|
ążąŠčĆą╝ą░čé WAV ąĖąĘąĮą░čćą░ą╗čīąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗čüčÅ ą▓ čüąĖčüč鹥ą╝ąĄ Windows ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čåąĖčäčĆąŠą▓čŗčģ ą░čāą┤ąĖąŠą┤ą░ąĮąĮčŗčģ. ąŁč鹊 čüą░ą╝čŗą╣ ąĖąĘą▓ąĄčüčéąĮčŗą╣ ąĖ čłąĖčĆąŠą║ąŠ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄą╝čŗą╣ č乊čĆą╝ą░čé ą▒ą╗ą░ą│ąŠą┤ą░čĆčÅ ą┐ąŠą┐čāą╗čÅčĆąĮąŠčüčéąĖ ą┐ą╗ą░čéč乊čĆą╝čŗ Windows ąĖ ą▒ąŠą╗čīčłąŠą╝čā ą║ąŠą╗ąĖč湥čüčéą▓čā ąĮą░ą┐ąĖčüą░ąĮąĮčŗčģ ą┤ą╗čÅ ąĮąĄčæ ą┐čĆąŠą│čĆą░ą╝ą╝. ą¤ąŠčćčéąĖ ą╗čÄą▒ą░čÅ čüąŠą▓čĆąĄą╝ąĄąĮąĮą░čÅ ą┐čĆąŠą│čĆą░ą╝ą╝ą░, čĆą░ą▒ąŠčéą░čÄčēą░čÅ čüąŠ ąĘą▓čāą║ąŠą╝, ą╝ąŠąČąĄčé ą┐čĆąŠčćąĖčéą░čéčī ąĖą╗ąĖ ąĘą░ą┐ąĖčüą░čéčī č乊čĆą╝ą░čé WAV, ą┐ąŠčŹč鹊ą╝čā čŹč鹊čé č乊čĆą╝ą░čé ąŠč湥ąĮčī ąĖąĮč鹥čĆąĄčüąĄąĮ ą┤ą╗čÅ čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ąŠą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖčÅ. ąöą░ą╗ąĄąĄ ą┐ąŠą┤čĆąŠą▒ąĮąŠ ąŠą┐ąĖčüčŗą▓ą░čÄčéčüčÅ čüčéčĆčāą║čéčāčĆčŗ ą┤ą░ąĮąĮčŗčģ č乊čĆą╝ą░čéą░ WAV.
[ążąŠčĆą╝ą░čéčŗ ą┤ą░ąĮąĮčŗčģ]
ą¤ąŠčüą║ąŠą╗čīą║čā č乊čĆą╝ą░čé WAV-čäą░ą╣ą╗ą░ ą┐čĆąĖčłąĄą╗ ąŠčé ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ Windows, ą▓ ą║ąŠč鹊čĆąŠą╣ čéčĆą░ą┤ąĖčåąĖąŠąĮąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ąĖčüčī ą┐čĆąŠčåąĄčüčüąŠčĆčŗ Intel, ą▓čüąĄ ąĘąĮą░č湥ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ č乊čĆą╝ą░čéą░ čģčĆą░ąĮčÅčéčüčÅ ą║ą░ą║ Little-Endian, čé. ąĄ. čüą░ą╝čŗą╣ ą╝ą╗ą░ą┤čłąĖą╣ ąĘąĮą░čćą░čēąĖą╣ ą▒ą░ą╣čé ąĖą┤ąĄčé ą┐ąĄčĆą▓čŗą╝.
WAV-čäą░ą╣ą╗čŗ ą╝ąŠą│čāčé čüąŠą┤ąĄčƹȹ░čéčī čüčéčĆąŠą║ąĖ č鹥ą║čüčéą░, ąĮą░ą┐čĆąĖą╝ąĄčĆ ą╝ąĄčéą║ąĖ čüąĄą║čåąĖą╣, ąĖąĮč乊čĆą╝ą░čåąĖąŠąĮąĮčŗąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖąĖ ąĖ čé. ą┤. ąĪčéčĆąŠą║ąĖ čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊 ą┐ąĄčĆą▓čŗą╣ ą▒ą░ą╣čé čāą║ą░ąĘčŗą▓ą░ąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ą░ą╣čé č鹥ą║čüčéą░ ASCII ą▓ čüčéčĆąŠą║ąĄ.
| 7 |
'e' |
'x' |
'a' |
'm' |
'p' |
'l' |
'e' |
ą¤čĆąĖą╝ąĄčĆ č乊čĆą╝ą░čéą░ čüčéčĆąŠą║ąĖ Wave
[ąĪčéčĆčāą║čéčāčĆą░ čäą░ą╣ą╗ą░]
WAV-čäą░ą╣ą╗ ąĖčüą┐ąŠą╗čīąĘčāąĄčé čüčéą░ąĮą┤ą░čĆčéąĮčāčÄ RIFF-čüčéčĆčāą║čéčāčĆčā, ą║ąŠč鹊čĆą░čÅ ą│čĆčāą┐ą┐ąĖčĆčāąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čäą░ą╣ą╗ą░ ąĖąĘ ąŠčéą┤ąĄą╗čīąĮčŗčģ čüąĄą║čåąĖą╣ (chunks) - č乊čĆą╝ą░čé ą▓čŗą▒ąŠčĆąŠą║ ą░čāą┤ąĖąŠą┤ą░ąĮąĮčŗčģ, ą░čāą┤ąĖąŠą┤ą░ąĮąĮčŗąĄ, ąĖ čé. ą┐. ąÜą░ąČą┤ą░čÅ čüąĄą║čåąĖčÅ ąĖą╝ąĄąĄčé čüą▓ąŠą╣ ąŠčéą┤ąĄą╗čīąĮčŗą╣ ąĘą░ą│ąŠą╗ąŠą▓ąŠą║ čüąĄą║čåąĖąĖ ąĖ ąŠčéą┤ąĄą╗čīąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ čüąĄą║čåąĖąĖ. ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąĄą║čåąĖąĖ čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ čéąĖą┐ čüąĄą║čåąĖąĖ ąĖ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čüąŠą┤ąĄčƹȹ░čēąĖčģčüčÅ ą▓ čüąĄą║čåąĖąĖ ą▒ą░ą╣čé. ąóą░ą║ąŠą╣ ą┐čĆąĖąĮčåąĖą┐ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖąĖ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐čĆąŠą│čĆą░ą╝ą╝ą░ą╝ ą░ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī č鹊ą╗čīą║ąŠ ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗąĄ čüąĄą║čåąĖąĖ, ą┐čĆąŠą┐čāčüą║ą░čÅ ąŠčüčéą░ą╗čīąĮčŗąĄ čüąĄą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ąĮąĄ ąĖąĘą▓ąĄčüčéąĮčŗ ąĖą╗ąĖ ą║ąŠč鹊čĆčŗąĄ ąĮąĄ čéčĆąĄą▒čāčÄčé ąŠą▒čĆą░ą▒ąŠčéą║ąĖ. ąØąĄą║ąŠč鹊čĆčŗąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ čüąĄą║čåąĖąĖ ą╝ąŠą│čāčé ąĖą╝ąĄčéčī ą▓ čüą▓ąŠąĄą╝ čüąŠčüčéą░ą▓ąĄ ą┐ąŠą┤čüąĄą║čåąĖąĖ (sub-chunks). ąØą░ą┐čĆąĖą╝ąĄčĆ, ą║ą░ą║ ą╝ąŠąČąĮąŠ čāą▓ąĖą┤ąĄčéčī ąĮą░ ą┤ąĖą░ą│čĆą░ą╝ą╝ąĄ, ąŠą┐ąĖčüčŗą▓ą░čÄčēąĖą╣ ąŠčüąĮąŠą▓ąĮąŠą╣ č乊čĆą╝ą░čé WAV-čäą░ą╣ą╗ą░, čüąĄą║čåąĖąĖ "fmt " ąĖ "data" čÅą▓ą╗čÅčÄčéčüčÅ ą┐ąŠą┤čüąĄą║čåąĖčÅą╝ąĖ čüąĄą║čåąĖąĖ "RIFF".
Chunk ID "RIFF"
Chunk Data Size |
| RIFF Type ID "WAVE" |
Chunk ID "fmt "
Chunk Data Size |
| Sample Format Info |
|
Chunk ID "data"
Chunk Data Size |
| Digital Audio Samples |
|
|
|
|
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąĄą║čåąĖąĖ (Chunk Header) |
|
|
ąöą░ąĮąĮčŗąĄ čüąĄą║čåąĖąĖ (Chunk Data Bytes) |
ą×ą┤ąĮą░ čģąĖčéčĆą░čÅ ą▓ąĄčēčī, čüą▓čÅąĘą░ąĮąĮą░čÅ čü čüąĄą║čåąĖčÅą╝ąĖ čäą░ą╣ą╗ą░ RIFF, čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, čćč鹊 ą░ą┤čĆąĄčüą░ ąĮą░čćą░ą╗ą░ čüąĄą║čåąĖą╣ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą▓čŗčĆąŠą▓ąĮąĄąĮčŗ ąĮą░ čĆą░ąĘą╝ąĄčĆ čüą╗ąŠą▓ą░ (2 ą▒ą░ą╣čéą░). ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ąŠą▒čēąĖą╣ čĆą░ąĘą╝ąĄčĆ čüąĄą║čåąĖąĖ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą║čĆą░č鹥ąĮ 2. ąĢčüą╗ąĖ čüąĄą║čåąĖčÅ čüąŠą┤ąĄčƹȹĖčé ąĮąĄč湥čéąĮąŠąĄ čćąĖčüą╗ąŠ ą▒ą░ą╣čé ą┤ą░ąĮąĮčŗčģ (ąĮąĄą▓čŗčĆą░ą▓ąĮąĄąĮąĮąŠąĄ ą┤ąŠ 2 ą▒ą░ą╣čé), č鹊 ą┤ąŠą▒ą░ą▓ą╗čÅąĄčéčüčÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗą╣ ąĮčāą╗ąĄą▓ąŠą╣ ą▒ą░ą╣čé ą┤ą░ąĮąĮčŗčģ ą▓ ą║ąŠąĮąĄčå ą┤ą░ąĮąĮčŗčģ čüąĄą║čåąĖąĖ. ąŁč鹊čé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗą╣ ą▒ą░ą╣čé ąĮąĄ čāčćąĖčéčŗą▓ą░ąĄčéčüčÅ ą▓ čĆą░ąĘą╝ąĄčĆąĄ čüąĄą║čåąĖąĖ ąĘą░ą│ąŠą╗ąŠą▓ą║ą░, čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą▓čüąĄą│ą┤ą░ ą┤ąŠą╗ąČąĮą░ čāčćąĖčéčŗą▓ą░čéčī ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą┤ą╗čÅ čĆą░čüč湥čéą░ čüą╝ąĄčēąĄąĮąĖčÅ ąĮą░čćą░ą╗ą░ čüą╗ąĄą┤čāčÄčēąĄą╣ čüąĄą║čåąĖąĖ.
[ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ WAV-čäą░ą╣ą╗ą░, čüąĄą║čåąĖčÅ čéąĖą┐ą░ RIFF]
ąŚą░ą│ąŠą╗ąŠą▓ą║ąĖ WAV-čäą░ą╣ą╗ą░ ąĖčüą┐ąŠą╗čīąĘčāčÄčé čüčéą░ąĮą┤ą░čĆčéąĮčŗą╣ č乊čĆą╝ą░čé RIFF. ą¤ąĄčĆą▓čŗąĄ 8 ą▒ą░ą╣čé čäą░ą╣ą╗ą░ - čüčéą░ąĮą┤ą░čĆčéąĮčŗą╣ ąĘą░ą│ąŠą╗ąŠą▓ąŠą║ čüąĄą║čåąĖąĖ RIFF, ą║ąŠč鹊čĆčŗą╣ ąĖą╝ąĄąĄčé ID čüąĄą║čåąĖąĖ "RIFF" ąĖ čĆą░ąĘą╝ąĄčĆ čüąĄą║čåąĖąĖ, čĆą░ą▓ąĮčŗą╣ čĆą░ąĘą╝ąĄčĆčā čäą░ą╣ą╗ą░ ą╝ąĖąĮčāčü 8 ą▒ą░ą╣čé, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ą┤ą╗čÅ RIFF-ąĘą░ą│ąŠą╗ąŠą▓ą║ą░. ą¤ąĄčĆą▓čŗąĄ 4 ą▒ą░ą╣čéą░ ą┤ą░ąĮąĮčŗčģ ą▓ čüąĄą║čåąĖąĖ "RIFF" ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčé čéąĖą┐ čĆąĄčüčāčĆčüą░, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĮąŠ ąĮą░ą╣čéąĖ ą▓ čüąĄą║čåąĖąĖ. WAV-čäą░ą╣ą╗čŗ ą▓čüąĄą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāčÄčé čéąĖą┐ čĆąĄčüčāčĆčüą░ "WAVE". ą¤ąŠčüą╗ąĄ čéąĖą┐ą░ čĆąĄčüčāčĆčüą░ (ID "WAVE") ąĖą┤čāčé ą▓čüąĄ čüąĄą║čåąĖąĖ ąĘą▓čāą║ąŠą▓ąŠą│ąŠ čäą░ą╣ą╗ą░, ą║ąŠč鹊čĆčŗąĄ ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčé ą░čāą┤ąĖąŠčüąĖą│ąĮą░ą╗.
| ąĪą╝ąĄčēąĄąĮąĖąĄ |
ąĀą░ąĘą╝ąĄčĆ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
ąŚąĮą░č湥ąĮąĖąĄ |
| 0x00 |
4 |
Chunk ID |
"RIFF" (0x52494646) |
| 0x04 |
4 |
Chunk Data Size |
(file size) - 8 |
| 0x08 |
4 |
RIFF Type |
"WAVE" (0x57415645) |
| 0x10 |
Wave chunks (čüąĄą║čåąĖąĖ WAV-čäą░ą╣ą╗ą░) |
| ąŚąĮą░č湥ąĮąĖčÅ ą┐ąŠą╗ąĄą╣ čüąĄą║čåąĖąĖ RIFF |
[ąĪąĄą║čåąĖąĖ WAV-čäą░ą╣ą╗ą░]
ąĪčāčēąĄčüčéą▓čāąĄčé ą┤ąŠą▓ąŠą╗čīąĮąŠ ą╝ąĮąŠą│ąŠ čéąĖą┐ąŠą▓ čüąĄą║čåąĖą╣, ąĘą░ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ čäą░ą╣ą╗ąŠą▓ WAV, ąĮąŠ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąŠ WAV-čäą░ą╣ą╗ąŠą▓ čüąŠą┤ąĄčƹȹ░čé č鹊ą╗čīą║ąŠ ą┤ą▓ąĄ ąĖąĘ ąĮąĖčģ - čüąĄą║čåąĖčÄ č乊čĆą╝ą░čéą░ ("fmt ") ąĖ čüąĄą║čåąĖčÄ ą┤ą░ąĮąĮčŗčģ ("data"). ąŁč鹊 ąĖą╝ąĄąĮąĮąŠ č鹥 čüąĄą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗ ą┤ą╗čÅ ąŠą┐ąĖčüą░ąĮąĖčÅ č乊čĆą╝ą░čéą░ ą▓čŗą▒ąŠčĆąŠą║ ą░čāą┤ąĖąŠą┤ą░ąĮąĮčŗčģ, ąĖ ą┤ą╗čÅ čģčĆą░ąĮąĄąĮąĖčÅ čüą░ą╝ąĖčģ ą░čāą┤ąĖąŠą┤ą░ąĮąĮčŗčģ. ąźąŠčéčÅ ąŠčäąĖčåąĖą░ą╗čīąĮą░čÅ čüą┐ąĄčåąĖčäąĖą║ą░čåąĖčÅ ąĮąĄ ąĘą░ą┤ą░ąĄčé ąČąĄčüčéą║ąĖą╣ ą┐ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ čüąĄą║čåąĖą╣, ąĮą░ąĖą╗čāčćčłąĄą╣ ą┐čĆą░ą║čéąĖą║ąŠą╣ ą▒čāą┤ąĄčé čĆą░ąĘą╝ąĄčēąĄąĮąĖąĄ čüąĄą║čåąĖąĖ č乊čĆą╝ą░čéą░ ą┐ąĄčĆąĄą┤ čüąĄą║čåąĖąĄą╣ ą┤ą░ąĮąĮčŗčģ. ą£ąĮąŠą│ąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąŠąČąĖą┤ą░čÄčé ąĖą╝ąĄąĮąĮąŠ čéą░ą║ąŠą╣ ą┐ąŠčĆčÅą┤ąŠą║ čüąĄą║čåąĖą╣, ąĖ ąŠąĮ ąĮą░ąĖą▒ąŠą╗ąĄąĄ čĆą░ąĘčāą╝ąĄąĮ ą┤ą╗čÅ ą┐ąĄčĆąĄą┤ą░čćąĖ ą░čāą┤ąĖąŠą┤ą░ąĮąĮčŗčģ č湥čĆąĄąĘ ą╝ąĄą┤ą╗ąĄąĮąĮčŗąĄ, ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗąĄ ąĖčüč鹊čćąĮąĖą║ąĖ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ ąśąĮč鹥čĆąĮąĄčé. ąśąĮą░č湥 ąĄčüą╗ąĖ č乊čĆą╝ą░čé ą┐čĆąĖą┤ąĄčé ą┐ąŠčüą╗ąĄ ą┤ą░ąĮąĮčŗčģ, č鹊 ą┐ąĄčĆąĄą┤ čüčéą░čĆč鹊ą╝ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖčÅ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ čüčćąĖčéą░čéčī ąĖ ąĘą░ą┐ąŠą╝ąĮąĖčéčī ą▓čüąĄ ą░čāą┤ąĖąŠą┤ą░ąĮąĮčŗąĄ, č鹊ą╗čīą║ąŠ ą┐ąŠčüą╗ąĄ ą┐ąŠą╗čāč湥ąĮąĖčÅ č乊čĆą╝ą░čéą░ ąĘą░ą┐čāčüą║ą░čéčī ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖąĄ.
ąÆčüąĄ čüąĄą║čåąĖąĖ č乊čĆą╝ą░čéą░ RIFF ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ čüąĄą║čåąĖąĖ Wave čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╝ č乊čĆą╝ą░č鹥 (čüą╝. ą┤ąĖą░ą│čĆą░ą╝ą╝čā). ąŚą░ą╝ąĄčéčīč鹥, čćč鹊 ą┤ą░ąČąĄ ą▓čŗčłąĄčāą┐ąŠą╝čÅąĮčāčéą░čÅ čüąĄą║čåąĖčÅ RIFF čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé čŹč鹊ą╝čā č乊čĆą╝ą░čéčā.
| ąĪą╝ąĄčēąĄąĮąĖąĄ |
ąĀą░ąĘą╝ąĄčĆ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
| 0x00 |
4 |
Chunk ID |
| 0x04 |
4 |
Chunk Data Size |
| 0x08 |
Chunk Data Bytes |
ążąŠčĆą╝ą░čé čüąĄą║čåąĖą╣ RIFF ąĖ Wave
|
ą×čüčéą░ą╗čīąĮą░čÅ čćą░čüčéčī čŹč鹊ą╣ čüčéą░čéčīąĖ ą┐ąŠčüą▓čÅčēąĄąĮą░ ąŠą┐ąĖčüą░ąĮąĖčÄ čĆą░ąĘą╗ąĖčćąĮčŗčģ čéąĖą┐ąŠą▓ čüąĄą║čåąĖą╣ Wave, ąĖčģ č乊čĆą╝ą░čéčā ą┤ą░ąĮąĮčŗčģ ąĖ čćč鹊 čŹčéąĖ ą┤ą░ąĮąĮčŗąĄ ąŠąĘąĮą░čćą░čÄčé.
[ąĪąĄą║čåąĖčÅ č乊čĆą╝ą░čéą░ - "fmt "]
ąĪąĄą║čåąĖčÅ č乊čĆą╝ą░čéą░ čüąŠą┤ąĄčƹȹĖčé ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠčé č鹊ą╝, ą║ą░ą║ čüąŠčģčĆą░ąĮąĄąĮčŗ ą░čāą┤ąĖąŠą┤ą░ąĮąĮčŗąĄ ąĖ ą║ą░ą║ ąŠąĮąĖ ą┤ąŠą╗ąČąĮčŗ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčéčīčüčÅ. ąśąĮč乊čĆą╝ą░čåąĖčÅ ą▓ą║ą╗čÄčćą░ąĄčé ą▓ čüąĄą▒čÅ čéąĖą┐ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą╣ ą║ąŠą╝ą┐čĆąĄčüčüąĖąĖ, ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą║ą░ąĮą░ą╗ąŠą▓, čüą║ąŠčĆąŠčüčéčī ą▓čŗą┤ą░čćąĖ ą▓čŗą▒ąŠčĆąŠą║ (sample rate), ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé ą▓ ą▓čŗą▒ąŠčĆą║ąĄ (bits per sample) ąĖ ą┤čĆčāą│ąĖąĄ ą░čéčĆąĖą▒čāčéčŗ.
| ąĪą╝ąĄčēąĄąĮąĖąĄ |
ąĀą░ąĘą╝ąĄčĆ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
ąŚąĮą░č湥ąĮąĖąĄ |
| 0x00 |
4 |
Chunk ID |
"fmt " (0x666D7420) |
| 0x04 |
4 |
Chunk Data Size |
16 + extra format bytes |
| 0x08 |
2 |
Compression code |
1 - 65,535 |
| 0x0a |
2 |
Number of channels |
1 - 65,535 |
| 0x0c |
4 |
Sample rate |
1 - 0xFFFFFFFF |
| 0x10 |
4 |
Average bytes per second |
1 - 0xFFFFFFFF |
| 0x14 |
2 |
Block align |
1 - 65,535 |
| 0x16 |
2 |
Significant bits per sample |
2 - 65,535 |
| 0x18 |
2 |
Extra format bytes |
0 - 65,535 |
| 0x1a |
ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ č乊čĆą╝ą░čéą░ (Extra format bytes) * |
ąŚąĮą░č湥ąĮąĖčÅ čüąĄą║čåąĖąĖ č乊čĆą╝ą░čéą░ (Wave Format Chunk), * čćąĖčéą░ą╣č鹥 ą┤ą╗čÅ ą┐ąŠą┤čĆąŠą▒ąĮąŠčüč鹥ą╣ č鹥ą║čüčé ą┤ą░ą╗ąĄąĄ
ąśą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ čüąĄą║čåąĖąĖ (Chunk ID) ąĖ ąŠą▒čŖąĄą╝ ą┤ą░ąĮąĮčŗčģ (Data Size)
ąśą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ čüąĄą║čåąĖąĖ ą▓čüąĄą│ą┤ą░ "fmt " (0x666D7420) ąĖ ąŠą▒čŖąĄą╝ ą┤ą░ąĮąĮčŗčģ čĆą░ą▓ąĄąĮ čĆą░ąĘą╝ąĄčĆčā čüčéą░ąĮą┤ą░čĆčéąĮąŠą│ąŠ č乊čĆą╝ą░čéą░ WAV (16 ą▒ą░ą╣čé) ą┐ą╗čÄčü čĆą░ąĘą╝ąĄčĆ ą▓čüąĄčģ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ą▒ą░ą╣čé č乊čĆą╝ą░čéą░, ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗčģ ą┤ą╗čÅ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ čüą┐ąĄčåąĖčäąĖč湥čüą║ąĖčģ č乊čĆą╝ą░č鹊ą▓ ąĘą▓čāą║ą░, ąĄčüą╗ąĖ ąŠąĮ ąĮąĄ čüąŠą┤ąĄčƹȹĖčé ąĮąĄčüąČą░čéčŗčģ ą┤ą░ąĮąĮčŗčģ PCM. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ čüąĄą║čåąĖąĖ "fmt " ąŠą║ą░ąĮčćąĖą▓ą░ąĄčéčüčÅ ąĮą░ čüąĖą╝ą▓ąŠą╗ ą┐čĆąŠą▒ąĄą╗ą░ (0x20).
ąÜąŠą┤ čüąČą░čéąĖčÅ (Compression Code)
ą¤ąĄčĆą▓ąŠąĄ čüą╗ąŠą▓ąŠ ą┤ą░ąĮąĮčŗčģ č乊čĆą╝ą░čéą░ čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ čéąĖą┐ čüąČą░čéąĖčÅ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą│ąŠ ą┤ą╗čÅ ą┤ą░ąĮąĮčŗčģ ąĘą▓čāą║ą░. ąÆ čéą░ą▒ą╗ąĖčåąĄ čüąŠą┤ąĄčƹȹĖčéčüčÅ čüą┐ąĖčüąŠą║ ą║ąŠą┤ąŠą▓ čüąČą░čéąĖčÅ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ą▓ ąĮą░čüč鹊čÅčēąĄąĄ ą▓čĆąĄą╝čÅ.
| ąÜąŠą┤ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
| 0 (0x0000) |
Unknown |
| 1 (0x0001) |
PCM/uncompressed |
| 2 (0x0002) |
Microsoft ADPCM |
| 6 (0x0006) |
ITU G.711 a-law |
| 7 (0x0007) |
ITU G.711 ├é┬Ą-law |
| 17 (0x0011) |
IMA ADPCM |
| 20 (0x0016) |
ITU G.723 ADPCM (Yamaha) |
| 49 (0x0031) |
GSM 6.10 |
| 64 (0x0040) |
ITU G.721 ADPCM |
| 80 (0x0050) |
MPEG |
| 65,535 (0xFFFF) |
Experimental |
ą×ą▒čēąĄąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ ą║ąŠą┤čŗ čüąČą░čéąĖčÅ
(Common Wave Compression Codes)
ąÜąŠą╗ąĖč湥čüčéą▓ąŠ ą║ą░ąĮą░ą╗ąŠą▓ (Number of Channels)
ąÜąŠą╗ąĖč湥čüčéą▓ąŠ ą║ą░ąĮą░ą╗ąŠą▓ čāą║ą░ąĘčŗą▓ą░ąĄčé, čüą║ąŠą╗čīą║ąŠ ąŠčéą┤ąĄą╗čīąĮčŗčģ ą░čāą┤ąĖąŠčüąĖą│ąĮą░ą╗ąŠą▓ ąĘą░ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąŠ ą▓ čüąĄą║čåąĖąĖ ą┤ą░ąĮąĮčŗčģ ąĘą▓čāą║ą░ (wave data chunk). ąŚąĮą░č湥ąĮąĖąĄ 1 ąŠąĘąĮą░čćą░ąĄčé ą╝ąŠąĮąŠč乊ąĮąĖč湥čüą║ąĖą╣ čüąĖą│ąĮą░ą╗, 2 ąŠąĘąĮą░čćą░ąĄčé čüč鹥čĆąĄąŠ, ąĖ čé. ą┐.
ąĪą║ąŠčĆąŠčüčéčī ą▓čŗą▒ąŠčĆąŠą║ (Sample Rate)
ą¦ąĖčüą╗ąŠ ą▓čŗą▒ąŠčĆąŠą║ ą░čāą┤ąĖąŠčüąĖą│ąĮą░ą╗ą░, ą┐čĆąĖčģąŠą┤čÅčēąĖčģčüčÅ ąĮą░ čüąĄą║čāąĮą┤čā. ąØą░ čŹčéčā ą▓ąĄą╗ąĖčćąĖąĮčā ąĮąĄ ą▓ą╗ąĖčÅąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą║ą░ąĮą░ą╗ąŠą▓.
ąĪčĆąĄą┤ąĮąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ą░ą╣čé ą▓ čüąĄą║čāąĮą┤čā (Average Bytes Per Second)
ąÆąĄą╗ąĖčćąĖąĮą░, ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčēą░čÅ, čüą║ąŠą╗čīą║ąŠ ą▒ą░ą╣čé ąĘą░ čüąĄą║čāąĮą┤čā ą┤ą░ąĮąĮčŗčģ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą┐čĆąŠą┐čāčēąĄąĮąŠ č湥čĆąĄąĘ čåąĖčäčĆąŠą░ąĮą░ą╗ąŠą│ąŠą▓čŗą╣ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░č鹥ą╗čī (D/A converter, DAC) ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖčÅ čäą░ą╣ą╗ą░. čŹčéą░ ąĖąĮč乊čĆą╝ą░čåąĖčÅ ą┐ąŠą╗ąĄąĘąĮą░, čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī - ą╝ąŠą│čāčé ą╗ąĖ ą┤ą░ąĮąĮčŗąĄ ą┐ąŠčüčéčāą┐ą░čéčī ąŠčé ąĖčüč鹊čćąĮąĖą║ą░ čü ąĮčāąČąĮąŠą╣ čüą║ąŠčĆąŠčüčéčīčÄ, čćč鹊ą▒čŗ ąĮąĄ ąŠčéčüčéą░ą▓ą░čéčī ąŠčé ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖčÅ. ąŁčéą░ ą▓ąĄą╗ąĖčćąĖąĮą░ ą┐čĆąŠčüč鹊 ą▓čŗčćąĖčüą╗čÅąĄčéčüčÅ ą┐ąŠ č乊čĆą╝čāą╗ąĄ:
AvgBytesPerSec = SampleRate * BlockAlign
ąÆčŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą▒ą╗ąŠą║ą░ (Block Align)
ąÜąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ą░ą╣čé ąĮą░ ąŠą┤ąĮčā ą▓čŗą▒ąŠčĆą║čā. ąŁčéą░ ą▓ąĄą╗ąĖčćąĖąĮą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗčćąĖčüą╗ąĄąĮą░ ą┐ąŠ č乊čĆą╝čāą╗ąĄ:
BlockAlign = SignificantBitsPerSample / 8 * NumChannels
ąÜąŠą╗ąĖč湥čüčéą▓ąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ą▒ąĖčé ąĮą░ ą▓čŗą▒ąŠčĆą║čā (Significant Bits Per Sample)
ąÆąĄą╗ąĖčćąĖąĮą░ čāą║ą░ąĘčŗą▓ą░ąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé, č乊čĆą╝ąĖčĆčāčÄčēąĖčģ ą║ą░ąČą┤čāčÄ ą▓čŗą▒ąŠčĆą║čā čüąĖą│ąĮą░ą╗ą░. ą×ą▒čŗčćąĮąŠ čŹčéą░ ą▓ąĄą╗ąĖčćąĖąĮą░ 8, 16, 24 ąĖą╗ąĖ 32. ąĢčüą╗ąĖ čćąĖčüą╗ąŠ ą▒ąĖčé ąĮąĄ ą▓čŗčĆą░ą▓ąĮąĄąĮąŠ ą┐ąŠ ą▒ą░ą╣čéčā (ąĮąĄ ą┤ąĄą╗ąĖčéčüčÅ ąĮą░čåąĄą╗ąŠ ąĮą░ 8), ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ą▒ą░ą╣čé ąĮą░ ą▓čŗą▒ąŠčĆą║čā ąŠą║čĆčāą│ą╗čÅąĄčéčüčÅ ą▓ą▓ąĄčĆčģ ą║ ąĮą░ąĖą╝ąĄąĮčīčłąĄą╝čā ą║ąŠą╗ąĖč湥čüčéą▓čā ą▒ą░ą╣čé. ąØąĄąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ ą▒ąĖčéčŗ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čÄčéčüčÅ ą▓ 0 ąĖ ąĖą│ąĮąŠčĆąĖčĆčāčÄčéčüčÅ. ąóą░ą║ąĖąĄ č乊čĆą╝ą░čéčŗ (čü čćąĖčüą╗ąŠą╝ ą▒ąĖčé ąĮą░ ą▓čŗą▒ąŠčĆą║čā, ąĮąĄą║čĆą░čéąĮčŗą╝ 8) ą▓čüčéčĆąĄčćą░čÄčéčüčÅ čĆąĄą┤ą║ąŠ.
ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ č乊čĆą╝ą░čéą░ (Extra Format Bytes)
ąÆąĄą╗ąĖčćąĖąĮą░ čāą║ą░ąĘčŗą▓ą░ąĄčé, čüą║ąŠą╗čīą║ąŠ ą┤ą░ą╗ąĄąĄ ąĖą┤ąĄčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ą┤ą░ąĮąĮčŗčģ, ąŠą┐ąĖčüčŗą▓ą░čÄčēąĖčģ č乊čĆą╝ą░čé. ą×ąĮą░ ąŠčéčüčāčéčüčéą▓čāąĄčé, ąĄčüą╗ąĖ ą║ąŠą┤ čüąČą░čéąĖčÅ 1 (uncompressed PCM file), ąĮąŠ ą╝ąŠąČąĄčé ą┐čĆąĖčüčāčéčüčéą▓ąŠą▓ą░čéčī ąĖ ąĖą╝ąĄčéčī ą╗čÄą▒čāčÄ ą┤čĆčāą│čāčÄ ą▓ąĄą╗ąĖčćąĖąĮčā ą┤ą╗čÅ ą┤čĆčāą│ąĖčģ čéąĖą┐ąŠą▓ čüąČą░čéąĖčÅ, ąĘą░ą▓ąĖčüčÅčēčāčÄ ąŠčé ą║ąŠą╗ąĖč湥čüčéą▓ą░ ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗčģ ą┤ą╗čÅ ą┤ąĄą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ. ąĢčüą╗ąĖ ą▓ąĄą╗ąĖčćąĖąĮą░ ąĮąĄ ą▓čŗčĆą░ą▓ąĮąĄąĮą░ ąĮą░ čüą╗ąŠą▓ąŠ (ąĮąĄ ą┤ąĄą╗ąĖčéčüčÅ ąĮą░čåąĄą╗ąŠ ąĮą░ 2), ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą┤ąŠą▒ą░ą▓ą╗ąĄąĮ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗą╣ ą▒ą░ą╣čé ą▓ ą║ąŠąĮąĄčå ą┤ą░ąĮąĮčŗčģ, ąĮąŠ ą▓ąĄą╗ąĖčćąĖąĮą░ ą┤ąŠą╗ąČąĮą░ ąŠčüčéą░ą▓ą░čéčīčüčÅ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą╣.
ą×ą▒ą╗ą░čüčéčī Extra format bytes ąŠč湥ąĮčī čāą┤ąŠą▒ąĮą░ ą┤ą╗čÅ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ą▓ WAV-čäą░ą╣ą╗. ąŁč鹊 ą╝ąŠąČąĄčé ą┐ąŠąĮą░ą┤ąŠą▒ąĖčéčīčüčÅ, ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ąŠą│ą┤ą░ ąĮčāąČąĮąŠ ą▓ WAV-čäą░ą╣ą╗ čüąŠčģčĆą░ąĮąĖčéčī ą║ą░ą║čāčÄ-č鹊 ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ, ą┐čĆąĖą▓čÅąĘą░ąĮąĮčāčÄ ą║ ąĘą░ą┐ąĖčüą░ąĮąĮčŗą╝ ąĘą▓čāą║ąŠą▓čŗą╝ ą┤ą░ąĮąĮčŗą╝. ąĢčüą╗ąĖ ąÆą░čł ą┐čĆąĖą▒ąŠčĆ čüąŠčģčĆą░ąĮčÅąĄčé ąĖąĘą╝ąĄčĆąĄąĮąĖčÅ ą▓ ąĘą▓čāą║ąŠą▓čŗąĄ ą┤ą░ąĮąĮčŗąĄ WAV-čäą░ą╣ą╗ą░, č鹊 ąŠąĮ čéą░ą║ąČąĄ ą┐ąŠą╗čāčćą░ąĄčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą┤ąŠą▒ą░ą▓ąĖčéčī ą║ą░ą║ąĖąĄ-č鹊 ąŠą┐ąĖčüą░č鹥ą╗čīąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ - ą║ą░ą║ąŠą╣ ą▓čģąŠą┤ ą┐čĆąĖą▒ąŠčĆą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗čüčÅ, ą║ą░ą║ąĖąĄ ą▒čŗą╗ąĖ ąĮą░čüčéčĆąŠą╣ą║ąĖ ą▓čģąŠą┤ą░ (ą┐ąŠčüč鹊čÅąĮąĮčŗą╣ č鹊ą║, ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╣ č鹊ą║), ą║ą░ą║ąŠą╣ ą║ąŠčŹčäčäąĖčåąĖąĄąĮčé čāčüąĖą╗ąĄąĮąĖčÅ ą▒čŗą╗ ąĘą░ą┤ą░ąĮ ąĖ čé. ą┐. ąØąĖąČąĄ ąĮą░ čĆąĖčüčāąĮą║ą░čģ ą┐ąŠą║ą░ąĘą░ąĮčŗ ą┐čĆąĖą╝ąĄčĆčŗ ą┤ą░ą╝ą┐ąŠą▓ ą┤ą▓čāčģ WAV-čäą░ą╣ą╗ąŠą▓. ąÆ čäą░ą╣ą╗ąĄ čüą╗ąĄą▓ą░ ąĘą░ą│ąŠą╗ąŠą▓ąŠą║ čćąĖčüčéčŗą╣ (čĆą░ąĘą╝ąĄčĆ ąŠą▒ą╗ą░čüčéąĖ Extra format bytes čĆą░ą▓ąĄąĮ ąĮčāą╗čÄ), ą░ ą▓ čäą░ą╣ą╗ąĄ čüą┐čĆą░ą▓ą░ ą▓ čüąĄą║čåąĖčÄ "fmt " ą┤ąŠą▒ą░ą▓ą╗ąĄąĮčŗ 256 ą▒ą░ą╣čé ą┤ą░ąĮąĮčŗčģ Extra format bytes.
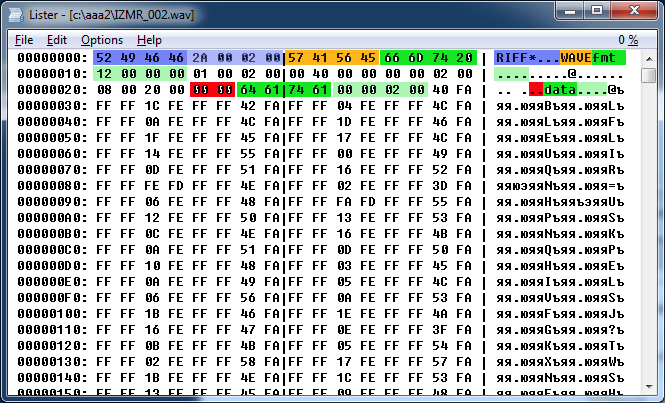 |
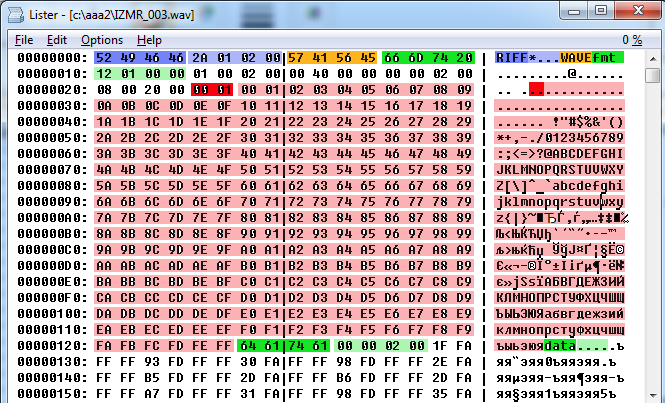 |
| ą¤čĆąĖą╝ąĄčĆ ą┤ą░ą╝ą┐ą░ WAV-čäą░ą╣ą╗ą░ ą▒ąĄąĘ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ą┤ą░ąĮąĮčŗčģ. |
ą¤čĆąĖą╝ąĄčĆ ą┤ą░ą╝ą┐ą░ WAV-čäą░ą╣ą╗ą░, ą│ą┤ąĄ ą▓ ąĘą░ą│ąŠą╗ąŠą▓ąŠą║ "fmt " ą┤ąŠą▒ą░ą▓ą╗ąĄąĮčŗ 256 ą▒ą░ą╣čé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ą┤ą░ąĮąĮčŗčģ Extra Format Bytes. |
ąöą╗čÅ ąĮą░ą│ą╗čÅą┤ąĮąŠčüčéąĖ ąŠčéą┤ąĄą╗čīąĮčŗąĄ čüąĄą║čåąĖąĖ čüčéą░ąĮą┤ą░čĆčéąĮąŠą│ąŠ ąĘą░ą│ąŠą╗ąŠą▓ą║ą░ ą▓čŗą┤ąĄą╗ąĄąĮčŗ čĆą░ąĘąĮčŗą╝ąĖ čåą▓ąĄčéą░ą╝ąĖ. 256 ą▒ą░ą╣čé ą▓ ąŠą▒ą╗ą░čüčéąĖ Extra Format Bytes ą┐ąŠą║ą░ąĘą░ąĮčŗ čĆąŠąĘąŠą▓čŗą╝ čåą▓ąĄč鹊ą╝, ą░ ąĖčģ čĆą░ąĘą╝ąĄčĆ - ą║čĆą░čüąĮčŗą╝.
[ąĪąĄą║čåąĖčÅ ą┤ą░ąĮąĮčŗčģ - "data"]
ąĪąĄą║čåąĖčÅ ą┤ą░ąĮąĮčŗčģ Wave (Wave Data Chunk) čüąŠą┤ąĄčƹȹĖčé ą┤ą░ąĮąĮčŗąĄ čåąĖčäčĆąŠą▓čŗčģ ą▓čŗą▒ąŠčĆąŠą║ ą░čāą┤ąĖąŠčüąĖą│ąĮą░ą╗ą░, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠąČąĮąŠ ą┤ąĄą║ąŠą┤ąĖčĆąŠą▓ą░čéčī čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ č乊čĆą╝ą░čéą░ ąĖ ą╝ąĄč鹊ą┤ą░ ą║ąŠą╝ą┐čĆąĄčüčüąĖąĖ, čāą║ą░ąĘą░ąĮąĮčŗčģ ą▓ čüąĄą║čåąĖąĖ č乊čĆą╝ą░čéą░ Wave (Wave Format Chunk). ąĢčüą╗ąĖ ą║ąŠą┤ ą║ąŠą╝ą┐čĆąĄčüčüąĖąĖ 1 (ąĮąĄčüąČą░čéčŗą╣ PCM, Pulse Code Modulation), č鹊 ą┤ą░ąĮąĮčŗąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮčŗ ą▓ ą▓ąĖą┤ąĄ čüčŗčĆčŗčģ, ąĮąĄą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĮčŗčģ (raw) ą▓ąĄą╗ąĖčćąĖąĮ ą▓čŗą▒ąŠčĆąŠą║. ąŁčéą░ čüčéą░čéčīčÅ ąŠą┐ąĖčüčŗą▓ą░ąĄčé, ą║ą░ą║ čüąŠčģčĆą░ąĮąĄąĮčŗ ąĮąĄčüąČą░čéčŗąĄ ą┤ą░ąĮąĮčŗąĄ PCM, ąŠą┤ąĮą░ą║ąŠ ąĮąĄ ą▓ą┤ą░ąĄčéčüčÅ ą▓ ą┐ąŠą┤čĆąŠą▒ąĮąŠčüčéąĖ ą╝ąĮąŠą│ąĖčģ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ č乊čĆą╝ą░č鹊ą▓ čü ą║ąŠą╝ą┐čĆąĄčüčüąĖąĄą╣.
WAV-čäą░ą╣ą╗čŗ ąŠą▒čŗčćąĮąŠ čüąŠą┤ąĄčƹȹ░čé č鹊ą╗čīą║ąŠ ąŠą┤ąĮčā čüąĄą║čåąĖčÄ ą┤ą░ąĮąĮčŗčģ, ąĮąŠ čüąĄą║čåąĖą╣ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ, ąĄčüą╗ąĖ ąŠąĮąĖ čüąŠą┤ąĄčƹȹ░čéčüčÅ ą▓ čüąĄą║čåąĖąĖ čüą┐ąĖčüą║ą░ Wave (Wave List Chunk "wavl").
| ąĪą╝ąĄčēąĄąĮąĖąĄ |
ąöą╗ąĖąĮą░ |
ąóąĖą┐ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
ąŚąĮą░č湥ąĮąĖąĄ |
| 0x00 |
4 |
char[4] |
chunk ID |
"data" (0x64617461) |
| 0x04 |
4 |
dword |
chunk size |
ąĘą░ą▓ąĖčüąĖčé ąŠčé ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą▓čŗą▒ąŠčĆąŠą║ ąĖ ą║ąŠą╝ą┐čĆąĄčüčüąĖąĖ |
| 0x08 |
ą┤ą░ąĮąĮčŗąĄ ą▓čŗą▒ąŠčĆąŠą║ (sample data) |
ążąŠčĆą╝ą░čé čüąĄą║čåąĖąĖ ą┤ą░ąĮąĮčŗčģ "data"
ąÉčāą┤ąĖąŠą▓čŗą▒ąŠčĆą║ąĖ ą╝ąĮąŠą│ąŠą║ą░ąĮą░ą╗čīąĮąŠą│ąŠ čåąĖčäčĆąŠą▓ąŠą│ąŠ ą░čāą┤ąĖąŠ čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ ą║ą░ą║ č湥čĆąĄą┤čāąĄą╝čŗąĄ (interlaced) ą┤ą░ąĮąĮčŗąĄ, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąŠčüč鹊 ąŠąĘąĮą░čćą░čÄčé ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗąĄ ą░čāą┤ąĖąŠą▓čŗą▒ąŠčĆą║ąĖ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą║ą░ąĮą░ą╗ąŠą▓ (čéą░ą║ąĖčģ ą║ą░ą║ čüč鹥čĆąĄąŠ ąĖ ą║ą░ąĮą░ą╗čŗ ąŠą║čĆčāąČąĄąĮąĖčÅ surround). ąÆčŗą▒ąŠčĆą║ąĖ ą║ą░ąĮą░ą╗ąŠą▓ čüąŠčģčĆą░ąĮąĄąĮčŗ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ ą┤čĆčāą│ ąĘą░ ą┤čĆčāą│ąŠą╝, ą┐ąĄčĆąĄą┤ č鹥ą╝ ą║ą░ą║ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą┐ąĄčĆąĄčģąŠą┤ ą║ čüą╗ąĄą┤čāčÄčēąĄą╝čā ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗą▒ąŠčĆą║ąĖ. ąŁč鹊 čüą┤ąĄą╗ą░ąĮąŠ čü čåąĄą╗čīčÄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠą│ąŠ ą┐čĆąŠąĖą│čĆčŗą▓ą░ąĮąĖčÅ čäą░ą╣ą╗ą░ ą┤ą░ąČąĄ č鹊ą│ą┤ą░, ą║ąŠą│ą┤ą░ ąĄčēąĄ ąĮąĄ ą▓ąĄčüčī čäą░ą╣ą╗ ą┐čĆąŠčćąĖčéą░ąĮ čåąĄą╗ąĖą║ąŠą╝. ąŁč鹊 čāą┤ąŠą▒ąĮąŠ, ą║ąŠą│ą┤ą░ ą┐čĆąŠąĖą│čĆčŗą▓ą░ąĄčéčüčÅ ą▒ąŠą╗čīčłąŠą╣ čäą░ą╣ą╗ čü ą┤ąĖčüą║ą░ (ą║ąŠč鹊čĆčŗą╣ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī čĆą░ąĘą╝ąĄčēąĄąĮ čåąĄą╗ąĖą║ąŠą╝ ą▓ ą┐ą░ą╝čÅčéąĖ) ąĖą╗ąĖ čäą░ą╣ą╗ ą┐ąĄčĆąĄą┤ą░ąĄčéčüčÅ ą▓ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠą╝ ą┐ąŠč鹊ą║ąĄ ą┤ą░ąĮąĮčŗčģ č湥čĆąĄąĘ čüąĄč鹥ą▓ąŠąĄ čüąŠąĄą┤ąĖąĮąĄąĮąĖąĄ (ąĮą░ą┐čĆąĖą╝ąĄčĆ ąśąĮč鹥čĆąĮąĄčé). ąŚąĮą░č湥ąĮąĖčÅ ą▓ ą┤ąĖą░ą│čĆą░ą╝ą╝ąĄ ąĮąĖąČąĄ ą▒čŗą╗ąĖ ą▒čŗ čüąŠčģčĆą░ąĮąĄąĮčŗ ą▓ WAV-čäą░ą╣ą╗ąĄ ą▓ ą┐ąŠčĆčÅą┤ą║ąĄ, ą║ą░ą║ ąŠąĮąĖ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮčŗ ą▓ čüč鹊ą╗ą▒čåąĄ ąĘąĮą░č湥ąĮąĖą╣ (ąŠčé ąĮą░čćą░ą╗ą░ ą┤ąŠ ą║ąŠąĮčåą░).
| ąÆčĆąĄą╝čÅ |
ąÜą░ąĮą░ą╗ |
ąŚąĮą░č湥ąĮąĖąĄ |
| 0 |
1 (ą╗ąĄą▓čŗą╣) |
0x0053 |
| 2 (ą┐čĆą░ą▓čŗą╣) |
0x0024 |
| 1 |
1 (ą╗ąĄą▓čŗą╣) |
0x0057 |
| 2 (ą┐čĆą░ą▓čŗą╣) |
0x0029 |
| 2 |
1 (ą╗ąĄą▓čŗą╣) |
0x0063 |
| 2 (ą┐čĆą░ą▓čŗą╣) |
0x003C |
ą¦ąĄčĆąĄą┤čāąĄą╝čŗąĄ ą▓čŗą▒ąŠčĆą║ąĖ čüč鹥čĆąĄąŠ Wave
ą×ą┤ąĖąĮ ą╝ąŠą╝ąĄąĮčé, ą║ą░čüą░čÄčēąĖą╣čüčÅ ą┤ą░ąĮąĮčŗčģ ą▓čŗą▒ąŠčĆąŠą║, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ą▓čŗąĘą▓ą░čéčī ąĮąĄą║ąŠč鹊čĆąŠąĄ ąĘą░ą╝ąĄčłą░č鹥ą╗čīčüčéą▓ąŠ - ą║ąŠą│ą┤ą░ ą▓čŗą▒ąŠčĆą║ąĖ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮčŗ 8 ą▒ąĖčéą░ą╝ąĖ, ąŠąĮąĖ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮčŗ ą║ą░ą║ ąĘąĮą░č湥ąĮąĖčÅ ą▒ąĄąĘ ąĘąĮą░ą║ą░ (unsigned). ąÆčüąĄ ą┤čĆčāą│ąĖąĄ ą▒ąĖč鹊ą▓čŗąĄ čĆą░ąĘą╝ąĄčĆčŗ čāą║ą░ąĘčŗą▓ą░čÄčéčüčÅ ą║ą░ą║ ą▓ąĄą╗ąĖčćąĖąĮčŗ čüąŠ ąĘąĮą░ą║ąŠą╝ (signed). ąØą░ą┐čĆąĖą╝ąĄčĆ, ą▓čŗą▒ąŠčĆą║ą░ 16 ą▒ąĖčé ą╝ąŠąČąĄčé ąĖą╝ąĄčéčī ąĘąĮą░č湥ąĮąĖąĄ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ ąŠčé -32768 ą┤ąŠ +32767, ą│ą┤ąĄ čüčĆąĄą┤ąĮčÅčÅ č鹊čćą║ą░ (ąĮą░ą┐čĆčÅąČąĄąĮąĖąĄ čüąĖą│ąĮą░ą╗ą░ čĆą░ą▓ąĮąŠ 0) čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ąĘąĮą░č湥ąĮąĖčÄ 0.
ąÜą░ą║ čāąČąĄ ą▒čŗą╗ąŠ čāą║ą░ąĘą░ąĮąŠ čĆą░ąĮąĄąĄ, ą▓čüąĄ čüąĄą║čåąĖąĖ RIFF (ą▓ą║ą╗čÄčćą░čÅ čüąĄą║čåąĖąĖ WAVE "data") ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą▓čŗčĆąŠą▓ąĮąĄąĮčŗ ą┐ąŠ čĆą░ąĘą╝ąĄčĆčā ąĮą░ čüą╗ąŠą▓ąŠ (2 ą▒ą░ą╣čéą░). ąĢčüą╗ąĖ ą┤ą░ąĮąĮčŗąĄ ą▓čŗą▒ąŠčĆąŠą║ čüąŠą┤ąĄčƹȹ░čéčüčÅ ą▓ ąĮąĄč湥čéąĮąŠą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąĄ ą▒ą░ą╣čé, ą▓ ą║ąŠąĮąĄčå ą┤ą░ąĮąĮčŗčģ ą▓čŗą▒ąŠčĆąŠą║ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą┤ąŠą▒ą░ą▓ą╗ąĄąĮ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░čÄčēąĖą╣ ąĮčāą╗ąĄą▓ąŠą╣ ą▒ą░ą╣čé. ąŚą░ ąĘą░ą│ąŠą╗ąŠą▓ą║ąĄ čüąĄą║čåąĖąĖ "data" čĆą░ąĘą╝ąĄčĆ ąĮąĄ ą┤ąŠą╗ąČąĄąĮ čāčćąĖčéčŗą▓ą░čéčī čŹč鹊čé ą▓čŗčĆą░ą▓ąĮąĖą▓ą░čÄčēąĖą╣ ą▒ą░ą╣čé.
ąöą░ą╗ąĄąĄ ąŠą┐ąĖčüčŗą▓ą░čÄčéčüčÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ čüąĄą║čåąĖąĖ WAV-čäą░ą╣ą╗ą░, ą║ąŠč鹊čĆčŗąĄ ą┤ąŠą▓ąŠą╗čīąĮąŠ čĆąĄą┤ą║ąŠ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ. ą¤ąŠčŹč鹊ą╝čā ą┤ą╗čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą┐čĆąŠčüč鹥ą╣čłąĄą│ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ ą░ąĮą░ą╗ąĖąĘą░ WAV-čäą░ą╣ą╗ą░ ąŠą▒čĆą░ą▒ąŠčéą║čā čŹčéąĖčģ čüąĄą║čåąĖą╣ ą╝ąŠąČąĮąŠ ąŠą┐čāčüčéąĖčéčī.
ąĪąĄą║čåąĖčÅ fact čüąŠą┤ąĄčƹȹĖčé ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠ čüąŠą┤ąĄčƹȹĖą╝ąŠą╝ WAV-čäą░ą╣ą╗ą░, ąĘą░ą▓ąĖčüčÅčēčāčÄ ąŠčé ą║ąŠą┤ą░ ą║ąŠą╝ą┐čĆąĄčüčüąĖąĖ. ą×ąĮą░ čéčĆąĄą▒čāąĄčéčüčÅ ą┤ą╗čÅ ą▓čüąĄčģ č乊čĆą╝ą░č鹊ą▓ WAVE čüąŠ čüąČą░čéąĖąĄą╝, ąĖ čéčĆąĄą▒čāąĄčéčüčÅ, ąĄčüą╗ąĖ ą┤ą░ąĮąĮčŗąĄ čüąĖą│ąĮą░ą╗ą░ čüąŠą┤ąĄčƹȹ░čéčüčÅ ą▓ąĮčāčéčĆąĖ čüąĄą║čåąĖąĖ čüą┐ąĖčüą║ą░ (LIST) "wavl", ąĮąŠ ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ ą┤ą╗čÅ ąĮąĄčüąČą░č鹊ą│ąŠ č乊čĆą╝ą░čéą░ PCM WAVE (ą║ąŠą┤ ą║ąŠą╝ą┐čĆąĄčüčüąĖąĖ 1), ą║ąŠč鹊čĆčŗą╣ čüąŠą┤ąĄčƹȹĖčé ą░čāą┤ąĖąŠą┤ą░ąĮąĮčŗąĄ ą▓ čüąĄą║čåąĖąĖ "data".
| ąĪą╝ąĄčēąĄąĮąĖąĄ |
ąĀą░ąĘą╝ąĄčĆ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
ąÆąĄą╗ąĖčćąĖąĮą░ |
| 0x00 |
4 |
Chunk ID |
"fact" (0x66616374) |
| 0x04 |
4 |
Chunk Data Size |
ąĘą░ą▓ąĖčüąĖčé ąŠčé č乊čĆą╝ą░čéą░ |
| 0x08 |
ąöą░ąĮąĮčŗąĄ, ąĘą░ą▓ąĖčüčÅčēąĖąĄ ąŠčé č乊čĆą╝ą░čéą░ (Format Dependant Data) |
ążąŠčĆą╝ą░čé čüąĄą║čåąĖąĖ Fact
ąöą░ąĮąĮčŗąĄ, ąĘą░ą▓ąĖčüčÅčēąĖąĄ ąŠčé č乊čĆą╝ą░čéą░ (Format Dependant Data)
ąÆ ąĮą░čüč鹊čÅčēąĖą╣ ą╝ąŠą╝ąĄąĮčé ąĘą░ą┤ą░ąĮąŠ č鹊ą╗čīą║ąŠ ąŠą┤ąĮąŠ ą┐ąŠą╗ąĄ ą┤ą╗čÅ ą┤ą░ąĮąĮčŗčģ, ąĘą░ą▓ąĖčüčÅčēąĖčģ ąŠčé č乊čĆą╝ą░čéą░. ąŁč鹊 ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮąŠąĄ 4-ą▒ą░ą╣čéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ čāą║ą░ąĘčŗą▓ą░ąĄčé čćąĖčüą╗ąŠ ą▓čŗą▒ąŠčĆąŠą║ ą▓ čüąĄą║čåąĖąĖ ą┤ą░ąĮąĮčŗčģ ą░čāą┤ąĖąŠčüąĖą│ąĮą░ą╗ą░. ąŁčéą░ ą▓ąĄą╗ąĖčćąĖąĮą░ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą▓ą╝ąĄčüč鹥 čü ą║ąŠą╗ąĖč湥čüčéą▓ąŠą╝ ą▓čŗą▒ąŠčĆąŠą║ ą▓ čüąĄą║čāąĮą┤čā (Samples Per Second value) čāą║ą░ąĘą░ąĮąĮąŠą╝ ą▓ čüąĄą║čåąĖąĖ č乊čĆą╝ą░čéą░ - ą┤ą╗čÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ ą┐čĆąŠą┤ąŠą╗ąČąĖč鹥ą╗čīąĮąŠčüčéąĖ ąĘą▓čāčćą░ąĮąĖčÅ čüąĖą│ąĮą░ą╗ą░ ą▓ čüąĄą║čāąĮą┤ą░čģ.
ą¤ąŠ ą╝ąĄčĆąĄ ą┐ąŠčÅą▓ą╗ąĄąĮąĖčÅ ąĮąŠą▓čŗčģ č乊čĆą╝ą░č鹊ą▓ WAVE čüąĄą║čåąĖčÅ fact ą▒čāą┤ąĄčé čĆą░čüčłąĖčĆąĄąĮą░ čü ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄą╝ ą┐ąŠą╗ąĄą╣ ą┐ąŠčüą╗ąĄ ą┐ąŠą╗čÅ čćąĖčüą╗ą░ ą▓čŗą▒ąŠčĆąŠą║. ą¤čĆąŠą│čĆą░ą╝ą╝čŗ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čĆą░ąĘą╝ąĄčĆ čüąĄą║čåąĖąĖ fact ą┤ą╗čÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ, ą║ą░ą║ąĖąĄ ą┐ąŠą╗čÅ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮčŗ ą▓ čüąĄą║čåąĖąĖ.
ąĪąĄą║čåąĖčÅ čüą┐ąĖčüą║ą░ wave (wave list chunk) ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ čāą║ą░ąĘą░ąĮąĖčÅ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ č湥čĆąĄą┤ąŠą▓ą░ąĮąĖą╣ čüąĄą║čåąĖą╣ "slnt" ąĖ "data". ąŁčéąĖ čüąĄą║čåąĖąĖ ą╝ąŠą│čāčé ą┐ąŠą╝ąŠčćčī čāą╝ąĄąĮčīčłąĖčéčī čĆą░ąĘą╝ąĄčĆ čäą░ą╣ą╗ą░ ą┐čāč鹥ą╝ čāą║ą░ąĘą░ąĮąĖčÅ čüą╗čŗčłąĖą╝čŗčģ čüąĄą│ą╝ąĄąĮč鹊ą▓ ą▓čŗą▒ąŠčĆąŠą║, ą║ąŠą│ą┤ą░ ą┐ąŠč鹊ą║ ą░čāą┤ąĖąŠą┤ą░ąĮąĮčŗčģ čüąŠą┤ąĄčƹȹĖčé ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĖąĮč鹥čĆą▓ą░ą╗ąŠą▓ čéąĖčłąĖąĮčŗ.
ąŁč鹊čé čéąĖą┐ čüąĄą║čåąĖąĖ ą┐ąŠ ą╝ąĮąĄąĮąĖčÄ ą╝ąĮąŠą│ąĖčģ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüč鹊ą▓ čÅą▓ą╗čÅąĄčéčüčÅ ąĘą╗ąŠčāą┐ąŠčéčĆąĄą▒ą╗ąĄąĮąĖąĄą╝ ą▓ č乊čĆą╝ą░č鹥 WAV-čäą░ą╣ą╗ą░, ąĖ ąĄą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąĮąĄ čĆąĄą║ąŠą╝ąĄąĮą┤čāąĄčéčüčÅ. ąóą░ą║ąČąĄ ą╝ąĮąŠą│ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ ąĮąĄ ą▒čāą┤čāčé čĆą░čüą┐ąŠąĘąĮą░ą▓ą░čéčī čŹč鹊čé čéąĖą┐ čüąĄą║čåąĖąĖ, ą┐čĆąŠčüč鹊 ąĖą│ąĮąŠčĆąĖčĆčāčÅ ąĄą│ąŠ. ąŁčéą░ č乊čĆą╝ą░ čüąČą░čéąĖčÅ čāčüą╗ąŠąČąĮčÅąĄčé ą▒ąĄąĘ ąĮą░ą┤ąŠą▒ąĮąŠčüčéąĖ čüčéčĆčāą║čéčāčĆčā WAV-čäą░ą╣ą╗ą░ ąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą│ąŠą┤ąĮąŠ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮą░ ą┤čĆčāą│ąĖą╝ąĖ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ, ą▓ą║ą╗čÄčćą░čÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ čüčāčēąĄčüčéą▓čāčÄčēąĖčģ č乊čĆą╝ą░č鹊ą▓ ą║ąŠą╝ą┐čĆąĄčüčüąĖąĖ.
| ąĪą╝ąĄčēąĄąĮąĖąĄ |
ąĀą░ąĘą╝ąĄčĆ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
ąŚąĮą░č湥ąĮąĖąĄ |
| 0x00 |
4 |
Chunk ID |
"wavl" (0x736C6E74) |
| 0x04 |
4 |
Chunk Data Size |
ąĘą░ą▓ąĖčüąĖčé ąŠčé čĆą░ąĘą╝ąĄčĆą░ čüąĄą║čåąĖą╣ "data" ąĖ "slnt" |
| 0x08 |
ąĪą┐ąĖčüąŠą║ č湥čĆąĄą┤ąŠą▓ą░ąĮąĖčÅ čüąĄą║čåąĖą╣ "slnt" ąĖ "data" |
ążąŠčĆą╝ą░čé čüąĄą║čåąĖąĖ Wave List
ąĪąĄą║čåąĖčÅ čéąĖčłąĖąĮčŗ (silent chunk) ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ čāą║ą░ąĘą░ąĮąĖčÅ čüąĄą│ą╝ąĄąĮčéą░ ą┐ą░čāąĘčŗ ąĘą▓čāčćą░ąĮąĖčÅ, ą║ąŠč鹊čĆą░čÅ ąĖą╝ąĄąĄčé ąĮąĄą║ąŠč鹊čĆčāčÄ ą┐čĆąŠą┤ąŠą╗ąČąĖč鹥ą╗čīąĮąŠčüčéčī ą▓ ą▓čŗą▒ąŠčĆą║ą░čģ čüąĖą│ąĮą░ą╗ą░. ąĪąĄą║čåąĖčÅ čéąĖčłąĖąĮčŗ ą▓čüąĄą│ą┤ą░ čüąŠą┤ąĄčƹȹĖčéčüčÅ č鹊ą╗čīą║ąŠ ą▓ąĮčāčéčĆąĖ čüąĄą║čåąĖąĖ čüą┐ąĖčüą║ą░ wave (wave list chunk). ąÜąŠą│ą┤ą░ čŹčéą░ čüąĄą║čåąĖčÅ ąŠą▒čŖčÅą▓ą╗čÅąĄčé čéąĖčłąĖąĮčā, ąĮąĄ ąĮčāąČąĮąŠ ąĘą░ą┤ą░ą▓ą░čéčī ąĮčāą╗ąĄą▓čāčÄ ą│čĆąŠą╝ą║ąŠčüčéčī ąĖą╗ąĖ ą▒ą░ąĘąŠą▓čāčÄ ą▓čŗą▒ąŠčĆą║čā. ąŁč鹊 čäą░ą║čéąĖč湥čüą║ąĖ čāą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ ą┐ąŠčüą╗ąĄą┤ąĮčÅčÅ ą▓čŗą▒ąŠčĆą║ą░ čüąĖą│ąĮą░ą╗ą░, čüčćąĖčéą░ąĮąĮą░čÅ ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ čüąĄą║čåąĖąĖ ą┤ą░ąĮąĮčŗčģ ((Wave Data Chunk)) čüąĄą║čåąĖąĖ čüą┐ąĖčüą║ą░ Wave (wave list chunk). ąĢčüą╗ąĖ ąĮąĄ ą▒čŗą╗ąŠ ą┐čĆąĄą┤čŗą┤čāčēąĖčģ čüąĄą║čåąĖą╣ ą┤ą░ąĮąĮčŗčģ, ą┤ąŠą╗ąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą▒ą░ąĘąŠą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą▓čŗą▒ąŠčĆą║ąĖ, čĆą░ą▓ąĮąŠąĄ 127 ą┤ą╗čÅ 8-ą▒ąĖčéąĮčŗčģ ą┤ą░ąĮąĮčŗčģ, 0 ą┤ą╗čÅ 16-ą▒ąĖčéąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ąĖą╗ąĖ ą▓čüąĄčģ ą┤ą░ąĮąĮčŗčģ čü ą▒ą×ą╗čīčłąĖą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąŠą╝ ą▒ąĖčé ąĮą░ ą▓čŗą▒ąŠčĆą║čā. ąŁčéąĖ čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅ ą╝ąŠą│čāčé ą║ą░ąĘą░čéčīčüčÅ čéčĆąĖą▓ąĖą░ą╗čīąĮčŗą╝ąĖ, ąĮąŠ ąĄčüą╗ąĖ čŹč鹊 ąĮąĄ ą▓čŗą┐ąŠą╗ąĮąĖčéčī, č鹊 ą╝ąŠą│čāčé ą┐ąŠčÅą▓ąĖčéčüčÅ ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮčŗąĄ čēąĄą╗čćą║ąĖ ąĖ ą┐ąĄčĆąĄą┐ą░ą┤čŗ ą▓ ą░čāą┤ąĖąŠčüąĖą│ąĮą░ą╗ąĄ.
| ąĪą╝ąĄčēąĄąĮąĖąĄ |
ąĀą░ąĘą╝ąĄčĆ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
ąÆąĄą╗ąĖčćąĖąĮą░ |
| 0x00 |
4 |
Chunk ID |
"slnt" (0x736C6E74) |
| 0x04 |
4 |
Chunk Data Size |
4 |
| 0x08 |
4 |
Number of Silent Samples |
0 - 0xFFFFFFFF |
Silent Chunk Format
ąÜąŠą╗ąĖč湥čüčéą▓ąŠ ą▓čŗą▒ąŠčĆąŠą║ čéąĖčłąĖąĮčŗ (Number of Silent Samples)
ąŁčéą░ ą▓ąĄą╗ąĖčćąĖąĮą░ čāą║ą░ąĘčŗą▓ą░ąĄčé čćąĖčüą╗ąŠ ą▓čŗą▒ąŠčĆąŠą║ čéąĖčłąĖąĮčŗ, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ ą┐ąŠčÅą▓ąĖčéčīčüčÅ ą▓ ą░čāą┤ąĖąŠčüąĖą│ąĮą░ą╗ąĄ ąĮą░ č鹊čćą║ąĄ čüą┐ąĖčüą║ą░ wave (wave list chunk).
ąĪąĄą║čåąĖčÅ cue ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ąŠą┤ąĖąĮ ąĖą╗ąĖ ą▒ąŠą╗ąĄąĄ čüą╝ąĄčēąĄąĮąĖčÅ ą▓čŗą▒ąŠčĆąŠą║, ą║ąŠč鹊čĆčŗąĄ čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ, čćč鹊ą▒čŗ ąŠčéą╝ąĄčéąĖčéčī ą┐čĆąĖą╝ąĄčćą░č鹥ą╗čīąĮčŗąĄ čĆą░ąĘą┤ąĄą╗čŗ ą░čāą┤ąĖąŠ. ąØą░ą┐čĆąĖą╝ąĄčĆ, čā ąĮą░čćą░ą╗ą░ ąĖ ą║ąŠąĮčåą░ čüčéąĖčģą░ ą▓ ą┐ąĄčüąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą╝ąĄčéą║ąĖ, ą┐ąŠ ą║ąŠč鹊čĆčŗą╝ ą╗ąĄą│č湥 ąĮą░ą╣čéąĖ ąĮą░čćą░ą╗ąŠ ąĖ ą║ąŠąĮąĄčå čüčéąĖčģą░. ąĪąĄą║čåąĖčÅ cue čÅą▓ą╗čÅąĄčéčüčÅ ąĮąĄąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠą╣, ąĖ ąĄčüą╗ąĖ ąŠąĮą░ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮą░, č鹊 ąŠą┤ąĮą░ čüąĄą║čåąĖčÅ cue ą┤ąŠą╗ąČąĮą░ čāą║ą░ąĘą░čéčī ą▓čüąĄ ą┐čĆąĖą╝ąĄčćą░č鹥ą╗čīąĮčŗąĄ č鹊čćą║ąĖ ą┤ą╗čÅ čüąĄą║čåąĖąĖ "WAVE". ąØąĄ ą┤ąŠą┐čāčüą║ą░ąĄčéčüčÅ ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą╣ čüąĄą║čåąĖąĖ cue ą▓ąĮčāčéčĆąĖ čüąĄą║čåąĖąĖ "WAVE".
| ąĪą╝ąĄčēąĄąĮąĖąĄ |
ąĀą░ąĘą╝ąĄčĆ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
ąŚąĮą░č湥ąĮąĖąĄ |
| 0x00 |
4 |
Chunk ID |
"cue " (0x63756520) |
| 0x04 |
4 |
Chunk Data Size |
depends on Num Cue Points |
| 0x08 |
4 |
Num Cue Points |
ą║ąŠą╗ąĖč湥čüčéą▓ąŠ č鹊č湥ą║ cue ą▓ čüą┐ąĖčüą║ąĄ |
| 0x0c |
ąĪą┐ąĖčüąŠą║ ąĖąĮč鹥čĆąĄčüčāčÄčēąĖčģ č鹊č湥ą║ (List of Cue Points) |
ążąŠčĆą╝ą░čé čüąĄą║čåąĖąĖ Cue
ąśą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ID čüąĄą║čåąĖąĖ ąĖ ąŠą▒čŖąĄą╝ ą┤ą░ąĮąĮčŗčģ (Chunk ID and Data Size)
ąśą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ID čüąĄą║čåąĖąĖ ą┤ą╗čÅ čüąĄą║čåąĖąĖ cue ą▓čüąĄą│ą┤ą░ "cue " (0x666D7420). ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čüčéčĆąŠą║ą░ ID ąŠą║ą░ąĮčćąĖą▓ą░ąĄčéčüčÅ ąĮą░ čüąĖą╝ą▓ąŠą╗ ą┐čĆąŠą▒ąĄą╗ą░ (0x20). ąĀą░ąĘą╝ąĄčĆ ą┤ą░ąĮąĮčŗčģ čüąĄą║čåąĖąĖ čĆą░ą▓ąĄąĮ čĆą░ąĘą╝ąĄčĆčā Num Cue Points (4) ą┐ą╗čÄčü ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖčģ č鹊č湥ą║ cue, ą┐ąŠą╝ąĮąŠąČąĄąĮąĮąŠąĄ ąĮą░ čĆą░ąĘą╝ąĄčĆ ą┤ą░ąĮąĮčŗčģ ą║ą░ąČą┤ąŠą╣ č鹊čćą║ąĖ cue (24). ąĪą╗ąĄą┤čāčÄčēą░čÅ č乊čĆą╝čāą╗ą░ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ čĆą░ąĘą╝ąĄčĆą░ ą┤ą░ąĮąĮčŗčģ čüąĄą║čåąĖąĖ Cue:
ChunkDataSize = 4 + (NumCuePoints * 24)
ąÜąŠą╗ąĖč湥čüčéą▓ąŠ ą┐čĆąĖą╝ąĄčćą░č鹥ą╗čīąĮčŗčģ č鹊č湥ą║ (Num Cue Points)
ąŁčéą░ ą▓ąĄą╗ąĖčćąĖąĮą░ čāą║ą░ąĘčŗą▓ą░ąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖčģ cue-č鹊č湥ą║ ą▓ čŹč鹊ą╣ čüąĄą║čåąĖąĖ.
ąĪą┐ąĖčüąŠą║ ą┐čĆąĖą╝ąĄčćą░č鹥ą╗čīąĮčŗčģ č鹊č湥ą║ (List of Cue Points)
ąĪą┐ąĖčüąŠą║ č鹊č湥ą║ cue - ą┐čĆąŠčüč鹊 ąĮą░ą▒ąŠčĆ ąŠą┐ąĖčüą░ąĮąĖą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗčģ č鹊č湥ą║, ą║ąŠč鹊čĆčŗą╣ ąĖą╝ąĄąĄčé čüą╗ąĄą┤čāčÄčēąĖą╣ č乊čĆą╝ą░čé.
| ąĪą╝ąĄčēąĄąĮąĖąĄ |
ąĀą░ąĘą╝ąĄčĆ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
ąŚąĮą░č湥ąĮąĖąĄ |
| 0x00 |
4 |
ID |
unique identification value |
| 0x04 |
4 |
Position |
play order position |
| 0x08 |
4 |
Data Chunk ID |
RIFF ID of corresponding data chunk |
| 0x0c |
4 |
Chunk Start |
Byte Offset of Data Chunk * |
| 0x10 |
4 |
Block Start |
Byte Offset to sample of First Channel |
| 0x14 |
4 |
Sample Offset |
Byte Offset to sample byte of First Channel |
ążąŠčĆą╝ą░čé č鹊čćą║ąĖ Cue
ID
ąÜą░ąČą┤ą░čÅ ą┐čĆąĖą╝ąĄčćą░č鹥ą╗čīąĮą░čÅ (cue) č鹊čćą║ą░ ąĖą╝ąĄąĄčé čāąĮąĖą║ą░ą╗čīąĮąŠąĄ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░čåąĖąŠąĮąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠąĄ ą┤ą╗čÅ čüą▓čÅąĘąĖ č鹊č湥ą║ cue čü ąĖąĮč乊čĆą╝ą░čåąĖąĄą╣ ą▓ ą┤čĆčāą│ąĖčģ čüąĄą║čåąĖčÅčģ. ąØą░ą┐čĆąĖą╝ąĄčĆ, čüąĄą║čåąĖčÅ ą╝ąĄčéą║ąĖ (Label chunk) čüąŠą┤ąĄčƹȹĖčé č鹥ą║čüčé, ą║ąŠč鹊čĆčŗą╣ ąŠą┐ąĖčüčŗą▓ą░ąĄčé č鹊čćą║čā ą▓ WAV-čäą░ą╣ą╗ąĄ čüąŠ čüčüčŗą╗ą║ąŠą╣ ąĮą░ čüą▓čÅąĘą░ąĮąĮčāčÄ č鹊čćą║čā cue.
ą¤ąŠąĘąĖčåąĖčÅ (Position)
ą¤ąŠąĘąĖčåąĖčÅ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé čüą╝ąĄčēąĄąĮąĖąĄ ą▓čŗą▒ąŠčĆą║ąĖ, čüą▓čÅąĘą░ąĮąĮąŠąĄ č鹊čćą║ąŠą╣ cue, čü č鹊čćą║ąĖ ąĘčĆąĄąĮąĖčÅ ą┐ąŠąĘąĖčåąĖąĖ ą▓čŗą▒ąŠčĆą║ąĖ ą▓ ąĘą░ą║ą╗čÄčćąĖč鹥ą╗čīąĮąŠą╝ ą┐ąŠč鹊ą║ąĄ ą▓čŗą▒ąŠčĆąŠą║, čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąĮčŗčģ čüą┐ąĖčüą║ąŠą╝ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖčÅ. ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ąĄčüą╗ąĖ čāą║ą░ąĘą░ąĮą░ čüąĄą║čåąĖčÅ čüą┐ąĖčüą║ą░ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖčÅ (play list chunk), ąĘąĮą░č湥ąĮąĖąĄ ą┐ąŠąĘąĖčåąĖąĖ čĆą░ą▓ąĮąŠ ąĮąŠą╝ąĄčĆčā ą▓čŗą▒ąŠčĆą║ąĖ, ąĮą░ ą║ąŠč鹊čĆąŠą╣ čŹčéą░ č鹊čćą║ą░ cue ą▓čüčéčĆąĄčéąĖčéčüčÅ ą┐čĆąĖ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖąĖ ą▓čüąĄą│ąŠ čüą┐ąĖčüą║ą░ (play list) ą▓ ąĘą░ą┤ą░ąĮąĮąŠą╝ ą┐ąŠčĆčÅą┤ą║ąĄ. ąĢčüą╗ąĖ ąĮąĄčé čüąĄą║čåąĖąĖ čüą┐ąĖčüą║ą░ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖčÅ (play list chunk), č鹊 ąĘąĮą░č湥ąĮąĖąĄ ą┐ąŠąĘąĖčåąĖąĖ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čĆą░ą▓ąĮąŠ 0.
ID čüąĄą║čåąĖąĖ ą┤ą░ąĮąĮčŗčģ (Data Chunk ID)
ąŁčéą░ ą▓ąĄą╗ąĖčćąĖąĮą░ čāą║ą░ąĘčŗą▓ą░ąĄčé ID ąĖąĘ 4 ą▒ą░ą╣čé, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ čüąĄą║čåąĖąĄą╣, čüąŠą┤ąĄčƹȹ░čēąĄą╣ ą▓čŗą▒ąŠčĆą║čā, ą║ąŠč鹊čĆą░čÅ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé čŹč鹊ą╣ č鹊čćą║ąĄ cue. WAV-čäą░ą╣ą╗ ą▒ąĄąĘ čüą┐ąĖčüą║ą░ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖčÅ (play list chunk) ą▓čüąĄą│ą┤ą░ ąĖą╝ąĄąĄčé "data". WAV-čäą░ą╣ą╗, ąĖą╝ąĄčÄčēąĖą╣ čüą┐ąĖčüąŠą║ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖčÅ (play list chunk) čü čüąĄą║čåąĖčÅą╝ąĖ ą┤ą░ąĮąĮčŗčģ ąĖ čéąĖčłąĖąĮčŗ, ą╝ąŠąČąĄčé ą▒čŗčéčī ą╗ąĖą▒ąŠ "data", ą╗ąĖą▒ąŠ "slnt".
ąØą░čćą░ą╗ąŠ čüąĄą║čåąĖąĖ (Chunk Start)
ąŚąĮą░č湥ąĮąĖąĄ ąĮą░čćą░ą╗ą░ čüąĄą║čåąĖąĖ čāą║ą░ąĘčŗą▓ą░ąĄčé ą▒ą░ą╣č鹊ą▓ąŠąĄ čüą╝ąĄčēąĄąĮąĖąĄ ą▓ čüąĄą║čåąĖąĖ čüą┐ąĖčüą║ą░ Wave (Wave List Chunk) čüąĄą║čåąĖąĖ, čüąŠą┤ąĄčƹȹ░čēąĄą╣ ą▓čŗą▒ąŠčĆą║čā, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēčāčÄ čŹč鹊ą╣ č鹊čćą║ąĄ. ąŁč鹊 čéą░ ąČąĄ čüą░ą╝ą░čÅ čüąĄą║čåąĖčÅ, ąŠą┐ąĖčüą░ąĮąĮą░čÅ ąĘąĮą░č湥ąĮąĖąĄą╝ ID čüąĄą║čåąĖąĖ ą┤ą░ąĮąĮčŗčģ (Data Chunk ID). ąĢčüą╗ąĖ ą▓ WAV-čäą░ą╣ą╗ąĄ ąĮąĄčé čüąĄą║čåąĖąĖ čüą┐ąĖčüą║ą░ Wave (Wave List Chunk), čŹčéą░ ą▓ąĄą╗ąĖčćąĖąĮą░ čĆą░ą▓ąĮą░ 0, ąĖąĮą░č湥 čŹčéą░ ą▓ąĄą╗ąĖčćąĖąĮą░ čĆą░ą▓ąĮą░ čüą╝ąĄčēąĄąĮąĖčÄ. ą▓ čüąĄą║čåąĖčÄ "wavl". ą¤ąĄčĆą▓ą░čÅ čüąĄą║čåąĖčÅ ą▓ čüąĄą║čåąĖąĖ čüą┐ąĖčüą║ą░ (Wave List Chunk) ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī čāą║ą░ąĘą░ąĮą░ čüąŠ ąĘąĮą░č湥ąĮąĖąĄą╝ 0.
ąØą░čćą░ą╗ąŠ ą▒ą╗ąŠą║ą░ (Block Start)
ąŚąĮą░č湥ąĮąĖąĄ Block Start čāą║ą░ąĘčŗą▓ą░ąĄčé čüą╝ąĄčēąĄąĮąĖąĄ ą▓ ą▒ą░ą╣čéą░čģ ą▓ čüąĄą║čåąĖčÄ "data" ąĖą╗ąĖ čüąĄą║čåąĖčÄ "slnt" ą┤ą╗čÅ ąĮą░čćą░ą╗ą░ ą▒ą╗ąŠą║ą░, čüąŠą┤ąĄčƹȹ░čēąĄą│ąŠ ą▓čŗą▒ąŠčĆą║čā. ąØą░čćą░ą╗ąŠ ą▒ą╗ąŠą║ą░ ąĘą░ą┤ą░ąĄčé ą┐ąĄčĆą▓čŗą╣ ą▒ą░ą╣čé ąĮąĄčüąČą░čéčŗčģ ą┤ą░ąĮąĮčŗčģ ąĘą▓čāą║ą░ PCM ąĖą╗ąĖ ą┐ąŠčüą╗ąĄą┤ąĮąĖą╣ ą▒ą░ą╣čé ą▓ čüąČą░čéčŗčģ ą┤ą░ąĮąĮčŗčģ ąĘą▓čāą║ą░, ą│ą┤ąĄ ą┤ąĄą║ąŠą╝ą┐čĆąĄčüčüąĖčÅ ą╝ąŠąČąĄčé ąĮą░čćą░čéčīčüčÅ ą┤ą╗čÅ ąĮą░čģąŠąČą┤ąĄąĮąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ ą▓čŗą▒ąŠčĆą║ąĖ.
ąĪą╝ąĄčēąĄąĮąĖąĄ ą▓čŗą▒ąŠčĆą║ąĖ (Sample Offset)
ąĪą╝ąĄčēąĄąĮąĖąĄ ą▓čŗą▒ąŠčĆą║ąĖ čāą║ą░ąĘčŗą▓ą░ąĄčé čüą╝ąĄčēąĄąĮąĖąĄ ą▓ ą▒ą╗ąŠą║ (čāą║ą░ąĘą░ąĮąĮčŗą╣ Block Start) ą┤ą╗čÅ ą▓čŗą▒ąŠčĆą║ąĖ, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą╣ ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ č鹊čćą║ąĄ (cue point). ąÆ ąĮąĄčüąČą░čéčŗčģ ą┤ą░ąĮąĮčŗčģ ąĘą▓čāą║ą░ PCM čŹč鹊 ą┐čĆąŠčüč鹊 ą▒ą░ą╣č鹊ą▓ąŠąĄ čüą╝ąĄčēąĄąĮąĖąĄ ą▓ čüąĄą║čåąĖčÄ "data". ąÆ čüąČą░čéčŗčģ ą┤ą░ąĮąĮčŗčģ ąĘą▓čāą║ą░ čŹč鹊 ąĘąĮą░č湥ąĮąĖąĄ čĆą░ą▓ąĮąŠ ą║ąŠą╗ąĖč湥čüčéą▓čā ą▓čŗą▒ąŠčĆąŠą║ (ą║ąŠč鹊čĆąŠąĄ ą╝ąŠąČąĄčé ąĖ ąĮąĄ ą▒čŗčéčī ą▓ ą▒ą░ą╣čéą░čģ) ąŠčé Block Start ą┤ąŠ ą▓čŗą▒ąŠčĆą║ąĖ, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą╣ ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ č鹊čćą║ąĄ (cue point).
ąĪąĄą║čåąĖčÅ ą┐ą╗ąĄą╣ą╗ąĖčüčéą░ čāą║ą░ąĘčŗą▓ą░ąĄčé ą┐ąŠčĆčÅą┤ąŠą║ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖčÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ ąĖąĮč鹥čĆąĄčüčāčÄčēąĖčģ č鹊č湥ą║ (cue points). ąŁčéąĖ č鹊čćą║ąĖ ąĘą░ą┤ą░ąĮčŗ ą▓ čüąĄą║čåąĖąĖ "cue ", ą│ą┤ąĄ-č鹊 ą▓ ą┤čĆčāą│ąŠą╝ ą╝ąĄčüč鹥 čäą░ą╣ą╗ą░. ą¤ą╗ąĄą╣ą╗ąĖčüčé čüąŠčüč鹊ąĖčé ąĖąĘ ą╝ą░čüčüąĖą▓ą░ čüąĄą│ą╝ąĄąĮč鹊ą▓, ą║ą░ąČą┤čŗą╣ ąĖąĘ ą║ąŠč鹊čĆčŗčģ čüąŠą┤ąĄčƹȹĖčé ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠ č鹊ą╝, ą║ą░ą║ąŠą╣ čüąĄą│ą╝ąĄąĮčé ąŠčéą║čāą┤ą░ ą┤ąŠą╗ąČąĄąĮ čüčéą░čĆč鹊ą▓ą░čéčī ąĮą░ ą┐čĆąŠąĖą│čĆčŗą▓ą░ąĮąĖąĄ, ą║ą░ą║ąŠą╣ ą┤ą╗ąĖč鹥ą╗čīąĮąŠčüčéąĖ čüąĄą│ą╝ąĄąĮčé ą┐čĆąŠąĖą│čĆčŗą▓ą░ąĮąĖčÅ (ą▓ ą▓čŗą▒ąŠčĆą║ą░čģ) ąĖ čüą║ąŠą╗čīą║ąŠ čĆą░ąĘ ą┤ąŠą╗ąČąĄąĮ ą┐ąŠą▓č鹊čĆąĖčéčīčüčÅ čüąĄą│ą╝ąĄąĮčé ą┐ąĄčĆąĄą┤ ą┐ąĄčĆąĄčģąŠą┤ąŠą╝ ą║ čüą╗ąĄą┤čāčÄčēąĄą╝čā ą┐ąŠ čüą┐ąĖčüą║čā čüąĄą│ą╝ąĄąĮčéčā.
| ąĪą╝ąĄčēąĄąĮąĖąĄ |
ąĀą░ąĘą╝ąĄčĆ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
ąÆąĄą╗ąĖčćąĖąĮą░ |
| 0x00 |
4 |
Chunk ID |
"plst" (0x736C6E74) |
| 0x04 |
4 |
Chunk Data Size |
num segments * 12 |
| 0x08 |
4 |
Number of Segments |
1 - 0xFFFFFFFF |
| 0x0a |
List of Segments |
ążąŠčĆą╝ą░čé čüąĄą║čåąĖąĖ Playlist
ąÜąŠą╗ąĖč湥čüčéą▓ąŠ čüąĄą│ą╝ąĄąĮč鹊ą▓ (Number of Segments)
ąŁč鹊 ąĘąĮą░č湥ąĮąĖąĄ ąĘą░ą┤ą░ąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖčģ čüąĄą│ą╝ąĄąĮč鹊ą▓ ą▓ čüąĄą║čåąĖąĖ ą┐ą╗ąĄą╣ą╗ąĖčüčéą░.
ąĪą┐ąĖčüąŠą║ čüąĄą│ą╝ąĄąĮč鹊ą▓ (List of Segments)
ąĪą┐ąĖčüąŠą║ čüąĄą│ą╝ąĄąĮč鹊ą▓ - ą┐čĆąŠčüč鹊 ąĮą░ą▒ąŠčĆ čüą╗ąĄą┤čāčÄčēąĖčģ ą┤čĆčāą│ ąĘą░ ą┤čĆčāą│ąŠą╝ ąŠą┐ąĖčüą░ąĮąĖą╣ čüąĄą│ą╝ąĄąĮč鹊ą▓, ą║ąŠč鹊čĆčŗąĄ čüąŠčüčéą░ą▓ą╗ąĄąĮčŗ ą┐ąŠ č乊čĆą╝ą░čéčā, ą┐čĆąĖą▓ąĄą┤ąĄąĮąĮąŠą╝čā ą▓ čéą░ą▒ą╗ąĖčåąĄ ąĮąĖąČąĄ. ąĪąĄą│ą╝ąĄąĮčéčŗ ąĮąĄ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąĮąĖ ą▓ ą║ą░ą║ąŠą╝ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╝ ą┐ąŠčĆčÅą┤ą║ąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 ą┤ą╗čÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą┐ąŠčĆčÅą┤ą║ą░ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖčÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┐ąŠąĘąĖčåąĖčÅ ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ č鹊čćą║ąĖ (cue point position), čüą▓čÅąĘą░ąĮąĮą░čÅ čü ą║ą░ąČą┤čŗą╝ ąŠą┐ąĖčüą░ąĮąĖąĄą╝ čüą┐ąĖčüą║ą░.
| ąĪą╝ąĄčēąĄąĮąĖąĄ |
ąĀą░ąĘą╝ąĄčĆ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
ąÆąĄą╗ąĖčćąĖąĮą░ |
| 0x00 |
4 |
Cue Point ID |
0 - 0xFFFFFFFF |
| 0x04 |
4 |
Length (in samples) |
1 - 0xFFFFFFFF |
| 0x08 |
4 |
Number of Repeats |
1 - 0xFFFFFFFF |
ążąŠčĆą╝ą░čé čüąĄą│ą╝ąĄąĮčéą░ ą┐ą╗ąĄą╣ą╗ąĖčüčéą░
ID ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ č鹊čćą║ąĖ (Cue Point ID)
Cue Point ID čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░čćą░ą╗čīąĮčāčÄ ą▓čŗą▒ąŠčĆą║čā ą┤ą╗čÅ čŹč鹊ą│ąŠ čüąĄą│ą╝ąĄąĮčéą░ ą┐čāč鹥ą╝ čāą║ą░ąĘą░ąĮąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ Cue Point, ąĘą░ą┤ą░ąĮąĮąŠą│ąŠ ą▓ čüą┐ąĖčüą║ąĄ Cue Point List. ID čüą▓čÅąĘčŗą▓ą░čÄčēąĖą╣ čŹč鹊čé čüąĄą│ą╝ąĄąĮčé čü ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ č鹊čćą║ąŠą╣ (Cue Point), ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čāąĮąĖą║ą░ą╗čīąĮčŗą╝ ą┐ąŠ ąŠčéąĮąŠčłąĄąĮąĖčÄ ą║ąŠ ą▓čüąĄą╝ ą┤čĆčāą│ąĖą╝ ID ąĖąĮč鹥čĆąĄčüčāčÄčēąĖčģ č鹊č湥ą║ (Cue Point ID).
ąöą╗ąĖąĮą░ (Length)
ąöą╗ąĖąĮą░ čüąĄą│ą╝ąĄąĮčéą░ čāą║ą░ąĘčŗą▓ą░ąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▓čŗą▒ąŠčĆąŠą║ ą┤ą╗čÅ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖčÅ ąĖą╗ąĖ ąĘą░čåąĖą║ą╗ąĖą▓ą░ąĮąĖčÅ ąŠčé ąĮą░čćą░ą╗čīąĮąŠą╣ ą▓čŗą▒ąŠčĆą║ąĖ, ąĘą░ą┤ą░ąĮąĮąŠą╣ ą▓ čüą▓čÅąĘą░ąĮąĮąŠą╣ Cue Point.
ąÜąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠą▓č鹊čĆąĄąĮąĖą╣ (Number of Repeats)
ąÜąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠą▓č鹊čĆąĄąĮąĖą╣ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé, čüą║ąŠą╗čīą║ąŠ čĆą░ąĘ čüąĄą│ą╝ąĄąĮčé ą┤ąŠą╗ąČąĄąĮ ą┐ąŠą▓č鹊čĆąĖčéčī čüą▓ąŠąĄ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖąĄ, ą┐ąĄčĆąĄą┤ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖąĄą╝ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖčÅ ąĮą░ čüą╗ąĄą┤čāčÄčēąĄą╝ čüąĄą│ą╝ąĄąĮč鹥.
ąĪąĄą║čåąĖčÅ čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ čüą┐ąĖčüą║ą░ ą┤ą░ąĮąĮčŗčģ (Associated Data List Chunk) ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ąĘą░ą┤ą░ąĮąĖčÅ č鹥ą║čüč鹊ą▓čŗčģ ą╝ąĄč鹊ą║ ąĖ ąĖą╝ąĄąĮ, ą║ąŠč鹊čĆčŗąĄ čüą▓čÅąĘą░ąĮčŗ čü ąĖąĮč鹥čĆąĄčüčāčÄčēąĖą╝ąĖ č鹊čćą║ą░ą╝ąĖ - ą┤ą╗čÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĖčÅ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ą┐ąŠąĘąĖčåąĖąĖ č鹥ą║čüč鹊ą▓ąŠą╣ ą╝ąĄčéą║ąĖ ąĖą╗ąĖ ąĖą╝ąĄąĮąĖ.
| ąĪą╝ąĄčēąĄąĮąĖąĄ |
ąĀą░ąĘą╝ąĄčĆ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
ąÆąĄą╗ąĖčćąĖąĮą░ |
| 0x00 |
4 |
Chunk ID |
"list" (0x6C696E74) |
| 0x04 |
4 |
Chunk Data Size |
ąĘą░ą▓ąĖčüąĖčé ąŠčé čüąŠą┤ąĄčƹȹ░čēąĄą│ąŠčüčÅ č鹥ą║čüčéą░ |
| 0x08 |
4 |
Type ID |
"adtl" (0x6164746C) |
| 0x0c |
čüą┐ąĖčüąŠą║ č鹥ą║čüč鹊ą▓čŗčģ ą╝ąĄč鹊ą║ ąĖ ąĖą╝ąĄąĮ |
ążąŠčĆą╝ą░čé čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ čüą┐ąĖčüą║ą░ ą┤ą░ąĮąĮčŗčģ
Type ID
ąśą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ čéąĖą┐ą░ (type ID) ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ąŠą▒ąŠąĘąĮą░č湥ąĮąĖąĄ čéąĖą┐ą░ čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ čüą┐ąĖčüą║ą░ ą┤ą░ąĮąĮčŗčģ ąĖ ą▓čüąĄą│ą┤ą░ ąĖą╝ąĄąĄčé ąĘąĮą░č湥ąĮąĖąĄ "adtl".
ąĪą┐ąĖčüąŠą║ č鹥ą║čüč鹊ą▓čŗčģ ą╝ąĄč鹊ą║ ąĖ ąĖą╝ąĄąĮ
ąĪą┐ąĖčüąŠą║ č鹥ą║čüč鹊ą▓čŗčģ ą╝ąĄč鹊ą║ ąĖ ąĖą╝ąĄąĮ - ą┐čĆąŠčüč鹊 čüą┐ąĖčüąŠą║ čĆą░čüčüąŠčĆčéąĖčĆąŠą▓ą░ąĮąĮčŗčģ čüąĄą║čåąĖą╣, ą║ąŠč鹊čĆčŗąĄ ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčé č鹥ą║čüčé čĆą░ąĘą╗ąĖčćąĮčŗą╝ąĖ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ. ąÆ čäą░ą╣ą╗ą░čģ WAVE ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ čéčĆąĖ ąŠčüąĮąŠą▓ąĮčŗąĄ čéąĖą┐čŗ čüąĄą║čåąĖą╣ - čüąĄą║čåąĖčÅ ą╝ąĄčéą║ąĖ (Label Chunk), čüąĄą║čåąĖčÅ ą┐čĆąĖą╝ąĄčćą░ąĮąĖčÅ (Note Chunk) ąĖ čüąĄą║čåąĖčÅ ą┐ąŠą╝ąĄč湥ąĮąĮąŠą│ąŠ č鹥ą║čüčéą░ (Labeled Text Chunk).
ąĪąĄą║čåąĖčÅ ą╝ąĄčéą║ąĖ (Label Chunk) ą▓čüąĄą│ą┤ą░ čüąŠą┤ąĄčƹȹĖčéčüčÅ ą▓ąĮčāčéčĆąĖ čüąĄą║čåąĖąĖ čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ čüą┐ąĖčüą║ą░ ą┤ą░ąĮąĮčŗčģ (associated data list chunk). ą×ąĮą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ čüą▓čÅąĘčŗą▓ą░ąĮąĖčÅ č鹥ą║čüč鹊ą▓ąŠą╣ ą╝ąĄčéą║ąĖ čü ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ č鹊čćą║ąŠą╣ (Cue Point). ąŁčéą░ ąĖąĮč乊čĆą╝ą░čåąĖčÅ čćą░čüč鹊 ąŠč鹊ą▒čĆą░ąČą░ąĄčéčüčÅ ąĮą░ ą╝ą░čĆą║ąĄčĆą░čģ ąĖą╗ąĖ čäą╗ą░ąČą║ą░čģ ą▓ ą░čāą┤ąĖąŠčĆąĄą┤ą░ą║č鹊čĆą░čģ.
| ąĪą╝ąĄčēąĄąĮąĖąĄ |
ąĀą░ąĘą╝ąĄčĆ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
ąÆąĄą╗ąĖčćąĖąĮą░ |
| 0x00 |
4 |
Chunk ID |
"labl" (0x6C61626C) |
| 0x04 |
4 |
Chunk Data Size |
ąĘą░ą▓ąĖčüąĖčé ąŠčé čüąŠą┤ąĄčƹȹ░čēąĄą│ąŠčüčÅ č鹥ą║čüčéą░ |
| 0x08 |
4 |
Cue Point ID |
0 - 0xFFFFFFFF |
| 0x0c |
č鹥ą║čüčé |
ążąŠčĆą╝ą░čé čüąĄą║čåąĖąĖ ą╝ąĄčéą║ąĖ
Cue Point ID
ąśą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ č鹊čćą║ąĖ (Cue Point ID) čāą║ą░ąĘčŗą▓ą░ąĄčé č鹊čćą║čā čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĖčÅ ą▓čŗą▒ąŠčĆą║ąĖ, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą╣ čŹč鹊ą╣ č鹥ą║čüč鹊ą▓ąŠą╣ ą╝ąĄčéą║ąĄ, ą┐čāč鹥ą╝ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĖčÅ ID ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ č鹊čćą║ąĖ (Cue Point), ąĘą░ą┤ą░ąĮąĮąŠą╣ ą▓ čüą┐ąĖčüą║ąĄ ąĖąĮč鹥čĆąĄčüčāčÄčēąĖčģ č鹊č湥ą║ (Cue Point List). ID, ą║ąŠč鹊čĆčŗą╣ čüą▓čÅąĘčŗą▓ą░ąĄčé čŹčéčā ą╝ąĄčéą║čā čü ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ č鹊čćą║ąŠą╣ (Cue Point), ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čāąĮąĖą║ą░ą╗čīąĮčŗą╝ ą┐ąŠ ąŠčéąĮąŠčłąĄąĮąĖčÄ ą║ąŠ ą▓čüąĄą╝ ą┤čĆčāą│ąĖą╝ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆą░ą╝ ąĖąĮč鹥čĆąĄčüčāčÄčēąĖčģ č鹊č湥ą║ (Cue Point ID).
ąóąĄą║čüčé
ąóąĄą║čüčé - čüčéčĆąŠą║ą░ čüąĖą╝ą▓ąŠą╗ąŠą▓, ąŠą║ą░ąĮčćąĖą▓ą░čÄčēąĖčģčüčÅ ąĮčāą╗ąĄą╝. ąĢčüą╗ąĖ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čüąĖą╝ą▓ąŠą╗ąŠą▓ ą▓ čüčéčĆąŠą║ąĄ ąĮąĄč湥čéąĮąŠ, ą║ čüčéčĆąŠą║ąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąŠ ąŠą┤ąĮąŠą▒ą░ą╣č鹊ą▓ąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ. ąöąŠą▒ą░ą▓ą╗ąĄąĮąĮąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ąĮąĄ čāčćąĖčéčŗą▓ą░ąĄčéčüčÅ ą▓ ą┐ąŠą╗ąĄ čĆą░ąĘą╝ąĄčĆą░ čüąĄą║čåąĖąĖ ą╝ąĄčéą║ąĖ.
ąĪąĄą║čåąĖčÅ ą┐čĆąĖą╝ąĄčćą░ąĮąĖčÅ (Note Chunk) ą▓čüąĄą│ą┤ą░ čüąŠą┤ąĄčƹȹĖčéčüčÅ ą▓ąĮčāčéčĆąĖ čüąĄą║čåąĖąĖ čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ čüą┐ąĖčüą║ą░ ą┤ą░ąĮąĮčŗčģ (associated data list chunk). ą×ąĮą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ čüą▓čÅąĘčŗą▓ą░ąĮąĖčÅ č鹥ą║čüč鹊ą▓ąŠą│ąŠ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖčÅ čü ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ č鹊čćą║ąŠą╣ (Cue Point). ąŁčéą░ ąĖąĮč乊čĆą╝ą░čåąĖčÅ čüąŠčģčĆą░ąĮčÅąĄčéčüčÅ č鹥ą╝ ąČąĄ čüą░ą╝čŗą╝ čüą┐ąŠčüąŠą▒ąŠą╝, ą║ą░ą║ ąĖ ą╝ąĄčéą║ąĖ ą▓ čüąĄą║čåąĖąĖ ą╝ąĄčéą║ąĖ.
| ąĪą╝ąĄčēąĄąĮąĖąĄ |
ąĀą░ąĘą╝ąĄčĆ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
ąÆąĄą╗ąĖčćąĖąĮą░ |
| 0x00 |
4 |
Chunk ID |
"note" (0x6E6F7465) |
| 0x04 |
4 |
Chunk Data Size |
ąĘą░ą▓ąĖčüąĖčé ąŠčé čüąŠą┤ąĄčƹȹ░čēąĄą│ąŠčüčÅ č鹥ą║čüčéą░ |
| 0x08 |
4 |
Cue Point ID |
0 - 0xFFFFFFFF |
| 0x0C |
č鹥ą║čüčé |
ążąŠčĆą╝ą░čé čüąĄą║čåąĖąĖ ą┐čĆąĖą╝ąĄčćą░ąĮąĖčÅ
Cue Point ID
ąśą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ č鹊čćą║ąĖ (Cue Point ID) čāą║ą░ąĘčŗą▓ą░ąĄčé č鹊čćą║čā čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĖčÅ ą▓čŗą▒ąŠčĆą║ąĖ, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą╣ čŹč鹊ą╝čā č鹥ą║čüč鹊ą▓ąŠą╝čā ą┐čĆąĖą╝ąĄčćą░ąĮąĖčÄ, ą┐čāč鹥ą╝ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĖčÅ ID ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ č鹊čćą║ąĖ (Cue Point), ąĘą░ą┤ą░ąĮąĮąŠą╣ ą▓ čüą┐ąĖčüą║ąĄ ąĖąĮč鹥čĆąĄčüčāčÄčēąĖčģ č鹊č湥ą║ (Cue Point List). ID, ą║ąŠč鹊čĆčŗą╣ čüą▓čÅąĘčŗą▓ą░ąĄčé čŹč鹊 ą┐čĆąĖą╝ąĄčćą░ąĮąĖąĄ čü ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ č鹊čćą║ąŠą╣ (Cue Point), ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čāąĮąĖą║ą░ą╗čīąĮčŗą╝ ą┐ąŠ ąŠčéąĮąŠčłąĄąĮąĖčÄ ą║ąŠ ą▓čüąĄą╝ ą┤čĆčāą│ąĖą╝ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆą░ą╝ ąĖąĮč鹥čĆąĄčüčāčÄčēąĖčģ č鹊č湥ą║ (Cue Point ID).
Text
ąóąĄą║čüčé - čüčéčĆąŠą║ą░ čüąĖą╝ą▓ąŠą╗ąŠą▓, ąŠą║ą░ąĮčćąĖą▓ą░čÄčēąĖčģčüčÅ ąĮčāą╗ąĄą╝. ąĢčüą╗ąĖ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čüąĖą╝ą▓ąŠą╗ąŠą▓ ą▓ čüčéčĆąŠą║ąĄ ąĮąĄč湥čéąĮąŠ, ą║ čüčéčĆąŠą║ąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąŠ ąŠą┤ąĮąŠą▒ą░ą╣č鹊ą▓ąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ. ąöąŠą▒ą░ą▓ą╗ąĄąĮąĮąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ąĮąĄ čāčćąĖčéčŗą▓ą░ąĄčéčüčÅ ą▓ ą┐ąŠą╗ąĄ čĆą░ąĘą╝ąĄčĆą░ čüąĄą║čåąĖąĖ ą┐čĆąĖą╝ąĄčćą░ąĮąĖčÅ (ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖčÅ).
ąĪąĄą║čåąĖčÅ ą┐ąŠą╝ąĄč湥ąĮąĮąŠą│ąŠ č鹥ą║čüčéą░ (Labeled Text Chunk) ą▓čüąĄą│ą┤ą░ čüąŠą┤ąĄčƹȹĖčéčüčÅ ą▓ąĮčāčéčĆąĖ čüąĄą║čåąĖąĖ čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ čüą┐ąĖčüą║ą░ ą┤ą░ąĮąĮčŗčģ (associated data list chunk). ą×ąĮą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ čüą▓čÅąĘčŗą▓ą░ąĮąĖčÅ č鹥ą║čüč鹊ą▓ąŠą╣ ą╝ąĄčéą║ąĖ čü čĆąĄą│ąĖąŠąĮąŠą╝ ąĖą╗ąĖ čüąĄą║čåąĖąĄą╣ ą┤ą░ąĮąĮčŗčģ ąĘą▓čāą║ą░. ąŁčéą░ ąĖąĮč乊čĆą╝ą░čåąĖčÅ čćą░čüč鹊 ąŠč鹊ą▒čĆą░ąČą░ąĄčéčüčÅ ą▓ ą┐ąŠą╝ąĄč湥ąĮąĮčŗčģ čĆąĄą│ąĖąŠąĮą░čģ ąĘą▓čāą║ą░ ą▓ ą░čāą┤ąĖąŠčĆąĄą┤ą░ą║č鹊čĆą░čģ.
| ąĪą╝ąĄčēąĄąĮąĖąĄ |
ąĀą░ąĘą╝ąĄčĆ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
ąÆąĄą╗ąĖčćąĖąĮą░ |
| 0x00 |
4 |
Chunk ID |
"ltxt" (0x6C747874) |
| 0x04 |
4 |
Chunk Data Size |
ąĘą░ą▓ąĖčüąĖčé ąŠčé čüąŠą┤ąĄčƹȹ░čēąĄą│ąŠčüčÅ č鹥ą║čüčéą░ |
| 0x08 |
4 |
Cue Point ID |
0 - 0xFFFFFFFF |
| 0x0c |
4 |
Sample Length |
0 - 0xFFFFFFFF |
| 0x10 |
4 |
Purpose ID |
0 - 0xFFFFFFFF |
| 0x12 |
2 |
Country |
0 - 0xFFFF |
| 0x14 |
2 |
Language |
0 - 0xFFFF |
| 0x16 |
2 |
Dialect |
0 - 0xFFFF |
| 0x18 |
2 |
Code Page |
0 - 0xFFFF |
| 0x1A |
č鹥ą║čüčé |
ążąŠčĆą╝ą░čé čüąĄą║čåąĖąĖ ą┐ąŠą╝ąĄč湥ąĮąĮąŠą│ąŠ č鹥ą║čüčéą░
Cue Point ID
ąśą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ č鹊čćą║ąĖ (Cue Point ID) čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░čćą░ą╗čīąĮčāčÄ ą▓čŗą▒ąŠčĆą║čā, ą║ąŠč鹊čĆą░čÅ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé čŹč鹊ą╣ č鹥ą║čüč鹊ą▓ąŠą╣ ą╝ąĄčéą║ąĄ, čü ą┐ąŠą╝ąŠčēčīčÄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĖčÅ ID ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ č鹊čćą║ąĖ, ąĘą░ą┤ą░ąĮąĮąŠą│ąŠ ą▓ čüą┐ąĖčüą║ąĄ ąĖąĮč鹥čĆąĄčüčāčÄčēąĖčģ č鹊č湥ą║ (Cue Point List). ID ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ č鹊čćą║ąĖ, čüą▓čÅąĘą░ąĮąĮčŗą╣ čü čŹč鹊ą╣ ą╝ąĄčéą║ąŠą╣, ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čāąĮąĖą║ą░ą╗čīąĮčŗą╝ ą┐ąŠ ąŠčéąĮąŠčłąĄąĮąĖčÄ ą║ąŠ ą▓čüąĄą╝ ą┤čĆčāą│ąĖą╝ ID ąĖąĮč鹥čĆąĄčüčāčÄčēąĖčģ č鹊č湥ą║.
Sample Length
ąöą╗ąĖąĮą░ ą▓čŗą▒ąŠčĆąŠą║ (sample length) ąĘą░ą┤ą░ąĄčé, čüą║ąŠą╗čīą║ąŠ ą▓čŗą▒ąŠčĆąŠą║ ą▓čģąŠą┤ąĖčé ą▓ čĆąĄą│ąĖąŠąĮ ąĖą╗ąĖ ąĖąĮč鹥čĆą▓ą░ą╗ čüąĄą║čåąĖąĖ, ąĮą░čćąĖąĮą░čÅ čü ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ č鹊čćą║ąĖ.
Purpose ID
ą¤ąŠą╗ąĄ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĖčÅ čāą║ą░ąĘčŗą▓ą░ąĄčé, ą┤ą╗čÅ č湥ą│ąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ č鹥ą║čüčé. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĘąĮą░č湥ąĮąĖąĄ "scrp" ąŠąĘąĮą░čćą░ąĄčé č鹥ą║čüčé čüą║čĆąĖą┐čéą░, "capt" ąŠąĘąĮą░čćą░ąĄčé close-caption (ą┐ąŠčÅčüąĮčÅčÄčēą░čÅ ą┐ąŠą┤ą┐ąĖčüčī, čüčāą▒čéąĖčéčĆ). ąśą╝ąĄąĄčéčüčÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▒ąŠą╗čīčłąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĘąĮą░č湥ąĮąĖą╣ purpose ID, ąĮąŠ ąŠąĮąĖ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮčŗ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čü ą┤čĆčāą│ąĖą╝ąĖ čéąĖą┐ą░ą╝ąĖ čäą░ą╣ą╗ąŠą▓ č乊čĆą╝ą░čéą░ RIFF (ą║ąŠč鹊čĆčŗąĄ ąŠą▒čŗčćąĮąŠ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą▓ čäą░ą╣ą╗ą░čģ WAVE).
Country, Language, Dialect, Code Page
ąŁčéąĖ ą┐ąŠą╗čÅ (čüčéčĆą░ąĮą░, čÅąĘčŗą║, ą┤ąĖą░ą╗ąĄą║čé, ą║ąŠą┤ąŠą▓ą░čÅ čüčéčĆą░ąĮąĖčåą░) ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ čāą║ą░ąĘą░ąĮąĖčÅ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ąŠ ą╝ąĄčüč鹊čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĖąĖ ąĖ čÅąĘčŗą║ąĄ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ą▓ č鹥ą║čüč鹥. ą×ą▒čŗčćąĮąŠ ąŠąĮąĖ ąĮčāąČąĮčŗ ą┤ą╗čÅ ąĘą░ą┐čĆąŠčüąŠą▓ ąŠ ą┐ąŠą╗čāč湥ąĮąĖąĖ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ąŠčé ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ.
Text
ąóąĄą║čüčé - čüčéčĆąŠą║ą░ čüąĖą╝ą▓ąŠą╗ąŠą▓, ąŠą║ą░ąĮčćąĖą▓ą░čÄčēąĖčģčüčÅ ąĮčāą╗ąĄą╝. ąĢčüą╗ąĖ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čüąĖą╝ą▓ąŠą╗ąŠą▓ ą▓ čüčéčĆąŠą║ąĄ ąĮąĄč湥čéąĮąŠ, ą║ čüčéčĆąŠą║ąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąŠ ąŠą┤ąĮąŠą▒ą░ą╣č鹊ą▓ąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ. ąöąŠą▒ą░ą▓ą╗ąĄąĮąĮąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ąĮąĄ čāčćąĖčéčŗą▓ą░ąĄčéčüčÅ ą▓ ą┐ąŠą╗ąĄ čĆą░ąĘą╝ąĄčĆą░ čüąĄą║čåąĖąĖ.
ąĪąĄą║čåąĖčÅ čüąĄą╝ą┐ą╗ąĄčĆą░ (Sampler Chunk) ąĘą░ą┤ą░ąĄčé ąŠčüąĮąŠą▓ąĮčŗąĄ ą┐ą░čĆą░ą╝ąĄčéčĆčŗ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░, ą║ą░ą║ ąĮą░ą┐čĆąĖą╝ąĄčĆ čüąĄą╝ą┐ą╗ąĄčĆ MIDI, ą║ąŠč鹊čĆčŗą╣ ą┤ąŠą╗ąČąĄąĮ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ ąĘą▓čāą║ą░. ąØą░ąĖą▒ąŠą╗ąĄąĄ ą▓ą░ąČąĮąŠ, čćč鹊 ąŠąĮ ą▓ą║ą╗čÄčćą░ąĄčé ą▓ čüąĄą▒čÅ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠ ąĘą░čåąĖą║ą╗ąĖą▓ą░ąĮąĖčÅčģ ąĘą▓čāą║ą░ ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖčÅ. ąÜąŠąĮąĄčćąĮąŠ, ąÆčŗ ą╝ąŠąČąĄč鹥 ąĮą░ą╣čéąĖ, čćč鹊 čŹč鹊 čÅą▓ą╗čÅąĄčéčüčÅ ą┤čāą▒ą╗ąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ąĖąĮč乊čĆą╝ą░čåąĖąĖ, ą║ąŠč鹊čĆčāčÄ ą╝ąŠąČąĮąŠ ąĮą░ą╣čéąĖ ą▓ čüąĄą║čåąĖčÅčģ Cue ąĖ Playlist č乊čĆą╝ą░čéą░ WAVE, ąĮąŠ, ą║ čüčćą░čüčéčīčÄ, ą▓ čüąĄą║čåąĖąĖ čüąĄą╝ą┐ą╗ąĄčĆą░ čŹč鹊 čüą┤ąĄą╗ą░ąĮąŠ ą▒ąŠą╗ąĄąĄ ą│ąĖą▒ą║ąŠ, ąĮąĄą┐čĆąŠčéąĖą▓ąŠčĆąĄčćąĖą▓ąŠ, ąĖ ą╗čāčćčłąĄ ąĘą░ą┤ąŠą║čāą╝ąĄąĮčéąĖčĆąŠą▓ą░ąĮąĮčŗą╝ čüą┐ąŠčüąŠą▒ąŠą╝.
| ąĪą╝ąĄčēąĄąĮąĖąĄ |
ąĀą░ąĘą╝ąĄčĆ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
ąÆąĄą╗ąĖčćąĖąĮą░ |
| 0x00 |
4 |
Chunk ID |
"smpl" (0x736D706C) |
| 0x04 |
4 |
Chunk Data Size |
36 + (Num Sample Loops * 24) + Sampler Data |
| 0x08 |
4 |
Manufacturer |
0 - 0xFFFFFFFF |
| 0x0C |
4 |
Product |
0 - 0xFFFFFFFF |
| 0x10 |
4 |
Sample Period |
0 - 0xFFFFFFFF |
| 0x14 |
4 |
MIDI Unity Note |
0 - 127 |
| 0x18 |
4 |
MIDI Pitch Fraction |
0 - 0xFFFFFFFF |
| 0x1C |
4 |
SMPTE Format |
0, 24, 25, 29, 30 |
| 0x20 |
4 |
SMPTE Offset |
0 - 0xFFFFFFFF |
| 0x24 |
4 |
Num Sample Loops |
0 - 0xFFFFFFFF |
| 0x28 |
4 |
Sampler Data |
0 - 0xFFFFFFFF |
| 0x2C |
List of Sample Loops |
ążąŠčĆą╝ą░čé čüąĄą║čåąĖąĖ čüąĄą╝ą┐ą╗ąĄčĆą░
Manufacturer
ą¤ąŠą╗ąĄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čÅ (manufacturer) čāą║ą░ąĘčŗą▓ą░ąĄčé ą║ąŠą┤ MIDI Manufacturer's Association (MMA) ą┤ą╗čÅ čüąĄą╝ą┐ą╗ąĄčĆą░ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĮąŠą│ąŠ ą┤ą╗čÅ ą┐čĆąĖąĄą╝ą░ ąĘą▓čāą║ą░ čŹč鹊ą│ąŠ čäą░ą╣ą╗ą░. ąÜą░ąČą┤čŗą╣ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čī ą┐čĆąŠą┤čāą║čéą░ MIDI ąĖą╝ąĄąĄčé čüą▓ąŠą╣ čāąĮąĖą║ą░ą╗čīąĮčŗą╣ ID, ą║ąŠč鹊čĆčŗą╣ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāąĄčé ą║ąŠą╝ą┐ą░ąĮąĖčÄ. ąĢčüą╗ąĖ ąĮąĄ čāą║ą░ąĘą░ąĮ ą║ąŠąĮą║čĆąĄčéąĮčŗą╣ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čī, č鹊 ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą┐ąŠą┤čüčéą░ą▓ą╗ąĄąĮąŠ ąĘąĮą░č湥ąĮąĖąĄ 0.
ąÆ ąĘąĮą░č湥ąĮąĖąĖ ąĖą╝ąĄąĄčéčüčÅ ąĮąĄą║ąŠč鹊čĆą░čÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮą░čÅ ąĖąĮč乊čĆą╝ą░čåąĖčÅ, ą║ąŠč鹊čĆčāčÄ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ čéčĆą░ąĮčüą╗čÅčåąĖąĖ ą▓ ą▓ąĄą╗ąĖčćąĖąĮčā, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čāčÄ ą▓ ą┐ąĄčĆąĄą┤ą░č湥 ąĮą░ čüąĄą╝ą┐ą╗ąĄčĆ č乊čĆą╝ą░čéą░ MIDI System Exclusive. ąĪčéą░čĆčłąĖą╣ ą▒ą░ą╣čé ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą╝ą╗ą░ą┤čłąĖčģ ą▒ą░ą╣čé (1 ąĖą╗ąĖ 3), ą║ąŠč鹊čĆčŗąĄ ąĘąĮą░čćąĖą╝čŗ ą┤ą╗čÅ ą║ąŠą┤ą░ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čÅ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĘąĮą░č湥ąĮąĖąĄ ą┤ą╗čÅ Digidesign ą▒čāą┤ąĄčé 0x01000013 (0x13) ąĖ ąĘąĮą░č湥ąĮąĖąĄ ą┤ą╗čÅ Microsoft ą▒čāą┤ąĄčé 0x30000041 (0x00, 0x00, 0x41). ąĪą╝. čüą┐ąĖčüąŠą║ MIDI Manufacturers List.
Product
ą¤ąŠą╗ąĄ ą┐čĆąŠą┤čāą║čéą░ čāą║ą░ąĘčŗą▓ą░ąĄčé ID ą╝ąŠą┤ąĄą╗ąĖ MIDI, ąĘą░ą┤ą░ąĮąĮčŗą╣ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗ąĄą╝. ąöą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆąŠą▓ ą┐čĆąŠą┤čāą║čéą░ čüą▓čÅąĘčŗą▓ą░ą╣č鹥čüčī čü ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗ąĄą╝ čüąĄą╝ą┐ą╗ąĄčĆą░. ąĢčüą╗ąĖ ąĮąĄ čāą║ą░ąĘą░ąĮ ą║ąŠąĮą║čĆąĄčéąĮčŗą╣ ą┐čĆąŠą┤čāą║čé ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čÅ, č鹊 ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą┐ąŠą┤čüčéą░ą▓ą╗ąĄąĮąŠ ąĘąĮą░č湥ąĮąĖąĄ 0.
Sample Period
ą¤ąĄčĆąĖąŠą┤ ą▓čŗą▒ąŠčĆą║ąĖ čāą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗ąĖč鹥ą╗čīąĮąŠčüčéčī ą▓čĆąĄą╝ąĄąĮąĖ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖčÅ ąŠą┤ąĮąŠą╣ ą▓čŗą▒ąŠčĆą║ąĖ ą▓ ąĮą░ąĮąŠčüąĄą║čāąĮą┤ą░čģ (ąŠą▒čŗčćąĮąŠ čĆą░ą▓ąĮąŠ 1 / [ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▓čŗą▒ąŠčĆąŠą║ ą▓ čüąĄą║čāąĮą┤čā], ą│ą┤ąĄ [ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▓čŗą▒ąŠčĆąŠą║ ą▓ čüąĄą║čāąĮą┤čā] čĆą░ą▓ąĮąŠ ą▓ąĄą╗ąĖčćąĖąĮąĄ, čāą║ą░ąĘą░ąĮąĮąŠą╣ ą▓ čüąĄą║čåąĖąĖ č乊čĆą╝ą░čéą░).
MIDI Unity Note
MIDI unity note (čćč鹊-č鹊 čéąĖą┐ą░ č鹊ąĮą░ą╗čīąĮąŠčüčéąĖ MIDI, čĆąĄčłąĖą╗ čŹč鹊čé č鹥čĆą╝ąĖąĮ ąĮąĄ ą┐ąĄčĆąĄą▓ąŠą┤ąĖčéčī) - ą▓ąĄą╗ąĖčćąĖąĮą░, ąĖą╝ąĄčÄčēą░čÅ č鹊 ąČąĄ čüą░ą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą║ą░ą║ ąĖ MIDI Unshifted Note čüąĄą║čåąĖąĖ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░ (instrument chunk). ą¤ąŠą╗ąĄ MIDI Unshifted Note čāą║ą░ąĘčŗą▓ą░ąĄčé ą╝čāąĘčŗą║ą░ą╗čīąĮčāčÄ ąĮąŠčéčā, ąĮą░ ą║ąŠč鹊čĆąŠą╣ ą▓čŗą▒ąŠčĆą║ą░ ą▒čāą┤ąĄčé ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮą░ ąĮą░ ąĄčæ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮąŠą╣ čüą║ąŠčĆąŠčüčéąĖ ą▓čŗą▒ąŠčĆąŠą║ sample rate (sample rate čāą║ą░ąĘą░ąĮąŠ ą▓ čüąĄą║čåąĖąĖ č乊čĆą╝ą░čéą░).
MIDI Pitch Fraction
MIDI pitch fraction (č鹊ąČąĄ ą║ą░ą║ąŠą╣-č鹊 čüą┐ąĄčåąĖčäąĖč湥čüą║ąĖą╣ ą╝čāąĘčŗą║ą░ą╗čīąĮčŗą╣ č鹥čĆą╝ąĖąĮ, čćč鹊-č鹊 čéąĖą┐ą░ "ą┤ąŠą╗čÅ ą▓čŗčüąŠčéčŗ ąĘą▓čāą║ą░") čāą║ą░ąĘčŗą▓ą░ąĄčé ą┤ąŠą╗ąĖ ą┐ąŠą╗čāč鹊ąĮą░ ą▓ą▓ąĄčĆčģ ąŠčé ą▓ąĄą╗ąĖčćąĖąĮčŗ, čāą║ą░ąĘą░ąĮąĮąŠą╣ ą▓ ą┐ąŠą╗ąĄ MIDI unity note. ąŚąĮą░č湥ąĮąĖąĄ 0x80000000 ąŠąĘąĮą░čćą░ąĄčé 1/2 ą┐ąŠą╗čāč鹊ąĮą░ (50 cents) ąĖ ąĘąĮą░č湥ąĮąĖąĄ 0x00000000 ąŠąĘąĮą░čćą░ąĄčé ąĮąĄč鹊čćąĮčāčÄ ąĮą░čüčéčĆąŠą╣ą║čā ą╝ąĄąČą┤čā ą┐ąŠą╗čāč鹊ąĮą░ą╝ąĖ (ą╗ąĖčćąĮąŠ ą┤ą╗čÅ ą╝ąĄąĮčÅ čŹč鹊 ą▓čüąĄ ąĘą▓čāčćąĖčé ą║ą░ą║ ą║ąĖčéą░ą╣čüą║ą░čÅ ą│čĆą░ą╝ąŠčéą░).
SMPTE Format
SMPTE č乊čĆą╝ą░čé čāą║ą░ąĘčŗą▓ą░ąĄčé č乊čĆą╝ą░čé ą▓čĆąĄą╝ąĄąĮąĖ Society of Motion Pictures and Television E, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┐ąŠą╗ąĄ SMPTE Offset. ąĢčüą╗ąĖ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ ąĘąĮą░č湥ąĮąĖąĄ 0, SMPTE Offset čéą░ą║ąČąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čĆą░ą▓ąĮąŠ 0.
| ąŚąĮą░č湥ąĮąĖąĄ |
SMPTE Format |
| 0 |
ąĮąĄčé čüą╝ąĄčēąĄąĮąĖčÅ SMPTE offset |
| 24 |
24 čäčĆąĄą╣ą╝ą░ ą▓ čüąĄą║čāąĮą┤čā |
| 25 |
25 čäčĆąĄą╣ą╝ąŠą▓ ą▓ čüąĄą║čāąĮą┤čā |
| 29 |
30 čäčĆąĄą╣ą╝ąŠą▓ ą▓ čüąĄą║čāąĮą┤čā čü ą▓čŗą┐ą░ą┤ąĄąĮąĖąĄą╝ čäčĆąĄą╣ą╝ą░ (30 ą▓čŗą┐ą░ą┤ą░ąĄčé) |
| 30 |
30 čäčĆąĄą╣ą╝ąŠą▓ ą▓ čüąĄą║čāąĮą┤čā |
ąŚąĮą░č湥ąĮąĖčÅ č乊čĆą╝ą░čéą░ SMPTE
SMPTE Offset
ąĪą╝ąĄčēąĄąĮąĖąĄ SMPTE Offset - ą▓ąĄą╗ąĖčćąĖąĮą░, čāą║ą░ąĘčŗą▓ą░čÄčēą░čÅ ąĮą░ čüą╝ąĄčēąĄąĮąĖąĄ ą▓čĆąĄą╝ąĄąĮąĖ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠąĄ ą┤ą╗čÅ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ / ą║ą░ą╗ąĖą▒čĆąŠą▓ą║ąĖ ą┐ąĄčĆą▓ąŠą╣ ą▓čŗą▒ąŠčĆą║ąĖ ąĘą▓čāą║ą░. ąŚą┤ąĄčüčī ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ č乊čĆą╝ą░ 0xhhmmssff, ą│ą┤ąĄ hh - čćąĖčüą╗ąŠ čüąŠ ąĘąĮą░ą║ąŠą╝, čāą║ą░ąĘčŗą▓ą░čÄčēąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čćą░čüąŠą▓ (-23 .. 23), mm - ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ą░čÅ ą▓ąĄą╗ąĖčćąĖąĮą░ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą╝ąĖąĮčāčé (0 .. 59), ss - (0 .. 59) ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ą░čÅ ą▓ąĄą╗ąĖčćąĖąĮą░ ą║ąŠą╗ąĖč湥čüčéą▓ą░ čüąĄą║čāąĮą┤ ąĖ ff - ą▒ąĄąĘąĘąĮą░ą║ąŠą▓ą░čÅ ą▓ąĄą╗ąĖčćąĖąĮą░ ą║ąŠą╗ąĖč湥čüčéą▓ą░ čäčĆąĄą╣ą╝ąŠą▓ (0 .. -1).
Sample Loops
ą¤ąŠą╗ąĄ čåąĖą║ą╗ąŠą▓ ą▓čŗą▒ąŠčĆąŠą║ čāą║ą░ąĘčŗą▓ą░ąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖą╣ ąĘą░čåąĖą║ą╗ąĖą▓ą░ąĮąĖčÅ ą▓čŗą▒ąŠčĆąŠą║ ą▓ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĄą╝ čüą┐ąĖčüą║ąĄ (čüą╝. list of sample loops). ąŁč鹊 ąĘąĮą░č湥ąĮąĖąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ ą▓ 0, čćč鹊 ąŠąĘąĮą░čćą░ąĄčé ąŠčéčüčāčéčüčéą▓ąĖąĄ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖčģ ąĘą░čåąĖą║ą╗ąĖą▓ą░ąĮąĖą╣.
Sampler Data
ąÆąĄą╗ąĖčćąĖąĮą░ ą┤ą░ąĮąĮčŗčģ čüąĄą╝ą┐ą╗ąĄčĆą░ (sampler data value) čāą║ą░ąĘčŗą▓ą░ąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ą░ą╣čé, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠčüą╗ąĄą┤čāčÄčé ąĘą░ čŹč鹊ą╣ čüąĄą║čåąĖąĄą╣ (ą▓ą║ą╗čÄčćą░čÅ ą▓ąĄčüčī čüą┐ąĖčüąŠą║ sample loop list). ąŁčéą░ ą▓ąĄą╗ąĖčćąĖąĮą░ ą▒ąŠą╗čīčłąĄ, č湥ą╝ 0, ą║ąŠą│ą┤ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ąĮčāąČą┤ą░ąĄčéčüčÅ ą▓ čüąŠčģčĆą░ąĮąĄąĮąĖąĖ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ. ąŁčéą░ ą▓ąĄą╗ąĖčćąĖąĮą░ ąŠčéčĆą░ąČąĄąĮą░ ą▓ ąĘąĮą░č湥ąĮąĖąĖ chunks data size.
List of Sample Loops
ąĪą┐ąĖčüąŠą║ ąĘą░čåąĖą║ą╗ąĖą▓ą░ąĮąĖą╣ (list of sample loops) - ą┐čĆąŠčüč鹊ą╣ ąĮą░ą▒ąŠčĆ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗčģ ąŠą┐ąĖčüą░ąĮąĖą╣ čåąĖą║ą╗ąŠą▓, ą║ąŠč鹊čĆčŗąĄ čüą╗ąĄą┤čāčÄčé ąĮąĖąČąĄąŠą┐ąĖčüą░ąĮąĮąŠą╝čā č乊čĆą╝ą░čéčā. ąŚą░čåąĖą║ą╗ąĖą▓ą░ąĮąĖčÅ ąĮąĄ ąĖą╝ąĄčÄčé ą║ą░ą║ąŠą╣-ą╗ąĖą▒ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╣ ą┐ąŠčĆčÅą┤ąŠą║, ą┐ąŠčüą║ąŠą╗čīą║čā ą║ą░ąČą┤čŗą╣ čåąĖą║ą╗ ą▓čŗą▒ąŠčĆąŠą║, čüą▓čÅąĘą░ąĮąĮčŗą╣ čü ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ č鹊čćą║ąŠą╣, ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą┐ąŠčĆčÅą┤ą║ą░ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖčÅ. ąĪąĄą║čåąĖčÅ čüąĄą╝ą┐ą╗ąĄčĆą░ ąĮąĄ čÅą▓ą╗čÅąĄčéčüčÅ ąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠą╣.
| ąĪą╝ąĄčēąĄąĮąĖąĄ |
ąĀą░ąĘą╝ąĄčĆ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
ąÆąĄą╗ąĖčćąĖąĮą░ |
| 0x00 |
4 |
Cue Point ID |
0 - 0xFFFFFFFF |
| 0x04 |
4 |
Type |
0 - 0xFFFFFFFF |
| 0x08 |
4 |
Start |
0 - 0xFFFFFFFF |
| 0x0C |
4 |
End |
0 - 0xFFFFFFFF |
| 0x10 |
4 |
Fraction |
0 - 0xFFFFFFFF |
| 0x14 |
4 |
Play Count |
0 - 0xFFFFFFFF |
ążąŠčĆą╝ą░čé čåąĖą║ą╗ą░ ą▓čŗą▒ąŠčĆąŠą║
Cue Point ID
ąśą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ąĖąĮč鹥čĆąĄčüčāčÄčēąĄą╣ č鹊čćą║ąĖ (Cue Point ID) - čāą║ą░ąĘčŗą▓ą░ąĄčé čāąĮąĖą║ą░ą╗čīąĮčŗą╣ ID, ą║ąŠč鹊čĆčŗą╣ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ąŠą┤ąĮąŠą╣ ąĖąĘ ąĘą░ą┤ą░ąĮąĮčŗčģ ąĖąĮč鹥čĆąĄčüčāčÄčēąĖčģ č鹊č湥ą║ ą▓ čüą┐ąĖčüą║ąĄ (cue point list). ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, čŹč鹊čé ID čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ą╗čÄą▒ąŠą╣ ąĖąĘ ą╝ąĄč鹊ą║, ąĘą░ą┤ą░ąĮąĮčŗčģ ą▓ čüą▓čÅąĘą░ąĮąĮąŠą╣ čüąĄą║čåąĖąĖ ą┤ą░ąĮąĮčŗčģ (data list chunk), ą║ąŠč鹊čĆą░čÅ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĮą░ąĘąĮą░čćą░čéčī č鹥ą║čüč鹊ą▓čŗąĄ ą╝ąĄčéą║ąĖ čĆą░ąĘą╗ąĖčćąĮčŗą╝ čåąĖą║ą╗ą░ą╝ ą▓čŗą▒ąŠčĆąŠą║.
Type
ą¤ąŠą╗ąĄ čéąĖą┐ą░ ąĘą░ą┤ą░ąĄčé, ą║ą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ąĘą░čåąĖą║ą╗ąĖą▓ą░čÄčéčüčÅ ą▓čŗą▒ąŠčĆą║ąĖ ąĘą▓čāą║ą░.
| ąŚąĮą░č湥ąĮąĖąĄ |
Loop Type (čéąĖą┐ ąĘą░čåąĖą║ą╗ąĖą▓ą░ąĮąĖčÅ)
|
| 0 |
ą”ąĖą║ą╗ ą▓ą┐ąĄčĆąĄą┤ (ąŠą▒čŗčćąĮčŗą╣) |
| 1 |
ąÉą╗čīč鹥čĆąĮą░čéąĖą▓ąĮčŗą╣ čåąĖą║ą╗ (ą▓ą┐ąĄčĆąĄą┤/ąĮą░ąĘą░ą┤, ąĖąĘą▓ąĄčüčéąĮčŗą╣ čéą░ą║ąČąĄ ą║ą░ą║ Ping Pong) |
| 2 |
ą”ąĖą║ą╗ ąĮą░ąĘą░ą┤ (ąŠą▒čĆą░čéąĮčŗą╣) |
| 3 - 31 |
ąŚą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąŠ ą┤ą╗čÅ ą▒čāą┤čāčēąĖčģ čüčéą░ąĮą┤ą░čĆčéąĮčŗčģ čéąĖą┐ąŠą▓ |
| 32 - 0xFFFFFFFF |
ąĪą┐ąĄčåąĖčäąĖč湥čüą║ąĖąĄ čéąĖą┐čŗ, ąŠčéąĮąŠčüčÅčēąĖąĄčüčÅ ą║ čüąĄą╝ą┐ą╗ąĄčĆčā (ąĘą░ą┤ą░čÄčéčüčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗ąĄą╝) |
ąŚąĮą░č湥ąĮąĖčÅ Loop Type
Start
ąŚąĮą░č湥ąĮąĖąĄ čüčéą░čĆčéą░ čāą║ą░ąĘčŗą▓ą░ąĄčé ą▒ą░ą╣č鹊ą▓ąŠąĄ čüą╝ąĄčēąĄąĮąĖąĄ ą▓ ą┤ą░ąĮąĮčŗąĄ ąĘą▓čāą║ą░ ą┐ąĄčĆą▓ąŠą╣ ą▓čŗą▒ąŠčĆą║ąĖ, ą┐čĆąŠąĖą│čĆčŗą▓ą░ąĄą╝ąŠą╣ ą▓ čåąĖą║ą╗ąĄ.
End
ąŚąĮą░č湥ąĮąĖąĄ ąŠą║ąŠąĮčćą░ąĮąĖčÅ čāą║ą░ąĘčŗą▓ą░ąĄčé ą▒ą░ą╣č鹊ą▓ąŠąĄ čüą╝ąĄčēąĄąĮąĖąĄ ą▓ ą┤ą░ąĮąĮčŗąĄ ąĘą▓čāą║ą░ ą┐ąŠčüą╗ąĄą┤ąĮąĄą╣ ą▓čŗą▒ąŠčĆą║ąĖ, ą┐čĆąŠąĖą│čĆčŗą▓ą░ąĄą╝ąŠą╣ ą▓ čåąĖą║ą╗ąĄ.
Fraction
ąöčĆąŠą▒ąĮąŠąĄ (fractional) ąĘąĮą░č湥ąĮąĖąĄ čāą║ą░ąĘčŗą▓ą░ąĄčé ą┤čĆąŠą▒ąĮčāčÄ čćą░čüčéčī ą▓čŗą▒ąŠčĆą║ąĖ, ą║ąŠč鹊čĆą░čÅ ą┐čĆąĖąĮą░ą┤ą╗ąĄąČąĖčé čåąĖą║ą╗čā. ąŁč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé č鹊čćąĮąŠ ąĮą░čüčéčĆąŠąĖčéčī ą┤ą╗ąĖč鹥ą╗čīąĮąŠčüčéčī čåąĖą║ą╗ą░ čü č鹊čćąĮąŠčüčéčīčÄ ą▓čŗčłąĄ, č湥ą╝ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąŠą┤ąĮą░ ą▓čŗą▒ąŠčĆą║ą░. ąÆąĄą╗ąĖčćąĖąĮą░ ą╝ąŠąČąĄčé ąĮą░čģąŠą┤ąĖčéčīčüčÅ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 0x00000000 .. 0xFFFFFFFF. ąŚąĮą░č湥ąĮąĖąĄ 0 ąŠąĘąĮą░čćą░ąĄčé ąŠčéčüčāčéčüčéą▓ąĖąĄ ą┤čĆąŠą▒ąĮąŠą╣ čćą░čüčéąĖ, ąĘąĮą░č湥ąĮąĖąĄ 0x80000000 ąŠąĘąĮą░čćą░ąĄčé 1/2 ąŠčé ą┤ą╗ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą▓čŗą▒ąŠčĆą║ąĖ. ąŚąĮą░č湥ąĮąĖąĄ 0xFFFFFFFF čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠą╣ ą┤čĆąŠą▒ąĮąŠą╣ čćą░čüčéąĖ ą▓čŗą▒ąŠčĆą║ąĖ, ą║ąŠč鹊čĆčāčÄ ą╝ąŠąČąĮąŠ ąĘą░ą┤ą░čéčī.
Play Count
ąŚąĮą░č湥ąĮąĖąĄ čüč湥čéčćąĖą║ą░ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖą╣ (play count) ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐čĆąŠąĖą│čĆčŗą▓ą░ąĮąĖą╣ čåąĖą║ą╗ą░. 0 ąŠąĘąĮą░čćą░ąĄčé ą┐ąŠčüč鹊čÅąĮąĮčŗą╣ ą▒ąĄčüą║ąŠąĮąĄčćąĮčŗą╣ čåąĖą║ą╗, ą║ąŠč鹊čĆčŗą╣ ąĮąĄ ą┐čĆąĄčĆą▓ąĄčéčüčÅ, ą┐ąŠą║ą░ ąĮąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠąĄ ą▓ąĮąĄčłąĮąĄąĄ ą▓ą╝ąĄčłą░č鹥ą╗čīčüčéą▓ąŠ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą╝čāąĘčŗą║ą░ąĮčé ąŠčéą┐čāčüčéąĖčé ą║ą╗ą░ą▓ąĖčłčā). ąÆčüąĄ ą┤čĆčāą│ąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ čāą║ą░ąĘčŗą▓ą░čÄčé ą░ą▒čüąŠą╗čÄčéąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐čĆąŠąĖą│čĆčŗą▓ą░ąĮąĖą╣ čåąĖą║ą╗ą░.
ąĪąĄą║čåąĖčÅ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░ (instrument chunk) ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ąŠą┐ąĖčüą░ąĮąĖčÅ - ą║ą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ąĘą▓čāą║ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą┐čĆąŠąĖą│čĆą░ąĮ ą║ą░ą║ ąĘą▓čāą║ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░. ąŁčéą░ ąĖąĮč乊čĆą╝ą░čåąĖčÅ ą┐ąŠą╗ąĄąĘąĮą░ ą┤ą╗čÅ ąŠą▒ą╝ąĄąĮą░ ą╝čāąĘčŗą║ą░ą╗čīąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĄą╣ ą╝ąĄąČą┤čā ą╝čāąĘčŗą║ą░ą╗čīąĮčŗą╝ąĖ čĆąĄą┤ą░ą║č鹊čĆą░ą╝ąĖ-čüąĄą╝ą┐ą╗ąĄčĆą░ą╝ąĖ, ąŠčüąĮąŠą▓ą░ąĮąĮčŗą╝ąĖ ąĮą░ ą▓čŗą▒ąŠčĆą║ą░čģ (čüąĄą╝ą┐ą╗ą░čģ), čéčĆąĄą║ąĄčĆą░ą╝ąĖ ąĖą╗ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗą╝ąĖ čéą░ą▒ą╗ąĖčåą░ą╝ąĖ ąĘą▓čāą║ą░. ąŁčéą░ čüąĄą║čåąĖčÅ čÅą▓ą╗čÅąĄčéčüčÅ ąĮąĄąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠą╣, ąĖ ąĮąĄ ą╝ąŠąČąĄčé ą▓čüčéčĆąĄčćą░čéčīčüčÅ ą▓ WAVE-čäą░ą╣ą╗ąĄ ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą│ąŠ čĆą░ąĘą░.
| ąĪą╝ąĄčēąĄąĮąĖąĄ |
ąĀą░ąĘą╝ąĄčĆ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
ąÆąĄą╗ąĖčćąĖąĮą░ |
| 0x00 |
4 |
Chunk ID |
"ltxt" (0x6C747874) |
| 0x04 |
4 |
Chunk Data Size |
7 |
| 0x08 |
1 |
Unshifted Note |
0 - 127 |
| 0x09 |
1 |
Fine Tune (dB) |
-50 - +50 |
| 0x0A |
1 |
Gain |
-64 - +64 |
| 0x0B |
1 |
Low Note |
0 - 127 |
| 0x0C |
1 |
High Note |
0 - 127 |
| 0x0D |
1 |
Low Velocity |
1 - 127 |
| 0x0E |
1 |
High Velocity |
1 - 127 |
ążąŠčĆą╝ą░čé čüąĄą║čåąĖąĖ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░
Unshifted Note
ą¤ąŠą╗ąĄ ąĮąĄčüą╝ąĄčēąĄąĮąĮąŠą╣ ąĮąŠčéčŗ (unshifted note) ąĖą╝ąĄąĄčé č鹊 ąČąĄ čüą░ą╝ąŠąĄ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĖąĄ, čćč鹊 ąĖ čā MIDI Unity Note čüąĄą║čåąĖąĖ čüąĄą╝ą┐ą╗ąĄčĆą░ - čāą║ą░ąĘčŗą▓ą░ąĄčé ą╝čāąĘčŗą║ą░ą╗čīąĮčāčÄ ąĮąŠčéčā, ąĮą░ ą║ąŠč鹊čĆąŠą╣ ą▓čŗą▒ąŠčĆą║ą░ ą▒čāą┤ąĄčé ą┐čĆąŠąĖą│čĆą░ąĮą░ čü ąĄčæ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮąŠą╣ čüą║ąŠčĆąŠčüčéčīčÄ (sample rate, čāą║ą░ąĘčŗą▓ą░ąĄčéčüčÅ ą▓ čüąĄą║čåąĖąĖ č乊čĆą╝ą░čéą░).
Fine Tune
ąŚąĮą░č湥ąĮąĖąĄ č鹊čćąĮąŠą╣ ąĮą░čüčéčĆąŠą╣ą║ąĖ (fine tune) čāą║ą░ąĘčŗą▓ą░ąĄčé, ąĮą░čüą║ąŠą╗čīą║ąŠ ą┐ąŠą┤ą░čćą░ ą▓čŗą▒ąŠčĆą║ąĖ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ąĖąĘą╝ąĄąĮąĄąĮą░, ą║ąŠą│ą┤ą░ ąĘą▓čāą║ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮ ą▓ čåąĄąĮčéą░čģ (1/100 ą┐ąŠą╗čāč鹊ąĮą░). ą×čéčĆąĖčåą░č鹥ą╗čīąĮą░čÅ ą▓ąĄą╗ąĖčćąĖąĮą░ ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą▓čŗčüąŠčéą░ č鹊ąĮą░ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī čüąĮąĖąČąĄąĮą░, ą░ ą┐ąŠąĘąĖčéąĖą▓ąĮą░čÅ ą▓ąĄą╗ąĖčćąĖąĮą░ ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą▓čŗčüąŠčéą░ č鹊ąĮą░ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ą┐ąŠą▓čŗčłąĄąĮą░.
Gain
ąŚąĮą░č湥ąĮąĖąĄ čāčüąĖą╗ąĄąĮąĖčÅ (gain) čāą║ą░ąĘčŗą▓ą░ąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┤ąĄčåąĖą▒ąĄą╗ ą┤ą╗čÅ ąĮą░čüčéčĆąŠą╣ą║ąĖ ą▓čŗčģąŠą┤ą░ ą┐čĆąĖ ą┐čĆąŠąĖą│čĆčŗą▓ą░ąĮąĖąĖ. ąŚąĮą░č湥ąĮąĖąĄ 0 dB ąŠąĘąĮą░čćą░ąĄčé ąŠčéčüčāčéčüčéą▓ąĖąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖą╣, 6 dB ąŠąĘąĮą░čćą░ąĄčé čāą┤ą▓ąŠąĄąĮąĖąĄ ą░ą╝ą┐ą╗ąĖčéčāą┤čŗ ą║ą░ąČą┤ąŠą╣ ą▓čŗą▒ąŠčĆą║ąĖ, -6 dB ąŠąĘąĮą░čćą░ąĄčé čāą╝ąĄąĮčīčłąĄąĮąĖąĄ ą░ą╝ą┐ą╗ąĖčéčāą┤čŗ ą║ą░ąČą┤ąŠą╣ ą▓čŗą▒ąŠčĆą║ąĖ ą▓ą┤ą▓ąŠąĄ. ąÜą░ąČą┤čŗąĄ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ +/- 6 dB čāą┤ą▓ą░ąĖą▓ą░čÄčé ąĖą╗ąĖ ą┤ąĄą╗čÅčé ą░ą╝ą┐ą╗ąĖčéčāą┤čā ąĮą░ą┤ą▓ąŠąĄ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ.
Low Note ąĖ High Note
ą¤ąŠą╗čÅ ąĮąŠčé čāą║ą░ąĘčŗą▓ą░čÄčé ą┤ąĖą░ą┐ą░ąĘąŠąĮ ąĮąŠčé MIDI, ą▓ ą║ąŠč鹊čĆčŗčģ ąĘą▓čāą║ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą┐čĆąŠąĖą│čĆą░ąĮ, ą║ąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé čüąŠą▒čŗčéąĖąĄ ą┐čĆąĖąĄą╝ą░ ąĮąŠčéčŗ MIDI (ąŠčé ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖčÅ ąĖą╗ąĖ ą║ąŠą╝ą░ąĮą┤čŗ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ MIDI. ąÜąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą╝ ą╝ąŠąČąĄčé ą▓čŗčüčéčāą┐ą░čéčī, ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ą╗ą░ą▓ąĖą░čéčāčĆą░ MIDI). ąŁč鹊čé ą┤ąĖą░ą┐ą░ąĘąŠąĮ ąĮąĄąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ ą┤ąŠą╗ąČąĄąĮ ą▓ą║ą╗čÄčćą░čéčī ąĘąĮą░č湥ąĮąĖąĄ Unshifted Note.
Low Velocity ąĖ High Velocity
ą¤ąŠą╗čÅ čüą║ąŠčĆąŠčüčéąĖ (velocity) čāą║ą░ąĘčŗą▓ą░čÄčé ą┤ąĖą░ą┐ą░ąĘąŠąĮ čüą║ąŠčĆąŠčüč鹥ą╣ MIDI (MIDI velocity), čü ą║ąŠč鹊čĆčŗą╝ąĖ ą┤ąŠą╗ąČąĄąĮ ą┐čĆąŠąĖą│čĆčŗą▓ą░čéčīčüčÅ ąĘą▓čāą║. 1 ąŠčéąĮąŠčüąĖčéčüčÅ ą║ čüą░ą╝ąŠą╝čā ą╗ąĄą│ą║ąŠą╝čā ą┐čĆąŠąĖą│čĆčŗą▓ą░ąĮąĖčÄ, 127 ą║ čüą░ą╝ąŠą╝čā ąČąĄčüčéą║ąŠą╝čā.
[ąśąĘą╝ąĄąĮąĄąĮąĖčÅ č乊čĆą╝ą░čéą░]
ą×ą▒čĆą░čéąĮą░čÅ čüč鹊čĆąŠąĮą░ ą┐ąŠą┐čāą╗čÅčĆąĮąŠčüčéąĖ č乊čĆą╝ą░čéą░ čäą░ą╣ą╗ą░ WAVE - ąĖąĘ čüąŠč鹥ąĮ ą┐čĆąŠą│čĆą░ą╝ą╝, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé čŹč鹊čé č乊čĆą╝ą░čé, ą╝ąĮąŠą│ąĖąĄ ąĘą╗ąŠčāą┐ąŠčéčĆąĄą▒ą╗čÅčÄčé ąĖą╗ąĖ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāčÄčé č乊čĆą╝ą░čé ąĖąĘ-ąĘą░ ą┐ą╗ąŠčģąŠą│ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ąĖ/ąĖą╗ąĖ ą┐ą╗ąŠčģąŠą╣ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ. ąÜą░ą║ č鹊ą╗čīą║ąŠ ąĮąĄą║ąŠč鹊čĆčŗąĄ ąĖąĘ čŹčéąĖčģ "ąĮąĄą┐ąŠčüą╗čāčłąĮčŗčģ" ą┐čĆąŠą│čĆą░ą╝ą╝ čüčéą░ąĮąŠą▓čÅčéčüčÅ ą┤ąŠą▓ąŠą╗čīąĮąŠ ą┐ąŠą┐čāą╗čÅčĆąĮčŗą╝ąĖ ąĖ ą┐čĆąŠąĖąĘą▓ąŠą┤čÅčé ą▓ ą▒ąŠą╗čīčłąŠą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąĄ ą╝ąĖą╗ą╗ąĖąŠąĮčŗ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮčŗčģ WAVE čäą░ą╣ą╗ąŠą▓, ąŠčüčéą░ą╗čīąĮą░čÅ čćą░čüčéčī ąŠčéčĆą░čüą╗ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖčÅ ą▓čŗąĮčāąČą┤ąĄąĮą░ ąĖą╝ąĄčéčī ą┤ąĄą╗ąŠ čü čŹčéąĖą╝ ąĖ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčéčī ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé čĆą░čüą┐ąŠąĘąĮą░ą▓ą░čéčī čŹčéąĖ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮčŗąĄ čäą░ą╣ą╗čŗ. ąØąŠą▓čŗą╣ ą║ąŠą┤ ąĮąĄ ą┤ąŠą╗ąČąĄąĮ ąĘą░ą┐ąĖčüčŗą▓ą░čéčī čŹčéąĖ ąŠčłąĖą▒ą║ąĖ, ąĮąŠ ą┤ąŠą╗ąČąĄąĮ čćąĖčéą░čéčī ąŠčłąĖą▒ąŠčćąĮčŗą╣ WAVE-čäą░ą╣ą╗. ąØąĖąČąĄ ąŠą┐ąĖčüą░ąĮąŠ ąĮąĄčüą║ąŠą╗čīą║ąŠ čéą░ą║ąĖčģ ąĖčüą║ą╗čÄč湥ąĮąĖą╣, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ čüą┤ąĄą╗ą░ąĮčŗ ą▓ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ čüčéčĆąŠą│ąŠą╝čā/ąĖčüčģąŠą┤ąĮąŠą╝čā č乊čĆą╝ą░čéčā WAVE.
* ąØąĄą║ąŠčĆčĆąĄą║čéąĮą░čÅ ą▓ąĄą╗ąĖčćąĖąĮą░ ą▒ą╗ąŠą║ą░ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ (Block Alignment) - čü čŹčéąĖą╝ ą╝ąŠąČąĮąŠ ąĖą╝ąĄčéčī ą┤ąĄą╗ąŠ, ą▓čŗčćąĖčüą╗čÅčÅ Block Alignment ą┐ąŠ čāą║ą░ąĘą░ąĮąĮąŠą╣ čĆą░ąĮąĄąĄ č乊čĆą╝čāą╗ąĄ.
* ąØąĄą║ąŠčĆčĆąĄą║čéąĮą░čÅ ą▓ąĄą╗ąĖčćąĖąĮą░ čüčĆąĄą┤ąĮąĄą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą▓čŗą▒ąŠčĆąŠą║ ą▓ čüąĄą║čāąĮą┤čā (Average Samples Per Second) - čü čŹčéąĖą╝ ą╝ąŠąČąĮąŠ ąĖą╝ąĄčéčī ą┤ąĄą╗ąŠ, ą▓čŗčćąĖčüą╗čÅčÅ Average Samples Per Second ą┐ąŠ čāą║ą░ąĘą░ąĮąĮąŠą╣ čĆą░ąĮąĄąĄ č乊čĆą╝čāą╗ąĄ.
* ą×čéčüčāčéčüčéą▓ąĖąĄ ą┐čāčüčéčŗčģ ą▒ą░ą╣čé ą┤ą╗čÅ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ ąĮą░ čüą╗ąŠą▓ąŠ (Missing word alignment padding) - čü čŹčéąĖą╝ čéčĆčāą┤ąĮąŠ ą▒ąŠčĆąŠčéčīčüčÅ, ąĮąŠ ą╝ąŠąČąĮąŠ ą┤ą░ą▓ą░čéčī ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÄ ą┐čĆąĄą┤čāą┐čĆąĄąČą┤ąĄąĮąĖąĄ, ąĄčüą╗ąĖ ąĖą╝ąĄąĄčéčüčÅ ąĮąĄčĆą░čüą┐ąŠąĘąĮą░ąĮąĮčŗą╣ ID ą▒ą╗ąŠą║ą░, ąĖ ąŠą┤ąĮąŠ čüą╝ąĄčēąĄąĮąĖąĄ ą┐ąŠą▒ą░ą╣č鹊ą▓ąŠą│ąŠ čćč鹥ąĮąĖčÅ ą┤ą░ąĄčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī čĆą░čüą┐ąŠąĘąĮą░čéčī ID ą▒ą╗ąŠą║ą░. ąŁč鹊 ąĮąĄ ą┐ąŠą╗ąĮąŠąĄ čĆąĄčłąĄąĮąĖąĄ, ąĮąŠ ąŠąĮąŠ ąŠą▒čŗčćąĮąŠ čĆą░ą▒ąŠčéą░ąĄčé, ą┤ą░ąČąĄ ąĄčüą╗ąĖ čā ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĮąĄčé ą┐ąŠą╗ąĮąŠą│ąŠ čüą┐ąĖčüą║ą░ ą╗ąĄą│ą░ą╗čīąĮčŗčģ ID.
[ąĪčüčŗą╗ą║ąĖ]
1. ą¤čĆąĖą╝ąĄčĆ ą┐čĆąŠčüč鹥ą╣čłąĄą╣ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ WAV-čäą░ą╣ą╗ą░ (ą┤ąŠą┐čāčüą║ą░ąĄčéčüčÅ č鹊ą╗čīą║ąŠ ąĮąĄčüąČą░čéčŗą╣ PCM).
2. ą¤čĆąŠčüč鹊ą╣ SD/microSD ąĘą▓čāą║ąŠą▓ąŠą╣ ą┐ą╗ąĄąĄčĆ ąĮą░ 8-ą▓čŗą▓ąŠą┤ąĮąŠą╝ ą╝ąĖą║čĆąŠą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąĄ ATtiny85.
3. ąæąĖą▒ą╗ąĖąŠč鹥ą║ą░ Petit FatFS: ą╝ąŠą┤čāą╗čī čäą░ą╣ą╗ąŠą▓ąŠą╣ čüąĖčüč鹥ą╝čŗ FAT.
4. ą¤ąŠč湥ą╝čā čā čüąĄą║čåąĖąĖ "fmt " čĆą░ąĘą╝ąĄčĆ ąĮąĄ čĆą░ą▓ąĄąĮ 16 ą▒ą░ą╣čéą░ą╝?
5. Audio File Format Specifications site:ece.mcgill.ca. |




ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖąĖ
microsin: ą▒ą╗ą░ą│ąŠą┤ą░čĆčÄ, ąĖčüą┐čĆą░ą▓ąĖą╗.
microsin: ą▓ čüčéą░čéčīąĄ ą┤ąŠčüčéą░č鹊čćąĮąŠ ą┐ąŠą┤čĆąŠą▒ąĮąŠ čŹč鹊čé ą╝ąŠą╝ąĄąĮčé ąŠą┐ąĖčüą░ąĮ (čüą╝. čéą░ą║ąČąĄ ą▓čĆąĄąĘą║čā, ą│ą┤ąĄ ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąĖą╝ąĄčĆ). ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą╝ąŠą│čāčé ą┐ąŠčÅą▓ą╗čÅčÄčéčüčÅ ą┐ąŠčüą╗ąĄ ąĘą░ą│ąŠą╗ąŠą▓ą║ą░, ą░ ą╝ąŠą│čāčé ąĖ ąĮąĄ ą┐ąŠčÅą▓ą╗čÅčéčīčüčÅ. ąĢčüą╗ąĖ čŹčéąĖčģ ą┤ą░ąĮąĮčŗčģ ąĮąĄčé, č鹊 ą┤ą░, ą┐ąŠčüą╗ąĄ ąĘą░ą│ąŠą╗ąŠą▓ą║ą░ čüčĆą░ąĘčā ąĖą┤čāčé čüčŗčĆčŗąĄ ą░čāą┤ąĖąŠą┤ą░ąĮąĮčŗąĄ.
microsin: ą▓ č乊čĆą╝ą░č鹥 WAV ąĮąĖč湥ą│ąŠ ą┐ąŠą┤ąŠą▒ąĮąŠą│ąŠ ąĮąĄ ą┐čĆąĄą┤čāčüą╝ąŠčéčĆąĄąĮąŠ. ą×ą┤ąĮą░ą║ąŠ ą╝ąŠąČąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖ ąĄ čüąĄą║čåąĖąĖ ą┤ą░ąĮąĮčŗčģ, ą│ą┤ąĄ ąÆčŗ ą╝ąŠąČąĄč鹥 čāą║ą░ąĘą░čéčī ąĮčāąČąĮčāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ.
http://www.sonicspot.com/guide/wavefiles.html
ąĪą┐ą░čüąĖą▒ąŠ!
microsin: ąĮą░ą▓ąĄčĆąĮąŠąĄ, ąÆčŗ ą┐čĆąŠčüč鹊 ąĮąĄ ą▓ąĄčüčī ą╝ą░č鹥čĆąĖą░ą╗ ą┐ąŠąĮčÅą╗ąĖ. ą£ąĮąĄ ą║ą░ąČąĄčéčüčÅ - ąĮą░ąŠą▒ąŠčĆąŠčé, ą░ą▓č鹊čĆ ąŠčéą╗ąĖčćąĮąŠ čĆą░ąĘą▒ąĖčĆą░ąĄčéčüčÅ ą▓ ą▓ąŠą┐čĆąŠčüąĄ, ąĖ ąŠč湥ąĮčī ą┐ąŠą┤čĆąŠą▒ąĮąŠ ąĖ ą┤ąŠčģąŠą┤čćąĖą▓ąŠ ąĖąĘą╗ą░ą│ą░ąĄčé čüčéčĆčāą║čéčāčĆčā č乊čĆą╝ą░čéą░ WAV-čäą░ą╣ą╗ą░.
RSS ą╗ąĄąĮčéą░ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖąĄą▓ čŹč鹊ą╣ ąĘą░ą┐ąĖčüąĖ