ąÆ čŹč鹊ą╝ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮą░ ą▓č鹊čĆą░čÅ čćą░čüčéčī ą┐ąĄčĆąĄą▓ąŠą┤ą░ ą┤ą░čéą░čłąĖčéą░ "Blackfin DSP Instruction Set Reference" [1], ą│ą┤ąĄ ąŠą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ čüąĖčüč鹥ą╝ą░ ą║ąŠą╝ą░ąĮą┤ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin . ąÆ ą┐ąĄčĆą▓ąŠą╣ čćą░čüčéąĖ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ą░ čüąĮą░čćą░ą╗ą░ ąŠą▒čŖčÅčüąĮčÅčÄčéčüčÅ ąŠčüąĮąŠą▓ąĮčŗąĄ ą┐ąŠąĮčÅčéąĖčÅ ąĖ č鹥čĆą╝ąĖąĮčŗ, ąĘą░č鹥ą╝ ąŠą▒čüčāąČą┤ą░ąĄčéčüčÅ čüą╝čŗčüą╗ ą║ą░ąČą┤ąŠą╣ ąŠčéą┤ąĄą╗čīąĮąŠą╣ ą║ąŠą╝ą░ąĮą┤čŗ (ąĖąĮčüčéčĆčāą║čåąĖąĖ) ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░.
ąÆčüąĄ ąĮąĄą┐ąŠąĮčÅčéąĮčŗąĄ č鹥čĆą╝ąĖąĮčŗ ąĖ čüąŠą║čĆą░čēąĄąĮąĖčÅ čüą╝. ą▓ čĆą░ąĘą┤ąĄą╗ąĄ ąĪą╗ąŠą▓ą░čĆąĖą║ ą┐ąĄčĆą▓ąŠą╣ čćą░čüčéąĖ ą┐ąĄčĆąĄą▓ąŠą┤ą░, ą░ čéą░ą║ąČąĄ ą▓ čĆą░ąĘą┤ąĄą╗ąĄ čüą╗ąŠą▓ą░čĆąĖą║ ąŠą▒čēąĄą╣ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ ą┐ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆčā Blackfin ADSP-BF538 [2]. ą¤ąĄčĆą▓ą░čÅ čćą░čüčéčī ą┐ąĄčĆąĄą▓ąŠą┤ą░ ąĘą┤ąĄčüčī: "Blackfin: čüąĖčüč鹥ą╝ą░ ą║ąŠą╝ą░ąĮą┤ (ą░čüčüąĄą╝ą▒ą╗ąĄčĆ) - čćą░čüčéčī 1 ".
[ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ]
ąÆ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ ąŠą▒čüčāąČą┤ą░čÄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ąĘą░ą┤ą░čÄčé ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ. ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĖ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹčéąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ą╗čÅ čüą╗ąŠąČąĄąĮąĖčÅ (add), ą▓čŗčćąĖčéą░ąĮąĖčÅ (subtract), ą┤ąĄą╗ąĄąĮąĖčÅ (divide) ąĖ čāą╝ąĮąŠąČąĄąĮąĖčÅ (multiply), ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą░ą▒čüąŠą╗čÄčéąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣, ąŠą┐čĆąĄą┤ąĄą╗čÅčéčī 菹║čüą┐ąŠąĮąĄąĮčéčŗ, ąŠą║čĆčāą│ą╗čÅčéčī, ą▓čŗą┐ąŠą╗ąĮčÅčéčī ąĮą░čüčŗčēąĄąĮąĖąĄ, ą▓ąŠąĘą▓čĆą░čēą░čéčī ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé ąĘąĮą░ą║ą░.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓čŗčćąĖčüą╗čÅąĄčé ą░ą▒čüąŠą╗čÄčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = ABS src_reg
ąĪąĖąĮčéą░ą║čüąĖčü:
A0 = ABS A0; // (b)1
A0 = ABS A1; // (b)
A1 = ABS A0; // (b)
A1 = ABS A1; // (b)
A1 = ABS A1, A0 = ABS A0; // (b)
Dreg = ABS Dreg; // (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Absolute Value ą▓čŗčćąĖčüą╗čÅąĄčé ą░ą▒čüąŠą╗čÄčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ąŠčé ą▓ąĄą╗ąĖčćąĖąĮčŗ ą▓ 32-ą▒ąĖčéąĮąŠą╝ čĆąĄą│ąĖčüčéčĆąĄ ąĖčüč鹊čćąĮąĖą║ąĄ (src_reg) ąĖ čüąŠčģčĆą░ąĮčÅąĄčé ąĄą│ąŠ ą▓ 32-ą▒ąĖčéąĮąŠą╝ čĆąĄą│ąĖčüčéčĆąĄ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ (dest_reg) ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čüąŠ čüą╗ąĄą┤čāčÄčēąĖą╝ąĖ ą┐čĆą░ą▓ąĖą╗ą░ą╝ąĖ:
ŌĆó ąĢčüą╗ąĖ ą▓čģąŠą┤ąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠąĄ, ąĖą╗ąĖ 0, č鹊 ąŠąĮąŠ ą▒ąĄąĘ ąĖąĘą╝ąĄąĮąĄąĮąĖą╣ ą║ąŠą┐ąĖčĆčāąĄčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ą×ą┐ąĄčĆą░čåąĖčÅ ABS čéą░ą║ąČąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ čü ąŠą▒ąŠąĖą╝ąĖ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ą╝ąĖ, ą┐čĆąĖč湥ą╝ ą┤ą░ąČąĄ ą▓ ąŠą┤ąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
[ążą╗ą░ą│ąĖ ]
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ. ąÆ čüą╗čāčćą░ąĄ 2 ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣ AZ ą┐čĆąĄą┤čüčéą░ą▓ąĖčé ą╗ąŠą│ąĖč湥čüą║ąŠąĄ ąśąøąś ąŠčé čŹčéąĖčģ ą┤ą▓čāčģ čäą╗ą░ą│ąŠą▓ ąĮčāą╗čÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮą░čÅ ą▓ąĄčĆčüąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
a0 = abs a0;
a0 = abs a1;
a1 = abs a0;
a1 = abs a1;
a1 = abs a1, a0 = abs a0;
r3 = abs r1;
ąĪą╝. čéą░ą║ąČąĄ Vector Absolute Value (ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ąÆąĄą║č鹊čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ").
ąśąĮčüčéčĆčāą║čåąĖčÅ čüą╗ąŠąČąĄąĮąĖčÅ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = src_reg_1 + src_reg_2
ąĪąĖąĮčéą░ą║čüąĖčü ą┤ą╗čÅ čüą╗ąŠąČąĄąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓-čāą║ą░ąĘą░č鹥ą╗ąĄą╣:
Preg = Preg + Preg; // (a)1
ąĪąĖąĮčéą░ą║čüąĖčü ą┤ą╗čÅ 32-ą▒ąĖčéąĮčŗčģ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ ąĖ 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄąĘčāą╗čīčéą░čéą░:
Dreg = Dreg + Dreg; /* ąĮą░čüčŗčēąĄąĮąĖąĄ ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ, ąĮąŠ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą║ąŠčĆąŠč湥 (a) */
Dreg = Dreg + Dreg (sat_flag); /* ąĮą░čüčŗčēąĄąĮąĖąĄ ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ, ąĮąŠ čåąĄąĮąŠą╣ čāą▓ąĄą╗ąĖč湥ąĮąĖčÅ ą┤ą╗ąĖąĮčŗ ąĖąĮčüčéčĆčāą║čåąĖąĖ (b) */
ąĪąĖąĮčéą░ą║čüąĖčü ą┤ą╗čÅ 16-ą▒ąĖčéąĮčŗčģ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ ąĖ 16-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄąĘčāą╗čīčéą░čéą░:
Dreg_lo_hi = Dreg_lo_hi + Dreg_lo_hi (sat_flag); // (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Preg: čĆąĄą│ąĖčüčéčĆčŗ P0, ..., P5, SP, FP.
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
Dreg_lo_hi: ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L, R0.H, ..., R7.H.
sat_flag: ąŠą▒čÅąĘą░č鹥ą╗čīąĮčŗą╣ čäą╗ą░ą│ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąĮą░čüčŗčēąĄąĮąĖąĄą╝, (S) ąĖą╗ąĖ (NS).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Add čüą║ą╗ą░ą┤čŗą▓ą░ąĄčé ą┤ą▓ąĄ ą▓ąĄą╗ąĖčćąĖąĮčŗ ąĖąĘ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖčüč鹊čćąĮąĖą║ą░ ą┐ąŠą╝ąĄčēą░ąĄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ąĢčüčéčī 2 čüą┐ąŠčüąŠą▒ą░ čüą╗ąŠąČąĄąĮąĖčÅ 32-ą▒ąĖčéąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ą▓ D-čĆąĄą│ąĖčüčéčĆą░čģ. ą×ą┤ąĖąĮ čü ą┤ą╗ąĖąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé, ą▒ąĄąĘ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ ąĮą░čüčŗčēąĄąĮąĖčÅ. ąöčĆčāą│ąŠą╣ čü ą┤ą╗ąĖąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░, ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ąĮą░čüčŗčēąĄąĮąĖąĄ. ąæąŠą╗ąĄąĄ ą┤ą╗ąĖąĮąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ DSP ąĖąĮąŠą│ą┤ą░ ą╝ąŠąČąĄčé 菹║ąŠąĮąŠą╝ąĖčéčī ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąĮą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ (čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣").
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┤ą╗čÅ 16-ą▒ąĖčéąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čüą╗ąŠą▓ą░ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ą┤ą░ąĮąĮčŗčģ ąĖ čüąŠčģčĆą░ąĮčÅąĄčé čĆąĄąĘčāą╗čīčéą░čé čéą░ą║ąČąĄ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā čüą╗ąŠą▓ą░ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ.
ąÆčüąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ą╗čÅ 16-ą▒ąĖčéąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ąĖą╝ąĄčÄčé ą┤ą╗ąĖąĮčā 32 ą▒ąĖčéą░.
ą×ą┐čåąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░: čéą░ą╝, ą│ą┤ąĄ ą┐ąŠčÅą▓ą╗čÅąĄčéčüčÅ sat_flag, ąŠąĮ ąĘą░ą╝ąĄąĮčÅąĄčéčüčÅ ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ:
ŌĆó (S) ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ąĮą░čüčŗčēąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ąĮą░čüčŗčēąĄąĮąĖąĄ čüą╝. čüąĄą║čåąĖčÄ "Saturation (ąĮą░čüčŗčēąĄąĮąĖąĄ)".
[ążą╗ą░ą│ąĖ ]
ąÆąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü D-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ą▓ą╗ąĖčÅčÄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ. ąÆ čüą╗čāčćą░ąĄ 2 ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣ AZ ą┐čĆąĄą┤čüčéą░ą▓ąĖčé ą╗ąŠą│ąĖč湥čüą║ąŠąĄ ąśąøąś ąŠčé čŹčéąĖčģ ą┤ą▓čāčģ čäą╗ą░ą│ąŠą▓ ąĮčāą╗čÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
ąÆąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü P-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ąĮąĄ ą▓ą╗ąĖčÅčÄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣". 16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹčéąĖčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r5 = r2 + r1; // ąĖąĮčüčéčĆčāą║čåąĖčÅ čüą╗ąŠąČąĄąĮąĖčÅ ą┤ą╗ąĖąĮąŠą╣ 16 ą▒ąĖčé, ą▒ąĄąĘ ąĮą░čüčŗčēąĄąĮąĖčÅ
r5 = r2 + r1(ns); /* č鹊 ąČąĄ čüą░ą╝ąŠąĄ, ąĮąŠ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ą╗ąĖąĮąŠą╣ 32 ą▒ąĖčéą░ */
r5 = r2 + r1(s); // ąĮą░čüčŗčēąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░
p5 = p3 + p0 ;
// ąĢčüą╗ąĖ r0.l = 0x7000 ąĖ r7.l = 0x2000, č鹊 ...
r4.l = r0.l + r7.l (ns);
/* ... ą┐ąŠą╗čāčćąĖčéčüčÅ r4.l = 0x9000, ą┐ąŠč鹊ą╝čā čćč鹊 ąĮąĄ ą▒čŗą╗ąŠ
ąĮą░čüčŗčēąĄąĮąĖčÅ. */
// ąĢčüą╗ąĖ r0.l = 0x7000 ąĖ r7.h = 0x2000, č鹊 ...
r4.l = r0.l + r7.h (s);
/* ... ą┐ąŠą╗čāčćąĖčéčüčÅ r4.l = 0x7FFF, ą┐ąŠč鹊ą╝čā čćč鹊 čĆąĄąĘčāą╗čīčéą░čé ą┐ąŠą╗čāčćąĖą╗ ąĮą░čüčŗčēąĄąĮąĖąĄ ą┤ąŠ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠą╣ ą▓ąĄą╗ąĖčćąĖąĮčŗ */
r0.l = r2.h + r4.l(ns);
r1.l = r3.h + r7.h(ns);
r4.h = r0.l + r7.l (ns);
r4.h = r0.l + r7.h (ns);
r0.h = r2.h + r4.l(s); // ąĮą░čüčŗčēąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░
r1.h = r3.h + r7.h(ns);
ąĪą╝. čéą░ą║ąČąĄ Modify - Increment, Round - 12-bit, Round - 20-bit, Shift with Add ąĖ Add with Shift (čŹčéąĖ ąŠą┐ąĄčĆą░čåąĖąĖ ąŠą▒ąĄ ąĮą░čģąŠą┤čÅčéčüčÅ ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ą×ą┐ąĄčĆą░čåąĖąĖ čüą┤ą▓ąĖą│ą░ ąĖ ą┐čĆąŠą║čĆčāčéą║ąĖ"), Vector Add/Subtract (ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ąÆąĄą║č鹊čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ").
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĖą▒ą░ą▓ą╗ąĄąĮąĖčÅ ą║ čĆąĄą│ąĖčüčéčĆčā ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠą╣ ą║ąŠąĮčüčéą░ąĮčéčŗ (čé. ąĄ. čéą░ą║ąŠą╣ ą║ąŠąĮčüčéą░ąĮčéčŗ, ą║ąŠč鹊čĆą░čÅ čāą║ą░ąĘą░ąĮą░ ą┐čĆčÅą╝ąŠ ą▓ ą║ąŠą╝ą░ąĮą┤ąĄ). ą×ą▒čēą░čÅ č乊čĆą╝ą░:
register += constant
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg += imm7; // Dreg = Dreg + ą║ąŠąĮčüčéą░ąĮčéą░ (a)1
Preg += imm7; // Preg = Preg + ą║ąŠąĮčüčéą░ąĮčéą░ (a)
Ireg += 2; /* ąĖąĮą║čĆąĄą╝ąĄąĮčé Ireg ąĮą░ 2, ąĖąĮą║čĆąĄą╝ąĄąĮčé ą░ą┤čĆąĄčüą░ a) */
Ireg += 4; // ąĖąĮą║čĆąĄą╝ąĄąĮčé ą░ą┤čĆąĄčüą░ čāą║ą░ąĘą░č鹥ą╗čÅ ąĮą░ čüą╗ąŠą▓ąŠ (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7.
Preg: čĆąĄą│ąĖčüčéčĆčŗ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ P0, ..., P5, SP, FP.
Ireg: ąĖąĮą┤ąĄą║čüąĮčŗąĄ čĆąĄą│ąĖčüčéčĆčŗ I0, ..., I3.
imm7: 7-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ čüąŠ ąĘąĮą░ą║ąŠą╝, ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ -64 .. 63.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Add Immediate ą┐čĆąĖą▒ą░ą▓ą╗čÅąĄčé ąĘąĮą░č湥ąĮąĖąĄ ą║ąŠąĮčüčéą░ąĮčéčŗ ą║ ąĘąĮą░č湥ąĮąĖčÄ čĆąĄą│ąĖčüčéčĆą░ ą▒ąĄąĘ ąĮą░čüčŗčēąĄąĮąĖčÅ.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: čćč鹊ą▒čŗ ą▓čŗč湥čüčéčī ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ ąĖąĘ I-čĆąĄą│ąĖčüčéčĆąŠą▓, ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ąĖąĮčüčéčĆčāą║čåąĖčÄ Subtract Immediate.
[ążą╗ą░ą│ąĖ ]
ąÆąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü D-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ą▓ą╗ąĖčÅčÄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ. ąÆ čüą╗čāčćą░ąĄ 2 ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣ AZ ą┐čĆąĄą┤čüčéą░ą▓ąĖčé ą╗ąŠą│ąĖč湥čüą║ąŠąĄ ąśąøąś ąŠčé čŹčéąĖčģ ą┤ą▓čāčģ čäą╗ą░ą│ąŠą▓ ąĮčāą╗čÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
ąÆąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü P-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ąĖ I-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ąĮąĄ ą▓ą╗ąĖčÅčÄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąÆąĄčĆčüąĖąĖ čü D-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ąĖ P-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
ąÆąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü I-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r0 += 40 ;
p5 += - 4 ; // ą┤ąĄą║čĆąĄą╝ąĄąĮčé ą┐čāč鹥ą╝ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ
i0 += 2 ;
i1 += 4 ;
ąĪą╝. čéą░ą║ąČąĄ Subtract Immediate.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
DIVS ( čĆąĄą│ąĖčüčéčĆ_ą┤ąĄą╗ąĖą╝ąŠą│ąŠ, čĆąĄą│ąĖčüčéčĆ_ą┤ąĄą╗ąĖč鹥ą╗čÅ )
DIVQ ( čĆąĄą│ąĖčüčéčĆ_ą┤ąĄą╗ąĖą╝ąŠą│ąŠ, čĆąĄą│ąĖčüčéčĆ_ą┤ąĄą╗ąĖč鹥ą╗čÅ )
ąĪąĖąĮčéą░ą║čüąĖčü:
DIVS (Dreg, Dreg); /* ąśąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ ą┤ą╗čÅ DIVQ. ąŻčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé čäą╗ą░ą│ AQ ąĮą░ ą▒ą░ąĘąĄ 32-ą▒ąĖčéąĮąŠą│ąŠ ą┤ąĄą╗ąĖą╝ąŠą│ąŠ ąĖ 16-ą▒ąĖčéąĮąŠą│ąŠ ą┤ąĄą╗ąĖč鹥ą╗čÅ . LSB ą┤ąĄą╗ąĖą╝ąŠą│ąŠ. (a)1 */
DIVQ (Dreg, Dreg); /* ąæą░ąĘąĖčĆčāčÅčüčī ąĮą░ čäą╗ą░ą│ąĄ AQ ą╗ąĖą▒ąŠ ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé, ą╗ąĖą▒ąŠ ąŠčéąĮąĖą╝ą░ąĄčé AQ MSB 32-ą▒ąĖčéąĮąŠą│ąŠ ą┤ąĄą╗ąĖą╝ąŠą│ąŠ ąĖ 16-ą▒ąĖčéąĮąŠą│ąŠ AQ ą▓ ą▒ąĖčé LSB ą┤ąĄą╗ąĖą╝ąŠą│ąŠ. (a) */
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąÆąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ Divide Primitive čÅą▓ą╗čÅčÄčéčüčÅ ąŠčüąĮąŠą▓ąĮčŗą╝ąĖ 菹╗ąĄą╝ąĄąĮčéą░ą╝ąĖ ą┤ą╗čÅ ą░ą╗ą│ąŠčĆąĖčéą╝ą░ ąĮąĄ ą▓ąŠčüčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄą╝ąŠą│ąŠ čāčüą╗ąŠą▓ąĮąŠą│ąŠ ą┤ąĄą╗ąĄąĮąĖčÅ ą╝ąĄč鹊ą┤ąŠą╝ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ-ą▓čŗčćąĖčéą░ąĮąĖčÅ (non-restoring conditional add-subtract division). ąĪą╝. "ą¤čĆąĖą╝ąĄčĆ" ą┤ą╗čÅ čéą░ą║ąŠą│ąŠ ą░ą╗ą│ąŠčĆąĖčéą╝ą░.
ąöąĄą╗ąĖą╝ąŠąĄ (ąĮčāą╝ąĄčĆą░č鹊čĆ) ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé 32-ą▒ąĖčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ. ąöąĄą╗ąĖč鹥ą╗čī (ą┤ąĄąĮąŠą╝ąĖąĮą░č鹊čĆ) čÅą▓ą╗čÅąĄčéčüčÅ 16-ą▒ąĖčéąĮčŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝ ąĖąĘ ą╝ą╗ą░ą┤čłąĄą╣ čĆąĄą│ąĖčüčéčĆą░-ą┤ąĄą╗ąĖč鹥ą╗čÅ. ąĪčéą░čĆčłą░čÅ ą┐ąŠą╗ąŠą▓ąĖąĮą░ čĆąĄą│ąĖčüčéčĆą░-ą┤ąĄą╗ąĖč鹥ą╗čÅ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąĖą│ąĮąŠčĆąĖčĆčāąĄčéčüčÅ.
ąöąĄą╗ąĄąĮąĖąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī čüąŠ ąĘąĮą░ą║ąŠą╝ ąĖą╗ąĖ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ąĮąŠ ą┤ąĄą╗ąĖą╝ąŠąĄ ąĖ ą┤ąĄą╗ąĖč鹥ą╗čī ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąŠą┤ąĮąŠą│ąŠ čéąĖą┐ą░. ąöąĄą╗ąĖč鹥ą╗čī ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠčéčĆąĖčåą░č鹥ą╗čīąĮčŗą╝. ą×ą┐ąĄčĆą░čåąĖčÅ ą┤ąĄą╗ąĄąĮąĖčÅ čüąŠ ąĘąĮą░ą║ąŠą╝, ą║ąŠą│ą┤ą░ ą┤ąĄą╗ąĖą╝ąŠąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠčéčĆąĖčåą░č鹥ą╗čīąĮčŗą╝, ąĮą░čćąĖąĮą░ąĄčé ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī čü ąĖąĮčüčéčĆčāą║čåąĖąĖ DIVS (ąŠčé čüą╗ąŠą▓ą░ divide-sign, ą┤ąĄą╗ąĄąĮąĖąĄ čüąŠ ąĘąĮą░ą║ąŠą╝), ąĘą░ ą║ąŠč鹊čĆąŠą╣ ąĖą┤čāčé ą┐ąŠą▓č鹊čĆčÅčÄčēąĖąĄčüčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ DIVQ (ąŠčé čüą╗ąŠą▓ divide-quotient, ą┤ąĄą╗ąĄąĮąĖąĄ-čćą░čüčéąĮąŠąĄ). ą¤čĆąĖ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠą╝ ą┤ąĄą╗ąĄąĮąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅ DIVS ąŠą┐čāčüą║ą░ąĄčéčüčÅ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą┤ąŠą╗ąČąĄąĮ ą▓čĆčāčćąĮčāčÄ ąŠčćąĖčüčéąĖčéčī čäą╗ą░ą│ AQ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ASTAT ą┐ąĄčĆąĄą┤ ąĘą░ą┐čāčüą║ąŠą╝ ąĖąĮčüčéčĆčāą║čåąĖą╣ DIVQ.
ą¤čĆąĖ čĆą░ąĘčĆąĄčłą░čÄčēąĄą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ 16 ą▒ąĖčé ą┤ąĄą╗ąĄąĮąĖąĄ čüąŠ ąĘąĮą░ą║ąŠą╝ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗčćąĖčüą╗ąĄąĮąŠ ą▓čŗą┤ą░č湥ą╣ ąŠą┤ąĖąĮ čĆą░ąĘ ąĖąĮčüčéčĆčāą║čåąĖąĖ DIVS, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ąĖąĮčüčéčĆčāą║čåąĖčÅ DIVQ ą┐ąŠą▓č鹊čĆčÅąĄčéčüčÅ 15 čĆą░ąĘ. 16-ą▒ąĖčéąĮąŠąĄ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ čćą░čüčéąĮąŠąĄ ą▓čŗčćąĖčüą╗čÅąĄčéčüčÅ čü ą┐čĆąŠą┐čāčüą║ąŠą╝ DIVS, ąŠčćąĖčüčéą║ąŠą╣ čäą╗ą░ą│ą░ AQ, ąĘą░č鹥ą╝ ą▓čŗą┤ą░č湥ą╣ 16 čĆą░ąĘ ąĖąĮčüčéčĆčāą║čåąĖąĖ DIVQ.
ą£ąĄąĮčīčłą░čÅ č鹊čćąĮąŠčüčéčī čćą░čüčéąĮąŠą│ąŠ ą┤ąŠčüčéąĖą│ą░ąĄčéčüčÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ą╝ąĄąĮčīčłąĄą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą┐ąŠą▓č鹊čĆąĄąĮąĖą╣ DIVQ.
ąĀąĄąĘčāą╗čīčéą░čé ą║ą░ąČą┤ąŠą│ąŠ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠą│ąŠ čüą╗ąŠąČąĄąĮąĖčÅ ąĖą╗ąĖ ą▓čŗčćąĖčéą░ąĮąĖčÅ ą┐ąŠčÅą▓ą╗čÅąĄčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ą┤ąĄą╗ąĖą╝ąŠą│ąŠ, čü ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄą╝ ąĖ ą│ąŠč鹊ą▓ąĮąŠčüčéčīčÄ ą┤ą╗čÅ čüą╗ąĄą┤čāčÄčēąĄą│ąŠ čłą░ą│ą░ ą┐čĆąĖą▒ą░ą▓ą╗ąĄąĮąĖčÅ ąĖą╗ąĖ ą▓čŗčćąĖčéą░ąĮąĖčÅ. ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čĆąĄą│ąĖčüčéčĆą░-ą┤ąĄą╗ąĖč鹥ą╗čÅ.
ąÜąŠąĮąĄčćąĮąŠąĄ čćą░čüčéąĮąŠąĄ ą┐ąŠčÅą▓ą╗čÅąĄčéčüčÅ ą▓ ą╝ą╗ą░ą┤čłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮąĄ čĆąĄą│ąĖčüčéčĆą░ ą┤ąĄą╗ąĖą╝ąŠą│ąŠ ą┐ąŠ ąŠą║ąŠąĮčćą░ąĮąĖąĖ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ čüą╗ąŠąČąĄąĮąĖą╣/ą▓čŗčćąĖčéą░ąĮąĖą╣.
DIVS ą▓čŗčćąĖčüą╗čÅąĄčé ą▒ąĖčé ąĘąĮą░ą║ą░ čćą░čüčéąĮąŠą│ąŠ ąĮą░ ą▒ą░ąĘąĄ ąĘąĮą░ą║ąŠą▓ ą┤ąĄą╗ąĖą╝ąŠą│ąŠ ąĖ ą┤ąĄą╗ąĖč鹥ą╗čÅ. DIVS ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāąĄčé čäą╗ą░ą│ AQ ąĮą░ ą▒ą░ąĘąĄ čŹč鹊ą│ąŠ ąĘąĮą░ą║ą░, ąĖ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāąĄčé ą┤ąĄą╗ąĖą╝ąŠąĄ ą┤ą╗čÅ ą┐ąĄčĆą▓ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ čüą╗ąŠąČąĄąĮąĖčÅ ąĖą╗ąĖ ą▓čŗčćąĖčéą░ąĮąĖčÅ. DIVS ąĮąĄ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé čüą╗ąŠąČąĄąĮąĖąĄ ąĖą╗ąĖ ą▓čŗčćąĖčéą░ąĮąĖąĄ.
DIVQ ą╗ąĖą▒ąŠ čüą║ą╗ą░ą┤čŗą▓ą░ąĄčé (ą┤ąĄą╗ąĖą╝ąŠąĄ + ą┤ąĄą╗ąĖč鹥ą╗čī), ą╗ąĖą▒ąŠ ą▓čŗčćąĖčéą░ąĄčé (ą┤ąĄą╗ąĖą╝ąŠąĄ ŌĆō ą┤ąĄą╗ąĖč鹥ą╗čī) ąĮą░ ą▒ą░ąĘąĄ čäą╗ą░ą│ą░ AQ, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ąĘą░ąĮąŠą▓ąŠ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāąĄčé čäą╗ą░ą│ AQ ąĖ ą┤ąĄą╗ąĖą╝ąŠąĄ ą┤ą╗čÅ čüą╗ąĄą┤čāčÄčēąĄą╣ ąĖč鹥čĆą░čåąĖąĖ. ąĢčüą╗ąĖ AQ ą▓ ą╗ąŠą│. 1, č鹊 ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ čüą╗ąŠąČąĄąĮąĖąĄ; ąĄčüą╗ąĖ AQ ą▓ ą╗ąŠą│. 0, č鹊 ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą▓čŗčćąĖčéą░ąĮąĖąĄ.
ąĪą╝. ąĮąĖąČąĄ čüąĄą║čåąĖčÄ "ążą╗ą░ą│ąĖ", ą│ą┤ąĄ ą│ąŠą▓ąŠčĆąĖčéčüčÅ ą┐čĆąŠ čāčüą╗ąŠą▓ąĖčÅ čāčüčéą░ąĮąŠą▓ą║ąĖ ąĖ ąŠčćąĖčüčéą║ąĖ čäą╗ą░ą│ą░ AQ.
ą×ą▒ąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░čÄčé ą┤ąĄą╗ąĖą╝ąŠąĄ ą┤ą╗čÅ čüą╗ąĄą┤čāčÄčēąĄą╣ ąĖč鹥čĆą░čåąĖąĖ čüą┤ą▓ąĖą│ąŠą╝ ą┤ąĄą╗ąĖą╝ąŠą│ąŠ ą▓ą╗ąĄą▓ąŠ ąĮą░ 1 ą▒ąĖčé (ą▒ąĄąĘ ą┐ąĄčĆąĄąĮąŠčüą░). ąŁč鹊čé čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé čéčā ąČąĄ čäčāąĮą║čåąĖčÄ, ą║ą░ą║ ąĖ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą┤ąĄą╗ąĖč鹥ą╗čÅ ąĮą░ 1 ą▒ąĖčé ą▓ą┐čĆą░ą▓ąŠ, čéą░ą║čāčÄ, ą║ą░ą║ ą▒čŗą╗ą░ ą▒čŗ ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ ą┐čĆąĖ čĆčāčćąĮąŠą╝ ą┤ą▓ąŠąĖčćąĮąŠą╝ ą┤ąĄą╗ąĄąĮąĖąĖ.
ążąŠčĆą╝ą░čé čćą░čüčéąĮąŠą│ąŠ ą┤ą╗čÅ ą╗čÄą▒ąŠą│ąŠ čćąĖčüą╗ąŠą▓ąŠą│ąŠ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖčÅ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ ą┐ąŠ č乊čĆą╝ą░čéčā ą┤ąĄą╗ąĖą╝ąŠą│ąŠ ąĖ ą┤ąĄą╗ąĖč鹥ą╗čÅ. ą¤ąŠąĘą▓ąŠą╗čÅąĄčéčüčÅ...
ŌĆó NL ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé čüą╗ąĄą▓ą░ ąŠčé ą┤ą▓ąŠąĖčćąĮąŠą╣ č鹊čćą║ąĖ, ąĖ
ąŚą░č鹥ą╝ ą▓ čćą░čüčéąĮąŠą╝ ą▒čāą┤ąĄčé NL ŌĆō DL + 1 ą▒ąĖčé čüą╗ąĄą▓ą░ ąŠčé ą┤ą▓ąŠąĖčćąĮąŠą╣ č鹊čćą║ąĖ, ąĖ NR ŌĆō DR ŌĆō 1 ą▒ąĖčé čüą┐čĆą░ą▓ą░ ąŠčé ą┤ą▓ąŠąĖčćąĮąŠą╣ č鹊čćą║ąĖ. ąĪą╝. ąĮąĖąČąĄ ąĖą╗ą╗čÄčüčéčĆą░čåąĖčÄ ą┐čĆąĖą╝ąĄčĆą░.
ą£ąŠą│čāčé ą┐ąŠčéčĆąĄą▒ąŠą▓ą░čéčīčüčÅ ąĮąĄą║ąŠč鹊čĆčŗąĄ ą╝ą░ąĮąĖą┐čāą╗čÅčåąĖąĖ ąĮą░ą┤ č乊čĆą╝ą░č鹊ą╝, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ą┤ąŠą┐čāčüčéąĖą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ čćą░čüčéąĮąŠą│ąŠ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ąŠą▒ą░ ąŠą┐ąĄčĆą░ąĮą┤ą░ čüąŠ ąĘąĮą░ą║ąŠą╝, ąĖ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą┤čĆąŠą▒ąĮčŗąĄ (ą┤ąĄą╗ąĖą╝ąŠąĄ ą▓ č乊čĆą╝ą░č鹥 1.31, ąĖ ą┤ąĄą╗ąĖč鹥ą╗čī ą▓ č乊čĆą╝ą░č鹥 1.15), č鹊 čĆąĄąĘčāą╗čīčéą░čé ą▒čāą┤ąĄčé ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą┤čĆąŠą▒ąĮčŗą╝ (ą▓ č乊čĆą╝ą░č鹥 1.15), čéą░ą║ čćč鹊 čüčéą░čĆčłąĖąĄ 16 ą▒ąĖčé čćą░čüčéąĮąŠą│ąŠ ą┤ąŠą╗ąČąĮčŗ ąĖą╝ąĄčéčī ą╝ą░ą│ąĮąĖčéčāą┤čā ą╝ąĄąĮčīčłąĄ, č湥ą╝ čā ą┤ąĄą╗ąĖč鹥ą╗čÅ, čćč鹊ą▒čŗ ąĖąĘą▒ąĄąČą░čéčī ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ čüą▓ąĄčĆčģ 16 ą▒ąĖčé. ąĢčüą╗ąĖ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ, č鹊 čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ AV0. ą¤čĆąŠą│čĆą░ą╝ą╝ąĮąŠąĄ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ą╝ąŠąČąĄčé ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ, ąĘą░ąĮąŠą▓ąŠ čüą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░čéčī ąŠą┐ąĄčĆą░ąĮą┤, ąĖ ą┐ąŠą▓č鹊čĆąĖčéčī ą┤ąĄą╗ąĄąĮąĖąĄ.
ąöąĄą╗ąĄąĮąĖąĄ ą┤ą▓čāčģ čåąĄą╗čŗčģ čćąĖčüąĄą╗ (32.0 dividend by a 16.0 divisor) ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠą╝čā č乊čĆą╝ą░čéčā čćą░čüčéąĮąŠą│ąŠ, ą┐ąŠč鹊ą╝čā čćč鹊 čĆąĄąĘčāą╗čīčéą░čé ąĮąĄ čāą╗ąŠąČąĖčéčüčÅ ą▓ 16-čĆą░ąĘčĆčÅą┤ąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ. ąöą╗čÅ ą┤ąĄą╗ąĄąĮąĖčÅ ą┤ą▓čāčģ čåąĄą╗čŗčģ čćąĖčüąĄą╗ (ą║ąŠą│ą┤ą░ ą┤ąĄą╗ąĖą╝ąŠąĄ ą▓ č乊čĆą╝ą░č鹥 32.0, ąĖ ą┤ąĄą╗ąĖč鹥ą╗čī ą▓ č乊čĆą╝ą░č鹥 16.0) ąĖ ą┐ąŠą╗čāč湥ąĮąĖčÅ čåąĄą╗ąŠą│ąŠ čćą░čüčéąĮąŠą│ąŠ (ą▓ č乊čĆą╝ą░č鹥 16.0), ą┐ąĄčĆąĄą┤ ą┤ąĄą╗ąĄąĮąĖąĄą╝ ąĮčāąČąĮąŠ čüą┤ą▓ąĖąĮčāčéčī ą┤ąĄą╗ąĖą╝ąŠąĄ ąĮą░ 1 ą▒ąĖčé ą▓ą╗ąĄą▓ąŠ (čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī č乊čĆą╝ą░čé 31.1). ąŁč鹊 čéčĆąĄą▒ąŠą▓ą░ąĮąĖąĄ čüą┤ą▓ąĖą│ą░ ą▓ą╗ąĄą▓ąŠ ąŠą│čĆą░ąĮąĖčćąĖą▓ą░ąĄčé ą┤ąĖą░ą┐ą░ąĘąŠąĮ ą┤ąĄą╗ąĖą╝ąŠą│ąŠ 31 ą▒ąĖčéą░ą╝ąĖ. ąØą░čĆčāčłąĄąĮąĖąĄ čŹč鹊ą│ąŠ ą┤ąĖą░ą┐ą░ąĘąŠąĮą░ ą┤ą░čüčé ąĮąĄą▓ąĄčĆąĮčŗą╣ čĆąĄąĘčāą╗čīčéą░čé ąŠą┐ąĄčĆą░čåąĖąĖ ą┤ąĄą╗ąĄąĮąĖčÅ.
ąÆ ą░ą╗ą│ąŠčĆąĖčéą╝ąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮ ą▓ č乊čĆą╝ą░č鹥 čćą░čüčéąĮąŠą│ąŠ, ą║ą░ą║ ą▒čŗą╗ąŠ ą▓čŗčćąĖčüą╗ąĄąĮąŠ ą▓čŗčłąĄ, ąĖą╗ąĖ ą║ąŠą│ą┤ą░ ą┤ąĄą╗ąĖč鹥ą╗čī 0 ąĖą╗ąĖ ą╝ąĄąĮčīčłąĄ č湥ą╝ čüčéą░čĆčłąĖąĄ 16 ą▒ąĖčé ą╝ą░ą│ąĮąĖčéčāą┤čŗ ą┤ąĄą╗ąĖą╝ąŠą│ąŠ (ą║ąŠč鹊čĆčŗą╣ 菹║ą▓ąĖą▓ą░ą╗ąĄąĮč鹥ąĮ čāą╝ąĮąŠąČąĄąĮąĖčÄ).
[ąŻčüą╗ąŠą▓ąĖčÅ ąŠčłąĖą▒ą║ąĖ ]
ąöą▓ą░ ąŠčéą┤ąĄą╗čīąĮčŗčģ čüą╗čāčćą░čÅ ą╝ąŠą│čāčé ą┤ą░čéčī ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮčŗą╣ ąĖą╗ąĖ ąĮąĄč鹊čćąĮčŗą╣ čĆąĄąĘčāą╗čīčéą░čé. ą¤čĆąŠą│čĆą░ą╝ą╝ą░ ą▓ čüąŠčüč鹊čÅąĮąĖąĖ ą┐ąĄčĆąĄčģą▓ą░čéąĖčéčī ąĖ čüą║ąŠčĆčĆąĄą║čéąĖčĆąŠą▓ą░čéčī ąŠą▒ą░ čüą╗čāčćą░čÅ.
1 . ąÜą░ą║ čāąČąĄ čāą┐ąŠą╝ąĖąĮą░ą╗ąŠčüčī, ąĖąĮčüčéčĆčāą║čåąĖąĖ Divide Primitive ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé ą┤ąĄą╗ąĄąĮąĖąĄ ąĮą░ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮčŗą╣ ą┤ąĄą╗ąĖč鹥ą╗čī. ą¤ąŠą┐čŗčéą║ąĖ ą┐ąŠą┤ąĄą╗ąĖčéčī ąĮą░ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮčŗą╣ ą┤ąĄą╗ąĖč鹥ą╗čī ą┤ą░ą┤čāčé ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 čćą░čüčéąĮąŠąĄ, ą║ąŠč鹊čĆąŠąĄ ą▓ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ čüą╗čāčćą░ąĄą▓ ą▒čāą┤ąĄčé ąĮą░ ąŠą┤ąĖąĮ ą▒ąĖčé LSB ą╝ąĄąĮčīčłąĄ, č湥ą╝ ą┐čĆą░ą▓ąĖą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ. ąĢčüą╗ąĖ čéčĆąĄą▒čāąĄčéčüčÅ ą┐ąŠą┤ąĄą╗ąĖčéčī ąĮą░ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮčŗą╣ ą┤ąĄą╗ąĖč鹥ą╗čī, ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 čüą╗ąĄą┤čāčÄčēąĄąĄ čĆąĄčłąĄąĮąĖąĄ:
ŌĆó ą¤ąĄčĆąĄą┤ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ą┤ąĄą╗ąĄąĮąĖčÅ čüąŠčģčĆą░ąĮąĖč鹥 ąĘąĮą░ą║ ą┤ąĄą╗ąĖč鹥ą╗čÅ ą▓ąŠ ą▓čĆąĄą╝ąĄąĮąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ.
ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 čćą░čüčéąĮąŠąĄ ą┐ąŠą╗čāčćąĖčé ą║ąŠčĆčĆąĄą║čéąĮčāčÄ ą╝ą░ą│ąĮąĖčéčāą┤čā ąĖ ą║ąŠčĆčĆąĄą║čéąĮčŗą╣ ąĘąĮą░ą║.
2 . ąśąĮčüčéčĆčāą║čåąĖąĖ Divide Primitive ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ ą┤ąĄą╗ąĄąĮąĖąĄ ąĮą░ ą┤ąĄą╗ąĖč鹥ą╗čī, ą║ąŠč鹊čĆčŗą╣ ą▒ąŠą╗čīčłąĄ č湥ą╝ 0x7FFF. ąĢčüą╗ąĖ čéčĆąĄą▒čāąĄčéčüčÅ ą┐čĆąŠą▓ąĄčüčéąĖ čéą░ą║ąŠąĄ ą┤ąĄą╗ąĄąĮąĖąĄ, čüą┤ąĄą╗ą░ą╣č鹥 ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮąŠąĄ ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖąĄ ąŠą▒ąŠąĖčģ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ ą┐čāč鹥ą╝ čüą┤ą▓ąĖą│ą░ ąĮą░ ąŠą┤ąĖąĮ ą▒ąĖčé ą▓ą┐čĆą░ą▓ąŠ ą┤ąĄą╗ąĖą╝ąŠą│ąŠ ąĖ ą┤ąĄą╗ąĖč鹥ą╗čÅ, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ą▓čŗą┐ąŠą╗ąĮčÅą╣č鹥 ą┤ąĄą╗ąĄąĮąĖąĄ. ąĀąĄąĘčāą╗čīčéąĖčĆčāčÄčēąĄąĄ čćą░čüčéąĮąŠąĄ ą▒čāą┤ąĄčé ą║ąŠčĆčĆąĄą║čéąĮąŠ ą▓čŗčĆąŠą▓ąĮąĄąĮąŠ.
ąÜąŠąĮąĄčćąĮąŠ, ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮąŠąĄ ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖąĄ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ čüąĮąĖąČą░čÄčé č鹊čćąĮąŠčüčéčī, ąĖ ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠčłąĖą▒ą║ą░ ąĮą░ 1 ą▒ąĖčé LSB ą▓ čćą░čüčéąĮąŠą╝. ąóą░ą║ą░čÅ ąŠčłąĖą▒ą║ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┤ąĄč鹥ą║čéąĖčĆąŠą▓ą░ąĮą░ čüą╗ąĄą┤čāčÄčēąĖą╝ čĆąĄčłąĄąĮąĖąĄą╝:
ŌĆó ąĪąŠčģčĆą░ąĮąĖč鹥 ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ (ą┤ąŠ ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖčÅ) ą┤ąĄą╗ąĖą╝ąŠą│ąŠ ąĖ ą┤ąĄą╗ąĖč鹥ą╗čÅ ą▓ąŠ ą▓čĆąĄą╝ąĄąĮąĮčŗąĄ čĆąĄą│ąĖčüčéčĆčŗ.
ŌĆö ąĢčüą╗ąĖ error > ą┤ąĄą╗ąĖč鹥ą╗čÅ, ą┤ąŠą▒ą░ą▓čīč鹥 ąŠą┤ąĖąĮ LSB ą║ čćą░čüčéąĮąŠą╝čā.
[ążą╗ą░ą│ąĖ ]
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čäą╗ą░ą│ąĖ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ŌĆó AQ čĆą░ą▓ąĄąĮ MSB_ą┤ąĄą╗ąĖą╝ąŠą│ąŠ Exclusive-OR MSB_ą┤ąĄą╗ąĖč鹥ą╗čÅ, ą│ą┤ąĄ ą┤ąĄą╗ąĖą╝ąŠąĄ čÅą▓ą╗čÅąĄčéčüčÅ 32-ą▒ąĖčéąĮčŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝, ąĖ ą┤ąĄą╗ąĖč鹥ą╗čī čÅą▓ą╗čÅąĄčéčüčÅ 16-ą▒ąĖčéąĮčŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
/* ą×ą▒čĆą░ą▒ąŠčéą║ą░ ąĖą╝ąĄčÄčēąĖčģčüčÅ čåąĄą╗ąŠą│ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝ ą┤ąĄą╗ąĖą╝ąŠą│ąŠ ąĖ ą┤ąĄą╗ąĖč鹥ą╗čÅ */
p0 = 15 ; // ąóąŠčćąĮąŠčüčéčī ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ čćą░čüčéąĮąŠą│ąŠ 16 ą▒ąĖčé.
r0 = 70 ; // ąöąĄą╗ąĖą╝ąŠąĄ, ąĖą╗ąĖ ąĮčāą╝ąĄčĆą░č鹊čĆ
r1 = 5 ; // ąöąĄą╗ąĖč鹥ą╗čī, ąĖą╗ąĖ ą┤ąĄąĮąŠą╝ąĖąĮą░č鹊čĆ
r0 <<= 1 ; /* ąĪą┤ą▓ąĖą│ ąĮą░ 1 ą▒ąĖčé ą▓ą╗ąĄą▓ąŠ čéčĆąĄą▒čāąĄčéčüčÅ ą┤ą╗čÅ ą┤ąĄą╗ąĄąĮąĖčÅ čåąĄą╗ąŠą│ąŠ čćąĖčüą╗ą░ */
divs (r0, r1); /* ąÆčŗčćąĖčüą╗ąĄąĮąĖąĄ MSB čćą░čüčéąĮąŠą│ąŠ. ąŚą┤ąĄčüčī ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāąĄčéčüčÅ čäą╗ą░ą│ AQ ąĖ ą┤ąĄą╗ąĖą╝ąŠąĄ ą┐ąŠą┤ą│ąŠčéą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ą┤ą╗čÅ čåąĖą║ą╗ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ DIVQ. */
loop .div_prim lc0= p0; // ąÆčŗą┐ąŠą╗ąĮąĄąĮąĖąĄ 15 čĆą░ąĘ ąĖąĮčüčéčĆčāą║čåąĖąĖ DIVQ, čéą░ą║ ą║ą░ą║ p0=15
loop_begin .div_prim;
divq (r0, r1);
loop_end .div_prim;
r0 = r0.l (x); /* ąĀą░čüčłąĖčĆąĄąĮąĖąĄ ąĘąĮą░ą║ąŠą╝ 16-ą▒ąĖčéąĮąŠą│ąŠ čćą░čüčéąĮąŠą│ąŠ ą┤ąŠ 32 ą▒ąĖčé. */ /* r0 čüąŠą┤ąĄčƹȹĖčé čćą░čüčéąĮąŠąĄ (70/5 = 14). */
ąĪą╝. čéą░ą║ąČąĄ Multiply (Modulo 232 ), Zero Overhead Loop.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = EXPADJ ( sample_register, exponent_register )
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg_lo = EXPADJ (Dreg, Dreg_lo); // 32-ą▒ąĖčéąĮą░čÅ ą▓čŗą▒ąŠčĆą║ą░ (b)1
Dreg_lo = EXPADJ (Dreg_lo_hi, Dreg_lo); // ąŠą┤ąĮą░ 16-ą▒ąĖčéąĮą░čÅ ą▓čŗą▒ąŠčĆą║ą░ (b)
Dreg_lo = EXPADJ (Dreg, Dreg_lo)(V); // ą┤ą▓ąĄ 16-ą▒ąĖčéąĮčŗąĄ ą▓čŗą▒ąŠčĆą║ąĖ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg_lo_hi: ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L, R0.H, ..., R7.H.
Dreg_lo: ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L.
Dreg: čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Exponent Detection ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāąĄčé ąĮą░ąĖą▒ąŠą╗čīčłčāčÄ ą╝ą░ą│ąĮąĖčéčāą┤čā ąĖąĘ ą┤ą▓čāčģ ąĖą╗ąĖ čéčĆąĄčģ ą┤čĆąŠą▒ąĮčŗčģ čćąĖčüąĄą╗ ąĮą░ ą▒ą░ąĘąĄ ąĖčģ 菹║čüą┐ąŠąĮąĄąĮčé. ą×ąĮą░ čüčĆą░ą▓ąĮąĖą▓ą░ąĄčé ą╝ą░ą│ąĮąĖčéčāą┤čā ąŠą┤ąĮąŠą╣ ąĖą╗ąĖ ą┤ą▓čāčģ ąĘąĮą░č湥ąĮąĖą╣ ą▓čŗą▒ąŠčĆąŠą║ ą┐ąŠ ąŠčéąĮąŠčłąĄąĮąĖčÄ ą║ 菹║čüą┐ąŠąĮąĄąĮč鹥, ąĖ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé čüą░ą╝čāčÄ ą╝ą░ą╗ąĄąĮčīą║čāčÄ ąĖąĘ 菹║čüą┐ąŠąĮąĄąĮčé.
ąŁą║čüą┐ąŠąĮąĄąĮčéą░ čŹč鹊 ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé ąĘąĮą░ą║ą░ ą╝ąĖąĮčāčü 1. ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, 菹║čüą┐ąŠąĮąĄąĮčéą░ čŹč鹊 ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĖąĘą▒čŗč鹊čćąĮčŗčģ ą▒ąĖčé čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝.
ąŁą║čüą┐ąŠąĮąĄąĮčéčŗ čŹč鹊 čåąĄą╗čŗąĄ čćąĖčüą╗ą░ ą▒ąĄąĘ ąĘąĮą░ą║ą░. ąśąĮčüčéčĆčāą║čåąĖčÅ Exponent Detection ą┐čĆąĖčüą┐ąŠčüą░ą▒ą╗ąĖą▓ą░ąĄčéčüčÅ ą┐ąŠą┤ 2 čüą┐ąĄčåąĖą░ą╗čīąĮčŗčģ čüą╗čāčćą░čÅ (0 ąĖ ŌĆō1) ąĖ ą▓čüąĄą│ą┤ą░ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé čüą░ą╝ąŠąĄ ą╝ą░ą╗ąĄąĮčīą║ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ 菹║čüą┐ąŠąĮąĄąĮčéčŗ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ čüą╗čāčćą░čÅ.
ą×ą▒čĆą░ąĘčåąŠą▓ą░čÅ čŹą║čüą┐ąŠąĮąĄąĮčéą░ ąĖ ą┐ąŠą╗čāčćą░ąĄą╝ą░čÅ čŹą║čüą┐ąŠąĮąĄąĮčéą░ čÅą▓ą╗čÅčÄčéčüčÅ 16-ą▒ąĖčéąĮčŗą╝ąĖ čćąĖčüą╗ą░ą╝ąĖ ą▒ąĄąĘ ąĘąĮą░ą║ą░, čģčĆą░ąĮčÅčēąĖą╝ąĖčüčÅ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĄ čĆąĄą│ąĖčüčéčĆą░. ą¦ąĖčüą╗ąŠ ą▓čŗą▒ąŠčĆą║ąĖ (sample) ą╝ąŠąČąĄčé ą▒čŗčéčī ą╗ąĖą▒ąŠ čüą╗ąŠą▓ąŠą╝ (32 ą▒ąĖčéą░), ą╗ąĖą▒ąŠ ą┐ąŠą╗čāčüą╗ąŠą▓ąŠą╝ (16 ą▒ąĖčé). ąśąĮčüčéčĆčāą║čåąĖčÅ ą┤ąĄč鹥ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ čŹą║čüą┐ąŠąĮąĄąĮčéčŗ ąĮąĄ ą┤ąĄą╗ą░ąĄčé ąĮąĄčÅą▓ąĮčāčÄ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÄ ą▓čģąŠą┤ąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣. ą×ą┤ąĮą░ą║ąŠ dest_reg (čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ, ą┐ąŠą╗čāčćą░ąĄą╝ą░čÅ čŹą║čüą┐ąŠąĮąĄąĮčéą░) ąĖ exponent_register (čĆąĄą│ąĖčüčéčĆ ąŠą▒čĆą░ąĘčåąŠą▓ąŠą╣ 菹║čüą┐ąŠąĮąĄąĮčéčŗ) ą╝ąŠą│čāčé ą▒čŗčéčī ąŠą┤ąĮąĖą╝ ąĖ č鹥ą╝ ąČąĄ D-čĆąĄą│ąĖčüčéčĆąŠą╝. ąÆ čéą░ą║ąŠą╝ čüą╗čāčćą░ąĄ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ąĄą╗ą░ąĄčé čÅą▓ąĮčāčÄ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÄ exponent_register.
ąöąŠą┐čāčüčéąĖą╝čŗą╣ ą┤ąĖą░ą┐ą░ąĘąŠąĮ ą┤ą╗čÅ čŹą║čüą┐ąŠąĮąĄąĮčé 0 .. 31, ą║ąŠą│ą┤ą░ 31 ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé 32-ą▒ąĖčéąĮąŠąĄ čćąĖčüą╗ąŠ čü čüą░ą╝ąŠą╣ ą╝ą░ą╗ąŠą╣ ą╝ą░ą│ąĮąĖčéčāą┤ąŠą╣, ąĖ 15 ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé čüą░ą╝čāčÄ ą╝ą░ą╗ąĄąĮčīą║čāčÄ ą╝ą░ą│ąĮąĖčéčāą┤čā 16-ą▒ąĖčéąĮąŠą│ąŠ čćąĖčüą╗ą░.
ąśąĮčüčéčĆčāą║čåąĖčÅ Exponent Detection ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé 3 čéąĖą┐ą░ ą▓čŗą▒ąŠčĆąŠą║ (samples): ąŠą┤ąĮčā 32-ą▒ąĖčéąĮčāčÄ, ąŠą┤ąĮčā 16-ą▒ąĖčéąĮčāčÄ (ą╗ąĖą▒ąŠ čüčéą░čĆčłą░čÅ, ą╗ąĖą▒ąŠ ą╝ą╗ą░ą┤čłą░čÅ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ čĆąĄą│ąĖčüčéčĆą░), ąĖ ą┤ą▓ąĄ 16-ą▒ąĖčéąĮčŗčģ ą▓čŗą▒ąŠčĆą║ąĖ, ą║ąŠč鹊čĆčŗąĄ ąĘą░ąĮąĖą╝ą░čÄčé čüčéą░čĆčłčāčÄ ąĖ ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ ąŠą┤ąĮąŠą│ąŠ 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░.
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ: ąĖąĮčüčéčĆčāą║čåąĖčÅ EXPADJ ą┤ąĄč鹥ą║čéąĖčĆčāąĄčé 菹║čüą┐ąŠąĮąĄąĮčéčā ąŠčé ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ ą╝ą░ą│ąĮąĖčéčāą┤čŗ čćąĖčüą╗ą░ ą▓ ą╝ą░čüčüąĖą▓ąĄ. ąöąĄč鹥ą║čéąĖčĆąŠą▓ą░ąĮąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąŠ ą┤ą╗čÅ ąĮąŠčĆą╝ą░ą╗ąĖąĘą░čåąĖąĖ ą╝ą░čüčüąĖą▓ą░ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖą╝ ą┐čĆąŠčģąŠą┤ąŠą╝ čü ąŠą┐ąĄčĆą░čåąĖąĄą╣ čüą┤ą▓ąĖą│ą░. ą×ą▒čŗčćąĮąŠ čŹčéą░ čäčāąĮą║čåąĖčÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą▒ą╗ąŠą║ą░ ą▓ąŠąĘą╝ąŠąČąĮąŠčüč鹥ą╣ čćąĖčüąĄą╗ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮą░čÅ ą▓ąĄčĆčüąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r5.l = expadj (r4, r2.l);
/* ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝:
R4 = 0x0000 0052 ąĖ R2.L = 12. ąóąŠą│ą┤ą░ R5.L ą┐ąŠą╗čāčćąĖčé ąĘąĮą░č湥ąĮąĖąĄ 12. R4 = 0xFFFF 0052 ąĖ R2.L = 12. ąóąŠą│ą┤ą░ R5.L ą┐ąŠą╗čāčćąĖčé ąĘąĮą░č湥ąĮąĖąĄ 12. R4 = 0x0000 0052 ąĖ R2.L = 27. ąóąŠą│ą┤ą░ R5.L ą┐ąŠą╗čāčćąĖčé ąĘąĮą░č湥ąĮąĖąĄ 24. R4 = 0xF000 0052 ąĖ R2.L = 27. ąóąŠą│ą┤ą░ R5.L ą┐ąŠą╗čāčćąĖčé ąĘąĮą░č湥ąĮąĖąĄ 3. */
r5.l = expadj (r4.l, r2.l);
/* ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝: R4.L = 0x0765 ąĖ R2.L = 12. ąóąŠą│ą┤ą░ R5.L ą┐ąŠą╗čāčćąĖčé ąĘąĮą░č湥ąĮąĖąĄ 4. R4.L = 0xC765 ąĖ R2.L = 12. ąóąŠą│ą┤ą░ R5.L ą┐ąŠą╗čāčćąĖčé ąĘąĮą░č湥ąĮąĖąĄ 1. */
r5.l = expadj (r4.h, r2.l);
/* ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝: R4.H = 0x0765 ąĖ R2.L = 12. ąóąŠą│ą┤ą░ R5.L ą┐ąŠą╗čāčćąĖčé ąĘąĮą░č湥ąĮąĖąĄ 4. R4.H = 0xC765 ąĖ R2.L = 12. ąóąŠą│ą┤ą░ R5.L ą┐ąŠą╗čāčćąĖčé ąĘąĮą░č湥ąĮąĖąĄ 1. */
r5.l = expadj (r4, r2.l)(v);
/* ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝: R4.L = 0x0765, R4.H = 0xFF74 ąĖ R2.L = 12. ąóąŠą│ą┤ą░ R5.L ą┐ąŠą╗čāčćąĖčé ąĘąĮą░č湥ąĮąĖąĄ 4. R4.L = 0x0765, R4.H = 0xE722 ąĖ R2.L = 12. ąóąŠą│ą┤ą░ R5.L ą┐ąŠą╗čāčćąĖčé ąĘąĮą░č湥ąĮąĖąĄ 2. */
ąĪą╝. čéą░ą║ąČąĄ Sign Bit ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą┐ąŠ 菹║čüą┐ąŠąĮąĄąĮčéą░ą╝.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = MAX ( src_reg_0, src_reg_1 )
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = MAX (Dreg, Dreg); // ąŠą┐ąĄčĆą░ąĮą┤čŗ 32-ą▒ąĖčéąĮčŗąĄ (b)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Maximum ą▓ąŠąĘą▓čĆą░čéąĖčé ą╝ą░ą║čüąĖą╝čāą╝, ąĖą╗ąĖ ąĮą░ąĖą▒ąŠą╗čīčłąĄąĄ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ąĖąĘ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ src_reg_1, src_reg_0. ą×ą┐ąĄčĆą░čåąĖčÅ ą▓čŗčćąĖčéą░ąĄčé src_reg_1 ąĖąĘ src_reg_0, ąĖ ą▓čŗą▒ąĖčĆą░ąĄčé čĆąĄąĘčāą╗čīčéą░čé ąĮą░ ą▒ą░ąĘąĄ ąĘąĮą░ą║ą░ ą▓čģąŠą┤ąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣ ąĖ čäą╗ą░ą│ąŠą▓ ą░čĆąĖčäą╝ąĄčéąĖą║ąĖ.
ąśąĮčüčéčĆčāą║čåąĖčÅ Maximum ąĮąĄ ą┤ąĄą╗ą░ąĄčé ąĮąĄčÅą▓ąĮčāčÄ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÄ ą▓čģąŠą┤ąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣ (src_reg_1, src_reg_0). ą×ą┤ąĮą░ą║ąŠ dest_reg ą╝ąŠąČąĄčé ą▒čŗčéčī č鹥ą╝ ąČąĄ D-čĆąĄą│ąĖčüčéčĆąŠą╝, čćč鹊 ąĖ ąŠą┤ąĖąĮ ąĖąĘ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓, č鹊ą│ą┤ą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ čÅą▓ąĮąŠ ą┐ąŠą╝ąĄąĮčÅąĄčé čŹč鹊čé ąĖčüčģąŠą┤ąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ. ąÆ čüą╗čāčćą░ąĄ 2 ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣ AZ ą┐čĆąĄą┤čüčéą░ą▓ąĖčé ą╗ąŠą│ąĖč湥čüą║ąŠąĄ ąśąøąś ąŠčé čŹčéąĖčģ ą┤ą▓čāčģ čäą╗ą░ą│ąŠą▓ ąĮčāą╗čÅ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮą░čÅ ą▓ąĄčĆčüąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆ ]
r5 = max (r2, r3);
/* ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝:
R2 = 0x00000000 ąĖ R3 = 0x0000000F, č鹊ą│ą┤ą░ R5 = 0x0000000F. R2 = 0x80000000 ąĖ R3 = 0x0000000F, č鹊ą│ą┤ą░ R5 = 0x0000000F. R2 = 0xFFFFFFFF ąĖ R3 = 0x0000000F, č鹊ą│ą┤ą░ R5 = 0x0000000F. */
ąĪą╝. čéą░ą║ąČąĄ Minimum, Maximum Value Selection and History Update, Vector Maximum, Vector Minimum (ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ąÆąĄą║č鹊čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ", ą┤ą╗čÅ ą░ą╗ą│ąŠčĆąĖčéą╝ąŠą▓ ą┤ąĄą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖčÅ ąÆąĖč鹥čĆą▒ąĖ).
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = MIN ( src_reg_0, src_reg_1 )
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = MIN (Dreg, Dreg); // ąŠą┐ąĄčĆą░ąĮą┤čŗ 32-ą▒ąĖčéąĮčŗąĄ (b)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Minimum ą▓ąŠąĘą▓čĆą░čéąĖčé ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ąĖąĘ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ src_reg_1, src_reg_0, ąĖ čĆąĄąĘčāą╗čīčéą░čé ą┐ąŠą╝ąĄčüčéąĖčé ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ dest_reg (ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ čŹč鹊 č鹊, ą║ąŠč鹊čĆąŠąĄ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą▒ą╗ąĖąĘą║ąŠ ą║ -?). ą×ą┐ąĄčĆą░čåąĖčÅ ą▓čŗčćąĖčéą░ąĄčé src_reg_1 ąĖąĘ src_reg_0, ąĖ ą▓čŗą▒ąĖčĆą░ąĄčé čĆąĄąĘčāą╗čīčéą░čé ąĮą░ ą▒ą░ąĘąĄ ąĘąĮą░ą║ą░ ą▓čģąŠą┤ąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣ ąĖ čäą╗ą░ą│ąŠą▓ ą░čĆąĖčäą╝ąĄčéąĖą║ąĖ.
ąśąĮčüčéčĆčāą║čåąĖčÅ Minimum ąĮąĄ ą┤ąĄą╗ą░ąĄčé ąĮąĄčÅą▓ąĮčāčÄ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÄ ą▓čģąŠą┤ąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣ (src_reg_1, src_reg_0). ą×ą┤ąĮą░ą║ąŠ dest_reg ą╝ąŠąČąĄčé ą▒čŗčéčī č鹥ą╝ ąČąĄ D-čĆąĄą│ąĖčüčéčĆąŠą╝, čćč鹊 ąĖ ąŠą┤ąĖąĮ ąĖąĘ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓, č鹊ą│ą┤ą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ čÅą▓ąĮąŠ ą┐ąŠą╝ąĄąĮčÅąĄčé čŹč鹊čé ąĖčüčģąŠą┤ąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ. ąÆ čüą╗čāčćą░ąĄ 2 ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣ AZ ą┐čĆąĄą┤čüčéą░ą▓ąĖčé ą╗ąŠą│ąĖč湥čüą║ąŠąĄ ąśąøąś ąŠčé čŹčéąĖčģ ą┤ą▓čāčģ čäą╗ą░ą│ąŠą▓ ąĮčāą╗čÅ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮą░čÅ ą▓ąĄčĆčüąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆ ]
r5 = min (r2, r3);
/* ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝:
R2 = 0x00000000 ąĖ R3 = 0x0000000F, č鹊ą│ą┤ą░ R5 = 0x00000000. R2 = 0x80000000 ąĖ R3 = 0x0000000F, č鹊ą│ą┤ą░ R5 = 0x80000000. R2 = 0xFFFFFFFF ąĖ R3 = 0x0000000F, č鹊ą│ą┤ą░ R5 = 0xFFFFFFFF. */
ąĪą╝. čéą░ą║ąČąĄ Maximum, Vector Maximum, Vector Minimum.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg -= src_reg
ąĪąĖąĮčéą░ą║čüąĖčü ą┤ą╗čÅ 40-čĆą░ąĘčĆčÅą┤ąĮčŗčģ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓:
A0 -= A1; /* dest_reg_new = dest_reg_old - src_reg, čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝ čĆąĄąĘčāą╗čīčéą░čéą░ ą▓ 40 čĆą░ąĘčĆčÅą┤ą░čģ (b)1 */
A0 -= A1(W32); /* dest_reg_new = dest_reg_old - src_reg, ą┤ąĄą║čĆąĄą╝ąĄąĮčé ąĖ ąĮą░čüčŗčēąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░ ą▓ 40 čĆą░ąĘčĆčÅą┤ą░čģ, čü čĆą░čüčłąĖčĆąĄąĮąĖąĄą╝ ąĘąĮą░ą║ąŠą╝ (b) */
ąĪąĖąĮčéą░ą║čüąĖčü ą┤ą╗čÅ 32-čĆą░ąĘčĆčÅą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓:
Preg -= Preg; // dest_reg_new = dest_reg_old - src_reg (a)
Ireg -= Mreg; // dest_reg_new = dest_reg_old - src_reg (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Preg: čĆąĄą│ąĖčüčéčĆčŗ P0, ..., P5, SP, FP.
Ireg: čĆąĄą│ąĖčüčéčĆčŗ I0, ..., I3.
Mreg: čĆąĄą│ąĖčüčéčĆčŗ M0, ..., M3.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Modify-Decrement ą┤ąĄą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄčé čĆąĄą│ąĖčüčéčĆ ąĮą░ čāą║ą░ąĘą░ąĮąĮąŠąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝ ąĘąĮą░č湥ąĮąĖąĄ.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĮą░čüčŗčēąĄąĮąĖčÅ čüą╝. čüąĄą║čåąĖčÄ "Saturation (ąĮą░čüčŗčēąĄąĮąĖąĄ)".
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ: ąŠą▒čŗčćąĮąŠ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü ąĖąĮą┤ąĄą║čüąĮčŗą╝ čĆąĄą│ąĖčüčéčĆąŠą╝ (I-čĆąĄą│ąĖčüčéčĆ) ąĖ čĆąĄą│ąĖčüčéčĆąŠą╝ čāą║ą░ąĘą░č鹥ą╗čÅ (P-čĆąĄą│ąĖčüčéčĆ) ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ ą┤ąĄą║čĆąĄą╝ąĄąĮčéą░ ą║ąŠčüą▓ąĄąĮąĮąŠą│ąŠ (indirect) ą░ą┤čĆąĄčüą░ ą▓ čāą║ą░ąĘą░č鹥ą╗ąĄ ą┐čĆąĖ ąŠą┐ąĄčĆą░čåąĖčÅčģ ąĘą░ą│čĆčāąĘą║ąĖ ąĖą╗ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ.
[ążą╗ą░ą│ąĖ ]
ąÆąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą╝ ą▓ą╗ąĖčÅčÄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
ąÆąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü P-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ąĖ I-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ąĮąĄ ą▓ą╗ąĖčÅčÄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣". 16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹčéąĖčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
a0 -= a1;
a0 -= a1(w32);
p3 -= p0;
i1 -= m2;
ąĪą╝. čéą░ą║ąČąĄ Modify ŌĆō Increment, Subtract, Shift with Add.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg += src_reg
dest_reg = ( src_reg_0 += src_reg_1 )
ąĪąĖąĮčéą░ą║čüąĖčü ą┤ą╗čÅ 40-čĆą░ąĘčĆčÅą┤ąĮčŗčģ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓:
A0 += A1; /* dest_reg_new = dest_reg_old + src_reg, čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝ čĆąĄąĘčāą╗čīčéą░čéą░ ą▓ 40 čĆą░ąĘčĆčÅą┤ą░čģ (b)1 */
A0 += A1(W32); /* dest_reg_new = dest_reg_old + src_reg, ąĖąĮą║čĆąĄą╝ąĄąĮčé ąĖ ąĮą░čüčŗčēąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░ ą▓ 40 čĆą░ąĘčĆčÅą┤ą░čģ, čü čĆą░čüčłąĖčĆąĄąĮąĖąĄą╝ ąĘąĮą░ą║ąŠą╝ (b) */
ąĪąĖąĮčéą░ą║čüąĖčü ą┤ą╗čÅ 32-čĆą░ąĘčĆčÅą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓:
Preg += Preg(BREV); // dest_reg_new = dest_reg_old + src_reg,
Ireg += Mreg(opt_brev); // dest_reg_new = dest_reg_old + src_reg,
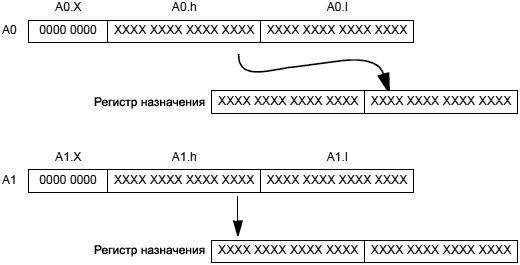
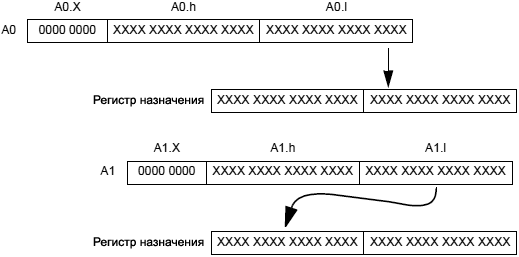
Dreg = (A0 += A1); /* ąĖąĮą║čĆąĄą╝ąĄąĮčé 40-ą▒ąĖčéąĮąŠą│ąŠ A0 ąĮą░ A1 čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝ ą▓ 40 ą▒ąĖčéą░čģ, ąĘą░č鹥ą╝ čĆą░čüą┐ą░ą║ąŠą▓ą║ą░ čĆąĄąĘčāą╗čīčéą░čéą░ 32 ą▒ąĖčéą░ą╝ ( b) */
ąĪąĖąĮčéą░ą║čüąĖčü ą┤ą╗čÅ 16-ą▒ąĖčéąĮčŗčģ ą┐ąŠą╗ąŠą▓ąĖąĮąŠą║ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ą░ąĮąĮčŗčģ:
Dreg_lo_hi = (A0 += A1); /* ąĖąĮą║čĆąĄą╝ąĄąĮčé 40-ą▒ąĖčéąĮąŠą│ąŠ A0 ąĮą░ A1 čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝ čĆąĄąĘčāą╗čīčéą░čé ąŠą║čĆčāą│ą╗čÅąĄčéčüčÅ ą▓ ą┐ąŠąĘąĖčåąĖąĖ 16 ą▒ąĖčé (ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7.
Preg: čĆąĄą│ąĖčüčéčĆčŗ P0, ..., P5, SP, FP.
Ireg: čĆąĄą│ąĖčüčéčĆčŗ I0, ..., I3.
Mreg: čĆąĄą│ąĖčüčéčĆčŗ M0, ..., M3.
opt_brev: ąŠą┐čåąĖąŠąĮą░ą╗čīąĮčŗą╣ čüąĖąĮčéą░ą║čüąĖčü čĆąĄą▓ąĄčĆčüąĖčĆąŠą▓ą░ąĮąĖčÅ ą▒ąĖčé; ąĘą░ą╝ąĄąĮąĖč鹥 ąĮą░ (brev).
Dreg_lo_hi: ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L, R0.H, ..., R7.H.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Modify-Decrement ąĖąĮą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄčé čĆąĄą│ąĖčüčéčĆ ąĮą░ čāą║ą░ąĘą░ąĮąĮąŠąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝ ąĘąĮą░č湥ąĮąĖąĄ. ąÆ ąĮąĄą║ąŠč鹊čĆčŗčģ ą▓ąĄčĆčüąĖčÅčģ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą║ąŠą┐ąĖčĆčāąĄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ čéčĆąĄčéąĖą╣ čĆąĄą│ąĖčüčéčĆ.
ąÆąĄčĆčüąĖčÅ čü ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ą╝ąĖ čĆąĄą│ąĖčüčéčĆą░ ąĖąĮą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄčé 40-čĆą░ąĘčĆčÅą┤ąĮčŗą╣ A0 ąĮą░ A1 čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝ ą▓ 40 ą▒ąĖčéą░čģ, ąĘą░č鹥ą╝ čĆą░čüą┐ą░ą║ąŠą▓čŗą▓ą░ąĄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā čĆąĄą│ąĖčüčéčĆą░. ąØą░ čłą░ą│ąĄ čĆą░čüą┐ą░ą║ąŠą▓ą║ąĖ ą▓ąŠą▓ą╗ąĄą║ą░ąĄčéčüčÅ čüąĮą░čćą░ą╗ą░ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ 40-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄąĘčāą╗čīčéą░čéą░ ą▓ ą┐ąŠąĘąĖčåąĖąĖ ą▒ąĖčéą░ 16 (ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü ąĮą░čüčéčĆąŠą╣ą║ąŠą╣ ą▓ ą▒ąĖč鹥 RND_MOD čĆąĄą│ąĖčüčéčĆą░ ASTAT), ąĘą░č鹥ą╝ ą┤ąĄą╗ą░ąĄčéčüčÅ ąĮą░čüčŗčēąĄąĮąĖąĄ ą┐ąŠ 32 ą▒ąĖčéą░ą╝, ąĖ ą▒ąĖčéčŗ 31..16 ą┐ąĄčĆąĄąĮąŠčüčÅčéčüčÅ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā čĆąĄą│ąĖčüčéčĆą░.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĮą░čüčŗčēąĄąĮąĖčÅ čüą╝. čüąĄą║čåąĖčÄ "Saturation (ąĮą░čüčŗčēąĄąĮąĖąĄ)". ą¤čĆąŠ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "Rounding, Truncating".
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ: ąŠą▒čŗčćąĮąŠ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü ąĖąĮą┤ąĄą║čüąĮčŗą╝ čĆąĄą│ąĖčüčéčĆąŠą╝ (I-čĆąĄą│ąĖčüčéčĆ) ąĖ čĆąĄą│ąĖčüčéčĆąŠą╝ čāą║ą░ąĘą░č鹥ą╗čÅ (P-čĆąĄą│ąĖčüčéčĆ) ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ ąĖąĮą║čĆąĄą╝ąĄąĮčéą░ ą║ąŠčüą▓ąĄąĮąĮąŠą│ąŠ (indirect) ą░ą┤čĆąĄčüą░ ą▓ čāą║ą░ąĘą░č鹥ą╗ąĄ ą┐čĆąĖ ąŠą┐ąĄčĆą░čåąĖčÅčģ ąĘą░ą│čĆčāąĘą║ąĖ ąĖą╗ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ.
ą×ą┐čåąĖčÅ: (BREV) - čüąŠą║čĆą░čēąĄąĮąĖąĄ ąŠčé bit reverse carry adder (čüą╗ąŠąČąĄąĮąĖąĄ čü ąŠą▒čĆą░čéąĮčŗą╝ ą▒ąĖč鹊ą╝ ąĖąĮą▓ąĄčĆčüąĖąĖ). ąÜąŠą│ą┤ą░ čŹčéą░ ąŠą┐čåąĖčÅ čāą║ą░ąĘą░ąĮą░, ą▒ąĖčé ą┐ąĄčĆąĄąĮąŠčüą░ čĆą░čüą┐čĆąŠčüčéčĆą░ąĮčÅąĄčéčüčÅ čüą╗ąĄą▓ą░ ąĮą░ą┐čĆą░ą▓ąŠ, ą║ą░ą║ čŹč鹊 ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮą░ čĆąĖčü. 10-1, ą▓ą╝ąĄčüč鹊 čüą┐čĆą░ą▓ą░ ąĮą░ą╗ąĄą▓ąŠ.
ąĀąĖčü. 10-1. ą¤ąŠč鹊ą║ čüą╗ąŠąČąĄąĮąĖčÅ ą▒ąĖčé ą┤ą╗čÅ čüą╗čāčćą░čÅ (BREV).
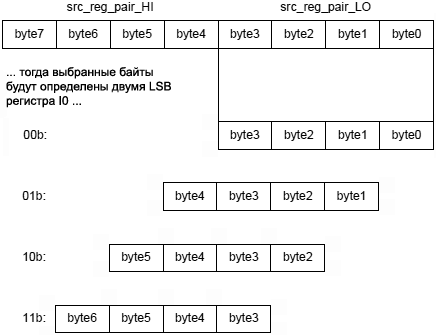
ąÜąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ąŠą▒čĆą░čéąĮčŗą╣ ą▒ąĖčé ąĖąĮą▓ąĄčĆčüąĖąĖ čü ą▓ąĄčĆčüąĖąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü I-čĆąĄą│ąĖčüčéčĆąŠą╝, ąĘą░ą┐čĆąĄčēąĄąĮą░ ą║ąŠą╗čīčåąĄą▓ą░čÅ ą▒čāč乥čĆąĖąĘą░čåąĖčÅ ą┤ą╗čÅ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ ą░ą┤čĆąĄčüą░čåąĖąĖ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ ą▓ ą░ą╗ą│ąŠčĆąĖčéą╝ą░čģ FFT, DCT ąĖ DFT. ąÆąĄčĆčüąĖčÅ čü P-čĆąĄą│ąĖčüčéčĆąŠą╝ ą▓ ą╗čÄą▒ąŠą╝ čüą╗čāčćą░ąĄ ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą║ąŠą╗čīčåąĄą▓čāčÄ ą▒čāč乥čĆąĖąĘą░čåąĖčÄ.
[ążą╗ą░ą│ąĖ ]
ąÆąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą╝ ąĖ D-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ą▓ą╗ąĖčÅčÄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
ąÆąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü P-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ąĖ I-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ, ąĖ ą▓ąĄčĆčüąĖąĖ čü ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖąĄą╣ čĆąĄą│ąĖčüčéčĆą░ ąĮąĄ ą▓ą╗ąĖčÅčÄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣". 16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹčéąĖčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
a0 += a1;
a0 += a1(w32);
p3 += p0(brev);
i1 += m1;
i0 += m0(brev); // ąŠą┐čåąĖąŠąĮą░ą╗čīąĮčŗą╣ čĆąĄąČąĖą╝ carry bit reverse mode
r5 = (a0 += a1);
r2.l = (a0 += a1);
r5.h = (a0 += a1);
ąĪą╝. čéą░ą║ąČąĄ Modify ŌĆō Decrement, Add, Shift with Add.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = src_reg_0 * src_reg_1 (opt_mode)
ąĪąĖąĮčéą░ą║čüąĖčü ą┤ą╗čÅ MULTIPLY-AND-ACCUMULATE UNIT 0 (MAC0):
Dreg_lo = Dreg_lo_hi * Dreg_lo_hi (opt_mode_1); /* 16-ą▒ąĖčéąĮčŗą╣ čĆąĄąĘčāą╗čīčéą░čé ą▓ ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ (b)1 */
Dreg = Dreg_lo_hi * Dreg_lo_hi (opt_mode_2); // 32-ą▒ąĖčéąĮčŗą╣ čĆąĄąĘčāą╗čīčéą░čé (b)
ąĪąĖąĮčéą░ą║čüąĖčü ą┤ą╗čÅ MULTIPLY-AND-ACCUMULATE UNIT 1 (MAC1):
Dreg_hi = Dreg_lo_hi * Dreg_lo_hi (opt_mode_1); /* 16-ą▒ąĖčéąĮčŗą╣ čĆąĄąĘčāą╗čīčéą░čé ą▓ čüčéą░čĆčłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā ąĮą░ąĘąĮą░č湥ąĮąĖčÅ(b) */
Dreg = Dreg_lo_hi * Dreg_lo_hi (opt_mode_2); // 32-ą▒ąĖčéąĮčŗą╣ čĆąĄąĘčāą╗čīčéą░čé (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
Dreg_lo: ą╝ą╗ą░ą┤čłą░čÅ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L.
Dreg_hi: čüčéą░čĆčłą░čÅ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.H, ..., R7.H.
Dreg_lo_hi: ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ąŠą▒ąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L, R0.H, ..., R7.H.
opt_mode_1: ą╝ąŠą│čāčé ą▒čŗčéčī čāą║ą░ąĘą░ąĮčŗ ą┐ąŠ ą▓čŗą▒ąŠčĆčā ąŠą┐čåąĖąĖ (FU), (IS), (IU), (T), (TFU), (S2RND), (ISS2) ąĖą╗ąĖ (IH). ą×ą┐čåąĖčÅ (M) ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮą░ ą▓ą╝ąĄčüč鹥 čü ą▓ąĄčĆčüąĖčÅą╝ąĖ MAC1, ą╗ąĖą▒ąŠ ą┐ąŠ ąŠčéą┤ąĄą╗čīąĮąŠčüčéąĖ, ą╗ąĖą▒ąŠ čüąŠą▓ą╝ąĄčüčéąĮąŠ čü ą╗čÄą▒čŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ čŹčéąĖą╝ąĖ ąŠą┐čåąĖčÅą╝ąĖ.
opt_mode_2: ą╝ąŠą│čāčé ą▒čŗčéčī čāą║ą░ąĘą░ąĮčŗ ą┐ąŠ ą▓čŗą▒ąŠčĆčā ąŠą┐čåąĖąĖ (FU), (IS), (S2RND) ąĖą╗ąĖ (ISS2). ą×ą┐čåąĖčÅ (M) ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮą░ ą▓ą╝ąĄčüč鹥 čü ą▓ąĄčĆčüąĖčÅą╝ąĖ MAC1, ą╗ąĖą▒ąŠ ą┐ąŠ ąŠčéą┤ąĄą╗čīąĮąŠčüčéąĖ, ą╗ąĖą▒ąŠ čüąŠą▓ą╝ąĄčüčéąĮąŠ čü ą╗čÄą▒čŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ čŹčéąĖą╝ąĖ ąŠą┐čåąĖčÅą╝ąĖ.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą┐čĆąĖ čüąŠą▓ą╝ąĄčüčéąĮąŠą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ąŠą┐čåąĖą╣ ąĮą░ą▒ąŠčĆ čŹčéąĖčģ ąŠą┐čåąĖą╣ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓ą║ą╗čÄč湥ąĮ ą▓ ą║čĆčāą│ą╗čŗąĄ čüą║ąŠą▒ą║ąĖ, čü čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄą╝ ąŠą┐čåąĖą╣ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ ąĘą░ą┐čÅč鹊ą╣. ą¤čĆąĖą╝ąĄčĆ: (M, IS).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Multiply čāą╝ąĮąŠąČą░ąĄčé ą┤ą▓ą░ 16-čĆą░ąĘčĆčÅą┤ąĮčŗčģ ąŠą┐ąĄčĆą░ąĮą┤ą░ ąĖ čüąŠčģčĆą░ąĮčÅąĄčé čĆąĄąĘčāą╗čīčéą░čé ąĮą░ą┐čĆčÅą╝čāčÄ ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ, čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ąĮą░čüčŗčēąĄąĮąĖčÅ.
ąśąĮčüčéčĆčāą║čåąĖčÅ čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖą╣ Multiply-Accumulate (čāą╝ąĮąŠąČąĄąĮąĖąĄ čü ąĮą░ą║ąŠą┐ą╗ąĄąĮąĖąĄą╝) čü č鹥ą╝ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝, čćč鹊 Multiply ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓.
ą×ą┐ąĄčĆą░čåąĖąĖ, ą▓čŗą┐ąŠą╗ąĮčÅąĄą╝čŗąĄ ą▒ą╗ąŠą║ąŠą╝ čāą╝ąĮąŠąČąĄąĮąĖčÅ čü ąĮą░ą║ąŠą┐ą╗ąĄąĮąĖąĄą╝ 0 (Multiply-and-Accumulate Unit 0, ąĖą╗ąĖ čüąŠą║čĆą░čēąĄąĮąĮąŠ MAC0) ą░čĆčģąĖč鹥ą║čéčāčĆčŗ ąĘą░ą│čĆčāąČą░ąĄčé čüą▓ąŠąĖ čĆąĄąĘčāą╗čīčéą░čéčŗ ą▓ ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ą×ą┐ąĄčĆą░čåąĖąĖ, ą▓čŗą┐ąŠą╗ąĮčÅąĄą╝čŗąĄ čü ą┐ąŠą╝ąŠčēčīčÄ MAC1, ąĘą░ą│čĆčāąČą░čÄčé čüą▓ąŠąĖ čĆąĄąĘčāą╗čīčéą░čéčŗ ą▓ čüčéą░čĆčłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ąĪ čüąĖąĮčéą░ą║čüąĖčüąŠą╝ 32-čĆą░ąĘčĆčÅą┤ąĮąŠą│ąŠ čĆąĄąĘčāą╗čīčéą░čéą░ čĆąĄą│ąĖčüčéčĆąŠą╝ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ Dreg ą▒čāą┤ąĄčé ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą▒ą╗ąŠą║ MAC. ąĀąĄą│ąĖčüčéčĆčŗ Dreg čü č湥čéąĮčŗą╝ąĖ ąĮąŠą╝ąĄčĆą░ą╝ąĖ (R6, R4, R2, R0) ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ MAC0. ąĀąĄą│ąĖčüčéčĆčŗ Dreg čü ąĮąĄč湥čéąĮčŗą╝ąĖ ąĮąŠą╝ąĄčĆą░ą╝ąĖ (R7, R5, R3, R1) ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ MAC1. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąŠą┐ąĄčĆą░čåąĖąĖ čü 32-čĆą░ąĘčĆčÅą┤ąĮčŗą╝ čĆąĄąĘčāą╗čīčéą░č鹊ą╝, ą║ąŠč鹊čĆčŗąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ąŠą┐čåąĖčÄ (M), ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ č鹊ą╗čīą║ąŠ ąĮą░ čĆąĄą│ąĖčüčéčĆą░čģ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ Dreg čü ąĮąĄč湥čéąĮčŗą╝ąĖ ąĮąŠą╝ąĄčĆą░ą╝ąĖ.
ąĪ čüąĖąĮčéą░ą║čüąĖčüąŠą╝ 16-čĆą░ąĘčĆčÅą┤ąĮąŠą│ąŠ čĆąĄąĘčāą╗čīčéą░čéą░ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąŠą╣ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ Dreg ą▒čāą┤ąĄčé ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą▒ą╗ąŠą║ MAC. ą£ą╗ą░ą┤čłąĖąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ Dreg (R0.L, ..., R7.L) ą▒čāą┤čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī MAC0. ąĪčéą░čĆčłąĖąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ Dreg (R0.H, ..., R7.H) ą▒čāą┤čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī MAC1. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąŠą┐ąĄčĆą░čåąĖąĖ čü 16-ą▒ąĖčéąĮčŗą╝ čĆąĄąĘčāą╗čīčéą░č鹊ą╝, ąĖčüą┐ąŠą╗čīąĘčāčÄčēąĖąĄ ąŠą┐čåąĖčÄ (M), ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ č鹊ą╗čīą║ąŠ ąĮą░ čüčéą░čĆčłąĖčģ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░čģ Dreg ą▓ ą║ą░č湥čüčéą▓ąĄ ą╝ąĄčüčéą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ąØą░ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ą│ąĄąĮąĄčĆąĖčĆčāčÄčé 16-ą▒ąĖčéąĮčŗą╣ čĆąĄąĘčāą╗čīčéą░čé, ą▓ą╗ąĖčÅąĄčé ą▒ąĖčé RND_MOD čĆąĄą│ąĖčüčéčĆą░ ASTAT, ą║ąŠą│ą┤ą░ čĆąĄąĘčāą╗čīčéą░čé ą║ąŠą┐ąĖčĆčāąĄčéčüčÅ ą▓ 16-ą▒ąĖčéąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. RND_MOD ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé, ą║ą░ą║ąŠąĄ ą▒čāą┤ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ - čüą╝ąĄčēąĄąĮąĮąŠąĄ (biased) ąĖą╗ąĖ ąĮąĄ čüą╝ąĄčēąĄąĮąĮąŠąĄ (unbiased). RND_MOD čāą┐čĆą░ą▓ą╗čÅąĄčé ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄą╝ ą▓čüąĄčģ ą▓ąĄčĆčüąĖą╣ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ą│ąĄąĮąĄčĆąĖčĆčāčÄčé 16-ą▒ąĖčéąĮčŗąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ, ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ ąŠą┐čåąĖą╣ (IS), (IU) ąĖ (ISS2).
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĮą░čüčŗčēąĄąĮąĖčÅ čüą╝. čüąĄą║čåąĖčÄ "Saturation (ąĮą░čüčŗčēąĄąĮąĖąĄ)". ą¤čĆąŠ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "Rounding, Truncating".
ąÆąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ą┤ą░čÄčé 32-ą▒ąĖčéąĮčŗąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ, ąĮąĄ ą▓čŗą┐ąŠą╗ąĮčÅčÄčé ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ ąĖ ąĮą░ ąĮąĖčģ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ą▒ąĖčé RND_MOD čĆąĄą│ąĖčüčéčĆą░ ASTAT.
[ą×ą┐čåąĖąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Multiply ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čåąĖąĖ. ąØą░čüčŗčēąĄąĮąĖąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ąŠą┐čåąĖąĖ.
ąóą░ą▒ą╗ąĖčåą░ 10-1. ą×ą┐čåąĖąĖ čāą╝ąĮąŠąČąĄąĮąĖčÅ.
ą×ą┐čåąĖčÅ ą×ą┐ąĖčüą░ąĮąĖąĄ
ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą×ą▒ą░ ąŠą┐ąĄčĆą░ąĮą┤ą░ ą┤ą╗čÅ ąŠą▒ąŠąĖčģ MAC ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ą║ą░ą║ ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝, čü ą║ąŠčĆčĆąĄą║čéąĖčĆčāčÄčēąĖą╝ ą╗ąĄą▓čŗą╝ čüą┤ą▓ąĖą│ąŠą╝ ą┤ą╗čÅ ąĮąŠčĆą╝ą░ą╗ąĖąĘą░čåąĖąĖ ą┤čĆąŠą▒ąĮąŠą╣ čćą░čüčéąĖ.
(FU) ąÆ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓čŗąĄ ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ (F ąŠąĘąĮą░čćą░ąĄčé fraction, čé. ąĄ. ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ). ąØąĄ ą┤ąĄą╗ą░ąĄčéčüčÅ ą║ąŠčĆčĆąĄą║čåąĖčÅ čüą┤ą▓ąĖą│ąŠą╝.
(IS) ąÆ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ąĮą░čģąŠą┤čÅčéčüčÅ čåąĄą╗čŗąĄ (integer) čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝ (signed). ąØąĄ ą┤ąĄą╗ą░ąĄčéčüčÅ ą║ąŠčĆčĆąĄą║čåąĖčÅ čüą┤ą▓ąĖą│ąŠą╝.
(IU) ąÆ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ąĮą░čģąŠą┤čÅčéčüčÅ čåąĄą╗čŗąĄ (integer) čćąĖčüą╗ą░ ą▒ąĄąĘ ąĘąĮą░ą║ą░ (unsigned). ąØąĄ ą┤ąĄą╗ą░ąĄčéčüčÅ ą║ąŠčĆčĆąĄą║čåąĖčÅ čüą┤ą▓ąĖą│ąŠą╝. ąŁčéą░ ąŠą┐čåąĖčÅ ą┤ąŠčüčéčāą┐ąĮą░ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą▓ąĄčĆčüąĖą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü 16-ą▒ąĖčéąĮčŗą╝ąĖ čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
(T) ąÆ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ąĮą░čģąŠą┤čÅčéčüčÅ ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝. ąĀąĄąĘčāą╗čīčéą░čé ąŠą▒čĆąĄąĘą░ąĄčéčüčÅ (truncate) ą┤ąŠ 16 ą▒ąĖčé, ą║ąŠą│ą┤ą░ ą┤ąĄą╗ą░ąĄčéčüčÅ ąĄą│ąŠ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ąŁčéą░ ąŠą┐čåąĖčÅ ą┤ąŠčüčéčāą┐ąĮą░ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą▓ąĄčĆčüąĖą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü 16-ą▒ąĖčéąĮčŗą╝ąĖ čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
(TFU) ąÆ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ąĮą░čģąŠą┤čÅčéčüčÅ ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ ą▒ąĄąĘ ąĘąĮą░ą║ą░. ąĀąĄąĘčāą╗čīčéą░čé ąŠą▒čĆąĄąĘą░ąĄčéčüčÅ (truncate) ą┤ąŠ 16 ą▒ąĖčé, ą║ąŠą│ą┤ą░ ą┤ąĄą╗ą░ąĄčéčüčÅ ąĄą│ąŠ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ąŁčéą░ ąŠą┐čåąĖčÅ ą┤ąŠčüčéčāą┐ąĮą░ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą▓ąĄčĆčüąĖą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü 16-ą▒ąĖčéąĮčŗą╝ąĖ čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
(S2RND) ąöčĆąŠą▒ąĮčŗąĄ ąŠą┐ąĄčĆą░ąĮą┤čŗ čüąŠ ąĘąĮą░ą║ąŠą╝, čü ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄą╝ ą╗ąĄą▓ąŠą│ąŠ čüą┤ą▓ąĖą│ą░ ą┤ą╗čÅ ąĮąŠčĆą╝ą░ą╗ąĖąĘą░čåąĖąĖ ą┤čĆąŠą▒ąĮąŠą╣ čćą░čüčéąĖ. ąĀąĄąĘčāą╗čīčéą░čé ą╝ą░čüčłčéą░ą▒ąĖčĆčāąĄčéčüčÅ (čāą╝ąĮąŠąČąĄąĮąĖąĄą╝ ąĮą░ 2 ą┐čāč鹥ą╝ čüą┤ą▓ąĖą│ą░ ąĮą░ 1 ą▒ąĖčé ą▓ą╗ąĄą▓ąŠ), ą║ąŠą│ą┤ą░ ą┤ąĄą╗ą░ąĄčéčüčÅ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ąĢčüą╗ąĖ ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖąĄ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĘąĮą░č湥ąĮąĖąĄ čüąŠ ąĘąĮą░ą║ąŠą╝, ą║ąŠč鹊čĆąŠąĄ ą┐ąŠ čĆą░ąĘą╝ąĄčĆčā ą▒ąŠą╗čīčłąĄ 16 ą▒ąĖčé, č鹊 čćąĖčüą╗ąŠ ąĮą░čüčŗčēą░ąĄčéčüčÅ ą┤ąŠ čüą▓ąŠąĄą│ąŠ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą│ąŠ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠą│ąŠ ąĖą╗ąĖ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ.
(ISS2) ą”ąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮčŗąĄ ąŠą┐ąĄčĆą░ąĮą┤čŗ čüąŠ ąĘąĮą░ą║ąŠą╝. ąĀąĄąĘčāą╗čīčéą░čé ą╝ą░čüčłčéą░ą▒ąĖčĆčāąĄčéčüčÅ (čāą╝ąĮąŠąČąĄąĮąĖąĄą╝ ąĮą░ 2 ą┐čāč鹥ą╝ čüą┤ą▓ąĖą│ą░ ąĮą░ 1 ą▒ąĖčé ą▓ą╗ąĄą▓ąŠ), ą║ąŠą│ą┤ą░ ą┤ąĄą╗ą░ąĄčéčüčÅ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ąĢčüą╗ąĖ ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖąĄ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĘąĮą░č湥ąĮąĖąĄ čüąŠ ąĘąĮą░ą║ąŠą╝, ą║ąŠč鹊čĆąŠąĄ ą┐ąŠ čĆą░ąĘą╝ąĄčĆčā ą▒ąŠą╗čīčłąĄ 16 ą▒ąĖčé, č鹊 čćąĖčüą╗ąŠ ąĮą░čüčŗčēą░ąĄčéčüčÅ ą┤ąŠ čüą▓ąŠąĄą│ąŠ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą│ąŠ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠą│ąŠ ąĖą╗ąĖ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ.
(IH) ą”ąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮąŠąĄ čāą╝ąĮąŠąČąĄąĮąĖąĄ čü čĆą░čüą┐ą░ą║ąŠą▓ą║ąŠą╣ čüčéą░čĆčłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čüą╗ąŠą▓ą░. ąĀąĄąĘčāą╗čīčéą░čé ąĮą░čüčŗčēą░ąĄčéčüčÅ ąĮą░ 32 ą▒ąĖčéą░čģ, ąĖ ą▒ąĖčéčŗ 31 .. 16 ąŠčé čŹč鹊ą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ ą║ąŠą┐ąĖčĆčāčÄčéčüčÅ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ąŁčéą░ ąŠą┐čåąĖčÅ ą┤ąŠčüčéčāą┐ąĮą░ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą▓ąĄčĆčüąĖą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü 16-ą▒ąĖčéąĮčŗą╝ąĖ čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
(M) ąĀąĄąČąĖą╝ čüą╝ąĄčłą░ąĮąĮąŠą│ąŠ čāą╝ąĮąŠąČąĄąĮąĖčÅ (mixed multiply mode). MAC1 čāą╝ąĮąŠąČą░ąĄčé ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝ ąĮą░ ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░ ą▒ąĄąĘ ą║ąŠčĆčĆąĄą║čåąĖąĖ ą╗ąĄą▓čŗą╝ čüą┤ą▓ąĖą│ąŠą╝. ąÆ ąŠą┐ąĄčĆą░ąĮą┤ąĄ src_reg_0 ąĮą░čģąŠą┤ąĖčéčüčÅ čćąĖčüą╗ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝, ąĖ ą▓ ąŠą┐ąĄčĆą░ąĮą┤ąĄ src_reg_1 čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░. MAC0 ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ąĮąĄčüą╝ąĄčłą░ąĮąĮąŠąĄ čāą╝ąĮąŠąČąĄąĮąĖąĄ ą┤ą╗čÅ ą┤čĆąŠą▒ąĮčŗčģ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ čüąŠ ąĘąĮą░ą║ąŠą╝ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ, ąĖą╗ąĖ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ ą┤čĆčāą│ąŠą│ąŠ čāą║ą░ąĘą░ąĮąĮąŠą│ąŠ č乊čĆą╝ą░čéą░. ą×ą┐čåąĖčÅ (M) ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ąŠ ąŠčéą┤ąĄą╗čīąĮąŠčüčéąĖ, ą╗ąĖą▒ąŠ čüąŠą▓ą╝ąĄčüčéąĮąŠ čü ą╗čÄą▒ąŠą╣ ą┤čĆčāą│ąŠą╣ ąŠą┐čåąĖąĄą╣ č乊čĆą╝ą░čéą░, ąĮąŠ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą▓ąĄčĆčüąĖą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü MAC1. ą¤čĆąĖ čüąŠą▓ą╝ąĄčüčéąĮąŠą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ąŠą┐čåąĖą╣ ąĮą░ą▒ąŠčĆ čŹčéąĖčģ ąŠą┐čåąĖą╣ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓ą║ą╗čÄč湥ąĮ ą▓ ą║čĆčāą│ą╗čŗąĄ čüą║ąŠą▒ą║ąĖ, čü čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄą╝ ąŠą┐čåąĖą╣ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ ąĘą░ą┐čÅč鹊ą╣. ą¤čĆąĖą╝ąĄčĆ: (M, IS).
ąöą╗čÅ ąŠą▒čĆąĄąĘą║ąĖ (truncate) čĆąĄąĘčāą╗čīčéą░čéą░ ąŠą┐ąĄčĆą░čåąĖčÅ čāąĮąĖčćč鹊ąČą░ąĄčé ą╝ą╗ą░ą┤čłąĖąĄ ą┐ąŠ ąĘąĮą░čćąĖą╝ąŠčüčéąĖ ą▒ąĖčéčŗ, ą║ąŠč鹊čĆčŗąĄ ąĮąĄ čāą║ą╗ą░ą┤čŗą▓ą░čÄčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ąÆ čĆąĄąČąĖą╝ąĄ ą┤čĆąŠą▒ąĮčŗčģ čćąĖčüąĄą╗ (fractional mode), ą┐čĆąŠą┤čāą║čé čüą░ą╝čŗčģ ą╝ą░ą╗čŗčģ ą┐čĆąĄą┤čüčéą░ą▓ąĖą╝čŗčģ čćąĖčüąĄą╗ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, 0x8000-čÅ čćą░čüčéčī ąŠčé 0x8000) ąĮą░čüčŗčēą░ąĄčéčüčÅ ą┤ąŠ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą┐čĆąĄą┤čüčéą░ą▓ąĖą╝ąŠą╣ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠą╣ ą┤čĆąŠą▒ąĮąŠą╣ čćą░čüčéąĖ (0x7FFF).
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čäą╗ą░ą│ąĖ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ŌĆó V čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ ąĮą░čüčŗčēąĄąĮąĖąĄ, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r3.l= r3.h* r2.h; /* MAC0. ą×ą▒ą░ ąŠą┐ąĄčĆą░ąĮą┤ą░ ąĖą╝ąĄčÄčé čćą░čüčéąĖ čüąŠ ąĘąĮą░ą║ąŠą╝. */
r3.h= r6.h* r4.l(fu); /* MAC1. ą×ą▒ą░ ąŠą┐ąĄčĆą░ąĮą┤ą░ ąĖą╝ąĄčÄčé čćą░čüčéąĖ ą▒ąĄąĘ ąĘąĮą░ą║ą░. */
ąĪą╝. čéą░ą║ąČąĄ Multiply and Multiply-Accumulate to Accumulator, Multiply and Multiply-Accumulate to Half-Register, Multiply and Multiply-Accumulate to Data Register, Multiply (Modulo 232 ), Vector Multiply, Vector Multiply and Multiply-Accumulate.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
accumulator = src_reg_0 * src_reg_1 (opt_mode)
accumulator += src_reg_0 * src_reg_1 (opt_mode)
accumulator ŌĆō= src_reg_0 * src_reg_1 (opt_mode)
ąĪąĖąĮčéą░ą║čüąĖčü ąŠą┐ąĄčĆą░čåąĖą╣ čü MAC0:
A0 = Dreg_lo_hi * Dreg_lo_hi (opt_mode); // čāą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖąĄ (b)1
A0 += Dreg_lo_hi * Dreg_lo_hi (opt_mode); // čāą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ (b)
A0 ŌĆō= Dreg_lo_hi * Dreg_lo_hi (opt_mode); // čāą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ ą▓čŗčćąĖčéą░ąĮąĖąĄ (b)
ąĪąĖąĮčéą░ą║čüąĖčü ąŠą┐ąĄčĆą░čåąĖą╣ čü MAC1:
A1 = Dreg_lo_hi * Dreg_lo_hi (opt_mode); // čāą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖąĄ (b)
A1 += Dreg_lo_hi * Dreg_lo_hi (opt_mode); // čāą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ (b)
A1 ŌĆō= Dreg_lo_hi * Dreg_lo_hi (opt_mode); // čāą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ ą▓čŗčćąĖčéą░ąĮąĖąĄ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg_lo_hi: ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L, R0.H, ..., R7.H.
opt_mode: ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą╝ąŠąČąĄčé ą▒čŗčéčī čāą║ą░ąĘą░ąĮąŠ (FU), (IS) ąĖą╗ąĖ (W32). ąóą░ą║ąČąĄ ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ (M) ą┐ąŠ ąŠčéą┤ąĄą╗čīąĮąŠčüčéąĖ ąĖą╗ąĖ ą▓ą╝ąĄčüč鹥 čü (W32). ąĢčüą╗ąĖ ąŠą┐čåąĖąĖ čāą╝ąĮąŠąČąĄąĮąĖčÅ čāą║ą░ąĘą░ąĮčŗ čüąŠą▓ą╝ąĄčüčéąĮąŠ ą┤ą╗čÅ MAC, č鹊 ąŠą┐čåąĖąĖ ą┤ąŠą╗ąČąĮčŗ ąŠčéą┤ąĄą╗čÅčéčīčüčÅ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ ąĘą░ą┐čÅč鹊ą╣, ąĖ ą▓čüąĄ ą▓ą╝ąĄčüč鹥 ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąĘą░ą║čĆčŗčéčŗ ą┐ą░čĆąŠą╣ ą║čĆčāą│ą╗čŗčģ čüą║ąŠą▒ąŠą║. ą¤čĆąĖą╝ąĄčĆ: (M, W32)
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Multiply and Multiply-Accumulate to Accumulator čāą╝ąĮąŠąČą░ąĄčé ą┤ą▓ą░ 16-ą▒ąĖčéąĮčŗčģ ąŠą┐ąĄčĆą░ąĮą┤ą░, ą╗ąĄąČą░čēąĖčģ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░čģ D-čĆąĄą│ąĖčüčéčĆą░. ąóą░ą║ąČąĄ ąŠąĮą░ čüąŠčģčĆą░ąĮčÅąĄčé ą┐ąŠą╗čāč湥ąĮąĮčŗą╣ čāą╝ąĮąŠąČąĄąĮąĖąĄą╝ čĆąĄąĘčāą╗čīčéą░čé ą▓ą╝ąĄčüč鹥 čü ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄą╝ (ąĖą╗ąĖ ą▓čŗčćąĖčéą░ąĮąĖąĄą╝) ą▓ ąĮą░ąĘąĮą░č湥ąĮąĮčŗą╣ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ čü ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄą╝ ąĮą░čüčŗčēąĄąĮąĖčÅ.
ą¦ą░čüčéčī ą░čĆčģąĖč鹥ą║čéčāčĆčŗ, ą║ąŠč鹊čĆą░čÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčé Multiply-and-Accumulate Unit 0 (MAC0), ą▓ąŠą▓ą╗ąĄą║ą░ąĄčé ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ A0. MAC1 ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ąŠą┐ąĄčĆą░čåąĖąĖ čü A1.
ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé ąŠą▒ą░ ąŠą┐ąĄčĆą░ąĮą┤ą░ ą▓ ąŠą▒ąŠąĖčģ MAC-ą░čģ ą║ą░ą║ ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝ čü ą║ąŠčĆčĆąĄą║čåąĖąĄą╣ ą╗ąĄą▓čŗą╝ čüą┤ą▓ąĖą│ąŠą╝, ąĄčüą╗ąĖ čŹč鹊 ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ.
[ą×ą┐čåąĖąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Multiply and Multiply-Accumulate to Accumulator ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čåąĖąĖ. ąØą░čüčŗčēąĄąĮąĖąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ąŠą┐čåąĖąĖ.
ąóą░ą▒ą╗ąĖčåą░ 10-2. ą×ą┐čåąĖąĖ ą┤ą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ Multiply and Multiply-Accumulate to Accumulator.
ą×ą┐čåąĖčÅ ą×ą┐ąĖčüą░ąĮąĖąĄ
(FU) ąÆ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓čŗąĄ (U ąŠąĘąĮą░čćą░ąĄčé unsigned) ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ (F ąŠąĘąĮą░čćą░ąĄčé fraction, čé. ąĄ. ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ). ąØąĄ ą┤ąĄą╗ą░ąĄčéčüčÅ ą║ąŠčĆčĆąĄą║čåąĖčÅ čüą┤ą▓ąĖą│ąŠą╝.
(IS) ąÆ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ąĮą░čģąŠą┤čÅčéčüčÅ čåąĄą╗čŗąĄ (integer) čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝ (signed). ąØąĄ ą┤ąĄą╗ą░ąĄčéčüčÅ ą║ąŠčĆčĆąĄą║čåąĖčÅ čüą┤ą▓ąĖą│ąŠą╝.
(W32 ) ąÆ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ąĮą░čģąŠą┤čÅčéčüčÅ ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝, čü čĆą░čüčłąĖčĆąĄąĮąĖąĄą╝ ąĘąĮą░ą║ąŠą╝; ąŠą▒ą░ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ ąĮą░čüčŗčēą░čÄčéčüčÅ ą┐ąŠ 32 ą▒ąĖčéą░ą╝. ąĢčüą╗ąĖ čéčĆąĄą▒čāąĄčéčüčÅ, ą┤ąĄą╗ą░ąĄčéčüčÅ ą║ąŠčĆčĆąĄą║čéąĖčĆčāčÄčēą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ ą╗ąĄą▓ąŠą│ąŠ čüą┤ą▓ąĖą│ą░. ąśčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą░ą╗ą│ąŠčĆąĖčéą╝ąŠą▓ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą│ąŠą╗ąŠčüąŠą▓čŗčģ ą┤ą░ąĮąĮčŗčģ legacy GSM ą▓ąŠą║ąŠą┤ąĄčĆą░, ąĮą░ą┐ąĖčüą░ąĮąĮčŗčģ ą┤ą╗čÅ 32-ą▒ąĖčéąĮčŗčģ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓. ąźąŠčéčÅ ą▒ąĖčéčŗ čĆą░čüčłąĖčĆąĄąĮąĖčÅ A0.X ąĖ A1.X ąĮąĄ čÅą▓ą╗čÅčÄčéčüčÅ ą▓ čŹč鹊ą╝ čĆąĄąČąĖą╝ąĄ čćą░čüčéčīčÄ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣, ąĮą░ ą▒ąĖčéčŗ čĆą░čüčłąĖčĆąĄąĮąĖčÅ ą▓čüąĄ ąČąĄ ą▓ą╗ąĖčÅąĄčé čĆą░čüą┐čĆąŠčüčéčĆą░ąĮąĄąĮąĖąĄ ąĘąĮą░ą║ą░.
(M) ąĀąĄąČąĖą╝ čüą╝ąĄčłą░ąĮąĮąŠą│ąŠ čāą╝ąĮąŠąČąĄąĮąĖčÅ (mixed multiply mode) ąĮą░ ą▒ą╗ąŠą║ąĄ MAC1. MAC1 čāą╝ąĮąŠąČą░ąĄčé ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝ ąĮą░ ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░ ą▒ąĄąĘ ą║ąŠčĆčĆąĄą║čåąĖąĖ ą╗ąĄą▓čŗą╝ čüą┤ą▓ąĖą│ąŠą╝. ąÆ ąŠą┐ąĄčĆą░ąĮą┤ąĄ src_reg_0 ąĮą░čģąŠą┤ąĖčéčüčÅ čćąĖčüą╗ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝, ąĖ ą▓ ąŠą┐ąĄčĆą░ąĮą┤ąĄ src_reg_1 čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░. MAC0 ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ąĮąĄčüą╝ąĄčłą░ąĮąĮąŠąĄ čāą╝ąĮąŠąČąĄąĮąĖąĄ ą┤ą╗čÅ ą┤čĆąŠą▒ąĮčŗčģ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ čüąŠ ąĘąĮą░ą║ąŠą╝ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ, ąĖą╗ąĖ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ ą┤čĆčāą│ąŠą│ąŠ čāą║ą░ąĘą░ąĮąĮąŠą│ąŠ č乊čĆą╝ą░čéą░. ą×ą┐čåąĖčÅ (M) ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ąŠ ąŠčéą┤ąĄą╗čīąĮąŠčüčéąĖ, ą╗ąĖą▒ąŠ čüąŠą▓ą╝ąĄčüčéąĮąŠ čü ąŠą┐čåąĖąĄą╣ (W32), ąĮąŠ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą▓ąĄčĆčüąĖą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü MAC1; ąĮąĖą║ą░ą║ąĖąĄ ą┤čĆčāą│ąĖąĄ ąŠą┐čåąĖąĖ MAC1 ąĮąĄ ą┤ąŠą┐čāčüą║ą░čÄčéčüčÅ ą┤ą╗čÅ čüąŠą▓ą╝ąĄčüčéąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čü (M). ą¤čĆąĖ čüąŠą▓ą╝ąĄčüčéąĮąŠą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ąŠą┐čåąĖą╣ ąĮą░ą▒ąŠčĆ čŹčéąĖčģ ąŠą┐čåąĖą╣ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓ą║ą╗čÄč湥ąĮ ą▓ ą║čĆčāą│ą╗čŗąĄ čüą║ąŠą▒ą║ąĖ, čü čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄą╝ ąŠą┐čåąĖą╣ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ ąĘą░ą┐čÅč鹊ą╣. ą¤čĆąĖą╝ąĄčĆ: (M, W32).
ąÜąŠą│ą┤ą░ ąŠą┐čåąĖąĖ (M) ąĖ (W32) ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą▓ą╝ąĄčüč鹥, ąŠą▒ą░ MAC ą┤ąĄą╗ą░čÄčé ąĮą░čüčŗčēąĄąĮąĖąĄ čüą▓ąŠąĖčģ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąĄ ą┐ąŠ 32 ą▒ąĖčéą░ą╝. MAC1 čāą╝ąĮąŠąČą░ąĄčé ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝ ąĮą░ ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ąĖ MAC0 čāą╝ąĮąŠąČą░ąĄčé ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝.
ą¤čĆąĖ čüąŠą▓ą╝ąĄčüčéąĮąŠą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ąŠą┐čåąĖą╣ ąĖčģ ą┐ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą┤čĆčāą│ ąĘą░ ą┤čĆčāą│ąŠą╝ ąĮąĄ ąĖą╝ąĄąĄčé ąĘąĮą░č湥ąĮąĖčÅ.
ąÆ čĆąĄąČąĖą╝ąĄ ą┤čĆąŠą▒ąĮčŗčģ čćąĖčüąĄą╗ (fractional mode), ą┐čĆąŠą┤čāą║čé čüą░ą╝čŗčģ ą╝ą░ą╗čŗčģ ą┐čĆąĄą┤čüčéą░ą▓ąĖą╝čŗčģ čćąĖčüąĄą╗ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, 0x8000-čÅ čćą░čüčéčī ąŠčé 0x8000) ąĮą░čüčŗčēą░ąĄčéčüčÅ ą┤ąŠ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą┐čĆąĄą┤čüčéą░ą▓ąĖą╝ąŠą╣ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠą╣ ą┤čĆąŠą▒ąĮąŠą╣ čćą░čüčéąĖ (0x7FFF) ą┤ąŠ ą╝ąŠą╝ąĄąĮčéą░ ąĮą░ą║ąŠą┐ą╗ąĄąĮąĖčÅ.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĮą░čüčŗčēąĄąĮąĖčÅ čüą╝. čüąĄą║čåąĖčÄ "Saturation (ąĮą░čüčŗčēąĄąĮąĖąĄ)".
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ: ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ čäąĖą╗čīčéčĆą░ DSP čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāčÄčé ąĖąĮčüčéčĆčāą║čåąĖčÄ Multiply and Multiply-Accumulate to Accumulator ą┤ą╗čÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ čĆąĄąĘčāą╗čīčéą░čéą░ ą┤ą▓čāčģ ą▓ąĄą║č鹊čĆąŠą▓ čüąĖą│ąĮą░ą╗ą░.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čäą╗ą░ą│ąĖ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ŌĆó AV0 čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąĄ A0 (ąŠą┐ąĄčĆą░čåąĖčÅ čü MAC0) ą┐ąŠą╗čāčćąĖą╗ ąĮą░čüčŗčēąĄąĮąĖąĄ. ą×čćąĖčüčéąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé A0 ąĮąĄ ą┐ąŠą╗čāčćąĖą╗ ąĮą░čüčŗčēąĄąĮąĖčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆ ]
a0= r3.h* r2.h; /* ąĀą░ą▒ąŠčéą░ąĄčé č鹊ą╗čīą║ąŠ MAC0, only. ą×ą▒ą░ ąŠą┐ąĄčĆą░ąĮą┤ą░ čŹč鹊 ą┤čĆąŠą▒ąĮčŗąĄ
čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝. ąĀąĄąĘčāą╗čīčéą░čé ą▒čāą┤ąĄčé ą┐ąŠą╝ąĄčēąĄąĮ ą▓ A0. */
a1+= r6.h* r4.l(fu); /* ąĀą░ą▒ąŠčéą░ąĄčé č鹊ą╗čīą║ąŠ MAC1. ą×ą▒ą░ ąŠą┐ąĄčĆą░ąĮą┤ą░ čŹč鹊 ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ ą▒ąĄąĘ ąĘąĮą░ą║ą░. ąĀąĄąĘčāą╗čīčéą░čé ą▒čāą┤ąĄčé ą┐ąŠą╝ąĄčēąĄąĮ ą▓ A1. */
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Multiply, Multiply and Multiply-Accumulate to Half-Register, Multiply and Multiply-Accumulate to Data Register, Multiply (Modulo 232 ), Vector Multiply, Vector Multiply and Multiply-Accumulate.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg_half = (accumulator = src_reg_0 * src_reg_1) (opt_mode)
dest_reg_half = (accumulator += src_reg_0 * src_reg_1) (opt_mode)
dest_reg_half = (accumulator ŌĆō= src_reg_0 * src_reg_1) (opt_mode)
ąĪąĖąĮčéą░ą║čüąĖčü ąŠą┐ąĄčĆą░čåąĖą╣ čü MAC0:
Dreg_lo = (A0 = Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // čāą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖąĄ (b)1
Dreg_lo = (A0 += Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // čāą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ (b)
Dreg_lo = (A0 ŌĆō= Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // čāą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ ą▓čŗčćąĖčéą░ąĮąĖąĄ (b)
ąĪąĖąĮčéą░ą║čüąĖčü ąŠą┐ąĄčĆą░čåąĖą╣ čü MAC1:
Dreg_hi = (A1 = Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // čāą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖąĄ (b)
Dreg_hi = (A1 += Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // čāą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ (b)
Dreg_hi = (A1 ŌĆō= Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // čāą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ ą▓čŗčćąĖčéą░ąĮąĖąĄ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg_lo_hi: ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L, R0.H, ..., R7.H.
Dreg_lo: ą╝ą╗ą░ą┤čłąĖąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L.
Dreg_hi: čüčéą░čĆčłąĖąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.H, ..., R7.H.
opt_mode: ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą╝ąŠąČąĄčé ą▒čŗčéčī čāą║ą░ąĘą░ąĮąŠ (FU), (IS), (IU), (T), (TFU), (S2RND), (ISS2) ąĖą╗ąĖ (IH). ąóą░ą║ąČąĄ ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ (M) ą▓ ą▓ąĄčĆčüąĖčÅčģ čü MAC1, ą┐ąŠ ąŠčéą┤ąĄą╗čīąĮąŠčüčéąĖ ąĖą╗ąĖ ą▓ą╝ąĄčüč鹥 čü ą╗čÄą▒ąŠą╣ ą┤čĆčāą│ąŠą╣ ąŠą┐čåąĖąĄą╣. ąĢčüą╗ąĖ ąŠą┐čåąĖąĖ čāą╝ąĮąŠąČąĄąĮąĖčÅ čāą║ą░ąĘą░ąĮčŗ čüąŠą▓ą╝ąĄčüčéąĮąŠ ą┤ą╗čÅ MAC, č鹊 ąŠą┐čåąĖąĖ ą┤ąŠą╗ąČąĮčŗ ąŠčéą┤ąĄą╗čÅčéčīčüčÅ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ ąĘą░ą┐čÅč鹊ą╣, ąĖ ą▓čüąĄ ą▓ą╝ąĄčüč鹥 ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąĘą░ą║čĆčŗčéčŗ ą┐ą░čĆąŠą╣ ą║čĆčāą│ą╗čŗčģ čüą║ąŠą▒ąŠą║. ą¤čĆąĖą╝ąĄčĆ: (M, TFU).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Multiply and Multiply-Accumulate to Half-Register čāą╝ąĮąŠąČą░ąĄčé ą┤ą▓ą░ 16-ą▒ąĖčéąĮčŗčģ ąŠą┐ąĄčĆą░ąĮą┤ą░ čĆą░ąĘą╝ąĄčēąĄąĮąĮčŗčģ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░čģ čĆąĄą│ąĖčüčéčĆą░. ąóą░ą║ąČąĄ ąŠąĮą░ čüąŠčģčĆą░ąĮčÅąĄčé ą┐ąŠą╗čāč湥ąĮąĮčŗą╣ čāą╝ąĮąŠąČąĄąĮąĖąĄą╝ čĆąĄąĘčāą╗čīčéą░čé ą▓ą╝ąĄčüč鹥 čü ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄą╝ (ąĖą╗ąĖ ą▓čŗčćąĖčéą░ąĮąĖąĄą╝) ą▓ ąĮą░ąĘąĮą░č湥ąĮąĮčŗą╣ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ čü ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄą╝ ąĮą░čüčŗčēąĄąĮąĖčÅ. ąŚą░č鹥ą╝ 16 ą▒ąĖčé (čü ąŠą┐ąĄčĆą░čåąĖąĄą╣ ąĮą░čüčŗčēąĄąĮąĖčÅ ą┐ąŠ 16 ą▒ąĖčéą░ą╝) ąĖąĘ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ ą║ąŠą┐ąĖčĆčāčÄčéčüčÅ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā D-čĆąĄą│ąĖčüčéčĆą░.
ąÆąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, čĆą░ą▒ąŠčéą░čÄčēąĖąĄ čü ą┤čĆąŠą▒ąĮčŗą╝ąĖ čćąĖčüą╗ą░ą╝ąĖ (ąŠą┐čåąĖąĖ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĖ (FU)) ą┐ąĄčĆąĄąĮąŠčüčÅčé čĆąĄąĘčāą╗čīčéą░čé ąĖąĘ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü ą┤ąĖą░ą│čĆą░ą╝ą╝ąŠą╣, ą┐ąŠą║ą░ąĘą░ąĮąĮąŠą╣ ąĮąĖąČąĄ:
ą”ąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ (ąŠą┐čåąĖąĖ (IS) ąĖ (IU)) ą┐ąĄčĆąĄąĮąŠčüčÅčé čĆąĄąĘčāą╗čīčéą░čé ąĖąĘ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü ą┤ąĖą░ą│čĆą░ą╝ą╝ąŠą╣, ą┐ąŠą║ą░ąĘą░ąĮąĮąŠą╣ ąĮąĖąČąĄ:
ą×ą┐ąĄčĆą░čåąĖąĖ, ą▓čŗą┐ąŠą╗ąĮčÅąĄą╝čŗąĄ ą▒ą╗ąŠą║ąŠą╝ čāą╝ąĮąŠąČąĄąĮąĖčÅ čü ąĮą░ą║ąŠą┐ą╗ąĄąĮąĖąĄą╝ 0 (Multiply-and-Accumulate Unit 0, ąĖą╗ąĖ čüąŠą║čĆą░čēąĄąĮąĮąŠ MAC0), ą▓ąŠą▓ą╗ąĄą║ą░čÄčé ą▓ ąŠą▒čĆą░ą▒ąŠčéą║čā ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ A0, ąĖ ąĘą░ą│čĆčāąČą░čÄčé čüą▓ąŠąĖ čĆąĄąĘčāą╗čīčéą░čéčŗ ą▓ ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ą×ą┐ąĄčĆą░čåąĖąĖ, ą▓čŗą┐ąŠą╗ąĮčÅąĄą╝čŗąĄ čü ą┐ąŠą╝ąŠčēčīčÄ MAC1, ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ A1 ąĖ ąĘą░ą│čĆčāąČą░čÄčé čüą▓ąŠąĖ čĆąĄąĘčāą╗čīčéą░čéčŗ ą▓ čüčéą░čĆčłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ąÆčüąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ (rounding), ąĮą░ ą║ąŠč鹊čĆąŠąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą▓ą╗ąĖčÅąĮąĖąĄ ą▒ąĖčé RND_MOD ą▓ čĆąĄą│ąĖčüčéčĆąĄ ASTAT, ą║ąŠą│ą┤ą░ čĆąĄąĘčāą╗čīčéą░čéčŗ ą║ąŠą┐ąĖčĆčāčÄčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. RND_MOD ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé, ą║ą░ą║ąŠąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ - čüą╝ąĄčēąĄąĮąĮąŠąĄ (biased rounding) ąĖą╗ąĖ ąĮąĄ čüą╝ąĄčēąĄąĮąĮąŠąĄ (unbiased rounding).
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ čüą╝. čĆą░ąĘą┤ąĄą╗ "Rounding, Truncating".
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ: ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ čäąĖą╗čīčéčĆą░ DSP čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāčÄčé ąĖąĮčüčéčĆčāą║čåąĖčÄ Multiply-Accumulate Half-Register ą┤ą╗čÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ č鹊čćą║ąĖ ą╝ąĄąČą┤čā ą┤ą▓čāčģ ą▓ąĄą║č鹊čĆąŠą▓ čüąĖą│ąĮą░ą╗ą░.
[ą×ą┐čåąĖąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Multiply and Multiply-Accumulate to Half-Register ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ąŠą┐čåąĖąĖ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ ąĖ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░.
ąóą░ą▒ą╗ąĖčåą░ 10-3. ą×ą┐čåąĖąĖ ą┤ą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ Multiply and Multiply-Accumulate to Half-Register.
ą×ą┐čåąĖčÅ ąÜą░ą║ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ąŠą┐ąĄčĆą░ąĮą┤čŗ ążąŠčĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐čĆąĖ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĖ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░
ą×ą┐čåąĖčÅ ąÜą░ą║ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ąŠą┐ąĄčĆą░ąĮą┤čŗ ążąŠčĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐čĆąĖ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĖ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░
ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą×ą▒ą░ ąŠą┐ąĄčĆą░ąĮą┤ą░ ąĮą░ ąŠą▒ąŠąĖčģ MAC ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ą║ą░ą║ ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝, čü ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄą╝ ą╗ąĄą▓ąŠą│ąŠ čüą┤ą▓ąĖą│ą░ ą┤ą╗čÅ ąĮąŠčĆą╝ą░ą╗ąĖąĘą░čåąĖąĖ ą┤čĆąŠą▒ąĮąŠą╣ čćą░čüčéąĖ.
ąĀą░čüą┐ą░ą║ąŠą▓ą║ą░ čüčéą░čĆčłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čüą╗ąŠą▓ą░ ąĖąĘ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ čü 16-ą▒ąĖčéąĮčŗą╝ ąĮą░čüčŗčēąĄąĮąĖąĄą╝ (saturation) ąĖ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄą╝ (rounding). ąĀąĄąČąĖą╝ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ąĘą░ą┤ą░ąĄčéčüčÅ ą▒ąĖč鹊ą╝ RND_MOD čĆąĄą│ąĖčüčéčĆą░ ASTAT.
(FU) ąÆ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓čŗąĄ (U ąŠąĘąĮą░čćą░ąĄčé unsigned) ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ (F ąŠąĘąĮą░čćą░ąĄčé fraction, čé. ąĄ. ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ). ąØąĄ ą┤ąĄą╗ą░ąĄčéčüčÅ ą║ąŠčĆčĆąĄą║čåąĖčÅ čüą┤ą▓ąĖą│ąŠą╝.
ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ, ą║ą░ą║ ąĖ ą▓ ąŠą┐čåąĖąĖ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ.
(IS) ąÆ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ąĮą░čģąŠą┤čÅčéčüčÅ čåąĄą╗čŗąĄ (integer) čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝ (signed). ąØąĄ ą┤ąĄą╗ą░ąĄčéčüčÅ ą║ąŠčĆčĆąĄą║čåąĖčÅ čüą┤ą▓ąĖą│ąŠą╝.
ąĀą░čüą┐ą░ą║ąŠą▓ą║ą░ ąĖąĘ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ ą╝ą╗ą░ą┤čłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čüą╗ąŠą▓ą░ čü ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄą╝ 16-ą▒ąĖčéąĮąŠą│ąŠ ąĮą░čüčŗčēąĄąĮąĖčÅ.
(IU) ąÆ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ąĮą░čģąŠą┤čÅčéčüčÅ čåąĄą╗čŗąĄ čćąĖčüą╗ą░ ą▒ąĄąĘ ąĘąĮą░ą║ą░. ąØąĄ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ą║ąŠčĆčĆąĄą║čåąĖčÅ čüą┤ą▓ąĖą│ąŠą╝.
ąĀą░čüą┐ą░ą║ąŠą▓ą║ą░ ąĖąĘ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ ą╝ą╗ą░ą┤čłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čüą╗ąŠą▓ą░ čü ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄą╝ 16-ą▒ąĖčéąĮąŠą│ąŠ ąĮą░čüčŗčēąĄąĮąĖčÅ (č鹊 ąČąĄ čüą░ą╝ąŠąĄ, čćč鹊 ąĖ ą▓ ąŠą┐čåąĖąĖ IS).
(T) ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ, ą║ą░ą║ ąĖ ą▓ ąŠą┐čåąĖąĖ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ.
ąĀą░čüą┐ą░ą║ąŠą▓ą║ą░ ąĖąĘ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ čüčéą░čĆčłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čüą╗ąŠą▓ą░ čü ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄą╝ ąĮą░čüčŗčēąĄąĮąĖčÅ. ą×ą▒čĆąĄąĘą░ąĄčéčüčÅ ą╝ą╗ą░ą┤čłą░čÅ ą┐ąŠą╗ąŠą▓ąĖąĮą░ čüą╗ąŠą▓ą░ ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąĄ.
(TFU) ąÆ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ąĮą░čģąŠą┤čÅčéčüčÅ ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ ą▒ąĄąĘ ąĘąĮą░ą║ą░. ąØąĄ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ą║ąŠčĆčĆąĄą║čåąĖčÅ čüą┤ą▓ąĖą│ąŠą╝.
ąĀą░čüą┐ą░ą║ąŠą▓ą║ą░ ąĖąĘ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ čüčéą░čĆčłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čüą╗ąŠą▓ą░. ą×ą▒čĆąĄąĘą░ąĄčéčüčÅ ą╝ą╗ą░ą┤čłą░čÅ ą┐ąŠą╗ąŠą▓ąĖąĮą░ čüą╗ąŠą▓ą░ ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąĄ.
(S2RND) ąÆ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ąĮą░čģąŠą┤čÅčéčüčÅ ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝, čü ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄą╝ ą╗ąĄą▓ąŠą│ąŠ čüą┤ą▓ąĖą│ą░ ą┤ą╗čÅ ąĮąŠčĆą╝ą░ą╗ąĖąĘą░čåąĖąĖ ą┤čĆąŠą▒ąĮąŠą│ąŠ čćąĖčüą╗ą░.
ąĀą░čüą┐ą░ą║ąŠą▓ą║ą░ čüčéą░čĆčłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čüą╗ąŠą▓ą░ čü ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖąĄą╝, ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄą╝ ąĖ 16-ą▒ąĖčéąĮčŗą╝ ąĮą░čüčŗčēąĄąĮąĖąĄą╝. ąĀąĄąČąĖą╝ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ ą▒ąĖč鹊ą╝ RND_MOD čĆąĄą│ąĖčüčéčĆą░ ASTAT. ą¤ąĄčĆąĄą┤ ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖąĄą╝ (truncating) ą╝ą╗ą░ą┤čłąĖčģ 16 ą▒ąĖčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ ą╝ą░čüčłčéą░ą▒ąĖčĆčāąĄčéčüčÅ (čāą╝ąĮąŠąČą░ąĄčéčüčÅ ąĮą░ 2 ą┐čāč鹥ą╝ ąŠą┤ąĖąĮąŠčćąĮąŠą│ąŠ čüą┤ą▓ąĖą│ą░ ą▓ą╗ąĄą▓ąŠ) ąĖ ąŠą║čĆčāą│ą╗čÅąĄčéčüčÅ ą┐ąŠ čüčéą░čĆčłąĖą╝ 16 ą▒ąĖčéą░ą╝.
(ISS2) ąÆ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ąĮą░čģąŠą┤čÅčéčüčÅ čåąĄą╗čŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝. ąØąĄ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ą║ąŠčĆčĆąĄą║čåąĖčÅ čüą┤ą▓ąĖą│ąŠą╝.
ąĀą░čüą┐ą░ą║ąŠą▓ą║ą░ ą╝ą╗ą░ą┤čłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čüą╗ąŠą▓ą░ čü ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ąĖ 16-ą▒ąĖčé ąĮą░čüčŗčēąĄąĮąĖąĄą╝. ą£ą░čüčłčéą░ą▒ąĖčĆčāąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ (čāą╝ąĮąŠąČąĄąĮąĖąĄą╝ ąĮą░ 2 ą┐čāč鹥ą╝ ąŠą┤ąĖąĮąŠčćąĮąŠą│ąŠ čüą┤ą▓ąĖą│ą░ ą▓ą╗ąĄą▓ąŠ) ą┐ąĄčĆąĄą┤ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ą╝ą╗ą░ą┤čłąĖčģ 16 ą▒ąĖčé.
(IH) ąÆ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ąĮą░čģąŠą┤čÅčéčüčÅ čåąĄą╗čŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝. ąØąĄ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ą║ąŠčĆčĆąĄą║čåąĖčÅ čüą┤ą▓ąĖą│ąŠą╝.
ąĀą░čüą┐ą░ą║ąŠą▓ą║ą░ čüčéą░čĆčłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čüą╗ąŠą▓ą░ čü 32-ą▒ąĖčéąĮčŗą╝ ąĮą░čüčŗčēąĄąĮąĖąĄą╝, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ą┤ąĄą╗ą░ąĄčéčüčÅ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ ą┐ąŠ čüčéą░čĆčłąĖą╝ 16 ą▒ąĖčéą░ą╝. ąĀąĄąČąĖą╝ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ ą▒ąĖč鹊ą╝ RND_MOD čĆąĄą│ąĖčüčéčĆą░ ASTAT.
(M) ąŻą╝ąĮąŠąČąĄąĮąĖąĄ ą┤čĆąŠą▒ąĮąŠą│ąŠ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝ ąĮą░ ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░ (čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝ąŠąĄ čüą╝ąĄčłą░ąĮąĮąŠąĄ, mixed čāą╝ąĮąŠąČąĄąĮąĖąĄ). ąØąĄ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ą║ąŠčĆčĆąĄą║čåąĖčÅ čüą┤ą▓ąĖą│ąŠą╝. ąÆ ąŠą┐ąĄčĆą░ąĮą┤ąĄ src_reg_0 ąĮą░čģąŠą┤ąĖčéčüčÅ čćąĖčüą╗ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝, ąĖ ą▓ ąŠą┐ąĄčĆą░ąĮą┤ąĄ src_reg_1 čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░. ąĪą╝ąĄčłą░ąĮąĮąŠąĄ čāą╝ąĮąŠąČąĄąĮąĖąĄ ą┐čĆąĖą╝ąĄąĮąĖą╝ąŠ č鹊ą╗čīą║ąŠ ą║ ą▓ąĄčĆčüąĖčÅą╝ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü MAC1. ąśąĮčüčéčĆčāą║čåąĖąĖ čü MAC0 ą┤ąĄą╗ą░čÄčé ąĮąĄčüą╝ąĄčłą░ąĮąĮąŠąĄ čāą╝ąĮąŠąČąĄąĮąĖąĄ, ą║ą░ą║ čŹč鹊 ąĘą░ą┤ą░ąĮąŠ čäą╗ą░ą│ą░ą╝ąĖ ąŠą┐čåąĖą╣ (ąĖą╗ąĖ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ, ąĄčüą╗ąĖ čäą╗ą░ą│ąĖ ąŠą┐čåąĖą╣ ąĮąĄ ąĘą░ą┤ą░ąĮčŗ). ą×ą┐čåąĖčÅ (M) ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ MAC1 ąŠą┤ąĮą░, ąĖą╗ąĖ čüąŠą▓ą╝ąĄčüčéąĮąŠ čü ąŠą┤ąĮąŠą╣ ąĖąĘ ą┤čĆčāą│ąŠą╣ ąŠą┐čåąĖą╣ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖčÅ. ąĢčüą╗ąĖ čāą║ą░ąĘą░ąĮąŠ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąŠą┐čåąĖą╣, č鹊 ąŠąĮąĖ ą▓čüąĄ čüčĆą░ąĘčā ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąĘą░ą║ą╗čÄč湥ąĮčŗ ą▓ ąŠą┤ąĖąĮąŠčćąĮčāčÄ ą┐ą░čĆčā ą║čĆčāą│ą╗čŗčģ čüą║ąŠą▒ąŠą║, ąĖ ąŠčéą┤ąĄą╗ąĄąĮčŗ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ ąĘą░ą┐čÅč鹊ą╣. ą¤čĆąĖą╝ąĄčĆ: (M, TFU).
ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ, ą║ą░ą║ ąĖ ą▓ ąŠą┐čåąĖąĖ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ.
ą¦č鹊ą▒čŗ čüą┤ąĄą╗ą░čéčī ąŠą▒čĆąĄąĘą║čā (truncate) čĆąĄąĘčāą╗čīčéą░čéą░, ąŠą┐ąĄčĆą░čåąĖčÅ čāąĮąĖčćč鹊ąČą░ąĄčé ą╝ą╗ą░ą┤čłąĖąĄ ąĘąĮą░čćą░čēąĖąĄ ą▒ąĖčéčŗ, ą║ąŠč鹊čĆčŗąĄ ąĮąĄ čāą║ą╗ą░ą┤čŗą▓ą░čÄčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ąÜąŠą│ą┤ą░ čŹč鹊 ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ, ą┐ąŠčüą╗ąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ (rounding) ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ąĮą░čüčŗčēąĄąĮąĖąĄ (saturation).
ąÆ čĆąĄąČąĖą╝ąĄ ą┤čĆąŠą▒ąĮčŗčģ čćąĖčüąĄą╗ (fractional mode), ą┐čĆąŠą┤čāą║čé čüą░ą╝čŗčģ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮčŗčģ ą┐čĆąĄą┤čüčéą░ą▓ąĖą╝čŗčģ ą┤čĆąŠą▒ąĮčŗčģ čćąĖčüąĄą╗ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, 0x8000-čÅ čćą░čüčéčī ąŠčé 0x8000) ąĮą░čüčŗčēą░ąĄčéčüčÅ ą┤ąŠ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą┐čĆąĄą┤čüčéą░ą▓ąĖą╝ąŠą╣ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠą╣ ą┤čĆąŠą▒ąĮąŠą╣ čćą░čüčéąĖ (0x7FFF) ą┤ąŠ ą╝ąŠą╝ąĄąĮčéą░ ąĮą░ą║ąŠą┐ą╗ąĄąĮąĖčÅ.
ąĢčüą╗ąĖ ąÆčŗ čģąŠč鹥ą╗ąĖ ą▒čŗ čüąŠčģčĆą░ąĮąĖčéčī čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąĄ ąĮąĄ ąĖąĘą╝ąĄąĮąĄąĮąĮčŗą╝, ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ą┐čĆąŠčüčéčāčÄ ąĖąĮčüčéčĆčāą║čåąĖčÄ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ (Move), čćč鹊ą▒čŗ čüą┤ąĄą╗ą░čéčī ą║ąŠą┐ąĖčÄ A.x ąĖą╗ąĖ A.w ą▓ ą║ą░ą║ąŠą╝-ąĮąĖą▒čāą┤čī čĆąĄą│ąĖčüčéčĆąĄ.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĮą░čüčŗčēąĄąĮąĖčÅ čüą╝. čüąĄą║čåąĖčÄ "Saturation (ąĮą░čüčŗčēąĄąĮąĖąĄ)".
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čäą╗ą░ą│ąĖ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ŌĆó V čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé, čĆą░čüą┐ą░ą║ąŠą▓ą░ąĮąĮčŗą╣ ą▓ Dreg, ą┐čĆąĄč鹥čĆą┐ąĄą╗ ąĮą░čüčŗčēąĄąĮąĖąĄ; ąŠčćąĖčüčéąĖčéčüčÅ, ąĄčüą╗ąĖ ąĮą░čüčŗčēąĄąĮąĖčÅ ąĮąĄ ą▒čŗą╗ąŠ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆ ]
r3.l= (a0= r3.h* r2.h); /* ąĀą░ą▒ąŠčéą░ąĄčé č鹊ą╗čīą║ąŠ MAC0. ą×ą▒ą░ ąŠą┐ąĄčĆą░ąĮą┤ą░ - ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░
čüąŠ ąĘąĮą░ą║ąŠą╝. ąĀąĄąĘčāą╗čīčéą░čé ą▒čāą┤ąĄčé ąĘą░ą┐ąĖčüą░ąĮ ą▓ A0, ąĘą░č鹥ą╝ čüą║ąŠą┐ąĖčĆąŠą▓ą░ąĮ ą▓ r3.l. */
r3.h= (a1+= r6.h* r4.l)(fu); /* ąĀą░ą▒ąŠčéą░ąĄčé č鹊ą╗čīą║ąŠ MAC1. ą×ą▒ą░ ąŠą┐ąĄčĆą░ąĮą┤ą░ - ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ ą▒ąĄąĘ ąĘąĮą░ą║ą░. ąĀąĄąĘčāą╗čīčéą░čé ą▒čāą┤ąĄčé ąĘą░ą┐ąĖčüą░ąĮ ą▓ A1, ąĘą░č鹥ą╝ čüą║ąŠą┐ąĖčĆąŠą▓ą░ąĮ ą▓ r3.h. */
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Multiply and Multiply-Accumulate to Accumulator, Multiply and Multiply-Accumulate to Data Register, Multiply (Modulo 232 ), Vector Multiply, Vector Multiply and Multiply-Accumulate.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = (accumulator = src_reg_0 * src_reg_1) (opt_mode)
dest_reg = (accumulator += src_reg_0 * src_reg_1) (opt_mode)
dest_reg = (accumulator ŌĆō= src_reg_0 * src_reg_1) (opt_mode)
ąĪąĖąĮčéą░ą║čüąĖčü ąŠą┐ąĄčĆą░čåąĖą╣ čü MAC0:
Dreg_even = (A0 = Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // čāą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖąĄ (b)1
Dreg_even = (A0 += Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // čāą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ (b)
Dreg_even = (A0 ŌĆō= Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // čāą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ ą▓čŗčćąĖčéą░ąĮąĖąĄ (b)
ąĪąĖąĮčéą░ą║čüąĖčü ąŠą┐ąĄčĆą░čåąĖą╣ čü MAC1:
Dreg_hi = (A1 = Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // čāą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖąĄ (b)
Dreg_hi = (A1 += Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // čāą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ (b)
Dreg_hi = (A1 ŌĆō= Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // čāą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ ą▓čŗčćąĖčéą░ąĮąĖąĄ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg_lo_hi: ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L, R0.H, ..., R7.H.
Dreg_even: čĆąĄą│ąĖčüčéčĆčŗ čü č湥čéąĮčŗą╝ąĖ ąĮąŠą╝ąĄčĆą░ą╝ąĖ R0, R2, R4, R6.
Dreg_odd: čĆąĄą│ąĖčüčéčĆčŗ čü ąĮąĄč湥čéąĮčŗą╝ąĖ ąĮąŠą╝ąĄčĆą░ą╝ąĖ R1, R3, R5, R7.
opt_mode: ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą╝ąŠąČąĄčé ą▒čŗčéčī čāą║ą░ąĘą░ąĮąŠ (FU), (IS), (S2RND) ąĖą╗ąĖ (ISS2). ąóą░ą║ąČąĄ ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ (M) ą▓ ą▓ąĄčĆčüąĖčÅčģ čü MAC1, ą┐ąŠ ąŠčéą┤ąĄą╗čīąĮąŠčüčéąĖ ąĖą╗ąĖ ą▓ą╝ąĄčüč鹥 čü ą╗čÄą▒ąŠą╣ ą┤čĆčāą│ąŠą╣ ąŠą┐čåąĖąĄą╣. ąĢčüą╗ąĖ ąŠą┐čåąĖąĖ čāą╝ąĮąŠąČąĄąĮąĖčÅ čāą║ą░ąĘą░ąĮčŗ čüąŠą▓ą╝ąĄčüčéąĮąŠ ą┤ą╗čÅ MAC, č鹊 ąŠą┐čåąĖąĖ ą┤ąŠą╗ąČąĮčŗ ąŠčéą┤ąĄą╗čÅčéčīčüčÅ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ ąĘą░ą┐čÅč鹊ą╣, ąĖ ą▓čüąĄ ą▓ą╝ąĄčüč鹥 ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąĘą░ą║čĆčŗčéčŗ ą┐ą░čĆąŠą╣ ą║čĆčāą│ą╗čŗčģ čüą║ąŠą▒ąŠą║. ą¤čĆąĖą╝ąĄčĆ: (M, IS).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐ąĄčĆąĄą╝ąĮąŠąČą░ąĄčé ą┤ą▓ą░ 16-čĆą░ąĘčĆčÅą┤ąĮčŗčģ ąŠą┐ąĄčĆą░ąĮą┤ą░, ąĮą░čģąŠą┤čÅčēąĖčģčüčÅ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░čģ čĆąĄą│ąĖčüčéčĆąŠą▓. ąśąĮčüčéčĆčāą║čåąĖčÅ ą┤ąĄą╗ą░ąĄčé ąŠą┐ąĄčĆą░čåąĖčÄ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ, ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ ąĖą╗ąĖ ą▓čŗčćąĖčéą░ąĮąĖčÅ čĆąĄąĘčāą╗čīčéą░čéą░ ą▓ ą▓čŗą▒čĆą░ąĮąĮčŗą╣ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ. ąŚą░č鹥ą╝ ąĖąĘ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ ą║ąŠą┐ąĖčĆčāčÄčéčüčÅ 32 ą▒ąĖčéą░ ą▓ čĆąĄą│ąĖčüčéčĆ ą┤ą░ąĮąĮčŗčģ. 32 ą▒ąĖčéą░ ąĮą░čüčŗčēą░čÄčéčüčÅ ą┐ąŠ 32 ą▒ąĖčéą░ą╝.
ą¦ą░čüčéčī ą░čĆčģąĖč鹥ą║čéčāčĆčŗ, čĆą░ą▒ąŠčéą░čÄčēą░čÅ čü ą▒ą╗ąŠą║ąŠą╝ Multiply-and-Accumulate Unit 0 (MAC0) ą▓ąŠą▓ą╗ąĄą║ą░čÄčé ą▓ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ A0; ą┐čĆąĖ čŹč鹊ą╝ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé ąĘą░ą│čĆčāąĘąĖčéčī čĆąĄąĘčāą╗čīčéą░čé ą▓ D-čĆąĄą│ąĖčüčéčĆ čü č湥čéąĮčŗą╝ ąĮąŠą╝ąĄčĆąŠą╝. MAC1 ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ąŠą┐ąĄčĆą░čåąĖąĖ čü A1, ąĖ ąĘą░ą│čĆčāąČą░ąĄčé čĆąĄąĘčāą╗čīčéą░čéčŗ ą▓ D-čĆąĄą│ąĖčüčéčĆčŗ čü ąĮąĄč湥čéąĮčŗą╝ąĖ ąĮąŠą╝ąĄčĆą░ą╝ąĖ.
ąÜąŠą╝ą▒ąĖąĮą░čåąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖą╣ čü MAC0 ąĖ MAC1 ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠą▒čŖąĄą┤ąĖąĮąĄąĮą░ ą▓ ąŠą┤ąĮčā ąĖąĮčüčéčĆčāą║čåąĖčÄ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ąÆąĄą║č鹊čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ".
ą¤čĆąĖą╗ąŠąČąĄąĮąĖčÅ DSP čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāčÄčé ąĖąĮčüčéčĆčāą║čåąĖčÄ Multiply and Multiply-Accumulate to Data Register ąĖą╗ąĖ ą▓ąĄą║č鹊čĆąĮčāčÄ ą▓ąĄčĆčüąĖčÄ (čüą╝. čĆą░ąĘą┤ąĄą╗ "ąÆąĄą║č鹊čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ") ą┤ą╗čÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ č鹊čćą║ąĖ ą╝ąĄąČą┤čā ą┤ą▓čāčģ ą▓ąĄą║č鹊čĆąŠą▓ čüąĖą│ąĮą░ą╗ą░.
[ą×ą┐čåąĖąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Multiply and Multiply-Accumulate to Data Register ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ąŠą┐čåąĖąĖ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ ąĖ č乊čĆą╝ą░čéą░ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ (čüą╝. čéą░ą▒ą╗ąĖčåčā 10-4).
ąóą░ą▒ą╗ąĖčåą░ 10-4. ą×ą┐čåąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ Multiply and Multiply-Accumulate to Data Register.
ą×ą┐čåąĖčÅ ąÜą░ą║ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ąŠą┐ąĄčĆą░ąĮą┤čŗ ążąŠčĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐čĆąĖ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĖ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░
ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą×ą▒ą░ ąŠą┐ąĄčĆą░ąĮą┤ą░ ąĮą░ ąŠą▒ąŠąĖčģ MAC ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ą║ą░ą║ ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝, čü ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄą╝ ą╗ąĄą▓ąŠą│ąŠ čüą┤ą▓ąĖą│ą░ ą┤ą╗čÅ ąĮąŠčĆą╝ą░ą╗ąĖąĘą░čåąĖąĖ ą┤čĆąŠą▒ąĮąŠą╣ čćą░čüčéąĖ.
ąĀą░čüą┐ą░ą║ąŠą▓ą║ą░ 32 ą▒ąĖčé ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ čü 32-ą▒ąĖčéąĮčŗą╝ ąĮą░čüčŗčēąĄąĮąĖąĄą╝ (saturation).
(FU) ąÆ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓čŗąĄ (U ąŠąĘąĮą░čćą░ąĄčé unsigned) ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ (F ąŠąĘąĮą░čćą░ąĄčé fraction, čé. ąĄ. ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ). ąØąĄ ą┤ąĄą╗ą░ąĄčéčüčÅ ą║ąŠčĆčĆąĄą║čåąĖčÅ čüą┤ą▓ąĖą│ąŠą╝.
ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ, ą║ą░ą║ ąĖ ą▓ ąŠą┐čåąĖąĖ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ.
(IS) ąÆ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ąĮą░čģąŠą┤čÅčéčüčÅ čåąĄą╗čŗąĄ (integer) čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝ (signed). ąØąĄ ą┤ąĄą╗ą░ąĄčéčüčÅ ą║ąŠčĆčĆąĄą║čåąĖčÅ čüą┤ą▓ąĖą│ąŠą╝.
ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ, ą║ą░ą║ ąĖ ą▓ ąŠą┐čåąĖąĖ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ.
(S2RND) ąÆ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ąĮą░čģąŠą┤čÅčéčüčÅ ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝, čü ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄą╝ ą╗ąĄą▓ąŠą│ąŠ čüą┤ą▓ąĖą│ą░ ą┤ą╗čÅ ąĮąŠčĆą╝ą░ą╗ąĖąĘą░čåąĖąĖ ą┤čĆąŠą▒ąĮąŠą│ąŠ čćąĖčüą╗ą░.
ąĀą░čüą┐ą░ą║ąŠą▓ą║ą░ 32 ą▒ąĖčé ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ čü 32-ą▒ąĖčéąĮčŗą╝ ąĮą░čüčŗčēąĄąĮąĖąĄą╝ (saturation). ą£ą░čüčłčéą░ą▒ąĖčĆčāąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ (čāą╝ąĮąŠąČąĄąĮąĖąĄą╝ ąĮą░ 2 ą┐čāč鹥ą╝ čüą┤ą▓ąĖą│ą░ ąĮą░ 1 ą▒ąĖčé ą▓ą╗ąĄą▓ąŠ).
(ISS2) ąÆ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ąĮą░čģąŠą┤čÅčéčüčÅ čåąĄą╗čŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝. ąØąĄ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ą║ąŠčĆčĆąĄą║čåąĖčÅ čüą┤ą▓ąĖą│ąŠą╝.
ąĀą░čüą┐ą░ą║ąŠą▓ą║ą░ 32 ą▒ąĖčé ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ čü 32-ą▒ąĖčéąĮčŗą╝ ąĮą░čüčŗčēąĄąĮąĖąĄą╝ (saturation). ą£ą░čüčłčéą░ą▒ąĖčĆčāąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ (čāą╝ąĮąŠąČąĄąĮąĖąĄą╝ ąĮą░ 2 ą┐čāč鹥ą╝ čüą┤ą▓ąĖą│ą░ ąĮą░ 1 ą▒ąĖčé ą▓ą╗ąĄą▓ąŠ).
(M) ąŻą╝ąĮąŠąČąĄąĮąĖąĄ ą┤čĆąŠą▒ąĮąŠą│ąŠ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝ ąĮą░ ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░ (čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝ąŠąĄ čüą╝ąĄčłą░ąĮąĮąŠąĄ, mixed čāą╝ąĮąŠąČąĄąĮąĖąĄ). ąØąĄ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ą║ąŠčĆčĆąĄą║čåąĖčÅ čüą┤ą▓ąĖą│ąŠą╝. ąÆ ąŠą┐ąĄčĆą░ąĮą┤ąĄ src_reg_0 ąĮą░čģąŠą┤ąĖčéčüčÅ čćąĖčüą╗ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝, ąĖ ą▓ ąŠą┐ąĄčĆą░ąĮą┤ąĄ src_reg_1 čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░. ąĪą╝ąĄčłą░ąĮąĮąŠąĄ čāą╝ąĮąŠąČąĄąĮąĖąĄ ą┐čĆąĖą╝ąĄąĮąĖą╝ąŠ č鹊ą╗čīą║ąŠ ą║ ą▓ąĄčĆčüąĖčÅą╝ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü MAC1. ąśąĮčüčéčĆčāą║čåąĖąĖ čü MAC0 ą┤ąĄą╗ą░čÄčé ąĮąĄčüą╝ąĄčłą░ąĮąĮąŠąĄ čāą╝ąĮąŠąČąĄąĮąĖąĄ, ą║ą░ą║ čŹč鹊 ąĘą░ą┤ą░ąĮąŠ čäą╗ą░ą│ą░ą╝ąĖ ąŠą┐čåąĖą╣ (ąĖą╗ąĖ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ, ąĄčüą╗ąĖ čäą╗ą░ą│ąĖ ąŠą┐čåąĖą╣ ąĮąĄ ąĘą░ą┤ą░ąĮčŗ). ą×ą┐čåąĖčÅ (M) ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ MAC1 ąŠą┤ąĮą░, ąĖą╗ąĖ čüąŠą▓ą╝ąĄčüčéąĮąŠ čü ąŠą┤ąĮąŠą╣ ąĖąĘ ą┤čĆčāą│ąŠą╣ ąŠą┐čåąĖą╣ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖčÅ. ąĢčüą╗ąĖ čāą║ą░ąĘą░ąĮąŠ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąŠą┐čåąĖą╣, č鹊 ąŠąĮąĖ ą▓čüąĄ čüčĆą░ąĘčā ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąĘą░ą║ą╗čÄč湥ąĮčŗ ą▓ ąŠą┤ąĖąĮąŠčćąĮčāčÄ ą┐ą░čĆčā ą║čĆčāą│ą╗čŗčģ čüą║ąŠą▒ąŠą║, ąĖ ąŠčéą┤ąĄą╗ąĄąĮčŗ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ ąĘą░ą┐čÅč鹊ą╣. ą¤čĆąĖą╝ąĄčĆ: (M, IS).
ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ, ą║ą░ą║ ąĖ ą▓ ąŠą┐čåąĖąĖ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ.
ąĪąĖąĮčéą░ą║čüąĖčü ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé č鹊ą╗čīą║ąŠ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ čüąŠ čüą╝ąĄčēąĄąĮąĖąĄą╝ (biased rounding). ąæąĖčé RND_MOD čĆąĄą│ąĖčüčéčĆą░ ASTAT ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą▓ą╗ąĖčÅąĮąĖąĄ ąĮą░ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ą┤ą╗čÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ čüą╝. čĆą░ąĘą┤ąĄą╗ "Rounding, Truncating".
ąÆ čĆąĄąČąĖą╝ąĄ ą┤čĆąŠą▒ąĮčŗčģ čćąĖčüąĄą╗ (fractional mode), ą┐čĆąŠą┤čāą║čé čüą░ą╝čŗčģ ą╝ą░ą╗čŗčģ ą┐čĆąĄą┤čüčéą░ą▓ąĖą╝čŗčģ čćąĖčüąĄą╗ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, 0x8000-čÅ čćą░čüčéčī ąŠčé 0x8000) ąĮą░čüčŗčēą░ąĄčéčüčÅ ą┤ąŠ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą┐čĆąĄą┤čüčéą░ą▓ąĖą╝ąŠą╣ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠą╣ ą┤čĆąŠą▒ąĮąŠą╣ čćą░čüčéąĖ (0x7FFF) ą┤ąŠ ą╝ąŠą╝ąĄąĮčéą░ ąĮą░ą║ąŠą┐ą╗ąĄąĮąĖčÅ.
ąĢčüą╗ąĖ ąÆčŗ čģąŠč鹥ą╗ąĖ ą▒čŗ čüąŠčģčĆą░ąĮąĖčéčī čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąĄ ąĮąĄ ąĖąĘą╝ąĄąĮąĄąĮąĮčŗą╝, ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ą┐čĆąŠčüčéčāčÄ ąĖąĮčüčéčĆčāą║čåąĖčÄ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ (Move), čćč鹊ą▒čŗ čüą┤ąĄą╗ą░čéčī ą║ąŠą┐ąĖčÄ A.x ąĖą╗ąĖ A.w ą▓ ą║ą░ą║ąŠą╝-ąĮąĖą▒čāą┤čī čĆąĄą│ąĖčüčéčĆąĄ.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĮą░čüčŗčēąĄąĮąĖčÅ čüą╝. čüąĄą║čåąĖčÄ "Saturation (ąĮą░čüčŗčēąĄąĮąĖąĄ)".
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čäą╗ą░ą│ąĖ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ŌĆó V čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé, čĆą░čüą┐ą░ą║ąŠą▓ą░ąĮąĮčŗą╣ ą▓ Dreg, ą┐čĆąĄč鹥čĆą┐ąĄą╗ ąĮą░čüčŗčēąĄąĮąĖąĄ; ąŠčćąĖčüčéąĖčéčüčÅ, ąĄčüą╗ąĖ ąĮą░čüčŗčēąĄąĮąĖčÅ ąĮąĄ ą▒čŗą╗ąŠ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆ ]
r4= (a0= r3.h* r2.h); /* ąĀą░ą▒ąŠčéą░ąĄčé č鹊ą╗čīą║ąŠ MAC0. ąÆ ąŠą▒ąŠąĖčģ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ąĮą░čģąŠą┤čÅčéčüčÅ
ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝. ąĀąĄąĘčāą╗čīčéą░čé ąĘą░ą│čĆčāąĘąĖčéčüčÅ ą▓ A0, ąĘą░č鹥ą╝ ą▓ r4. */
r3= (a1+= r6.h* r4.l)(fu); /* ąĀą░ą▒ąŠčéą░ąĄčé č鹊ą╗čīą║ąŠ MAC1. ąÆ ąŠą▒ąŠąĖčģ ąŠą┐ąĄčĆą░ąĮą┤ą░čģ ąĮą░čģąŠą┤čÅčéčüčÅ ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ ą▒ąĄąĘ ąĘąĮą░ą║ą░. ąĀąĄąĘčāą╗čīčéą░čé ąĘą░ą│čĆčāąĘąĖčéčüčÅ ą▓ A1, ąĘą░č鹥ą╝ ą▓ r3. */
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Move Register, Move Register Half, Multiply and Multiply-Accumulate to Accumulator, Multiply and Multiply-Accumulate to Half-Register, Multiply (Modulo 232 ), Vector Multiply, Vector Multiply and Multiply-Accumulate.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg *= multiple_register
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg *= Dreg; // čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮąŠąĄ čāą╝ąĮąŠąČąĄąĮąĖąĄ 32 x 32 (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Multiply (Modulo 232 ) čāą╝ąĮąŠąČą░ąĄčé ą┤ą▓ą░ 32-čĆą░ąĘčĆčÅą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ dest_reg ąĖ multiple_register, ąĖ čüąŠčģčĆą░ąĮčÅąĄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ dest_reg. ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓čŗą│ą╗čÅą┤ąĖčé č鹊čćąĮąŠ čéą░ą║ ąČąĄ, ą║ą░ą║ ąĖ ą░ąĮą░ą╗ąŠą│ąĖčćąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ ąĮą░ čÅąĘčŗą║ąĄ C, ą║ąŠč鹊čĆą░čÅ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ą┤ąĄą╣čüčéą▓ąĖąĄ Dreg1 = (Dreg1 * Dreg2) modulo 232 . ą¤ąŠčüą║ąŠą╗čīą║čā ąĖąĮčüčéčĆčāą║čåąĖčÅ čĆą░ą▒ąŠčéą░ąĄčé čü modulo 232 , č鹊 čĆąĄąĘčāą╗čīčéą░čé ą▓čüąĄą│ą┤ą░ ą┐ąŠą╝ąĄčēą░ąĄčéčüčÅ ą▓ 32-čĆą░ąĘčĆčÅą┤ąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ dest_reg, ąĖ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĮąĄą▓ąŠąĘą╝ąŠąČąĮąŠ; čäą╗ą░ą│ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ASTAT ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ.
ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą┤ąŠą╗ąČąĄąĮ ą┐ąŠąĘą░ą▒ąŠčéąĖčéčīčüčÅ ąŠą▒ ąŠą│čĆą░ąĮąĖč湥ąĮąĖąĖ ąĘąĮą░č湥ąĮąĖčÅ ą▓čģąŠą┤ąĮčŗčģ čćąĖčüąĄą╗, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ą▓ čĆąĄąĘčāą╗čīčéą░čé ąĮąĄ ą┐čĆąĄą▓čŗčüąĖčé čĆą░ąĘčĆčÅą┤ąĮąŠčüčéčī 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ dest_reg. ąĢčüą╗ąĖ čéčĆąĄą▒čāąĄčéčüčÅ ąŠą┐ąŠą▓ąĄčēąĄąĮąĖąĄ ąŠ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĖ, č鹊 ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčé ą┤ąŠą╗ąČąĄąĮ ąĮą░ą┐ąĖčüą░čéčī čüąŠą▒čüčéą▓ąĄąĮąĮčŗą╣ ą╝ą░ą║čĆąŠčü ą┤ą╗čÅ čāą╝ąĮąŠąČąĄąĮąĖčÅ čü ą┐ąŠą┤ą┤ąĄčƹȹ║ąŠą╣ čéą░ą║ąŠą╣ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ.
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąĄąĮčÅąĄčé ą░ą║ą║čāą╝čāą╗čÅč鹊čĆčŗ A0 ąĖ A1.
ąśąĮčüčéčĆčāą║čåąĖčÅ Multiply (Modulo 232 ) ąĮąĄ ą┤ąĄą╗ą░ąĄčé ąĮąĄčÅą▓ąĮčāčÄ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÄ ąĘąĮą░č湥ąĮąĖčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ multiple_register.
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą╝ąĄč鹊ą┤ą░ ą║ąŠąĮą│čĆčā菹ĮčéąĮąŠčüčéąĖ ą┐čĆąĖ ą│ąĄąĮąĄčĆą░čåąĖąĖ čüą╗čāčćą░ą╣ąĮčŗčģ čćąĖčüąĄą╗:
x[n+1] = (a*x[n]) mod 2^32
ąŚą┤ąĄčüčī x[n] ąĮą░čćą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą│ąĄąĮąĄčĆą░č鹊čĆą░ (seed value), a čŹč鹊 ą▒ąŠą╗čīčłąŠąĄ čćąĖčüą╗ąŠ, ąĖ x[n+1] čŹč鹊 čĆąĄąĘčāą╗čīčéą░čé, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ą▒čŗčéčī čāą╝ąĮąŠąČąĄąĮ čüąĮąŠą▓ą░ ą┤ą╗čÅ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ ą┐čüąĄą▓ą┤ąŠčüą╗čāčćą░ą╣ąĮąŠą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Divide Primitive, Arithmetic Shift, Shift with Add, Add with Shift. ąÆ čĆą░ąĘą┤ąĄą╗ąĄ "ąÆąĄą║č鹊čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ" čüą╝. Vector Multiply and Multiply-Accumulate, Vector Multiply.
ą×ą┐ąĄčĆą░čåąĖčÅ ąŠčéčĆąĖčåą░ąĮąĖčÅ (ą┤ą▓ąŠąĖčćąĮąŠąĄ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ). ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = ŌĆōsrc_reg
dest_accumulator = ŌĆōsrc_accumulator
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = ŌĆōDreg; // (a)1
Dreg = ŌĆōDreg (sat_flag); // (b)
A0 = ŌĆōA0; // (b)
A0 = ŌĆōA1; // (b)
A1 = ŌĆōA0; // (b)
A1 = ŌĆōA1; // (b)
A1 = ŌĆōA1, A0 = ŌĆōA0; // ąŠčéčĆąĖčåą░ąĮąĖąĄ ąŠą▒ąŠąĖčģ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓ ą▓ ąŠą┤ąĮąŠą╣ 32-ą▒ąĖčéąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7.
sat_flag: ąŠą▒čÅąĘą░č鹥ą╗čīąĮčŗą╣ čäą╗ą░ą│ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąĮą░čüčŗčēąĄąĮąĖąĄą╝, (S) ąĖą╗ąĖ (NS).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Negate (TwoŌĆÖs Complement) ą▓ąŠąĘą▓čĆą░čéąĖčé ąĘąĮą░č湥ąĮąĖąĄ č鹊ą╣ ąČąĄ čüą░ą╝ąŠą╣ ą╝ą░ą│ąĮąĖčéčāą┤čŗ, ąĮąŠ čü ąŠą▒čĆą░čéąĮčŗą╝ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╝ ąĘąĮą░ą║ąŠą╝. ąÆąĄčĆčüąĖąĖ čü ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą╝ ą┤ąĄą╗ą░čÄčé ąĮą░čüčŗčēąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░ ą┐ąŠ 40 ą▒ąĖčéą░ą╝. ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠą╗čāčćą░ąĄčé čĆąĄąĘčāą╗čīčéą░čé ą▓čŗčćąĖčéą░ąĮąĖąĄą╝ ąĖąĘ ąĮčāą╗čÅ.
ąÆąĄčĆčüąĖčÅ čü Dreg ą▒ąĄąĘ ąŠą┐čåąĖąĖ sat_flag ąĮąĄ ą┤ąĄą╗ą░ąĄčé ąĮą░čüčŗčēąĄąĮąĖąĄ. ąæčāą┤ąĄčé č鹊ą╗čīą║ąŠ č鹊ą│ą┤ą░ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Negate ą▒ąĄąĘ ąĮą░čüčŗčēąĄąĮąĖčÅ, ą║ąŠą│ą┤ą░ ą▓čģąŠą┤ąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ čĆą░ą▓ąĮąŠ 0x8000 0000. ąÆąĄčĆčüąĖčÅ čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝ ą▓ąĄčĆąĮąĄčé; ą▓ąĄčĆčüąĖčÅ ą▒ąĄąĘ ąĮą░čüčŗčēąĄąĮąĖčÅ ą▓ąĄčĆąĮąĄčé 0x8000 0000.
ąÆ čüąĖąĮčéą░ą║čüąĖčüąĄ, ą│ą┤ąĄ ą┐ąŠčÅą▓ą╗čÅąĄčéčüčÅ ąŠą┐čåąĖčÅ sat_flag, ąŠąĮą░ ąĘą░ą╝ąĄąĮčÅąĄčéčüčÅ ąŠą┤ąĮąĖą╝ ąĖąĘ čüą╗ąĄą┤čāčÄčēąĖčģ ąĘąĮą░č湥ąĮąĖą╣:
ŌĆó (S) ŌĆō ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ąĮą░čüčŗčēąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĮą░čüčŗčēąĄąĮąĖčÅ čüą╝. čüąĄą║čåąĖčÄ "Saturation (ąĮą░čüčŗčēąĄąĮąĖąĄ)".
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čäą╗ą░ą│ąĖ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ąŠą┐ąĄčĆą░čåąĖąĖ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆ ]
r5 = - r0;
a0 = - a0;
a0 = - a1;
a1 = - a0;
a1 = - a1;
a1 = - a1, a0 = - a0;
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Vector Negate (TwoŌĆÖs Complement) ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ąÆąĄą║č鹊čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ".
ą×ą║čĆčāą│ą╗ąĄąĮąĖąĄ ą┤ąŠ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čüą╗ąŠą▓ą░. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = src_reg (RND)
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg_lo_hi = Dreg(RND); // ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ ąĖ ąĮą░čüčŗčēąĄąĮąĖąĄ ąĖčüč鹊čćąĮąĖą║ą░ ą┤ąŠ 16 ą▒ąĖčé (b)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
Dreg_lo_hi: ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L, R0.H, ..., R7.H.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Round Half-Word ąŠą║čĆčāą│ą╗čÅąĄčé 32-ą▒ąĖčéąĮąŠąĄ, ąĮąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮąĮąŠąĄ ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ ą▓ 16-ą▒ąĖčéąĮąŠąĄ, ąĮąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮąĮąŠąĄ ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ ą┐čāč鹥ą╝ čĆą░čüą┐ą░ą║ąŠą▓ą║ąĖ ąĖ ąĮą░čüčŗčēąĄąĮąĖčÅ ą▒ąĖčé 31:16, ąĘą░č鹥ą╝ ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖčÅ ą▒ąĖčé 15:0. ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé č鹊ą╗čīą║ąŠ čüą╝ąĄčēąĄąĮąĮąŠąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ (biased rounding), ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé ą┐ąŠą╗ąŠą▓ąĖąĮą║čā LSB (ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ, ą▒ąĖčé bit 15) ą┐ąĄčĆąĄą┤ ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖąĄą╝ ą▒ąĖčé 15:0. ALU ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ. ąæąĖčé RND_MOD ą▓ čĆąĄą│ąĖčüčéčĆąĄ ASTAT ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą▓ą╗ąĖčÅąĮąĖąĄ ąĮą░ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ą▓ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
ąöčĆąŠą▒ąĮčŗąĄ čéąĖą┐čŗ ą┤ą░ąĮąĮčŗčģ, ą║ą░ą║ąĖąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą▓ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą▓čüąĄą│ą┤ą░ čüąŠ ąĘąĮą░ą║ąŠą╝.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĮą░čüčŗčēąĄąĮąĖčÅ čüą╝. čüąĄą║čåąĖčÄ "Saturation (ąĮą░čüčŗčēąĄąĮąĖąĄ)". ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ čüą╝. čĆą░ąĘą┤ąĄą╗ "Rounding, Truncating".
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čäą╗ą░ą│ąĖ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ąŠą┐ąĄčĆą░čåąĖąĖ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆ ]
// ąĢčüą╗ąĖ r6 = 0xFFFC FFFF, č鹊 ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ ą┤ąŠ 16 ą▒ąĖčé ąŠą┐ąĄčĆą░čåąĖąĄą╣ ...
r1.l = r6 (rnd);// ... ą┤ą░čüčé ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 r1.l = 0xFFFD
// ąĢčüą╗ąĖ r7 = 0x0001 8000, č鹊 ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ ą┤ąŠ 16 ą▒ąĖčé ąŠą┐ąĄčĆą░čåąĖąĄą╣ ...
r1.h = r7 (rnd);// ... ą┤ą░čüčé ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 r1.h = 0x0002
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Round ŌĆō 12 Bit, Round ŌĆō 20 Bit, Add.
ąĪą╗ąŠąČąĄąĮąĖąĄ ąĖą╗ąĖ ą▓čŗčćąĖčéą░ąĮąĖąĄ čü ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄą╝ ą┤ąŠ 12 ą▒ąĖčé čüą╗ąŠą▓ą░. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = src_reg_0 + src_reg_1 (RND12)
dest_reg = src_reg_0 - src_reg_1 (RND12)
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg_lo_hi = Dreg + Dreg (RND12); // (b)1
Dreg_lo_hi = Dreg - Dreg (RND12); // (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
Dreg_lo_hi: ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L, R0.H, ..., R7.H.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Round - 12 bit čüą║ą╗ą░ą┤čŗą▓ą░ąĄčé ąĖą╗ąĖ ą▓čŗčćąĖčéą░ąĄčé ą┤ą▓ą░ 32-ą▒ąĖčéąĮčŗčģ ąĘąĮą░č湥ąĮąĖčÅ, ąĘą░č鹥ą╝ ąŠą║čĆčāą│ą╗čÅąĄčé čĆąĄąĘčāą╗čīčéą░čé ą┐ąŠ ą┐ąŠąĘąĖčåąĖąĖ ą▒ąĖčéą░ 12. ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ čüąŠčģčĆą░ąĮčÅąĄčé 16 ą▒ąĖčé čćąĖčüą╗ą░ čĆą░čüą┐ą░ą║ąŠą▓ą║ąŠą╣ ą▒ąĖč鹊ą▓ 27:12 čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝ čĆąĄąĘčāą╗čīčéą░čéą░.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé č鹊ą╗čīą║ąŠ čüą╝ąĄčēąĄąĮąĮąŠąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ (biased rounding), ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé ą┐ąŠą╗ąŠą▓ąĖąĮą║čā LSB (ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ, ą▒ąĖčé bit 11) ą┐ąĄčĆąĄą┤ ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖąĄą╝ ą▒ąĖčé 11:0. ąæąĖčé RND_MOD ą▓ čĆąĄą│ąĖčüčéčĆąĄ ASTAT ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą▓ą╗ąĖčÅąĮąĖąĄ ąĮą░ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ą▓ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĮą░čüčŗčēąĄąĮąĖčÅ čüą╝. čüąĄą║čåąĖčÄ "Saturation (ąĮą░čüčŗčēąĄąĮąĖąĄ)". ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ čüą╝. čĆą░ąĘą┤ąĄą╗ "Rounding, Truncating".
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ: ąŠą▒čŗčćąĮąŠ Round ŌĆō 12 Bit ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą┤ą╗čÅ ą░ą╗ą│ąŠčĆąĖčéą╝ą░ ąŠą┐ąĄčĆą░čåąĖąĖ 2D 8x8 inverse discrete cosine transform, čüąŠą▓ą╝ąĄčüčéąĖą╝ąŠą╣ čüąŠ čüčéą░ąĮą┤ą░čĆč鹊ą╝ IEEE 1180.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čäą╗ą░ą│ąĖ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ąŠą┐ąĄčĆą░čåąĖąĖ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r1.l = r6+ r7(rnd12);
r1.l = r6- r7(rnd12);
r1.h = r6+ r7(rnd12);
r1.h = r6- r7(rnd12);
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Round ŌĆō Half-Word, Round ŌĆō 20 Bit, Add.
ąĪą╗ąŠąČąĄąĮąĖąĄ ąĖą╗ąĖ ą▓čŗčćąĖčéą░ąĮąĖąĄ čü ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄą╝ ą┤ąŠ 20 ą▒ąĖčé čüą╗ąŠą▓ą░. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = src_reg_0 + src_reg_1 (RND20)
dest_reg = src_reg_0 - src_reg_1 (RND20)
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg_lo_hi = Dreg + Dreg (RND20); // (b)1
Dreg_lo_hi = Dreg - Dreg (RND20); // (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
Dreg_lo_hi: ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L, R0.H, ..., R7.H.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Round - 20 bit čüą║ą╗ą░ą┤čŗą▓ą░ąĄčé ąĖą╗ąĖ ą▓čŗčćąĖčéą░ąĄčé ą┤ą▓ą░ 32-ą▒ąĖčéąĮčŗčģ ąĘąĮą░č湥ąĮąĖčÅ, ąŠą║čĆčāą│ą╗čÅąĄčé čĆąĄąĘčāą╗čīčéą░čé ą┐ąŠ ą┐ąŠąĘąĖčåąĖąĖ ą▒ąĖčéą░ 20, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ čĆą░čüą┐ą░ą║ąŠą▓čŗą▓ą░ąĄčé ą▒ąĖčéčŗ 31:20 ą▓ 16-ą▒ąĖčéąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé č鹊ą╗čīą║ąŠ čüą╝ąĄčēąĄąĮąĮąŠąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ (biased rounding), ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé ą┐ąŠą╗ąŠą▓ąĖąĮą║čā LSB (ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ, ą▒ąĖčé bit 19) ą┐ąĄčĆąĄą┤ ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖąĄą╝ ą▒ąĖčé 19:0. ąæąĖčé RND_MOD ą▓ čĆąĄą│ąĖčüčéčĆąĄ ASTAT ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą▓ą╗ąĖčÅąĮąĖąĄ ąĮą░ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ą▓ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
ą¤čĆą░ą║čéąĖč湥čüą║ąĖ čŹčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ąĄą╗ą░ąĄčé ą┐čĆą░ą▓čŗą╣ čüą┤ą▓ąĖą│ ąĮą░ 4 ą▒ąĖčéą░ ą║ą░ąČą┤ąŠą│ąŠ ą▓čģąŠą┤ąĮąŠą│ąŠ čüą╗ąŠą▓ą░, čćč鹊ą▒čŗ ą┐čĆąĄą┤ąŠčéą▓čĆą░čéąĖčéčī ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░, čüą║ą╗ą░ą┤čŗą▓ą░ąĄčé ąĖą╗ąĖ ą▓čŗčćąĖčéą░ąĄčé 2 čüą╗ąŠą▓ą░, ąĘą░č鹥ą╝ ą┤ąĄą╗ą░ąĄčé ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░ ą▓ ą┐ąŠąĘąĖčåąĖąĖ ą▒ąĖčéą░ 16. ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ čüąŠčģčĆą░ąĮčÅąĄčé čüčéą░čĆčłąĖąĄ 16 ą▒ąĖčé čćąĖčüą╗ą░.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ čüą╝. čĆą░ąĘą┤ąĄą╗ "Rounding, Truncating".
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ: ąŠą▒čŗčćąĮąŠ Round ŌĆō 20 Bit ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą┤ą╗čÅ ą░ą╗ą│ąŠčĆąĖčéą╝ą░ ąŠą┐ąĄčĆą░čåąĖąĖ 2D 8x8 inverse discrete cosine transform, čüąŠą▓ą╝ąĄčüčéąĖą╝ąŠą╣ čüąŠ čüčéą░ąĮą┤ą░čĆč鹊ą╝ IEEE 1180.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čäą╗ą░ą│ąĖ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ąŠą┐ąĄčĆą░čåąĖąĖ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r1.l = r6+r7(rnd20);
r1.l = r6-r7(rnd20);
r1.h = r6+r7(rnd20);
r1.h = r6-r7(rnd20);
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Round ŌĆō 12 Bit, Round ŌĆō Half-Word, Add.
ą×ą┐ąĄčĆą░čåąĖčÅ ąĮą░čüčŗčēąĄąĮąĖčÅ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = src_reg (S)
ąĪąĖąĮčéą░ą║čüąĖčü:
A0 = A0 (S); // (b)1
A1 = A1 (S); // (b)
A1 = A1 (S), A0 = A0 (S); // ąĮą░čüčŗčēąĄąĮąĖąĄ čüąŠ ąĘąĮą░ą║ąŠą╝ ą┤ą╗čÅ ąŠą▒ąŠąĖčģ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓ // ą┐ąŠ ą│čĆą░ąĮąĖčåąĄ 32 ą▒ąĖčéą░ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Saturate ą┤ąĄą╗ą░ąĄčé ąĮą░čüčŗčēąĄąĮąĖąĄ 40-čĆą░ąĘčĆčÅą┤ąĮčŗčģ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓ ą┐ąŠ 32 ą▒ąĖčéą░ą╝. ąĀąĄąĘčāą╗čīčéąĖčĆčāčÄčēąĄąĄ ąĮą░čüčŗčēąĄąĮąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┐ąŠą╗čāčćą░ąĄčé čĆą░čüčłąĖčĆąĄąĮąĖąĄ ąĘąĮą░ą║ąŠą╝ ą▓ ą▒ąĖčéą░čģ čĆą░čüčłąĖčĆąĄąĮąĖčÅ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ (extension bits).
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĮą░čüčŗčēąĄąĮąĖčÅ čüą╝. čüąĄą║čåąĖčÄ "Saturation (ąĮą░čüčŗčēąĄąĮąĖąĄ)".
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čäą╗ą░ą│ąĖ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ąŠą┐ąĄčĆą░čåąĖąĖ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ. ąÆ čüą╗čāčćą░ąĄ ą┤ą▓čāčģ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣ AZ ą┐čĆąĄą┤čüčéą░ą▓ąĖčé čĆąĄąĘčāą╗čīčéą░čé ą╗ąŠą│ąĖč湥čüą║ąŠą│ąŠ ąśąøąś ąŠčé čŹčéąĖčģ ą┤ą▓čāčģ ąŠą┐ąĄčĆą░čåąĖą╣.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
a0 = a0 (s);
a1 = a1 (s);
a1 = a1 (s), a0 = a0 (s);
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Subtract (ąŠą┐čåąĖąĖ ąĮą░čüčŗčēąĄąĮąĖčÅ), Add (ąŠą┐čåąĖąĖ ąĮą░čüčŗčēąĄąĮąĖčÅ).
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = SIGNBITS sample_register
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg_lo = SIGNBITS Dreg; // 32-ą▒ąĖčéąĮą░čÅ ą▓čŗą▒ąŠčĆą║ą░ (b)1
Dreg_lo = SIGNBITS Dreg_lo_hi; // 16-ą▒ąĖčéąĮą░čÅ ą▓čŗą▒ąŠčĆą║ą░ (b)
Dreg_lo = SIGNBITS A0; // 40-ą▒ąĖčéąĮą░čÅ ą▓čŗą▒ąŠčĆą║ą░ (b)
Dreg_lo = SIGNBITS A1; // 40-ą▒ąĖčéąĮą░čÅ ą▓čŗą▒ąŠčĆą║ą░ (b)
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
Dreg_lo: ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L.
Dreg_lo_hi: ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L, R0.H, ..., R7.H.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Sign Bit ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé ąĘąĮą░ą║ą░ ą▓ čćąĖčüą╗ąĄ, ąĖ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ čüąŠą▓ą╝ąĄčüčéąĮąŠ čüąŠ čüą┤ą▓ąĖą│ąŠą╝ ą┤ą╗čÅ ąĮąŠčĆą╝ą░ą╗ąĖąĘą░čåąĖąĖ čćąĖčüąĄą╗. ąśąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé čĆą░ą▒ąŠčéą░čéčī čü ą▓čģąŠą┤ąĮčŗą╝ąĖ čćąĖčüą╗ą░ą╝ąĖ 16 ą▒ąĖčé, 32 ą▒ąĖčéą░ ąĖą╗ąĖ 40 ą▒ąĖčé.
ŌĆó ąöą╗čÅ 16-ą▒ąĖčéąĮčŗčģ ą▓čģąŠą┤ąĮčŗčģ čćąĖčüąĄą╗ Sign Bit ą▓ąĄčĆąĮąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĮą░čćą░ą╗čīąĮčŗčģ ąĘąĮą░ą║ąŠą▓čŗčģ ą▒ąĖčé ą╝ąĖąĮčāčü 1, ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą┐ąŠą╗čāčćąĖčéčüčÅ čćąĖčüą╗ąŠ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 15. ąŚą┤ąĄčüčī ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī čüą┐ąĄčåąĖą░ą╗čīąĮčŗčģ čüą╗čāčćą░ąĄą▓: ą║ąŠą│ą┤ą░ ąĮą░ ą▓čģąŠą┤ąĄ ą▓čüąĄ ąĮčāą╗ąĖ, č鹊 ą▒čāą┤ąĄčé ą▓ąŠąĘą▓čĆą░čēąĄąĮąŠ +15 (ą▓čüąĄ ą▒ąĖčéčŗ ąĘąĮą░ą║ąŠą▓čŗąĄ), ąĖ ą║ąŠą│ą┤ą░ ąĮą░ ą▓čģąŠą┤ąĄ ą▓čüąĄ ąĄą┤ąĖąĮąĖčćą║ąĖ, č鹊 ą▒čāą┤ąĄčé čéą░ą║ąČąĄ ą▓ąŠąĘą▓čĆą░čēąĄąĮąŠ +15.
ŌĆó ąöą╗čÅ 32-ą▒ąĖčéąĮčŗčģ ą▓čģąŠą┤ąĮčŗčģ čćąĖčüąĄą╗ Sign Bit ą▓ąĄčĆąĮąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĮą░čćą░ą╗čīąĮčŗčģ ąĘąĮą░ą║ąŠą▓čŗčģ ą▒ąĖčé ą╝ąĖąĮčāčü 1, ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą┐ąŠą╗čāčćąĖčéčüčÅ čćąĖčüą╗ąŠ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 31. ąÜąŠą│ą┤ą░ ąĮą░ ą▓čģąŠą┤ąĄ ą▓čüąĄ ąĮčāą╗ąĖ ąĖą╗ąĖ ą▓čüąĄ ąĄą┤ąĖąĮąĖčćą║ąĖ, ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ąŠąĘą▓čĆą░čéąĖčé +31 (ą▓čüąĄ ąĘąĮą░ą║ąŠą▓čŗąĄ ą▒ąĖčéčŗ).
ŌĆó ąöą╗čÅ 40-ą▒ąĖčéąĮčŗčģ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓ ąĮą░ ą▓čģąŠą┤ąĄ Sign Bit ą▓ąĄčĆąĮąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĮą░čćą░ą╗čīąĮčŗčģ ąĘąĮą░ą║ąŠą▓čŗčģ ą▒ąĖčé ą╝ąĖąĮčāčü 9, ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą┐ąŠą╗čāčćąĖčéčüčÅ čćąĖčüą╗ąŠ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ -8 .. 31. ą×čéčĆąĖčåą░č鹥ą╗čīąĮąŠąĄ čćąĖčüą╗ąŠ ą▒čāą┤ąĄčé ą▓ąŠąĘą▓čĆą░čēąĄąĮąŠ, ą║ąŠą│ą┤ą░ čĆąĄąĘčāą╗čīčéą░čé ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąĄ čĆą░čüčłąĖčĆąĖą╗čüčÅ ąĮą░ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ą▒ąĖčéčŗ (extension bits); čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēą░čÅ ąĮąŠčĆą╝ą░ą╗ąĖąĘą░čåąĖčÅ čüą┤ą▓ąĖąĮąĄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ąĮąĖąĘ ą┤ąŠ 32-čĆą░ąĘčĆčÅą┤ąŠą▓ (čü ą┐ąŠč鹥čĆąĄą╣ č鹊čćąĮąŠčüčéąĖ). ąÆčüąĄ ą▓čģąŠą┤ąĮčŗąĄ ąĮčāą╗ąĖ ąĖą╗ąĖ ą▓čüąĄ ąĄą┤ąĖąĮąĖčåčŗ ą▓ąĄčĆąĮąĄčé ąĘąĮą░č湥ąĮąĖąĄ +31.
ąĀąĄąĘčāą╗čīčéą░čé ąĖąĮčüčéčĆčāą║čåąĖąĖ SIGNBITS ą╝ąŠąČąĄčé ąĮą░ą┐čĆčÅą╝čāčÄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą║ą░ą║ ą░čĆą│čāą╝ąĄąĮčé ąĖąĮčüčéčĆčāą║čåąĖąĖ ASHIFT ą┤ą╗čÅ ąĮąŠčĆą╝ą░ą╗ąĖąĘą░čåąĖąĖ čćąĖčüą╗ą░. ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 ą┐ąŠą╗čāčćą░čéčüčÅ čćąĖčüą╗ą░ ą▓ čüą╗ąĄą┤čāčÄčēąĖčģ č乊čĆą╝ą░čéą░čģ (S == ą▒ąĖčéčŗ ąĘąĮą░ą║ą░, M == ą▒ąĖčéčŗ ą╝ą░ą│ąĮąĖčéčāą┤čŗ).
16-bit: S.MMM MMMM MMMM MMMM 32-bit: S.MMM MMMM MMMM MMMM MMMM MMMM MMMM MMMM 40-bit: SSSS SSSS S.MMM MMMM MMMM MMMM MMMM MMMM MMMM MMMM
ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ čĆąĄąĘčāą╗čīčéą░čé SIGNBITS ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮą░ą┐čĆčÅą╝čāčÄ ą▓čŗčćč鹥ąĮ ą┤ą╗čÅ č乊čĆą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ąĮąŠą▓ąŠą╣ 菹║čüą┐ąŠąĮąĄąĮčéčŗ.
ąśąĮčüčéčĆčāą║čåąĖčÅ Sign Bit ąĮąĄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčé ąĮąĄčÅą▓ąĮčāčÄ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÄ ą▓čģąŠą┤ąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ. ąöą╗čÅ 32-ą▒ąĖčéąĮčŗčģ ąĖ 16-ą▒ąĖčéąĮčŗčģ ą▓čģąŠą┤ąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣ dest_reg ąĖ sample_register ą╝ąŠą│čāčé ą▒čŗčéčī ąŠą┤ąĮąĖą╝ ąĖ č鹥ą╝ ąČąĄ D-čĆąĄą│ąĖčüčéčĆąŠą╝, ą▓ čéą░ą║ąŠą╝ čüą╗čāčćą░ąĄ ą▒čāą┤ąĄčé ą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮą░ čÅą▓ąĮą░čÅ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÅ sample_register.
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ: ąÆčŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī 菹║čüą┐ąŠąĮąĄąĮčéčā ą║ą░ą║ ą╝ą░ą│ąĮąĖčéčāą┤čā čüą┤ą▓ąĖą│ą░ ą┤ą╗čÅ ąĮąŠčĆą╝ą░ą╗ąĖąĘą░čåąĖąĖ ą╝ą░čüčüąĖą▓ą░. ąÆčŗ ą╝ąŠąČąĄč鹥 ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąĮąŠčĆą╝ą░ą╗ąĖąĘą░čåąĖčÄ ą┐čĆčÅą╝čŗą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ąĖąĮčüčéčĆčāą║čåąĖąĖ ASHIFT, ą▒ąĄąĘ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüą┐ąĄčåąĖą░ą╗čīąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĮąŠčĆą╝ą░ą╗ąĖąĘą░čåąĖąĖ, ą║ą░ą║ čŹč鹊 čéčĆąĄą▒čāąĄčéčüčÅ ą▓ ą┤čĆčāą│ąĖčģ ą░čĆčģąĖč鹥ą║čéčāčĆą░čģ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r2.l = signbits r7;
r1.l = signbits r5.l;
r0.l = signbits r4.h;
r6.l = signbits a0;
r5.l = signbits a1;
ąĪą╝. čéą░ą║ąČąĄ Exponent Detection.
ąÆčŗčćąĖčéą░ąĮąĖąĄ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = src_reg_1 - src_reg_2
ąĪąĖąĮčéą░ą║čüąĖčü ą┤ą╗čÅ 32-ą▒ąĖčéąĮčŗčģ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ ąĖ 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄąĘčāą╗čīčéą░čéą░:
Dreg = Dreg - Dreg; // ąĮąĄčé ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ ąĮą░čüčŗčēąĄąĮąĖčÅ, ąĮąŠ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą║ąŠčĆąŠč湥 (a)1
Dreg = Dreg - Dreg (sat_flag); // ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ ąĮą░čüčŗčēąĄąĮąĖąĄ čåąĄąĮąŠą╣ // čāą▓ąĄą╗ąĖč湥ąĮąĖčÅ ą┤ą╗ąĖąĮčŗ ąĖąĮčüčéčĆčāą║čåąĖąĖ (b)
ąĪąĖąĮčéą░ą║čüąĖčü ą┤ą╗čÅ 16-ą▒ąĖčéąĮčŗčģ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ ąĖ 16-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄąĘčāą╗čīčéą░čéą░:
Dreg_lo_hi = Dreg_lo_hi ŌĆō Dreg_lo_hi (sat_flag); // (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7.
Dreg_lo_hi: ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L, R0.H, ..., R7.H.
sat_flag: ąŠą▒čÅąĘą░č鹥ą╗čīąĮčŗą╣ čäą╗ą░ą│ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąĮą░čüčŗčēąĄąĮąĖąĄą╝, (S) ąĖą╗ąĖ (NS).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Subtract ą▓čŗčćąĖčéą░ąĄčé src_reg_2 ąĖąĘ src_reg_1, ąĖ ą┐ąŠą╝ąĄčēą░ąĄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ąĢčüčéčī 2 čüą┐ąŠčüąŠą▒ą░ ąĘą░ą┤ą░čéčī ą▓čŗčćąĖčéą░ąĮąĖąĄ 32-ą▒ąĖčéąĮčŗčģ ą┤ą░ąĮąĮčŗčģ. ą×ą┤ąĖąĮ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąĖąĮčüčéčĆčāą║čåąĖčÄ ą┤ą╗ąĖąĮąŠą╣ 16-ą▒ąĖčé, ąĮąŠ ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ąĮą░čüčŗčēąĄąĮąĖąĄ. ąöčĆčāą│ą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ 32-ą▒ąĖčéąĮąŠą╣ ą┤ą╗ąĖąĮčŗ ą╝ąŠąČąĄčé ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čéčī ąĮą░čüčŗčēąĄąĮąĖąĄ. ąśąĮčüčéčĆčāą║čåąĖčÅ DSP čĆą░ąĘą╝ąĄčĆąŠą╝ ą▒ąŠą╗čīčłąĄ ą╝ąŠąČąĄčé ąĖąĮąŠą│ą┤ą░ 菹║ąŠąĮąŠą╝ąĖčéčī ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąĮą░ ą╝ąŠąČąĄčé ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ (čüą╝. "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ").
ąśąĮčüčéčĆčāą║čåąĖąĖ ą┤ą╗čÅ 16-ą▒ąĖčéąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ąŠą┐ąĄčĆą░ąĮą┤čŗ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░čģ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ, ąĖ čüąŠčģčĆą░ąĮčÅąĄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ.
ąÆčüąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ą╗čÅ 16-ą▒ąĖčéąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ąĖą╝ąĄčÄčé ą┤ą╗ąĖąĮčā 32-ą▒ąĖčéą░.
ąÆ čüąĖąĮčéą░ą║čüąĖčüąĄ, ą│ą┤ąĄ ą┐ąŠčÅą▓ą╗čÅąĄčéčüčÅ ąŠą┐čåąĖčÅ sat_flag, ąŠąĮą░ ąĘą░ą╝ąĄąĮčÅąĄčéčüčÅ ąŠą┤ąĮąĖą╝ ąĖąĘ čüą╗ąĄą┤čāčÄčēąĖčģ ąĘąĮą░č湥ąĮąĖą╣:
ŌĆó (S) ŌĆō ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ąĮą░čüčŗčēąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĮą░čüčŗčēąĄąĮąĖčÅ čüą╝. čüąĄą║čåąĖčÄ "Saturation (ąĮą░čüčŗčēąĄąĮąĖąĄ)".
ąśąĮčüčéčĆčāą║čåąĖčÅ Subtract ąĮąĄ ąĖą╝ąĄąĄčé 菹║ą▓ąĖą▓ą░ą╗ąĄąĮčéą░ ą▓čŗčćąĖčéą░ąĮąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ čüą╗ąŠąČąĄąĮąĖčÅ ą┤ą╗čÅ P-čĆąĄą│ąĖčüčéčĆąŠą▓.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čäą╗ą░ą│ąĖ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ąŠą┐ąĄčĆą░čåąĖąĖ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣". 16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą▓ą╝ąĄčüč鹥 čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r5 = r2 - r1; // ą▓čŗčćąĖčéą░ąĮąĖąĄ čü 16-ą▒ąĖčéąĮąŠą╣ ą┤ą╗ąĖąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą▒ąĄąĘ ąĮą░čüčŗčēąĄąĮąĖčÅ
r5 = r2 - r1(ns); // č鹊čé ąČąĄ čĆąĄąĘčāą╗čīčéą░čé, čćč鹊 ąĖ ą▓čŗčłąĄ, ąĮąŠ čü 32-ą▒ąĖčéąĮąŠą╣ ą┤ą╗ąĖąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ
r5 = r2 - r1(s); // ąĮą░čüčŗčēąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░
r4.l = r0.l - r7.l (ns);
r4.l = r0.l - r7.h (s); // ąĮą░čüčŗčēąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░
r0.l = r2.h - r4.l(ns);
r1.l = r3.h - r7.h(ns);
r4.h = r0.l - r7.l (ns);
r4.h = r0.l - r7.h (ns);
r0.h = r2.h - r4.l(s); // ąĮą░čüčŗčēąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░
r1.h = r3.h - r7.h(ns);
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Modify ŌĆō Decrement, Vector Add/Subtract (ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ąÆąĄą║č鹊čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ").
ąÆčŗčćąĖčéą░ąĮąĖąĄ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠą╣ ą║ąŠąĮčüčéą░ąĮčéčŗ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
register -= constant
ąĪąĖąĮčéą░ą║čüąĖčü:
Ireg -= 2; // ą┤ąĄą║čĆąĄą╝ąĄąĮčé Ireg ąĮą░ 2, čćč鹊 čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÄ // čāą║ą░ąĘą░č鹥ą╗čÅ ąĮą░ ą┐ąŠą╗čāčüą╗ąŠą▓ąŠ (a)1
Ireg -= 4; // ą┤ąĄą║čĆąĄą╝ąĄąĮčé ą░ą┤čĆąĄčüą░ čāą║ą░ąĘą░č鹥ą╗čÅ ąĮą░ čüą╗ąŠą▓ąŠ (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Ireg: ąĖąĮą┤ąĄą║čüąĮčŗąĄ čĆąĄą│ąĖčüčéčĆčŗ I0, ..., I3.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Subtract Immediate ą▓čŗčćąĖčéą░ąĄčé ąĘąĮą░č湥ąĮąĖąĄ ą║ąŠąĮčüčéą░ąĮčéčŗ ąĖąĘ ąĖąĮą┤ąĄą║čüąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░, ą▒ąĄąĘ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ ąĮą░čüčŗčēąĄąĮąĖčÅ.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą┤ą╗čÅ ą▓čŗčćąĖčéą░ąĮąĖčÅ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠą╣ ą║ąŠąĮčüčéą░ąĮčéčŗ ąĖąĘ D-čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖą╗ąĖ P-čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ąŠčéčĆąĖčåą░č鹥ą╗čīąĮčāčÄ ą║ąŠąĮčüčéą░ąĮčéčā ą▓ ąĖąĮčüčéčĆčāą║čåąĖąĖ Add Immediate.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąŁčéąĖ 16-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Add Immediate, Subtract.
[ą×ą▒čĆą░ą▒ąŠčéą║ą░ ą▓ąĮąĄčłąĮąĖčģ čüąŠą▒čŗčéąĖą╣ (External Event Management) ]
ąÆ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░čÄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą▓ąĮąĄčłąĮąĖą╝ąĖ čüąŠą▒čŗčéąĖčÅą╝ąĖ. ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĖ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹčéąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ą╗čÅ čĆą░ąĘčĆąĄčłąĄąĮąĖčÅ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ [3], ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ąĮčāąČąĮąŠąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ ąĖą╗ąĖ čüą▒čĆąŠčü [4], ąĖą╗ąĖ ą┐ąĄčĆąĄą▓ąĄčüčéąĖ ą┐čĆąŠčåąĄčüčüąŠčĆ ą▓ čüąŠčüč鹊čÅąĮąĖąĄ ąŠąČąĖą┤ą░ąĮąĖčÅ (idle state). ąśąĮčüčéčĆčāą║čåąĖčÅ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ čÅą┤čĆą░ (Core Synchronize, CSYNC) ą┤ąŠąČąĖą┤ą░ąĄčéčüčÅ ąŠą║ąŠąĮčćą░ąĮąĖčÅ ą▓čüąĄčģ ąŠą┐ąĄčĆą░čåąĖą╣, čüč鹊čÅčēąĖčģ ą▓ ąŠč湥čĆąĄą┤ąĖ, ąĖ čüąĖąĮčģčĆąŠąĮąĖąĘąĖčĆčāąĄčé (čüą▒čĆą░čüčŗą▓ą░ąĄčé, flushes) ą▒čāč乥čĆ čģčĆą░ąĮąĄąĮąĖčÅ čÅą┤čĆą░ ą┐ąĄčĆąĄą┤ ąĮą░čćą░ą╗ąŠą╝ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čüą╗ąĄą┤čāčÄčēąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąśąĮčüčéčĆčāą║čåąĖčÅ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ čüąĖčüč鹥ą╝čŗ (System Synchronize, SSYNC) ą┐čĆąĖąĮčāąČą┤ą░ąĄčé ą║ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÄ ą▓čüąĄ čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮčŗąĄ, ą┐ąĄčĆąĄčģąŠą┤ąĮčŗąĄ čüąŠčüč鹊čÅąĮąĖčÅ ą▓ čÅą┤čĆąĄ ąĖ čüąĖčüč鹥ą╝ąĄ ą┐ąĄčĆąĄą┤ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖąĄą╝ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ąöčĆčāą│ąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąŠčéą╗ą░ą┤ą║ąĖ (emulation exception), ą┐ąĄčĆąĄą▓ąĄčüčéąĖ ą┐čĆąŠčåąĄčüčüąŠčĆ ą▓ čĆąĄąČąĖą╝ 菹╝čāą╗čÅčåąĖąĖ/ąŠčéą╗ą░ą┤ą║ąĖ (Emulation mode), ą┐čĆąŠą▓ąĄčĆąĖčéčī ąĘąĮą░č湥ąĮąĖąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ, ą║ąŠčüą▓ąĄąĮąĮąŠ ą░ą┤čĆąĄčüčāąĄą╝ąŠą│ąŠ (indirectly address) ą▒ą░ą╣čéą░, ąĖą╗ąĖ ąĖąĮą║čĆąĄą╝ąĄąĮčéąĖčĆąŠą▓ą░čéčī čüč湥čéčćąĖą║ ą┐čĆąŠą│čĆą░ą╝ą╝ (Program Counter) ą▒ąĄąĘ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐ąŠą╗ąĄąĘąĮąŠą╣ čĆą░ą▒ąŠčéčŗ.
ąĪąĖąĮčéą░ą║čüąĖčü:
IDLE; // (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Idle čÅą▓ą╗čÅąĄčéčüčÅ čćą░čüčéčīčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ, ą┐ąŠą╝ąĄčēą░čÄčēąĄą╣ Blackfin ą▓ ąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ, čéą░ą║ čćč鹊ą▒čŗ ą▓ąĮąĄčłąĮčÅčÅ čüąĖčüč鹥ą╝ą░ ą╝ąŠą│ą╗ą░ ą┐ąĄčĆąĄą║ą╗čÄčćąĖčéčīčüčÅ ą╝ąĄąČą┤čā čéą░ą║č鹊ą▓čŗą╝ąĖ čćą░čüč鹊čéą░ą╝ąĖ čÅą┤čĆą░.
ąśąĮčüčéčĆčāą║čåąĖčÅ Idle ąĘą░ą┐čĆą░čłąĖą▓ą░ąĄčé ą▓čģąŠą┤ ą▓ čüąŠčüč鹊čÅąĮąĖąĄ ąŠąČąĖą┤ą░ąĮąĖčÅ ą┐čāč鹥ą╝ čāčüčéą░ąĮąŠą▓ą║ąĖ ą▒ąĖčéą░ idle_req ą▓ čĆąĄą│ąĖčüčéčĆąĄ SEQSTAT. ąŻčüčéą░ąĮąŠą▓ą║ą░ ą▒ąĖčéą░ idle_req ą┐čĆąĄą┤čłąĄčüčéą▓čāąĄčé ą┐ąŠą╝ąĄčēąĄąĮąĖčÄ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin ą▓ ąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ. ąśąĮčüčéčĆčāą║čåąĖčÅ Idle čÅą▓ą╗čÅąĄčéčüčÅ ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮčŗą╝ čüą┐ąŠčüąŠą▒ąŠą╝ čāčüčéą░ąĮąŠą▓ąĖčéčī ą▒ąĖčé idle_req ą▓ čĆąĄą│ąĖčüčéčĆąĄ SEQSTAT. ąÉčĆčģąĖč鹥ą║čéčāčĆą░ ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé čÅą▓ąĮčŗąĄ ąĘą░ą┐ąĖčüąĖ ą▓ SEQSTAT.
ąĢčüą╗ąĖ ąÆčŗ čģąŠčéąĖč鹥 ą┐ąŠą╝ąĄčüčéąĖčéčī ą┐čĆąŠčåąĄčüčüąŠčĆ ą▓ Idle mode, ąĖąĮčüčéčĆčāą║čåąĖčÅ IDLE ą┤ąŠą╗ąČąĮą░ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ ą┐čĆąĄą┤čłąĄčüčéą▓ąŠą▓ą░čéčī ąĖąĮčüčéčĆčāą║čåąĖąĖ SSYNC. ą¤ąĄčĆą▓ą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ, ą║ąŠč鹊čĆą░čÅ ąĖą┤ąĄčé ą┐ąŠčüą╗ąĄ SSYNC, ą▒čāą┤ąĄčé ą┐ąĄčĆą▓ąŠą╣ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣, ą║ąŠą│ą┤ą░ ą┐čĆąŠčåąĄčüčüąŠčĆ ą▓čŗą╣ą┤ąĄčé ąĖąĘ Idle mode.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Idle čĆą░ą▒ąŠčéą░ąĄčé č鹊ą╗čīą║ąŠ ą▓ čĆąĄąČąĖą╝ąĄ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode). ąĢčüą╗ąĖ čüą┤ąĄą╗ą░čéčī ą┐ąŠą┐čŗčéą║čā ąĄčæ ą▓čŗąĘąŠą▓ą░ ą▓ čĆąĄąČąĖą╝ąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode), č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ą│ąĄąĮąĄčĆą░čåąĖąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąĘą░čēąĖčēąĄąĮąĮąŠą│ąŠ čĆąĄčüčāčĆčüą░ (Illegal Use of Protected Resource exception).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ System Synchronize.
ąĪąĖąĮčéą░ą║čüąĖčü:
CSYNC; // (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Core Synchronize (CSYNC) ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠą╣ ąŠčüčéą░ąĮąŠą▓ą║ąĄ čģąŠą┤ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ą┐ąŠą║ą░ ąĮąĄ ąĘą░ą▓ąĄčĆčłą░čéčüčÅ ą▓čüąĄ ąŠąČąĖą┤ą░čÄčēąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ čÅą┤čĆą░ (pending core operations) ąĖ ąĮąĄ ą▒čāą┤čāčé ąĘą░čüąĖąĮčģčĆąŠąĮąĖąĘąĖčĆąŠą▓ą░ąĮčŗ ą▓čüąĄ ą▒čāč乥čĆčŗ čģčĆą░ąĮąĄąĮąĖčÅ čÅą┤čĆą░ (flushing core store buffer). ąó. ąĄ. čüą╗ąĄą┤čāčÄčēą░čÅ ą┐ąŠčüą╗ąĄ CSYNC ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓čŗą┐ąŠą╗ąĮąĖčéčüčÅ, ą┐ąŠą║ą░ ąĮąĄ ąĘą░ą▓ąĄčĆčłą░čéčüčÅ ą▓čüąĄ čŹčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ. Pending core operations ą▓ą║ą╗čÄčćą░čÄčé ą╗čÄą▒čŗąĄ čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮčŗąĄ čüąŠčüč鹊čÅąĮąĖčÅ (ąĮą░ą┐čĆąĖą╝ąĄčĆ branch prediction, čé. ąĄ. ą┐čĆąĄą┤čüą║ą░ąĘą░ąĮąĖąĄ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ) ąĖą╗ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ (exceptions). ąæčāč乥čĆ čģčĆą░ąĮąĄąĮąĖčÅ čÅą┤čĆą░ (core store buffer) čĆą░čüą┐ąŠą╗ąŠąČąĄąĮ ą╝ąĄąČą┤čā ą┐čĆąŠčåąĄčüčüąŠčĆąŠą╝ ąĖ ą┐ą░ą╝čÅčéčīčÄ ą║čŹčł L1.
CCYNC ąŠą▒čŗčćąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┐ąŠčüą╗ąĄ ąĘą░ą┐ąĖčüąĖ čÅą┤čĆąŠą╝ MMR, čćč鹊ą▒čŗ ąĖąĘą▒ąĄąČą░čéčī ąĮąĄč鹊čćąĮąŠą│ąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ: ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 CSYNC ą┤ą╗čÅ ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠą│ąŠ č湥čéą║ąŠą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ ą║ąŠą╝ą░ąĮą┤ ą┐čĆąĖ ąĘą░ą│čĆčāąĘą║ąĄ ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖąĖ (čĆą░ą▒ąŠčéą░ čü ą╝ąĄą┤ą╗ąĄąĮąĮąŠą╣ ą┐ą░ą╝čÅčéčīčÄ), ąĖą╗ąĖ ą┤ą╗čÅ č鹊ą│ąŠ, čćč鹊ą▒čŗ ąĘą░ą▓ąĄčĆčłąĖčéčī ą▓čüąĄ ą┐ąĄčĆąĄčģąŠą┤ąĮčŗąĄ čüąŠčüč鹊čÅąĮąĖčÅ čÅą┤čĆą░ ą┐ąĄčĆąĄą┤ ą┐ąĄčĆąĄą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄą╝ čĆąĄąČąĖą╝ąŠą▓ čÅą┤čĆą░. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą▓čŗą┐ąŠą╗ąĮąĖč鹥 CSYNC ą┐ąĄčĆąĄą┤ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄą╝ čĆąĄą│ąĖčüčéčĆąŠą▓, ąŠč鹊ą▒čĆą░ąČąĄąĮąĮčŗčģ ąĮą░ ą┐ą░ą╝čÅčéčī (memory-mapped registers, MMRs). CSYNC ą┤ąŠą╗ąČąĮą░ čéą░ą║ąČąĄ ą▓čŗą┤ą░ą▓ą░čéčīčüčÅ ą┐ąŠčüą╗ąĄ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą▓ MMR-čĆąĄą│ąĖčüčéčĆčŗ, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ą┤ą░ąĮąĮčŗąĄ ą┤ąŠčüčéąĖą│ą╗ąĖ čåąĄą╗ąĄą▓ąŠą│ąŠ ą╝ąĄčüčéą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą▓ MMR ą┐ąĄčĆąĄą┤ ą▓čŗą▒ąŠčĆą║ąŠą╣ ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čüą╗ąĄą┤čāčÄčēąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
ą×ą▒čŗčćąĮąŠ ą┐čĆąŠčåąĄčüčüąŠčĆ Blackfin ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ą▓čüąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĘą░ą│čĆčāąĘą║ąĖ č鹊čćąĮąŠ ą▓ č鹊ą╝ ą┐ąŠčĆčÅą┤ą║ąĄ, ą║ą░ą║ čŹč鹊 ąĘą░ą┤ą░ąĮąŠ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ. ą×ą┤ąĮą░ą║ąŠ ąĖąĘ čüąŠąŠą▒čĆą░ąČąĄąĮąĖą╣ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą░čĆčģąĖč鹥ą║čéčāčĆą░ ąĮąĄ ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé čāą┐ąŠčĆčÅą┤ąŠč湥ąĮąĮąŠčüčéčī ą╝ąĄąČą┤čā ąŠą┐ąĄčĆą░čåąĖčÅą╝ąĖ ąĘą░ą│čĆčāąĘą║ąĖ (load) ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ (store). ąŁč鹊 ąŠą▒čŗčćąĮąŠ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąŠą┐ąĄčĆą░čåąĖčÅą╝ ąĘą░ą│čĆčāąĘą║ąĖ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ ą▓ąĮąĄ ą┐ąŠčĆčÅą┤ą║ą░ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ą┐ąŠ ąŠčéąĮąŠčłąĄąĮąĖčÄ ą║ ąŠą┐ąĄčĆą░čåąĖčÅą╝ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čŹč鹊 ąŠą▒čŗčćąĮąŠ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮčŗąĄ ąĘą░ą│čĆčāąĘą║ąĖ ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ ą┐ą░ą╝čÅčéąĖ. ąĪą┐ąĄą║čāą╗čÅčéąĖą▓ąĮčŗąĄ - čŹč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą┤ąĄą╣čüčéą▓ąĖąĄ ąĘą░ą│čĆčāąĘą║ąĖ ąĘą░ą┤ą░ąĮąŠ č鹥ąŠčĆąĄčéąĖč湥čüą║ąĖ, čé. ąĄ. čÅą┤čĆąŠ ą╝ąŠąČąĄčé ą┐ąŠąĘąČąĄ ąŠčéą╝ąĄąĮąĖčéčī ąĖą╗ąĖ ą┐ąĄčĆąĄąĘą░ą┐čāčüčéąĖčéčī čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮčŗąĄ ąĘą░ą│čĆčāąĘą║ąĖ. ąĪ ą┐ąŠą╝ąŠčēčīčÄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖą╣ Core Synchronize ąĖą╗ąĖ System Synchronize ąĖ ą┐čĆą░ą▓ąĖą╗čīąĮąŠą╣ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ ąÆčŗ ą╝ąŠąČąĄč鹥 ąĖąĘą▒ąĄąČą░čéčī ąĮąĄčāą┐ąŠčĆčÅą┤ąŠč湥ąĮąĮąŠą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĖą╗ąĖ čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮąŠą│ąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ ą║ąŠą┤ą░.
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĖąĮčüčéčĆčāą║čåąĖąĖ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ (store) ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą┤ąĄą╗ą░čÄčé čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
if cc jump away_from_here; // ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčé čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮąŠąĄ ą┐čĆąĄą┤čüą║ą░ąĘą░ąĮąĖąĄ ą▓ąĄčéą▓ą╗ąĄąĮąĖą╣
csync;
r0 = [p0]; // ąĘą░ą│čĆčāąĘą║ą░ (load)
ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ąĖąĮčüčéčĆčāą║čåąĖčÅ CSYNC ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ (load) ąĮąĄ ą▒čāą┤ąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮąŠ. CSYNC ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ąŠą┐ąĄčĆą░čåąĖčÅ čāčüą╗ąŠą▓ąĮąŠą│ąŠ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ ą▒čāą┤ąĄčé ąŠą▒čĆą░ą▒ąŠčéą░ąĮą░ ąĖ ą╗čÄą▒čŗąĄ ąĖą╝ąĄčÄčēąĖąĄčüčÅ ą┤ą░ąĮąĮčŗąĄ ą▓ ą┐čĆąŠą╝ąĄąČčāč鹊čćąĮąŠą╝ ą▒čāč乥čĆąĄ čģčĆą░ąĮąĄąĮąĖčÅ čÅą┤čĆą░ ą▒čāą┤čāčé čüą▒čĆąŠčłąĄąĮčŗ ą▓ ąĖčģ ą╝ąĄčüčéą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ (flushed). ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ ą▒čāą┤čāčé ąĘą░ą▓ąĄčĆčłąĄąĮčŗ ą▓čüąĄ čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮčŗąĄ čüąŠčüč鹊čÅąĮąĖčÅ ąĖą╗ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ CSYNC.
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ System Synchronize.
ąĪąĖąĮčéą░ą║čüąĖčü:
SSYNC; // (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ System Synchronize (CSYNC) ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠą╣ ąŠčüčéą░ąĮąŠą▓ą║ąĄ čģąŠą┤ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ą┐ąŠą║ą░ ąĮąĄ ąĘą░ą▓ąĄčĆčłą░čéčüčÅ ą▓čüąĄ čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮčŗąĄ, ą┐ąĄčĆąĄčģąŠą┤ąĮčŗąĄ čüąŠčüč鹊čÅąĮąĖčÅ čÅą┤čĆą░ ąĖ čüąĖčüč鹥ą╝čŗ. ąó. ąĄ. ą┐ąŠą║ą░ SSYNC ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓čŗą┐ąŠą╗ąĮąĖčéčüčÅ, ąĮąĖą║ą░ą║ą░čÅ ąĖčģ čüą╗ąĄą┤čāčÄčēąĖčģ ąĘą░ čŹč鹊ą╣ ą║ąŠą╝ą░ąĮą┤ąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĮąĄ ą┐ąŠą┐ą░ą┤ąĄčé ą▓ ą║ąŠąĮą▓ąĄą╣ąĄčĆ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
ąśąĮčüčéčĆčāą║čåąĖčÅ SSYNC ą▓čŗą┐ąŠą╗ąĮčÅąĄčé čéčā ąČąĄ čäčāąĮą║čåąĖčÄ, čćč鹊 ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅ Core Synchronize (CSYNC). ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ SSYNC čüą▒čĆą░čüčŗą▓ą░ąĄčé (flushes, ą┤čĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, čüąĖąĮčģčĆąŠąĮąĖąĘąĖčĆčāąĄčé ą║čŹčł) ą╗čÄą▒čŗąĄ ą▒čāč乥čĆčŗ ąĘą░ą┐ąĖčüąĖ (ą╝ąĄąČą┤čā ą┐ą░ą╝čÅčéčīčÄ L1 ąĖ čüąĖčüč鹥ą╝ąĮčŗą╝ ąĖąĮč鹥čĆč乥ą╣čüąŠą╝), ąĖ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé čüąĖą│ąĮą░ą╗ ąĘą░ą┐čĆąŠčüą░ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ (Synch request signal) ą┤ą╗čÅ ą▓ąĮąĄčłąĮąĄą╣ čüąĖčüč鹥ą╝čŗ. ąŁčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ čéčĆąĄą▒čāąĄčé ą┐ąŠčüčéčāą┐ą╗ąĄąĮąĖčÅ čüąĖą│ąĮą░ą╗ą░ ą┐ąŠą┤čéą▓ąĄčƹȹ┤ąĄąĮąĖčÅ Synch_Ack ąŠčé čüąĖčüč鹥ą╝čŗ ą┤ąŠ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ SSYNC.
ąĢčüą╗ąĖ ą▒ąĖčé idle_req ą▓ čĆąĄą│ąĖčüčéčĆąĄ SEQSTAT čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą┐čĆąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ SSYNC, č鹊 ą┐čĆąŠčåąĄčüčüąŠčĆ ą┐ąĄčĆąĄčģąŠą┤ąĖčé ą▓ čüąŠčüč鹊čÅąĮąĖąĄ ąŠąČąĖą┤ą░ąĮąĖčÅ (Idle state), ąĖ ą▓čŗčüčéą░ą▓ą╗čÅąĄčé ą▓ąĮąĄčłąĮąĖą╣ čüąĖą│ąĮą░ą╗ Idle ą┐ąŠčüą╗ąĄ ą┐čĆąĖąĄą╝ą░ čüąĖą│ąĮą░ą╗ą░ Synch_Ack signal. ą¤ąŠčüą╗ąĄ ą▓čŗčüčéą░ą▓ą╗ąĄąĮąĖčÅ ą▓ąĮąĄčłąĮąĄą│ąŠ čüąĖą│ąĮą░ą╗ą░ Idle ą▓čŗčģąŠą┤ ąĖąĘ čüąŠčüč鹊čÅąĮąĖčÅ Idle čéčĆąĄą▒čāąĄčé ą┐ąŠčüčéčāą┐ą╗ąĄąĮąĖčÅ ą▓ąĮąĄčłąĮąĄą│ąŠ čüąĖą│ąĮą░ą╗ą░ ą┐čĆąŠą▒čāąČą┤ąĄąĮąĖčÅ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ (Wakeup signal).
SSYNC ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ čüčĆą░ąĘčā ą┐ąĄčĆąĄą┤ ąĖ ą┐ąŠčüą╗ąĄ ąĘą░ą┐ąĖčüąĖ ą▓ čüąĖčüč鹥ą╝ąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ MMR. ąśąĮą░č湥 čŹčäč乥ą║čé ąŠčé ąĘą░ą┐ąĖčüąĖ ą▓ MMR ą╝ąŠąČąĄčé ąĮą░čüčéčāą┐ąĖčéčī ą▓ ąĮąĄąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╣ ą╝ąŠą╝ąĄąĮčé ą▓čĆąĄą╝ąĄąĮąĖ ą┐ąŠ ąŠčéąĮąŠčłąĄąĮąĖčÄ ą║ ą┐ąŠč鹊ą║čā ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ (čé. ąĄ. ą║ ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąŠčüčéą░ą╗čīąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖą╣), ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą╝ąŠąČąĄčé ą┐ąŠą╗čāčćąĖčéčīčüčÅ ąĮąĄč鹊čćąĮąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ: ąŠą▒čŗčćąĮąŠ SSYNC ą┐ąŠą┤ą│ąŠčéą░ą▓ą╗ąĖą▓ą░ąĄčé ą░čĆčģąĖč鹥ą║čéčāčĆčā ą║ ą┐čĆąĄą║čĆą░čēąĄąĮąĖčÄ čéą░ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ ąĖą╗ąĖ ą║ ąĖąĘą╝ąĄąĮąĄąĮąĖčÄ čéą░ą║č鹊ą▓ąŠą╣ čćą░čüč鹊čéčŗ. ąÆ čéą░ą║ąĖčģ čüą╗čāčćą░čÅčģ čéąĖą┐ąĖčćąĮąŠą╣ ą▒čāą┤ąĄčé čüą╗ąĄą┤čāčÄčēą░čÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ąĖąĮčüčéčĆčāą║čåąĖą╣:
ąĖąĮčüčéčĆčāą║čåąĖčÅ...
ąĖąĮčüčéčĆčāą║čåąĖčÅ...
CLI r0; // ąĘą░ą┐čĆąĄčé ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣
idle; // čĆą░ąĘčĆąĄčłąĄąĮąĖąĄ čüąŠčüč鹊čÅąĮąĖčÅ ąŠąČąĖą┤ą░ąĮąĖčÅ (Idle state)
ssync; /* ąŚą░ą▓ąĄčĆčłąĖčéčī ą▓čüąĄ čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮčŗąĄ čüąŠčüč鹊čÅąĮąĖčÅ, ą▓čŗčüčéą░ą▓ąĖčéčī
ą▓ąĮąĄčłąĮąĖą╣ čüąĖą│ąĮą░ą╗ Sync, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ąČą┤ą░čéčī čüąĖą│ąĮą░ą╗ Synch_Ack, ąĘą░č鹥ą╝ ą▓čŗčüčéą░ą▓ąĖčéčī ą▓ąĮąĄčłąĮąĖą╣ čüąĖą│ąĮą░ą╗ Idle, ąĖ ąŠčüčéą░ą▓ą░čéčīčüčÅ ą▓ čüąŠčüč鹊čÅąĮąĖąĖ Idle, ą┐ąŠą║ą░ ąĮąĄ ą┐ąŠčüčéčāą┐ąĖčé čüąĖą│ąĮą░ą╗ Wakeup. ąÆąŠ ą▓čĆąĄą╝čÅ čŹč鹊ą│ąŠ čüąŠčüč鹊čÅąĮąĖčÅ ąŠąČąĖą┤ą░ąĮąĖčÅ čéą░ą║č鹊ą▓ą░čÅ čćą░čüč鹊čéą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖąĘą╝ąĄąĮąĄąĮą░. */
sti r0; /* ą¤čĆąĖčłąĄą╗ čüąĖą│ąĮą░ą╗ Wakeup, ą▓ąŠčüčüčéą░ąĮąŠą▓ąĖčéčī ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ. */
ąĖąĮčüčéčĆčāą║čåąĖčÅ...
ąĖąĮčüčéčĆčāą║čåąĖčÅ...
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
ąĀą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗ąĄą┤čāčÄčēčāčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ą║ąŠą┤ą░.
if cc jump away_from_here; // ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčé čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮąŠąĄ ą┐čĆąĄą┤čüą║ą░ąĘą░ąĮąĖąĄ ą▓ąĄčéą▓ą╗ąĄąĮąĖą╣
ssync;
r0 = [p0]; // ąĘą░ą│čĆčāąĘą║ą░ (load)
ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ąĖąĮčüčéčĆčāą║čåąĖčÅ SSYNC ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ (load) ąĮąĄ ą▒čāą┤ąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮąŠ. SSYNC ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ąŠą┐ąĄčĆą░čåąĖčÅ čāčüą╗ąŠą▓ąĮąŠą│ąŠ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ ą▒čāą┤ąĄčé ąŠą▒čĆą░ą▒ąŠčéą░ąĮą░ ąĖ ą╗čÄą▒čŗąĄ ąĖą╝ąĄčÄčēąĖąĄčüčÅ ą┤ą░ąĮąĮčŗąĄ ą▓ ą┐čĆąŠą╝ąĄąČčāč鹊čćąĮąŠą╝ ą▒čāč乥čĆąĄ čģčĆą░ąĮąĄąĮąĖčÅ čÅą┤čĆą░ ąĖ ą▒čāč乥čĆąĄ ąĘą░ą┐ąĖčüąĖ ą▒čāą┤čāčé čüą▒čĆąŠčłąĄąĮčŗ ą▓ ąĖčģ ą╝ąĄčüčéą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ (flushed). ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ ą▒čāą┤čāčé ąĘą░ą▓ąĄčĆčłąĄąĮčŗ ą▓čüąĄ čüąŠčüč鹊čÅąĮąĖčÅ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ SSYNC.
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Core Synchronize, Idle.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąĄčĆąĄą▓ąŠą┤ąĖčé ą┐čĆąŠčåąĄčüčüąŠčĆ ą▓ čĆąĄąČąĖą╝ ąŠčéą╗ą░ą┤ą║ąĖ. ąĪąĖąĮčéą░ą║čüąĖčü:
EMUEXCPT; // (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Force Emulation ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąŠčéą╗ą░ą┤ą║ąĖ (emulation exception), čćč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐ąĄčĆąĄą▓ąĄčüčéąĖ ą┐čĆąŠčåąĄčüčüąŠčĆ ą▓ čüąŠčüč鹊čÅąĮąĖąĄ 菹╝čāą╗čÅčåąĖąĖ (ąŠčéą╗ą░ą┤ą║ąĖ). ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ čüąŠą▒čŗčéąĖčÅ ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ čüą╝. [4].
ąÜąŠą│ą┤ą░ 菹╝čāą╗čÅčåąĖčÅ čĆą░ąĘčĆąĄčłąĄąĮą░, ą┐čĆąŠčåąĄčüčüąŠčĆ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ ą┐ąŠą╗čāčćą░ąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ, ąĖ čŹč鹊 ą┐ąĄčĆąĄą▓ąŠą┤ąĖčé ąĄą│ąŠ ą▓ čĆąĄąČąĖą╝ ąŠčéą╗ą░ą┤ą║ąĖ (emulation mode). ąÜąŠą│ą┤ą░ 菹╝čāą╗čÅčåąĖčÅ ąĘą░ą┐čĆąĄčēąĄąĮą░, EMUEXCPT ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĮąĄą┤ąŠą┐čāčüčéąĖą╝ąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ (illegal instruction exception).
ąśčüą║ą╗čÄč湥ąĮąĖąĄ 菹╝čāą╗čÅčåąĖąĖ ąĖą╝ąĄąĄčé čüą░ą╝čŗą╣ ą▓čŗčüąŠą║ąĖą╣ ą┐čĆąĖąŠčĆąĖč鹥čé ą╝ąĄąČą┤čā ą▓čüąĄą╝ąĖ čüąŠą▒čŗčéąĖčÅą╝ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Force Interrupt / Reset.
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą┐čĆąĄčēą░ąĄčé ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ. ąĪąĖąĮčéą░ą║čüąĖčü:
CLI Dreg; // ą┐čĆąĄą┤čŗą┤čāčēąĄąĄ čüąŠčüč鹊čÅąĮąĖąĄ ą▓ IMASK ą┐ąŠą╝ąĄčēą░ąĄčéčüčÅ ą▓ Dreg (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Disable Interrupts ą│ą╗ąŠą▒ą░ą╗čīąĮąŠ ąĘą░ą┐čĆąĄčēą░ąĄčé ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąĘą░ą┐ąĖčüčīčÄ ąĮčāą╗ąĄą╣ ą▓ąŠ ą▓čüąĄ ą▒ąĖčéčŗ IMASK. ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ ą┐ąĄčĆąĄą┤ čŹč鹊ą╣ ąĘą░ą┐ąĖčüčīčÄ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐ąĄčĆąĄąĮąŠčüąĖčé ą▓čüąĄ ą▒ąĖčéčŗ IMASK ą▓ čĆąĄą│ąĖčüčéčĆ, čāą║ą░ąĘą░ąĮąĮčŗą╣ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝, čćč鹊ą▒čŗ čüąŠčģčĆą░ąĮąĖčéčī č鹥ą║čāčēąĄąĄ čüąŠčüč鹊čÅąĮąĖąĄ čüąĖčüč鹥ą╝čŗ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣.
ąśąĮčüčéčĆčāą║čåąĖčÅ Disable Interrupts ąĮąĄ ą╝ą░čüą║ąĖčĆčāąĄčé (ąĮąĄ ąŠčéą╝ąĄąĮčÅąĄčé) ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ NMI, čüą▒čĆąŠčüą░ (reset), ąĖčüą║ą╗čÄč湥ąĮąĖčÅ (exceptions) ąĖ ąŠčéą╗ą░ą┤ą║ąĖ (emulation).
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ: ąĖąĮčüčéčĆčāą║čåąĖčÅ CLI čćą░čüč鹊 ą▓čüčéą░ą▓ą╗čÅąĄčéčüčÅ ą┐ąĄčĆąĄą┤ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ IDLE.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ č鹊ą╗čīą║ąŠ ą▓ čĆąĄąČąĖą╝ąĄ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode). ąĢčüą╗ąĖ ą┐ąŠą┐čŗčéą░čéčīčüčÅ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąĖąĮčüčéčĆčāą║čåąĖčÄ ą▓ čĆąĄąČąĖą╝ąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode), č鹊 ą▒čāą┤ąĄčé čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąĘą░čēąĖčēąĄąĮąĮąŠą│ąŠ čĆąĄčüčāčĆčüą░ (Illegal Use of Protected Resource).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Enable Interrupts.
ąśąĮčüčéčĆčāą║čåąĖčÅ čĆą░ąĘčĆąĄčłą░ąĄčé ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ. ąĪąĖąĮčéą░ą║čüąĖčü:
STI Dreg; // ą┐čĆąĄą┤čŗą┤čāčēąĄąĄ čüąŠčüč鹊čÅąĮąĖąĄ ąĖąĘ čĆąĄą│ąĖčüčéčĆą░ Dreg ą▒čāą┤ąĄčé ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ ą▓ IMASK (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Enable Interrupts ą│ą╗ąŠą▒ą░ą╗čīąĮąŠ čĆą░ąĘčĆąĄčłą░ąĄčé ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ą┐čāč鹥ą╝ ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖčÅ ą┐čĆąĄą┤čŗą┤čāčēąĄą│ąŠ čüąŠčüč鹊čÅąĮąĖčÅ čüąĖčüč鹥ą╝čŗ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ (čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ IMASK).
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ: ąĖąĮčüčéčĆčāą║čåąĖčÅ STI čćą░čüč鹊 ą▓čüčéą░ą▓ą╗čÅąĄčéčüčÅ ą┐ąŠčüą╗ąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ IDLE, č湥ą╝ ą▒čāą┤čāčé ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮčŗ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ą┐ąŠčüą╗ąĄ ą┐čĆąŠą▒čāąČą┤ąĄąĮąĖčÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ č鹊ą╗čīą║ąŠ ą▓ čĆąĄąČąĖą╝ąĄ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode). ąĢčüą╗ąĖ ą┐ąŠą┐čŗčéą░čéčīčüčÅ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąĖąĮčüčéčĆčāą║čåąĖčÄ ą▓ čĆąĄąČąĖą╝ąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode), č鹊 ą▒čāą┤ąĄčé čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąĘą░čēąĖčēąĄąĮąĮąŠą│ąŠ čĆąĄčüčāčĆčüą░ (Illegal Use of Protected Resource).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Disable Interrupts.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓čŗąĘčŗą▓ą░ąĄčé čüčĆą░ą▒ą░čéčŗą▓ą░ąĮąĖąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ. ąĪąĖąĮčéą░ą║čüąĖčü:
RAISE uimm4; // (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
uimm4: 4-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ą┤ąĖą░ą┐ą░ąĘąŠąĮ ąĘąĮą░č湥ąĮąĖą╣ 0 .. 15.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Force Interrupt / Reset ą▓čŗąĘčŗą▓ą░ąĄčé ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮčāčÄ ą│ąĄąĮąĄčĆą░čåąĖčÄ čāą║ą░ąĘą░ąĮąĮąŠą│ąŠ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąĖą╗ąĖ čüą▒čĆąŠčüą░ (čüą╝. [4]). ą×ą▒čŗčćąĮąŠ čŹč鹊 čÅą▓ą╗čÅąĄčéčüčÅ ą╝ąĄč鹊ą┤ąŠą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ ą▓čŗąĘąŠą▓ą░ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ čüąŠą▒čŗčéąĖčÅ, čćč鹊 ą╝ąŠąČąĄčé ą┐čĆąĖą╝ąĄąĮčÅčéčīčüčÅ ą▓ čåąĄą╗čÅčģ ąŠčéą╗ą░ą┤ą║ąĖ.
ąÜąŠą│ą┤ą░ ąĮą░čćąĖąĮą░ąĄčé ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ RAISE, ą┐čĆąŠčåąĄčüčüąŠčĆ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé ą▒ąĖčé čĆąĄą│ąĖčüčéčĆą░ ILAT, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╣ ą▓ąĄą║č鹊čĆčā ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ, čāą║ą░ąĘą░ąĮąĮąŠą╝čā ą║ąŠąĮčüčéą░ąĮč鹊ą╣ uimm4 ą▓ č鹥ą╗ąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ą¤čĆąĄčĆčŗą▓ą░ąĮąĖąĄ ą▒čāą┤ąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąŠ, ą║ąŠą│ą┤ą░ ąĄą│ąŠ ą┐čĆąĖąŠčĆąĖč鹥čé ąŠą║ą░ąČąĄčéčüčÅ ą┤ąŠčüčéą░č鹊čćąĮčŗą╝ ą┤ą╗čÅ čĆą░čüą┐ąŠąĘąĮą░ą▓ą░ąĮąĖčÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą╝. ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ą│ąĄąĮąĄčĆą░čåąĖąĖ čüą╗ąĄą┤čāčÄčēąĖčģ čüąŠą▒čŗčéąĖą╣ (ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣) ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ąĘąĮą░č湥ąĮąĖčÅ ą┐ąŠą╗čÅ uimm4 (čåąĖčäčĆčŗ 0 .. 15 ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčé ąĘąĮą░č湥ąĮąĖąĄ ą┐ąŠą╗čÅ).
0. ąŚą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąŠ.
ąśąĮčüčéčĆčāą║čåąĖčÅ Force Interrupt / Reset ąĮąĄ ą╝ąŠąČąĄčé ą▓čŗąĘčŗą▓ą░čéčī čüąŠą▒čŗčéąĖčÅ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ Exception (EXC) ąĖą╗ąĖ 菹╝čāą╗čÅčåąĖąĖ Emulation (EMU); ą┤ą╗čÅ ą│ąĄąĮąĄčĆą░čåąĖąĖ čŹčéąĖčģ čüąŠą▒čŗčéąĖą╣ ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ąĖąĮčüčéčĆčāą║čåąĖąĖ EXCPT ąĖ EMUEXCPT čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ.
ąśąĮčüčéčĆčāą║čåąĖčÅ RAISE ąĮąĄ čüčĆą░ą▒ąŠčéą░ąĄčé, ą┐ąŠą║ą░ ąĮąĄ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ čüčéą░ą┤ąĖčÅ ąŠą▒čĆą░čéąĮąŠą╣ ąĘą░ą┐ąĖčüąĖ ą▓ ą║ąŠąĮą▓ąĄą╣ąĄčĆąĄ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ č鹊ą╗čīą║ąŠ ą▓ čĆąĄąČąĖą╝ąĄ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode). ąĢčüą╗ąĖ ą┐ąŠą┐čŗčéą░čéčīčüčÅ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąĖąĮčüčéčĆčāą║čåąĖčÄ ą▓ čĆąĄąČąĖą╝ąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode), č鹊 ą▒čāą┤ąĄčé čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąĘą░čēąĖčēąĄąĮąĮąŠą│ąŠ čĆąĄčüčāčĆčüą░ (Illegal Use of Protected Resource).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
raise 1 ; // ąĪą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī čüą▒čĆąŠčü (RST)
raise 6 ; // ąĪą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ čéą░ą╣ą╝ąĄčĆą░ (IVTMR)
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Force Exception (EXCPT), Force Emulation (EMUEXCPT).
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓čŗąĘčŗą▓ą░ąĄčé čüčĆą░ą▒ą░čéčŗą▓ą░ąĮąĖąĄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ. ąĪąĖąĮčéą░ą║čüąĖčü:
EXCPT uimm4; // (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
uimm4: 4-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ą┤ąĖą░ą┐ą░ąĘąŠąĮ ąĘąĮą░č湥ąĮąĖą╣ 0 .. 15.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Force Exception ą▓čŗąĘčŗą▓ą░ąĄčé ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮčāčÄ ą│ąĄąĮąĄčĆą░čåąĖčÄ čāą║ą░ąĘą░ąĮąĮąŠą│ąŠ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ (exception) čü ą║ąŠą┤ąŠą╝ ą▓ ą┐ąŠą╗ąĄ uimm4 (čćč鹊 čéą░ą║ąŠąĄ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ, čüą╝. [4]). ąÜąŠą│ą┤ą░ ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ EXCPT, čüąĄą║ą▓ąĄąĮčüąĄčĆ ą┐ąĄčĆąĄą┤ą░ąĄčé čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ąĮą░ ą▓ąĄą║č鹊čĆ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī.
ąÜąŠą┤ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ąĮą░ čāčĆąŠą▓ąĮąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąĖąĮčüčéčĆčāą║čåąĖčÄ Force Exception ą┤ą╗čÅ ą▓čŗąĘąŠą▓ą░ čäčāąĮą║čåąĖą╣ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ. ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé ą▒ąĖčé EVSW (ą▒ąĖčé 3) čĆąĄą│ąĖčüčéčĆą░ ILAT.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
ąĪąĖąĮčéą░ą║čüąĖčü:
TESTSET (Preg); // (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Preg: P0, ..., P5 (SP ąĖ FP ąĮąĄ čĆą░ąĘčĆąĄčłą░ąĄčéčüčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓ ą║ą░č湥čüčéą▓ąĄ čĆąĄą│ąĖčüčéčĆą░ ą┤ą╗čÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Test and Set Byte (Atomic) ąĘą░ą│čĆčāąČą░ąĄčé ą║ąŠčüą▓ąĄąĮąĮąŠ (indirectly) ą░ą┤čĆąĄčüčāąĄą╝čŗą╣ ą▒ą░ą╣čé, ą┐čĆąŠą▓ąĄčĆčÅąĄčé ąĄą│ąŠ ąĘąĮą░č湥ąĮąĖąĄ ąĮą░ 0, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé ą▓ ąĮąĄą╝ čüą░ą╝čŗą╣ čüčéą░čĆčłąĖą╣ ąĘąĮą░čćą░čēąĖą╣ ą▒ąĖčé (most significant bit, MSB), ąĮąĄ ą╝ąĄąĮčÅčÅ ąĘąĮą░č湥ąĮąĖąĄ ą▓čüąĄčģ ąŠčüčéą░ą╗čīąĮčŗčģ ą▒ąĖč鹊ą▓. ąĢčüą╗ąĖ ą▒ą░ą╣čé ąĖąĘąĮą░čćą░ą╗čīąĮąŠ ą▒čŗą╗ čĆą░ą▓ąĄąĮ 0, č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ čāčüčéą░ąĮąŠą▓ąĖčé ą▒ąĖčé CC. ąĢčüą╗ąĖ ąČąĄ ą▒ą░ą╣čé ąĖąĘąĮą░čćą░ą╗čīąĮąŠ ąĮąĄ ą▒čŗą╗ čĆą░ą▓ąĄąĮ 0, č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ąŠčćąĖčüčéąĖčé ą▒ąĖčé CC. ąÆčüčÅ čŹčéą░ čéčĆą░ąĮąĘą░ą║čåąĖčÅ ą┐čĆąĖ ąŠą▒čĆą░čēąĄąĮąĖąĖ ą║ ą┐ą░ą╝čÅčéąĖ čÅą▓ą╗čÅąĄčéčüčÅ ą░č鹊ą╝ą░čĆąĮąŠą╣.
TESTSET ą╝ąŠąČąĄčé ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ąŠ ą▓čüąĄą╝čā ą╗ąŠą│ąĖč湥čüą║ąŠą╝ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓čā ą░ą┤čĆąĄčüąŠą▓ ą┐ą░ą╝čÅčéąĖ, ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ ąŠą▒ą╗ą░čüčéąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ čÅą┤čĆą░ MMR (Memory-Mapped Register, ąŠč鹊ą▒čĆą░ąČąĄąĮąĮčŗąĄ ąĮą░ ą░ą┤čĆąĄčüąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ą┐ą░ą╝čÅčéąĖ čĆąĄą│ąĖčüčéčĆčŗ). ąĪąĖčüč鹥ą╝ą░ čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮą░ čéą░ą║, čćč鹊 ą┤ąŠą╗ąČąĮą░ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ą░č鹊ą╝ą░čĆąĮąŠčüčéčī ą┤ąŠčüčéčāą┐ą░ ą┤ą╗čÅ ą▓čüąĄčģ ąŠą▒ą╗ą░čüč鹥ą╣ ą┐ą░ą╝čÅčéąĖ, ą┤ą╗čÅ ą║ąŠč鹊čĆčŗčģ čĆą░ąĘčĆąĄčłąĄąĮ ą┤ąŠčüčéčāą┐ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ TESTSET. ąÉą┐ą┐ą░čĆą░čéčāčĆą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĮąĄ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ą░č鹊ą╝ą░čĆąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ L1, čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĮąŠą╣ ą║ą░ą║ SRAM. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čüąĄą╝ą░č乊čĆčŗ ąĮąĄ ą┤ąŠą╗ąČąĮčŗ ąĮą░čģąŠą┤ąĖčéčīčüčÅ ą▓ ą┐ą░ą╝čÅčéąĖ čÅą┤čĆą░.
ąÉčĆčģąĖč鹥ą║čéčāčĆą░ ą┐ą░ą╝čÅčéąĖ ą▓čüąĄą│ą┤ą░ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé ą░č鹊ą╝ą░čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ą║ą░ą║ ą┤ąŠčüčéčāą┐ čü ąĘą░ą┐čĆąĄčēąĄąĮąĮčŗą╝ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĄą╝, ą┤ą░ąČąĄ ąĄčüą╗ąĖ ą┤ąĄčüą║čĆąĖą┐č鹊čĆ CPLB ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗čÅ čŹč鹊ą│ąŠ ą░ą┤čĆąĄčüą░ čĆą░ąĘčĆąĄčłąĄąĮąĮčŗą╣ ą┤ąŠčüčéčāą┐ č湥čĆąĄąĘ ą║čŹčł. ąĢčüą╗ąĖ ą┤ąĄč鹥ą║čéąĖčĆąŠą▓ą░ąĮąŠ ą┐ąŠą┐ą░ą┤ą░ąĮąĖąĄ ą▓ ą║čŹčł, č鹊 ąŠą┐ąĄčĆą░čåąĖčÅ čüąĖąĮčģčĆąŠąĮąĖąĘąĖčĆčāąĄčé ą║čŹčł (flushes) ąĖ ą┤ąĄą╗ą░ąĄčé ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą╣ čüčéčĆąŠą║čā ą║čŹčłą░ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ą▒čāą┤ąĄčé čĆą░ąĘčĆąĄčłąĄąĮąŠ ą▓čŗą┐ąŠą╗ąĮąĖčéčīčüčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ TESTSET.
ąĀą░ąĘčĆą░ą▒ąŠčéčćąĖą║ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖčÅ ąŠčéą▓ąĄčćą░ąĄčé ąĘą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą░č鹊ą╝ą░čĆąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣ ą▓ ą┐čĆą░ą▓ąĖą╗čīąĮąŠą╝ (ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ / ąĮąĄ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ) ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąĄ ą┐ą░ą╝čÅčéąĖ. ą×ą▒čŗčćąĮąŠ čŹčéąĖ ąŠą┐ąĄčĆą░čåąĖąĖ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┤ą╗čÅ ąĮąĄ ą║čŹčłąĖčĆčāąĄą╝ąŠą╣, ąĮą░čģąŠą┤čÅčēąĄą╣čüčÅ ą▓ąĮąĄ čÅą┤čĆą░ ą┐ą░ą╝čÅčéąĖ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą▓ąĮąĄčłąĮčÅčÅ ą┐ą░ą╝čÅčéčī SDRAM). ąÆ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čćąĖą┐ą░, ą║ąŠč鹊čĆą░čÅ čéčĆąĄą▒čāąĄčé ąČąĄčüčéą║ąŠą╣ ą┐čĆąĖą▓čÅąĘą║ąĖ ą┐ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą╝ąĄąČą┤čā ą┐čĆąŠčåąĄčüčüąŠčĆą░ą╝ąĖ ąĖą╗ąĖ ą┐čĆąŠčåąĄčüčüą░ą╝ąĖ, čĆą░ąĘčĆą░ą▒ą░čéčŗą▓ą░ąĄą╝ą░čÅ čüąĖčüč鹥ą╝ą░ ą┤ąŠą╗ąČąĮą░ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗą╣, ąĮąĄ ą║čŹčłąĖčĆčāąĄą╝čŗą╣ ą▒ą╗ąŠą║ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗą╣ čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆčÅąĄčé čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅ čüąĖčüč鹥ą╝čŗ ą┐ąŠ ą╗ą░č鹥ąĮčéąĮąŠčüčéąĖ (ą▓čĆąĄą╝ąĄąĮąĖ ąĘą░ą┤ąĄčƹȹ║ąĖ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą┤ą░ąĮąĮčŗą╝).
TESTSET ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĄčĆą▓ą░ąĮą░ ą┐ąĄčĆąĄą┤ čüčéą░ą┤ąĖąĄą╣ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ ą▓ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąĢčüą╗ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅ TESTSET ą▒čŗą╗ą░ ą┐čĆąĄčĆą▓ą░ąĮą░, č鹊 ąŠąĮą░ ąĘą░ąĮąŠą▓ąŠ ą▓čŗą┐ąŠą╗ąĮąĖčéčüčÅ ą┐čĆąĖ ą▓ąŠąĘą▓čĆą░č鹥 ąĖąĘ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ. ą¤ąŠčüą╗ąĄ čüčéą░ą┤ąĖą╣ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ ąĖą╗ąĖ ąĘą░ą│čĆčāąĘą║ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅ TESTSET ąĘą░ą▓ąĄčĆčłąĖčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ, ąĖ ą▓čüčÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī čüčéą░ą┤ąĖą╣ TESTSET ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮąĖč湥ą╝ ą┐čĆąĄčĆą▓ą░ąĮą░ (ą▒čāą┤ąĄčé ą░č鹊ą╝ą░čĆąĮąŠą╣). ąØą░ą┐čĆąĖą╝ąĄčĆ, ą╗čÄą▒čŗąĄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, čüą▓čÅąĘą░ąĮąĮčŗąĄ čü ą┐čĆąŠčüą╝ąŠčéčĆąŠą╝ CPLB ą║ą░ą║ ą┤ą╗čÅ ąŠą┐ąĄčĆą░čåąĖąĖ ąĘą░ą│čĆčāąĘą║ąĖ (load), čéą░ą║ ąĖ ą┤ą╗čÅ ąŠą┐ąĄčĆą░čåąĖą╣ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ (store) ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąĘą░ą▓ąĄčĆčłąĄąĮčŗ ą┐ąĄčĆąĄą┤ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄą╝ čüčéą░ą┤ąĖąĖ ąĘą░ą│čĆčāąĘą║ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ TESTSET.
ą”ąĄą╗ąŠčüčéąĮąŠčüčéčī ąŠą┐ąĄčĆą░čåąĖąĖ ą░č鹊ą╝ą░čĆąĮąŠčüčéąĖ TESTSET ąĘą░ą▓ąĖčüąĖčé ąŠčé ą╝ąĄčģą░ąĮąĖąĘą╝ą░ ą┤ąŠčüčéčāą┐ą░ ą║ čĆąĄčüčāčĆčüčā ą┐ą░ą╝čÅčéąĖ L2. ąĢčüą╗ąĖ ą┐ą░ą╝čÅčéčī L2 ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą░č鹊ą╝ą░čĆąĮčŗą╣ ąĘą░čģą▓ą░čé ą┤ą╗čÅ ąŠą▒ą╗ą░čüčéąĖ ą░ą┤čĆąĄčüąŠą▓, ą║ ą║ąŠč鹊čĆčŗą╝ ąÆčŗ ąŠą▒čĆą░čēą░ąĄč鹥čüčī, č鹊 ą┤ą╗čÅ ąÆą░čłąĄą│ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖčÅ ąĮąĄčé ą│ą░čĆą░ąĮčéąĖąĖ ą║ąŠčĆčĆąĄą║čéąĮąŠą│ąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ ą┤ą╗čÅ čüąĄą╝ą░č乊čĆą░. ąĪą╝. ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖčÄ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą┐ąŠ ą┐ą░ą╝čÅčéąĖ L2 ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖąĖ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą┐ąŠ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ.
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ: ąŠą▒čŗčćąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 TESTSET ą▓ ą║ą░č湥čüčéą▓ąĄ ą╝ąĄč鹊ą┤ą░ ą▓čŗą▒ąŠčĆą║ąĖ čüąĄą╝ą░č乊čĆą░ ą┤ą╗čÅ ąŠą▒ą╝ąĄąĮą░ ą┤ą░ąĮąĮčŗą╝ąĖ ą╝ąĄąČą┤čā čüąŠą┐čĆąŠčåąĄčüčüąŠčĆą░ą╝ąĖ ąĖą╗ąĖ čüą╝ąĄąČąĮčŗą╝ąĖ ą┐čĆąŠčåąĄčüčüą░ą╝ąĖ.
[ążą╗ą░ą│ąĖ ]
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé č鹊ą╗čīą║ąŠ ą░ ąŠą┤ąĖąĮ čäą╗ą░ą│ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ŌĆó CC čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ ą░ą┤čĆąĄčüčāąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ čĆą░ą▓ąĮąŠ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
ą¤ąĄčĆąĄą┤ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ TESTSET ą╝ąŠąČąĄčé ąĮą░čģąŠą┤ąĖčéčīčüčÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ CSYNC ąĖą╗ąĖ SSYNC, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ą▓čüąĄ ą┐čĆąĄą┤čŗą┤čāčēąĖąĄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĖą╗ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ą▒čŗą╗ąĖ ąŠą▒čĆą░ą▒ąŠčéą░ąĮčŗ ą┤ąŠ ąĮą░čćą░ą╗ą░ ą░č鹊ą╝ą░čĆąĮąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ.
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Core Synchronize, System Synchronize.
ą¤čāčüčéą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ. ąĪąĖąĮčéą░ą║čüąĖčü:
NOP; // (a)1
MNOP; // (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ No Op ąĖąĮą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄčé PC, ąĖ ąĮąĄ ą┤ąĄą╗ą░ąĄčé ąĮąĖą║ą░ą║ąĖčģ ą┤čĆčāą│ąĖčģ ą┤ąĄą╣čüčéą▓ąĖą╣.
ą×ą▒čŗčćąĮąŠ ąĖąĮčüčéčĆčāą║čåąĖčÅ No Op ą┤ą░ąĄčé ą▓čĆąĄą╝čÅ ą┤ą╗čÅ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐čĆąĄą┤čŗą┤čāčēąĖčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ą▒čāą┤ąĄčé ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ čüą╗ąĄą┤čāčÄčēąĖčģ ąĖąĮčüčéčĆčāą║čåąĖą╣. ąöčĆčāą│ąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ - ą│ąĄąĮąĄčĆą░čåąĖčÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ ąĘą░ą┤ąĄčƹȹĄą║ ą▓ čåąĖą║ą╗ą░čģ ąĖą╗ąĖ ą┤ą╗čÅ čĆą░ą▒ąŠčéčŗ ą▓ ą║ą░č湥čüčéą▓ąĄ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ čéą░ą╣ą╝ąĄčĆą░ ąĖ ą│ąĄąĮąĄčĆą░č鹊čĆą░ čüą║ąŠčĆąŠčüčéąĖ, ą║ąŠą│ą┤ą░ ąĮąĄčé ą▒ąŠą╗čīčłąĄ ą┤ąŠčüčéčāą┐ąĮčŗčģ čéą░ą╣ą╝ąĄčĆąŠą▓ ąĖą╗ąĖ ą│ąĄąĮąĄčĆą░č鹊čĆąŠą▓ čüą║ąŠčĆąŠčüčéąĖ.
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ: MNOP ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮą░ ą┤ą╗čÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą╣ ą▓čŗą┤ą░čćąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĘą░ą│čĆčāąĘą║ąĖ (load) ąĖą╗ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ (store) ą▒ąĄąĘ ą▓ąŠą▓ą╗ąĄč湥ąĮąĖčÅ ą▓ ąŠą┐ąĄčĆą░čåąĖąĖ 32-bit MAC ąĖą╗ąĖ ALU. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆ ]
[ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ]
ąÆ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ ąŠą▒čüčāąČą┤ą░čÄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĮčŗąĄ ą┤ą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą║čŹčłąĄą╝ (cache control). ąśčüą┐ąŠą╗čīąĘčāčÅ čŹčéąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĖ ą╝ąŠą│čāčé ą┤ąĄą╗ą░čéčī ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮąŠąĄ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ (prefetch) ąĖą╗ąĖ ąĄą│ąŠ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÄ čü ą╝ąĄčüč鹊ą╝ čģčĆą░ąĮąĄąĮąĖčÅ (flush), ą┤ąĄą╗ą░čéčī ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝ąĖ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ (invalidate data cache lines), ąĖą╗ąĖ čüąĖąĮčģčĆąŠąĮąĖąĘąĖčĆąŠą▓ą░čéčī ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣ (flush instruction cache).
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┤ąĄą╗ą░ąĄčé ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮąŠąĄ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║čŹčłą░ ą┤ą░ąĮąĮčŗą╝ąĖ. ąĪąĖąĮčéą░ą║čüąĖčü:
PREFETCH [Preg]; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ (a)1
PREFETCH [Preg++]; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Preg: P0, ..., P5, SP, FP.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Data Cache Prefetch ą┤ąĄą╗ą░ąĄčé ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮčāčÄ ą▓čŗą▒ąŠčĆą║čā čüčéčĆąŠą║ąĖ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ ą┐ąŠ čŹčäč乥ą║čéąĖą▓ąĮąŠą╝čā ą░ą┤čĆąĄčüčā, čāą║ą░ąĘą░ąĮąĮąŠą╝čā ą▓ P-čĆąĄą│ąĖčüčéčĆąĄ. ą×ą┐ąĄčĆą░čåąĖčÅ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ č鹊ą╝čā, čćč鹊 čāą║ą░ąĘą░ąĮąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▒čāą┤čāčé ą┐ąŠą╝ąĄčēąĄąĮčŗ ą▓ ą║čŹčł, ąĄčüą╗ąĖ ąŠąĮąĖ čéą░ą╝ ąĄčēąĄ ąĮąĄ ąĮą░čģąŠą┤čÅčéčüčÅ, ąĖ ąĄčüą╗ąĖ ą░ą┤čĆąĄčü ą║čŹčłąĖčĆčāąĄą╝čŗą╣ (čé. ąĄ. ąĄčüą╗ąĖ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą▒ąĖčé CPLB_L1_CHBL). ąĢčüą╗ąĖ čüčéčĆąŠą║ą░ čāąČąĄ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą║čŹčłąĄ, ąĖą╗ąĖ ąĄčüą╗ąĖ ą║čŹčł čāąČąĄ ąĘą░čģą▓ą░čéąĖą╗ą░ čüčéčĆąŠą║čā, č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą┤ąĄą╗ą░ąĄčé ąĮąĖą║ą░ą║ąĖčģ ą┤ąĄą╣čüčéą▓ąĖą╣, ąĖ ą▓ąĄą┤ąĄčé čüąĄą▒čÅ čéą░ą║ ąČąĄ, ą║ą░ą║ ąĖąĮčüčéčĆčāą║čåąĖčÅ NOP.
ą×ą┐čåąĖčÅ: ąĖąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé ą┤ąĄą╗ą░čéčī ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮčé čāą║ą░ąĘą░č鹥ą╗čÅ ąĮą░ čüčéčĆąŠą║čā ą║čŹčłą░ ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ čĆą░ąĘą╝ąĄčĆą░ čüčéčĆąŠą║ąĖ ą║čŹčłą░.
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ąŠčłąĖą▒ą║ą░ą╝/ąĖčüą║ą╗čÄč湥ąĮąĖčÅą╝ ą┤ąŠčüčéčāą┐ą░ ą┐ąŠ ą░ą┤čĆąĄčüčā (address exception violations). ąĢčüą╗ąĖ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĮą░čĆčāčłąĄąĮąĖąĄ ąĘą░čēąĖčéčŗ, čüą▓čÅąĘą░ąĮąĮąŠą╣ čü ą░ą┤čĆąĄčüąŠą╝, č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ąĄą┤ąĄčé čüąĄą▒čÅ ą║ą░ą║ NOP, ąĖ ąĮąĄ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĮą░čĆčāčłąĄąĮąĖčÅ ąĘą░čēąĖčéčŗ (protection violation exception).
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
prefetch [p2];
prefetch [p0++ ];
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┤ąĄą╗ą░ąĄčé čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÄ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ. ąĪąĖąĮčéą░ą║čüąĖčü:
FLUSH [Preg]; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ (a)1
FLUSH [Preg++]; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Preg: P0, ..., P5, SP, FP.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Data Cache Flush ą┤ąĄą╗ą░ąĄčé čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÄ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ ą║čŹčłą░ čü ą┐ą░ą╝čÅčéčīčÄ ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ, ą║ąŠč鹊čĆą░čÅ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄčéčüčÅ ą║čŹčłąĄą╝. ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓čŗą▒ąĖčĆą░ąĄčé čüčéčĆąŠą║čā ą║čŹčłą░, čüą▓čÅąĘą░ąĮąĮčāčÄ čü čāą║ą░ąĘą░ąĮąĮčŗą╝ čŹčäč乥ą║čéąĖą▓ąĮčŗą╝ ą░ą┤čĆąĄčüąŠą╝, čāą║ą░ąĘą░ąĮąĮąŠą╝ ą▓ P-čĆąĄą│ąĖčüčéčĆąĄ. ąĢčüą╗ąĖ ą┤ą░ąĮąĮčŗąĄ ą▓ ą║čŹčłąĄ "ą│čĆčÅąĘąĮčŗąĄ" (čé. ąĄ. ąŠąĮąĖ ą▒čŗą╗ąĖ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮčŗ), č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé ą┤ą░ąĮąĮčŗąĄ ą║čŹčłą░ (čŹčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ flush, ąĖą╗ąĖ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÅ) ą▓ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝čāčÄ ą┐ą░ą╝čÅčéčī ą▓čŗčüąŠą║ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ, ąĖ ą┐ąŠą╝ąĄčćą░ąĄčé čŹčéčā čüčéčĆąŠą║čā ą║čŹčłą░ ą║ą░ą║ "čćąĖčüčéčāčÄ". ąĢčüą╗ąĖ čāą║ą░ąĘą░ąĮąĮą░čÅ (ą┐ąŠ ą░ą┤čĆąĄčüčā ą▓ P-čĆąĄą│ąĖčüčéčĆąĄ) čüčéčĆąŠą║ą░ ą║čŹčłą░ ąĖ čéą░ą║ "čćąĖčüčéą░čÅ", ąĖą╗ąĖ ąĄčüą╗ąĖ ą║čŹčł ąĮąĄ čüąŠą┤ąĄčƹȹĖčé čāą║ą░ąĘą░ąĮąĮąŠą│ąŠ ą░ą┤čĆąĄčüą░, č鹊 čŹčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĖč湥ą│ąŠ ąĮąĄ ą┤ąĄą╗ą░ąĄčé, ąĖ ą▓ąĄą┤ąĄčé čüąĄą▒čÅ čéą░ą║ ąČąĄ, ą║ą░ą║ ąĖąĮčüčéčĆčāą║čåąĖčÅ NOP.
ą×ą┐čåąĖčÅ: ąĖąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé ą┤ąĄą╗ą░čéčī ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮčé čāą║ą░ąĘą░č鹥ą╗čÅ ąĮą░ čüčéčĆąŠą║čā ą║čŹčłą░ ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ čĆą░ąĘą╝ąĄčĆą░ čüčéčĆąŠą║ąĖ ą║čŹčłą░.
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ąŠčłąĖą▒ą║ą░ą╝/ąĖčüą║ą╗čÄč湥ąĮąĖčÅą╝ ą┤ąŠčüčéčāą┐ą░ ą┐ąŠ ą░ą┤čĆąĄčüčā (address exception violations). ąĢčüą╗ąĖ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĮą░čĆčāčłąĄąĮąĖąĄ ąĘą░čēąĖčéčŗ, čüą▓čÅąĘą░ąĮąĮąŠą╣ čü ą░ą┤čĆąĄčüąŠą╝, č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ąĄą┤ąĄčé čüąĄą▒čÅ ą║ą░ą║ NOP, ąĖ ąĮąĄ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĮą░čĆčāčłąĄąĮąĖčÅ ąĘą░čēąĖčéčŗ (protection violation exception).
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
flush [p2];
flush [p0++ ];
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąĄčĆąĄą▓ąŠą┤ąĖčé čüčéčĆąŠą║čā ą║čŹčłą░ ą▓ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠąĄ (ąĖą╗ąĖ "ą│čĆčÅąĘąĮąŠąĄ") čüąŠčüč鹊čÅąĮąĖąĄ. ąĪąĖąĮčéą░ą║čüąĖčü:
FLUSHINV [Preg]; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ (a)1
FLUSHINV [Preg++]; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Preg: P0, ..., P5, SP, FP.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Data Cache Invalidate ą┤ąĄą╗ą░ąĄčé ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╣ čüčéčĆąŠą║ąĖ ą║čŹčłą░. ąĪąŠą┤ąĄčƹȹĖą╝ąŠąĄ P-čĆąĄą│ąĖčüčéčĆą░ ąĘą░ą┤ą░ąĄčé čüčéčĆąŠą║čā ą║čŹčłą░ (ą┐ąŠ ą░ą┤čĆąĄčüčā). ąĢčüą╗ąĖ čüčéčĆąŠą║ą░ ą┤ą░ąĮąĮčŗčģ ą┐ąŠ čāą║ą░ąĘą░ąĮąĮąŠą╝čā ą░ą┤čĆąĄčüčā ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą║čŹčłąĄ ąĖ čÅą▓ą╗čÅąĄčéčüčÅ "ą│čĆčÅąĘąĮąŠą╣", č鹊 čüčéčĆąŠą║ą░ ą║čŹčłą░ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą▓ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝čāčÄ ą┐ą░ą╝čÅčéčī ą▓čŗčüąŠą║ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ. ąĢčüą╗ąĖ čāą║ą░ąĘą░ąĮąĮą░čÅ (ą┐ąŠ ą░ą┤čĆąĄčüčā ą▓ P-čĆąĄą│ąĖčüčéčĆąĄ) čüčéčĆąŠą║ą░ ąĮąĄ čüąŠą┤ąĄčƹȹĖčéčüčÅ ą▓ ą║čŹčłąĄ, č鹊 čŹčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĖč湥ą│ąŠ ąĮąĄ ą┤ąĄą╗ą░ąĄčé, ąĖ ą▓ąĄą┤ąĄčé čüąĄą▒čÅ čéą░ą║ ąČąĄ, ą║ą░ą║ ąĖąĮčüčéčĆčāą║čåąĖčÅ NOP.
ą×ą┐čåąĖčÅ: ąĖąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé ą┤ąĄą╗ą░čéčī ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮčé čāą║ą░ąĘą░č鹥ą╗čÅ ąĮą░ čüčéčĆąŠą║čā ą║čŹčłą░ ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ čĆą░ąĘą╝ąĄčĆą░ čüčéčĆąŠą║ąĖ ą║čŹčłą░.
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ąŠčłąĖą▒ą║ą░ą╝/ąĖčüą║ą╗čÄč湥ąĮąĖčÅą╝ ą┤ąŠčüčéčāą┐ą░ ą┐ąŠ ą░ą┤čĆąĄčüčā (address exception violations). ąĢčüą╗ąĖ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĮą░čĆčāčłąĄąĮąĖąĄ ąĘą░čēąĖčéčŗ, čüą▓čÅąĘą░ąĮąĮąŠą╣ čü ą░ą┤čĆąĄčüąŠą╝, č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ąĄą┤ąĄčé čüąĄą▒čÅ ą║ą░ą║ NOP, ąĖ ąĮąĄ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĮą░čĆčāčłąĄąĮąĖčÅ ąĘą░čēąĖčéčŗ (protection violation exception).
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
flushinv [p2];
flushinv [p0++ ];
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┤ąĄą╗ą░ąĄčé čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÄ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣. ąĪąĖąĮčéą░ą║čüąĖčü:
IFLUSH [Preg]; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ (a)1
IFLUSH [Preg++]; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Preg: P0, ..., P5, SP, FP.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Instruction Cache Flush ą┤ąĄą╗ą░ąĄčé ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą╣ čāą║ą░ąĘą░ąĮąĮčāčÄ čüčéčĆąŠą║čā ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣. ąĪąŠą┤ąĄčƹȹĖą╝ąŠąĄ P-čĆąĄą│ąĖčüčéčĆą░ ąĘą░ą┤ą░ąĄčé čüčéčĆąŠą║čā, ą║ąŠč鹊čĆčāčÄ ąĮčāąČąĮąŠ čüą┤ąĄą╗ą░čéčī ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą╣. ąÜčŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĮąĄ čüąŠą┤ąĄčƹȹĖčé ą▒ąĖčé "čćąĖčüč鹊čéčŗ" ą║čŹčłą░. ąĪąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ, čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ čüą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ ą▓ ą┐ą░ą╝čÅčéčī ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ.
ą×ą┐čåąĖčÅ: ąĖąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé ą┤ąĄą╗ą░čéčī ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮčé čāą║ą░ąĘą░č鹥ą╗čÅ ąĮą░ čüčéčĆąŠą║čā ą║čŹčłą░ ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ čĆą░ąĘą╝ąĄčĆą░ čüčéčĆąŠą║ąĖ ą║čŹčłą░.
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ąŠčłąĖą▒ą║ą░ą╝/ąĖčüą║ą╗čÄč湥ąĮąĖčÅą╝ ą┤ąŠčüčéčāą┐ą░ ą┐ąŠ ą░ą┤čĆąĄčüčā (address exception violations). ąĢčüą╗ąĖ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĮą░čĆčāčłąĄąĮąĖąĄ ąĘą░čēąĖčéčŗ, čüą▓čÅąĘą░ąĮąĮąŠą╣ čü ą░ą┤čĆąĄčüąŠą╝, č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ąĄą┤ąĄčé čüąĄą▒čÅ ą║ą░ą║ NOP, ąĖ ąĮąĄ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĮą░čĆčāčłąĄąĮąĖčÅ ąĘą░čēąĖčéčŗ (protection violation exception).
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
iflush [p2];
iflush [p0++ ];
[ą×ą┐ąĄčĆą░čåąĖąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą▓ąĖą┤ąĄąŠ (Video Pixel Operations) ]
ąÆ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░čÄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą┐ąŠąĘą▓ąŠą╗čÅčÄčēąĖąĄ ą╝ą░ąĮąĖą┐čāą╗ąĖčĆąŠą▓ą░čéčī č鹊čćą║ą░ą╝ąĖ ąĖąĘąŠą▒čĆą░ąČąĄąĮąĖčÅ ą▓ąĖą┤ąĄąŠ. ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĖ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹčéąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ą╗čÅ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ, ąĘą░ą┐čĆąĄčéą░ ąĖčüą║ą╗čÄč湥ąĮąĖą╣ ąĖąĘ-ąĘą░ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠą│ąŠ ą┐ąŠ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÄ ą┤ąŠčüčéčāą┐ą░ ą║ 32-ą▒ąĖčéąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ, ąĖ ą╝ąŠą│čāčé ą▓čŗą┐ąŠą╗ąĮčÅčéčī ą┤ą▓ąŠą╣ąĮčŗąĄ ąĖ čüč湥čéą▓ąĄčĆąĄąĮąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ čüą╗ąŠąČąĄąĮąĖčÅ, ą▓čŗčćąĖčéą░ąĮąĖčÅ ąĖ čāčüčĆąĄą┤ąĮąĄąĮąĖčÅ ą┤ą╗čÅ 8- ąĖ 16-čĆą░ąĘčĆčÅą┤ąĮčŗčģ ą┤ą░ąĮąĮčŗčģ.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = ALIGN8 ( src_reg_1, src_reg_0 )
dest_reg = ALIGN16 (src_reg_1, src_reg_0 )
dest_reg = ALIGN24 (src_reg_1, src_reg_0 )
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = ALIGN8 (Dreg, Dreg); // overlay 1 byte (b)1
Dreg = ALIGN16 (Dreg, Dreg); // overlay 2 bytes (b)
Dreg = ALIGN24 (Dreg, Dreg); // overlay 3 bytes (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Byte Align ą┤ąĄą╗ą░ąĄčé ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ č湥čéčŗčĆąĄčģą▒ą░ą╣čéąĮąŠą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ ąĮąĄ ą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą│ąŠ čüą╗ąŠą▓ą░ ąĖąĘ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ ą┤ą▓čāčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ą░ąĮąĮčŗčģ. ąÆąĄčĆčüąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé, ą║ą░ą║ąĖąĄ ą▒ą░ą╣čéčŗ ąĮą░ą┤ąŠ ą║ąŠą┐ąĖčĆąŠą▓ą░čéčī, ą┤čĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą▒ą░ą╣čé ą║ąŠą┐ąĖčĆčāąĄą╝ąŠą│ąŠ čüą╗ąŠą▓ą░.
ą×ą┐čåąĖąĖ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ ą╝ąŠą│čāčé ą▒čŗčéčī čéą░ą║ąĖą╝ąĖ:
ąÆąĄčĆčüąĖčÅ ALIGN16 ą▓čŗą┐ąŠą╗ąĮčÅąĄčé čéčā ąČąĄ ąŠą┐ąĄčĆą░čåąĖčÄ, čćč鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ Vector Pack, ąĖčüą┐ąŠą╗čīąĘčāčÄčēą░čÅ čüąĖąĮčéą░ą║čüąĖčü dest_reg = PACK (Dreg_lo, Dreg_hi).
ąśčüą┐ąŠą╗čīąĘčāą╣č鹥 ąĖąĮčüčéčĆčāą║čåąĖčÄ Byte Align ą┤ą╗čÅ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ ą▒ą░ą╣čé ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĄą╣ ąŠą┤ąĖąĮąŠčćąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčēąĄą╣ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐ąŠčĆčåąĖą╣ ą┤ą░ąĮąĮčŗčģ (multiple-data instructions, ąĖą╗ąĖ SIMD, čé. ąĄ. single instruction multiple data, ąŠą┤ąĖąĮąŠčćąĮčŗą╣ ą┐ąŠč鹊ą║ ąĖąĮčüčéčĆčāą║čåąĖą╣ - ą╝ąĮąŠąČąĄčüčéą▓ąĄąĮąĮčŗą╣ ą┐ąŠč鹊ą║ ą┤ą░ąĮąĮčŗčģ).
ąÆčģąŠą┤ąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ ąĮąĄ ą▒čāą┤čāčé ąĮąĄčÅą▓ąĮąŠ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮčŗ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣. ą×ą┤ąĮą░ą║ąŠ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą╝ąŠąČąĄčé ą▒čŗčéčī č鹥ą╝ ąČąĄ čüą░ą╝čŗą╝ D-čĆąĄą│ąĖčüčéčĆąŠą╝, ą║ą░ą║ ąĖ ąŠą┤ąĖąĮ ąĖąĘ čĆąĄą│ąĖčüčéčĆąŠą▓-ąĖčüč鹊čćąĮąĖą║ąŠą▓. ąÆ čéą░ą║ąŠą╝ čüą╗čāčćą░ąĄ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ąĄą╗ą░ąĄčé čÅą▓ąĮčāčÄ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÄ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ ąĖčüčģąŠą┤ąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
// ąĢčüą╗ąĖ r3 = 0xABCD 1234, ąĖ r4 = 0xBEEF DEAD, č鹊 ...
r0 = align8 (r3, r4); // ... ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé r0 = 0x34BE EFDE
r0 = align16 (r3, r4); // ... ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé r0 = 0x1234 BEEF
r0 = align24 (r3, r4); // ... ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé r0 = 0xCD12 34BE
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Vector Pack.
ąĪąĖąĮčéą░ą║čüąĖčü:
DISALGNEXCPT; // (b)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Disable Alignment Exception ą┤ą╗čÅ ąĘą░ą│čĆčāąĘą║ąĖ ą┐čĆąĄą┤ąŠčéą▓čĆą░čēą░ąĄčé ą┐ąŠčÅą▓ą╗ąĄąĮąĖąĄ ąĖčüą║ą╗čÄč湥ąĮąĖą╣, ą║ąŠč鹊čĆčŗąĄ ąĖąĮą░č湥 ą▓ąŠąĘąĮąĖą║ą╗ąĖ ą▒čŗ ą┐čĆąĖ ąŠą┐ąĄčĆą░čåąĖčÅčģ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą║ 32-ą▒ąĖčéąĮčŗą╝ čÅč湥ą╣ą║ą░ą╝ ą┐ą░ą╝čÅčéąĖ, ąĘą░ą┐čāčēąĄąĮąĮčŗčģ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ. ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé č鹊ą╗čīą║ąŠ ąĮą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ 32-ą▒ąĖčéąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░, ą┐čĆąŠąĖąĘą▓ąŠą┤čÅčēąĖąĄ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠąĄ ąŠą▒čĆą░čēąĄąĮąĖąĄ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą║ąŠčüą▓ąĄąĮąĮąŠą╣ (indirect) ą░ą┤čĆąĄčüą░čåąĖąĖ č湥čĆąĄąĘ I-čĆąĄą│ąĖčüčéčĆ.
ą¦č鹊ą▒čŗ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą┐ąŠ 32-ą▒ąĖčéąĮąŠą╣ ą│čĆą░ąĮąĖčåąĄ, ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąŠčćąĖčēąĄąĮčŗ 2 ą╝ą╗ą░ą┤čłąĖčģ ą▒ąĖčéą░ (LSB) ą░ą┤čĆąĄčüą░, ą┐ąĄčĆąĄą┤ č鹥ą╝ ą║ą░ą║ ą░ą┤čĆąĄčü ą▒čāą┤ąĄčé ą┐ąĄčĆąĄą┤ą░ąĮ ą░ą┐ą┐ą░čĆą░čéčāčĆąĄ čüąĖčüč鹥ą╝čŗ. I-čĆąĄą│ąĖčüčéčĆ ąĮąĄ ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāąĄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ DISALIGNEXCPT. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ąĮą░ ą╗čÄą▒čŗąĄ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖąĖ I-čĆąĄą│ąĖčüčéčĆą░, ą▓čŗą┐ąŠą╗ąĮąĄąĮąĮčŗąĄ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ, ąĖąĮčüčéčĆčāą║čåąĖčÅ DISALIGNEXCPT ąĮąĖą║ą░ą║ ąĮąĄ ą▓ą╗ąĖčÅąĄčé.
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ: ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ąĖąĮčüčéčĆčāą║čåąĖčÄ DISALGNEXCPT, ą║ąŠą│ą┤ą░ ąĘą░ą┐ąŠą╗ąĮčÅąĄč鹥 čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ Quad 8-Bit SIMD.
ąśąĮčüčéčĆčāą║čåąĖąĖ Quad 8-Bit SIMD čéčĆąĄą▒čāčÄčé čåąĄą╗čŗčģ 16 ą▓ąŠčüčīą╝ąĖą▒ąĖčéąĮčŗčģ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓, č湥čéčŗčĆąĄ D-čĆąĄą│ąĖčüčéčĆą░, ą║ąŠč鹊čĆčŗąĄ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąĘą░ą│čĆčāąČąĄąĮčŗ ą▓ ą║ą░č湥čüčéą▓ąĄ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓. ą×ą┐ąĄčĆą░ąĮą┤čŗ 8-ą▒ąĖčéąĮčŗąĄ, ąĖ ąĮąĄ ąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ ąŠąĮąĖ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą▓čŗčĆąŠą▓ąĮąĄąĮčŗ ą▓ ą┐ą░ą╝čÅčéąĖ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 DISALGNEXCPT ą┤ą╗čÅ ą┐čĆąĄą┤ąŠčéą▓čĆą░čēąĄąĮąĖčÅ čüą╗čāčćą░ą╣ąĮąŠą│ąŠ ą┐ąŠčÅą▓ą╗ąĄąĮąĖčÅ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą┤ą╗čÅ čéą░ą║ąĖčģ ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮčŗčģ ą┤ąŠčüčéčāą┐ąŠą▓ ą║ ą┐ą░ą╝čÅčéąĖ.
ąÆąŠ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ, ą║ąŠą│ą┤ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ Quad 8-Bit SIMD ą▓čŗą┐ąŠą╗ąĮčÅčÄčé ą┐ąŠą▒ą░ą╣čéąĮčŗą╣ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ, ą┤ą╗čÅ ąĮąĖčģ ą▒čāą┤ąĄčé ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ąŠčéą╝ąĄąĮąĄąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ. ą¤čĆąĖ čŹč鹊ą╝ ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ ą▓ą╝ąĄčłą░č鹥ą╗čīčüčéą▓ąŠ čüąŠ čüč鹊čĆąŠąĮčŗ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
disalgnexcpt || r1 = [i0++ ] || r3 = [i1++ ]; // čéčĆąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ
disalgnexcpt || [p0 ++ p1] = r5 || r3 = [i1++ ]; // č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ąĘą░ą│čĆčāąĘą║ąĖ ą▒čāą┤ąĄčé
// ąŠčéą╝ąĄąĮąĄąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ
disalgnexcpt || r0 = [p2++ ] || r3 = [i1++ ]; // č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ąĘą░ą│čĆčāąĘą║ąĖ č湥čĆąĄąĘ I-čĆąĄą│ąĖčüčéčĆ
// ąŠčéą╝ąĄąĮąĄąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Quad 8-Bit Byte Align.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = BYTEOP3P ( src_reg_0, src_reg_1 ) (LO)
dest_reg = BYTEOP3P ( src_reg_0, src_reg_1 ) (HI)
dest_reg = BYTEOP3P ( src_reg_0, src_reg_1 ) (LO, R)
dest_reg = BYTEOP3P ( src_reg_0, src_reg_1 ) (HI, R)
ąĪąĖąĮčéą░ą║čüąĖčü:
// ąŠą┐ąĄčĆą░ąĮą┤čŗ čü ą┐čĆčÅą╝čŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą▒ą░ą╣čé Dreg = BYTEOP3P (Dreg_pair,Dreg_pair) (LO); // čüčāą╝ą╝ą░ ą▓ ą╝ą╗ą░ą┤čłąĖčģ ą▒ą░ą╣čéą░čģ (b)1 Dreg = BYTEOP3P (Dreg_pair,Dreg_pair) (HI); // čüčāą╝ą╝ą░ ą▓ čüčéą░čĆčłąĖčģ ą▒ą░ą╣čéą░čģ (b)
// ąŠą┐ąĄčĆą░ąĮą┤čŗ čü ąŠą▒čĆą░čéąĮčŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą▒ą░ą╣čé Dreg = BYTEOP3P (Dreg_pair,Dreg_pair) (LO, R); // čüčāą╝ą╝ą░ ą▓ ą╝ą╗ą░ą┤čłąĖčģ ą▒ą░ą╣čéą░čģ (b) Dreg = BYTEOP3P (Dreg_pair,Dreg_pair) (HI, R); // čüčāą╝ą╝ą░ ą▓ čüčéą░čĆčłąĖčģ ą▒ą░ą╣čéą░čģ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7.
Dreg_pair: č鹊ą╗čīą║ąŠ ą┐ą░čĆčŗ čĆąĄą│ąĖčüčéčĆąŠą▓ R1:0, R3:2.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Dual 16-Bit Add / Clip ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé ą┤ą▓ą░ 8-ą▒ąĖčéąĮčŗčģ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓čŗčģ ąĘąĮą░č湥ąĮąĖčÅ ą║ ą┤ą▓čāą╝ 16-ą▒ąĖčéąĮčŗą╝ ąĘąĮą░č湥ąĮąĖčÅą╝ čüąŠ ąĘąĮą░ą║ąŠą╝, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ąŠą│čĆą░ąĮąĖčćąĖą▓ą░ąĄčé (ąĖą╗ąĖ ąŠą▒čĆąĄąĘą░ąĄčé, clip) čĆąĄąĘčāą╗čīčéą░čé ą┤ąŠ 8-ą▒ąĖčéąĮąŠą│ąŠ ą┤ąĖą░ą┐ą░ąĘąŠąĮą░ ą▒ąĄąĘ ąĘąĮą░ą║ą░ 0 .. 255, ą▓ą║ą╗čÄčćąĖč鹥ą╗čīąĮąŠ. ąŁč鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąČą░ąĄčé čĆąĄąĘčāą╗čīčéą░čéčŗ ą║ą░ą║ ą▒ą░ą╣čéčŗ ąĮą░ ą│čĆą░ąĮąĖčåą░čģ ą┐ąŠą╗ąŠą▓ąĖąĮ čüą╗ąŠą▓ ą▓ ąŠą┤ąĖąĮ 32-ą▒ąĖčéąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ą×ą┤ąĖąĮ ą▓ą░čĆąĖą░ąĮčé čüąĖąĮčéą░ą║čüąĖčüą░ ąĘą░ą│čĆčāąČą░ąĄčé čüčéą░čĆčłąĖą╣ ą▒ą░ą╣čé ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮąĄ čüą╗ąŠą▓ą░, ąĖ ą┤čĆčāą│ąŠą╣ ą▓ą░čĆąĖą░ąĮčé ąĘą░ą│čĆčāąČą░ąĄčé ą╝ą╗ą░ą┤čłąĖą╣ ą▒ą░ą╣čé, ą║ą░ą║ čŹč鹊 ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮąĖąČąĄ.
ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ąĖčüčģąŠą┤ąĮčŗąĄ čĆąĄą│ąĖčüčéčĆčŗ čüąŠą┤ąĄčƹȹ░čé čüą╗ąĄą┤čāčÄčēąĄąĄ:
... č鹊ą│ą┤ą░ ą▓ąĄčĆčüąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ąĘą░ą│čĆčāąČą░čÄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ ą╝ą╗ą░ą┤čłąĖą╣ ą▒ą░ą╣čé (LO), ą┐čĆąĖą▓ąĄą┤čāčé ą║ čüą╗ąĄą┤čāčÄčēąĄą╝čā čĆąĄąĘčāą╗čīčéą░čéčā:
... ąĖ ą▓ąĄčĆčüąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ąĘą░ą│čĆčāąČą░čÄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ čüčéą░čĆčłąĖą╣ ą▒ą░ą╣čé (HI), ą┐čĆąĖą▓ąĄą┤čāčé ą║ čüą╗ąĄą┤čāčÄčēąĄą╝čā čĆąĄąĘčāą╗čīčéą░čéčā:
ąÆ ą╗čÄą▒ąŠą╝ čüą╗čāčćą░ąĄ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĮčŗąĄ ą▒ą░ą╣čéčŗ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą▒čāą┤čāčé ąĘą░ą┐ąŠą╗ąĮąĄąĮčŗ 0x00.
8-ą▒ąĖčéąĮąŠąĄ ąĖ 16-ą▒ąĖčéąĮąŠąĄ čüą╗ąŠąČąĄąĮąĖąĄ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą║ą░ą║ ąŠą┐ąĄčĆą░čåąĖčÅ čüąŠ ąĘąĮą░ą║ąŠą╝. 16-ą▒ąĖčéąĮčŗą╣ ąŠą┐ąĄčĆą░ąĮą┤ ą┐ąĄčĆąĄą┤ čüą╗ąŠąČąĄąĮąĖąĄą╝ čĆą░čüčłąĖčĆčÅąĄčéčüčÅ ąĘąĮą░ą║ąŠą╝ ą┤ąŠ 32 ą▒ąĖčé.
ąÆ ą║ą░č湥čüčéą▓ąĄ ą▓čģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ąŠą┐čāčüčéąĖą╝čŗ č鹊ą╗čīą║ąŠ ą┐ą░čĆčŗ R1:0 ąĖ R3:2.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą▒ą░ą╣čé ą┐čĆčÅą╝ąŠ ą▓ ą┐ą░čĆą░čģ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ R1:0 ąĖ R3:2, ą▒ą░ąĘąĖčĆčāčÅčüčī ąĮą░ čĆąĄą│ąĖčüčéčĆą░čģ I0 ąĖ I1.
ŌĆó ąöą▓ą░ LSB čĆąĄą│ąĖčüčéčĆą░ I0 ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčé ą▒ą░ą╣č鹊ą▓ąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą┤ą╗čÅ ąĖčüčģąŠą┤ąĮąŠą╣ ą┐ą░čĆčŗ čĆąĄą│ąĖčüčéčĆąŠą▓ R1:0.
ąÆąĘą░ąĖą╝ąŠčüą▓čÅąĘčī ą╝ąĄąČą┤čā ą▒ąĖčéą░ą╝ąĖ I-čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄą╝ ą▒ą░ą╣čé ą┐ąŠą║ą░ąĘą░ąĮą░ ąĮąĖąČąĄ.
ąÆ čüą╗čāčćą░ąĄ ą┐ąŠčĆčÅą┤ą║ą░ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą╗čÅ ąĖčüč鹊čćąĮąĖą║ą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą▒ąĄąĘ ( ŌĆō , R)), ą┐čĆąĄą┤ą┐ąŠą╗ą░ą│ą░ąĄčéčüčÅ, čćč鹊 ą┐ą░čĆą░ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖčüč鹊čćąĮąĖą║ą░ čüąŠą┤ąĄčƹȹĖčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčéą▓čĆą░čēą░ąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ąĖąĮą░č湥 ą▓ąŠąĘąĮąĖą║ą╗ąĖ ą▒čŗ ą┐čĆąĖ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗčģ 32-ą▒ąĖčéąĮčŗčģ ąĘą░ą│čĆčāąĘą║ą░čģ ą┐ą░ą╝čÅčéąĖ, ąĘą░ą┐čāčēąĄąĮąĮčŗčģ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ.
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ: ąŠąĮą░ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮą░ ą┤ą╗čÅ ą░ą╗ą│ąŠčĆąĖčéą╝ąŠą▓ ą║ąŠą╝ą┐ąĄąĮčüą░čåąĖąĖ ą┤ą▓ąĖąČąĄąĮąĖčÅ ą▓ ą▓ąĖą┤ąĄąŠ (video motion compensation). ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ ąŠčüčéą░čéą║ą░ ą║ ąĘąĮą░č湥ąĮąĖčÄ ą┐ąĖą║čüąĄą╗čÅ ą▓ąĖą┤ąĄąŠ, ąĘą░ ą║ąŠč鹊čĆčŗą╝ čüą╗ąĄą┤čāąĄčé ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ ąĮą░čüčŗčēąĄąĮąĖąĄ ą▒ą░ą╣čéą░.
[ą×ą┐čåąĖąĖ ]
ąĪąĖąĮčéą░ą║čüąĖčü ( ŌĆō , R) ą╝ąĄąĮčÅąĄčé ąĮą░ ąŠą▒čĆą░čéąĮčŗą╣ ą┐ąŠčĆčÅą┤ąŠą║ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą▓ ą║ą░ąČą┤ąŠą╣ ą┐ą░čĆąĄ čĆąĄą│ąĖčüčéčĆąŠą▓. ą×ą▒čŗčćąĮčŗąĄ ą▓čŗčüąŠą║ąŠą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮčŗąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĮąĄ ą╝ąŠą│čāčé ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī čĆą░čüčģąŠą┤čŗ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą┤ą╗čÅ ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ąĖ ąŠą▒ąŠąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓čŗčģ ą┐ą░čĆ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓, čćč鹊ą▒čŗ ąŠą▒ąĄčüą┐ąĄčćąĖčéčī ą┐ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą▒ą░ą╣čé ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ. ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ąŠąĮąĖ č湥čĆąĄą┤čāčÄčé ąĖ ąĘą░ą│čĆčāąČą░čÄčé č鹊ą╗čīą║ąŠ ąŠą┤ąĮčā ą┐ą░čĆčā čĆąĄą│ąĖčüčéčĆąŠą▓ ą║ą░ąČą┤čŗą╣ čĆą░ąĘ, ąĖ ą┤ąĄą╗ą░čÄčé č湥čĆąĄą┤ąŠą▓ą░ąĮąĖąĄ ą╝ąĄąČą┤čā ą▓ąĄčĆčüąĖčÅą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü ą┐čĆčÅą╝čŗą╝ ąĖ ąŠą▒čĆą░čéąĮčŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ ą▒ą░ą╣čé. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą▒ą░ą╣čéčŗ ą╝ą╗ą░ą┤čłąĄą│ąŠ ą┐ąŠčĆčÅą┤ą║ą░ ą┐ąŠčüčéčāą┐ą░čÄčé ąĖąĘ ą╝ą╗ą░ą┤čłąĄą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą▓ ą┐ą░čĆąĄ čĆąĄą│ąĖčüčéčĆąŠą▓. ą×ą┐čåąĖčÅ ( ŌĆō , R) ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ č鹊ą╝čā, čćč鹊 ą▒ą░ą╣čéčŗ ą╝ą╗ą░ą┤čłąĄą│ąŠ ą┐ąŠčĆčÅą┤ą║ą░ ą┐ąŠčüčéčāą┐ą░čÄčé ąĖąĘ čüčéą░čĆčłąĄą│ąŠ čĆąĄą│ąĖčüčéčĆą░.
ąÆ čüą╗čāčćą░ąĄ čü ąŠą┐čåąĖąĄą╣ čĆąĄą▓ąĄčĆčüąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐ąŠčĆčÅą┤ą║ą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čüąĖąĮčéą░ą║čüąĖčü ( ŌĆō , R)), ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮą░čÅ čĆą░ąĘąĮąĖčåą░ čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, ą║ą░ą║ ą╝ąĄąĮčÅąĄčéčüčÅ ą▓ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆą░čģ ą╝ąĄčüčéą░ ą▓ąĮčāčéčĆąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ąŠą╣ ą┐ą░čĆčŗ ą▓ ąĖčģ ą┐ąŠčĆčÅą┤ą║ąĄ ą▒ą░ą╣čé. ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ą┐ą░čĆą░ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ čüąŠą┤ąĄčƹȹĖčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r3 = byteop3p (r1: 0 , r3: 2 ) (lo);
r3 = byteop3p (r1: 0 , r3: 2 ) (hi);
r3 = byteop3p (r1: 0 , r3: 2 ) (lo, r);
r3 = byteop3p (r1: 0 , r3: 2 ) (hi, r);
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Quad 8-Bit Add.
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = A1.L + A1.H, Dreg = A0.L + A0.H; // (b)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Dual 16-Bit Accumulator Extraction with Addition čüą║ą╗ą░ą┤čŗą▓ą░ąĄčé ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝ čüčéą░čĆčłąĖąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čüą╗ąŠą▓ą░ (ą▒ąĖčéčŗ 31 .. 16) ąĖ ą╝ą╗ą░ą┤čłąĖąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čüą╗ąŠą▓ą░ (ą▒ąĖčéčŗ 15 .. 0) ą▓ ą║ą░ąČą┤ąŠą╝ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąĄ ąĖ ąĘą░ą│čĆčāąČą░ąĄčé ą║ą░ąČą┤čŗą╣ ąĖąĘ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ą▓ 32-ą▒ąĖčéąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ąÜą░ąČą┤ą░čÅ 16-ą▒ąĖčéąĮą░čÅ ą┐ąŠą╗ąŠą▓ąĮąĖą║ą░ čüą╗ąŠą▓ą░ ą▓ ą║ą░ąČą┤ąŠą╝ ąĖąĘ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓ čĆą░čüčłąĖčĆčÅąĄčéčüčÅ ąĘąĮą░ą║ąŠą╝ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ąŠąĮąĖ ą▒čāą┤čāčé čüą╗ąŠąČąĄąĮčŗ ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝.
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ: Dual 16-Bit Accumulator Extraction with Addition ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ ą░ą╗ą│ąŠčĆąĖčéą╝ąŠą▓ ąŠčåąĄąĮą║ąĖ ą┤ą▓ąĖąČąĄąĮąĖčÅ (motion estimation) čüąŠą▓ą╝ąĄčüčéąĮąŠ čü ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ Quad 8-Bit Subtract-Absolute-Accumulate.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆ ]
r4= a1.l+ a1.h, r7= a0.l+ a0.h;
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Quad 8-Bit Subtract-Absolute-Accumulate.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
( dest_reg_1, dest_reg_0 ) = BYTEOP16P ( src_reg_0, src_reg_1 )
( dest_reg_1, dest_reg_0 ) = BYTEOP16P ( src_reg_0, src_reg_1 ) (R)
ąĪąĖąĮčéą░ą║čüąĖčü:
// ąŠą┐ąĄčĆą░ąĮą┤čŗ čü ą┐čĆčÅą╝čŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą▒ą░ą╣čé (Dreg, Dreg) = BYTEOP16P (Dreg_pair, Dreg_pair); // (b)1
// ąŠą┐ąĄčĆą░ąĮą┤čŗ čü ąŠą▒čĆą░čéąĮčŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą▒ą░ą╣čé (Dreg, Dreg) = BYTEOP16P (Dreg_pair, Dreg_pair) (R); // (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7.
Dreg_pair: č鹊ą╗čīą║ąŠ ą┐ą░čĆčŗ čĆąĄą│ąĖčüčéčĆąŠą▓ R1:0, R3:2.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Quad 8-Bit Add čüą║ą╗ą░ą┤čŗą▓ą░ąĄčé ą┤ą▓ą░ ąĮą░ą▒ąŠčĆą░ čćąĖčüąĄą╗ ąĖąĘ 4 ą▒ą░ą╣čé ą┐ąŠą▒ą░ą╣čéąĮąŠ, čü ą┐ąŠą▒ą░ą╣čéąĮčŗą╝ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄą╝. ąæą░ą╣č鹊ą▓čŗąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ ąĘą░ą│čĆčāąČą░čÄčéčüčÅ ą║ą░ą║ 16-ą▒ąĖčéąĮčŗąĄ, čĆą░čüčłąĖčĆąĄąĮąĮčŗąĄ ąĘąĮą░ą║ąŠą╝, ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čüą╗ąŠą▓ ą▓ ą┤ą▓ą░ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ, ą║ą░ą║ čŹč鹊 ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮąĖąČąĄ.
ąÆ ą║ą░č湥čüčéą▓ąĄ ą▓čģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ąŠą┐čāčüčéąĖą╝čŗ č鹊ą╗čīą║ąŠ ą┐ą░čĆčŗ R1:0 ąĖ R3:2.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą▒ą░ą╣čé ą┐čĆčÅą╝ąŠ ą▓ ą┐ą░čĆą░čģ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ R1:0 ąĖ R3:2, ą▒ą░ąĘąĖčĆčāčÅčüčī ąĮą░ čĆąĄą│ąĖčüčéčĆą░čģ I0 ąĖ I1.
ŌĆó ąöą▓ą░ LSB čĆąĄą│ąĖčüčéčĆą░ I0 ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčé ą▒ą░ą╣č鹊ą▓ąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą┤ą╗čÅ ąĖčüčģąŠą┤ąĮąŠą╣ ą┐ą░čĆčŗ čĆąĄą│ąĖčüčéčĆąŠą▓ R1:0.
ąÆąĘą░ąĖą╝ąŠčüą▓čÅąĘčī ą╝ąĄąČą┤čā ą▒ąĖčéą░ą╝ąĖ I-čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄą╝ ą▒ą░ą╣čé ą┐ąŠą║ą░ąĘą░ąĮą░ ąĮąĖąČąĄ.
ąÆ čüą╗čāčćą░ąĄ ą┐ąŠčĆčÅą┤ą║ą░ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą╗čÅ ąĖčüč鹊čćąĮąĖą║ą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą▒ąĄąĘ (R)), ą┐čĆąĄą┤ą┐ąŠą╗ą░ą│ą░ąĄčéčüčÅ, čćč鹊 ą┐ą░čĆą░ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖčüč鹊čćąĮąĖą║ą░ čüąŠą┤ąĄčƹȹĖčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčéą▓čĆą░čēą░ąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ąĖąĮą░č湥 ą▓ąŠąĘąĮąĖą║ą╗ąĖ ą▒čŗ ą┐čĆąĖ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗčģ 32-ą▒ąĖčéąĮčŗčģ ąĘą░ą│čĆčāąĘą║ą░čģ ą┐ą░ą╝čÅčéąĖ, ąĘą░ą┐čāčēąĄąĮąĮčŗčģ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ.
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ: čŹčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą░čĆąĖčäą╝ąĄčéąĖą║čā ą┤ą╗čÅ čāą┐ą░ą║ąŠą▓ą░ąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ, čćč鹊 čéąĖą┐ąĖčćąĮąŠ ą┤ą╗čÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą▓ąĖą┤ąĄąŠ ąĖ ąĖąĘąŠą▒čĆą░ąČąĄąĮąĖą╣.
[ą×ą┐čåąĖąĖ ]
ąĪąĖąĮčéą░ą║čüąĖčü (R) ą╝ąĄąĮčÅąĄčé ąĮą░ ąŠą▒čĆą░čéąĮčŗą╣ ą┐ąŠčĆčÅą┤ąŠą║ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą▓ ą║ą░ąČą┤ąŠą╣ ą┐ą░čĆąĄ čĆąĄą│ąĖčüčéčĆąŠą▓. ą×ą▒čŗčćąĮčŗąĄ ą▓čŗčüąŠą║ąŠą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮčŗąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĮąĄ ą╝ąŠą│čāčé ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī čĆą░čüčģąŠą┤čŗ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą┤ą╗čÅ ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ąĖ ąŠą▒ąŠąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓čŗčģ ą┐ą░čĆ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓, čćč鹊ą▒čŗ ąŠą▒ąĄčüą┐ąĄčćąĖčéčī ą┐ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą▒ą░ą╣čé ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ. ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ąŠąĮąĖ č湥čĆąĄą┤čāčÄčé ąĖ ąĘą░ą│čĆčāąČą░čÄčé č鹊ą╗čīą║ąŠ ąŠą┤ąĮčā ą┐ą░čĆčā čĆąĄą│ąĖčüčéčĆąŠą▓ ą║ą░ąČą┤čŗą╣ čĆą░ąĘ, ąĖ ą┤ąĄą╗ą░čÄčé č湥čĆąĄą┤ąŠą▓ą░ąĮąĖąĄ ą╝ąĄąČą┤čā ą▓ąĄčĆčüąĖčÅą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü ą┐čĆčÅą╝čŗą╝ ąĖ ąŠą▒čĆą░čéąĮčŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ ą▒ą░ą╣čé. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą▒ą░ą╣čéčŗ ą╝ą╗ą░ą┤čłąĄą│ąŠ ą┐ąŠčĆčÅą┤ą║ą░ ą┐ąŠčüčéčāą┐ą░čÄčé ąĖąĘ ą╝ą╗ą░ą┤čłąĄą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą▓ ą┐ą░čĆąĄ čĆąĄą│ąĖčüčéčĆąŠą▓. ą×ą┐čåąĖčÅ (R) ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ č鹊ą╝čā, čćč鹊 ą▒ą░ą╣čéčŗ ą╝ą╗ą░ą┤čłąĄą│ąŠ ą┐ąŠčĆčÅą┤ą║ą░ ą┐ąŠčüčéčāą┐ą░čÄčé ąĖąĘ čüčéą░čĆčłąĄą│ąŠ čĆąĄą│ąĖčüčéčĆą░.
ąÆ čüą╗čāčćą░ąĄ čü ąŠą┐čåąĖąĄą╣ čĆąĄą▓ąĄčĆčüąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐ąŠčĆčÅą┤ą║ą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čüąĖąĮčéą░ą║čüąĖčü (R)), ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮą░čÅ čĆą░ąĘąĮąĖčåą░ čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, ą║ą░ą║ ą╝ąĄąĮčÅąĄčéčüčÅ ą▓ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆą░čģ ą╝ąĄčüčéą░ ą▓ąĮčāčéčĆąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ąŠą╣ ą┐ą░čĆčŗ ą▓ ąĖčģ ą┐ąŠčĆčÅą┤ą║ąĄ ą▒ą░ą╣čé. ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ą┐ą░čĆą░ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ čüąŠą┤ąĄčƹȹĖčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
ą£ąĮąĄą╝ąŠąĮąĖą║ą░ ą┐ąŠą╗čāčćąĖą╗ą░ čüą▓ąŠąĄ ąĖą╝čÅ ąĖąĘ č鹊ą│ąŠ čäą░ą║čéą░, čćč鹊 ąŠą┐ąĄčĆą░ąĮą┤čŗ čÅą▓ą╗čÅčÄčéčüčÅ ą▒ą░ą╣čéą░ą╝ąĖ, čĆąĄąĘčāą╗čīčéą░čé 16-ą▒ąĖčéąĮčŗą╣, ąĖ ąĖą╝ąĄąĄčéčüčÅ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ plus ą┤ą╗čÅ čüą╗ąŠąČąĄąĮąĖčÅ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
(r1,r2)= byteop16p (r3: 2 ,r1: 0 );
(r1,r2)= byteop16p (r3: 2 ,r1: 0 ) (r);
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Quad 8-Bit Subtract.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = BYTEOP1P ( src_reg_0, src_reg_1 )
dest_reg = BYTEOP1P ( src_reg_0, src_reg_1 ) (T)
dest_reg = BYTEOP1P ( src_reg_0, src_reg_1 ) (R)
dest_reg = BYTEOP1P ( src_reg_0, src_reg_1 ) (T, R)
ąĪąĖąĮčéą░ą║čüąĖčü:
// ąŠą┐ąĄčĆą░ąĮą┤čŗ čü ą┐čĆčÅą╝čŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ ą▒ą░ą╣čé: Dreg = BYTEOP1P (Dreg_pair,Dreg_pair); // (b)1 Dreg = BYTEOP1P (Dreg_pair,Dreg_pair) (T); // ąŠą▒čĆąĄąĘą║ą░ (b)
// ąŠą┐ąĄčĆą░ąĮą┤čŗ čü ąŠą▒čĆą░čéąĮčŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ ą▒ą░ą╣čé: Dreg = BYTEOP1P (Dreg_pair,Dreg_pair) (R); // (b) Dreg = BYTEOP1P (Dreg_pair,Dreg_pair) (T, R); // ąŠą▒čĆąĄąĘą║ą░ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7.
Dreg_pair: č鹊ą╗čīą║ąŠ ą┐ą░čĆčŗ čĆąĄą│ąĖčüčéčĆąŠą▓ R1:0, R3:2.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Quad 8-Bit Average ŌĆō Byte ą▓čŗčćąĖčüą╗čÅąĄčé ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠąĄ čüčĆąĄą┤ąĮąĄąĄ ąŠčé ą┤ą▓čāčģ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓čŗčģ ąĮą░ą▒ąŠčĆą░ ąĖąĘ 4 ą▒ą░ą╣čé, čüą║ą╗ą░ą┤čŗą▓ą░čÅ ąĖčģ ą▒ą░ą╣čé ąĘą░ ą▒ą░ą╣č鹊ą╝, čü ą┐ąŠą▒ą░ą╣čéąĮčŗą╝ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄą╝. ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąČą░ąĄčé ą┐ąŠą▒ą░ą╣čéąĮąŠ ą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ ą║ą░ą║ čüąŠąĄą┤ąĖąĮąĄąĮąĮčŗąĄ ą▒ą░ą╣čéčŗ ą▓ ąŠą┤ąĖąĮ 32-ą▒ąĖčéąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ, čćč鹊 ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮąĖąČąĄ.
ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠąĄ čüčĆąĄą┤ąĮąĄąĄ (ąĖą╗ąĖ čćč鹊 ą┐ąŠą┤ čŹčéąĖą╝ ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčéčüčÅ) ą▓čŗčćąĖčüą╗čÅąĄčéčüčÅ čüą╗ąŠąČąĄąĮąĖąĄą╝ ą┤ą▓čāčģ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ ąĮą░ 1 ą▒ąĖčé, čćč鹊 ąŠąĘąĮą░čćą░ąĄčé ą┤ąĄą╗ąĄąĮąĖąĄ ąĮą░ 2.
ąśą╝ąĄąĄčéčüčÅ ą┤ą▓ąĄ ąŠą┐čåąĖąĖ ą┤ą╗čÅ čüą╝ąĄčēąĄąĮąĖčÅ čĆąĄąĘčāą╗čīčéą░čéą░ - ąŠą▒čĆąĄąĘą║ą░ (truncation) ąĖą╗ąĖ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ ą▓ą▓ąĄčĆčģ (rounding up). ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą░čĆčģąĖč鹥ą║čéčāčĆą░ ąŠą║čĆčāą│ą╗čÅąĄčé ą▓ą▓ąĄčĆčģ, ą║ąŠą│ą┤ą░ čüčāą╝ą╝ą░ ąĮąĄč湥čéąĮą░. ą×ą┤ąĮą░ą║ąŠ čüąĖąĮčéą░ą║čüąĖčü ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ąŠą┐čåąĖčÄ ąŠą▒čĆąĄąĘą║ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ąĖ ąŠą▒čĆąĄąĘą║ąĖ čüą╝. čĆą░ąĘą┤ąĄą╗ "Rounding, Truncating".
ąæąĖčé RND_MOD čĆąĄą│ąĖčüčéčĆą░ ASTAT ąĮąĖą║ą░ą║ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ą▓ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
ąÆ ą║ą░č湥čüčéą▓ąĄ ą▓čģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ąŠą┐čāčüčéąĖą╝čŗ č鹊ą╗čīą║ąŠ ą┐ą░čĆčŗ R1:0 ąĖ R3:2.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą▒ą░ą╣čé ą┐čĆčÅą╝ąŠ ą▓ ą┐ą░čĆą░čģ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ R1:0 ąĖ R3:2, ą▒ą░ąĘąĖčĆčāčÅčüčī ąĮą░ čĆąĄą│ąĖčüčéčĆą░čģ I0 ąĖ I1.
ŌĆó ąöą▓ą░ LSB čĆąĄą│ąĖčüčéčĆą░ I0 ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčé ą▒ą░ą╣č鹊ą▓ąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą┤ą╗čÅ ąĖčüčģąŠą┤ąĮąŠą╣ ą┐ą░čĆčŗ čĆąĄą│ąĖčüčéčĆąŠą▓ R1:0.
ąÆąĘą░ąĖą╝ąŠčüą▓čÅąĘčī ą╝ąĄąČą┤čā ą▒ąĖčéą░ą╝ąĖ I-čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄą╝ ą▒ą░ą╣čé ą┐ąŠą║ą░ąĘą░ąĮą░ ąĮąĖąČąĄ.
ąÆ čüą╗čāčćą░ąĄ ą┐ąŠčĆčÅą┤ą║ą░ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą╗čÅ ąĖčüč鹊čćąĮąĖą║ą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą▒ąĄąĘ (R)), ą┐čĆąĄą┤ą┐ąŠą╗ą░ą│ą░ąĄčéčüčÅ, čćč鹊 ą┐ą░čĆą░ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖčüč鹊čćąĮąĖą║ą░ čüąŠą┤ąĄčƹȹĖčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčéą▓čĆą░čēą░ąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ąĖąĮą░č湥 ą▓ąŠąĘąĮąĖą║ą╗ąĖ ą▒čŗ ą┐čĆąĖ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗčģ 32-ą▒ąĖčéąĮčŗčģ ąĘą░ą│čĆčāąĘą║ą░čģ ą┐ą░ą╝čÅčéąĖ, ąĘą░ą┐čāčēąĄąĮąĮčŗčģ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ.
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ: čŹčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą┤ą▓ąŠąĖčćąĮčāčÄ ąĖąĮč鹥čĆą┐ąŠą╗čÅčåąĖčÄ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čāčÄ ą▓ ą░ą╗ą│ąŠčĆąĖčéą╝ą░čģ ą┐ąŠąĖčüą║ą░ ą┤ą▓ąĖąČąĄąĮąĖčÅ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ ąĘą░ą┐čÅč鹊ą╣ ąĖ ą░ą╗ą│ąŠčĆąĖčéą╝ą░čģ ą║ąŠą╝ą┐ąĄąĮčüą░čåąĖąĖ ą┤ą▓ąĖąČąĄąĮąĖčÅ.
[ą×ą┐čåąĖąĖ ]
ąÆ čéą░ą▒ą╗ąĖčåąĄ ąĮąĖąČąĄ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮčŗ ąŠą┐čåąĖąĖ, ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄą╝čŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣.
ąóą░ą▒ą╗ąĖčåą░ 13-1. ą×ą┐čåąĖąĖ ą┤ą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ Options for Quad 8-Bit Average ŌĆō Byte.
ą×ą┐čåąĖčÅ ą×ą┐čåąĖčÅ
ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ ą▓ą▓ąĄčĆčģ.
(T) ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠąĄ čāčüąĄč湥ąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░.
(R) ą£ąĄąĮčÅąĄčé ą┐ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓ ą▓ ą║ą░ąČą┤ąŠą╣ ą┐ą░čĆąĄ čĆąĄą│ąĖčüčéčĆąŠą▓. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą╝ą╗ą░ą┤čłąĖąĄ ą▒ą░ą╣čéčŗ ą┐ąŠčüčéčāą┐ą░čÄčé ąĖąĘ ą╝ą╗ą░ą┤čłąĄą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą▓ čĆąĄą│ąĖčüčéčĆąŠą▓ąŠą╣ ą┐ą░čĆčŗ. ą×ą┐čåąĖčÅ (R) ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ č鹊ą╝čā, čćč鹊 ą╝ą╗ą░ą┤čłąĖąĄ ą▒ą░ą╣čéčŗ ą┐ąŠčüčéčāą┐ą░čÄčé ąĖčģ čüčéą░čĆčłąĄą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą┐ą░čĆčŗ. ą×ą┐čåąĖčÄ ą▓čŗą│ąŠą┤ąĮąŠ ą┐čĆąĖą╝ąĄąĮčÅčéčī ą┤ą╗čÅ čŹą║ąŠąĮąŠą╝ąĖąĖ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą▓ ą▓čŗčüąŠą║ąŠą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮčŗčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅčģ.
(T, R) ąÜąŠą╝ą▒ąĖąĮąĖčĆčāąĄčé ą┤ą▓ąĄ ą┐čĆąĄą┤čŗą┤čāčēąĖąĄ ąŠą┐čåąĖąĖ.
ąÆ čüą╗čāčćą░ąĄ čü ąŠą┐čåąĖąĄą╣ čĆąĄą▓ąĄčĆčüąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐ąŠčĆčÅą┤ą║ą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čüąĖąĮčéą░ą║čüąĖčü (R)), ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮą░čÅ čĆą░ąĘąĮąĖčåą░ čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, ą║ą░ą║ ą╝ąĄąĮčÅąĄčéčüčÅ ą▓ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆą░čģ ą╝ąĄčüčéą░ ą▓ąĮčāčéčĆąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ąŠą╣ ą┐ą░čĆčŗ ą▓ ąĖčģ ą┐ąŠčĆčÅą┤ą║ąĄ ą▒ą░ą╣čé. ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ą┐ą░čĆą░ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ čüąŠą┤ąĄčƹȹĖčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
ą£ąĮąĄą╝ąŠąĮąĖą║ą░ ą┐ąŠą╗čāčćąĖą╗ą░ čüą▓ąŠąĄ ąĖą╝čÅ ąĖąĘ č鹊ą│ąŠ čäą░ą║čéą░, čćč鹊 ąŠą┐ąĄčĆą░ąĮą┤čŗ čÅą▓ą╗čÅčÄčéčüčÅ ą▒ą░ą╣čéą░ą╝ąĖ, čĆąĄąĘčāą╗čīčéą░č鹊ą╝ čÅą▓ą╗čÅąĄčéčüčÅ čüą╗ąŠą▓ąŠ (word), ąĖ ąĖą╝ąĄąĄčéčüčÅ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ plus ą┤ą╗čÅ čüą╗ąŠąČąĄąĮąĖčÅ. ąĢą┤ąĖąĮčüčéą▓ąĄąĮąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé čāčüčĆąĄą┤ąĮąĄąĮąĖąĄ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r3 = byteop1p (r1: 0 , r3: 2 );
r3 = byteop1p (r1: 0 , r3: 2 ) (r);
r3 = byteop1p (r1: 0 , r3: 2 ) (t);
r3 = byteop1p (r1: 0 , r3: 2 ) (t,r);
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Quad 8-Bit Add.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = BYTEOP2P ( src_reg_0, src_reg_1 ) (RNDL)
dest_reg = BYTEOP2P ( src_reg_0, src_reg_1 ) (RNDH)
dest_reg = BYTEOP2P ( src_reg_0, src_reg_1 ) (TL)
dest_reg = BYTEOP2P ( src_reg_0, src_reg_1 ) (TH)
dest_reg = BYTEOP2P ( src_reg_0, src_reg_1 ) (RNDL, R)
dest_reg = BYTEOP2P ( src_reg_0, src_reg_1 ) (RNDH, R)
dest_reg = BYTEOP2P ( src_reg_0, src_reg_1 ) (TL, R)
dest_reg = BYTEOP2P ( src_reg_0, src_reg_1 ) (TH, R)
ąĪąĖąĮčéą░ą║čüąĖčü:
// ąŠą┐ąĄčĆą░ąĮą┤čŗ čü ą┐čĆčÅą╝čŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ ą▒ą░ą╣čé: Dreg = BYTEOP2P (Dreg_pair,Dreg_pair) (RNDL); // ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ ą▓ ą╝ą╗ą░ą┤čłąĖčģ ą▒ą░ą╣čéą░čģ (b)1 Dreg = BYTEOP2P (Dreg_pair,Dreg_pair) (RNDH); // ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ ą▓ čüčéą░čĆčłąĖčģ ą▒ą░ą╣čéą░čģ (b) Dreg = BYTEOP2P (Dreg_pair,Dreg_pair) (TL); // ąŠą▒čĆąĄąĘą║ą░ ą▓ ą╝ą╗ą░ą┤čłąĖčģ ą▒ą░ą╣čéą░čģ (b) Dreg = BYTEOP2P (Dreg_pair,Dreg_pair) (TH); // ąŠą▒čĆąĄąĘą║ą░ ą▓ čüčéą░čĆčłąĖčģ ą▒ą░ą╣čéą░čģ (b)
// ąŠą┐ąĄčĆą░ąĮą┤čŗ čü ąŠą▒čĆą░čéąĮčŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ ą▒ą░ą╣čé: Dreg = BYTEOP2P (Dreg_pair,Dreg_pair) (RNDL, R); // ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ ą▓ ą╝ą╗ą░ą┤čłąĖčģ ą▒ą░ą╣čéą░čģ (b) Dreg = BYTEOP2P (Dreg_pair,Dreg_pair) (RNDH, R); // ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ ą▓ čüčéą░čĆčłąĖčģ ą▒ą░ą╣čéą░čģ (b) Dreg = BYTEOP2P (Dreg_pair,Dreg_pair) (TL, R); // ąŠą▒čĆąĄąĘą║ą░ ą▓ ą╝ą╗ą░ą┤čłąĖčģ ą▒ą░ą╣čéą░čģ (b) Dreg = BYTEOP2P (Dreg_pair,Dreg_pair) (TH, R); // ąŠą▒čĆąĄąĘą║ą░ ą▓ čüčéą░čĆčłąĖčģ ą▒ą░ą╣čéą░čģ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7.
Dreg_pair: č鹊ą╗čīą║ąŠ ą┐ą░čĆčŗ čĆąĄą│ąĖčüčéčĆąŠą▓ R1:0, R3:2.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Quad 8-Bit Average ŌĆō Half-Word ą▓čŗčćąĖčüą╗čÅąĄčé ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠąĄ čüčĆąĄą┤ąĮąĄąĄ ąŠčé ą┤ą▓čāčģ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓čŗčģ ąĮą░ą▒ąŠčĆą░ ąĖąĘ 4 ą▒ą░ą╣čé, čüą║ą╗ą░ą┤čŗą▓ą░čÅ ąĖčģ ą▒ą░ą╣čé ąĘą░ ą▒ą░ą╣č鹊ą╝, čü ą┐ąŠą▒ą░ą╣čéąĮčŗą╝ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄą╝. ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą┤ą░ąĄčé čüčĆąĄą┤ąĮąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ ąŠčé 4 ą▒ą░ą╣čé. ą×ąĮą░ ąĘą░ą│čĆčāąČą░ąĄčé ą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗąĄ ą┐ąŠ ą│čĆą░ąĮąĖčåąĄ čüą╗ąŠą▓ą░ čĆąĄąĘčāą╗čīčéą░čéčŗ ą║ą░ą║ ą▒ą░ą╣čéčŗ ą▓ ąŠą┤ąĖąĮ 32-ą▒ąĖčéąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ, čćč鹊 ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮąĖąČąĄ.
ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ąĖčüčģąŠą┤ąĮčŗąĄ čĆąĄą│ąĖčüčéčĆčŗ čüąŠą┤ąĄčƹȹ░čé ...
... č鹊ą│ą┤ą░ ą▓ąĄčĆčüąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ąĘą░ą│čĆčāąČą░čÄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ ą╝ą╗ą░ą┤čłąĖą╣ ą▒ą░ą╣čé (čü ąŠą┐čåąĖčÅą╝ąĖ RNDL ąĖ TL) ą┤ą░ą┤čāčé čĆąĄąĘčāą╗čīčéą░čé ...
... č鹊ą│ą┤ą░ ą▓ąĄčĆčüąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ąĘą░ą│čĆčāąČą░čÄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ čüčéą░čĆčłąĖą╣ ą▒ą░ą╣čé (čü ąŠą┐čåąĖčÅą╝ąĖ RNDH ąĖ TH) ą┤ą░ą┤čāčé čĆąĄąĘčāą╗čīčéą░čé ...
ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠąĄ čüčĆąĄą┤ąĮąĄąĄ (ąĖą╗ąĖ čćč鹊 ą┐ąŠą┤ čŹčéąĖą╝ ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčéčüčÅ) ą▓čŗčćąĖčüą╗čÅąĄčéčüčÅ čüą╗ąŠąČąĄąĮąĖąĄą╝ ą┤ą▓čāčģ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ ąĮą░ 2 ą▒ąĖčéą░, čćč鹊 ąŠąĘąĮą░čćą░ąĄčé ą┤ąĄą╗ąĄąĮąĖąĄ ąĮą░ 4. ąÜąŠą│ą┤ą░ ą┐čĆąŠą╝ąĄąČčāč鹊čćąĮą░čÅ čüčāą╝ą╝ą░ ąĖąĮąŠą│ą┤ą░ ąĮąĄ ą┤ąĄą╗ąĖčéčüčÅ ąĮą░ 4, č鹊čćąĮąŠčüčéčī ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠč鹥čĆčÅąĮą░.
ąśą╝ąĄąĄčéčüčÅ ą┤ą▓ąĄ ąŠą┐čåąĖąĖ ą┤ą╗čÅ čüą╝ąĄčēąĄąĮąĖčÅ čĆąĄąĘčāą╗čīčéą░čéą░ - ąŠą▒čĆąĄąĘą║ą░ (truncation) ąĖą╗ąĖ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ ą▓ą▓ąĄčĆčģ (rounding up). ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ąĖ ąŠą▒čĆąĄąĘą║ąĖ čüą╝. čĆą░ąĘą┤ąĄą╗ "Rounding, Truncating".
ąæąĖčé RND_MOD čĆąĄą│ąĖčüčéčĆą░ ASTAT ąĮąĖą║ą░ą║ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ą▓ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
ąÆ ą║ą░č湥čüčéą▓ąĄ ą▓čģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ąŠą┐čāčüčéąĖą╝čŗ č鹊ą╗čīą║ąŠ ą┐ą░čĆčŗ R1:0 ąĖ R3:2.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą▒ą░ą╣čé ą┐čĆčÅą╝ąŠ ą▓ ą┐ą░čĆą░čģ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ R1:0 ąĖ R3:2, ą▒ą░ąĘąĖčĆčāčÅčüčī ąĮą░ čĆąĄą│ąĖčüčéčĆąĄ I0. ąæą░ą╣č鹊ą▓ąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą▓ ąŠą▒ąŠąĖčģ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆą░čģ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ąŠą┤ąĖąĮą░ą║ąŠą▓čŗą╝, ą┐ąŠčüą║ąŠą╗čīą║čā ą╗ąĖčłčī 1 čĆąĄą│ąĖčüčéčĆ čāą║ą░ąĘčŗą▓ą░ąĄčé ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ čüčĆą░ąĘčā ą┤ą╗čÅ ą┤ą▓čāčģ ą▓čģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓.
ąÆąĘą░ąĖą╝ąŠčüą▓čÅąĘčī ą╝ąĄąČą┤čā ą▒ąĖčéą░ą╝ąĖ I-čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄą╝ ą▒ą░ą╣čé ą┐ąŠą║ą░ąĘą░ąĮą░ ąĮąĖąČąĄ.
ąÆ čüą╗čāčćą░ąĄ ą┐ąŠčĆčÅą┤ą║ą░ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą╗čÅ ąĖčüč鹊čćąĮąĖą║ą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą▒ąĄąĘ (R)), ą┐čĆąĄą┤ą┐ąŠą╗ą░ą│ą░ąĄčéčüčÅ, čćč鹊 ą┐ą░čĆą░ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖčüč鹊čćąĮąĖą║ą░ čüąŠą┤ąĄčƹȹĖčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčéą▓čĆą░čēą░ąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ąĖąĮą░č湥 ą▓ąŠąĘąĮąĖą║ą╗ąĖ ą▒čŗ ą┐čĆąĖ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗčģ 32-ą▒ąĖčéąĮčŗčģ ąĘą░ą│čĆčāąĘą║ą░čģ ą┐ą░ą╝čÅčéąĖ, ąĘą░ą┐čāčēąĄąĮąĮčŗčģ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ.
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ: čŹčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą┤ą▓ąŠąĖčćąĮčāčÄ ąĖąĮč鹥čĆą┐ąŠą╗čÅčåąĖčÄ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čāčÄ ą▓ ą░ą╗ą│ąŠčĆąĖčéą╝ą░čģ ą┐ąŠąĖčüą║ą░ ą┤ą▓ąĖąČąĄąĮąĖčÅ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ ąĘą░ą┐čÅč鹊ą╣ ąĖ ą░ą╗ą│ąŠčĆąĖčéą╝ą░čģ ą║ąŠą╝ą┐ąĄąĮčüą░čåąĖąĖ ą┤ą▓ąĖąČąĄąĮąĖčÅ.
[ą×ą┐čåąĖąĖ ]
ąÆ čéą░ą▒ą╗ąĖčåąĄ ąĮąĖąČąĄ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮčŗ ąŠą┐čåąĖąĖ, ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄą╝čŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣.
ąóą░ą▒ą╗ąĖčåą░ 13-1. ą×ą┐čåąĖąĖ ą┤ą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ Options for Quad 8-Bit Average ŌĆō Byte.
ą×ą┐čåąĖčÅ ą×ą┐čåąĖčÅ
(RND-) ą×ąĘąĮą░čćą░ąĄčé ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░.
(T-) ą×ąĘąĮą░čćą░ąĄčé ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠąĄ čāčüąĄč湥ąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░ (ąŠą▒čĆąĄąĘą║ą░, čé. ąĄ. ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖąĄ ą▒ąĖčé).
(-L) ąŚą░ą│čĆčāąČą░ąĄčé čĆąĄąĘčāą╗čīčéą░čéčŗ ą▓ ą╝ą╗ą░ą┤čłąĖąĄ ą▒ą░ą╣čéčŗ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čüą╗ąŠą▓ą░ ą║ą░ąČą┤ąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
(-H) ąŚą░ą│čĆčāąČą░ąĄčé čĆąĄąĘčāą╗čīčéą░čéčŗ ą▓ čüčéą░čĆčłąĖąĄ ą▒ą░ą╣čéčŗ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čüą╗ąŠą▓ą░ ą║ą░ąČą┤ąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ..
( , R) ą£ąĄąĮčÅąĄčé ą┐ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą▒ą░ą╣čé ą▓ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆą░čģ, ą▓ ą║ą░ąČą┤ąŠą╣ čĆąĄą│ąĖčüčéčĆąŠą▓ąŠą╣ ą┐ą░čĆąĄ. ą×ą▒čŗčćąĮąŠ ą▓čŗčüąŠą║ąŠą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮčŗąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĮąĄ ą╝ąŠą│čāčé čüąĄą▒ąĄ ą┐ąŠąĘą▓ąŠą╗ąĖčéčī čéčĆą░čéąĖčéčī ą╗ąĖčłąĮąĖąĄ čéą░ą║čéčŗ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĮą░ ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║čā ąŠą▒ąŠąĖčģ ą┐ą░čĆ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓, čćč鹊ą▒čŗ ąŠą▒ąĄčüą┐ąĄčćąĖčéčī ąĮčāąČąĮčŗą╣ ą┐ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą▒ą░ą╣čé ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ. ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ąŠąĮąĖ ąĘą░ą│čĆčāąČą░čÄčé ą║ą░ąČą┤čŗą╣ čĆą░ąĘ č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ čĆąĄą│ąĖčüčéčĆ ą▓ ą┐ą░čĆąĄ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ ąĖ ą╝ąĄąĮčÅčÄčé ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü ą┐čĆčÅą╝čŗą╝ ąĖ ąŠą▒čĆą░čéąĮčŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ ą▒ą░ą╣čé. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą╝ą╗ą░ą┤čłąĖąĄ ą▒ą░ą╣čéčŗ ą┐ąŠčüčéčāą┐ą░čÄčé ąĖąĘ ą╝ą╗ą░ą┤čłąĄą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą▓ čĆąĄą│ąĖčüčéčĆąŠą▓ąŠą╣ ą┐ą░čĆąĄ. ą×ą┐čåąĖčÅ (R) ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ č鹊ą╝čā, čćč鹊 ą╝ą╗ą░ą┤čłąĖąĄ ą▒ą░ą╣čéčŗ ą┐ąŠčüčéčāą┐ą░čÄčé ąĖąĘ čüčéą░čĆčłąĄą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą┐ą░čĆčŗ.
ąÜąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąŠą┐čåąĖą╣ ą▓ ą║čĆčāą│ą╗čŗčģ čüą║ąŠą▒ą║ą░čģ (čāą║ą░ąĘą░ąĮąĮčŗąĄ č湥čĆąĄąĘ ąĘą░ą┐čÅčéčāčÄ), č鹊 ąĖčģ ą┐ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą┤čĆčāą│ ąĘą░ ą┤čĆčāą│ąŠą╝ ąĮąĄ ąĖą╝ąĄąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ.
ąÆ čüą╗čāčćą░ąĄ čü ąŠą┐čåąĖąĄą╣ čĆąĄą▓ąĄčĆčüąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐ąŠčĆčÅą┤ą║ą░ ą▒ą░ą╣čé (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čüąĖąĮčéą░ą║čüąĖčü (R)), ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮą░čÅ čĆą░ąĘąĮąĖčåą░ čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, ą║ą░ą║ ą╝ąĄąĮčÅąĄčéčüčÅ ą▓ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆą░čģ ą╝ąĄčüčéą░ ą▓ąĮčāčéčĆąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ąŠą╣ ą┐ą░čĆčŗ ą▓ ąĖčģ ą┐ąŠčĆčÅą┤ą║ąĄ ą▒ą░ą╣čé. ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ą┐ą░čĆą░ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ čüąŠą┤ąĄčƹȹĖčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
ą£ąĮąĄą╝ąŠąĮąĖą║ą░ ą┐ąŠą╗čāčćąĖą╗ą░ čüą▓ąŠąĄ ąĖą╝čÅ ąĖąĘ č鹊ą│ąŠ čäą░ą║čéą░, čćč鹊 ąŠą┐ąĄčĆą░ąĮą┤čŗ čÅą▓ą╗čÅčÄčéčüčÅ ą▒ą░ą╣čéą░ą╝ąĖ, čĆąĄąĘčāą╗čīčéą░č鹊ą╝ čÅą▓ą╗čÅąĄčéčüčÅ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čüą╗ąŠą▓ą░ (half word), ąĖ ąĖą╝ąĄąĄčéčüčÅ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ plus ą┤ą╗čÅ čüą╗ąŠąČąĄąĮąĖčÅ. ąĢą┤ąĖąĮčüčéą▓ąĄąĮąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé čāčüčĆąĄą┤ąĮąĄąĮąĖąĄ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r3 = byteop2p (r1: 0 , r3: 2 ) (rndl);
r3 = byteop2p (r1: 0 , r3: 2 ) (rndh);
r3 = byteop2p (r1: 0 , r3: 2 ) (tl);
r3 = byteop2p (r1: 0 , r3: 2 ) (th);
r3 = byteop2p (r1: 0 , r3: 2 ) (rndl, r);
r3 = byteop2p (r1: 0 , r3: 2 ) (rndh, r);
r3 = byteop2p (r1: 0 , r3: 2 ) (tl, r);
r3 = byteop2p (r1: 0 , r3: 2 ) (th, r);
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Quad 8-Bit Average - Byte.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = BYTEPACK ( src_reg_0, src_reg_1 )
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = BYTEPACK (Dreg, Dreg); // (b) 1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Quad 8-Bit Pack čāą┐ą░ą║ąŠą▓čŗą▓ą░ąĄčé ą▓ ąŠą┤ąĖąĮ čĆąĄą│ąĖčüčéčĆ č湥čéčŗčĆąĄ 8-ą▒ąĖčéąĮčŗčģ ąĘąĮą░č湥ąĮąĖčÅ, ą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗčģ ąĮą░ ą┐ąŠą╗ąŠą▓ąĖąĮčā čüą╗ąŠą▓ą░, čüąŠą┤ąĄčƹȹ░čēąĖąĄčüčÅ ą▓ ą┤ą▓čāčģ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆą░čģ.
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčéą▓čĆą░čēą░ąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ąĖąĮą░č湥 ą▓ąŠąĘąĮąĖą║ą╗ąĖ ą▒čŗ ą┐čĆąĖ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗčģ 32-ą▒ąĖčéąĮčŗčģ ąĘą░ą│čĆčāąĘą║ą░čģ ą┐ą░ą╝čÅčéąĖ, ąĘą░ą┐čāčēąĄąĮąĮčŗčģ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆ ]
ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊
R4 = 0xFEED FACE
ąóąŠą│ą┤ą░ čŹčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ąĄčĆąĮąĄčé:
R2 = 0xEFDD EDCE
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Quad 8-Bit Unpack.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
( dest_reg_1, dest_reg_0 ) = BYTEOP16M ( src_reg_0, src_reg_1 )
( dest_reg_1, dest_reg_0 ) = BYTEOP16M ( src_reg_0, src_reg_1 ) (R)
ąĪąĖąĮčéą░ą║čüąĖčü:
// ąŠą┐ąĄčĆą░ąĮą┤čŗ čü ą┐čĆčÅą╝čŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ ą▒ą░ą╣čé: (Dreg, Dreg) = BYTEOP16M ( Dreg_pair , Dreg_pair ); // (b)1
// ąŠą┐ąĄčĆą░ąĮą┤čŗ čü ąŠą▒čĆą░čéąĮčŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ ą▒ą░ą╣čé: (Dreg, Dreg) = BYTEOP16M (Dreg-pair, Dreg-pair) (R); // (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7.
Dreg_pair: č鹊ą╗čīą║ąŠ ą┐ą░čĆčŗ čĆąĄą│ąĖčüčéčĆąŠą▓ R1:0, R3:2.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Quad 8-Bit Subtract ą┐ąŠą▒ą░ą╣čéąĮąŠ ą▓čŗčćąĖčéą░ąĄčé ą┤ą▓ą░ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓čŗčģ č湥čéčŗčĆąĄčģą▒ą░ą╣čéąĮčŗčģ ąĮą░ą▒ąŠčĆą░ čćąĖčüąĄą╗, čü ą┐ąŠą▒ą░ą╣čéąĮčŗą╝ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄą╝. ą×ąĮą░ ąĘą░ą│čĆčāąČą░ąĄčé čĆąĄąĘčāą╗čīčéą░čéčŗ ą▓ ą▓ąĖą┤ąĄ ą▒ą░ą╣čé ą║ą░ą║ čĆą░čüčłąĖčĆąĄąĮąĮčŗąĄ ąĘąĮą░ą║ąŠą╝ ą┐ąŠą╗čāčüą╗ąŠą▓ą░ ą▓ ą┤ą▓ą░ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ, čćč鹊 ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮąĖąČąĄ.
ąÆ ą║ą░č湥čüčéą▓ąĄ ą▓čģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ąŠą┐čāčüčéąĖą╝čŗ č鹊ą╗čīą║ąŠ ą┐ą░čĆčŗ R1:0 ąĖ R3:2.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą▒ą░ą╣čé ą┐čĆčÅą╝ąŠ ą▓ ą┐ą░čĆą░čģ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ R1:0 ąĖ R3:2, ą▒ą░ąĘąĖčĆčāčÅčüčī ąĮą░ čĆąĄą│ąĖčüčéčĆą░čģ I0 ąĖ I1.
ŌĆó ąöą▓ą░ LSB čĆąĄą│ąĖčüčéčĆą░ I0 ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčé ą▒ą░ą╣č鹊ą▓ąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą┤ą╗čÅ ąĖčüčģąŠą┤ąĮąŠą╣ ą┐ą░čĆčŗ čĆąĄą│ąĖčüčéčĆąŠą▓ R1:0.
ąÆąĘą░ąĖą╝ąŠčüą▓čÅąĘčī ą╝ąĄąČą┤čā ą▒ąĖčéą░ą╝ąĖ I-čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄą╝ ą▒ą░ą╣čé ą┐ąŠą║ą░ąĘą░ąĮą░ ąĮąĖąČąĄ.
ąÆ čüą╗čāčćą░ąĄ ą┐ąŠčĆčÅą┤ą║ą░ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą╗čÅ ąĖčüč鹊čćąĮąĖą║ą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą▒ąĄąĘ (R)), ą┐čĆąĄą┤ą┐ąŠą╗ą░ą│ą░ąĄčéčüčÅ, čćč鹊 ą┐ą░čĆą░ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖčüč鹊čćąĮąĖą║ą░ čüąŠą┤ąĄčƹȹĖčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčéą▓čĆą░čēą░ąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ąĖąĮą░č湥 ą▓ąŠąĘąĮąĖą║ą╗ąĖ ą▒čŗ ą┐čĆąĖ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗčģ 32-ą▒ąĖčéąĮčŗčģ ąĘą░ą│čĆčāąĘą║ą░čģ ą┐ą░ą╝čÅčéąĖ, ąĘą░ą┐čāčēąĄąĮąĮčŗčģ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ.
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ: čŹčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čāą┐ą░ą║ąŠą▓ą░ąĮąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą┤ą╗čÅ ą┐čĆąŠą│čĆą░ą╝ą╝ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą▓ąĖą┤ąĄąŠ ąĖ ąĖąĘąŠą▒čĆą░ąČąĄąĮąĖą╣.
[ą×ą┐čåąĖąĖ ]
ąĪąĖąĮčéą░ą║čüąĖčü (R) ą╝ąĄąĮčÅąĄčé ą┐ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą▓ąĮčāčéčĆąĖ ą║ą░ąČą┤ąŠą╣ ą┐ą░čĆčŗ čĆąĄą│ąĖčüčéčĆąŠą▓. ą×ą▒čŗčćąĮčŗąĄ ą▓čŗčüąŠą║ąŠą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮčŗąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĮąĄ ą╝ąŠą│čāčé ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī čĆą░čüčģąŠą┤čŗ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą┤ą╗čÅ ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ąĖ ąŠą▒ąŠąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓čŗčģ ą┐ą░čĆ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓, čćč鹊ą▒čŗ ąŠą▒ąĄčüą┐ąĄčćąĖčéčī ą┐ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą▒ą░ą╣čé ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ. ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ąŠąĮąĖ č湥čĆąĄą┤čāčÄčé ąĖ ąĘą░ą│čĆčāąČą░čÄčé č鹊ą╗čīą║ąŠ ąŠą┤ąĮčā ą┐ą░čĆčā čĆąĄą│ąĖčüčéčĆąŠą▓ ą║ą░ąČą┤čŗą╣ čĆą░ąĘ, ąĖ ą┤ąĄą╗ą░čÄčé č湥čĆąĄą┤ąŠą▓ą░ąĮąĖąĄ ą╝ąĄąČą┤čā ą▓ąĄčĆčüąĖčÅą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü ą┐čĆčÅą╝čŗą╝ ąĖ ąŠą▒čĆą░čéąĮčŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ ą▒ą░ą╣čé. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą▒ą░ą╣čéčŗ ą╝ą╗ą░ą┤čłąĄą│ąŠ ą┐ąŠčĆčÅą┤ą║ą░ ą┐ąŠčüčéčāą┐ą░čÄčé ąĖąĘ ą╝ą╗ą░ą┤čłąĄą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą▓ ą┐ą░čĆąĄ čĆąĄą│ąĖčüčéčĆąŠą▓. ą×ą┐čåąĖčÅ (R) ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ č鹊ą╝čā, čćč鹊 ą▒ą░ą╣čéčŗ ą╝ą╗ą░ą┤čłąĄą│ąŠ ą┐ąŠčĆčÅą┤ą║ą░ ą┐ąŠčüčéčāą┐ą░čÄčé ąĖąĘ čüčéą░čĆčłąĄą│ąŠ čĆąĄą│ąĖčüčéčĆą░.
ąÆ čüą╗čāčćą░ąĄ čü ąŠą┐čåąĖąĄą╣ čĆąĄą▓ąĄčĆčüąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐ąŠčĆčÅą┤ą║ą░ ą▒ą░ą╣čé (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čüąĖąĮčéą░ą║čüąĖčü (R)), ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮą░čÅ čĆą░ąĘąĮąĖčåą░ čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, ą║ą░ą║ ą╝ąĄąĮčÅąĄčéčüčÅ ą▓ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆą░čģ ą╝ąĄčüčéą░ ą▓ąĮčāčéčĆąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ąŠą╣ ą┐ą░čĆčŗ ą▓ ąĖčģ ą┐ąŠčĆčÅą┤ą║ąĄ ą▒ą░ą╣čé. ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ą┐ą░čĆą░ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ čüąŠą┤ąĄčƹȹĖčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
ą£ąĮąĄą╝ąŠąĮąĖą║ą░ ą┐ąŠą╗čāčćąĖą╗ą░ čüą▓ąŠąĄ ąĖą╝čÅ ąĖąĘ č鹊ą│ąŠ čäą░ą║čéą░, čćč鹊 ąŠą┐ąĄčĆą░ąĮą┤čŗ čÅą▓ą╗čÅčÄčéčüčÅ ą▒ą░ą╣čéą░ą╝ąĖ, čĆąĄąĘčāą╗čīčéą░čé 16-ą▒ąĖčéąĮčŗą╣, ąĖ ąĖą╝ąĄąĄčéčüčÅ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ minus ą┤ą╗čÅ ą▓čŗčćąĖčéą░ąĮąĖčÅ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
(r1,r2)= byteop16m (r3: 2 ,r1: 0 );
(r1,r2)= byteop16m (r3: 2 ,r1: 0 ) (r);
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Quad 8-Bit Add.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
SAA ( src_reg_0, src_reg_1 )
SAA ( src_reg_0, src_reg_1 ) (R)
ąĪąĖąĮčéą░ą║čüąĖčü:
// ąŠą┐ąĄčĆą░ąĮą┤čŗ čü ą┐čĆčÅą╝čŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ ą▒ą░ą╣čé: SAA (Dreg_pair , Dreg_pair); // (b)1
// ąŠą┐ąĄčĆą░ąĮą┤čŗ čü ąŠą▒čĆą░čéąĮčŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ ą▒ą░ą╣čé: SAA (Dreg_pair , Dreg_pair) (R); // (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg_pair: č鹊ą╗čīą║ąŠ ą┐ą░čĆčŗ čĆąĄą│ąĖčüčéčĆąŠą▓ R1:0, R3:2.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Quad 8-Bit Subtract-Absolute-Accumulate ą▓čŗčćąĖčéą░ąĄčé č湥čéčŗčĆąĄ ą┐ą░čĆčŗ ąĘąĮą░č湥ąĮąĖą╣, ą▒ąĄčĆąĄčé ą░ą▒čüąŠą╗čÄčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ąŠčé ą║ą░ąČą┤ąŠą╣ čĆą░ąĘąĮąĖčåčŗ, ąĖ ąĮą░ą║ą░ą┐ą╗ąĖą▓ą░ąĄčé ą║ą░ąČą┤čŗą╣ čĆąĄąĘčāą╗čīčéą░čé ą▓ 16-čĆą░ąĘčĆčÅą┤ąĮčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░. ąĀąĄąĘčāą╗čīčéą░čéčŗ ą┐ąŠą╝ąĄčēą░čÄčéčüčÅ ą▓ čüčéą░čĆčłčāčÄ ąĖ ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓ A0.H, A0.L, A1.H ąĖ A1.L.
ąöą╗čÅ čŹč鹊ą╣ ąŠą┐ąĄčĆą░čåąĖąĖ ąĮąĄ ą┤ąĄą╗ą░ąĄčéčüčÅ ąĮą░čüčŗčēąĄąĮąĖąĄ.
ąÆ ą║ą░č湥čüčéą▓ąĄ ą▓čģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ąŠą┐čāčüčéąĖą╝čŗ č鹊ą╗čīą║ąŠ ą┐ą░čĆčŗ R1:0 ąĖ R3:2.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé čüą╗ąĄą┤čāčÄčēčāčÄ ą┐ąŠą▒ą░ą╣čéąĮčāčÄ čüčāą╝ą╝čā ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ ą░ą▒čüąŠą╗čÄčéąĮąŠą╣ čĆą░ąĘąĮąĖčåčŗ (sum of absolute difference, SAD):
ąóąĖą┐ąĖčćąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ ą┤ą╗čÅ N ą▒čāą┤čāčé 8 ąĖ 16, čćč鹊 čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé čĆą░ąĘą╝ąĄčĆčā ą▓ąĖą┤ąĄąŠą▒ą╗ąŠą║ą░ 8x8 ąĖ 16x16 č鹊č湥ą║ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ. 16-ą▒ąĖčéąĮčŗąĄ čĆąĄą│ąĖčüčéčĆčŗ ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąĄ ąŠą│čĆą░ąĮąĖčćąĖą▓ą░čÄčé ąŠą▒ą╗ą░čüčéčī č鹊č湥ą║ ąĖą╗ąĖ čĆą░ąĘą╝ąĄčĆ ą▒ą╗ąŠą║ą░ ą┤ąŠ čĆą░ąĘą╝ąĄčĆą░ 32x32 č鹊č湥ą║.
ą¤ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ SAA ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮąĖąČąĄ.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą▒ą░ą╣čé ą┐čĆčÅą╝ąŠ ą▓ ą┐ą░čĆą░čģ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ R1:0 ąĖ R3:2, ą▒ą░ąĘąĖčĆčāčÅčüčī ąĮą░ čĆąĄą│ąĖčüčéčĆą░čģ I0 ąĖ I1.
ŌĆó ąöą▓ą░ LSB čĆąĄą│ąĖčüčéčĆą░ I0 ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčé ą▒ą░ą╣č鹊ą▓ąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą┤ą╗čÅ ąĖčüčģąŠą┤ąĮąŠą╣ ą┐ą░čĆčŗ čĆąĄą│ąĖčüčéčĆąŠą▓ src_reg_0.
ąÆąĘą░ąĖą╝ąŠčüą▓čÅąĘčī ą╝ąĄąČą┤čā ą▒ąĖčéą░ą╝ąĖ I-čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄą╝ ą▒ą░ą╣čé ą┐ąŠą║ą░ąĘą░ąĮą░ ąĮąĖąČąĄ.
ąÆ čüą╗čāčćą░ąĄ ą┐ąŠčĆčÅą┤ą║ą░ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą╗čÅ ąĖčüč鹊čćąĮąĖą║ą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą▒ąĄąĘ (R)), ą┐čĆąĄą┤ą┐ąŠą╗ą░ą│ą░ąĄčéčüčÅ, čćč鹊 ą┐ą░čĆą░ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖčüč鹊čćąĮąĖą║ą░ čüąŠą┤ąĄčƹȹĖčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčéą▓čĆą░čēą░ąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ąĖąĮą░č湥 ą▓ąŠąĘąĮąĖą║ą╗ąĖ ą▒čŗ ą┐čĆąĖ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗčģ 32-ą▒ąĖčéąĮčŗčģ ąĘą░ą│čĆčāąĘą║ą░čģ ą┐ą░ą╝čÅčéąĖ, ąĘą░ą┐čāčēąĄąĮąĮčŗčģ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ.
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ: ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ąĖąĮčüčéčĆčāą║čåąĖčÄ Quad 8-Bit Subtract-Absolute-Accumulate ą┤ą╗čÅ ą░ą╗ą│ąŠčĆąĖčéą╝ąŠą▓ ąŠčåąĄąĮą║ąĖ ą┤ą▓ąĖąČąĄąĮąĖčÅ ąĮą░ ą▓ąĖą┤ąĄąŠ ąĮą░ ą▒ą░ąĘąĄ ą▒ą╗ąŠą║ą░, ą┐čĆąĖą╝ąĄąĮčÅčÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ čüčāą╝ą╝čŗ ą░ą▒čüąŠą╗čÄčéąĮčŗčģ čĆą░ąĘą╗ąĖčćąĖą╣ (SAD) ą┤ą╗čÅ ąĖąĘą╝ąĄčĆąĄąĮąĖčÅ ąĖčüą║ą░ąČąĄąĮąĖčÅ.
[ą×ą┐čåąĖąĖ ]
ąĪąĖąĮčéą░ą║čüąĖčü (R) ą╝ąĄąĮčÅąĄčé ą┐ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą▓ąĮčāčéčĆąĖ ą║ą░ąČą┤ąŠą╣ ą┐ą░čĆčŗ čĆąĄą│ąĖčüčéčĆąŠą▓. ą×ą▒čŗčćąĮčŗąĄ ą▓čŗčüąŠą║ąŠą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮčŗąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĮąĄ ą╝ąŠą│čāčé ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī čĆą░čüčģąŠą┤čŗ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą┤ą╗čÅ ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ąĖ ąŠą▒ąŠąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓čŗčģ ą┐ą░čĆ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓, čćč鹊ą▒čŗ ąŠą▒ąĄčüą┐ąĄčćąĖčéčī ą┐ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą▒ą░ą╣čé ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ. ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ąŠąĮąĖ č湥čĆąĄą┤čāčÄčé ąĖ ąĘą░ą│čĆčāąČą░čÄčé č鹊ą╗čīą║ąŠ ąŠą┤ąĮčā ą┐ą░čĆčā čĆąĄą│ąĖčüčéčĆąŠą▓ ą║ą░ąČą┤čŗą╣ čĆą░ąĘ, ąĖ ą┤ąĄą╗ą░čÄčé č湥čĆąĄą┤ąŠą▓ą░ąĮąĖąĄ ą╝ąĄąČą┤čā ą▓ąĄčĆčüąĖčÅą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü ą┐čĆčÅą╝čŗą╝ ąĖ ąŠą▒čĆą░čéąĮčŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ ą▒ą░ą╣čé. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą▒ą░ą╣čéčŗ ą╝ą╗ą░ą┤čłąĄą│ąŠ ą┐ąŠčĆčÅą┤ą║ą░ ą┐ąŠčüčéčāą┐ą░čÄčé ąĖąĘ ą╝ą╗ą░ą┤čłąĄą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą▓ ą┐ą░čĆąĄ čĆąĄą│ąĖčüčéčĆąŠą▓. ą×ą┐čåąĖčÅ (R) ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ č鹊ą╝čā, čćč鹊 ą▒ą░ą╣čéčŗ ą╝ą╗ą░ą┤čłąĄą│ąŠ ą┐ąŠčĆčÅą┤ą║ą░ ą┐ąŠčüčéčāą┐ą░čÄčé ąĖąĘ čüčéą░čĆčłąĄą│ąŠ čĆąĄą│ąĖčüčéčĆą░.
ąÆ čüą╗čāčćą░ąĄ čü ąŠą┐čåąĖąĄą╣ čĆąĄą▓ąĄčĆčüąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐ąŠčĆčÅą┤ą║ą░ ą▒ą░ą╣čé (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čüąĖąĮčéą░ą║čüąĖčü (R)), ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮą░čÅ čĆą░ąĘąĮąĖčåą░ čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, ą║ą░ą║ ą╝ąĄąĮčÅąĄčéčüčÅ ą▓ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆą░čģ ą╝ąĄčüčéą░ ą▓ąĮčāčéčĆąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ąŠą╣ ą┐ą░čĆčŗ ą▓ ąĖčģ ą┐ąŠčĆčÅą┤ą║ąĄ ą▒ą░ą╣čé. ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ą┐ą░čĆą░ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ čüąŠą┤ąĄčƹȹĖčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
ąśąĮčüčéčĆčāą║čåąĖčÅ SAA ą▓čŗčćąĖčüą╗čÅąĄčé ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ 12 ąŠą┐ąĄčĆą░čåąĖą╣ ąĮą░ą┤ č鹊čćą║ą░ą╝ąĖ - 3 ąŠą┐ąĄčĆą░čåąĖąĖ subtract-absolute-accumulate ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ ąĮą░ 4 ą┐ą░čĆą░čģ ą▒ą░ą╣č鹊ą▓čŗčģ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
saa (r1: 0 , r3: 2 ) || r0 = [i0++ ] || r2 = [i1++ ]; // ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą│ąŠ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ
saa (r1: 0 , r3: 2 ) (R) || r1 = [i0++ ] || r3 = [i1++ ]; // č鹊 ąČąĄ čüą░ą╝ąŠąĄ, ąĮąŠ čü ąŠą▒čĆą░čéąĮčŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝
saa (r1: 0 , r3: 2 ); // ą┐ąŠčüą╗ąĄą┤ąĮčÅčÅ ąŠą┐ąĄčĆą░čåąĖčÅ SAA ą▓ čåąĖą║ą╗ąĄ, ą▒ąŠą╗čīčłąĄ ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ
ąĪą╝. čéą░ą║ąČąĄ Disable Alignment Exception for Load, Load Data Register.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
( dest_reg_1, dest_reg_0 ) = BYTEUNPACK src_reg_pair
( dest_reg_1, dest_reg_0 ) = BYTEUNPACK src_reg_pair (R)
ąĪąĖąĮčéą░ą║čüąĖčü:
(Dreg, Dreg) = BYTEUNPACK Dreg_pair; // (b)1
(Dreg, Dreg) = BYTEUNPACK Dreg_pair (R); // ąŠą▒čĆą░čéąĮčŗą╣ ą┐ąŠčĆčÅą┤ąŠą║ ą▓ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆą░čģ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7.
Dreg_pair: č鹊ą╗čīą║ąŠ ą┐ą░čĆčŗ čĆąĄą│ąĖčüčéčĆąŠą▓ R1:0, R3:2.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Quad 8-Bit Unpack ą║ąŠą┐ąĖčĆčāąĄčé 4 ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗčģ ą▒ą░ą╣čéą░ ąĖąĘ ą┐ą░čĆčŗ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓, ą┐ąŠą▒ą░ą╣čéąĮčŗą╝ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄą╝. ąśąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąČą░ąĄčé ą▓čŗą▒čĆą░ąĮąĮčŗąĄ ą▒ą░ą╣čéčŗ ą▓ 2 ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮąŠ ą▓čŗą▒čĆą░ąĮąĮčŗčģ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ čü ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄą╝ ąĮą░ ą┐ąŠą╗ąŠą▓ąĖąĮčā čüą╗ąŠą▓ą░.
ąÆ ą║ą░č湥čüčéą▓ąĄ ą▓čģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ąŠą┐čāčüčéąĖą╝čŗ č鹊ą╗čīą║ąŠ ą┐ą░čĆčŗ R1:0 ąĖ R3:2.
ąöą▓ą░ LSB ą▒ąĖčéą░ čĆąĄą│ąĖčüčéčĆą░ I0 ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčé ą▒ą░ą╣č鹊ą▓ąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ ą▓ čĆąĄą│ąĖčüčéčĆą░čģ ąĖčüč鹊čćąĮąĖą║ą░, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮąĖąČąĄ.
ąÆ čüą╗čāčćą░ąĄ ą┐ąŠčĆčÅą┤ą║ą░ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą╗čÅ ąĖčüč鹊čćąĮąĖą║ą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą▒ąĄąĘ (R)), ą┐čĆąĄą┤ą┐ąŠą╗ą░ą│ą░ąĄčéčüčÅ, čćč鹊 ą┐ą░čĆą░ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖčüč鹊čćąĮąĖą║ą░ čüąŠą┤ąĄčƹȹĖčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčéą▓čĆą░čēą░ąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ąĖąĮą░č湥 ą▓ąŠąĘąĮąĖą║ą╗ąĖ ą▒čŗ ą┐čĆąĖ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗčģ 32-ą▒ąĖčéąĮčŗčģ ąĘą░ą│čĆčāąĘą║ą░čģ ą┐ą░ą╝čÅčéąĖ, ąĘą░ą┐čāčēąĄąĮąĮčŗčģ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ.
[ą×ą┐čåąĖąĖ ]
ąĪąĖąĮčéą░ą║čüąĖčü (R) ą╝ąĄąĮčÅąĄčé ąĮą░ ąŠą▒čĆą░čéąĮčŗą╣ ą┐ąŠčĆčÅą┤ąŠą║ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą▓ ą║ą░ąČą┤ąŠą╣ ą┐ą░čĆąĄ čĆąĄą│ąĖčüčéčĆąŠą▓. ą×ą▒čŗčćąĮčŗąĄ ą▓čŗčüąŠą║ąŠą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮčŗąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĮąĄ ą╝ąŠą│čāčé ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī čĆą░čüčģąŠą┤čŗ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą┤ą╗čÅ ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ąĖ ąŠą▒ąŠąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓čŗčģ ą┐ą░čĆ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓, čćč鹊ą▒čŗ ąŠą▒ąĄčüą┐ąĄčćąĖčéčī ą┐ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą▒ą░ą╣čé ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ. ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ąŠąĮąĖ č湥čĆąĄą┤čāčÄčé ąĖ ąĘą░ą│čĆčāąČą░čÄčé č鹊ą╗čīą║ąŠ ąŠą┤ąĮčā ą┐ą░čĆčā čĆąĄą│ąĖčüčéčĆąŠą▓ ą║ą░ąČą┤čŗą╣ čĆą░ąĘ, ąĖ ą┤ąĄą╗ą░čÄčé č湥čĆąĄą┤ąŠą▓ą░ąĮąĖąĄ ą╝ąĄąČą┤čā ą▓ąĄčĆčüąĖčÅą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü ą┐čĆčÅą╝čŗą╝ ąĖ ąŠą▒čĆą░čéąĮčŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ ą▒ą░ą╣čé. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą▒ą░ą╣čéčŗ ą╝ą╗ą░ą┤čłąĄą│ąŠ ą┐ąŠčĆčÅą┤ą║ą░ ą┐ąŠčüčéčāą┐ą░čÄčé ąĖąĘ ą╝ą╗ą░ą┤čłąĄą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą▓ ą┐ą░čĆąĄ čĆąĄą│ąĖčüčéčĆąŠą▓. ą×ą┐čåąĖčÅ (R) ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ č鹊ą╝čā, čćč鹊 ą▒ą░ą╣čéčŗ ą╝ą╗ą░ą┤čłąĄą│ąŠ ą┐ąŠčĆčÅą┤ą║ą░ ą┐ąŠčüčéčāą┐ą░čÄčé ąĖąĘ čüčéą░čĆčłąĄą│ąŠ čĆąĄą│ąĖčüčéčĆą░.
ąÆ čüą╗čāčćą░ąĄ čü ąŠą┐čåąĖąĄą╣ čĆąĄą▓ąĄčĆčüąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐ąŠčĆčÅą┤ą║ą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čüąĖąĮčéą░ą║čüąĖčü (R)), ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮą░čÅ čĆą░ąĘąĮąĖčåą░ čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, ą║ą░ą║ ą╝ąĄąĮčÅąĄčéčüčÅ ą▓ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆą░čģ ą╝ąĄčüčéą░ ą▓ąĮčāčéčĆąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ąŠą╣ ą┐ą░čĆčŗ ą▓ ąĖčģ ą┐ąŠčĆčÅą┤ą║ąĄ ą▒ą░ą╣čé. ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ą┐ą░čĆą░ ąĖčüčģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ čüąŠą┤ąĄčƹȹĖčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
ą£ąĮąĄą╝ąŠąĮąĖą║ą░ ą┐ąŠą╗čāčćąĖą╗ą░ čüą▓ąŠąĄ ąĖą╝čÅ ąĖąĘ č鹊ą│ąŠ čäą░ą║čéą░, čćč鹊 ąŠą┐ąĄčĆą░ąĮą┤čŗ čÅą▓ą╗čÅčÄčéčüčÅ ą▒ą░ą╣čéą░ą╝ąĖ, čĆąĄąĘčāą╗čīčéą░čé 16-ą▒ąĖčéąĮčŗą╣, ąĖ ąĖą╝ąĄąĄčéčüčÅ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ plus ą┤ą╗čÅ čüą╗ąŠąČąĄąĮąĖčÅ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
(r6,r5) = byteunpack r1: 0 ; // ąĖčüčģąŠą┤ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ čü ąĮąŠčĆą╝ą░ą╗čīąĮčŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ ą┤ą░ąĮąĮčŗčģ
ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊
R1 = 0xFEED FACE
ąĢčüą╗ąĖ ą┤ą▓ą░ ą▒ąĖčéą░ LSB čĆąĄą│ąĖčüčéčĆą░ I0 = 00b, č鹊 čŹčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ąŠąĘą▓čĆą░čéąĖčé
R6 = 0x00BE 00EF
ąĢčüą╗ąĖ ą┤ą▓ą░ ą▒ąĖčéą░ LSB čĆąĄą│ąĖčüčéčĆą░ I0 = 01b, č鹊 čŹčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ąŠąĘą▓čĆą░čéąĖčé
R6 = 0x00CE 00BE
ąĢčüą╗ąĖ ą┤ą▓ą░ ą▒ąĖčéą░ LSB čĆąĄą│ąĖčüčéčĆą░ I0 = 10b, č鹊 čŹčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ąŠąĘą▓čĆą░čéąĖčé
R6 = 0x00FA 00CE
ąĢčüą╗ąĖ ą┤ą▓ą░ ą▒ąĖčéą░ LSB čĆąĄą│ąĖčüčéčĆą░ I0 = 11b, č鹊 čŹčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ąŠąĘą▓čĆą░čéąĖčé
R6 = 0x00FA 00CE
(r6,r5) = byteunpack r1: 0 (R ); // ąĖčüčģąŠą┤ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ čü ąŠą▒čĆą░čéąĮčŗą╝ ą┐ąŠčĆčÅą┤ą║ąŠą╝ ą┤ą░ąĮąĮčŗčģ
ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊
R1 = 0xFEED FACE
ąĢčüą╗ąĖ ą┤ą▓ą░ ą▒ąĖčéą░ LSB čĆąĄą│ąĖčüčéčĆą░ I0 = 00b, č鹊 čŹčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ąŠąĘą▓čĆą░čéąĖčé
R6 = 0x00FE 00ED
ąĢčüą╗ąĖ ą┤ą▓ą░ ą▒ąĖčéą░ LSB čĆąĄą│ąĖčüčéčĆą░ I0 = 01b, č鹊 čŹčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ąŠąĘą▓čĆą░čéąĖčé
R6 = 0x00DD 00FE
ąĢčüą╗ąĖ ą┤ą▓ą░ ą▒ąĖčéą░ LSB čĆąĄą│ąĖčüčéčĆą░ I0 = 10b, č鹊 čŹčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ąŠąĘą▓čĆą░čéąĖčé
R6 = 0x00BA 00DD
ąĢčüą╗ąĖ ą┤ą▓ą░ ą▒ąĖčéą░ LSB čĆąĄą│ąĖčüčéčĆą░ I0 = 11b, č鹊 čŹčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ąŠąĘą▓čĆą░čéąĖčé
R6 = 0x00EF 00BA
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Quad 8-bit Pack.
[ąÆąĄą║č鹊čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ]
ąÆ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ ąŠą▒čüčāąČą┤ą░čÄčéčüčÅ ą▓ąĄą║č鹊čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ, čü ą┐ąŠą╝ąŠčēčīčÄ ą║ąŠč鹊čĆčŗčģ ą╝ąŠąČąĮąŠ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčéčī čāą╝ąĮąŠąČąĄąĮąĖąĄ 16-ą▒ąĖčéąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣, ą▓ą║ą╗čÄčćą░čÅ čüą╗ąŠąČąĄąĮąĖąĄ, ą▓čŗčćąĖčéą░ąĮąĖąĄ, čāą╝ąĮąŠąČąĄąĮąĖąĄ, čüą┤ą▓ąĖą│, ąŠčéčĆąĖčåą░ąĮąĖąĄ, čāą┐ą░ą║ąŠą▓ą║čā ąĖ ą┐ąŠąĖčüą║. ąóą░ą║ąČąĄ ą▓ čŹč鹊čé čĆą░ąĘą┤ąĄą╗ ą▓ą║ą╗čÄč湥ąĮčŗ ąŠą┐ąĄčĆą░čåąĖąĖ Compare-Select ąĖ Add-On-Sign.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_hi = dest_lo = SIGN ( src0_hi ) * src1_hi + SIGN ( src0_lo ) * src1_lo
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg_hi = Dreg_lo = SIGN (Dreg_hi) * Dreg_hi + SIGN (Dreg_lo) * Dreg_lo; // (b)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
ąĢčüčéčī ąŠą│čĆą░ąĮąĖč湥ąĮąĖčÅ ą┐ąŠ čĆąĄą│ąĖčüčéčĆą░ą╝: čĆąĄą│ąĖčüčéčĆčŗ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ dest_hi ąĖ dest_lo ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ą╝ąĖ ąŠą┤ąĮąŠą│ąŠ ąĖ č鹊ą│ąŠ ąČąĄ 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ (D-čĆąĄą│ąĖčüčéčĆ, Dreg). ą¤ąŠą┤ąŠą▒ąĮąŠąĄ ąŠčéąĮąŠčüąĖčéčüčÅ ąĖ ą║ čĆąĄą│ąĖčüčéčĆą░ą╝ - ąĖčüč鹊čćąĮąĖą║ą░ą╝, src0_hi ąĖ src0_lo ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ą╝ąĖ ąŠą┤ąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ąĖ src1_hi ąĖ src1_lo ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ą╝ąĖ ąŠą┤ąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg_hi: R0.H, ..., R7.H.
Dreg_lo: R0.L, ..., R7.L.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Add on Sign ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ą┤ą▓čāčģčłą░ą│ąŠą▓čāčÄ čäčāąĮą║čåąĖčÄ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
1 . ąŻą╝ąĮąŠąČą░ąĄčé ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╣ ąĘąĮą░ą║ čćąĖčüą╗ą░, ąĮą░čģąŠą┤čÅčēąĄą│ąŠčüčÅ ą▓ 16-ą▒ąĖčéąĮąŠą╣ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĄ čüą╗ąŠą▓ą░ ą▓ src0 ąĮą░ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄąĄ čćąĖčüą╗ąŠ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĄ čüą╗ąŠą▓ą░ src1. ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╣ ąĘąĮą░ą║ src0 čŹč鹊 ą╗ąĖą▒ąŠ (+1), ą╗ąĖą▒ąŠ (ŌĆō1), ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą▒ąĖčéą░ ąĘąĮą░ą║ą░ src0. ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé čŹčéčā ąŠą┐ąĄčĆą░čåąĖčÄ ąĮą░ ą▓ąĄčĆčģąĮąĄą╣ ąĖ ąĮąĖąČąĮąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░čģ ąŠą┤ąĮąŠą│ąŠ ąĖ č鹊ą│ąŠ ąČąĄ D-čĆąĄą│ąĖčüčéčĆą░.
ąĀąĄąĘčāą╗čīčéą░čéčŗ čŹč鹊ą│ąŠ čłą░ą│ą░ ą┐ąŠą┤čćąĖąĮčÅčÄčéčüčÅ ą┐čĆą░ą▓ąĖą╗ą░ą╝ čāą╝ąĮąŠąČąĄąĮąĖčÅ čüąŠ ąĘąĮą░ą║ąŠą╝, ą║ąŠč鹊čĆčŗąĄ ą▓ ąŠą▒čēąĄą╝ ą▓ąĖą┤ąĄ ą┐ąŠą║ą░ąĘą░ąĮčŗ ąĮąĖąČąĄ. ąÆ čéą░ą▒ą╗ąĖčåąĄ Y čŹč鹊 čćąĖčüą╗ąŠ ą▓ src0, ąĖ Z čćąĖčüą╗ąŠ ą▓ src1. ą¦ąĖčüą╗ą░ ą▓ src0 ąĖ src1 ą╝ąŠą│čāčé ą▒čŗčéčī ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮčŗą╝ąĖ ąĖą╗ąĖ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮčŗą╝ąĖ.
SRC0 SRC1 Sign-Adjusted SRC1
+Y
+Z
+Z
+Y
-Z
-Z
-Y
+Z
-Z
-Y
-Z
+Z
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čĆąĄąĘčāą╗čīčéą░čé ą▓čüąĄą│ą┤ą░ ą┐ąŠą╗čāčćą░ąĄčé ą░ą╝ą┐ą╗ąĖčéčāą┤čā Z, ąĖ ą╝ąŠąČąĄčé č鹊ą╗čīą║ąŠ ą╗ąĖčłčī ą┐ąŠą╝ąĄąĮčÅčéčī čüą▓ąŠą╣ ąĘąĮą░ą║.
2 . ą¤ąŠčüą╗ąĄ čŹč鹊ą│ąŠ čüą║ą╗ą░ą┤čŗą▓ą░ąĄčéčüčÅ čĆąĄąĘčāą╗čīčéą░čé src1 čü ąĖčüą┐čĆą░ą▓ą╗ąĄąĮąĮčŗą╝ ąĘąĮą░ą║ąŠą╝ ą▓ čüčéą░čĆčłąĄą╝ ą┐ąŠą╗čāčüą╗ąŠą▓ąĄ ąĖ ą╝ą╗ą░ą┤čłąĄą╝ ą┐ąŠą╗čāčüą╗ąŠą▓ąĄ, ąĖ čüąŠčģčĆą░ąĮčÅąĄčéčüčÅ čéą░ ąČąĄ čüą░ą╝ą░čÅ 16-ą▒ąĖčéąĮą░čÅ čüčāą╝ą╝ą░ ą▓ čüčéą░čĆčłąĄą╝ ąĖ ą╝ą╗ą░ą┤čłąĄą╝ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░čģ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮą░ čĆąĖčüčāąĮą║ąĄ ąĮąĖąČąĄ.
ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ąĖčüčģąŠą┤ąĮčŗąĄ čĆąĄą│ąĖčüčéčĆčŗ čüąŠą┤ąĄčƹȹ░čé...
... č鹊ą│ą┤ą░ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą▒čāą┤ąĄčé čüąŠą┤ąĄčƹȹ░čéčī:
ąÜ čüčāą╝ą╝ąĄ ąĮąĄ ą▒čāą┤ąĄčé ą┐čĆąĖą╝ąĄąĮčÅčéčīčüčÅ ąĮą░čüčŗčēąĄąĮąĖąĄ, ąĄčüą╗ąĖ čüą╗ąŠąČąĄąĮąĖąĄ ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé, ą║ąŠč鹊čĆčŗą╣ ąĮąĄ čāą╝ąĄčēą░ąĄčéčüčÅ ą▓ 16 ą▒ąĖčé.
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ: ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ąĖąĮčüčéčĆčāą║čåąĖčÄ Sum on Sign ą┐čĆąĖ ą▓čŗčćąĖčüą╗ąĄąĮąĖąĖ ą╝ąĄčéčĆąĖą║ąĖ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ ą┤ą╗čÅ ą░ą╗ą│ąŠčĆąĖčéą╝ą░ Viterbi Butterfly.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r7.h= r7.l= sign(r2.h)* r3.h+ sign(r2.l)* r3.l;
ąĢčüą╗ąĖ ...
R2.H = 2
č鹊ą│ą┤ą░ ...
R7.H = 1257 (ąĖą╗ąĖ 1234 + 23)
ąĢčüą╗ąĖ ...
R2.H = ŌĆō2
č鹊ą│ą┤ą░ ...
R7.H = 1211 (ąĖą╗ąĖ 1234 ŌĆō 23)
ąĢčüą╗ąĖ ...
R2.H = 2
č鹊ą│ą┤ą░ ...
R7.H = ŌĆō1211 (ąĖą╗ąĖ (ŌĆō1234) + 23)
ąĢčüą╗ąĖ ...
R2.H = ŌĆō2
č鹊ą│ą┤ą░ ...
R7.H = ŌĆō1257 (ąĖą╗ąĖ (ŌĆō1234) ŌĆō 23)
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = VIT_MAX ( src_reg_0, src_reg_1 ) (ASL)
dest_reg = VIT_MAX ( src_reg_0, src_reg_1 ) (ASR)
dest_reg_lo = VIT_MAX ( src_reg ) (ASL)
dest_reg_lo = VIT_MAX ( src_reg ) (ASR)
ąĪąĖąĮčéą░ą║čüąĖčü ą┤ą▓ąŠą╣ąĮąŠą╣ 16-ą▒ąĖčéąĮąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ:
Dreg = VIT_MAX (Dreg, Dreg) (ASL); // čüą┤ą▓ąĖą│ ą▒ąĖčé ąĖčüč鹊čĆąĖąĖ ą▓ą╗ąĄą▓ąŠ (b)1 Dreg = VIT_MAX (Dreg, Dreg) (ASR); // čüą┤ą▓ąĖą│ ą▒ąĖčé ąĖčüč鹊čĆąĖąĖ ą▓ą┐čĆą░ą▓ąŠ (b)
ąĪąĖąĮčéą░ą║čüąĖčü ąŠą┤ąĖąĮąŠčćąĮąŠą╣ 16-ą▒ąĖčéąĮąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ:
Dreg_lo = VIT_MAX (Dreg, Dreg) (ASL); // čüą┤ą▓ąĖą│ ą▒ąĖčé ąĖčüč鹊čĆąĖąĖ ą▓ą╗ąĄą▓ąŠ (b) Dreg_lo = VIT_MAX (Dreg, Dreg) (ASR); // čüą┤ą▓ąĖą│ ą▒ąĖčé ąĖčüč鹊čĆąĖąĖ ą▓ą┐čĆą░ą▓ąŠ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: R0, ..., R7.
Dreg_lo: R0.L, ..., R7.L.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Compare-Select (VIT_MAX) ą▓čŗą▒ąĖčĆą░ąĄčé ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ ą┐ą░čĆ 16-ą▒ąĖčéąĮčŗčģ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓, ą▓ąŠąĘą▓čĆą░čēą░čÅ ąĮą░ąĖą▒ąŠą╗čīčłąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ, ąĖ ą┐čĆąĖ čŹč鹊ą╝ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ ąĘą░ą┐ąĖčüčŗą▓ą░čÅ ą▓ A0.W ąĖčüč鹊čćąĮąĖą║ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ. ąŁčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ čĆą░ą▒ąŠčéą░ąĄčé čü čāč湥č鹊ą╝ ąĘąĮą░ą║ą░ čćąĖčüą╗ą░. ą×ą┐ąĄčĆą░ąĮą┤čŗ čüčĆą░ą▓ąĮąĖą▓ą░čÄčéčüčÅ ą║ą░ą║ čćąĖčüą╗ą░ ą▓ č乊čĆą╝ą░č鹥 ą┐ąĄčĆąĄą┤ą░čćąĖ ąĘąĮą░ą║ą░ ą▓ ą▓ąĖą┤ąĄ ą┤ą▓ąŠąĖčćąĮąŠą│ąŠ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖčÅ (twoŌĆÖs complements).
ąöąŠčüčéčāą┐ąĮčŗ ą▓ąĄčĆčüąĖąĖ ą┤ą╗čÅ ą┤ą▓ąŠą╣ąĮąŠą╣ ąĖ ąŠą┤ąĖąĮąŠčćąĮąŠą╣ 16-ą▒ąĖčéąĮąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ. ąÆąĄčĆčüąĖąĖ ą┤ą▓ąŠą╣ąĮąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ čüčĆą░ą▓ąĮąĖą▓ą░čÄčé č湥čéčŗčĆąĄ ąŠą┐ąĄčĆą░ąĮą┤ą░ ąĖ ą▓ąŠąĘą▓čĆą░čēą░čÄčé ą┤ą▓ą░ ą╝ą░ą║čüąĖą╝čāą╝ą░, č鹊ą│ą┤ą░ ą║ą░ą║ ąŠą┤ąĖąĮąŠčćąĮą░čÅ ą▓ąĄčĆčüąĖčÅ ąŠą┐ąĄčĆą░čåąĖąĖ čüčĆą░ą▓ąĮąĖą▓ą░ąĄčé 2 ąŠą┐ąĄčĆą░ąĮą┤ą░ ąĖ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ąŠą┤ąĖąĮ ą╝ą░ą║čüąĖą╝čāą╝.
ąæąĖčéčŗ čĆą░čüčłąĖčĆąĄąĮąĖčÅ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ The (ą▒ąĖčéčŗ 39 .. 32) ą┐ąĄčĆąĄą┤ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąŠčćąĖčēąĄąĮčŗ. ąØąĖąČąĄ ą┐ąŠą║ą░ąĘą░ąĮąŠ, ą║ą░ą║ čĆą░ą▒ąŠčéą░ąĄčé ąĖąĮčüčéčĆčāą║čåąĖčÅ.
ąöą▓ąŠą╣ąĮą░čÅ ą▓ąĄčĆčüąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ . ąĢčüą╗ąĖ ąĖčüčģąŠą┤ąĮčŗąĄ čĆąĄą│ąĖčüčéčĆčŗ čüąŠą┤ąĄčƹȹ░čé:
... č鹊 čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą▒čāą┤ąĄčé čüąŠą┤ąĄčƹȹ░čéčī:
ąÆąĄčĆčüąĖčÅ ASL čüą┤ą▓ąĖą│ą░ąĄčé A0 ą▓ą╗ąĄą▓ąŠ ąĮą░ 2 ą┐ąŠąĘąĖčåąĖąĖ ą▒ąĖčéą░, ąĖ ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé ą┤ą▓ą░ LSB, ą┐ąŠą║ą░ąĘčŗą▓ą░čÅ ąĖčüč鹊čćąĮąĖą║ ą║ą░ąČą┤ąŠą│ąŠ ą┐ąŠą╗čāč湥ąĮąĮąŠą│ąŠ ą╝ą░ą║čüąĖą╝čāą╝ą░.
ąŚą┤ąĄčüčī BB ąŠąĘąĮą░čćą░ąĄčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
BB ąōą┤ąĄ ą╝ą░ą║čüąĖą╝čāą╝
00
z0 ąĖ y0
01
z0 ąĖ y1
10
z1 ąĖ y0
11
z1 ąĖ y1
ąÉąĮą░ą╗ąŠą│ąĖčćąĮąŠ ASR-ą▓ąĄčĆčüąĖčÅ čüą┤ą▓ąĖą│ą░ąĄčé ą▓ą┐čĆą░ą▓ąŠ A0 ąĮą░ 2 ą┐ąŠąĘąĖčåąĖąĖ ą▒ąĖčé ąĖ ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé ą┤ą▓ą░ MSB, čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī ąĖčüč鹊čćąĮąĖą║ąĖ ą║ą░ąČą┤ąŠą│ąŠ ą╝ą░ą║čüąĖą╝čāą╝ą░.
ąŚą┤ąĄčüčī BB ąŠąĘąĮą░čćą░ąĄčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
BB ąōą┤ąĄ ą╝ą░ą║čüąĖą╝čāą╝
00
y0 ąĖ z0
01
z0 ąĖ z1
10
y1 ąĖ z0
11
y1 ąĖ z1
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĖčüč鹊čĆąĖčÅ ą▓ ą▓ąĖą┤ąĄ ą▒ąĖč鹊ą▓ąŠą│ąŠ ą║ąŠą┤ą░ ąĘą░ą▓ąĖčüąĖčé ąŠčé ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čüą┤ą▓ąĖą│ą░ A0. ąæąĖčé src_reg_1 ą▓čüąĄą│ą┤ą░ ą▓ą┤ą▓ąĖą│ą░ąĄčéčüčÅ ą▓ A0 ą┐ąĄčĆą▓čŗą╝, ąĘą░ ąĮąĖą╝ čüą╗ąĄą┤čāąĄčé ą▒ąĖčé ą┤ą╗čÅ src_reg_0.
ą×ą┤ąĖąĮąŠčćąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čĆą░ą▒ąŠčéą░čÄčé ą░ąĮą░ą╗ąŠą│ąĖčćąĮąŠ.
ą×ą┤ąĖąĮąŠčćąĮą░čÅ ą▓ąĄčĆčüąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ . ąĢčüą╗ąĖ ąĖčüčģąŠą┤ąĮčŗąĄ čĆąĄą│ąĖčüčéčĆčŗ čüąŠą┤ąĄčƹȹ░čé:
... č鹊 čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą▒čāą┤ąĄčé čüąŠą┤ąĄčƹȹ░čéčī:
ąÆąĄčĆčüąĖčÅ ASL čüą┤ą▓ąĖą│ą░ąĄčé A0 ą▓ą╗ąĄą▓ąŠ ąĮą░ 1 ą┐ąŠąĘąĖčåąĖčÄ ą▒ąĖčéą░, ąĖ ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé ąŠą┤ąĖąĮ LSB, ą┐ąŠą║ą░ąĘčŗą▓ą░čÅ ąĖčüč鹊čćąĮąĖą║ ą┐ąŠą╗čāč湥ąĮąĮąŠą│ąŠ ą╝ą░ą║čüąĖą╝čāą╝ą░.
ąÉąĮą░ą╗ąŠą│ąĖčćąĮąŠ ASR-ą▓ąĄčĆčüąĖčÅ čüą┤ą▓ąĖą│ą░ąĄčé ą▓ą┐čĆą░ą▓ąŠ A0 ąĮą░ 1 ą┐ąŠąĘąĖčåąĖčÄ ą▒ąĖčé ąĖ ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé ąŠą┤ąĖąĮ MSB, čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī ąĖčüč鹊čćąĮąĖą║ ą╝ą░ą║čüąĖą╝čāą╝ą░.
ąŚą┤ąĄčüčī B ąŠąĘąĮą░čćą░ąĄčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
B ąōą┤ąĄ ą╝ą░ą║čüąĖą╝čāą╝
0
y0
1
y1
ąĀą░ąĘčĆąĄčłąĄąĮčŗ ą╝ąĄčéčĆąĖą║ąĖ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ, ąĖ čüčĆą░ą▓ąĮąĄąĮąĖąĄ ąĮą░ ąĮą░ ą╝ą░ą║čüąĖą╝čāą╝ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą┐ąŠ ą║čĆčāą│ąŠą▓ąŠą╝čā čåąĖą║ą╗čā ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┤ąŠ 2 (2's complement). ąóą░ą║ąŠąĄ čüčĆą░ą▓ąĮąĄąĮąĖąĄ ą┤ą░ąĄčé ą╗čāčćčłčāčÄ ąĖąĮą┤ąĖą║ą░čåąĖčÄ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠą╣ ą╝ą░ą│ąĮąĖčéčāą┤čŗ ą┤ą▓čāčģ ą▒ąŠą╗čīčłąĖčģ čćąĖčüąĄą╗, ą║ąŠą│ą┤ą░ ą╝ą░ą╗čŗąĄ čćąĖčüą╗ą░ ą┤ąŠą▒ą░ą▓ą╗čÅčÄčéčüčÅ ąŠčéąĮąĖą╝ą░čÄčéčüčÅ ąŠčé ąŠą▒ąŠąĖčģ.
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ: ąĖąĮčüčéčĆčāą║čåąĖčÅ Compare-Select (VIT_MAX) čÅą▓ą╗čÅąĄčéčüčÅ ą║ą╗čÄč湥ą▓čŗą╝ 菹╗ąĄą╝ąĄąĮč鹊ą╝ čäčāąĮą║čåąĖąĖ Add-Compare-Select (ACS) ą┤ąĄą║ąŠą┤ąĄčĆąŠą▓ ąÆąĖč鹥čĆą▒ąĖ. ąĢčæ ą║ąŠą╝ą▒ąĖąĮąĖčĆčāčÄčé čü ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ Vector Add ą┤ą╗čÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ "čĆąĄčłąĄčéą║ąĖ ą▒ą░ą▒ąŠčćą║ąĖ" (trellis butterfly), ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą╣ ą▓ čäčāąĮą║čåąĖčÅčģ ACS.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r5 = vit_max(r3, r2)(asl); // čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ, ą┤ą▓ąŠą╣ąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ
ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝:
R3 = 0xFFFF 0000
ąóąŠą│ą┤ą░ čŹč鹊čé ą┐čĆąĖą╝ąĄčĆ ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé:
R5 = 0x0000 0000
r7 = vit_max(r1, r0)(asr); // čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ, ą┤ą▓ąŠą╣ąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ
ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝:
R1 = 0xFEED BEEF
ąóąŠą│ą┤ą░ čŹč鹊čé ą┐čĆąĖą╝ąĄčĆ ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé:
R7 = 0xFEED 0000
r3.l = vit_max(r1)(asl); // čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ, ąŠą┤ąĖąĮąŠčćąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ
ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝:
R1 = 0xFFFF 0000
ąóąŠą│ą┤ą░ čŹč鹊čé ą┐čĆąĖą╝ąĄčĆ ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé:
R3.L = 0x0000
r3.l = vit_max(r1)(asr); // čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ, ąŠą┤ąĖąĮąŠčćąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ
ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝:
R1 = 0x1234 FADE
ąóąŠą│ą┤ą░ čŹč鹊čé ą┐čĆąĖą╝ąĄčĆ ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé:
R3.L = 0x1234
ąĪą╝. čéą░ą║ąČąĄ ąŠą┐ąĄčĆą░čåąĖčÄ ą╝ą░ą║čüąĖą╝čāą╝ą░ (ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ").
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = ABS source_reg (V)
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = ABS Dreg (V); // (b)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Vector Absolute Value ą▓čŗčćąĖčüą╗čÅąĄčé ąĖąĮą┤ąĖą▓ąĖą┤čāą░ą╗čīąĮčŗąĄ ą░ą▒čüąŠą╗čÄčéąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ čüčéą░čĆčłąĄą╣ ąĖ ą╝ą╗ą░ą┤čłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮ ąŠą┤ąĮąŠą│ąŠ 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ. ąĀąĄąĘčāą╗čīčéą░čéčŗ ą┐ąŠą╝ąĄčēą░čÄčéčüčÅ ą▓ 32-ą▒ąĖčéąĮčŗą╣ dest_reg, ąĖčüą┐ąŠą╗čīąĘčāčÅ čüą╗ąĄą┤čāčÄčēąĖąĄ ą┐čĆą░ą▓ąĖą╗ą░:
ŌĆó ąĢčüą╗ąĖ ą▓čģąŠą┤ąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠąĄ ąĖą╗ąĖ 0, č鹊 ąŠąĮąŠ ą▒ąĄąĘ ąĖąĘą╝ąĄąĮąĄąĮąĖą╣ ą║ąŠą┐ąĖčĆčāąĄčéčüčÅ ą▓ ą╝ąĄčüč鹊 ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ąĖčüčģąŠą┤ąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ čüąŠą┤ąĄčƹȹĖčé:
... č鹊 čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą▒čāą┤ąĄčé čüąŠą┤ąĄčƹȹ░čéčī:
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ąĄą╗ą░ąĄčé ąĮą░čüčŗčēąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ ąŠą▒ą░ ąĖą╗ąĖ ą╗čÄą▒ąŠą╣ ąĖąĘ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ čĆą░ą▓ąĄąĮ 0; ąŠčćąĖčēą░ąĄčéčüčÅ, ąĄčüą╗ąĖ ąŠą▒ą░ čĆąĄąĘčāą╗čīčéą░čéą░ ąĮąĄ čĆą░ą▓ąĮčŗ 0.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆ ]
// ąĢčüą╗ąĖ r1 = 0xFFFF 7FFF, č鹊 ...
r3 = abs r1 (v);
// ... ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé 0x0001 7FFF
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Absolute Value (ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ").
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest = src_reg_0+ |+ src_reg_1
dest = src_reg_0 ŌĆō|+ src_reg_1
dest = src_reg_0 +|ŌĆō src_reg_1
dest = src_reg_0 ŌĆō|ŌĆō src_reg_1
dest_0 = src_reg_0 +|+ src_reg_1, dest_1 = src_reg_0 ŌĆō|ŌĆō src_reg_1
dest_0 = src_reg_0 +|ŌĆō src_reg_1, dest_1 = src_reg_0 ŌĆō|+ src_reg_1
dest_0 = src_reg_0 + src_reg_1, dest_1 = src_reg_0 ŌĆō src_reg_1
dest_0 = A1 + A0, dest_1 = A1 ŌĆō A0
dest_0 = A0 + A1, dest_1 = A0 ŌĆō A1
ąĪąĖąĮčéą░ą║čüąĖčü ą┤ą▓ąŠą╣ąĮčŗčģ 16-ą▒ąĖčéąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣:
Dreg = Dreg +|+ Dreg (opt_mode0); // add | add (b)1 Dreg = Dreg ŌĆō|+ Dreg (opt_mode0); // subtract | add (b) Dreg = Dreg +|ŌĆō Dreg (opt_mode0); // add | subtract (b) Dreg = Dreg ŌĆō|ŌĆō Dreg (opt_mode0); // subtract | subtract (b)
ąĪąĖąĮčéą░ą║čüąĖčü čüč湥čéą▓ąĄčĆąĄąĮąĮčŗčģ 16-ą▒ąĖčéąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣:
// add | add, subtract | subtract; ąĮą░ą▒ąŠčĆ ąĖčüčģąŠą┤ąĮčŗčģ (source) čĆąĄą│ąĖčüčéčĆąŠą▓ // ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī č鹊čé ąČąĄ čüą░ą╝čŗą╝ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ (b): Dreg = Dreg +|+ Dreg, Dreg = Dreg ŌĆō|ŌĆō Dreg (opt_mode1, opt_mode2);
// add | subtract, subtract | add; ąĮą░ą▒ąŠčĆ ąĖčüčģąŠą┤ąĮčŗčģ (source) čĆąĄą│ąĖčüčéčĆąŠą▓ // ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī č鹊čé ąČąĄ čüą░ą╝čŗą╝ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ (b): Dreg = Dreg +|ŌĆō Dreg, Dreg = Dreg ŌĆō|+ Dreg (opt_mode1, opt_mode2);
ąĪąĖąĮčéą░ą║čüąĖčü ą┤ą▓ąŠą╣ąĮčŗčģ 32-ą▒ąĖčéąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣:
// add, subtract; ąĮą░ą▒ąŠčĆ ąĖčüčģąŠą┤ąĮčŗčģ (source) čĆąĄą│ąĖčüčéčĆąŠą▓ // ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī č鹊čé ąČąĄ čüą░ą╝čŗą╝ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ (b): Dreg = Dreg + Dreg, Dreg = Dreg ŌĆō Dreg (opt_mode1);
ąĪąĖąĮčéą░ą║čüąĖčü ą┤ą▓ąŠą╣ąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣ čü 40-ą▒ąĖčéąĮčŗą╝ąĖ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ą╝ąĖ:
// add, subtract; ą┐čĆąĖ subtract ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓čŗčćąĖčéą░ąĮąĖąĄ A0 ąĖąĘ A1 (b): Dreg = A1 + A0, Dreg = A1 ŌĆō A0 (opt_mode1); // add, subtract; ą┐čĆąĖ subtract ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓čŗčćąĖčéą░ąĮąĖąĄ A1 ąĖąĘ A0 (b): Dreg = A0 + A1, Dreg = A0 ŌĆō A1 (opt_mode1);
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: R0, ..., R7
opt_mode0: ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ (S), (CO) ąĖą╗ąĖ (SCO)
opt_mode1: ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ (S)
opt_mode2: ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ (ASR) ąĖą╗ąĖ (ASL)
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Vector Add / Subtract ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ čüą║ą╗ą░ą┤čŗą▓ą░ąĄčé ąĖ/ąĖą╗ąĖ ą▓čŗčćąĖčéą░ąĄčé ą┤ą▓ąĄ ą┐ą░čĆčŗ čćąĖčüąĄą╗, čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĮčŗčģ ą▓ čĆąĄą│ąĖčüčéčĆą░čģ. ąŚą░č鹥ą╝ ąŠąĮą░ čüąŠčģčĆą░ąĮčÅąĄčé čĆąĄąĘčāą╗čīčéą░čéčŗ ą║ą░ąČą┤ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ ą▓ ąŠčéą┤ąĄą╗čīąĮąŠą╝ 32-ą▒ąĖčéąĮąŠą╝ čĆąĄą│ąĖčüčéčĆąĄ ą┤ą░ąĮąĮčŗčģ ąĖą╗ąĖ 16-ą▒ąĖčéąĮąŠą╣ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĄ čĆąĄą│ąĖčüčéčĆą░, ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╝ čüąĖąĮčéą░ą║čüąĖčüąŠą╝. ąĀąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ čüč湥čéą▓ąĄčĆąĄąĮąĮąŠą╣ ąĖą╗ąĖ ą┤ą▓ąŠą╣ąĮąŠą╣ ą▓ąĄčĆčüąĖąĖ ąŠą┐ąĄčĆą░čåąĖąĖ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čāąĮąĖą║ą░ą╗čīąĮčŗą╝.
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ: ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ FFT butterfly, ą│ą┤ąĄ ą║ą░ąČą┤čŗą╣ ąĖąĘ čĆąĄą│ąĖčüčéčĆąŠą▓ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ąĄčéčüčÅ ą║ą░ą║ ąŠą┤ąĮąŠ ą║ąŠą╝ą┐ą╗ąĄą║čüąĮąŠąĄ čćąĖčüą╗ąŠ, ąĖ ą│ą┤ąĄ čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ čüą╗ąŠąČąĄąĮąĖčÅ/ą▓čŗčćąĖčéą░ąĮąĖčÅ ą▓ąĄą║č鹊čĆą░ (Vector Add / Subtract).
// ąĢčüą╗ąĖ r1 = 0x0003 0004 ąĖ r2 = 0x0001 0002, č鹊ą│ą┤ą░ ...
r0 = r2 + | - r1(co);// ... ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé r0 = 0xFFFE 0004
[ą×ą┐čåąĖąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Vector Add / Subtract ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čéčĆąĖ čĆąĄąČąĖą╝ą░, ąĮą░čüčéčĆą░ąĖą▓ą░ąĄą╝čŗąĄ ąŠą┐čåąĖčÅą╝ąĖ:
ŌĆó opt_mode0 ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą┤ą▓ąŠą╣ąĮčŗąĄ 16-ą▒ąĖčéąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ.
ąÆ čéą░ą▒ą╗ąĖčåąĄ 14.6 ąŠą┐ąĖčüą░ąĮčŗ ąŠą┐čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé 3 čĆąĄąČąĖą╝ą░ ąŠą┐čåąĖą╣ opt_mode.
ąóą░ą▒ą╗ąĖčåą░ 14-1. ą×ą┐čåąĖąĖ ą┤ą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ Vector Add / Subtract.
ąĀąĄąČąĖą╝ ą×ą┐čåąĖčÅ ą×ą┐ąĖčüą░ąĮąĖąĄ
opt_mode0
S
ąØą░čüčŗčēąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░ ą┐ąŠ 16 ą▒ąĖčéą░ą╝.
CO
ąÜčĆąŠčüčü-ąŠą┐čåąĖčÅ. ą¤ąĄčĆąĄčüčéą░ą▓ą╗čÅąĄčé ą┐ąŠčĆčÅą┤ąŠą║ čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĖčÅ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ
SCO
ąØą░čüčŗčēąĄąĮąĖąĄ ąĖ ą║čĆąŠčüčü-ąŠą┐čåąĖčÅ. ąĪąŠčüčéą░ą▓ą╗čÅąĄčé ą║ąŠą╝ą▒ąĖąĮą░čåąĖčÄ ąŠą┐čåąĖą╣ (S) ąĖ (CO).
opt_mode1
S
ąØą░čüčŗčēąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░ ą┐ąŠ 16 ąĖą╗ąĖ 32 ą▒ąĖčéą░ą╝, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čĆą░ąĘą╝ąĄčĆą░ ąŠą┐ąĄčĆą░ąĮą┤ą░.
opt_mode2
ASR
ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ (arithmetic shift right, čüąŠą║čĆą░čēąĄąĮąĮąŠ ASR). ą×ą┐ąŠą╗ąŠą▓ąĖąĮąĖą▓ą░ąĄčé čĆąĄąĘčāą╗čīčéą░čé (ą┤ąĄą╗ąĄąĮąĖąĄą╝ ąĮą░ 2) ą┐ąĄčĆąĄą┤ čüąŠčģčĆą░ąĮąĄąĮąĖąĄą╝ ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ąĢčüą╗ąĖ čŹčéą░ ąŠą┐čåąĖčÅ čāą║ą░ąĘą░ąĮą░ čüąŠą▓ą╝ąĄčüčéąĮąŠ čü čäą╗ą░ą│ąŠą╝ S (saturation, čé. ąĄ. ąĮą░čüčŗčēąĄąĮąĖąĄ) ą▓ ą▓ąĄčĆčüąĖčÅčģ čüąŠ čüč湥čéą▓ąĄčĆąĄąĮąĮčŗą╝ 16-ą▒ąĖčéąĮčŗą╝ ąŠą┐ąĄčĆą░ąĮą┤ąŠą╝, č鹊 ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖąĄ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą┐ąĄčĆąĄą┤ ąĮą░čüčŗčēąĄąĮąĖąĄą╝.
ASL
ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ (arithmetic shift left, čüąŠą║čĆą░čēąĄąĮąĮąŠ ASL). ąŻą┤ą▓ą░ąĖą▓ą░ąĄčé čĆąĄąĘčāą╗čīčéą░čé (čāą╝ąĮąŠąČąĄąĮąĖąĄą╝ ąĮą░ 2 ąĖ ąŠą▒čĆąĄąĘą║ąŠą╣) ą┐ąĄčĆąĄą┤ čüąŠčģčĆą░ąĮąĄąĮąĖąĄą╝ ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ąĢčüą╗ąĖ čŹčéą░ ąŠą┐čåąĖčÅ čāą║ą░ąĘą░ąĮą░ čüąŠą▓ą╝ąĄčüčéąĮąŠ čü čäą╗ą░ą│ąŠą╝ S (saturation, čé. ąĄ. ąĮą░čüčŗčēąĄąĮąĖąĄ) ą▓ ą▓ąĄčĆčüąĖčÅčģ čüąŠ čüč湥čéą▓ąĄčĆąĄąĮąĮčŗą╝ 16-ą▒ąĖčéąĮčŗą╝ ąŠą┐ąĄčĆą░ąĮą┤ąŠą╝, č鹊 ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖąĄ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą┐ąĄčĆąĄą┤ ąĮą░čüčŗčēąĄąĮąĖąĄą╝.
ą×ą┐čåąĖąĖ, ą┐ąŠą║ą░ąĘą░ąĮąĮčŗąĄ ą┤ą╗čÅ opt_mode2, ąŠčéąĮąŠčüčÅčéčüčÅ ą║ ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖčÄ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ ą╗čÄą▒ąŠą╣ ąĖąĘ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ čĆą░ą▓ąĄąĮ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r5= r3+|+ r4; // ą┤ą▓ąŠą╣ąĮčŗąĄ 16-ą▒ąĖčéąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ, add|add
r6= r0-|+ r1(s); // č鹊 ąČąĄ čüą░ą╝ąŠąĄ, č鹊ą╗čīą║ąŠ subtract|add čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝
r0= r2+|- r1(co); // add|subtract čü čĆąĄąĘčāą╗čīčéą░čéą░ą╝ąĖ ą┐ąŠą╗čāčüą╗ąŠą▓, ą┐ąĄčĆąĄčüčéą░ą▓ą╗ąĄąĮąĮčŗą╝ąĖ
// ą▓ čĆąĄą│ąĖčüčéčĆąĄ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ
r7= r3-|- r6(sco); // subtract|subtract čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝ ąĖ ą┐ąĄčĆąĄčüčéą░ąĮąŠą▓ą║ąŠą╣ ą┐ąŠą╗čāčüą╗ąŠą▓
// čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ
r5= r3+|+ r4, r7= r3-|- r4; // čüč湥čéą▓ąĄčĆąĄąĮąĮčŗąĄ 16-ą▒ąĖčéąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ, add|add,
// subtract|subtract
r5= r3+|- r4, r7= r3-|+ r4; // čüč湥čéą▓ąĄčĆąĄąĮąĮčŗąĄ 16-ą▒ąĖčéąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ, add|subtract,
// subtract|add
r5= r3+|- r4, r7= r3-|+ r4(asr); // čüč湥čéą▓ąĄčĆąĄąĮąĮčŗąĄ 16-ą▒ąĖčéąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ, add|subtract,
// subtract|add, čü čĆąĄąĘčāą╗čīčéą░čéą░ą╝ąĖ, ą┐ąŠą┤ąĄą╗ąĄąĮąĮčŗą╝ąĖ ąĮą░ 2
// (ą┐čāč鹥ą╝ čüą┤ą▓ąĖą│ą░ ą▓ą┐čĆą░ą▓ąŠ ąĮą░ 1 ą▒ąĖčé) ą┐ąĄčĆąĄą┤ čüąŠčģčĆą░ąĮąĄąĮąĖąĄą╝ ą▓
// čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ
r5= r3+|- r4, r7= r3-|+ r4(asl); // čüč湥čéą▓ąĄčĆąĄąĮąĮčŗąĄ 16-ą▒ąĖčéąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ, add|subtract,
// subtract|add, čü čĆąĄąĘčāą╗čīčéą░čéą░ą╝ąĖ, čāą╝ąĮąŠąČąĄąĮąĮčŗą╝ąĖ ąĮą░ 2
// (ą┐čāč鹥ą╝ čüą┤ą▓ąĖą│ą░ ą▓ą╗ąĄą▓ąŠ ąĮą░ 1 ą▒ąĖčé) ą┐ąĄčĆąĄą┤ čüąŠčģčĆą░ąĮąĄąĮąĖąĄą╝ ą▓
// čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
r2= r0+ r1, r3= r0- r1; // 32-ą▒ąĖčéąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ
r2= r0+ r1, r3= r0- r1(s); // ą┤ą▓ąŠą╣ąĮčŗąĄ 32-ą▒ąĖčéąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝
r4= a1+ a0, r6= a1- a0; // ą┤ą▓ąŠą╣ąĮčŗąĄ 40-ą▒ąĖčéąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ čü čāčćą░čüčéąĖąĄą╝ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓,
// ą│ą┤ąĄ ąĖąĘ A1 ą▓čŗčćąĖčéą░ąĄčéčüčÅ A0
r4= a1+ a0, r6= a1- a0(s); // ą┤ą▓ąŠą╣ąĮčŗąĄ 40-ą▒ąĖčéąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ čü čāčćą░čüčéąĖąĄą╝ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓,
// ą│ą┤ąĄ ąĖąĘ A0 ą▓čŗčćąĖčéą░ąĄčéčüčÅ A1
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Add, Subtract (ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ").
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = src_reg >>> shift_magnitude (V)
dest_reg = ASHIFT src_reg BY shift_magnitude (V)
ąĪąĖąĮčéą░ą║čüąĖčü čü ą╝ą░ą│ąĮąĖčéčāą┤ąŠą╣ čüą┤ą▓ąĖą│ą░ ą▓ ą▓ąĖą┤ąĄ ą║ąŠąĮčüčéą░ąĮčéčŗ:
Dreg = Dreg >>> uimm4 (V); // ą░čĆąĖčäą╝. čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ, čü ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠą╣ ą║ąŠąĮčüčéą░ąĮč鹊ą╣ (b)1 Dreg = Dreg << uimm4 (V,S); // ą░čĆąĖčäą╝. čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ, ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮą░čÅ ą║ąŠąĮčüčéą░ąĮčéą░ ąĖ ąĮą░čüčŗčēąĄąĮąĖąĄ (b)
ąĪąĖąĮčéą░ą║čüąĖčü čü ą╝ą░ą│ąĮąĖčéčāą┤ąŠą╣ čüą┤ą▓ąĖą│ą░ ą▓ čĆąĄą│ąĖčüčéčĆąĄ:
Dreg = ASHIFT Dreg BY Dreg_lo (V); // ą░čĆąĖčäą╝. čüą┤ą▓ąĖą│ (b) Dreg = ASHIFT Dreg BY Dreg_lo (V, S); // ą░čĆąĖčäą╝. čüą┤ą▓ąĖą│ čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝ (b)
ąØąĄčé čüą┐ąĄčåąĖą░ą╗čīąĮąŠą│ąŠ čüąĖąĮčéą░ą║čüąĖčüą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ą╗čÅ ą▓ąĄą║č鹊čĆąĮąŠą│ąŠ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠą│ąŠ čüą┤ą▓ąĖą│ą░ ą▓ą╗ąĄą▓ąŠ čü ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠą╣ ą║ąŠąĮčüčéą░ąĮč鹊ą╣ (vector arithmetic left shift immediate). ąśčüą┐ąŠą╗čīąĘčāą╣č鹥 ąĖąĮčüčéčĆčāą║čåąĖčÄ Vector Logical Shift ą┤ą╗čÅ čüą┤ą▓ąĖą│ą░ ą▓ąĄą║č鹊čĆą░ ą▓ą╗ąĄą▓ąŠ, ą║ąŠč鹊čĆą░čÅ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé čéčā ąČąĄ čüą░ą╝čāčÄ čäčāąĮą║čåąĖčÄ ą┤ą╗čÅ čćąĖčüąĄą╗, čĆą░čüčłąĖčĆąĄąĮąĮčŗčģ ąĘąĮą░ą║ąŠą╝ ą▓ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ą░čģ ąĮąŠčĆą╝ą░ą╗ąĖąĘą░čåąĖąĖ čćąĖčüąĄą╗. ąĪą╝. ą┐čĆąĖą╝ąĄčćą░ąĮąĖčÅ ą║ čüąĖąĮčéą░ą║čüąĖčüčā >>> ą┤ą╗čÅ č鹊ąĮą║ąŠčüč鹥ą╣ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: R0, ..., R7.
Dreg_lo: R0.L, ..., R7.L.
uimm4: 4-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░, čü ą┤ąĖą░ą┐ą░ąĘąŠąĮąŠą╝ ąŠčé 0 ą┤ąŠ 15.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Vector Arithmetic Shift ą┤ąĄą╗ą░ąĄčé ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ čüą┤ą▓ąĖą│ąĖ ą┐ą░čĆ čćąĖčüąĄą╗, čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĮčŗčģ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░čģ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ čāą║ą░ąĘą░ąĮąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé ąĖ ą▓ čāą║ą░ąĘą░ąĮąĮąŠą╝ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĖ. ąźąŠčéčÅ ą┤ą▓ąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆą░ čüą┤ą▓ąĖą│ą░čÄčéčüčÅ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ, ąŠąĮąĖ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ, ą║ą░ą║ ą┤ą▓ą░ ąŠčéą┤ąĄą╗čīąĮčŗčģ čćąĖčüą╗ą░.
ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ čüą┤ą▓ąĖą│ąĖ ą▓ą┐čĆą░ą▓ąŠ čüąŠčģčĆą░ąĮčÅčÄčé ąĘąĮą░ą║ čüą┤ą▓ąĖą│ą░ąĄą╝ąŠą╣ ą▓ąĄą╗ąĖčćąĖąĮčŗ. ąæąĖčé ąĘąĮą░ą║ą░ ą▓ąŠčüčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ą▓ ą║čĆą░ą╣ąĮąĄą╣ ą╗ąĄą▓ąŠą╣ ą┐ąŠąĘąĖčåąĖąĖ, ą║ąŠą│ą┤ą░ ąŠąĮą░ ąŠčüą▓ąŠą▒ąŠąČą┤ą░ąĄčéčüčÅ ą┐čĆąĖ čüą┤ą▓ąĖą│ąĄ ą▓ą┐čĆą░ą▓ąŠ. ąöą╗čÅ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮčŗčģ čćąĖčüąĄą╗ čŹč鹊 ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ 菹║ą▓ąĖą▓ą░ą╗ąĄąĮčéąĮąŠ ą╗ąŠą│ąĖč湥čüą║ąŠą╝čā čüą┤ą▓ąĖą│čā ą▓ą┐čĆą░ą▓ąŠ ą┤ą╗čÅ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓čŗčģ čćąĖčüąĄą╗.
ą¤ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ č鹊ą╗čīą║ąŠ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ čüą┤ą▓ąĖą│ąĖ ą▓ą┐čĆą░ą▓ąŠ. ąĪą┤ą▓ąĖą│ąĖ ą▓ą╗ąĄą▓ąŠ ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ą║ą░ą║ ą╗ąŠą│ąĖč湥čüą║ąĖąĄ čüą┤ą▓ąĖą│ąĖ ą▓ą╗ąĄą▓ąŠ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ąĮąĄ čüąŠčģčĆą░ąĮčÅčéčī čüą┤ą▓ąĖą│ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮąŠą│ąŠ čćąĖčüą╗ą░. ąÆ čüą╗čāčćą░ąĄ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ (ą▒ąĄąĘ čāą║ą░ąĘą░ąĮąĮąŠą╣ ąŠą┐čåąĖąĖ ąĮą░čüčŗčēąĄąĮąĖčÅ) čćąĖčüą╗ą░ ą╝ąŠą│čāčé ą▒čŗčéčī čüą┤ą▓ąĖąĮčāčéčŗ ą▓ą╗ąĄą▓ąŠ čéą░ą║ ą┤ą░ą╗ąĄą║ąŠ, čćč鹊 ą▒ąĖčé ąĘąĮą░ą║ą░ čāą╣ą┤ąĄčé ąĖąĘ čĆąĄą│ąĖčüčéčĆą░ ąĖ ą▒čāą┤ąĄčé ą┐ąŠč鹥čĆčÅąĮ. ą×ą┤ąĮą░ą║ąŠ, ą║ąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮą░ ąŠą┐čåąĖčÅ ąĮą░čüčŗčēąĄąĮąĖčÅ, čüą┤ą▓ąĖą│ a ą▓ą╗ąĄą▓ąŠ ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ąĮą░čüčŗčēą░ąĄčé ąĘąĮą░č湥ąĮąĖąĄ ą║ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠą╣ ąĖą╗ąĖ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠą╣ ą▓ąĄą╗ąĖčćąĖąĮąĄ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąĄčüą╗ąĖ ąĮą░čüčŗčēąĄąĮąĖąĄ čĆą░ąĘčĆąĄčłąĄąĮąŠ, č鹊 čĆąĄąĘčāą╗čīčéą░čé ą▓čüąĄą│ą┤ą░ čüąŠčģčĆą░ąĮąĖčé č鹊čé ąČąĄ ąĘąĮą░ą║, čćč鹊 ą▒čŗą╗ čā ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮąŠą│ąŠ čćąĖčüą╗ą░.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ąĮą░čüčŗčēąĄąĮąĖąĄ čüą╝. čüąĄą║čåąĖčÄ "Saturation (ąĮą░čüčŗčēąĄąĮąĖąĄ)".
ąĪąĖąĮčéą░ą║čüąĖčü >>> ąĖ <<< . ąöą▓ąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆą░ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ dest_reg čüą┤ą▓ąĖą│ą░čÄčéčüčÅ ą▓ą┐čĆą░ą▓ąŠ ąĮą░ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé, čāą║ą░ąĘą░ąĮąĮąŠąĄ ą▓ shift_magnitude, ąĖ čĆąĄąĘčāą╗čīčéą░čé čüąŠčģčĆą░ąĮčÅąĄčéčüčÅ ą▓ dest_reg. ąöą░ąĮąĮčŗąĄ ą▓čüąĄą│ą┤ą░ ąĮą░čģąŠą┤čÅčéčüčÅ ą▓ ą┐ą░čĆąĄ 16-ą▒ąĖčéąĮčŗčģ ą┐ąŠą╗ąŠą▓ąĖąĮąŠą║ čĆąĄą│ąĖčüčéčĆą░. ąöąŠą┐čāčüčéąĖą╝ą░čÅ ą▓ąĄą╗ąĖčćąĖąĮą░ čüą┤ą▓ąĖą│ą░ shift_magnitude ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą┐čĆąĄą┤ąĄą╗ą░čģ 0 .. 15.
ąĪąĖąĮčéą░ą║čüąĖčü ASHIFT . ą×ą▒ąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆą░ ą▓ src_reg čüą┤ą▓ąĖą│ą░čÄčéčüčÅ ąĮą░ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé, ąŠą┐ąĖčüą░ąĮąĮąŠąĄ ą▓ shift_magnitude, ąĖ čĆąĄąĘčāą╗čīčéą░čé ą┐ąŠą╝ąĄčēą░ąĄčéčüčÅ ą▓ dest_reg.
ąŚąĮą░ą║ ą╝ą░ą│ąĮąĖčéčāą┤čŗ čüą┤ą▓ąĖą│ą░ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čüą┤ą▓ąĖą│ą░ ą┤ą╗čÅ ą▓ąĄčĆčüąĖą╣ ASHIFT čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ŌĆó ą¤ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą╝ą░ą│ąĮąĖčéčāą┤čŗ ą┤ąĄą╗ą░ąĄčé čüą┤ą▓ąĖą│ ą▒ąĄąĘ čäą╗ą░ą│ą░ ąĮą░čüčŗčēąĄąĮąĖčÅ ( ŌĆō , S) ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčé ąøą×ąōąśą¦ąĢąĪąÜąśąĢ čüą┤ą▓ąĖą│ąĖ ąÆąøąĢąÆą×.
ąÆ čüčāčēąĮąŠčüčéąĖ ą╝ą░ą│ąĮąĖčéčāą┤ą░ čŹč鹊 čüč鹥ą┐ąĄąĮčī čćąĖčüą╗ą░ 2, čāą╝ąĮąŠąČąĄąĮąĮą░čÅ ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ ą▓ src_reg. ą¤ąŠą╗ąŠąČąĖč鹥ą╗čīąĮčŗąĄ ą╝ą░ą│ąĮąĖčéčāą┤čŗ ą┤ą░čÄčé čāą╝ąĮąŠąČąĄąĮąĖąĄ ( N x 2n ), č鹊ą│ą┤ą░ ą║ą░ą║ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮčŗąĄ ą╝ą░ą│ąĮąĖčéčāą┤čŗ ą┐čĆąŠąĖąĘą▓ąŠą┤čÅčé ą┤ąĄą╗ąĄąĮąĖąĄ ( N x 2-n ąĖą╗ąĖ N / 2n ).
ą×ą▒ą░ čĆąĄą│ąĖčüčéčĆą░ dest_reg ąĖ src_reg čÅą▓ą╗čÅčÄčéčüčÅ ą┐ą░čĆą░ą╝ąĖ 16-ą▒ąĖčéąĮčŗčģ ą┐ąŠą╗ąŠą▓ąĖąĮąŠą║ čĆąĄą│ąĖčüčéčĆą░. ą×ą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĖą╝ąĄąĮąĄąĮąŠ ąĮą░čüčŗčēąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░.
ąöą╗čÅ 16-ą▒ąĖčéąĮąŠą│ąŠ src_reg ą┤ąŠą┐čāčüčéąĖą╝čŗ ą╝ą░ą│ąĮąĖčéčāą┤čŗ čüą┤ą▓ąĖą│ą░ ŌĆō16 .. +15, ą▓ą║ą╗čÄčćą░čÅ 0. ąĢčüą╗ąĖ ą╝ą░ą│ąĮąĖčéčāą┤ą░ čüą┤ą▓ąĖą│ą░ ą▒ąŠą╗čīčłąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄą╝ąŠą╣, č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ą╝ą░čüą║ąĖčĆčāąĄčé ąĖ ąĖą│ąĮąŠčĆąĖčĆčāąĄčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ąĮąĄ ąĘąĮą░čćą░čēąĖąĄ ą▒ąĖčéčŗ ą╝ą░ą│ąĮąĖčéčāą┤čŗ.
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą┤ąĄą╗ą░ąĄčé ąĮąĄčÅą▓ąĮčāčÄ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÄ ąĘąĮą░č湥ąĮąĖą╣ src_reg. ą×ą┤ąĮą░ą║ąŠ ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ dest_reg ą╝ąŠąČąĄčé ą▒čŗčéčī č鹥ą╝ ąČąĄ čüą░ą╝čŗą╝ D-čĆąĄą│ąĖčüčéčĆąŠą╝, čćč鹊 ąĖ src_reg. ąÆ čüą╗čāčćą░ąĄ, ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ č鹊čé ąČąĄ D-čĆąĄą│ąĖčüčéčĆ ąĖ ą┤ą╗čÅ dest_reg, ąĖ ą┤ą╗čÅ src_reg, ą┤ąĄą╗ą░ąĄčéčüčÅ čÅą▓ąĮą░čÅ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÅ ąĖčüčģąŠą┤ąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░.
ą×ą┐čåąĖąĖ . ąśąĮčüčéčĆčāą║čåąĖčÅ ASHIFT ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ąŠą┐čåąĖčÄ ( ŌĆō , S), ą║ąŠč鹊čĆą░čÅ ą┤ąĄą╗ą░ąĄčé ąĮą░čüčŗčēąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ ą╗čÄą▒ąŠą╣ ąĖąĘ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ čĆą░ą▓ąĄąĮ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r4= r5>>> 3 (v); // ą░čĆąĖčäą╝. čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ R5.H ąĖ R5.L ąĮą░ 3 ą▒ąĖčéą░,
// ą╝ą░ą│ąĮąĖčéčāą┤ą░ čüą┤ą▓ąĖą│ą░ čāą║ą░ąĘą░ąĮą░ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠą╣
// ą║ąŠąĮčüčéą░ąĮč鹊ą╣ (čüą┤ą▓ąĖą│ ą┤ąĄą╗ąĖčé ą║ą░ąČą┤ąŠąĄ ą┐ąŠą╗čāčüą╗ąŠą▓ąŠ
// ąĮą░ 8). ąĢčüą╗ąĖ r5 = 0x8004 000F, č鹊 čĆąĄąĘčāą╗čīčéą░čé
// ą▒čāą┤ąĄčé r4 = 0xF000 0001
r4= r5>>> 3 (v, s); // č鹊 ąČąĄ čüą░ą╝ąŠąĄ, čćč鹊 ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ,
// ąĮąŠ čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝ čĆąĄąĘčāą╗čīčéą░čéą░
r2= ashift r7 by r5.l (v); // ą░čĆąĖčäą╝. čüą┤ą▓ąĖą│ (ą▓ą┐čĆą░ą▓ąŠ ąĖą╗ąĖ ą▓ą╗ąĄą▓ąŠ, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ
// ąŠčé ąĘąĮą░ą║ą░ r5.l) R7.H ąĖ R7.L ąĮą░ ą╝ą░ą│ąĮąĖčéčāą┤čā čüą┤ą▓ąĖą│ą░,
// čāą║ą░ąĘą░ąĮąĮčāčÄ ą▓ R5.L
r2= ashift r7 by r5.l (v, s); // č鹊 ąČąĄ čüą░ą╝ąŠąĄ, čćč鹊 ąĖ ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ,
// ąĮąŠ čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝ čĆąĄąĘčāą╗čīčéą░čéą░
r2 = r5 << 7 (v,s); // ą╗ąŠą│ąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ R5.H ąĖ R5.L ąĮą░ 7 ą▒ąĖčé
// (ą╝ą░ą│ąĮąĖčéčāą┤ą░ čüą┤ą▓ąĖą│ą░ čāą║ą░ąĘą░ąĮą░ ą▓ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠą╣
// ą║ąŠąĮčüčéą░ąĮč鹥 ą║ąŠą╝ą░ąĮą┤čŗ), čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Vector Logical Shift, Arithmetic Shift, Logical Shift (ą┐ąŠčüą╗ąĄą┤ąĮąĖąĄ ą┤ą▓ąĄ ą║ąŠą╝ą░ąĮą┤čŗ ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "Shift / Rotate", čé. ąĄ. čüą┤ą▓ąĖą│ / čåąĖą║ą╗ąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│).
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = src_reg >> shift_magnitude (V)
dest_reg = src_reg << shift_magnitude (V)
dest_reg = LSHIFT src_reg BY shift_magnitude (V)
ąĪąĖąĮčéą░ą║čüąĖčü čü ą╝ą░ą│ąĮąĖčéčāą┤ąŠą╣ čüą┤ą▓ąĖą│ą░ ą▓ ą▓ąĖą┤ąĄ ą║ąŠąĮčüčéą░ąĮčéčŗ:
Dreg = Dreg >> uimm4 (V); // ą╗ąŠą│. čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ, čü ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠą╣ ą║ąŠąĮčüčéą░ąĮč鹊ą╣ (b)1 Dreg = Dreg << uimm4 (V); // ą╗ąŠą│. čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ, čü ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠą╣ ą║ąŠąĮčüčéą░ąĮč鹊ą╣ (b)
ąĪąĖąĮčéą░ą║čüąĖčü čü ą╝ą░ą│ąĮąĖčéčāą┤ąŠą╣ čüą┤ą▓ąĖą│ą░ ą▓ čĆąĄą│ąĖčüčéčĆąĄ:
Dreg = LSHIFT Dreg BY Dreg_lo (V); // ą╗ąŠą│ąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: R0, ..., R7.
Dreg_lo: R0.L, ..., R7.L.
uimm4: 4-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░, čü ą┤ąĖą░ą┐ą░ąĘąŠąĮąŠą╝ ąŠčé 0 ą┤ąŠ 15.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Vector Logical Shift ą┤ąĄą╗ą░ąĄčé ą╗ąŠą│ąĖč湥čüą║ąĖąĄ čüą┤ą▓ąĖą│ąĖ ą┐ą░čĆ čćąĖčüąĄą╗, čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĮčŗčģ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░čģ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ čāą║ą░ąĘą░ąĮąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé ąĖ ą▓ čāą║ą░ąĘą░ąĮąĮąŠą╝ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĖ. ąźąŠčéčÅ ą┤ą▓ąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆą░ čüą┤ą▓ąĖą│ą░čÄčéčüčÅ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ, ąŠąĮąĖ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ, ą║ą░ą║ ą┤ą▓ą░ ąŠčéą┤ąĄą╗čīąĮčŗčģ čćąĖčüą╗ą░.
ąøąŠą│ąĖč湥čüą║ąĖąĄ čüą┤ą▓ąĖą│ąĖ ąŠčéą▒čĆą░čüčŗą▓ą░čÄčé ą▓čŗą┤ą▓ąĖą│ą░ąĄą╝čŗąĄ ąĮą░čĆčāąČčā ą▒ąĖčéčŗ, ąĖ ąĘą░ą┐ąŠą╗ąĮčÅčÄčé ąĮčāą╗čÅą╝ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ą░čÄčēąĖąĄčüčÅ ą╝ąĄčüčéą░ ą▒ąĖčé.
ąĪąĖąĮčéą░ą║čüąĖčü >> ąĖ << . ąöą▓ąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆą░ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ dest_reg čüą┤ą▓ąĖą│ą░čÄčéčüčÅ ąĮą░ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé, čāą║ą░ąĘą░ąĮąĮąŠąĄ ą▓ shift_magnitude, ąĖ čĆąĄąĘčāą╗čīčéą░čé čüąŠčģčĆą░ąĮčÅąĄčéčüčÅ ą▓ dest_reg. ąöą░ąĮąĮčŗąĄ ą▓čüąĄą│ą┤ą░ ąĮą░čģąŠą┤čÅčéčüčÅ ą▓ ą┐ą░čĆąĄ 16-ą▒ąĖčéąĮčŗčģ ą┐ąŠą╗ąŠą▓ąĖąĮąŠą║ čĆąĄą│ąĖčüčéčĆą░. ąöąŠą┐čāčüčéąĖą╝ą░čÅ ą▓ąĄą╗ąĖčćąĖąĮą░ čüą┤ą▓ąĖą│ą░ shift_magnitude ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą┐čĆąĄą┤ąĄą╗ą░čģ 0 .. 15.
ąĪąĖąĮčéą░ą║čüąĖčü LSHIFT . ą×ą▒ąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆą░ ą▓ src_reg čüą┤ą▓ąĖą│ą░čÄčéčüčÅ ąĮą░ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé, ąŠą┐ąĖčüą░ąĮąĮąŠąĄ ą▓ shift_magnitude, ąĖ čĆąĄąĘčāą╗čīčéą░čé ą┐ąŠą╝ąĄčēą░ąĄčéčüčÅ ą▓ dest_reg.
ąŚąĮą░ą║ ą╝ą░ą│ąĮąĖčéčāą┤čŗ čüą┤ą▓ąĖą│ą░ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čüą┤ą▓ąĖą│ą░ ą┤ą╗čÅ ą▓ąĄčĆčüąĖą╣ LSHIFT čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ŌĆó ą¤ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą╝ą░ą│ąĮąĖčéčāą┤čŗ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčé ąøą×ąōąśą¦ąĢąĪąÜąśąĢ čüą┤ą▓ąĖą│ąĖ ąÆąøąĢąÆą×.
ą×ą▒ą░ čĆąĄą│ąĖčüčéčĆą░ dest_reg ąĖ src_reg čÅą▓ą╗čÅčÄčéčüčÅ ą┐ą░čĆą░ą╝ąĖ 16-ą▒ąĖčéąĮčŗčģ ą┐ąŠą╗ąŠą▓ąĖąĮąŠą║ čĆąĄą│ąĖčüčéčĆą░.
ąöą╗čÅ 16-ą▒ąĖčéąĮąŠą│ąŠ src_reg ą┤ąŠą┐čāčüčéąĖą╝čŗ ą╝ą░ą│ąĮąĖčéčāą┤čŗ čüą┤ą▓ąĖą│ą░ ŌĆō16 .. +15, ą▓ą║ą╗čÄčćą░čÅ 0. ąĢčüą╗ąĖ ą╝ą░ą│ąĮąĖčéčāą┤ą░ čüą┤ą▓ąĖą│ą░ ą▒ąŠą╗čīčłąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄą╝ąŠą╣, č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ą╝ą░čüą║ąĖčĆčāąĄčé ąĖ ąĖą│ąĮąŠčĆąĖčĆčāąĄčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ąĮąĄ ąĘąĮą░čćą░čēąĖąĄ ą▒ąĖčéčŗ ą╝ą░ą│ąĮąĖčéčāą┤čŗ.
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą┤ąĄą╗ą░ąĄčé ąĮąĄčÅą▓ąĮčāčÄ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÄ ąĘąĮą░č湥ąĮąĖą╣ src_reg. ą×ą┤ąĮą░ą║ąŠ ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ dest_reg ą╝ąŠąČąĄčé ą▒čŗčéčī č鹥ą╝ ąČąĄ čüą░ą╝čŗą╝ D-čĆąĄą│ąĖčüčéčĆąŠą╝, čćč鹊 ąĖ src_reg. ąÆ čüą╗čāčćą░ąĄ, ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ č鹊čé ąČąĄ D-čĆąĄą│ąĖčüčéčĆ ąĖ ą┤ą╗čÅ dest_reg, ąĖ ą┤ą╗čÅ src_reg, ą┤ąĄą╗ą░ąĄčéčüčÅ čÅą▓ąĮą░čÅ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÅ ąĖčüčģąŠą┤ąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ ą╗čÄą▒ąŠą╣ ąĖąĘ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ čĆą░ą▓ąĄąĮ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r4 = r5 >> 3 (v); // ą╗ąŠą│ąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ R5.H ąĖ R5.L ąĮą░ 3 ą▒ąĖčéą░
// (čŹč鹊 čāą║ą░ąĘą░ąĮąŠ ą▓ ą▓ąĖą┤ąĄ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠą╣ ą║ąŠąĮčüčéą░ąĮčéčŗ)
r4 = r5 << 3 (v); // ą╗ąŠą│ąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ R5.H ąĖ R5.L ąĮą░ 3 ą▒ąĖčéą░
// (čŹč鹊 čāą║ą░ąĘą░ąĮąŠ ą▓ ą▓ąĖą┤ąĄ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠą╣ ą║ąŠąĮčüčéą░ąĮčéčŗ)
r2 = lshift r7 by r5.l (v); // ą╗ąŠą│ąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ R7.H ąĖ R7.L ąĮą░ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ
// ą▒ąĖčé, čāą║ą░ąĘą░ąĮąĮąŠąĄ ą▓ R5.L (ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą▓ą┐čĆą░ą▓ąŠ ąĖą╗ąĖ
// ą▓ą╗ąĄą▓ąŠ ąĘą░ą▓ąĖčüąĖčé čéą░ą║ąČąĄ ąŠčé ąĘąĮą░ą║ą░ čćąĖčüą╗ą░ ą▓ r5.l)
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Vector Arithmetic Shift, Arithmetic Shift, Logical Shift (ą┐ąŠčüą╗ąĄą┤ąĮąĖąĄ ą┤ą▓ąĄ ą║ąŠą╝ą░ąĮą┤čŗ ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "Shift / Rotate", čé. ąĄ. čüą┤ą▓ąĖą│ / čåąĖą║ą╗ąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│).
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = MAX ( src_reg_0, src_reg_1 ) (V)
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = MAX (Dreg, Dreg) (V); // ą┤ą▓ąŠą╣ąĮčŗąĄ 16-ą▒ąĖčéąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ (b)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Vector Maximum ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ (ąĖą╝ąĄąĄčéčüčÅ ą▓ ą▓ąĖą┤čā ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą▒ą╗ąĖąĘą║ąŠąĄ ą║ 0x7FFF) ąĖąĘ 16-ą▒ąĖčéąĮčŗčģ ą┐ąŠą╗čāčüą╗ąŠą▓ čĆąĄą│ąĖčüčéčĆąŠą▓, ąĖ ą┐ąŠą╝ąĄčēą░ąĄčé čŹč鹊 ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą▓ dest_reg.
ąśąĮčüčéčĆčāą║čåąĖčÅ čüčĆą░ą▓ąĮąĖą▓ą░ąĄčé čüčéą░čĆčłąĖąĄ ą┐ąŠą╗čāčüą╗ąŠą▓ą░ čĆąĄą│ąĖčüčéčĆąŠą▓ src_reg_0 ąĖ src_reg_1 ą▓ąŠąĘą▓čĆą░čéąĖčé ą╝ą░ą║čüąĖą╝čāą╝ ą▓ čüčéą░čĆčłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮąĄ čĆąĄą│ąĖčüčéčĆą░ dest_reg. ąśąĮčüčéčĆčāą║čåąĖčÅ čéą░ą║ąČąĄ čüčĆą░ą▓ąĮąĖą▓ą░ąĄčé ą╝ą╗ą░ą┤čłąĖąĄ ą┐ąŠą╗čāčüą╗ąŠą▓ą░ src_reg_0 ąĖ src_reg_1, ąĖ ą▓ąŠąĘą▓čĆą░čéąĖčé ą╝ą░ą║čüąĖą╝čāą╝ ą▓ ą╝ą╗ą░ą┤čłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮąĄ čĆąĄą│ąĖčüčéčĆą░ dest_reg. ąĀąĄąĘčāą╗čīčéą░čé ą▒čāą┤ąĄčé ą║ąŠąĮą║ą░č鹥ąĮą░čåąĖąĄą╣ čŹčéąĖčģ ą┤ą▓čāčģ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčŗčģ 16-ą▒ąĖčéąĮčŗčģ ą▓ąĄą╗ąĖčćąĖąĮ.
ąśąĮčüčéčĆčāą║čåąĖčÅ Vector Maximum ąĮąĄ ą┤ąĄą╗ą░ąĄčé ąĮąĄčÅą▓ąĮąŠąĄ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĖąĄ ą▓čģąŠą┤ąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣. ą×ą┤ąĮą░ą║ąŠ dest_reg ą╝ąŠąČąĄčé ą▒čŗčéčī č鹥ą╝ ąČąĄ čüą░ą╝čŗą╝ D-čĆąĄą│ąĖčüčéčĆąŠą╝, čćč鹊 ąĖ ąĖčüčģąŠą┤ąĮčŗąĄ čĆąĄą│ąĖčüčéčĆčŗ. ąÆ čéą░ą║ąŠą╝ čüą╗čāčćą░ąĄ ąĖąĮčüčéčĆčāą║čåąĖčÅ čÅą▓ąĮąŠ ą┐čĆąŠąĖąĘą▓ąĄą┤ąĄčé ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÄ ąĖčüčģąŠą┤ąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ ą╗čÄą▒ąŠą╣ ąĖąĘ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ čĆą░ą▓ąĄąĮ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆ ]
ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝:
R1 = 0x0007 0000 ąĖ R0 = 0x0000 000F, č鹊ą│ą┤ą░ R7 = 0x0007 000F.
R1 = 0xFFF7 8000 ąĖ R0 = 0x000A 7FFF, č鹊ą│ą┤ą░ R7 = 0x000A 7FFF.
R1 = 0x1234 5678 ąĖ R0 = 0x0000 000F, č鹊ą│ą┤ą░ R7 = 0x1234 5678.
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Vector Search, Vector Minimum, ąĖą╗ąĖ Maximum ąĖ Minimum ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ".
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = MIN ( src_reg_0, src_reg_1 ) (V)
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = MIN (Dreg, Dreg) (V); // ą┤ą▓ąŠą╣ąĮčŗąĄ 16-ą▒ąĖčéąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ (b)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Vector Minimum ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ (ąĖą╝ąĄąĄčéčüčÅ ą▓ ą▓ąĖą┤čā ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠąĄ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą▒ą╗ąĖąĘą║ąŠąĄ ą║ 0x8000) ąĖąĘ 16-ą▒ąĖčéąĮčŗčģ ą┐ąŠą╗čāčüą╗ąŠą▓ čĆąĄą│ąĖčüčéčĆąŠą▓, ąĖ ą┐ąŠą╝ąĄčēą░ąĄčé čŹč鹊 ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą▓ dest_reg.
ąśąĮčüčéčĆčāą║čåąĖčÅ čüčĆą░ą▓ąĮąĖą▓ą░ąĄčé čüčéą░čĆčłąĖąĄ ą┐ąŠą╗čāčüą╗ąŠą▓ą░ čĆąĄą│ąĖčüčéčĆąŠą▓ src_reg_0 ąĖ src_reg_1 ą▓ąŠąĘą▓čĆą░čéąĖčé ą╝ąĖąĮąĖą╝čāą╝ ą▓ čüčéą░čĆčłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮąĄ čĆąĄą│ąĖčüčéčĆą░ dest_reg. ąśąĮčüčéčĆčāą║čåąĖčÅ čéą░ą║ąČąĄ čüčĆą░ą▓ąĮąĖą▓ą░ąĄčé ą╝ą╗ą░ą┤čłąĖąĄ ą┐ąŠą╗čāčüą╗ąŠą▓ą░ src_reg_0 ąĖ src_reg_1, ąĖ ą▓ąŠąĘą▓čĆą░čéąĖčé ą╝ąĖąĮąĖą╝čāą╝ ą▓ ą╝ą╗ą░ą┤čłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮąĄ čĆąĄą│ąĖčüčéčĆą░ dest_reg. ąĀąĄąĘčāą╗čīčéą░čé ą▒čāą┤ąĄčé ą║ąŠąĮą║ą░č鹥ąĮą░čåąĖąĄą╣ čŹčéąĖčģ ą┤ą▓čāčģ ą╝ąĖąĮąĖą╝ą░ą╗čīąĮčŗčģ 16-ą▒ąĖčéąĮčŗčģ ą▓ąĄą╗ąĖčćąĖąĮ.
ąśąĮčüčéčĆčāą║čåąĖčÅ Vector Minimum ąĮąĄ ą┤ąĄą╗ą░ąĄčé ąĮąĄčÅą▓ąĮąŠąĄ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĖąĄ ą▓čģąŠą┤ąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣. ą×ą┤ąĮą░ą║ąŠ dest_reg ą╝ąŠąČąĄčé ą▒čŗčéčī č鹥ą╝ ąČąĄ čüą░ą╝čŗą╝ D-čĆąĄą│ąĖčüčéčĆąŠą╝, čćč鹊 ąĖ ąĖčüčģąŠą┤ąĮčŗąĄ čĆąĄą│ąĖčüčéčĆčŗ. ąÆ čéą░ą║ąŠą╝ čüą╗čāčćą░ąĄ ąĖąĮčüčéčĆčāą║čåąĖčÅ čÅą▓ąĮąŠ ą┐čĆąŠąĖąĘą▓ąĄą┤ąĄčé ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÄ ąĖčüčģąŠą┤ąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ ą╗čÄą▒ąŠą╣ ąĖąĘ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ čĆą░ą▓ąĄąĮ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆ ]
ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝:
R1 = 0x0007 0000 ąĖ R0 = 0x0000 000F, č鹊ą│ą┤ą░ R7 = 0x0000 0000.
R1 = 0xFFF7 8000 ąĖ R0 = 0x000A 7FFF, č鹊ą│ą┤ą░ R7 = 0xFFF7 8000.
R1 = 0x1234 5678 ąĖ R0 = 0x0000 000F, č鹊ą│ą┤ą░ R7 = 0x0000 000F.
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Vector Search, Vector Maximum, ąĖą╗ąĖ Maximum ąĖ Minimum ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ".
[ą¤čĆąŠą▒ą╗ąĄą╝čŗ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖą╣ ]
ą¤ą░čĆą░ čüąŠą▓ą╝ąĄčüčéąĖą╝čŗčģ, čüą║ą░ą╗čÅčĆąĮčŗčģ (ąĖąĮą┤ąĖą▓ąĖą┤čāą░ą╗čīąĮąŠ) ąĖąĮčüčéčĆčāą║čåąĖą╣ Multiply ąĖąĘ čüąĄą║čåąĖąĖ "ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ" ą╝ąŠąČąĄčé ą▒čŗčéčī čüą║ąŠą╝ą▒ąĖąĮąĖčĆąŠą▓ą░ąĮą░ čü ąŠą┤ąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ Vector Multiply. ąÆąĄą║č鹊čĆąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą┤ą▓ąĄ čüą║ą░ą╗čÅčĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ąĖ čüąŠčģčĆą░ąĮčÅąĄčé čĆąĄąĘčāą╗čīčéą░čéčŗ ą║ą░ą║ ą▓ąĄą║č鹊čĆąĮčŗą╣ ą║čāą┐ą╗ąĄčé.
ąøčÄą▒ą░čÅ čüą║ą░ą╗čÅčĆąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ MAC0 Multiply ą╝ąŠąČąĄčé ą▒čŗčéčī čüą║ąŠą╝ą▒ąĖąĮąĖčĆąŠą▓ą░ąĮą░ čü čüąŠą▓ą╝ąĄčüčéąĖą╝ąŠą╣ čüą║ą░ą╗čÅčĆąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ MAC1 Multiply čü čüąŠą▒ą╗čÄą┤ąĄąĮąĖąĄą╝ čüą╗ąĄą┤čāčÄčēąĖčģ čāčüą╗ąŠą▓ąĖą╣:
1 . ą×ą▒ąĄ čüą║ą░ą╗čÅčĆąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ąŠą╗ąČąĮčŗ čĆą░ąĘą┤ąĄą╗čÅčéčī ąŠą┤ąĮčā ąĖ čéčā ąČąĄ ąŠą┐čåąĖčÄ čĆąĄąČąĖą╝ą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ: ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ, IS, IU, T, ąĖ čé. ą┐.).
ąśčüą║ą╗čÄč湥ąĮąĖąĄ: ąĖąĮčüčéčĆčāą║čåąĖčÅ MAC1 ą╝ąŠąČąĄčé ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čüą╝ąĄčłą░ąĮąĮčŗą╣ čĆąĄąČąĖą╝ (mixed mode, (M)), ą║ąŠč鹊čĆčŗą╣ ąĮąĄ ą┐čĆąĖą╝ąĄąĮąĖą╝ ą║ MAC0.
2 . ą×ą▒ąĄ čüą║ą░ą╗čÅčĆąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ąŠą╗ąČąĮčŗ čĆą░ąĘą┤ąĄą╗čÅčéčī čéčā ąČąĄ čüą░ą╝čāčÄ ą┐ą░čĆčā čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖčüč鹊čćąĮąĖą║ąŠą▓ ą┤ą░ąĮąĮčŗčģ, ąĮąŠ ą╝ąŠą│čāčé ąŠą▒čĆą░čēą░čéčīčüčÅ ą║ čĆą░ąĘąĮčŗą╝ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ą╝ čŹčéąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓.
3 . ą×ą▒ąĄ čüą║ą░ą╗čÅčĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ą┤ąŠą╗ąČąĮčŗ ąĘą░ą┐ąĖčüčŗą▓ą░čéčī ą▓ čĆąĄą│ąĖčüčéčĆčŗ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░, ą╗ąĖą▒ąŠ 16-, ą╗ąĖą▒ąŠ 32-ą▒ąĖčéąĮčŗąĄ.
4 . ąĀąĄą│ąĖčüčéčĆčŗ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą┤ą╗čÅ ąŠą▒ąŠąĖčģ čüą║ą░ą╗čÅčĆąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣ ą┤ąŠą╗ąČąĮčŗ č乊čĆą╝ąĖčĆąŠą▓ą░čéčī ą▓ąĄą║č鹊čĆąĮčŗą╣ ą║čāą┐ą╗ąĄčé, ą║ą░ą║ ąŠą┐ąĖčüą░ąĮąŠ ąĮąĖąČąĄ.
a . 16-ą▒ąĖčé: čüąŠčģčĆą░ąĮąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ą▓ čüčéą░čĆčłčāčÄ ąĖ ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ ąŠą┤ąĮąŠą│ąŠ ąĖ č鹊ą│ąŠ ąČąĄ 32-ą▒ąĖčéąĮąŠą│ąŠ Dreg. MAC0 ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé ą▓ ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā, ąĖ MAC1 ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé ą▓ čüčéą░čĆčłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā.b . 32-ą▒ąĖčé: čüąŠčģčĆą░ąĮąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ą▓ ą┤ąŠą┐čāčüčéąĖą╝čāčÄ ą┐ą░čĆčā čĆąĄą│ąĖčüčéčĆąŠą▓ Dreg. MAC0 ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé ą▓ ą╝ą╗ą░ą┤čłčāčÄ čćą░čüčéčī ą┐ą░čĆčŗ (čü č湥čéąĮčŗą╝ ąĮąŠą╝ąĄčĆąŠą╝) Dreg, ąĖ MAC1 ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé ą▓ čüčéą░čĆčłčāčÄ čćą░čüčéčī ą┐ą░čĆčŗ (čü ąĮąĄč湥čéąĮčŗą╝ ąĮąŠą╝ąĄčĆąŠą╝) Dreg. ąÜ ą┤ąŠą┐čāčüčéąĖą╝čŗą╝ ą┐ą░čĆą░ą╝ čĆąĄą│ąĖčüčéčĆąŠą▓ ąŠčéąĮąŠčüčÅčéčüčÅ R7:6, R5:4, R3:2 ąĖ R1:0.
[ąĪąĖąĮčéą░ą║čüąĖčü ]
ą×čéą┤ąĄą╗ąĖč鹥 ąĘą░ą┐čÅč鹊ą╣ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ ą┤ą▓ąĄ čüąŠą▓ą╝ąĄčüčéąĖą╝čŗčģ čüą║ą░ą╗čÅčĆąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖąĖ, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖą╗ą░čüčī ą▓ąĄą║č鹊čĆąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ. ąÆ ą║ąŠąĮąĄčå čéą░ą║ąŠą╣ ą║ąŠą╝ą▒ąĖąĮąĖčĆąŠą▓ą░ąĮąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ąŠą▒ą░ą▓čīč鹥 č鹊čćą║čā čü ąĘą░ą┐čÅč鹊ą╣, ą║ą░ą║ ąŠą▒čŗčćąĮąŠ. ą¤ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą┤čĆčāą│ ąĘą░ ą┤čĆčāą│ąŠą╝ ąŠą┐ąĄčĆą░čåąĖą╣ MAC ą▓ ąŠą┤ąĮąŠą╣ čüčéčĆąŠą║ąĄ ą║ąŠą╝ą░ąĮą┤čŗ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮčŗą╝.
[ąöą╗ąĖąĮą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ ]
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĖą╝ąĄąĄčé ą┤ą╗ąĖąĮčā 32 ą▒ąĖčéą░.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó V čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ ą▓ ą╗čÄą▒ąŠą╝ ąĖąĘ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ą▒čŗą╗ąŠ ąĮą░čüčŗčēąĄąĮąĖąĄ; ąŠčćąĖčüčéąĖčéčüčÅ, ąĄčüą╗ąĖ ąĮąĖ ą▓ ąŠą┤ąĮąŠą╝ ąĖąĘ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ąĮą░čüčŗčēąĄąĮąĖčÅ ąĮąĄ ą▒čŗą╗ąŠ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r2.h= r7.l* r6.h, r2.l= r7.h* r6.h; // ą×ą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ MAC0 ąĖ MAC1,
// 16-ą▒ąĖčéąĮčŗąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ. ą×ą▒ą░ čĆąĄąĘčāą╗čīčéą░čéą░
// čŹč鹊 ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝.
r4.l= r1.l* r0.l, r4.h= r1.h* r0.h; // ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ, čćč鹊 ąĖ ą┐čĆąĄą┤čŗą┤čāčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ.
// ą¤ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ MAC ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮčŗą╣.
r0.h= r3.h* r2.l(m), r0.l= r3.l* r2.l; // MAC1 čāą╝ąĮąŠąČą░ąĄčé ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝
// ąĮą░ ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░. MAC0 čāą╝ąĮąŠąČą░ąĄčé
// ą┤ą▓ą░ ą┤čĆąŠą▒ąĮčŗčģ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝.
r5.h= r3.h* r2.h(m), r5.l= r3.l* r2.l(fu); // MAC1 čāą╝ąĮąŠąČą░ąĄčé ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝
// ąĮą░ ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░. MAC0 čāą╝ąĮąŠąČą░ąĄčé
// ą┤ą▓ą░ ą┤čĆąŠą▒ąĮčŗčģ čćąĖčüą╗ą░ ą▒ąĄąĘ ąĘąĮą░ą║ą░.
r0.h= r3.h* r2.h, r0.l= r3.l* r2.l(is); // ą×ą▒ąĄ ąŠą┐ąĄčĆą░čåąĖąĖ MAC ą▓čŗą┐ąŠą╗ąĮčÅčÄčé čāą╝ąĮąŠąČąĄąĮąĖąĄ
// čåąĄą╗čŗčģ čćąĖčüąĄą╗ čüąŠ ąĘąĮą░ą║ąŠą╝.
r3.h= r0.h* r1.h, r3.l= r0.l* r1.l(s2rnd); // MAC1 ąĖ MAC0 čāą╝ąĮąŠąČą░čÄčé ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ čüąŠ
// ąĘąĮą░ą║ąŠą╝. ą×ą▒ąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ą╝ą░čüčłčéą░ą▒ąĖčĆčāčÄčé čĆąĄąĘčāą╗čīčéą░čé
// ą┤ą╗čÅ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
r0.l= r7.l* r6.l, r0.h= r7.h* r6.h (iss2); // ą×ą▒ąĄ ąŠą┐ąĄčĆą░čåąĖąĖ MAC ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčé čåąĄą╗čŗąĄ ąŠą┐ąĄčĆą░ąĮą┤čŗ
// čüąŠ ąĘąĮą░ą║ąŠą╝, ą╝ą░čüčłčéą░ą▒ąĖčĆčāčÄčé ąĖ ąŠą║čĆčāą│ą╗čÅčÄčé čĆąĄąĘčāą╗čīčéą░čé
// ą┤ą╗čÅ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
r7= r2.l* r5.l, r6= r2.h* r5.h; // ą×ą▒ąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ą┤ą░čÄčé 32-ą▒ąĖčéąĮčŗąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ,
// ąĖ čüąŠčģčĆą░ąĮčÅčÄčé ąĖčģ ą▓ ą┐ą░čĆąĄ čĆąĄą│ąĖčüčéčĆąŠą▓ Dreg.
r0= r4.l* r7.l, r1= r4.h* r7.h (s2rnd); // ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ, čćč鹊 ąĖ ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ,
// ąĮąŠ ą▓ čĆąĄąČąĖą╝ąĄ ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤čĆąŠą▒ąĮąŠą│ąŠ čćąĖčüą╗ą░
// čüąŠ ąĘąĮą░ą║ąŠą╝. ą¤ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖą╣ MAC
// ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮčŗą╝.
[ą¤čĆąŠą▒ą╗ąĄą╝čŗ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖą╣ ]
ą¤ą░čĆčā čüąŠą▓ą╝ąĄčüčéąĖą╝čŗčģ, čüą║ą░ą╗čÅčĆąĮčŗčģ (ą┐ąŠ ąŠčéą┤ąĄą╗čīąĮąŠčüčéąĖ) ąĖąĮčüčéčĆčāą║čåąĖą╣ ...
ŌĆó Multiply and Multiply-Accumulate to Accumulator
... (čüą╝. čĆą░ąĘą┤ąĄą╗ "ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ" ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ą┐ąŠą┤čĆąŠą▒ąĮąŠčüč鹥ą╣ ą┐ąŠ čüą║ą░ą╗čÅčĆąĮčŗą╝ ąŠą┐ąĄčĆą░čåąĖčÅą╝) ą╝ąŠąČąĮąŠ čüą║ąŠą╝ą▒ąĖąĮąĖčĆąŠą▓ą░čéčī ą▓ ąŠą┤ąĮčā ą▓ąĄą║č鹊čĆąĮčāčÄ ąĖąĮčüčéčĆčāą║čåąĖčÄ. ąŁčéą░ ą▓ąĄą║č鹊čĆąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ą┤ą▓ąĄ čüą║ą░ą╗čÅčĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ąĖ čüąŠčģčĆą░ąĮčÅąĄčé čĆąĄąĘčāą╗čīčéą░čé ą║ą░ą║ ą▓ąĄą║č鹊čĆąĮčŗą╣ ą║čāą┐ą╗ąĄčé.
ąøčÄą▒ą░čÅ čüą║ą░ą╗čÅčĆąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ MAC0 ąĖąĘ ą┐čĆąĖą▓ąĄą┤ąĄąĮąĮąŠą│ąŠ ą▓čŗčłąĄ čüą┐ąĖčüą║ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī čüą║ąŠą╝ą▒ąĖąĮąĖčĆąŠą▓ą░ąĮą░ čü čüąŠą▓ą╝ąĄčüčéąĖą╝ąŠą╣ čüą║ą░ą╗čÅčĆąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ MAC1 Multiply čü čüąŠą▒ą╗čÄą┤ąĄąĮąĖąĄą╝ čüą╗ąĄą┤čāčÄčēąĖčģ čāčüą╗ąŠą▓ąĖą╣:
1 . ą×ą▒ąĄ čüą║ą░ą╗čÅčĆąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ąŠą╗ąČąĮčŗ čĆą░ąĘą┤ąĄą╗čÅčéčī ąŠą┤ąĮčā ąĖ čéčā ąČąĄ ąŠą┐čåąĖčÄ čĆąĄąČąĖą╝ą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ: ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ, IS, IU, T, ąĖ čé. ą┐.).
ąśčüą║ą╗čÄč湥ąĮąĖąĄ: ąĖąĮčüčéčĆčāą║čåąĖčÅ MAC1 ą╝ąŠąČąĄčé ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čüą╝ąĄčłą░ąĮąĮčŗą╣ čĆąĄąČąĖą╝ (mixed mode, (M)), ą║ąŠč鹊čĆčŗą╣ ąĮąĄ ą┐čĆąĖą╝ąĄąĮąĖą╝ ą║ MAC0.
2 . ą×ą▒ąĄ čüą║ą░ą╗čÅčĆąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ąŠą╗ąČąĮčŗ čĆą░ąĘą┤ąĄą╗čÅčéčī čéčā ąČąĄ čüą░ą╝čāčÄ ą┐ą░čĆčā čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖčüč鹊čćąĮąĖą║ąŠą▓ ą┤ą░ąĮąĮčŗčģ, ąĮąŠ ą╝ąŠą│čāčé ąŠą▒čĆą░čēą░čéčīčüčÅ ą║ čĆą░ąĘąĮčŗą╝ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ą╝ čŹčéąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓.
3 . ąĢčüą╗ąĖ ąŠą▒ąĄ čüą║ą░ą╗čÅčĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ čĆąĄą│ąĖčüčéčĆ ą┤ą░ąĮąĮčŗčģ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ (Dreg), č鹊 ąŠąĮąĖ ą┤ąŠą╗ąČąĮčŗ ąĘą░ą┐ąĖčüčŗą▓ą░čéčī ą▓ čĆąĄą│ąĖčüčéčĆčŗ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░, ą╗ąĖą▒ąŠ 16-, ą╗ąĖą▒ąŠ 32-ą▒ąĖčéąĮčŗąĄ.
4 . ąĀąĄą│ąĖčüčéčĆčŗ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ (ąĄčüą╗ąĖ čŹč鹊 ą┐čĆąĖą╝ąĄąĮąĖą╝ąŠ) ą┤ą╗čÅ ąŠą▒ąŠąĖčģ čüą║ą░ą╗čÅčĆąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣ ą┤ąŠą╗ąČąĮčŗ č乊čĆą╝ąĖčĆąŠą▓ą░čéčī ą▓ąĄą║č鹊čĆąĮčŗą╣ ą║čāą┐ą╗ąĄčé, ą║ą░ą║ ąŠą┐ąĖčüą░ąĮąŠ ąĮąĖąČąĄ.
a . 16-ą▒ąĖčé: čüąŠčģčĆą░ąĮąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ą▓ čüčéą░čĆčłčāčÄ ąĖ ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ ąŠą┤ąĮąŠą│ąŠ ąĖ č鹊ą│ąŠ ąČąĄ 32-ą▒ąĖčéąĮąŠą│ąŠ Dreg. MAC0 ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé ą▓ ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā, ąĖ MAC1 ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé ą▓ čüčéą░čĆčłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā.b . 32-ą▒ąĖčé: čüąŠčģčĆą░ąĮąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ą▓ ą┤ąŠą┐čāčüčéąĖą╝čāčÄ ą┐ą░čĆčā čĆąĄą│ąĖčüčéčĆąŠą▓ Dreg. MAC0 ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé ą▓ ą╝ą╗ą░ą┤čłčāčÄ čćą░čüčéčī ą┐ą░čĆčŗ (čü č湥čéąĮčŗą╝ ąĮąŠą╝ąĄčĆąŠą╝) Dreg, ąĖ MAC1 ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé ą▓ čüčéą░čĆčłčāčÄ čćą░čüčéčī ą┐ą░čĆčŗ (čü ąĮąĄč湥čéąĮčŗą╝ ąĮąŠą╝ąĄčĆąŠą╝) Dreg. ąÜ ą┤ąŠą┐čāčüčéąĖą╝čŗą╝ ą┐ą░čĆą░ą╝ čĆąĄą│ąĖčüčéčĆąŠą▓ ąŠčéąĮąŠčüčÅčéčüčÅ R7:6, R5:4, R3:2 ąĖ R1:0.
[ąĪąĖąĮčéą░ą║čüąĖčü ]
ą×čéą┤ąĄą╗ąĖč鹥 ąĘą░ą┐čÅč鹊ą╣ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ ą┤ą▓ąĄ čüąŠą▓ą╝ąĄčüčéąĖą╝čŗčģ čüą║ą░ą╗čÅčĆąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖąĖ, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖą╗ą░čüčī ą▓ąĄą║č鹊čĆąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ. ąÆ ą║ąŠąĮąĄčå čéą░ą║ąŠą╣ ą║ąŠą╝ą▒ąĖąĮąĖčĆąŠą▓ą░ąĮąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ąŠą▒ą░ą▓čīč鹥 č鹊čćą║čā čü ąĘą░ą┐čÅč鹊ą╣, ą║ą░ą║ ąŠą▒čŗčćąĮąŠ. ą¤ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą┤čĆčāą│ ąĘą░ ą┤čĆčāą│ąŠą╝ ąŠą┐ąĄčĆą░čåąĖą╣ MAC ą▓ ąŠą┤ąĮąŠą╣ čüčéčĆąŠą║ąĄ ą║ąŠą╝ą░ąĮą┤čŗ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮčŗą╝.
[ąöą╗ąĖąĮą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ ]
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĖą╝ąĄąĄčé ą┤ą╗ąĖąĮčā 32 ą▒ąĖčéą░.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó V čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ ą▓ ą╗čÄą▒ąŠą╝ ąĖąĘ čĆąĄąĘčāą╗čīčéą░č鹊ą▓, čĆą░čüą┐ą░ą║ąŠą▓ą░ąĮąĮąŠą╝ ą▓ Dreg, ą▒čŗą╗ąŠ ąĮą░čüčŗčēąĄąĮąĖąĄ; ąŠčćąĖčüčéąĖčéčüčÅ, ąĄčüą╗ąĖ ąĮąĖ ą▓ ąŠą┤ąĮąŠą╝ ąĖąĘ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ąĮą░čüčŗčēąĄąĮąĖčÅ ąĮąĄ ą▒čŗą╗ąŠ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
ąĀąĄąĘčāą╗čīčéą░čé ą▓ 40-ą▒ąĖčéąĮąŠą╝ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąĄ.
a1= r2.l* r3.h, a0= r2.h* r3.h; // ą×ą▒ą░ čāą╝ąĮąŠąČą░ąĄą╝čŗčģ ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ ą┐ąŠą┐ą░ą┤ą░čÄčé
// ą▓ ąŠčéą┤ąĄą╗čīąĮčŗąĄ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆčŗ.
a0= r1.l* r0.l, a1+= r1.h* r0.h; // ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ, čćč鹊 ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ,
// ąĮąŠ čĆąĄąĘčāą╗čīčéą░čé čüčāą╝ą╝ąĖčĆčāąĄčéčüčÅ ą▓ A1. ą¤ąŠčĆčÅą┤ąŠą║
// ąŠą┐ąĄčĆą░čåąĖą╣ MAC ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮčŗą╝.
a1+= r3.h* r3.l, a0= r3.h* r3.h; // ąĪčāą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓ A1, ą▓čŗčćąĖčéą░ąĮąĖąĄ
// ąĖąĘ A0.
a1= r3.h* r2.l (m), a0+= r3.l* r2.l; // MAC1 čāą╝ąĮąŠąČą░ąĄčé ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝ ą▓ r3.h
// ąĮą░ ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░ ą▓ r2.l. MAC0
// čāą╝ąĮąŠąČą░ąĄčé ą┤ą▓ą░ ą┤čĆąŠą▒ąĮčŗčģ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝.
a1= r7.h* r4.h (m), a0+= r7.l* r4.l (fu); // MAC1 čāą╝ąĮąŠąČą░ąĄčé ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝ ąĮą░
// ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░. MAC0 čāą╝ąĮąŠąČą░ąĄčé
// ąĖ ąĮą░ą║ą░ą┐ą╗ąĖą▓ą░ąĄčé 2 ą┤čĆąŠą▒ąĮčŗčģ čćąĖčüą╗ą░ ą▒ąĄąĘ ąĘąĮą░ą║ą░.
a1+= r3.h* r2.h, a0= r3.l* r2.l (is); // ą×ą▒ą░ MAC-ą░ ą▓čŗą┐ąŠą╗ąĮčÅčÄčé čāą╝ąĮąŠąČąĄąĮąĖąĄ čåąĄą╗čŗčģ čćąĖčüąĄą╗
// čüąŠ ąĘąĮą░ą║ąŠą╝.
a1= r6.h* r7.h, a0+= r6.l* r7.l (w32); // ą×ą▒ą░ MAC-ą░ čāą╝ąĮąŠąČą░čÄčé ą┤ą▓ą░ ą┤čĆąŠą▒ąĮčŗčģ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝,
// ą┐čĆąŠąĖčüčģąŠą┤ąĖčé čĆą░čüčłąĖčĆąĄąĮąĖąĄ ą▒ąĖčé ąĘąĮą░ą║ą░ ąĖ ąĮą░čüčŗčēąĄąĮąĖąĄ
// ą▓ ąŠą▒ąŠąĖčģ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░čģ ąĮą░ ą┐ąŠąĘąĖčåąĖąĖ ą▒ąĖčéą░ 31.
ąĀąĄąĘčāą╗čīčéą░čé ą▓ 16-ą▒ąĖčéąĮąŠą╣ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĄ D-čĆąĄą│ąĖčüčéčĆą░.
r2.h= (a1= r7.l* r6.h), r2.l= (a0= r7.h* r6.h); // ą×ą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąŠą┐ąĄčĆą░čåąĖą╣ čü MAC0 ąĖ MAC1,
// ąŠą▒ąĄ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčé ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝,
// ąŠą▒ą░ čĆąĄąĘčāą╗čīčéą░čéą░ ąĘą░ą│čĆčāąČą░čÄčéčüčÅ ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆčŗ,
// MAC1 ąĘą░ą│čĆčāąČą░ąĄčé ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā čĆąĄą│ąĖčüčéčĆąŠą▓.
r4.l= (a0= r1.l* r0.l), r4.h= (a1+= r1.h* r0.h); // ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ, čćč鹊 ąĖ ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ, ąĮąŠ
// čĆąĄąĘčāą╗čīčéą░čé čüčāą╝ą╝čŗ ą┐ąŠą╝ąĄčēą░ąĄčéčüčÅ ą▓ A1. ą¤ąŠčĆčÅą┤ąŠą║
// ąŠą┐ąĄčĆą░čåąĖą╣ MAC ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮčŗą╝.
r7.h= (a1+= r6.h* r5.l), r7.l= (a0= r6.h* r5.h); // ąĪčāą╝ą╝ą░ ą▓ A1, ą▓čŗčćąĖčéą░ąĮąĖąĄ ą▓ A0.
r0.h= (a1= r7.h* r4.l) (m), r0.l= (a0+= r7.l* r4.l); // MAC1 čāą╝ąĮąŠąČą░ąĄčé ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝ ąĮą░
// ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░. MAC0 čāą╝ąĮąŠąČą░ąĄčé ą┤ą▓ą░
// ą┤čĆąŠą▒ąĮčŗčģ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝.
r5.h= (a1= r3.h* r2.h) (m), r5.l= (a0+= r3.l* r2.l) (fu); // MAC1 čāą╝ąĮąŠąČą░ąĄčé ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝ ąĮą░
// ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░. MAC0 čāą╝ąĮąŠąČą░ąĄčé ą┤ą▓ą░
// ą┤čĆąŠą▒ąĮčŗčģ čćąĖčüą╗ą░ ą▒ąĄąĘ ąĘąĮą░ą║ą░.
r0.h= (a1+= r3.h* r2.h), r0.l= (a0= r3.l* r2.l) (is); // ą×ą▒ą░ MAC-ą░ ą▓čŗą┐ąŠą╗ąĮčÅčÄčé čāą╝ąĮąŠąČąĄąĮąĖąĄ čåąĄą╗čŗčģ čćąĖčüąĄą╗
// čüąŠ ąĘąĮą░ą║ąŠą╝.
r5.h= (a1= r2.h* r1.h), a0+= r2.l* r1.l; // ą×ą▒ą░ MAC-ą░ čāą╝ąĮąŠąČą░čÄčé ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝.
// MAC0 ąĮąĄ ą┤ąĄą╗ą░ąĄčé ą║ąŠą┐ąĖčÄ čĆąĄąĘčāą╗čīčéą░čéą░ ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąĄ.
r3.h= (a1= r2.h* r1.h) (m), a0= r2.l* r1.l; // MAC1 čāą╝ąĮąŠąČą░ąĄčé ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝ ąĮą░
// ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░ ąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą┐čĆąĖ čŹč鹊ą╝
// ą▓čüąĄ 40 ą▒ąĖčé ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ A1.
// MAC0 čāą╝ąĮąŠąČą░ąĄčé ą┤ą▓ą░ ą┤čĆąŠą▒ąĮčŗčģ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝.
r3.h= a1, r3.l= (a0+= r0.l* r1.l) (s2rnd); // MAC1 ą║ąŠą┐ąĖčĆčāąĄčé ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā čĆąĄą│ąĖčüčéčĆą░.
// MAC0 čāą╝ąĮąŠąČą░ąĄčé ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝. ą×ą▒ą░
// ą╝ą░čüčłčéą░ą▒ąĖčĆčāčÄčé ąĖ ąŠą║čĆčāą│ą╗čÅčÄčé čĆąĄąĘčāą╗čīčéą░čé ąĮą░ ą┐čāčéąĖ
// ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
r0.l= (a0+= r7.l* r6.l), r0.h= (a1+= r7.h* r6.h) (iss2); // ą×ą▒ą░ MAC-ą░ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčé čåąĄą╗čŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝
// ąĖ ą┐ąŠą╝ąĄčēą░čÄčé čĆąĄąĘčāą╗čīčéą░čéčŗ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓.
ąĀąĄąĘčāą╗čīčéą░čé ą▓ 32-ą▒ąĖčéąĮąŠą╝ D-čĆąĄą│ąĖčüčéčĆąĄ.
r3= (a1= r6.h* r7.h), r2= (a0= r6.l* r7.l); // ą×ą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąŠą┐ąĄčĆą░čåąĖą╣ čü MAC0 ąĖ MAC1,
// ąŠą▒ą░ čĆą░ą▒ąŠčéą░čÄčé čü ą┤čĆąŠą▒ąĮčŗą╝ąĖ čćąĖčüą╗ą░ą╝ąĖ čüąŠ ąĘąĮą░ą║ąŠą╝, ąŠą▒ą░
// čĆąĄąĘčāą╗čīčéą░čéą░ ąĘą░ą│čĆčāąČą░čÄčéčüčÅ ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆčŗ.
r4= (a0= r6.l* r7.l), r5= (a1+= r6.h* r7.h); // ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ, čćč鹊 ąĖ ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ, ąĮąŠ
// čĆąĄąĘčāą╗čīčéą░čé čüčāą╝ą╝čŗ ą┐ąŠą╝ąĄčēą░ąĄčéčüčÅ ą▓ A1. ą¤ąŠčĆčÅą┤ąŠą║
// ąŠą┐ąĄčĆą░čåąĖą╣ MAC ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮčŗą╝.
r7= (a1+= r3.h* r5.h), r6= (a0-= r3.l* r5.l); // ąĪčāą╝ą╝ą░ ą┐ąŠą╝ąĄčēą░ąĄčéčüčÅ ą▓ A1, ą▓čŗčćąĖčéą░ąĮąĖąĄ ą▓ A0.
r1= (a1= r7.l* r4.l) (m), r0= (a0+= r7.h* r4.h); // MAC1 čāą╝ąĮąŠąČą░ąĄčé ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝ ąĮą░
// ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░. MAC0 čāą╝ąĮąŠąČą░ąĄčé ą┤ą▓ą░ ą┤čĆąŠą▒ąĮčŗčģ
// čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝.
r5= (a1= r3.h* r7.h) (m), r4= (a0+= r3.l* r7.l) (fu); // MAC1 čāą╝ąĮąŠąČą░ąĄčé ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝ ąĮą░
// ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░. MAC0 čāą╝ąĮąŠąČą░ąĄčé ą┤ą▓ą░ ą┤čĆąŠą▒ąĮčŗčģ
// čćąĖčüą╗ą░ ą▒ąĄąĘ ąĘąĮą░ą║ą░.
r1= (a1+= r3.h* r2.h), r0= (a0= r3.l* r2.l) (is); // ą×ą▒ą░ MAC-ą░ ą▓čŗą┐ąŠą╗ąĮčÅčÄčé čāą╝ąĮąŠąČąĄąĮąĖąĄ čåąĄą╗čŗčģ čćąĖčüąĄą╗
// čüąŠ ąĘąĮą░ą║ąŠą╝.
r5= (a1-= r6.h* r7.h), a0+= r6.l* r7.l; // ą×ą▒ą░ MAC-ą░ čāą╝ąĮąŠąČą░čÄčé ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝. MAC0
// ąĮąĄ ą┤ąĄą╗ą░ąĄčé ą║ąŠą┐ąĖčÄ čĆąĄąĘčāą╗čīčéą░čéą░ ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąĄ.
r3= (a1= r6.h* r7.h) (m), a0-= r6.l* r7.l; // MAC1 čāą╝ąĮąŠąČą░ąĄčé ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝ ąĮą░ ą┤čĆąŠą▒ąĮąŠąĄ
// čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░ ąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą┐čĆąĖ čŹč鹊ą╝ ą▓čüąĄ 40 ą▒ąĖčé A1.
// MAC0 čāą╝ąĮąŠąČą░ąĄčé ą┤ą▓ą░ ą┤čĆąŠą▒ąĮčŗčģ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝.
r3= a1, r2= (a0+= r0.l* r1.l) (s2rnd); // MAC1 ą┐ąĄčĆąĄą╝ąĄčēą░ąĄčé ąĘąĮą░č湥ąĮąĖąĄ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ ą▓ čĆąĄą│ąĖčüčéčĆ.
// MAC0 čāą╝ąĮąŠąČą░ąĄčé ą┤čĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝. ą×ą▒ąĄ ąŠą┐ąĄčĆą░čåąĖąĖ
// ą┤ąĄą╗ą░čÄčé ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░
// ąĮą░ ą┐čāčéąĖ ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
r0= (a0+= r7.l* r6.l), r1= (a1+= r7.h* r6.h) (iss2); // ą×ą▒ą░ MAC-ą░ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčé ąŠą┐ąĄčĆą░ąĮą┤čŗ ą║ą░ą║ čåąĄą╗čŗąĄ
// čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝, ąĖ ą╝ą░čüčłčéą░ą▒ąĖčĆčāčÄčé čĆąĄąĘčāą╗čīčéą░čé ąĮą░ ą┐čāčéąĖ
// ą▓ čĆąĄą│ąĖčüčéčĆčŗ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = ŌĆō source_reg (V)
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = ŌĆō Dreg (V); // ą┤ą▓ąŠą╣ąĮą░čÅ 16-ą▒ąĖčéąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ (b)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Vector Negate ą▓ąŠąĘą▓čĆą░čēą░ąĄčé čéčā ąČąĄ čüą░ą╝čāčÄ ą╝ą░ą│ąĮąĖčéčāą┤čā čćąĖčüą╗ą░, ąĮąŠ čü ą┐čĆąŠčéąĖą▓ąŠą┐ąŠą╗ąŠąČąĮčŗą╝ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╝ ąĘąĮą░ą║ąŠą╝, čü ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄą╝ ąĮą░čüčŗčēąĄąĮąĖčÅ ą║ą░ąČą┤ąŠą│ąŠ 16-ą▒ąĖčéąĮąŠą│ąŠ ą┐ąŠą╗čāčüą╗ąŠą▓ą░ ą▓ čĆąĄą│ąĖčüčéčĆąĄ-ąĖčüč鹊čćąĮąĖą║ąĄ. ąśąĮčüčéčĆčāą║čåąĖčÅ ą┤ąĄą╗ą░ąĄčé čéą░ą║ąŠąĄ ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ ą┐čāč鹥ą╝ ą▓čŗčćąĖčéą░ąĮąĖčÅ ąĖčüčģąŠą┤ąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ąĖąĘ ąĮčāą╗čÅ.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ąĮą░čüčŗčēąĄąĮąĖąĄ čüą╝. čüąĄą║čåąĖčÄ "Saturation (ąĮą░čüčŗčēąĄąĮąĖąĄ)".
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ ą╗čÄą▒ąŠą╣ ąĖąĘ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ (ąĖą╗ąĖ ąŠą▒ą░ čĆąĄąĘčāą╗čīčéą░čéą░) čĆą░ą▓ąĄąĮ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆ ]
r5 = -r3 (v); // R5.H ą┐ąŠą╗čāčćąĖčé čĆąĄąĘčāą╗čīčéą░čé, čĆą░ą▓ąĮčŗą╣ ąĖ ą┐čĆąŠčéąĖą▓ąŠą┐ąŠą╗ąŠąČąĮčŗą╣
// ą┐ąŠ ąĘąĮą░ą║čā R3.H, ąĖ R5.L ą┐ąŠą╗čāčćąĖčé čĆąĄąĘčāą╗čīčéą░čé, čĆą░ą▓ąĮčŗą╣
// ąĖ ą┐čĆąŠčéąĖą▓ąŠą┐ąŠą╗ąŠąČąĮčŗą╣ ą┐ąŠ ąĘąĮą░ą║čā R3.L.
// ąĢčüą╗ąĖ r3 = 0x0004 7FFF, č鹊 čĆąĄąĘčāą╗čīčéą░čé r5 = 0xFFFC 8001.
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Negate (TwoŌĆÖs Complement) ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ".
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
Dest_reg = PACK ( src_half_0, src_half_1 )
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = PACK (Dreg_lo_hi, Dreg_lo_hi); // (b)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: R0, ..., R7.
Dreg_lo_hi: R0.L, ..., R7.L, R0.H, ..., R7.H.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Vector Pack čāą┐ą░ą║ąŠą▓čŗą▓ą░ąĄčé ą┤ą▓ąĄ 16-ą▒ąĖčéąĮčŗąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ ą▓ ąŠą┤ąĖąĮ 32-ą▒ąĖčéąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ ą┤ą░ąĮąĮčŗčģ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r3= pack(r4.l, r5.l);
r1= pack(r6.l, r4.h);
r0= pack(r2.h, r4.l);
r5= pack(r7.h, r2.h);
// ąĢčüą╗ąĖ r4.l = 0xDEAD ąĖ r5.l = 0xBEEF, č鹊 ...
r3 = pack (r4.l, r5.l);// ... ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ čĆąĄąĘčāą╗čīčéą░čéčā r3 = 0xDEAD BEEF.
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Quad 8-Bit Pack (ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ą×ą┐ąĄčĆą░čåąĖąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą▓ąĖą┤ąĄąŠ (Video Pixel Operations)").
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
(dest_pointer_hi, dest_pointer_lo) = SEARCH src_reg (searchmode)
ąĪąĖąĮčéą░ą║čüąĖčü:
(Dreg, Dreg) = SEARCH Dreg (searchmode); // (b)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: R0, ..., R7.
searchmode: (GT), (GE), (LE) ąĖą╗ąĖ (LT).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą▓ čåąĖą║ą╗ąĄ, čćč鹊ą▒čŗ ąĮą░ą╣čéąĖ ą╝ą░ą║čüąĖą╝čāą╝ ąĖą╗ąĖ ą╝ąĖąĮąĖą╝čāą╝ ą▓ ą╝ą░čüčüąĖą▓ąĄ 16-ą▒ąĖčéąĮąŠ čāą┐ą░ą║ąŠą▓ą░ąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ. ąŚą░ ąŠą┤ąĖąĮ čĆą░ąĘ ą┐čĆąŠą▓ąĄčĆčÅąĄčéčüčÅ čüčĆą░ąĘčā 2 ąĘąĮą░č湥ąĮąĖčÅ.
ąśąĮčüčéčĆčāą║čåąĖčÅ Vector Search čüčĆą░ą▓ąĮąĖą▓ą░ąĄčé ą┤ą▓ą░ 16-ą▒ąĖčéąĮčŗčģ ą┐ąŠą╗čāčüą╗ąŠą▓ą░ ą║ą░ą║ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝ čüąŠ ąĘąĮą░č湥ąĮąĖčÅą╝ąĖ, čüąŠčģčĆą░ąĮąĄąĮąĮčŗą╝ąĖ ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░čģ. ąŚą░č鹥ą╝ ąŠąĮą░ ą┐ąŠ ąĘą░ą┤ą░ąĮąĮąŠą╝čā čāčüą╗ąŠą▓ąĖčÄ ąŠą▒ąĮąŠą▓ą╗čÅąĄčé ą║ą░ąČą┤čŗą╣ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ ąĖ čĆąĄąĘčāą╗čīčéąĖčĆčāčÄčēąĖą╣ čāą║ą░ąĘą░č鹥ą╗čī, ąŠčüąĮąŠą▓čŗą▓ą░čÅčüčī ąĮą░ čĆąĄąĘčāą╗čīčéą░čéą░čģ čüčĆą░ą▓ąĮąĄąĮąĖčÅ.
ąŻą║ą░ąĘą░č鹥ą╗čī ą▓ čĆąĄą│ąĖčüčéčĆąĄ P0 ą▓čüąĄą│ą┤ą░ ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčéčüčÅ ą║ą░ą║ čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹╗ąĄą╝ąĄąĮčéčŗ ą╝ą░čüčüąĖą▓ą░, ą┐ąŠ ą║ąŠč鹊čĆčŗą╝ ą▓ąĄą┤ąĄčéčüčÅ ą┐ąŠąĖčüą║.
ąĢčüą╗ąĖ čĆą░čüčüą╝ąŠčéčĆąĄčéčī ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ, čüčéą░čĆčłąĄąĄ ą┐ąŠą╗čāčüą╗ąŠą▓ąŠ ą║ą░ą║ čćąĖčüą╗ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝ ą▓ src_reg čüčĆą░ą▓ąĮąĖą▓ą░ąĄčéčüčÅ čü 16 ą╝ą╗ą░ą┤čłąĖą╝ąĖ ą▒ąĖčéą░ą╝ąĖ ą▓ A1. ąĢčüą╗ąĖ src_reg_hi čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆčÅąĄčé ą║čĆąĖč鹥čĆąĖčÄ čüčĆą░ą▓ąĮąĄąĮąĖčÅ, č鹊 A1 ąŠą▒ąĮąŠą▓ą╗čÅąĄčéčüčÅ ąĘąĮą░č湥ąĮąĖąĄą╝ src_reg_hi, ąĖ ąĘąĮą░č湥ąĮąĖąĄ ą▓ čĆąĄą│ąĖčüčéčĆąĄ čāą║ą░ąĘą░č鹥ą╗čÅ P0 čüąŠčģčĆą░ąĮčÅąĄčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ dest_pointer_hi. ąóą░ ąČąĄ čüą░ą╝ą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčéčüčÅ ą┤ą╗čÅ src_reg_low ąĖ A0.
ąæą░ąĘąĖčĆčāčÅčüčī ąĮą░ čāą║ą░ąĘą░ąĮąĮąŠą╝ čĆąĄąČąĖą╝ąĄ ą┐ąŠąĖčüą║ą░, ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąŠą▓ąĄčĆčÅąĄčé ąĘąĮą░č湥ąĮąĖčÅ ą╝ą░čüčüąĖą▓ą░ ąĮą░ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčŗąĄ ąĖą╗ąĖ ą╝ąĖąĮąĖą╝ą░ą╗čīąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ (ą║ą░ą║ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝).
ąŚąĮą░č湥ąĮąĖčÅ ąĘąĮą░ą║ą░ čĆą░čüčłąĖčĆčÅčÄčéčüčÅ ąŠčüčéą░ą╗čīąĮčŗąĄ ą▒ąĖčéčŗ, ą║ąŠą│ą┤ą░ čćąĖčüą╗ąŠ ą║ąŠą┐ąĖčĆčāąĄčéčüčÅ ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ (ą░ą║ą║čāą╝čāą╗čÅč鹊čĆčŗ).
ą¤čĆąĖą╝ąĄčĆ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ čåąĖą║ą╗ąĄ čüą╝. ą▓ čüąĄą║čåąĖąĖ "ą¤čĆąĖą╝ąĄčĆ". ą¤ąŠčüą╗ąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ čåąĖą║ą╗ą░ ą┐ąŠąĖčüą║ą░ ą▓ąĄą║č鹊čĆą░ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆčŗ A1 ąĖ A0 čüąŠą┤ąĄčƹȹ░čé ą┤ą▓ą░ ąŠčüčéą░ą▓čłąĖčģčüčÅ (ąĮą░ą╣ą┤ąĄąĮąĮčŗčģ?) 菹╗ąĄą╝ąĄąĮčéą░, ąĖ dest_pointer_hi ąĖ dest_pointer_lo čüąŠą┤ąĄčƹȹ░čé ąĖčģ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖąĄ ą░ą┤čĆąĄčüą░. ąĪą╗ąĄą┤čāčÄčēąĖą╝ čłą░ą│ąŠą╝ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ą▒čāą┤ąĄčé ą▓čŗą▒ąŠčĆ ą║ąŠąĮąĄčćąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ ąĖąĘ čŹčéąĖčģ ą┤ą▓čāčģ ąŠčüčéą░ą▓čłąĖčģčüčÅ čŹą╗ąĄą╝ąĄąĮč鹊ą▓.
[ąĀąĄąČąĖą╝čŗ ą┐ąŠąĖčüą║ą░ ]
ą¤ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ 4 čĆąĄąČąĖą╝ą░ čüčĆą░ą▓ąĮąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ čāą║ą░ąĘčŗą▓ą░čÄčéčüčÅ ąŠą▒čÅąĘą░č鹥ą╗čīąĮčŗą╝ čäą╗ą░ą│ąŠą╝ čĆąĄąČąĖą╝ą░ ą┐ąŠąĖčüą║ą░ searchmode. ą×ąĮąĖ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮčŗ ą▓ čéą░ą▒ą╗ąĖčåąĄ ąĮąĖąČąĄ.
ąóą░ą▒ą╗ąĖčåą░ 14-2. Compare Modes.
Mode ą×ą┐ąĖčüą░ąĮąĖąĄ
(GT)
ąæąŠą╗ąĄąĄ č湥ą╝ (greater than). ąæčāą┤ąĄčé ąĮą░ą╣ą┤ąĄąĮąŠ ą┐ąĄčĆą▓ąŠąĄ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ čćąĖčüą╗ąŠ ą▓ ą╝ą░čüčüąĖą▓ąĄ.
(GE)
ąæąŠą╗ąĄąĄ č湥ą╝ ąĖą╗ąĖ čĆą░ą▓ąĮąŠ (greater than or equal). ąæčāą┤ąĄčé ąĮą░ą╣ą┤ąĄąĮąŠ ą┐ąŠčüą╗ąĄą┤ąĮąĄąĄ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ čćąĖčüą╗ąŠ ą▓ ą╝ą░čüčüąĖą▓ąĄ.
(LT)
ą£ąĄąĮčīčłąĄ č湥ą╝ (less than). ąæčāą┤ąĄčé ąĮą░ą╣ą┤ąĄąĮąŠ ą┐ąĄčĆą▓ąŠąĄ ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠąĄ čćąĖčüą╗ąŠ ą▓ ą╝ą░čüčüąĖą▓ąĄ.
(LE)
ą£ąĄąĮčīčłąĄ č湥ą╝ ąĖą╗ąĖ čĆą░ą▓ąĮąŠ (less than or equal). ąæčāą┤ąĄčé ąĮą░ą╣ą┤ąĄąĮąŠ ą┐ąŠčüą╗ąĄą┤ąĮąĄąĄ ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠąĄ čćąĖčüą╗ąŠ ą▓ ą╝ą░čüčüąĖą▓ąĄ.
ą¤ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčéčüčÅ ą┤ą╗čÅ čāą║ą░ąĘą░č鹥ą╗čÅ P0:
src_reg_hi čüčĆą░ą▓ąĮąĖą▓ą░ąĄčéčüčÅ čü ą╝ą╗ą░ą┤čłąĖą╝ąĖ 16 ą▒ąĖčéą░ą╝ąĖ A1. ąĢčüą╗ąĖ čāčüą╗ąŠą▓ąĖąĄ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąŠ, č鹊 ą▒čāą┤čāčé ą┐ąĄčĆąĄąĘą░ą┐ąĖčüą░ąĮčŗ ą╝ą╗ą░ą┤čłąĖąĄ 16 ą▒ąĖčé A1, ąĖ ąĘąĮą░č湥ąĮąĖąĄ P0 ą▒čāą┤ąĄčé čüą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąŠ ą▓ dest_pointer_hi.
src_reg_lo čüčĆą░ą▓ąĮąĖą▓ą░ąĄčéčüčÅ čü ą╝ą╗ą░ą┤čłąĖą╝ąĖ 16 ą▒ąĖčéą░ą╝ąĖ A0. ąĢčüą╗ąĖ čāčüą╗ąŠą▓ąĖąĄ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąŠ, č鹊 ą▒čāą┤čāčé ą┐ąĄčĆąĄąĘą░ą┐ąĖčüą░ąĮčŗ ą╝ą╗ą░ą┤čłąĖąĄ 16 ą▒ąĖčé A0, ąĖ ąĘąĮą░č湥ąĮąĖąĄ P0 ą▒čāą┤ąĄčé čüą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąŠ ą▓ dest_pointer_ho.
ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ: čŹčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ąĮą░čģąŠąČą┤ąĄąĮąĖčÅ čŹą╗ąĄą╝ąĄąĮčéą░ ą▓ ą▓ąĄą║č鹊čĆąĄ ą┐ąŠ ąĘąĮą░č湥ąĮąĖčÄ (čü ą┐ąŠą╝ąŠčēčīčÄ čåąĖą║ą╗ą░).
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąŠą┤ąĮąŠą╣ 32-ą▒ąĖčéąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣, ą┐čĆąĖ ą║ąŠč鹊čĆąŠą╣ ąĘą░ą│čĆčāąĘą║ą░ ąŠčüąĮąŠą▓čŗą▓ą░ąĄčéčüčÅ ąĮą░ ąĘąĮą░č湥ąĮąĖąĖ čĆąĄą│ąĖčüčéčĆą░ čāą║ą░ąĘą░č鹥ą╗čÅ P0. ąŁč鹊 čāčüą╗ąŠą▓ąĖąĄ - ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮčŗą╣ čüą╗čāčćą░ą╣, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą▓ą╝ąĄčüč鹥 čü ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ Vector Search.
[ą¤čĆąĖą╝ąĄčĆ ]
/* ąśąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╝ ąĘąĮą░č湥ąĮąĖąĄą╝ ą┤ą╗čÅ ąĮčāąČąĮąŠą│ąŠ čéąĖą┐ą░ ą┐ąŠąĖčüą║ą░. */
r0.l= 0x7fff ;
r0.h= 0 ;
a0= r0; // ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠąĄ 16-ą▒ąĖčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ
a1= r0; // ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠąĄ 16-ą▒ąĖčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ /* ąśąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ R2. */
r2= [p0++ ];
lsetup (search_loop, search_loop) lc0= p1>> 1 ; // ąĮą░čüčéčĆąŠą╣ą║ą░ čåąĖą║ą╗ą░ search_loop:
(r1,r0) = search r2 (le) || r2= [p0++ ]; // ą┐ąŠąĖčüą║ ą┐ąŠčüą╗ąĄą┤ąĮąĄą│ąŠ ą╝ąĖąĮąĖą╝čāą╝ą░ ą▓ ą╝ą░čüčüąĖą▓ąĄ
(r1,r0) = search r2 (le); // ą┐ąŠ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĖ ą┐ąŠąĖčüą║ ą┐ąŠčüą╗ąĄą┤ąĮąĄą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░ /* ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą╝ą╗ą░ą┤čłąĖąĄ 16 ą▒ąĖčé ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓ A1 ąĖ A0 čüąŠą┤ąĄčƹȹ░čé ą┐ąŠčüą╗ąĄą┤ąĮąĖąĄ ą╝ąĖąĮąĖą╝čāą╝čŗ, ąĮą░ą╣ą┤ąĄąĮąĮčŗąĄ ą▓ ą╝ą░čüčüąĖą▓ąĄ. R1 čüąŠą┤ąĄčƹȹĖčé ąĘąĮą░č湥ąĮąĖąĄ P0, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄąĄ ąĘąĮą░č湥ąĮąĖčÄ ą▓ A1. R0 čüąŠą┤ąĄčƹȹĖčé ąĘąĮą░č湥ąĮąĖąĄ P0, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄąĄ ąĘąĮą░č湥ąĮąĖčÄ ą▓ A0. ą¤ąŠčüą╗ąĄ čŹč鹊ą│ąŠ čüčĆą░ą▓ąĮąĖą▓ą░čÄčéčüčÅ ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝ A1 ąĖ A0, čćč鹊ą▒čŗ ąĮą░ą╣čéąĖ ąŠą┤ąĖąĮ ą┐ąŠčüą╗ąĄą┤ąĮąĖą╣ ą╝ąĖąĮąĖą╝čāą╝ ą▓ ą╝ą░čüčüąĖą▓ąĄ. ąŁč鹊 ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╝ čāą║ą░ąĘą░č鹥ą╗ąĄą╝ ąĖąĘ R1 ąĖą╗ąĖ R0.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą▓ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ čĆąĄąĘčāą╗čīčéąĖčĆčāčÄčēąĖąĄ čāą║ą░ąĘą░č鹥ą╗ąĖ čāą║ą░ąĘčŗą▓ą░čÄčé ąĮą░ ą░ą┤čĆąĄčü čÅč湥ą╣ą║ąĖ, ąĮą░čģąŠą┤čÅčēąĄą╣čüčÅ ąĮą░ 4 ą▒ą░ą╣čéą░ ą┐ąŠčüą╗ąĄ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠą│ąŠ (ąĮą░ą╣ą┤ąĄąĮąĮąŠą│ąŠ?) 菹╗ąĄą╝ąĄąĮčéą░ ą╝ą░čüčüąĖą▓ą░. ąŁč鹊 ą┐ąŠ č鹊ą╣ ą┐čĆąĖčćąĖąĮąĄ, čćč鹊 ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ąŠą┐ąĄčĆą░čåąĖčÅ ą┐ąŠčüčé-ąĖąĮą║čĆąĄą╝ąĄąĮčéą░. ą×čéąĮąĖą╝ąĖč鹥 4 ą┐ąĄčĆąĄą┤ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą┐ąŠą╗čāč湥ąĮąĮąŠą│ąŠ ą║ąŠąĮąĄčćąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ čāą║ą░ąĘą░č鹥ą╗čÅ. */
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Vector Maximum, Vector Minimum, ąĖą╗ąĖ Maximum and Minimum.
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ ]
ą¤čĆąŠčåąĄčüčüąŠčĆ Blackfin ąĮąĄ čÅą▓ą╗čÅąĄčéčüčÅ čüčāą┐ąĄčĆčüą║ą░ą╗čÅčĆąĮčŗą╝; ąŠąĮ ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮąŠąĄ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖą╣. ą×ą┤ąĮą░ą║ąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ąŠą│čĆą░ąĮąĖč湥ąĮąĖčÅą╝ąĖ ą╝ąŠąČąĮąŠ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ ą┤ąŠ 3 ąĖąĮčüčéčĆčāą║čåąĖą╣. ąśąĮčüčéčĆčāą║čåąĖčÅ čü ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčīčÄ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠčüčéąĖ ą▒čāą┤ąĄčé ą┤ą╗ąĖąĮąŠą╣ 64 ą▒ąĖčéą░, ąĖ ą▒čāą┤ąĄčé čüąŠčüč鹊čÅčéčī ąĖąĘ ąŠą┤ąĮąŠą╣ 32-ą▒ąĖčéąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖ ą┤ą▓čāčģ 16-ą▒ąĖčéąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖą╣. ąÆčüąĄ 3 ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ą▓ ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ ąĖąĮč鹥čĆą▓ą░ą╗ ą▓čĆąĄą╝ąĄąĮąĖ, ą║ą░ą║ čüą░ą╝ą░čÅ ą╝ąĄą┤ą╗ąĄąĮąĮą░čÅ ąĖąĘ čŹčéąĖčģ čéčĆąĄčģ ąĖąĮčüčéčĆčāą║čåąĖą╣.
ą¤ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄą╝čŗąĄ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ. ąØąĖąČąĄ ąĮą░ ą┤ąĖą░ą│čĆą░ą╝ą╝ąĄ ą┐ąŠą║ą░ąĘą░ąĮčŗ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé Blackfin.
32-ą▒ąĖčéąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ALU/MAC
16-ą▒ąĖčéąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ
16-ą▒ąĖčéąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ
ąĪąĖąĮčéą░ą║čüąĖčü ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖą╣ . ąĪąĖąĮčéą░ą║čüąĖčü ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čüą╗ąĄą┤čāčÄčēąĖą╣.
32-bit ALU/MAC instruction || A 16-bit instructions || A 16-bit instruction;
ąÆąĄčĆčéąĖą║ą░ą╗čīąĮčŗąĄ ą┐ą░ą╗ą║ąĖ (||) ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčé, čćč鹊 ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┐čĆąĄą┤čŗą┤čāčēąĄą╣. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĘą░ą▓ąĄčĆčłą░čÄčēą░čÅ č鹊čćą║ą░ čü ąĘą░ą┐čÅč鹊ą╣ ą┐ąŠčÅą▓ą╗čÅąĄčéčüčÅ č鹊ą╗čīą║ąŠ ą▓ ą║ąŠąĮčåąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ą░.
ą£ąŠąČąĮąŠ ąĘą░ą┐čāčüą║ą░čéčī ąĖąĮčüčéčĆčāą║čåąĖčÄ, ąŠčüąĮąŠą▓ą░ąĮąĮčāčÄ ąĮą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ 32-bit ALU/MAC, ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąŠą╣ 16-ą▒ąĖčéąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ ą┐ąŠ čüą╗ąĄą┤čāčÄčēąĄą╝čā čüąĖąĮčéą░ą║čüąĖčüčā. ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 ą▓čüąĄ čéą░ą║ ąČąĄ ą┐ąŠą╗čāčćąĖčéčüčÅ 64-ą▒ąĖčéąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ, ą│ą┤ąĄ ą▒čāą┤ąĄčé ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą▓čüčéą░ą▓ą╗ąĄąĮą░ 16-ą▒ąĖčéąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐čāčüč鹊ą╣ ąŠą┐ąĄčĆą░čåąĖąĖ (no-op) ą▓ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą╝ 16-ą▒ąĖčéąĮąŠą╝ čüą╗ąŠč鹥.
32-bit ALU/MAC instruction || A 16-bit instruction;
ąÉą╗čīč鹥čĆąĮą░čéąĖą▓ąĮąŠ čéą░ą║ąČąĄ ą╝ąŠąČąĮąŠ ą▓čŗą┐ąŠą╗ąĮčÅčéčī ą┤ą▓ąĄ 16-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąŠą┤ąĮąŠą╣ ą┤čĆčāą│ąŠą╣ ą▒ąĄąĘ ą░ą║čéąĖą▓ąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ 32-bit ALU/MAC, ą┐čāč鹥ą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ MNOP, ą║ą░ą║ čŹč鹊 ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮąĖąČąĄ. ąś ąŠą┐čÅčéčī ą┐ąŠą╗čāčćą░ąĄčéčüčÅ 64-ą▒ąĖčéąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ.
MNOP || A 16-bit instructions || A 16-bit instruction;
ą×ą┐ąĖčüą░ąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ MNOP (32-ą▒ąĖčéąĮčŗą╣ NOP) čüą╝. ą▓ąŠ ą▓čĆąĄąĘą║ąĄ, ąŠą┐ąĖčüčŗą▓ą░čÄčēąĄą╣ ą║ąŠą╝ą░ąĮą┤čā "No Op". ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▒čāą┤ąĄčé čÅą▓ąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüč鹊ą╝; ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░čĆąĖą╣ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé ąĄčæ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ. ąśąĮčüčéčĆčāą║čåąĖčÅ MNOP ą▒čāą┤ąĄčé ą▓ąĖą┤ąĮą░ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ ą┤ąĖąĘą░čüčüąĄą╝ą▒ą╗ąĄčĆą░ ą▓ą╝ąĄčüč鹥 čü ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ ą▓čŗą┐ąŠą╗ąĮčÅčÄčēąĖą╝ąĖčüčÅ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ALU/MAC . ąĪą┐ąĖčüąŠą║ 32-ą▒ąĖčéąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖą╣, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠąČąĮąŠ ąĘą░ą┐čāčüą║ą░čéčī ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ, ą┐ąŠą║ą░ąĘą░ąĮ ąĮąĖąČąĄ ą▓ čéą░ą▒ą╗ąĖčåąĄ.
ąóą░ą▒ą╗ąĖčåą░ 15-1. 32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ DSP.
ąĪąĄą║čåąĖčÅ ąśąĮčüčéčĆčāą║čåąĖčÅ ą¤čĆąĖą╝ąĄčćą░ąĮąĖčÅ
ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ
Absolute Value
Add
ąóąŠą╗čīą║ąŠ ą┤ą╗čÅ ą▓ąĄčĆčüąĖą╣, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąĮą░čüčŗčēąĄąĮąĖąĄ.
Exponent Detection
Maximum
Minimum
Modify ŌĆō Decrement
ąĀą░ą▒ąŠčéą░ąĄčé č鹊ą╗čīą║ąŠ čü ą▓ąĄčĆčüąĖčÅą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ čü ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ą╝ąĖ.
Modify ŌĆō Increment
ąĀą░ą▒ąŠčéą░ąĄčé č鹊ą╗čīą║ąŠ čü ą▓ąĄčĆčüąĖčÅą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ čü ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ą╝ąĖ.
Negate (TwoŌĆÖs Complement)
Round Half-Word
Round ŌĆō 12 Bit
Round ŌĆō 20 Bit
Saturate
Sign Bit
Subtract
ąóąŠą╗čīą║ąŠ ą┤ą╗čÅ ą▓ąĄčĆčüąĖą╣ čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝.
ą×ą┐ąĄčĆą░čåąĖąĖ ąĮą░ą┤ ą▒ąĖčéą░ą╝ąĖ
Bit Field Deposit
Bit Field Extract
Bit Multiplex
Ones Population Count
ąøąŠą│ąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ
Bit-Wise XOR
ąśąĮčüčéčĆčāą║čåąĖąĖ Move
Move Register
ąóąŠą╗čīą║ąŠ ą┤ą╗čÅ 40-ą▒ąĖčéąĮčŗčģ ą▓ąĄčĆčüąĖą╣ čü ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ą╝ąĖ.
Move Register Half
ą×ą┐ąĄčĆą░čåąĖąĖ čüą┤ą▓ąĖą│ą░ ąĖ ą┐čĆąŠą║čĆčāčéą║ąĖ
Arithmetic Shift
ąóąŠą╗čīą║ąŠ ą┤ą╗čÅ ą▓ąĄčĆčüąĖą╣ čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝ ąĖ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ą╝ąĖ.
Logical Shift
ąóąŠą╗čīą║ąŠ ą┤ą╗čÅ ą▓ąĄčĆčüąĖą╣ čü 32-ą▒ąĖčéąĮčŗą╝ čĆą░ąĘą╝ąĄčĆąŠą╝ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
Rotate
External Event Management
No Op
ąóąŠą╗čīą║ąŠ ą┤ą╗čÅ 32-ą▒ąĖčéąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ MNOP.
ąÆąĄą║č鹊čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ
Compare-Select (VIT_MAX)
Add on Sign
Multiply and Multiply-Accumulate to Accumulator
Multiply and Multiply-Accumulate to Half-Register
Multiply and Multiply-Accumulate to Data Register
Vector Absolute Value
Vector Add / Subtract
Vector Arithmetic Shift
Vector Logical Shift
Vector Maximum
Vector Minimum
Multiply
Vector Negate (TwoŌĆÖs Complement)
Vector Pack
Vector Search
Video Pixel Operations
Byte Align
Disable Alignment Exception for Load
Quad 8-Bit Subtract-Absolute-Accumulate
Quad 8-Bit SAA Accumulator Extract
Quad 8-Bit Add
Quad 8-Bit Subtract
Quad 8-Bit Average ŌĆō Byte
Quad 8-Bit Average ŌĆō Half-Word
Quad 8-Bit Add / Clip
Quad 8-Bit Pack
Quad 8-Bit Unpack
16-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ . ąśą╝ąĄčÄčéčüčÅ ą┤ą▓ąĄ 16-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ, čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ ą┐ąŠ ą│čĆčāą┐ą┐ą░ą╝ 1 ąĖ 2, čćč鹊 ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ čéą░ą▒ą╗ąĖčåą░čģ.
ąóą░ą▒ą╗ąĖčåą░ 15-2. ąōčĆčāą┐ą┐ą░ 1 čüąŠą▓ą╝ąĄčüčéąĖą╝čŗčģ 16-ą▒ąĖčéąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖą╣.
ąĪąĄą║čåąĖčÅ ąśąĮčüčéčĆčāą║čåąĖčÅ ą¤čĆąĖą╝ąĄčćą░ąĮąĖčÅ
ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ
Add Immediate
ąóąŠą╗čīą║ąŠ ą┤ą╗čÅ ą▓ąĄčĆčüąĖą╣ čü Ireg.
Modify ŌĆō Decrement
Modify ŌĆō Increment
Subtract Immediate
ąśąĮčüčéčĆčāą║čåąĖąĖ Load / Store
Load Pointer Register
Load Data Register
Load Half-Word ŌĆō Zero-Extended
Load Half-Word ŌĆō Sign-Extended
Load High Data Register Half
Load Low Data Register Half
Load Byte ŌĆō Zero-Extended
Load Byte ŌĆō Sign-Extended
Store Pointer Register
Store Data Register
Store High Data Register Half
Store Low Data Register Half
Store Byte
ąóą░ą▒ą╗ąĖčåą░ 15-3. ąōčĆčāą┐ą┐ą░ 2 čüąŠą▓ą╝ąĄčüčéąĖą╝čŗčģ 16-ą▒ąĖčéąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖą╣.
ąĪąĄą║čåąĖčÅ ąśąĮčüčéčĆčāą║čåąĖčÅ ą¤čĆąĖą╝ąĄčćą░ąĮąĖčÅ
ąśąĮčüčéčĆčāą║čåąĖąĖ Load / Store
Load Data Register
ąóąŠą╗čīą║ąŠ ą┤ą╗čÅ ą▓ąĄčĆčüąĖą╣ čü Ireg.
Load High Data Register Half
Load Low Data Register Half
Store Data Register
Store High Data Register Half
Store Low Data Register Half
ąĢčüčéčī ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ąŠą│čĆą░ąĮąĖč湥ąĮąĖčÅ, čüą▓čÅąĘą░ąĮąĮčŗąĄ čü 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ, ąĘą░ą┐čāčüą║ą░ąĄą╝čŗą╝ąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ:
ŌĆó ąóąŠą╗čīą║ąŠ ąŠą┤ąĮą░ ąĖąĘ 16-ą▒ąĖčéąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ (store instruction).
[ą¤čĆąĖą╝ąĄčĆčŗ ]
ąśąĮčüčéčĆčāą║čåąĖąĖ ą┤ą▓čāčģ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗčģ ąŠą▒čĆą░čēąĄąĮąĖą╣ ą║ ą┐ą░ą╝čÅčéąĖ.
/* Subtract-Absolute-Accumulate ą▓čŗą┤ą░ąĄčéčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ ą▓ą╝ąĄčüč鹥 čü ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗąĄ ą▓čŗą▒ąĖčĆą░čÄčé ą┤ą░ąĮąĮčŗąĄ ą┤ą╗čÅ čüą╗ąĄą┤čāčÄčēąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ SAA. ąŁčéą░ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą▓ čåąĖą║ą╗ąĄ ą┤ą╗čÅ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ ąĮą░ąĘą░ą┤ ąĖ ą▓ą┐ąĄčĆąĄą┤ ą╝ąĄąČą┤čā ą┤ą░ąĮąĮčŗą╝ąĖ ą▓ R1 ąĖ R3, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ą┤ą░ąĮąĮčŗąĄ ą┐ąŠčÅą▓čÅčéčüčÅ ą▓ R0 ąĖ R2. */
saa (r1: 0 , r3: 2 ) || r0= [i0++ ] || r2= [i1++ ];
saa (r1: 0 , r3: 2 )(r) || r1= [i0++ ] || r3= [i1++ ];
mnop || r1 = [i0++ ] || r3 = [i1++ ];
ąśąĮčüčéčĆčāą║čåąĖčÅ čü ą┤ąŠčüčéčāą┐ąŠą╝ ą║ Ireg ąĖ ąŠą┤ąĮąĖą╝ ą┤ąŠčüčéčāą┐ąŠą╝ ą║ ą┐ą░ą╝čÅčéąĖ.
/* Add on Sign ą┐čĆąĖ ąĖąĮą║čĆąĄą╝ąĄąĮčéąĖčĆąŠą▓ą░ąĮąĖąĖ Ireg, ąĖ ąĘą░ą│čĆčāąĘą║ą░ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ, ą▒ą░ąĘąĖčĆčāčÅčüčī ąĮą░ ą┐čĆąĄą┤čŗą┤čāčēąĄą╝ ąĘąĮą░č湥ąĮąĖąĖ Ireg. */
r7.h= r7.l= sign(r2.h)* r3.h + sign(r2.l)* r3.l || i0+= m3 || r0= [i0];/* Add/subtract ą┤ą▓ą░ ąĘąĮą░č湥ąĮąĖčÅ ą▓ąĄą║č鹊čĆą░ ą┐čĆąĖ ąĖąĮą║čĆąĄą╝ąĄąĮčéąĖčĆąŠą▓ą░ąĮąĖąĖ Ireg, ąĖ ąĘą░ą│čĆčāąĘą║ą░ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ. */
R2 = R2 +|+ R4, R4 = R2 -|- R4 (ASR) || I0 += M0 (BREV) || R1 = [I0];/* ąŻą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ ąĮą░ą║ąŠą┐ą╗ąĄąĮąĖąĄ ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąĄ ą┐čĆąĖ ąĘą░ą│čĆčāąĘą║ąĄ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ, ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖąĖ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ, ąĖčüą┐ąŠą╗čīąĘčāčÅ čāą║ą░ąĘą░č鹥ą╗čī ą▓ Ireg. */
A1= R2.L* R1.L, A0= R2.H* R1.H || R2.H= W[I2++ ] || [I3++ ]= R3;/* ąŻą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ ąĮą░ą║ąŠą┐ą╗ąĄąĮąĖąĄ ą┐čĆąĖ ąĘą░ą│čĆčāąĘą║ąĄ ą┤ą▓čāčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ą░ąĮąĮčŗčģ. ą×ą┤ąĮą░ ąĘą░ą│čĆčāąĘą║ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčé čāą║ą░ąĘą░č鹥ą╗čī Ireg. */
A1+= R0.L* R2.H,A0+= R0.L* R2.L || R2.L= W[I2++ ] || R0= [I1-- ];
R3.H= (A1+= R0.L* R1.H), R3.L= (A0+= R0.L* R1.L) || R0= [P0++ ] || R1= [I0];/* ąŻą┐ą░ą║ąŠą▓ą║ą░ ą┤ą▓čāčģ ąĘąĮą░č湥ąĮąĖą╣ ą▓ąĄą║č鹊čĆą░ ą┐čĆąĖ čüąŠčģčĆą░ąĮąĄąĮąĖąĖ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ čāą║ą░ąĘą░č鹥ą╗čÅ Ireg ąĖ ąĘą░ą│čĆčāąĘą║ąŠą╣ ą┤čĆčāą│ąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ. */
R1= PACK(R1.H,R0.H) || [I0++ ]= R0 || R2.L= W[I2++ ];
ą×ą┤ąĮą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ čü Ireg.
// ą×ą┐ąĄčĆą░čåąĖčÅ Multiply-Accumulate čü čĆąĄą│ąĖčüčéčĆąŠą╝ ą┤ą░ąĮąĮčŗčģ, ą┐čĆąĖ ą║ąŠč鹊čĆąŠą╣ ąĖąĮą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄčéčüčÅ Ireg.
r6= (a0+= r3.h* r2.h)(fu) || i2-= m0;
[ąĪčüčŗą╗ą║ąĖ ]
1 . Blackfin Instruction Set Reference site:analog.com .2 . Blackfin ADSP-BF538 .3 . Blackfin: ąĮą░čüčéčĆąŠą╣ą║ą░ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ .4 . ADSP-BF538: ąŠą▒čĆą░ą▒ąŠčéą║ą░ čüąŠą▒čŗčéąĖą╣ (ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ, ąĖčüą║ą╗čÄč湥ąĮąĖčÅ) .