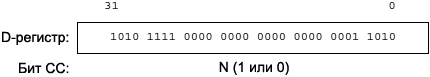ąÆ čŹč鹊ą╝ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮą░ ą┐ąĄčĆą▓ą░čÅ čćą░čüčéčī ą┐ąĄčĆąĄą▓ąŠą┤ą░ ą┤ą░čéą░čłąĖčéą░ "Blackfin DSP Instruction Set Reference" [1], ą│ą┤ąĄ ąŠą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ čüąĖčüč鹥ą╝ą░ ą║ąŠą╝ą░ąĮą┤ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin . ąÆč鹊čĆą░čÅ čćą░čüčéčī ąĘą┤ąĄčüčī: "Blackfin: čüąĖčüč鹥ą╝ą░ ą║ąŠą╝ą░ąĮą┤ (ą░čüčüąĄą╝ą▒ą╗ąĄčĆ) - čćą░čüčéčī 2 " [4].
[ąÆą▓ąĄą┤ąĄąĮąĖąĄ ]
ąöąŠą║čāą╝ąĄąĮčé [1] ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┐ąŠą┤čĆąŠą▒ąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖą╣ čÅąĘčŗą║ą░ ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ čÅą┤čĆąŠą╝ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ BlackfinDSP (čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮąŠ čüąŠą▓ą╝ąĄčüčéąĮąŠ ą║ąŠą╝ą┐ą░ąĮąĖčÅą╝ąĖ Analog Devices, Inc. ąĖ Intel). ąÆ čŹč鹊ą╣ čüąĄą║čåąĖąĖ ą┐čĆąĖą▓ąĄą┤ąĄąĮčŗ ąŠą▒čēąĖąĄ čüąŠą│ą╗ą░čłąĄąĮąĖčÅ ą┐ąŠ čüąŠą┤ąĄčƹȹĖą╝ąŠą╝čā ą┤ąŠą║čāą╝ąĄąĮčéą░. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĮąĄą║ąŠč鹊čĆčŗąĄ č鹥čĆą╝ąĖąĮčŗ ąĮąĄ ą┐ąĄčĆąĄą▓ąĄą┤ąĄąĮčŗ - čü čåąĄą╗čīčÄ ąĮą░ąĖą▒ąŠą╗ąĄąĄ ą┐ąŠą╗ąĮąŠą╣ ą┐ąĄčĆąĄą┤ą░čćąĖ čüą╝čŗčüą╗ą░ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ. ąÆčüąĄ ąĮąĄą┐ąŠąĮčÅčéąĮčŗąĄ č鹥čĆą╝ąĖąĮčŗ ąĖ čüąŠą║čĆą░čēąĄąĮąĖčÅ čüą╝. ą▓ čĆą░ąĘą┤ąĄą╗ąĄ ąĪą╗ąŠą▓ą░čĆąĖą║ ą▓ ą║ąŠąĮčåąĄ čüčéą░čéčīąĖ, ą░ čéą░ą║ąČąĄ ą▓ čĆą░ąĘą┤ąĄą╗ąĄ čüą╗ąŠą▓ą░čĆąĖą║ ąŠą▒čēąĄą╣ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ ą┐ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆčā Blackfin ADSP-BF538.
ąÆ čŹč鹊ą╣ ą┐ąĄčĆą▓ąŠą╣ čćą░čüčéąĖ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ą░ čüąĮą░čćą░ą╗ą░ ąŠą▒čŖčÅčüąĮčÅčÄčéčüčÅ ąŠčüąĮąŠą▓ąĮčŗąĄ ą┐ąŠąĮčÅčéąĖčÅ ąĖ č鹥čĆą╝ąĖąĮčŗ, ąĘą░č鹥ą╝ ąŠą▒čüčāąČą┤ą░ąĄčéčüčÅ čüą╝čŗčüą╗ ą║ą░ąČą┤ąŠą╣ ąŠčéą┤ąĄą╗čīąĮąŠą╣ ą║ąŠą╝ą░ąĮą┤čŗ (ąĖąĮčüčéčĆčāą║čåąĖąĖ) ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░.
ąĀčāą║ąŠą▓ąŠą┤čüčéą▓ąŠ ąŠčĆą│ą░ąĮąĖąĘąŠą▓ą░ąĮąŠ čéą░ą║, čćč鹊 ąĖąĮčüčéčĆčāą║čåąĖąĖ ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░ čüą│čĆčāą┐ą┐ąĖčĆąŠą▓ą░ąĮčŗ ą┐ąŠ čüą▓ąŠąĖą╝ ą▓čŗą┐ąŠą╗ąĮčÅąĄą╝čŗą╝ čäčāąĮą║čåąĖčÅą╝. ąÆ ą┐čĆąĄą┤ąĄą╗ą░čģ ą│čĆčāą┐ą┐ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąŠą▒čŗčćąĮąŠ čĆą░čüą┐ąŠą╗ąŠąČąĄąĮčŗ ą▓ ą░ą╗čäą░ą▓ąĖčéąĮąŠą╝ ą┐ąŠčĆčÅą┤ą║ąĄ, ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ čüą╗čāčćą░ąĄą▓, ą║ąŠą│ą┤ą░ ą┤čĆčāą│ąŠąĄ čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĖąĄ ąĮąĄ ą┤ąĄą╗ą░ąĄčé ą┤čĆčāą│ąŠą╣ ą┐ąŠčĆčÅą┤ąŠą║ ą▒ąŠą╗ąĄąĄ čāą┤ąŠą▒ąĮčŗą╝ ąĖ č湥čéą║ąĖą╝ ą┤ą╗čÅ ą┐ąŠąĮąĖą╝ą░ąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüč鹊ą╝. ą×ą┤ąĖąĮ ąĖąĘ ą┐čĆąĖą╝ąĄčĆąŠą▓ ąĮąĄ ą░ą╗čäą░ą▓ąĖčéąĮąŠą│ąŠ ą┐ąŠčĆčÅą┤ą║ą░ - čüąĄą║čåąĖčÅ Load / Store, ą│ą┤ąĄ Load Pointer Register ą┐ąŠčÅą▓ą╗čÅąĄčéčüčÅ ą┐ąĄčĆąĄą┤ ąĮą░ą▒ąŠčĆąŠą╝ ąĖąĘ čüąĄą╝ąĖ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮčŗčģ ąŠčé Load Data Register. ąśąĮčüčéčĆčāą║čåąĖąĖ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮčŗ ą▓ ąĮą░čćą░ą╗ąĄ ą║ą░ąČą┤ąŠą╣ čćą░čüčéąĖ, ąĖ ą▓ č鹊ą╝ ą┐ąŠčĆčÅą┤ą║ąĄ, ą▓ ą║ą░ą║ąŠą╝ ą┐ąŠčÅą▓ą╗čÅčÄčéčüčÅ ą▓ ąŠą┐ąĖčüą░ąĮąĖąĖ.
ąōčĆčāą┐ą┐čŗ ąĖąĮčüčéčĆčāą║čåąĖą╣, ąĖą╗ąĖ čćą░čüčéąĖ čŹč鹊ą│ąŠ ą┤ąŠą║čāą╝ąĄąĮčéą░, ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮčŗ ą┤čĆčāą│ ąĘą░ ą┤čĆčāą│ąŠą╝ ą▓ ą┐ąŠčĆčÅą┤ą║ąĄ čāą▓ąĄą╗ąĖč湥ąĮąĖčÅ čüą╗ąŠąČąĮąŠčüčéąĖ, ąĮą░čćąĖąĮą░čÅ čü čćą░čüč鹥ą╣ ą▒ą░ąĘąŠą▓čŗčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ Program Flow Control ąĖ Load / Store, ąĖ ą┤ą░ą╗ąĄąĄ ą┐čĆąŠą│čĆąĄčüčüąĖčĆčāčÅ ą┤ąŠ ąĖąĮčüčéčĆčāą║čåąĖą╣ Video Pixel Operations ąĖ Vector Operations.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ ą┐ąĄčĆąĄą▓ąŠą┤čćąĖą║ą░: ą┤ą╗čÅ č鹥čģ, ą║č鹊 ą┐čĆąĖą▓čŗą║ ą┐ąŠ čéą░ą║čéą░ą╝ ą▓čŗčćąĖčüą╗čÅčéčī ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░, ą▒čāą┤ąĄčé ąĮąĄąŠąČąĖą┤ą░ąĮąĮąŠčüčéčīčÄ, čćč鹊 ą▓ ąŠą┐ąĖčüą░ąĮąĖąĖ čüąĖčüč鹥ą╝čŗ ą║ąŠą╝ą░ąĮą┤ ąĮąĄčé ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą┐ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ą░ąČą┤ąŠą╣ ą║ąŠą╝ą░ąĮą┤čŗ. ąöąĄą╗ąŠ ą▓ č鹊ą╝, čćč鹊 čŹč鹊 ą▓čĆąĄą╝čÅ ąĮąĄą╗čīąĘčÅ čüą┐čĆąŠą│ąĮąŠąĘąĖčĆąŠą▓ą░čéčī, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąĮąŠ ąĘą░ą▓ąĖčüąĖčé ąĮąĄ č鹊ą╗čīą║ąŠ ąŠčé čéą░ą║č鹊ą▓ąŠą╣ čćą░čüč鹊čéčŗ čÅą┤čĆą░, ąĮąŠ ąĖ ąŠčé ą╝ąĮąŠą│ąĖčģ ą┤čĆčāą│ąĖčģ čäą░ą║č鹊čĆąŠą▓: ąĘą░ą│čĆčāąČąĄąĮąĮąŠčüčéąĖ ą║ąŠąĮą▓ąĄą╣ąĄčĆą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░, čĆą░ąĘą╝ąĄčēąĄąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ ą┐ą░ą╝čÅčéąĖ, ąŠčé ą╝ąĄčüčéą░ čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĖčÅ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓, čćą░čüč鹊čéčŗ čüąĖčüč鹥ą╝ąĮąŠą╣ čłąĖąĮčŗ, ąĮą░čüčéčĆąŠą╣ą║ąĖ čüąĖčüč鹥ą╝čŗ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ ą║ąŠą╝ą░ąĮą┤ ąĖ ą┤ą░ąĮąĮčŗčģ, ąĖ ą┤ą░ąČąĄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą╝ą░ąĮą┤.
[ąĪąĖąĮčéą░ą║čüąĖčü ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░ ]
ąØą░ą▒ąŠčĆ ąĖąĮčüčéčĆčāą║čåąĖą╣ Blackfin ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ąĮąĄą║ąŠč鹊čĆčŗąĄ čüąŠą│ą╗ą░čłąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠčÅą▓ą╗čÅčÄčéčüčÅ ą▓ąŠ ą▓čüąĄą╝ ąĖąĘą╗ąŠąČąĄąĮąĖąĖ čŹč鹊ą│ąŠ ą┤ąŠą║čāą╝ąĄąĮčéą░. ąŚą┤ąĄčüčī ą┐čĆąĖą▓ąĄą┤ąĄąĮąŠ ąŠą┐ąĖčüą░ąĮąĖąĄ čŹčéąĖčģ čüąŠą│ą╗ą░čłąĄąĮąĖą╣. ąÆ ąŠčüąĮąŠą▓ąĮąŠą╝ čüąĖąĮčéą░ą║čüąĖčü čüąŠą│ą╗ą░čłąĄąĮąĖą╣ čüąŠą▓ą┐ą░ą┤ą░ąĄčé čü čüąĖąĮčéą░ą║čüąĖčüąŠą╝ čÅąĘčŗą║ą░ C.
ą¦čāą▓čüčéą▓ąĖč鹥ą╗čīąĮąŠčüčéčī ą║ čĆąĄą│ąĖčüčéčĆčā čüąĖą╝ą▓ąŠą╗ąŠą▓ (Case Sensitivity). ąĪąĖąĮčéą░ą║čüąĖčü ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĮąĄ čćčāą▓čüčéą▓ąĖč鹥ą╗ąĄąĮ ą║ čĆąĄą│ąĖčüčéčĆčā, čé. ąĄ. ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ ą▒čāą║ą▓čŗ ą╝ąŠą│čāčé ą▒čŗčéčī ą║ą░ą║ ąĘą░ą│ą╗ą░ą▓ąĮčŗąĄ, čéą░ą║ ąĖ čüčéčĆąŠčćąĮčŗąĄ.
ąóąŠčćąĮąŠ čéą░ą║ ąČąĄ ą░čüčüąĄą╝ą▒ą╗ąĄčĆ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé ąĖ ąĖą╝ąĄąĮą░ čĆąĄą│ąĖčüčéčĆąŠą▓, ąĖ ą║ą╗čÄč湥ą▓čŗąĄ čüą╗ąŠą▓ą░ čÅąĘčŗą║ą░ ą░čüčüąĄą╝ą▒ą╗ąĄčĆ - ąĮąĄ ąŠą▒čĆą░čēą░čÅ ą▓ąĮąĖą╝ą░ąĮąĖčÅ ąĮą░ čĆąĄą│ąĖčüčéčĆ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą║ ą┐čĆąĖą╝ąĄčĆčā, ąĖą╝ąĄąĮą░ čĆąĄą│ąĖčüčéčĆąŠą▓ R3.l, R3.L, r3.l, r3.L ą▓čüąĄ ą▒čāą┤čāčé ą┤ąŠą┐čāčüčéąĖą╝čŗą╝ąĖ. ą×ą┤ąĮą░ą║ąŠ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆčŗ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ čćčāą▓čüčéą▓ąĖč鹥ą╗čīąĮčŗ ą║ čĆąĄą│ąĖčüčéčĆčā čüąĖą╝ą▓ąŠą╗ąŠą▓. ąÆ čŹč鹊ą╝ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąĄ ąĖą╝ąĄąĮą░ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖ ą║ą╗čÄč湥ą▓čŗąĄ čüą╗ąŠą▓ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą┐ąŠą║ą░ąĘą░ąĮčŗ ą▓ ąĮąĖąČąĮąĄą╝ čĆąĄą│ąĖčüčéčĆąĄ. ąÆ ąĮąĄą║ąŠč鹊čĆčŗčģ čüą╗čāčćą░čÅčģ, ą║ąŠą│ą┤ą░ ąĮčāąČąĮąŠ čüą┤ąĄą╗ą░čéčī ą░ą║čåąĄąĮčé, čŹč鹊 čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą┤ą╗čÅ ąĖą╝ąĄąĮ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą▓ąĄčĆčģąĮąĖą╣ čĆąĄą│ąĖčüčéčĆ.
ąĪą▓ąŠą▒ąŠą┤ąĮčŗą╣ č乊čĆą╝ą░čé . ąÉčüčüąĄą╝ą▒ą╗ąĄčĆąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖą╝ąĄčÄčé čüą▓ąŠą▒ąŠą┤ąĮčŗą╣ č乊čĆą╝ą░čé, ąĖ ą╝ąŠą│čāčé ą┐ąŠčÅą▓ą╗čÅčéčīčüčÅ ą▓ ą╗čÄą▒ąŠą╝ ą╝ąĄčüč鹥 čüčéčĆąŠą║ąĖ. ą×ą┤ąĮą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠą┤ąŠą╗ąČąĄąĮą░ ąĮą░ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čüčéčĆąŠą║ą░čģ, ąĖą╗ąĖ ą▓ ąŠą┤ąĮąŠą╣ čüčéčĆąŠą║ąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĖąĮčüčéčĆčāą║čåąĖą╣. ąĀą░ąĘą┤ąĄą╗ąĖč鹥ą╗ąĖ (space, tab, ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖąĖ, or newline) ą╝ąŠą│čāčé ą┐ąŠčÅą▓ą╗čÅčéčīčüčÅ ą▓ ą╗čÄą▒ąŠą╝ ą╝ąĄčüč鹥 ą╝ąĄąČą┤čā čćą░čüčéčÅą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣. ą×čéą┤ąĄą╗čīąĮą░čÅ čćą░čüčéčī ąĖąĮčüčéčĆčāą║čåąĖą╣ (č鹊ą║ąĄąĮ) ąĮąĄ ą┤ąŠą╗ąČąĮą░ ą▓ą║ą╗čÄčćą░čéčī ą▓ čüąĄą▒ąĄ čĆą░ąĘą┤ąĄą╗ąĖč鹥ą╗ąĄą╣. ąÜ č鹊ą║ąĄąĮą░ą╝ ąŠčéąĮąŠčüčÅčéčüčÅ čćąĖčüą╗ą░, ąĖą╝ąĄąĮą░ čĆąĄą│ąĖčüčéčĆąŠą▓, ą║ą╗čÄč湥ą▓čŗąĄ čüą╗ąŠą▓ą░, ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆčŗ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╣, ą░ čéą░ą║ąČąĄ ą╝ąĮąŠą│ąŠčüąĖą╝ą▓ąŠą╗čīąĮčŗąĄ ą║ąŠą┤čŗ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖąĄą▓ ąĖą╗ąĖ ąŠą┐ąĄčĆą░čåąĖą╣ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ "+=", "/*" ąĖą╗ąĖ "||".
ąĀą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖą╣ . ąśąĮčüčéčĆčāą║čåąĖąĖ ą┤ąŠą╗ąČąĮčŗ ą▓čüąĄą│ą┤ą░ ąĘą░ą▓ąĄčĆčłą░čéčīčüčÅ č鹊čćą║ąŠą╣ čü ąĘą░ą┐ąĖč鹊ą╣ ';'. ąØąĄčüą║ąŠą╗čīą║ąŠ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą╝ąŠąČąĮąŠ čĆą░ąĘą╝ąĄčüčéąĖčéčī ąĮą░ ąŠą┤ąĮąŠą╣ čüčéčĆąŠą║ąĄ ą┐ąŠ čāčüą╝ąŠčéčĆąĄąĮąĖčÄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčéą░, ąĄčüą╗ąĖ ą║ą░ąČą┤ą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▒čāą┤ąĄčé ąĘą░ą▓ąĄčĆčłą░čéčīčüčÅ č鹊čćą║ąŠą╣ čü ąĘą░ą┐čÅč鹊ą╣.
ąÜą░ąČą┤ą░čÅ ą┐ąŠą╗ąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą▓ąĄčĆčłą░ąĄčéčüčÅ č鹊čćą║ąŠą╣ čü ąĘą░ą┐čÅč鹊ą╣. ąśąĮąŠą│ą┤ą░ ą┐ąŠą╗ąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ ą▒čāą┤ąĄčé čüąŠčüč鹊čÅčéčī ąĖąĘ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ąŠą┐ąĄčĆą░čåąĖą╣. ąŚą┤ąĄčüčī ą╝ąŠąČąĄčé ą▒čŗčéčī 2 čüą╗čāčćą░čÅ:
ŌĆó ąĪą║ąŠą╝ą▒ąĖąĮąĖčĆąŠą▓ą░ąĮčŗ 2 ąŠčüąĮąŠą▓ąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ. ą×ą▒čŗčćąĮąŠ ą▓ čŹčéąĖčģ ąŠą┐ąĄčĆą░čåąĖčÅčģ ąŠčéą┤ąĄą╗čīąĮčŗąĄ čćą░čüčéąĖ ąŠčéą┤ąĄą╗ąĄąĮčŗ ąĘą░ą┐čÅč鹊ą╣, ąĮą░ą┐čĆąĖą╝ąĄčĆ:
a0 = r3.h * r2.l , a1 = r3.l * r2.h;
ŌĆó ą×čüąĮąŠą▓ąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąŠą▒čŖąĄą┤ąĖąĮąĄąĮą░ čü ąŠą┤ąĮąŠą╣ ąĖą╗ąĖ ą┤ą▓čāą╝čÅ čüčüčŗą╗ą║ą░ą╝ąĖ ąĮą░ ą┐ą░ą╝čÅčéčī ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ čüąŠą▓ą╝ąĄčüčéąĮąŠą│ąŠ čĆąĄąĘčāą╗čīčéą░čéą░. ą¤ąŠčüą╗ąĄą┤ąĮąĖąĄ čćą░čüčéąĖ ąĮą░ą▒ąŠčĆą░ ąŠčéą║ą╗ą░ą┤čŗą▓ą░čÄčéčüčÅ č鹊ą║ąĄąĮąŠą╝ "||". ąØą░ą┐čĆąĖą╝ąĄčĆ:
a0 = r3.h * r2.l || r1 = [p3++ ], r4 = [i2++ ];
ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖąĖ . ą£ąŠą│čāčé ą▒čŗčéčī 2 ą▓ąĖą┤ą░ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖąĄą▓ ą▓ č鹥ą║čüč鹥 ą║ąŠą┤ą░ ąĮą░ ą░čüčüąĄą╝ą▒ą╗ąĄčĆąĄ:
ŌĆó ąöąŠ ą║ąŠąĮčåą░ čüčéčĆąŠą║ąĖ: ą┤ą▓ąŠą╣ąĮąŠą╣ čüą╗ąĄčł ("//") ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čü čŹč鹊ą│ąŠ ą╝ąĄčüčéą░ ąĮą░čćąĖąĮą░ąĄčéčüčÅ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣, ąĖ ą┐čĆąŠą┤ąŠą╗ąČą░ąĄčéčüčÅ ą┤ąŠ ą┐ąŠčÅą▓ą╗ąĄąĮąĖčÅ čüąĖą╝ą▓ąŠą╗ą░ newline.
ŌĆó ą×čüąĮąŠą▓ąĮąŠą╣ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣: ąĮą░čćąĖąĮą░ąĄčéčüčÅ čü č鹊ą║ąĄąĮą░ "/*" ąĖ ąŠą║ą░ąĮčćąĖą▓ą░ąĄčéčüčÅ č鹊ą║ąĄąĮąŠą╝ "*/". ąŁč鹊čé ą▓ąĖą┤ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖčÅ ą╝ąŠąČąĄčé čüąŠą┤ąĄčƹȹ░čéčī ą▓ čüąĄą▒ąĄ ą╗čÄą▒čŗąĄ čüąĖą╝ą▓ąŠą╗čŗ, ąĖ ą╝ąŠąČąĄčé čĆą░čüą┐čĆąŠčüčéčĆą░ąĮčÅčéčīčüčÅ ąĮą░ ąĮąĄčüą║ąŠą╗čīą║ąŠ čüčéčĆąŠą║.
ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖąĖ ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé čĆąĄą║čāčĆčüąĖą▓ąĮąŠčüčéčī; ąĄčüą╗ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░ čāą▓ąĖą┤ąĄą╗ "/*" ą▓ č鹥ą╗ąĄ ąŠčüąĮąŠą▓ąĮąŠą│ąŠ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖčÅ, č鹊 ą▓čŗą┤ą░čüčé ą┐čĆąĄą┤čāą┐čĆąĄąČą┤ąĄąĮąĖąĄ. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ čäčāąĮą║čåąĖąŠąĮąĖčĆčāąĄčé čéą░ą║ ąČąĄ, ą║ą░ą║ ąĖ čĆą░ąĘą┤ąĄą╗ąĖč鹥ą╗čī.
[ą×ą▒ąŠąĘąĮą░č湥ąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ (Notation Conventions) ]
ŌĆó ąśą╝ąĄąĮą░ čĆąĄą│ąĖčüčéčĆąŠą▓ čüąŠčüč鹊čÅčé ąĖąĘ ąŠą┤ąĮąŠą╣ ąĖą╗ąĖ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą▒čāą║ą▓, ąĘą░ ą║ąŠč鹊čĆąŠą╣ ą╝ąŠąČąĄčé čüą╗ąĄą┤ąŠą▓ą░čéčī čćąĖčüą╗ąŠ ą▓ čüą╗čāčćą░ąĄ ąĄčüą╗ąĖ ą▓ ą╗ąŠą│ąĖč湥čüą║ąŠą╣ ą│čĆčāą┐ą┐ąĄ ąĮą░čģąŠą┤ąĖčéčüčÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąŠą┤ąĮąŠčéąĖą┐ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓, čĆą░ąĘą╗ąĖčćą░ąĄą╝čŗčģ ą┐ąŠ ąĮąŠą╝ąĄčĆą░ą╝. ąØą░ą┐čĆąĖą╝ąĄčĆ: ASTAT, FP, R3 ąĖ M2.
ŌĆó ąØąĄą║ąŠč鹊čĆčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ čéčĆąĄą▒čāčÄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┐ą░čĆčŗ čĆąĄą│ąĖčüčéčĆąŠą▓. ą¤ą░čĆčŗ ą▓čüąĄą│ą┤ą░ čÅą▓ą╗čÅčÄčéčüčÅ Data Register, ąĖ čĆąĄą│ąĖčüčéčĆąĄ ą▓ ą┐ą░čĆąĄ čĆą░ąĘą┤ąĄą╗ąĄąĮčŗ ą┤ą▓ąŠąĄč鹊čćąĖąĄą╝, ąĮą░ą┐čĆąĖą╝ąĄčĆ R3:2. ąØąŠą╝ąĄčĆ čü ą▒ąŠą╗čīčłąĖą╝ ąĘąĮą░č湥ąĮąĖąĄą╝ ą┤ąŠą╗ąČąĄąĮ ąĖą┤čéąĖ ą┐ąĄčĆą▓čŗą╝. ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą░ą┐ą┐ą░čĆą░čéčāčĆą░ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé č鹊ą╗čīą║ąŠ ą┐ą░čĆčŗ ąĮąĄč湥ąĮčéčŗą╣-č湥čéąĮčŗą╣, čé. ąĄ. R7:6, R5:4, R3:2 ąĖ R1:0.
ŌĆó ąØąĄą║ąŠč鹊čĆčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ čéčĆąĄą▒čāčÄčé ą│čĆčāą┐ą┐čŗ čüąŠčüąĄą┤ąĮąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓. ąöąĖą░ą┐ą░ąĘąŠąĮ čüąŠčüąĄą┤ąĮąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĘą░ą┤ą░ąĄčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ ą┤ą▓čāčģ ąĮąŠą╝ąĄčĆąŠą▓ čĆąĄą│ąĖčüčéčĆąŠą▓ (ąĮą░čćą░ą╗čīąĮčŗą╣ ąĖ ą┐ąŠčüą╗ąĄą┤ąĮąĖą╣ čĆąĄą│ąĖčüčéčĆ ą▓ą║ą╗čÄčćąĖč鹥ą╗čīąĮąŠ), ą┤ą▓ąŠąĄč鹊čćąĖčÅ ą╝ąĄąČą┤čā ąĮąĖą╝ąĖ, ąĖ ą▓čüąĄ čŹč鹊 ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą║ą▓ą░ą┤čĆą░čéąĮčŗčģ čüą║ąŠą▒ą║ą░čģ, ąĮą░ą┐čĆąĖą╝ąĄčĆ R[7:3]. ąś ąŠą┐čÅčéčī ą▒ąŠą╗čīčłąĄąĄ čćąĖčüą╗ąŠ ą┤ąŠą╗ąČąĮąŠ ąĖą┤čéąĖ ą┐ąĄčĆą▓čŗą╝.
ŌĆó ą£ąŠąČąĮąŠ ą┐ąŠ ąŠčéą┤ąĄą╗čīąĮąŠčüčéąĖ ąŠą▒čĆą░čēą░čéčīčüčÅ ą║ čćą░čüčéčÅą╝ čĆąĄą│ąĖčüčéčĆą░. ąŁč鹊 ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ č鹊čćą║ąĖ (".") ą┐ąŠčüą╗ąĄ ąĖą╝ąĄąĮąĖ čĆąĄą│ąĖčüčéčĆą░, ąĘą░ ą║ąŠč鹊čĆąŠą╣ ąĖą┤ąĄčé ą▒čāą║ą▓ą░, ąŠą▒ąŠąĘąĮą░čćą░čÄčēą░čÅ ąĮčāąČąĮčāčÄ čćą░čüčéčī čĆąĄą│ąĖčüčéčĆą░. ąöą╗čÅ 32-ą▒ąĖčéąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ".H" ąŠą▒ąŠąĘąĮą░čćą░ąĄčé čüčéą░čĆčłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā (ąŠčé čüą╗ąŠą▓ą░ "High"), ".L" ąŠą▒ąŠąĘąĮą░čćą░ąĄčé ą╝ą╗ą░ą┤čłčāčÄ (ąŠčé čüą╗ąŠą▓ą░ "Low"). ąÜą░ą║ čĆą░ąĘą┤ąĄą╗čÅčÄčéčüčÅ 40-čĆą░ąĘčĆčÅą┤ąĮčŗąĄ čĆąĄą│ąĖčüčéčĆčŗ ą▒čāą┤ąĄčé ąŠą┐ąĖčüą░ąĮąŠ ą┐ąŠąĘąČąĄ.
ąśą╝ąĄąĮą░ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮčŗ ąĖ ąĮąĄ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ą║ą░ą║ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆčŗ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ. ąÆ čŹč鹊ą╝ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮčŗ čüą╗ąĄą┤čāčÄčēąĖąĄ čüąŠą│ą╗ą░čłąĄąĮąĖčÅ:
ŌĆó ąÜąŠą│ą┤ą░ ą▓ąŠąĘą╝ąŠąČąĄąĮ ą▓čŗą▒ąŠčĆ ą╗čÄą▒ąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ąĖąĘ ą│čĆčāą┐ą┐čŗ čĆąĄą│ąĖčüčéčĆąŠą▓, čŹč鹊 ą▒čāą┤ąĄčé ą┐ąŠą║ą░ąĘą░ąĮąŠ čü ą┐ąŠą╝ąŠčēčīčÄ ą╝ąĮąŠą│ąŠč鹊čćąĖčÅ ("..."). ąØą░ą┐čĆąĖą╝ąĄčĆ, "R0, ..., R7" ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą╝ąŠąČąĮąŠ ą▓čŗą▒čĆą░čéčī ą╗čÄą▒ąŠą╣ ąĖąĘ ą▓ąŠčüčīą╝ąĖ čāą║ą░ąĘą░ąĮąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓.
ŌĆó ąØąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ (immediate value) ąŠą▒ąŠąĘąĮą░čćą░čÄčéčüčÅ ą║ą░ą║ "imm" čüąŠ čüą╗ąĄą┤čāčÄčēąĖą╝ąĖ ą╝ąŠą┤ąĖčäąĖą║ą░č鹊čĆą░ą╝ąĖ:
ŌĆö "imm" ąŠą▒ąŠąĘąĮą░čćą░ąĄčé ąĘąĮą░č湥ąĮąĖąĄ čüąŠ ąĘąĮą░ą║ąŠą╝ (signed); ąĮą░ą┐čĆąĖą╝ąĄčĆ imm7.
Accumulator Saturation . ąÆčüąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ą┤ą░čÄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąĄ čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝ čü ą┤ąŠ 40 ą▒ąĖčé, ąĄčüą╗ąĖ ąĮąĄ čāą║ą░ąĘą░ąĮąŠ čćč鹊-č鹊 ą┤čĆčāą│ąŠąĄ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ąŠ ąĮą░čüčŗčēąĄąĮąĖąĖ ąĮą░ą┐ąĖčüą░ąĮąŠ ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "Saturation (ąĮą░čüčŗčēąĄąĮąĖąĄ)" (čüą╝. ą┤ą░ą╗ąĄąĄ).
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ ]
ąÆ čŹč鹊ą╝ ą┤ąŠą║čāą╝ąĄąĮč鹥 ą┐ąŠčÅą▓ą╗čÅčÄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĖąĄ č鹥čĆą╝ąĖąĮčŗ. ąóąĄčĆą╝ąĖąĮčŗ ąŠčéąĮąŠčüčÅčéčüčÅ ą║ ą░čĆčģąĖč鹥ą║čéčāčĆąĄ Blackfin, ą║ąŠč鹊čĆą░čÅ ąĮąĄ ąŠą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą▓ čŹč鹊ą╣ čüčéą░čéčīąĄ (ąŠą▒čēąĄąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ą░ą┐ą┐ą░čĆą░čéčāčĆčŗ Blackfin čüą╝. ą▓ [2], ąĖą╗ąĖ čüą╝. čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąŠ ADSP-21535 Blackfin DSP Hardware Reference).
ąśą╝ąĄąĮą░ čĆąĄą│ąĖčüčéčĆąŠą▓ . ąÉčĆčģąĖč鹥ą║čéčāčĆą░ ą▓ą║ą╗čÄčćą░ąĄčé čüą╗ąĄą┤čāčÄčēąĖąĄ ąĖą╝ąĄąĮą░:
ąóą░ą▒ą╗ąĖčåą░ 1-1. ąĀąĄą│ąĖčüčéčĆčŗ Blackfin.
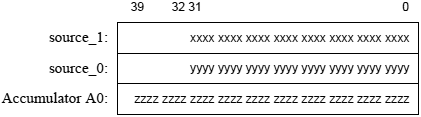
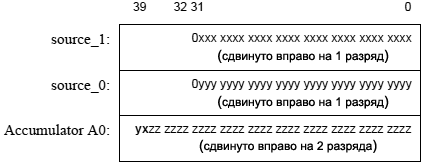
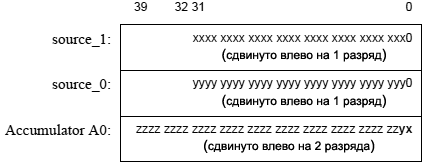
ąĀąĄą│ąĖčüčéčĆ ą×ą┐ąĖčüą░ąĮąĖąĄ
ąÉą║ą║čāą╝čāą╗čÅč鹊čĆčŗ 40-čĆą░ąĘčĆčÅą┤ąĮčŗąĄ čĆąĄą│ąĖčüčéčĆčŗ A1 ąĖ A0 ąŠą▒čŗčćąĮąŠ čüąŠą┤ąĄčƹȹ░čé ą┤ą░ąĮąĮčŗąĄ, ąĮą░ą┤ ą║ąŠč鹊čĆčŗą╝ąĖ ą┐čĆąŠąĖąĘą▓ąŠą┤čÅčéčüčÅ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ ąĖ ą╗ąŠą│ąĖč湥čüą║ąĖąĄ ą╝ą░ąĮąĖą┐čāą╗čÅčåąĖąĖ. ąÜą░ąČą┤čŗą╣ ąĖąĘ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┤ąŠčüčéčāą┐ąĄąĮ čĆą░ąĘą╗ąĖčćąĮčŗą╝ąĖ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ - ą║ą░ą║ 32-ą▒ąĖčéąĮčŗąĄ čĆąĄą│ąĖčüčéčĆčŗ (ąŠą▒ąŠąĘąĮą░čćą░ąĄą╝čŗąĄ ą║ą░ą║ A1.W ąĖ A0.W), ą║ą░ą║ ą┤ą▓ą░ 16-ą▒ąĖčéąĮčŗčģ čĆąĄą│ąĖčüčéčĆą░ (A1.H, A0.H, A1.L, A0.L) ąĖ ą║ą░ą║ ąŠą┤ąĖąĮ 8-ą▒ąĖčéąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ (A1.X, A0.X) ą┤ą╗čÅ čüčéą░čĆčłąĖčģ ą▒ąĖč鹊ą▓ (39..32).
Data Register ąØą░ą▒ąŠčĆ ąĖąĘ ą▓ąŠčüčīą╝ąĖ 32-ą▒ąĖčéąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ R0 , R1 , ..., R7 , ą║ąŠč鹊čĆčŗąĄ ąŠą▒čŗčćąĮąŠ čüąŠą┤ąĄčƹȹ░čé ą┤ą░ąĮąĮčŗąĄ ą┤ą╗čÅ ąŠą┐ąĄčĆą░čåąĖą╣. ąÜčĆą░čéą║ąŠ ą│čĆčāą┐ą┐ą░ čŹčéąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ D-čĆąĄą│ąĖčüčéčĆ ąĖą╗ąĖ Dreg . ąÜ ą┤ą░ąĮąĮčŗą╝ ą▓ čĆąĄą│ąĖčüčéčĆą░čģ ą╝ąŠąČąĮąŠ ąŠą▒čĆą░čēą░čéčīčüčÅ ą┤ą▓čāą╝čÅ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ - ą╗ąĖą▒ąŠ ą║ą░ą║ ą║ 32-ą▒ąĖčéąĮąŠą╝čā čĆąĄą│ąĖčüčéčĆčā, ą╗ąĖą▒ąŠ ą║ą░ą║ ą║ ą┤ą▓čāą╝ čĆąĄą│ąĖčüčéčĆą░ą╝, čüčéą░čĆčłąĄą╝čā High ąĖ ą╝ą╗ą░ą┤čłąĄą╝čā Low (ą║ąŠč鹊čĆčŗąĄ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ ąŠą▒ąŠąĘąĮą░čćą░čÄčéčüčÅ č湥čĆąĄąĘ čüčāčäčäąĖą║čüčŗ .H ąĖ .L, ąĮą░ą┐čĆąĖą╝ąĄčĆ R7.H, R2.L, r0.L, r5.h ąĖ čé. ą┐.).
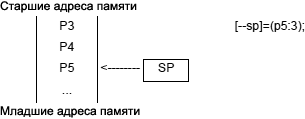
Pointer Register ąØą░ą▒ąŠčĆ ąĖąĘ čłąĄčüčéąĖ 32-ą▒ąĖčéąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ P0 , ..., P5 , ą▓ą║ą╗čÄčćą░čÅ čāą║ą░ąĘą░č鹥ą╗ąĖ čüč鹥ą║ą░ SP ąĖ FP, ą║ąŠč鹊čĆčŗąĄ ąŠą▒čŗčćąĮąŠ čüąŠą┤ąĄčƹȹ░čé ą▒ą░ą╣č鹊ą▓čŗąĄ ą░ą┤čĆąĄčüą░ čüčéčĆčāą║čéčāčĆ ą┤ą░ąĮąĮčŗčģ ą▓ ą┐ą░ą╝čÅčéąĖ. ąöąŠčüčéčāą┐ ą║ čĆąĄą│ąĖčüčéčĆą░ą╝ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ą▓ąŠąĘą╝ąŠąČąĄąĮ č鹊ą╗čīą║ąŠ ą║ą░ą║ ą║ 32-ą▒ąĖčéąĮčŗą╝ čĆąĄą│ąĖčüčéčĆą░ą╝. ąĪąŠą║čĆą░čēąĄąĮąĮąŠ ą│čĆčāą┐ą┐ą░ čĆąĄą│ąĖčüčéčĆąŠą▓ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ P-čĆąĄą│ąĖčüčéčĆ ąĖą╗ąĖ Preg .
Stack Pointer ąŁč鹊 čāą║ą░ąĘą░č鹥ą╗čī čüč鹥ą║ą░, čüąŠą║čĆą░čēąĄąĮąĮąŠ SP . ąĪąŠą┤ąĄčƹȹĖčé 32-ą▒ąĖčéąĮčŗą╣ ą▒ą░ą╣č鹊ą▓čŗą╣ ą░ą┤čĆąĄčü ą┐ąŠčüą╗ąĄą┤ąĮąĄą╣ ąĘą░ąĮčÅč鹊ą╣ čÅč湥ą╣ą║ąĖ ą▓ ą┐ą░ą╝čÅčéąĖ. ąĪč鹥ą║ čĆą░čüč鹥čé ą▓ čüč鹊čĆąŠąĮčā čāą╝ąĄąĮčīčłąĄąĮąĖčÅ ą░ą┤čĆąĄčüąŠą▓, čé. ąĄ. čü ą┐ąŠą╝ąĄčēąĄąĮąĖąĄą╝ ą┤ą░ąĮąĮčŗčģ ą▓ čüč鹥ą║ (PUSH) čĆąĄą│ąĖčüčéčĆ SP ą┤ąĄą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄčéčüčÅ, ą┐čĆąĖ ą▓čŗą▒ąŠčĆą║ąĄ ą┤ą░ąĮąĮčŗčģ ąĖąĘ čüč鹥ą║ą░ (POP) čĆąĄą│ąĖčüčéčĆ SP ąĖąĮą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄčéčüčÅ. SP ąŠčéąĮąŠčüąĖčéčüčÅ ą║ ą│čĆčāą┐ą┐ąĄ čĆąĄą│ąĖčüčéčĆąŠą▓ Preg.
Frame Pointer ąŁč鹊 čāą║ą░ąĘą░č鹥ą╗čī čäčĆąĄą╣ą╝ą░, čüąŠą║čĆą░čēąĄąĮąĮąŠ FP . ąĪąŠą┤ąĄčƹȹĖčé 32-ą▒ąĖčéąĮčŗą╣ ą▒ą░ą╣č鹊ą▓čŗą╣ ą░ą┤čĆąĄčü ą┐čĆąĄą┤čŗą┤čāčēąĄą│ąŠ čāą║ą░ąĘą░č鹥ą╗čÅ čäčĆąĄą╣ą╝ą░ ą▓ čüč鹥ą║ąĄ, čĆą░ąĘą╝ąĄčēąĄąĮąĮąŠą│ąŠ ą▓ ą▓ąĄčĆčģąĮąĄą╣ čćą░čüčéąĖ čäčĆąĄą╣ą╝ą░. FP ąŠčéąĮąŠčüąĖčéčüčÅ ą║ ą│čĆčāą┐ą┐ąĄ čĆąĄą│ąĖčüčéčĆąŠą▓ Preg.
Loop Top ąĀąĄą│ąĖčüčéčĆčŗ LT0 ąĖ LT1 , čüąŠą┤ąĄčƹȹ░čé 32-ą▒ąĖčéąĮčŗą╣ ą░ą┤čĆąĄčü ą▓ąĄčĆčłąĖąĮčŗ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ čåąĖą║ą╗ą░ (zero overhead loop).
Loop Count ąĀąĄą│ąĖčüčéčĆčŗ LC0 ąĖ LC1 , čüąŠą┤ąĄčƹȹ░čé 32-ą▒ąĖčéąĮčŗą╣ čüč湥čéčćąĖą║ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ čåąĖą║ą╗ą░.
Loop Bottom ąĀąĄą│ąĖčüčéčĆčŗ LB0 ąĖ LB1 , čüąŠą┤ąĄčƹȹ░čé 32-ą▒ąĖčéąĮčŗą╣ ą░ą┤čĆąĄčü ą┤ąĮą░ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ čåąĖą║ą╗ą░.
Index Pegister ąśąĮą┤ąĄą║čüąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ, ą║ ąĮąĖą╝ ąŠčéąĮąŠčüčÅčéčüčÅ č湥čéčŗčĆąĄ čĆąĄą│ąĖčüčéčĆą░ I0 , I1 , I2 , I3 . ą×ą▒čŗčćąĮąŠ čüąŠą┤ąĄčƹȹ░čé ą▒ą░ą╣č鹊ą▓čŗą╣ ą░ą┤čĆąĄčü ą▓ čüčéčĆčāą║čéčāčĆą░čģ ą┤ą░ąĮąĮčŗčģ ąĖ ą╝ą░čüčüąĖą▓ą░čģ. ąĪąŠą║čĆą░čēąĄąĮąĮąŠ ą│čĆčāą┐ą┐ą░ ąĖąĮą┤ąĄą║čüąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ I-čĆąĄą│ąĖčüčéčĆ ąĖą╗ąĖ Ireg .
Modify Register ąĀąĄą│ąĖčüčéčĆ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖąĖ. ąÜ čŹčéąĖą╝ čĆąĄą│ąĖčüčéčĆą░ą╝ ąŠčéąĮąŠčüąĖčéčüčÅ ą│čĆčāą┐ą┐ą░ ąĖąĘ č湥čéčŗčĆąĄčģ 32-ą▒ąĖčéąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ M0 , M1 , M2 , M3 , čüąŠą║čĆą░čēąĄąĮąĮąŠ ąĮą░ąĘčŗą▓ą░ąĄą╝ą░čÅ Mreg . ąĀąĄą│ąĖčüčéčĆ Mreg ąŠą▒čŗčćąĮąŠ čüąŠą┤ąĄčƹȹĖčé čüą╝ąĄčēąĄąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą▒ą░ą▓ą╗čÅąĄčéčüčÅ ąĖą╗ąĖ ąŠčéąĮąĖą╝ą░ąĄčéčüčÅ ąŠčé ą░ą┤čĆąĄčüą░ ą▓ ąŠą┤ąĮąŠą╝ ąĖąĘ čĆąĄą│ąĖčüčéčĆąŠą▓ Ireg.
Length Register ąĀąĄą│ąĖčüčéčĆ ą┤ą╗ąĖąĮčŗ. ąØą░ą▒ąŠčĆ ąĖąĘ č湥čéčŗčĆąĄčģ 32-ą▒ąĖčéąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ L0 , L1 , L2 , L3 , ąŠą▒čŗčćąĮąŠ čüąŠą┤ąĄčƹȹ░čēąĖąĄ ą┤ą╗ąĖąĮčā (ą▓ ą▒ą░ą╣čéą░čģ) ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░. ąĪąŠą║čĆą░čēąĄąĮąĮąŠ ą│čĆčāą┐ą┐ą░ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ą╗ąĖąĮčŗ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ Lreg .
Base Registers ąĀąĄą│ąĖčüčéčĆ ą▒ą░ąĘčŗ. ąØą░ą▒ąŠčĆ ąĖąĘ č湥čéčŗčĆąĄčģ 32-ą▒ąĖčéąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ B0 , B1 , B2 , B3 , ąŠą▒čŗčćąĮąŠ čüąŠą┤ąĄčƹȹ░čēąĖą╣ ą▒ą░ąĘąŠą▓čŗą╣ ą░ą┤čĆąĄčü (ą░ą┤čĆąĄčü ą▒ą░ą╣čéą░) ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░. ąĪąŠą║čĆą░čēąĄąĮąĮąŠ ą│čĆčāą┐ą┐ą░ čĆąĄą│ąĖčüčéčĆąŠą▓ ą▒ą░ąĘčŗ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ Breg .
ą¤čĆąŠčåąĄčüčüąŠčĆ ą╝ąŠąČąĄčé čĆą░ą▒ąŠčéą░čéčī ą▓ ąŠą▒čŗčćąĮąŠą╝ čĆąĄąČąĖą╝ąĄ (user mode) ąĖ ą▓ čĆąĄąČąĖą╝ąĄ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (supervisor mode). ą×ą▒čŗčćąĮčŗą╣ čĆąĄąČąĖą╝ - čŹč鹊 ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą▓ąĮąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣, čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ - ą▓ąŠ ą▓čĆąĄą╝čÅ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ. ąöą╗čÅ ąŠą▒čŗčćąĮąŠą│ąŠ čĆąĄąČąĖą╝ą░ ąĖ ą┤ą╗čÅ čĆąĄąČąĖą╝ą░ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ąŠčéą┤ąĄą╗čīąĮčŗąĄ čāą║ą░ąĘą░č鹥ą╗ąĖ čüč鹥ą║ą░, čéą░ą║ čćč鹊 ąŠčé čĆąĄąČąĖą╝ą░ čĆą░ą▒ąŠčéčŗ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĘą░ą▓ąĖčüąĖčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ čüč鹥ą║ą░. ąÆčüąĄą│ąŠ čā ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin ąĄčüčéčī 3 čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░, ą┤ąŠčüčéčāą┐ ą║ ą║ąŠč鹊čĆčŗą╝ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┐ąŠ čüą╗ąĄą┤čāčÄčēąĖą╝ ąĖą╝ąĄąĮą░ą╝:
SP Stack Pointer. ąÆąŠ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąŠčüąĮąŠą▓ąĮąŠą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ (user mode, ąĮąĄ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░) čŹč鹊 ąŠą▒čŗčćąĮčŗą╣ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖą╣ čüč鹥ą║. ąĢčüą╗ąĖ ą░ą║čéąĖą▓ąĄąĮ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░, č鹊 ąĖą╝čÅ SP čüčüčŗą╗ą░ąĄčéčüčÅ ąĮą░ čüč鹥ą║ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░. ąŻą║ą░ąĘą░č鹥ą╗čī čüč鹥ą║ą░ čüąŠą┤ąĄčƹȹĖčé 32-ą▒ąĖčéąĮčŗą╣ ą▒ą░ą╣č鹊ą▓čŗą╣ ą░ą┤čĆąĄčü ą┐ąŠčüą╗ąĄą┤ąĮąĄą│ąŠ ąĘą░ąĮčÅč鹊ą│ąŠ ą╝ąĄčüčéą░ ą▓ čüč鹥ą║ąĄ. ąĪč鹥ą║ čĆą░čüč鹥čé ą┐ąŠ ą╝ąĄčĆąĄ čāą╝ąĄąĮčīčłąĄąĮąĖčÅ čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░, čé. ąĄ. ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖąĄ ą▓ čüč鹥ą║ čāą╝ąĄąĮčīčłą░ąĄčé ąĘąĮą░č湥ąĮąĖąĄ čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░, ą░ ą▓čŗą▒ąŠčĆą║ą░ ąĖąĘ čüč鹥ą║ą░ čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčé ąĘąĮą░č湥ąĮąĖąĄ čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░.
USP User Stack Pointer. ą¤čüąĄą▓ą┤ąŠąĮąĖą╝ ąŠą▒čŗčćąĮąŠą│ąŠ čüč鹥ą║ą░, ą║ąŠč鹊čĆčŗą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą▓ąŠ ą▓čĆąĄą╝čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ (supervisor mode, čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░). ą¤čüąĄą▓ą┤ąŠąĮąĖą╝ USP ąĮąĄą┤ąŠčüčéčāą┐ąĄąĮ ą▓ user mode.
FP Frame Pointer. ąĀąĄą│ąĖčüčéčĆ čāą║ą░ąĘą░č鹥ą╗čÅ čäčĆąĄą╣ą╝ą░, čüąŠą┤ąĄčƹȹĖčé 32-ą▒ąĖčéąĮčŗą╣ ą░ą┤čĆąĄčü ą┐čĆąĄą┤čŗą┤čāčēąĄą│ąŠ čāą║ą░ąĘą░č鹥ą╗čÅ čäčĆąĄą╣ą╝ą░ ą▓ čüč鹥ą║ąĄ.
[ąĀąĄą│ąĖčüčéčĆčŗ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ]
ąØą░ą▒ąŠčĆ 32-ą▒ąĖčéąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ P0, P1, P2, P3, P4, P5, SP ąĖ FP ąŠą▒čŗčćąĮąŠ čüąŠą┤ąĄčƹȹ░čé ą▒ą░ą╣č鹊ą▓čŗą╣ ą░ą┤čĆąĄčü čüčéčĆčāą║čéčāčĆ ą┤ą░ąĮąĮčŗčģ. ąĀąĄą│ąĖčüčéčĆčŗ Px ąĮą░ąĘčŗą▓ą░čÄčé P-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ąĖą╗ąĖ Preg.
[ąŻą║ą░ąĘą░č鹥ą╗ąĖ čäčĆąĄą╣ą╝ą░ ąĖ čüč鹥ą║ą░ ]
ąÆąŠ ą╝ąĮąŠą│ąĖčģ ąŠčéąĮąŠčłąĄąĮąĖčÅčģ čĆąĄą│ąĖčüčéčĆčŗ čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░ ąĖ čāą║ą░ąĘą░č鹥ą╗čÅ čäčĆąĄą╣ą╝ą░ ą▓čŗčüčéčāą┐ą░čÄčé ą║ą░ą║ ą┤čĆčāą│ąĖąĄ P-čĆąĄą│ąĖčüčéčĆčŗ, P[5:0]. ą×ąĮąĖ ą╝ąŠą│čāčé čĆą░ą▒ąŠčéą░čéčī ą║ą░ą║ ą│ą╗ą░ą▓ąĮčŗąĄ čāą║ą░ąĘą░č鹥ą╗ąĖ ą▓ ą╗čÄą▒čŗčģ ąĖąĮčüčéčĆčāą║čåąĖčÅčģ ąĘą░ą│čĆčāąĘą║ąĖ/čüąŠčģčĆą░ąĮąĄąĮąĖčÅ, ąĮą░ą┐čĆąĖą╝ąĄčĆ R1 = B[SP] (Z). ą×ą┤ąĮą░ą║ąŠ čā čĆąĄą│ąĖčüčéčĆąŠą▓ FP ąĖ SP ąĖą╝ąĄąĄčéčüčÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮą░čÅ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčī.
ąĀąĄą│ąĖčüčéčĆčŗ čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░ ą▓ą║ą╗čÄčćą░čÄčé:
ŌĆó user stack pointer, čāą║ą░ąĘą░č鹥ą╗čī čüč鹥ą║ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (USP ą▓ čĆąĄąČąĖą╝ąĄ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░, SP ą▓ čĆąĄąČąĖą╝ąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ).
ąÜ čĆąĄą│ąĖčüčéčĆčā user stack pointer register ąĖ čĆąĄą│ąĖčüčéčĆčā supervisor stack pointer ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ č湥čĆąĄąĘ čĆąĄą│ąĖčüčéčĆąŠą▓čŗą╣ ą┐čüąĄą▓ą┤ąŠąĮąĖą╝ SP. ąÆ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé č鹥ą║čāčēąĄą│ąŠ čĆą░ą▒ąŠč湥ą│ąŠ čĆąĄąČąĖą╝ą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░, č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ ąĖąĘ čŹčéąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą░ą║čéąĖą▓ąĄąĮ ąĖ ą┤ąŠčüčéčāą┐ąĄąĮ ą║ą░ą║ SP:
ŌĆó ąÆ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąŠą╝ čĆąĄąČąĖą╝ąĄ ą╗čÄą▒ą░čÅ čüčüčŗą╗ą║ą░ ąĮą░ SP (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą▓čŗą▒ąŠčĆą║ą░ ąĖąĘ čüč鹥ą║ą░, stack pop R0 = [ SP++ ];) ąĮąĄčÅą▓ąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčé USP ą▓ ą║ą░č湥čüčéą▓ąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠą│ąŠ ą░ą┤čĆąĄčüą░.
ą¦č鹊ą▒čŗ ą╝ą░ąĮąĖą┐čāą╗ąĖčĆąŠą▓ą░čéčī čāą║ą░ąĘą░č鹥ą╗ąĄą╝ čüč鹥ą║ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąŠą│ąŠ čĆąĄąČąĖą╝ą░ (user stack pointer) ą┤ą╗čÅ ą║ąŠą┤ą░, čĆą░ą▒ąŠčéą░čÄčēąĄą│ąŠ ą▓ čĆąĄąČąĖą╝ąĄ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░, ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čĆąĄą│ąĖčüčéčĆąŠą▓čŗą╣ ą┐čüąĄą▓ą┤ąŠąĮąĖą╝ USP. ąÜąŠą│ą┤ą░ ą░ą║čéąĖą▓ąĄąĮ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░, ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ čĆąĄą│ąĖčüčéčĆą░ ąĖąĘ USP (ąĮą░ą┐čĆąĖą╝ąĄčĆ, R0 = USP;) ą┐ąĄčĆąĄą╝ąĄčēą░ąĄčé č鹥ą║čāčēąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (ą▓ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą▓ R0). ąśą╝čÅ čĆąĄą│ąĖčüčéčĆą░ USP ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī č鹊ą╗čīą║ąŠ ą▓ supervisor mode.
ąØąĄą║ąŠč鹊čĆčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĘą░ą│čĆčāąĘą║ąĖ/čüąŠčģčĆą░ąĮąĄąĮąĖčÅ (load/store) ąĮąĄčÅą▓ąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāčÄčé FP ąĖ SP:
ŌĆó ąśąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ąĘą░ą│čĆčāąĘą║ą░/čüąŠčģčĆą░ąĮąĄąĮąĖąĄ č湥čĆąĄąĘ FP (FP-indexed load/store), ą║ąŠč鹊čĆą░čÅ čĆą░čüčłąĖčĆčÅąĄčé ą┤ąĖą░ą┐ą░ąĘąŠąĮ ą░ą┤čĆąĄčüą░čåąĖąĖ ą┤ą╗čÅ ą║ąŠą┤ąĖčĆčāąĄą╝čŗčģ 16 ą▒ąĖčéą░ą╝ąĖ ąŠą┐ąĄčĆą░čåąĖą╣ ąĘą░ą│čĆčāąĘą║ąĖ/čüąŠčģčĆą░ąĮąĄąĮąĖčÅ.
ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮčŗąĄ ą▒ą╗ąŠą║ąĖ . ąÉčĆčģąĖč鹥ą║čéčāčĆą░ ą▓ą║ą╗čÄčćą░ąĄčé 2 ą░ą┐ą┐ą░čĆą░čéąĮčŗąĄ čüąĄą║čåąĖąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░:
ąóą░ą▒ą╗ąĖčåą░ 1-2. ąÉą┐ą┐ą░čĆą░čéąĮčŗąĄ čüąĄą║čåąĖąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ (processor).
Processor ą×ą┐ąĖčüą░ąĮąĖąĄ
Data Address Generator (DAG) ąōąĄąĮąĄčĆą░č鹊čĆ ą░ą┤čĆąĄčüą░, ą▓čŗčćąĖčüą╗čÅąĄčé čŹčäč乥ą║čéąĖą▓ąĮčŗą╣ ą░ą┤čĆąĄčü ą┤ą╗čÅ ą║ąŠčüą▓ąĄąĮąĮąŠą│ąŠ (indirect) ąĖ ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ. ąĪąŠčüč鹊ąĖčé ąĖąĘ 2 čüąĄą║čåąĖą╣ - DAG0 ąĖ DAG1.
Multiply and Accumulate Unit (MAC) ą¤čĆąŠąĖąĘą▓ąŠą┤ąĖčé ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ąĮą░ą┤ ą┤ą░ąĮąĮčŗą╝ąĖ. ąĪąŠčüč鹊ąĖčé ąĖąĘ 2 čüąĄą║čåąĖą╣ MAC0 ąĖ MAC1, ą║ą░ąČą┤ą░čÅ čüą▓čÅąĘą░ąĮą░ čü ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą╝ (A0 ąĖ A1 čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ).
[ążą╗ą░ą│ąĖ ą░čĆąĖčäą╝ąĄčéąĖą║ąĖ ]
ąŁč鹊 ą┐čĆąĖąĘąĮą░ą║ąĖ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖčģ ąŠą┐ąĄčĆą░čåąĖą╣ (Arithmetic Status Flags). Micro Signal Architecture (MSA) ą▓ą║ą╗čÄčćą░ąĄčé 12 ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖčģ čäą╗ą░ą│ąŠą▓, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčé čüąŠčüč鹊čÅąĮąĖąĄ č鹊ą╗čīą║ąŠ čćč鹊 ą▓čŗą┐ąŠą╗ąĮąĄąĮąĮąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ. ąŁčéąĖ čäą╗ą░ą│ąĖ ąĮą░čģąŠą┤čÅčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ASTAT (Arithmetic Status Register). ąØąĖąČąĄ ą┐ąŠą║ą░ąĘą░ąĮąŠ ąŠą┐ąĖčüą░ąĮąĖąĄ čŹčéąĖčģ čäą╗ą░ą│ąŠą▓. ąŻ ą▓čüąĄčģ čäą╗ą░ą│ąŠą▓ ą░ą║čéąĖą▓ąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ą╗ąŠą│. 1. ąśąĮčüčéčĆčāą║čåąĖąĖ, ąŠčéąĮąŠčüčÅčēąĖąĄčüčÅ ą║ P-čĆąĄą│ąĖčüčéčĆą░ą╝, I-čĆąĄą│ąĖčüčéčĆą░ą╝, L-čĆąĄą│ąĖčüčéčĆą░ą╝, M-čĆąĄą│ąĖčüčéčĆą░ą╝ ąĖą╗ąĖ B-čĆąĄą│ąĖčüčéčĆą░ą╝, ąĮąĖą║ą░ą║ ąĮąĄ ą▓ą╗ąĖčÅčÄčé ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ čäą╗ą░ą│ąŠą▓. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. [2] ąĖ ADSP-21535 Blackfin DSP Hardware Reference.
ąóą░ą▒ą╗ąĖčåą░ 1-3. ą×ą▒čēąĄąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ Arithmetic Status Flag.
ążą╗ą░ą│ ą×ą┐ąĖčüą░ąĮąĖąĄ
AC0 Carry, čäą╗ą░ą│ ą┐ąĄčĆąĄąĮąŠčüą░. ą×čéąĮąŠčüąĖčéčüčÅ ą║ ą▒ą╗ąŠą║čā ALU0.
AC1 Carry, čäą╗ą░ą│ ą┐ąĄčĆąĄąĮąŠčüą░. ą×čéąĮąŠčüąĖčéčüčÅ ą║ ą▒ą╗ąŠą║čā ALU1.
AN Negative, čäą╗ą░ą│ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ.
AQ Quotient, čäą╗ą░ą│ čćą░čüčéąĮąŠą│ąŠ.
AV0 Accumulator 0 Overflow, čäą╗ą░ą│ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ A0.
AVS0 Accumulator 0 Sticky Overflow. ąŻčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ, ą║ąŠą│ą┤ą░ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ AV0, ąĮąŠ ąŠčüčéą░ąĄčéčüčÅ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮčŗą╝, ą┐ąŠą║ą░ ąĮąĄ ą▒čāą┤ąĄčé čÅą▓ąĮąŠ ąŠčćąĖčēąĄąĮ ą┐čĆąŠą│čĆą░ą╝ą╝ąŠą╣ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ.
AV1 Accumulator 1 Overflow, čäą╗ą░ą│ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ A1.
AVS1 Accumulator 1 Sticky Overflow. ąŻčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ, ą║ąŠą│ą┤ą░ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ AV1, ąĮąŠ ąŠčüčéą░ąĄčéčüčÅ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮčŗą╝, ą┐ąŠą║ą░ ąĮąĄ ą▒čāą┤ąĄčé čÅą▓ąĮąŠ ąŠčćąĖčēąĄąĮ ą┐čĆąŠą│čĆą░ą╝ą╝ąŠą╣ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ.
AZ Zero, čäą╗ą░ą│ ąĮčāą╗ąĄą▓ąŠą│ąŠ čĆąĄąĘčāą╗čīčéą░čéą░.
CC Control Code bit, čäą╗ą░ą│ ą╝ąĮąŠąČąĄčüčéą▓ąĄąĮąĮąŠą│ąŠ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ, ąŠčćąĖčēą░ąĄčéčüčÅ ąĖ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ąŠčéą┤ąĄą╗čīąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
V Overflow, čäą╗ą░ą│ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┤ą╗čÅ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ą▓ čĆąĄą│ąĖčüčéčĆą░čģ Dreg.
VS Sticky Overflow ą┤ą╗čÅ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ą▓ čĆąĄą│ąĖčüčéčĆą░čģ Dreg. ąŻčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ, ą║ąŠą│ą┤ą░ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ V, ąĮąŠ ąŠčüčéą░ąĄčéčüčÅ ąŠčćąĖčēąĄąĮąĮčŗą╝, ą┐ąŠą║ą░ ąĮąĄ ą▒čāą┤ąĄčé čÅą▓ąĮąŠ čüą▒čĆąŠčłąĄąĮ ą║ąŠą┤ąŠą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ.
[ąÜąŠą┤ąĖčĆąŠą▓ą░ąĮąĖąĄ ą┤čĆąŠą▒ąĮčŗčģ čćąĖčüąĄą╗ ]
ąöčĆąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ - čŹč鹊 č鹥 čćąĖčüą╗ą░, ą▓ čüąŠčüčéą░ą▓ąĄ ą║ąŠč鹊čĆčŗčģ ąĄčüčéčī ą║ąŠą╝ą┐ąŠąĮąĄąĮčéą░, ą╝ąĄąĮčīčłą░čÅ ą┐ąŠ ą░ą▒čüąŠą╗čÄčéąĮąŠą╝čā ąĘąĮą░č湥ąĮąĖčÄ č湥ą╝ ┬▒1. ąÜą░ą║ ąĖ čü ą┤ąĄčüčÅčéąĖčćąĮčŗą╝ąĖ ą┤čĆąŠą▒ąĮčŗą╝ąĖ čćąĖčüą╗ą░ą╝ąĖ, ą│ą┤ąĄ ą┤čĆąŠą▒ąĮą░čÅ čćą░čüčéčī ąĮą░čģąŠą┤ąĖčéčüčÅ čüą┐čĆą░ą▓ą░ ąŠčé ą┤ąĄčüčÅčéąĖčćąĮąŠą╣ č鹊čćą║ąĖ, ą▓ ą┤ą▓ąŠąĖčćąĮąŠą╝ ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖąĖ ą┤čĆąŠą▒ąĮčŗčģ čćąĖčüąĄą╗ ą┤čĆąŠą▒ąĮą░čÅ čćą░čüčéčī čéą░ą║ąČąĄ ą┐ąŠčÅą▓ą╗čÅąĄčéčüčÅ čüą┐čĆą░ą▓ą░ ąŠčé č鹊čćą║ąĖ.
ąĀąĖčü. 1-1. ąĀą░ąĘą╝ąĄčēąĄąĮąĖąĄ ą┤ą▓ąŠąĖčćąĮąŠą╣ č鹊čćą║ąĖ ą▓ 40-, 32- ąĖ 16-ą▒ąĖčéąĮčŗčģ ą┤ą░ąĮąĮčŗčģ.
[Saturation (ąĮą░čüčŗčēąĄąĮąĖąĄ) ]
ąÜąŠą│ą┤ą░ čĆąĄąĘčāą╗čīčéą░čé ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ ą┐čĆąĄą▓čŗčłą░ąĄčé ą┤ąĖą░ą┐ą░ąĘąŠąĮ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ, č鹊 ąĘąĮą░čćą░čēąĖąĄ ą┤ą░ąĮąĮčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą┐ąŠč鹥čĆčÅąĮčŗ. ąÆ čŹč鹊ą╝ ą║ąŠąĮč鹥ą║čüč鹥 Saturation čÅą▓ą╗čÅąĄčéčüčÅ č鹥čģąĮąĖą║ąŠą╣, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą╣ ą┤ą╗čÅ čāą┤ąĄčƹȹ░ąĮąĖčÅ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ąĘąĮą░č湥ąĮąĖą╣, ą║ąŠč鹊čĆąŠąĄ ą╝ąŠąČąĄčé čüąŠą┤ąĄčƹȹ░čéčī čĆąĄą│ąĖčüčéčĆ čĆąĄąĘčāą╗čīčéą░čéą░. ąÜąŠą│ą┤ą░ ą▓čŗčćąĖčüą╗ąĄąĮąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┐čĆąĄą▓čŗčłą░ąĄčé čĆą░ąĘą╝ąĄčĆ čĆąĄą│ąĖčüčéčĆą░ čĆąĄąĘčāą╗čīčéą░čéą░, č鹊ą│ą┤ą░ ąĘąĮą░č湥ąĮąĖąĄ, ąĘą░ą┐ąĖčüą░ąĮąĮąŠąĄ ą▓ čĆąĄą│ąĖčüčéčĆ, čüąŠą┤ąĄčƹȹĖčé čüą░ą╝ąŠąĄ ą▒ąŠą╗čīčłąŠąĄ čćąĖčüą╗ąŠ, ą║ąŠč鹊čĆąŠąĄ čĆąĄą│ąĖčüčéčĆ ą╝ąŠąČąĄčé čüąŠą┤ąĄčƹȹ░čéčī, ąĖ čü č鹥ą╝ ąČąĄ ąĘąĮą░ą║ąŠą╝, čćč鹊 ąĖ ąŠčĆąĖą│ąĖąĮą░ą╗.
ŌĆó ąĢčüą╗ąĖ ąŠą┐ąĄčĆą░čåąĖčÅ ą┤ąŠą╗ąČąĮą░ ą▒čŗą╗ą░ ą▒čŗ ąĘą░ą▓ąĄčĆčłąĖčéčīčüčÅ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮčŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝, ą║ąŠč鹊čĆąŠąĄ ą┐čĆąĖ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĖ ą┐čĆąĄą▓čĆą░čéąĖčéčüčÅ ą▓ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠąĄ, čäčāąĮą║čåąĖčÅ saturation ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ąŠą│čĆą░ąĮąĖčćąĖčé čĆąĄąĘčāą╗čīčéą░čé ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčŗą╝ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮčŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝, ą║ąŠč鹊čĆąŠąĄ ą╝ąŠąČąĄčé čüąŠą┤ąĄčƹȹ░čéčī čĆąĄą│ąĖčüčéčĆ.
ŌĆó ą¤ąŠą┤ąŠą▒ąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝, ąĄčüą╗ąĖ ąŠą┐ąĄčĆą░čåąĖčÅ ą┤ąŠą╗ąČąĮą░ ą▒čŗą╗ą░ ą▒čŗ ąĘą░ą▓ąĄčĆčłąĖčéčīčüčÅ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮčŗą╝ čćąĖčüą╗ąŠą╝, ąĮąŠ ąĖąĘ-ąĘą░ ąŠą│čĆą░ąĮąĖč湥ąĮąĮąŠą╣ čĆą░ąĘčĆčÅą┤ąĮąŠčüčéąĖ ą┐čĆąĖą▓ąĄą╗ą░ ą▒čŗ ą║ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÄ ąĖ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠą╝čā čĆąĄąĘčāą╗čīčéą░čéčā, č鹊 ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ saturation ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé ą▓ ą▓ąĖą┤ąĄ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą│ąŠ (ą┐ąŠ ą░ą▒čüąŠą╗čÄčéąĮąŠą╝čā ąĘąĮą░č湥ąĮąĖčÄ) ą┤ą╗čÅ čŹč鹊ą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ.
ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╣ čäą╗ą░ą│ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ąĮą░ ąŠą┐ąĄčĆą░čåąĖąĖ, ą║ąŠč鹊čĆą░čÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąĮą░čüčŗčēąĄąĮąĖąĄ.
ą£ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ 16-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ čĆą░ą▓ąĮąŠ 0x7FFF. ą£ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ (ą┐ąŠ ą░ą▒čüąŠą╗čÄčéąĮąŠą╝čā ąĘąĮą░č湥ąĮąĖčÄ) ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┤ą╗čÅ ąĮąĄą│ąŠ čĆą░ą▓ąĮąŠ 0x8000. ąöą╗čÅ čćąĖčüąĄą╗ čüąŠ ąĘąĮą░ą║ąŠą╝, ą║ąŠą┤ąĖčĆčāąĄą╝čŗčģ čü ą┤ą▓ąŠąĖčćąĮčŗą╝ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ (signed 2ŌĆÖs complement) ą▓ ą┤čĆąŠą▒ąĮąŠą╣ ąĮąŠčéą░čåąĖąĖ 1.15 ą┤ąŠą┐čāčüčéąĖą╝čŗą╣ ą┤ąĖą░ą┐ą░ąĘąŠąĮ čćąĖčüąĄą╗ čüąŠčüčéą░ą▓ą╗čÅąĄčé ąŠčé -1 ą┤ąŠ (1-2-15 ).
ą£ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ čĆą░ą▓ąĮąŠ 0x7FFF FFFF. ą£ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ (ą┐ąŠ ą░ą▒čüąŠą╗čÄčéąĮąŠą╝čā ąĘąĮą░č湥ąĮąĖčÄ) ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┤ą╗čÅ ąĮąĄą│ąŠ čĆą░ą▓ąĮąŠ 0x8000 0000. ąöą╗čÅ čćąĖčüąĄą╗ čüąŠ ąĘąĮą░ą║ąŠą╝, ą║ąŠą┤ąĖčĆčāąĄą╝čŗčģ čü ą┤ą▓ąŠąĖčćąĮčŗą╝ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ (signed 2ŌĆÖs complement) ą▓ ą┤čĆąŠą▒ąĮąŠą╣ ąĮąŠčéą░čåąĖąĖ 1.31 ą┤ąŠą┐čāčüčéąĖą╝čŗą╣ ą┤ąĖą░ą┐ą░ąĘąŠąĮ čćąĖčüąĄą╗ čüąŠčüčéą░ą▓ą╗čÅąĄčé ąŠčé -1 ą┤ąŠ (1-2-31 ).
ą£ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ 40-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ čĆą░ą▓ąĮąŠ 0x7F FFFF FFFF. ą£ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ (ą┐ąŠ ą░ą▒čüąŠą╗čÄčéąĮąŠą╝čā ąĘąĮą░č湥ąĮąĖčÄ) ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┤ą╗čÅ ąĮąĄą│ąŠ čĆą░ą▓ąĮąŠ 0x80 0000 0000. ąöą╗čÅ čćąĖčüąĄą╗ čüąŠ ąĘąĮą░ą║ąŠą╝, ą║ąŠą┤ąĖčĆčāąĄą╝čŗčģ čü ą┤ą▓ąŠąĖčćąĮčŗą╝ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ (signed 2ŌĆÖs complement) ą▓ ą┤čĆąŠą▒ąĮąŠą╣ ąĮąŠčéą░čåąĖąĖ 9.31 ą┤ąŠą┐čāčüčéąĖą╝čŗą╣ ą┤ąĖą░ą┐ą░ąĘąŠąĮ čćąĖčüąĄą╗ čüąŠčüčéą░ą▓ą╗čÅąĄčé ąŠčé -256 ą┤ąŠ (256-2-31 ).
ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ 16-ą▒ąĖčéąĮčŗčģ čĆąĄą│ąĖčüčéčĆ čüąŠą┤ąĄčƹȹĖčé 0x1000 (ą┤ąĄčüčÅčéąĖčćąĮąŠąĄ čåąĄą╗ąŠąĄ +4096) ąĖ ą▒čŗą╗ čüą┤ą▓ąĖąĮčāčé ą▓ą╗ąĄą▓ąŠ 3 čĆą░ąĘą░ ą▒ąĄąĘ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čäčāąĮą║čåąĖąĖ ąĮą░čüčŗčēąĄąĮąĖčÅ, č鹊 ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ 0x8000 (ą┤ąĄčüčÅčéąĖčćąĮąŠąĄ čćąĖčüą╗ąŠ -32768). ąĪ ąŠą┐ąĄčĆą░čåąĖąĄą╣ ąĮą░čüčŗčēąĄąĮąĖčÅ čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ 3 čĆą░ąĘą░ ą┤ą░čüčé ą▓ ą║ą░č湥čüčéą▓ąĄ čĆąĄąĘčāą╗čīčéą░čéą░ ąĘąĮą░č湥ąĮąĖąĄ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą│ąŠ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠą│ąŠ 16-ą▒ąĖčéąĮąŠą│ąŠ čćąĖčüą╗ą░, čé. ąĄ. 0x7FFF (ą┤ąĄčüčÅčéąĖčćąĮąŠąĄ +32767).
ąöčĆčāą│ąŠą╣ ąŠą▒čēąĖą╣ ą┐čĆąĖą╝ąĄčĆ - ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ ą╝ą╗ą░ą┤čłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą▓ 16-ą▒ąĖčéąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ. ąĢčüą╗ąĖ 32-ą▒ąĖčéąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ čüąŠą┤ąĄčƹȹĖčé 0xFEED 0ACE, ąĖ ą╝ą╗ą░ą┤čłą░čÅ ą┐ąŠą╗ąŠą▓ąĖąĮą░ čŹč鹊ą│ąŠ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠą│ąŠ čćąĖčüą╗ą░ ą║ąŠą┐ąĖčĆčāąĄčéčüčÅ ą▓ 16-ą▒ąĖčéąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ ą▒ąĄąĘ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąĮą░čüčŗčēąĄąĮąĖčÅ, č鹊 ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą┐ąŠą╗čāčćąĖčéčüčÅ 0x0ACE, čćč鹊 čÅą▓ą╗čÅąĄčéčüčÅ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮčŗą╝ čćąĖčüą╗ąŠą╝. ąØąŠ ą┐čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ąĮą░čüčŗčēąĄąĮąĖčÅ, 16-ą▒ąĖčéąĮčŗą╣ čĆąĄąĘčāą╗čīčéą░čé ąŠčüčéą░ąĮąĄčéčüčÅ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮčŗą╝, ąĖ čüčéą░ąĮąĄčé 0x8000.
ąÆ MSA čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮąŠ 40-ą▒ąĖčéąĮąŠąĄ ąĮą░čüčŗčēąĄąĮąĖąĄ ą┤ą╗čÅ ą▓čüąĄčģ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖčģ ąŠą┐ąĄčĆą░čåąĖą╣, ą║ąŠč鹊čĆčŗąĄ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąĄ, ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ ąŠčéą┤ąĄą╗čīąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖą╣, čćč鹊 čāą║ą░ąĘą░ąĮąŠ ą▓ ąĖčģ ąŠą┐ąĖčüą░ąĮąĖąĖ, ą║ąŠą│ą┤ą░ ąŠą┐čåąĖąŠąĮą░ą╗čīąĮčŗą╣ 32-ą▒ąĖčéąĮčŗą╣ čĆąĄąČąĖą╝ ą╝ąŠąČąĄčé ąŠą│čĆą░ąĮąĖčćąĖčéčī 40-bit Accumulator ą▓ 32-ą▒ąĖčéąĮąŠą╝ čĆąĄą│ąĖčüčéčĆąŠą▓ąŠą╝ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ. MSA ą▓čŗą┐ąŠą╗ąĮąĖčé 32-ą▒ąĖčéąĮąŠąĄ ąĮą░čüčŗčēąĄąĮąĖčÅ ą┤ą╗čÅ 32-ą▒ąĖčéąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ č鹊ą╗čīą║ąŠ ą║ąŠą│ą┤ą░ čŹč鹊 čāą║ą░ąĘą░ąĮąŠ ą▓ ąŠą┐ąĖčüą░ąĮąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣.
[ą¤ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ (Overflow) ]
ąŁčéą░ čäčāąĮą║čåąĖčÅ čÅą▓ą╗čÅąĄčéčüčÅ ą░ą╗čīč鹥čĆąĮą░čéąĖą▓ąŠą╣ čäčāąĮą║čåąĖąĖ ąĮą░čüčŗčēąĄąĮąĖčÅ. ą¦ąĖčüą╗čā čĆą░ąĘčĆąĄčłą░ąĄčéčüčÅ ą┐čĆąŠčüč鹊 ą┐ąĄčĆąĄą▓ą░ą╗ąĖčéčī ąĘą░ čüą▓ąŠąĖ ą│čĆą░ąĮąĖčåčŗ, čéą░ą║ čćč鹊 ą▒čāą┤čāčé ą┐ąŠč鹥čĆčÅąĮčŗ ąĄą│ąŠ čüą░ą╝čŗąĄ čüčéą░čĆčłąĖąĄ ą▒ąĖčéčŗ (ąŠą┤ąĖąĮ ąĖą╗ąĖ ąĮąĄčüą║ąŠą╗čīą║ąŠ); ą┐čĆąĖ čŹč鹊ą╝ ą╝ąŠą│čāčé ą▒čŗčéčī čüąŠčģčĆą░ąĮąĄąĮčŗ č鹊ą╗čīą║ąŠ ą╝ą╗ą░ą┤čłąĖąĄ (ąĮą░ąĖą╝ąĄąĮąĄąĄ ąĘąĮą░čćąĖą╝čŗąĄ) ą▒ąĖčéčŗ čĆąĄąĘčāą╗čīčéą░čéą░ čćąĖčüą╗ą░. ą¤ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ, ą║ąŠą│ą┤ą░ 40-ą▒ąĖčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą▓ 32-ą▒ąĖčéąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ąĢčüą╗ąĖ ą▒čŗą╗ą░ ą║ą░ą║ą░čÅ-č鹊 ą┐ąŠą╗ąĄąĘąĮą░čÅ ąĖąĮč乊čĆą╝ą░čåąĖčÅ ą▓ čüčéą░čĆčłąĖčģ 8 ą▒ąĖčéą░čģ 40-čĆą░ąĘčĆčÅą┤ąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ, č鹊 ąŠąĮą░ ą▒čāą┤ąĄčé ą┐ąŠč鹥čĆčÅąĮą░. ąØąĄą║ąŠč鹊čĆčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą╝ąŠą│čāčé čüąŠąŠą▒čēą░čéčī ąŠ čüąŠą▒čŗčéąĖčÅčģ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╝ąĖ čäą╗ą░ą│ą░ą╝ (ąĮą░čģąŠą┤čÅčēąĖą╝ąĖčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ASTAT), ą║ą░ą║ čŹč鹊 čāą║ą░ąĘą░ąĮąŠ ą▓ ąŠą┐ąĖčüą░ąĮąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ čĆąĄą│ąĖčüčéčĆą░ ASTAT čüą╝. ą▓ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąĄ ADSP-21535 Blackfin DSP Hardware Reference.
[Rounding , Truncating ]
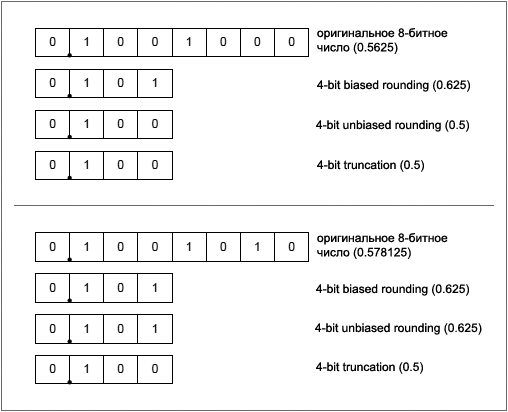
Rounding (ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ), Truncating (ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖąĄ čćą░čüčéąĖ čĆąĄąĘčāą╗čīčéą░čéą░). Rounding ąŠąĘąĮą░čćą░ąĄčé ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ. ąŁčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ ąĘą░ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ čāą╝ąĄąĮčīčłąĄąĮąĖąĖ č鹊čćąĮąŠčüčéąĖ čćąĖčüą╗ą░ ą┐čāč鹥ą╝ čāą┤ą░ą╗ąĄąĮąĖčÅ ąĮąĄą║ąŠč鹊čĆąŠą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą╝ą╗ą░ą┤čłąĖčģ ą▒ąĖčé, ą▓ą║ą╗čÄčćą░čÅ ą▓ąŠąĘą╝ąŠąČąĮčāčÄ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÄ čŹčéąĖčģ ą╝ą╗ą░ą┤čłąĖčģ ą▒ąĖčé čéą░ą║, čćč鹊ą▒čŗ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ č鹊čćąĮąŠ čüąŠąŠčéą▓ąĄčéčüčéą▓ąŠą▓ą░čéčī ąĖčüčģąŠą┤ąĮąŠą╝čā čćąĖčüą╗čā. ąØą░ą┐čĆąĖą╝ąĄčĆ, čā ąĖčüčģąŠą┤ąĮąŠą│ąŠ čćąĖčüą╗ą░ ą▒čŗą╗ąŠ N ą▒ąĖčé č鹊čćąĮąŠčüčéąĖ, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ąĮąŠą▓ąŠąĄ čćąĖčüą╗ąŠ ą▒čāą┤ąĄčé ąĖą╝ąĄčéčī č鹊ą╗čīą║ąŠ M ą▒ąĖčé č鹊čćąĮąŠčüčéąĖ (ą│ą┤ąĄ N>M), č鹊ą│ą┤ą░ N-M ą▒ąĖčé č鹊čćąĮąŠčüčéąĖ ą▒čāą┤čāčé čāą┤ą░ą╗ąĄąĮčŗ ą▓ ą┐čĆąŠčåąĄčüčüąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ.
ą£ąĄč鹊ą┤ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ą┤ąŠ ą▒ą╗ąĖąČą░ą╣čłąĄą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ (round-to-nearest) ą▓ąĄčĆąĮąĄčé čćąĖčüą╗ąŠ, ą▒ą╗ąĖąČą░ą╣čłąĄąĄ ą┐ąŠ ąĘąĮą░č湥ąĮąĖčÄ ą║ ąŠčĆąĖą│ąĖąĮą░ą╗čā. ąŻčüą╗ąŠą▓ąĖą╗ąĖčüčī, čćč鹊 ą║ąŠą│ą┤ą░ ąĖčüčģąŠą┤ąĮąŠąĄ čćąĖčüą╗ąŠ, ąĮą░čģąŠą┤ąĖčéčüčÅ č鹊čćąĮąŠ ą┐ąŠčüąĄčĆąĄą┤ąĖąĮąĄ ą╝ąĄąČą┤čā ą┤ą▓čāą╝čÅ ą▓ąŠąĘą╝ąŠąČąĮčŗą╝ąĖ čĆąĄąĘčāą╗čīčéą░čéą░ą╝ąĖ ą┤ą╗čÅ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ, ą▓čüąĄą│ą┤ą░ ą┐čĆąĖ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĖ ą▒čāą┤ąĄčé ą▓čŗą▒čĆą░ąĮąŠ ą▒ąŠą╗čīčłąĄąĄ ą┐ąŠ čĆąĄąĘčāą╗čīčéą░čéčā čćąĖčüą╗ąŠ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą║ąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ 3 ą▒ąĖčé, ą┤čĆąŠą▒ąĮąŠąĄ čćąĖčüą╗ąŠ 0.25 (ą▓ ą┤ą▓ąŠąĖčćąĮąŠą╝ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĖ 0.01) ą┐čĆąĖ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĖ ą┤ą░čüčé 0.5 (ą┤ą▓ąŠąĖčćąĮąŠąĄ 0.1). ą×čĆąĖą│ąĖąĮą░ą╗čīąĮąŠąĄ ą┤ą▓ąŠąĖčćąĮąŠąĄ čćąĖčüą╗ąŠ ą╗ąĄąČąĖčé č鹊čćąĮąŠ ą╝ąĄąČą┤čā čćąĖčüą╗ą░ą╝ąĖ 0.5 ąĖ 0.0, čéą░ą║ čćč鹊 ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą▓ą▓ąĄčĆčģ. ą¤ąŠčüą║ąŠą╗čīą║čā ą▓ čŹč鹊ą╝ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĖ ą▓čüąĄą│ą┤ą░ ąĖą┤ąĄčé ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ ą▓ą▓ąĄčĆčģ, čŹč鹊čé ą╝ąĄč鹊ą┤ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ biased rounding (čüą╝ąĄčēąĄąĮąĮąŠąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ).
ą£ąĄč鹊ą┤ ą║ąŠąĮą▓ąĄčĆą│ąĄąĮčéąĮąŠą│ąŠ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ (convergent rounding) čéą░ą║ąČąĄ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ą▒ą╗ąĖąČą░ą╣čłąĄąĄ ą║ ąŠčĆąĖą│ąĖąĮą░ą╗čā čćąĖčüą╗ąŠ. ą×ą┤ąĮą░ą║ąŠ ą┤ą╗čÅ čüą╗čāčćą░čÅ, ą║ąŠą│ą┤ą░ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮąŠąĄ čćąĖčüą╗ąŠ ą╗ąĄąČąĖčé ą┐ąŠčüąĄčĆąĄą┤ąĖąĮąĄ ą╝ąĄąČą┤čā ą┤ą▓čāą╝čÅ ą▓ąŠąĘą╝ąŠąČąĮčŗą╝ąĖ ą▒ą╗ąĖąČą░ą╣čłąĖą╝ąĖ čĆąĄąĘčāą╗čīčéą░čéą░ą╝ąĖ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ, čŹč鹊čé ą╝ąĄč鹊ą┤ ą▓ąĄčĆąĮąĄčé ą▒ą╗ąĖąČą░ą╣čłąĄąĄ č湥čéąĮąŠąĄ čćąĖčüą╗ąŠ, ą▓ ą║ąŠč鹊čĆąŠą╝ čüą░ą╝čŗą╣ ą╝ą╗ą░ą┤čłąĖą╣ ą▒ąĖčé LSB čĆą░ą▓ąĄąĮ 0. ąöą╗čÅ čĆą░ąĮąĄąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮąĮąŠą│ąŠ ą┐čĆąĖą╝ąĄčĆą░ čĆąĄąĘčāą╗čīčéą░čé čüčéą░ąĮąĄčé 0.0, ą┐ąŠčüą║ąŠą╗čīą║čā ąŠąĮ ą▒čāą┤ąĄčé č湥čéąĮčŗą╝ ąĖąĘ ą┤ą▓čāčģ ą▓ą░čĆąĖą░ąĮč鹊ą▓ 0.5 ąĖ 0.0. ą¤ąŠčüą║ąŠą╗čīą║čā ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ ą║ą░ą║ ą▓ą▓ąĄčĆčģ, čéą░ą║ ąĖ ą▓ąĮąĖąĘ, čŹč鹊čé ą╝ąĄč鹊ą┤ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ unbiased rounding (ąĮąĄčüą╝ąĄčēąĄąĮąĮąŠąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ).
ąØąĄą║ąŠč鹊čĆčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Blackfin ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé biased ąĖ unbiased ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ. ąæąĖčé RND_MOD ą▓ čĆąĄą│ąĖčüčéčĆąĄ ASTAT ąĘą░ą┤ą░ąĄčé, ą║ą░ą║ąŠą╣ čĆąĄąČąĖą╝ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ. ą¤ąŠą┤čĆąŠą▒ąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ čĆąĄą│ąĖčüčéčĆą░ ASTAT čüą╝. ą▓ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąĄ ADSP-21535 Blackfin DSP Hardware Reference.
ąöčĆčāą│ąŠą╣ ąŠą▒čēąĖą╣ ą╝ąĄč鹊ą┤ čāą╝ąĄąĮčīčłąĄąĮąĖąĄ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ąĘąĮą░čćą░čēąĖčģ ą▒ąĖčé čćąĖčüą╗ą░ - ą┐čĆąŠčüč鹊ąĄ ą╝ą░čüą║ąĖčĆąŠą▓ą░ąĮąĖąĄ N-M ą╝ą╗ą░ą┤čłąĖčģ ą▒ąĖčé. ąŁč鹊čé ą┐čĆąŠčåąĄčüčü ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ truncation (čāčüąĄč湥ąĮąĖąĄ, ąĖą╗ąĖ ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖąĄ ą╝ą╗ą░ą┤čłąĖčģ ą▒ąĖč鹊ą▓), ąĖ ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą┐ąŠą╗čāčćą░ąĄčéčüčÅ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ ą▒ąŠą╗čīčłą░čÅ ąŠčłąĖą▒ą║ą░ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ.
ąØąĖąČąĄ ąĮą░ čĆąĖčüčāąĮą║ąĄ ą┐ąŠą║ą░ąĘą░ąĮčŗ ą┐čĆąĖą╝ąĄčĆčŗ ą╝ąĄč鹊ą┤ąŠą▓ rounding ąĖ truncation.
ąĀąĖčü. 1-2. ąöą▓ą░ ą┐čĆąĖą╝ąĄčĆą░, ą▓ ą║ąŠč鹊čĆčŗčģ ą┐ąŠą║ą░ąĘą░ąĮąŠ čāą╝ąĄąĮčīčłąĄąĮąĖąĄ č鹊čćąĮąŠčüčéąĖ 8-ą▒ąĖčéąĮąŠą│ąŠ čćąĖčüą╗ą░ ą┤ąŠ 4 ą▒ąĖčé.
[ąÜąŠčüą▓ąĄąĮąĮą░čÅ ąĖ ąĖąĮą┤ąĄą║čüąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░ ]
ążąŠčĆą╝ą░ čüąĖąĮčéą░ą║čüąĖčüą░ Dest = [ Src_1 ++ Src_2 ] ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ ą║ąŠčüą▓ąĄąĮąĮąŠą╣ (indirect) ą░ą┤čĆąĄčüą░čåąĖąĄą╣ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░ ą░ą┤čĆąĄčüą░. ąŁč鹊 čāą║ąŠčĆąŠč湥ąĮąĮą░čÅ č乊čĆą╝ą░ čüą╗ąĄą┤čāčÄčēąĄą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ:
Dest = [Src_1]; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ąĘą░ą│čĆčāąĘą║ą░ 32-ą▒ąĖčéąĮąŠą│ąŠ ą░ą┤čĆąĄčüą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ
Src_1 += Src_2; // ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮčé Src_1 ąĮą░ ą▓ąĄą╗ąĖčćąĖąĮčā ąĖąĮą┤ąĄą║čüą░ ą▓ Src_2
ą│ą┤ąĄ:
ŌĆó Dest čŹč鹊 čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ (Dreg ą▓ ą┐čĆąĖą╝ąĄčĆąĄ čüąĖąĮčéą░ą║čüąĖčüą░).
ąÜąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčé-ąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ąĮą░čüčéčĆą░ąĖą▓ą░ąĄą╝čāčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ą║ąŠčüą▓ąĄąĮąĮąŠą╣ ą░ą┤čĆąĄčüą░čåąĖąĖ. ąÜąŠčüą▓ąĄąĮąĮą░čÅ, čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░ ą▓ąĄčĆčüąĖčÅ ą┤ąŠą╗ąČąĮą░ ą┐ąŠą╗čāčćą░čéčī ą▓ ą║ą░č湥čüčéą▓ąĄ ą▓čģąŠą┤ąĮčŗčģ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ ą┤ą▓ą░ ąŠčéą┤ąĄą╗čīąĮčŗčģ P-čĆąĄą│ąĖčüčéčĆą░. ąĢčüą╗ąĖ ąČąĄ ą▒čāą┤ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ąŠą┤ąĖąĮ ąŠą▒čēąĖą╣ Preg ą┤ą╗čÅ ąŠą▒ąŠąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓, č鹊 čäčāąĮą║čåąĖčÅ ą░ą▓č鹊ąĖąĮą║čĆąĄą╝ąĄąĮčéą░ čĆą░ą▒ąŠčéą░čéčī ąĮąĄ ą▒čāą┤ąĄčé.
[ąśąĮčüčéčĆčāą║čåąĖąĖ Program Flow Control ]
ąÜ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ Program Flow Control ąŠčéąĮąŠčüčÅčé ą║ąŠą╝ą░ąĮą┤čŗ ą┐ąĄčĆąĄą┤ą░čćąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ, čé. ąĄ. ą┐ąĄčĆąĄčģąŠą┤čŗ ą▓ąĮčāčéčĆąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ąŁč鹊 ą║ąŠą╝ą░ąĮą┤čŗ ą▒ąĄąĘčāčüą╗ąŠą▓ąĮąŠą│ąŠ ą┐ąĄčĆąĄčģąŠą┤ą░ (JUMP, JUMP.S, JUMP.L), ą┐ąĄčĆąĄčģąŠą┤ą░ ą┐ąŠ čāčüą╗ąŠą▓ąĖčÄ (IF CC JUMP, IF !CC JUMP), ą▓čŗąĘąŠą▓ą░ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ (CALL), ą▓ąŠąĘą▓čĆą░čéą░ ąĖąĘ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ (RTS, RTI, RTX, RTN, RTE), ąĮą░čüčéčĆąŠą╣ą║ąĖ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ čåąĖą║ą╗ą░ (LSETUP, LOOP, LOOP_BEGIN, LOOP_END).
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąĖ ą╗ąĖąĮą║ąĄčĆ VisualDSP++ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé čĆą░čüčłąĖčĆąĄąĮąĖąĄ ą║ąŠą╝ą░ąĮą┤ CALL ąĖ JUMP ą▓ ą▓ąĖą┤ąĄ čüčāčäčäąĖą║čüą░ ".X". ąØą░ą┐čĆąĖą╝ąĄčĆ, ą┤ąŠą┐čāčüčéąĖą╝čŗ ą║ąŠą╝ą░ąĮą┤čŗ CALL.X ąĖ JUMP.X, ąŠąĮąĖ čćą░čüč鹊 ą▓čüčéčĆąĄčćą░čÄčéčüčÅ ą▓ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą│ąĄąĮąĄčĆąĖčĆčāąĄą╝ąŠą╝ ą║ąŠą┤ąĄ ąĘą░ą┐čāčüą║ą░ ą┐čĆąŠąĄą║čéą░ VisualDSP++. ąŁč鹊 ąĮą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ ą┐čüąĄą▓ą┤ąŠą║ąŠą╝ą░ąĮą┤čŗ, ą║ąŠč鹊čĆčŗąĄ ąĮą░ čŹčéą░ą┐ąĄ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ąĖ ą╗ąĖąĮą║ąŠą▓ą║ąĖ ą▒čāą┤čāčé ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ąĘą░ą╝ąĄąĮąĄąĮčŗ ąĮą░ ąĮą░ąĖą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮčŗąĄ čü č鹊čćą║ąĖ ąĘčĆąĄąĮąĖčÅ ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĖ čĆą░ąĘą╝ąĄčĆą░. ąĀąĄčłąĄąĮąĖąĄ ą▒čāą┤ąĄčé ą┐čĆąĖąĮčÅč鹊 ą▓ ąĘą░ą▓ąĖčüą╝ąŠčüčéąĖ ąŠčé č鹊ą│ąŠ, ąĮą░čüą║ąŠą╗čīą║ąŠ ą┤ą░ą╗ąĄą║ąŠ ąĮą░čģąŠą┤ąĖčéčüčÅ ą░ą┤čĆąĄčü ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ č鹥ą║čāčēąĄą│ąŠ ą░ą┤čĆąĄčüą░ - čŹčäč乥ą║čéąĖą▓ąĮčŗąĄ ą║ąŠą╝ą░ąĮą┤čŗ ą┐ąĄčĆąĄčģąŠą┤ą░ ąĖ ą▓čŗąĘąŠą▓ą░ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĖą╝ąĄčÄčé ąŠą│čĆą░ąĮąĖč湥ąĮąĖčÅ ą┐ąŠ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ.
CąĖąĮčéą░ą║čüąĖčü:
JUMP (Preg); // ą┐ąĄčĆąĄčģąŠą┤ ą┐ąŠ ą░ą▒čüąŠą╗čÄčéąĮąŠą╝čā (ąĮąĄ ą┐čĆąĖą▓čÅąĘą░ąĮąĮąŠą╝čā ą║ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą╝čā // čüč湥čéčćąĖą║čā PC) ą░ą┤čĆąĄčüčā (a)1
JUMP (PC + Preg); // ą┐ąĄčĆąĄčģąŠą┤ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ PC (b)
JUMP pcrelm2; // ą┐ąĄčĆąĄčģąŠą┤ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ PC, ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮčŗą╣2 (a), // ąĖą╗ąĖ (b), čüą╝. čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ.
JUMP.S pcrel13m2; // ą┐ąĄčĆąĄčģąŠą┤ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ PC, ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮčŗą╣, ą║ąŠčĆąŠčéą║ąĖą╣ (short (a))
JUMP.L pcrel25m2; // ą┐ąĄčĆąĄčģąŠą┤ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ PC, ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮčŗą╣, ą┤ą░ą╗čīąĮąĖą╣ (long (b))
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 2: čŹčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ą░čģ ąĮą░ čāčĆąŠą▓ąĮąĄ ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░, ą║ąŠą│ą┤ą░ ą║ąŠąĮąĄčćąĮąŠąĄ čĆą░čüčüč鹊čÅąĮąĖąĄ ą┤ąŠ čåąĄą╗ąĖ ą▓ąŠ ą▓čĆąĄą╝čÅ ąĮą░ą┐ąĖčüą░ąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą┐ąŠą║ą░ ąĮąĄ ąĖąĘą▓ąĄčüčéąĮąŠ. ąÉčüčüąĄą╝ą▒ą╗ąĄčĆ ą┐čĆąĖ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ čüą░ą╝ ą┐ąŠą┤čüčéą░ą▓ąĖčé ą║ąŠą┤čŗ ąĖąĮčüčéčĆčāą║čåąĖą╣ JUMP.S ąĖą╗ąĖ JUMP.L, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą┤ą╗ąĖąĮčŗ ą┐ąĄčĆąĄčģąŠą┤ą░. ąöąĖąĘą░čüčüąĄą╝ą▒ą╗ąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą║ąŠą┤ ą┐ąŠą║ą░ąČąĄčé ą▓ą╝ąĄčüč鹊 ąĖąĮčüčéčĆčāą║čåąĖąĖ JUMP ą╝ąĮąĄą╝ąŠąĮąĖą║čā JUMP.S ąĖą╗ąĖ JUMP.L.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Preg: P0, ..., P5, SP, FP.
pcrelm2: ąĮąĄąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠąĄ 25-ą▒ąĖčéąĮąŠąĄ (ąĖą╗ąĖ čü ą╝ąĄąĮčīčłąĖą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąŠą╝ ą▒ąĖčé čüąŠ ąĘąĮą░ą║ąŠą╝) č湥čéąĮąŠąĄ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠąĄ čüą╝ąĄčēąĄąĮąĖąĄ, čü ą┤ąĖą░ą┐ą░ąĘąŠąĮąŠą╝ -16,777,216 .. 16,777,214 ą▒ą░ą╣čé (0xFF00 0000 .. 0x00FF FFFE).
pcrel13m2: 13-ą▒ąĖčéąĮąŠąĄ čüąŠ ąĘąĮą░ą║ąŠą╝ č湥čéąĮąŠąĄ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠąĄ čüą╝ąĄčēąĄąĮąĖąĄ, čü ą┤ąĖą░ą┐ą░ąĘąŠąĮąŠą╝ -4096 .. 4094 ą▒ą░ą╣čé (0xF000 .. 0x0FFE).
pcrel25m2: 25-ą▒ąĖčéąĮąŠąĄ čüąŠ ąĘąĮą░ą║ąŠą╝ č湥čéąĮąŠąĄ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠąĄ čüą╝ąĄčēąĄąĮąĖąĄ, čü ą┤ąĖą░ą┐ą░ąĘąŠąĮąŠą╝ -16,777,216 .. 16,777,214 ą▒ą░ą╣čé (0xFF00 0000 .. 0x00FF FFFE).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąĄčĆąĄčģąŠą┤ą░ ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ ąĘą░ą│čĆčāąČą░ąĄčé ąĮąŠą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą▓ čüč湥čéčćąĖą║ ą┐čĆąŠą│čĆą░ą╝ą╝ (Program Counter, PC), čćč鹊ą▒čŗ ą┐ąŠą╝ąĄąĮčÅčéčī ą┐ąŠčĆčÅą┤ąŠą║ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ (program flow).
ąÆ ą║ąŠčüą▓ąĄąĮąĮąŠą╣ ąĖą╗ąĖ ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą╣ ą▓ąĄčĆčüąĖčÅčģ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĘąĮą░č湥ąĮąĖąĄ ą▓ Preg ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī č湥čéąĮčŗą╝ čćąĖčüą╗ąŠą╝ (ą▓ ą║ąŠč鹊čĆąŠą╝ bit0 = 0), čćč鹊ą▒čŗ čüąŠčģčĆą░ąĮąĖčéčī 16-ą▒ąĖčéąĮąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą░ą┤čĆąĄčüą░. ąśąĮą░č湥 ąĮąĄč湥čéąĮąŠąĄ čüą╝ąĄčēąĄąĮąĖąĄ ą▓ Preg ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ą│ąĄąĮąĄčĆą░čåąĖąĖ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą╝ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ (alignment exception).
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
jump (p5);
jump (pc + p2);
jump 0x224 ; // čüą╝ąĄčēąĄąĮąĖąĄ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠąĄ, ą▓ 13 ą▒ąĖčéą░čģ, čéą░ą║ čćč鹊 čåąĄą╗ąĄą▓ąŠą╣ ą░ą┤čĆąĄčü
// ą▒čāą┤ąĄčé PC + 0x224, čćč鹊 ąŠąĘąĮą░čćą░ąĄčé ą┐ąĄčĆąĄčģąŠą┤ ą▓ą┐ąĄčĆąĄą┤
jump.s 0x224 ; // č鹊 ąČąĄ čüą░ą╝ąŠąĄ, čćč鹊 jump čü ą║ąŠčĆąŠčéą║ąĖą╝ čüąĖąĮčéą░ą║čüąĖčüąŠą╝
jump.l 0xFFFACE86 ; // čüą╝ąĄčēąĄąĮąĖąĄ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠąĄ, ą▓ 25 ą▒ąĖčéą░čģ, čéą░ą║ čćč鹊 čåąĄą╗ąĄą▓ąŠą╣ ą░ą┤čĆąĄčü
// ą▒čāą┤ąĄčé PC + 0x1FA CE86, čćč鹊 ąŠąĘąĮą░čćą░ąĄčé ąŠą▒čĆą░čéąĮčŗą╣ ą┐ąĄčĆąĄčģąŠą┤
jump get_new_sample; // ą░čüčüąĄą╝ą▒ą╗ąĄčĆ čüą░ą╝ ą┐ąŠ ą╝ąĄčéą║ąĄ ą▓čŗčćąĖčüą╗ąĖčé čåąĄą╗ąĄą▓ąŠą╣ ą░ą┤čĆąĄčü, ą▒ą╗ą░ą│ąŠą┤ą░čĆčÅ
// ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÄ ą╝ąĄčéą║ąĖ ąĘą┤ąĄčüčī čāą║ą░ąĘą░ąĮąŠ ą░ą▒čüčéčĆą░ą║čéąĮąŠąĄ čüą╝ąĄčēąĄąĮąĖąĄ
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ (IF CC JUMP, IF !CC JUMP), CALL.
ąŁč鹊 ą║ąŠą╝ą░ąĮą┤čŗ ą┐ąĄčĆąĄčģąŠą┤ą░ ą┐ąŠ čāčüą╗ąŠą▓ąĖčÄ (ą▓ąĄčéą▓ą╗ąĄąĮąĖąĄ, Branch). ąĪąĖąĮčéą░ą║čüąĖčü:
IF CC JUMP pcrell1m2; // ą┐ąĄčĆąĄčģąŠą┤, ąĄčüą╗ąĖ CC=1, ą▓ąĄčéą▓ą╗ąĄąĮąĖąĄ ą┐čĆąĄą┤čüą║ą░ąĘą░ąĮąŠ ą║ą░ą║ 2 (a)1
IF CC JUMP pcrel11m2 (bp); // ą┐ąĄčĆąĄčģąŠą┤, ąĄčüą╗ąĖ CC=1, ą▓ąĄčéą▓ą╗ąĄąĮąĖąĄ ą┐čĆąĄą┤čüą║ą░ąĘą░ąĮąŠ ą║ą░ą║ 2 (a)
IF !CC JUMP pcrel11m2; // ą┐ąĄčĆąĄčģąŠą┤, ąĄčüą╗ąĖ CC=0, ą▓ąĄčéą▓ą╗ąĄąĮąĖąĄ ą┐čĆąĄą┤čüą║ą░ąĘą░ąĮąŠ ą║ą░ą║ 3 (a)
IF !CC JUMP pcrel11m2 (bp); // ą┐ąĄčĆąĄčģąŠą┤, ąĄčüą╗ąĖ CC=0, ą▓ąĄčéą▓ą╗ąĄąĮąĖąĄ ą┐čĆąĄą┤čüą║ą░ąĘą░ąĮąŠ ą║ą░ą║3 (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 2: ąĘąĮą░č湥ąĮąĖąĄ ą▒ąĖčéą░ CC=1 ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ą┐ąĄčĆąĄčģąŠą┤čā ą┐ąŠ ą░ą┤čĆąĄčüčā, ą▓čŗčćąĖčüą╗ąĄąĮąĮąŠą╝čā ą║ą░ą║ č湥čéąĮąŠąĄ čüą╝ąĄčēąĄąĮąĖąĄ čüąŠ ąĘąĮą░ą║ąŠą╝ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ č鹥ą║čāčēąĄą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ čüč湥čéčćąĖą║ą░ PC.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 3: ąĘąĮą░č湥ąĮąĖąĄ ą▒ąĖčéą░ CC=0 ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ą┐ąĄčĆąĄčģąŠą┤čā ą┐ąŠ ą░ą┤čĆąĄčüčā, ą▓čŗčćąĖčüą╗ąĄąĮąĮąŠą╝čā ą║ą░ą║ č湥čéąĮąŠąĄ čüą╝ąĄčēąĄąĮąĖąĄ čüąŠ ąĘąĮą░ą║ąŠą╝ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ č鹥ą║čāčēąĄą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ čüč湥čéčćąĖą║ą░ PC.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
pcrel11m2: 11-ą▒ąĖčéąĮąŠąĄ, č湥čéąĮąŠąĄ čüą╝ąĄčēąĄąĮąĖąĄ čüąŠ ąĘąĮą░ą║ąŠą╝, ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ -1024 .. 1022 ą▒ą░ą╣čé (0xFC00 .. 0x03FE). ąŁč鹊 ąĘąĮą░č湥ąĮąĖąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ąĘą░ą╝ąĄąĮąĄąĮąŠ ą╝ąĄčéą║ąŠą╣ ą░ą┤čĆąĄčüą░, ą║ąŠč鹊čĆą░čÅ ą▒čāą┤ąĄ ą▓čŗčćąĖčüą╗ąĄąĮą░ ąĖ ąĘą░ą╝ąĄąĮąĄąĮą░ ąĮą░ čĆąĄą░ą╗čīąĮčŗą╣ ą░ą┤čĆąĄčü ą▓ąŠ ą▓čĆąĄą╝čÅ ą╗ąĖąĮą║ąŠą▓ą║ąĖ.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąĄčĆąĄčģąŠą┤ą░ ą┐ąŠ čāčüą╗ąŠą▓ąĖčÄ (Conditional Jump) ąĘą░ą│čĆčāąČą░ąĄčé ąĮąŠą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗą╣ čüč湥čéčćąĖą║ (Program Counter, PC), čćč鹊 ąĖąĘą╝ąĄąĮąĖčé ą┐ąŠčĆčÅą┤ąŠą║ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ąĘąĮą░č湥ąĮąĖčÅ ą▒ąĖčéą░ CC. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąŠčé ą▒ąĖčéą░ CC ąĘą░ą▓ąĖčüąĖčé, ą║ą░ą║ą░čÅ ą▓ąĄčéą▓čī (Branch) ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą▒čāą┤ąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮą░.
[ą×ą┐čåąĖčÅ ą┐čĆąĄą┤čüą║ą░ąĘčŗą▓ą░ąĮąĖčÅ ]
ą×ą┐čåąĖčÅ ą┐čĆąĄą┤čüą║ą░ąĘčŗą▓ą░ąĮąĖčÅ ((bp), čüąŠą║čĆą░čēąĄąĮąĖąĄ ąŠčé Branch Prediction) ą┐ąŠą╝ąŠą│ą░ąĄčé ą┐čĆąŠčåąĄčüčüąŠčĆčā čāą╗čāčćčłąĖčéčī ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┐čĆąĄą┤čüą║ą░ąĘčŗą▓ą░ąĮąĖąĄ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ. ą¤čāč鹥ą╝ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ ąŠą┐čåąĖąĖ (bp) ą║ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ąĄčéą▓ą╗ąĄąĮąĖąĄ ą┐ąŠą╗čāčćą░ąĄčé ą┐čĆąĄą┤čüą║ą░ąĘą░ąĮąĖąĄ.
ą×ą▒čŗčćąĮąŠ ą░ąĮą░ą╗ąĖąĘ ą║ąŠą┤ą░ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čģąŠčĆąŠčłąĄąĄ čāčüą╗ąŠą▓ąĖąĄ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą╗čÅ ą┐čĆąĄą┤čüą║ą░ąĘčŗą▓ą░ąĮąĖčÅ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ ąĮą░ ą┐čĆąĄą┤čŗą┤čāčēąĖą╣ ą░ą┤čĆąĄčü (ąŠą▒čĆą░čéąĮąŠąĄ ą▓ąĄčéą▓ą╗ąĄąĮąĖąĄ), ąĖ ą┤ą╗čÅ ą┐čĆąĄą┤čüą║ą░ąĘčŗą▓ą░ąĮąĖčÅ ąŠčéčüčāčéčüčéą▓ąĖčÅ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ ą┤ą╗čÅ ą┐ąĄčĆąĄčģąŠą┤ąŠą▓ ą║ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖą╝ ą░ą┤čĆąĄčüą░ą╝ (ą▓ąĄčéą▓ą╗ąĄąĮąĖąĄ ą▓ą┐ąĄčĆąĄą┤).
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
if cc jump 0xFFFFFE08 (bp); // čüą╝ąĄčēąĄąĮąĖąĄ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠąĄ ąĖąĘ 11 ą▒ąĖčé, čéą░ą║ čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé
// ą┐ąĄčĆąĄčģąŠą┤ ąĮą░ąĘą░ą┤, ą▓ąĄčéą▓ą╗ąĄąĮąĖąĄ čü ą┐čĆąĄą┤čüą║ą░ąĘą░ąĮąĖąĄą╝ if cc jump 0x0B4 ; // čüą╝ąĄčēąĄąĮąĖąĄ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠąĄ, čéą░ą║ čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐ąĄčĆąĄčģąŠą┤
// ą▓ą┐ąĄčĆąĄą┤, ą▒ąĄąĘ ą┐čĆąĄą┤čüą║ą░ąĘą░ąĮąĖčÅ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ if ! cc jump 0xFFFFFC22 (bp); // čüą╝ąĄčēąĄąĮąĖąĄ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠąĄ ąĖąĘ 11 ą▒ąĖčé, čéą░ą║ čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé
// ą┐ąĄčĆąĄčģąŠą┤ ąĮą░ąĘą░ą┤, ą▓ąĄčéą▓ą╗ąĄąĮąĖąĄ čü ą┐čĆąĄą┤čüą║ą░ąĘą░ąĮąĖąĄą╝ if ! cc jump 0x120 ; // ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠąĄ čüą╝ąĄčēąĄąĮąĖąĄ, čéą░ą║ čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐ąĄčĆąĄčģąŠą┤
// ą▓ą┐ąĄčĆąĄą┤, ą▒ąĄąĘ ą┐čĆąĄą┤čüą║ą░ąĘą░ąĮąĖčÅ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ if cc jump dest_label; // ą░čüčüąĄą╝ą▒ą╗ąĄčĆ čüą░ą╝ ąŠą┐čĆąĄą┤ąĄą╗ąĖčé čåąĄą╗ąĄą▓ąŠą╣ ą░ą┤čĆąĄčü, čüą╝ąĄčēąĄąĮąĖąĄ
// čāą║ą░ąĘą░ąĮąŠ ą░ą▒čüčéčĆą░ą║čéąĮąŠ ą▒ą╗ą░ą│ąŠą┤ą░čĆčÅ ą╝ąĄčéą║ąĄ
ąĪą╝. čéą░ą║ąČąĄ JUMP, CALL.
ąÜąŠą╝ą░ąĮą┤ą░ ą▓čŗąĘąŠą▓ą░ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ąĪąĖąĮčéą░ą║čüąĖčü:
CALL (Preg); // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ ą┐ąŠ ą░ą▒čüąŠą╗čÄčéąĮąŠą╝čā (ą▒ąĄąĘ // ą┐čĆąĖą▓čÅąĘą║ąĖ ą║ ą░ą┤čĆąĄčüčā ą▓ PC) ą░ą┤čĆąĄčüčā (a)1
CALL (PC + Preg); // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ PC (a)
CALL pcrel25m2; // ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ PC (b)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Preg: P0, ..., P5 (čĆąĄą│ąĖčüčéčĆčŗ SP ąĖ FP ąĮąĄ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą║ą░ą║ ąĖčüč鹊čćąĮąĖą║ ą░ą┤čĆąĄčüą░ ą┤ą╗čÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ).
pcrel25m2: 25-ą▒ąĖčéąĮąŠąĄ čüąŠ ąĘąĮą░ą║ąŠą╝, č湥čéąĮąŠąĄ, ą┐čĆąĖą▓čÅąĘą░ąĮąĮąŠąĄ ą║ PC čüą╝ąĄčēąĄąĮąĖąĄ; ą╝ąŠąČąĄčé ą▒čŗčéčī čāą║ą░ąĘą░ąĮąŠ ą║ą░ą║ čüąĖą╝ą▓ąŠą╗ąĖč湥čüą║ą░čÅ ą░ą┤čĆąĄčüąĮą░čÅ ą╝ąĄčéą║ą░, čü ą┤ąĖą░ą┐ą░ąĘąŠąĮąŠą╝ -16,777,216 .. 16,777,214 (0xFF00 0000 .. 0x00FF FFFE) ą▒ą░ą╣čé.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ CALL ą▓čŗąĘčŗą▓ą░ąĄčé ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čā ą┐ąŠ ą░ą┤čĆąĄčüčā, ąĮą░ ą║ąŠč鹊čĆčŗą╣ čāą║ą░ąĘčŗą▓ą░ąĄčé P-čĆąĄą│ąĖčüčéčĆ ąĖą╗ąĖ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ čüą╝ąĄčēąĄąĮąĖčÅ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ č鹥ą║čāčēąĄą│ąŠ čüč湥čéčćąĖą║ą░ ą║ąŠą╝ą░ąĮą┤ (PC). ą¤ąŠčüą╗ąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ CALL čĆąĄą│ąĖčüčéčĆ RETS čüąŠą┤ąĄčƹȹĖčé ą░ą┤čĆąĄčü čüą╗ąĄą┤čāčÄčēąĄą╣ ą┐ąŠčüą╗ąĄ CALL ąĖąĮčüčéčĆčāą║čåąĖąĖ.
ąŚąĮą░č湥ąĮąĖąĄ ą▓ Preg ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī č湥čéąĮčŗą╝, čćč鹊ą▒čŗ čüąŠčģčĆą░ąĮąĖčéčī 16-ą▒ąĖčéąĮąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ.
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
call (p5);
call (pc + p2) ;
call 0x123456 ;
call get_next_sample;
ąĪą╝. čéą░ą║ąČąĄ RTS, RTI, RTX, RTN, RTE, JUMP, IF CC JUMP, IF !CC JUMP.
ąśąĮčüčéčĆčāą║čåąĖąĖ ą┤ą╗čÅ ą▓ąŠąĘą▓čĆą░čéą░ ąĖąĘ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ąĪąĖąĮčéą░ą║čüąĖčü:
RTS; // ąÆąŠąĘą▓čĆą░čé ąĖąĘ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ (a)
RTI; // ąÆąŠąĘą▓čĆą░čé ąĖąĘ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ (a)
RTX; // ąÆąŠąĘą▓čĆą░čé ąĖąĘ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, exception (a)
RTN; // ąÆąŠąĘą▓čĆą░čé ąĖąĘ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ąĮąĄą╝ą░čüą║ąĖčĆčāąĄą╝ąŠą│ąŠ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ, NMI (a)
RTE; // ąÆąŠąĘą▓čĆą░čé ąĖąĘ čĆąĄąČąĖą╝ą░ 菹╝čāą╗čÅčåąĖąĖ (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ąŠąĘą▓čĆą░čéą░ ą┤ąĄą╗ą░ąĄčé ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮčŗą╣ ą▓ąŠąĘą▓čĆą░čé ą┐ąŠč鹊ą║ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĖąĘ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ąĮąĄą╝ą░čüą║ąĖčĆčāąĄą╝ąŠą│ąŠ (NMI) ąĖą╗ąĖ ą╝ą░čüą║ąĖčĆčāąĄą╝ąŠą│ąŠ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ISR, ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĖą╗ąĖ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ 菹╝čāą╗čÅčåąĖąĖ (čüą╝. čéą░ą▒ą╗ąĖčåčā 2-1).
ąóą░ą▒ą╗ąĖčåą░ 2-1. ąóąĖą┐čŗ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą▓ąŠąĘą▓čĆą░čéą░.
ą£ąĮąĄą╝ąŠąĮąĖą║ą░ ą×ą┐ąĖčüą░ąĮąĖąĄ
RTS ąöąĄą╗ą░ąĄčé ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮčŗą╣ ą▓ąŠąĘą▓čĆą░čé ąĖąĘ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą┐čāč鹥ą╝ ąĘą░ą│čĆčāąĘą║ąĖ ąĘąĮą░č湥ąĮąĖčÅ ąĖąĘ čĆąĄą│ąĖčüčéčĆą░ RETS ą▓ čüč湥čéčćąĖą║ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ (Program Counter, PC), čćč鹊 ą┐čĆąĖą▓ąŠą┤ąĖčé ą┐čĆąŠčåąĄčüčüąŠčĆ ą║ ą▓čŗą▒ąŠčĆą║ąĄ čüą╗ąĄą┤čāčÄčēąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąŠčé ą░ą┤čĆąĄčüą░, čüąŠą┤ąĄčƹȹ░čēąĄą│ąŠčüčÅ ą▓ RETS. ąöą╗čÅ ą▓ą╗ąŠąČąĄąĮąĮčŗčģ ą▓čŗąĘąŠą▓ąŠą▓ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ ąÆčŗ ą┤ąŠą╗ąČąĮčŗ čüąŠčģčĆą░ąĮąĖčéčī (ąŠą▒čŗčćąĮąŠ ą┤ą╗čÅ čŹč鹊ą│ąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čüč鹥ą║) ąĘąĮą░č湥ąĮąĖąĄ čĆąĄą│ąĖčüčéčĆą░ RETS. ąśąĮą░č湥 čüą╗ąĄą┤čāčÄčēąĖą╣ ą▓čŗąĘąŠą▓ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ CALL ą┐ąĄčĆąĄąĘą░ą┐ąĖčłąĄčé čĆąĄą│ąĖčüčéčĆ RETS.
RTI ąöąĄą╗ą░ąĄčé ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮčŗą╣ ą▓ąŠąĘą▓čĆą░čé ąĖąĘ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ą┐čāč鹥ą╝ ąĘą░ą│čĆčāąĘą║ąĖ ąĘąĮą░č湥ąĮąĖčÅ ąĖąĘ čĆąĄą│ąĖčüčéčĆą░ RETI ą▓ čüč湥čéčćąĖą║ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ (Program Counter, PC). ąÜąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ, ą┐čĆąŠčåąĄčüčüąŠčĆ ą▓čģąŠą┤ąĖčé ą▓ čüąŠčüč鹊čÅąĮąĖąĄ, ą║ąŠą│ą┤ą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąĮąĄą▓ąŠąĘą╝ąŠąČąĮčŗ. ąĪąŠčģčĆą░ąĮąĄąĮąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ čĆąĄą│ąĖčüčéčĆą░ RETI ą▓ čüč鹥ą║ čĆą░ąĘčĆąĄčłąĖčé ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ, čéą░ą║ čćč鹊 ą▓čüąĄ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ čü ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ ą╝ąŠą│čāčé ą┐čĆąĄčĆčŗą▓ą░čéčī ąŠą▒čĆą░ą▒ąŠčéą║čā č鹥ą║čāčēąĄą│ąŠ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ (čŹčéąĖą╝ ą┤ąŠčüčéąĖą│ą░ąĄčéčüčÅ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą▓ą╗ąŠąČąĄąĮąĮčŗčģ ą┤čĆčāą│ ą▓ ą┤čĆčāą│ą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣). ąĢčüą╗ąĖ RETI ąĮąĄ ą▒čŗą╗ čüąŠčģčĆą░ąĮąĄąĮ ą▓ čüč鹥ą║, č鹊 ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąŠčāčĆąŠą▓ąĮąĄą▓ąŠąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ ą▒čāą┤ąĄčé ą░ą┐ą┐ą░čĆą░čéąĮąŠ ąĘą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮąŠ ą▓ čüąĖčüč鹥ą╝ąĄ ą┐čĆąŠčåąĄčüčüąŠčĆą░, ąĮąŠ ąŠąĮąŠ ąĮąĄ ą▒čāą┤ąĄčé ąŠą▒čüą╗čāąČąĖą▓ą░čéčīčüčÅ, ą┐ąŠą║ą░ ąĮąĄ ąĘą░ą▓ąĄčĆčłąĖčé čüą▓ąŠčÄ čĆą░ą▒ąŠčéčā č鹥ą║čāčēąĖą╣ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ. ąÆąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖąĄ RETI ąŠą▒čĆą░čéąĮąŠ ąĖąĘ čüč鹥ą║ą░ ą┐ąŠ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĖ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ą╝ą░čüą║ąĖčĆčāąĄčé ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ, ą┐ąŠą║ą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ RTI. ąÆ ą╗čÄą▒ąŠą╝ čüą╗čāčćą░ąĄ RETI ąĘą░čēąĖčēąĄąĮ ąŠčé ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮąŠą│ąŠ ą┐ąŠą▓čĆąĄąČą┤ąĄąĮąĖčÅ čüąŠ čüč鹊čĆąŠąĮčŗ ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąŠčāčĆąŠą▓ąĮąĄą▓čŗčģ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣.
RTX ąöąĄą╗ą░ąĄčé ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮčŗą╣ ą▓ąŠąĘą▓čĆą░čé ąĖąĘ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą┐čāč鹥ą╝ ąĘą░ą│čĆčāąĘą║ąĖ ą▓ PC ąĘąĮą░č湥ąĮąĖčÅ čĆąĄą│ąĖčüčéčĆą░ RETX.
RTN ąöąĄą╗ą░ąĄčé ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮčŗą╣ ą▓ąŠąĘą▓čĆą░čé ąĖąĘ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ NMI ą┐čāč鹥ą╝ ąĘą░ą│čĆčāąĘą║ąĖ ą▓ PC ąĘąĮą░č湥ąĮąĖčÅ čĆąĄą│ąĖčüčéčĆą░ RETN.
RTE ąöąĄą╗ą░ąĄčé ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮčŗą╣ ą▓ąŠąĘą▓čĆą░čé ąĖąĘ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ 菹╝čāą╗čÅčåąĖąĖ ąĖ ą▓čŗčģąŠą┤ ąĖąĘ čĆąĄąČąĖą╝ą░ 菹╝čāą╗čÅčåąĖąĖ ą┐čāč鹥ą╝ ąĘą░ą│čĆčāąĘą║ąĖ ąĘąĮą░č湥ąĮąĖčÅ čĆąĄą│ąĖčüčéčĆą░ RETE ą▓ PC. ą¤ąŠčüą║ąŠą╗čīą║čā č鹊ą╗čīą║ąŠ ąŠą┤ąĮą░ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ 菹╝čāą╗čÅčåąĖąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ą┐čāčēąĄąĮą░ ą▓ ą╗čÄą▒ąŠą╣ ą┐čĆąŠą╝ąĄąČčāč鹊ą║ ą▓čĆąĄą╝ąĄąĮąĖ (ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓ą╗ąŠąČąĄąĮąĮąŠą│ąŠ ą▓čŗąĘąŠą▓ą░ ą┤ą╗čÅ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ 菹╝čāą╗čÅčåąĖąĖ), č鹊 ą┐ąŠą┤ą┤ąĄčƹȹ║ą░ ą▓ą╗ąŠąČąĄąĮąĮąŠčüčéąĖ ąĮąĄ ąĮčāąČąĮą░, ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ čĆąĄą│ąĖčüčéčĆą░ RETE ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ.
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąÆ čéą░ą▒ą╗ąĖčåąĄ 2-2 ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāąĄčé čĆąĄąČąĖą╝čŗ, čéčĆąĄą▒čāąĄą╝čŗąĄ ą┤ą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ąŠąĘą▓čĆą░čéą░.
ąóą░ą▒ą╗ąĖčåą░ 2-1. ąóąĖą┐čŗ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą▓ąŠąĘą▓čĆą░čéą░.
ą£ąĮąĄą╝ąŠąĮąĖą║ą░ ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ą┐čĆąŠčåąĄčüčüąŠčĆą░
RTS User ąĖ Supervisor.
RTI, RTX ąĖ RTN ąóąŠą╗čīą║ąŠ čĆąĄąČąĖą╝ Supervizor. ąøčÄą▒ą░čÅ ą┐ąŠą┐čŗčéą║ą░ ą▓čŗą┐ąŠą╗ąĮąĖčéčī čŹčéąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ čĆąĄąČąĖą╝ąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User) ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÄ ąĮą░čĆčāčłąĄąĮąĖčÅ ąĘą░čēąĖčéčŗ (protection violation exception).
RTE ąóąŠą╗čīą║ąŠ čĆąĄąČąĖą╝ 菹╝čāą╗čÅčåąĖąĖ (Emulation). ąøčÄą▒ą░čÅ ą┐ąŠą┐čŗčéą║ą░ ą▓čŗą┐ąŠą╗ąĮąĖčéčī čŹčéąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ čĆąĄąČąĖą╝ąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User) ąĖą╗ąĖ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervizor) ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÄ (exception).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
ąĪą╝. čéą░ą║ąČąĄ CALL, PUSH, POP.
ąŁč鹊 čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝čŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ą╗čÅ ąĘą░ą┐čāčüą║ą░ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ čåąĖą║ą╗ą░ (Zero-Overhead Loop Setup). ą”ąĖą║ą╗ ą╝ąŠąČąĮąŠ ąĘą░ą┤ą░ą▓ą░čéčī ą▓ ą┤ą▓čāą╝čÅ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ:
LSETUP (Begin_Loop, End_Loop) Loop_Counter
ąĖ
LOOP loop_name loop_counter
ąĪąĖąĮčéą░ą║čüąĖčü:
ąöą╗čÅ Loop0
LSETUP (pcrel5m2, lppcrel11m2) LC0; // (b) LSETUP (pcrel5m2, lppcrel11m2) LC0 = Preg; // ą░ą▓č鹊ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ LC0 (b)1 LSETUP (pcrel5m2, lppcrel11m2) LC0 = Preg >> 1; // ą░ą▓č鹊ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ LC0 (b) LOOP loop_name LC0; // (b) LOOP loop_name LC0 = Preg; // ą░ą▓č鹊ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ LC0 (b) LOOP loop_name LC0 = Preg >> 1; // ą░ą▓č鹊ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ LC0 (b)
ąöą╗čÅ Loop1
LSETUP (pcrel5m2, lppcrel11m2) LC1; // (b) LSETUP (pcrel5m2, lppcrel11m2) LC1 = Preg; // ą░ą▓č鹊ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ LC1 (b) LSETUP (pcrel5m2, lppcrel11m2) LC1 = Preg >> 1; // ą░ą▓č鹊ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ LC1 (b) LOOP loop_name LC1; // (b) LOOP loop_name LC1 = Preg; // ą░ą▓č鹊ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ LC1 (b) LOOP loop_name LC1 = Preg >> 1; // ą░ą▓č鹊ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ LC1 (b)
LOOP_BEGIN loop_name; // ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą┐ąĄčĆą▓ąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ą╗čÅ čåąĖą║ą╗ą░ (b) LOOP_END loop_name; // ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą┐ąŠčüą╗ąĄą┤ąĮąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ą╗čÅ čåąĖą║ą╗ą░ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Preg: P0, ..., P5 (čĆąĄą│ąĖčüčéčĆčŗ SP ąĖ FP ąĮąĄ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą║ą░ą║ ąĖčüč鹊čćąĮąĖą║ ą░ą┤čĆąĄčüą░ ą┤ą╗čÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ).
pcrel5m2: 5-ą▒ąĖčéąĮąŠąĄ čüąŠ ąĘąĮą░ą║ąŠą╝, č湥čéąĮąŠąĄ, ą┐čĆąĖą▓čÅąĘą░ąĮąĮąŠąĄ ą║ PC čüą╝ąĄčēąĄąĮąĖąĄ; ą╝ąŠąČąĄčé ą▒čŗčéčī čāą║ą░ąĘą░ąĮąŠ ą║ą░ą║ čüąĖą╝ą▓ąŠą╗ąĖč湥čüą║ą░čÅ ą░ą┤čĆąĄčüąĮą░čÅ ą╝ąĄčéą║ą░, čü ą┤ąĖą░ą┐ą░ąĘąŠąĮąŠą╝ 4 .. 30, ąĖą╗ąĖ 25 -2.
lppcrel11m2: 11-ą▒ąĖčéąĮąŠąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ą┐čĆąĖą▓čÅąĘą░ąĮąĮąŠąĄ ą║ PC čüą╝ąĄčēąĄąĮąĖąĄ ą┤ą╗čÅ čåąĖą║ą╗ą░; ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ą╝ąĄąĮąĄąĮąŠ čüąĖą╝ą▓ąŠą╗ąĖč湥čüą║ąŠą╣ ą╝ąĄčéą║ąŠą╣. ąöąĖą░ą┐ą░ąĘąŠąĮ 4 .. 2046 (0x0004 .. 0x07FE), ąĖą╗ąĖ 211 -2.
loop_name: čüąĖą╝ą▓ąŠą╗ąĖč湥čüą║ą░čÅ ą░ą┤čĆąĄčüąĮą░čÅ ą╝ąĄčéą║ą░.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮą░čüčéčĆąŠą╣ą║ąĖ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ čåąĖą║ą╗ą░ (Zero-Overhead Loop Setup) ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą│ąĖą▒ą║ąĖą╣, ąŠčüąĮąŠą▓ą░ąĮąĮčŗą╣ ąĮą░ čüč湥čéčćąĖą║ąĄ, ą╝ąĄčģą░ąĮąĖąĘą╝ ąĘą░ą┐čāčüą║ą░ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ čåąĖą║ą╗ą░, čćč鹊 ą┤ą░ąĄčé ąŠč湥ąĮčī čŹčäč乥ą║čéąĖą▓ąĮčŗą╣, čü ą╝ąĖąĮąĖą╝ą░ą╗čīąĮčŗą╝ąĖ ą┐ąŠč鹥čĆčÅą╝ąĖ, čåąĖą║ą╗ ą┤ą╗čÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ąÆ čŹč鹊ą╝ ą║ąŠąĮč鹥ą║čüč鹥 zero-overhead (ą┤ąŠčüą╗ąŠą▓ąĮąŠ ą┐ąĄčĆąĄą▓ąŠą┤ąĖčéčüčÅ ą║ą░ą║ "ąĮčāą╗ąĄą▓čŗąĄ ą┐ąŠč鹥čĆąĖ") ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą▓ čåąĖą║ą╗ąĄ ąĮąĄ ąĮčāąČą┤ą░ąĄčéčüčÅ ą▓ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅčģ ą┤ą╗čÅ ą┤ąĄą║čĆąĄą╝ąĄąĮčéąĖčĆąŠą▓ą░ąĮąĖčÅ čüč湥čéčćąĖą║ą░, ą┐čĆąŠą▓ąĄčĆą║ąĄ čāčüą╗ąŠą▓ąĖčÅ čåąĖą║ą╗ą░, čćč鹊ą▒čŗ ą▓čŗčćąĖčüą╗ąĖčéčī ąĖ čüą┤ąĄą╗ą░čéčī ą┐ąĄčĆąĄčģąŠą┤ ąĮą░ ąĮąŠą▓čŗą╣ čåąĄą╗ąĄą▓ąŠą╣ ą░ą┤čĆąĄčü - ą▓čüąĄ čŹčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ ą┐čĆąŠąĖčüčģąŠą┤čÅčé ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ, ą┐ąŠą┤ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄą╝ ą░ą┐ą┐ą░čĆą░čéčāčĆčŗ ą┐čĆąŠčåąĄčüčüąŠčĆą░. ąæą╗ą░ą│ąŠą┤ą░čĆčÅ čŹč鹊ą╝čā ą╝ąŠą│čāčé ą▒čŗčéčī ąŠčĆą│ą░ąĮąĖąĘąŠą▓ą░ąĮčŗ ąŠčüąŠą▒ąĄąĮąĮąŠ ą▒čŗčüčéčĆčŗąĄ ąĖ čŹčäč乥ą║čéąĖą▓ąĮčŗąĄ čåąĖą║ą╗čŗ.
ąÉčĆčģąĖč鹥ą║čéčāčĆą░ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé 2 ąĮą░ą▒ąŠčĆą░, ą║ą░ąČą┤čŗą╣ ąĖąĘ 3 čĆąĄą│ąĖčüčéčĆąŠą▓, ą┤ą╗čÅ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ ą┤ą▓čāčģ ąĮąĄ ąĘą░ą▓ąĖčüąĖą╝čŗčģ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ čåąĖą║ą╗ą░, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓ą╗ąŠąČąĄąĮčŗ ą┤čĆčāą│ ą▓ ą┤čĆčāą│ą░ (Loop0 ąĖ Loop1). ąŁč鹊 čĆąĄą│ąĖčüčéčĆčŗ Loop_Top (LTn), Loop_Bottom (LBn) ąĖ Loop_Count (LCn). ąŚą┤ąĄčüčī ą▒čāą║ą▓ą░ n ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ą╝ąĄąĮąĄąĮą░ ąĮą░ 0 ąĖą╗ąĖ 1, čéą░ą║ čćč鹊 ą┐ąŠą╗čāčćą░čÄčéčüčÅ čĆąĄą│ąĖčüčéčĆčŗ LT0, LB0 ąĖ LC0 ą┤ą╗čÅ ąŠą┐ąĖčüą░ąĮąĖčÅ Loop0, ąĖ LT1, LB1 ąĖ LC1 ą┤ą╗čÅ ąŠą┐ąĖčüą░ąĮąĖčÅ Loop1.
ąśąĮčüčéčĆčāą║čåąĖąĖ LSETUP ąĖ LOOP ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé čāą┤ąŠą▒ąĮčŗą╣ čüą┐ąŠčüąŠą▒ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ ą▓čüąĄčģ čéčĆąĄčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą▓ ąŠą┤ąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąĀą░ąĘą╝ąĄčĆ ąĖąĮčüčéčĆčāą║čåąĖą╣ LSETUP ąĖ LOOP ą╝ąŠąČąĄčé ą┐ąŠą┤ą┤ąĄčƹȹ░čéčī ąĮąĄ čéą░ą║ ą╝ąĮąŠą│ąŠ ą▒ąĖčé, čéą░ą║ čćč鹊 čĆą░ąĘą╝ąĄčĆ č鹥ą╗ą░ čåąĖą║ą╗ą░ ąŠą│čĆą░ąĮąĖč湥ąĮ. ą×ą┤ąĮą░ą║ąŠ LT0 ąĖ LT1, LB0 ąĖ LB1 ąĖ LC0 ąĖ LC1 ą╝ąŠą│čāčé ą▒čŗčéčī ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮčŗ ą▓čĆčāčćąĮčāčÄ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ Move, ąĄčüą╗ąĖ ą┤ą╗ąĖąĮą░ čåąĖą║ą╗ą░ ąĖ čüč湥čéčćąĖą║ ą┐ąŠą▓č鹊čĆąŠą▓ ą┤ąŠą╗ąČąĄąĮ ą▓čŗą╣čéąĖ ąĘą░ ą┐čĆąĄą┤ąĄą╗čŗ, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄą╝čŗąĄ čüąĖąĮčéą░ą║čüąĖčüąŠą╝ LSETUP ąĖą╗ąĖ LOOP. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąŠą┤ąĖąĮ čåąĖą║ą╗ ą╝ąŠąČąĄčé ą┐ąŠą║čĆčŗčéčī ą▓ąĄčüčī ą┤ąĖą░ą┐ą░ąĘąŠąĮ ą░ą┤čĆąĄčüąĮąŠą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ 4 ą│ąĖą│ą░ą▒ą░ą╣čéą░.
ąśąĮčüčéčĆčāą║čåąĖčÅ LSETUP ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą┐čĆąĖąĮąĖą╝ą░ąĄčé ąĘąĮą░č湥ąĮąĖąĄ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ ąĖąĘ P-čĆąĄą│ąĖčüčéčĆą░, ąĖą╗ąĖ ąĖąĘ P-čĆąĄą│ąĖčüčéčĆą░, ą┐ąŠą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ąĮą░ 2.
ąÉą╗čīč鹥čĆąĮą░čéąĖą▓ąĮčŗą╣ čüąĖąĮčéą░ą║čüąĖčü ą┤ą╗čÅ ą┤ąŠčüčéąĖąČąĄąĮąĖčÅ č鹊ą│ąŠ ąČąĄ čĆąĄąĘčāą╗čīčéą░čéą░ čüąŠčüč鹊ąĖčé ąĖąĘ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ LOOP, LOOP_BEGIN, LOOP_END. ąŁč鹊čé čüąĖąĮčéą░ą║čüąĖčü ą┐ąĄčĆąĄą┤ą░ąĄčé ą▓ čüąĄą▒ąĄ čéčā ąČąĄ čüą░ą╝čāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ, čćč鹊 ąĖ čüąĖąĮčéą░ą║čüąĖčü LSETUP, ąĮąŠ ą▓ąŠąĘą╝ąŠąČąĮąŠ ąĄą│ąŠ č乊čĆą╝ą░čé ą▒ąŠą╗ąĄąĄ čāą┤ąŠą▒ąŠčćąĖčéą░ąĄą╝čŗą╣, ąĖ ą▒ąŠą╗ąĄąĄ ą┐ąŠąĮčÅč鹥ąĮ ą┤ą╗čÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ.
ąĢčüą╗ąĖ LCn ąĮąĄ ąĮąŠą╗čī, ą║ąŠą│ą┤ą░ ą▓čŗą▒čĆą░ąĮąĮčŗą╣ ą░ą┤čĆąĄčü čĆą░ą▓ąĄąĮ LBn, ą┐čĆąŠčåąĄčüčüąŠčĆ ą┤ąĄą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄčé LCn ąĖ ą┐ąŠą╝ąĄčēą░ąĄčé ą░ą┤čĆąĄčü ąĖąĘ LTn ą▓ PC. ą”ąĖą║ą╗ ą▓čüąĄą│ą┤ą░ ą┐čĆąŠčģąŠą┤ąĖčé ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝ ąŠą┤ąĖąĮ čĆą░ąĘ čüą║ą▓ąŠąĘčī č鹥ą╗ąŠ čåąĖą║ą╗ą░, čéą░ą║ ą║ą░ą║ čāčüą╗ąŠą▓ąĖąĄ čåąĖą║ą╗ą░ ą┐čĆąŠą▓ąĄčĆčÅąĄčéčüčÅ ą▓ ą║ąŠąĮčåąĄ ą┐ąĄčéą╗ąĖ.
ąŚąĮą░č湥ąĮąĖąĄ 0 (zero) ą▓ Loop_Count ąĘą░ą┐čĆąĄčēą░ąĄčé ą╝ąĄčģą░ąĮąĖąĘą╝ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ čåąĖą║ą╗ą░, čćč鹊 ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ č鹊ą╝čā, čćč鹊 ąĖąĮčüčéčĆčāą║čåąĖąĖ, ąĘą░ą║ą╗čÄč湥ąĮąĮčŗąĄ ą╝ąĄąČą┤čā čāą║ą░ąĘą░č鹥ą╗čÅą╝ąĖ ąĮą░čćą░ą╗ą░ ąĖ ą║ąŠąĮčåą░ čåąĖą║ą╗ą░, ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ą║ą░ą║ ąŠą▒čŗčćąĮčŗą╣, ą╗ąĖąĮąĄą╣ąĮąŠ ąĖčüą┐ąŠą╗ąĮčÅąĄą╝čŗą╣ ą║ąŠą┤.
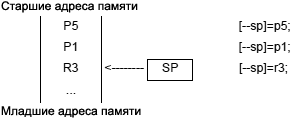
ąÆ čüąĖąĮčéą░ą║čüąĖčüąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ čüč湥čéčćąĖą║ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ čåąĖą║ą╗ą░ ŌĆō LC0 ąĖą╗ąĖ LC1 ŌĆō ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé, ą║ą░ą║ąŠą╣ čāčĆąŠą▓ąĄąĮčī čåąĖą║ą╗ą░ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮ. ąĪąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ, ą┤ą╗čÅ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ Loop0 ą║ąŠą┤ąĖčĆčāą╣č鹥 LC0; ą┤ą╗čÅ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ Loop1 ą║ąŠą┤ąĖčĆčāą╣č鹥 LC1.
ąÆ čüą╗čāčćą░ąĄ ą▓ą╗ąŠąČąĄąĮąĮąŠčüčéąĖ čåąĖą║ą╗ąŠą▓, ą║ąŠč鹊čĆčŗąĄ ąŠą║ą░ąĮčćąĖą▓ą░čÄčéčüčÅ ąĮą░ ąŠą┤ąĮčā ąĖ čéčā ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ, ą┐čĆąŠčåąĄčüčüąŠčĆ čéčĆąĄą▒čāąĄčé, čćč鹊ą▒čŗ Loop0 ą▒čŗą╗ ąŠą┐ąĖčüą░ąĮ ą┤ą╗čÅ ą▓ąĮąĄčłąĮąĄą│ąŠ čåąĖą║ą╗ą░, ąĖ Loop1 ą┤ą╗čÅ ą▓ąĮčāčéčĆąĄąĮąĮąĄą│ąŠ čåąĖą║ą╗ą░. ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ąŠčéą▓ąĄčćą░ąĄčé ąĘą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ čŹč鹊ą│ąŠ čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅ.
ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ LB0=LB1, č鹊 ą┐čĆąŠčåąĄčüčüąŠčĆ ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčé, čćč鹊 loop 1 ą▓ąĮčāčéčĆąĄąĮąĮąĖą╣, ąĖ loop 0 ą▓ąĮąĄčłąĮąĖą╣.
ąóąŠčćąĮąŠ čéą░ą║ ąČąĄ, ą║ą░ą║ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą┤čĆčāą│ąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓, čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čĆąĄą│ąĖčüčéčĆąŠą▓ čåąĖą║ą╗ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī čüąŠčģčĆą░ąĮąĄąĮąŠ ąĖ ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ. ąĢčüą╗ąĖ čéčĆąĄą▒čāąĄčéčüčÅ ą▓ą╗ąŠąČąĄąĮąĖąĄ čåąĖą║ą╗ąŠą▓ ąĮą░ ą▒ąŠą╗čīčłąĄ, č湥ą╝ 2 čāčĆąŠą▓ąĮčÅ, č鹊 ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą╝ąŠąČąĄčé čÅą▓ąĮąŠ čüąŠčģčĆą░ąĮąĖčéčī ąĘąĮą░č湥ąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓ ą▓ąĮąĄčłąĮąĄą│ąŠ čåąĖą║ą╗ą░, ąĘą░ąĮąŠą▓ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹčéąĖ čĆąĄą│ąĖčüčéčĆčŗ, ąĘą░č鹥ą╝ ą▓ąŠčüčüčéą░ąĮąŠą▓ąĖčéčī čĆąĄą│ąĖčüčéčĆčŗ ą▓ąĮąĄčłąĮąĄą│ąŠ čåąĖą║ą╗ą░ ą┐ąĄčĆąĄą┤ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄą╝ ą▓ąĮčāčéčĆąĄąĮąĮąĄą│ąŠ čåąĖą║ą╗ą░. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ loop 0 ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓čüąĄą│ą┤ą░ ą▓ąĮąĄčłąĮąĖą╝ ą┐ąŠ ąŠčéąĮąŠčłąĄąĮąĖčÄ ą║ loop 1. ąÉą╗čīč鹥čĆąĮą░čéąĖą▓ąĮąŠ, ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą╝ąŠąČąĄčé čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ą▓ąĮąĄčłąĮąĖąĄ čåąĖą║ą╗čŗ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ, čü ą┐ąŠą╝ąŠčēčīčÄ čüčéčĆčāą║čéčāčĆ čü ą║ąŠą╝ą░ąĮą┤ą░ą╝ąĖ čāčüą╗ąŠą▓ąĮąŠą│ąŠ ą┐ąĄčĆąĄčģąŠą┤ą░.
ąĪ Begin_Loop ąĘąĮą░č湥ąĮąĖąĄ ąĘą░ą│čĆčāąČą░ąĄčéčüčÅ ą▓ LTn. ąŁč鹊 5-čĆą░ąĘčĆčÅą┤ąĮąŠąĄ, ą┐čĆąĖą▓čÅąĘą░ąĮąĮąŠąĄ ą║ PC, č湥čéąĮąŠąĄ čüą╝ąĄčēąĄąĮąĖąĄ ąŠčé č鹥ą║čāčēąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ąŠ ą┐ąĄčĆą▓ąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ č鹥ą╗ąĄ čåąĖą║ą╗ą░. ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą┤ąŠą╗ąČąĄąĮ čüąŠčģčĆą░ąĮąĖčéčī ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą┤ąŠ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čüą╗ąŠą▓ą░ (ąĮą░ 2 ą▒ą░ą╣čéą░), ą┐čāč鹥ą╝ ąĘą░ą┐ąĖčüąĖ č湥čéąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ ą▓ čŹč鹊čé čĆąĄą│ąĖčüčéčĆ. ąĪą╝ąĄčēąĄąĮąĖąĄ ąĖąĮč鹥čĆą┐čĆąĄčéąĖčĆčāąĄčéčüčÅ ą║ą░ą║ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ čćąĖčüą╗ąŠ čü ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ą┤ąŠ ąĄą┤ąĖąĮąĖčåčŗ, ąĮąĄ ą┤ąŠą┐čāčüą║ą░čÄčēąĄąĄ ąŠą▒čĆą░čéąĮčŗčģ čåąĖą║ą╗ąŠą▓.
ąĪ End_Loop ąĘąĮą░č湥ąĮąĖąĄ ąĘą░ą│čĆčāąČą░ąĄčéčüčÅ ą▓ LBn. ąŁč鹊 11-čĆą░ąĘčĆčÅą┤ąĮąŠąĄ, ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ, č湥čéąĮąŠąĄ, ą┐čĆąĖą▓čÅąĘą░ąĮąĮąŠąĄ ą║ PC čüą╝ąĄčēąĄąĮąĖąĄ ąŠčé č鹥ą║čāčēąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ąŠ ą┐ąŠčüą╗ąĄą┤ąĮąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ čåąĖą║ą╗ąĄ.
ąÜąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ LSETUP, č鹊 Begin_Loop ąĖ End_Loop čÅą▓ą╗čÅčÄčéčüčÅ ąŠą▒čŗčćąĮąŠ ą░ą┤čĆąĄčüąĮčŗą╝ąĖ ą╝ąĄčéą║ą░ą╝ąĖ. ąøąĖąĮą║ąĄčĆ ąĘą░ą╝ąĄąĮčÅąĄčé ą╝ąĄčéą║ąĖ ąĮą░ ąĘąĮą░č湥ąĮąĖčÅ čüą╝ąĄčēąĄąĮąĖčÅ, ą║ą░ą║ ąŠą▒čŗčćąĮąŠ.
ąĀąĄą│ąĖčüčéčĆ čüč湥čéčćąĖą║ą░ čåąĖą║ą╗ą░ (LC0 ąĖą╗ąĖ LC1) čüčćąĖčéą░ąĄčé ą┐čĆąŠčģąŠą┤čŗ čüą║ą▓ąŠąĘčī č鹥ą╗ąŠ čåąĖą║ą╗ą░. ąŁč鹊čé čĆąĄą│ąĖčüčéčĆ čüąŠą┤ąĄčƹȹĖčé 32-ą▒ąĖčéąĮąŠąĄ čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░, čćč鹊 ą┤ą░čüčé ą┤ąŠ 4,294,967,294 ą┐ąŠą▓č鹊čĆąŠą▓ č鹥ą╗ą░ čåąĖą║ą╗ą░. ą”ąĖą║ą╗ ąĘą░ą┐čĆąĄčēą░ąĄčéčüčÅ (ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖąĄ ą┐čĆąŠčģąŠąČą┤ąĄąĮąĖčÅ čüą║ą▓ąŠąĘčī č鹥ą╗ąŠ čåąĖą║ą╗ą░ ą┐čĆąŠąĖąĘąŠą╣ą┤čāčé ą▒ąĄąĘ ą┐ąŠą▓č鹊čĆąŠą▓), ą║ąŠą│ą┤ą░ ąĘąĮą░č湥ąĮąĖąĄ čüč湥čéčćąĖą║ą░ čåąĖą║ą╗ą░ čĆą░ą▓ąĮąŠ 0.
ą¤ąŠčüą╗ąĄą┤ąĮčÅčÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ čåąĖą║ą╗ą░ LSETUP ąĮąĄ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ čāčüą╗ąŠą▓ąĮąŠą│ąŠ ą┐ąĄčĆąĄčģąŠą┤ą░ (ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ). ą¤ąŠą║ą░ ą░ą┐ą┐ą░čĆą░čéąĮčŗą╣ čåąĖą║ą╗ ą░ą║čéąĖą▓ąĄąĮ (čé. ąĄ. ą┐ąŠą║ą░ Loop_Count ąĮąĄ čĆą░ą▓ąĄąĮ 0), ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ ą┐ąŠ ą░ą┤čĆąĄčüčā End_Loop ą┐čĆąŠąĖąĘą▓ąĄą┤ąĄčé ąĮąĄąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ. ąĢčüą╗ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ ą┐ąŠčÅą▓ąĖčéčüčÅ ą┐ąŠčüą╗ąĄ čåąĖą║ą╗ą░ LSETUP, č鹊 ąĮąĄ ą▒čāą┤ąĄčé čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ. ąśąĮčüčéčĆčāą║čåąĖąĖ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ, čĆą░ąĘą╝ąĄčēąĄąĮąĮčŗąĄ ą│ą┤ąĄ-ąĮąĖą▒čāą┤čī ąĄčēąĄ ą▓ąĮčāčéčĆąĖ č鹥ą╗ą░ čåąĖą║ą╗ą░, ą▒čāą┤čāčé ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ ąĮąŠčĆą╝ą░ą╗čīąĮąŠ, ą║ą░ą║ ąŠą▒čŗčćąĮąŠ.
ąóą░ą║ąČąĄ ą┐ąŠčüą╗ąĄą┤ąĮčÅčÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ LSETUP ąĮąĄ ą┤ąŠą╗ąČąĮą░ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░čéčī čĆąĄą│ąĖčüčéčĆčŗ, ą║ąŠč鹊čĆčŗąĄ ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčé č鹥ą║čāčēąĖą╣ ą░ą║čéąĖą▓ąĮčŗą╣ čåąĖą║ą╗ (LCn, LTn ąĖą╗ąĖ LBn). ą£ąŠą┤ąĖčäąĖą║ą░čåąĖčÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝ čŹčéąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ ąĮąĖą╝ čüąŠ čüč鹊čĆąŠąĮčŗ ą░ą┐ą┐ą░čĆą░čéčāčĆčŗ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĮąĄąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╝čā ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÄ. ą¤čĆąŠą│čĆą░ą╝ą╝ą░ ą╝ąŠąČąĄčé ą╗ąĄą│ą░ą╗čīąĮąŠ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░čéčī čüč湥čéčćąĖą║ čåąĖą║ą╗ą░ ą▓ ą╗čÄą▒ąŠą╝ ą┤čĆčāą│ąŠą╝ ą╝ąĄčüč鹥 č鹥ą╗ą░ čåąĖą║ą╗ą░.
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
lsetup (4 , 4 ) lc0;
lsetup (poll_bit, end_poll_bit) lc0;
lsetup (4 , 6 ) lc1;
lsetup (FIR_filter, bottom_of_FIR_filter) lc1;
lsetup (4 , 8 ) lc0 = p1;
lsetup (4 , 8 ) lc0 = p1>> 1 ;
loop DoItSome LC0; /* ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čåąĖą║ą╗ą░ ŌĆśDoItSomeŌĆÖ čü Loop
Counter 0 (čüąŠ čüč湥čéčćąĖą║ąŠą╝ čåąĖą║ą╗ą░ 0) */
loop_begin DoItSome; /* ą┐ąŠą╝ąĄčüčéąĖčéčī ą┐ąĄčĆąĄą┤ ą┐ąĄčĆą▓ąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ čåąĖą║ą╗ą░ */
loop_end DoItSome; /* ą┐ąŠą╝ąĄčüčéąĖčéčī ą┐ąŠčüą╗ąĄ ą┐ąŠčüą╗ąĄą┤ąĮąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ čåąĖą║ą╗ą░ */
loop MyLoop LC1; /* ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī čåąĖą║ą╗ ŌĆśMyLoopŌĆÖ čüąŠ čüč湥čéčćąĖą║ąŠą╝
čåąĖą║ą╗ą░ 1 (Loop Counter 1) */
loop_begin MyLoop; /* ą┐ąŠą╝ąĄčüčéąĖčéčī ą┐ąĄčĆąĄą┤ ą┐ąĄčĆą▓ąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ čåąĖą║ą╗ą░ */
loop_end MyLoop; /* ą┐ąŠą╝ąĄčüčéąĖčéčī ą┐ąŠčüą╗ąĄ ą┐ąŠčüą╗ąĄą┤ąĮąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ čåąĖą║ą╗ą░ */
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▒ąĄąĘčāčüą╗ąŠą▓ąĮąŠą│ąŠ (JUMP, JUMP.S, JUMP.L) ąĖ čāčüą╗ąŠą▓ąĮąŠą│ąŠ ą┐ąĄčĆąĄčģąŠą┤ą░ (IF CC JUMP, IF !CC JUMP).
[ąśąĮčüčéčĆčāą║čåąĖąĖ Load / Store ]
ąÆ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ ąŠą▒čüčāąČą┤ą░čÄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĘą░ą│čĆčāąĘą║ąĖ (load) / čüąŠčģčĆą░ąĮąĄąĮąĖčÅ (store). ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĖ ą╝ąŠą│čāčé ą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ čéą░ą║ąĖą╝ąĖ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčÅą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣, ą║ą░ą║ ąĘą░ą│čĆčāąĘą║ą░ ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖąĄ ą┐čĆčÅą╝čŗčģ (immediate) ąĘąĮą░č湥ąĮąĖą╣, čĆąĄą│ąĖčüčéčĆąŠą▓ čāą║ą░ąĘą░č鹥ą╗ąĄą╣, čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ą░ąĮąĮčŗčģ, ą┐ąŠą╗ąŠą▓ąĖąĮąŠą║ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ą░ąĮąĮčŗčģ ąĖ ą┐ąŠą╗čāčüą╗ąŠą▓ (ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĮčŗčģ ąĮčāą╗ąĄą╝ ąĖą╗ąĖ ąĘąĮą░ą║ąŠą╝ čćąĖčüą╗ą░).
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąČą░ąĄčé ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠąĄ (immediate) ąĘąĮą░č湥ąĮąĖąĄ ą▓ čĆąĄą│ąĖčüčéčĆ. ąØąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ - čŹč鹊 ąĘąĮą░č湥ąĮąĖąĄ, čāą║ą░ąĘą░ąĮąĮąŠąĄ ą┐čĆčÅą╝ąŠ ą▓ ą║ąŠą╝ą░ąĮą┤ąĄ, čé. ąĄ. ą║ąŠąĮčüčéą░ąĮčéą░. ąśąĮčüčéčĆčāą║čåąĖąĖ Load Immediate ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ ąĘąĮą░č湥ąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓. ą×ą▒čēą░čÅ č乊čĆą╝ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ:
čĆąĄą│ąĖčüčéčĆ = ą║ąŠąĮčüčéą░ąĮčéą░ A1 = A0 = 0
ąØąĄ čĆą░čüčłąĖčĆąĄąĮąĮčŗą╣ (not extended) čüąĖąĮčéą░ą║čüąĖčü:
reg_lo = uimm16 ; // 16-ą▒ąĖčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą▒čāą┤ąĄčé ąĘą░ą│čĆčāąČąĄąĮąŠ ą▓ ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā // čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ ąĖą╗ąĖ čĆąĄą│ąĖčüčéčĆą░ ą░ą┤čĆąĄčüą░ (b)1 reg_hi = uimm16 ; // 16-ą▒ąĖčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą▒čāą┤ąĄčé ąĘą░ą│čĆčāąČąĄąĮąŠ ą▓ čüčéą░čĆčłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā
ąĀą░čüčłąĖčĆąĄąĮąĮčŗą╣ ąĮčāą╗ąĄą╝ (zero-extended) čüąĖąĮčéą░ą║čüąĖčü:
reg = uimm16 (Z); // 16-ą▒ąĖčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĮąŠąĄ ąĮčāą╗ąĄą╝, ą▒čāą┤ąĄčé ąĘą░ą│čĆčāąČąĄąĮąŠ
A0 = 0; // ą×čćąĖčüčéą║ą░ čĆąĄą│ąĖčüčéčĆą░ A0 (b) A1 = 0; // ą×čćąĖčüčéą║ą░ čĆąĄą│ąĖčüčéčĆą░ A1 (b) A1 = A0 = 0; // ą×čćąĖčüčéą║ą░ ą┤ą▓čāčģ čĆąĄą│ąĖčüčéčĆąŠą▓ A1 ąĖ A0 čüčĆą░ąĘčā (b)
ąĀą░čüčłąĖčĆąĄąĮąĮčŗą╣ ąĘąĮą░ą║ąŠą╝ (sign-extended) čüąĖąĮčéą░ą║čüąĖčü:
Dreg = imm7 (X); // 7-ą▒ąĖčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, čĆą░čüčłąĖčĆąĄąĮąĮąŠąĄ ąĘąĮą░ą║ąŠą╝, ą▒čāą┤ąĄčé ąĘą░ą│čĆčāąČąĄąĮąŠ ą▓ Dreg (a) Preg = imm7 (X); // 7-ą▒ąĖčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, čĆą░čüčłąĖčĆąĄąĮąĮąŠąĄ ąĘąĮą░ą║ąŠą╝, ą▒čāą┤ąĄčé ąĘą░ą│čĆčāąČąĄąĮąŠ ą▓ Preg (a)
reg = imm16 (X); // 16-ą▒ąĖčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, čĆą░čüčłąĖčĆąĄąĮąĮąŠąĄ ąĘąĮą░ą║ąŠą╝, ą▒čāą┤ąĄčé ąĘą░ą│čĆčāąČąĄąĮąŠ ą▓ čĆąĄą│ąĖčüčéčĆ // ą┤ą░ąĮąĮčŗčģ ąĖą╗ąĖ ą▓ čĆąĄą│ąĖčüčéčĆ ą░ą┤čĆąĄčüą░ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: R0, ..., R7.
Preg: P0, ..., P5, SP, FP.
reg_lo: R0.L, ..., R7.L, P0.L, ..., P5.L, SP.L, FP.L, I0.L, ..., I3.L, M0.L, ..., M3.L, B0.L, ..., B3.L, L0.L, ..., L3.L.
reg_hi: R0.H, ..., R7.H, P0.H, ..., P5.H, SP.H, FP.H, I0.H, ..., I3.H, M0.H, ..., M3.H, B0.H, ..., B3.H, L0.H, ..., L3.H.
reg: R0, ..., R7, P0, ..., P5P0, ..., P5, SP, FP, I0, ..., I3, M0, ..., M3, B0, ..., B3, L0, ..., L3.
imm7: 7-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ čüąŠ ąĘąĮą░ą║ąŠą╝, čćąĖčüą╗ąŠ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ -64 .. 63 (0x40 .. 0x3F).
imm16: 16-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ čüąŠ ąĘąĮą░ą║ąŠą╝, čćąĖčüą╗ąŠ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ -32,768 .. 32,767 (0x8000 .. 0x7FFF).
uimm16: 16-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░, čćąĖčüą╗ąŠ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 65,535 (0x0000 .. 0xFFFF)
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Load Immediate ąĘą░ą│čĆčāąČą░ąĄčé ą▓ čĆąĄą│ąĖčüčéčĆ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ (čé. ąĄ. ą║ąŠąĮčüčéą░ąĮčéčā, čāą║ą░ąĘą░ąĮąĮčāčÄ ą▓ ą║ąŠą╝ą░ąĮą┤ąĄ). ąśąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąĘąĖčé 7-ą▒ąĖčéąĮčāčÄ ąĖą╗ąĖ 16-ą▒ąĖčéąĮčāčÄ ą▓ąĄą╗ąĖčćąĖąĮčā, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čĆą░ąĘą╝ąĄčĆą░ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ. ąöąĖą░ą┐ą░ąĘąŠąĮ ąĘą░ą│čĆčāąČą░ąĄą╝čŗčģ ą║ąŠąĮčüčéą░ąĮčé ą╝ąŠąČąĄčé ą▒čŗčéčī 0x8000 .. 0x7FFF, čćč鹊 菹║ą▓ąĖą▓ą░ą╗ąĄąĮčéąĮąŠ ŌĆō32768 .. +32767.
ąÆ 40-čĆą░ąĘčĆčÅą┤ąĮčŗą╣ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ (A1 ąĖą╗ąĖ A0) ą╝ąŠą│čāčé ą▒čŗčéčī ąĘą░ą│čĆčāąČąĄąĮčŗ č鹊ą╗čīą║ąŠ ąĮčāą╗ąĖ.
16-ą▒ąĖčéąĮčŗąĄ ą┐ąŠą╗čāčüą╗ąŠą▓ą░ ą╝ąŠą│čāčé ą▒čŗčéčī ąĘą░ą│čĆčāąČąĄąĮčŗ ą╗ąĖą▒ąŠ ą▓ čüčéą░čĆčłčāčÄ, ą╗ąĖą▒ąŠ ą▓ ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā čĆąĄą│ąĖčüčéčĆą░. ą×ą┐ąĄčĆą░čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ ąŠčüčéą░ą▓ą╗čÅąĄčé ąĮąĄčéčĆąŠąĮčāč鹊ą╣ ąĮąĄ ąĘą░ą┤ąĄą╣čüčéą▓ąŠą▓ą░ąĮąĮčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā čĆąĄą│ąĖčüčéčĆą░.
ąÆąĄčĆčüąĖąĖ zero-extended ąĘą░ą┐ąŠą╗ąĮąĖčé ąĮčāą╗čÅą╝ąĖ čüčéą░čĆčłąĖąĄ ą▒ąĖčéčŗ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ąÆąĄčĆčüąĖąĖ sign-extended ąĘą░ą┐ąŠą╗ąĮčÅčé čüčéą░čĆčłąĖąĄ ą▒ąĖčéčŗ ąĘąĮą░ą║ąŠą╝ ą║ąŠąĮčüčéą░ąĮčéčŗ.
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r7 = 63 (z);
p3 = 12 (z);
r0 = - 344 (x);
r7 = 436 (z);
m2 = 0x89ab (z);
p1 = 0x1234 (z);
m3 = 0x3456 (x);
l3.h = 0xbcde ;
a0 = 0 ;
a1 = 0 ;
a1 = a0 = 0 ;
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Load Data Register, Load Pointer Register.
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąČą░ąĄčé ąĘąĮą░č湥ąĮąĖąĄ ą▓ ą░ą┤čĆąĄčüąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ (ąĖą╗ąĖ ą┤čĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, čĆąĄą│ąĖčüčéčĆ čāą║ą░ąĘą░č鹥ą╗čÅ pointer register, Preg) čü ą┐ąŠą╝ąŠčēčīčÄ ą║ąŠčüą▓ąĄąĮąĮąŠą╣ (indirect) ą░ą┤čĆąĄčüą░čåąĖąĖ. ąÜąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü - čŹč鹊 ą░ą┤čĆąĄčü, čāą║ą░ąĘą░ąĮąĮčŗą╣ č湥čĆąĄąĘ ą░ą┤čĆąĄčüąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ. ą×ą▒čēą░čÅ č乊čĆą╝ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ:
P-čĆąĄą│ąĖčüčéčĆ = [ ą║ąŠčüą▓ąĄąĮąĮčŗą╣_ą░ą┤čĆąĄčü ]
ąĪąĖąĮčéą░ą║čüąĖčü:
Preg = [Preg]; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ąĘą░ą│čĆčāąĘą║ą░ (a)
Preg = [Preg ++]; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ąĘą░ą│čĆčāąĘą║ą░ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)1
Preg = [Preg --]; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ąĘą░ą│čĆčāąĘą║ą░ čü ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
Preg = [Preg + uimm6m4]; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ąĘą░ą│čĆčāąĘą║ą░ čü ą╝ą░ą╗čŗą╝ čüą╝ąĄčēąĄąĮąĖąĄą╝ (a)
Preg = [Preg + uimm17m4]; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ąĘą░ą│čĆčāąĘą║ą░ čü ą▒ąŠą╗čīčłąĖą╝ čüą╝ąĄčēąĄąĮąĖąĄą╝ (b)
Preg = [Preg - uimm17m4]; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ąĘą░ą│čĆčāąĘą║ą░ čü ą▒ąŠą╗čīčłąĖą╝ čüą╝ąĄčēąĄąĮąĖąĄą╝ (b)
Preg = [FP - uimm7m4]; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ąĘą░ą│čĆčāąĘą║ą░ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ FP (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
ąÜą▓ą░ą┤čĆą░čéąĮčŗąĄ čüą║ąŠą▒ą║ąĖ ąŠąĘąĮą░čćą░čÄčé ą▓ąĘčÅčéąĖąĄ ą░ą┤čĆąĄčüą░, čé. ąĄ. ąĖčüčģąŠą┤ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▒ąĄčĆčāčéčüčÅ ąĖąĘ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ čüčüčŗą╗ą░ąĄčéčüčÅ ą░ą┤čĆąĄčü čĆąĄą│ąĖčüčéčĆą░, čāą║ą░ąĘą░ąĮąĮąŠą│ąŠ ą▓ ą║ą▓ą░ą┤čĆą░čéąĮčŗčģ čüą║ąŠą▒ą║ą░čģ (ą╗ąĖą▒ąŠ ą░ą┤čĆąĄčü čü čāč湥č鹊ą╝ čüą╝ąĄčēąĄąĮąĖčÅ).
Preg: P0, ..., P5, SP, FP.
uimm6m4: 6-ą▒ąĖčéąĮąŠąĄ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ ą┐ąŠą╗ąĄ, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░čåąĄą╗ąŠ ąĮą░ 4. ąŚą░ą┤ą░ąĄčé čüą╝ąĄčēąĄąĮąĖąĄ ą░ą┤čĆąĄčüą░ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 60 ą▒ą░ą╣čé.
uimm7m4: 7-ą▒ąĖčéąĮąŠąĄ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ ą┐ąŠą╗ąĄ, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░čåąĄą╗ąŠ ąĮą░ 4. ąŚą░ą┤ą░ąĄčé čüą╝ąĄčēąĄąĮąĖąĄ ą░ą┤čĆąĄčüą░ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 4 .. 128 ą▒ą░ą╣čé.
uimm17m4: 17-ą▒ąĖčéąĮąŠąĄ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ ą┐ąŠą╗ąĄ, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░čåąĄą╗ąŠ ąĮą░ 4. ąŚą░ą┤ą░ąĄčé čüą╝ąĄčēąĄąĮąĖąĄ ą░ą┤čĆąĄčüą░ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 131068 ą▒ą░ą╣čé (0x0000 0000 .. 0x0001 FFFC).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ čāą║ą░ąĘą░č鹥ą╗čÅ (Load Pointer Register) ąĘą░ą│čĆčāąČą░ąĄčé 32-ą▒ąĖčéąĮčŗą╣ P-čĆąĄą│ąĖčüčéčĆ 32-ą▒ąĖčéąĮčŗą╝ čüą╗ąŠą▓ąŠą╝, ąĮą░čģąŠą┤čÅčēąĖą╝čüčÅ ą┐ąŠ ą░ą┤čĆąĄčüčā, čāą║ą░ąĘą░ąĮąĮąŠą╝čā čéą░ą║ąČąĄ č湥čĆąĄąĘ P-čĆąĄą│ąĖčüčéčĆ (ąĖą╗ąĖ č湥čĆąĄąĘ čĆąĄą│ąĖčüčéčĆ čāą║ą░ąĘą░č鹥ą╗čÅ čäčĆąĄą╣ą╝ą░ FP). ą¤ąŠčŹč鹊ą╝čā čéą░ą║ą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ ą║ąŠčüą▓ąĄąĮąĮąŠą╣ (indirect).
ąÜąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü ąĖ čüą╝ąĄčēąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮąŠ čüąŠąŠčéą▓ąĄčéčüčéą▓ąŠą▓ą░čéčī č湥čéąĮąŠą╝čā čāą╝ąĮąŠąČąĄąĮąĖčÄ ąĮą░ 4, čćč鹊ą▒čŗ čüąŠčģčĆą░ąĮąĖčéčī 4-ą▒ą░ą╣čéąĮąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą░ą┤čĆąĄčüą░ (ąĘąĮą░č湥ąĮąĖąĄ ą░ą┤čĆąĄčüą░ ą┤ąŠą╗ąČąĮąŠ ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░ 4). ąØąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÄ ąŠčłąĖą▒ą║ąĖ ą┤ąŠčüčéčāą┐ą░ ą┐ąŠ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą╝čā ą░ą┤čĆąĄčüčā (misaligned memory access exception).
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čåąĖąĖ:
ŌĆó ą¤ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮčé čĆąĄą│ąĖčüčéčĆą░ čāą║ą░ąĘą░č鹥ą╗čÅ ąĖčüč鹊čćąĮąĖą║ą░ ąĮą░ 4 ą▒ą░ą╣čéą░.
ążąŠčĆą╝ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ FP, ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą╗ąŠą║ą░ą╗čīąĮčŗą╝ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝ ą▓ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ąĖą╗ąĖ čäčāąĮą║čåąĖąĖ. ą¤ąŠą╗ąŠąČąĖč鹥ą╗čīąĮčŗąĄ čüą╝ąĄčēąĄąĮąĖčÅ ąŠąĮąŠčüąĖč鹥ą╗čīąĮąŠ FP (ą┐ąŠą╗ąĄąĘąĮčŗąĄ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą░čĆą│čāą╝ąĄąĮčéą░ą╝ ąĖąĘ ą▓čŗąĘą▓ą░ąĮąĮąŠą╣ čäčāąĮą║čåąĖąĖ) ą╝ąŠą│čāčé ą▒čŗčéčī ąŠčüčāčēąĄčéą▓ą╗ąĄąĮčŗ ą┤čĆčāą│ąĖą╝ąĖ ą▓ąĄčĆčüąĖčÅą╝ąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. Preg ą▓ą║ą╗čÄčćą░ąĄčé Frame Pointer (FP, čāą║ą░ąĘą░č鹥ą╗čī čäčĆąĄą╣ą╝ą░) ąĖ Stack Pointer (SP, čāą║ą░ąĘą░č鹥ą╗čī čüč鹥ą║ą░).
ąÉą▓č鹊ąĖąĮą║čĆąĄą╝ąĄąĮčé ąĖą╗ąĖ ą░ą▓č鹊ą┤ąĄą║čĆąĄą╝ąĄąĮčé čĆąĄą│ąĖčüčéčĆąŠą▓ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ čéą░ą║ąČąĄ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą╝ąĄčüč鹊ą╝ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĘą░ą│čĆčāąĘą║ąĖ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĖąĮčüčéčĆčāą║čåąĖčÅ sp=[sp++] ą▒čāą┤ąĄčé ąĮąĄą┤ąŠą┐čāčüčéąĖą╝ąŠą╣, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąĮą░ ąŠą┐ąĖčüčŗą▓ą░ąĄčé ą┤ą▓ą░ ą║ąŠąĮą║čāčĆąĖčĆčāčÄčēąĖčģ ąĘąĮą░č湥ąĮąĖčÅ ą┤ą╗čÅ čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░ - ąŠą┤ąĮąŠ ą┤ą╗čÅ ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗąĄ ą▓čŗą▒čĆą░ąĮčŗ ąĖąĘ ą┐ą░ą╝čÅčéąĖ, ą░ ą┤čĆčāą│ąŠąĄ ą┤ą╗čÅ ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮčéą░. ą¤ąŠą┤ąŠą▒ąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝ P0=[P0++] ąĖ P1=[P1++], ąĖ čé. ą┤., čéą░ą║ąČąĄ ąĮąĄą┤ąŠą┐čāčüčéąĖą╝čŗ. ąóą░ą║ąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐čĆąĖą▓ąŠą┤čÅčé ą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÄ ąĮąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ (undefined instruction exception).
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
p3 = [p2];
p5 = [p0++ ];
p2 = [sp-- ];
p3 = [p2 + 8 ];
p0 = [p2 + 0x4008 ];
p1 = [fp - 16 ];
ąóą░ą║ąČąĄ čüą╝. ąĖąĮčüčéčĆčāą║čåąĖąĖ Immediate, Pop, Pop Multiple.
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąČą░ąĄčé ąĘąĮą░č湥ąĮąĖąĄ ą▓ čĆąĄą│ąĖčüčéčĆ ą┤ą░ąĮąĮčŗčģ čü ą┐ąŠą╝ąŠčēčīčÄ ą║ąŠčüą▓ąĄąĮąĮąŠą╣ (indirect) ą░ą┤čĆąĄčüą░čåąĖąĖ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
D-čĆąĄą│ąĖčüčéčĆ = [ ą║ąŠčüą▓ąĄąĮąĮčŗą╣_ą░ą┤čĆąĄčü ]
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = [Preg]; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ (a)1
Dreg = [Preg++]; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
Dreg = [Preg --]; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
Dreg = [Preg + uimm6m4] ; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą╝ą░ą╗čŗą╝ čüą╝ąĄčēąĄąĮąĖąĄą╝ (a)
Dreg = [Preg + uimm17m4]; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą▒ąŠą╗čīčłąĖą╝ čüą╝ąĄčēąĄąĮąĖąĄą╝ (b)
Dreg = [Preg - uimm17m4]; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą▒ąŠą╗čīčłąĖą╝ čüą╝ąĄčēąĄąĮąĖąĄą╝ (b)
Dreg = [Preg ++ Preg]; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ, čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░2 (a)
Dreg = [FP - uimm7m4]; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ FP (a)
Dreg = [Ireg]; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ (a)
Dreg = [Ireg ++]; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
Dreg = [Ireg --]; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
Dreg = [Ireg ++ Mreg]; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░2 (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 2: ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ąÜąŠčüą▓ąĄąĮąĮą░čÅ ąĖ ąĖąĮą┤ąĄą║čüąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░".
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
ąÜą▓ą░ą┤čĆą░čéąĮčŗąĄ čüą║ąŠą▒ą║ąĖ ąŠąĘąĮą░čćą░čÄčé ą▓ąĘčÅčéąĖąĄ ą░ą┤čĆąĄčüą░, čé. ąĄ. ąĖčüčģąŠą┤ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▒ąĄčĆčāčéčüčÅ ąĖąĘ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ čüčüčŗą╗ą░ąĄčéčüčÅ ą░ą┤čĆąĄčü, čāą║ą░ąĘą░ąĮąĮčŗą╣ ą▓ ą║ą▓ą░ą┤čĆą░čéąĮčŗčģ čüą║ąŠą▒ą║ą░čģ (ą╗ąĖą▒ąŠ ą░ą┤čĆąĄčü čü čāč湥č鹊ą╝ čüą╝ąĄčēąĄąĮąĖčÅ).
Dreg: R0, ..., R7.
Preg: P0, ..., P5, SP, FP.
Ireg: I0, ..., I3.
Mreg: M0, ..., M3.
uimm6m4: 6-ą▒ąĖčéąĮąŠąĄ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ ą┐ąŠą╗ąĄ, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░čåąĄą╗ąŠ ąĮą░ 4. ąŚą░ą┤ą░ąĄčé čüą╝ąĄčēąĄąĮąĖąĄ ą░ą┤čĆąĄčüą░ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 60 ą▒ą░ą╣čé.
uimm7m4: 7-ą▒ąĖčéąĮąŠąĄ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ ą┐ąŠą╗ąĄ, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░čåąĄą╗ąŠ ąĮą░ 4. ąŚą░ą┤ą░ąĄčé čüą╝ąĄčēąĄąĮąĖąĄ ą░ą┤čĆąĄčüą░ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 4 .. 128 ą▒ą░ą╣čé.
uimm17m4: 17-ą▒ąĖčéąĮąŠąĄ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ ą┐ąŠą╗ąĄ, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░čåąĄą╗ąŠ ąĮą░ 4. ąŚą░ą┤ą░ąĄčé čüą╝ąĄčēąĄąĮąĖąĄ ą░ą┤čĆąĄčüą░ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 131068 ą▒ą░ą╣čé (0x0000 0000 .. 0x0001 FFFC).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ (Load Data Register) ąĘą░ą│čĆčāąČą░ąĄčé 32-ą▒ąĖčéąĮčŗą╣ D-čĆąĄą│ąĖčüčéčĆ ąĖąĘ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ. ąÉą┤čĆąĄčü čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ ą╝ąŠąČąĄčé ąĘą░ą┤ą░ą▓ą░čéčīčüčÅ č湥čĆąĄąĘ P-čĆąĄą│ąĖčüčéčĆ, I-čĆąĄą│ąĖčüčéčĆ ąĖą╗ąĖ čāą║ą░ąĘą░č鹥ą╗čī čäčĆąĄą╣ą╝ą░ (Frame Pointer, FP). ąŁč鹊 čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝ą░čÅ ą║ąŠčüą▓ąĄąĮąĮą░čÅ (indirect) ą░ą┤čĆąĄčüą░čåąĖčÅ.
ąÜąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü ąĖ čüą╝ąĄčēąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮąŠ ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░ 4, čćč鹊ą▒čŗ čüąŠčģčĆą░ąĮąĖčéčī ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą░ą┤čĆąĄčüą░ ąĮą░ 4. ą×čłąĖą▒ą║ą░ ą▓ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĖ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÄ ąŠčłąĖą▒ą║ąĖ ą┤ąŠčüčéčāą┐ą░ ą┐ąŠ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą╝čā ą░ą┤čĆąĄčüčā (misaligned memory access exception).
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čåąĖąĖ:
ŌĆó ą¤ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮčé ą░ą┤čĆąĄčüą░ ąĖčüč鹊čćąĮąĖą║ą░ ąĮą░ 4 ą▒ą░ą╣čéą░, čü čüąŠčģčĆą░ąĮąĄąĮąĖąĄą╝ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ ą░ą┤čĆąĄčüą░ ąĮą░ čüą╗ąŠą▓ąŠ.
ążąŠčĆą╝ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ FP, ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą╗ąŠą║ą░ą╗čīąĮčŗą╝ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝ ą▓ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ąĖą╗ąĖ čäčāąĮą║čåąĖąĖ. ą¤ąŠą╗ąŠąČąĖč鹥ą╗čīąĮčŗąĄ čüą╝ąĄčēąĄąĮąĖčÅ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ FP (ą┐ąŠą╗ąĄąĘąĮčŗąĄ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą░čĆą│čāą╝ąĄąĮčéą░ą╝ ąĖąĘ ą▓čŗąĘą▓ą░ąĮąĮąŠą╣ čäčāąĮą║čåąĖąĖ) ą╝ąŠą│čāčé ą▒čŗčéčī ąŠčüčāčēąĄčüčéą▓ą╗ąĄąĮčŗ ą┤čĆčāą│ąĖą╝ąĖ ą▓ąĄčĆčüąĖčÅą╝ąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. Preg ą▓ą║ą╗čÄčćą░ąĄčé Frame Pointer (FP, čāą║ą░ąĘą░č鹥ą╗čī čäčĆąĄą╣ą╝ą░) ąĖ Stack Pointer (SP, čāą║ą░ąĘą░č鹥ą╗čī čüč鹥ą║ą░).
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r3 = [p0];
r7 = [p1++ ];
r2 = [sp-- ];
r6 = [p2+ 12 ];
r0 = [p4 + 0x800C ];
r1 = [p0 ++ p1];
r5 = [fp- 12 ];
r2 = [i2];
r0 = [i0++ ];
r0 = [i0-- ];
// ą¤ąĄčĆąĄą┤ ą║ąŠčüą▓ąĄąĮąĮąŠą╣ ą░ą┤čĆąĄčüą░čåąĖąĄą╣ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░
r7 = 0 ;
i3 = 0x4000 ; // ąÜ ą┐čĆąĖą╝ąĄčĆčā, čÅč湥ą╣ą║ą░ ą┐ą░ą╝čÅčéąĖ čüąŠą┤ąĄčƹȹĖčé 15.
m0 = 4 ;
r7 = [i3 ++ m0];// ą¤ąŠčüą╗ąĄ č湥ą│ąŠ ... // r7 = 15 ąĖąĘ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ 0x4000 // i3 = i3 + m0 = 0x4004 // m0 ą▓čüąĄ ąĄčēąĄ čĆą░ą▓ąĮąŠ 4
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Load Immediate.
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąČą░ąĄčé ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā čĆąĄą│ąĖčüčéčĆą░, ąĘą░ą┐ąŠą╗ąĮčÅčÅ ą▒ąĖčéčŗ čüčéą░čĆčłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ ąĮčāą╗čÅą╝ąĖ. ą×ą▒čēą░čÅ č乊čĆą╝ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ Load Half-Word - Zero-Extended:
D-čĆąĄą│ąĖčüčéčĆ = W[ ą║ąŠčüą▓ąĄąĮąĮčŗą╣_ą░ą┤čĆąĄčü ](Z)
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = W[Preg](Z); // ąĘą░ą│čĆčāąĘą║ą░ ą┐ąŠ ą║ąŠčüą▓ąĄąĮąĮąŠą╝čā ą░ą┤čĆąĄčüčā (a)1
Dreg = W[Preg++](Z); // ąĘą░ą│čĆčāąĘą║ą░ ą┐ąŠ ą║ąŠčüą▓ąĄąĮąĮąŠą╝čā ą░ą┤čĆąĄčüčā čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
Dreg = W[Preg--](Z); // ąĘą░ą│čĆčāąĘą║ą░ ą┐ąŠ ą║ąŠčüą▓ąĄąĮąĮąŠą╝čā ą░ą┤čĆąĄčüčā čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
Dreg = W[Preg+uimm5m2](Z); // ąĘą░ą│čĆčāąĘą║ą░ čü ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ą┐ąŠ ą╝ą░ą╗ąŠą╝čā čüą╝ąĄčēąĄąĮąĖčÄ (a)
Dreg = W[Preg+uimm16m2](Z); // ąĘą░ą│čĆčāąĘą║ą░ čü ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ą┐ąŠ ą▒ąŠą╗čīčłąŠą╝čā čüą╝ąĄčēąĄąĮąĖčÄ (b)
Dreg = W[Preg-uimm16m2](Z); // ąĘą░ą│čĆčāąĘą║ą░ čü ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ą┐ąŠ ą▒ąŠą╗čīčłąŠą╝čā čüą╝ąĄčēąĄąĮąĖčÄ (b)
Dreg = W[Preg++Preg](Z); // ąĘą░ą│čĆčāąĘą║ą░ čü ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ąĖ ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝2 (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 2: ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ąÜąŠčüą▓ąĄąĮąĮą░čÅ ąĖ ąĖąĮą┤ąĄą║čüąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░".
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
ąÜą▓ą░ą┤čĆą░čéąĮčŗąĄ čüą║ąŠą▒ą║ąĖ ąŠąĘąĮą░čćą░čÄčé ą▓ąĘčÅčéąĖąĄ ą░ą┤čĆąĄčüą░, čé. ąĄ. ąĖčüčģąŠą┤ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▒ąĄčĆčāčéčüčÅ ąĖąĘ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ čüčüčŗą╗ą░ąĄčéčüčÅ ą░ą┤čĆąĄčü, čāą║ą░ąĘą░ąĮąĮčŗą╣ ą▓ ą║ą▓ą░ą┤čĆą░čéąĮčŗčģ čüą║ąŠą▒ą║ą░čģ (ą╗ąĖą▒ąŠ ą░ą┤čĆąĄčü čü čāč湥č鹊ą╝ čüą╝ąĄčēąĄąĮąĖčÅ).
Dreg: R0, ..., R7.
Preg: P0, ..., P5, SP, FP.
uimm5m2: 5-ą▒ąĖčéąĮąŠąĄ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ ą┐ąŠą╗ąĄ, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░čåąĄą╗ąŠ ąĮą░ 2. ąŚą░ą┤ą░ąĄčé čüą╝ąĄčēąĄąĮąĖąĄ ą░ą┤čĆąĄčüą░ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 30 ą▒ą░ą╣čé.
uimm16m2: 16-ą▒ąĖčéąĮąŠąĄ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ ą┐ąŠą╗ąĄ, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░čåąĄą╗ąŠ ąĮą░ 2. ąŚą░ą┤ą░ąĄčé čüą╝ąĄčēąĄąĮąĖąĄ ą░ą┤čĆąĄčüą░ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 65534 ą▒ą░ą╣čé (0x0000 .. 0xFFFC).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ ą┐ąŠą╗čāčüą╗ąŠą▓ą░ ą┤ą░ąĮąĮčŗčģ čü ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ąĮčāą╗ąĄą╝ (Load Half-Word - Zero-Extended) ąĘą░ą│čĆčāąČą░ąĄčé 16 ą▒ąĖčé ąĖąĘ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ ą▓ ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ. ąĪčéą░čĆčłą░čÅ ą┐ąŠą╗ąŠą▓ąĖąĮą░ ąĘą░ą│čĆčāąČą░ąĄą╝ąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą┐čĆąĖ čŹč鹊ą╝ ąŠą▒ąĮčāą╗čÅąĄčéčüčÅ. ą»č湥ą╣ą║ą░ ą┐ą░ą╝čÅčéąĖ (2 ą▒ą░ą╣čéą░), ąŠčéą║čāą┤ą░ ą▒čāą┤čāčé ą▒čĆą░čéčīčüčÅ ą┤ą░ąĮąĮčŗąĄ ą┤ą╗čÅ ąĘą░ą│čĆčāąĘą║ąĖ, čāą║ą░ąĘčŗą▓ą░ąĄčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ ą║ąŠčüą▓ąĄąĮąĮąŠą╣ ą░ą┤čĆąĄčüą░čåąĖąĖ č湥čĆąĄąĘ P-čĆąĄą│ąĖčüčéčĆ.
ąÜąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü ąĖ čüą╝ąĄčēąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮčŗ čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆčÅčéčī čāčüą╗ąŠą▓ąĖčÄ č湥čéąĮąŠčüčéąĖ, čćč鹊ą▒čŗ ą░ą┤čĆąĄčü ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖą╗čüčÅ ąĮą░ 2 ąĖ čüąŠčģčĆą░ąĮčÅą╗ąŠčüčī ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą░ą┤čĆąĄčüą░ ąĮą░ ą┐ąŠą╗čāčüą╗ąŠą▓ąŠ (2 ą▒ą░ą╣čéą░). ą×čłąĖą▒ą║ą░ ą▓ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĖ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÄ ą┐ąŠ ąŠčłąĖą▒ą║ąĄ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ ą┐ąŠ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą╝čā ą░ą┤čĆąĄčüčā (misaligned memory access exception).
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čåąĖąĖ:
ŌĆó ą¤ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮčé ą░ą┤čĆąĄčüą░ ąĖčüč鹊čćąĮąĖą║ą░ ąĮą░ 2 ą▒ą░ą╣čéą░.
ąśą╝ąĄą╣č鹥 ą▓ ą▓ąĖą┤čā, čćč鹊 ą║ąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓čāčÄčēąĖą╣ ą░ą╗ą│ąŠčĆąĖčéą╝ DSP, č鹊 ą┤ą╗čÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠą│ąŠ čćč鹥ąĮąĖčÅ ą╗ąĄąČą░čēąĖčģ ą▓ ą┐ą░ą╝čÅčéąĖ 16-ą▒ąĖčéąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣ ą┐čĆąĄą┤ą┐ąŠčćčéąĖč鹥ą╗čīąĮąĄąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĖąĮčüčéčĆčāą║čåąĖčÄ Load Data Register ą▓ą╝ąĄčüč鹊 čćč鹥ąĮąĖčÅ ą┐ąŠą╗ąŠą▓ąĖąĮąŠą║ čĆąĄą│ąĖčüčéčĆąŠą▓. Load Data Register čĆą░ą▒ąŠčéą░ąĄčé ą▓ 2 čĆą░ąĘą░ ą▒čŗčüčéčĆąĄąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 ąĘą░ ąŠą┤ąĮčā ą║ąŠą╝ą░ąĮą┤čā ą╝ąŠąČąĄčé ą▓čŗą▒čĆą░čéčī ąĖąĘ ą┐ą░ą╝čÅčéąĖ čüčĆą░ąĘčā 2 ą┐ąŠą╗čāčüą╗ąŠą▓ą░. ąÜąŠą╝ą░ąĮą┤ą░, ąĘą░ą│čĆčāąČą░čÄčēą░čÅ ą┤ą░ąĮąĮčŗąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ą╝ąĖ, ąĖčüą┐ąŠą╗čīąĘčāąĄčé č鹊ą╗čīą║ąŠ ą┐ąŠą╗ąŠą▓ąĖąĮčā ąŠčé ą┤ąŠčüčéčāą┐ąĮąŠą╣ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ 32-ą▒ąĖčéąĮąŠą╣ čłąĖąĮčŗ, čćč鹊 ą╝ąŠąČąĄčé čüąĮąĖąĘąĖčéčī čüą║ąŠčĆąŠčüčéčī ąŠą▒ą╝ąĄąĮą░ ą┤ą░ąĮąĮčŗą╝ąĖ ą╝ąĄąČą┤čā ą┐čĆąŠčåąĄčüčüąŠčĆąŠą╝ ąĖ ą┐ą░ą╝čÅčéčīčÄ.
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r3 = w[p0](z);
r7 = w[p1++ ](z);
r2 = w[sp-- ](z);
r6 = w[p2+ 12 ](z);
r0 = w[p4+ 0x8004 ](z);
r1 = w[p0++ p1](z);
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Load Half-Word Sign-Extended, Load Low Data Register Half, Load High Data Register Half, Load Data Register.
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąČą░ąĄčé ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā čĆąĄą│ąĖčüčéčĆą░, ą┤ąŠą┐ąŠą╗ąĮčÅčÅ ą▒ąĖčéčŗ čüčéą░čĆčłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ ąĘąĮą░ą║ąŠą╝ čćąĖčüą╗ą░. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
D-čĆąĄą│ąĖčüčéčĆ = W [ ą║ąŠčüą▓ąĄąĮąĮčŗą╣_ą░ą┤čĆąĄčü ]
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = W[Preg](X); // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ (a)1
Dreg = W[Preg++](X); // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
Dreg = W[Preg--](X); // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
Dreg = W[Preg+uimm5m2](X); // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą╝ą░ą╗čŗą╝ čüą╝ąĄčēąĄąĮąĖąĄą╝ (a)
Dreg = W[Preg+uimm16m2](X); // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą▒ąŠą╗čīčłąĖą╝ čüą╝ąĄčēąĄąĮąĖąĄą╝ (b)
Dreg = W[Preg-uimm16m2](X); // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą▒ąŠą╗čīčłąĖą╝ čüą╝ąĄčēąĄąĮąĖą╝ąĄą╝ (b)
Dreg = W[Preg++Preg](X); // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░2 (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 2: ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ąÜąŠčüą▓ąĄąĮąĮą░čÅ ąĖ ąĖąĮą┤ąĄą║čüąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░".
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
ąÜą▓ą░ą┤čĆą░čéąĮčŗąĄ čüą║ąŠą▒ą║ąĖ ąŠąĘąĮą░čćą░čÄčé ą▓ąĘčÅčéąĖąĄ ą░ą┤čĆąĄčüą░, čé. ąĄ. ąĖčüčģąŠą┤ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▒ąĄčĆčāčéčüčÅ ąĖąĘ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ čüčüčŗą╗ą░ąĄčéčüčÅ ą░ą┤čĆąĄčü, čāą║ą░ąĘą░ąĮąĮčŗą╣ ą▓ ą║ą▓ą░ą┤čĆą░čéąĮčŗčģ čüą║ąŠą▒ą║ą░čģ (ą╗ąĖą▒ąŠ ą░ą┤čĆąĄčü čü čāč湥č鹊ą╝ čüą╝ąĄčēąĄąĮąĖčÅ).
Dreg: R0, ..., R7.
Preg: P0, ..., P5, SP, FP.
uimm5m2: 5-ą▒ąĖčéąĮąŠąĄ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ ą┐ąŠą╗ąĄ, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░čåąĄą╗ąŠ ąĮą░ 2. ąŚą░ą┤ą░ąĄčé čüą╝ąĄčēąĄąĮąĖąĄ ą░ą┤čĆąĄčüą░ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 30 ą▒ą░ą╣čé.
uimm16m2: 16-ą▒ąĖčéąĮąŠąĄ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ ą┐ąŠą╗ąĄ, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░čåąĄą╗ąŠ ąĮą░ 2. ąŚą░ą┤ą░ąĄčé čüą╝ąĄčēąĄąĮąĖąĄ ą░ą┤čĆąĄčüą░ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 65534 ą▒ą░ą╣čé (0x0000 .. 0xFFFC).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ ą┐ąŠą╗čāčüą╗ąŠą▓ą░ čü ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ąĘąĮą░ą║ąŠą╝ (Load Half-Word - Sign-Extended) ąĘą░ą│čĆčāąČą░ąĄčé ą╝ą╗ą░ą┤čłąĖąĄ 16 ą▒ąĖčé 32-ą▒ąĖčéąĮąŠą│ąŠ D-čĆąĄą│ąĖčüčéčĆą░ (čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ) ąĖąĘ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ. ąĀąĄą│ąĖčüčéčĆąŠą╝ čāą║ą░ąĘą░č鹥ą╗čÅ ąĮą░ čÅč湥ą╣ą║čā čÅą▓ą╗čÅąĄčéčüčÅ P-čĆąĄą│ąĖčüčéčĆ. ąĪą░ą╝čŗą╣ čüčéą░čĆčłąĖą╣ ą▒ąĖčé čćąĖčüą╗ą░ čĆąĄą┐ą╗ąĖčåąĖčĆčāąĄčéčüčÅ ą▓ čüčéą░čĆčłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā 32-ą▒ąĖčéąĮąŠą│ąŠ D-čĆąĄą│ąĖčüčéčĆą░.
ąÜąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü ąĖ čüą╝ąĄčēąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮčŗ čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆčÅčéčī čāčüą╗ąŠą▓ąĖčÄ č湥čéąĮąŠčüčéąĖ, čćč鹊ą▒čŗ ą░ą┤čĆąĄčü ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖą╗čüčÅ ąĮą░ 2 ąĖ čüąŠčģčĆą░ąĮčÅą╗ąŠčüčī ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą░ą┤čĆąĄčüą░ ąĮą░ ą┐ąŠą╗čāčüą╗ąŠą▓ąŠ (2 ą▒ą░ą╣čéą░). ą×čłąĖą▒ą║ą░ ą▓ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĖ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÄ ą┐ąŠ ąŠčłąĖą▒ą║ąĄ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ ą┐ąŠ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą╝čā ą░ą┤čĆąĄčüčā (misaligned memory access exception).
ą×ą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą║ čüąĖąĮčéą░ą║čüąĖčüčā ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┤ąŠą▒ą░ą▓ą╗ąĄąĮ čüčāčäčäąĖą║čü (X), čćč鹊ą▒čŗ čÅčüąĮąŠ ą┐ąŠą║ą░ąĘą░čéčī čĆą░čüčłąĖčĆąĄąĮąĖąĄ čüąŠ ąĘąĮą░ą║ąŠą╝ (sign extended). ąŁč鹊čé ąŠą┐čåąĖąŠąĮą░ą╗čīąĮčŗą╣ čäą╗ą░ą│ ąĮąĖą║ą░ą║ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ąĄčæ čäčāąĮą║čåąĖąŠąĮąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖą╗ąĖ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ ą┐ąĄčĆąĄą▓ąŠą┤čćąĖą║ą░: čÅ čŹč鹊 ą┐ąŠąĮčÅą╗ čéą░ą║, čćč鹊 ąĄčüą╗ąĖ (X) ąĮąĄ čāą║ą░ąĘą░ąĮ, č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▒čāą┤ąĄčé ą▓čüąĄ čĆą░ą▓ąĮąŠ čĆą░ą▒ąŠčéą░čéčī čéą░ą║ ąČąĄ, ą║ą░ą║ ąĄčüą╗ąĖ ą▒čŗ (X) čāą║ą░ąĘčŗą▓ą░ą╗čüčÅ. ąó. ąĄ. ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ čĆą░ą▒ąŠčéą░ąĄčé ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ čüąŠ ąĘąĮą░ą║ąŠą╝, ą░ čćč鹊ą▒čŗ čĆą░ą▒ąŠčéą░ą╗ąŠ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĮčāą╗čÅą╝ąĖ, ąĮčāąČąĮąŠ čāą║ą░ąĘčŗą▓ą░čéčī čüčāčäčäąĖą║čü (Z), čüą╝. ąŠą┐ąĖčüą░ąĮąĖąĄ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ Load Half-Word - Zero-Extended.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čåąĖąĖ:
ŌĆó ą¤ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮčé ą░ą┤čĆąĄčüą░ ąĖčüč鹊čćąĮąĖą║ą░ ąĮą░ 2 ą▒ą░ą╣čéą░.
ąśą╝ąĄą╣č鹥 ą▓ ą▓ąĖą┤čā, čćč鹊 ą║ąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓čāčÄčēąĖą╣ ą░ą╗ą│ąŠčĆąĖčéą╝ DSP, č鹊 ą┤ą╗čÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠą│ąŠ čćč鹥ąĮąĖčÅ ą╗ąĄąČą░čēąĖčģ ą▓ ą┐ą░ą╝čÅčéąĖ 16-ą▒ąĖčéąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣ ą┐čĆąĄą┤ą┐ąŠčćčéąĖč鹥ą╗čīąĮąĄąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĖąĮčüčéčĆčāą║čåąĖčÄ Load Data Register ą▓ą╝ąĄčüč鹊 čćč鹥ąĮąĖčÅ ą┐ąŠą╗ąŠą▓ąĖąĮąŠą║ čĆąĄą│ąĖčüčéčĆąŠą▓. Load Data Register čĆą░ą▒ąŠčéą░ąĄčé ą▓ 2 čĆą░ąĘą░ ą▒čŗčüčéčĆąĄąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 ąĘą░ ąŠą┤ąĮčā ą║ąŠą╝ą░ąĮą┤čā ą╝ąŠąČąĄčé ą▓čŗą▒čĆą░čéčī ąĖąĘ ą┐ą░ą╝čÅčéąĖ čüčĆą░ąĘčā 2 ą┐ąŠą╗čāčüą╗ąŠą▓ą░. ąÜąŠą╝ą░ąĮą┤ą░, ąĘą░ą│čĆčāąČą░čÄčēą░čÅ ą┤ą░ąĮąĮčŗąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ą╝ąĖ, ąĖčüą┐ąŠą╗čīąĘčāąĄčé č鹊ą╗čīą║ąŠ ą┐ąŠą╗ąŠą▓ąĖąĮčā ąŠčé ą┤ąŠčüčéčāą┐ąĮąŠą╣ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ 32-ą▒ąĖčéąĮąŠą╣ čłąĖąĮčŗ, čćč鹊 ą╝ąŠąČąĄčé čüąĮąĖąĘąĖčéčī čüą║ąŠčĆąŠčüčéčī ąŠą▒ą╝ąĄąĮą░ ą┤ą░ąĮąĮčŗą╝ąĖ ą╝ąĄąČą┤čā ą┐čĆąŠčåąĄčüčüąŠčĆąŠą╝ ąĖ ą┐ą░ą╝čÅčéčīčÄ.
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r3 = w[p0](x);
r7 = w[p1++ ](x);
r2 = w[sp-- ](x);
r6 = w[p2+ 12 ](x);
r0 = w[p4+ 0x800E ](x);
r1 = w[p0++ p1](x);
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Load Half-Word - Zero Extended, Load Low Data Register Half, Load High Data Register Half.
ąŚą░ą│čĆčāąČą░ąĄčé čüčéą░čĆčłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
Dreg.H = W [ ą║ąŠčüą▓ąĄąĮąĮčŗą╣_ą░ą┤čĆąĄčü ]
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg.h = W[Ireg]; // ą║ąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü (DAG) (a)1
Dreg.h = W[Ireg++]; // ą║ąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ (DAG) (a)
Dreg.h = W[Ireg--]; // ą║ąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü čü ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (DAG) (a)
Dreg.h = W[Preg]; // ą║ąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü (a)
Dreg.h = W[Preg++Preg]; // ą║ąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░2 (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 2: ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ąÜąŠčüą▓ąĄąĮąĮą░čÅ ąĖ ąĖąĮą┤ąĄą║čüąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░".
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
ąÜą▓ą░ą┤čĆą░čéąĮčŗąĄ čüą║ąŠą▒ą║ąĖ ąŠąĘąĮą░čćą░čÄčé ą▓ąĘčÅčéąĖąĄ ą░ą┤čĆąĄčüą░, čé. ąĄ. ąĖčüčģąŠą┤ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▒ąĄčĆčāčéčüčÅ ąĖąĘ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ čüčüčŗą╗ą░ąĄčéčüčÅ ą░ą┤čĆąĄčü, čāą║ą░ąĘą░ąĮąĮčŗą╣ ą▓ ą║ą▓ą░ą┤čĆą░čéąĮčŗčģ čüą║ąŠą▒ą║ą░čģ (ą╗ąĖą▒ąŠ ą░ą┤čĆąĄčü čü čāč湥č鹊ą╝ čüą╝ąĄčēąĄąĮąĖčÅ).
Dreg.h: čüčéą░čĆčłąĖąĄ 16 ą▒ąĖčé čĆąĄą│ąĖčüčéčĆąŠą▓ R0, ..., R7.
Preg: P0, ..., P5, SP, FP.
Ireg: I0, ..., I3.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ čüčéą░čĆčłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čĆąĄą│ąĖčüčéčĆą░ (Load High Data Register Half) ąĘą░ą│čĆčāąČą░ąĄčé 16 ą▒ąĖčé ąĖąĘ 2-ą▒ą░ą╣čéąĮąŠą╣ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ čāą║ą░ąĘčŗą▓ą░ąĄčé I-čĆąĄą│ąĖčüčéčĆ ąĖą╗ąĖ P-čĆąĄą│ąĖčüčéčĆ, ą▓ čüčéą░čĆčłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ. ąŁčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ ąĮąĖą║ą░ą║ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ ąŠčüčéą░ą╗čīąĮčāčÄ čćą░čüčéčī ąĘą░ą│čĆčāąČą░ąĄą╝ąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ - ą╝ą╗ą░ą┤čłąĖąĄ 16 ą▒ąĖčé.
ąÜąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü ąĖ čüą╝ąĄčēąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮčŗ čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆčÅčéčī čāčüą╗ąŠą▓ąĖčÄ č湥čéąĮąŠčüčéąĖ, čćč鹊ą▒čŗ ą░ą┤čĆąĄčü ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖą╗čüčÅ ąĮą░ 2 ąĖ čüąŠčģčĆą░ąĮčÅą╗ąŠčüčī ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą░ą┤čĆąĄčüą░ ąĮą░ ą┐ąŠą╗čāčüą╗ąŠą▓ąŠ (2 ą▒ą░ą╣čéą░). ą×čłąĖą▒ą║ą░ ą▓ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĖ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÄ ą┐ąŠ ąŠčłąĖą▒ą║ąĄ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ ą┐ąŠ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą╝čā ą░ą┤čĆąĄčüčā (misaligned memory access exception).
ąśąĮčüčéčĆčāą║čåąĖčÅ Load High Data Register Half ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čåąĖąĖ:
ŌĆó ą¤ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮčé čĆąĄą│ąĖčüčéčĆą░ ąĖčüč鹊čćąĮąĖą║ą░ Ireg ąĮą░ 2 ą▒ą░ą╣čéą░ ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ ąĮą░ ą┐ąŠą╗čāčüą╗ąŠą▓ąŠ.
ąśą╝ąĄą╣č鹥 ą▓ ą▓ąĖą┤čā, čćč鹊 ą║ąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓čāčÄčēąĖą╣ ą░ą╗ą│ąŠčĆąĖčéą╝ DSP, č鹊 ą┤ą╗čÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠą│ąŠ čćč鹥ąĮąĖčÅ ą╗ąĄąČą░čēąĖčģ ą▓ ą┐ą░ą╝čÅčéąĖ 16-ą▒ąĖčéąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣ ą┐čĆąĄą┤ą┐ąŠčćčéąĖč鹥ą╗čīąĮąĄąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĖąĮčüčéčĆčāą║čåąĖčÄ Load Data Register ą▓ą╝ąĄčüč鹊 čćč鹥ąĮąĖčÅ ą┐ąŠą╗ąŠą▓ąĖąĮąŠą║ čĆąĄą│ąĖčüčéčĆąŠą▓. Load Data Register čĆą░ą▒ąŠčéą░ąĄčé ą▓ 2 čĆą░ąĘą░ ą▒čŗčüčéčĆąĄąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 ąĘą░ ąŠą┤ąĮčā ą║ąŠą╝ą░ąĮą┤čā ą╝ąŠąČąĄčé ą▓čŗą▒čĆą░čéčī ąĖąĘ ą┐ą░ą╝čÅčéąĖ čüčĆą░ąĘčā 2 ą┐ąŠą╗čāčüą╗ąŠą▓ą░. ąÜąŠą╝ą░ąĮą┤ą░, ąĘą░ą│čĆčāąČą░čÄčēą░čÅ ą┤ą░ąĮąĮčŗąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ą╝ąĖ, ąĖčüą┐ąŠą╗čīąĘčāąĄčé č鹊ą╗čīą║ąŠ ą┐ąŠą╗ąŠą▓ąĖąĮčā ąŠčé ą┤ąŠčüčéčāą┐ąĮąŠą╣ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ 32-ą▒ąĖčéąĮąŠą╣ čłąĖąĮčŗ, čćč鹊 ą╝ąŠąČąĄčé čüąĮąĖąĘąĖčéčī čüą║ąŠčĆąŠčüčéčī ąŠą▒ą╝ąĄąĮą░ ą┤ą░ąĮąĮčŗą╝ąĖ ą╝ąĄąČą┤čā ą┐čĆąŠčåąĄčüčüąŠčĆąŠą╝ ąĖ ą┐ą░ą╝čÅčéčīčÄ.
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r3.h = w[i1];
r7.h = w[i3++ ];
r1.h = w[i0-- ];
r2.h = w[p4];
r5.h = w[p2++ p0];
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Load Low Data Register Half, Load Half-Word - Zero-Extended, Load Half-Word - Sign-Extended.
ąŚą░ą│čĆčāąČą░ąĄčé ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
Dreg.L = W [ ą║ąŠčüą▓ąĄąĮąĮčŗą╣_ą░ą┤čĆąĄčü ]
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg.l = W[Ireg]; // ą║ąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü (DAG) (a)1
Dreg.l = W[Ireg++]; // ą║ąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ (DAG) (a)
Dreg.l = W[Ireg--]; // ą║ąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü čü ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (DAG) (a)
Dreg.l = W[Preg]; // ą║ąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü (a)
Dreg.l = W[Preg++Preg]; // ą║ąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░2 (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 2: ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ąÜąŠčüą▓ąĄąĮąĮą░čÅ ąĖ ąĖąĮą┤ąĄą║čüąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░".
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
ąÜą▓ą░ą┤čĆą░čéąĮčŗąĄ čüą║ąŠą▒ą║ąĖ ąŠąĘąĮą░čćą░čÄčé ą▓ąĘčÅčéąĖąĄ ą░ą┤čĆąĄčüą░, čé. ąĄ. ąĖčüčģąŠą┤ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▒ąĄčĆčāčéčüčÅ ąĖąĘ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ čüčüčŗą╗ą░ąĄčéčüčÅ ą░ą┤čĆąĄčü, čāą║ą░ąĘą░ąĮąĮčŗą╣ ą▓ ą║ą▓ą░ą┤čĆą░čéąĮčŗčģ čüą║ąŠą▒ą║ą░čģ (ą╗ąĖą▒ąŠ ą░ą┤čĆąĄčü čü čāč湥č鹊ą╝ čüą╝ąĄčēąĄąĮąĖčÅ).
Dreg.L: ą╝ą╗ą░ą┤čłąĖąĄ 16 ą▒ąĖčé čĆąĄą│ąĖčüčéčĆąŠą▓ R0, ..., R7.
Preg: P0, ..., P5, SP, FP.
Ireg: I0, ..., I3.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ ą╝ą╗ą░ą┤čłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čĆąĄą│ąĖčüčéčĆą░ (Load Low Data Register Half) ąĘą░ą│čĆčāąČą░ąĄčé 16 ą▒ąĖčé ąĖąĘ 2-ą▒ą░ą╣čéąĮąŠą╣ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ čāą║ą░ąĘčŗą▓ą░ąĄčé I-čĆąĄą│ąĖčüčéčĆ ąĖą╗ąĖ P-čĆąĄą│ąĖčüčéčĆ, ą▓ ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ. ąŁčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ ąĮąĖą║ą░ą║ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ ąŠčüčéą░ą╗čīąĮčāčÄ čćą░čüčéčī ąĘą░ą│čĆčāąČą░ąĄą╝ąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ - čüčéą░čĆčłąĖąĄ 16 ą▒ąĖčé.
ąÜąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü ąĖ čüą╝ąĄčēąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮčŗ čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆčÅčéčī čāčüą╗ąŠą▓ąĖčÄ č湥čéąĮąŠčüčéąĖ, čćč鹊ą▒čŗ ą░ą┤čĆąĄčü ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖą╗čüčÅ ąĮą░ 2 ąĖ čüąŠčģčĆą░ąĮčÅą╗ąŠčüčī ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą░ą┤čĆąĄčüą░ ąĮą░ ą┐ąŠą╗čāčüą╗ąŠą▓ąŠ (2 ą▒ą░ą╣čéą░). ą×čłąĖą▒ą║ą░ ą▓ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĖ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÄ ą┐ąŠ ąŠčłąĖą▒ą║ąĄ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ ą┐ąŠ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą╝čā ą░ą┤čĆąĄčüčā (misaligned memory access exception).
ąśąĮčüčéčĆčāą║čåąĖčÅ Load Low Data Register Half ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čåąĖąĖ:
ŌĆó ą¤ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮčé čĆąĄą│ąĖčüčéčĆą░ ąĖčüč鹊čćąĮąĖą║ą░ Ireg ąĮą░ 2 ą▒ą░ą╣čéą░ ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ ąĮą░ ą┐ąŠą╗čāčüą╗ąŠą▓ąŠ.
ąśą╝ąĄą╣č鹥 ą▓ ą▓ąĖą┤čā, čćč鹊 ą║ąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓čāčÄčēąĖą╣ ą░ą╗ą│ąŠčĆąĖčéą╝ DSP, č鹊 ą┤ą╗čÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠą│ąŠ čćč鹥ąĮąĖčÅ ą╗ąĄąČą░čēąĖčģ ą▓ ą┐ą░ą╝čÅčéąĖ 16-ą▒ąĖčéąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣ ą┐čĆąĄą┤ą┐ąŠčćčéąĖč鹥ą╗čīąĮąĄąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĖąĮčüčéčĆčāą║čåąĖčÄ Load Data Register ą▓ą╝ąĄčüč鹊 čćč鹥ąĮąĖčÅ ą┐ąŠą╗ąŠą▓ąĖąĮąŠą║ čĆąĄą│ąĖčüčéčĆąŠą▓. Load Data Register čĆą░ą▒ąŠčéą░ąĄčé ą▓ 2 čĆą░ąĘą░ ą▒čŗčüčéčĆąĄąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 ąĘą░ ąŠą┤ąĮčā ą║ąŠą╝ą░ąĮą┤čā ą╝ąŠąČąĄčé ą▓čŗą▒čĆą░čéčī ąĖąĘ ą┐ą░ą╝čÅčéąĖ čüčĆą░ąĘčā 2 ą┐ąŠą╗čāčüą╗ąŠą▓ą░. ąÜąŠą╝ą░ąĮą┤ą░, ąĘą░ą│čĆčāąČą░čÄčēą░čÅ ą┤ą░ąĮąĮčŗąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ą╝ąĖ, ąĖčüą┐ąŠą╗čīąĘčāąĄčé č鹊ą╗čīą║ąŠ ą┐ąŠą╗ąŠą▓ąĖąĮčā ąŠčé ą┤ąŠčüčéčāą┐ąĮąŠą╣ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ 32-ą▒ąĖčéąĮąŠą╣ čłąĖąĮčŗ, čćč鹊 ą╝ąŠąČąĄčé čüąĮąĖąĘąĖčéčī čüą║ąŠčĆąŠčüčéčī ąŠą▒ą╝ąĄąĮą░ ą┤ą░ąĮąĮčŗą╝ąĖ ą╝ąĄąČą┤čā ą┐čĆąŠčåąĄčüčüąŠčĆąŠą╝ ąĖ ą┐ą░ą╝čÅčéčīčÄ.
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r3.L = w[i1];
r7.L = w[i3++ ];
r1.L = w[i0-- ];
r2.L = w[p4];
r5.L = w[p2++ p0];
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Load High Data Register Half, Load Half-Word - Zero-Extended, Load Half-Word - Sign-Extended.
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąČą░ąĄčé ą▒ą░ą╣čé ą▓ čĆąĄą│ąĖčüčéčĆ ą┤ą░ąĮąĮčŗčģ, ą┤ąŠą┐ąŠą╗ąĮčÅčÅ ąŠčüčéą░ą╗čīąĮčŗąĄ ą▒ąĖčéčŗ ąĘą░ą│čĆčāąČą░ąĄą╝ąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ąĮčāą╗čÅą╝ąĖ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
D-čĆąĄą│ąĖčüčéčĆ = B [ ą║ąŠčüą▓ąĄąĮąĮčŗą╣_ą░ą┤čĆąĄčü ] (Z)
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = B[Preg](Z); // ą║ąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü (a)1
Dreg = B[Preg++](Z); // ą║ąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
Dreg = B[Preg--](Z); // ą║ąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü čü ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
Dreg = B[Preg+uimm15](Z); // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą░ą┤čĆąĄčü čüąŠ čüą╝ąĄčēąĄąĮąĖąĄą╝ (b)
Dreg = B[Preg-uimm15](Z); // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą░ą┤čĆąĄčü čüąŠ čüą╝ąĄčēąĄąĮąĖąĄą╝ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
ąÜą▓ą░ą┤čĆą░čéąĮčŗąĄ čüą║ąŠą▒ą║ąĖ ąŠąĘąĮą░čćą░čÄčé ą▓ąĘčÅčéąĖąĄ ą░ą┤čĆąĄčüą░, čé. ąĄ. ąĖčüčģąŠą┤ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▒ąĄčĆčāčéčüčÅ ąĖąĘ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ čüčüčŗą╗ą░ąĄčéčüčÅ ą░ą┤čĆąĄčü, čāą║ą░ąĘą░ąĮąĮčŗą╣ ą▓ ą║ą▓ą░ą┤čĆą░čéąĮčŗčģ čüą║ąŠą▒ą║ą░čģ (ą╗ąĖą▒ąŠ ą░ą┤čĆąĄčü čü čāč湥č鹊ą╝ čüą╝ąĄčēąĄąĮąĖčÅ).
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
Preg: P0, ..., P5, SP, FP.
uimm15: 15-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ, čüąŠą┤ąĄčƹȹ░čēąĄąĄ čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ ąŠčé 0 ą┤ąŠ 32767 ą▒ą░ą╣čé (0x0000 .. 0x7FFF).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ ą▒ą░ą╣čéą░ (Load Byte - Zero-Extended) ąĘą░ą│čĆčāąČą░ąĄčé 8 ą▒ąĖčé ą▓ ą╝ą╗ą░ą┤čłąĖąĄ ąĖąĘ 32 ą▒ąĖčé čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ ąĖąĘ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ čāą║ą░ąĘčŗą▓ą░ąĄčé I-čĆąĄą│ąĖčüčéčĆ ąĖą╗ąĖ P-čĆąĄą│ąĖčüčéčĆ. ą¤čĆąĖ čŹč鹊ą╝ ą▒ąĖčéčŗ 31..8 ąĘą░ą│čĆčāąČą░ąĄą╝ąŠą│ąŠ D-čĆąĄą│ąĖčüčéčĆą░ ąĘą░ą┐ąŠą╗ąĮčÅčÄčéčüčÅ ąĮčāą╗čÅą╝ąĖ.
ąÜąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü ąĖ čüą╝ąĄčēąĄąĮąĖąĄ ąĮąĄ ąĖą╝ąĄčÄčé ąĮąĖą║ą░ą║ąĖčģ ąŠą│čĆą░ąĮąĖč湥ąĮąĖą╣ ą┐ąŠ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÄ ą░ą┤čĆąĄčüą░ ą┐ą░ą╝čÅčéąĖ.
ąśąĮčüčéčĆčāą║čåąĖąĄą╣ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čåąĖąĖ:
ŌĆó ą¤ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮčé ą░ą┤čĆąĄčüą░ ąĖčüč鹊čćąĮąĖą║ą░ ąĮą░ 1 ą▒ą░ą╣čé.
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r3 = b[p0](z);
r7 = b[p1++ ](z);
r2 = b[sp-- ](z);
r0 = b[p4+ 0xFFFF800F ](z);
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Load Byte - Sign-Extended.
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąČą░ąĄčé ą▒ą░ą╣čé ą▓ čĆąĄą│ąĖčüčéčĆ ą┤ą░ąĮąĮčŗčģ, ą┤ąŠą┐ąŠą╗ąĮčÅčÅ ąŠčüčéą░ą╗čīąĮčŗąĄ ą▒ąĖčéčŗ ąĘą░ą│čĆčāąČą░ąĄą╝ąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ąĘąĮą░ą║ąŠą╝ čćąĖčüą╗ą░. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
D-čĆąĄą│ąĖčüčéčĆ = B [ ą║ąŠčüą▓ąĄąĮąĮčŗą╣_ą░ą┤čĆąĄčü ]
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = B[Preg](X); // ą║ąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü (a)1
Dreg = B[Preg++](X); // ą║ąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
Dreg = B[Preg--](X); // ą║ąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü čü ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
Dreg = B[Preg+uimm15](X); // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą░ą┤čĆąĄčü čüąŠ čüą╝ąĄčēąĄąĮąĖąĄą╝ (b)
Dreg = B[Preg-uimm15](X); // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą░ą┤čĆąĄčü čüąŠ čüą╝ąĄčēąĄąĮąĖąĄą╝ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
ąÜą▓ą░ą┤čĆą░čéąĮčŗąĄ čüą║ąŠą▒ą║ąĖ ąŠąĘąĮą░čćą░čÄčé ą▓ąĘčÅčéąĖąĄ ą░ą┤čĆąĄčüą░, čé. ąĄ. ąĖčüčģąŠą┤ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▒ąĄčĆčāčéčüčÅ ąĖąĘ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ čüčüčŗą╗ą░ąĄčéčüčÅ ą░ą┤čĆąĄčü, čāą║ą░ąĘą░ąĮąĮčŗą╣ ą▓ ą║ą▓ą░ą┤čĆą░čéąĮčŗčģ čüą║ąŠą▒ą║ą░čģ (ą╗ąĖą▒ąŠ ą░ą┤čĆąĄčü čü čāč湥č鹊ą╝ čüą╝ąĄčēąĄąĮąĖčÅ).
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
Preg: P0, ..., P5, SP, FP.
uimm15: 15-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ, čüąŠą┤ąĄčƹȹ░čēąĄąĄ čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ ąŠčé 0 ą┤ąŠ 32767 ą▒ą░ą╣čé (0x0000 .. 0x7FFF).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ ą▒ą░ą╣čéą░ čü ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ąĘąĮą░ą║ąŠą╝ čćąĖčüą╗ą░ (Load Byte - Sign-Extended) ąĘą░ą│čĆčāąČą░ąĄčé 8 ą▒ąĖčé ą▓ ą╝ą╗ą░ą┤čłąĖąĄ ąĖąĘ 32 ą▒ąĖčé čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ ąĖąĘ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ čāą║ą░ąĘčŗą▓ą░ąĄčé I-čĆąĄą│ąĖčüčéčĆ ąĖą╗ąĖ P-čĆąĄą│ąĖčüčéčĆ. ą¤čĆąĖ čŹč鹊ą╝ ą▒ąĖčéčŗ 31 .. 8 ąĘą░ą│čĆčāąČą░ąĄą╝ąŠą│ąŠ D-čĆąĄą│ąĖčüčéčĆą░ ąĘą░ą┐ąŠą╗ąĮčÅčÄčéčüčÅ ąĘąĮą░ą║ąŠą▓čŗą╝ ą▒ąĖč鹊ą╝ ąĘą░ą│čĆčāąČą░ąĄą╝ąŠą│ąŠ ą▒ą░ą╣čéą░.
ąÜąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü ąĖ čüą╝ąĄčēąĄąĮąĖąĄ ąĮąĄ ąĖą╝ąĄčÄčé ąĮąĖą║ą░ą║ąĖčģ ąŠą│čĆą░ąĮąĖč湥ąĮąĖą╣ ą┐ąŠ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÄ ą░ą┤čĆąĄčüą░ ą┐ą░ą╝čÅčéąĖ.
ą×ą┐čåąĖąŠąĮą░ą╗čīąĮąŠ čüčāčäčäąĖą║čü (X) ą╝ąŠąČąĄčé ą▒čŗčéčī čāą║ą░ąĘą░ąĮ (čćč鹊 ąĮąĄ ąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ) ą┤ą╗čÅ čāą╗čāčćčłąĄąĮąĖčÅ čćąĖčéą░ąĄą╝ąŠčüčéąĖ čüąĖąĮčéą░ą║čüąĖčüą░ - čćč鹊ą▒čŗ ą▒čŗą╗ąŠ čÅčüąĮąĄąĄ ą▓ąĖą┤ąĮąŠ, čćč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĘąĮą░ą║ąŠą╝ (sign extended). ąŻą║ą░ąĘą░ąĮąĖąĄ ąĖą╗ąĖ ąĮąĄ čāą║ą░ąĘą░ąĮąĖąĄ čŹč鹊ą│ąŠ čüčāčäčäąĖą║čüą░ ąĮąĖą║ą░ą║ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ąĄčæ čäčāąĮą║čåąĖąŠąĮąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ. ąśąĮčüčéčĆčāą║čåąĖąĄą╣ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čåąĖąĖ:
ŌĆó ą¤ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮčé ą░ą┤čĆąĄčüą░ ąĖčüč鹊čćąĮąĖą║ą░ ąĮą░ 1 ą▒ą░ą╣čé.
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r3 = b[p0](x);
r7 = b[p1++ ](x);
r2 = b[sp-- ](x);
r0 = b[p4+ 0xFFFF800F ](x);
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Load Byte - Zero-Extended.
ąĪąŠčģčĆą░ąĮčÅąĄčé čĆąĄą│ąĖčüčéčĆ čāą║ą░ąĘą░č鹥ą╗čÅ ą▓ čÅč湥ą╣ą║čā ą┐ą░ą╝čÅčéąĖ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
[ ą║ąŠčüą▓ąĄąĮąĮčŗą╣_ą░ą┤čĆąĄčü ] = P-čĆąĄą│ąĖčüčéčĆ
ąĪąĖąĮčéą░ą║čüąĖčü:
[Preg] = Preg; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ (a)1 [Preg++] = Preg; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ (a) [Preg--] = Preg; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (a) [Preg+uimm6m4] = Preg // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą╝ą░ą╗čŗą╝ čüą╝ąĄčēąĄąĮąĖąĄą╝ (a) [Preg+uimm17m4] = Preg; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą▒ąŠą╗čīčłąĖą╝ čüą╝ąĄčēąĄąĮąĖąĄą╝ (b) [Preg-uimm17m4] = Preg; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą▒ąŠą╗čīčłąĖą╝ čüą╝ąĄčēąĄąĮąĖąĄą╝ (b) [FP-uimm7m4] = Preg; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ FP (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
ąÜą▓ą░ą┤čĆą░čéąĮčŗąĄ čüą║ąŠą▒ą║ąĖ ąŠąĘąĮą░čćą░čÄčé ą▓ąĘčÅčéąĖąĄ ą░ą┤čĆąĄčüą░, čé. ąĄ. ąĖčüčģąŠą┤ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▒ąĄčĆčāčéčüčÅ ąĖąĘ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ čüčüčŗą╗ą░ąĄčéčüčÅ ą░ą┤čĆąĄčü, čāą║ą░ąĘą░ąĮąĮčŗą╣ ą▓ ą║ą▓ą░ą┤čĆą░čéąĮčŗčģ čüą║ąŠą▒ą║ą░čģ (ą╗ąĖą▒ąŠ ą░ą┤čĆąĄčü čü čāč湥č鹊ą╝ čüą╝ąĄčēąĄąĮąĖčÅ).
Preg: P0, ..., P5, SP, FP.
uimm6m4: 6-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░ 4, ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 60 ą▒ą░ą╣čé.
uimm7m4: 7-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░ 4, ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 4 .. 128 ą▒ą░ą╣čé.
uimm17m4: 17-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░ 4, čü ą┤ąĖą░ą┐ą░ąĘąŠąĮąŠą╝ 0 .. 131068 ą▒ą░ą╣čé (0x000 0000 .. 0x0001 FFFC).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čāą║ą░ąĘą░č鹥ą╗čÅ (Store Pointer Register) čüąŠčģčĆą░ąĮčÅąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ 32-ą▒ąĖčéąĮąŠą│ąŠ P-čĆąĄą│ąĖčüčéčĆą░ ą▓ 32-ą▒ąĖčéąĮčāčÄ čÅč湥ą╣ą║čā ą┐ą░ą╝čÅčéąĖ. ąØą░ ą░ą┤čĆąĄčü čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ čéą░ą║ąČąĄ čāą║ą░ąĘčŗą▓ą░ąĄčé P-čĆąĄą│ąĖčüčéčĆ.
ąÜąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü ąĖ čüą╝ąĄčēąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮčŗ čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆčÅčéčī čāčüą╗ąŠą▓ąĖčÄ č湥čéąĮąŠčüčéąĖ, čćč鹊ą▒čŗ ą░ą┤čĆąĄčü ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖą╗čüčÅ ąĮą░ 4 ąĖ čüąŠčģčĆą░ąĮčÅą╗ąŠčüčī ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą░ą┤čĆąĄčüą░ ąĮą░ čüą╗ąŠą▓ąŠ (4 ą▒ą░ą╣čéą░). ą×čłąĖą▒ą║ą░ ą▓ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĖ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÄ ą┐ąŠ ąŠčłąĖą▒ą║ąĄ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ ą┐ąŠ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą╝čā ą░ą┤čĆąĄčüčā (misaligned memory access exception).
ą¤ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čåąĖąĖ:
ŌĆó ą¤ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮčé čāą║ą░ąĘą░č鹥ą╗čÅ čÅč湥ą╣ą║ąĖ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąĮą░ 4 ą▒ą░ą╣čéą░.
ążąŠčĆą╝ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ FP ąŠą▒čŗčćąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą╗ąŠą║ą░ą╗čīąĮčŗą╝ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝ ą▓ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ą░čģ ąĖą╗ąĖ čäčāąĮą║čåąĖčÅčģ. ą¤ąŠą╗ąŠąČąĖč鹥ą╗čīąĮčŗąĄ čüą╝ąĄčēąĄąĮąĖčÅ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ FP (čćč鹊 ą┐ąŠą╗ąĄąĘąĮąŠ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą░čĆą│čāą╝ąĄąĮčéą░ą╝ ąĖąĘ ą▓čŗąĘą▓ą░ąĮąĮąŠą╣ čäčāąĮą║čåąĖąĖ) ą╝ąŠą│čāčé ą▒čŗčéčī ąŠčüčāčēąĄčüčéą▓ą╗ąĄąĮčŗ ą┤čĆčāą│ąĖą╝ąĖ ą▓ąĄčĆčüąĖčÅą╝ąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. Preg ą▓ą║ą╗čÄčćą░ąĄčé Frame Pointer (čāą║ą░ąĘą░č鹥ą╗čī čäčĆąĄą╣ą╝ą░, FP) ąĖ Stack Pointer (čāą║ą░ąĘą░č鹥ą╗čī čüč鹥ą║ą░, SP).
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
[p2] = p3;
[sp++ ] = p5;
[p0-- ] = p2;
[p2+ 8 ] = p3;
[p2+ 0x4444 ] = p0;
[fp- 12 ] = p1;
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Push, Push Multiple.
ąĪąŠčģčĆą░ąĮčÅąĄčé čĆąĄą│ąĖčüčéčĆ ą┤ą░ąĮąĮčŗčģ ą▓ čÅč湥ą╣ą║čā ą┐ą░ą╝čÅčéąĖ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
[ ą║ąŠčüą▓ąĄąĮąĮčŗą╣_ą░ą┤čĆąĄčü ] = D-čĆąĄą│ąĖčüčéčĆ
ąĪąĖąĮčéą░ą║čüąĖčü čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ čĆąĄą│ąĖčüčéčĆąŠą▓ čāą║ą░ąĘą░č鹥ą╗čÅ:
[Preg] = Dreg; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ (a)1 [Preg++] = Dreg; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ (a) [Preg--] = Dreg; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (a) [Preg+uimm6m4] = Dreg // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą╝ą░ą╗čŗą╝ čüą╝ąĄčēąĄąĮąĖąĄą╝ (a) [Preg+uimm17m4] = Dreg; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą▒ąŠą╗čīčłąĖą╝ čüą╝ąĄčēąĄąĮąĖąĄą╝ (b) [Preg-uimm17m4] = Dreg; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą▒ąŠą╗čīčłąĖą╝ čüą╝ąĄčēąĄąĮąĖąĄą╝ (b) [Preg++Preg] = Dreg; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░2 (a) [FP-uimm7m4] = Dreg; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ FP (a)
ąĪąĖąĮčéą░ą║čüąĖčü čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ čĆąĄą│ąĖčüčéčĆąŠą▓ DAG:
[Ireg] = Dreg; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ (a) [Ireg++] = Dreg; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ (a) [Ireg--] = Dreg; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (a) [Ireg++Mreg] = Dreg; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░2 (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 2: ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ąÜąŠčüą▓ąĄąĮąĮą░čÅ ąĖ ąĖąĮą┤ąĄą║čüąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░".
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
ąÜą▓ą░ą┤čĆą░čéąĮčŗąĄ čüą║ąŠą▒ą║ąĖ ąŠąĘąĮą░čćą░čÄčé ą▓ąĘčÅčéąĖąĄ ą░ą┤čĆąĄčüą░, čé. ąĄ. ąĖčüčģąŠą┤ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▒ąĄčĆčāčéčüčÅ ąĖąĘ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ čüčüčŗą╗ą░ąĄčéčüčÅ ą░ą┤čĆąĄčü, čāą║ą░ąĘą░ąĮąĮčŗą╣ ą▓ ą║ą▓ą░ą┤čĆą░čéąĮčŗčģ čüą║ąŠą▒ą║ą░čģ (ą╗ąĖą▒ąŠ ą░ą┤čĆąĄčü čü čāč湥č鹊ą╝ čüą╝ąĄčēąĄąĮąĖčÅ).
Dreg: R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ (Store Data Register) čüąŠčģčĆą░ąĮčÅąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ 32-ą▒ąĖčéąĮąŠą│ąŠ D-čĆąĄą│ąĖčüčéčĆą░ ą▓ 32-ą▒ąĖčéąĮčāčÄ čÅč湥ą╣ą║čā ą┐ą░ą╝čÅčéąĖ. ąØą░ ą░ą┤čĆąĄčü čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ čāą║ą░ąĘčŗą▓ą░ąĄčé P-čĆąĄą│ąĖčüčéčĆ, I-čĆąĄą│ąĖčüčéčĆ ąĖą╗ąĖ čāą║ą░ąĘą░č鹥ą╗čī čäčĆąĄą╣ą╝ą░ (Frame Pointer, FP).
ąÜąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü ąĖ čüą╝ąĄčēąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮčŗ čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆčÅčéčī čāčüą╗ąŠą▓ąĖčÄ č湥čéąĮąŠčüčéąĖ, čćč鹊ą▒čŗ ą░ą┤čĆąĄčü ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖą╗čüčÅ ąĮą░ 4 ąĖ čüąŠčģčĆą░ąĮčÅą╗ąŠčüčī ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą░ą┤čĆąĄčüą░ ąĮą░ čüą╗ąŠą▓ąŠ (4 ą▒ą░ą╣čéą░). ą×čłąĖą▒ą║ą░ ą▓ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĖ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÄ ą┐ąŠ ąŠčłąĖą▒ą║ąĄ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ ą┐ąŠ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą╝čā ą░ą┤čĆąĄčüčā (misaligned memory access exception).
ą¤ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čåąĖąĖ:
ŌĆó ą¤ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮčé čāą║ą░ąĘą░č鹥ą╗čÅ čÅč湥ą╣ą║ąĖ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąĮą░ 4 ą▒ą░ą╣čéą░.
ążąŠčĆą╝ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ FP ąŠą▒čŗčćąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą╗ąŠą║ą░ą╗čīąĮčŗą╝ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝ ą▓ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ą░čģ ąĖą╗ąĖ čäčāąĮą║čåąĖčÅčģ. ą¤ąŠą╗ąŠąČąĖč鹥ą╗čīąĮčŗąĄ čüą╝ąĄčēąĄąĮąĖčÅ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ FP (čćč鹊 ą┐ąŠą╗ąĄąĘąĮąŠ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą░čĆą│čāą╝ąĄąĮčéą░ą╝ ąĖąĘ ą▓čŗąĘą▓ą░ąĮąĮąŠą╣ čäčāąĮą║čåąĖąĖ) ą╝ąŠą│čāčé ą▒čŗčéčī ąŠčüčāčēąĄčüčéą▓ą╗ąĄąĮčŗ ą┤čĆčāą│ąĖą╝ąĖ ą▓ąĄčĆčüąĖčÅą╝ąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. Preg ą▓ą║ą╗čÄčćą░ąĄčé Frame Pointer (čāą║ą░ąĘą░č鹥ą╗čī čäčĆąĄą╣ą╝ą░, FP) ąĖ Stack Pointer (čāą║ą░ąĘą░č鹥ą╗čī čüč鹥ą║ą░, SP).
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
[p0] = r3;
[p1++ ] = r7;
[sp-- ] = r2;
[p2+ 12 ] = r6;
[p4- 0x1004 ] = r0;
[p0++ p1] = r1;
[fp- 28 ] = r5;
[i2] = r2;
[i0++ ] = r0;
[i0-- ] = r0;
[i3++ m0] = r7;
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Load Immediate.
ąśąĮčüčéčĆčāą║čåąĖčÅ čüąŠčģčĆą░ąĮčÅąĄčé ą▓ ą┐ą░ą╝čÅčéąĖ čüčéą░čĆčłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
W [ ą║ąŠčüą▓ąĄąĮąĮčŗą╣_ą░ą┤čĆąĄčü ] = Dreg.H
ąĪąĖąĮčéą░ą║čüąĖčü:
W [Ireg] = Dreg.H; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ (DAG) (a)1
W [Ireg++] = Dreg.H; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ (DAG) (a)
W [Ireg--] = Dreg.H ; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (DAG) (a)
W [Preg] = Dreg.H; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ (a)
W [Preg++Preg] = Dreg.H; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░2 (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 2: ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ąÜąŠčüą▓ąĄąĮąĮą░čÅ ąĖ ąĖąĮą┤ąĄą║čüąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░".
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
ąÜą▓ą░ą┤čĆą░čéąĮčŗąĄ čüą║ąŠą▒ą║ąĖ ąŠąĘąĮą░čćą░čÄčé ą▓ąĘčÅčéąĖąĄ ą░ą┤čĆąĄčüą░, čé. ąĄ. ąĖčüčģąŠą┤ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▒ąĄčĆčāčéčüčÅ ąĖąĘ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ čüčüčŗą╗ą░ąĄčéčüčÅ ą░ą┤čĆąĄčü, čāą║ą░ąĘą░ąĮąĮčŗą╣ ą▓ ą║ą▓ą░ą┤čĆą░čéąĮčŗčģ čüą║ąŠą▒ą║ą░čģ (ą╗ąĖą▒ąŠ ą░ą┤čĆąĄčü čü čāč湥č鹊ą╝ čüą╝ąĄčēąĄąĮąĖčÅ).
Dreg.H: čüčéą░čĆčłąĖąĄ 16 ą▒ąĖčé čĆąĄą│ąĖčüčéčĆąŠą▓ R0, ..., R7.
Preg: P0, ..., P5, SP, FP.
Ireg: I0, ..., I3.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čüčéą░čĆčłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ (Store High Data Register Half) ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé ą▓ 2-ą▒ą░ą╣čéąĮčāčÄ čÅč湥ą╣ą║čā ą┐ą░ą╝čÅčéąĖ čüčéą░čĆčłąĖąĄ 16 ą▒ąĖčé 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ. ąÆ ą║ą░č湥čüčéą▓ąĄ ą░ą┤čĆąĄčüą░ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čĆąĄą│ąĖčüčéčĆ čāą║ą░ąĘą░č鹥ą╗čÅ P-čĆąĄą│ąĖčüčéčĆ ąĖą╗ąĖ I-čĆąĄą│ąĖčüčéčĆ.
ąÜąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü ąĖ čüą╝ąĄčēąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮčŗ čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆčÅčéčī čāčüą╗ąŠą▓ąĖčÄ č湥čéąĮąŠčüčéąĖ, čćč鹊ą▒čŗ ą░ą┤čĆąĄčü ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖą╗čüčÅ ąĮą░ 2 ąĖ čüąŠčģčĆą░ąĮčÅą╗ąŠčüčī ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą░ą┤čĆąĄčüą░ ąĮą░ ą┐ąŠą╗čāčüą╗ąŠą▓ąŠ (2 ą▒ą░ą╣čéą░). ą×čłąĖą▒ą║ą░ ą▓ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĖ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÄ ą┐ąŠ ąŠčłąĖą▒ą║ąĄ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ ą┐ąŠ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą╝čā ą░ą┤čĆąĄčüčā (misaligned memory access exception).
ą¤ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čåąĖąĖ:
ŌĆó ą¤ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮčé čāą║ą░ąĘą░č鹥ą╗čÅ čÅč湥ą╣ą║ąĖ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ I-čĆąĄą│ąĖčüčéčĆ ąĮą░ 2 ą▒ą░ą╣čéą░.
ąśą╝ąĄą╣č鹥 ą▓ ą▓ąĖą┤čā, čćč鹊 ą║ąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓čāčÄčēąĖą╣ ą░ą╗ą│ąŠčĆąĖčéą╝ DSP, č鹊 ą┤ą╗čÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠą│ąŠ čćč鹥ąĮąĖčÅ ą╗ąĄąČą░čēąĖčģ ą▓ ą┐ą░ą╝čÅčéąĖ 16-ą▒ąĖčéąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣ ą┐čĆąĄą┤ą┐ąŠčćčéąĖč鹥ą╗čīąĮąĄąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĖąĮčüčéčĆčāą║čåąĖčÄ Load Data Register ą▓ą╝ąĄčüč鹊 čćč鹥ąĮąĖčÅ ą┐ąŠą╗ąŠą▓ąĖąĮąŠą║ čĆąĄą│ąĖčüčéčĆąŠą▓. Load Data Register čĆą░ą▒ąŠčéą░ąĄčé ą▓ 2 čĆą░ąĘą░ ą▒čŗčüčéčĆąĄąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 ąĘą░ ąŠą┤ąĮčā ą║ąŠą╝ą░ąĮą┤čā ą╝ąŠąČąĄčé ą▓čŗą▒čĆą░čéčī ąĖąĘ ą┐ą░ą╝čÅčéąĖ čüčĆą░ąĘčā 2 ą┐ąŠą╗čāčüą╗ąŠą▓ą░. ąÜąŠą╝ą░ąĮą┤ą░, ąĘą░ą│čĆčāąČą░čÄčēą░čÅ ą┤ą░ąĮąĮčŗąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ą╝ąĖ, ąĖčüą┐ąŠą╗čīąĘčāąĄčé č鹊ą╗čīą║ąŠ ą┐ąŠą╗ąŠą▓ąĖąĮčā ąŠčé ą┤ąŠčüčéčāą┐ąĮąŠą╣ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ 32-ą▒ąĖčéąĮąŠą╣ čłąĖąĮčŗ, čćč鹊 ą╝ąŠąČąĄčé čüąĮąĖąĘąĖčéčī čüą║ąŠčĆąŠčüčéčī ąŠą▒ą╝ąĄąĮą░ ą┤ą░ąĮąĮčŗą╝ąĖ ą╝ąĄąČą┤čā ą┐čĆąŠčåąĄčüčüąŠčĆąŠą╝ ąĖ ą┐ą░ą╝čÅčéčīčÄ.
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
w[i1] = r3.h;
w[i3++ ] = r7.h;
w[i0-- ] = r1.h;
w[p4] = r2.h;
w[p2++ p0] = r5.h;
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Store Low Data Register Half.
ąśąĮčüčéčĆčāą║čåąĖčÅ čüąŠčģčĆą░ąĮčÅąĄčé ą▓ ą┐ą░ą╝čÅčéąĖ ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
W [ ą║ąŠčüą▓ąĄąĮąĮčŗą╣_ą░ą┤čĆąĄčü ] = Dreg.L
W [ ą║ąŠčüą▓ąĄąĮąĮčŗą╣_ą░ą┤čĆąĄčü ] = Dreg
ąĪąĖąĮčéą░ą║čüąĖčü:
W [Ireg] = Dreg.L; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ (DAG) (a)1
W [Ireg++] = Dreg.L; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ (DAG) (a)
W [Ireg--] = Dreg.L; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (DAG) (a)
W [Preg] = Dreg.L; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ (a)
W [Preg] = Dreg; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ (a)
W [Preg++] = Dreg; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
W [Preg--] = Dreg; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
W [Preg+uimm5m2] = Dreg; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą╝ą░ą╗čŗą╝ čüą╝ąĄčēąĄąĮąĖąĄą╝ (a)
W [Preg+uimm16m2] = Dreg; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą▒ąŠą╗čīčłąĖą╝ čüą╝ąĄčēąĄąĮąĖąĄą╝ (b)
W [Preg-uimm16m2] = Dreg; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą▒ąŠą╗čīčłąĖą╝ čüą╝ąĄčēąĄąĮąĖąĄą╝ (b)
W [Preg++Preg] = Dreg.L; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░ 2 (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 2: ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ąÜąŠčüą▓ąĄąĮąĮą░čÅ ąĖ ąĖąĮą┤ąĄą║čüąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ ąĖąĮą┤ąĄą║čüą░".
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
ąÜą▓ą░ą┤čĆą░čéąĮčŗąĄ čüą║ąŠą▒ą║ąĖ ąŠąĘąĮą░čćą░čÄčé ą▓ąĘčÅčéąĖąĄ ą░ą┤čĆąĄčüą░, čé. ąĄ. ąĖčüčģąŠą┤ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▒ąĄčĆčāčéčüčÅ ąĖąĘ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ čüčüčŗą╗ą░ąĄčéčüčÅ ą░ą┤čĆąĄčü, čāą║ą░ąĘą░ąĮąĮčŗą╣ ą▓ ą║ą▓ą░ą┤čĆą░čéąĮčŗčģ čüą║ąŠą▒ą║ą░čģ (ą╗ąĖą▒ąŠ ą░ą┤čĆąĄčü čü čāč湥č鹊ą╝ čüą╝ąĄčēąĄąĮąĖčÅ).
Dreg.L: ą╝ą╗ą░ą┤čłąĖąĄ 16 ą▒ąĖčé čĆąĄą│ąĖčüčéčĆąŠą▓ R0, ..., R7.
Preg: P0, ..., P5, SP, FP.
Ireg: I0, ..., I3.
Dreg: R0, ..., R7.
uimm5m2: 5-ą▒ąĖčéąĮąŠąĄ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ ą┐ąŠą╗ąĄ, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ čüąŠą┤ąĄčƹȹ░čéčī čüą╝ąĄčēąĄąĮąĖąĄ, ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗čÅčēąĄąĄčüčÅ ąĮą░ 2, ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 30 ą▒ą░ą╣čé.
uimm16m2: 16-ą▒ąĖčéąĮąŠąĄ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ ą┐ąŠą╗ąĄ, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ čüąŠą┤ąĄčƹȹ░čéčī čüą╝ąĄčēąĄąĮąĖąĄ, ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗čÅčēąĄąĄčüčÅ ąĮą░ 2, ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 65534 ą▒ą░ą╣čé (0x0000 .. 0xFFFE).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą╝ą╗ą░ą┤čłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ (Store Low Data Register Half) ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé ą▓ 2-ą▒ą░ą╣čéąĮčāčÄ čÅč湥ą╣ą║čā ą┐ą░ą╝čÅčéąĖ ą╝ą╗ą░ą┤čłąĖąĄ 16 ą▒ąĖčé 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ. ąÆ ą║ą░č湥čüčéą▓ąĄ ą░ą┤čĆąĄčüą░ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čĆąĄą│ąĖčüčéčĆ čāą║ą░ąĘą░č鹥ą╗čÅ P-čĆąĄą│ąĖčüčéčĆ ąĖą╗ąĖ I-čĆąĄą│ąĖčüčéčĆ.
ąÜąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü ąĖ čüą╝ąĄčēąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮčŗ čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆčÅčéčī čāčüą╗ąŠą▓ąĖčÄ č湥čéąĮąŠčüčéąĖ, čćč鹊ą▒čŗ ą░ą┤čĆąĄčü ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖą╗čüčÅ ąĮą░ 2 ąĖ čüąŠčģčĆą░ąĮčÅą╗ąŠčüčī ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą░ą┤čĆąĄčüą░ ąĮą░ ą┐ąŠą╗čāčüą╗ąŠą▓ąŠ (2 ą▒ą░ą╣čéą░). ą×čłąĖą▒ą║ą░ ą▓ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĖ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÄ ą┐ąŠ ąŠčłąĖą▒ą║ąĄ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ ą┐ąŠ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą╝čā ą░ą┤čĆąĄčüčā (misaligned memory access exception).
ą¤ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čåąĖąĖ:
ŌĆó ą¤ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮčé čāą║ą░ąĘą░č鹥ą╗čÅ čÅč湥ą╣ą║ąĖ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąĮą░ 2 ą▒ą░ą╣čéą░.
ąśą╝ąĄą╣č鹥 ą▓ ą▓ąĖą┤čā, čćč鹊 ą║ąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓čāčÄčēąĖą╣ ą░ą╗ą│ąŠčĆąĖčéą╝ DSP, č鹊 ą┤ą╗čÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠą│ąŠ čćč鹥ąĮąĖčÅ ą╗ąĄąČą░čēąĖčģ ą▓ ą┐ą░ą╝čÅčéąĖ 16-ą▒ąĖčéąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣ ą┐čĆąĄą┤ą┐ąŠčćčéąĖč鹥ą╗čīąĮąĄąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĖąĮčüčéčĆčāą║čåąĖčÄ Load Data Register ą▓ą╝ąĄčüč鹊 čćč鹥ąĮąĖčÅ ą┐ąŠą╗ąŠą▓ąĖąĮąŠą║ čĆąĄą│ąĖčüčéčĆąŠą▓. Load Data Register čĆą░ą▒ąŠčéą░ąĄčé ą▓ 2 čĆą░ąĘą░ ą▒čŗčüčéčĆąĄąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 ąĘą░ ąŠą┤ąĮčā ą║ąŠą╝ą░ąĮą┤čā ą╝ąŠąČąĄčé ą▓čŗą▒čĆą░čéčī ąĖąĘ ą┐ą░ą╝čÅčéąĖ čüčĆą░ąĘčā 2 ą┐ąŠą╗čāčüą╗ąŠą▓ą░. ąÜąŠą╝ą░ąĮą┤ą░, ąĘą░ą│čĆčāąČą░čÄčēą░čÅ ą┤ą░ąĮąĮčŗąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ą╝ąĖ, ąĖčüą┐ąŠą╗čīąĘčāąĄčé č鹊ą╗čīą║ąŠ ą┐ąŠą╗ąŠą▓ąĖąĮčā ąŠčé ą┤ąŠčüčéčāą┐ąĮąŠą╣ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ 32-ą▒ąĖčéąĮąŠą╣ čłąĖąĮčŗ, čćč鹊 ą╝ąŠąČąĄčé čüąĮąĖąĘąĖčéčī čüą║ąŠčĆąŠčüčéčī ąŠą▒ą╝ąĄąĮą░ ą┤ą░ąĮąĮčŗą╝ąĖ ą╝ąĄąČą┤čā ą┐čĆąŠčåąĄčüčüąŠčĆąŠą╝ ąĖ ą┐ą░ą╝čÅčéčīčÄ.
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
w[i1] = r3.l;
w[p0] = r3;
w[i3++ ] = r7.l;
w[i0-- ] = r1.l;
w[p4] = r2.l;
w[p1++ ] = r7;
w[sp-- ] = r2;
w[p2+ 12 ] = r6;
w[p4- 0x200C ] = r0;
w[p2++ p0] = r5.l;
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Store High Data Register Half, Store Data Register.
ąśąĮčüčéčĆčāą║čåąĖčÅ čüąŠčģčĆą░ąĮčÅąĄčé ą▓ ą┐ą░ą╝čÅčéąĖ ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
B [ ą║ąŠčüą▓ąĄąĮąĮčŗą╣_ą░ą┤čĆąĄčü ] = D-čĆąĄą│ąĖčüčéčĆ
ąĪąĖąĮčéą░ą║čüąĖčü:
B [Preg] = Dreg; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ (a)1
B [Preg++] = Dreg; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
B [Preg--] = Dreg; // ą║ąŠčüą▓ąĄąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čü ą┐ąŠčüčéą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ (a)
B [Preg+uimm15] = Dreg; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čüąŠ čüą╝ąĄčēąĄąĮąĖąĄą╝ (b)
B [Preg-uimm15] = Dreg; // ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą░ą┤čĆąĄčüą░čåąĖčÅ čüąŠ čüą╝ąĄčēąĄąĮąĖąĄą╝ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
ąÜą▓ą░ą┤čĆą░čéąĮčŗąĄ čüą║ąŠą▒ą║ąĖ ąŠąĘąĮą░čćą░čÄčé ą▓ąĘčÅčéąĖąĄ ą░ą┤čĆąĄčüą░, čé. ąĄ. ąĖčüčģąŠą┤ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▒ąĄčĆčāčéčüčÅ ąĖąĘ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ čüčüčŗą╗ą░ąĄčéčüčÅ ą░ą┤čĆąĄčü, čāą║ą░ąĘą░ąĮąĮčŗą╣ ą▓ ą║ą▓ą░ą┤čĆą░čéąĮčŗčģ čüą║ąŠą▒ą║ą░čģ (ą╗ąĖą▒ąŠ ą░ą┤čĆąĄčü čü čāč湥č鹊ą╝ čüą╝ąĄčēąĄąĮąĖčÅ).
Dreg: R0, ..., R7.
Preg: P0, ..., P5, SP, FP.
uimm15: 15-ą▒ąĖčéąĮąŠąĄ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ ą┐ąŠą╗ąĄ, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ čüąŠą┤ąĄčƹȹ░čéčī čüą╝ąĄčēąĄąĮąĖąĄ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 32767 ą▒ą░ą╣čé (0x0000 .. 0x7FFF).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą▒ą░ą╣čéą░ (Store Byte) ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé ą▓ 1-ą▒ą░ą╣čéąĮčāčÄ čÅč湥ą╣ą║čā ą┐ą░ą╝čÅčéąĖ ą╝ą╗ą░ą┤čłąĖąĄ 8 ą▒ąĖčé 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ. ąÆ ą║ą░č湥čüčéą▓ąĄ ą░ą┤čĆąĄčüą░ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čĆąĄą│ąĖčüčéčĆ čāą║ą░ąĘą░č鹥ą╗čÅ P-čĆąĄą│ąĖčüčéčĆ.
ąÜąŠčüą▓ąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü ąĖ čüą╝ąĄčēąĄąĮąĖąĄ ąĮąĄ ąĖą╝ąĄčÄčé ąĮąĖą║ą░ą║ąĖčģ ąŠą│čĆą░ąĮąĖč湥ąĮąĖą╣ ą┐ąŠ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÄ ą░ą┤čĆąĄčüą░ ą┐ą░ą╝čÅčéąĖ.
ą¤ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čåąĖąĖ:
ŌĆó ą¤ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮčé čāą║ą░ąĘą░č鹥ą╗čÅ čÅč湥ą╣ą║ąĖ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąĮą░ 1 ą▒ą░ą╣čé.
ąśą╝ąĄą╣č鹥 ą▓ ą▓ąĖą┤čā, čćč鹊 ą║ąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓čāčÄčēąĖą╣ ą░ą╗ą│ąŠčĆąĖčéą╝ DSP, č鹊 ą┤ą╗čÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠą│ąŠ čćč鹥ąĮąĖčÅ ą╗ąĄąČą░čēąĖčģ ą▓ ą┐ą░ą╝čÅčéąĖ 8-ą▒ąĖčéąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣ ą┐čĆąĄą┤ą┐ąŠčćčéąĖč鹥ą╗čīąĮąĄąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĖąĮčüčéčĆčāą║čåąĖčÄ Load Data Register ą▓ą╝ąĄčüč鹊 čćč鹥ąĮąĖčÅ ą┐ąŠą╗ąŠą▓ąĖąĮąŠą║ čĆąĄą│ąĖčüčéčĆąŠą▓. Load Data Register čĆą░ą▒ąŠčéą░ąĄčé ą▓ 4 čĆą░ąĘą░ ą▒čŗčüčéčĆąĄąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 ąĘą░ ąŠą┤ąĮčā ą║ąŠą╝ą░ąĮą┤čā ą╝ąŠąČąĄčé ą▓čŗą▒čĆą░čéčī ąĖąĘ ą┐ą░ą╝čÅčéąĖ čüčĆą░ąĘčā 4 ą▒ą░ą╣čéą░. ąÜąŠą╝ą░ąĮą┤ą░, čüąŠčģčĆą░ąĮčÅčÄčēą░čÅ ą┤ą░ąĮąĮčŗąĄ ą┐ąŠą▒ą░ą╣čéąĮąŠ, ąĖčüą┐ąŠą╗čīąĘčāąĄčé č鹊ą╗čīą║ąŠ 1/8 ąŠčé ą┤ąŠčüčéčāą┐ąĮąŠą╣ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ 32-ą▒ąĖčéąĮąŠą╣ čłąĖąĮčŗ, čćč鹊 ą╝ąŠąČąĄčé čüąĮąĖąĘąĖčéčī čüą║ąŠčĆąŠčüčéčī ąŠą▒ą╝ąĄąĮą░ ą┤ą░ąĮąĮčŗą╝ąĖ ą╝ąĄąČą┤čā ą┐čĆąŠčåąĄčüčüąŠčĆąŠą╝ ąĖ ą┐ą░ą╝čÅčéčīčÄ.
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
b[p0] = r3;
b[p1++ ] = r7;
b[sp-- ] = r2;
b[p4+ 0x100F ] = r0;
b[p4- 0x53F ] = r0;
[ąśąĮčüčéčĆčāą║čåąĖąĖ Move ]
ąÆ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ ąŠą▒čüčāąČą┤ą░čÄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ (move) ą┤ą░ąĮąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓. ąĪ čŹčéąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą╝ąŠąČąĄčé ą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ čéą░ą║ąĖą╝ąĖ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčÅą╝ąĖ, ą║ą░ą║ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ čĆąĄą│ąĖčüčéčĆąŠą▓ (ąĖą╗ąĖ ąĖčģ ą┐ąŠą╗ąŠą▓ąĖąĮąŠą║), ą┐ąŠą╗čāčüą╗ąŠą▓ čü ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ąĮčāą╗ąĄą╝ ąĖą╗ąĖ ąĘąĮą░ą║ąŠą╝, ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ ą▒ą░ą╣čé, ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ ą┐ąŠ čāčüą╗ąŠą▓ąĖčÄ.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ ą┐ąĄčĆąĄą▓ąŠą┤čćąĖą║ą░: čÅ ąĮąĄ ą┐ąŠąĮčÅą╗, ą┐ąŠč湥ą╝čā ą│čĆčāą┐ą┐ą░ čŹčéąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĮą░ąĘą▓ą░ąĮą░ Move (ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ). ą¤čĆą░ą▓ąĖą╗čīąĮąĄąĄ ą▒čŗą╗ąŠ ą▒čŗ ąĮą░ąĘčŗą▓ą░čéčī ąĄčæ Copy (ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ).
ą×ą▒čēą░čÅ č乊čĆą╝ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ:
čĆąĄą│ąĖčüčéčĆ_ąĮą░ąĘąĮą░č湥ąĮąĖčÅ = čĆąĄą│ąĖčüčéčĆ_ąĖčüč鹊čćąĮąĖą║
ąĪąĖąĮčéą░ą║čüąĖčü:
ą╗čÄą▒ąŠą╣_čĆąĄą│ąĖčüčéčĆ = ą╗čÄą▒ąŠą╣_čĆąĄą│ąĖčüčéčĆ // (a)1
ą¤čĆąĄą┤čāą┐čĆąĄąČą┤ąĄąĮąĖąĄ: ą┤ąŠą┐čāčüčéąĖą╝čŗ ąĮąĄ ą▓čüąĄ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ čĆąĄą│ąĖčüčéčĆąŠą▓. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
A0 = A1; // 40-čĆą░ąĘčĆčÅą┤ąĮčŗą╣ Accumulator (b)
A1 = A0; // 40-čĆą░ąĘčĆčÅą┤ąĮčŗą╣ Accumulator (b)
A0 = Dreg; // 32 čĆą░ąĘčĆčÅą┤ą░ D-čĆąĄą│ąĖčüčéčĆą░ ą▓ 32 čĆą░ąĘčĆčÅą┤ą░ A0.W (b)
A1 = Dreg; // 32 čĆą░ąĘčĆčÅą┤ą░ D-čĆąĄą│ąĖčüčéčĆą░ ą▓ 32 čĆą░ąĘčĆčÅą┤ą░ A1.W (b)
sysreg = Preg; // 32 čĆą░ąĘčĆčÅą┤ąĮčŗą╣ P-čĆąĄą│ąĖčüčéčĆ ą▓ sysreg (a)
ą¤ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄą╝ ą╝ąĄąČą┤čā ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą╝ ąĖ D-čĆąĄą│ąĖčüčéčĆąŠą╝:
Dreg_even = A0 ; // ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ A0 ą▓ č湥čéąĮčŗą╣ Dreg (b)
Dreg_odd = A1; // ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ A1 ą▓ ąĮąĄč湥čéąĮčŗą╣ Dreg (b)
Dreg_even = A0, Dreg_odd = A1 (opt_mode); // ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ ąŠą▒ąŠąĖčģ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓ ą▓
Dreg_odd = A1, Dreg_even = A0 (opt_mode); // ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ ąŠą▒ąŠąĖčģ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓ ą▓
Dreg_even = A0.X; // ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ 8 ą▒ąĖčé A0.X, čĆą░čüčłąĖčĆąĄąĮąĮąŠąĄ ąĘąĮą░ą║ąŠą╝, reg_even (b)
Dreg_odd = A1.X; // ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ 8-bit A1.X, čĆą░čüčłąĖčĆąĄąĮąĮąŠąĄ ąĘąĮą░ą║ąŠą╝, Dreg_odd (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
ą╗čÄą▒ąŠą╣_čĆąĄą│ąĖčüčéčĆ: R0, ..., R7, P0, ..., P5, SP, FP, I0, ..., I3, M0, ..., M3, B0, ..., B3, L0, ..., L3, A0.X, A0.W, A1.X, A1.W, ASTAT, RETS, RETI, RETX, RETN, RETE, LC0 ąĖ LC1, LT0 ąĖ LT1, LB0 ąĖ LB1, EMUDAT, USP, SEQSTAT ąĖ SYSCFG.
Dreg: R0, ..., R7.
Preg: P0, ..., P5, SP, FP.
sysreg: ASTAT, SEQSTAT, SYSCFG, RETI, RETX, RETN, RETE, RETS, LC0 ąĖ LC1, LT0 ąĖ LT1, LB0 ąĖ LB1, ąĖ EMUDAT.
Dreg_even: R0, R2, R4, R6 (č湥čéąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ ą┤ą░ąĮąĮčŗčģ).
Dreg_odd: R1, R3, R5, R7 (ąĮąĄč湥čéąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ ą┤ą░ąĮąĮčŗčģ).
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą║ąŠą│ą┤ą░ 2 ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ ą║ąŠą╝ą▒ąĖąĮąĖčĆčāčÄčéčüčÅ ą▓ ąŠą┤ąĮąŠą╣ ąĖ č鹊ą╣ ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ąŠą┐ąĄčĆą░ąĮą┤čŗ Dreg_even ąĖ Dreg_odd ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čćą╗ąĄąĮą░ą╝ąĖ ąŠą┤ąĮąŠą╣ ąĖ č鹊ą╣ ąČąĄ čĆąĄą│ąĖčüčéčĆąŠą▓ąŠą╣ ą┐ą░čĆčŗ, ąĮą░ą┐čĆąĖą╝ąĄčĆ ąĖąĘ ąĮą░ą▒ąŠčĆą░ R1:0, R3:2, R5:4, R7:6.
opt_mode: ąŠą┐čåąĖąŠąĮą░ą╗čīąĮčŗą╣ čĆąĄąČąĖą╝ (ISS2).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ čĆąĄą│ąĖčüčéčĆą░ (Move Register) ą║ąŠą┐ąĖčĆčāąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čĆąĄą│ąĖčüčéčĆą░-ąĖčüč鹊čćąĮąĖą║ą░ ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ą×ą┐ąĄčĆą░čåąĖčÅ ąĮąĖą║ą░ą║ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čĆąĄą│ąĖčüčéčĆą░-ąĖčüč鹊čćąĮąĖą║ą░.
ąØąĄ ą▓čüąĄ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ čĆą░ąĘčĆąĄčłąĄąĮčŗ. ąŚą░ą┐čĆąĄčēą░čÄčéčüčÅ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ ą╝ąĄąČą┤čā čüą╗ąĄą┤čāčÄčēąĖą╝ąĖ ą│čĆčāą┐ą┐ą░ą╝ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓:
1 . sysreg = sysreg,
2 . sysreg = Ireg, Mreg, Breg ąĖą╗ąĖ Lreg,
3 . Ireg, Mreg, Breg ąĖą╗ąĖ Lreg = sysreg,
4 . Preg ąĖą╗ąĖ USP = sysreg,
ą│ą┤ąĄ ŌĆ£sysregŌĆØ ą▓ą║ą╗čÄčćą░ąĄčé ASTAT, SEQSTAT, SYSCFG, RETI, RETX, RETN, RETE, RETS, LC0 ąĖ LC1, LT0 ąĖ LT1, LB0 ąĖ LB1, ąĖ EMUDAT.
ąĀą░ąĘčĆąĄčłąĄąĮčŗ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ ąĖąĘ Preg ąĖą╗ąĖ USP ą▓ sysreg.
ąĀąĄą│ąĖčüčéčĆčŗ čĆą░čüčłąĖčĆąĄąĮąĖčÅ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ A0.X ąĖ A1.X ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮčŗ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ 8 ą╝ą╗ą░ą┤čłąĖčģ ą▒ąĖčé A0.X[7:0] ąĖ A1.X[7:0]. ąøčÄą▒čŗąĄ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ ą▓ čüčéą░čĆčłąĖąĄ ą▒ąĖčéčŗ (ąĖą╗ąĖ ąĖąĘ čüčéą░čĆčłąĖčģ ą▒ąĖčé) A0.X[31:8] ąĖą╗ąĖ A1.X[31:8] ąĮąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮčŗ.
ąÆčüąĄ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ ąĖąĘ ą╝ąĄąĮčīčłąĖčģ ą┐ąŠ čĆą░ąĘą╝ąĄčĆčā čĆąĄą│ąĖčüčéčĆąŠą▓ ą▓ ą▒ąŠą╗čīčłąĖąĄ ą┐ąŠ čĆą░ąĘą╝ąĄčĆčā čĆąĄą│ąĖčüčéčĆčŗ čĆą░čüčłąĖčĆčÅčÄčéčüčÅ ąĘąĮą░ą║ąŠą╝ (sign extended).
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ ą▓ čĆąĄą│ąĖčüčéčĆ ą┤ą░ąĮąĮčŗčģ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čåąĖąĖ:
ŌĆó ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ: 32-ą▒ąĖčéąĮą░čÅ čĆą░čüą┐ą░ą║ąŠą▓ą║ą░ ąĖąĘ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ čü 32-ą▒ąĖčéąĮčŗą╝ ąĮą░čüčŗčēąĄąĮąĖąĄą╝ (saturation).
ąĢčüą╗ąĖ ąÆčŗ čģąŠčéąĖč鹥 čüąŠčģčĆą░ąĮąĖčéčī ąĮąĄąĖąĘą╝ąĄąĮąĮąŠąĄ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░, ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ą┐čĆąŠčüčéčāčÄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Move ą┤ą╗čÅ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ A.x ąĖą╗ąĖ A.w ą▓ čĆąĄą│ąĖčüčéčĆ ąĖą╗ąĖ ąĖąĘ čĆąĄą│ąĖčüčéčĆą░. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ąĮą░čüčŗčēąĄąĮąĖąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ", ąŠą▒čŖčÅčüąĮąĄąĮąĖąĄ č鹥čĆą╝ąĖąĮą░ Saturation.
[ążą╗ą░ą│ąĖ ]
ąĀąĄą│ąĖčüčéčĆ ASTAT čüąŠą┤ąĄčƹȹĖčé čäą╗ą░ą│ąĖ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī čÅą▓ąĮąŠ ąĖąĘą╝ąĄąĮąĄąĮčŗ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣.
ąÆąĄčĆčüąĖąĖ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ ą▓ D-čĆąĄą│ąĖčüčéčĆ ą┤ą╗čÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ą╗ąĖčÅčÄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ.
ŌĆó V čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé, ąĘą░ą┐ąĖčüą░ąĮąĮčŗą╣ ą▓ D-čĆąĄą│ąĖčüčéčĆ ąĮą░čüčŗčéąĖčé 32 ą▒ąĖčéą░; ąŠčćąĖčüčéąĖčéčüčÅ, ąĄčüą╗ąĖ ąĮąĄ ą▒čŗą╗ąŠ ąĮą░čüčŗčēąĄąĮąĖčÅ. ąÆ čüą╗čāčćą░ąĄ 2 ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣ V ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé ą╗ąŠą│ąĖč湥čüą║ąŠąĄ ąśąøąś ąŠčé čŹčéąĖčģ 2 ąŠą┐ąĄčĆą░čåąĖą╣.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ąĖąĘą╝ąĄąĮčÅčéčüčÅ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąÆ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ čüą╗čāčćą░ąĄą▓ čŹč鹊 čĆąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
ąĪą╗čāčćą░ąĖ čÅą▓ąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą║ USP, SEQSTAT, SYSCFG, RETI, RETX, RETN ąĖ RETE čéčĆąĄą▒čāčÄčé čĆąĄąČąĖą╝ą░ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░. ąĢčüą╗ąĖ ą║ ą╗čÄą▒ąŠą╝čā ąĖąĘ čŹčéąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé čÅą▓ąĮąŠąĄ ąŠą▒čĆą░čēąĄąĮąĖąĄ ąĖąĘ čĆąĄąČąĖą╝ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ, č鹊 ą▓ąŠąĘąĮąĖą║ą░ąĄčé exception (ąĖčüą║ą╗čÄč湥ąĮąĖąĄ) čéąĖą┐ą░ Illegal Use of Protected Resource (ąĮąĄą┤ąŠą┐čāčüčéąĖą╝ąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąĘą░čēąĖčēąĄąĮąĮąŠą│ąŠ čĆąĄčüčāčĆčüą░).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r3 = r0;
r7 = p2;
r2 = a0.w;
r2.l = a0.x;
r0 = a0.x;
a0 = a1;
a1 = a0;
a0 = r7; // ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ R7 ą▓ 32 ą▒ąĖčéą░ A0.W
a1 = r3; // ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ R3 ą▓ 32 ą▒ąĖčéą░ A1.W
retn = p0; // ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮąŠ ą▓ čĆąĄąČąĖą╝ąĄ Supervisor
r2 = a0; // 32 ą▒ąĖčéąĮąŠąĄ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝
r7 = a1; // 32 ą▒ąĖčéąĮąŠąĄ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝
r0 = a0 (iss2); // 32 ą▒ąĖčéąĮąŠąĄ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ čü ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖąĄą╝,
// ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖąĄą╝ čćą░čüčéąĖ čĆąĄąĘčāą╗čīčéą░čéą░ ąĖ ąĮą░čüčŗčēąĄąĮąĖąĄą╝
ąĪą╝. čéą░ą║ąČąĄ: ąĖąĮčüčéčĆčāą║čåąĖčÄ Load Immediate ą┤ą╗čÅ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ čĆąĄą│ąĖčüčéčĆąŠą▓; Move Half-Register ą┤ą╗čÅ čÅą▓ąĮąŠą│ąŠ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ ąĘąĮą░č湥ąĮąĖą╣ ą▓ čĆąĄą│ąĖčüčéčĆčŗ A0.X ąĖ A1.X; Zero Overhead Loop Setup ą┤ą╗čÅ čÅą▓ąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą║ čĆąĄą│ąĖčüčéčĆą░ą╝ LC0, LT0, LB0, LC1, LT1 ąĖ LB1; Call, Raise ąĖ Return ą┤ą╗čÅ ąĮąĄčÅą▓ąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą║ čĆąĄą│ąĖčüčéčĆą░ą╝ RETI, RETN ąĖ RETS; Force Exception ąĖ Force Emulation ą┤ą╗čÅ ąĮąĄčÅą▓ąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą║ čĆąĄą│ąĖčüčéčĆą░ą╝ RETX ąĖ RETE.
ąÜąŠą╝ą░ąĮą┤ą░ ąĘą░ą│čĆčāąČą░ąĄčé čĆąĄą│ąĖčüčéčĆ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čüąŠčüč鹊čÅąĮąĖčÅ ą▒ąĖčéą░ CC. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
IF CC čĆąĄą│ąĖčüčéčĆ_ąĮą░ąĘąĮą░č湥ąĮąĖčÅ = čĆąĄą│ąĖčüčéčĆ_ąĖčüč鹊čćąĮąĖą║
IF !CC čĆąĄą│ąĖčüčéčĆ_ąĮą░ąĘąĮą░č湥ąĮąĖčÅ = čĆąĄą│ąĖčüčéčĆ_ąĖčüč鹊čćąĮąĖą║
ąĪąĖąĮčéą░ą║čüąĖčü:
IF CC DPreg = DPreg; // ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ, ąĄčüą╗ąĖ CC = 1 (a)1
IF !CC DPreg = DPreg; // ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ, ąĄčüą╗ąĖ CC = 0 (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
DPreg: R0, ..., R7, P0, ..., P5, SP, FP.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ ą┐ąŠ čāčüą╗ąŠą▓ąĖčÄ (Move Conditional) ą┐ąĄčĆąĄą╝ąĄčüčéąĖčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čĆąĄą│ąĖčüčéčĆą░-ąĖčüč鹊čćąĮąĖą║ą░ ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ąĘąĮą░č湥ąĮąĖčÅ ą▒ąĖčéą░ CC.
ąöą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ IF CC DPreg = DPreg ą┤ą░ąĮąĮčŗąĄ ą▒čāą┤čāčé čüą║ąŠą┐ąĖčĆąŠą▓ą░ąĮčŗ č鹊ą╗čīą║ąŠ č鹊ą│ą┤ą░, ą║ąŠą│ą┤ą░ CC = 1.
ąöą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ IF !CC DPreg = DPreg ą┤ą░ąĮąĮčŗąĄ ą▒čāą┤čāčé čüą║ąŠą┐ąĖčĆąŠą▓ą░ąĮčŗ č鹊ą╗čīą║ąŠ č鹊ą│ą┤ą░, ą║ąŠą│ą┤ą░ CC = 0.
ąÆ ą║ą░č湥čüčéą▓ąĄ čĆąĄą│ąĖčüčéčĆą░ ąĖčüč鹊čćąĮąĖą║ą░ ąĖ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą╝ąŠą│čāčé ą▓čŗčüčéčāą┐ą░čéčī ą╗čÄą▒čŗąĄ D-čĆąĄą│ąĖčüčéčĆčŗ ąĖą╗ąĖ P-čĆąĄą│ąĖčüčéčĆčŗ.
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Move Conditional ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
// ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ, ąĄčüą╗ąĖ CC=1: if cc r3 = r0;if cc r2 = p4;if cc p0 = r7;if cc p2 = p5;// ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ, ąĄčüą╗ąĖ CC=0: if ! cc r3 = r0;if ! cc r2 = p4;if ! cc p0 = r7;if ! cc p2 = p5;
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Compare, Move CC, Negate CC, Conditional Jump.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąĄčĆąĄą╝ąĄčēą░ąĄčé ą┐ąŠą╗ąŠą▓ąĖąĮčā čüą╗ąŠą▓ą░, ą┤ąŠą┐ąŠą╗ąĮčÅčÅ ąŠčüčéą░ą╗čīąĮčŗąĄ ą▒ąĖčéčŗ čĆąĄą│ąĖčüčéčĆą░ ąĮčāą╗čÅą╝ąĖ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
čĆąĄą│ąĖčüčéčĆ_ąĮą░ąĘąĮą░č湥ąĮąĖčÅ = čĆąĄą│ąĖčüčéčĆ_ąĖčüč鹊čćąĮąĖą║ (Z)
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = Dreg.L (Z); // (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: R0, ..., R7.
Dreg.L: R0.L, ..., R7.L.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čüą╗ąŠą▓ą░ čü ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ąĮčāą╗ąĄą╝ (Move Half-Word - Zero-Extended) ą┐čĆąĄąŠą▒čĆą░ąĘčāąĄčé čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░ čĆą░ąĘą╝ąĄčĆąŠą╝ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮčā čüą╗ąŠą▓ą░ (16 ą▒ąĖčé) ą▓ čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░ čĆą░ąĘą╝ąĄčĆąŠą╝ ą▓ čüą╗ąŠą▓ąŠ (32 ą▒ąĖčéą░).
ąśąĮčüčéčĆčāą║čåąĖčÅ ą║ąŠą┐ąĖčĆčāąĄčé ą╝ą╗ą░ą┤čłąĖąĄ 16 ą▒ąĖčé ąĖąĘ 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ąĖčüč鹊čćąĮąĖą║ą░ ą▓ ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░. ąĪčéą░čĆčłą░čÅ ą┐ąŠą╗ąŠą▓ąĖąĮą░ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą▒čāą┤ąĄčé ąĘą░ą┐ąŠą╗ąĮąĄąĮą░ ąĮčāą╗čÅą╝ąĖ. ąŁčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ čĆą░ą▒ąŠčéą░ąĄčé č鹊ą╗čīą║ąŠ čü D-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ. ąĀą░čüčłąĖčĆąĄąĮąĖąĄ ąĮčāą╗čÅą╝ąĖ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠą│ąŠ 16-ą▒ąĖčéąĮąŠą│ąŠ čćąĖčüą╗ą░ ą▓ąŠ ą╝ąĮąŠą│ąĖčģ čüą╗čāčćą░čÅčģ ą┐ąŠą▓čĆąĄą┤ąĖčé ąĘąĮą░ą║ čćąĖčüą╗ą░ ąĖ ą░ą╝ą┐ą╗ąĖčéčāą┤čā čüąĖą│ąĮą░ą╗ą░ (ąŠč湥ą▓ąĖą┤ąĮąŠąĄ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ: čā ą▓čŗą▒ąŠčĆą║ąĖ 0x8000 čéą░ ąČąĄ čüą░ą╝ą░čÅ ą░ą╝ą┐ą╗ąĖčéčāą┤ą░, ą║ą░ą║ ą▒čŗ ąĮąĖ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ą╗ąŠčüčī čŹč鹊 čćąĖčüą╗ąŠ - ą║ą░ą║ čüąŠ ąĘąĮą░ą║ąŠą╝ ąĖą╗ąĖ ą║ą░ą║ ą▒ąĄąĘ ąĘąĮą░ą║ą░).
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Move Half-Word - Zero-Extended ąŠą║ą░ąČąĄčé ą▓ą╗ąĖčÅąĮąĖąĄ ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ąŠą┐ąĄčĆą░čåąĖąĖ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
// ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 r0.l = 0xFFFF. // ąŁčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ ą▒čāą┤ąĄčé 菹║ą▓ąĖą▓ą░ą╗ąĄąĮčéąĮą░ ą┤ą▓čāą╝ ąŠą┐ąĄčĆą░čåąĖčÅą╝ r4.l = r0.l ąĖ r4.h = 0:
r4 = r0.l(z);// ą¤ąŠčüą╗ąĄ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ r4 = 0x0000FFFF.
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Move Half-Word - Sign-Extended, Move Register Half.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąĄčĆąĄą╝ąĄčēą░ąĄčé ą┐ąŠą╗ąŠą▓ąĖąĮčā čüą╗ąŠą▓ą░, ą┤ąŠą┐ąŠą╗ąĮčÅčÅ ąŠčüčéą░ą╗čīąĮčŗąĄ ą▒ąĖčéčŗ ąĘąĮą░ą║ąŠą╝ čćąĖčüą╗ą░. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
čĆąĄą│ąĖčüčéčĆ_ąĮą░ąĘąĮą░č湥ąĮąĖčÅ = čĆąĄą│ąĖčüčéčĆ_ąĖčüč鹊čćąĮąĖą║
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = Dreg.L (X); // (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
ąśąĮčüčéčĆčāą║čåąĖčÄ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čéą░ą║ąČąĄ ąĖ ą▒ąĄąĘ čüčāčäčäąĖą║čüą░ (X). ąŁč鹊čé čüčāčäčäąĖą║čü ą┐čĆąŠčüč鹊 ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé ą║ąŠą┤čā čāą┤ąŠą▒čüčéą▓ą░ čćąĖčéą░ąĄą╝ąŠčüčéąĖ. ąŁč鹊 ąĮąĖą║ą░ą║ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ąĮąĖ ąĮą░ čäčāąĮą║čåąĖąŠąĮąĖčĆąŠą▓ą░ąĮąĖąĄ, ąĮąĖ ąĮą░ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: R0, ..., R7.
Dreg.L: R0.L, ..., R7.L.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čüą╗ąŠą▓ą░ čü ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ąĘąĮą░ą║ąŠą╝ (Move Half-Word - Sign-Extended) ą┐čĆąĄąŠą▒čĆą░ąĘčāąĄčé čćąĖčüą╗ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝ čĆą░ąĘą╝ąĄčĆąŠą╝ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮčā čüą╗ąŠą▓ą░ (16 ą▒ąĖčé) ą▓ čćąĖčüą╗ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝ čĆą░ąĘą╝ąĄčĆąŠą╝ ą▓ čüą╗ąŠą▓ąŠ (32 ą▒ąĖčéą░). ąśąĮčüčéčĆčāą║čåąĖčÅ ą║ąŠą┐ąĖčĆčāąĄčé ą╝ą╗ą░ą┤čłąĖąĄ 16 ą▒ąĖčé ąĖąĘ 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ąĖčüč鹊čćąĮąĖą║ą░ ą▓ ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░, čĆą░čüčłąĖčĆčÅčÅ ą┐čĆąĖ čŹč鹊ą╝ čüčéą░čĆčłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮą░ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąĘąĮą░ą║ąŠą╝ čćąĖčüą╗ą░ čĆąĄą│ąĖčüčéčĆą░ ąĖčüč鹊čćąĮąĖą║ą░. ąŁčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ čĆą░ą▒ąŠčéą░ąĄčé č鹊ą╗čīą║ąŠ čü D-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Move Half-Word - Zero-Extended ąŠą║ą░ąČąĄčé ą▓ą╗ąĖčÅąĮąĖąĄ ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ąŠą┐ąĄčĆą░čåąĖąĖ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Move Half-Word - Zero-Extended, Move Register Half.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąŠą▒ą╝ąĄąĮąĖą▓ą░čéčīčüčÅ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ą╝ąĖ čĆąĄą│ąĖčüčéčĆą░. ą×čüąĮąŠą▓ąĮą░čÅ č乊čĆą╝ą░:
ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░_čĆąĄą│ąĖčüčéčĆą░_ąĮą░ąĘąĮą░č湥ąĮąĖčÅ = ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░_čĆąĄą│ąĖčüčéčĆą░_ąĖčüč鹊čćąĮąĖą║ą░
ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░_čĆąĄą│ąĖčüčéčĆą░_ąĮą░ąĘąĮą░č湥ąĮąĖčÅ = accumulator (opt_mode)
ąĪąĖąĮčéą░ą║čüąĖčü ą▒ąĄąĘ čĆąĄąČąĖą╝ą░ ąŠą┐čåąĖą╣:
A0.X = Dreg_lo; // ą║ąŠą┐ąĖčĆčāąĄčé ą╝ą╗ą░ą┤čłąĖąĄ 8 ą▒ąĖčé ąĖąĘ Dreg ą▓ A0.X2 (b)1
A1.X = Dreg_lo; // ą║ąŠą┐ąĖčĆčāąĄčé ą╝ą╗ą░ą┤čłąĖąĄ 8 ą▒ąĖčé ąĖąĘ Dreg ą▓ A1.X (b)
Dreg.L = A0.X; // ą║ąŠą┐ąĖčĆčāąĄčé 8 ą▒ąĖčé A0.X, čĆą░čüčłąĖčĆąĄąĮąĮčŗąĄ ąĘąĮą░ą║ąŠą╝, ą▓ ą╝ą╗ą░ą┤čłąĖąĄ // 16 ą▒ąĖčé čĆąĄą│ąĖčüčéčĆą░ Dreg (b)
Dreg.L = A1.X; // ą║ąŠą┐ąĖčĆčāąĄčé 8 ą▒ąĖčé A1.X, čĆą░čüčłąĖčĆąĄąĮąĮčŗąĄ ąĘąĮą░ą║ąŠą╝, ą▓ ą╝ą╗ą░ą┤čłąĖąĄ // 16 ą▒ąĖčé čĆąĄą│ąĖčüčéčĆą░ Dreg (b)
A0.L = Dreg.L; // ą║ąŠą┐ąĖčĆčāąĄčé ą╝ą╗ą░ą┤čłąĖąĄ 16 ą▒ąĖčé Dreg ą▓ ą╝ą╗ą░ą┤čłąĖąĄ // 16 ą▒ąĖčé čĆąĄą│ąĖčüčéčĆą░ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ A0.W (b)
A1.L = Dreg.L; // ą║ąŠą┐ąĖčĆčāąĄčé ą╝ą╗ą░ą┤čłąĖąĄ 16 ą▒ąĖčé Dreg ą▓ ą╝ą╗ą░ą┤čłąĖąĄ // 16 ą▒ąĖčé čĆąĄą│ąĖčüčéčĆą░ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ A1.W (b)
A0.H = Dreg.H; // ą║ąŠą┐ąĖčĆčāąĄčé čüčéą░čĆčłąĖąĄ 16 ą▒ąĖčé Dreg ą▓ čüčéą░čĆčłąĖąĄ // 16 ą▒ąĖčé čĆąĄą│ąĖčüčéčĆą░ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ A0.W (b)
A1.H = Dreg.H; // ą║ąŠą┐ąĖčĆčāąĄčé čüčéą░čĆčłąĖąĄ 16 ą▒ąĖčé Dreg ą▓ čüčéą░čĆčłąĖąĄ // 16 ą▒ąĖčé čĆąĄą│ąĖčüčéčĆą░ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ A1.W (b)
ąĪąĖąĮčéą░ą║čüąĖčü čü ąŠą┐čåąĖčÅą╝ąĖ ą┤ą╗čÅ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā D-čĆąĄą│ąĖčüčéčĆą░:
Dreg.L = A0 (opt_mode); // ą║ąŠą┐ąĖčĆčāąĄčé A0 ą▓ ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā Dreg (b)
Dreg.H = A1 (opt_mode); // ą║ąŠą┐ąĖčĆčāąĄčé A1 ą▓ čüčéą░čĆčłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā Dreg (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 2: čĆąĄą│ąĖčüčéčĆčŗ čĆą░čüčłąĖčĆąĄąĮąĖčÅ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ (Accumulator Extension registers) A0.X ąĖ A1.X ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮčŗ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ 8 ą╝ą╗ą░ą┤čłąĖčģ ą▒ąĖčé A0.X[7:0] ąĖ A1.X[7:0]. ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąŠčéą▒čĆą░čüčŗą▓ą░ąĄčé čüčéą░čĆčłąĖą╣ ą▒ą░ą╣čé Dreg.L ą┐ąĄčĆąĄą┤ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ąĘąĮą░č湥ąĮąĖčÅ ą▓ Accumulator Extension register (A0.X ąĖą╗ąĖ A1.X).
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg.L: R0.L, ..., R7.L (ą╝ą╗ą░ą┤čłąĖąĄ 16 ą▒ąĖčé čĆąĄą│ąĖčüčéčĆą░ R0, ..., R7).
Dreg.H: R0.H, ..., R7.H (čüčéą░čĆčłąĖąĄ 16 ą▒ąĖčé čĆąĄą│ąĖčüčéčĆą░ R0, ..., R7).
A0.L: ą╝ą╗ą░ą┤čłąĖąĄ 16 ą▒ąĖčé ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ A0.W.
A1.L: ą╝ą╗ą░ą┤čłąĖąĄ 16 ą▒ąĖčé ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ A1.W.
A0.H: čüčéą░čĆčłąĖąĄ 16 ą▒ąĖčé ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ A0.W.
A1.H: čüčéą░čĆčłąĖąĄ 16 ą▒ąĖčé ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ A1.W.
opt_mode: ąŠą┐čåąĖąŠąĮą░ą╗čīąĮčŗąĄ čüčāčäčäąĖą║čüčŗ (IS), (IU), (T), (S2RND), (ISS2) ąĖą╗ąĖ (IH).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Move Register Half ą║ąŠą┐ąĖčĆčāąĄčé 16 ąĖąĘ čĆąĄą│ąĖčüčéčĆą░-ąĖčüč鹊čćąĮąĖą║ą░ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮčā 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĖą║ą░ą║ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čāčÄ čćą░čüčéčī čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą▓ ą║ą░č湥čüčéą▓ąĄ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ č鹊ą╗čīą║ąŠ D-čĆąĄą│ąĖčüčéčĆčŗ ąĖ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ.
ą×ą┤ąĮą░ ą▓ąĄčĆčüąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ą┐čĆąŠčüč鹊 ą║ąŠą┐ąĖčĆčāąĄčé 16 ą▒ąĖčé (ąĮą░čüčŗčēąĄąĮąĖąĄ ą┐ąŠ 16 ą▒ąĖčéą░ą╝) ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ ą▓ ą┤ą░ąĮąĮčŗąĄ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆą░. ąŁč鹊čé čüąĖąĮčéą░ą║čüąĖčü ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖąĄ čćą░čüčéąĖ ąĘąĮą░č湥ąĮąĖčÅ (truncation) ąĖ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ ą▓ąĮąĄ ą┐čĆąŠčüč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ Move Register Half.
ą¦ą░čüčéąĖčćąĮą░čÅ ą▓ąĄčĆčüąĖčÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ (ąŠą┐čåąĖčÅ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ) ą┐ąĄčĆąĄąĮąŠčüąĖčé čĆąĄąĘčāą╗čīčéą░čé ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü ą┤ąĖą░ą│čĆą░ą╝ą╝ąŠą╣, ą┐ąŠą║ą░ąĘą░ąĮąĮąŠą╣ ąĮąĖąČąĄ ąĮą░ čĆąĖčüčāąĮą║ąĄ:
ą”ąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮą░čÅ ą▓ąĄčĆčüąĖčÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ (čü ąŠą┐čåąĖąĄą╣ IS) ą┐ąĄčĆąĄąĮąŠčüąĖčé čĆąĄąĘčāą╗čīčéą░čé ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü ą┤ąĖą░ą│čĆą░ą╝ą╝ąŠą╣, ą┐ąŠą║ą░ąĘą░ąĮąĮąŠą╣ ąĮąĖąČąĄ ąĮą░ čĆąĖčüčāąĮą║ąĄ:
ąØą░ ąĮąĄą║ąŠč鹊čĆčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ą╗ąĖčÅąĄčé ą▒ąĖčé RND_MOD ą▓ čĆąĄą│ąĖčüčéčĆąĄ ASTAT, ą║ąŠą│ą┤ą░ čĆąĄąĘčāą╗čīčéą░čé ą║ąŠą┐ąĖčĆčāąĄčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ąæąĖčé RND_MOD ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą▓ą░čĆąĖą░ąĮčé ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ - čüą╝ąĄčēąĄąĮąĮčŗą╣ (biased rounding) ąĖą╗ąĖ ąĮąĄ čüą╝ąĄčēąĄąĮąĮčŗą╣ (unbiased rounding). ąæąĖčé RND_MOD čāą┐čĆą░ą▓ą╗čÅąĄčé ą▓čüąĄą╝ąĖ ą▓ąĄčĆčüąĖčÅą╝ąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║čĆąŠą╝ąĄ ąŠą┐čåąĖą╣ (IS) ąĖ (ISS2).
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ čüą╝. čüąĄą║čåąĖčÄ ŌĆ£Rounding, TruncatingŌĆØ.
ąŻ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆą░čÅ ą║ąŠą┐ąĖčĆčāąĄčé ą┤ą░ąĮąĮčŗąĄ ąĖąĘ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā D-čĆąĄą│ąĖčüčéčĆą░, ąĄčüčéčī čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čåąĖąĖ:
ąóą░ą▒ą╗ąĖčåą░ 4-2. ą×ą┐čåąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ Accumulator to Half D-Register Move.
ą×ą┐čåąĖčÅ ążąŠčĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐čĆąĖ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĖ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░
ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĪčéą░čĆčłą░čÅ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ čĆą░čüą┐ą░ą║ąŠą▓čŗą▓ą░ąĄčéčüčÅ ąĖąĘ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ čü 16-ą▒ąĖčéąĮčŗą╝ ąĮą░čüčŗčēąĄąĮąĖąĄą╝ (saturation) ąĖ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄą╝ (rounding). ą×ą║čĆčāą│ą╗ąĄąĮąĖąĄ čāą┐čĆą░ą▓ą╗čÅąĄčéčüčÅ ą▒ąĖč鹊ą╝ RND_MOD čĆąĄą│ąĖčüčéčĆą░ ASTAT.
(IS) ą£ą╗ą░ą┤čłą░čÅ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ čĆą░čüą┐ą░ą║ąŠą▓čŗą▓ą░ąĄčéčüčÅ ąĖąĘ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ čü 16-ą▒ąĖčéąĮčŗą╝ ąĮą░čüčŗčēąĄąĮąĖąĄą╝ (saturation). ą×ą║čĆčāą│ą╗ąĄąĮąĖąĄ ąĮąĄ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ.
(IU) ą£ą╗ą░ą┤čłą░čÅ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ čĆą░čüą┐ą░ą║ąŠą▓čŗą▓ą░ąĄčéčüčÅ ąĖąĘ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ čü 16-ą▒ąĖčéąĮčŗą╝ ąĮą░čüčŗčēąĄąĮąĖąĄą╝ (saturation) ąĖ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄą╝ (rounding). ą×ą║čĆčāą│ą╗ąĄąĮąĖąĄ čāą┐čĆą░ą▓ą╗čÅąĄčéčüčÅ ą▒ąĖč鹊ą╝ RND_MOD čĆąĄą│ąĖčüčéčĆą░ ASTAT.
(T) ąĪčéą░čĆčłą░čÅ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ ą┤ą░ąĮąĮčŗčģ čĆą░čüą┐ą░ą║ąŠą▓čŗą▓ą░ąĄčéčüčÅ ąĖąĘ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░. ą¤čĆąŠąĖčüčģąŠą┤ąĖčé ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖąĄ ą╝ą╗ą░ą┤čłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čüą╗ąŠą▓ą░ (truncation) čü ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄą╝ (rounding). ą×ą║čĆčāą│ą╗ąĄąĮąĖąĄ čāą┐čĆą░ą▓ą╗čÅąĄčéčüčÅ ą▒ąĖč鹊ą╝ RND_MOD čĆąĄą│ąĖčüčéčĆą░ ASTAT.
(S2RND) ąĪčéą░čĆčłą░čÅ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ ą┤ą░ąĮąĮčŗčģ čĆą░čüą┐ą░ą║ąŠą▓čŗą▓ą░ąĄčéčüčÅ čü ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖąĄą╝ (scaling), ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄą╝ (rounding) ąĖ 16-ą▒ąĖčéąĮčŗą╝ ąĮą░čüčŗčēąĄąĮąĖąĄą╝ (saturation). ą×ą║čĆčāą│ą╗ąĄąĮąĖąĄ čāą┐čĆą░ą▓ą╗čÅąĄčéčüčÅ ą▒ąĖč鹊ą╝ RND_MOD čĆąĄą│ąĖčüčéčĆą░ ASTAT. ą×ą┐ąĄčĆą░čåąĖčÅ ą╝ą░čüčłčéą░ą▒ąĖčĆčāąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ (čāą╝ąĮąŠąČąĄąĮąĖąĄą╝ ąĮą░ 2 ą┐čāč鹥ą╝ ąŠą┤ąĖąĮąŠčćąĮąŠą│ąŠ čüą┤ą▓ąĖą│ą░ ą▓ą╗ąĄą▓ąŠ) ąĖ ąŠą║čĆčāą│ą╗čÅąĄčé ą▓ąĄčĆčģąĮąĖąĄ 16 ą▒ąĖčé ą┐ąĄčĆąĄą┤ ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖąĄą╝ ą╝ą╗ą░ą┤čłąĖčģ 16 ą▒ąĖčé.
(ISS2) ą£ą╗ą░ą┤čłą░čÅ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ ą┤ą░ąĮąĮčŗčģ čĆą░čüą┐ą░ą║ąŠą▓čŗą▓ą░ąĄčéčüčÅ čü ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖąĄą╝ (scaling) ąĖ 16-ą▒ąĖčéąĮčŗą╝ ąĮą░čüčŗčēąĄąĮąĖąĄą╝ (saturation). ą×ą║čĆčāą│ą╗ąĄąĮąĖąĄ ąĮąĄ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ. ą×ą┐ąĄčĆą░čåąĖčÅ ą╝ą░čüčłčéą░ą▒ąĖčĆčāąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ (čāą╝ąĮąŠąČąĄąĮąĖąĄą╝ ąĮą░ 2 ą┐čāč鹥ą╝ ąŠą┤ąĖąĮąŠčćąĮąŠą│ąŠ čüą┤ą▓ąĖą│ą░ ą▓ą╗ąĄą▓ąŠ) ąĖ ąŠą║čĆčāą│ą╗čÅąĄčé ą▓ąĄčĆčģąĮąĖąĄ 16 ą▒ąĖčé ą┐ąĄčĆąĄą┤ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ą╝ą╗ą░ą┤čłąĖčģ 16 ą▒ąĖčé.
(IH) ąĪčéą░čĆčłą░čÅ ą┐ąŠą╗ąŠą▓ąĖąĮą║ą░ ą┤ą░ąĮąĮčŗčģ čĆą░čüą┐ą░ą║ąŠą▓čŗą▓ą░ąĄčéčüčÅ čü 32-ą▒ąĖčéąĮčŗą╝ ąĮą░čüčŗčēąĄąĮąĖąĄą╝ (saturation), ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ (rounding) ąĮą░ čüčéą░čĆčłąĖčģ 16 ą▒ąĖčéą░čģ. ą×ą║čĆčāą│ą╗ąĄąĮąĖąĄ čāą┐čĆą░ą▓ą╗čÅąĄčéčüčÅ ą▒ąĖč鹊ą╝ RND_MOD čĆąĄą│ąĖčüčéčĆą░ ASTAT.
ąöą╗čÅ ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖčÅ čćą░čüčéąĖ ą┤ą░ąĮąĮčŗčģ (truncate) čĆąĄąĘčāą╗čīčéą░čéą░ ąŠą┐ąĄčĆą░čåąĖčÅ čāąĮąĖčćč鹊ąČą░ąĄčé ą╝ą╗ą░ą┤čłąĖąĄ ą▒ąĖčéčŗ, ą║ąŠč鹊čĆčŗąĄ ąĮąĄ čāą╝ąĄčēą░čÄčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ąÜąŠą│ą┤ą░ čŹč鹊 ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ, ą┐ąŠčüą╗ąĄ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ąĮą░čüčŗčēąĄąĮąĖąĄ.
ąĢčüą╗ąĖ ąÆčŗ čģąŠčéąĖč鹥 čüąŠčģčĆą░ąĮąĖčéčī ąĮąĄčéčĆąŠąĮčāčéčŗą╝ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ Accumulator, ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ą┐čĆąŠčüčéčāčÄ ą▓ąĄčĆčüąĖčÄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Move ą┤ą╗čÅ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ A.x ąĖą╗ąĖ A.w ą▓ ąĮčāąČąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ ąĖą╗ąĖ ąĖąĘ ąĮčāąČąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ąĮą░čüčŗčēąĄąĮąĖąĄ čüą╝. čüąĄą║čåąĖčÄ "Saturation (ąĮą░čüčŗčēąĄąĮąĖąĄ)".
[ążą╗ą░ą│ąĖ ]
ąÆąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ Accumulator to Half D-register Move ą▓ą╗ąĖčÅčÄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó V čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé, ąĘą░ą┐ąĖčüą░ąĮąĮčŗą╣ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā D-čĆąĄą│ąĖčüčéčĆą░, ą┐čĆąĄč鹥čĆą┐ąĄą╗ ąĮą░čüčŗčēąĄąĮąĖąĄ ą┐ąŠ 16 ą▒ąĖčéą░ą╝, ąĖą╗ąĖ ąŠčćąĖčüčéąĖčéčüčÅ, ąĄčüą╗ąĖ ąĮąĄ ą▒čŗą╗ąŠ ąĮą░čüčŗčēąĄąĮąĖčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
a0.x = r1.l;
a1.x = r4.l;
r7.l = a0.x;
r0.l = a1.x;
a0.l = r2.l;
a1.l = r1.l;
a0.l = r5.l;
a1.l = r3.l;
a0.h = r7.h;
a1.h = r0.h;
r7.l = a0; // ąÜąŠą┐ąĖčĆčāąĄčéčüčÅ A0.H ą▓ R7.L čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝.
r2.h = a1; // ąÜąŠą┐ąĖčĆčāąĄčéčüčÅ A0.H ą▓ R2.H čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝.
r0.h = a1(is); // ąÜąŠą┐ąĖčĆčāąĄčéčüčÅ A1.L ą▓ R0.H čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝.
r5.l = a0 (t); // ąÜąŠą┐ąĖčĆčāąĄčéčüčÅ A0.H ą▓ R5.L; ąŠčéą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ A0.L;
// ąĮą░čüčŗčēąĄąĮąĖąĄ ąĮąĄ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ.
r1.l = a0(s2rnd); // ąÜąŠą┐ąĖčĆčāąĄčéčüčÅ A0.H ą▓ R1.L čü ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖąĄą╝,
// ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄą╝ ąĖ ąĮą░čüčŗčēąĄąĮąĖąĄą╝.
r2.h = a1 iss2); // ąÜąŠą┐ąĖčĆčāąĄčéčüčÅ A1.L ą▓ R2.H čü ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖąĄą╝
// ąĖ ąĮą░čüčŗčēąĄąĮąĖąĄą╝.
r6.l = a0(ih); // ąÜąŠą┐ąĖčĆčāąĄčéčüčÅ A0.H ą▓ R6.L čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝.
// ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ą┤ąĄą╗ą░ąĄčéčüčÅ ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ.
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Move Half-Word - Zero-Extended, Move Half-Word - Sign-Extended.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą║ąŠą┐ąĖčĆčāąĄčé ą▒ą░ą╣čé čü ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ą▒ąĖčé čĆąĄą│ąĖčüčéčĆą░ ąĮčāą╗čÅą╝ąĖ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
čĆąĄą│ąĖčüčéčĆ_ąĮą░ąĘąĮą░č湥ąĮąĖčÅ = ą▒ą░ą╣čé_čĆąĄą│ąĖčüčéčĆą░_ąĖčüč鹊čćąĮąĖą║ą░ (Z)
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = Dreg_byte (Z); // (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
Dreg_byte: R[7:0].B, ą╝ą╗ą░ą┤čłąĖą╣ ą▒ą░ą╣čé ą╗čÄą▒ąŠą│ąŠ D-čĆąĄą│ąĖčüčéčĆą░.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Move Byte - Zero-Extended ą┐čĆąĄąŠą▒čĆą░ąĘčāąĄčé ą▒ą░ą╣čé ą▒ąĄąĘ ąĘąĮą░ą║ą░ ą▓ čüą╗ąŠą▓ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░ (čćąĖčüą╗ąŠ 32 ą▒ąĖčéą░). ąśąĮčüčéčĆčāą║čåąĖčÅ ą║ąŠą┐ąĖčĆčāąĄčé ą╝ą╗ą░ą┤čłąĖąĄ ą╝ą╗ą░ą┤čłąĖąĄ 8 ą▒ąĖčé ąĖąĘ čĆąĄą│ąĖčüčéčĆą░ ąĖčüč鹊čćąĮąĖą║ą░ ą▓ ą╝ą╗ą░ą┤čłąĖąĄ 8 ą▒ąĖčé 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ą¤čĆąĖ čŹč鹊ą╝ ąŠčüčéą░ą╗čīąĮčŗąĄ ą▒ąĖčéčŗ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąĘą░ą┐ąŠą╗ąĮčÅčÄčéčüčÅ ąĮčāą╗čÅą╝ąĖ. ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé čĆą░ą▒ąŠčéą░čéčī č鹊ą╗čīą║ąŠ čü D-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Move Half-Word - Zero-Extended ąŠą║ą░ąČąĄčé ą▓ą╗ąĖčÅąĮąĖąĄ ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ąŠą┐ąĄčĆą░čåąĖąĖ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Move Register Half ą┤ą╗čÅ čÅą▓ąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą║ čĆą░čüčłąĖčĆąĄąĮąĖčÅą╝ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ (Accumulator Extension registers) A0.X ąĖ A1.X. ąóą░ą║ąČąĄ čüą╝. ąĖąĮčüčéčĆčāą║čåąĖčÄ Move Byte - Sign-Extended.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą║ąŠą┐ąĖčĆčāąĄčé ą▒ą░ą╣čé čü ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ąĘąĮą░ą║ąŠą╝ čćąĖčüą╗ą░. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
čĆąĄą│ąĖčüčéčĆ_ąĮą░ąĘąĮą░č湥ąĮąĖčÅ = ą▒ą░ą╣čé_čĆąĄą│ąĖčüčéčĆą░_ąĖčüč鹊čćąĮąĖą║ą░
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = Dreg_byte (X); // (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
ąśąĮčüčéčĆčāą║čåąĖčÄ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čéą░ą║ąČąĄ ąĖ ą▒ąĄąĘ čüčāčäčäąĖą║čüą░ (X). ąŁč鹊čé čüčāčäčäąĖą║čü ą┐čĆąŠčüč鹊 ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé ą║ąŠą┤čā čāą┤ąŠą▒čüčéą▓ą░ čćąĖčéą░ąĄą╝ąŠčüčéąĖ. ąŁč鹊 ąĮąĖą║ą░ą║ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ąĮąĖ ąĮą░ čäčāąĮą║čåąĖąŠąĮąĖčĆąŠą▓ą░ąĮąĖąĄ, ąĮąĖ ąĮą░ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
Dreg_byte: R[7:0].B, ą╝ą╗ą░ą┤čłąĖą╣ ą▒ą░ą╣čé ą╗čÄą▒ąŠą│ąŠ D-čĆąĄą│ąĖčüčéčĆą░.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Move Byte - Zero-Extended ą┐čĆąĄąŠą▒čĆą░ąĘčāąĄčé ą▒ą░ą╣čé čüąŠ ąĘąĮą░ą║ąŠą╝ ą▓ čüą╗ąŠą▓ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝ (čćąĖčüą╗ąŠ 32 ą▒ąĖčéą░). ąśąĮčüčéčĆčāą║čåąĖčÅ ą║ąŠą┐ąĖčĆčāąĄčé ą╝ą╗ą░ą┤čłąĖąĄ ą╝ą╗ą░ą┤čłąĖąĄ 8 ą▒ąĖčé ąĖąĘ čĆąĄą│ąĖčüčéčĆą░ ąĖčüč鹊čćąĮąĖą║ą░ ą▓ ą╝ą╗ą░ą┤čłąĖąĄ 8 ą▒ąĖčé 32-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ą¤čĆąĖ čŹč鹊ą╝ ąŠčüčéą░ą╗čīąĮčŗąĄ ą▒ąĖčéčŗ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąĘą░ą┐ąŠą╗ąĮčÅčÄčéčüčÅ ąĘąĮą░č湥ąĮąĖąĄą╝ ą▒ąĖčéą░ ąĘąĮą░ą║ą░ ą▒ą░ą╣čéą░ ąĖčüč鹊čćąĮąĖą║ą░. ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé čĆą░ą▒ąŠčéą░čéčī č鹊ą╗čīą║ąŠ čü D-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Move Half-Word - Zero-Extended ąŠą║ą░ąČąĄčé ą▓ą╗ąĖčÅąĮąĖąĄ ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ąŠą┐ąĄčĆą░čåąĖąĖ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Move Byte - Zero-Extended.
[ąśąĮčüčéčĆčāą║čåąĖąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čüč鹥ą║ąŠą╝ ]
ąÆ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ ąŠą▒čüčāąČą┤ą░čÄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ą╗čÅ ą╝ą░ąĮąĖą┐čāą╗čÅčåąĖąĖ čüąŠ čüč鹥ą║ąŠą╝ (Push, Push Multiple, Pop, Pop Multiple, Linkage). ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĖ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĖčģ ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą▓ čüč鹥ą║ąĄ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ ąŠą┤ąĮąŠą│ąŠ ąĖą╗ąĖ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓, ąĖą╗ąĖ ą┤ą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄą╝ ąŠą▒ą╗ą░čüčéčīčÄ ą┐ą░ą╝čÅčéąĖ čüč鹥ą║ą░ ąĖ čāą║ą░ąĘą░č鹥ą╗čÅ čäčĆąĄą╣ą╝ą░ (Frame Pointer, FP).
ąÜąŠą╝ą░ąĮą┤ą░ ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĄčé ą▓ čüč鹥ą║ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čĆąĄą│ąĖčüčéčĆą░. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
[--SP] = čĆąĄą│ąĖčüčéčĆ
ąĪąĖąĮčéą░ą║čüąĖčü:
[--SP] = ą╗čÄą▒ąŠą╣_čĆąĄą│ąĖčüčéčĆ; // ą┤ą╗čÅ čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░ SP ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┐čĆąĄą┤ą┤ąĄą║čĆąĄą╝ąĄąĮčé (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
ą╗čÄą▒ąŠą╣_čĆąĄą│ąĖčüčéčĆ: R0, ..., R7, P0, ..., P5, FP, I0, ..., I3, M0, ..., M3, B0, ..., B3, L0, ..., L3, A0.X, A0.W, A1.X, A1.W, ASTAT, RETS, RETI, RETX, RETN, RETE, LC0 ąĖ LC1, LT0 ąĖ LT1, LB0 ąĖ LB1, EMUDAT, USP, SEQSTAT ąĖ SYSCFG.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Push čüąŠčģčĆą░ąĮčÅąĄčé ąĘąĮą░č湥ąĮąĖąĄ čāą║ą░ąĘą░ąĮąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą▓ čüč鹥ą║ąĄ. ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąĄčĆąĄą┤ čüąŠčģčĆą░ąĮąĄąĮąĖąĄą╝ ą┤ąĄą╗ą░ąĄčé ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮčŗą╣ ą┤ąĄą║čĆąĄą╝ąĄąĮčé čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░ (Stack Pointer, SP), čćč鹊ą▒čŗ ąŠąĮ čāą║ą░ąĘčŗą▓ą░ą╗ ąĮą░ čüą╗ąĄą┤čāčÄčēąĄąĄ čüą▓ąŠą▒ąŠą┤ąĮąŠąĄ ą╝ąĄčüč鹊 ą▓ čüč鹥ą║ąĄ, ą║čāą┤ą░ ą╝ąŠąČąĮąŠ ą┐ąŠą╝ąĄčüčéąĖčéčī č鹥ą║čāčēąĖą╣ čĆąĄą│ąĖčüčéčĆ. ąóąŠą╗čīą║ąŠ ąĖąĮčüčéčĆčāą║čåąĖąĖ Push ąĖ Push Multiple ą▓čŗą┐ąŠą╗ąĮčÅčÄčé čéą░ą║ąĖąĄ ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮčŗąĄ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖąĖ čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░.
ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čüč鹥ą║ čĆą░čüč鹥čé ąŠčé čüčéą░čĆčłąĖčģ ą░ą┤čĆąĄčüąŠą▓ ą┐ą░ą╝čÅčéąĖ ą║ ą╝ą╗ą░ą┤čłąĖą╝ (čŹč鹊 čéčĆą░ą┤ąĖčåąĖąŠąĮąĮą░čÅ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖčÅ čüč鹥ą║ą░). ąĪąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ ą┤ąĄą║čĆąĄą╝ąĄąĮčé SP (čāą╝ąĄąĮčīčłąĄąĮąĖąĄ ą░ą┤čĆąĄčüą░) ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖčÅ ą▓ čüč鹥ą║ (Push, čüąŠčģčĆą░ąĮąĄąĮąĖąĄ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą▓ čüč鹥ą║ąĄ), ąĖ ąĖąĮą║čĆąĄą╝ąĄąĮčé SP (čāą▓ąĄą╗ąĖč湥ąĮąĖąĄ SP) ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ąĖąĘą▓ą╗ąĄč湥ąĮąĖčÅ ąĖąĘ čüč鹥ą║ą░ (Pop, čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čĆąĄą│ąĖčüčéčĆą░ ą▓ąŠčüčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ąĖąĘ čüč鹥ą║ą░). SP ą▓čüąĄą│ą┤ą░ čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ ą┐ąŠčüą╗ąĄą┤ąĮčÄčÄ ąĘą░ąĮčÅčéčāčÄ čÅč湥ą╣ą║čā ą▓ čüč鹥ą║ąĄ. ąóą░ą║ čćč鹊 čŹčäč乥ą║čéąĖą▓ąĮčŗą╣ ą░ą┤čĆąĄčü ą┤ą╗čÅ ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖčÅ ą▓ čüč鹥ą║ ą▒čāą┤ąĄčé čĆą░ą▓ąĄąĮ SP-4.
ąØą░ čüą╗ąĄą┤čāčÄčēąĄą╣ ą║ą░čĆčéąĖąĮą║ąĄ ą┐ąŠą║ą░ąĘą░ąĮąŠ, ą║ą░ą║ ą▒čāą┤ąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī čüč鹥ą║ ą┐ąŠčüą╗ąĄ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ąŠą┐ąĄčĆą░čåąĖą╣ ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖčÅ ą▓ čüč鹥ą║.
ąöą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ Stack Pointer ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓čüąĄą│ą┤ą░ ą▓čŗčĆąŠą▓ąĮąĄąĮ ąĮą░ 32 ą▒ąĖčéą░ (ą░ą┤čĆąĄčü ą▓ SP ą┤ąŠą╗ąČąĄąĮ ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░ 4). ąĢčüą╗ąĖ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ, č鹊 ą▒čāą┤ąĄčé čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ (exception), ąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▒čāą┤ąĄčé ą┐čĆąĄčĆą▓ą░ąĮąŠ.
Push/pop ąĮą░ RETS ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüąĖčüč鹥ą╝čā ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣.
Push/pop ąĮą░ RETI ą▓ą╗ąĖčÅąĄčé ąĮą░ čüąĖčüč鹥ą╝čā ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣. ą¤čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖąĄ ą▓ čüč鹥ą║ RETI (Push) čĆą░ąĘčĆąĄčłą░ąĄčé čĆą░ą▒ąŠčéčā čüąĖčüč鹥ą╝čŗ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ą▓čŗą▒ąŠčĆą║ą░ ąĖąĘ čüč鹥ą║ą░ RETI (Pop) ąĘą░ą┐čĆąĄčēą░ąĄčé čüąĖčüč鹥ą╝čā ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣.
ą¤čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖąĄ ą▓ čüč鹥ą║ čüą░ą╝ąŠą│ąŠ SP ą▒ąĄčüčüą╝čŗčüą╗ąĄąĮąĮąŠ, ą┐ąŠč鹊ą╝čā čćč鹊 SP ąĮąĄą╗čīąĘčÅ ąĖąĘą▓ą╗ąĄčćčī ąĖąĘ čüč鹥ą║ą░. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ Stack Pointer ą▓ ą║ą░č湥čüčéą▓ąĄ ąŠą┐ąĄčĆą░ąĮą┤ą░ ą┤ą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ Pop (ą║ą░ą║ ąĄčüą╗ąĖ ą▒čŗ ą▒čŗą╗ą░ čāą║ą░ąĘą░ąĮą░ čäąĖą║čéąĖą▓ąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ SP=[SP++]) ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĮąĄą┐čĆąĄą┤čüą║ą░ąĘčāąĄą╝ąŠą╝čā ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÄ (ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ąĖą╝ąĄąĮą░ čĆąĄą│ąĖčüčéčĆąŠą▓ čüą╝. čĆą░ąĘą┤ąĄą╗ "ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ").
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąÆ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ čüą╗čāčćą░ąĄą▓ čŹč鹊 čĆąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
ą»ą▓ąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ čĆąĄą│ąĖčüčéčĆą░ą╝ USP, SEQSTAT, SYSCFG, RETI, RETX, RETN ąĖ RETE čéčĆąĄą▒čāąĄčé čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░. ąĢčüą╗ąĖ ą┐ąŠą┐čĆąŠą▒ąŠą▓ą░čéčī čÅą▓ąĮąŠ ąŠą▒čĆą░čéąĖčéčīčüčÅ ą║ čŹčéąĖą╝ čĆąĄą│ąĖčüčéčĆą░ą╝ ąĖąĘ čĆąĄąČąĖą╝ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ, č鹊 ą▓ąŠąĘąĮąĖą║ąĮąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĘą░čēąĖčéčŗ ąĮą░čĆčāčłąĄąĮąĖčÅ ą┤ąŠčüčéčāą┐ą░ (protection violation exception).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Push ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
[-- sp] = r0;
[-- sp] = r1;
[-- sp] = p0;
[-- sp] = i0;
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Push Multiple, Pop.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĄčé ą▓ čüč鹥ą║ čüčĆą░ąĘčā ąĮąĄčüą║ąŠą╗čīą║ąŠ čĆąĄą│ąĖčüčéčĆąŠą▓. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
[--SP] = (ą┤ąĖą░ą┐ą░ąĘąŠąĮ_ąĖčüčģąŠą┤ąĮčŗčģ_čĆąĄą│ąĖčüčéčĆąŠą▓)
ąĪąĖąĮčéą░ą║čüąĖčü:
[--SP] = (R7:Dreglim, P5:Preglim); // čĆąĄą│ąĖčüčéčĆčŗ Dreg ąĖ ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮčŗąĄ Preg (a)1
[--SP] = (R7:Dreglim); // č鹊ą╗čīą║ąŠ čĆąĄą│ąĖčüčéčĆčŗ Dreg (a)
[--SP] = (P5:Preglim); // č鹊ą╗čīą║ąŠ ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮčŗąĄ čĆąĄą│ąĖčüčéčĆčŗ Preg (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreglim: ą╗čÄą▒ąŠąĄ čćąĖčüą╗ąŠ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ ąŠčé 7 ą┤ąŠ 0.
Preglim: ą╗čÄą▒ąŠąĄ čćąĖčüą╗ąŠ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ ąŠčé 5 ą┤ąŠ 0.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Push Multiple čüąŠčģčĆą░ąĮčÅąĄčé ą▓ čüč鹥ą║ąĄ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ą░ąĮąĮčŗčģ (Dreg) ąĖ/ąĖą╗ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ čāą║ą░ąĘą░č鹥ą╗čÅ (Preg). ąöąĖą░ą┐ą░ąĘąŠąĮ čüąŠčģčĆą░ąĮčÅąĄą╝čŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą▓čüąĄą│ą┤ą░ ą▓ą║ą╗čÄčćą░ąĄčé čüą░ą╝čŗą╣ ą▒ąŠą╗čīčłąŠą╣ ąĖąĮą┤ąĄą║čü čĆąĄą│ąĖčüčéčĆą░ (R7 ąĖ/ąĖą╗ąĖ P5) ą┐ą╗čÄčü ą╗čÄą▒ąŠą╣ ąĮąĖąČąĄą╗ąĄąČą░čēąĖą╣ ąĖąĮą┤ąĄą║čü čĆąĄą│ąĖčüčéčĆą░, ą║ąŠč鹊čĆčŗą╣ ą┤ą░ą╗ąĄąĄ čāą║ą░ąĘčŗą▓ą░ąĄčé ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī, ą║ąŠč鹊čĆčŗą╣ ą▓ą║ą╗čÄčćą░ąĄčé R0 ąĖ/ąĖą╗ąĖ P0. ąóąŠą╗čīą║ąŠ ąĖąĮčüčéčĆčāą║čåąĖąĖ Push ąĖ Push Multiple ąŠą▒ą╗ą░ą┤ą░čÄčé čäčāąĮą║čåąĖčÅą╝ąĖ ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮąŠą╣ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖąĖ čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░.
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮą░čćąĖčéą░ąĄčéčüčÅ čü čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čĆąĄą│ąĖčüčéčĆą░, čā ą║ąŠč鹊čĆąŠą│ąŠ ąĮą░ąĖą╝ąĄąĮčīčłąĖą╣ ąĖąĮą┤ąĄą║čü, ąĖ ąĘą░č鹥ą╝ ą┐ąĄčĆąĄčģąŠą┤ąĖčé ą║ čĆąĄą│ąĖčüčéčĆčā čü ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąĖą╝ ąĖąĮą┤ąĄą║čüąŠą╝. ąśąĮą┤ąĄą║čü ą┐ąĄčĆą▓ąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ čüąŠčģčĆą░ąĮčÅąĄą╝ąŠą│ąŠ ą▓ čüč鹥ą║ąĄ, čāą║ą░ąĘčŗą▓ą░ąĄčéčüčÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąĀąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░čÄčéčüčÅ ą▓ čüč鹥ą║ ą┐ąĄčĆąĄą┤ čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ čāą║ą░ąĘą░č鹥ą╗ąĄą╣, ąĄčüą╗ąĖ ąŠąĮąĖ ą▓ą╝ąĄčüč鹥 čāą║ą░ąĘą░ąĮčŗ ą▓ ąŠą┤ąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
ą¤ąĄčĆąĄą┤ ą┤ąŠčüčéčāą┐ąŠą╝ ą║ čüą╗ąĄą┤čāčÄčēąĄą╝čā ą┤ąŠčüčéčāą┐ąĮąŠą╝čā ą╝ąĄčüčéčā ą▓ čüč鹥ą║ąĄ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ąĄą╗ą░ąĄčé ą┐čĆąĄą┤ą┤ąĄą║čĆąĄą╝ąĄąĮčé čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░ (Stack Pointer, SP).
ąĪč鹥ą║ čĆą░čüč鹥čé ą▓ąĮąĖąĘ ąŠčé čüčéą░čĆčłąĖčģ ą░ą┤čĆąĄčüąŠą▓ ą┐ą░ą╝čÅčéąĖ ą║ ą╝ą╗ą░ą┤čłąĖą╝, čéą░ą║ čćč鹊 ąŠą┐ąĄčĆą░čåąĖčÅ ą┤ąĄą║čĆąĄą╝ąĄąĮčéą░ SP ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖčÅ ą▓ čüč鹥ą║ (pushing), ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ ąŠą┐ąĄčĆą░čåąĖčÅ ąĖąĮą║čĆąĄą╝ąĄąĮčéą░ SP ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ąĖąĘą▓ą╗ąĄč湥ąĮąĖčÅ ąĘąĮą░č湥ąĮąĖą╣ ąĖąĘ čüč鹥ą║ą░ (popping). ąŻą║ą░ąĘą░č鹥ą╗čī čüč鹥ą║ą░ ą▓čüąĄą│ą┤ą░ čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ ą┐ąŠčüą╗ąĄą┤ąĮąĄąĄ ąĘą░ąĮčÅč鹊ąĄ ą╝ąĄčüč鹊 ą▓ čüč鹥ą║ąĄ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čŹčäč乥ą║čéąĖą▓ąĮčŗą╣ ą░ą┤čĆąĄčü ą┤ą╗čÅ čüą╗ąĄą┤čāčÄčēąĄą│ąŠ ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖčÅ ą▓ čüč鹥ą║ ą▒čāą┤ąĄčé čĆą░ą▓ąĄąĮ SP-4.
ąØą░ čüą╗ąĄą┤čāčÄčēąĄą╣ ą║ą░čĆčéąĖąĮą║ąĄ ą┐ąŠą║ą░ąĘą░ąĮąŠ, ą║ą░ą║ ą▒čāą┤ąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī ą▓ čüč鹥ą║, ą║ąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą╝ąĮąŠąČąĄčüčéą▓ąĄąĮąĮąŠąĄ ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖąĄ ą▓ čüč鹥ą║ (push multiple).
ąśąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 čĆąĄą│ąĖčüčéčĆčŗ čü čüą░ą╝čŗą╝ ą╝ą░ą╗ąĄąĮčīą║ąĖą╝ ąĖąĮą┤ąĄą║čüąŠą╝ ą▒čāą┤čāčé čüąŠčģčĆą░ąĮąĄąĮčŗ ą▓ čüč鹥ą║ąĄ ą┐ąĄčĆą▓čŗą╝ąĖ, č鹊 ąČąĄą╗ą░č鹥ą╗čīąĮąŠ, čćč鹊ą▒čŗ ą▓ čĆąĄą░ą╗čéą░ą╣ą╝-čüąĖčüč鹥ą╝ąĄ ą┤ą╗čÅ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ ą▒čŗą╗ąĖ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮčŗ scratch-čĆąĄą│ąĖčüčéčĆčŗ čü čüą░ą╝čŗą╝ąĖ ą╝ą░ą╗ąĄąĮčīą║ąĖą╝ąĖ ąĖąĮą┤ąĄą║čüą░ą╝ąĖ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą┤ą╗čÅ ą┐čĆąŠčüč鹥ą╣čłąĄą│ąŠ čüąŠą│ą╗ą░čłąĄąĮąĖčÅ ąŠ ą▓čŗąĘąŠą▓ą░čģ ą┤ąŠą╗ąČąĮčŗ ą▓ ą║ą░č湥čüčéą▓ąĄ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ąĖ P0 ą┤ąŠą╗ąČąĄąĮ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą║ą░ą║ čĆąĄą│ąĖčüčéčĆ ą┤ą╗čÅ ą▓ąŠąĘą▓čĆą░čéą░ ąĘąĮą░č湥ąĮąĖčÅ.
ąźąŠčéčÅ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ą░čĆčīąĖčĆčāąĄčéčüčÅ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą║ąŠą╗ąĖč湥čüčéą▓ą░ čüąŠčģčĆą░ąĮčÅąĄą╝čŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓, ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ąĄčæ čāą╝ąĄąĮčīčłą░ąĄčé čĆą░ąĘą╝ąĄčĆ ą║ąŠą┤ą░.
ąśąĮčüčéčĆčāą║čåąĖčÄ Push Multiple ąĮąĄą╗čīąĘčÅ ą┐čĆąĄčĆą▓ą░čéčī ą▓ąŠ ą▓čĆąĄą╝čÅ ąĄčæ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ. ą×ą▒čĆą░ą▒ąŠčéą║ą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ, ą▓čŗčüčéą░ą▓ą╗ąĄąĮąĮąŠą│ąŠ ą┐ąŠčüą╗ąĄ ą┐ąĄčĆą▓ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ ąĘą░ą┐ąĖčüąĖ ą▓ čüč鹥ą║, ąŠčéą║ą╗ą░ą┤čŗą▓ą░ąĄčéčüčÅ ą┤ąŠ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ą▓čüąĄčģ ąŠą┐ąĄčĆą░čåąĖą╣ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ Push Multiple. ą×ą┤ąĮą░ą║ąŠ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą▓ąŠąĘąĮąĖą║ąĮčāčé ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą┐čĆąĖą▓ąĄą┤čāčé ą║ ą║ąŠčĆčĆąĄą║čéąĮąŠą╝čā ąĄčæ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÄ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ąŠą┐ąĄčĆą░čåąĖčÅ load/store ą╝ąŠąČąĄčé ąĮą░čĆčāčłąĖčéčī ąĘą░čēąĖčéčā ą┤ąŠčüčéčāą┐ą░ ą┐čĆąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ Push Multiple. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ SP čüą▒čĆąŠčüąĖčéčüčÅ ą║ čüą▓ąŠąĄą╝čā ąĘąĮą░č湥ąĮąĖčÄ, ą║ąŠč鹊čĆąŠąĄ ą▒čŗą╗ąŠ ą┐ąĄčĆąĄą┤ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąóą░ą║ąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąĄčĆąĄąĘą░ą┐čāčēąĄąĮą░ ą┐ąŠčüą╗ąĄ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą║ąŠą│ą┤ą░ ąŠą┐ąĄčĆą░čåąĖčÅ Push Multiple ą▒čŗą╗ą░ ąŠą▒ąŠčĆą▓ą░ąĮą░ ąĖąĘ-ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, čüąŠčüč鹊čÅąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ąĖąĘą╝ąĄąĮąĖčéčüčÅ ąŠą┐ąĄčĆą░čåąĖčÅą╝ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ čāąČąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┤ąŠ ą╝ąŠą╝ąĄąĮčéą░ ą▓ąŠąĘąĮąĖą║ąĮąŠą▓ąĄąĮąĖčÅ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ.
ąöą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ Push Multiple (ą║ą░ą║, ą▓ą┐čĆąŠč湥ą╝, ąĖ ą┤ą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ Push) čāą║ą░ąĘą░č鹥ą╗čī čüč鹥ą║ą░ (Stack Pointer, SP) ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓čüąĄą│ą┤ą░ ą▓čŗčĆąŠą▓ąĮąĄąĮ ąĮą░ 32 ą▒ąĖčéą░ (ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░čåąĄą╗ąŠ ąĮą░ 4). ąĢčüą╗ąĖ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ, č鹊 ą▓ąŠąĘąĮąĖą║ąĮąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ, ąĖ čĆą░ą▒ąŠčéą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▒čāą┤ąĄčé ą┐čĆąĄčĆą▓ą░ąĮą░, ą║ą░ą║ čŹč鹊 ą▒čŗą╗ąŠ č鹊ą╗čīą║ąŠ čćč鹊 ąŠą┐ąĖčüą░ąĮąŠ.
ą×ą┐ąĄčĆą░ąĮą┤ą░ą╝ąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī č鹊ą╗čīą║ąŠ čĆąĄą│ąĖčüčéčĆčŗ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ P0, ..., P5, ąĮąŠ ąĮąĖą║ą░ą║ ąĮąĄ čĆąĄą│ąĖčüčéčĆčŗ SP ąĖ FP. ąÆčüąĄ čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7 ą╝ąŠą│čāčé ą▒čŗčéčī ąŠą┐ąĄčĆą░ąĮą┤ą░ą╝ąĖ ą┤ą╗čÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
[-- sp] = (r7: 5 , p5: 0 ); // D-čĆąĄą│ąĖčüčéčĆčŗ R[4:0] ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ąĖčüą║ą╗čÄč湥ąĮčŗ
[-- sp] = (r7: 2 ); // ąĖčüą║ą╗čÄč湥ąĮčŗ R[1:0]
[-- sp] = (p5: 4 ); // ąĖčüą║ą╗čÄč湥ąĮčŗ P[3:0]
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Push, Pop, Pop Multiple.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ąŠčüčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé ąĖąĘ čüč鹥ą║ą░ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čāą║ą░ąĘą░ąĮąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
čĆąĄą│ąĖčüčéčĆ_ąĮą░ąĘąĮą░č湥ąĮąĖčÅ = [SP++]
ąĪąĖąĮčéą░ą║čüąĖčü:
ą╗čÄą▒ąŠą╣_čĆąĄą│ąĖčüčéčĆ = [SP++]; // ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮčé SP (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
ą╗čÄą▒ąŠą╣_čĆąĄą│ąĖčüčéčĆ: R0, ..., R7, P0, ..., P5, FP, I0, ..., I3, M0, ..., M3, B0, ..., B3, L0, ..., L3, A0.X, A0.W, A1.X, A1.W, ASTAT, RETS, RETI, RETX, RETN, RETE, LC0 ąĖ LC1, LT0 ąĖ LT1, LB0 ąĖ LB1, EMUDAT, USP, SEQSTAT ąĖ SYSCFG.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Pop ąĘą░ą│čĆčāąČą░ąĄčé ą▓ čāą║ą░ąĘą░ąĮąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ąĖąĘ čüč鹥ą║ą░ ą┐ąŠ ąĖąĮą┤ąĄą║čüčā ąĖąĘ č鹥ą║čāčēąĄą│ąŠ čüąŠčüč鹊čÅąĮąĖčÅ čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░ (Stack Pointer, SP). ąśąĮčüčéčĆčāą║čåąĖčÅ ą┤ąĄą╗ą░ąĄčé ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮčé SP, čéą░ą║ čćč鹊 SP ą┐ąŠčüą╗ąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ą▒čāą┤ąĄčé čāą║ą░ąĘčŗą▓ą░čéčī ąĮą░ čüą╗ąĄą┤čāčÄčēąĄąĄ ąĘą░ąĮčÅč鹊ąĄ ą╝ąĄčüč鹊 ą▓ čüč鹥ą║ąĄ.
ąĪč鹥ą║ čĆą░čüč鹥čé ą▓ąĮąĖąĘ ąŠčé čüčéą░čĆčłąĖčģ ą░ą┤čĆąĄčüąŠą▓ ą┐ą░ą╝čÅčéąĖ ą║ ą╝ą╗ą░ą┤čłąĖą╝, čéą░ą║ čćč鹊 ąŠą┐ąĄčĆą░čåąĖčÅ ą┤ąĄą║čĆąĄą╝ąĄąĮčéą░ čüč鹥ą║ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓ ą▓ čüč鹥ą║ (push), ąĖ ąŠą┐ąĄčĆą░čåąĖčÅ ąĖąĮą║čĆąĄą╝ąĄąĮčéą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą▓čŗą▒ąŠčĆą║ąĖ ąĘąĮą░č湥ąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖąĘ čüč鹥ą║ą░. Stack Pointer ą▓čüąĄą│ą┤ą░ čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ ą┐ąŠčüą╗ąĄą┤ąĮčÄčÄ ąĘą░ąĮčÅčéčāčÄ čÅč湥ą╣ą║čā ą▓ čüč鹥ą║ąĄ. ąÜąŠą│ą┤ą░ ą┤ąĄą╗ą░ąĄčéčüčÅ ąŠą┐ąĄčĆą░čåąĖčÅ pop, č鹊 ąĘąĮą░č湥ąĮąĖąĄ, ąĮą░ ą║ąŠč鹊čĆąŠąĄ čāą║ą░ąĘčŗą▓ą░ąĄčé SP, ą┐ąĄčĆąĄą╝ąĄčēą░ąĄčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆ, ąĖ ąĘąĮą░č湥ąĮąĖąĄ SP čüčéą░ąĮąŠą▓ąĖčéčüčÅ čĆą░ą▓ąĮčŗą╝ SP+4.
ąØą░ čüą╗ąĄą┤čāčÄčēąĄą╣ ą║ą░čĆčéąĖąĮą║ąĄ ą┐ąŠą║ą░ąĘą░ąĮąŠ, ą║ą░ą║ ą┤ąŠą╗ąČąĄąĮ ą▓čŗą│ą╗čÅą┤ąĄčéčī čüč鹥ą║, ą║ąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą▓čŗčéą░ą╗ą║ąĖą▓ą░ąĮąĖąĄ ąĖąĘ čüč鹥ą║ą░ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ R3 = [SP++]:
ąŚąĮą░č湥ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ą▒čŗą╗ąŠ ą▓čŗą▒čĆą░ąĮąŠ (pop) ąĖąĘ ą┐ą░ą╝čÅčéąĖ čüč鹥ą║ą░, čäąĖąĘąĖč湥čüą║ąĖ ąŠčüčéą░ąĄčéčüčÅ ą▓ čŹč鹊ą╣ ą┐ą░ą╝čÅčéąĖ, ą┐ąŠą║ą░ ąĮąĄ ą▒čāą┤ąĄčé ą┐ąĄčĆąĄąĘą░ą┐ąĖčüą░ąĮąŠ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖą╝ąĖ ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖčÅą╝ąĖ (push) ą▓ čüč鹥ą║.
ąÜąŠąĮąĄčćąĮąŠ, ąŠą▒čŗčćąĮąŠąĄ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĖąĄ pop čŹč鹊 ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ čĆą░ąĮąĄąĄ ą▓čŗą┤ą▓ąĖąĮčāčéčŗ ą▓ čüč鹥ą║ ą║ąŠą╝ą░ąĮą┤ąŠą╣ push. ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą┐čĆąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĖ ą┤ąŠą╗ąČąĄąĮ čüčéčĆąŠą│ąŠ ą┐čĆąĖą┤ąĄčƹȹĖą▓ą░čéčīčüčÅ ą┤ąĖčüčåąĖą┐ą╗ąĖąĮčŗ ą┤ą╗čÅ ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖčÅ ąĘąĮą░č湥ąĮąĖą╣ ąĖąĘ čüč鹥ą║ą░ - ą┐čĆąĖąĮčåąĖą┐ "ą┐ąĄčĆą▓čŗą╝ ą▓ąŠčłąĄą╗, ą┐ąŠčüą╗ąĄą┤ąĮąĖą╝ ą▓čŗčłąĄą╗" ą┤ąŠą╗ąČąĄąĮ ą▓čüąĄą│ą┤ą░ čüąŠą▒ą╗čÄą┤ą░čéčīčüčÅ. Pop ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮ ą░ą▒čüąŠą╗čÄčéąĮąŠ č鹊čćąĮąŠ ą┤ą╗čÅ č鹥čģ ąČąĄ čĆąĄą│ąĖčüčéčĆąŠą▓, ą┤ą╗čÅ ą║ąŠč鹊čĆčŗčģ ą▒čŗą╗ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ čĆą░ąĮąĄąĄ ąŠą┐ąĄčĆą░čåąĖčÅ Push, č鹊ą╗čīą║ąŠ ą▓ ąŠą▒čĆą░čéąĮąŠą╝ ą┐ąŠčĆčÅą┤ą║ąĄ.
ąöą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ Stack Pointer ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓čüąĄą│ą┤ą░ ą▓čŗčĆąŠą▓ąĮąĄąĮ ąĮą░ 32 ą▒ąĖčéą░ (ą░ą┤čĆąĄčü ą▓ SP ą┤ąŠą╗ąČąĄąĮ ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░ 4). ąĢčüą╗ąĖ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ, č鹊 ą▒čāą┤ąĄčé čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ (exception), ąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▒čāą┤ąĄčé ą┐čĆąĄčĆą▓ą░ąĮąŠ.
ąŚąĮą░č湥ąĮąĖąĄ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą▒čĆą░ąĮąŠ ąĖąĘ čüč鹥ą║ą░ ą┤ą╗čÅ ą┐čĆčÅą╝ąŠą│ąŠ ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖčÅ čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░ Stack Pointer, čéą░ą║ čćč鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ SP = [SP++] čÅą▓ą╗čÅąĄčéčüčÅ ąĮąĄą┤ąŠą┐čāčüčéąĖą╝ąŠą╣. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. ąĖą╝ąĄąĮą░ čĆąĄą│ąĖčüčéčĆąŠą▓ ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ".
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąÆ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ čüą╗čāčćą░ąĄą▓ čŹč鹊 čĆąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
ą»ą▓ąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ čĆąĄą│ąĖčüčéčĆą░ą╝ USP, SEQSTAT, SYSCFG, RETI, RETX, RETN ąĖ RETE čéčĆąĄą▒čāąĄčé čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░. ąĢčüą╗ąĖ ą┐ąŠą┐čĆąŠą▒ąŠą▓ą░čéčī čÅą▓ąĮąŠ ąŠą▒čĆą░čéąĖčéčīčüčÅ ą║ čŹčéąĖą╝ čĆąĄą│ąĖčüčéčĆą░ą╝ ąĖąĘ čĆąĄąČąĖą╝ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ, č鹊 ą▓ąŠąĘąĮąĖą║ąĮąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĘą░čēąĖčéčŗ ąĮą░čĆčāčłąĄąĮąĖčÅ ą┤ąŠčüčéčāą┐ą░ (protection violation exception).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Pop ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r0 = [sp++ ];
p4 = [sp++ ];
i1 = [sp++ ];
reti = [sp++ ]; // ąĘą┤ąĄčüčī čéčĆąĄą▒čāąĄčéčüčÅ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Push, Push Multiple, Pop Multiple.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┤ąĄą╗ą░ąĄčé ą▓čŗą▒ąŠčĆą║čā ąĖąĘ čüč鹥ą║ą░ čüčĆą░ąĘčā ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
(ą┤ąĖą░ą┐ą░ąĘąŠąĮ_čĆąĄą│ąĖčüčéčĆąŠą▓_ąĮą░ąĘąĮą░č湥ąĮąĖčÅ) = [SP++]
ąĪąĖąĮčéą░ą║čüąĖčü:
(R7:Dreglim, P5:Preglim) = [SP++]; // čĆąĄą│ąĖčüčéčĆčŗ Dreg ąĖ ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮčŗąĄ Preg (a)1
(R7:Dreglim) = [SP++]; // č鹊ą╗čīą║ąŠ čĆąĄą│ąĖčüčéčĆčŗ Dreg (a)
(P5:Preglim) = [SP++]; // č鹊ą╗čīą║ąŠ ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮčŗąĄ čĆąĄą│ąĖčüčéčĆčŗ Preg (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreglim: ą╗čÄą▒ąŠąĄ čćąĖčüą╗ąŠ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ ąŠčé 7 ą┤ąŠ 0.
Preglim: ą╗čÄą▒ąŠąĄ čćąĖčüą╗ąŠ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ ąŠčé 5 ą┤ąŠ 0.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Push Multiple ą▓ąŠčüčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé ąĖąĘ čüč鹥ą║ą░ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ą░ąĮąĮčŗčģ (Dreg) ąĖ/ąĖą╗ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ čāą║ą░ąĘą░č鹥ą╗čÅ (Preg). ąöąĖą░ą┐ą░ąĘąŠąĮ ą▓ąŠčüčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄą╝čŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą▓čüąĄą│ą┤ą░ ą▓ą║ą╗čÄčćą░ąĄčé čüą░ą╝čŗą╣ ą▒ąŠą╗čīčłąŠą╣ ąĖąĮą┤ąĄą║čü čĆąĄą│ąĖčüčéčĆą░ (R7 ąĖ/ąĖą╗ąĖ P5) ą┐ą╗čÄčü ą╗čÄą▒ąŠą╣ ąĮąĖąČąĄą╗ąĄąČą░čēąĖą╣ ąĖąĮą┤ąĄą║čü čĆąĄą│ąĖčüčéčĆą░, ą║ąŠč鹊čĆčŗą╣ ą┤ą░ą╗ąĄąĄ čāą║ą░ąĘčŗą▓ą░ąĄčé ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī, ą║ąŠč鹊čĆčŗą╣ ą▓ą║ą╗čÄčćą░ąĄčé R0 ąĖ/ąĖą╗ąĖ P0.
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮą░čćąĖčéą░ąĄčéčüčÅ čü čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čĆąĄą│ąĖčüčéčĆą░, čā ą║ąŠč鹊čĆąŠą│ąŠ ąĮą░ąĖą▒ąŠą╗čīčłąĖą╣ ąĖąĮą┤ąĄą║čü, ąĖ ąĘą░č鹥ą╝ ą┐ąĄčĆąĄčģąŠą┤ąĖčé ą║ čĆąĄą│ąĖčüčéčĆčā čü ą╝ąĄąĮąĄąĄ ą▓čŗčüąŠą║ąĖą╝ ąĖąĮą┤ąĄą║čüąŠą╝. ąśąĮą┤ąĄą║čü ą┐ąŠčüą╗ąĄą┤ąĮąĄą│ąŠ čĆąĄą│ąĖčüčéčĆą░, ą▓ąŠčüčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄą╝ąŠą│ąŠ ąĖąĘ čüč鹥ą║ą░, čāą║ą░ąĘčŗą▓ą░ąĄčéčüčÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąĀąĄą│ąĖčüčéčĆčŗ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ą▓čŗą▒ąĖčĆą░čÄčéčüčÅ ąĖąĘ čüč鹥ą║ ą┐ąĄčĆąĄą┤ čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ą┤ą░ąĮąĮčŗčģ, ąĄčüą╗ąĖ ąŠąĮąĖ ą▓ą╝ąĄčüč鹥 čāą║ą░ąĘą░ąĮčŗ ą▓ ąŠą┤ąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
ą¤ąĄčĆąĄą┤ ą┤ąŠčüčéčāą┐ąŠą╝ ą║ čüą╗ąĄą┤čāčÄčēąĄą╝čā ąĘą░ąĮčÅč鹊ą╝čā ą╝ąĄčüčéčā ą▓ čüč鹥ą║ąĄ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ąĄą╗ą░ąĄčé ą┐ąŠčüčéąĖąĮą║čĆąĄą╝ąĄąĮčé čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░ (Stack Pointer, SP).
ąĪč鹥ą║ čĆą░čüč鹥čé ą▓ąĮąĖąĘ ąŠčé čüčéą░čĆčłąĖčģ ą░ą┤čĆąĄčüąŠą▓ ą┐ą░ą╝čÅčéąĖ ą║ ą╝ą╗ą░ą┤čłąĖą╝, čéą░ą║ čćč鹊 ąŠą┐ąĄčĆą░čåąĖčÅ ą┤ąĄą║čĆąĄą╝ąĄąĮčéą░ SP ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖčÅ ą▓ čüč鹥ą║ (pushing), ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ ąŠą┐ąĄčĆą░čåąĖčÅ ąĖąĮą║čĆąĄą╝ąĄąĮčéą░ SP ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ąĖąĘą▓ą╗ąĄč湥ąĮąĖčÅ ąĘąĮą░č湥ąĮąĖą╣ ąĖąĘ čüč鹥ą║ą░ (popping). ąŻą║ą░ąĘą░č鹥ą╗čī čüč鹥ą║ą░ ą▓čüąĄą│ą┤ą░ čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ ą┐ąŠčüą╗ąĄą┤ąĮąĄąĄ ąĘą░ąĮčÅč鹊ąĄ ą╝ąĄčüč鹊 ą▓ čüč鹥ą║ąĄ. ąÜąŠą│ą┤ą░ ą┤ąĄą╗ą░ąĄčéčüčÅ ąŠą┐ąĄčĆą░čåąĖčÅ ą▓čŗą▒ąŠčĆą║ąĖ ąĖąĘ čüč鹥ą║ą░ (pop), č鹊 ąĘąĮą░č湥ąĮąĖąĄ, ąĮą░ ą║ąŠč鹊čĆąŠąĄ čāą║ą░ąĘčŗą▓ą░ąĄčé SP, ą┐ąĄčĆąĄą┤ą░ąĄčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆ, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ SP čüčéą░ąĮąŠą▓ąĖčéčüčÅ čĆą░ą▓ąĮčŗą╝ SP+4.
ąØą░ čüą╗ąĄą┤čāčÄčēąĄą╣ ą║ą░čĆčéąĖąĮą║ąĄ ą┐ąŠą║ą░ąĘą░ąĮąŠ, ą║ą░ą║ ą▒čāą┤ąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī ą▓ čüč鹥ą║, ą║ąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą╝ąĮąŠąČąĄčüčéą▓ąĄąĮąĮą░čÅ ą▓čŗą▒ąŠčĆą║ą░ ąĖąĘ čüč鹥ą║ą░ (pop multiple).
ąŚąĮą░č湥ąĮąĖąĄ (ąĖą╗ąĖ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĘąĮą░č湥ąĮąĖą╣), ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ č鹊ą╗čīą║ąŠ čćč鹊 ą▓čŗą▒čĆą░ąĮčŗ ąĖąĘ čüč鹥ą║ą░, čäąĖąĘąĖč湥čüą║ąĖ čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ ą▓ ą┐ą░ą╝čÅčéąĖ čüč鹥ą║ą░, ą┐ąŠą║ą░ ąĮąĄ ą▒čāą┤čāčé ą┐ąĄčĆąĄąĘą░ą┐ąĖčüą░ąĮčŗ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖą╝ąĖ ąŠą┐ąĄčĆą░čåąĖčÅą╝ąĖ ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖčÅ ą▓ čüč鹥ą║.
ąÜąŠąĮąĄčćąĮąŠ, ąŠą▒čŗčćąĮąŠąĄ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĖąĄ pop čŹč鹊 ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ čĆą░ąĮąĄąĄ ą▓čŗą┤ą▓ąĖąĮčāčéčŗ ą▓ čüč鹥ą║ ą║ąŠą╝ą░ąĮą┤ąŠą╣ push. ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą┐čĆąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĖ ą┤ąŠą╗ąČąĄąĮ čüčéčĆąŠą│ąŠ ą┐čĆąĖą┤ąĄčƹȹĖą▓ą░čéčīčüčÅ ą┤ąĖčüčåąĖą┐ą╗ąĖąĮčŗ ą┤ą╗čÅ ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖčÅ ąĘąĮą░č湥ąĮąĖą╣ ąĖąĘ čüč鹥ą║ą░ - ą┐čĆąĖąĮčåąĖą┐ "ą┐ąĄčĆą▓čŗą╝ ą▓ąŠčłąĄą╗, ą┐ąŠčüą╗ąĄą┤ąĮąĖą╝ ą▓čŗčłąĄą╗" ą┤ąŠą╗ąČąĄąĮ ą▓čüąĄą│ą┤ą░ čüąŠą▒ą╗čÄą┤ą░čéčīčüčÅ. Pop ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮ ą░ą▒čüąŠą╗čÄčéąĮąŠ č鹊čćąĮąŠ ą┤ą╗čÅ č鹥čģ ąČąĄ čĆąĄą│ąĖčüčéčĆąŠą▓, ą┤ą╗čÅ ą║ąŠč鹊čĆčŗčģ ą▒čŗą╗ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ čĆą░ąĮąĄąĄ ąŠą┐ąĄčĆą░čåąĖčÅ Push, č鹊ą╗čīą║ąŠ ą▓ ąŠą▒čĆą░čéąĮąŠą╝ ą┐ąŠčĆčÅą┤ą║ąĄ.
ąźąŠčéčÅ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ Pop Multiple ą▓ą░čĆčīąĖčĆčāąĄčéčüčÅ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą▓ąŠčüčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄą╝čŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓, ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ąĄčæ čāą╝ąĄąĮčīčłą░ąĄčé čĆą░ąĘą╝ąĄčĆ ą║ąŠą┤ą░.
ąśąĮčüčéčĆčāą║čåąĖčÄ Pop Multiple ąĮąĄą╗čīąĘčÅ ą┐čĆąĄčĆą▓ą░čéčī ą▓ąŠ ą▓čĆąĄą╝čÅ ąĄčæ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ. ą×ą▒čĆą░ą▒ąŠčéą║ą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ, ą▓čŗčüčéą░ą▓ą╗ąĄąĮąĮąŠą│ąŠ ą┐ąŠčüą╗ąĄ ą┐ąĄčĆą▓ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ čćč鹥ąĮąĖčÅ ąĖąĘ čüč鹥ą║ą░, ąŠčéą║ą╗ą░ą┤čŗą▓ą░ąĄčéčüčÅ ą┤ąŠ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ą▓čüąĄčģ ąŠą┐ąĄčĆą░čåąĖą╣ ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖčÅ Pop Multiple. ą×ą┤ąĮą░ą║ąŠ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą▓ąŠąĘąĮąĖą║ąĮčāčé ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą┐čĆąĖą▓ąĄą┤čāčé ą║ ą║ąŠčĆčĆąĄą║čéąĮąŠą╝čā ąĄčæ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÄ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ąŠą┐ąĄčĆą░čåąĖčÅ load/store ą╝ąŠąČąĄčé ąĮą░čĆčāčłąĖčéčī ąĘą░čēąĖčéčā ą┤ąŠčüčéčāą┐ą░ ą┐čĆąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ Pop Multiple. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ SP čüą▒čĆąŠčüąĖčéčüčÅ ą║ čüą▓ąŠąĄą╝čā ąĘąĮą░č湥ąĮąĖčÄ, ą║ąŠč鹊čĆąŠąĄ ą▒čŗą╗ąŠ ą┐ąĄčĆąĄą┤ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąóą░ą║ąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąĄčĆąĄąĘą░ą┐čāčēąĄąĮą░ ą┐ąŠčüą╗ąĄ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą║ąŠą│ą┤ą░ ąŠą┐ąĄčĆą░čåąĖčÅ Pop Multiple ą▒čŗą╗ą░ ąŠą▒ąŠčĆą▓ą░ąĮą░ ąĖąĘ-ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, čüąŠčüč鹊čÅąĮąĖąĄ ąĮąĄą║ąŠč鹊čĆčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖąĘą╝ąĄąĮąĖčéčüčÅ ąŠą┐ąĄčĆą░čåąĖčÅą╝ąĖ ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ čāąČąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┤ąŠ ą╝ąŠą╝ąĄąĮčéą░ ą▓ąŠąĘąĮąĖą║ąĮąŠą▓ąĄąĮąĖčÅ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ.
ąöą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ Pop Multiple (ą║ą░ą║, ą▓ą┐čĆąŠč湥ą╝, ąĖ ą┤ą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ Pop) čāą║ą░ąĘą░č鹥ą╗čī čüč鹥ą║ą░ (Stack Pointer, SP) ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓čüąĄą│ą┤ą░ ą▓čŗčĆąŠą▓ąĮąĄąĮ ąĮą░ 32 ą▒ąĖčéą░ (ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░čåąĄą╗ąŠ ąĮą░ 4). ąĢčüą╗ąĖ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ, č鹊 ą▓ąŠąĘąĮąĖą║ąĮąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ, ąĖ čĆą░ą▒ąŠčéą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▒čāą┤ąĄčé ą┐čĆąĄčĆą▓ą░ąĮą░, ą║ą░ą║ čŹč鹊 ą▒čŗą╗ąŠ č鹊ą╗čīą║ąŠ čćč鹊 ąŠą┐ąĖčüą░ąĮąŠ.
ą×ą┐ąĄčĆą░ąĮą┤ą░ą╝ąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī č鹊ą╗čīą║ąŠ čĆąĄą│ąĖčüčéčĆčŗ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ P0, ..., P5, ąĮąŠ ąĮąĖą║ą░ą║ ąĮąĄ čĆąĄą│ąĖčüčéčĆčŗ SP ąĖ FP. ąÆčüąĄ čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ R0, ..., R7 ą╝ąŠą│čāčé ą▒čŗčéčī ąŠą┐ąĄčĆą░ąĮą┤ą░ą╝ąĖ ą┤ą╗čÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
(p5: 4 ) = [sp++ ]; // P[3:0] ąĖčüą║ą╗čÄč湥ąĮčŗ
(r7: 2 ) = [sp++ ]; // R[1:0] ąĖčüą║ą╗čÄč湥ąĮčŗ
(r7: 5 , p5: 0 ) = [sp++ ]; // D-čĆąĄą│ąĖčüčéčĆčŗ R[4:0] ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ąĖčüą║ą╗čÄč湥ąĮčŗ
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Push, Push Multiple, Pop.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓čŗą┤ąĄą╗čÅąĄčé ą╝ąĄčüč鹊 ą┐ąŠą┤ čüč鹥ą║. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
LINK, UNLINK
ąĪąĖąĮčéą░ą║čüąĖčü:
LINK uimm18m4; // ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ čäčĆąĄą╣ą╝ą░ čüč鹥ą║ą░ čāą║ą░ąĘą░ąĮąĮąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░ (b)1
UNLINK; // ąŠčéą╝ąĄąĮą░ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ čäčĆąĄą╣ą╝ą░ čüč鹥ą║ą░ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
uimm18m4: 18-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ąĘąĮą░č湥ąĮąĖąĄ ą║ąŠč鹊čĆąŠą│ąŠ ą┤ąŠą╗ąČąĮąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░čåąĄą╗ąŠ ąĮą░ 4, čü ą┤ąĖą░ą┐ą░ąĘąŠąĮąŠą╝ ąŠčé 8 ą┤ąŠ 262,152 ą▒ą░ą╣čé (0x00008 .. 0x3FFFC).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Linkage čāą┐čĆą░ą▓ą╗čÅąĄčé ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠą╝ ąŠą▒ą╗ą░čüčéąĖ čüč鹥ą║ą░ (stack frame) ą┤ą╗čÅ čüč鹥ą║ą░ ąĖ čāą║ą░ąĘą░č鹥ą╗čÅ čäčĆąĄą╣ą╝ą░ (Frame Pointer, FP) ą┤ą╗čÅ čŹč鹊ą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░. LINK ą▓čŗą┤ąĄą╗čÅąĄčé ą╝ąĄčüč鹊 ą▓ čüč鹥ą║ąĄ ąĖ UNLINK ąŠčüą▓ąŠą▒ąŠąČą┤ą░ąĄčé čŹč鹊 ą╝ąĄčüč鹊. ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĖą▓čÅąĘą║ąĖ ąŠą║ąĮą░ čüč鹥ą║ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą▓ ąĮą░čüčéčĆąŠą╣ą║ąĄ ąĖ ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖčÅ ąŠą▒ą╗ą░čüč鹥ą╣ ą┐ą░ą╝čÅčéąĖ ą▓ čüč鹥ą║ąĄ ą┤ą╗čÅ ą▓čŗčüąŠą║ąŠčāčĆąŠą▓ąĮąĄą▓ąŠą│ąŠ čÅąĘčŗą║ą░ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ C/C++.
LINK čüąŠčģčĆą░ąĮčÅąĄčé č鹥ą║čāčēąĄąĄ čüąŠčüč鹊čÅąĮąĖąĄ čĆąĄą│ąĖčüčéčĆąŠą▓ RETS ąĖ FP ą▓ čüč鹥ą║, ąĘą░ą│čĆčāąČą░ąĄčé čĆąĄą│ąĖčüčéčĆ FP ąĮąŠą▓čŗą╝ ą░ą┤čĆąĄčüąŠą╝ ąŠą▒ą╗ą░čüčéąĖ čüč鹥ą║ą░ (frame), ąĖ ąĘą░č鹥ą╝ ą┤ąĄą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄčé SP ąĮą░ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮąŠąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝ ąĘąĮą░č湥ąĮąĖąĄ čĆą░ąĘą╝ąĄčĆą░ ąŠą▒ą╗ą░čüčéąĖ čüč鹥ą║ą░.
ą×ą▒čŗčćąĮąŠ ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ ąĘą░ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ LINK ąĖčüą┐ąŠą╗čīąĘčāčÄčé ąĖąĮčüčéčĆčāą║čåąĖčÄ Push Multiple ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą▓ čüč鹥ą║ čĆąĄą│ąĖčüčéčĆąŠą▓ čāą║ą░ąĘą░č鹥ą╗čÅ ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ą░ąĮąĮčŗčģ.
ą¤čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗą╣ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝ ą░čĆą│čāą╝ąĄąĮčé ąĖąĮčüčéčĆčāą║čåąĖąĖ LINK ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé čĆą░ąĘą╝ąĄčĆ ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ą▓ čüč鹥ą║ąĄ. LINK ą▓čüąĄą│ą┤ą░ čüąŠčģčĆą░ąĮčÅąĄčé ą▓ čüč鹥ą║ čĆąĄą│ąĖčüčéčĆčŗ RETS ąĖ FP, čéą░ą║ čćč鹊 ą╝ąĖąĮąĖą╝ą░ą╗čīąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ ąŠą▒ą╗ą░čüčéąĖ čäčĆąĄą╣ą╝ą░ čüąŠčüčéą░ą▓ą╗čÅąĄčé 2 čüą╗ąŠą▓ą░, ąĄčüą╗ąĖ ą░čĆą│čāą╝ąĄąĮčé ąĖąĮčüčéčĆčāą║čåąĖąĖ LINK ą▒čŗą╗ čāą║ą░ąĘą░ąĮ čĆą░ą▓ąĮčŗą╝ 0. ą£ą░ą║čüąĖą╝ą░ą╗čīąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ ąŠą▒ą╗ą░čüčéąĖ čäčĆąĄą╣ą╝ą░ ą▒čāą┤ąĄčé 218 + 8 = 262152 ą▒ą░ą╣čé ą▓ ąĖąĮą║čĆąĄą╝ąĄąĮčéą░čģ ą┐ąŠ 4 ą▒ą░ą╣čéą░.
UNLINK ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ąŠą▒čĆą░čéąĮąŠąĄ, ą▓ąĘą░ąĖą╝ąŠą┤ąŠą┐ąŠą╗ąĮčÅčÄčēąĄąĄ ą┤ąĄą╣čüčéą▓ąĖąĄ ą┤ą╗čÅ LINK, čé. ąĄ. ąŠčéą╝ąĄąĮčÅąĄčé ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ąŠą▒ą╗ą░čüčéąĖ ą▓ čüč鹥ą║ąĄ ą┐čāč鹥ą╝ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ č鹥ą║čāčēąĄą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ FP ą▓ SP ąĖ ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖčÅ ą┐čĆąĄą┤čŗą┤čāčēąĖčģ ąĘąĮą░č湥ąĮąĖą╣ FP ąĖ RETS, ą▓čŗą▒ąĖčĆą░čÅ ąĖčģ ąĖąĘ čüč鹥ą║ą░.
ąśąĮčüčéčĆčāą║čåąĖčÅ UNLINK ąŠą▒čŗčćąĮąŠ čüą╗ąĄą┤čāąĄčé ąĘą░ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ Pop Multiple, ą║ąŠč鹊čĆčŗąĄ ą▓ąŠčüčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čÄčé čĆąĄą│ąĖčüčéčĆčŗ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ąĖ ą┤ą░ąĮąĮčŗčģ, čĆą░ąĮąĄąĄ čüąŠčģčĆą░ąĮąĄąĮąĮčŗąĄ ą▓ čüč鹥ą║ąĄ.
ąŚąĮą░č湥ąĮąĖčÅ čäčĆąĄą╣ą╝ą░ ą▓ čüč鹥ą║ąĄ ąŠčüčéą░čÄčéčüčÅ čéą░ą╝, ą┐ąŠą║ą░ ąĖčģ ąĮąĄ ą┐ąĄčĆąĄąĘą░ą┐ąĖčłčāčé ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ čüąŠ čüč鹥ą║ąŠą╝ Push, Push Multiple ąĖą╗ąĖ LINK.
ąÜąŠąĮąĄčćąĮąŠ, FP ąĮąĄ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮ ą║ąŠą┤ąŠą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ą╝ąĄąČą┤čā ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ LINK ąĖ UNLINK, čćč鹊ą▒čŗ čüąŠčģčĆą░ąĮąĖčéčī čåąĄą╗ąŠčüčéąĮąŠčüčéčī čüč鹥ą║ą░.
ąØąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĄčĆą▓ą░ąĮą░ ąĮąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅ LINK, ąĮąĖ UNLINK. ą×ą┤ąĮą░ą║ąŠ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą▓ąŠąĘąĮąĖą║ą╗ąĖ ą┐čĆąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ ą╗čÄą▒ąŠą╣ ąĖąĘ čŹčéąĖčģ ąĖąĮčüčéčĆčāą║čåąĖą╣, ą┐čĆąĖą▓ąĄą┤čāčé ą║ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÄ ąĖčģ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąŠą┐ąĄčĆą░čåąĖčÅ load/store ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ąĮą░čĆčāčłąĄąĮąĖčÄ ąĘą░čēąĖčéčŗ ą┐čĆąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ LINK. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ SP ąĖ FP čüą▒čĆąŠčüčÅčéčüčÅ ą║ čüą▓ąŠąĖą╝ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮčŗą╝ ąĘąĮą░č湥ąĮąĖčÅą╝, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ ą┤ąŠ ąĮą░čćą░ą╗ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąóą░ą║ąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ą┐čĆąĄčĆą▓ą░ąĮąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąĄčĆąĄąĘą░ą┐čāčēąĄąĮą░ ą┐ąŠčüą╗ąĄ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ.
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą║ąŠą│ą┤ą░ ąŠą┐ąĄčĆą░čåąĖčÅ LINK ąŠą▒čĆčŗą▓ą░ąĄčéčüčÅ ąĖąĘ-ąĘą░ čüčĆą░ą▒ą░čéčŗą▓ą░ąĮąĖčÅ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ą┐ą░ą╝čÅčéčī ą▓ čüč鹥ą║ąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖąĘą╝ąĄąĮąĄąĮą░ ąĖąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 ą▓ ąĮąĄčæ čāąČąĄ ą▒čŗą╗ąĖ čüąŠčģčĆą░ąĮąĄąĮčŗ ąĮąĄą║ąŠč鹊čĆčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ ą┤ąŠ č鹊ą│ąŠ ą╝ąŠą╝ąĄąĮčéą░, ą║ą░ą║ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▒čŗą╗ąŠ ą┐čĆąĄčĆą▓ą░ąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝. ąÉąĮą░ą╗ąŠą│ąĖčćąĮąŠ, ąŠą▒ąŠčĆą▓ą░ąĮąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ UNLINK ą╝ąŠąČąĄčé ąŠčüčéą░ą▓ąĖčéčī ąĖąĘą╝ąĄąĮąĄąĮąĮčŗą╝ąĖ čĆąĄą│ąĖčüčéčĆčŗ FP ąĖ RETS, ą┐ąŠč鹊ą╝čā čćč鹊 ąĖčģ ąĘą░ą│čĆčāąĘą║ą░ čāąČąĄ ą▒čŗą╗ą░ ą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮą░ ą┐ąĄčĆąĄą┤ čüčĆą░ą▒ą░čéčŗą▓ą░ąĮąĖąĄą╝ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ.
ąØą░ čĆąĖčüčāąĮą║ą░čģ ąĮąĖąČąĄ ą┐ąŠą║ą░ąĘą░ąĮąŠ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čüč鹥ą║ą░ ą┐ąŠčüą╗ąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ LINK, ąĘą░ ą║ąŠč鹊čĆąŠą╣ ąĖą┤ąĄčé ąĖąĮčüčéčĆčāą║čåąĖčÅ Push Multiple.
ąöą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ čāą║ą░ąĘą░č鹥ą╗čī čüč鹥ą║ą░ (Stack Pointer, SP) ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓čüąĄą│ą┤ą░ ą▓čŗčĆąŠą▓ąĮąĄąĮ ąĮą░ 32 ą▒ąĖčéą░ (ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░čåąĄą╗ąŠ ąĮą░ 4). ąĢčüą╗ąĖ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ, č鹊 ą▓ąŠąĘąĮąĖą║ąĮąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ, ąĖ čĆą░ą▒ąŠčéą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▒čāą┤ąĄčé ą┐čĆąĄčĆą▓ą░ąĮą░, ą║ą░ą║ čŹč鹊 ą▒čŗą╗ąŠ č鹊ą╗čīą║ąŠ čćč鹊 ąŠą┐ąĖčüą░ąĮąŠ.
[ążą╗ą░ą│ąĖ ]
ąÜąŠą╝ą░ąĮą┤ą░ ąĮąĄ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ čäą╗ą░ą│ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
link 8 ; // ąŻčüčéą░ąĮąŠą▓ą║ą░ čäčĆąĄą╣ą╝ą░ čĆą░ąĘą╝ąĄčĆąŠą╝ ą▓ 8 čüą╗ąŠą▓,
// ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ą┤ą╗čÅ ą╗ąŠą║ą░ą╗čīąĮčŗčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ.
[-- sp] = (r7: 0 , p5: 0 ); // ąĪąŠčģčĆą░ąĮąĄąĮąĖąĄ D-čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖ P-čĆąĄą│ąĖčüčéčĆąŠą▓.
(r7: 0 , p5: 0 ) = [sp++ ]; // ąÆąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖąĄ D-čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖ P-čĆąĄą│ąĖčüčéčĆąŠą▓.
unlink; // ąŚą░ą║čĆčŗčéąĖąĄ čäčĆąĄą╣ą╝ą░.
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Push Multiple, Pop Multiple.
[ąśąĮčüčéčĆčāą║čåąĖąĖ ą┐čĆąŠą▓ąĄčĆą║ąĖ, ą▓ą╗ąĖčÅčÄčēąĖąĄ ąĮą░ ą▒ąĖčé CC ]
ąÆ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ ąŠą▒čüčāąČą┤ą░čÄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ą▓ą╗ąĖčÅčÄčé ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ ą▒ąĖčéą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą║ąŠą┤ąŠą╝ (ą▒ąĖčé Control Code, CC) ą▓ čĆąĄą│ąĖčüčéčĆąĄ ASTAT. ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĖ ą╝ąŠą│čāčé ą┐čĆąĖą╝ąĄąĮčÅčéčī čŹčéąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ, čćč鹊ą▒čŗ čāčüčéą░ąĮąŠą▓ąĖčéčī ą▒ąĖčé CC ąĮą░ ąŠčüąĮąŠą▓ąĄ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ąĘąĮą░č湥ąĮąĖą╣ ą┤ą▓čāčģ čĆąĄą│ąĖčüčéčĆąŠą▓, čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ąĖą╗ąĖ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓. ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ čŹčéąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą┐ąĄčĆąĄą╝ąĄčüčéąĖčéčī čüąŠčüč鹊čÅąĮąĖąĄ ą▒ąĖčéą░ CC ąĖą╗ąĖ ą▒ąĖčé čüąŠčüč鹊čÅąĮąĖčÅ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ ą▓ čĆąĄą│ąĖčüčéčĆ ą┤ą░ąĮąĮčŗčģ ąĖ ąĖąĘ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ, ąĖą╗ąĖ ąŠąĮąĖ ą╝ąŠą│čāčé ąĖąĮą▓ąĄčĆčéąĖčĆąŠą▓ą░čéčī čüąŠčüč鹊čÅąĮąĖąĄ ą▒ąĖčéą░ CC.
ąśąĮčüčéčĆčāą║čåąĖčÅ čüčĆą░ą▓ąĮąĖą▓ą░ąĄčé čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ ąĖ ą┐ąŠ čĆąĄąĘčāą╗čīčéą░čéčā ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāąĄčé CC. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
CC = operand_1 == operand_2
CC = operand_1 < operand _2
CC = operand _1 < = operand _2
CC = operand _1 < operand _2 ( IU )
CC = operand _1 < = operand _2 ( IU )
ąĪąĖąĮčéą░ą║čüąĖčü:
CC = Dreg == Dreg; // ą┐čĆąŠą▓ąĄčĆą║ą░ ąĮą░ čĆą░ą▓ąĄąĮčüčéą▓ąŠ čĆąĄą│ąĖčüčéčĆąŠą▓ čü čāč湥č鹊ą╝ ąĘąĮą░ą║ą░ (a)1
CC = Dreg == imm3; // ą┐čĆąŠą▓ąĄčĆą║ą░ ąĮą░ čĆą░ą▓ąĄąĮčüčéą▓ąŠ ą║ąŠąĮčüčéą░ąĮč鹥 čü čāč湥č鹊ą╝ ąĘąĮą░ą║ą░ (a)
CC = Dreg < Dreg; // ą╝ąĄąĮčīčłąĄ č湥ą╝, čüčĆą░ą▓ąĮąĖą▓ą░čÄčéčüčÅ čĆąĄą│ąĖčüčéčĆčŗ čü čāč湥č鹊ą╝ ąĘąĮą░ą║ą░ (a)
CC = Dreg < imm3; // ą╝ąĄąĮčīčłąĄ č湥ą╝, čüčĆą░ą▓ąĮąĄąĮąĖąĄ čü ą║ąŠąĮčüčéą░ąĮč鹊ą╣ čü čāč湥č鹊ą╝ ąĘąĮą░ą║ą░ (a)
CC = Dreg < = Dreg; // ą╝ąĄąĮčīčłąĄ ąĖą╗ąĖ čĆą░ą▓ąĮąŠ, čüčĆą░ą▓ąĮąĄąĮąĖąĄ čĆąĄą│ąĖčüčéčĆą░ čü čāč湥č鹊ą╝ ąĘąĮą░ą║ą░ (a)
CC = Dreg < = imm3; // ą╝ąĄąĮčīčłąĄ ąĖą╗ąĖ čĆą░ą▓ąĮąŠ, čüčĆą░ą▓ąĮąĄąĮąĖąĄ čĆąĄą│ąĖčüčéčĆą░ čü ą║ąŠąĮčüčéą░ąĮč鹊ą╣
CC = Dreg < Dreg(IU); // ą╝ąĄąĮčīčłąĄ, ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ čüčĆą░ą▓ąĮąĄąĮąĖąĄ čĆąĄą│ąĖčüčéčĆąŠą▓ (a)
CC = Dreg < uimm3(IU); // ą╝ąĄąĮčīčłąĄ, ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ čüčĆą░ą▓ąĮąĄąĮąĖąĄ čĆąĄą│ąĖčüčéčĆą░
CC = Dreg < = Dreg(IU); // ą╝ąĄąĮčīčłąĄ ąĖą╗ąĖ čĆą░ą▓ąĮąŠ, ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ čüčĆą░ą▓ąĮąĄąĮąĖąĄ čĆąĄą│ąĖčüčéčĆąŠą▓ (a)
CC = Dreg < = uimm3(IU); // ą╝ąĄąĮčīčłąĄ ąĖą╗ąĖ čĆą░ą▓ąĮąŠ, ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ čüčĆą░ą▓ąĮąĄąĮąĖąĄ čĆąĄą│ąĖčüčéčĆą░
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
imm3: 3-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ čüąŠ ąĘąĮą░ą║ąŠą╝, ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ -4 .. 3.
uimm3: 3-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ą░ąĮąĮčŗčģ (Compare Data Register) čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé ą▒ąĖčé CC (Control Code bit, ą▒ąĖčé čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą▓ąĄčéą▓ą╗ąĄąĮąĖąĄą╝ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ) ąĮą░ ąŠčüąĮąŠą▓ąĄ čĆąĄąĘčāą╗čīčéą░čéą░ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą┤ą▓čāčģ ąĘąĮą░č湥ąĮąĖą╣. ąÆ ą║ą░č湥čüčéą▓ąĄ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ ąĖčüą┐ąŠą╗čīąĘčāčÄčé D-čĆąĄą│ąĖčüčéčĆčŗ.
ą×ą┐ąĄčĆą░čåąĖąĖ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ąĮąĄ ą┤ąĄčüčéčĆčāą║čéąĖą▓ąĮčŗ, čé. ąĄ. ąŠąĮąĖ ąĮąĄ ą▓ą╗ąĖčÅčÄčé ąĮą░ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čüčĆą░ą▓ąĮąĖą▓ą░ąĄą╝čŗčģ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓, ąĖ ą▓ą╗ąĖčÅčÄčé č鹊ą╗čīą║ąŠ ąĮą░ čüąŠčüč鹊čÅąĮąĖąĄ ą▒ąĖčéą░ CC ąĖ ąĮą░ čäą╗ą░ą│ąĖ. ąŚąĮą░č湥ąĮąĖąĄ ą▒ąĖčéą░ CC ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ čāčüą╗ąŠą▓ąĮąŠą│ąŠ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ.
ąĀą░ąĘą╗ąĖčćąĮčŗąĄ č乊čĆą╝čŗ ąĖąĮčüčéčĆčāą║čåąĖąĖ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą▓čŗą┐ąŠą╗ąĮčÅčÄčé ąŠą┐ąĄčĆą░čåąĖčÄ čüčĆą░ą▓ąĮąĄąĮąĖčÅ 32-čĆą░ąĘčĆčÅą┤ąĮčŗčģ čćąĖčüąĄą╗ čüąŠ ąĘąĮą░ą║ąŠą╝, ąĖą╗ąĖ čüčĆą░ą▓ąĮąĖą▓ą░čÄčé ąĖčģ ą║ą░ą║ ą▓ąĄą╗ąĖčćąĖąĮčŗ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ąĄčüą╗ąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ čüčāčäčäąĖą║čü (IU). ą×ą┐ąĄčĆą░čåąĖąĖ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą▓čŗą┐ąŠą╗ąĮčÅčÄčé ą▓čŗčćąĖčéą░ąĮąĖąĄ ąĖ ąŠčéą▒čĆą░čüčŗą▓ą░čÄčé čĆąĄąĘčāą╗čīčéą░čé ą▒ąĄąĘ ą║ą░ą║ąŠą│ąŠ-ą╗ąĖą▒ąŠ ą▓ą╗ąĖčÅąĮąĖčÅ ąĮą░ čĆąĄą│ąĖčüčéčĆčŗ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ. ą×ą┐ąĄčĆą░čåąĖčÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ, ą║ąŠč鹊čĆčāčÄ ąÆčŗ čāą║ą░ąČąĄč鹥, ąŠą┐čĆąĄą┤ąĄą╗ąĖčé ą║ąŠąĮąĄčćąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ ą▒ąĖčéą░ CC.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖčüą┐ąŠą╗čīąĘčāąĄčé čüą╗ąĄą┤čāčÄčēąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ ą▓ ąŠą┐ąĄčĆą░čåąĖčÅčģ čüčĆą░ą▓ąĮąĄąĮąĖčÅ čüąŠ ąĘąĮą░ą║ąŠą╝ ąĖ ą▒ąĄąĘ ąĘąĮą░ą║ą░:
ąĪčĆą░ą▓ąĮąĄąĮąĖąĄ ąĪąŠ ąĘąĮą░ą║ąŠą╝ (signed) ąæąĄąĘ ąĘąĮą░ą║ą░ (unsigned)
ąĀą░ą▓ąĮąŠ
AZ=1
ąĮąĄ ą┐čĆąĖą╝ąĄąĮąĖą╝ąŠ
ą£ąĄąĮčīčłąĄ
AN=1
AC=0
ą£ąĄąĮčīčłąĄ ąĖą╗ąĖ čĆą░ą▓ąĮąŠ
AN ąĖą╗ąĖ AZ=1
AC=0 ąĖą╗ąĖ AZ=1
ąśąĮčüčéčĆčāą║čåąĖčÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ ą░čĆąĖčäą╝ąĄčéąĖą║ąĖ, ąĮą░čģąŠą┤čÅčēąĖąĄčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ASTAT:
ŌĆó CC čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ą▓čŗčĆą░ąČąĄąĮąĖčÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą▓ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ąĄčĆąĄąĮ, ąĖąĮą░č湥 čüą▒čĆąŠčüąĖčéčüčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
cc = r3 == r2;
cc = r7 == 1 ;
/* ąĢčüą╗ąĖ r0 = 0x8FFF FFFF ąĖ r3 = 0x0000 0001,
č鹊 ąŠą┐ąĄčĆą░čåąĖčÅ čüąŠ ąĘąĮą░ą║ąŠą╝ ... */
cc = r0 < r3;
/* ... ą┤ą░čüčé cc = 1, ą┐ąŠč鹊ą╝čā čćč鹊 r0 čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ąĄčéčüčÅ ą║ą░ą║ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ */
cc = r2 < - 4 ;
cc = r6 < = r1;
cc = r4 < = 3 ;
/* ąĢčüą╗ąĖ r0 = 0x8FFF FFFF ąĖ r3 = 0x0000 0001, č鹊 ąŠą┐ąĄčĆą░čåąĖčÅ ą▒ąĄąĘ ąĘąĮą░ą║ą░ ... cc = r5 < r3 (iu); /* ... ą┤ą░čüčé CC = 0, ą┐ąŠč鹊ą╝čā čćč鹊 r0 čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ąĄčéčüčÅ ą║ą░ą║ ą▒ąŠą╗čīčłąŠąĄ čćąĖčüą╗ąŠ ą▒ąĄąĘ ąĘąĮą░ą║ą░ */
cc = r1 < 0x7 (iu);
cc = r2 < = r0 (iu);
cc = r3 < = 2 (iu);
ąĪą╝. čéą░ą║ąČąĄ Compare Pointer, Compare Accumulator, Conditional Jump.
ąśąĮčüčéčĆčāą║čåąĖčÅ čüčĆą░ą▓ąĮąĖą▓ą░ąĄčé čĆąĄą│ąĖčüčéčĆčŗ-čāą║ą░ąĘą░č鹥ą╗ąĖ ąĖ ą┐ąŠ čĆąĄąĘčāą╗čīčéą░čéčā ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāąĄčé CC. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
CC = operand_1 == operand_2
CC = operand_1 < operand _2
CC = operand _1 < = operand _2
CC = operand _1 < operand _2 ( IU )
CC = operand _1 < = operand _2 ( IU )
ąĪąĖąĮčéą░ą║čüąĖčü:
CC = Preg == Preg; // ą┐čĆąŠą▓ąĄčĆą║ą░ ąĮą░ čĆą░ą▓ąĄąĮčüčéą▓ąŠ čĆąĄą│ąĖčüčéčĆąŠą▓ čü čāč湥č鹊ą╝ ąĘąĮą░ą║ą░ (a)1
CC = Preg == imm3; // ą┐čĆąŠą▓ąĄčĆą║ą░ ąĮą░ čĆą░ą▓ąĄąĮčüčéą▓ąŠ ą║ąŠąĮčüčéą░ąĮč鹥 čü čāč湥č鹊ą╝ ąĘąĮą░ą║ą░ (a)
CC = Preg < Preg; // ą╝ąĄąĮčīčłąĄ č湥ą╝, čüčĆą░ą▓ąĮąĖą▓ą░čÄčéčüčÅ čĆąĄą│ąĖčüčéčĆčŗ čü čāč湥č鹊ą╝ ąĘąĮą░ą║ą░ (a)
CC = Preg < imm3; // ą╝ąĄąĮčīčłąĄ č湥ą╝, čüčĆą░ą▓ąĮąĄąĮąĖąĄ čü ą║ąŠąĮčüčéą░ąĮč鹊ą╣ čü čāč湥č鹊ą╝ ąĘąĮą░ą║ą░ (a)
CC = Preg < = Preg; // ą╝ąĄąĮčīčłąĄ ąĖą╗ąĖ čĆą░ą▓ąĮąŠ, čüčĆą░ą▓ąĮąĄąĮąĖąĄ čĆąĄą│ąĖčüčéčĆą░ čü čāč湥č鹊ą╝ ąĘąĮą░ą║ą░ (a)
CC = Preg < = imm3; // ą╝ąĄąĮčīčłąĄ ąĖą╗ąĖ čĆą░ą▓ąĮąŠ, čüčĆą░ą▓ąĮąĄąĮąĖąĄ čĆąĄą│ąĖčüčéčĆą░ čü ą║ąŠąĮčüčéą░ąĮč鹊ą╣
CC = Preg < Preg(IU); // ą╝ąĄąĮčīčłąĄ, ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ čüčĆą░ą▓ąĮąĄąĮąĖąĄ čĆąĄą│ąĖčüčéčĆąŠą▓ (a)
CC = Preg < uimm3(IU); // ą╝ąĄąĮčīčłąĄ, ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ čüčĆą░ą▓ąĮąĄąĮąĖąĄ čĆąĄą│ąĖčüčéčĆą░
CC = Preg < = Preg(IU); // ą╝ąĄąĮčīčłąĄ ąĖą╗ąĖ čĆą░ą▓ąĮąŠ, ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ čüčĆą░ą▓ąĮąĄąĮąĖąĄ čĆąĄą│ąĖčüčéčĆąŠą▓ (a)
CC = Preg < = uimm3(IU); // ą╝ąĄąĮčīčłąĄ ąĖą╗ąĖ čĆą░ą▓ąĮąŠ, ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ čüčĆą░ą▓ąĮąĄąĮąĖąĄ čĆąĄą│ąĖčüčéčĆą░
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Preg: čĆąĄą│ąĖčüčéčĆčŗ P0, ..., P5, SP, FP.
imm3: 3-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ čüąŠ ąĘąĮą░ą║ąŠą╝, ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ -4 .. 3.
uimm3: 3-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓ čāą║ą░ąĘą░č鹥ą╗čÅ (Compare Pointer) čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé ą▒ąĖčé CC (Control Code bit, ą▒ąĖčé čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą▓ąĄčéą▓ą╗ąĄąĮąĖąĄą╝ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ) ąĮą░ ąŠčüąĮąŠą▓ąĄ čĆąĄąĘčāą╗čīčéą░čéą░ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą┤ą▓čāčģ ąĘąĮą░č湥ąĮąĖą╣. ąÆ ą║ą░č湥čüčéą▓ąĄ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ ąĖčüą┐ąŠą╗čīąĘčāčÄčé P-čĆąĄą│ąĖčüčéčĆčŗ.
ą×ą┐ąĄčĆą░čåąĖąĖ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ąĮąĄ ą┤ąĄčüčéčĆčāą║čéąĖą▓ąĮčŗ, čé. ąĄ. ąŠąĮąĖ ąĮąĄ ą▓ą╗ąĖčÅčÄčé ąĮą░ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čüčĆą░ą▓ąĮąĖą▓ą░ąĄą╝čŗčģ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓, ąĖ ą▓ą╗ąĖčÅčÄčé č鹊ą╗čīą║ąŠ ąĮą░ čüąŠčüč鹊čÅąĮąĖąĄ ą▒ąĖčéą░ CC ąĖ ąĮą░ čäą╗ą░ą│ąĖ. ąŚąĮą░č湥ąĮąĖąĄ ą▒ąĖčéą░ CC ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ čāčüą╗ąŠą▓ąĮąŠą│ąŠ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ.
ąĀą░ąĘą╗ąĖčćąĮčŗąĄ č乊čĆą╝čŗ ąĖąĮčüčéčĆčāą║čåąĖąĖ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą▓čŗą┐ąŠą╗ąĮčÅčÄčé ąŠą┐ąĄčĆą░čåąĖčÄ čüčĆą░ą▓ąĮąĄąĮąĖčÅ 32-čĆą░ąĘčĆčÅą┤ąĮčŗčģ čćąĖčüąĄą╗ čüąŠ ąĘąĮą░ą║ąŠą╝, ąĖą╗ąĖ čüčĆą░ą▓ąĮąĖą▓ą░čÄčé ąĖčģ ą║ą░ą║ ą▓ąĄą╗ąĖčćąĖąĮčŗ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ąĄčüą╗ąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ čüčāčäčäąĖą║čü (IU). ą×ą┐ąĄčĆą░čåąĖąĖ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą▓čŗą┐ąŠą╗ąĮčÅčÄčé ą▓čŗčćąĖčéą░ąĮąĖąĄ ąĖ ąŠčéą▒čĆą░čüčŗą▓ą░čÄčé čĆąĄąĘčāą╗čīčéą░čé ą▒ąĄąĘ ą║ą░ą║ąŠą│ąŠ-ą╗ąĖą▒ąŠ ą▓ą╗ąĖčÅąĮąĖčÅ ąĮą░ čĆąĄą│ąĖčüčéčĆčŗ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ. ą×ą┐ąĄčĆą░čåąĖčÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ, ą║ąŠč鹊čĆčāčÄ ąÆčŗ čāą║ą░ąČąĄč鹥, ąŠą┐čĆąĄą┤ąĄą╗ąĖčé ą║ąŠąĮąĄčćąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ ą▒ąĖčéą░ CC.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ą▓ą╗ąĖčÅąĄčé č鹊ą╗čīą║ąŠ ąĮą░ 1 čäą╗ą░ą│:
ŌĆó CC čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ą▓čŗčĆą░ąČąĄąĮąĖčÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą▓ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ąĄčĆąĄąĮ, ąĖąĮą░č湥 čüą▒čĆąŠčüąĖčéčüčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
cc = p3 == p2;
cc = p0 == 1 ;
cc = p0 < p3;
cc = p2 < - 4 ;
cc = p1 < = p0;
cc = p4 < = 3 ;
cc = p5 < p3(iu);
cc = p1 < 0x7 (iu);
cc = p2 < = p0(iu);
cc = p3 < = 2 (iu);
ąĪą╝. čéą░ą║ąČąĄ Compare Data Register, Compare Accumulator, Conditional Jump.
ąśąĮčüčéčĆčāą║čåąĖčÅ čüčĆą░ą▓ąĮąĖą▓ą░ąĄčé ą░ą║ą║čāą╝čāą╗čÅč鹊čĆčŗ ąĖ ą┐ąŠ čĆąĄąĘčāą╗čīčéą░čéčā ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāąĄčé CC. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
CC = A0 == A1
CC = A0 < A1
CC = A0 < = A1
ąĪąĖąĮčéą░ą║čüąĖčü:
CC = A0 == A1; // ą┐čĆąŠą▓ąĄčĆą║ą░ ąĮą░ čĆą░ą▓ąĄąĮčüčéą▓ąŠ čĆąĄą│ąĖčüčéčĆąŠą▓ čü čāč湥č鹊ą╝ ąĘąĮą░ą║ą░ (a)1
CC = A0 < A1; // ą╝ąĄąĮčīčłąĄ č湥ą╝, čüčĆą░ą▓ąĮąĖą▓ą░čÄčéčüčÅ čĆąĄą│ąĖčüčéčĆčŗ čü čāč湥č鹊ą╝ ąĘąĮą░ą║ą░ (a)
CC = A0 < = A1; // ą╝ąĄąĮčīčłąĄ ąĖą╗ąĖ čĆą░ą▓ąĮąŠ, čüčĆą░ą▓ąĮąĄąĮąĖąĄ čĆąĄą│ąĖčüčéčĆą░ čü čāč湥č鹊ą╝ ąĘąĮą░ą║ą░ (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓ (Compare Accumulator) čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé ą▒ąĖčé CC (Control Code bit, ą▒ąĖčé čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą▓ąĄčéą▓ą╗ąĄąĮąĖąĄą╝ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ) ąĮą░ ąŠčüąĮąŠą▓ąĄ čĆąĄąĘčāą╗čīčéą░čéą░ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą┤ą▓čāčģ ąĘąĮą░č湥ąĮąĖą╣. ąÆ ą║ą░č湥čüčéą▓ąĄ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą░ą║ą║čāą╝čāą╗čÅč鹊čĆčŗ.
ąŁčéąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓čŗą┐ąŠą╗ąĮčÅčÄčé 40-čĆą░ąĘčĆčÅą┤ąĮąŠąĄ čüčĆą░ą▓ąĮąĄąĮąĖąĄ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓, ą▓ąŠčüą┐čĆąĖąĮąĖą╝ą░čÅ ąĖčģ ą║ą░ą║ čćąĖčüą╗ą░ čüąŠ ąĘąĮą░ą║ąŠą╝. ą×ą┐ąĄčĆą░čåąĖąĖ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą▓čŗą┐ąŠą╗ąĮčÅčÄčé ą▓čŗčćąĖčéą░ąĮąĖąĄ ąĖ ąŠčéą▒čĆą░čüčŗą▓ą░čÄčé čĆąĄąĘčāą╗čīčéą░čé ą▒ąĄąĘ ą║ą░ą║ąŠą│ąŠ-ą╗ąĖą▒ąŠ ą▓ą╗ąĖčÅąĮąĖčÅ ąĮą░ čĆąĄą│ąĖčüčéčĆčŗ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ. ą×ą┐ąĄčĆą░čåąĖčÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ, ą║ąŠč鹊čĆčāčÄ ąÆčŗ čāą║ą░ąČąĄč鹥, ąŠą┐čĆąĄą┤ąĄą╗ąĖčé ą║ąŠąĮąĄčćąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ ą▒ąĖčéą░ CC.
ąØąĄ ą┐čĆąĄą┤čāčüą╝ąŠčéčĆąĄąĮčŗ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ą╗čÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓ ą║ą░ą║ čćąĖčüąĄą╗ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ąĖ čéą░ą║ąČąĄ ąĮąĄčé ąĖąĮčüčéčĆčāą║čåąĖą╣ ą┤ą╗čÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓ čü ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮčŗą╝ąĖ ą║ąŠąĮčüčéą░ąĮčéą░ą╝ąĖ.
ą×ą┐ąĄčĆą░čåąĖąĖ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ąĮąĄ ą┤ąĄčüčéčĆčāą║čéąĖą▓ąĮčŗ, čé. ąĄ. ąŠąĮąĖ ąĮąĄ ą▓ą╗ąĖčÅčÄčé ąĮą░ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čüčĆą░ą▓ąĮąĖą▓ą░ąĄą╝čŗčģ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓, ąĖ ą▓ą╗ąĖčÅčÄčé č鹊ą╗čīą║ąŠ ąĮą░ čüąŠčüč鹊čÅąĮąĖąĄ ą▒ąĖčéą░ CC ąĖ ąĮą░ čäą╗ą░ą│ąĖ. ąŚąĮą░č湥ąĮąĖąĄ ą▒ąĖčéą░ CC ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ čāčüą╗ąŠą▓ąĮąŠą│ąŠ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖčüą┐ąŠą╗čīąĘčāąĄčé čüą╗ąĄą┤čāčÄčēąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ ą▓ ąŠą┐ąĄčĆą░čåąĖčÅčģ čüčĆą░ą▓ąĮąĄąĮąĖčÅ čüąŠ ąĘąĮą░ą║ąŠą╝ ąĖ ą▒ąĄąĘ ąĘąĮą░ą║ą░:
ąĪčĆą░ą▓ąĮąĄąĮąĖąĄ ąĪąŠ ąĘąĮą░ą║ąŠą╝ (signed)
ąĀą░ą▓ąĮąŠ
AZ=1
ą£ąĄąĮčīčłąĄ
AN=1
ą£ąĄąĮčīčłąĄ ąĖą╗ąĖ čĆą░ą▓ąĮąŠ
AN ąĖą╗ąĖ AZ=1
ąśąĮčüčéčĆčāą║čåąĖčÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą▓ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ ą░čĆąĖčäą╝ąĄčéąĖą║ąĖ, ąĮą░čģąŠą┤čÅčēąĖąĄčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ASTAT:
ŌĆó CC čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ą▓čŗčĆą░ąČąĄąĮąĖčÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą▓ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ąĄčĆąĄąĮ, ąĖąĮą░č湥 čüą▒čĆąŠčüąĖčéčüčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
cc = A0 == A1;
cc = A0 < A1;
cc = A0 < = A1;
ąĪą╝. čéą░ą║ąČąĄ Compare Pointer, Compare Data Register, Conditional Jump.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┤ąĄą╗ą░ąĄčé ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ ą▒ąĖčéą░ CC. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest = CC
dest |= CC
dest &= CC
dest ^= CC
CC = source
CC |= source
CC &= source
CC ^= source
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = CC; // ą║ąŠą┐ąĖčĆčāąĄčé CC ą▓ 32-ą▒ąĖčéąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ ą┤ą░ąĮąĮčŗčģ (a)1
statbit = CC; // ą▒ąĖčé čüčéą░čéčāčüą░ čüčéą░ąĮąŠą▓ąĖčéčüčÅ čĆą░ą▓ąĮčŗą╝ CC (a)
statbit |= CC; // ą▒ąĖčé čüčéą░čéčāčüą░ čüčéą░ąĮąŠą▓ąĖčéčüčÅ čĆąĄąĘčāą╗čīčéą░č鹊ą╝ ą╗ąŠą│ąĖč湥čüą║ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ
// ąśąøąś (OR) ąĮą░ą┤ ąĮąĖą╝ ąĖ CC (a)
statbit &= CC; // ą▒ąĖčé čüčéą░čéčāčüą░ čüčéą░ąĮąŠą▓ąĖčéčüčÅ čĆąĄąĘčāą╗čīčéą░č鹊ą╝ ą╗ąŠą│ąĖč湥čüą║ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ // ąś (AND) ąĮą░ą┤ ąĮąĖą╝ ąĖ CC (a)
statbit ^= CC; // ą▒ąĖčé čüčéą░čéčāčüą░ čüčéą░ąĮąŠą▓ąĖčéčüčÅ čĆąĄąĘčāą╗čīčéą░č鹊ą╝ ą╗ąŠą│ąĖč湥čüą║ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ // ąśąĪąÜąøą«ą¦ąÉą«ą®ąĢąĢ ąśąøąś (XOR) ąĮą░ą┤ ąĮąĖą╝ ąĖ CC (a)
CC = Dreg; // CC čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ąĮąĄ ąĮąŠą╗čī (a)
CC = statbit; // CC čüčéą░ąĮąŠą▓ąĖčéčüčÅ čĆą░ą▓ąĮčŗą╝ ą▒ąĖčéčā čüčéą░čéčāčüą░ (a)
CC |= statbit; // CC čüčéą░ąĮąŠą▓ąĖčéčüčÅ čĆą░ą▓ąĮčŗą╝ CC OR ą▒ąĖčé čüčéą░čéčāčüą░ (a)
CC &= statbit; // CC čüčéą░ąĮąŠą▓ąĖčéčüčÅ čĆą░ą▓ąĮčŗą╝ CC AND ą▒ąĖčé čüčéą░čéčāčüą░ (a)
CC ^= statbit; // CC čüčéą░ąĮąŠą▓ąĖčéčüčÅ čĆą░ą▓ąĮčŗą╝ CC XOR ą▒ąĖčé čüčéą░čéčāčüą░ (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
statbit: AZ, AN, AC0, AC1, V, VS, AV0, AV0S, AV1, AV1S, AQ.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Move CC ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčé ąŠą┐ąĄčĆą░čåąĖčÄ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ ą╝ąĄąČą┤čā ąĘąĮą░č湥ąĮąĖąĄą╝ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠą│ąŠ ą▒ąĖčéą░ čüčéą░čéčāčüą░ ąĖ ą▒ąĖčéą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą▓ąĄčéą▓ą╗ąĄąĮąĖąĄą╝ (Control Code bit, CC).
ą¤čĆąĖ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĖ CC ą▓ 32-ą▒ąĖčéąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ ą┤ą░ąĮąĮčŗčģ, ąŠą┐ąĄčĆą░čåąĖčÅ ą┐ąŠą╝ąĄčēą░ąĄčé ąĘąĮą░č湥ąĮąĖąĄ ą▒ąĖčéą░ CC ą▓ čüą░ą╝čŗą╣ ą╝ą╗ą░ą┤čłąĖą╣ ąĘąĮą░čćą░čēąĖą╣ ą▒ąĖčé čĆąĄą│ąĖčüčéčĆą░ (LSB), ąĘą░ą┐ąŠą╗ąĮčÅčÅ ąŠčüčéą░ą╗čīąĮčŗąĄ ą▒ąĖčéčŗ ąĮčāą╗čÅą╝ąĖ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą╝ąŠąČąĄčé ą▒čŗčéčī 2 čüą╗čāčćą░čÅ:
ąĢčüą╗ąĖ CC = 0, Dreg čüčéą░ąĮąŠą▓ąĖčéčüčÅ čĆą░ą▓ąĮčŗą╝ 0x00000000.
ąÜąŠą│ą┤ą░ ą║ąŠą┐ąĖčĆčāąĄčéčüčÅ čĆąĄą│ąĖčüčéčĆ ą┤ą░ąĮąĮčŗčģ ą▓ ą▒ąĖčé CC ąŠą┐ąĄčĆą░čåąĖčÅ čāčüčéą░ąĮąŠą▓ąĖčé ą▒ąĖčé CC ą▓ 1, ąĄčüą╗ąĖ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą╗čÄą▒ąŠą╣ ą▒ąĖčé ą▓ čĆąĄą│ąĖčüčéčĆąĄ-ąĖčüč鹊čćąĮąĖą║ąĄ (čé. ąĄ. ąĄčüą╗ąĖ čĆąĄą│ąĖčüčéčĆ ąĮąĄ čĆą░ą▓ąĄąĮ 0). ąśąĮą░č湥 čŹčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ ąŠčćąĖčüčéąĖčé ą▒ąĖčé CC.
ąØąĄą║ąŠč鹊čĆčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ąĄą╗ą░čÄčé ą╗ąŠą│ąĖč湥čüą║čāčÄ čāčüčéą░ąĮąŠą▓ą║čā ąĖą╗ąĖ ąŠčćąĖčüčéą║čā ą▒ąĖčéą░ CC ąĖą╗ąĖ ą▒ąĖčéą░ čüčéą░čéčāčüą░ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ ą┐ąŠ čĆąĄąĘčāą╗čīčéą░čéčā ą╗ąŠą│ąĖč湥čüą║ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ ąĮą░ ą▒ą░ąĘąĄ ą▒ąĖčéą░ čüčéą░čéčāčüą░ ąĖ ą▒ąĖčéą░ CC.
ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą▒ąĖčéą░ CC ą▓ ą║ą░č湥čüčéą▓ąĄ ąĖčüč鹊čćąĮąĖą║ą░ (source) ąĖ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ (dst) ą▓ ąŠą┤ąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĘą░ą┐čĆąĄčēąĄąĮąŠ. ąĪą╝. ąĮąĖąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ ąŠčéčĆąĖčåą░ąĮąĖčÅ CC (NEGATE CC), ą┐ąŠąĘą▓ąŠą╗čÅčÄčēčāčÄ ą┐ąŠą╝ąĄąĮčÅčéčī ąĘąĮą░č湥ąĮąĖąĄ CC ąĮą░ ąŠčüąĮąŠą▓ąĄ čüą▓ąŠąĄą│ąŠ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Move CC ą▓ą╗ąĖčÅąĄčé ąĮą░ čäą╗ą░ą│ąĖ CC, AZ, AN, AC0, AC1, V, VS, AV0, AV0S, AV1, AV1S, AQ, ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čüąŠ ąĘąĮą░č湥ąĮąĖąĄą╝ ą▒ąĖčéą░ čüčéą░čéčāčüą░ ąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╝ čüąĖąĮčéą░ą║čüąĖčüąŠą╝. ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ, ąĮąĄ čāą║ą░ąĘą░ąĮąĮčŗąĄ čÅą▓ąĮąŠ ą║ą░ą║ ą▒ąĖčé ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą▓ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ąĮąĄ ą▒čāą┤čāčé ąĖąĘą╝ąĄąĮąĄąĮčŗ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r0 = cc;
az = cc;
an |= cc;
ac0 &= cc;
av0 ^= cc;
cc = r4;
cc = av1;
cc |= aq;
cc &= an;
cc ^= ac1;
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ NEGATE CC.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ą╗ąŠą│ąĖč湥čüą║čāčÄ ąĖąĮą▓ąĄčĆčüąĖčÄ ąĘąĮą░č湥ąĮąĖčÅ ą▒ąĖčéą░ CC. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
CC = !CC
ąöą╗ąĖąĮą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ CC ą▓ą╗ąĖčÅąĄčé č鹊ą╗čīą║ąŠ ąĮą░ ą▒ąĖčé CC, ą┐ąĄčĆąĄą║ą╗čÄčćą░čÅ ąĄą│ąŠ ąĘąĮą░č湥ąĮąĖąĄ ąĮą░ ą┐čĆąŠčéąĖą▓ąŠą┐ąŠą╗ąŠąČąĮąŠąĄ. ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą▒čāą┤čāčé ąĖąĘą╝ąĄąĮąĄąĮčŗ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Move CC.
[ąøąŠą│ąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ]
ąŁč鹊čé čĆą░ąĘą┤ąĄą╗ ą┐ąŠčüą▓čÅčēąĄąĮ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝, ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčēąĖą╝ ą╗ąŠą│ąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ. ąśą╝ąĄčÄčéčüčÅ ą▒ą░ąĘąŠą▓čŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ąś (AND), ąØąĢąó (NOT, ąĖą╗ąĖ ą┤ą▓ąŠąĖčćąĮąŠąĄ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┤ąŠ 1), ąśąøąś (OR), ąśąĪąÜąøą«ą¦ąÉą«ą®ąĢąĢ ąśąøąś (XOR), ą░ čéą░ą║ąČąĄ ąĮąĄą║ąŠč鹊čĆčŗąĄ čüą┐ąĄčåąĖčäąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ą┤ą╗čÅ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖčÅ/ą┤ąĄą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖčÅ čü ą┐ąŠą╝ąŠčēčīčÄ LFSR, čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝čŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Bit-Wise Exclusive-OR.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
čĆąĄą│ąĖčüčéčĆ_ąĮą░ąĘąĮą░č湥ąĮąĖčÅ = čĆąĄą│ąĖčüčéčĆ_ąĖčüč鹊čćąĮąĖą║ą░_0 & čĆąĄą│ąĖčüčéčĆ_ąĖčüč鹊čćąĮąĖą║ą░_1
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = Dreg & Dreg; // (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ AND ą▓čŗą┐ąŠą╗ąĮčÅąĄčé 32-čĆą░ąĘčĆčÅą┤ąĮčāčÄ, ą┐ąŠą▒ąĖčéąĮčāčÄ ąŠą┐ąĄčĆą░čåąĖčÄ ą╗ąŠą│ąĖą║ąĖ ąś (AND) ąĮą░ą┤ čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ-ąĖčüč鹊čćąĮąĖą║ą░ą╝ąĖ, ąĖ čüąŠčģčĆą░ąĮčÅąĄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāąĄčé čÅą▓ąĮąŠ čĆąĄą│ąĖčüčéčĆčŗ ąĖčüč鹊čćąĮąĖą║ą░. ąØąŠ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąĖ ąŠą┤ąĖąĮ ąĖąĘ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖčüč鹊čćąĮąĖą║ą░ ą╝ąŠą│čāčé ą▒čŗčéčī ąŠą┤ąĮąĖą╝ ąĖ č鹥ą╝ ąČąĄ D-čĆąĄą│ąĖčüčéčĆąŠą╝, č鹊ą│ą┤ą░ ąŠą┐ąĄčĆą░čåąĖčÅ ąĖąĘą╝ąĄąĮąĖčé čŹč鹊čé čĆąĄą│ąĖčüčéčĆ ąĖčüč鹊čćąĮąĖą║ą░.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ ą░čĆąĖčäą╝ąĄčéąĖą║ąĖ, ąĮą░čģąŠą┤čÅčēąĖąĄčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ASTAT:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé čĆą░ą▓ąĄąĮ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ OR.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
čĆąĄą│ąĖčüčéčĆ_ąĮą░ąĘąĮą░č湥ąĮąĖčÅ = ~ čĆąĄą│ąĖčüčéčĆ_ąĖčüč鹊čćąĮąĖą║ą░
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = ~Dreg; // (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ NOT (ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĄą┤ąĖąĮąĖčåą░ą╝ąĖ) ą┐ąĄčĆąĄą║ą╗čÄčćą░ąĄčé ą▓ ą┐čĆąŠčéąĖą▓ąŠą┐ąŠą╗ąŠąČąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ ą║ą░ąČą┤čŗą╣ ą▒ąĖčé ą▓ 32-čĆą░ąĘčĆčÅą┤ąĮąŠą╝ čĆąĄą│ąĖčüčéčĆąĄ-ąĖčüč鹊čćąĮąĖą║ąĄ, ąĖ čüąŠčģčĆą░ąĮčÅąĄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ čĆąĄą│ąĖčüčéčĆąĄ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāąĄčé čÅą▓ąĮąŠ čĆąĄą│ąĖčüčéčĆčŗ ąĖčüč鹊čćąĮąĖą║ą░. ąØąŠ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąĖ čĆąĄą│ąĖčüčéčĆ ąĖčüč鹊čćąĮąĖą║ą░ ą╝ąŠą│čāčé ą▒čŗčéčī ąŠą┤ąĮąĖą╝ ąĖ č鹥ą╝ ąČąĄ D-čĆąĄą│ąĖčüčéčĆąŠą╝, č鹊ą│ą┤ą░ ąŠą┐ąĄčĆą░čåąĖčÅ ąĖąĘą╝ąĄąĮąĖčé čĆąĄą│ąĖčüčéčĆ ąĖčüč鹊čćąĮąĖą║ą░.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ ą░čĆąĖčäą╝ąĄčéąĖą║ąĖ, ąĮą░čģąŠą┤čÅčēąĖąĄčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ASTAT:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé čĆą░ą▓ąĄąĮ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Negate (ą┤ą▓ąŠąĖčćąĮąŠąĄ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ).
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
čĆąĄą│ąĖčüčéčĆ_ąĮą░ąĘąĮą░č湥ąĮąĖčÅ = čĆąĄą│ąĖčüčéčĆ_ąĖčüč鹊čćąĮąĖą║ą░_0 | čĆąĄą│ąĖčüčéčĆ_ąĖčüč鹊čćąĮąĖą║ą░_1
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = Dreg | Dreg; // (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ OR ą▓čŗą┐ąŠą╗ąĮčÅąĄčé 32-čĆą░ąĘčĆčÅą┤ąĮčāčÄ, ą┐ąŠą▒ąĖčéąĮčāčÄ ąŠą┐ąĄčĆą░čåąĖčÄ ą╗ąŠą│ąĖą║ąĖ ąśąøąś (OR) ąĮą░ą┤ čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ-ąĖčüč鹊čćąĮąĖą║ą░ą╝ąĖ, ąĖ čüąŠčģčĆą░ąĮčÅąĄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāąĄčé čÅą▓ąĮąŠ čĆąĄą│ąĖčüčéčĆčŗ ąĖčüč鹊čćąĮąĖą║ą░. ąØąŠ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąĖ ąŠą┤ąĖąĮ ąĖąĘ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖčüč鹊čćąĮąĖą║ą░ ą╝ąŠą│čāčé ą▒čŗčéčī ąŠą┤ąĮąĖą╝ ąĖ č鹥ą╝ ąČąĄ D-čĆąĄą│ąĖčüčéčĆąŠą╝, č鹊ą│ą┤ą░ ąŠą┐ąĄčĆą░čåąĖčÅ ąĖąĘą╝ąĄąĮąĖčé čŹč鹊čé čĆąĄą│ąĖčüčéčĆ ąĖčüč鹊čćąĮąĖą║ą░.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ ą░čĆąĖčäą╝ąĄčéąĖą║ąĖ, ąĮą░čģąŠą┤čÅčēąĖąĄčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ASTAT:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé čĆą░ą▓ąĄąĮ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Exclusive-OR, Bit-Wise Exclusive-OR.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
čĆąĄą│ąĖčüčéčĆ_ąĮą░ąĘąĮą░č湥ąĮąĖčÅ = čĆąĄą│ąĖčüčéčĆ_ąĖčüč鹊čćąĮąĖą║ą░_0 ^ čĆąĄą│ąĖčüčéčĆ_ąĖčüč鹊čćąĮąĖą║ą░_1
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = Dreg ^ Dreg; // (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĖčüą║ą╗čÄčćą░čÄčēąĄą│ąŠ ąśąøąś (Exclusive-OR, čüąŠą║čĆą░čēąĄąĮąĮąŠ XOR) ą▓čŗą┐ąŠą╗ąĮčÅąĄčé 32-čĆą░ąĘčĆčÅą┤ąĮčāčÄ, ą┐ąŠą▒ąĖčéąĮčāčÄ ąŠą┐ąĄčĆą░čåąĖčÄ ą╗ąŠą│ąĖą║ąĖ ąĖčüą║ą╗čÄčćą░čÄčēąĄąĄ ąśąøąś (XOR) ąĮą░ą┤ čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ-ąĖčüč鹊čćąĮąĖą║ą░ą╝ąĖ, ąĖ čüąŠčģčĆą░ąĮčÅąĄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāąĄčé čÅą▓ąĮąŠ čĆąĄą│ąĖčüčéčĆčŗ ąĖčüč鹊čćąĮąĖą║ą░. ąØąŠ čĆąĄą│ąĖčüčéčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąĖ ąŠą┤ąĖąĮ ąĖąĘ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖčüč鹊čćąĮąĖą║ą░ ą╝ąŠą│čāčé ą▒čŗčéčī ąŠą┤ąĮąĖą╝ ąĖ č鹥ą╝ ąČąĄ D-čĆąĄą│ąĖčüčéčĆąŠą╝, č鹊ą│ą┤ą░ ąŠą┐ąĄčĆą░čåąĖčÅ ąĖąĘą╝ąĄąĮąĖčé čŹč鹊čé čĆąĄą│ąĖčüčéčĆ ąĖčüč鹊čćąĮąĖą║ą░.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ ą░čĆąĖčäą╝ąĄčéąĖą║ąĖ, ąĮą░čģąŠą┤čÅčēąĖąĄčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ASTAT:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé čĆą░ą▓ąĄąĮ 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ OR, Bit-Wise Exclusive-OR.
ą×ą▒čēą░čÅ č乊čĆą╝ą░:
čĆąĄą│ąĖčüčéčĆ_ąĮą░ąĘąĮą░č湥ąĮąĖčÅ = CC = BXORSHIFT (A0, src_reg)
čĆąĄą│ąĖčüčéčĆ_ąĮą░ąĘąĮą░č湥ąĮąĖčÅ = CC = BXOR (A0, src_reg)
čĆąĄą│ąĖčüčéčĆ_ąĮą░ąĘąĮą░č湥ąĮąĖčÅ = CC = BXOR (A0, A1, CC)
A0 = BXORSHIFT (A0, A1, CC)
ąĪąĖąĮčéą░ą║čüąĖčü LFSR TYPE I (ą▒ąĄąĘ ąŠą▒čĆą░čéąĮąŠą╣ čüą▓čÅąĘąĖ):
Dreg_lo = CC = BXORSHIFT (A0, Dreg); // (b)1
Dreg_lo = CC = BXOR (A0, Dreg); // (b)
ąĪąĖąĮčéą░ą║čüąĖčü LFSR TYPE I (čü ąŠą▒čĆą░čéąĮąŠą╣ čüą▓čÅąĘčīčÄ):
Dreg_lo = CC = BXOR (A0, A1, CC); // (b)
A0 = BXORSHIFT (A0, A1, CC); // (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
Dreg_lo: RL[7:0]
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
4 ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐ąŠą▒ąĖčéąĮąŠą│ąŠ ąĖčüą║ą╗čÄčćą░čÄčēąĄą│ąŠ ąśąøąś (Bit-wise Exclusive-OR, BXOR) ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčéčüčÅ 2 čéąĖą┐ą░ą╝ąĖ LFSR-čĆąĄą░ą╗ąĖąĘą░čåąĖą╣.
Type I LFSR (ą▒ąĄąĘ ąŠą▒čĆą░čéąĮąŠą╣ čüą▓čÅąĘąĖ) ąĮą░ą║ą╗ą░ą┤čŗą▓ą░ąĄčé 32-ą▒ąĖčéąĮčāčÄ čĆąĄą│ąĖčüčéčĆąŠą▓čāčÄ ą╝ą░čüą║čā ąĮą░ 40-ą▒ąĖčéąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ, ąĮą░čģąŠą┤čÅčēąĄąĄčüčÅ ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąĄ A0, ąĘą░ ą║ąŠč鹊čĆčŗą╝ čüą╗ąĄą┤čāąĄčé ąŠą┐ąĄčĆą░čåąĖčÅ čĆąĄą┤čāą║čåąĖąĖ ą┐ąŠą▒ąĖčéąĮąŠą│ąŠ ąĖčüą║ą╗čÄčćą░čÄčēąĄą│ąŠ ąśąøąś. ąĀąĄąĘčāą╗čīčéą░čé ą┐ąŠą╝ąĄčēą░ąĄčéčüčÅ ą▓ CC ąĖ ą┐ąŠą╗ąŠą▓ąĖąĮčā čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
Type I LFSR (čü ąŠą▒čĆą░čéąĮąŠą╣ čüą▓čÅąĘčīčÄ) ąĮą░ą║ą╗ą░ą┤čŗą▓ą░ąĄčé 40-ą▒ąĖčéąĮčāčÄ ą╝ą░čüą║čā ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąĄ A1 ąĮą░ 40-ą▒ąĖčéąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ, ąĮą░čģąŠą┤čÅčēąĄąĄčüčÅ ą▓ A0. ąĀąĄąĘčāą╗čīčéą░čé ą▓čŗą┤ą▓ąĖą│ą░ąĄčéčüčÅ ą▓ A0.
ąÆ čüą╗ąĄą┤čāčÄčēąĖčģ čüčģąĄą╝ą░čģ, ąŠą┐ąĖčüčŗą▓ą░čÄčēąĖčģ ą│čĆčāą┐ą┐čā ąĖąĮčüčéčĆčāą║čåąĖą╣ BXOR, ą┐ąŠą▒ąĖčéąĮą░čÅ XOR-čĆąĄą┤čāą║čåąĖčÅ ąĘą░ą┤ą░ąĮą░ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
Out = ((((B0 ? B1 ) ? B2 ) ? B1 )... ? BN-1 )
ą│ą┤ąĄ B0 .. BN-1 ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅčÄčé N ą▒ąĖčé, čÅą▓ą╗čÅčÄčēąĖąĄčüčÅ čĆąĄąĘčāą╗čīčéą░č鹊ą╝ ą╝ą░čüą║ąĖčĆąŠą▓ą░ąĮąĖčÅ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ A0 ą┐ąŠą╗ąĖąĮąŠą╝ąŠą╝, čüąŠčģčĆą░ąĮąĄąĮąĮčŗą╝ ą╗ąĖą▒ąŠ ą▓ A1, ą╗ąĖą▒ąŠ ą▓ 32-ą▒ąĖčéąĮąŠą╝ čĆąĄą│ąĖčüčéčĆąĄ. ą×ą┐ąĖčüą░ąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮą░ čĆąĖčü. 7-1.
ąĀąĖčü. 7-1. ą¤ąŠą▒ąĖčéąĮą░čÅ čĆąĄą┤čāą║čåąĖčÅ ąĖčüą║ą╗čÄčćą░čÄčēąĄą│ąŠ ąśąøąś (Bit-Wise Exclusive OR Reduction).
ąØą░ čŹč鹊ą╝ čĆąĖčüčāąĮą║ąĄ ą▒ąĖčéčŗ A0[0] ąĖ A0[1] ą┐čĆąĄč鹥čĆą┐ąĄą▓ą░čÄčé ąŠą┐ąĄčĆą░čåąĖčÄ ą╗ąŠą│ąĖč湥čüą║ąŠą│ąŠ ąś čü ą▒ąĖčéą░ą╝ąĖ D[0] ąĖ D[1]. ąĀąĄąĘčāą╗čīčéą░čé čŹč鹊ą╣ ąŠą┐ąĄčĆą░čåąĖąĖ ą┐čĆąŠčģąŠą┤ąĖčé XOR-čĆąĄą┤čāą║čåąĖčÄ ą┐ąŠ čüą╗ąĄą┤čāčÄčēąĄą╣ č乊čĆą╝čāą╗ąĄ:
s(D) = ( A0[0] ŌĆó D[0] ) ? ( A0[1] ŌĆó D[1] )
Modified Type I LSFR (without feedback) . ąöą▓ąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé LSFR ą▒ąĄąĘ ąŠą▒čĆą░čéąĮąŠą╣ čüą▓čÅąĘąĖ. ąÆąŠčé ąŠąĮąĖ:
Dreg_lo = BXORSHIFT(A0,dreg), ąĖ
ąÆ ą┐ąĄčĆą▓ąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ A0 čüą┤ą▓ąĖą│ą░ąĄčéčüčÅ ą▓ą╗ąĄą▓ąŠ ąĮą░ 1 čĆą░ąĘčĆčÅą┤ ą┐ąĄčĆąĄą┤ XOR-čĆąĄą┤čāą║čåąĖąĄą╣. ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┐ąŠą▒ąĖčéąĮčāčÄ ąŠą┐ąĄčĆą░čåąĖčÄ XOR ąĮą░ą┤ čĆąĄąĘčāą╗čīčéą░č鹊ą╝ ą╗ąŠą│ąĖč湥čüą║ąŠą│ąŠ ąś ąĮą░ą┤ A0 ąĖ D-čĆąĄą│ąĖčüčéčĆąŠą╝. ąĀąĄąĘčāą╗čīčéą░čé ąŠą┐ąĄčĆą░čåąĖąĖ ą┐ąŠą╝ąĄčēą░ąĄčéčüčÅ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą▓ čäą╗ą░ą│ CC ąĖ ą▓ ą╝ą╗ą░ą┤čłąĖą╣ ąĘąĮą░čćą░čēąĖą╣ ą▒ąĖčé čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ąŁčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ ą┐ąŠą║ą░ąĘą░ąĮą░ ąĮąĖąČąĄ ąĮą░ čĆąĖčü. 7-2.
ąĪčéą░čĆčłąĖąĄ 15 ą▒ąĖčé Dreg_lo ą┐ąĄčĆąĄąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ ąĮčāą╗ąĄą╝, ąĖ ą┐ąŠčüą╗ąĄ ąŠą┐ąĄčĆą░čåąĖąĖ dr[0] = IN.
ąĀąĖčü. 7-2. A0, čüą┤ą▓ąĖąĮčāčéčŗą╣ ą▓ą╗ąĄą▓ąŠ ąĮą░ 1, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ąĖą┤ąĄčé XOR-čĆąĄą┤čāą║čåąĖčÅ.
ąÆč鹊čĆą░čÅ čĆąĄą┤ą░ą║čåąĖčÅ ą▓ čŹč鹊ą╝ ą║ą╗ą░čüčüąĄ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ą┐ąŠą▒ąĖčéąĮčāčÄ ąŠą┐ąĄčĆą░čåąĖčÄ XOR čĆąĄąĘčāą╗čīčéą░čéą░ ąŠą┐ąĄčĆą░čåąĖąĖ ąś ąŠčé A0 ąĖ Dreg. ąÆčŗčģąŠą┤ ąŠą┐ąĄčĆą░čåąĖąĖ ą┐ąŠą╝ąĄčēą░ąĄčéčüčÅ ą▓ ą╝ą╗ą░ą┤čłąĖą╣ ąĘąĮą░čćą░čēąĖą╣ ą▒ąĖčé čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąĖ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą▓ ą▒ąĖčé CC. ąÉą║ą║čāą╝čāą╗čÅč鹊čĆ A0 ąĮąĄ ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāąĄčéčüčÅ čŹč鹊ą╣ ąŠą┐ąĄčĆą░čåąĖąĄą╣. ąĪą░ą╝ą░ ąŠą┐ąĄčĆą░čåąĖčÅ ąĖą╗ą╗čÄčüčéčĆąĖčĆčāąĄčéčüčÅ ąĮą░ čĆąĖčü. 7-3.
ąĪčéą░čĆčłąĖąĄ 15 ą▒ąĖčé dreg_lo ą┐ąĄčĆąĄąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ ąĮčāą╗čÅą╝ąĖ, ąĖ ą┐ąŠčüą╗ąĄ čŹč鹊ą╣ ąŠą┐ąĄčĆą░čåąĖąĖ dr[0] = IN.
ąĀąĖčü. 7-3. XOR ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ A0, ą╗ąŠą│ąĖč湥čüą║ąŠąĄ ąś čü čüąŠą┤ąĄčƹȹĖą╝čŗą╝ D-čĆąĄą│ąĖčüčéčĆą░.
Modified Type I LFSR (with feedback) . ąöą▓ąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé LFSR čü ąŠą▒čĆą░čéąĮąŠą╣ čüą▓čÅąĘčīčÄ. ąÆąŠčé ąŠąĮąĖ:
A0 = BXORSHIFT(A0,A1,CC), ąĖ
ą¤ąĄčĆą▓ą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┐ąŠą▒ąĖčéąĮčāčÄ ąŠą┐ąĄčĆą░čåąĖčÄ XOR ąŠčé čĆąĄąĘčāą╗čīčéą░čéą░ ąŠą┐ąĄčĆą░čåąĖąĖ ąś ą╝ąĄąČą┤čā A0 ąĖ A1. ąĀąĄąĘčāą╗čīčéąĖčĆčāčÄčēąĖą╣ ą┐čĆąŠą╝ąĄąČčāč鹊čćąĮčŗą╣ ą▒ąĖčé ą┐čĆąĄč鹥čĆą┐ąĄą▓ą░ąĄčé ąŠą┐ąĄčĆą░čåąĖčÄ XOR čü čäą╗ą░ą│ąŠą╝ CC. ą¤ąŠčüą╗ąĄ čŹč鹊ą│ąŠ čĆąĄąĘčāą╗čīčéą░čé ąŠą┐ąĄčĆą░čåąĖąĖ čüą┤ą▓ąĖą│ą░ąĄčéčüčÅ ą▓ą╗ąĄą▓ąŠ ą▓ ą╝ą╗ą░ą┤čłąĖą╣ ąĘąĮą░čćą░čēąĖą╣ ą▒ąĖčé A0. ąŁčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ ą┐ąŠą║ą░ąĘą░ąĮą░ ąĮą░ čĆąĖčü. 7-4. ąŁčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ ąĮąĄ ąĖąĘą╝ąĄąĮčÅąĄčé ą▒ąĖčé CC.
ąĀąĖčü. 7-4. XOR ąĮą░ą┤ čĆąĄąĘčāą╗čīčéą░č鹊ą╝ ą╗ąŠą│ąĖč湥čüą║ąŠą╣ ąś ą╝ąĄąČą┤čā A0 ąĖ A1, čüąŠ čüą┤ą▓ąĖą│ąŠą╝ čĆąĄąĘčāą╗čīčéą░čéą░ ą▓ LSB A0.
ąÆč鹊čĆą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ čŹč鹊ą╝ ą║ą╗ą░čüčüąĄ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ą┐ąŠą▒ąĖčéąĮčāčÄ ąŠą┐ąĄčĆą░čåąĖčÄ XOR ąŠčé ąŠą┐ąĄčĆą░čåąĖąĖ ą╗ąŠą│ąĖč湥čüą║ąŠą│ąŠ ąś ą╝ąĄąČą┤čā A0 ąĖ A1. ąĀąĄąĘčāą╗čīčéąĖčĆčāčÄčēąĖą╣ ą┐čĆąŠą╝ąĄąČčāč鹊čćąĮčŗą╣ ą▒ąĖčé ą┐čĆąĄč鹥čĆą┐ąĄą▓ą░ąĄčé ąŠą┐ąĄčĆą░čåąĖčÄ XOR čü čäą╗ą░ą│ąŠą╝ CC. ąĀąĄąĘčāą╗čīčéą░čé ąŠą┐ąĄčĆą░čåąĖąĖ ą┐ąŠą╝ąĄčēą░ąĄčéčüčÅ ą║ą░ą║ ą▓ąŠ čäą╗ą░ą│ CC, čéą░ą║ ąĖ ą▓ ą╝ą╗ą░ą┤čłąĖą╣ ąĘąĮą░čćą░čēąĖą╣ ą▒ąĖčé čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ąŁčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ ą┐ąŠą║ą░ąĘą░ąĮą░ ąĮą░ čĆąĖčü. 7-5.
ąĀąĖčü. 7-5. XOR ąĮą░ą┤ čĆąĄąĘčāą╗čīčéą░č鹊ą╝ ą╗ąŠą│ąĖč湥čüą║ąŠą╣ ąś ą╝ąĄąČą┤čā A0 ąĖ A1, čü čĆąĄąĘčāą╗čīčéą░č鹊ą╝, čĆą░ąĘą╝ąĄčēąĄąĮąĮčŗą╝ ą▓ čäą╗ą░ą│ąĄ CC ąĖ LSB čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ąŁčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ ąĮąĄ ą╝ąĄąĮčÅąĄčé ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ A0. ąĪčéą░čĆčłąĖąĄ 15 čĆąĄą│ąĖčüčéčĆą░ Dreg_lo ą┐ąĄčĆąĄąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ ąĮčāą╗čÅą╝ąĖ, ąĖ dr[0] = IN.
[ążą╗ą░ą│ąĖ ]
ą¦ąĄčéčŗčĆčīą╝čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ Bit-wise Exclusive-OR ą▒čāą┤ąĄčé ąĖąĘą╝ąĄąĮąĄąĮ č鹊ą╗čīą║ąŠ čäą╗ą░ą│ CC čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝: CC čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ ąĖą╗ąĖ ąŠčćąĖčüčéąĖčéčüčÅ ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮčŗą╝ ąŠą┐ąĖčüą░ąĮąĖąĄą╝ ą┤ą╗čÅ BXOR ąĖ ą▓ąĄčĆčüąĖąĄą╣ ą▒ąĄąĘ ąŠą▒čĆą░čéąĮąŠą╣ čüą▓čÅąĘąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ BXORSHIFT. ąÆąĄčĆčüąĖčÅ čü ąŠą▒čĆą░čéąĮąŠą╣ čüą▓čÅąĘčīčÄ ąĖąĮčüčéčĆčāą║čåąĖąĖ BXORSHIFT ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąŠčüčéą░ąĮčāčéčüčÅ ąĮąĄčéčĆąŠąĮčāčéčŗą╝ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r0.l = cc = bxorshift (a0, r1);
r0.l = cc = bxor (a0, r1);
r0.l = cc = bxor (a0, a1, cc);
a0 = bxorshift (a0, a1, cc);
[ąĪą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ]
ąĀąĄą│ąĖčüčéčĆčŗ LFSR ą╝ąŠą│čāčé čāą╝ąĮąŠąČą░čéčī ąĖ ą┤ąĄą╗ąĖčéčī ą┐ąŠą╗ąĖąĮąŠą╝čŗ ąĖ čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čåąĖą║ą╗ąĖč湥čüą║ąĖčģ ą║ąŠą┤ąĄčĆąŠą▓ ąĖ ą┤ąĄą║ąŠą┤ąĄčĆąŠą▓. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą┤ą╗čÅ ą│ąĄąĮąĄčĆą░čåąĖąĖ ą┐čüąĄą▓ą┤ąŠčüą╗čāčćą░ą╣ąĮčŗčģ čćąĖčüą╗ąŠą▓čŗčģ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüč鹥ą╣ [3].
LFSR ąĖčüą┐ąŠą╗čīąĘčāčÄčé ąĮą░ą▒ąŠčĆ ąĖąĮčüčéčĆčāą║čåąĖą╣ Bit-wise XOR ą┤ą╗čÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ ą▒ąĖč鹊ą▓ąŠą╣ XOR-čĆąĄą┤čāą║čåąĖąĖ ąŠčé čüąŠčüč鹊čÅąĮąĖčÅ, ąĘą░ą╝ą░čüą║ąĖčĆąŠą▓ą░ąĮąĮąŠąĄ ą┐ąŠą╗ąĖąĮąŠą╝ąŠą╝.
[ą×ą┐ąĄčĆą░čåąĖąĖ ąĮą░ą┤ ą▒ąĖčéą░ą╝ąĖ ]
ąÆ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ ąŠą▒čüčāąČą┤ą░čÄčéčüčÅ ą▒ąĖč鹊ą▓čŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ, ą┐ąŠąĘą▓ąŠą╗čÅčÄčēąĖąĄ čāčüčéą░ąĮąŠą▓ąĖčéčī, ąŠčćąĖčüčéąĖčéčī, ą┐ąĄčĆąĄą║ą╗čÄčćąĖčéčī ą▓ ą┐čĆąŠčéąĖą▓ąŠą┐ąŠą╗ąŠąČąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ, ą░ čéą░ą║ąČąĄ ą┐čĆąŠą▓ąĄčĆąĖčéčī ą▒ąĖčéčŗ. ą×ąĮąĖ čéą░ą║ąČąĄ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ąŠą▒čŖąĄą┤ąĖąĮčÅčéčī ą▒ąĖč鹊ą▓čŗąĄ ą┐ąŠą╗čÅ ąĖ čüąŠčģčĆą░ąĮčÅčéčī čĆąĄąĘčāą╗čīčéą░čé, čĆą░čüą┐ą░ą║ąŠą▓ą░čéčī ąŠčéą┤ąĄą╗čīąĮčŗąĄ ą▒ąĖčéčŗ ąĖąĘ čĆąĄą│ąĖčüčéčĆą░, čüąŠąĄą┤ąĖąĮąĖčéčī ą┐ąŠč鹊ą║ąĖ ą▒ąĖčé, ąĖ ą┐ąŠą┤čüčćąĖčéą░čéčī ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĄą┤ąĖąĮąĖčå ą▓ čĆąĄą│ąĖčüčéčĆąĄ.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąŠčćąĖčüčéąĖčéčī čāą║ą░ąĘą░ąĮąĮčŗą╣ ą▒ąĖčé ą▓ čĆąĄą│ąĖčüčéčĆąĄ ą┤ą░ąĮąĮčŗčģ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
BITCLR ( D-čĆąĄą│ąĖčüčéčĆ, ąĮąŠą╝ąĄčĆ_ą▒ąĖčéą░ )
ąĪąĖąĮčéą░ą║čüąĖčü:
BITCLR(Dreg, uimm5); // (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
uimm5: 5-čĆą░ąĘčĆčÅą┤ąĮąŠąĄ ą┐ąŠą╗ąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 31.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąŠčćąĖčüčéą║ąĖ ą▒ąĖčéą░ ąŠčćąĖčēą░ąĄčé čāą║ą░ąĘą░ąĮąĮčŗą╣ ą┐ąŠ ąĮąŠą╝ąĄčĆčā ą▒ąĖčé ą▓ čāą║ą░ąĘą░ąĮąĮąŠą╝ D-čĆąĄą│ąĖčüčéčĆąĄ. ą×ąĮą░ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ ąŠčüčéą░ą╗čīąĮčŗąĄ ą▒ąĖčéčŗ ą▓ čŹč鹊ą╝ čĆąĄą│ąĖčüčéčĆąĄ.
ąöąĖą░ą┐ą░ąĘąŠąĮ ąĮąŠą╝ąĄčĆąŠą▓ ą┐ąŠąĘąĖčåąĖąĖ ą▒ąĖčéą░ čüąŠčüčéą░ą▓ą╗čÅąĄčé 0 .. 31, ą│ą┤ąĄ 0 čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé LSB ąĖ 31 čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé MSB ą▓ 32-čĆą░ąĘčĆčÅą┤ąĮąŠą╝ D-čĆąĄą│ąĖčüčéčĆąĄ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Bit Clear ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ą▒čāą┤ąĄčé 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
bitclr(r2, 3 ); // ąŠčćąĖčüčéąĖčéčī ą▒ąĖčé 3 (č湥čéą▓ąĄčĆčéčŗą╣ ą┐ąŠ čüč湥čéčā ą▒ąĖčé ą┐ąŠčüą╗ąĄ LSB) ą▓ R2
ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą▓ R2 čüąŠą┤ąĄčƹȹ░ą╗ąŠčüčī 0xFFFFFFFF ą┤ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, č鹊 ą┐ąŠčüą╗ąĄ ąĄčæ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą▓ R2 ą▒čāą┤ąĄčé čüąŠą┤ąĄčƹȹ░čéčīčüčÅ 0xFFFFFFF7.
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Bit Set, Bit Test, Bit Toggle.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čāčüčéą░ąĮąŠą▓ąĖčéčī čāą║ą░ąĘą░ąĮąĮčŗą╣ ą▒ąĖčé ą▓ čĆąĄą│ąĖčüčéčĆąĄ ą┤ą░ąĮąĮčŗčģ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
BITSET ( D-čĆąĄą│ąĖčüčéčĆ, ąĮąŠą╝ąĄčĆ_ą▒ąĖčéą░ )
ąĪąĖąĮčéą░ą║čüąĖčü:
BITSET(Dreg, uimm5); // (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
uimm5: 5-čĆą░ąĘčĆčÅą┤ąĮąŠąĄ ą┐ąŠą╗ąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 31.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ čāčüčéą░ąĮąŠą▓ą║ąĖ ą▒ąĖčéą░ čāčüčéą░ąĮąŠą▓ąĖčé ą▓ 1 čāą║ą░ąĘą░ąĮąĮčŗą╣ ą┐ąŠ ąĮąŠą╝ąĄčĆčā ą▒ąĖčé ą▓ čāą║ą░ąĘą░ąĮąĮąŠą╝ D-čĆąĄą│ąĖčüčéčĆąĄ. ą×ąĮą░ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ ąŠčüčéą░ą╗čīąĮčŗąĄ ą▒ąĖčéčŗ ą▓ čŹč鹊ą╝ čĆąĄą│ąĖčüčéčĆąĄ.
ąöąĖą░ą┐ą░ąĘąŠąĮ ąĮąŠą╝ąĄčĆąŠą▓ ą┐ąŠąĘąĖčåąĖąĖ ą▒ąĖčéą░ čüąŠčüčéą░ą▓ą╗čÅąĄčé 0 .. 31, ą│ą┤ąĄ 0 čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé LSB ąĖ 31 čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé MSB ą▓ 32-čĆą░ąĘčĆčÅą┤ąĮąŠą╝ D-čĆąĄą│ąĖčüčéčĆąĄ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Bit Set ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
bitset(r2, 7 ); // čāčüčéą░ąĮąŠą▓ąĖčéčī ą▒ąĖčé 7 (ą▓ąŠčüčīą╝ąŠą╣ ą┐ąŠ čüč湥čéčā ą▒ąĖčé ą┐ąŠčüą╗ąĄ LSB) ą▓ R2
ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą▓ R2 čüąŠą┤ąĄčƹȹ░ą╗ąŠčüčī 0x00000000 ą┤ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, č鹊 ą┐ąŠčüą╗ąĄ ąĄčæ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą▓ R2 ą▒čāą┤ąĄčé čüąŠą┤ąĄčƹȹ░čéčīčüčÅ 0x00000080.
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Bit Clear, Bit Test, Bit Toggle.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐ąĄčĆąĄą║ą╗čÄčćąĖčéčī ą▓ ą┐čĆąŠčéąĖą▓ąŠą┐ąŠą╗ąŠąČąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ čāą║ą░ąĘą░ąĮąĮčŗą╣ ą▒ąĖčé ą▓ čĆąĄą│ąĖčüčéčĆąĄ ą┤ą░ąĮąĮčŗčģ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
BITTGL ( D-čĆąĄą│ąĖčüčéčĆ, ąĮąŠą╝ąĄčĆ_ą▒ąĖčéą░ )
ąĪąĖąĮčéą░ą║čüąĖčü:
BITTGL(Dreg, uimm5); // (a)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
uimm5: 5-čĆą░ąĘčĆčÅą┤ąĮąŠąĄ ą┐ąŠą╗ąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 31.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ čüąŠčüč鹊čÅąĮąĖčÅ ą▒ąĖčéą░ ą┐čĆąŠąĖąĮą▓ąĄčĆčéąĖčĆčāąĄčé čāą║ą░ąĘą░ąĮąĮčŗą╣ ą┐ąŠ ąĮąŠą╝ąĄčĆčā ą▒ąĖčé ą▓ čāą║ą░ąĘą░ąĮąĮąŠą╝ D-čĆąĄą│ąĖčüčéčĆąĄ. ą×ąĮą░ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ ąŠčüčéą░ą╗čīąĮčŗąĄ ą▒ąĖčéčŗ ą▓ čŹč鹊ą╝ čĆąĄą│ąĖčüčéčĆąĄ.
ąöąĖą░ą┐ą░ąĘąŠąĮ ąĮąŠą╝ąĄčĆąŠą▓ ą┐ąŠąĘąĖčåąĖąĖ ą▒ąĖčéą░ čüąŠčüčéą░ą▓ą╗čÅąĄčé 0 .. 31, ą│ą┤ąĄ 0 čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé LSB ąĖ 31 čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé MSB ą▓ 32-čĆą░ąĘčĆčÅą┤ąĮąŠą╝ D-čĆąĄą│ąĖčüčéčĆąĄ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Bit Toggle ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ą▒čāą┤ąĄčé 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
bittgl(r2, 24 ); // ą┐ąĄčĆąĄą║ą╗čÄčćąĖčéčī ą▒ąĖčé 24 (25-ą╣ ą┐ąŠ čüč湥čéčā ą▒ąĖčé ą┐ąŠčüą╗ąĄ LSB) ą▓ R2
ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą▓ R2 čüąŠą┤ąĄčƹȹ░ą╗ąŠčüčī 0xF1FFFFFF ą┤ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, č鹊 ą┐ąŠčüą╗ąĄ ąĄčæ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą▓ R2 ą▒čāą┤ąĄčé čüąŠą┤ąĄčƹȹ░čéčīčüčÅ 0xF0FFFFFF. ąĢčüą╗ąĖ ą▓čŗąĘą▓ą░čéčī ąĖąĮčüčéčĆčāą║čåąĖčÄ ą▓č鹊čĆąŠą╣ čĆą░ąĘ, č鹊 ą▓ čĆąĄą│ąĖčüčéčĆąĄ čüąĮąŠą▓ą░ ąŠą║ą░ąČąĄčéčüčÅ ąĘąĮą░č湥ąĮąĖąĄ 0xF1FFFFFF.
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Bit Clear, Bit Test, Bit Set.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐čĆąŠą▓ąĄčĆąĖčéčī ąĮčāąČąĮčŗą╣ ą▒ąĖčé ą▓ čĆąĄą│ąĖčüčéčĆąĄ ą┤ą░ąĮąĮčŗčģ, ąĖ ą┐ąŠ čĆąĄąĘčāą╗čīčéą░čéčā ą┐čĆąŠą▓ąĄčĆą║ąĖ ąĖąĘą╝ąĄąĮąĖčéčī ąĘąĮą░č湥ąĮąĖąĄ ą▒ąĖčéą░ CC. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
CC = BITTST ( D-čĆąĄą│ąĖčüčéčĆ, ąĮąŠą╝ąĄčĆ_ą▒ąĖčéą░ )
CC = !BITTST ( D-čĆąĄą│ąĖčüčéčĆ, ąĮąŠą╝ąĄčĆ_ą▒ąĖčéą░ )
ąĪąĖąĮčéą░ą║čüąĖčü:
CC = BITTST(Dreg, uimm5); // čāčüčéą░ąĮąŠą▓ąĖčéčī CC, ąĄčüą╗ąĖ ą▒ąĖčé = 1 (a)1
CC = !BITTST(Dreg, uimm5); // čāčüčéą░ąĮąŠą▓ąĖčéčī CC, ąĄčüą╗ąĖ ą▒ąĖčé = 0 (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
uimm5: 5-čĆą░ąĘčĆčÅą┤ąĮąŠąĄ ą┐ąŠą╗ąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░, ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 31.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąŠą▓ąĄčĆą║ąĖ čüąŠčüč鹊čÅąĮąĖčÅ ą▒ąĖčéą░ čāčüčéą░ąĮąŠą▓ąĖčé ąĖą╗ąĖ čüą▒čĆąŠčüąĖčé ą▒ąĖčé CC, ą▒ą░ąĘąĖčĆčāčÅčüčī ąĮą░ č鹥ą║čāčēąĄą╝ čüąŠčüč鹊čÅąĮąĖąĖ čāą║ą░ąĘą░ąĮąĮąŠą│ąŠ ą┐ąŠ ąĮąŠą╝ąĄčĆčā ą▒ąĖčéą░ ą▓ čāą║ą░ąĘą░ąĮąĮąŠą╝ D-čĆąĄą│ąĖčüčéčĆąĄ. ą×ą┤ąĮą░ ą▓ąĄčĆčüąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐čĆąŠą▓ąĄčĆčÅąĄčé, čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą╗ąĖ ąĮčāąČąĮčŗą╣ ą▒ąĖčé ą▓ čĆąĄą│ąĖčüčéčĆąĄ, ą┤čĆčāą│ą░čÅ ą┐čĆąŠą▓ąĄčĆčÅąĄčé čüą▒čĆąŠčłąĄąĮ ą╗ąĖ ąŠąĮ. ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ ą▒ąĖčéčŗ ą▓ čŹč鹊ą╝ čĆąĄą│ąĖčüčéčĆąĄ.
ąöąĖą░ą┐ą░ąĘąŠąĮ ąĮąŠą╝ąĄčĆąŠą▓ ą┐ąŠąĘąĖčåąĖąĖ ą▒ąĖčéą░ čüąŠčüčéą░ą▓ą╗čÅąĄčé 0 .. 31, ą│ą┤ąĄ 0 čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé LSB ąĖ 31 čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé MSB ą▓ 32-čĆą░ąĘčĆčÅą┤ąĮąŠą╝ D-čĆąĄą│ąĖčüčéčĆąĄ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé č鹊ą╗čīą║ąŠ ąĮą░ čäą╗ą░ą│ CC. ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆ ]
CC = bittst(r7, 15 ); // ą┐čĆąŠą▓ąĄčĆąĖčéčī ą▒ąĖčé 15 ąĮą░ ą╗ąŠą│. 1 ą▓ R7
ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą▓ R7 čüąŠą┤ąĄčƹȹ░ą╗ąŠčüčī 0xFFFFFFFF ą┤ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, č鹊 ą┐ąŠčüą╗ąĄ ąĄčæ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ CC čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ ą▓ 1, ąĖ R7 ą▒čāą┤ąĄčé ą▓čüąĄ čéą░ą║ąČąĄ čüąŠą┤ąĄčƹȹ░čéčī 0xFFFFFFFF.
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Bit Clear, Bit Toggle, Bit Set.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąŠą▒čŖąĄą┤ąĖąĮčÅčéčī ą┐ąŠą╗čÅ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ą░ąĮąĮčŗčģ. ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ą┤ą╗čÅ ą░ą╗ą│ąŠčĆąĖčéą╝ąŠą▓ ąŠą▓ąĄčĆą╗ąĄčÅ ą▓ąĖą┤ąĄąŠąĖąĘąŠą▒čĆą░ąČąĄąĮąĖčÅ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = DEPOSIT ( backgnd_reg, foregnd_reg )
dest_reg = DEPOSIT ( backgnd_reg, foregnd_reg ) (X)
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = DEPOSIT (Dreg, Dreg); // ą▒ąĄąĘ čĆą░čüčłąĖčĆąĄąĮąĖčÅ (b)1
Dreg = DEPOSIT (Dreg, Dreg)(X); // čü čĆą░čüčłąĖčĆąĄąĮąĖąĄą╝ ąĘąĮą░ą║ąŠą╝ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Bit Field Deposit čüąŠąĄą┤ąĖąĮčÅąĄčé č乊ąĮąŠą▓ąŠąĄ ą▒ąĖč鹊ą▓ąŠąĄ ą┐ąŠą╗ąĄ (background bit field) ą▓ čĆąĄą│ąĖčüčéčĆąĄ backgnd_reg čü ą┐ąĄčĆąĄą┤ąĮąĖą╝ ą▒ąĖč鹊ą▓čŗą╝ ą┐ąŠą╗ąĄą╝ (foreground bit field) ą▓ čüčéą░čĆčłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮąĄ čĆąĄą│ąĖčüčéčĆą░ foregnd_reg, ąĖ čüąŠčģčĆą░ąĮčÅąĄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ čĆąĄą│ąĖčüčéčĆ dest_reg. ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ą┤ą╗ąĖąĮčā foreground-ą┐ąŠą╗čÅ ą▒ąĖčé ąĖ ąĄą│ąŠ ą┐ąŠąĘąĖčåąĖčÄ ą▓ ą┐ąŠą╗ąĄ background.
ą×ą┐čåąĖčÅ: čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ čüąĖąĮčéą░ą║čüąĖčüą░ (X) ą╝ąŠąČąĮąŠ čĆą░čüčłąĖčĆąĖčéčī ąĘąĮą░ą║ąŠą╝ ą▓ąĮąĄčüąĄąĮąĮąŠąĄ (deposited) ą┐ąŠą╗ąĄ ą▒ąĖčé. ąĢčüą╗ąĖ ąÆčŗ čāą║ą░ąČąĄč鹥 čüąĖąĮčéą░ą║čüąĖčü čĆą░čüčłąĖčĆąĄąĮąĖčÅ ąĘąĮą░ą║ąŠą╝, č鹊 ąŠą┐ąĄčĆą░čåąĖčÅ ąĮąĄ ą┐ąŠą▓ą╗ąĖčÅąĄčé ąĮą░ ą▒ąĖčéčŗ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ dest_reg, ą║ąŠč鹊čĆčŗąĄ ą╝ąĄąĮąĄąĄ ąĘąĮą░čćąĖą╝čŗąĄ, č湥ą╝ ą▓ąĮąĄčüąĄąĮąĮąŠąĄ ą┐ąŠą╗ąĄ ą▒ąĖčé.
ąØąĖąČąĄ ą┐ąŠą║ą░ąĘą░ąĮčŗ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą▒ąĖč鹊ą▓ąŠą│ąŠ ą┐ąŠą╗čÅ ą▓čģąŠą┤ąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░.
ąŚą┤ąĄčüčī b čŹč鹊 čĆąĄą│ąĖčüčéčĆ ą┐ąŠą╗čÅ ą▒ąĖčé background (32 ą▒ąĖčéą░), n čŹč鹊 ą┐ąŠą╗ąĄ ą▒ąĖčé foreground (16 ą▒ąĖčé), ą┐ąŠą╗ąĄ L ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ą░ą║čéčāą░ą╗čīąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ą▒ąĖčé foreground (ą┤ą╗ąĖąĮą░ ą┐ąŠą╗čÅ ą▒ąĖčé foreground, ą┤ąŠą┐čāčüčéąĖą╝čŗą╣ ą┤ąĖą░ą┐ą░ąĘąŠąĮ 0 .. 16), p ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąŠ ą┤ą╗čÅ ą┐ąŠąĘąĖčåąĖąĖ ą▒ąĖčéą░ LSB ą┐ąŠą╗čÅ foreground ą▓ čĆąĄą│ąĖčüčéčĆąĄ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ dest_reg (ą┤ąŠą┐čāčüčéąĖą╝čŗą╣ ą┤ąĖą░ą┐ą░ąĘąŠąĮ 0 .. 31).
ą×ą┐ąĄčĆą░čåąĖčÅ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé ą▒ąĖč鹊ą▓ąŠąĄ ą┐ąŠą╗ąĄ foreground ą┤ą╗ąĖąĮąŠą╣ L ą┐ąŠą▓ąĄčĆčģ ą▒ąĖč鹊ą▓ąŠą│ąŠ ą┐ąŠą╗čÅ background, čü ą▒ąĖč鹊ą╝ LSB, čĆą░ąĘą╝ąĄčēąĄąĮąĮčŗą╝ ą▓ ą┐ąŠąĘąĖčåąĖąĖ p ą┐ąŠą╗čÅ background. ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ čüą╝. ą┐čĆąĖą╝ąĄčĆ ąĮąĖąČąĄ.
ąōčĆą░ąĮąĖčćąĮčŗąĄ čüą╗čāčćą░ąĖ . ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ ą║čĆą░ą╣ąĮąĖąĄ čüą╗čāčćą░ąĖ:
ŌĆó ąæąĄąĘąĘąĮą░ą║ąŠą▓čŗą╣ (unsigned) čüąĖąĮčéą░ą║čüąĖčü, L = 0: ą░čĆčģąĖč鹥ą║čéčāčĆą░ ą║ąŠą┐ąĖčĆčāąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čĆąĄą│ąĖčüčéčĆą░ backgnd_reg ą▒ąĄąĘ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖąĖ čĆąĄą│ąĖčüčéčĆą░ dest_reg. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ foreground-ą┐ąŠą╗ąĄ ą┤ą╗ąĖąĮąŠą╣ 0 ą▒čāą┤ąĄčé ą┐čĆąŠąĘčĆą░čćąĮčŗą╝.
ŌĆó ąĀą░čüčłąĖčĆąĄąĮąĖąĄ ąĘąĮą░ą║ąŠą╝ (sign-extended), L = 0 ąĖ p = 0: ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą▓ čĆąĄą│ąĖčüčéčĆ dest_reg ąĘą░ą│čĆčāąĘąĖčéčüčÅ 0x0000 0000. ąŚąĮą░ą║ ąĮčāą╗ąĄą▓ąŠą╣ ą┤ą╗ąĖąĮčŗ, ą┐ąŠąĘąĖčåąĖčÅ ąĮčāą╗čÅ čéą░ą║ąČąĄ 0, ą┐ąŠčŹč鹊ą╝čā čĆą░čüčłąĖčĆąĄąĮąĖąĄ ąĘąĮą░ą║ąŠą╝ ą▒čāą┤ąĄčé ą▓čüąĄą╝ąĖ ąĮčāą╗čÅą╝ąĖ.
ŌĆó ąĀą░čüčłąĖčĆąĄąĮąĖąĄ ąĘąĮą░ą║ąŠą╝ (sign-extended), L = 0 ąĖ p ? 0: ą░čĆčģąĖč鹥ą║čéčāčĆą░ ą║ąŠą┐ąĖčĆčāąĄčé ą╝ą╗ą░ą┤čłąĖąĄ ą▒ąĖčéčŗ čĆąĄą│ąĖčüčéčĆą░ backgnd_reg ąĮąĖąČąĄ ą┐ąŠąĘąĖčåąĖąĖ p ą▓ čĆąĄą│ąĖčüčéčĆ dest_reg, ąĘą░č鹥ą╝ čĆą░čüčłąĖčĆčÅąĄčé čŹč鹊 čćąĖčüą╗ąŠ ąĘąĮą░ą║ąŠą╝. ąŚąĮą░č湥ąĮąĖąĄ foreground ąĮąĖą║ą░ą║ ąĮąĄ ą▓ą╗ąĖčÅąĄčé. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ...
backgnd_reg = 0x0000 8123,
č鹊...
dest_reg = 0xFFFF 8123.
ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą░čĆčģąĖč鹥ą║čéčāčĆą░ ą║ąŠą┐ąĖčĆčāąĄčé ą▒ąĖčéčŗ 15:0 ąĖąĘ backgnd_reg ą▓ dest_reg, ąĘą░č鹥ą╝ čŹč鹊 čćąĖčüą╗ąŠ čĆą░čüčłąĖčĆčÅąĄčé ąĘąĮą░ą║ąŠą╝.
ŌĆó ąĀą░čüčłąĖčĆąĄąĮąĖąĄ ąĘąĮą░ą║ąŠą╝ (sign-extended), L + p > 32: ąøčÄą▒čŗąĄ foreground-ą▒ąĖčéčŗ, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠą┐ą░ą┤ą░čÄčé ą▓ąĮąĄ ą┤ąĖą░ą┐ą░ąĘąŠąĮą░ ą▒ąĖčé 31 .. 0, ą▒čāą┤čāčé ąŠčéą▒čĆąŠčłąĄąĮčŗ. ąśąĮčüčéčĆčāą║čåąĖčÅ Bit Field Deposit ąĮąĄ ą▒čāą┤ąĄčé ą╝ąĄąĮčÅčéčī čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą┤ą▓čāčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖčüč鹊čćąĮąĖą║ą░. ą×ą┤ąĖąĮ ąĖąĘ čŹčéąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓ čéą░ą║ąČąĄ ą╝ąŠąČąĄčé ą▓čŗčüčéčāą┐ą░čéčī ąĖ ą║ą░ą║ dest_reg.
[ążą╗ą░ą│ąĖ ]
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé 0; ąŠčćąĖčüčéąĖčéčüčÅ, ąĄčüą╗ąĖ ąĮąĄ 0.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąŠčüčéą░ąĮčāčéčüčÅ ąĮąĄčéčĆąŠąĮčāčéčŗą╝ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ (ą░ ąŠąĮą░ 32-ą▒ąĖčéąĮą░čÅ) ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆ čĆą░ą▒ąŠčéčŗ ąĖąĮčüčéčĆčāą║čåąĖąĖ Bit Field Deposit Unsigned ]
ąĢčüą╗ąĖ ...
... ąĖ ...
... č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé ...
ąĢčüą╗ąĖ ...
... ąĖ ...
... č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé ...
[ą¤čĆąĖą╝ąĄčĆ čĆą░ą▒ąŠčéčŗ ąĖąĮčüčéčĆčāą║čåąĖąĖ Bit Field Deposit Sign-Extended ]
r7 = deposit (r4, r3)(x); // sign-extended
ąĢčüą╗ąĖ ...
... ąĖ ...
... č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé ...
ąĢčüą╗ąĖ ...
... ąĖ ...
... č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé ...
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Bit Field Extraction.
ąśąĮčüčéčĆčāą║čåąĖčÅ čĆą░čüą┐ą░ą║ąŠą▓čŗą▓ą░ąĄčé ą┐ąŠą╗ąĄ ą▒ąĖčé ąĖąĘ čĆąĄą│ąĖčüčéčĆą░. ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ą▓ ą░ą╗ą│ąŠčĆąĖčéą╝ą░čģ čĆą░čüą┐ąŠąĘąĮą░ą▓ą░ąĮąĖčÅ ą▓ąĖą┤ąĄąŠąĖąĘąŠą▒čĆą░ąČąĄąĮąĖčÅ ąĖ ą░ą╗ą│ąŠčĆąĖčéą╝ą░čģ čĆą░ąĘą┤ąĄą╗ąĄąĮąĖčÅ. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = EXTRACT (scene_reg, pattern_reg) (Z)
dest_reg = EXTRACT (scene_reg, pattern_reg) (X)
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg = EXTRACT (Dreg, Dreg_lo) (Z); // zero-extended (b)1
Dreg = EXTRACT (Dreg, Dreg_lo) (X); // sign-extended (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
Dreg_lo: R0.L, ..., R7.L.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Bit Field Extraction ą║ąŠą┐ąĖčĆčāąĄčé ąĮąĄą║ąŠč鹊čĆčāčÄ ąŠčéą┤ąĄą╗čīąĮčāčÄ ą┐ąŠčĆčåąĖčÄ ą▒ąĖčé ąĖąĘ čĆąĄą│ąĖčüčéčĆą░ scene_reg (ą┐ąŠą╗ąĄ čüčåąĄąĮčŗ) ą▓ ą╝ą╗ą░ą┤čłąĖąĄ ą▒ąĖčéčŗ čĆąĄą│ąĖčüčéčĆą░ dest_reg. ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ą┤ą╗ąĖąĮčā ą╝ą░čüą║ąĖ ą▒ąĖčé ąĖ ąĄčæ ą┐ąŠąĘąĖčåąĖčÄ ą▓ ą┐ąŠą╗ąĄ čüčåąĄąĮčŗ. ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą╝ąŠąČąĄčé ą▓čŗą▒čĆą░čéčī čüąĖąĮčéą░ą║čüąĖčü čü čüčāčäčäąĖą║čüąŠą╝ (X), čćč鹊ą▒čŗ ą▓čŗą┐ąŠą╗ąĮąĖčéčī čĆą░čüą┐ą░ą║ąŠą▓ą║čā ą┐ąŠą╗čÅ ą▒ąĖčé čü ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ąĘąĮą░ą║ąŠą╝, ąĖą╗ąĖ čüąĖąĮčéą░ą║čüąĖčü čü čüčāčäčäąĖą║čüąŠą╝ (Z) ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čĆą░čüą┐ą░ą║ąŠą▓ą║ąĖ čü ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ąĮčāą╗čÅą╝ąĖ.
ąØąĖąČąĄ ą┐ąŠą║ą░ąĘą░ąĮčŗ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą┐ąŠą╗ąĄą╣ ą▓čģąŠą┤ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓.
ąŚą┤ąĄčüčī s čŹč鹊 ą┐ąŠą╗ąĄ ą▒ąĖčé čüčåąĄąĮčŗ (scene bit field, 32 ą▒ąĖčéą░), p ą┐ąŠąĘąĖčåąĖčÅ ą▒ąĖčéą░ LSB ą┐ąŠą╗čÅ ą▒ąĖčé ą╝ą░čüą║ąĖ ą▓ scene_reg (pattern bit field, ą┤ąŠą┐čāčüčéąĖą╝čŗą╣ ą┤ąĖą░ą┐ą░ąĘąŠąĮ 0 .. 31), L ą┤ą╗ąĖąĮą░ ą┐ąŠą╗čÅ ą▒ąĖčé ą╝ą░čüą║ąĖ (pattern bit field, ą┤ąŠą┐čāčüčéąĖą╝čŗą╣ ą┤ąĖą░ą┐ą░ąĘąŠąĮ 0 .. 31).
ą×ą┐ąĄčĆą░čåąĖčÅ čćąĖčéą░ąĄčé ą┐ąŠ ą┐ąŠą╗čÄ ą╝ą░čüą║ąĖ ą┤ą╗ąĖąĮąŠą╣ L ąĖąĘ ą┐ąŠą╗čÅ ą▒ąĖčé čüčåąĄąĮčŗ, ą┐čĆąĖ čŹč鹊ą╝ ą▒ąĖčé LSB čĆą░ąĘą╝ąĄčēą░ąĄčéčüčÅ ą▓ ą┐ąŠąĘąĖčåąĖąĖ p čüčåąĄąĮčŗ. ąöą╗čÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ čüą╝. ą┐čĆąĖą╝ąĄčĆčŗ ąĮąĖąČąĄ.
ąōčĆą░ąĮąĖčćąĮčŗą╣ čüą╗čāčćą░ą╣ . ąĢčüą╗ąĖ p + L > 32, č鹊 ą▓ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ zero-extended (ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĮčāą╗ąĄą╝) ąĖ sign-extended (ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĘąĮą░ą║ąŠą╝) ą░čĆčģąĖč鹥ą║čéčāčĆą░ ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčé, čćč鹊 ą▓čüąĄ ą▒ąĖčéčŗ ą┤ąŠ ą╗ąĄą▓ąŠą╣ čćą░čüčéąĖ scene_reg čĆą░ą▓ąĮčŗ 0. ąÆ čéą░ą║ąŠą╝ čüą╗čāčćą░ąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą┐čŗčéą░ąĄčéčüčÅ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ ą▒ąŠą╗čīčłąĄą╝čā ą║ąŠą╗ąĖč湥čüčéą▓čā ą▒ąĖčé, č湥ą╝ čĆąĄą│ąĖčüčéčĆ čüąŠą┤ąĄčƹȹĖčé ą▓ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠčüčéąĖ. ąĪą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ, ą░čĆčģąĖč鹥ą║čéčāčĆą░ ąĘą░ą┐ąŠą╗ąĮčÅąĄčé ąĮčāą╗čÅą╝ąĖ ą╗čÄą▒čŗąĄ ąĮąĄąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ ą▒ąĖčéčŗ ą▓ąŠąĘą╗ąĄ MSB scene_reg.
ąśąĮčüčéčĆčāą║čåąĖčÅ Bit Field Extraction ąĮąĄ ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą┤ą▓čāčģ čĆąĄą│ąĖčüčéčĆąŠą▓ - ąĖčüč鹊čćąĮąĖą║ąŠą▓. ą×ą┤ąĖąĮ ąĖąĘ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖčüč鹊čćąĮąĖą║ą░ ą╝ąŠąČąĄčé čéą░ą║ąČąĄ ą▒čŗčéčī dest_reg, č鹊ą│ą┤ą░ ąŠąĮ ą▒čāą┤ąĄčé ąĖąĘą╝ąĄąĮąĄąĮ.
[ążą╗ą░ą│ąĖ ]
ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé 0; ąŠčćąĖčüčéąĖčéčüčÅ, ąĄčüą╗ąĖ ąĮąĄ 0.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąŠčüčéą░ąĮčāčéčüčÅ ąĮąĄčéčĆąŠąĮčāčéčŗą╝ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ (ą░ ąŠąĮą░ 32-ą▒ąĖčéąĮą░čÅ) ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆ Bit Field Extraction Unsigned ]
r7 = extract (r4, r3.l)(z); // zero-extended
ąĢčüą╗ąĖ ...
... ąĖ ...
... č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé ...
ąĢčüą╗ąĖ ...
... ąĖ ...
... č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé ...
[ą¤čĆąĖą╝ąĄčĆ Bit Field Extraction Sign-Extended ]
r7 = extract (r4, r3.l)(x); // sign-extended
ąĢčüą╗ąĖ ...
... ąĖ ...
... č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé ...
ąĢčüą╗ąĖ ...
... ąĖ ...
... č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé ...
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖčÄ Bit Field Deposit.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą╝čāą╗čīčéąĖą┐ą╗ąĄą║čüąĖčĆąŠą▓ą░ąĮąĖčÅ ą▒ąĖčé ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą▓ ą░ą╗ą│ąŠčĆąĖčéą╝ą░čģ ą║ąŠąĮą▓ąŠą╗čÄčåąĖąŠąĮąĮąŠą│ąŠ ą║ąŠą┤ąĄčĆą░. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
BITMUX ( source_1, source_0, A0 ) (ASR)
BITMUX ( source_1, source_0, A0 ) (ASL)
ąĪąĖąĮčéą░ą║čüąĖčü:
BITMUX (Dreg, Dreg, A0) (ASR); // čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ, LSB ą▓čŗą┤ą▓ąĖą│ą░ąĄčéčüčÅ ąĮą░čĆčāąČčā (b)1
BITMUX (Dreg, Dreg, A0) (ASL); // čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ, MSB ą▓čŗą┤ą▓ąĖą│ą░ąĄčéčüčÅ ąĮą░čĆčāąČčā (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Bit Multiplex čüąŠąĄą┤ąĖąĮčÅąĄčé ą┐ąŠč鹊ą║ąĖ ą▒ąĖčé. ąŻ ąĮąĄčæ ąĄčüčéčī 2 ą▓ąĄčĆčüąĖąĖ, čüąŠ čüą┤ą▓ąĖą│ąŠą╝ ą▓ą┐čĆą░ą▓ąŠ (Shift Right) ąĖ čüąŠ čüą┤ą▓ąĖą│ąŠą╝ ą▓ą╗ąĄą▓ąŠ (Shift Left). ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐ąĄčĆąĄąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čĆąĄą│ąĖčüčéčĆąŠą▓-ąĖčüč鹊čćąĮąĖą║ąŠą▓ source_1 ąĖ source_0.
ąÆ ą▓ąĄčĆčüąĖąĖ Shift Right ą┐čĆąŠčåąĄčüčüąŠčĆ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé čüą╗ąĄą┤čāčÄčēčāčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ą┤ąĄą╣čüčéą▓ąĖą╣.
1 . ąĪą┤ą▓ąĖą│ą░ąĄčé ą▓ą┐čĆą░ą▓ąŠ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ A0 ąĮą░ 1 ą▒ąĖčé. ą¤čĆąĖ čŹč鹊ą╝ ą▒ąĖčé LSB ąĖąĘ source_1 ą▓ą┤ą▓ąĖą│ą░ąĄčéčüčÅ ą▓ ą▒ąĖčé MSB ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░.2 . ąĪą┤ą▓ąĖą│ą░ąĄčé ą▓ą┐čĆą░ą▓ąŠ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ A0 ąĮą░ 1 ą▒ąĖčé. ą¤čĆąĖ čŹč鹊ą╝ ą▒ąĖčé LSB ąĖąĘ source_0 ą▓ą┤ą▓ąĖą│ą░ąĄčéčüčÅ ą▓ ą▒ąĖčé MSB ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░.
ąÆ ą▓ąĄčĆčüąĖąĖ Shift Left ą┐čĆąŠčåąĄčüčüąŠčĆ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé čüą╗ąĄą┤čāčÄčēčāčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ą┤ąĄą╣čüčéą▓ąĖą╣.
1 . ąĪą┤ą▓ąĖą│ą░ąĄčé ą▓ą╗ąĄą▓ąŠ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ A0 ąĮą░ 1 ą▒ąĖčé. ą¤čĆąĖ čŹč鹊ą╝ ą▒ąĖčé MSB ąĖąĘ source_0 ą▓ą┤ą▓ąĖą│ą░ąĄčéčüčÅ ą▓ ą▒ąĖčé LSB ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░.2 . ąĪą┤ą▓ąĖą│ą░ąĄčé ą▓ą╗ąĄą▓ąŠ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ A0 ąĮą░ 1 ą▒ąĖčé. ą¤čĆąĖ čŹč鹊ą╝ ą▒ąĖčé MSB ąĖąĘ source_1 ą▓ą┤ą▓ąĖą│ą░ąĄčéčüčÅ ą▓ ą▒ąĖčé LSB ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░.
ąĀąĄą│ąĖčüčéčĆčŗ source_1 ąĖ source_0 ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ąŠą┤ąĮąĖą╝ ąĖ č鹥ą╝ ąČąĄ D-čĆąĄą│ąĖčüčéčĆąŠą╝.
ąĢčüą╗ąĖ ...
... ąĖąĮčüčéčĆčāą║čåąĖčÅ čüąŠ čüą┤ą▓ąĖą│ąŠą╝ ą▓ą┐čĆą░ą▓ąŠ čüą┤ąĄą╗ą░ąĄčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
... ąĖąĮčüčéčĆčāą║čåąĖčÅ čüąŠ čüą┤ą▓ąĖą│ąŠą╝ ą▓ą╗ąĄą▓ąŠ čüą┤ąĄą╗ą░ąĄčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ (ą░ ąŠąĮą░ 32-ą▒ąĖčéąĮą░čÅ) ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
bitmux(r2, r3, a0)(asr); // čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ
ąĢčüą╗ąĖ ...
... ąĖ ...
... ąĖ ...
... č鹊 čĆąĄąĘčāą╗čīčéą░č鹊ą╝ čüą┤ą▓ąĖą│ą░ ą▓ą┐čĆą░ą▓ąŠ ą▒čāą┤ąĄčé ...
... ąĖ ...
... ąĖ ...
bitmux(r3, r2, a0)(asl); // čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ
ąĢčüą╗ąĖ ...
... ąĖ ...
... ąĖ ...
... č鹊 čĆąĄąĘčāą╗čīčéą░č鹊ą╝ čüą┤ą▓ąĖą│ą░ ą▓ą╗ąĄą▓ąŠ ą▒čāą┤ąĄčé ...
... ąĖ ...
... ąĖ ...
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐ąŠą┤čüč湥čéą░ ą▒ąĖčé-ąĄą┤ąĖąĮąĖč湥ą║ Ones Population Count ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮą░ ą┤ą╗čÅ ą┐čĆąŠą▓ąĄčĆą║ąĖ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą▒ąĖčé ąĮą░ č湥čéąĮąŠčüčéčī. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = ONES src_reg
ąĪąĖąĮčéą░ą║čüąĖčü:
Dreg_lo = ONES Dreg; // (b)1
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
Dreg_lo: ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Ones Population Count ąĘą░ą│čĆčāąČą░ąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé čü ą╗ąŠą│. 1, čüąŠą┤ąĄčƹȹ░čēąĖčģčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ src_reg, ą▓ ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮą║čā čĆąĄą│ąĖčüčéčĆą░ dest_reg.
ąöąĖą░ą┐ą░ąĘąŠąĮ ą▓ąŠąĘą╝ąŠąČąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ąĘą░ą│čĆčāąČąĄąĮčŗ ą▓ dest_reg, ą▒čāą┤ąĄčé 0 .. 32.
ąĀąĄą│ąĖčüčéčĆčŗ dest_reg ąĖ src_reg ą╝ąŠą│čāčé ą▒čŗčéčī ąŠą┤ąĮąĖą╝ ąĖ č鹥ą╝ ąČąĄ D-čĆąĄą│ąĖčüčéčĆąŠą╝. ąĢčüą╗ąĖ čŹčéąĖ čĆąĄą│ąĖčüčéčĆčŗ čĆą░ąĘąĮčŗąĄ, č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ Ones Population Count ąĮąĄ ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čĆąĄą│ąĖčüčéčĆą░-ąĖčüč鹊čćąĮąĖą║ą░ src_reg.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ (ą░ ąŠąĮą░ 32-ą▒ąĖčéąĮą░čÅ) ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆ ]
ąĢčüą╗ąĖ ą▓ čĆąĄą│ąĖčüčéčĆąĄ R7 čüąŠą┤ąĄčƹȹĖčéčüčÅ 0xA5A5A5A5, č鹊 R3.L ą┐ąŠą╗čāčćąĖčé ąĘąĮą░č湥ąĮąĖąĄ 16, ąĖą╗ąĖ 0x0010. ąĢčüą╗ąĖ ą▓ R7 čüąŠą┤ąĄčƹȹĖčéčüčÅ 0x00000081, č鹊 R3.L ą┐ąŠą╗čāčćąĖčé ąĘąĮą░č湥ąĮąĖąĄ 2, ąĖą╗ąĖ 0x0002.
[ą×ą┐ąĄčĆą░čåąĖąĖ čüą┤ą▓ąĖą│ą░ ąĖ ą┐čĆąŠą║čĆčāčéą║ąĖ ]
ąÆ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░čÄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ą╝ą░ąĮąĖą┐čāą╗ąĖčĆčāčÄčé ą┐ąŠąĘąĖčåąĖčÅą╝ąĖ ą▒ąĖčé. ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĖ ą╝ąŠą│čāčé ą┐čĆąĖą╝ąĄąĮčÅčéčī čéą░ą║ąĖąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣, ą║ą░ą║ ą╗ąŠą│ąĖč湥čüą║ąĖąĄ ąĖ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ čüą┤ą▓ąĖą│ąĖ, ą║ąŠą╝ą▒ąĖąĮąĖčĆąŠą▓ą░ąĮąĖąĄ čüą╗ąŠąČąĄąĮąĖčÅ čüąŠ čüą┤ą▓ąĖą│ąŠą╝, ą┐čĆąŠą║čĆčāčéą║čā čćąĖčüą╗ą░ ą▓ čĆąĄą│ąĖčüčéčĆąĄ č湥čĆąĄąĘ ą▒ąĖčé CC.
ąĪą╗ąŠąČąĄąĮąĖąĄ čüąŠ čüą┤ą▓ąĖą│ąŠą╝. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_pntr = (dest_pntr + src_reg) << 1
dest_pntr = (dest_pntr + src_reg) << 2
dest_reg = (dest_reg + src_reg) << 1
dest_reg = (dest_reg + src_reg) << 2
ąĪąĖąĮčéą░ą║čüąĖčü ąŠą┐ąĄčĆą░čåąĖą╣ čü čāą║ą░ąĘą░č鹥ą╗čÅą╝ąĖ:
Preg = ( Preg + Preg ) << 1; // dest_reg = (dest_reg + src_reg) x 2 (a)1
Preg = ( Preg + Preg ) << 2; // dest_reg = (dest_reg + src_reg) x 4 (a)
ąĪąĖąĮčéą░ą║čüąĖčü ąŠą┐ąĄčĆą░čåąĖą╣ čü ą┤ą░ąĮąĮčŗą╝ąĖ:
Dreg = (Dreg + Dreg) << 1; // dest_reg = (dest_reg + src_reg) x 2 (a)
Dreg = (Dreg + Dreg) << 2; // dest_reg = (dest_reg + src_reg) x 4 (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Preg: čĆąĄą│ąĖčüčéčĆčŗ P0, ..., P5.
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ čüą╗ąŠąČąĄąĮąĖčÅ čüąŠ čüą┤ą▓ąĖą│ąŠą╝ (Add with Shift) ą║ąŠą╝ą▒ąĖąĮąĖčĆčāąĄčé ąŠą┐ąĄčĆą░čåąĖčÄ čüą╗ąŠąČąĄąĮąĖčÅ čü ąŠą┤ąĖąĮąŠčćąĮčŗą╝ ąĖą╗ąĖ ą┤ą▓ąŠą╣ąĮčŗą╝ ą╗ąŠą│ąĖč湥čüą║ąĖą╝ čüą┤ą▓ąĖą│ąŠą╝ ą▓ą╗ąĄą▓ąŠ. ąÜąŠąĮąĄčćąĮąŠ, čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé čāą╝ąĮąŠąČąĄąĮąĖčÄ ąĮą░ 2 čćąĖčüąĄą╗, čĆą░čüčłąĖčĆąĄąĮąĮčŗčģ ąĘąĮą░ą║ąŠą╝. ąØą░čüčŗčēąĄąĮąĖąĄ ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ.
ąśąĮčüčéčĆčāą║čåąĖčÅ čüą╗ąŠąČąĄąĮąĖčÅ čüąŠ čüą┤ą▓ąĖą│ąŠą╝ ą▓ąĮčāčéčĆąĄąĮąĮąĄ ąĮąĄ ą╝ąĄąĮčÅąĄčé ąĘąĮą░č湥ąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓, ą║ąŠč鹊čĆčŗąĄ ą┐ąĄčĆąĄą┤ą░ąĮčŗ ąĮą░ ą▓čģąŠą┤. ą×ą┤ąĮą░ą║ąŠ ąĄčüą╗ąĖ čĆąĄą│ąĖčüčéčĆ dest_reg ą▓čŗčüčéčāą┐ą░ąĄčé ą║ą░ą║ ą▓čģąŠą┤ąĮąŠą╣ čĆąĄą│ąĖčüčéčĆ, č鹊 ąŠąĮ ą▒čāą┤ąĄčé ąĖąĘą╝ąĄąĮąĄąĮ.
[ążą╗ą░ą│ąĖ ]
ąÆąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ čü D-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ą▓ą╗ąĖčÅčÄčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé 0; ąŠčćąĖčüčéąĖčéčüčÅ, ąĄčüą╗ąĖ ąĮąĄ 0.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąŠčüčéą░ąĮčāčéčüčÅ ąĮąĄčéčĆąŠąĮčāčéčŗą╝ąĖ.
ąÆąĄčĆčüąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü P-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
p3 = (p3+ p2) << 1 ; // p3 = (p3 + p2) * 2
p3 = (p3+ p2) << 2 ; // p3 = (p3 + p2) * 4
r3 = (r3+ r2) << 1 ; // r3 = (r3 + r2) * 2
r3 = (r3+ r2) << 2 ; // r3 = (r3 + r2) * 4
ąĪą╝. čéą░ą║ąČąĄ Add, Multiply (Modulo 232 ), Logical Shift, Arithmetic Shift, Add.
ąĪą┤ą▓ąĖą│ čüąŠ čüą╗ąŠąČąĄąĮąĖąĄą╝. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_pntr = adder_pntr + ( src_pntr << 1 )
dest_pntr = adder_pntr + ( src_pntr << 2 )
ąĪąĖąĮčéą░ą║čüąĖčü:
Preg = Preg + ( Preg << 1 ); // adder_pntr + (src_pntr x 2) (a)1
Preg = Preg + ( Preg << 2 ); // adder_pntr + (src_pntr x 4) (a)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Preg: čĆąĄą│ąĖčüčéčĆčŗ P0, ..., P5.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ čüą┤ą▓ąĖą│ą░ čüąŠ čüą╗ąŠąČąĄąĮąĖąĄą╝ (Shift with Add) ą║ąŠą╝ą▒ąĖąĮąĖčĆčāąĄčé ąŠą┤ąĖąĮąŠčćąĮčŗą╣ ąĖą╗ąĖ ą┤ą▓ąŠą╣ąĮąŠą╣ ą╗ąŠą│ąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ čü ąŠą┐ąĄčĆą░čåąĖąĄą╣ čüą╗ąŠąČąĄąĮąĖčÅ. ąÜąŠąĮąĄčćąĮąŠ, čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé čāą╝ąĮąŠąČąĄąĮąĖčÄ ąĮą░ 2 čćąĖčüąĄą╗, čĆą░čüčłąĖčĆąĄąĮąĮčŗčģ ąĘąĮą░ą║ąŠą╝. ąØą░čüčŗčēąĄąĮąĖąĄ ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą╝ąĄč鹊ą┤ čüą┤ą▓ąĖą│-ąĘą░č鹥ą╝-čüą╗ąŠąČąĄąĮąĖąĄ, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé čĆčāą┤ąĖą╝ąĄąĮčéą░čĆąĮčāčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī čāą╝ąĮąŠąČąĄąĮąĖčÅ, ą┐ąŠą╗ąĄąĘąĮčāčÄ ą┤ą╗čÅ ą╝ą░ąĮąĖą┐čāą╗čÅčåąĖčÄ čāą║ą░ąĘą░č鹥ą╗ąĄą╝ ąĮą░ ą╝ą░čüčüąĖą▓.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
p3 = p0+ (p3 << 1 ); // p3 = (p3 * 2) + p0
p3 = p0+ (p3 << 2 ); // p3 = (p3 * 4) + p0
ąĪą╝. čéą░ą║ąČąĄ Add with Shift, Multiply (Modulo 232 ), Logical Shift, Arithmetic Shift, Add.
ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│. ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ąŠą▒čŗčćąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą┤ą╗čÅ čāą╝ąĮąŠąČąĄąĮąĖčÅ, ą┤ąĄą╗ąĄąĮąĖčÅ ąĖ ąĮąŠčĆą╝ą░ą╗ąĖąĘą░čåąĖąĖ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮčŗčģ čćąĖčüąĄą╗. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg >>>= shift_magnitude
dest_reg = src_reg >>> shift_magnitude (opt_sat)
dest_reg = src_reg << shift_magnitude (S)
accumulator = accumulator >>> shift_magnitude
dest_reg = ASHIFT src_reg BY shift_magnitude (opt_sat)
accumulator = ASHIFT accumulator BY shift_magnitude
ąĪąĖąĮčéą░ą║čüąĖčü čüą┤ą▓ąĖą│ą░ ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ ą║ąŠąĮčüčéą░ąĮčéčŗ:
Dreg >>>= uimm5; // ą░čĆąĖčä. čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ (a)1
Dreg << = uimm5; // ą╗ąŠą│. čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ (a)
Dreg_lo_hi = Dreg_lo_hi >>> uimm4; // ą░čĆąĖčä. čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ (b)
Dreg_lo_hi = Dreg_lo_hi << uimm4(S); // ą░čĆąĖčä. čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ (b)
Dreg = Dreg >>> uimm5; // ą░čĆąĖčä. čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ b)
Dreg = Dreg << uimm5 (S); // ą░čĆąĖčä. čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ (b)
A0 = A0 >>> uimm5; // ą░čĆąĖčä. čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ (b)
A0 = A0 << uimm5; // ą╗ąŠą│. čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ (b)
A1 = A1 >>> uimm5; // ą░čĆąĖčä. čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ (b)
A1 = A1 << uimm5; // ą╗ąŠą│. čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ (b)
ąĪąĖąĮčéą░ą║čüąĖčü čüą┤ą▓ąĖą│ą░ ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ ą▓ čĆąĄą│ąĖčüčéčĆąĄ:
Dreg >>>= Dreg; // ą░čĆąĖčä. čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ (a)
Dreg << = Dreg; // ą╗ąŠą│. čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ (a)
Dreg_lo_hi = ASHIFT Dreg_lo_hi BY Dreg_lo (opt_sat); // ą░čĆąĖčä. čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ (b)
Dreg = ASHIFT Dreg BY Dreg_lo (opt_sat); // ą░čĆąĖčä. čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ (b)
A0 = ASHIFT A0 BY Dreg_lo; // ą░čĆąĖčä. čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ (b)
A1 = ASHIFT A1 BY Dreg_lo; // ą░čĆąĖčä. čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
Dreg_lo_hi: ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L, R0.H, ..., R7.H.
Dreg_lo: ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L.
uimm4: 4-ą▒ąĖčéąĮąŠąĄ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ ą┐ąŠą╗ąĄ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 15.
uimm5: 5-ą▒ąĖčéąĮąŠąĄ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ ą┐ąŠą╗ąĄ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 31.
opt_sat: ąŠą┐čåąĖąŠąĮą░ą╗čīąĮčŗą╣ čüčāčäčäąĖą║čü (S) ą▓ąŠą▓ą╗ąĄą║ą░ąĄčé ąĮą░čüčŗčēąĄąĮąĖąĄ ą┤ą╗čÅ čĆąĄąĘčāą╗čīčéą░čéą░. ąŁč鹊 ąĮąĄ ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą┤ą╗čÅ ą▓ąĄčĆčüąĖą╣, ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠč鹊čĆčŗčģ ą┐ąŠą║ą░ąĘą░ąĮ čüčāčäčäąĖą║čü (S).
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖąĖ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠą│ąŠ čüą┤ą▓ąĖą│ą░ (Arithmetic Shift) čüą┤ą▓ąĖą│ą░čÄčé čćąĖčüą╗ąŠ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ąĮą░ čāą║ą░ąĘą░ąĮąĮčāčÄ ą▓ąĄą╗ąĖčćąĖąĮčā ą▒ąĖčé (distance) ą▓ čāą║ą░ąĘą░ąĮąĮąŠą╝ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĖ, čüąŠčģčĆą░ąĮčÅčÅ ą┐čĆąĖ čŹč鹊ą╝ ąĘąĮą░ą║ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮąŠą│ąŠ čćąĖčüą╗ą░. ąæąĖčé ąĘąĮą░ą║ą░ ąĘą░ą┐ąŠą╗ąĮąĖčé čüą░ą╝čāčÄ ą╗ąĄą▓čāčÄ (čüčéą░čĆčłčāčÄ) ą┐ąŠąĘąĖčåąĖčÄ, ą║ąŠč鹊čĆą░čÅ ąŠčüą▓ąŠą▒ąŠąČą┤ą░ąĄčéčüčÅ ą┐čĆąĖ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠą╝ čüą┤ą▓ąĖą│ąĄ ą▓ą┐čĆą░ą▓ąŠ.
ąóą░ą║ąČąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčéčüčÅ ąŠčéą┤ąĄą╗čīąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠą│ąŠ čüą┤ą▓ąĖą│ą░ ą▓ą╗ąĄą▓ąŠ. ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ ą┤ąĄą╗ą░ąĄčé ąĮą░čüčŗčēąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░, ąĄčüą╗ąĖ ąĘąĮą░č湥ąĮąĖąĄ ą▒čŗą╗ąŠ čüą┤ą▓ąĖąĮčāč鹊 čüą╗ąĖčłą║ąŠą╝ ą┤ą░ą╗ąĄą║ąŠ. ąĪą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠč鹥čĆčÅą╗ ą▒čŗ ą┤ąĄą╣čüčéą▓čāčÄčēąĖą╣ ą▒ąĖčé ąĘąĮą░ą║ą░, ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą┤ąĄą╗ą░ąĄčé ąĮą░čüčŗčēąĄąĮąĖąĄ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą│ąŠ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠą│ąŠ ąĖą╗ąĖ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠą│ąŠ čĆąĄąĘčāą╗čīčéą░čéą░.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: čŹčéąĖą╝ čüąŠą▒čüčéą▓ąĄąĮąĮąŠ ąĖ ąŠčéą╗ąĖčćą░ąĄčéčüčÅ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ąŠčé ą╗ąŠą│ąĖč湥čüą║ąŠą│ąŠ - ą╗ąŠą│ąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ąĮąĄ ąĘą░ą▒ąŠčéąĖčéčüčÅ ąŠ ąĘąĮą░ą║ąŠą▓ąŠą╝ ą▒ąĖč鹥 ąĖ ąĮąĄ ą┤ąĄą╗ą░ąĄčé ąĮą░čüčŗčēąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░.
ąÆąĄčĆčüąĖąĖ ASHIFT čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé 2 čĆąĄąČąĖą╝ą░:
1 . ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ - ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ ąĖ ą╗ąŠą│ąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ. ąøąŠą│ąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ąĮąĄ ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé čüąŠčģčĆą░ąĮąĄąĮąĖąĄ ą▒ąĖčéą░ ąĘąĮą░ą║ą░. ąÆąĄčĆčüąĖąĖ ASHIFT ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą▓čŗą▒ąĖčĆą░čÄčé čĆąĄąČąĖą╝čŗ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠą│ąŠ ąĖ ą╗ąŠą│ąĖč湥čüą║ąŠą│ąŠ čüą┤ą▓ąĖą│ą░ ąĮą░ ą▒ą░ąĘąĄ ąĘąĮą░ą║ą░ ą▓ąĄą╗ąĖčćąĖąĮčŗ čüą┤ą▓ąĖą│ą░ (shift_magnitude).2 . ąĀąĄąČąĖą╝ ąĮą░čüčŗčēąĄąĮąĖčÅ (saturation) - ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ čüą┤ą▓ąĖą│ąĖ ą▓ą┐čĆą░ą▓ąŠ ąĖ ą▓ą╗ąĄą▓ąŠ, ą║ąŠč鹊čĆčŗąĄ ąĮą░čüčŗčēą░čÄčé čĆąĄąĘčāą╗čīčéą░čé, ąĄčüą╗ąĖ čüą┤ą▓ąĖą│ ą┐čĆąŠąĖąĘąŠčłąĄą╗ čüą╗ąĖčłą║ąŠą╝ ą┤ą░ą╗ąĄą║ąŠ.
ąÆąĄčĆčüąĖąĖ >>>= ąĖ >>> čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé č鹊ą╗čīą║ąŠ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ čüą┤ą▓ąĖą│ąĖ ą▓ą┐čĆą░ą▓ąŠ. ąĢčüą╗ąĖ ąĮčāąČąĮčŗ ą╗ąĄą▓čŗąĄ čüą┤ą▓ąĖą│ąĖ, č鹊 ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčé ą┤ąŠą╗ąČąĄąĮ čÅą▓ąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĖąĮčüčéčĆčāą║čåąĖąĖ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠą│ąŠ << (čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝) ąĖą╗ąĖ ą╗ąŠą│ąĖč湥čüą║ąŠą│ąŠ << (ą▒ąĄąĘ ąĮą░čüčŗčēąĄąĮąĖčÅ) čüą┤ą▓ąĖą│ą░.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╗ąŠą│ąĖč湥čüą║ąŠą│ąŠ čüą┤ą▓ąĖą│ą░ ą▓ą╗ąĄą▓ąŠ ą┤ą╗čÅ čāą┤ąŠą▒čüčéą▓ą░ čāą║ą░ąĘą░ąĮčŗ ą┤ą▓ą░ąČą┤čŗ ą▓ čüąĄą║čåąĖąĖ čüąĖąĮčéą░ą║čüąĖčüą░. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ąŠ ąĖąĮčüčéčĆčāą║čåąĖčÅčģ ą╗ąŠą│ąĖč湥čüą║ąŠą│ąŠ čüą┤ą▓ąĖą│ą░ čüą╝. čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖąĄ ą▓čĆąĄąĘą║ąĖ.
ąśąĮčüčéčĆčāą║čåąĖąĖ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠą│ąŠ čüą┤ą▓ąĖą│ą░ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ 16-ą▒ąĖčéąĮąŠą╣ ąĖ 32-ą▒ąĖčéąĮąŠą╣ ą┤ą╗ąĖąĮčŗ.
ŌĆó ąśąĮčüčéčĆčāą║čåąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ >>> = ą▒čāą┤ąĄčé 16-ą▒ąĖčéąĮąŠą╣ ą┤ą╗ąĖąĮčŗ, ą┐ąŠąĘą▓ąŠą╗čÅčÅ ą┐ąĖčüą░čéčī ą║ąŠą┤ ą╝ąĄąĮčīčłąĄą│ąŠ čĆą░ąĘą╝ąĄčĆą░ čåąĄąĮąŠą╣ ą┐ąŠč鹥čĆąĖ ą│ąĖą▒ą║ąŠčüčéąĖ.
ą×ą▒ą░ čüąĖąĮčéą░ą║čüąĖčüą░ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé ą╝ą░ą│ąĮąĖčéčāą┤čŗ čüą┤ą▓ąĖą│ą░ (čé. ąĄ. ąĮą░ čüą║ąŠą╗čīą║ąŠ čĆą░ąĘčĆčÅą┤ąŠą▓ čüą┤ą▓ąĖą│ą░čéčī), čāą║ą░ąĘą░ąĮąĮčŗąĄ ą║ą░ą║ ą▓ ą▓ąĖą┤ąĄ ą║ąŠąĮčüčéą░ąĮčéčŗ ą▓ ą║ąŠą╝ą░ąĮą┤ąĄ, čéą░ą║ ąĖ ą▓ ąĘąĮą░č湥ąĮąĖąĖ čĆąĄą│ąĖčüčéčĆą░.
ąóą░ą▒ą╗ąĖčåą░ 9-1. ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ čüą┤ą▓ąĖą│ąĖ.
ąĪąĖąĮčéą░ą║čüąĖčü ą×ą┐ąĖčüą░ąĮąĖąĄ
>>>= ąŚąĮą░č湥ąĮąĖąĄ ą▓ dest_reg čüą┤ą▓ąĖą│ą░ąĄčéčüčÅ ą▓ą┐čĆą░ą▓ąŠ ąĮą░ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé, čāą║ą░ąĘą░ąĮąĮąŠąĄ ą▓ shift_magnitude. ąĀą░ąĘą╝ąĄčĆ ą┤ą░ąĮąĮčŗčģ ą▓čüąĄą│ą┤ą░ 32 ą▒ąĖčéą░ ą┤ą╗ąĖąĮąŠą╣. ąÆčüąĄ 32 ą▒ąĖčéą░ shift_magnitude ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčé ąĘąĮą░č湥ąĮąĖąĄ čüą┤ą▓ąĖą│ą░. ąŚąĮą░č湥ąĮąĖąĄ čüą┤ą▓ąĖą│ą░ ą▒ąŠą╗čīčłąĄ, č湥ą╝ 0x1F ą┤ą░ą┤čāčé ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 0x00000000 (ą║ąŠą│ą┤ą░ ą▓čģąŠą┤ąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠąĄ) ąĖą╗ąĖ 0xFFFFFFFF (ą║ąŠą│ą┤ą░ ą▓čģąŠą┤ąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠąĄ).
>>> , << ąĖ ASHIFT ąŚąĮą░č湥ąĮąĖąĄ ą▓ src_reg čüą┤ą▓ąĖą│ą░ąĄčéčüčÅ ąĮą░ čāą║ą░ąĘą░ąĮąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé ą▓ shift_magnitude, ąĖ čĆąĄąĘčāą╗čīčéą░čé čüąŠčģčĆą░ąĮčÅąĄčéčüčÅ ą▓ dest_reg. ąÆąĄčĆčüąĖąĖ čü ASHIFT ą╝ąŠą│čāčé čüą┤ą▓ąĖą│ą░čéčī 32-ą▒ąĖčéąĮčŗą╣ Dreg ąĖ 40-ą▒ąĖčéąĮčŗą╣ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ ąĮą░ ą┤ąĖą░ą┐ą░ąĘąŠąĮ čüą┤ą▓ąĖą│ą░ -32 .. 31 ą▒ąĖčéą░; ą▓ąĄą╗ąĖčćąĖąĮą░ čüą┤ą▓ąĖą│ą░ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ ą╝ą╗ą░ą┤čłąĖą╝ąĖ 6 ą▒ąĖčéą░ą╝ąĖ (čü čĆą░čüčłąĖčĆąĄąĮąĖąĄą╝ ąĘąĮą░ą║ąŠą╝) ąĘąĮą░č湥ąĮąĖčÅ ą▓ shift_magnitude.
ąöą╗čÅ ą▓ąĄčĆčüąĖą╣ ASHIFT ąĘąĮą░ą║ ą▓ ą╝ą░ą│ąĮąĖčéčāą┤ąĄ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čüą┤ą▓ąĖą│ą░.
ŌĆó ą¤ąŠą╗ąŠąČąĖč鹥ą╗čīąĮą░čÅ ą╝ą░ą│ąĮąĖčéčāą┤ą░ ąĘą░ą┤ą░ąĄčé ąøą×ąōąśą¦ąĢąĪąÜąśąÖ čüą┤ą▓ąĖą│ ąÆąøąĢąÆą×.
ąÆ čüčāčēąĮąŠčüčéąĖ, ą╝ą░ą│ąĮąĖčéčāą┤ą░ (magnitude) čŹč鹊 čüč鹥ą┐ąĄąĮčī čćąĖčüą╗ą░ 2, ąĮą░ ą║ąŠč鹊čĆčāčÄ čāą╝ąĮąŠąČą░ąĄčéčüčÅ čćąĖčüą╗ąŠ src_reg. ą¤ąŠą╗ąŠąČąĖč鹥ą╗čīąĮčŗąĄ ą╝ą░ą│ąĮąĖčéčāą┤čŗ ą┤ąĄą╗ą░čÄčé čāą╝ąĮąŠąČąĄąĮąĖąĄ (N x 2n ), ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮčŗąĄ ą╝ą░ą│ąĮąĖčéčāą┤čŗ ą┤ąĄą╗ą░čÄčé ą┤ąĄą╗ąĄąĮąĖąĄ (N x 2-n ąĖą╗ąĖ N / 2n ).
ąĀąĄą│ąĖčüčéčĆčŗ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ (dest_reg) ąĖ ąĖčüč鹊čćąĮąĖą║ą░ (src_reg) ą╝ąŠą│čāčé ą▒čŗčéčī 16-, 32- ąĖą╗ąĖ 40-ą▒ąĖčéąĮčŗą╝ąĖ čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ. ąØąĄą║ąŠč鹊čĆčŗąĄ ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠą│ąŠ čüą┤ą▓ąĖą│ą░ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé ąŠą┐čåąĖčÄ ąĮą░čüčŗčēąĄąĮąĖčÅ.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĮą░čüčŗčēąĄąĮąĖčÅ čüą╝. čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╣ čĆą░ąĘą┤ąĄą╗ ą▓ ąĮą░čćą░ą╗ąĄ čüčéą░čéčīąĖ.
ąöą╗čÅ 16-ą▒ąĖčéąĮčŗčģ src_reg ą┤ąŠą┐čāčüčéąĖą╝čŗ ą╝ą░ą│ąĮąĖčéčāą┤čŗ čüą┤ą▓ąĖą│ą░ ŌĆō16 .. +15, ą▓ą║ą╗čÄčćą░čÅ 0. ąöą╗čÅ 32- ąĖ 40-ą▒ąĖčéąĮčŗčģ src_reg ą┤ąŠą┐čāčüčéąĖą╝čŗ ą╝ą░ą│ąĮąĖčéčāą┤čŗ čüą┤ą▓ąĖą│ą░ ŌĆō32 .. +31, ą▓ą║ą╗čÄčćą░čÅ 0. ąśąĮčüčéčĆčāą║čåąĖąĖ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠą│ąŠ čüą┤ą▓ąĖą│ą░ ą╝ą░čüą║ąĖčĆčāčÄčé ąĖ ąĖą│ąĮąŠčĆąĖčĆčāčÄčé ą▒ąĖčéčŗ, ą║ąŠč鹊čĆčŗąĄ čÅą▓ą╗čÅčÄčéčüčÅ ą▒ąŠą╗ąĄąĄ ąĘąĮą░čćą░čēąĖą╝ąĖ, č湥ą╝ čŹč鹊 čĆą░ąĘčĆąĄčłąĄąĮąŠ.
ąÆąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü D-čĆąĄą│ąĖčüčéčĆąŠą╝ čüą┤ą▓ąĖą│ą░čÄčé 16 ąĖą╗ąĖ 32 ą▒ąĖčéą░ ą┤ą╗čÅ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┐ąŠą╗čāčüą╗ąŠą▓ą░ ąĖ čüą╗ąŠą▓ą░ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ. ąÆąĄčĆčüąĖąĖ čü ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą╝ čüą┤ą▓ąĖą│ą░čÄčé ą▓čüąĄ 40 ą▒ąĖčé čŹčéąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓.
ąÆąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü D-čĆąĄą│ąĖčüčéčĆąŠą╝ ąĮąĄ ą┤ąĄą╗ą░čÄčé ąĮąĄčÅą▓ąĮčāčÄ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÄ ąĘąĮą░č湥ąĮąĖčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ src_reg (čĆąĄą│ąĖčüčéčĆ ąĖčüč鹊čćąĮąĖą║ą░). ą×ą┤ąĮą░ą║ąŠ ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ dest_reg ą╝ąŠąČąĄčé ą▒čŗčéčī č鹥ą╝ ąČąĄ čüą░ą╝čŗą╝ D-čĆąĄą│ąĖčüčéčĆąŠą╝, čćč鹊 ąĖ src_reg, ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ąĖąĮčüčéčĆčāą║čåąĖčÅ čÅą▓ąĮąŠ ąĖąĘą╝ąĄąĮąĖčé čĆąĄą│ąĖčüčéčĆ ąĖčüč鹊čćąĮąĖą║ą░ .
ąÆąĄčĆčüąĖąĖ čü ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą╝ ą▓čüąĄą│ą┤ą░ ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāčÄčé ąĘąĮą░č湥ąĮąĖąĄ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ąĖčüč鹊čćąĮąĖą║ą░.
[ą×ą┐čåąĖąĖ ]
ą×ą┐čåąĖčÅ (S) ą▓ąŠą▓ą╗ąĄą║ą░ąĄčé ąĮą░čüčŗčēąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░.
ąÆ čüą╗čāčćą░ąĄ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ, ą║ąŠą│ą┤ą░ ąŠą┐čåąĖčÅ ąĮą░čüčŗčēąĄąĮąĖčÅ ąĮąĄ čāą║ą░ąĘą░ąĮą░, čćąĖčüą╗ą░ ą╝ąŠą│čāčé ą▒čŗčéčī čüą┤ą▓ąĖąĮčāčéčŗ ą▓ą╗ąĄą▓ąŠ čéą░ą║ ą┤ą░ą╗ąĄą║ąŠ, čćč鹊 ą▓čüąĄ ąĘąĮą░ą║ąŠą▓čŗąĄ ą▒ąĖčéčŗ ą┐ąĄčĆąĄą┐ąŠą╗ąĮčÅčéčüčÅ, ąĖ ąĘąĮą░ą║ čćąĖčüą╗ą░ ą▒čāą┤ąĄčé ą┐ąŠč鹥čĆčÅąĮ. ą×ą┤ąĮą░ą║ąŠ, ą║ąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮą░ ąŠą┐čåąĖčÅ ąĮą░čüčŗčēąĄąĮąĖčÅ, ą╗ąĄą▓čŗą╣ čüą┤ą▓ąĖą│ ą▒čāą┤ąĄčé čüą┤ą▓ąĖą│ą░čéčī ąĮąĄ ąĘąĮą░ą║ąŠą▓čŗąĄ ą▒ąĖčéčŗ, čéą░ą║ čćč鹊 ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą▒čāą┤ąĄčé ą┐čĆąŠąĖčüčģąŠą┤ąĖčéčī ąĮą░čüčŗčēąĄąĮąĖąĄ ą┤ąŠ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠą╣ ąĖą╗ąĖ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠą╣ ą▓ąĄą╗ąĖčćąĖąĮčŗ. ąĪą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ, ą║ąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮąŠ ąĮą░čüčŗčēąĄąĮąĖąĄ, čĆąĄąĘčāą╗čīčéą░čé ą▓čüąĄą│ą┤ą░ čüąŠčģčĆą░ąĮąĖčé ąĘąĮą░ą║, ą║ąŠč鹊čĆčŗą╣ ą▒čŗą╗ čā ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮąŠą│ąŠ čćąĖčüą╗ą░ ą┤ąŠ čüą┤ą▓ąĖą│ą░.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĮą░čüčŗčēąĄąĮąĖčÅ čüą╝. čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╣ čĆą░ąĘą┤ąĄą╗ ą▓ ąĮą░čćą░ą╗ąĄ čüčéą░čéčīąĖ.
[ążą╗ą░ą│ąĖ ]
ąÆąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠčüčŗą╗ą░čÄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ Dreg, ą╝ąĄąĮčÅčÄčé čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ą▒čāą┤ąĄčé 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
ąÆąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠčüčŗą╗ą░čÄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ A0, ą╝ąĄąĮčÅčÄčé čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ą▒čāą┤ąĄčé 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
ąÆąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠčüčŗą╗ą░čÄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ A1, ą╝ąĄąĮčÅčÄčé čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ą▒čāą┤ąĄčé 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣". 16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹčéąĖčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r0 >>>= 19 ; /* ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ą╗ąĖąĮąŠą╣ 16 ą▒ąĖčé ą┤ąĄą╗ą░ąĄčé
ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ */
r3.l = r0.h >>> 7 ; // ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čüą╗ąŠą▓ą░
r3.h = r0.h >>> 5 ; /* č鹊 ąČąĄ čüą░ą╝ąŠąĄ, ą║ą░ą║ ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ; ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ ą╗čÄą▒ą░čÅ ą║ąŠą╝ą▒ąĖąĮą░čåąĖčÅ čüčéą░čĆčłąĄą╣ ąĖ ą╝ą╗ą░ą┤čłąĄą╣ ą┐ąŠą╗ąŠą▓ąĖąĮ čüą╗ąŠą▓ą░ */
r3.l = r0.h >>> 7 (s); // ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ, ą┐ąŠą╗ąŠą▓ąĖąĮą░ čüą╗ąŠą▓ą░, čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝
r4 = r2 >>> 20 ; // ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ, čüą╗ąŠą▓ąŠ
A0 = A0 >>> 1 ; // ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ, ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ
r0 >>>= r2; /* ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ą╗ąĖąĮąŠą╣ 16 ą▒ąĖčé ą┤ąĄą╗ą░ąĄčé ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ */
r3.l = r0.h << 12 (S); // ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ
r5 = r2 << 24 (S); // ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ
r3.l = ashift r0.h by r7.l; // čüą┤ą▓ąĖą│ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čüą╗ąŠą▓ą░
r3.h = ashift r0.l by r7.l;
r3.h = ashift r0.h by r7.l;
r3.l = ashift r0.l by r7.l;
r3.l = ashift r0.h by r7.l(s); // čüą┤ą▓ąĖą│ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čüą╗ąŠą▓ą░ čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝
r3.h = ashift r0.l by r7.l(s); // čüą┤ą▓ąĖą│ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ čüą╗ąŠą▓ą░ čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝
r3.h = ashift r0.h by r7.l(s);
r3.l = ashift r0.l by r7.l(s);
r4 = ashift r2 by r7.l; // čüą┤ą▓ąĖą│ čüą╗ąŠą▓ą░
r4 = ashift r2 by r7.l(s); // čüą┤ą▓ąĖą│ čüą╗ąŠą▓ą░ čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝
A0 = ashift A0 by r7.l; // čüą┤ą▓ąĖą│ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░
A1 = ashift A1 by r7.l; // čüą┤ą▓ąĖą│ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░
// ąĢčüą╗ąĖ r0.h = -64, č鹊 ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ...
r3.h = r0.h >>> 4 ; // ... ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé r3.h = -4 čü čüąŠčģčĆą░ąĮąĄąĮąĖąĄą╝ ąĘąĮą░ą║ą░.
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Vector Arithmetic Shift, Vector Logical Shift, Logical Shift, Shift with Add, Rotate.
ąøąŠą│ąĖč湥čüą║ąĖą╣ čüą┤ą▓ąĖą│. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_pntr = src_pntr >> 1
dest_pntr = src_pntr >> 2
dest_pntr = src_pntr << 1
dest_pntr = src_pntr << 2
dest_reg >>= shift_magnitude
dest_reg <<= shift_magnitude
dest_reg = src_reg >> shift_magnitude
dest_reg = src_reg << shift_magnitude
dest_reg = LSHIFT src_reg BY shift_magnitude
ąĪąĖąĮčéą░ą║čüąĖčü čüą┤ą▓ąĖą│ą░ ąĮą░ čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé:
Preg = Preg >> 1; // čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ ąĮą░ 1 ą▒ąĖčé (a)1
Preg = Preg >> 2; // čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ ąĮą░ 2 ą▒ąĖčéą░ (a)
Preg = Preg << 1; // čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ ąĮą░ 1 ą▒ąĖčé (a)
Preg = Preg << 2; // čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ ąĮą░ 2 ą▒ąĖčéą░ (a)
ąĪąĖąĮčéą░ą║čüąĖčü čüą┤ą▓ąĖą│ą░ ąĮą░ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé, čāą║ą░ąĘą░ąĮąĮąŠąĄ ą▓ ą║ąŠąĮčüčéą░ąĮč鹥 ą║ąŠą╝ą░ąĮą┤čŗ:
Dreg >>= uimm5; // čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ (a)
Dreg << = uimm5; // čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ (a)
Dreg_lo_hi = Dreg_lo_hi >> uimm4; // čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ (b)
Dreg_lo_hi = Dreg_lo_hi << uimm4; // čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ (b)
Dreg = Dreg >> uimm5; // čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ (b)
Dreg = Dreg << uimm5; // čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ (b)
A0 = A0 >> uimm5; // čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ (b)
A0 = A0 << uimm5; // čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ (b)
A1 = A1 << uimm5; // čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ (b)
A1 = A1 >> uimm5; // čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ (b)
ąĪą┤ą▓ąĖą│ ą┤ą░ąĮąĮčŗčģ, ą▓ąĄą╗ąĖčćąĖąĮą░ čüą┤ą▓ąĖą│ą░ čāą║ą░ąĘą░ąĮą░ ą▓ čĆąĄą│ąĖčüčéčĆąĄ:
Dreg >>= Dreg; // čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ (a)
Dreg << = Dreg; // čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ (a)
Dreg_lo_hi = LSHIFT Dreg_lo_hi BY Dreg_lo; // (b)
Dreg = LSHIFT Dreg BY Dreg_lo; // (b)
A0 = LSHIFT A0 BY Dreg_lo; // (b)
A1 = LSHIFT A1 BY Dreg_lo; // (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (a) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 16 ą▒ąĖčé. ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
Dreg_lo: ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L.
Dreg_lo_hi: ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ R0.L, ..., R7.L, R0.H, ..., R7.H.
Preg: P0, ..., P5.
uimm4: 4-ą▒ąĖčéąĮąŠąĄ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ ą┐ąŠą╗ąĄ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 15.
uimm5: 5-ą▒ąĖčéąĮąŠąĄ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ąŠąĄ ą┐ąŠą╗ąĄ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0 .. 31.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖąĖ ą╗ąŠą│ąĖč湥čüą║ąŠą│ąŠ čüą┤ą▓ąĖą│ą░ (Logical Shift) čüą┤ą▓ąĖą│ą░čÄčé čćąĖčüą╗ąŠ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ąĮą░ čāą║ą░ąĘą░ąĮąĮčāčÄ ą▓ąĄą╗ąĖčćąĖąĮčā ą▒ąĖčé (distance) ą▓ čāą║ą░ąĘą░ąĮąĮąŠą╝ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĖ. ąøąŠą│ąĖč湥čüą║ąĖąĄ čüą┤ą▓ąĖą│ąĖ ąŠčéą▒čĆą░čüčŗą▓ą░čÄčé ą▓čŗą┤ą▓ąĖą│ą░ąĄą╝čŗąĄ ą▒ąĖčéčŗ, ąĘą░ą┐ąŠą╗ąĮčÅčÅ ąĮčāą╗čÅą╝ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ą░čÄčēąĖąĄčüčÅ čĆą░ąĘčĆčÅą┤čŗ.
4 ą▓ąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╗ąŠą│ąĖč湥čüą║ąŠą│ąŠ čüą┤ą▓ąĖą│ą░ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé čüą┤ą▓ąĖą│ čāą║ą░ąĘą░č鹥ą╗ąĄą╣. ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄ ą┤ąĄą╗ą░ąĄčé ąĮąĄčÅą▓ąĮčŗą╣ čüą┤ą▓ąĖą│ ą▓čģąŠą┤ąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ src_pntr. ąöą╗čÅ ą▓ąĄčĆčüąĖą╣ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü P-čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ, dest_pntr ą╝ąŠąČąĄčé ą▒čŗčéčī č鹥ą╝ ąČąĄ čüą░ą╝čŗą╝ P-čĆąĄą│ąĖčüčéčĆąŠą╝, čćč鹊 ąĖ src_pntr, ą▓ čéą░ą║ąŠą╝ čüą╗čāčćą░ąĄ čĆąĄą│ąĖčüčéčĆ ąĖčüč鹊čćąĮąĖą║ą░ ą▒čāą┤ąĄčé čÅą▓ąĮąŠ ąĖąĘą╝ąĄąĮąĄąĮ.
ą×čüčéą░ą╗čīąĮą░čÅ čćą░čüčéčī čŹč鹊ą│ąŠ ąŠą┐ąĖčüą░ąĮąĖčÅ ąŠčéąĮąŠčüąĖčéčüčÅ ą║ ą▓ąĄčĆčüąĖčÅą╝ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ą╗čÅ čüą┤ą▓ąĖą│ą░ ą┤ą░ąĮąĮčŗčģ ą▓ D-čĆąĄą│ąĖčüčéčĆą░čģ ąĖ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░čģ.
ąśąĮčüčéčĆčāą║čåąĖąĖ ą╗ąŠą│ąĖč湥čüą║ąŠą│ąŠ čüą┤ą▓ąĖą│ą░ ą╝ąŠą│čāčé ą▒čŗčéčī ą┤ą╗ąĖąĮąŠą╣ 16 ąĖ 32 ą▒ąĖčéą░.
ŌĆó ąśąĮčüčéčĆčāą║čåąĖąĖ čüąĖąĮčéą░ą║čüąĖčüą░ >>= ąĖ << = čü ą┤ą╗ąĖąĮąŠą╣ 16 ą▒ąĖčé ą┐ąŠąĘą▓ąŠą╗čÅčÄčé 菹║ąŠąĮąŠą╝ąĖčéčī ą╝ąĄčüč鹊 ą┐ąŠą┤ ą║ąŠą┤ čåąĄąĮąŠą╣ čāą╝ąĄąĮčīčłąĄąĮąĖčÅ ą│ąĖą▒ą║ąŠčüčéąĖ.
ą×ą▒ą░ čüąĖąĮčéą░ą║čüąĖčüą░ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé ą┤ąĖą░ą┐ą░ąĘąŠąĮčŗ čüą┤ą▓ąĖą│ą░, čāą║ą░ąĘą░ąĮąĮčŗąĄ ą║ą░ą║ ą║ąŠąĮčüčéą░ąĮč鹊ą╣ ą▓ ą║ąŠą╝ą░ąĮą┤ąĄ, čéą░ą║ ąĖ ą▓ čĆąĄą│ąĖčüčéčĆąĄ.
ąóą░ą▒ą╗ąĖčåą░ 9-2. ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ čüą┤ą▓ąĖą│ąĖ.
ąĪąĖąĮčéą░ą║čüąĖčü ą×ą┐ąĖčüą░ąĮąĖąĄ
>>= ąĖ << = ąŚąĮą░č湥ąĮąĖąĄ ą▓ dest_reg čüą┤ą▓ąĖą│ą░ąĄčéčüčÅ ąĮą░ čāą║ą░ąĘą░ąĮąĮąŠąĄ čćąĖčüą╗ąŠ ą▒ąĖčé ą▓ shift_magnitude. ąĀą░ąĘą╝ąĄčĆ čüą┤ą▓ąĖą│ą░ąĄą╝čŗčģ ą┤ą░ąĮąĮčŗčģ ą▓čüąĄą│ą┤ą░ 32 ą▒ąĖčéą░. ąÆčüąĄ 32 ą▒ąĖčéą░ ąĘąĮą░č湥ąĮąĖčÅ shift_magnitude ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčé ą▓ąĄą╗ąĖčćąĖąĮčā čüą┤ą▓ąĖą│ą░. ą£ą░ą│ąĮąĖčéčāą┤ą░ čüą┤ą▓ąĖą│ą░ ą▒ąŠą╗čīčłąĄ 0x1F ą┤ą░čüčé ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 0x00000000.
>> , << ąĖ LSHIFT ąŚąĮą░č湥ąĮąĖąĄ ą▓ src_reg čüą┤ą▓ąĖą│ą░ąĄčéčüčÅ ąĮą░ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé, čāą║ą░ąĘą░ąĮąĮąŠąĄ ą▓ shift_magnitude, ąĖ čĆąĄąĘčāą╗čīčéą░čé čüąŠčģčĆą░ąĮčÅąĄčéčüčÅ ą▓ dest_reg. ąÆąĄčĆčüąĖąĖ čü LSHIFT ą╝ąŠą│čāčé čüą┤ą▓ąĖą│ą░čéčī 32-ą▒ąĖčéąĮčŗą╣ Dreg ąĖ 40-ą▒ąĖčéąĮčŗą╣ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ ąĮą░ ą┤ąĖą░ą┐ą░ąĘąŠąĮ -32 .. 31 ą▒ąĖčéą░; ą┤ąĖą░ą┐ą░ąĘąŠąĮ čüą┤ą▓ąĖą│ą░ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ ą╝ą╗ą░ą┤čłąĖą╝ąĖ 6 ą▒ąĖčéą░ą╝ąĖ (čü čĆą░čüčłąĖčĆąĄąĮąĖąĄą╝ ąĘąĮą░ą║ąŠą╝) ąĘąĮą░č湥ąĮąĖčÅ shift_magnitude.
ąöą╗čÅ ą▓ąĄčĆčüąĖčÅ LSHIFT ąĘąĮą░ą║ ą╝ą░ą│ąĮąĖčéčāą┤čŗ čüą┤ą▓ąĖą│ą░ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čüą┤ą▓ąĖą│ą░.
ŌĆó ą¤ąŠą╗ąŠąČąĖč鹥ą╗čīąĮą░čÅ ą╝ą░ą│ąĮąĖčéčāą┤ą░ čüą┤ą▓ąĖą│ą░ ą▒čāą┤ąĄčé ą┤ąĄą╗ą░čéčī čüą┤ą▓ąĖą│ ąÆąøąĢąÆą×.
ąĀąĄą│ąĖčüčéčĆčŗ dest_reg ąĖ src_reg ą╝ąŠą│čāčé ą▒čŗčéčī 16-, 32- ąĖą╗ąĖ 40-ą▒ąĖčéąĮčŗą╝ąĖ čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ.
ąöą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ LSHIFT ą╝ą░ą│ąĮąĖčéčāą┤ą░ čüą┤ą▓ąĖą│ą░ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ ą╝ą╗ą░ą┤čłąĖą╝ąĖ 6 ą▒ąĖčéą░ą╝ąĖ Dreg_lo, čü čĆą░čüčłąĖčĆąĄąĮąĖąĄą╝ ąĘąĮą░ą║ąŠą╝. ąśąĮčüčéčĆčāą║čåąĖąĖ Dreg >>= Dreg ąĖ Dreg << = Dreg ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą┤ą╗čÅ čüą┤ą▓ąĖą│ą░ ą▓čüčÄ 32-ą▒ąĖčéąĮčāčÄ ą╝ą░ą│ąĮąĖčéčāą┤čā.
ąÆąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü D-čĆąĄą│ąĖčüčéčĆąŠą╝ čüą┤ą▓ąĖą│ą░čÄčé 16 ąĖą╗ąĖ 32 ą▒ąĖčéą░ ą┤ą╗čÅ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┐ąŠą╗čāčüą╗ąŠą▓ą░ ąĖ čüą╗ąŠą▓ą░ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ. ąÆąĄčĆčüąĖąĖ čü ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą╝ čüą┤ą▓ąĖą│ą░čÄčé ą▓čüąĄ 40 ą▒ąĖčé čŹčéąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĮą░ ą┤ąĖą░ą┐ą░ąĘąŠąĮ -32 .. +31 ą▒ąĖčé.
ą£ą░ą│ąĮąĖčéčāą┤čŗ čüą┤ą▓ąĖą│ą░, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąĄą▓čŗčüčÅčé čĆą░ąĘą╝ąĄčĆ čĆąĄą│ąĖčüčéčĆą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ, ą┤ą░ą┤čāčé ą▓ ą║ą░č湥čüčéą▓ąĄ čĆąĄąĘčāą╗čīčéą░čéą░ 0. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ąĘąĮą░č湥ąĮąĖąĄ 16-ą▒ąĖčéąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ ą▒čāą┤ąĄčé čüą┤ą▓ąĖąĮčāč鹊 20 čĆą░ąĘ (čŹč鹊 ą┤ąŠą┐čāčüčéąĖą╝ą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ), č鹊 čĆąĄąĘčāą╗čīčéą░čé ą▒čāą┤ąĄčé 0x00000000.
ąĪą┤ą▓ąĖą│ čü ąĮčāą╗ąĄą▓ąŠą╣ ą╝ą░ą│ąĮąĖčéčāą┤ąŠą╣ ąĮąĄ ą┤ąĄą╗ą░ąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ čüą┤ą▓ąĖą│ą░.
ąÆąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü D-čĆąĄą│ąĖčüčéčĆąŠą╝ ąĮąĄ ą┤ąĄą╗ą░čÄčé ąĮąĄčÅą▓ąĮčāčÄ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÄ ąĘąĮą░č湥ąĮąĖčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ src_reg (čĆąĄą│ąĖčüčéčĆ ąĖčüč鹊čćąĮąĖą║ą░). ą×ą┤ąĮą░ą║ąŠ ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ dest_reg ą╝ąŠąČąĄčé ą▒čŗčéčī č鹥ą╝ ąČąĄ čüą░ą╝čŗą╝ D-čĆąĄą│ąĖčüčéčĆąŠą╝, čćč鹊 ąĖ src_reg, ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ąĖąĮčüčéčĆčāą║čåąĖčÅ čÅą▓ąĮąŠ ąĖąĘą╝ąĄąĮąĖčé čĆąĄą│ąĖčüčéčĆ ąĖčüč鹊čćąĮąĖą║ą░ .
[ążą╗ą░ą│ąĖ ]
ąÆąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü P-čĆąĄą│ąĖčüčéčĆąŠą╝ ąĮąĄ ą▓ą╗ąĖčÅčÄčé ąĮąĖ ąĮą░ ą║ą░ą║ąĖąĄ čäą╗ą░ą│ąĖ.
ąÆąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠčüčŗą╗ą░čÄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ Dreg, ą╝ąĄąĮčÅčÄčé čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ą▒čāą┤ąĄčé 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
ąÆąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠčüčŗą╗ą░čÄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ A0, ą╝ąĄąĮčÅčÄčé čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ą▒čāą┤ąĄčé 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
ąÆąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠčüčŗą╗ą░čÄčé čĆąĄąĘčāą╗čīčéą░čé ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆ A1, ą╝ąĄąĮčÅčÄčé čüą╗ąĄą┤čāčÄčēąĖąĄ čäą╗ą░ą│ąĖ:
ŌĆó AZ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ą▒čāą┤ąĄčé 0, ąĖąĮą░č湥 ąŠčćąĖčüčéąĖčéčüčÅ.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣". 16-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹčéąĖčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ą┤čĆčāą│ąĖą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
p3 = p2 >> 1 ; // čüą┤ą▓ąĖą│ čāą║ą░ąĘą░č鹥ą╗čÅ ą▓ą┐čĆą░ą▓ąŠ ąĮą░ 1
p3 = p3 >> 2 ; // čüą┤ą▓ąĖą│ čāą║ą░ąĘą░č鹥ą╗čÅ ą▓ą┐čĆą░ą▓ąŠ ąĮą░ 2
p4 = p5 << 1 ; // čüą┤ą▓ąĖą│ čāą║ą░ąĘą░č鹥ą╗čÅ ą▓ą╗ąĄą▓ąŠ ąĮą░ 1
p0 = p1 << 2 ; // čüą┤ą▓ąĖą│ čāą║ą░ąĘą░č鹥ą╗čÅ ą▓ą╗ąĄą▓ąŠ ąĮą░ 2
r3 >>= 17 ; // čüą┤ą▓ąĖą│ ą┤ą░ąĮąĮčŗčģ ą▓ą┐čĆą░ą▓ąŠ
r3 <<= 17 ; // čüą┤ą▓ąĖą│ ą┤ą░ąĮąĮčŗčģ ą▓ą╗ąĄą▓ąŠ
r3.l = r0.l >> 4 ; // čüą┤ą▓ąĖą│ ą┤ą░ąĮąĮčŗčģ ą▓ą┐čĆą░ą▓ąŠ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮąĄ čĆąĄą│ąĖčüčéčĆą░
r3.l = r0.h >> 4 ; /* č鹊 ąČąĄ čüą░ą╝ąŠąĄ; ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą▒čĆą░ąĮčŗ ą╗čÄą▒čŗąĄ
ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ ą┐ąŠą╗ąŠą▓ąĖąĮąŠą║ čĆąĄą│ąĖčüčéčĆą░ */
r3.h = r0.l << 12 ; // čüą┤ą▓ąĖą│ ą┤ą░ąĮąĮčŗčģ ą▓ą╗ąĄą▓ąŠ ą▓ ą┐ąŠą╗ąŠą▓ąĖąĮąĄ čĆąĄą│ąĖčüčéčĆą░
r3.h = r0.h << 14 ; /* č鹊 ąČąĄ čüą░ą╝ąŠąĄ; ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą▒čĆą░ąĮčŗ ą╗čÄą▒čŗąĄ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ ą┐ąŠą╗ąŠą▓ąĖąĮąŠą║ čĆąĄą│ąĖčüčéčĆą░ */
r3 = r6 >> 4 ; // čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ 32-čĆą░ąĘčĆčÅą┤ąĮąŠą│ąŠ čüą╗ąŠą▓ą░
r3 = r6 << 4 ; // čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ 32-čĆą░ąĘčĆčÅą┤ąĮąŠą│ąŠ čüą╗ąŠą▓ą░
a0 = a0 >> 7 ; // čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░
a1 = a1 >> 25 ; // čüą┤ą▓ąĖą│ ą▓ą┐čĆą░ą▓ąŠ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░
a0 = a0 << 7 ; // čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░
a1 = a1 << 14 ; // čüą┤ą▓ąĖą│ ą▓ą╗ąĄą▓ąŠ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░
r3 >>= r0; // čüą┤ą▓ąĖą│ ą┤ą░ąĮąĮčŗčģ ą▓ą┐čĆą░ą▓ąŠ
r3 <<= r1; // čüą┤ą▓ąĖą│ ą┤ą░ąĮąĮčŗčģ ą▓ą╗ąĄą▓ąŠ
r3.l = lshift r0.l by r2.l; // ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čüą┤ą▓ąĖą│ą░ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ ąĘąĮą░ą║ąŠą╝ R2.L
r3.h = lshift r0.l by r2.l;
a0 = lshift a0 by r7.l;
a1 = lshift a1 by r7.l;
// ąĢčüą╗ąĖ r0.h = -64 (ąĖą╗ąĖ 0xFFC0), č鹊 ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ...
r3.h = r0.h >> 4 ; /* ... ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé r3.h = 0x0FFC (ąĖą╗ąĖ 4092), ąĘąĮą░ą║ čćąĖčüą╗ą░ ą▒čāą┤ąĄčé ą┐ąŠč鹥čĆčÅąĮ */
ąĪą╝. čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ Arithmetic Shift, Rotate, Shift with Add, Vector Arithmetic Shift, Vector Logical Shift.
ą¤čĆąŠą║čĆčāčéą║ą░ č湥čĆąĄąĘ ą▒ąĖčé CC. ą×ą▒čēą░čÅ č乊čĆą╝ą░:
dest_reg = ROT src_reg BY rotate_magnitude
accumulator_new = ROT accumulator_old BY rotate_magnitude
ąĪąĖąĮčéą░ą║čüąĖčü ą┐čĆąŠą║čĆčāčéą║ąĖ ąĮą░ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé, čāą║ą░ąĘą░ąĮąĮąŠąĄ ą▓ ą║ąŠąĮčüčéą░ąĮč鹥 ą║ąŠą╝ą░ąĮą┤čŗ:
Dreg = ROT Dreg BY imm6; // (b)1
A0 = ROT A0 BY imm6; // (b)
A1 = ROT A1 BY imm6; // (b)
ąĪąĖąĮčéą░ą║čüąĖčü ą┐čĆąŠą║čĆčāčéą║ąĖ ąĮą░ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé, čāą║ą░ąĘą░ąĮąĮąŠąĄ ą▓ čĆąĄą│ąĖčüčéčĆąĄ:
Dreg = ROT Dreg BY Dreg_lo; // (b)
A0 = ROT A0 BY Dreg_lo; // (b)
A1 = ROT A1 BY Dreg_lo; // (b)
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: ą▓ čüąĖąĮčéą░ą║čüąĖčüąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ (b) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖąĖ 32 ą▒ąĖčéą░.
[ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ ]
Dreg: čĆąĄą│ąĖčüčéčĆčŗ R0, ..., R7.
imm6: 6-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ čüąŠ ąĘąĮą░ą║ąŠą╝, ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ -32 .. 31.
[ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ Rotate ą┐čĆąŠą║čĆčāčćąĖą▓ą░ąĄčé ą┐ąŠ ą║ąŠą╗čīčåčā ąĘąĮą░č湥ąĮąĖąĄ ą▓ čĆąĄą│ąĖčüčéčĆąĄ č湥čĆąĄąĘ ą▒ąĖčé CC ąĮą░ čāą║ą░ąĘą░ąĮąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé ą▓ čāą║ą░ąĘą░ąĮąĮąŠą╝ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĖ. ąæąĖčé CC ą▓čģąŠą┤ąĖčé ą▓ ą║ąŠą╗čīčåąŠ ą┐čĆąŠą║čĆčāčéą║ąĖ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą┐ąĄčĆą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ą▒čŗą╗ąŠ ą▓ą┤ą▓ąĖąĮčāč鹊 ą▓ čĆąĄą│ąĖčüčéčĆ, ą▒čāą┤ąĄčé ąĘąĮą░č湥ąĮąĖąĄą╝ ą▒ąĖčéą░ CC.
ąĀąŠčéą░čåąĖčÅ čüą┤ą▓ąĖą│ą░ąĄčé ą▓čüąĄ ą▒ąĖčéčŗ ą╗ąĖą▒ąŠ ą▓ą┐čĆą░ą▓ąŠ, ą╗ąĖą▒ąŠ ą▓ą╗ąĄą▓ąŠ. ąÜą░ąČą┤čŗą╣ ą▒ąĖčé, ą║ąŠč鹊čĆčŗą╣ ą▓čŗą┤ą▓ąĖą│ą░ąĄčéčüčÅ ąĖąĘ čĆąĄą│ąĖčüčéčĆą░ (čŹč鹊 ą▒ąĖčé LSB ą┤ą╗čÅ čĆąŠčéą░čåąĖąĖ ą▓ą┐čĆą░ą▓ąŠ ąĖ ą▒ąĖčé MSB ą┤ą╗čÅ čĆąŠčéą░čåąĖąĖ ą▓ą╗ąĄą▓ąŠ), čüąŠčģčĆą░ąĮčÅąĄčéčüčÅ ą▓ ą▒ąĖč鹥 CC, ąĖ ąĘąĮą░č湥ąĮąĖąĄ ą▒ąĖčéą░ CC čüąŠčģčĆą░ąĮčÅąĄčéčüčÅ ą▓ ąŠčüą▓ąŠą▒ąŠąČą┤ą░čÄčēąĄą╣čüčÅ ą┐ąŠąĘąĖčåąĖąĖ ą┐čĆąŠčéąĖą▓ąŠą┐ąŠą╗ąŠąČąĮąŠą│ąŠ ą║ąŠąĮčåą░ čĆąĄą│ąĖčüčéčĆą░.
ąĢčüą╗ąĖ ...
... č鹊 čĆąŠčéą░čåąĖčÅ ą▓ą╗ąĄą▓ąŠ ąĮą░ 1 ą▒ąĖčé ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé:
ąĀąŠčéą░čåąĖčÅ ą▓ą╗ąĄą▓ąŠ ąĄčēąĄ ąĮą░ 1 ą▒ąĖčé ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé:
ąĢčüą╗ąĖ ...
... č鹊 čĆąŠčéą░čåąĖčÅ ą▓ą┐čĆą░ą▓ąŠ ąĮą░ 1 ą▒ąĖčé ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé:
ąĀąŠčéą░čåąĖčÅ ą▓ą┐čĆą░ą▓ąŠ ąĄčēąĄ ąĮą░ 1 ą▒ąĖčé ą┤ą░čüčé čĆąĄąĘčāą╗čīčéą░čé:
ąŚąĮą░ą║ ą▓ ąĘąĮą░č湥ąĮąĖąĖ ą╝ą░ą│ąĮąĖčéčāą┤čŗ (magnitude, ąĘą░ą┤ą░ąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé čĆąŠčéą░čåąĖąĖ) ąĘą░ą┤ą░ąĄčé ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čĆąŠčéą░čåąĖąĖ:
ŌĆó ą¤ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą╝ą░ą│ąĮąĖčéčāą┤čŗ ąĘą░ą┤ą░ąĄčé čĆąŠčéą░čåąĖčÄ ąÆąøąĢąÆą×.
ąöąŠą┐čāčüčéąĖą╝čŗąĄ ąĘąĮą░č湥ąĮąĖčÅ ą╝ą░ą│ąĮąĖčéčāą┤čŗ ŌĆō32 .. +31, ą▓ą║ą╗čÄčćą░čÅ 0. ąśąĮčüčéčĆčāą║čåąĖčÅ Rotate ą╝ą░čüą║ąĖčĆčāąĄčé ąĖ ąĖą│ąĮąŠčĆąĖčĆčāąĄčé ą▒ąĖčéčŗ ą╝ą░ą│ąĮąĖčéčāą┤čŗ, ą║ąŠč鹊čĆčŗąĄ ąĘą░ą┤ą░čÄčé ąĘąĮą░č湥ąĮąĖąĄ, ą▒ąŠą╗čīčłąĄ čĆą░ąĘčĆąĄčłąĄąĮąĮąŠą│ąŠ.
ąÆ ąŠčéą╗ąĖčćąĖąĄ ąŠčé ąŠą┐ąĄčĆą░čåąĖą╣ čüą┤ą▓ąĖą│ą░, ąŠą┐ąĄčĆą░čåąĖčÅ Rotate ąĮąĄ č鹥čĆčÅąĄčé ą▒ąĖčéčŗ ą┤ą░ąĮąĮčŗčģ čĆąĄą│ąĖčüčéčĆą░-ąĖčüč鹊čćąĮąĖą║ą░. ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą▒ąĖčéčŗ ą┐ąĄčĆąĄčĆą░čüą┐čĆąĄą┤ąĄą╗čÅčÄčéčüčÅ ą┐ąŠ ą║čĆčāą│čā. ą×ą┤ąĮą░ą║ąŠ ą┐ąŠčüą╗ąĄą┤ąĮąĖą╣ ą▓čŗą┤ą▓ąĖąĮčāčéčŗą╣ ą▒ąĖčé ą┐ąŠą┐ą░ą┤ą░ąĄčé ą▓ ą▒ąĖčé CC, ąĖ ąĮąĄ ą▓ąŠąĘą▓čĆą░čēą░ąĄčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆ. ąśąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 čüą┤ą▓ąĖą│ąĖ ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ čüčĆą░ąĘčā ąĮą░ą┤ ą▓čüąĄą╝ąĖ ą▒ąĖčéą░ą╝ąĖ, ąĮąĄ ą┐ąŠ ąŠą┤ąĮąŠą╝čā, ą┐ąŠą▓ąŠčĆąŠčé ą▓ ąŠą┤ąĮąŠą╝ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĖ ąĖą╗ąĖ ą▓ ą┤čĆčāą│ąŠą╝ ąĮąĄ ąĖą╝ąĄąĄčé ą║ą░ą║ąĖčģ-č鹊 ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ ą▓čŗą│ąŠą┤. ąØą░ą┐čĆąĖą╝ąĄčĆ, čĆąŠčéą░čåąĖčÅ ą▓ą┐čĆą░ą▓ąŠ ąĮą░ 2 ą▒ąĖčéą░ ąĮąĄ ą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮą░, č湥ą╝ čĆąŠčéą░čåąĖčÅ ą▓ą╗ąĄą▓ąŠ ąĮą░ 30 ą▒ąĖčé. ą×ą▒ą░ ą╝ąĄč鹊ą┤ą░ ą┤ą░ą┤čāčé ąŠą┤ąĖąĮą░ą║ąŠą▓čŗą╣ čĆąĄąĘčāą╗čīčéą░čé, ąĖ ą▒čāą┤čāčé ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ąĘą░ ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠąĄ ą▓čĆąĄą╝čÅ.
ąÆąĄčĆčüąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü D-čĆąĄą│ąĖčüčéčĆąŠą╝ ą┤ąĄą╗ą░čÄčé čĆąŠčéą░čåąĖčÄ ą▓čüąĄčģ 32 ą▒ąĖčé. ąÆąĄčĆčüąĖąĖ čü ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąŠą╝ ą┤ąĄą╗ą░čÄčé čĆąŠčéą░čåąĖčÄ ą▓čüąĄčģ 40 ą▒ąĖčé.
ąÆąĄčĆčüąĖąĖ čü D-čĆąĄą│ąĖčüčéčĆąŠą╝ ąĮąĄ ą┤ąĄą╗ą░čÄčé ąĮąĄčÅą▓ąĮąŠą╣ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖąĖ ąĘąĮą░č湥ąĮąĖčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ src_reg. ą×ą┐čåąĖąŠąĮą░ą╗čīąĮąŠ dest_reg ą╝ąŠąČąĄčé ą▒čŗčéčī č鹥ą╝ ąČąĄ čĆąĄą│ąĖčüčéčĆąŠą╝, čćč鹊 ąĖ src_reg, ą▓ čéą░ą║ąŠą╝ čüą╗čāčćą░ąĄ čĆąĄą│ąĖčüčéčĆ ąĖčüčģąŠą┤ąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ą▒čāą┤ąĄčé ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮ.
[ążą╗ą░ą│ąĖ ]
ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé č鹊ą╗čīą║ąŠ ąĮą░ čäą╗ą░ą│ CC: ąŠąĮ ą▒čāą┤ąĄčé čüąŠą┤ąĄčƹȹ░čéčī ą┐ąŠčüą╗ąĄą┤ąĮąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ą▒čŗą╗ąŠ ą▓ ąĮąĄą│ąŠ ą▓ą┤ą▓ąĖąĮčāč鹊.
ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅčÄčé čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
[ąóčĆąĄą▒čāąĄą╝čŗą╣ čĆąĄąČąĖą╝ ]
ąĀąĄąČąĖą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode).
[ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ]
32-ą▒ąĖčéąĮčŗąĄ ą▓ąĄčĆčüąĖąĖ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠą│čāčé ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ 16-ą▒ąĖčéąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
[ą¤čĆąĖą╝ąĄčĆčŗ ]
r4 = rot r1 by 8 ; // čĆąŠčéą░čåąĖčÅ ą▓ą╗ąĄą▓ąŠ
r4 = rot r1 by - 5 ; // čĆąŠčéą░čåąĖčÅ ą▓ą┐čĆą░ą▓ąŠ
a0 = rot a0 by 22 ; // čĆąŠčéą░čåąĖčÅ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ ą▓ą╗ąĄą▓ąŠ
a1 = rot a1 by - 31 ; // čĆąŠčéą░čåąĖčÅ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░ ą▓ą┐čĆą░ą▓ąŠ
r4 = rot r1 by r2.l;
a0 = rot a0 by r3.l;
a1 = rot a1 by r7.l;
ąĪą╝. čéą░ą║ąČąĄ Arithmetic Shift, Logical Shift.
[ąĪą╗ąŠą▓ą░čĆąĖą║ ]
DAG Data Address Generator, čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ ą░ą┐ą┐ą░čĆą░čéąĮčŗą╣ ą▒ą╗ąŠą║ ą┤ą╗čÅ ą│ąĄąĮąĄčĆą░čåąĖąĖ ą░ą┤čĆąĄčüą░ [2].
Data Register čĆąĄą│ąĖčüčéčĆ ą┤ą░ąĮąĮčŗčģ. ąÜ čĆąĄą│ąĖčüčéčĆą░ą╝ ą┤ą░ąĮąĮčŗčģ ąŠčéąĮąŠčüčÅčé 32-ą▒ąĖčéąĮčŗąĄ čĆąĄą│ąĖčüčéčĆčŗ R0, R1, ..., R7, ą│čĆčāą┐ą┐ą░ čŹčéąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓ čüąŠą║čĆą░čēąĄąĮąĮąŠ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ D-čĆąĄą│ąĖčüčéčĆ ąĖą╗ąĖ Dreg.
die ą║čĆąĖčüčéą░ą╗ą╗, ą║čĆąĄą╝ąĮąĖąĄą▓čŗą╣ čćąĖą┐. ąóąĄčĆą╝ąĖąĮ ą▓čüčéčĆąĄčćą░ąĄčéčüčÅ čü č鹥čģąĮąĖč湥čüą║ąŠą╣ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆčŗ Blackfin. ąÆ čćą░čüčéąĮąŠčüčéąĖ, ADSP-BF538F ąĖ ADSP-BF539F čüąŠą┤ąĄčƹȹ░čé ą┤ą▓ą░ čĆą░ąĘą┤ąĄą╗čīąĮčŗčģ ą║čĆąĖčüčéą░ą╗ą╗ą░ ą▓ ą║ąŠčĆą┐čāčüąĄ (die), ąŠą┤ąĖąĮ čüąŠą┤ąĄčƹȹĖčé čüą░ą╝ ą┐čĆąŠčåąĄčüčüąŠčĆ, ą┤čĆčāą│ąŠą╣ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆčāąĄą╝čāčÄ FLASH-ą┐ą░ą╝čÅčéčī.
DSP Digital Signal Processing, čåąĖčäčĆąŠą▓ą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ čüąĖą│ąĮą░ą╗ąŠą▓ (ą”ą×ąĪ).
ISR Interrupt Service Routine, ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ.
LFSR Linear feedback shift register, ą╗ąĖąĮąĄą╣ąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ čüą┤ą▓ąĖą│ą░ čü ąŠą▒čĆą░čéąĮąŠą╣ čüą▓čÅąĘčīčÄ (čüą╝. [3]).
Load / Store ą│čĆčāą┐ą┐ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣, čĆą░ą▒ąŠčéą░čÄčēą░čÅ čü čüąŠą┤ąĄčƹȹĖą╝čŗą╝ ą░ą┤čĆąĄčüąĮąŠą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ąĮą░ čćč鹥ąĮąĖąĄ (Load) ąĖ ąĘą░ą┐ąĖčüčī (Store).
Load Pointer Register čĆąĄą│ąĖčüčéčĆ čāą║ą░ąĘą░č鹥ą╗čÅ, ą▓ ą║ąŠč鹊čĆčŗą╣ ąĘą░ąĮąŠčüąĖčéčüčÅ ą░ą┤čĆąĄčü čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ, ą║čāą┤ą░ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ ąĮą░ čćč鹥ąĮąĖąĄ.
MAC Multiply-And-Accumulate, ąŠą┐ąĄčĆą░čåąĖčÅ čāą╝ąĮąŠąČąĄąĮąĖčÅ čü ąĮą░ą║ąŠą┐ą╗ąĄąĮąĖąĄą╝. ąÆ ą║ąŠąĮč鹥ą║čüč鹥 čüąĖčüč鹥ą╝čŗ ą║ąŠą╝ą░ąĮą┤ Blackfin ą┤ą░ąĮąĮąŠąĄ čüąŠą║čĆą░čēąĄąĮąĖąĄ čüą▓čÅąĘą░ąĮąŠ čü ą▒ą╗ąŠą║ą░ą╝ąĖ Multiply-and-Accumulate Unit 0 (MAC0) ąĖ Multiply-and-Accumulate Unit 1 (MAC1), ą║ąŠč鹊čĆčŗą╝ąĖ čĆą░ą▒ąŠčéą░čÄčé ąĮąĄą║ąŠč鹊čĆčŗąĄ ą║ąŠą╝ą░ąĮą┤čŗ.
MSA Micro Signal Architecture.
newline čüąĖą╝ą▓ąŠą╗ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ, LF ('\n', čüąĖą╝ą▓ąŠą╗ čü ą║ąŠą┤ąŠą╝ ASCII 0x0A). ą¦ą░čüč鹊 ąĖą┤ąĄčé ą▓ ą┐ą░čĆąĄ čü čüąĖą╝ą▓ąŠą╗ąŠą╝ ą┐ąĄčĆąĄą▓ąŠą┤ą░ ą║ą░čĆąĄčéą║ąĖ CR ('\r, čüąĖą╝ą▓ąŠą╗ čü ą║ąŠą┤ąŠą╝ ASCII 0x0D).
NMI Not Masked Interrupt, ąĮąĄą╝ą░čüą║ąĖčĆčāąĄą╝ąŠąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ. ąŁč鹊 ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ čĆą░ą▒ąŠčéą░ąĄčé ą▓čüąĄą│ą┤ą░, ąĄą│ąŠ ąĮąĄą╗čīąĘčÅ ąŠčéą╝ąĄąĮąĖčéčī ąĖą╗ąĖ ąĘą░ą┐čĆąĄčéąĖčéčī, ąĖ ąŠąĮąŠ ąĖą╝ąĄąĄčé čüą░ą╝čŗą╣ ą▓čŗčüąŠą║ąĖą╣ ą┐čĆąĖąŠčĆąĖč鹥čé ą▓ čüąĖčüč鹥ą╝ąĄ ą┐ąŠčüą╗ąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ čŹą╝čāą╗čÅčåąĖąĖ.
PC Program Counter, ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗą╣ čüč湥čéčćąĖą║, ąĖą╗ąĖ čüč湥čéčćąĖą║ ą░ą┤čĆąĄčüą░ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ - čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ 32-ą▒ąĖčéąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ, ą║ąŠč鹊čĆčŗą╣ čüąŠą┤ąĄčƹȹĖčé ą░ą▒čüąŠą╗čÄčéąĮčŗą╣ ą░ą┤čĆąĄčü č鹥ą║čāčēąĄą╣ ą▓čŗą┐ąŠą╗ąĮčÅąĄą╝ąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
Program Flow Control čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čģąŠą┤ąŠą╝ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ - ąĖą╝ąĄąĄčéčüčÅ ą▓ ą▓ąĖą┤čā ą│čĆčāą┐ą┐ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ čāčüą╗ąŠą▓ąĮąŠą│ąŠ ąĖ ą▒ąĄąĘčāčüą╗ąŠą▓ąĮąŠą│ąŠ ą┐ąĄčĆąĄčģąŠą┤ą░ (JMP), ą▓čŗąĘąŠą▓ą░ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ (CALL).
scratch-čĆąĄą│ąĖčüčéčĆčŗ čĆąĄą│ąĖčüčéčĆčŗ ą┤ą╗čÅ čģčĆą░ąĮąĄąĮąĖčÅ ą▓čĆąĄą╝ąĄąĮąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą╗ąŠą║ą░ą╗čīąĮčŗčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ).
SIMD (ą░ąĮą│ą╗. single instruction, multiple data - ąŠą┤ąĖąĮąŠčćąĮčŗą╣ ą┐ąŠč鹊ą║ ą║ąŠą╝ą░ąĮą┤, ą╝ąĮąŠąČąĄčüčéą▓ąĄąĮąĮčŗą╣ ą┐ąŠč鹊ą║ ą┤ą░ąĮąĮčŗčģ) ą┐čĆąĖąĮčåąĖą┐ ą║ąŠą╝ą┐čīčÄč鹥čĆąĮčŗčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣, ą┐ąŠąĘą▓ąŠą╗čÅčÄčēąĖą╣ ąŠą▒ąĄčüą┐ąĄčćąĖčéčī ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ ąĮą░ čāčĆąŠą▓ąĮąĄ ą┤ą░ąĮąĮčŗčģ (ąĖąĘ ąÆąĖą║ąĖą┐ąĄą┤ąĖąĖ).
space čüąĖą╝ą▓ąŠą╗ ą┐čĆąŠą▒ąĄą╗ą░, ą║ąŠą┤ ASCII 0x20.
tab čüąĖą╝ą▓ąŠą╗ ą│ąŠčĆąĖąĘąŠąĮčéą░ą╗čīąĮąŠą╣ čéą░ą▒čāą╗čÅčåąĖąĖ, ą║ąŠą┤ ASCII 0x09.
Vector Operations ą▓ąĄą║č鹊čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ, ą│ą┤ąĄ ą▓ ą║ą░č湥čüčéą▓ąĄ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ ą╝ąŠą│čāčé ą▓čŗčüčéčāą┐ą░čéčī čāą┐ąŠčĆčÅą┤ąŠč湥ąĮąĮčŗąĄ ą╝ą░čüčüąĖą▓čŗ ą┤ą░ąĮąĮčŗčģ. ąŁčéąĖą╝ ą▓ąĄą║č鹊čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ąŠčéą╗ąĖčćą░čÄčéčüčÅ ąŠčé ąŠą▒čŗčćąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣, ą│ą┤ąĄ ą▓ ą║ą░ąČą┤čāčÄ ąĄą┤ąĖąĮąĖčåčā ą▓čĆąĄą╝ąĄąĮąĖ ą▓ąŠąĘą╝ąŠąČąĮą░ ąŠą▒čĆą░ą▒ąŠčéą║ą░ č鹊ą╗čīą║ąŠ ąŠą┤ąĮąŠą│ąŠ ąĖą╗ąĖ ą┤ą▓čāčģ ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓.
Video Pixel Operations čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ ą▓ąĖą┤ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą┐čĆąŠčåąĄčüčüąŠčĆą░, ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĮčŗą╣ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą│čĆą░čäąĖą║ąĖ ą▓ąĖą┤ąĄąŠ. ąĀą░čüčüą╝ą░čéčĆąĖą▓ą░ąĄčéčüčÅ ą▓ąŠ ą▓č鹊čĆąŠą╣ čćą░čüčéąĖ čŹč鹊ą│ąŠ ą┤ąŠą║čāą╝ąĄąĮčéą░ (čüą╝. [4]).
zero overhead loop ą┤ąŠčüą╗ąŠą▓ąĮąŠ ą┐ąĄčĆąĄą▓ąŠą┤ąĖčéčüčÅ ą║ą░ą║ "čåąĖą║ą╗ čü ąĮčāą╗ąĄą▓čŗą╝ąĖ ąĘą░čéčĆą░čéą░ą╝ąĖ". ąæčŗčüčéčĆčŗą╣ čåąĖą║ą╗, ąŠą▒čĆą░ą▒ąŠčéą║ą░ ą║ąŠč鹊čĆąŠą│ąŠ ą░ą┐ą┐ą░čĆą░čéąĮąŠ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ ąĮą░ čāčĆąŠą▓ąĮąĄ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
ąóąŠą║ąĄąĮ ą▓ ą┤ą░ąĮąĮąŠą╝ ą║ąŠąĮč鹥ą║čüč鹥 ąĖą╝ąĄąĄčéčüčÅ ą▓ ą▓ąĖą┤čā ąĮąĄą┤ąĄą╗ąĖą╝ą░čÅ čćą░čüčéčī ą░čüčüąĄą╝ą▒ą╗ąĄčĆąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąÜ č鹊ą║ąĄąĮą░ą╝ ąŠčéąĮąŠčüčÅčéčüčÅ čćąĖčüą╗ą░, ąĖą╝ąĄąĮą░ čĆąĄą│ąĖčüčéčĆąŠą▓, ą║ą╗čÄč湥ą▓čŗąĄ čüą╗ąŠą▓ą░, ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆčŗ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╣, ą░ čéą░ą║ąČąĄ ą╝ąĮąŠą│ąŠčüąĖą╝ą▓ąŠą╗čīąĮčŗąĄ ą║ąŠą┤čŗ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖąĄą▓ ąĖą╗ąĖ ąŠą┐ąĄčĆą░čåąĖą╣ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ "+=", "/*" ąĖą╗ąĖ "||".
[ąĪčüčŗą╗ą║ąĖ ]
1 . Blackfin Instruction Set Reference site:analog.com .2 . Blackfin ADSP-BF538 .3 . LFSR: ą│ąĄąĮąĄčĆą░čåąĖčÅ ą┐čüąĄą▓ą┤ąŠčüą╗čāčćą░ą╣ąĮčŗčģ čćąĖčüąĄą╗ ąĮą░ čĆąĄą│ąĖčüčéčĆąĄ čüą┤ą▓ąĖą│ą░ .4 . Blackfin: čüąĖčüč鹥ą╝ą░ ą║ąŠą╝ą░ąĮą┤ (ą░čüčüąĄą╝ą▒ą╗ąĄčĆ) - čćą░čüčéčī 2 .