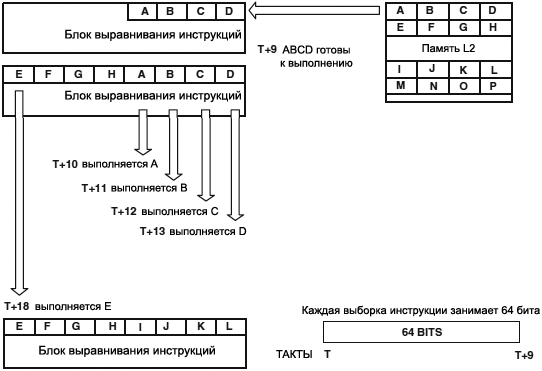
ą¤čĆąŠčåąĄčüčüąŠčĆ čüąĄą╝ąĄą╣čüčéą▓ą░ Blackfin ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ąĖąĄčĆą░čĆčģąĖč湥čüą║čāčÄ ą╝ąŠą┤ąĄą╗čī ą┐ą░ą╝čÅčéąĖ čü čĆą░ąĘąĮčŗą╝ąĖ ą┐ą░čĆą░ą╝ąĄčéčĆą░ą╝ąĖ ą┐ąŠ čĆą░ąĘą╝ąĄčĆčā ąĖ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖčÄ, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čĆą░ąĘą╝ąĄčēąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ą▓ čŹč鹊ą╣ ąĖąĄčĆą░čĆčģąĖąĖ. ą¤ą░ą╝čÅčéčī Level 1 (L1) čĆą░ąĘą╝ąĄčēąĄąĮą░ ąĮą░ ą║čĆąĖčüčéą░ą╗ą╗ąĄ čćąĖą┐ą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░, ąĖ ąŠą▒ą╗ą░ą┤ą░ąĄčé čüą░ą╝čŗą╝ ą▒ąŠą╗čīčłąĖą╝ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄą╝. ą¤ą░ą╝čÅčéčī Level 2 (L2) ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ąĮąĄ čćąĖą┐ą░, ąĖ čā ąĮąĄčæ ą▒ąŠą╗čīčłąĄ ąĘą░ą┤ąĄčƹȹ║ąĖ ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ąĮą░ čćč鹥ąĮąĖąĄ ąĖ ąĘą░ą┐ąĖčüčī. ąĪą░ą╝ą░čÅ ą▒čŗčüčéčĆą░čÅ ą┐ą░ą╝čÅčéčī L1 ąŠą▒čŗčćąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą║ą░ą║ ą┐čāą╗ ą┤ą╗čÅ ą▓čĆąĄą╝ąĄąĮąĮčŗčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ (scratchpad memory) ąĖą╗ąĖ ą┤ą╗čÅ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤čĆčāą│ąĖčģ, ą▒ąŠą╗ąĄąĄ ą╝ąĄą┤ą╗ąĄąĮąĮčŗčģ, ąŠą▒ą╗ą░čüč鹥ą╣ ą┐ą░ą╝čÅčéąĖ. ąŚą┤ąĄčüčī ą┐čĆąĖą▓ąĄą┤ąĄąĮ ą┐ąĄčĆąĄą▓ąŠą┤ čĆą░ąĘą┤ąĄą╗ą░ "Memory" ąĖąĘ ą┤ą░čéą░čłąĖčéą░ [1]. ąÆčüąĄ ąĮąĄą┐ąŠąĮčÅčéąĮčŗąĄ č鹥čĆą╝ąĖąĮčŗ ąĖ čüąŠą║čĆą░čēąĄąĮąĖčÅ čüą╝. ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ąĪą╗ąŠą▓ą░čĆąĖą║" ąĖ ą▓čĆąĄąĘą║ą░čģ čüčéą░čéčīąĖ [2].
[ąÉčĆčģąĖč鹥ą║čéčāčĆą░ ą┐ą░ą╝čÅčéąĖ ]
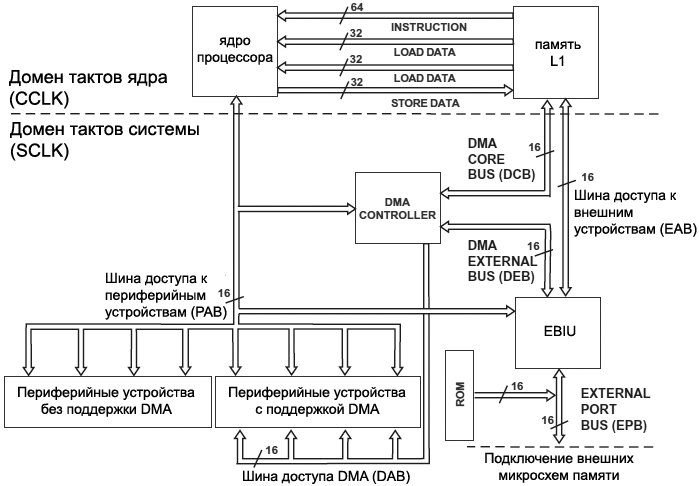
ą¤čĆąŠčåąĄčüčüąŠčĆ ąŠą▒ą╗ą░ą┤ą░ąĄčé ą┐ą╗ąŠčüą║ąĖą╝, čāąĮąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮčŗą╝ ą░ą┤čĆąĄčüąĮčŗą╝ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠą╝ čĆą░ąĘą╝ąĄčĆąŠą╝ ą▓ 4 ą│ąĖą│ą░ą▒ą░ą╣čéą░ (32-ą▒ąĖčéąĮčŗą╣ ą░ą┤čĆąĄčü), ą║ąŠč鹊čĆąŠąĄ ą┐ąŠą║čĆčŗą▓ą░ąĄčé ą║ąŠą╝ą▒ąĖąĮą░čåąĖčÄ ąŠą▒ą╗ą░čüč鹥ą╣ ą┐ą░ą╝čÅčéąĖ, čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĮčŗčģ ąĮą░ ą║čĆąĖčüčéą░ą╗ą╗ąĄ ąĖ ą▓ąĮąĄ ą║čĆąĖčüčéą░ą╗ą╗ą░, ą░ čéą░ą║ąČąĄ čĆąĄą│ąĖčüčéčĆčŗ ą▓ą▓ąŠą┤ą░/ą▓čŗą▓ąŠą┤ą░ ąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ, ą░ą┤čĆąĄčüčāąĄą╝čŗąĄ čéą░ą║ ąČąĄ, ą║ą░ą║ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ (memory-mapped I/O resources). ąÆčüąĄ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ąŠą┤ąĮąŠą╝ ą░ą┤čĆąĄčüąĮąŠą╝ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąĄ, čćč鹊 ąŠč湥ąĮčī čāą┤ąŠą▒ąĮąŠ ą┤ą╗čÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ. ąÆ čŹč鹊ą╝ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ ą░ą┤čĆąĄčüąŠą▓ 4 ą│ąĖą│ą░ą▒ą░ą╣čéą░ ąĮąĄą║ąŠč鹊čĆčŗąĄ ąŠą▒ą╗ą░čüčéąĖ ąČąĄčüčéą║ąŠ ą▓čŗą┤ąĄą╗ąĄąĮčŗ ą┤ą╗čÅ ą▓ąĮčāčéčĆąĄąĮąĮąĖčģ čĆąĄčüčāčĆčüąŠą▓ čćąĖą┐ą░. ą¤ąŠčĆčåąĖąĖ ą░ą┤čĆąĄčüąĮąŠą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┐ąŠą┤ čüą╗ąĄą┤čāčÄčēąĖąĄ čåąĄą╗ąĖ:
ŌĆó ąĪčéą░čéąĖč湥čüą║ą░čÅ ą┐ą░ą╝čÅčéčī L1 čü ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮčŗą╝ ą┤ąŠčüčéčāą┐ąŠą╝ ąĖ ą╝ąĖąĮąĖą╝ą░ą╗čīąĮčŗą╝ąĖ ąĘą░ą┤ąĄčƹȹ║ą░ą╝ąĖ (SRAM).
ą¦ą░čüčéčī ą┐ą░ą╝čÅčéąĖ, ąŠčéą▓ąĄą┤ąĄąĮąĮąŠą╣ ą┐ąŠą┤ L1 SRAM, ą╝ąŠąČąĄčé ą▒čŗčéčī čéą░ą║ąČąĄ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮą░ ą┐ąŠą┤ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą║ą░ą║ ą║čŹčł. ą¤čĆąŠčåąĄčüčüąŠčĆ čéą░ą║ąČąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┐ąŠą┤ą┤ąĄčƹȹ║čā ą▓ąĮąĄčłąĮąĄą│ąŠ ą░ą┤čĆąĄčüąĮąŠą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░, ą║ąŠč鹊čĆą░čÅ ą▓ą║ą╗čÄčćą░ąĄčé ąŠą▒ą╗ą░čüčéčī ą░čüąĖąĮčģčĆąŠąĮąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ (ąŠą▒čŗčćąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗčģ ą╝ąĖą║čĆąŠčüčģąĄą╝ ą┐ą░ą╝čÅčéąĖ FLASH) ąĖ ąŠą▒ą╗ą░čüčéčī čüąĖąĮčģčĆąŠąĮąĮąŠą╣ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą╣ ą┐ą░ą╝čÅčéąĖ (synchronous DRAM, SDRAM). ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "External Bus Interface Unit", ą│ą┤ąĄ ąŠą┐ąĖčüą░ąĮ ą║ą░ąČą┤čŗą╣ ąĖąĘ čŹčéąĖčģ čĆąĄą│ąĖąŠąĮąŠą▓ ą┐ą░ą╝čÅčéąĖ ąĖ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆčŗ ąĖčģ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ.
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą▓ ą░čĆčģąĖč鹥ą║čéčāčĆąĄ ąĮąĄčé ąŠčéą┤ąĄą╗čīąĮąŠą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ą░ą┤čĆąĄčüąŠą▓ ą┤ą╗čÅ ą▓ą▓ąŠą┤ą░/ą▓čŗą▓ąŠą┤ą░. ąÜą░ą║ čāąČąĄ čāą┐ąŠą╝ąĖąĮą░ą╗ąŠčüčī, ą▓čüąĄ čĆąĄčüčāčĆčüčŗ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąŠč鹊ą▒čĆą░ąČąĄąĮčŗ ąĮą░ ąŠą▒čēąĄąĄ ą┐ą╗ąŠčüą║ąŠąĄ 32-ą▒ąĖčéąĮąŠąĄ ą░ą┤čĆąĄčüąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ. ą»č湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ ą░ą┤čĆąĄčüčāčÄčéčüčÅ ą┐ąŠą▒ą░ą╣čéąĮąŠ.
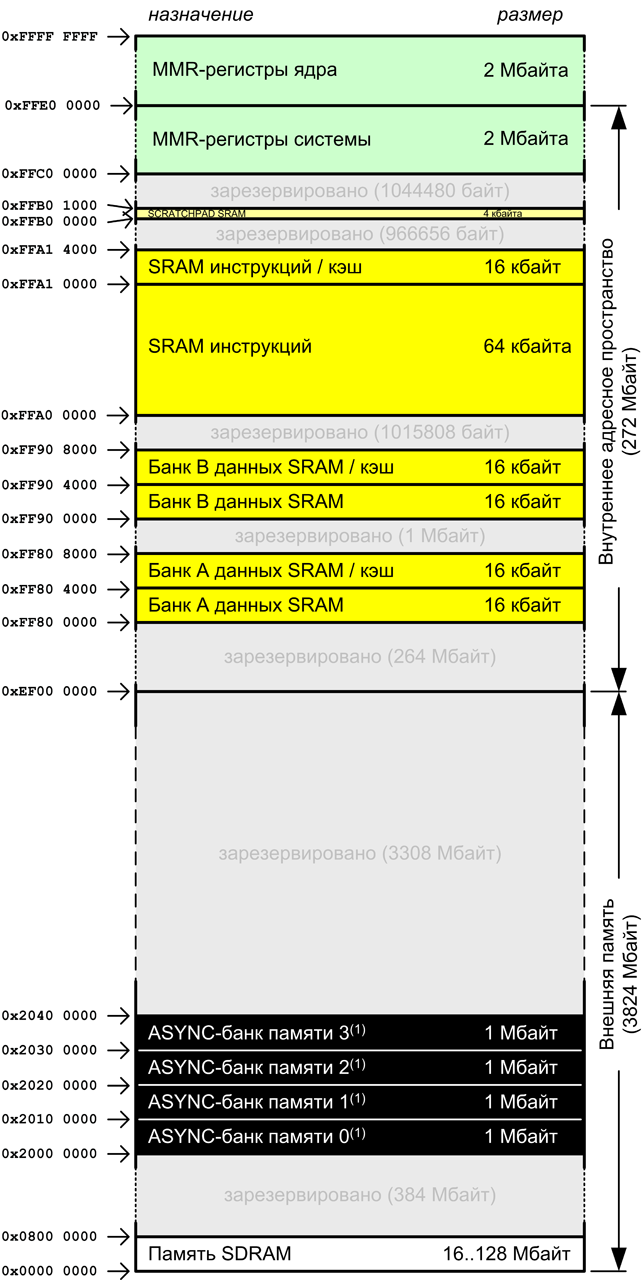
ąÜą░čĆčéą░ ą┐ą░ą╝čÅčéąĖ ADSP-BF538/ADSP-BF538F.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą▓ ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąĮąŠą╣ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ, ąĮą░čćąĖąĮą░čÅ čü ą░ą┤čĆąĄčüą░ 0xEF000000, ąĮą░čģąŠą┤ąĖčéčüčÅ ą║ąŠą┤ BootROM (ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. [6]).
ąĀąĖčü. 6-1. ąÉčĆčģąĖč鹥ą║čéčāčĆą░ ą┐ą░ą╝čÅčéąĖ ADSP-BF538/ADSP-BF538F.
ąÆąĄčĆčģąĮčÅčÅ ąŠą▒ą╗ą░čüčéčī ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ (čüą░ą╝čŗąĄ čüčéą░čĆčłąĖąĄ ą░ą┤čĆąĄčüą░) ą▓čŗą┤ąĄą╗ąĄąĮą░ ą┐ąŠą┤ čÅą┤čĆąŠ ąĖ čüąĖčüč鹥ą╝ąĮčŗąĄ MMR. ąöąŠčüčéčāą┐ ą║ čŹč鹊ą╣ ąŠą▒ą╗ą░čüčéąĖ čüąŠ čüč鹊čĆąŠąĮčŗ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ čĆą░ąĘčĆąĄčłąĄąĮ č鹊ą╗čīą║ąŠ ą▓ čĆąĄąČąĖą╝ąĄ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ąŠą│ą┤ą░ ąŠąĮ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ ąĖą╗ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ, ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. [2]), ąĖą╗ąĖ ą▓ čĆąĄąČąĖą╝ąĄ 菹╝čāą╗čÅčåąĖąĖ.
ą£ą╗ą░ą┤čłą░čÅ čćą░čüčéčī ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ čĆą░ąĘą╝ąĄčĆąŠą╝ 1 ą║ąĖą╗ąŠą▒ą░ą╣čé ąŠčéą▓ąĄą┤ąĄąĮą░ ą┐ąŠą┤ ą║ąŠą┤ ąĘą░ą│čĆčāąĘą║ąĖ (boot ROM). ąÆ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą▓čŗą▒čĆą░ąĮąĮąŠą│ąŠ čĆąĄąČąĖą╝ą░ ąĘą░ą│čĆčāąĘą║ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēą░čÅ ąĘą░ą│čĆčāąĘąŠčćąĮą░čÅ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą▒čāą┤ąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ ąĖąĘ čŹč鹊ą╣ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ, ą║ąŠą│ą┤ą░ ą┐čĆąŠčåąĄčüčüąŠčĆ čüą▒čĆąŠčłąĄąĮ (čüą╝. ą▓čĆąĄąĘą║čā "ąĀąĄąČąĖą╝čŗ ąĘą░ą│čĆčāąĘą║ąĖ" čüčéą░čéčīąĖ [2]).
ą×ą▒ą╗ą░čüčéąĖ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ą░ą┤čĆąĄčüąĮąŠą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ čüąŠą┤ąĄčƹȹ░čé 4 ą▒ą░ąĮą║ą░ ą░čüąĖąĮčģčĆąŠąĮąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ ąĖ ąŠą┤ąĖąĮ ą▒ą░ąĮą║ ą┐ą░ą╝čÅčéąĖ SDRAM. ąÜą░ąČą┤čŗą╣ ąĖąĘ ą░čüąĖąĮčģčĆąŠąĮąĮčŗčģ ą▒ą░ąĮą║ąŠą▓ ąĖą╝ąĄąĄčé čĆą░ąĘą╝ąĄčĆ 1 ą╝ąĄą│ą░ą▒ą░ą╣čé, ąĖ čā ą▒ą░ąĮą║ą░ SDRAM čĆą░ąĘą╝ąĄčĆ ą▓ 128 ą╝ąĄą│ą░ą▒ą░ą╣čé.
ą×ą▒ąĘąŠčĆ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ
ąÆ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ ą║čŹčłą░ą╝ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖ ą┤ą░ąĮąĮčŗčģ (SRAM ą▓ą╝ąĄčüč鹥 čü ą░ą┐ą┐ą░čĆą░čéčāčĆąŠą╣ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĄą╝) ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ąĖ ą▓čŗčüąŠą║ąŠąĄ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ, ąĖ čāą┐čĆąŠčēąĄąĮąĮą░čÅ ą╝ąŠą┤ąĄą╗čī ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ. ąÜčŹčłąĖ čāčüčéčĆą░ąĮčÅčÄčé ąŠčé ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ čÅą▓ąĮąŠ čāą┐čĆą░ą▓ą╗čÅčéčī ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅą╝ąĖ ą┤ą░ąĮąĮčŗčģ ą╝ąĄąČą┤čā ą┐ą░ą╝čÅčéčīčÄ L1 ąĖ ą┤čĆčāą│ąĖą╝ąĖ ąŠą▒ą╗ą░čüčéčÅą╝ąĖ ą┐ą░ą╝čÅčéąĖ, čā ą║ąŠč鹊čĆčŗčģ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ ąĮąĖąČąĄ. ąÜąŠą┤ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▒čŗčüčéčĆąŠąĄ ą┐ąŠčĆčéąĖčĆąŠą▓ą░ąĮ ąĖą╗ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮ ą▒ąĄąĘ čüą┐ąĄčåąĖą░ą╗čīąĮčŗčģ čāčüąĖą╗ąĖą╣ ą┐ąŠ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ, ą┐čĆąĖą▓čÅąĘą░ąĮąĮčŗčģ ą║ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖąĖ ą┐ą░ą╝čÅčéąĖ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╣ ą╝ąŠą┤ąĄą╗ąĖ čćąĖą┐ą░.
ą¤ą░ą╝čÅčéčī L1 ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé:
ŌĆó ą£ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮčāčÄ ąōą░čĆą▓ą░čĆą┤čüą║čāčÄ ą░čĆčģąĖč鹥ą║čéčāčĆčā, ą║ąŠą│ą┤ą░ ą▓ąŠąĘą╝ąŠąČąĄąĮ ą┤ąŠ 4 ą┤ąŠčüčéčāą┐ąŠą▓ ą║ ą┐ą░ą╝čÅčéąĖ čÅą┤čĆą░ ąĮą░ ąŠą┤ąĖąĮ čéą░ą║čé (ąĘą░čģą▓ą░čé ąŠą┤ąĮąŠą╣ 64-čĆą░ąĘčĆčÅą┤ąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą┤ą▓čāčģ 32-čĆą░ąĘčĆčÅą┤ąĮčŗčģ ąĘą░ą│čĆčāąĘąŠą║ ą┤ą░ąĮąĮčŗčģ, ąĖ ąŠą┤ąĖąĮ ąŠą┤ąĮąŠ ą║ąŠąĮą▓ąĄą╣ąĄčĆąĖąĘąĖčĆąŠą▓ą░ąĮąĮąŠąĄ čüąŠčģčĆą░ąĮąĄąĮąĖąĄ 32-ą▒ąĖčéąĮčŗčģ ą┤ą░ąĮąĮčŗčģ).
ą×ą▒ąĘąŠčĆ Scratchpad Data SRAM
ąÜą░ą║ čāąČąĄ čāą┐ąŠą╝ąĖąĮą░ą╗ąŠčüčī, ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ L1 ą╝ąŠą│čāčé čĆą░ą▒ąŠčéą░čéčī ąĮą░ čćą░čüč鹊č鹥 čéą░ą║č鹊ą▓ čÅą┤čĆą░ (CCLK). ąÜ scratchpad data SRAM ąĮąĄ ą╝ąŠąČąĄčé ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ DMA.
[ą¤ą░ą╝čÅčéčī ąĖąĮčüčéčĆčāą║čåąĖą╣ L1 ]
ą¤ą░ą╝čÅčéčī ąĖąĮčüčéčĆčāą║čåąĖą╣ L1 čüąŠčüč鹊ąĖčé ąĖąĘ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą╣ SRAM ąĖ ą▒ą░ąĮą║ąŠą▓, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮčŗ ą║ą░ą║ SRAM ąĖą╗ąĖ ą║čŹčł. ąöą╗čÅ 16-ą║ąĖą╗ąŠą▒ą░ą╣čéąĮąŠą│ąŠ ą▒ą░ąĮą║ą░, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ą▒čŗčéčī ą╗ąĖą▒ąŠ ą║čŹčłąĄą╝, ą╗ąĖą▒ąŠ SRAM, ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▒ąĖčéčŗ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ IMEM_CONTROL, čćč鹊ą▒čŗ ąŠčĆą│ą░ąĮąĖąĘąŠą▓ą░čéčī ą▓čüąĄ 4 ą┐ąŠą┤ą▒ą░ąĮą║ą░ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ L1 ą║ą░ą║:
ŌĆó ą¤čĆąŠčüčéą░čÅ ą┐ą░ą╝čÅčéčī SRAM.
ą¤ą░ą╝čÅčéčī ąĖąĮčüčéčĆčāą║čåąĖą╣ L1 ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮą░ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ čģčĆą░ąĮąĄąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖą╣ (ą║ąŠą┤ą░ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ).
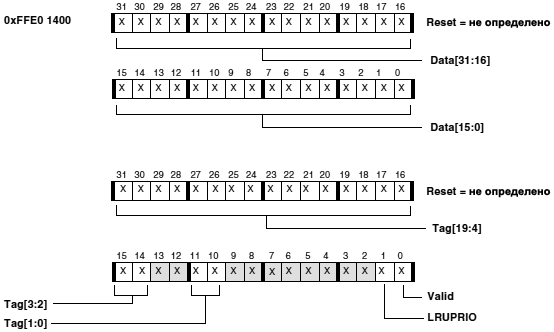
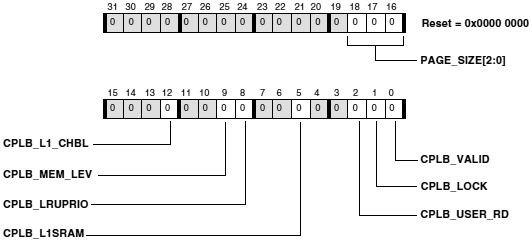
ąĀąĄą│ąĖčüčéčĆ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéčīčÄ ąĖąĮčüčéčĆčāą║čåąĖą╣ (Instruction Memory Control, IMEM_CONTROL) čüąŠą┤ąĄčƹȹĖčé ą▒ąĖčéčŗ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┤ą╗čÅ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ L1. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┐ąŠčüą╗ąĄ čüą▒čĆąŠčüą░ ą║čŹčł ąĖ čüąĖčüč鹥ą╝ą░ ą┐čĆąŠą▓ąĄčĆą║ąĖ ą░ą┤čĆąĄčüą░ ąĘą░čēąĖčéčŗ ą║čŹčłą░ (cacheability protection lookaside buffer, CPLB) ąĘą░ą┐čĆąĄčēąĄąĮčŗ (čüą╝. čĆą░ąĘą┤ąĄą╗ "ąÜčŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣ L1").
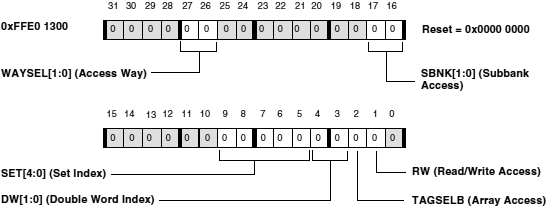
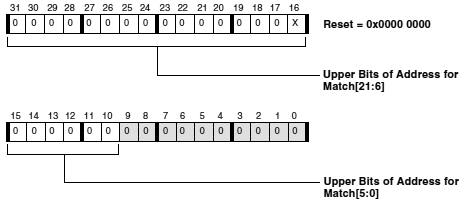
ąĀąĖčü. 6-2. ąĀąĄą│ąĖčüčéčĆ L1 Instruction Memory Control (IMEM_CONTROL, čĆąĄą│ąĖčüčéčĆ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéčīčÄ L1) ADSP-BF5xx.
LRUPRIORST . ąÜąŠą│ą┤ą░ ą▒ąĖčé LRUPRIORST čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą▓ 1, č鹊 ąŠčćąĖčēą░ąĄčéčüčÅ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ ą▓čüąĄčģ ą▒ąĖč鹊ą▓ CPLB_LRUPRIO (čüą╝. "ąĀąĄą│ąĖčüčéčĆčŗ ąĖąĮčüčéčĆčāą║čåąĖą╣ CPLB Data (ICPLB_DATAx)"). ąŁč鹊 ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą┐ąĄčĆąĄą▓ąŠą┤ąĖčé ą▓čüąĄ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĮčŗąĄ čüčéčĆąŠą║ąĖ ą▓ ąĮąĖąĘą║čāčÄ ą▓ą░ąČąĮąŠčüčéčī. ą¤ąŠą╗ąĖčéąĖą║ą░ ąĘą░ą╝ąĄąĮčŗ ą║čŹčłą░ ą▒ą░ąĘąĖčĆčāąĄčéčüčÅ ąĮą░ ą┐ąĄčĆą▓ąŠą╣ ą┐ąŠ ą▓ą░ąČąĮąŠčüčéąĖ čüčéčĆąŠą║ąĄ, čćč鹊 ąĖąĮą┤ąĖčåąĖčĆčāąĄčéčüčÅ ą┐ąŠ čüąŠčüč鹊čÅąĮąĖčÄ ą▒ąĖčé ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ CPLB_LRUPRIO, ąĖ ąĘą░č鹥ą╝ ąĮą░ LRU (least recently used, čüą░ą╝čŗąĄ ą┐ąŠčüą╗ąĄą┤ąĮąĖąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ). ą¤ąŠą┤čĆąŠą▒ąĮąŠčüčéąĖ čüą╝. ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "Instruction Cache Locking by Line". ąŁč鹊čé ą▒ąĖčé ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čüą▒čĆąŠčłąĄąĮ ą▓ 0, čćč鹊ą▒čŗ ą┐ąŠąĘą▓ąŠą╗ąĖčéčī ą▒čŗčéčī čüąŠčģčĆą░ąĮąĄąĮąĮčŗą╝ čüąŠčüč鹊čÅąĮąĖčÄ ą▒ąĖčé CPLB_LRUPRIO, ą║ąŠą│ą┤ą░ ą▒čāą┤ąĄčé ą║čŹčłąĖčĆąŠą▓ą░ąĮčŗ ąĮąŠą▓čŗąĄ čüčéčĆąŠą║ąĖ.
ILOC[3:0] . ąŁčéąĖ ą▒ąĖčéčŗ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ą┐ąŠą╗ąĄąĘąĮčāčÄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī č鹊ą╗čīą║ąŠ ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ą║ąŠą┤ ą▒čŗą╗ ą▓čĆčāčćąĮčāčÄ ąĘą░ą│čĆčāąČąĄąĮ ą▓ ą║čŹčł, čüą╝. čĆą░ąĘą┤ąĄą╗ "Instruction Cache Locking by Way". ąŁčéąĖ ą▒ąĖčéčŗ ąĘą░ą┤ą░čÄčé, ą║ą░ą║ ą▒čāą┤ąĄčé ą┐čĆąŠąĖčüčģąŠą┤ąĖčéčī čāą┤ą░ą╗ąĄąĮąĖąĄ ąĖąĘ ą║čŹčłą░ ą▓ ą┐ąŠą╗ąĖčéąĖą║ąĄ ąĘą░ą╝ąĄąĮčŗ. ąŁč鹊 ą▓ą╗ąĖčÅąĄčé ąĮą░ č鹊, ą║ą░ą║ ąĮą░ą╗ąĖčćąĖąĄ ąĘą░čģą▓ą░č湥ąĮąĮąŠą│ąŠ ą║ąŠą┤ą░ ą▓ ąŠčéčüčāčéčüčéą▓čāčÄčēąĖčģ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅčģ. ąÜąŠą┤ ą▓ ąŠčéčüčāčéčüčéą▓čāčÄčēąĖčģ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅčģ ą▓čüąĄ ąĄčēąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī čāą┤ą░ą╗ąĄąĮ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ IFLUSH. ąĢčüą╗ąĖ ą▒ąĖčé ą▓ ILOC[3:0] čĆą░ą▓ąĄąĮ 0, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╣ ą┐čāčéčī ąĮąĄ ąĘą░čģą▓ą░č湥ąĮ, ąĖ čŹč鹊čé ą┐čāčéčī čāčćą░čüčéą▓čāąĄčé ą▓ ą┐ąŠą╗ąĖčéąĖą║ąĄ ąĘą░ą╝ąĄąĮčŗ ą║čŹčłą░. ąĢčüą╗ąĖ ą▒ąĖčé ILOC[3:0] čĆą░ą▓ąĄąĮ 1, č鹊 čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╣ ą┐čāčéčī ąĘą░čģą▓ą░č湥ąĮ, ąĖ ąĮąĄ čāčćą░čüčéą▓čāąĄčé ą▓ ą┐ąŠą╗ąĖčéąĖą║ąĄ ąĘą░ą╝ąĄąĮčŗ ą║čŹčłą░.
IMC . ąŁč鹊čé ą▒ąĖčé čĆąĄąĘąĄčĆą▓ąĖčĆčāąĄčé čćą░čüčéčī SRAM-ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ L1 ą┤ą╗čÅ čĆą░ą▒ąŠčéčŗ ą▓ ą║ą░č湥čüčéą▓ąĄ ą║čŹčłą░. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÅ ą▓ ą║ą░č湥čüčéą▓ąĄ ą║čŹčłą░ ąĮąĄ ą┐ąŠąĘą▓ąŠą╗čÅčé čüą░ą╝ąŠ ą┐ąŠ čüąĄą▒ąĄ ą║čŹčłąĖčĆąŠą▓ą░čéčī ąŠą▒čĆą░čēąĄąĮąĖčÅ ą║ ą┐ą░ą╝čÅčéąĖ L2. ąóą░ą║ąČąĄ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čĆą░ąĘčĆąĄčłąĄąĮčŗ ą▒ą╗ąŠą║ąĖ CPLB čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą▒ąĖčéą░ EN_ICPLB ąĖ ą┤ąĄčüą║čĆąĖą┐č鹊čĆčŗ CPLB (ą▓ čĆąĄą│ąĖčüčéčĆą░čģ ICPLB_DATAx ąĖ ICPLB_ADDRx) ą┤ąŠą╗ąČąĮčŗ čāą║ą░ąĘčŗą▓ą░čéčī ąĮčāąČąĮčŗąĄ čüčéčĆą░ąĮąĖčåčŗ ą┐ą░ą╝čÅčéąĖ, ą┤ą╗čÅ ą║ąŠč鹊čĆčŗčģ čĆą░ąĘčĆąĄčłąĄąĮąŠ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĄ.
ENICPLB . ąæąĖčé čĆą░ąĘčĆąĄčłąĄąĮąĖčÅ CPLB ąĖąĮčüčéčĆčāą║čåąĖą╣ (Instruction CPLB Enable). ąĢčüą╗ąĖ 0, č鹊 ą▓čüąĄ CPLB ąĘą░ą┐čĆąĄčēąĄąĮčŗ, ąĖą╝ąĄąĄčéčüčÅ č鹊ą╗čīą║ąŠ ą╝ąĖąĮąĖą╝ą░ą╗čīąĮą░čÅ ą┐čĆąŠą▓ąĄčĆą║ą░ ą░ą┤čĆąĄčüą░. ąĢčüą╗ąĖ 1, č鹊 CPLB čĆą░ąĘčĆąĄčłąĄąĮčŗ.
ą¤ąŠčüą╗ąĄ čüą▒čĆąŠčüą░ ą▒ą╗ąŠą║ąĖ CPLB ą┤ą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĘą░ą┐čĆąĄčēąĄąĮčŗ. ąÜąŠą│ą┤ą░ čŹčéą░ čäčāąĮą║čåąĖčÅ ąĘą░ą┐čĆąĄčēąĄąĮą░, ąĖąĮč鹥čĆč乥ą╣čüąŠą╝ ą┐ą░ą╝čÅčéąĖ LI ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčéčüčÅ č鹊ą╗čīą║ąŠ ą╝ąĖąĮąĖą╝ą░ą╗čīąĮą░čÅ ą┐čĆąŠą▓ąĄčĆą║ą░ ą░ą┤čĆąĄčüą░. ąŁčéą░ ą╝ąĖąĮąĖą╝ą░ą╗čīąĮą░čÅ ą┐čĆąŠą▓ąĄčĆą║ą░ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą▓čüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ čüą┤ąĄą╗ą░ąĮą░ ą┐ąŠą┐čŗčéą║ą░ ą▓čŗą▒ąŠčĆą║ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖąĘ:
ŌĆó ąŚą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąĮąŠą╣ (ąĮąĄ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĮąŠą╣) ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ L1.
CPLB ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąĘą░ą┐čĆąĄčēąĄąĮčŗ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ čŹč鹊ą│ąŠ ą▒ąĖčéą░ ą┤ąŠ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ ąĖčģ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ (čĆąĄą│ąĖčüčéčĆąŠą▓ DCPLB_DATAx ąĖ DCPLB_ADDRx registers). ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą┐ąŠčüą║ąŠą╗čīą║čā ą┐ąŠčĆčÅą┤ąŠą║ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čüą╗ą░ą▒čŗą╣ (čüą╝. "Ordering of Loads and Stores"), ąĘą░ą┐čĆąĄčé CPLB ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą┐čĆąŠą┤ąŠą╗ąČąĄąĮ ąĖą╝ą┐čāą╗čīčüą░ą╝ąĖ CSYNC.
ąÜąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłą░čÄčéčüčÅ ąĖą╗ąĖ ąĘą░ą┐čĆąĄčēą░čÄčéčüčÅ ą║čŹčł ąĖą╗ąĖ CPLB, ą┤ąŠą╗ąČąĮą░ ą┐čĆąŠąĖąĘąŠą╣čéąĖ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮą░čÅ ąĘą░ą┐ąĖčüčī ą▓ IMEM_CONTROL ą▓ą╝ąĄčüč鹥 čü CSYNC, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ą║ąŠčĆčĆąĄą║čéąĮčāčÄ čĆą░ą▒ąŠčéčā. ą¦č鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ą┐čĆą░ą▓ąĖą╗čīąĮąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą║ąŠą┤ą░ ąĖ ą▒čāą┤čāčēčāčÄ čüąŠą▓ą╝ąĄčüčéąĖą╝ąŠčüčéčī, ą▓čüąĄ ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ą▒ąĖčéčŗ ą▓ čŹč鹊ą╝ čĆąĄą│ąĖčüčéčĆąĄ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮčŗ ą▓ 0 ą▓čüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ čŹč鹊čé čĆąĄą│ąĖčüčéčĆ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ.
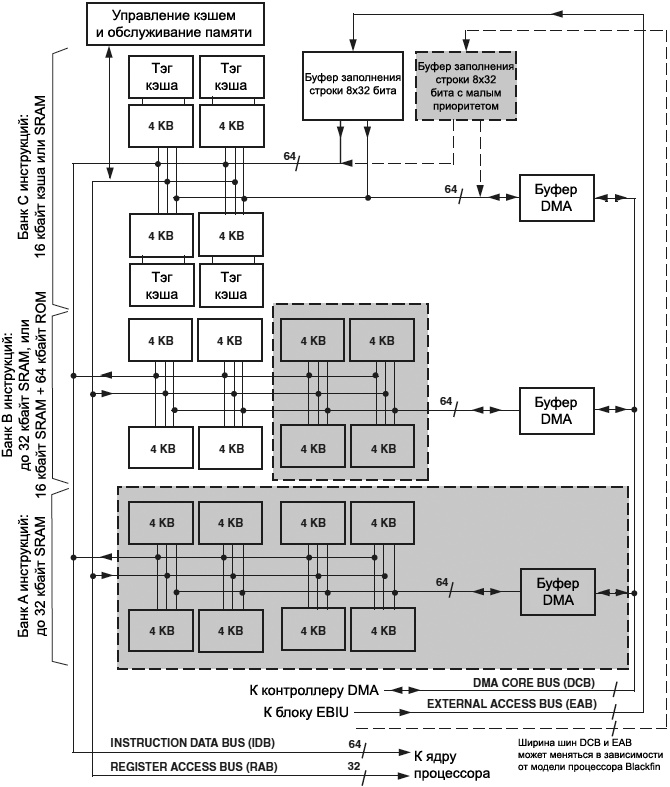
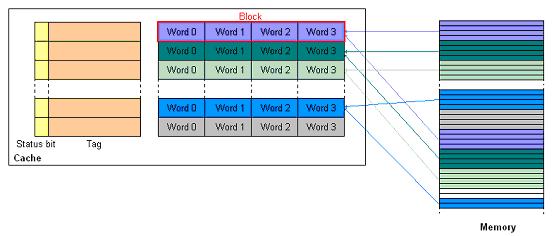
L1 Instruction SRAM . ą»ą┤čĆąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░ čćąĖčéą░ąĄčé ą┐ą░ą╝čÅčéčī ąĖąĮčüčéčĆčāą║čåąĖą╣ č湥čĆąĄąĘ 64-ą▒ąĖčéąĮčāčÄ čłąĖąĮčā ą▓čŗą▒ąŠčĆą║ąĖ. ąÆčüąĄ ą░ą┤čĆąĄčüą░ ąĮą░ čŹč鹊ą╣ čłąĖąĮąĄ ą▓čŗčĆąŠą▓ąĮąĄąĮčŗ ąĮą░ 64 ą▒ąĖčéą░. ąÜą░ąČą┤ą░čÅ ą▓čŗą▒ąŠčĆą║ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠąČąĄčé ą▓ąŠąĘą▓čĆą░čéąĖčéčī ą╗čÄą▒čāčÄ ą║ąŠą╝ą▒ąĖąĮą░čåąĖčÄ ąĖąĘ 16-, 32- ąĖą╗ąĖ 64-ą▒ąĖčéąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, č湥čéčŗčĆąĄ 16-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą┤ą▓ąĄ 16-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖ ąŠą┤ąĮčā 32-ą▒ąĖčéąĮčāčÄ ąĖąĮčüčéčĆčāą║čåąĖčÄ, ąĖą╗ąĖ ąŠą┤ąĮčā 64-ą▒ąĖčéąĮčāčÄ ąĖąĮčüčéčĆčāą║čåąĖčÄ). DAG-ąĖ, ą║ąŠč鹊čĆčŗąĄ ąŠą┐ąĖčüą░ąĮčŗ ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "Data Address Generators", ąĮąĄ ą╝ąŠą│čāčé ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĮą░ą┐čĆčÅą╝čāčÄ. DAG, ą║ąŠč鹊čĆčŗą╣ ąŠą▒čĆą░čéąĖą╗čüčÅ ą║ ąŠą▒ą╗ą░čüčéąĖ ą░ą┤čĆąĄčüąŠą▓ SRAM, čüą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ (čüą╝. čĆą░ąĘą┤ąĄą╗ "ąśčüą║ą╗čÄč湥ąĮąĖčÅ" ą▓ [3]).
ąöąŠčüčéčāą┐ ąĮą░ ąĘą░ą┐ąĖčüčī ą║ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ L1 SRAM ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī čüą┤ąĄą╗ą░ąĮą░ č湥čĆąĄąĘ 64-ą▒ąĖčéąĮčŗą╣ čüąĖčüč鹥ą╝ąĮčŗą╣ ą┐ąŠčĆčé DMA. ą¤ąŠčüą║ąŠą╗čīą║čā SRAM čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮą░ ą▓ ą▓ąĖą┤ąĄ ąĮą░ą▒ąŠčĆą░ ąŠą┤ąĖąĮąŠčćąĮčŗčģ, čĆą░ąĘą┤ąĄą╗ąĄąĮąĮčŗčģ ąĮą░ ą┐ąŠčĆčéčŗ ą┐ąŠą┤ą▒ą░ąĮą║ąŠą▓, č鹊 ą┐ą░ą╝čÅčéčī ąĖąĮčüčéčĆčāą║čåąĖą╣ čŹčäč乥ą║čéąĖą▓ąĮąŠ čĆą░ą▒ąŠčéą░ąĄčé ą║ą░ą║ ą┤ą▓čāčģą┐ąŠčĆč鹊ą▓ą░čÅ ą┐ą░ą╝čÅčéčī.
ąÆ čéą░ą▒ą╗ąĖčåąĄ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮčŗ ąĮą░čćą░ą╗čīąĮčŗąĄ ąŠą▒ą╗ą░čüčéąĖ ą┐ąŠą┤ą▒ą░ąĮą║ąŠą▓ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ L1.
ą¤ąŠą┤ą▒ą░ąĮą║ ą┐ą░ą╝čÅčéąĖ ą£ąĄčüč鹊 čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĖčÅ ą▓ ą┐ą░ą╝čÅčéąĖ
0
0xFFA0 0000
1
0xFFA0 1000
2
0xFFA0 2000
3
0xFFA0 3000
4
0xFFA0 4000
5
0xFFA0 5000
6
0xFFA0 6000
7
0xFFA0 7000
8
0xFFA0 8000
9
0xFFA0 9000
10
0xFFA0 A000
11
0xFFA0 B000
12
0xFFA0 C000
13
0xFFA0 D000
14
0xFFA0 E000
15
0xFFA0 F000
ąØą░ čĆąĖčü. 6-4 ą┐ąŠą║ą░ąĘą░ąĮą░ ą░čĆčģąĖč鹥ą║čéčāčĆą░ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ L1. ąÜą░ą║ ą▓ąĖą┤ąĮąŠ ąĮą░ čĆąĖčüčāąĮą║ąĄ, ą║ą░ąČą┤čŗą╣ 16-ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗą╣ ą▒ą░ąĮą║ čĆą░ąĘą┤ąĄą╗ąĄąĮ ąĮą░ č湥čéčŗčĆąĄ ą┐ąŠą┤ą▒ą░ąĮą║ą░ ą┐ąŠ 4 ą║ąĖą╗ąŠą▒ą░ą╣čéą░.
ąĀąĖčü. 6-4. ąÉčĆčģąĖč鹥ą║čéčāčĆą░ ą▒ą░ąĮą║ą░ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ L1.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąĘą░ą║čĆą░čłąĄąĮąĮčŗąĄ čüąĄčĆčŗą╝ čåą▓ąĄč鹊ą╝ ą▒ą╗ąŠą║ąĖ ąĖą╝ąĄčÄčéčüčÅ ąĮąĄ ą▓ąŠ ą▓čüąĄčģ ą╝ąŠą┤ąĄą╗čÅčģ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin. ąöą╗čÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ąŠą▒čĆą░čēą░ą╣č鹥čüčī ą║ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą╝čā čĆčāą║ąŠą▓ąŠą┤čüčéą▓čā ą┐ąŠ ą░ą┐ą┐ą░čĆą░čéčāčĆąĄ ąÆą░čłąĄą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ([1] ą┤ą╗čÅ BF538).
L1 Instruction ROM . ąØąĄą║ąŠč鹊čĆčŗąĄ ą╝ąŠą┤ąĄą╗ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin ąĖą╝ąĄčÄčé ąĮą░ ą▒ąŠčĆčéčā ą┤ąŠ 64 ą║ąĖą╗ąŠą▒ą░ą╣čé ą¤ąŚąŻ ąĖąĮčüčéčĆčāą║čåąĖą╣ L1 (L1 instruction ROM). ąĢčüą╗ąĖ čŹč鹊 ROM ąĄčüčéčī, č鹊 ąŠąĮąŠ ą▓čüčéčĆą░ąĖą▓ą░ąĄčéčüčÅ ą▓ ą░čĆčģąĖč鹥ą║čéčāčĆčā L1 Instruction SRAM, ą┐ąŠą║ą░ąĘą░ąĮąĮčāčÄ ąĮą░ čĆąĖčü. 6-4. L1 instruction ROM ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠčćąĖčéą░ąĮąŠ čüąĄą║ą▓ąĄąĮčüąĄčĆąŠą╝ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĖ DMA, ąĮąŠ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠčćąĖčéą░ąĮąŠ ą╝ąĄčģą░ąĮąĖąĘą╝ąŠą╝ ITEST. ąóą░ą║ čćč鹊 čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ L1 instruction ROMS ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠč鹊ą▒čĆą░ąČąĄąĮąŠ ą▓ 菹╝čāą╗čÅč鹊čĆąĄ CrossCore Embedded Studio.
L1 Instruction Cache . ą¤ą░ą╝čÅčéčī ąĖąĮčüčéčĆčāą║čåąĖą╣ L1 ą╝ąŠąČąĄčé ą▒čŗčéčī čéą░ą║ąČąĄ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮą░, čćč鹊ą▒čŗ čüąŠą┤ąĄčƹȹ░čéčī 4-ą║ą░ąĮą░ą╗čīąĮčŗą╣ ą░čüčüąŠčåąĖą░čéąĖą▓ąĮčŗą╣ 16-ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗą╣ ą║čŹčł. ą¦č鹊ą▒čŗ čāą╗čāčćčłąĖčéčī čüčĆąĄą┤ąĮąĄąĄ ą▓čĆąĄą╝čÅ ą┤ąŠčüčéčāą┐ą░ ą┤ą╗čÅ ą║čĆąĖčéąĖč湥čüą║ąĖčģ čüąĄą║čåąĖą╣ ą║ąŠą┤ą░, ą║ą░ąČą┤ą░čÅ 2-čÅ čüčéčĆąŠą║ą░ ą║čŹčłą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮą░ ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ. ąÜąŠą│ą┤ą░ ą┐ą░ą╝čÅčéčī čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮą░ ą║ą░ą║ ą║čŹčł, č鹊 ą║ ąĮąĄą╣ ąĮąĄą╗čīąĘčÅ ą┐ąŠą╗čāčćąĖčéčī ą┐čĆčÅą╝ąŠą╣ ą┤ąŠčüčéčāą┐.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąŠ č鹥čĆą╝ąĖąĮą░čģ, ą║ąŠč鹊čĆčŗąĄ ą▒čāą┤čāčé ą▓čüčéčĆąĄčćą░čéčīčüčÅ ą▓ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ, čüą╝. ą▓čĆąĄąĘą║čā "ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ ą┐ą░ą╝čÅčéąĖ". ąØąĄąĘąĮą░ą║ąŠą╝čŗąĄ čüąŠą║čĆą░čēąĄąĮąĖčÅ ąĖ č鹥čĆą╝ąĖąĮčŗ čéą░ą║ąČąĄ čüą╝. ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ąĪą╗ąŠą▓ą░čĆąĖą║" čüčéą░čéčīąĖ [2].
ąÜąŠą│ą┤ą░ ą║čŹčł čĆą░ąĘčĆąĄčłąĄąĮ, ą▒čāą┤čāčé ą║čŹčłąĖčĆąŠą▓ą░čéčīčüčÅ č鹊ą╗čīą║ąŠ čüčéčĆą░ąĮąĖčåčŗ ą┐ą░ą╝čÅčéąĖ, ąĮą░ąĘąĮą░č湥ąĮąĮčŗąĄ č湥čĆąĄąĘ CPLB ą║ą░ą║ ą║čŹčłąĖčĆčāąĄą╝čŗąĄ. ąÜąŠą│ą┤ą░ CPLB čĆą░ąĘčĆąĄčłąĄąĮčŗ, č鹊 ą╗čÄą▒ąŠąĄ ą╝ąĄčüč鹊 ą▓ ą┐ą░ą╝čÅčéąĖ, ą║čāą┤ą░ ąĮčāąČąĄąĮ ą┤ąŠčüčéčāą┐, ą┤ąŠą╗ąČąĄąĮ ąĖą╝ąĄčéčī čüą▓čÅąĘą░ąĮąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ čüčéčĆą░ąĮąĖčåčŗ, ąĖąĮą░č湥 ą▒čāą┤ąĄčé čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ CPLB. CPLB ąŠą┐ąĖčüą░ąĮčŗ ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ąŚą░čēąĖčéą░ ąĖ čüą▓ąŠą╣čüčéą▓ą░ ą┐ą░ą╝čÅčéąĖ".
ąØą░ čĆąĖčüčāąĮą║ąĄ 6-5 ą┐ąŠą║ą░ąĘą░ąĮą░ ąŠą▒čēą░čÅ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖčÅ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin.
ąĀąĖčü. 6-5. ą×čĆą│ą░ąĮąĖąĘą░čåąĖčÅ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĮą░ ą┐ąŠą┤ą▒ą░ąĮą║ąĄ.
ąĪčéčĆąŠą║ąĖ ą║čŹčłą░. ąÜą░ą║ ą╝čŗ ą▓ąĖą┤ąĖą╝ ąĮą░ čĆąĖčü. 6-5, ą║čŹčł čüąŠčüč鹊ąĖčé ąĖąĘ ąĮą░ą▒ąŠčĆą░ čüčéčĆąŠą║ ą║čŹčłą░. ąÜą░ąČą┤ą░čÅ čüčéčĆąŠą║ą░ ą║čŹčłą░ čüąŠą┤ąĄčƹȹĖčé ą║ąŠą╝ą┐ąŠąĮąĄąĮčé čé菹│ą░ ąĖ ą║ąŠą╝ą┐ąŠąĮąĄąĮčé ą┤ą░ąĮąĮčŗčģ.
ŌĆó ąÆ ą║ąŠą╝ą┐ąŠąĮąĄąĮč鹥 čé菹│ą░ ąĖą╝ąĄąĄčéčüčÅ 20-čĆą░ąĘčĆčÅą┤ąĮą░čÅ ą╝ąĄčéą║ą░ ą░ą┤čĆąĄčüą░, ą▒ąĖčéčŗ LRU (ą║ą░ą║ ą┤ąŠą╗ą│ąŠ čüčéčĆąŠą║ą░ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ą░čüčī), ą▒ąĖčé Valid (ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéčī čüčéčĆąŠą║ąĖ ą║čŹčłą░) ąĖ ą▒ąĖčé Line Lock (ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ čüčéčĆąŠą║ąĖ ą║čŹčłą░).
ąÜąŠą╝ą┐ąŠąĮąĄąĮčéčŗ č鹥ą│ą░ ąĖ ą┤ą░ąĮąĮčŗčģ čüčéčĆąŠą║ ą║čŹčłą░ čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ ą▓ ą╝ą░čüčüąĖą▓čŗ čé菹│ą░ ąĖ ą┤ą░ąĮąĮčŗčģ.
ą£ąĄčéą║ą░ ą░ą┤čĆąĄčüą░ čüąŠčüč鹊ąĖčé ąĖąĘ 18 ą▒ąĖčé ą┐ą╗čÄčü ą▒ąĖčéčŗ 11 ąĖ 10 čäąĖąĘąĖč湥čüą║ąŠą│ąŠ ą░ą┤čĆąĄčüą░. ąæąĖčéčŗ 12 ąĖ 13 čäąĖąĘąĖč湥čüą║ąŠą│ąŠ ą░ą┤čĆąĄčüą░ ąĮąĄ ą▓čģąŠą┤čÅčé ą▓ ą╝ąĄčéą║čā ą░ą┤čĆąĄčüą░. ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ čŹčéąĖ ą▒ąĖčéčŗ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ 4-ą║ąĖą╗ąŠą▒ą░ą╣čéąĮąŠą│ąŠ ą┐ąŠą┤ą▒ą░ąĮą║ą░, ą║ ą║ąŠč鹊čĆąŠą╝čā ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą┤ąŠčüčéčāą┐.
ąæąĖčéčŗ LRU čÅą▓ą╗čÅčÄčéčüčÅ čćą░čüčéčīčÄ ą░ą╗ą│ąŠčĆąĖčéą╝ą░ LRU, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą│ąŠ ą┤ą╗čÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ ą║čŹčłą░, ą║ąŠč鹊čĆą░čÅ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ąĘą░ą╝ąĄąĮąĄąĮą░ ą┐čĆąĖ ą┐čĆąŠą╝ą░čģąĄ ą║čŹčłą░.
ąæąĖčé Valid ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čüąŠčüč鹊čÅąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░. ąĪčéčĆąŠą║ą░ ą║čŹčłą░ ą▓čüąĄą│ą┤ą░ ą╗ąĖą▒ąŠ ą┤ąŠčüč鹊ą▓ąĄčĆąĮą░, ą╗ąĖą▒ąŠ ąĮąĄ ą┤ąŠčüč鹊ą▓ąĄčĆąĮą░.
ŌĆó ąÆ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗčģ čüčéčĆąŠą║ą░čģ ą║čŹčłą░ ą▒ąĖčé Valid ąŠčćąĖčēąĄąĮ, ą┐ąŠą║ą░ąĘčŗą▓ą░čÅ čŹčéąĖą╝, čćč鹊 čüčéčĆąŠą║ą░ ą▒čāą┤ąĄčé ąĖą│ąĮąŠčĆąĖčĆąŠą▓ą░čéčīčüčÅ ą┐čĆąĖ ąŠą┐ąĄčĆą░čåąĖąĖ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą╝ąĄčéą║ąĖ ą░ą┤čĆąĄčüą░.
ąÜąŠą╝ą┐ąŠąĮąĄąĮčéčŗ čé菹│ą░ ąĖ ą┤ą░ąĮąĮčŗčģ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ą┐ąŠą║ą░ąĘą░ąĮčŗ ąĮą░ čĆąĖčüčāąĮą║ąĄ 6-6. ąÜą░ąČą┤čŗą╣ 4-ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗą╣ ą┐ąŠą┤ą▒ą░ąĮą║ ąĖą╝ąĄčÄčé čéą░ą║čāčÄ ąČąĄ čüčéčĆčāą║čéčāčĆčā.
ąĀąĖčü. 6-6. ąĪčéčĆąŠą║ą░ ą║čŹčłą░ ŌĆō čćą░čüčéąĖ čé菹│ą░ ąĖ ą┤ą░ąĮąĮčŗčģ.
ą¤ąŠą┐ą░ą┤ą░ąĮąĖčÅ ąĖ ą┐čĆąŠą╝ą░čģąĖ ą║čŹčłą░ . ą¤ąŠą┐ą░ą┤ą░ąĮąĖąĄ ą║čŹčłą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé č鹊ą│ą┤ą░, ą║ąŠą│ą┤ą░ ą░ą┤čĆąĄčü ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ ąĘą░ą┐čĆąŠčüąĄ ąĮą░ ą▓čŗą▒ąŠčĆą║čā ąĖąĘ ą┐ą░ą╝čÅčéąĖ čüąŠą▓ą┐ą░ą┤ą░ąĄčé čü ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą╣ ąĘą░ą┐ąĖčüčīčÄ ą▓ ą║čŹčłąĄ. ąÆ čćą░čüčéąĮąŠčüčéąĖ ą┐ąŠą┐ą░ą┤ą░ąĮąĖąĄ ą║čŹčłą░ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ čüčĆą░ą▓ąĮąĄąĮąĖąĄą╝ čüčéą░čĆčłąĖčģ 18 ą▒ąĖč鹊ą▓ ąĖ ą▒ąĖč鹊ą▓ 11 ąĖ 10 ą░ą┤čĆąĄčüą░ ą▓čŗą▒ąŠčĆą║ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü ą╝ąĄčéą║ąŠą╣ ą░ą┤čĆąĄčüą░ ą┤ąŠą┐čāčüčéąĖą╝čŗčģ čüčéčĆąŠą║ ą║čŹčłą░. ąØą░ą▒ąŠčĆ ą║čŹčłą░ (čüčéčĆąŠą║ąĖ ą║čŹčłą░, čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ ą┐ąŠ ą║ą░ąĮą░ą╗ą░ą╝) ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą▒ąĖč鹊ą▓ 9 .. 5 ą░ą┤čĆąĄčüą░ ą▓čŗą▒ąŠčĆą║ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ą×ą┐ąĄčĆą░čåąĖčÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą░ą┤čĆąĄčü-čé菹│ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čüąŠą▓ą┐ą░ą┤ąĄąĮąĖąĄ ą▓ ą╗čÄą▒ąŠą╝ ąĖąĘ 4 ą║ą░ąĮą░ą╗ąŠą▓, ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēą░čÅ čüčéčĆąŠą║ą░ ą┤ąŠčüč鹊ą▓ąĄčĆąĮą░, č鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐ąŠą┐ą░ą┤ą░ąĮąĖąĄ ą▓ ą║čŹčł. ąĢčüą╗ąĖ ąŠą┐ąĄčĆą░čåąĖčÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą░ą┤čĆąĄčüą░ ąĮąĄ ą┐ąŠą║ą░ąĘą░ą╗ą░ čüąŠą▓ą┐ą░ą┤ąĄąĮąĖčÅ ą▓ ą╗čÄą▒ąŠą╝ ąĖąĘ 4 ą║ą░ąĮą░ą╗ąŠą▓, ąĖą╗ąĖ ą┐čĆąĖ čüąŠą▓ą┐ą░ą┤ąĄąĮąĖąĖ ąĮąĄ ąĮą░ą╣ą┤ąĄąĮąŠ ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą╣ čüčéčĆąŠą║ąĖ, č鹊 ą┐čĆąŠąĖąĘąŠčłąĄą╗ ą┐čĆąŠą╝ą░čģ ą║čŹčłą░.
ą¤čĆąĖ ą┐čĆąŠą╝ą░čģąĄ ą║čŹčłą░ ą▒ą╗ąŠą║ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ą┤ąŠčüčéčāą┐ ąĮą░ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ąŠčéčüčāčéčüčéą▓čāčÄčēčāčÄ ą▓ ą║čŹčłąĄ čüčéčĆąŠą║čā ąĖąĘ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆą░čÅ čÅą▓ą╗čÅąĄčéčüčÅ ą▓ąĮąĄčłąĮąĄą╣ ą┤ą╗čÅ čÅą┤čĆą░. ąÉą┤čĆąĄčü ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ čÅą▓ą╗čÅąĄčéčüčÅ ą░ą┤čĆąĄčüąŠą╝ čüą╗ąŠą▓ą░ čåąĄą╗ąĄą▓ąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąÜąŠą│ą┤ą░ ą┐čĆąŠąĖąĘąŠčłąĄą╗ ą┐čĆąŠą╝ą░čģ ą║čŹčłą░, čÅą┤čĆąŠ ą┐čĆąĖąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ, ą┐ąŠą║ą░ čåąĄą╗ąĄą▓ąŠąĄ čüą╗ąŠą▓ąŠ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĮąĄ ą▒čāą┤ąĄčé ą┐ąŠą╗čāč湥ąĮąŠ ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ.
ąŚą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ ą║čŹčłą░ . ąŚą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ čüąŠčüč鹊ąĖčé ąĖąĘ ą▓čŗą▒ąŠčĆą║ąĖ ąĖąĘ ą┐ą░ą╝čÅčéąĖ 32 ą▒ą░ą╣čé ą┤ą░ąĮąĮčŗčģ. ą×ą┐ąĄčĆą░čåąĖčÅ ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ, ą║ąŠą│ą┤ą░ ą▒ą╗ąŠą║ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĘą░ą┐čĆą░čłąĖą▓ą░ąĄčé ą┐ąĄčĆąĄą┤ą░čćčā čćąĖčéą░ąĄą╝ąŠą╣ čüčéčĆąŠą║ąĖ ąĮą░ ąĄą│ąŠ ą▓ąĮąĄčłąĮąĄą╝ ą┐ąŠčĆč鹥 čćč鹥ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ. ąŁč鹊 ą┐ą░ą║ąĄčé ąĖąĘ č湥čéčŗčĆąĄčģ 64-ą▒ąĖčéąĮčŗčģ čüą╗ąŠą▓ ą┤ą░ąĮąĮčŗčģ ąĖčģ čüčéčĆąŠą║ąĖ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ ą▒čāč乥čĆą░. ąŚą░č鹥ą╝ čüčéčĆąŠą║ą░ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ ą▒čāč乥čĆą░ čéčĆą░ąĮčüą╗ąĖčĆčāąĄčéčüčÅ ą║ čłąĖčĆąĖąĮąĄ čłąĖąĮčŗ ą▓ąĮąĄčłąĮąĄą│ąŠ ą┤ąŠčüčéčāą┐ą░ (External Access Bus, EAB).
ąÉą┤čĆąĄčü ą┤ą╗čÅ ą┐ąĄčĆąĄą┤ą░čćąĖ čćč鹥ąĮąĖčÅ čÅą▓ą╗čÅąĄčéčüčÅ ą░ą┤čĆąĄčüąŠą╝ čüą╗ąŠą▓ą░ čåąĄą╗ąĄą▓ąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąÜąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąŠčéą▓ąĄčé ąĮą░ ąĘą░ą┐čĆąŠčü čćč鹥ąĮąĖčÅ čüčéčĆąŠą║ąĖ ąŠčé ą▒ą╗ąŠą║ą░ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą▓ąĮąĄčłąĮčÅčÅ ą┐ą░ą╝čÅčéčī ą▓ąŠąĘą▓čĆą░čéąĖčé čüąĮą░čćą░ą╗ą░ čüą╗ąŠą▓ąŠ čåąĄą╗ąĄą▓ąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ą¤ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ą▒čāą┤ąĄčé ą▓ąŠąĘą▓čĆą░čēąĄąĮąŠ 3 čüą╗ąĄą┤čāčÄčēąĖčģ čüą╗ąŠą▓ą░, ą▓čŗą▒čĆą░ąĮąĮčŗčģ ąĖąĘ ą┐ą░ą╝čÅčéąĖ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ čü čāą▓ąĄą╗ąĖč湥ąĮąĖąĄą╝ ą░ą┤čĆąĄčüą░. ą¤čĆąĖ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ ą▓čŗą▒ąŠčĆą║ą░ ą┐ąŠą▓č鹊čĆčÅąĄčéčüčÅ ą┐ąŠ ą║čĆčāą│čā, ą║ą░ą║ čŹč鹊 ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ čéą░ą▒ą╗ąĖčåąĄ 6-1.
ąóą░ą▒ą╗ąĖčåą░ 6-1. ą¤ąŠčĆčÅą┤ąŠą║ ą▓čŗą▒ąŠčĆą║ąĖ čüą╗ąŠą▓ čüčéčĆąŠą║ąĖ ą║čŹčłą░.
ą”ąĄą╗ąĄą▓ąŠąĄ čüą╗ąŠą▓ąŠ ą¤ąŠčĆčÅą┤ąŠą║ ą▓čŗą▒ąŠčĆą║ąĖ ą┤ą╗čÅ čüą╗ąĄą┤čāčÄčēąĖčģ 3 čüą╗ąŠą▓
WD0
WD0, WD1, WD2, WD3
WD1
WD1, WD2, WD3, WD0
WD2
WD2, WD3, WD0, WD1
WD3
WD3, WD0, WD1, WD2
ąÜą░ą║ č鹊ą╗čīą║ąŠ čüčéčĆąŠą║ą░ ą║čŹčłą░ ąĘą░ą┐ąŠą╗ąĮąĄąĮą░, č湥čéčŗčĆąĄ 64-ą▒ąĖčéąĮčŗčģ čüą╗ąŠą▓ą░ ąĖą╝ąĄčÄčé čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą┐ąŠčĆčÅą┤ąŠą║ ą▓ ą║čŹčłąĄ, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮą░ čĆąĖčü. 6-5. ąŁč鹊 ąĖąĘą▒ą░ą▓ą╗čÅąĄčé ąŠčé ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ čüąŠčģčĆą░ąĮčÅčéčī ą╝ą╗ą░ą┤čłąĖąĄ 5 ą▒ąĖčé (ą▓čŗą▒ąŠčĆą║ą░ ą▒ą░ą╣čéą░) ą┐ąŠą╗ąĮąŠą│ąŠ ą░ą┤čĆąĄčüą░ čüą╗ąŠą▓ą░ ą▓ ąĘą░ą┐ąĖčüąĖ ą║čŹčłą░.
ąæčāč乥čĆ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ ą║čŹčłą░ . ąÜą░ą║ č鹊ą╗čīą║ąŠ ąĮąŠą▓ą░čÅ čüčéčĆąŠą║ą░ ą║čŹčłą░ ą┐ąŠą╗čāč湥ąĮą░ ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, ą║ą░ąČą┤ąŠąĄ 64-ą▒ąĖčéąĮąŠąĄ čüą╗ąŠą▓ąŠ ą▒čāč乥čĆąĖąĘąĖčĆčāąĄčéčüčÅ ą▓ čüčéčĆąŠą║ąĄ ą▒čāč乥čĆą░ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║čŹčłą░ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ čŹč鹊 ą▒čāą┤ąĄčé ąĘą░ą┐ąĖčüą░ąĮąŠ ą▓ 4-ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗą╣ ą▒ą░ąĮą║ ą┐ą░ą╝čÅčéąĖ L1. ąæčāč乥čĆ čüčéčĆąŠą║ąĖ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čÅą┤čĆčā ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ ą┤ą░ąĮąĮčŗą╝ ąĖčģ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ą║ą░ą║ č鹊ą╗čīą║ąŠ čüčéčĆąŠą║ą░ ą▒čŗą╗ą░ ą┐ąŠą╗čāč湥ąĮą░ ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, ą▒ąĄąĘ ąŠąČąĖą┤ą░ąĮąĖčÅ, ą┐ąŠą║ą░ ąŠąĮą░ ąĘą░ą┐ąĖčłąĄčéčüčÅ ą▓ ą║čŹčł. ąÆ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ą┐ąŠčĆčé L1 ą▒čāč乥čĆą░ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ ą▓čüąĄą│ą┤ą░ čłąĖčĆąĖąĮąŠą╣ 64 ą▒ąĖčéą░, čłąĖčĆąĖąĮą░ ą┐ąŠčĆčéą░ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ąĖą╗ąĖ ą║ ą┐ą░ą╝čÅčéąĖ L2 ą▓ą░čĆčīąĖčĆčāąĄčéčüčÅ ą╝ąĄąČą┤čā ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮčŗą╝ąĖ.
ąØąĄą║ąŠč鹊čĆčŗąĄ ą┐čĆąŠčåąĄčüčüąŠčĆčŗ Blackfin ąĖą╝ąĄčÄčé ą┐ą░ą╝čÅčéčī L2 čü ą┤ą▓čāą╝čÅ ąŠčéą┤ąĄą╗čīąĮčŗą╝ąĖ ą▒čāč乥čĆą░ą╝ąĖ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ, čćč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĘą░ą│čĆčāąĘą║ąĄ ąĖąĘ ą╝ąĄą┤ą╗ąĄąĮąĮąŠą╣ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ą┐čĆąŠą┤ąŠą╗ąČąĖčéčīčüčÅ ą▒ąĄąĘ ą┐ąĄčĆąĄčģąŠą┤ą░ ą┤ą╗čÅ ąŠčüčéą░ąĮąŠą▓ą║ąĖ ą║ ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąŠą╣ čüą║ąŠčĆąŠčüčéąĖ ą▓čüčéčĆąŠąĄąĮąĮąŠą╣ ą▓ čćąĖą┐ ą┐ą░ą╝čÅčéąĖ L2. ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ, ą║ą░ą║ąŠą╣ ą▒čāč乥čĆ čüčéčĆąŠą║ąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ, ąĘą░ą▓ąĖčüąĖčé ąŠčé ą▒ąĖčéą░ CPLB_MEMLEV čüčéčĆą░ąĮąĖčåą░čģ ą┐ą░ą╝čÅčéąĖ CPLB. ąĪą╝. čĆą░ąĘą┤ąĄą╗ "ąŚą░čēąĖčéą░ ąĖ čüą▓ąŠą╣čüčéą▓ą░ ą┐ą░ą╝čÅčéąĖ".
ąŚą░ą╝ąĄąĮą░ čüčéčĆąŠą║ąĖ ą║čŹčłą░ . ąÜąŠą│ą┤ą░ ą▒ą╗ąŠą║ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮ ą║ą░ą║ ą║čŹčł, ą▒ąĖčéčŗ 9 .. 5 ą░ą┤čĆąĄčüą░ ą▓čŗą▒ąŠčĆą║ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą║ą░ą║ ąĖąĮą┤ąĄą║čü ą┤ą╗čÅ ą▓čŗą▒ąŠčĆą║ąĖ ąĮą░ą▒ąŠčĆą░ ą║čŹčłą░ ą┤ą╗čÅ ąŠą┐ąĄčĆą░čåąĖąĖ čüčĆą░ą▓ąĮąĄąĮąĖčÅ čé菹│-ą░ą┤čĆąĄčü. ąĢčüą╗ąĖ ąŠą┐ąĄčĆą░čåąĖčÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ čé菹│-ą░ą┤čĆąĄčü ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ą┐čĆąŠą╝ą░čģčā ą║čŹčłą░, č鹊 ą▒ąĖčéčŗ Valid ąĖ LRU ą┤ą╗čÅ ą▓čŗą▒čĆą░ąĮąĮąŠą│ąŠ ąĮą░ą▒ąŠčĆą░ ą┐čĆąŠą▓ąĄčĆčÅčÄčéčüčÅ ą▒ą╗ąŠą║ąŠą╝ ąĘą░ą╝ąĄąĮčŗ čüčéčĆąŠą║ąĖ ą║čŹčłą░, čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ąĘą░ą┐ąĖčüčī ą┤ą╗čÅ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ ą║čŹčłą░, čé. ąĄ. ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą╗ąĖ Way0, Way1, Way2 ąĖą╗ąĖ Way3. ąĪą╝. čĆąĖčü. 6-5.
ąæą╗ąŠą║ ąĘą░ą╝ąĄąĮčŗ čüčéčĆąŠą║ąĖ ą║čŹčłą░ čüąĮą░čćą░ą╗ą░ ą┐čĆąŠą▓ąĄčĆčÅąĄčé ą║čŹčł ąĮą░ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗąĄ ąĘą░ą┐ąĖčüąĖ (čé. ąĄ. ą▓ ą║ąŠč鹊čĆčŗčģ ą▒ąĖčé Valid ąŠčćąĖčēąĄąĮ). ąĢčüą╗ąĖ ąĮą░ą╣ą┤ąĄąĮą░ č鹊ą╗čīą║ąŠ ąŠą┤ąĮą░ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮą░čÅ ąĘą░ą┐ąĖčüčī, č鹊 čŹčéą░ ąĘą░ą┐ąĖčüčī ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ą┤ą╗čÅ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ ą║čŹčłą░. ąĢčüą╗ąĖ ąĮą░ą╣ą┤ąĄąĮąŠ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗčģ ąĘą░ą┐ąĖčüąĄą╣, č鹊 ąĘą░ą╝ąĄąĮčÅąĄą╝ą░čÅ ąĘą░ą┐ąĖčüčī ą┤ą╗čÅ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ą┐ąŠ čüą╗ąĄą┤čāčÄčēąĄą╝čā ą┐čĆąĖąŠčĆąĖč鹥čéčā:
ŌĆó ąĪąĮą░čćą░ą╗ą░ Way0
ąØą░ą┐čĆąĖą╝ąĄčĆ:
ŌĆó ąĢčüą╗ąĖ Way3 ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĄąĮ, ąĖ Ways0, 1, 2 ą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗ, č鹊 Way3 ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ą┤ą╗čÅ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ ą║čŹčłą░.
ąÜąŠą│ą┤ą░ ąĮąĄ ąĮą░ą╣ą┤ąĄąĮąŠ ąĮąĖ ąŠą┤ąĮąŠą╣ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą╣ ąĘą░ą┐ąĖčüąĖ, č鹊 ą╗ąŠą│ąĖą║ą░ ąĘą░ą╝ąĄąĮčŗ ą║čŹčłą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą░ą╗ą│ąŠčĆąĖčéą╝ LRU.
ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą║čŹčłąĄą╝ ąĖąĮčüčéčĆčāą║čåąĖą╣ . ąĪąĖčüč鹥ą╝ąĮčŗą╣ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ DMA ąĖ DAG-ąĖ čÅą┤čĆą░ ąĮąĄ ą╝ąŠą│čāčé ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ ą║čŹčłčā ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĮą░ą┐čĆčÅą╝čāčÄ. ąÜąŠą╝ą▒ąĖąĮą░čåąĖąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ MMR čÅą┤čĆą░ ą╝ąŠąČąĮąŠ ą║ąŠčüą▓ąĄąĮąĮąŠ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī ą╝ą░čüčüąĖą▓čŗ čé菹│ą░ ąĖ ą┤ą░ąĮąĮčŗčģ, ąĖ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī ą╝ąĄčģą░ąĮąĖąĘą╝ ą┤ą╗čÅ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ, ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ ąĖ ąŠčéą╗ą░ą┤ą║ąĖ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣. ąĪą╝. čĆą░ąĘą┤ąĄą╗ "ąĪą▒čĆąŠčü ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéąĖ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣".
ąÜąŠą│ąĄčĆąĄąĮčéąĮąŠčüčéčīčÄ ą║čŹčłą░ ąĮčāąČąĮąŠ čÅą▓ąĮąŠ čāą┐čĆą░ą▓ą╗čÅčéčī. ą¦č鹊ą▒čŗ ą▓čŗą┐ąŠą╗ąĮąĖčéčī čŹč鹊 ąĖ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĘą░ą┐ąŠą╗ąĮąĄąĮ ą┐ąŠčüą╗ąĄą┤ąĮąĄą╣ ą▓ąĄčĆčüąĖąĄą╣ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣, ąĮčāąČąĮą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéąĖ ąĘą░ą┐ąĖčüąĄą╣ čüčéčĆąŠą║ąĖ ą║čŹčłą░.
ą¤ąŠčüčéčĆąŠčćąĮą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ . ąæąĖčéčŗ CPLB_LRUPRIO ą▓ čĆąĄą│ąĖčüčéčĆą░čģ ICPLB_DATAx (čüą╝. čĆą░ąĘą┤ąĄą╗ "ąŚą░čēąĖčéą░ ąĖ čüą▓ąŠą╣čüčéą▓ą░ ą┐ą░ą╝čÅčéąĖ") ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ čāą╗čāčćčłąĄąĮąĖčÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą║ąŠą┤ąŠą╝, ą║ąŠč鹊čĆčŗą╣ ąŠčüčéą░ąĄčéčüčÅ čĆąĄąĘąĖą┤ąĄąĮčéąĮčŗą╝ ą▓ ą║čŹčłąĄ ąĖąĮčüčéčĆčāą║čåąĖą╣. ąÜąŠą│ą┤ą░ čüčéčĆąŠą║ą░ ą║čŹčłą░ ąĘą░ą┐ąŠą╗ąĮąĄąĮą░, čüąŠčüč鹊čÅąĮąĖąĄ čŹčéąĖčģ ą▒ąĖčé čüąŠčģčĆą░ąĮčÅąĄčéčüčÅ ą▓ą╝ąĄčüč鹥 čü č鹥ą│ąŠą╝ čüčéčĆąŠą║ąĖ. ąŁč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą▓ čüąŠąĄą┤ąĖąĮąĄąĮąĖąĖ čü ą┐ąŠą╗ąĖčéąĖą║ąŠą╣ LRU, čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, ą║ą░ą║ąŠą╣ ą║ą░ąĮą░ą╗ (Way) ą▒čāą┤ąĄčé ąČąĄčĆčéą▓ąŠą╣, ą║ąŠą│ą┤ą░ ą▓čüąĄ ą║ą░ąĮą░ą╗čŗ ą║čŹčłą░ ąĘą░ąĮčÅčéčŗ ą┐čĆąĖ ą▓čŗą▒ąŠčĆą║ąĄ ąĮąŠą▓ąŠą╣ ą║čŹčłąĖčĆčāąĄą╝ąŠą╣ čüčéčĆąŠą║ąĖ. ąŁč鹊čé ą▒ąĖčé ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą▓ą░ąČąĮąŠčüčéčī čüčéčĆąŠą║ąĖ - "low" (ąĮąĖąĘą║ą░čÅ) ąĖą╗ąĖ "high" (ą▓čŗčüąŠą║ą░čÅ). ąÆ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮąŠą╣ ą┐ąŠą╗ąĖčéąĖą║ąĄ LRU, high ą╝ąŠąČąĄčé ąĘą░ą╝ąĄąĮąĖčéčī low, ąĮąŠ low ąĮąĄ ą╝ąŠąČąĄčé ąĘą░ą╝ąĄąĮąĖčéčī high. ąĢčüą╗ąĖ ą▓čüąĄ ą║ą░ąĮą░ą╗čŗ ąĘą░ąĮčÅčéčŗ čüčéčĆąŠą║ą░ą╝ąĖ high, ą║čŹčłąĖčĆčāąĄą╝čŗąĄ low ą▓čüąĄ ąĄčēąĄ ą▒čāą┤čāčé ą▓čŗą▒ąĖčĆą░čéčīčüčÅ čÅą┤čĆąŠą╝, ąĮąŠ ąĮąĄ ą▒čāą┤čāčé ą║čŹčłąĖčĆąŠą▓ą░čéčīčüčÅ. ąÆčŗą▒ąŠčĆą║ą░ čüčéčĆąŠą║ high čüčéčĆąĄą╝čÅčéčüčÅ čüąĮą░čćą░ą╗ą░ ąĘą░ą╝ąĄąĮąĖčéčī ąĮąĄ ąĘą░ąĮčÅčéčŗąĄ Way, ąĘą░č鹥ą╝ čüą░ą╝čŗąĄ čĆąĄą┤ą║ąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ, ąĖ ąĮą░ą║ąŠąĮąĄčå ą┤čĆčāą│ąĖąĄ high-čüčéčĆąŠą║ąĖ ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü ą┐ąŠą╗ąĖčéąĖą║ąŠą╣ LRU. Low-čüčéčĆąŠą║ąĖ ą╝ąŠą│čāčé ąĘą░ą╝ąĄąĮąĖčéčī č鹊ą╗čīą║ąŠ ąĮąĄ ąĘą░ąĮčÅčéčŗąĄ Way ąĖą╗ąĖ ą┤čĆčāą│ąĖąĄ low-čüčéčĆąŠą║ąĖ, ąĖ čéą░ą║ąČąĄ ą┐čĆąĖ čŹč鹊ą╝ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą┐ąŠą╗ąĖčéąĖą║čā LRU. ąöą░ąČąĄ ąĄčüą╗ąĖ ą▓čüąĄ čĆą░ąĮąĄąĄ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĮčŗąĄ high-čüčéčĆąŠą║ąĖ čüčéą░ą╗ąĖ ą╝ąĄąĮąĄąĄ ą▓ą░ąČąĮčŗ, ąŠąĮąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮčŗ ą▓ low-čüčéčĆąŠą║ąĖ ą┐čāč鹥ą╝ ąĘą░ą┐ąĖčüąĖ ą▒ąĖčéą░ LRUPRIRST ą▓ čĆąĄą│ąĖčüčéčĆąĄ IMEM_CONTROL (čüą╝. čĆą░ąĘą┤ąĄą╗ "ąĀąĄą│ąĖčüčéčĆ IMEM_CONTROL").
ą¤ąŠą║ą░ąĮą░ą╗čīąĮą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ . ąÜčŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖą╝ąĄąĄčé 4 ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗąĄ ą▒ąĖčéą░ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ (ILOC[3:0]), ą║ąŠč鹊čĆčŗąĄ čāą┐čĆą░ą▓ą╗čÅčÄčé ą║ą░ąČą┤čŗą╝ ąĖąĘ 4 ą║ą░ąĮą░ą╗ąŠą▓ (Way) ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąÜąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮ ą║čŹčł, ą┐ą░ą╝čÅčéčī ąĖąĮčüčéčĆčāą║čåąĖą╣ L1 ąĖą╝ąĄąĄčé 4 ą┤ąŠčüčéčāą┐ąĮčŗąĄ ą║ą░ąĮą░ą╗ą░. ąŻčüčéą░ąĮąŠą▓ą║ą░ ą▒ąĖčéą░ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą┤ą╗čÅ ąŠčéą┤ąĄą╗čīąĮąŠą│ąŠ ą║ą░ąĮą░ą╗ą░ ą▓čŗą▓ąŠą┤ąĖčé čŹč鹊čé ą║ą░ąĮą░ą╗ ąĖąĘ čāčćą░čüčéąĖčÅ ą▓ ą┐ąŠą╗ąĖčéąĖą║ąĄ ąĘą░ą╝ąĄąĮčŗ LRU. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ąĖąĮčüčéčĆčāą║čåąĖčÅ, ąĘą░ą║čŹčłąĖčĆąŠą▓ą░ąĮąĮą░čÅ čŹčéąĖą╝ ą║ą░ąĮą░ą╗ąŠą╝, ą▒čāą┤ąĄčé ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮą░, ąĖ ąĄčæ ą╝ąŠąČąĮąŠ čāą┤ą░ą╗ąĖčéčī č鹊ą╗čīą║ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ąĖąĮčüčéčĆčāą║čåąĖąĖ IFLUSH, ąĖą╗ąĖ "č湥čĆąĮčŗą╝ čģąŠą┤ąŠą╝" ą┐čĆąĖ ą╝ą░ąĮąĖą┐čāą╗čÅčåąĖąĖ ą╝ą░čüčüąĖą▓ąŠą╝ č鹥ą│ąŠą▓ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ MMR.
ąØąĖąČąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮ ą┐čĆąĖą╝ąĄčĆ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ ą┤ą╗čÅ ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąĖ, ą║ą░ą║ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░čéčī Way0:
ŌĆó ąĢčüą╗ąĖ ąĖąĮč鹥čĆąĄčüčāčÄčēąĖą╣ ą║ąŠą┤ čāąČąĄ ą╝ąŠąČąĄčé ąĮą░čģąŠą┤ąĖčéčīčüčÅ ą▓ ą║čŹčłąĄ ąĖąĮčüčéčĆčāą║čåąĖą╣, čüąĮą░čćą░ą╗ą░ čüą┤ąĄą╗ą░ą╣č鹥 ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝ ą▓ąĄčüčī ą║čŹčł (ą┤ą╗čÅ ą┐čĆąĖą╝ąĄčĆą░ čüą╝. čĆą░ąĘą┤ąĄą╗ "ąĪą▒čĆąŠčü ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéąĖ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣").
ąĢčüą╗ąĖ ą▓čüąĄ 4 ą║ą░ąĮą░ą╗ą░ ą║čŹčłą░ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮčŗ, č鹊 ą▓čüąĄ ą▒čāą┤čāčēąĖąĄ čĆą░ąĘą╝ąĄčēąĄąĮąĖčÅ ą║ąŠą┤ą░ ą▓ ą║čŹčłąĄ ąŠčüčāčēąĄčüčéą▓ą╗čÅčéčīčüčÅ ąĮąĄ ą▒čāą┤čāčé.
ąĪą▒čĆąŠčü ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéąĖ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ . ąÜčŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣ ą╝ąŠąČąĮąŠ čüą┤ąĄą╗ą░čéčī ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝ ą┐ąŠ ą░ą┤čĆąĄčüčā, ą┐ąŠ čüčéčĆąŠą║ąĄ ą║čŹčłą░, ąĖą╗ąĖ ą┐ąŠą╗ąĮąŠčüčéčīčÄ čüą┤ąĄą╗ą░čéčī ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝ ą▓ąĄčüčī ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣. ąśąĮčüčéčĆčāą║čåąĖčÅ IFLUSH ą╝ąŠąČąĄčé čÅą▓ąĮąŠ ąŠčéą╝ąĄąĮąĖčéčī ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéčī čüčéčĆąŠą║ ą║čŹčłą░ ąĮą░ ą▒ą░ąĘąĄ ąĖčģ ą░ą┤čĆąĄčüąŠą▓ čüčéčĆąŠą║. ą”ąĄą╗ąĄą▓ąŠą╣ ą░ą┤čĆąĄčü ąĖąĮčüčéčĆčāą║čåąĖąĖ ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ąĖąĘ P-čĆąĄą│ąĖčüčéčĆąŠą▓. ą¤ąŠčüą║ąŠą╗čīą║čā ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĮąĄ ą┤ąŠą╗ąČąĄąĮ čüąŠą┤ąĄčƹȹ░čéčī ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮčŗčģ (ą│čĆčÅąĘąĮčŗčģ) ą┤ą░ąĮąĮčŗčģ, č鹊 čüčéčĆąŠą║ą░ ą║čŹčłą░ ą┐čĆąŠčüč鹊 ą┤ąĄą╗ą░ąĄčéčüčÅ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą╣, ąĄčæ ąĮąĄ ąĮą░ą┤ąŠ čüąĖąĮčģčĆąŠąĮąĖąĘąĖčĆąŠą▓ą░čéčī čü ą▓ąĮąĄčłąĮąĖą╝ ąĮąŠčüąĖč鹥ą╗ąĄą╝ (čé. ąĄ. ąĮąĄ ąĮčāąČąĮą░ ąŠą┐ąĄčĆą░čåąĖčÅ čüą▒čĆąŠčüą░ "flush").
ąÆ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ čĆąĄą│ąĖčüčéčĆ P2 čüąŠą┤ąĄčƹȹĖčé ą░ą┤čĆąĄčü ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą│ąŠ ą╝ąĄčüčéą░ ą▓ ą┐ą░ą╝čÅčéąĖ. ąĢčüą╗ąĖ čŹč鹊čé ą░ą┤čĆąĄčü ą▒čŗą╗ ą▓ąĮąĄčüąĄąĮ ą▓ ą║čŹčł, č鹊 čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēą░čÅ čüčéčĆąŠą║ą░ ą║čŹčłą░ čüčéą░ąĮąĄčé ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą╣ ą┐ąŠčüą╗ąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
ąŁč鹊čé ą┐čĆąĖą╝ąĄčĆ ąĖąĮčüčéčĆčāą║čåąĖąĖ IFLUSH:
iflush [p2]; /* ąĪą▒čĆąŠčü ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéąĖ čüčéčĆąŠą║ąĖ ą║čŹčłą░, čüąŠą┤ąĄčƹȹ░čēąĄą╣ ą░ą┤čĆąĄčü,
ąĮą░ ą║ąŠč鹊čĆčŗą╣ čāą║ą░ąĘčŗą▓ą░ąĄčé P2. */
ą¤ąŠčüą║ąŠą╗čīą║čā ąĖąĮčüčéčĆčāą║čåąĖčÅ IFLUSH ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ čüą▒čĆąŠčüą░ ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéąĖ ąŠčéą┤ąĄą╗čīąĮąŠą│ąŠ ą░ą┤čĆąĄčüą░ ą▓ ą║ą░čĆč鹥 ą┐ą░ą╝čÅčéąĖ, ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą╣ ąĄą╝čā čüčéčĆąŠą║ąĖ ą║čŹčłą░, č鹊 čŹč鹊 čÅą▓ą╗čÅąĄčéčüčÅ čüą░ą╝čŗą╝ ą┐ąŠą╗ąĄąĘąĮčŗą╝, ą║ąŠą│ą┤ą░ ą┐ąĄčĆąĄą▓ąŠą┤ąĖą╝čŗą╣ ą▓ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ ą▒čāč乥čĆ ą╝ąĄąĮčīčłąĄ, č湥ą╝ čĆą░ąĘą╝ąĄčĆ ą▓čüąĄą│ąŠ ą║čŹčłą░. ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ą┐ąŠ ąĖąĮčüčéčĆčāą║čåąĖąĖ IFLUSH čüą╝. ą▓ čĆą░ąĘą┤ąĄą╗ąĄ 17 "Cache Control" [5]. ąÆč鹊čĆą░čÅ č鹥čģąĮąĖą║ą░ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ą┐čĆčÅą╝ąŠą│ąŠ ą┐ąĄčĆąĄą▓ąŠą┤ą░ ą▓ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ ą▒ąŠą╗čīčłąĖčģ ą┐ąŠčĆčåąĖą╣ ą║čŹčłą░. ąÆ čŹč鹊ą╣ č鹥čģąĮąĖą║ąĄ ąĮą░ą┐čĆčÅą╝čāčÄ ą┤ąĄą╗ą░ąĄčé ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝ąĖ ą▒ąĖčéčŗ Valid ą┐čāč鹥ą╝ čāčüčéą░ąĮąŠą▓ą║ąĖ ą▒ąĖčéą░ Invalid ą║ą░ąČą┤ąŠą╣ čüčéčĆąŠą║ąĖ ą║čŹčłą░, ą┐ąĄčĆąĄą▓ąŠą┤čÅ ąĄčæ ą▓ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ. ąöą╗čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čŹč鹊ą╣ č鹥čģąĮąĖą║ąĖ ąĖą╝ąĄčÄčéčüčÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ MMR (ITEST_COMMAND ąĖ ITEST_DATA[1:0]), ą║ąŠč鹊čĆčŗąĄ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮąŠ čćąĖčéą░čéčī/ąĘą░ą┐ąĖčüčŗą▓ą░čéčī ą▓čüąĄ ąĘą░ą┐ąĖčüąĖ ą║čŹčłą░. ąŁč鹊čé ą╝ąĄč鹊ą┤ ąŠą▒čüčāąČą┤ą░ąĄčéčüčÅ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╣ čüąĄą║čåąĖąĖ čüčéą░čéčīąĖ.
ą¦č鹊ą▒čŗ čüą┤ąĄą╗ą░čéčī ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝ ą▓ąĄčüčī ą║čŹčł, ąĄčüčéčī čéčĆąĄčéąĖą╣ ą╝ąĄč鹊ą┤. ą¤čāč鹥ą╝ ąŠčćąĖčüčéą║ąĖ ą▒ąĖčéą░ IMC ą▓ čĆąĄą│ąĖčüčéčĆąĄ IMEM_CONTROL (čüą╝. čĆąĖčü. 6-2), ą▓čüąĄ ą▒ąĖčéčŗ Valid ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čÄčéčüčÅ ą▓ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ. ąÆč鹊čĆą░čÅ ąĘą░ą┐ąĖčüčī ą▓ čĆąĄą│ąĖčüčéčĆ IMEM_CONTROL ą┤ą╗čÅ čāčüčéą░ąĮąŠą▓ą║ąĖ ą▒ąĖčéą░ IMC ąĘą░ąĮąŠą▓ąŠ ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄčé ą┐ą░ą╝čÅčéčī ąĖąĮčüčéčĆčāą║čåąĖą╣ ą║ą░ą║ ą║čŹčł. ą¤ąĄčĆąĄą┤ ą┐ąĄčĆąĄą▓ąŠą┤ąŠą╝ ą║čŹčłą░ ą▓ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ SSYNC, ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅ CSYNC ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ą▓čüčéą░ą▓ą╗ąĄąĮą░ ą┐ąŠčüą╗ąĄ ą║ą░ąČą┤ąŠą╣ ąĖąĘ čŹčéąĖčģ ąŠą┐ąĄčĆą░čåąĖą╣.
[ąĀąĄą│ąĖčüčéčĆčŗ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ]
ą£ąĄčģą░ąĮąĖąĘą╝ąŠą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ čćč鹥ąĮąĖčÅ ąĖ ą╝ą░ąĮąĖą┐čāą╗čÅčåąĖąĖ ą┐ą░ą╝čÅčéčīčÄ ąĖąĮčüčéčĆčāą║čåąĖą╣ L1 (ą▓ąĮąĄ DMA) čÅą▓ą╗čÅčÄčéčüčÅ čĆąĄą│ąĖčüčéčĆčŗ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ (Instruction Test registers). ąŁčéąĖ čĆąĄą│ąĖčüčéčĆčŗ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé čéą░ą║ąČąĄ ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮąŠ ąĮą░ą┐čĆčÅą╝čāčÄ čćąĖčéą░čéčī/ąĘą░ą┐ąĖčüčŗą▓ą░čéčī ą▓čüąĄ ąĘą░ą┐ąĖčüąĖ ą║čŹčłą░ L1. ąĀąĄą│ąĖčüčéčĆčŗ ą┐čĆąŠą▓ąĄčĆą║ąĖ ą┤ąĄą╗ą░čÄčé ą▓ąŠąĘą╝ąŠąČąĮčŗą╝ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī ą╝ą░čüčüąĖą▓čŗ čé菹│ąŠą▓ ąĖ ą┤ą░ąĮąĮčŗčģ ą║čŹčłą░ ąĖ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčéčī ą╝ąĄčģą░ąĮąĖąĘą╝ ą┤ą╗čÅ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ ąĖ ąŠčéą╗ą░ą┤ą║ąĖ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣. ąĪąŠą┤ąĄčƹȹĖą╝ąŠąĄ ROM ąĖąĮčüčéčĆčāą║čåąĖą╣ L1 ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠčćąĖčéą░ąĮąŠ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą╝ąĄčģą░ąĮąĖąĘą╝ą░ ITEST.
ąÜąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čĆąĄą│ąĖčüčéčĆ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ (Instruction Test Command register, ITEST_COMMAND), ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ ą║ ą╝ą░čüčüąĖą▓ą░ą╝ č鹥ą│ąŠą▓ ąĖ ą┤ą░ąĮąĮčŗčģ ą║čŹčłą░ L1, ąĖ ą┤ą░ąĮąĮčŗąĄ ą┐ąĄčĆąĄą┤ą░čÄčéčüčÅ č湥čĆąĄąĘ čĆąĄą│ąĖčüčéčĆčŗ ą┐čĆąŠą▓ąĄčĆą║ąĖ ą┤ą░ąĮąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖąĖ (Instruction Test Data registers, ITEST_DATA[1:0]). ąĀąĄą│ąĖčüčéčĆčŗ ITEST_DATAx čüąŠą┤ąĄčƹȹ░čé ą╗ąĖą▒ąŠ 64-ą▒ąĖčéąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ čü ą┤ąŠčüčéčāą┐ąŠą╝ ąĮą░ ąĘą░ą┐ąĖčüčī, ą╗ąĖą▒ąŠ 64-ą▒ąĖčéąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ ą┐čĆąŠčćąĖčéą░ąĮčŗ ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ. ą£ą╗ą░ą┤čłąĖąĄ 32 ą▒ąĖčéą░ čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ITEST_DATA[0], ąĖ čüčéą░čĆčłąĖąĄ 32 ą▒ąĖčéą░ čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ITEST_DATA[1]. ąÜąŠą│ą┤ą░ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ ą║ ą╝ą░čüčüąĖą▓ą░ą╝ čé菹│ąŠą▓, č鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ITEST_DATA[0]. ąōčĆą░čäąĖč湥čüą║ąŠąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ čĆąĄą│ąĖčüčéčĆąŠą▓ ITEST ąĮą░čćąĖąĮą░ąĄčéčüčÅ ąĮą░ čĆąĖčüčāąĮą║ąĄ 6-8.
ąöąŠčüčéčāą┐ ą║ čŹčéąĖą╝ čĆąĄą│ąĖčüčéčĆą░ą╝ ą▓ąŠąĘą╝ąŠąČąĄąĮ č鹊ą╗čīą║ąŠ ą▓ čĆąĄąČąĖą╝ąĄ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ ąĖą╗ąĖ 菹╝čāą╗čÅčåąĖąĖ. ąÜąŠą│ą┤ą░ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ čĆąĄą│ąĖčüčéčĆčŗ ITEST, ą▓čüąĄą│ą┤ą░ čüąĮą░čćą░ą╗ą░ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ čĆąĄą│ąĖčüčéčĆčŗ ITEST_DATAx, ąĖ ąĘą░č鹥ą╝ čĆąĄą│ąĖčüčéčĆčŗ ITEST_COMMAND. ąÜąŠą│ą┤ą░ čćąĖčéą░čÄčéčüčÅ čĆąĄą│ąĖčüčéčĆčŗ ITEST, ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ąŠą▒čĆą░čéąĮą░čÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī - čüąĮą░čćą░ą╗ą░ čćąĖčéą░ąĄčéčüčÅ ITEST_COMMAND, ąĘą░č鹥ą╝ čĆąĄą│ąĖčüčéčĆčŗ ITEST_DATAx.
ąÜąŠą│ą┤ą░ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ čĆąĄą│ąĖčüčéčĆ ą┐čĆąŠą▓ąĄčĆą║ąĖ ą║ąŠą╝ą░ąĮą┤čŗ (Instruction Test Command register, ITEST_COMMAND), ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ ą║ ą╝ą░čüčüąĖą▓ą░ą╝ ą┤ą░ąĮąĮčŗčģ ąĖą╗ąĖ čé菹│ąŠą▓ ą║čŹčłą░ L1, ąĖ ą┤ą░ąĮąĮčŗąĄ ą┐ąĄčĆąĄą┤ą░čÄčéčüčÅ č湥čĆąĄąĘ čĆąĄą│ąĖčüčéčĆčŗ ą┐čĆąŠą▓ąĄčĆą║ąĖ ą┤ą░ąĮąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖąĖ (Instruction Test Data registers, ITEST_DATA[1:0]).
ąĀąĖčü. 6-7. Instruction Test Command Register (ADSP-BF5xx).
WAYSEL[1:0] (Access Way). ąŁčéąĖ ą▒ąĖčéčŗ ą▓čŗą▒ąĖčĆą░čÄčé ą║ą░ąĮą░ą╗ ą┤ąŠčüčéčāą┐ą░ (ą▒ąĖčéčŗ ą░ą┤čĆąĄčüą░ 11..10 SRAM).
00: ą┤ąŠčüčéčāą┐ č湥čĆąĄąĘ ą║ą░ąĮą░ą╗ Way0.
SBNK[1:0] (Subbank Access). ąŁčéąĖ ą▒ąĖčéčŗ ą▓čŗą▒ąĖčĆą░čÄčé ą┐ąŠą┤ą▒ą░ąĮą║ (ą▒ąĖčéčŗ ą░ą┤čĆąĄčüą░ 13..12 SRAM).
00: ą┤ąŠčüčéčāą┐ ą║ subbank 0.
SET[4:0] (Set Index). ąŻčüčéą░ąĮąŠą▓ą║ą░ ąĖąĮą┤ąĄą║čüą░ - ą▓čŗą▒ąĖčĆą░ąĄčé ąŠą┤ąĖąĮ ąĖąĘ 32 ąĮą░ą▒ąŠčĆąŠą▓ (ą▒ąĖčéčŗ ą░ą┤čĆąĄčüą░ 9..5 SRAM).
DW[1:0] (Double Word Index). ąśąĮą┤ąĄą║čü ą┤ą▓ąŠą╣ąĮąŠą│ąŠ čüą╗ąŠą▓ą░ - ą▓čŗą▒ąĖčĆą░ąĄčé ąŠą┤ąĮąŠ ąĖąĘ č湥čéčŗčĆąĄčģ 64-ą▒ąĖčéąĮčŗčģ ą┤ą▓ąŠą╣ąĮčŗčģ čüą╗ąŠą▓ ą▓ 256-ą▒ąĖčéąĮąŠą╣ čüčéčĆąŠą║ąĄ (ą▒ąĖčéčŗ 4..3 ą░ą┤čĆąĄčüą░ SRAM).
RW (Read/Write Access). ąŁč鹊čé ą▒ąĖčé ą▓čŗą▒ąĖčĆą░ąĄčé čĆąĄąČąĖą╝ ą┤ąŠčüčéčāą┐ą░: 0 čćč鹥ąĮąĖąĄ, 1 ąĘą░ą┐ąĖčüčī.
TAGSELB (Array Access). ąŁč鹊čé ą▒ąĖčé ą▓čŗą▒ąĖčĆą░ąĄčé, ą║ ą║ą░ą║ąŠą╝čā ą╝ą░čüčüąĖą▓čā ąĮčāąČąĄąĮ ą┤ąŠčüčéčāą┐: 0 ą╝ą░čüčüąĖą▓ čé菹│ąŠą▓, 1 ą╝ą░čüčüąĖą▓ ą┤ą░ąĮąĮčŗčģ.
ąĪčéą░čĆčłąĖą╣ ąĖąĘ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┐čĆąŠą▓ąĄčĆą║ąĖ ą┤ą░ąĮąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖąĖ (Instruction Test Data registers, ITEST_DATA[1:0]) ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą╝ą░čüčüąĖą▓ą░ą╝ ą┤ą░ąĮąĮčŗčģ ąĖ ą╝ą░čüčüąĖą▓ą░ą╝ č鹥ą│ąŠą▓ ą║čŹčłą░ L1. ą×ą▒ą░ čŹčéąĖčģ čĆąĄą│ąĖčüčéčĆą░ čüąŠą┤ąĄčƹȹ░čé ą╗ąĖą▒ąŠ 64-ą▒ąĖčéąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ, ą╗ąĖą▒ąŠ 64-ą▒ąĖčéąĮčŗąĄ ą┐čĆąŠčćąĖčéą░ąĮąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ. ITEST_DATA1 čüąŠą┤ąĄčƹȹĖčé čüčéą░čĆčłąĖąĄ 32 ą▒ąĖčéą░. ą¤čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ ą╝ą░čüčüąĖą▓čā ą┤ą░ąĮąĮčŗčģ ąĘą┤ąĄčüčī čüąŠą┤ąĄčƹȹ░čéčüčÅ 32 čüčéą░čĆčłąĖčģ ą▒ąĖčéą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖąĘ 64-ą▒ąĖčéąĮąŠą│ąŠ čüą╗ąŠą▓ą░ - ą╗ąĖą▒ąŠ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ, ą╗ąĖą▒ąŠ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ.
ąĀąĖčü. 6-9. Instruction Test Data 1 Register.
ąĀąĄą│ąĖčüčéčĆ ą┐čĆąŠą▓ąĄčĆą║ąĖ ą┤ą░ąĮąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖąĖ 0 (Instruction Test Data 0 register, ITEST_DATA0) čģčĆą░ąĮąĖčé ą╝ą╗ą░ą┤čłąĖąĄ 32 ą▒ąĖčéą░ ąĖąĘ 64-ą▒ąĖčéąĮčŗčģ ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗąĄ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ ąĖą╗ąĖ čćąĖčéą░čÄčéčüčÅ ą┐čĆąĖ ąŠčüčāčēąĄčüčéą▓ą╗ąĄąĮąĖąĖ ą┤ąŠčüčéčāą┐ą░ ą║ ą║čŹčłčā L1. ąĀąĄą│ąĖčüčéčĆ ITEST_DATA0 čéą░ą║ąČąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą╝ą░čüčüąĖą▓ą░ą╝ č鹥ą│ąŠą▓. ąóą░ą║ąČąĄ čŹč鹊čé čĆąĄą│ąĖčüčéčĆ čüąŠą┤ąĄčƹȹĖčé ą▒ąĖčéčŗ Valid ąĖ Dirty, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčé čüąŠčüč鹊čÅąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░. ą£ą╗ą░ą┤čłąĖąĄ 32 ą▒ąĖčéą░ čĆąĄą│ąĖčüčéčĆą░ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą╝ą░čüčüąĖą▓ą░ą╝ čé菹│ąŠą▓ ą║čŹčłą░ L1.
ąĀąĖčü. 6-10. Instruction Test Data 0 Register.
Data [31:0] . ą£ą╗ą░ą┤čłąĖąĄ 32 ą▒ąĖčéą░ 64-ą▒ąĖčéąĮčŗčģ ą┤ą░ąĮąĮčŗčģ.
Tag[19:4] , Tag[3:2] , Tag[1:0] . ąÉą┤čĆąĄčü čé菹│ą░ čüąŠčüč鹊ąĖčé ąĖąĘ čüčéą░čĆčłąĖčģ 18 ą▒ąĖčé ąĖ ą▒ąĖč鹊ą▓ 11 ąĖ 10 čäąĖąĘąĖč湥čüą║ąŠą│ąŠ ą░ą┤čĆąĄčüą░ (ą┐ąŠą╗čÅ Tag[19:4], Tag[3:2], Tag[1:0] čüąŠą┤ąĄčƹȹ░čé 20 ą▒ąĖčé ą░ą┤čĆąĄčüą░ č鹥ą│ą░).
Valid . ąĢčüą╗ąĖ ą▓ čŹč鹊ą╝ ą▒ąĖč鹥 0, č鹊 čüčéčĆąŠą║ą░ ą║čŹčłą░ ąĮąĄ ą┤ąŠčüč鹊ą▓ąĄčĆąĮą░.
LRUPRIO . ąĢčüą╗ąĖ ą▓ čŹč鹊ą╝ ą▒ąĖč鹥 0, č鹊 ą┤ą╗čÅ čŹč鹊ą╣ ąĘą░ą┐ąĖčüąĖ LRUPRIO ąŠčćąĖčēąĄąĮ. ąĢčüą╗ąĖ 1, č鹊 ą┤ą╗čÅ čŹč鹊ą╣ ąĘą░ą┐ąĖčüąĖ LRUPRIO čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ.
[ą¤ą░ą╝čÅčéčī ą┤ą░ąĮąĮčŗčģ L1 ]
L1 ą┤ą░ąĮąĮčŗąĄ SRAM/ą║čŹčł ą┐ąŠčüčéčĆąŠąĄąĮčŗ ąĖąĘ ąŠą┤ąĮąŠą┐ąŠčĆč鹊ą▓čŗčģ ą┐ąŠą┤čĆą░ąĘą┤ąĄą╗ąŠą▓, ąĮąŠ ąŠčĆą│ą░ąĮąĖąĘąŠą▓ą░ąĮčŗ ą┤ą╗čÅ čāą╝ąĄąĮčīčłąĄąĮąĖčÅ ą▓ąĄčĆąŠčÅčéąĮąŠčüčéąĖ ą║ąŠą╗ą╗ąĖąĘąĖą╣ ą┤ąŠčüčéčāą┐ą░. ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 čŹčéą░ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖčÅ ą▓ąĄą┤ąĄčé čüąĄą▒čÅ ą║ą░ą║ ą╝ąĮąŠą│ąŠą┐ąŠčĆč鹊ą▓ą░čÅ. ąÜąŠą│ą┤ą░ ąĮąĄčé ą║ąŠą╗ą╗ąĖąĘąĖą╣, čüą╗ąĄą┤čāčÄčēąĖą╣ čéčĆą░čäąĖą║ ą┤ą░ąĮąĮčŗčģ L1 ą╝ąŠąČąĄčé ą┐čĆąŠčģąŠą┤ąĖčéčī ąĘą░ ąŠą┤ąĖąĮ čéą░ą║č鹊ą▓čŗą╣ čåąĖą║ą╗ čÅą┤čĆą░:
ŌĆó ąöą▓ąĄ 32-čĆą░ąĘčĆčÅą┤ąĮčŗąĄ ąĘą░ą│čĆčāąĘą║ąĖ ą┤ą░ąĮąĮčŗčģ
ą¤ą░ą╝čÅčéčī ą┤ą░ąĮąĮčŗčģ L1 ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ.
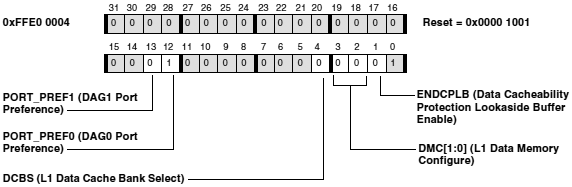
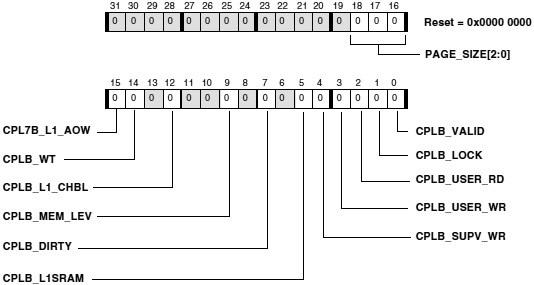
ąĀąĄą│ąĖčüčéčĆ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéčīčÄ ą┤ą░ąĮąĮčŗčģ (Data Memory Control register, DMEM_CONTROL) čüąŠą┤ąĄčƹȹĖčé ą▒ąĖčéčŗ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┤ą╗čÅ L1 Data Memory.
ąĀąĖčü. 6-11. L1 Data Memory Control Register (ADSP-BF5xx).
PORT_PREF1 . ąæąĖčé ą▓čŗą▒ąĖčĆą░ąĄčé ą┐ąŠčĆčé ą┤ą░ąĮąĮčŗčģ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ DAG1 ąĮąĄą║čŹčłąĖčĆčāąĄą╝čŗčģ ą▓čŗą▒ąŠčĆąŠą║ L2. ąÜčŹčłąĖčĆčāąĄą╝čŗąĄ ą▓čŗą▒ąŠčĆą║ąĖ ą▓čüąĄą│ą┤ą░ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ą┐ąŠčĆč鹊ą╝ ą┤ą░ąĮąĮčŗčģ, čäąĖąĘąĖč湥čüą║ąĖ čüą▓čÅąĘą░ąĮąĮčŗą╝ čü čåąĄą╗ąĄą▓ąŠą╣ ą┐ą░ą╝čÅčéčīčÄ ą║čŹčłą░. ąØą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ DAG0, DAG1 ąĖ čéčĆą░čäąĖą║ ą║čŹčłą░ ąĮą░ čĆą░ąĘąĮčŗąĄ ą┐ąŠčĆčéčŗ ąŠą┐čéąĖą╝ąĖąĘąĖčĆčāąĄčé ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ ą┐čāč鹥ą╝ čāą┤ąĄčƹȹ░ąĮąĖčÅ ąĮą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ ąŠč湥čĆąĄą┤ąĖ ą┐ą░ą╝čÅčéąĖ L2.
PORT_PREF0 . ąæąĖčé ą▓čŗą▒ąĖčĆą░ąĄčé ą┐ąŠčĆčé ą┤ą░ąĮąĮčŗčģ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ DAG0 ąĮąĄą║čŹčłąĖčĆčāąĄą╝čŗčģ ą▓čŗą▒ąŠčĆąŠą║ L2. ąÜčŹčłąĖčĆčāąĄą╝čŗąĄ ą▓čŗą▒ąŠčĆą║ąĖ ą▓čüąĄą│ą┤ą░ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ą┐ąŠčĆč鹊ą╝ ą┤ą░ąĮąĮčŗčģ, čäąĖąĘąĖč湥čüą║ąĖ čüą▓čÅąĘą░ąĮąĮčŗą╝ čü čåąĄą╗ąĄą▓ąŠą╣ ą┐ą░ą╝čÅčéčīčÄ ą║čŹčłą░. ąØą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ DAG0, DAG1 ąĖ čéčĆą░čäąĖą║ ą║čŹčłą░ ąĮą░ čĆą░ąĘąĮčŗąĄ ą┐ąŠčĆčéčŗ ąŠą┐čéąĖą╝ąĖąĘąĖčĆčāąĄčé ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ ą┐čāč鹥ą╝ čāą┤ąĄčƹȹ░ąĮąĖčÅ ąĮą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ ąŠč湥čĆąĄą┤ąĖ ą┐ą░ą╝čÅčéąĖ L2.
ąöą╗čÅ ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠą│ąŠ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖčÅ čü ą┤ą▓ąŠą╣ąĮčŗą╝ čćč鹥ąĮąĖąĄą╝ DAG, DAG0 ąĖ DAG1 ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮčŗ ąĮą░ čĆą░ąĘąĮčŗąĄ ą┐ąŠčĆčéčŗ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ PORT_PREF0 čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮ ą║ą░ą║ 1, č鹊 PORT_PREF1 ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ąĘą░ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮ ą▓ 0.
DCBS . ąæąĖčé ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ąĮąĄą║ąŠąĄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą░ą╗ąĖą░čüą░ą╝ąĖ ą░ą┤čĆąĄčüąŠą▓, čāą║ą░ąĘčŗą▓ą░čÄčēąĖą╝ąĖ ą▓ č鹊čé ąČąĄ ąĮą░ą▒ąŠčĆ. ąŁč鹊čé ą▒ąĖčé ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ, čćč鹊ą▒čŗ ą▓ą╗ąĖčÅčéčī ąĮą░ č鹊, ą║ą░ą║ąĖąĄ ą░ą┤čĆąĄčüą░ ąĖą╝ąĄčÄčé č鹥ąĮą┤ąĄąĮčåąĖčÄ ąŠčüčéą░ą▓ą░čéčīčüčÅ ą▓ ą║čŹčłąĄ čĆąĄąĘąĖą┤ąĄąĮčéąĮčŗą╝ąĖ, ąĖąĘą▒ąĄą│ą░čÅ ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖčÅ ąĘą░ą┐ąĖčüąĄą╣ ą║čŹčłą░ ą┐čĆąĖ ą┐ąŠą▓č鹊čĆąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ąĮą░ą▒ąŠčĆą░čģ. ąŁč鹊 ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ čĆą░ą▒ąŠčéčā, ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ čüąĖčéčāą░čåąĖą╣, ą║ąŠą│ą┤ą░ ąŠą▒ą░ ą▒ą░ąĮą║ą░ Data Bank A ąĖ Data Bank B čĆą░ą▒ąŠčéą░čÄčé ą║ą░ą║ ą║čŹčł (ą▒ąĖčéčŗ DMC[1:0] ą▓ čŹč鹊ą╝ čĆąĄą│ąĖčüčéčĆąĄ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮčŗ ą▓ 11).
ENDCPLB . ąæąĖčé ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ čĆą░ąĘčĆąĄčłąĄąĮąĖčÅ/ąĘą░ą┐čĆąĄčéą░ 16 Cacheability Protection Lookaside Buffers (CPLBs), ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ą┤ą╗čÅ ą┤ą░ąĮąĮčŗčģ (čüą╝. čĆą░ąĘą┤ąĄą╗ "ąÜčŹčł ą┤ą░ąĮąĮčŗčģ L1"). ą¤ąŠčüą╗ąĄ čüą▒čĆąŠčüą░ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą░ąĮąĮčŗąĄ CPLB ąĘą░ą┐čĆąĄčēąĄąĮčŗ. ą¤čĆąĖ ąĘą░ą┐čĆąĄč鹥 ąĖąĮč鹥čĆč乥ą╣čüąŠą╝ L1 ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčéčüčÅ č鹊ą╗čīą║ąŠ ą╝ąĖąĮąĖą╝ą░ą╗čīąĮą░čÅ ą┐čĆąŠą▓ąĄčĆą║ą░ ą░ą┤čĆąĄčüą░. ąŁčéą░ ą╝ąĖąĮąĖą╝ą░ą╗čīąĮą░čÅ ą┐čĆąŠą▓ąĄčĆą║ą░ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ, ą║ąŠą│ą┤ą░ ą┐čĆąŠčåąĄčüčüąŠčĆ:
ŌĆó ąÉą┤čĆąĄčüčāąĄčé ąĮąĄ čüčāčēąĄčüčéą▓čāčÄčēąĄąĄ (ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąĮąŠąĄ) ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ą┐ą░ą╝čÅčéąĖ L1
CPLB ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąĘą░ą┐čĆąĄčēąĄąĮčŗ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ą▒čāą┤čāčé ąŠą▒ąĮąŠą▓ą╗ąĄąĮčŗ ąĖčģ ą┤ąĄčüą║čĆąĖą┐č鹊čĆčŗ (čĆąĄą│ąĖčüčéčĆčŗ DCPLB_DATAx ąĖ DCPLB_ADDRx). ąśą╝ąĄą╣č鹥 ą▓ ą▓ąĖą┤čā, čćč鹊 ą┐ąŠčüą║ąŠą╗čīą║čā ą┐ąŠčĆčÅą┤ąŠą║ ąĘą░ą│čĆčāąĘą║ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čüą╗ą░ą▒čŗą╣ (čüą╝. "Ordering of Loads and Stores"), č鹊 ąĘą░ą┐čĆąĄčéčā CPLB ą┤ąŠą╗ąČąĮą░ ą┐čĆąĄą┤čłąĄčüčéą▓ąŠą▓ą░čéčī ąĖąĮčüčéčĆčāą║čåąĖčÅ CSYNC.
ąÜąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłą░ąĄčéčüčÅ ąĖą╗ąĖ ąĘą░ą┐čĆąĄčēą░ąĄčéčüčÅ ą║čŹčł ąĖą╗ąĖ CPLB, čüčĆą░ąĘčā ą┤ąĄą╗ą░ą╣č鹥 ąĘą░ą┐ąĖčüčī DMEM_CONTROL ą▓ą╝ąĄčüč鹥 čü SSYNC, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ą┐čĆą░ą▓ąĖą╗čīąĮąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ.
DMC[1:0] . ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┐ąŠčüą╗ąĄ čüą▒čĆąŠčüą░ ą▓čüčÅ L1 Data Memory čĆą░ą▒ąŠčéą░ąĄčé ą║ą░ą║ SRAM. ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą▒ąĖčéčŗ DMC[1:0] ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐ąŠčĆčåąĖą╣ čŹč鹊ą╣ ą┐ą░ą╝čÅčéąĖ ą║ą░ą║ ą║čŹčł. ąĀąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą┐ąŠą┤ ą║čŹčł ąĮąĄ čĆą░ąĘčĆąĄčłą░ąĄčé ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĄ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ L2. ą¦č鹊ą▒čŗ čüą┤ąĄą╗ą░čéčī čŹč鹊, ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čéą░ą║ąČąĄ čĆą░ąĘčĆąĄčłąĄąĮčŗ CPLB (čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą▒ąĖčéą░ ENDCPLB) ąĖ ą┤ąĄčüą║čĆąĖą┐č鹊čĆčŗ CPLB (čĆąĄą│ąĖčüčéčĆčŗ DCPLB_DATAx ąĖ DCPLB_ADDRx) ą┤ąŠą╗ąČąĮčŗ čāą║ą░ąĘčŗą▓ą░čéčī ą▓čŗą▒čĆą░ąĮąĮčŗąĄ čüčéčĆą░ąĮąĖčåčŗ ą┐ą░ą╝čÅčéąĖ, ą┤ą╗čÅ ą║ąŠč鹊čĆčŗčģ čĆą░ąĘčĆąĄčłąĄąĮ ą║čŹčł. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┐ąŠčüą╗ąĄ čüą▒čĆąŠčüą░ ąĘą░ą┐čĆąĄčēąĄąĮčŗ ą║ą░ą║ ą║čŹčł, čéą░ą║ ąĖ ą┐čĆąŠą▓ąĄčĆą║ą░ ą░ą┤čĆąĄčüą░ CPLB.
ą¦č鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ą┐čĆą░ą▓ąĖą╗čīąĮąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĖ čüąŠą▓ą╝ąĄčüčéąĖą╝ąŠčüčéčī ą▓ ą▒čāą┤čāčēąĄą╝, ą▓čüąĄ ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ą▒ąĖčéčŗ ą▓ čŹč鹊ą╝ čĆąĄą│ąĖčüčéčĆąĄ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮčŗ ą▓ 0 ą▓čüčÅą║ąĖą╣ čĆą░ąĘ ą┐čĆąĖ ąĘą░ą┐ąĖčüąĖ čŹč鹊ą│ąŠ čĆąĄą│ąĖčüčéčĆą░.
ąæąĖčéčŗ RDCHK ą▓ čŹč鹊ą╝ čĆąĄą│ąĖčüčéčĆąĄ ą┐ąŠą┤ąŠą▒ąĮčŗ ą▒ąĖčéą░ą╝ čĆą░ąĘčĆąĄčłąĄąĮąĖčÅ ą║čŹčłą░ (cache enable bits, CEN[1:0]). ąŚą░ą┐ąĖčüčī ą▓ ą▒ąĖčéčŗ RDCHK ąĮąĄ ą▓čüčéčāą┐ąĖčé ą▓ čüąĖą╗čā, ą┐ąŠą║ą░ ąĮąĄ ą▒čāą┤ąĄčé ą▓čŗą┤ą░ąĮą░ SSYNC. ąĪąŠčüč鹊čÅąĮąĖąĄ čŹč鹊ą│ąŠ ą▒ąĖčéą░ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ ą┤ąŠčüčéčāą┐ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ; ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ąĮą░ ąĘą░ą┐ąĖčüčī ą▓čüąĄą│ą┤ą░ ą▓čŗčćąĖčüą╗čÅčÄčéčüčÅ ąĖ čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ ą▒ąĖčéčŗ č湥čéąĮąŠčüčéąĖ. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ čŹč鹊čé ą┐ąŠčüą╗ąĄ čüą▒čĆąŠčüą░ čŹč鹊čé ą▒ąĖčé čüąĮąĖą╝ą░ąĄčéčüčÅ.
ąæąĖčéčŗ CBYPASS ą▓ čŹč鹊ą╝ čĆąĄą│ąĖčüčéčĆąĄ ą┐ąŠą┤ąŠą▒ąĮčŗ ą▒ąĖčéą░ą╝ čĆą░ąĘčĆąĄčłąĄąĮąĖčÅ ą║čŹčłą░ (cache enable bits, CEN[1:0]). ąŚą░ą┐ąĖčüčī ą▓ ą▒ąĖčéčŗ CBYPASS ąĮąĄ ą▓čüčéčāą┐ąĖčé ą▓ čüąĖą╗čā, ą┐ąŠą║ą░ ąĮąĄ ą▒čāą┤ąĄčé ą▓čŗą┤ą░ąĮą░ SSYNC. ąŁč鹊čé ą▒ąĖčé ąĮąĄ ą▒ą╗ąŠą║ąĖčĆčāąĄčé ą║ąŠą╝ą░ąĮą┤čā DTEST_COMMAND, čĆąĄą│ąĖčüčéčĆąŠą▓čŗą╣ "č湥čĆąĮčŗą╣ čģąŠą┤" ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą║čŹčłčā.
ąÜą░ą║ ąĖ čü ą┤čĆčāą│ąĖą╝ąĖ ą▒ąĖčéą░ą╝ąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ MMR, ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ čüąŠčüč鹊čÅąĮąĖčÅ ą▒ąĖč鹊ą▓ PARCTL ąĖ PARSEL ą┤ąŠą╗ąČąĮčŗ čüąŠą┐čĆąŠą▓ąŠąČą┤ą░čéčīčüčÅ SSYNC, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ą▓čüčéčāą┐ą╗ąĄąĮąĖąĄ ą▓ čüąĖą╗čā ąĮąŠą▓ąŠą│ąŠ čüąŠčüč鹊čÅąĮąĖčÅ.
L1 Data SRAM . ą¤čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ SRAM ąĮąĄčé ą║ąŠą╗ą╗ąĖąĘąĖą╣, ąĄčüą╗ąĖ ą▓čüąĄ ąĖąĘ čüą╗ąĄą┤čāčÄčēąĄą│ąŠ ą▓ąĄčĆąĮąŠ: ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ čü ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠą╣ ą┐ąŠą╗čÅčĆąĮąŠčüčéąĖ 32-ą▒ąĖčéąĮčŗčģ čüą╗ąŠą▓ (ą▒ąĖčéčŗ 2 ą░ą┤čĆąĄčüąŠą▓ čüąŠą▓ą┐ą░ą┤ą░čÄčé), ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ ą┐ąŠą┤ą▒ą░ąĮą║ 4 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ (čüąŠą▓ą┐ą░ą┤ą░čÄčé ą▒ąĖčéčŗ ą░ą┤čĆąĄčüą░ 13 ąĖ 12), ąŠą┤ąĖąĮą░ą║ąŠą▓čŗą╣ ą┐ąŠą╗čāą▒ą░ąĮą║ 16 ą║ąĖą╗ąŠą▒ą░ą╣čé (ą▒ąĖčéčŗ 16 ą░ą┤čĆąĄčüą░ čüąŠą▓ą┐ą░ą┤ą░čÄčé), ąĖ čŹč鹊 ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ ą▒ą░ąĮą║ (ą▒ąĖčéčŗ ą░ą┤čĆąĄčüą░ 21 ąĖ 20 čüąŠą▓ą┐ą░ą┤ą░čÄčé). ąÜąŠą│ą┤ą░ ą▒čŗą╗ą░ ą┤ąĄč鹥ą║čéąĖčĆąŠą▓ą░ąĮą░ ą║ąŠą╗ą╗ąĖąĘąĖčÅ ą┤ą░ąĮąĮčŗčģ, čüąĮą░čćą░ą╗ą░ ą┤ąŠčüčéčāą┐ ąĮąŠą╝ąĖąĮą░ą╗čīąĮąŠ ą┤ą░ąĄčéčüčÅ ą┤ą╗čÅ DAG-ąŠą▓, ąĘą░č鹥ą╝ ą┤ą╗čÅ ą▒čāč乥čĆą░ čģčĆą░ąĮąĄąĮąĖčÅ, ąĖ ąĮą░ą║ąŠąĮąĄčå ą┤ą╗čÅ DMA ąĖ čéčĆą░čäąĖą║ą░ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ/ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖčÅ ą║čŹčłą░. ą¦č鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ą░ą┤ąĄą║ą▓ą░čéąĮčāčÄ ą┐ąŠą╗ąŠčüčā DMA, DMA ąŠčéą┤ą░ąĮ čüą░ą╝čŗą╣ ą▓čŗčüąŠą║ąĖą╣ ą┐čĆąĖąŠčĆąĖč鹥čé, ąĄčüą╗ąĖ čŹč鹊 ą▒čŗą╗ąŠ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąŠ ąĮą░ ą▒ąŠą╗čīčłąĄ č湥ą╝ 16 ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗčģ čéą░ą║č鹊ą▓ čÅą┤čĆą░, ąĖą╗ąĖ ąĄčüą╗ąĖ ą▓č鹊čĆąŠą╣ DMA I/O ą┐ąŠčüčéą░ą▓ą╗ąĄąĮ ą▓ ąŠč湥čĆąĄą┤čī ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ą▒čŗą╗ ąŠą▒čĆą░ą▒ąŠčéą░ąĮ ą┐ąĄčĆą▓čŗą╣ DMA I/O.
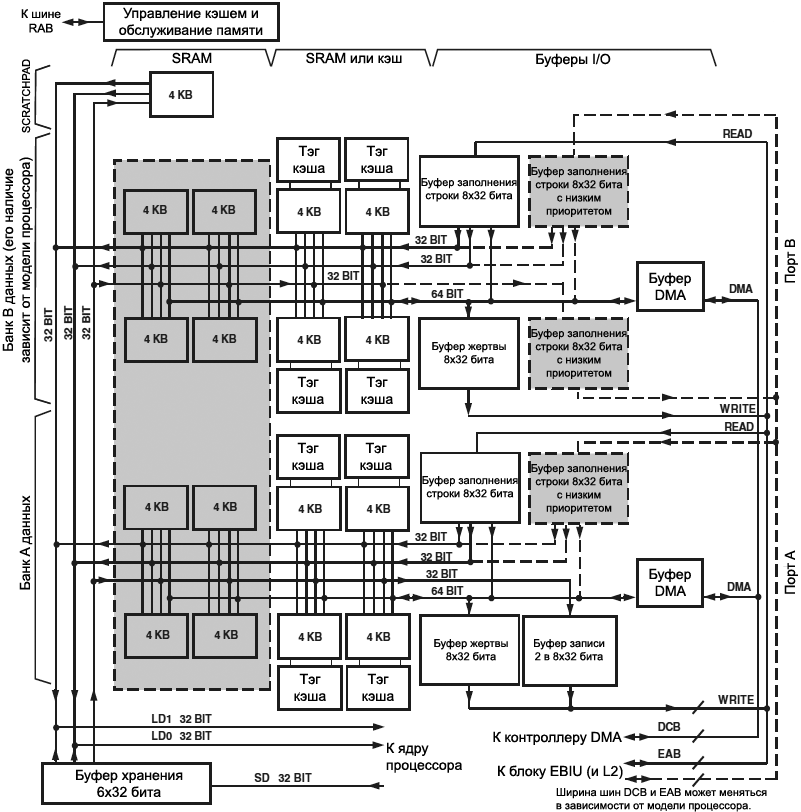
ąØą░ čĆąĖčüčāąĮą║ąĄ 6-13 ą┐ąŠą║ą░ąĘą░ąĮą░ ą░čĆčģąĖč鹥ą║čéčāčĆą░ L1 Data Memory. ą¤čāąĮą║čéąĖčĆąĮčŗą╝ąĖ ą╗ąĖąĮąĖčÅą╝ąĖ ą┐ąŠą║ą░ąĘą░ąĮčŗ čäčāąĮą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ąĄčüčéčī č鹊ą╗čīą║ąŠ ą▓ ąĮąĄą║ąŠč鹊čĆčŗčģ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ Blackfin (ą┐ąŠą┤čĆąŠą▒ąĮąŠčüčéąĖ čüą╝. ą▓ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ą┐ąŠ ą║ąŠąĮą║čĆąĄčéąĮąŠą╝čā ą┐čĆąŠčåąĄčüčüąŠčĆčā). ąÆ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ąĮą░ ąĮąĄą║ąŠč鹊čĆčŗčģ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ čłąĖąĮčŗ EAB ąĖ DCB ą┐ąŠą┤ą║ą╗čÄč湥ąĮčŗ ąĮą░ą┐čĆčÅą╝čāčÄ ą║ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ą╝ EBIU ąĖ DMA, ąĮą░ ą┤čĆčāą│ąĖčģ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮčŗčģ ą╝ąŠą┤ąĄą╗čÅčģ čü ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ čÅą┤čĆą░ą╝ąĖ ąĖą╗ąĖ ą▓čüčéčĆąŠąĄąĮąĮąŠą╣ ą▓ ą║čĆąĖčüčéą░ą╗ą╗ ą┐ą░ą╝čÅčéčīčÄ L2 ąŠąĮąĖ ą┤ąŠą╗ąČąĮčŗ ą┐ąĄčĆąĄčüąĄčćčī ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ą╝ąŠą┤čāą╗ąĖ ą░čĆą▒ąĖčéčĆą░ąČą░. ąóą░ą║ąČąĄ čŹčéąĖ čłąĖąĮčŗ ąĮą░ ąĮąĄą║ąŠč鹊čĆčŗčģ ą╝ąŠą┤ąĄą╗čÅčģ čłąĖčĆąĄ 16 ą▒ąĖčé.
ąĀąĖčü. 6-13. ąÉčĆčģąĖč鹥ą║čéčāčĆą░ L1 Data Memory.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąĘą░ą║čĆą░čłąĄąĮąĮčŗąĄ čüąĄčĆčŗą╝ čåą▓ąĄč鹊ą╝ ą▒ą╗ąŠą║ąĖ ąĖą╝ąĄčÄčéčüčÅ ąĮąĄ ą▓ąŠ ą▓čüąĄčģ ą╝ąŠą┤ąĄą╗čÅčģ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin. ąöą╗čÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ąŠą▒čĆą░čēą░ą╣č鹥čüčī ą║ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą╝čā čĆčāą║ąŠą▓ąŠą┤čüčéą▓čā ą┐ąŠ ą░ą┐ą┐ą░čĆą░čéčāčĆąĄ ąÆą░čłąĄą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ([1] ą┤ą╗čÅ BF538).
L1 Data Cache . ą¤ąŠą┤čĆąŠą▒ąĮąŠčüčéąĖ ą┐ąŠ č鹥čĆą╝ąĖąĮąŠą╗ąŠą│ąĖąĖ ą║čŹčłą░ čüą╝. ą▓ąŠ ą▓čĆąĄąĘą║ąĄ "ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ ą┐ą░ą╝čÅčéąĖ".
ąÆ ąŠčéą╗ąĖčćąĖąĄ ąŠčé ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣, ą║ąŠč鹊čĆą░čÅ 4-Way set associative, ą║čŹčł ą┤ą░ąĮąĮčŗčģ 2-Way set associative. ąÜąŠą│ą┤ą░ ą┤ąŠčüčéčāą┐ąĮąŠ ąĖ čĆą░ąĘčĆąĄčłąĄąĮąŠ 2 ą▒ą░ąĮą║ą░ ą┤ą╗čÅ ą║čŹčłą░, č鹊 čüąŠąĘą┤ą░čÄčéčüčÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ąĮą░ą▒ąŠčĆčŗ, ą░ ąĮąĄ ą║ą░ąĮą░ą╗čŗ (Ways). ąÜąŠą│ą┤ą░ čā ąŠą▒ąŠąĖčģ ą▒ą░ąĮą║ąŠą▓ Data Bank A ąĖ Data Bank B ąĄčüčéčī ą┐ą░ą╝čÅčéčī, čĆą░ą▒ąŠčéą░čÄčēą░čÅ ą║čŹčłąĄą╝, ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą▒ąĖčé DCBS ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMEM_CONTROL, čćč鹊ą▒čŗ čāą┐čĆą░ą▓ą╗čÅčéčī, ą║ą░ą║ą░čÅ ą┐ąŠą╗ąŠą▓ąĖąĮą░ ą░ą┤čĆąĄčüąĮąŠą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ čĆą░ą▒ąŠčéą░ąĄčé čü ą║ą░ą║ąĖą╝ ą▒ą░ąĮą║ąŠą╝ ą┐ą░ą╝čÅčéąĖ ą║čŹčłą░. ąæąĖčé DCBS ą▓čŗą▒ąĖčĆą░ąĄčé ą╗ąĖą▒ąŠ ą▒ąĖčé ą░ą┤čĆąĄčüą░ 14, ą╗ąĖą▒ąŠ ą▒ąĖčé ą░ą┤čĆąĄčüą░ 23, čćč鹊ą▒čŗ ąĮą░ą┐čĆą░ą▓ą╗čÅčéčī čéčĆą░čäąĖą║ ą╝ąĄąČą┤čā ą▒ą░ąĮą║ą░ą╝ąĖ ą║čŹčłą░. ąŁč鹊 ą┤ą░ąĄčé ąĮąĄą║ąŠč鹊čĆąŠąĄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą░ą╗ąĖą░čüą░ą╝ąĖ ą░ą┤čĆąĄčüąŠą▓, čāą║ą░ąĘčŗą▓ą░čÄčēąĖą╝ąĖ ą▓ č鹊čé ąČąĄ ąĮą░ą▒ąŠčĆ. ą¤ąŠčŹč鹊ą╝čā čéą░ą║ą░čÅ čäčāąĮą║čåąĖčÅ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ, čćč鹊ą▒čŗ ą▓ą╗ąĖčÅčéčī ąĮą░ č鹊, ą║ą░ą║ąĖąĄ ą░ą┤čĆąĄčüą░ ąĖą╝ąĄčÄčé č鹥ąĮą┤ąĄąĮčåąĖčÄ ąŠčüčéą░ą▓ą░čéčīčüčÅ ą▓ ą║čŹčłąĄ čĆąĄąĘąĖą┤ąĄąĮčéąĮčŗą╝ąĖ, ąĖąĘą▒ąĄą│ą░čÅ ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖčÅ ąĘą░ą┐ąĖčüąĄą╣ ą║čŹčłą░ ą┐čĆąĖ ą┐ąŠą▓č鹊čĆąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ąĮą░ą▒ąŠčĆą░čģ.
ąöąŠčüčéčāą┐ ą║ ą║čŹčłčā ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▒ąĄąĘ ą║ąŠą╗ą╗ąĖąĘąĖą╣, ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ čüąĖčéčāą░čåąĖą╣, ą║ąŠą│ą┤ą░ čŹč鹊 č鹊čé ąČąĄ 4 ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗą╣ ą┐ąŠą┤ą▒ą░ąĮą║, ąĖ č鹊čé ąČąĄ čüą░ą╝čŗą╣ ą▒ą░ąĮą║. ąÜčŹčł ąĖą╝ąĄąĄčé ą╝ąĄąĮąĄąĄ ąŠč湥ą▓ąĖą┤ąĮąŠąĄ ą╝ąĮąŠą│ąŠą┐ąŠčĆč鹊ą▓ąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ, č湥ą╝ SRAM, ąĖąĘ-ąĘą░ ąĘą░čéčĆą░čé ąĮą░ ą┐ąŠą┤ą┤ąĄčƹȹ║čā čé菹│ąŠą▓. ąÜąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą║ąŠą╗ą╗ąĖąĘąĖčÅ ą░ą┤čĆąĄčüąŠą▓, čüąĮą░čćą░ą╗ą░ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ ą┤ą╗čÅ čĆąĄą│ąĖčüčéčĆą░ DTEST, ąĘą░č鹥ą╝ ą║ ą▒čāč乥čĆčā čģčĆą░ąĮąĄąĮąĖčÅ, ąĖ ąĮą░ą║ąŠąĮąĄčå ą║ čéčĆą░čäąĖą║čā ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ/ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖčÅ ą║čŹčłą░.
ąöąŠčüčéčāą┐ąĮąŠ 3 čĆą░ąĘąĮčŗčģ čĆąĄąČąĖą╝ą░ ą║čŹčłą░.
ŌĆó ąĪą║ą▓ąŠąĘąĮą░čÅ ąĘą░ą┐ąĖčüčī (Write-through) čüąŠ čüčéčĆąŠą║ąŠą╣ ą║čŹčłą░, ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą╣ č鹊ą╗čīą║ąŠ ąĮą░ čćč鹥ąĮąĖąĄ.
ąĀąĄąČąĖą╝ ą║čŹčłą░ ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ą╝ąĖ DCPLB (čüą╝. čĆą░ąĘą┤ąĄą╗ "ąŚą░čēąĖčéą░ ąĖ čüą▓ąŠą╣čüčéą▓ą░ ą┐ą░ą╝čÅčéąĖ"). ąøčÄą▒ą░čÅ ą║ąŠą╝ą▒ąĖąĮą░čåąĖčÅ čŹčéąĖčģ čĆąĄąČąĖą╝ąŠą▓ ą║čŹčłą░ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ, ą┐ąŠčüą║ąŠą╗čīą║čā čĆąĄąČąĖą╝ ą║čŹčłą░ ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ čüčéčĆą░ąĮąĖčåčŗ ą┐ą░ą╝čÅčéąĖ.
ąĢčüą╗ąĖ ą║čŹčł čĆą░ąĘčĆąĄčłąĄąĮą░ (čŹč鹊 čāą┐čĆą░ą▓ą╗čÅąĄčéčüčÅ ą▒ąĖčéą░ą╝ąĖ DMC[1:0] čĆąĄą│ąĖčüčéčĆą░ DMEM_CONTROL), ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čéą░ą║ąČąĄ čĆą░ąĘčĆąĄčłąĄąĮčŗ CPLB ą┤ą░ąĮąĮčŗčģ (čāą┐čĆą░ą▓ą╗čÅąĄčéčüčÅ ą▒ąĖč鹊ą╝ ENDCPLB ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMEM_CONTROL). ąæčāą┤čāčé ą║čŹčłąĖčĆąŠą▓ą░čéčīčüčÅ č鹊ą╗čīą║ąŠ č鹥 čüčéčĆą░ąĮąĖčåčŗ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗąĄ čāą║ą░ąĘą░ąĮčŗ ą║ą░ą║ ą║čŹčłąĖčĆčāąĄą╝čŗąĄ CPLB ą┤ą░ąĮąĮčŗčģ. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ CPLB ą┤ą░ąĮąĮčŗčģ ąĘą░ą┐čĆąĄčēąĄąĮčŗ, ąĖ ąĮąĖą║ą░ą║ąŠą│ąŠ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ ąĮąĄčé.
ą×čłąĖą▒ąŠčćąĮąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 čüąĖčéčāą░čåąĖąĖ, ą║ąŠą│ą┤ą░ ąŠą▒ą╗ą░čüčéčī MMR čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮą░ ą║ą░ą║ ą║čŹčłąĖčĆčāąĄą╝ą░čÅ č湥čĆąĄąĘ CPLB ą┤ą░ąĮąĮčŗčģ, ąĖą╗ąĖ ą║ąŠą│ą┤ą░ ą▒ą░ąĮą║ąĖ ą┤ą░ąĮąĮčŗčģ, čĆą░ą▒ąŠčéą░čÄčēąĖąĄ ą║ą░ą║ L1 SRAM, čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮčŗ ą║ą░ą║ ą║čŹčłąĖčĆčāąĄą╝čŗąĄ č湥čĆąĄąĘ CPLB ą┤ą░ąĮąĮčŗčģ.
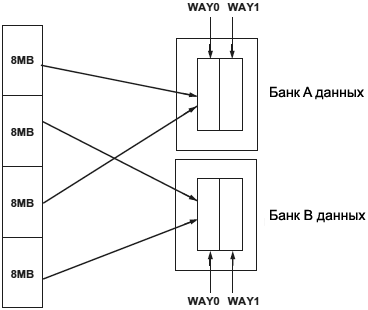
ąØąĖąČąĄ ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąĖą╝ąĄčĆ, ą║ą░ą║ ą║čŹčłąĖčĆčāąĄą╝ąŠąĄ ą░ą┤čĆąĄčüąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ą┐čĆąĖą▓čÅąĘą░ąĮąŠ ą║ ą┤ą▓čāą╝ ą▒ą░ąĮą║ą░ą╝ ą┤ą░ąĮąĮčŗčģ.
ąÜąŠą│ą┤ą░ 2 ą▒ą░ąĮą║ą░ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮčŗ ą║ą░ą║ ą║čŹčł, ąŠąĮąĖ čĆą░ą▒ąŠčéą░čÄčé ą║ą░ą║ 2 ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗčģ, čĆą░ąĘą╝ąĄčĆąŠą╝ 16 ą║ąĖą╗ąŠą▒ą░ą╣čé, 2-Way set associative ą║čŹčłą░, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠąČąĮąŠ ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ ą┐čĆąĖą▓čÅąĘą░čéčī ą║ ą░ą┤čĆąĄčüąĮąŠą╝čā ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓čā ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin.
ąĢčüą╗ąĖ ąŠą▒ą░ ą▒ą░ąĮą║ą░ ą┤ą░ąĮąĮčŗčģ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮčŗ ą║ą░ą║ ą║čŹčł, ą▒ąĖčé DCBS ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMEM_CONTROL ąŠą▒ąŠąĘąĮą░čćą░ąĄčé ą▒ąĖčé ą░ą┤čĆąĄčüą░ A[14] ąĖą╗ąĖ A[23] ą▒čāą┤ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą║ą░ą║ čüąĄą╗ąĄą║č鹊čĆ ą║čŹčłą░. ąæąĖčé ą░ą┤čĆąĄčüą░ A[14] ąĖą╗ąĖ A[23] ą▓čŗą▒ąĖčĆą░ąĄčé, čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮą░ ą║čŹčł ą▒ą░ąĮą║ąŠą╝ Data Bank A, ąĖą╗ąĖ ą▒ą░ąĮą║ąŠą╝ Data Bank B.
ŌĆó ąĢčüą╗ąĖ DCBS = 0, č鹊 A[14] čÅą▓ą╗čÅąĄčéčüčÅ čćą░čüčéčīčÄ ąĖąĮą┤ąĄą║čüą░ ą░ą┤čĆąĄčüą░, ąĖ ą▓čüąĄ ą░ą┤čĆąĄčüą░, ą│ą┤ąĄ A[14] = 0, ąĖčüą┐ąŠą╗čīąĘčāčÄčé Data Bank B. ąÆčüąĄ ą░ą┤čĆąĄčüą░, ą│ą┤ąĄ A[14] = 1, ąĖčüą┐ąŠą╗čīąĘčāčÄčé Data Bank A.
ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ A[23] ąĖąĮč鹥čĆą┐čĆąĄčéąĖčĆčāąĄčéčüčÅ ą║ą░ą║ ą┐čĆąŠčüč鹊 ą┤čĆčāą│ąŠą╣ ą▒ąĖčé ą▓ ą░ą┤čĆąĄčüąĄ, ą║ąŠč鹊čĆčŗą╣ čüąŠčģčĆą░ąĮčÅąĄčéčüčÅ čü č鹥ą│ąŠą╝ ą║čŹčłą░ ąĖ čüčĆą░ą▓ąĮąĖą▓ą░ąĄčéčüčÅ čü čåąĄą╗ąĄą▓čŗą╝ ą░ą┤čĆąĄčüąŠą╝ ą┤ą╗čÅ ą░ąĮą░ą╗ąĖąĘą░ ą┐ąŠą┐ą░ą┤ą░ąĮąĖčÅ/ą┐čĆąŠą╝ą░čģą░ ą║čŹčłą░.
ŌĆó ąĢčüą╗ąĖ DCBS = 1, č鹊 A[23] čÅą▓ą╗čÅąĄčéčüčÅ čćą░čüčéčīčÄ ąĖąĮą┤ąĄą║čüą░ ą░ą┤čĆąĄčüą░, ąĖ ą▓čüąĄ ą░ą┤čĆąĄčüą░, ą│ą┤ąĄ A[23] = 0, ąĖčüą┐ąŠą╗čīąĘčāčÄčé Data Bank B. ąÆčüąĄ ą░ą┤čĆąĄčüą░, ą│ą┤ąĄ A[23] = 1, ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą▒ą░ąĮą║ Data Bank A.
ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ A[14] ąĖąĮč鹥čĆą┐čĆąĄčéąĖčĆčāąĄčéčüčÅ ą║ą░ą║ ą┐čĆąŠčüč鹊 ą┤čĆčāą│ąŠą╣ ą▒ąĖčé ą▓ ą░ą┤čĆąĄčüąĄ, ą║ąŠč鹊čĆčŗą╣ čüąŠčģčĆą░ąĮčÅąĄčéčüčÅ čü č鹥ą│ąŠą╝ ą║čŹčłą░ ąĖ čüčĆą░ą▓ąĮąĖą▓ą░ąĄčéčüčÅ čü čåąĄą╗ąĄą▓čŗą╝ ą░ą┤čĆąĄčüąŠą╝ ą┤ą╗čÅ ą░ąĮą░ą╗ąĖąĘą░ ą┐ąŠą┐ą░ą┤ą░ąĮąĖčÅ/ą┐čĆąŠą╝ą░čģą░ ą║čŹčłą░.
ąĀąĄąĘčāą╗čīčéą░čé ą▓čŗą▒ąŠčĆą░ DCBS = 0 ąĖą╗ąĖ DCBS = 1 čüą╗ąĄą┤čāčÄčēąĖą╣:
ŌĆó ąĢčüą╗ąĖ DCBS = 0, A[14] ą▓čŗą▒ąĖčĆą░ąĄčé Data Bank A ą▓ą╝ąĄčüč鹊 Data Bank B.
ą¦ąĄčĆąĄą┤ąŠą▓ą░ąĮąĖąĄ 16 ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗčģ čüčéčĆą░ąĮąĖčå ą║ą░čĆčéčŗ ą┐ą░ą╝čÅčéąĖ ąŠč鹊ą▒čĆą░ąČą░ąĄčéčüčÅ ąĮą░ ą║ą░ąČą┤čāčÄ ąĖąĘ ą┤ą▓čāčģ 16 ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗčģ ą║čŹčłąĄą╣, čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮąĮčŗčģ ą┤ą▓čāą╝čÅ ą▒ą░ąĮą║ą░ą╝ąĖ ą┤ą░ąĮąĮčŗčģ. ąĪą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ:
ąøčÄą▒čŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▓ ą┐ąĄčĆą▓ąŠą╝ ą▒ą╗ąŠą║ąĄ ą┐ą░ą╝čÅčéąĖ 16 ą║ąĖą╗ąŠą▒ą░ą╣čé ą╝ąŠą│čāčé ą▒čŗčéčī čüąŠčģčĆą░ąĮąĄąĮčŗ č鹊ą╗čīą║ąŠ ą▓ Data Bank B.
ąøčÄą▒čŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ ą░ą┤čĆąĄčüąŠą▓ (ąŠčé 16K ą┤ąŠ 32K ą▒ą░ą╣čé)-1 ą╝ąŠą│čāčé ą▒čŗčéčī čüąŠčģčĆą░ąĮąĄąĮčŗ č鹊ą╗čīą║ąŠ ą▓ Data Bank A.
ąøčÄą▒čŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ (ąŠčé 32K ą┤ąŠ 48K ą▒ą░ą╣čé)ŌĆō1 ą▒čŗą╗ąĖ ą▒čŗ čüąŠčģčĆą░ąĮąĄąĮčŗ ą▓ Data Bank B. ąś čéą░ą║ ą┤ą░ą╗ąĄąĄ - č湥čĆąĄą┤ąŠą▓ą░ąĮąĖąĄ ą▒ą░ąĮą║ąŠą▓ ą▒čāą┤ąĄčé ą┐čĆąŠą┤ąŠą╗ąČą░čéčīčüčÅ.
ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 ą║čŹčł čĆą░ą▒ąŠčéą░ąĄčé, ą║ą░ą║ ą▒čāą┤č鹊 čŹč鹊 ąŠą┤ąĖąĮąŠčćąĮą░čÅ, ąĮąĄą┐čĆąĄčĆčŗą▓ąĮą░čÅ, 2-Way set associative 32K ą▒ą░ą╣čé ą║čŹčł. ąÜą░ąČą┤čŗą╣ ą║ą░ąĮą░ą╗ (Way) ą┤ą╗ąĖąĮąŠą╣ 16K ą▒ą░ą╣čé, ąĖ ą▓čüąĄ 菹╗ąĄą╝ąĄąĮčéčŗ ą┤ą░ąĮąĮčŗčģ čü ąŠą┤ąĖąĮą░ą║ąŠą▓čŗą╝ąĖ ą┐ąĄčĆą▓čŗą╝ąĖ 14 ą▒ąĖčéą░ą╝ąĖ ą░ą┤čĆąĄčüą░ ąĖąĮą┤ąĄą║čüąĖčĆčāčÄčé čāąĮąĖą║ą░ą╗čīąĮčŗą╣ ąĮą░ą▒ąŠčĆ, ą▓ ą║ąŠč鹊čĆąŠą╝ ą╝ąŠąČąĮąŠ čüąŠčģčĆą░ąĮąĖčéčī ą┤ąŠ 2 菹╗ąĄą╝ąĄąĮč鹊ą▓ (ąŠą┤ąĖąĮ ąĮą░ ą║ą░ąČą┤čŗą╣ ą║ą░ąĮą░ą╗).
ŌĆó ąĢčüą╗ąĖ DCBS = 1, A[23] ą▓čŗą▒ąĖčĆą░ąĄčé Data Bank A ą▓ą╝ąĄčüč鹊 Data Bank B.
ąĪ DCBS = 1 čüąĖčüč鹥ą╝ą░ čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ 2 ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗčģ ą║čŹčłąĄą╣, ą║ą░ąČą┤ą░čÅ 2-Way set associative ą║čŹčł, ą┐ąŠ 16K ą▒ą░ą╣čé. ąÜą░ąČą┤čŗą╣ ą▒ą░ąĮą║ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄčé č湥čĆąĄą┤čāčÄčēąĖą╣čüčÅ ąĮą░ą▒ąŠčĆ ą▒ą╗ąŠą║ąŠą▓ ą┐ą░ą╝čÅčéąĖ 8 ą╝ąĄą│ą░ą▒ą░ą╣čé.
ąØą░ą┐čĆąĖą╝ąĄčĆ, Data Bank B ą║čŹčłąĖčĆčāąĄčé ą▓čüąĄ ą┤ąŠčüčéčāą┐čŗ ą║ ą┐ąĄčĆą▓ąŠą╝čā ą┤ąĖą░ą┐ą░ąĘąŠąĮčā ą░ą┤čĆąĄčüąĮąŠą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ čĆą░ąĘą╝ąĄčĆąŠą╝ 8M ą▒ą░ą╣čé. ąó. ąĄ. ą║ą░ąČą┤čŗą╣ ą┤ąĖą░ą┐ą░ąĘąŠąĮ 8M ą▒ą░ą╣čé čüąŠą┐ąĄčĆąĮąĖčćą░ąĄčé ą┤ą╗čÅ 2 ąĘą░ą┐ąĖčüąĄą╣ čüčéčĆąŠą║ (ą░ ąĮąĄ ą║ą░ąČą┤ąŠąĄ ą┐ąŠą▓č鹊čĆąĄąĮąĖąĄ ą┐ąŠ 16K ą▒ą░ą╣čé). ąĪąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ Data Bank A ą║čŹčłąĖčĆčāąĄčé ą┤ą░ąĮąĮčŗąĄ ą▓čŗčłąĄ 8M ą▒ą░ą╣čé ąĖ ąĮąĖąČąĄ 16M ą▒ą░ą╣čé.
ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ čĆą░ą▒ąŠčéą░ąĄčé čü ąĮą░ą▒ąŠčĆąŠą╝ ą┤ą░ąĮąĮčŗčģ čĆą░ąĘą╝ąĄčĆąŠą╝ 1M ą╝ąĄą│ą░ą▒ą░ą╣čé, ąĖ ąŠąĮ čĆą░ąĘą╝ąĄčēąĄąĮ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą▓ ą┐ąĄčĆą▓ąŠą╝ 8M ą▒ą░ą╣čéąĮąŠą╝ ą▒ą╗ąŠą║ąĄ ą┐ą░ą╝čÅčéąĖ, ąŠąĮ čŹčäč乥ą║čéąĖą▓ąĮąŠ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄčéčüčÅ č鹊ą╗čīą║ąŠ ąŠą┤ąĮąŠą╣ ą┐ąŠą╗ąŠą▓ąĖąĮąŠą╣ ą║čŹčłą░, čé. ąĄ. ą▒ą░ąĮą║ąŠą╝ Data Bank B (2-Way set associative 16K ą▒ą░ą╣čé ą║čŹčł). ąÆ čéą░ą║ąŠą╝ čüčåąĄąĮą░čĆąĖąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą┐ąŠą╗čāčćą░ąĄčé ą┐čĆąĄąĖą╝čāčēąĄčüčéą▓ ąŠčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ Data Bank A.
ąöą╗čÅ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ ą╗čāčćčłąĄ ą▓čüąĄą│ąŠ čĆą░ą▒ąŠčéą░čéčī čü DCBS = 0.
ą×ą┤ąĮą░ą║ąŠ ąĄčüą╗ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ čĆą░ą▒ąŠčéą░ąĄčé čü 2 ąĮą░ą▒ąŠčĆą░ą╝ąĖ ą┤ą░ąĮąĮčŗčģ, čĆą░ąĘą╝ąĄčēąĄąĮąĮčŗčģ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ ą▓ ą┤ą▓čāčģ ąŠą▒ą╗ą░čüčéčÅčģ ą┐ą░ą╝čÅčéąĖ, čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĮčŗčģ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ ąĮą░ čĆą░čüčüč鹊čÅąĮąĖąĖ ąĮąĄ ą╝ąĄąĮąĄąĄ 8M ą▒ą░ą╣čé, ą╝ąŠąČąĮąŠ č鹊čćąĮąĄąĄ čāą┐čĆą░ą▓ą╗čÅčéčī č鹥ą╝, ą║ą░ą║ ą║čŹčł ą┐čĆąĖą▓čÅąĘą░ąĮ ą║ ą┤ą░ąĮąĮčŗą╝. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą┤ąĄą╗ą░ąĄčé čüąĄčĆąĖčÄ ą┤ą▓ąŠą╣ąĮčŗčģ MAC-ąŠą┐ąĄčĆą░čåąĖą╣, ą▓ ą║ąŠč鹊čĆčŗčģ ąŠą▒ą░ DAG-ą░ ąŠą▒čĆą░čēą░čÄčéčüčÅ ą║ ą┤ą░ąĮąĮčŗą╝ ą▓ ą║ą░ąČą┤ąŠą╝ čåąĖą║ą╗ąĄ, č鹊 ą┐čāč鹥ą╝ čĆą░ąĘą╝ąĄčēąĄąĮąĖčÅ ąĮą░ą▒ąŠčĆą░ ą┤ą░ąĮąĮčŗčģ DAG0 ą▓ ąŠą┤ąĮąŠą╝ ą▒ą╗ąŠą║ąĄ, ąĖ ąĮą░ą▒ąŠčĆą░ ą┤ą░ąĮąĮčŗčģ DAG1 ą▓ ą┤čĆčāą│ąŠą╝, č鹊 čüąĖčüč鹥ą╝ą░ ą╝ąŠąČąĄčé čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī čüą╗ąĄą┤čāčÄčēąĄąĄ:
ŌĆó DAG0 ą┐ąŠą╗čāčćą░ąĄčé čüą▓ąŠąĖ ą┤ą░ąĮąĮčŗąĄ ąĖąĘ Data Bank A ą┤ą╗čÅ ą▓čüąĄčģ čüą▓ąŠąĖčģ ąŠą▒čĆą░čēąĄąĮąĖą╣, ąĖ
ąŁč鹊 čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ąĘą░čüčéą░ą▓ą╗čÅąĄčé čÅą┤čĆąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąŠą▒ąĄ čłąĖąĮčŗ ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ ą┐ąĄčĆąĄą┤ą░čć čüčéčĆąŠą║ąĖ ą║čŹčłą░, ąĖ ą┤ąŠčüčéąĖą│ą░ąĄčéčüčÅ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮą░čÅ ą┐čĆąŠą┐čāčüą║ąĮą░čÅ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī ą┐ąŠ ą┐ąĄčĆąĄą┤ą░č湥 ą┤ą░ąĮąĮčŗčģ ą╝ąĄąČą┤čā ą║čŹčłąĄą╝ ąĖ čÅą┤čĆąŠą╝.
ąØą░ čĆąĖčü. 6-14 ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąĖą╝ąĄčĆ, ą║ą░ą║ąŠąĄ ą┐ąŠą╗čāčćą░ąĄčéčüčÅ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą┐čĆąĖ DCBS = 1.
ąÆčŗą▒ąŠčĆ DCBS ą╝ąŠąČąĮąŠ ą╝ąĄąĮčÅčéčī ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąĖ; ąŠą┤ąĮą░ą║ąŠ, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ąŠčéčüčāčéčüčéą▓ąĖąĄ ą┐ąŠč鹥čĆčī ą┤ą░ąĮąĮčŗčģ, čüąĮą░čćą░ą╗ą░ ąĘą░čüąĖąĮčģčĆąŠąĮąĖąĘąĖčĆčāą╣č鹥 (flush) ą║čŹčł, ąĖ čüą┤ąĄą╗ą░ą╣č鹥 ąĄą│ąŠ čåąĄą╗ąĖą║ąŠą╝ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝.
Figure 6-14. ą£ą░ą┐ą┐ąĖąĮą│ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ ą┐čĆąĖ DCBS = 1.
ąöąŠčüčéčāą┐ ą║ ą║čŹčłčā ą┤ą░ąĮąĮčŗčģ . ąÜąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą║čŹčłą░ ą┐čĆąŠą▓ąĄčĆčÅąĄčé ą░ą┤čĆąĄčü ąŠčé DAG-ąŠą▓ ąĮą░ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĄ ą▒ąĖč鹊ą▓ čé菹│ąŠą▓. ąĢčüą╗ąĖ ą╗ąŠą│ąĖč湥čüą║ąĖą╣ ą░ą┤čĆąĄčü ą┐čĆąĖčüčāčéčüčéą▓čāąĄčé ą▓ ą║čŹčłąĄ L1, č鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐ąŠą┐ą░ą┤ą░ąĮąĖąĄ ą▓ ą║čŹčł (cache hit), ąĖ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┤ąŠčüčéčāą┐ ą║ ą┤ą░ąĮąĮčŗą╝, ąĮą░čģąŠą┤čÅčēąĖą╝čüčÅ ą▓ L1. ąĢčüą╗ąĖ ą╗ąŠą│ąĖč湥čüą║ąĖą╣ ą░ą┤čĆąĄčü ąŠčéčüčāčéčüčéą▓čāąĄčé ą▓ ą║čŹčłąĄ, č鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐čĆąŠą╝ą░čģ ą║čŹčłą░ (cache miss), ąĖ čéčĆą░ąĮąĘą░ą║čåąĖčÅ ą┐ąŠ ą┐ą░ą╝čÅčéąĖ ą┐ąĄčĆąĄčģąŠą┤ąĖčé ąĮą░ čüą╗ąĄą┤čāčÄčēąĖą╣ čāčĆąŠą▓ąĄąĮčī ą┐ą░ą╝čÅčéąĖ č湥čĆąĄąĘ ąĖąĮč鹥čĆč乥ą╣čü čüąĖčüč鹥ą╝čŗ. ąśąĮą┤ąĄą║čü čüčéčĆąŠą║ąĖ ąĖ ą┐ąŠą╗ąĖčéąĖą║ą░ ąĘą░ą╝ąĄąĮčŗ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ ą║čŹčłą░ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé čé菹│ ą║čŹčłą░ ąĖ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆąŠąĄ ą▓čŗą┤ąĄą╗čÅąĄčéčüčÅ ą┤ą╗čÅ ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗąĄ ą▓ąŠąĘą▓čĆą░čēą░čÄčéčüčÅ ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ.
ąĪčéčĆąŠą║ą░ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ąŠą┤ąĮąŠą╝ ąĖąĘ 3 čüąŠčüč鹊čÅąĮąĖą╣: ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮą░čÅ (invalid), 菹║čüą║ą╗čĹʹĖą▓ąĮą░čÅ (ą┤ąŠčüč鹊ą▓ąĄčĆąĮą░čÅ ąĖ čćąĖčüčéą░čÅ, valid and clean), ąĖ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮą░čÅ (ą┤ąŠčüč鹊ą▓ąĄčĆąĮą░čÅ ąĖ ą│čĆčÅąĘąĮą░čÅ, valid and dirty, čé. ąĄ. ąĮąĄ ąĘą░čüąĖąĮčģčĆąŠąĮąĖąĘąĖčĆąŠą▓ą░ąĮąĮą░čÅ čü ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéčīčÄ). ąĢčüą╗ąĖ ą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ čāąČąĄ ąĘą░ąĮąĖą╝ą░čÄčé ą▓čŗą┤ąĄą╗ąĄąĮąĮčāčÄ čüčéčĆąŠą║čā ąĖ ą║čŹčł čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮ ą║ą░ą║ čģčĆą░ąĮąĖą╗ąĖčēąĄ write-back, ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą┐čĆąŠą▓ąĄčĆčÅąĄčé čüąŠčüč鹊čÅąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ąĖ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé čŹč鹊 čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ŌĆó ąĢčüą╗ąĖ čüąŠčüč鹊čÅąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ 菹║čüą║ą╗čĹʹĖą▓ąĮąŠąĄ (čćąĖčüč鹊ąĄ), č鹊 ąĮąŠą▓čŗą╣ čé菹│ ąĖ ą┤ą░ąĮąĮčŗąĄ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ ą┐ąŠą▓ąĄčĆčģ čüčéą░čĆąŠą╣ čüčéčĆąŠą║ąĖ.
ą¤čĆąŠčåąĄčüčüąŠčĆ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą▒čāč乥čĆčŗ-ąČąĄčĆčéą▓čŗ ąĖ ą▒čāč乥čĆčŗ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ. ąŁčéąĖ ą▒čāč乥čĆčŗ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ, ąĄčüą╗ąĖ ą┐čĆąŠą╝ą░čģ ąĘą░ą│čĆčāąĘą║ąĖ ą║čŹčłą░ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéčī ąĘą░ą╝ąĄąĮčŗ čüčéčĆąŠą║ąĖ-ąČąĄčĆčéą▓čŗ ą║čŹčłą░. ą×ą┐ąĄčĆą░čåąĖčÅ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ ą┐ąĄčĆąĄčģąŠą┤ąĖčé ąĮą░ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī. ąÜčŹčł ą┤ą░ąĮąĮčŗčģ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ąĘą░ą┐čĆąŠčü ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ ą┤ą╗čÅ čüąĖčüč鹥ą╝čŗ ą║ą░ą║ ą║čĆąĖčéąĖč湥čüą║ąĖą╣ (ąĖą╗ąĖ ąĘą░ą┐čĆąŠčłąĄąĮąĮčŗą╣), ąĖ ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗čÅąĄčé ą┤ą░ąĮąĮčŗąĄ ą║ ąŠąČąĖą┤ą░čÄčēąĄą╝čā DAG, ą┐ąŠčüą║ąŠą╗čīą║čā čŹč鹊 ąŠą▒ąĮąŠą▓ąĖčé čüčéčĆąŠą║čā ą║čŹčłą░. ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ą║čŹčł ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą║čĆąĖčéąĖč湥čüą║ąŠą│ąŠ čüą╗ąŠą▓ą░.
ąÜčŹčł ą┤ą░ąĮąĮčŗčģ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą┐čĆąŠą╝ą░čģąĖ čéąĖą┐ą░ hit-under-a-store (čüąŠą▓ą┐ą░ą┤ąĄąĮąĖąĄ ą┐čĆąĖ čüąŠčģčĆą░ąĮąĄąĮąĖąĖ) ąĖ hit-under-a-prefetch (čüąŠą▓ą┐ą░ą┤ąĄąĮąĖąĄ ąĮą░ ąŠą┐ąĄčĆą░čåąĖąĖ ą┐čĆąĄą┤ą▓čŗą▒ąŠčĆą║ąĖ). ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ą┐čĆąĖ ą┐čĆąŠą╝ą░čģąĄ ąĮą░ ąĘą░ą┐ąĖčüąĖ ąĖą╗ąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ PREFETCH, ą║ąŠč鹊čĆą░čÅ ą┐čĆąŠą╝ą░čģąĮčāą╗ą░čüčī ą▓ ą║čŹčłąĄ (ąĖ čŹč鹊 ą║čŹčłąĖčĆčāąĄą╝čŗą╣ čĆąĄą│ąĖąŠąĮ), ą▓ ą║ąŠąĮą▓ąĄą╣ąĄčĆąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą║ą░ ą╝ąĖąĮąĖą╝čāą╝ ąĮą░ 4-čåąĖą║ą╗ą░. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ą┐ąŠčüą╗ąĄą┤čāčÄčēą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ ąĖą╗ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą╝ąŠąČąĄčé ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą┐ąŠą┐ą░ą┤ą░ąĮąĖąĄ ą▓ ą║čŹčł L1, ą║ąŠą│ą┤ą░ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ.
ą¤čĆąĄčĆčŗą▓ą░ąĮąĖčÅ čü ą┤ąŠčüčéą░č鹊čćąĮčŗą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ (ą┐ąŠ ąŠčéąĮąŠčłąĄąĮąĖčÄ ą║ č鹥ą║čāčēąĄą╝čā ą║ąŠąĮč鹥ą║čüčéčā ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ) ąŠčéą╝ąĄąĮčÅąĄčé ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮčāčÄ ąĖąĮčüčéčĆčāą║čåąĖčÄ ąĘą░ą│čĆčāąĘą║ąĖ. ąĪą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ, ąĄčüą╗ąĖ ąŠą┐ąĄčĆą░čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ ą┐čĆąŠą╝ą░čģąĮąĄčéčüčÅ ą╝ąĖą╝ąŠ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ L1 ąĖ ąĮą░ čüąĖčüč鹥ą╝ąĮąŠą╝ ąĖąĮč鹥čĆč乥ą╣čüąĄ čüą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ą▓čŗčüąŠą║ąŠą╗ą░č鹥ąĮčéąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ, č鹊 ą╝ąŠąČąĮąŠ ą┐čĆąĄčĆčŗą▓ą░čéčī čÅą┤čĆąŠ ąĖ ą┐ąĄčĆąĄą╣čéąĖ ą║ ąŠą▒čĆą░ą▒ąŠčéą║ąĄ ą┤čĆčāą│ąŠą│ąŠ ą║ąŠąĮč鹥ą║čüčéą░. ąöąŠčüčéčāą┐ čüąĖčüč鹥ą╝čŗ ą║ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÄ ą║čŹčłą░ ąĮąĄ ąŠčéą╝ąĄąĮčÅąĄčéčüčÅ, ąĖ ą║čŹčł ą┤ą░ąĮąĮčŗčģ ąŠą▒ąĮąŠą▓ąĖčéčüčÅ ąĮąŠą▓čŗą╝ąĖ ą┤ą░ąĮąĮčŗą╝ąĖ ą┤ą╗čÅ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą│ąŠ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ ą▒ą░ąĮą║ą░, ą┤ąŠ ą╗čÄą▒ąŠą╣ ą▒čāą┤čāčēąĄą╣ ąŠą┐ąĄčĆą░čåąĖąĖ čü ą┐čĆąŠą╝ą░čģąŠą╝.
ą£ąĄč鹊ą┤čŗ ąĘą░ą┐ąĖčüąĖ ą▓ ą║čŹčł . ą×ą┐ąĄčĆą░čåąĖąĖ ąĘą░ą┐ąĖčüąĖ ą▓ ą║čŹčł ą╝ąŠą│čāčé ą▒čŗčéčī čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮčŗ ą╗ąĖą▒ąŠ čüą║ą▓ąŠąĘąĮąŠą╣ ąĘą░ą┐ąĖčüčīčÄ (write-through), ą╗ąĖą▒ąŠ ąŠą▒čĆą░čéąĮąŠą╣ ąĘą░ą┐ąĖčüčīčÄ (write-back):
ŌĆó ąöą╗čÅ ą║ą░ąČą┤ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čüą║ą▓ąŠąĘąĮą░čÅ ąĘą░ą┐ąĖčüčī ą▓ ą║čŹčł (write-through) ąĖąĮąĖčåąĖąĖčĆčāąĄčé ąĘą░ą┐ąĖčüčī ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī čüčĆą░ąĘčā ą┐ąŠčüą╗ąĄ ąĘą░ą┐ąĖčüąĖ ą▓ ą║čŹčł.
ąĢčüą╗ąĖ čüčéčĆąŠą║ą░ ą║čŹčłą░ ąĘą░ą╝ąĄąĮąĄąĮą░, ąĖą╗ąĖ čÅą▓ąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝ čüą▒čĆąŠčłąĄąĮą░ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗą╝ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖąĄą╝ ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī (flushed), č鹊 čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ą┤ąĄą╗ą░ąĄčéčüčÅ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝, ą░ ąĮąĄ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ąŠą▒čĆą░čéąĮąŠ ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī.
ŌĆó ą×ą▒čĆą░čéąĮą░čÅ ąĘą░ą┐ąĖčüčī ą▓ ą║čŹčł (write-back) ąĮąĄ ą▒čāą┤ąĄčé ąŠčüčāčēąĄčüčéą▓ą╗čÅčéčī ąĘą░ą┐ąĖčüčī ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī, ą┐ąŠą║ą░ čüčéčĆąŠą║ą░ ąĮąĄ ą▒čāą┤ąĄčé ąĘą░ą╝ąĄąĮąĄąĮą░ ąŠą┐ąĄčĆą░čåąĖąĄą╣ ąĘą░ą│čĆčāąĘą║ąĖ, ą║ąŠč鹊čĆą░čÅ ą▒čāą┤ąĄčé ąĮčāąČą┤ą░čéčīčüčÅ ą▓ čŹč鹊ą╣ čüčéčĆąŠą║ąĄ.
ąöą╗čÅ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ ą║čŹčł write-back ą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĄąĮ, č湥ą╝ ą║čŹčł write-through, ą┐ąŠčüą║ąŠą╗čīą║čā ąŠą▒čĆą░čēąĄąĮąĖčÅ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ą╝ąĄąĮąĄąĄ čćą░čüčéčŗąĄ.
ąÆ čŹč鹊ą╝ čĆąĄąČąĖą╝ąĄ ąĮą░ ą┐čĆąŠą╝ą░čģąĄ ą║čŹčłą░, ą║ąŠč鹊čĆąŠąĄ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐čĆąĖ ąĘą░ą┐ąĖčüąĖ ą▓ ą┐ą░ą╝čÅčéčī, ą▓čüčÅ 32-ą▒ą░ą╣čéąĮą░čÅ čüčéčĆąŠą║ą░, čüąŠą┤ąĄčƹȹ░čēą░čÅ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄą╝čŗąĄ ą▒ą░ą╣čéčŗ, čüąĮą░čćą░ą╗ą░ ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ą▓ ą║čŹčł. ąŚą░č鹥ą╝ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ą▒ą░ą╣čéčŗ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ ą▓ ą║čŹčł. ąŁčéą░ čüčéčĆąŠą║ą░ ąĮąĄ ą▒čāą┤ąĄčé ąĘą░ą┐ąĖčüą░ąĮą░ ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī, ą┐ąŠą║ą░ ąĮąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąŠą┐ąĄčĆą░čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ, ą║ąŠč鹊čĆą░čÅ ą┐ąŠčéčĆąĄą▒čāąĄčé ąĘą░ą╝ąĄąĮčŗ ą┤ą░ąĮąĮčŗčģ čŹč鹊ą╣ čüčéčĆąŠą║ąĖ.
ą¤ą░ą╝čÅčéčī ą┤ą░ąĮąĮčŗčģ L1 ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą▒ą░ąĮą║ą░ ą▒čāč乥čĆ ąŠą▒čĆą░čéąĮąŠą│ąŠ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ ąĮą░ ą┐ąŠą╗ąĮčāčÄ čłąĖčĆąĖąĮčā čüčéčĆąŠą║ąĖ. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ą▒čāč乥čĆ ąĘą░ą┐ąĖčüąĖ čü ą┤ą▓čāą╝čÅ čÅč湥ą╣ą║ą░ą╝ąĖ ą▓ ą┐ą░ą╝čÅčéąĖ ą┤ą░ąĮąĮčŗčģ L1 ą┐čĆąĖąĮąĖą╝ą░ąĄčé ą▓čüąĄ čģčĆą░ąĮąĖą╗ąĖčēą░ čü ąĘą░ą┐čĆąĄčēąĄąĮąĮčŗą╝ ą║čŹčłąĄą╝ ąĖą╗ąĖ ąĘą░čēąĖč鹊ą╣ store-through. ąśąĮčüčéčĆčāą║čåąĖčÅ SSYNC čüą▒čĆą░čüčŗą▓ą░ąĄčé (flushes) ą▒čāč乥čĆ ąĘą░ą┐ąĖčüąĖ.
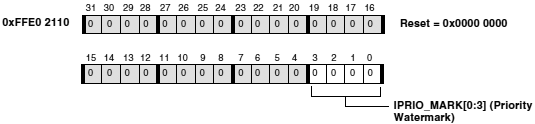
ąĀąĄą│ąĖčüčéčĆ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ (Interrupt Priority register, IPRIO) ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čĆą░ąĘą╝ąĄčĆąŠą╝ ą▒čāč乥čĆą░ ąĘą░ą┐ąĖčüąĖ ą┤ą╗čÅ Port A (čüą╝. "L1 Data Memory Architecture").
ąĀąĖčü. 6-15. Interrupt Priority Register.
IPRIO_MARK[0:3] (Priority Watermark) . ąŁčéąĖ ą▒ąĖčéčŗ ą╝ąŠą│čāčé ą▒čŗčéčī ąĘą░ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮčŗ ą┤ą╗čÅ ąŠčéčĆą░ąČąĄąĮąĖčÅ ą│čĆą░ąĮąĖčåčŗ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąĮąĖąĘą║ąŠą│ąŠ ą┐čĆąĖąŠčĆąĖč鹥čéą░. ąÜąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ, čćč鹊 ą┐čĆąĖąĮčāąČą┤ą░ąĄčé ą┐čĆąŠčåąĄčüčüąŠčĆ ą┐ąĄčĆąĄą╣čéąĖ ąŠčé ą╝ąĄąĮąĄąĄ ą┐čĆąĖąŠčĆąĖč鹥čéąĮąŠą│ąŠ ISR ą║ ą▒ąŠą╗ąĄąĄ ą┐čĆąĖąŠčĆąĖč鹥čéąĮąŠą╝čā, čĆą░ąĘą╝ąĄčĆ ą▒čāč乥čĆą░ ąĘą░ą┐ąĖčüąĖ čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčéčüčÅ ą▓ ą│ą╗čāą▒ąĖąĮčā ąŠčé 2 ą┤ąŠ 8 čüą╗ąŠą▓ ą┐ąŠ 32 ą▒ąĖčéą░. ąŁč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ISR ąĘą░ą┐čāčüčéąĖčéčīčüčÅ ąĖ ąŠčéą┐čĆą░ą▓ąĖčéčī ąĘą░ą┐ąĖčüąĖ ą▒ąĄąĘ ąĮą░čćą░ą╗čīąĮąŠą╣ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą║ąĖ ą▓ čüą╗čāčćą░ąĄ, ą║ąŠą│ą┤ą░ ą▒čāč乥čĆ čāąČąĄ ą▒čŗą╗ ąĘą░ą┐ąŠą╗ąĮąĄąĮ ą▓ ą╝ąĄąĮąĄąĄ ą┐čĆąĖąŠčĆąĖč鹥čéąĮąŠą╝ ISR. ąŁč鹊 ąŠčüąŠą▒ąĄąĮąĮąŠ ą┐ąŠą╗ąĄąĘąĮąŠ, ą║ąŠą│ą┤ą░ ąŠčéą┐čĆą░ą▓ą╗ąĄąĮčŗ ąĘą░ą┐ąĖčüąĖ ą▓ ą╝ąĄą┤ą╗ąĄąĮąĮąŠąĄ ą▓ąĮąĄčłąĮąĄąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ą┐ą░ą╝čÅčéąĖ. ąÜąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓ąŠąĘą▓čĆą░čé ąĖąĘ ą▓čŗčüąŠą║ąŠą┐čĆąĖąŠčĆąĖč鹥čéąĮąŠą│ąŠ ISR ą▓ ąĮąĖąĘą║ąŠą┐čĆąĖąŠčĆąĖč鹥čéąĮčŗą╣ ISR ąĖą╗ąĖ ą▓ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖą╣ čĆąĄąČąĖą╝, čÅą┤čĆąŠ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ą┐ąŠą║ą░ ąĘą░ą┐ąĖčüčī ą▒čāč乥čĆą░ ąĮąĄ ąĘą░ą▓ąĄčĆčłąĖčé ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗąĄ ąĘą░ą┐ąĖčüąĖ ąĖ ą▓ąŠąĘą▓čĆą░čéąĖčéčüčÅ ą▓ čüąŠčüč鹊čÅąĮąĖąĄ ą┤ą▓ąŠą╣ąĮąŠą╣ ą│ą╗čāą▒ąĖąĮčŗ. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą▒čāč乥čĆ ąĘą░ą┐ąĖčüąĖ čĆą░ą▒ąŠčéą░ąĄčé ą║ą░ą║ FIFO ą┤ą▓ąŠą╣ąĮąŠą╣ ą│ą╗čāą▒ąĖąĮčŗ.
0000: čüąŠčüč鹊čÅąĮąĖąĄ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ, ą▓čüąĄ ą┐čĆąĖąŠčĆąĖč鹥čéčŗ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ ąĮąĖąĘą║ąĖąĄ.
ąśąĮčüčéčĆčāą║čåąĖąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą║čŹčłąĄą╝ ą┤ą░ąĮąĮčŗčģ . ąÆ ą┐čĆąŠčåąĄčüčüąŠčĆąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮčŗ 3 ąĖąĮčüčéčĆčāą║čåąĖąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą║čŹčłąĄą╝ ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓ čĆąĄąČąĖą╝ą░čģ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode) - PREFETCH, FLUSH ąĖ FLUSHINV. ą¤čĆąĖą╝ąĄčĆčŗ ą║ą░ąČą┤ąŠą╣ ąĖąĘ čŹčéąĖčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą╝ąŠąČąĮąŠ ąĮą░ą╣čéąĖ ą▓ ą│ą╗ą░ą▓ąĄ 17 "Cache Control" čĆčāą║ąŠą▓ąŠą┤čüčéą▓ą░ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ [5].
ŌĆó PREFETCH (Data Cache Prefetch, ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮą░čÅ ą▓čŗą▒ąŠčĆą║ą░ ą┤ą░ąĮąĮčŗčģ ą║čŹčłą░) ą┐čŗčéą░ąĄčéčüčÅ ą▓čŗą┤ąĄą╗ąĖčéčī čüčéčĆąŠą║čā ą▓ ą║čŹčłąĄ L1. ąĢčüą╗ąĖ ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮą░čÅ ą▓čŗą▒ąŠčĆą║ą░ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ą┐ąŠą┐ą░ą┤ą░ąĮąĖčÄ ą▓ ą║čŹčł, ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ, ąĖą╗ąĖ ą░ą┤čĆąĄčüčāąĄčéčüčÅ ą║čŹčł ąĘą░ą┐čĆąĄčēąĄąĮąĮąŠą╣ ąŠą▒ą╗ą░čüčéąĖ, č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ PREFETCH čĆą░ą▒ąŠčéą░ąĄčé ą║ą░ą║ NOP. ąŁč鹊 ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ, čćč鹊ą▒čŗ ąĮą░čćą░čéčī ą▓čŗą▒ąŠčĆą║čā ą┤ą░ąĮąĮčŗčģ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ą┐čĆąŠčåąĄčüčüąŠčĆčā ąŠąĮąĖ ą┐ąŠąĮą░ą┤ąŠą▒čÅčéčüčÅ, čćč鹊ą▒čŗ ą┐ąŠą▓čŗčüąĖčéčī ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ.
ŌĆó FLUSH (Data Cache Flush, čüą▒čĆąŠčü ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ) ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ č鹊ą╝čā, čćč鹊 ą║čŹčł ą┤ą░ąĮąĮčŗčģ čüąĖąĮčģčĆąŠąĮąĖąĘąĖčĆčāąĄčé čāą║ą░ąĘą░ąĮąĮčāčÄ čüčéčĆąŠą║čā ą║čŹčłą░ čü ą▓ąĮąĄčłąĮąĄą╣ (ą╝ąĄą┤ą╗ąĄąĮąĮąŠą╣) ą┐ą░ą╝čÅčéčīčÄ. ąĢčüą╗ąĖ ą║čŹčłąĖčĆčāąĄą╝ą░čÅ čüčéčĆąŠą║ą░ ą┤ą░ąĮąĮčŗčģ ą│čĆčÅąĘąĮą░čÅ, ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé čüčéčĆąŠą║čā ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī ąĖ ą┐ąŠą╝ąĄčćą░ąĄčé čüčéčĆąŠą║čā ą▓ ą║čŹčłąĄ ą┤ą░ąĮąĮčŗčģ ą║ą░ą║ čćąĖčüčéčāčÄ. ąĢčüą╗ąĖ čāą║ą░ąĘą░ąĮąĮą░čÅ čüčéčĆąŠą║ą░ ą┤ą░ąĮąĮčŗčģ ą║čŹčłą░ čāąČąĄ čćąĖčüčéą░čÅ ąĖą╗ąĖ ąĮąĄ čüčāčēąĄčüčéą▓čāąĄčé, č鹊 FLUSH čüčĆą░ą▒ą░čéčŗą▓ą░ąĄčé ą║ą░ą║ NOP.
ŌĆó FLUSHINV (Data Cache Line Flush and Invalidate, čüą▒čĆąŠčü čüčéčĆąŠą║ąĖ ą┐ą░ą╝čÅčéąĖ ąĖ ą┐ąĄčĆąĄą▓ąŠą┤ ąĄčæ ą▓ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ) čüčĆą░ą▒ą░čéčŗą▓ą░ąĄčé čéą░ą║ ąČąĄ, ą║ą░ą║ ąĖ FLUSH, ąĖ ąĘą░č鹥ą╝ ą┤ąĄą╗ą░ąĄčé čāą║ą░ąĘą░ąĮąĮčāčÄ čüčéčĆąŠą║čā ą║čŹčłą░ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠąĄ. ąĢčüą╗ąĖ čüčéčĆąŠą║ą░ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą║čŹčłąĄ ąĖ ą│čĆčÅąĘąĮą░čÅ, č鹊 ąŠąĮą░ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī. ąŚą░č鹥ą╝ ąŠčćąĖčēą░ąĄčéčüčÅ ą▒ąĖčé Valid čüčéčĆąŠą║ąĖ ą║čŹčłą░. ąĢčüą╗ąĖ čüčéčĆąŠą║ą░ ąĮąĄ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą║čŹčłąĄ, č鹊 FLUSHINV čĆą░ą▒ąŠčéą░ąĄčé ą║ą░ą║ NOP.
ąĢčüą╗ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠąĄ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖąĄ čéčĆąĄą▒čāąĄčé čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ čü ą░ą┐ą┐ą░čĆą░čéčāčĆąŠą╣ čüąĖčüč鹥ą╝čŗ, ą┐ąŠą╝ąĄčüčéąĖč鹥 ąĖąĮčüčéčĆčāą║čåąĖčÄ SSYNC ą┐ąŠčüą╗ąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ FLUSH, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ąŠą┐ąĄčĆą░čåąĖčÅ flush ąĘą░ą▓ąĄčĆčłąĖą╗ą░čüčī. ąĢčüą╗ąĖ čéčĆąĄą▒čāąĄčéčüčÅ čāą┐ąŠčĆčÅą┤ąŠčćąĖą▓ą░ąĮąĖąĄ, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ą┐čĆąĄą┤čŗą┤čāčēąĖąĄ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą▒čŗą╗ąĖ ą▓čŗč鹊ą╗ą║ąĮčāčéčŗ č湥čĆąĄąĘ ą▓čüąĄ ąŠč湥čĆąĄą┤ąĖ, ą┐ąŠą╝ąĄčüčéąĖč鹥 ąĖąĮčüčéčĆčāą║čåąĖčÄ SSYNC ą┐ąĄčĆąĄą┤ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ FLUSH.
ą¤ąĄčĆąĄą▓ąŠą┤ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ ą▓ čüąŠčüč鹊čÅąĮąĖąĄ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéąĖ (Data Cache Invalidation). ą¤ąŠą╝ąĖą╝ąŠ ąĖąĮčüčéčĆčāą║čåąĖąĖ FLUSHINV, ąŠą┐ąĖčüą░ąĮąĮąŠą╣ ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ čüąĄą║čåąĖąĖ, ąĄčüčéčī ą┤ą▓ą░ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ą╝ąĄč鹊ą┤ą░ ą┤ą╗čÅ č鹊ą│ąŠ, čćč鹊ą▒čŗ čüą┤ąĄą╗ą░čéčī ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝ąĖ ą┤ą░ąĮąĮčŗąĄ ą║čŹčłą░, ą║ąŠą│ą┤ą░ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÅ ą║čŹčłą░ (flushing) ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ. ą¤ąĄčĆą▓ą░čÅ č鹥čģąĮąĖą║ą░ čéčĆąĄą▒čāąĄčé ą┐čĆčÅą╝ąŠą│ąŠ ą┐ąĄčĆąĄą▓ąŠą┤ą░ ą▒ąĖč鹊ą▓ Valid ą▓ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéčī ą┐čāč鹥ą╝ čāčüčéą░ąĮąŠą▓ą║ąĖ ą▒ąĖčéą░ Invalid ą║ą░ąČą┤ąŠą╣ čüčéčĆąŠą║ąĖ ą║čŹčłą░, ą║ąŠč鹊čĆą░čÅ ą┐ąĄčĆąĄą▓ąŠą┤ąĖčéčüčÅ ą▓ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ. ą¦č鹊ą▒čŗ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī čŹčéčā č鹥čģąĮąĖą║čā, ąĖą╝ąĄčÄčéčüčÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ MMR (DTEST_COMMAND ąĖ DTEST_DATA[1:0]), čćč鹊ą▒čŗ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ąĮą░ą┐čĆčÅą╝čāčÄ, ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮąŠ čćąĖčéą░čéčī/ąĘą░ą┐ąĖčüčŗą▓ą░čéčī ą▓čüąĄ ą▓čüąĄ ąĘą░ą┐ąĖčüąĖ ą║čŹčłą░. ąŁč鹊čé ą╝ąĄč鹊ą┤ ąŠą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╣ čüąĄą║čåąĖąĖ.
ą¦č鹊ą▒čŗ čüą┤ąĄą╗ą░čéčī ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝ ą▓ąĄčüčī ą║čŹčł, ąĄčüčéčī ą▓č鹊čĆąŠą╣ ą╝ąĄč鹊ą┤. ą¤čāč鹥ą╝ ąŠčćąĖčüčéą║ąĖ ą▒ąĖč鹊ą▓ DMC[1:0] ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMEM_CONTROL (čüą╝. čĆąĖčü. 6-11) ą▓čüąĄ ą▒ąĖčéčŗ Valid ą▓ ą║čŹčłąĄ ą┤ą░ąĮąĮčŗčģ ą┐ąĄčĆąĄčģąŠą┤čÅčé ą▓ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ. ąÆč鹊čĆą░čÅ ąĘą░ą┐ąĖčüčī ą▓ DMEM_CONTROL ą┤ą╗čÅ čāčüčéą░ąĮąŠą▓ą║ąĖ DMC[1:0] ą▓ ąĖčģ ą┐čĆąĄą┤čŗą┤čāčēąĄąĄ čüąŠčüč鹊čÅąĮąĖąĄ ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄčé ą┐ą░ą╝čÅčéčī ą┤ą░ąĮąĮčŗčģ ąŠą▒čĆą░čéąĮąŠ ą▓ čüą▓ąŠčÄ ą┐čĆąĄą┤čŗą┤čāčēčāčÄ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÄ ą║čŹčł/SRAM. ą¤ąĄčĆąĄą┤ ą┐ąĄčĆąĄą▓ąŠą┤ąŠą╝ ą║čŹčłą░ ą▓ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ ąĮčāąČąĮąŠ ąĘą░ą┐čāčüčéąĖčéčī ąĖąĮčüčéčĆčāą║čåąĖčÄ SSYNC, ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅ CSYNC ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ą▓čüčéą░ą▓ą╗ąĄąĮą░ ą┐ąŠčüą╗ąĄ ą║ą░ąČą┤ąŠą╣ ąĖąĘ čŹčéąĖčģ ąŠą┐ąĄčĆą░čåąĖą╣. ąŁč鹊čé ą╝ąĄč鹊ą┤ ą┐ąŠą╗ąĄąĘąĄąĮ, ąĄčüą╗ąĖ ą▒čāč乥čĆ ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗą╣ ą┤ąĄą╗ą░ąĄčéčüčÅ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝, ą▒ąŠą╗čīčłąĄ, č湥ą╝ čĆą░ąĘą╝ąĄčĆ ą║čŹčłą░.
[ąĀąĄą│ąĖčüčéčĆčŗ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ (Data Test Registers) ]
ąØą░ą┐ąŠą┤ąŠą▒ąĖąĄ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ L1 (L1 Instruction Memory), ą┐ą░ą╝čÅčéčī ą┤ą░ąĮąĮčŗčģ L1 (L1 Data Memory) čüąŠą┤ąĄčƹȹĖčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ MMR, čćč鹊ą▒čŗ ą┐ąŠąĘą▓ąŠą╗ąĖčéčī ą┐čĆčÅą╝čŗąĄ, ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ čćč鹥ąĮąĖąĄ/ąĘą░ą┐ąĖčüčī ą▓čüąĄčģ čÅč湥ąĄą║ ą║čŹčłą░. ąĀąĄą│ąĖčüčéčĆčŗ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ą╝ąĄčģą░ąĮąĖąĘą╝ ą┤ą╗čÅ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ, ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ ąĖ ąŠčéą╗ą░ą┤ą║ąĖ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ.
ąÜąŠą│ą┤ą░ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ čĆąĄą│ąĖčüčéčĆ ą║ąŠą╝ą░ąĮą┤ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ (Data Test Command register, DTEST_COMMAND), ą╝ą░čüčüąĖą▓čŗ ą┤ą░ąĮąĮčŗčģ ąĖą╗ąĖ čé菹│ąŠą▓ ą║čŹčłą░ L1 čüčéą░ąĮąŠą▓čÅčéčüčÅ ą┤ąŠčüčéčāą┐ąĮčŗ, ąĖ ąĖčģ ą┤ą░ąĮąĮčŗąĄ ą┐ąĄčĆąĄą┤ą░čÄčéčüčÅ č湥čĆąĄąĘ čĆąĄą│ąĖčüčéčĆčŗ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ (Data Test Data registers, DTEST_DATA[1:0]). ąĀąĄą│ąĖčüčéčĆčŗ DTEST_DATA[1:0] čüąŠą┤ąĄčƹȹ░čé 64-ą▒ąĖčéąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ, ąĖą╗ąĖ čüąŠą┤ąĄčƹȹ░čé ą╝ąĄčüč鹊 ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą┤ą╗čÅ 64-ą▒ąĖčéąĮčŗčģ čćąĖčéą░ąĄą╝čŗčģ ą┤ą░ąĮąĮčŗčģ. ą£ą╗ą░ą┤čłąĖąĄ 32 ą▒ąĖčéą░ čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ DTEST_DATA[0], ąĖ čüčéą░čĆčłąĖąĄ 32 ą▒ąĖčéą░ ą▓ DTEST_DATA[1]. ąÜąŠą│ą┤ą░ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ ą║ ą╝ą░čüčüąĖą▓ą░ą╝ č鹥ą│ąŠą▓, č鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čĆąĄą│ąĖčüčéčĆ DTEST_DATA[0].
ą¤ąŠčüą╗ąĄ ąĘą░ą┐ąĖčüąĖ DTEST_COMMAND MMR čéčĆąĄą▒čāąĄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ SSYNC.
ąöąŠčüčéčāą┐ ą║ čŹčéąĖą╝ čĆąĄą│ąĖčüčéčĆą░ą╝ ą▓ąŠąĘą╝ąŠąČąĄąĮ č鹊ą╗čīą║ąŠ ą▓ čĆąĄąČąĖą╝ą░čģ Supervisor ąĖą╗ąĖ Emulation. ąÜąŠą│ą┤ą░ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ąĘą░ą┐ąĖčüčī ą▓ čĆąĄą│ąĖčüčéčĆčŗ DTEST, ą▓čüąĄą│ą┤ą░ čüąĮą░čćą░ą╗ą░ ąĘą░ą┐ąĖčüčŗą▓ą░ą╣č鹥 DTEST_DATA, ąĘą░č鹥ą╝ čĆąĄą│ąĖčüčéčĆ DTEST_COMMAND.
ąÜąŠą│ą┤ą░ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ čĆąĄą│ąĖčüčéčĆ ą║ąŠą╝ą░ąĮą┤ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ (Data Test Command register, DTEST_COMMAND), ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ ą║ ą╝ą░čüčüąĖą▓ą░ą╝ ą┤ą░ąĮąĮčŗčģ ąĖą╗ąĖ č鹥ą│ąŠą▓ ą║čŹčłą░ L1, ąĖ ą┤ą░ąĮąĮčŗąĄ ą┐ąĄčĆąĄą┤ą░čÄčéčüčÅ č湥čĆąĄąĘ čĆąĄą│ąĖčüčéčĆčŗ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ (Data Test Data registers, DTEST DATA[1:0]).
ąæąĖčé Data/Instruction Access ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐čĆčÅą╝ąŠą╣ ą┤ąŠčüčéčāą┐ č湥čĆąĄąĘ DTEST_COMMAND MMR ą║ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ L1 (L1 instruction SRAM).
ąĀąĖčü. 6-16. Data Test Command Register (ADSP-BF5xx)
ąÜą░ą║ čü ą┤čĆčāą│ąĖą╝ąĖ čāą┐čĆą░ą▓ą╗čÅčÄčēąĖą╝ąĖ ą▒ąĖčéą░ą╝ąĖ MMR, ąĖąĘą╝ąĄąĮąĄąĮąĖąĄ čüąŠčüč鹊čÅąĮąĖčÅ ą▒ąĖč鹊ą▓ PARCTL ąĖ PARSEL ą┤ąŠą╗ąČąĮąŠ čüąŠą┐čĆąŠą▓ąŠąČą┤ą░čéčīčüčÅ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ SSYNC, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ąĮąŠą▓ąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ ą▓čüčéčāą┐ąĖą╗ąŠ ą▓ čüąĖą╗čā.
Access Way/Instruction Address Bit 11 . ąĢčüą╗ąĖ 0, č鹊 Access Way/Instruction Address Bit 11 = 0, ąĖąĮą░č湥 ąŠąĮ čĆą░ą▓ąĄąĮ 1.
Data/Instruction Access . 0: ą┤ąŠčüčéčāą┐ ą║ ą┤ą░ąĮąĮčŗą╝, 1: ą┤ąŠčüčéčāą┐ ą║ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
Data Bank Access . ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ąŠ ąĘąĮą░č湥ąĮąĖąĖ čŹč鹊ą│ąŠ ą▒ąĖčéą░ čüą╝. ą░ą┐ą┐ą░čĆą░čéąĮąŠąĄ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąŠ ą┐ąŠ ąÆą░čłąĄą╝čā ą┐čĆąŠčåąĄčüčüąŠčĆčā. ąÜ ą┐čĆąĖą╝ąĄčĆčā, ą┤ą╗čÅ ADSP-BF538 čŹč鹊čé ą▒ąĖčé ąŠąĘąĮą░čćą░ąĄčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
0: ą┤ąŠčüčéčāą┐ ą║ ą▒ą░ąĮą║čā A ą┤ą░ąĮąĮčŗčģ / ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ 0xFFA0 0000.
Subbank Access[1:0] (SRAM ADDR[13:12]) . ąæąĖčéčŗ ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčé, ą║ ą║ą░ą║ąŠą╝čā ą┐ąŠą┤ą▒ą░ąĮą║čā ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐.
00: ą┤ąŠčüčéčāą┐ ą║ subbank 0.
Data Cache Select/Address Bit 14 . 0 - ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąŠ/Instruction bit 14 = 0, 1 - ą▓čŗą▒ąŠčĆ ą▒ą░ąĮą║ą░ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ/Instruction bit 14 = 1.
Set Index[5:0] . ąÆčŗą▒ąĖčĆą░ąĄčé ąŠą┤ąĖąĮ ąĖąĘ 64 ąĮą░ą▒ąŠčĆąŠą▓.
Double Word Index[1:0] . ąśąĮą┤ąĄą║čü ą┤ą▓ąŠą╣ąĮąŠą│ąŠ čüą╗ąŠą▓ą░. ąÆčŗą▒ąĖčĆą░ąĄčé ąŠą┤ąĮąŠ ąĖąĘ č湥čéčŗčĆąĄčģ 64-ą▒ąĖčéąĮčŗčģ ą┤ą▓ąŠą╣ąĮčŗčģ čüą╗ąŠą▓ ą▓ 256-ą▒ąĖčéąĮąŠą╣ čüčéčĆąŠą║ąĄ.
Array Access . ą×ą┐čĆąĄą┤ąĄą╗čÅąĄčé, ą║ ą║ą░ą║ąŠą╝čā ą╝ą░čüčüąĖą▓čā ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐: 0 ą║ ą╝ą░čüčüąĖą▓čā čé菹│ąŠą▓, 1 ą║ ą╝ą░čüčüąĖą▓čā ą┤ą░ąĮąĮčŗčģ.
Read/Write Access . ą×ą┐čĆąĄą┤ąĄą╗čÅąĄčé ą▓ąĖą┤ ą┤ąŠčüčéčāą┐ą░: 0 čćč鹥ąĮąĖąĄ, 1 ąĘą░ą┐ąĖčüčī.
ąĀąĄą│ąĖčüčéčĆčŗ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ (Data Test Data registers, DTEST_DATA[1:0]) čüąŠą┤ąĄčƹȹ░čé 64-ą▒ąĖčéąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ, ąĖą╗ąĖ čüąŠą┤ąĄčƹȹ░čé 64-ą▒ąĖčéąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ ą┐čĆąŠčćąĖčéą░ąĮčŗ. ąĀąĄą│ąĖčüčéčĆ DTEST_DATA1 čģčĆą░ąĮąĖčé čüčéą░čĆčłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā ąĖąĘ 32 ą▒ąĖčé.
ąĀąĖčü. 6-18. Data Test Data 1 Register.
ą¤čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ ą╝ą░čüčüąĖą▓ą░ą╝ čé菹│ąŠą▓ ą▓čüąĄ ą┐ąŠą╝ąĄč湥ąĮąĮčŗąĄ čüąĄčĆčŗą╝ čåą▓ąĄč鹊ą╝ ą▒ąĖčéčŗ ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮčŗ.
ąĀąĄą│ąĖčüčéčĆčŗ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ (Data Test Data registers, DTEST_DATA[1:0]) čüąŠą┤ąĄčƹȹ░čé 64-ą▒ąĖčéąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ, ąĖą╗ąĖ čüąŠą┤ąĄčƹȹ░čé 64-ą▒ąĖčéąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ ą┐čĆąŠčćąĖčéą░ąĮčŗ. ąĀąĄą│ąĖčüčéčĆ DTEST_DATA0 čģčĆą░ąĮąĖčé ą╝ą╗ą░ą┤čłčāčÄ ą┐ąŠą╗ąŠą▓ąĖąĮčā ąĖąĘ 32 ą▒ąĖčé. DTEST_DATA0 čéą░ą║ąČąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą╝ą░čüčüąĖą▓ą░ą╝ č鹥ą│ąŠą▓, ą║ąŠč鹊čĆčŗąĄ čüąŠą┤ąĄčƹȹ░čé ą▒ąĖčéčŗ Valid ąĖ Dirty, ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčēąĖąĄ čüąŠčüč鹊čÅąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░. ą£ą╗ą░ą┤čłąĖąĄ 32 ą▒ąĖčéą░ čĆąĄą│ąĖčüčéčĆą░ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą╝ą░čüčüąĖą▓ą░ą╝ čé菹│ąŠą▓ ą║čŹčłą░ L1. ąÉą┤čĆąĄčü čé菹│ą░ čüąŠčüč鹊ąĖčé ąĖąĘ čüčéą░čĆčłąĖčģ 18 ą▒ąĖčé ąĖ ą▒ąĖčéą░ 11 čäąĖąĘąĖč湥čüą║ąŠą│ąŠ ą░ą┤čĆąĄčüą░.
ąĀąĖčü. 6-19. Data Test Data 0 Register.
Data [31:0] . ą£ą╗ą░ą┤čłąĖąĄ 32 ą▒ąĖčéą░ 64-ą▒ąĖčéąĮčŗčģ ą┤ą░ąĮąĮčŗčģ.
Tag[19:4] , Tag[3:2] , Tag . ąÉą┤čĆąĄčü čé菹│ą░ čüąŠčüč鹊ąĖčé ąĖąĘ čüčéą░čĆčłąĖčģ 18 ą▒ąĖčé ąĖ ą▒ąĖčéą░ 11 čäąĖąĘąĖč湥čüą║ąŠą│ąŠ ą░ą┤čĆąĄčüą░ (ą┐ąŠą╗čÅ Tag[19:4], Tag[3:2], Tag čüąŠą┤ąĄčƹȹ░čé 19 ą▒ąĖčé ą░ą┤čĆąĄčüą░ č鹥ą│ą░).
LRU . 0: ą┐ąŠčüą╗ąĄą┤ąĮąĖą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗čüčÅ ą║ą░ąĮą░ą╗ Way0, 1: ą┐ąŠčüą╗ąĄą┤ąĮąĖą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗čüčÅ ą║ą░ąĮą░ą╗ Way1.
Valid . ąĢčüą╗ąĖ ą▓ čŹč鹊ą╝ ą▒ąĖč鹥 0, č鹊 čüčéčĆąŠą║ą░ ą║čŹčłą░ ąĮąĄ ą┤ąŠčüč鹊ą▓ąĄčĆąĮą░.
Dirty . 0: čüčéčĆąŠą║ą░ ą║čŹčłą░ ąĮąĄ ą▒čŗą╗ą░ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮą░, ą┐ąŠčüą║ąŠą╗čīą║čā ą▒čŗą╗ą░ čüą║ąŠą┐ąĖčĆąŠą▓ą░ąĮą░ ąĖąĘ ąĖčüčģąŠą┤ąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ. 1: čüčéčĆąŠą║ą░ ą║čŹčłą░ ą▒čŗą╗ą░ ąĖąĘą╝ąĄąĮąĄąĮą░ ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ą▒čŗą╗ą░ čüą║ąŠą┐ąĖčĆąŠą▓ą░ąĮą░ ąĖąĘ ąĖčüčģąŠą┤ąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ.
[ąÆčüčéčĆąŠąĄąĮąĮą░čÅ ą▓ ą║čĆąĖčüčéą░ą╗ą╗ ą┐ą░ą╝čÅčéčī Level 2 (L2) ]
ąØąĄą║ąŠč鹊čĆčŗąĄ ą┐čĆąŠčåąĄčüčüąŠčĆčŗ Blackfin ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčāčÄ ąĮąĖąĘą║ąŠą╗ą░č鹥ąĮčéąĮčāčÄ, čłąĖčĆąŠą║ąŠą┐ąŠą╗ąŠčüąĮčāčÄ ą┐ą░ą╝čÅčéčī, ą║ąŠč鹊čĆą░čÅ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ Level 2 Memory (L2). ą¤ą░ą╝čÅčéčī L2 čĆą░ą▒ąŠčéą░ąĄčé čü čćą░čüč鹊č鹊ą╣ CCLK, čćč鹊 čéčĆąĄą▒čāąĄčé ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ąĮąĄčüą║ąŠą╗čīą║ąŠ čåąĖą║ą╗ąŠą▓.
ą×ą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą╝ąĮąŠą│ąŠą▒ą░ąĮą║ąŠą▓ąŠą╣, ą▓čüčéčĆąŠąĄąĮąĮąŠą╣ ą▓ čćąĖą┐ ą┐ą░ą╝čÅčéąĖ L2 čüąŠ čüč鹊čĆąŠąĮčŗ čÅą┤čĆą░ ąĖ čüąĖčüč鹥ą╝čŗ DMA ą╝ąŠąČąĄčé ą┐čĆąŠąĖčüčģąŠą┤ąĖčéčī ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ ą┐čĆąĖ čāčüą╗ąŠą▓ąĖąĖ, čćč鹊 ąŠąĮąĖ ąŠčüčāčēąĄčüčéą▓ą╗čÅčÄčé ą┤ąŠčüčéčāą┐ ą║ čĆą░ąĘąĮčŗą╝ ą▒ą░ąĮą║ą░ą╝. ąÜąŠąĮčäą╗ąĖą║čéčŗ čĆą░ąĘčĆčāą╗ąĖą▓ą░ąĄčé čüčģąĄą╝ą░ ą░čĆą▒ąĖčéčĆą░ąČą░ čü čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮčŗą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝. ąÆčüčéčĆąŠąĄąĮąĮčŗąĄ ą▓ čćąĖą┐ čüąĖčüč鹥ą╝ąĮčŗąĄ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆčŗ DMA čüąŠą▓ą╝ąĄčüčéąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāčÄčé čüą┐ąĄčåąĖą░ą╗čīąĮčāčÄ 32-ą▒ąĖčéąĮčāčÄ čłąĖąĮčā ą┤ą░ąĮąĮčŗčģ ą║ čüąĖčüč鹥ą╝ąĄ ą┐ą░ą╝čÅčéąĖ L2. ąŁč鹊čé ąĖąĮč鹥čĆč乥ą╣čü čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ čćą░čüč鹊č鹥 SCLK.
ą£ąŠą┤ąĄą╗ąĖ čüąŠ ą▓čüčéčĆąŠąĄąĮąĮąŠą╣ ą┐ą░ą╝čÅčéčīčÄ L2 ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ąĮąĄ č鹊ą╗čīą║ąŠ ą┐čĆąŠčüčéčāčÄ ą┐ą░ą╝čÅčéčī ą║ą░ą║ čéą░ą║ąŠą▓čāčÄ. ąÜ ąĮąĄą╣ čéą░ą║ąČąĄ ą┐čĆąĖą╗ą░ą│ą░ąĄčéčüčÅ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēą░čÅ ąĖąĮčäčĆą░čüčéčĆčāą║čéčāčĆą░ čłąĖąĮčŗ ąĖ DMA. ą©ąĖčĆąŠą║ąĖąĄ čłąĖąĮčŗ ą╝ąĄąČą┤čā L1 ąĖ L2 ą│ą░čĆą░ąĮčéąĖčĆčāčÄčé ą▓čŗčüąŠą║čāčÄ ą┐čĆąŠą┐čāčüą║ąĮčāčÄ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī ą┤ą╗čÅ ą┤ą░ąĮąĮčŗčģ.
ąÆ čüą╗ąĄą┤čāčÄčēąĖčģ čüąĄą║čåąĖčÅčģ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮčŗ ą┐čĆąĖą╝ąĄčĆčŗ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ L2. ą×ą▒čĆą░čéąĖč鹥čüčī ą║ čĆčāą║ąŠą▓ąŠą┤čüčéą▓čā ą┐ąŠ ą░ą┐ą┐ą░čĆą░čéčāčĆąĄ ą┤ą╗čÅ ą║ąŠąĮą║čĆąĄčéąĮąŠą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ [1]), čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ą┐ąŠą┤čĆąŠą▒ąĮčāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ą┐ąŠ ąĮąĄą╝čā.
ąöąŠčüčéčāą┐ ą║ ą▒ą░ąĮą║čā ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ L2. ąöą▓ą░ ą┐ąŠčĆčéą░ ą┤ąŠčüčéčāą┐ą░ L2, ą┐ąŠčĆčé čÅą┤čĆą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĖ čüąĖčüč鹥ą╝ąĮčŗą╣ ą┐ąŠčĆčé, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ L2 ą┐čĆąĖ čāčüą╗ąŠą▓ąĖąĖ, čćč鹊 čŹčéąĖ 2 ą┐ąŠčĆčéą░ ąŠčüčāčēąĄčüčéą▓ą╗čÅčÄčé ą┤ąŠčüčéčāą┐ ą▓ čĆą░ąĘąĮčŗąĄ ą┐ąŠą┤ą▒ą░ąĮą║ąĖ ą┐ą░ą╝čÅčéąĖ. ąĢčüą╗ąĖ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą┐ąŠą┐čŗčéą║ą░ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą║ ąŠą┤ąĮąŠą╝čā ąĖ č鹊ą╝čā ąČąĄ ą▒ą░ąĮą║čā, ą╗ąŠą│ąĖą║ą░ ą┤ąĄč鹥ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ ą║ąŠą╗ą╗ąĖąĘąĖąĖ ą┤ąŠčüčéčāą┐ą░ ą║ L2 ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčé ą░čĆą▒ąĖčéčĆą░ąČ. ąŁč鹊 ą░čĆą▒ąĖčéčĆ čü čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮčŗą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝; ą┐ąŠčĆčé DMA ą▓čüąĄą│ą┤ą░ ąĖą╝ąĄąĄčé ą┐čĆąĖąŠčĆąĖč鹥čé ą▓čŗčłąĄ, ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ čüą╗čāčćą░čÅ, ą║ąŠą│ą┤ą░ čÅą┤čĆčā ą┤ą░ąĮ ą┤ąŠčüčéčāą┐ ą║ ą┐ąŠą┤ą▒ą░ąĮą║čā ą┤ą╗čÅ čāčüą║ąŠčĆąĄąĮąĮąŠą╣/ą┐ą░ą║ąĄčéąĮąŠą╣ ą┐ąĄčĆąĄą┤ą░čćąĖ (burst transfer). ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ L2 ąĘą░ą║ąŠąĮčćąĖčé burst transfer ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ą▒čāą┤ąĄčé ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮ ą┤ąŠčüčéčāą┐ čüąĖčüč鹥ą╝ąĮąŠą╣ čłąĖąĮąĄ.
ąøą░č鹥ąĮčéąĮąŠčüčéčī (Latency, ąĘą░ą┤ąĄčƹȹ║ąĖ). ąÜąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮ ą║čŹčł, čłąĖąĮą░ ą╝ąĄąČą┤čā čÅą┤čĆąŠą╝ ąĖ ą┐ą░ą╝čÅčéčīčÄ L2 ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą║ąŠąĮą▓ąĄą╣ąĄčĆąĖąĘąĖčĆąŠą▓ą░ąĮą░ ą┤ą╗čÅ ąĮąĄą┐čĆąĄčĆčŗą▓ąĮčŗčģ ą┐ą░ą║ąĄčéąĮčŗčģ ą┐ąĄčĆąĄą┤ą░čć (burst transfers). ąŚą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ąĖąĘ ą▓čüčéčĆąŠąĄąĮąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé čéą░ą║ ąČąĄ, ą║ą░ą║ ą▓čŗą▒ąĖčĆą░čÄčéčüčÅ ą┤ą░ąĮąĮčŗąĄ ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ą×ą┐ąĄčĆą░čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąŠą╝ą░čģąĖą▓ą░čÄčéčüčÅ ą╝ąĖą╝ąŠ ą║čŹčłą░, ą▓čŗąĘčŗą▓ą░čÄčé čüčĆą░ą▒ą░čéčŗą▓ą░ąĮąĖąĄ ąĘą░ą╝ąĄąĮčŗ čüčéčĆąŠą║ąĖ ą║čŹčłą░. ąŁčéą░ ąĘą░ą╝ąĄąĮą░ ąĘą░ą┐ąŠą╗ąĮčÅąĄčé ąŠą┤ąĮčā 256-ą▒ąĖčéąĮčāčÄ (32 ą▒ą░ą╣čéą░) čüčéčĆąŠą║čā č湥čéčŗčĆčīą╝čÅ 64-ą▒ąĖčéąĮčŗą╝ąĖ čćč鹥ąĮąĖčÅą╝ąĖ. ą¤čĆąĖ čŹč鹊ą╝ čüčéčĆąŠą║ą░ ą║čŹčłą░ L1 ąĘą░ą┐ąŠą╗ąĮčÅąĄčéčüčÅ ąĖąĘ L2 SRAM ą▓ č鹥č湥ąĮąĖąĄ 9+2+2+2=15 čåąĖą║ą╗ąŠą▓ čÅą┤čĆą░. ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ą┐ąŠčüą╗ąĄ 9 čåąĖą║ą╗ąŠą▓ čÅą┤čĆą░ ą┐ąĄčĆą▓čŗąĄ 64 ą▒ąĖčéą░ (8 ą▒ą░ą╣čé) čüčéą░ąĮčāčé ą┤ąŠčüčéčāą┐ąĮčŗ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░. ąØą░ čĆąĖčü. 6-20 ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąĖą╝ąĄčĆ ą╗ą░č鹥ąĮčéąĮąŠčüčéąĖ L2 čü ą▓ą║ą╗čÄč湥ąĮąĮčŗą╝ ą║čŹčłąĄą╝.
ąĀąĖčü. 6-20. ąøą░č鹥ąĮčéąĮąŠčüčéčī L2 čü ą▓ą║ą╗čÄč湥ąĮąĮčŗą╝ ą║čŹčłąĄą╝.
ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą┐ąŠ ąŠą║ąŠąĮčćą░ąĮąĖąĖ 15 čåąĖą║ą╗ąŠą▓ čÅą┤čĆą░ 32 ą▒ą░ą╣čéą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖą╗ąĖ ą┤ą░ąĮąĮčŗčģ ą┐ąĄčĆąĄą╣ą┤čāčé ą▓ ą║čŹčł ąĖ čüčéą░ąĮčāčé ą┤ąŠčüčéčāą┐ąĮčŗ ą┤ą╗čÅ čüąĄą║ą▓ąĄąĮčüąĄčĆą░. ąĢčüą╗ąĖ ą▓čüąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ čüąŠą┤ąĄčƹȹ░čé 16 ą▒ąĖčé, č鹊 16 ąĖąĮčüčéčĆčāą║čåąĖą╣ ą┐ąŠą┐ą░ą┤čāčé ą▓ ą║čŹčł ą┐ąŠ ąŠą║ąŠąĮčćą░ąĮąĖąĖ 15 čéą░ą║č鹊ą▓ čÅą┤čĆą░. ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ ą┐ąĄčĆą▓ą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ, ą║ąŠč鹊čĆą░čÅ ą▒čāą┤ąĄčé čćą░čüčéčīčÄ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ ą║čŹčłą░, ą▒čāą┤ąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ ąĮą░ 10 čåąĖą║ą╗ąĄ; ą▓č鹊čĆą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓čŗą┐ąŠą╗ąĮąĖčéčüčÅ ąĮą░ 11 čåąĖą║ą╗ąĄ, ąĖ čéčĆąĄčéčīčÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓čŗą┐ąŠą╗ąĮąĖčéčüčÅ ąĮą░ 12 čåąĖą║ą╗ąĄ - ą▓čüąĄ čŹč鹊 ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ čüčéčĆąŠą║ąĖ ą║čŹčłą░.
ąÜą░ąČą┤ąŠąĄ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ą▒čāą┤ąĄčé ą▓čŗčĆąŠą▓ąĮąĄąĮąŠ ą┐ąŠ 32-ą▒ą░ą╣čéąĮąŠą╣ ą│čĆą░ąĮąĖčåąĄ ą▒ą╗ąŠą║ą░. ąÜąŠą│ą┤ą░ ąĘą░ą┐čĆą░čłąĖą▓ą░ąĄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĖą╗ąĖ ą┤ą░ąĮąĮčŗąĄ, ą║ąŠč鹊čĆčŗąĄ ąĮąĄ ą▓čŗčĆąŠą▓ąĮąĄąĮčŗ ąĮą░ 32 ą▒ą░ą╣čéą░, ąŚą░ą┐čĆąŠčłąĄąĮąĮčŗą╣ 菹╗ąĄą╝ąĄąĮčé ą▓čüąĄą│ą┤ą░ ą▒čāą┤ąĄčé ąĘą░ą│čĆčāąČąĄąĮ ąĮą░ ą┐ąĄčĆą▓ąŠą╝ čćč鹥ąĮąĖąĖ; ą║ą░ąČą┤ąŠąĄ čćč鹥ąĮąĖąĄ ą▒čāą┤ąĄčé ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąŠ čÅą┤čĆčā ą┐ąŠ ą╝ąĄčĆąĄ ąĮą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ. ą¤ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ ą┐čĆąŠą╝ą░čģąĖą▓ą░ąĄčéčüčÅ ą╝ąĖą╝ąŠ ą║čŹčłą░ č鹊ą╗čīą║ąŠ ą║ąŠą│ą┤ą░ ą┤ąŠčüčéčāą┐ ą┤ąŠčłąĄą╗ ą┤ąŠ ą║ąŠąĮčåą░ čüčéčĆąŠą║ąĖ ą║čŹčłą░.
ąÜąŠą│ą┤ą░ on-chip L2 memory čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮą░ ą║ą░ą║ ąĮąĄ ą║čŹčłąĖčĆčāąĄą╝ą░čÅ, ą▓čŗą▒ąŠčĆą║ąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ ą▓čŗą▒ąŠčĆą║ąĖ ą┤ą░ąĮąĮčŗčģ ą┐čĆąŠąĖčüčģąŠą┤čÅčé 64-ą▒ąĖčéąĮčŗą╝ąĖ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅą╝ąĖ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą║ą░ąČą┤ąŠąĄ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĘą░ąĮąĖą╝ą░ąĄčé 7 čéą░ą║č鹊ą▓ čÅą┤čĆą░. ąØą░ čĆąĖčüčāąĮą║ąĄ 6-21 ą┐ąŠą║ą░ąĘą░ąĮą░ čüąĖčéčāą░čåąĖčÅ ą║ąŠą│ą┤ą░ ą▓čüčéčĆąŠąĄąĮąĮą░čÅ ą┐ą░ą╝čÅčéčī L2 čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮą░ ą║ą░ą║ ąĮąĄ ą║čŹčłąĖčĆčāąĄą╝ą░čÅ. ą¦č鹊ą▒čŗ ą┐čĆąŠąĖą╗ą╗čÄčüčéčĆąĖčĆąŠą▓ą░čéčī ą║ąŠąĮčåąĄą┐čåąĖčÄ ą╗ą░č鹥ąĮčéąĮąŠčüčéąĖ L2, ą║ąŠą│ą┤ą░ ą║čŹčł ą▓čŗą║ą╗čÄč湥ąĮą░, ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┐čĆąŠčüčéčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ąĮąĄ čéčĆąĄą▒čāčÄčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ą▓čŗą▒ąŠčĆąŠą║ ą▓ąĮąĄčłąĮąĖčģ ą┤ą░ąĮąĮčŗčģ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓čŗą┤ą░čÄčéčüčÅ ąĮą░ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗčģ čéą░ą║čéą░čģ čÅą┤čĆą░, ąĄčüą╗ąĖ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą┐ąŠą┐ą░ą╗ąĖ ą▓ čÅą┤čĆąŠ ą┐čĆąĖ ąĖą╝ąĄčÄčēąĄą╣čüčÅ ą▓čŗą▒ąŠčĆą║ąĄ.
ąĀąĖčü. 6-21. ąøą░č鹥ąĮčéąĮąŠčüčéčī L2 čü ą▓čŗą║ą╗čÄč湥ąĮąĮčŗą╝ ą║čŹčłąĄą╝.
[ąÆčüčéčĆąŠąĄąĮąĮą░čÅ ą▓ ą║čĆąĖčüčéą░ą╗ą╗ ą┐ą░ą╝čÅčéčī Level 3 (L3) ]
ą£ąĮąŠą│ąĖąĄ ą┐čĆąŠčåąĄčüčüąŠčĆčŗ Blackfin čéą░ą║ąČąĄ ąĖą╝ąĄčÄčé ąĮą░ ą║čĆąĖčüčéą░ą╗ą╗ąĄ ą┐ąŠčüč鹊čÅąĮąĮčāčÄ ą┐ą░ą╝čÅčéčī čü ą║ąŠą┤ąŠą╝ ąĘą░ą│čĆčāąĘčćąĖą║ą░ (Boot ROM), ą║ąŠč鹊čĆą░čÅ čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ čćą░čüč鹊č鹥 SCLK. ą×ąĮą░ čĆą░ą▒ąŠčéą░ąĄčé č湥čĆąĄąĘ ą▒ą╗ąŠą║ ąĖąĮč鹥čĆč乥ą╣čüą░ ą▓ąĮąĄčłąĮąĄą╣ čłąĖąĮčŗ (External Bus Interface Unit, EBIU), ąĖ ąĖą╝ąĄąĄčé čéą░ą║ąĖąĄ ąČąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ, ą║ą░ą║ ąĖ ą┤čĆčāą│ą░čÅ ą┐ą░ą╝čÅčéčī, ą┐ąŠą┤ą║ą╗čÄčćą░ąĄą╝ą░čÅ ą║ čćąĖą┐čā čüąĮą░čĆčāąČąĖ, č鹊 č鹊ą╗čīą║ąŠ ą┐ąŠ čüą▓ąŠąĄą╣ ą┐čĆąĖčĆąŠą┤ąĄ ąŠąĮą░ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮą░ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ. ąÜ ą┐ą░ą╝čÅčéąĖ L3 ą╝ąŠąČąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ąĮąĄ č鹊ą╗čīą║ąŠ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą▓čŗą▒ąŠčĆą║ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ąĮąŠ čéą░ą║ąČąĄ ą╝ąŠąČąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ č湥čĆąĄąĘ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĘą░ą│čĆčāąĘą║ąĖ ąĖ DMA. ą¤ą░ą╝čÅčéčī L3 ą╝ąŠąČąĄčé ą║čŹčłąĖčĆąŠą▓ą░čéčīčüčÅ č湥čĆąĄąĘ ą┐ą░ą╝čÅčéčī L1.
ą¤ąŠčüą║ąŠą╗čīą║čā ą┐ą░ą╝čÅčéčī L3 ąĮąĄ čéčĆąĄą▒čāąĄčé čåąĖą║ą╗ąŠą▓ ąŠąČąĖą┤ą░ąĮąĖčÅ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░, č鹊 ąŠąĮą░ ąŠą▒čŗčćąĮąŠ ą▒čŗčüčéčĆąĄąĄ, č湥ą╝ ą╗čÄą▒ą░čÅ ą▓ąĮąĄčłąĮčÅčÅ ą┐ą░ą╝čÅčéčī, ą┐ąŠą┤ą║ą╗čÄčćą░ąĄą╝ą░čÅ ą║ čćąĖą┐čā čüąĮą░čĆčāąČąĖ. ą×ą▒čĆą░čéąĖč鹥čüčī ą║ čĆčāą║ąŠą▓ąŠą┤čüčéą▓čā ą┐ąŠ ą░ą┐ą┐ą░čĆą░čéčāčĆąĄ ą║ąŠąĮą║čĆąĄčéąĮąŠą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░, čćč鹊ą▒čŗ čāąĘąĮą░čéčī čĆą░ąĘą╝ąĄčĆ ąĄą│ąŠ ą┐ą░ą╝čÅčéąĖ L3, ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąĖ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąĮą░ą┐čĆąĖą╝ąĄčĆ, čā ą┐čĆąŠčåąĄčüčüąŠčĆą░ ADSP-538F (ąŠą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, ą▓ ą║ąŠąĮčåąĄ ą▒čāą║ą▓ą░ F) ąĖą╝ąĄąĄčéčüčÅ ąĮą░ ą║čĆąĖčüčéą░ą╗ą╗ąĄ 1 ą╝ąĄą│ą░ą▒ą░ą╣čé ą┐ą░ą╝čÅčéąĖ FLASH, ą║ąŠč鹊čĆą░čÅ čĆą░ą▒ąŠčéą░ąĄčé ą║ą░ą║ ą┐ą░ą╝čÅčéčī L3, ąĖ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą▓ čĆą░ąĘąĮčŗčģ ąŠą▒ą╗ą░čüčéčÅčģ ą║ą░čĆčéčŗ ą┐ą░ą╝čÅčéąĖ - ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé č鹊ą│ąŠ, ą║ą░ą║ čŹč鹊 čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąŠ ą▓ąĮąĄčłąĮąĖą╝ąĖ ą▓čŗą▓ąŠą┤ą░ą╝ąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. [2].
[ąŚą░čēąĖčéą░ ąĖ čüą▓ąŠą╣čüčéą▓ą░ ą┐ą░ą╝čÅčéąĖ ]
ąŁčéą░ čüąĄą║čåąĖčÅ ąŠą┐ąĖčüčŗą▓ą░ąĄčé ą▒ą╗ąŠą║ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéčīčÄ (Memory Management Unit, MMU), čüčéčĆą░ąĮąĖčåčŗ ą┐ą░ą╝čÅčéąĖ, čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ CPLB, čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ MMU, ąĖ čĆąĄą│ąĖčüčéčĆčŗ CPLB.
Memory Management Unit . ą¤čĆąŠčåąĄčüčüąŠčĆ Blackfin čüąŠą┤ąĄčƹȹĖčé ąŠčüąĮąŠą▓ą░ąĮąĮčŗą╣ ąĮą░ čüčéčĆą░ąĮąĖčåą░čģ ą▒ą╗ąŠą║ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéčīčÄ (Memory Management Unit, MMU). ąŁč鹊čé ą╝ąĄčģą░ąĮąĖąĘą╝ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĄą╝ čāčćą░čüčéą║ąŠą▓ ą┐ą░ą╝čÅčéąĖ, ą░ čéą░ą║ąČąĄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą░čéčĆąĖą▒čāčéą░ą╝ąĖ ąĘą░čēąĖčéčŗ ąĮą░ čāčĆąŠą▓ąĮąĄ čüčéčĆą░ąĮąĖčå. MMU ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą▒ąŠą╗čīčłčāčÄ ą│ąĖą▒ą║ąŠčüčéčī ą▓ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĖ ą┐ą░ą╝čÅčéąĖ ąĖ čĆąĄčüčāčĆčüąŠą▓ I/O ąĖ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĖ ąĖčģ ą╝ąĄąČą┤čā ąĘą░ą┤ą░čćą░ą╝ąĖ, čü ą┐ąŠą╗ąĮčŗą╝ ą║ąŠąĮčéčĆąŠą╗ąĄą╝ ą┐čĆą░ą▓ ą┤ąŠčüčéčāą┐ą░ ąĖ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ ą║čŹčłą░.
MMU čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮ ą║ą░ą║ ą┤ą▓ą░ ą▒ą╗ąŠą║ą░ Content Addressable Memory (CAM) ą┐ąŠ 16 ąĘą░ą┐ąĖčüąĄą╣. ąÜą░ąČą┤ą░čÅ ąĘą░ą┐ąĖčüčī ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ ą║ą░ą║ ą┤ąĄčüą║čĆąĖą┐č鹊čĆ ą▒čāč乥čĆą░ čü ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčīčÄ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ ąĖ ąĘą░čēąĖčéčŗ, Cacheability Protection Lookaside Buffer (CPLB) descriptor. ąÜąŠą│ą┤ą░ čŹč鹊 čĆą░ąĘčĆąĄčłąĄąĮąŠ, ą║ą░ąČą┤ą░čÅ ąĘą░ą┐ąĖčüčī ą▓ MMU ą┐čĆąŠą▓ąĄčĆčÅąĄčéčüčÅ ąĮą░ ą╗čÄą▒čāčÄ ąŠą┐ąĄčĆą░čåąĖčÄ ą▓čŗą▒ąŠčĆą║ąĖ, ąĘą░ą│čĆčāąĘą║ąĖ ąĖą╗ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ, čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, ąĄčüčéčī ą╗ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĄ ą╝ąĄąČą┤čā ąĘą░ą┐čĆąŠčłąĄąĮąĮčŗą╝ ą░ą┤čĆąĄčüąŠą╝ ąĖ ą░čéčĆąĖą▒čāčéą░ą╝ąĖ ąĘą░čēąĖčéčŗ čüčéčĆą░ąĮąĖčåčŗ, čüąŠą┤ąĄčƹȹ░čēąĖą╝ąĖčüčÅ ą▓ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąĄ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą╝ ą┤ą╗čÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą┐ąŠ ą┐ą░ą╝čÅčéąĖ, ą▒ąĄąĘ ąĘą░čéčĆą░čé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ čåąĖą║ą╗ąŠą▓ ą┐čĆąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
ąśąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ L1 čĆą░ąĘą┤ąĄą╗ąĄąĮčŗ ąĮą░ ą┐ą░ą╝čÅčéčī ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ ą┐ą░ą╝čÅčéčī ą┤ą░ąĮąĮčŗčģ, ąĘą░ą┐ąĖčüąĖ CPLB čéą░ą║ąČąĄ ą┤ąĄą╗čÅčéčüčÅ ąĮą░ CPLB ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ ą┤ą░ąĮąĮčŗčģ. 16 ąĘą░ą┐ąĖčüąĄą╣ CPLB ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ ąĘą░ą┐čĆąŠčüąŠą▓ ą▓čŗą▒ąŠčĆą║ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ; ąŠąĮąĖ ąĮą░ąĘčŗą▓ą░čÄčéčüčÅ ICPLB. ąöčĆčāą│ąĖąĄ 16 ąĘą░ą┐ąĖčüąĄą╣ CPLB ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ čéčĆą░ąĮąĘą░ą║čåąĖą╣ ą┤ą░ąĮąĮčŗčģ; ąŠąĮąĖ ąĮą░ąĘčŗą▓ą░čÄčéčüčÅ DCPLB. ICPLB ąĖ DCPLB čĆą░ąĘčĆąĄčłą░čÄčéčüčÅ ą┐čāč鹥ą╝ čāčüčéą░ąĮąŠą▓ą║ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖčģ ą▒ąĖčé ą▓ čĆąĄą│ąĖčüčéčĆą░čģ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéčīčÄ L1 (L1 Instruction Memory Control, IMEM_CONTROL) ąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéčīčÄ ą┤ą░ąĮąĮčŗčģ L1 (L1 Data Memory Control, DMEM_CONTROL) čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ. ąŁčéąĖ čĆąĄą│ąĖčüčéčĆčŗ ą┐ąŠą║ą░ąĘą░ąĮčŗ ąĮą░ čĆąĖčü. 6-2 (ą▓čĆąĄąĘą║ą░ "ąĀąĄą│ąĖčüčéčĆ IMEM_CONTROL ...") ąĖ 6-11 (ą▓čĆąĄąĘą║ą░ "ąĀąĄą│ąĖčüčéčĆ DMEM_CONTROL ...") čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ.
ąÜą░ąČą┤ą░čÅ ąĘą░ą┐ąĖčüčī CPLB čüąŠą┤ąĄčƹȹĖčé ą┐ą░čĆčā 32-ą▒ąĖčéąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣. ąöą╗čÅ ą▓čŗą▒ąŠčĆąŠą║ ąĖąĮčüčéčĆčāą║čåąĖąĖ:
ŌĆó ICPLB_ADDR[n] ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ąĮą░čćą░ą╗čīąĮčŗą╣ ą░ą┤čĆąĄčü čüčéčĆą░ąĮąĖčåčŗ, ąŠą┐ąĖčüą░ąĮąĮąŠą╣ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą╝ CPLB.
ąöą╗čÅ ąŠą┐ąĄčĆą░čåąĖą╣ čü ą┤ą░ąĮąĮčŗą╝ąĖ ą┐čĆąĖąĮčåąĖą┐ č鹊čé ąČąĄ:
ŌĆó DCPLB_ADDR[m] ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ąĮą░čćą░ą╗čīąĮčŗą╣ ą░ą┤čĆąĄčü čüčéčĆą░ąĮąĖčåčŗ, ąŠą┐ąĖčüą░ąĮąĮąŠą╣ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą╝ CPLB.
ąĢčüčéčī 2 ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ CPLB ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą┤ą░ąĮąĮčŗą╝ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ scratchpad, ąĖ ą║ ąŠą▒ą╗ą░čüčéąĖ čüąĖčüč鹥ą╝čŗ ąĖ MMR čÅą┤čĆą░. ąŁčéąĖ ą┤ąĄčüą║čĆąĖą┐č鹊čĆčŗ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĘą░ą┤ą░čÄčé ą▓čŗčłąĄčāą║ą░ąĘą░ąĮąĮčŗąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ą┐ą░ą╝čÅčéąĖ ą║ą░ą║ ąĮąĄ ą║čŹčłąĖčĆčāąĄą╝čŗąĄ, čéą░ą║ čćč鹊 ąĮąĄ ąĮčāąČąĮčŗ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ CPLB ą┤ą╗čÅ ąĮą░čüčéčĆąŠą╣ą║ąĖ ą┤ąŠčüčéčāą┐ą░ ą║ čŹčéąĖą╝ čĆąĄą│ąĖąŠąĮą░ą╝ ą┐ą░ą╝čÅčéąĖ.
ąĢčüą╗ąĖ ą┤ąŠą┐čāčüčéąĖą╝čŗąĄ CPLB ą▒čŗą╗ąĖ ąĮą░čüčéčĆąŠąĄąĮčŗ ą┤ą╗čÅ čŹč鹊ą╣ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ, č鹊 CPLB ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĖą│ąĮąŠčĆąĖčĆčāčÄčéčüčÅ.
ąĪčéčĆą░ąĮąĖčåčŗ ą┐ą░ą╝čÅčéąĖ . ąÉą┤čĆąĄčüąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ 4 ą│ąĖą│ą░ą▒ą░ą╣čéą░ (4G ą▒ą░ą╣čé) ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą╝ąŠąČąĮąŠ ą┐ąŠą┤ąĄą╗ąĖčéčī ąĮą░ čāčćą░čüčéą║ąĖ ą┐ą░ą╝čÅčéąĖ ąĖą╗ąĖ I/O, čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝čŗąĄ čüčéčĆą░ąĮąĖčåčŗ ą┐ą░ą╝čÅčéąĖ. ąÜą░ąČą┤čŗą╣ ą░ą┤čĆąĄčü, ąĮą░čģąŠą┤čÅčēąĖą╣čüčÅ ą▓ ą┐čĆąĄą┤ąĄą╗ą░čģ čüčéčĆą░ąĮąĖčåčŗ, ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąŠą┤ąĮąĖ ąĖ č鹥 ąČąĄ ą░čéčĆąĖą▒čāčéčŗ, ąĘą░ą┤ą░ąĮąĮčŗąĄ ą┤ą╗čÅ čŹč鹊ą╣ čüčéčĆą░ąĮąĖčåčŗ. ąÉčĆčģąĖč鹥ą║čéčāčĆą░ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé č湥čéčŗčĆąĄ čĆą░ąĘąĮčŗąĄ čĆą░ąĘą╝ąĄčĆą░ čüčéčĆą░ąĮąĖčå:
ŌĆó 1K ą▒ą░ą╣čé
ąĀą░ąĘą╗ąĖčćąĮčŗąĄ čĆą░ąĘą╝ąĄčĆčŗ čüčéčĆą░ąĮąĖčå ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ą│ąĖą▒ą║ąĖą╣ ą╝ąĄčģą░ąĮąĖąĘą╝ ą┤ą╗čÅ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖčÅ ą░čéčĆąĖą▒čāč鹊ą▓ ą┐čĆąĖą▓čÅąĘą║ąĖ ą║ čĆą░ąĘąĮčŗą╝ ą▓ąĖą┤ą░ą╝ ą┐ą░ą╝čÅčéąĖ ąĖ I/O.
ąÉčéčĆąĖą▒čāčéčŗ čüčéčĆą░ąĮąĖčåčŗ ą┐ą░ą╝čÅčéąĖ . ąÜą░ąČą┤ą░čÅ čüčéčĆą░ąĮąĖčåą░ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮą░ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą╝ ąĖąĘ 2 čüą╗ąŠą▓. ąŁč鹊 čüą╗ąŠą▓ąŠ ą░ą┤čĆąĄčüą░ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ xCPLB_ADDR[n] ąĖ čüą╗ąŠą▓ąŠ čüą▓ąŠą╣čüčéą▓ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ xCPLB_DATA[n]. ąĪą╗ąŠą▓ąŠ ą░ą┤čĆąĄčüą░ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą▒ą░ąĘąŠą▓čŗą╣ ą░ą┤čĆąĄčü čüčéčĆą░ąĮąĖčåčŗ ą▓ ą┐ą░ą╝čÅčéąĖ. ąĪčéčĆą░ąĮąĖčåčŗ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą▓čŗčĆąŠą▓ąĮąĄąĮčŗ ą┐ąŠ ą░ą┤čĆąĄčüčā, ą║ąŠč鹊čĆčŗą╣ ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖčéčüčÅ ąĮą░ čĆą░ąĘą╝ąĄčĆ čüčéčĆą░ąĮąĖčåčŗ. ąØą░ą┐čĆąĖą╝ąĄčĆ, čüčéčĆą░ąĮąĖčåą░ čĆą░ąĘą╝ąĄčĆąŠą╝ 4M ą▒ą░ą╣čéą░ ą┤ąŠą╗ąČąĮą░ ąĮą░čćąĖąĮą░čéčīčüčÅ čü ą░ą┤čĆąĄčüą░, ą║ąŠč鹊čĆčŗą╣ ą┤ąĄą╗ąĖčéčüčÅ ąĮą░ 4M ą▒ą░ą╣čé; čüčéčĆą░ąĮąĖčåą░ čĆą░ąĘą╝ąĄčĆąŠą╝ 1 ą║ąĖą╗ąŠą▒ą░ą╣čé ą╝ąŠąČąĄčé ąĮą░čćąĖąĮą░čéčīčüčÅ čü ą╗čÄą▒ąŠą╣ ą│čĆą░ąĮąĖčåčŗ ą▒ą╗ąŠą║ą░ 1K ą▒ą░ą╣čé. ąÆč鹊čĆąŠąĄ čüą╗ąŠą▓ąŠ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ čāą║ą░ąĘčŗą▓ą░ąĄčé ą┤čĆčāą│ąĖąĄ čüą▓ąŠą╣čüčéą▓ą░ (ąĖą╗ąĖ ą░čéčĆąĖą▒čāčéčŗ) čüčéčĆą░ąĮąĖčåčŗ. ąŁčéąĖ čüą▓ąŠą╣čüčéą▓ą░ ą▓ą║ą╗čÄčćą░čÄčé:
ŌĆó ąĀą░ąĘą╝ąĄčĆ čüčéčĆą░ąĮąĖčåčŗ (1K ą▒ą░ą╣čé, 4K ą▒ą░ą╣čé, 1M ą▒ą░ą╣čé, 4M ą▒ą░ą╣čé).
ąóą░ą▒ą╗ąĖčåą░ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ čüčéčĆą░ąĮąĖčå (Page Descriptor Table). ąöą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ č湥čĆąĄąĘ ą║čŹčł, ą║ąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮčŗ CPLB ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą┤ą░ąĮąĮčŗą╝, ąĖą╗ąĖ ą┤ą╗čÅ č鹊ą│ąŠ ąĖ ą┤čĆčāą│ąŠą│ąŠ, ą▓ ą┐ą░čĆąĄ MMR ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ą┤ąŠą┐čāčüčéąĖą╝ą░čÅ ąĘą░ą┐ąĖčüčī CPLB. ą×ą▒ą╗ą░čüčéąĖ čģčĆą░ąĮąĄąĮąĖčÅ MMR ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĄą╣ CPLB ąŠą│čĆą░ąĮąĖč湥ąĮčŗ 16 ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ą╝ąĖ ą┤ą╗čÅ ą▓čŗą▒ąŠčĆąŠą║ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖ 16 ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ą╝ąĖ ą┤ą╗čÅ ąŠą┐ąĄčĆą░čåąĖą╣ ąĘą░ą│čĆčāąĘą║ąĖ ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ.
ąöą╗čÅ ą╝ą░ą╗ąĄąĮčīą║ąĖčģ ąĖ/ąĖą╗ąĖ ą┐čĆąŠčüčéčŗčģ ą╝ąŠą┤ąĄą╗ąĄą╣ ą┐ą░ą╝čÅčéąĖ ą╝ąŠąČąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ąĮą░ą▒ąŠčĆ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ CPLB, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠą╝ąĄčüčéčÅčéčüčÅ ą▓ čŹčéąĖ 32 ąĘą░ą┐ąĖčüąĖ, ą┐ąŠą║čĆčŗą▓ą░čÄčēąĖąĄ ą▓čüąĄ ą░ą┤čĆąĄčüčāąĄą╝ąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ čéą░ą║, čćč鹊 ąĖčģ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą┐ąŠąĮą░ą┤ąŠą▒ąĖčéčüčÅ ąĘą░ą╝ąĄąĮčÅčéčī. ąŁč鹊čé čéąĖą┐ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ čüčéą░čéąĖč湥čüą║ąŠą╣ ą╝ąŠą┤ąĄą╗čīčÄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéčīčÄ.
ą×ą┤ąĮą░ą║ąŠ čĆą░ą▒ąŠčćąĖąĄ ąŠą║čĆčāąČąĄąĮąĖčÅ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčŗčģ čüąĖčüč鹥ą╝čŗ ąŠą▒čŗčćąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčé ą▒ąŠą╗čīčłąĄ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ CPLB, čćč鹊ą▒čŗ ąĮą░ą║čĆčŗčéčī ą▓čüčÄ ą░ą┤čĆąĄčüčāąĄą╝čāčÄ ą┐ą░ą╝čÅčéčī ąĖ ąŠą▒ą╗ą░čüčéąĖ I/O, č湥ą╝ ą┤ąŠčüčéčāą┐ąĮąŠ ą▓ CPLB MMR ą║čĆąĖčüčéą░ą╗ą╗ą░. ąÜąŠą│ą┤ą░ čŹč鹊 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ, č鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ąŠčüąĮąŠą▓ą░ąĮąĮą░čÅ ąĮą░ ą┐ą░ą╝čÅčéąĖ čüčéčĆčāą║čéčāčĆą░ ą┤ą░ąĮąĮčŗčģ, ąĮą░ąĘčŗą▓ą░ąĄą╝ą░čÅ Page Descriptor Table (čéą░ą▒ą╗ąĖčåą░ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ čüčéčĆą░ąĮąĖčå); ą▓ ąĮąĄą╣ ą╝ąŠą│čāčé ą▒čŗčéčī čüąŠčģčĆą░ąĮąĄąĮčŗ ą▓čüąĄ ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗąĄ ą┤ąĄčüą║čĆąĖą┐č鹊čĆčŗ CPLB. ąÜąŠąĮą║čĆąĄčéąĮčŗą╣ č乊čĆą╝ą░čé čŹč鹊ą╣ čéą░ą▒ą╗ąĖčåčŗ ąĮąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ ą║ą░ą║ čćą░čüčéčī ą░čĆčģąĖč鹥ą║čéčāčĆčŗ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin. ąĀą░ąĘą╗ąĖčćąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčŗąĄ čüąĖčüč鹥ą╝čŗ, ą║ąŠč鹊čĆčŗąĄ ąĖą╝ąĄčÄčé čĆą░ąĘąĮčŗąĄ ą╝ąŠą┤ąĄą╗ąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéčīčÄ, ą╝ąŠą│čāčé čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī čüčéčĆčāą║čéčāčĆčŗ Page Descriptor Table ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅą╝ąĖ OS. ąŁč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┤ąĄą╗ą░čéčī ą┐ąŠą┤čüčéčĆąŠą╣ą║ąĖ ą║ąŠą╝ą┐čĆąŠą╝ąĖčüčüą░ ą╝ąĄąČą┤čā čāčĆąŠą▓ąĮąĄą╝ ąĘą░čēąĖčéčŗ ąĖ ą░čéčĆąĖą▒čāčéą░ą╝ąĖ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖčÅ ą▓ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ą░čģ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéčīčÄ.
[ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ CPLB ]
ąÜąŠą│ą┤ą░ ą┐čĆąŠčåąĄčüčüąŠčĆ Blackfin ą▓čŗą┤ą░ąĄčé ąŠą┐ąĄčĆą░čåąĖčÄ čü ą┐ą░ą╝čÅčéčīčÄ, ą┤ą╗čÅ ą║ąŠč鹊čĆąŠą╣ ą▓ ą┐ą░čĆąĄ MMR ąĮąĄčé ą┤ąŠą┐čāčüčéąĖą╝ąŠą│ąŠ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ CPLB (cacheability protection lookaside buffer), ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ. ąŁč鹊 ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ą┐ąĄčĆąĄą▓ąĄą┤ąĄčé ą┐čĆąŠčåąĄčüčüąŠčĆ ą▓ čĆąĄąČąĖą╝ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░, ąĖ ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ąĖčé ą┐ąŠč鹊ą║ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĮą░ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ MMU (ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. "ąśčüą║ą╗čÄč湥ąĮąĖčÅ" ą▓ [3]). ą×ą▒čĆą░ą▒ąŠčéčćąĖą║ ąŠą▒čŗčćąĮąŠ čÅą▓ą╗čÅąĄčéčüčÅ čćą░čüčéčīčÄ čÅą┤čĆą░ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ (OS), ą║ąŠč鹊čĆąŠąĄ čĆąĄą░ą╗ąĖąĘčāąĄčé ą┐ąŠą╗ąĖčéąĖą║čā ąĘą░ą╝ąĄčēąĄąĮąĖčÅ CPLB.
ą¤ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ čĆą░ąĘčĆąĄčłąĖčéčī CPLB, ą┤ąŠą╗ąČąĮčŗ čüčāčēąĄčüčéą▓ąŠą▓ą░čéčī ą┤ąŠą┐čāčüčéąĖą╝čŗąĄ ą┤ąĄčüą║čĆąĖą┐č鹊čĆčŗ CPLB ąĖ ą┤ą╗čÅ Page Descriptor Table, ąĖ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ MMU. ąæąĖčéčŗ LOCK čŹčéąĖčģ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ CPLB ąŠą▒čŗčćąĮąŠ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čÄčéčüčÅ, čćč鹊ą▒čŗ ąĖčģ čüą╗čāčćą░ą╣ąĮąŠ ąĮąĄ ąĖčüą┐ąŠčĆčéąĖą╗ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠąĄ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖąĄ.
ą×ą▒čĆą░ą▒ąŠčéčćąĖą║ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąŠčłąĖą▒ąŠčćąĮčŗą╣ ą░ą┤čĆąĄčü ą┤ą╗čÅ ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐ąŠ čüčéčĆčāą║čéčāčĆąĄ Page Descriptor Table, čćč鹊ą▒čŗ ąĮą░ą╣čéąĖ ą║ąŠčĆčĆąĄą║čéąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ CPLB, čćč鹊ą▒čŗ ąĘą░ą│čĆčāąĘąĖčéčī ąĖčģ ą▓ ąŠą┤ąĮčā ąĖąĘ ą┐ą░čĆ ą▓čüčéčĆąŠąĄąĮąĮčŗčģ ą▓ ą║čĆąĖčüčéą░ą╗ą╗ čĆąĄą│ąĖčüčéčĆąŠą▓čŗčģ ą┐ą░čĆ CPLB. ąĢčüą╗ąĖ ą▓čüąĄ ą▓čüčéčĆąŠąĄąĮąĮčŗąĄ ą▓ ą║čĆąĖčüčéą░ą╗ą╗ čĆąĄą│ąĖčüčéčĆčŗ čüąŠą┤ąĄčƹȹ░čé ą┤ąŠą┐čāčüčéąĖą╝čŗąĄ ąĘą░ą┐ąĖčüąĖ CPLB, č鹊 ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ą▓čŗą▒ąĄčĆąĄčé ąŠą┤ąĖąĮ ąĖąĘ čŹčéąĖčģ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ ą┤ą╗čÅ ąĘą░ą╝ąĄąĮčŗ, ąĖ ą▓ ąĮąĄą│ąŠ ą▒čāą┤ąĄčé ąĘą░ą│čĆčāąČąĄąĮą░ ąĮąŠą▓ą░čÅ ąĖąĮč乊čĆą╝ą░čåąĖčÅ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░. ą¤ąĄčĆąĄą┤ ąĘą░ą│čĆčāąĘą║ąŠą╣ ąĮąŠą▓čŗčģ ą┤ą░ąĮąĮčŗčģ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ ą▓ ą╗čÄą▒ąŠą╣ CPLB, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēą░čÅ ą│čĆčāą┐ą┐ą░ ąĖąĘ 16 CPLB ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ąĘą░ą┐čĆąĄčēąĄąĮą░ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝:
ŌĆó ąæąĖč鹊ą╝ Enable DCPLB (ENDCPLB) ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMEM_CONTROL ą┤ą╗čÅ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ ą┤ą░ąĮąĮčŗčģ, ąĖą╗ąĖ
ąŚą░ ą┐ąŠą╗ąĖčéąĖą║čā ąĘą░ą╝ąĄąĮčŗ CPLB ąĖ ąĄčæ ą░ą╗ą│ąŠčĆąĖčéą╝ ąŠčéą▓ąĄčćą░ąĄčé čüąĖčüč鹥ą╝ąĮčŗą╣ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ MMU. ąŁčéą░ ą┐ąŠą╗ąĖčéąĖą║ą░, ą║ąŠč鹊čĆą░čÅ ą┤ąĖą║čéčāąĄčéčüčÅ čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅą╝ąĖ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ, ąŠą▒čŗčćąĮąŠ čĆąĄą░ą╗ąĖąĘčāąĄčé ą┐čĆąĖąĮčåąĖą┐čŗ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ LRU (Least Recently Used, čé. ąĄ. ą┐ąŠčüą╗ąĄą┤ąĮąĖą╣ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĮčŗą╣), čłąĄą┤čāą╗ąĖąĮą│ round robin (ąĘą░ą╝ąĄąĮą░ ą┐ąŠ ą║čĆčāą│čā), ąĖą╗ąĖ ą┐čüąĄą▓ą┤ąŠčüą╗čāčćą░ą╣ąĮčāčÄ ąĘą░ą╝ąĄąĮčā.
ą¤ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ąĘą░ą│čĆčāąČąĄąĮ ąĮąŠą▓čŗą╣ ą┤ąĄčüą║čĆąĖą┐č鹊čĆ CPLB, ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓čŗčģąŠą┤ ąĖąĘ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ąĖ ąŠą┐ąĄčĆą░čåąĖčÅ čü ą┐ą░ą╝čÅčéčīčÄ, ą║ąŠč鹊čĆą░čÅ čüą┐ąŠčéą║ąĮčāą╗ą░čüčī ą┐ąŠ ąŠčłąĖą▒ą║ąĄ, ą┐ąĄčĆąĄąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ. ąóąĄą┐ąĄčĆčī čŹčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ ą┤ąŠą╗ąČąĮą░ čüąŠąŠčéą▓ąĄčéčüčéą▓ąŠą▓ą░čéčī ąĮąŠą▓ąŠą╝čā ą┤ąŠą┐čāčüčéąĖą╝ąŠą╝čā ą┤ą╗čÅ ąĮąĄčæ ą┤ąĄčüą║čĆąĖą┐č鹊čĆčā CPLB ą┤ą╗čÅ ąĘą░ą┐čĆąŠčłąĄąĮąĮąŠą│ąŠ ą░ą┤čĆąĄčüą░, ąĖ ąŠą┐ąĄčĆą░čåąĖčÅ čāčüą┐ąĄčłąĮąŠ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ.
ą×ą┤ąĮą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ą║ą░ą║ ą▓čŗą▒ąŠčĆą║čā ąĖąĮčüčéčĆčāą║čåąĖąĖ, čéą░ą║ ąĖ ąŠą┤ąĖąĮ ąĖą╗ąĖ ą┤ą▓ą░ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ. ą£ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ čéą░ą║ąŠąĄ, čćč鹊 ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą╣ ąĖąĘ čŹčéąĖčģ ąŠą┐ąĄčĆą░čåąĖą╣ čü ą┐ą░ą╝čÅčéčīčÄ ąĮąĄ ąĖą╝ąĄčÄčé ą┤ąŠą┐čāčüčéąĖą╝ąŠą│ąŠ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ CPLB ą▓ ą┐ą░čĆąĄ MMR. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą┐čĆąĖąŠčĆąĖč鹥ąĘąĖčĆčāčÄčéčüčÅ ąĖ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┐ąŠčĆčÅą┤ą║ąĄ:
ŌĆó ą¤čĆąŠą╝ą░čģ čüčéčĆą░ąĮąĖčåčŗ ąĖąĮčüčéčĆčāą║čåąĖąĖ
ą¤čĆąĖą╝ąĄąĮąĄąĮąĖąĄ MMU . ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéčīčÄ čÅą▓ą╗čÅąĄčéčüčÅ ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠą╣ (ąĮąĄ ąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠą╣ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ) čäčāąĮą║čåąĖąĄą╣ ą▓ ą░čĆčģąĖč鹥ą║čéčāčĆąĄ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĄčæ ąĖą╗ąĖ ąĮąĄčé - ąĘą░ą▓ąĖčüąĖčé ąŠčé čéčĆąĄą▒ąŠą▓ą░ąĮąĖą╣ ą║ čüąĖčüč鹥ą╝ąĄ ą┤ą╗čÅ ą║ąŠąĮą║čĆąĄčéąĮąŠą│ąŠ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. ą¤ąŠčüą╗ąĄ čüą▒čĆąŠčüą░ ą▓čüąĄ CPLB ąĘą░ą┐čĆąĄčēąĄąĮčŗ, ąĖ ą▒ą╗ąŠą║ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéčīčÄ (Memory Management Unit, MMU) ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ.
MMU ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą░ą┐ą┐ą░čĆą░čéąĮčāčÄ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║čāčÄ čéčĆą░ąĮčüą╗čÅčåąĖčÄ ą░ą┤čĆąĄčüąŠą▓.
ąĢčüą╗ąĖ ą▓čüčÅ ą┐ą░ą╝čÅčéčī L1 čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮą░ ą║ą░ą║ SRAM, č鹊 čäčāąĮą║čåąĖąĖ ą┤ą░ąĮąĮčŗčģ ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ MMU ąĮąĄ ąŠą▒čÅąĘą░č鹥ą╗čīąĮčŗ, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čéčĆąĄą▒ąŠą▓ą░ąĮąĖą╣ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą┐ąŠ ąĘą░čēąĖč鹥 ąŠą▒ą╗ą░čüč鹥ą╣ ą┐ą░ą╝čÅčéąĖ ą╗ąĖą▒ąŠ ą╝ąĄąČą┤čā ąĘą░ą┤ą░čćą░ą╝ąĖ, ą╗ąĖą▒ąŠ ą╝ąĄąČą┤čā čĆąĄąČąĖą╝ą░ą╝ąĖ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode) ąĖ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (Supervisor mode). ąöą╗čÅ ąĘą░čēąĖčéčŗ ą┐ą░ą╝čÅčéąĖ ą╝ąĄąČą┤čā ąĘą░ą┤ą░čćą░ą╝ąĖ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮą░čÅ čüąĖčüč鹥ą╝ą░ ą╝ąŠąČąĄčé čüąŠą┤ąĄčƹȹ░čéčī ąŠčéą┤ąĄą╗čīąĮčŗąĄ čéą░ą▒ą╗ąĖčåčŗ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ/ąĖą╗ąĖ ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ čüčéčĆą░ąĮąĖčå ą┐ą░ą╝čÅčéąĖ, ą┤ąŠčüčéčāą┐ąĮčŗčģ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ąĘą░ą┤ą░čćąĖ, ąĖ čüą┤ąĄą╗ą░čéčī čŹčéąĖ čüčéčĆą░ąĮąĖčåčŗ ą┤ąŠčüčéčāą┐ąĮčŗą╝ąĖ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ č鹊ą╣ ąĖą╗ąĖ ąĖąĮąŠą╣ ąĘą░ą┐čāčēąĄąĮąĮąŠą╣ ąĘą░ą┤ą░čćąĖ. ąÜąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą╝ąĄąČą┤čā ąĘą░ą┤ą░čćą░ą╝ąĖ, ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮą░čÅ čüąĖčüč鹥ą╝ą░ ą╝ąŠąČąĄčé ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ąŠčéą╝ąĄąĮčā ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéąĖ ą╗čÄą▒ąŠą│ąŠ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ CPLB čćąĖą┐ą░, ą║ąŠč鹊čĆčŗą╣ ą▒ąŠą╗čīčłąĄ ąĮąĄ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą┤ąŠčüčéčāą┐ąĄąĮ ą┤ą╗čÅ ąĮąŠą▓ąŠą╣ ąĘą░ą┤ą░čćąĖ. ąóą░ą║ąČąĄ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮą░čÅ čüąĖčüč鹥ą╝ą░ ą╝ąŠąČąĄčé ą┐ąŠą┤ą│čĆčāąĘąĖčéčī ą┤ąĄčüą║čĆąĖą┐č鹊čĆčŗ, ą┐ąŠą┤čģąŠą┤čÅčēąĖąĄ ą┤ą╗čÅ ąĮąŠą▓ąŠą╣ ąĘą░ą┤ą░čćąĖ.
ąöą╗čÅ ą╝ąĮąŠą│ąĖčģ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčŗčģ čüąĖčüč鹥ą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ čĆą░ą▒ąŠčéą░ąĄčé ą▓ User mode, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮą░čÅ čüąĖčüč鹥ą╝ą░ ąĖ ąĄčæ čüą╗čāąČą▒čŗ čĆą░ą▒ąŠčéą░čÄčé ą▓ Supervisor mode. ąŁč鹊 ąČąĄą╗ą░č鹥ą╗čīąĮąŠ ą┤ą╗čÅ ąĘą░čēąĖčéčŗ ą║ąŠą┤ą░ ąĖ čüčéčĆčāą║čéčāčĆ ą┤ą░ąĮąĮčŗčģ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝ąŠą╣, ąŠčé ąĮąĄą┐čĆąĄą┤ąĮą░ą╝ąĄčĆąĄąĮąĮąŠą╣ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖąĖ čüąŠ čüč鹊čĆąŠąĮčŗ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, čĆą░ą▒ąŠčéą░čÄčēąĄą│ąŠ ą▓ User mode. ąŁčéą░ ąĘą░čēąĖčéą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┤ąŠčüčéąĖą│ąĮčāčéą░ ą┐čāč鹥ą╝ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ CPLB ą┤ą╗čÅ ąĘą░čēąĖčéčŗ ą┤ąĖą░ą┐ą░ąĘąŠąĮąŠą▓ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗąĄ ą▒čāą┤čāčé ą┐ąŠąĘą▓ąŠą╗čÅčéčī ą┤ąŠčüčéčāą┐ ąĮą░ ąĘą░ą┐ąĖčüčī č鹊ą╗čīą║ąŠ ą▓ čĆąĄąČąĖą╝ąĄ Supervisor. ąĢčüą╗ąĖ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą┐ąŠą┐čŗčéą║ą░ ąĘą░ą┐ąĖčüąĖ ąĘą░čēąĖčēąĄąĮąĮąŠą╣ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ ą▓ User mode, ą▒čāą┤ąĄčé čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ą┐ą░ą╝čÅčéčī ą▒čāą┤ąĄčé ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮą░. ą×ą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÄ ą▓ User mode ą╝ąŠąČąĄčé ą▒čŗčéčī ą┤ą░ąĮ ą┤ąŠčüčéčāą┐ ąĮą░ čćč鹥ąĮąĖąĄ ą┤ą╗čÅ čüčéčĆčāą║čéčāčĆ, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠą╗ąĄąĘąĮčŗ ą┤ą╗čÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. ąöą░ąČąĄ ą┤ą╗čÅ čäčāąĮą║čåąĖą╣, čĆą░ą▒ąŠčéą░čÄčēąĖčģ ą▓ Supervisor mode, ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮ ą┤ąŠčüčéčāą┐ ąĮą░ ąĘą░ą┐ąĖčüčī ąĮąĄą║ąŠč鹊čĆčŗčģ čüčéčĆą░ąĮąĖčå ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗąĄ čüąŠą┤ąĄčƹȹ░čé ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ąĮąĄ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮ ą┤ą╗čÅ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖąĖ. ą¤ąŠčüą║ąŠą╗čīą║čā ąĘą░ą┐ąĖčüąĖ CPLB čŹč鹊 MMR, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ąĘą░ą┐ąĖčüą░ąĮčŗ č鹊ą╗čīą║ąŠ ą▓ Supervisor mode, ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ąĮąĄ ą╝ąŠą│čāčé ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ čĆąĄčüčāčĆčüą░ą╝, ąĘą░čēąĖčēąĄąĮąĮčŗą╝ čŹčéąĖą╝ čüą┐ąŠčüąŠą▒ąŠą╝.
ąĢčüą╗ąĖ ą╗ąĖą▒ąŠ ą┐ą░ą╝čÅčéčī ąĖąĮčüčéčĆčāą║čåąĖą╣ L1, ą╗ąĖą▒ąŠ ą┐ą░ą╝čÅčéčī ą┤ą░ąĮąĮčŗčģ L1 čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮą░ čćą░čüčéąĖčćąĮąŠ ąĖą╗ąĖ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą║ą░ą║ ą║čŹčł, ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čĆą░ąĘčĆąĄčłąĄąĮčŗ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖąĄ CPLB. ąÜąŠą│ą┤ą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ą┤ąŠčüčéčāą┐ ąĘą░ą┐čĆąŠčü ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ, ąĖ ą║čŹčł čĆą░ąĘčĆąĄčłąĄąĮ, č鹊 ą┐čĆąŠčåąĄčüčüąŠčĆ čüąĮą░čćą░ą╗ą░ ą┐čĆąŠą▓ąĄčĆčÅąĄčé ICPLB, čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, ąĮą░čģąŠą┤ąĖčéčüčÅ ą╗ąĖ ą░ą┤čĆąĄčü ą▓ ą║čŹčłąĖčĆčāąĄą╝ąŠą╝ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ ą░ą┤čĆąĄčüąŠą▓. ąĢčüą╗ąĖ ąĮąĄčé ą┤ąŠą┐čāčüčéąĖą╝ąŠą╣ ąĘą░ą┐ąĖčüąĖ ICPLB ą▓ ą┐ą░čĆąĄ MMR, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą╣ ąĘą░ą┐čĆąŠčłąĄąĮąĮąŠą╝čā ą░ą┤čĆąĄčüčā, č鹊 ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ MMU, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠą┐čāčüčéąĖą╝čŗąĄ ą┤ąĄčüą║čĆąĖą┐č鹊čĆčŗ ICPLB ąĖ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, ą║čŹčłąĖčĆčāąĄčéčüčÅ ą┐ą░ą╝čÅčéčī ąĖą╗ąĖ ąĮąĄčé. ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 ąĄčüą╗ąĖ L1 Instruction Memory čĆą░ąĘčĆąĄčłąĄąĮą░ ą▓ ą║ą░č湥čüčéą▓ąĄ ą║čŹčłą░, č鹊 ą╗čÄą▒ąŠą╣ čĆąĄą│ąĖąŠąĮ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗą╣ čüąŠą┤ąĄčƹȹĖčé ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą┤ąŠą╗ąČąĄąĮ ąĖą╝ąĄčéčī ą┤ąŠą┐čāčüčéąĖą╝čŗą╣ ą┤ąĄčüą║čĆąĖą┐č鹊čĆ ICPLB, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╣ ą┤ą╗čÅ čŹč鹊ą│ąŠ čĆąĄą│ąĖąŠąĮą░. ąŁčéąĖ ą┤ąĄčüą║čĆąĖą┐č鹊čĆčŗ ą┤ąŠą╗ąČąĮčŗ ąĮą░čģąŠą┤ąĖčéčīčüčÅ ą╗ąĖą▒ąŠ ą▓čüąĄą│ą┤ą░ ą▓ MMR, ą╗ąĖą▒ąŠ ą▓ čüą┐ąĄčåąĖą░ą╗čīąĮąŠą╣ čéą░ą▒ą╗ąĖčåąĄ (ąĮą░čģąŠą┤čÅčēąĄą╣čüčÅ ą│ą┤ąĄ-č鹊 ą▓ ą┐ą░ą╝čÅčéąĖ) Page Descriptor Table, ą║ąŠč鹊čĆąŠą╣ čāą┐čĆą░ą▓ą╗čÅąĄčé ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ MMU. ąÉąĮą░ą╗ąŠą│ąĖčćąĮąŠ, ąĄčüą╗ąĖ ą╗ąĖą▒ąŠ ąŠą┤ąĖąĮ, ą╗ąĖą▒ąŠ ąŠą▒ą░ ą▒ą░ąĮą║ą░ ą┤ą░ąĮąĮčŗčģ L1 čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮčŗ ą║ą░ą║ ą║čŹčł, ą▓čüąĄ ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮčŗąĄ ą┤ąĖą░ą┐ą░ąĘąŠąĮčŗ ą┐ą░ą╝čÅčéąĖ ą┤ą░ąĮąĮčŗčģ ą┤ąŠą╗ąČąĮčŗ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čéčīčüčÅ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ą╝ąĖ DCPLB.
ą¤ąĄčĆąĄą┤ čĆą░ąĘčĆąĄčłąĄąĮąĖąĄą╝ ą║čŹčłą░ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąĮą░čüčéčĆąŠąĄąĮčŗ ąĖ čĆą░ąĘčĆąĄčłąĄąĮčŗ MMU ąĖ ąĖčģ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖąĄ čüčéčĆčāą║čéčāčĆčŗ ą┤ą░ąĮąĮčŗčģ.
ą¤čĆąĖą╝ąĄčĆčŗ ąĘą░čēąĖčēąĄąĮąĮčŗčģ čĆąĄą│ąĖąŠąĮąŠą▓ ą┐ą░ą╝čÅčéąĖ . ąØą░ čĆąĖčüčāąĮą║ąĄ 6-22 ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮą░ ąĮą░čćą░ą╗čīąĮą░čÅ č鹊čćą║ą░ ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ CPLB ą┤ą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ ą┤ą░ąĮąĮčŗčģ. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĮąĄą║ąŠč鹊čĆčŗąĄ ICPLB ąĖ DCPLB ąĖą╝ąĄčÄčé ąŠą▒čēąĖąĄ ą┤ąĄčüą║čĆąĖą┐č鹊čĆčŗ ą┤ą╗čÅ ąŠą┤ąĮąŠą│ąŠ ąĖ č鹊ą│ąŠ ąČąĄ ą░ą┤čĆąĄčüąĮąŠą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░.
ąĀąĖčü. 6-22. ą¤čĆąĖą╝ąĄčĆčŗ ąĘą░čēąĖčēąĄąĮąĮčŗčģ ąŠą▒ą╗ą░čüč鹥ą╣ ą┐ą░ą╝čÅčéąĖ.
ąØąĖąČąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮčŗ ąŠą┐ąĖčüą░ąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓, ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĮčŗčģ ą┤ą╗čÅ ąĮą░čüčéčĆąŠą╣ą║ąĖ CPLB. ąÉą┤čĆąĄčüą░ MMR ą┤ą░ąĮčŗ ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖčģ čéą░ą▒ą╗ąĖčåą░čģ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░.
ąĀąĖčüčāąĮąŠą║ 6-23 ąŠą┐ąĖčüčŗą▓ą░ąĄčé čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ ICPLB (ICPLB_DATAx).
ą¦č鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ą┐čĆą░ą▓ąĖą╗čīąĮąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĖ čüąŠą▓ą╝ąĄčüčéąĖą╝ąŠčüčéčī ą▓ ą▒čāą┤čāčēąĄą╝, ą▓čüąĄ ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ą▒ąĖčéčŗ ą▓ čŹč鹊ą╝ čĆąĄą│ąĖčüčéčĆąĄ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮčŗ ą▓ 0 ą▓čüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ čŹč鹊čé čĆąĄą│ąĖčüčéčĆ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ.
ąĀąĖčü. 6-23. ąĀąĄą│ąĖčüčéčĆčŗ ICPLB Data.
PAGE_SIZE[2:0] . ąĀą░ąĘą╝ąĄčĆ čüčéčĆą░ąĮąĖčåčŗ.
000 - 1K ą▒ą░ą╣čé
CPLB_L1_CHBL . ą×čćąĖčüčéąĖč鹥 čŹč鹊čé ą▒ąĖčé ą▓čüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ą┐ą░ą╝čÅčéčī L1 čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮą░ ą║ą░ą║ SRAM. 0 - ąĮąĄ ą║čŹčłąĖčĆčāąĄčéčüčÅ ą▓ L1, 1 - ą║čŹčłąĖčĆčāąĄčéčüčÅ ą▓ L1.
CPLB_MEM_LEV . ąŁč鹊čé ą▒ąĖčé ą┤ąŠčüčéčāą┐ąĄąĮ č鹊ą╗čīą║ąŠ ą▓ č鹥čģ čāčüčéčĆąŠą╣čüčéą▓ą░čģ, čā ą║ąŠč鹊čĆčŗčģ ąĮą░ ą║čĆąĖčüčéą░ą╗ą╗ąĄ ąĄčüčéčī ą┐ą░ą╝čÅčéčī L2 - čüą╝. čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąŠ ą┐ąŠ ą░ą┐ą┐ą░čĆą░čéčāčĆąĄ ąÆą░čłąĄą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░. ąØą░ą┐čĆąĖą╝ąĄčĆ, čā BF538 [1] čŹč鹊čé ą▒ąĖčé ąŠčéčüčāčéčüčéą▓čāąĄčé.
CPLB_LRUPRIO . ą¤čĆąĖąŠčĆąĖč鹥čé ą┐ąŠą╗ąĖčéąĖą║ąĖ LRU, ą┐čĆąĖą▓čÅąĘą░ąĮąĮčŗą╣ ą║ čüčéčĆąŠą║ąĄ, ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. "ą¤ąŠčüčéčĆąŠčćąĮą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣". 0 ąĮąĖąĘą║ąĖą╣ ą┐čĆąĖąŠčĆąĖč鹥čé, 1 ą▓čŗčüąŠą║ąĖą╣ ą┐čĆąĖąŠčĆąĖč鹥čé.
CPLB_L1SRAM . ąóąĖą┐ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čüąĖčéčāą░čåąĖąĖ ąŠą▒čĆą░čēąĄąĮąĖčÅ ą║ ąĮąĄčĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮąĮąŠą╣ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ L1. 0: ą┤ąŠčüčéčāą┐ ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗čÅąĄčéčüčÅ ą▒ą╗ąŠą║čā EBIU (ąĄčüą╗ąĖ ąĘą░ą┐čĆąŠčü ąĮąĄą╗ąĄą│ą░ą╗ąĄąĮ, č鹊 ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ą░ą┐ą┐ą░čĆą░čéąĮą░čÅ ąŠčłąĖą▒ą║ą░), 1: ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ (ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčé ąĖą╝ąĄąĄčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą║ąŠčĆčĆąĄą║čéąĮąŠ ąŠą▒čĆą░ą▒ąŠčéą░čéčī čüąĖčéčāą░čåąĖčÄ ąĮąĄ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮąĮąŠą╣ ąŠą▒ą╗ą░čüčéąĖ L1).
CPLB_USER_RD . 0: ą┐ąŠą┐čŗčéą║ą░ ą┤ąŠčüčéčāą┐ą░ ąĮą░ čćč鹥ąĮąĖąĄ ą▓ User mode čüą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĮą░čĆčāčłąĄąĮąĖčÅ ą┤ąŠčüčéčāą┐ą░, 1: čĆą░ąĘčĆąĄčłąĄąĮ ą┤ąŠčüčéčāą┐ ąĮą░ čćč鹥ąĮąĖąĄ ą▓ User mode.
CPLB_VALID . 0: ąĮąĄą┤ąŠą┐čāčüčéąĖą╝ą░čÅ (ąĘą░ą┐čĆąĄčēąĄąĮąĮą░čÅ) ąĘą░ą┐ąĖčüčī CPLB, 1: ą┤ąŠą┐čāčüčéąĖą╝ą░čÅ (čĆą░ąĘčĆąĄčłąĄąĮąĮą░čÅ) ąĘą░ą┐ąĖčüčī CPLB.
CPLB_LOCK . ąŁč鹊čé ą▒ąĖčé ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą▓ ą░ą╗ą│ąŠčĆąĖčéą╝ą░čģ ąĘą░ą╝ąĄąĮčŗ CPLB ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖčÅ. 0: ąĮąĄ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąŠ, ąĘą░ą┐ąĖčüčī CPLB ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ą╝ąĄąĮąĄąĮą░, 1: ąĘą░ą┐ąĖčüčī CPLB ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮą░ ąĖ ąĮąĄ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ąĖąĘą╝ąĄąĮąĄąĮą░.
ąóą░ą▒ą╗ąĖčåą░ 6-2. ą¤čĆąĖą▓čÅąĘą░ąĮąĮčŗąĄ ą║ ą┐ą░ą╝čÅčéąĖ ą░ą┤čĆąĄčüą░ čĆąĄą│ąĖčüčéčĆąŠą▓ ICPLB Data (MMR).
ąśą╝čÅ čĆąĄą│ąĖčüčéčĆą░ ą£ąĄčüč鹊 čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĖčÅ ą▓ ą┐ą░ą╝čÅčéąĖ
ICPLB_DATA0
0xFFE0 1200
ICPLB_DATA1
0xFFE0 1204
ICPLB_DATA2
0xFFE0 1208
ICPLB_DATA3
0xFFE0 120C
ICPLB_DATA4
0xFFE0 1210
ICPLB_DATA5
0xFFE0 1214
ICPLB_DATA6
0xFFE0 1218
ICPLB_DATA7
0xFFE0 121C
ICPLB_DATA8
0xFFE0 1220
ICPLB_DATA9
0xFFE0 1224
ICPLB_DATA10
0xFFE0 1228
ICPLB_DATA11
0xFFE0 122C
ICPLB_DATA12
0xFFE0 1230
ICPLB_DATA13
0xFFE0 1234
ICPLB_DATA14
0xFFE0 1238
ICPLB_DATA15
0xFFE0 123C
ąØą░ čĆąĖčüčāąĮą║ąĄ 6-24 ą┐ąŠą║ą░ąĘą░ąĮčŗ čĆąĄą│ąĖčüčéčĆčŗ ą┤ą░ąĮąĮčŗčģ DCPLB (DCPLB_DATAx).
ą¦č鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ą┐čĆą░ą▓ąĖą╗čīąĮąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĖ čüąŠą▓ą╝ąĄčüčéąĖą╝ąŠčüčéčī ą▓ ą▒čāą┤čāčēąĄą╝, ą▓čüąĄ ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ą▒ąĖčéčŗ ą▓ čŹč鹊ą╝ čĆąĄą│ąĖčüčéčĆąĄ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮčŗ ą▓ 0 ą▓čüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ čŹč鹊čé čĆąĄą│ąĖčüčéčĆ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ.
ąĀąĖčü. 6-24. ąĀąĄą│ąĖčüčéčĆčŗ DCPLB Data.
PAGE_SIZE[2:0] . ąĀą░ąĘą╝ąĄčĆ čüčéčĆą░ąĮąĖčåčŗ.
000 - 1K ą▒ą░ą╣čé
CPL7B_L1_AOW . ąöąŠą┐čāčüčéąĖą╝ č鹊ą╗čīą║ąŠ ąĄčüą╗ąĖ ą┐čĆąĖą╝ąĄąĮąĄąĮąŠ čüą║ą▓ąŠąĘąĮąŠąĄ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĄ (CPLB_VALID = 1, CPLB_WT = 1). 0: ą▓čŗą┤ąĄą╗čÅčÄčéčüčÅ čüčéčĆąŠą║ąĖ ą║čŹčłą░ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ąŠą┐ąĄčĆą░čåąĖą╣ čćč鹥ąĮąĖčÅ, 1: ą▓čŗą┤ąĄą╗čÅčÄčéčüčÅ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ąĖ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ, ąĖ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ.
CPLB_WT . ąĀą░ą▒ąŠčéą░ąĄčé č鹊ą╗čīą║ąŠ ą▓ čĆąĄąČąĖą╝ąĄ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ. 0: ą┐čĆąĖąĮčåąĖą┐ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ ąĘą░ą┐ąĖčüąĖ "ąŠą▒čĆą░čéąĮą░čÅ ąĘą░ą┐ąĖčüčī" (write-back), 1: čüą║ą▓ąŠąĘąĮąŠą╣ ą┐čĆąĖąĮčåąĖą┐ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ ąĘą░ą┐ąĖčüąĖ (write-through).
CPLB_L1_CHBL . ą×čćąĖčüčéąĖč鹥 čŹč鹊čé ą▒ąĖčé ą▓čüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ą┐ą░ą╝čÅčéčī L1 čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮą░ ą║ą░ą║ SRAM. 0 - ąĮąĄ ą║čŹčłąĖčĆčāąĄčéčüčÅ ą▓ L1, 1 - ą║čŹčłąĖčĆčāąĄčéčüčÅ ą▓ L1.
CPLB_MEM_LEV . ąŁč鹊čé ą▒ąĖčé ą┤ąŠčüčéčāą┐ąĄąĮ č鹊ą╗čīą║ąŠ ą▓ č鹥čģ čāčüčéčĆąŠą╣čüčéą▓ą░čģ, čā ą║ąŠč鹊čĆčŗčģ ąĮą░ ą║čĆąĖčüčéą░ą╗ą╗ąĄ ąĄčüčéčī ą┐ą░ą╝čÅčéčī L2 - čüą╝. čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąŠ ą┐ąŠ ą░ą┐ą┐ą░čĆą░čéčāčĆąĄ ąÆą░čłąĄą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░. ąØą░ą┐čĆąĖą╝ąĄčĆ, čā BF538 [1] čŹč鹊čé ą▒ąĖčé ąŠčéčüčāčéčüčéą▓čāąĄčé.
CPLB_DIRTY . ąöąŠą┐čāčüčéąĖą╝ č鹊ą╗čīą║ąŠ ą▓ čüą╗čāčćą░ąĄ write-back ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ. (CPLB_VALID = 1, CPLB_WT = 0 ąĖ CPLB_L1_CHBL = 1). 0: ą║čŹčł "čćąĖčüčéą░čÅ", 1: "ą│čĆčÅąĘąĮą░čÅ". ąÜąŠą│ą┤ą░ čŹč鹊čé ą▒ąĖčé 0, č鹊 ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ čŹč鹊ą╣ čüčéčĆą░ąĮąĖčåąĄ ąĮą░ čüąŠčģčĆą░ąĮąĄąĮąĖąĄ ą▒čāą┤ąĄčé ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčīčüčÅ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĮą░čĆčāčłąĄąĮąĖčÅ ąĘą░čēąĖčéčŗ. ąĪąŠčüč鹊čÅąĮąĖąĄ čŹč鹊ą│ąŠ ą▒ąĖčéą░ ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāąĄčéčüčÅ č鹊ą╗čīą║ąŠ ąĘą░ą┐ąĖčüčīčÄ ą▓ čŹč鹊čé čĆąĄą│ąĖčüčéčĆ. ą×ą▒čĆą░ą▒ąŠčéčćąĖą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą┤ąŠą╗ąČąĄąĮ čāčüčéą░ąĮąŠą▓ąĖčéčī čŹč鹊čé ą▒ąĖčé.
CPLB_L1SRAM . ąóąĖą┐ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čüąĖčéčāą░čåąĖąĖ ąŠą▒čĆą░čēąĄąĮąĖčÅ ą║ ąĮąĄčĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮąĮąŠą╣ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ L1. 0: ą┤ąŠčüčéčāą┐ ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗čÅąĄčéčüčÅ ą▒ą╗ąŠą║čā EBIU (ąĄčüą╗ąĖ ąĘą░ą┐čĆąŠčü ąĮąĄą╗ąĄą│ą░ą╗ąĄąĮ, č鹊 ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ą░ą┐ą┐ą░čĆą░čéąĮą░čÅ ąŠčłąĖą▒ą║ą░), 1: ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ (ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčé ąĖą╝ąĄąĄčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą║ąŠčĆčĆąĄą║čéąĮąŠ ąŠą▒čĆą░ą▒ąŠčéą░čéčī čüąĖčéčāą░čåąĖčÄ ąĮąĄ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮąĮąŠą╣ ąŠą▒ą╗ą░čüčéąĖ L1).
CPLB_SUPV_WR . 0: ą┤ąŠčüčéčāą┐ ąĮą░ ąĘą░ą┐ąĖčüčī ą▓ Supervisor mode čüą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĮą░čĆčāčłąĄąĮąĖčÅ ąĘą░čēąĖčéčŗ, 1: ą┤ąŠčüčéčāą┐ ąĮą░ ąĘą░ą┐ąĖčüčī ą▓ Supervisor mode čĆą░ąĘčĆąĄčłąĄąĮ.
CPLB_USER_WR . 0: ą┤ąŠčüčéčāą┐ ąĮą░ ąĘą░ą┐ąĖčüčī ą▓ User mode čüą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĮą░čĆčāčłąĄąĮąĖčÅ ąĘą░čēąĖčéčŗ, 1: ą┤ąŠčüčéčāą┐ ąĮą░ ąĘą░ą┐ąĖčüčī ą▓ User mode čĆą░ąĘčĆąĄčłąĄąĮ.
CPLB_USER_RD . ą┤ąŠčüčéčāą┐ ąĮą░ čćč鹥ąĮąĖąĄ ą▓ User mode čüą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĮą░čĆčāčłąĄąĮąĖčÅ ąĘą░čēąĖčéčŗ, 1: ą┤ąŠčüčéčāą┐ ąĮą░ čćč鹥ąĮąĖąĄ ą▓ User mode čĆą░ąĘčĆąĄčłąĄąĮ.
CPLB_VALID . 0: ąĮąĄą┤ąŠą┐čāčüčéąĖą╝ą░čÅ (ąĘą░ą┐čĆąĄčēąĄąĮąĮą░čÅ) ąĘą░ą┐ąĖčüčī CPLB, 1: ą┤ąŠą┐čāčüčéąĖą╝ą░čÅ (čĆą░ąĘčĆąĄčłąĄąĮąĮą░čÅ) ąĘą░ą┐ąĖčüčī CPLB.
CPLB_LOCK . ąŁč鹊čé ą▒ąĖčé ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą▓ ą░ą╗ą│ąŠčĆąĖčéą╝ą░čģ ąĘą░ą╝ąĄąĮčŗ CPLB ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖčÅ. 0: ąĮąĄ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąŠ, ąĘą░ą┐ąĖčüčī CPLB ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ą╝ąĄąĮąĄąĮą░, 1: ąĘą░ą┐ąĖčüčī CPLB ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮą░ ąĖ ąĮąĄ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ąĖąĘą╝ąĄąĮąĄąĮą░.
ąóą░ą▒ą╗ąĖčåą░ 6-3. ą¤čĆąĖą▓čÅąĘą░ąĮąĮčŗąĄ ą║ ą┐ą░ą╝čÅčéąĖ ą░ą┤čĆąĄčüą░ čĆąĄą│ąĖčüčéčĆąŠą▓ DCPLB Data.
ąśą╝čÅ čĆąĄą│ąĖčüčéčĆą░ ą£ąĄčüč鹊 čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĖčÅ ą▓ ą┐ą░ą╝čÅčéąĖ
DCPLB_DATA0
0xFFE0 0200
DCPLB_DATA1
0xFFE0 0204
DCPLB_DATA2
0xFFE0 0208
DCPLB_DATA3
0xFFE0 020C
DCPLB_DATA4
0xFFE0 0210
DCPLB_DATA5
0xFFE0 0214
DCPLB_DATA6
0xFFE0 0218
DCPLB_DATA7
0xFFE0 021C
DCPLB_DATA8
0xFFE0 0220
DCPLB_DATA9
0xFFE0 0224
DCPLB_DATA10
0xFFE0 0228
DCPLB_DATA11
0xFFE0 022C
DCPLB_DATA12
0xFFE0 0230
DCPLB_DATA13
0xFFE0 0234
DCPLB_DATA14
0xFFE0 0238
DCPLB_DATA15
0xFFE0 023C
ąĀąĖčüčāąĮąŠą║ 6-25 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čĆąĄą│ąĖčüčéčĆčŗ ą░ą┤čĆąĄčüą░ DCPLB (DCPLB_ADDRx).
ąĀąĖčü. 6-25. ąĀąĄą│ąĖčüčéčĆčŗ DCPLB Address.
Upper Bits of Address for Match[21:6] , Upper Bits of Address for Match[5:0] . ąĪčéą░čĆčłąĖąĄ ą▒ąĖčéčŗ ą░ą┤čĆąĄčüą░ ą┤ą╗čÅ čüąŠą▓ą┐ą░ą┤ąĄąĮąĖčÅ.
ąóą░ą▒ą╗ąĖčåą░ 6-4. ąÉą┤čĆąĄčüą░ čĆąĄą│ąĖčüčéčĆąŠą▓ DCPLB Address, ąŠč鹊ą▒čĆą░ąČąĄąĮąĮčŗąĄ ąĮą░ ą┐ą░ą╝čÅčéčī.
ąśą╝čÅ čĆąĄą│ąĖčüčéčĆą░ ą£ąĄčüč鹊 čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĖčÅ ą▓ ą┐ą░ą╝čÅčéąĖ
DCPLB_ADDR0
0xFFE0 0100
DCPLB_ADDR1
0xFFE0 0104
DCPLB_ADDR2
0xFFE0 0108
DCPLB_ADDR3
0xFFE0 010C
DCPLB_ADDR4
0xFFE0 0110
DCPLB_ADDR5
0xFFE0 0114
DCPLB_ADDR6
0xFFE0 0118
DCPLB_ADDR7
0xFFE0 011C
DCPLB_ADDR8
0xFFE0 0120
DCPLB_ADDR9
0xFFE0 0124
DCPLB_ADDR10
0xFFE0 0128
DCPLB_ADDR11
0xFFE0 012C
DCPLB_ADDR12
0xFFE0 0130
DCPLB_ADDR13
0xFFE0 0134
DCPLB_ADDR14
0xFFE0 0138
DCPLB_ADDR15
0xFFE0 013C
ąĀąĖčüčāąĮąŠą║ 6-26 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čĆąĄą│ąĖčüčéčĆčŗ ą░ą┤čĆąĄčüą░ ICPLB (ICPLB_ADDRx).
ąĀąĖčü. 6-26. ąĀąĄą│ąĖčüčéčĆčŗ ICPLB Address.
Upper Bits of Address for Match[21:6] , Upper Bits of Address for Match[5:0] . ąĪčéą░čĆčłąĖąĄ ą▒ąĖčéčŗ ą░ą┤čĆąĄčüą░ ą┤ą╗čÅ čüąŠą▓ą┐ą░ą┤ąĄąĮąĖčÅ.
ąóą░ą▒ą╗ąĖčåą░ 6-5. ąÉą┤čĆąĄčüą░ čĆąĄą│ąĖčüčéčĆąŠą▓ ICPLB Address, ąŠč鹊ą▒čĆą░ąČąĄąĮąĮčŗąĄ ąĮą░ ą┐ą░ą╝čÅčéčī.
ąśą╝čÅ čĆąĄą│ąĖčüčéčĆą░ ą£ąĄčüč鹊 čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĖčÅ ą▓ ą┐ą░ą╝čÅčéąĖ
ICPLB_ADDR0
0xFFE0 1100
ICPLB_ADDR1
0xFFE0 1104
ICPLB_ADDR2
0xFFE0 1108
ICPLB_ADDR3
0xFFE0 110C
ICPLB_ADDR4
0xFFE0 1110
ICPLB_ADDR5
0xFFE0 1114
ICPLB_ADDR6
0xFFE0 1118
ICPLB_ADDR7
0xFFE0 111C
ICPLB_ADDR8
0xFFE0 1120
ICPLB_ADDR9
0xFFE0 1124
ICPLB_ADDR10
0xFFE0 1128
ICPLB_ADDR11
0xFFE0 112C
ICPLB_ADDR12
0xFFE0 1130
ICPLB_ADDR13
0xFFE0 1134
ICPLB_ADDR14
0xFFE0 1138
ICPLB_ADDR15
0xFFE0 113C
ąæąĖčéčŗ ą▓ čĆąĄą│ąĖčüčéčĆąĄ čüąŠčüč鹊čÅąĮąĖčÅ DCPLB (DCPLB_STATUS) ąĖ čĆąĄą│ąĖčüčéčĆąĄ čüąŠčüč鹊čÅąĮąĖčÅ ICPLB (ICPLB_STATUS) ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāčÄčé ąĘą░ą┐ąĖčüčī CPLB, ą║ąŠč鹊čĆą░čÅ ąĘą░ą┐čāčüčéąĖą╗ą░ čüą▓čÅąĘą░ąĮąĮčŗąĄ čü CPLB ąĖčüą║ą╗čÄč湥ąĮąĖčÅ. ą×ą▒čĆą░ą▒ąŠčéčćąĖą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą╝ąŠąČąĄčé ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą┐čĆąĖčćąĖąĮčā ąŠčéą║ą░ąĘą░, ąĖčüčüą╗ąĄą┤čāčÅ ąĘą░ą┐ąĖčüąĖ CPLB.
ąĀąĄą│ąĖčüčéčĆčŗ DCPLB_STATUS ąĖ ICPLB_STATUS čÅą▓ą╗čÅčÄčéčüčÅ ą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝ąĖ č鹊ą╗čīą║ąŠ ą▓ čüą▒ąŠą╣ąĮąŠą╣ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ.
ąæąĖčéčŗ FAULT_DAG, FAULT_USERSUPV ąĖ FAULT_RW ą▓ čĆąĄą│ąĖčüčéčĆąĄ čüąŠčüč鹊čÅąĮąĖčÅ DCPLB (DCPLB_STATUS) ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ ąĘą░ą┐ąĖčüąĖ CPLB, ą║ąŠč鹊čĆą░čÅ ą▓čŗąĘą▓ą░ą╗ą░ čüą▓čÅąĘą░ąĮąĮąŠąĄ čü CPLB ąĖčüą║ą╗čÄč湥ąĮąĖąĄ (čüą╝. čĆąĖčü. 6-27).
ąĀąĖčü. 6-27. ąĀąĄą│ąĖčüčéčĆ čüąŠčüč鹊čÅąĮąĖčÅ DCPLB. ąæąĖčé FAULT_USERSUPV ą▓ čĆąĄą│ąĖčüčéčĆąĄ čüąŠčüč鹊čÅąĮąĖčÅ ICPLB (ICPLB_STATUS) ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ ąĘą░ą┐ąĖčüąĖ CPLB, ą║ąŠč鹊čĆą░čÅ ą▓čŗąĘą▓ą░ą╗ą░ čüą▓čÅąĘą░ąĮąĮąŠąĄ čü CPLB ąĖčüą║ą╗čÄč湥ąĮąĖąĄ (čüą╝. čĆąĖčü. 6-28).
FAULT_ILLADDR . 0: ąĮąĄ ą▒čŗą╗ąŠ čüą▒ąŠčÅ, 1: ą▒čŗą╗ą░ ą┐ąŠą┐čŗčéą║ą░ ąĘą░ą┐ąĖčüąĖ ą▓ ąĮąĄ čüčāčēąĄčüčéą▓čāčÄčēčāčÄ ą┐ą░ą╝čÅčéčī.
FAULT_DAG . 0: ą┤ąŠčüčéčāą┐ ą▒čŗą╗ čüą┤ąĄą╗ą░ąĮ č湥čĆąĄąĘ DAG0, 1: č湥čĆąĄąĘ DAG1.
FAULT_USERSUPV . 0: ą┤ąŠčüčéčāą┐ ą▒čŗą╗ čüą┤ąĄą╗ą░ąĮ ą▓ User mode, 1: ą▓ Supervisor mode.
FAULT_RW . 0: ą▒čŗą╗ ą┤ąŠčüčéčāą┐ ąĮą░ čćč鹥ąĮąĖąĄ, 1: ąĮą░ ąĘą░ą┐ąĖčüčī.
FAULT[15:0] . ąÜą░ąČą┤čŗą╣ ą▒ąĖčé ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čüąŠčüč鹊čÅąĮąĖąĄ ą┐ąŠą┐ą░ą┤ą░ąĮąĖąĄ/ą┐čĆąŠą╝ą░čģ čüą▓čÅąĘą░ąĮąĮąŠą╣ ąĘą░ą┐ąĖčüąĖ CPLB.
ąĀąĖčü. 6-28. ąĀąĄą│ąĖčüčéčĆ čüąŠčüč鹊čÅąĮąĖčÅ ICPLB.
FAULT_ILLADDR . 0: ąĮąĄ ą▒čŗą╗ąŠ čüą▒ąŠčÅ, 1: ą▒čŗą╗ą░ ą┐ąŠą┐čŗčéą║ą░ ąĘą░ą┐ąĖčüąĖ ą▓ ąĮąĄ čüčāčēąĄčüčéą▓čāčÄčēčāčÄ ą┐ą░ą╝čÅčéčī.
FAULT_USERSUPV . 0: ą┤ąŠčüčéčāą┐ ą▒čŗą╗ čüą┤ąĄą╗ą░ąĮ ą▓ User mode, 1: ą▓ Supervisor mode.
FAULT[15:0] . ąÜą░ąČą┤čŗą╣ ą▒ąĖčé ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čüąŠčüč鹊čÅąĮąĖąĄ ą┐ąŠą┐ą░ą┤ą░ąĮąĖąĄ/ą┐čĆąŠą╝ą░čģ čüą▓čÅąĘą░ąĮąĮąŠą╣ ąĘą░ą┐ąĖčüąĖ CPLB.
ąĀąĄą│ąĖčüčéčĆ ą░ą┤čĆąĄčüą░ DCPLB (DCPLB_FAULT_ADDR) ąĖ čĆąĄą│ąĖčüčéčĆ ą░ą┤čĆąĄčüą░ čüą▒ąŠčÅ ICPLB (ICPLB_FAULT_ADDR) čüąŠą┤ąĄčƹȹ░čé ą░ą┤čĆąĄčü, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ ą┐čĆąĖčćąĖąĮąŠą╣ čüą▒ąŠčÅ ą▓ L1 Data Memory ąĖą╗ąĖ L1 Instruction Memory, čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ. ąĪą╝. čĆąĖčü. 6-29 ąĖ čĆąĖčü. 6-30.
ąĀąĄą│ąĖčüčéčĆčŗ DCPLB_FAULT_ADDR ąĖ ICPLB_FAULT_ADDR ą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗ č鹊ą╗čīą║ąŠ ą▓ čüą▒ąŠą╣ąĮąŠą╣ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ.
ąĀąĖčü. 6-29. ąĀąĄą│ąĖčüčéčĆ ą░ą┤čĆąĄčüą░ DCPLB.
FAULT_ADDR[31:16] , FAULT_ADDR[15:0] . ąÉą┤čĆąĄčü ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĖą▓ąĄą╗ ą║ ąŠčłąĖą▒ą║ąĄ ą▓ ą┐ą░ą╝čÅčéąĖ ą┤ą░ąĮąĮčŗčģ L1.
ąĀąĖčü. 6-30. ąĀąĄą│ąĖčüčéčĆ ą░ą┤čĆąĄčüą░ čüą▒ąŠčÅ ICPLB.
FAULT_ADDR[31:16] , FAULT_ADDR[15:0] . ąÉą┤čĆąĄčü ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĖą▓ąĄą╗ ą║ ąŠčłąĖą▒ą║ąĄ ą▓ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ L1.
[ą£ąŠą┤ąĄą╗čī čéčĆą░ąĮąĘą░ą║čåąĖą╣ ą┐ą░ą╝čÅčéąĖ ]
ąś ą▓ąĮčāčéčĆąĄąĮąĮčÅčÅ, ąĖ ą▓ąĮąĄčłąĮčÅčÅ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ ą┤ąŠčüčéčāą┐ąĮčŗ ą▓ ą┐ąŠčĆčÅą┤ą║ąĄ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą▒ą░ą╣čé little endian. ąĀąĖčü. 6-31 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čüą╗ąŠą▓ąŠ ą┤ą░ąĮąĮčŗčģ, čüąŠčģčĆą░ąĮąĄąĮąĮąŠąĄ ą▓ čĆąĄą│ąĖčüčéčĆąĄ R0 ąĖ ą▓ ą┐ą░ą╝čÅčéąĖ ą┐ąŠ ą░ą┤čĆąĄčüčā addr. B0 ąŠčéąĮąŠčüąĖčéčüčÅ ą║ čüą░ą╝ąŠą╝čā ą╝ą╗ą░ą┤čłąĄą╝čā ą▒ą░ą╣čéčā 32-ą▒ąĖčéąĮąŠą│ąŠ čüą╗ąŠą▓ą░.
ąĀąĖčü. 6-31. ąöą░ąĮąĮčŗąĄ, čüąŠčģčĆą░ąĮąĄąĮąĮčŗąĄ ą▓ ą┐ąŠčĆčÅą┤ą║ąĄ Little Endian.
ąĀąĖčüčāąĮąŠą║ 6-32 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé 16- ąĖ 32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ, čüąŠčģčĆą░ąĮąĄąĮąĮčŗąĄ ą▓ ą┐ą░ą╝čÅčéąĖ. ąöąĖą░ą│čĆą░ą╝ą╝ą░ čüą╗ąĄą▓ą░ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé 16-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ, čüąŠčģčĆą░ąĮąĄąĮąĮčŗąĄ ą▓ ą┐ą░ą╝čÅčéąĖ, ą│ą┤ąĄ čüą░ą╝čŗą╣ čüčéą░čĆčłąĖą╣ ą┐ąŠ ąĘąĮą░čćąĖą╝ąŠčüčéąĖ ą▒ą░ą╣čé čģčĆą░ąĮąĖčéčüčÅ ą▓ ą▒ąŠą╗čīčłąĄą╝ ą┐ąŠ ąĘąĮą░č湥ąĮąĖčÄ ą░ą┤čĆąĄčüąĄ (ą▒ą░ą╣čé B1 ąĮą░čģąŠą┤ąĖčéčüčÅ ą┐ąŠ ą░ą┤čĆąĄčüčā addr+1), ąĖ čüą░ą╝čŗą╣ ą╝ą╗ą░ą┤čłąĖą╣ ą┐ąŠ ąĘąĮą░čćąĖą╝ąŠčüčéąĖ ą▒ą░ą╣čé ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą╝ąĄąĮčīčłąĄą╝ ą░ą┤čĆąĄčüąĄ (ą▒ą░ą╣čé B0 ąĮą░čģąŠą┤ąĖčéčüčÅ ą┐ąŠ ą░ą┤čĆąĄčüčā addr).
ąĀąĖčü. 6-32. ąśąĮčüčéčĆčāą║čåąĖąĖ, čüąŠčģčĆą░ąĮąĄąĮąĮčŗąĄ ą▓ ą┐ąŠčĆčÅą┤ą║ąĄ Little Endian.
ąöąĖą░ą│čĆą░ą╝ą╝ą░ čüą┐čĆą░ą▓ą░ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé 32-ą▒ąĖčéąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ, čüąŠčģčĆą░ąĮąĄąĮąĮčŗąĄ ą▓ ą┐ą░ą╝čÅčéąĖ. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čüą░ą╝ąŠąĄ čüčéą░čĆčłąĄąĄ 16-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗čāčüą╗ąŠą▓ąŠ ąĖąĮčüčéčĆčāą║čåąĖąĖ (ą▒ą░ą╣čéčŗ B3 ąĖ B2) čüąŠčģčĆą░ąĮąĄąĮąŠ ą▓ ą╝ą╗ą░ą┤čłąĖčģ ą░ą┤čĆąĄčüą░čģ (addr+1 ąĖ addr), ąĖ čüą░ą╝ąŠąĄ ą╝ą╗ą░ą┤čłąĄąĄ ą┐ąŠą╗čāčüą╗ąŠą▓ąŠ (ą▒ą░ą╣čéčŗ B1 ąĖ B0) čüąŠčģčĆą░ąĮąĄąĮąŠ ą▓ čüčéą░čĆčłąĖčģ ą░ą┤čĆąĄčüą░čģ (addr+3 ąĖ addr+2).
[ą×ą┐ąĄčĆą░čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ/čüąŠčģčĆą░ąĮąĄąĮąĖčÅ (Load/Store) ]
ąÉčĆčģąĖč鹥ą║čéčāčĆą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą║ąŠąĮčåąĄą┐čåąĖčÄ RISC ą╝ą░čłąĖąĮčŗ Load/Store. ąŁčéą░ ą╝ą░čłąĖąĮą░ - čģą░čĆą░ą║č鹥čĆąĖčüčéąĖą║ą░ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ RISC, ą│ą┤ąĄ ąŠą┐ąĄčĆą░čåąĖąĖ čü ą┐ą░ą╝čÅčéčīčÄ (ąĘą░ą│čĆčāąĘą║ąĖ ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ) ą┐čĆąĄą┤ąĮą░ą╝ąĄčĆąĄąĮąĮąŠ ąŠčéą┤ąĄą╗ąĄąĮčŗ ąŠčé ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖčģ čäčāąĮą║čåąĖą╣, ą║ąŠč鹊čĆčŗąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčé čåąĄą╗ąĖ ąŠą┐ąĄčĆą░čåąĖą╣ ą┐ą░ą╝čÅčéąĖ. ąĀą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ čüą┤ąĄą╗ą░ąĮąŠ ą┐ąŠč鹊ą╝čā, čćč鹊 ąŠą┐ąĄčĆą░čåąĖąĖ čü ą┐ą░ą╝čÅčéčīčÄ, ą▓ čćą░čüčéąĮąŠčüčéąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ąŠą▒čĆą░čēą░čÄčéčüčÅ ą║ ą┐ą░ą╝čÅčéąĖ ą▓ąĮąĄ čćąĖą┐ą░ ąĖą╗ąĖ ą║ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ I/O, čćą░čüč鹊 ąĘą░ąĮąĖą╝ą░čÄčé ąĮąĄčüą║ąŠą╗čīą║ąŠ čåąĖą║ą╗ąŠą▓ ą┤ą╗čÅ čüą▓ąŠąĄą│ąŠ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ, čćč鹊 ąŠą▒čŗčćąĮąŠ ąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ą╗ąŠ ą▒čŗ ą┐čĆąŠčåąĄčüčüąŠčĆ, ąĮąĄ ą┤ą░ą▓ą░čÅ ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ą┐ąŠ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĘą░ ąŠą┤ąĖąĮ čåąĖą║ą╗.
ą¤čĆąĖ ąŠą┐ąĄčĆą░čåąĖčÅčģ ąĘą░ą┐ąĖčüąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅ store čüčćąĖčéą░ąĄčéčüčÅ ąĘą░ą▓ąĄčĆčłąĄąĮąĮąŠą╣, ą║ą░ą║ č鹊ą╗čīą║ąŠ ąŠąĮą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ, ą┤ą░ąČąĄ ąĄčüą╗ąĖ ą╝ąŠą│čāčé ą┐čĆąŠą╣čéąĖ ąĮąĄčüą║ąŠą╗čīą║ąŠ čåąĖą║ą╗ąŠą▓ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ą┤ą░ąĮąĮčŗąĄ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠ ą▒čāą┤čāčé ąĘą░ą┐ąĖčüą░ąĮčŗ ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī ąĖą╗ąĖ čÅč湥ą╣ą║čā I/O. ąóą░ą║ą░čÅ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖčÅ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐čĆąŠčåąĄčüčüąŠčĆčā ą▓čŗą┐ąŠą╗ąĮčÅčéčī ąŠą┤ąĮčā ąĖąĮčüčéčĆčāą║čåąĖčÄ ąĘą░ ą║ą░ąČą┤čŗą╣ čéą░ą║čé, ąĖ čŹč鹊 ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčé ąŠčéčüčāčéčüčéą▓ąĖąĄ ą│ą░čĆą░ąĮčéąĖąĖ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ ą╝ąĄąČą┤čā č鹥ą╝, ą║ąŠą│ą┤ą░ ąĘą░ą┐ąĖčüčī ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ ąĖ ą║ąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮąĖčéčüčÅ čüą╗ąĄą┤čāčÄčēą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, čŹčéą░ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÅ čüčćąĖčéą░ąĄčéčüčÅ ąĮąĄ ąĖą╝ąĄčÄčēąĄą╣ ąĘąĮą░č湥ąĮąĖčÅ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ą▒ąŠą╗čīčłąĖąĮčüčéą▓ą░ ąŠą┐ąĄčĆą░čåąĖą╣ čü ą┐ą░ą╝čÅčéčīčÄ.
Interlocked Pipeline . ą¤čĆąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą░čĆčģąĖč鹥ą║čéčāčĆą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin čĆąĄą░ą╗ąĖąĘčāąĄčé interlocked pipeline (ą▓ąĘą░ąĖą╝ąĮąŠ ą▒ą╗ąŠą║ąĖčĆčāąĄą╝čŗą╣ ą║ąŠąĮą▓ąĄą╣ąĄčĆ). ąÜąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ, č鹊 čåąĄą╗ąĄą▓ąŠą╣ čĆąĄą│ąĖčüčéčĆ ąŠą┐ąĄčĆą░čåąĖąĖ čćč鹥ąĮąĖčÅ ą┐ąŠą╝ąĄčćą░ąĄčéčüčÅ ąĘą░ąĮčÅčéčŗą╝, ą┐ąŠą║ą░ ąĘąĮą░č湥ąĮąĖąĄ ą┤ą╗čÅ ąĮąĄą│ąŠ ąĮąĄ ą▒čāą┤ąĄčé ą▓ąŠąĘą▓čĆą░čēąĄąĮąŠ čüąĖčüč鹥ą╝ąŠą╣ ą┐ą░ą╝čÅčéąĖ. ąĢčüą╗ąĖ ą┐ąŠčüą╗ąĄą┤čāčÄčēą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐čŗčéą░ąĄčéčüčÅ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ čŹč鹊ą╝čā čĆąĄą│ąĖčüčéčĆčā ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ąĮąŠą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┐ąŠą╗čāč湥ąĮąŠ, ą║ąŠąĮą▓ąĄą╣ąĄčĆ ąŠčüčéą░ąĮąŠą▓ąĖčéčüčÅ ą┤ąŠ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąŠą┐ąĄčĆą░čåąĖąĖ čü ą┐ą░ą╝čÅčéčīčÄ. ąŁčéą░ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą║ą░ ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ čéčĆąĄą▒čāčÄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ čĆąĄąĘčāą╗čīčéą░čéą░ ąĘą░ą│čĆčāąĘą║ąĖ, ąĮąĄ ą▒čāą┤čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┐čĆąĄą┤čŗą┤čāčēąĖąĄ ąĖą╗ąĖ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▓ čĆąĄą│ąĖčüčéčĆąĄ, ą┤ą░ąČąĄ ą┐čĆąĖ č鹊ą╝, čćč鹊 ąĖąĮčüčéčĆčāą║čåąĖąĖ čĆą░ąĘčĆąĄčłąĄąĮąŠ ąĘą░ą┐čāčüčéąĖčéčüčÅ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ čćč鹥ąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ.
ąŁč鹊čé ą╝ąĄčģą░ąĮąĖąĘą╝ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ (čé. ąĄ. č鹥čģ, ą┤ą╗čÅ ą║ąŠč鹊čĆčŗčģ ąĮąĄ ąĮčāąČąĮą░ ąĘą░ą┤ąĄčƹȹ║ą░) ą╝ąĄąČą┤čā ąĘą░ą│čĆčāąĘą║ąŠą╣ ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣, ą║ąŠč鹊čĆą░čÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčé čĆąĄąĘčāą╗čīčéą░čé čćč鹥ąĮąĖčÅ ą▒ąĄąĘ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ ą┤ą╗čÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčéą░ ąĖą╗ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ ąĘąĮą░čéčī, čüą║ąŠą╗čīą║ąŠ čåąĖą║ą╗ąŠą▓ ą▓ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠčüčéąĖ ąĮčāąČąĮąŠ ą┤ą╗čÅ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąŠą┐ąĄčĆą░čåąĖąĖ čćč鹥ąĮąĖčÅ. ąĢčüą╗ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅ, ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ čüą╗ąĄą┤čāčÄčēą░čÅ ąĘą░ ąĘą░ą│čĆčāąĘą║ąŠą╣, ąĖčüą┐ąŠą╗čīąĘčāąĄčé č鹊čé ąČąĄ čĆąĄą│ąĖčüčéčĆ, ą║ąŠąĮą▓ąĄą╣ąĄčĆ ą┐čĆąŠčüč鹊 ąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ, ą┐ąŠą║ą░ ąĮąĄ ą▒čāą┤ąĄčé ą▓ąŠąĘą▓čĆą░čēąĄąĮąŠ ąĘąĮą░č湥ąĮąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ čćč鹥ąĮąĖčÅ. ąĪą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ, čŹč鹊 čĆą░ą▒ąŠčéą░ąĄčé čéą░ą║, ą║ą░ą║ ąŠąČąĖą┤ą░ą╗ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčé. ą×ą┤ąĮą░ą║ąŠ ąĄčüą╗ąĖ 4 ą┤čĆčāą│ąĖčģ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▒čāą┤čāčé ą┐ąŠą╝ąĄčēąĄąĮčŗ ą┐ąŠčüą╗ąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĘą░ą│čĆčāąĘą║ąĖ, ąĖ ą┤ąŠ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆą░čÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčé č鹊čé ąČąĄ čüą░ą╝čŗą╣ čĆąĄą│ąĖčüčéčĆ, č鹊 ą▓čüąĄ ąŠąĮąĖ ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ ą▒ąĄąĘ ąĘą░ą┤ąĄčƹȹ║ąĖ, ąĖ ąŠą▒čēąĄąĄ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ ą┐čĆąŠčåąĄčüčüąŠčĆą░ čāą╗čāčćčłąĖčéčüčÅ.
ą¤ąŠčĆčÅą┤ąŠą║ ąĘą░ą│čĆčāąĘąŠą║ ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖą╣ . ąĀąĄą╗ą░ą║čüą░čåąĖčÅ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ ą╝ąĄąČą┤čā ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ ąĖ ąŠą║čĆčāąČą░čÄčēąĖą╝ąĖ ąĖčģ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ čāą┐ąŠą╝ąĖąĮą░ąĄčéčüčÅ ą║ą░ą║ čüą╗ą░ą▒ąŠąĄ čāą┐ąŠčĆčÅą┤ąŠčćąĖą▓ą░ąĮąĖąĄ ąĘą░ą│čĆčāąĘąŠą║ ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖą╣. ąĪą╗ą░ą▒ąŠąĄ čāą┐ąŠčĆčÅą┤ąŠčćąĖą▓ą░ąĮąĖąĄ ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčé, čćč鹊 ą▓čĆąĄą╝čÅ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠą│ąŠ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąŠą┐ąĄčĆą░čåąĖą╣ čü ą┐ą░ą╝čÅčéčīčÄ - ą┤ą░ąČąĄ ą┐ąŠčĆčÅą┤ąŠą║, ą▓ ą║ąŠč鹊čĆąŠą╝ čŹčéąĖ čüąŠą▒čŗčéąĖčÅ ą┐čĆąŠąĖčüčģąŠą┤čÅčé - ą╝ąŠą│čāčé ąĮąĄ čüąŠąŠčéą▓ąĄčéčüčéą▓ąŠą▓ą░čéčī č鹊ą╝čā, čćč鹊 ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčé ą▓ąĖą┤ąĖčé ą▓ ąĖčüčģąŠą┤ąĮąŠą╝ ą║ąŠą┤ąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ąÆąŠčé ą▓čüąĄ, čćč鹊 ą│ą░čĆą░ąĮčéąĖčĆčāąĄčéčüčÅ:
ŌĆó ą×ą┐ąĄčĆą░čåąĖąĖ ąĘą░ą│čĆčāąĘą║ąĖ ąĘą░ą▓ąĄčĆčłą░čéčüčÅ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ą▓ąŠąĘą▓čĆą░čēąĄąĮąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▒čāą┤čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ čüą╗ąĄą┤čāčÄčēąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣.
ąśąĘ-ąĘą░ čüą╗ą░ą▒ąŠą│ąŠ čāą┐ąŠčĆčÅą┤ąŠčćąĖą▓ą░ąĮąĖčÅ čüąĖčüč鹥ą╝ą░ ą┐ą░ą╝čÅčéąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą┐čĆąĖąŠčĆąĖč鹥čé čćč鹥ąĮąĖą╣ ą┐ąĄčĆąĄą┤ ąĘą░ą┐ąĖčüčÅą╝ąĖ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ąĘą░ą┐ąĖčüčī, ą║ąŠč鹊čĆą░čÅ ą┐ąŠčüčéą░ą▓ą╗ąĄąĮą░ ą▓ ąŠč湥čĆąĄą┤čī ąĮą░ ą║ąŠąĮą▓ąĄą╣ąĄčĆąĄ, ąĮąŠ ąĄčēąĄ ąĮąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĮą░čÅ, ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠčéą╗ąŠąČąĄąĮą░ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĄą╣ ąŠą┐ąĄčĆą░čåąĖąĄą╣ čćč鹥ąĮąĖčÅ, ąĖ čćč鹥ąĮąĖčÄ čĆą░ąĘčĆąĄčłąĄąĮąŠ ąĘą░ą▓ąĄčĆčłąĖčéčīčüčÅ ą┤ąŠ ąĘą░ą┐ąĖčüąĖ. ą¦č鹥ąĮąĖčÅ ąĖą╝ąĄčÄčé ą┐čĆąĖąŠčĆąĖč鹥čé ą┐ąĄčĆąĄą┤ ąĘą░ą┐ąĖčüčÅą╝ąĖ ą┐ąŠč鹊ą╝čā, čćč鹊 ąŠą┐ąĄčĆą░čåąĖčÅ čćč鹥ąĮąĖčÅ ąĘą░ą▓ąĖčüąĖčé ąŠčé ąŠąČąĖą┤ą░ąĮąĖčÅ ąĄčæ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ą┐čĆąŠčåąĄčüčüąŠčĆ čüčćąĖčéą░ąĄčé ąĘą░ą┐ąĖčüčī čüčĆą░ąĘčā ąĘą░ą▓ąĄčĆčłąĄąĮąĮąŠą╣, ąĖ ąĘą░ą┐ąĖčüčī ąĮąĄ ąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé ą║ąŠąĮą▓ąĄą╣ąĄčĆ, ą┤ą░ąČąĄ ąĄčüą╗ąĖ ą▓ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą┐ąŠąĮą░ą┤ąŠą▒ąĖčéčüčÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ čåąĖą║ą╗ąŠą▓, čćč鹊ą▒čŗ ąĘą░ą┐ąĖčüą░ąĮąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┐ąŠą┐ą░ą╗ąŠ ą▓ ą┐ą░ą╝čÅčéčī. ąóą░ą║ čćč鹊 čćč鹥ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ą▓ ą║ąŠą┤ąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ čüč鹊ąĖčé ą┐ąŠąĘąČąĄ ąĘą░ą┐ąĖčüąĖ, ąĮą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ ą╝ąŠą│ą╗ąŠ ą▒čŗ ąĘą░ą▓ąĄčĆčłąĖčéčīčüčÅ čĆą░ąĮčīčłąĄ ąĖ ą▓ąĄčĆąĮčāčéčī ąĘąĮą░č湥ąĮąĖąĄ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ą▒čāą┤ąĄčé ąĘą░ą▓ąĄčĆčłąĄąĮą░ ąĘą░ą┐ąĖčüčī. ąóą░ą║ąŠąĄ čāą┐ąŠčĆčÅą┤ąŠčćąĖą▓ą░ąĮąĖąĄ ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠ ą┐ąŠą▓čŗčłą░ąĄčé ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣, čĆą░ą▒ąŠčéą░čÄčēąĖčģ čü ą┐ą░ą╝čÅčéčīčÄ. ą×ą┤ąĮą░ą║ąŠ čŹč鹊 ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą┐ąŠą▒ąŠčćąĮčŗą╝ čŹčäč乥ą║čéą░ą╝, ą║ąŠč鹊čĆčŗčģ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčé ą┤ąŠą╗ąČąĄąĮ ąĖąĘą▒ąĄą│ą░čéčī, čćč鹊ą▒čŗ ąĮąĄ ą┤ąŠą┐čāčüčéąĖčéčī ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠą╣ čĆą░ą▒ąŠčéčŗ čüąĖčüč鹥ą╝čŗ.
ąÜąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĘą░ą┐ąĖčüčī ą▓ ąŠą▒ą╗ą░čüčéąĖ, ąĮąĄ ą┐čĆąĖąĮą░ą┤ą╗ąĄąČą░čēąĖąĄ ą┐ą░ą╝čÅčéąĖ, ąĖą╗ąĖ čćč鹥ąĮąĖąĄ ąĖąĘ čéą░ą║ąĖčģ ąŠą▒ą╗ą░čüč鹥ą╣, ąĮą░ą┐čĆąĖą╝ąĄčĆ čĆąĄą│ąĖčüčéčĆčŗ čāčüčéčĆąŠą╣čüčéą▓ I/O ą▓ąĮąĄ ą║čĆąĖčüčéą░ą╗ą╗ą░, č鹊 ą┐ąŠčĆčÅą┤ąŠą║, ą▓ ą║ąŠč鹊čĆąŠą╝ ą┐čĆąŠąĖčüčģąŠą┤čÅčé ąŠą┐ąĄčĆą░čåąĖąĖ čćč鹥ąĮąĖčÅ ąĖ ąĘą░ą┐ąĖčüąĖ, čćą░čüč鹊 ąĖą╝ąĄąĄčé ą▒ąŠą╗čīčłąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ. ąØą░ą┐čĆąĖą╝ąĄčĆ, čćč鹥ąĮąĖąĄ čĆąĄą│ąĖčüčéčĆą░ čüąŠčüč鹊čÅąĮąĖčÅ ą╝ąŠąČąĄčé ąĘą░ą▓ąĖčüąĄčéčī ąŠčé ąĘą░ą┐ąĖčüąĖ ą▓ čĆąĄą│ąĖčüčéčĆ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ. ąĢčüą╗ąĖ ą░ą┤čĆąĄčü č鹊čé ąČąĄ čüą░ą╝čŗą╣, č鹊 čćč鹥ąĮąĖąĄ ą▓ąĄčĆąĮčāą╗ąŠ ą▒čŗ ąĘąĮą░č湥ąĮąĖąĄ ąĖąĘ ą▒čāč乥čĆą░ čģčĆą░ąĮąĄąĮąĖčÅ, ą░ ąĮąĄ ąĖąĘ čĆąĄą░ą╗čīąĮąŠą│ąŠ čĆąĄą│ąĖčüčéčĆą░ I/O čāčüčéčĆąŠą╣čüčéą▓ą░, ąĖ ą┐ąŠčĆčÅą┤ąŠą║ čćč鹥ąĮąĖčÅ ąĖ ąĘą░ą┐ąĖčüąĖ čĆąĄą│ąĖčüčéčĆą░ ą╝ąŠąČąĄčé ą┐ąŠą╝ąĄąĮčÅčéčīčüčÅ ąĮą░ ąŠą▒čĆą░čéąĮčŗą╣. ą×ą▒ą░ čŹčéąĖčģ čüą╗čāčćą░čÅ ą╝ąŠą│čāčé ą┤ą░čéčī ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮčŗąĄ ą┐ąŠą▒ąŠčćąĮčŗąĄ čŹčäč乥ą║čéčŗ ą▓ čĆą░ą▒ąŠč鹥 ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĖ ą┐ąĄčĆąĖč乥čĆąĖąĖ - ą▓čüąĄ ą▒čāą┤ąĄčé čĆą░ą▒ąŠčéą░čéčī ąĮąĄ čéą░ą║, ą║ą░ą║ ąŠąČąĖą┤ą░ą╗ąŠčüčī. ą¦č鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 čŹčéąĖ čŹčäč乥ą║čéčŗ ąĮąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤čāčé ą▓ ą║ąŠą┤ąĄ, ą║ąŠč鹊čĆčŗą╣ čéčĆąĄą▒čāčÄčé č鹊čćąĮąŠą│ąŠ (ąČąĄčüčéą║ąŠą│ąŠ) ą┐ąŠčĆčÅą┤ą║ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĘą░ą│čĆčāąĘą║ąĖ ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ, ą┤ąŠą╗ąČąĮčŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ (CSYNC ąĖą╗ąĖ SSYNC).
ąśąĮčüčéčĆčāą║čåąĖąĖ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ . ąÜąŠą│ą┤ą░ čéčĆąĄą▒čāąĄčéčüčÅ čāą┐ąŠčĆčÅą┤ąŠčćąĖą▓ą░ąĮąĖąĄ ąĘą░ą│čĆčāąĘąŠą║ ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖą╣, ą║ą░ą║ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓ čüą╗čāčćą░ąĄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗčģ ąĘą░ą┐ąĖčüąĄą╣ ą▓ čāčüčéčĆąŠą╣čüčéą▓ąŠ I/O ą┤ą╗čÅ ąĮą░čüčéčĆąŠą╣ą║ąĖ ąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ, ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ąĖąĮčüčéčĆčāą║čåąĖąĖ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ čÅą┤čĆą░ ąĖą╗ąĖ čüąĖčüč鹥ą╝čŗ, CSYNC ąĖą╗ąĖ SSYNC čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ.
ąśąĮčüčéčĆčāą║čåąĖčÅ CSYNC ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ą▓čüąĄ ąŠąČąĖą┤ą░čÄčēąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ čÅą┤čĆą░ ąĘą░ą▓ąĄčĆčłąĄąĮčŗ, ąĖ ą▒čāč乥čĆ čģčĆą░ąĮąĄąĮąĖčÅ (ą╝ąĄąČą┤čā čÅą┤čĆąŠą╝ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĖ ą┐ą░ą╝čÅčéčīčÄ L1) ą▒čŗą╗ čüą▒čĆąŠčłąĄąĮ ą┐ąĄčĆąĄą┤ ą┐ąĄčĆąĄčģąŠą┤ąŠą╝ ą║ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÄ čüą╗ąĄą┤čāčÄčēąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ą×ąČąĖą┤ą░čÄčēąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ čÅą┤čĆą░ ą╝ąŠą│čāčé ą▓ą║ą╗čÄčćą░čéčī ą╗čÄą▒čŗąĄ ąŠąČąĖą┤ą░čÄčēąĖąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ, čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮčŗąĄ čüąŠčüč鹊čÅąĮąĖčÅ (čéą░ą║ąĖąĄ ą║ą░ą║ ą┐čĆąĄą┤čüą║ą░ąĘą░ąĮąĖčÅ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ), ąĖą╗ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ.
ąĀą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗ąĄą┤čāčÄčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ ą║ąŠą┤ą░:
IF CC JUMP away_from_here;
CSYNC;
R0 = [P0];
away_from_here:
ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ąĖąĮčüčéčĆčāą║čåąĖčÅ CSYNC ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé:
ŌĆó ąÆąĄčéą▓ą╗ąĄąĮąĖąĄ ą┐ąŠ čāčüą╗ąŠą▓ąĖčÄ (IF CC JUMP away_from_here) ąŠą▒čĆą░ą▒ąŠčéą░ąĮąŠ, ą┐čĆąĖ čŹč鹊ą╝ ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą║ąŠąĮą▓ąĄą╣ąĄčĆ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┤ąŠ ą╝ąŠą╝ąĄąĮčéą░ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čāčüą╗ąŠą▓ąĖčÅ, ąĖ ą╗čÄą▒čŗąĄ ąĘą░ą┐ąĖčüąĖ ą▓ ą▒čāč乥čĆąĄ čģčĆą░ąĮąĄąĮąĖčÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą▒čŗą╗ąĖ čüą▒čĆąŠčłąĄąĮčŗ (flushed).
ąŚą░ą│čĆčāąĘą║ąĖ ą┤ą░ąĮąĮčŗčģ ąĖ ą▓čŗą▒ąŠčĆą║ąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ čāčüą╗ąŠą▓ąĖčÅ (ąĖąĮčüčéčĆčāą║čåąĖąĖ CALL) ą▓ č鹥ąĮąĖ ą┐ąĄčĆąĄčģąŠą┤ą░ ą┐ąŠ čāčüą╗ąŠą▓ąĖčÄ ąŠą▒čŗčćąĮąŠ ąĮąĄ ą┐ąŠč鹥čĆą┐čÅčé čüą▒ąŠą╣, ą║ąŠą│ą┤ą░ ąŠąĮąĖ ąĮąĄ ąĘą░čēąĖčēąĄąĮčŗ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ CSYNC, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą┐čĆąĖą╝ąĄčĆąĄ ą▓čŗčłąĄ. ą×ą┤ąĮą░ą║ąŠ ąĄčüą╗ąĖ ą▒čāą┤ąĄčé ą┐ąŠą┐čŗčéą║ą░ ąĘą░ą│čĆčāąĘą║ąĖ ąĖą╗ąĖ ą▓čŗą▒ąŠčĆą║ąĖ ąĖąĘ čĆąĄą│ąĖąŠąĮąŠą▓ ąĮąĄą┤ąŠą┐čāčüčéąĖą╝ąŠą╣ ąĖą╗ąĖ ąĮąĄ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ, ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą┐ą░ą╝čÅčéąĖ ą╝ąŠąČąĄčé ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ą░ą┐ą┐ą░čĆą░čéąĮčāčÄ ąŠčłąĖą▒ą║čā ąĖąĘ-ąĘą░ ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░, ą┤ą░ąČąĄ ąĄčüą╗ąĖ ąŠąĮ ą▒čāą┤ąĄčé ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ ą┐čĆąĄčĆą▓ą░ąĮ. ą×čüąŠą▒ąĄąĮąĮąŠąĄ ą▓ąĮąĖą╝ą░ąĮąĖąĄ ąĮčāąČąĮąŠ čāą┤ąĄą╗ąĖčéčī čüąĖčéčāą░čåąĖčÅą╝, ą║ąŠą│ą┤ą░ čāčüą╗ąŠą▓ąĮčŗą╣ ą┐ąĄčĆąĄčģąŠą┤ ąĘą░čēąĖčēą░ąĄčé ąŠčé ą┤ąŠčüčéčāą┐ą░ ą┐ąŠ ąĮčāą╗ąĄą▓ąŠą╝čā čāą║ą░ąĘą░č鹥ą╗čÄ (NULL). ą¤ąŠą╝ąĮąĖč鹥, čćč鹊 ą░ą┤čĆąĄčü 0x00000000 ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ąŠą▒ą╗ą░čüčéąĖ SDRAM.
ąśąĮčüčéčĆčāą║čåąĖčÅ SSYNC ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ą▓čüąĄ ą┐ąŠą▒ąŠčćąĮčŗąĄ čŹčäč乥ą║čéčŗ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ ąŠą┐ąĄčĆą░čåąĖąĖ čĆą░čüą┐čĆąŠčüčéčĆą░ąĮąĖą╗ąĖčüčī ąĮą░čĆčāąČčā č湥čĆąĄąĘ ąĖąĮč鹥čĆč乥ą╣čü ą╝ąĄąČą┤čā ą┐ą░ą╝čÅčéčīčÄ L1 ąĖ ąŠčüčéą░ą╗čīąĮčŗą╝ ą║čĆąĖčüčéą░ą╗ą╗ąŠą╝. ąÆ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ čäčāąĮą║čåąĖčÅą╝ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ čÅą┤čĆą░ CSYNC, ąĖąĮčüčéčĆčāą║čåąĖčÅ SSYNC čüą▒čĆą░čüčŗą▓ą░ąĄčé ą╗čÄą▒čŗąĄ ą▒čāč乥čĆčŗ ąĘą░ą┐ąĖčüąĖ ą╝ąĄąČą┤čā ą┐ą░ą╝čÅčéčīčÄ L1 ąĖ ą┤ąŠą╝ąĄąĮąŠą╝ čüąĖčüč鹥ą╝čŗ, ąĖ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĘą░ą┐čĆąŠčü čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ ą║ čüąĖčüč鹥ą╝ąĄ, ą║ąŠč鹊čĆčŗą╣ čéčĆąĄą▒čāąĄčé ą┐ąŠą┤čéą▓ąĄčƹȹ┤ąĄąĮąĖčÅ ą┤ąŠ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ SSYNC.
ąĪą┐ąĄą║čāą╗čÅčéąĖą▓ąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ čćč鹥ąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ . ą×ą┐ąĄčĆą░čåąĖąĖ ąĘą░ą│čĆčāąĘą║ąĖ ąĖąĘ ą┐ą░ą╝čÅčéąĖ ąĮąĄ ą╝ąĄąĮčÅčÄčé ąĘąĮą░č湥ąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ. ąĪą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ, ą▓čŗą┤ą░čćą░ čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ čćč鹥ąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĄą╣ ąŠą┐ąĄčĆą░čåąĖąĖ ąĘą░ą│čĆčāąĘą║ąĖ ąŠą▒čŗčćąĮąŠ ąĮąĄ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮčŗą╝ ą┐ąŠą▒ąŠčćąĮčŗą╝ čŹčäč乥ą║čéą░ą╝. ąÆ ąĮąĄą║ąŠč鹊čĆčŗčģ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčÅčģ ą║ąŠą┤ą░, čéą░ą║ąĖčģ ą║ą░ą║ ąĖąĮčüčéčĆčāą║čåąĖčÅ čāčüą╗ąŠą▓ąĮąŠą│ąŠ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ, ąĘą░ ą║ąŠč鹊čĆąŠą╣ ąĖą┤ąĄčé ąĘą░ą│čĆčāąĘą║ą░, ą╝ąŠąČąĄčé ą▒čŗčéčī čāą╗čāčćčłąĄąĮąŠ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮąŠą╣ ą▓čŗą┤ą░č湥ą╣ ąĘą░ą┐čĆąŠčüą░ ąĮą░ čćč鹥ąĮąĖąĄ ą║ ą┐ąŠą┤čüąĖčüč鹥ą╝ąĄ ą┐ą░ą╝čÅčéąĖ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ą▒čāą┤ąĄčé čĆą░čüą┐ąŠąĘąĮą░ąĮąŠ ą▓ąĄčéą▓ą╗ąĄąĮąĖąĄ ą┐ąŠ čāčüą╗ąŠą▓ąĖčÄ. ą¤čĆąĖą╝ąĄčĆ:
IF CC JUMP away_from_here
RO = [P2];
...
away_from_here:
ąĢčüą╗ąĖ ą▓ąĘčÅč鹊 ą▓ąĄčéą▓ą╗ąĄąĮąĖąĄ, č鹊 ąĘą░ą│čĆčāąĘą║ą░ ą▒čāą┤ąĄčé čüą▒čĆąŠčłąĄąĮą░ ąĖąĘ ą║ąŠąĮą▓ąĄą╣ąĄčĆą░, ąĖ ą╗čÄą▒čŗąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ ą▓ąŠąĘą▓čĆą░čēąĄąĮčŗ, ą╝ąŠą│čāčé ąĖą│ąĮąŠčĆąĖčĆąŠą▓ą░čéčīčüčÅ. ąĪ ą┤čĆčāą│ąŠą╣ čüč鹊čĆąŠąĮčŗ, ąĄčüą╗ąĖ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ ąĮąĄ ą▒čāą┤ąĄčé, ą┐ą░ą╝čÅčéčī ą▓ąĄčĆąĮąĄčé ą║ąŠčĆčĆąĄą║čéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ čĆą░ąĮčīčłąĄ, č湥ą╝ ąĄčüą╗ąĖ ą▒čŗ čĆą░ą▒ąŠčéą░ ą▒čŗą╗ą░ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮą░ ą┤ąŠ ą╝ąŠą╝ąĄąĮčéą░ ąŠą║ąŠąĮčćą░ąĮąĖčÅ čĆą░čüą┐ąŠąĘąĮą░ą▓ą░ąĮąĖčÅ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ.
ą×ą┤ąĮą░ą║ąŠ ą▓ čüą╗čāčćą░ąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ I/O ą▓ąĮąĄ ą║čĆąĖčüčéą░ą╗ą╗ą░, čŹč鹊 ą╝ąŠą│ą╗ąŠ ą▒čŗ ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮąŠą╝čā ą┐ąŠą▒ąŠčćąĮąŠą╝čā čŹčäč乥ą║čéčā ą┤ą╗čÅ ą┐ąĄčĆąĖč乥čĆąĖąĖ, ą║ąŠč鹊čĆą░čÅ ą▓ąŠąĘą▓čĆą░čéąĖčé ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ąĖąĘ FIFO ąĖą╗ąĖ čĆąĄą│ąĖčüčéčĆą░, ą║ąŠč鹊čĆčŗą╣ ąĖąĘą╝ąĄąĮąĖčé ąĘąĮą░č湥ąĮąĖąĄ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą║ąŠą╗ąĖč湥čüčéą▓ą░ ąĘą░ą┐čĆąŠčłąĄąĮąĮąŠą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ čćč鹥ąĮąĖą╣. ą¦č鹊ą▒čŗ ąĖąĘą▒ąĄąČą░čéčī čŹč鹊ą│ąŠ čŹčäč乥ą║čéą░, ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ąĖąĮčüčéčĆčāą║čåąĖąĖ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ (CSYNC ąĖą╗ąĖ SSYNC), čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ą║ąŠčĆčĆąĄą║čéąĮąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą╝ąĄąČą┤čā ąŠą┐ąĄčĆą░čåąĖčÅą╝ąĖ čćč鹥ąĮąĖčÅ.
ą×ą┐ąĄčĆą░čåąĖąĖ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ąŠčüčāčēąĄčüčéą▓ą╗čÅčÄčé čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 ą╝ąŠą│ą╗ąŠ ą▒čŗ ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖąĖ ąĘąĮą░č湥ąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ą┤ąŠ č鹊ą│ąŠ ą║ą░ą║ ą▒čāą┤ąĄčé ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąŠ, ą┤ąŠą╗ąČąĮą░ ą╗ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ.
ąÆčüąĄ ą┐čĆąŠčåąĄčüčüąŠčĆčŗ, ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ ADSP-BF535, ąĘą░čēąĖčēą░čÄčé ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ ą║čĆąĖčüčéą░ą╗ą╗ą░ ąŠčé čĆą░ąĘčĆčāčłąĄąĮąĖčÅ ąĖąĘ-ąĘą░ čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮčŗčģ čćč鹥ąĮąĖą╣. ąŚą┤ąĄčüčī ąŠčéą┤ąĄą╗čīąĮčŗą╣ čüčéčĆąŠą▒ ąĖąĮąĖčåąĖąĖčĆčāąĄčé ą┐ąŠą▒ąŠčćąĮčŗą╣ čŹčäč乥ą║čé čćč鹥ąĮąĖčÅ, ą║ąŠą│ą┤ą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ.
ą¤ąŠą▓ąĄą┤ąĄąĮąĖąĄ čćč鹥ąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ą┐ąŠ čāčüą╗ąŠą▓ąĖčÄ . ąśąĮčüčéčĆčāą║čåąĖąĖ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ ąĘą░čüčéą░ą▓ą╗čÅčÄčé čĆą░čüą┐ąŠąĘąĮą░čéčī ą▓čüąĄ čüą┐ąĄą║čāą╗čÅčéąĖą▓ąĮčŗąĄ čüąŠčüč鹊čÅąĮąĖčÅ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ ąĖąĮąĖčåąĖąĖčĆčāąĄčé ąŠą▒čĆą░čēąĄąĮąĖąĄ ą║ ą┐ą░ą╝čÅčéąĖ. ą×ą┤ąĮą░ą║ąŠ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ čüą░ą╝ą░ ą╝ąŠąČąĄčé ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ čćč鹥ąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 čŹč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĄčĆą▓ą░ąĮąŠ. ąĢčüą╗ąĖ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ čü ą┤ąŠčüčéą░č鹊čćąĮčŗą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ ą╝ąĄąČą┤čā ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄą╝ ąĖąĮčüčéčĆčāą║čåąĖąĖ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ ąĖ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄą╝ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĘą░ą│čĆčāąĘą║ąĖ, č鹊 čüąĄą║ą▓ąĄąĮčüąĄčĆ ąŠčéą╝ąĄąĮąĖčé ąĖąĮčüčéčĆčāą║čåąĖčÄ ąĘą░ą│čĆčāąĘą║ąĖ. ą¤ąŠčüą╗ąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ą┐čĆąĄčĆą▓ą░ąĮąĮą░čÅ ąĘą░ą│čĆčāąĘą║ą░ ą▓čŗą┐ąŠą╗ąĮąĖčéčüčÅ čüąĮąŠą▓ą░. ąŁč鹊 ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą╝ąĖąĮąĖą╝ąĖąĘąĖčĆčāąĄčé ą╗ą░č鹥ąĮčéąĮąŠčüčéčī ą┤ą╗čÅ ąĘą░ą┐čāčüą║ą░ ISR. ą×ą┤ąĮą░ą║ąŠ ą╝ąŠąČąĄčé čüą╗čāčćąĖčéčīčüčÅ, čćč鹊 čåąĖą║ą╗ čćč鹥ąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ą▒čŗą╗ ąĖąĮąĖčåąĖąĖčĆąŠą▓ą░ąĮ ą┤ąŠ ąŠčéą╝ąĄąĮčŗ ąĘą░ą│čĆčāąĘą║ąĖ, ąĖ ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą┐ąŠčüą╗ąĄą┤čāąĄčé ą▓č鹊čĆą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ čćč鹥ąĮąĖčÅ ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ąĘą░ą│čĆčāąĘą║ą░ ąĘą░ą┐čāčüčéąĖčéčüčÅ čüąĮąŠą▓ą░. ąöą╗čÅ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ą░ ą┤ąŠčüčéčāą┐ąŠą▓ ą║ ą┐ą░ą╝čÅčéąĖ ą╝ąĮąŠąČąĄčüčéą▓ąĄąĮąĮąŠąĄ čćč鹥ąĮąĖąĄ ą┐ąŠ ąŠą┤ąĮąŠą╝čā ąĖ č鹊ą╝čā ąČąĄ ą░ą┤čĆąĄčüčā ąĮąĄ čüąŠčüčéą░ą▓ąĖčé ąĮąĖą║ą░ą║ąĖčģ ą┐čĆąŠą▒ą╗ąĄą╝. ą×ą┤ąĮą░ą║ąŠ ą┤ą╗čÅ ąĮąĄą║ąŠč鹊čĆčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ą▓ąĮąĄ ą║čĆąĖčüčéą░ą╗ą╗ą░, ąŠč鹊ą▒čĆą░ąČąĄąĮąĮčŗčģ ąĮą░ ą░ą┤čĆąĄčüą░ ą┐ą░ą╝čÅčéąĖ, čéą░ą║ąĖčģ ą║ą░ą║ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ FIFO ą┤ą░ąĮąĮčŗčģ, ą╗ąĖčłąĮąĖąĄ čćč鹥ąĮąĖčÅ ąŠą║ą░ąČčāčéčüčÅ ą┤ąĄčüčéčĆčāą║čéąĖą▓ąĮčŗą╝ąĖ. ąÜą░ąČą┤čŗą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ čāčüčéčĆąŠą╣čüčéą▓ąŠ čćąĖčéą░ąĄčéčüčÅ, čüč鹥ą║ FIFO čüą┤ą▓ąĖą│ą░ąĄčéčüčÅ, ąĖ ą┤ą░ąĮąĮčŗąĄ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮčŗ ąĖ ą┐čĆąŠčćąĖčéą░ąĮčŗ ąĘą░ąĮąŠą▓ąŠ.
ąÜąŠą│ą┤ą░ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ ą║ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ ą▓ąĮąĄ ą║čĆąĖčüčéą░ą╗ą╗ą░, ąŠč鹊ą▒čĆą░ąČąĄąĮąĮčŗą╝ ąĮą░ ą░ą┤čĆąĄčüą░ ą┐ą░ą╝čÅčéąĖ, ąĖ čā čŹčéąĖčģ čāčüčéčĆąŠą╣čüčéą▓ ąĖą╝ąĄąĄčéčüčÅ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéčī ąŠčé ą║ąŠą╗ąĖč湥čüčéą▓ą░ ąŠą┐ąĄčĆą░čåąĖą╣ čćč鹥ąĮąĖčÅ ą┐ąŠ čāą║ą░ąĘą░ąĮąĮąŠą╝čā ą░ą┤čĆąĄčüčā, ąĘą░ą┐čĆąĄčéąĖč鹥 ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ą┐ąĄčĆąĄą┤ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ąŠą┐ąĄčĆą░čåąĖąĖ ąĘą░ą│čĆčāąĘą║ąĖ. ąÆ čŹčéąĖčģ čāčüą╗ąŠą▓ąĖčÅčģ ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 čüą╗ąĄą┤čāčÄčēčāčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ą┤ą╗čÅ ąĘą░ą┐čĆąĄčéą░ ąĖ čĆą░ąĘčĆąĄčłąĄąĮąĖčÅ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ (ą┐čĆąĖą╝ąĄčĆ ą║ąŠą┤ą░, ą┐čĆąĖą▓ąĄą┤ąĄąĮąĮčŗą╣ ąĮąĖąČąĄ). ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ ąĮą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ NOP ą┐ąŠčüą╗ąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ CLI. ąŁčéą░ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī čéčĆąĄą▒čāąĄčéčüčÅ ą┤ą╗čÅ ąĘą░čēąĖčéčŗ čäą░ąĘčŗ čćč鹥ąĮąĖčÅ ą║ąŠąĮą▓ąĄą╣ąĄčĆą░ ąŠčé č鹊ą│ąŠ, čćč鹊 ąŠąĮ čāą▓ąĖą┤ąĖčé ąĖąĮčüčéčĆčāą║čåąĖčÄ čćč鹥ąĮąĖčÅ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ą▒čāą┤čāčé ą▓čŗą║ą╗čÄč湥ąĮčŗ.
CLI R0;
NOP; NOP; NOP; /* ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąŠ ą┤ą╗čÅ ąĘą░čēąĖčéčŗ ą║ąŠąĮą▓ąĄą╣ąĄčĆą░ */
R1 = [P0];
STI R0;
ąÆčüąĄ ą┐čĆąŠčåąĄčüčüąŠčĆčŗ, ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ ADSP-BF535, ąĘą░čēąĖčēą░čÄčé ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ ą▓ąĮąĄ ą║čĆąĖčüčéą░ą╗ą╗ą░ ąŠčé čŹč鹊ą╣ ą┐čĆąŠą▒ą╗ąĄą╝čŗ. ąóą░ą║ čćč鹊 ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ADSP-BF535 ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 čŹčéčā ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ą║ą░ą║ ą┤ą╗čÅ čāčüčéčĆąŠą╣čüčéą▓ ą▓ ą║čĆąĖčüčéą░ą╗ą╗ąĄ, čéą░ą║ ąĖ ą┤ą╗čÅ čāčüčéčĆąŠą╣čüčéą▓ ą▓ąĮąĄ ą║čĆąĖčüčéą░ą╗ą╗ą░.
[ąĀą░ą▒ąŠčéą░ čü ą┐ą░ą╝čÅčéčīčÄ ]
ąŁčéą░ čüąĄą║čåąĖčÅ čüąŠą┤ąĄčƹȹĖčé ąĖąĮč乊čĆą╝ą░čåąĖčÄ ą┐ąŠ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÄ ą┤ą░ąĮąĮčŗčģ ą▓ ą┐ą░ą╝čÅčéąĖ ąĖ ąŠą┐ąĄčĆą░čåąĖčÅčģ čü ą┐ą░ą╝čÅčéčīčÄ, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé čüąĄą╝ą░č乊čĆčŗ ą╝ąĄąČą┤čā ąĘą░ą┤ą░čćą░ą╝ąĖ. ąóą░ą║ąČąĄ ą║čĆą░čéą║ąŠ čĆą░čüčüą╝ąŠčéčĆąĄąĮčŗ čĆąĄą│ąĖčüčéčĆčŗ MMR ąĖ ą┐čĆąĖą╝ąĄčĆčŗ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ MMR čÅą┤čĆą░.
ąÆčŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ . ąØąĄ ą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ čü ą┐ą░ą╝čÅčéčīčÄ ąĮą░ą┐čĆčÅą╝čāčÄ ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčéčüčÅ. ąØąĄ ą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗąĄ ąŠą▒čĆą░čēąĄąĮąĖčÅ ą║ ą┐ą░ą╝čÅčéąĖ ą│ąĄąĮąĄčĆąĖčĆčāčÄčé čüąŠą▒čŗčéąĖąĄ ąĮąĄ ą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą│ąŠ ąŠą▒čĆą░čēąĄąĮąĖčÅ ą║ ą┐ą░ą╝čÅčéąĖ (Misaligned Access exception event, čüą╝. "ąśčüą║ą╗čÄč湥ąĮąĖčÅ" [l3]). ą×ą┤ąĮą░ą║ąŠ, ą┐ąŠčüą║ąŠą╗čīą║čā ąĮąĄą║ąŠč鹊čĆčŗąĄ ą┐ąŠč鹊ą║ąĖ ą┤ą░ąĮąĮčŗčģ (čéą░ą║ąĖąĄ ą║ą░ą║ 8-ą▒ąĖčéąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▓ąĖą┤ąĄąŠ) ą╝ąŠą│čāčé ą▒čŗčéčī ąĮąŠčĆą╝ą░ą╗čīąĮąŠ ąĮąĄ ą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗą╝ąĖ ą▓ ą┐ą░ą╝čÅčéąĖ, ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ ą╝ąŠą│čāčé ą▒čŗčéčī ąĘą░ą┐čĆąĄčēąĄąĮčŗ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ DISALGNEXCPT. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ąĮąĄą║ąŠč鹊čĆčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ ą│čĆčāą┐ą┐ąĄ quad 8-bit ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ąĘą░ą┐čĆąĄčēą░čÄčé ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ.
ąÜąŠą│ąĄčĆąĄąĮčéąĮąŠčüčéčī ą║čŹčłą░ . ąöą╗čÅ ąŠą▒čēąĖčģ ą┤ą░ąĮąĮčŗčģ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠąĄ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖąĄ ą┤ąŠą╗ąČąĮąŠ ąŠą▒ąĄčüą┐ąĄčćąĖčéčī čéčĆąĄą▒čāąĄą╝čāčÄ ą┐ąŠą┤ą┤ąĄčƹȹ║čā ą║ąŠą│ąĄčĆąĄąĮčéąĮąŠčüčéąĖ ą┤ą░ąĮąĮčŗčģ. ą¦č鹊ą▒čŗ ą┤ąŠčüčéąĖčćčī čŹč鹊ą│ąŠ, ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ąĖąĮčüčéčĆčāą║čåąĖčÄ FLUSH (čüą╝. "ąśąĮčüčéčĆčāą║čåąĖąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą║čŹčłąĄą╝ ą┤ą░ąĮąĮčŗčģ"), ąĖ/ąĖą╗ąĖ čÅą▓ąĮąŠąĄ ą▓čŗą▓ąĄą┤ąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ąĖąĘ ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéąĖ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ MMR čÅą┤čĆą░ (čüą╝. čĆą░ąĘą┤ąĄą╗ "ąĀąĄą│ąĖčüčéčĆčŗ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ").
ąÉč鹊ą╝ą░čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ . ą¤čĆąŠčåąĄčüčüąŠčĆ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ąŠą┤ąĮčā ą░č鹊ą╝ą░čĆąĮčāčÄ ąŠą┐ąĄčĆą░čåąĖčÄ: TESTSET. ąÉč鹊ą╝ą░čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĖčÅ ąĮąĄ ą┐čĆąĄčĆčŗą▓ą░ąĄą╝čŗčģ ąŠą┐ąĄčĆą░čåąĖą╣ čü ą┐ą░ą╝čÅčéčīčÄ ą▓ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĄ čüąĄą╝ą░č乊čĆąŠą▓ ą╝ąĄąČą┤čā ąĘą░ą┤ą░čćą░ą╝ąĖ. ąśąĮčüčéčĆčāą║čåąĖčÅ TESTSET ąĘą░ą│čĆčāąČą░ąĄčé ą║ąŠčüą▓ąĄąĮąĮąŠ ą░ą┤čĆąĄčüąŠą▓ą░ąĮąĮąŠąĄ ą▓ ą┐ą░ą╝čÅčéąĖ ą┐ąŠą╗čāčüą╗ąŠą▓ąŠ, ą┐čĆąŠą▓ąĄčĆčÅąĄčé, čÅą▓ą╗čÅąĄčéčüčÅ ą╗ąĖ ą╝ą╗ą░ą┤čłąĖą╣ ą▒ą░ą╣čé ąĮčāą╗ąĄą╝, ąĖ ąĘą░č鹥ą╝ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé čüą░ą╝čŗą╣ čüčéą░čĆčłąĖą╣ ą▒ąĖčé (MSB) ą╝ą╗ą░ą┤čłąĄą│ąŠ ą▒ą░ą╣čéą░ ą┐ą░ą╝čÅčéąĖ, ąĮąĄ ą▓ą╗ąĖčÅčÅ ąĮą░ ą▓čüąĄ ąŠčüčéą░ą╗čīąĮčŗąĄ ą▒ąĖčéčŗ. ąĢčüą╗ąĖ ą┐ąĄčĆą▓ąŠąĮą░čćą░ą╗čīąĮąŠ ą▒ą░ą╣čé čĆą░ą▓ąĄąĮ 0, č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé ą▒ąĖčé CC. ąĢčüą╗ąĖ ą┐ąĄčĆą▓ąŠąĮą░čćą░ą╗čīąĮąŠ ą▒ą░ą╣čé ąĮąĄ čĆą░ą▓ąĄąĮ 0, č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ąŠčćąĖčüčéąĖčé ą▒ąĖčé CC. ą¤ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī čŹč鹊ą╣ čéčĆą░ąĮąĘą░ą║čåąĖąĖ čü ą┐ą░ą╝čÅčéčīčÄ ą░č鹊ą╝ą░čĆąĮą░čÅ - ą░ą┐ą┐ą░čĆą░čéąĮą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ čłąĖąĮčŗ ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ąĮąĄ ą╝ąŠą│čāčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ ą┤čĆčāą│ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ čü ą┐ą░ą╝čÅčéčīčÄ ą╝ąĄąČą┤čā ą┐ąŠčĆčåąĖčÅą╝ąĖ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąĖ čāčüčéą░ąĮąŠą▓ą║ąĖ ą▓ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąśąĮčüčéčĆčāą║čåąĖčÅ TESTSET ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĄčĆą▓ą░ąĮą░ čÅą┤čĆąŠą╝. ąĢčüą╗ąĖ čŹč鹊 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ, č鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ TESTSET ą▓čŗą┐ąŠą╗ąĮąĖčéčüčÅ čüąĮąŠą▓ą░ ą┐ąŠčüą╗ąĄ ą▓ąŠąĘą▓čĆą░čéą░ ąĖąĘ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ.
ąśąĮčüčéčĆčāą║čåąĖčÅ TESTSET ą╝ąŠąČąĄčé ą░ą┤čĆąĄčüąŠą▓ą░čéčī ą▓čüąĄ ą░ą┤čĆąĄčüąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ 4 ą│ąĖą│ą░ą▒ą░ą╣čéą░, ąŠą┤ąĮą░ą║ąŠ ąŠąĮą░ ąĮąĄ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮą░ ąĮą░ ą┐ą░ą╝čÅčéčī čÅą┤čĆą░ (ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ L1 ąĖą╗ąĖ MMR) ą┐ąŠčüą║ąŠą╗čīą║čā ą░č鹊ą╝ą░čĆąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ čŹč鹊ą╣ ą┐ą░ą╝čÅčéąĖ ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ.
ąÉčĆčģąĖč鹥ą║čéčāčĆą░ ą┐ą░ą╝čÅčéąĖ ą▓čüąĄą│ą┤ą░ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé ą░č鹊ą╝ą░čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ą║ą░ą║ ą┤ąŠčüčéčāą┐ ą▒ąĄąĘ ą║čŹčłą░, ą┤ą░ąČąĄ ąĄčüą╗ąĖ ą┤ąĄčüą║čĆąĖą┐č鹊čĆ CPLB ą┤ą╗čÅ ą░ą┤čĆąĄčüą░ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ąŠčüčéčāą┐ čü čĆą░ąĘčĆąĄčłąĄąĮąĮčŗą╝ ą║čŹčłąĄą╝. ą×ą┤ąĮą░ą║ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąŠą┐ąĄčĆą░čåąĖą╣ TESTSET ąĮą░ ą║čŹčłąĖčĆčāąĄą╝čŗčģ čĆąĄą│ąĖąŠąĮą░čģ ą┐ą░ą╝čÅčéąĖ ąĮąĄ čĆąĄą║ąŠą╝ąĄąĮą┤čāąĄčéčüčÅ, ą┐ąŠčüą║ąŠą╗čīą║čā ą░čĆčģąĖč鹥ą║čéčāčĆą░ ąĮąĄ ą╝ąŠąČąĄčé ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ą║čŹčłąĖčĆčāąĄą╝ąŠąĄ ą╝ąĄčüč鹊 ą▓ ą┐ą░ą╝čÅčéąĖ ą║ąŠą│ąĄčĆąĄąĮčéąĮąŠ ą▓ ą╝ąŠą╝ąĄąĮčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ TESTSET.
ą×č鹊ą▒čĆą░ąČąĄąĮąĮčŗąĄ ąĮą░ ą┐ą░ą╝čÅčéčī čĆąĄą│ąĖčüčéčĆčŗ (Memory-Mapped Registers, MMR). ą¤ąŠą┤ MMR ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮą░ ąŠą▒ą╗ą░čüčéčī ą▓ ą▓ąĄčĆčģąĮąĄą╣ čćą░čüčéąĖ ą░ą┤čĆąĄčüąĮąŠą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ (ąĮą░čćąĖąĮą░čÅ čü 0xFFC00000). ąŁč鹊čé čĆąĄą│ąĖąŠąĮ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ ą║ą░ą║ ąĮąĄ ą║čŹčłąĖčĆčāąĄą╝čŗą╣, ąĖ ąŠąĮ ą┐ąŠą┤ąĄą╗ąĄąĮ ą╝ąĄąČą┤čā čüąĖčüč鹥ą╝ąĮčŗą╝ąĖ MMR (0xFFC00000 .. 0xFFE00000) ąĖ MMR čÅą┤čĆą░ (0xFFE00000 .. 0xFFFFFFFF).
ąÜą░ą║ ąĖ čĆąĄą│ąĖčüčéčĆčŗ, ąĮąĄ ąŠč鹊ą▒čĆą░ąČąĄąĮąĮčŗąĄ ąĮą░ ą┐ą░ą╝čÅčéčī, MMR čÅą┤čĆą░ ą┐ąŠą┤ą║ą╗čÄč湥ąĮčŗ ą║ 32-čĆą░ąĘčĆčÅą┤ąĮąŠą╝čā čĆąĄą│ąĖčüčéčĆčā ą┤ąŠčüčéčāą┐ą░ ą║ čłąĖąĮąĄ (Register Access Bus, RAB). ą×ąĮąĖ čĆą░ą▒ąŠčéą░čÄčé ąĮą░ čćą░čüč鹊č鹥 CCLK.
ąĪąĖčüč鹥ą╝ąĮčŗąĄ MMRs ą┐ąŠą┤ą║ą╗čÄč湥ąĮčŗ ą║ čłąĖąĮąĄ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ąĄčĆąĖč乥čĆąĖąĖ (Peripheral Access Bus, PAB), ą║ąŠč鹊čĆą░čÅ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮą░ ą╗ąĖą▒ąŠ ą║ą░ą║ 16-ą▒ąĖčéąĮą░čÅ, ą╗ąĖą▒ąŠ ą║ą░ą║ 32-ą▒ąĖčéąĮą░čÅ čłąĖąĮą░, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą╝ąŠą┤ąĄą╗ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░. ą©ąĖąĮą░ PAB čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ čćą░čüč鹊č鹥 SCLK. ąŚą░ą┐ąĖčüąĖ ą▓ čüąĖčüč鹥ą╝ąĮčŗąĄ MMR ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ąĮąĖ č湥čĆąĄąĘ ą▒čāč乥čĆčŗ ąĘą░ą┐ąĖčüąĖ, ąĮąĖ č湥čĆąĄąĘ ą▒čāč乥čĆčŗ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ. ąĪą║ąŠčĆąĄąĄ ąĄčüčéčī ą┐čĆąŠčüč鹊ą╣ ą╝ąŠčüčé ą╝ąĄąČą┤čā čłąĖąĮą░ą╝ąĖ RAB ąĖ PAB, ą║ąŠč鹊čĆčŗą╣ č鹊ą╗čīą║ąŠ ą┤ąĄą╗ą░ąĄčé čéčĆą░ąĮčüą╗čÅčåąĖčÄ ą╝ąĄąČą┤čā ą┤ąŠą╝ąĄąĮą░ą╝ąĖ čéą░ą║č鹊ą▓čŗčģ čćą░čüč鹊čé (ąĖ čłąĖčĆąĖąĮąŠą╣ čłąĖąĮčŗ).
ąóąŠą╗čīą║ąŠ ą┤ą╗čÅ ADSP-BF535: čüąĖčüč鹥ą╝ąĮčŗąĄ MMR ąĮą░čģąŠą┤čÅčéčüčÅ ąĘą░ ą▒čāč乥čĆą░ą╝ąĖ čģčĆą░ąĮąĄąĮąĖčÅ ąĖ ąĘą░ą┐ąĖčüąĖ. ąŚą┤ąĄčüčī čüąĖčüč鹥ą╝ąĮčŗąĄ MMR ą▓ąĄą┤čāčé čüąĄą▒čÅ ą║ą░ą║ čāčüčéčĆąŠą╣čüčéą▓ą░ I/O ą▓ąĮąĄ ą║čĆąĖčüčéą░ą╗ą╗ą░, ą║ą░ą║ čŹč鹊 ąŠą┐ąĖčüą░ąĮąŠ ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ą×ą┐ąĄčĆą░čåąĖąĖ ąĘą░ą│čĆčāąĘą║ąĖ/čüąŠčģčĆą░ąĮąĄąĮąĖčÅ". ąĪą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ, ąĮčāąČąĮčŗ ąĖąĮčüčéčĆčāą║čåąĖąĖ SSYNC ą┐ąŠčüą╗ąĄ ąĖąĮčüčéčĆčāą║čåąĖą╣ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī čüčéčĆąŠą│ąŠąĄ čāą┐ąŠčĆčÅą┤ąŠčćąĖą▓ą░ąĮąĖąĄ ą┤ąŠčüčéčāą┐ąŠą▓ ą║ MMR.
ąÜąŠ ą▓čüąĄą╝ MMR ą╝ąŠąČąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ č鹊ą╗čīą║ąŠ ą▓ Supervisor mode. ąöąŠčüčéčāą┐ ą║ MMR ą▓ User mode ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ą│ąĄąĮąĄčĆą░čåąĖąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĮą░čĆčāčłąĄąĮąĖčÅ ąĘą░čēąĖčéčŗ ą┤ąŠčüčéčāą┐ą░ (protection violation exception). ą¤ąŠą┐čŗčéą║ąĖ ą┤ąŠčüčéčāą┐ą░ ą║ MMR čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ DAG1 čéą░ą║ąČąĄ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąĖčÄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĮą░čĆčāčłąĄąĮąĖčÅ ąĘą░čēąĖčéčŗ ą┤ąŠčüčéčāą┐ą░.
ąÆčüąĄ MMR čÅą┤čĆą░ čćąĖčéą░čÄčéčüčÅ ąĖ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ 32-ą▒ąĖčéąĮąŠą│ąŠ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ. ą×ą┤ąĮą░ą║ąŠ čā ąĮąĄą║ąŠč鹊čĆčŗčģ MMR ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąŠ ą╝ąĄąĮčīčłąĄ 32 ą▒ąĖčé. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄčé ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ ą▒ąĖčéčŗ ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮčŗ. ąĪąĖčüč鹥ą╝ąĮčŗąĄ MMR ą╝ąŠą│čāčé ą▒čŗčéčī 16-čĆą░ąĘčĆčÅą┤ąĮčŗąĄ.
ą¤ąŠą┐čŗčéą║ąĖ ą┤ąŠčüčéčāą┐ą░ ą║ ąĮąĄčüčāčēąĄčüčéą▓čāčÄčēąĖą╝ MMR ą│ąĄąĮąĄčĆąĖčĆčāčÄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĮąĄą┤ąŠą┐čāčüčéąĖą╝ąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░. ąĪąĖčüč鹥ą╝ą░ ąĖą│ąĮąŠčĆąĖčĆčāąĄčé ąĘą░ą┐ąĖčüąĖ ą▓ MMR, ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĮčŗąĄ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ.
ąÉą┐ą┐ą░čĆą░čéčāčĆą░ ą┐ąŠčĆąŠąČą┤ą░ąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ, ą║ąŠą│ą┤ą░ multi-issue ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐čŗčéą░ąĄčéčüčÅ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą┤ą▓ą░ ą┤ąŠčüčéčāą┐ą░ ą▓ ąŠą▒ą╗ą░čüčéčī MMR.
ąÆ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ B ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčéčüčÅ ąŠą▒čēąĄąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ą▓čüąĄčģ MMR čÅą┤čĆą░.
ą¤čĆąĖą╝ąĄčĆ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ MMR čÅą┤čĆą░. ąÜ MMR čÅą┤čĆą░ ą╝ąŠąČąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ č鹊ą╗čīą║ąŠ ą║ą░ą║ ą║ ą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗą╝ ąĮą░ 32 ą▒ąĖčéą░ čüą╗ąŠą▓ą░ą╝. ąØąĄ ą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ čĆąĄą│ąĖčüčéčĆą░ą╝ MMR ą│ąĄąĮąĄčĆąĖčĆčāąĄčé čüąŠą▒čŗčéąĖąĄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ. ąøąĖčüčéąĖąĮą│ 6-1 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čéčĆąĄą▒čāąĄą╝čŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ą╗čÅ ą╝ą░ąĮąĖą┐čāą╗čÅčåąĖąĖ čüčéą░ąĮą┤ą░čĆčéąĮčŗą╝ąĖ MMR čÅą┤čĆą░.
ąøąĖčüčéąĖąĮą│ 6-1. ą¤čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ Core MMR.
CLI R0; /* ąŠčüčéą░ąĮąŠą▓ą║ą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖąĄ IMASK */
P0 = MMR_BASE; /* 32-ą▒ąĖčéąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ą╗čÅ ąĘą░ą│čĆčāąĘą║ąĖ ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą░ą┤čĆąĄčüą░ ąŠą▒ą╗ą░čüčéąĖ MMR */
R1 = [P0 + TIMER_CONTROL_REG]; /* ą┐ąŠą╗čāčćąĖčéčī ąĘąĮą░č湥ąĮąĖąĄ čĆąĄą│ąĖčüčéčĆą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ */
BITSET R1, #N; /* čāčüčéą░ąĮąŠą▓ąĖčéčī ą▒ąĖčé N */
[P0 + TIMER_CONTROL_REG] = R1; /* ą▓ąŠčüčüčéą░ąĮąŠą▓ąĖčéčī čĆąĄą│ąĖčüčéčĆ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ */
CSYNC; /* čŹč鹊 ą┤ą░ąĄčé ą│ą░čĆą░ąĮčéąĖčÄ, čćč鹊 čĆąĄą│ąĖčüčéčĆ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą▒čŗą╗ ąĘą░ą┐ąĖčüą░ąĮ */
STI R0; /* čĆą░ąĘčĆąĄčłąĖčéčī ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ */
ąśąĮčüčéčĆčāą║čåąĖčÅ CLI čüąŠčģčĆą░ąĮčÅąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čĆąĄą│ąĖčüčéčĆą░ IMASK ąĖ ąĘą░ą┐čĆąĄčēą░ąĄčé ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąŠčćąĖčüčéą║ąŠą╣ IMASK. ąśąĮčüčéčĆčāą║čåąĖčÅ STI ą▓ąŠčüčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ IMASK, čćč鹊 čĆą░ąĘčĆąĄčłą░ąĄčé ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ. ąÜąŠą┤ ą╝ąĄąČą┤čā CLI ąĖ STI ąĮąĄą┐čĆąĄčĆčŗą▓ąĄąĮ (ą▓ąŠ ą▓čĆąĄą╝čÅ ąĄą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĮąĄ ą╝ąŠą│čāčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ).
ąöą╗čÅ ąŠą┐ąĖčüą░ąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čüą╗ąĄą┤čāčÄčēą░čÅ č鹥čĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ. ąöčĆčāą│ąĖąĄ č鹥čĆą╝ąĖąĮčŗ ąĖ čüąŠą║čĆą░čēąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗčģ ąĮąĄčé ą▓ čŹč鹊ą╣ ą▓čĆąĄąĘą║ąĄ, čüą╝. ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ąĪą╗ąŠą▓ą░čĆąĖą║" ąĖ ą▓čĆąĄąĘą║ą░čģ čüčéą░čéčīąĖ [2].
ąæą╗ąŠą║ ą║čŹčłą░ (cache block). ąĪą░ą╝čŗą╣ ą╝ą░ą╗ąĄąĮčīą║ąĖą╣ ą▒ą╗ąŠą║ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąĄčĆąĄą┤ą░ąĮ ą╝ąĄąČą┤čā čāčĆąŠą▓ąĮčÅą╝ąĖ ą┐ą░ą╝čÅčéąĖ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ąĖąĘ ą┐ą░ą╝čÅčéąĖ L2 ą▓ ą┐ą░ą╝čÅčéčī L1 ąĖą╗ąĖ ąĮą░ąŠą▒ąŠčĆąŠčé) ą║ą░ą║ čĆąĄąĘčāą╗čīčéą░čé ą┐čĆąŠą╝ą░čģą░ ą║čŹčłą░.
ą¤ąŠą┐ą░ą┤ą░ąĮąĖąĄ ą║čŹčłą░ (cache hit). ąöąŠčüčéčāą┐ ą║ ą╝ąĄą┤ą╗ąĄąĮąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ č湥čĆąĄąĘ ą║čŹčł, ą┤ą╗čÅ ą║ąŠč鹊čĆąŠą╣ ąĄčüčéčī ą┤ąŠą┐čāčüčéąĖą╝čŗą╣ ąŠą▒čĆą░ąĘ ą▓ ą║čŹčłąĄ.
ąĪčéčĆąŠą║ą░, ą╗ąĖąĮąĖčÅ ą║čŹčłą░ (cache line). ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ, čćč鹊 ąĖ ą▒ą╗ąŠą║ ą║čŹčłą░. ąÆ čŹč鹊ą╣ čüčéą░čéčīąĄ č鹥čĆą╝ąĖąĮ "čüčéčĆąŠą║ą░ ą║čŹčłą░" ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą▓ ą║ą░č湥čüčéą▓ąĄ č鹥čĆą╝ąĖąĮą░ "ą▒ą╗ąŠą║ ą║čŹčłą░".
ą¤čĆąŠą╝ą░čģ ą║čŹčłą░ (cache miss). ąöąŠčüčéčāą┐ ą║ ą╝ąĄą┤ą╗ąĄąĮąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ č湥čĆąĄąĘ ą║čŹčł, ą║ąŠą│ą┤ą░ ą▓ ą║čŹčłąĄ ąĮąĄčé ą┤ąŠą┐čāčüčéąĖą╝ąŠą│ąŠ ąŠą▒čĆą░ąĘą░ ą┤ą╗čÅ čŹč鹊ą╣ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ.
ą¤čĆčÅą╝ąŠąĄ ąŠč鹊ą▒čĆą░ąČąĄąĮąĖąĄ (direct-mapped). ąÉčĆčģąĖč鹥ą║čéčāčĆą░ ą║čŹčłą░, ą║ąŠą│ą┤ą░ ą║ą░ąČą┤ą░čÅ čüčéčĆąŠą║ą░ ą║čŹčłą░ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé č鹊ą╗čīą║ąŠ ąŠą┤ąĮąŠą╝čā ą╝ąĄčüčéčā, ą║ąŠč鹊čĆąŠąĄ ą╝ąŠąČąĄčé ą┐ąŠčÅą▓ąĖčéčīčüčÅ ą▓ ą║čŹčłąĄ. ąóą░ą║ąČąĄ čŹč鹊 ąŠą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą║ą░ą║ ą║čŹčł 1-way associative. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. [4]. ąØą░ čĆąĖčüčāąĮą║ąĄ ąĮąĖąČąĄ ą┐ąŠą║ą░ąĘą░ąĮ 1-way ą░čüčüąŠčåąĖą░čéąĖą▓ąĮčŗą╣ ą║čŹčł.
ąōčĆčÅąĘąĮčŗą╣ ąĖą╗ąĖ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮčŗą╣ (dirty or modified). ąæąĖčé čüąŠčüč鹊čÅąĮąĖčÅ, čüąŠčģčĆą░ąĮąĄąĮąĮčŗą╣ ą▓ą╝ąĄčüč鹥 čü čé菹│ąŠą╝, ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčēąĖą╣, ą▒čŗą╗ąĖ ą╗ąĖ ą┤ą░ąĮąĮčŗąĄ ą▓ čüčéčĆąŠą║ąĄ ą║čŹčłą░ ąĖąĘą╝ąĄąĮąĄąĮčŗ, ą║ąŠą│ą┤ą░ ąŠąĮąĖ ą▒čŗą╗ąĖ čüą║ąŠą┐ąĖčĆąŠą▓ą░ąĮčŗ ąĖąĘ ąĖčüčģąŠą┤ąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ ąĖ, čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąŠą▒ąĮąŠą▓ą╗ąĄąĮčŗ ą▓ ąĖčüčģąŠą┤ąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ.
ąŁą║čüą║ą╗čĹʹĖą▓ąĮčŗą╣, čćąĖčüčéčŗą╣ (exclusive, clean). ąĪąŠčüč鹊čÅąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░, ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčēąĄąĄ, čćč鹊 čüčéčĆąŠą║ą░ ą║čŹčłą░ ą┤ąŠčüč鹊ą▓ąĄčĆąĮą░, ąĖ ą┤ą░ąĮąĮčŗąĄ ą▓ ąĮąĄą╣ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčé ąĖčüčģąŠą┤ąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ. ąöą░ąĮąĮčŗąĄ ą▓ čćąĖčüč鹊ą╝ ą║čŹčłąĄ ąĮąĄ ąĮčāąČą┤ą░čÄčéčüčÅ ą▓ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ čü ąĖčüčģąŠą┤ąĮąŠą╣ ą┐ą░ą╝čÅčéčīčÄ ą┤ąŠ ąĖčģ ąĘą░ą╝ąĄąĮčŗ.
ą¤ąŠą╗ąĮąŠčüčéčīčÄ ą░čüčüąŠčåąĖą░čéąĖą▓ąĮčŗą╣ (fully associative). ąÉčĆčģąĖč鹥ą║čéčāčĆą░ ą║čŹčłą░, ą▓ ą║ąŠč鹊čĆąŠą╣ ą║ą░ąČą┤ą░čÅ čüčéčĆąŠą║ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī čĆą░ąĘą╝ąĄčēąĄąĮą░ ą▓ ą╗čÄą▒ąŠą╝ ą╝ąĄčüč鹥 ą║čŹčłą░. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. [4]. ąØą░ čĆąĖčüčāąĮą║ąĄ ąĮąĖąČąĄ ą┐ąŠą║ą░ąĘą░ąĮ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą░čüčüąŠčåąĖą░čéąĖą▓ąĮčŗą╣ ą║čŹčł.
ąśąĮą┤ąĄą║čü . ą¦ą░čüčéčī ą░ą┤čĆąĄčüą░, ą║ąŠč鹊čĆą░čÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą▓čŗą▒ąŠčĆą░ 菹╗ąĄą╝ąĄąĮčéą░ ą╝ą░čüčüąĖą▓ą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ąĖąĮą┤ąĄą║čü čüčéčĆąŠą║ąĖ ą║čŹčłą░).
ąØąĄą┤ąŠą┐čāčüčéąĖą╝ą░čÅ, ąĮąĄ ą┤ąŠčüč鹊ą▓ąĄčĆąĮą░čÅ (invalid). ą×ą┐ąĖčüčŗą▓ą░ąĄčé čüąŠčüč鹊čÅąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░. ąÜąŠą│ą┤ą░ čüčéčĆąŠą║ą░ ą║čŹčłą░ ąĮąĄ ą┤ąŠčüč鹊ą▓ąĄčĆąĮą░, ąĮąĄ ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ čüąŠą▓ą┐ą░ą┤ąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ ą║čŹčłą░.
ąÉą╗ą│ąŠčĆąĖčéą╝ ą┐ąŠčüą╗ąĄą┤ąĮąĄą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĮąŠą│ąŠ (least recently used, LRU). ąÉą╗ą│ąŠčĆąĖčéą╝ ąĘą░ą╝ąĄąĮčŗ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą▓ ą║čŹčłąĄ, ą▓ ą║ąŠč鹊čĆąŠą╝ ą▒čāą┤čāčé ąĘą░ą╝ąĄąĮąĄąĮčŗ čüčéčĆąŠą║ąĖ, ą║ąŠč鹊čĆčŗąĄ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ąĖčüčī ą┤ąŠą╗čīčłąĄ ą▓čüąĄą│ąŠ.
ą¤ą░ą╝čÅčéčī Level 1 (L1) . ąĪą░ą╝ą░čÅ ą▒čŗčüčéčĆą░čÅ ą┐ą░ą╝čÅčéčī, ą║ ą║ąŠč鹊čĆąŠą╣ ą╝ąŠąČąĄčé ąĮą░ą┐čĆčÅą╝čāčÄ ąŠą▒čĆą░čéąĖčéčīčüčÅ čÅą┤čĆąŠ ą▒ąĄąĘ ą▓ą╝ąĄčłą░č鹥ą╗čīčüčéą▓ą░ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ą┐ąŠą┤čüąĖčüč鹥ą╝ ą┐ą░ą╝čÅčéąĖ (ąŠčüčāčēąĄčüčéą▓ą╗čÅčÄčēąĖčģ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÄ, ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖą╗ąĖ čüąŠą│ą╗ą░čüąŠą▓ą░ąĮąĖąĄ ą▓čĆąĄą╝ąĄąĮąĖ ą┤ąŠčüčéčāą┐ą░).
little endian . ąĪčéą░ąĮą┤ą░čĆčéąĮčŗą╣ č乊čĆą╝ą░čé čģčĆą░ąĮąĄąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin. ąĪą╗ąŠą▓ą░ ąĖ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĖ čüą╗ąŠą▓ čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ ą▓ ą┐ą░ą╝čÅčéąĖ (ąĖ čĆąĄą│ąĖčüčéčĆą░čģ) čéą░ą║, čćč鹊 čüą░ą╝čŗą╣ ą╝ą╗ą░ą┤čłąĖą╣ ą┐ąŠ ąĘąĮą░čćąĖą╝ąŠčüčéąĖ ą▒ą░ą╣čé ąĖą╝ąĄąĄčé čüą░ą╝čŗą╣ ą╝ąĄąĮčīčłąĖą╣ ą░ą┤čĆąĄčü ą┐ąŠ ąŠčéąĮąŠčłąĄąĮąĖčÄ ą║ ą┤čĆčāą│ąĖą╝ ą▒ą░ą╣čéą░ą╝ ą▓ čüą╗ąŠą▓ąĄ (ąĖą╗ąĖ ą┐ąŠą╗ąŠą▓ąĖąĮą║ąĄ čüą╗ąŠą▓ą░), ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ čüą░ą╝čŗą╣ ąĘąĮą░čćąĖą╝čŗą╣ ą▒ą░ą╣čé ąĖą╝ąĄąĄčé čüą░ą╝čŗą╣ ą▒ąŠą╗čīčłąŠą╣ ą░ą┤čĆąĄčü ą┐ą░ą╝čÅčéąĖ čģčĆą░ąĮąĄąĮąĖčÅ.
ą¤ąŠą╗ąĖčéąĖą║ą░ ąĘą░ą╝ąĄąĮčŗ (replacement policy). ążčāąĮą║čåąĖčÅ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ą░čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą╝, čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī čüčéčĆąŠą║čā ą┤ą╗čÅ ąĘą░ą╝ąĄąĮčŗ ą┐čĆąĖ ą┐čĆąŠą╝ą░čģąĄ ą║čŹčłą░. ą¦ą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą░ą╗ą│ąŠčĆąĖčéą╝ LRU.
ąØą░ą▒ąŠčĆ (set). ąōčĆčāą┐ą┐ą░ ąĖąĘ N čüčéčĆąŠą║ ą║čŹčłą░ ą▓ ą║ą░ąĮą░ą╗ą░čģ N-ą║ą░ąĮą░ą╗čīąĮąŠą│ąŠ ą║čŹčłą░, ą▓čŗą▒čĆą░ąĮąĮą░čÅ ą┐ąŠ ą┐ąŠą╗čÄ ąĖąĮą┤ąĄą║čü INDEX ą░ą┤čĆąĄčüą░ (čüą╝. čĆąĖčü. 6-5).
ąÉčüčüąŠčåąĖą░čéąĖą▓ąĮčŗą╣ ąĮą░ą▒ąŠčĆ (set associative). ąÉčĆčģąĖč鹥ą║čéčāčĆą░ ą║čŹčłą░, ą║ąŠč鹊čĆą░čÅ ąŠą│čĆą░ąĮąĖčćąĖą▓ą░ąĄčé čĆą░ąĘą╝ąĄčēąĄąĮąĖąĄ čüčéčĆąŠą║ ą║čŹčłą░ ą║ąŠą╗ąĖč湥čüčéą▓ąŠą╝ ąĮą░ą▒ąŠčĆąŠą▓ (ąĖą╗ąĖ ą║ą░ąĮą░ą╗ąŠą▓).
ąó菹│ (tag). ąĪčéą░čĆčłąĖąĄ ą▒ąĖčéčŗ ą░ą┤čĆąĄčüą░, čüąŠčģčĆą░ąĮąĄąĮąĮčŗąĄ ą▓ą╝ąĄčüč鹥 čü ą║čŹčłąĖčĆąŠą▓ą░ąĮąĮąŠą╣ čüčéčĆąŠą║ąŠą╣ ą┤ą░ąĮąĮčŗčģ, čćč鹊ą▒čŗ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆąŠą▓ą░čéčī ąŠčéą┤ąĄą╗čīąĮčŗą╣ ą░ą┤čĆąĄčü ąĖčüč鹊čćąĮąĖą║ą░ ą▓ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅčÄčé ą║čŹčłąĖčĆąŠą▓ą░ąĮąĮčāčÄ čüčéčĆąŠą║čā.
ąöąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéčī (valid). ąæąĖčé čüąŠčüč鹊čÅąĮąĖčÅ, čüąŠčģčĆą░ąĮčÅąĄą╝čŗą╣ ą▓ą╝ąĄčüč鹥 čü čé菹│ąŠą╝, ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčēąĖą╣, čćč鹊 čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╣ čé菹│ąĖ ą┤ą░ąĮąĮčŗąĄ čÅą▓ą╗čÅčÄčéčüčÅ č鹥ą║čāčēąĖą╝ąĖ ąĖ ą║ąŠčĆčĆąĄą║čéąĮčŗą╝ąĖ, ąĖ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆąĄąĮąĖčÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ.
ą¢ąĄčĆčéą▓ą░ (victim). ąōčĆčÅąĘąĮą░čÅ čüčéčĆąŠą║ą░ ą║čŹčłą░, ą║ąŠč鹊čĆą░čÅ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ąĘą░ą┐ąĖčüą░ąĮą░ ą▓ ą╝ąĄą┤ą╗ąĄąĮąĮčāčÄ ą┐ą░ą╝čÅčéčī ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ąĄčæ ą╝ąŠąČąĮąŠ ąĘą░ą╝ąĄąĮąĖčéčī ąĮą░ čüą▓ąŠą▒ąŠą┤ąĮąŠąĄ ą╝ąĄčüč鹊 ą┤ą╗čÅ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ą┐ąŠą┤ ą┤čĆčāą│ąĖąĄ ą┤ą░ąĮąĮčŗąĄ.
ąÜą░ąĮą░ą╗ (Way). ą£ą░čüčüąĖą▓ 菹╗ąĄą╝ąĄąĮč鹊ą▓ čģčĆą░ąĮąĄąĮąĖčÅ čüčéčĆąŠą║ ą▓ N-ą║ą░ąĮą░ą╗čīąĮąŠą╝ ą║čŹčłąĄ (čüą╝. čĆąĖčü. 6-5).
ą×ą▒čĆą░čéąĮą░čÅ ąĘą░ą┐ąĖčüčī (write back). ą¤ąŠą╗ąĖčéąĖą║ą░ ąĘą░ą┐ąĖčüąĖ ą║čŹčłą░, čéą░ą║ąČąĄ ąĖąĘą▓ąĄčüčéąĮą░čÅ ą║ą░ą║ ąŠą▒čĆą░čéąĮąŠąĄ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ (copyback). ąŚą░ą┐ąĖčüčŗą▓ą░ąĄą╝čŗąĄ ą┤ą░ąĮąĮčŗąĄ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ č鹊ą╗čīą║ąŠ ą▓ čüčéčĆąŠą║čā ą║čŹčłą░. ą£ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮą░čÅ čüčéčĆąŠą║ą░ ą║čŹčłą░ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą▓ ąĖčüčģąŠą┤ąĮčāčÄ ą┐ą░ą╝čÅčéčī č鹊ą╗čīą║ąŠ ą║ąŠą│ą┤ą░ ąŠąĮą░ ą▒čŗą╗ą░ ąĘą░ą╝ąĄąĮąĄąĮą░. ąĪčéčĆąŠą║ąĖ ą║čŹčłą░ ą▓čŗą┤ąĄą╗čÅčÄčéčüčÅ ą║ą░ą║ ą┤ą╗čÅ čćč鹥ąĮąĖą╣, čéą░ą║ ąĖ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĄą╣.
ąĪą║ą▓ąŠąĘąĮą░čÅ ąĘą░ą┐ąĖčüčī (write through). ą¤ąŠą╗ąĖčéąĖą║ą░ ą║čŹčłą░, ąĖąĘą▓ąĄčüčéąĮą░čÅ čéą░ą║ąČąĄ ą║ą░ą║ ą┐čĆčÅą╝ąŠąĄ čüąŠčģčĆą░ąĮąĄąĮąĖąĄ (store through). ąöą░ąĮąĮčŗąĄ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ ą║ą░ą║ ą▓ čüčéčĆąŠą║čā ą║čŹčłą░, čéą░ą║ ąĖ ą▓ ąĖčüčģąŠą┤ąĮčāčÄ ą┐ą░ą╝čÅčéčī. ą£ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮą░čÅ čüčéčĆąŠą║ą░ ą║čŹčłą░ ąĮąĄ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą▓ ąĖčüčģąŠą┤ąĮčāčÄ ą┐ą░ą╝čÅčéčī, ą║ąŠą│ą┤ą░ ąŠąĮąĖ ąĘą░ą╝ąĄąĮčÅąĄčéčüčÅ. ąĪčéčĆąŠą║ąĖ ą║čŹčłą░ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą▓čŗą┤ąĄą╗ąĄąĮčŗ ą┤ą╗čÅ čćč鹥ąĮąĖą╣, ąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┤ąĄą╗ąĄąĮčŗ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĄą╣ (ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čĆąĄąČąĖą╝ą░).
ąĀąĄą│ąĖčüčéčĆčŗ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin, ąŠč鹊ą▒čĆą░ąČąĄąĮąĮčŗąĄ ąĮą░ ą░ą┤čĆąĄčüąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ą┐ą░ą╝čÅčéąĖ (memory-mapped registers, MMR) ąĮą░čģąŠą┤čÅčéčüčÅ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ ą░ą┤čĆąĄčüąŠą▓ 0xFFE00000 .. 0xFFFFFFFF.
ąÜąŠ ą▓čüąĄą╝ MMR čÅą┤čĆą░ ą┤ąŠčüčéčāą┐ ą┤ąŠą╗ąČąĄąĮ ąŠčüčāčēąĄčüčéą▓ą╗čÅčéčīčüčÅ ą║ą░ą║ 32-ą▒ąĖčéąĮąŠąĄ čćč鹥ąĮąĖąĄ ąĖą╗ąĖ ąĘą░ą┐ąĖčüčī.
ąÆ čŹč鹊ą╝ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮčŗ ą░ą┤čĆąĄčüą░ MMR čÅą┤čĆą░ ąĖčģ ąĖą╝ąĄąĮą░. ą¦č鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ą▒ąŠą╗čīčłąĄ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą┐čĆąŠ MMR, čüą╝. čüč鹊ą╗ą▒ąĄčå "ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą▓ čĆą░ąĘą┤ąĄą╗ąĄ".
ąĀąĄą│ąĖčüčéčĆčŗ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ ą┐ą░ą╝čÅčéąĖ ą┤ą░ąĮąĮčŗčģ L1 (0xFFE00000 ŌĆō 0xFFE00404)
ąóą░ą▒ą╗ąĖčåą░ B-1. ąĀąĄą│ąĖčüčéčĆčŗ L1 Data Memory Controller.
ąÉą┤čĆąĄčü MMR ąśą╝čÅ čĆąĄą│ąĖčüčéčĆą░ ąĪą╝. čüąĄą║čåąĖčÄ
0xFFE0 0004
DMEM_CONTROL
ąĀąĄą│ąĖčüčéčĆ DMEM_CONTROL
0xFFE0 0008
DCPLB_STATUS
ąĀąĄą│ąĖčüčéčĆčŗ DCPLB_STATUS ąĖ ICPLB_STATUS
0xFFE0 000C
DCPLB_FAULT_ADDR
ąĀąĄą│ąĖčüčéčĆčŗ DCPLB_FAULT_ADDR ąĖ ICPLB_FAULT_ADDR
0xFFE0 0100
DCPLB_ADDR0
ąĀąĄą│ąĖčüčéčĆčŗ DCPLB_ADDRx
0xFFE0 0104
DCPLB_ADDR1
0xFFE0 0108
DCPLB_ADDR2
0xFFE0 010C
DCPLB_ADDR3
0xFFE0 0110
DCPLB_ADDR4
0xFFE0 0114
DCPLB_ADDR5
0xFFE0 0118
DCPLB_ADDR6
0xFFE0 011C
DCPLB_ADDR7
0xFFE0 0120
DCPLB_ADDR8
0xFFE0 0124
DCPLB_ADDR9
0xFFE0 0128
DCPLB_ADDR10
0xFFE0 012C
DCPLB_ADDR11
0xFFE0 0130
DCPLB_ADDR12
0xFFE0 0134
DCPLB_ADDR13
0xFFE0 0138
DCPLB_ADDR14
0xFFE0 013C
DCPLB_ADDR15
0xFFE0 0200
DCPLB_DATA0
ąĀąĄą│ąĖčüčéčĆčŗ DCPLB_DATAx
0xFFE0 0204
DCPLB_DATA1
0xFFE0 0208
DCPLB_DATA2
0xFFE0 020C
DCPLB_DATA3
0xFFE0 0210
DCPLB_DATA4
0xFFE0 0214
DCPLB_DATA5
0xFFE0 0218
DCPLB_DATA6
0xFFE0 021C
DCPLB_DATA7
0xFFE0 0220
DCPLB_DATA8
0xFFE0 0224
DCPLB_DATA9
0xFFE0 0228
DCPLB_DATA10
0xFFE0 022C
DCPLB_DATA11
0xFFE0 0230
DCPLB_DATA12
0xFFE0 0234
DCPLB_DATA13
0xFFE0 0238
DCPLB_DATA14
0xFFE0 023C
DCPLB_DATA15
0xFFE0 0300
DTEST_COMMAND
ąĀąĄą│ąĖčüčéčĆ DTEST_COMMAND
0xFFE0 0400
DTEST_DATA0
ąĀąĄą│ąĖčüčéčĆ DTEST_DATA0
0xFFE0 0404
DTEST_DATA1
ąĀąĄą│ąĖčüčéčĆ DTEST_DATA1
ąĀąĄą│ąĖčüčéčĆčŗ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ L1 (0xFFE01004 ŌĆō 0xFFE01404)
ąóą░ą▒ą╗ąĖčåą░ B-2. ąĀąĄą│ąĖčüčéčĆčŗ L1 Instruction Memory Controller.
ąÉą┤čĆąĄčü MMR ąśą╝čÅ čĆąĄą│ąĖčüčéčĆą░ ąĪą╝. čüąĄą║čåąĖčÄ
0xFFE0 1004
IMEM_CONTROL
ąĀąĄą│ąĖčüčéčĆ IMEM_CONTROL
0xFFE0 1008
ICPLB_STATUS
ąĀąĄą│ąĖčüčéčĆčŗ DCPLB_STATUS ąĖ ICPLB_STATUS
0xFFE0 100C
ICPLB_FAULT_ADDR
ąĀąĄą│ąĖčüčéčĆčŗ DCPLB_FAULT_ADDR ąĖ ICPLB_FAULT_ADDR
0xFFE0 1100
ICPLB_ADDR0
ąĀąĄą│ąĖčüčéčĆčŗ ICPLB_ADDRx
0xFFE0 1104
ICPLB_ADDR1
0xFFE0 1108
ICPLB_ADDR2
0xFFE0 110C
ICPLB_ADDR3
0xFFE0 1110
ICPLB_ADDR4
0xFFE0 1114
ICPLB_ADDR5
0xFFE0 1118
ICPLB_ADDR6
0xFFE0 111C
ICPLB_ADDR7
0xFFE0 1120
ICPLB_ADDR8
0xFFE0 1124
ICPLB_ADDR9
0xFFE0 1128
ICPLB_ADDR10
0xFFE0 112C
ICPLB_ADDR11
0xFFE0 1130
ICPLB_ADDR12
0xFFE0 1134
ICPLB_ADDR13
0xFFE0 1138
ICPLB_ADDR14
0xFFE0 113C
ICPLB_ADDR15
0xFFE0 1200
ICPLB_DATA0
ąĀąĄą│ąĖčüčéčĆčŗ ICPLB_DATAx
0xFFE0 1204
ICPLB_DATA1
0xFFE0 1208
ICPLB_DATA2
0xFFE0 120C
ICPLB_DATA3
0xFFE0 1210
ICPLB_DATA4
0xFFE0 1214
ICPLB_DATA5
0xFFE0 1218
ICPLB_DATA6
0xFFE0 121C
ICPLB_DATA7
0xFFE0 1220
ICPLB_DATA8
0xFFE0 1224
ICPLB_DATA9
0xFFE0 1228
ICPLB_DATA10
0xFFE0 122C
ICPLB_DATA11
0xFFE0 1230
ICPLB_DATA12
0xFFE0 1234
ICPLB_DATA13
0xFFE0 1238
ICPLB_DATA14
0xFFE0 123C
ICPLB_DATA15
0xFFE0 1300
ITEST_COMMAND
ąĀąĄą│ąĖčüčéčĆ ITEST_COMMAND
0xFFE0 1400
ITEST_DATA0
ąĀąĄą│ąĖčüčéčĆ ITEST_DATA0
0xFFE0 1404
ITEST_DATA1
ąĀąĄą│ąĖčüčéčĆ ITEST_DATA1
ąĀąĄą│ąĖčüčéčĆčŗ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ (0xFFE02000 ŌĆō 0xFFE02110)
ąóą░ą▒ą╗ąĖčåą░ B-3. ąĀąĄą│ąĖčüčéčĆčŗ Interrupt Controller.
ąÉą┤čĆąĄčü MMR ąśą╝čÅ čĆąĄą│ąĖčüčéčĆą░ ąĪą╝. čüąĄą║čåąĖčÄ
0xFFE0 2000
EVT0 (EMU)
ąóą░ą▒ą╗ąĖčåą░ ą▓ąĄą║č鹊čĆąŠą▓ čüąŠą▒čŗčéąĖą╣ čÅą┤čĆą░ [3]
0xFFE0 2004
EVT1 (RST)
0xFFE0 2008
EVT2 (NMI)
0xFFE0 200C
EVT3 (EVX)
0xFFE0 2010
EVT4
0xFFE0 2014
EVT5 (IVHW)
0xFFE0 2018
EVT6 (TMR)
0xFFE0 201C
EVT7 (IVG7)
0xFFE0 2020
EVT8 (IVG8)
0xFFE0 2024
EVT9 (IVG9)
0xFFE0 2028
EVT10 (IVG10)
0xFFE0 202C
EVT11 (IVG11)
0xFFE0 2030
EVT12 (IVG12)
0xFFE0 2034
EVT13 (IVG13)
0xFFE0 2038
EVT14 (IVG14)
0xFFE0 203C
EVT15 (IVG15)
0xFFE0 2104
IMASK
ąĀąĄą│ąĖčüčéčĆ IMASK [3]
0xFFE0 2108
IPEND
ąĀąĄą│ąĖčüčéčĆ IPEND [3]
0xFFE0 210C
ILAT
ąĀąĄą│ąĖčüčéčĆ ILAT [3]
0xFFE0 2110
IPRIO
ąĀąĄą│ąĖčüčéčĆ IPRIO ąĖ ą│ą╗čāą▒ąĖąĮą░ ą▒čāč乥čĆą░ ąĘą░ą┐ąĖčüąĖ
ąĀąĄą│ąĖčüčéčĆčŗ Debug, MP ąĖ Emulation Unit (0xFFE05000 ŌĆō 0xFFE05008)
ąóą░ą▒ą╗ąĖčåą░ B-4. ąĀąĄą│ąĖčüčéčĆčŗ Debug ąĖ Emulation Unit.
ąÉą┤čĆąĄčü MMR ąśą╝čÅ čĆąĄą│ąĖčüčéčĆą░ ąĪą╝. čüąĄą║čåąĖčÄ
0xFFE0 5000
DSPID
DSPID Register [5]
ąĀąĄą│ąĖčüčéčĆčŗ ą▒ą╗ąŠą║ą░ čéčĆą░čüčüąĖčĆąŠą▓ą║ąĖ (0xFFE06000 ŌĆō 0xFFE06100)
ąóą░ą▒ą╗ąĖčåą░ B-5. ąĀąĄą│ąĖčüčéčĆčŗ Trace Unit.
ąÉą┤čĆąĄčü MMR ąśą╝čÅ čĆąĄą│ąĖčüčéčĆą░ ąĪą╝. čüąĄą║čåąĖčÄ
0xFFE0 6000
TBUFCTL
TBUFCTL Register [5]
0xFFE0 6004
TBUFSTAT
TBUFSTAT Register [5]
0xFFE0 6100
TBUF
TBUF Register [5]
ąĀąĄą│ąĖčüčéčĆčŗ č鹊č湥ą║ ąŠčüčéą░ąĮąŠą▓ą░ ąĖ ą┐čāčéąĖ (0xFFE07000 ŌĆō 0xFFE07200)
ąóą░ą▒ą╗ąĖčåą░ B-6. ąĀąĄą│ąĖčüčéčĆčŗ Watchpoint ąĖ Patch.
ąÉą┤čĆąĄčü MMR ąśą╝čÅ čĆąĄą│ąĖčüčéčĆą░ ąĪą╝. čüąĄą║čåąĖčÄ
0xFFE0 7000
WPIACTL
WPIACTL Register [5]
0xFFE0 7040
WPIA0
WPIAx Registers [5]
0xFFE0 7044
WPIA1
0xFFE0 7048
WPIA2
0xFFE0 704C
WPIA3
0xFFE0 7050
WPIA4
0xFFE0 7054
WPIA5
0xFFE0 7080
WPIACNT0
WPIACNTx Registers [5]
0xFFE0 7084
WPIACNT1
0xFFE0 7088
WPIACNT2
0xFFE0 708C
WPIACNT3
0xFFE0 7090
WPIACNT4
0xFFE0 7094
WPIACNT5
0xFFE0 7100
WPDACTL
WPDACTL Register [5]
0xFFE0 7140
WPDA0
WPDAx Registers [5]
0xFFE0 7144
WPDA1
0xFFE0 7180
WPDACNT0
WPDACNTx Registers [5]
0xFFE0 7184
WPDACNT1
0xFFE0 7200
WPSTAT
WPSTAT Register [5]
ąĀąĄą│ąĖčüčéčĆčŗ ą╝ąŠąĮąĖč鹊čĆą░ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖčÅ (0xFFE08000 ŌĆō 0xFFE08104)
ąóą░ą▒ą╗ąĖčåą░ B-7. ąĀąĄą│ąĖčüčéčĆčŗ Performance Monitor.
ąÉą┤čĆąĄčü MMR ąśą╝čÅ čĆąĄą│ąĖčüčéčĆą░ ąĪą╝. čüąĄą║čåąĖčÄ
0xFFE0 8000
PFCTL
PFCTL Register [5]
0xFFE0 8100
PFCNTR0
PFCNTRx Register [5]
0xFFE0 8104
PFCNTR1
[ąĪčüčŗą╗ą║ąĖ ]
1 . ADSP-BF538/ADSP-BF538F Blackfin┬« Processor Hardware Reference site:analog.com .2 . Blackfin ADSP-BF538 .3 . ADSP-BF538: ąŠą▒čĆą░ą▒ąŠčéą║ą░ čüąŠą▒čŗčéąĖą╣ (ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ, ąĖčüą║ą╗čÄč湥ąĮąĖčÅ) .4 . ąÜčŹčł ą┐čĆąŠčåąĄčüčüąŠčĆą░ site:wikipedia.org .5 . Blackfin┬« Processor Programming Reference site:analog.com .6 . Blackfin Boot ROM .