|
ąŻą║ą░ąĘą░č鹥ą╗čī (pointer) čŹč鹊 ąŠčüąĮąŠą▓ąĮą░čÅ ą║ąŠąĮčåąĄą┐čåąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ, ąŠą▒ąŠąĘąĮą░čćą░čÄčēą░čÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ, ą▓ ą║ąŠč鹊čĆąŠą╣ čģčĆą░ąĮąĖčéčüčÅ ą░ą┤čĆąĄčü ą┐ą░ą╝čÅčéąĖ. ąŁč鹊čé ą░ą┤čĆąĄčü čüčüčŗą╗ą░ąĄčéčüčÅ, ąĖą╗ąĖ "čāą║ą░ąĘčŗą▓ą░ąĄčé" (ąŠčéčüčÄą┤ą░ ąĮą░ąĘą▓ą░ąĮąĖąĄ) ąĮą░ ą║ą░ą║ąĖąĄ-č鹊 ą┤čĆčāą│ąĖąĄ ą┤ą░ąĮąĮčŗąĄ (ą┤čĆčāą│čāčÄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ ąĖą╗ąĖ ąŠą▒čŖąĄą║čé ą▓ ą┐ą░ą╝čÅčéąĖ). ąØą░ąĖą▒ąŠą╗ąĄąĄ čĆą░čüą┐čĆąŠčüčéčĆą░ąĮąĄąĮąĮčŗą╝ čāą║ą░ąĘą░č鹥ą╗ąĄą╝ ą▓ Rust čÅą▓ą╗čÅąĄčéčüčÅ čüčüčŗą╗ą║ą░ (reference), čćč鹊 ą╝čŗ ąĖąĘčāčćąĖą╗ąĖ ą▓ ą│ą╗ą░ą▓ąĄ 4 [2]. ąĪčüčŗą╗ą║ąĖ ąŠą▒ąŠąĘąĮą░čćą░čÄčéčüčÅ čüąĖą╝ą▓ąŠą╗ąŠą╝ &, ąĖ ąŠąĮąĖ ąĘą░ąĖą╝čüčéą▓čāčÄčé (borrow) ąĘąĮą░č湥ąĮąĖąĄ, ąĮą░ ą║ąŠč鹊čĆąŠąĄ čāą║ą░ąĘčŗą▓ą░čÄčé. ąŻ čüčüčŗą╗ąŠą║ ąĮąĄčé ą║ą░ą║ąĖčģ-ą╗ąĖą▒ąŠ ą▓ąŠąĘą╝ąŠąČąĮąŠčüč鹥ą╣ ą║čĆąŠą╝ąĄ č鹊ą│ąŠ, čćč鹊ą▒čŗ čüčüčŗą╗ą░čéčīčüčÅ ąĮą░ ą┤ą░ąĮąĮčŗąĄ, ąĖ čŹč鹊 ąĮąĄ ą▓ąĮąŠčüąĖčé ąĮąĖą║ą░ą║ąĖčģ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ čĆą░čüčģąŠą┤ąŠą▓, ą▓ą╗ąĖčÅčÄčēąĖčģ ąĮą░ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī.
ąśąĮč鹥ą╗ą╗ąĄą║čéčāą░ą╗čīąĮčŗąĄ, ąĖą╗ąĖ čāą╝ąĮčŗąĄ čāą║ą░ąĘą░č鹥ą╗ąĖ (smart pointers), čü ą┤čĆčāą│ąŠą╣ čüč鹊čĆąŠąĮčŗ, čŹč鹊 čüčéčĆčāą║čéčāčĆčŗ ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗąĄ ą┤ąĄą╣čüčéą▓čāčÄčé ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ čāą║ą░ąĘą░č鹥ą╗čÅ, ąŠą┤ąĮą░ą║ąŠ čüąŠą┤ąĄčƹȹ░čé ą▓ čüąĄą▒ąĄ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ą╝ąĄčéą░ą┤ą░ąĮąĮčŗąĄ ąĖ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ. ąÜąŠąĮčåąĄą┐čåąĖčÅ čāą╝ąĮčŗčģ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ąĮąĄ čāąĮąĖą║ą░ą╗čīąĮą░ ą┤ą╗čÅ Rust: čāą╝ąĮčŗąĄ čāą║ą░ąĘą░č鹥ą╗ąĖ ą┐ąŠčÅą▓ąĖą╗ąĖčüčī ą▓ C++, ąĖ čéą░ą║ąČąĄ čüčāčēąĄčüčéą▓čāčÄčé ąĖ ą▓ ą┤čĆčāą│ąĖčģ čÅąĘčŗą║ą░čģ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ. Rust ąĖą╝ąĄąĄčé ą╝ąĮąŠąČąĄčüčéą▓ąŠ čāą╝ąĮčŗčģ smart-čāą║ą░ąĘą░č鹥ą╗ąĄą╣, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ ą▓ čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĄ, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčī, ą┐čĆąĄą▓čŗčłą░čÄčēčāčÄ čäčāąĮą║čåąĖąŠąĮą░ą╗ ąŠą▒čŗčćąĮčŗčģ čüčüčŗą╗ąŠą║. ą¦č鹊ą▒čŗ ąĖąĘčāčćąĖčéčī čŹčéčā ąŠčüąĮąŠą▓ąĮčāčÄ ą║ąŠąĮčåąĄą┐čåąĖčÄ, ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐čĆąĖą╝ąĄčĆąŠą▓ smart-čāą║ą░ąĘą░č鹥ą╗ąĄą╣, ą▓ą║ą╗čÄčćą░čÅ čéąĖą┐ smart-čāą║ą░ąĘą░č鹥ą╗čÅ ą┤ą╗čÅ ą┐ąŠą┤čüč湥čéą░ čüčüčŗą╗ąŠą║. ąŁč鹊čé čāą║ą░ąĘą░č鹥ą╗čī ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą▓ą╗ą░ą┤ąĄčéčī ą┤ą░ąĮąĮčŗą╝ąĖ ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ ą▓ą╗ą░ą┤ąĄą╗čīčåą░ą╝ąĖ, ąŠčéčüą╗ąĄąČąĖą▓ą░čÅ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą▓, čćč鹊ą▒čŗ ą┤ą░ąĮąĮčŗąĄ ą▒čŗą╗ąĖ ąŠčćąĖčēąĄąĮčŗ, ą║ąŠą│ą┤ą░ ą▒ąŠą╗čīčłąĄ ąĮąĄčé ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą▓ čŹčéąĖčģ ą┤ą░ąĮąĮčŗčģ.
Rust, čü ąĄą│ąŠ ą║ąŠąĮčåąĄą┐čåąĖąĄą╣ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ (ownership) ąĖ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ (borrowing) [2], čĆąĄą░ą╗ąĖąĘčāąĄčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠąĄ ąŠčéą╗ąĖčćąĖąĄ ą╝ąĄąČą┤čā čüčüčŗą╗ą║ą░ą╝ąĖ ąĖ smart-čāą║ą░ąĘą░č鹥ą╗čÅą╝ąĖ: ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ čüčüčŗą╗ą║ąĖ č鹊ą╗čīą║ąŠ ą╗ąĖčłčī ąĘą░ąĖą╝čüčéą▓čāčÄčé ą┤ą░ąĮąĮčŗąĄ, smart-čāą║ą░ąĘą░č鹥ą╗ąĖ ą▓ąŠ ą╝ąĮąŠą│ąĖčģ čüą╗čāčćą░čÅčģ ąŠčüčāčēąĄčüčéą▓ą╗čÅčÄčé ą▓ą╗ą░ą┤ąĄąĮąĖąĄ ą┤ą░ąĮąĮčŗą╝ąĖ, ąĮą░ ą║ąŠč鹊čĆčŗąĄ čāą║ą░ąĘčŗą▓ą░čÄčé.
ą£čŗ čāąČąĄ ą▓čüčéčĆąĄčćą░ą╗ąĖčüčī čü ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ smart-čāą║ą░ąĘą░č鹥ą╗čÅą╝ąĖ, čģąŠčéčÅ ą┐ąŠą║ą░ ąĮąĄ ąĮą░ąĘčŗą▓ą░ą╗ąĖ ąĖčģ čéą░ą║ąŠą▓čŗą╝ąĖ, ąĮą░ą┐čĆąĖą╝ąĄčĆ String ąĖ Vec< T> ą▓ ą│ą╗ą░ą▓ąĄ 8 [3]. ą×ą▒ą░ čŹčéąĖčģ čéąĖą┐ą░ čüčćąĖčéą░čÄčéčüčÅ smart-čāą║ą░ąĘą░č鹥ą╗čÅą╝ąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąĮąĖ ą▓ą╗ą░ą┤ąĄčÄčé ąĮąĄą║ąŠč鹊čĆąŠą╣ ą┐ą░ą╝čÅčéčīčÄ, ąĖ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ą▓ą░ą╝ ąĄą╣ ą╝ą░ąĮąĖą┐čāą╗ąĖčĆąŠą▓ą░čéčī. ąŻ ąĮąĖčģ ąĄčüčéčī čéą░ą║ąČąĄ ą╝ąĄčéą░ą┤ą░ąĮąĮčŗąĄ, ąĖ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ, ąĖą╗ąĖ ą│ą░čĆą░ąĮčéąĖąĖ. ąóąĖą┐ String, ąĮą░ą┐čĆąĖą╝ąĄčĆ, čüąŠčģčĆą░ąĮčÅąĄčé čĆą░ąĘą╝ąĄčĆ ą▓ ą║ą░č湥čüčéą▓ąĄ ą╝ąĄčéą░ą┤ą░ąĮąĮčŗčģ, ąĖ ąĖą╝ąĄąĄčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčāčÄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą│ą░čĆą░ąĮčéąĖąĖ, čćč鹊 ą┤ą░ąĮąĮčŗąĄ čüčéčĆąŠą║ąĖ ą▓čüąĄą│ą┤ą░ ą▒čāą┤čāčé ą▓ ą┤ąŠą┐čāčüčéąĖą╝ąŠą╣ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĄ UTF-8.
Smart-čāą║ą░ąĘą░č鹥ą╗ąĖ ąŠą▒čŗčćąĮąŠ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮčŗ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ čüčéčĆčāą║čéčāčĆ. ąÆ ąŠčéą╗ąĖčćąĖąĄ ąŠčé ąŠą▒čŗčćąĮąŠą╣ čüčéčĆčāą║čéčāčĆčŗ, smart-čāą║ą░ąĘą░č鹥ą╗ąĖ čĆąĄą░ą╗ąĖąĘčāčÄčé čéčĆąĄą╣čéčŗ Deref ąĖ Drop. ąóčĆąĄą╣čé Deref ą┐ąŠąĘą▓ąŠą╗čÅąĄčé 菹║ąĘąĄą╝ą┐ą╗čÅčĆčā čüčéčĆčāą║čéčāčĆčŗ smart-čāą║ą░ąĘą░č鹥ą╗čÅ ą▓ąĄčüčéąĖ čüąĄą▒čÅ ą║ą░ą║ čüčüčŗą╗ą║ą░, čéą░ą║ čćč鹊 ą▓čŗ ą╝ąŠąČąĄč鹥 ą┐ąĖčüą░čéčī čüą▓ąŠą╣ ą║ąŠą┤ čéą░ą║, čćč鹊 ąŠąĮ ą▒čāą┤ąĄčé ąĮąŠčĆą╝ą░ą╗čīąĮąŠ čĆą░ą▒ąŠčéą░čéčī ą║ą░ą║ čü čāą║ą░ąĘą░č鹥ą╗čÅą╝ąĖ, čéą░ą║ ąĖ čüąŠ smart-čāą║ą░ąĘą░č鹥ą╗čÅą╝ąĖ. ąóčĆąĄą╣čé Drop ą┐ąŠąĘą▓ąŠą╗ąĖčé ą▓ą░ą╝ ąĮą░čüčéčĆąŠąĖčéčī ą║ąŠą┤, ąĘą░ą┐čāčüą║ą░ąĄą╝čŗą╣ ą┐čĆąĖ ą▓čģąŠą┤ąĄ smart-čāą║ą░ąĘą░č鹥ą╗čÅ ąĘą░ ą┐čĆąĄą┤ąĄą╗čŗ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ. ąÆ čŹč鹊ą╣ ą│ą╗ą░ą▓ąĄ (ą┐ąĄčĆąĄą▓ąŠą┤ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ [1] ą│ą╗ą░ą▓čŗ 15) ą╝čŗ ąŠą▒čüčāą┤ąĖą╝ ąŠą▒ą░ čŹčéąĖčģ čéčĆąĄą╣čéą░, ąĖ ą┐čĆąŠą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄą╝ ąĖčģ ą▓ą░ąČąĮąŠčüčéčī ą┤ą╗čÅ smart-čāą║ą░ąĘą░č鹥ą╗ąĄą╣.
ąĪ čāč湥č鹊ą╝ č鹊ą│ąŠ, čćč鹊 čłą░ą▒ą╗ąŠąĮ smart-čāą║ą░ąĘą░č鹥ą╗čÅ čÅą▓ą╗čÅąĄčéčüčÅ ąŠą▒čēąĖą╝ čłą░ą▒ą╗ąŠąĮąŠą╝ ą┤ąĖąĘą░ą╣ąĮą░ ąĖ čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą▓ Rust, čŹčéą░ ą│ą╗ą░ą▓ą░ ąĮąĄ ą▒čāą┤ąĄčé ą┐čĆąĄč鹥ąĮą┤ąŠą▓ą░čéčī ąĮą░ čĆą░čüčüą╝ąŠčéčĆąĄąĮąĖąĄ ą▓čüąĄčģ čüčāčēąĄčüčéą▓čāčÄčēąĖčģ čéąĖą┐ąŠą▓ smart-čāą║ą░ąĘą░č鹥ą╗ąĄą╣. ą£ąĮąŠą│ąĖąĄ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ąĖą╝ąĄčÄčé čüą▓ąŠąĖ čüąŠą▒čüčéą▓ąĄąĮąĮčŗąĄ smart-čāą║ą░ąĘą░č鹥ą╗čÅ, ąĖ ą▓čŗ ą╝ąŠąČąĄč鹥 ą┤ą░ąČąĄ ą┐ąĖčüą░čéčī čüą▓ąŠąĖ smart-čāą║ą░ąĘą░č鹥ą╗ąĖ. ą£čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ą┤ą░ą╗ąĄąĄ ąĮą░ąĖą▒ąŠą╗ąĄąĄ čĆą░čüą┐čĆąŠčüčéčĆą░ąĮąĄąĮąĮčŗąĄ smart-čāą║ą░ąĘą░č鹥ą╗ąĖ čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ Rust:
ŌĆó Box< T> ą┤ą╗čÅ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ąĘąĮą░č湥ąĮąĖą╣ ą▓ ą║čāč湥.
ŌĆó Rc< T>, čéąĖą┐ čüč湥čéčćąĖą║ą░ čüčüčŗą╗ąŠą║, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą╝ąĮąŠąČąĄčüčéą▓ąĄąĮąĮąŠąĄ ą▓ą╗ą░ą┤ąĄąĮąĖąĄ (multiple ownership).
ŌĆó Ref< T> ąĖ RefMut< T>, ą┤ąŠčüčéčāą┐ąĮčŗąĄ č湥čĆąĄąĘ RefCell< T>. ąŁč鹊 čéąĖą┐, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ ą┐čĆąĖą╝ąĄąĮčÅąĄčé ą┐čĆą░ą▓ąĖą╗ą░ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ runtime ą▓ą╝ąĄčüč鹊 compile time.
ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ čłą░ą▒ą╗ąŠąĮ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ ąĖąĘą╝ąĄąĮčćąĖą▓ąŠčüčéąĖ (interior mutability pattern), ą│ą┤ąĄ immutable-čéąĖą┐ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé API ą┤ą╗čÅ ą╝čāčéąĖčĆąŠą▓ą░ąĮąĖčÅ ą▓ąĮčāčéčĆąĄąĮąĮąĄą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ. ą£čŗ čéą░ą║ąČąĄ čĆą░čüčüą╝ąŠčéčĆąĖą╝ reference-čåąĖą║ą╗čŗ: ą║ą░ą║ ąŠąĮąĖ ą╝ąŠą│čāčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ čāč鹥čćą║ąĄ ą┐ą░ą╝čÅčéąĖ, ąĖ ą║ą░ą║ čŹč鹊 ą┐čĆąĄą┤ąŠčéą▓čĆą░čéąĖčéčī.
[ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ Box< T> ą┤ą╗čÅ čāą║ą░ąĘą░ąĮąĖčÅ ąĮą░ ą┤ą░ąĮąĮčŗąĄ ą▓ ą║čāč湥]
ąĪą░ą╝čŗą╣ ą┐čĆąŠčüč鹊ą╣ smart-čāą║ą░ąĘą░č鹥ą╗čī čŹč鹊 box, čéąĖą┐ ą║ąŠč鹊čĆąŠą│ąŠ Box< T>. Box-čŗ ą┐ąŠąĘą▓ąŠą╗čÅčé ą▓ą░ą╝ čüąŠčģčĆą░ąĮąĖčéčī ą┤ą░ąĮąĮčŗąĄ ą▓ ą║čāč湥 ą▓ą╝ąĄčüč鹊 čüč鹥ą║ą░. ąÆ čüč鹥ą║ąĄ ąŠčüčéą░ąĄčéčüčÅ čāą║ą░ąĘą░č鹥ą╗čī čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ą┤ą░ąĮąĮčŗąĄ ą║čāčćąĖ. ąĪą╝. ą│ą╗ą░ą▓čā 4 [2] ą┤ą╗čÅ ąŠą▒ąĘąŠčĆą░ čĆą░ąĘą╗ąĖčćąĖą╣ ą╝ąĄąČą┤čā čüč鹥ą║ąŠą╝ ąĖ ą║čāč湥ą╣.
Box-čŗ ąĮąĄ ą▓ąĮąŠčüčÅčé ąĮą░ą║ą╗ą░ą┤ąĮčŗčģ čĆą░čüčģąŠą┤ąŠą▓ ą▓ ą┐ą╗ą░ąĮąĄ ą┐ąŠč鹥čĆčī ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ, ą║čĆąŠą╝ąĄ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čüą▓ąŠąĖčģ ą┤ą░ąĮąĮčŗčģ ą▓ ą║čāč湥 ą▓ą╝ąĄčüč鹊 čüč鹥ą║ą░. ąØąŠ ąĖ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ą▓ąŠąĘą╝ąŠąČąĮąŠčüč鹥ą╣ čā ąĮąĖčģ ąĮąĄ čéą░ą║ ą╝ąĮąŠą│ąŠ. ąÆčŗ ą▒čāą┤ąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĖčģ čćą░čēąĄ ą▓čüąĄą│ąŠ ą▓ čüą╗ąĄą┤čāčÄčēąĖčģ čüąĖčéčāą░čåąĖčÅčģ:
ŌĆó ąÜąŠą│ą┤ą░ čā ą▓ą░čü ąĄčüčéčī čéąĖą┐, čĆą░ąĘą╝ąĄčĆ ą║ąŠč鹊čĆąŠą│ąŠ ą▓čŗ ąĮąĄ ą╝ąŠąČąĄč鹥 ąĘąĮą░čéčī ą▓ ą╝ąŠą╝ąĄąĮčé ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ, ąĖ ą▓čŗ čģąŠčéąĖč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĘąĮą░č湥ąĮąĖąĄ čŹč鹊ą│ąŠ čéąĖą┐ą░ ą▓ ą║ąŠąĮč鹥ą║čüč鹥, ą│ą┤ąĄ čéčĆąĄą▒čāąĄčéčüčÅ č鹊čćąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ.
ŌĆó ąÜąŠą│ą┤ą░ čā ą▓ą░čü ąĄčüčéčī ą▒ąŠą╗čīčłąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┤ą░ąĮąĮčŗčģ, ąĖ ą▓čŗ čģąŠčéąĖč鹥 ą┐ąĄčĆąĄą╝ąĄčüčéąĖčéčī ą▓ą╗ą░ą┤ąĄąĮąĖąĄ ąĖą╝ąĖ, ą┐čĆąĖč湥ą╝ čéčĆąĄą▒čāąĄčéčüčÅ ą│ą░čĆą░ąĮčéąĖčÅ, čćč鹊 ą┤ą░ąĮąĮčŗąĄ ą┐čĆąĖ čŹč鹊ą╝ ąĮąĄ ą▒čāą┤čāčé ą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░čéčīčüčÅ.
ŌĆó ąÜąŠą│ą┤ą░ ą▓čŗ čģąŠčéąĖč鹥 ą▓ą╗ą░ą┤ąĄčéčī ąĘąĮą░č湥ąĮąĖąĄą╝, ąĖ ą▓ą░ą╝ ą▓ą░ąČąĮąŠ č鹊ą╗čīą║ąŠ, čćč鹊ą▒čŗ čŹč鹊 ą▒čŗą╗ čéąĖą┐, ą║ąŠč鹊čĆčŗą╣ čĆąĄą░ą╗ąĖąĘčāąĄčé ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╣ čéčĆąĄą╣čé ą▓ą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ ą▒čŗčéčī ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ čéąĖą┐ą░.
ą¤ąĄčĆą▓čāčÄ ąĖąĘ čŹčéąĖčģ čüąĖčéčāą░čåąĖą╣ ą╝čŗ ą┐čĆąŠą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄą╝ ą▓ čüąĄą║čåąĖąĖ "ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ čĆąĄą║čāčĆčüąĖą▓ąĮčŗčģ čéąĖą┐ąŠą▓ ąĮą░ ąŠčüąĮąŠą▓ąĄ Box". ąÆąŠ ą▓č鹊čĆąŠą╝ čüą╗čāčćą░ąĄ ą┐ąĄčĆąĄą┤ą░čćą░ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ ą▒ąŠą╗čīčłąĖą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąŠą╝ ą┤ą░ąĮąĮčŗčģ ą╝ąŠąČąĄčé ąĘą░ąĮčÅčéčī ą╝ąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 ą┤ą░ąĮąĮčŗąĄ ą║ąŠą┐ąĖčĆčāčÄčéčüčÅ ą▓ čüč鹥ą║ąĄ. ąöą╗čÅ čāą╗čāčćčłąĄąĮąĖčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą▓ čŹč鹊ą╣ čüąĖčéčāą░čåąĖąĖ ą╝čŗ ą╝ąŠąČąĄą╝ čüąŠčģčĆą░ąĮąĖčéčī ą▒ąŠą╗čīčłąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┤ą░ąĮąĮčŗčģ ąĮą░ ą║čāč湥 čü ą┐ąŠą╝ąŠčēčīčÄ box. ąŚą░č鹥ą╝ ą▓ čüč鹥ą║ąĄ ą▒čāą┤ąĄčé ą║ąŠą┐ąĖčĆąŠą▓ą░čéčīčüčÅ č鹊ą╗čīą║ąŠ ą╝ą░ą╗ąĄąĮčīą║ąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ čāą║ą░ąĘą░č鹥ą╗čÅ, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ čüą░ą╝ąĖ ą┤ą░ąĮąĮčŗąĄ ą▒čāą┤čāčé ąŠčüčéą░ą▓ą░čéčīčüčÅ ą▓ ąŠą┤ąĮąŠą╝ ąĖą╝ č鹊ą╝ ąČąĄ ą╝ąĄčüč鹥 ą║čāčćąĖ. ąóčĆąĄčéčīčÅ čüąĖčéčāą░čåąĖčÅ ąĖąĘą▓ąĄčüčéąĮą░ ą║ą░ą║ ąŠą▒čŖąĄą║čé čéčĆąĄą╣čéą░, ąĖ ą│ą╗ą░ą▓ą░ 17 ą┐ąŠčüą▓čÅčēąĄąĮą░ čåąĄą╗ąŠą╝čā čĆą░ąĘą┤ąĄą╗čā "Using Trait Objects That Allow for Values of Different Types", č鹊ą╗čīą║ąŠ čŹč鹊ą╣ č鹥ą╝ąĄ. ąóą░ą║ čćč鹊 č鹊, čćč鹊 ą▓čŗ čāąĘąĮą░ąĄč鹥 ąĘą┤ąĄčüčī, ą╝ąŠąČąĮąŠ ą▒čāą┤ąĄčé čüąĮąŠą▓ą░ ą┐čĆąĖą╝ąĄąĮąĖčéčī ą▓ ą│ą╗ą░ą▓ąĄ 17.
ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ Box< T> ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ ą▓ ą║čāč湥. ą¤ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ą╝čŗ ąŠą▒čüčāą┤ąĖą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą║čāčćąĖ ą▓ čüą╗čāčćą░ąĄ ą┤ą╗čÅ Box< T>, ą┤ą░ą▓ą░ą╣č鹥 čĆą░čüčüą╝ąŠčéčĆąĖą╝, ą║ą░ą║ ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąŠą▓ą░čéčī čüąŠ ąĘąĮą░č湥ąĮąĖčÅą╝ąĖ, čüąŠčģčĆą░ąĮąĄąĮąĮčŗą╝ąĖ ą▓ Box< T>.
ąøąĖčüčéąĖąĮą│ 15-1 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, ą║ą░ą║ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī box ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ i32 ą▓ ą║čāč湥 (čäą░ą╣ą╗ src/main.rs):
fn main() {
let b = Box::new(5);
println!("b = {b}");
}
ąøąĖčüčéąĖąĮą│ 15-1. ąĪąŠčģčĆą░ąĮąĄąĮąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ i32 ą▓ ą║čāč湥 čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ box.
ą£čŗ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄą╝ ąĘą┤ąĄčüčī ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ b, čćč鹊ą▒čŗ čā ąĮąĄčæ ą▒čŗą╗ąŠ ąĘąĮą░č湥ąĮąĖąĄ Box, čāą║ą░ąĘčŗą▓ą░čÄčēąĄąĄ ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ 5, ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠąĄ ą▓ ą║čāč湥. ąŁčéą░ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ąĮą░ą┐ąĄčćą░čéą░ąĄčé print b = 5; ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą╝čŗ ą╝ąŠąČąĄą╝ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ ą┤ą░ąĮąĮčŗą╝ ą▓ box ą┐ąŠą┤ąŠą▒ąĮąŠ č鹊ą╝čā, ą║ą░ą║ ąĄčüą╗ąĖ ą▒čŗ ąŠąĮąĖ ą▒čŗą╗ąĖ ą▓ čüč鹥ą║ąĄ. ąóąŠčćąĮąŠ čéą░ą║ ąČąĄ, ą║ą░ą║ ąĖ čü ą╗čÄą▒čŗą╝ ą▓ą╗ą░ą┤ąĄąĄą╝čŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝, ą║ąŠą│ą┤ą░ box ą▓čŗą╣ą┤ąĄčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ, ą║ą░ą║ čŹč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐ąŠ ąŠą║ąŠąĮčćą░ąĮąĖąĖ č鹥ą╗ą░ main, ąŠąĮ ą▒čāą┤ąĄčé ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮ ąĖąĘ ą║čāčćąĖ. ą×čüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą║ą░ą║ ą┤ą╗čÅ box (čüąŠčģčĆą░ąĮąĄąĮąĮąŠą│ąŠ ą▓ čüč鹥ą║ąĄ), čéą░ą║ ąĖ ą┤ą╗čÅ ą┤ą░ąĮąĮčŗčģ, ąĮą░ ą║ąŠč鹊čĆčŗąĄ ąŠąĮ čāą║ą░ąĘčŗą▓ą░ąĄčé (čüąŠčģčĆą░ąĮąĄąĮąĮčŗčģ ą▓ čüč鹥ą║ąĄ).
ąĀą░ąĘą╝ąĄčēąĄąĮąĖąĄ ąŠą┤ąĖąĮąŠčćąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ ą▓ ą║čāč湥 ąĮąĄ ąŠč湥ąĮčī ą┐ąŠą╗ąĄąĘąĮąŠ, ą┐ąŠčŹč鹊ą╝čā ą▓čŗ ą▓čĆčÅą┤ ą╗ąĖ ą▒čāą┤ąĄč鹥 čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī box-čŗ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝. ąÆ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ čüąĖčéčāą░čåąĖą╣ čāą╝ąĄčüčéąĮąĄąĄ ą▒čāą┤ąĄčé čĆą░ąĘą╝ąĄčüčéąĖčéčī ą▓ čüč鹥ą║ąĄ čéą░ą║ąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ, ą║ą░ą║ ąŠą┤ąĖąĮąŠčćąĮąŠąĄ čćąĖčüą╗ąŠ i32, ą│ą┤ąĄ ąŠąĮąĖ ąĖ čĆą░ąĘą╝ąĄčēą░čÄčéčüčÅ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ. ąöą░ą▓ą░ą╣č鹥 čĆą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗čāčćą░ą╣, ą║ąŠą│ą┤ą░ box-čŗ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ąĮą░ą╝ ąŠą┐čĆąĄą┤ąĄą╗čÅčéčī čéą░ą║ąĖąĄ čéąĖą┐čŗ, ą║ą░ą║ąĖąĄ ąĮą░ą╝ ą▒čŗą╗ąŠ ą▒čŗ ąĮąĄ čĆą░ąĘčĆąĄčłąĄąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗čÅčéčī ą▒ąĄąĘ box-ąŠą▓.
ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ čĆąĄą║čāčĆčüąĖą▓ąĮčŗčģ čéąĖą┐ąŠą▓ ąĮą░ ąŠčüąĮąŠą▓ąĄ Box. ąŚąĮą░č湥ąĮąĖąĄ čĆąĄą║čāčĆčüąĖą▓ąĮąŠą│ąŠ čéąĖą┐ą░ ą╝ąŠąČąĄčé ąĖą╝ąĄčéčī ąĘąĮą░č湥ąĮąĖąĄ čéą░ą║ąŠą│ąŠ ąČąĄ čéąĖą┐ą░ ą║ą░ą║ čćą░čüčéčī čüąĄą▒čÅ. ąóą░ą║ąĖąĄ čéąĖą┐čŗ ą╝ąŠą│čāčé čüąŠąĘą┤ą░ą▓ą░čéčī ą┐čĆąŠą▒ą╗ąĄą╝čā, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ Rust-čā ąĮčāąČąĮąŠ ąĘąĮą░čéčī čüą║ąŠą╗čīą║ąŠ ą╝ąĄčüčéą░ ąĘą░ąĮąĖą╝ą░ąĄčé čéąĖą┐. ą×ą┤ąĮą░ą║ąŠ ą▓ą╗ąŠąČąĄąĮąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ čĆąĄą║čāčĆčüąĖą▓ąĮčŗčģ čéąĖą┐ąŠą▓ č鹥ąŠčĆąĄčéąĖč湥čüą║ąĖ ą╝ąŠą│čāčé ą┐čĆąŠą┤ąŠą╗ąČą░čéčīčüčÅ ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠ, čéą░ą║ čćč鹊 Rust ąĮąĄ ą╝ąŠąČąĄčé ąĘąĮą░čéčī, čüą║ąŠą╗čīą║ąŠ ąĮčāąČąĮąŠ ą╝ąĄčüčéą░ ą┤ą╗čÅ ąĘąĮą░č湥ąĮąĖčÅ. ą¤ąŠčüą║ąŠą╗čīą║čā box-čŗ ąĖą╝ąĄčÄčé ąĖąĘą▓ąĄčüčéąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ, ą╝čŗ ą╝ąŠąČąĄą╝ ą┐ąŠą╗čāčćąĖčéčī čĆąĄą║čāčĆčüąĖą▓ąĮčŗąĄ čéąĖą┐čŗ ą┐čāč鹥ą╝ ą▓čüčéą░ą▓ą║ąĖ box ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čĆąĄą║čāčĆčüąĖą▓ąĮąŠą│ąŠ čéąĖą┐ą░.
ąÆ ą║ą░č湥čüčéą▓ąĄ ą┐čĆąĖą╝ąĄčĆą░ čĆąĄą║čāčĆčüąĖą▓ąĮąŠą│ąŠ čéąĖą┐ą░ čĆą░čüčüą╝ąŠčéčĆąĖą╝ čüą┐ąĖčüąŠą║ cons (cons list). ąŁč鹊 čéąĖą┐ ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĮąŠ ąŠą▒čŗčćąĮąŠ ąŠą▒ąĮą░čĆčāąČąĖčéčī ą▓ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░čģ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮčŗčģ čÅąĘčŗą║ąŠą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ. ąóąĖą┐ cons list ą╝čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖą╝ ą┐čĆąŠčüčéčŗą╝ ąŠą▒čĆą░ąĘąŠą╝, ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ čĆąĄą║čāčĆčüąĖąĖ; ą┐ąŠčŹč鹊ą╝čā ą║ąŠąĮčåąĄą┐čåąĖąĖ ą▓ ą┐čĆąĖą╝ąĄčĆąĄ, čü ą║ąŠč鹊čĆčŗą╝ ą╝čŗ ą▒čāą┤ąĄą╝ čĆą░ą▒ąŠčéą░čéčī, ą▒čāą┤čāčé ą┐ąŠą╗ąĄąĘąĮčŗ ą║ą░ąČą┤čŗą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ą▓čŗ ą┐ąŠą┐ą░ą┤ą░ąĄč鹥 ą▓ ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮčŗąĄ čüąĖčéčāą░čåąĖąĖ, čüą▓čÅąĘą░ąĮąĮčŗąĄ čü čĆąĄą║čāčĆčüąĖą▓ąĮčŗą╝ąĖ čéąĖą┐ą░ą╝ąĖ.
ą¦č鹊 čéą░ą║ąŠąĄ Cons List. ąóąĖą┐ cons list čŹč鹊 čüčéčĆčāą║čéčāčĆą░ ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆą░čÅ ą┐čĆąĖčłą╗ą░ ąĖąĘ ąĖąĘ čÅąĘčŗą║ą░ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ Lisp ąĖ ąĄą│ąŠ ą┤ąĖą░ą╗ąĄą║č鹊ą▓. ąŁč鹊čé čéąĖą┐ čüąŠčüč鹊ąĖčé ąĖąĘ ą▓ą╗ąŠąČąĄąĮąĮčŗčģ ą┐ą░čĆ, ą░ čéą░ą║ąČąĄ čÅą▓ą╗čÅąĄčéčüčÅ Lisp-ą▓ąĄčĆčüąĖąĄą╣ čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ čüą┐ąĖčüą║ą░ (linked list). ąśą╝čÅ cons list ą┐čĆąŠąĖąĘąŠčłą╗ąŠ ąŠčé Lisp-čäčāąĮą║čåąĖąĖ cons (čüąŠą║čĆą░čēąĄąĮąĖąĄ ąŠčé "construct function"), ą║ąŠč鹊čĆą░čÅ ą║ąŠąĮčüčéčĆčāąĖčĆčāąĄčé ąĮąŠą▓čāčÄ ą┐ą░čĆčā ąĖąĘ čüą▓ąŠąĖčģ ą┤ą▓čāčģ ą░čĆą│čāą╝ąĄąĮč鹊ą▓. ąÆčŗąĘąŠą▓ąŠą╝ cons ąĮą░ ą┐ą░čĆąĄ, čüąŠčüč鹊čÅčēąĄą╣ ąĖąĘ ąĘąĮą░č湥ąĮąĖčÅ ąĖ ą┤čĆčāą│ąŠą╣ ą┐ą░čĆčŗ, ą╝čŗ ą╝ąŠąČąĄą╝ ą║ąŠąĮčüčéčĆčāąĖčĆąŠą▓ą░čéčī čüą┐ąĖčüą║ąĖ cons, čüąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗąĄ ąĖąĘ čĆąĄą║čāčĆčüąĖą▓ąĮčŗčģ ą┐ą░čĆ.
ąØą░ą┐čĆąĖą╝ąĄčĆ, ą▓ąŠčé ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ ąĮą░ ą┐čüąĄą▓ą┤ąŠą║ąŠą┤ąĄ cons list, čüąŠą┤ąĄčƹȹ░čēąĖą╣ čüą┐ąĖčüąŠą║ 1, 2, 3, ą│ą┤ąĄ ą║ą░ąČą┤ą░čÅ ą┐ą░čĆą░ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ čüą║ąŠą▒ą║ą░čģ:
(1, (2, (3, Nil)))
ąÜą░ąČą┤čŗą╣ 菹╗ąĄą╝ąĄąĮčé ą▓ cons list čüąŠą┤ąĄčƹȹĖčé ą┤ą▓ą░ čćą╗ąĄąĮą░: ąĘąĮą░č湥ąĮąĖąĄ ąĖ čüą╗ąĄą┤čāčÄčēąĖą╣ 菹╗ąĄą╝ąĄąĮčé. ą¤ąŠčüą╗ąĄą┤ąĮąĖą╣ 菹╗ąĄą╝ąĄąĮčé ą▓ čüą┐ąĖčüą║ąĄ čüąŠą┤ąĄčƹȹĖčé č鹊ą╗čīą║ąŠ ąĘąĮą░č湥ąĮąĖąĄ Nil ą▒ąĄąĘ čüą╗ąĄą┤čāčÄčēąĄą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░. ąĪą░ą╝ cons list ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ čĆąĄą║čāčĆčüąĖą▓ąĮčŗą╝ąĖ ą▓čŗąĘąŠą▓ą░ą╝ąĖ čäčāąĮą║čåąĖąĖ cons. ąÜą░ąĮąŠąĮąĖč湥čüą║ąŠąĄ ąĖą╝čÅ ą┤ą╗čÅ ąŠą▒ąŠąĘąĮą░č湥ąĮąĖčÅ ą▒ą░ąĘčŗ čĆąĄą║čāčĆčüąĖąĖ Nil. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čŹč鹊 ąĮąĄ č鹊 ąČąĄ čüą░ą╝ąŠąĄ, čćč鹊 ą║ąŠąĮčåąĄą┐čåąĖčÅ "null" ąĖą╗ąĖ "nil", čćč鹊 ąŠą▒čüčāąČą┤ą░ą╗ąŠčüčī ą▓ ą│ą╗ą░ą▓ąĄ 6 [4] ("null" ąĖą╗ąĖ "nil" čÅą▓ą╗čÅąĄčéčüčÅ ąĮąĄą┤ąŠą┐čāčüčéąĖą╝čŗą╝ ąĖą╗ąĖ ąŠčéčüčāčéčüčéą▓čāčÄčēąĖą╝ ąĘąĮą░č湥ąĮąĖąĄą╝).
ąóąĖą┐ cons list ąĮąĄ čÅą▓ą╗čÅąĄčéčüčÅ čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą╣ čüčéčĆčāą║čéčāčĆąŠą╣ ą┤ą░ąĮąĮčŗčģ ą▓ Rust. ąÆ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ čüą╗čāčćą░ąĄą▓, ą║ąŠą│ą┤ą░ čā ą▓ą░čü ąĄčüčéčī čüą┐ąĖčüąŠą║ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą▓ Rust, ą╗čāčćčłąĖą╝ ą▓čŗą▒ąŠčĆąŠą╝ ą▒čāą┤ąĄčé čéąĖą┐ Vec< T>. ąöčĆčāą│ąĖąĄ, ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮčŗąĄ čĆąĄą║čāčĆčüąĖą▓ąĮčŗąĄ čéąĖą┐čŗ ą┤ą░ąĮąĮčŗčģ ą┐ąŠą╗ąĄąĘąĮčŗ ą▓ čĆą░ąĘą╗ąĖčćąĮčŗčģ čüąĖčéčāą░čåąĖčÅčģ, ąĮąŠ ąĮą░čćą░ą▓ ą▓ čŹč鹊ą╣ ą│ą╗ą░ą▓ąĄ čü čéąĖą┐ą░ cons list, ą╝čŗ ą╝ąŠąČąĄą╝ ąĖčüčüą╗ąĄą┤ąŠą▓ą░čéčī, ą║ą░ą║ box-čŗ ą┐ąŠąĘą▓ąŠą╗čÅčé ąĮą░ą╝ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī čĆąĄą║čāčĆčüąĖą▓ąĮčŗą╣ čéąĖą┐ ą┤ą░ąĮąĮčŗčģ ą▒ąĄąĘ ąŠčüąŠą▒ąŠą│ąŠ ąŠčéą▓ą╗ąĄč湥ąĮąĖčÅ ąĮą░ ą┤čĆčāą│ąĖąĄ ą┤ąĄčéą░ą╗ąĖ.
ąøąĖčüčéąĖąĮą│ 15-2 čüąŠą┤ąĄčƹȹĖčé ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖąĄ enum ą┤ą╗čÅ cons list. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čŹč鹊čé ą║ąŠą┤ ą┐ąŠą║ą░ ąĮąĄ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ, ą┐ąŠč鹊ą╝čā čćč鹊 čéąĖą┐ List ąĮąĄ ąĖą╝ąĄąĄčé ąĖąĘą▓ąĄčüčéąĮąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░, ą║ąŠč鹊čĆčŗą╣ ą╝čŗ ą┐čĆąŠą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄą╝ (čäą░ą╣ą╗ src/main.rs).
enum List {
Cons(i32, List),
Nil,
}
ąøąĖčüčéąĖąĮą│ 15-2. ą¤ąĄčĆą▓ą░čÅ ą┐ąŠą┐čŗčéą║ą░ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī enum ą┤ą╗čÅ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖčÅ čüčéčĆčāą║čéčāčĆčŗ ą┤ą░ąĮąĮčŗčģ cons list čüąŠ ąĘąĮą░č湥ąĮąĖčÅą╝ąĖ i32.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ą▓ čåąĄą╗čÅčģ čŹč鹊ą│ąŠ ą┐čĆąĖą╝ąĄčĆą░ ą╝čŗ čĆąĄą░ą╗ąĖąĘčāąĄą╝ cons list, ą║ąŠč鹊čĆčŗą╣ ą▒čāą┤ąĄčé čģčĆą░ąĮąĖčéčī č鹊ą╗čīą║ąŠ ąĘąĮą░č湥ąĮąĖčÅ i32. ą£čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ąĄą│ąŠ, ąĖčüą┐ąŠą╗čīąĘčāčÅ generic-čéąĖą┐čŗ, ą║ą░ą║ ąŠą▒čüčāąČą┤ą░ą╗ąŠčüčī ą▓ ą│ą╗ą░ą▓ąĄ 10 [5], čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī čéąĖą┐ cons list, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠą│ ą▒čŗ čģčĆą░ąĮąĖčéčī ą▓ čüąĄą▒ąĄ ą╗čÄą▒ąŠą╣ čéąĖą┐.
ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čéąĖą┐ą░ List ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čüą┐ąĖčüą║ą░ 1, 2, 3 ą▓ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ list ą╝ąŠą│ą╗ąŠ ą▒čŗ ą▓čŗą│ą╗čÅą┤ąĄčéčī ą║ą░ą║ ą╗ąĖčüčéąĖąĮą│ 15-3 (čäą░ą╣ą╗ src/main.rs, čŹč鹊čé ą║ąŠą┤ ąĮąĄ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ):
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Cons(2, Cons(3, Nil)));
}
ąøąĖčüčéąĖąĮą│ 15-3. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖčÅ List ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čüą┐ąĖčüą║ą░ 1, 2, 3 ą▓ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ list.
ą¤ąĄčĆą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ Cons čüąŠą┤ąĄčƹȹĖčé 1 ąĖ ą┤čĆčāą│ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ List. ąŁč鹊 ąĘąĮą░č湥ąĮąĖąĄ List ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé čüąŠą▒ąŠą╣ ą┤čĆčāą│ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ Cons, čüąŠą┤ąĄčƹȹ░čēąĄąĄ 2 ąĖ ą┤čĆčāą│ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ List. ąŁč鹊 ąĘąĮą░č湥ąĮąĖąĄ List ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé ąĄčēąĄ ąŠą┤ąĮąŠ ąĘąĮą░č湥ąĮąĖąĄ Cons, čüąŠą┤ąĄčƹȹ░čēąĄąĄ 3 ąĖ ąĘą░ą▓ąĄčĆčłą░čÄčēąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ List, čĆą░ą▓ąĮąŠąĄ Nil, ąĮąĄ čĆąĄą║čāčĆčüąĖą▓ąĮčŗą╣ ą▓ą░čĆąĖą░ąĮčé, čüąĖą│ąĮą░ą╗ąĖąĘąĖčĆčāčÄčēąĖą╣ ąŠ ą║ąŠąĮčåąĄ čüą┐ąĖčüą║ą░.
ąĢčüą╗ąĖ ą╝čŗ ą┐ąŠą┐čŗčéą░ąĄą╝čüčÅ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░čéčī ą║ąŠą┤ ą╗ąĖčüčéąĖąĮą│ą░ 15-3, č鹊 ą┐ąŠą╗čāčćąĖą╝ ąŠčłąĖą▒ą║čā, ą┐ąŠą║ą░ąĘą░ąĮąĮčāčÄ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-4:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0072]: recursive type `List` has infinite size
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
2 | Cons(i32, List),
| ---- recursive without indirection
|
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box< List>),
| ++++ +
error[E0391]: cycle detected when computing when `List` needs drop
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
|
= note: ...which immediately requires computing when `List` needs drop again
= note: cycle used when computing whether `List` needs drop
= note: see https://rustc-dev-guide.rust-lang.org/overview.html#queries and
https://rustc-dev-guide.rust-lang.org/query.html for more information
Some errors have detailed explanations: E0072, E0391.
For more information about an error, try `rustc --explain E0072`.
error: could not compile `cons-list` (bin "cons-list") due to 2 previous errors
ąøąĖčüčéąĖąĮą│ 15-4. ą×čłąĖą▒ą║ą░, ą║ąŠč鹊čĆčāčÄ ą╝čŗ ą┐ąŠą╗čāčćąĖą╝ ą┐čĆąĖ ą┐ąŠą┐čŗčéą║ąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī čĆąĄą║čāčĆčüąĖą▓ąĮąŠąĄ enum.
ą×čłąĖą▒ą║ą░ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čā čŹč鹊ą│ąŠ čéąĖą┐ą░ "ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ" (has infinite size). ą¤čĆąĖčćąĖąĮą░ ą▓ č鹊ą╝, čćč鹊 ą╝čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖą╗ąĖ List čü ą▓ą░čĆąĖą░ąĮč鹊ą╝, ą║ąŠč鹊čĆčŗą╣ čĆąĄą║čāčĆčüąĖą▓ąĮčŗą╣: ąŠąĮ čģčĆą░ąĮąĖčé ą┤čĆčāą│ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ čüą░ą╝ąŠą│ąŠ čüąĄą▒čÅ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ. ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 Rust ąĮąĄ ą╝ąŠąČąĄčé ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, čüą║ąŠą╗čīą║ąŠ ą╝ąĄčüčéą░ ąĮčāąČąĮąŠ ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ List. ąöą░ą▓ą░ą╣č鹥 čĆą░ąĘą▒ąĄčĆąĄą╝čüčÅ, ą┐ąŠč湥ą╝čā ą╝čŗ ą┐ąŠą╗čāčćąĖą╗ąĖ čéą░ą║čāčÄ ąŠčłąĖą▒ą║čā. ąĪąĮą░čćą░ą╗ą░ čĆą░čüčüą╝ąŠčéčĆąĖą╝, ą║ą░ą║ Rust ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé, čüą║ąŠą╗čīą║ąŠ ąĮčāąČąĮąŠ ą╝ąĄčüčéą░ ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ ąĮąĄ čĆąĄą║čāčĆčüąĖą▓ąĮąŠą│ąŠ čéąĖą┐ą░.
ąÆčŗčćąĖčüą╗ąĄąĮąĖąĄ čĆą░ąĘą╝ąĄčĆą░ ąĮąĄ čĆąĄą║čāčĆčüąĖą▓ąĮąŠą│ąŠ čéąĖą┐ą░. ąÆčüą┐ąŠą╝ąĮąĖą╝ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖąĄ Message, ą║ąŠč鹊čĆąŠąĄ ą╝čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖą╗ąĖ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 6-2, ą║ąŠą│ą┤ą░ ąŠą▒čüčāąČą┤ą░ą╗ąĖ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ enum ą▓ ą│ą╗ą░ą▓ąĄ 6 [4]:
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
ą¦č鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, čüą║ąŠą╗čīą║ąŠ ą╝ąĄčüčéą░ ą▓čŗą┤ąĄą╗čÅąĄčéčüčÅ ą┤ą╗čÅ ąĘąĮą░č湥ąĮąĖčÅ Message, Rust ą┐čĆąŠčüą╝ą░čéčĆąĖą▓ą░ąĄčé ą║ą░ąČą┤čŗą╣ ąĖąĘ ą▓ą░čĆąĖą░ąĮč鹊ą▓ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖčÅ, čćč鹊ą▒čŗ čāą▓ąĖą┤ąĄčéčī, ą║ą░ą║ąŠą╝čā ąĖąĘ ą▓ą░čĆąĖą░ąĮč鹊ą▓ ąĮčāąČąĮąŠ ą▒ąŠą╗čīčłąĄ ą▓čüąĄą│ąŠ ą╝ąĄčüčéą░. Rust ą▓ąĖą┤ąĖčé, čćč鹊 Message::Quit ąĮąĄ čéčĆąĄą▒čāąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░, Message::Move čéčĆąĄą▒čāąĄčé ą┤ąŠčüčéą░č鹊čćąĮąŠ ą╝ąĄčüčéą░ ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą┤ą▓čāčģ ąĘąĮą░č湥ąĮąĖą╣ i32, ąĖ čéą░ą║ ą┤ą░ą╗ąĄąĄ. ą¤ąŠčüą║ąŠą╗čīą║čā ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ ą▓ą░čĆąĖą░ąĮčé, č鹊 ąĮą░ąĖą▒ąŠą╗čīčłąĄąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ, ą║ąŠč鹊čĆąŠąĄ čéčĆąĄą▒čāąĄčéčüčÅ ą┤ą╗čÅ ąĘąĮą░č湥ąĮąĖčÅ Message, čŹč鹊 ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ, ą║ąŠč鹊čĆąŠąĄ čéčĆąĄą▒čāąĄčéčüčÅ ą┤ą╗čÅ čģčĆą░ąĮąĄąĮąĖčÅ ąĮą░ąĖą▒ąŠą╗čīčłąĄą│ąŠ ąĖąĘ ąĄą│ąŠ ą▓ą░čĆąĖą░ąĮč鹊ą▓.
ąĪčĆą░ą▓ąĮąĖč鹥 čŹč鹊 čü č鹥ą╝, čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé, ą║ąŠą│ą┤ą░ Rust ą┐čŗčéą░ąĄčéčüčÅ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, čüą║ąŠą╗čīą║ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ čéčĆąĄą▒čāąĄčéčüčÅ ą┤ą╗čÅ čĆąĄą║čāčĆčüąĖą▓ąĮąŠą│ąŠ čéąĖą┐ą░ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖčÅ List ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-2. ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąĮą░čćąĖąĮą░ąĄčé ą┐čĆąŠčüą╝ąŠčéčĆ čü ą▓ą░čĆąĖą░ąĮčéą░ Cons, ą║ąŠč鹊čĆčŗą╣ čģčĆą░ąĮąĖčé ąĘąĮą░č湥ąĮąĖąĄ čéąĖą┐ą░ i32 ąĖ ąĘąĮą░č湥ąĮąĖąĄ čéąĖą┐ą░ List. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, Cons čéčĆąĄą▒čāąĄčé ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ, čĆą░ąĘą╝ąĄčĆčā i32 ą┐ą╗čÄčü čĆą░ąĘą╝ąĄčĆ List. ą¦č鹊ą▒čŗ čāąĘąĮą░čéčī, čüą║ąŠą╗čīą║ąŠ ą┐ą░ą╝čÅčéąĖ čéčĆąĄą▒čāąĄčéčüčÅ čéąĖą┐čā List, ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą┐čĆąŠčüą╝ą░čéčĆąĖą▓ą░ąĄčé ąĄą│ąŠ ą▓ą░čĆąĖą░ąĮčéčŗ, ąĮą░čćąĖąĮą░čÅ čü ą▓ą░čĆąĖą░ąĮčéą░ Cons. ąÆą░čĆąĖą░ąĮčé Cons čģčĆą░ąĮąĖčé ąĘąĮą░č湥ąĮąĖąĄ čéąĖą┐ą░ i32 ąĖ ąĘąĮą░č湥ąĮąĖąĄ čéąĖą┐ą░ List, ąĖ čŹč鹊čé ą┐čĆąŠčåąĄčüčü ą┐čĆąŠą┤ąŠą╗ąČą░ąĄčéčüčÅ ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠ, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮą░ čĆąĖčü. 15-1.
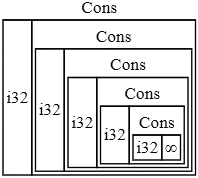
ąĀąĖčü. 15-1. ąæąĄčüą║ąŠąĮąĄčćąĮčŗą╣ List, čüąŠčüč鹊čÅčēąĖą╣ ąĖąĘ ą▒ąĄčüą║ąŠąĮąĄčćąĮčŗčģ ą▓ą░čĆąĖą░ąĮč鹊ą▓ Cons.
ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ Box< T> ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ čĆąĄą║čāčĆčüąĖą▓ąĮąŠą│ąŠ čéąĖą┐ą░ ąĖąĘą▓ąĄčüčéąĮąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░. ą¤ąŠčüą║ąŠą╗čīą║čā Rust ąĮąĄ ą╝ąŠąČąĄčé ą┐ąŠąĮčÅčéčī, čüą║ąŠą╗čīą║ąŠ ąĮčāąČąĮąŠ ą╝ąĄčüčéą░ ą┤ą╗čÅ čĆąĄą║čāčĆčüąĖą▓ąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄą╝čŗčģ čéąĖą┐ąŠą▓, č鹊 ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą▓čŗą┤ą░ąĄčé ąŠčłąĖą▒ą║čā, ą▓ ą║ąŠč鹊čĆąŠą╣ čāą║ą░ąĘčŗą▓ą░ąĄčé ą┐ąŠą╗ąĄąĘąĮčŗą╣ čüąŠą▓ąĄčé ą┤ą╗čÅ čĆąĄčłąĄąĮąĖčÅ ą┐čĆąŠą▒ą╗ąĄą╝čŗ:
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box< List>),
| ++++ +
ąŚą┤ąĄčüčī "indirection" ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą▓ą╝ąĄčüč鹊 čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ ąĮą░ą┐čĆčÅą╝čāčÄ ą╝čŗ ą┤ąŠą╗ąČąĮčŗ ą┐ąŠą╝ąĄąĮčÅčéčī čüčéčĆčāą║čéčāčĆčā ą┤ą░ąĮąĮčŗčģ čéą░ą║, čćč鹊ą▒čŗ ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ čģčĆą░ąĮąĖčéčī ą▓ ąĮąĄą╣ ąĘąĮą░č湥ąĮąĖąĄ ą║ąŠčüą▓ąĄąĮąĮąŠ, čü ą┐ąŠą╝ąŠčēčīčÄ čāą║ą░ąĘą░č鹥ą╗čÅ.
ą¤ąŠčüą║ąŠą╗čīą║čā Box< T> čŹč鹊 čāą║ą░ąĘą░č鹥ą╗čī, Rust ą▓čüąĄą│ą┤ą░ ą▒čāą┤ąĄčé ąĘąĮą░čéčī, čüą║ąŠą╗čīą║ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ąĮčāąČąĮąŠ ą┤ą╗čÅ Box< T>: čĆą░ąĘą╝ąĄčĆ čāą║ą░ąĘą░č鹥ą╗čÅ ąĮąĄ ąĘą░ą▓ąĖčüąĖčé ąŠčé ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą┤ą░ąĮąĮčŗčģ, ąĮą░ ą║ąŠč鹊čĆčŗąĄ ąŠąĮ čāą║ą░ąĘčŗą▓ą░ąĄčé. ąŁč鹊 ąĘąĮą░čćąĖčé, čćč鹊 ą╝čŗ ą╝ąŠąČąĄą╝ ą┐ąŠą╝ąĄčüčéąĖčéčī Box< T> ą▓ąĮčāčéčĆąĖ ą▓ą░čĆąĖą░ąĮčéą░ Cons ą▓ą╝ąĄčüč鹊 ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠą│ąŠ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ List. Box< T> ą▒čāą┤ąĄčé čāą║ą░ąĘčŗą▓ą░čéčī ąĮą░ čüą╗ąĄą┤čāčÄčēąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ List, ą║ąŠč鹊čĆąŠąĄ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą║čāč湥 ą▓ą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ ą▒čŗčéčī ą▓ąĮčāčéčĆąĖ ą▓ą░čĆąĖą░ąĮčéą░ Cons. ąÜąŠąĮčåąĄą┐čéčāą░ą╗čīąĮąŠ čā ąĮą░čü ą▓čüąĄ ąĄčēąĄ ą▒čāą┤ąĄčé ą┐ąŠą╗čāčćą░čéčīčüčÅ čüą┐ąĖčüąŠą║, ą│ą┤ąĄ ą║ą░ąČą┤čŗą╣ čüą┐ąĖčüąŠą║ čģčĆą░ąĮąĖčé čüčüčŗą╗ą║čā ąĮą░ ą┤čĆčāą│ąŠą╣ čüą┐ąĖčüąŠą║, ąŠą┤ąĮą░ą║ąŠ čŹčéą░ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ č鹥ą┐ąĄčĆčī ą▒ąŠą╗čīčłąĄ ą┐ąŠčģąŠąČą░ ąĮą░ čĆą░ąĘą╝ąĄčēąĄąĮąĖąĄ 菹╗ąĄą╝ąĄąĮč鹊ą▓ čĆčÅą┤ąŠą╝ ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝, ą░ ąĮąĄ ą▓ąĮčāčéčĆąĖ ą┤čĆčāą│ ą┤čĆčāą│ą░.
ą¤ąŠą╝ąĄąĮčÅąĄą╝ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ List enum ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-2 ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ List ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-3 ąĮą░ ą║ąŠą┤ ąĖąĘ ą╗ąĖčüčéąĖąĮą│ą░ 15-5, ą║ąŠč鹊čĆčŗą╣ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ ąĮąŠčĆą╝ą░ą╗čīąĮąŠ (čäą░ą╣ą╗ src/main.rs):
enum List {
Cons(i32, Box< List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil))))));
}
ąøąĖčüčéąĖąĮą│ 15-5. ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ List, ąĖčüą┐ąŠą╗čīąĘčāčÄčēąĄąĄ Box< T>, čćč鹊ą▒čŗ ąĖą╝ąĄčéčī ą┐ąŠą╗čāčćąĖčéčī čĆą░ąĘą╝ąĄčĆ ą▓ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖąĖ ą┤ą╗čÅ Cons.
ąöą╗čÅ ą▓ą░čĆąĖą░ąĮčéą░ Cons čéčĆąĄą▒čāąĄčéčüčÅ čĆą░ąĘą╝ąĄčĆ i32 ą┐ą╗čÄčü ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čāą║ą░ąĘą░č鹥ą╗čÅ ąĮą░ ą┤ą░ąĮąĮčŗąĄ box. ąÆą░čĆąĖą░ąĮčé Nil ąĮąĄ čüąŠčģčĆą░ąĮčÅąĄčé ąĘąĮą░č湥ąĮąĖčÅ, čéą░ą║ čćč鹊 ąĄą╝čā ąĮčāąČąĮąŠ ą╝ąĄąĮčīčłąĄ ą╝ąĄčüčéą░, č湥ą╝ ą┤ą╗čÅ ą▓ą░čĆąĖą░ąĮčéą░ Cons. ąóąĄą┐ąĄčĆčī ą╝čŗ ąĘąĮą░ąĄą╝, čćč鹊 ą╗čÄą▒ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ List ąĘą░ą╣ą╝ąĄčé čĆą░ąĘą╝ąĄčĆ i32 ą┐ą╗čÄčü čĆą░ąĘą╝ąĄčĆ čāą║ą░ąĘą░č鹥ą╗čÅ ąĮą░ ą┤ą░ąĮąĮčŗąĄ box. ąĪ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ box ą╝čŗ čĆą░ąĘą▒ąĖą╗ąĖ ą▒ąĄčüą║ąŠąĮąĄčćąĮčāčÄ, čĆąĄą║čāčĆčüąĖą▓ąĮčāčÄ čåąĄą┐ąŠčćą║čā, čéą░ą║ čćč鹊 ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą╝ąŠąČąĄčé ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī čĆą░ąĘą╝ąĄčĆ, čéčĆąĄą▒čāąĄą╝čŗą╣ ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ List. ąĀąĖčü. 15-2 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, ą║ą░ą║ č鹥ą┐ąĄčĆčī ą▓čŗą│ą╗čÅą┤ąĖčé ą▓ą░čĆąĖą░ąĮčé Cons.
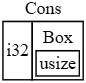
ąĀąĖčü. 15-2. List, ą║ąŠč鹊čĆčŗą╣ ąĮąĄ ą┐ąŠą╗čāčćą░ąĄčé ą▒ąĄčüą║ąŠąĮąĄčćąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ, ą┐ąŠč鹊ą╝čā čćč鹊 Cons čüąŠą┤ąĄčƹȹĖčé Box.
Box-čŗ č鹊ą╗čīą║ąŠ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ą║ąŠčüą▓ąĄąĮąĮąŠąĄ ą▓čüčéčĆą░ąĖą▓ą░ąĮąĖąĄ ąĖ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ ą▓ ą║čāč湥; čā ąĮąĖčģ ąĮąĄčé ąĮąĖą║ą░ą║ąĖčģ ą┤čĆčāą│ąĖčģ čüą┐ąĄčåąĖą░ą╗čīąĮčŗčģ ą▓ąŠąĘą╝ąŠąČąĮąŠčüč鹥ą╣, ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ č鹥čģ, ą║ąŠč鹊čĆčŗąĄ ą╝čŗ ą▓ąĖą┤ąĖą╝ ą▓ ą┤čĆčāą│ąĖčģ čéąĖą┐ą░čģ smart-čāą║ą░ąĘą░č鹥ą╗ąĄą╣. ąŻ ąĮąĖčģ čéą░ą║ąČąĄ ąĮąĄčé ąĮą░ą║ą╗ą░ą┤ąĮčŗčģ čĆą░čüčģąŠą┤ąŠą▓, čüąĮąĖąČą░čÄčēąĖčģ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī, ą║ ą║ąŠč鹊čĆčŗą╝ ą┐čĆąĖą▓ąŠą┤čÅčé čŹčéąĖ čüą┐ąĄčåąĖą░ą╗čīąĮčŗąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ, čéą░ą║ čćč鹊 box-čŗ ą╝ąŠą│čāčé ą▒čŗčéčī ą┐ąŠą╗ąĄąĘąĮčŗ ą▓ čéą░ą║ąĖčģ čüą╗čāčćą░čÅčģ, ą║ą░ą║ čüą┐ąĖčüąŠą║ cons, ą│ą┤ąĄ čéčĆąĄą▒čāąĄčéčüčÅ č鹊ą╗čīą║ąŠ ą║ąŠčüą▓ąĄąĮąĮąŠąĄ ą▓čüčéčĆą░ąĖą▓ą░ąĮąĖąĄ ą▓ čéąĖą┐. ą£čŗ čéą░ą║ąČąĄ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ą┤čĆčāą│ąĖąĄ ą▓ą░čĆąĖą░ąĮčéčŗ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ box ą▓ ą│ą╗ą░ą▓ąĄ 17.
ąóąĖą┐ Box< T> čŹč鹊 smart-čāą║ą░ąĘą░č鹥ą╗čī, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąĮ čĆąĄą░ą╗ąĖąĘčāąĄčé čéčĆąĄą╣čé Deref, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĘąĮą░č湥ąĮąĖčÅą╝ Box< T> ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčīčüčÅ čéą░ą║ ąČąĄ, ą║ą░ą║ ąĖ čüčüčŗą╗ą║ąĖ. ąÜąŠą│ą┤ą░ ąĘąĮą░č湥ąĮąĖąĄ Box< T> ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ, ą┤ą░ąĮąĮčŗąĄ ą║čāčćąĖ, ąĮą░ ą║ąŠč鹊čĆčŗąĄ čāą║ą░ąĘčŗą▓ą░ąĄčé box, ąŠčćąĖčēą░čÄčéčüčÅ ą▒ą╗ą░ą│ąŠą┤ą░čĆčÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čéčĆąĄą╣čéčā Drop. ąŁčéąĖ ą┤ą▓ą░ čéčĆąĄą╣čéą░ ą▒čāą┤čāčé ąĄčēąĄ ą▒ąŠą╗ąĄąĄ ą▓ą░ąČąĮčŗą╝ąĖ ą┤ą╗čÅ čäčāąĮą║čåąĖąŠąĮą░ą╗ą░, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄą╝ąŠą│ąŠ ą┤čĆčāą│ąĖą╝ąĖ čéąĖą┐ą░ą╝ąĖ smart-čāą║ą░ąĘą░č鹥ą╗čÅ, ą║ąŠč鹊čĆčŗąĄ ą╝čŗ ąŠą▒čüčāą┤ąĖą╝ ą▓ ąŠčüčéą░ą╗čīąĮąŠą╣ čćą░čüčéąĖ čŹč鹊ą╣ ą│ą╗ą░ą▓čŗ. ąöą░ą▓ą░ą╣č鹥 čĆą░čüčüą╝ąŠčéčĆąĖą╝ čŹčéąĖ čéčĆąĄą╣čéčŗ ą▒ąŠą╗ąĄąĄ ą┐ąŠą┤čĆąŠą▒ąĮąŠ.
[ąóčĆąĄą╣čé Deref: čĆą░ą▒ąŠčéą░ čüąŠ smart-čāą║ą░ąĘą░č鹥ą╗čÅą╝ąĖ ą║ą░ą║ čü ąŠą▒čŗčćąĮčŗą╝ąĖ čüčüčŗą╗ą║ą░ą╝ąĖ]
ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ čéčĆąĄą╣čéą░ Deref ą┐ąŠąĘą▓ąŠą╗ąĖčé ą▓ą░ą╝ ąĮą░čüčéčĆąŠąĖčéčī ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąŠą┐ąĄčĆą░č鹊čĆą░ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖčÅ * (ąĮąĄ ą┐čāčéą░ą╣č鹥 ąĄą│ąŠ čü čāą╝ąĮąŠąČąĄąĮąĖąĄą╝ ąĖą╗ąĖ ąŠą┐ąĄčĆą░č鹊čĆąŠą╝ glob). ą¤čāč鹥ą╝ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ Deref čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ą╝ąŠąČąĮąŠ čĆą░ą▒ąŠčéą░čéčī čüąŠ smart-čāą║ą░ąĘą░č鹥ą╗čÅą╝ąĖ čéą░ą║ ąČąĄ, ą║ą░ą║ ąĖ čü ąŠą▒čŗčćąĮąŠą╣ čüčüčŗą╗ą║ąŠą╣, čé. ąĄ. ą▓čŗ ą╝ąŠąČąĄč鹥 ą┐ąĖčüą░čéčī ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ą▒čāą┤ąĄčé ąĮąŠčĆą╝ą░ą╗čīąĮąŠ čĆą░ą▒ąŠčéą░čéčī ą║ą░ą║ čüąŠ čüčüčŗą╗ą║ą░ą╝ąĖ, čéą░ą║ ąĖ čüąŠ smart-čāą║ą░ąĘą░č鹥ą╗čÅą╝ąĖ.
ąĪąĮą░čćą░ą╗ą░ ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝, ą║ą░ą║ ąŠą┐ąĄčĆą░č鹊čĆ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖčÅ čĆą░ą▒ąŠčéą░ąĄčé čü ąŠą▒čŗčćąĮčŗą╝ąĖ čüčüčŗą╗ą║ą░ą╝ąĖ. ąŚą░č鹥ą╝ ą┐ąŠą┐čĆąŠą▒čāąĄą╝ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖą╣ čéąĖą┐, ą║ąŠč鹊čĆčŗą╣ ą▓ąĄą┤ąĄčé čüąĄą▒čÅ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ Box< T>, ąĖ ą┐ąŠčüą╝ąŠčéčĆąĖą╝, ą┐ąŠč湥ą╝čā ąŠą┐ąĄčĆą░č鹊čĆ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖčÅ ąĮąĄ čĆą░ą▒ąŠčéą░ąĄčé čü ąĮąĖą╝ ą║ą░ą║ čüąŠ čüčüčŗą╗ą║ąŠą╣. ąöą░ą╗ąĄąĄ ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝, ą║ą░ą║ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ą┤ą╗čÅ čŹč鹊ą│ąŠ čéąĖą┐ą░ čéčĆąĄą╣čé Deref, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čĆą░ą▒ąŠčéą░čéčī smart-čāą║ą░ąĘą░č鹥ą╗čÄ ąĮą░ ąĮąĄą│ąŠ čéą░ą║ ąČąĄ, ą║ą░ą║ čĆą░ą▒ąŠčéą░čÄčé čüčüčŗą╗ą║ąĖ. ąŚą░č鹥ą╝ čĆą░čüčüą╝ąŠčéčĆąĖą╝ čäčāąĮą║čåąĖąŠąĮą░ą╗ deref coercion čÅąĘčŗą║ą░ Rust, ąĖ ą║ą░ą║ ąŠąĮ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĮą░ą╝ čĆą░ą▒ąŠčéą░čéčī ą╗ąĖą▒ąŠ čüąŠ čüčüčŗą╗ą║ą░ą╝ąĖ, ą╗ąĖą▒ąŠ čüąŠ smart-čāą║ą░ąĘą░č鹥ą╗čÅą╝ąĖ.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: čüčāčēąĄčüčéą▓čāąĄčé ą▒ąŠą╗čīčłą░čÅ čĆą░ąĘąĮąĖčåą░ ą╝ąĄąČą┤čā čéąĖą┐ąŠą╝ MyBox< T>, ą║ąŠč鹊čĆčŗą╣ ą╝čŗ čüąŠąĘą┤ą░ą┤ąĖą╝, ąĖ čĆąĄą░ą╗čīąĮčŗą╝ Box< T>: ąĮą░čłą░ ą▓ąĄčĆčüąĖčÅ ąĮąĄ čüąŠčģčĆą░ąĮčÅąĄčé čüą▓ąŠąĖ ą┤ą░ąĮąĮčŗąĄ ą▓ ą║čāč湥. ą£čŗ ąĘą┤ąĄčüčī č乊ą║čāčüąĖčĆčāąĄą╝čüčÅ ąĮą░ ą┐čĆąĖą╝ąĄčĆąĄ Deref, čéą░ą║ čćč鹊 ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ smart-čāą║ą░ąĘą░č鹥ą╗čÅ ą║ą░ą║ čüčüčŗą╗ą║ąĖ ąĮąĄ čéą░ą║ ą▓ą░ąČąĮąŠ, ą│ą┤ąĄ ąĮą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ čģčĆą░ąĮčÅčéčüčÅ ą┤ą░ąĮąĮčŗąĄ.
ąÜą░ą║ ą┐ąŠ čāą║ą░ąĘą░č鹥ą╗čÄ ą┐ąŠą╗čāčćąĖčéčī ąĘąĮą░č湥ąĮąĖąĄ. ą×ą▒čŗčćąĮą░čÅ čüčüčŗą╗ą║ą░ čŹč鹊 čéąĖą┐ čāą║ą░ąĘą░č鹥ą╗čÅ, ąĖ ąŠą┤ąĖąĮ ąĖąĘ čüą┐ąŠčüąŠą▒ąŠą▓ ą┤čāą╝ą░čéčī ą┐čĆąŠ čāą║ą░ąĘą░č鹥ą╗čī - čŹč鹊 čüčéčĆąĄą╗ą║ą░, čāą║ą░ąĘčŗą▓ą░čÄčēą░čÅ ąĮą░ ą╝ąĄčüč鹊, ą│ą┤ąĄ čģčĆą░ąĮąĖčéčüčÅ ąĘąĮą░č湥ąĮąĖąĄ. ąÆ ą╗ąĖčüčéąĖąĮą│ąĄ 15-6, ą╝čŗ čüąŠąĘą┤ą░ą╗ąĖ čüčüčŗą╗ą║čā ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ i32, ąĖ ąĘą░č鹥ą╝ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ ąŠą┐ąĄčĆą░č鹊čĆ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖčÅ * ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ ą┐ąŠ čŹč鹊ą╣ čüčüčŗą╗ą║ąĄ (čäą░ą╣ą╗ src/main.rs):
fn main() {
let x = 5;
let y = &x;
assert_eq!(5, x);
assert_eq!(5, *y);
}
ąøąĖčüčéąĖąĮą│ 15-6. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąŠą┐ąĄčĆą░č鹊čĆą░ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖčÅ, čćč鹊ą▒čŗ čüą╗ąĄą┤ąŠą▓ą░čéčī čüčüčŗą╗ą║ąĄ ąĖ ą┐ąŠą╗čāčćąĖčéčī ąĘąĮą░č湥ąĮąĖąĄ i32.
ą¤ąĄčĆąĄą╝ąĄąĮąĮą░čÅ x čģčĆą░ąĮąĖčé ąĘąĮą░č湥ąĮąĖąĄ 5 čéąĖą┐ą░ i32. ą£čŗ čāčüčéą░ąĮąŠą▓ąĖą╗ąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ y čĆą░ą▓ąĮąŠą╣ čüčüčŗą╗ą║ąĄ ąĮą░ x. ą£čŗ ą╝ąŠąČąĄą╝ čāčéą▓ąĄčƹȹ┤ą░čéčī (assert), čćč鹊 x čĆą░ą▓ąĮąŠ 5. ą×ą┤ąĮą░ą║ąŠ ąĄčüą╗ąĖ ą╝čŗ ąĘą░čģąŠčéąĖą╝ čüą┤ąĄą╗ą░čéčī č鹊 ąČąĄ čüą░ą╝ąŠąĄ čüąŠ ąĘąĮą░č湥ąĮąĖąĄą╝ ą▓ y, č鹊 ąĮčāąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī *y, čćč鹊ą▒čŗ čüą╗ąĄą┤ąŠą▓ą░čéčī čüčüčŗą╗ą║ąĄ ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ, ąĮą░ ą║ąŠč鹊čĆąŠąĄ ąŠąĮą░ čāą║ą░ąĘčŗą▓ą░ąĄčé (čüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ ą┐čĆąŠą▓ąĄčüčéąĖ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖąĄ), čćč鹊ą▒čŗ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą╝ąŠą│ ą┐čĆąŠą▓ąĄčüčéąĖ čüčĆą░ą▓ąĮąĄąĮąĖąĄ čü čĆąĄą░ą╗čīąĮčŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝. ąĢčüą╗ąĖ ą╝čŗ ą┤ąĄą╗ą░ąĄą╝ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖąĄ y, č鹊 ą┐ąŠą╗čāčćą░ąĄą╝ ą┤ąŠčüčéčāą┐ ą║ integer-ąĘąĮą░č湥ąĮąĖčÄ, ą║ąŠč鹊čĆąŠąĄ ą╝čŗ ą╝ąŠąČąĄą╝ čüčĆą░ą▓ąĮąĖčéčī čü 5.
ąĢčüą╗ąĖ ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą╝čŗ ą┐ąŠą┐čŗčéą░ąĄą╝čüčÅ ąĮą░ą┐ąĖčüą░čéčī assert_eq!(5, y);, č鹊 ą┐ąŠą╗čāčćąĖą╝ ąŠčłąĖą▒ą║čā ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:6:5
|
6 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}`
|
= help: the trait `PartialEq< &{integer}>` is not implemented for `{integer}`
= note: this error originates in the macro `assert_eq` (in Nightly builds, run
with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0277`.
error: could not compile `deref-example` (bin "deref-example") due to 1 previous error
ąĪčĆą░ą▓ąĮąĄąĮąĖąĄ čćąĖčüą╗ą░ ąĖ čüčüčŗą╗ą║ąĖ ąĮą░ čćąĖčüą╗ąŠ ąĮąĄ ą┤ąŠąĘą▓ąŠą╗čÅąĄčéčüčÅ, ą┐ąŠč鹊ą╝čā čćč鹊 čŹč鹊 čĆą░ąĘąĮčŗąĄ čéąĖą┐čŗ. ą£čŗ ą┤ąŠą╗ąČąĮčŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąŠą┐ąĄčĆą░č鹊čĆ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖčÅ *, čćč鹊ą▒čŗ čüą╗ąĄą┤ąŠą▓ą░čéčī čüčüčŗą╗ą║ąĄ ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ, ąĮą░ ą║ąŠč鹊čĆąŠąĄ ąŠąĮą░ čāą║ą░ąĘčŗą▓ą░ąĄčé.
ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ Box< T> ą▓ ą║ą░č湥čüčéą▓ąĄ čüčüčŗą╗ą║ąĖ. ą£čŗ ą╝ąŠąČąĄą╝ ą┐ąĄčĆąĄą┐ąĖčüą░čéčī ą║ąŠą┤ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-6 ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ Box< T> ą▓ą╝ąĄčüč鹊 čüčüčŗą╗ą║ąĖ; ąŠą┐ąĄčĆą░č鹊čĆ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖčÅ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ąĮą░ Box< T> ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-7 čĆą░ą▒ąŠčéą░ąĄčé č鹊čćąĮąŠ čéą░ą║ ąČąĄ, ą║ą░ą║ ąĄčüą╗ąĖ ą▒čŗ ąŠąĮ čĆą░ą▒ąŠčéą░ą╗ čü ąŠą▒čŗčćąĮąŠą╣ čüčüčŗą╗ą║ąŠą╣ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-6:
fn main() {
let x = 5;
let y = Box::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}
ąøąĖčüčéąĖąĮą│ 15-7. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąŠą┐ąĄčĆą░č鹊čĆą░ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖčÅ ąĮą░ čéąĖą┐ąĄ Box< i32>.
ą×čüąĮąŠą▓ąĮąŠąĄ ąŠčéą╗ąĖčćąĖąĄ ą╝ąĄąČą┤čā ą╗ąĖčüčéąĖąĮą│ąŠą╝ 15-7 ąĖ ą╗ąĖčüčéąĖąĮą│ąŠą╝ 15-6 čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, čćč鹊 ą╝čŗ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄą╝ y ą▓ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ Box< T>, čāą║ą░ąĘčŗą▓ą░čÄčēąĖą╣ ąĮą░ ą║ąŠą┐ąĖčÄ ąĘąĮą░č湥ąĮąĖčÅ x ą▓ą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ čāčüčéą░ąĮąŠą▓ąĖčéčī y ą▓ čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ x. ąÆ ą┐ąŠčüą╗ąĄą┤ąĮąĄą╝ assert ą╝čŗ ą╝ąŠąČąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąŠą┐ąĄčĆą░č鹊čĆ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖčÅ, čćč鹊ą▒čŗ čüą╗ąĄą┤ąŠą▓ą░čéčī čāą║ą░ąĘą░č鹥ą╗čÄ Box< T> čéą░ą║ąĖą╝ ąČąĄ ąŠą▒čĆą░ąĘąŠą╝, ą║ą░ą║ čŹč鹊 ą┤ąĄą╗ą░ą╗ąĖ čüąŠ čüčüčŗą╗ą║ąŠą╣. ąöą░ą╗ąĄąĄ ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ąŠčüąŠą▒ąĄąĮąĮąŠčüčéčī Box< T>, ą║ąŠč鹊čĆą░čÅ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĮą░ą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čü ąĮąĖą╝ ąŠą┐ąĄčĆą░č鹊čĆ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖčÅ, ą┤ą╗čÅ čŹč鹊ą│ąŠ ą╝čŗ čüąŠąĘą┤ą░ą╗ąĖ čüą▓ąŠą╣ čüąŠą▒čüčéą▓ąĄąĮąĮčŗą╣ čéąĖą┐.
[ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąŠą│ąŠ smart-čāą║ą░ąĘą░č鹥ą╗čÅ]
ąöą░ą▓ą░ą╣č鹥 čüąŠąĘą┤ą░ą┤ąĖą╝ smart-čāą║ą░ąĘą░č鹥ą╗čī, ą┐ąŠą┤ąŠą▒ąĮčŗą╣ čéąĖą┐čā Box< T>, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄą╝ąŠą╝čā ą▓ čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĄ, čćč鹊ą▒čŗ ą┐ąŠąĮčÅčéčī, ą║ą░ą║ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ smart-čāą║ą░ąĘą░č鹥ą╗ąĖ ą▓ąĄą┤čāčé čüąĄą▒čÅ ąĖąĮą░č湥, č湥ą╝ čüčüčŗą╗ą║ąĖ. ąŚą░č鹥ą╝ ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝, ą║ą░ą║ ą┤ąŠą▒ą░ą▓ąĖčéčī ą▓ ąĮą░čł čéąĖą┐ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąŠą┐ąĄčĆą░č鹊čĆą░ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖčÅ.
ąóąĖą┐ Box< T> ą▓ ą║ąŠąĮąĄčćąĮąŠą╝ čüč湥č鹥 ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ ą║ą░ą║ čüčéčĆčāą║čéčāčĆą░ ą║ąŠčĆč鹥ąČą░ čü ąŠą┤ąĮąĖą╝ 菹╗ąĄą╝ąĄąĮč鹊ą╝, ą┐ąŠčŹč鹊ą╝čā ą╗ąĖčüčéąĖąĮą│ 15-8 ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé čéąĖą┐ MyBox< T> čéą░ą║ąĖą╝ ąČąĄ ąŠą▒čĆą░ąĘąŠą╝. ą£čŗ čéą░ą║ąČąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĖą╝ čäčāąĮą║čåąĖčÄ new, čćč鹊ą▒čŗ ąŠąĮą░ čüąŠąŠčéą▓ąĄčéčüčéą▓ąŠą▓ą░ą╗ą░ ą░ąĮą░ą╗ąŠą│ąĖčćąĮąŠą╣ čäčāąĮą║čåąĖąĖ ą▓ Box< T>.
struct MyBox< T>(T);
impl< T> MyBox< T> {
fn new(x: T) -> MyBox< T> {
MyBox(x)
}
}
ąøąĖčüčéąĖąĮą│ 15-8. ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čéąĖą┐ą░ MyBox< T> (čäą░ą╣ą╗ src/main.rs).
ą£čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖą╗ąĖ čüčéčĆčāą║čéčāčĆčā čü ąĖą╝ąĄąĮąĄą╝ MyBox ąĖ ą┤ąĄą║ą╗ą░čĆąĖčĆąŠą▓ą░ą╗ąĖ generic-ą┐ą░čĆą░ą╝ąĄčéčĆ T, ą┐ąŠč鹊ą╝čā čćč鹊 ą╝čŗ čģąŠčéąĖą╝, čćč鹊ą▒čŗ ąĮą░čł čéąĖą┐ ą╝ąŠą│ čģčĆą░ąĮąĖčéčī ąĘąĮą░č湥ąĮąĖčÅ ą╗čÄą▒ąŠą│ąŠ čéąĖą┐ą░. ąóąĖą┐ MyBox čŹč鹊 čüčéčĆčāą║čéčāčĆą░ ą║ąŠčĆč鹥ąČą░ čü ąŠą┤ąĮąĖą╝ 菹╗ąĄą╝ąĄąĮč鹊ą╝ čéąĖą┐ą░ T. ążčāąĮą║čåąĖčÅ MyBox::new ą┐čĆąĖąĮąĖą╝ą░ąĄčé ąŠą┤ąĖąĮ ą┐ą░čĆą░ą╝ąĄčéčĆ čéąĖą┐ą░ T ąĖ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé 菹║ąĘąĄą╝ą┐ą╗čÅčĆ MyBox, ą║ąŠč鹊čĆčŗą╣ čģčĆą░ąĮąĖčé ą┐ąĄčĆąĄą┤ą░ąĮąĮąŠąĄ ą▓ čäčāąĮą║čåąĖčÄ new ąĘąĮą░č湥ąĮąĖąĄ.
ąöą░ą▓ą░ą╣č鹥 ą┐ąŠą┐čĆąŠą▒čāąĄą╝ ą┤ąŠą▒ą░ą▓ąĖčéčī čäčāąĮą║čåąĖčÄ main ąĖąĘ ą╗ąĖčüčéąĖąĮą│ą░ 15-7 ą▓ ą╗ąĖčüčéąĖąĮą│ 15-8, ąĖ ą┐ąŠą╝ąĄąĮčÅąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąĮą░čłąĄą│ąŠ čéąĖą┐ą░ MyBox< T> ą▓ą╝ąĄčüč鹊 čéąĖą┐ą░ Box< T>. ąÜąŠą┤ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-9 ąĮąĄ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ, ą┐ąŠč鹊ą╝čā čćč鹊 Rust ąĮąĄ ąĘąĮą░ąĄčé, ą║ą░ą║ ą▓čŗą┐ąŠą╗ąĮąĖčéčī čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖąĄ MyBox.
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}
ąøąĖčüčéąĖąĮą│ 15-9. ą¤ąŠą┐čŗčéą║ą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī MyBox< T> čéą░ą║ ąČąĄ, ą║ą░ą║ ą╝čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ čüčüčŗą╗ą║ąĖ ąĖ Box< T> (čäą░ą╣ą╗ src/main.rs).
ą¤čĆąĖ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ą╝čŗ ą┐ąŠą╗čāčćąĖą╝ čüą╗ąĄą┤čāčÄčēčāčÄ ąŠčłąĖą▒ą║čā:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0614]: type `MyBox< {integer}>` cannot be dereferenced
--> src/main.rs:14:19
|
14 | assert_eq!(5, *y);
| ^^
For more information about this error, try `rustc --explain E0614`.
error: could not compile `deref-example` (bin "deref-example") due to 1 previous error
ąØą░čł čéąĖą┐ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī čĆą░ąĘąĖą╝ąĄąĮąŠą▓ą░ąĮ MyBox< T>, ą┐ąŠč鹊ą╝čā čćč鹊 ą╝čŗ ąĮąĄ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ą╗ąĖ ą┤ą╗čÅ ąĮąĄą│ąŠ čéą░ą║čāčÄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī. ą¦č鹊ą▒čŗ čĆą░ąĘčĆąĄčłąĖčéčī čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖąĄ ąŠą┐ąĄčĆą░č鹊čĆąŠą╝ *, ą╝čŗ čĆąĄą░ą╗ąĖąĘčāąĄą╝ čéčĆąĄą╣čé Deref.
ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čéčĆąĄą╣čéą░ Deref, čćč鹊ą▒čŗ čéąĖą┐ ą╝ąŠą│ čĆą░ą▒ąŠčéą░čéčī ą║ą░ą║ čüčüčŗą╗ą║ą░. ąÜą░ą║ ąŠą▒čüčāąČą┤ą░ą╗ąŠčüčī ą▓ čüąĄą║čåąĖąĖ "ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ čéčĆąĄą╣čéą░ ąĮą░ čéąĖą┐ąĄ" ą│ą╗ą░ą▓čŗ 10 [5], ą┤ą╗čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čéčĆąĄą╣čéą░ ąĮą░ą╝ ąĮčāąČąĮąŠ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą╝ąĄč鹊ą┤ąŠą▓, ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗčģ ą┤ą╗čÅ čéčĆąĄą╣čéą░. ąóčĆąĄą╣čé Deref, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄą╝čŗą╣ čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąŠą╣, čéčĆąĄą▒čāąĄčé ąŠčé ąĮą░čü čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ąŠą┤ąĮąŠą│ąŠ ą╝ąĄč鹊ą┤ą░ čü ąĖą╝ąĄąĮąĄą╝ deref, ą║ąŠč鹊čĆčŗą╣ ą┤ąĄą╗ą░ąĄčé ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖąĄ self, ąĖ ą▓ąŠąĘą▓čĆą░čéąĖčé čüčüčŗą╗ą║čā ąĮą░ ą▓ąĮčāčéčĆąĄąĮąĮąĖąĄ ą┤ą░ąĮąĮčŗąĄ. ąøąĖčüčéąĖąĮą│ 15-10 čüąŠą┤ąĄčƹȹĖčé čĆąĄą░ą╗ąĖąĘą░čåąĖčÄ Deref ą┤ą╗čÅ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ MyBox (čäą░ą╣ą╗ src/main.rs):
use std::ops::Deref;
impl< T> Deref for MyBox< T> {
type Target = T;
fn deref(&self) -> &Self::Target {
&self.0
}
}
ąøąĖčüčéąĖąĮą│ 15-10. ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ Deref ąĮą░ MyBox< T>.
ąĪąĖąĮčéą░ą║čüąĖčü type Target = T; ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé čüą▓čÅąĘą░ąĮąĮčŗą╣ čéąĖą┐ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čéčĆąĄą╣č鹊ą╝ Deref. ąĪą▓čÅąĘą░ąĮąĮčŗąĄ čéąĖą┐čŗ čŹč鹊 ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĖąĮąŠą╣ čüą┐ąŠčüąŠą▒ ąŠą▒čŖčÅą▓ą╗ąĄąĮąĖčÅ generic-ą┐ą░čĆą░ą╝ąĄčéčĆą░, ąĮąŠ ą┐ąŠą║ą░ čćč鹊 ą▓ą░ą╝ ąĮąĄ ąĮčāąČąĮąŠ ąŠą▒ čŹč鹊ą╝ ą▒ąĄčüą┐ąŠą║ąŠąĖčéčīčüčÅ, ą▒ąŠą╗ąĄąĄ ą┐ąŠą┤čĆąŠą▒ąĮąŠ čŹč鹊 ą▒čāą┤ąĄčé čĆą░čüčüą╝ąŠčéčĆąĄąĮąŠ ą▓ ą│ą╗ą░ą▓ąĄ 19.
ą£čŗ ąĘą░ą┐ąŠą╗ąĮąĖą╗ąĖ č鹥ą╗ąŠ ą╝ąĄč鹊ą┤ą░ deref ą▓čŗčĆą░ąČąĄąĮąĖąĄą╝ &self.0, čćč鹊ą▒čŗ deref ą▓ąŠąĘą▓čĆą░čéąĖą╗ čüčüčŗą╗ą║čā ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ, ą║ ą║ąŠč鹊čĆąŠą╝čā ą╝čŗ čģąŠčéąĖą╝ ąŠą▒čĆą░čēą░čéčīčüčÅ č湥čĆąĄąĘ ąŠą┐ąĄčĆą░č鹊čĆ *. ąÆčüą┐ąŠą╝ąĮąĖč鹥 ąĖąĘ čüąĄą║čåąĖąĖ "ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüčéčĆčāą║čéčāčĆ ą║ąŠčĆč鹥ąČą░ ą▒ąĄąĘ ąĖą╝ąĄąĮąŠą▓ą░ąĮąĮčŗčģ ą┐ąŠą╗ąĄą╣ ą┤ą╗čÅ čüąŠąĘą┤ą░ąĮąĖčÅ ą┤čĆčāą│ąĖčģ čéąĖą┐ąŠą▓" ą│ą╗ą░ą▓čŗ 5 [6], čćč鹊 .0 ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčé ą┤ąŠčüčéčāą┐ ą║ ą┐ąĄčĆą▓ąŠą╝čā ąĘąĮą░č湥ąĮąĖčÄ ą▓ čüčéčĆčāą║čéčāčĆąĄ ą║ąŠčĆč鹥ąČą░. ążčāąĮą║čåąĖčÅ main ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-9, ą║ąŠč鹊čĆą░čÅ ą▓čŗąĘčŗą▓ą░ąĄčé * ąĮą░ ąĘąĮą░č湥ąĮąĖąĖ MyBox< T>, č鹥ą┐ąĄčĆčī čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ, ąĖ assert ąŠą▒čĆą░ą▒ąŠčéą░ąĄčéčüčÅ ąĮąŠčĆą╝ą░ą╗čīąĮąŠ!
ąæąĄąĘ čéčĆąĄą╣čéą░ Deref ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą╝ąŠąČąĄčé č鹊ą╗čīą║ąŠ ą╗ąĖčłčī čĆą░ąĘčŗą╝ąĄąĮąŠą▓čŗą▓ą░čéčī & čüčüčŗą╗ą║ąĖ. ą£ąĄč鹊ą┤ deref ą┤ą░ąĄčé ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆčā ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą┐ąŠą╗čāčćąĖčéčī ąĘąĮą░č湥ąĮąĖąĄ ą╗čÄą▒ąŠą│ąŠ čéąĖą┐ą░, ą▓ ą║ąŠč鹊čĆąŠą╝ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮ čéčĆąĄą╣čé Deref, ąĖ ą▓čŗąĘą▓ą░čéčī ą╝ąĄč鹊ą┤ deref, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī & čüčüčŗą╗ą║čā, ą║ąŠč鹊čĆčāčÄ ą┐ąŠąĮčÅčéąĮąŠ, ą║ą░ą║ čĆą░ąĘčŗą╝ąĄąĮąŠą▓čŗą▓ą░čéčī.
ąÜąŠą│ą┤ą░ ą╝čŗ ą▓ą▓ąĄą╗ąĖ *y ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-9, ą▓ąĮčāčéčĆąĖ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĮą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ čüą╗ąĄą┤čāčÄčēąĄąĄ:
*(y.deref())
Rust ąĘą░ą╝ąĄąĮčÅąĄčé ąŠą┐ąĄčĆą░č鹊čĆ * ąĮą░ ą▓čŗąĘąŠą▓ ą╝ąĄč鹊ą┤ą░ deref, ąĖ ąĘą░č鹥ą╝ čćąĖčüč鹊ąĄ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖąĄ, čéą░ą║ čćč鹊 ąĮą░ą╝ ąĮąĄ ąĮčāąČąĮąŠ ą┤čāą╝ą░čéčī, čćč鹊 ąĮą░ą┤ąŠ ą▓čŗąĘčŗą▓ą░čéčī ą╝ąĄč鹊ą┤ deref. ąŁčéą░ čäąĖčćą░ Rust ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĮą░ą╝ ą┐ąĖčüą░čéčī ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ čäčāąĮą║čåąĖąŠąĮąĖčĆčāąĄčé ąĖą┤ąĄąĮčéąĖčćąĮąŠ ą║ą░ą║ ą┤ą╗čÅ ąŠą▒čŗčćąĮčŗčģ čüčüčŗą╗ąŠą║, čéą░ą║ ąĖ ą┤ą╗čÅ čéąĖą┐ą░, ą▓ ą║ąŠč鹊čĆąŠą╝ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮ Deref.
ą¤čĆąĖčćąĖąĮą░, ą┐ąŠ ą║ąŠč鹊čĆąŠą╣ ą╝ąĄč鹊ą┤ deref ą▓ąŠąĘą▓čĆą░čēą░ąĄčé čüčüčŗą╗ą║čā ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ, ąĖ čćč鹊 ą┐čĆąŠčüč鹊ąĄ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖąĄ ą▓ąĮąĄ čüą║ąŠą▒ąŠą║ *(y.deref()) ą▓čüąĄ ąĄčēąĄ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ, ąĘą░ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ čĆą░ą▒ąŠč鹥 čüąĖčüč鹥ą╝čŗ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ. ąĢčüą╗ąĖ ą╝ąĄč鹊ą┤ deref ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ąĘąĮą░č湥ąĮąĖąĄ ąĮą░ą┐čĆčÅą╝čāčÄ ą▓ą╝ąĄčüč鹊 čüčüčŗą╗ą║ąĖ ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ, č鹊 ąĘąĮą░č湥ąĮąĖąĄ ą▒čāą┤ąĄčé ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąŠ ąĖąĘ self. ą£čŗ ąĮąĄ čģąŠčéąĖą╝ ą▒čĆą░čéčī ą▓ąŠ ą▓ą╗ą░ą┤ąĄąĮąĖąĄ ą▓ąĮčāčéčĆąĄąĮąĮąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ ą▓ MyBox< T> ą║ą░ą║ ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ, čéą░ą║ ąĖ ą▓ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ čüą╗čāčćą░ąĄą▓, ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ ąŠą┐ąĄčĆą░č鹊čĆ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖčÅ.
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąŠą┐ąĄčĆą░č鹊čĆ * ąĘą░ą╝ąĄąĮčÅąĄčéčüčÅ ąĮą░ ą▓čŗąĘąŠą▓ ą╝ąĄč鹊ą┤ą░ deref, ąĖ ąĘą░č鹥ą╝ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé č鹊ą╗čīą║ąŠ ąŠą┤ąĮąŠą║čĆą░čéąĮąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ąŠą┐ąĄčĆą░č鹊čĆą░ *, ą║ą░ąČą┤čŗą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ą╝čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ * ą▓ čüą▓ąŠąĄą╝ ą║ąŠą┤ąĄ. ą¤ąŠčüą║ąŠą╗čīą║čā ąĘą░ą╝ąĄąĮą░ ąŠą┐ąĄčĆą░č鹊čĆą░ * ąĮąĄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčé ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠą╣ čĆąĄą║čāčĆčüąĖąĖ, ą╝čŗ ąĘą░ą▓ąĄčĆčłą░ąĄą╝ ą┐ąŠą╗čāč湥ąĮąĖąĄą╝ ą┤ą░ąĮąĮčŗčģ čéąĖą┐ą░ i32, ąĘąĮą░č湥ąĮąĖąĄ ą║ąŠč鹊čĆąŠą│ąŠ čüąŠą▓ą┐ą░ą┤ąĄčé čü 5 ą▓ assert_eq! ą╗ąĖčüčéąĖąĮą│ą░ 15-9.
ąØąĄčÅą▓ąĮčŗąĄ deref coercion čü čäčāąĮą║čåąĖčÅą╝ąĖ ąĖ ą╝ąĄč鹊ą┤ą░ą╝ąĖ. Deref coercion ą┐čĆąĄąŠą▒čĆą░ąĘčāąĄčé čüčüčŗą╗ą║čā ąĮą░ čéąĖą┐, ą║ąŠč鹊čĆčŗą╣ čĆąĄą░ą╗ąĖąĘčāąĄčé čéčĆąĄą╣čé Deref, ą▓ čüčüčŗą╗ą║čā ąĮą░ ą┤čĆčāą│ąŠą╣ čéąĖą┐. ąØą░ą┐čĆąĖą╝ąĄčĆ, deref coercion ą╝ąŠąČąĄčé ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░čéčī &String ą▓ &str, ą┐ąŠč鹊ą╝čā čćč鹊 String čĆąĄą░ą╗ąĖąĘčāąĄčé čéčĆąĄą╣čé Deref, ą║ąŠč鹊čĆčŗą╣ ą▓ąĄčĆąĮąĄčé &str. Deref coercion čŹč鹊 ą┤ąĄą╣čüčéą▓ąĖąĄ čāą┤ąŠą▒čüčéą▓ą░, ą║ąŠč鹊čĆąŠąĄ Rust ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ąĮą░ ą░čĆą│čāą╝ąĄąĮčéą░čģ ą┤ą╗čÅ čäčāąĮą║čåąĖą╣ ąĖ ą╝ąĄč鹊ą┤ąŠą▓, ąĖ čŹč鹊 čĆą░ą▒ąŠčéą░ąĄčé č鹊ą╗čīą║ąŠ ąĮą░ čéąĖą┐ą░čģ, ą║ąŠč鹊čĆčŗąĄ čĆąĄą░ą╗ąĖąĘčāčÄčé čéčĆąĄą╣čé Deref. ąŁč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ, ą║ąŠą│ą┤ą░ ą╝čŗ ą┐ąĄčĆąĄą┤ą░ąĄą╝ čüčüčŗą╗ą║čā ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ čéąĖą┐ą░ ą▓ ą║ą░č湥čüčéą▓ąĄ ą░čĆą│čāą╝ąĄąĮčéą░ čäčāąĮą║čåąĖąĖ ąĖą╗ąĖ ą╝ąĄč鹊ą┤ą░, ą║ąŠč鹊čĆčŗą╣ ąĮąĄ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé čéąĖą┐čā ą┐ą░čĆą░ą╝ąĄčéčĆą░ ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĖ čäčāąĮą║čåąĖąĖ ąĖą╗ąĖ ą╝ąĄč鹊ą┤ą░. ą¤ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ą▓čŗąĘąŠą▓ąŠą▓ ą╝ąĄč鹊ą┤ą░ deref ą┐čĆąĄąŠą▒čĆą░ąĘčāąĄčé ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗą╣ ąĮą░ą╝ąĖ čéąĖą┐ čéąĖą┐, ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗą╣ ą┐ą░čĆą░ą╝ąĄčéčĆčā.
ążąĖčćą░ deref coercion ą▒čŗą╗ą░ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮą░ ą▓ Rust, čćč鹊ą▒čŗ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčéčŗ ą┐čĆąĖ ąĮą░ą┐ąĖčüą░ąĮąĖąĖ čäčāąĮą║čåąĖąĖ ąĖ ą╝ąĄč鹊ą┤ą░ ąĮąĄ ą┤ąŠą╗ąČąĮčŗ ą▒čŗą╗ąĖ ą┤ąŠą▒ą░ą▓ą╗čÅčéčī čÅą▓ąĮčŗąĄ čüčüčŗą╗ą║ąĖ ąĖ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖčÅ čü & ąĖ *. ążąĖčćą░ deref coercion čéą░ą║ąČąĄ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĮą░ą╝ ą┐ąĖčüą░čéčī ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠ čĆą░ą▒ąŠčéą░čéčī ą║ą░ą║ čüąŠ čüčüčŗą╗ą║ą░ą╝ąĖ, čéą░ą║ ąĖ čüąŠ smart-čāą║ą░ąĘą░č鹥ą╗čÅą╝ąĖ.
ą¦č鹊ą▒čŗ ą┐ąŠčüą╝ąŠčéčĆąĄčéčī ąĮą░ deref coercion ą▓ ą┤ąĄą╣čüčéą▓ąĖąĖ, ą┤ą░ą▓ą░ą╣č鹥 ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ čéąĖą┐ MyBox< T>, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╣ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-8, ą░ čéą░ą║ąČąĄ čĆąĄą░ą╗ąĖąĘą░čåąĖčÄ Deref, ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĮčāčÄ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-10. ąøąĖčüčéąĖąĮą│ 15-11 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čäčāąĮą║čåąĖąĖ, čā ą║ąŠč鹊čĆąŠą╣ ą┐ą░čĆą░ą╝ąĄčéčĆ čŹč鹊 čüą╗ą░ą╣čü čüčéčĆąŠą║ąĖ (čäą░ą╣ą╗ src/main.rs):
fn hello(name: &str) {
println!("Hello, {name}!");
}
ąøąĖčüčéąĖąĮą│ 15-11. ążčāąĮą║čåąĖčÅ hello, ą║ąŠč鹊čĆą░čÅ ąĖą╝ąĄąĄčé ą┐ą░čĆą░ą╝ąĄčéčĆ name čéąĖą┐ą░ &str.
ą£čŗ ą╝ąŠąČąĄą╝ ą▓čŗąĘą▓ą░čéčī čäčāąĮą║čåąĖčÄ hello čüąŠ čüą╗ą░ą╣čüąŠą╝ čüčéčĆąŠą║ąĖ ą▓ ą║ą░č湥čüčéą▓ąĄ ą░čĆą│čāą╝ąĄąĮčéą░, ą║ą░ą║ ąĮą░ą┐čĆąĖą╝ąĄčĆ hello("Rust");. Deref coercion ą┤ąĄą╗ą░ąĄčé čŹč鹊 ą▓ąŠąĘą╝ąŠąČąĮčŗą╝ ą┤ą╗čÅ ą▓čŗąĘąŠą▓ą░ hello čüąŠ čüčüčŗą╗ą║ąŠą╣ ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ čéąĖą┐ą░ MyBox< String>, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-12 (čäą░ą╣ą╗ src/main.rs):
fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&m);
}
ąøąĖčüčéąĖąĮą│ 15-12. ąÆčŗąĘąŠą▓ hello čüąŠ čüčüčŗą╗ą║ąŠą╣ ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ MyBox< String>, čćč鹊 čĆą░ą▒ąŠčéą░ąĄčé ą▒ą╗ą░ą│ąŠą┤ą░čĆčÅ deref coercion.
ąŚą┤ąĄčüčī ą╝čŗ ą▓čŗąĘčŗą▓ą░ąĄą╝ čäčāąĮą║čåąĖčÄ hello čü ą░čĆą│čāą╝ąĄąĮč鹊ą╝ &m, ą║ąŠč鹊čĆą░čÅ čÅą▓ą╗čÅąĄčéčüčÅ čüčüčŗą╗ą║ąŠą╣ ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ MyBox< String>. ą¤ąŠčüą║ąŠą╗čīą║čā ą╝čŗ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ą╗ąĖ čéčĆąĄą╣čé Deref ąĮą░ MyBox< T> ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-10, Rust ą╝ąŠąČąĄčé ą┐čĆąĄą▓čĆą░čéąĖčéčī &MyBox< String> ą▓ &String ą┐čāč鹥ą╝ ą▓čŗąĘąŠą▓ą░ deref. ąĪčéą░ąĮą┤ą░čĆčéąĮą░čÅ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čĆąĄą░ą╗ąĖąĘą░čåąĖčÄ Deref ąĮą░ čéąĖą┐ąĄ String, ą║ąŠč鹊čĆą░čÅ ą▓ąŠąĘą▓čĆą░čéąĖčé čüą╗ą░ą╣čü čüčéčĆąŠą║ąĖ, ąĖ čŹč鹊 ąŠą┐ąĖčüą░ąĮąŠ ą▓ API-ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ ą┤ą╗čÅ Deref. Rust čüąĮąŠą▓ą░ ą▓čŗąĘąŠą▓ąĄčé deref, čćč鹊ą▒čŗ ą┐čĆąĄą▓čĆą░čéąĖčéčī &String ą▓ &str, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠą┤ąŠą╣ą┤ąĄčé ą║ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÄ čäčāąĮą║čåąĖąĖ hello.
ąĢčüą╗ąĖ ą▒čŗ ą▓ Rust ąĮąĄ ą▒čŗą╗ąŠ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ deref coercion, č鹊 ąĮą░ą╝ ąĮą░ą┤ąŠ ą▒čŗą╗ąŠ ą▒čŗ ą┐ąĖčüą░čéčī ą║ąŠą┤ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-13 ą▓ą╝ąĄčüč鹊 ą║ąŠą┤ą░ ą▓ ą╗ąĖčüčéąĖąĮą│ 15-12, čćč鹊ą▒čŗ ą▓čŗąĘčŗą▓ą░čéčī hello čüąŠ ąĘąĮą░č湥ąĮąĖąĄą╝ čéąĖą┐ą░ &MyBox< String>.
fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&(*m)[..]);
}
ąøąĖčüčéąĖąĮą│ 15-13. ąÜąŠą┤, ą║ąŠč鹊čĆčŗą╣ ą╝čŗ ą┤ąŠą╗ąČąĮčŗ ą▒čŗą╗ąĖ ą▒čŗ ąĮą░ą┐ąĖčüą░čéčī, ąĄčüą╗ąĖ ą▒čŗ ą▓ Rust ąĮąĄ ą▒čŗą╗ąŠ čäąĖčćąĖ deref coercion (čäą░ą╣ą╗ src/main.rs).
ąŚą┤ąĄčüčī (*m) čĆą░ąĘčŗą╝ąĄąĮąŠą▓čŗą▓ą░ąĄčé MyBox< String> ą▓ String. ąŚą░č鹥ą╝ & ąĖ [..] ą▒ąĄčĆčāčé čüą╗ą░ą╣čü čüčéčĆąŠą║ąĖ ąĖąĘ String, čĆą░ą▓ąĮčŗą╣ ą▓čüąĄą╣ čüčéčĆąŠą║ąĄ, čćč鹊 ą▒čāą┤ąĄčé čüąŠąŠčéą▓ąĄčéčüčéą▓ąŠą▓ą░čéčī čüąĖą│ąĮą░čéčāčĆąĄ hello. ąŁč鹊čé ą║ąŠą┤ ą▒ąĄąĘ deref coercion čéčĆčāą┤ąĮąĄąĄ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ, ąĮą░ą┐ąĖčüą░ąĮąĖčÅ ąĖ ą┐ąŠąĮąĖą╝ą░ąĮąĖčÅ, čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé čüąŠ ą▓čüąĄą╝ąĖ čŹčéąĖą╝ąĖ čüąĖą╝ą▓ąŠą╗ą░ą╝ąĖ. Deref coercion ą┐ąŠąĘą▓ąŠą╗čÅąĄčé Rust ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą▓čüąĄ čŹčéąĖ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ.
ąÜąŠą│ą┤ą░ ą▓ąŠą▓ą╗ąĄą║ą░ąĄčéčüčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čéčĆąĄą╣čéą░ Deref ą┤ą╗čÅ čéąĖą┐ąŠą▓, Rust ą▒čāą┤ąĄčé ą░ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī čéąĖą┐čŗ ąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčé Deref::deref čüč鹊ą╗čīą║ąŠ čĆą░ąĘ, čüą║ąŠą╗čīą║ąŠ čŹč鹊 ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī čüčüčŗą╗ą║čā, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēčāčÄ čéąĖą┐čā ą┐ą░čĆą░ą╝ąĄčéčĆą░. ąØąĄąŠą▒čģąŠą┤ąĖą╝ąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▓čüčéą░ą▓ą╗ąĄąĮąĮčŗčģ ą▓čŗąĘąŠą▓ąŠą▓ Deref::deref ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ, čéą░ą║ čćč鹊 deref coercion ąĮąĄ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ čüąĮąĖąČąĄąĮąĖčÄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ.
ąÜą░ą║ deref coercion ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓čāąĄčé čü ą╝čāčéąĖčĆčāąĄą╝ąŠčüčéčīčÄ. ą¤ąŠą┤ąŠą▒ąĮąŠ č鹊ą╝čā, ą║ą░ą║ ą▓čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄč鹥 čéčĆąĄą╣čé Deref ą┤ą╗čÅ ą┐ąĄčĆąĄąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąŠą┐ąĄčĆą░č鹊čĆą░ * ąĮą░ ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗčģ (immutable) čüčüčŗą╗ą║ą░čģ, ą▓čŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čéčĆąĄą╣čé DerefMut ą┤ą╗čÅ ą┐ąĄčĆąĄąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąŠą┐ąĄčĆą░č鹊čĆą░ * ąĮą░ ą╝čāčéąĖčĆčāąĄą╝čŗčģ (mutable) čüčüčŗą╗ą║ą░čģ.
Rust ą┤ąĄą╗ą░ąĄčé deref coercion, ą║ąŠą│ą┤ą░ ąĮą░čģąŠą┤ąĖčé čéąĖą┐čŗ ąĖ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čéčĆąĄą╣čéą░ ą▓ čüą╗ąĄą┤čāčÄčēąĖčģ čéčĆąĄčģ čüą╗čāčćą░čÅčģ:
ŌĆó ą×čé &T ą┤ąŠ &U, ą║ąŠą│ą┤ą░ T: Deref< Target=U>.
ŌĆó ą×čé &mut T ą┤ąŠ &mut U, ą║ąŠą│ą┤ą░ T: DerefMut< Target=U>.
ŌĆó ą×čé &mut T ą┤ąŠ &U, ą║ąŠą│ą┤ą░ T: Deref< Target=U>.
ą¤ąĄčĆą▓čŗąĄ ą┤ą▓ą░ čüą╗čāčćą░čÅ čüąŠą▓ą┐ą░ą┤ą░čÄčé, čü ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮčŗą╝ ąŠčéą╗ąĖčćąĖąĄą╝, čćč鹊 ą▓č鹊čĆąŠą╣ čĆąĄą░ą╗ąĖąĘčāąĄčé ą╝čāčéąĖčĆčāąĄą╝ąŠčüčéčī. ą¤ąĄčĆą▓čŗą╣ čüą╗čāčćą░ą╣ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé, čćč鹊 ąĄčüą╗ąĖ čā ą▓ą░čü &T, ąĖ T čĆąĄą░ą╗ąĖąĘčāąĄčé Deref ą┤ą╗čÅ ą║ą░ą║ąŠą│ąŠ-č鹊 čéąĖą┐ą░ U, č鹊 ą▓čŗ ą╝ąŠąČąĄč鹥 ą┐čĆąŠąĘčĆą░čćąĮąŠ ą┐ąŠą╗čāčćąĖčéčī &U. ąÆč鹊čĆąŠą╣ čüą╗čāčćą░ą╣ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé, čćč鹊 č鹊 ąČąĄ čüą░ą╝ąŠąĄ deref coercion ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┤ą╗čÅ mutable-čüčüčŗą╗ąŠą║.
ąóčĆąĄčéąĖą╣ čüą╗čāčćą░ą╣ čģąĖčéčĆąĄąĄ: Rust ą▒čāą┤ąĄčé čéą░ą║ąČąĄ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓čŗą▓ą░čéčī ą╝čāčéąĖčĆčāąĄą╝čāčÄ čüčüčŗą╗ą║čā ą▓ ąĮąĄą╝čāčéąĖčĆčāąĄą╝čāčÄ. ąØąŠ ąŠą▒čĆą░čéąĮąŠąĄ ą┐čĆąŠą▓ąĄčĆąĮčāčéčī ąĮąĄą▓ąŠąĘą╝ąŠąČąĮąŠ: ąĮąĄą╝čāčéąĖčĆčāąĄą╝ą░čÅ čüčüčŗą╗ą║ą░ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮą░ ą▓ ą╝čāčéąĖčĆčāąĄą╝čāčÄ. ąśąĘ-ąĘą░ ą┐čĆą░ą▓ąĖą╗ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ, ąĄčüą╗ąĖ čā ą▓ą░čü ąĄčüčéčī ą╝čāčéąĖčĆčāąĄą╝ą░čÅ čüčüčŗą╗ą║ą░, č鹊 čŹčéą░ ą╝čāčéąĖčĆčāąĄą╝ą░čÅ čüčüčŗą╗ą║ą░ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮąŠą╣ ą┤ą╗čÅ čŹčéąĖčģ ą┤ą░ąĮąĮčŗčģ (ąĖąĮą░č湥 ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ąĮąĄ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ). ą¤čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ ąŠą┤ąĮąŠą╣ ą╝čāčéąĖčĆčāąĄą╝ąŠą╣ čüčüčŗą╗ą║ąĖ ą▓ ąŠą┤ąĮčā ąĮąĄą╝čāčéąĖčĆčāąĄą╝čāčÄ čüčüčŗą╗ą║čā ąĮąĄ ąĮą░čĆčāčłąĖčé ą┐čĆą░ą▓ąĖą╗ą░ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ. ą¤čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ ąĮąĄą╝čāčéąĖčĆčāąĄą╝ąŠą╣ čüčüčŗą╗ą║ąĖ ą▓ ą╝čāčéąĖčĆčāąĄą╝čāčÄ ą┐ąŠčéčĆąĄą▒ąŠą▓ą░ą╗ąŠ ą▒čŗ, čćč鹊ą▒čŗ ąĖčüčģąŠą┤ąĮą░čÅ ąĮąĄąĖąĘą╝ąĄąĮčÅąĄą╝ą░čÅ čüčüčŗą╗ą║ą░ ą▒čŗą╗ą░ ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮąŠą╣ ąĮąĄąĖąĘą╝ąĄąĮčÅąĄą╝ąŠą╣ čüčüčŗą╗ą║ąŠą╣ ąĮą░ čŹčéąĖ ą┤ą░ąĮąĮčŗąĄ, ąĮąŠ ą┐čĆą░ą▓ąĖą╗ą░ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ čŹč鹊ą│ąŠ ąĮąĄ ą│ą░čĆą░ąĮčéąĖčĆčāčÄčé. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, Rust ąĮąĄ ą╝ąŠąČąĄčé ą┐čĆąĄą┤ą┐ąŠą╗ąŠąČąĖčéčī, čćč鹊 ą▓ąŠąĘą╝ąŠąČąĮąŠ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ ąĮąĄą╝čāčéąĖčĆčāąĄą╝ąŠą╣ čüčüčŗą╗ą║ąĖ ą▓ ą╝čāčéąĖčĆčāąĄą╝čāčÄ.
[ąóčĆąĄą╣čé Drop: ąĘą░ą┐čāčüą║ ą║ąŠą┤ą░ ą┐čĆąĖ ąŠčćąĖčüčéą║ąĄ]
ąÆč鹊čĆąŠą╣ čéčĆąĄą╣čé, ą▓ą░ąČąĮčŗą╣ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čłą░ą▒ą╗ąŠąĮą░ smart-čāą║ą░ąĘą░č鹥ą╗čÅ, čŹč鹊 Drop, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠąĘą▓ąŠą╗ąĖčé ą▓ą░ą╝ ąĮą░čüčéčĆąŠąĖčéčī čćč鹊-ąĮąĖą▒čāą┤čī, ą║ąŠą│ą┤ą░ ąĘąĮą░č湥ąĮąĖąĄ čéąĖą┐ą░ ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ (čé. ąĄ. ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ ą┐ąŠ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąŠčćąĖčüčéą║ąĄ). ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī čĆąĄą░ą╗ąĖąĘą░čåąĖčÄ čéčĆąĄą╣čéą░ Drop ąĮą░ ą╗čÄą▒ąŠą╝ čéąĖą┐ąĄ, ąĖ ąĄą│ąŠ ą║ąŠą┤ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ čĆąĄčüčāčĆčüąŠą▓ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ čäą░ą╣ą╗ąŠą▓ ąĖą╗ąĖ čüąĄč鹥ą▓čŗčģ čüąŠąĄą┤ąĖąĮąĄąĮąĖą╣.
ą£čŗ ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄą╝ Drop ą▓ ą║ąŠąĮč鹥ą║čüč鹥 smart-čāą║ą░ąĘą░č鹥ą╗ąĄą╣, ą┐ąŠč鹊ą╝čā čćč鹊 čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčī čéčĆąĄą╣čéą░ Drop ą┐ąŠčćčéąĖ ą▓čüąĄą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ, ą║ąŠą│ą┤ą░ čĆąĄą░ą╗ąĖąĘčāąĄčéčüčÅ smart-čāą║ą░ąĘą░č鹥ą╗čī. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą║ąŠą│ą┤ą░ ą▓čŗą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ Box< T>, ą▒čāą┤ąĄčé ąŠčüą▓ąŠą▒ąŠąČą┤ą░čéčīčüčÅ ą┐ą░ą╝čÅčéčī ą▓ ą║čāč湥, ąĮą░ ą║ąŠč鹊čĆčāčÄ čāą║ą░ąĘčŗą▓ą░ą╗ box.
ąÆ ąĮąĄą║ąŠč鹊čĆčŗčģ čÅąĘčŗą║ą░čģ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ, ą┤ą╗čÅ ąĮąĄą║ąŠč鹊čĆčŗčģ čéąĖą┐ąŠą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčé ą┤ąŠą╗ąČąĄąĮ ą▓čŗąĘą▓ą░čéčī ą║ąŠą┤ ą┤ą╗čÅ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ąĖą╗ąĖ čĆąĄčüčāčĆčüąŠą▓ ą║ą░ąČą┤čŗą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ąĘą░ą▓ąĄčĆčłąĖą╗ąŠčüčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ čŹčéąĖčģ čéąĖą┐ąŠą▓. ą¤čĆąĖą╝ąĄčĆčŗ čéą░ą║ąŠą│ąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ ą▓ą║ą╗čÄčćą░čÄčé ą┤ąĄčüą║čĆąĖą┐č鹊čĆčŗ čäą░ą╣ą╗ąŠą▓ (file handles), čüąŠą║ąĄčéčŗ (sockets) ąĖą╗ąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ (locks). ąĢčüą╗ąĖ ąĘą░ą▒čŗčéčī čŹč鹊 čüą┤ąĄą╗ą░čéčī, č鹊 čüąĖčüč鹥ą╝ą░ ą╝ąŠąČąĄčé ąŠą║ą░ąĘą░čéčīčüčÅ ą┐ąĄčĆąĄą│čĆčāąČąĄąĮąĮąŠą╣ ąĖą╗ąĖ ą┐ąŠč鹥čĆą┐ąĄčéčī čüą▒ąŠą╣. ąÆ Rust ą▓čŗ ą╝ąŠąČąĄč鹥 čāą║ą░ąĘą░čéčī, ą║ą░ą║ąŠą╣ ą║čāčüąŠč湥ą║ ą║ąŠą┤ą░ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ąĘą░ą┐čāčēąĄąĮ ą▓čüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ąĘąĮą░č湥ąĮąĖąĄ ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ, ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą▓čüčéą░ą▓ąĖčé čŹč鹊čé ą║ąŠą┤ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ. ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 ą▓ą░ą╝ ąĮąĄ ąĮčāąČąĮąŠ ąĘą░ą▒ąŠčéąĖčéčīčüčÅ ąŠ č鹊ą╝, čćč鹊ą▒čŗ ą▓čüčéą░ą▓ą╗čÅčéčī čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ ą║ąŠą┤ ąŠčćąĖčüčéą║ąĖ ą▓ąŠ ą▓čüąĄčģ ą╝ąĄčüčéą░čģ, ą│ą┤ąĄ ąĘą░ą▓ąĄčĆčłąĄąĮą░ čĆą░ą▒ąŠčéą░ čü ą║ą░ą║ąĖą╝-ą╗ąĖą▒ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╝ čéąĖą┐ąŠą╝, čéą░ą║ čćč鹊 ą▓čŗ ąĮąĄ čüč鹊ą╗ą║ąĮąĄč鹥čüčī čü čāč鹥čćą║ąŠą╣ čĆąĄčüčāčĆčüąŠą▓!
ąŻą║ą░ąĘą░čéčī, ą║ą░ą║ąŠą╣ ą║ąŠą┤ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ąĘą░ą┐čāčēąĄąĮ, ą║ąŠą│ą┤ą░ ąĘąĮą░č湥ąĮąĖąĄ ą▓čŗčłą╗ąŠ ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ, ą╝ąŠąČąĮąŠ čĆąĄą░ą╗ąĖąĘą░čåąĖąĄą╣ čéčĆąĄą╣čéą░ Drop. ąóčĆąĄą╣čé Drop čéčĆąĄą▒čāąĄčé ąŠčé ą▓ą░čü čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą╝ąĄč鹊ą┤ą░ drop, ą║ąŠč鹊čĆčŗą╣ ą▒ąĄčĆąĄčé ą╝čāčéąĖčĆčāąĄą╝čāčÄ čüčüčŗą╗ą║čā ąĮą░ self. ą¦č鹊ą▒čŗ čāą▓ąĖą┤ąĄčéčī, ą║ąŠą│ą┤ą░ Rust ą▓čŗąĘąŠą▓ąĄčé drop, ą┤ą░ą▓ą░ą╣č鹥 čüąĄą╣čćą░čü čĆąĄą░ą╗ąĖąĘčāąĄą╝ čü ą▓čŗąĘąŠą▓ą░ą╝ąĖ println!.
ąøąĖčüčéąĖąĮą│ 15-14 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čüčéčĆčāą║čéčāčĆčā CustomSmartPointer, čā ą║ąŠč鹊čĆąŠą╣ č鹊ą╗čīą║ąŠ ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮčŗą╣ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖą╣ čäčāąĮą║čåąĖąŠąĮą░ą╗, ą║ąŠč鹊čĆčŗą╣ ą┐ąĄčćą░čéą░ąĄčé "ą×čćąĖčüčéą║ą░ CustomSmartPointer", ą║ąŠą│ą┤ą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ, čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī, ą║ąŠą│ą┤ą░ Rust ąĘą░ą┐čāčüą║ą░ąĄčé čäčāąĮą║čåąĖčÄ drop.
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("ą×čćąĖčüčéą║ą░ CustomSmartPointer čü ą┤ą░ąĮąĮčŗą╝ąĖ `{}`", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("my stuff"),
};
let d = CustomSmartPointer {
data: String::from("other stuff"),
};
println!("CustomSmartPointers created.");
}
ąøąĖčüčéąĖąĮą│ 15-14. ąĪčéčĆčāą║čéčāčĆą░ CustomSmartPointer, ą║ąŠč鹊čĆą░čÅ čĆąĄą░ą╗ąĖąĘčāąĄčé čéčĆąĄą╣čé Drop, ą│ą┤ąĄ ą╝čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ ą┐ąŠą╝ąĄčüčéąĖčéčī ąĮą░čł ą║ąŠą┤ ąŠčćąĖčüčéą║ąĖ (čäą░ą╣ą╗ src/main.rs).
ąóčĆąĄą╣čé Drop ą┐ąŠą┤ą║ą╗čÄč湥ąĮ ą▓ prelude, čéą░ą║ čćč鹊 ąĮą░ą╝ ąĮąĄ ąĮčāąČąĮąŠ ą┐čĆąĖą▓ąŠą┤ąĖčéčī ąĄą│ąŠ ą▓ ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ. ą£čŗ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ą╗ąĖ čéčĆąĄą╣čé Drop ąĮą░ CustomSmartPointer ąĖ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖą╗ąĖ čĆąĄą░ą╗ąĖąĘą░čåąĖčÄ ą╝ąĄč鹊ą┤ą░ drop, ą║ąŠč鹊čĆčŗą╣ ą▓čŗąĘčŗą▓ą░ąĄčé println!. ąóąĄą╗ąŠ čäčāąĮą║čåąĖąĖ drop čŹč鹊 č鹊 ą╝ąĄčüč鹊, ą│ą┤ąĄ ą▓čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ ą▓čüčéą░ą▓ąĖčéčī ą╗čÄą▒čāčÄ ą╗ąŠą│ąĖą║čā, ą║ąŠč鹊čĆčāčÄ čģąŠč鹥ą╗ąĖ ą▒čŗ ąĘą░ą┐čāčüčéąĖčéčī, ą║ąŠą│ą┤ą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▓ą░čłąĄą│ąŠ čéąĖą┐ą░ ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ. ą£čŗ ą┐ąĄčćą░čéą░ąĄą╝ ąĘą┤ąĄčüčī ąĮąĄą║ąŠč鹊čĆčŗą╣ č鹥ą║čüčé, čćč鹊ą▒čŗ ą▓ąĖąĘčāą░ą╗čīąĮąŠ ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆąŠą▓ą░čéčī, ą║ąŠą│ą┤ą░ Rust ą▓čŗąĘąŠą▓ąĄčé drop.
ąÆ main ą╝čŗ čüąŠąĘą┤ą░ą╗ąĖ ą┤ą▓ą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ CustomSmartPointer, ąĖ ąĘą░č鹥ą╝ ą┐ąĄčćą░čéą░ąĄą╝ "CustomSmartPointers created". ąÆ ą║ąŠąĮčåąĄ main ąĮą░čłąĖ 菹║ąĘąĄą╝ą┐ą╗čÅčĆčŗ ą▓čŗčģąŠą┤čÅčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ, ąĖ Rust ą▓čŗąĘąŠą▓ąĄčé ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ą╝čŗ ą┐ąŠą╝ąĄčüčéąĖą╗ąĖ ą▓ ą╝ąĄč鹊ą┤ drop, čćč鹊 ą┐ąĄčćą░čéą░ąĄčé ąĮą░čłąĄ ąĘą░ą▓ąĄčĆčłą░čÄčēąĄąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĮą░ą╝ ąĮąĄ ąĮčāąČąĮąŠ čÅą▓ąĮąŠ ą▓čŗąĘčŗą▓ą░čéčī ą╝ąĄč鹊ą┤ drop.
ąÜąŠą│ą┤ą░ ą╝čŗ ąĘą░ą┐čāčüčéąĖą╝ čŹčéčā ą┐čĆąŠą│čĆą░ą╝ą╝čā, č鹊 čāą▓ąĖą┤ąĖą╝ čüą╗ąĄą┤čāčÄčēąĖą╣ ą▓čŗą▓ąŠą┤:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.60s
Running `target/debug/drop-example`
CustomSmartPointers created.
ą×čćąĖčüčéą║ą░ CustomSmartPointer čü ą┤ą░ąĮąĮčŗą╝ąĖ `other stuff`
ą×čćąĖčüčéą║ą░ CustomSmartPointer čü ą┤ą░ąĮąĮčŗą╝ąĖ `my stuff`
Rust ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą▓čŗąĘąŠą▓ąĄčé ą┤ą╗čÅ ąĮą░čü drop, ą║ąŠą│ą┤ą░ ąĮą░čłąĖ 菹║ąĘąĄą╝ą┐ą╗čÅčĆčŗ ą▓čŗą╣ą┤čāčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ. ą¤ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ ą▓čŗą▒čĆą░čüčŗą▓ą░čÄčéčüčÅ ą▓ ą┐ąŠčĆčÅą┤ą║ąĄ, ąŠą▒čĆą░čéąĮąŠą╝ č鹊ą╝čā, ą▓ ą║ąŠč鹊čĆąŠą╝ ąŠąĮąĖ ą▒čŗą╗ąĖ čüąŠąĘą┤ą░ąĮčŗ, čéą░ą║ čćč鹊 d ą▒čāą┤ąĄčé ą▓čŗą▒čĆąŠčłąĄąĮą░ ą┐ąĄčĆąĄą┤ c. ąØą░ąĘąĮą░č湥ąĮąĖąĄ čŹč鹊ą│ąŠ ą┐čĆąĖą╝ąĄčĆą░ - ą┤ą░čéčī ąĮą░ą│ą╗čÅą┤ąĮąŠąĄ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąŠ, ą║ą░ą║ čĆą░ą▒ąŠčéą░ąĄčé ą╝ąĄč鹊ą┤ drop; ąŠą▒čŗčćąĮąŠ ą▓čŗ čāą║ą░ąĘą░ą╗ąĖ ą▒čŗ ą▓ ą╝ąĄč鹊ą┤ąĄ drop ą▒ąŠą╗ąĄąĄ ą┐ąŠą╗ąĄąĘąĮčŗą╣ ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ą┤ąĄą╗ą░ąĄčé ąŠčćąĖčüčéą║čā, ą▓ą╝ąĄčüč鹊 ą┐ąĄčćą░čéąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ.
std::mem::drop: čĆą░ąĮąĮąĄąĄ ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ. ąÜ čüąŠąČą░ą╗ąĄąĮąĖčÄ, ąĮąĄ čüčāčēąĄčüčéą▓čāąĄčé ą┐čĆąŠčüč鹊ą│ąŠ čüą┐ąŠčüąŠą▒ą░ ąĘą░ą┐čĆąĄčéą░ čäčāąĮą║čåąĖąŠąĮą░ą╗ą░ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąŠą│ąŠ drop. ąŚą░ą┐čĆąĄčé drop ąŠą▒čŗčćąĮąŠ ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ; ą▓ąĄčüčī čüą╝čŗčüą╗ čéčĆąĄą╣čéą░ Drop čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, čćč鹊ą▒čŗ ą┤ąĄą╗ą░čéčī ąŠčćąĖčüčéą║čā ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ. ą×ą┤ąĮą░ą║ąŠ ąĖąĮąŠą│ą┤ą░ ą╝ąŠąČąĄčé ą┐ąŠčéčĆąĄą▒ąŠą▓ą░čéčīčüčÅ čĆą░ąĮąĮčÅčÅ ąŠčćąĖčüčéą║ą░ ąĘąĮą░č湥ąĮąĖčÅ. ą×ą┤ąĖąĮ ąĖąĘ ą┐čĆąĖą╝ąĄčĆąŠą▓ - ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ smart-čāą║ą░ąĘą░č鹥ą╗ąĖ ą┤ą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ą╝ąĖ: ą▓ą░ą╝ ą╝ąŠąČąĄčé ą┐ąŠąĮą░ą┤ąŠą▒ąĖčéčīčüčÅ ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ ą▓čŗąĘą▓ą░čéčī ą╝ąĄč鹊ą┤ drop, ą║ąŠč鹊čĆčŗą╣ ąŠčüą▓ąŠą▒ąŠą┤ąĖčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā, čćč鹊ą▒čŗ ą┤čĆčāą│ąŠą╣ ą║ąŠą┤ ą▓ č鹊ą╣ ąČąĄ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ ą╝ąŠą│ ą▒čŗ ą▓ąĘčÅčéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā. Rust ąĮąĄ ą┐ąŠąĘą▓ąŠą╗ąĖčé ą▓ą░ą╝ ą▓čĆčāčćąĮčāčÄ ą▓čŗąĘą▓ą░čéčī ą╝ąĄč鹊ą┤ drop čéčĆąĄą╣čéą░ Drop; ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą▓čŗ ą┤ąŠą╗ąČąĮčŗ ą▓čŗąĘą▓ą░čéčī čäčāąĮą║čåąĖčÄ std::mem::drop, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄą╝čāčÄ čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąŠą╣, ąĄčüą╗ąĖ ą▓čŗ čģąŠčéąĖč鹥 ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ ą▓čŗą▒čĆąŠčüąĖčéčī ąĘąĮą░č湥ąĮąĖąĄ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ąŠąĮąŠ ą▓čŗą╣ą┤ąĄčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ.
ąĢčüą╗ąĖ ą╝čŗ ą┐ąŠą┐čĆąŠą▒čāąĄą╝ ą▓čŗąĘą▓ą░čéčī ą╝ąĄč鹊ą┤ drop čéčĆąĄą╣čéą░ Drop ą▓čĆčāčćąĮčāčÄ ą┐čāč鹥ą╝ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖąĖ čäčāąĮą║čåąĖąĖ main ąĖąĘ ą╗ąĖčüčéąĖąĮą│ą░ 15-14, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-15, č鹊 ą┐ąŠą╗čāčćąĖą╝ ąŠčłąĖą▒ą║čā ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ (čäą░ą╣ą╗ src/main.rs):
fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created.");
c.drop();
println!("CustomSmartPointer dropped before the end of main.");
}
ąøąĖčüčéąĖąĮą│ 15-15. ą¤ąŠą┐čŗčéą║ą░ ą▓čĆčāčćąĮčāčÄ ą▓čŗąĘą▓ą░čéčī ą╝ąĄč鹊ą┤ drop ąĖąĘ čéčĆąĄą╣čéą░ Drop ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čĆą░ąĮąĮąĄą╣ ąŠčćąĖčüčéą║ąĖ.
ąÜąŠą│ą┤ą░ ą╝čŗ ą┐ąŠą┐čŗčéą░ąĄą╝čüčÅ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░čéčī čŹč鹊čé ą║ąŠą┤, č鹊 ą┐ąŠą╗čāčćąĖą╝ ąŠčłąĖą▒ą║čā:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
error[E0040]: explicit use of destructor method
--> src/main.rs:16:7
|
16 | c.drop();
| ^^^^ explicit destructor calls not allowed
|
help: consider using `drop` function
|
16 | drop(c);
| +++++ ~
For more information about this error, try `rustc --explain E0040`.
error: could not compile `drop-example` (bin "drop-example") due to 1 previous error
ąŁčéą░ ąŠčłąĖą▒ą║ą░ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé, čćč鹊 ąĮą░ą╝ ąĮąĄ čĆą░ąĘčĆąĄčłąĄąĮąŠ čÅą▓ąĮąŠ ą▓čŗąĘčŗą▓ą░čéčī drop. ąĪąŠąŠą▒čēąĄąĮąĖąĄ ąŠą▒ ąŠčłąĖą▒ą║ąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčé č鹥čĆą╝ąĖąĮ destructor, ą║ąŠč鹊čĆčŗą╣ čÅą▓ą╗čÅąĄčéčüčÅ ąŠą▒čēąĖą╝ č鹥čĆą╝ąĖąĮąŠą╝ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĖ ą┤ą╗čÅ čäčāąĮą║čåąĖąĖ, ą║ąŠč鹊čĆą░čÅ ą┤ąĄą╗ą░ąĄčé ąŠčćąĖčüčéą║čā 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░. ąöąĄčüčéčĆčāą║č鹊čĆ čŹč鹊 ą░ąĮčéąĖą┐ąŠą┤ ą║ąŠąĮčüčéčĆčāą║č鹊čĆą░, ą║ąŠč鹊čĆčŗą╣ čüąŠąĘą┤ą░ąĄčé 菹║ąĘąĄą╝ą┐ą╗čÅčĆ. ążčāąĮą║čåąĖčÅ drop ą▓ Rust čŹč鹊 ąŠą┤ąĖąĮ ąĖąĘ ą║ąŠąĮą║čĆąĄčéąĮčŗčģ ą┤ąĄčüčéčĆčāą║č鹊čĆąŠą▓.
Rust ąĮąĄ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĮą░ą╝ čÅą▓ąĮąŠ ą▓čŗąĘą▓ą░čéčī drop, ą┐ąŠč鹊ą╝čā čćč鹊 Rust ą▓čüąĄ ąĄčēąĄ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą▓čŗąĘąŠą▓ąĄčé drop ąĮą░ ąĘąĮą░č湥ąĮąĖąĖ, ą║ąŠą│ą┤ą░ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ main. ąŁč鹊 ą▓čŗąĘą▓ą░ą╗ąŠ ą▒čŗ ąŠčłąĖą▒ą║čā ą┤ą▓ąŠą╣ąĮąŠą│ąŠ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ, ą┐ąŠč鹊ą╝čā čćč鹊 Rust ą┐ąŠą┐čŗčéą░ą╗čüčÅ ą▒čŗ ą┤ą▓ą░ąČą┤čŗ ąŠčüą▓ąŠą▒ąŠą┤ąĖčéčī ąŠą┤ąĮąŠ ąĖ č鹊 ąČąĄ ąĘąĮą░č湥ąĮąĖąĄ.
ą£čŗ ąĮąĄ ą╝ąŠąČąĄą╝ ąĘą░ą┐čĆąĄčéąĖčéčī ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║čāčÄ ą▓čüčéą░ą▓ą║čā drop, ą║ąŠą│ą┤ą░ ąĘąĮą░č湥ąĮąĖąĄ ą▓čŗą╣ą┤ąĄčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ, ąĖ ąĮąĄ ą╝ąŠąČąĄą╝ ą▓čŗąĘčŗą▓ą░čéčī ą╝ąĄč鹊ą┤ drop čÅą▓ąĮąŠ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąĄčüą╗ąĖ ąĮą░ą╝ ąĮčāąČąĮąŠ ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ ą▓čŗą┐ąŠą╗ąĮąĖčéčī čĆą░ąĮąĮčÄčÄ ąŠčćąĖčüčéą║čā ąĘąĮą░č湥ąĮąĖčÅ, č鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čäčāąĮą║čåąĖčÅ std::mem::drop.
ążčāąĮą║čåąĖčÅ std::mem::drop ąŠčéą╗ąĖčćą░ąĄčéčüčÅ ąŠčé ą╝ąĄč鹊ą┤ą░ drop ą▓ čéčĆąĄą╣č鹥 Drop. ą£čŗ ą▓čŗąĘčŗą▓ą░ąĄą╝ ąĄčæ ą┐čāč鹥ą╝ ą┐ąĄčĆąĄą┤ą░čćąĖ ą▓ ą║ą░č湥čüčéą▓ąĄ ą░čĆą│čāą╝ąĄąĮčéą░ ąĘąĮą░č湥ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ čģąŠčéąĖą╝ ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ ą▓čŗą▒čĆąŠčüąĖčéčī. ąŁčéą░ čäčāąĮą║čåąĖčÅ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ prelude, čéą░ą║ čćč鹊 ą╝čŗ ą╝ąŠąČąĄą╝ ąĖąĘą╝ąĄąĮąĖčéčī main ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-15, čćč鹊ą▒čŗ ą▓čŗąĘą▓ą░čéčī čäčāąĮą║čåąĖčÄ drop, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-16 (čäą░ą╣ą╗ src/main.rs):
fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created.");
drop(c);
println!("CustomSmartPointer dropped before the end of main.");
}
ąøąĖčüčéąĖąĮą│ 15-16. ąÆčŗąĘąŠą▓ std::mem::drop ą┤ą╗čÅ čÅą▓ąĮąŠą│ąŠ ą▓čŗą▒čĆą░čüčŗą▓ą░ąĮąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ąŠąĮąŠ ą▓čŗą╣ą┤ąĄčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ.
ąŚą░ą┐čāčüą║ čŹč鹊ą│ąŠ ą║ąŠą┤ą░ ąĮą░ą┐ąĄčćą░čéą░ąĄčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/drop-example`
CustomSmartPointer created.
Dropping CustomSmartPointer with data `some data`!
CustomSmartPointer dropped before the end of main.
ąóąĄą║čüčé "Dropping CustomSmartPointer with data `some data`!" ąĮą░ą┐ąĄčćą░čéą░ąĄčéčüčÅ ą╝ąĄąČą┤čā ą┐ąĄčćą░čéčīčÄ "CustomSmartPointer created." ąĖ "CustomSmartPointer dropped before the end of main.", ą┐ąŠą║ą░ąĘčŗą▓ą░čÅ, čćč鹊 ą║ąŠą┤ ą╝ąĄč鹊ą┤ą░ drop ą▒čŗą╗ ą▓čŗąĘą▓ą░ąĮ ą▓ čŹč鹊ą╝ ą╝ąĄčüč鹥 ą┤ą╗čÅ ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖčÅ c.
ąÆčŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą║ąŠą┤ ą▓ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čéčĆąĄą╣čéą░ Drop ą╝ąĮąŠą│ąĖą╝ąĖ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ, čćč鹊ą▒čŗ čüą┤ąĄą╗ą░čéčī ąŠčćąĖčüčéą║čā čāą┤ąŠą▒ąĮąŠą╣ ąĖ ą▒ąĄąĘąŠą┐ą░čüąĮąŠą╣: ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą▓čŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹč鹊 ą┤ą╗čÅ čüąŠąĘą┤ą░ąĮąĖčÅ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą│ąŠ ą▓čŗą┤ąĄą╗ąĖč鹥ą╗čÅ ą┐ą░ą╝čÅčéąĖ! ąĪ čéčĆąĄą╣č鹊ą╝ Drop ąĖ čüąĖčüč鹥ą╝ąŠą╣ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ Rust ą▓ą░ą╝ ąĮąĄ ąĮčāąČąĮąŠ ą┐ąŠą╝ąĮąĖčéčī ą┐čĆąŠ ąŠčćąĖčéą║čā ą┐ąŠč鹊ą╝čā čćč鹊 Rust čüą┤ąĄą╗ą░ąĄčé čŹč鹊 ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ.
ąÆą░ą╝ čéą░ą║ąČąĄ ąĮąĄ ąĮą░ą┤ąŠ ą▒ąĄčüą┐ąŠą║ąŠąĖčéčīčüčÅ ąŠ ą┐čĆąŠą▒ą╗ąĄą╝ą░čģ, ą▓ąŠąĘąĮąĖą║ą░čÄčēąĖčģ ąĖąĘ-ąĘą░ čüą╗čāčćą░ą╣ąĮąŠą╣ ąŠčćąĖčüčéą║ąĖ ąĘąĮą░č湥ąĮąĖą╣, ą▓čüąĄ ąĄčēąĄ ąĮą░čģąŠą┤čÅčēąĖčģčüčÅ ą▓ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ: čüąĖčüč鹥ą╝ą░ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ, ą║ąŠč鹊čĆą░čÅ ą▓čüąĄą│ą┤ą░ ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéčī čüčüčŗą╗ąŠą║, čéą░ą║ąČąĄ ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 drop ą▓čŗąĘąŠą▓ąĄčéčüčÅ č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ąĘąĮą░č湥ąĮąĖąĄ ą▒ąŠą╗čīčłąĄ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ.
ąóąĄą┐ąĄčĆčī, ą║ąŠą│ą┤ą░ ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĄą╗ąĖ Box< T> ąĖ ąĮąĄą║ąŠč鹊čĆčŗąĄ čģą░čĆą░ą║č鹥čĆąĖčüčéąĖą║ąĖ smart-čāą║ą░ąĘą░č鹥ą╗ąĄą╣, ą┤ą░ą▓ą░ą╣č鹥 čĆą░čüčüą╝ąŠčéčĆąĖą╝ ą┤čĆčāą│ąĖąĄ smart-čāą║ą░ąĘą░č鹥ą╗ąĖ, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ ą▓ čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĄ.
[Rc< T>: smart-čāą║ą░ąĘą░č鹥ą╗čī čü ą┐ąŠą┤čüč湥č鹊ą╝ čüčüčŗą╗ąŠą║]
ąÆ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ čüą╗čāčćą░ąĄą▓ ą▓ą╗ą░ą┤ąĄąĮąĖąĄ čĆą░ą▒ąŠčéą░ąĄčé ą┐ąŠąĮčÅčéąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝: ą▓čŗ č鹊čćąĮąŠ ąĘąĮą░ąĄč鹥, ą║ą░ą║ą░čÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ ą▓ą╗ą░ą┤ąĄąĄčé ą┤ą░ąĮąĮčŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝. ą×ą┤ąĮą░ą║ąŠ ą▓ ąĮąĄą║ąŠč鹊čĆčŗčģ čüą╗čāčćą░čÅčģ ąŠą┤ąĮąŠ ąĘąĮą░č湥ąĮąĖąĄ ą╝ąŠąČąĄčé ąĖą╝ąĄčéčī ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą▓. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą▓ čüčéčĆčāą║čéčāčĆą░čģ ą┤ą░ąĮąĮčŗčģ ą│čĆą░čäą░ ąĮąĄčüą║ąŠą╗čīą║ąŠ čĆąĄą▒ąĄčĆ ą╝ąŠą│čāčé čāą║ą░ąĘčŗą▓ą░čéčī ąĮą░ ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ čāąĘąĄą╗, ąĖ čŹč鹊čé čāąĘąĄą╗ ą║ąŠąĮčåąĄą┐čéčāą░ą╗čīąĮąŠ ą┐čĆąĖąĮą░ą┤ą╗ąĄąČąĖčé ą▓čüąĄą╝ čĆąĄą▒čĆą░ą╝, ą║ąŠč鹊čĆčŗąĄ ąĮą░ ąĮąĄą│ąŠ čāą║ą░ąĘčŗą▓ą░čÄčé. ąŻąĘąĄą╗ ąĮąĄ ą┤ąŠą╗ąČąĄąĮ ąŠčćąĖčēą░čéčīčüčÅ ą┤ąŠ č鹥čģ ą┐ąŠčĆ, ą┐ąŠą║ą░ čüčāčēąĄčüčéą▓čāąĄčé čģąŠčéčÅ ą▒čŗ ąŠą┤ąĖąĮ ąĄą│ąŠ ą▓ą╗ą░ą┤ąĄą╗ąĄčå.
ąÆčŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čÅą▓ąĮąŠ ą╝ąĮąŠąČąĄčüčéą▓ąĄąĮąĮąŠąĄ ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖąĄ ą┐čāč鹥ą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ Rust-čéąĖą┐ą░ Rc< T>, ąĖą╝čÅ čŹč鹊ą│ąŠ čéąĖą┐ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąŠčé ą░ą▒ą▒čĆąĄą▓ąĖą░čéčāčĆčŗ reference counting. ąóąĖą┐ Rc< T> ąŠčéčüą╗ąĄąČąĖą▓ą░ąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čüčüčŗą╗ąŠą║ ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ, čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą╗ąĖ čŹč鹊 ąĘąĮą░č湥ąĮąĖąĄ, ąĖą╗ąĖ čāąČąĄ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ. ąĢčüą╗ąĖ ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ čüčāčēąĄčüčéą▓čāąĄčé 0 čüčüčŗą╗ąŠą║, č鹊 ąŠąĮąŠ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠčćąĖčēąĄąĮąŠ, ąĖ ą┐čĆąĖ čŹč鹊ą╝ ąĮąĖ ąŠą┤ąĮą░ ąĖąĘ čüčüčŗą╗ąŠą║ ąĮąĄ čüčéą░ąĮąĄčé ąĮąĄą┤ąŠą┐čāčüčéąĖą╝ąŠą╣.
Rc< T> ą╝ąŠąČąĮąŠ ą┐čĆąĄą┤čüčéą░ą▓ąĖčéčī čüąĄą▒ąĄ ą║ą░ą║ č鹥ą╗ąĄą▓ąĖąĘąŠčĆ ą▓ čüąĄą╝ąĄą╣ąĮąŠą╣ ą║ąŠą╝ąĮą░č鹥. ąÜąŠą│ą┤ą░ ąŠą┤ąĖąĮ č湥ą╗ąŠą▓ąĄą║ ą▓čģąŠą┤ąĖčé, čćč鹊ą▒čŗ ą┐ąŠčüą╝ąŠčéčĆąĄčéčī č鹥ą╗ąĄą▓ąĖąĘąŠčĆ, č鹊 ąŠąĮ ąĄą│ąŠ ą▓ą║ą╗čÄčćąĖčé. ąöčĆčāą│ąĖąĄ ąĘčĆąĖč鹥ą╗ąĖ ą╝ąŠą│čāčé čéą░ą║ąČąĄ ą┐čĆąĖą╣čéąĖ ą▓ čŹčéčā ą║ąŠą╝ąĮą░čéčā, čćč鹊ą▒čŗ ą┐ąŠčüą╝ąŠčéčĆąĄčéčī č鹥ą╗ąĄą▓ąĖąĘąŠčĆ. ąÜąŠą│ą┤ą░ ą┐ąŠčüą╗ąĄą┤ąĮąĖą╣ ąĖąĘ ąĘčĆąĖč鹥ą╗ąĄą╣ ą┐ąŠą║ąĖąĮąĄčé ą║ąŠą╝ąĮą░čéčā čü č鹥ą╗ąĄą▓ąĖąĘąŠčĆąŠą╝, ąŠąĮ ąĄą│ąŠ ą▓čŗą║ą╗čÄčćąĖčé, ą┐ąŠč鹊ą╝čā čćč鹊 č鹥ą╗ąĄą▓ąĖąĘąŠčĆ ą▒ąŠą╗čīčłąĄ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ. ąĢčüą╗ąĖ ąČąĄ ą║č鹊-č鹊 ą▓čŗą║ą╗čÄčćąĖčéčī č鹥ą╗ąĄą▓ąĖąĘąŠčĆ, ą║ąŠą│ą┤ą░ ąĄčēąĄ ą║č鹊-č鹊 ąĄą│ąŠ čüą╝ąŠčéčĆąĖčé, č鹊 čŹč鹊 ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ą▓ąŠąĘą╝čāčēąĄąĮąĮčŗą╝ ą║čĆąĖą║ą░ą╝!
ą£čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ čéąĖą┐ Rc< T>, ą║ąŠą│ą┤ą░ čģąŠčéąĖą╝ ą▓čŗą┤ąĄą╗ąĖčéčī ąĮąĄą║ąŠč鹊čĆčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▓ ą║čāč湥 ą┤ą╗čÅ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čćą░čüč鹥ą╣ ąĮą░čłąĄą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ, ąĖ ą╝čŗ ąĮąĄ ą╝ąŠąČąĄą╝ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ, ą║ą░ą║ą░čÅ ąĖąĘ čćą░čüč鹥ą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą▒čāą┤ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹčéąĖ ą┤ą░ąĮąĮčŗąĄ ą┐ąŠčüą╗ąĄą┤ąĮąĄą╣. ąĢčüą╗ąĖ ą▒čŗ ą╝čŗ ąĘąĮą░ą╗ąĖ, ą║ą░ą║ą░čÅ čćą░čüčéčī ąĘą░ą▓ąĄčĆčłąĖčé čĆą░ą▒ąŠčéčā ą┐ąŠčüą╗ąĄą┤ąĮąĄą╣, č鹊 ą╝čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ čüą┤ąĄą╗ą░čéčī čŹčéčā čćą░čüčéčī ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą╝ ą┤ą░ąĮąĮčŗčģ, ąĖ č鹊ą│ą┤ą░ ą▓čüčéčāą┐ąĖą╗ąĖ ą▒čŗ ą▓ ą┤ąĄą╣čüčéą▓ąĖčÅ ąŠą▒čŗčćąĮčŗąĄ ą┐čĆą░ą▓ąĖą╗ą░ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ.
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 Rc< T> ą┐ąŠą┤ąŠą╣ą┤ąĄčé č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ąŠą┤ąĮąŠą┐ąŠč鹊čćąĮčŗčģ čüčåąĄąĮą░čĆąĖąĄą▓. ąÜąŠą│ą┤ą░ ą╝čŗ ą▒čāą┤ąĄą╝ ąŠą▒čüčāąČą┤ą░čéčī ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ (concurrency) ą▓ ą│ą╗ą░ą▓ąĄ 16, ą▒čāą┤čāčé čĆą░čüčüą╝ąŠčéčĆąĄąĮčŗ čüą┐ąŠčüąŠą▒čŗ ą┐ąŠą┤čüč湥čéą░ čüčüčŗą╗ąŠą║ ą▓ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮčŗčģ ą┐čĆąŠą│čĆą░ą╝ą╝ą░čģ.
Rc< T> ą┤ą╗čÅ čüąŠą▓ą╝ąĄčüčéąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ. ąöą░ą▓ą░ą╣č鹥 ą▓ąĄčĆąĮąĄą╝čüčÅ ą║ ąĮą░čłąĄą╝čā ą┐čĆąĖą╝ąĄčĆčā čüą┐ąĖčüą║ą░ cons list ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-5. ąÆčüą┐ąŠą╝ąĮąĖą╝, čćč鹊 ą╝čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖą╗ąĖ ąĄą│ąŠ ąĮą░ ąŠčüąĮąŠą▓ąĄ Box< T>. ąØą░ čŹč鹊čé čĆą░ąĘ ą╝čŗ čüąŠąĘą┤ą░ą┤ąĖą╝ 2 čüą┐ąĖčüą║ą░, ą║ąŠč鹊čĆčŗąĄ čüąŠą▓ą╝ąĄčüčéąĮąŠ ą▓ą╗ą░ą┤ąĄčÄčé čéčĆąĄčéčīąĖą╝ čüą┐ąĖčüą║ąŠą╝. ąÜąŠąĮčåąĄą┐čéčāą░ą╗čīąĮąŠ čŹč鹊 ą▓čŗą│ą╗čÅą┤ąĖčé, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮą░ čĆąĖčü. 15-3:
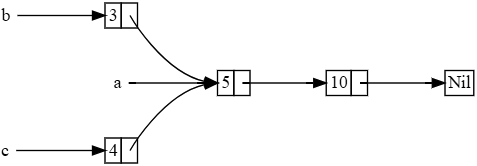
ąĀąĖčü. 15-3. ąöą▓ą░ čüą┐ąĖčüą║ą░ b ąĖ c, čüąŠą▓ą╝ąĄčüčéąĮąŠ ą▓ą╗ą░ą┤ąĄčÄčēąĖąĄ čéčĆąĄčéčīąĖą╝ čüą┐ąĖčüą║ąŠą╝ a.
ąĪąŠąĘą┤ą░ą┤ąĖą╝ čüą┐ąĖčüąŠą║, čüąŠą┤ąĄčƹȹ░čēąĖą╣ 5 ąĖ ąĘą░č鹥ą╝ 10. ąŚą░č鹥ą╝ čüąŠąĘą┤ą░ą┤ąĖą╝ ąĄčēąĄ 2 čüą┐ąĖčüą║ą░: b, ą║ąŠč鹊čĆčŗą╣ ąĮą░čćąĖąĮą░ąĄčéčüčÅ čü 3, ąĖ c, ą║ąŠč鹊čĆčŗą╣ ąĮą░čćąĖąĮą░ąĄčéčüčÅ čü 4. ą×ą▒ą░ čüą┐ąĖčüą║ą░ b ąĖ c ą▒čāą┤čāčé č鹊ą│ą┤ą░ ą┐čĆąŠą┤ąŠą╗ąČą░čéčīčüčÅ ą┐ąĄčĆą▓čŗą╝ čüą┐ąĖčüą║ąŠą╝, čüąŠą┤ąĄčƹȹ░čēąĖą╝ 5 ąĖ 10. ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ąŠą▒ą░ čüą┐ąĖčüą║ą░ ą▒čāą┤čāčé čüąŠą▓ą╝ąĄčüčéąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┐ąĄčĆą▓čŗą╣ čüą┐ąĖčüąŠą║, čüąŠą┤ąĄčƹȹ░čēąĖą╣ 5 ąĖ 10.
ą¤ąŠą┐čŗčéą║ą░ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī čŹč鹊čé čüčåąĄąĮą░čĆąĖą╣ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ąĮą░čłąĄą│ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ List č湥čĆąĄąĘ Box< T>, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-17, ąĮąĄ čüčĆą░ą▒ąŠčéą░ąĄčé (čäą░ą╣ą╗ src/main.rs):
enum List {
Cons(i32, Box< List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
let b = Cons(3, Box::new(a));
let c = Cons(4, Box::new(a));
}
ąøąĖčüčéąĖąĮą│ 15-17. ąöąĄą╝ąŠąĮčüčéčĆą░čåąĖčÅ, čćč鹊 ąĮąĄą╗čīąĘčÅ ą┐ąŠą╗čāčćąĖčéčī ą┤ą▓ą░ čüą┐ąĖčüą║ą░, ąĖčüą┐ąŠą╗čīąĘčāčÅ Box< T>, ą║ąŠą│ą┤ą░ ą┤ąĄą╗ą░ąĄčéčüčÅ ą┐ąŠą┐čŗčéą║ą░ čĆą░ąĘą┤ąĄą╗ąĖčéčī ą▓ą╗ą░ą┤ąĄąĮąĖąĄ ąĮą░ą┤ čéčĆąĄčéčīąĖą╝ čüą┐ąĖčüą║ąŠą╝.
ąÜąŠą│ą┤ą░ ą╝čŗ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄą╝ čŹč鹊čé ą║ąŠą┤, ą┐ąŠą╗čāčćąĖą╝ čüą╗ąĄą┤čāčÄčēčāčÄ ąŠčłąĖą▒ą║čā:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0382]: use of moved value: `a`
--> src/main.rs:11:30
|
9 | let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
| - move occurs because `a` has type `List`, which does not implement the `Copy` trait
10 | let b = Cons(3, Box::new(a));
| - value moved here
11 | let c = Cons(4, Box::new(a));
| ^ value used here after move
For more information about this error, try `rustc --explain E0382`.
error: could not compile `cons-list` (bin "cons-list") due to 1 previous error
ąÆą░čĆąĖą░ąĮčéčŗ Cons ą▓ą╗ą░ą┤ąĄčÄčé ą┤ą░ąĮąĮčŗą╝ąĖ, ą║ąŠč鹊čĆčŗąĄ čģčĆą░ąĮčÅčé, čéą░ą║ čćč鹊 ą║ąŠą│ą┤ą░ ą╝čŗ čüąŠąĘą┤ą░ąĄą╝ čüą┐ąĖčüąŠą║ b, čüą┐ąĖčüąŠą║ a ą┐ąĄčĆąĄą╝ąĄčēą░ąĄčéčüčÅ ą▓ b, ąĖ b ą▓ą╗ą░ą┤ąĄąĄčé a. ąŚą░č鹥ą╝, ą║ąŠą│ą┤ą░ ą╝čŗ ą┐čŗčéą░ąĄą╝čüčÅ čüąĮąŠą▓ą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čüą┐ąĖčüąŠą║ a, ą║ąŠą│ą┤ą░ čüąŠąĘą┤ą░ąĄą╝ c, ąĮą░ą╝ čŹč鹊 ąĮąĄ čĆą░ąĘčĆąĄčłą░ąĄčéčüčÅ, ą┐ąŠč鹊ą╝čā čćč鹊 a ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą┐ąĄčĆąĄą╝ąĄčēąĄąĮ.
ą£čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ ąĖąĘą╝ąĄąĮąĖčéčī ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ Cons, čćč鹊ą▒čŗ čģčĆą░ąĮąĖčéčī ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ čüčüčŗą╗ą║ąĖ, ąĮąŠ č鹊ą│ą┤ą░ ąĮą░ą╝ ą┐čĆąĖčłą╗ąŠčüčī ą▒čŗ čāą║ą░ąĘčŗą▓ą░čéčī ą┐ą░čĆą░ą╝ąĄčéčĆčŗ ą▓čĆąĄą╝ąĄąĮąĖ ąČąĖąĘąĮąĖ. ąŻą║ą░ąĘą░ąĮąĖąĄą╝ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ ą▓čĆąĄą╝ąĄąĮąĖ ąČąĖąĘąĮąĖ ą╝čŗ čāą║ą░ąĘą░ą╗ąĖ ą▒čŗ, čćč鹊 ą║ą░ąČą┤čŗą╣ 菹╗ąĄą╝ąĄąĮčé ą▓ čüą┐ąĖčüą║ąĄ ąČąĖą▓ąĄčé ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝ čüč鹊ą╗čīą║ąŠ ąČąĄ, čüą║ąŠą╗čīą║ąŠ ą▓ąĄčüčī čüą┐ąĖčüąŠą║. ąŁč鹊 čüą╗čāčćą░ą╣ ą┤ą╗čÅ čŹą╗ąĄą╝ąĄąĮč鹊ą▓ ąĖ čüą┐ąĖčüą║ąŠą▓ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-17, ąĮąŠ ąĮąĄ ą┐čĆąĖą╝ąĄąĮąĖą╝ąŠ ą║ ą╗čÄą▒ąŠą╝čā čüčåąĄąĮą░čĆąĖčÄ.
ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą╝čŗ ą┐ąŠą╝ąĄąĮčÅąĄą╝ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ List ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ Rc< T> ą▓ą╝ąĄčüč鹊 Box< T>, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-18. ąÜą░ąČą┤čŗą╣ ą▓ą░čĆąĖą░ąĮčé Cons ą▒čāą┤ąĄčé č鹥ą┐ąĄčĆčī čģčĆą░ąĮąĖčéčī ąĘąĮą░č湥ąĮąĖąĄ value ąĖ Rc< T>, čāą║ą░ąĘčŗą▓ą░čÄčēąĖą╣ ąĮą░ List. ąÜąŠą│ą┤ą░ ą╝čŗ čüąŠąĘą┤ą░ąĄą╝ b, ą▓ą╝ąĄčüč鹊 ą┐ąŠą╗čāč湥ąĮąĖąĄ ą▓ąŠ ą▓ą╗ą░ą┤ąĄąĮąĖąĄ ąĮą░ą┤ a ą║ą╗ąŠąĮąĖčĆčāąĄą╝ Rc< List>, ą║ąŠč鹊čĆčŗą╣ ąĄą│ąŠ čüąŠą┤ąĄčƹȹĖčé, čāą▓ąĄą╗ąĖčćąĖą▓ą░čÅ č鹥ą╝ čüą░ą╝čŗą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čüčüčŗą╗ąŠą║ čü ąŠą┤ąĮąŠą│ąŠ ą┤ąŠ ą┤ą▓čāčģ, ąĖ ą┐ąŠąĘą▓ąŠą╗čÅčÅ a ąĖ b čüąŠą▓ą╝ąĄčüčéąĮąŠ ą▓ą╗ą░ą┤ąĄčéčī ą┤ą░ąĮąĮčŗą╝ąĖ ą▓ čŹč鹊ą╝ Rc< List>. ąæčāą┤ąĄą╝ čéą░ą║ąČąĄ ą║ą╗ąŠąĮąĖčĆąŠą▓ą░čéčī a ą┐čĆąĖ čüąŠąĘą┤ą░ąĮąĖąĖ c, čāą▓ąĄą╗ąĖčćąĖą▓ą░čÅ čüč湥čéčćąĖą║ čüčüčŗą╗ąŠą║ čü ą┤ą▓čāčģ ą┤ąŠ čéčĆąĄčģ. ąÜą░ąČą┤čŗą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ą╝čŗ ą▓čŗąĘčŗą▓ą░ąĄą╝ Rc::clone, čüč湥čéčćąĖą║ čüčüčŗą╗ąŠą║ ąĮą░ ą┤ą░ąĮąĮčŗąĄ ą▓ Rc< List> ą▒čāą┤ąĄčé čāą▓ąĄą╗ąĖčćąĖą▓ą░čéčīčüčÅ, ąĖ ą┤ą░ąĮąĮčŗąĄ ąĮąĄ ą▒čāą┤čāčé ąŠčćąĖčēąĄąĮčŗ, ą┐ąŠą║ą░ ąĮąĄ ą┤ąŠčüčéąĖą│ąĮąĄčé ąĮčāą╗čÅ čüč湥čéčćąĖą║ čüčüčŗą╗ąŠą║ ąĮą░ ąĮąĖčģ.
enum List {
Cons(i32, Rc< List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
let b = Cons(3, Rc::clone(&a));
let c = Cons(4, Rc::clone(&a));
}
ąøąĖčüčéąĖąĮą│ 15-18. ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ List, ą║ąŠč鹊čĆčŗą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄčé Rc< T> (čäą░ą╣ą╗ src/main.rs).
ąØą░ą╝ ąĮčāąČąĮąŠ ą┤ąŠą▒ą░ą▓ąĖčéčī ąŠą┐ąĄčĆą░č鹊čĆ use, čćč鹊ą▒čŗ ą┐čĆąĖą▓ąĄčüčéąĖ ą▓ ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ čéąĖą┐ Rc< T>, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąĮ ąĮąĄ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ prelude. ąÆ main ą╝čŗ čüąŠąĘą┤ą░ą╗ąĖ čüą┐ąĖčüąŠą║, čüąŠą┤ąĄčƹȹ░čēąĖą╣ 5 ąĖ 10, ąĖ čüąŠčģčĆą░ąĮąĖą╗ąĖ ąĄą│ąŠ ą▓ ąĮąŠą▓čŗą╣ Rc< List> ą▓ a. ąŚą░č鹥ą╝ ą╝čŗ čüąŠąĘą┤ą░ą╗ąĖ b ąĖ c, ą▓čŗąĘą▓ą░ą▓ čäčāąĮą║čåąĖčÄ Rc::clone čü ą┐ąĄčĆąĄą┤ą░č湥ą╣ ą▓ ąĮąĄčæ čüčüčŗą╗ą║ąĖ ąĮą░ Rc< List> ą▓ ą║ą░č湥čüčéą▓ąĄ ą░čĆą│čāą╝ąĄąĮčéą░.
ą£čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ ą▓čŗąĘą▓ą░čéčī a.clone() ą▓ą╝ąĄčüč鹊 Rc::clone(&a), ąŠą┤ąĮą░ą║ąŠ čüąŠą│ą╗ą░čłąĄąĮąĖąĄ Rust ą│ąŠą▓ąŠčĆąĖčé ąŠą▒ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ Rc::clone ą┤ą╗čÅ čéą░ą║ąŠą│ąŠ čüą╗čāčćą░čÅ. ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ Rc::clone ąĮąĄ ą┤ąĄą╗ą░ąĄčé ą│ą╗čāą▒ąŠą║čāčÄ ą║ąŠą┐ąĖčÄ ą▓čüąĄčģ ą┤ą░ąĮąĮčŗčģ, ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ č鹊ą│ąŠ, ą║ą░ą║ čŹč鹊 ą┤ąĄą╗ą░čÄčé čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ą░ čéąĖą┐ąŠą▓. ąÆčŗąĘąŠą▓ Rc::clone čĆąĄą░ą╗ąĖąĘčāąĄčé č鹊ą╗čīą║ąŠ čüč湥čéčćąĖą║ čüčüčŗą╗ąŠą║, čćč鹊 ąĮąĄ ąĘą░ąĮąĖą╝ą░ąĄčé ą╝ąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ. ąōą╗čāą▒ąŠą║ąŠąĄ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ ą╝ąŠąČąĄčé ąĘą░ąĮčÅčéčī ą╝ąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ Rc::clone ą┤ą╗čÅ ą┐ąŠą┤čüč湥čéą░ čüčüčŗą╗ąŠą║ ą╝čŗ ą╝ąŠąČąĄą╝ ą▓ąĖąĘčāą░ą╗čīąĮąŠ čĆą░ąĘą╗ąĖčćą░čéčī ą▓ąĖą┤čŗ ą║ą╗ąŠąĮąĖčĆąŠą▓ą░ąĮąĖčÅ čü ą│ą╗čāą▒ąŠą║ąŠą╣ ą║ąŠą┐ąĖąĄą╣ ąĖ ą║ą╗ąŠąĮąĖčĆąŠą▓ą░ąĮąĖčÅ čāą▓ąĄą╗ąĖč湥ąĮąĖąĄą╝ čüč湥čéčćąĖą║ą░ čüčüčŗą╗ąŠą║. ą¤čĆąĖ ą┐ąŠąĖčüą║ąĄ ą▓ ą║ąŠą┤ąĄ ą┐čĆąŠą▒ą╗ąĄą╝ čü ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄą╝, ąĮą░ą╝ č鹊ą╗čīą║ąŠ ąĮčāąČąĮąŠ čĆą░čüčüą╝ąŠčéčĆąĄčéčī ą║ą╗ąŠąĮąĖčĆąŠą▓ą░ąĮąĖąĄ ą│ą╗čāą▒ąŠą║ąŠą│ąŠ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ, ąĖ ą╝čŗ ą╝ąŠąČąĄą╝ ąĖą│ąĮąŠčĆąĖčĆąŠą▓ą░čéčī ą▓čŗąĘąŠą▓čŗ Rc::clone.
ąÜą╗ąŠąĮąĖčĆąŠą▓ą░ąĮąĖąĄ Rc< T> čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčé čüč湥čéčćąĖą║ čüčüčŗą╗ąŠą║. ąöą░ą▓ą░ą╣č鹥 ąĖąĘą╝ąĄąĮąĖą╝ ąĮą░čł čĆą░ą▒ąŠčćąĖą╣ ą┐čĆąĖą╝ąĄčĆ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-18, čćč鹊ą▒čŗ ą╝čŗ ą╝ąŠą│ą╗ąĖ čāą▓ąĖą┤ąĄčéčī, čāą▓ąĖą┤ąĄčéčī ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ čüč湥čéčćąĖą║ą░ čüčüčŗą╗ąŠą║ ą┐ąŠ ą╝ąĄčĆąĄ č鹊ą│ąŠ, ą║ą░ą║ ą╝čŗ čüąŠąĘą┤ą░ąĄą╝ ąĖ ą▓čŗą▒čĆą░čüčŗą▓ą░ąĄą╝ čüčüčŗą╗ą║ąĖ ąĮą░ a ą▓ Rc< List>.
ąÆ ą╗ąĖčüčéąĖąĮą│ąĄ 15-19 ą╝čŗ ą┐ąŠą╝ąĄąĮčÅą╗ąĖ main čéą░ą║, čćč鹊 čā ąĮą░čü ąĄčüčéčī ą▓ąĮčāčéčĆąĄąĮąĮčÅčÅ ąŠą▒ą╗ą░čüčéčī ą▓ąŠą║čĆčāą│ čüą┐ąĖčüą║ą░ c; ąĘą░č鹥ą╝ ą╝čŗ ą╝ąŠąČąĄą╝ ą▓ąĖą┤ąĄčéčī, ą║ą░ą║ ą╝ąĄąĮčÅąĄčéčüčÅ čüč湥čéčćąĖą║ čüčüčŗą╗ąŠą║, ą║ąŠą│ą┤ą░ c ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ.
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
println!("count after creating a = {}", Rc::strong_count(&a));
let b = Cons(3, Rc::clone(&a));
println!("count after creating b = {}", Rc::strong_count(&a));
{
let c = Cons(4, Rc::clone(&a));
println!("count after creating c = {}", Rc::strong_count(&a));
}
println!("count after c goes out of scope = {}", Rc::strong_count(&a));
}
ąøąĖčüčéąĖąĮą│ 15-19. ą¤ąĄčćą░čéčī čüč湥čéčćąĖą║ą░ čüčüčŗą╗ąŠą║ (čäą░ą╣ą╗ src/main.rs).
ąÆ ą║ą░ąČą┤ąŠą╝ ą╝ąĄčüč鹥 ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ą│ą┤ąĄ ą╝ąĄąĮčÅąĄčéčüčÅ čüč湥čéčćąĖą║ čüčüčŗą╗ąŠą║, ą╝čŗ ąĄą│ąŠ ą┐ąĄčćą░čéą░ąĄą╝ čü ą┐ąŠą╝ąŠčēčīčÄ ą▓čŗąĘąŠą▓ą░ čäčāąĮą║čåąĖąĖ Rc::strong_count. ąŁčéą░ čäčāąĮą║čåąĖčÅ ąĮąŠčüąĖčé ąĖą╝čÅ strong_count ą▓ą╝ąĄčüč鹊 count, ą┐ąŠč鹊ą╝čā čćč鹊 čéąĖą┐ Rc< T> čéą░ą║ąČąĄ ąĖą╝ąĄąĄčé weak_count; ą╝čŗ čāą▓ąĖą┤ąĖą╝, ą┤ą╗čÅ č湥ą│ąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ weak_count ą▓ čüąĄą║čåąĖąĖ "ą¤čĆąĄą┤ąŠčéą▓čĆą░čēąĄąĮąĖąĄ čåąĖą║ą╗ąŠą▓ čüčüčŗą╗ąŠą║: ą┐čĆąĄą▓čĆą░čēąĄąĮąĖąĄ Rc< T> ą▓ Weak< T>".
ąŁč鹊čé ą║ąŠą┤ ąĮą░ą┐ąĄčćą░čéą░ąĄčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.45s
Running `target/debug/cons-list`
count after creating a = 1
count after creating b = 2
count after creating c = 3
count after c goes out of scope = 2
ą£čŗ ą╝ąŠąČąĄą╝ čāą▓ąĖą┤ąĄčéčī, čćč鹊 Rc< List> ą▓ a ąĖą╝ąĄąĄčé ąĘąĮą░č湥ąĮąĖąĄ čüč湥čéčćąĖą║ą░ čüčüčŗą╗ąŠą║ 1; ąĘą░č鹥ą╝ ą║ą░ąČą┤čŗą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ą╝čŗ ą▓čŗąĘčŗą▓ą░ąĄą╝ clone, čüč湥čéčćąĖą║ čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčéčüčÅ ąĮą░ 1. ąŚą░č鹥ą╝, ą║ąŠą│ą┤ą░ c ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ, čüč湥čéčćąĖą║ čāą╝ąĄąĮčīčłą░ąĄčéčüčÅ ąĮą░ 1. ąØą░ą╝ ąĮąĄ ąĮčāąČąĮąŠ ą▓čŗąĘčŗą▓ą░čéčī čäčāąĮą║čåąĖčÄ ą┤ą╗čÅ čāą╝ąĄąĮčīčłąĄąĮąĖčÅ čüč湥čéčćąĖą║ą░ čüčüčŗą╗ąŠą║, ą║ą░ą║ ą╝čŗ ą┤ąŠą╗ąČąĮčŗ ą▓čŗąĘčŗą▓ą░čéčī Rc::clone ą┤ą╗čÅ čāą▓ąĄą╗ąĖč湥ąĮąĖčÅ ą║ąŠą╗ąĖč湥čüčéą▓ą░ čüčüčŗą╗ąŠą║: čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ čéčĆąĄą╣čéą░ Drop ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ čāą╝ąĄąĮčīčłą░ąĄčé čüč湥čéčćąĖą║ čüčüčŗą╗ąŠą║, ą║ąŠą│ą┤ą░ ąĘąĮą░č湥ąĮąĖąĄ Rc< T> ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ.
ą¦č鹊 ą╝čŗ ąĮąĄ ą╝ąŠąČąĄą╝ čāą▓ąĖą┤ąĄčéčī ą▓ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ, čéą░ą║ čŹč鹊 č鹊, čćč鹊 ą║ąŠą│ą┤ą░ b ąĖ ąĘą░č鹥ą╝ a ą▓čŗčģąŠą┤čÅčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ ą┐ąŠ ąŠą║ąŠąĮčćą░ąĮąĖčÄ main, čüč湥čéčćąĖą║ č鹊ą│ą┤ą░ čüčéą░ąĮąŠą▓ąĖčéčüčÅ čĆą░ą▓ąĮčŗą╝ 0, ąĖ Rc< List> ąŠčćąĖčēą░ąĄčéčüčÅ ą┐ąŠą╗ąĮąŠčüčéčīčÄ. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ Rc< T> ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąŠą┤ąĖąĮąŠčćąĮąŠą╝čā ąĘąĮą░č湥ąĮąĖčÄ ąĖą╝ąĄčéčī ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą▓, ąĖ čüč湥čéčćąĖą║ ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ąĘąĮą░č湥ąĮąĖąĄ ąŠčüčéą░ąĄčéčüčÅ ą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝, ą┐ąŠą║ą░ čüčāčēąĄčüčéą▓čāąĄčé čģąŠčéčÅ ą▒čŗ ąŠą┤ąĖąĮ ąĄą│ąŠ ą▓ą╗ą░ą┤ąĄą╗ąĄčå.
ąĪ ą┐ąŠą╝ąŠčēčīčÄ ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗčģ čüčüčŗą╗ąŠą║ Rc< T> ą┐ąŠąĘą▓ąŠą╗ąĖčé ą▓ą░ą╝ čüąŠą▓ą╝ąĄčüčéąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą░ąĮąĮčŗąĄ ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ čćą░čüčéčÅą╝ąĖ ą▓ą░čłąĄą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ąĮąŠ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ. ąĢčüą╗ąĖ Rc< T> ą┐ąŠąĘą▓ąŠą╗ąĖčé ą▓ą░ą╝ ąĖą╝ąĄčéčī čéą░ą║ąČąĄ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą╝čāčéąĖčĆčāąĄą╝čŗčģ čüčüčŗą╗ąŠą║, č鹊 ą▓čŗ ą╝ąŠąČąĄč鹥 ąĮą░čĆčāčłąĖčéčī ąŠą┤ąĮąŠ ąĖąĘ ą┐čĆą░ą▓ąĖą╗ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ, ą║ąŠč鹊čĆąŠąĄ ą╝čŗ ąŠą▒čüčāąČą┤ą░ą╗ąĖ ą▓ ą│ą╗ą░ą▓ąĄ 4 [2]: ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĖąĘą╝ąĄąĮčÅąĄą╝čŗčģ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖą╣ ą┤ą╗čÅ ąŠą┤ąĮąŠą│ąŠ ąĖ č鹊ą│ąŠ ąČąĄ ą╝ąĄčüčéą░ ą╝ąŠą│čāčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą│ąŠąĮą║ąĄ ą┤ą░ąĮąĮčŗčģ (data races) ąĖ ąĮąĄčüąŠąŠčéą▓ąĄčéčüčéą▓ąĖčÄ (inconsistencies). ąØąŠ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą╝čāčéą░čåąĖąĖ ą┤ą░ąĮąĮčŗčģ ąŠč湥ąĮčī ą┐ąŠą╗ąĄąĘąĮą░! ąÆ čüą╗ąĄą┤čāčÄčēąĄą╣ čüąĄą║čåąĖąĖ ą╝čŗ ąŠą▒čüčāą┤ąĖą╝ čłą░ą▒ą╗ąŠąĮ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ ą╝čāčéąĖčĆčāąĄą╝ąŠčüčéąĖ ąĖ čéąĖą┐ RefCell< T>, ą║ąŠč鹊čĆčŗą╣ ą▓čŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čüąŠą▓ą╝ąĄčüčéąĮąŠ čü Rc< T>, čćč鹊ą▒čŗ čĆą░ąĘąŠą▒čĆą░čéčīčüčÅ čü čŹčéąĖą╝ ąŠą│čĆą░ąĮąĖč湥ąĮąĖąĄą╝ ąĮąĄ ą╝čāčéąĖčĆčāąĄą╝ąŠčüčéąĖ.
[RefCell< T> ąĖ čłą░ą▒ą╗ąŠąĮ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ ąĖąĘą╝ąĄąĮčćąĖą▓ąŠčüčéąĖ]
ąÆąĮčāčéčĆąĄąĮąĮčÅčÅ ąĖąĘą╝ąĄąĮčćąĖą▓ąŠčüčéčī (interior mutability) čŹč鹊 čłą░ą▒ą╗ąŠąĮ ą┤ąĖąĘą░ą╣ąĮą░ ą▓ Rust, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą▓ą░ą╝ ą╝čāčéąĖčĆąŠą▓ą░čéčī ą┤ą░ąĮąĮčŗąĄ ą┤ą░ąČąĄ ą║ąŠą│ą┤ą░ čüčāčēąĄčüčéą▓čāčÄčé ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗąĄ čüčüčŗą╗ą║ąĖ ąĮą░ čŹčéąĖ ą┤ą░ąĮąĮčŗąĄ; ąŠą▒čŗčćąĮąŠ čŹč鹊 ą┤ąĄą╣čüčéą▓ąĖąĄ ąĮąĄ čĆą░ąĘčĆąĄčłąĄąĮąŠ čüąŠą│ą╗ą░čüąĮąŠ ą┐čĆą░ą▓ąĖą╗ą░ą╝ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ (borrowing rules). ąöą╗čÅ ą╝čāčéąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ čłą░ą▒ą╗ąŠąĮ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąĮąĄą▒ąĄąĘąŠą┐ą░čüąĮčŗą╣ (unsafe) ą║ąŠą┤ ą▓ąĮčāčéčĆąĖ čüčéčĆčāą║čéčāčĆčŗ ą┤ą░ąĮąĮčŗčģ, čćč鹊ą▒čŗ ąŠą▒ąŠą╣čéąĖ ąŠą▒čŗčćąĮčŗąĄ ą┐čĆą░ą▓ąĖą╗ą░ Rust, čĆąĄą│čāą╗ąĖčĆčāčÄčēąĖąĄ ą╝čāčéą░čåąĖčÄ ąĖ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖąĄ. ąØąĄą▒ąĄąĘąŠą┐ą░čüąĮčŗą╣ ą║ąŠą┤ čāą║ą░ąĘčŗą▓ą░ąĄčé ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆčā, čćč鹊 ą╝čŗ ą┐čĆąŠą▓ąĄčĆčÅąĄą╝ ą┐čĆą░ą▓ąĖą╗ą░ ą▓čĆčāčćąĮčāčÄ, ą░ ąĮąĄ ą┐ąŠą╗ą░ą│ą░ąĄą╝čüčÅ ąĮą░ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ, čćč鹊ą▒čŗ ąŠąĮ ą┐čĆąŠą▓ąĄčĆčÅą╗ čŹčéąĖ ą┐čĆą░ą▓ąĖą╗ą░ ąĘą░ ąĮą░čü; čŹč鹊čé ąĮąĄą▒ąĄąĘąŠą┐ą░čüąĮčŗą╣ ą║ąŠą┤ ą╝čŗ ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ą▓ ą│ą╗ą░ą▓ąĄ 19.
ą£čŗ ą╝ąŠąČąĄą╝ ą┐čĆąĖą╝ąĄąĮčÅčéčī čéąĖą┐čŗ, ą║ąŠč鹊čĆčŗąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčé čłą░ą▒ą╗ąŠąĮ interior mutability pattern č鹊ą╗čīą║ąŠ ą║ąŠą│ą┤ą░ ą╝čŗ ą╝ąŠąČąĄą╝ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ą┐čĆą░ą▓ąĖą╗ą░ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ ą▒čāą┤čāčé čüąŠą▒ą╗čÄą┤ą░čéčīčüčÅ runtime, čģąŠčéčÅ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąĮąĄ ą╝ąŠąČąĄčé čŹč鹊ą│ąŠ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī. ąØąĄą▒ąĄąĘąŠą┐ą░čüąĮčŗą╣ ą║ąŠą┤ ąĘą░č鹥ą╝ čāą┐ą░ą║ąŠą▓čŗą▓ą░ąĄčéčüčÅ ą▓ ą▒ąĄąĘąŠą┐ą░čüąĮčŗą╣ API, ą░ ą▓ąĮąĄčłąĮąĖą╣ čéąĖą┐ ą▓čüąĄ ąĄčēąĄ ąŠčüčéą░ąĄčéčüčÅ ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗą╝.
ąöą░ą▓ą░ą╣č鹥 čĆą░čüčüą╝ąŠčéčĆąĖą╝ čŹčéčā ą║ąŠąĮčåąĄą┐čåąĖčÄ ąĮą░ čéąĖą┐ąĄ RefCell< T>, ą║ąŠč鹊čĆčŗą╣ čüą╗ąĄą┤čāąĄčé čłą░ą▒ą╗ąŠąĮčā interior mutability.
RefCell< T>: ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ą┐čĆą░ą▓ąĖą╗ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ runtime. ąÆ ąŠčéą╗ąĖčćąĖąĄ ąŠčé Rc< T>, čéąĖą┐ RefCell< T> ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé ąŠą┤ąĖąĮąŠčćąĮąŠąĄ ą▓ą╗ą░ą┤ąĄąĮąĖąĄ ąĮą░ą┤ čģčĆą░ąĮčÅčēąĖą╝ąĖčüčÅ ą▓ ąĮąĄą╝ ą┤ą░ąĮąĮčŗą╝ąĖ. ąśčéą░ą║, čćč鹊 ąŠčéą╗ąĖčćą░ąĄčé RefCell< T> ąŠčé čéąĖą┐ą░ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ Box< T>? ąÆčüą┐ąŠą╝ąĮąĖą╝ ą┐čĆą░ą▓ąĖą╗ą░ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ, ą║ąŠč鹊čĆčŗą╝ ą╝čŗ ąĮą░čāčćąĖą╗ąĖčüčī ą▓ ą│ą╗ą░ą▓ąĄ 4 [2]:
ŌĆó ąÆ ą╗čÄą▒ąŠą╣ ą╝ąŠą╝ąĄąĮčé ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗ ą╝ąŠąČąĄč鹥 ą╗ąĖą▒ąŠ (ąĮąŠ ąĮąĄ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ) ąĖą╝ąĄčéčī ąŠą┤ąĮčā ą╝čāčéąĖčĆčāąĄą╝čāčÄ čüčüčŗą╗ą║čā, ą╗ąĖą▒ąŠ ą╗čÄą▒ąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗčģ čüčüčŗą╗ąŠą║.
ŌĆó ąĪčüčŗą╗ą║ąĖ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą▓čüąĄą│ą┤ą░ ą║ąŠčĆčĆąĄą║čéąĮčŗą╝ąĖ.
ą¤čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ čüčüčŗą╗ąŠą║ ąĖ Box< T> ąĖąĮą▓ą░čĆąĖą░ąĮčéčŗ ą┐čĆą░ą▓ąĖą╗ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ ą┐čĆąĖą╝ąĄąĮčÅčÄčéčüčÅ ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ. ą¤čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ RefCell< T> čŹčéąĖ ąĖąĮą▓ą░čĆąĖą░ąĮčéčŗ ą┐čĆąĖą╝ąĄąĮčÅčÄčéčüčÅ ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ (runtime). ą¤čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ čüčüčŗą╗ąŠą║, ąĄčüą╗ąĖ ą▓čŗ ąĮą░čĆčāčłąĖč鹥 čŹčéąĖ ą┐čĆą░ą▓ąĖą╗ą░, č鹊 ą┐ąŠą╗čāčćąĖč鹥 ąŠčłąĖą▒ą║čā ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░. ą¤čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ RefCell< T>, ąĄčüą╗ąĖ ą▓čŗ ąĮą░čĆčāčłąĖč鹥 čŹčéąĖ ą┐čĆą░ą▓ąĖą╗ą░, č鹊 ą▓ą░čłą░ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ čüą│ąĄąĮąĄčĆąĖčĆčāąĄčé panic ąĖ ąĘą░ą▓ąĄčĆčłąĖčé čĆą░ą▒ąŠčéčā (exit).
ąöąŠčüč鹊ąĖąĮčüčéą▓ąŠ ą┐čĆąŠą▓ąĄčĆą║ąĖ ą┐čĆą░ą▓ąĖą╗ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ą▓ č鹊ą╝, čćč鹊 ąŠčłąĖą▒ą║ąĖ ą┐ąĄčĆąĄčģą▓ą░čéčŗą▓ą░čÄčéčüčÅ ąĮą░ čĆą░ąĮąĮąĄą╣ čüčéą░ą┤ąĖąĖ, ą▓ ą┐čĆąŠčåąĄčüčüąĄ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ, ąĖ čŹč鹊 ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ą║ąŠą┤ą░, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓ąĄčüčī ą░ąĮą░ą╗ąĖąĘ ąĘą░ą▓ąĄčĆčłąĄąĮ ąĘą░čĆą░ąĮąĄąĄ. ą¤ąŠ čŹčéąĖą╝ ą┐čĆąĖčćąĖąĮą░ą╝ ą┐čĆąŠą▓ąĄčĆą║ą░ ą┐čĆą░ą▓ąĖą╗ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ą╗čāčćčłąĖą╣ ą▓čŗą▒ąŠčĆ ą┤ą╗čÅ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ą░ čüą╗čāčćą░ąĄą▓, ą┐ąŠčŹč鹊ą╝čā čéą░ą║ąŠą╣ ą▓čŗą▒ąŠčĆ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ą▓ Rust ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ.
ąöąŠčüč鹊ąĖąĮčüčéą▓ąŠ ą┐čĆąŠą▓ąĄčĆą║ąĖ ą┐čĆą░ą▓ąĖą╗ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ runtime čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, čćč鹊 ąĘą░č鹥ą╝ ą┤ąŠą┐čāčüą║ą░čÄčéčüčÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ čüčåąĄąĮą░čĆąĖąĖ, ą▒ąĄąĘąŠą┐ą░čüąĮčŗąĄ ą┤ą╗čÅ ą┐ą░ą╝čÅčéąĖ, ą│ą┤ąĄ ąŠąĮąĖ ą▒čŗą╗ąĖ ą▒čŗ ąĘą░ą┐čĆąĄčēąĄąĮčŗ ą┐čĆąŠą▓ąĄčĆą║ą░ą╝ąĖ ą▓čĆąĄą╝ąĄąĮąĖ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ. ąĪčéą░čéąĖč湥čüą║ąĖą╣ ą░ąĮą░ą╗ąĖąĘ, ą║ą░ą║ ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ Rust, ą┐ąŠ čüą▓ąŠąĄą╣ čüčāčéąĖ ą║ąŠąĮčüąĄčĆą▓ą░čéąĖą▓ąĄąĮ. ąØąĄą║ąŠč鹊čĆčŗąĄ čüą▓ąŠą╣čüčéą▓ą░ ą║ąŠą┤ą░ ąĮąĄą▓ąŠąĘą╝ąŠąČąĮąŠ ąŠą▒ąĮą░čĆčāąČąĖčéčī ą┐čāč鹥ą╝ ąĄą│ąŠ ą░ąĮą░ą╗ąĖąĘą░: čüą░ą╝čŗą╝ ąĖąĘą▓ąĄčüčéąĮčŗą╝ ą┐čĆąĖą╝ąĄčĆąŠą╝ ą╝ąŠąČąĄčé čüčćąĖčéą░čéčīčüčÅ ą¤čĆąŠą▒ą╗ąĄą╝ą░ ą×čüčéą░ąĮąŠą▓ą║ąĖ [7], ą║ąŠč鹊čĆą░čÅ ą▓čŗčģąŠą┤ąĖčé ąĘą░ čĆą░ą╝ą║ąĖ ąĮą░čłąĄą│ąŠ ąŠą┐ąĖčüą░ąĮąĖčÅ, čģąŠčéčÅ ąĖ ąŠčüčéą░ąĄčéčüčÅ ąĖąĮč鹥čĆąĄčüąĮąŠą╣ č鹥ą╝ąŠą╣ ą┤ą╗čÅ ąĖčüčüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ.
ą¤ąŠčüą║ąŠą╗čīą║čā ąĮąĄ ą╗čÄą▒ąŠą╣ ą░ąĮą░ą╗ąĖąĘ ą▓ąŠąĘą╝ąŠąČąĄąĮ, ąĄčüą╗ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ Rust ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī čāą▓ąĄčĆąĄąĮ, čćč鹊 ą║ąŠą┤ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ą┐čĆą░ą▓ąĖą╗ą░ą╝ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ, ąŠąĮ ą╝ąŠąČąĄčé ąŠčéą║ą╗ąŠąĮąĖčéčī čāčüą┐ąĄčłąĮąŠąĄ ą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░ąĮąĖąĄ ą║ąŠčĆčĆąĄą║čéąĮąŠą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ; čŹč鹊čé ą▓ą░čĆąĖą░ąĮčé ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ ą║ąŠąĮčüąĄčĆą▓ą░čéąĖą▓ąĄąĮ. ąĢčüą╗ąĖ ą▒čŗ Rust ą┐čĆąĖąĮčÅą╗ ąĮąĄą║ąŠčĆčĆąĄą║čéąĮčāčÄ ą┐čĆąŠą│čĆą░ą╝ą╝čā, ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĖ ąĮąĄ čüą╝ąŠą│ą╗ąĖ ą▒čŗ ą┤ąŠą▓ąĄčĆčÅčéčī ą│ą░čĆą░ąĮčéąĖčÅą╝, ą║ąŠč鹊čĆčŗąĄ ą┤ą░ąĄčé Rust. ą×ą┤ąĮą░ą║ąŠ ąĄčüą╗ąĖ Rust ąŠčéą║ą╗ąŠąĮąĖčé ą║ąŠčĆčĆąĄą║čéąĮčāčÄ ą┐čĆąŠą│čĆą░ą╝ą╝čā, ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčéčā čŹč鹊 ą▒čāą┤ąĄčé ąĮąĄčāą┤ąŠą▒ąĮąŠ, ąĮąŠ ąĮąĖč湥ą│ąŠ ą║ą░čéą░čüčéčĆąŠčäąĖč湥čüą║ąŠą│ąŠ ąĮąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé. ąóąĖą┐ RefCell< T> ą┐ąŠą╗ąĄąĘąĄąĮ, ą║ąŠą│ą┤ą░ ą▓ą░čł ą║ąŠą┤ čüą╗ąĄą┤čāąĄčé ą┐čĆą░ą▓ąĖą╗ą░ą╝ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ, ąŠą┤ąĮą░ą║ąŠ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąĮąĄ ą╝ąŠąČąĄčé čŹč鹊ą│ąŠ ą┐ąŠąĮčÅčéčī ąĖ čćč鹊-ą╗ąĖą▒ąŠ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī.
ą¤ąŠą┤ąŠą▒ąĮąŠ Rc< T>, čéąĖą┐ RefCell< T> ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ąŠą┤ąĮąŠą┐ąŠč鹊čćąĮčŗčģ čüčåąĄąĮą░čĆąĖąĄą▓, ąĖ ą┤ą░čüčé ąŠčłąĖą▒ą║čā ą▓čĆąĄą╝ąĄąĮąĖ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ, ąĄčüą╗ąĖ ą▓čŗ ą┐ąŠą┐čŗčéą░ąĄč鹥čüčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĄą│ąŠ ą▓ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠą╝ ą║ąŠąĮč鹥ą║čüč鹥. ąÆ ą│ą╗ą░ą▓ąĄ 16 ą╝čŗ ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐ąŠą│ąŠą▓ąŠčĆąĖą╝ ąŠ č鹊ą╝, ą║ą░ą║ ą┐ąŠą╗čāčćąĖčéčī čäčāąĮą║čåąĖąŠąĮą░ą╗ RefCell< T> ą▓ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠą╣ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ.
ąÆąŠčé ą║čĆą░čéą║ąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ą┐čĆąĖčćąĖąĮ ą▓čŗą▒ąŠčĆą░ Box< T>, Rc< T> ąĖą╗ąĖ RefCell< T>:
ŌĆó Rc< T> čĆą░ąĘčĆąĄčłą░ąĄčé ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą▓ ąĮą░ą┤ ąŠą┤ąĮąĖą╝ąĖ ąĖ č鹥ą╝ąĖ ąČąĄ ą┤ą░ąĮąĮčŗą╝ąĖ; Box< T> ąĖ RefCell< T> ąĖą╝ąĄčÄčé ąŠą┤ąĖąĮąŠčćąĮčŗčģ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą▓.
ŌĆó Box< T> ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐čĆąŠą▓ąĄčĆčÅčéčī ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗąĄ ąĖą╗ąĖ ą╝čāčéąĖčĆčāąĄą╝čŗąĄ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ; Rc< T> ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐čĆąŠą▓ąĄčĆčÅčéčī č鹊ą╗čīą║ąŠ ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗąĄ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ; RefCell< T> ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐čĆąŠą▓ąĄčĆčÅčéčī ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗąĄ ąĖą╗ąĖ ą╝čāčéąĖčĆčāąĄą╝čŗąĄ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ (runtime).
ŌĆó ą¤ąŠčüą║ąŠą╗čīą║čā RefCell< T> ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐čĆąŠą▓ąĄčĆčÅčéčī ą╝čāčéąĖčĆčāąĄą╝čŗąĄ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ runtime, ą▓čŗ ą╝ąŠąČąĄč鹥 ą╝čāčéąĖčĆąŠą▓ą░čéčī ąĘąĮą░č湥ąĮąĖąĄ ą▓ąĮčāčéčĆąĖ RefCell< T>, ą┤ą░ąČąĄ ą║ąŠą│ą┤ą░ RefCell< T> ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗą╣.
ą£čāčéą░čåąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ ą▓ąĮčāčéčĆąĖ ąĮąĄą╝čāčéąĖčĆčāąĄą╝ąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ čŹč鹊 ąĖ ąĄčüčéčī čłą░ą▒ą╗ąŠąĮ interior mutability. ąöą░ą▓ą░ą╣č鹥 čĆą░čüčüą╝ąŠčéčĆąĖą╝ čüąĖčéčāą░čåąĖčÄ, ą▓ ą║ąŠč鹊čĆąŠą╣ ą┐ąŠą╗ąĄąĘąĮą░ interior mutability, ąĖ čĆą░ąĘą▒ąĄčĆąĄą╝čüčÅ, ą║ą░ą║ čŹč鹊 čüčéą░ą╗ąŠ ą▓ąŠąĘą╝ąŠąČąĮčŗą╝.
Interior Mutability: ą╝čāčéąĖčĆčāąĄą╝ąŠąĄ ąĘą░ąĖą╝čüčéą▓čāąĄčé ąĮąĄą╝čāčéąĖčĆčāąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ. ąĪą╗ąĄą┤čüčéą▓ąĖąĄą╝ ą┐čĆą░ą▓ąĖą╗ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ čÅą▓ą╗čÅąĄčéčüčÅ č鹊, čćč鹊 ą║ąŠą│ą┤ą░ čā ą▓ą░čü ąĄčüčéčī ąĮąĄą╝čāčéąĖčĆčāąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, ą▓čŗ ąĮąĄ ą╝ąŠąČąĄč鹥 ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąĄčæ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖąĄ ą╝čāčéąĖčĆčāąĄą╝čŗą╝ čüą┐ąŠčüąŠą▒ąŠą╝. ąØą░ą┐čĆąĖą╝ąĄčĆ, čüą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤ ąĮąĄ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ:
fn main() {
let x = 5;
let y = &mut x;
}
ąĢčüą╗ąĖ ą▓čŗ ą┐ąŠą┐čŗčéą░ąĄč鹥čüčī čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░čéčī čéą░ą║ąŠą╣ ą║ąŠą┤, č鹊 ą┐ąŠą╗čāčćąĖč鹥 čüą╗ąĄą┤čāčÄčēčāčÄ ąŠčłąĖą▒ą║čā:
$ cargo run
Compiling borrowing v0.1.0 (file:///projects/borrowing)
error[E0596]: cannot borrow `x` as mutable, as it is not declared as mutable
--> src/main.rs:3:13
|
3 | let y = &mut x;
| ^^^^^^ cannot borrow as mutable
|
help: consider changing this to be mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `borrowing` (bin "borrowing") due to 1 previous error
ą×ą┤ąĮą░ą║ąŠ ąĄčüčéčī čüąĖčéčāą░čåąĖąĖ, ą▓ ą║ąŠč鹊čĆčŗčģ ą▒čŗą╗ąŠ ą▒čŗ ą┐ąŠą╗ąĄąĘąĮąŠ, čćč鹊ą▒čŗ ąĘąĮą░č湥ąĮąĖąĄ ą╝čāčéąĖčĆąŠą▓ą░ą╗ąŠ čüąĄą▒čÅ ą▓ čüą▓ąŠąĖčģ ą╝ąĄč鹊ą┤ą░čģ, ąĮąŠ ąŠčüčéą░ą▓ą░ą╗ąŠčüčī ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗą╝ ą┤ą╗čÅ ą┤čĆčāą│ąŠą│ąŠ ą║ąŠą┤ą░. ąÜąŠą┤ ą▓ąĮąĄ ą╝ąĄč鹊ą┤ąŠą▓ ąĘąĮą░č湥ąĮąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ąĖąĘą╝ąĄąĮąĖčéčī (ą╝čāčéąĖčĆąŠą▓ą░čéčī) ąĘąĮą░č湥ąĮąĖąĄ. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ RefCell< T> čŹč鹊 ąŠą┤ąĖąĮ ąĖąĘ čüą┐ąŠčüąŠą▒ąŠą▓ ą┐ąŠą╗čāčćąĖčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī interior mutability, ąŠą┤ąĮą░ą║ąŠ RefCell< T> ąĮąĄ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąŠą▒čģąŠą┤ąĖčé ą┐čĆą░ą▓ąĖą╗ą░ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ: ą┐čĆąŠą▓ąĄčĆą║ą░ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ ą▓ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆąĄ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čŹčéčā interior mutability, ą░ ą┐čĆą░ą▓ąĖą╗ą░ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ ą┐čĆąŠą▓ąĄčĆčÅčÄčéčüčÅ ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ runtime. ąĢčüą╗ąĖ ą▓čŗ ąĮą░čĆčāčłąĖč鹥 ą┐čĆą░ą▓ąĖą╗ą░, ą┐ąŠ ą┐ąŠą╗čāčćąĖč鹥 panic! ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą▓ą╝ąĄčüč鹊 ąŠčłąĖą▒ą║ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░.
ąöą░ą▓ą░ą╣č鹥 čĆą░ąĘą▒ąĄčĆąĄą╝ ą┐čĆą░ą║čéąĖč湥čüą║ąĖą╣ ą┐čĆąĖą╝ąĄčĆ, ą│ą┤ąĄ ą╝čŗ ą╝ąŠąČąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī RefCell< T> ą┤ą╗čÅ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ąĮąĄą╝čāčéąĖčĆčāąĄą╝ąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ, ąĖ ą┐ąŠčüą╝ąŠčéčĆąĖą╝, ą┐ąŠč湥ą╝čā čŹč鹊 ą┐ąŠą╗ąĄąĘąĮąŠ.
ąĪą╗čāčćą░ą╣ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ Interior Mutability: čäąĖą║čéąĖą▓ąĮčŗąĄ ąŠą▒čŖąĄą║čéčŗ. ąśąĮąŠą│ą┤ą░ ą▓ąŠ ą▓čĆąĄą╝čÅ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčé ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąŠą┤ąĖąĮ čéąĖą┐ ą▓ą╝ąĄčüč鹊 ą┤čĆčāą│ąŠą│ąŠ, čćč鹊ą▒čŗ ąĮą░ą▒ą╗čÄą┤ą░čéčī ąĘą░ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╝ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄą╝ ąĖ čāčéą▓ąĄčƹȹ┤ą░čéčī (assert), čćč鹊 ąŠąĮąŠ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮąŠ ą┐čĆą░ą▓ąĖą╗čīąĮąŠ. ąŁč鹊čé ąĘą░ą╝ąĄčēą░čÄčēąĖą╣ čéąĖą┐ ąĮą░ąĘčŗą▓ą░čÄčé test double. ą£ąŠąČąĮąŠ čŹč鹊 ą┐čĆąĄą┤čüčéą░ą▓ąĖčéčī čüąĄą▒ąĄ ą║ą░ą║ "ą┤ą▓ąŠą╣ąĮąŠą╣ čéčĆčÄą║" (stunt double) ą▓ ą║ąĖąĮąĄą╝ą░č鹊ą│čĆą░č乥, ą║ąŠą│ą┤ą░ ą┤čāą▒ą╗ąĄčĆ ąĘą░ą╝ąĄąĮčÅąĄčé ą░ą║č鹥čĆą░ ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ą░ą║ąŠą╣-ąĮąĖą▒čāą┤čī čüą╗ąŠąČąĮąŠą╣ čüčåąĄąĮčŗ. ąóąĖą┐čŗ test double čüč鹊čÅčé ąĘą░ ą┤čĆčāą│ąĖą╝ąĖ čéąĖą┐ą░ą╝ąĖ, ą║ąŠą│ą┤ą░ ą╝čŗ ąĘą░ą┐čāčüą║ą░ąĄą╝ č鹥čüčéčŗ. ążąĖą║čéąĖą▓ąĮčŗąĄ ąŠą▒čŖąĄą║čéčŗ (mock objects) čŹč鹊 čüą┐ąĄčåąĖą░ą╗čīąĮčŗąĄ čéąĖą┐čŗ test double, ą║ąŠč鹊čĆčŗąĄ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčé, čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓ąŠ ą▓čĆąĄą╝čÅ č鹥čüčéą░, čéą░ą║ čćč鹊 ą▓čŗ ą╝ąŠąČąĄč鹥 čāčéą▓ąĄčƹȹ┤ą░čéčī, čćč鹊 ą▒čŗą╗ąĖ ąŠčüčāčēąĄčüčéą▓ą╗ąĄąĮčŗ ą┐čĆą░ą▓ąĖą╗čīąĮčŗąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ.
Rust ąĮąĄ ąĖą╝ąĄąĄčé ąŠą▒čŖąĄą║č鹊ą▓ ą▓ č鹊ą╝ ąČąĄ čüą╝čŗčüą╗ąĄ, čćč鹊 ąĖ ą┤čĆčāą│ąĖąĄ čÅąĘčŗą║ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ, ąĖ Rust ąĮąĄ ąĖą╝ąĄąĄčé čäčāąĮą║čåąĖąŠąĮą░ą╗ą░ mock-ąŠą▒čŖąĄą║čéą░, ą▓čüčéčĆąŠąĄąĮąĮąŠą│ąŠ ą▓ čüčéą░ąĮą┤ą░čĆčéąĮčāčÄ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║čā, ą║ą░ą║ ąĖą╝ąĄąĄčé ą╝ąĄčüč鹊 ąĮą░ ą┤čĆčāą│ąĖčģ čÅąĘčŗą║ą░čģ. ąóąĄą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ ą▓čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠ ą╝ąŠąČąĄč鹥 čüąŠąĘą┤ą░čéčī čüčéčĆčāą║čéčāčĆčā, ą║ąŠč鹊čĆą░čÅ ą▒čāą┤ąĄčé čüą╗čāąČąĖčéčī č鹥ą╝ ąČąĄ čåąĄą╗čÅą╝, čćč鹊 ąĖ mock-ąŠą▒čŖąĄą║čé.
ąÆąŠčé čüčåąĄąĮą░čĆąĖą╣, ą║ąŠč鹊čĆčŗą╣ ą╝čŗ ą┐čĆąŠč鹥čüčéąĖčĆčāąĄą╝: čüąŠąĘą┤ą░ą┤ąĖą╝ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║čā, ą║ąŠč鹊čĆą░čÅ ąŠčéčüą╗ąĄąČąĖą▓ą░ąĄčé ąĘąĮą░č湥ąĮąĖąĄ ąĮą░ ą╝ą░ą║čüąĖą╝čāą╝, ąĖ ąŠčéą┐čĆą░ą▓ą╗čÅąĄčé čüąŠąŠą▒čēąĄąĮąĖčÅ ąĮą░ ąŠčüąĮąŠą▓ąĄ č鹊ą│ąŠ, ąĮą░čüą║ąŠą╗čīą║ąŠ ą▒ą╗ąĖąĘą║ąŠ ą║ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╝čā č鹥ą║čāčēąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ. ąŁčéą░ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ, ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą┤ą╗čÅ ąŠčéčüą╗ąĄąČąĖą▓ą░ąĮąĖčÅ ą║ą▓ąŠčéčŗ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ąĮą░ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▓čŗąĘąŠą▓ąŠą▓ API, ą║ąŠč鹊čĆčŗąĄ ąĄą╝čā čĆą░ąĘčĆąĄčłąĄąĮąŠ ą▓čŗą┐ąŠą╗ąĮčÅčéčī.
ąØą░čłą░ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░ ą▒čāą┤ąĄčé č鹊ą╗čīą║ąŠ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčéčī čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčī ąŠčéčüą╗ąĄąČąĖą▓ą░ąĮąĖčÅ č鹊ą│ąŠ, ąĮą░čüą║ąŠą╗čīą║ąŠ ą▒ą╗ąĖąĘą║ąŠ ą║ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╝čā ąĘąĮą░č湥ąĮąĖčÄ č鹥ą║čāčēąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ, ąĖ ą║ą░ą║ąĖą╝ąĖ ąĖ ą▓ ą║ą░ą║ąŠą╣ ą▓čĆąĄą╝čÅ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čüąŠąŠą▒čēąĄąĮąĖčÅ. ą¤ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčéčüčÅ, čćč鹊 ąĖčüą┐ąŠą╗čīąĘčāčÄčēąĖąĄ ąĮą░čłčā ą▒ąĖą▒ą╗ąĖąŠč鹥ą║čā ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓čÅčé ą╝ąĄčģą░ąĮąĖąĘą╝ ąŠčéą┐čĆą░ą▓ą║ąĖ čüąŠąŠą▒čēąĄąĮąĖą╣: ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ą╝ąŠąČąĄčé ą┐ąŠą╝ąĄčüčéąĖčéčī čüąŠąŠą▒čēąĄąĮąĖąĄ ą▓ ąŠč湥čĆąĄą┤čī, ąŠčéą┐čĆą░ą▓ąĖčéčī email, ąĮą░ą┐ąĄčćą░čéą░čéčī č鹥ą║čüčé čüąŠąŠą▒čēąĄąĮąĖčÅ ą▓ ą║ąŠąĮčüąŠą╗ąĖ ąĖą╗ąĖ čüą┤ąĄą╗ą░čéčī čćč鹊-č鹊 ą┐ąŠą┤ąŠą▒ąĮąŠąĄ. ąæąĖą▒ą╗ąĖąŠč鹥ą║ąĄ ąĘąĮą░čéčī čŹčéąĖ ą┤ąĄčéą░ą╗ąĖ ąĮąĄ ąĮčāąČąĮąŠ. ąÆčüąĄ, čćč鹊 ą┤ą╗čÅ ąĮąĄčæ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ - čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī čéčĆąĄą╣čé Messenger. ąøąĖčüčéąĖąĮą│ 15-20 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą║ąŠą┤ čŹč鹊ą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ (čäą░ą╣ą╗ src/lib.rs):
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker< 'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl< 'a, T> LimitTracker< 'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker< 'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
ąøąĖčüčéąĖąĮą│ 15-20. ąæąĖą▒ą╗ąĖąŠč鹥ą║ą░ ą┤ą╗čÅ ąŠčéčüą╗ąĄąČąĖą▓ą░ąĮąĖčÅ, ąĮą░čüą║ąŠą╗čīą║ąŠ ą▒ą╗ąĖąĘą║ąŠ ąĘąĮą░č湥ąĮąĖąĄ ą║ ą╝ą░ą║čüąĖą╝čāą╝čā, ąĖ ą▓čŗą┤ą░čćąĖ ą┐čĆąĄą┤čāą┐čĆąĄąČą┤ąĄąĮąĖčÅ, ą║ąŠą│ą┤ą░ ąĘąĮą░č湥ąĮąĖąĄ ą┤ąŠčüčéąĖą│ąĮąĄčé ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ čāčĆąŠą▓ąĮąĄą╣.
ą×ą┤ąĮą░ ąĖąĘ ą▓ą░ąČąĮčŗčģ čćą░čüč鹥ą╣ čŹč鹊ą│ąŠ ą║ąŠą┤ą░ - čéčĆąĄą╣čé Messenger čü ąŠą┤ąĮąĖą╝ ą╝ąĄč鹊ą┤ąŠą╝ send, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĖąĮąĖą╝ą░ąĄčé ąĮąĄą╝čāčéąĖčĆčāąĄą╝čāčÄ čüčüčŗą╗ą║čā ąĮą░ self ąĖ č鹥ą║čüčé čüąŠąŠą▒čēąĄąĮąĖčÅ. ąŁč鹊čé čéčĆąĄą╣čé čÅą▓ą╗čÅąĄčéčüčÅ ąĖąĮč鹥čĆč乥ą╣čüąŠą╝, ą║ąŠč鹊čĆčŗą╣ ąĮą░čł mock-ąŠą▒čŖąĄą║čé ą┤ąŠą╗ąČąĄąĮ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī, čćč鹊ą▒čŗ ą╝ą░ą║ąĄčé (mock) ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čéą░ą║ ąČąĄ, ą║ą░ą║ ąĖ čĆąĄą░ą╗čīąĮčŗą╣ ąŠą▒čŖąĄą║čé. ąöčĆčāą│ą░čÅ ą▓ą░ąČąĮą░čÅ čćą░čüčéčī ąĘą░ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ č鹊ą╝, čćč鹊 ą╝čŗ čģąŠčéąĖą╝ ą┐čĆąŠą▓ąĄčĆąĖčéčī ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą╝ąĄč鹊ą┤ą░ set_value ąĮą░ LimitTracker. ą£čŗ ą╝ąŠąČąĄą╝ ąĖąĘą╝ąĄąĮąĖčéčī č鹊, čćč鹊 ą┐ąĄčĆąĄą┤ą░ąĄą╝ ą▓ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ value, ąĮąŠ set_value ąĮąĖč湥ą│ąŠ ąĮąĄ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ąĮą░ą╝, čćč鹊ą▒čŗ čüčĆą░ą▒ą░čéčŗą▓ą░ą╗ assert. ą£čŗ čģąŠčéąĖą╝ ąĖą╝ąĄčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī čüą║ą░ąĘą░čéčī, čćč鹊 ąĄčüą╗ąĖ ą╝čŗ čüąŠąĘą┤ą░ąĄą╝ LimitTracker čü č湥ą╝-č鹊, čćč鹊 čĆąĄą░ą╗ąĖąĘčāąĄčé čéčĆąĄą╣čé Messenger ąĖ ą║ąŠąĮą║čĆąĄčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┤ą╗čÅ max, ą║ąŠą│ą┤ą░ ą╝čŗ ą┐ąĄčĆąĄą┤ą░ąĄą╝ čĆą░ąĘą╗ąĖčćąĮčŗąĄ čćąĖčüą╗ą░ ą┤ą╗čÅ value, ą╝ąĄčüčüąĄąĮą┤ąČąĄčĆ ą┐ąŠčüčŗą╗ą░ąĄčé čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ.
ąØą░ą╝ ąĮčāąČąĄąĮ mock-ąŠą▒čŖąĄą║čé, ą║ąŠč鹊čĆčŗą╣ ą▓ą╝ąĄčüč鹊 ąŠčéą┐čĆą░ą▓ą║ąĖ email ąĖą╗ąĖ č鹥ą║čüč鹊ą▓ąŠą│ąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ, ą║ąŠą│ą┤ą░ ą╝čŗ ą▓čŗąĘčŗą▓ą░ąĄą╝ send, ą▒čāą┤ąĄčé ąŠčéčüą╗ąĄąČąĖą▓ą░čéčī č鹊ą╗čīą║ąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ąĄą╝čā ą▒čŗą╗ąŠ čāą║ą░ąĘą░ąĮąŠ ąŠčéą┐čĆą░ą▓ąĖčéčī. ą£čŗ ą╝ąŠąČąĄą╝ čüąŠąĘą┤ą░čéčī ąĮąŠą▓čŗą╣ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ mock-ąŠą▒čŖąĄą║čéą░, čüąŠąĘą┤ą░čéčī LimitTracker, ą║ąŠč鹊čĆčŗą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄčé mock-ąŠą▒čŖąĄą║čé, ą▓čŗąĘčŗą▓ą░čéčī ą╝ąĄč鹊ą┤ set_value ąĮą░ LimitTracker, ąĖ ąĘą░č鹥ą╝ ą┐čĆąŠą▓ąĄčĆąĖčéčī, čćč鹊 mock-ąŠą▒čŖąĄą║čé ąĖą╝ąĄąĄčé čüąŠąŠą▒čēąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą╝čŗ ąŠąČąĖą┤ą░ąĄą╝. ąøąĖčüčéąĖąĮą│ 15-21 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┐ąŠą┐čŗčéą║čā čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī mock-ąŠą▒čŖąĄą║čé ą┤ą╗čÅ čŹč鹊ą╣ čåąĄą╗ąĖ, ąĮąŠ ą┐čĆąŠą▓ąĄčĆą║ą░ ą┐čĆą░ą▓ąĖą╗ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ ąĮąĄ ą┐ąŠąĘą▓ąŠą╗ąĖčé čŹč鹊 (čäą░ą╣ą╗ src/lib.rs):
#[cfg(test)]
mod tests {
use super::*;
struct MockMessenger {
sent_messages: Vec< String>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: vec![],
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.len(), 1);
}
}
ąøąĖčüčéąĖąĮą│ 15-21. ą¤ąŠą┐čŗčéą║ą░ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī MockMessenger, ą┐čĆąŠą▓ą░ą╗ąĄąĮąĮą░čÅ ąĖąĘ-ąĘą░ borrow checker.
ąŁč鹊čé č鹥čüčé-ą║ąŠą┤ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé čüčéčĆčāą║čéčāčĆčā MockMessenger, ą▓ ą║ąŠč鹊čĆąŠą╣ ąĄčüčéčī ą┐ąŠą╗ąĄ sent_messages čüąŠ ąĘąĮą░č湥ąĮąĖčÅą╝ąĖ ą▓ąĄą║č鹊čĆą░ čüčéčĆąŠą║ (Vec ąŠčé String), čćč鹊ą▒čŗ ąŠčéčüą╗ąĄąČąĖą▓ą░čéčī čüąŠąŠą▒čēąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą╝čŗ ą│ąŠą▓ąŠčĆąĖą╝ ą┐ąŠčüčŗą╗ą░čéčī. ą£čŗ čéą░ą║ąČąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĖą╗ąĖ čüą▓čÅąĘą░ąĮąĮčāčÄ čäčāąĮą║čåąĖčÄ new, čćč鹊ą▒čŗ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ čāą┤ąŠą▒ąĮąŠ čüąŠąĘą┤ą░ą▓ą░čéčī ąĮąŠą▓čŗąĄ ąĘąĮą░č湥ąĮąĖčÅ MockMessenger, ą║ąŠč鹊čĆčŗąĄ čüčéą░čĆčéčāčÄčé čü ą┐čāčüčéčŗą╝ čüą┐ąĖčüą║ąŠą╝ čüąŠąŠą▒čēąĄąĮąĖą╣. ąŚą░č鹥ą╝ ą╝čŗ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ą╗ąĖ čéčĆąĄą╣čé Messenger ą┤ą╗čÅ MockMessenger, čćč鹊ą▒čŗ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī MockMessenger ą┤ą╗čÅ LimitTracker. ąÆ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĖ ą╝ąĄč鹊ą┤ą░ send ą╝čŗ ą┐čĆąĖąĮąĖą╝ą░ąĄą╝ čüčéčĆąŠą║čā message, ą┐ąĄčĆąĄą┤ą░ąĮąĮčāčÄ ą▓ ą║ą░č湥čüčéą▓ąĄ ą┐ą░čĆą░ą╝ąĄčéčĆą░, ąĖ čüąŠčģčĆą░ąĮčÅąĄą╝ ąĄčæ ą▓ čüą┐ąĖčüą║ąĄ sent_messages.
ąÆ č鹥čüč鹥 ą╝čŗ ą┐čĆąŠą▓ąĄčĆčÅąĄą╝, čćč鹊 ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé, ą║ąŠą│ą┤ą░ ą┤ą╗čÅ LimitTracker ą│ąŠą▓ąŠčĆčÅčé čāčüčéą░ąĮąŠą▓ąĖčéčī ąĘąĮą░č湥ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ čüąŠčüčéą░ą▓ą╗čÅąĄčé ą▒ąŠą╗ąĄąĄ 75% ąŠčé ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ. ąĪąĮą░čćą░ą╗ą░ ą╝čŗ čüąŠąĘą┤ą░ąĄą╝ ąĮąŠą▓čŗą╣ MockMessenger, ą║ąŠč鹊čĆčŗą╣ ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ čü ą┐čāčüčéčŗą╝ čüą┐ąĖčüą║ąŠą╝ čüąŠąŠą▒čēąĄąĮąĖą╣. ąŚą░č鹥ą╝ ą╝čŗ čüąŠąĘą┤ą░ąĄą╝ ąĮąŠą▓čŗą╣ LimitTracker ąĖ ą┤ą░ąĄą╝ ąĄą╝čā čüčüčŗą╗ą║čā ąĮą░ ąĮąŠą▓čŗą╣ MockMessenger ąĖ ąĘąĮą░č湥ąĮąĖąĄ max 100. ą£čŗ ą▓čŗąĘčŗą▓ą░ąĄą╝ ą╝ąĄč鹊ą┤ set_value ąĮą░ LimitTracker čüąŠ ąĘąĮą░č湥ąĮąĖąĄą╝ 80, ą║ąŠč鹊čĆąŠąĄ ą▒ąŠą╗čīčłąĄ 75 ą┐čĆąŠčåąĄąĮč鹊ą▓ ąŠčé 100. ąŚą░č鹥ą╝ ą╝čŗ ą┤ąĄą╗ą░ąĄą╝ assert, čćč鹊 ą▓ čüą┐ąĖčüą║ąĄ čüąŠąŠą▒čēąĄąĮąĖą╣ MockMessenger č鹥ą┐ąĄčĆčī ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ąŠą┤ąĮąŠ čüąŠąŠą▒čēąĄąĮąĖąĄ.
ą×ą┤ąĮą░ą║ąŠ čü čŹčéąĖą╝ č鹥čüč鹊ą╝ ąĄčüčéčī ą┐čĆąŠą▒ą╗ąĄą╝ą░, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ čüąŠąŠą▒čēąĄąĮąĖąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
error[E0596]: cannot borrow `self.sent_messages` as mutable, as it is behind a `&` reference
--> src/lib.rs:58:13
|
58 | self.sent_messages.push(String::from(message));
| ^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot
| be borrowed as mutable
|
help: consider changing this to be a mutable reference
|
2 | fn send(&mut self, msg: &str);
| ~~~~~~~~~
For more information about this error, try `rustc --explain E0596`.
error: could not compile `limit-tracker` (lib test) due to 1 previous error
ą£čŗ ąĮąĄ ą╝ąŠąČąĄą╝ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░čéčī MockMessenger ą┤ą╗čÅ ąŠčéčüą╗ąĄąČąĖą▓ą░ąĮąĖčÅ čüąŠąŠą▒čēąĄąĮąĖą╣, ą┐ąŠč鹊ą╝čā čćč鹊 ą╝ąĄč鹊ą┤ send ą┐čĆąĖąĮąĖą╝ą░ąĄčé ąĮąĄą╝čāčéąĖčĆčāąĄą╝čāčÄ čüčüčŗą╗ą║čā ąĮą░ self. ą£čŗ čéą░ą║ąČąĄ ąĮąĄ ą╝ąŠąČąĄą╝ ą┐čĆąĖąĮčÅčéčī čüąŠą▓ąĄčé ąĖąĘ č鹥ą║čüčéą░ čüąŠąŠą▒čēąĄąĮąĖčÅ ąŠą▒ ąŠčłąĖą▒ą║ąĄ, čćč鹊ą▒čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ &mut self, ą┐ąŠč鹊ą╝čā čćč鹊 č鹊ą│ą┤ą░ čüąĖą│ąĮą░čéčāčĆą░ send ąĮąĄ ą▒čāą┤ąĄčé čüąŠąŠčéą▓ąĄčéčüčéą▓ąŠą▓ą░čéčī čüąĖą│ąĮą░čéčāčĆąĄ ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĖ čéčĆąĄą╣čéą░ Messenger (ą┐ąŠčŹą║čüą┐ąĄčĆąĖą╝ąĄąĮčéąĖčĆčāą╣č鹥 ąĖ ą┐ąŠčüą╝ąŠčéčĆąĖč鹥, ą║ą░ą║ąŠąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ ąŠą▒ ąŠčłąĖą▒ą║ąĄ ą▓čŗ ą┐čĆąĖ čŹč鹊ą╝ ą┐ąŠą╗čāčćąĖč鹥).
ąŁč鹊 čéą░ čüąĖčéčāą░čåąĖčÅ, ą▓ ą║ąŠč鹊čĆąŠą╣ ą╝ąŠąČąĄčé ą┐ąŠą╝ąŠčćčī interior mutability! ą£čŗ čüąŠčģčĆą░ąĮąĖą╝ sent_messages ą▓ąĮčāčéčĆąĖ RefCell< T>, ąĖ č鹊ą│ą┤ą░ ą╝ąĄč鹊ą┤ send čüą╝ąŠąČąĄčé ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░čéčī sent_messages, čćč鹊ą▒čŗ čüąŠčģčĆą░ąĮčÅčéčī čüąŠąŠą▒čēąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą╝čŗ ą▓ąĖą┤ąĄą╗ąĖ. ąøąĖčüčéąĖąĮą│ 15-22 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, ą║ą░ą║ čŹč鹊 ą▒čāą┤ąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī (čäą░ą╣ą╗ src/lib.rs):
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell< Vec< String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.borrow_mut().push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}
ąøąĖčüčéąĖąĮą│ 15-22. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ RefCell< T> ą┤ą╗čÅ ą╝čāčéąĖčĆąŠą▓ą░ąĮąĖčÅ ą▓ąĮčāčéčĆąĄąĮąĮąĄą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ą▓ąĮąĄčłąĮąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ čüčćąĖčéą░ąĄčéčüčÅ ąĮąĄąĖąĘą╝ąĄąĮčÅąĄą╝čŗą╝.
ą¤ąŠą╗ąĄ sent_messages č鹥ą┐ąĄčĆčī čéąĖą┐ą░ RefCell< Vec< String>> ą▓ą╝ąĄčüč鹊 Vec< String>. ąÆ čäčāąĮą║čåąĖąĖ new ą╝čŗ čüąŠąĘą┤ą░ąĄą╝ ąĮąŠą▓čŗą╣ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ RefCell< Vec< String>> ą▓ąŠą║čĆčāą│ ą┐čāčüč鹊ą│ąŠ ą▓ąĄą║č鹊čĆą░.
ąöą╗čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą╝ąĄč鹊ą┤ą░ send, ą┐ąĄčĆą▓čŗą╣ ą┐ą░čĆą░ą╝ąĄčéčĆ ą┐ąŠ ą┐čĆąĄąČąĮąĄą╝čā čŹč鹊 ąĮąĄą╝čāčéąĖčĆčāąĄą╝ąŠąĄ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖąĄ self, ą║ąŠč鹊čĆąŠąĄ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÄ čéčĆąĄą╣čéą░. ą£čŗ ą▓čŗąĘčŗą▓ą░ąĄą╝ borrow_mut ąĮą░ RefCell< Vec< String>> ą▓ self.sent_messages, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ą╝čāčéąĖčĆčāąĄą╝čāčÄ čüčüčŗą╗ą║čā ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ ą▓ąĮčāčéčĆąĖ RefCell< Vec< String>>, ą║ąŠč鹊čĆąŠąĄ čÅą▓ą╗čÅąĄčéčüčÅ ą▓ąĄą║č鹊čĆąŠą╝. ąŚą░č鹥ą╝ ą╝čŗ ą▓čŗąĘčŗą▓ą░ąĄą╝ push ąĮą░ ą╝čāčéąĖčĆčāąĄą╝ąŠą╣ čüčüčŗą╗ą║ąĄ ąĮą░ ą▓ąĄą║č鹊čĆ, čćč鹊ą▒čŗ ąŠčéčüą╗ąĄą┤ąĖčéčī čüąŠąŠą▒čēąĄąĮąĖčÅ, ąŠčéą┐čĆą░ą▓ą╗ąĄąĮąĮčŗąĄ ą▓ąŠ ą▓čĆąĄą╝čÅ č鹥čüčéą░.
ą¤ąŠčüą╗ąĄą┤ąĮąĄąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖąĄ, čćč鹊 ą╝čŗ ą┤ąŠą╗ąČąĮčŗ čüą┤ąĄą╗ą░čéčī, ąĘą░ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ assert: čćč鹊ą▒čŗ čāą▓ąĖą┤ąĄčéčī, čüą║ąŠą╗čīą║ąŠ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ąŠ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╝ ą▓ąĄą║č鹊čĆąĄ, ą╝čŗ ą▓čŗąĘąŠą▓ąĄą╝ borrow ąĮą░ RefCell< Vec< String>>, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ąĮąĄą╝čāčéąĖčĆčāąĄą╝čāčÄ čüčüčŗą╗ą║čā ąĮą░ ą▓ąĄą║č鹊čĆ.
ąöą░ą▓ą░ą╣č鹥 č鹥ą┐ąĄčĆčī čĆą░ąĘą▒ąĄčĆąĄą╝čüčÅ, ą║ą░ą║ čŹč鹊 čĆą░ą▒ąŠčéą░ąĄčé.
RefCell< T>: ąŠčéčüą╗ąĄąČąĖą▓ą░ąĮąĖąĄ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖą╣ runtime. ąÜąŠą│ą┤ą░ ą╝čŗ čüąŠąĘą┤ą░ąĄą╝ ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗąĄ ąĖ ą╝čāčéąĖčĆčāąĄą╝čŗąĄ čüčüčŗą╗ą║ąĖ, č鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ ą┤ą╗čÅ čŹč鹊ą│ąŠ čüąĖąĮčéą░ą║čüąĖčü & ąĖ &mut čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ. ąĪ čéąĖą┐ąŠą╝ RefCell< T>, ą╝čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ ą╝ąĄč鹊ą┤čŗ borrow ąĖ borrow_mut, ą║ąŠč鹊čĆčŗąĄ ą▓čģąŠą┤čÅčé ą▓ safe API, ą┐čĆąĖąĮą░ą┤ą╗ąĄąČą░čēąĄąĄ RefCell< T>. ą£ąĄč鹊ą┤ borrow ą▓ąŠąĘą▓čĆą░čéąĖčé smart-čāą║ą░ąĘą░č鹥ą╗čī čéąĖą┐ą░ Ref< T>, ą░ borrow_mut ą▓ąĄčĆąĮąĄčé smart-čāą║ą░ąĘą░č鹥ą╗čī čéąĖą┐ą░ RefMut< T>. ą×ą▒ą░ čŹčéąĖčģ čéąĖą┐ą░ čĆąĄą░ą╗ąĖąĘčāčÄčé čéčĆąĄą╣čé Deref, čéą░ą║ čćč鹊 ą╝čŗ ą╝ąŠąČąĄą╝ čĆą░ą▒ąŠčéą░čéčī čü ąĮąĖą╝ąĖ čéą░ą║ ąČąĄ, ą║ą░ą║ ąĖ čü ąŠą▒čŗčćąĮčŗą╝ąĖ čüčüčŗą╗ą║ą░ą╝ąĖ.
RefCell< T> ąŠčéčüą╗ąĄąČąĖą▓ą░ąĄčé, čüą║ąŠą╗čīą║ąŠ smart-čāą║ą░ąĘą░č鹥ą╗ąĄą╣ Ref< T> ąĖ RefMut< T> ą▓ ąĮą░čüč鹊čÅčēąĖą╣ ą╝ąŠą╝ąĄąĮčé ą░ą║čéąĖą▓ąĮąŠ. ąÜą░ąČą┤čŗą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ą╝čŗ ą▓čŗąĘčŗą▓ą░ąĄą╝ borrow, RefCell< T> čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčé čüą▓ąŠą╣ čüč湥čéčćąĖą║, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╣ ą║ąŠą╗ąĖč湥čüčéą▓čā ą░ą║čéąĖą▓ąĮčŗčģ ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗčģ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖą╣. ąÜąŠą│ą┤ą░ ąĘąĮą░č湥ąĮąĖąĄ Ref< T> ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ, čüč湥čéčćąĖą║ ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗčģ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖą╣ čāą╝ąĄąĮčīčłą░ąĄčéčüčÅ ąĮą░ ąĄą┤ąĖąĮąĖčåčā. ąóąŠčćąĮąŠ čéą░ą║ ąČąĄ, ą║ą░ą║ ąĖ čü ą┐čĆą░ą▓ąĖą╗ą░ą╝ąĖ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ ą▓čĆąĄą╝ąĄąĮąĖ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ, RefCell< T> ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĮą░ą╝ ą┐ąŠą╗čāčćąĖčéčī ą╝ąĮąŠąČąĄčüčéą▓ąŠ ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗčģ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖą╣ ąĖą╗ąĖ ąŠą┤ąĮčā ą╝čāčéąĖčĆčāąĄą╝čāčÄ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéčī ą▓ ą╗čÄą▒ąŠą╣ ą╝ąŠą╝ąĄąĮčé ą▓čĆąĄą╝ąĄąĮąĖ.
ąĢčüą╗ąĖ ą╝čŗ ą┐ąŠą┐čĆąŠą▒čāąĄą╝ ąĮą░čĆčāčłąĖčéčī čŹčéąĖ ą┐čĆą░ą▓ąĖą╗ą░, č鹊 ą▓ą╝ąĄčüč鹊 ąŠčłąĖą▒ą║ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ RefCell< T> čüą│ąĄąĮąĄčĆąĖčĆčāąĄčé ą┐ą░ąĮąĖą║čā runtime. ąøąĖčüčéąĖąĮą│ 15-23 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÄ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ send ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-22. ą£čŗ ąĮą░ą╝ąĄčĆąĄąĮąĮąŠ ą┐čŗčéą░ąĄą╝čüčÅ čüąŠąĘą┤ą░čéčī ą┤ą▓ą░ ą╝čāčéąĖčĆčāąĄą╝čŗčģ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ, ą░ą║čéąĖą▓ąĮčŗčģ ą▓ ąŠą┤ąĮąŠą╣ ąĖ č鹊ą╣ ąČąĄ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ, čćč鹊ą▒čŗ ą┐čĆąŠąĖą╗ą╗čÄčüčéčĆąĖčĆąŠą▓ą░čéčī, čćč鹊 RefCell< T> ąĮąĄ ą┤ą░čüčé ąĮą░ą╝ čŹč鹊 čüą┤ąĄą╗ą░čéčī runtime (čäą░ą╣ą╗ src/lib.rs).
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
let mut one_borrow = self.sent_messages.borrow_mut();
let mut two_borrow = self.sent_messages.borrow_mut();
one_borrow.push(String::from(message));
two_borrow.push(String::from(message));
}
}
ąøąĖčüčéąĖąĮą│ 15-23. ąĪąŠąĘą┤ą░ąĮąĖąĄ ą┤ą▓čāčģ ą╝čāčéąĖčĆčāąĄą╝čŗčģ čüčüčŗą╗ąŠą║ ą▓ ąŠą┤ąĮąŠą╣ ąĖ č鹊ą╣ ąČąĄ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ, čćč鹊ą▒čŗ čāą▓ąĖą┤ąĄčéčī, ą║ą░ą║ RefCell< T> ą▓čŗąĘąŠą▓ąĄčé ą┐ą░ąĮąĖą║čā.
ą£čŗ čüąŠąĘą┤ą░ą╗ąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ one_borrow ą┤ą╗čÅ smart-čāą║ą░ąĘą░č鹥ą╗čÅ RefMut< T>, ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝ąŠą│ąŠ ąĖąĘ borrow_mut. ąŚą░č鹥ą╝ ą╝čŗ čüąŠąĘą┤ą░ą╗ąĖ ą╝čāčéąĖčĆčāąĄą╝ąŠąĄ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖąĄ čéą░ą║ąĖą╝ ąČąĄ čüą┐ąŠčüąŠą▒ąŠą╝ ą▓ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ two_borrow. ąŁč鹊 ą┤ąĄą╗ą░ąĄčé ą┤ą▓ąĄ ą╝čāčéąĖčĆčāąĄą╝čŗąĄ čüčüčŗą╗ą║ąĖ ą▓ ąŠą┤ąĮąŠą╣ ąĖ č鹊ą╣ ąČąĄ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ, čćč鹊 ąĮąĄ ą┤ąŠą┐čāčüą║ą░ąĄčéčüčÅ. ąÜąŠą│ą┤ą░ ą╝čŗ ąĘą░ą┐čāčüčéąĖą╝ č鹥čüčéčŗ ą┤ą╗čÅ ąĮą░čłąĄą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ, č鹊 ą║ąŠą┤ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-23 čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ ą▒ąĄąĘ ą║ą░ą║ąĖčģ-ą╗ąĖą▒ąŠ ąŠčłąĖą▒ąŠą║, č鹊 test ą┐čĆąŠą▓ą░ą╗ąĖčéčüčÅ:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/limit_tracker-e599811fa246dbde)
running 1 test
test tests::it_sends_an_over_75_percent_warning_message ... FAILED
failures:
---- tests::it_sends_an_over_75_percent_warning_message stdout ----
thread 'tests::it_sends_an_over_75_percent_warning_message' panicked at src/lib.rs:60:53:
already borrowed: BorrowMutError
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_sends_an_over_75_percent_warning_message
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą║ąŠą┤ ą┐ą░ąĮąĖą║čāąĄčé čü čüąŠąŠą▒čēąĄąĮąĖąĄą╝ already borrowed: BorrowMutError. ąóą░ą║ RefCell< T> ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé ąĮą░čĆčāčłąĄąĮąĖčÅ ą┐čĆą░ą▓ąĖą╗ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ runtime.
ąÆčŗą▒ąŠčĆ runtime-ą┐ąĄčĆąĄčģą▓ą░čéą░ ąŠčłąĖą▒ąŠą║ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ ą▓ą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ čŹč鹊 ą┤ąĄą╗ą░čéčī ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ, ą║ą░ą║ ą▒čŗą╗ąŠ čüą┤ąĄą╗ą░ąĮąŠ ą▓ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ, ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ čćčĆąĄą▓ą░č鹊 ą┐ąŠąĘą┤ąĮąĖą╝ąĖ ąŠą▒ąĮą░čĆčāąČąĄąĮąĖčÅą╝ąĖ ąŠčłąĖą▒ąŠą║ ą▓ ą┐čĆąŠčåąĄčüčüąĄ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ: ą▓ąŠąĘą╝ąŠąČąĮčŗ ą┤ą░ąČąĄ čüą╗čāčćą░ąĖ, ą║ąŠą│ą┤ą░ ąŠčłąĖą▒ą║ą░ ąĮąĄ ą▒čāą┤ąĄčé ąŠą▒ąĮą░čĆčāąČąĄąĮą░ ą┤ąŠ ą▓čŗčģąŠą┤ą░ ą║ąŠą┤ą░ ą▓ čĆąĄą╗ąĖąĘ. ąóą░ą║ąČąĄ ą▓ą░čł ą║ąŠą┤ ą▒čāą┤ąĄčé ą┐ąŠą┤ą▓ąĄčƹȹĄąĮ ąĮąĄą▒ąŠą╗čīčłąĖą╝ čüąĮąĖąČąĄąĮąĖąĄą╝ runtime-ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ č鹥ą┐ąĄčĆčī ąŠčéčüą╗ąĄąČąĖą▓ą░čÄčéčüčÅ runtime, ą░ ąĮąĄ ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ. ąóąĄą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ RefCell< T> ą┤ąĄą╗ą░ąĄčé ą▓ąŠąĘą╝ąŠąČąĮčŗą╝ ą┐ąĖčüą░čéčī ą║ąŠą┤ ą┤ą╗čÅ mock-ąŠą▒čŖąĄą║čéą░, ą║ąŠč鹊čĆčŗą╣ ąĖą╝ąĄąĄčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░čéčī čüąĄą▒čÅ, čćč鹊ą▒čŗ ąŠčéčüą╗ąĄąČąĖą▓ą░čéčī čüąŠąŠą▒čēąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ąŠąĮ ą▓ąĖą┤ąĄą╗ runtime, ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗čüčÅ ą▓ ą║ąŠąĮč鹥ą║čüč鹥, ą│ą┤ąĄ čĆą░ąĘčĆąĄčłąĄąĮčŗ č鹊ą╗čīą║ąŠ ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗąĄ ąĘąĮą░č湥ąĮąĖčÅ. ąÆčŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī RefCell< T>, ąĮąĄčüą╝ąŠčéčĆčÅ ąĮą░ ąĄą│ąŠ ą║ąŠą╝ą┐čĆąŠą╝ąĖčüčüčŗ, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ą▒ąŠą╗čīčłąĄ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮčŗčģ ą▓ąŠąĘą╝ąŠąČąĮąŠčüč鹥ą╣, č湥ą╝ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ąŠą▒čŗčćąĮčŗąĄ čüčüčŗą╗ą║ąĖ.
ąÜąŠą╝ą▒ąĖąĮą░čåąĖčÅ Rc< T> ąĖ RefCell< T> ą┤ą╗čÅ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą▓ ą╝čāčéąĖčĆčāąĄą╝čŗčģ ą┤ą░ąĮąĮčŗčģ. ąŁč鹊 ąŠą▒čēąĖą╣ ą╝ąĄč鹊ą┤ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ RefCell< T> ą▓ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ čü Rc< T>. ąÆčüą┐ąŠą╝ąĮąĖą╝, čćč鹊 Rc< T> ą┐ąŠąĘą▓ąŠą╗ąĖčé ą▓ą░ą╝ ą┐ąŠą╗čāčćąĖčéčī ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą▓ ą║ą░ą║ąĖčģ-č鹊 ą┤ą░ąĮąĮčŗčģ, ąĮąŠ ą┐čĆąĖ čŹč鹊ą╝ ą║ čŹčéąĖą╝ ą┤ą░ąĮąĮčŗą╝ ą▒čāą┤ąĄčé č鹊ą╗čīą║ąŠ ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗą╣ ą┤ąŠčüčéčāą┐. ąĢčüą╗ąĖ čā ą▓ą░čü ąĄčüčéčī Rc< T>, ą║ąŠč鹊čĆčŗą╣ čģčĆą░ąĮąĖčé RefCell< T>, č鹊 ą▓čŗ ą╝ąŠąČąĄč鹥 ą┐ąŠą╗čāčćąĖčéčī ąĘąĮą░č湥ąĮąĖąĄ, čā ą║ąŠč鹊čĆąŠą│ąŠ ą▒čāą┤ąĄčé ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą▓, ąĖ ą▓čŗ ą┐čĆąĖ čŹč鹊ą╝ čüą╝ąŠąČąĄč鹥 čŹč鹊 ąĘąĮą░č湥ąĮąĖąĄ ąĖąĘą╝ąĄąĮčÅčéčī!
ąÆčüą┐ąŠą╝ąĮąĖą╝ čüą┐ąĖčüąŠą║ cons ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-18, ą│ą┤ąĄ ą╝čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ąĖ Rc< T>, čćč鹊ą▒čŗ ąĮąĄčüą║ąŠą╗čīą║ąŠ čüą┐ąĖčüą║ąŠą▓ ą╝ąŠą│ą╗ąĖ čüąŠą▓ą╝ąĄčüčéąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤čĆčāą│ąŠą╣ čüą┐ąĖčüąŠą║. ą¤ąŠčüą║ąŠą╗čīą║čā Rc< T> čģčĆą░ąĮąĖčé č鹊ą╗čīą║ąŠ ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗąĄ ąĘąĮą░č湥ąĮąĖčÅ, ą╝čŗ ąĮąĄ ą╝ąŠąČąĄą╝ ą┐ąŠą╝ąĄąĮčÅčéčī ą╗čÄą▒čŗąĄ ąĘąĮą░č湥ąĮąĖčÅ ą▓ čüą┐ąĖčüą║ąĄ, ą║ą░ą║ č鹊ą╗čīą║ąŠ ąĄą│ąŠ čüąŠąĘą┤ą░ą╗ąĖ. ąöą░ą▓ą░ą╣č鹥 ą┤ąŠą▒ą░ą▓ąĖą╝ RefCell< T> ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ą╝ąĄąĮčÅčéčī ąĘąĮą░č湥ąĮąĖčÅ ą▓ čüą┐ąĖčüą║ą░čģ. ąøąĖčüčéąĖąĮą│ 15-24 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ RefCell< T> ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĖ Cons, čéą░ą║ąĖą╝ čüą┐ąŠčüąŠą▒ąŠą╝ ą╝čŗ ą╝ąŠąČąĄą╝ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░čéčī ąĘąĮą░č湥ąĮąĖąĄ, čüąŠčģčĆą░ąĮąĄąĮąĮąŠąĄ ą▓ąŠ ą▓čüąĄčģ čüą┐ąĖčüą║ą░čģ (čäą░ą╣ą╗ src/main.rs):
#[derive(Debug)]
enum List {
Cons(Rc< RefCell< i32>>, Rc< List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
fn main() {
let value = Rc::new(RefCell::new(5));
let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil)));
let b = Cons(Rc::new(RefCell::new(3)), Rc::clone(&a));
let c = Cons(Rc::new(RefCell::new(4)), Rc::clone(&a));
*value.borrow_mut() += 10;
println!("a after = {a:?}");
println!("b after = {b:?}");
println!("c after = {c:?}");
}
ąøąĖčüčéąĖąĮą│ 15-24. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ Rc< RefCell< i32>> ą┤ą╗čÅ čüąŠąĘą┤ą░ąĮąĖčÅ čüą┐ąĖčüą║ą░ List, ą║ąŠč鹊čĆčŗą╣ ą╝čŗ ą╝ąŠąČąĄą╝ ą╝čāčéąĖčĆąŠą▓ą░čéčī.
ą£čŗ čüąŠąĘą┤ą░ąĄą╝ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ value, ą║ąŠč鹊čĆą░čÅ čÅą▓ą╗čÅąĄčéčüčÅ čŹą║ąĘąĄą╝ą┐ą╗čÅčĆąŠą╝ Rc< RefCell< i32>>, ą║ ą║ąŠč鹊čĆąŠą╣ čüą╝ąŠąČąĄą╝ ą▓ą┐ąŠčüą╗ąĄą┤čüčéą▓ąĖąĖ ąĮą░ą┐čĆčÅą╝čāčÄ ąŠą▒čĆą░čéąĖčéčīčüčÅ. ąŚą░č鹥ą╝ ą╝čŗ čüąŠąĘą┤ą░ąĄą╝ List ą▓ a čü ą▓ą░čĆąĖą░ąĮč鹊ą╝ Cons, ą│ą┤ąĄ čģčĆą░ąĮąĖčéčüčÅ value. ąØą░ą╝ ąĮčāąČąĮąŠ ą║ą╗ąŠąĮąĖčĆąŠą▓ą░čéčī value, čćč鹊ą▒čŗ ąĖ a, ąĖ value ąĖą╝ąĄą╗ąĖ ą▓ą╗ą░ą┤ąĄąĮąĖąĄ ąĮą░ą┤ ą▓ąĮčāčéčĆąĄąĮąĮąĖą╝ ąĘąĮą░č湥ąĮąĖąĄą╝ 5 ą▓ą╝ąĄčüč鹊 ą┐ąĄčĆąĄą┤ą░čćąĖ ą┐čĆą░ą▓ą░ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ ąŠčé value ą║ a, ąĖą╗ąĖ čćč鹊ą▒čŗ a ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ą╗ąŠ ąĖąĘ value.
ą£čŗ ąŠą▒ąĄčĆąĮčāą╗ąĖ čüą┐ąĖčüąŠą║ a ą▓ Rc< T>, čéą░ą║ čćč鹊 ą║ąŠą│ą┤ą░ ą╝čŗ čüąŠąĘą┤ą░ą┤ąĖą╝ čüą┐ąĖčüą║ąĖ b ąĖ c, ąŠąĮąĖ ą╝ąŠą│ą╗ąĖ ąŠą▒ą░ ą╝ąŠą│ą╗ąĖ čüčüčŗą╗ą░čéčīčüčÅ ąĮą░ a, čćč鹊 ą╝čŗ ąĖ čüą┤ąĄą╗ą░ą╗ąĖ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-18.
ą¤ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ą╝čŗ čüąŠąĘą┤ą░ą╗ąĖ čüą┐ąĖčüą║ąĖ ą▓ a, b ąĖ c, ą╝čŗ čģąŠčéąĖą╝ ą┤ąŠą▒ą░ą▓ąĖčéčī 10 ą▓ ąĘąĮą░č湥ąĮąĖąĄ value. ąŁč鹊 ą╝čŗ ą┤ąĄą╗ą░ąĄą╝ ą▓čŗąĘąŠą▓ąŠą╝ borrow_mut ąĮą░ value, čćč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄčé čäąĖčćčā ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąŠą│ąŠ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖčÅ, ą║ąŠč鹊čĆčāčÄ ą╝čŗ ąŠą▒čüčāąČą┤ą░ą╗ąĖ ą▓ ą│ą╗ą░ą▓ąĄ 5 [6] (čüą╝. ą▓čĆąĄąĘą║čā "ąōą┤ąĄ ąČąĄ ąŠą┐ąĄčĆą░č鹊čĆ -> ?"), čćč鹊ą▒čŗ ą▓čŗą┐ąŠą╗ąĮąĖčéčī čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖąĄ Rc< T> ąĮą░ ą▓ąĮčāčéčĆąĄąĮąĮąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ RefCell< T>. ą£ąĄč鹊ą┤ borrow_mut ą▓ąĄčĆąĮąĄčé smart-čāą║ą░ąĘą░č鹥ą╗čī RefMut< T>, ąĖ ą╝čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ ąĮą░ ąĮąĄą╝ ąŠą┐ąĄčĆą░č鹊čĆ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖčÅ, ą╝ąĄąĮčÅčÅ č鹥ą╝ čüą░ą╝čŗą╝ ą▓ąĮčāčéčĆąĄąĮąĮąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ.
ąÜąŠą│ą┤ą░ ą╝čŗ ą┐ąĄčćą░čéą░ąĄą╝ a, b ąĖ c, ą╝ąŠąČąĮąŠ čāą▓ąĖą┤ąĄčéčī, čćč鹊 čā ą▓čüąĄčģ čā ąĮąĖčģ ąĖąĘą╝ąĄąĮąĄąĮąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ 15 ą▓ą╝ąĄčüč鹊 5:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.63s
Running `target/debug/cons-list`
a after = Cons(RefCell { value: 15 }, Nil)
b after = Cons(RefCell { value: 3 }, Cons(RefCell { value: 15 }, Nil))
c after = Cons(RefCell { value: 4 }, Cons(RefCell { value: 15 }, Nil))
ąŁčéą░ č鹥čģąĮąĖą║ą░ ą┤ąŠą▓ąŠą╗čīąĮąŠ ą░ą║ą║čāčĆą░čéąĮą░! ąśčüą┐ąŠą╗čīąĘčāčÅ RefCell< T>, ą╝čŗ ą┐ąŠą╗čāčćą░ąĄą╝ ąĮąĄ ąĖąĘą╝ąĄąĮčÅąĄą╝ąŠąĄ čüąĮą░čĆčāąČąĖ ąĘąĮą░č湥ąĮąĖąĄ List value. ą×ą┤ąĮą░ą║ąŠ ą╝čŗ ą╝ąŠąČąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą╝ąĄč鹊ą┤čŗ ąĮą░ RefCell< T>, ą║ąŠč鹊čĆčŗąĄ ąŠą▒ąĄčüą┐ąĄčćąĖą▓ą░čÄčé ą┤ąŠčüčéčāą┐ ą║ ąĄą│ąŠ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ ąĖąĘą╝ąĄąĮčćąĖą▓ąŠčüčéąĖ (interior mutability), čćč鹊ą▒čŗ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą╝ąĄąĮčÅčéčī ąĮą░čłąĖ ą┤ą░ąĮąĮčŗąĄ, ą║ąŠą│ą┤ą░ čŹč鹊 ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ. Runtime-ą┐čĆąŠą▓ąĄčĆą║ąĖ ą┐čĆą░ą▓ąĖą╗ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ ąĘą░čēąĖčēą░čÄčé ąĮą░čü ąŠčé čĆąĄą╣čüąĖąĮą│ą░ ą┤ą░ąĮąĮčŗčģ, ąĖ ąĖąĮąŠą│ą┤ą░ čĆąĄąĘąŠąĮąĮčŗą╝ ą▒čāą┤ąĄčé čüą╝ąĄčüčéąĖčéčī ą║ąŠą╝ą┐čĆąŠą╝ąĖčüčü ą▓ čüč鹊čĆąŠąĮčā ąĮąĄąĘąĮą░čćąĖč鹥ą╗čīąĮąŠą╣ ą┐ąŠč鹥čĆąĖ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī čŹčéčā ą│ąĖą▒ą║ąŠčüčéčī ą▓ ąĮą░čłąĖčģ čüčéčĆčāą║čéčāčĆą░čģ ą┤ą░ąĮąĮčŗčģ. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 RefCell< T> ąĮąĄ čĆą░ą▒ąŠčéą░ąĄčé ą▓ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠą╝ ą║ąŠą┤ąĄ! Mutex< T> čŹč鹊 thread-safe ą▓ąĄčĆčüąĖčÅ RefCell< T>, ąĖ Mutex< T> ą╝čŗ ąŠą▒čüčāą┤ąĖą╝ ą▓ ą│ą╗ą░ą▓ąĄ 16.
[ą”ąĖą║ą╗čŗ čüčüčŗą╗ąŠą║ ą╝ąŠą│čāčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ čāč鹥čćą║ąĄ ą┐ą░ą╝čÅčéąĖ]
ążčāąĮą║čåąĖąŠąĮą░ą╗ Rust, ąŠą▒ąĄčüą┐ąĄčćąĖą▓ą░čÄčēąĖą╣ ą│ą░čĆą░ąĮčéąĖąĖ ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéąĖ ą┐ą░ą╝čÅčéąĖ, ą┤ąĄą╗ą░ąĄčé čüą╗ąŠąČąĮčŗą╝, ąĮąŠ ąĮąĄ ąĮąĄą▓ąŠąĘą╝ąŠąČąĮčŗą╝ čüą╗čāčćą░ą╣ąĮąŠąĄ čüąŠąĘą┤ą░ąĮąĖąĄ ą║ąŠą┤ą░, ą║ąŠą│ą┤ą░ ą┐ą░ą╝čÅčéčī ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ąŠčüą▓ąŠą▒ąŠąČą┤ą░ąĄčéčüčÅ (čćč鹊 ąĖąĘą▓ąĄčüčéąĮąŠ ą║ą░ą║ čāč鹥čćą║ą░ ą┐ą░ą╝čÅčéąĖ, memory leak). ą¤ąŠą╗ąĮąŠąĄ ą┐čĆąĄą┤ąŠčéą▓čĆą░čēąĄąĮąĖąĄ čāč鹥č湥ą║ ą┐ą░ą╝čÅčéąĖ ąĮąĄ čÅą▓ą╗čÅąĄčéčüčÅ ąŠą┤ąĮąŠą╣ ąĖąĘ ą│ą░čĆą░ąĮčéąĖą╣ Rust, čé. ąĄ. čāč鹥čćą║ąĖ ą┐ą░ą╝čÅčéąĖ ą▒ąĄąĘąŠą┐ą░čüąĮčŗ ą▓ Rust. ą£čŗ ą╝ąŠąČąĄą╝ čāą▓ąĖą┤ąĄčéčī, čćč鹊 Rust ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čāč鹥čćą║ąĖ ą┐ą░ą╝čÅčéąĖ ą┐čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ Rc< T> ąĖ RefCell< T>: ąĄčüčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī čüąŠąĘą┤ą░čéčī čüčüčŗą╗ą║ąĖ, ą│ą┤ąĄ 菹╗ąĄą╝ąĄąĮčéčŗ čüčüčŗą╗ą░čÄčéčüčÅ ą┤čĆčāą│ ąĮą░ ą┤čĆčāą│ą░ ą▓ čåąĖą║ą╗ąĄ. ąŁč鹊 čüąŠąĘą┤ą░čüčé čāč鹥čćą║ąĖ ą┐ą░ą╝čÅčéąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 čüč湥čéčćąĖą║ čüčüčŗą╗ąŠą║ ą║ą░ąČą┤ąŠą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░ ą▓ čåąĖą║ą╗ąĄ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą┤ąŠčüčéąĖą│ąĮąĄčé 0, ąĖ ąĘąĮą░č湥ąĮąĖčÅ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą▒čāą┤čāčé ąŠčéą▒čĆąŠčłąĄąĮčŗ.
ąĪąŠąĘą┤ą░ąĮąĖąĄ čåąĖą║ą╗ą░ čüčüčŗą╗ąŠą║. ąöą░ą▓ą░ą╣č鹥 čĆą░čüčüą╝ąŠčéčĆąĖą╝, ą║ą░ą║ ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ čüąĖčéčāą░čåąĖčÅ čü čåąĖą║ą╗ąŠą╝ čüčüčŗą╗ąŠą║, ąĖ ą║ą░ą║ ąĄčæ ą┐čĆąĄą┤ąŠčéą▓čĆą░čéąĖčéčī, ąĮą░čćąĖąĮą░čÅ čü ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖčÅ List ąĖ ą╝ąĄč鹊ą┤ą░ tail ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-25 (čäą░ą╣ą╗ src/main.rs):
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
enum List {
Cons(i32, RefCell< Rc< List>>),
Nil,
}
impl List {
fn tail(&self) -> Option< &RefCell< Rc< List>>> {
match self {
Cons(_, item) => Some(item),
Nil => None,
}
}
}
fn main() {}
ąøąĖčüčéąĖąĮą│ 15-25. ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čüą┐ąĖčüą║ą░ cons, ą║ąŠč鹊čĆčŗą╣ čģčĆą░ąĮąĖčé RefCell< T>, čćč鹊ą▒čŗ ą╝čŗ ą╝ąŠą│ą╗ąĖ ąĖąĘą╝ąĄąĮąĖčéčī č鹊, ąĮą░ čćč鹊 čüčüčŗą╗ą░ąĄčéčüčÅ ą▓ą░čĆąĖą░ąĮčé Cons.
ą£čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ ą┤čĆčāą│čāčÄ ą▓ą░čĆąĖą░čåąĖčÄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ List ąĖąĘ ą╗ąĖčüčéąĖąĮą│ą░ 15-5. ąÆč鹊čĆąŠą╣ 菹╗ąĄą╝ąĄąĮčé ą▓ ą▓ą░čĆąĖą░ąĮč鹥 Cons č鹥ą┐ąĄčĆčī RefCell< Rc< List>>, čé. ąĄ. ą▓ą╝ąĄčüč鹊 ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ą╝ąĄąĮčÅčéčī ąĘąĮą░č湥ąĮąĖąĄ i32, ą║ą░ą║ ą╝čŗ čŹč鹊 ą┤ąĄą╗ą░ą╗ąĖ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-24, ą╝čŗ čģąŠčéąĖą╝ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░čéčī ąĘąĮą░č湥ąĮąĖąĄ List, ąĮą░ ą║ąŠč鹊čĆąŠąĄ čāą║ą░ąĘčŗą▓ą░ąĄčé ą▓ą░čĆąĖą░ąĮčé Cons. ą£čŗ čéą░ą║ąČąĄ ą┤ąŠą▒ą░ą▓ąĖą╗ąĖ ą╝ąĄč鹊ą┤ tail ą┤ą╗čÅ čāą┤ąŠą▒ąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą║ąŠ ą▓č鹊čĆąŠą╝čā 菹╗ąĄą╝ąĄąĮčéčā, ąĄčüą╗ąĖ čā ąĮą░čü ąĄčüčéčī ą▓ą░čĆąĖą░ąĮčé Cons.
ąÆ ą╗ąĖčüčéąĖąĮą│ąĄ 15-26 ą╝čŗ ą┤ąŠą▒ą░ą▓ą╗čÅąĄą╝ čäčāąĮą║čåąĖčÄ main, ą║ąŠč鹊čĆą░čÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-25. ąŁč鹊čé ą║ąŠą┤ čüąŠąĘą┤ą░ąĄčé čüą┐ąĖčüąŠą║ ą▓ a, ąĖ čüą┐ąĖčüąŠą║ a ą▓ b, ą║ąŠč鹊čĆčŗą╣ čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ čüą┐ąĖčüąŠą║ ą▓ a. ąŚą░č鹥ą╝ ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāąĄčéčüčÅ čüą┐ąĖčüąŠą║ ą▓ a, čćč鹊ą▒čŗ čāą║ą░ąĘčŗą▓ą░čéčī ąĮą░ b, čüąŠąĘą┤ą░ą▓ą░čÅ č鹥ą╝ čüą░ą╝čŗą╝ čåąĖą║ą╗ čüčüčŗą╗ąŠą║. ą×ą┐ąĄčĆą░č鹊čĆčŗ println! ą▓ čŹč鹊ą╝ ą┐čĆąŠčåąĄčüčüąĄ ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčé, ą║ą░ą║ ą╝ąĄąĮčÅąĄčéčüčÅ čüč湥čéčćąĖą║ čüčüčŗą╗ąŠą║ ą▓ čĆą░ąĘą╗ąĖčćąĮčŗčģ č鹊čćą║ą░čģ ą║ąŠą┤ą░.
fn main() {
let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil))));
println!("a initial rc count = {}", Rc::strong_count(&a));
println!("a next item = {:?}", a.tail());
let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a))));
println!("a rc count after b creation = {}", Rc::strong_count(&a));
println!("b initial rc count = {}", Rc::strong_count(&b));
println!("b next item = {:?}", b.tail());
if let Some(link) = a.tail() {
*link.borrow_mut() = Rc::clone(&b);
}
println!("b rc count after changing a = {}", Rc::strong_count(&b));
println!("a rc count after changing a = {}", Rc::strong_count(&a));
// ąĀą░čüą║ąŠą╝ą╝ąĄąĮčéąĖčĆčāą╣č鹥 čüą╗ąĄą┤čāčÄčēčāčÄ čüčéčĆąŠčćą║čā, čćč鹊ą▒čŗ čāą▓ąĖą┤ąĄčéčī, čćč鹊 ą┐ąŠą╗čāčćąĖą╗čüčÅ čåąĖą║ą╗;
// čŹč鹊 ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÄ čüč鹥ą║ą░:
// println!("a next item = {:?}", a.tail());
}
ąøąĖčüčéąĖąĮą│ 15-26. ąĪąŠąĘą┤ą░ąĮąĖąĄ čåąĖą║ą╗ą░ čüčüčŗą╗ąŠą║, ą║ąŠą│ą┤ą░ ą┤ą▓ą░ ąĘąĮą░č湥ąĮąĖčÅ List čāą║ą░ąĘčŗą▓ą░čÄčé ą┤čĆčāą│ ąĮą░ ą┤čĆčāą│ą░ (čäą░ą╣ą╗ src/main.rs).
ą£čŗ čüąŠąĘą┤ą░ą╗ąĖ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ Rc< List>, čģčĆą░ąĮčÅčēąĖą╣ ąĘąĮą░č湥ąĮąĖąĄ List ą▓ ą┐ąĄčĆąĄą╝ąĄąĮąŠą╣ a, ą│ą┤ąĄ ąĖąĘąĮą░čćą░ą╗čīąĮąŠ ą▒čŗą╗ čüą┐ąĖčüąŠą║ 5, Nil. ąŚą░č鹥ą╝ ą╝čŗ čüąŠąĘą┤ą░ą╗ąĖ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ Rc< List>, čģčĆą░ąĮčÅčēąĖą╣ ą┤čĆčāą│ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ List ą▓ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ b, ą║ąŠč鹊čĆčŗą╣ čüąŠą┤ąĄčƹȹĖčé ąĘąĮą░č湥ąĮąĖąĄ 10 ąĖ čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ čüą┐ąĖčüąŠą║ ą▓ a.
ą£čŗ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ą╗ąĖ a čéą░ą║, čćč鹊ą▒čŗ ąŠąĮ čāą║ą░ąĘčŗą▓ą░ą╗ ąĮą░ b ą▓ą╝ąĄčüč鹊 Nil, č湥ą╝ čüąŠąĘą┤ą░ą╗ąĖ čåąĖą║ą╗. ą£čŗ čüą┤ąĄą╗ą░ą╗ąĖ čŹč鹊 čü ą┐ąŠą╝ąŠčēčīčÄ ą╝ąĄč鹊ą┤ą░ tail, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī čüčüčŗą╗ą║čā ąĮą░ RefCell< Rc< List>> ą▓ a, ą║ąŠč鹊čĆčāčÄ ą╝čŗ ą┐ąŠą╝ąĄčüčéąĖą╗ąĖ ą▓ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ link. ąŚą░č鹥ą╝ ą╝čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ąĖ ą╝ąĄč鹊ą┤ borrow_mut ąĮą░ RefCell< Rc< List>>, čćč鹊ą▒čŗ ą┐ąŠą╝ąĄąĮčÅčéčī ąĘąĮą░č湥ąĮąĖąĄ ą▓ąĮčāčéčĆąĖ Rc< List> ą║ąŠč鹊čĆąŠąĄ čģčĆą░ąĮąĖą╗ąŠ ąĘąĮą░č湥ąĮąĖąĄ Nil, ąĮą░ Rc< List> ą▓ b.
ąÜąŠą│ą┤ą░ ą╝čŗ ąĘą░ą┐čāčüčéąĖą╝ čŹč鹊čé ą║ąŠą┤, čāą┤ąĄčƹȹĖą▓ą░čÅ ą┐ąŠą║ą░ ąĘą░ą║ąŠą╝ą╝ąĄąĮčéąĖčĆąŠą▓ą░ąĮąĮąŠą╣ ą┐ąŠčüą╗ąĄą┤ąĮčÄčÄ čüčéčĆąŠčćą║čā čü println!, č鹊 ą┐ąŠą╗čāčćąĖą╝ čüą╗ąĄą┤čāčÄčēąĖą╣ ą▓čŗą▓ąŠą┤:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.53s
Running `target/debug/cons-list`
a initial rc count = 1
a next item = Some(RefCell { value: Nil })
a rc count after b creation = 2
b initial rc count = 1
b next item = Some(RefCell { value: Cons(5, RefCell { value: Nil }) })
b rc count after changing a = 2
a rc count after changing a = 2
ąĪč湥čéčćąĖą║ čüčüčŗą╗ąŠą║ ą▓ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░čģ Rc< List> čĆą░ą▓ąĮčŗ 2 ą┤ą╗čÅ ąŠą▒ąŠąĖčģ a ąĖ b, ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ ą║ą░ą║ ą╝čŗ ą┐ąŠą╝ąĄąĮčÅą╗ąĖ čüą┐ąĖčüąŠą║ ą▓ a, čćč鹊ą▒čŗ ąŠąĮ čāą║ą░ąĘčŗą▓ą░ą╗ ąĮą░ b. ąÆ ą║ąŠąĮčåąĄ main, Rust ą▓čŗą▒čĆą░čüčŗą▓ą░ąĄčé ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ b, čćč鹊 čāą╝ąĄąĮčīčłą░ąĄčé čüč湥čéčćąĖą║ čüčüčŗą╗ąŠą║ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ b Rc< List> čü 2 ą┤ąŠ 1. ąÆ čŹč鹊ą╣ č鹊čćą║ąĄ ą┐ą░ą╝čÅčéčī Rc< List> ą║čāčćąĖ ąĮąĄ ąŠčćąĖčēą░ąĄčéčüčÅ, ą┐ąŠč鹊ą╝čā čćč鹊 čüč湥čéčćąĖą║ čüčüčŗą╗ąŠą║ 1, ąĮąĄ 0. ąŚą░č鹥ą╝ Rust ąŠčéą▒čĆą░čüčŗą▓ą░ąĄčé a, čćč鹊 čéą░ą║ąČąĄ čāą╝ąĄąĮčīčłą░ąĄčé čüč湥čéčćąĖą║ čüčüčŗą╗ąŠą║ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ a Rc< List> čü 2 ą┤ąŠ 1. ą¤ą░ą╝čÅčéčī čŹč鹊ą│ąŠ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ čéą░ą║ąČąĄ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠčćąĖčēąĄąĮą░, ą┐ąŠč鹊ą╝čā čćč鹊 ąĮą░ ąĮąĄą│ąŠ čüčüčŗą╗ą░ąĄčéčüčÅ ą┤čĆčāą│ąŠą╣ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ Rc< List>. ą¤ą░ą╝čÅčéčī, ą▓čŗą┤ąĄą╗ąĄąĮąĮą░čÅ ą┤ą╗čÅ čüą┐ąĖčüą║ą░, ąŠčüčéą░ąĄčéčüčÅ ą▓ąŠčüčéčĆąĄą▒ąŠą▓ą░ąĮąĮąŠą╣ ąĮą░ą▓čüąĄą│ą┤ą░. ąŁč鹊čé čåąĖą║ą╗ čüčüčŗą╗ąŠą║ ąĖą╗ą╗čÄčüčéčĆąĖčĆčāąĄčé čĆąĖčü. 15-4.
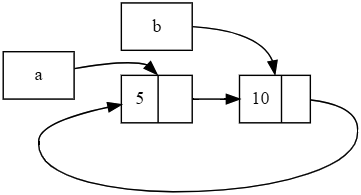
ąĀąĖčü. 15-4. ą”ąĖą║ą╗ čüčüčŗą╗ąŠą║ čüą┐ąĖčüą║ąŠą▓, ą║ąŠą│ą┤ą░ čüą┐ąĖčüą║ąĖ a ąĖ b čāą║ą░ąĘčŗą▓ą░čÄčé ą┤čĆčāą│ ąĮą░ ą┤čĆčāą│ą░.
ąĢčüą╗ąĖ ą▓čŗ čĆą░čüą║ąŠą╝ą╝ąĄąĮčéąĖčĆčāąĄč鹥 ą┐ąŠčüą╗ąĄą┤ąĮąĖą╣ println! ąĖ ąĘą░ą┐čāčüčéąĖč鹥 program, Rust ą┐ąŠą┐čŗčéą░ąĄčéčüčÅ ąĮą░ą┐ąĄčćą░čéą░čéčī čŹč鹊čé čåąĖą║ą╗, ą│ą┤ąĄ a čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ b, čāą║ą░ąĘčŗą▓ą░čÄčēąĖą╣ ąĮą░ a, ąĖ čéą░ą║ ą┤ą░ą╗ąĄąĄ, ą┐ąŠą║ą░ ąĮąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ čüč鹥ą║ą░.
ą¤ąŠ čüčĆą░ą▓ąĮąĄąĮąĖčÄ čü čĆąĄą░ą╗čīąĮąŠą╣ ą┐čĆąŠą│čĆą░ą╝ą╝ąŠą╣, ą┐ąŠčüą╗ąĄą┤čüčéą▓ąĖčÅ čüąŠąĘą┤ą░ąĮąĖčÅ čåąĖą║ą╗ą░ čüčüčŗą╗ąŠą║ ą▓ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ąĮąĄ ąŠč湥ąĮčī čüčéčĆą░čłąĮčŗ: čüčĆą░ąĘčā ą┐ąŠčüą╗ąĄ čüąŠąĘą┤ą░ąĮąĖčÅ čåąĖą║ą╗ą░ čüčüčŗą╗ąŠą║ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ. ąóąĄą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ ąĄčüą╗ąĖ ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮą░čÅ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą▒čāą┤ąĄčé ą▓čŗą┤ąĄą╗čÅčéčī ą┐ą░ą╝čÅčéčī ą▓ čåąĖą║ą╗ąĄ, ąĖ čāą┤ąĄčƹȹĖą▓ą░čéčī ąĄčæ ą▓ č鹥č湥ąĮąĖąĄ ą┤ą╗ąĖč鹥ą╗čīąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ, č鹊 ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą▒čāą┤ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▒ąŠą╗čīčłąĄ ą┐ą░ą╝čÅčéąĖ, č湥ą╝ ąĄą╣ ąĮčāąČąĮąŠ, čćč鹊 ą╝ąŠąČąĄčé ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĖčéčī čüąĖčüč鹥ą╝čā, čćč鹊 ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĖčüč湥čĆą┐ą░ąĮąĖčÄ ą┤ąŠčüčéčāą┐ąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ.
ąĪąŠąĘą┤ą░ąĮąĖąĄ čåąĖą║ą╗ą░ čüčüčŗą╗ąŠą║ ąĮąĄ čéą░ą║ ą┐čĆąŠčüč鹊, ąĮąŠ ą▓čüąĄ-čéą░ą║ąĖ ą▓ąŠąĘą╝ąŠąČąĮąŠ. ąĢčüą╗ąĖ čā ą▓ą░čü ąĄčüčéčī ąĘąĮą░č湥ąĮąĖčÅ RefCell< T>, ą║ąŠč鹊čĆčŗąĄ čüąŠą┤ąĄčƹȹ░čé ąĘąĮą░č湥ąĮąĖčÅ Rc< T> ąĖą╗ąĖ ą┐ąŠą┤ąŠą▒ąĮčŗąĄ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ čéąĖą┐ąŠą▓ čü čäčāąĮą║čåąĖąŠąĮą░ą╗ąŠą╝ interior mutability ąĖ ą┐ąŠą┤čüč湥č鹊ą╝ čüčüčŗą╗ąŠą║, č鹊 ą▓čŗ ą┤ąŠą╗ąČąĮčŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ąĮąĄ čüąŠąĘą┤ą░ą╗ąĖ čåąĖą║ą╗ąŠą▓ ą▓ąĘą░ąĖą╝ąĮčŗčģ čüčüčŗą╗ąŠą║; ą▓ ą┐ąĄčĆąĄčģą▓ą░č鹥 ą┐ąŠą┤ąŠą▒ąĮčŗčģ ąŠčłąĖą▒ąŠą║ ą▓čŗ ąĮąĄ čüą╝ąŠąČąĄč鹥 ą┐ąŠą╗ą░ą│ą░čéčīčüčÅ ąĮą░ Rust. ąĪąŠąĘą┤ą░ąĮąĖąĄ čåąĖą║ą╗ą░ čüčüčŗą╗ąŠą║ ą▒čŗą╗ąŠ ą▒čŗ ąŠčłąĖą▒ą║ąŠą╣ ą╗ąŠą│ąĖą║ąĖ ą▓ą░čłąĄą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ą║ąŠč鹊čĆčāčÄ ą┤ąŠą╗ąČąĮčŗ ą▓čŗčÅą▓ą╗čÅčéčī ą░ą▓č鹊ą╝ą░čéąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗąĄ č鹥čüčéčŗ, čĆąĄą▓ąĖąĘąĖąĖ ą║ąŠą┤ą░ ąĖ ą┤čĆčāą│ąĖąĄ ą┐čĆą░ą║čéąĖą║ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ą¤ą×.
ąöčĆčāą│ąĖą╝ čĆąĄčłąĄąĮąĖąĄą╝, ą┐ąŠąĘą▓ąŠą╗čÅčÄčēąĖą╝ ąĖąĘą▒ąĄąČą░čéčī čåąĖą║ą╗ąŠą▓ čüčüčŗą╗ąŠą║, čÅą▓ą╗čÅąĄčéčüčÅ čĆąĄąŠčĆą│ą░ąĮąĖąĘą░čåąĖčÅ čüčéčĆčāą║čéčāčĆ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊ą▒čŗ ąĮąĄą║ąŠč鹊čĆčŗąĄ čüčüčŗą╗ą║ąĖ ą▓čŗčĆą░ąČą░ą╗ąĖ ą┐čĆąĖąĮą░ą┤ą╗ąĄąČąĮąŠčüčéčī, ą░ ąĮąĄą║ąŠč鹊čĆčŗąĄ ąĮąĄčé. ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 ą╝ąŠą│čāčé čüčāčēąĄčüčéą▓ąŠą▓ą░čéčī čåąĖą║ą╗čŗ, čüąŠčüč鹊čÅčēąĖąĄ ąĖąĘ ąĮąĄą║ąŠč鹊čĆčŗčģ ąŠčéąĮąŠčłąĄąĮąĖą╣ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ ąĖ ąĮąĄą║ąŠč鹊čĆčŗčģ ąŠčéąĮąŠčłąĄąĮąĖą╣ ąŠčéčüčāčéčüčéą▓ąĖčÅ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ, ąĖ č鹊ą╗čīą║ąŠ ąŠčéąĮąŠčłąĄąĮąĖčÅ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ ą▓ą╗ąĖčÅčÄčé ąĮą░ č鹊, ą╝ąŠąČąĄčé ą╗ąĖ ą▒čŗčéčī ąĘąĮą░č湥ąĮąĖąĄ ąŠčéą▒čĆąŠčłąĄąĮąŠ. ąÆ ą╗ąĖčüčéąĖąĮą│ąĄ 15-25 ą╝čŗ ą▓čüąĄą│ą┤ą░ čģąŠčéąĖą╝ ą┐ąŠą╗čāčćąĖčéčī ą▓ą░čĆąĖą░ąĮčéčŗ Cons, čćč鹊ą▒čŗ ąŠąĮąĖ ą▓ą╗ą░ą┤ąĄą╗ąĖ čüą▓ąŠąĖą╝ čüą┐ąĖčüą║ąŠą╝, ą┐ąŠčŹč鹊ą╝čā čĆąĄąŠčĆą│ą░ąĮąĖąĘą░čåąĖčÅ čüčéčĆčāą║čéčāčĆčŗ ą┤ą░ąĮąĮčŗčģ ąĮąĄą▓ąŠąĘą╝ąŠąČąĮą░. ąöą░ą▓ą░ą╣č鹥 čĆą░čüčüą╝ąŠčéčĆąĖą╝ ą┐čĆąĖą╝ąĄčĆ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą│čĆą░č乊ą▓, čüąŠčüč鹊čÅčēąĖčģ ąĖąĘ čĆąŠą┤ąĖč鹥ą╗čīčüą║ąĖčģ čāąĘą╗ąŠą▓ ąĖ ą┤ąŠč湥čĆąĮąĖčģ čāąĘą╗ąŠą▓, čćč鹊ą▒čŗ čāą▓ąĖą┤ąĄčéčī, ą║ąŠą│ą┤ą░ ą▓ąĘą░ąĖą╝ąŠąŠčéąĮąŠčłąĄąĮąĖčÅ ąŠčéčüčāčéčüčéą▓ąĖčÅ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ čÅą▓ą╗čÅčÄčéčüčÅ ą┐ąŠą┤čģąŠą┤čÅčēąĖą╝ čüą┐ąŠčüąŠą▒ąŠą╝ ą┐čĆąĄą┤ąŠčéą▓čĆą░čēąĄąĮąĖčÅ čåąĖą║ą╗ąŠą▓ čüčüčŗą╗ąŠą║.
ą¤čĆąĄą┤ąŠčéą▓čĆą░čēąĄąĮąĖąĄ čåąĖą║ą╗ą░ čüčüčŗą╗ąŠą║: ą┐čĆąĄą▓čĆą░čēąĄąĮąĖąĄ Rc< T> ą▓ Weak< T>. ąöąŠ čüąĖčģ ą┐ąŠčĆ ą╝čŗ ą┐čĆąŠą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆąŠą▓ą░ą╗ąĖ, čćč鹊 ą▓čŗąĘąŠą▓ Rc::clone čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčé strong_count 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ Rc< T>, ą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ Rc< T> ąŠčćąĖčēą░ąĄčéčüčÅ č鹊ą╗čīą║ąŠ ąĄčüą╗ąĖ ąĄą│ąŠ strong_count čĆą░ą▓ąĄąĮ 0. ąÆčŗ čéą░ą║ąČąĄ ą╝ąŠąČąĄč鹥 čüąŠąĘą┤ą░čéčī čüą╗ą░ą▒čāčÄ (weak) čüčüčŗą╗ą║čā ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ ą▓ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąĄ Rc< T> ą▓čŗąĘąŠą▓ąŠą╝ Rc::downgrade ąĖ ą┐ąĄčĆąĄą┤ą░č湥ą╣ čüčüčŗą╗ą║ąĖ ąĮą░ Rc< T>. ąĪąĖą╗čīąĮčŗąĄ (strong) čüčüčŗą╗ą║ąĖ čŹč鹊 čüą┐ąŠčüąŠą▒čŗ čüąŠą▓ą╝ąĄčüčéąĮąŠą│ąŠ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ čŹą║ąĘąĄą╝ą┐ą╗čÅčĆąŠą╝ Rc< T>. Weak-čüčüčŗą╗ą║ąĖ ąĮąĄ ą▓čŗčĆą░ąČą░čÄčé ą▓ąĘą░ąĖą╝ąŠčüą▓čÅąĘčī ą▓ą╗ą░ą┤ąĄąĮąĖčÅ, ąĖ ąĖčģ čüč湥čéčćąĖą║ ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ č鹊, ą║ąŠą│ą┤ą░ ąŠčćąĖčēą░ąĄčéčüčÅ čŹą║ąĘąĄą╝ą┐ą╗čÅčĆ Rc< T>. ą×ąĮąĖ ąĮąĄ ą▓čŗąĘąŠą▓čāčé čüčüčŗą╗ąŠčćąĮčŗą╣ čåąĖą║ą╗, ą┐ąŠč鹊ą╝čā čćč鹊 ą╗čÄą▒ąŠą╣ čåąĖą║ą╗, ą▓ą║ą╗čÄčćą░čÄčēąĖą╣ ąĮąĄą║ąŠč鹊čĆčŗąĄ weak-čüčüčŗą╗ą║ąĖ, ą▒čāą┤ąĄčé čĆą░ąĘą▒ąĖčé, ą║ą░ą║ č鹊ą╗čīą║ąŠ ąĘąĮą░č湥ąĮąĖčÅ čüč湥čéčćąĖą║ąŠą▓ ąĘą░ą┤ąĄą╣čüčéą▓ąŠą▓ą░ąĮąĮčŗčģ strong-čüčüčŗą╗ąŠą║ čüčéą░ąĮčāčé 0.
ąÜąŠą│ą┤ą░ ą▓čŗ ą▓čŗąĘą▓ą░ą╗ąĖ Rc::downgrade, č鹊 ą┐ąŠą╗čāčćąĖč鹥 smart-čāą║ą░ąĘą░č鹥ą╗čī čéąĖą┐ą░ Weak< T>. ąÆą╝ąĄčüč鹊 čāą▓ąĄą╗ąĖč湥ąĮąĖčÅ strong_count ą▓ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąĄ Rc< T> ąĮą░ 1, ą▓čŗąĘąŠą▓ Rc::downgrade čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčé weak_count ąĮą░ 1. ąóąĖą┐ Rc< T> ąĖčüą┐ąŠą╗čīąĘčāąĄčé weak_count ą┤ą╗čÅ ąŠčéčüą╗ąĄąČąĖą▓ą░ąĮąĖčÅ, čüą║ąŠą╗čīą║ąŠ čüčāčēąĄčüčéą▓čāąĄčé čüčüčŗą╗ąŠą║ Weak< T>, ą┐ąŠą┤ąŠą▒ąĮąŠ strong_count. ąĀą░ąĘąĮąĖčåą░ ą╝ąĄąČą┤čā čŹčéąĖą╝ąĖ čéąĖą┐ą░ą╝ąĖ čüčüčŗą╗ąŠą║ ą▓ č鹊ą╝, čćč鹊 weak_count ąĮąĄ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī 0 ą┤ą╗čÅ č鹊ą│ąŠ, čćč鹊ą▒čŗ ą▒čŗą╗ ąŠčćąĖčēąĄąĮ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ Rc< T>.
ą¤ąŠčüą║ąŠą╗čīą║čā ąĘąĮą░č湥ąĮąĖąĄ, ąĮą░ ą║ąŠč鹊čĆąŠą╝ ą╝ąŠą│ą╗ąĖ ą▒čŗčéčī ąŠčéą▒čĆąŠčłąĄąĮčŗ čüčüčŗą╗ą║ąĖ Weak< T>, čćč鹊ą▒čŗ čćč鹊-ą╗ąĖą▒ąŠ čüą┤ąĄą╗ą░čéčī čüąŠ ąĘąĮą░č湥ąĮąĖąĄą╝, ąĮą░ ą║ąŠč鹊čĆąŠąĄ čāą║ą░ąĘčŗą▓ą░ąĄčé Weak< T>, ą▓čŗ ą┤ąŠą╗ąČąĮčŗ čāą▒ąĄą┤ąĖčéčīčüčÅ, čćč鹊 ąĘąĮą░č湥ąĮąĖąĄ ą▓čüąĄ ąĄčēąĄ čüčāčēąĄčüčéą▓čāąĄčé. ąöą╗čÅ čŹč鹊ą│ąŠ ą▓čŗąĘąŠą▓ąĖč鹥 ą╝ąĄč鹊ą┤ upgrade ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąĄ Weak< T>, ą║ąŠč鹊čĆčŗą╣ ą▓ąŠąĘą▓čĆą░čéąĖčé Option< Rc< T>>. ąÆčŗ ą┐ąŠą╗čāčćąĖč鹥 čĆąĄąĘčāą╗čīčéą░čé Some, ąĄčüą╗ąĖ ąĘąĮą░č湥ąĮąĖąĄ Rc< T> ąĮąĄ ąŠčéą▒čĆąŠčłąĄąĮąŠ, ąĖ čĆąĄąĘčāą╗čīčéą░čé None, ąĄčüą╗ąĖ ąĘąĮą░č湥ąĮąĖąĄ Rc< T> ą▒čŗą╗ąŠ ąŠčéą▒čĆąŠčłąĄąĮąŠ. ą¤ąŠčüą║ąŠą╗čīą║čā upgrade ą▓ąŠąĘą▓čĆą░čéąĖčé Option< Rc< T>>, Rust ą▒čāą┤ąĄčé ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ą▒čāą┤čāčé ąŠą▒čĆą░ą▒ąŠčéą░ąĮčŗ čüą╗čāčćą░ą╣ Some ąĖ čüą╗čāčćą░ą╣ None, ąĖ ąĮąĄ ą▒čāą┤ąĄčé ąĮąĄą┤ąŠą┐čāčüčéąĖą╝ąŠą│ąŠ čāą║ą░ąĘą░č鹥ą╗čÅ.
ąÆ ą║ą░č湥čüčéą▓ąĄ ą┐čĆąĖą╝ąĄčĆą░ ą▓ą╝ąĄčüč鹊 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüą┐ąĖčüą║ą░, 菹╗ąĄą╝ąĄąĮčéčŗ ą║ąŠč鹊čĆąŠą│ąŠ ąĘąĮą░čÄčé č鹊ą╗čīą║ąŠ ąŠ čüą╗ąĄą┤čāčÄčēąĄą╝ 菹╗ąĄą╝ąĄąĮč鹥, ą╝čŗ čüąŠąĘą┤ą░ą┤ąĖą╝ ą┤ąĄčĆąĄą▓ąŠ, 菹╗ąĄą╝ąĄąĮčéčŗ ą║ąŠč鹊čĆąŠą│ąŠ ąĘąĮą░čÄčé ąŠ čüą▓ąŠąĖčģ ą┤ąŠč湥čĆąĮąĖčģ ąĖ čüą▓ąŠąĖčģ čĆąŠą┤ąĖč鹥ą╗čīčüą║ąĖčģ 菹╗ąĄą╝ąĄąĮčéą░čģ.
ąĪąŠąĘą┤ą░ąĮąĖąĄ čüčéčĆčāą║čéčāčĆčŗ ą┤ą░ąĮąĮčŗčģ ą┤ąĄčĆąĄą▓ą░: čāąĘą╗čŗ čü ą┤ąŠč湥čĆąĮąĖą╝ąĖ čāąĘą╗ą░ą╝ąĖ. ąöą╗čÅ ąĮą░čćą░ą╗ą░ ą╝čŗ ą┐ąŠčüčéčĆąŠąĖą╝ ą┤ąĄčĆąĄą▓ąŠ čü čāąĘą╗ą░ą╝ąĖ, ą║ąŠč鹊čĆčŗąĄ ąĘąĮą░čÄčé ąŠ čüą▓ąŠąĖčģ ą┤ąŠč湥čĆąĮąĖčģ čāąĘą╗ą░čģ. ą£čŗ čüąŠąĘą┤ą░ą┤ąĖą╝ čüčéčĆčāą║čéčāčĆčā čü ąĖą╝ąĄąĮąĄą╝ Node, ą║ąŠč鹊čĆą░čÅ čģčĆą░ąĮąĖčé ą║ą░ą║ čüąŠą▒čüčéą▓ąĄąĮąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ i32, čéą░ą║ ąĖ čüčüčŗą╗ą║ąĖ ąĮą░ ąĖčģ ą┤ąŠč湥čĆąĮąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ Node (čäą░ą╣ą╗ src/main.rs):
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Node {
value: i32,
children: RefCell< Vec< Rc< Node>>>,
}
ą£čŗ čģąŠčéąĖą╝, čćč鹊ą▒čŗ Node ą▓ą╗ą░ą┤ąĄą╗ čüą▓ąŠąĖą╝ąĖ ą┐ąŠč鹊ą╝ą║ą░ą╝ąĖ children, ąĖ ą╝čŗ čģąŠčéąĖą╝ čĆą░ąĘą┤ąĄą╗ąĖčéčī čŹč鹊 ą▓ą╗ą░ą┤ąĄąĮąĖąĄ čü ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝ąĖ, čéą░ą║ čćč鹊ą▒čŗ ą╝čŗ ą╝ąŠą│ą╗ąĖ ąŠą▒čĆą░čēą░čéčīčüčÅ ą║ ą║ą░ąČą┤ąŠą╝čā Node ą▓ ą┤ąĄčĆąĄą▓ąĄ ąĮą░ą┐čĆčÅą╝čāčÄ. ą¦č鹊ą▒čŗ čüą┤ąĄą╗ą░čéčī čŹč鹊, ą╝čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖą╗ąĖ 菹╗ąĄą╝ąĄąĮčéčŗ Vec< T> ą┤ą╗čÅ ąĘąĮą░č湥ąĮąĖą╣ čéąĖą┐ą░ Rc< Node>. ą£čŗ čéą░ą║ąČąĄ čģąŠčéąĖą╝ ąĖąĘą╝ąĄąĮąĖčéčī, ą║ą░ą║ąĖąĄ čāąĘą╗čŗ čÅą▓ą╗čÅčÄčéčüčÅ ą┤ąŠč湥čĆąĮąĖą╝ąĖ ą┤ą╗čÅ ą┤čĆčāą│ąŠą│ąŠ čāąĘą╗ą░, čéą░ą║ čćč鹊 čā ąĮą░čü ąĄčüčéčī RefCell< T> ą▓ children ą▓ąŠą║čĆčāą│ Vec< Rc< Node>>.
ąöą░ą╗ąĄąĄ ą╝čŗ ą▒čāą┤ąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĮą░čłąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čüčéčĆčāą║čéčāčĆčŗ ąĖ čüąŠąĘą┤ą░ą┤ąĖą╝ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ Node čü ąĖą╝ąĄąĮąĄą╝ leaf (ą┐ąĄčĆąĄą▓ąŠą┤ąĖčéčüčÅ ą║ą░ą║ "ą╗ąĖčüčé"), ąĘąĮą░č湥ąĮąĖąĄą╝ 3 ąĖ ą▒ąĄąĘ ą┤ąŠč湥čĆąĮąĄą│ąŠ čāąĘą╗ą░, ąĖ ą┤čĆčāą│ąŠą╣ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ čü ąĖą╝ąĄąĮąĄą╝ branch (ą┐ąĄčĆąĄą▓ąŠą┤ąĖčéčüčÅ ą║ą░ą║ "ą▓ąĄčéą▓čī"), ąĘąĮą░č湥ąĮąĖąĄą╝ 5 ąĖ leaf ą║ą░ą║ ąŠą┤ąĮąĖą╝ ąĖąĘ čüą▓ąŠąĖčģ ą┤ąŠč湥čĆąĮąĖčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-27 (čäą░ą╣ą╗ src/main.rs):
fn main() {
let leaf = Rc::new(Node {
value: 3,
children: RefCell::new(vec![]),
});
let branch = Rc::new(Node {
value: 5,
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
}
ąøąĖčüčéąĖąĮą│ 15-27. ąĪąŠąĘą┤ą░ąĮąĖąĄ čāąĘą╗ą░ leaf ą▒ąĄąĘ ą┤ąŠč湥čĆąĮąĖčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ąĖ čāąĘą╗ą░ branch čü leaf ą║ą░ą║ čü ąŠą┤ąĮąĖą╝ ąĖąĘ čüą▓ąŠąĖčģ ą┤ąŠč湥čĆąĮąĖčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓.
ą£čŗ ą║ą╗ąŠąĮąĖčĆąŠą▓ą░ą╗ąĖ Rc< Node> ą▓ leaf ąĖ čüąŠčģčĆą░ąĮąĖą╗ąĖ ąĄą│ąŠ ą▓ branch, čé. ąĄ. Node ą▓ leaf č鹥ą┐ąĄčĆčī ąĖą╝ąĄąĄčé ą┤ą▓čāčģ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą▓: leaf ąĖ branch. ą£čŗ ą╝ąŠąČąĄą╝ ąŠą▒čĆą░čéąĖčéčīčüčÅ ą║ leaf ąŠčé branch č湥čĆąĄąĘ branch.children, ąĮąŠ ąĮąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ čüą┐ąŠčüąŠą▒ą░ ąŠą▒čĆą░čéąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░, ąŠčé leaf ą║ branch. ą¤čĆąĖčćąĖąĮą░ ą▓ č鹊ą╝, čćč鹊 čā leaf ąĮąĄčé čüčüčŗą╗ą║ąĖ ąĮą░ branch ąĖ ąŠąĮ ąĮąĄ ąĘąĮą░ąĄčé, čćč鹊 ąŠąĮąĖ čüą▓čÅąĘą░ąĮčŗ. ąØąŠ ą╝čŗ čģąŠčéąĖą╝, čćč鹊ą▒čŗ leaf ąĘąĮą░ą╗, čćč鹊 branch čÅą▓ą╗čÅąĄčéčüčÅ ąĄą│ąŠ čĆąŠą┤ąĖč鹥ą╗ąĄą╝. ąŁčéąĖą╝ ąĘą░ą╣ą╝ąĄą╝čüčÅ ą┤ą░ą╗ąĄąĄ.
ąöąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ čüčüčŗą╗ą║ąĖ ąŠčé ą┤ąŠč湥čĆąĮąĄą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░ ą║ ąĄą│ąŠ čĆąŠą┤ąĖč鹥ą╗čÄ. ą¦č鹊ą▒čŗ čüą┤ąĄą╗ą░čéčī ą┤ąŠč湥čĆąĮąĖą╣ čāąĘąĄą╗ ąŠčüą▓ąĄą┤ąŠą╝ą╗ąĄąĮąĮčŗą╝ ąŠ čüą▓ąŠąĄą╝ čĆąŠą┤ąĖč鹥ą╗ąĄ, ąĮą░ ąĮčāąČąĮąŠ ą┤ąŠą▒ą░ą▓ąĖčéčī ą┐ąŠą╗ąĄ parent ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ąĮą░čłąĄą╣ čüčéčĆčāą║čéčāčĆčŗ Node. ą¤čĆąŠą▒ą╗ąĄą╝ ą▓ č鹊ą╝, čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, ą║ą░ą║ąĖą╝ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čéąĖą┐ ą┐ąŠą╗čÅ parent. ą£čŗ ąĘąĮą░ąĄą╝, čćč鹊 ąŠąĮ ąĮąĄ ą╝ąŠąČąĄčé čüąŠą┤ąĄčƹȹ░čéčī Rc< T>, ą┐ąŠčüą║ąŠą╗čīą║čā čŹč鹊 čüąŠąĘą┤ą░ą╗ąŠ ą▒čŗ čåąĖą║ą╗ čüčüčŗą╗ąŠą║ čü leaf.parent, čāą║ą░ąĘčŗą▓ą░čÄčēąĖą╣ ąĮą░ branch, ąĖ branch.children, čāą║ą░ąĘčŗą▓ą░čÄčēąĖą╣ ąĮą░ leaf, čćč鹊 ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ č鹊ą╝čā, čćč鹊 ąĖčģ ąĘąĮą░č湥ąĮąĖčÅ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ čüčéą░ąĮčāčé 0.
ąĢčüą╗ąĖ ą┤čāą╝ą░čéčī ąŠą▒ čŹčéąĖčģ ą▓ąĘą░ąĖą╝ąŠąŠčéąĮąŠčłąĄąĮąĖčÅčģ ą┐ąŠ-ą┤čĆčāą│ąŠą╝čā, č鹊 čāąĘąĄą╗ parent ą┤ąŠą╗ąČąĄąĮ ą▓ą╗ą░ą┤ąĄčéčī čüą▓ąŠąĖą╝ąĖ children: ąĄčüą╗ąĖ čāąĘąĄą╗ parent ąŠčéą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ, č鹊 čéą░ą║ąČąĄ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąŠčéą▒čĆąŠčłąĄąĮčŗ ąĖ ąĄą│ąŠ ą┤ąŠč湥čĆąĮąĖąĄ 菹╗ąĄą╝ąĄąĮčéčŗ. ą×ą┤ąĮą░ą║ąŠ ą┤ąŠč湥čĆąĮąĖą╣ 菹╗ąĄą╝ąĄąĮčé ąĮąĄ ą▓ą╗ą░ą┤ąĄąĄčé čüą▓ąŠąĖą╝ čĆąŠą┤ąĖč鹥ą╗ąĄą╝: ąĄčüą╗ąĖ ą╝čŗ ąŠčéą▒čĆąŠčüąĖą╝ ą┤ąŠč湥čĆąĮąĖą╣ čāąĘąĄą╗, čĆąŠą┤ąĖč鹥ą╗čī ąŠčüčéą░ąĄčéčüčÅ. ąŁč鹊 ą║ą░ą║ čĆą░ąĘ čüą╗čāčćą░ą╣ ą┤ą╗čÅ weak-čüčüčŗą╗ąŠą║!
ąóą░ą║ čćč鹊 ą▓ą╝ąĄčüč鹊 Rc< T> ą╝čŗ čüą┤ąĄą╗ą░ąĄą╝ čéąĖą┐ parent ąĖčüą┐ąŠą╗čīąĘčāčÄčēąĖą╝ Weak< T>, ą░ ąĖą╝ąĄąĮąĮąŠ RefCell< Weak< Node>>. ąóąĄą┐ąĄčĆčī ąĮą░čłąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čüčéčĆčāą║čéčāčĆčŗ Node ą▒čāą┤ąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī čéą░ą║ (čäą░ą╣ą╗ src/main.rs):
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell< Weak< Node>>,
children: RefCell< Vec< Rc< Node>>>,
}
ąŻąĘąĄą╗ ą╝ąŠąČąĄčé čüčüčŗą╗ą░čéčīčüčÅ ąĮą░ čüą▓ąŠą╣ čĆąŠą┤ąĖč鹥ą╗čīčüą║ąĖą╣ čāąĘąĄą╗, ąĮąŠ ąĮąĄ ą▓ą╗ą░ą┤ąĄąĄčé ąĖą╝. ąÆ ą╗ąĖčüčéąĖąĮą│ąĄ 15-28 ą╝čŗ ąŠą▒ąĮąŠą▓ąĖą╗ąĖ main ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čŹč鹊ą│ąŠ ąĮąŠą▓ąŠą│ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ, čéą░ą║ čćč鹊ą▒čŗ čāąĘąĄą╗ leaf ąĖą╝ąĄą╗ čüą┐ąŠčüąŠą▒ ąŠą▒čĆą░čéąĖčéčīčüčÅ ą║ čüą▓ąŠąĄą╝čā čĆąŠą┤ąĖč鹥ą╗čÄ branch (čäą░ą╣ą╗ src/main.rs):
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
}
ąøąĖčüčéąĖąĮą│ 15-28. ąŻąĘąĄą╗ leaf čü weak-čüčüčŗą╗ą║ąŠą╣ ąĮą░ čüą▓ąŠą╣ čĆąŠą┤ąĖč鹥ą╗čīčüą║ąĖą╣ čāąĘąĄą╗ branch.
ąĪąŠąĘą┤ą░ąĮąĖąĄ čāąĘą╗ą░ leaf ą▓čŗą│ą╗čÅą┤ąĖčé ą┐ąŠą┤ąŠą▒ąĮąŠ ą╗ąĖčüčéąĖąĮą│čā 15-27 čü ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ ą┐ąŠą╗čÅ parent: leaf ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ ą▒ąĄąĘ parent, čéą░ą║ čćč鹊 ą╝čŗ čüąŠąĘą┤ą░ąĄą╝ ąĮąŠą▓čŗą╣, ą┐čāčüč鹊ą╣ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ čüčüčŗą╗ą║ąĖ Weak< Node>.
ąØą░ čŹč鹊ą╣ čüčéą░ą┤ąĖąĖ, ą║ąŠą│ą┤ą░ ą╝čŗ ą┐ąŠą┐čŗčéą░ąĄą╝čüčÅ ą┐ąŠą╗čāčćąĖčéčī čüčüčŗą╗ą║čā ąĮą░ čĆąŠą┤ąĖč鹥ą╗čÅ leaf ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą╝ąĄč鹊ą┤ą░ upgrade, č鹊 ą┐ąŠą╗čāčćąĖą╝ ąĘąĮą░č湥ąĮąĖąĄ None. ą£čŗ ą▓ąĖą┤ąĖą╝ čŹč鹊 ą▓ ą▓čŗą▓ąŠą┤ąĄ ąĖąĘ ą┐ąĄčĆą▓ąŠą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░ println!:
leaf parent = None
ąÜąŠą│ą┤ą░ ą╝čŗ čüąŠąĘą┤ą░ąĄą╝ čāąĘąĄą╗ branch, čā ąĮąĄą│ąŠ ą▒čāą┤ąĄčé čéą░ą║ąČąĄ ąĮąŠą▓ą░čÅ čüčüčŗą╗ą║ą░ Weak< Node> ą▓ ą┐ąŠą╗ąĄ parent, ą┐ąŠč鹊ą╝čā čćč鹊 čā branch ąĮąĄčé čĆąŠą┤ąĖč鹥ą╗čīčüą║ąŠą│ąŠ čāąĘą╗ą░. ąŻ ąĮą░čü ą▓čüąĄ ąĄčēąĄ ąĄčüčéčī leaf ą║ą░ą║ ąŠą┤ąĖąĮ ąĖąĘ ą┤ąŠč湥čĆąĮąĖčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓ branch. ąÜą░ą║ č鹊ą╗čīą║ąŠ čā ąĮą░čü ą▒čāą┤ąĄčé 菹║ąĘąĄą╝ą┐ą╗čÅčĆ Node ą▓ branch, ą╝čŗ čüą╝ąŠąČąĄą╝ ąĖąĘą╝ąĄąĮąĖčéčī leaf čćč鹊ą▒čŗ ą┤ą░čéčī ąĄą╝čā čüčüčŗą╗ą║čā Weak< Node> ąĮą░ čüą▓ąŠąĄą│ąŠ čĆąŠą┤ąĖč鹥ą╗čÅ. ą£čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ ą╝ąĄč鹊ą┤ borrow_mut ąĮą░ RefCell< Weak< Node>> ą▓ ą┐ąŠą╗ąĄ parent 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ leaf, ąĖ ąĘą░č鹥ą╝ ą╝čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ čäčāąĮą║čåąĖčÄ Rc::downgrade, čćč鹊ą▒čŗ čüąŠąĘą┤ą░čéčī čüčüčŗą╗ą║čā Weak< Node> ąĮą░ branch ąĖąĘ Rc< Node> ą▓ branch.
ąÜąŠą│ą┤ą░ ą╝čŗ čüąĮąŠą▓ą░ ąĮą░ą┐ąĄčćą░čéą░ąĄą╝ parent ą┤ą╗čÅ leaf, č鹊 ąĮą░ čŹč鹊čé čĆą░ąĘ ą╝čŗ ą┐ąŠą╗čāčćąĖą╝ ą▓ą░čĆąĖą░ąĮčé Some, čüąŠą┤ąĄčƹȹ░čēąĖą╣ branch: č鹥ą┐ąĄčĆčī leaf ą╝ąŠąČąĄčé ąŠą▒čĆą░čéąĖčéčīčüčÅ ą║ čüą▓ąŠąĄą╝čā čĆąŠą┤ąĖč鹥ą╗čÄ parent! ąÜąŠą│ą┤ą░ ą╝čŗ ą┐ąĄčćą░čéą░ąĄą╝ leaf, ą╝čŗ čéą░ą║ąČąĄ ąĖąĘą▒ąĄą│ą░ąĄą╝ čåąĖą║ą╗ą░, ą║ąŠč鹊čĆčŗą╣ ą▓ ą║ąŠąĮąĄčćąĮąŠą╝ čüč湥č鹥 ąĘą░ą║ąŠąĮčćąĖčéčüčÅ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ čüč鹥ą║ą░, ą║ą░ą║ čā ąĮą░čü ą▒čŗą╗ąŠ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-26; čüčüčŗą╗ą║ąĖ Weak< Node> ą┐ąĄčćą░čéą░čÄčéčüčÅ ą║ą░ą║ (Weak):
leaf parent = Some(Node { value: 5, parent: RefCell { value: (Weak) },
children: RefCell { value: [Node { value: 3, parent: RefCell { value: (Weak) },
children: RefCell { value: [] } }] } })
ą×čéčüčāčéčüčéą▓ąĖąĄ ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠą│ąŠ ą▓čŗą▓ąŠą┤ą░ ą│ąŠą▓ąŠčĆąĖčé ąŠ č鹊ą╝, čćč鹊 čŹč鹊čé ą║ąŠą┤ ąĮąĄ čüąŠąĘą┤ą░ąĄčé čåąĖą║ą╗ą░ čüčüčŗą╗ąŠą║. ą£čŗ čéą░ą║ąČąĄ ą╝ąŠąČąĄą╝ čüą║ą░ąĘą░čéčī čŹč鹊, ą▓ąĘą│ą╗čÅąĮčā ąĮą░ ąĘąĮą░č湥ąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą╝čŗ ą┐ąŠą╗čāčćą░ąĄą╝ ąĖąĘ ą▓čŗąĘąŠą▓ą░ Rc::strong_count ąĖ Rc::weak_count.
ąÆąĖąĘčāą░ą╗ąĖąĘą░čåąĖčÅ ąĖąĘą╝ąĄąĮąĄąĮąĖą╣ strong_count ąĖ weak_count. ąöą░ą▓ą░ą╣č鹥 ą┐ąŠčüą╝ąŠčéčĆąĖą╝, ą║ą░ą║ ą╝ąĄąĮčÅčÄčéčüčÅ ąĘąĮą░č湥ąĮąĖčÅ strong_count ąĖ weak_count 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą▓ Rc< Node> ą┐čāč鹥ą╝ čüąŠąĘą┤ą░ąĮąĖčÅ ąĮąŠą▓ąŠą╣ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ ąŠą▒ą╗ą░čüčéąĖ ąĖ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ čüąŠąĘą┤ą░ąĮąĖčÅ branch ą▓ čŹčéčā ąŠą▒ą╗ą░čüčéčī. ąĢčüą╗ąĖ čŹč鹊 čüą┤ąĄą╗ą░čéčī, č鹊 ą╝čŗ čāą▓ąĖą┤ąĖą╝, čćč鹊 ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé, ą║ąŠą│ą┤ą░ čüąŠąĘą┤ą░ąĄčéčüčÅ branch, ą░ ąĘą░č鹥ą╝ čāą┤ą░ą╗ąĄąĮą░, ą║ąŠą│ą┤ą░ ąŠąĮą░ ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ. ą£ąŠą┤ąĖčäąĖą║ą░čåąĖąĖ ą┐ąŠą║ą░ąĘą░ąĮčŗ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 15-29 (čäą░ą╣ą╗ src/main.rs):
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
{
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!(
"branch strong = {}, weak = {}",
Rc::strong_count(&branch),
Rc::weak_count(&branch),
);
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
}
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
}
ąøąĖčüčéąĖąĮą│ 15-29. ąĪąŠąĘą┤ą░ąĮąĖąĄ branch ą▓ąŠ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ ąŠą▒ą╗ą░čüčéąĖ, ąĖ ąĖčüčüą╗ąĄą┤ąŠą▓ą░ąĮąĖąĄ čüč湥čéčćąĖą║ąŠą▓ čüąĖą╗čīąĮčŗčģ ąĖ čüą╗ą░ą▒čŗčģ čüčüčŗą╗ąŠą║.
ą¤ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ čüąŠąĘą┤ą░ąĮ leaf, ą▓ ąĄą│ąŠ Rc< Node> strong-čüč湥čéčćąĖą║ąĄ 1, ąĖ weak-čüč湥čéčćąĖą║ąĄ 0. ąÆąŠ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ ąŠą▒ą╗ą░čüčéąĖ ą╝čŗ čüąŠąĘą┤ą░ąĄą╝ branch, ąĖ čüą▓čÅąĘčŗą▓ą░ąĄą╝ ąĄčæ čü leaf, ąĖ ą▓ čŹč鹊ą╣ č鹊čćą║ąĄ, ą║ąŠą│ą┤ą░ ą╝čŗ ą┐ąĄčćą░čéą░ąĄą╝ čüč湥čéčćąĖą║ąĖ, Rc< Node> ą▓ branch ą▒čāą┤ąĄčé ąĖą╝ąĄčéčī strong-čüč湥čéčćąĖą║ 1 ąĖ weak-čüč湥čéčćąĖą║ 1 (ą┤ą╗čÅ leaf.parent, čāą║ą░ąĘčŗą▓ą░čÄčēąĄą│ąŠ ąĮą░ branch čü ą┐ąŠą╝ąŠčēčīčÄ Weak< Node>). ąÜąŠą│ą┤ą░ ą╝čŗ ą┐ąĄčćą░čéą░ąĄą╝ čüč湥čéčćąĖą║ąĖ ą▓ leaf, č鹊 ą▓ąĖą┤ąĖą╝, čćč鹊 ąĄą│ąŠ strong-čüč湥čéčćąĖą║ 2, ą┐ąŠč鹊ą╝čā čćč鹊 branch č鹥ą┐ąĄčĆčī ąĖą╝ąĄąĄčé ą║ą╗ąŠąĮ Rc< Node> leaf, čüąŠčģčĆą░ąĮąĄąĮąĮčŗą╣ ą▓ branch.children, ąĮąŠ čā ąĮąĄą│ąŠ ą▓čüąĄ ąĄčēąĄ weak-čüč湥čéčćąĖą║ 0.
ąÜąŠą│ą┤ą░ ą▓ąĮčāčéčĆąĄąĮąĮčÅčÅ ąŠą▒ą╗ą░čüčéčī ąĘą░ą║ą░ąĮčćąĖą▓ą░ąĄčéčüčÅ, branch ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ, ąĖ strong-čüč湥čéčćąĖą║ Rc< Node> čāą╝ąĄąĮčīčłą░ąĄčéčüčÅ ą┤ąŠ 0, čéą░ą║ čćč鹊 čŹč鹊čé Node ąŠčéą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ. Weak-čüč湥čéčćąĖą║ 1 ąĖąĘ leaf.parent ąĮąĄ ąĖą╝ąĄąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ąŠčéąĮąŠčłąĄąĮąĖčÅ ą║ č鹊ą╝čā, čüą▒čĆąŠčłąĄąĮ ąĖą╗ąĖ ąĮąĄčé Node, ą┐ąŠčŹč鹊ą╝čā ą╝čŗ ąĮąĄ ą┐ąŠą╗čāčćą░ąĄą╝ ąĮąĖą║ą░ą║ąĖčģ čāč鹥č湥ą║ ą┐ą░ą╝čÅčéąĖ!
ąĢčüą╗ąĖ ą╝čŗ ą┐ąŠą┐čŗčéą░ąĄą╝čüčÅ ąŠą▒čĆą░čéąĖčéčīčüčÅ ą║ čĆąŠą┤ąĖč鹥ą╗čÄ leaf ą┐ąŠčüą╗ąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ, č鹊 čüąĮąŠą▓ą░ ą┐ąŠą╗čāčćąĖą╝ None. ąÆ ą║ąŠąĮčåąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ Rc< Node> ą▓ leaf ąĖą╝ąĄąĄčé strong-čüč湥čéčćąĖą║ 1 ąĖ weak-čüč湥čéčćąĖą║ 0, ą┐ąŠč鹊ą╝čā čćč鹊 ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ leaf č鹥ą┐ąĄčĆčī čüąĮąŠą▓ą░ čÅą▓ą╗čÅąĄčéčüčÅ ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮąŠą╣ čüčüčŗą╗ą║ąŠą╣ ąĮą░ Rc< Node>.
ąÆčüčÅ ą╗ąŠą│ąĖą║ą░, ą║ąŠč鹊čĆą░čÅ čāą┐čĆą░ą▓ą╗čÅąĄčé čüč湥čéčćąĖą║ą░ą╝ąĖ ąĖ ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖąĄą╝ ąĘąĮą░č湥ąĮąĖčÅ, ą▓čüčéčĆąŠąĄąĮą░ ą▓ Rc< T> ąĖ Weak< T>, ą░ čéą░ą║ąČąĄ ą▓ ąĖčģ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅčģ čéčĆąĄą╣čéą░ Drop. ąŻą║ą░ąĘą░ąĮąĖąĄą╝ ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĖ Node, čćč鹊 čüą▓čÅąĘčī ą╝ąĄąČą┤čā ą┤ąŠč湥čĆąĮąĖą╝ 菹╗ąĄą╝ąĄąĮč鹊ą╝ ąĖ ąĄą│ąŠ čĆąŠą┤ąĖč鹥ą╗ąĄą╝ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī čüčüčŗą╗ą║ąŠą╣ Weak< T>, ą▓čŗ ą╝ąŠąČąĄč鹥 ąĖą╝ąĄčéčī čĆąŠą┤ąĖč鹥ą╗čīčüą║ąĖąĄ čāąĘą╗čŗ, čāą║ą░ąĘčŗą▓ą░čÄčēąĖąĄ ąĮą░ ą┤ąŠč湥čĆąĮąĖąĄ čāąĘą╗čŗ, ąĖ ąĮą░ąŠą▒ąŠčĆąŠčé, ą┐čĆąĖąĄą╝ ą▒ąĄąĘ čüąŠąĘą┤ą░ąĮąĖčÅ čåąĖą║ą╗ą░ čüčüčŗą╗ąŠą║ ąĖ čāč鹥č湥ą║ ą┐ą░ą╝čÅčéąĖ.
[ą×ą▒čēąĖąĄ ą▓čŗą▓ąŠą┤čŗ]
ąÆ čŹč鹊ą╣ ą│ą╗ą░ą▓ąĄ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ą╗ąŠčüčī, ą║ą░ą║ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī smart-čāą║ą░ąĘą░č鹥ą╗ąĖ, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī čĆą░ąĘą╗ąĖčćąĮčŗąĄ ą│ą░čĆą░ąĮčéąĖąĖ ąĖ ą║ąŠą╝ą┐čĆąŠą╝ąĖčüčüčŗ ąĖąĘ č鹥čģ, ą║ąŠč鹊čĆčŗąĄ Rust ą┤ąĄą╗ą░ąĄčé ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ čü ąŠą▒čŗčćąĮčŗą╝ąĖ čüčüčŗą╗ą║ą░ą╝ąĖ. ąóąĖą┐ Box< T> ąĖą╝ąĄąĄčé ąĖąĘą▓ąĄčüčéąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ, ąĖ čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ ą┤ą░ąĮąĮčŗąĄ, čĆą░ąĘą╝ąĄčēąĄąĮąĮčŗąĄ ą▓ ą║čāč湥 (heap). ąóąĖą┐ Rc< T> ąŠčéčüą╗ąĄąČąĖą▓ą░ąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čüčüčŗą╗ąŠą║ ąĮą░ ą┤ą░ąĮąĮčŗąĄ ą▓ ą║čāč湥, čéą░ą║ čćč鹊 čā čŹčéąĖčģ ą┤ą░ąĮąĮčŗčģ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą▓. ąóąĖą┐ RefCell< T> čü č鹥čģąĮąŠą╗ąŠą│ąĖąĄą╣ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ ąĖąĘą╝ąĄąĮčćąĖą▓ąŠčüčéąĖ (interior mutability) ą┤ą░ąĄčé ąĮą░ą╝ čéąĖą┐, ą║ąŠč鹊čĆčŗą╣ ą╝čŗ ą╝ąŠąČąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī, ą║ąŠą│ą┤ą░ ąĮčāąČąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗą╣ čéąĖą┐, ąŠą┤ąĮą░ą║ąŠ čéčĆąĄą▒čāąĄčéčüčÅ ą╝ąĄąĮčÅčéčī ą▓ąĮčāčéčĆąĄąĮąĮąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ čéą░ą║ąŠą│ąŠ čéąĖą┐ą░; čŹč鹊 čéą░ą║ąČąĄ ą┐čĆąĖą╝ąĄąĮčÅąĄčé ą┐čĆą░ą▓ąĖą╗ą░ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ runtime ą▓ą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ ąŠąĮąĖ ą┐čĆąĖą╝ąĄąĮčÅą╗ąĖčüčī ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ.
ąóą░ą║ąČąĄ ąŠą▒čüčāąČą┤ą░ą╗ąĖčüčī čéčĆąĄą╣čéčŗ Deref ąĖ Drop, ą║ąŠč鹊čĆčŗąĄ ąŠą▒ąĄčüą┐ąĄčćąĖą▓ą░čÄčé ą▒ąŠą╗čīčłčāčÄ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčī smart-čāą║ą░ąĘą░č鹥ą╗ąĄą╣. ą£čŗ ąĖčüčüą╗ąĄą┤ąŠą▓ą░ą╗ąĖ čåąĖą║ą╗čŗ čüčüčŗą╗ąŠą║, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ čāč鹥čćą║ą░ą╝ ą┐ą░ą╝čÅčéąĖ, ąĖ čüą┐ąŠčüąŠą▒čŗ ąĖčģ ą┐čĆąĄą┤ąŠčéą▓čĆą░čēąĄąĮąĖčÅ čü ą┐ąŠą╝ąŠčēčīčÄ Weak< T>.
ąĢčüą╗ąĖ čŹčéą░ ą│ą╗ą░ą▓ą░ ąĘą░ąĖąĮč鹥čĆąĄčüąŠą▓ą░ą╗ą░ ą▓ą░čü, ąĖ ą▓čŗ čģąŠčéąĖč鹥 čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī čüą▓ąŠąĖ čüąŠą▒čüčéą▓ąĄąĮąĮčŗąĄ smart-čāą║ą░ąĘą░č鹥ą╗ąĖ, č鹊 ą┤ą╗čÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ąŠą▒čĆą░čéąĖč鹥čüčī ą║ ą║ąĮąĖą│ąĄ [8].
ąöą░ą╗ąĄąĄ ą╝čŗ ą┐ąŠą│ąŠą▓ąŠčĆąĖą╝ ąŠ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠčüčéąĖ (concurrency) ą▓ Rust. ąÆčŗ ąĖąĘčāčćąĖč鹥 ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĮąŠą▓čŗčģ smart-čāą║ą░ąĘą░č鹥ą╗ąĄą╣.
[ąĪčüčŗą╗ą║ąĖ]
1. Rust Smart Pointers site:rust-lang.org.
2. Rust: čćč鹊 čéą░ą║ąŠąĄ Ownership.
3. Rust: ą║ąŠą╗ą╗ąĄą║čåąĖąĖ čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ.
4. Rust: ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖčÅ (enum) ąĖ čüąŠą▓ą┐ą░ą┤ąĄąĮąĖąĄ čłą░ą▒ą╗ąŠąĮąŠą▓ (match).
5. Rust: generic-čéąĖą┐čŗ, traits, lifetimes.
6. Rust: ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüčéčĆčāą║čéčāčĆčŗ ą┤ą╗čÅ ą▓ąĘą░ąĖą╝ąŠčüą▓čÅąĘą░ąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ.
7. What is Halting Problem site:startup-house.com.
8. The Rustonomicon site:rust-lang.org. |



