊čĆą░čÅ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąÆą░ą╝ čŹčäč乥ą║čéąĖą▓ąĮąŠ čüąŠąĘą┤ą░ą▓ą░čéčī ą╝ąĮąŠąČąĄčüčéą▓ąŠ ą▒čŗčüčéčĆąŠ ą▓čŗą┐ąŠą╗ąĮčÅčÄčēąĖčģčüčÅ ą┤ąŠč湥čĆąĮąĖčģ ąĘą░ą┤ą░čć ą▒ąĄąĘ ą▓ąŠąĘąĮąĖą║ąĮąŠą▓ąĄąĮąĖčÅ ąĮą░ą║ą╗ą░ą┤ąĮčŗčģ čĆą░čüčģąŠą┤ąŠą▓ ąĮą░ ą║ąŠąĮą║čāčĆąĄąĮčåąĖčÄ, ą║ąŠč鹊čĆą░čÅ ąĖąĮą░č湥 ą▓ąŠąĘąĮąĖą║ą╗ą░ ą▒čŗ čü ąŠą┤ąĮąŠą╣ čĆą░ą▒ąŠč湥ą╣ ąŠč湥čĆąĄą┤čīčÄ.
ąæąĖą▒ą╗ąĖąŠč鹥ą║ą░ TLP (Task Parallel Library) ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąÆą░ą╝ čüąŠąĘą┤ą░čéčī čüąŠčéąĮąĖ (ąĖą╗ąĖ ą┤ą░ąČąĄ čéčŗčüčÅčćąĖ) ąĘą░ą┤ą░čć čü ą╝ąĖąĮąĖą╝ą░ą╗čīąĮčŗą╝ąĖ ąĘą░čéčĆą░čéą░ą╝ąĖ. ąØąŠ ąĄčüą╗ąĖ ąÆčŗ čģąŠčéąĖč鹥 čüąŠąĘą┤ą░čéčī ą╝ąĖą╗ą╗ąĖąŠąĮčŗ ąĘą░ą┤ą░čć, č鹊 ą┐ąŠąĮą░ą┤ąŠą▒ąĖčéčüčÅ čĆą░ąĘą┤ąĄą╗ąĖčéčī čŹčéąĖ ąĘą░ą┤ą░čćąĖ ąĮą░ ą▒ąŠą╗čīčłąĖąĄ ą▒ą╗ąŠą║ąĖ čĆą░ą▒ąŠčéčŗ, čćč鹊ą▒čŗ čüąŠčģčĆą░ąĮąĖčéčī čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéčī. ąÜą╗ą░čüčü Parallel ąĖ PLINQ ą┤ąĄą╗ą░čÄčé čŹč鹊 ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ.
Visual Studio 2010 ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ąĮąŠą▓ąŠąĄ ąŠą║ąĮąŠ ą┤ą╗čÅ ą╝ąŠąĮąĖč鹊čĆąĖąĮą│ą░ ąĘą░ą┤ą░čć (Debug -> Window -> Parallel Tasks). ąŁč鹊 菹║ą▓ąĖą▓ą░ą╗ąĄąĮčéąĮąŠ ąŠą║ąĮčā Threads, ąĮąŠ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ąĘą░ą┤ą░čć. ą×ą║ąĮąŠ Parallel Stacks čéą░ą║ąČąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ čĆąĄąČąĖą╝ ą┐čĆąŠčüą╝ąŠčéčĆą░ ąŠčéą╗ą░ą┤ąŠčćąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą┤ą╗čÅ ąĘą░ą┤ą░čć.
ąĪąŠąĘą┤ą░ąĮąĖąĄ ąĖ ąĘą░ą┐čāčüą║ ąĘą░ą┤ą░čć . ąÆ ąŠą┐ąĖčüą░ąĮąĖąĖ ą┐čāą╗ą░ ą┐ąŠč鹊ą║ąŠą▓ [2] čāąČąĄ ąŠą▒čüčāąČą┤ą░ą╗ąŠčüčī, čćč鹊 ąÆčŗ ą╝ąŠąČąĄč鹥 čüąŠąĘą┤ą░čéčī ąĖ ąĘą░ą┐čāčüčéąĖčéčī Task ą▓čŗąĘąŠą▓ąŠą╝ Task.Factory.StartNew čü ą┐ąĄčĆąĄą┤ą░č湥ą╣ ą┤ąĄą╗ąĄą│ą░čéą░ ą▓ Action:
Task.Factory.StartNew (() => Console.WriteLine ("Hello from a task!" ));
ąÆ ąŠą▒čŗčćąĮąŠą╣ ą▓ąĄčĆčüąĖąĖ Task< TResult> (ą┐ąŠą┤ą║ą╗ą░čüčü Task) ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąÆą░ą╝ ą┐ąŠą╗čāčćąĖčéčī ą┤ą░ąĮąĮčŗąĄ ąĖąĘ ąĘą░ą┤ą░čćąĖ ą┐ąŠčüą╗ąĄ ąĄčæ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ:
Task< string > task = Task.Factory.StartNew<string > (() => // ąŚą░ą┐čāčüą║ ąĘą░ą┤ą░čćąĖ
{
using (var wc = new System.Net.WebClient())
return wc.DownloadString ("http://www.linqpad.net" );
});
RunSomeOtherMethod(); // ą£čŗ ą╝ąŠąČąĄą╝ ą┤ąĄą╗ą░čéčī ą┤čĆčāą│čāčÄ čĆą░ą▒ąŠčéčā ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ...
string result = task.Result; // ą×ąČąĖą┤ą░ąĮąĖąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąĘą░ą┤ą░čćąĖ ąĖ ą┐ąŠą╗čāč湥ąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░.
Task.Factory.StartNew čüąŠąĘą┤ą░ąĄčé ąĖ ąĘą░ą┐čāčüą║ą░ąĄčé ąĘą░ą┤ą░čćčā ąĘą░ ąŠą┤ąĖąĮ čłą░ą│. ąÆčŗ ą╝ąŠąČąĄč鹥 čĆą░ąĘą┤ąĄą╗ąĖčéčī čŹčéąĖ ąŠą┐ąĄčĆą░čåąĖąĖ, ąĄčüą╗ąĖ čüąĮą░čćą░ą╗ą░ ąĖąĮčüčéą░ąĮčåąĖąĖčĆąŠą▓ą░čéčī ąŠą▒čŖąĄą║čé Task, ąĖ ąĘą░č鹥ą╝ ą▓čŗąĘą▓ą░čéčī Start:
var task = new Task (() => Console.Write ("Hello" ));
...
task.Start();
ąŚą░ą┤ą░čćą░, ą║ąŠč鹊čĆčāčÄ ąÆčŗ čüąŠąĘą┤ą░ąĄč鹥 čéą░ą║ąĖą╝ čüą┐ąŠčüąŠą▒ąŠą╝, ą╝ąŠąČąĮąŠ čéą░ą║ąČąĄ ąĘą░ą┐čāčüčéąĖčéčī čüąĖąĮčģčĆąŠąĮąĮąŠ (ą▓ č鹊ą╝ ąČąĄ ą┐ąŠč鹊ą║ąĄ) ą▓čŗąĘąŠą▓ąŠą╝ RunSynchronously ą▓ą╝ąĄčüč鹊 Start.
ąÆčŗ ą╝ąŠąČąĄč鹥 ąŠčéčüą╗ąĄąČąĖą▓ą░čéčī čüąŠčüč鹊čÅąĮąĖąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĘą░ą┤ą░čćąĖ č湥čĆąĄąĘ ąĄčæ čüą▓ąŠą╣čüčéą▓ąŠ Status.
ąŻą║ą░ąĘą░ąĮąĖąĄ čüąŠčüč鹊čÅąĮąĖčÅ ąŠą▒čŖąĄą║čéą░ . ąÜąŠą│ą┤ą░ ąĖąĮčüčéą░ąĮčåąĖąĖčĆčāąĄčéčüčÅ ąĘą░ą┤ą░čćą░, ąĖą╗ąĖ ą▓čŗąĘčŗą▓ą░ąĄčéčüčÅ Task.Factory.StartNew, ą╝ąŠąČąĮąŠ čāą║ą░ąĘą░čéčī ąŠą▒čŖąĄą║čé čüąŠčüč鹊čÅąĮąĖčÅ (state object), ą║ąŠč鹊čĆčŗą╣ ą┐ąĄčĆąĄą┤ą░ąĄčéčüčÅ čåąĄą╗ąĄą▓ąŠą╝čā ą╝ąĄč鹊ą┤čā. ąŁč鹊 ą┐ąŠą╗ąĄąĘąĮąŠ, ąĄčüą╗ąĖ ąÆčŗ čģąŠč鹥ą╗ąĖ ą▒čŗ ą▓čŗąĘą▓ą░čéčī ą╝ąĄč鹊ą┤ ąĮą░ą┐čĆčÅą╝čāčÄ ą▓ą╝ąĄčüč鹊 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ lambda-ą▓čŗčĆą░ąČąĄąĮąĖčÅ:
static void Main ()
{
var task = Task.Factory.StartNew (Greet, "Hello" );
task.Wait(); // ą×ąČąĖą┤ą░ąĮąĖąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąĘą░ą┤ą░čćąĖ.
}
static void Greet (object state) { Console.Write (state); } // Hello
ąŻčćąĖčéčŗą▓ą░čÅ, čćč鹊 čā ąĮą░čü ą▓ C# ąĄčüčéčī lambda-ą▓čŗčĆą░ąČąĄąĮąĖčÅ, ą╝ąŠąČąĮąŠ ą▓ą▓ąĄčüčéąĖ ąŠą▒čŖąĄą║čé čüąŠčüč鹊čÅąĮąĖčÅ ą┤ą╗čÅ ą╗čāčćčłąĄą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ, ą║ąŠą│ą┤ą░ ąĘą░ą┤ą░č湥 ąĮą░ąĘąĮą░čćą░ąĄčéčüčÅ ąŠčüą╝čŗčüą╗ąĄąĮąĮąŠąĄ ąĖą╝čÅ. ą£čŗ ą╝ąŠąČąĄą╝ č鹊ą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī AsyncState ą┤ą╗čÅ ąŠą┐čĆąŠčüą░ čŹč鹊ą│ąŠ ąĖą╝ąĄąĮąĖ:
static void Main ()
{
var task = Task.Factory.StartNew (state => Greet ("Hello" ), "Greeting" );
Console.WriteLine (task.AsyncState); // Greeting
task.Wait();
}
static void Greet (string message) { Console.Write (message); }
Visual Studio ąŠč鹊ą▒čĆą░ąĘąĖčé AsyncState ą║ą░ąČą┤ąŠą╣ ąĘą░ą┤ą░čćąĖ ą▓ ąŠą║ąĮąĄ Parallel Tasks, čéą░ą║ čćč鹊 ąĖą╝ąĄčÅ ą┐ąŠąĮčÅčéąĮąŠąĄ ąĖą╝čÅ ąĘą░ą┤ą░čćąĖ, ą╝ąŠąČąĮąŠ ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠ čāą┐čĆąŠčüčéąĖčéčī ąŠčéą╗ą░ą┤ą║čā.
TaskCreationOptions . ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐ąŠą┤čüčéčĆąŠąĖčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĘą░ą┤ą░čćąĖ, čāą║ą░ąĘą░ą▓ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖąĄ TaskCreationOptions, ą║ąŠą│ą┤ą░ ą▓čŗąĘčŗą▓ą░ąĄč鹥 StartNew (ąĖą╗ąĖ ą║ąŠą│ą┤ą░ ąĖąĮčüčéą░ąĮčåąĖąĖčĆčāąĄč鹥 ąĘą░ą┤ą░čćčā Task). TaskCreationOptions čŹč鹊 ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖąĄ čäą╗ą░ą│ąŠą▓, čüąŠą┤ąĄčƹȹ░čēąĄąĄ čüą╗ąĄą┤čāčÄčēąĖąĄ (ą║ąŠą╝ą▒ąĖąĮąĖčĆčāąĄą╝čŗąĄ ą┐ąŠ ąśąøąś) ąĘąĮą░č湥ąĮąĖčÅ:
LongRunning PreferFairness AttachedToParent
LongRunning čüąŠą▓ąĄčéčāąĄčé ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║čā ą▓čŗą┤ąĄą╗ąĖčéčī ą┤ą╗čÅ ąĘą░ą┤ą░čćąĖ ąŠčéą┤ąĄą╗čīąĮčŗą╣ ą┐ąŠč鹊ą║. ąŁč鹊 ą▓čŗą│ąŠą┤ąĮąŠ ą┤ą╗čÅ ą┤ąŠą╗ą│ąŠ čĆą░ą▒ąŠčéą░čÄčēąĖčģ ąĘą░ą┤ą░čć, ą┐ąŠč鹊ą╝čā čćč鹊 ąĖąĮą░č湥 ą╝ąŠąČąĄčé ąŠą▒čĆą░ąĘąŠą▓ą░čéčīčüčÅ ą┐ąŠąČąĖčĆą░čÄčēą░čÅ čĆąĄčüčāčĆčüčŗ ąŠč湥čĆąĄą┤čī, čü ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠą╣ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą║ąŠą╣ ą▒čŗčüčéčĆąŠ ą▓čŗą┐ąŠą╗ąĮčÅčÄčēąĖčģčüčÅ ąĘą░ą┤ą░čć ąĮą░ ąĮąĄčĆą░ąĘčāą╝ąĮąŠ ą┤ąŠą╗ą│ąŠąĄ ą▓čĆąĄą╝čÅ. LongRunning čéą░ą║ąČąĄ čģąŠčĆąŠčłąŠ ą┐čĆąĖą╝ąĄąĮčÅčéčī ą┤ą╗čÅ ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĖčģčüčÅ ąĘą░ą┤ą░čć.
ą¤čĆąŠą▒ą╗ąĄą╝ą░ ą┐ąŠčüčéą░ąĮąŠą▓ą║ąĖ ąĘą░ą┤ą░čć ą▓ ąŠč湥čĆąĄą┤čī ą▓ąŠąĘąĮąĖą║ą░ąĄčé ą┐ąŠč鹊ą╝čā, čćč鹊 ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ ąĘą░ą┤ą░čć ąŠą▒čŗčćąĮąŠ ą┐čŗčéą░ąĄčéčüčÅ čüąŠčģčĆą░ąĮąĖčéčī ą┤ąŠčüčéą░č鹊čćąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą░ą║čéąĖą▓ąĮčŗčģ ąĘą░ą┤ą░čć ąĮą░ ą┐ąŠč鹊ą║ą░čģ, čćč鹊ą▒čŗ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čéčī ąĘą░ąĮčÅč鹊čüčéčī ą║ą░ąČą┤ąŠą│ąŠ čÅą┤čĆą░ CPU. ą×ą│čĆą░ąĮąĖč湥ąĮąĖąĄ ąĮą░ą│čĆčāąĘą║ąĖ CPU čüą╗ąĖčłą║ąŠą╝ ą▒ąŠą╗čīčłąĖą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąŠą╝ ą░ą║čéąĖą▓ąĮčŗčģ ą┐ąŠč鹊ą║ąŠą▓ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĖąĘą▒ąĄąČą░čéčī ą┤ąĄą│čĆą░ą┤ą░čåąĖąĖ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ, ą║ąŠč鹊čĆą░čÅ ą┐čĆąŠąĖąĘąŠčłą╗ą░ ą▒čŗ, ąĄčüą╗ąĖ ą▒čŗ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮą░čÅ čüąĖčüč鹥ą╝ą░ ą▒čŗą╗ą░ ą▒čŗ ą▓čŗąĮčāąČą┤ąĄąĮą░ čéčĆą░čéąĖčéčī čüą╗ąĖčłą║ąŠą╝ ą╝ąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ąĮą░ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖąĄ čéąĖą║ąŠą▓ (expensive time slicing) ąĖ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą║ąŠąĮč鹥ą║čüčéą░ (context switching).
PreferFairness ą│ąŠą▓ąŠčĆąĖčé ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║čā ą┐ąŠą┐čŗčéą░čéčīčüčÅ ąŠą▒ąĄčüą┐ąĄčćąĖčéčī čāčüą╗ąŠą▓ąĖčÅ, čćč鹊ą▒čŗ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĘą░ą┤ą░čć ą▒čŗą╗ąŠ ąĘą░ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąŠ ą▓ č鹊ą╝ ąČąĄ ą┐ąŠčĆčÅą┤ą║ąĄ, ą▓ ą║ą░ą║ąŠą╝ ąŠąĮąĖ ą▒čŗą╗ąĖ ąĘą░ą┐čāčēąĄąĮčŗ. ą×ą▒čŗčćąĮąŠ ą┐ąŠčĆčÅą┤ąŠą║ ąĘą░ą┐čāčüą║ą░ ąĘą░ą┤ą░čć ą╝ąŠą│ą╗ąŠ ą▒čŗ ą▒čŗčéčī ą┤čĆčāą│ąĖą╝, ą┐ąŠč鹊ą╝čā čćč鹊 ąĖą╝ąĄąĄčéčüčÅ ą▓ąĮčāčéčĆąĄąĮąĮčÅčÅ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖčÅ ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąĖčÅ ąĘą░ą┤ą░čć čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą╗ąŠą║ą░ą╗čīąĮčŗčģ čĆą░ą▒ąŠčćąĖčģ ąŠč湥čĆąĄą┤ąĄą╣. ąŁčéą░ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖčÅ ą┤ą░ąĄčé ą┐čĆą░ą║čéąĖč湥čüą║čāčÄ ą▓čŗą│ąŠą┤čā čü ąŠč湥ąĮčī ą╝ą░ą╗ąĄąĮčīą║ąĖą╝ąĖ (č湥čéą║ąŠ ąŠč湥čĆč湥ąĮąĮčŗą╝ąĖ) ąĘą░ą┤ą░čćą░ą╝ąĖ.
AttachedToParent ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ čüąŠąĘą┤ą░ąĮąĖčÅ ą┤ąŠč湥čĆąĮąĖčģ ąĘą░ą┤ą░čć.
ąöąŠč湥čĆąĮąĖąĄ ąĘą░ą┤ą░čćąĖ . ąÜąŠą│ą┤ą░ ąŠą┤ąĮą░ ąĘą░ą┤ą░čćą░ ąĘą░ą┐čāčüą║ą░ąĄčé ą┤čĆčāą│čāčÄ, ąÆčŗ ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą╝ąŠąČąĄč鹥 čāčüčéą░ąĮąŠą▓ąĖčéčī ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąĖąĄ parent-child ą┐čāč鹥ą╝ čāą║ą░ąĘą░ąĮąĖčÅ TaskCreationOptions.AttachedToParent:
Task parent = Task.Factory.StartNew (() =>
{
Console.WriteLine ("I am a parent" );
Task.Factory.StartNew (() => // ą×čéčüąŠąĄą┤ąĖąĮąĄąĮąĮą░čÅ (čé. ąĄ. čĆąŠą┤ąĖč鹥ą╗čīčüą║ą░čÅ) ąĘą░ą┤ą░čćą░
{
Console.WriteLine ("I am detached" );
});
Task.Factory.StartNew (() => // ąöąŠč湥čĆąĮčÅčÅ ąĘą░ą┤ą░čćą░ (child)
{
Console.WriteLine ("I am a child" );
}, TaskCreationOptions.AttachedToParent);
});
ą×čüąŠą▒ąĄąĮąĮąŠčüčéčī ą┤ąŠč湥čĆąĮąĖčģ (child) ąĘą░ą┤ą░čć ą▓ č鹊ą╝, čćč鹊 ą║ąŠą│ą┤ą░ ąÆčŗ ąČą┤ąĄč鹥 ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ čĆąŠą┤ąĖč鹥ą╗čīčüą║ąŠą╣ (parent) ąĘą░ą┤ą░čćąĖ, č鹊 ąŠąĮą░ ąČą┤ąĄčé, ą┐ąŠą║ą░ ąĘą░ą▓ąĄčĆčłą░čéčüčÅ ą▓čüąĄ ąĄčæ ą┤ąŠč湥čĆąĮąĖąĄ ąĘą░ą┤ą░čćąĖ. ąŁč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓ čćą░čüčéąĮąŠčüčéąĖ ą┐ąŠą╗ąĄąĘąĮąŠ, ą║ąŠą│ą┤ą░ ą┤ąŠč湥čĆąĮčÅčÅ ąĘą░ą┤ą░čćą░ čÅą▓ą╗čÅąĄčéčüčÅ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖąĄą╝ (continuation), ą║ą░ą║ ą╝čŗ čüą║ąŠčĆąŠ čāą▓ąĖą┤ąĖą╝.
ą×ąČąĖą┤ą░ąĮąĖąĄ ąĮą░ ąĘą░ą┤ą░čćą░čģ . ąÆčŗ ą╝ąŠąČąĄč鹥 čÅą▓ąĮąŠ ąČą┤ą░čéčī ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąĘą░ą┤ą░čćąĖ ą┤ą▓čāą╝čÅ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ:
ŌĆó ąÆčŗąĘąŠą▓ąŠą╝ ąĄčæ ą╝ąĄč鹊ą┤ą░ Wait (ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ čü čéą░ą╣ą╝ą░čāč鹊ą╝)
ąÆčŗ ą╝ąŠąČąĄč鹥 čéą░ą║ąČąĄ ąČą┤ą░čéčī ąĮą░ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ąĘą░ą┤ą░čćą░čģ čüčĆą░ąĘčā čü ą┐ąŠą╝ąŠčēčīčÄ čüčéą░čéąĖč湥čüą║ąĖčģ ą╝ąĄč鹊ą┤ąŠą▓ Task.WaitAll (ąČą┤ąĄčé ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ą▓čüąĄčģ čāą║ą░ąĘą░ąĮąĮčŗčģ ąĘą░ą┤ą░čć) ąĖ Task.WaitAny (ąČą┤ąĄčé ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ č鹊ą╗čīą║ąŠ ąŠą┤ąĮąŠą╣ ąĘą░ą┤ą░čćąĖ).
WaitAll čĆą░ą▒ąŠčéą░ąĄčé ą┐ąŠą┤ąŠą▒ąĮąŠ ąŠąČąĖą┤ą░ąĮąĖčÄ ą║ą░ąČą┤ąŠą╣ ąĘą░ą┤ą░čćąĖ ą┐ąŠ ąŠčéą┤ąĄą╗čīąĮąŠčüčéąĖ, ąĮąŠ ą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠ č鹥ą╝, čćč鹊 čŹč鹊 čéčĆąĄą▒čāąĄčé (čüą░ą╝ąŠąĄ ą▒ąŠą╗čīčłąĄąĄ) č鹊ą╗čīą║ąŠ ąŠą┤ąĮąŠą│ąŠ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ ą║ąŠąĮč鹥ą║čüčéą░. ąóą░ą║ąČąĄ ąĄčüą╗ąĖ ąŠą┤ąĮą░ ąĖą╗ąĖ ą▒ąŠą╗čīčłąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĘą░ą┤ą░čć ą▓čŗą▒čĆąŠčüčÅčé ąĮąĄąŠą▒čĆą░ą▒ąŠčéą░ąĮąĮąŠąĄ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ, WaitAll ą▓čüąĄ ąĄčēąĄ ą▒čāą┤ąĄčé ąČą┤ą░čéčī ą║ą░ąČą┤čāčÄ ąĘą░ą┤ą░čćčā - ąĖ ąĘą░č鹥ą╝ ą┐ąĄčĆąĄą▒čĆąŠčüąĖčéčī ąŠą┤ąĮąŠ AggregateException, ą▓ ą║ąŠč鹊čĆąŠą╝ ą░ą║ą║čāą╝čāą╗ąĖčĆąŠą▓ą░ąĮčŗ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąŠčé ą║ą░ąČą┤ąŠą╣ ąĘą░ą┤ą░čćąĖ, ą▓ ą║ąŠč鹊čĆąŠą╣ čéą░ą║ąŠąĄ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ą┐čĆąŠąĖąĘąŠčłą╗ąŠ. ąŁč鹊 菹║ą▓ąĖą▓ą░ą╗ąĄąĮčéąĮąŠ čüą╗ąĄą┤čāčÄčēąĄą╝čā:
// ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 t1, t2 ąĖ t3 čŹč鹊 ąĘą░ą┤ą░čć: var exceptions = new List< Exception>();try { t1.Wait(); } catch (AggregateException ex) { exceptions.Add (ex); }try { t2.Wait(); } catch (AggregateException ex) { exceptions.Add (ex); }try { t3.Wait(); } catch (AggregateException ex) { exceptions.Add (ex); }if (exceptions.Count > 0 ) throw new AggregateException (exceptions);
ąÆčŗąĘąŠą▓ WaitAny 菹║ą▓ąĖą▓ą░ą╗ąĄąĮčéąĮąŠ ąŠąČąĖą┤ą░ąĮąĖčÄ ManualResetEventSlim, čćč鹊 čüąĖą│ąĮą░ą╗ąĖąĘąĖčĆčāąĄčéčüčÅ ą║ą░ąČą┤ąŠą╣ ąĘą░ą▓ąĄčĆčłą░čÄčēąĄą╣čüčÅ ąĘą░ą┤ą░č湥ą╣.
ąóą░ą║ ąČąĄ, ą║ą░ą║ ąĖ čéą░ą╣ą╝ą░čāčé, ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐ąĄčĆąĄą┤ą░čéčī ą╝ą░čĆą║ąĄčĆ ąŠčéą╝ąĄąĮčŗ (cancellation token) ą╝ąĄč鹊ą┤ą░ą╝ Wait: čŹč鹊 ą┐ąŠąĘą▓ąŠą╗ąĖčé ąÆą░ą╝ ąŠčéą╝ąĄąĮąĖčéčī ąŠąČąĖą┤ą░ąĮąĖąĄ, ą░ ąĮąĄ čüą░ą╝čā ąĘą░ą┤ą░čćčā.
ąŚą░ą┤ą░čćąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖą╣ . ąÜąŠą│ą┤ą░ ąÆčŗ čģąŠčéąĖč鹥 ąČą┤ą░čéčī ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąĘą░ą┤ą░čćąĖ (ą▓čŗąĘąŠą▓ąŠą╝ ąĄčæ ą╝ąĄč鹊ą┤ą░ Wait ąĖą╗ąĖ ą┤ąŠčüčéčāą┐ąŠą╝ ą║ ąĄčæ čüą▓ąŠą╣čüčéą▓čā Result), č鹊 ą╗čÄą▒čŗąĄ ąĮąĄ ąŠą▒čĆą░ą▒ąŠčéą░ąĮąĮčŗąĄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą┐ąĄčĆąĄą▒čĆą░čüčŗą▓ą░čÄčéčüčÅ ą▓ ą▓čŗąĘčŗą▓ą░čÄčēąĖą╣ ą║ąŠą┤, ąŠą▒ąĄčĆąĮčāčéčŗąĄ ą▓ ąŠą▒čŖąĄą║čé AggregateException. ąŁč鹊 ąŠą▒čŗčćąĮąŠ ą┤ą░ąĄčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ąĖąĘą▒ąĄą│ą░čéčī ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ ąĮą░ą┐ąĖčüą░ąĮąĖčÅ ą║ąŠą┤ą░ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖą╣ ą▓ č鹥ą╗ąĄ ąĘą░ą┤ą░čć; ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą╝čŗ ą╝ąŠąČąĄą╝ čüą┤ąĄą╗ą░čéčī čüą╗ąĄą┤čāčÄčēąĄąĄ:
int x = 0 ;
Task< int > calc = Task.Factory.StartNew (() => 7 / x);try
{
Console.WriteLine (calc.Result);
}catch (AggregateException aex)
{
Console.Write (aex.InnerException.Message); // ą¤ąŠą┐čŗčéą║ą░ ą┐ąŠą┤ąĄą╗ąĖčéčī ąĮą░ 0
}
ąÆą░ą╝ ą▓čüąĄ ąĄčēąĄ ąĮčāąČąĮąŠ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ąŠą▒čĆą░ą▒ąŠčéą║čā ąĖčüą║ą╗čÄč湥ąĮąĖą╣ ą┤ą╗čÅ ąŠčéą║ą╗čÄč湥ąĮąĮčŗčģ ą░ą▓č鹊ąĮąŠą╝ąĮčŗčģ ąĘą░ą┤ą░čć (ąĮąĄ ą┐ąŠčĆąŠąČą┤ąĄąĮąĮčŗąĄ ąĘą░ą┤ą░čćąĖ, ąĮą░ ą║ąŠč鹊čĆčŗčģ ąĮąĄčé ąŠąČąĖą┤ą░ąĮąĖčÅ) čćč鹊ą▒čŗ ą┐čĆąĄą┤ąŠčéą▓čĆą░čéąĖčéčī ą▓ąŠąĘąĮąĖą║ąĮąŠą▓ąĄąĮąĖąĄ ąĮąĄąŠą▒čĆą░ą▒ąŠčéą░ąĮąĮąŠą│ąŠ ąĖ ąŠčéą║ą░ąĘą░ ą▓čüąĄą│ąŠ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, ą║ąŠą│ą┤ą░ ąĘą░ą┤ą░čćą░ ą▓čŗą┐ą░ą┤ą░ąĄčé ąĖąĘ ą┐čĆąŠčåąĄčüčüą░ ąĖ čāą▒ąĖčĆą░ąĄčéčüčÅ čüą▒ąŠčĆčēąĖą║ąŠą╝ ą╝čāčüąŠčĆą░ (ą║ čŹč鹊ą╣ čüąĖčéčāą░čåąĖąĖ ąŠčéąĮąŠčüąĖčéčüčÅ čüą╗ąĄą┤čāčÄčēąĄąĄ ąĘą░ą╝ąĄčćą░ąĮąĖąĄ). ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ ąŠčéąĮąŠčüąĖčéčüčÅ ą║ ąĘą░ą┤ą░čćą░ą╝, ąĮą░ ą║ąŠč鹊čĆčŗčģ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąŠąČąĖą┤ą░ąĮąĖąĄ čü čéą░ą╣ą╝ą░čāč鹊ą╝, ą┐ąŠč鹊ą╝čā čćč鹊 ąĖčüą║ą╗čÄč湥ąĮąĖąĄ, ą▓čŗą▒čĆąŠčłąĄąĮąĮąŠąĄ ą┐ąŠ ąĖčüč鹥č湥ąĮąĖąĖ ąĖąĮč鹥čĆą▓ą░ą╗ą░ čéą░ą╣ą╝ą░čāčéą░, ą▒čāą┤ąĄčé ąĖąĮą░č湥 "ąĮąĄ ąŠą▒čĆą░ą▒ąŠčéą░ąĮąĮčŗą╝" (unhandled).
ąĪčéą░čéąĖč湥čüą║ąŠąĄ čüąŠą▒čŗčéąĖąĄ TaskScheduler.UnobservedTaskException ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┐ąŠčüą╗ąĄą┤ąĮąĖą╣ čłą░ąĮčü ąŠą▒čĆą░ą▒ąŠčéą░čéčī ąĮąĄąŠą▒čĆą░ą▒ąŠčéą░ąĮąĮčŗąĄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĘą░ą┤ą░čćąĖ. ą¤čāč鹥ą╝ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čŹč鹊ą│ąŠ čüąŠą▒čŗčéąĖčÅ ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐ąĄčĆąĄčģą▓ą░čéąĖčéčī ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĘą░ą┤ą░čćąĖ, ą║ąŠč鹊čĆčŗąĄ ąĖąĮą░č湥 ą╝ąŠą│čāčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą┐ą░ą┤ąĄąĮąĖčÄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ - ąĖ ąŠą▒ąĄčüą┐ąĄčćąĖčéčī čüą▓ąŠčÄ čüąŠą▒čüčéą▓ąĄąĮąĮčāčÄ ą╗ąŠą│ąĖą║čā čĆąĄčłąĖčéčī ą┐čĆąŠą▒ą╗ąĄą╝čā ąĖčüą║ą╗čÄč湥ąĮąĖčÅ (ąĖą╗ąĖ ąĘą░ą┐ąĖčüą░čéčī ą▓ ą╗ąŠą│ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠą▒ ąĖčüą║ą╗čÄč湥ąĮąĖąĖ).
ąöą╗čÅ ą┐ąŠčĆąŠąČą┤ąĄąĮąĮčŗčģ ąĘą░ą┤ą░čć ąŠąČąĖą┤ą░ąĮąĖąĄ čĆąŠą┤ąĖč鹥ą╗čÅ ąĮąĄčÅą▓ąĮąŠ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ąŠąČąĖą┤ą░ąĮąĖčÄ ą┤ąŠč湥čĆąĮąĖčģ ąĘą░ą┤ą░čć - ąĖ č鹊ą│ą┤ą░ ą▓čüą┐ą╗čŗą▓čāčé ą┤ąŠč湥čĆąĮąĖąĄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ:
TaskCreationOptions atp = TaskCreationOptions.AttachedToParent;
var parent = Task.Factory.StartNew (() =>
{
Task.Factory.StartNew (() => // ąĪčŗąĮ
{
Task.Factory.StartNew (() => { throw null ; }, atp); // ąÆąĮčāą║
}, atp);
});
// ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą▓čŗąĘąŠą▓ ą▓čŗą▒čĆąŠčüąĖčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ NullReferenceException (ąŠą▒ąĄčĆąĮčāč鹊ąĄ // ą▓ą╗ąŠąČąĄąĮąĖąĄą╝ ą▓ AggregateExceptions):
parent.Wait();
ąśąĮč鹥čĆąĄčüąĮąŠ, čćč鹊 ąĄčüą╗ąĖ ąÆčŗ ą┐čĆąŠą▓ąĄčĆąĖč鹥 čüą▓ąŠą╣čüčéą▓ąŠ ąĘą░ą┤ą░čćąĖ Exception ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ąŠąĮą░ ą▓čŗą▒čĆąŠčüąĖą╗ą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ, č鹊 ą░ą║čé čćč鹥ąĮąĖčÅ čŹč鹊ą│ąŠ čüą▓ąŠą╣čüčéą▓ą░ ą┐čĆąĄą┤ąŠčéą▓čĆą░čéąĖčé ą┐ąŠčüą╗ąĄą┤čāčÄčēąĄąĄ ą┐ą░ą┤ąĄąĮąĖąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. ąĀą░čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčī čéą░ą║ąŠą│ąŠ ą┐ąŠą┤čģąŠą┤ą░ ą▓ č鹊ą╝, čćč鹊 čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ąĖ PFX ąĮąĄ čģąŠčéčÅčé, čćč鹊ą▒čŗ ąÆčŗ ąĖą│ąĮąŠčĆąĖčĆąŠą▓ą░ą╗ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ - ą┐ąŠą║ą░ ąÆčŗ ąĮąĄ ą┐ąŠą┤čéą▓ąĄčĆą┤ąĖč鹥 ąĖčģ ą║ą░ą║ąĖą╝-č鹊 čüą┐ąŠčüąŠą▒ąŠą╝, ąŠąĮąĖ ąÆą░čü ąĮąĄ ąĮą░ą║ą░ąČčāčé ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄą╝ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
ąØąĄ ąŠą▒čĆą░ą▒ąŠčéą░ąĮąĮąŠąĄ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĮą░ ąĘą░ą┤ą░č湥 ąĮąĄ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠą╝čā ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ: ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄ ą▒čāą┤ąĄčé ąĘą░ą┤ąĄčƹȹ░ąĮąŠ ą┤ąŠ č鹥čģ ą┐ąŠčĆ, ą┐ąŠą║ą░ čüą▒ąŠčĆčēąĖą║ ą╝čāčüąŠčĆą░ ąĮąĄ ąĘą░čģą▓ą░čéąĖčé ąĘą░ą┤ą░čćčā ąĖ ąĮąĄ ą▓čŗąĘąŠą▓ąĄčé ąĄčæ "ąĘą░ą▓ąĄčĆčłą░č鹥ą╗čī". ąŚą░ą▓ąĄčĆčłąĄąĮąĖąĄ ąŠčéą║ą╗ą░ą┤čŗą▓ą░ąĄčéčüčÅ, ą┐ąŠč鹊ą╝čā čćč鹊 ąĮąĄą╗čīąĘčÅ ąĘąĮą░čéčī č鹊čćąĮąŠ, čģąŠčéąĖč鹥 ą╗ąĖ ąÆčŗ ą▓čŗąĘą▓ą░čéčī Wait ąĖą╗ąĖ ą┐čĆąŠą▓ąĄčĆąĖčéčī čüą▓ąŠą╣čüčéą▓ąŠ Result ąĖą╗ąĖ Exception ą┤ąŠ ą╝ąŠą╝ąĄąĮčéą░, ą║ąŠą│ą┤ą░ ąĘą░ą┤ą░čćą░ ą▒čāą┤ąĄčé čāąĮąĖčćč鹊ąČąĄąĮą░ čüą▒ąŠčĆčēąĖą║ąŠą╝ ą╝čāčüąŠčĆą░. ąŁčéą░ ąĘą░ą┤ąĄčƹȹ║ą░ ą╝ąŠąČąĄčé ąĖąĮąŠą│ą┤ą░ ą▓ą▓ąĄčüčéąĖ ąÆą░čü ą▓ ąĘą░ą▒ą╗čāąČą┤ąĄąĮąĖąĄ ą┐ąŠ ą┐ąŠą▓ąŠą┤čā ąĖčüč鹊čćąĮąĖą║ą░ ąŠčłąĖą▒ą║ąĖ (čģąŠčéčÅ ąŠčéą╗ą░ą┤čćąĖą║ Visual Studio ą╝ąŠąČąĄčé ą┐ąŠą╝ąŠčćčī, ąĄčüą╗ąĖ ąÆčŗ čĆą░ąĘčĆąĄčłąĖč鹥 č鹊čćą║čā ąŠčüčéą░ąĮąŠą▓ą░ ąĮą░ ąĖčüą║ą╗čÄč湥ąĮąĖčÅčģ first-chance).
ąÜą░ą║ ą╝čŗ čāą▓ąĖą┤ąĖą╝, ą░ą╗čīč鹥čĆąĮą░čéąĖą▓ąĮą░čÅ čüčéčĆą░č鹥ą│ąĖčÅ čĆą░ąĘą▒ąŠčĆąŠą║ čü ąĖčüą║ą╗čÄč湥ąĮąĖčÅą╝ąĖ čüąŠčüč鹊ąĖčé ą▓ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖą╣ (continuations).
ą×čéą╝ąĄąĮą░ ąĘą░ą┤ą░čć . ąÆčŗ ą╝ąŠąČąĄč鹥 ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą┐ąĄčĆąĄą┤ą░čéčī ą╝ą░čĆą║ąĄčĆ ąŠčéą╝ąĄąĮčŗ (cancellation token), ą║ąŠą│ą┤ą░ ąĘą░ą┐čāčüą║ą░ąĄč鹥 ąĘą░ą┤ą░čćčā. ąŁč鹊 ą┐ąŠąĘą▓ąŠą╗ąĖčé ąÆą░ą╝ ąŠčéą╝ąĄąĮąĖčéčī ąĘą░ą┤ą░čćąĖ č湥čĆąĄąĘ čłą░ą▒ą╗ąŠąĮ čüąŠą▓ą╝ąĄčüčéąĮąŠą╣ ąŠčéą╝ąĄąĮčŗ (cooperative cancellation), ą║ą░ą║ ąŠą┐ąĖčüčŗą▓ą░ą╗ąŠčüčī čĆą░ąĮąĄąĄ:
var cancelSource = new CancellationTokenSource();
CancellationToken token = cancelSource.Token;
Task task = Task.Factory.StartNew (() =>
{
// ąóčāčé čćč鹊-č鹊 ą┤ąĄą╗ą░ąĄą╝...
token.ThrowIfCancellationRequested(); // ą¤čĆąŠą▓ąĄčĆą║ą░ ąĘą░ą┐čĆąŠčüą░ ąĮą░ ąŠčéą╝ąĄąĮčā
// ąóčāčé čćč鹊-č鹊 ą┤ąĄą╗ą░ąĄą╝...
}, token);
...
cancelSource.Cancel();
ą¦č鹊ą▒čŗ ą┤ąĄč鹥ą║čéąĖčĆąŠą▓ą░čéčī ąŠčéą╝ąĄąĮąĄąĮąĮčāčÄ ąĘą░ą┤ą░čćčā, ąĘą░čģą▓ą░čéąĖč鹥 (catch) ąĖčüą║ą╗čÄč湥ąĮąĖąĄ AggregateException, ąĖ ą┐čĆąŠą▓ąĄčĆčīč鹥 ą▓ąĮčāčéčĆąĄąĮąĮąĄąĄ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
try
{
task.Wait();
}catch (AggregateException ex)
{
if (ex.InnerException is OperationCanceledException)
Console.Write ("ąŚą░ą┤ą░čćą░ ąŠčéą╝ąĄąĮąĄąĮą░!" );
}
ąĢčüą╗ąĖ ąÆčŗ čģąŠčéąĖč鹥 čÅą▓ąĮąŠ ą▓čŗą▒čĆąŠčüąĖčéčī ąĖčüą║ą╗čÄč湥ąĮąĖąĄ OperationCanceledException (ą▓ą╝ąĄčüč鹊 ą▓čŗąĘąŠą▓ą░ token.ThrowIfCancellationRequested), č鹊 ą┤ąŠą╗ąČąĮčŗ ą┐ąĄčĆąĄą┤ą░čéčī ą╝ą░čĆą║ąĄčĆ ąŠčéą╝ąĄąĮčŗ ą▓ ą║ąŠąĮčüčéčĆčāą║č鹊čĆ OperationCanceledException. ąĢčüą╗ąĖ ąÆčŗ ąĮąĄ čüą┤ąĄą╗ą░ąĄč鹥 čŹč鹊ą│ąŠ, ąĘą░ą┤ą░čćą░ ąĮąĄ ąĘą░ą║ąŠąĮčćąĖčéčüčÅ čüąŠ čüčéą░čéčāčüąŠą╝ TaskStatus.Canceled, ąĖ ąĮąĄ čüčĆą░ą▒ąŠčéą░čÄčé ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ OnlyOnCanceled.
ąĢčüą╗ąĖ ąĘą░ą┤ą░čćą░ ąŠčéą╝ąĄąĮąĄąĮą░ ą┐ąĄčĆąĄą┤ ąĄčæ ąĘą░ą┐čāčüą║ąŠą╝, č鹊 ąĮąĄ ą▒čāą┤ąĄčé ąĘą░ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąŠ ąĄčæ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ - ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ąĮą░ ąĘą░ą┤ą░č湥 ą▒čāą┤ąĄčé ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ ą▓čŗą▒čĆąŠčłąĄąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ OperationCanceledException.
ąśąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 ą╝ą░čĆą║ąĄčĆčŗ ąŠčéą╝ąĄąĮčŗ (cancellation tokens) čĆą░čüą┐ąŠąĘąĮą░čÄčéčüčÅ ą┤čĆčāą│ąĖą╝ API, ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐ąĄčĆąĄą┤ą░čéčī ąĖčģ ą▓ ą┤čĆčāą│ąĖąĄ ą║ąŠąĮčüčéčĆčāą║čåąĖąĖ ąĖ ąŠčéą╝ąĄąĮčŗ ą▒čāą┤čāčé čĆą░čüą┐čĆąŠčüčéčĆą░ąĮąĄąĮčŗ ą▒ąĄčüą┐čĆąĄą┐čÅčéčüčéą▓ąĄąĮąĮąŠ:
var cancelSource = new CancellationTokenSource();
CancellationToken token = cancelSource.Token;
Task task = Task.Factory.StartNew (() =>
{
// ą¤ąĄčĆąĄą┤ą░čćą░ ąĮą░čłąĄą│ąŠ ą╝ą░čĆą║ąĄčĆą░ ąŠčéą╝ąĄąĮčŗ ą▓ ąĘą░ą┐čĆąŠčü PLINQ:
var query = someSequence.AsParallel().WithCancellation (token)...
... ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖąĄ ąĘą░ą┐čĆąŠčüą░ ...
});
ąÆčŗąĘąŠą▓ Cancel ąĮą░ cancelSource ą▓ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ąŠčéą╝ąĄąĮąĖčé ąĘą░ą┐čĆąŠčü PLINQ, ą║ąŠč鹊čĆčŗą╣ ą▓čŗą▒čĆąŠčüąĖčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ OperationCanceledException ąĮą░ č鹥ą╗ąĄ ąĘą░ą┤ą░čćąĖ, ą║ąŠč鹊čĆąŠąĄ č鹊ą│ą┤ą░ ąŠčéą╝ąĄąĮąĖčé ąĘą░ą┤ą░čćčā.
ą£ą░čĆą║ąĄčĆčŗ ąŠčéą╝ąĄąĮčŗ, ą║ąŠč鹊čĆčŗąĄ ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐ąĄčĆąĄą┤ą░čéčī ą▓ čéą░ą║ąĖąĄ ą╝ąĄč鹊ą┤čŗ, ą║ą░ą║ Wait ąĖ CancelAndWait, ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ąÆą░ą╝ ąŠčéą╝ąĄąĮąĖčéčī ąŠą┐ąĄčĆą░čåąĖčÄ ąŠąČąĖą┤ą░ąĮąĖčÅ, ąĮąŠ ąĮąĄ čüą░ą╝čā ąĘą░ą┤ą░čćčā.
ą¤čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ (continuations). ąśąĮąŠą│ą┤ą░ ą┐ąŠą╗ąĄąĘąĮąŠ ąĘą░ą┐čāčüčéąĖčéčī ąĘą░ą┤ą░čćčā čüčĆą░ąĘčā ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ą┤čĆčāą│ą░čÅ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ (ąĖą╗ąĖ ą▓ ąĮąĄą╣ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąŠčłąĖą▒ą║ą░/ąĖčüą║ą╗čÄč湥ąĮąĖąĄ). ą£ąĄč鹊ą┤ ContinueWith ą▓ ą║ą╗ą░čüčüąĄ Task ą┤ąĄą╗ą░ąĄčé ąĖą╝ąĄąĮąĮąŠ čŹč鹊:
Task task1 = Task.Factory.StartNew (() => Console.Write ("antecedant.." ));
Task task2 = task1.ContinueWith (ant => Console.Write ("..continuation" ));
ąÜą░ą║ č鹊ą╗čīą║ąŠ task1 (ą┐čĆąĄą┤čłąĄčüčéą▓čāčÄčēą░čÅ ąĘą░ą┤ą░čćą░) ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ, ą┐ąŠč鹥čĆą┐ąĖčé čüą▒ąŠą╣ ąĖą╗ąĖ ą▒čāą┤ąĄčé ąŠčéą╝ąĄąĮąĄąĮą░, ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ąĘą░ą┐čāčüčéąĖčéčüčÅ task2 (ąĘą░ą┤ą░čćą░ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ, continuation). ąĢčüą╗ąĖ task1 ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ąĘą░ą┐čāčüčéąĖčéčüčÅ ą▓č鹊čĆą░čÅ čüčéčĆąŠą║ą░, č鹊 ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ task2 ą▒čāą┤ąĄčé ąĘą░ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąŠ ąĮą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐čĆą░ą▓ąĖą╗čīąĮčŗą╝ čüą┐ąŠčüąŠą▒ąŠą╝. ąÉčĆą│čāą╝ąĄąĮčé ant, ą┐ąĄčĆąĄą┤ą░ąĮąĮčŗą╣ ą▓ lambda-ą▓čŗčĆą░ąČąĄąĮąĖąĄ ąĘą░ą┤ą░čćąĖ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ, čÅą▓ą╗čÅąĄčéčüčÅ čüčüčŗą╗ą║ąŠą╣ ąĮą░ ą┐čĆąĄą┤čłąĄčüčéą▓čāčÄčēčāčÄ ąĘą░ą┤ą░čćčā.
ąØą░čł ą┐čĆąĖą╝ąĄčĆ ą┐čĆąŠą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆąŠą▓ą░ą╗ ą┐čĆąŠčüč鹥ą╣čłąĖą╣ ą▓ąĖą┤ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ, ąĖ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠ ąŠąĮ ą┤ąĄą╗ą░ąĄčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
Task task = Task.Factory.StartNew (() =>
{
Console.Write ("antecedent.." );
Console.Write ("..continuation" );
});
ą×ą┤ąĮą░ą║ąŠ ą░ą╗ą│ąŠčĆąĖčéą╝, ąŠčüąĮąŠą▓ą░ąĮąĮčŗą╣ ąĮą░ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖąĖ, ą▒ąŠą╗ąĄąĄ ą│ąĖą▒ą║ąĖą╣, ą┐ąŠč鹊ą╝čā čćč鹊 ąÆčŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ čüąĮą░čćą░ą╗ą░ ąŠąČąĖą┤ą░čéčī ąĮą░ task1, ąĖ ąĘą░č鹥ą╝ ąŠąČąĖą┤ą░čéčī ąĮą░ task2. ąŁč鹊 ą▓ čćą░čüčéąĮąŠčüčéąĖ ą┐ąŠą╗ąĄąĘąĮąŠ, ąĄčüą╗ąĖ task1 ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ą┤ą░ąĮąĮčŗąĄ.
ąöčĆčāą│ąŠąĄ (ą▒ąŠą╗ąĄąĄ č鹊ąĮą║ąŠąĄ) čĆą░ąĘą╗ąĖčćąĖąĄ ą▓ č鹊ą╝, čćč鹊 ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┐čĆąĄą┤čłąĄčüčéą▓čāčÄčēą░čÅ ąĘą░ą┤ą░čćą░ ąĖ ąĘą░ą┤ą░čćą░ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą▓ čĆą░ąĘąĮčŗčģ ą┐ąŠč鹊ą║ą░čģ. ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ ąĘą░ą┐čāčüčéąĖčéčī ąĖčģ ą▓ ąŠą┤ąĮąŠą╝ ą┐ąŠč鹊ą║ąĄ, ąĄčüą╗ąĖ čāą║ą░ąČąĄč鹥 TaskContinuationOptions.ExecuteSynchronously, ą║ąŠą│ą┤ą░ ą▓čŗąĘčŗą▓ą░ąĄč鹥 ContinueWith: čŹč鹊 ą╝ąŠąČąĄčé čāą╗čāčćčłąĖčéčī ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ą▓ čüą╗čāčćą░ąĄ ąŠč湥ąĮčī čćą░čüčéčŗčģ ą╝ąĄą╗ą║ąĖčģ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖą╣ ą┐čāč鹥ą╝ čāą╝ąĄąĮčīčłąĄąĮąĖčÅ ą║ąŠčüą▓ąĄąĮąĮčŗčģ ąŠą▒čĆą░čēąĄąĮąĖą╣.
ą¤čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ ąĖ Task< TResult> . ąÜą░ą║ ąĖ ąŠą▒čŗčćąĮčŗąĄ ąĘą░ą┤ą░čćąĖ, ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ ą╝ąŠą│čāčé ą▒čŗčéčī čéąĖą┐ą░ Task< TResult> čü ą▓ąŠąĘą▓čĆą░č鹊ą╝ ą┤ą░ąĮąĮčŗčģ. ąÆ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą╝čŗ ą▓čŗčćąĖčüą╗čÅąĄą╝ Math.Sqrt(8*2) čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą┐ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗčģ ą▓ čåąĄą┐ąŠčćą║čā ąĘą░ą┤ą░čć, ąĖ ąĘą░č鹥ą╝ ąŠč鹊ą▒čĆą░ąČą░ąĄą╝ čĆąĄąĘčāą╗čīčéą░čé:
Task.Factory.StartNew< int > (() => 8 )
.ContinueWith (ant => ant.Result * 2 )
.ContinueWith (ant => Math.Sqrt (ant.Result))
.ContinueWith (ant => Console.WriteLine (ant.Result)); // 4
ąØą░čł ą┐čĆąĖą╝ąĄčĆ ą▓ąŠąĘą╝ąŠąČąĮąŠ ąĖąĘą╗ąĖčłąĮąĄ čāą┐čĆąŠčēąĄąĮ; ą▓ čĆąĄą░ą╗čīąĮąŠą╣ ąČąĖąĘąĮąĖ čŹčéąĖ lambda-ą▓čŗčĆą░ąČąĄąĮąĖčÅ ą╝ąŠą│ą╗ąĖ ą▒čŗ ą▓čŗąĘčŗą▓ą░čéčī čäčāąĮą║čåąĖąĖ čü ąĖąĮč鹥ąĮčüąĖą▓ąĮčŗą╝ąĖ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅą╝ąĖ.
ą¤čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ . ąŚą░ą┤ą░čćą░ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ (continuation) ą╝ąŠąČąĄčé čāąĘąĮą░čéčī, ą┐čĆąŠąĖąĘąŠčłą╗ąŠ ą╗ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ą▓ č湥čĆąĄąĘ čüą▓ąŠą╣čüčéą▓ąŠ Exception ą┐čĆąĄą┤čłąĄčüčéą▓čāčÄčēąĄą╣ ąĘą░ą┤ą░čćąĖ (antecedent task). ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤ ąĘą░ą┐ąĖčłąĄčé ą▓ ą║ąŠąĮčüąŠą╗čī ą┐ąŠą┤čĆąŠą▒ąĮąŠčüčéąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ NullReferenceException:
Task task1 = Task.Factory.StartNew (() => { throw null ; });
Task task2 = task1.ContinueWith (ant => Console.Write (ant.Exception));
ąĢčüą╗ąĖ antecedent-ąĘą░ą┤ą░čćą░ ą▓čŗą▒čĆąŠčüąĖą╗ą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ continuation-ąĮąĄ ąŠą┐čĆąŠčüąĖą╗ą░ čüą▓ąŠą╣čüčéą▓ąŠ Exception antecedent-ąĘą░ą┤ą░čćąĖ (ąĖ ąĮą░ antecedent-ąĘą░ą┤ą░č湥 ąĮąĄčé ąŠąČąĖą┤ą░ąĮąĖčÅ), č鹊 ąĖčüą║ą╗čÄč湥ąĮąĖąĄ čüčćąĖčéą░ąĄčéčüčÅ ąĮąĄ ąŠą▒čĆą░ą▒ąŠčéą░ąĮąĮčŗą╝ ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ ą┐ąŠ ąŠčłąĖą▒ą║ąĄ (ąĄčüą╗ąĖ ąĮąĄ ą▒čāą┤ąĄčé ąŠą▒čĆą░ą▒ąŠčéą░ąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ č湥čĆąĄąĘ TaskScheduler.UnobservedTaskException).
ąæąĄąĘąŠą┐ą░čüąĮčŗą╣ čłą░ą▒ą╗ąŠąĮ - ą┐ąĄčĆąĄą▒čĆąŠčüąĖčéčī ąĖčüą║ą╗čÄč湥ąĮąĖčÅ antecedent-ąĘą░ą┤ą░čćąĖ. ą¤ąŠą║ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąŠąČąĖą┤ą░ąĮąĖąĄ ąĮą░ continuation-ąĘą░ą┤ą░č湥, ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ą▒čāą┤ąĄčé čĆą░čüą┐čĆąŠčüčéčĆą░ąĮąĄąĮąŠ ąĖ ą┐ąĄčĆąĄą▒čĆąŠčłąĄąĮąŠ ąĮą░ ąŠąČąĖą┤ą░čÄčēąĖą╣ ą║ąŠą┤:
Task continuation = Task.Factory.StartNew (() => { throw null ; })
.ContinueWith (ant =>
{
if (ant.Exception != null ) throw ant.Exception; // ą¤čĆąŠą┤ąŠą╗ąČąĄąĮąĖąĄ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ...
});
continuation.Wait(); // ąśčüą║ą╗čÄč湥ąĮąĖąĄ č鹥ą┐ąĄčĆčī ą┐ąĄčĆąĄą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ ąŠą▒čĆą░čéąĮąŠ ą▓ ą▓čŗąĘčŗą▓ą░čÄčēąĖą╣ ą║ąŠą┤
ąöčĆčāą│ąŠą╣ čüą┐ąŠčüąŠą▒ čĆą░ąĘąŠą▒čĆą░čéčīčüčÅ čü ąĖčüą║ą╗čÄč湥ąĮąĖčÅą╝ąĖ - čāą║ą░ąĘą░čéčī ą┤čĆčāą│ąĖąĄ continuation-ąĘą░ą┤ą░čćąĖ ą┤ą╗čÅ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ čü ąĖčüą║ą╗čÄč湥ąĮąĖčÅą╝ąĖ, ąŠčéą╗ąĖčćą░čÄčēąĖąĄčüčÅ ąŠčé continuation-ąĘą░ą┤ą░čć ą┤ą╗čÅ ąĮąŠčĆą╝ą░ą╗čīąĮąŠą│ąŠ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ. ąŁč鹊 čĆąĄčłą░ąĄčéčüčÅ č湥čĆąĄąĘ TaskContinuationOptions:
Task task1 = Task.Factory.StartNew (() => { throw null ; });
Task error = task1.ContinueWith (ant => Console.Write (ant.Exception),
TaskContinuationOptions.OnlyOnFaulted);
Task ok = task1.ContinueWith (ant => Console.Write ("Success!" ),
TaskContinuationOptions.NotOnFaulted);
ąÜą░ą║ ą╝čŗ čāą▓ąĖą┤ąĖą╝ ą┐ąŠąĘąČąĄ, čŹč鹊čé čłą░ą▒ą╗ąŠąĮ ą▓ čćą░čüčéąĮąŠčüčéąĖ ą┐ąŠą╗ąĄąĘąĄąĮ čüąŠą▓ą╝ąĄčüčéąĮąŠ čü ą┤ąŠč湥čĆąĮąĖą╝ąĖ ąĘą░ą┤ą░čćą░ą╝ąĖ.
ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą╝ąĄč鹊ą┤ čĆą░čüčłąĖčĆąĄąĮąĖčÅ "ą│ą╗ąŠčéą░ąĄčé" ąĮąĄ ąŠą▒čĆą░ą▒ąŠčéą░ąĮąĮčŗąĄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĘą░ą┤ą░čćąĖ:
public static void IgnoreExceptions (this Task task)
{
task.ContinueWith (t => { var ignore = t.Exception; },
TaskContinuationOptions.OnlyOnFaulted);
ąÆąŠčé, ą║ą░ą║ čŹč鹊 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ąŠčüčī ą▒čŗ (čŹč鹊 ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą▒čŗ čāą╗čāčćčłąĖčéčī ą┐čāč鹥ą╝ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ ą║ąŠą┤ą░ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ ą▓ ą╗ąŠą│ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ):
Task.Factory.StartNew (() => { throw null ; }).IgnoreExceptions();
ą¤čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ ąĖ ą┤ąŠč湥čĆąĮąĖąĄ ąĘą░ą┤ą░čćąĖ . ą£ąŠčēąĮą░čÅ čäčāąĮą║čåąĖčÅ continuation-ąĘą░ą┤ą░čć ą▓ č鹊ą╝, čćč鹊 ąŠąĮąĖ ąĮą░čćąĖąĮą░čÄčéčüčÅ č鹊ą╗čīą║ąŠ č鹊ą│ą┤ą░, ą║ąŠą│ą┤ą░ ą▓čüąĄ ą┤ąŠč湥čĆąĮąĖąĄ ąĘą░ą┤ą░čćąĖ ąĘą░ą▓ąĄčĆčłąĖą╗ąĖčüčī. ąØą░čćąĖąĮą░čÅ čü čŹč鹊ą│ąŠ ą╝ąĄčüčéą░ ą╗čÄą▒čŗąĄ ą▓čŗą▒čĆąŠčłąĄąĮąĮčŗąĄ ą┤ąŠč湥čĆąĮąĖą╝ąĖ ąĘą░ą┤ą░čćą░ą╝ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗čÅčÄčéčüčÅ ą▓ continuation-ąĘą░ą┤ą░čćčā.
ąÆ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą╝čŗ ąĘą░ą┐čāčüčéąĖą╝ 3 ą┤ąŠč湥čĆąĮąĖąĄ ąĘą░ą┤ą░čćąĖ, ą║ą░ąČą┤ą░čÅ ąĖąĘ ąĮąĖčģ ą▓čŗą▒čĆą░čüčŗą▓ą░ąĄčé NullReferenceException. ąŚą░č鹥ą╝ ą╝čŗ ą┐ąĄčĆąĄčģą▓ą░čéčŗą▓ą░ąĄą╝ čŹčéąĖ ą▓čüąĄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĘą░ ąŠą┤ąĖąĮ čĆą░ąĘ č湥čĆąĄąĘ continuation čĆąŠą┤ąĖč鹥ą╗čīčüą║ąŠą╣ ąĘą░ą┤ą░čćąĖ:
TaskCreationOptions atp = TaskCreationOptions.AttachedToParent;
Task.Factory.StartNew (() =>
{
Task.Factory.StartNew (() => { throw null ; }, atp);
Task.Factory.StartNew (() => { throw null ; }, atp);
Task.Factory.StartNew (() => { throw null ; }, atp);
})
.ContinueWith (p => Console.WriteLine (p.Exception),
TaskContinuationOptions.OnlyOnFaulted);
ą¤čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ ą┐ąŠ čāčüą╗ąŠą▓ąĖčÄ . ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĘą░ą┐čāčüą║ ąĘą░ą┤ą░čćąĖ-ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ ą┐ą╗ą░ąĮąĖčĆčāąĄčéčüčÅ ą▒ąĄąĘčāčüą╗ąŠą▓ąĮąŠ - ą▓čüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ą┐čĆąĄą┤čłąĄčüčéą▓čāčÄčēą░čÅ ąĘą░ą┤ą░čćą░ ąĘą░ą▓ąĄčĆčłą░ąĄčéčüčÅ, ą▓čŗą▒čĆą░čüčŗą▓ą░ąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĖą╗ąĖ ąŠčéą╝ąĄąĮčÅąĄčéčüčÅ. ąÆčŗ ą╝ąŠąČąĄč鹥 ąĖąĘą╝ąĄąĮąĖčéčī čŹč鹊 ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ čāčüčéą░ąĮąŠą▓ą║ąŠą╣ (ą║ąŠą╝ą▒ąĖąĮąĖčĆčāąĄą╝čŗčģ ą┐ąŠ ąśąøąś) čäą╗ą░ą│ąŠą▓, ąĮą░čģąŠą┤čÅčēąĖčģčüčÅ ą▓ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖąĖ TaskContinuationOptions. ąÆąŠčé 3 ąŠčüąĮąŠą▓ąĮčŗčģ čäą╗ą░ą│ą░, čāą┐čĆą░ą▓ą╗čÅčÄčēąĖčģ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖąĄą╝ ą┐ąŠ čāčüą╗ąŠą▓ąĖčÄ (conditional continuation):
NotOnRanToCompletion = 0 x10000,
NotOnFaulted = 0 x20000,
NotOnCanceled = 0 x40000,
ąŁčéąĖ čäą╗ą░ą│ąĖ "ąŠčéąĮąĖą╝ą░čÄčēąĖąĄ" ą▓ č鹊ą╝ čüą╝čŗčüą╗ąĄ, čćč鹊 č湥ą╝ ą▒ąŠą╗čīčłąĄ ąÆčŗ ąĖčģ ą┐čĆąĖą╝ąĄąĮčÅąĄč鹥, č鹥ą╝ ą╝ąĄąĮčīčłąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ čā continuation-ąĘą░ą┤ą░čćąĖ ą▓čŗą┐ąŠą╗ąĮąĖčéčīčüčÅ. ąöą╗čÅ čāą┤ąŠą▒čüčéą▓ą░ ą▓ąŠčé čéą░ą║ąČąĄ čüą╗ąĄą┤čāčÄčēąĖąĄ ąĘą░čĆą░ąĮąĄąĄ čüą║ąŠą╝ą▒ąĖąĮąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ:
OnlyOnRanToCompletion = NotOnFaulted | NotOnCanceled,
OnlyOnFaulted = NotOnRanToCompletion | NotOnCanceled,
OnlyOnCanceled = NotOnRanToCompletion | NotOnFaulted
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą║ąŠą╝ą▒ąĖąĮąĖčĆąŠą▓ą░ąĮąĖąĄ ą▓čüąĄčģ Not* čäą╗ą░ą│ąŠą▓ (NotOnRanToCompletion, NotOnFaulted, NotOnCanceled) ą▒ąĄčüčüą╝čŗčüą╗ąĄąĮąĮąŠ, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 continuation ą▓čüąĄą│ą┤ą░ ą▒čāą┤ąĄčé ąŠčéą╝ąĄąĮąĄąĮąŠ.
"RanToCompletion" ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ąĘą░ą┐čāčüą║ ą▒čāą┤ąĄčé ąŠčüčāčēąĄčüčéą▓ą╗ąĄąĮ ą┐čĆąĖ čāčüą┐ąĄčłąĮąŠą╝ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĖ antecedent-ąĘą░ą┤ą░čćąĖ, čé. ąĄ. ą║ąŠą│ą┤ą░ ąĮąĄ ą▒čŗą╗ąŠ ąŠčéą╝ąĄąĮčŗ (cancellation) ąĖą╗ąĖ ąĮąĄ ąŠą▒čĆą░ą▒ąŠčéą░ąĮąĮčŗčģ ąĖčüą║ą╗čÄč湥ąĮąĖą╣.
"Faulted" ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ąĮą░ antecedent-ąĘą░ą┤ą░č湥 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ ąĮąĄ ąŠą▒čĆą░ą▒ąŠčéą░ąĮąĮąŠąĄ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ.
"Canceled" ąŠąĘąĮą░čćą░ąĄčé ąŠą┤ąĮąŠ ąĖąĘ ą┤ą▓čāčģ čüą╗čāčćą░ąĄą▓:
ŌĆó ąŚą░ą┤ą░čćą░ antecedent ą▒čŗą╗ą░ ąŠčéą╝ąĄąĮąĄąĮą░ (canceled) č湥čĆąĄąĘ ąĄčæ ą╝ą░čĆą║ąĄčĆ ąŠčéą╝ąĄąĮčŗ (cancellation token). ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ą▒čŗą╗ąŠ ą▓čŗą▒čĆąŠčłąĄąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ą▓ąĮčāčéčĆąĖ antecedent-ąĘą░ą┤ą░čćąĖ - čćčīąĄ čüą▓ąŠą╣čüčéą▓ąŠ CancellationToken čüąŠą▓ą┐ą░ą╗ąŠ ą┐ąĄčĆąĄą┤ą░ąĮąĮąŠą╝čā ą▓ antecedent-ąĘą░ą┤ą░čćčā, ą║ąŠą│ą┤ą░ ąŠąĮą░ ą▒čŗą╗ą░ ąĘą░ą┐čāčēąĄąĮą░.
ąÆą░ąČąĮąŠ ąŠčüąŠąĘąĮą░ą▓ą░čéčī, čćč鹊 ą║ąŠą│ą┤ą░ continuation ąĮąĄ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ąĮą░ ąŠčüąĮąŠą▓ą░ąĮąĖąĖ čŹčéąĖčģ čäą╗ą░ą│ąŠą▓, č鹊 continuation ąĮąĄ ąĘą░ą▒čŗč鹊 ąĖ ąĮąĄ ąŠčéą▒čĆąŠčłąĄąĮąŠ, ąŠąĮąŠ ąŠčéą╝ąĄąĮąĄąĮąŠ (canceled). ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą╗čÄą▒čŗąĄ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ ąĮą░ čüą░ą╝ąŠą╝ continuation ąĘą░č鹥ą╝ ą▒čāą┤čāčé ąĘą░ą┐čāčēąĄąĮčŗ - ą║čĆąŠą╝ąĄ čüą╗čāčćą░čÅ, ą║ąŠą│ą┤ą░ ąÆčŗ ą┐čĆąĖą╝ąĄąĮąĖą╗ąĖ NotOnCanceled. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą┐čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝ čüą╗ąĄą┤čāčÄčēąĄąĄ:
Task t1 = Task.Factory.StartNew (...);
Task fault = t1.ContinueWith (ant => Console.WriteLine ("fault" ),
TaskContinuationOptions.OnlyOnFaulted);
Task t3 = fault.ContinueWith (ant => Console.WriteLine ("t3" ));
ąÜą░ą║ ąĘą┤ąĄčüčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ, t3 ą▓čüąĄą│ą┤ą░ ąĘą░ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąŠ ąĮą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ - ą┤ą░ąČąĄ ąĄčüą╗ąĖ t1 ą▓čŗą▒čĆąŠčüąĖčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ. ąŁč鹊 ą┐ąŠč鹊ą╝čā, čćč鹊 ąĄčüą╗ąĖ t1 čāčüą┐ąĄčłąĮąŠ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ, č鹊 ąĘą░ą┤ą░čćą░ fault ą▒čāą┤ąĄčé ąŠčéą╝ąĄąĮąĄąĮą░, ąĖ ąĮąĄ ą▒čāą┤ąĄčé ąŠą│čĆą░ąĮąĖč湥ąĮąĖą╣ ąĮą░ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖąĄ ą┤ą╗čÅ t3, ąĖ t3 ąĘą░ą┐čāčüčéąĖčéčüčÅ ą▒ąĄąĘ čāčüą╗ąŠą▓ąĖčÅ.
ąĢčüą╗ąĖ ą╝čŗ čģąŠčéąĖą╝ ą▓čŗą┐ąŠą╗ąĮąĖčéčī t3 č鹊ą╗čīą║ąŠ ąĄčüą╗ąĖ fault čĆąĄą░ą╗čīąĮąŠ ąĘą░ą┐čāčüčéąĖčéčüčÅ, č鹊 ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ąĮčāąČąĮąŠ ąĮą░ą┐ąĖčüą░čéčī čüą╗ąĄą┤čāčÄčēąĄąĄ:
Task t3 = fault.ContinueWith (ant => Console.WriteLine ("t3" ),
TaskContinuationOptions.NotOnCanceled);
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą░ą╗čīč鹥čĆąĮą░čéąĖą▓ąĮąŠ ą╝čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ čāą║ą░ąĘą░čéčī OnlyOnRanToCompletion; čĆą░ąĘąĮąĖčåą░ ą▒čāą┤ąĄčé ą▓ č鹊ą╝, čćč鹊 t3 č鹊ą│ą┤ą░ ąĮąĄ ąĘą░ą┐čāčüčéąĖą╗ą░čüčī ą▒čŗ, ąĄčüą╗ąĖ ą▒čŗą╗ąŠ ą▒čŗ ą▓čŗą▒čĆąŠčłąĄąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ą▓ ąĘą░ą┤ą░č湥 fault.
ą¤čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ čü ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ ą┐čĆąĄą┤čłąĄčüčéą▓ąĄąĮąĮąĖą║ą░ą╝ąĖ . ąöčĆčāą│ą░čÅ ą┐ąŠą╗ąĄąĘąĮą░čÅ ąŠčüąŠą▒ąĄąĮąĮąŠčüčéčī ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖą╣ - ą╝ąŠąČąĮąŠ ąĘą░ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░čéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ continuation-ąĘą░ą┤ą░čć, ą▒ą░ąĘąĖčĆčāčÅčüčī ąĮą░ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĖ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą┐čĆąĄą┤čłąĄčüčéą▓čāčÄčēąĖčģ (antecedent) ąĘą░ą┤ą░čć. ContinueWhenAll ą┐ą╗ą░ąĮąĖčĆčāąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ, ą║ąŠą│ą┤ą░ ą▓čüąĄ antecedent-ąĘą░ą┤ą░čćąĖ ą▒čŗą╗ąĖ ąĘą░ą▓ąĄčĆčłąĄąĮčŗ; ContinueWhenAny ą┐ą╗ą░ąĮąĖčĆčāąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ, ą║ąŠą│ą┤ą░ ąŠą┤ąĮą░ antecedent-ąĘą░ą┤ą░čćą░ ąĘą░ą▓ąĄčĆčłąĖą╗ą░čüčī. ą×ą▒ą░ ą╝ąĄč鹊ą┤ą░ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮčŗ ą▓ ą║ą╗ą░čüčüąĄ TaskFactory:
var task1 = Task.Factory.StartNew (() => Console.Write ("X" ));var task2 = Task.Factory.StartNew (() => Console.Write ("Y" ));
var continuation = Task.Factory.ContinueWhenAll (
new [] { task1, task2 }, tasks => Console.WriteLine ("Done" ));
ąŁč鹊čé ą┐čĆąĖą╝ąĄčĆ ą║ąŠą┤ą░ ą▓čŗą▓ąĄą┤ąĄčé "Done" ą┐ąŠčüą╗ąĄ ą▓čŗą▓ąŠą┤ą░ "XY" ąĖą╗ąĖ "YX". ąÉčĆą│čāą╝ąĄąĮčé tasks ą▓ lambda-ą▓čŗčĆą░ąČąĄąĮąĖąĖ ą┤ą░ąĄčé ąÆą░ą╝ ą┤ąŠčüčéčāą┐ ą║ ą╝ą░čüčüąĖą▓čā ąĘą░ą▓ąĄčĆčłąĄąĮąĮčŗčģ ąĘą░ą┤ą░čć, čćč鹊 ą┐ąŠą╗ąĄąĘąĮąŠ, ą║ąŠą│ą┤ą░ antecedent-ąĘą░ą┤ą░čćąĖ ą▓ąŠąĘą▓čĆą░čēą░čÄčé ą┤ą░ąĮąĮčŗąĄ. ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ čüą║ą╗ą░ą┤čŗą▓ą░ąĄčé ą▓ą╝ąĄčüč鹥 čćąĖčüą╗ą░, ą▓ąŠąĘą▓čĆą░čēąĄąĮąĮčŗąĄ ąĖąĘ ą┤ą▓čāčģ antecedent-ąĘą░ą┤ą░čć:
// ąÆ čĆąĄą░ą╗čīąĮąŠą╣ ąČąĖąĘąĮąĖ task1 ąĖ task2 ą▓čŗąĘčŗą▓ą░ą╗ąĖ čüą╗ąŠąČąĮčŗąĄ čäčāąĮą║čåąĖąĖ:
Task<int > task1 = Task.Factory.StartNew (() => 123 );
Task<int > task2 = Task.Factory.StartNew (() => 456 );
Task<int > task3 = Task<int >.Factory.ContinueWhenAll (
new [] { task1, task2 }, tasks => tasks.Sum (t => t.Result));
Console.WriteLine (task3.Result); // 579
ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą╝čŗ ą▓ą║ą╗čÄčćą░ą╗ąĖ ą░čĆą│čāą╝ąĄąĮčé čéąĖą┐ą░ < int> ą┤ą╗čÅ ą▓čŗąĘąŠą▓ą░ Task.Factory, čćč鹊ą▒čŗ čĆą░ąĘčŖčÅčüąĮąĖčéčī, čćč鹊 ą╝čŗ ą┐ąŠą╗čāčćą░ąĄą╝ ąŠą▒čŗčćąĮčāčÄ čäą░ą▒čĆąĖą║čā ąĘą░ą┤ą░čćąĖ (generic task factory). ąÉčĆą│čāą╝ąĄąĮčé čéąĖą┐ą░ ąĮąĄ ąŠą▒čÅąĘą░č鹥ą╗ąĄąĮ, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąĮ ą▒čāą┤ąĄčé ą▓čŗą▓ąĄą┤ąĄąĮ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆąŠą╝.
ąØąĄčüą║ąŠą╗čīą║ąŠ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖą╣ ąĮą░ ąŠą┤ąĮąŠą╝ ą┐čĆąĄą┤čłąĄčüčéą▓ąĄąĮąĮąĖą║ąĄ . ąÆčŗąĘąŠą▓ ContinueWith ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą│ąŠ čĆą░ąĘą░ ąĮą░ ąŠą┤ąĮąŠą╣ ąĖ č鹊ą╣ ąČąĄ ąĘą░ą┤ą░č湥 čüąŠąĘą┤ą░ąĄčé ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖą╣ (continuation-ąĘą░ą┤ą░čć) ąĮą░ ąŠą┤ąĮąŠą╝ ą┐čĆąĄą┤čłąĄčüčéą▓ąĄąĮąĮąĖą║ąĄ (antecedent-ąĘą░ą┤ą░č湥). ąÜąŠą│ą┤ą░ antecedent-ąĘą░ą┤ą░čćą░ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ, č鹊 ą▓čüąĄ continuation-ąĘą░ą┤ą░čćąĖ ąĘą░ą┐čāčüčéčÅčéčüčÅ ą▓ą╝ąĄčüč鹥 (ąĄčüą╗ąĖ ąÆčŗ ąĮąĄ čāą║ą░ąĘą░ą╗ąĖ TaskContinuationOptions.ExecuteSynchronously, ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ continuation-ąĘą░ą┤ą░čćąĖ ą▒čāą┤čāčé ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ).
ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤ ąČą┤ąĄčé 1 čüąĄą║čāąĮą┤čā, ąĖ ąĘą░č鹥ą╝ ą▓čŗą▓ąĄą┤ąĄčé ą╗ąĖą▒ąŠ "XY", ą╗ąĖą▒ąŠ "YX":
var t = Task.Factory.StartNew (() => Thread.Sleep (1000 ));
t.ContinueWith (ant => Console.Write ("X" ));
t.ContinueWith (ant => Console.Write ("Y" ));
ą¤ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ąĖ ąĘą░ą┤ą░čć ąĖ ąĖąĮč鹥čĆč乥ą╣čü ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ . ą¤ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ ąĘą░ą┤ą░čć (scheduler) ą▓čŗą┤ąĄą╗čÅąĄčé ąĘą░ą┤ą░čćąĖ ą┐ąŠč鹊ą║ą░ą╝. ąÆčüąĄ ąĘą░ą┤ą░čćąĖ čüą▓čÅąĘą░ąĮčŗ čü ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ąŠą╝ ąĘą░ą┤ą░čćąĖ, ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĮčŗą╝ ą░ą▒čüčéčĆą░ą║čéąĮčŗą╝ ą║ą╗ą░čüčüąŠą╝ TaskScheduler. Framework ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┤ą▓ąĄ ą║ąŠąĮą║čĆąĄčéąĮčŗąĄ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ: ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ (default scheduler), ą║ąŠč鹊čĆčŗą╣ čĆą░ą▒ąŠčéą░ąĄčé ą▓ čéą░ąĮą┤ąĄą╝ąĄ čü ą┐čāą╗ąŠą╝ ą┐ąŠč鹊ą║ąŠą▓ CLR, ąĖ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ąŠą╝ ą║ąŠąĮč鹥ą║čüčéą░ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ (synchronization context scheduler). ą¤ąŠčüą╗ąĄą┤ąĮąĖą╣ čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮ (ą│ą╗ą░ą▓ąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝), čćč鹊ą▒čŗ ą┐ąŠą╝ąŠčćčī ąÆą░ą╝ čü ą╝ąŠą┤ąĄą╗čīčÄ ą┐ąŠč鹊ą║ąŠą▓ WPF ąĖ Windows Forms, ą║ąŠč鹊čĆčŗąĄ čéčĆąĄą▒čāčÄčé, čćč鹊ą▒čŗ ą║ 菹╗ąĄą╝ąĄąĮčéą░ą╝ ą│čĆą░čäąĖč湥čüą║ąŠą│ąŠ ąĖąĮč鹥čĆč乥ą╣čüą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (UI) ąĖ ąŠčĆą│ą░ąĮą░ą╝ ąĄą│ąŠ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ (controls) ą┤ąŠčüčéčāą┐ ąŠčüčāčēąĄčüčéą▓ą╗čÅą╗čüčÅ č鹊ą╗čīą║ąŠ ąĖąĘ čüąŠąĘą┤ą░ą▓čłąĄą│ąŠ ąĖčģ ą┐ąŠč鹊ą║ą░. ąØą░ą┐čĆąĖą╝ąĄčĆ ą┐čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ą╝čŗ čģąŠčéąĖą╝ ą┐ąŠą╗čāčćąĖčéčī ąĮąĄą║ąĖąĄ ą┤ą░ąĮąĮčŗąĄ ąĖąĘ ą▓ąĄą▒-čüąĄčĆą▓ąĖčüą░ ą▓ ą▓ąĖą┤ąĄ č乊ąĮąŠą▓ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ, ąĖ ąĘą░č鹥ą╝ ąŠą▒ąĮąŠą▓ąĖčéčī ą╝ąĄčéą║čā WPF čü ąĖą╝ąĄąĮąĄą╝ lblResult, ąŠčéčĆą░ąČą░čÄčēčāčÄ čĆąĄąĘčāą╗čīčéą░čé čŹč鹊ą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ. ą£čŗ ą╝ąŠąČąĄą╝ ą┐ąŠą┤ąĄą╗ąĖčéčī čŹčéčā čĆą░ą▒ąŠčéčā ąĮą░ 2 ąĘą░ą┤ą░čćąĖ (task):
1 . ąÆčŗąĘą▓ą░čéčī ą╝ąĄč鹊ą┤, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ą┤ą░ąĮąĮčŗąĄ ąĖąĘ web-čüąĄčĆą▓ąĖčüą░ (ą┐čĆąĄą┤čłąĄčüčéą▓čāčÄčēą░čÅ ąĘą░ą┤ą░čćą░, antecedent task).2 . ą×ą▒ąĮąŠą▓ąĖčéčī lblResult ą┐ąŠą╗čāč湥ąĮąĮčŗą╝ąĖ čĆąĄąĘčāą╗čīčéą░čéą░ą╝ąĖ (ąĘą░ą┤ą░čćą░ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ, continuation task).
ąĢčüą╗ąĖ ą┤ą╗čÅ ąĘą░ą┤ą░čćąĖ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ (continuation task) čāą║ą░ąĘčŗą▓ą░ąĄą╝ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ ą║ąŠąĮč鹥ą║čüčéą░ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ, ą┐ąŠą╗čāč湥ąĮąĮčŗą╣, ą║ąŠą│ą┤ą░ ą▒čŗą╗ąŠ čüą║ąŠąĮčüčéčĆčāąĖčĆąŠą▓ą░ąĮąŠ ąŠą║ąĮąŠ, ą╝čŗ ą╝ąŠąČąĄą╝ ą▒ąĄąĘąŠą┐ą░čüąĮąŠ ąŠą▒ąĮąŠą▓ąĖčéčī lblResult:
public partial class MyWindow : Window
{
TaskScheduler _uiScheduler; // ąöąĄą║ą╗ą░čĆąĖčĆčāąĄą╝ ą║ą░ą║ ą┐ąŠą╗ąĄ, čéą░ą║ čćč鹊 ą╝čŗ ą╝ąŠąČąĄą╝
// ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹč鹊 ą▓čüčÄą┤čā ą▓ ąĮą░čłąĄą╝ ą║ą╗ą░čüčüąĄ.
public MyWindow ()
{
InitializeComponent();
// ą¤ąŠą╗čāč湥ąĮąĖąĄ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ą░ UI ą┤ą╗čÅ ą┐ąŠč鹊ą║ą░, ą║ąŠč鹊čĆčŗą╣ čüąŠąĘą┤ą░ą╗ č乊čĆą╝čā:
_uiScheduler = TaskScheduler.FromCurrentSynchronizationContext();
Task.Factory.StartNew< string > (SomeComplexWebService)
.ContinueWith (ant => lblResult.Content = ant.Result, _uiScheduler);
}
string SomeComplexWebService () { ... }
}
ąóą░ą║ąČąĄ ąĄčüčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ąĮą░ą┐ąĖčüą░čéčī čüą▓ąŠą╣ čüąŠą▒čüčéą▓ąĄąĮąĮčŗą╣ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ ąĘą░ą┤ą░čć (č湥čĆąĄąĘ ą┐ąŠą┤ą║ą╗ą░čüčü TaskScheduler), čģąŠčéčÅ čŹč鹊 ąĮąĄčćč鹊 čéą░ą║ąŠąĄ, čćč鹊 ąÆčŗ ą┤ąĄą╗ą░ą╗ąĖ ą▒čŗ č鹊ą╗čīą║ąŠ ą▓ ąŠč湥ąĮčī čüą┐ąĄčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗčģ čüčåąĄąĮą░čĆąĖčÅčģ. ąöą╗čÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąŠą│ąŠ ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąĖčÅ ąÆčŗ čćą░čēąĄ ą▓čüąĄą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ąĖ ą▒čŗ TaskCompletionSource, čćč鹊 ą╝čŗ čüą║ąŠčĆąŠ čĆą░čüčüą╝ąŠčéčĆąĖą╝.
TaskFactory . ąÜąŠą│ą┤ą░ ąÆčŗ ą▓čŗąĘčŗą▓ą░ąĄč鹥 Task.Factory, č鹊 čüąŠąĘą┤ą░ąĄč鹥 čüčéą░čéąĖč湥čüą║ąŠąĄ čüą▓ąŠą╣čüčéą▓ąŠ ąĮą░ Task, ą║ąŠč鹊čĆąŠąĄ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ąŠą▒čŖąĄą║čé TaskFactory ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ. ąØą░ąĘąĮą░č湥ąĮąĖąĄ task factory - čüąŠąĘą┤ą░ą▓ą░čéčī ąĘą░ą┤ą░čćąĖ, ąŠčüąŠą▒ąĄąĮąĮąŠ čéčĆąĖ ą▓ąĖą┤ą░ ąĘą░ą┤ą░čć:
ŌĆó "ą×ą▒čŗčćąĮčŗąĄ" ąĘą░ą┤ą░čćąĖ (č湥čĆąĄąĘ StartNew).
ąśąĮč鹥čĆąĄčüąĮąŠ, čćč鹊 TaskFactory čÅą▓ą╗čÅąĄčéčüčÅ ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮčŗą╝ čüą┐ąŠčüąŠą▒ąŠą╝ ą┤ąŠčüčéąĖčćčī ą┐ąŠčüą╗ąĄą┤ąĮąĖčģ ą┤ą▓čāčģ čåąĄą╗ąĄą╣. ąÆ čüą╗čāčćą░ąĄ StartNew čŹč鹊 TaskFactory - ą┐čĆąŠčüč鹊 čāą┤ąŠą▒čüčéą▓ąŠ ąĖ č鹥čģąĮąĖč湥čüą║ąĖ ąĖąĘą▒čŗč鹊čćąĮąŠ, ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐čĆąŠčüč鹊 ąĖąĮčüčéą░ąĮčåąĖąĖčĆąŠą▓ą░čéčī ąŠą▒čŖąĄą║čéčŗ Task ąĖ ą▓čŗąĘą▓ą░čéčī ąĮą░ ąĮąĖčģ Start.
ąĪąŠąĘą┤ą░ąĮąĖąĄ čüą▓ąŠąĖčģ čüąŠą▒čüčéą▓ąĄąĮąĮčŗčģ task factorčā . TaskFactory ąĮąĄ ą░ą▒čüčéčĆą░ą║čéąĮą░čÅ čäą░ą▒čĆąĖą║ą░: ąÆčŗ ą╝ąŠąČąĄč鹥 ą▓ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠčüčéąĖ ąĖąĮčüčéą░čåąĖąĖčĆąŠą▓ą░čéčī čŹč鹊čé ą║ą╗ą░čüčü, ąĖ čŹč鹊 ą┐ąŠą╗ąĄąĘąĮąŠ, ą║ąŠą│ą┤ą░ ąÆčŗ čģąŠčéąĖč鹥 ą┐ąŠčüč鹊čÅąĮąĮąŠ čüąŠąĘą┤ą░ą▓ą░čéčī ąĘą░ą┤ą░čćąĖ, ąĖčüą┐ąŠą╗čīąĘčāčÅ č鹥 ąČąĄ čüą░ą╝čŗąĄ (ąĮąĄ čüčéą░ąĮą┤ą░čĆčéąĮčŗąĄ) ąĘąĮą░č湥ąĮąĖčÅ ą┤ą╗čÅ TaskCreationOptions, TaskContinuationOptions ąĖą╗ąĖ TaskScheduler. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą╝čŗ čģąŠčéąĖą╝ ąĮąĄąŠą┤ąĮąŠą║čĆą░čéąĮąŠ čüąŠąĘą┤ą░ą▓ą░čéčī ą┤ąŠą╗ą│ąŠ čĆą░ą▒ąŠčéą░čÄčēąĖąĄ ą┐ąŠčĆąŠąČą┤ąĄąĮąĮčŗąĄ ąĘą░ą┤ą░čćąĖ, č鹊 ą╝čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ čüąŠąĘą┤ą░čéčī ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║čāčÄ čäą░ą▒čĆąĖą║čā čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
var factory = new TaskFactory (
TaskCreationOptions.LongRunning | TaskCreationOptions.AttachedToParent,
TaskContinuationOptions.None);
ąĪąŠąĘą┤ą░ąĮąĖąĄ ąĘą░ą┤ą░čć č鹊ą│ą┤ą░ ą┐čĆąŠčüč鹊 ą┤ąĄą╗ą░ąĄčéčüčÅ ą▓čŗąĘąŠą▓ąŠą╝ StartNew ąĮą░ čäą░ą▒čĆąĖą║ąĄ:
Task task1 = factory.StartNew (Method1);
Task task2 = factory.StartNew (Method2);
...
ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖąĄ ąŠą┐čåąĖąĖ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ ą┐čĆąĖą╝ąĄąĮčÅčÄčéčüčÅ, ą║ąŠą│ą┤ą░ ą▓čŗąĘčŗą▓ą░ąĄčéčüčÅ ContinueWhenAll ąĖ ContinueWhenAny.
TaskCompletionSource . ąÜą╗ą░čüčü Task ą┤ąŠčüčéąĖą│ą░ąĄčé ą┤ą▓čāčģ čĆą░ąĘąĮčŗčģ ą▓ąĄčēąĄą╣:
ŌĆó ą¤ą╗ą░ąĮąĖčĆčāąĄčé ąĘą░ą┐čāčüą║ ą┤ąĄą╗ąĄą│ą░čéą░ ąĮą░ ą┐ąŠč鹊ą║ąĄ ąĖąĘ ą┐čāą╗ą░.
ąśąĮč鹥čĆąĄčüąĮąŠ, čćč鹊 čŹčéąĖ ą┤ą▓ąĄ ą▓ąĄčēąĖ ąĮąĄ čüąĖą╗čīąĮąŠ čüą▓čÅąĘą░ąĮčŗ: ąÆčŗ ą╝ąŠąČąĄč鹥 ąĘą░ą┤ąĄą╣čüčéą▓ąŠą▓ą░čéčī čäčāąĮą║čåąĖąĖ ąĘą░ą┤ą░čćąĖ ą┤ą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čĆą░ą▒ąŠčćąĖą╝ąĖ 菹╗ąĄą╝ąĄąĮčéą░ą╝ąĖ ą▒ąĄąĘ ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąĖčÅ ąĘą░ą┐čāčüą║ą░ č湥ą│ąŠ-ą╗ąĖą▒ąŠ ąĮą░ ą┐čāą╗ąĄ ą┐ąŠč鹊ą║ąŠą▓. ąÜą╗ą░čüčü, ą║ąŠč鹊čĆčŗą╣ ą▓ą║ą╗čÄčćą░ąĄčé čŹč鹊čé čłą░ą▒ą╗ąŠąĮ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ, ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ TaskCompletionSource.
ą¦č鹊ą▒čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī TaskCompletionSource, ąÆčŗ ą┐čĆąŠčüč鹊 ąĖąĮčüčéą░ąĮčåąĖąĖčĆčāąĄč鹥 čŹč鹊čé ą║ą╗ą░čüčü. ą×ąĮ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čüą▓ąŠą╣čüčéą▓ąŠ Task, ą▓ąŠąĘą▓čĆą░čēą░čÄčēąĄąĄ ąĘą░ą┤ą░čćčā, ąĮą░ ą║ąŠč鹊čĆąŠą╣ ąÆčŗ ą╝ąŠąČąĄč鹥 ąČą┤ą░čéčī ąĖ ą┐ąŠą┤ą║ą╗čÄčćą░čéčī ą║ ąĮąĄą╣ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ - č鹊čćąĮąŠ čéą░ą║ ąČąĄ, ą║ą░ą║ ąĖ čü ą╗čÄą▒ąŠą╣ ą┤čĆčāą│ąŠą╣ ąĘą░ą┤ą░č湥ą╣. ą×ą┤ąĮą░ą║ąŠ ąĘą░ą┤ą░čćą░ ą┐ąŠą╗ąĮąŠčüčéčīčÄ čāą┐čĆą░ą▓ą╗čÅąĄčéčüčÅ ąŠą▒čŖąĄą║č鹊ą╝ TaskCompletionSource č湥čĆąĄąĘ čüą╗ąĄą┤čāčÄčēąĖąĄ ą╝ąĄč鹊ą┤čŗ:
public class TaskCompletionSource < TResult>
{
public void SetResult (TResult result);
public void SetException (Exception exception);
public void SetCanceled ();
public bool TrySetResult (TResult result);
public bool TrySetException (Exception exception);
public bool TrySetCanceled ();
...
}
ą¤čĆąĖ ą▓čŗąĘąŠą▓ąĄ ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą│ąŠ čĆą░ąĘą░ SetResult, SetException ąĖą╗ąĖ SetCanceled ą▓čŗą▒čĆąŠčüčÅčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ; ą╝ąĄč鹊ą┤čŗ Try* ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą▓ąĄčĆąĮčāčé false.
TResult čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé čéąĖą┐čā čĆąĄąĘčāą╗čīčéą░čéą░ ąĘą░ą┤ą░čćąĖ, čéą░ą║ čćč鹊 TaskCompletionSource< int> ą┤ą░čüčé ąÆą░ą╝ Task< int>. ąĢčüą╗ąĖ ąÆčŗ čģąŠčéąĖč鹥 ąĖą╝ąĄčéčī ąĘą░ą┤ą░čćčā ą▒ąĄąĘ čĆąĄąĘčāą╗čīčéą░čéą░, čüąŠąĘą┤ą░ą╣č鹥 ąŠą▒čŖąĄą║čé TaskCompletionSource ąĖ ą┐ąĄčĆąĄą┤ą░ą╣č鹥 null, ą║ąŠą│ą┤ą░ ą▓čŗąĘčŗą▓ą░ąĄč鹥 SetResult. ąóąŠą│ą┤ą░ ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐čĆąĖą▓ąĄčüčéąĖ čéąĖą┐ Task< object> ą║ čéąĖą┐čā Task.
ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ ąĮą░ą┐ąĄčćą░čéą░ąĄčé 123 ą┐ąŠčüą╗ąĄ ąŠąČąĖą┤ą░ąĮąĖčÅ 5 čüąĄą║čāąĮą┤:
var source = new TaskCompletionSource<int >();
new Thread (() => { Thread.Sleep (5000 ); source.SetResult (123 ); })
.Start();
Task< int > task = source.Task; // ąØą░čłą░ "ą┐ąŠą┤čćąĖąĮąĄąĮąĮą░čÅ" ąĘą░ą┤ą░čćą░.
Console.WriteLine (task.Result); // 123
ą¤ąŠąĘąČąĄ ą╝čŗ ą┐ąŠą║ą░ąČąĄą╝, ą║ą░ą║ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī BlockingCollection ą┤ą╗čÅ ąĮą░ą┐ąĖčüą░ąĮąĖčÅ ąŠč湥čĆąĄą┤ąĖ producer/consumer. ąóąŠą│ą┤ą░ ą╝čŗ ą┐čĆąŠą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄą╝, ą║ą░ą║ TaskCompletionSource čāą╗čāčćčłą░ąĄčé čĆąĄčłąĄąĮąĖąĄ, ą┐ąŠąĘą▓ąŠą╗čÅčÅ ą┐ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗą╝ ą▓ ąŠč湥čĆąĄą┤čī čĆą░ą▒ąŠčćąĖą╝ 菹╗ąĄą╝ąĄąĮčéą░ą╝ ąŠčüčāčēąĄčüčéą▓ą╗čÅčéčī ąŠąČąĖą┤ą░ąĮąĖąĄ ąĖ ąŠčéą╝ąĄąĮčā.
[ąĀą░ą▒ąŠčéą░ čü AggregateException ]
ąÜą░ą║ ą╝čŗ ą▓ąĖą┤ąĄą╗ąĖPLINQ, ą║ą╗ą░čüčü Parallel ąĖ Tasks ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗čÅčÄčé ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗čÄ ą┤ą░ąĮąĮčŗčģ (consumer). ą¦č鹊ą▒čŗ čāą▓ąĖą┤ąĄčéčī, ą┐ąŠč湥ą╝čā čŹč鹊 ą▓ą░ąČąĮąŠ, čĆą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗ąĄą┤čāčÄčēąĖą╣ ąĘą░ą┐čĆąŠčü LINQ, ą║ąŠč鹊čĆčŗą╣ ą▓čŗą▒čĆą░čüčŗą▓ą░ąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ DivideByZeroException ą▓ ą┐ąĄčĆą▓ąŠą╣ ąĖč鹥čĆą░čåąĖąĖ:
try
{
var query = from i in Enumerable.Range (0 , 1000000 )
select 100 / i;
...
}catch (DivideByZeroException)
{
...
}
ąĢčüą╗ąĖ ą╝čŗ ą▒čāą┤ąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī PLINQ ą┤ą╗čÅ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖą▓ą░ąĮąĖčÅ čŹč鹊ą│ąŠ ąĘą░ą┐čĆąŠčüą░ čü ąĖą│ąĮąŠčĆąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖą╣, č鹊 DivideByZeroException ą▓ąĄčĆąŠčÅčéąĮąŠ ą▒čŗą╗ąŠ ą▒čŗ ą▓čŗą▒čĆąŠčłąĄąĮąŠ ąĮą░ ąŠčéą┤ąĄą╗čīąĮąŠą╝ ą┐ąŠč鹊ą║ąĄ čü ą┐čĆąŠą┐čāčüą║ąŠą╝ ąĮą░čłąĄą│ąŠ catch-ą▒ą╗ąŠą║ą░, čćč鹊 ą┐čĆąĖą▓ąĄą╗ąŠ ą▒čŗ ą║ ą┐ą░ą┤ąĄąĮąĖčÄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ.
ąĪą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ, ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą┐ąĄčĆąĄčģą▓ą░čéčŗą▓ą░čÄčéčüčÅ ąĖ ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗čÅčÄčéčüčÅ ą▓ ą▓čŗąĘčŗą▓ą░čÄčēąĖą╣ ą║ąŠą┤. ąØąŠ ą║ čüąŠąČą░ą╗ąĄąĮąĖčÄ, čŹč鹊 ąĮąĄ čüąŠą▓čüąĄą╝ čéą░ą║ ąČąĄ ą┐čĆąŠčüč鹊, ą║ą░ą║ ą┐ąĄčĆąĄčģą▓ą░čé DivideByZeroException. ą¤čĆąĖčćąĖąĮą░ ą▓ č鹊ą╝, čćč鹊 čŹčéąĖ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ąĘą░ą┤ąĄą╣čüčéą▓čāčÄčé ą╝ąĮąŠą│ąĖąĄ ą┐ąŠč鹊ą║ąĖ, ąĖ ą▓ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī čéą░ą║, čćč鹊 ą┤ą▓ą░ ąĖą╗ąĖ ą▒ąŠą╗čīčłąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĖčüą║ą╗čÄč湥ąĮąĖą╣ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą▒čĆąŠčłąĄąĮčŗ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ. ąöą╗čÅ ą│ą░čĆą░ąĮčéąĖąĖ, čćč鹊 ąŠ ą▓čüąĄčģ ąĖčüą║ą╗čÄč湥ąĮąĖčÅčģ ą▒čāą┤ąĄčé čüąŠąŠą▒čēąĄąĮąŠ, ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąŠą▒ąĄčĆčéčŗą▓ą░čÄčéčüčÅ ą▓ ą║ąŠąĮč鹥ą╣ąĮąĄčĆ AggregateException, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čüą▓ąŠą╣čüčéą▓ąŠ InnerExceptions, čüąŠą┤ąĄčƹȹ░čēąĄąĄ ą┐ąĄčĆąĄčģą▓ą░č湥ąĮąĮąŠąĄ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ (ąĖą╗ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ):
try
{
var query = from i in ParallelEnumerable.Range (0 , 1000000 )
select 100 / i;
// ą¤ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖąĄ ąĘą░ą┐čĆąŠčüą░
...
}catch (AggregateException aex)
{
foreach (Exception ex in aex.InnerExceptions)
Console.WriteLine (ex.Message);
}
ąś PLINQ, ąĖ ą║ą╗ą░čüčü Parallel ąĘą░ą▓ąĄčĆčłą░čÄčé ąĘą░ą┐čĆąŠčü ąĖą╗ąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ čåąĖą║ą╗ą░, ą║ąŠą│ą┤ą░ ą▓čüčéčĆąĄčéąĖčéčüčÅ ą┐ąĄčĆą▓ąŠąĄ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ - ą┐čĆąĖ čŹč鹊ą╝ ąĮąĄ ą▒čāą┤čāčé ąŠą▒čĆą░ą▒ąŠčéą░ąĮčŗ ą║ą░ą║ąĖąĄ-ą╗ąĖą▒ąŠ ą┤čĆčāą│ąĖąĄ 菹╗ąĄą╝ąĄąĮčéčŗ ąĖą╗ąĖ ą┐čĆąŠą║čĆčāčéą║ąĖ č鹥ą╗ą░ čåąĖą║ą╗ą░. ą×ą┤ąĮą░ą║ąŠ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą▒čĆąŠčłąĄąĮąŠ ą▒ąŠą╗čīčłąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĖčüą║ą╗čÄč湥ąĮąĖą╣ ą┐ąĄčĆąĄą┤ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄą╝ č鹥ą║čāčēąĄą│ąŠ čåąĖą║ą╗ą░. ą¤ąĄčĆą▓ąŠąĄ ą▓ąŠąĘąĮąĖą║čłąĄąĄ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ AggregateException ą▒čāą┤ąĄčé ą▓čŗą┤ą░ąĮąŠ ą▓ čüą▓ąŠą╣čüčéą▓ąĄ InnerException.
Flatten ąĖ Handle . ąÜą╗ą░čüčü AggregateException ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ąĮąĄčüą║ąŠą╗čīą║ąŠ ą╝ąĄč鹊ą┤ąŠą▓ ą┤ą╗čÅ čāą┐čĆąŠčēąĄąĮąĖčÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ: Flatten ąĖ Handle.
Flatten . AggregateExceptions ą▒čāą┤čāčé ą┤ąŠą▓ąŠą╗čīąĮąŠ čćą░čüč鹊 čüąŠą┤ąĄčƹȹ░čéčī ą┤čĆčāą│ąĖąĄ AggregateExceptions. ą¤čĆąĖą╝ąĄčĆ, ą║ąŠą│ą┤ą░ čŹč鹊 ą╝ąŠąČąĄčé čüą╗čāčćąĖčéčīčüčÅ - ąĄčüą╗ąĖ ą┤ąŠč湥čĆąĮčÅčÅ ąĘą░ą┤ą░čć ą▓čŗą▒čĆąŠčüąĖčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ. ąÆčŗ ą╝ąŠąČąĄč鹥 ąĖčüą║ą╗čÄčćąĖčéčī ą╗čÄą▒ąŠą╣ čāčĆąŠą▓ąĄąĮčī ą▓ą╗ąŠąČąĄąĮąĮąŠčüčéąĖ ą┤ą╗čÅ čāą┐čĆąŠčēąĄąĮąĖčÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┐čāč鹥ą╝ ą▓čŗąĘąŠą▓ą░ Flatten. ąŁč鹊čé ą╝ąĄč鹊ą┤ ą▓ąĄčĆąĮąĄčé ąĮąŠą▓čŗą╣ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ AggregateException čü ą┐čĆąŠčüčéčŗą╝ ą┐ą╗ąŠčüą║ąĖą╝ čüą┐ąĖčüą║ąŠą╝ ą▓ąĮčāčéčĆąĄąĮąĮąĖčģ ąĖčüą║ą╗čÄč湥ąĮąĖą╣:
catch (AggregateException aex)
{
foreach (Exception ex in aex.Flatten().InnerExceptions)
myLogWriter.LogException (ex);
}
Handle . ąśąĮąŠą│ą┤ą░ ą┐ąŠą╗ąĄąĘąĮąŠ ą┐ąĄčĆąĄčģą▓ą░čéčŗą▓ą░čéčī č鹊ą╗čīą║ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ čéąĖą┐čŗ ąĖčüą║ą╗čÄč湥ąĮąĖą╣, čćč鹊ą▒čŗ ą┤čĆčāą│ąĖąĄ čéąĖą┐čŗ ą▓čŗą▒čĆą░čüčŗą▓ą░ą╗ąĖčüčī ąĘą░ąĮąŠą▓ąŠ. ą£ąĄč鹊ą┤ Handle ą▓ AggregateException ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čÅčĆą╗čŗč湊ą║ ą┤ą╗čÅ čŹč鹊ą╣ čäčāąĮą║čåąĖąĖ. ą×ąĮ ą┐čĆąĖąĮąĖą╝ą░ąĄčé ą┐čĆąĄą┤ąĖą║ą░čé ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ąĘą░ą┐čāčüą║ą░ąĄą╝čŗą╣ čü ą║ą░ąČą┤čŗą╝ ą▓ąĮčāčéčĆąĄąĮąĮąĖą╝ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝:
public void Handle (Func< Exception, bool > predicate)
ąĢčüą╗ąĖ čŹč鹊čé ą┐čĆąĄą┤ąĖą║ą░čé ą▓ąĄčĆąĮąĄčé true, č鹊 čüčćąĖčéą░ąĄčéčüčÅ, čćč鹊 ąĖčüą║ą╗čÄč湥ąĮąĖąĄ "ąŠą▒čĆą░ą▒ąŠčéą░ąĮąŠ". ą¤ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ą┤ąĄą╗ąĄą│ą░čé ąĘą░ą┐čāčüčéąĖčéčüčÅ ąĮą░ ą║ą░ąČą┤ąŠą╝ ąĖčüą║ą╗čÄč湥ąĮąĖąĖ, ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
ŌĆó ąĢčüą╗ąĖ ą▓čüąĄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą▒čŗą╗ąĖ "ąŠą▒čĆą░ą▒ąŠčéą░ąĮčŗ" (ą┤ąĄą╗ąĄą│ą░čé ą▓ąĄčĆąĮčāą╗ true), ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĮąĄ ą▒čāą┤ąĄčé ą▓čŗą▒čĆąŠčłąĄąĮąŠ ą┐ąŠą▓č鹊čĆąĮąŠ.
ąØą░ą┐čĆąĖą╝ąĄčĆ, čüą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ ą┐ąŠą▓č鹊čĆąĮčŗą╝ ą▓čŗą▒čĆą░čüčŗą▓ą░ąĮąĖąĄą╝ ą┤čĆčāą│ąŠą│ąŠ AggregateException, ą║ąŠč鹊čĆąŠąĄ čüąŠą┤ąĄčƹȹĖčé ąŠą┤ąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ NullReferenceException:
var parent = Task.Factory.StartNew (() =>
{
// ąÆčŗą▒čĆąŠčüąĖą╝ 3 ąĖčüą║ą╗čÄč湥ąĮąĖčÅ čüčĆą░ąĘčā čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ 3 ą┤ąŠč湥čĆąĮąĖčģ ąĘą░ą┤ą░čć:
int [] numbers = { 0 };
var childFactory = new TaskFactory
(TaskCreationOptions.AttachedToParent, TaskContinuationOptions.None);
childFactory.StartNew (() => 5 / numbers[0 ]); // ąöąĄą╗ąĄąĮąĖąĄ ąĮą░ 0
childFactory.StartNew (() => numbers [1 ]); // ąśąĮą┤ąĄą║čü ą▓ąĮąĄ ą┤ąĖą░ą┐ą░ąĘąŠąĮą░
childFactory.StartNew (() => { throw null ; }); // Null-čüčüčŗą╗ą║ą░
});
try { parent.Wait(); }catch (AggregateException aex)
{
// ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĮą░ą╝ ą▓čüąĄ ąĄčēąĄ ąĮčāąČąĮąŠ ą▓čŗąĘą▓ą░čéčī Flatten:
aex.Flatten().Handle (ex =>
{
if (ex is DivideByZeroException)
{
Console.WriteLine ("Divide by zero" );
return true ; // ąŁč鹊 ąĖčüą║ą╗čÄč湥ąĮąĖąĄ "ąŠą▒čĆą░ą▒ąŠčéą░ąĮąŠ"
}
if (ex is IndexOutOfRangeException)
{
Console.WriteLine ("Index out of range" );
return true ; // ąŁč鹊 ąĖčüą║ą╗čÄč湥ąĮąĖąĄ "ąŠą▒čĆą░ą▒ąŠčéą░ąĮąŠ"
}
return false ; // ąÆčüąĄ ą┤čĆčāą│ąĖąĄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą▒čāą┤čāčé ą▓čŗą▒čĆąŠčłąĄąĮčŗ ą┐ąŠą▓č鹊čĆąĮąŠ
});
}
[ąÜąŠąĮą║čāčĆąĄąĮčéąĮčŗąĄ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ ]
Framework 4.0 ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĮąŠą▓čŗčģ ą║ąŠą╗ą╗ąĄą║čåąĖą╣ ą▓ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąĄ ąĖą╝ąĄąĮ System.Collections.Concurrent. ąÆčüąĄ ąŠąĮąĖ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą▒ąĄąĘąŠą┐ą░čüąĮčŗ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čü ą┐ąŠč鹊ą║ą░ą╝ąĖ:
ąÜąŠąĮą║čāčĆąĄąĮčéąĮą░čÅ ą║ąŠą╗ą╗ąĄą║čåąĖčÅ ąØąĄ ą║ąŠąĮą║čāčĆąĄąĮčéąĮčŗą╣ 菹║ą▓ąĖą▓ą░ą╗ąĄąĮčé
ConcurrentStack< T>
Stack< T>
ConcurrentQueue< T>
Queue< T>
ConcurrentBag< T>
ąĮąĄčé ą░ąĮą░ą╗ąŠą│ą░
BlockingCollection< T>
ąĮąĄčé ą░ąĮą░ą╗ąŠą│ą░
ConcurrentDictionary< TKey,TValue>
Dictionary< TKey,TValue>
ąŁčéąĖ ą║ąŠąĮą║čāčĆąĄąĮčéąĮčŗąĄ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ąĖąĮąŠą│ą┤ą░ ą┐ąŠą╗ąĄąĘąĮčŗ ą▓ ąŠą▒čŗčćąĮąŠą╣ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠčüčéąĖ, ą║ąŠą│ą┤ą░ ąÆą░ą╝ ąĮčāąČąĮą░ thread-safe ą║ąŠą╗ą╗ąĄą║čåąĖčÅ. ą×ą┤ąĮą░ą║ąŠ čéčāčé ąĄčüčéčī ąĮąĄą║ąŠč鹊čĆčŗąĄ ą┐ąŠą┤ą▓ąŠą┤ąĮčŗąĄ ą║ą░ą╝ąĮąĖ:
ŌĆó ąÜąŠąĮą║čāčĆąĄąĮčéąĮčŗąĄ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ ąĮą░čüčéčĆąŠąĄąĮčŗ ąĮą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ. ąĪčéą░ąĮą┤ą░čĆčéąĮčŗąĄ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ ą▓čŗąĖą│čĆčŗą▓ą░čÄčé čā ąĮąĖčģ ą┐ąŠčćčéąĖ ą▓čüąĄą│ą┤ą░, ą║čĆąŠą╝ąĄ ąŠč湥ąĮčī ą║ąŠąĮą║čāčĆąĄąĮčéąĮčŗčģ čüčåąĄąĮą░čĆąĖąĄą▓.
ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, čŹčéąĖ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ ą┐čĆąŠčüč鹊 ąĮąĄ ąŠą▒ąĄčüą┐ąĄčćąĖą▓ą░čÄčé čÅčĆą╗čŗą║ąĖ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąŠą▒čŗčćąĮąŠą╣ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ čü ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąŠą╣. ąöą╗čÅ ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąĖ, ąĄčüą╗ąĖ ą╝čŗ ąĘą░ą┐čāčüčéąĖą╝ čüą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤ ą▓ ąŠą┤ąĮąŠą╝ ą┐ąŠč鹊ą║ąĄ:
var d = new ConcurrentDictionary< int ,int >();for (int i = 0 ; i < 1000000 ; i++) d[i] = 123 ;
č鹊 ąŠąĮ ą▓čŗą┐ąŠą╗ąĮąĖčéčüčÅ ą▓ 3 čĆą░ąĘą░ ą╝ąĄą┤ą╗ąĄąĮąĮąĄąĄ, č湥ą╝ čŹč鹊čé ą║ąŠą┤:
var d = new Dictionary< int ,int >();for (int i = 0 ; i < 1000000 ; i++) lock (d) d[i] = 123 ;
ą×ą┤ąĮą░ą║ąŠ čćč鹥ąĮąĖąĄ ąĖąĘ ConcurrentDictionary ą▒čāą┤ąĄčé ą▒čŗčüčéčĆąŠąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 čćč鹥ąĮąĖąĄ čĆą░ą▒ąŠčéą░ąĄčé ą▒ąĄąĘ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ.
ąÜąŠąĮą║čāčĆąĄąĮčéąĮčŗąĄ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ čéą░ą║ąČąĄ ąŠčéą╗ąĖčćą░čÄčéčüčÅ ąŠčé ąŠą▒čŗčćąĮčŗčģ ą║ąŠą╗ą╗ąĄą║čåąĖą╣ č鹥ą╝, čćč鹊 ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé čüą┐ąĄčåąĖą░ą╗čīąĮčŗąĄ ą╝ąĄč鹊ą┤čŗ ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą░č鹊ą╝ą░čĆąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣ ą┐čĆąŠą▓ąĄčĆą║ą░-ąĖ-ą┤ąĄą╣čüčéą▓ąĖąĄ, čéą░ą║ąĖąĄ ą║ą░ą║ TryPop. ąæąŠą╗čīčłąĖąĮčüčéą▓ąŠ čŹčéąĖčģ ą╝ąĄč鹊ą┤ąŠą▓ čāąĮąĖčäąĖčåąĖčĆąŠą▓ą░ąĮčŗ č湥čĆąĄąĘ ąĖąĮč鹥čĆč乥ą╣čü IProducerConsumerCollection< T>.
IProducerConsumerCollection< T> . ąÜąŠą╗ą╗ąĄą║čåąĖčÅ producer/consumer čŹč鹊 ąŠą┤ąĮą░ ąĖąĘ ą║ąŠą╗ą╗ąĄą║čåąĖą╣, ą┤ą╗čÅ ą║ąŠč鹊čĆčŗčģ čüčāčēąĄčüčéą▓čāąĄčé ą┤ą▓ą░ ąŠčüąĮąŠą▓ąĮčŗčģ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ:
ŌĆó ąöąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ 菹╗ąĄą╝ąĄąĮčéą░ (čäčāąĮą║čåąĖčÅ "producer").
ąÜą╗ą░čüčüąĖč湥čüą║ąĖąĄ ą┐čĆąĖą╝ąĄčĆčŗ - čüč鹥ą║ąĖ ąĖ ąŠč湥čĆąĄą┤ąĖ. ąÜąŠą╗ą╗ąĄą║čåąĖąĖ producer/consumer ą▓ą░ąČąĮčŗ ą▓ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąĮąĖ čüą┐ąŠčüąŠą▒čüčéą▓čāčÄčé čĆąĄą░ą╗ąĖąĘą░čåąĖčÅą╝ ą▒ąĄąĘ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║.
ąśąĮč鹥čĆč乥ą╣čü IProducerConsumerCollection< T> ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé ą┐ąŠč鹊ą║ąŠą▒ąĄąĘąŠą┐ą░čüąĮčāčÄ ą║ąŠą╗ą╗ąĄą║čåąĖčÄ producer/consumer. ąĪą╗ąĄą┤čāčÄčēąĖąĄ ą║ą╗ą░čüčüčŗ čĆąĄą░ą╗ąĖąĘčāčÄčé čŹč鹊čé ąĖąĮč鹥čĆč乥ą╣čü:
ConcurrentStack< T>
ConcurrentQueue< T>
ConcurrentBag< T>
IProducerConsumerCollection< T> čĆą░čüčłąĖčĆčÅąĄčé ICollection, ą┤ąŠą▒ą░ą▓ą╗čÅčÅ čüą╗ąĄą┤čāčÄčēąĖąĄ ą╝ąĄč鹊ą┤čŗ:
void CopyTo (T[] array, int index);
T[] ToArray ();bool TryAdd (T item);bool TryTake (out T item);
ą£ąĄč鹊ą┤čŗ TryAdd ąĖ TryTake ą┐čĆąŠą▓ąĄčĆčÅčÄčé, ą╝ąŠąČąĄčé ą╗ąĖ ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ ąŠą┐ąĄčĆą░čåąĖčÅ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ/čāą┤ą░ą╗ąĄąĮąĖąĄ, ąĖ ąĄčüą╗ąĖ čéą░ą║, čćč鹊 ą▓čŗą┐ąŠą╗ąĮąĖčé ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ/čāą┤ą░ą╗ąĄąĮąĖąĄ. ą¤čĆąŠą▓ąĄčĆą║ą░ ąĖ ą┤ąĄą╣čüčéą▓ąĖąĄ ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ą░č鹊ą╝ą░čĆąĮąŠ, čü čāčüčéčĆą░ąĮąĄąĮąĖąĄą╝ ąĮą░ą┤ąŠą▒ąĮąŠčüčéąĖ ą▓ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĄ, ą║ąŠč鹊čĆą░čÅ ą▒čŗą╗ą░ ą▒čŗ ą▓ąŠą║čĆčāą│ ąŠą▒čŗčćąĮąŠą╣ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ:
int result;lock (myStack) if (myStack.Count > 0 ) result = myStack.Pop();
TryTake ą▓ąĄčĆąĮąĄčé false, ąĄčüą╗ąĖ ą║ąŠą╗ą╗ąĄą║čåąĖčÅ ą┐čāčüčéą░čÅ. TryAdd ą▓čüąĄą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮąĖčéčüčÅ čāčüą┐ąĄčłąĮąŠ ąĖ ą▓ąĄčĆąĮąĄčé true ą▓ čéčĆąĄčģ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗčģ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅčģ. ą×ą┤ąĮą░ą║ąŠ ąĄčüą╗ąĖ ąÆčŗ ąĮą░ą┐ąĖčłąĄč鹥 čüą▓ąŠčÄ čüąŠą▒čüčéą▓ąĄąĮąĮčāčÄ ą║ąŠą╗ą╗ąĄą║čåąĖčÄ, ą║ąŠč鹊čĆą░čÅ ąĘą░ą┐čĆąĄčēą░ąĄčé ą┤čāą▒ą╗ąĖą║ą░čéčŗ, č鹊 ąĘą░čüčéą░ą▓ąĖą╗ąĖ ą▒čŗ TryAdd ą▓ąĄčĆąĮčāčéčī false, ąĄčüą╗ąĖ 菹╗ąĄą╝ąĄąĮčé čāąČąĄ čüčāčēąĄčüčéą▓čāąĄčé (ąĄčüą╗ąĖ ą▒čŗ ąÆčŗ ą┐ąĖčüą░ą╗ąĖ ą║ąŠąĮą║čāčĆąĄąĮčéąĮčŗą╣ ąĮą░ą▒ąŠčĆ).
ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╣ 菹╗ąĄą╝ąĄąĮčé, ą║ąŠč鹊čĆčŗą╣ čāą┤ą░ą╗čÅąĄčé TryTake, ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ č湥čĆąĄąĘ ą┐ąŠą┤ą║ą╗ą░čüčü:
ŌĆó ąĪąŠ čüč鹥ą║ąŠą╝ TryTake čāą┤ą░ą╗čÅąĄčé č鹊čé 菹╗ąĄą╝ąĄąĮčé, ą║ąŠč鹊čĆčŗą╣ ą▒čŗą╗ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮ čüą░ą╝čŗą╝ ą┐ąŠčüą╗ąĄą┤ąĮąĖą╝.
ąŁčéąĖ čéčĆąĖ ą║ąŠąĮą║čĆąĄčéąĮčŗąĄ ą║ą╗ą░čüčüą░ čćą░čüč鹊 čÅą▓ąĮąŠ čĆąĄą░ą╗ąĖąĘčāčÄčé ą╝ąĄč鹊ą┤čŗ TryTake ąĖ TryAdd, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÅ č鹊čé ąČąĄ čäčāąĮą║čåąĖąŠąĮą░ą╗ č湥čĆąĄąĘ čéą░ą║ąĖąĄ ą▒ąŠą╗ąĄąĄ čüą┐ąĄčåąĖčäąĖč湥čüą║ąĖąĄ ą┐čāą▒ą╗ąĖčćąĮčŗąĄ ą╝ąĄč鹊ą┤čŗ, ą║ą░ą║ TryDequeue ąĖ TryPop.
ConcurrentBag< T> . ConcurrentBag< T> čüąŠčģčĆą░ąĮčÅąĄčé ąĮąĄ čāą┐ąŠčĆčÅą┤ąŠč湥ąĮąĮčāčÄ ą║ąŠą╗ą╗ąĄą║čåąĖčÄ ąŠą▒čŖąĄą║č鹊ą▓ (čü čĆą░ąĘčĆąĄčłąĄąĮąĮčŗą╝ąĖ ą┤čāą▒ą╗ąĖą║ą░čéą░ą╝ąĖ). ConcurrentBag< T> ą┐ąŠą┤čģąŠą┤ąĖčé ą┤ą╗čÅ čüąĖčéčāą░čåąĖą╣, ą║ąŠą│ą┤ą░ ąÆą░ą╝ ąĮąĄ ąĮčāąČąĮąŠ ąĘą░ą▒ąŠčéąĖčéčīčüčÅ ąŠ č鹊ą╝, ą║ą░ą║ąŠą╣ 菹╗ąĄą╝ąĄąĮčé ąÆčŗ ą┐ąŠą╗čāčćąĖč鹥 ą┐čĆąĖ ą▓čŗąĘąŠą▓ąĄ Take ąĖą╗ąĖ TryTake.
ą¤čĆąĄąĖą╝čāčēąĄčüčéą▓ąŠ ConcurrentBag< T> ąĮą░ą┤ ą║ąŠąĮą║čāčĆąĄąĮčéąĮąŠą╣ ąŠč湥čĆąĄą┤čīčÄ ąĖą╗ąĖ čüč鹥ą║ąŠą╝ ą▓ č鹊ą╝, čćč鹊 ą╝ąĄč鹊ą┤ Add ą┐ąŠčćčéąĖ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ čüąŠčüčéčÅąĘą░ąĮąĖčÄ ą┐čĆąĖ ą▓čŗąĘąŠą▓ąĄ ą▒ąŠą╗ąĄąĄ ąŠą┤ąĮąŠą│ąŠ čĆą░ąĘą░. ąÆ ąŠčéą╗ąĖčćąĖąĄ ąŠčé čŹč鹊ą│ąŠ ą▓čŗąĘąŠą▓ Add ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ ą▓ ąŠč湥čĆąĄą┤ąĖ ąĖą╗ąĖ ą▓ čüč鹥ą║ąĄ ą▓ą▓ąŠą┤ąĖčé ąĮąĄą║ąŠąĄ čüąŠčüčéčÅąĘą░ąĮąĖąĄ (čģąŠčéčÅ ą╝ąĄąĮčīčłąĄąĄ, č湥ą╝ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą▓ąŠą║čĆčāą│ ąĮąĄ ą║ąŠąĮą║čāčĆąĄąĮčéąĮčŗčģ ą║ąŠą╗ą╗ąĄą║čåąĖą╣). ąÆčŗąĘąŠą▓ Take ąĮą░ ą║ąŠąĮą║čāčĆąĄąĮčéąĮąŠą╝ bag čéą░ą║ąČąĄ ąŠč湥ąĮčī čŹčäč乥ą║čéąĖą▓ąĮąŠ - ą┐ąŠą║ą░ ą║ą░ąČą┤čŗą╣ ą┐ąŠč鹊ą║ ąĮąĄ ą▒ąĄčĆąĄčé ą▒ąŠą╗čīčłąĄ 菹╗ąĄą╝ąĄąĮč鹊ą▓, č湥ą╝ ą▒čŗą╗ąŠ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąŠ.
ąÆąĮčāčéčĆąĖ ą║ąŠąĮą║čāčĆąĄąĮčéąĮąŠą│ąŠ bag ą║ą░ąČą┤čŗą╣ ą┐ąŠč鹊ą║ ą┐ąŠą╗čāčćą░ąĄčé čüą▓ąŠą╣ čüąŠą▒čüčéą▓ąĄąĮąĮčŗą╣ ą┐čĆąĖą▓ą░čéąĮčŗą╣ čüą▓čÅąĘą░ąĮąĮčŗą╣ čüą┐ąĖčüąŠą║. ąŁą╗ąĄą╝ąĄąĮčéčŗ, ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĮčŗąĄ ą║ čŹč鹊ą╝čā ą┐čĆąĖą▓ą░čéąĮąŠą╝čā čüą┐ąĖčüą║čā, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąĖąĮą░ą┤ą╗ąĄąČą░čé ą┐ąŠč鹊ą║čā, ą▓čŗąĘą▓ą░ą▓čłąĄą╝čā Add, čāčüčéčĆą░ąĮčÅčÄčé čüąŠčüčéčÅąĘą░ąĮąĖąĄ. ąÜąŠą│ą┤ą░ ąÆčŗ ą┐ąĄčĆąĄčćąĖčüą╗čÅąĄč鹥 čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ bag, ą┐ąĄčĆąĄčćąĖčüą╗ąĖč鹥ą╗čī ą┐čĆąŠą│čāą╗ąĖą▓ą░ąĄčéčüčÅ č湥čĆąĄąĘ ą┐čĆąĖą▓ą░čéąĮčŗą╣ čüą┐ąĖčüąŠą║ ą║ą░ąČą┤ąŠą│ąŠ ą┐ąŠč鹊ą║ą░, čāčüčéčāą┐ą░čÅ ą║ą░ąČą┤čŗą╣ ąĖąĘ ąĖčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą┐ąŠąŠč湥čĆąĄą┤ąĮąŠ.
ąÜąŠą│ą┤ą░ ąÆčŗ ą▓čŗąĘčŗą▓ą░ąĄč鹥 Take, bag čüąĮą░čćą░ą╗ą░ čüą╝ąŠčéčĆąĖčé ąĮą░ ą┐čĆąĖą▓ą░čéąĮčŗą╣ čüą┐ąĖčüąŠą║ č鹥ą║čāčēąĄą│ąŠ ą┐ąŠč鹊ą║ą░. ąĢčüą╗ąĖ ą▓ ąĮąĄą╝ ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝ ąŠą┤ąĖąĮ 菹╗ąĄą╝ąĄąĮčé, ąŠąĮ ą╗ąĄą│ą║ąŠ ą╝ąŠąČąĄčé ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąĘą░ą┤ą░čćčā, ąĖ (ą▓ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ čüą╗čāčćą░ąĄą▓) ą▒ąĄąĘ čüąŠčüčéčÅąĘą░ąĮąĖčÅ. ąØąŠ ąĄčüą╗ąĖ čŹč鹊čé čüą┐ąĖčüąŠą║ ą┐čāčüčé, ąŠąĮ ą┤ąŠą╗ąČąĄąĮ "čāą║čĆą░čüčéčī" 菹╗ąĄą╝ąĄąĮčé ąĖąĘ ą┐čĆąĖą▓ą░čéąĮąŠą│ąŠ čüą┐ąĖčüą║ą░ ą┤čĆčāą│ąŠą│ąŠ ą┐ąŠč鹊ą║ą░, čćč鹊 ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ čüąŠčüčéčÅąĘą░ąĮąĖčÄ.
ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą┤ą╗čÅ č鹊čćąĮąŠčüčéąĖ, ą▓čŗąĘąŠą▓ Take ą┤ą░čüčé ąĮą░ą╝ 菹╗ąĄą╝ąĄąĮčé, ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĮčŗą╣ ą┐ąŠčüą╗ąĄą┤ąĮąĖą╣ čĆą░ąĘ ą▓ čŹč鹊ą╝ ą┐ąŠč鹊ą║ąĄ; ąĄčüą╗ąĖ ąĮąĄčé 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą▓ čŹč鹊ą╝ ą┐ąŠč鹊ą║ąĄ, č鹊 ąŠąĮ ą┤ą░čüčé ąÆą░ą╝ 菹╗ąĄą╝ąĄąĮčé, ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĮčŗą╝ ą┐ąŠčüą╗ąĄą┤ąĮąĖą╝ ą▓ ą┤čĆčāą│ąŠą╝ ą┐ąŠč鹊ą║ąĄ, ą▓čŗą▒čĆą░ąĮąĮąŠą╝ čüą╗čāčćą░ą╣ąĮąŠ.
ąÜąŠąĮą║čāčĆąĄąĮčéąĮčŗąĄ bag ąĖą┤ąĄą░ą╗čīąĮčŗą╣ ą▓čŗą▒ąŠčĆ, ą║ąŠą│ą┤ą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ ąĮą░ą┤ ąÆą░čłąĄą╣ ą║ąŠą╗ą╗ąĄą║čåąĖąĄą╣ čćą░čēąĄ ą▓čüąĄą│ąŠ čüąŠčüč鹊ąĖčé ą▓ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĖ 菹╗ąĄą╝ąĄąĮč鹊ą▓ - ąĖą╗ąĖ ą║ąŠą│ą┤ą░ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ (Add) ąĖ ą▓ąĘčÅčéąĖčÅ (Take) ąĮą░ ą┐ąŠč鹊ą║ąĄ čüą▒ą░ą╗ą░ąĮčüąĖčĆąŠą▓ą░ąĮčŗ. ą£čŗ čĆą░ąĮąĄąĄ ą▓ąĖą┤ąĄą╗ąĖ ą┐ąŠą┤ąŠą▒ąĮčŗą╣ ą┐čĆąĖą╝ąĄčĆ, ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ąĖ Parallel.ForEach ą┤ą╗čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą╣ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąŠčĆč乊ą│čĆą░čäąĖąĖ:
var misspellings = new ConcurrentBag< Tuple< int ,string >>();
Parallel.ForEach (wordsToTest, (word, state, i) =>
{
if (!wordLookup.Contains (word))
misspellings.Add (Tuple.Create ((int ) i, word));
});
ąÜąŠąĮą║čāčĆąĄąĮčéąĮčŗą╣ bag ą▒čŗą╗ ą▒čŗ ą┐ą╗ąŠčģąĖą╝ ą▓čŗą▒ąŠčĆąŠą╝ ą┤ą╗čÅ ąŠč湥čĆąĄą┤ąĖ producer/consumer, ą┐ąŠč鹊ą╝čā čćč鹊 菹╗ąĄą╝ąĄąĮčéčŗ ą┤ąŠą▒ą░ą▓ą╗čÅčÄčéčüčÅ ąĖ čāą┤ą░ą╗čÅčÄčéčüčÅ ą▓ čĆą░ąĘąĮčŗčģ ą┐ąŠč鹊ą║ą░čģ.
BlockingCollection< T> . ąĢčüą╗ąĖ ąÆčŗ ą▓čŗąĘąŠą▓ąĖč鹥 TryTake ąĮą░ ą╗čÄą▒ąŠą╣ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ producer/consumer, ą║ąŠč鹊čĆčŗąĄ ą╝čŗ ąŠą▒čüčāąČą┤ą░ą╗ąĖ čĆą░ąĮąĄąĄ:
ConcurrentStack< T>
ConcurrentQueue< T>
ConcurrentBag< T>
ąĖ ą║ąŠą╗ą╗ąĄą║čåąĖčÅ ą┐čāčüčéą░čÅ, č鹊 ą╝ąĄč鹊ą┤ ą▓ąĄčĆąĮąĄčé false. ąśąĮąŠą│ą┤ą░ ą▒čŗą╗ąŠ ą▒čŗ ą┐ąŠą╗ąĄąĘąĮąĄąĄ ą▓ čéą░ą║ąŠą╝ čüčåąĄąĮą░čĆąĖąĖ ąČą┤ą░čéčī, ą┐ąŠą║ą░ 菹╗ąĄą╝ąĄąĮčé ąĮąĄ čüčéą░ąĮąĄčé ą┤ąŠčüčéčāą┐ąĮčŗą╝.
ąÆą╝ąĄčüč鹊 ą┐ąĄčĆąĄą│čĆčāąĘą║ąĖ ą╝ąĄč鹊ą┤ąŠą▓ TryTake čü čéą░ą║ąŠą╣ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčīčÄ (ą║ąŠč鹊čĆą░čÅ ą▓čŗąĘą▓ą░ą╗ą░ ą▒čŗ ą┐čĆąŠčĆčŗą▓ čāčćą░čüčéąĮąĖą║ąŠą▓ ą┐ąŠčüą╗ąĄ čĆą░ąĘčĆąĄčłąĄąĮąĖčÅ ą╝ą░čĆą║ąĄčĆąŠą▓ ąŠčéą╝ąĄąĮąĖ ąĖ čéą░ą╣ą╝ą░čāč鹊ą▓), čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ąĖ PFX ąĖąĮą║ą░ą┐čüčāą╗ąĖčĆąŠą▓ą░ą╗ąĖ čŹč鹊čé čäčāąĮą║čåąĖąŠąĮą░ą╗ ą▓ ąŠą▒ąŠčĆą░čćąĖą▓ą░čÄčēąĖą╣ ą║ą╗ą░čüčü BlockingCollection< T>. ąæą╗ąŠą║ąĖčĆčāčÄčēą░čÅ ą║ąŠą╗ą╗ąĄą║čåąĖčÅ ąŠą▒ąĄčĆčéčŗą▓ą░ąĄčé ą╗čÄą▒čāčÄ ą║ąŠą╗ą╗ąĄą║čåąĖčÄ, ą║ąŠč鹊čĆą░čÅ čĆąĄą░ą╗ąĖąĘčāąĄčé IProducerConsumerCollection< T>, ąĖ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąÆą░ą╝ ą▓ąĘčÅčéčī (Take) 菹╗ąĄą╝ąĄąĮčé ąĖąĘ ąŠą▒ąĄčĆąĮčāč鹊ą╣ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ - čü ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąŠą╣, ąĄčüą╗ąĖ ąĮąĄčé ą┤ąŠčüčéčāą┐ąĮčŗčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓.
ąæą╗ąŠą║ąĖčĆčāčÄčēą░čÅ ą║ąŠą╗ą╗ąĄą║čåąĖčÅ čéą░ą║ąČąĄ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąÆą░ą╝ ąŠą│čĆą░ąĮąĖčćąĖčéčī ą╗ąŠą║ą░ą╗čīąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ, ą▒ą╗ąŠą║ąĖčĆčāčÅ ą┐čĆąŠą┤čÄčüąĄčĆą░, ąĄčüą╗ąĖ ą┐čĆąĄą▓čŗčłąĄąĮ čŹč鹊čé čĆą░ąĘą╝ąĄčĆ. ąÜąŠą╗ą╗ąĄą║čåąĖčÅ, ąŠą│čĆą░ąĮąĖč湥ąĮąĮą░čÅ čéą░ą║ąĖą╝ čüą┐ąŠčüąŠą▒ą░, ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ ąĮą░ą▒ąŠčĆąŠą╝, ąŠą│čĆą░ąĮąĖč湥ąĮąĮčŗą╝ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąŠą╣ (bounded blocking collection).
ą¦č鹊ą▒čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī BlockingCollection< T>:
1. ąśąĮčüčéą░ąĮčåąĖąĖčĆčāą╣č鹥 ą║ą╗ą░čüčü, ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ čāą║ą░ąĘčŗą▓ą░čÅ IProducerConsumerCollection< T> ą┤ą╗čÅ ąŠą▒ąĄčĆčéą║ąĖ ąĖ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ (ą│čĆą░ąĮąĖčåčā) ą║ąŠą╗ą╗ąĄą║čåąĖąĖ.
ąĢčüą╗ąĖ ąÆčŗ ą▓čŗąĘąŠą▓ąĖč鹥 ą║ąŠąĮčüčéčĆčāą║č鹊čĆ ą▒ąĄąĘ ą┐ąĄčĆąĄą┤ą░čćąĖ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ, č鹊 čŹč鹊čé ą║ą╗ą░čüčü ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ąĖąĮčüčéą░ąĮčåąĖąĖčĆčāąĄčé ConcurrentQueue< T>. ą£ąĄč鹊ą┤čŗ ą│ąĄąĮąĄčĆą░čåąĖąĖ (producing) ąĖ ą┐ąŠčéčĆąĄą▒ą╗ąĄąĮąĖčÅ (consuming) ą┐ąŠąĘą▓ąŠą╗čÅčé ąÆą░ą╝ čāą║ą░ąĘą░čéčī ą╝ą░čĆą║ąĄčĆčŗ ąŠčéą╝ąĄąĮčŗ (cancellation tokens) ąĖ čéą░ą╣ą╝ą░čāčéčŗ. Add ąĖ TryAdd ą╝ąŠą│čāčé ą▓čŗąĘą▓ą░čéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā, ąĄčüą╗ąĖ čĆą░ąĘą╝ąĄčĆ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ ąŠą│čĆą░ąĮąĖč湥ąĮ; Take ąĖ TryTake ą▒čāą┤čāčé ą▓čŗąĘčŗą▓ą░čéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā, ą┐ąŠą║ą░ ą║ąŠą╗ą╗ąĄą║čåąĖčÅ ą┐čāčüčéą░.
ąöčĆčāą│ąŠą╣ čüą┐ąŠčüąŠą▒ ą┐ąŠčéčĆąĄą▒ą╗čÅčéčī 菹╗ąĄą╝ąĄąĮčéčŗ - ą▓čŗąĘą▓ą░čéčī GetConsumingEnumerable. ąŁč鹊 ą▓ąĄčĆąĮąĄčé (ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ) ą▒ąĄčüą║ąŠąĮąĄčćąĮčāčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī, ą║ąŠč鹊čĆą░čÅ ą▓čŗą┤ą░ąĄčé 菹╗ąĄą╝ąĄąĮčéčŗ ą┐ąŠ ą╝ąĄčĆąĄ ąĖčģ ą┤ąŠčüčéčāą┐ąĮąŠčüčéąĖ. ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐čĆąĖąĮčāą┤ąĖčéčī ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ąĘą░ą▓ąĄčĆčłąĖčéčīčüčÅ ą▓čŗąĘąŠą▓ąŠą╝ CompleteAdding: čŹč鹊čé ą╝ąĄč鹊ą┤ čéą░ą║ąČąĄ ą┐čĆąĄą┤ąŠčéą▓čĆą░čéąĖčé ąŠčé ą┐ąŠčüčéą░ąĮąŠą▓ą║ąĖ ą▓ ąŠč湥čĆąĄą┤čī ą┤ą░ą╗čīąĮąĄą╣čłąĖčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓.
ąĀą░ąĮąĄąĄ ą╝čŗ ąĮą░ą┐ąĖčüą░ą╗ąĖ ąŠč湥čĆąĄą┤čī producer/consumer čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ Wait ąĖ Pulse. ąÆąŠčé č鹊čé ąČąĄ čüą░ą╝čŗą╣ ą║ą╗ą░čüčü, ą┐ąĄčĆąĄčĆą░ą▒ąŠčéą░ąĮąĮčŗą╣ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ BlockingCollection< T> (ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖčüą║ą╗čÄč湥ąĮąĖą╣ ąŠčüčéą░ą▓ą╗ąĄąĮą░ ą▓ čüč鹊čĆąŠąĮąĄ):
public class PCQueue : IDisposable
{
BlockingCollection _taskQ = new BlockingCollection();
public PCQueue (int workerCount)
{
// ąĪąŠąĘą┤ą░ąĮąĖąĄ ąĖ ąĘą░ą┐čāčüą║ ąŠčéą┤ąĄą╗čīąĮąŠą╣ ąĘą░ą┤ą░čćąĖ (Task) ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ consumer:
for (int i = 0 ; i < workerCount; i++)
Task.Factory.StartNew (Consume);
}
public void Dispose () { _taskQ.CompleteAdding(); }
public void EnqueueTask (Action action) { _taskQ.Add (action); }
void Consume ()
{
// ąŁčéą░ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī, ą║ąŠč鹊čĆčāčÄ ą╝čŗ ą┐ąĄčĆąĄčćąĖčüą╗čÅąĄą╝, ą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ,
// ą║ąŠą│ą┤ą░ ąĮąĄčé ą┤ąŠčüčéčāą┐ąĮčŗčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓, ąĖ ąĄčæ ą╝čŗ ąĘą░ą▓ąĄčĆčłąĖą╝ ą▓čŗąĘąŠą▓ąŠą╝ CompleteAdding.
foreach (Action action in _taskQ.GetConsumingEnumerable())
action(); // ąÆčŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĘą░ą┤ą░čćąĖ.
}
}
ąśąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 ą╝čŗ ąĮąĖč湥ą│ąŠ ąĮąĄ ą┐ąĄčĆąĄą┤ą░ą╗ąĖ ą▓ ą║ąŠąĮčüčéčĆčāą║č鹊čĆ BlockingCollection, ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ąĖąĮčüčéą░ąĮčåąĖąĖčĆčāąĄčéčüčÅ ą║ąŠąĮą║čāčĆąĄąĮčéąĮą░čÅ ąŠč湥čĆąĄą┤čī. ąĢčüą╗ąĖ ą▒čŗ ą╝čŗ ą┐ąĄčĆąĄą┤ą░ą╗ąĖ ConcurrentStack, č鹊 ąĘą░ą▓ąĄčĆčłąĖą╗ąĖčüčī ą▒čŗ čüč鹥ą║ąŠą╝ producer/consumer.
BlockingCollection čéą░ą║ąČąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čüčéą░čéąĖč湥čüą║ąĖąĄ ą╝ąĄč鹊ą┤čŗ AddToAny ąĖ TakeFromAny, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ąĮą░ą╝ ą┤ąŠą▒ą░ą▓ą╗čÅčéčī ąĖą╗ąĖ ą┐ąŠą╗čāčćą░čéčī 菹╗ąĄą╝ąĄąĮčé ą┐čĆąĖ čāą║ą░ąĘą░ąĮąĖąĖ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĖčģ ą║ąŠą╗ą╗ąĄą║čåąĖą╣. ąöąĄą╣čüčéą▓ąĖąĄ action č鹊ą│ą┤ą░ čüčĆą░ą▒ąŠčéą░ąĄčé ąĮą░ ą┐ąĄčĆą▓ąŠą╣ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ, ą║ąŠč鹊čĆą░čÅ ą▓ čüąŠčüč鹊čÅąĮąĖąĖ ąŠą▒čüą╗čāąČąĖčéčī ąĘą░ą┐čĆąŠčü.
ąŁčäč乥ą║čéąĖą▓ąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ TaskCompletionSource . ą¤čĆąĖą╝ąĄčĆ producer/consumer, ą║ąŠč鹊čĆčŗąĄ č鹊ą╗čīą║ąŠ čćč鹊 ąĮą░ą┐ąĖčüą░ą╗ąĖ, ąĮąĄą┤ąŠčüčéą░č鹊čćąĮąŠ ą│ąĖą▒ą║ąĖą╣ ą▓ č鹊ą╝, čćč鹊 ą╝čŗ ąĮąĄ ą╝ąŠąČąĄą╝ ąŠčéčüą╗ąĄąČąĖą▓ą░čéčī čĆą░ą▒ąŠčćąĖąĄ 菹╗ąĄą╝ąĄąĮčéčŗ ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ąŠąĮąĖ ą┐ąŠčüčéą░ą▓ą╗ąĄąĮčŗ ą▓ ąŠč湥čĆąĄą┤čī. ąæčŗą╗ąŠ ą▒čŗ čģąŠčĆąŠčłąŠ, ąĄčüą╗ąĖ ą▒čŗ ą╝čŗ ą╝ąŠą│ą╗ąĖ:
ŌĆó ąŻąĘąĮą░čéčī, ą║ąŠą│ą┤ą░ čĆą░ą▒ąŠčćąĖą╣ 菹╗ąĄą╝ąĄąĮčé ąĘą░ą▓ąĄčĆčłąĄąĮ.
ąśą┤ąĄą░ą╗čīąĮąŠąĄ čĆąĄčłąĄąĮąĖąĄ čüąŠčüč鹊čÅą╗ąŠ ą▒čŗ ą▓ ą▓ąŠąĘą▓čĆą░č鹥 ą╝ąĄč鹊ą┤ąŠą╝ EnqueueTask ąĮąĄą║ąŠč鹊čĆąŠą│ąŠ ąŠą▒čŖąĄą║čéą░, ą║ąŠč鹊čĆčŗą╣ ą┤ą░ą▓ą░ą╗ ą▒čŗ čŹč鹊čé ąŠą┐ąĖčüą░ąĮąĮčŗą╣ čäčāąĮą║čåąĖąŠąĮą░ą╗. ąźąŠčĆąŠčłą░čÅ ąĮąŠą▓ąŠčüčéčī ą▓ č鹊ą╝, čćč鹊 čéą░ą║ąŠą╣ ą║ą╗ą░čüčü ąĄčüčéčī, ąĖ čŹč鹊 ą▓čüąĄ ąŠąĮ čāąČąĄ ą┤ąĄą╗ą░ąĄčé - ą║ą╗ą░čüčü Task. ąÆčüąĄ, čćč鹊 ąĮą░ą╝ ąĮčāąČąĮąŠ - ą┐ąĄčĆąĄčģą▓ą░čéąĖčéčī čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ąĘą░ą┤ą░č湥ą╣ č湥čĆąĄąĘ TaskCompletionSource:
public class PCQueue : IDisposable
{
class WorkItem
{
public readonly TaskCompletionSource< object > TaskSource;
public readonly Action Action;
public readonly CancellationToken? CancelToken;
public WorkItem (
TaskCompletionSource< object > taskSource,
Action action,
CancellationToken? cancelToken)
{
TaskSource = taskSource;
Action = action;
CancelToken = cancelToken;
}
}
BlockingCollection< WorkItem> _taskQ = new BlockingCollection< WorkItem>();
public PCQueue (int workerCount)
{
// ąĪąŠąĘą┤ą░ąĮąĖąĄ ąĖ ąĘą░ą┐čāčüą║ ąŠčéą┤ąĄą╗čīąĮąŠą╣ Task ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗čÅ (consumer):
for (int i = 0 ; i < workerCount; i++)
Task.Factory.StartNew (Consume);
}
public void Dispose () { _taskQ.CompleteAdding(); }
public Task EnqueueTask (Action action)
{
return EnqueueTask (action, null );
}
public Task EnqueueTask (Action action, CancellationToken? cancelToken)
{
var tcs = new TaskCompletionSource< object >();
_taskQ.Add (new WorkItem (tcs, action, cancelToken));
return tcs.Task;
}
void Consume ()
{
foreach (WorkItem workItem in _taskQ.GetConsumingEnumerable())
{
if (workItem.CancelToken.HasValue &&
workItem.CancelToken.Value.IsCancellationRequested)
{
workItem.TaskSource.SetCanceled();
}
else
try
{
workItem.Action();
workItem.TaskSource.SetResult (null ); // ą¤ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄ
}
catch (OperationCanceledException ex)
{
if (ex.CancellationToken == workItem.CancelToken)
workItem.TaskSource.SetCanceled();
else
workItem.TaskSource.SetException (ex);
}
catch (Exception ex)
{
workItem.TaskSource.SetException (ex);
}
}
}
}
ąÆ EnqueueTask ą╝čŗ čüčéą░ą▓ąĖą╝ ą▓ ąŠč湥čĆąĄą┤čī čĆą░ą▒ąŠčćąĖą╣ 菹╗ąĄą╝ąĄąĮčé, ą║ąŠč鹊čĆčŗą╣ ąĖąĮą║ą░ą┐čüčāą╗ąĖčĆčāąĄčé čåąĄą╗ąĄą▓ąŠą╣ ą┤ąĄą╗ąĄą│ą░čé ąĖ ąĖčüč鹊čćąĮąĖą║ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąĘą░ą┤ą░čćąĖ - ą║ąŠč鹊čĆčŗą╣ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĮą░ą╝ ą┐ąŠąĘąČąĄ čāą┐čĆą░ą▓ą╗čÅčéčī ąĘą░ą┤ą░č湥ą╣, ą║ąŠč鹊čĆčāčÄ ą╝čŗ ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝ ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗čÄ (consumer).
ąÆ Consume ą╝čŗ čüąĮą░čćą░ą╗ą░ ą┐čĆąŠą▓ąĄčĆčÅąĄą╝, ą▒čŗą╗ą░ ą╗ąĖ ąĘą░ą┤ą░čćą░ (task) ąŠčéą╝ąĄąĮąĄąĮą░ ą┐ąŠčüą╗ąĄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĖąĘ ąŠč湥čĆąĄą┤ąĖ čĆą░ą▒ąŠč湥ą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░. ąĢčüą╗ąĖ ąĮąĄčé, č鹊 ą╝čŗ ąĘą░ą┐čāčüą║ą░ąĄą╝ ą┤ąĄą╗ąĄą│ą░čéą░ ąĖ ąĘą░č鹥ą╝ ą▓čŗąĘčŗą▓ą░ąĄą╝ SetResult ąĮą░ ąĖčüč鹊čćąĮąĖą║ąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąĘą░ą┤ą░čćąĖ, čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī ąĄčæ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄ.
ąóąĄą┐ąĄčĆčī ą╝čŗ ą╝ąŠąČąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹč鹊čé ą║ą╗ą░čüčü:
var pcQ = new PCQueue (1 );
Task task = pcQ.EnqueueTask (() => Console.WriteLine ("Easy!" ));
...
ą£čŗ čüąĄą╣čćą░čü ą╝ąŠąČąĄą╝ ąČą┤ą░čéčī ąĘą░ą┤ą░čćčā, ą▓čŗą┐ąŠą╗ąĮčÅčéčī ąĮą░ ąĮąĄą╣ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ, čĆą░čüą┐čĆąŠčüčéčĆą░ąĮčÅčéčī ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĮą░ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ čĆąŠą┤ąĖč鹥ą╗čīčüą║ąĖčģ ąĘą░ą┤ą░čć, ąĖ čéą░ą║ ą┤ą░ą╗ąĄąĄ. ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, čā ąĮą░čü ąĄčüčéčī ą▒ąŠą│ą░čéčüčéą▓ąŠ ą╝ąŠą┤ąĄą╗ąĖ ąĘą░ą┤ą░čćąĖ čü čŹčäč乥ą║č鹊ą╝ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą│ąŠ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ą░.
SpinLock ąĖ SpinWait ]
ąÆ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĖ čćą░čüčéąĮčŗą╣ čüą╗čāčćą░ą╣ ą┐čĆąŠą║čĆčāč鹊ą║ čćą░čüč鹊 ą┐čĆąĄą┤ą┐ąŠčćčéąĖč鹥ą╗čīąĮąĄąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ, čéą░ą║ ą║ą░ą║ čŹč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĖąĘą▒ąĄąČą░čéčī ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ ą║ąŠąĮč鹥ą║čüčéą░ ąĖ ą┐ąĄčĆąĄčģąŠą┤čŗ čüąŠčüč鹊čÅąĮąĖčÅ čÅą┤čĆą░. SpinLock ąĖ SpinWait čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮčŗ ą┤ą╗čÅ ą┐ąŠą╝ąŠčēąĖ ą▓ čéą░ą║ąĖčģ čüą╗čāčćą░čÅčģ. ąśčģ ą│ą╗ą░ą▓ąĮąŠąĄ ąĮą░ąĘąĮą░č湥ąĮąĖąĄ - ąĮą░ą┐ąĖčüą░ąĮąĖąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖčģ ą║ąŠąĮčüčéčĆčāą║čåąĖą╣ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ.
SpinLock ąĖ SpinWait čŹč鹊 čüčéčĆčāą║čéčāčĆčŗ, ą░ ąĮąĄ ą║ą╗ą░čüčüčŗ! ąŁč鹊 ą┤ąĖąĘą░ą╣ąĮąĄčĆčüą║ąŠąĄ čĆąĄčłąĄąĮąĖąĄ ąŠčéąĮąŠčüąĖčéčüčÅ ą║ 菹║čüčéčĆąĄą╝ą░ą╗čīąĮąŠą╣ č鹥čģąĮąĖą║ąĄ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ, ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĮąŠą╣ ą┤ą╗čÅ č鹊ą│ąŠ, čćč鹊ą▒čŗ ąĖąĘą▒ąĄąČą░čéčī ąĮą░ą║ą╗ą░ą┤ąĮčŗčģ čĆą░čüčģąŠą┤ąŠą▓ ą║ąŠčüą▓ąĄąĮąĮąŠą╣ ą░ą┤čĆąĄčüą░čåąĖąĖ ąĖ čüą▒ąŠčĆą║ąĖ ą╝čāčüąŠčĆą░. ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ąÆčŗ ą┤ąŠą╗ąČąĮčŗ ąŠčüč鹥čĆąĄą│ą░čéčīčüčÅ ąĮąĄčāą╝čŗčłą╗ąĄąĮąĮąŠ ą║ąŠą┐ąĖčĆąŠą▓ą░čéčī 菹║ąĘąĄą╝ą┐ą╗čÅčĆčŗ - ą┐ąĄčĆąĄą┤ą░ą▓ą░čÅ ąĖčģ, ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą▓ ą┤čĆčāą│ąŠą╣ ą╝ąĄč鹊ą┤ ą▒ąĄąĘ ą╝ąŠą┤ąĖčäąĖą║ą░č鹊čĆą░ čüčüčŗą╗ą║ąĖ (ref), ąĖą╗ąĖ ą┤ąĄą║ą╗ą░čĆąĖčĆčāčÅ ąĖčģ ą║ą░ą║ ą┐ąŠą╗čÅ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ (readonly). ąŁč鹊 ą▓ čćą░čüčéąĮąŠčüčéąĖ ą▓ą░ąČąĮąŠ ą┤ą╗čÅ čüą╗čāčćą░čÅ SpinLock.
SpinLock . ąŁčéą░ čüčéčĆčāą║čéčāčĆą░ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąÆą░ą╝ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ą▒ąĄąĘ čéčĆą░čé ąĮą░ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą║ąŠąĮč鹥ą║čüčéą░, čåąĄąĮąŠą╣ ąŠčüčéą░ą▓ą╗ąĄąĮąĖčÅ ą┐ąŠč鹊ą║ą░ ą▓ čåąĖą║ą╗ą░čģ (ą▒ąĄčüą┐ąŠą╗ąĄąĘąĮą░čÅ ąĘą░ąĮčÅč鹊čüčéčī). ąŁč鹊čé ą╝ąĄč鹊ą┤ ą┤ąŠą┐čāčüčéąĖą╝ ą▓ čüčåąĄąĮą░čĆąĖčÅčģ ą▓čŗčüąŠą║ąŠą╣ ą║ąŠąĮą║čāčĆąĄąĮčåąĖąĖ, ą║ąŠą│ą┤ą░ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą▒čāą┤ąĄčé ąŠč湥ąĮčī ą║ąŠčĆąŠčéą║ąŠą╣ (ąĮą░ą┐čĆąĖą╝ąĄčĆ ą┐čĆąĖ ąĮą░ą┐ąĖčüą░ąĮąĖąĖ čü ąĮčāą╗čÅ ą┐ąŠč鹊ą║ąŠą▒ąĄąĘąŠą┐ą░čüąĮčŗčģ čüą▓čÅąĘą░ąĮąĮčŗčģ čüą┐ąĖčüą║ąŠą▓).
ąĢčüą╗ąĖ ąÆčŗ ąŠčüčéą░ą▓ąĖč鹥 spinlock ąĮą░ čāą┤ąĄčƹȹ░ąĮąĖąĖ čüą╗ąĖčłą║ąŠą╝ ą┤ąŠą╗ą│ąŠ (čüą░ą╝ąŠąĄ ą▒ąŠą╗čīčłąĄąĄ ąĮą░ ą╝ąĖą╗ą╗ąĖčüąĄą║čāąĮą┤čā), čŹč鹊 čüą┤ąĄą╗ą░ąĄčé ąĄčæ ą▓čĆąĄą╝čÅ čüčĆą░ą▓ąĮąĖą╝čŗą╝ čüąŠ čüą╗ą░ą╣čüąŠą╝ ą▓čĆąĄą╝ąĄąĮąĖ, ą┐ąŠčĆąŠąČą┤ą░čÅ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą║ąŠąĮč鹥ą║čüčéą░ č鹊čćąĮąŠ čéą░ą║ ąČąĄ, ą║ą░ą║ čŹč鹊 ą▒čŗą╗ąŠ ą▒čŗ čü ąŠą▒čŗčćąĮąŠą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąŠą╣. ąÜąŠą│ą┤ą░ ą▒čāą┤ąĄčé ąĘą░ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąŠ ąĮąŠą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ čŹč鹊ą│ąŠ ą║ąŠą┤ą░ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ąŠą╝, čŹč鹊čé ą║ąŠą┤ čüąĮąŠą▓ą░ čāčüčéčāą┐ąĖčé čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ - ą┐ąŠą╗čāčćąĖčéčüčÅ ą┐čĆąŠą┤ąŠą╗ąČą░čÄčēąĖą╣čüčÅ "čåąĖą║ą╗ čāčüčéčāą┐ąŠą║". ąŁč鹊 ą▒čāą┤ąĄčé ą┐ąŠčéčĆąĄą▒ą╗čÅčéčī ą│ąŠčĆą░ąĘą┤ąŠ ą╝ąĄąĮčīčłąĄ čĆąĄčüčāčĆčüąŠą▓ CPU, č湥ą╝ ą┐čĆčÅą╝ą░čÅ ą┐čĆąŠą║čĆčāčéą║ą░ - ąĮąŠ ą▒ąŠą╗čīčłąĄ, č湥ą╝ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĖąĄ.
ąØą░ ąŠą┤ąĮąŠčÅą┤ąĄčĆąĮąŠą╣ ą╝ą░čłąĖąĮąĄ spinlock ąĮą░čćąĮąĄčé "čåąĖą║ą╗ čāčüčéčāą┐ąŠą║" ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ, ąĄčüą╗ąĖ ąĖą╝ąĄąĄčé ą╝ąĄčüč鹊 čüą┐ąŠčĆ ąĘą░ čĆąĄčüčāčĆčü.
ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ SpinLock ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐ąŠą┤ąŠą▒ąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÄ ąŠą▒čŗčćąĮąŠą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ, ą║čĆąŠą╝ąĄ:
ŌĆó Spinlock čŹč鹊 čüčéčĆčāą║čéčāčĆą░ (ą║ą░ą║ ą▒čŗą╗ąŠ čāą┐ąŠą╝čÅąĮčāč鹊 čĆą░ąĮąĄąĄ).
ąöčĆčāą│ąŠąĄ ąŠčéą╗ąĖčćąĖąĄ ą▓ č鹊ą╝, čćč鹊 ą║ąŠą│ą┤ą░ ąÆčŗ ą▓čŗąĘą▓ą░ą╗ąĖ Enter, č鹊 ą┤ąŠą╗ąČąĮčŗ čüą╗ąĄą┤ąŠą▓ą░čéčī čłą░ą▒ą╗ąŠąĮčā čāčüč鹊ą╣čćąĖą▓ąŠčüčéąĖ čü ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĖąĄą╝ ą░čĆą│čāą╝ąĄąĮčéą░ lockTaken (ą║ąŠč鹊čĆčŗą╣ ą┐ąŠčćčéąĖ ą▓čüąĄą│ą┤ą░ ą┤ąĄą╗ą░ąĄčéčüčÅ čü ą▒ą╗ąŠą║ąŠą╝ try/finally).
ąÆąŠčé ą┐čĆąĖą╝ąĄčĆ:
var spinLock = new SpinLock (true ); // ąĀą░ąĘčĆąĄčłąĄąĮąŠ ąŠčéčüą╗ąĄąČąĖą▓ą░ąĮąĖąĄ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą╝ bool lockTaken = false ;try
{
spinLock.Enter (ref lockTaken);
// ąóčāčé ą║ą░ą║ąĖąĄ-č鹊 ą┤ąĄą╣čüčéą▓ąĖčÅ...
}finally
{
if (lockTaken) spinLock.Exit();
}
ąÜą░ą║ čü ąŠą▒čŗčćąĮąŠą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąŠą╣ lock, ąĘąĮą░č湥ąĮąĖąĄ lockTaken ą▒čāą┤ąĄčé false ą┐ąŠčüą╗ąĄ ą▓čŗąĘąŠą▓ą░ Enter ąĄčüą╗ąĖ (ąĖ č鹊ą╗čīą║ąŠ ąĄčüą╗ąĖ) ą╝ąĄč鹊ą┤ Enter ą▓čŗą▒čĆąŠčüąĖčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ąĮąĄ ą▒čŗą╗ą░ ą▓ąĘčÅčéą░. ąŁč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓ ąŠč湥ąĮčī čĆąĄą┤ą║ąĖčģ čüčåąĄąĮą░čĆąĖčÅčģ (čéą░ą║ąĖčģ ą║ą░ą║ ą▓čŗąĘąŠą▓ Abort ąĮą░ ą┐ąŠč鹊ą║ąĄ, ąĖą╗ąĖ ą║ąŠą│ą┤ą░ ą▓čŗą▒čĆąŠčłąĄąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ OutOfMemoryException), ąĖ ą┐ąŠąĘą▓ąŠą╗ąĖčé ąÆą░ą╝ ąĮą░ą┤ąĄąČąĮąŠ čāąĘąĮą░čéčī, ą▓čŗąĘą▓ą░ąĮ ą╗ąĖ ą▒čŗą╗ ą▓ą┐ąŠčüą╗ąĄą┤čüčéą▓ąĖąĖ Exit.
SpinLock čéą░ą║ąČąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą╝ąĄč鹊ą┤ TryEnter, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĖąĮąĖą╝ą░ąĄčé čéą░ą╣ą╝ą░čāčé.
ąŻčćąĖčéčŗą▓ą░čÅ ąĮąĄą╗ąŠą▓ą║čāčÄ čüąĄą╝ą░ąĮčéąĖą║čā SpinLock ąĖąĘ-ąĘą░ ąĄą│ąŠ čéąĖą┐ą░ ąĘąĮą░č湥ąĮąĖčÅ ąĖ ąŠčéčüčāčéčüčéą▓ąĖąĄ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ čüąŠ čüč鹊čĆąŠąĮčŗ čÅąĘčŗą║ą░, čüąŠąĘą┤ą░ąĄčéčüčÅ ą▓ą┐ąĄčćą░čéą╗ąĄąĮąĖąĄ, čćč鹊ą▒čŗ ą╝čŗ čüčéčĆą░ą┤ą░ą╗ąĖ ą║ą░ąČą┤čŗą╣ čĆą░ąĘ ą┐čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ SpinLock! ąöą▓ą░ąČą┤čŗ ą┐ąŠą┤čāą╝ą░ą╣č鹥, ą┐čĆąĄąČą┤ąĄ č湥ą╝ ąŠčéą║ą░ąĘčŗą▓ą░čéčīčüčÅ ąŠčé ąŠą▒čŗčćąĮąŠą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ.
SpinLock ąĖą╝ąĄąĄčé čüą╝čŗčüą╗ čćą░čēąĄ ą▓čüąĄą│ąŠ ą┐čĆąĖ ąĮą░ą┐ąĖčüą░ąĮąĖąĖ ąÆą░čłąĖčģ čüąŠą▒čüčéą▓ąĄąĮąĮčŗčģ ą║ąŠąĮčüčéčĆčāą║čåąĖą╣ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ. ąś ą┤ą░ąČąĄ č鹊ą│ą┤ą░ spinlock ąĮąĄ ąĮą░čüč鹊ą╗čīą║ąŠ ą┐ąŠą╗ąĄąĘąĄąĮ, ą║ą░ą║ čŹč鹊 ąĘą▓čāčćąĖčé. ą×ąĮ ą▓čüąĄ ąĄčēąĄ ąŠą│čĆą░ąĮąĖčćąĖą▓ą░ąĄčé ą║ąŠąĮą║čāčĆąĄąĮčåąĖčÄ, ąĖ ąĘčĆčÅ čéčĆą░čéąĖčé ą▓čĆąĄą╝čÅ CPU, ąĮąĄ ą┤ąĄą╗ą░čÅ ąĮąĖč湥ą│ąŠ ą┐ąŠą╗ąĄąĘąĮąŠą│ąŠ. ą¦ą░čüč鹊 ą┤ą╗čÅ ą╗čāčćčłąĖą╣ ą▓čŗą▒ąŠčĆ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹč鹊 ą▓čĆąĄą╝čÅ, ą┤ąĄą╗ą░čÅ čćč鹊-č鹊 čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮąŠąĄ - čü ą┐ąŠą╝ąŠčēčīčÄ SpinWait.
SpinWait . ąŁč鹊 ą┐ąŠą╝ąŠą│ą░ąĄčé ąĮą░ą┐ąĖčüą░čéčī ą║ąŠą┤ ą▒ąĄąĘ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ, ą║ąŠč鹊čĆčŗą╣ ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą┐čĆąŠą║čĆčāčćąĖą▓ą░ąĄčé čåąĖą║ą╗čŗ. ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 ąĖąĘą▒ąĄą│ą░ąĄą╝ ąŠą┐ą░čüąĮąŠčüčéąĖ ąĖčüč湥čĆą┐ą░ąĮąĖčÅ čĆąĄčüčāčĆčüąŠą▓ čüąĖčüč鹥ą╝čŗ ąĖ ąĖąĮą▓ąĄčĆčüąĖąĖ ą┐čĆąĖąŠčĆąĖč鹥čéą░, čćč鹊 ąĖąĮą░č湥 ą╝ąŠą│ą╗ąŠ ą▒čŗ ą▓ąŠąĘąĮąĖą║ąĮčāčéčī ą▓ čüą╗čāčćą░ąĄ SpinLock.
ą¤čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ ą▒ąĄąĘ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║ čü ą┐ąŠą╝ąŠčēčīčÄ SpinWait ą┤ąŠą▓ąŠą╗čīąĮąŠ čéčĆčāą┤ąĮąŠąĄ, ą┐ąŠčüą║ąŠą╗čīą║čā ąŠąĮą░ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮą░ ą┤ą╗čÅ čĆąĄčłąĄąĮąĖčÅ ą┐čĆąŠą▒ą╗ąĄą╝ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠčüčéąĖ, ą║ąŠč鹊čĆčŗąĄ ąĮąĄ čĆąĄčłąĖčé ąĮąĖą║ą░ą║ą░čÅ ą┤čĆčāą│ą░čÅ ą║ąŠąĮčüčéčĆčāą║čåąĖčÅ ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ. ąØąŠ čüąĮą░čćą░ą╗ą░ ąĮčāąČąĮąŠ ą┐ąŠąĮčÅčéčī, čćč鹊 čéą░ą║ąŠąĄ ąĮąĄ ą▒ą╗ąŠą║ąĖčĆčāčÄčēą░čÅ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÅ [5].
ą¤ąŠč湥ą╝čā ąĮą░ą╝ ąĮčāąČąĮą░ SpinWait . ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ą╝čŗ ą┐ąĖčłąĄą╝ čüąĖčüč鹥ą╝čā čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖąĖ ąĮą░ ą┐čĆąŠčüč鹊ą╝ čäą╗ą░ą│ąĄ, ąŠčüąĮąŠą▓ą░ąĮąĮčāčÄ ąĮą░ čåąĖą║ą╗ąĄ:
bool _proceed;void Test ()
{
// ą”ąĖą║ą╗, ą┐ąŠą║ą░ ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║ ąĮąĄ čāčüčéą░ąĮąŠą▓ąĖčé _proceed ą▓ ąĘąĮą░č湥ąĮąĖąĄ true:
while (!_proceed) Thread.MemoryBarrier();
...
}
ąŁč鹊 ą▓čüąĄą│ą┤ą░ ą▒čāą┤ąĄčé ąŠč湥ąĮčī čŹčäč乥ą║čéąĖą▓ąĮąŠ, ąĄčüą╗ąĖ Test ąĘą░ą┐čāčüčéąĖčéčüčÅ, ą║ąŠą│ą┤ą░ _proceed čāąČąĄ ą▒čŗą╗ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą▓ true, ąĖą╗ąĖ čāčüčéą░ąĮąŠą▓ą║ą░ _proceed ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą▒čŗčüčéčĆąŠ, ą▓ č鹥č湥ąĮąĖąĄ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čåąĖą║ą╗ąŠą▓. ąØąŠ č鹥ą┐ąĄčĆčī ą┐čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 _proceed ąŠčüčéą░ą╗čüčÅ ą▓ ąĘąĮą░č湥ąĮąĖąĖ false ąĮą░ ąĮąĄčüą║ąŠą╗čīą║ąŠ čüąĄą║čāąĮą┤ - ąĖ 4 ą┐ąŠč鹊ą║ą░ ą▓čŗąĘą▓ą░ą╗ąĖ Test ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ. ąóąŠą│ą┤ą░ čŹčéąĖ čåąĖą║ą╗čŗ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąĘą░ą▒čīčÄčé ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠąĄ ą▓čĆąĄą╝čÅ č湥čéčŗčĆąĄčģčÅą┤ąĄčĆąĮąŠą│ąŠ CPU! ąŁč鹊 ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ č鹊ą╝čā, čćč鹊 ą┤čĆčāą│ąĖąĄ ą┐ąŠč鹊ą║ąĖ ą▒čāą┤čāčé čĆą░ą▒ąŠčéą░čéčī ąŠč湥ąĮčī ą╝ąĄą┤ą╗ąĄąĮąĮąŠ (ąĮąĄčģą▓ą░čéą║ą░ čĆąĄčüčāčĆčüąŠą▓ čüąĖčüč鹥ą╝čŗ) - ą▓ą║ą╗čÄčćą░čÅ č鹊čé čüą░ą╝čŗą╣ ą┐ąŠč鹊ą║, ą║ąŠč鹊čĆčŗą╣ ą┤ąŠą╗ąČąĄąĮ ą▒čŗą╗ ą▒čŗ čāčüčéą░ąĮąŠą▓ąĖčéčī _proceed ą▓ true (ąĖąĮą▓ąĄčĆčüąĖčÅ ą┐čĆąĖąŠčĆąĖč鹥čéą░). ąŁčéą░ čüąĖčéčāą░čåąĖčÅ ąŠą▒ąŠčüčéčĆčÅąĄčéčüčÅ ąĮą░ ąŠą┤ąĮąŠčÅą┤ąĄčĆąĮčŗčģ ą╝ą░čłąĖąĮą░čģ, ą│ą┤ąĄ ą┐čĆąŠą║čĆčāčéą║ąĖ ą┐ąŠčćčéąĖ ą▓čüąĄą│ą┤ą░ ą┐čĆąĖą▓ąĄą┤čāčé ą║ čüą╝ąĄąĮąĄ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓ (ąĖ čģąŠčéčÅ čüąĄą│ąŠą┤ąĮčÅ ąŠą┤ąĮąŠčÅą┤ąĄčĆąĮčŗąĄ ą╝ą░čłąĖąĮčŗ ą▓čüčéčĆąĄčćą░čÄčéčüčÅ čĆąĄą┤ą║ąŠ, ąŠą┤ąĮąŠčÅą┤ąĄčĆąĮčŗąĄ ą▓ąĖčĆčéčāą░ą╗čīąĮčŗąĄ ą╝ą░čłąĖąĮčŗ ąŠą▒čŗčćąĮčŗą╣ čüą╗čāčćą░ą╣).
SpinWait čĆąĄčłą░ąĄčé čŹčéąĖ ą┐čĆąŠą▒ą╗ąĄą╝čŗ ą┤ą▓čāą╝čÅ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ. ąÆąŠ-ą┐ąĄčĆą▓čŗčģ, ąŠąĮą░ ąŠą│čĆą░ąĮąĖčćąĖą▓ą░ąĄčé ąĖąĮč鹥ąĮčüąĖą▓ąĮčāčÄ čéčĆą░čéčā čĆąĄčüčāčĆčüąŠą▓ CPU ąĮą░ ą┐čĆąŠą║čĆčāčéą║ąĖ čåąĖą║ą╗ą░ ą┐čāč鹥ą╝ čāčüčéą░ąĮąŠą▓ą║ąĖ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ąĖč鹥čĆą░čåąĖą╣, ą┐ąŠčüą╗ąĄ ą║ąŠč鹊čĆčŗčģ čüą╗ą░ą╣čü ą▓čĆąĄą╝ąĄąĮąĖ ą▒čāą┤ąĄčé čāčüčéčāą┐ą░čéčīčüčÅ ą┐ąŠčüą╗ąĄ ą║ą░ąČą┤ąŠą╣ ą┐čĆąŠą║čĆčāčéą║ąĖ (ą▓čŗąĘąŠą▓ąŠą╝ Thread.Yield ąĖ Thread.Sleep), čüąĮąĖąČą░čÅ ą┐ąŠčéčĆąĄą▒ą╗ąĄąĮąĖąĄ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ. ąÆąŠ-ą▓č鹊čĆčŗčģ, ąŠąĮą░ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé, čĆą░ą▒ąŠčéą░ąĄčé ą╗ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ąĮą░ ąŠą┤ąĮąŠčÅą┤ąĄčĆąĮąŠą╣ ą╝ą░čłąĖąĮąĄ, ąĖ ąĄčüą╗ąĖ čŹč鹊 čéą░ą║, č鹊 čāčüčéčāą┐ą║ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĮą░ ą║ą░ąČą┤ąŠą╝ čåąĖą║ą╗ąĄ.
ąÜą░ą║ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī SpinWait . ąĢčüčéčī ą┤ą╗čÅ čŹč鹊ą│ąŠ ą┤ą▓ą░ čüą┐ąŠčüąŠą▒ą░. ą¤ąĄčĆą▓čŗą╣ ąĘą░ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ ą▓čŗąĘąŠą▓ąĄ čüčéą░čéąĖč湥čüą║ąŠą│ąŠ ą╝ąĄč鹊ą┤ą░ SpinUntil. ąŁč鹊čé ą╝ąĄč鹊ą┤ ą┐čĆąĖąĮąĖą╝ą░ąĄčé ą┐čĆąĄą┤ąĖą║ą░čé (ąĖ ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ čéą░ą╣ą╝ą░čāčé):
bool _proceed;void Test ()
{
SpinWait.SpinUntil (() => { Thread.MemoryBarrier(); return _proceed; });
...
}
ąöčĆčāą│ąŠą╣ čüą┐ąŠčüąŠą▒ (ą▒ąŠą╗ąĄąĄ ą│ąĖą▒ą║ąĖą╣) ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ SpinWait - ąĖąĮčüčéą░ąĮčåąĖą░čåąĖčÅ čüčéčĆčāą║čéčāčĆčŗ ąĖ ąĘą░č鹥ą╝ ą▓čŗąĘąŠą▓ SpinOnce ą▓ čåąĖą║ą╗ąĄ:
bool _proceed;void Test ()
{
var spinWait = new SpinWait();
while (!_proceed) { Thread.MemoryBarrier(); spinWait.SpinOnce(); }
...
}
ą¤ąĄčĆą▓čŗą╣ čüą┐ąŠčüąŠą▒ čÅą▓ą╗čÅąĄčéčüčÅ čÅčĆą╗čŗčćą║ąŠą╝ ą▓č鹊čĆąŠą│ąŠ.
ąÜą░ą║ čĆą░ą▒ąŠčéą░ąĄčé SpinWait . ąÆ čüą▓ąŠąĄą╣ č鹥ą║čāčēąĄą╣ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ SpinWait ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ąČąĄčüčéą║ąĖąĄ ą┐čĆąŠą║čĆčāčéą║ąĖ čåąĖą║ą╗ąŠą▓ CPU ą┤ą╗čÅ 10 ąĖč鹥čĆą░čåąĖą╣ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ čāčüčéčāą┐ąĖčéčī ą║ąŠąĮč鹥ą║čüčé ą┤čĆčāą│ąĖą╝ ą┐ąŠč鹊ą║ą░ą╝. ą×ą┤ąĮą░ą║ąŠ ąŠąĮą░ ąĮąĄ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą▓ ą▓čŗąĘčŗą▓ą░čÄčēąĖą╣ ą║ąŠą┤ ą┐ąŠčüą╗ąĄ ą║ą░ąČą┤ąŠą│ąŠ ąĖąĘ čéą░ą║ąĖčģ čåąĖą║ą╗ąŠą▓: ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ąŠąĮą░ ą▓čŗąĘčŗą▓ą░ąĄčé Thread.SpinWait čćč鹊ą▒čŗ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą┐čĆąŠą║čĆčāčéą║čā č湥čĆąĄąĘ CLR (ąĖ ą▓ ą║ąŠąĮąĄčćąĮąŠą╝ čüč湥č鹥 č湥čĆąĄąĘ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčāčÄ čüąĖčüč鹥ą╝čā) ą┤ą╗čÅ čāčüčéą░ąĮąŠą▓ą║ąĖ ą┐ąĄčĆąĖąŠą┤ą░ ą▓čĆąĄą╝ąĄąĮąĖ. ąŁč鹊čé ą┐ąĄčĆąĖąŠą┤ ą▓čĆąĄą╝ąĄąĮąĖ ąĖąĘąĮą░čćą░ą╗čīąĮąŠ čĆą░ą▓ąĄąĮ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┤ąĄčüčÅčéą║ąŠą▓ ąĮą░ąĮąŠčüąĄą║čāąĮą┤, ąĮąŠ čāą┤ą▓ą░ąĖą▓ą░ąĄčéčüčÅ čü ą║ą░ąČą┤ąŠą╣ ąĖč鹥čĆą░čåąĖąĄą╣, ą┐ąŠą║ą░ ąĮąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé 10 ąĖč鹥čĆą░čåąĖą╣. ąŁč鹊 ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé ąĮąĄą║čāčÄ ą┐čĆąĄą┤čüą║ą░ąĘčāąĄą╝ąŠčüčéčī ąĮą░ čéčĆą░č鹥 ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą▓ čäą░ąĘąĄ ąĖąĮč鹥ąĮčüąĖą▓ąĮčŗčģ čåąĖą║ą╗ąŠą▓ CPU, ą║ąŠč鹊čĆčāčÄ CLR ąĖ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮą░čÅ čüąĖčüč鹥ą╝ą░ ą╝ąŠąČąĄčé ąĮą░čüčéčĆąŠąĖčéčī ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü čĆą░ą▒ąŠčćąĖą╝ąĖ čāčüą╗ąŠą▓ąĖčÅą╝ąĖ. ąÜą░ą║ ą┐čĆą░ą▓ąĖą╗ąŠ čŹč鹊 ąĘą░ąĮąĖą╝ą░ąĄčé ąĖąĮč鹥čĆą▓ą░ą╗ ąĮąĄą╝ąĮąŠą│ąĖčģ ą┤ąĄčüčÅčéą║ąŠą▓ ą╝ąĖą║čĆąŠčüąĄą║čāąĮą┤ - ą╝ą░ą╗ąŠ, ąĮąŠ ą▒ąŠą╗čīčłąĄ, č湥ą╝ čåąĄąĮą░ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą║ąŠąĮč鹥ą║čüčéą░.
ąØą░ ąŠą┤ąĮąŠčÅą┤ąĄčĆąĮąŠą╣ ą╝ą░čłąĖąĮąĄ SpinWait čāčüčéčāą┐ą░ąĄčé ą║ąŠąĮč鹥ą║čüčé ąĮą░ ą║ą░ąČą┤ąŠą╣ ąĖč鹥čĆą░čåąĖąĖ. ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐čĆąŠą▓ąĄčĆąĖčéčī, čāčüčéčāą┐ąĖčé ą╗ąĖ SpinWait ą║ąŠąĮč鹥ą║čüčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĄą╣ ąĖč鹥čĆą░čåąĖąĖ, ą┐čāč鹥ą╝ ą┐čĆąŠą▓ąĄčĆą║ąĖ čüą▓ąŠą╣čüčéą▓ą░ NextSpinWillYield.
ąĢčüą╗ąĖ SpinWait ąŠčüčéą░ąĄčéčüčÅ ą▓ čĆąĄąČąĖą╝ąĄ "čåąĖą║ą╗ą░ čü čāčüčéčāą┐ą║ą░ą╝ąĖ" ą┤ąŠčüčéą░č鹊čćąĮąŠ ą┤ąŠą╗ą│ąŠ (ą▓ąŠąĘą╝ąŠąČąĮąŠ 20 čåąĖą║ą╗ąŠą▓), č鹊 ąŠąĮą░ ą▒čāą┤ąĄčé ą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║ąĖ ąĘą░čüčŗą┐ą░čéčī ąĮą░ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą╝ąĖą╗ą╗ąĖčüąĄą║čāąĮą┤, čćč鹊ą▒čŗ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ 菹║ąŠąĮąŠą╝ąĖčéčī čĆąĄčüčāčĆčüčŗ ąĖ ą┐ąŠą╝ąŠčćčī ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ ą┤čĆčāą│ąĖą╝ ą┐ąŠč鹊ą║ą░ą╝.
ą×ą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ ą▒ąĄąĘ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ čü ą┐ąŠą╝ąŠčēčīčÄ SpinWait ąĖ Interlocked.CompareExchange. SpinWait ą▓ą╝ąĄčüč鹥 čü Interlocked.CompareExchange ą╝ąŠąČąĄčé ą░č鹊ą╝ą░čĆąĮąŠ ąŠą▒ąĮąŠą▓ą╗čÅčéčī ą┐ąŠą╗čÅ ąĘąĮą░č湥ąĮąĖąĄą╝, ą▓čŗčćąĖčüą╗ąĄąĮąĮčŗą╝ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ ąĄą│ąŠ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ (ąŠą┐ąĄčĆą░čåąĖčÅ read-modify-write). ąöą╗čÅ ą┐čĆąĖą╝ąĄčĆą░ ą┐čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ą╝čŗ čģąŠčéąĖą╝ čāą╝ąĮąŠąČąĖčéčī ą┐ąŠą╗ąĄ x ąĮą░ 10. ąĢčüą╗ąĖ čŹč鹊 čüą┤ąĄą╗ą░čéčī ąĮą░ą┐čĆčÅą╝čāčÄ, č鹊 čŹč鹊 ąĮąĄ ą▒čāą┤ąĄčé ą┐ąŠč鹊ą║ąŠą▒ąĄąĘąŠą┐ą░čüąĮąŠ:
ą¤ąŠ č鹊ą╣ ąČąĄ ą┐čĆąĖčćąĖąĮąĄ ąĖąĮą║čĆąĄą╝ąĄąĮčé ą┐ąŠą╗čÅ ąĮąĄ ą▒čāą┤ąĄčé ą┐ąŠč鹊ą║ąŠą▒ąĄąĘąŠą┐ą░čüąĮčŗą╝, ą║ą░ą║ čŹč鹊 čāąČąĄ ąŠą▒čüčāąČą┤ą░ą╗ąŠčüčī ą▓ ąŠą┐ąĖčüą░ąĮąĖąĖ ąĮąĄ ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĄą╣ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ [5].
ąÆąŠčé čéą░ą║ čŹč鹊 ą┐čĆą░ą▓ąĖą╗čīąĮąŠ ą┤ąĄą╗ą░ąĄčéčüčÅ ą▒ąĄąĘ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ:
1 . ąæąĄčĆąĄčéčüčÅ čüąĮąĖą╝ąŠą║ x ą▓ ą╗ąŠą║ą░ą╗čīąĮčāčÄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ.2 . ąÆčŗčćąĖčüą╗čÅąĄčéčüčÅ ąĮąŠą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ (ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ čüąĮąĖą╝ąŠą║ čāą╝ąĮąŠąČą░ąĄčéčüčÅ ąĮą░ 10).3 . ąŚą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą▓čŗčćąĖčüą╗ąĄąĮąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ąŠą▒čĆą░čéąĮąŠ, ąĄčüą╗ąĖ čüąĮąĖą╝ąŠą║ ą▓čüąĄ ąĄčēąĄ ą░ą║čéčāą░ą╗ąĄąĮ (čŹč鹊čé čłą░ą│ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čüą┤ąĄą╗ą░ąĮ ą░č鹊ą╝ą░čĆąĮąŠ ą▓čŗąĘąŠą▓ąŠą╝ Interlocked.CompareExchange).4 . ąĢčüą╗ąĖ čüąĮąĖą╝ąŠą║ čāčüčéą░čĆąĄą╗, č鹊 ą▓ąŠąĘą▓čĆą░čé ą║ čłą░ą│čā 1.
ąØą░ą┐čĆąĖą╝ąĄčĆ:
int x;
void MultiplyXBy (int factor)
{
var spinWait = new SpinWait();
while (true )
{
int snapshot1 = x;
Thread.MemoryBarrier();
int calc = snapshot1 * factor;
int snapshot2 = Interlocked.CompareExchange (ref x, calc, snapshot1);
if (snapshot1 == snapshot2) return ; // ąØąĖą║č鹊 ąĮą░čü ąĮąĄ ą▓čŗč鹥čüąĮčÅą╗.
spinWait.SpinOnce();
}
}
ą£čŗ (ąĮąĄą╝ąĮąŠą│ąŠ) ą╝ąŠąČąĄą╝ čāą╗čāčćčłąĖčéčī ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī čü ą┐ąŠą╝ąŠčēčīčÄ ą▓čŗąĘąŠą▓ą░ Thread.MemoryBarrier. ąØą░ą╝ čŹč鹊 ą╝ąŠąČąĄčé čüąŠą╣čéąĖ čü čĆčāą║, ą┐ąŠč鹊ą╝čā čćč鹊 CompareExchange ą▓čüąĄ čĆą░ą▓ąĮąŠ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ą▒ą░čĆčīąĄčĆ ą┐ą░ą╝čÅčéąĖ - čéą░ą║ čćč鹊 čüą░ą╝ąŠąĄ čģčāą┤čłąĄąĄ, čćč鹊 ą╝ąŠąČąĄčé čüą╗čāčćąĖčéčīčüčÅ, čŹč鹊 ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮą░čÅ ą┐čĆąŠą║čĆčāčéą║ą░, ąĄčüą╗ąĖ ąŠą║ą░ąČąĄčéčüčÅ, čćč鹊 ą▓ snapshot1 ą┐čĆąŠčćąĖčéą░ąĮąŠ čāčüčéą░čĆąĄą▓čłąĄąĄ ąĮą░ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ ąĖč鹥čĆą░čåąĖąĖ ąĘąĮą░č湥ąĮąĖąĄ.
Interlocked.CompareExchange ąŠą▒ąĮąŠą▓ą╗čÅąĄčé ą┐ąŠą╗ąĄ čāą║ą░ąĘą░ąĮąĮčŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝, ąĄčüą╗ąĖ č鹥ą║čāčēąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┐ąŠą╗čÅ čüąŠą▓ą┐ą░ą┤ą░ąĄčé čü čéčĆąĄčéčīąĖą╝ ą░čĆą│čāą╝ąĄąĮč鹊ą╝. ąóąŠą│ą┤ą░ ą▒čāą┤ąĄčé ą▓ąŠąĘą▓čĆą░čēąĄąĮąŠ čüčéą░čĆąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┐ąŠą╗čÅ, čéą░ą║ čćč鹊 ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐čĆąŠą▓ąĄčĆąĖčéčī čāčüą┐ąĄčģ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ ą┐čāč鹥ą╝ čüčĆą░ą▓ąĮąĄąĮąĖčÅ čü ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮčŗą╝ snapshot. ąĢčüą╗ąĖ ąĘąĮą░č湥ąĮąĖčÅ čĆą░ąĘą╗ąĖčćą░čÄčéčüčÅ, č鹊 čŹč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║ ą▓čŗč鹥čüąĮąĖą╗ ąÆą░čü, č鹊ą│ą┤ą░ ąĮčāąČąĮąŠ ą▓ąĄčĆąĮčāčéčīčüčÅ ą▓ ąĮą░čćą░ą╗ąŠ ąĖ čüą┤ąĄą╗ą░čéčī ą┤čĆčāą│čāčÄ ą┐ąŠą┐čŗčéą║čā ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖąĖ ąĘąĮą░č湥ąĮąĖčÅ.
CompareExchange ą┐ąĄčĆąĄą│čĆčāąČąĄąĮ, čćč鹊ą▒čŗ čéą░ą║ąČąĄ čĆą░ą▒ąŠčéą░čéčī čü čéąĖą┐ąŠą╝ object. ą£čŗ ą╝ąŠąČąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹčéčā ą┐ąĄčĆąĄą│čĆčāąĘą║čā ą┐čāč鹥ą╝ ąĮą░ą┐ąĖčüą░ąĮąĖčÅ ą╝ąĄč鹊ą┤ą░ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ ą▒ąĄąĘ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ, ą║ąŠč鹊čĆčŗą╣ čĆą░ą▒ąŠčéą░ąĄčé čüąŠ ą▓čüąĄą╝ąĖ čüčüčŗą╗ąŠčćąĮčŗą╝ąĖ čéąĖą┐ą░ą╝ąĖ:
static void LockFreeUpdate< T> (ref T field, Func < T, T> updateFunction)
where T : class
{
var spinWait = new SpinWait();
while (true )
{
T snapshot1 = field;
T calc = updateFunction (snapshot1);
T snapshot2 = Interlocked.CompareExchange (ref field, calc, snapshot1);
if (snapshot1 == snapshot2) return ;
spinWait.SpinOnce();
}
}
ąÆąŠčé čéą░ą║ ą╝čŗ ą╝ąŠąČąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹč鹊čé ą╝ąĄč鹊ą┤, čćč鹊ą▒čŗ ąĮą░ą┐ąĖčüą░čéčī ą┐ąŠč鹊ą║ąŠą▒ąĄąĘąŠą┐ą░čüąĮąŠąĄ čüąŠą▒čŗčéąĖąĄ ą▒ąĄąĘ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║ (čŹč鹊 č鹊, čćč鹊 čäą░ą║čéąĖč湥čüą║ąĖ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ čü čüąŠą▒čŗčéąĖčÅą╝ąĖ ą┤ąĄą╗ą░ąĄčé ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ C# 4.0):
EventHandler _someDelegate;
public event EventHandler SomeEvent
{
add { LockFreeUpdate (ref _someDelegate, d => d + value ); }
remove { LockFreeUpdate (ref _someDelegate, d => d - value ); }
}
SpinWait ą┐čĆąŠčéąĖą▓ SpinLock . ą£čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ čĆąĄčłąĖčéčī čŹčéąĖ ą┐čĆąŠą▒ą╗ąĄą╝čŗ ą┐ąŠ-ą┤čĆčāą│ąŠą╝čā, ąŠą▒ąĄčĆąĮčāą▓ ą┤ąŠčüčéčāą┐ ą║ ąŠą▒čēąĄą╝čā ą┐ąŠą╗čÄ ą▓ąŠą║čĆčāą│ SpinLock. ąźąŠčéčÅ ą┐čĆąŠą▒ą╗ąĄą╝ą░ čüąŠ spin locking čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, čćč鹊 čŹč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą▓ ą╗čÄą▒ąŠą╣ ą╝ąŠą╝ąĄąĮčé ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗą┐ąŠą╗ąĮčÅčéčī č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ ą┐ąŠč鹊ą║ - ą┤ą░ąČąĄ ą┐čĆąĖ č鹊ą╝, čćč鹊 spinlock (ąŠą▒čŗčćąĮąŠ) čāčüčéčĆą░ąĮčÅąĄčé ąĮą░ą║ą╗ą░ą┤ąĮčŗąĄ čĆą░čüčģąŠą┤čŗ ąĮą░ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą║ąŠąĮč鹥ą║čüčéą░. ąÆą╝ąĄčüč鹥 čüąŠ SpinWait ą╝čŗ ą╝ąŠąČąĄą╝ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą┐ąŠč鹊ą║ čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮąŠ ąĖ ą┐čĆąĄą┤ą┐ąŠą╗ąŠąČąĖčéčī ąŠčéčüčāčéčüčéą▓ąĖąĄ čüąŠčüčéčÅąĘą░ąĮąĖčÅ. ąĢčüą╗ąĖ ąĮą░čü ą▓čŗč鹥čüąĮąĖą╗ąĖ, č鹊 ą┐čĆąŠčüč鹊 ą┐ąŠą┐čŗčéą░ąĄą╝čüčÅ čüąĮąŠą▓ą░. ąóčĆą░čéą░ ą▓čĆąĄą╝ąĄąĮąĖ CPU ąĮą░ čćč鹊-č鹊 ą┐ąŠą╗ąĄąĘąĮąŠąĄ ąĮą░ą╝ąĮąŠą│ąŠ ą╗čāčćčłąĄ, č湥ą╝ čéčĆą░čéą░ ąĄą│ąŠ ąĮą░ spinlock!
ąÆ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄ čĆą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗ąĄą┤čāčÄčēąĖą╣ ą║ą╗ą░čüčü:
class Test
{
ProgressStatus _status = new ProgressStatus (0 , "Starting" );
class ProgressStatus // ąØąĄ ąĖąĘą╝ąĄąĮąĄąĮąĮčŗą╣ ą║ą╗ą░čüčü
{
public readonly int PercentComplete;
public readonly string StatusMessage;
public ProgressStatus (int percentComplete, string statusMessage)
{
PercentComplete = percentComplete;
StatusMessage = statusMessage;
}
}
}
ą£čŗ ą╝ąŠąČąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĮą░čł ą╝ąĄč鹊ą┤ LockFreeUpdate ą┤ą╗čÅ "ąĖąĮą║čĆąĄą╝ąĄąĮčéą░" ą┐ąŠą╗čÅ PercentComplete ą▓ _status čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
LockFreeUpdate (ref _status,
s => new ProgressStatus (s.PercentComplete + 1 , s.StatusMessage));
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą╝čŗ čüąŠąĘą┤ą░ąĄą╝ ąĮąŠą▓čŗą╣ ąŠą▒čŖąĄą║čé ProgressStatus ąĮą░ ąŠčüąĮąŠą▓ąĄ čüčāčēąĄčüčéą▓čāčÄčēąĖčģ ąĘąĮą░č湥ąĮąĖą╣. ąæą╗ą░ą│ąŠą┤ą░čĆčÅ ą╝ąĄč鹊ą┤čā LockFreeUpdate ą░ą║čé čćč鹥ąĮąĖčÅ čüčāčēąĄčüčéą▓čāčÄčēąĄą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ PercentComplete, ąĄą│ąŠ ąĖąĮą║čĆąĄą╝ąĄąĮčé ąĘą░ą┐ąĖčüčī ąŠą▒čĆą░čéąĮąŠ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗč鹥čüąĮąĄąĮčŗ ąĮąĄą▒ąĄąĘąŠą┐ą░čüąĮąŠ: ą╗čÄą▒ąŠąĄ ą▓čŗč鹥čüąĮąĄąĮąĖąĄ ą▒čāą┤ąĄčé ąĮą░ą┤ąĄąČąĮąŠ ą┤ąĄč鹥ą║čéąĖčĆąŠą▓ą░ąĮąŠ, čćč鹊 ą▓čŗąĘąŠą▓ąĄčé ą┐čĆąŠą║čĆčāčéą║čā ąĖ ą┐ąŠą▓č鹊čĆąĮčāčÄ ą┐ąŠą┐čŗčéą║čā.
[ąĪčüčŗą╗ą║ąĖ ]
1 . Threading in C# PART 5: PARALLEL PROGRAMMING site:albahari.com.2 . ą¤ąŠč鹊ą║ąĖ ąĮą░ C#. ą¦ą░čüčéčī 1: ą▓ą▓ąĄą┤ąĄąĮąĖąĄ .3 . ą¤ąŠč鹊ą║ąĖ ąĮą░ C#. ą¦ą░čüčéčī 2: ąŠčüąĮąŠą▓čŗ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ .4 . ą¤ąŠč鹊ą║ąĖ ąĮą░ C#. ą¦ą░čüčéčī 3: ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą┐ąŠč鹊ą║ąŠą▓ .5 . ą¤ąŠč鹊ą║ąĖ ąĮą░ C#. ą¦ą░čüčéčī 4: ą┐čĆąŠą┤ą▓ąĖąĮčāč鹊ąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ .6 . The .NET ProgrammerŌĆÖs Playground site:linqpad.net.7 . ąŚą░ą║ąŠąĮ ąÉą╝ą┤ą░ą╗ą░ site:wikipedia.org.




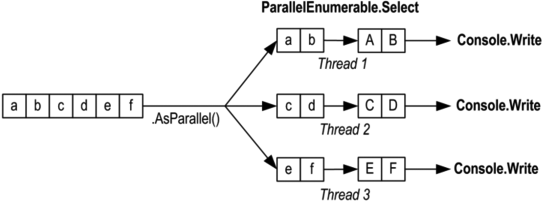



ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖąĖ
RSS ą╗ąĄąĮčéą░ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖąĄą▓ čŹč鹊ą╣ ąĘą░ą┐ąĖčüąĖ