|
ą£ąĮąŠą│ąĖąĄ ą┤čāą╝ą░čÄčé, čćč鹊 ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░čéčī ą┐ąŠą┤ Blackfin čéčĆčāą┤ąĮąŠ, ąĮąŠ ąĮą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ čŹč鹊 ąĮąĄ čéą░ą║. ą¤čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░čéčī ą╗ąĄą│ą║ąŠ, ąĮąŠ čéčĆčāą┤ąĮąŠ ą┐ąŠč鹊ą╝ ąĮą░čģąŠą┤ąĖčéčī ąŠčłąĖą▒ą║ąĖ. ąŁč鹊čé ą┤ąŠą║čāą╝ąĄąĮčé ąŠą┐ąĖčüčŗą▓ą░ąĄčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ą┐ąŠ ąŠčéą╗ą░ą┤ą║ąĄ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin┬« ąĖ čüčĆąĄą┤čüčéą▓ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ VisualDSP++┬« (ą┐ąĄčĆąĄą▓ąŠą┤ ą┤ąŠą║čāą╝ąĄąĮčéą░ EE-307 ąŠčé ą║ąŠą╝ą┐ą░ąĮąĖąĖ Analog Devices [1]).
[ą¤ąŠą┤čüą║ą░ąĘą║ąĖ ąĖ čüąŠą▓ąĄčéčŗ ą┤ą╗čÅ ąŠčéą╗ą░ą┤ą║ąĖ]
ąæčāą┤čāčé čĆą░čüčüą╝ąŠčéčĆąĄąĮčŗ čüą╗ąĄą┤čāčÄčēąĖąĄ ą▓ąŠą┐čĆąŠčüčŗ:
ŌĆó ą×čéą╗ąĖčćąĖčÅ ąĘą░ą┐čāčüą║ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą▓ 菹╝čāą╗čÅč鹊čĆąĄ ąĖ ąĘą░ą┐čāčüą║ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ č湥čĆąĄąĘ ąĘą░ą│čĆčāąĘą║čā (booting). ą×čüąŠą▒ąĄąĮąĮąŠ čŹč鹊 ąŠčéąĮąŠčüąĖčéčüčÅ ą║ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ ą┐ą░ą╝čÅčéąĖ SDRAM.
ŌĆó ąĀą░ąĘą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ čÅą┤čĆą░ B ą┤ą╗čÅ ą┤ą▓čāčģčÅą┤ąĄčĆąĮčŗčģ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓. ąŁą╝čāą╗čÅč鹊čĆ ą┤ąĄą╗ą░ąĄčé čŹč鹊 ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ; ąŠą┤ąĮą░ą║ąŠ, ą║ąŠą│ą┤ą░ ą║ąŠą┤ ąĘą░ą│čĆčāąČą░ąĄčéčüčÅ, čÅą┤čĆąŠ B ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čĆą░ąĘą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąŠ ą▓čĆčāčćąĮčāčÄ.
ŌĆó ąÉą┐ą┐ą░čĆą░čéąĮčŗąĄ ąŠčłąĖą▒ą║ąĖ ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
ŌĆó ążčāąĮą║čåąĖąĖ ąĖ ąĖąĮčüčéčĆčāą╝ąĄąĮčéčŗ ąŠčéą╗ą░ą┤ą║ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin, ą▓ą║ą╗čÄčćą░čÅ:
- ąæčāč乥čĆ čéčĆą░čüčüąĖčĆąŠą▓ą║ąĖ.
- ąóąŠčćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░ (ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗąĄ, ą▓čüčéčĆąŠąĄąĮąĮčŗąĄ ąĖ ą░ą┐ą┐ą░čĆą░čéąĮčŗąĄ).
- ą×čéą╗ą░ą┤ą║ą░ VDK (VDK Status window ąĖ VDK State History window).
ŌĆó ą¤čĆąŠą▒ą╗ąĄą╝čŗ čü ąŠčéą╗ą░ą┤ą║ąŠą╣, ą║ąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮąŠ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĄ.
ŌĆó ą¤čĆąĄčĆčŗą▓ą░ąĮąĖčÅ.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: čŹč鹊čé EE-Note ąĮąĄ ą║ą░čüą░ąĄčéčüčÅ ą┐čĆąŠą▒ą╗ąĄą╝, čüą▓čÅąĘą░ąĮąĮčŗčģ čü ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗą╝ąĖ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ąĖ.
ą¤ąŠčüą║ąŠą╗čīą║čā ąŠčéą╗ą░ą┤čćąĖą║ JTAG čĆą░ą▒ąŠčéą░ąĄčé ą┤ąŠą▓ąŠą╗čīąĮąŠ ą╝ąĄą┤ą╗ąĄąĮąĮąŠ, č鹊 ą┤ą╗čÅ čāčüą║ąŠčĆąĄąĮąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą╗čāčćčłąĄ ą┐ąŠčüč鹊čÅąĮąĮąŠ ą┤ąĄčƹȹ░čéčī čüąĄčüčüąĖčÄ ąŠčéą╗ą░ą┤čćąĖą║ą░ ą░ą║čéąĖą▓ąĮąŠą╣, ą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║ąĖ čĆąĄą┤ą░ą║čéąĖčĆčāčÅ ą║ąŠą┤ ąĖ čüčĆą░ąĘčā ąĘą░ą┐čāčüą║ą░čÅ ąĄą│ąŠ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖčÄ ąĖ ąŠčéą╗ą░ą┤ą║čā ą║ą╗ą░ą▓ąĖčłąĄą╣ F7. ąóą░ą║ąČąĄ čüčéą░čĆą░ą╣č鹥čüčī ąŠą▒čŖąĄą╝ąĮčŗą╣ ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ čāąČąĄ ąŠčéą╗ą░ąČąĄąĮ ąĖ ą┐čĆąŠą▓ąĄčĆąĄąĮ (ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ čĆą░ą▒ąŠčéčŗ čü ą│čĆą░čäąĖą║ąŠą╣) ą┐ąŠą╝ąĄčüčéąĖčéčī ą▓ ąĘą░čĆą░ąĮąĄąĄ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ *.dlb. ąŁč鹊 ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠ 菹║ąŠąĮąŠą╝ąĖčé ą▓čĆąĄą╝čÅ ąĮą░ ą┐ąĄčĆąĄą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ą║ąŠą┤ą░.
[ą×čéą╗ąĖčćąĖčÅ čŹą╝čāą╗čÅčåąĖąĖ ąŠčé čüą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮąŠą╣ ąĘą░ą│čĆčāąĘą║ąĖ]
ą¤čĆąŠą│čĆą░ą╝ą╝ąĮąŠąĄ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖąĄ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ 菹╝čāą╗čÅč鹊čĆą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčé čäą░ą╣ą╗čŗ .xml ą┤ą╗čÅ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖčÅ čĆąĄčüčāčĆčüąŠą▓, čéą░ą║ąĖčģ ą║ą░ą║ ą┐ą░čĆą░ą╝ąĄčéčĆčŗ ą▓čĆąĄą╝ąĄąĮąĖ SDRAM, ą║ ą┐čĆąĖą╝ąĄčĆčā ą┤ą╗čÅ ąŠčåąĄąĮąŠčćąĮąŠą╣ ą┐ą╗ą░čéčŗ čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ą░ EZ-KIT Lite┬«. ąŁč鹊 .xml čäą░ą╣ą╗čŗ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą▓čüąĄčģ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin, ą┤ą╗čÅ ą║ąŠč鹊čĆčŗčģ ąĄčüčéčī ąŠčåąĄąĮąŠčćąĮčŗąĄ ą┐ą╗ą░čéč乊čĆą╝čŗ (čé. ąĄ. čĆą░ą▒ąŠčćąĖąĄ čüąĖčüč鹥ą╝čŗ, ąĮą░ ą║ąŠč鹊čĆčŗčģ ą╝ąŠąČąĮąŠ ąĘą░ą┐čāčüčéąĖčéčī ą║ąŠą┤, ąĮą░ą┐čĆąĖą╝ąĄčĆ ą┐ą╗ą░čéčŗ EZKIT Lite), ą│ą┤ąĄ čüąŠąĘą┤ą░ąĮčŗ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą┤ą╗čÅ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ ąŠčüąĮąŠą▓ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┐čĆąĖ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖąĖ 菹╝čāą╗čÅč鹊čĆą░.
ąØąĖąČąĄ ą▓ ą║ą░č湥čüčéą▓ąĄ ą┐čĆąĖą╝ąĄčĆą░ ą┐čĆąĖą▓ąĄą┤ąĄąĮ ą║čāčüąŠą║ ąĖąĘ čäą░ą╣ą╗ą░ ADSP-BF537-proc.xml, ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĮąŠą│ąŠ ą┤ą╗čÅ Blackfin-ą┐čĆąŠčåąĄčüčüąŠčĆą░ ADSP-BF537:
< register-reset-definitions>
< register name="EBIU_SDRRC" resetvalue="0x03A0" core="Common" />
< register name="EBIU_SDBCTL" resetvalue="0x25" core="Common" />
< register name="EBIU_SDGCTL" resetvalue="0x0091998d" core="Common" />
< register name="EBIU_AMGCTL" resetvalue="0xff" core="Common" />
< /register-reset-definitions>
ąŁčéąĖą╝ čüą┐ąŠčüąŠą▒ąŠą╝ SDRAM ą▒čāą┤ąĄčé ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮą░ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ, ą║ąŠą│ą┤ą░ čĆą░ąĘčĆą░ą▒ą░čéčŗą▓ą░ąĄčéčüčÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ą┤ą╗čÅ ą┐ą╗ą░čéčŗ ADSP-BF537 EZ-KIT Lite, ąĖ ą┤ą╗čÅ ąĘą░ą┐čāčüą║ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗čüčÅ čŹą╝čāą╗čÅč鹊čĆ.
ą×ą┤ąĮą░ą║ąŠ, ą║ąŠą│ą┤ą░ ą║ąŠą┤ ą┐ąĄčĆąĄąĮąŠčüąĖčéčüčÅ ąĮą░ čüą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮąŠąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ (ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ą▒čāą┤ąĄčé ąĘą░ą│čĆčāąČą░čéčīčüčÅ ą▓ą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ ąĘą░ą┐ąĖčüčŗą▓ą░čéčīčüčÅ ą▓ ą┐ą░ą╝čÅčéčī ą┐čĆąŠčåąĄčüčüąŠčĆą░ 菹╝čāą╗čÅč鹊čĆąŠą╝), ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī čüą░ą╝ ą┤ąŠą╗ąČąĄąĮ ą┐ąŠąĘą░ą▒ąŠčéąĖčéčīčüčÅ ąŠ čĆą░ąĘčĆąĄčłąĄąĮąĖąĖ ą║ąŠąĮčéčĆąŠą╗ąĄčĆą░ SDRAM, ąĄčüą╗ąĖ ą▓ čüąĖčüč鹥ą╝ąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ SDRAM. ąŁč鹊 čĆąĄą░ą╗ąĖąĘčāąĄčéčüčÅ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖąĄą╝ čäą░ą╣ą╗ą░ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ ąĮą░ čüčéčĆą░ąĮąĖčåąĄ Loader ą┤ąĖą░ą╗ąŠą│ą░ Project Options, ą║ąŠą│ą┤ą░ čüąŠąĘą┤ą░ąĄčéčüčÅ čäą░ą╣ą╗ ą┤ą╗čÅ ąĘą░ą│čĆčāąĘčćąĖą║ą░. ą¤ąŠą┤čĆąŠą▒ąĮąŠčüčéąĖ čüą╝. ą▓ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąĄ ADSP-BF533 Blackfin Booting Process (EE-240)[2].
ąöčĆčāą│ąŠąĄ ąŠčéą╗ąĖčćąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ą╝ąŠąČąĄčé ą▓čŗąĘą▓ą░čéčī ą┐čĆąŠą▒ą╗ąĄą╝čŗ ą┐čĆąĖ ą┐ąĄčĆąĄąĮąŠčüąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĖąĘ čüąĄčüčüąĖąĖ 菹╝čāą╗čÅč鹊čĆą░ ą▓ čüą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮąŠ ąĘą░ą│čĆčāąČą░ąĄą╝čŗą╣ ą║ąŠą┤, čüą▓čÅąĘą░ąĮ čü ą┤ą▓čāčģčÅą┤ąĄčĆąĮčŗą╝ąĖ čüąĖčüč鹥ą╝ą░ą╝ąĖ ąĮą░ Blackfin ADSP-BF561. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠąĄ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖąĄ "čĆą░ąĘą▒ą╗ąŠą║ąĖčĆčāąĄčé" čÅą┤čĆąŠ B, ąĖ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĄą╝čā ąĘą░ą┐čāčüčéąĖčéčīčüčÅ čü ąĮą░čćą░ą╗ą░ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ L1. ąÜąŠą│ą┤ą░ ą┤ąŠą╗ąČąĮčŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ąŠą▒ą░ čÅą┤čĆą░, čÅą┤čĆąŠ B ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čĆą░ąĘą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąŠ čÅą┤čĆąŠą╝ A, čćč鹊 ą┤ąĄą╗ą░ąĄčéčüčÅ ąŠčćąĖčüčéą║ąŠą╣ ą▒ąĖčéą░ 5 ą▓ čĆąĄą│ąĖčüčéčĆąĄ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ čüą▒čĆąŠčüą░ čüąĖčüč鹥ą╝čŗ (system reset configuration register, SICA_SYSCR).
ąĢčēąĄ ąŠą┤ąĮą░ ą┐čĆąŠą▒ą╗ąĄą╝ą░, ą║ąŠč鹊čĆą░čÅ ąĖąĮąŠą│ą┤ą░ ą▓ąŠąĘąĮąĖą║ą░ąĄčé ą║ą░ą║ čĆąĄąĘčāą╗čīčéą░čé čĆą░ąĘą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĖčÅ čŹą╝čāą╗čÅč鹊čĆąŠą╝ čÅą┤čĆą░ B, čüą▓čÅąĘą░ąĮą░ čü ąĖąĘą╝ąĄąĮąĄąĮąĖąĄą╝ čĆą░ą▒ąŠčćąĖčģ čĆąĄąČąĖą╝ąŠą▓ ąĖą╗ąĖ čéą░ą║č鹊ą▓čŗčģ čćą░čüč鹊čé. ąÆ čćą░čüčéąĮąŠčüčéąĖ čÅą┤čĆąŠ B ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą▓ čüąŠčüč鹊čÅąĮąĖąĖ ąŠąČąĖą┤ą░ąĮąĖčÅ idle (ąĮąĄ ą┐čĆąŠčüč鹊 ąĮą░čģąŠą┤ąĖčéčīčüčÅ ą▓ č鹊čćą║ąĄ ąŠčüčéą░ąĮąŠą▓ą░), ą║ąŠą│ą┤ą░ ą┤ąĄą╗ą░čÄčéčüčÅ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą▓ PLL ąĖą╗ąĖ čĆąĄą│čāą╗čÅč鹊čĆąĄ ąĮą░ą┐čĆčÅąČąĄąĮąĖčÅ. ąŁč鹊 ą╝ąŠąČąĄčé ą┤ąŠčüčéą░ą▓ąĖčéčī ąĮąĄą┐čĆąĖčÅčéąĮąŠčüčéąĖ, ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ąŠą│ą┤ą░ č鹊čćą║ą░ ąŠčüčéą░ąĮąŠą▓ą░ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮą░ ą▓ čÅą┤čĆąĄ B, ąĖ ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ą╝ąĄąĮčÅąĄčé čćą░čüč鹊čéčā PLL, čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ čÅą┤čĆąĄ A. ąŻą▒ąĄą┤ąĖč鹥čüčī ą▓ č鹊ą╝, čćč鹊 ą▓čŗą┐ąŠą╗ąĮčÅčÄčēąĖą╣čüčÅ ą║ąŠą┤ ą┐ąŠą╝ąĄčēą░ąĄčé čÅą┤čĆąŠ B ą▓ čüąŠčüč鹊čÅąĮąĖąĄ idle ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ą▒čāą┤ąĄčé ąĖąĘą╝ąĄąĮąĄąĮą░ čćą░čüč鹊čéą░ PLL. ąŁč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī čüą┤ąĄą╗ą░ąĮąŠ čü ą┐ąŠą╝ąŠčēčīčÄ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ ąĖą╗ąĖ ą▓čŗą▓ąŠą┤ąŠą▓ GPIO.
[ą×čłąĖą▒ą║ąĖ ą░ą┐ą┐ą░čĆą░čéčāčĆčŗ ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗąĄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ]
ą×čłąĖą▒ą║ąĖ ą░ą┐ą┐ą░čĆą░čéčāčĆčŗ (hardware errors) ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗąĄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ (software exceptions) - ą┤ą▓ą░ čüą┐ąĄčåąĖčäąĖčćąĮčŗčģ čéąĖą┐ą░ čüąŠą▒čŗčéąĖą╣, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▓ąŠąĘąĮąĖą║ą░čéčī ą▓ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ Blackfin. ąÜą░ąČą┤ąŠąĄ ąĖąĘ čŹčéąĖčģ čüąŠą▒čŗčéąĖą╣ ąĖą╝ąĄąĄčé ąŠčéą┤ąĄą╗čīąĮčāčÄ ąĘą░ą┐ąĖčüčī ą▓ čéą░ą▒ą╗ąĖčåąĄ ą▓ąĄą║č鹊čĆąŠą▓ čüąŠą▒čŗčéąĖą╣ (event vector table, EVT). ąöą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ąĖąĘ čŹčéąĖčģ čüąŠą▒čŗčéąĖą╣ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮčŗ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ, ą┐čĆąĖč湥ą╝ čéą░ą║, čćč鹊ą▒čŗ ąŠąĮąĖ ą╝ąŠą│ą╗ąĖ ą▒čŗčéčī ą┐ąĄčĆąĄčģą▓ą░č湥ąĮčŗ ą╗čÄą▒čŗą╝ ąĖąĘ ą╝ąĄč鹊ą┤ąŠą▓ č鹊č湥ą║ ąŠčüčéą░ąĮąŠą▓ą░ (ą║ąŠč鹊čĆčŗąĄ ą▒čāą┤čāčé ąŠą┐ąĖčüą░ąĮčŗ ą┤ą░ą╗ąĄąĄ ą▓ čŹč鹊ą╝ ą┤ąŠą║čāą╝ąĄąĮč鹥). ąÆ čŹč鹊ą╣ č鹊čćą║ąĄ čüąŠčüč鹊čÅąĮąĖąĄ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠą░ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮąŠ, čćč鹊ą▒čŗ ą┐ąŠąĮčÅčéčī, ą▓ č湥ą╝ ą▒čŗą╗ą░ ą┐čĆąĖčćąĖąĮą░ ąŠčéą┤ąĄą╗čīąĮąŠą│ąŠ čüąŠą▒čŗčéąĖčÅ. ąÆ čĆąĄą│ąĖčüčéčĆąĄ čüąŠčüč鹊čÅąĮąĖčÅ čüąĄą║ą▓ąĄąĮčüąĄčĆą░ (sequencer status register, SEQSTAT) ąĄčüčéčī 2 ą┐ąŠą╗čÅ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ ą▒ąŠą╗čīčłąĄą│ąŠ ą┐ąŠąĮąĖą╝ą░ąĮąĖčÅ ą┐čĆąĖčćąĖąĮčŗ ąĮąĄą┤ąŠą┐čāčüčéąĖą╝ąŠą│ąŠ čüąŠą▒čŗčéąĖčÅ. ą¤ąŠą╗ąĄ HWERRCAUSE ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ čāčüą╗ąŠą▓ąĖčÅ, ą║ąŠč鹊čĆąŠąĄ ą┐čĆąĖą▓ąĄą╗ąŠ ą║ ą│ąĄąĮąĄčĆą░čåąĖąĖ ą░ą┐ą┐ą░čĆą░čéąĮąŠą╣ ąŠčłąĖą▒ą║ąĖ, ąĖ ą┐ąŠą╗ąĄ EXCAUSE ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ čāčüą╗ąŠą▓ąĖčÅ, ą║ąŠč鹊čĆąŠąĄ čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ą╗ąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ.
ąÉą┐ą┐ą░čĆą░čéąĮą░čÅ ąŠčłąĖą▒ą║ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮą░ čĆą░ąĘąĮčŗą╝ąĖ ą┐čĆąĖčćąĖąĮą░ą╝ąĖ, čéą░ą║ąĖą╝ąĖ ą║ą░ą║ ą┤ąŠčüčéčāą┐ ą║ MMR čü ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮčŗą╝ čĆą░ąĘą╝ąĄčĆąŠą╝ čüą╗ąŠą▓ą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ 16-ą▒ąĖčéąĮąŠą╝čā MMR ąŠą▒čĆą░čēą░čÄčéčüčÅ ą║ą░ą║ ą║ 32-ą▒ąĖčéąĮąŠą╝čā, ąĖą╗ąĖ ąĮą░ąŠą▒ąŠčĆąŠčé), ąĖą╗ąĖ ą║ąŠą│ą┤ą░ čÅą┤čĆąŠ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ DMA ą┐čŗčéą░ąĄčéčüčÅ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąĮąŠą╝čā ąĖą╗ąĖ ąĮąĄ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮąĮąŠą╝čā ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓čā ą▓ ą┐ą░ą╝čÅčéąĖ. ąÉą┤čĆąĄčü RETI ą▒čāą┤ąĄčé čüąŠą┤ąĄčƹȹ░čéčī ą░ą┤čĆąĄčü, ą▒ą╗ąĖąĘą║ąĖą╣ ą║ 10 ąĖąĮčüčéčĆčāą║čåąĖčÅą╝, ą▓ ą║ąŠč鹊čĆčŗčģ ą▓ąŠąĘąĮąĖą║ą╗ą░ ąŠčłąĖą▒ą║ą░. ąĢčüą╗ąĖ ą░ą┐ą┐ą░čĆą░čéąĮčŗąĄ ąŠčłąĖą▒ą║ąĖ čĆą░ąĘčĆąĄčłąĄąĮčŗ ąĖ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčéčüčÅ čüąŠą▒čŗčéąĖąĄ, č鹊 čāčüą╗ąŠą▓ąĖąĄ ą▒čāą┤ąĄčé ąŠčćąĖčēąĄąĮąŠ, ąĮąŠ ą┐čĆąĖčćąĖąĮą░ ą░ą┐ą┐ą░čĆą░čéąĮąŠą╣ ąŠčłąĖą▒ą║ąĖ ąŠčüčéą░ąĮąĄčéčüčÅ ąŠčé ą┐ąŠčüą╗ąĄą┤ąĮąĄą│ąŠ čāčüą╗ąŠą▓ąĖčÅ ąŠčłąĖą▒ą║ąĖ.
ąöą╗čÅ ą┤ą▓čāčģčÅą┤ąĄčĆąĮčŗčģ ADSP-BF561 Blackfin ą░ą┐ą┐ą░čĆą░čéąĮčŗąĄ ąŠčłąĖą▒ą║ąĖ ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ąŠčéą┤ąĄą╗čīąĮčŗą╝ čÅą┤čĆąŠą╝, ą▒čāą┤čāčé ą║ą░čüą░čéčīčüčÅ č鹊ą╗čīą║ąŠ čŹč鹊ą│ąŠ čÅą┤čĆą░. ąĢčüą╗ąĖ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ DMA čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ą╗ ą░ą┐ą┐ą░čĆą░čéąĮčāčÄ ąŠčłąĖą▒ą║čā, č鹊 ąŠčłąĖą▒ą║ą░ ą▒čāą┤ąĄčé ą┐ąŠčüą╗ą░ąĮą░ ąĮą░ ąŠą▒ą░ čÅą┤čĆą░.
ąÜą░ąČą┤čŗą╣ ąĖąĘ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąŠą▓ (ą░ą┐ą┐ą░čĆą░čéąĮąŠą╣ ąŠčłąĖą▒ą║ąĖ ąĖą╗ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ) ą╝ąŠąČąĄčé ą┐čĆąŠčćąĖčéą░čéčī ą┐ąŠą╗čÅ HWERRCAUSE ąĖ EXCAUSE ą┤ą╗čÅ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ ą┐čĆąĖčćąĖąĮčŗ čüąŠą▒čŗčéąĖčÅ. ąÉą╗čīč鹥čĆąĮą░čéąĖą▓ąĮąŠ, ą║ąŠą│ą┤ą░ ą┤ą╗čÅ ąŠčéą╗ą░ą┤ą║ąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čŹą╝čāą╗čÅč鹊čĆ, ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ą╝ąŠą│čāčé ą▒čŗčéčī ą┐ąŠą╝ąĄčēąĄąĮčŗ ą▓ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ, čéą░ą║ąĖąĄ ą║ą░ą║ emuxcept, čéą░ą║ čćč鹊ą▒čŗ ą┐čĆąŠčåąĄčüčüąŠčĆ ąŠčüčéą░ąĮąŠą▓ąĖą╗čüčÅ ą▓čüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ą┐čĆąŠąĖąĘąŠčłą╗ą░ ą░ą┐ą┐ą░čĆą░čéąĮą░čÅ ąŠčłąĖą▒ą║ą░ ąĖ/ąĖą╗ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ. ąŚą░č鹥ą╝ ą▓ čĆąĄą│ąĖčüčéčĆąĄ SEQSTAT ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠą░ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮąŠ ą┐ąŠą┤čģąŠą┤čÅčēąĄąĄ ą┐ąŠą╗ąĄ, čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą┐čĆąĖčćąĖąĮčā čüąŠą▒čŗčéąĖčÅ.
ąóąĄą┐ąĄčĆčī, ą║ąŠą│ą┤ą░ ą┐čĆąĖčćąĖąĮą░ čüąŠą▒čŗčéąĖčÅ ąĖąĘą▓ąĄčüčéąĮą░, ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą┐ąŠą╝ąĄč湥ąĮ ą░ą┤čĆąĄčü ąĮąĄąĘą░ą║ąŠąĮąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, čćč鹊ą▒čŗ ąĮą░ą╣čéąĖ ą┐čĆąŠą▒ą╗ąĄą╝čā ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ. ąöą╗čÅ ąĖčüą║ą╗čÄč湥ąĮąĖą╣ čĆąĄą│ąĖčüčéčĆ ą▓ąŠąĘą▓čĆą░čéą░ ąĖąĘ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ (RETX) čüąŠą┤ąĄčƹȹĖčé ą░ą┤čĆąĄčü "ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠą╣" ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖą╗ąĖ ą░ą┤čĆąĄčü čüą╗ąĄą┤čāčÄčēąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆą░čÅ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░. ąÉą┤čĆąĄčü ą▓ RETX ąĘą░ą▓ąĖčüąĖčé ąŠčé čéąĖą┐ą░ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ: service (S) ąĖą╗ąĖ error (E). ąÆ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ADSP-BF53x/BF56x Blackfin Processor Programming Reference [3] ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮčŗ čüąŠą▒čŗčéąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą┐čĆąĖčćąĖąĮąŠą╣ ąĖčüą║ą╗čÄč湥ąĮąĖą╣, ą░ čéą░ą║ąČąĄ ąĖąĘ čéąĖą┐čŗ (service ąĖą╗ąĖ error). ąöą╗čÅ čāą┤ąŠą▒čüčéą▓ą░ čŹčéą░ čéą░ą▒ą╗ąĖčåą░ ą┐čĆąĖą▓ąĄą┤ąĄąĮą░ ą▓ ą¤čĆąĖą╗ąŠąČąĄąĮąĖąĖ A.
ąöą╗čÅ ąĖčüą║ą╗čÄč湥ąĮąĖą╣ čéąĖą┐ą░ E čĆąĄą│ąĖčüčéčĆ RETX čüąŠą┤ąĄčƹȹĖčé ą░ą┤čĆąĄčü "ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠą╣" ąĖąĮčüčéčĆčāą║čåąĖąĖ; ą┤ą╗čÅ ąĖčüą║ą╗čÄč湥ąĮąĖą╣ čéąĖą┐ą░ S čĆąĄą│ąĖčüčéčĆ RETX čüąŠą┤ąĄčƹȹĖčé ą░ą┤čĆąĄčü čüą╗ąĄą┤čāčÄčēąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐ąŠčüą╗ąĄ "ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠą╣".
ąÆ čŹč鹊ą╝ ą╝ąĄčüč鹥 ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖčüčüą╗ąĄą┤ąŠą▓ą░ąĮą░, čćč鹊ą▒čŗ ą╗čāčćčłąĄ ą┐ąŠąĮčÅčéčī ą┐čĆąŠą▒ą╗ąĄą╝čā. ąśąĮčüčéčĆčāą║čåąĖčÅ ąŠą▒čĆą░čēą░ąĄčéčüčÅ ą║ ą┐ą░ą╝čÅčéąĖ, ą┤ą╗čÅ ą║ąŠč鹊čĆąŠą╣ ąĮąĄčé ą┤ąŠą┐čāčüčéąĖą╝ąŠą│ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ CPLB? ąśąĮčüčéčĆčāą║čåąĖčÅ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé load/store ąĖąĘ/ą▓ ą╝ąĄčüč鹊 čü ąŠčłąĖą▒ąŠčćąĮčŗą╝ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄą╝? ąŻą║ą░ąĘą░č鹥ą╗čī ąĖą╗ąĖ ąĖąĮą┤ąĄą║čü čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ ąĮąĄą┤ąŠą┐čāčüčéąĖą╝čāčÄ ąŠą▒ą╗ą░čüčéčī ą┐ą░ą╝čÅčéąĖ?
ą£ąŠąČąĮąŠ čāčüčéą░ąĮąŠą▓ąĖčéčī breakpoint ą┐ąŠą▒ą╗ąĖąĘąŠčüčéąĖ ąŠčé ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆą░čÅ ą▓čŗąĘą▓ą░ą╗ą░ ą░ą┐ą┐ą░čĆą░čéąĮčāčÄ ąŠčłąĖą▒ą║čā ąĖą╗ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ, ąĖ ą║ąŠą┤ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠčéą╗ą░ąČąĄąĮ ą▓ ą┐ąŠčłą░ą│ąŠą▓ąŠą╝ čĆąĄąČąĖą╝ąĄ, čü ąŠčéčüą╗ąĄąČąĖą▓ą░ąĮąĖąĄą╝ čĆąĄą│ąĖčüčéčĆąŠą▓ ą░ą┤čĆąĄčüą░ (Ix ąĖą╗ąĖ Px). ąŻčüčéą░ąĮąŠą▓ą║ą░ breakpoint-ąŠą▓ ąĖ/ąĖą╗ąĖ čłą░ą│ą░ąĮąĖąĄ ą┐ąŠ ą║ąŠą┤čā ą┤ąŠ ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖąĮąŠą│ą┤ą░ ą╝ąŠąČąĄčé ą┐ąŠą╝ąĄąĮčÅčéčī ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐čĆąŠą▒ą╗ąĄą╝čŗ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą┐čĆąŠą▒ą╗ąĄą╝ą░ ą┐čĆąĖ čŹčéąĖčģ čāčüą╗ąŠą▓ąĖčÅčģ ą╝ąŠąČąĄčé ą▒ąŠą╗čīčłąĄ ąĮąĄ ąĮą░ą▒ą╗čÄą┤ą░čéčīčüčÅ). ąÆ čéą░ą║ąĖčģ čüą╗čāčćą░čÅčģ breakpoint ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠą╝ąĄčēąĄąĮ ą┐ąŠčüą╗ąĄ ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą┐čĆąŠčåąĄčüčüąŠčĆ ą┐ąĄčĆąĄą┤ą░ąĄčé čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą▓ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ čüąŠą▒čŗčéąĖčÅ, čéą░ą║ čćč鹊 breakpoint ą▒čāą┤ąĄčé čĆą░ąĘą╝ąĄčēąĄąĮ ąĮą░ ą┐ąĄčĆą▓čāčÄ ąĖąĮčüčéčĆčāą║čåąĖčÄ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ čüąŠą▒čŗčéąĖčÅ (ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĖą╗ąĖ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ą░ą┐ą┐ą░čĆą░čéąĮąŠą╣ ąŠčłąĖą▒ą║ąĖ).
[ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą▒čāč乥čĆą░ čéčĆą░čüčüąĖčĆąŠą▓ą║ąĖ]
16-čüą╗ąŠč鹊ą▓čŗą╣ ą▒čāč乥čĆ čéčĆą░čüčüąĖčĆąŠą▓ą║ąĖ, ąĖą╝ąĄčÄčēąĖą╣čüčÅ ą▓ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ Blackfin, ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĘą░čģą▓ą░čéąĖčéčī ą┐ąŠčüą╗ąĄą┤ąĮąĖąĄ ąĮąĄ čüą╝ąĄąČąĮčŗąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą┐ąŠč鹊ą║ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ (ąĖčüą║ą╗čÄčćą░čÄčéčüčÅ ą░ą┐ą┐ą░čĆą░čéąĮčŗąĄ čåąĖą║ą╗čŗ čü ąĮčāą╗ąĄą▓čŗą╝ąĖ ą┐ąŠč鹥čĆčÅą╝ąĖ, zero-overhead hardware loops). ąśąĮč乊čĆą╝ą░čåąĖčÅ ą▓ ą▒čāč乥čĆąĄ čéčĆą░čüčüąĖčĆąŠą▓ą║ąĖ ą╝ąŠąČąĄčé čüą┐ąŠčüąŠą▒čüčéą▓ąŠą▓ą░čéčī ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÄ ą┐čĆąĖčćąĖąĮčŗ ą┐čĆąŠą▒ą╗ąĄą╝čŗ ąĖą╗ąĖ, čćč鹊 ą▒ąŠą╗ąĄąĄ ą▓ą░ąČąĮąŠ, čüčāąČąĄąĮąĖčÄ ąŠą▒ą╗ą░čüčéąĖ ą┐ąŠąĖčüą║ą░ ą┐čĆąŠą▒ą╗ąĄą╝čŗ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠą╗čāč湥ąĮ ąĮąĄą▒ąŠą╗čīčłąŠą╣ č鹥čüč鹊ą▓čŗą╣ čüčåąĄąĮą░čĆąĖą╣, ą┐ąŠąĘą▓ąŠą╗čÅčÄčēąĖą╣ ą┐ąŠčüč鹊čÅąĮąĮąŠ ąĮą░ą▒ą╗čÄą┤ą░čéčī ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ. ąÆ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ čüąĄą║čåąĖąĖ ą▒čŗą╗ąĖ ąŠą┐ąĖčüą░ąĮčŗ ą╝ąĄč鹊ą┤čŗ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą▓čŗąĘą▓ą░ą▓čłąĄą╣ čćą░čüčéąĮąŠąĄ čüąŠą▒čŗčéąĖąĄ; ąŠą┤ąĮą░ą║ąŠ ą▓ąŠ ą╝ąĮąŠą│ąĖčģ čüą╗čāčćą░čÅčģ čéą░ ąČąĄ čüą░ą╝ą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ ąĖąĘąŠą╗čÅčåąĖąĖ ąĮąĄ ą▒čāą┤ąĄčé ą┐ąŠą║ą░ąĘčŗą▓ą░čéčī ą┐čĆąŠą▒ą╗ąĄą╝čā. ąŁč鹊 č鹊, čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▒čŗą╗ą░ ą▓čŗą▒čĆą░ąĮą░ ąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ (ą▓ ąĮąĄą║ąŠč鹊čĆčŗčģ čüą╗čāčćą░čÅčģ ąŠąĮą░ ą┤ą░ąČąĄ ąĮąĄ ą┤ąŠą▒ąĖčĆą░ąĄčéčüčÅ ą┤ąŠ čŹčéą░ą┐ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ), čŹč鹊 ą║čĆąĖčéąĖčćąĮąŠ ąĮą░ ąŠą▒ąĮčāą╗ąĄąĮąĖąĖ ą▓ ą┐ąĄčĆą▓ąŠą┐čĆąĖčćąĖąĮąĄ. ąØą░ą┐čĆąĖą╝ąĄčĆ ą┐čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ, ą▓čŗą┐ąŠą╗ąĮčÅčÄčēą░čÅ ąĘą░ą│čĆčāąĘą║čā ąĖąĘ ą┐ą░ą╝čÅčéąĖ, ąĖčüą┐ąŠą╗čīąĘčāąĄčé čĆąĄą│ąĖčüčéčĆ P2. ąØąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ ą┐ąĄčĆąĄą┤ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ čŹč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▒čāą┤ąĄčé ą┐ąŠą╗čāč湥ąĮąŠ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ, ą┐ąŠ ą┐ą╗ąŠčģąŠą╣ ą┐čĆą░ą║čéąĖą║ąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ, ąĮąĄ ą┤ąĄą╗ą░ąĄčé čüąŠčģčĆą░ąĮąĄąĮąĖąĄ ąĖ ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓. ąÜąŠą┤ ISR čüą╗čāčćą░ą╣ąĮąŠ ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāąĄčé čĆąĄą│ąĖčüčéčĆ čāą║ą░ąĘą░č鹥ą╗čÅ P2, ąĖ ą┐čĆąĖ ą▓ąŠąĘą▓čĆą░č鹥 ąĖąĘ ISR ą▒čāą┤ąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ ąĖąĘ ą┐ą░ą╝čÅčéąĖ. ą×ą┤ąĮą░ą║ąŠ P2 ą▒ąŠą╗čīčłąĄ ąĮąĄ čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ ąĮčāąČąĮąŠąĄ ą╝ąĄčüč鹊 ą▓ ą┐ą░ą╝čÅčéąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąĮ ą▒čŗą╗ ą┐ąĄčĆąĄąĘą░ą┐ąĖčüą░ąĮ ą░čüąĖąĮčģčĆąŠąĮąĮčŗą╝ čüąŠą▒čŗčéąĖąĄą╝, čćč鹊 ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą╝ąŠąČąĄčé ą┐ąŠčüą╗čāąČąĖčéčī ąĖčüč鹊čćąĮąĖą║ąŠą╝ čĆą░ąĮąĄąĄ ąŠą▒čüčāąČą┤ąĄąĮąĮčŗčģ čüąŠą▒čŗčéąĖą╣. ąöą░ąĮąĮčŗąĄ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ/čćąĖčéą░čÄčéčüčÅ ąĖąĘ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠą╣ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ. ą¤ąŠčüą╗ąĄą┤ąĮąĄąĄ ąŠą▒čŗčćąĮąŠ ąŠą▒ąĮą░čĆčāąČąĖčéčī čéčĆčāą┤ąĮąĄąĄ.
ąæčāč乥čĆ čéčĆą░čüčüąĖčĆąŠą▓ą║ąĖ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čüąŠčģčĆą░ąĮąĖčéčī ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą┐ąŠč鹊ą║ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąŠąĖąĘąŠčłą╗ąĖ ą┐ąĄčĆąĄą┤ ą▓ąŠąĘąĮąĖą║ąĮąŠą▓ąĄąĮąĖąĄą╝ ą┐čĆąŠą▒ą╗ąĄą╝čŗ, ą┐čĆąĄąČą┤ąĄ č湥ą╝ ąŠąĮąĖ ą╝ąŠą│ą╗ąĖ ą▒čŗ ą▒čŗčéčī ą╗ąĄą│ą║ąŠ ąĘą░ą╝ąĄč湥ąĮčŗ ą▓ ąŠą║ąĮąĄ. ąŚą░ą┐ąĖčłčāčéčüčÅ ą┐ąŠčüą╗ąĄą┤ąĮąĖąĄ 16 ą┐ą░čĆ ą┐ąĄčĆąĄčģąŠą┤ąŠą▓. ą¤ąĄčĆą▓ą░čÅ ąĘą░ą┐ąĖčüčī ą▓ ą┐ą░čĆąĄ čŹč鹊 ąĖčüč鹊čćąĮąĖą║ ą┐ąĄčĆąĄčģąŠą┤ą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓čŗąĘąŠą▓ą░), ąĖ ą▓č鹊čĆą░čÅ ą╝ąĄčüč鹊 ąĮą░ąĘąĮą░č湥ąĮąĖčÅ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą┐ąĄčĆą▓ą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓čŗąĘą▓ą░ąĮąĮąŠą╣ čäčāąĮą║čåąĖąĖ). ąÆ ą┐čĆąĖą▓ąĄą┤ąĄąĮąĮąŠą╝ čĆą░ąĮąĄąĄ ą┐čĆąĖą╝ąĄčĆąĄ čü P2 ą┐ąĄčĆą▓ą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┤ą░ąĮąĮąŠą╣ ą┐ą░čĆčŗ čéčĆą░čüčüąĖčĆąŠą▓ą║ąĖ ą▒čŗą╗ą░ ą▒čŗ ą▓ąŠąĘą▓čĆą░č鹊ą╝ ąĖąĘ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ (RTI), ąĖ ą▓č鹊čĆą░čÅ ą▒čŗą╗ą░ ą▒čŗ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą│čĆčāąĘą║ąĖ ąĖą╗ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐ąĄčĆąĄą┤ ąĮąĄą╣. ąóą░ą║ ą║ą░ą║ ą▒čāč乥čĆ čéčĆą░čüčüąĖčĆąŠą▓ą║ąĖ ą║čĆąŠą╝ąĄ ąĖąĮčüčéčĆčāą║čåąĖą╣ čéą░ą║ąČąĄ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĖ ą░ą┤čĆąĄčüą░ ąĮąĄąŠą┤ąĮąŠčĆąŠą┤ąĮąŠčüč鹥ą╣ ą┐ąŠč鹊ą║ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ, ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠą░ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮ ą░ą┤čĆąĄčü ąĖąĮčüčéčĆčāą║čåąĖąĖ RTI ą▓ ISR, čćč鹊ą▒čŗ ąĮą░ą╣čéąĖ, čćč鹊 P2 ą▒čŗą╗ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮ, ąĖ ąĮąĄ ą▒čŗą╗ ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą┐ąĄčĆąĄą┤ ą▓čŗčģąŠą┤ąŠą╝ ąĖąĘ ISR. ąŁč鹊čé ISR ą╝ąŠą│ ą▒čŗ ą▒čŗčéčī čćą░čüčéčīčÄ čłąĄą┤čāą╗ąĄčĆą░ RTOS, ą║ąŠč鹊čĆčŗą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ. ąÜąŠąĮąĄčćąĮąŠ, čĆą░čüčüą╝ąŠčéčĆąĄąĮąĮčŗą╣ ąĘą┤ąĄčüčī ą┐čĆąĖą╝ąĄčĆ čüąĖą╗čīąĮąŠ čāą┐čĆąŠčēąĄąĮ. ą£ąŠą│ą╗ąŠ ą▒čŗ ąŠą║ą░ąĘą░čéčīčüčÅ, čćč鹊 ISR ąĮąĄ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ą╗ ąŠą▒čģąŠą┤ąĮąŠąĄ čĆąĄčłąĄąĮąĖąĄ ąĖąĘą▓ąĄčüčéąĮąŠą╣ ą┐čĆąŠą▒ą╗ąĄą╝čŗ.
ąÆčŗ ą╝ąŠąČąĄč鹥 čüč鹊ą╗ą║ąĮčāčéčīčüčÅ čü č鹥ą╝, čćč鹊 ąĮąĖč湥ą│ąŠ ąĮąĄ ą▒čāą┤ąĄčé ąŠč湥ą▓ąĖą┤ąĮąŠ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, čüąŠ ą▓čüąĄą╝ čŹčéąĖą╝ ą░ąĮą░ą╗ąĖąĘąŠą╝ ą▓čüąĄ ąĄčēąĄ ąĮąĄ ą▒čāą┤ąĄčé ą▓čŗčÅčüąĮąĄąĮą░ ą┐čĆąĖčćąĖąĮą░ ą┐čĆąŠą▒ą╗ąĄą╝čŗ). ąŚąĮą░ąĮąĖąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖą╣, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąŠąĖčüčģąŠą┤ąĖą╗ąĖ ą┐ąĄčĆąĄą┤ ą▓ąŠąĘąĮąĖą║ąĮąŠą▓ąĄąĮąĖąĄą╝ ą┐čĆąŠą▒ą╗ąĄą╝čŗ, ą╝ąŠąČąĄčé ą┐ąŠą╝ąŠčćčī ą▓ čüąŠąĘą┤ą░ąĮąĖąĖ ą╝ą░ą╗ąĄąĮčīą║ąŠą│ąŠ č鹥čüčéą░, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠč湥ąĮčī ą┐ąŠą╗ąĄąĘąĄąĮ ą║ąŠą╝ą░ąĮą┤ąĄ čüą╗čāąČą▒čŗ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ, čćč鹊ą▒čŗ ą▒čŗčüčéčĆąŠ ąĖčüčüą╗ąĄą┤ąŠą▓ą░čéčī ą┐čĆąŠą▒ą╗ąĄą╝čā ąĖ čĆą░ąĘąŠą▒čĆą░čéčīčüčÅ ą▓ ąĮąĄą╣.
ąØą░ čĆąĖčüčāąĮą║ąĄ 1 ą┐ąŠą║ą░ąĘą░ąĮąŠ, ą║ą░ą║ ąĘą░ą┐ąĖčüąĖ čüčéčĆčāą║čéčāčĆąĖčĆčāčÄčéčüčÅ ą▓ ą▒čāč乥čĆąĄ čéčĆą░čüčüąĖčĆąŠą▓ą║ąĖ. ąÆ ą║čĆą░ą╣ąĮąĄą╝ ą╗ąĄą▓ąŠą╝ čüč鹊ą╗ą▒čåąĄ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮčŗ čåąĖą║ą╗čŗ ąŠčé 0 ą┤ąŠ 31. ą”ąĖą║ą╗čŗ 0 ąĖ 1 čÅą▓ą╗čÅčÄčéčüčÅ ą┐ąŠčüą╗ąĄą┤ąĮąĄą╣ ą┐ą░čĆąŠą╣ ąĘą░ą┐ąĖčüą░ąĮąĮčŗčģ ą┐ąĄčĆąĄčģąŠą┤ąŠą▓, čåąĖą║ą╗ąĖ 2 ąĖ 3 ą┐čĆąĄą┤ą┐ąŠčüą╗ąĄą┤ąĮąĄą╣, ąĖ čé. ą┤. ąÆč鹊čĆąŠą╣ čüč鹊ą╗ą▒ąĄčå čüą╗ąĄą▓ą░ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą│čĆčāą┐ą┐ąĖčĆąŠą▓ą║čā ą┐ą░čĆ. ąØą░ą┐čĆąĖą╝ąĄčĆ, čåąĖą║ą╗čŗ 0 ąĖ 1 čÅą▓ą╗čÅčÄčéčüčÅ 15-ą╣ ą┐ą░čĆąŠą╣ (0xf), čåąĖą║ą╗čŗ 2 ąĖ 3 čÅą▓ą╗čÅčÄčéčüčÅ 14-ą╣ ą┐ą░čĆąŠą╣ (0xe), ąĖ čåąĖą║ą╗čŗ 0x1e ąĖ 0x1f čÅą▓ą╗čÅčÄčéčüčÅ ąĮčāą╗ąĄą▓ąŠą╣ ą┐ą░čĆąŠą╣ (0x0). ą¤ąĄčĆą▓ą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▓ ą┐ą░čĆąĄ čŹč鹊 ąĖčüč鹊čćąĮąĖą║ ą┐ąĄčĆąĄčģąŠą┤ą░, ąĖ ą▓č鹊čĆą░čÅ ą╝ąĄčüč鹊 ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ąöą╗čÅ ą┐ą░čĆčŗ 0xf cycle 0 čÅą▓ą╗čÅąĄčéčüčÅ ąĖčüč鹊čćąĮąĖą║ąŠą╝ (ąĖąĮčüčéčĆčāą║čåąĖčÅ RTS), ąĖ cycle 1 čÅą▓ą╗čÅąĄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ (CALL Initialize__3VDKFv). ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čŹčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▒čŗą╗ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ ą┐ąĄčĆą▓ąŠą╣ ą┐ąŠčüą╗ąĄ ą▓ąŠąĘą▓čĆą░čēąĄąĮąĖčÅ ąĖąĘ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ąĘą░ą║ą░ąĮčćąĖą▓ą░čÄčēąĄą╣čüčÅ ąĮą░ ą░ą┤čĆąĄčüąĄ 0xffa086be.
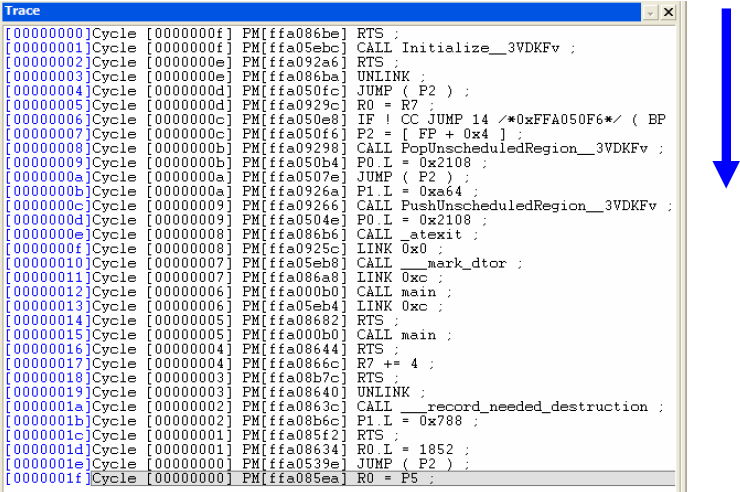
ąĀąĖčü. 1. ą¤čĆąĖą╝ąĄčĆ ą▒čāč乥čĆą░ čéčĆą░čüčüąĖčĆąŠą▓ą║ąĖ.
[ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ č鹊č湥ą║ ąŠčüčéą░ąĮąŠą▓ą░ (Breakpoints)]
ąŁčéą░ čüąĄą║čåąĖčÅ ąŠą┐ąĖčüčŗą▓ą░ąĄčé čĆą░ąĘą╗ąĖčćąĖčÅ ą╝ąĄąČą┤čā čĆą░ąĘąĮčŗą╝ąĖ ą▓ąĖą┤ą░ą╝ąĖ č鹊č湥ą║ ąŠčüčéą░ąĮąŠą▓ą░: software, embedded ąĖ hardware, ąĖ ąŠą▒čŖčÅčüąĮčÅąĄčé, ą║ą░ą║ ąĖčģ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī.
Software Breakpoints. ą¤čĆąŠą│čĆą░ą╝ą╝ąĮčŗąĄ č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░ čāą┤ąŠą▒ąĮčŗ ąĖ ą┐čĆąŠčüčéčŗ ą▓ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ. ą¤čĆąŠčüč鹊 čüą┤ąĄą╗ą░ą╣č鹥 ą┤ą▓ąŠą╣ąĮąŠą╣ ą║ą╗ąĖą║ ąĮą░ ąĖąĮčüčéčĆčāą║čåąĖčÄ ą▓ ąŠą║ąĮąĄ čĆąĄą┤ą░ą║č鹊čĆą░ ą║ąŠą┤ą░ ąĖą╗ąĖ ąŠą║ąĮą░ ą┤ąĖąĘą░čüčüąĄą╝ą▒ą╗ąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ ą║ąŠą┤ą░ IDDE, čćč鹊ą▒čŗ čāčüčéą░ąĮąŠą▓ąĖčéčī breakpoint, ąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ą║ąŠą│ą┤ą░ ą┤ąŠčüčéąĖą│ąĮąĄčé čŹč鹊ą╣ čüčéčĆąŠą║ąĖ ą║ąŠą┤ą░. ąÆčüąĄ ą┐čĆąŠčüč鹊, ąĮąŠ čéčāčé ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĮąĄčćč鹊, čćč鹊 ą╝čŗ ąĮąĄ ą▓ąĖą┤ąĖą╝ - ą╝ąĄčüč鹊, ą║čāą┤ą░ ą┐ąŠą╝ąĄčēąĄąĮą░ č鹊čćą║ą░ ąŠčüčéą░ąĮąŠą▓ą░, "ą║čŹčłąĖčĆčāąĄčéčüčÅ" ą▓ 菹╝čāą╗čÅč鹊čĆąĄ. ąŁą╝čāą╗čÅč鹊čĆ čćąĖčéą░ąĄčé ą┐ą░ą╝čÅčéčī, ą│ą┤ąĄ ąĮą░čģąŠą┤ąĖčéčüčÅ č鹊čćą║ą░ ąŠčüčéą░ąĮąŠą▓ą░, ąĖ čüąŠčģčĆą░ąĮčÅąĄčé ąĄčæ ą▓ čüą▓ąŠąĄą╝ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╝ čüą┐ąĖčüą║ąĄ č鹊č湥ą║ ąŠčüčéą░ąĮąŠą▓ą░. ąÜąŠą│ą┤ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ, ąŠąĮ ąĘą░ą╝ąĄčēą░ąĄčé ąĖąĮčüčéčĆčāą║čåąĖčÄ ą▓ čŹč鹊ą╝ ą╝ąĄčüč鹥 ąĮą░ ąĖąĮčüčéčĆčāą║čåąĖčÄ ą╗ąŠą▓čāčłą║ąĖ. ąÜąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┤ąŠčüčéąĖą│ą░ąĄčé ą╗čÄą▒ąŠą╣ ąĖąĘ č鹊č湥ą║ ąŠčüčéą░ąĮąŠą▓ą░, ąĖą╗ąĖ ą║ąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą╗čÄą▒ą░čÅ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą║ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ, ąĖąĮčüčéčĆčāą║čåąĖčÅ ą╗ąŠą▓čāčłą║ąĖ ąĘą░ą╝ąĄąĮčÅąĄčéčüčÅ ąŠą▒čĆą░čéąĮąŠ ąĮą░ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮčāčÄ ąĖąĮčüčéčĆčāą║čåąĖčÄ, ą║ąŠč鹊čĆą░čÅ ą▒čŗą╗ą░ "ą║čŹčłąĖčĆąŠą▓ą░ąĮą░". ą×čéčüčÄą┤ą░ ą┐ąŠąĮčÅčéąĮąŠ, čćč鹊 ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗąĄ č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░ ą┐ąŠ čüą▓ąŠąĄą╣ ą┐čĆąĖčĆąŠą┤ąĄ ą┤ąĄčüčéčĆčāą║čéąĖą▓ąĮčŗ ą▓ č鹊ą╝ čüą╝čŗčüą╗ąĄ, čćč鹊 ą▓čĆąĄą╝ąĄąĮąĮąŠ ą╝ąĄąĮčÅčÄčé ą║ąŠą┤. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą╝ąĮąŠąČąĄčüčéą▓ąŠ ą▓čüčéčĆąĄčćą░čÄčēąĖčģčüčÅ ą┐čĆąŠą▒ą╗ąĄą╝ ą╝ąŠą│čāčé čāą╣čéąĖ, ą║ąŠą│ą┤ą░ ą┤ą╗čÅ ą┤ąĖą░ą│ąĮąŠčüčéąĖą║ąĖ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗąĄ č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą▒čŗą╗ąŠ ąĖąĘą╝ąĄąĮąĄąĮąŠ ąĖąĘ-ąĘą░ ą┐čĆąĖčĆąŠą┤čŗ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗčģ č鹊č湥ą║ ąŠčüčéą░ąĮąŠą▓ą░. ąØą░ čĆąĖčü. 2 ą┐ąŠą║ą░ąĘą░ąĮąŠ, ą║ą░ą║ software breakpoint ą▓čŗą│ą╗čÅą┤čÅčé ą▓ čüąĄčüčüąĖąĖ IDDE VisualDSP++.

ąĀąĖčü. 2. ą¤čĆąĖą╝ąĄčĆ Software Breakpoint.
Embedded Breakpoints. ąÆčüčéčĆąŠąĄąĮąĮą░čÅ č鹊čćą║ą░ ąŠčüčéą░ąĮąŠą▓ą░ čÅą▓ą╗čÅąĄčéčüčÅ čćą░čüčéčīčÄ čüą░ą╝ąŠą│ąŠ ą║ąŠą┤ą░. ą×ąĮą░ ą┐ąŠčģąŠąČą░ ąĮą░ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčāčÄ č鹊čćą║čā ąŠčüčéą░ąĮąŠą▓ą░, ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ č鹊ą│ąŠ, čćč鹊 ąŠčéą╗ą░ą┤čćąĖą║čā ąĮąĄ ąĮčāąČąĮąŠ ą┐čĆąŠčüą╝ą░čéčĆąĖą▓ą░čéčī čéą░ą▒ą╗ąĖčåčā č鹊č湥ą║ ąŠčüčéą░ąĮąŠą▓ą░ ąĖą╗ąĖ ą▓čüčéą░ą▓ą╗čÅčéčī ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ "ąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čÄčēąĖąĄ" ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąóą░ą║ čćč鹊 čŹč鹊čé ą║ą╗ą░čüčü č鹊č湥ą║ ąŠčüčéą░ąĮąŠą▓ą░ "ą║ą░ą║ ą▒čŗ ąĮąĄ ą┤ąĄčüčéčĆčāą║čéąĖą▓ąĄąĮ". ąśąĮčüčéčĆčāą║čåąĖčÅ emuexcpt ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ąŠčüčéą░ąĮąŠą▓ą║ąĄ, ą║ąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą╝. ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĖą╝ąĄąĄčé ąĘąĮą░č湥ąĮąĖąĄ č鹊ą╗čīą║ąŠ č鹊ą│ą┤ą░, ą║ąŠą│ą┤ą░ ą┐ąŠą┤ą║ą╗čÄč湥ąĮ 菹╝čāą╗čÅč鹊čĆ; ąĖąĮą░č湥 ąŠąĮą░ ą▒čāą┤ąĄčé čĆą░ą▒ąŠčéą░čéčī ą║ą░ą║ ąĖąĮčüčéčĆčāą║čåąĖčÅ NOP. ąźąŠčĆąŠčłąĄą╣ ą┐čĆą░ą║čéąĖą║ąŠą╣ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓čüčéčĆąŠąĄąĮąĮčŗąĄ č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░ ą▓ąĮčāčéčĆąĖ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąŠą▓ čüąŠą▒čŗčéąĖą╣, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąĮąĖ ąĮąĄ ą▓ąĮąŠčüčÅčé ąĮąĖą║ą░ą║ąĖčģ ąĖąĘą╝ąĄąĮąĄąĮąĖą╣ ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ, ą║čĆąŠą╝ąĄ ą║ą░ą║ ąĘą░ąĮąĖą╝ą░čÄčé ą╝ąĄčüč鹊 ą▓ ą║ąŠą┤ąĄ, ąĖ ąĮąĄ ą▓ą╗ąĖčÅčÄčé ąĮą░ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, čćč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čāą▓ąĄčĆąĄąĮąĮąŠ ą┐čĆąŠčüą╝ąŠčéčĆąĄčéčī čüąŠčüč鹊čÅąĮąĖąĄ ą┐čĆąŠčåąĄčüčüąŠčĆą░, ą║ą░ą║ č鹊ą╗čīą║ąŠ ą┐čĆąŠąĖąĘąŠčłą╗ąŠ čüąŠą▒čŗčéąĖąĄ. ą¤čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ čüąŠą▓ą╝ąĄčüčéąĮąŠ čü ąĖąĮč乊čĆą╝ą░čåąĖąĄą╣ ą▒čāč乥čĆą░ čéčĆą░čüčüąĖčĆąŠą▓ą║ąĖ, ąÆčŗ ą╝ąŠąČąĄč鹥 ąĖčüčüą╗ąĄą┤ąŠą▓ą░čéčī čüąŠčüč鹊čÅąĮąĖąĄ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĖ ą┐ąĄčĆąĄčģąŠą┤čŗ, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąŠąĖčüčģąŠą┤ąĖą╗ąĖ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ čüąŠą▒čŗčéąĖąĄ ą┐čĆąŠąĖąĘąŠčłą╗ąŠ. ąØą░ čĆąĖčü. 3 ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąĖą╝ąĄčĆ ą▓čüčéčĆąŠąĄąĮąĮąŠą╣ č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░.
EX_INTERRUPT_HANDLER(Timer0_ISR)
{
asm("EMUEXCPT;"); //ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝ą░čÅ č鹊čćą║ą░ ąŠčüčéą░ąĮąŠą▓ą░
// ą┐ąŠą┤čéą▓ąĄčƹȹ┤ąĄąĮąĖąĄ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ:
*pTIMER_STATUS = 0x0001;
brkptcounter++; //čüč湥čéčćąĖą║ ą░ą┐ą┐ą░čĆą░čéąĮčŗčģ č鹊č湥ą║ ąŠčüčéą░ąĮąŠą▓ą░
// čüą┤ą▓ąĖą│ čüčéą░čĆąŠą╣ ą╝ą░čüą║ąĖ LED:
if(sRight_Move_Direction)
{
if((ucActive_LED = ucActive_LED >> 1) < = 0x0020)
ucActive_LED = 0x1000;
}
else
{
if((ucActive_LED = ucActive_LED << 1) == 0x1000)
ucActive_LED = 0x0020;
}
// ąĘą░ą┐ąĖčüčī ąĮąŠą▓ąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ LED ą▓ PORTF
*pPORTFIO_TOGGLE = ucActive_LED;
}
ąĀąĖčü. 3. ą¤čĆąĖą╝ąĄčĆ Embedded Breakpoint.
Hardware Breakpoints. ąÆ ąŠčéą╗ąĖčćąĖąĄ ąŠčé ą┤čĆčāą│ąĖčģ ą▓ąĖą┤ąŠą▓ č鹊č湥ą║ ąŠčüčéą░ąĮąŠą▓ą░, ą░ą┐ą┐ą░čĆą░čéąĮčŗąĄ breakpoint-čŗ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąĮąĄ ą┤ąĄčüčéčĆčāą║čéąĖą▓ąĮčŗ, čéą░ą║ ą║ą░ą║ ąŠąĮąĖ ąĮąĖą║ą░ą║ ąĮąĄ ą╝ąĄąĮčÅčÄčé ą║ąŠą┤ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ Hardware Breakpoints ąĘą░ą┤ąĄą╣čüčéą▓čāčÄčé ą░ą┐ą┐ą░čĆą░čéčāčĆčā ą╗ąŠą│ąĖą║ąĖ čćąĖą┐ą░, ą║ąŠč鹊čĆą░čÅ ą╝ąŠąĮąĖč鹊čĆąĖčé ąĖ čłąĖąĮčā ą┤ą░ąĮąĮčŗčģ, ąĖ čłąĖąĮčā ąĖąĮčüčéčĆčāą║čåąĖą╣. ąØą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ Blackfin ą░ą┐ą┐ą░čĆą░čéąĮčŗąĄ č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮčŗ ą▒ą╗ąŠą║ąŠą╝ ąŠčéčüą╗ąĄąČąĖą▓ą░ąĮąĖčÅ čüąŠčüč鹊čÅąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓ (watchpoint register unit). ąŚą┤ąĄčüčī ąĄčüčéčī 6 čĆąĄą│ąĖčüčéčĆąŠą▓ ąŠčéčüą╗ąĄąČąĖą▓ą░ąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ 2 čĆąĄą│ąĖčüčéčĆą░ ąŠčéčüą╗ąĄąČąĖą▓ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ. ąÉą┐ą┐ą░čĆą░čéąĮčŗąĄ č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░ ą┤ą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą╝ąŠąČąĮąŠ čāčüčéą░ąĮąŠą▓ąĖčéčī ą┤ą╗čÅ 6 ą░ą┤čĆąĄčüąŠą▓ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖą╗ąĖ ąĮą░ 3 ą┤ąĖą░ą┐ą░ąĘąŠąĮą░čģ ą░ą┤čĆąĄčüąŠą▓ ąĖąĮčüčéčĆčāą║čåąĖą╣. ąÉą┐ą┐ą░čĆą░čéąĮčŗąĄ č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░ ą┤ą░ąĮąĮčŗčģ ą╝ąŠą│čāčé ą▒čŗčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮčŗ ąĮą░ 2 ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ ą░ą┤čĆąĄčüą░čģ ą┤ą░ąĮąĮčŗčģ ąĖą╗ąĖ ąĮą░ ąŠą┤ąĮąŠą╝ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ ą░ą┤čĆąĄčüąŠą▓ ą┤ą░ąĮąĮčŗčģ. ąÉą┐ą┐ą░čĆą░čéąĮčŗąĄ č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą╗ąĖą▒ąŠ ą▓ ą┐ą░ą╝čÅčéąĖ čéąĖą┐ąŠą▓ RAM ąĖą╗ąĖ ROM.
ą¦č鹊ą▒čŗ čĆą░ąĘčĆąĄčłąĖčéčī ą░ą┐ą┐ą░čĆą░čéąĮčŗąĄ č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░ ąĖąĘ IDDE VisualDSP++, ą┐ąĄčĆąĄą╣ą┤ąĖč鹥 ą▓ Settings ąĖ ą▓čŗą▒ąĄčĆąĖč鹥 Hardware Breakpoints. ąØą░ čĆąĖčüčāąĮą║ąĄ 4 ą┐ąŠą║ą░ąĘą░ąĮą░ ąŠą┤ąĮą░ ąĖąĘ čüčéčĆą░ąĮąĖčå Instruction ąŠą║ąĮą░ Hardware Breakpoints.
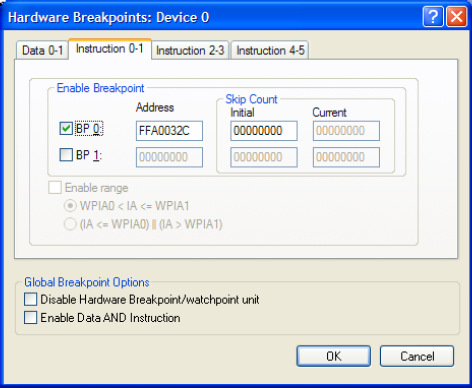
ąĀąĖčü. 4. Hardware Breakpoints (Instruction).
ąŚą░č鹥ą╝ ą╝ąŠąČąĄčé ą▒čŗčéčī čāą║ą░ąĘą░ąĮ ą░ą┤čĆąĄčü ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖą╗ąĖ ą┤ąĖą░ą┐ą░ąĘąŠąĮ ą░ą┤čĆąĄčüąŠą▓, čćč鹊ą▒čŗ ąĘą░čüčéą░ą▓ąĖčéčī ą┐čĆąŠčåąĄčüčüąŠčĆ ąŠčüčéą░ąĮąŠą▓ąĖčéčīčüčÅ, ą║ąŠą│ą┤ą░ čŹčéąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ąŠą╗ąČąĮčŗ ą▓čŗą┐ąŠą╗ąĮąĖčéčīčüčÅ.
ąöą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą┤ą░ąĮąĮčŗą╝ ą╝ąŠąČąĄčé ą▒čŗčéčī čāą║ą░ąĘą░ąĮ čéąĖą┐ ą┤ąŠčüčéčāą┐ą░ (čćč鹥ąĮąĖąĄ, ąĘą░ą┐ąĖčüčī, ąĖą╗ąĖ ąĖ č鹊, ąĖ ą┤čĆčāą│ąŠąĄ), čćč鹊ą▒čŗ čüčĆą░ą▒ąŠčéą░ą╗ą░ ąŠčüčéą░ąĮąŠą▓ą║ą░ 菹╝čāą╗čÅčåąĖąĖ. ąØą░ čĆąĖčüčāąĮą║ąĄ 5 ą┐ąŠą║ą░ąĘą░ąĮą░ čüčéčĆą░ąĮąĖčåą░ Data ąŠą║ąĮą░ Hardware Breakpoints.

ąĀąĖčü. 5. Hardware Breakpoints (Data).
ąŚą░č鹥ą╝ ą║ąŠą┤ ą╝ąŠąČąĮąŠ ąĘą░ą┐čāčüčéąĖčéčī, ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆ ąŠčüčéą░ąĮąŠą▓ąĖčéčüčÅ, ąĄčüą╗ąĖ ą▒čŗą╗ąŠ čüąŠą▓ą┐ą░ą┤ąĄąĮąĖąĄ ą╝ąĄąČą┤čā ą▓ąĮčāčéčĆąĄąĮąĮąĖą╝ ą░ą┤čĆąĄčüąŠą╝ čłąĖąĮ ąĖąĮčüčéčĆčāą║čåąĖąĖ/ą┤ą░ąĮąĮčŗčģ ąĖ ą░ą┤čĆąĄčüąŠą╝, čāą║ą░ąĘą░ąĮąĮčŗą╝ ą▓ čĆąĄą│ąĖčüčéčĆą░čģ ą░ą┐ą┐ą░čĆą░čéąĮčŗčģ č鹊č湥ą║ ąŠčüčéą░ąĮąŠą▓ą░.
ąöą╗čÅ ą░ą┐ą┐ą░čĆą░čéąĮčŗčģ č鹊č湥ą║ ąŠčüčéą░ąĮąŠą▓ą░ ąĄčüčéčī čäčāąĮą║čåąĖčÅ čüč湥čéčćąĖą║ą░ ą┐čĆąŠą┐čāčüą║ą░, ą║ąŠč鹊čĆą░čÅ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮą░, čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī, čüą║ąŠą╗čīą║ąŠ čĆą░ąĘ ąĖą│ąĮąŠčĆąĖčĆąŠą▓ą░čéčī ą┤ąŠčüčéčāą┐ ą▓ čāą║ą░ąĘą░ąĮąĮčāčÄ ąŠą▒ą╗ą░čüčéčī ą┤ąŠ ą╝ąŠą╝ąĄąĮčéą░, ą║ąŠą│ą┤ą░ ą┐čĆąŠčåąĄčüčüąŠčĆ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ čüč湥čéčćąĖą║ ą┐čĆąŠą┐čāčüą║ąŠą▓ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą▓ 0xA, č鹊 ą┐čĆąŠčåąĄčüčüąŠčĆ ąŠčüčéą░ąĮąŠą▓ąĖčéčüčÅ ąĮą░ ą┤ąĄčüčÅč鹊ą╝ čüąŠą▓ą┐ą░ą┤ąĄąĮąĖąĖ ą░ą┤čĆąĄčüą░.
[VisualDSP++ Kernel (VDK)]
VDK čŹč鹊 čÅą┤čĆąŠ čĆąĄą░ą╗čīąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ (čüąŠ čüčéčĆą░ąĮąĮčŗą╝ ąĮą░ąĘą▓ą░ąĮąĖąĄą╝), ą║ąŠč鹊čĆąŠąĄ čāą┐čĆąŠčēą░ąĄčé čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐čĆąŠąĄą║čéą░ą╝ąĖ čü ą╝ąĮąŠą│ąĖą╝ąĖ ąĘą░ą┤ą░čćą░ą╝ąĖ. ą×ą┤ąĮą░ą║ąŠ čŹč鹊 ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé ą║ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÄ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗą╣ čāčĆąŠą▓ąĄąĮčī ą░ą▒čüčéčĆą░ą║čåąĖąĖ. ą¤ąŠ čŹč鹊ą╣ ą┐čĆąĖčćąĖąĮąĄ, ą║ą░ą║ ąĖ ą▓ ą╗čÄą▒ąŠą╣ RTOS, ą▒čŗą▓ą░ąĄčé ąĮą░ą╝ąĮąŠą│ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą╝ąĄčüč鹊 ąŠčłąĖą▒ą║ąĖ ą▓ čüąĖčüč鹥ą╝ąĄ.
VisualDSP++ ąĖą╝ąĄąĄčé ąŠčéą╗ą░ą┤čćąĖą║, ąĖą╝ąĄčÄčēąĖą╣ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠ čÅą┤čĆąĄ, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ą┐ąŠą║ą░ąĘą░čéčī ą┐ąŠą┤čĆąŠą▒ąĮąŠčüčéąĖ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖčÅ čüąĖčüč鹥ą╝čŗ, čćč鹊 ą┐ąŠą╝ąŠąČąĄčé ą▓ ąĮą░čüčéčĆąŠą╣ą║ąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĖ ą▓ ąŠčéą╗ą░ą┤ą║ąĄ čüąĖčüč鹥ą╝čŗ ąĮą░ ą▒ą░ąĘąĄ RTOS. ąŁč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąÆą░ą╝ ą▓ąĖąĘčāą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī čĆą░ąĘąĮčŗąĄ ą┐ąŠč鹊ą║ąĖ ą┐ąŠ ąĘą░čéčĆą░čćąĖą▓ą░ąĄą╝ąŠą╝čā ą▓čĆąĄą╝ąĄąĮąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ąŠą│ą┤ą░ ąŠąĮąĖ ą▓ čüąŠčüč鹊čÅąĮąĖąĖ čĆą░ą▒ąŠčéčŗ, ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĖčÅ, ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ ąĖ čé. ą┤.). ąĪčĆąĄą┤ąĖ ą┤čĆčāą│ąĖčģ ąĮčāąČą┤ ąŠčéą╗ą░ą┤ą║ąĖ čŹč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖąĮčüčéčĆčāą╝ąĄąĮč鹊ą╝ ą┤ą╗čÅ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąĖ ą┐čĆąŠą▒ą╗ąĄą╝čŗ, ą┐ąŠč湥ą╝čā ą║ą░ą║ąŠą╣-č鹊 ąŠčéą┤ąĄą╗čīąĮčŗą╣ ą┐ąŠč鹊ą║ ąĮąĄ ą╝ąŠąČąĄčé ąĘą░ą┐čāčüčéąĖčéčīčüčÅ. ąØą░ čĆąĖčüčāąĮą║ąĄ 6 ą┐ąŠą║ą░ąĘą░ąĮąŠ ąŠą║ąĮąŠ VDK State History.
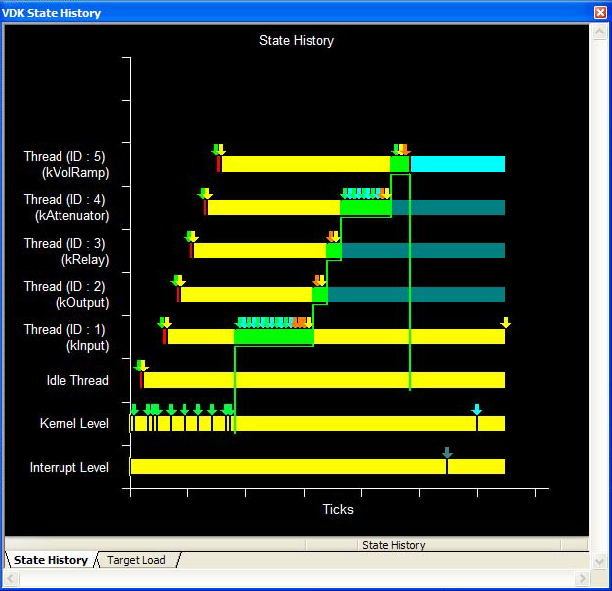
ąĀąĖčü. 6. ą×ą║ąĮąŠ VDK State History (ąŠą║ąĮąŠ ąĖčüč鹊čĆąĖąĖ čüąŠčüč鹊čÅąĮąĖą╣ VDK).
ąŻą▒ąĄą┤ąĖč鹥čüčī ą▓ č鹊ą╝, čćč鹊 ą┐čĆą░ą▓ąĖą╗čīąĮąŠ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮčŗ ą┐čĆąĖąŠčĆąĖč鹥čéčŗ ą┐ąŠč鹊ą║ąŠą▓. ąÆčŗ ą┤ąŠą╗ąČąĮčŗ ąĘąĮą░čéčī ą┐ąŠčéčĆąĄą▒ąĮąŠčüčéąĖ ą║ą░ąČą┤ąŠą╣ ąĘą░ą┤ą░čćąĖ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 čĆą░ą▒ąŠčéčŗ ą▓ čĆąĄą░ą╗čīąĮąŠą╝ ą▓čĆąĄą╝ąĄąĮąĖ. ą×ą║ąĮąŠ VDK State History ą╝ąŠąČąĄčé ą┤ą░čéčī ąĖąĮčüčéčĆčāą╝ąĄąĮčé ą░ąĮą░ą╗ąĖąĘą░ ąŠą▒čēąĄą│ąŠ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą▒ą░ą╗ą░ąĮčüą░ ą▓čĆąĄą╝ąĄąĮąĖ ą╝ąĄąČą┤čā ą┐ąŠč鹊ą║ą░ą╝ąĖ.
ąĢčüčéčī ąĄčēąĄ ąŠą┤ąĮąŠ ą┐ąŠą╗ąĄąĘąĮąŠąĄ ąŠą║ąĮąŠ ąŠčéą╗ą░ą┤ą║ąĖ - VDK Status, ąŠč鹊ą▒čĆą░ąČą░čÄčēąĄąĄ ą┐čĆąĖčćąĖąĮčā ąŠčłąĖą▒ą║ąĖ ą┐ą░ąĮąĖą║ąĖ čÅą┤čĆą░ (kernel panic error).
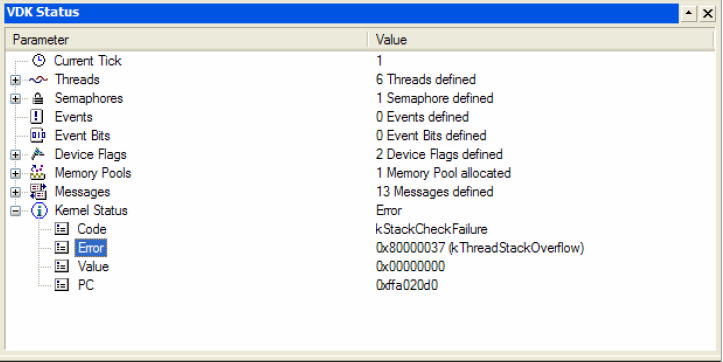
ąĀąĖčü. 7. ą×ą║ąĮąŠ VDK Status.
ą¤čĆąĖą╝ąĄčĆ ąĮą░ čĆąĖčüčāąĮą║ąĄ 7 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ čüč鹥ą║ą░, ą║ąŠč鹊čĆąŠąĄ ą┐čĆąĖą▓ąĄą╗ąŠ ą║ ą┐ą░ąĮąĖą║ąĄ čÅą┤čĆą░. ą¤ąŠą║ą░ąĘą░ąĮąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāąĄčé ą┐ąŠč鹊ą║ (ąĮą░čģąŠą┤čÅčēąĖą╣čüčÅ ą▓ čüąŠčüč鹊čÅąĮąĖąĖ IDLE), ą┤ą╗čÅ ą║ąŠč鹊čĆąŠą│ąŠ čĆą░ąĘą╝ąĄčĆ čüč鹥ą║ą░ ąŠą║ą░ąĘą░ą╗čüčÅ ąĮąĄą┤ąŠčüčéą░č鹊čćąĮčŗą╝.
[ą¤čĆąŠą▒ą╗ąĄą╝čŗ čü ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąĖą╝ąĖ ąŠą▒čŖąĄą║čéą░ą╝ąĖ ąĖ čāą┤ą░ą╗ąĄąĮąĖąĄą╝ ą┐ąŠč鹊ą║ąŠą▓]
ąæčāą┤čīč鹥 ą▓ąĮąĖą╝ą░č鹥ą╗čīąĮčŗ čü ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąĖą╝ąĖ ąŠą▒čŖąĄą║čéą░ą╝ąĖ, ą║ąŠč鹊čĆčŗąĄ čüąŠąĘą┤ą░čÄčéčüčÅ ą▓ ą┐ąŠč鹊ą║ąĄ (čüąŠąĘą┤ą░ąĮąĖąĄ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą▓ ą║ą╗ą░čüčüą░ ąŠą┐ąĄčĆą░č鹊čĆą░ą╝ąĖ new, ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ą▒ą╗ąŠą║ąŠą▓ ą┐ą░ą╝čÅčéąĖ ąĖ ą┐čĆąĖą▓čÅąĘą║ą░ ą║ ąĮąĖą╝ čāą║ą░ąĘą░č鹥ą╗ąĄą╣). ąĢčüą╗ąĖ čŹč鹊čé ą┐ąŠč鹊ą║ ą┐ąŠč鹊ą╝čā ą▒čāą┤ąĄčé čāąĮąĖčćč鹊ąČąĄąĮ, ąĖ ą┐ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ą▒čāą┤ąĄčé čüąŠąĘą┤ą░ąĮ ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║, č鹊 ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąĖ ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗąĄ ąŠą▒čŖąĄą║čéčŗ čü ą▒ąŠą╗čīčłąŠą╣ ą▓ąĄčĆąŠčÅčéąĮąŠčüčéčīčÄ ą▒čāą┤čāčé ą┐ąŠą▓čĆąĄąČą┤ąĄąĮčŗ.
ąĪą░ą╝čŗą╣ ą┐čĆąŠčüč鹊ą╣ čüą┐ąŠčüąŠą▒ ąĖąĘą▒ąĄąČą░čéčī čŹč鹊ą╣ ą┐čĆąŠą▒ą╗ąĄą╝čŗ - čüąŠąĘą┤ą░čéčī ą▓čüąĄ ą┐ąŠč鹊ą║ąĖ ą┐čĆąĖ čüčéą░čĆč鹥 ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ VDK ąĖ ąĮąĖą║ąŠą│ą┤ą░ ą▒ąŠą╗čīčłąĄ ąĮąĄ čāą┤ą░ą╗čÅčéčī ąĖ ąĮąĄ čüąŠąĘą┤ą░ą▓ą░čéčī ą┐ąŠč鹊ą║ąĖ. ąöčĆčāą│ąŠą╣ čüą┐ąŠčüąŠą▒ - ą▓čŗą┤ąĄą╗čÅčéčī ą┐ą░ą╝čÅčéčī/čüąŠąĘą┤ą░ą▓ą░čéčī ąŠą▒čŖąĄą║čéčŗ čüčéą░čéąĖč湥čüą║ąĖ, ą╗ąĖą▒ąŠ ą▓ č鹊ą╝ ą┐ąŠč鹊ą║ąĄ, ą║ąŠč鹊čĆčŗą╣ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čāąĮąĖčćč鹊ąČąĄąĮ.
[ą¤čĆąŠą▒ą╗ąĄą╝čŗ, čüą▓čÅąĘą░ąĮąĮčŗąĄ čü ą║čŹčłąĄą╝]
ąÜąŠą│ą┤ą░ ąĄčüčéčī ą┐ąŠą┤ąŠąĘčĆąĄąĮąĖąĄ ąĮą░ ą┐čĆąŠą▒ą╗ąĄą╝čā čü ą║čŹčłąĄą╝, čüąĮą░čćą░ą╗ą░ ą┐čĆąŠą║ąŠąĮčüčāą╗čīčéąĖčĆčāą╣č鹥čüčī čü ą┐ąŠą┤čģąŠą┤čÅčēąĖą╝ čüą┐ąĖčüą║ąŠą╝ ą▒ą░ą│ąŠą▓ ą┐čĆąŠčåąĄčüčüąŠčĆą░ (processor anomaly list), čćč鹊ą▒čŗ ą┐čĆąŠą▓ąĄčĆąĖčéčī, ąĮąĄ ą┐ąŠą┤čģąŠą┤ąĖčé ą╗ąĖ ąŠčéą┤ąĄą╗čīąĮąŠąĄ ąĮą░ą▒ą╗čÄą┤ą░ąĄą╝ąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐ąŠą┤ ą║ą░ą║ąĖąĄ-č鹊 čģą░čĆą░ą║č鹥čĆąĖčüčéąĖą║ąĖ čüą┐ąĖčüą║ą░.
ąĢčüą╗ąĖ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąŠą║ą░ąĘą░ą╗ąŠčüčī ąĮąĄ ąŠčéąĮąŠčüčÅčēąĖą╝čüčÅ ą║ ąĖąĘą▓ąĄčüčéąĮčŗą╝ ą┐čĆąŠą▒ą╗ąĄą╝ą░ą╝ ą┐čĆąŠčåąĄčüčüąŠčĆą░, ą┐ąŠą┐čŗčéą░ą╣č鹥čüčī ąĖčüą║ą╗čÄčćąĖčéčī ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą║čŹčłą░ ą║ą░ą║ ą┐čĆąĖčćąĖąĮčā, ą┐ąĄčĆąĄą╝ąĄčüčéąĖą▓ ąĖąĮč鹥čĆąĄčüčāčÄčēčāčÄ ąŠą▒ą╗ą░čüčéčī ą▓ ą┐ą░ą╝čÅčéčī L1. ąÆ ą┐čĆąĄą┤čŗą┤čāčēąĖčģ čüąĄą║čåąĖčÅčģ ą▒čŗą╗ąŠ ą┐ąŠą║ą░ąĘą░ąĮąŠ, ą║ą░ą║ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī čŹč鹊čé čĆąĄą│ąĖąŠąĮ. ąŚą░ą┐čāčüčéąĖč鹥 ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ąŠą┤ąĖąĮ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ą║čŹčł ą▓ą║ą╗čÄč湥ąĮą░, ąĖ ą▓č鹊čĆąŠą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ą║čŹčł ą▓čŗą║ą╗čÄč湥ąĮą░. ą¤čĆąŠą░ąĮą░ą╗ąĖąĘąĖčĆčāą╣č鹥, ą▓ č湥ą╝ ąĄčüčéčī ąŠčéą╗ąĖčćąĖčÅ ą▓ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ąĢčüą╗ąĖ ą┐čĆąŠą▒ą╗ąĄą╝ą░ ą▓čüąĄ ąĄčēąĄ ąĮą░ą▒ą╗čÄą┤ą░ąĄčéčüčÅ ą┐čĆąĖ ą▓čŗą║ą╗čÄč湥ąĮąĮąŠą╝ ą║čŹčłąĄ, čŹč鹊 ą╝ąŠąČąĄčé čāą║ą░ąĘčŗą▓ą░čéčī ąĮą░ čāčüą╗ąŠą▓ąĖąĄ ą│ąŠąĮą║ąĖ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą╝ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖąĖ. ąÆčŗą║ą╗čÄč湥ąĮąĖąĄ ą║čŹčłą░ ą╝ąŠąČąĄčé ąĖąĘą╝ąĄąĮąĖčéčī ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąŠčüčéą░ą╗čīąĮąŠą╣ čćą░čüčéąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, čćč鹊 čéą░ą║ąČąĄ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ č鹊ą╝čā, čćč鹊 ąŠčłąĖą▒ą║ą░ ą┐ąĄčĆąĄčüčéą░ąĮąĄčé ąĮą░ą▒ą╗čÄą┤ą░čéčīčüčÅ. ą¤ąŠčŹč鹊ą╝čā ą┐ąŠą┐čĆąŠą▒čāą╣č鹥 ą┐ąĄčĆąĄąĮąĄčüčéąĖ ąĖąĮč鹥čĆąĄčüčāčÄčēąĖą╣ čĆąĄą│ąĖąŠąĮ ą┐ą░ą╝čÅčéąĖ ą▓ L1 ąĖ ąŠčüčéą░ą▓čīč鹥 ą║čŹčł ą▓ą║ą╗čÄč湥ąĮąĮąŠą╣. ąĢčüą╗ąĖ ą┐čĆąŠą▒ą╗ąĄą╝ą░ ąŠčüčéą░ą╗ą░čüčī, ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĖ/ąĖą╗ąĖ ą░ą┐ą┐ą░čĆą░čéąĮą░čÅ ąŠčłąĖą▒ą║ą░ ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ą▓ ąŠą▒ą╗ą░čüčéąĖ ą║ąŠą┤ą░, ą║ąŠč鹊čĆčŗą╣ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ L1, č鹊 čŹč鹊 ąĮąĄ čüą▓čÅąĘą░ąĮąŠ čü ą┐čĆąŠą▒ą╗ąĄą╝ąŠą╣ čåąĄą╗ąŠčüčéąĮąŠčüčéąĖ ą║čŹčłą░.
ąĢčüą╗ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĮą░ą▒ą╗čÄą┤ą░čÄčéčüčÅ, ąŠą▒čĆą░čéąĖč鹥čüčī ą║ čĆą░ąĮąĄąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮąĮąŠą╣ čüąĄą║čåąĖąĖ čüčéą░čéčīąĖ, ą┐ąŠčüą▓čÅčēąĄąĮąĮąŠą╣ ą░ą┐ą┐ą░čĆą░čéąĮčŗą╝ ąŠčłąĖą▒ą║ą░ą╝ ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗą╝ ąĖčüą║ą╗čÄč湥ąĮąĖčÅą╝.
ąÜąŠą│ąĄčĆąĄąĮčéąĮąŠčüčéčī ą║čŹčłą░. ą¤čĆąŠčåąĄčüčüąŠčĆčŗ Blackfin ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé ą║ąŠą│ąĄčĆąĄąĮčéąĮąŠčüčéčī ą╝ąĄąČą┤čā ą┐ą░ą╝čÅčéčīčÄ ą║čŹčłą░ ąĖ ąŠčüąĮąŠą▓ąĮąŠą╣ ą┐ą░ą╝čÅčéčīčÄ. ą×ą▒čŗčćąĮąŠ ą║ąŠą│ąĄčĆąĄąĮčéąĮąŠčüčéčī ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠą▒ą╗ąĄą╝ąŠą╣ ą▓ čüąĖčüč鹥ą╝ą░čģ, ą│ą┤ąĄ ą║ą░ąĮą░ą╗ DMA ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ąŠą▒čĆą░čēą░ąĄčéčüčÅ ą║ ąŠą▒ą╗ą░čüčéąĖ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, ą┤ą╗čÅ ą║ąŠč鹊čĆąŠą╣ ąĘą░ą┤ą░ąĮąŠ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĄ. ąŻ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ ą║čŹčłą░ ąĮąĄčé ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą┐čĆąŠ čéą░ą║ąĖąĄ ą┐ąŠą┐čŗčéą║ąĖ ą┤ąŠčüčéčāą┐ą░, ąĖ ą║ą░ą║ čĆąĄąĘčāą╗čīčéą░čé ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗąĄ (čāčüčéą░čĆąĄą▓čłąĖąĄ) ą┤ą░ąĮąĮčŗąĄ, čćč鹊 ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĮąĄą┐čĆąĄą┤čüą║ą░ąĘčāąĄą╝čŗą╝ čĆąĄąĘčāą╗čīčéą░čéą░ą╝. ą¤čĆąŠą│čĆą░ą╝ą╝ąĮąŠąĄ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖąĄ ą┤ąŠą╗ąČąĮąŠ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ą║ąŠą│ąĄčĆąĄąĮčéąĮąŠčüčéčī ą┐čāč鹥ą╝ čüąĮčÅčéąĖčÅ ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéąĖ čüčéčĆąŠą║ ą║čŹčłą░, ą║ ą┐ą░ą╝čÅčéąĖ ą║ąŠč鹊čĆąŠą│ąŠ ą▒čŗą╗ąŠ ąŠą▒čĆą░čēąĄąĮąĖąĄ čüąŠ čüč鹊čĆąŠąĮčŗ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ DMA.
[ą¤čĆąŠą▒ą╗ąĄą╝čŗ, čüą▓čÅąĘą░ąĮąĮčŗąĄ čü ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅą╝ąĖ]
ąÆ ą║ąŠą┤ąĄ ISR čāą▒ąĄą┤ąĖč鹥čüčī, čćč鹊 ąŠą┐ąĄčĆą░čåąĖąĖ ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖčÅ ą▓ čüč鹥ą║ / ą▓čŗą▒ąŠčĆą║ąĖ ąĖąĘ čüč鹥ą║ą░ (push/pop) čĆąĄčüčāčĆčüąŠą▓ ą┐čĆąŠąĖčüčģąŠą┤čÅčé ą▓ ą┐čĆą░ą▓ąĖą╗čīąĮąŠą╝ ą┐ąŠčĆčÅą┤ą║ąĄ. ąóą░ą║ąČąĄ ąŠą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ ąĮą░ ąŠčéą┤ąĄą╗čīąĮčāčÄ ą▓ą░ąČąĮąŠčüčéčī ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖčÅ/ą▓čŗą▒ąŠčĆą║ąĖ RETI. ąÜąŠą│ą┤ą░ RETI ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĄčéčüčÅ ą▓ čüč鹥ą║, ą▓ą╗ąŠąČąĄąĮąĮąŠčüčéčī ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ čĆą░ąĘčĆąĄčłą░ąĄčéčüčÅ; ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ ą▓čŗą▒ąŠčĆą║ą░ ąĖąĘ čüč鹥ą║ą░ RETI čüąĮąŠą▓ą░ ąĘą░ą┐čĆąĄčēą░ąĄčé ą▓ą╗ąŠąČąĄąĮąĮąŠčüčéčī ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ [4]. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąĄčüą╗ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ čü ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ ąĮąĄ ą┤ąŠą╗ąČąĮčŗ ą┐čĆąĄčĆą▓ą░čéčī čĆą░ą▒ąŠčéčā ą║ąŠą┤ą░ ISR, č鹊 ąĮąĄ ą┤ąĄą╗ą░ą╣č鹥 ą▓ čŹč鹊ą╝ ISR ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖąĄ RETI ą▓ čüč鹥ą║. ąĢčüą╗ąĖ ąÆčŗ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆčāąĄč鹥 ąĮą░ C/C++, ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ISR, ąĮąĄ ą┐ąŠąĘą▓ąŠą╗čÅčÄčēąĖą╣ ą▓ą╗ąŠąČąĄąĮąĮąŠčüčéčī:
EX_INTERRUPT_HANDLER(Timer_handler)
ąĢčüą╗ąĖ ą▓ą╗ąŠąČąĄąĮąĮąŠčüčéčī ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī čĆą░ąĘčĆąĄčłąĄąĮą░ ą┤ą╗čÅ čćą░čüčéąĮąŠą│ąŠ ISR, ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 čüą╗ąĄą┤čāčÄčēąĄąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ISR:
EX_REENTRANT_HANDLER(Timer_handler)
ąŁč鹊čé čĆąĄąĄąĮčéčĆą░ąĮčéąĮčŗą╣ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĄčé ą▓ čüč鹥ą║ RETI ą▓ ąĮą░čćą░ą╗ąĄ čüą▓ąŠąĄą│ąŠ ą║ąŠą┤ą░, ąĖ ą▓čŗą▒ąĖčĆą░ąĄčé ąĄą│ąŠ ą▓ ą║ąŠąĮčåąĄ čüą▓ąŠąĄą│ąŠ ą║ąŠą┤ą░ (ą┤ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ RTI).
ą¦č鹊ą▒čŗ ą┐čĆąĄą┤ąŠčéą▓čĆą░čéąĖčéčī ą╝ąĮąŠą│ąŠą║čĆą░čéąĮčŗą╣ ą▓čģąŠą┤ ą▓ č鹊čé ąČąĄ čüą░ą╝čŗą╣ ISR, ąŠčćąĖčüčéąĖč鹥 ą▓ ISR ą┐čĆąĖčćąĖąĮčā ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ą┐ąĄčĆąĄą┤ ą▓čŗčģąŠą┤ąŠą╝ ąĖąĘ ISR. ąØą░ą┐čĆąĖą╝ąĄčĆ ą┤ą╗čÅ čéą░ą╣ą╝ąĄčĆą░ čÅą┤čĆą░ ąŠčćąĖčüčéą║ą░ ą▒ąĖčéą░ TINT (timer interrupt) ą▓ čĆąĄą│ąĖčüčéčĆąĄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čéą░ą╣ą╝ąĄčĆąŠą╝ čÅą┤čĆą░ ąŠčćąĖčüčéąĖčé ą┐čĆąĖčćąĖąĮčā ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ.
ąÜąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą▓ą╗ąŠąČąĄąĮąĮčŗąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąĖąĘą▒ąĄą│ą░ą╣č鹥 ą┐čĆąŠą▒ą╗ąĄą╝, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▓ąŠąĘąĮąĖą║ąĮčāčéčī ąĖąĘ-ąĘą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąŠą▒čēąĖčģ čĆąĄčüčāčĆčüąŠą▓. ą£ąĖąĮąĖą╝ąĖąĘą░čåąĖčÅ ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ISR ą┐ąŠąĘą▓ąŠą╗ąĖčé ąĮąĖąĘą║ąŠą┐čĆąĖąŠčĆąĖč鹥čéąĮčŗą╝ ISR ą▒čŗčéčī čéą░ą║ąČąĄ ąŠą▒čĆą░ą▒ąŠčéą░ąĮąĮčŗą╝ąĖ ą▓ ąĮčāąČąĮąŠąĄ ą▓čĆąĄą╝čÅ. ąĪąŠčģčĆą░ąĮąĄąĮąĖąĄ ISR ą║ąŠčĆąŠčéą║ąĖą╝ čéą░ą║ąČąĄ čāą╝ąĄąĮčīčłą░ąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ą▓ ISR čĆąĄčüčāčĆčüąŠą▓, čćč鹊 ąŠą▒ą╗ąĄą│čćą░ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüč鹥ą║ą░. ą¤čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ą▓ą╗ąŠąČąĄąĮąĮčŗčģ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ ą╝ąŠąČąĄčé ą▓ąŠąĘąĮąĖą║ąĮčāčéčī ą┤čĆčāą│ą░čÅ ą┐čĆąŠą▒ą╗ąĄą╝ą░ - ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ čüč鹥ą║ą░. ą×ą┤ąĖąĮ ąĖąĘ čüą┐ąŠčüąŠą▒ąŠą▓ ą┤ąĄč鹥ą║čéąĖčĆąŠą▓ą░čéčī ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ čüč鹥ą║ą░ (ą┤ą░ąČąĄ ą║ ą│ą╗čāą▒ąŠą║ąŠ ą▓ą╗ąŠąČąĄąĮąĮčŗčģ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ą░čģ) čŹč鹊 čćč鹥ąĮąĖąĄ čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░ (SP) ą▓ ąĮą░čćą░ą╗ąĄ ISR, čćč鹊ą▒čŗ ą┐čĆąŠą▓ąĄčĆąĖčéčī, ąĮą░čģąŠą┤ąĖčéčüčÅ ą╗ąĖ ąŠąĮ ą▓ą▒ą╗ąĖąĘąĖ ą║ąŠąĮčåą░ čüč鹥ą║ą░.
[ą¤ąŠą╗ąĄąĘąĮčŗąĄ ą║ąŠą╝ą░ąĮą┤čŗ ą▓ čüčĆąĄą┤ąĄ VisualDSP++]
ąĪą╗ąĄą┤čāčÄčēąĖąĄ ą║ąŠą╝ą░ąĮą┤čŗ ą┐ąŠą╗ąĄąĘąĮčŗ ą┤ą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąŠčéą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░ąĮąĮčŗą╝ ą┐čĆąŠąĄą║č鹊ą╝ ąĖ ąĄą│ąŠ ąŠčéą╗ą░ą┤ą║ąĖ:
| ąÜąŠą╝ą░ąĮą┤ą░ |
ą¤čāąĮą║čé ą╝ąĄąĮčÄ |
Shortcut |
ąŚą░ą╝ąĄčćą░ąĮąĖčÅ |
| ąŚą░ą┐čāčüą║ čüąĄčüčüąĖąĖ ąŠčéą╗ą░ą┤ą║ąĖ |
Session ŌåÆ Connect to target |
|
ą×čüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖąĄ ąŠčéą╗ą░ą┤čćąĖą║ą░ (ICE) ą║ ą┐čĆąŠčåąĄčüčüąŠčĆčā DSP č湥čĆąĄąĘ JTAG. ą¤ąŠčüą╗ąĄ čāčüą┐ąĄčłąĮąŠą│ąŠ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖčÅ ą║ ą┐čĆąŠčåąĄčüčüąŠčĆčā ąĮą░ ą┐ą╗ą░čłą║ąĄ ąŠą║ąĮą░ VisualDSP++ ąŠč鹊ą▒čĆą░ąĘąĖčéčüčÅ ąĖą╝čÅ čüąĄčüąĖąĖ (ąŠą▒čŗčćąĮąŠ ąĖą╝čÅ čüąĄčüčüąĖąĖ čüąŠčüč鹊ąĖčé ąĖąĘ target, ą╝ąŠą┤ąĄą╗ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĖ ą╝ąŠą┤ąĄą╗ąĖ 菹╝čāą╗čÅč鹊čĆą░ JTAG, ąĮą░ą┐čĆąĖą╝ąĄčĆ "ADSP-BF538 via ICE-100B"). |
| ąŚą░ą▓ąĄčĆčłąĄąĮąĖąĄ čüąĄčüčüąĖąĖ ąŠčéą╗ą░ą┤ą║ąĖ |
Session ŌåÆ Disconnect from target |
|
ą×čéą║ą╗čÄč湥ąĮąĖąĄ ąŠčéą╗ą░ą┤čćąĖą║ą░ ąŠčé ą┐čĆąŠčåąĄčüčüąŠčĆą░ DSP. |
| ąŚą░ą│čĆčāąĘą║ą░ ąĖčüą┐ąŠą╗ąĮčÅąĄą╝ąŠą│ąŠ ą║ąŠą┤ą░ (*.dxe) |
File ŌåÆ Load Program... |
Ctrl + L |
ąśčüą┐ąŠą╗ąĮčÅąĄą╝čŗą╣ ą║ąŠą┤ ą▒čāą┤ąĄčé ąĘą░ą│čĆčāąČąĄąĮ ą▓ ąŠą┐ąĄčĆą░čéąĖą▓ąĮčāčÄ ą┐ą░ą╝čÅčéčī (ąŠą▒čŗčćąĮąŠ čŹč鹊 L1 ąĖą╗ąĖ L1, L3) ą┐čĆąŠčåąĄčüčüąŠčĆą░ DSP. ą¤ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆ ą▒čāą┤ąĄčé ąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą▓ ąĮą░čćą░ą╗ąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ (ąŠą▒čŗčćąĮąŠ čŹč鹊 ąĮą░čćą░ą╗ąŠ č鹥ą╗ą░ čäčāąĮą║čåąĖąĖ main). |
| ąŚą░ą┐čāčüą║ ą║ąŠą┤ą░ ąĮą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ |
Debug ŌåÆ Run |
F5 |
ąŁč鹊čé ą┐čāąĮą║čé ą╝ąĄąĮčÄ čüčéą░ąĮąŠą▓ąĖčéčüčÅ ą░ą║čéąĖą▓ąĮčŗą╝ ą┐ąŠčüą╗ąĄ ąĘą░ą┐čāčüą║ą░ čüąĄčüčüąĖąĖ ąŠčéą╗ą░ą┤ą║ąĖ. ąŚą░ą│čĆčāąČąĄąĮąĮčŗą╣ ą║ąŠą┤ ąĘą░ą┐čāčüčéąĖčéčüčÅ ąĮą░ ąĮąĄą┐čĆąĄčĆčŗą▓ąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ (ą┐ąŠą║ą░ ąĮąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąĖčüą╗čÄč湥ąĮąĖąĄ ąŠčłąĖą▒ą║ąĖ ąĖą╗ąĖ ąĮąĄ ą▓čüčéčĆąĄčéąĖčéčüčÅ č鹊čćą║ą░ ąŠčüčéą░ąĮąŠą▓ą░). |
| ą×čüčéą░ąĮąŠą▓ą║ą░ čĆą░ą▒ąŠčéą░čÄčēąĄą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ |
Debug ŌåÆ Halt |
Shift + F5 |
ąŁčéąĖ čäčāąĮą║čåąĖąĖ (ąĖ ą┐čāąĮą║čéčŗ ą╝ąĄąĮčÄ) ą┤ąŠčüčéčāą┐ąĮčŗ č鹊ą╗čīą║ąŠ ą┐ąŠčüą╗ąĄ ąĘą░ą┐čāčüą║ą░ čüąĄčüčüąĖąĖ ąŠčéą╗ą░ą┤ą║ąĖ. |
| ą¤čĆąŠčüą╝ąŠčéčĆ čüč鹥ą║ą░ ą▓čŗąĘąŠą▓ąŠą▓ |
View ŌåÆ Debug windows ŌåÆ Call stack |
|
| ą¤čĆąŠčüą╝ąŠčéčĆ ą┤ąĖąĘą░čüčüąĄą╝ą▒ą╗ąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ ą║ąŠą┤ą░ |
View ŌåÆ Debug windows ŌåÆ Disassembly |
|
| ą¤čĆąŠčüą╝ąŠčéčĆ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ ą┐ą░ą╝čÅčéąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ |
Memory ŌåÆ Blackfin Memory |
|
Call Stack. ąŁč鹊 ąŠč湥ąĮčī ą┐ąŠą╗ąĄąĘąĮąŠąĄ ąĖąĮč乊čĆą╝ą░čåąĖąŠąĮąĮąŠąĄ ąŠą║ąĮąŠ, ą┐ąŠą╝ąŠą│ą░čÄčēąĄąĄ ąĖąĮąŠą│ą┤ą░ ą▓ čüą╗čāčćą░ąĄ ą┐čĆąŠą▒ą╗ąĄą╝ ąĮą░ą╣čéąĖ ąŠčłąĖą▒ąŠčćąĮąŠąĄ ą╝ąĄčüč鹊 ą▓ ą║ąŠą┤ąĄ. ąÜąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ąŠą┤ą░ ąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ ą▓ ąŠčéą╗ą░ą┤čćąĖą║ąĄ, ąŠą║ąĮąŠ Call Stack ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé č鹥ą║čāčēčāčÄ ąĖčüč鹊čĆąĖčÄ ą▓čŗąĘąŠą▓ąŠą▓ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ ą┐ąŠ ąŠčéąĮąŠčłąĄąĮąĖčÄ ą║ čüč鹥ą║čā. ąØąĖąČąĄ ą┐čĆąĖą╝ąĄčĆ čüą║čĆąĖąĮčłąŠčéą░ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čüąĄą╣čćą░čü ą▓čŗąĘą▓ą░ąĮą░ ąĮąĄą║ą░čÅ čäčāąĮą║čåąĖčÅ sportCallbackFunctionRX, čćč鹊 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ ą┐ąŠčüą╗ąĄ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ DMACallback (čüčāą┤čÅ ą┐ąŠ ąĮą░ąĘą▓ą░ąĮąĖčÄ, čŹč鹊 čäčāąĮą║čåąĖąĖ ąŠą▒čĆą░čéąĮąŠą│ąŠ ą▓čŗąĘąŠą▓ą░, ąŠą▒čŗčćąĮąŠ ą┐čĆąĖą╝ąĄąĮčÅąĄą╝čŗąĄ ą▓ čüčéą░ąĮą┤ą░čĆčéąĮčŗčģ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░čģ VDK ąĖ System Services ADI). ąÆ čüą░ą╝ąŠą╝ ąĮąĖąĘčā čüą┐ąĖčüą║ą░ ą▓ąĖą┤ąĄąĮ čüą░ą╝čŗą╣ ą┐ąĄčĆą▓čŗą╣ ą▓čŗąĘąŠą▓ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ: čäčāąĮą║čåąĖčÅ VDK::Thread::RunFunc.
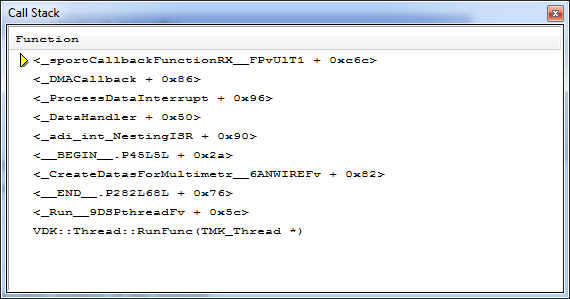
ą×ą║ąĮąŠ Call Stack ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé č鹥ą║čāčēąĖą╣ čüąĮąĖą╝ąŠą║ čüąŠčüč鹊čÅąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ą¤čĆąĖ ąĮą░ą╗ąĖčćąĖąĖ čüą╗ąŠąČąĮąŠą│ąŠ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ ą┐čĆąŠąĄą║čéą░ VDK, ą║ąŠąĮč鹥ą║čüčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮ čÅą┤čĆąŠą╝ ąĖą╗ąĖ ą┐ąŠ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÄ, čéą░ą║ čćč鹊 ą╝čŗ ą╝ąŠąČąĄą╝ čāą▓ąĖą┤ąĄčéčī ą▓ čŹč鹊ą╝ ąŠą║ąĮąĄ čüąŠą▓ąĄčĆčłąĄąĮąĮąŠ ą┤čĆčāą│čāčÄ ą║ą░čĆčéąĖąĮčā ą┤ą░ąČąĄ č湥čĆąĄąĘ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą╝ąĖą║čĆąŠčüąĄą║čāąĮą┤. ąØąĖąČąĄ ą▓ ą║ą░č湥čüčéą▓ąĄ ą┐čĆąĖą╝ąĄčĆą░ ą┐ąŠą║ą░ąĘą░ąĮ ąĄčēąĄ ąŠą┤ąĖąĮ čüą║čĆąĖąĮčłąŠčé ąŠą║ąĮą░ Call Stack č鹊ą│ąŠ ąČąĄ čüą░ą╝ąŠą│ąŠ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, ąŠą┤ąĮą░ą║ąŠ ąĘą┤ąĄčüčī ą╝čŗ ą▓ąĖą┤ąĖą╝ ąŠčüčéą░ąĮąŠą▓ą║čā ą▓ čäčāąĮą║čåąĖąĖ ą┐ąŠč鹊ą║ą░ ąŠąČąĖą┤ą░ąĮąĖčÅ, ą▓čŗąĘąŠą▓ ą║ąŠč鹊čĆąŠą╣ ą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║ąĖ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ čÅą┤čĆąŠą╝ VDK.
Disassembly. ą×ą║ąĮąŠ ą┤ąĖąĘą░čüčüąĄą╝ą▒ą╗ąĄčĆą░ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą░čüčüąĄą╝ą▒ą╗ąĄčĆąĮčŗą╣ ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ą╗ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ (ąŠą▒čŗčćąĮąŠ čŹč鹊 ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ C/C++). ąÜąŠą│ą┤ą░ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ąĘą░ą│čĆčāąČąĄąĮą░, ąĮąŠ ąĄčēąĄ ąĮąĄ ąĘą░ą┐čāčēąĄąĮą░, č鹊 ą╝čŗ čāą▓ąĖą┤ąĖą╝ ąŠą║ąĮąŠ ą┤ąĖąĘą░čüčüąĄą╝ą▒ą╗ąĄčĆą░ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ čüą╗ąĄą┤čāčÄčēąĄą│ąŠ:

ąæąŠą╗čīčłąĄ ą▓čüąĄą│ąŠ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖ ą▓ ąŠą║ąĮąĄ ą┤ąĖąĘą░čüčüąĄą╝ą▒ą╗ąĄčĆą░ ą▒čāą┤ąĄčé ą┐čĆąĖ ąŠčéą┤ą░ą┤ą║ąĄ ą┐čĆąŠąĄą║čéą░, čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ ą▓ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ Debug (ą╝čŗ čāą▓ąĖą┤ąĖą╝ ąĖą╝ąĄąĮą░ čäčāąĮą║čåąĖą╣ ąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ). ąśąĮč乊čĆą╝ą░čåąĖčÅ ąŠą║ąĮą░ ą┤ąĖąĘą░čüčüąĄą╝ą▒ą╗ąĄčĆą░ ą┐čĆąŠąĄą║čéą░, čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ ą▓ Release, ą▒čāą┤ąĄčé čüčāčēąĄčüčéą▓ąĄąĮąĮąŠ ą▒ąĄą┤ąĮąĄąĄ.
Memory. ą¦č鹊ą▒čŗ ą┐čĆąŠąĖąĮčüą┐ąĄą║čéąĖčĆąŠą▓ą░čéčī čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░, ą▓čŗą┐ąŠą╗ąĮąĖč鹥 čüą╗ąĄą┤čāčÄčēąĖąĄ čłą░ą│ąĖ:
1. ąŚą░ą│čĆčāąĘąĖč鹥 ąĖ ąĘą░ą┐čāčüčéąĖč鹥 čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░ąĮąĮąŠąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ą▓ čüčĆąĄą┤ąĄ VisualDSP++.
2. ąØą░ąČą╝ąĖč鹥 ą║ąŠą╝ą▒ąĖąĮą░čåąĖčÄ ą║ą╗ą░ą▓ąĖčł Shift+F5 ą┤ą╗čÅ ąŠčüčéą░ąĮąŠą▓ą║ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
3. ąÆčŗą▒ąĄčĆąĖč鹥 ą▓ ą╝ąĄąĮčÄ Memory -> BLACKFIN Memory.
4. ąÆą▓ąĄą┤ąĖč鹥 ą▓ ą┐čāčüč鹊ą╝ ą┐ąŠą╗ąĄ ą▓čŗą┐ą░ą┤ą░čÄčēąĄą│ąŠ čüą┐ąĖčüą║ą░ ą░ą▒čüąŠą╗čÄčéąĮčŗą╣ čłąĄčüčéąĮą░ą┤čåą░č鹥čĆąĖčćąĮčŗą╣ ą░ą┤čĆąĄčü ąĮą░čćą░ą╗ą░ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčāčÄ čģąŠčéąĖč鹥 ą┐čĆąŠčüą╝ąŠčéčĆąĄčéčī, ąĖą╗ąĖ ą╝ąĄčéą║čā, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēčāčÄ čüąĖą╝ą▓ąŠą╗ąĖč湥čüą║ąŠą╝čā ąĖą╝ąĄąĮąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣, čäčāąĮą║čåąĖąĖ ąĖą╗ąĖ ą╝ą░čüčüąĖą▓ą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą▓ą▓ąĄą┤ąĖč鹥 ąĖą╝čÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ __Processor_cycles_per_sec).
5. ąØą░ąČą╝ąĖč鹥 ą║ą╗ą░ą▓ąĖčłčā Enter, ąĖ ąÆčŗ čāą▓ąĖą┤ąĖč鹥 ą▓ ąŠą║ąĮąĄ ąŠč鹊ą▒čĆą░ąČąĄąĮąĖąĄ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ čāą║ą░ąĘą░ąĮąĮąŠą│ąŠ čāčćą░čüčéą║ą░ ą┐ą░ą╝čÅčéąĖ.
6. ąÜąŠąĮč鹥ą║čüčéąĮąŠąĄ ą╝ąĄąĮčÄ ąŠą║ąĮą░ BLACKFIN Memory (ą┤ąŠčüčéčāą┐ąĮąŠąĄ ą┐čĆą░ą▓čŗą╝ ą║ą╗ąĖą║ąŠą╝ ą╝čŗčłąĖ) ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą▓čŗą▒čĆą░čéčī ąŠą┤ąĖąĮ ąĖąĘ ą▓ąŠąĘą╝ąŠąČąĮčŗčģ č乊čĆą╝ą░č鹊ą▓ ąŠč鹊ą▒čĆą░ąČąĄąĮąĖčÅ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ ą┐ą░ą╝čÅčéąĖ (č湥čĆąĄąĘ ą┐čāąĮą║čé Select Format).
Statistical Profiling. ąĪčéą░čéąĖčüčéąĖč湥čüą║ąĖą╣ ą┐čĆąŠčäąĖą╗ąĖčĆąŠą▓čēąĖą║ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą▓čŗčÅą▓ąĖčéčī ą▓čŗčüąŠą║ąŠąĮą░ą│čĆčāąČąĄąĮąĮčŗąĄ čāčćą░čüčéą║ąĖ ą║ąŠą┤ą░, čé. ąĄ. ą▓ ą║ą░ą║ąŠą╣ čćą░čüčéąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą┐čĆąŠčåąĄčüčüąŠčĆ ą▒ąŠą╗čīčłąĄ ą▓čüąĄą│ąŠ čéčĆą░čéąĖčé čüą▓ąŠąĄą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ. ąŁč鹊 ąŠą▒ą╗ąĄą│čćą░ąĄčé ą░ą╗ą│ąŠčĆąĖčéą╝ąĖč湥čüą║čāčÄ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖčÄ ą║ąŠą┤ą░, ąĖ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┤ąŠą▒ąĖčéčīčüčÅ čŹčäč乥ą║čéąĖą▓ąĮąŠą│ąŠ ąĖ ą▒čŗčüčéčĆąŠ čĆą░ą▒ąŠčéą░čÄčēąĄą│ąŠ ą║ąŠą┤ą░ (ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. [7]).
[ą×ą▒čēąĖąĄ ą▓čŗą▓ąŠą┤čŗ]
ąŁč鹊čé EE-Note ąŠą┐ąĖčüčŗą▓ą░ąĄčé ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░čĆąĖą╣ VDK ąĖ čäčāąĮą║čåąĖąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin, ą║ąŠč鹊čĆčŗąĄ ą┤ąŠčüčéčāą┐ąĮčŗ ą┤ą╗čÅ ą┐ąŠą╝ąŠčēąĖ ą▓ ą┐ąŠąĖčüą║ąĄ čĆąĄčłąĄąĮąĖčÅ ą┐čĆąŠą▒ą╗ąĄą╝.
ą¤čĆąĄąČą┤ąĄ ą▓čüąĄą│ąŠ ą┐čĆąŠą▓ąĄčĆčÅą╣č鹥 čüą┐ąĖčüąŠą║ ąŠčłąĖą▒ąŠą║ ą┤ą╗čÅ ąÆą░čłąĄą╣ čĆąĄą▓ąĖąĘąĖąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ (anomaly list), čćč鹊ą▒čŗ ą┐čĆąŠą▓ąĄčĆąĖčéčī, čćč鹊 ą┐ąŠą┤ąŠą▒ąĮą░čÅ ą┐čĆąŠą▒ą╗ąĄą╝ą░ čāąČąĄ ąĖąĘą▓ąĄčüčéąĮą░. ąĢčüą╗ąĖ čŹč鹊 čéą░ą║, čćč鹊 čĆąĄą░ą╗ąĖąĘčāą╣č鹥 ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮąŠąĄ ąŠą▒čģąŠą┤ąĮąŠąĄ čĆąĄčłąĄąĮąĖąĄ ą┐čĆąŠą▒ą╗ąĄą╝čŗ. ą¦č鹊ą▒čŗ ą░ą▓č鹊ą╝ą░čéąĖąĘąĖčĆąŠą▓ą░čéčī ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčāčÄ ą┐ąŠą┤ą┤ąĄčƹȹ║čā ąĖąĘą▓ąĄčüčéąĮčŗčģ silicon errata, čāą▒ąĄą┤ąĖč鹥čüčī, čćč鹊 ą┐ąŠą╗čīąĘčāąĄč鹥čüčī ą┐ąŠčüą╗ąĄą┤ąĮąĖą╝ąĖ ą▓ąĄčĆčüąĖčÅą╝ąĖ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░čĆąĖčÅ, ąĖ čĆą░ąĘčĆąĄčłąĄąĮčŗ ą╝ąĄč鹊ą┤čŗ ąŠą▒čģąŠą┤ą░ ą┐čĆąŠą▒ą╗ąĄą╝ ą║čĆąĄą╝ąĮąĖčÅ (silicon workarounds).
ą¤čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą┤ąŠą╗ąČąĮčŗ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čéčī ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ čüąŠą▒čŗčéąĖą╣ (ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖą╣, ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣) ą┤ąŠ ąĘą░ą┐čāčüą║ą░ ąŠčüąĮąŠą▓ąĮąŠą│ąŠ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, čćč鹊ą▒čŗ ąÆčŗ ą╝ąŠą│ą╗ąĖ ą┐ąĄčĆąĄčģą▓ą░čéčŗą▓ą░čéčī ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗąĄ čüąŠą▒čŗčéąĖčÅ.
ą¤čĆąŠą▓ąĄčĆčīč鹥, ą║ą░ą║ čĆą░ą▒ąŠčéą░ąĄčé čüąĖčüč鹥ą╝ą░. ą¦č鹊 č鹊čćąĮąŠ ąĮąĄ čĆą░ą▒ąŠčéą░ąĄčé ą┤ąŠą╗ąČąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝? ąōąĄąĮąĄčĆąĖčĆčāčÄčéčüčÅ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ/ą░ą┐ą┐ą░čĆą░čéąĮčŗąĄ ąŠčłąĖą▒ą║ąĖ? ąĢčüą╗ąĖ čŹč鹊 čéą░ą║, č鹊 čćč鹊 ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĖ/ąĖą╗ąĖ ą░ą┐ą┐ą░čĆą░čéąĮą░čÅ ąŠčłąĖą▒ą║ą░? ąóą░ą▒ą╗ąĖčåčŗ ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ A ą┐ąŠą╝ąŠą│čāčé ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī čŹč鹊. ąØą░ą▒ą╗čÄą┤ą░čÄčéčüčÅ ą╗ąĖ ąĮą░ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ą░čģ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ/ąŠą┐čāčüč鹊賹ĄąĮąĖąĄ ą▒čāč乥čĆą░? ąōąĄąĮąĄčĆąĖčĆčāčÄčéčüčÅ ą╗ąĖ ąŠčłąĖą▒ą║ąĖ DMA?
ąØą░ą╣ą┤ąĖč鹥 čüą┐ąŠčüąŠą▒ čāą▓ąĄą╗ąĖčćąĖčéčī ą▓ąĄčĆąŠčÅčéąĮąŠčüčéčī ą┐ąŠą▓č鹊čĆąĄąĮąĖčÅ ąŠčłąĖą▒ą║ąĖ. ąźąŠčéčÅ čŹč鹊 ąĮąĄ ą▓čüąĄą│ą┤ą░ ą┐ąŠą╗čāčćą░ąĄčéčüčÅ, čāą▓ąĄą╗ąĖč湥ąĮąĖąĄ čćą░čüč鹊čéčŗ ą▓ąŠąĘąĮąĖą║ąĮąŠą▓ąĄąĮąĖčÅ ą┐čĆąŠą▒ą╗ąĄą╝čŗ čāą▓ąĄą╗ąĖčćąĖą▓ą░čÄčé čłą░ąĮčüčŗ ą┤ą╗čÅ ąĖčüą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐čĆąŠą▒ą╗ąĄą╝čŗ. ąÜ čāą▓ąĄą╗ąĖč湥ąĮąĖčÄ ą┐ąŠą▓č鹊čĆčÅąĄą╝ąŠčüčéąĖ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ čāą▓ąĄą╗ąĖč湥ąĮąĖąĄ ąĖą╗ąĖ čüąŠą║čĆą░čēąĄąĮąĖąĄ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ąĖč鹥čĆą░čåąĖą╣ čåąĖą║ą╗ą░, ąĖąĘą╝ąĄąĮąĄąĮąĖąĄ ąĮą░ą┐čĆčÅąČąĄąĮąĖčÅ ą┐ąĖčéą░ąĮąĖčÅ čÅą┤čĆą░, ą┐ąŠą┤čüčéčĆąŠą╣ą║ą░ čćą░čüč鹊čé čÅą┤čĆą░ ąĖ/ąĖą╗ąĖ čüąĖčüč鹥ą╝čŗ, ąĖ čé. ą┤. ąĪą╗ąĄą┤čāąĄčé ąĘą░ą╝ąĄčéąĖčéčī, čćč鹊 ąĮčāąČąĮąŠ ą┤ąĄą╗ą░čéčī č鹊ą╗čīą║ąŠ ąŠą┤ąĮąŠ ąĖąĘą╝ąĄąĮąĄąĮąĖąĄ ąĘą░ ąŠą┤ąĖąĮ čĆą░ąĘ. ąĢčüą╗ąĖ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ ąŠčłąĖą▒ą║čā, ąŠčüčéą░ą▓čīč鹥 ą┐čĆąĄąČąĮąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ąĖ čüą┤ąĄą╗ą░ą╣č鹥 ą║ą░ą║ąŠąĄ-č鹊 ą┤čĆčāą│ąŠąĄ ąĮąŠą▓ąŠąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖąĄ.
ąśčüą┐ąŠą╗čīąĘčāą╣č鹥 ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗąĄ č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░ ą┤ą╗čÅ ąĖčüčüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ čüąŠčüč鹊čÅąĮąĖčÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą┤ąŠ čüčĆą░ą▒ą░čéčŗą▓ą░ąĮąĖčÅ ąŠčłąĖą▒ą║ąĖ. ąĢčüą╗ąĖ čüą▒ąŠą╣ čüčĆą░ą▒ą░čéčŗą▓ą░ąĄčé, ą║ąŠą│ą┤ą░ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮčŗ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗąĄ č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░, č鹊 ą┐ąŠą┐čĆąŠą▒čāą╣č鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓čüčéčĆąŠąĄąĮąĮčŗąĄ č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░, ąĖą╗ąĖ, ą║ą░ą║ čüą░ą╝ąŠąĄ ąČąĄčüčéą║ąŠąĄ čüčĆąĄą┤čüčéą▓ąŠ, ą░ą┐ą┐ą░čĆą░čéąĮčŗąĄ č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░.
ąĢčüą╗ąĖ ą│ąĄąĮąĄčĆąĖčĆčāčÄčéčüčÅ ą░ą┐ą┐ą░čĆą░čéąĮčŗąĄ ąŠčłąĖą▒ą║ąĖ/ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ąĮą░ą╣ą┤ąĖč鹥 čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖąĄ ą┐čĆąĖčćąĖąĮčŗ ąĖąĘ čĆąĄą│ąĖčüčéčĆą░ čüąŠčüč鹊čÅąĮąĖčÅ čüąĄą║ą▓ąĄąĮčüąĄčĆą░, ąĖ ą┐čĆąŠą▓ąĄčĆčīč鹥 čéą░ą▒ą╗ąĖčåčŗ ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ A, čćč鹊ą▒čŗ čāą▓ąĖą┤ąĄčéčī, čćč鹊 ą╝ąŠą│ą╗ąŠ čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī čéą░ą║ąĖąĄ čüąŠą▒čŗčéąĖčÅ.
ą¤ąĄčĆąĄčģą▓ą░čéčŗą▓ą░ą╣č鹥 ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖčģ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░čģ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ąĖčüą┐ąŠą╗čīąĘčāčÅ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗąĄ ąĖą╗ąĖ ą░ą┐ą┐ą░čĆą░čéąĮčŗąĄ č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░.
ąśčüą┐ąŠą╗čīąĘčāą╣č鹥 ąŠą║ąĮąŠ čéčĆą░čüčüąĖčĆąŠą▓ą║ąĖ (Trace window), čćč鹊ą▒čŗ ąĖčüčüą╗ąĄą┤ąŠą▓ą░čéčī ą┐ąĄčĆąĄčģąŠą┤čŗ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą┤ąŠ ą╝ąŠą╝ąĄąĮčéą░ ą▓ąŠąĘąĮąĖą║ąĮąŠą▓ąĄąĮąĖčÅ ą┐čĆąŠą▒ą╗ąĄą╝čŗ.
ąĪąŠčģčĆą░ąĮąĖč鹥 ą▓čüąĄ čĆąĄą│ąĖčüčéčĆčŗ ą┤ą╗čÅ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĄą│ąŠ ą░ąĮą░ą╗ąĖąĘą░, čćč鹊 ą╝ąŠąČąĮąŠ ą▓ VisualDSP++ čüą┤ąĄą╗ą░čéčī ą▓čŗą▒ąŠčĆąŠą╝ ą╝ąĄąĮčÄ Register->Save Registers, ą║ą░ą║ čŹč鹊 ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮą░ čĆąĖčüčāąĮą║ąĄ 8.
ąĀąĖčü. 8. ążčāąĮą║čåąĖčÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓.
ąĢčüą╗ąĖ ą┐ąŠčüą╗ąĄ ą▓čüąĄčģ ą▓čŗčłąĄąŠą┐ąĖčüą░ąĮąĮčŗčģ čłą░ą│ąŠą▓ ąĖčüą┐čĆą░ą▓ąĖčéčī ąŠčłąĖą▒ą║čā ąĮąĄ ą┐ąŠą╗čāčćą░ąĄčéčüčÅ, č鹊 ąĘąĮą░čÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī čüąŠą▒čŗčéąĖą╣, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąĖą▓ąŠą┤čÅčé ą║ ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮąŠą╝čā ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÄ, ąÆčŗ čüą╝ąŠąČąĄč鹥 čüąŠąĘą┤ą░čéčī ą╝ą░ą╗ąĄąĮčīą║ąŠąĄ č鹥čüč鹊ą▓ąŠąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ą┤ą╗čÅ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖčÅ ąŠčłąĖą▒ą║ąĖ. ąÜą░ą║ č鹊ą╗čīą║ąŠ čéą░ą║ąŠą╣ č鹥čüč鹊ą▓čŗą╣ ą║ąĄą╣čü čüąŠąĘą┤ą░ąĮ, čüą┤ąĄą╗ą░ą╣č鹥 ąŠą▒ąŠą▒čēąĄąĮąĖąĄ ąĮą░ą╣ą┤ąĄąĮąĮąŠą╣ ąÆą░ą╝ąĖ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą┤ą╗čÅ čüą╗čāąČą▒čŗ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ, ąĖ ą▓čŗčłą╗ąĖč鹥 čŹčéčā ąĖąĮč乊čĆą╝ą░čåąĖčÄ ą▓ą╝ąĄčüč鹥 čü č鹥čüč鹊ą▓čŗą╝ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄą╝. ąŁč鹊 ą┐ąŠąĘą▓ąŠą╗ąĖčé ą▒čŗčüčéčĆąŠ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄčüčéąĖ ą┐čĆąŠą▒ą╗ąĄą╝čā, čćč鹊 ąŠč湥ąĮčī ą┐ąŠą╝ąŠąČąĄčé ą▓ ąĄčæ čĆąĄčłąĄąĮąĖąĖ.
[ą×čéą╗ą░ą┤ą║ą░ Release]
ą¦ą░čüč鹊 ą▓čüčéčĆąĄčćą░čÄčéčüčÅ čüąĖčéčāą░čåąĖąĖ, ą║ąŠą│ą┤ą░ ą┐čĆąŠąĄą║čé čĆą░ą▒ąŠčéą░ąĄčé ą▓ Debug, ą░ ą▓ Release ąĮąĄčé. ąŁč鹊 čüąĖą│ąĮą░ą╗ąĖąĘąĖčĆčāąĄčé ąŠ čÅą▓ąĮąŠą╣ ąŠčłąĖą▒ą║ąĄ. ą×ą┤ąĮą░ą║ąŠ ąĮąĄčüą╝ąŠčéčĆčÅ ąĮą░ č鹊, čćč鹊 ąÆčŗ ą╝ąŠąČąĄč鹥 ą▓ ąŠčéą╗ą░ą┤čćąĖą║ąĄ ąĘą░ą┐čāčüčéąĖčéčī ą┐čĆąŠąĄą║čé, čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą▓ Release, ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ąŠčéą╗ą░ą┤ą║ąĖ čéą░ą║ąŠą╣ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ čüčāčēąĄčüčéą▓ąĄąĮąĮąŠ ąŠą│čĆą░ąĮąĖč湥ąĮčŗ. ąØąĄą╗čīąĘčÅ čüčéą░ą▓ąĖčéčī č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░ ą▓ ąĖčüčģąŠą┤ąĮąŠą╝ ą║ąŠą┤ąĄ (ą╝ąŠąČąĮąŠ čüčéą░ą▓ąĖčéčī č鹊ą╗čīą║ąŠ ą▓ ąŠą║ąĮąĄ Disassembler), ąĘą░čéčĆčāą┤ąĮąĄąĮ (čģąŠčéčÅ ą▓ąŠąĘą╝ąŠąČąĄąĮ, ąŠ č湥ą╝ ą┤ą░ą╗ąĄąĄ) ą┐čĆąŠčüą╝ąŠčéčĆ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ ą┐ąŠ ąĖčģ ąĖą╝ąĄąĮą░ą╝ ąĖ čé. ą┤. ą¦č鹊 ą╝ąŠąČąĮąŠ čüą┤ąĄą╗ą░čéčī ą▓ čéą░ą║ąŠą╝ čüą╗čāčćą░ąĄ? ąØąĖąČąĄ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮčŗ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐ąŠą╗ąĄąĘąĮčŗčģ čüąŠą▓ąĄč鹊ą▓ ą┐ąŠ ąŠčéą╗ą░ą┤ą║ąĄ ą▓ čéą░ą║ąŠą╣ čüąĖčéčāą░čåąĖąĖ.
ąĪą▓ąĄč鹊ą┤ąĖąŠą┤. ąŁč鹊 čüą░ą╝čŗą╣ ą┐čĆąŠčüč鹊ą╣ ąĖ ą▒čŗčüčéčĆčŗą╣ ą╝ąĄč鹊ą┤ ą┤ąĖą░ą│ąĮąŠčüčéąĖą║ąĖ, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ ą░ąĮą░ą╗ąĖąĘą░ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ą£ąŠąČąĮąŠ ąĖąĘą╝ąĄčĆčÅčéčī (čü ą┐ąŠą╝ąŠčēčīčÄ ąŠčüčåąĖą╗ą╗ąŠą│čĆą░čäą░) ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąŠčéą┤ąĄą╗čīąĮčŗčģ čāčćą░čüčéą║ąŠą▓ ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą│ąŠ ą║ąŠą┤ą░, ą░ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī ą┐čĆąŠčģąŠą┤ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą┐ąŠ čĆą░ąĘąĮčŗą╝ ą▓ąĄčéą║ą░ą╝ ą║ąŠą┤ą░ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
ą×čĆą│ą░ąĮąĖąĘą░čåąĖčÅ ą╗ąŠą│ą░. ą£ąŠąČąĮąŠ čüą┤ąĄą╗ą░čéčī č鹥ą║čüč鹊ą▓čŗą╣ ą╗ąŠą│, ą▓ ą║ąŠč鹊čĆčŗą╣ ą▓čŗą▓ąŠą┤čÅčéčüčÅ ą┤ąĖą░ą│ąĮąŠčüčéąĖč湥čüą║ąĖąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ. ąśą£ąźą× ąĖą┤ąĄą░ą╗čīąĮčŗą╣ ą╗ąŠą│ - ą▓čŗą▓ąŠą┤ ą┤ąĖą░ą│ąĮąŠčüčéąĖą║ąĖ ą▓ ą║ąŠąĮčüąŠą╗čī č鹥čĆą╝ąĖąĮą░ą╗ą░ č湥čĆąĄąĘ ą┐ąŠčĆčé UART. ą¤ąŠą┤čĆąŠą▒ąĮąŠ čüą┐ąŠčüąŠą▒čŗ ą▓ą▓ąŠą┤ą░/ą▓čŗą▓ąŠą┤ą░ ąŠą┐ąĖčüą░ąĮčŗ ą▓ [5].
ąśą╝ąĄą╣č鹥 ą▓ ą▓ąĖą┤čā, čćč鹊 ą▓čŗą▓ąŠą┤ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ (printf), ąĮą░čüčéčĆąŠąĄąĮąĮčŗą╣ ą▓ ąĮą░ ąŠč鹊ą▒čĆą░ąČąĄąĮąĖąĄ čüąŠąŠą▒čēąĄąĮąĖą╣ ą▓ ąŠą║ąĮąĄ Console VisualDSP++, čĆą░ą▒ąŠčéą░ąĄčé ąŠč湥ąĮčī ą╝ąĄą┤ą╗ąĄąĮąĮąŠ, ą┐ąŠčŹč鹊ą╝čā ą┤ą╗čÅ ąŠčéą╗ą░ą┤ą║ąĖ ąŠč湥ąĮčī ąĮąĄčāą┤ąŠą▒ąĄąĮ, ą┐ąŠčüą║ąŠą╗čīą║čā ą▓ą╗ąĖčÅąĄčé ąĮą░ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą▓ čĆąĄą░ą╗čīąĮąŠą╝ ą▓čĆąĄą╝ąĄąĮąĖ.
ąÜą░ą║ ą▓ą░čĆąĖą░ąĮčé ą╝ąŠąČąĮąŠ čüą┤ąĄą╗ą░čéčī ąĘą░ą┐ąĖčüčī ą╗ąŠą│ą░ ą▓ ą┐ą░ą╝čÅčéčī. ąĪą┐ąŠčüąŠą▒ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖąĖ čéą░ą║ąŠą│ąŠ ą╗ąŠą│ą░ ąĘą░ą▓ąĖčüąĖčé ąŠčé ąŠčüąŠą▒ąĄąĮąĮąŠčüč鹥ą╣ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čüąĖčüč鹥ą╝čŗ ąĖ ąĮą░ą╗ąĖčćąĖčÅ čüą▓ąŠą▒ąŠą┤ąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ.
ą¤čĆąŠčüą╝ąŠčéčĆ ąĘąĮą░č湥ąĮąĖą╣ ą│ą╗ąŠą▒ą░ą╗čīąĮčŗčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ. ąöą╗čÅ č鹊ą│ąŠ, čćč鹊ą▒čŗ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą┐čĆąŠčüą╝ąŠčéčĆąĄčéčī ą▓ ąŠčéą╗ą░ą┤čćąĖą║ąĄ ąĘąĮą░č湥ąĮąĖąĄ ą│ą╗ąŠą▒ą░ą╗čīąĮčŗčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ ą┐čĆąŠąĄą║čéą░ Release, ąĮčāąČąĮąŠ čüąĮą░čćą░ą╗ą░ čāąĘąĮą░čéčī ąĖčģ ą░ą▒čüąŠą╗čÄčéąĮčŗąĄ ą░ą┤čĆąĄčüą░. ąóąŠą│ą┤ą░ ą╝ąŠąČąĮąŠ ąĮą░ą╣čéąĖ čŹčéąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ ąĮą░ ą║ą░čĆč鹥 ą┐ą░ą╝čÅčéąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░, ąĖ ą┐čĆąŠčüą╝ąŠčéčĆąĄčéčī ąĖčģ ąĘąĮą░č湥ąĮąĖčÅ ą▓ ąŠą║ąĮą░čģ Blackfin MEMORY, Disassembly ąĖ ą┤ą░ąČąĄ ą▓ ąŠą║ąĮąĄ Expressions (ą║ąŠąĮąĄčćąĮąŠ, ąĮčāąČąĮąŠ ąŠčüčéą░ąĮąŠą▓ąĖčéčī ą▓ ąŠčéą╗ą░ą┤čćąĖą║ąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ąĮą░ąČą░ą▓ Shift-F5).
ąÉą┤čĆąĄčü ąĮčāąČąĮąŠą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ą╝ąŠąČąĮąŠ čāąĘąĮą░čéčī ą┐ąŠ ąĄčæ ąĖą╝ąĄąĮąĖ ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ. ąÆąŠ-ą┐ąĄčĆą▓čŗčģ, ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ ą╝ąŠąČąĮąŠ ąĮą░ą╣čéąĖ ą┐ąŠ ąĖą╝ąĄąĮąĖ, ąĄčüą╗ąĖ ą┐ąŠčüčéą░ą▓ąĖčéčī ą▓ą┐ąĄčĆąĄą┤ąĖ čüąĖą╝ą▓ąŠą╗ ą┐ąŠą┤č湥čĆą║ąĖą▓ą░ąĮąĖčÅ (demangle-ąĖą╝čÅ). ąØąĖąČąĄ ą┐ąŠą║ą░ąĘą░ąĮ čüą║čĆąĖąĮčłąŠčé, ą│ą┤ąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ inSB ąĮą░ą╣ą┤ąĄąĮą░ ą┐ąŠ ąĄčæ ąĖą╝ąĄąĮąĖ _inSB.
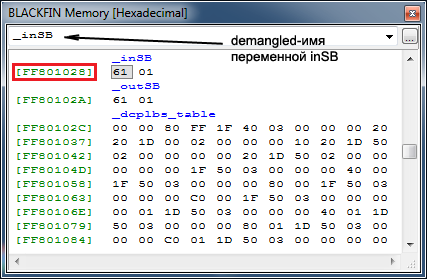
ąÆąŠ-ą▓č鹊čĆčŗčģ, ą╝ąŠąČąĮąŠ ąĮą░ą╣čéąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ ą▓ map-čäą░ą╣ą╗ąĄ, ą║ąŠč鹊čĆčŗą╣ ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ą▓ ą┐čĆąŠčåąĄčüčüąĄ ą╗ąĖąĮą║ąŠą▓ą║ąĖ (ąĄčüą╗ąĖ ą┐ąŠčüčéą░ą▓ąĖčéčī ą│ą░ą╗ąŠčćą║čā "Generate symbol map" ą▓ čüą▓ąŠą╣čüčéą▓ą░čģ ą┐čĆąŠąĄą║čéą░, čüą╝. Project Options -> Link -> General -> Additional Output), ąĖ ąŠčéčéčāą┤ą░ čāąĘąĮą░čéčī ąĄčæ ą░ą▒čüąŠą╗čÄčéąĮčŗą╣ ą░ą┤čĆąĄčü. ą¤ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ą╝ąŠąČąĮąŠ ąĮą░ą╣čéąĖ ąĖ ą┐čĆąŠčüą╝ąŠčéčĆąĄčéčī ąĘąĮą░č湥ąĮąĖąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ą┐ąŠ ąĄą│ąŠ ą░ą┤čĆąĄčüčā ą▓ ąŠą║ąĮąĄ Expressions (čüą╝. čüą║čĆąĖąĮčłąŠčé ąĮąĖąČąĄ).

ą¤ąŠąĖčüą║ ąĮčāąČąĮąŠą│ąŠ ą║ąŠą┤ą░ ą▓ ą┤ą░ą╝ą┐ąĄ Disassembly. ąÉąĮą░ą╗ąŠą│ąĖčćąĮčŗą╝ąĖ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ, ą║ą░ą║ ąĮą░čģąŠą┤čÅčé ą│ą╗ąŠą▒ą░ą╗čīąĮčŗąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ, ą╝ąŠąČąĮąŠ ąĮą░ą╣čéąĖ ą║ąŠą┤ ą▓ ąŠą║ąĮąĄ Disassembly - č湥čĆąĄąĘ demangled ąĖą╝ąĄąĮą░ čäčāąĮą║čåąĖą╣ ąĖ čü ą┐ąŠą╝ąŠčēčīčÄ map-čäą░ą╣ą╗ą░. ąóąŠą│ą┤ą░ ą╝ąŠąČąĮąŠ čüčéą░ą▓ąĖčéčī č鹊čćą║čā ąŠčüčéą░ąĮąŠą▓ą░ ą┐čĆčÅą╝ąŠ ą▓ ą┤ą░ą╝ą┐ Disassembly. ąØąĖąČąĄ ąĮą░ čüą║čĆąĖąĮčłąŠčéą░čģ ą▓ ą║ą░č湥čüčéą▓ąĄ ą┐čĆąĖą╝ąĄčĆą░ ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąŠčåąĄčüčü ą┐ąŠąĖčüą║ą░ ą║ąŠą┤ą░ čäčāąĮą║čåąĖąĖ ą┐ąŠ ąĖą╝ąĄąĮąĖ ą▓ map-čäą░ą╣ą╗ąĄ.
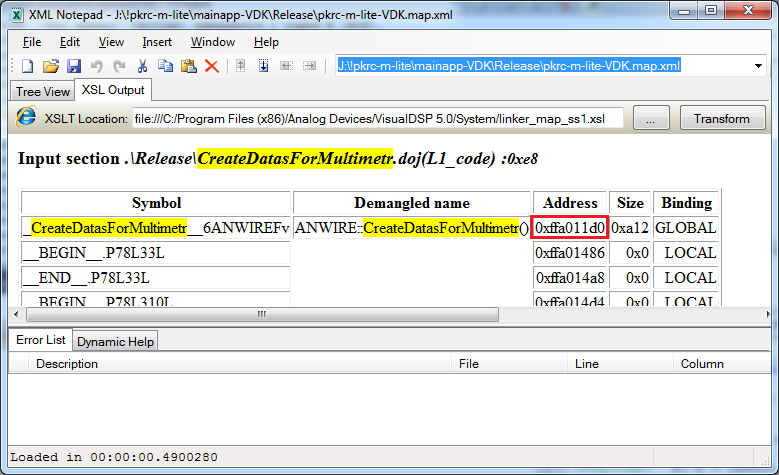

ąöąĄą╗ąĄąĮąĖąĄ ą║ąŠą┤ą░ ąĮą░ čćą░čüčéąĖ. ą¤čĆąĖ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ ąĖčüčüą╗ąĄą┤čāąĄą╝čāčÄ čćą░čüčéčī ą║ąŠą┤ą░, ą║ąŠč鹊čĆą░čÅ ą┐ąŠą┤ąŠąĘčĆąĄą▓ą░ąĄčéčüčÅ ąĮą░ ąŠčłąĖą▒ą║čā, ą╝ąŠąČąĮąŠ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░čéčī ą▒ąĄąĘ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ, ą░ ą▓ąĄčüčī ąŠčüčéą░ą╗čīąĮąŠą╣ ą┐čĆąŠąĄą║čé čü ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĄą╣, ą▓ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ Release. ąóąŠą│ą┤ą░ ą▓ čāčćą░čüčéą║ąĄ ą║ąŠą┤ą░, ą║ąŠč鹊čĆčŗą╣ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░ąĮ ą▒ąĄąĘ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ, ą╝ąŠąČąĮąŠ čüčéą░ą▓ąĖčéčī č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░ ą║ą░ą║ ąŠą▒čŗčćąĮąŠ, ąĖ ą║ą░ą║ ąŠą▒čŗčćąĮąŠ ą┐čĆąŠčüą╝ą░čéčĆąĖą▓ą░čéčī čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ.
ąöą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĄą╣ čü ą┐ąŠą╝ąŠčēčīčÄ ą┤ąĖčĆąĄą║čéąĖą▓čŗ #pragma optimize, čü ą┐ąŠą╝ąŠčēčīčÄ ąĮąĄčæ ą╝ąŠąČąĮąŠ ąŠčéą║ą╗čÄčćą░čéčī ąŠą┐čéąĖą╝ąĖąĘą░čåąĖčÄ ą┤ą╗čÅ ąŠčéą┤ąĄą╗čīąĮčŗčģ čäčāąĮą║čåąĖą╣ (čüą╝. [8]). ąśąĮąŠą│ą┤ą░ čāą┤ąŠą▒ąĮąĄąĄ ą┐ąĄčĆąĄąĮąĄčüčéąĖ ąĖčüčüą╗ąĄą┤čāąĄą╝čŗą╣ ą║ąŠą┤ ą▓ ąŠčéą┤ąĄą╗čīąĮčŗą╣ ą╝ąŠą┤čāą╗čī, ąĖ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░čéčī ąĄą│ąŠ ąŠčéą┤ąĄą╗čīąĮąŠ ą▒ąĄąĘ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ ą▓ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║čā.
ąóą░ą▒ą╗ąĖčåą░ 1. ąĪąŠą▒čŗčéąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąĖą▓ąŠą┤čÅčé ą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÅą╝.
| ąśčüą║ą╗čÄč湥ąĮąĖąĄ |
EXCAUSE |
ąóąĖą┐(1) |
ą¤čĆąĖą╝ąĄčćą░ąĮąĖčÅ/ą┐čĆąĖą╝ąĄčĆčŗ |
| ąśąĮčüčéčĆčāą║čåąĖčÅ EXCPT, ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ ąĘą░ą┐čāčüą║ą░čÄčēą░čÅ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ, čü 4-ą▒ąĖčéąĮčŗą╝ ą┐ąŠą╗ąĄą╝ m. |
ą┐ąŠą╗ąĄ m |
S |
ąśąĮčüčéčĆčāą║čåąĖčÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé 4-ą▒ąĖčéąĮčŗą╣ ą║ąŠą┤ ą┤ą╗čÅ ą┐ąŠą╗čÅ EXCAUSE. |
| ą×ą┤ąĖąĮ čłą░ą│. |
0x10 |
S |
ąÜąŠą│ą┤ą░ ą┐čĆąŠčåąĄčüčüąŠčĆ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą┐ąŠčłą░ą│ąŠą▓ąŠą╝ čĆąĄąČąĖą╝ąĄ, ą║ą░ąČą┤ą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą║ąŠą┤ą░ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ. ą×ą▒čŗčćąĮąŠ čŹč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ąŠčéą╗ą░ą┤ą║ąĖ. |
| ąśčüą║ą╗čÄč湥ąĮąĖąĄ, ą║ ą║ąŠč鹊čĆąŠą╝čā ą┐čĆąĖą▓ąĄą┤ąĄčé ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ ą▒čāč乥čĆą░ čéčĆą░čüčüąĖčĆąŠą▓ą║ąĖ. |
0x11 |
S |
ą¤čĆąŠčåąĄčüčüąŠčĆ ą┐ąŠą╗čāčćą░ąĄčé čŹč鹊 ąĖčüą║ą╗čÄč湥ąĮąĖąĄ, ą║ąŠą│ą┤ą░ ą┐ąĄčĆąĄą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą▒čāč乥čĆ čéčĆą░čüčüąĖčĆąŠą▓ą║ąĖ (č鹊ą╗čīą║ąŠ ą║ąŠą│ą┤ą░ čŹčéą░ čäčāąĮą║čåąĖčÅ čĆą░ąĘčĆąĄčłąĄąĮą░ čĆąĄą│ąĖčüčéčĆąŠą╝ Trace Unit Control). |
| Undefined instruction (ąĮąĄąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ). |
0x21 |
E |
ą£ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ čŹą╝čāą╗čÅčåąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣, ą║ąŠč鹊čĆą░čÅ ąĮąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮą░ ą┤ą╗čÅ čŹč鹊ą╣ ą╝ąŠą┤ąĄą╗ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ (čé. ąĄ. ą┤ą╗čÅ čĆą░čüčłąĖčĆąĄąĮąĖčÅ čüąĖčüč鹥ą╝čŗ ą║ąŠą╝ą░ąĮą┤ ą┐čĆąŠčåąĄčüčüąŠčĆą░). |
| Illegal instruction combination (ąĮąĄą┤ąŠą┐čāčüčéąĖą╝ą░čÅ ą║ąŠą╝ą▒ąĖąĮą░čåąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ). |
0x22 |
E |
ąĪą╝. čüąĄą║čåąĖčÄ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ą░ [1], ą┐ąŠčüą▓čÅčēąĄąĮąĮčāčÄ ą┐čĆą░ą▓ąĖą╗ą░ą╝ ą╝ąĮąŠąČąĄčüčéą▓ąĄąĮąĮčŗčģ ąŠčłąĖą▒ąŠą║ (multi-issue rules). |
| Data access CPLB protection violation |
0x23 |
E |
ąĪą┤ąĄą╗ą░ąĮą░ ą┐ąŠą┐čŗčéą║ą░ ą┐čĆąŠčćąĖčéą░čéčī ąĖą╗ąĖ ąĘą░ą┐ąĖčüą░čéčī čĆąĄčüčāčĆčü, ą┤ąŠčüčéčāą┐ąĮčŗą╣ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ čĆąĄąČąĖą╝ą░ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░, ąĖą╗ąĖ ą▒čŗą╗ ąĮąĄą┤ąŠą┐čāčüčéąĖą╝čŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ. ąĀąĄčüčāčĆčüą░ą╝ąĖ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ čÅą▓ą╗čÅčÄčéčüčÅ čĆąĄą│ąĖčüčéčĆčŗ ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮčŗ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆąŠą╝: čĆąĄą│ąĖčüčéčĆčŗ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░, ą▓čüąĄ MMR ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ąŠčéąĮąŠčüčÅčēąĖąĄčüčÅ č鹊ą╗čīą║ąŠ ą║ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆčā (ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗą╣, ą┤ą▓ąŠą╣ąĮąŠą╣ ą┤ąŠčüčéčāą┐ ą║ ą┤ą▓čāą╝ MMR čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ DAG-ąŠą▓ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé čéą░ą║ąŠą╣ čéąĖą┐ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ). ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ čŹčéą░ ąĘą░ą┐ąĖčüčī ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖąĖ ąŠ ąĮą░čĆčāčłąĄąĮąĖąĖ ąĘą░čēąĖčéčŗ, ą▓čŗąĘą▓ą░ąĮąĮąŠą╝ ąĮąĄčĆą░ąĘčĆąĄčłąĄąĮąĮčŗą╝ ą┤ąŠčüčéčāą┐ąŠą╝ ą║ ą┐ą░ą╝čÅčéąĖ, ąĖ čŹč鹊 ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąŠ ą▒ą╗ąŠą║ąŠą╝ Memory Management Unit (MMU) ąĘą░čēąĖčēąĄąĮąĮąŠą│ąŠ ą║čŹčłąĖčĆčāąĄą╝ąŠą│ąŠ ą▒čāč乥čĆą░ (cacheability protection lookaside buffer, CPLB). |
| Data access misaligned address violation |
0x24 |
E |
ąĪą┤ąĄą╗ą░ąĮą░ ą┐ąŠą┐čŗčéą║ą░ ąĮąĄ ą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą│ąŠ ą┐ąŠ ą░ą┤čĆąĄčüčā ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ ą┤ą░ąĮąĮčŗčģ ąĖą╗ąĖ ą┤ą░ąĮąĮčŗą╝ ą║čŹčłą░. |
| Unrecoverable event |
0x25 |
E |
ąØąĄą▓ąŠčüčüčéą░ąĮąŠą▓ąĖą╝ąŠąĄ čüąŠą▒čŗčéąĖąĄ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ą▒čŗą╗ąŠ čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąŠ ą┐čĆąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĄ ą┐čĆąĄą┤čŗą┤čāčēąĄą│ąŠ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ. |
| Data access CPLB miss |
0x26 |
E |
ąśčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą▒ą╗ąŠą║ąŠą╝ MMU ą┤ą╗čÅ čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖąĖ ąŠ ą┐čĆąŠą╝ą░čģąĄ CPLB ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ ą┤ą░ąĮąĮčŗą╝. |
| Data access multiple CPLB hits |
0x27 |
E |
ąöą╗čÅ ą▓čŗą▒ąŠčĆą║ąĖ ą░ą┤čĆąĄčüą░ ą┤ą░ąĮąĮčŗčģ ąĄčüčéčī ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą╣ čüąŠą▓ą┐ą░ą┤ą░čÄčēąĄą╣ ąĘą░ą┐ąĖčüąĖ CPLB. |
| Watchpoint match |
0x28 |
E |
ąśčüą║ą╗čÄč湥ąĮąĖąĄ, ą▓čŗąĘą▓ą░ąĮąĮąŠąĄ čüąŠą▓ą┐ą░ą┤ąĄąĮąĖąĄą╝ č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░ ąŠčéą╗ą░ą┤ą║ąĖ. ą¤čĆąĖ čŹč鹊ą╝ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ąŠą┤ąĖąĮ ąĖąĘ ą▒ąĖč鹊ą▓ EMUSW ą▓ čĆąĄą│ąĖčüčéčĆąĄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čāčüčéą░ąĮąŠą▓ą║ąĖ ą║ąŠąĮčéčĆąŠą╗čīąĮąŠą╣ č鹊čćą║ąĖ (Watchpoint Instruction Address Control register, WPIACTL). |
| Instruction fetch misaligned address violation |
0x2A |
E |
ąĪą┤ąĄą╗ą░ąĮą░ ą┐ąŠą┐čŗčéą║ą░ ąĮąĄ ą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą╣ ą▓čŗą▒ąŠčĆą║ąĖ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ą¤čĆąĖ čéą░ą║ąŠą╝ ą▓ąĖą┤ąĄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą░ą┤čĆąĄčü ą▓ąŠąĘą▓čĆą░čéą░ ą▒čāą┤ąĄčé ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮ ą▓ čĆąĄą│ąĖčüčéčĆąĄ RETX, ąĖ ąĖą╝ąĄąĮąĮąŠ čŹč鹊čé ą░ą┤čĆąĄčü ą▓čŗčĆąŠą▓ąĮąĄąĮ ąŠčłąĖą▒ąŠčćąĮąŠ, ą░ ąĮąĄ ą░ą┤čĆąĄčü ąĮą░čĆčāčłą░čÄčēąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą┐čĆąŠąĖąĘąŠčłą╗ąŠ ą║ąŠčüą▓ąĄąĮąĮąŠąĄ ą▓ąĄčéą▓ą╗ąĄąĮąĖąĄ ąĮą░ ąŠčłąĖą▒ąŠčćąĮąŠ ą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗą╣ ą░ą┤čĆąĄčü ą▓ čĆąĄą│ąĖčüčéčĆąĄ P0, č鹊 ą░ą┤čĆąĄčü ą▓ąŠąĘą▓čĆą░čéą░ ą▓ RETX ą▒čāą┤ąĄčé čĆą░ą▓ąĄąĮ P0, ą░ ąĮąĄ ą░ą┤čĆąĄčüčā ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ. (ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čŹč鹊 ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą▒čāą┤ąĄčé čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąŠ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮčŗą╝ąĖ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅą╝ąĖ ąŠčé PC, ąŠąĮąŠ ą▒čāą┤ąĄčé ą┤ąĄą╣čüčéą▓ąŠą▓ą░čéčī č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą║ąŠčüą▓ąĄąĮąĮąŠą│ąŠ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ.) ąöą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ADSP-BF535 ąĄčüčéčī čüą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ. |
| Instruction fetch CPLB protection violation |
0x2B |
E |
ąØąĄą┤ąŠą┐čāčüčéąĖą╝ą░čÅ ą▓čŗą▒ąŠčĆą║ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ąŠčüčéčāą┐ą░ (memory protection violation, ąĮą░čĆčāčłąĄąĮąĖąĄ ąĘą░čēąĖčéčŗ ą┐ą░ą╝čÅčéąĖ). |
| Instruction fetch CPLB miss |
0x2C |
E |
ą¤čĆąŠą╝ą░čģ CPLB ąĮą░ ą▓čŗą▒ąŠčĆą║ąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ. |
| Instruction fetch multiple CPLB hits |
0x2D |
E |
ąÉą┤čĆąĄčüčā ą▓čŗą▒ąŠčĆą║ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą╣ čüąŠą▓ą┐ą░ą┤ą░čÄčēąĄą╣ ąĘą░ą┐ąĖčüąĖ CPLB. |
| Illegal use of supervisor resource |
0x2E |
E |
ąĪą┤ąĄą╗ą░ąĮą░ ą┐ąŠą┐čŗčéą║ą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čĆąĄą│ąĖčüčéčĆą░ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ ąĖą╗ąĖ ąĄą│ąŠ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖąĘ čĆąĄąČąĖą╝ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (User mode). ąĀąĄčüčāčĆčüčŗ ąĖ čĆąĄą│ąĖčüčéčĆčŗ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮčŗ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą▓ čĆąĄąČąĖą╝ąĄ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░. ąŁč鹊 čĆąĄą│ąĖčüčéčĆčŗ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░, ą▓čüąĄ MMR, ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĮčŗąĄ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░. |
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: E ąŠąĘąĮą░čćą░ąĄčé ąŠčłąĖą▒ą║čā (Error), S ąŠąĘąĮą░čćą░ąĄčé čüą╗čāąČą▒čā (Service).
ąóą░ą▒ą╗ąĖčåą░ 2. ąÉą┐ą┐ą░čĆą░čéąĮčŗąĄ čāčüą╗ąŠą▓ąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąĖą▓ąŠą┤čÅčé ą║ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅą╝ ą░ą┐ą┐ą░čĆą░čéąĮąŠą╣ ąŠčłąĖą▒ą║ąĖ.
| ąÉą┐ą┐ą░čĆą░čéąĮąŠąĄ čāčüą╗ąŠą▓ąĖąĄ |
HWERRCAUSE (hex)
|
ą¤čĆąĖą╝ąĄčćą░ąĮąĖčÅ/ą┐čĆąĖą╝ąĄčĆčŗ |
| System MMR Error |
0x02 |
ą×čłąĖą▒ą║ą░ ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ, ąĄčüą╗ąĖ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┤ąŠčüčéčāą┐ ą║ ąĮąĄą┤ąŠą┐čāčüčéąĖą╝ąŠą╝čā čüąĖčüč鹥ą╝ąĮąŠą╝čā MMR, ąĄčüą╗ąĖ ą║ 32-čĆą░ąĘčĆčÅą┤ąĮąŠą╝čā čĆąĄą│ąĖčüčéčĆčā ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąŠą▒čĆą░čēąĄąĮąĖąĄ ąĖąĘ 16-čĆą░ąĘčĆčÅą┤ąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ąĖą╗ąĖ ąĄčüą╗ąĖ ą║ 16-čĆą░ąĘčĆčÅą┤ąĮąŠą╝čā čĆąĄą│ąĖčüčéčĆčā ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ ąĖąĘ 32-čĆą░ąĘčĆčÅą┤ąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. |
| External Memory Addressing Error |
0x03 |
(ąØąĄ ą┐čĆąĖą╝ąĄąĮąĖą╝ąŠ ą║ BF535) ą▒čŗą╗ą░ čüą┤ąĄą╗ą░ąĮą░ ą┐ąŠą┐čŗčéą║ą░ čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąĖčÅ ąĮąĄ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ. |
| Performance Monitor Overflow |
0x12 |
ą¤ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ ą╝ąŠąĮąĖč鹊čĆą░ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖčÅ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆą░ąĘą┤ąĄą╗ "Performance Monitor Unit" čĆčāą║ąŠą▓ąŠą┤čüčéą▓ą░ [1]. |
| RAISE 5 instruction |
0x18 |
ą¤čĆąŠą│čĆą░ą╝ą╝ą░ ą▓čŗą┤ą░ą╗ą░ ąĖąĮčüčéčĆčāą║čåąĖčÄ RAISE 5 ą┤ą╗čÅ ą▓čŗąĘąŠą▓ą░ Hardware Error Interrupt (IVHW). |
| ąŚą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąŠ |
ą▓čüąĄ ą┤čĆčāą│ąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ |
|
[ąĪčüčŗą╗ą║ąĖ]
1. Blackfin® Processor Troubleshooting Tips Using VisualDSP++® Tools site:analog.com.
2. ADSP-BF533 Blackfin Booting Process (EE-240) site:analog.com.
3. ADSP-BF53x/ADSP-BF56x Programming Reference site:analog.com.
4. ADSP-BF538: ąŠą▒čĆą░ą▒ąŠčéą║ą░ čüąŠą▒čŗčéąĖą╣ (ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ).
5. Blackfin: č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą▓čŗą▓ąŠą┤ ą▓ ąŠą║ąĮąŠ č鹥čĆą╝ąĖąĮą░ą╗ą░ č湥čĆąĄąĘ UART.
6. ąÜąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖ ąŠčéą╗ą░ą┤ą║ą░ ą┐čĆąŠąĄą║č鹊ą▓ VDK.
7. VisualDSP++: ą┐ąŠą┤čüč湥čé čåąĖą║ą╗ąŠą▓ ąĖ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│.
8. VisualDSP: čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĄą╣ ą║ąŠą┤ą░.
9. ą×čéą╗ą░ą┤čćąĖą║ąĖ Blackfin. |



