|
[ąØąĄ ą▒ą╗ąŠą║ąĖčĆčāčÄčēą░čÅ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÅ]
ąĀą░ąĮąĄąĄ ą▒čŗą╗ąŠ ą┐ąŠą║ą░ąĘą░ąĮąŠ [2], čćč鹊 ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéčī čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ ą▓ąŠąĘąĮąĖą║ą░ąĄčé ą┤ą░ąČąĄ ą▓ ą┐čĆąŠčüč鹊ą╝ čüą╗čāčćą░ąĄ ą┐čĆąĖčüą▓ąŠąĄąĮąĖčÅ ąĖą╗ąĖ ąĖąĮą║čĆąĄą╝ąĄąĮč鹥 ą┐ąŠą╗čÅ. ąæą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą▓čüąĄą│ą┤ą░ ą╝ąŠąČąĄčé čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆąĖčéčī čŹč鹊ą╝čā čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÄ; ąŠą┤ąĮą░ą║ąŠ ąĄčüą╗ąĖ čüčāčēąĄčüčéą▓čāąĄčé čüąĖčéčāą░čåąĖčÅ, ą║ąŠą│ą┤ą░ ą▓ ąŠčüąŠą▒ąŠ ą║čĆąĖčéąĖč湥čüą║ąĖčģ ą┐ąŠ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ čüčåąĄąĮą░čĆąĖčÅčģ ą╝ąĮąŠąČąĄčüčéą▓ąŠ ą┐ąŠč鹊ą║ąŠą▓ ą║ąŠąĮą║čāčĆąĖčĆčāčÄčé ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝ ąĮą░ čŹč鹊ą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĄ, č鹊 čŹč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤čÅčé čćčĆąĄąĘą╝ąĄčĆąĮčŗąĄ ąĘą░čéčĆą░čéčŗ ąĮą░ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą║ąŠąĮč鹥ą║čüčéą░ ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ ą┤ąŠą▒ą░ą▓ą╗čÅčÄčéčüčÅ ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮčŗąĄ ąĘą░ą┤ąĄčƹȹ║ąĖ. ąÜąŠąĮčüčéčĆčāą║čåąĖąĖ ąĮąĄ ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĄą╣ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÅ .NET Framework ą╝ąŠą│čāčé ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčéčī ą┐čĆąŠčüčéčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ą▒ąĄąĘ ą║ą░ą║ąŠą│ąŠ-ą╗ąĖą▒ąŠ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĖčÅ, ą┐ąŠčüčéą░ąĮąŠą▓ą║ąĖ ąĮą░ ą┐ą░čāąĘčā ąĖą╗ąĖ ąŠąČąĖą┤ą░ąĮąĖčÅ.
ą¤čĆą░ą▓ąĖą╗čīąĮąŠąĄ ąĮą░ą┐ąĖčüą░ąĮąĖąĄ ąĮąĄ ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĄą│ąŠ ąĖą╗ąĖ čüą▓ąŠą▒ąŠą┤ąĮąŠą│ąŠ ąŠčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠą│ąŠ ą║ąŠą┤ą░ ą┤ąŠą▓ąŠą╗čīąĮąŠ čģąĖčéčĆąŠąĄ! ąæą░čĆčīąĄčĆčŗ ą┐ą░ą╝čÅčéąĖ, ą▓ čćą░čüčéąĮąŠčüčéąĖ, čŹč鹊 čćą░čüč鹊 čüą░ą╝ąŠąĄ čćą░čüč鹊ąĄ ą┐ąŠą┐ą░ą┤ą░ą╗ąŠą▓ąŠ ąĮą░ ą▒ą░ą│ąĖ (ą┐čĆąĖą╝ąĄčĆąĮąŠ č鹊 ąČąĄ čüą░ą╝ąŠąĄ čü ą║ą╗čÄč湥ą▓čŗą╝ čüą╗ąŠą▓ąŠą╝ volatile, čü ą║ąŠč鹊čĆčŗą╝ č鹊ąČąĄ ą┐čĆąŠčēąĄ ą▓čüąĄą│ąŠ ąĮą░ą║ąŠčüčÅčćąĖčéčī [5]). ąöą▓ą░ąČą┤čŗ ą┐ąŠą┤čāą╝ą░ą╣č鹥 - ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠ ą╗ąĖ ąÆą░ą╝ ąĮčāąČąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ą▓čŗą│ąŠą┤čā ą┐ąŠ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖčÄ, ą┐čĆąĄąČą┤ąĄ č湥ą╝ čĆąĄčłąĖč鹥 ąŠčéą║ą░ąĘą░čéčīčüčÅ ąŠčé ąŠą▒čŗčćąĮčŗčģ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║. ą¤ąŠą╝ąĮąĖč鹥 ąŠ č鹊ą╝, čćč鹊 ąĘą░čģą▓ą░čé ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ ąĮąĄčé ą║ąŠąĮą║čāčĆąĄąĮčéąĮąŠą│ąŠ ąĘą░ą┐čĆąŠčüą░, ą▓ čŹčĆčā 2010 ą│ąŠą┤ąŠą▓ ąĘą░ą╣ą╝ąĄčé ąĮą░ ąŠą▒čŗčćąĮčŗčģ ą┤ąĄčüą║č鹊ą┐ą░čģ ą▓čĆąĄą╝čÅ ą┐ąŠčĆčÅą┤ą║ą░ 20 ąĮčü.
ąØąĄ ą▒ą╗ąŠą║ąĖčĆčāčÄčēą░čÅ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÅ čéą░ą║ąČąĄ čĆą░ą▒ąŠčéą░ąĄčé ąĖ ą╝ąĄąČą┤čā ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ ą┐čĆąŠčåąĄčüčüą░ą╝ąĖ, čé. ąĄ. ą│ą╗ąŠą▒ą░ą╗čīąĮąŠ ąĮą░ ą║ąŠą╝ą┐čīčÄč鹥čĆąĄ PC Windows. ą¤čĆąĖą╝ąĄčĆ č鹊ą│ąŠ, ą│ą┤ąĄ čŹč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠą╗ąĄąĘąĮąŠ - čćč鹥ąĮąĖąĄ ąĖ ąĘą░ą┐ąĖčüčī ąŠą▒čēąĄą╣ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠą▓ ą┐ą░ą╝čÅčéąĖ (process-shared memory).
ąæą░čĆčīąĄčĆčŗ ą┐ą░ą╝čÅčéąĖ ąĖ ąĖąĘą╝ąĄąĮčćąĖą▓ąŠčüčéčī ą┤ą░ąĮąĮčŗčģ (volatility). ąĀą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗ąĄą┤čāčÄčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ:
class Foo
{
int _answer;
bool _complete;
void A()
{
_answer = 123;
_complete = true;
}
void B()
{
if (_complete) Console.WriteLine (_answer);
}
}
ąĢčüą╗ąĖ ą╝ąĄč鹊ą┤čŗ A ąĖ B ąĘą░ą┐čāčüą║ą░čÄčéčüčÅ ą║ąŠąĮą║čāčĆąĄąĮčéąĮąŠ ą▓ čĆą░ąĘąĮčŗčģ ą┐ąŠč鹊ą║ą░čģ, č鹊 ąĄčüčéčī ą╗ąĖ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą┤ą╗čÅ B ą▓čŗą▓ąĄčüčéąĖ "0"? ą×čéą▓ąĄčé ą▒čāą┤ąĄčé "ą┤ą░" ą┐ąŠ čüą╗ąĄą┤čāčÄčēąĖą╝ ą┐čĆąĖčćąĖąĮą░ą╝:
ŌĆó ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆ, CLR ąĖą╗ąĖ CPU ą╝ąŠą│čāčé ą┐ąŠą╝ąĄąĮčÅčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą┤ą╗čÅ ą┐ąŠą▓čŗčłąĄąĮąĖčÅ čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéąĖ.
ŌĆó ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆ, CLR ąĖą╗ąĖ CPU ą╝ąŠą│čāčé ą▓ą▓ąĄčüčéąĖ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖčÄ ą║čŹčłą░, ą┐čĆąĖ ą║ąŠč鹊čĆąŠą╣ ą┐čĆąĖčüą▓ąŠąĄąĮąĖąĄ ąĘąĮą░č湥ąĮąĖą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝ ąĮąĄ ą▒čāą┤ąĄčé ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░ąĮąĮąŠ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ ą▒čŗčéčī ą▓ąĖą┤ąĖą╝čŗą╝ ą┤ą╗čÅ ą┤čĆčāą│ąĖčģ ą┐ąŠč鹊ą║ąŠą▓.
C# ąĖ ą┐ąŠą┤čüąĖčüč鹥ą╝ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░ čĆąĄą░ą╗čīąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ čéčēą░č鹥ą╗čīąĮąŠ ą│ą░čĆą░ąĮčéąĖčĆčāčÄčé, čćč鹊ą▒čŗ čéą░ą║ąĖąĄ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ ąĮąĄ ąĮą░čĆčāčłąĖą╗ąĖ čĆą░ą▒ąŠčéčā ąŠą▒čŗčćąĮąŠą│ąŠ ąŠą┤ąĮąŠą┐ąŠč鹊čćąĮąŠą│ąŠ ą║ąŠą┤ą░ - ąĖą╗ąĖ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠą│ąŠ ą║ąŠą┤ą░, ą║ąŠč鹊čĆčŗą╣ ą┐čĆą░ą▓ąĖą╗čīąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ. ąÆąĮąĄ čŹčéąĖčģ čüčåąĄąĮą░čĆąĖąĄą▓ ąÆčŗ ą┤ąŠą╗ąČąĮčŗ čÅą▓ąĮąŠ ąĘą░čēąĖčēą░čéčīčüčÅ ąŠčé čéą░ą║ąĖčģ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖą╣ čüąŠąĘą┤ą░ąĮąĖąĄą╝ ą▒ą░čĆčīąĄčĆąŠą▓ ą┐ą░ą╝čÅčéąĖ (ą║ąŠč鹊čĆčŗąĄ čéą░ą║ąČąĄ ąĮą░ąĘčŗą▓ą░čÄčé "ąĘą░ą▒ąŠčĆą░ą╝ąĖ" ą┐ą░ą╝čÅčéąĖ, memory fences), čćč鹊ą▒čŗ ąŠą│čĆą░ąĮąĖčćąĖčé čŹčäč乥ą║čéčŗ ą┐ąĄčĆąĄčāą┐ąŠčĆčÅą┤ąŠčćąĖą▓ą░ąĮąĖčÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ čćč鹥ąĮąĖčÅ/ąĘą░ą┐ąĖčüąĖ.
ą¤ąŠą╗ąĮčŗą╣ ą▒ą░čĆčīąĄčĆ ą┐ą░ą╝čÅčéąĖ. ąĪą░ą╝čŗą╣ ą┐čĆąŠčüč鹊ą╣ ą▒ą░čĆčīąĄčĆ ą┐ą░ą╝čÅčéąĖ čŹč鹊 ą┐ąŠą╗ąĮčŗą╣ ą▒ą░čĆčīąĄčĆ (full fence), ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĄą┤ąŠčéą▓čĆą░čēą░ąĄčé ą╗čÄą▒ąŠą╣ ą▓ąĖą┤ ą┐ąĄčĆąĄčāą┐ąŠčĆčÅą┤ąŠčćąĖą▓ą░ąĮąĖčÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖą╗ąĖ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĄ ą▓ąŠą║čĆčāą│ ą▒ą░čĆčīąĄčĆą░. ąÆčŗąĘąŠą▓ Thread.MemoryBarrier ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ą┐ąŠą╗ąĮčŗą╣ ą▒ą░čĆčīąĄčĆ (full fence); ą╝čŗ ą╝ąŠąČąĄą╝ ąĖčüą┐čĆą░ą▓ąĖčéčī ąĮą░čł ą┐čĆąĖą╝ąĄčĆ ą┐čāč鹥ą╝ ąĮą░ą╗ąŠąČąĄąĮąĖčÅ č湥čéčŗčĆąĄčģ ą┐ąŠą╗ąĮčŗčģ ą▒ą░čĆčīąĄčĆąŠą▓ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
class Foo
{
int _answer;
bool _complete;
void A()
{
_answer = 123;
Thread.MemoryBarrier(); // ąæą░čĆčīąĄčĆ 1
_complete = true;
Thread.MemoryBarrier(); // ąæą░čĆčīąĄčĆ 2
}
void B()
{
Thread.MemoryBarrier(); // ąæą░čĆčīąĄčĆ 3
if (_complete)
{
Thread.MemoryBarrier(); // ąæą░čĆčīąĄčĆ 4
Console.WriteLine (_answer);
}
}
}
ąæą░čĆčīąĄčĆčŗ 1 ąĖ 4 ąĮąĄ ą┤ą░ą┤čāčé čŹč鹊ą╝čā ą┐čĆąĖą╝ąĄčĆčā ą▓čŗą▓ąĄčüčéąĖ "0". ąæą░čĆčīąĄčĆčŗ 2 ąĖ 3 ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ą│ą░čĆą░ąĮčéąĖčÄ "čüą▓ąĄąČąĄčüčéąĖ": ąĄčüą╗ąĖ B ąĘą░ą┐čāčüčéąĖčéčüčÅ ą┐ąŠčüą╗ąĄ A, čćč鹥ąĮąĖąĄ _complete ą▒čāą┤ąĄčé ą▓čŗčćąĖčüą╗ąĄąĮąŠ ą║ą░ą║ true.
ą¤ąŠą╗ąĮčŗą╣ ą▒ą░čĆčīąĄčĆ čŹčĆčā ą┤ąĄčüą║č鹊ą┐ąŠą▓ 2010 ą│ąŠą┤ą░ ąĘą░ąĮąĖą╝ą░ąĄčé ą┐ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ąŠą║ąŠą╗ąŠ 10 ąĮą░ąĮąŠčüąĄą║čāąĮą┤.
ąĪą╗ąĄą┤čāčÄčēąĖąĄ ą║ąŠąĮčüčéčĆčāą║čåąĖąĖ ąĮąĄčÅą▓ąĮąŠ ą│ąĄąĮąĄčĆąĖčĆčāčÄčé ą┐ąŠą╗ąĮčŗą╣ ą▒ą░čĆčīąĄčĆ:
ŌĆó ą×ą┐ąĄčĆą░č鹊čĆ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ lock (Monitor.Enter/Monitor.Exit).
ŌĆó ąÆčüąĄ ą╝ąĄč鹊ą┤čŗ ą║ą╗ą░čüčüą░ Interlocked (čćč鹊 ą▒čāą┤ąĄčé čĆą░čüčüą╝ąŠčéčĆąĄąĮąŠ ą┤ą░ą╗ąĄąĄ).
ŌĆó ąÉčüąĖąĮčģčĆąŠąĮąĮčŗąĄ čäčāąĮą║čåąĖąĖ ąŠą▒čĆą░čéąĮąŠą│ąŠ ą▓čŗąĘąŠą▓ą░ (callback), ą║ąŠč鹊čĆčŗąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą┐čāą╗ ą┐ąŠč鹊ą║ąŠą▓. ąŁč鹊 ą▓ą║ą╗čÄčćą░ąĄčé ą░čüąĖąĮčģčĆąŠąĮąĮčŗąĄ ą┤ąĄą╗ąĄą│ą░čéčŗ, čäčāąĮą║čåąĖąĖ ąŠą▒čĆą░čéąĮąŠą│ąŠ ą▓čŗąĘąŠą▓ą░ APM, ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ Task.
ŌĆó ąŻčüčéą░ąĮąŠą▓ą║ą░ ąĖ ąŠąČąĖą┤ą░ąĮąĖąĄ ą║ąŠąĮčüčéčĆčāą║čåąĖąĖ čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖąĖ.
ŌĆó ąÆčüąĄ čćč鹊 ą┐ąŠą╗ą░ą│ą░ąĄčéčüčÅ ąĮą░ čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖčÄ, čćč鹊 ąĘą░ą┐čāčüą║ą░ąĄčé Task ąĖ ąČą┤ąĄčé Task.
ąØą░ ąŠčüąĮąŠą▓ą░ąĮąĖąĖ ą┐ąŠčüą╗ąĄą┤ąĮąĄą│ąŠ čüą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤ ą▒ąĄąĘąŠą┐ą░čüąĄąĮ ą┤ą╗čÅ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠčüčéąĖ:
int x = 0;
Task t = Task.Factory.StartNew (() => x++);
t.Wait();
Console.WriteLine (x); // 1
ąØąĄąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ ąĮčāąČąĄąĮ ą┐ąŠą╗ąĮčŗą╣ ą▒ą░čĆčīąĄčĆ čü ą║ą░ąČą┤čŗą╝ ąŠčéą┤ąĄą╗čīąĮčŗą╝ čćč鹥ąĮąĖąĄą╝ ąĖą╗ąĖ ąĘą░ą┐ąĖčüčīčÄ. ąĢčüą╗ąĖ čā ąĮą░čü ąĄčüčéčī čéčĆąĖ ą┐ąŠą╗čÅ _answerX, č鹊 ąĮą░ą╝ ą▓čüąĄ ąĄčēąĄ ąĮčāąČąĮąŠ ą┐čĆąĖą╝ąĄąĮąĖčéčī č鹊ą╗čīą║ąŠ 4 ą▒ą░čĆčīąĄčĆą░:
class Foo
{
int _answer1, _answer2, _answer3;
bool _complete;
void A()
{
_answer1 = 1; _answer2 = 2; _answer3 = 3;
Thread.MemoryBarrier();
_complete = true;
Thread.MemoryBarrier();
}
void B()
{
Thread.MemoryBarrier();
if (_complete)
{
Thread.MemoryBarrier();
Console.WriteLine (_answer1 + _answer2 + _answer3);
}
}
}
ąźąŠčĆąŠčłąĖą╣ čüą┐ąŠčüąŠą▒ čĆą░ą▒ąŠčéčŗ čü ą▒ą░čĆčīąĄčĆą░ą╝ąĖ - ą┐ąŠą╝ąĄčēą░čéčī ąĖčģ ą┐ąĄčĆąĄą┤ ąĖ ą┐ąŠčüą╗ąĄ ą║ą░ąČą┤ąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆą░čÅ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé ąĖą╗ąĖ čćąĖčéą░ąĄčé ąŠą▒čēąĄąĄ ą┐ąŠą╗ąĄ, ąĖ ąĘą░č鹥ą╝ ą▓čŗą▓ąŠą┤ąĖčéčī ąĘą░ ą┐čĆąĄą┤ąĄą╗čŗ ą▒ą░čĆčīąĄčĆąŠą▓ ą▓čüąĄ, čćč鹊 ąĮąĄ ąĮčāąČąĮąŠ ą┤ą╗čÅ čŹč鹊ą╣ čåąĄą╗ąĖ. ąĢčüą╗ąĖ ąĮąĄ čāą▓ąĄčĆąĄąĮčŗ ą▓ ą║ą░ą║ąŠą╝-č鹊 ą║ąŠą┤ąĄ, ąŠčüčéą░ą▓čīč鹥 ąĄą│ąŠ ą▓ąĮčāčéčĆąĖ ą▒ą░čĆčīąĄčĆą░. ąśą╗ąĖ, čćč鹊 ą╗čāčćčłąĄ: ą▓ąĄčĆąĮąĖč鹥čüčī ą║ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║!
ąĀą░ą▒ąŠčéą░čéčī čü ąŠą▒čēąĖą╝ąĖ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄą╝čŗą╝ąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝ąĖ (ą┐ąŠą╗čÅą╝ąĖ) ą▒ąĄąĘ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║ ąĖą╗ąĖ ą▒ą░čĆčīąĄčĆąŠą▓ ąŠąĘąĮą░čćą░ąĄčé ąĖčüą║ą░čéčī čüąĄą▒ąĄ ą╗ąĖčłąĮąĖčģ ą┐čĆąĖą║ą╗čÄč湥ąĮąĖą╣. ąĢčüčéčī ą╝ąĮąŠą│ąŠ ą▓ą▓ąŠą┤čÅčēąĄą╣ ą▓ ąĘą░ą▒ą╗čāąČą┤ąĄąĮąĖąĄ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą┐ąŠ čŹč鹊ą╣ č鹥ą╝ąĄ (ą▓ą║ą╗čÄčćą░čÅ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖčÄ MSDN), ą│ą┤ąĄ čāčéą▓ąĄčƹȹ┤ą░ąĄčéčüčÅ, čćč鹊 MemoryBarrier čéčĆąĄą▒čāąĄčéčüčÅ č鹊ą╗čīą║ąŠ ąĮą░ ą╝ąĮąŠą│ąŠą┐čĆąŠčåąĄčüčüąŠčĆąĮčŗčģ čüąĖčüč鹥ą╝ą░čģ čüąŠ čüą╗ą░ą▒čŗą╝ čāą┐ąŠčĆčÅą┤ąŠčćąĖą▓ą░ąĮąĖąĄą╝ ą┐ą░ą╝čÅčéąĖ, čéą░ą║ąĖčģ ą║ą░ą║ čüąĖčüč鹥ą╝čŗ čü ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ą╝ąĖ Itanium. ąÆ čüą╗ąĄą┤čāčÄčēąĄą╣ ą║ąŠčĆąŠčéą║ąŠą╣ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ą╝čŗ ą╝ąŠąČąĄą╝ ą┐čĆąŠą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆąŠą▓ą░čéčī, čćč鹊 ą▒ą░čĆčīąĄčĆčŗ ą┐ą░ą╝čÅčéąĖ ą▓ą░ąČąĮčŗ ąĖ ąĮą░ ąŠą▒čŗčćąĮčŗčģ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ Intel Core-2 ąĖ Pentium. ąÆą░ą╝ ąĮčāąČąĮąŠ ąĘą░ą┐čāčüčéąĖčéčī čŹč鹊čé ą║ąŠą┤ čü čĆą░ąĘčĆąĄčłąĄąĮąĮčŗą╝ąĖ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖčÅą╝ąĖ ąĖ ą▒ąĄąĘ ąŠčéą╗ą░ą┤čćąĖą║ą░ (ą▓ Visual Studio ą▓čŗą▒ąĄčĆąĖč鹥 čĆąĄąČąĖą╝ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ Release, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ąĘą░ą┐čāčüčéąĖč鹥 čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░ąĮąĮčāčÄ ą┐čĆąŠą│čĆą░ą╝ą╝čā ą▒ąĄąĘ ąŠčéą╗ą░ą┤ą║ąĖ):
static void Main()
{
bool complete = false;
var t = new Thread (() =>
{
bool toggle = false;
while (!complete) toggle = !toggle;
});
t.Start();
Thread.Sleep (1000);
complete = true;
t.Join(); // ąæąĄčüą║ąŠąĮąĄčćąĮą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░
}
ąŁčéą░ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ, ą┐ąŠč鹊ą╝čā čćč鹊 ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ complete ą║čŹčłąĖčĆčāąĄčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ CPU. ąĢčüą╗ąĖ ą▓čüčéą░ą▓ąĖčéčī ą▓čŗąĘąŠą▓ Thread.MemoryBarrier ą▓ąĮčāčéčĆčī čåąĖą║ą╗ą░ while (ąĖą╗ąĖ ą▓ąŠą║čĆčāą│ čćč鹥ąĮąĖčÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ complete), č鹊 čŹčéą░ ąŠčłąĖą▒ą║ą░ ąĖčüą┐čĆą░ą▓ąĖčéčüčÅ.
ąÜą╗čÄč湥ą▓ąŠąĄ čüą╗ąŠą▓ąŠ volatile. ąöčĆčāą│ąŠą╣ (ą▒ąŠą╗ąĄąĄ ą┐čĆąŠą┤ą▓ąĖąĮčāčéčŗą╣, ąĮąŠ ą╝ąĄąĮąĄąĄ ą┐ąŠąĮčÅčéąĮčŗą╣) čüą┐ąŠčüąŠą▒ čĆąĄčłąĖčéčī čŹčéčā ą┐čĆąŠą▒ą╗ąĄą╝čā - ą┐čĆąĖą╝ąĄąĮąĖčéčī ą║ą╗čÄč湥ą▓ąŠąĄ čüą╗ąŠą▓ąŠ volatile ą║ ą┐ąŠą╗čÄ _complete:
ąÜą╗čÄč湥ą▓ąŠąĄ čüą╗ąŠą▓ąŠ volatile ąĖąĮčüčéčĆčāą║čéąĖčĆčāąĄčé ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ą▒ą░čĆčīąĄčĆ ąĮą░ ąĖčüą║ą╗čÄčćąĖč鹥ą╗čīąĮčŗą╣ ąĘą░čģą▓ą░čé (acquire-fence) ąĮą░ ą║ą░ąČą┤ąŠą╝ čćč鹥ąĮąĖąĖ ąĖąĘ čŹč鹊ą│ąŠ ą┐ąŠą╗čÅ, ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ą▒ą░čĆčīąĄčĆą░ (release-fence) ąĮą░ ą║ą░ąČą┤ąŠą╣ ąĘą░ą┐ąĖčüąĖ ą▓ čŹč鹊 ą┐ąŠą╗ąĄ. Acquire-fence ą┐čĆąĄą┤ąŠčéą▓čĆą░čēą░ąĄčé čüąĖčéčāą░čåąĖąĖ, ą║ąŠą│ą┤ą░ ą┤čĆčāą│ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ čćč鹥ąĮąĖčÅ/ąĘą░ą┐ąĖčüąĖ ą┐čĆąŠąĖčüčģąŠą┤čÅčé ą┐ąĄčĆąĄą┤ ą▒ą░čĆčīąĄčĆąŠą╝; release-fence ą┐čĆąĄą┤ąŠčéą▓čĆą░čēą░ąĄčé čüąĖčéčāą░čåąĖąĖ, ą║ąŠą│ą┤ą░ ą┤čĆčāą│ąĖąĄ čćč鹥ąĮąĖčÅ/ąĘą░ą┐ąĖčüąĖ ą┐ąĄčĆąĄą╝ąĄčēą░čÄčéčüčÅ ąĘą░ ą▒ą░čĆčīąĄčĆ. ąóą░ą║ąŠą╣ "ą┐ąŠą╗ąŠą▓ąĖąĮčćą░čéčŗą╣" ą▒ą░čĆčīąĄčĆ čĆą░ą▒ąŠčéą░ąĄčé ą▒čŗčüčéčĆąĄąĄ "ą┐ąŠą╗ąĮąŠą│ąŠ", ą┐ąŠč鹊ą╝čā čćč鹊 ą┤ą░ąĄčé čĆą░čüčłąĖčĆąĄąĮąĮčŗąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ą┐ąŠ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ ą┤ą╗čÅ ą║ąŠą┤ą░ čĆąĄą░ą╗čīąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ąĖ ą░ą┐ą┐ą░čĆą░čéčāčĆčŗ.
ąóą░ą║ čāąČ ą┐ąŠą╗čāčćąĖą╗ąŠčüčī, čćč鹊 ą┐čĆąŠčåąĄčüčüąŠčĆčŗ Intel X86 ąĖ X64 ą▓čüąĄą│ą┤ą░ ą┐čĆąĖą╝ąĄąĮčÅčÄčé ą▒ą░čĆčīąĄčĆčŗ acquire-fence ą┤ą╗čÅ čćč鹥ąĮąĖą╣ ąĖ release-fence ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĄą╣ - ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ ąŠčé č鹊ą│ąŠ, ąĖčüą┐ąŠą╗čīąĘčāąĄč鹥 ą╗ąĖ ąÆčŗ ą║ą╗čÄč湥ą▓ąŠąĄ čüą╗ąŠą▓ąŠ volatile ąĖą╗ąĖ ąĮąĄčé, čé. ąĄ. ąŠąĮąŠ ąĮąĄ ą┤ą░ąĄčé čŹčäč乥ą║čéą░ ą▓ ą░ą┐ą┐ą░čĆą░čéčāčĆąĄ, ąĄčüą╗ąĖ ąÆčŗ ąĖčüą┐ąŠą╗čīąĘčāąĄč鹥 čŹčéąĖ ą┐čĆąŠčåąĄčüčüąŠčĆčŗ. ą×ą┤ąĮą░ą║ąŠ volatile čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖčÅčģ, ą▓čŗą┐ąŠą╗ąĮčÅąĄą╝čŗčģ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆąŠą╝ ąĖ CLR - ą║ą░ą║ ąĮą░ 64-ą▒ąĖčéąĮčŗčģ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ AMD, čéą░ą║ ąĖ (ą▓ ą▒ąŠą╗čīčłąĄą╣ čüč鹥ą┐ąĄąĮąĖ) ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ Itanium. ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ąĮąĄ čüą╗ąĄą┤čāąĄčé čĆą░čüčüą╗ą░ą▒ą╗čÅčéčīčüčÅ ąĮą░ ąŠčüąĮąŠą▓ą░ąĮąĖąĖ ą║ą░ą║ąĖčģ-č鹊 čüąŠąŠą▒čĆą░ąČąĄąĮąĖą╣, čćč鹊 ąÆą░čłąĖ ą║ą╗ąĖąĄąĮčéčŗ ąĖčüą┐ąŠą╗čīąĘčāčÄčé č鹊ą╗čīą║ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╣ "ą┐čĆąŠą▓ąĄčĆąĄąĮąĮčŗą╣" čéąĖą┐ CPU.
ąś ąĄčēąĄ: ą┤ą░ąČąĄ ąĄčüą╗ąĖ ąÆčŗ ąĖčüą┐ąŠą╗čīąĘčāąĄč鹥 volatile, ą▓čüąĄ čĆą░ą▓ąĮąŠ ąĮčāąČąĮąŠ ą▒čŗčéčī ą▓ ąĘą┤ąŠčĆąŠą▓ąŠą╝ č鹊ąĮčāčüąĄ ą▒ąĄčüą┐ąŠą║ąŠą╣čüčéą▓ą░, čćč鹊 ą╝čŗ čüą║ąŠčĆąŠ čāą▓ąĖą┤ąĖą╝. ąÜąŠčĆąŠč湥 ą│ąŠą▓ąŠčĆčÅ, volatile ąĮą░ ą┐ą░ąĮą░čåąĄčÅ ąŠčé ą▓čüąĄčģ ą┐čĆąŠą▒ą╗ąĄą╝!
ąŁčäč乥ą║čé ąŠčé ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ volatile ą╝ąŠąČąĮąŠ ąŠą▒ąŠą▒čēąĖčéčī čüą╗ąĄą┤čāčÄčēąĄą╣ čéą░ą▒ą╗ąĖčåąĄą╣:
| ą¤ąĄčĆą▓ą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ |
ąÆč鹊čĆą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ |
ą£ąŠą│čāčé ą╗ąĖ ąŠąĮąĖ ą┐ąŠą╝ąĄąĮčÅčéčī ą┐ąŠčĆčÅą┤ąŠą║ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ? |
| Read |
Read |
ąĮąĄčé |
| Read |
Write |
ąĮąĄčé |
| Write |
Write |
ąĮąĄčé (CLR ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ąŠą┐ąĄčĆą░čåąĖąĖ ąĘą░ą┐ąĖčüčī-ąĘą░ą┐ąĖčüčī ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé ą┐ąŠčĆčÅą┤ąŠą║ čüą▓ąŠąĄą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ, ą┤ą░ąČąĄ ąĄčüą╗ąĖ ąĮąĄ ą┐čĆąĖą╝ąĄąĮčÅą╗ąŠčüčī ą║ą╗čÄč湥ą▓ąŠąĄ čüą╗ąŠą▓ąŠ volatile) |
| Write |
Read |
ąöąÉ! |
ąśą╝ąĄą╣č鹥 ą▓ ą▓ąĖą┤čā, čćč鹊 ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ volatile ąĮąĄ ąĘą░čēąĖčé ąŠčé ąĘą░ą┐ąĖčüąĖ, ąĘą░ ą║ąŠč鹊čĆčŗą╝ ąĖą┤ąĄčé čćč鹥ąĮąĖąĄ, ąŠčé ąĖčģ ą┐ąĄčĆąĄčüčéą░ąĮąŠą▓ą║ąĖ, ąĖ čŹč鹊 ą╝ąŠąČąĄčé čüąŠąĘą┤ą░čéčī ą│ąŠą╗ąŠą▓ąŠą╗ąŠą╝ą║čā. Joe Duffy čģąŠčĆąŠčłąŠ ąĖą╗ą╗čÄčüčéčĆąĖčĆčāąĄčé ą┐čĆąŠą▒ą╗ąĄą╝čā ąĮą░ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ: ąĄčüą╗ąĖ Test1 ąĖ Test2 ąĘą░ą┐čāčēąĄąĮčŗ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą▓ čĆą░ąĘąĮčŗčģ ą┐ąŠč鹊ą║ą░čģ, č鹊 ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ čüąĖčéčāą░čåąĖčÅ, ą║ąŠą│ą┤ą░ ąĖ a, ąĖ b ąŠą▒ą░ ąĘą░ą▓ąĄčĆčłąĖą╗ąĖčüčī čüąŠ ąĘąĮą░č湥ąĮąĖąĄą╝ 0 (ąĮąĄčüą╝ąŠčéčĆčÅ ąĮą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ volatile ąĮą░ ąŠą▒ąŠąĖčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ x ąĖ y):
class IfYouThinkYouUnderstandVolatile
{
volatile int x, y;
void Test1() // ąĀą░ą▒ąŠčéą░ąĄčé ą▓ ąŠą┤ąĮąŠą╝ ą┐ąŠč鹊ą║ąĄ
{
x = 1; // Volatile write (release-fence)
int a = y; // Volatile read (acquire-fence)
...
}
void Test2() // ąĀą░ą▒ąŠčéą░ąĄčé ą▓ ą┤čĆčāą│ąŠą╝ ą┐ąŠč鹊ą║ąĄ
{
y = 1; // Volatile write (release-fence)
int b = x; // Volatile read (acquire-fence)
...
}
}
ąöąŠą║čāą╝ąĄąĮčéą░čåąĖčÅ MSDN čāčéą▓ąĄčƹȹ┤ą░ąĄčé, čćč鹊 ą║ą╗čÄč湥ą▓ąŠąĄ čüą╗ąŠą▓ąŠ volatile ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ą▓ ą┐ąŠą╗ąĄ ą▓čüąĄą│ą┤ą░ ą┐čĆąĖčüčāčéčüčéą▓čāąĄčé čüą░ą╝ąŠąĄ ą░ą║čéčāą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ. ąÜą░ą║ ą╝čŗ čāą▓ąĖą┤ąĄą╗ąĖ, čŹč鹊 ąĮąĄą▓ąĄčĆąĮąŠ, ą┐ąŠčĆčÅą┤ąŠą║ ą┤ąĄą╣čüčéą▓ąĖą╣ "ąĘą░ą┐ąĖčüčī ą┐ąŠč鹊ą╝ čćč鹥ąĮąĖąĄ" ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖąĘą╝ąĄąĮąĄąĮ.
ąŁč鹊 ą┤ą░ąĄčé ą▓ąĄčüą║ąĖąĄ ą┤ąŠą▓ąŠą┤čŗ ąĖąĘą▒ąĄą│ą░čéčī volatile: ą┤ą░ąČąĄ ąĄčüą╗ąĖ ąÆčŗ ą┐ąŠąĮąĖą╝ą░ąĄč鹥, čćč鹊 ąĮą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ, ą┐ąŠą╣ą╝čāčé ą╗ąĖ čŹč鹊 čéą░ą║ąČąĄ ąĖ ą┤čĆčāą│ąĖąĄ čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ąĖ, čĆą░ą▒ąŠčéą░čÄčēąĖąĄ čü ą┐ąŠą┤ąŠą▒ąĮčŗą╝ ą║ąŠą┤ąŠą╝? ą¤ąŠą╗ąĮčŗą╣ ą▒ą░čĆčīąĄčĆ (full fence) ą╝ąĄąČą┤čā ą║ą░ąČą┤čŗą╝ ąĖąĘ čŹčéąĖčģ ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĮąĖą╣ ą▓ Test1 ąĖ Test2 (ąĖą╗ąĖ čéčĆą░ą┤ąĖčåąĖąŠąĮąĮą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░) čĆąĄčłąĖčé čŹčéčā ą┐čĆąŠą▒ą╗ąĄą╝čā.
ąÜą╗čÄč湥ą▓ąŠąĄ čüą╗ąŠą▓ąŠ volatile ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ ą▓ ą░čĆą│čāą╝ąĄąĮčéą░čģ, ą┐ąĄčĆąĄą┤ą░ą▓ą░ąĄą╝čŗčģ ą┐ąŠ čüčüčŗą╗ą║ąĄ, ąĖą╗ąĖ ą▓ ąĘą░čģą▓ą░č湥ąĮąĮčŗčģ ą╗ąŠą║ą░ą╗čīąĮčŗčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ (captured local variables): ą▓ čŹčéąĖčģ čüą╗čāčćą░čÅčģ ąĮčāąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą╝ąĄč鹊ą┤čŗ VolatileRead ąĖ VolatileWrite.
VolatileRead, VolatileWrite. ąĪčéą░čéąĖč湥čüą║ąĖąĄ ą╝ąĄč鹊ą┤čŗ VolatileRead ąĖ VolatileWrite ą▓ ą║ą╗ą░čüčüąĄ Thread čćąĖčéą░čÄčé ąĖ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčé ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ čü ą│ą░čĆą░ąĮčéąĖąĄą╣ (č鹥čģąĮąĖč湥čüą║ąĖ ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąŠą╣), ą║ąŠč鹊čĆą░čÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą║ą╗čÄč湥ą▓ąŠąĄ čüą╗ąŠą▓ąŠ volatile. ąśčģ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ ąĮąĄ čŹčäč乥ą║čéąĖą▓ąĮčŗ, čģąŠčéčÅ ąŠąĮąĖ ą▓ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą│ąĄąĮąĄčĆąĖčĆčāčÄčé ą┐ąŠą╗ąĮčŗąĄ ą▒ą░čĆčīąĄčĆčŗ. ąÆąŠčé ąĖčģ ą┐ąŠą╗ąĮčŗąĄ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą┤ą╗čÅ čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮąŠą│ąŠ čéąĖą┐ą░:
public static void VolatileWrite (ref int address, int value)
{
MemoryBarrier(); address = value;
}
public static int VolatileRead (ref int address)
{
int num = address; MemoryBarrier(); return num;
}
ąÆčŗ ą╝ąŠąČąĄč鹥 ą▓ąĖą┤ąĄčéčī, čćč鹊 ąĄčüą╗ąĖ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą▓čŗąĘąŠą▓ VolatileWrite, ąĘą░ ą║ąŠč鹊čĆčŗą╝ ą▒čāą┤ąĄčé ąĖą┤čéąĖ ą▓čŗąĘąŠą▓ VolatileRead, č鹊 ą╝ąĄąČą┤čā ąĮąĖą╝ąĖ ąĮąĄ ą▒čāą┤ąĄčé čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮ ą▒ą░čĆčīąĄčĆ: čŹč鹊 ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčé č鹊čé ąČąĄ čüčåąĄąĮą░čĆąĖą╣ ą│ąŠą╗ąŠą▓ąŠą╗ąŠą╝ą║ąĖ, ą║ąŠč鹊čĆčŗą╣ ą╝čŗ ą▓čŗą┤ąĄą╗ąĖ čĆą░ąĮąĄąĄ.
ąæą░čĆčīąĄčĆčŗ ą┐ą░ą╝čÅčéąĖ ąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░. ąÜą░ą║ ą╝čŗ ąĘą░ą╝ąĄčéąĖą╗ąĖ čĆą░ąĮčīčłąĄ, Monitor.Enter ąĖ Monitor.Exit ąŠą▒ą░ ą│ąĄąĮąĄčĆąĖčĆčāčÄčé ą┐ąŠą╗ąĮčŗąĄ ą▒ą░čĆčīąĄčĆčŗ. ą¤ąŠčŹč鹊ą╝čā ąĄčüą╗ąĖ ą╝čŗ ąĖą│ąĮąŠčĆąĖčĆčāąĄą╝ ą│ą░čĆą░ąĮčéąĖčÄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą▓ąĘą░ąĖą╝ąĮąŠą│ąŠ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, č鹊 ą╝ąŠąČąĮąŠ čüą║ą░ąĘą░čéčī, čćč鹊:
lock (ą║ą░ą║ąŠąĄ_ąĮąĖą▒čāą┤čī_ą┐ąŠą╗ąĄ) { ... }
čÅą▓ą╗čÅąĄčéčüčÅ čŹą║ą▓ąĖą▓ą░ą╗ąĄąĮč鹊ą╝ čŹč鹊ą│ąŠ:
Thread.MemoryBarrier(); { ... } Thread.MemoryBarrier();
ąÜą╗ą░čüčü Interlocked. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▒ą░čĆčīąĄčĆčŗ ą┐ą░ą╝čÅčéąĖ ąĮąĄ ą▓čüąĄą│ą┤ą░ ą┤ąŠčüčéą░č鹊čćąĮąŠ, ą║ąŠą│ą┤ą░ ą║ąŠą┤ ą▒ąĄąĘ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║ čćąĖčéą░ąĄčé ąĖą╗ąĖ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé ą┐ąŠą╗čÅ. ą×ą┐ąĄčĆą░čåąĖąĖ čü 64-ą▒ąĖčéąĮčŗą╝ąĖ ą┐ąŠą╗čÅą╝ąĖ, ąĖąĮą║čĆąĄą╝ąĄąĮčéčŗ ąĖ ą┤ąĄą║čĆąĄą╝ąĄąĮčéčŗ čü ąĮąĖą╝ąĖ čéčĆąĄą▒čāčÄčé ą▒ąŠą╗ąĄąĄ ąČąĄčüčéą║ąŠą╣ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čü ą┐ąŠą╝ąŠčēčīčÄ ą▓čüą┐ąŠą╝ąŠą│ą░č鹥ą╗čīąĮąŠą│ąŠ ą║ą╗ą░čüčüą░ Interlocked. Interlocked čéą░ą║ąČąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą╝ąĄč鹊ą┤čŗ Exchange ąĖ CompareExchange, ą┐ąŠčüą╗ąĄą┤ąĮąĖą╣ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąŠą┐ąĄčĆą░čåąĖąĖ read-modify-write ą▒ąĄąĘ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ, čü ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄą╝ ą╝ą░ą╗ąŠą│ąŠ ą┐ąŠ ąŠą▒čŖąĄą╝čā ą║ąŠą┤ą░.
ą×ą┐ąĄčĆą░č鹊čĆ ąĖąĘąĮą░čćą░ą╗čīąĮąŠ ą░č鹊ą╝ą░čĆąĮčŗą╣, ąĄčüą╗ąĖ ąŠąĮ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą║ą░ą║ ąŠą┤ąĮą░ ąĮąĄą┤ąĄą╗ąĖą╝ą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮą░ ąĮąĖąČąĄą╗ąĄąČą░čēąĄą╝ ą┐čĆąŠčåąĄčüčüąŠčĆąĄ. ąĪčéčĆąŠą│ą░čÅ ą░č鹊ą╝ą░čĆąĮąŠčüčéčī ąŠą┐ąĄčĆą░č鹊čĆą░ ąĖčüą║ą╗čÄčćą░ąĄčé ą╗čÄą▒čāčÄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą▓čŗč鹥čüąĮąĄąĮąĖčÅ ą▓ąŠ ą▓čĆąĄą╝čÅ ąĄą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ. ą¤čĆąŠčüč鹊ąĄ čćč鹥ąĮąĖąĄ ąĖą╗ąĖ ąĘą░ą┐ąĖčüčī ą┐ąŠą╗čÅ 32 ą▒ąĖčéą░ ąĖą╗ąĖ ą╝ąĄąĮčīčłąĄ ą▓čüąĄą│ą┤ą░ ą░č鹊ą╝ą░čĆąĮąŠąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 čĆą░ąĘčĆčÅą┤ąĮąŠčüčéčī čĆąĄą│ąĖčüčéčĆąŠą▓ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą║ą░ą║ ą┐čĆą░ą▓ąĖą╗ąŠ ąĮąĄ ą╝ąĄąĮčīčłąĄ 32 ą▒ąĖčé. ą×ą┐ąĄčĆą░čåąĖąĖ čü 64-ą▒ąĖčéąĮčŗą╝ąĖ ą┐ąŠą╗čÅą╝ąĖ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░ąĮąĮąŠ ą░č鹊ą╝ą░čĆąĮčŗą╝ąĖ ą▒čāą┤čāčé č鹊ą╗čīą║ąŠ ą▓ 64-ą▒ąĖčéąĮąŠą╣ čüčĆąĄą┤ąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ, ąĖ ąŠą┐ąĄčĆą░č鹊čĆčŗ, ą║ąŠč鹊čĆčŗąĄ ą║ąŠą╝ą▒ąĖąĮąĖčĆčāčÄčé ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ čćč鹥ąĮąĖčÅ/ąĘą░ą┐ąĖčüąĖ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą▒čāą┤čāčé ą░č鹊ą╝ą░čĆąĮčŗą╝ąĖ:
class Atomicity
{
static int _x, _y;
static long _z;
static void Test()
{
long myLocal;
_x = 3; // ąÉč鹊ą╝ą░čĆąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ
_z = 3; // ąØąĄ ą░č鹊ą╝ą░čĆąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ ą▓ 32-ą▒ąĖčéąĮąŠą╝ ąŠą║čĆčāąČąĄąĮąĖąĖ
// (ą┐ąŠč鹊ą╝čā čćč鹊 ą┐ąŠą╗ąĄ _z ąĖą╝ąĄąĄčé čĆą░ąĘčĆčÅą┤ąĮąŠčüčéčī 64 ą▒ąĖčéą░)
myLocal = _z; // ąØąĄ ą░č鹊ą╝ą░čĆąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ ą▓ 32-ą▒ąĖčéąĮąŠą╝ ąŠą║čĆčāąČąĄąĮąĖąĖ
_y += _x; // ąØąĄ ą░č鹊ą╝ą░čĆąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ (čüąŠčüč鹊ąĖčé ąĖąĘ ąŠą┐ąĄčĆą░čåąĖą╣ čćč鹥ąĮąĖčÅ ąś ąĘą░ą┐ąĖčüąĖ)
_x++; // ąØąĄ ą░č鹊ą╝ą░čĆąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ (čüąŠčüč鹊ąĖčé ąĖąĘ ąŠą┐ąĄčĆą░čåąĖą╣ čćč鹥ąĮąĖčÅ ąś ąĘą░ą┐ąĖčüąĖ)
}
}
ą¦č鹥ąĮąĖąĄ ąĖ ąĘą░ą┐ąĖčüčī 64-ą▒ąĖčéąĮčŗčģ ą┐ąŠą╗ąĄą╣ ąĮąĄ ą░č鹊ą╝ą░čĆąĮčŗąĄ ą▓ 32-ą▒ąĖčéąĮąŠą╝ ąŠą║čĆčāąČąĄąĮąĖąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąĮąĖ čéčĆąĄą▒čāčÄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ 2 ąŠčéą┤ąĄą╗čīąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖą╣: ą┐ąŠ ąŠą┤ąĮąŠą╣ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ 32-ą▒ąĖčéąĮąŠą╣ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąĄčüą╗ąĖ ą┐ąŠč鹊ą║ X čćąĖčéą░ąĄčé 64-ą▒ąĖčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, ą║ąŠą│ą┤ą░ ą┐ąŠč鹊ą║ Y ąŠą▒ąĮąŠą▓ą╗čÅąĄčé ąĄą│ąŠ, č鹊 ą▓čŗč鹥čüąĮąĄąĮąĖąĄ ą┐ąŠč鹊ą║ą░ X ą┐ąŠč鹊ą║ąŠą╝ Y (ąĖą╗ąĖ ąĮą░ąŠą▒ąŠčĆąŠčé) ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ąĮąĄą┐čĆąĄą┤čüą║ą░ąĘčāąĄą╝čŗą╝ čĆąĄąĘčāą╗čīčéą░čéą░ą╝ ąŠą┐ąĄčĆą░čåąĖąĖ čćč鹥ąĮąĖčÅ: ą╝ąŠąČąĄčé ą┐ąŠą╗čāčćąĖčéčīčüčÅ čéą░ą║, čćč鹊 čĆąĄąĘčāą╗čīčéą░č鹊ą╝ ą▒čāą┤ąĄčé ą▒ąĖč鹊ą▓ą░čÅ ą║ąŠą╝ą▒ąĖąĮą░čåąĖčÅ ąĮąŠą▓čŗčģ ąĖ čüčéą░čĆčŗčģ ąĘąĮą░č湥ąĮąĖą╣ (čĆą▓ą░ąĮąŠąĄ čćč鹥ąĮąĖąĄ).
ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆ čĆąĄą░ą╗ąĖąĘčāąĄčé čāąĮą░čĆąĮčŗąĄ ąŠą┐ąĄčĆą░č鹊čĆčŗ ą▓ąĖą┤ą░ x++ ą┐čāč鹥ą╝ čćč鹥ąĮąĖčÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣, ąĄčæ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĖ ąĘą░č鹥ą╝ ąĘą░ą┐ąĖčüąĖ ąŠą▒čĆą░čéąĮąŠ ą▓ čéčā ąČąĄ čÅč湥ą╣ą║čā ą┐ą░ą╝čÅčéąĖ. ąĀą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗ąĄą┤čāčÄčēąĖą╣ ą║ą╗ą░čüčü:
class ThreadUnsafe
{
static int _x = 1000;
static void Go() { for (int i = 0; i < 100; i++) _x--; }
}
ą×čéą╗ąŠąČąĖą▓ ą┐čĆąŠą▒ą╗ąĄą╝čā ą▒ą░čĆčīąĄčĆąŠą▓ ą┐ą░ą╝čÅčéąĖ, ąÆčŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ ąŠąČąĖą┤ą░čéčī, čćč鹊 ąĄčüą╗ąĖ 10 ą┐ąŠč鹊ą║ąŠą▓ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ąĘą░ą┐čāčüčéčÅčé Go, č鹊 ą┐ąŠčüą╗ąĄą┤ąĮąĖą╣ ą┤ąĄą║čĆąĄą╝ąĄąĮčé _x ą┤ąŠą╗ąČąĄąĮ ąĘą░ą║ąŠąĮčćąĖčéčīčüčÅ ąĮą░ ąĘąĮą░č湥ąĮąĖąĖ 0. ą×ą┤ąĮą░ą║ąŠ čŹč鹊 ąĮąĄ ą│ą░čĆą░ąĮčéąĖčĆčāąĄčéčüčÅ, ą┐ąŠč鹊ą╝čā čćč鹊 čüąŠą▒čŗčéąĖąĄ ą│ąŠąĮą║ąĖ ą╝ąĄąČą┤čā ą┐ąŠč鹊ą║ą░ą╝ąĖ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ č鹊ą╝čā, čćč鹊 ą║ą░ą║ąŠą╣-č鹊 ą┐ąŠč鹊ą║ ą┐čĆąŠąĖąĘą▓ąĄą┤ąĄčé ą▓čŗč鹥čüąĮąĄąĮąĖąĄ ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čāąĮą░čĆąĮąŠą│ąŠ ąŠą┐ąĄčĆą░č鹊čĆą░ ą┤ąĄą║čĆąĄą╝ąĄąĮčéą░ _x--, ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 č湥ą│ąŠ ąĘąĮą░č湥ąĮąĖąĄ ąŠą▒čēąĄą│ąŠ ą┐ąŠą╗čÅ _x čüčéą░ąĮąĄčé ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝.
ąÜąŠąĮąĄčćąĮąŠ, čŹčéčā ą┐čĆąŠą▒ą╗ąĄą╝čā ą╝ąŠąČąĮąŠ čĆąĄčłąĖčéčī, ąŠą▒ąĄčĆąĮčāą▓ ąĮąĄ ą░č鹊ą╝ą░čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ąŠą┐ąĄčĆą░č鹊čĆąŠą╝ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ. ąæą╗ąŠą║ąĖčĆąŠą▓ą║ą░, ąĄčüą╗ąĖ ąŠąĮą░ ą┐čĆąĖą╝ąĄąĮąĄąĮą░ ą┐čĆą░ą▓ąĖą╗čīąĮąŠ, čäą░ą║čéąĖč湥čüą║ąĖ čüąĖą╝čāą╗ąĖčĆčāąĄčé ą░č鹊ą╝ą░čĆąĮąŠčüčéčī. ą×ą┤ąĮą░ą║ąŠ ą║ą╗ą░čüčü Interlocked ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą▒ąŠą╗ąĄąĄ ą┐čĆąŠčüč鹊ąĄ ąĖ ą▒čŗčüčéčĆąŠąĄ čĆąĄčłąĄąĮąĖąĄ ą┤ą╗čÅ čéą░ą║ąĖčģ ą┐čĆąŠčüčéčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣:
class Program
{
static long _sum;
static void Main()
{ // _sum
// ą¤čĆąŠčüčéčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ąĖąĮą║čĆąĄą╝ąĄąĮčéą░/ą┤ąĄą║čĆąĄą╝ąĄąĮčéą░:
Interlocked.Increment (ref _sum); // 1
Interlocked.Decrement (ref _sum); // 0
// ąöąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ/ą▓čŗčćąĖčéą░ąĮąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ:
Interlocked.Add (ref _sum, 3); // 3
// ą¦č鹥ąĮąĖąĄ 64-ą▒ąĖčéąĮąŠą│ąŠ ą┐ąŠą╗čÅ:
Console.WriteLine (Interlocked.Read (ref _sum)); // 3
// ąŚą░ą┐ąĖčüčī 64-ą▒ąĖčéąĮąŠą│ąŠ ą┐ąŠą╗čÅ čü ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮčŗą╝ čćč鹥ąĮąĖąĄą╝ ą┐čĆąĄą┤čŗą┤čāčēąĄą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ.
// ąŁčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ ą▓čŗą▓ąĄą┤ąĄčé "3", ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ąŠą▒ąĮąŠą▓ąĖčé _sum ąĘąĮą░č湥ąĮąĖąĄą╝ 10:
Console.WriteLine (Interlocked.Exchange (ref _sum, 10)); // 10
// ą×ą▒ąĮąŠą▓ąĖčé ą┐ąŠą╗ąĄ č鹊ą╗čīą║ąŠ ą▓ č鹊ą╝ čüą╗čāčćą░ąĄ, ąĄčüą╗ąĖ ąŠąĮąŠ čüąŠą▓ą┐ą░ą┤ą░ąĄčé čü ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╝
// ąĘąĮą░č湥ąĮąĖąĄą╝ (10):
Console.WriteLine (Interlocked.CompareExchange (ref _sum,
123, 10); // 123
}
}
ąÆčüąĄ ą╝ąĄč鹊ą┤čŗ ą║ą╗ą░čüčüą░ Interlocked ą│ąĄąĮąĄčĆąĖčĆčāčÄčé ą┐ąŠą╗ąĮčŗą╣ ą▒ą░čĆčīąĄčĆ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ą┐ąŠą╗čÅ, ą║ ą║ąŠč鹊čĆčŗą╝ ąÆčŗ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄč鹥 ą┤ąŠčüčéčāą┐ č湥čĆąĄąĘ Interlocked, ąĮąĄ ąĮčāąČą┤ą░čÄčéčüčÅ ą▓ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ą▒ą░čĆčīąĄčĆą░čģ ą┐ą░ą╝čÅčéąĖ - ąĄčüą╗ąĖ ą▓ ą┤čĆčāą│ąĖčģ ą╝ąĄčüčéą░čģ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą║ ąĮąĖą╝ ąĮąĄ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ ą▒ąĄąĘ Interlocked ąĖą╗ąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ.
ą£ą░č鹥ą╝ą░čéąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ Interlocked ąŠą│čĆą░ąĮąĖč湥ąĮčŗ ąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ (Increment), ą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (Decrement), ąĖ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄą╝ (Add). ąĢčüą╗ąĖ ąÆčŗ čģąŠčéąĖč鹥 ą┐čĆąĖą╝ąĄąĮąĖčéčī čāą╝ąĮąŠąČąĄąĮąĖąĄ - ąĖą╗ąĖ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą┤čĆčāą│ąŠąĄ ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ - č鹊 ą╝ąŠąČąĄč鹥 ą▓čŗą┐ąŠą╗ąĮąĖčéčī čŹč鹊 ą▓ čüčéąĖą╗ąĄ ą▒ąĄąĘ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą╝ąĄč鹊ą┤ą░ CompareExchange (ąŠą▒čŗčćąĮąŠ ą▓ą╝ąĄčüč鹥 čü čåąĖą║ą╗ąĖč湥čüą║ąĖą╝ ąŠąČąĖą┤ą░ąĮąĖąĄą╝). ą¤čĆąĖą╝ąĄčĆ ą▒čāą┤ąĄčé ą┤ą░ąĮ ą▓ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ ą┐ąŠ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą╝čā ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÄ [6].
Interlocked čĆą░ą▒ąŠčéą░ąĄčé ą┐ąŠ ą┐čĆąĖąĮčåąĖą┐čā ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĖčÅ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ąŠą▒ ą░č鹊ą╝ą░čĆąĮąŠčüčéąĖ ą┤ą╗čÅ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ ąĖ ą▓ąĖčĆčéčāą░ą╗čīąĮąŠą╣ ą╝ą░čłąĖąĮčŗ.
ą£ąĄč鹊ą┤čŗ Interlocked ąŠą▒čŗčćąĮąŠ ą▓ąŠą▓ą╗ąĄą║ą░čÄčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčāčÄ ąĮą░ą│čĆčāąĘą║čā 10 ąĮčü, ą┐ąŠą╗ąŠą▓ąĖąĮą░ ą║ąŠč鹊čĆąŠą╣ - ą▓ą┤ą▓ąŠąĄ ą╝ąĄąĮčīčłąĄ, č湥ą╝ ąŠą▒čŗčćąĮą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░, ąĮą░ ą║ąŠč鹊čĆąŠą╣ ąĮąĄčé ą║ąŠąĮą║čāčĆąĄąĮčéąĮąŠą│ąŠ ąŠąČąĖą┤ą░ąĮąĖčÅ. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą╝ąĄč鹊ą┤ąŠą▓ Interlocked ąĮąĄ ą▓ąĮąŠčüąĖčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ąĘą░čéčĆą░čé ąĮą░ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą║ąŠąĮč鹥ą║čüčéą░ ąĖąĘ-ąĘą░ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ. ą×ą▒čĆą░čéąĮą░čÅ čüč鹊čĆąŠąĮą░ ą╝ąĄą┤ą░ą╗ąĖ - Interlocked ą▓ąĮčāčéčĆąĖ čåąĖą║ą╗ą░ čü ą▒ąŠą╗čīčłąĖą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąŠą╝ ąĖč鹥čĆą░čåąĖą╣ ą╝ąĄąĮąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠ, č湥ą╝ ąŠą┤ąĮą░ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą▓ąŠą║čĆčāą│ ą▓čüąĄą│ąŠ čåąĖą║ą╗ą░ (čģąŠčéčÅ Interlocked ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čāą╗čāčćčłąĖčéčī ą║ąŠąĮą║čāčĆąĄąĮčéąĮąŠčüčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐ąŠč鹊ą║ąŠą▓).
[ą×ą▒ą╝ąĄąĮ čüąĖą│ąĮą░ą╗ą░ą╝ąĖ č湥čĆąĄąĘ Wait ąĖ Pulse]
ąĀą░ąĮąĄąĄ ą╝čŗ ąŠą▒čüčāąČą┤ą░ą╗ąĖ čüąŠą▒čŗčéąĖčÅ čü ąŠą▒čĆą░ą▒ąŠčéą║ąŠą╣ ąŠąČąĖą┤ą░ąĮąĖčÅ (Event Wait Handles [3]) - ą┐čĆąŠčüč鹊ą╣ ą╝ąĄčģą░ąĮąĖąĘą╝ čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖąĖ, ą│ą┤ąĄ ą┐ąŠč鹊ą║ ą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ ą┤ąŠ ą╝ąŠą╝ąĄąĮčéą░ ą┐ąŠą╗čāč湥ąĮąĖčÅ ąŠą┐ąŠą▓ąĄčēąĄąĮąĖčÅ ąŠčé ą┤čĆčāą│ąŠą│ąŠ ą┐ąŠč鹊ą║ą░.
ąæąŠą╗ąĄąĄ ą╝ąŠčēąĮą░čÅ ą║ąŠąĮčüčéčĆčāą║čåąĖčÅ čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖąĖ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčéčüčÅ ą║ą╗ą░čüčüąŠą╝ Monitor č湥čĆąĄąĘ čüčéą░čéąĖč湥čüą║ąĖąĄ ą╝ąĄč鹊ą┤čŗ Wait ąĖ Pulse (ąĖ PulseAll). ą¤čĆąĖąĮčåąĖą┐ čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, čćč鹊 ąÆčŗ ą┐ąĖčłąĄč鹥 ą╗ąŠą│ąĖą║čā čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖąĖ čüą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮąŠ, ąĖčüą┐ąŠą╗čīąĘčāčÅ čüą▓ąŠąĖ čäą╗ą░ą│ąĖ ąĖ ą┐ąŠą╗čÅ (ąŠą▒čĆą░ą╝ą╗ąĄąĮąĮčŗąĄ ąŠą┐ąĄčĆą░č鹊čĆą░ą╝ąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ lock), ąĖ ąĘą░č鹥ą╝ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄč鹥 ą║ąŠą╝ą░ąĮą┤čŗ Wait ąĖ Pulse, čćč鹊ą▒čŗ ą┐čĆąĄą┤ąŠčéą▓čĆą░čéąĖčéčī čåąĖą║ą╗čŗ ąŠąČąĖą┤ą░ąĮąĖčÅ. ąĪ čŹčéąĖą╝ąĖ ąČąĄ ą╝ąĄč鹊ą┤ą░ą╝ąĖ ąĖ ąŠą┐ąĄčĆą░č鹊čĆąŠą╝ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ lock ąÆčŗ ą╝ąŠąČąĄč鹥 ą┤ąŠčüčéąĖčćčī čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéąĖ AutoResetEvent, ManualResetEvent ąĖ Semaphore, ą║ą░ą║ ąĖ (čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ąŠą│ąŠą▓ąŠčĆą║ą░ą╝ąĖ) čüčéą░čéąĖč湥čüą║ąĖčģ ą╝ąĄč鹊ą┤ąŠą▓ WaitAll ąĖ WaitAny ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ ąŠąČąĖą┤ą░ąĮąĖčÅ WaitHandle.
ą×ą┤ąĮą░ą║ąŠ čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖčÅ Wait ąĖ Pulse ąĖą╝ąĄąĄčé ąĮąĄą║ąŠč鹊čĆčŗąĄ ąĮąĄą┤ąŠčüčéą░čéą║ąĖ ą┐ąŠ čüčĆą░ą▓ąĮąĄąĮąĖčÄ čü ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ą╝ąĖ čüąŠą▒čŗčéąĖą╣ ąŠąČąĖą┤ą░ąĮąĖčÅ:
ŌĆó Wait/Pulse ąĮąĄ ą╝ąŠą│čāčé ą┐ąĄčĆąĄčüąĄą║ą░čéčī ą┤ąŠą╝ąĄąĮčŗ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ (ąĖą╗ąĖ ą┐čĆąŠčåąĄčüčüčŗ) ąĮą░ ą║ąŠą╝ą┐čīčÄč鹥čĆąĄ.
ŌĆó ąÆą░ą╝ ąĮčāąČąĮąŠ ą┐ąŠą╝ąĮąĖčéčī ąŠ ąĘą░čēąĖč鹥 ą▓čüąĄčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ, čüą▓čÅąĘą░ąĮąĮčŗčģ čü ą╗ąŠą│ąĖą║ąŠą╣ čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖąĖ čü ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ą╝ąĖ.
ŌĆó ą¤čĆąŠą│čĆą░ą╝ą╝čŗ Wait/Pulse ą╝ąŠą│čāčé ąĘą░ą┐čāčéą░čéčī čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ąŠą▓, ą┐ąŠą╗ą░ą│ą░čÄčēąĖčģčüčÅ ąĮą░ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖčÄ Microsoft.
ą¤čĆąŠą▒ą╗ąĄą╝ą░ čŹč鹊ą╣ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ ą▓ąŠąĘąĮąĖą║ą░ąĄčé ą┐ąŠč鹊ą╝čā, čćč鹊 ąĮąĄ ąŠč湥ą▓ąĖą┤ąĮąŠ, ą║ą░ą║ ą┐čĆąĄą┤ą┐ąŠą╗ą░ą│ą░ąĄčéčüčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī Wait ąĖ Pulse, ą┤ą░ąČąĄ ą║ąŠą│ą┤ą░ ąÆčŗ ą┐čĆąŠčćąĖčéą░ą╗ąĖ ąŠ č鹊ą╝, ą║ą░ą║ ąŠąĮąĖ čĆą░ą▒ąŠčéą░čÄčé. Wait ąĖ Pulse čéą░ą║ąČąĄ ąĖą╝ąĄčÄčé ąŠčüąŠą▒čāčÄ ąĮąĄąĮą░ą▓ąĖčüčéčī ą║ ą┤ąĖą╗ąĄčéą░ąĮčéą░ą╝: ą▒čāą┤čāčé ąĖčüą║ą░čéčī ą╗čÄą▒čŗąĄ ą┐čĆąŠčĆąĄčģąĖ ą▓ ą┐ąŠąĮąĖą╝ą░ąĮąĖąĖ ąĖčģ ą┐čĆąĖąĮčåąĖą┐ą░ čĆą░ą▒ąŠčéčŗ, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ą▒čāą┤čāčé ąĖąĘą▓čĆą░čēąĄąĮąĮąŠ ąĮą░ą┤ ąÆą░ą╝ąĖ ąĖąĘą┤ąĄą▓ą░čéčīčüčÅ! ąÜ čüčćą░čüčéčīčÄ, ąĄčüčéčī ą┐čĆąŠčüčéčŗąĄ ą┐čĆąĖą╝ąĄčĆčŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ Wait ąĖ Pulse.
ąĪ č鹊čćą║ąĖ ąĘčĆąĄąĮąĖčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą▓čŗąĘąŠą▓ Pulse ąĘą░ąĮąĖą╝ą░ąĄčé ąĮąĄčüą║ąŠą╗čīą║ąŠ čüąŠč鹥ąĮ ąĮą░ąĮąŠčüąĄą║čāąĮą┤ ą▓ 菹┐ąŠčģčā ą║ąŠą╝ą┐čīčÄč鹥čĆąŠą▓ 2010-čģ ą│ąŠą┤ąŠą▓ - ąŠą║ąŠą╗ąŠ čéčĆąĄčéąĖ ą▓čĆąĄą╝ąĄąĮąĖ, ą║ąŠč鹊čĆąŠąĄ ąĘą░ąĮąĖą╝ą░ąĄčé ą▓čŗąĘąŠą▓ Set ąĮą░ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąĄ ąŠąČąĖą┤ą░ąĮąĖčÅ. ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮą░čÅ ąĮą░ą│čĆčāąĘą║ą░ ąĮą░ ąŠąČąĖą┤ą░ąĮąĖąĄ čüąĖą│ąĮą░ą╗ą░, ą║ąŠą│ą┤ą░ ąĮąĄčé ą║ąŠąĮą║čāčĆąĄąĮčéąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░, ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąĘą░ą▓ąĖčüąĖčé ąŠčé ąÆą░čü - ą┐ąŠč鹊ą╝čā čćč鹊 ąĖą╝ąĄąĮąĮąŠ ąÆčŗ čüą░ą╝ąĖ čĆąĄą░ą╗ąĖąĘčāąĄč鹥 ą╗ąŠą│ąĖą║čā čü ąŠą▒čŗčćąĮčŗą╝ąĖ ą┐ąŠą╗čÅą╝ąĖ ąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝ąĖ. ąØą░ ą┐čĆą░ą║čéąĖą║ąĄ čŹč鹊 ąŠč湥ąĮčī ą┐čĆąŠčüč鹊, ąĖ ą▓čŗčćąĖčüą╗ąĖč鹥ą╗čīąĮčŗąĄ čĆą░čüčģąŠą┤čŗ ąĮąĄ ą┐čĆąĄą▓čŗčłą░čÄčé ą▓čĆąĄą╝čÅ, ąĘą░čéčĆą░čćąĖą▓ą░ąĄą╝ąŠąĄ ąĮą░ ą▓ąĘčÅčéąĖąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ.
ąÜą░ą║ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī Wait ąĖ Pulse. ąĀą░čüčüą╝ąŠčéčĆąĖą╝ ą┐čĆąĖą╝ąĄčĆ:
1. ą×ą┐čĆąĄą┤ąĄą╗ąĖą╝ ąŠą┤ąĮąŠ ą┐ąŠą╗ąĄ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą▓ ą║ą░č湥čüčéą▓ąĄ ąŠą▒čŖąĄą║čéą░ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ:
readonly object _locker = new object();
2. ą×ą┐čĆąĄą┤ąĄą╗ąĖą╝ ą┐ąŠą╗ąĄ (ąĖą╗ąĖ ą┐ąŠą╗čÅ) ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą▓ ąÆą░čłąĄą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąŠą╝ čāčüą╗ąŠą▓ąĖąĖ (čāčüą╗ąŠą▓ąĖčÅčģ) ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ. ą¤čĆąĖą╝ąĄčĆ:
ąĖą╗ąĖ:
3. ąÆčüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ąÆčŗ čģąŠčéąĖč鹥 ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā, ą┤ąŠą▒ą░ą▓čīč鹥 čüą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤:
lock (_locker)
while ( < čāčüą╗ąŠą▓ąĖąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ > )
Monitor.Wait (_locker);
4. ąÆčüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ąÆčŗ ą╝ąĄąĮčÅąĄč鹥 (ąĖą╗ąĖ ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ ą╝ąĄąĮčÅąĄč鹥) čāčüą╗ąŠą▓ąĖąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ, ą┤ąŠą▒ą░ą▓čīč鹥 čüą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤:
lock (_locker)
{
// ąŚą┤ąĄčüčī ąĖąĘą╝ąĄąĮčÅą╣č鹥 ą┐ąŠą╗ąĄ (ą┐ąŠą╗čÅ) ąĖą╗ąĖ ą┤ą░ąĮąĮčŗąĄ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą┐ąŠą▓ą╗ąĖčÅčéčī ąĮą░
// čāčüą╗ąŠą▓ąĖąĄ (čāčüą╗ąŠą▓ąĖčÅ) ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ:
// ...
Monitor.Pulse(_locker); // ąĖą╗ąĖ: Monitor.PulseAll (_locker);
}
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąĄčüą╗ąĖ ąÆčŗ ą╝ąĄąĮčÅąĄč鹥 čāčüą╗ąŠą▓ąĖąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ąĖ čģąŠčéąĖč鹥 ąČą┤ą░čéčī, č鹊 ą╝ąŠąČąĄč鹥 čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī čłą░ą│ąĖ 3 ąĖ 4 ą▓ ąŠą┤ąĮąŠą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĄ.
ąŁč鹊čé čłą░ą▒ą╗ąŠąĮ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą╗čÄą▒ąŠą╝čā ą┐ąŠč鹊ą║čā ąČą┤ą░čéčī ą╗čÄą▒ąŠąĄ ą▓čĆąĄą╝čÅ ą╗čÄą▒ąŠą│ąŠ čāčüą╗ąŠą▓ąĖčÅ. ąØąĖąČąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮ ą┐čĆąŠčüč鹊ą╣ ą┐čĆąĖą╝ąĄčĆ, ą│ą┤ąĄ čĆą░ą▒ąŠčćąĖą╣ ą┐ąŠč鹊ą║ ąČą┤ąĄčé, ą║ąŠą│ą┤ą░ ą┐ąŠą╗ąĄ _go čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ ą▓ true:
class SimpleWaitPulse
{
static readonly object _locker = new object();
static bool _go;
static void Main()
{ // ąØąŠą▓čŗą╣ ą┐ąŠč鹊ą║ ąĘą░ą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ,
new Thread (Work).Start(); // ą┐ąŠč鹊ą╝čā čćč鹊 _go==false.
Console.ReadLine(); // ą×ąČąĖą┤ą░ąĮąĖąĄ, ą║ąŠą│ą┤ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ąĮą░ąČą╝ąĄčé Enter.
lock (_locker) // ą¤ąŠąĘą▓ąŠą╗ąĖą╝ ą┐ąŠč鹊ą║čā ą┐čĆąŠą▒čāą┤ąĖčéčīčüčÅ ą┐čāč鹥ą╝ čāčüčéą░ąĮąŠą▓ą║ąĖ
{ // _go=true ąĖ ą▓čŗąĘąŠą▓ą░ Pulse.
_go = true;
Monitor.Pulse (_locker);
}
}
static void Work()
{
lock (_locker)
while (!_go)
Monitor.Wait (_locker); // ą×čüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą▓ąŠ ą▓čĆąĄą╝čÅ ąŠąČąĖą┤ą░ąĮąĖčÅ.
Console.WriteLine ("ą¤čĆąŠčüąĮčāą╗čüčÅ!!!");
}
}
ąŁč鹊čé ą║ąŠą┤ ą▓čŗą▓ąĄą┤ąĄčé čüą╗ąĄą┤čāčÄčēąĄąĄ (ą┐ąŠčüą╗ąĄ ąĮą░ąČą░čéąĖčÅ Enter):
ąöą╗čÅ ą▒ąĄąĘąŠą┐ą░čüąĮąŠą╣ čĆą░ą▒ąŠčéčŗ ą┐ąŠč鹊ą║ąŠą▓ ą╝čŗ ą│ą░čĆą░ąĮčéąĖčĆčāąĄą╝, čćč鹊 ą║ąŠ ą▓čüąĄą╝ ąŠą▒čēąĖą╝ ą┐ąŠą╗čÅą╝ ą┤ąŠčüčéčāą┐ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ č湥čĆąĄąĘ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā. ąĪą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ, ą╝čŗ ą┤ąŠą▒ą░ą▓ą╗čÅąĄą╝ ąŠą┐ąĄčĆą░č鹊čĆčŗ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ lock ą▓ąŠą║čĆčāą│ čćč鹥ąĮąĖčÅ ąĖ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ čäą╗ą░ą│ą░ _go. ąŁč鹊 ąŠčüąĮąŠą▓ą░ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠą╣ ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéąĖ (ąĄčüą╗ąĖ ąÆčŗ ąĮąĄ čüąŠą▒ąĖčĆą░ąĄč鹥čüčī čüą╗ąĄą┤ąŠą▓ą░čéčī ą┐čĆąĖąĮčåąĖą┐ą░ą╝ ąĮąĄ ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĄą╣ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ).
ą£ąĄč鹊ą┤ ą▒ą╗ąŠą║ čŹč鹊 č鹊 ą╝ąĄčüč鹊, ą│ą┤ąĄ ą╝čŗ ą▒ą╗ąŠą║ąĖčĆčāąĄą╝ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ąŠą┤ą░ ąĮą░ ą┤ąŠčüčéčāą┐ąĄ ą║ ąŠą▒čēąĄą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣, čü ąŠąČąĖą┤ą░ąĮąĖąĄą╝, ą║ąŠą│ą┤ą░ čäą╗ą░ą│ _go čüčéą░ąĮąĄčé true. ą£ąĄč鹊ą┤ Monitor.Wait ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ą▓ąŠčé čŹčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ, ą▓ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┐ąŠčĆčÅą┤ą║ąĄ:
1. ą×čüą▓ąŠą▒ąŠąČą┤ą░ąĄčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ąĮą░ _locker.
2. ąæą╗ąŠą║ąĖčĆčāąĄčéčüčÅ, ą┐ąŠą║ą░ ąĮąĄ ą▒čāą┤ąĄčé ą▓čŗąĘą▓ą░ąĮ Pulse ąĮą░ _locker.
3. ąŚą░ąĮąŠą▓ąŠ ąĘą░ą┐čĆą░čłąĖą▓ą░ąĄčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ąĮą░ _locker. ąĢčüą╗ąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą║ąŠąĮą║čāčĆąĄąĮčéąĮąŠ ąĘą░ąĮčÅčéą░, č鹊 ą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ ą┤ąŠ č鹥čģ ą┐ąŠčĆ, ą┐ąŠą║ą░ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ąĮąĄ čüčéą░ąĮąĄčé ą┤ąŠčüčéčāą┐ąĮąŠą╣.
ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą▓ ą╗čÄą▒ąŠą╝ čüą╗čāčćą░ąĄ ąĮąĄ čāą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ąĮą░ ąŠą▒čŖąĄą║č鹥 čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ, ą┐ąŠą║ą░ Monitor.Wait ąŠąČąĖą┤ą░ąĄčé Pulse:
lock (_locker)
{
while (!_go)
Monitor.Wait (_locker); // ąæą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮą░.
// ąæą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą▓ąĘčÅčéą░ čüąĮąŠą▓ą░.
...
}
ąŚą░č鹥ą╝ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐čĆąŠą┤ąŠą╗ąČą░ąĄčéčüčÅ ąĮą░ čüą╗ąĄą┤čāčÄčēąĄą╝ ąŠą┐ąĄčĆą░č鹊čĆąĄ. Monitor.Wait čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą▓ąĮčāčéčĆąĖ ąŠą┐ąĄčĆą░č鹊čĆą░ lock; ąĄčüą╗ąĖ ąŠąĮ ą▒čāą┤ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮ ą┐ąŠ-ą┤čĆčāą│ąŠą╝čā, č鹊 ą▒čāą┤ąĄčé ą▓čŗą▒čĆąŠčłąĄąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ. ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ ą║ą░čüą░ąĄčéčüčÅ ąĖ Monitor.Pulse.
ąÆ ą╝ąĄč鹊ą┤ąĄ Main ą╝čŗ ą┐ąŠą┤ą░ąĄą╝ čüąĖą│ąĮą░ą╗ ą┤ą╗čÅ čĆą░ą▒ąŠč湥ą│ąŠ ą┐ąŠč鹊ą║ą░ Work čāčüčéą░ąĮąŠą▓ą║ąŠą╣ čäą╗ą░ą│ą░ _go (ą▓ąĮčāčéčĆąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ) ąĖ ą▓čŗąĘąŠą▓ąŠą╝ Pulse. ąÜą░ą║ č鹊ą╗čīą║ąŠ ą╝čŗ ąŠčüą▓ąŠą▒ąŠą┤ąĖą╗ąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā, čĆą░ą▒ąŠčćąĖą╣ ą┐ąŠč鹊ą║ ą▓ąŠąĘąŠą▒ąĮąŠą▓ąĖčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ, ą┐čĆąŠą║čĆčāčéąĖą▓ čåąĖą║ą╗ while.
ą£ąĄč鹊ą┤čŗ Pulse ąĖ PulseAll ąŠčüą▓ąŠą▒ąŠąČą┤ą░čÄčé ą┐ąŠč鹊ą║ąĖ, ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ąĮą░ ąŠą┐ąĄčĆą░č鹊čĆąĄ Wait. Pulse ąŠčüą▓ąŠą▒ąŠą┤ąĖčé ą╝ą░ą║čüąĖą╝čāą╝ 1 ą┐ąŠč鹊ą║; PulseAll ąŠčüą▓ąŠą▒ąŠą┤ąĖčé ąĖčģ ą▓čüąĄ. ąÆ ąĮą░čłąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ čéą░ą║ ą║ą░ą║ č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ ą┐ąŠč鹊ą║ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮ, č鹊 ąĮąĄ ąĖą╝ąĄąĄčé ąĘąĮą░č湥ąĮąĖąĄ ą║ą░ą║ąŠą╣ ą╝ąĄč鹊ą┤ ą▓čŗąĘą▓ą░čéčī - Pulse ąĖą╗ąĖ PulseAll, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąĮąĖ ą▒čāą┤čāčé ą┤ąĄą╣čüčéą▓ąŠą▓ą░čéčī ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠ. ąĢčüą╗ąĖ ąŠąČąĖą┤ą░čÄčé ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą│ąŠ ą┐ąŠč鹊ą║ą░, č鹊 ą▓čŗąĘąŠą▓ PulseAll ąŠą▒čŗčćąĮąŠ čüą░ą╝čŗą╣ ą▒ąĄąĘąŠą┐ą░čüąĮčŗą╣ čłą░ą▒ą╗ąŠąĮ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ.
ą¦č鹊ą▒čŗ ąČą┤ą░čéčī (Wait) ąŠą▒ą╝ąĄąĮą░ čü ą┐ąŠą╝ąŠčēčīčÄ Pulse ąĖą╗ąĖ PulseAll, čüąĖąĮčģčĆąŠąĮąĖąĘąĖčĆčāčÄčēąĖą╣ ąŠą▒čŖąĄą║čé (ą▓ ąĮą░čłąĄą╝ čüą╗čāčćą░ąĄ _locker) ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ.
ąÆ ąĮą░čłąĄą╝ čłą░ą▒ą╗ąŠąĮąĄ ą▓čŗąĘąŠą▓ Pulse ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čćč鹊-č鹊 ą╝ąŠą│ą╗ąŠ ą┐ąŠą╝ąĄąĮčÅčéčīčüčÅ, ąĖ čŹč鹊čé ąŠąČąĖą┤ą░čÄčēąĖą╣ ą┐ąŠč鹊ą║ ą┤ąŠą╗ąČąĄąĮ ą┐čĆąŠą▓ąĄčĆąĖčéčī ąĘą░ąĮąŠą▓ąŠ čüą▓ąŠąĖ čāčüą╗ąŠą▓ąĖčÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ. ąÆ ą╝ąĄč鹊ą┤ąĄ ą┐ąŠč鹊ą║ą░ Work, čŹčéą░ ą┐čĆąŠą▓ąĄčĆą║ą░ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą▓ čāčüą╗ąŠą▓ąĖąĖ čåąĖą║ą╗ą░ while. ąóąŠą│ą┤ą░ ąŠąČąĖą┤ą░čÄčēąĖą╣ ą┐ąŠč鹊ą║ ą┐čĆąĖąĮąĖą╝ą░ąĄčé čĆąĄčłąĄąĮąĖąĄ ąŠ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖąĖ, ą░ ąĮąĄ ąŠą┐ąŠą▓ąĄčēą░čÄčēąĖą╣ ą┐ąŠč鹊ą║. ąĢčüą╗ąĖ ą▓čŗąĘąŠą▓ Pulse čüą░ą╝ąŠ ą┐ąŠ čüąĄą▒ąĄ ą▒ąĄčĆąĄčéčüčÅ ą║ą░ą║ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąŠą┤ąŠą╗ąČąĖčéčīčüčÅ, ą║ąŠąĮčüčéčĆčāą║čåąĖčÅ Wait ą╗ąĖčłą░ąĄčéčüčÅ ą╗čÄą▒ąŠą╣ čĆąĄą░ą╗čīąĮąŠą╣ ąĘąĮą░čćąĖą╝ąŠčüčéąĖ; ąÆčŗ ąĘą░ą║ą░ąĮčćąĖą▓ą░ąĄč鹥 čü ąĮąĖąĘčłąĄą╣ ą▓ąĄčĆčüąĖąĄą╣ AutoResetEvent.
ąĢčüą╗ąĖ ą╝čŗ čüčéą░ą▓ąĖą╝ ąĮą░čł čłą░ą▒ą╗ąŠąĮ čāą┤ą░ą╗ąĄąĮąĖąĄą╝ čåąĖą║ą╗ą░ while, čäą╗ą░ą│ą░ _go ąĖ ReadLine, č鹊 ą┐čĆąĖą┤ąĄą╝ ą║ ą┐čĆąŠčüč鹥ą╣čłąĄą╝čā ą┐čĆąĖą╝ąĄčĆčā Wait/Pulse:
static void Main()
{
new Thread (Work).Start();
lock (_locker) Monitor.Pulse (_locker);
}
static void Work()
{
lock (_locker) Monitor.Wait (_locker);
Console.WriteLine ("ą¤čĆąŠčüąĮčāą╗čüčÅ!!!");
}
ąŁč鹊 ąĮąĄ čüą╝ąŠąČąĄčé ąŠč鹊ą▒čĆą░ąĘąĖčéčī ą▓čŗą▓ąŠą┤, ą┐ąŠč鹊ą╝čā čćč鹊 ąĄą│ąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĮąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠąĄ! ą¤čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą│ąŠąĮą║ą░ ą╝ąĄąČą┤čā ą│ą╗ą░ą▓ąĮčŗą╝ ą┐ąŠč鹊ą║ąŠą╝ (č鹥ą╗ąŠ ą┐čĆąŠčåąĄą┤čāčĆčŗ Main) ąĖ čĆą░ą▒ąŠčćąĖą╝ ą┐ąŠč鹊ą║ąŠą╝ (č鹥ą╗ąŠ ą┐čĆąŠčåąĄą┤čāčĆčŗ Work). ąĢčüą╗ąĖ čüąĮą░čćą░ą╗ą░ ą▓čŗą┐ąŠą╗ąĮąĖčéčüčÅ Wait, č鹊 čüąĖą│ąĮą░ą╗ čüčĆą░ą▒ąŠčéą░ąĄčé. ąĢčüą╗ąĖ čüąĮą░čćą░ą╗ą░ ą▓čŗą┐ąŠą╗ąĮąĖčéčüčÅ Pulse, č鹊 čŹč鹊čé čüąĖą│ąĮą░ą╗ ą┐čĆąŠą┐ą░ą┤ąĄčé, ąĖ čĆą░ą▒ąŠčćąĖą╣ ą┐ąŠč鹊ą║ ąĮą░ą▓čüąĄą│ą┤ą░ ąŠčüčéą░ąĮąĄčéčüčÅ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĮčŗą╝. ąŁč鹊 ąŠčéą╗ąĖčćą░ąĄčéčüčÅ ąŠčé ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ AutoResetEvent, ą│ą┤ąĄ ą╝ąĄč鹊ą┤ Set ąĖą╝ąĄąĄčé čŹčäč乥ą║čé ą┐ą░ą╝čÅčéąĖ ąĖą╗ąĖ "ąĘą░čēąĄą╗ą║ąĖą▓ą░ąĮąĖčÅ", čéą░ą║ čćč鹊 ąŠąĮ ą▓čüąĄ ąĄčēąĄ ą▒čāą┤ąĄčé čŹčäč乥ą║čéąĖą▓ąĮčŗą╝, ąĄčüą╗ąĖ ą▓čŗąĘąŠą▓ąĄčéčüčÅ ą┐ąĄčĆąĄą┤ WaitOne.
ąŻ Pulse ąĮąĄčé čŹčäč乥ą║čéą░ ąĘą░čēąĄą╗ą║ąĖą▓ą░ąĮąĖčÅ, ą┐ąŠč鹊ą╝čā čćč鹊 ąÆčŗ ąŠąČąĖą┤ą░ąĄč鹥 ąĘą░ą┐ąĖčüąĖ ą▓ čüą░ą╝čā ąĘą░čēąĄą╗ą║čā, ą┤ą╗čÅ č湥ą│ąŠ ą╝čŗ čĆą░ąĮąĄąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ąĖ čäą╗ą░ą│ "_go". ąŁč鹊čé ą╝ąŠą╝ąĄąĮčé ą┤ąĄą╗ą░ąĄčé Wait ąĖ Pulse čāąĮąĖą▓ąĄčĆčüą░ą╗čīąĮčŗą╝ąĖ: čü ą┤ą▓ąŠąĖčćąĮčŗą╝ čäą╗ą░ą│ąŠą╝ ą╝čŗ ą╝ąŠąČąĄą╝ ąĘą░čüčéą░ą▓ąĖčéčī ąĖčģ čĆą░ą▒ąŠčéą░čéčī čéą░ą║ ąČąĄ, ą║ą░ą║ ąĖ AutoResetEvent; čü ą┐ąŠą╗ąĄą╝ int ą╝čŗ ą╝ąŠąČąĄą╝ ąĮą░ą┐ąĖčüą░čéčī CountdownEvent ąĖą╗ąĖ Semaphore. ąĪ ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮčŗą╝ąĖ čüčéčĆčāą║čéčāčĆą░ą╝ąĖ ą┤ą░ąĮąĮčŗčģ ą╝čŗ ą╝ąŠąČąĄą╝ ą┐ąŠą╣čéąĖ ą┤ą░ą╗čīčłąĄ ąĖ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī čéą░ą║ąĖąĄ ąČąĄ ą║ąŠąĮčüčéčĆčāą║čåąĖąĖ, ą║ą░ą║ ąŠč湥čĆąĄą┤čī ą│ąĄąĮąĄčĆą░č鹊čĆą░/ą┐ąŠą╗čāčćą░č鹥ą╗čÅ.
ą×č湥čĆąĄą┤čī ą│ąĄąĮąĄčĆą░č鹊čĆą░/ą┐ąŠą╗čāčćą░č鹥ą╗čÅ (Producer/Consumer Queue). ąĀą░ąĮąĄąĄ ą╝čŗ ąŠą┐ąĖčüčŗą▓ą░ą╗ąĖ ą║ąŠąĮčåąĄą┐čåąĖčÄ ąŠč湥čĆąĄą┤ąĖ producer/consumer, ąĖ ą║ą░ą║ ąĮą░ą┐ąĖčüą░čéčī ąĄčæ čü ą┐ąŠą╝ąŠčēčīčÄ AutoResetEvent. ąóąĄą┐ąĄčĆčī ą╝čŗ ą┐čĆąĖčüčéčāą┐ąĖą╝ ą║ ąĮą░ą┐ąĖčüą░ąĮąĖčÄ ą▒ąŠą╗ąĄąĄ ą╝ąŠčēąĮąŠą╣ ą▓ąĄčĆčüąĖąĖ čü ą┐ąŠą╝ąŠčēčīčÄ Wait ąĖ Pulse.
ąĪąĄą╣čćą░čü ą╝čŗ ą┐ąŠąĘą▓ąŠą╗ąĖą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čĆą░ą▒ąŠčćąĖčģ ą┐ąŠč鹊ą║ąŠą▓. ąÆčüąĄ ą┐ąŠč鹊ą║ąĖ ą▒čāą┤ąĄą╝ ąŠčéčüą╗ąĄąČąĖą▓ą░čéčī ą▓ ą╝ą░čüčüąĖą▓ąĄ:
ąŁč鹊 ą┤ą░čüčé ąĮą░ą╝ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą┐ąŠą┤ą║ą╗čÄčćą░čéčīčüčÅ (Join) ą║ čŹčéąĖą╝ ą┐ąŠč鹊ą║ą░ą╝ ą┐ąŠąĘąČąĄ, ą║ąŠą│ą┤ą░ ą╝čŗ ą▒čāą┤ąĄą╝ ąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čéčī ąŠč湥čĆąĄą┤čī.
ąÜą░ąČą┤čŗą╣ čĆą░ą▒ąŠčćąĖą╣ ą┐ąŠč鹊ą║ ą▒čāą┤ąĄčé ą▓čŗą┐ąŠą╗ąĮčÅčéčī ą╝ąĄč鹊ą┤ čü ąĖą╝ąĄąĮąĄą╝ Consume. ą£čŗ ą╝ąŠąČąĄą╝ čüąŠąĘą┤ą░čéčī ą┐ąŠč鹊ą║ąĖ ąĖ ąĘą░ą┐čāčüčéąĖčéčī ąĖčģ ą▓ ąŠą┤ąĮąŠą╝ čåąĖą║ą╗ąĄ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
public PCQueue (int workerCount)
{
_workers = new Thread [workerCount];
// ąĪąŠąĘą┤ą░ąĮąĖąĄ ąĖ ąĘą░ą┐čāčüą║ ąŠčéą┤ąĄą╗čīąĮąŠą│ąŠ ą┐ąŠč鹊ą║ą░.
for (int i = 0; i < workerCount; i++)
(_workers [i] = new Thread (Consume)).Start();
}
ąÆą╝ąĄčüč鹊 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┐čĆąŠčüč鹊ą╣ čüčéčĆąŠą║ąĖ ą┤ą╗čÅ ąŠą┐ąĖčüą░ąĮąĖčÅ ąĘą░ą┤ą░čćąĖ ą╝čŗ čĆąĄą░ą╗ąĖąĘčāąĄą╝ ą▒ąŠą╗ąĄąĄ ą│ąĖą▒ą║ąĖą╣ ą╝ąĄč鹊ą┤ čü ą┐ąŠą╝ąŠčēčīčÄ ą┤ąĄą╗ąĄą│ą░čéą░. ąæčāą┤ąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ąĄą╗ąĄą│ą░čéą░ System.Action ą▓ .NET Framework, ą║ąŠč鹊čĆčŗą╣ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
public delegate void Action();
ąŁč鹊čé ą┤ąĄą╗ąĄą│ą░čé čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ą╗čÄą▒ąŠą╝čā ą╝ąĄč鹊ą┤čā ą▒ąĄąĘ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ - ą▓ą╝ąĄčüč鹊 ą┤ąĄą╗ąĄą│ą░čéą░ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ ThreadStart. ą£čŗ ą▓čüąĄ ąĄčēąĄ ą╝ąŠąČąĄą╝ ą┐čĆąĄą┤čüčéą░ą▓ąĖčéčī ąĘą░ą┤ą░čćąĖ, ą║ąŠč鹊čĆčŗąĄ ą▓čŗąĘąŠą▓čāčé ą╝ąĄč鹊ą┤čŗ čü ą┐ą░čĆą░ą╝ąĄčéčĆą░ą╝ąĖ, čģąŠčéčÅ ą┐čāč鹥ą╝ ąŠą▒ąĄčĆčéą║ąĖ ą▓čŗąĘąŠą▓ą░ ą▓ ą░ąĮąŠąĮąĖą╝ąĮčŗą╣ ą┤ąĄą╗ąĄą│ą░čé ąĖą╗ąĖ lambda-ą▓čŗčĆą░ąČąĄąĮąĖčÅ:
Action myFirstTask = delegate
{
Console.WriteLine ("foo");
};
Action mySecondTask = () => Console.WriteLine ("foo");
Queue< Action> _itemQ = new Queue< Action>();
ą¤ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ą┐ąĄčĆąĄą╣čéąĖ ą║ ą╝ąĄč鹊ą┤ą░ą╝ EnqueueItem ąĖ Consume, ą┐ąŠčüą╝ąŠčéčĆąĖą╝ čüąĮą░čćą░ą╗ą░ ąĮą░ ą┐ąŠą╗ąĮčŗą╣ ą║ąŠą┤:
using System;
using System.Threading;
using System.Collections.Generic;
public class PCQueue
{
readonly object _locker = new object();
Thread[] _workers;
Queue< Action> _itemQ = new Queue< Action>();
public PCQueue (int workerCount)
{
_workers = new Thread [workerCount];
// ąĪąŠąĘą┤ą░ąĮąĖąĄ ąĖ ąĘą░ą┐čāčüą║ ąŠčéą┤ąĄą╗čīąĮąŠą│ąŠ ą┐ąŠč鹊ą║ą░ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ąĘą░ą┤ą░čćąĖ:
for (int i = 0; i < workerCount; i++)
(_workers [i] = new Thread (Consume)).Start();
}
public void Shutdown (bool waitForWorkers)
{
// ą¤ąŠčüčéą▓ąĖą╝ ą▓ ąŠč湥čĆąĄą┤čī ąŠą┤ąĖąĮ 菹╗ąĄą╝ąĄąĮčé null ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ąĘą░ą┤ą░čćąĖ,
// čćč鹊ą▒čŗ ąŠąĮą░ ąĘą░ą▓ąĄčĆčłąĖą╗ą░čüčī:
foreach (Thread worker in _workers)
EnqueueItem (null);
// ą×ąČąĖą┤ą░ąĮąĖąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ą▓čüąĄčģ čĆą░ą▒ąŠčćąĖčģ ąĘą░ą┤ą░čć:
if (waitForWorkers)
foreach (Thread worker in _workers)
worker.Join();
}
public void EnqueueItem (Action item)
{
lock (_locker)
{
_itemQ.Enqueue (item); // ą£čŗ ą┤ąŠą╗ąČąĮčŗ ą▓čŗąĘą▓ą░čéčī Pulse, ą┐ąŠč鹊ą╝čā čćč鹊
Monitor.Pulse (_locker); // ą┐ąŠą╝ąĄąĮčÅą╗ąĖ čāčüą╗ąŠą▓ąĖąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ.
}
}
void Consume()
{
while (true) // ą¤čĆąŠą┤ąŠą╗ąČąĖą╝ čĆą░ą▒ąŠčéčā, ą┐ąŠą║ą░ ąĮąĄ ą▒čāą┤ąĄčé
{ // čāą║ą░ąĘą░ąĮąŠ ąĮąĄčćč鹊 ą┤čĆčāą│ąŠąĄ.
Action item;
lock (_locker)
{
while (_itemQ.Count == 0) Monitor.Wait (_locker);
item = _itemQ.Dequeue();
}
if (item == null) return; // ąŁč鹊 ą┤ą░ąĄčé ąĮą░ą╝ čüąĖą│ąĮą░ą╗ ąĘą░ą▓ąĄčĆčłąĖčéčīčüčÅ.
item(); // ą×ą▒čĆą░ą▒ąŠčéą║ą░ 菹╗ąĄą╝ąĄąĮčéą░.
}
}
}
ąóčāčé čā ąĮą░čü čéą░ą║ąČąĄ ąĄčüčéčī čüčéčĆą░č鹥ą│ąĖčÅ ą┤ą╗čÅ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ čĆą░ą▒ąŠč湥ą╣ ąĘą░ą┤ą░čćąĖ: ą┐ąŠčüčéą░ąĮąŠą▓ą║ą░ ą▓ ąŠč湥čĆąĄą┤čī null čüąĖą│ąĮą░ą╗ąĖąĘąĖčĆčāąĄčé ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗čÄ ąĘą░ą▓ąĄčĆčłąĖčéčī čĆą░ą▒ąŠčéčā ą┐ąŠčüą╗ąĄ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą▓čüąĄčģ ąŠąČąĖą┤ą░čÄčēąĖčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓ (ąĄčüą╗ąĖ ą╝čŗ čģąŠčéąĖą╝ ą▓čŗą╣čéąĖ ą▒čŗčüčéčĆąĄąĄ, č鹊 čüą╗ąĄą┤čāąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗą╣ čäą╗ą░ą│ ąŠčéą╝ąĄąĮčŗ "cancel"). ą¤ąŠčüą║ąŠą╗čīą║čā ą╝čŗ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄą╝ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗ąĄą╣, č鹊 ą┤ąŠą╗ąČąĮčŗ ą┐ąŠčüčéą░ą▓ąĖčéčī ą▓ ąŠč湥čĆąĄą┤čī ąŠą┤ąĖąĮ null-菹╗ąĄą╝ąĄąĮčé ąĮą░ ą║ą░ąČą┤čŗą╣ ą┐ąŠč鹊ą║, čćč鹊ą▒čŗ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąŠčüčéą░ąĮąŠą▓ąĖčéčī ąŠč湥čĆąĄą┤čī.
ąØąĖąČąĄ ą┐ąŠą║ą░ąĘą░ąĮ ą║ąŠą┤ ą╝ąĄč鹊ą┤ą░ Main, ą║ąŠč鹊čĆčŗą╣ ąĘą░ą┐čāčüą║ą░ąĄčé ąŠč湥čĆąĄą┤čī producer/consumer, čāą║ą░ąĘčŗą▓ą░čÅ ą┤ą▓ą░ ą║ąŠąĮą║čāčĆąĖčĆčāčÄčēąĖčģ ą┐ąŠč鹊ą║ą░ - ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗čÅ, ąĖ ąĘą░č鹥ą╝ čüčéą░ą▓ąĖčé ą▓ ąŠč湥čĆąĄą┤čī 10 ą┤ąĄą╗ąĄą│ą░č鹊ą▓, ą║ąŠč鹊čĆčŗąĄ čüąŠą▓ą╝ąĄčüčéąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ čŹčéąĖą╝ąĖ ą┤ą▓čāą╝čÅ ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗čÅą╝ąĖ:
static void Main()
{
PCQueue q = new PCQueue (2);
Console.WriteLine ("ą¤ąŠčüčéą░ąĮąŠą▓ą║ą░ ą▓ ąŠč湥čĆąĄą┤čī 10 菹╗ąĄą╝ąĄąĮč鹊ą▓...");
for (int i = 0; i < 10; i++)
{
int itemNumber = i; // ą¦č鹊ą▒čŗ ąĖąĘą▒ąĄąČą░čéčī ąĘą░čģą▓ą░čéą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ą╗ąŠą▓čāčłą║ąŠą╣
q.EnqueueItem (() =>
{
Thread.Sleep (1000); // ąĪąĖą╝čāą╗čÅčåąĖčÅ ąĖąĮč鹥ąĮčüąĖą▓ąĮąŠą╣ ą▓čŗčćąĖčüą╗ąĖč鹥ą╗čīąĮąŠą╣ čĆą░ą▒ąŠčéčŗ
Console.Write (" Task" + itemNumber);
});
}
q.Shutdown (true);
Console.WriteLine();
Console.WriteLine ("ąĀą░ą▒ąŠčćąĖąĄ ą┐ąŠč鹊ą║ąĖ ąĘą░ą▓ąĄčĆčłąĖą╗ąĖčüčī!");
}
ąŁč鹊čé ą┐čĆąĖą╝ąĄčĆ ą▓čŗą▓ąĄą┤ąĄčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
ą¤ąŠčüčéą░ąĮąŠą▓ą║ą░ ą▓ ąŠč湥čĆąĄą┤čī 10 菹╗ąĄą╝ąĄąĮč鹊ą▓...
Task1 Task0 (pause...) Task2 Task3 (pause...) Task4 Task5 (pause...)
Task6 Task7 (pause...) Task8 Task9 (pause...)
ąĀą░ą▒ąŠčćąĖąĄ ą┐ąŠč鹊ą║ąĖ ąĘą░ą▓ąĄčĆčłąĖą╗ąĖčüčī!
ąóąĄą┐ąĄčĆčī ą┐ąŠčüą╝ąŠčéčĆąĖą╝ ąĮą░ ą╝ąĄč鹊ą┤ EnqueueItem:
public void EnqueueItem (Action item)
{
lock (_locker)
{
_itemQ.Enqueue (item); // ą£čŗ ą┤ąŠą╗ąČąĮčŗ ą▓čŗą┤ą░čéčī Pulse, ą┐ąŠč鹊ą╝čā čćč鹊
Monitor.Pulse (_locker); // ą┐ąŠą╝ąĄąĮčÅą╗ąĖ čāčüą╗ąŠą▓ąĖąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ.
}
}
ąóą░ą║ ą║ą░ą║ ąŠč湥čĆąĄą┤čī ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ ą┐ąŠč鹊ą║ą░ą╝ąĖ, č鹊 ą╝čŗ ą┤ąŠą╗ąČąĮčŗ ąŠą▒ąĄčĆąĮčāčéčī ą▓čüąĄ čćč鹥ąĮąĖčÅ/ąĘą░ą┐ąĖčüąĖ ą▓ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā. ąś ą┐ąŠč鹊ą╝čā, čćč鹊 ą╝čŗ ąĖąĘą╝ąĄąĮčÅąĄą╝ čāčüą╗ąŠą▓ąĖąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ (ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗čī ą╝ąŠąČąĄčé ą┐čĆąĖčüčéčāą┐ąĖčéčī ą║ ą┤ąĄą╣čüčéą▓ąĖčÄ ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą┐ąŠčüčéą░ąĮąŠą▓ą║ąĖ ą▓ ąŠč湥čĆąĄą┤čī ąĘą░ą┤ą░čćąĖ), ąĮą░ą╝ ąĮčāąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī Pulse.
ąĀą░ą┤ąĖ čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéąĖ ą╝čŗ ą╝čŗ ą▓čŗąĘčŗą▓ą░ąĄą╝ Pulse ą▓ą╝ąĄčüč鹊 PulseAll, ą║ąŠą│ą┤ą░ čüčéą░ą▓ąĖą╝ 菹╗ąĄą╝ąĄąĮčé ą▓ ąŠč湥čĆąĄą┤čī. ą¤čĆąĖčćąĖąĮą░ ą▓ č鹊ą╝, čćč鹊 (čüą░ą╝ąŠąĄ ą▒ąŠą╗čīčłąĄąĄ) ąŠą┤ąĖąĮ ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗čī ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čĆą░ąĘą▒čāąČąĄąĮ ąĮą░ ąŠą┤ąĖąĮ 菹╗ąĄą╝ąĄąĮčé. ąĢčüą╗ąĖ čā ąÆą░čü ąĄčüčéčī č鹊ą╗čīą║ąŠ ąŠą┤ąĮąŠ ą╝ąŠčĆąŠąČąĄąĮąŠąĄ, č鹊 ąĮąĄčé čüą╝čŗčüą╗ą░ ą▒čāą┤ąĖčéčī ą▓ąĄčüčī ą║ą╗ą░čüčü ąĖąĘ 30 čüą┐čÅčēąĖčģ ą┤ąĄč鹥ą╣, čćč鹊ą▒čŗ ą┐ąŠčüčéą░ą▓ąĖčéčī ąĖčģ ą▓ ąŠč湥čĆąĄą┤čī ąĮą░ ą┐ąŠčéčĆąĄą▒ą╗ąĄąĮąĖąĄ čŹč鹊ą│ąŠ ą╝ąŠčĆąŠąČąĄąĮąŠą│ąŠ; č鹊 ąČąĄ čüą░ą╝ąŠąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąĖ čü 30 ą┐ąŠč鹊ą║ą░ą╝ąĖ - ą╝čŗ ąĮąĄ ą┐ąŠą╗čāčćąĖą╝ ąĮąĖą║ą░ą║ąŠą╣ ą▓čŗą│ąŠą┤čŗ ąŠčé ą▓čŗą▓ąŠą┤ą░ ąĖąĘ ą▓čüąĄčģ ąĖąĘ čüąĮą░, ą┐ąŠč鹊ą╝čā čćč鹊 č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ ą┐čĆąĖčüčéčāą┐ąĖčé ą║ čĆą░ą▒ąŠč鹥, ąĖ ąŠčüčéą░ą╗čīąĮčŗąĄ 29 ą▒ąĄčüą┐ąŠą╗ąĄąĘąĮąŠ ą┐čĆąŠą║čĆčāčéčÅčé čüą▓ąŠą╣ čåąĖą║ą╗ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ čüąĮąŠą▓ą░ ą▓ąŠą╣čéąĖ ą▓ čüąŠąĮ. ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčī ąŠą┤ąĮą░ą║ąŠ ąĮąĄ ąĮą░čĆčāčłąĖčéčüčÅ, ąĄčüą╗ąĖ ą╝čŗ ąĘą░ą╝ąĄąĮąĖą╝ Pulse ąĮą░ PulseAll.
ąóąĄą┐ąĄčĆčī ą┐ąŠčüą╝ąŠčéčĆąĖą╝ ąĮą░ ą╝ąĄč鹊ą┤ Consume, ą│ą┤ąĄ čĆą░ą▒ąŠčćąĖą╣ ą┐ąŠč鹊ą║ ą▒ąĄčĆąĄčé 菹╗ąĄą╝ąĄąĮčé ąĖąĘ ąŠč湥čĆąĄą┤ąĖ ąĖ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé ąĄą│ąŠ. ą£čŗ čģąŠčéąĖą╝, čćč鹊ą▒čŗ čĆą░ą▒ąŠčćąĖą╣ ą┐ąŠč鹊ą║ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ą╗čüčÅ, ą║ąŠą│ą┤ą░ ąĄą╝čā ąĮąĄč湥ą│ąŠ ą┤ąĄą╗ą░čéčī, čé. ąĄ. ą║ąŠą│ą┤ą░ ąĮąĄčé 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą▓ ąŠč湥čĆąĄą┤ąĖ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąĮą░čłąĄ čāčüą╗ąŠą▓ąĖąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą▒čāą┤ąĄčé _itemQ.Count==0:
Action item;
lock (_locker)
{
while (_itemQ.Count == 0) Monitor.Wait (_locker);
item = _itemQ.Dequeue();
}
if (item == null) return; // ąŁč鹊 čüąĖą│ąĮą░ą╗ ą▓čŗą╣čéąĖ.
item(); // ąÆčŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐ąŠą╗ąĄąĘąĮąŠą╣ čĆą░ą▒ąŠčéčŗ (ąŠą▒čĆą░ą▒ąŠčéą║ą░
// 菹╗ąĄą╝ąĄąĮčéą░ ąĖąĘ ąŠč湥čĆąĄą┤ąĖ).
ąÆčŗčģąŠą┤ ąĖąĘ čåąĖą║ą╗ą░ while ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé č鹊ą│ą┤ą░, ą║ąŠą│ą┤ą░ _itemQ.Count ąĮąĄ čĆą░ą▓ąĮąŠ 0, čŹč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 (ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝) ąŠą┤ąĖąĮ 菹╗ąĄą╝ąĄąĮčé ąŠąČąĖą┤ą░ąĄčé ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą▓ ąŠč湥čĆąĄą┤ąĖ. ą£čŗ ą┤ąŠą╗ąČąĮčŗ ą▓čŗą▒čĆą░čéčī 菹╗ąĄą╝ąĄąĮčé ąĖąĘ ąŠč湥čĆąĄą┤ąĖ ą┐ąĄčĆąĄą┤ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄą╝ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ, ąĖąĮą░č湥 菹╗ąĄą╝ąĄąĮčé ą╝ąŠąČąĄčé čāąČąĄ ąĮąĄ ą▒čŗčéčī ą▓ ąŠč湥čĆąĄą┤ąĖ (čüčāčēąĄčüčéą▓čāčÄčēąĖą╣ ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║ ą╝ąŠąČąĄčé ą▓čŗą▒čĆą░čéčī čŹč鹊čé 菹╗ąĄą╝ąĄąĮčé). ąÆ čćą░čüčéąĮąŠčüčéąĖ, ą┤čĆčāą│ąŠą╣ ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗čī ą┤ą░ąĮąĮčŗčģ, č鹊ą╗čīą║ąŠ čćč鹊 ąĘą░ą▓ąĄčĆčłąĖą▓čłąĖą╣ ą┐čĆąĄą┤čŗą┤čāčēčāčÄ ąŠą▒čĆą░ą▒ąŠčéą║čā, ą╝ąŠą│ ą▒čŗ ą▓ąĮąĄąĘą░ą┐ąĮąŠ ąĘą░ą▒čĆą░čéčī ąĮą░čł čŹą╗ąĄą╝ąĄąĮčé, ąĄčüą╗ąĖ ą▓ čŹč鹊čé ą╝ąŠą╝ąĄąĮčé ąĮąĄ ą┤ąĄą╣čüčéą▓čāąĄčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░, ąĖ ą╝čŗ čüą┤ąĄą╗ą░ą╗ąĖ ą▒čŗ čćč鹊-č鹊 čéąĖą┐ą░ čŹč鹊ą│ąŠ:
Action item;
lock (_locker)
{
while (_itemQ.Count == 0) Monitor.Wait (_locker);
}
lock (_locker) // ąØąĢ ą¤ąĀąÉąÆąśąøą¼ąØą×!
{
item = _itemQ.Dequeue(); // ąŁą╗ąĄą╝ąĄąĮčé ą╝ąŠąČąĄčé čāąČąĄ ąĘą┤ąĄčüčī ąĮąĄ ąĮą░čģąŠą┤ąĖčéčīčüčÅ!
}
...
ą¤ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ 菹╗ąĄą╝ąĄąĮčé ą▓ąĘčÅčé ąĖąĘ ąŠč湥čĆąĄą┤ąĖ, ą╝čŗ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ ąŠčüą▓ąŠą▒ąŠąČą┤ą░ąĄą╝ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā. ąĢčüą╗ąĖ ą╝čŗ čāą┤ąĄčƹȹĖą╝ ąĄčæ ąĮą░ ą▓čĆąĄą╝čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĘą░ą┤ą░čćąĖ, č鹊 ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮąŠ ąĘą░ą▒ą╗ąŠą║ąĖčĆčāąĄą╝ ą┤čĆčāą│ąĖąĄ ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗ąĖ ą┤ą░ąĮąĮčŗčģ ąĖ ą│ąĄąĮąĄčĆą░č鹊čĆčŗ ą┤ą░ąĮąĮčŗčģ. ą£čŗ ąĮąĄ ą┤ąŠą╗ąČąĮčŗ ą▓čŗąĘčŗą▓ą░čéčī Pulse ą┐ąŠčüą╗ąĄ ą▓čŗą▒ąŠčĆą║ąĖ ąĖąĘ ąŠč湥čĆąĄą┤ąĖ, čéą░ą║ ą║ą░ą║ ąĮąĖą║ą░ą║ąŠą╣ ą┤čĆčāą│ąŠą╣ ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗čī ą┤ą░ąĮąĮčŗčģ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ čüą╝ąŠąČąĄčé čĆą░ąĘą▒ą╗ąŠą║ąĖčĆąŠą▓ą░čéčī ą┐čĆąĖ ąĮą░ą╗ąĖčćąĖąĖ ą╝ąĄąĮčīčłąĄą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą▓ ąŠč湥čĆąĄą┤ąĖ.
ąÜčĆą░čéą║ą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ąĖą╝ąĄąĄčé ą┐čĆąĄąĖą╝čāčēąĄčüčéą▓ąŠ, ą║ąŠą│ą┤ą░ Wait ąĖ Pulse (ąŠą▒čŗčćąĮąŠ) ąĖąĘą▒ąĄą│ą░ąĄčé ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮąŠą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą┤čĆčāą│ąĖčģ ą┐ąŠč鹊ą║ąŠą▓. ąæą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą┐ąŠ ą▒ąŠą╗čīčłąŠą╝čā ą║ąŠą╗ąĖč湥čüčéą▓čā čüčéčĆąŠą║ ą║ąŠą┤ą░ ą▓ą┐ąŠą╗ąĮąĄ ą┤ąŠą┐čāčüčéąĖą╝ą░, ąĄčüą╗ąĖ ąŠąĮą░ ą▓čŗą┐ąŠą╗ąĮąĖčéčüčÅ ąĘą░ ą║ąŠčĆąŠčéą║ąŠąĄ ą▓čĆąĄą╝čÅ. ą¤ąŠą╝ąĮąĖč鹥, čćč鹊 ąÆą░ą╝ ą┐ąŠą╝ąŠą│ą░ąĄčé Monitor.Wait ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄą╝ ąĮąĖąČąĄą╗ąĄąČą░čēąĄą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą┐čĆąĖ ąŠąČąĖą┤ą░ąĮąĖąĖ Pulse!
ąóą░ą╣ą╝ą░čāčéčŗ ąŠąČąĖą┤ą░ąĮąĖčÅ. ąÆčŗ ą╝ąŠąČąĄč鹥 čāą║ą░ąĘą░čéčī čéą░ą╣ą╝ą░čāčé, ą║ąŠą│ą┤ą░ ą▓čŗąĘčŗą▓ą░ąĄč鹥 Wait, ą╗ąĖą▒ąŠ ą▓ ą╝ąĖą╗ą╗ąĖčüąĄą║čāąĮą┤ą░čģ, ą╗ąĖą▒ąŠ č湥čĆąĄąĘ TimeSpan. ąóąŠą│ą┤ą░ ą╝ąĄč鹊ą┤ Wait ą▓ąĄčĆąĮąĄčé false, ąĄčüą╗ąĖ ąŠąĮ čüą┤ą░ą╗čüčÅ ą▓ ąŠąČąĖą┤ą░ąĮąĖąĖ čéą░ą╣ą╝ą░čāčéą░. ąóą░ą╣ą╝ą░čāčé ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ č鹊ą╗čīą║ąŠ ąĮą░ čäą░ąĘąĄ ąŠąČąĖą┤ą░ąĮąĖčÅ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, Wait čü čéą░ą╣ą╝ą░čāč鹊ą╝ ą┤ąĄą╗ą░ąĄčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
1. ą×čüą▓ąŠą▒ąŠąČą┤ą░ąĄčé ąĮąĖąČąĄą╗ąĄąČą░čēčāčÄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā.
2. ąæą╗ąŠą║ąĖčĆčāąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┤ąŠ ą┐ąŠčÅą▓ą╗ąĄąĮąĖčÅ Pulse, ąĖą╗ąĖ ą┤ąŠ ąĖčüč鹥č湥ąĮąĖčÅ čéą░ą╣ą╝ą░čāčéą░.
3. ąŚą░ąĮąŠą▓ąŠ ą▓ąĘą▓ąŠą┤ąĖčé ąĮąĖąČąĄą╗ąĄąČą░čēčāčÄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā.
ąŻą║ą░ąĘą░ąĮąĖąĄ čéą░ą╣ą╝ą░čāčéą░ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ ąĘą░ą┐čĆąŠčüą░ ą┤ą╗čÅ CLR ą▓čŗą┤ą░čéčī "ą▓ąĖčĆčéčāą░ą╗čīąĮčŗą╣ Pulse" ą┐ąŠčüą╗ąĄ ąĖčüč鹥č湥ąĮąĖčÅ ąĖąĮč鹥čĆą▓ą░ą╗ą░ čéą░ą╣ą╝ą░čāčéą░. Wait, ą║ąŠą│ą┤ą░ ą┐čĆąŠąĖąĘąŠčłąĄą╗ čéą░ą╣ą╝ą░čāčé, ą▓čüąĄ ąĄčēąĄ ą▓čŗą┐ąŠą╗ąĮąĖčé čłą░ą│ 3 ąĖ ą▓ąŠčüčüčéą░ąĮąŠą▓ąĖčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā, ą║ą░ą║ ąĄčüą╗ąĖ ą▒čŗ ą▒čŗą╗ čāčüą┐ąĄčłąĮąŠ ą┐ąŠą╗čāč湥ąĮ Pulse.
ąĢčüą╗ąĖ Wait ą▒ą╗ąŠą║ąĖčĆčāąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĮą░ čłą░ą│ąĄ 3 (ą┐čĆąĖ ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ), č鹊 ą╗čÄą▒ąŠą╣ čéą░ą╣ą╝ą░čāčé ąĖą│ąĮąŠčĆąĖčĆčāąĄčéčüčÅ. ąŁč鹊 čĆąĄą┤ą║ąŠ čüąŠčüčéą░ą▓ą╗čÅąĄčé ą┐čĆąŠą▒ą╗ąĄą╝čā, čģąŠčéčÅ č鹊ą╗čīą║ąŠ ą║ąŠą│ą┤ą░ ą┤čĆčāą│ąĖąĄ ą┐ąŠč鹊ą║ąĖ ą▒ą╗ąŠą║ąĖčĆčāčÄčéčüčÅ ąĮą░ ąŠč湥ąĮčī ą║ąŠčĆąŠčéą║ąŠąĄ ą▓čĆąĄą╝čÅ, ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ Wait/Pulse čģąŠčĆąŠčłąŠ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮąŠ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą┐ąŠą▓č鹊čĆąĮąŠąĄ ą┐ąŠą╗čāč湥ąĮąĖąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą┐ąŠčćčéąĖ ą╝ą│ąĮąŠą▓ąĄąĮąĮąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĄą╣.
ąóą░ą╣ą╝ą░čāčéčŗ ąŠąČąĖą┤ą░ąĮąĖčÅ ąĖą╝ąĄčÄčé ą┐ąŠą╗ąĄąĘąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ. ąśąĮąŠą│ą┤ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮčŗą╝ ąĖą╗ąĖ ąĮąĄą▓ąŠąĘą╝ąŠąČąĮčŗą╝ ą▓čŗą┤ą░ą▓ą░čéčī Pulse ą║ą░ąČą┤čŗą╣ čĆą░ąĘ ą┐čĆąĖ ą▓ąŠąĘąĮąĖą║ąĮąŠą▓ąĄąĮąĖąĖ čĆą░ąĘą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ. ąÆ ą║ą░č湥čüčéą▓ąĄ ą┐čĆąĖą╝ąĄčĆą░ ą╝ąŠąČąĄčé ą▒čŗčéčī čüąĖčéčāą░čåąĖčÅ, ą║ąŠą│ą┤ą░ čāčüą╗ąŠą▓ąĖąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą▓ąŠą▓ą╗ąĄą║ą░ąĄčé ą▓čŗąĘąŠą▓ ą╝ąĄč鹊ą┤ą░, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠą╗čāčćą░ąĄčé ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąĖąĘ ą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║ąĖčģ ąĘą░ą┐čĆąŠčüąŠą▓ ą║ ą▒ą░ąĘąĄ ą┤ą░ąĮąĮčŗčģ. ąĢčüą╗ąĖ ąĘą░ą┤ąĄčƹȹ║ą░ ą▓ ą┤ąŠčüčéčāą┐ąĄ ąĮąĄ čüąŠčüčéą░ą▓ą╗čÅąĄčé ą┐čĆąŠą▒ą╗ąĄą╝čŗ, č鹊 čĆąĄčłąĄąĮąĖąĄ ą┐čĆąŠčüč鹊ąĄ - ąÆčŗ ą╝ąŠąČąĄč鹥 čāą║ą░ąĘą░čéčī čéą░ą╣ą╝ą░čāčé ą┐čĆąĖ ą▓čŗąĘąŠą▓ąĄ Wait čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
lock (_locker)
while ( < blocking-condition> )
Monitor.Wait (_locker, < timeout> );
ąŁč鹊 ą┐čĆąĖąĮčāąČą┤ą░ąĄčé čāčüą╗ąŠą▓ąĖąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą║ ą┐ąŠą▓č鹊čĆąĮąŠą╣ ą┐čĆąŠą▓ąĄčĆą║ąĄ ą┐ąŠčüą╗ąĄ ąĖąĮč鹥čĆą▓ą░ą╗ą░, čāą║ą░ąĘą░ąĮąĮąŠą│ąŠ ą▓ timeout, ą║ą░ą║ ąĖ ą║ąŠą│ą┤ą░ ą┐čĆąŠąĖąĘąŠčłąĄą╗ ą▓čŗąĘąŠą▓ Pulse. ą¦ąĄą╝ ą┐čĆąŠčēąĄ čāčüą╗ąŠą▓ąĖąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ, č鹥ą╝ ą╝ąĄąĮčīčłąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī čéą░ą╣ą╝ą░čāčé, ąĮąĄ čüąŠąĘą┤ą░ą▓ą░čÅ ą┐čĆąŠą▒ą╗ąĄą╝čŗ čüąĮąĖąČąĄąĮąĖčÅ čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéąĖ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą╝čŗ ąĮąĄ ąĘą░ą▒ąŠčéąĖą╝čüčÅ ąŠ č鹊ą╝, ą┐ąŠą╗čāčćąĖą╗ ą╗ąĖ Wait ą▓čŗąĘąŠą▓ Pulse ąĖą╗ąĖ ą┐čĆąŠąĖąĘąŠčłąĄą╗ čéą░ą╣ą╝ą░čāčé, ąĖ ąĖą│ąĮąŠčĆąĖčĆčāąĄą╝ ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝ąŠąĄ Wait ąĘąĮą░č湥ąĮąĖąĄ.
ąóą░ ąČąĄ čüąĖčüč鹥ą╝ą░ čĆą░ą▒ąŠčéą░ąĄčé ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠ čģąŠčĆąŠčłąŠ, ąĄčüą╗ąĖ Pulse ąĮąĄ ą┐čĆąŠąĖąĘąŠčłąĄą╗ ąĖąĘ-ąĘą░ ąŠčłąĖą▒ą║ąĖ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ čüč鹊ąĖčé ą┤ąŠą▒ą░ą▓ąĖčéčī čéą░ą╣ą╝ą░čāčé ą║ąŠ ą▓čüąĄą╝ ą║ąŠą╝ą░ąĮą┤ą░ą╝ Wait ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ą░čģ, ą│ą┤ąĄ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÅ ąŠčüąŠą▒ąĄąĮąĮąŠ čüą╗ąŠąČąĮą░čÅ, ą║ą░ą║ čüą┐ąŠčüąŠą▒ ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖčÅ ąĖąĘ čüąĖčéčāą░čåąĖą╣ ąĮąĄčÅčüąĮčŗčģ, čüą╗čāčćą░ą╣ąĮąŠ ą┐ąŠčÅą▓ą╗čÅčÄčēąĖčģčüčÅ ąŠčłąĖą▒ąŠą║. ąŁč鹊 čéą░ą║ąČąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčāčÄ čüč鹥ą┐ąĄąĮčī ąĘą░čēąĖčéčŗ ąŠčé ąŠčłąĖą▒ąŠą║, ąĄčüą╗ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą▒čŗą╗ą░ ą┐ąŠąĘąČąĄ ąĖąĘą╝ąĄąĮąĄąĮą░, čćč鹊 ą┐čĆąĖą▓ąĄą╗ąŠ ą║ ą┐čĆąŠą┐ą░ą┤ą░ąĮąĖčÄ ą▓čŗąĘąŠą▓ą░ Pulse.
Monitor.Wait ą▓ąĄčĆąĮąĄčé ąĘąĮą░č湥ąĮąĖąĄ bool, ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčēąĄąĄ, ą▒čŗą╗ ą╗ąĖ čĆąĄą░ą╗čīąĮčŗą╣ ą▓čŗąĘąŠą▓ Pulse. ąĢčüą╗ąĖ ą▓ąŠąĘą▓čĆą░čēąĄąĮąŠ false, č鹊 čŹč鹊 ąŠąĘąĮą░čćą░ąĄčé ąĖčüč鹥č湥ąĮąĖąĄ čéą░ą╣ą╝ą░čāčéą░: ąĖąĮąŠą│ą┤ą░ ą┐ąŠą╗ąĄąĘąĮąŠ ąĘą░ą┐ąĖčüčŗą▓ą░čéčī ą▓ ą╗ąŠą│ čéą░ą║ąĖąĄ čüąŠą▒čŗčéąĖčÅ ąĖą╗ąĖ ą▓čŗą▒čĆą░čüčŗą▓ą░čéčī ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ąĄčüą╗ąĖ ąĖčüč鹥č湥ąĮąĖąĄ čéą░ą╣ą╝ą░čāčéą░ ą▒čŗą╗ąŠ ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮčŗą╝.
ąÜąŠą│ą┤ą░ ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą│ąŠ ą┐ąŠč鹊ą║ą░ ą▓čŗąĘą▓ą░ą╗ąĖ Waits ąĮą░ ąŠą┤ąĮąŠą╝ ąĖ č鹊ą╝ ąČąĄ ąŠą▒čŖąĄą║č鹥, č乊čĆą╝ąĖčĆčāąĄčéčüčÅ "ąŠč湥čĆąĄą┤čī ąŠąČąĖą┤ą░ąĮąĖčÅ" (waiting queue) ą┐ąŠąĘą░ą┤ąĖ ąŠą▒čŖąĄą║čéą░ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ (čŹč鹊 ąŠčéą╗ąĖčćą░ąĄčéčüčÅ ąŠčé ąŠč湥čĆąĄą┤ąĖ ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ "ready queue", ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą╣ ą┤ą╗čÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĖčÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĄ). ąóąŠą│ą┤ą░ ą║ą░ąČą┤čŗą╣ Pulse ąŠčüą▓ąŠą▒ąŠą┤ąĖčé ąŠą┤ąĖąĮ ą┐ąŠč鹊ą║ ą▓ ą│ąŠą╗ąŠą▓ąĄ ąŠč湥čĆąĄą┤ąĖ ąŠąČąĖą┤ą░ąĮąĖčÅ, čéą░ą║ čćč鹊 ąŠąĮ ą╝ąŠąČąĄčé ą▓ąŠą╣čéąĖ ą▓ ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ ąĖ ąĘą░ąĮąŠą▓ąŠ ą▓ąŠčüčüčéą░ąĮąŠą▓ąĖčéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā. ą£ąŠąČąĮąŠ čŹč鹊 ą┐čĆąĄą┤čüčéą░ą▓ąĖčéčī ą║ą░ą║ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ą░čÅ ą┐ą░čĆą║ąŠą▓ą║ą░ ą░ą▓č鹊ą╝ąŠą▒ąĖą╗ąĄą╣: ąÆčŗ čüčéą░ąĮąŠą▓ąĖč鹥čüčī ą▓ ąŠč湥čĆąĄą┤čī čüąĮą░čćą░ą╗ą░ ąĮą░ čüčéą░ąĮčåąĖąĖ ąŠą┐ą╗ą░čéčŗ, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī čüą▓ąŠą╣ ą▒ąĖą╗ąĄčé (ąŠč湥čĆąĄą┤čī ąŠąČąĖą┤ą░ąĮąĖčÅ, waiting queue); ąĖ čüąĮąŠą▓ą░ čüčéą░ąĮąŠą▓ąĖč鹥čüčī ą▓ ąŠč湥čĆąĄą┤čī ąĮą░ ą▒ą░čĆčīąĄčĆąĄ, ą║ąŠą│ą┤ą░ čģąŠčéąĖč鹥 čāąĄčģą░čéčī čü ą┐ą░čĆą║ąŠą▓ą║ąĖ (ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ, ready queue).
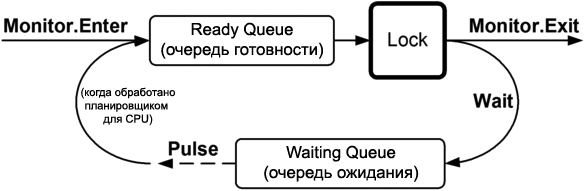
ą×ą┤ąĮą░ą║ąŠ ą┐ąŠčĆčÅą┤ąŠą║, čüą▓ąŠą╣čüčéą▓ąĄąĮąĮčŗą╣ čüčéčĆčāą║čéčāčĆąĄ ąŠč湥čĆąĄą┤ąĖ, čćą░čüč鹊 ąĮąĄ ąĖą╝ąĄąĄčé ąĘąĮą░č湥ąĮąĖčÅ ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅčģ Wait/Pulse, ąĖ ą▓ čéą░ą║ąĖčģ čüą╗čāčćą░čÅčģ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠčēąĄ ą┐čĆąĄą┤čüčéą░ą▓ąĖčéčī "ą┐čāą╗" ąŠąČąĖą┤ą░čÄčēąĖčģ ą┐ąŠč鹊ą║ąŠą▓. ąóąŠą│ą┤ą░ ą║ą░ąČą┤čŗą╣ Pulse ąŠčüą▓ąŠą▒ąŠą┤ąĖčé ąŠą┤ąĖąĮ ąŠąČąĖą┤ą░čÄčēąĖą╣ ą┐ąŠč鹊ą║ ąĖąĘ ą┐čāą╗ą░.
PulseAll ąŠčüą▓ąŠą▒ąŠą┤ąĖčé ą▓čüčÄ ąŠč湥čĆąĄą┤čī, ąĖą╗ąĖ ą┐čāą╗, ą┐ąŠč鹊ą║ąŠą▓ ąŠąČąĖą┤ą░ąĮąĖčÅ. ą×ą┤ąĮą░ą║ąŠ ą┐ąŠą╗čāčćąĖą▓čłąĖąĄ ąĖą╝ą┐čāą╗čīčü ą┐ąŠč鹊ą║ąĖ ąĮąĄ ąĘą░ą┐čāčüčéčÅčéčüčÅ č鹊čćąĮąŠ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ, čüą║ąŠčĆąĄąĄ ą▓ ąŠčĆą│ą░ąĮąĖąĘąŠą▓ą░ąĮąĮąŠą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ, ą┐ąŠčüą║ąŠą╗čīą║čā ą║ą░ąČą┤čŗą╣ ąĖąĘ ąĖčģ ąŠą┐ąĄčĆą░č鹊čĆąŠą▓ Wait ą┐čŗčéą░ąĄčéčüčÅ ą┐ąŠą▓č鹊čĆąĮąŠ ą┐ąŠą╗čāčćąĖčéčī čéčā ąČąĄ čüą░ą╝čāčÄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā. ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 PulseAll ą┐ąĄčĆąĄą╝ąĄčüčéąĖčé ą▓čüčÄ ąŠč湥čĆąĄą┤čī ąŠąČąĖą┤ą░ąĮąĖčÅ ą▓ ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ, čéą░ą║ čćč鹊 ą┐ąŠč鹊ą║ąĖ ą╝ąŠą│čāčé ąŠčĆą│ą░ąĮąĖąĘąŠą▓ą░ąĮąĮąŠ ą▓ąŠąĘąŠą▒ąĮąŠą▓ąĖčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ.
ąĪąĖą│ąĮą░ą╗ąĖąĘą░čåąĖčÅ ą▓ ąŠą▒ąŠąĖčģ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖčÅčģ ąĖ ą│ąŠąĮą║ąĖ. ąÆą░ąČąĮą░čÅ ąŠčüąŠą▒ąĄąĮąĮąŠčüčéčī Monitor.Pulse ą▓ č鹊ą╝, čćč鹊 čŹč鹊 ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą░čüąĖąĮčģčĆąŠąĮąĮąŠ, čé. ąĄ. ąĮąĖą║ą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ąĮąĄ ą▒ą╗ąŠą║ąĖčĆčāčÅ čüą░ą╝ąŠą│ąŠ čüąĄą▒čÅ ąĖ ąĮąĄ čüčéą░ą▓čÅ ąĮą░ ą┐ą░čāąĘčā. ąĢčüą╗ąĖ ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║ ąČą┤ąĄčé ąŠą▒čŖąĄą║čéą░ ąĖą╝ą┐čāą╗čīčüą░, č鹊 ąŠąĮ ą▒čāą┤ąĄčé čĆą░ąĘą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮ. ąśąĮą░č湥 ą▓čŗą┤ą░čćą░ ąĖą╝ą┐čāą╗čīčüą░ ąĮąĄ ą┤ą░čüčé ąĮąĖą║ą░ą║ąŠą│ąŠ čŹčäč乥ą║čéą░, ąĖ ą┐čĆąŠčüč鹊 ą▒čāą┤ąĄčé čéąĖčģąŠ ą┐čĆąŠąĖą│ąĮąŠčĆąĖčĆąŠą▓ą░ąĮą░.
ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, Pulse ą┤ą░ąĄčé ąŠą▒ą╝ąĄąĮ č鹊ą╗čīą║ąŠ ą▓ ąŠą┤ąĮčā čüč鹊čĆąŠąĮčā: ą┐čāą╗čīčüąĖčĆčāčÄčēąĖą╣ ą┐ąŠč鹊ą║ (ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ) ą┐ąŠą┤ą░ąĄčé čüąĖą│ąĮą░ą╗ ąŠąČąĖą┤ą░čÄčēąĄą╝čā ą┐ąŠč鹊ą║čā. ąŚą┤ąĄčüčī ąĮąĄčé ą▓ąĮčāčéčĆąĄąĮąĮąĄą│ąŠ ą╝ąĄčģą░ąĮąĖąĘą╝ą░ ą┐ąŠą┤čéą▓ąĄčƹȹ┤ąĄąĮąĖčÅ: ąĮąĄ ą▓ąĄčĆąĮąĄčé ąĘąĮą░č湥ąĮąĖąĄ, ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčēąĄąĄ, ą┐ąŠą╗čāčćąĖą╗ ą╗ąĖ ą║ą░ą║ąŠą╣-ą╗ąĖą▒ąŠ ą┐ąŠč鹊ą║ ąĖą╝ą┐čāą╗čīčü čĆą░ąĘą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ, ąĖą╗ąĖ ąĮąĄčé. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ą║ąŠą│ą┤ą░ ąŠą┐ąŠą▓ąĄčēą░čÄčēąĖą╣ ą┐ąŠč鹊ą║ ą▓čŗą┤ą░ą╗ ąĖą╝ą┐čāą╗čīčü ąĖ č鹥ą╝ čüą░ą╝čŗą╝ ąŠčüą▓ąŠą▒ąŠą┤ąĖą╗ ąĄą│ąŠ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā, ąĮąĄčé ąĮąĖą║ą░ą║ąŠą╣ ą│ą░čĆą░ąĮčéąĖąĖ, čćč鹊 ąŠąČąĖą┤ą░čÄčēąĖą╣ čĆą░ąĘą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą┐ąŠč鹊ą║ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ ąŠąČąĖą▓ąĄčé. ąŚą┤ąĄčüčī ą╝ąŠąČąĄčé ą▒čŗčéčī ą╝ą░ą╗ąĄąĮčīą║ą░čÅ ąĘą░ą┤ąĄčƹȹ║ą░ čü ą┤ąĖčüą║čĆąĄčéąĮąŠčüčéčīčÄ ąĄą┤ąĖąĮąĖčå ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ą░, ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠč鹊čĆąŠą╣ ąĮąĖ čā ąŠą┤ąĮąŠą│ąŠ ą┐ąŠč鹊ą║ą░ ąĮąĄčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ. ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą▓čŗą┤ą░čÄčēąĖą╣ ąĖą╝ą┐čāą╗čīčü ą┐ąŠč鹊ą║ ąĮąĄ ą╝ąŠąČąĄčé ąĘąĮą░čéčī, ą▓ąŠąĘąŠą▒ąĮąŠą▓ąĖą╗ ą╗ąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąŠąČąĖą┤ą░čÄčēąĖą╣ ą┐ąŠč鹊ą║ - ąĄčüą╗ąĖ ąÆčŗ ąĮąĄ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ą╗ąĖ čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ ą║ąŠą┤ ą┤ą╗čÅ ą┐ąĄčĆąĄą┤ą░čćąĖ čéą░ą║ąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, čü ą┐ąŠą╝ąŠčēčīčÄ ą┤čĆčāą│ąŠą│ąŠ čäą╗ą░ą│ą░ ąĖą╗ąĖ ą┤čĆčāą│ąŠą╣ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ Wait ąĖ Pulse).
ąöą╗čÅ ąĖą╗ą╗čÄčüčéčĆą░čåąĖąĖ ą┐čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ąĮą░ą╝ ąĮčāąČąĄąĮ čüąĖą│ąĮą░ą╗ 5 čĆą░ąĘ ą┐ąŠą┤čĆčÅą┤:
class Race
{
static readonly object _locker = new object();
static bool _go;
static void Main()
{
new Thread (SaySomething).Start();
for (int i = 0; i < 5; i++)
{
lock (_locker)
{
_go = true;
Monitor.PulseAll (_locker);
}
}
}
static void SaySomething()
{
for (int i = 0; i < 5; i++)
{
lock (_locker)
{
while (!_go) Monitor.Wait (_locker);
_go = false;
Console.WriteLine ("ą¦č鹊 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ?");
}
}
}
}
ą×ąČąĖą┤ą░ąĄą╝čŗą╣ ą▓čŗą▓ąŠą┤:
ą¦č鹊 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ?
ą¦č鹊 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ?
ą¦č鹊 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ?
ą¦č鹊 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ?
ą¦č鹊 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ?
ąÆąŠčé ą║ą░ą║ąŠą╣ ą▓čŗą▓ąŠą┤ ą▒čāą┤ąĄčé ą▓ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠčüčéąĖ:
ą¦č鹊 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ? (ąĘą░ą▓ąĖčüą░ąĮąĖąĄ)
ąŁčéą░ ą┐ą╗ąŠčģąŠ ąĮą░ą┐ąĖčüą░ąĮąĮą░čÅ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄčé čüąŠčüč鹊čÅąĮąĖąĄ ą│ąŠąĮą║ąĖ: čåąĖą║ą╗ for ą▓ ą│ą╗ą░ą▓ąĮąŠą╝ ą┐ąŠč鹊ą║ąĄ ą╝ąŠąČąĄčé čüą▓ąŠą▒ąŠą┤ąĮąŠ ą┐čĆąŠą║čĆčāčéąĖčéčī čüą▓ąŠąĖ 5 ąĖč鹥čĆą░čåąĖą╣ ą▓ ą╗čÄą▒ąŠąĄ ą▓čĆąĄą╝čÅ, ą║ąŠą│ą┤ą░ čĆą░ą▒ąŠčćąĖą╣ ą┐ąŠč鹊ą║ ąĮąĄ čāą┤ąĄčƹȹĖą▓ą░ąĄčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā, ąĖ čŹč鹊 ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ ą┤ą░ąČąĄ ą┐ąĄčĆąĄą┤ ąĘą░ą┐čāčüą║ąŠą╝ čĆą░ą▒ąŠč湥ą│ąŠ ą┐ąŠč鹊ą║ą░! ą¤čĆąĖą╝ąĄčĆ producer/consumer ąĮąĄ ą┐ąŠčüčéčĆą░ą┤ą░ą╗ ą▒čŗ ąŠčé čéą░ą║ąŠą╣ ą┐čĆąŠą▒ą╗ąĄą╝čŗ, ą┐ąŠč鹊ą╝čā čćč鹊 ąĄčüą╗ąĖ ą▒čŗ ąŠčüąĮąŠą▓ąĮąŠą╣ ą┐ąŠč鹊ą║ ąŠą▒ąŠą│ąĮą░ą╗ čĆą░ą▒ąŠčćąĖą╣ ą┐ąŠč鹊ą║, č鹊 ą║ą░ąČą┤čŗą╣ ąĘą░ą┐čĆąŠčü čüč鹊čÅą╗ ą▒čŗ ą▓ ąŠč湥čĆąĄą┤ąĖ. ąØąŠ ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ąĮą░ą╝ ąĮčāąČąĮąŠ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░čéčī ą│ą╗ą░ą▓ąĮčŗą╣ ą┐ąŠč鹊ą║ ąĮą░ ą║ą░ąČą┤ąŠą╣ ąĖč鹥čĆą░čåąĖąĖ, ąĄčüą╗ąĖ čĆą░ą▒ąŠčćąĖą╣ ą┐ąŠč鹊ą║ ą▓čüąĄ ąĄčēąĄ ąĘą░ąĮčÅčé ąŠą▒čĆą░ą▒ąŠčéą║ąŠą╣ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ ąĘą░ą┤ą░čćąĖ.
ą£čŗ ą╝ąŠąČąĄą╝ ąĖčüą┐čĆą░ą▓ąĖčéčī čŹč鹊čé ą║ąŠą┤ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄą╝ čäą╗ą░ą│ą░ _ready ą║ ą║ą╗ą░čüčüčā, čāą┐čĆą░ą▓ą╗čÅąĄą╝ąŠą╝čā čĆą░ą▒ąŠčćąĖą╝ ą┐ąŠč鹊ą║ąŠą╝. ąŚą░č鹥ą╝ ą│ą╗ą░ą▓ąĮčŗą╣ ą┐ąŠč鹊ą║ ąČą┤ąĄčé, ą┐ąŠą║ą░ čĆą░ą▒ąŠčćąĖą╣ ą┐ąŠč鹊ą║ ąĮąĄ ą▒čāą┤ąĄčé ą│ąŠč鹊ą▓ (ready) ą║ čāčüčéą░ąĮąŠą▓ą║ąĄ čäą╗ą░ą│ą░ _go.
ąŁč鹊 ą░ąĮą░ą╗ąŠą│ąĖčćąĮąŠ ą┐čĆąĄą┤čŗą┤čāčēąĄą╝čā ą┐čĆąĖą╝ąĄčĆčā, ą║ąŠč鹊čĆčŗą╣ ą┤ąĄą╗ą░ąĄčé č鹊 ąČąĄ čüą░ą╝ąŠąĄ čü ą┐ąŠą╝ąŠčēčīčÄ ą┤ą▓čāčģ AutoResetEvents.
ąśčüą┐čĆą░ą▓ą╗ąĄąĮąĮčŗą╣ ą▓ą░čĆąĖą░ąĮčé, ą║ąŠč鹊čĆčŗą╣ ą▓čŗą▓ąĄą┤ąĄčé "ą¦č鹊 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ?" 5 čĆą░ąĘ:
class Solved
{
static readonly object _locker = new object();
static bool _ready, _go;
static void Main()
{
new Thread (SaySomething).Start();
for (int i = 0; i < 5; i++)
{
lock (_locker)
{
while (!_ready) Monitor.Wait (_locker);
_ready = false;
_go = true;
Monitor.PulseAll (_locker);
}
}
}
static void SaySomething()
{
for (int i = 0; i < 5; i++)
{
lock (_locker)
{
_ready = true;
Monitor.PulseAll (_locker); // ą¤ąŠą╝ąĮąĖč鹥, čćč鹊 ą▓čŗąĘąŠą▓ Monitor.Wait
while (!_go) Monitor.Wait (_locker); // ąŠčüą▓ąŠą▒ąŠąČą┤ą░ąĄčé ąĖ ą┐ąŠą▓č鹊čĆąĮąŠ
go = false; // ąĘą░čģą▓ą░čéčŗą▓ą░ąĄčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā.
Console.WriteLine ("ą¦č鹊 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ?");
}
}
}
}
ąÆ ą╝ąĄč鹊ą┤ąĄ Main (ą│ą╗ą░ą▓ąĮčŗą╣ ą┐ąŠč鹊ą║) ą╝čŗ ąŠčćąĖčēą░ąĄą╝ čäą╗ą░ą│ _ready, čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄą╝ čäą╗ą░ą│ _go ąĖ ą▓čŗąĘčŗą▓ą░ąĄą╝ Pulse, ąĖ ą▓čüąĄ čŹč鹊 ą┤ąĄą╗ą░ąĄą╝ ą▓ ąŠą┤ąĮąŠą╝ ąŠą┐ąĄčĆą░č鹊čĆąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ lock. ą¤čĆąĄąĖą╝čāčēąĄčüčéą▓ąŠ čéą░ą║ąŠą│ąŠ ą┐ąŠą┤čģąŠą┤ą░ - čāčüč鹊ą╣čćąĖą▓ąŠčüčéčī, ąĄčüą╗ąĖ ą╝čŗ ą┐ąŠąĘąČąĄ ą┤ąŠą▒ą░ą▓ąĖą╝ čéčĆąĄčéąĖą╣ ą┐ąŠč鹊ą║. ą¤čĆąĄą┤čüčéą░ą▓ąĖą╝ čüąĄą▒ąĄ, čćč鹊 ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║ ą┐čŗčéą░ąĄčéčüčÅ ą▓ č鹊 ąČąĄ čüą░ą╝ąŠąĄ ą▓čĆąĄą╝čÅ ą┐ąŠą┤ą░ą▓ą░čéčī čüąĖą│ąĮą░ą╗ čĆą░ą▒ąŠč湥ą╝čā ą┐ąŠč鹊ą║čā. ąÆ čŹč鹊ą╝ čüčåąĄąĮą░čĆąĖąĖ ąĮą░čłą░ ą╗ąŠą│ąĖą║ą░ ąĮąĄ ąĮą░čĆčāčłąĖčéčüčÅ: ą▓ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą╝čŗ ą░č鹊ą╝ą░čĆąĮąŠ ą┤ąĄą╗ą░ąĄą╝ ą┤ąĄą╣čüčéą▓ąĖčÅ ą┐ąŠ ąŠčćąĖčüčéą║ąĄ _ready ąĖ čāčüčéą░ąĮąŠą▓ą║ąĄ _go.
ąĪąĖą╝čāą╗čÅčåąĖčÅ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ ąŠąČąĖą┤ą░ąĮąĖčÅ (Wait Handle). ąÆčŗ ą▓ąŠąĘą╝ąŠąČąĮąŠ ąĘą░ą╝ąĄčéąĖą╗ąĖ, čćč鹊 ą▓ čā čłą░ą▒ą╗ąŠąĮą░ ą┐čĆąĄą┤čŗą┤čāčēąĄą│ąŠ ą┐čĆąĖą╝ąĄčĆą░ čüą╗ąĄą┤čāčÄčēą░čÅ čüčéčĆčāą║čéčāčĆą░:
lock (_locker)
{
while (!_flag) Monitor.Wait (_locker);
_flag = false;
...
}
ąŚą┤ąĄčüčī _flag čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ą▓ true ą┤čĆčāą│ąĖą╝ ą┐ąŠč鹊ą║ąŠą╝. ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 ą┐ąŠą╗čāčćą░ąĄčéčüčÅ čŹčäč乥ą║čé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ AutoResetEvent. ąĢčüą╗ąĖ ą╝čŗ ą┐čĆąŠą┐čāčüčéąĖą╝ _flag=false, č鹊 ą┐ąŠą╗čāčćąĖą╝ ą▒ą░ąĘąŠą▓čŗą╣ čłą░ą▒ą╗ąŠąĮ ManualResetEvent.
ąöą░ą▓ą░ą╣č鹥 ą┐ąŠą┤čĆąŠą▒ąĮąŠ ą┐čĆąĄą┤čüčéą░ą▓ąĖą╝ ą║ąŠą┤ ą┤ą╗čÅ ManualResetEvent, ąĖčüą┐ąŠą╗čīąĘčāčÄčēąĄą│ąŠ Wait ąĖ Pulse:
readonly object _locker = new object();
bool _signal;
void WaitOne()
{
lock (_locker)
{
while (!_signal) Monitor.Wait (_locker);
}
}
void Set()
{
lock (_locker) { _signal = true; Monitor.PulseAll (_locker); }
}
void Reset() { lock (_locker) _signal = false; }
ą£čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ąĖ PulseAll, ą┐ąŠč鹊ą╝čā čćč鹊 ąĘą┤ąĄčüčī ą╝ąŠąČąĄčé ą▒čŗčéčī ą╗čÄą▒ąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĮčŗčģ ąŠąČąĖą┤ą░čÄčēąĖčģ ą┐ąŠč鹊ą║ąŠą▓.
ąØą░ą┐ąĖčüą░ąĮąĖąĄ AutoResetEvent ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą┐čĆąŠčüč鹊ą╣ ąĘą░ą╝ąĄąĮąŠą╣ ą║ąŠą┤ą░ ą▓ WaitOne ąĮą░ čüą╗ąĄą┤čāčÄčēąĖą╣:
lock (_locker)
{
while (!_signal) Monitor.Wait (_locker);
_signal = false;
}
ąĖ ąĘą░ą╝ąĄąĮąŠą╣ PulseAll ąĮą░ Pulse ą▓ ą╝ąĄč鹊ą┤ąĄ Set:
lock (_locker) { _signal = true; Monitor.Pulse (_locker); }
ąÆąŠąĘą┤ąĄčƹȹĖč鹥čüčī ąŠčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ PulseAll ąĮą░ ąŠč湥čĆąĄą┤ąĖ čü ąŠąČąĖą┤ą░čÄčēąĖą╝ąĖ ą┐ąŠč鹊ą║ą░ą╝ąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 ą║ą░ąČą┤čŗą╣ ą▓čŗąĘąŠą▓ PulseAll ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ą┐ąŠą▓čĆąĄąČą┤ąĄąĮąĖčÄ ąŠč湥čĆąĄą┤ąĖ ąĖ ąĘą░č鹥ą╝ ą║ ąĄčæ ą┐ąŠą▓č鹊čĆąĮąŠą╝čā č乊čĆą╝ąĖčĆąŠą▓ą░ąĮąĖčÄ.
ąŚą░ą╝ąĄąĮą░ _signal ąĮą░ čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮąŠąĄ ą┐ąŠą╗ąĄ čüąŠąĘą┤ą░čüčé ą▒ą░ąĘąŠą▓čŗą╣ čłą░ą▒ą╗ąŠąĮ ą┤ą╗čÅ Semaphore.
ąĪąĖą╝čāą╗čÅčåąĖčÅ čüčéą░čéąĖč湥čüą║ąĖčģ ą╝ąĄč鹊ą┤ąŠą▓, ą║ąŠč鹊čĆčŗąĄ čĆą░ą▒ąŠčéą░čÄčé čü ąĮą░ą▒ąŠčĆąŠą╝ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ ąŠąČąĖą┤ą░ąĮąĖčÅ, ą╗ąĄą│ą║ąŠ čĆąĄą░ą╗ąĖąĘčāąĄčéčüčÅ ą▓ ą┐čĆąŠčüčéčŗčģ čüčåąĄąĮą░čĆąĖčÅčģ. ąŁą║ą▓ąĖą▓ą░ą╗ąĄąĮčé ą▓čŗąĘąŠą▓ą░ WaitAll čŹč鹊 ąĮąĖčćč鹊 ąĖąĮąŠąĄ, ą║ą░ą║ čāčüą╗ąŠą▓ąĖąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ, ą▓ą║ą╗čÄčćą░čÄčēąĄąĄ ą▓čüąĄ čäą╗ą░ą│ąĖ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ ą▓ą╝ąĄčüč鹊 ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ ąŠąČąĖą┤ą░ąĮąĖčÅ:
lock (_locker)
while (!_flag1 && !_flag2 && !_flag3...)
Monitor.Wait (_locker);
ąŁč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠčüąŠą▒ąĄąĮąĮąŠ ą┐ąŠą╗ąĄąĘąĮąŠ, ąĄčüą╗ąĖ čāč湥čüčéčī, čćč鹊 WaitAll čćą░čüč鹊 ąĮąĄą╗čīąĘčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĖąĘ-ąĘą░ ą┐čĆąŠą▒ą╗ąĄą╝ čāčüčéą░čĆąĄą▓čłąĄą│ąŠ COM. ąĪąĖą╝čāą╗čÅčåąĖčÅ WaitAny čŹč鹊 ą┐čĆąŠčüč鹊 ą▓ąŠą┐čĆąŠčü ąĘą░ą╝ąĄąĮčŗ ąŠą┐ąĄčĆą░č鹊čĆą░ && ąŠą┐ąĄčĆą░č鹊čĆąŠą╝ ||.
ąĢčüą╗ąĖ čā ąÆą░čü ą╝ąĮąŠą│ąŠ čäą╗ą░ą│ąŠą▓, č鹊 čŹč鹊čé ą╝ąĄč鹊ą┤ čüčéą░ąĮąŠą▓ąĖčéčüčÅ ą╝ąĄąĮąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮčŗą╝, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓čüąĄ čŹčéąĖ čäą╗ą░ą│ąĖ ą┤ąŠą╗ąČąĮčŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąŠą┤ąĖąĮ ąŠą▒čŖąĄą║čé čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ, čćč鹊ą▒čŗ čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖčÅ čĆą░ą▒ąŠčéą░ą╗ą░ ą░č鹊ą╝ą░čĆąĮąŠ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ ąŠąČąĖą┤ą░ąĮąĖčÅ ą┐ąŠą╗čāčćą░ąĄčé ą┐čĆąĄąĖą╝čāčēąĄčüčéą▓ąŠ.
ąØą░ą┐ąĖčüą░ąĮąĖąĄ CountdownEvent. ąĪ ą┐ąŠą╝ąŠčēčīčÄ Wait ąĖ Pulse ą╝čŗ ą╝ąŠąČąĄą╝ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ą┐ąŠą╗ąĮčŗą╣ čäčāąĮą║čåąĖąŠąĮą░ą╗ CountdownEvent čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
public class Countdown
{
object _locker = new object ();
int _value;
public Countdown() { }
public Countdown (int initialCount) { _value = initialCount; }
public void Signal() { AddCount (-1); }
public void AddCount (int amount)
{
lock (_locker)
{
_value += amount;
if (_value < 1) Monitor.PulseAll (_locker);
}
}
public void Wait()
{
lock (_locker)
while (_value > 0)
Monitor.Wait (_locker);
}
}
ąŁč鹊čé čłą░ą▒ą╗ąŠąĮ ą║ąŠą┤ą░ ą┐ąŠčģąŠąČ ąĮą░ č鹊čé, čćč鹊 ą╝čŗ ą▓ąĖą┤ąĄą╗ąĖ čĆą░ąĮčīčłąĄ, ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ čāčüą╗ąŠą▓ąĖčÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ąĮą░ ąŠčüąĮąŠą▓ąĄ čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮąŠą│ąŠ ą┐ąŠą╗čÅ.
ąÆčüčéčĆąĄčćą░ ą┐ąŠč鹊ą║ąŠą▓. ą£čŗ ą╝ąŠąČąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą║ą╗ą░čüčü Countdown ą┤ą╗čÅ ąĮą░ą┐ąĖčüą░ąĮąĖčÅ čĆą░ąĮą┤ąĄą▓čā ą┤ą▓čāčģ ą┐ąŠč鹊ą║ąŠą▓ - ą║ą░ą║ ą╝čŗ čŹč鹊 ą┤ąĄą╗ą░ą╗ąĖ čĆą░ąĮąĄąĄ [3] čü WaitHandle.SignalAndWait:
class Rendezvous
{
static object _locker = new object();
// ąÆ Framework 4.0 ą╝čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī
// ą▓čüčéčĆąŠąĄąĮąĮčŗą╣ ą║ą╗ą░čüčü CountdownEvent.
static Countdown _countdown = new Countdown(2);
public static void Main()
{
// ą¤ąĄčĆąĄą▓ąŠą┤ ą║ą░ąČą┤ąŠą│ąŠ ą┐ąŠč鹊ą║ą░ ą▓ čüąŠąĮ ąĮą░ čüą╗čāčćą░ą╣ąĮąŠąĄ ą▓čĆąĄą╝čÅ.
Random r = new Random();
new Thread (Mate).Start (r.Next (10000));
Thread.Sleep (r.Next (10000));
_countdown.Signal();
_countdown.Wait();
Console.Write ("Mate! ");
}
static void Mate (object delay)
{
Thread.Sleep ((int) delay);
_countdown.Signal();
_countdown.Wait();
Console.Write ("Mate! ");
}
}
ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą║ą░ąČą┤čŗą╣ ą┐ąŠč鹊ą║ ąĘą░čüčŗą┐ą░ąĄčé ąĮą░ čüą╗čāčćą░ą╣ąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ąĖ ąĘą░č鹥ą╝ ąČą┤ąĄčé ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║, ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ąŠą▒ą░ ą▓čŗą▓ąŠą┤čÅčé čüąŠąŠą▒čēąĄąĮąĖąĄ "Mate" (čüą║ąŠčĆąĄąĄ ą▓čüąĄą│ąŠ) ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ. ąŁč鹊 ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ ą▒ą░čĆčīąĄčĆąŠą╝ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐ąŠč鹊ą║ą░ (thread execution barrier), ąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī čĆą░čüčłąĖčĆąĄąĮąŠ ąĮą░ ą╗čÄą▒ąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠč鹊ą║ąŠą▓ (ąĮą░čüčéčĆąŠą╣ą║ąŠą╣ ąĮą░čćą░ą╗čīąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ čüč湥čéčćąĖą║ą░ ąŠą▒čĆą░čéąĮąŠą│ąŠ ąŠčéčüč湥čéą░ Countdown).
ąæą░čĆčīąĄčĆčŗ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐ąŠč鹊ą║ą░ ą┐ąŠą╗ąĄąĘąĮčŗ, ą║ąŠą│ą┤ą░ ąÆčŗ čģąŠčéąĖč鹥 čāą┤ąĄčƹȹ░čéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐ąŠč鹊ą║ąŠą▓ ąĮą░ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╝ čłą░ą│ąĄ ą▓ ą┐čĆąŠčåąĄčüčüąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čüąĄčĆąĖąĖ ąĘą░ą┤ą░čć. ą×ą┤ąĮą░ą║ąŠ ąĮą░čłąĄ č鹥ą║čāčēąĄąĄ čĆąĄčłąĄąĮąĖąĄ ąŠą│čĆą░ąĮąĖč湥ąĮąŠ, ą▓ ąĮąĄą╝ ą╝čŗ ąĮąĄ ą╝ąŠąČąĄą╝ čüąĮąŠą▓ą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī č鹊čé ąČąĄ čüą░ą╝čŗą╣ ąŠą▒čŖąĄą║čé Countdown ą┤ą╗čÅ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖąĖ ą▓čüčéčĆąĄčćąĖ ą┐oč鹊ą║ąŠą▓ ą▓č鹊čĆąŠą╣ čĆą░ąĘ - ą┐ąŠ ą║čĆą░ą╣ąĮąĄą╣ ą╝ąĄčĆąĄ ąĮąĄ ą▒ąĄąĘ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ą║ąŠąĮčüčéčĆčāą║čåąĖą╣ čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖąĖ. ą¦č鹊ą▒čŗ čĆąĄčłąĖčéčī čŹčéčā ą┐čĆąŠą▒ą╗ąĄą╝čā, Framework 4.0 ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ąĮąŠą▓čŗą╣ ą║ą╗ą░čüčü Barrier.
[ąÜą╗ą░čüčü Barrier]
Barrier ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé ą▓ Framework 4.0 ąĮąŠą▓čāčÄ ą║ąŠąĮčüčéčĆčāą║čåąĖčÄ čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖąĖ. ą×ąĮ čĆąĄą░ą╗ąĖąĘčāąĄčé ą▒ą░čĆčīąĄčĆ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐ąŠč鹊ą║ą░, čćč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą╗čÄą▒ąŠą╝čā ą║ąŠą╗ąĖč湥čüčéą▓čā ą┐ąŠč鹊ą║ąŠą▓ ą▓čüčéčĆąĄčéąĖčéčīčüčÅ ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠąĄ ą▓čĆąĄą╝čÅ. ąŁč鹊čé ą║ą╗ą░čüčü ąŠč湥ąĮčī ą▒čŗčüčéčĆčŗą╣ ąĖ čŹčäč乥ą║čéąĖą▓ąĮčŗą╣, ą▓ ąŠąĮ ą┐ąŠčüčéčĆąŠąĄąĮ ąĮą░ ąŠčüąĮąŠą▓ąĄ Wait, Pulse ąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║ ą┐čĆąŠą║čĆčāč鹊ą║ čåąĖą║ą╗ą░ (spinlocks).
ą¦č鹊ą▒čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹč鹊čé ą║ą╗ą░čüčü:
1. ąśąĮčüčéą░ąĮčåąĖčĆčāą╣č鹥 ąĄą│ąŠ, čāą║ą░ąĘą░ą▓ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠč鹊ą║ąŠą▓, ą║ąŠč鹊čĆčŗąĄ ą┤ąŠą╗ąČąĮčŗ ą┐čĆąĖąĮčÅčéčī čāčćą░čüčéąĖąĄ ą▓ ą▓čüčéčĆąĄč湥 (ąÆčŗ čŹč鹊 ą╝ąŠąČąĄč鹥 ą┐ąŠą╝ąĄąĮčÅčéčī ą┐ąŠąĘąČąĄ ą▓čŗąĘąŠą▓ąŠą╝ AddParticipants/RemoveParticipants).
2. ąÆ ą║ą░ąČą┤ąŠą╝ ą┐ąŠč鹊ą║ąĄ ą▓čŗąĘąŠą▓ąĖč鹥 SignalAndWait, ą║ąŠą│ą┤ą░ čģąŠčéąĖč鹥, čćč鹊ą▒čŗ ąŠąĮ ąŠąČąĖą┤ą░ą╗ ą▓čüčéčĆąĄčćąĖ.
ąśąĮčüčéą░ąĮčåąĖą░čåąĖčÅ Barrier čüąŠ ąĘąĮą░č湥ąĮąĖąĄą╝ 3 ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ č鹊ą╝čā, čćč鹊 SignalAndWait ą▒čāą┤ąĄčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░čéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ, ą┐ąŠą║ą░ čŹč鹊čé ą╝ąĄč鹊ą┤ ąĮąĄ ą▒čāą┤ąĄčé ą▓čŗąĘą▓ą░ąĮ 3 čĆą░ąĘą░. ąØąŠ ą▓ ąŠčéą╗ąĖčćąĖąĄ ąŠčé CountdownEvent ą▒ą░čĆčīąĄčĆ ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ: ą▓čŗąĘąŠą▓ SignalAndWait čüąĮąŠą▓ą░ ąĘą░ą▒ą╗ąŠą║ąĖčĆčāąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ, ą┐ąŠą║ą░ ąĮąĄ ą▒čāą┤ąĄčé ą▓čŗąĘą▓ą░ąĮ ąĄčēąĄ 3 čĆą░ąĘą░. ąŁč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čüąŠčģčĆą░ąĮčÅčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐ąŠč鹊ą║ąŠą▓ ąĮą░ ąŠą┤ąĮąŠą╝ čłą░ą│ąĄ, ą║ąŠą│ą┤ą░ ąŠąĮąĖ ą▓čŗą┐ąŠą╗ąĮčÅčÄčé čüąĄčĆąĖčÄ ąĘą░ą┤ą░čć.

ąÆ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą║ą░ąČą┤čŗą╣ ąĖąĘ 3 ą┐ąŠč鹊ą║ąŠą▓ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé čćąĖčüą╗ą░ ąŠčé 0 ą┤ąŠ 4, ą┤ąĄą╗ą░čÅ čŹč鹊 ą┐ąŠ čłą░ą│ą░ą╝ čü ą┤čĆčāą│ąĖą╝ąĖ ą┐ąŠč鹊ą║ą░ą╝ąĖ:
static Barrier _barrier = new Barrier (3);
static void Main()
{
new Thread (Speak).Start();
new Thread (Speak).Start();
new Thread (Speak).Start();
}
static void Speak()
{
for (int i = 0; i < 5; i++)
{
Console.Write (i + " ");
_barrier.SignalAndWait();
}
}
ąĀąĄąĘčāą╗čīčéą░čé čĆą░ą▒ąŠčéčŗ čŹč鹊ą│ąŠ ą┐čĆąĖą╝ąĄčĆą░:
0 0 0 1 1 1 2 2 2 3 3 3 4 4 4
ąĀąĄą░ą╗čīąĮąŠ ą┐ąŠą╗ąĄąĘąĮą░čÅ čäčāąĮą║čåąĖčÅ Barrier ą▓ č鹊ą╝, čćč鹊 ą┐čĆąĖ ąĄą│ąŠ ą║ąŠąĮčüčéčĆčāąĖčĆąŠą▓ą░ąĮąĖąĖ čéą░ą║ąČąĄ ą╝ąŠąČąĮąŠ čāą║ą░ąĘą░čéčī ą┤ą╗čÅ ąĮąĄą│ąŠ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠąĄ ą┤ąĄą╣čüčéą▓ąĖąĄ (ą┤ąĄą╣čüčéą▓ąĖąĄ ą┐ąŠčüčé-čäą░ąĘčŗ), čüąŠą▓ą┐ą░ą┤ą░čÄčēąĄąĄ čüąŠ "ą▓čüčéčĆąĄč湥ą╣". ąŁč鹊 ą┤ąĄą╗ąĄą│ą░čé, ą║ąŠč鹊čĆčŗą╣ ą▒čāą┤ąĄčé ą▓čŗąĘą▓ą░ąĮ ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ SignalAndWait ą▒čŗą╗ ą▓čŗąĘą▓ą░ąĮ n čĆą░ąĘ, ąĮąŠ ą┐ąĄčĆąĄą┤ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ą┐ąŠč鹊ą║ąĖ ą▒čāą┤čāčé čĆą░ąĘą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮčŗ. ąÆ ąĮą░čłąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ, ąĄčüą╗ąĖ ą╝čŗ ąĖąĮčüčéą░ąĮčåąĖąĖčĆąŠą▓ą░ą╗ąĖ ą▒ą░čĆčīąĄčĆ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
static Barrier _barrier = new Barrier (3, barrier => Console.WriteLine());
č鹊 ą▓čŗą▓ąŠą┤ ą┐ąŠą╗čāčćąĖčéčüčÅ čéą░ą║ąĖą╝:
0 0 0
1 1 1
2 2 2
3 3 3
4 4 4
ąöąĄą╣čüčéą▓ąĖąĄ ą┐ąŠčüčé-čäą░ąĘčŗ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠą╗ąĄąĘąĮčŗą╝, ą║ąŠą│ą┤ą░ ąĮčāąČąĮąŠ ąŠą▒čŖąĄą┤ąĖąĮąĖčéčī ą┤ą░ąĮąĮčŗąĄ, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ ą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮčŗ ą║ą░ąČą┤čŗą╝ ąĖąĘ ą▓čüčéčĆąĄčéąĖą▓čłąĖčģčüčÅ čĆą░ą▒ąŠčćąĖčģ ą┐ąŠč鹊ą║ąŠą▓. ąØąĄ ąĮčāąČąĮąŠ ąĘą░ą▒ąŠčéąĖčéčīčüčÅ ąŠ ą▓čŗč鹥čüąĮąĄąĮąĖąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓čüąĄ čĆą░ą▒ąŠčćąĖąĄ ą┐ąŠč鹊ą║ąĖ ą▒ą╗ąŠą║ąĖčĆčāčÄčéčüčÅ ą▓ ąŠąČąĖą┤ą░ąĮąĖąĖ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ą║ą░ąČą┤čŗą╝ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čüą▓ąŠą╣ čćą░čüčéąĖ čĆą░ą▒ąŠčéčŗ.
[ąæą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ Reader/Writer]
ąöąŠą▓ąŠą╗čīąĮąŠ čćą░čüč鹊 菹║ąĘąĄą╝ą┐ą╗čÅčĆčŗ čéąĖą┐ą░ ą┐ąŠč鹊ą║ąŠą▒ąĄąĘąŠą┐ą░čüąĮčŗ ą┤ą╗čÅ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣ čćč鹥ąĮąĖčÅ, ąĮąŠ ąĮąĄ ą┤ą╗čÅ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ (ąĮąĖ č鹥ą╝ ą▒ąŠą╗ąĄąĄ ą┤ą╗čÅ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗčģ čćč鹥ąĮąĖčÅ ąĖ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ). ąŁč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī čüą┐čĆą░ą▓ąĄą┤ą╗ąĖą▓čŗą╝ čü čéą░ą║ąĖą╝ čĆąĄčüčāčĆčüąŠą╝, ą║ą░ą║ čäą░ą╣ą╗. ąźąŠčéčÅ ąĘą░čēąĖčéą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą▓ čéą░ą║ąŠą│ąŠ čéąĖą┐ą░ ą┐čĆąŠčüč鹊ą╣ ąĖčüą║ą╗čÄčćąĖč鹥ą╗čīąĮąŠą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąŠą╣ ą┤ą╗čÅ ą▓čüąĄčģ čĆąĄąČąĖą╝ąŠą▓ ą┤ąŠčüčéčāą┐ą░ ąŠą▒čŗčćąĮąŠ ą┤ąŠą▒ąĖą▓ą░ąĄčéčüčÅ čåąĄą╗ąĖ, ąŠąĮą░ ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮąŠ ąŠą│čĆą░ąĮąĖčćąĖą▓ą░ąĄčé ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗą╣ ą┤ąŠčüčéčāą┐, ąĄčüą╗ąĖ ąĄčüčéčī ą╝ąĮąŠąČąĄčüčéą▓ąŠ čćąĖčéą░čÄčēąĖčģ ą┐ąŠč鹊ą║ąŠą▓ ąĖ č鹊ą╗čīą║ąŠ ąĖąĮąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤čÅčé ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ. ą¤čĆąĖą╝ąĄčĆ čéą░ą║ąŠą│ąŠ čüą╗čāčćą░čÅ - čüąĄčĆą▓ąĄčĆ ą▒ąĖąĘąĮąĄčü-ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣, ą│ą┤ąĄ čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ ą┤ą░ąĮąĮčŗąĄ ą║čŹčłąĖčĆčāčÄčéčüčÅ ą▓ čüčéą░čéąĖč湥čüą║ąĖčģ ą┐ąŠą╗čÅčģ ą┤ą╗čÅ ą▒čŗčüčéčĆąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░. ąÜą╗ą░čüčü ReaderWriterLockSlim ą▒čŗą╗ čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮ ą┤ą╗čÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĖčÅ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ ą┤ąŠčüčéčāą┐ąĮąŠčüčéąĖ ą┤ą░ąĮąĮčŗčģ ą┐čĆąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĄ ą▓ čéą░ą║ąŠą╝ čüčåąĄąĮą░čĆąĖąĖ.
ąÜą╗ą░čüčü ReaderWriterLockSlim ą▒čŗą╗ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮ ą▓ Framework 3.5, ąĘą░ą╝ąĄąĮąĖą▓ čüčéą░čĆčŗą╣ "č鹊ą╗čüčéčŗą╣" ą║ą╗ą░čüčü ReaderWriterLock. ą¤ąŠčüą╗ąĄą┤ąĮąĖą╣ ąŠą▒ą╗ą░ą┤ą░ąĄčé ą┐ąŠčģąŠąČąĄą╣ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčīčÄ, ąĮąŠ ą▓ ąĮąĄčüą║ąŠą╗čīą║ąŠ čĆą░ąĘ ą╝ąĄą┤ą╗ąĄąĮąĮąĄąĄ ąĖ čüąŠą┤ąĄčƹȹĖčé ąŠčłąĖą▒ą║čā ą▓ čüą▓ąŠąĄą╝ ą╝ąĄčģą░ąĮąĖąĘą╝ąĄ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ. ą×ą┤ąĮą░ą║ąŠ ą▓ čüčĆą░ą▓ąĮąĄąĮąĖąĖ čü ąŠą▒čŗčćąĮąŠą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąŠą╣ (Monitor.Enter/Exit) ą║ą╗ą░čüčü ReaderWriterLockSlim čĆą░ą▒ąŠčéą░ąĄčé ą▓ 2 čĆą░ąĘą░ ą╝ąĄą┤ą╗ąĄąĮąĮąĄąĄ.
ąÆ ąŠą▒ąŠąĖčģ ą║ą╗ą░čüčüą░čģ ąĘą┤ąĄčüčī ąĄčüčéčī ą┤ą▓ą░ ą▒ą░ąĘąŠą▓čŗčģ ą▓ąĖą┤ą░ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ - ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ čćč鹥ąĮąĖčÅ (read lock) ąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ąĘą░ą┐ąĖčüąĖ (write lock):
ŌĆó ąæą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ąĘą░ą┐ąĖčüąĖ čāąĮąĖą▓ąĄčĆčüą░ą╗čīąĮąŠ ąĖčüą║ą╗čÄčćąĖč鹥ą╗čīąĮą░čÅ.
ŌĆó ąæą╗ąŠą║ąĖčĆąŠą▓ą║ą░ čćč鹥ąĮąĖčÅ čüąŠą▓ą╝ąĄčüčéąĖą╝ą░ čü ą┤čĆčāą│ąĖą╝ąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ą╝ąĖ čćč鹥ąĮąĖčÅ.
ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ą┐ąŠč鹊ą║, čāą┤ąĄčƹȹĖą▓ą░čÄčēąĖą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ąĘą░ą┐ąĖčüąĖ, ą▒čāą┤ąĄčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░čéčī ą▓čüąĄ ą┤čĆčāą│ąĖąĄ ą┐ąŠč鹊ą║ąĖ, ą┐čŗčéą░čÄčēąĖąĄčüčÅ ą┐ąŠą╗čāčćąĖčéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā čćč鹥ąĮąĖčÅ ąĖą╗ąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ąĘą░ą┐ąĖčüąĖ (ąĖ ąĮą░ąŠą▒ąŠčĆąŠčé). ąØąŠ ąĄčüą╗ąĖ ąĮąĄčé ą┐ąŠč鹊ą║ąŠą▓, čāą┤ąĄčƹȹĖą▓ą░čÄčēąĖčģ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ąĘą░ą┐ąĖčüąĖ, č鹊 ą╗čÄą▒ąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠč鹊ą║ąŠą▓ ą╝ąŠą│čāčé ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā čćč鹥ąĮąĖčÅ.
ReaderWriterLockSlim ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé čüą╗ąĄą┤čāčÄčēąĖąĄ ą╝ąĄč鹊ą┤čŗ ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║ čćč鹥ąĮąĖčÅ/ąĘą░ą┐ąĖčüąĖ:
public void EnterReadLock();
public void ExitReadLock();
public void EnterWriteLock();
public void ExitWriteLock();
ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ ąĄčüčéčī ą▓ąĄčĆčüąĖąĖ "Try" ą▓čüąĄčģ ą╝ąĄč鹊ą┤ąŠą▓ EnterXXX, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąĖąĮąĖą╝ą░čÄčé ą░čĆą│čāą╝ąĄąĮčé čéą░ą╣ą╝ą░čāčéą░ ą▓ čüčéąĖą╗ąĄ Monitor.TryEnter (čéą░ą╣ą╝ą░čāčéčŗ ą╝ąŠą│čāčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ ą┤ąŠą▓ąŠą╗čīąĮąŠ ą╗ąĄą│ą║ąŠ, ąĄčüą╗ąĖ ąĘą░ čĆąĄčüčāčĆčü ąŠč湥ąĮčī ą▓čŗčüąŠą║ą░čÅ ą║ąŠąĮą║čāčĆąĄąĮčåąĖčÅ). ReaderWriterLock ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┐ąŠą┤ąŠą▒ąĮčŗąĄ ą╝ąĄč鹊ą┤čŗ AcquireXXX ąĖ ReleaseXXX. ąÆą╝ąĄčüč鹊 ą▓ąŠąĘą▓čĆą░čéą░ false ąŠąĮąĖ ą▓čŗą▒čĆą░čüčŗą▓ą░čÄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ApplicationException, ąĄčüą╗ąĖ ą┐čĆąŠąĖąĘąŠčłąĄą╗ čéą░ą╣ą╝ą░čāčé.
ąĪą╗ąĄą┤čāčÄčēą░čÅ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄčé ReaderWriterLockSlim. 3 ą┐ąŠč鹊ą║ą░ ą┐ąŠčüč鹊čÅąĮąĮąŠ ą┐čĆąŠčģąŠą┤čÅčé ą┐ąŠ čüą┐ąĖčüą║čā, ą│ą┤ąĄ 2 ą┐ąŠč鹊ą║ą░ ą║ą░ąČą┤čāčÄ čüąĄą║čāąĮą┤čā ą┤ąŠą▒ą░ą▓ą╗čÅčÄčé čüą╗čāčćą░ą╣ąĮąŠąĄ čćąĖčüą╗ąŠ ą║ čüą┐ąĖčüą║čā. ąæą╗ąŠą║ąĖčĆąŠą▓ą║ą░ čćč鹥ąĮąĖčÅ ąĘą░čēąĖčēą░ąĄčé čćąĖčéą░čÄčēąĖąĄ čüą┐ąĖčüąŠą║ ą┐ąŠč鹊ą║ąĖ, ąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ąĘą░ą┐ąĖčüąĖ ąĘą░čēąĖčēą░ąĄčé ąĘą░ą┐ąĖčüčŗą▓ą░čÄčēąĖąĄ ą▓ čüą┐ąĖčüąŠą║ ą┐ąŠč鹊ą║ąĖ:
class SlimDemo
{
static ReaderWriterLockSlim _rw = new ReaderWriterLockSlim();
static List< int> _items = new List< int>();
static Random _rand = new Random();
static void Main()
{
new Thread (Read).Start();
new Thread (Read).Start();
new Thread (Read).Start();
new Thread (Write).Start ("A");
new Thread (Write).Start ("B");
}
static void Read()
{
while (true)
{
_rw.EnterReadLock();
foreach (int i in _items) Thread.Sleep (10);
_rw.ExitReadLock();
}
}
static void Write (object threadID)
{
while (true)
{
int newNumber = GetRandNum (100);
_rw.EnterWriteLock();
_items.Add (newNumber);
_rw.ExitWriteLock();
Console.WriteLine ("ą¤ąŠč鹊ą║ " + threadID + " ą┤ąŠą▒ą░ą▓ąĖą╗ " + newNumber);
Thread.Sleep (100);
}
}
static int GetRandNum (int max) { lock (_rand) return _rand.Next(max); }
}
ąÆ ą║ąŠą┤ąĄ čĆąĄą╗ąĖąĘą░ ąŠą▒čŗčćąĮąŠ ą┤ąŠą▒ą░ą▓ą╗čÅčÄčé ą▒ą╗ąŠą║ąĖ try/finally, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ą▓čüąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą▒čŗą╗ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮčŗ, ąĄčüą╗ąĖ ą▒čŗą╗ąŠ ą▓čŗą▒čĆąŠčłąĄąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ.
ąĀąĄąĘčāą╗čīčéą░čé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čŹč鹊ą│ąŠ ą┐čĆąĖą╝ąĄčĆą░:
ą¤ąŠč鹊ą║ B ą┤ąŠą▒ą░ą▓ąĖą╗ 61
ą¤ąŠč鹊ą║ A ą┤ąŠą▒ą░ą▓ąĖą╗ 83
ą¤ąŠč鹊ą║ B ą┤ąŠą▒ą░ą▓ąĖą╗ 55
ą¤ąŠč鹊ą║ A ą┤ąŠą▒ą░ą▓ąĖą╗ 33
...
ReaderWriterLockSlim ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą▒ąŠą╗čīčłąĄą╣ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠą╣ ą░ą║čéąĖą▓ąĮąŠčüčéąĖ čćč鹥ąĮąĖčÅ Read, č湥ą╝ ą┐čĆąŠčüčéą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░. ą£čŗ ą╝ąŠąČąĄčé ą┐ąŠą║ą░ąĘą░čéčī čŹč鹊 ą▓čüčéą░ą▓ą║ąŠą╣ čüą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤ ą▓ ą╝ąĄč鹊ą┤ Write, ą▓ ąĮą░čćą░ą╗ąŠ čåąĖą║ą╗ą░ while:
Console.WriteLine (_rw.CurrentReadCount + " ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ čćąĖčéą░čÄčēąĖčģ");
ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 ą▓čüąĄą│ą┤ą░ ą▒čāą┤čāčé ą▓čŗą▓ąĄą┤ąĄąĮčŗ "3 ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ čćąĖčéą░čÄčēąĖčģ" (ą╝ąĄč鹊ą┤čŗ Read čéčĆą░čéčÅčé ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąŠ čüą▓ąŠąĄą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą▓ąĮčāčéčĆąĖ čåąĖą║ą╗ąŠą▓ foreach). ąÜą░ą║ ąĖ CurrentReadCount, ą║ą╗ą░čüčü ReaderWriterLockSlim ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čüą╗ąĄą┤čāčÄčēąĖąĄ čüą▓ąŠą╣čüčéą▓ą░ ą┤ą╗čÅ ą╝ąŠąĮąĖč鹊čĆąĖąĮą│ą░ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║:
public bool IsReadLockHeld { get; }
public bool IsUpgradeableReadLockHeld { get; }
public bool IsWriteLockHeld { get; }
public int WaitingReadCount { get; }
public int WaitingUpgradeCount { get; }
public int WaitingWriteCount { get; }
public int RecursiveReadCount { get; }
public int RecursiveUpgradeCount { get; }
public int RecursiveWriteCount { get; }
ą×ą▒ąĮąŠą▓ą╗čÅąĄą╝čŗąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ąĖ čĆąĄą║čāčĆčüąĖčÅ. ąśąĮąŠą│ą┤ą░ ą┐ąŠą╗ąĄąĘąĮąŠ ą┐ąŠą╝ąĄąĮčÅčéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā čćč鹥ąĮąĖčÅ ąĮą░ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ąĘą░ą┐ąĖčüąĖ ą▓ ąŠą┤ąĮąŠą╣ ą░č鹊ą╝ą░čĆąĮąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ. ąöą╗čÅ ą┐čĆąĖą╝ąĄčĆą░ ą┐čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ąÆčŗ čģąŠčéąĖč鹥 ą┤ąŠą▒ą░ą▓ąĖčéčī 菹╗ąĄą╝ąĄąĮčé ą║ čüą┐ąĖčüą║čā č鹊ą╗čīą║ąŠ ąĄčüą╗ąĖ ąŠąĮ ą▓ ąĮąĄą╝ čāąČąĄ ąĮąĄ ą┐čĆąĖčüčāčéčüčéą▓čāąĄčé. ąśą┤ąĄą░ą╗čīąĮčŗą╝ ą▒čŗą╗ąŠ ą▒čŗ ą╝ąĖąĮąĖą╝ąĖąĘąĖčĆąŠą▓ą░čéčī ąĘą░čéčĆą░čéčŗ ą▓čĆąĄą╝ąĄąĮąĖ ąĮą░ čāą┤ąĄčƹȹ░ąĮąĖąĄ (ąĖčüą║ą╗čÄčćąĖč鹥ą╗čīąĮąŠą╣) ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ąĘą░ą┐ąĖčüąĖ, ą┤ą╗čÅ č湥ą│ąŠ ą╝ąŠąČąĮąŠ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąŠą▒čĆą░ą▒ąŠčéą║čā čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
1. ą¤ąŠą╗čāčćąĖčéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā čćč鹥ąĮąĖčÅ.
2. ą¤čĆąŠą▓ąĄčĆąĖčéčī, ąĄčüą╗ąĖ čāąČąĄ čŹč鹊čé 菹╗ąĄą╝ąĄąĮčé ą▓ čüą┐ąĖčüą║ąĄ, ąĖ ąĄčüą╗ąĖ čŹč鹊 čéą░ą║, ąŠčüą▓ąŠą▒ąŠą┤ąĖčéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ąĖ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą▓ąŠąĘą▓čĆą░čé.
3. ą×čüą▓ąŠą▒ąŠą┤ąĖčéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā čćč鹥ąĮąĖčÅ.
4. ą¤ąŠą╗čāčćąĖčéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ąĘą░ą┐ąĖčüąĖ.
5. ąöąŠą▒ą░ą▓ąĖčéčī 菹╗ąĄą╝ąĄąĮčé ą▓ čüą┐ąĖčüąŠą║.
ą¤čĆąŠą▒ą╗ąĄą╝ą░ čéčāčé ą▓ č鹊ą╝, čćč鹊 ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║ ą╝ąŠąČąĄčé ą┐ąŠą┤ą║čĆą░čüčéčīčüčÅ ąĖ ąĖąĘą╝ąĄąĮąĖčéčī čüą┐ąĖčüąŠą║ (čé. ąĄ. ą┤ąŠą▒ą░ą▓ąĖčéčī čéą░ą║ąŠą╣ ąČąĄ 菹╗ąĄą╝ąĄąĮčé) ą╝ąĄąČą┤čā čłą░ą│ą░ą╝ąĖ 3 ąĖ 4. ReaderWriterLockSlim čĆąĄčłą░ąĄčé čŹčéčā ą┐čĆąŠą▒ą╗ąĄą╝čā čéčĆąĄčéčīąĖą╝ ą▓ąĖą┤ąŠą╝ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ, ą║ąŠč鹊čĆą░čÅ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ ąŠą▒ąĮąŠą▓ą╗čÅąĄą╝ą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ (upgradeable lock). ą×ą▒ąĮąŠą▓ą╗čÅąĄą╝ą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą┐ąŠą┤ąŠą▒ąĮą░ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĄ čćč鹥ąĮąĖčÅ, čü č鹥ą╝ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝, čćč鹊 ąŠąĮą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠą▓čŗčłąĄąĮą░ ą┤ąŠ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ čćč鹥ąĮąĖčÅ ą▓ ą░č鹊ą╝ą░čĆąĮąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ. ąÆąŠčé ą║ą░ą║ čŹč鹊 čüą╗ąĄą┤čāąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī:
1. ąĪą┤ąĄą╗ą░čéčī ą▓čŗąĘąŠą▓ EnterUpgradeableReadLock.
2. ąÆčŗą┐ąŠą╗ąĮąĖčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ ą┐ąŠ čćč鹥ąĮąĖčÄ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą┐čĆąŠą▓ąĄčĆąĖčéčī, ąĄčüčéčī ą╗ąĖ ąĖąĮč鹥čĆąĄčüčāčÄčēąĖą╣ 菹╗ąĄą╝ąĄąĮčé ą▓ čüą┐ąĖčüą║ąĄ).
3. ąÆčŗąĘą▓ą░čéčī EnterWriteLock (čŹč鹊 ą┐čĆąĄąŠą▒čĆą░ąĘčāąĄčé ąŠą▒ąĮąŠą▓ą╗čÅąĄą╝čāčÄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ą▓ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ąĘą░ą┐ąĖčüąĖ).
4. ąÆčŗą┐ąŠą╗ąĮąĖčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ ą┐ąŠ ąĘą░ą┐ąĖčüąĖ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ čŹč鹊ą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░ ą▓ čüą┐ąĖčüąŠą║).
5. ąÆčŗąĘą▓ą░čéčī ExitWriteLock (čŹč鹊 ą┐čĆąĄąŠą▒čĆą░ąĘčāąĄčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ąĘą░ą┐ąĖčüąĖ ąŠą▒čĆą░čéąĮąŠ ą▓ ąŠą▒ąĮąŠą▓ą╗čÅąĄą╝čāčÄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā).
6. ąÆčŗą┐ąŠą╗ąĮąĖčéčī ą╗čÄą▒čŗąĄ ą┤čĆčāą│ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ą┐ąŠ čćč鹥ąĮąĖčÄ.
7. ąÆčŗąĘą▓ą░čéčī ExitUpgradeableReadLock.
ąĪ č鹊čćą║ąĖ ąĘčĆąĄąĮąĖčÅ ą▓čŗąĘčŗą▓ą░čÄčēąĄą│ąŠ ą║ąŠą┤ą░ čŹč鹊 čüą║ąŠčĆąĄąĄ ą┐ąŠčģąŠąČąĄ ąĮą░ ą▓ą╗ąŠąČąĄąĮąĮčāčÄ ąĖą╗ąĖ čĆąĄą║čāčĆčüąĖą▓ąĮčāčÄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā. ą×ą┤ąĮą░ą║ąŠ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠ ąĮą░ čłą░ą│ąĄ 3 ą║ą╗ą░čüčü ReaderWriterLockSlim ą░č鹊ą╝ą░čĆąĮąŠ ąŠčüą▓ąŠą▒ąŠą┤ąĖčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā čćč鹥ąĮąĖčÅ ąĖ ą┐ąŠą╗čāčćąĖčé čćąĖčüčéčāčÄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ąĘą░ą┐ąĖčüąĖ (ąŠą▒ąĄ čŹčéąĖ ąŠą┐ąĄčĆą░čåąĖąĖ ą▓čŗą┐ąŠą╗ąĮčÅčéčüčÅ ą░č鹊ą╝ą░čĆąĮąŠ, ą║ą░ą║ ąŠą┤ąĮąŠ ąĮąĄą┤ąĄą╗ąĖą╝ąŠąĄ ą┤ąĄą╣čüčéą▓ąĖąĄ).
ąĢčüčéčī ąĖ ą┤čĆčāą│ąŠąĄ ą▓ą░ąČąĮąŠąĄ ąŠčéą╗ąĖčćąĖąĄ ą╝ąĄąČą┤čā ąŠą▒ąĮąŠą▓ą╗čÅąĄą╝čŗą╝ąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ą╝ąĖ ąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ą╝ąĖ čćč鹥ąĮąĖčÅ. ąÆ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ąŠą▒ąĮąŠą▓ą╗čÅąĄą╝ą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą╝ąŠąČąĄčé čüąŠčüčāčēąĄčüčéą▓ąŠą▓ą░čéčī ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ čü ą╗čÄą▒čŗą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąŠą╝ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║ čćč鹥ąĮąĖčÅ, čüą░ą╝ą░ ą┐ąŠ čüąĄą▒ąĄ ąŠą▒ąĮąŠą▓ą╗čÅąĄą╝ą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą▓ ą╗čÄą▒ąŠą╣ ą╝ąŠą╝ąĄąĮčé ą▓čĆąĄą╝ąĄąĮąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī č鹊ą╗čīą║ąŠ ąŠą┤ąĮą░. ąŁč鹊 ą┐čĆąĄą┤ąŠčéą▓čĆą░čēą░ąĄčé ą┐ąŠčÅą▓ą╗ąĄąĮąĖąĄ ą│ą╗čāčģąŠą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą┐čĆąĖ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĖ čāčĆąŠą▓ąĮčÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ (conversion deadlock) ą┐čāč鹥ą╝ čüąĄčĆąĖą░ą╗ąĖąĘą░čåąĖąĖ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗčģ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ - čéą░ą║ąČąĄ ą║ą░ą║ čŹč鹊 ą┤ąĄą╗ą░ąĄčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ (update lock) SQL Server:
| SQL Server |
ReaderWriterLockSlim |
| Share lock |
Read lock |
| Exclusive lock |
Write lock |
| Update lock |
Upgradeable lock |
ą£čŗ ą╝ąŠąČąĄą╝ ą┐čĆąŠą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆąŠą▓ą░čéčī ąŠą▒ąĮąŠą▓ą╗čÅąĄą╝čāčÄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ąĖąĘą╝ąĄąĮąĄąĮąĖąĄą╝ ą╝ąĄč鹊ą┤ą░ Write ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ čéą░ą║, čćč鹊ą▒čŗ ąŠąĮ ą┤ąŠą▒ą░ą▓ą╗čÅą╗ čćąĖčüą╗ąŠ ą║ čüą┐ąĖčüą║čā č鹊ą╗čīą║ąŠ ąĄčüą╗ąĖ čŹč鹊ą│ąŠ čćąĖčüą╗ą░ ą┐ąŠą║ą░ ą▓ čüą┐ąĖčüą║ąĄ ąĮąĄčé:
while (true)
{
int newNumber = GetRandNum (100);
_rw.EnterUpgradeableReadLock();
if (!_items.Contains (newNumber))
{
_rw.EnterWriteLock();
_items.Add (newNumber);
_rw.ExitWriteLock();
Console.WriteLine ("ą¤ąŠč鹊ą║ " + threadID + " ą┤ąŠą▒ą░ą▓ąĖą╗ " + newNumber);
}
_rw.ExitUpgradeableReadLock();
Thread.Sleep (100);
}
ReaderWriterLock ą╝ąŠąČąĄčé čéą░ą║ąČąĄ ą┤ąĄą╗ą░čéčī ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ - ąĮąŠ čŹč鹊 ąĮąĄąĮą░ą┤ąĄąČąĮąŠ, ą┐ąŠč鹊ą╝čā čćč鹊 ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ ą║ąŠąĮčåąĄą┐čåąĖčÅ ąŠą▒ąĮąŠą▓ą╗čÅąĄą╝čŗčģ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║. ą¤ąŠ čŹč鹊ą╣ ą┐čĆąĖčćąĖąĮąĄ čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ąĖ ReaderWriterLockSlim čü ąĮčāą╗čÅ čĆą░ąĘčĆą░ą▒ąŠčéą░ą╗ąĖ ąĮąŠą▓čŗą╣ ą║ą╗ą░čüčü.
ąĀąĄą║čāčĆčüąĖčÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ. ą×ą▒čŗčćąĮąŠ ą▓ą╗ąŠąČąĄąĮąĮą░čÅ ąĖą╗ąĖ čĆąĄą║čāčĆčüąĖą▓ąĮą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ąĘą░ą┐čĆąĄčēąĄąĮą░ čü ReaderWriterLockSlim. ąĪą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ, čüą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤ ą▓čŗą▒čĆąŠčüąĖčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ:
var rw = new ReaderWriterLockSlim();
rw.EnterReadLock();
rw.EnterReadLock();
rw.ExitReadLock();
rw.ExitReadLock();
ą×ą┤ąĮą░ą║ąŠ čŹč鹊čé ą║ąŠą┤ ąĘą░ą┐čāčüčéąĖčéčüčÅ ą▒ąĄąĘ ąŠčłąĖą▒ą║ąĖ, ąĄčüą╗ąĖ ąÆčŗ čüą║ąŠąĮčüčéčĆčāąĖčĆčāąĄč鹥 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą║ą╗ą░čüčüą░ ReaderWriterLockSlim čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
var rw = new ReaderWriterLockSlim (LockRecursionPolicy.SupportsRecursion);
ąŁč鹊 ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ą╝ąŠąČąĄčé ą┐čĆąŠąĖčüčģąŠą┤ąĖčéčī čĆąĄą║čāčĆčüąĖą▓ąĮą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░, ąĄčüą╗ąĖ ąÆą░ą╝ čŹč鹊 ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠ ąĮčāąČąĮąŠ. ąĀąĄą║čāčĆčüąĖą▓ąĮčŗąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą┤ąŠą▒ą░ą▓ą╗čÅčÄčé ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮčāčÄ čüą╗ąŠąČąĮąŠčüčéčī ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝čā, ą┐ąŠč鹊ą╝čā čćč鹊 ą╝ąŠąČąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą│ąŠ ą▓ąĖą┤ą░ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ:
rw.EnterWriteLock();
rw.EnterReadLock();
Console.WriteLine (rw.IsReadLockHeld); // True
Console.WriteLine (rw.IsWriteLockHeld); // True
rw.ExitReadLock();
rw.ExitWriteLock();
ąæą░ąĘąŠą▓ąŠąĄ ą┐čĆą░ą▓ąĖą╗ąŠ čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, čćč鹊 ą║ą░ą║ č鹊ą╗čīą║ąŠ ąÆčŗ ą┐ąŠą╗čāčćąĖą╗ąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā, ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą╝ąĄąĮčīčłąĄ, ąĮąŠ ąĮąĄ ą▒ąŠą╗čīčłąĄ, čüą╗ąĄą┤ąŠą▓ą░čéčī čāčĆąŠą▓ąĮčÅą╝: Read Lock (ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ čćč鹥ąĮąĖčÅ), Upgradeable Lock (ąŠą▒ąĮąŠą▓ą╗čÅąĄą╝ą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░), Write Lock (ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ąĘą░ą┐ąĖčüąĖ).
ą×ą┤ąĮą░ą║ąŠ ąĘą░ą┐čĆąŠčü ąĮą░ ą┐ąŠą▓čŗčłąĄąĮąĖąĄ čāčĆąŠą▓ąĮčÅ ąŠą▒ąĮąŠą▓ą╗čÅąĄą╝ąŠą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ąĮą░ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ąĘą░ą┐ąĖčüąĖ ą▓čüąĄą│ą┤ą░ ąŠčüčéą░ąĄčéčüčÅ ą╗ąĄą│ą░ą╗čīąĮčŗą╝.
[Suspend ąĖ Resume]
ą¤ąŠč鹊ą║ ą╝ąŠąČąĄčé ą▒čŗčéčī čÅą▓ąĮąŠ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮ (suspend) ąĖ ąĘą░č鹥ą╝ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓ąŠąĘąŠą▒ąĮąŠą▓ą╗ąĄąĮąŠ ąĄą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ (resume) čü ą┐ąŠą╝ąŠčēčīčÄ čāčüčéą░čĆąĄą▓čłąĖčģ ą╝ąĄč鹊ą┤ąŠą▓ Thread.Suspend ąĖ Thread.Resume. ąŁč鹊čé ą╝ąĄčģą░ąĮąĖąĘą╝ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąŠčéą┤ąĄą╗ąĄąĮ ąŠčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║. ą×ą▒ąĄ čüąĖčüč鹥ą╝čŗ ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ ąĖ čĆą░ą▒ąŠčéą░čÄčé ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ.
ą¤ąŠč鹊ą║ ą╝ąŠąČąĄčé ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ąĖčéčī čüą░ą╝ąŠą│ąŠ čüąĄą▒čÅ ąĖą╗ąĖ ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║. ąÆčŗąĘąŠą▓ Suspend ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ą║čĆą░čéą║ąŠą╝čā ą▓čģąŠą┤čā ą┐ąŠč鹊ą║ą░ ą▓ čüąŠčüč鹊čÅąĮąĖąĄ SuspendRequested, ąĘą░č鹥ą╝ ą┐ąŠ ą┤ąŠčüčéąĖąČąĄąĮąĖčÄ č鹊čćą║ąĖ ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéąĖ ą┤ą╗čÅ čüą▒ąŠčĆą░ ą╝čāčüąŠčĆą░, ą┐ąŠč鹊ą║ ą▓čģąŠą┤ąĖčé ą▓ čüąŠčüč鹊čÅąĮąĖąĄ Suspended. ąØą░čćąĖąĮą░čÅ čü čŹč鹊ą│ąŠ ą╝ąŠą╝ąĄąĮčéą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐ąŠč鹊ą║ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓ąŠąĘąŠą▒ąĮąŠą▓ą╗ąĄąĮąŠ č鹊ą╗čīą║ąŠ čü ą┐ąŠą╝ąŠčēčīčÄ ą┤čĆčāą│ąŠą│ąŠ ą┐ąŠč鹊ą║ą░, ą║ąŠč鹊čĆčŗą╣ ą▓čŗąĘąŠą▓ąĄčé ąĄą│ąŠ ą╝ąĄč鹊ą┤ Resume. Resume ą▒čāą┤ąĄčé čĆą░ą▒ąŠčéą░čéčī č鹊ą╗čīą║ąŠ ąĮą░ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮąŠą╝ ą┐ąŠč鹊ą║ąĄ, ąĮąŠ ąĮąĄ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĮąŠą╝ ą┐ąŠč鹊ą║ąĄ.
ąØą░čćąĖąĮą░čÅ čü .NET 2.0 Suspend ąĖ Resume čüčéą░ą╗ąĖ čāčüčéą░čĆąĄą▓čłąĖą╝ąĖ, ąĖčģ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąĮąĄ čĆąĄą║ąŠą╝ąĄąĮą┤čāąĄčéčüčÅ ąĖąĘ-ąĘą░ ąŠą┐ą░čüąĮąŠčüčéąĖ ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮąŠą╣ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą║ąĖ ą┤čĆčāą│ąĖą╝ ą┐ąŠč鹊ą║ąŠą╝. ąĢčüą╗ąĖ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ąĖčéčī ą┐ąŠč鹊ą║, ą║ąŠč鹊čĆčŗą╣ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĄ ąĮą░ ą║čĆąĖčéąĖč湥čüą║ąŠą╝ čĆąĄčüčāčĆčüąĄ, č鹊 ą▓čüąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ (ąĖą╗ąĖ ą║ąŠą╝ą┐čīčÄč鹥čĆ) ą╝ąŠąČąĄčé ą┐ąŠą╗čāčćąĖčéčī deadlock. ąŁč鹊 ąĮą░ą╝ąĮąŠą│ąŠ ąŠą┐ą░čüąĮąĄąĄ, č湥ą╝ ą▓čŗąĘąŠą▓ Abort - ą║ąŠč鹊čĆčŗą╣ ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÄ ą╗čÄą▒čŗčģ čéą░ą║ąĖčģ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║ (ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝ č鹥ąŠčĆąĄčéąĖč湥čüą║ąĖ) ąĮą░ ąŠčüąĮąŠą▓ą░ąĮąĖąĖ ą║ąŠą┤ą░ ą▓ ą▒ą╗ąŠą║ą░čģ finally.
ą×ą┤ąĮą░ą║ąŠ ą▒ąĄąĘąŠą┐ą░čüąĮčŗą╝ čÅą▓ą╗čÅąĄčéčüčÅ ą▓čŗąĘąŠą▓ Suspend ąĮą░ č鹥ą║čāčēąĄą╝ ą┐ąŠč鹊ą║ąĄ - ąĖ čéą░ą║ąĖą╝ čüą┐ąŠčüąŠą▒ąŠą╝ ą╝ąŠąČąĮąŠ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ą┐čĆąŠčüč鹊ą╣ ą╝ąĄčģą░ąĮąĖąĘą╝ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ - čĆą░ą▒ąŠčćąĖą╣ ą┐ąŠč鹊ą║ ą▓ čåąĖą║ą╗ąĄ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé čüą▓ąŠčÄ ąĘą░ą┤ą░čćčā, ą▓čŗąĘčŗą▓ą░ąĄčé Suspend ą┤ą╗čÅ čüą░ą╝ąŠą│ąŠ čüąĄą▒čÅ, ąĖ ąĘą░č鹥ą╝ ąČą┤ąĄčé ą▓ąŠąĘąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ ("ą┐čĆąŠą▒čāąČą┤ąĄąĮąĖčÅ") ąŠčüąĮąŠą▓ąĮčŗą╝ ą┐ąŠč鹊ą║ąŠą╝, ą║ąŠą│ą┤ą░ ą▒čāą┤ąĄčé ą│ąŠč鹊ą▓ą░ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┤čĆčāą│ą░čÅ ąĘą░ą┤ą░čćą░. ąźąŠčéčÅ čéčāčé ąĄčüčéčī čüą╗ąŠąČąĮąŠčüčéčī ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĖ, ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą╗ąĖ ą┐ąŠč鹊ą║. ąĀą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤:
worker.NextTask = "MowTheLawn";
if ((worker.ThreadState & ThreadState.Suspended) > 0)
worker.Resume;
else
// ą£čŗ ąĮąĄ ą╝ąŠąČąĄą╝ ą▓čŗąĘčŗą▓ą░čéčī Resume, ą┐ąŠčüą║ąŠą╗čīą║čā ą┐ąŠč鹊ą║ čĆą░ą▒ąŠčéą░ąĄčé.
// ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą┤ą░ą╣č鹥 čüąĖą│ąĮą░ą╗ čĆą░ą▒ąŠč湥ą╝čā ą┐ąŠč鹊ą║čā č湥čĆąĄąĘ čäą╗ą░ą│:
worker.AnotherTaskAwaits = true;
ąŁč鹊 čāąČą░čüąĮąŠ ąĮąĄą▒ąĄąĘąŠą┐ą░čüąĮąŠ ą┤ą╗čÅ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠą╣ čĆą░ą▒ąŠčéčŗ: čŹč鹊čé ą║ąŠą┤ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗč鹥čüąĮąĄąĮ ą▓ ą╗čÄą▒ąŠą╝ ą╝ąĄčüč鹥 čŹčéąĖčģ čüčéčĆąŠą║, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ čĆą░ą▒ąŠčćąĖą╣ ą┐ąŠč鹊ą║ ą╝ąŠąČąĄčé ą┐ąŠą╝ąĄąĮčÅčéčī čüą▓ąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ. ąźąŠčéčÅ čŹčéčā ą┐čĆąŠą▒ą╗ąĄą╝čā ą╝ąŠąČąĮąŠ ąŠą▒ąŠą╣čéąĖ, čĆąĄčłąĄąĮąĖąĄ čüčéą░ąĮąŠą▓ąĖčéčüčÅ ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮčŗą╝, č湥ą╝ ą░ą╗čīč鹥čĆąĮą░čéąĖą▓ą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą║ąŠąĮčüčéčĆčāą║čåąĖčÄ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ, čéą░ą║čāčÄ ą║ą░ą║ AutoResetEvent ąĖą╗ąĖ Wait ąĖ Pulse. ąŁč鹊 ą┤ąĄą╗ą░ąĄčé Suspend ąĖ Resume čüąŠą▓ąĄčĆčłąĄąĮąĮąŠ ą▒ąĄčüą┐ąŠą╗ąĄąĘąĮčŗą╝ąĖ.
ąŻčüčéą░čĆąĄą▓čłąĖąĄ ą╝ąĄč鹊ą┤čŗ Suspend ąĖ Resume ąĖą╝ąĄčÄčé ą┤ą▓ą░ čĆąĄąČąĖą╝ą░: ąŠą┐ą░čüąĮąŠ ąĖ ą▒ąĄčüą┐ąŠą╗ąĄąĘąĮąŠ!
[ą¤čĆąĄą║čĆą░čēąĄąĮąĖąĄ čĆą░ą▒ąŠčéčŗ ą┐ąŠč鹊ą║ą░]
ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ ąĘą░ą▓ąĄčĆčłąĖčéčī ą┐ąŠč鹊ą║ ą╝ąĄč鹊ą┤ąŠą╝ Abort:
class Abort
{
static void Main()
{
Thread t = new Thread (delegate() { while(true); } ); // ąæąĄčüą║ąŠąĮąĄčćąĮąŠąĄ ąĘą░čåąĖą║ą╗ąĖą▓ą░ąĮąĖąĄ
t.Start();
Thread.Sleep (1000); // ą¤ąŠąĘą▓ąŠą╗ąĖą╝ čŹč鹊ą╝čā čåąĖą║ą╗čā ą║čĆčāčéąĖčéčīčüčÅ 1 čüąĄą║čāąĮą┤čā...
t.Abort(); // ... ąĘą░č鹥ą╝ ąŠą▒ąŠčĆą▓ąĄą╝.
}
}
ą¤ąŠč鹊ą║, čĆą░ą▒ąŠčéą░ ą║ąŠč鹊čĆąŠą│ąŠ ąŠą▒čĆčŗą▓ą░ąĄčéčüčÅ, ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ ą▓čģąŠą┤ąĖčé ą▓ čüąŠčüč鹊čÅąĮąĖąĄ AbortRequested. ąĢčüą╗ąĖ ąŠąĮ ąĘą░č鹥ą╝ ąĘą░ą▓ąĄčĆčłą░ąĄčéčüčÅ ą║ą░ą║ ąŠąČąĖą┤ą░ą╗ąŠčüčī, č鹊 ą┐ąĄčĆąĄčģąŠą┤ąĖčé ą▓ čüąŠčüč鹊čÅąĮąĖąĄ Stopped. ąÆčŗąĘą▓ą░ą▓čłąĖą╣ ą║ąŠą┤ ą╝ąŠąČąĄčé ąČą┤ą░čéčī ą┐ąŠčÅą▓ą╗ąĄąĮąĖčÅ čŹč鹊ą│ąŠ čüąŠčüč鹊čÅąĮąĖčÅ ą▓čŗąĘąŠą▓ąŠą╝ Join:
class Abort
{
static void Main()
{
Thread t = new Thread (delegate() { while (true); } );
Console.WriteLine (t.ThreadState); // ą¤ąŠč鹊ą║ t ąĮąĄ ąĘą░ą┐čāčēąĄąĮ (Unstarted)
t.Start();
Thread.Sleep (1000);
Console.WriteLine (t.ThreadState); // ąĀą░ą▒ąŠčéą░ąĄčé (Running)
t.Abort();
Console.WriteLine (t.ThreadState); // ąŚą░ą┐čĆąŠčü ąĮą░ ąŠą▒čĆčŗą▓ čĆą░ą▒ąŠčéčŗ (AbortRequested)
t.Join();
Console.WriteLine (t.ThreadState); // ą×čüčéą░ąĮąŠą▓ą╗ąĄąĮ (Stopped)
}
}
Abort ą▓čŗąĘčŗą▓ą░ąĄčé ą║ ą▓čŗą▒čĆąŠčüčā ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ThreadAbortException ąĮą░ čåąĄą╗ąĄą▓ąŠą╝ ą┐ąŠč鹊ą║ąĄ, ą▓ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ čüą╗čāčćą░ąĄą▓, ą║ąŠą│ą┤ą░ ą┐ąŠč鹊ą║ čĆą░ą▒ąŠčéą░ąĄčé. ą¤ąŠč鹊ą║, ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ąŠč鹊čĆąŠą│ąŠ ąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ čéą░ą║ąĖą╝ čüą┐ąŠčüąŠą▒ąŠą╝, ą╝ąŠąČąĄčé ą▓čŗą▒čĆą░čéčī ąŠą▒čĆą░ą▒ąŠčéą║čā čŹč鹊ą│ąŠ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ąŠą┤ąĮą░ą║ąŠ č鹊ą│ą┤ą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą┐ąŠą▓č鹊čĆąĮąŠ ą▓čŗą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ ą▓ ą║ąŠąĮąĄčå ą▒ą╗ąŠą║ą░ catch (čćč鹊ą▒čŗ ą┐ąŠą╝ąŠčćčī ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ą┐ąŠč鹊ą║čā ąĘą░ą▓ąĄčĆčłąĖčéčīčüčÅ čéą░ą║, ą║ą░ą║ čŹč鹊 ąŠąČąĖą┤ą░ą╗ąŠčüčī). ą×ą┤ąĮą░ą║ąŠ ąĄčüčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą┐čĆąĄą┤ąŠčéą▓čĆą░čéąĖčéčī ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąŠąĄ ą┐ąŠą▓č鹊čĆąĮąŠąĄ ą▓čŗą▒čĆą░čüčŗą▓ą░ąĮąĖąĄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą▓čŗąĘąŠą▓ąŠą╝ Thread.ResetAbort ą▓ąĮčāčéčĆąĖ ą▒ą╗ąŠą║ą░ catch. ąóąŠą│ą┤ą░ ą┐ąŠč鹊ą║ ą▓ąĄčĆąĮąĄčéčüčÅ ą▓ čüąŠčüč鹊čÅąĮąĖąĄ Running (čü ą║ąŠč鹊čĆąŠą│ąŠ ąŠąĮ ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ čüąĮąŠą▓ą░ ą╝ąŠąČąĄčé ą┐ąŠą╗čāčćąĖčéčī Abort). ąÆ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ čĆą░ą▒ąŠčćąĖą╣ ą┐ąŠč鹊ą║ ą▓ąŠąĘą▓čĆą░čēą░ąĄčéčüčÅ ą║ ąČąĖąĘąĮąĖ ą▓čüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ čüą┤ąĄą╗ą░ąĮą░ ą┐ąŠą┐čŗčéą║ą░ ąŠą▒ąŠčĆą▓ą░čéčī ąĄą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą▓čŗąĘąŠą▓ąŠą╝ Abort:
class Terminator
{
static void Main()
{
Thread t = new Thread (Work);
t.Start();
Thread.Sleep (1000); t.Abort();
Thread.Sleep (1000); t.Abort();
Thread.Sleep (1000); t.Abort();
}
static void Work()
{
while (true)
{
try { while (true); }
catch (ThreadAbortException) { Thread.ResetAbort(); }
Console.WriteLine ("I will not die!");
}
}
}
ThreadAbortException ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčéčüčÅ ą┐čĆąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ąĮąĄ ąĘą░čüčéą░ą▓ą╗čÅčÅ ąĘą░ą▓ąĄčĆčłą░čéčīčüčÅ ą▓čüąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ąĄčüą╗ąĖ ThreadAbortException ąĮąĄ ą▒čŗą╗ąŠ ąŠą▒čĆą░ą▒ąŠčéą░ąĮąŠ, ą▓ ąŠčéą╗ąĖčćąĖąĄ ąŠčé ą▓čüąĄčģ ą┤čĆčāą│ąĖčģ čéąĖą┐ąŠą▓ ąĖčüą║ą╗čÄč湥ąĮąĖą╣.
Abort ą▒čāą┤ąĄčé čĆą░ą▒ąŠčéą░čéčī ąĮą░ ą┐ąŠč鹊ą║ąĄ ą▓ ą╗čÄą▒ąŠą╝ ąĄą│ąŠ čüąŠčüč鹊čÅąĮąĖąĖ - running, blocked, suspended ąĖą╗ąĖ stopped. ą×ą┤ąĮą░ą║ąŠ ąĄčüą╗ąĖ ąŠą▒čĆčŗą▓ą░ąĄčéčüčÅ ą┐ąŠč鹊ą║ ą▓ čüąŠčüč鹊čÅąĮąĖąĖ suspended, ą▒čāą┤ąĄčé ą▓čŗą▒čĆąŠčłąĄąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ThreadStateException - ąĮą░ čŹč鹊čé čĆą░ąĘ ą▓ ą▓čŗąĘčŗą▓ą░čÄčēąĄą╝ ą┐ąŠč鹊ą║ąĄ - ąĖ ąŠčüčéą░ąĮąŠą▓ą║ą░ ą┐ąŠč鹊ą║ą░ ąĮąĄ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ, ą┐ąŠą║ą░ čĆą░ą▒ąŠčéą░ ąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄą╝ąŠą│ąŠ ą┐ąŠč鹊ą║ą░ ąĮąĄ ą▒čāą┤ąĄčé ą▓ąŠąĘąŠą▒ąĮąŠą▓ą╗ąĄąĮą░ (resume). ąÆąŠčé čéą░ą║ čüą╗ąĄą┤čāąĄčé ąŠą▒čĆčŗą▓ą░čéčī ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮčŗą╣ ą┐ąŠč鹊ą║:
try { suspendedThread.Abort(); }
catch (ThreadStateException) { suspendedThread.Resume(); }
// ąóąĄą┐ąĄčĆčī ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮčŗą╣ ą┐ąŠč鹊ą║ suspendedThread ą▒čāą┤ąĄčé ąŠą▒ąŠčĆą▓ą░ąĮ.
ąĪą╗ąŠąČąĮąŠčüčéąĖ, čüą▓čÅąĘą░ąĮąĮčŗąĄ čü Thread.Abort. ąĢčüą╗ąĖ ą┐čĆąĄą┤ą┐ąŠą╗ąŠąČąĖčéčī, čćč鹊 ąŠą▒čĆčŗą▓ą░ąĄą╝čŗą╣ ą┐ąŠč鹊ą║ ąĮąĄ ą▓čŗąĘą▓ą░ą╗ ResetAbort, č鹊 ąÆčŗ ą╝ąŠąČąĄč鹥 ąŠąČąĖą┤ą░čéčī, čćč鹊 ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄ ą┐ąŠč鹊ą║ą░ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąŠč湥ąĮčī ą▒čŗčüčéčĆąŠ. ą×ą┤ąĮą░ą║ąŠ ą║ą░ą║ čŹč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé čü čģąŠčĆąŠčłąĖą╝ ą░ą┤ą▓ąŠą║ą░č鹊ą╝, ą┐ąŠč鹊ą║ ą╝ąŠąČąĄčé ąŠčüčéą░ą▓ą░čéčīčüčÅ ą▓ ą║ą░ą╝ąĄčĆąĄ čüą╝ąĄčĆčéąĮąĖą║ąŠą▓ ą┤ąŠą▓ąŠą╗čīąĮąŠ ą┤ąŠą╗ą│ąŠ! ąÆąŠčé ąĮąĄčüą║ąŠą╗čīą║ąŠ čäą░ą║č鹊čĆąŠą▓, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé čüąŠčģčĆą░ąĮąĖčéčī ą┐ąŠč鹊ą║ ąĮą░ ąĮąĄą║ąŠč鹊čĆąŠąĄ ą▓čĆąĄą╝čÅ ą▓ čüąŠčüč鹊čÅąĮąĖąĖ AbortRequested:
ŌĆó ąÜąŠąĮčüčéčĆčāą║č鹊čĆčŗ čüčéą░čéąĖč湥čüą║ąŠą│ąŠ ą║ą╗ą░čüčüą░ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą┐čĆąĄčĆčŗą▓ą░čÄčéčüčÅ čéą░ą║ąĖą╝ čüą┐ąŠčüąŠą▒ąŠą╝ (čćč鹊ą▒čŗ ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ ąĮąĄ ąŠčéčĆą░ą▓ąĖčéčī ąŠčüčéą░ą▓čłčāčÄčüčÅ ąČąĖąĘąĮčī ą┤ąŠą╝ąĄąĮą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ).
ŌĆó ąÆčüąĄ ą▒ą╗ąŠą║ąĖ catch/finally čüąŠčģčĆą░ąĮčÅčÄčé čĆą░ą▒ąŠčéčā, ąĖ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ąŠą▒čĆčŗą▓ą░čÄčéčüčÅ ą┐ąŠčüąĄčĆąĄą┤ąĖąĮąĄ.
ŌĆó ąĢčüą╗ąĖ ąŠą▒čĆčŗą▓ą░ąĄčéčüčÅ ą┐ąŠč鹊ą║ ą▓ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą╝ ą║ąŠą┤ąĄ (unmanaged code), č鹊 ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐čĆąŠą┤ąŠą╗ąČąĖčéčüčÅ ą┤ąŠ ą╝ąŠą╝ąĄąĮčéą░ ą┤ąŠčüčéąĖąČąĄąĮąĖčÅ čüą╗ąĄą┤čāčÄčēąĄą│ąŠ ąŠą┐ąĄčĆą░č鹊čĆą░ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ ą║ąŠą┤ą░ (managed code).
ą¤ąŠčüą╗ąĄą┤ąĮąĖą╣ čäą░ą║č鹊čĆ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓ čćą░čüčéąĮąŠčüčéąĖ ą┐čĆąŠą▒ą╗ąĄą╝ą░čéąĖčćąĮčŗą╝ ą▓ č鹊ą╝, čćč鹊 čüą░ą╝ą░ ą┐ą╗ą░čéč乊čĆą╝ą░ .NET čćą░čüč鹊 ą▓čŗąĘčŗą▓ą░ąĄčé ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝čŗą╣ ą║ąŠą┤, ąŠčüčéą░ą▓ą░čÅčüčī ą▓ ąĮąĄą╝ ąĮą░ ą┤ąŠą▓ąŠą╗čīąĮąŠ ą┤ąŠą╗ą│ąŠąĄ ą▓čĆąĄą╝čÅ. ą¤čĆąĖą╝ąĄčĆą░ą╝ąĖ ą╝ąŠą│čāčé čüą╗čāąČąĖčéčī ą║ą╗ą░čüčü, ąŠą▒čüą╗čāąČąĖą▓ą░čÄčēąĖą╣ čĆą░ą▒ąŠčéčā čü čüąĄčéčīčÄ, ąĖą╗ąĖ ą║ą╗ą░čüčü, čĆą░ą▒ąŠčéą░čÄčēąĖą╣ čü ą▒ą░ąĘąŠą╣ ą┤ą░ąĮąĮčŗčģ. ąĢčüą╗ąĖ čüąĄč鹥ą▓ąŠą╣ čĆąĄčüčāčĆčü ąĮąĄą┤ąŠčüčéčāą┐ąĄąĮ, ąĖą╗ąĖ ą╝ąĄą┤ą╗ąĄąĮąĮąŠ ąŠčéą▓ąĄčćą░ąĄčé, č鹊 ąĄčüčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī, čćč鹊 ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąŠčüčéą░ąĮąĄčéčüčÅ ąĮą░ čŹč鹊 ą▓čĆąĄą╝čÅ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą▓ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą╝ ą║ąŠą┤ąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠ ąĮą░ ą╝ąĖąĮčāčéčŗ, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čŹč鹊ą│ąŠ ą║ą╗ą░čüčüą░. ąÆ čéą░ą║ąĖčģ čüą╗čāčćą░čÅčģ, ą║ąŠąĮąĄčćąĮąŠ, ąĮąĄ čģąŠč鹥ą╗ąŠčüčī ą▒čŗ ą┐ąŠą┤ą║ą╗čÄčćą░čéčīčüčÅ (Join) ą║ ąŠą▒čĆčŗą▓ą░ąĄą╝ąŠą╝čā ą┐ąŠč鹊ą║čā - ą┐ąŠ ą║čĆą░ą╣ąĮąĄą╣ ą╝ąĄčĆąĄ ą▒ąĄąĘ čéą░ą╣ą╝ą░čāčéą░!
ą×ą▒ąŠčĆą▓ą░čéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ąŠą┤ą░ .NET ą╝ąĄąĮąĄąĄ ą┐čĆąŠą▒ą╗ąĄą╝ą░čéąĖčćąĮąŠ, ą┐ąŠą║ą░ ą▒ą╗ąŠą║ąĖ try/finally ąĖą╗ąĖ ąŠą┐ąĄčĆą░č鹊čĆčŗ ą│ą░čĆą░ąĮčéąĖčĆčāčÄčé ą┐čĆą░ą▓ąĖą╗čīąĮčāčÄ ąŠčćąĖčüčéą║čā ą┐čĆąĖ ą▓čŗą▒čĆą░čüčŗą▓ą░ąĮąĖąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ThreadAbortException. ą×ą┤ąĮą░ą║ąŠ ą┤ą░ąČąĄ ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą▓čüąĄ ąĄčēąĄ ą╝ąŠąČąĮąŠ ą▒čŗčéčī čāčÅąĘą▓ąĖą╝čŗą╝ ą┤ą╗čÅ ąĮąĄą┐čĆąĖčÅčéąĮčŗčģ ąĮąĄąŠąČąĖą┤ą░ąĮąĮąŠčüč鹥ą╣. ąöą╗čÅ ą┐čĆąĖą╝ąĄčĆą░ čĆą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗ąĄą┤čāčÄčēąĄąĄ:
using (StreamWriter w = File.CreateText ("myfile.txt"))
w.Write ("Abort-Safe?");
ą×ą┐ąĄčĆą░č鹊čĆ using čÅąĘčŗą║ą░ C# čŹč鹊 ą┐čĆąŠčüč鹊 čüąĖąĮčéą░ą║čüąĖč湥čüą║ąĖą╣ čÅčĆą╗čŗč湊ą║, ą║ąŠč鹊čĆčŗą╣ ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ čĆą░čüą║čĆčŗą▓ą░ąĄčéčüčÅ ą▓ čüą╗ąĄą┤čāčÄčēąĄąĄ:
StreamWriter w;
w = File.CreateText ("myfile.txt");
try { w.Write ("Abort-Safe"); }
finally { w.Dispose(); }
ą£ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ čéą░ą║, čćč鹊 Abort ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ čüąŠąĘą┤ą░ąĮ StreamWriter, ąĮąŠ ą┐ąĄčĆąĄą┤ ąĮą░čćą░ą╗ąŠą╝ ą▒ą╗ąŠą║ą░ try. ążą░ą║čéąĖč湥čüą║ąĖ, ąĄčüą╗ąĖ čāą│ą╗čāą▒ąĖčéčīčüčÅ ą▓ ą┤ąĄą▒čĆąĖ IL (Intermediate Language, ą┐čĆąŠą╝ąĄąČčāč鹊čćąĮčŗą╣ čÅąĘčŗą║), ą╝ąŠąČąĮąŠ čāą▓ąĖą┤ąĄčéčī, čćč鹊 ąĘą░ą┐čāčüą║ Abort ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ ą╝ąĄąČą┤čā čüąŠąĘą┤ą░ąĮąĖąĄą╝ StreamWriter ąĖ ą┐čĆąĖčüą▓ąŠąĄąĮąĖąĄą╝ ąĄą│ąŠ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ w:
IL_0001: ldstr "myfile.txt"
IL_0006: call class [mscorlib]System.IO.StreamWriter
[mscorlib]System.IO.File::CreateText(string)
IL_000b: stloc.0
.try
{
...
ąóą░ą║ ąĖą╗ąĖ ąĖąĮą░č湥 ą▓čŗąĘąŠą▓ ą╝ąĄč鹊ą┤ą░ Dispose ą▓ ą▒ą╗ąŠą║ąĄ finally ą▒čāą┤ąĄčé ąŠą▒ąŠą╣ą┤ąĄąĮ, ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ąŠčüčéą░ąĮąĄčéčüčÅ ąĘą░ą▒čĆąŠčłąĄąĮąĮčŗą╝ ąŠčéą║čĆčŗčéčŗą╣ ą┤ąĄčüą║čĆąĖą┐č鹊čĆ čäą░ą╣ą╗ą░, čćč鹊 ąĮąĄ ą┤ą░čüčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖą╝ ą┐ąŠą┐čŗčéą║ą░ą╝ čüąŠąĘą┤ą░čéčī čäą░ą╣ą╗ myfile.txt ą┤ąŠ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ą┐čĆąŠčåąĄčüčüą░.
ąÆ čĆąĄą░ą╗čīąĮąŠą╣ čüąĖčéčāą░čåąĖąĖ čŹč鹊ą│ąŠ ą┐čĆąĖą╝ąĄčĆą░ ą▓čüąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĄčēąĄ čģčāąČąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 Abort ą╝ąŠą│ ą┐čĆąŠąĖąĘąŠą╣čéąĖ ą▓ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ File.CreateText. ąŁč鹊 čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝čŗą╣ ąĮąĄą┐čĆąŠąĘčĆą░čćąĮčŗą╣ ą║ąŠą┤, ą┤ą╗čÅ ą║ąŠč鹊čĆąŠą│ąŠ ąĮąĄčé ąĖčüčģąŠą┤ąĮąĖą║ą░. ąÜ čüčćą░čüčéčīčÄ, ą║ąŠą┤ .NET ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą▒čŗą▓ą░ąĄčé ą┐ąŠ-ąĮą░čüč鹊čÅčēąĄą╝čā ąĮąĄą┐čĆąŠąĘčĆą░čćąĮčŗą╝: ą╝čŗ ą▓čüąĄ ąĄčēąĄ ą╝ąŠąČąĄą╝ ą▓ąŠčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ILDASM - ąĖą╗ąĖ ąĄčēąĄ ą╗čāčćčłąĄ čāčéąĖą╗ąĖč鹊ą╣ Reflector ą░ą▓č鹊čĆą░ Lutz Roeder, ąĖ čāą▓ąĖą┤ąĄčéčī, čćč鹊 File.CreateText ą▓čŗąĘą▓ą░ą╗ ą║ąŠąĮčüčéčĆčāą║č鹊čĆ StreamWriter, čā ą║ąŠč鹊čĆąŠą│ąŠ čüą╗ąĄą┤čāčÄčēą░čÅ ą╗ąŠą│ąĖą║ą░:
public StreamWriter (string path, bool append, ...)
{
...
...
Stream stream1 = StreamWriter.CreateFile (path, append);
this.Init (stream1, ...);
}
ąØąĖą│ą┤ąĄ ą▓ čŹč鹊ą╝ ą║ąŠąĮčüčéčĆčāą║č鹊čĆąĄ ąĮąĄčé ą▒ą╗ąŠą║ą░ try/catch, čćč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ąĄčüą╗ąĖ Abort ą▒čāą┤ąĄčé ą▓čŗąĘą▓ą░ąĮ ą▓ (ąĮąĄ čéčĆąĖą▓ąĖą░ą╗čīąĮąŠą╝) ą╝ąĄč鹊ą┤ąĄ Init, ąĮąŠą▓čŗą╣ čüąŠąĘą┤ą░ąĮąĮčŗą╣ ą┐ąŠč鹊ą║ ą▒čāą┤ąĄčé ąĘą░ą▒čĆąŠčłąĄąĮ, ąĖ ąĮąĄ ąŠčüčéą░ąĮąĄčéčüčÅ čüą┐ąŠčüąŠą▒ą░ ąĘą░ą║čĆčŗčéčī ąĮąĖąČąĄą╗ąĄąČą░čēąĖą╣ ą┤ąĄčüą║čĆąĖą┐č鹊čĆ čäą░ą╣ą╗ą░.
ąŁč鹊 čüčéą░ą▓ąĖčé ą▓ąŠą┐čĆąŠčü ąŠ č鹊ą╝, ą║ą░ą║ ą▓čüąĄ-čéą░ą║ąĖ ąĮą░ą┐ąĖčüą░čéčī ą╝ąĄč鹊ą┤, ą┤čĆčāąČąĄčüčéą▓ąĄąĮąĮčŗą╣ ą║ Abort. ąĪą░ą╝čŗą╣ ąŠą▒čēąĖą╣ čüą┐ąŠčüąŠą▒ ąŠą▒ąŠą╣čéąĖ čŹčéčā ą┐čĆąŠą▒ą╗ąĄą╝čā - ą▓ąŠąŠą▒čēąĄ ąĮąĄ ąŠą▒čĆčŗą▓ą░čéčī ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║, čĆąĄą░ą╗ąĖąĘąŠą▓ą░ą▓ ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ čłą░ą▒ą╗ąŠąĮąŠą╝ ą║ąŠąŠą┐ąĄčĆą░čéąĖą▓ąĮąŠą╣ ąŠčéą╝ąĄąĮčŗ ą░ą║čéąĖą▓ąĮąŠčüčéąĖ, ą║ą░ą║ čŹč鹊 ą▒čŗą╗ąŠ ąŠą┐ąĖčüą░ąĮąŠ čĆą░ąĮąĄąĄ (čüą╝. [4], čüąĄą║čåąĖčÅ "ąæąĄąĘąŠą┐ą░čüąĮą░čÅ ąŠčéą╝ąĄąĮą░ ąŠą┐ąĄčĆą░čåąĖąĖ ą┐ąŠč鹊ą║ą░").
ąŚą░ą▓ąĄčĆčłąĄąĮąĖąĄ ą┤ąŠą╝ąĄąĮąŠą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. ąöčĆčāą│ąŠą╣ čüą┐ąŠčüąŠą▒ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī čĆą░ą▒ąŠčćąĖą╣ ą┐ąŠč鹊ą║, ą┤čĆčāąČąĄčüčéą▓ąĄąĮąĮčŗą╣ ą║ Abort - ąĘą░ą┐čāčüčéąĖčéčī ąĄą│ąŠ ą▓ čüą▓ąŠąĄą╝ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą╝ ą┤ąŠą╝ąĄąĮąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. ą¤ąŠčüą╗ąĄ ą▓čŗąĘąŠą▓ą░ Abort ąÆčŗ čüąĮąĄčüąĄč鹥 ą┐ąŠą┤ ą║ąŠčĆąĄąĮčī ąĖ ąĘą░ąĮąŠą▓ąŠ čüąŠąĘą┤ą░ą┤ąĖč鹥 ą┤ąŠą╝ąĄąĮ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. ąŁč鹊 ą┐ąŠąĘą░ą▒ąŠčéąĖčéčīčüčÅ ąŠ ą┐ą╗ąŠčģąŠą╝ čüąŠčüč鹊čÅąĮąĖąĖ, ą▓čŗąĘą▓ą░ąĮąĮąŠą╝ čćą░čüčéąĖčćąĮąŠą╣ ąĖą╗ąĖ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠą╣ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĄą╣ (čģąŠčéčÅ, ą║ čüąŠąČą░ą╗ąĄąĮąĖčÄ, ąĮąĄ ą┤ą░ąĄčé ą│ą░čĆą░ąĮčéąĖąĖ ąĘą░čēąĖčéčŗ ąŠčé čüčåąĄąĮą░čĆąĖąĄą▓ ąĮąĄčāą┤ą░čćąĮąŠą│ąŠ čüą╗čāčćą░čÅ, ąŠą┐ąĖčüą░ąĮąĮąŠą│ąŠ ą▓čŗčłąĄ - ąŠą▒čĆčŗą▓ čĆą░ą▒ąŠčéčŗ ą║ąŠąĮčüčéčĆčāą║č鹊čĆą░ StreamWriter ą▓čüąĄ ąĄčēąĄ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ čāč鹥čćą║ąĄ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░).
ąĪčéčĆąŠą│ąŠ ą│ąŠą▓ąŠčĆčÅ, ą┐ąĄčĆą▓čŗą╣ čłą░ą│ - Abort ą┐ąŠč鹊ą║ą░ - ąĮąĄ ąĮčāąČąĄąĮ, ą┐ąŠč鹊ą╝čā čćč鹊 ą║ąŠą│ą┤ą░ ą▓čŗą│čĆčāąČą░ąĄčéčüčÅ ą┤ąŠą╝ąĄąĮ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, ą▓čüąĄ ąĄą│ąŠ ą▓čŗą┐ąŠą╗ąĮčÅčÄčēąĖąĄčüčÅ ą┐ąŠč鹊ą║ąĖ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ąŠą▒čĆčŗą▓ą░čÄčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ. ą×ą┤ąĮą░ą║ąŠ ąĮąĄą┤ąŠčüčéą░č鹊ą║ čéą░ą║ąŠą│ąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ ą▓ č鹊ą╝, čćč鹊 ąĄčüą╗ąĖ ąŠą▒ąŠčĆą▓ą░ąĮąĮčŗąĄ ą┐ąŠč鹊ą║ąĖ čüą▓ąŠąĄą▓čĆąĄą╝ąĄąĮąĮąŠ ąĮąĄ ąĘą░ą▓ąĄčĆčłą░čéčüčÅ (ą▓ąŠąĘą╝ąŠąČąĮąŠ ąĖąĘ-ąĘą░ ąĘą░ą▓ąĖčüą░ąĮąĖčÅ ą▓ ą▒ą╗ąŠą║ą░čģ finally, ąĖą╗ąĖ ą┐ąŠ ą┤čĆčāą│ąĖą╝ ą┐čĆąĖčćąĖąĮą░ą╝, ą║ąŠč鹊čĆčŗąĄ ą╝čŗ ąŠą▒čüčāąČą┤ą░ą╗ąĖ čĆą░ąĮčīčłąĄ), č鹊 ą┤ąŠą╝ąĄąĮ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĮąĄ ą▒čāą┤ąĄčé ą▓čŗą│čĆčāąČąĄąĮ, ąĖ ą▓ ą▓čŗąĘčŗą▓ą░čÄčēąĄą╝ ą║ąŠą┤ąĄ ą▒čāą┤ąĄčé ą▓čŗą▒čĆąŠčłąĄąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ CannotUnloadAppDomainException. ą¤ąŠ čŹč鹊ą╣ ą┐čĆąĖčćąĖąĮąĄ ą╗čāčćčłąĄ čÅą▓ąĮąŠ ąŠą▒ąŠčĆą▓ą░čéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ čĆą░ą▒ąŠč湥ą│ąŠ ą┐ąŠč鹊ą║ą░, ąĘą░č鹥ą╝ ą▓čŗąĘą▓ą░čéčī Join čü ąĮąĄą║ąŠč鹊čĆčŗą╝ čéą░ą╣ą╝ą░čāč鹊ą╝ (ąĮą░ą┤ ą║ąŠč鹊čĆčŗą╝ ąÆčŗ ąĖą╝ąĄąĄč鹥 ą║ąŠąĮčéčĆąŠą╗čī) ą┐ąĄčĆąĄą┤ ą▓čŗą│čĆčāąĘą║ąŠą╣ ą┤ąŠą╝ąĄąĮą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ.
ąĪąŠąĘą┤ą░ąĮąĖąĄ ąĖ čāąĮąĖčćč鹊ąČąĄąĮąĖąĄ ą┤ąŠą╝ąĄąĮą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ ąĘą░čéčĆą░čéąĮąŠ ą┐ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą╝ąĖčĆąĄ, ą│ą┤ąĄ ą░ą║čéąĖą▓ąĮąŠ ą╝ąĮąŠąČąĄčüčéą▓ąŠ ą┐ąŠč鹊ą║ąŠą▓ (ą╝ąŠąČąĄčé ąĘą░ąĮčÅčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą╝ąĖą╗ą╗ąĖčüąĄą║čāąĮą┤, ąĄčüą╗ąĖ ąĮąĄ ą▒ąŠą╗čīčłąĄ), čéą░ą║ čćč鹊 čŹč鹊 ąĮąĄčćč鹊 čéą░ą║ąŠąĄ, čćč鹊 čüą╗ąĄą┤čāąĄčé ą┤ąĄą╗ą░čéčī ąĮąĄ čĆąĄą│čāą╗čÅčĆąĮąŠ, ąĖ čāąČ č鹊čćąĮąŠ ąĮąĄ ą▓ čåąĖą║ą╗ąĄ! ąóą░ą║ąČąĄ čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ ą║ąŠą┤ą░, ą▓ą▓ąŠą┤ąĖą╝ąŠąĄ ą┤ąŠą╝ąĄąĮąŠą╝ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, ą▓ą▓ąŠą┤ąĖčé ą┤čĆčāą│ąŠą╣ 菹╗ąĄą╝ąĄąĮčé, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ąĮąĄčüčéąĖ ą▓ čüąĄą▒ąĄ ą┐čĆąĄąĖą╝čāčēąĄčüčéą▓ąŠ ąĖą╗ąĖ ą▓čĆąĄą┤, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čåąĄą╗ąĖ, ą║ąŠč鹊čĆčāčÄ čüčéą░ą▓ąĖčé ą┐ąĄčĆąĄą┤ čüąŠą▒ąŠą╣ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ. ąÆ ą║ąŠąĮč鹥ą║čüč鹥 č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ ą╝ąŠą┤čāą╗ąĄą╣ (unit-testing), ąĮą░ą┐čĆąĖą╝ąĄčĆ, ąĘą░ą┐čāčüą║ ą┐ąŠč鹊ą║ąŠą▓ ą▓ ąŠčéą┤ąĄą╗čīąĮčŗčģ ą┤ąŠą╝ąĄąĮą░čģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą┤ą░ąĄčé ą▓čŗą│ąŠą┤čā.
ąŚą░ą▓ąĄčĆčłąĄąĮąĖąĄ ą┐čĆąŠčåąĄčüčüąŠą▓. ąöčĆčāą│ąŠą╣ čüą┐ąŠčüąŠą▒, ą║ą░ą║ąĖą╝ ą╝ąŠąČąĮąŠ ąĘą░ą▓ąĄčĆčłąĖčéčī ą┐ąŠč鹊ą║ - ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄ čĆąŠą┤ąĖč鹥ą╗čīčüą║ąŠą│ąŠ ą┐čĆąŠčåąĄčüčüą░. ą×ą┤ąĖąĮ ąĖąĘ ą┐čĆąĖą╝ąĄčĆąŠą▓ čéą░ą║ąŠą╣ čüąĖčéčāą░čåąĖąĖ - ą║ąŠą│ą┤ą░ čüą▓ąŠą╣čüčéą▓ąŠ IsBackground čĆą░ą▒ąŠč湥ą│ąŠ ą┐ąŠč鹊ą║ą░ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ ą▓ true (čĆą░ą▒ąŠčćąĖą╣ ą┐ąŠč鹊ą║ ą┐ąŠą╗čāčćą░ąĄčé čüą▓ąŠą╣čüčéą▓ąŠ č乊ąĮąŠą▓ąŠą│ąŠ ą┐ąŠč鹊ą║ą░), ąĖ ą│ą╗ą░ą▓ąĮčŗą╣ ą┐ąŠč鹊ą║ ąĘą░ą▓ąĄčĆčłą░ąĄčéčüčÅ, ą║ąŠą│ą┤ą░ čĆą░ą▒ąŠčćąĖą╣ ą┐ąŠč鹊ą║ ąĄčēąĄ čĆą░ą▒ąŠčéą░ąĄčé. ążąŠąĮąŠą▓čŗą╣ ą┐ąŠč鹊ą║ ąĮąĄ čüą┐ąŠčüąŠą▒ąĄąĮ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čéčī čĆą░ą▒ąŠčéčā ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, ąĖ ą┐ąŠčŹč鹊ą╝čā ą┐čĆąĖ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĖ ą┐čĆąŠčåąĄčüčüą░ č乊ąĮąŠą▓čŗą╣ ą┐ąŠč鹊ą║ ąĘą░ą▓ąĄčĆčłą░ąĄčéčüčÅ ą▓ą╝ąĄčüč鹥 čü ąĮąĖą╝.
ąÜąŠą│ą┤ą░ ą┐ąŠč鹊ą║ ąĘą░ą▓ąĄčĆčłą░ąĄčéčüčÅ ąĖąĘ-ąĘą░ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄ ąĄą│ąŠ čĆąŠą┤ąĖč鹥ą╗čīčüą║ąŠą│ąŠ ą┐čĆąŠčåąĄčüčüą░, ąŠąĮ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ čāą╝ąĖčĆą░ąĄčé, ąĖ ąĄą│ąŠ ą▒ą╗ąŠą║ąĖ finally ąĮąĄ ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ.
ąóą░ ąČąĄ čüą░ą╝ą░čÅ čüąĖčéčāą░čåąĖčÅ ą▓ąŠąĘąĮąĖą║ą░ąĄčé, ą║ąŠą│ą┤ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ąĘą░ą▓ąĄčĆčłą░ąĄčé ąĮąĄ ąŠčéą▓ąĄčćą░čÄčēąĄąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ čü ą┐ąŠą╝ąŠčēčīčÄ ą£ąĄąĮąĄą┤ąČąĄčĆą░ ąŚą░ą┤ą░čć Windows (čāčéąĖą╗ąĖčéą░ Task Manager), ąĖą╗ąĖ ą┐čĆąĖą▒ąĖą▓ą░ąĄčé ą┐čĆąŠčåąĄčüčü ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ ą▓čŗąĘąŠą▓ąŠą╝ Process.Kill.
[ąĪčüčŗą╗ą║ąĖ]
1. Threading in C# PART 4: ADVANCED THREADING site:albahari.com.
2. ą¤ąŠč鹊ą║ąĖ ąĮą░ C#. ą¦ą░čüčéčī 1: ą▓ą▓ąĄą┤ąĄąĮąĖąĄ.
3. ą¤ąŠč鹊ą║ąĖ ąĮą░ C#. ą¦ą░čüčéčī 2: ąŠčüąĮąŠą▓čŗ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ.
4. ą¤ąŠč鹊ą║ąĖ ąĮą░ C#. ą¦ą░čüčéčī 3: ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą┐ąŠč鹊ą║ąŠą▓.
5. 9 čüą┐ąŠčüąŠą▒ąŠą▓ ąĖčüą┐ąŠčĆčéąĖčéčī ą║ąŠą┤ čü ą┐ąŠą╝ąŠčēčīčÄ volatile.
6. SpinLock ąĖ SpinWait. |



