|
ąĪčĆąĄą┤ą░ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ VisualDSP++┬« ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čāčéąĖą╗ąĖčéčŗ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą▓ čåąĄą╗čÅčģ ą┐ąŠą▓čŗčłąĄąĮąĖčÅ ąĄą│ąŠ čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéąĖ (čüą║ąŠčĆąŠčüčéąĖ čĆą░ą▒ąŠčéčŗ). ąŁčéąĖ čāčéąĖą╗ąĖčéčŗ ą┤ą░čÄčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą░ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī ąÆą░čłąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ, ąŠą┐čĆąĄą┤ąĄą╗čÅčéčī ąĖ čāčüčéčĆą░ąĮčÅčéčī ą▓ ąĮąĄą╝ čāąĘą║ąĖąĄ, ą▓čŗčüąŠą║ąŠąĮą░ą│čĆčāąČąĄąĮąĮčŗąĄ ą╝ąĄčüčéą░ ąĖ ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░čéčī ą║ąŠą┤. ą¤čāč鹥ą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┐čĆąŠčäąĖą╗ąĄą╣ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░ (execution profiles), čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą╝ąŠą│čāčé č鹊ąĮą║ąŠ ąĮą░čüčéčĆąŠąĖčéčī čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ, čćč鹊ą▒čŗ ą┤ąŠčüčéąĖčćčī ąĮą░ąĖą╗čāčćčłąĄą╣ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ čüąĖčüč鹥ą╝čŗ. ą¤čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗą╣ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░čĆąĖą╣ ą▓ą║ą╗čÄčćą░ąĄčé:
ŌĆó ąøąĖąĮąĄą╣ąĮčŗą╣ ą┐čĆąŠčäą░ą╣ą╗ąĄčĆ (Linear Profiler), čĆą░ą▒ąŠčéą░čÄčēąĖą╣ č鹊ą╗čīą║ąŠ čüąŠą▓ą╝ąĄčüčéąĮąŠ čü čüąĖą╝čāą╗čÅč鹊čĆąŠą╝.
ŌĆó ąĪčéą░čéąĖčüčéąĖč湥čüą║ąĖą╣ ą┐čĆąŠčäą░ą╣ą╗ąĄčĆ (Statistical Profiler), čāčéąĖą╗ąĖčéą░ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čŹą╝čāą╗čÅč鹊čĆą░ ąĖ ąŠčéą╗ą░ąČąĖą▓ą░ąĄą╝čŗčģ čåąĄą╗ąĄą▓čŗčģ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ąĮą░ ą┐ą╗ą░čéą░čģ čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ą░ EZ-KIT Lite┬«.
ŌĆó ąÆčüčéčĆąŠąĄąĮąĮčŗą╣ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ (Embedded profiling), čĆąĄą░ą╗ąĖąĘčāąĄą╝čŗą╣ čü ą┐ąŠą╝ąŠčēčīčÄ ą▓čüčéčĆąŠąĄąĮąĮąŠą│ąŠ ą▓ ą┐čĆąŠčåąĄčüčüąŠčĆ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ čüč湥čéčćąĖą║ą░ čéą░ą║č鹊ą▓ (hardvare cycle count).
ąśąĮčüčéčĆčāą╝ąĄąĮčéčŗ Linear Profiling ąĖ Statistical Profiling, ą║ąŠč鹊čĆčŗąĄ ąĮąĄ ąĮą░čĆčāčłą░čÄčé ąĮąŠčĆą╝ą░ą╗čīąĮčŗą╣ čģąŠą┤ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ą┤ą░čÄčé ą┐čĆąŠčäąĖą╗čī, ąŠč鹊ą▒čĆą░ąČą░čÄčēąĖą╣ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐ąŠ čéą░ą║čéą░ą╝ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą║ąŠą┤ą░, čé. ąĄ. čüą║ąŠą╗čīą║ąŠ čéą░ą║č鹊ą▓ čéčĆą░čéąĖčéčüčÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą╝ ąĮą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ ą╝ąĄčüčé ą▓ ą║ąŠą┤ąĄ, ąĖ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čćč鹥ąĮąĖą╣ ąĖ ąĘą░ą┐ąĖčüąĄą╣ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗąĄ ąŠčüčāčēąĄčüčéą▓ą╗čÅą╗ąĖčüčī ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ.
Linear Profiler ą┤ąĄą╗ą░ąĄčé ą▓čŗą▒ąŠčĆą║ąĖ ą┐ąŠ ą║ą░ąČą┤ąŠą╣ ą▓čŗą┐ąŠą╗ąĮčÅąĄą╝ąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ (ą┐ąŠ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅą╝ ąĘąĮą░č湥ąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ čüč湥čéčćąĖą║ą░ PC), čćč鹊 čéą░ąĄčé ą┐ąŠą╗ąĮčāčÄ ąĖ č鹊čćąĮčāčÄ ą║ą░čĆčéąĖąĮčā čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéąĖ ą║ąŠą┤ą░. ą×ą┤ąĮą░ą║ąŠ ą┐ą╗ą░čéąĖčéčī ąĘą░ čŹčéčā č鹊čćąĮąŠčüčéčī ą┐čĆąĖčģąŠą┤ąĖčéčüčÅ č鹥ą╝, čćč鹊 čŹč鹊 ą╝ąĄą┤ą╗ąĄąĮąĮčŗą╣ ą╝ąĄč鹊ą┤ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, čĆą░ą▒ąŠčéą░čÄčēąĖą╣ č鹊ą╗čīą║ąŠ ą▓ čüąĖą╝čāą╗čÅč鹊čĆąĄ ą┐čĆąŠčåąĄčüčüąŠčĆą░, čéą░ą║ čćč鹊 čŹč鹊čé ą╝ąĄč鹊ą┤ ąĮąĄą┐čĆąĖą╝ąĄąĮąĖą╝ ą┤ą╗čÅ ą░ąĮą░ą╗ąĖąĘą░ ąĮą░ čĆąĄą░ą╗čīąĮąŠą╝ ą░ą┐ą┐ą░čĆą░čéąĮąŠą╝ čāčüčéčĆąŠą╣čüčéą▓ąĄ.
Statistical Profiler čĆą░ą▒ąŠčéą░ąĄčé ą▒čŗčüčéčĆąĄąĄ, ą┐ąŠąĘą▓ąŠą╗čÅčÅ ąÆą░ą╝ ą┤ąĄą╗ą░čéčī ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ ą▒ąĄąĘ ą║ą░ą║ąŠą│ąŠ-ą╗ąĖą▒ąŠ ą▓ą╗ąĖčÅąĮąĖčÅ ąĮą░ čģą░čĆą░ą║č鹥čĆąĖčüčéąĖą║ąĖ čĆąĄą░ą╗čīąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░ ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ. Statistical Profiler ą┤ąŠčüčéąĖą│ą░ąĄčé čŹč鹊ą│ąŠ ą┐čāč鹥ą╝ ą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║ąŠą│ąŠ ąŠą┐čĆąŠčüą░ PC. ąŁč鹊 ąĮąĄ ąĮą░čüč鹊ą╗čīą║ąŠ č鹊čćąĮąŠ, ą║ą░ą║ čā Linear Profiler, ąŠą┤ąĮą░ą║ąŠ ą┤ą░ąĄčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą░ąĮą░ą╗ąĖąĘą░ ą║ąŠą┤ą░ ąĮą░ ą░ą┐ą┐ą░čĆą░čéąĮąŠą╝ čāčüčéčĆąŠą╣čüčéą▓ąĄ.
ąæąĖą▒ą╗ąĖąŠč鹥ą║ąĖ VisualDSP++ čéą░ą║ąČąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą┐ąŠą╗čāčćąĖčéčī č鹊čćąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ čüč湥čéčćąĖą║ą░ čéą░ą║č鹊ą▓, ąĖ č鹥ą╝ čüą░ą╝čŗą╝ ąĖąĘą╝ąĄčĆčÅčéčī ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąŠčéą┤ąĄą╗čīąĮčŗčģ čāčćą░čüčéą║ąŠą▓ ą║ąŠą┤ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ (ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ ąĖ ą▓ąŠąĘą▓čĆą░čé ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ čüč湥čéčćąĖą║ą░ čéą░ą║č鹊ą▓). ąŁč鹊 čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮąŠ ąĮą░ ąŠčüąĮąŠą▓ąĄ čĆąĄą│ąĖčüčéčĆąŠą▓ čüč湥čéčćąĖą║ą░ čéą░ą║č鹊ą▓ ąĖ ą╝ą░ą║čĆąŠčüąŠą▓, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗčģ ą▓ čŹčéąĖčģ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░čģ.
ąŁč鹊čé ą┤ąŠą║čāą╝ąĄąĮčé (ą┐ąĄčĆąĄą▓ąŠą┤ ą┤ą░čéą░čłąĖčéą░ EE-332 [1]) ąŠą┐ąĖčüčŗą▓ą░ąĄčé čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą╝ąĄąĮč鹊ą▓ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ą░, ąĖčģ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ, ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ąĖ ąŠą│čĆą░ąĮąĖč湥ąĮąĖčÅ. ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ EE-332 čüąŠą┐čĆąŠą▓ąŠąČą┤ą░ąĄčéčüčÅ ą┐čĆąĖą╝ąĄčĆą░ą╝ąĖ ą║ąŠą┤ą░ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin, SHARC ąĖ TigerSHARC, čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī čĆą░ąĘą╗ąĖčćąĖčÅ ą╝ąĄąČą┤čā čĆąĄąĘčāą╗čīčéą░čéą░ą╝ąĖ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ą░, ą║ąŠč鹊čĆčŗąĄ ą▓ąŠąĘą▓čĆą░čēą░čÄčéčüčÅ ąŠčé čüąĖą╝čāą╗čÅč鹊čĆą░ ąĖ ąŠčé ą░ą┐ą┐ą░čĆą░čéčāčĆčŗ. ąĪą╗ąĄą┤čāčÄčēąĖąĄ čāą║ą░ąĘą░ąĮąĖčÅ ą┐čĆąĖą╝ąĄąĮąĖą╝čŗ ą║ąŠ ą▓čüąĄą╝ ą░čĆčģąĖč鹥ą║čéčāčĆą░ą╝: Blackfin┬«, SHARC┬« ąĖ TigerSHARC┬«.
[ąĪčéą░čéąĖčüčéąĖč湥čüą║ąĖą╣ ąĖ ą╗ąĖąĮąĄą╣ąĮčŗą╣ ą┐čĆąŠčäą░ą╣ą╗ąĄčĆčŗ]
Linear Profiler, ą║ąŠč鹊čĆčŗą╣ ą┤ąŠčüčéčāą┐ąĄąĮ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ čüąĄčüčüąĖą╣ čüąĖą╝čāą╗čÅč鹊čĆą░, ą▓ą║ą╗čÄčćą░ąĄčéčüčÅ č湥čĆąĄąĘ ą╝ąĄąĮčÄ Tools -> Linear Profiling.
Statistical Profiler, ą║ąŠč鹊čĆčŗą╣ ą┤ąŠčüčéčāą┐ąĄąĮ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ čüąĄčüčüąĖą╣ 菹╝čāą╗čÅč鹊čĆą░ ąĖą╗ąĖ ą┐ą╗ą░čé čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ą░ EZ-KIT Lite, ą▓ą║ą╗čÄčćą░ąĄčéčüčÅ č湥čĆąĄąĘ ą╝ąĄąĮčÄ Tools -> Statistical Profiling.
ą£ąŠąČąĮąŠ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░čéčī ąĮąĄą║ąŠč鹊čĆąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąŠą┐čåąĖą╣ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ą░ ą┤ą╗čÅ č鹊ąĮą║ąŠą╣ ąĮą░čüčéčĆąŠą╣ą║ąĖ čéčĆąĄą▒čāąĄą╝ąŠą╣ ą┤ą╗čÅ ąÆą░čü ą┐čĆąŠčäąĖą╗ąĖčĆčāąĄą╝ąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ. ąŁčéąĖ ąŠą┐čåąĖąĖ ą┤ąŠčüčéčāą┐ąĮčŗ č湥čĆąĄąĘ ą┐čāąĮą║čé Properties ą║ąŠąĮč鹥ą║čüčéąĮąŠą│ąŠ ą╝ąĄąĮčÄ ąŠą║ąĮą░ ą┐čĆąŠčäą░ą╣ą╗ąĄčĆą░ (ąŠčéą║čĆčŗą▓ą░ąĄčéčüčÅ ą┐čĆą░ą▓čŗą╝ ą║ą╗ąĖą║ąŠą╝).
ąŚą░ą║ą╗ą░ą┤ą║ą░ Display (čüą╝. čĆąĖčü. 1) ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąÆą░ą╝ čāą║ą░ąĘą░čéčī čéąĖą┐ ą┐ą░ą╝čÅčéąĖ ąĖ čüą▓čÅąĘą░ąĮąĮčŗąĄ ą╝ąĄčéčĆąĖą║ąĖ, ą║ąŠč鹊čĆčŗąĄ čģąŠčéąĖč鹥 ą┐čĆąŠčäąĖą╗ąĖčĆąŠą▓ą░čéčī. ąöąŠčüčéčāą┐ąĮčŗąĄ čéąĖą┐čŗ ą┐ą░ą╝čÅčéąĖ čüą┐ąĄčåąĖčäąĖčćąĮčŗ ą┤ą╗čÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╣ čåąĄą╗ąĖ ąŠčéą╗ą░ą┤ą║ąĖ (ą┐čĆąŠčåąĄčüčüąŠčĆ + ąŠčéą╗ą░ą┤čćąĖą║), ąĖ ą┤ąŠčüčéčāą┐ąĮčŗąĄ ą╝ąĄčéčĆąĖą║ąĖ čüą┐ąĄčåąĖčäąĖčćąĮčŗ ą┤ą╗čÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ čéąĖą┐ą░ ą┐ą░ą╝čÅčéąĖ. ą×ą┐čåąĖąŠąĮą░ą╗čīąĮčŗąĄ ą╝ąĄčéčĆąĖą║ąĖ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ąÆą░ą╝ ą┐ąŠą┤ą║ą╗čÄčćąĖčéčī čéą░ą║ąĖąĄ ą┤ą░ąĮąĮčŗąĄ, ą║ą░ą║ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čćč鹥ąĮąĖą╣/ąĘą░ą┐ąĖčüąĄą╣ ą┐ąŠ ą┐ą░ą╝čÅčéąĖ, ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠą┐ą░ą┤ą░ąĮąĖą╣/ą┐čĆąŠą╝ą░čģąŠą▓ ą║čŹčłą░, čüč湥čéčćąĖą║ąĖ čéą░ą║č鹊ą▓ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░, ąĖ čéą░ą║ ą┤ą░ą╗ąĄąĄ, čćč鹊 ą▒čāą┤ąĄčé ą┤ąŠčüčéčāą┐ąĮąŠ ą▓ ą┐čĆąŠčäąĖą╗ąĖčĆčāąĄą╝čŗčģ ą┤ą░ąĮąĮčŗčģ.
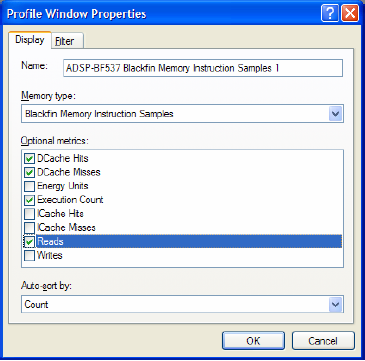
ąĀąĖčü. 1. ąÆąĮąĄčłąĮąĖą╣ ą▓ąĖą┤ ąĘą░ą║ą╗ą░ą┤ą║ąĖ Display ą┤ąĖą░ą╗ąŠą│ą░ ąĮą░čüčéčĆąŠą╣ą║ąĖ čüą▓ąŠą╣čüčéą▓ čüąĄčüčüąĖąĖ ąŠčéą╗ą░ą┤ą║ąĖ.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą┤ąĄčłąĄą▓čŗąĄ 菹╝čāą╗čÅč鹊čĆčŗ JTAG ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ ICE-100B ą┤ą░čÄčé ą┤ąŠą▓ąŠą╗čīąĮąŠ ą▒ąĄą┤ąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┤ą░ąĮąĮčŗčģ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ą░ - č鹊ą╗čīą║ąŠ ą┐čĆąŠčåąĄąĮčéąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čéą░ą║č鹊ą▓ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą┤ą╗čÅ čāčćą░čüčéą║ąŠą▓ ą║ąŠą┤ą░ čü ąĖčģ ą░ą┤čĆąĄčüą░ą╝ąĖ ąĖ čüąĖą╝ą▓ąŠą╗čīąĮčŗą╝ąĖ ą╝ąĄčéą║ą░ą╝ąĖ + ą│ąĖčüč鹊ą│čĆą░ą╝ą╝čā ąĘą░ą│čĆčāąĘą║ąĖ, ąĮąŠ čāąČąĄ ąĖ čŹč鹊 ąŠč湥ąĮčī ąĮąĄą┐ą╗ąŠčģąŠ. ąóą░ą║ąČąĄ čüą╗ąĄą┤čāąĄčé ąĖą╝ąĄčéčī ą▓ ą▓ąĖą┤čā, čćč鹊 ąŠą┐čåąĖąŠąĮą░ą╗čīąĮčŗąĄ ą╝ąĄčéčĆąĖą║ąĖ ąĖą╝ąĄčÄčéčüčÅ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ čüąĄčüčüąĖą╣ čüąĖą╝čāą╗čÅč鹊čĆą░ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin ąĖ TigerSHARC. ą×ąĮąĖ ąĮąĄą┤ąŠčüčéčāą┐ąĮčŗ ąĮą░ ą░ą┐ą┐ą░čĆą░čéąĮčŗčģ čüąĄčüčüąĖčÅčģ ąŠčéą╗ą░ą┤čćąĖą║ą░ ąĖą╗ąĖ čüąĄčüčüąĖčÅčģ čüąĖą╝čāą╗čÅč鹊čĆą░ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ SHARC.
ąŚą░ą║ą╗ą░ą┤ą║ą░ Filter (čĆąĖčü. 2) ą┐ąŠąĘą▓ąŠą╗ąĖčé ąÆą░ą╝ čāą║ą░ąĘą░čéčī, čćč鹊 ąĮčāąČąĮąŠ ą┐čĆąŠčäąĖą╗ąĖčĆąŠą▓ą░čéčī. ąÆčŗ ą╝ąŠąČąĄč鹥 ą▓čŗą▒čĆą░čéčī ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ ą▓čüąĄą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ą┐ą░ą╝čÅčéąĖ, ą▓čŗą▒čĆą░ąĮąĮčŗąĄ čäčāąĮą║čåąĖąĖ C/C++, ąĖą╗ąĖ čāą║ą░ąĘą░ąĮąĮčŗąĄ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ. ąŻą║ą░ąĘą░ąĮąĖąĄ čŹčéąĖčģ ąŠą┐čåąĖą╣ ą┐ąŠąĘą▓ąŠą╗ąĖčé ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ą▒ąŠą╗ąĄąĄ ą║čĆą░čéą║ąĖą╣ ą┐čĆąŠčäąĖą╗čī, čüąŠą┤ąĄčƹȹ░čēąĖą╣ č鹊ą╗čīą║ąŠ čéčĆąĄą▒čāąĄą╝čāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ.
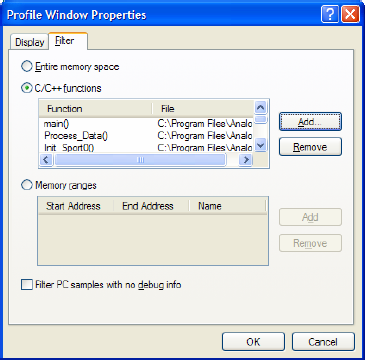
ąĀąĖčü. 2. ąÆąĮąĄčłąĮąĖą╣ ą▓ąĖą┤ ąĘą░ą║ą╗ą░ą┤ą║ąĖ Filter ą┤ąĖą░ą╗ąŠą│ą░ ąĮą░čüčéčĆąŠą╣ą║ąĖ čüą▓ąŠą╣čüčéą▓ čüąĄčüčüąĖąĖ ąŠčéą╗ą░ą┤ą║ąĖ.
ą¤ąŠčüą╗ąĄ čāą║ą░ąĘą░ąĮąĖčÅ čŹčéąĖčģ ąŠą┐čåąĖą╣ ąÆą░ą╝ ą┐čĆąŠčüč鹊 ąĮčāąČąĮąŠ ąĘą░ą┐čāčüčéąĖčéčī ą┐čĆąŠąĄą║čé ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, čćč鹊ą▒čŗ ą┐čĆąŠčäą░ą╣ą╗ąĄčĆ čüą╝ąŠą│ čüąŠą▒čĆą░čéčī ą▓čŗą▒ąŠčĆą║ąĖ ą┤ą░ąĮąĮčŗčģ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░.
ąśąĮč鹥čĆą┐čĆąĄčéą░čåąĖčÅ čĆąĄąĘčāą╗čīčéą░č鹊ą▓. ą¤ąŠčüą╗ąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąĮąĄą║ąŠč鹊čĆąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░ ą┐čĆąŠčäą░ą╣ą╗ąĄčĆ ąŠč鹊ą▒čĆą░ąĘąĖčé ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠ ąÆą░čłąĄą╝ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ. ąóąŠą│ą┤ą░ ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐čĆąŠčüą╝ąŠčéčĆąĄčéčī ą┐čĆąŠčäąĖą╗čī, čćč鹊ą▒čŗ ąŠčåąĄąĮąĖčéčī ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čéą░ą║č鹊ą▓, ąĘą░čéčĆą░č湥ąĮąĮąŠąĄ ąĮą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ąŠą┤ą░, čéą░ą║ąČąĄ ą▓čŗčĆą░ąČąĄąĮąĮąŠąĄ ą▓ ą┐čĆąŠčåąĄąĮčéą░čģ.
ąÜą╗ąĖą║ąŠą╝ ąĮą░ 菹╗ąĄą╝ąĄąĮč鹥 ą║ąŠą┤ą░ ą▓ ą╗ąĄą▓ąŠą╣ čćą░čüčéąĖ ąŠą║ąĮą░ ą┐čĆąŠčäą░ą╣ą╗ąĄčĆą░ (čĆąĖčü. 3) ąŠč鹊ą▒čĆą░ąĘąĖčéčüčÅ ąĖčüčģąŠą┤ąĮčŗą╣ ą║ąŠą┤ ą┤ą╗čÅ čŹč鹊ą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░ ą▓ ą┐čĆą░ą▓ąŠą╣ čćą░čüčéąĖ ąŠą║ąĮą░ (čĆąĖčü. 4), ąĖą╗ąĖ, ąĄčüą╗ąĖ čüąĖą╝ą▓ąŠą╗čīąĮą░čÅ ąĖąĮč乊čĆą╝ą░čåąĖčÅ ąĮąĄą┤ąŠčüčéčāą┐ąĮą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ ą║ąŠą┤ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░ąĮ ą▓ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ Release, ąĖą╗ąĖ čŹč鹊 ą║ą░ą║ą░čÅ-č鹊 ą▒ąĖą▒ą╗ąĖąŠč鹥čćąĮą░čÅ čäčāąĮą║čåąĖčÅ), č鹊 ąŠą║ąĮąŠ ą┤ąĖąĘą░čüčüąĄą╝ą▒ą╗ąĄčĆą░ ą┐ąŠą║ą░ąČąĄčé čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄąĄ ą╝ąĄčüč鹊 ą▓ ą║ąŠą┤ąĄ. ąŁč鹊 ą┐ąŠąĘą▓ąŠą╗ąĖčé ąÆą░ą╝ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆąŠą▓ą░čéčī čüčéčĆąŠą║ąĖ ą▓ ą║ąŠą┤ąĄ, ąĮą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ąŠč鹊čĆčŗčģ ą┐čĆąŠčåąĄčüčüąŠčĆ čéčĆą░čéąĖčé ą▒ąŠą╗čīčłąĄ ą▓čüąĄą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ.
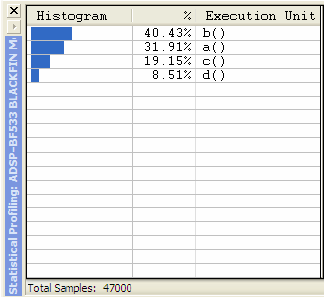
ąĀąĖčü. 3. ąøąĄą▓ą░čÅ čćą░čüčéčī ąŠą║ąĮą░ Statistical Profiler, ą│ą┤ąĄ ąŠč鹊ą▒čĆą░ąČąĄąĮą░ ąĖąĮč乊čĆą╝ą░čåąĖčÅ ąŠ ąĘą░ą│čĆčāąČąĄąĮąĮąŠčüčéąĖ ą║ąŠą┤ą░ čäčāąĮą║čåąĖčÅą╝ąĖ ą▓ ą┐čĆąŠčåąĄąĮčéąĮąŠą╝ ąŠčéąĮąŠčłąĄąĮąĖąĖ.

ąĀąĖčü. 4. ą¤čĆą░ą▓ą░čÅ čćą░čüčéčī ąŠą║ąĮą░ Statistical, ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčēą░čÅ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąĘą░ą│čĆčāąČąĄąĮąĮąŠčüčéąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ.
ąĀąĄąĘčāą╗čīčéą░čéčŗ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ą░ ą╝ąŠąČąĮąŠ čüąŠčģčĆą░ąĮąĖčéčī ą▓ čäą░ą╣ą╗ .txt, .xml ąĖą╗ąĖ .prf, čćč鹊 ą┐ąŠąĘą▓ąŠą╗ąĖčé (č鹊ą╗čīą║ąŠ ą┤ą╗čÅ č乊čĆą╝ą░č鹊ą▓ .prf ąĖ .xml) ąĘą░ą│čĆčāąĘąĖčéčī čŹčéąĖ čĆąĄąĘčāą╗čīčéą░čéčŗ ą┐ąŠąĘąČąĄ ą┤ą╗čÅ ą┐ąŠą▓č鹊čĆąĮąŠą│ąŠ ą░ąĮą░ą╗ąĖąĘą░, ąĖą╗ąĖ ą┤ą╗čÅ ąŠą▒čŖąĄą┤ąĖąĮąĄąĮąĖčÅ (č鹊ą╗čīą║ąŠ ą┤ą╗čÅ č乊čĆą╝ą░č鹊ą▓ .prf ąĖ .xml only) čü ąŠčéą║čĆčŗčéčŗą╝ ą┐čĆąŠčäąĖą╗ąĄą╝, čćč鹊ą▒čŗ ą┐čĆąĄą┤čüčéą░ą▓ąĖčéčī čüąŠąĄą┤ąĖąĮąĄąĮąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ, čćč鹊 ą┤ą░čüčé ą▒ąŠą╗ąĄąĄ čÅčüąĮčāčÄ ą║ą░čĆčéąĖąĮčā ąŠ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ čĆą░ą▒ąŠčéčŗ ąÆą░čłąĄą│ąŠ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą▓ čĆą░ąĘąĮčŗčģ ą▓ą░čĆąĖą░ąĮčéą░čģ ąĘą░ą┐čāčüą║ą░. ąöą╗čÅ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ čüąŠčģčĆą░ąĮąĄąĮąĮčŗą╣ ą┐čĆąŠčäąĖą╗čī ą┤ąŠą╗ąČąĄąĮ ąĖą╝ąĄčéčī ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ čéąĖą┐ čåąĄą╗ąĄą▓ąŠą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĖ ą┐ą░ą╝čÅčéąĖ, ą║ą░ą║ čā ąŠčéą║čĆčŗč鹊ą│ąŠ ą┐čĆąŠčäąĖą╗čÅ, ąĖ ą┤ąŠą╗ąČąĄąĮ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī č鹥 ąČąĄ ąŠą┐čåąĖąŠąĮą░ą╗čīąĮčŗąĄ ą╝ąĄčéčĆąĖą║ąĖ ą┐čĆąŠčäąĖą╗čÅ. ąÆčüąĄ čŹčéąĖ ąŠą┐čåąĖąĖ ą┤ąŠčüčéčāą┐ąĮčŗ č湥čĆąĄąĘ ą╝ąĄąĮčÄ Tools -> Statistical Profiling ąĖą╗ąĖ Tools -> Linear Profiling.
[ąæąĖą▒ą╗ąĖąŠč鹥čćąĮčŗąĄ čäčāąĮą║čåąĖąĖ ą┤ą╗čÅ ą┐ąŠą┤čüč湥čéą░ čéą░ą║č鹊ą▓]
ąÆąĮąĖą╝ą░ąĮąĖąĄ: ą╝ą░ą║čĆąŠčüčŗ ą┐ąŠą┤čüč湥čéą░ čéą░ą║č鹊ą▓ čéčĆąĄą▒čāčÄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąŠą┐čåąĖąĖ -DDO_CYCLE_COUNTS ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░.
ą£ą░ą║čĆąŠčüčŗ ą┐ąŠą┤čüč湥čéą░ čéą░ą║č鹊ą▓ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé 3 čĆą░ąĘąĮčŗčģ ą╝ąĄč鹊ą┤ą░ čüč湥čéą░ čéą░ą║č鹊ą▓:
ŌĆó ąæą░ąĘąŠą▓čŗą╣ čüč湥čé čéą░ą║č鹊ą▓ (Basic cycle count) - ą▓ąĄčĆąĮąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čéą░ą║č鹊ą▓, ą┐ąŠčéčĆą░č湥ąĮąĮčŗčģ ąĮą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ čüąĄą║čåąĖąĖ (ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ čāčćą░čüčéą║ą░) ą║ąŠą┤ą░.
ŌĆó ąĪč湥čé čéą░ą║č鹊ą▓ čüąŠ čüčéą░čéąĖčüčéąĖą║ąŠą╣ (Cycle count with statistics) - ą▓ąĄčĆąĮąĄčé čüčĆąĄą┤ąĮąĄąĄ, ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠąĄ ąĖ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čéą░ą║č鹊ą▓, ą┐ąŠčéčĆą░č湥ąĮąĮąŠąĄ ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čāčćą░čüčéą║ą░ ą║ąŠą┤ą░.
ŌĆó ąĪč湥čé ą▓čĆąĄą╝ąĄąĮąĖ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ time.h - ą▓ąĄčĆąĮąĄčé ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čāčćą░čüčéą║ą░ ą║ąŠą┤ą░, ą▓čŗčĆą░ąČąĄąĮąĮąŠąĄ ą▓ čüąĄą║čāąĮą┤ą░čģ.
ąÆ čĆąĄą╗ąĖąĘą░čģ VisualDSP++ ą┤ąŠ ą▓ąĄčĆčüąĖąĖ 5.0 ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮčŗ ą╝ą░ą║čĆąŠčüčŗ čü ą┐ą░čĆą░ą╝ąĄčéčĆą░ą╝ąĖ ą▓ ąĘą░ą│ąŠą╗ąŠą▓ąŠčćąĮčŗčģ čäą░ą╣ą╗ą░čģ cycle_count.h ąĖ cycles.h, ą║ąŠč鹊čĆčŗąĄ čĆą░ąĘą▓ąŠčĆą░čćąĖą▓ą░čÄčéčüčÅ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆąŠą╝ ąĮą░ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąŠą┐ąĄčĆą░č鹊čĆąŠą▓. ąŁčéą░ ą▓ąĄčĆčüąĖčÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą┐čĆąĖą▓ąĄą╗ą░ ą║ ąĮąĄąŠąČąĖą┤ą░ąĮąĮčŗą╝ ą┐ąŠą▒ąŠčćąĮčŗą╝ čŹčäč乥ą║čéą░ą╝, čéą░ą║ čćč鹊 ą▓ąŠąĘą╝ąŠąČąĮąŠ, čćč鹊 čŹčéąĖ ąŠą┐ąĄčĆą░č鹊čĆčŗ ąĮąĄ ą┤ą░ą┤čāčé č鹊čćąĮčŗčģ čĆąĄąĘčāą╗čīčéą░č鹊ą▓ ą┤ą╗čÅ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą║ąŠą┤ą░.
ąĀą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗ąĄą┤čāčÄčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ:
if (condition)
STOP_CYCLE_COUNT(cnt2, cnt2);
ą¤ąŠčüą║ąŠą╗čīą║čā ą╝ą░ą║čĆąŠčü STOP_CYCLE_COUNT čĆą░ąĘą▓ąŠčĆą░čćąĖą▓ą░ąĄčéčüčÅ ąĮą░ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąŠą┐ąĄčĆą░č鹊čĆąŠą▓, č鹊 č鹊ą╗čīą║ąŠ ą┐ąĄčĆą▓čŗą╣ ąŠą┐ąĄčĆą░č鹊čĆ čŹč鹊ą│ąŠ čĆą░ąĘą▓ąĄčĆąĮčāč鹊ą│ąŠ ą╝ą░ą║čĆąŠčüą░ ą▓čŗą┐ąŠą╗ąĮąĖčéčüčÅ ą┐ąŠą┤ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄą╝ ąĘą░ą┤ą░ąĮąĮąŠą│ąŠ čāčüą╗ąŠą▓ąĖčÅ. ą×čüčéą░ą╗čīąĮčŗąĄ ąŠą┐ąĄčĆą░č鹊čĆčŗ ą▒čāą┤čāčé ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą▓čüąĄą│ą┤ą░, čéą░ą║ čćč鹊 ą┐ąŠą┤čüč湥čé čéą░ą║č鹊ą▓ ą┤ą░čüčé ąĮąĄą║ąŠčĆčĆąĄą║čéąĮčŗąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ.
ą¦č鹊ą▒čŗ ąĖčüą┐čĆą░ą▓ąĖčéčī čŹčéčā ąŠčłąĖą▒ą║čā, čŹčéąĖ ą╝ą░ą║čĆąŠčüčŗ č鹥ą┐ąĄčĆčī čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮčŗ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą▒ą╗ąŠą║ą░ ąŠą┐ąĄčĆą░č鹊čĆąŠą▓ (čäąĖą│čāčĆąĮčŗąĄ čüą║ąŠą▒ą║ąĖ). ąĪ ą┐čĆąĄą┤čŗą┤čāčēąĖą╝ąĖ ą╝ą░ą║čĆąŠčüą░ą╝ąĖ, ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅčÄčēąĖą╝ąĖ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ąĖąĮčüčéčĆčāą║čåąĖą╣, ą▒čŗą╗ąŠ ą┤ąŠą┐čāčüčéąĖą╝ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą╝ą░ą║čĆąŠčü ą▒ąĄąĘ ąĘą░ą▓ąĄčĆčłą░čÄčēąĄą│ąŠ čüąĖą╝ą▓ąŠą╗ą░ č鹊čćą║ąĖ čü ąĘą░ą┐čÅč鹊ą╣; čŹč鹊 ą▒ąŠą╗čīčłąĄ ąĮąĄ čéą░ą║ ą┤ą╗čÅ čüą╗čāčćą░čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą▓ VisualDSP++ 5.0.
ą¦č鹊ą▒čŗ ą┐ąŠą╝ąŠčćčī ą┐ąŠčĆčéąĖčĆąŠą▓ą░čéčī čüčāčēąĄčüčéą▓čāčÄčēąĖą╣ ą║ąŠą┤, ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ ą╝ą░ą║čĆąŠčü ą▓čĆąĄą╝ąĄąĮąĖ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ __USE_CYCLE_MACRO_REL45__, čćč鹊ą▒čŗ čĆą░ąĘčĆąĄčłąĖčéčī ą┐ąŠą┤ą┤ąĄčƹȹ║čā čüčéą░čĆąŠą│ąŠ ą║ąŠą┤ą░ ąĖ ąĖąĘą▒ąĄąČą░čéčī ą║ą░ą║ąĖčģ-ą╗ąĖą▒ąŠ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖą╣ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čŹčéąĖčģ ą╝ą░ą║čĆąŠčüąŠą▓ ą┐ąŠą┤čüč湥čéą░ čéą░ą║č鹊ą▓.
ą¤ąŠą┤čüč湥čé čéą░ą║č鹊ą▓ ąĮą░ ą▓čüąĄčģ ą░čĆčģąĖč鹥ą║čéčāčĆą░čģ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą┤ą▓ą░ ą░ą┐ą┐ą░čĆą░čéąĮčŗčģ 32-ą▒ąĖčéąĮčŗčģ čĆąĄą│ąĖčüčéčĆą░. ąØą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ Blackfin čŹč鹊 čĆąĄą│ąĖčüčéčĆčŗ CYCLES ąĖ CYCLES2, ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ TigerSHARC čŹč鹊 čĆąĄą│ąĖčüčéčĆčŗ CCNT0 ąĖ CCNT1, ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ SHARC čŹč鹊 čĆąĄą│ąĖčüčéčĆčŗ EMUCLK ąĖ EMUCLK2. ą¤ąĄčĆą▓čŗą╣ ąĖąĘ čŹč鹊ą╣ ą┐ą░čĆčŗ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖąĮą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄčéčüčÅ ą║ą░ąČą┤čŗą╣ čéą░ą║čé, ąĖ ą┐ąĄčĆąĄą▓ą░ą╗ąĖą▓ą░ąĄčé ą▓ 0 ą┐ąŠčüą╗ąĄ ą┤ąŠčüčéąĖąČąĄąĮąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ 0xffffffff (ą┐ąĄčĆąĄčģąŠą┤ ąŠčé -1 ą║ 0). ąÜąŠą│ą┤ą░ ą┐ąĄčĆą▓čŗą╣ ąĖąĘ čŹčéąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĖčéčüčÅ ąĖ ą┐ąĄčĆąĄą╣ą┤ąĄčé ą▓ 0, ą▓č鹊čĆąŠą╣ čĆąĄą│ąĖčüčéčĆ ąĖąĮą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄčéčüčÅ ąĮą░ 1, čéą░ą║ čćč鹊 ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą┐ąŠą╗čāčćą░ąĄčéčüčÅ ąŠą┤ąĖąĮ 64-čĆą░ąĘčĆčÅą┤ąĮčŗą╣ čüč湥čéčćąĖą║. ąöą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin ąĖ TigerSHARC ąŠą▒ą░ čŹčéąĖčģ čĆąĄą│ąĖčüčéčĆą░ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą▓ ą╝ą░ą║čĆąŠčüą░čģ ą┐ąŠą┤čüč湥čéą░ čéą░ą║č鹊ą▓. ą×ą┤ąĮą░ą║ąŠ, čćč鹊ą▒čŗ 菹║ąŠąĮąŠą╝ąĖčéčī ą┐ą░ą╝čÅčéčī ąĖ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ, ą╝ą░ą║čĆąŠčüčŗ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ SHARC ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčé čĆąĄą│ąĖčüčéčĆ EMUCLK2. ąĢčüą╗ąĖ ą║ąŠą┤ ą░ąĮą░ą╗ąĖąĘąĖčĆčāąĄčéčüčÅ ą┤ą╗čÅ ą┤ą╗ąĖąĮąĮąŠą│ąŠ ą┐čĆąŠą╝ąĄąČčāčéą║ą░ ą▓čĆąĄą╝ąĄąĮąĖ, č鹊 čĆąĄą│ąĖčüčéčĆ EMUCLK ą╝ąŠąČąĄčé ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĖčéčīčüčÅ, čéą░ą║ čćč鹊 ąĮčāąČąĮąŠ ą▒čāą┤ąĄčé čéą░ą║ąČąĄ čāčćąĖčéčŗą▓ą░čéčī EMUCLK2, čćč鹊ą▒čŗ ą┐čĆąŠą▓ąŠą┤ąĖčéčī č鹊čćąĮčŗąĄ ąĖąĘą╝ąĄčĆąĄąĮąĖčÅ.
ąæą░ąĘąŠą▓čŗą╣ ą╝ąĄč鹊ą┤ čüč湥čéą░ čéą░ą║č鹊ą▓. ąŁč鹊 ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ čéčĆąĄą╝čÅ ą┐čĆąŠčüčéčŗą╝ąĖ ą╝ą░ą║čĆąŠčüą░ą╝ąĖ, ą║ąŠč鹊čĆčŗąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮčŗ ą▓ čäą░ą╣ą╗ąĄ cycle_count.h:
PRINT_CYCLES(T)
START_CYCLE_COUNT(S)
STOP_CYCLE_COUNT(T,S)
ą¤ą░čĆą░ą╝ąĄčéčĆ S ą▓ ą╝ą░ą║čĆąŠčüąĄ START_CYCLE_COUNT ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāąĄčé čüč湥čé č鹥ą║čāčēąĖą╝ ąĘąĮą░č湥ąĮąĖąĄą╝ (čé. ąĄ. ąĘą░ą┤ą░ąĄčé č鹊čćą║čā ąŠčéčüč湥čéą░ ą▓čĆąĄą╝ąĄąĮąĖ), ąĖ ą┐ą░čĆą░ą╝ąĄčéčĆ T ą▓ ą╝ą░ą║čĆąŠčüąĄ STOP_CYCLE_COUNT čŹč鹊 ąŠą▒čēąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čéą░ą║č鹊ą▓, ą┐ąŠą╗čāč湥ąĮąĮąŠąĄ ą▓čŗčćąĖčéą░ąĮąĖąĄą╝ S ąĖąĘ č鹥ą║čāčēąĄą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ čüč湥čéčćąĖą║ą░ čéą░ą║č鹊ą▓, ą║ąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą╝ą░ą║čĆąŠčü STOP_CYCLE_COUNT(T,S). ąóą░ą║ąČąĄ čāčćąĖčéčŗą▓ą░ąĄčéčüčÅ ąĖ čāą┤ą░ą╗čÅąĄčéčüčÅ ąĮąĄąĘąĮą░čćąĖč鹥ą╗čīąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čéą░ą║č鹊ą▓, ąĘą░čéčĆą░č湥ąĮąĮąŠąĄ ąĮą░ ą▓čŗąĘąŠą▓ ą╝ą░ą║čĆąŠčüą░ STOP_CYCLE_COUNT(), čćč鹊ą▒čŗ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī č鹊čćąĮčŗą╣ čĆąĄąĘčāą╗čīčéą░čé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čāčćą░čüčéą║ą░ ą║ąŠą┤ą░.
ą¤čĆąĖą╝ąĄčĆ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┤ą░ąĮ ą▓ ąøąĖčüčéąĖąĮą│ąĄ 1.
//ąøąĖčüčéąĖąĮą│ 1. ąæą░ąĘąŠą▓čŗą╣ ą╝ąĄč鹊ą┤ čüč湥čéą░ ąĘą░čéčĆą░č湥ąĮąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ.
#include < cycle_count.h >
#include < stdio.h >
int main(void)
{
cycle_t start_count;
cycle_t final_count;
START_CYCLE_COUNT(start_count);
Some_Function_Or_Code_To_Measure();
STOP_CYCLE_COUNT(final_count,start_count);
PRINT_CYCLES("Number of cycles: ",final_count);
}
ąĪč湥čé čéą░ą║č鹊ą▓ čü ąĮą░ą║ąŠą┐ą╗ąĄąĮąĖąĄą╝ čüčéą░čéąĖčüčéąĖą║ąĖ. ąŁčéą░ č鹥čģąĮąĖą║ą░ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé 5 ą╝ą░ą║čĆąŠčüąŠą▓:
CYCLES_INIT(S)
CYCLES_START(S)
CYCLES_STOP(S)
CYCLES_PRINT(S)
CYCLES_RESET(S)
ą¤ą░čĆą░ą╝ąĄčéčĆ S ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāąĄčéčüčÅ ą▓ 0 ą╝ą░ą║čĆąŠčüąŠą╝ CYCLES_INIT(S), ąĖ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ą▓ č鹥ą║čāčēąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ čĆąĄą│ąĖčüčéčĆą░ čüč湥čéčćąĖą║ą░ ą╝ą░ą║čĆąŠčüąŠą╝ CYCLES_START(S). ą£ą░ą║čĆąŠčü CYCLES_STOP(S) čĆą░čüą┐ą░ą║ąŠą▓čŗą▓ą░ąĄčé ąĘąĮą░č湥ąĮąĖąĄ č鹥ą║čāčēąĄą│ąŠ čüč湥čéčćąĖą║ą░ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖ ąĮą░ą║ą░ą┐ą╗ąĖą▓ą░ąĄčé čüčéą░čéąĖčüčéąĖą║čā ą▓ S, ąŠčüąĮąŠą▓čŗą▓ą░čÅčüčī ąĮą░ čüą░ą╝ąŠą╝ ą┐ąŠčüą╗ąĄą┤ąĮąĄą╝ ą▓čŗąĘąŠą▓ąĄ CYCLES_START(S). ą£ą░ą║čĆąŠčü CYCLES_PRINT(S) ą┐ąĄčćą░čéą░ąĄčé čüčéą░čéąĖčüčéąĖą║čā ą┤ą╗čÅ čĆą░ą▒ąŠčéą░čÄčēąĄą│ąŠ ą║ąŠą┤ą░, ą┤ą░ą▓ą░čÅ ą┐ąŠą┤čĆąŠą▒ąĮčāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ą┐ąŠ čüčĆąĄą┤ąĮąĄą╝čā, ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠą╝čā ąĖ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╝čā ą║ąŠą╗ąĖč湥čüčéą▓čā čéą░ą║č鹊ą▓ ą┤ą╗čÅ ąĖąĘą╝ąĄčĆčÅąĄą╝ąŠą│ąŠ čāčćą░čüčéą║ą░ ą║ąŠą┤ą░, ąĖ ą┤ą░ąĄčé ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ąĄ ą┐čĆąŠčģąŠą┤ąŠą▓ ą░ąĮą░ą╗ąĖąĘąĖčĆčāąĄą╝ąŠą╣ čüąĄą║čåąĖąĖ ą║ąŠą┤ą░.
ą¤čĆąĖą╝ąĄčĆ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┐ąŠą║ą░ąĘą░ąĮ ą▓ ąøąĖčüčéąĖąĮą│ąĄ 2.
//ąøąĖčüčéąĖąĮą│ 2. ą¤ąŠą┤čüč湥čé čéą░ą║č鹊ą▓ čü ąĮą░ą║ąŠą┐ą╗ąĄąĮąĖąĄą╝ čüčéą░čéąĖčüčéąĖą║ąĖ.
#include < cycles.h >
#include < stdio.h >
int main(void)
{
cycle_stats_t stats;
int i;
CYCLES_INIT(stats);
for (i = 0; i < LIMIT; i++)
{
CYCLES_START(stats);
Some_Function_Or_Code_To_Measure();
CYCLES_STOP(stats);
}
CYCLES_PRINT(stats);
CYCLES_RESET(stats);
}
ąĪč湥čé čéą░ą║č鹊ą▓ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ time.h. ąŁč鹊čé čäčāąĮą║čåąĖąŠąĮą░ą╗ ąĖčüą┐ąŠą╗čīąĘčāąĄčé čéąĖą┐ ą┤ą░ąĮąĮčŗčģ ą▓čĆąĄą╝ąĄąĮąĖ čéą░ą║č鹊ą▓ (clock_t) ą▓ą╝ąĄčüč鹥 čü ą╝ą░ą║čĆąŠčüąŠą╝ CLOCKS_PER_SEC, čćč鹊ą▒čŗ ą▓čŗčćąĖčüą╗ąĖčéčī ą▓čĆąĄą╝čÅ, ą║ąŠč鹊čĆąŠąĄ ą▒čŗą╗ąŠ ąĘą░čéčĆą░č湥ąĮąŠ ą▓ čäčāąĮą║čåąĖąĖ ąĖą╗ąĖ ą▒ą╗ąŠą║ąĄ ą║ąŠą┤ą░. ąśčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą▓ąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ čéąĖą┐ą░ clock_t: ąŠą┤ąĮą░ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāąĄčéčüčÅ ąĘąĮą░č湥ąĮąĖąĄą╝ čĆąĄą│ąĖčüčéčĆą░ čüč湥čéčćąĖą║ą░ čéą░ą║č鹊ą▓ ą▓ ąĮą░čćą░ą╗ąĄ ąĖąĘą╝ąĄčĆčÅąĄą╝ąŠą│ąŠ ą▒ą╗ąŠą║ą░ ą║ąŠą┤ą░, ąĖ ą▓č鹊čĆą░čÅ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ą▓ ąĘąĮą░č湥ąĮąĖąĄ čŹč鹊ą│ąŠ čĆąĄą│ąĖčüčéčĆą░ čüč湥čéčćąĖą║ą░, ą║ąŠą│ą┤ą░ ąĖąĘą╝ąĄčĆčÅąĄą╝čŗą╣ ą▒ą╗ąŠą║ ąĘą░ą║ą░ąĮčćąĖą▓ą░ąĄčéčüčÅ. ąĀą░ąĘąĮąĖčåą░ ą╝ąĄąČą┤čā čŹčéąĖą╝ąĖ ą┤ą▓čāą╝čÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝ąĖ ą┤ąĄą╗ąĖčéčüčÅ ąĮą░ čüą║ąŠčĆąŠčüčéčī čéą░ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ, ą║ąŠč鹊čĆą░čÅ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ ą╝ą░ą║čĆąŠčüąŠą╝ CLOCKS_PER_SEC, ą┤ą░ą▓ą░čÅ č鹊čćąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą▓čĆąĄą╝ąĄąĮąĖ, ą║ąŠč鹊čĆąŠąĄ ą┐ąŠčéčĆą░č湥ąĮąŠ ąĮą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ąŠą┤ą░.
ą¤čĆąĖą╝ąĄčĆ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┐ąŠą║ą░ąĘą░ąĮ ą▓ ąøąĖčüčéąĖąĮą│ąĄ 3.
//ąøąĖčüčéąĖąĮą│ 3. ą×čéčüč湥čé ą▓čĆąĄą╝ąĄąĮąĖ čĆą░ą▒ąŠčéčŗ ą║ąŠą┤ą░ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ time.h.
#include < time.h >
#include < stdio.h >
int main(void)
{
volatile clock_t clock_start;
volatile clock_t clock_stop;
double secs;
clock_start = clock();
Some_Function_Or_Code_To_Measure();
clock_stop = clock();
secs = ((double) (clock_stop - clock_start)) / CLOCKS_PER_SEC;
printf("Time taken is %e seconds\n",secs);
}
ą¤ąŠą┤čüč湥čé čéą░ą║č鹊ą▓ ą▓ ą║ąŠą┤ąĄ ąĮą░ ą░čüčüąĄą╝ą▒ą╗ąĄčĆąĄ. ą¦č鹊ą▒čŗ ąĖąĘą╝ąĄčĆąĖčéčī ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░ ą▓ ą┐čĆąŠąĄą║č鹥 ąĮą░ ą░čüčüąĄą╝ą▒ą╗ąĄčĆąĄ, ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐čĆąŠčüč鹊 ąĮą░ą┐čĆčÅą╝čāčÄ ąŠą▒čĆą░čēą░čéčīčüčÅ ą║ čĆąĄą│ąĖčüčéčĆą░ą╝ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ čüč湥čéčćąĖą║ą░ čéą░ą║č鹊ą▓. ąöą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin čüą╝. ą┐čĆąĖą╝ąĄčĆ ą▓ ąøąĖčüčéąĖąĮą│ąĄ 4, ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ TigerSHARC čüą╝. ąøąĖčüčéąĖąĮą│ 5, ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ SHARC čüą╝. ąøąĖčüčéąĖąĮą│ 6.
//ąøąĖčüčéąĖąĮą│ 4. ą¤ąŠą┤čüč湥čé čéą░ą║č鹊ą▓ ą┤ą╗čÅ Blackfin ąĮą░ ą░čüčüąĄą╝ą▒ą╗ąĄčĆąĄ.
R2 = 0;
CYCLES = R2;
CYCLES2 = R2;
R2 = SYSCFG;
BITSET(R2,1);
SYSCFG = R2;
/* ąĪčÄą┤ą░ ą▓čüčéą░ą▓čīč鹥 ą░ąĮą░ą╗ąĖąĘąĖčĆčāąĄą╝čŗą╣ ą║ąŠą┤ */
R2 = SYSCFG;
BITCLR(R2,1);
SYSCFG = R2;
R2 = CYCLES
R1 = CYCLES2
//ąøąĖčüčéąĖąĮą│ 5. ą¤ąŠą┤čüč湥čé čéą░ą║č鹊ą▓ ą┤ą╗čÅ TigerSHARC ąĮą░ ą░čüčüąĄą╝ą▒ą╗ąĄčĆąĄ.
xr2 = CCNT0;;
/* ąĪčÄą┤ą░ ą▓čüčéą░ą▓čīč鹥 ą░ąĮą░ą╗ąĖąĘąĖčĆčāąĄą╝čŗą╣ ą║ąŠą┤ */
xr3 = CCNT0;;
xr4 = r3 - r2;;
//ąøąĖčüčéąĖąĮą│ 6. ą¤ąŠą┤čüč湥čé čéą░ą║č鹊ą▓ ą┤ą╗čÅ SHARC ąĮą░ ą░čüčüąĄą╝ą▒ą╗ąĄčĆąĄ.
R6 = EMUCLK;
/* ąĪčÄą┤ą░ ą▓čüčéą░ą▓čīč鹥 ą░ąĮą░ą╗ąĖąĘąĖčĆčāąĄą╝čŗą╣ ą║ąŠą┤ */
R7 = EMUCLK;
R8 = R7 - R6;
[ą¦č鹊 ą▓ą╗ąĖčÅąĄčé ąĮą░ č鹊čćąĮąŠčüčéčī ą░ąĮą░ą╗ąĖąĘą░]
ąÆ čüą╗ąĄą┤čāčÄčēąĖčģ čüąĄą║čåąĖčÅ ąŠą┐ąĖčüą░ąĮčŗ čĆą░ąĘą╗ąĖčćąĖčÅ ą▓ ą╝ąĄč鹊ą┤ą░čģ ąĖąĘą╝ąĄčĆąĄąĮąĖčÅ ą▓čĆąĄą╝ąĄąĮąĖ ą║ąŠą┤ą░, ą▓ą╗ąĖčÅčÄčēąĖąĄ ąĮą░ č鹊čćąĮąŠčüčéčī ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ą░.
STDIO, č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░ ąĖ ą┐ąŠčłą░ą│ąŠą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĮą░ ą░ą┐ą┐ą░čĆą░čéčāčĆąĄ. ąÜąŠą│ą┤ą░ ąÆčŗ ąĘą░ą┐čāčüą║ą░ąĄč鹥 čüą▓ąŠąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ąĮą░ čĆąĄą░ą╗čīąĮąŠą╣ ą░ą┐ą┐ą░čĆą░čéčāčĆąĄ, čäą░ą╣ą╗ąŠą▓čŗą╣ ą▓ą▓ąŠą┤/ą▓čŗą▓ąŠą┤, STDIO, ąĖ ą┐ąŠčłą░ą│ąŠą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐čĆąĖą▓ąŠą┤čÅčé ą┐čĆąŠčåąĄčüčüąŠčĆ ą║ ąŠčüčéą░ąĮąŠą▓ą║ąĄ, ą║ą░ąČą┤ą░čÅ čéą░ą║ą░čÅ ąŠčüčéą░ąĮąŠą▓ą║ą░ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ čüą▒čĆąŠčüčā (čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ) ą║ąŠąĮą▓ąĄą╣ąĄčĆą░ (flush pipeline). ą¤čĆąĖ ą┐ąŠčłą░ą│ąŠą▓ąŠą╝ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ čüą▒čĆąŠčüčŗ ą║ąŠąĮą▓ąĄą╣ąĄčĆą░ ą┐čĆąŠąĖčüčģąŠą┤čÅčé ąĮą░ ą║ą░ąČą┤ąŠą╣ ą┐ąŠčłą░ą│ąŠą▓ąŠ ą▓čŗą┐ąŠą╗ąĮčÅąĄą╝ąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąöą╗čÅ ąŠą┐ąĄčĆą░čåąĖą╣ čäą░ą╣ą╗ąŠą▓ąŠą│ąŠ ą▓ą▓ąŠą┤ą░/ą▓čŗą▓ąŠą┤ą░ ąĖ STDIO ąŠčćąĖčüčéą║ą░ ą║ąŠąĮą▓ąĄą╣ąĄčĆą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĖąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ąĘą░ą┐čāčüą║/ąŠčüčéą░ąĮąŠą▓ą║ą░ (run/halt) ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ą░čÅ ą┐čĆąĖą╝ąĖčéąĖą▓ą░ą╝ąĖ ą▓ą▓ąŠą┤ą░/ą▓čŗą▓ąŠą┤ą░ ą┐čĆąĖ ą┐ąĄčĆąĄą┤ą░č湥 ąĖąĮč乊čĆą╝ą░čåąĖąĖ. ąóąĖą┐ąĖčćąĮčŗą╝ ą┐čĆąĖą╝ąĄčĆąŠą╝ čüą╗čāąČąĖčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ printf(), ą║ąŠč鹊čĆčŗą╣ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ą▓ čüąĄą▒ąĄ 3 ąŠą┐ąĄčĆą░čåąĖąĖ: ąŠčéą║čĆčŗčéąĖąĄ (open), čćč鹥ąĮąĖąĄ (read) ąĖ ąĘą░č鹥ą╝ ąĘą░ą║čĆčŗčéąĖąĄ (close). ąØą░ ą║ą░ąČą┤ąŠą╝ ąĖąĘ čŹčéąĖčģ čüąŠą▒čŗčéąĖą╣ ą┐čĆąŠčåąĄčüčüąŠčĆ ąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ąĮą░ čüą║čĆčŗč鹊ą╣ č鹊čćą║ąĄ ąŠčüčéą░ąĮąŠą▓ą░, ą║ąŠąĮą▓ąĄą╣ąĄčĆ čüą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ, ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ąĘą░ą┐čĆąŠčłąĄąĮąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ, ąĖ ąĘą░č鹥ą╝ ą┐čĆąŠčåąĄčüčüąŠčĆ čüąĮąŠą▓ą░ ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ.
ą£ą░ą║čĆąŠčüčŗ ą┐ąŠą┤čüč湥čéą░ čéą░ą║č鹊ą▓ ą╝ąŠą│čāčé ą┤ą░ą▓ą░čéčī čĆąĄąĘčāą╗čīčéą░čéčŗ čü čüąĖą╗čīąĮąŠą╣ čäą╗čāą║čéčāą░čåąĖąĄą╣, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé č鹊ą│ąŠ, ą║ą░ą║ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą┐ąŠ ąŠčéąĮąŠčłąĄąĮąĖčÄ ą║ čäčāąĮą║čåąĖčÅą╝ I/O ąĖ ą┐ąŠčłą░ą│ąŠą▓ąŠą╝čā ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÄ; ą▓čüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé čüą▒čĆąŠčü ą║ąŠąĮą▓ąĄą╣ąĄčĆą░, ą║ čĆąĄą│ąĖčüčéčĆą░ą╝ čüč湥čéčćąĖą║ą░ čéą░ą║č鹊ą▓ ą┤ąŠą▒ą░ą▓ą╗čÅčÄčéčüčÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ čéą░ą║čéčŗ. ąŁč鹊 ą╝ąŠąČąĄčé ą┤ą░čéčī ą▓ąĄčüčīą╝ą░ ąŠčéą╗ąĖčćą░čÄčēąĖąĄčüčÅ čĆąĄąĘčāą╗čīčéą░čéčŗ ąĘą░čéčĆą░čé ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą┐ąŠ čüčĆą░ą▓ąĮąĄąĮąĖčÄ čü čĆąĄą░ą╗čīąĮčŗą╝ąĖ čāčüą╗ąŠą▓ąĖčÅą╝ąĖ čĆą░ą▒ąŠčéčŗ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, ą║ąŠą│ą┤ą░ ą┐ąŠčłą░ą│ąŠą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĖ/ąĖą╗ąĖ ąŠčéą╗ą░ą┤ąŠčćąĮčŗą╣ ą▓ą▓ąŠą┤/ą▓čŗą▓ąŠą┤ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ.
ąÆ ą║ąŠąĮč鹥ą║čüč鹥 ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ą░ ąŠčüčéą░ąĮąŠą▓ą║ąĖ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą┐čĆąŠąĖčüčģąŠą┤ąĖčéčī ą┐čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ STDIO ąĖ ą┐ąŠčłą░ą│ąŠą▓ąŠą╝ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ, ą┐čĆąĖą▓ąŠą┤čÅčé ą║ ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖčÄ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ą░. ąĢčüą╗ąĖ ą┐čĆąŠčäąĖą╗ąĖčĆčāąĄą╝čŗą╣ ą║ąŠą┤ ą┐ąŠą╗ą░ą│ą░ąĄčéčüčÅ ąĮą░ STDIO, ąĖą╗ąĖ ą┐ąŠą┤ą▓ąĄčĆą│ą░ąĄčéčüčÅ čćą░čüčéčŗą╝ ąŠčüčéą░ąĮąŠą▓ą║ą░ą╝ (ą╗ąĖą▒ąŠ ą┐čĆąĖ ą┐ąŠčłą░ą│ąŠą▓ąŠą╝ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ, ą╗ąĖą▒ąŠ čü ąĘą░ą┤ąĄą╣čüčéą▓ąŠą▓ą░ąĮąĖąĄą╝ č鹊č湥ą║ ąŠčüčéą░ąĮąŠą▓ą░), č鹊 ą┐čĆąŠčäą░ą╣ą╗ąĄčĆ ąĮąĄ čüąŠą▒ąĄčĆąĄčé ą┤ąŠčüčéą░č鹊čćąĮąŠ ą┤ą░ąĮąĮčŗčģ ą▓čŗą▒ąŠčĆąŠą║ ą┤ą╗čÅ ą░ąĮą░ą╗ąĖąĘą░.
ąĢčüą╗ąĖ ą┤ą░ąĮąĮčŗąĄ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ą░ ą▒čŗą╗ąĖ ąŠčéą▒čĆąŠčłąĄąĮčŗ, č鹊 VisualDSP++ 5.0 IDDE čüą│ąĄąĮąĄčĆąĖčĆčāąĄčé čüą╗ąĄą┤čāčÄčēąĄąĄ ą┐čĆąĄą┤čāą┐čĆąĄąČą┤ąĄąĮąĖąĄ: "Statistical profiling information has been discarded". ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ čüą╝. ą▓ čĆą░ąĘą┤ąĄą╗ąĄ ąŠąĮą╗ą░ą╣ąĮ-ą┐ąŠą┤čüą║ą░ąĘą║ąĖ "Statistical Profiling of Short Run Programs".
[ąĪčĆą░ą▓ąĮąĄąĮąĖąĄ ą╗ąĖąĮąĄą╣ąĮąŠą│ąŠ ąĖ čüčéą░čéąĖčüčéąĖč湥čüą║ąŠą│ąŠ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ą░]
ąĪčĆą░ą▓ąĮąĄąĮąĖąĄ čüąĖą╝čāą╗čÅč鹊čĆą░ ąĖ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ ąŠčéą╗ą░ą┤čćąĖą║ą░ (ICE/EZ-KIT Lite). ą¦ą░čüčéčŗą╣ čüą╗čāčćą░ą╣, ą║ąŠą│ą┤ą░ čĆąĄąĘčāą╗čīčéą░čéčŗ ąĖąĘ ą┐čĆąŠčäą░ą╣ą╗ąĄčĆą░ ąŠčéą╗ąĖčćą░čÄčéčüčÅ ą┤ą╗čÅ čüąĖą╝čāą╗čÅč鹊čĆą░ ąĖ ą░ą┐ą┐ą░čĆą░čéąĮąŠą╣ čåąĄą╗ąĖ ąŠčéą╗ą░ą┤ą║ąĖ. ąÆ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą┐čĆąŠčåąĄčüčüąŠčĆą░, ą║ąŠč鹊čĆčŗą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ, ąÆčŗ ą╝ąŠąČąĄč鹥 čāą▓ąĖą┤ąĄčéčī čĆą░ąĘąĮčŗąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ ąĖąĘ ą┐čĆąŠčäą░ą╣ą╗ąĄčĆą░ ąĖą╗ąĖ ąĖąĘ ą╝ą░ą║čĆąŠčüąŠą▓ ą┐ąŠą┤čüč湥čéą░ čéą░ą║č鹊ą▓ ą▓ čüčĆą░ą▓ąĮąĄąĮąĖąĖ čü ą┤čĆčāą│ąĖą╝ąĖ čåąĄą╗čÅą╝ąĖ ąŠčéą╗ą░ą┤ą║ąĖ. ą×ą┤ąĮą░ ąĖąĘ ą▓ąŠąĘą╝ąŠąČąĮčŗčģ ą┐čĆąĖčćąĖąĮ ąŠčéą╗ąĖčćąĖą╣ ą╝ąĄąČą┤čā čüč湥čéčćąĖą║ą░ą╝ąĖ čéą░ą║č鹊ą▓ ą▓ čüąĖą╝čāą╗čÅč鹊čĆąĄ ąĖ čüč湥čéčćąĖą║ą░ą╝ąĖ ą┐čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ICE / EZ-KIT Lite čŹč鹊 čüą┐ąŠčüąŠą▒, ą║ąŠč鹊čĆčŗą╝ čüąĖą╝čāą╗čÅč鹊čĆ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāąĄčé ą╝ąŠą┤ąĄą╗čī čćąĖą┐ą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
ąØą░ čüąĖą╝čāą╗čÅč鹊čĆą░čģ TigerSHARC čŹč鹊 ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ąĘą░ą┐čāčüą║ąŠą╝ čćą░čüčéąĖ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ čÅą┤čĆą░ ąĘą░ą│čĆčāąĘčćąĖą║ą░ (loader kernel, čüą╝. čüąŠąŠą▒čēąĄąĮąĖąĄ ą▓ ąŠą║ąĮąĄ ą▓čŗą▓ąŠą┤ą░ "[Info: si1108] Running Default Loader: {ąĖą╝čÅ_čäą░ą╣ą╗ą░}"). ąŁč鹊čé ą║ąŠą┤ čĆą░ąĘčĆąĄčłą░ąĄčé ą║čŹčł ąĖ branch target buffer (BTB). ąÜąŠą│ą┤ą░ ą║ąŠą┤ ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ ąĮą░ ą░ą┐ą┐ą░čĆą░čéąĮąŠą╝ TigerSHARC, čŹč鹊 ąĮąĄ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī čüčĆą░ą▓ąĮąĖą╝čŗąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ, ą┐ąŠą┤ą║ą╗čÄčćąĖč鹥 ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÄ ą║čŹčłą░ ąĖ čĆą░ąĘčĆąĄčłąĖč鹥 BTB ą▓ ąÆą░čłąĄą╝ ą║ąŠą┤ąĄ.
ąĪąĖą╝čāą╗čÅč鹊čĆčŗ Blackfin ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāčÄčé ąĮąĄą║ąŠč鹊čĆąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą░čĆčģąĖč鹥ą║čéčāčĆąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą▓ ąĖčģ ąĘąĮą░č湥ąĮąĖąĄ ą┐ąŠčüą╗ąĄ čüą▒čĆąŠčüą░. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąŠ ą┐ąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą╝čā ą┐čĆąŠčåąĄčüčüąŠčĆčā (Processor Hardware Reference).
ąĪąĖą╝čāą╗čÅč鹊čĆčŗ SHARC ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāčÄčé ą╝ąĮąŠą│ąĖąĄ čüą▓ąŠąĖ čĆąĄą│ąĖčüčéčĆčŗ, ąŠčüąĮąŠą▓čŗą▓ą░čÅčüčī ąĮą░ ąĘąĮą░č湥ąĮąĖčÅčģ, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ ą▓ čäą░ą╣ą╗ą░čģ .xml (ąĮą░čģąŠą┤čÅčéčüčÅ ą▓ ą┐ą░ą┐ą║ąĄ System\Archdef ą║ą░čéą░ą╗ąŠą│ą░ ąĖąĮčüčéą░ą╗ą╗čÅčåąĖąĖ VisualDSP++).
ąÉą┐ą┐ą░čĆą░čéąĮčŗąĄ čåąĄą╗ąĖ ąŠčéą╗ą░ą┤ą║ąĖ (菹╝čāą╗čÅč鹊čĆ+ą┐čĆąŠčåąĄčüčüąŠčĆ) čéą░ą║ąČąĄ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāčÄčé ą╝ąĮąŠą│ąĖąĄ čüą▓ąŠąĖ čĆąĄą│ąĖčüčéčĆčŗ ąĮą░ ąŠčüąĮąŠą▓ąĄ ąĘąĮą░č湥ąĮąĖą╣, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ ą▓ čäą░ą╣ą╗ą░čģ .xml (čéą░ą║ąČąĄ ąĮą░čģąŠą┤čÅčéčüčÅ ą▓ ą┐ą░ą┐ą║ąĄ System\Archdef ą║ą░čéą░ą╗ąŠą│ą░ ąĖąĮčüčéą░ą╗ą╗čÅčåąĖąĖ VisualDSP++).
ą¤ąŠčüą║ąŠą╗čīą║čā ąĘąĮą░č湥ąĮąĖčÅ ą▓ čäą░ą╣ą╗ąĄ .xml ą╝ąŠąČąĄčé ąŠčéą╗ąĖčćą░čéčīčüčÅ ąŠčé ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ą┤ą╗čÅ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ čüąĖą╝čāą╗čÅč鹊čĆą░ Blackfin ąĖą╗ąĖ TigerSHARC, ą░ą┐ą┐ą░čĆą░čéčāčĆą░ ą╝ąŠąČąĄčé ą┐čĆąĖą╣čéąĖ ąĖąĘ čüą▒čĆąŠčüą░ čü ą┤čĆčāą│ąĖą╝ čüąŠčüč鹊čÅąĮąĖąĄą╝, ąĮąĄ čüąŠą▓ą┐ą░ą┤ą░čÄčēąĖą╝ čü čüąŠčüč鹊čÅąĮąĖąĄą╝ čüąĖą╝čāą╗čÅč鹊čĆą░. ąĪąĖą╝čāą╗čÅč鹊čĆčŗ SHARC ąŠčéą╗ąĖčćą░čÄčéčüčÅ, ą┐ąŠčüą║ąŠą╗čīą║čā čāčüčéą░ąĮąŠą▓ą║ą░ ąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓ čéą░ą║ą░čÅ ąČąĄ, ą║ą░ą║ ą┤ąĄą╗ą░čÄčé čāčüčéą░ąĮąŠą▓ą║čā ą░ą┐ą┐ą░čĆą░čéąĮčŗąĄ čåąĄą╗ąĖ ąŠčéą╗ą░ą┤ą║ąĖ.
ąĢčüą╗ąĖ ą░ąĮą░ą╗ąĖąĘąĖčĆčāąĄą╝čŗą╣ ą║ąŠą┤ ąČąĄčüčéą║ąŠ ą┐ąŠą╗ą░ą│ą░ąĄčéčüčÅ ąĮą░ ą░ą║čéąĖą▓ąĮąŠčüčéčī čłąĖąĮčŗ ąĖ/ąĖą╗ąĖ čĆą░ą▒ąŠčéčā čü ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéčīčÄ, č鹊 čüč湥čéčćąĖą║ąĖ čéą░ą║č鹊ą▓ čü čüąĖą╝čāą╗čÅč鹊čĆąĄ ąĖ ąĮą░ čĆąĄą░ą╗čīąĮąŠą╣ ą░ą┐ą┐ą░čĆą░čéčāčĆąĄ ą╝ąŠą│čāčé ąŠčéą╗ąĖčćą░čéčīčüčÅ. ąźąŠčéčÅ čüąĖą╝čāą╗čÅč鹊čĆ ą┤ąĄą╗ą░ąĄčé ą┐ąŠą┐čŗčéą║čā ą╝ąŠą┤ąĄą╗ąĖčĆąŠą▓ą░čéčī ą╗ą░č鹥ąĮčéąĮąŠčüčéčī ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ąĖ ąĘą░ą┤ąĄčƹȹ║ąĖ ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ (back to back load/store), ą▓čüąĄ-čéą░ą║ąĖ ąŠąĮąĖ ąĮąĄ ą▒čāą┤čāčé č鹊čćąĮčŗą╝ąĖ ą▓ čāč湥č鹥 čéą░ą║č鹊ą▓. ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ ą▓ąĄčĆąĮąŠ ą┤ą╗čÅ ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąĖčÅ čü ą╝ąĮąŠą│ąĖą╝ąĖ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗą╝ąĖ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ąĖ.
ąĪčĆą░ą▓ąĮąĄąĮąĖąĄ ą╗ąĖąĮąĄą╣ąĮąŠą│ąŠ ąĖ čüčéą░čéąĖčüčéąĖč湥čüą║ąŠą│ąŠ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ą░. ąśąĮąŠą│ą┤ą░, ą║ąŠą│ą┤ą░ Linear Profiler ą▓ąŠąĘą▓čĆą░čéąĖą╗ ą┐ąŠą╗ąĮčŗą╣ ą┐čĆąŠčäąĖą╗čī, ąŠą║ą░ąĘčŗą▓ą░ąĄčéčüčÅ ą┐čĆąŠą┐čāčēąĄąĮąĮąŠą╣ čäčāąĮą║čåąĖčÅ ą▓ Statistical Profiler, ąĖą╗ąĖ Statistical Profiler ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ąĮąĄą┐ąŠą╗ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą┐čĆąŠčäąĖą╗čÅ. ą¤čĆąĖčćąĖąĮą░ ą║čĆąŠąĄčéčüčÅ ą▓ čĆą░ąĘą╗ąĖčćąĮčŗčģ čüą┐ąŠčüąŠą▒ą░čģ, ą║ą░ą║ąĖą╝ ąĘą░čģą▓ą░čéčŗą▓ą░čÄčé ą┤ą░ąĮąĮčŗąĄ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ą░ Linear Profiler ąĖ Statistical Profiler.
ą¤ąŠčüą║ąŠą╗čīą║čā Linear Profiler ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé ą║ą░ąČą┤ąŠąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖąĄ PC, č鹊 ą▓ ą┐ąŠą╗čāč湥ąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ą┐čĆąĖčüčāčéčüčéą▓čāčÄčé ą▓čüąĄ čäčāąĮą║čåąĖąĖ ąĖ čĆąĄąĘčāą╗čīčéąĖčĆčāčÄčēąĖą╣ ą┐čĆąŠčäąĖą╗čī ąŠą║ą░ąĘčŗą▓ą░ąĄčéčüčÅ č鹊čćąĮčŗą╝. ąĪ ą┤čĆčāą│ąŠą╣ čüč鹊čĆąŠąĮčŗ, Statistical Profiler ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé PC ą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║ąĖ, čéą░ą║ čćč鹊 ąĄą╝čā ą┐ąŠą┐ą░ą┤ą░ąĄčéčüčÅ ą╝ąĄąĮčīčłąĄ čäčāąĮą║čåąĖą╣, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą┐čĆąŠą┐čāčēąĄąĮčŗ ą▓ čĆąĄąĘčāą╗čīčéąĖčĆčāčÄčēąĄą╝ ą┐čĆąŠčäąĖą╗ąĄ. ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ, ąĄčüą╗ąĖ ą┐čĆąŠčäąĖą╗ąĖčĆčāąĄą╝ąŠąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ą▒čŗą╗ąŠ ą┐čĆąĄčĆą▓ą░ąĮąŠ ąĮą░ ą║ąŠčĆąŠčéą║ąŠą╝ ąŠčéčĆąĄąĘą║ąĄ ą▓čĆąĄą╝ąĄąĮąĖ, č鹊 Statistical Profiler ą╝ąŠąČąĄčé ąĮąĄ ąĘą░čģą▓ą░čéąĖčéčī ą┤ąŠčüčéą░č鹊čćąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┤ą░ąĮąĮčŗčģ, čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī ą┐čĆąŠčäąĖą╗čī ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░, ą┤ą░ą▓ą░čÅ ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 čćąĖčüčéčŗą╣ ą┐čĆąŠčäąĖą╗čī.
ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ąĄčüą╗ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ą▒čŗą╗ąŠ čüą┐čĆąŠčäąĖą╗ąĖčĆąŠą▓ą░ąĮąŠ ąĮą░ ą▒ąŠą╗čīčłąŠą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąĄ ą▓čŗą▒ąŠčĆąŠą║ čü čĆą░ąĘąĮčŗą╝ąĖ ą░ą┤čĆąĄčüą░ą╝ąĖ PC, č鹊 ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠ ą┐ą░ą┤ą░ąĄčé čüą║ąŠčĆąŠčüčéčī ą▓čŗą▒ąŠčĆąŠą║ Statistical Profiler, čćč鹊 ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ąĮąĄąĮą░ą┤ąĄąČąĮčŗą╝ čĆąĄąĘčāą╗čīčéą░čéą░ą╝.
ąŁčäč乥ą║čéčŗ, ąĮą░ą▒ą╗čÄą┤ą░ąĄą╝čŗąĄ ąĮą░ ą░ą┐ą┐ą░čĆą░čéčāčĆąĄ. ąÉą┐ą┐ą░čĆą░čéčāčĆą░ č鹊ąČąĄ ą╝ąŠąČąĄčé ą┤ą░ą▓ą░čéčī čŹčäč乥ą║čéčŗ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ ą┐čāčüč鹊ą│ąŠ ąĖą╗ąĖ ąĮąĄą┐ąŠą╗ąĮąŠą│ąŠ ą┐čĆąŠčäąĖą╗čÅ. ąĀąĄąĘčāą╗čīčéą░čéčŗ ą╝ąŠą│čāčé ą╝ąĄąĮčÅčéčīčüčÅ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé č鹊ą│ąŠ, ą║ą░ą║ ą▒čŗčüčéčĆąŠ čĆą░ąĘąĮčŗąĄ 菹╝čāą╗čÅč鹊čĆčŗ ąĖ ą░ą│ąĄąĮčéčŗ ąŠčéą╗ą░ą┤ą║ąĖ (EZ-KIT Lite Debug Agent) čüą╝ąŠą│čāčé čüąŠą▒čĆą░čéčī ąĖąĮč乊čĆą╝ą░čåąĖčÄ ą┐čĆąŠčäąĖą╗čÅ. ą×čéą╗ą░ą┤čćąĖą║ąĖ HPPCI-ICE ąĖ HPUSB-ICE ą▒čŗčüčéčĆąŠ čüąŠą▒ąĖčĆą░čÄčé ą▓čŗą▒ąŠčĆą║ąĖ ą┤ą╗čÅ ą┐čĆąŠčäąĖą╗čÅ, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ USBICE ąĖ EZ-KIT Lite Debug Agent čüąŠą▒ąĖčĆą░čÄčé ą▓čŗą▒ąŠčĆą║ąĖ čüąŠ ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠ ą╝ąĄąĮčīčłąĄą╣ čüą║ąŠčĆąŠčüčéčīčÄ. ąĢčüą╗ąĖ ą▒čŗą╗ąŠ čüąŠą▒čĆą░ąĮąŠ čüą╗ąĖčłą║ąŠą╝ ą╝ą░ą╗ąŠ ą▓čŗą▒ąŠčĆąŠą║ ą┐čĆąŠčäąĖą╗čÅ, č鹊 ąŠą║ąĮąŠ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ą░ ą╝ąŠąČąĄčé ąĮąĄ ą┐ąŠą║ą░ąĘą░čéčī ą║ą░ą║čāčÄ-ą╗ąĖą▒ąŠ ąĖąĮč乊čĆą╝ą░čåąĖčÄ, ąĖą╗ąĖ čĆąĄąĘčāą╗čīčéą░čéčŗ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░ ą▒čāą┤čāčé ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮčŗ ąĮąĄč鹊čćąĮąŠ.
ą×čüąĮąŠą▓ąĮąŠąĄ ą┐čĆą░ą▓ąĖą╗ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ Statistical Profiler: ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą┤ąŠą╗ąČąĮą░ ąŠčéčĆą░ą▒ąŠčéą░čéčī ą┤ąŠčüčéą░č鹊čćąĮąŠ ą┤ąŠą╗ą│ąŠ, čćč鹊ą▒čŗ (a) čüąŠą▒čĆą░čéčī ą▓čŗą▒ąŠčĆą║ąĖ, ąĖ (b) čüąŠą▒čĆą░čéčī ą┤ąŠčüčéą░č鹊čćąĮąŠ ą▓čŗą▒ąŠčĆąŠą║, čćč鹊ą▒čŗ ą┐čĆąŠčäąĖą╗čī ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ čüčéą░ą╗ čüčéą░ą▒ąĖą╗čīąĮčŗą╝.
ąĪąĖą╝čāą╗čÅč鹊čĆčŗ Blackfin: Cycle-Accurate-čüąĖą╝čāą╗čÅč鹊čĆ ą▓ čüčĆą░ą▓ąĮąĄąĮąĖąĖ čü Compiled-čüąĖą╝čāą╗čÅč鹊čĆąŠą╝. ąöą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin ąĖą╝ąĄąĄčéčüčÅ 2 čüąĖą╝čāą╗čÅč鹊čĆą░: čüąĖą╝čāą╗čÅč鹊čĆ čü č鹊čćąĮąŠą╣ ąŠčéčĆą░ą▒ąŠčéą║ąŠą╣ čéą░ą║č鹊ą▓ (cycle-accurate) ąĖ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░ąĮąĮčŗą╣ čüąĖą╝čāą╗čÅč鹊čĆ (ąĖą╗ąĖ čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝čŗą╣ ą▒čŗčüčéčĆčŗą╣, "fast functional" čüąĖą╝čāą╗čÅč鹊čĆ). ą×ą▒ą░ čüąĖą╝čāą╗čÅč鹊čĆą░ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠ ą║ąŠčĆčĆąĄą║čéąĮčŗ; ąŠą┤ąĮą░ą║ąŠ, čā ą║ą░ąČą┤ąŠą│ąŠ čüąĖą╝čāą╗čÅč鹊čĆą░ ąŠčéą┤ąĄą╗čīąĮą░čÅ ąŠą▒ą╗ą░čüčéčī ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ. ąóąŠą╗čīą║ąŠ cycle-accurate čüąĖą╝čāą╗čÅč鹊čĆ ą╝ąŠąČąĄčé ą░ą┐ą┐čĆąŠą║čüąĖą╝ąĖčĆąŠą▓ą░čéčī ąĘą░ą┤ąĄčƹȹ║ąĖ ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ ąĖ ą┐ąŠą╗čāčćąĖčéčī čĆąĄą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ čéą░ą║č鹊ą▓ ąĖ č鹊čćąĮčŗąĄ ą║čĆąĖą▓čŗąĄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ.
ąæčŗčüčéčĆčŗą╣ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮčŗą╣ čüąĖą╝čāą╗čÅč鹊čĆ ąĮąĄ ą┐čŗčéą░ąĄčéčüčÅ ą▒čŗčéčī č鹊čćąĮčŗą╝ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ą┐ąŠą┤čüč湥čéą░ čéą░ą║č鹊ą▓. ąŁč鹊 ą┐čĆąŠčüč鹊 ąŠč湥ąĮčī ą▒čŗčüčéčĆąŠ čĆą░ą▒ąŠčéą░čÄčēąĖą╣ čüąĖą╝čāą╗čÅč鹊čĆ, ą║ąŠč鹊čĆčŗą╣ ą┐čĆą░ą▓ąĖą╗čīąĮąŠ čĆąĄą░ą╗ąĖąĘčāąĄčé ą╗ąŠą│ąĖą║čā ą░ą╗ą│ąŠčĆąĖčéą╝ą░. ą×ąĮ ąĮąĄ ą╝ąŠą┤ąĄą╗ąĖčĆčāąĄčé ąĘą░ą┤ąĄčƹȹ║ąĖ (ą║čĆąŠą╝ąĄ ąĮąĄą║ąŠč鹊čĆčŗčģ ąŠčüąĮąŠą▓ąĮčŗčģ, čüą▓čÅąĘą░ąĮąĮčŗčģ čü čĆą░ą▒ąŠč鹊ą╣ čüąĄą║ą▓ąĄąĮčüąŠčĆą░) ąĖ ąĮąĄ čāčćąĖčéčŗą▓ą░ąĄčé ąĖčģ ą┐čĆąĖ ą┐ąŠą┤čüč湥č鹥 čéą░ą║č鹊ą▓.
ąæčŗčüčéčĆčŗą╣ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮčŗą╣ čüąĖą╝čāą╗čÅč鹊čĆ ą▓čüąĄ ąĄčēąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé čüč湥čéčćąĖą║ čéą░ą║č鹊ą▓, ą┐ąŠč鹊ą╝čā čćč鹊 čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖąĄ čĆąĄą│ąĖčüčéčĆčŗ ą┐čĆąĖčüčāčéčüčéą▓čāčÄčé ą▓ ą░čĆčģąĖč鹥ą║čéčāčĆąĄ; ąŠą┤ąĮą░ą║ąŠ ąŠąĮ ąĮąĄ ą╝ąŠąČąĄčé ąĖčģ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░čéčī ą▓ ą║ąŠąĮč鹥ą║čüč鹥 čüč湥čéčćąĖą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣, čŹč鹊 ąĮąĄ čüč湥čéčćąĖą║ čéą░ą║č鹊ą▓ ą┤ą░ąĮąĮąŠą╝ čüąĖą╝čāą╗čÅč鹊čĆąĄ.
ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ąĮąĄčüą╝ąŠčéčĆčÅ ąĮą░ č鹊, čćč鹊 profiling API ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ ą▓ ąŠą▒ąŠąĖčģ čüąĖą╝čāą╗čÅč鹊čĆą░čģ, ąŠąĮąŠ ąĮąĄ čĆą░ą▒ąŠčéą░ąĄčé č鹊čćąĮąŠ ą┐ąŠ čåąĖą║ą╗ą░ą╝ ą┤ą╗čÅ ą▒čŗčüčéčĆąŠą│ąŠ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠą│ąŠ čüąĖą╝čāą╗čÅč鹊čĆą░.
[ą¤čĆąĖą╗ąŠąČąĄąĮąĖąĄ A: ą┐čĆąĖą╝ąĄčĆ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ą░]
ąØą░ąĘąĮą░č湥ąĮąĖąĄ ą┐čĆąĖą╝ąĄčĆą░. ąÜ čŹč鹊ą╝čā ą░ą┐ąĮąŠčāčéčā ą┐čĆąĖą╗ą░ą│ą░ąĄčéčüčÅ ą║ąŠą┤ ą┐čĆąĖą╝ąĄčĆą░ [3] ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą▓ą╝ąĄčüč鹥 čü EZ-KIT Lite Debug Agent ąĖ čüąĄčüčüąĖčÅą╝ąĖ čüąĖą╝čāą╗čÅč鹊čĆą░. ą×ąĮ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮ ą┤ą╗čÅ ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąĖ čĆą░ąĘą╗ąĖčćąĖą╣ ą▓ čĆąĄąĘčāą╗čīčéą░čéą░čģ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ą░ ą▓ čüąĖą╝čāą╗čÅč鹊čĆąĄ ąĖ ąĮą░ čĆąĄą░ą╗čīąĮąŠą╣ ą░ą┐ą┐ą░čĆą░čéčāčĆąĄ.
ą×ąČąĖą┤ą░ąĄą╝čŗąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ. ążčāąĮą║čåąĖąĖ a() ąĖ b() ą▓čŗą┐ąŠą╗ąĮčÅčÄčé ąŠą┤ąĖąĮą░ą║ąŠą▓čŗąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ čäčāąĮą║čåąĖčÅ c() ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ą┐ąŠą╗ąŠą▓ąĖąĮčā ąĖąĘ čŹčéąĖčģ ąŠą┐ąĄčĆą░čåąĖą╣, ąĖ d() ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ą┐ąŠą╗ąŠą▓ąĖąĮčā ąŠčé čŹč鹊ą╣ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ. ąÆ čüąĖą╝čāą╗čÅč鹊čĆąĄ ą┐čĆąŠčäą░ą╣ą╗ąĄčĆ ą┤ąŠą╗ąČąĄąĮ ą▓ąĄčĆąĮčāčéčī čĆąĄąĘčāą╗čīčéą░čéčŗ, ą▒ą╗ąĖąĘą║ąĖąĄ ą▓ čüąŠąŠčéąĮąŠčłąĄąĮąĖąĖ a:b:c:d ą║ą░ą║ 4:4:2:1. ąÆčŗ ą┤ąŠą╗ąČąĮčŗ čéą░ą║ąČąĄ ąĘą░ą╝ąĄčéąĖčéčī, čćč鹊 čéą░ą║ąĖąĄ čäčāąĮą║čåąĖąĖ ą║ą░ą║ start ąĖ main(), ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮčŗ ą▓ ą║ąŠąĮąĄčćąĮąŠą╝ ą┐čĆąŠčäąĖą╗ąĄ, ąĮąĄčüą╝ąŠčéčĆčÅ ąĮą░ č鹊, čćč鹊 ąŠąĮąĖ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ąĮą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąŠč湥ąĮčī ą╝ą░ą╗ąŠ čéą░ą║č鹊ą▓.
ąØą░ ą┐ą╗ą░čéą░čģ čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ą░ EZ-KIT Lite č湥čĆąĄąĘ Debug Agent čĆąĄąĘčāą╗čīčéą░čéčŗ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ą░ ą┤ąŠą╗ąČąĮčŗ ąŠčéą╗ąĖčćą░čéčīčüčÅ ąŠčé čĆąĄąĘčāą╗čīčéą░č鹊ą▓ čüąĖą╝čāą╗čÅč鹊čĆą░. ąŚą░ą┐čāčüą║ ąĖ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│ ą┐čĆąŠąĄą║čéą░ ąĮąĄčüą║ąŠą╗čīą║ąŠ čĆą░ąĘ ą┤ąŠą╗ąČąĄąĮ ą┐ąŠą║ą░ąĘą░čéčī čĆą░ąĘąĮčŗąĄ ą┐čĆąŠčåąĄąĮčéąĮčŗąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ čäčāąĮą║čåąĖą╣ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ąĘą░ą┐čāčüą║ą░, ąĖ ą▓ ąĮąĄą║ąŠč鹊čĆčŗčģ čüą╗čāčćą░čÅčģ ąÆčŗ ą┤ąŠą╗ąČąĮčŗ ą▓ąĖą┤ąĄčéčī čéą░ą║ąČąĄ, čćč鹊 čäčāąĮą║čåąĖčÅ d() ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąŠčéčüčāčéčüčéą▓čāąĄčé ą▓ ą┐čĆąŠčäąĖą╗ąĄ, ąĖ ą▓ąŠąĘą╝ąŠąČąĮąŠ ąĮąĄą║ąŠč鹊čĆčŗąĄ ą┤čĆčāą│ąĖąĄ čäčāąĮą║čåąĖąĖ čéą░ą║ąČąĄ ąŠčéčüčāčéčüčéą▓čāčÄčé. ą¤čĆąĖčćąĖąĮą░ ą▓ č鹊ą╝, čćč鹊 čćč鹊 čäčāąĮą║čåąĖčÅ ąĮąĄ čüąŠą▒čĆą░ą╗ą░ ą┤ąŠčüčéą░č鹊čćąĮąŠ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ, ąĖ ą┐ąŠčŹč鹊ą╝čā ąĮąĄ ą┐ąŠą┐ą░ą╗ą░ ą▓ ą▓čŗą▒ąŠčĆą║čā ąĖąĘ-ąĘą░ ą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║ąŠą│ąŠ čģą░čĆą░ą║č鹥čĆą░ ą▓čŗą▒ąŠčĆąŠą║, ą║ąŠč鹊čĆčŗą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄčé Statistical Profiler. ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ ąŠą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čéą░ą║ąĖąĄ čäčāąĮą║čåąĖąĖ, ą║ą░ą║ start ąĖ main() ąĮąĄ ą▓ąĖą┤ąĮčŗ ą▓ ą┐čĆąŠčäąĖą╗ąĄ ą┤ą╗čÅ čüąĄčüčüąĖąĖ EZ-KIT Lite.
ąĢčüą╗ąĖ čā ąÆą░čü ąĖą╝ąĄąĄčéčüčÅ ą▓čŗčüąŠą║ąŠą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮčŗą╣ ą░ą┐ą┐ą░čĆą░čéąĮčŗą╣ ąŠčéą╗ą░ą┤čćąĖą║, čéą░ą║ąŠą╣ ą║ą░ą║ HPUSB-ICE ąĖą╗ąĖ HPPCI-ICE, č鹊 ąĘą░ą┐čāčüą║ čŹč鹊ą│ąŠ ą┐čĆąŠąĄą║čéą░ ą┐ąŠčüč鹊čÅąĮąĮąŠ ą▒čāą┤ąĄčé ą┤ą░ą▓ą░čéčī ą┐čĆąŠčäąĖą╗čī, čüąŠą┤ąĄčƹȹ░čēąĖą╣ ą▓čüąĄ 4 čäčāąĮą║čåąĖąĖ; ąŠą┤ąĮą░ą║ąŠ čĆąĄąĘčāą╗čīčéą░čéčŗ ą▓čüąĄ ąĄčēąĄ ą▒čāą┤čāčé ąĮąĄ čéą░ą║ąĖą╝ąĖ ą┐ąŠą╗ąĮčŗą╝ąĖ, ą║ą░ą║ čĆąĄąĘčāą╗čīčéą░čé Linear Profiler ą▓ čüąĖą╝čāą╗čÅč鹊čĆąĄ.
[ą¤čĆąĖą╗ąŠąČąĄąĮąĖąĄ B: ą┐čĆąĖą╝ąĄčĆ ą┐ąŠą┤čüč湥čéą░ čéą░ą║č鹊ą▓]
ąØą░ąĘąĮą░č湥ąĮąĖąĄ ą┐čĆąĖą╝ąĄčĆą░. ą¤čĆąĖą╝ąĄčĆ ą║ąŠą┤ą░ ą┐ąŠą┤čüč湥čéą░ čéą░ą║č鹊ą▓ [3], ą┐čĆąĖą╗ą░ą│ą░ąĄą╝čŗą╣ ą┤ą╗čÅ čŹč鹊ą│ąŠ ą┤ąŠą║čāą╝ąĄąĮčéą░, ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čü ą╗čÄą▒čŗą╝ąĖ ą┐ąŠą┤čģąŠą┤čÅčēąĖą╝ąĖ čüąĄčüčüąĖčÅą╝ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin, SHARC ąĖ TigerSHARC, ąĖ ąĘą┤ąĄčüčī ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄčéčüčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čĆą░ąĘąĮčŗčģ č鹥čģąĮąĖą║ ą┐ąŠą┤čüč湥čéą░ čéą░ą║č鹊ą▓, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗčģ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░ą╝ąĖ.
ą×ąČąĖą┤ą░ąĄą╝čŗąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ. ąÜąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ą┐čĆąĖą╝ąĄčĆčŗ ą┐ąŠą┤čüč湥čéą░ čéą░ą║č鹊ą▓, č鹊 čĆąĄąĘčāą╗čīčéą░čéčŗ ą▒čāą┤čāčé ą▓čŗą▓ąĄą┤ąĄąĮčŗ ą▓ STDIO ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ąĖąĘ čéčĆąĄčģ ą╝ąĄč鹊ą┤ąŠą▓ ą┐ąŠą┤čüč湥čéą░ čéą░ą║č鹊ą▓. ąØąĖąČąĄ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ ą┐ąŠą║ą░ąĘą░ąĮ ą▓čŗą▓ąŠą┤ ą┐ąŠą┤čüč湥čéą░ čéą░ą║č鹊ą▓ čüąŠ čüčéą░čéąĖčüčéąĖą║ąŠą╣ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ADSP-BF533.
Cycle Counting Facilities
------------------------
Basic Cycle Count:
Number of cycles:420036
------------------------
Cycle Count With Statistics:
AVG : 420036
MIN : 420036
MAX : 420036
CALLS : 10
------------------------
Cycle Count Using time.h:
Time taken was 7.071499e-04 seconds
------------------------
[ąĪčüčŗą╗ą║ąĖ]
1. EE-332 Cycle Counting and Profiling site:analog.com.
2. ąæąĖą▒ą╗ąĖąŠč鹥ą║ą░ Blackfin DSP Run-Time, ąŠą▒čēąĄąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ.
3. 170419EE-332.zip - ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖčÅ ąĖ ą┐čĆąĖą╝ąĄčĆčŗ ą║ąŠą┤ą░. |



