Ownership (ą▓ą╗ą░ą┤ąĄąĮąĖąĄ, ą┐čĆą░ą▓ą░ čüąŠą▒čüčéą▓ąĄąĮąĮąŠčüčéąĖ) čŹč鹊 čüą░ą╝ą░čÅ čāąĮąĖą║ą░ą╗čīąĮą░čÅ ąŠčüąŠą▒ąĄąĮąĮąŠčüčéčī Rust , ąĖ ąŠąĮą░ ą▓ą▓ąŠą┤ąĖčé ą│ą╗čāą▒ąŠą║ąĖąĄ ą┐ąŠčüą╗ąĄą┤čüčéą▓ąĖčÅ ą┤ą╗čÅ ąŠčüčéą░ą╗čīąĮąŠą│ąŠ čäčāąĮą║čåąĖąŠąĮą░ą╗ą░ Rust. ąŁč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé Rust ąŠą▒ąĄčüą┐ąĄčćąĖčéčī ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéčī ą┐ą░ą╝čÅčéąĖ ą▒ąĄąĘ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ ą┐čĆąĖą▓ą╗ąĄč湥ąĮąĖčÅ čüą▒ąŠčĆčēąĖą║ą░ ą╝čāčüąŠčĆą░, ą┐ąŠčŹč鹊ą╝čā ą▓ą░ąČąĮąŠ ą┐ąŠąĮąĖą╝ą░čéčī ą┐čĆąĖąĮčåąĖą┐ čĆą░ą▒ąŠčéčŗ ownership. ąÆ čŹč鹊ą╣ ą│ą╗ą░ą▓ąĄ (ą┐ąĄčĆąĄą▓ąŠą┤ ą│ą╗ą░ą▓čŗ 4 [1]) ą╝čŗ ą┐ąŠą│ąŠą▓ąŠčĆąĖą╝ ą┐čĆąŠ ownership, ą░ čéą░ą║ąČąĄ čüą▓čÅąĘą░ąĮąĮčŗąĄ čü ąĮąĖą╝ čäąĖčćąĖ: ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖąĄ (borrowing ), čüą╗ą░ą╣čüčŗ (slices ), ąĖ ą║ą░ą║ Rust čĆą░čüą┐ąŠą╗ą░ą│ą░ąĄčé ą┤ą░ąĮąĮčŗąĄ ą▓ ą┐ą░ą╝čÅčéąĖ.
[ą¦č鹊 čéą░ą║ąŠąĄ Ownership ]
Ownership čŹč鹊 ąĮą░ą▒ąŠčĆ ą┐čĆą░ą▓ąĖą╗ ąŠ č鹊ą╝, ą║ą░ą║ Rust čāą┐čĆą░ą▓ą╗čÅąĄčé ą┐ą░ą╝čÅčéčīčÄ. ąÆčüąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą┤ąŠą╗ąČąĮčŗ ą║ą░ą║-č鹊 čāą┐čĆą░ą▓ą╗čÅčéčī č鹥ą╝, ą║ą░ą║ ąŠąĮąĖ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą┐ą░ą╝čÅčéčī ą▓ąŠ ą▓čĆąĄą╝čÅ čüą▓ąŠąĄą╣ čĆą░ą▒ąŠčéčŗ. ąÆ ąĮąĄą║ąŠč鹊čĆčŗčģ čÅąĘčŗą║ą░čģ ąĄčüčéčī čüąĖčüč鹥ą╝ą░ čüą▒ąŠčĆą░ ą╝čāčüąŠčĆą░, ą║ąŠč鹊čĆą░čÅ čĆąĄą│čāą╗čÅčĆąĮąŠ ą┐čĆąŠą▓ąĄčĆčÅąĄčé ą▓ąŠ ą▓čĆąĄą╝čÅ čĆą░ą▒ąŠčéčŗ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ą║ą░ą║ą░čÅ ą┐ą░ą╝čÅčéčī ą▒ąŠą╗čīčłąĄ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ. ąÆ ą┤čĆčāą│ąĖčģ čÅąĘčŗą║ą░čģ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčé ą┤ąŠą╗ąČąĄąĮ čÅą▓ąĮąŠ ą▓čŗą┤ąĄą╗čÅčéčī ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ą░čéčī ą┐ą░ą╝čÅčéčī. Rust ąĖčüą┐ąŠą╗čīąĘčāąĄčé čéčĆąĄčéąĖą╣ čüą┐ąŠčüąŠą▒: ą┐ą░ą╝čÅčéčī čāą┐čĆą░ą▓ą╗čÅąĄčéčüčÅ č湥čĆąĄąĘ čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝čāčÄ čüąĖčüč鹥ą╝čā ą▓ą╗ą░ą┤ąĄąĮąĖčÅ (ownership) čü ąĮą░ą▒ąŠčĆąŠą╝ ą┐čĆą░ą▓ąĖą╗, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąŠą▓ąĄčĆčÅąĄčé ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ. ąĢčüą╗ąĖ ąĮą░čĆčāčłąĄąĮąŠ ą╗čÄą▒ąŠąĄ ąĖąĘ ą┐čĆą░ą▓ąĖą╗, č鹊 ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ąĮąĄ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ. ąØąĖ ąŠą┤ąĮą░ ąĖąĘ ąŠčüąŠą▒ąĄąĮąĮąŠčüč鹥ą╣ čüąĖčüč鹥ą╝čŗ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ ąĮąĄ ąĘą░ą╝ąĄą┤ą╗ąĖčé čĆą░ą▒ąŠčéčā ą▓ą░čłąĄą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
ą¤ąŠčüą║ąŠą╗čīą║čā ownership čŹč鹊 ąĮąŠą▓ą░čÅ ą║ąŠąĮčåąĄą┐čåąĖčÅ ą┤ą╗čÅ ąĮąŠą▓čŗčģ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüč鹊ą▓, čéčĆąĄą▒čāąĄčéčüčÅ ąĮąĄą║ąŠč鹊čĆąŠąĄ ą▓čĆąĄą╝čÅ, čćč鹊ą▒čŗ ą║ ąĮąĄą╣ ą┐čĆąĖą▓čŗą║ąĮčāčéčī. ąźąŠčĆąŠčłąĄą╣ ąĮąŠą▓ąŠčüčéčīčÄ čÅą▓ą╗čÅąĄčéčüčÅ č鹊, čćč鹊 č湥ą╝ ą▒ąŠą╗ąĄąĄ ąŠą┐čŗčéąĮčŗą╝ ą▓čŗ čüčéą░ąĮąĄč鹥 čü Rust ąĖ ą┐čĆą░ą▓ąĖą╗ą░ą╝ąĖ čüąĖčüč鹥ą╝čŗ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ, č鹥ą╝ ą╗ąĄą│č湥 ą▒čāą┤ąĄčé ą┐čĆąĖą╝ąĄąĮčÅčéčī Rust ą┤ą╗čÅ ąĄčüč鹥čüčéą▓ąĄąĮąĮąŠą╣ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ą║ąŠą┤ą░, ą║ąŠč鹊čĆčŗą╣ ą▒čāą┤ąĄčé ą▒ąĄąĘąŠą┐ą░čüąĮčŗą╝ ąĖ čŹčäč乥ą║čéąĖą▓ąĮčŗą╝.
ą¤čĆąĖ čģąŠčĆąŠčłąĄą╝ ą┐ąŠąĮąĖą╝ą░ąĮąĖąĖ ownership ą▓čŗ ą┐ąŠą╗čāčćąĖč鹥 ą┐čĆąŠčćąĮčāčÄ ąŠčüąĮąŠą▓čā ą┤ą╗čÅ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ čäčāąĮą║čåąĖąŠąĮą░ą╗ą░ Rust, ą║ąŠč鹊čĆčŗą╣ ą┤ąĄą╗ą░ąĄčé ąĄą│ąŠ čāąĮąĖą║ą░ą╗čīąĮčŗą╝ čÅąĘčŗą║ąŠą╝. ąÆ čŹč鹊ą╣ ą│ą╗ą░ą▓ąĄ ą╝čŗ ąŠą▒čāčćąĖą╝čüčÅ ą┐čĆą░ą▓ąĖą╗ą░ą╝ ownership ą┐čāč鹥ą╝ ą┐čĆąŠčĆą░ą▒ąŠčéą║ąĖ ąĮąĄą║ąŠč鹊čĆčŗčģ ą┐čĆąĖą╝ąĄčĆąŠą▓, č乊ą║čāčüąĖčĆčāčÄčēąĖčģčüčÅ ąĮą░ čüą░ą╝ąŠą╣ ąŠą▒čēąĄą╣ čüčéčĆčāą║čéčāčĆąĄ ą┤ą░ąĮąĮčŗčģ: čüčéčĆąŠą║ąĖ (čéąĖą┐ String ).
ą£ąĮąŠą│ąĖąĄ ą▓čŗčüąŠą║ąŠčāčĆąŠą▓ąĮąĄą▓čŗąĄ čÅąĘčŗą║ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ąĮąĄ čéčĆąĄą▒čāčÄčé ąŠčé ą▓ą░čü ąŠč湥ąĮčī čćą░čüč鹊 ą▓čüą┐ąŠą╝ąĖąĮą░čéčī ąŠčé č鹊ą╝, čćč鹊 čéą░ą║ąŠąĄ čüč鹥ą║ (stack ), ąĖ čćč鹊 čéą░ą║ąŠąĄ ą║čāčćą░ (heap ). ą×ą┤ąĮą░ą║ąŠ ą▓ čüąĖčüč鹥ą╝ąĮčŗčģ čÅąĘčŗą║ą░čģ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ Rust ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą▓ąŠ ą╝ąĮąŠą│ąŠą╝ ąĘą░ą▓ąĖčüąĖčé ąŠčé č鹊ą│ąŠ, ą│ą┤ąĄ čģčĆą░ąĮąĖčéčüčÅ ąŠą▒čŖąĄą║čé ą▓ ą┐ą░ą╝čÅčéąĖ, ąĖ čŹč鹊 čéčĆąĄą▒čāąĄčé ąŠčé ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčéą░ ą┐čĆąĖąĮąĖą╝ą░čéčī čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖąĄ čĆąĄčłąĄąĮąĖčÅ ą┐čĆąĖ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĖ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ ąŠą▒čŖąĄą║č鹊ą▓. ą¦ą░čüčéąĖ ownership ą▒čāą┤čāčé ąŠą┐ąĖčüą░ąĮčŗ ą┤ą░ą╗ąĄąĄ ą┐ąŠ ąŠčéąĮąŠčłąĄąĮąĖčÄ ą║ čüč鹥ą║čā ąĖ ą║čāč湥, ą┐ąŠčŹč鹊ą╝čā ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗ ąĮąĄą║ąŠč鹊čĆčŗąĄ ą┐ąŠą┤ą│ąŠč鹊ą▓ąĖč鹥ą╗čīąĮčŗąĄ ąŠą▒čŖčÅčüąĮąĄąĮąĖčÅ.
ąś čüč鹥ą║, ąĖ ą║čāčćą░ čŹč鹊 ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ, ą┤ąŠčüčéčāą┐ąĮčŗąĄ ą┤ą╗čÅ ą▓ą░čłąĄą│ąŠ ą║ąŠą┤ą░ ą▓ąŠ ą▓čĆąĄą╝čÅ ąĄą│ąŠ čĆą░ą▒ąŠčéčŗ (runtime), ąŠą┤ąĮą░ą║ąŠ ąŠąĮąĖ čüčéčĆčāą║čéčāčĆąĖčĆąŠą▓ą░ąĮčŗ ąĖ čĆą░ą▒ąŠčéą░čÄčé ą┐ąŠ-čĆą░ąĘąĮąŠą╝čā. ąĪč鹥ą║ čüąŠčģčĆą░ąĮčÅąĄčé ąĘąĮą░č湥ąĮąĖčÅ ą▓ ą▓ ą┐ą░ą╝čÅčéąĖ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊ą▒čŗ ąĖąĘą▓ą╗ąĄą║ą░čéčī čŹčéąĖ ąĘąĮą░č湥ąĮąĖčÅ ą▓ ąŠą▒čĆą░čéąĮąŠą╝ ą┐ąŠčĆčÅą┤ą║ąĄ, čé. ąĄ. ą┐ąŠ ą┐čĆąĖąĮčåąĖą┐čā FILO (First Input Last Output, ą┐ąĄčĆą▓čŗą╝ ą▓ąŠčłąĄą╗ ą┐ąŠčüą╗ąĄą┤ąĮąĖą╝ ą▓čŗčłąĄą╗). ąŁč鹊 ą╝ąŠąČąĮąŠ ą┐čĆąĄą┤čüčéą░ą▓ąĖčéčī čüąĄą▒ąĄ ą▓ ą▓ąĖą┤ąĄ čüč鹊ą┐ą║ąĖ ą┐ą╗ą░čüčéąĖąĮąŠą║: ą║ąŠą│ą┤ą░ ą▓čŗ ąĮą░ą║ą╗ą░ą┤čŗą▓ą░ąĄč鹥 ą┐ą╗ą░čüčéąĖąĮą║ąĖ ąĮą░ čüč鹊ą┐ą║čā, ą┤ą╗čÅ ąĖąĘą▓ą╗ąĄč湥ąĮąĖčÅ ąĮąĖąČąĮąĄą╣ ą┐ą╗ą░čüčéąĖąĮą║ąĖ ąĮčāąČąĮąŠ čüąĮą░čćą░ą╗ą░ ąĖąĘą▓ą╗ąĄčćčī č鹥, ą║ąŠč鹊čĆčŗąĄ ąĮą░čģąŠą┤čÅčéčüčÅ ąĮą░ą┤ ąĮąĄą╣. ąöąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ ąĖą╗ąĖ čāą┤ą░ą╗ąĄąĮąĖąĄ ą┐ą╗ą░čüčéąĖąĮ ąĮą░ą┐čĆčÅą╝čāčÄ ą┐ąŠčüąĄčĆąĄą┤ąĖąĮąĄ čüč鹊ą┐ą║ąĖ ąĘą░ą┐čĆąĄčēąĄąĮąŠ! ąöąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ ąĮą░ąĘčŗą▓ą░čÄčé "ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖąĄą╝" ą▓ čüč鹥ą║ (push ), ą░ ąĖąĘą▓ą╗ąĄč湥ąĮąĖąĄ ąĮą░ąĘčŗą▓ą░čÄčé "ą▓čŗčéą░ą╗ą║ąĖą▓ą░ąĮąĖąĄą╝" ąĖąĘ čüč鹥ą║ą░ (pop ; ąĮą░ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ čÅąĘčŗą║ąŠą▓ ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░ čüčāčēąĄčüčéą▓čāčÄčé ą┤ą╗čÅ čŹč鹊ą│ąŠ čüą┐ąĄčåąĖą░ą╗čīąĮčŗąĄ ą║ąŠą╝ą░ąĮą┤čŗ PUSH ąĖ POP). ąÆčüąĄ ą┤ą░ąĮąĮčŗąĄ, ą║ąŠč鹊čĆčŗąĄ čüąŠčģčĆą░ąĮąĄąĮčŗ ą▓ čüč鹥ą║ąĄ, ą┤ąŠą╗ąČąĮčŗ ąĖą╝ąĄčéčī ąĖąĘą▓ąĄčüčéąĮčŗą╣, čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮčŗą╣ čĆą░ąĘą╝ąĄčĆe. ąöą░ąĮąĮčŗąĄ, čĆą░ąĘą╝ąĄčĆ ą║ąŠč鹊čĆčŗčģ ąĮąĄąĖąĘą▓ąĄčüč鹥ąĮ ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ, ąĖą╗ąĖ ą║ąŠą│ą┤ą░ čĆą░ąĘą╝ąĄčĆ ą╝ąŠąČąĄčé ą╝ąĄąĮčÅčéčīčüčÅ ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ą┤ąŠą╗ąČąĮčŗ čüąŠčģčĆą░ąĮčÅčéčīčüčÅ ą▓ ą║čāč湥 ą▓ą╝ąĄčüč鹊 čüč鹥ą║ą░.
ąÜčāčćą░ (heap) ą╝ąĄąĮąĄąĄ čāą┐ąŠčĆčÅą┤ąŠč湥ąĮą░: ą║ąŠą│ą┤ą░ ą▓čŗ ą┐ąŠą╝ąĄčēą░ąĄč鹥 ą┤ą░ąĮąĮčŗąĄ ą▓ ą║čāčćčā, ą▓čŗ ą┤ąĄą╗ą░ąĄč鹥 ąĘą░ą┐čĆąŠčü ąĮą░ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ čāą║ą░ąĘą░ąĮąĮąŠą│ąŠ ąŠą▒čŖąĄą╝ą░ ą┐ą░ą╝čÅčéąĖ ą▓ ą║čāč湥. ąĪąĖčüč鹥ą╝ą░ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ąĮą░čģąŠą┤ąĖčé ą▓ ą║čāč湥 čüą▓ąŠą▒ąŠą┤ąĮčāčÄ ąŠą▒ą╗ą░čüčéčī, ą║ąŠč鹊čĆą░čÅ ąĖą╝ąĄąĄčé ą┤ąŠčüčéą░č鹊čćąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ, ą┐ąŠą╝ąĄčćą░ąĄčé čŹčéčā ąŠą▒ą╗ą░čüčéčī ą║ą░ą║ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čāčÄ ąĖ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ąĮą░ ąĮąĄčæ čāą║ą░ąĘą░č鹥ą╗čī, ąĘąĮą░č湥ąĮąĖąĄ ą║ąŠč鹊čĆąŠą│ąŠ čĆą░ą▓ąĮąŠ ą░ą┤čĆąĄčüčā ąĮą░čćą░ą╗ą░ čŹč鹊ą╣ ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą╣ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ. ąŁč鹊čé ą┐čĆąŠčåąĄčüčü ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄą╝ ą┐ą░ą╝čÅčéąĖ ąĖąĘ ą║čāčćąĖ, allocating (ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖąĄ ąĘąĮą░č湥ąĮąĖą╣ ą▓ čüč鹥ą║ ąĮąĄ čüčćąĖčéą░ąĄčéčüčÅ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄą╝). ą¤ąŠčüą║ąŠą╗čīą║čā čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ą║čāčćčā ąĖą╝ąĄąĄčé ąĖąĘą▓ąĄčüčéąĮčŗą╣, čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ, ą▓čŗ ą╝ąŠąČąĄč鹥 čüąŠčģčĆą░ąĮąĖčéčī ąĘąĮą░č湥ąĮąĖąĄ čāą║ą░ąĘą░č鹥ą╗čÅ ą▓ čüč鹥ą║ąĄ, ąĮąŠ ą║ąŠą│ą┤ą░ ą▓čŗ čģąŠčéąĖč鹥 ą┐ąŠą╗čāčćąĖčéčī čĆąĄą░ą╗čīąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ąĖąĘ ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ ą▓ ą║čāč湥, ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ čüą╗ąĄą┤ąŠą▓ą░čéčī ą┐ąŠ ą░ą┤čĆąĄčüčā ą▓ čāą║ą░ąĘą░č鹥ą╗ąĄ.
ą¤čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖąĄ ą▓ čüč鹥ą║ čĆą░ą▒ąŠčéą░ąĄčé ą▒čŗčüčéčĆąĄąĄ, č湥ą╝ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą▓ ą║čāč湥, ą┐ąŠč鹊ą╝čā čćč鹊 ą┐čĆąĖ čüąŠčģčĆą░ąĮąĄąĮąĖąĖ ą▓ čüč鹥ą║ ąĮąĄ ąĮčāąČąĮąŠ ąĖčüą║ą░čéčī ą┤ą╗čÅ čŹč鹊ą│ąŠ čüą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą╝ąĄčüč鹊, ą║ą░ą║ ąĮčāąČąĮąŠ ą┤ąĄą╗ą░čéčī ą┐čĆąĖ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĖ ą┐ą░ą╝čÅčéąĖ ą▓ ą║čāč湥. ą¤čĆąĖ ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖąĖ ą▓ čüč鹥ą║ ą╝ąĄčüč鹊 čģčĆą░ąĮąĄąĮąĖčÅ ąĖąĘą▓ąĄčüčéąĮąŠ čüčĆą░ąĘčā - čŹč鹊 ą▓ąĄčĆčłąĖąĮą░ čüč鹥ą║ą░. ąöą╗čÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ, ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą▓ ą║čāč湥 čéčĆąĄą▒čāąĄčé ą▒ąŠą╗čīčłąĄ čĆą░ą▒ąŠčéčŗ, ą┐ąŠč鹊ą╝čā čćč鹊 ą░ą╗ąŠą║ą░č鹊čĆčā čüąĮą░čćą░ą╗ą░ ąĮą░ą┤ąŠ ąĮą░ą╣čéąĖ ą┤ąŠčüčéą░č鹊čćąĮčāčÄ ąŠą▒ą╗ą░čüčéčī ą▓ ą║čāč湥, ąĖ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ą▓ąĄčüčéąĖ ąČčāčĆąĮą░ą╗ čāč湥čéą░ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ, čćč鹊ą▒čŗ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą║ąŠčĆčĆąĄą║čéąĮąŠ ąŠą▒čüą╗čāąČąĖą▓ą░čéčī ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ.
ą×ą▒čĆą░čēąĄąĮąĖąĄ ą║ ą┤ą░ąĮąĮčŗą╝ ą▓ ą║čāč湥 ąĖąĮąŠą│ą┤ą░ čéą░ą║ąČąĄ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą╝ąĄą┤ą╗ąĄąĮąĮąĄąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ąĘą░ą│čĆčāąČą░čéčī čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ čŹčéąĖ ą┤ą░ąĮąĮčŗąĄ. ą¤čĆąŠčåąĄčüčüąŠčĆčŗ čĆą░ą▒ąŠčéą░čÄčé ą▒čŗčüčéčĆąĄąĄ, ąĄčüą╗ąĖ ąŠąĮąĖ ą╝ąĄąĮčīčłąĄ ą┤ąĄą╗ą░čÄčé ą┐čĆčŗąČą║ąŠą▓ ą┐ąŠ ą┐ą░ą╝čÅčéąĖ, ąĖ čĆą░ą▒ąŠčéą░čÄčé čü ą┤ą░ąĮąĮčŗą╝ąĖ, ą║ąŠč鹊čĆčŗąĄ čĆą░čüą┐ąŠą╗ąŠąČąĄąĮčŗ ą▒ą╗ąĖąĘą║ąŠ ą┤čĆčāą│ ą║ ą┤čĆčāą│čā (ąŠą┤ąĮą░ ąĖąĘ ą┐čĆąĖčćąĖąĮ - čāą╝ąĄąĮčīčłąĄąĮąĖąĄ ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą┐čĆąŠą╝ą░čģąŠą▓ ą║čŹčłą░).
ąÜąŠą│ą┤ą░ ą▓ą░čł ą║ąŠą┤ ą▓čŗąĘčŗą▓ą░ąĄčé čäčāąĮą║čåąĖčÄ, ą┐ąĄčĆąĄą┤ą░ą▓ą░ąĄą╝čŗąĄ ą▓ čäčāąĮą║čåąĖčÄ ąĘąĮą░č湥ąĮąĖčÅ (ą║ąŠč鹊čĆčŗąĄ ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ ą╝ąŠą│čāčé ą▓ą║ą╗čÄčćą░čéčī čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ą┤ą░ąĮąĮčŗąĄ ą▓ ą║čāč湥) ąĖ ą╗ąŠą║ą░ą╗čīąĮčŗąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ čäčāąĮą║čåąĖąĖ ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░čÄčéčüčÅ ą▓ čüč鹥ą║. ąÜąŠą│ą┤ą░ čäčāąĮą║čåąĖčÅ ąĘą░ą▓ąĄčĆčłą░ąĄčé čĆą░ą▒ąŠčéčā, čŹčéąĖ ąĘąĮą░č湥ąĮąĖčÅ ą▓čŗčéą░ą╗ą║ąĖą▓ą░čÄčéčüčÅ ąĖąĘ čüč鹥ą║ą░.
ą×čéčüą╗ąĄąČąĖą▓ą░ąĮąĖąĄ, ą║ą░ą║ąĖąĄ čćą░čüčéąĖ ą║ąŠą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą║ą░ą║ąĖąĄ ą┤ą░ąĮąĮčŗąĄ ą▓ ą║čāč湥, ą╝ąĖąĮąĖą╝ąĖąĘą░čåąĖčÅ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą┤čāą▒ą╗ąĖčĆąŠą▓ą░ąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ą▓ ą║čāč湥 ąĖ ąŠčćąĖčüčéą║ą░ ąĮąĄąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ą┤ą░ąĮąĮčŗčģ ą▓ ą║čāč湥, čćč鹊ą▒čŗ čā ą▓ą░čü ąĮąĄ ąĘą░ą║ąŠąĮčćąĖą╗ąŠčüčī ą╝ąĄčüč鹊 - ą▓čüąĄ čŹč鹊 ą┐čĆąŠą▒ą╗ąĄą╝čŗ, ą║ąŠč鹊čĆčŗąĄ čĆąĄčłą░ąĄčé ownership. ąÜą░ą║ č鹊ą╗čīą║ąŠ ą▓čŗ ą┐ąŠą╣ą╝ąĄč鹥 čüčāčéčī čŹč鹊ą╣ č鹥čģąĮąŠą╗ąŠą│ąĖąĖ, ą▓ą░ą╝ ąĮąĄ ą┐ąŠąĮą░ą┤ąŠą▒ąĖčéčüčÅ čćą░čüč鹊 ą┤čāą╝ą░čéčī ąŠ čüč鹥ą║ąĄ ąĖ ą║čāč湥, ąĮąŠ ąĘąĮą░ąĮąĖąĄ č鹊ą│ąŠ, čćč鹊 ąŠčüąĮąŠą▓ąĮą░čÅ čåąĄą╗čī ownership - čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┤ą░ąĮąĮčŗą╝ąĖ ą║čāčćąĖ, ą╝ąŠąČąĄčé ą┐ąŠą╝ąŠčćčī ąŠą▒čŖčÅčüąĮąĖčéčī, ą┐ąŠč湥ą╝čā ąŠąĮąŠ čĆą░ą▒ąŠčéą░ąĄčé čéą░ą║, ą║ą░ą║ čĆą░ą▒ąŠčéą░ąĄčé.
Ownership Rules . ąĪąĮą░čćą░ą╗ą░ ą┤ą░ą▓ą░ą╣č鹥 čĆą░čüčüą╝ąŠčéčĆąĖą╝ ą┐čĆą░ą▓ąĖą╗ą░ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ (ownership rules). ąśą╝ąĄą╣č鹥 ąĖčģ ą▓ ą▓ąĖą┤čā ą┐čĆąĖ čĆą░ą▒ąŠč鹥 čü ą┐čĆąĖą▓ąĄą┤ąĄąĮąĮčŗą╝ąĖ ąĘą┤ąĄčüčī ą┐čĆąĖą╝ąĄčĆą░ą╝ąĖ, ąĖą╗čÄčüčéčĆąĖčĆčāčēąĖąĄ ą┐čĆą░ą▓ąĖą╗ą░ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ:
ŌĆó ąÜą░ąČą┤ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą▓ Rust ąĖą╝ąĄąĄčé ą▓ą╗ą░ą┤ąĄą╗čīčåą░.
ą×ą▒ą╗ą░čüčéčī ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ (Variable Scope). ąÆ ą║ą░č湥čüčéą▓ąĄ ą┐ąĄčĆą▓ąŠą│ąŠ ą┐čĆąĖą╝ąĄčĆą░ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ąŠą▒ą╗ą░čüčéčī ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ ąĮąĄą║ąŠč鹊čĆčŗčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: č鹥ą┐ąĄčĆčī, ą║ąŠą│ą┤ą░ ą╝čŗ ąĖąĘčāčćąĖą╗ąĖ ą▒ą░ąĘąŠą▓čŗą╣ čüąĖąĮčéą░ą║čüąĖčü Rust ą▓ ą│ą╗ą░ą▓ą░čģ 1 ąĖ 3 [2, 3], ą╝čŗ ąĮąĄ ą▒čāą┤ąĄą╝ ą▓ą║ą╗čÄčćą░čéčī ą▓ąĄčüčī ą║ąŠą┤ fn main() { ą▓ ą┐čĆąĖą╝ąĄčĆą░čģ. ą¤ąŠčŹč鹊ą╝čā ą║ąŠą│ą┤ą░ ą▓čŗ ą▒čāą┤ąĄč鹥 čĆą░čüčüą╝ą░čéčĆąĖą▓ą░čéčī ą┐čĆąĖą╝ąĄčĆčŗ, ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖąĄ ą┤ą░ą╗ąĄąĄ, ą┐ąŠą╝ąĄčēą░ą╣č鹥 ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗą╣ ą║ąŠą┤ ą▓ čäčāąĮą║čåąĖčÄ main. ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 ąĮą░čłąĖ ą┐čĆąĖą╝ąĄčĆčŗ ą▒čāą┤čāčé ą▒ąŠą╗ąĄąĄ ą║čĆą░čéą║ąĖą╝ąĖ, čćč鹊 ą┐ąŠąĘą▓ąŠą╗ąĖčé ąĮą░ą╝ čüąŠčüčĆąĄą┤ąŠč鹊čćąĖčéčīčüčÅ ąĮą░ ąĖąĮč鹥čĆąĄčüčāčÄčēąĖčģ ą┤ąĄčéą░ą╗čÅčģ.
ą×ą▒ą╗ą░čüčéčī ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ą┤ą╗čÅ ą║ą░ą║ąŠą╣-č鹊 ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ čŹč鹊 ą╝ąĄčüč鹊 ą▓ ą║ąŠą┤ąĄ, ą▓ ą║ąŠč鹊čĆąŠą╝ čŹčéą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ ą┤ąŠčüč鹊ą▓ąĄčĆąĮą░ ąĖ ą┤ąŠčüčéčāą┐ąĮą░. ąÆąŠąĘčīą╝ąĄą╝ čüą╗ąĄą┤čāčÄčēčāčÄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ:
ąŁčéą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ ąŠčéąĮąŠčüąĖčéčüčÅ ą║ čüčéčĆąŠą║ąŠą▓ąŠą╝čā ą╗ąĖč鹥čĆą░ą╗čā, ą│ą┤ąĄ ąĘąĮą░č湥ąĮąĖąĄ čüčéčĆąŠą║ąĖ ąČąĄčüčéą║ąŠ ąĘą░ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąŠ ą▓ č鹥ą║čüč鹥 ąĮą░čłąĄą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ą¤ąĄčĆąĄą╝ąĄąĮąĮą░čÅ ą┤ąŠčüč鹊ą▓ąĄčĆąĮą░, ąĮą░čćąĖąĮą░čÅ ąŠčé č鹊čćą║ąĖ ąĄčæ ąŠą▒čŖčÅą▓ą╗ąĄąĮąĖčÅ ąĖ ą┤ąŠ ą║ąŠąĮčåą░ č鹥ą║čāčēąĄą╣ ąŠą▒ą╗ą░čüčéąĖ. ąøąĖčüčéąĖąĮą│ 4-1 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┐čĆąŠą│čĆą░ą╝ą╝čā čü ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖčÅą╝ąĖ, ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčēąĖą╝ąĖ, ą│ą┤ąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ čÅą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą╣.
{ // s ąĘą┤ąĄčüčī ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮą░, ą┐ąŠč鹊ą╝čā čćč鹊 ąĄčēąĄ ąĮąĄ ą┤ąĄą║ą╗ą░čĆąĖčĆąŠą▓ą░ąĮą░
let s = "hello" ; // s ąĮą░čćąĖąĮą░čÅ čü čŹč鹊ą│ąŠ ą╝ąĄčüčéą░ čüčéą░ąĮąŠą▓ąĖčéčüčÅ ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą╣ // ąŚą┤ąĄčüčī ą╝ąŠąČąĮąŠ ą▓čŗą┐ąŠą╗ąĮčÅčéčī čü ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ s ą║ą░ą║ąĖąĄ-č鹊 ą┤ąĄą╣čüčéą▓ąĖčÅ.
} // čŹčéą░ ąŠą▒ą╗ą░čüčéčī ąĘą░ą║ąŠąĮčćąĖą╗ą░čüčī, ąĖ ąĘą░ ąĮąĄą╣ s ą▒ąŠą╗čīčłąĄ
// ąĮąĄ ą▒čāą┤ąĄčé ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą╣
ąøąĖčüčéąĖąĮą│ 4-1. ą¤ąĄčĆąĄą╝ąĄąĮąĮą░čÅ ąĖ ąŠą▒ą╗ą░čüčéčī ąĄčæ ą┤ąĄą╣čüčéą▓ąĖčÅ (ą▓ ą║ąŠč鹊čĆąŠą╣ ąŠąĮą░ ąŠčüčéą░ąĄčéčüčÅ ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą╣).
ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ąĘą┤ąĄčüčī ąĄčüčéčī 2 ą▓ą░ąČąĮčŗčģ ą╝ąŠą╝ąĄąĮčéą░:
ŌĆó ąÜąŠą│ą┤ą░ s ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ąŠą▒ą╗ą░čüčéąĖ ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ, ąŠąĮą░ ą┤ąŠčüč鹊ą▓ąĄčĆąĮą░.
ąØą░ čŹč鹊ą╝ čŹčéą░ą┐ąĄ ą▓ąĘą░ąĖą╝ąŠčüą▓čÅąĘčī ą╝ąĄąČą┤čā ąŠą▒ą╗ą░čüčéčīčÄ ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ąĖ ąĄčæ ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéčīčÄ ąŠčüčéą░ąĄčéčüčÅ ą░ąĮą░ą╗ąŠą│ąĖčćąĮąŠą╣ ą┤čĆčāą│ąĖą╝ čÅąĘčŗą║ą░ą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ. ąóąĄą┐ąĄčĆčī ą╝čŗ ą┐ąŠą┐čĆąŠą▒čāąĄą╝ čĆą░čüčłąĖčĆąĖčéčī ąĮą░čłąĄ ą┐ąŠąĮąĖą╝ą░ąĮąĖąĄ ą┐čĆąŠąĖčüčģąŠą┤čÅčēąĄą│ąŠ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 čéąĖą┐ą░ String.
[ąóąĖą┐ String ]
ąöą╗čÅ ąĖą╗ą╗čÄčüčéčĆąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐čĆą░ą▓ąĖą╗ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ ąĮą░ą╝ ąĮčāąČąĄąĮ čéąĖą┐ ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗą╣ ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮčŗą╣, č湥ą╝ čéąĖą┐čŗ, čćč鹊 ą╝čŗ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ą╗ąĖ ą▓ čüąĄą║čåąĖąĖ "ąóąĖą┐čŗ ą┤ą░ąĮąĮčŗčģ" ą│ą╗ą░ą▓čŗ 3 [3]. ąŻ čĆą░ąĮąĄąĄ čĆą░čüčüą╝ąŠčéčĆąĄąĮąĮčŗčģ čéąĖą┐ąŠą▓ čĆą░ąĘą╝ąĄčĆ ą▒čŗą╗ ąĖąĘą▓ąĄčüč鹥ąĮ ąĘą░čĆą░ąĮąĄąĄ, ąĖ ąŠąĮ ą▒čŗą╗ čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮčŗą╣, čéą░ą║ čćč鹊 čŹčéąĖ ą┤ą░ąĮąĮčŗąĄ ą╝ąŠąČąĮąŠ ą╗ąĄą│ą║ąŠ čüąŠčģčĆą░ąĮčÅčéčī ą▓ čüč鹥ą║ąĄ ąĖ ąŠčéą▒čĆą░čüčŗą▓ą░čéčī, ą║ąŠą│ą┤ą░ ąĖčģ ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ ąĘą░ą║ą░ąĮčćąĖą▓ą░ąĄčéčüčÅ. ąóą░ą║ąĖąĄ ą┤ą░ąĮąĮčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▒čŗčüčéčĆąŠ ąĖ čéčĆąĖą▓ąĖą░ą╗čīąĮąŠ čüą║ąŠą┐ąĖčĆąŠą▓ą░ąĮčŗ ą▓ ąĮąŠą▓čŗą╣, ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗą╣ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ, ąĄčüą╗ąĖ ą┤čĆčāą│ą░čÅ čćą░čüčéčī ą║ąŠą┤ą░ ąĮčāąČą┤ą░ąĄčéčüčÅ ą▓ čéą░ą║ąŠą╝ ąČąĄ ąĘąĮą░č湥ąĮąĖąĖ ą┤ą╗čÅ ą┤čĆčāą│ąŠą╣ čćą░čüčéąĖ ą║ąŠą┤ą░ čü ą┤čĆčāą│ąŠą╣ ąŠą▒ą╗ą░čüčéčīčÄ ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ. ąØąŠ ą╝čŗ čģąŠčéąĖą╝ čĆą░čüčüą╝ąŠčéčĆąĄčéčī ą┤ą░ąĮąĮčŗąĄ, ą║ąŠč鹊čĆčŗąĄ čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ ą▓ ą║čāč湥, čćč鹊ą▒čŗ čĆą░ąĘąŠą▒čĆą░čéčīčüčÅ, ą║ą░ą║ Rust ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé, ą║ąŠą│ą┤ą░ ąĮčāąČąĮąŠ ąŠčćąĖčüčéąĖčéčī čŹčéąĖ ą┤ą░ąĮąĮčŗąĄ, ąĖ ą┤ą╗čÅ čŹč鹊ą│ąŠ čéąĖą┐ String ą┐ąŠčüą╗čāąČąĖčé čģąŠčĆąŠčłąĖą╝ ą┐čĆąĖą╝ąĄčĆąŠą╝.
ą£čŗ čüą║ąŠąĮčåąĄąĮčéčĆąĖčĆčāąĄą╝čüčÅ ąĮą░ č鹥čģ čćą░čüčéčÅčģ String, ą║ąŠč鹊čĆčŗąĄ ąŠčéąĮąŠčüčÅčéčüčÅ ą║ ownership. ąŁčéąĖ ą░čüą┐ąĄą║čéčŗ čéą░ą║ąČąĄ ą┐čĆąĖą╝ąĄąĮąĖą╝čŗ ą║ ą┤čĆčāą│ąĖą╝ čüą╗ąŠąČąĮčŗą╝ čéąĖą┐ą░ą╝ ą┤ą░ąĮąĮčŗčģ, ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ ąŠčé č鹊ą│ąŠ, ą▒čŗą╗ąĖ ą╗ąĖ čŹčéąĖ ą┤ą░ąĮąĮčŗąĄ čüąŠąĘą┤ą░ąĮčŗ ą▓ą░ą╝ąĖ, ą╗ąĖą▒ąŠ ąŠąĮąĖ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮčŗ čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąŠą╣. ąæąŠą╗ąĄąĄ ą┐ąŠą┤čĆąŠą▒ąĮąŠ čéąĖą┐ String čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ąĄčéčüčÅ ą▓ ą│ą╗ą░ą▓ąĄ 8.
ą£čŗ čāąČąĄ ą▓ąĖą┤ąĄą╗ąĖ ą╗ąĖč鹥čĆą░ą╗čŗ čüčéčĆąŠą║, ą║ąŠą│ą┤ą░ ąĘąĮą░č湥ąĮąĖąĄ čüčéčĆąŠą║ąĖ ąČąĄčüčéą║ąŠ ąĘą░ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąŠ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ. ąĪčéčĆąŠą║ąŠą▓čŗąĄ ą╗ąĖč鹥čĆą░ą╗čŗ čāą┤ąŠą▒ąĮčŗ, ąŠą┤ąĮą░ą║ąŠ ąŠąĮąĖ ąĮąĄ ą┐ąŠą┤čģąŠą┤čÅčé ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ čüąĖčéčāą░čåąĖąĖ, ą║ąŠą│ą┤ą░ ąĮą░ą╝ ąĮą░ą┤ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī č鹥ą║čüčé. ą×ą┤ąĮą░ ąĖąĘ ą┐čĆąŠą▒ą╗ąĄą╝ čüčéčĆąŠą║ąŠą▓čŗčģ ą╗ąĖč鹥čĆą░ą╗ąŠą▓ - ąŠąĮąĖ ąĮąĄ ą╝čāčéąĖčĆčāąĄą╝čŗąĄ (čé. ąĄ. ąĖčģ ąĘąĮą░č湥ąĮąĖąĄ ąĮąĄą╗čīąĘčÅ ą┐ąŠą╝ąĄąĮčÅčéčī runtime). ąöčĆčāą│ą░čÅ ą┐čĆąŠą▒ą╗ąĄą╝ą░ čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, čćč鹊 ąĮąĄ ą▓čüčÅą║ą░čÅ čüčéčĆąŠą║ą░ ąĘą░čĆą░ąĮąĄąĄ ąĖąĘą▓ąĄčüčéąĮą░ ą▓ąŠ ą▓čĆąĄą╝čÅ ąĮą░ą┐ąĖčüą░ąĮąĖčÅ ą║ąŠą┤ą░: ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ą░ą║ ą▒čŗčéčī, ąĄčüą╗ąĖ ą╝čŗ čģąŠčéąĖą╝ ą┐čĆąĖąĮčÅčéčī ą▓ą▓ąŠą┤ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ąĖ čüąŠčģčĆą░ąĮąĖčéčī ąĄą│ąŠ? ąöą╗čÅ čéą░ą║ąĖčģ čüąĖčéčāą░čåąĖą╣ ą▓ Rust ąĄčüčéčī ąĄčēąĄ ąŠą┤ąĖąĮ čüčéčĆąŠą║ąŠą▓čŗą╣ čéąĖą┐: String. ąŁč鹊čé čéąĖą┐ ą┤ą░ąĮąĮčŗčģ ą▓čŗą┤ąĄą╗čÅąĄčéčüčÅ ą▓ ą║čāč湥, čéą░ą║ čćč鹊 ą╝ąŠąČąĮąŠ čüąŠčģčĆą░ąĮčÅčéčī č鹥ą║čüčé, ą║ąŠą│ą┤ą░ ąĄą│ąŠ čĆą░ąĘą╝ąĄčĆ ąĮąĄąĖąĘą▓ąĄčüč鹥ąĮ ą▓ ą╝ąŠą╝ąĄąĮčé ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ą║ąŠą┤ą░. ąÆčŗ ą╝ąŠąČąĄč鹥 čüąŠąĘą┤ą░čéčī 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ čéąĖą┐ą░ String ąĖąĘ čüčéčĆąŠą║ąŠą▓ąŠą│ąŠ ą╗ąĖč鹥čĆą░ą╗ą░, ą┐čĆąĖą╝ąĄčĆąĮąŠ čéą░ą║:
let s = String:: from("hello" );
ąŚą┤ąĄčüčī ąŠą┐ąĄčĆą░č鹊čĆ ą┤ą▓ąŠą╣ąĮąŠą│ąŠ ą┤ą▓ąŠąĄč鹊čćąĖčÅ ::
ąŁč鹊čé ą▓ąĖą┤ čüčéčĆąŠą║ąĖ ą╝ąŠąČąĄčé ą╝čāčéąĖčĆąŠą▓ą░čéčī (ąĖąĘą╝ąĄąĮčÅčéčīčüčÅ runtime):
let mut s = String:: from("hello" );", world!" ); // push_str() ą┐čĆąĖą║čĆąĄą┐ą╗čÅąĄčé ą╗ąĖč鹥čĆą░ą╗ ą║ String ! ("{s}" ); // ąØą░ą┐ąĄčćą░čéą░ąĄčé 'hello, world!'
ąÆ č湥ą╝ ąČąĄ ąĘą┤ąĄčüčī ąŠčéą╗ąĖčćąĖąĄ? ą¤ąŠč湥ą╝čā String ą╝ąŠąČąĄčé ą╝ąĄąĮčÅčéčī ąĘąĮą░č湥ąĮąĖąĄ, ą░ ą╗ąĖč鹥čĆą░ą╗čŗ ąĮąĄ ą╝ąŠą│čāčé? ąĀą░ąĘą╗ąĖčćąĖąĄ čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, ą║ą░ą║ čŹčéąĖ ą┤ą▓ą░ čéąĖą┐ą░ ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓čāčÄčé čü ą┐ą░ą╝čÅčéčīčÄ.
[ą¤ą░ą╝čÅčéčī ąĖ ąĄčæ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ]
ąÆ čüą╗čāčćą░ąĄ čüčéčĆąŠą║ąŠą▓ąŠą│ąŠ ą╗ąĖč鹥čĆą░ą╗ą░ ą╝čŗ ąĘąĮą░ąĄą╝ ąĄą│ąŠ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą▓ ą╝ąŠą╝ąĄąĮčé ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ, čéą░ą║ čćč鹊 ąĄą│ąŠ č鹥ą║čüčé ąČąĄčüčéą║ąŠ ąĘą░ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮ ą▓ ą║ąŠąĮąĄčćąĮąŠą╝ ąĖčüą┐ąŠą╗ąĮčÅąĄą╝ąŠą╝ ą║ąŠą┤ąĄ. ą¤ąŠčŹč鹊ą╝čā čüčéčĆąŠą║ąŠą▓čŗąĄ ą╗ąĖč鹥čĆą░ą╗čŗ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ą▒čŗčüčéčĆąŠ ąĖ čŹčäč乥ą║čéąĖą▓ąĮąŠ. ą×ą┤ąĮą░ą║ąŠ čŹčéąĖ čüą▓ąŠą╣čüčéą▓ą░ ą┐ąŠą╗čāčćą░čÄčéčüčÅ č鹊ą╗čīą║ąŠ ą▒ą╗ą░ą│ąŠą┤ą░čĆčÅ č鹊ą╝čā, čćč鹊 ą╗ąĖč鹥čĆą░ą╗čŗ ąĮąĄ ą╝čāčéąĖčĆčāąĄą╝čŗąĄ. ąÜ čüąŠąČą░ą╗ąĄąĮąĖčÄ, ą╝čŗ ąĮąĄ ą╝ąŠąČąĄą╝ ą┐ąŠą╝ąĄčüčéąĖčéčī ą▒ąŠą╗čīčłąŠą╣ ą║čāčüąŠą║ ą┐ą░ą╝čÅčéąĖ (blob) ą▓ ą▒ąĖąĮą░čĆąĮčŗą╣ ą║ąŠą┤ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą║čāčüą║ą░ č鹥ą║čüčéą░, ą║ąŠą│ą┤ą░ ąĄą│ąŠ čĆą░ąĘą╝ąĄčĆ ąĮąĄąĖąĘą▓ąĄčüč鹥ąĮ ą▓ ą╝ąŠą╝ąĄąĮčé ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ, ąĖ ą║ąŠą│ą┤ą░ čĆą░ąĘą╝ąĄčĆ č鹥ą║čüčéą░ ą╝ąŠąČąĄčé ą┐ąŠą╝ąĄąĮčÅčéčīčüčÅ ą▓ąŠ ą▓čĆąĄą╝čÅ čĆą░ą▒ąŠčéčŗ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ (runtime).
ąĪ čéąĖą┐ąŠą╝ String ą┤ą╗čÅ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ ą╝čāčéąĖčĆčāąĄą╝ąŠčüčéąĖ ąĖ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ čĆą░ąĘčĆą░čüčéą░ąĮąĖčÅ čĆą░ąĘą╝ąĄčĆą░ čüąŠčģčĆą░ąĮčÅąĄą╝ąŠą│ąŠ č鹥ą║čüčéą░ ąĮą░ą╝ ąĮčāąČąĮąŠ ą▓čŗą┤ąĄą╗čÅčéčī ą┐ą░ą╝čÅčéčī ąĖąĘ ą║čāčćąĖ, ą║ąŠą│ą┤ą░ ą▓čŗą┤ąĄą╗čÅąĄą╝čŗą╣ čĆą░ąĘą╝ąĄčĆ ąĮąĄąĖąĘą▓ąĄčüč鹥ąĮ ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ. ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé:
ŌĆó ą¤ą░ą╝čÅčéčī ą┤ąŠą╗ąČąĮą░ ąĘą░ą┐čĆą░čłąĖą▓ą░čéčīčüčÅ čā čĆą░čüą┐čĆąĄą┤ąĄą╗ąĖč鹥ą╗čÅ ą┐ą░ą╝čÅčéąĖ runtime.
ą¤ąĄčĆą▓ą░čÅ čćą░čüčéčī čŹčéąĖčģ čéčĆąĄą▒ąŠą▓ą░ąĮąĖą╣ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ, ą║ąŠą│ą┤ą░ ą╝čŗ ą▓čŗąĘčŗą▓ą░ąĄą╝ čäčāąĮą║čåąĖčÄ String::from, ąĄčæ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ ąĘą░ą┐čĆą░čłąĖą▓ą░ąĄčé čüč鹊ą╗čīą║ąŠ ą┐ą░ą╝čÅčéąĖ, čüą║ąŠą╗čīą║ąŠ ąĮčāąČąĮąŠ. ąŁč鹊 čāąĮąĖą▓ąĄčĆčüą░ą╗čīąĮčŗą╣ čüą┐ąŠčüąŠą▒ ą▓ čÅąĘčŗą║ą░čģ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ.
ą×ą┤ąĮą░ą║ąŠ ą▓č鹊čĆą░čÅ čćą░čüčéčī ąĖą╝ąĄąĄčé ąŠčéą╗ąĖčćąĖčÅ. ąÆ čÅąĘčŗą║ą░čģ, ą│ą┤ąĄ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮ čüą▒ąŠčĆčēąĖą║ ą╝čāčüąŠčĆą░ (garbage collector, GC), GC ąŠčéčüą╗ąĄąČąĖą▓ą░ąĄčé ąĖ ąŠčćąĖčēą░ąĄčé čćą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗąĄ ą▒ąŠą╗čīčłąĄ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ, ąĖ ąĮą░ą╝ ąĮąĄ ąĮčāąČąĮąŠ ąĘą░ą▒ąŠčéąĖčéčīčüčÅ ąŠą▒ čŹč鹊ą╝. ąÆ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ čÅąĘčŗą║ąŠą▓, ą│ą┤ąĄ ąĮąĄčé GC, čŹčéą░ ąĘą░ą▒ąŠčéą░ ą╗ąŠąČąĖčéčüčÅ ąĮą░ ą┐ą╗ąĄčćąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčéą░ - ąĄą╝čā ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ čüą░ą╝ąŠą╝čā čÅą▓ąĮąŠ ą▓čŗą┤ąĄą╗čÅčéčī ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ą░čéčī ą┐ą░ą╝čÅčéčī ą┤ą╗čÅ ąŠą▒čŖąĄą║č鹊ą▓. ąÜąŠčĆčĆąĄą║čéąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ą║čāčćąĖ ą▓čüąĄą│ą┤ą░ čüąŠčüčéą░ą▓ą╗čÅą╗ą░ ą┐čĆąŠą▒ą╗ąĄą╝čā ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĖ. ąĢčüą╗ąĖ ą╝čŗ ąĘą░ą▒čāą┤ąĄą╝ ąŠčüą▓ąŠą▒ąŠą┤ąĖčéčī ą┐ą░ą╝čÅčéčī, č鹊 ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé čāč鹥čćą║ą░ ą┐ą░ą╝čÅčéąĖ. ąĢčüą╗ąĖ ąČąĄ ą╝čŗ ąŠčüą▓ąŠą▒ąŠą┤ąĖą╝ ą┐ą░ą╝čÅčéčī čüą╗ąĖčłą║ąŠą╝ čĆą░ąĮąŠ, č鹊 ą┐ąŠą╗čāčćąĖą╝ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčāčÄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ. ąĢčüą╗ąĖ ą╝čŗ ą┤ą▓ą░ąČą┤čŗ ąŠčüą▓ąŠą▒ąŠą┤ąĖą╝ ąŠą┤ąĮčā ąĖ čéčā ąČąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĮčāčÄ ąŠą▒ą╗ą░čüčéčī, č鹊 čŹč鹊 č鹊ąČąĄ čüąĄčĆčīąĄąĘąĮčŗą╣ ą▒ą░ą│. ąØą░ą╝ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ čüčéčĆąŠą│ąŠ čüąŠą▒ą╗čÄą┤ą░čéčī ą┐ą░čĆčŗ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ/ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą║čāčćąĖ.
ąŻ Rust ą┐čĆąĖąĮčÅčé ą┤čĆčāą│ąŠą╣ ą┐ąŠą┤čģąŠą┤ ą║ čŹč鹊ą╣ ą┐čĆąŠą▒ą╗ąĄą╝ąĄ: ą┐ą░ą╝čÅčéčī ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ą░ąĄčéčüčÅ, ą║ąŠą│ą┤ą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ ą▓čŗčģąŠą┤ąĖčé ąĖąĘ čüą▓ąŠąĄą╣ ąŠą▒ą╗ą░čüčéąĖ ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ. ąÆąŠčé ą▓ąĄčĆčüąĖčÅ ąĮą░čłąĄą│ąŠ ą┐čĆąĖą╝ąĄčĆą░ ąŠą▒ą╗ą░čüčéąĖ ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ ąĖąĘ ą╗ąĖčüčéąĖąĮą│ą░ 4-1, ąĖčüą┐ąŠą╗čīąĘčāčÄčēą░čÅ String ą▓ą╝ąĄčüč鹊 čüčéčĆąŠą║ąŠą▓ąŠą│ąŠ ą╗ąĖč鹥čĆą░ą╗ą░:
{
let s = String:: from("hello" ); // s ą┤ąŠčüč鹊ą▓ąĄčĆąĮą░ ąŠčé čŹč鹊ą│ąŠ ą╝ąĄčüčéą░ ąĖ ą┤ą░ą╗ąĄąĄ // ąĘą┤ąĄčüčī ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ą║ą░ą║ąĖąĄ-č鹊 ą┤ąĄą╣čüčéą▓ąĖčÅ čü čüąŠą┤ąĄčƹȹĖą╝čŗą╝ s
} // ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ s ąĘą░ą║ąŠąĮčćąĖą╗ą░čüčī,
// ą┤ą░ą╗ąĄąĄ ąŠąĮą░ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮą░
ąĪčāčēąĄčüčéą▓čāąĄčé ąĄčüč鹥čüčéą▓ąĄąĮąĮą░čÅ č鹊čćą║ą░, ą▓ ą║ąŠč鹊čĆąŠą╣ ą╝čŗ ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝ ą┐ą░ą╝čÅčéčī ąĮą░čłąĄą╣ String ąŠą▒čĆą░čéąĮąŠ ą▓ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĖč鹥ą╗čī: ą║ąŠą│ą┤ą░ ąĘą░ą║ą░ąĮčćąĖą▓ą░ąĄčéčüčÅ ąŠą▒ą╗ą░čüčéčī ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ s. ąÜąŠą│ą┤ą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ ą▓čŗčģąŠą┤ąĖčé ąĘą░ ą┐čĆąĄą┤ąĄą╗čŗ čüą▓ąŠąĄą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ, Rust ą▓čŗąĘčŗą▓ą░ąĄčé ą┤ą╗čÅ ąĮą░čü čüą┐ąĄčåąĖą░ą╗čīąĮčāčÄ čäčāąĮą║čåąĖčÄ. ąŁčéą░ čäčāąĮą║čåąĖčÅ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ drop, ąĖ čŹč鹊 č鹊 ą╝ąĄčüč鹊, ą│ą┤ąĄ ą░ą▓č鹊čĆ String ą╝ąŠąČąĄčé ą┐ąŠą╝ąĄčüčéąĖčéčī ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ą▓čŗą┤ąĄą╗ąĄąĮąĮčāčÄ ą┐ą░ą╝čÅčéčī. Rust ą▓čŗąĘąŠą▓ąĄčé drop ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ, ąĮą░ ą╝ąĄčüč鹥 ąĘą░ą║čĆčŗą▓ą░čÄčēąĄą╣ čäąĖą│čāčĆąĮąŠą╣ čüą║ąŠą▒ą║ąĖ.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąĮą░ čÅąĘčŗą║ąĄ C++ čŹč鹊čé ą▓ą░čĆąĖą░ąĮčé ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ čĆąĄčüčāčĆčüąŠą▓ ą┐ąŠ ąŠą║ąŠąĮčćą░ąĮąĖąĖ ą▓čĆąĄą╝ąĄąĮąĖ ąČąĖąĘąĮąĖ ąĖąĮąŠą│ą┤ą░ ąĮą░ąĘčŗą▓ą░čÄčé Resource Acquisition Is Initialization (RAII). ążčāąĮą║čåąĖčÅ drop ą▓ Rust ą▒čāą┤ąĄčé ą▓ą░ą╝ ąĘąĮą░ą║ąŠą╝ą░, ąĄčüą╗ąĖ ą▓čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ąĖ čłą░ą▒ą╗ąŠąĮčŗ RAII.
ąŁč鹊čé čłą░ą▒ą╗ąŠąĮ ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą│ą╗čāą▒ąŠą║ąŠąĄ ą▓ą╗ąĖčÅąĮąĖąĄ ąĮą░ čüą┐ąŠčüąŠą▒ ąĮą░ą┐ąĖčüą░ąĮąĖčÅ ą║ąŠą┤ą░ Rust. ąĪąĄą╣čćą░čü čŹč鹊 ą╝ąŠąČąĄčé ą┐ąŠą║ą░ąĘą░čéčīčüčÅ ą┐čĆąŠčüčéčŗą╝, ąŠą┤ąĮą░ą║ąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą║ąŠą┤ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮąĄąŠąČąĖą┤ą░ąĮąĮčŗą╝ ą▓ ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮčŗčģ čüąĖčéčāą░čåąĖčÅčģ, ą║ąŠą│ą┤ą░ ąĮą░ą╝ ąĮčāąČąĮąŠ ąĖą╝ąĄčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ ą┤ą╗čÅ ą┤ą░ąĮąĮčŗčģ, ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗčģ ą▓ ą║čāč湥. ąöą░ą▓ą░ą╣č鹥 čüąĄą╣čćą░čü čĆą░čüčüą╝ąŠčéčĆąĖą╝ ąĮąĄą║ąŠč鹊čĆčŗąĄ ą┐ąŠą┤ąŠą▒ąĮčŗąĄ čüą╗čāčćą░ąĖ.
ą¤ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ ąĖ ą┤ą░ąĮąĮčŗąĄ, ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓čāčÄčēąĖąĄ čü ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄą╝. ąØąĄčüą║ąŠą╗čīą║ąŠ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ ą▓ Rust ą╝ąŠą│čāčé ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąŠą▓ą░čéčī čü ąŠą┤ąĮąĖą╝ąĖ ąĖ č鹥ą╝ąĖ ąČąĄ ą┤ą░ąĮąĮčŗą╝ąĖ čĆą░ąĘąĮčŗą╝ąĖ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ. ąÆ ą╗ąĖčüčéąĖąĮą│ąĄ 4-2 ą┐čĆąĖą▓ąĄą┤ąĄąĮ ą┐čĆąĖą╝ąĄčĆ:
ąøąĖčüčéąĖąĮą│ 4-2. ą¤čĆąĖčüą▓ą░ąĖą▓ą░ąĮąĖąĄ čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ x ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ y.
ą£čŗ ą╝ąŠąČąĄą╝ ą┤ąŠą│ą░ą┤ą░čéčīčüčÅ, čćč鹊 ąĘą┤ąĄčüčī ą▓ąĄčĆąŠčÅčéąĮąŠ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé: "ą┐čĆąĖą▓čÅąĘą░čéčī ąĘąĮą░č湥ąĮąĖąĄ 5 ą║ x; ąĘą░č鹥ą╝ čüą┤ąĄą╗ą░čéčī ą║ąŠą┐ąĖčÄ ąĘąĮą░č湥ąĮąĖčÅ ą▓ x ąĖ ą┐čĆąĖą▓čÅąĘą░čéčī ąĄą│ąŠ ą║ y". ąóąĄą┐ąĄčĆčī čā ąĮą░čü ąĄčüčéčī ą┤ą▓ąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ x ąĖ y, ąĖ ąŠąĮąĖ ąŠą▒ąĄ čĆą░ą▓ąĮčŗ 5. ąś čŹč鹊 ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠ č鹊, čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé, ą┐ąŠč鹊ą╝čā čćč鹊 ąĘąĮą░č湥ąĮąĖčÅ čåąĄą╗čŗčģ čćąĖčüąĄą╗ ą┐čĆąŠčüčéčŗąĄ ąĖ ąĖčģ čĆą░ąĘą╝ąĄčĆ ąĖąĘą▓ąĄčüč鹥ąĮ ąĘą░čĆą░ąĮąĄąĄ, čéą░ą║ čćč鹊 ą┤ą▓ą░ ąĘąĮą░č湥ąĮąĖčÅ 5 ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░čÄčéčüčÅ ą▓ čüč鹥ą║.
ąóąĄą┐ąĄčĆčī ą┐ąŠčüą╝ąŠčéčĆąĖą╝, čćč鹊 ą▒čāą┤ąĄčé čü ą▓ąĄčĆčüąĖąĄą╣ č鹊ą│ąŠ ąČąĄ čüą░ą╝ąŠą│ąŠ ą║ąŠą┤ą░, ąĮąŠ čü čéąĖą┐ąŠą╝ String:
let s1 = String:: from("hello" );
let s2 = s1;
ąÆąĮąĄčłąĮąĄ ą▓čŗą│ą╗čÅą┤ąĖčé ą▓čüąĄ čéą░ą║ ąČąĄ, ą║ą░ą║ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 4-2, čéą░ą║ čćč鹊 ą╝ąŠąČąĮąŠ ą┐ąŠą┤čāą╝ą░čéčī, čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé č鹊 ąČąĄ čüą░ą╝ąŠąĄ: ą▓č鹊čĆą░čÅ čüčéčĆąŠą║ą░ ą┤ąĄą╗ą░ąĄčé ą║ąŠą┐ąĖčÄ ąĘąĮą░č湥ąĮąĖčÅ ą▓ s1 ąĖ ą┐čĆąĖą▓čÅąĘčŗą▓ą░ąĄčé ąĄą│ąŠ ą║ s2. ąØąŠ čŹč鹊 ąĮąĄ čüąŠą▓čüąĄą╝ č鹊, čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĮą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ.
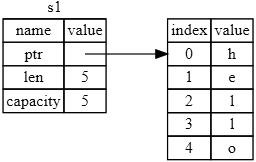
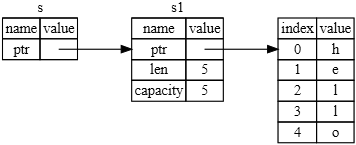
ą¤ąŠčüą╝ąŠčéčĆąĖč鹥 ąĮą░ čĆąĖčü. 4-1, čćč鹊ą▒čŗ čāą▓ąĖą┤ąĄčéčī, čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé čüąŠ String ą▓ąĮčāčéčĆąĖ. String čüąŠčüč鹊ąĖčé ąĖąĘ 3 čćą░čüč鹥ą╣, ą┐ąŠą║ą░ąĘą░ąĮąĮčŗčģ čüą╗ąĄą▓ą░: čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ą┐ą░ą╝čÅčéčī, ą│ą┤ąĄ čģčĆą░ąĮąĖčéčüčÅ čüčéčĆąŠą║ą░ (ptr), ą┤ą╗ąĖąĮą░ čŹč鹊ą╣ čüčéčĆąŠą║ąĖ (length), ąĖ ąĘą░ąĮąĖą╝ą░ąĄą╝čŗą╣ ąŠą▒čŖąĄą╝ (capacity). ąŁčéą░ ą│čĆčāą┐ą┐ą░ ą┤ą░ąĮąĮčŗčģ čüąŠčģčĆą░ąĮčÅąĄčéčüčÅ ą▓ čüč鹥ą║ąĄ. ąĪą┐čĆą░ą▓ą░ ąĮą░ čĆąĖčüčāąĮą║ąĄ ą┐ąŠą║ą░ąĘą░ąĮą░ ą┐ą░ą╝čÅčéčī ą║čāčćąĖ, ą║ąŠč鹊čĆą░čÅ čģčĆą░ąĮąĖčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ č鹥ą║čüčéą░ čüčéčĆąŠą║ąĖ.
ąĀąĖčü. 4-1. ą¤čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ ą▓ ą┐ą░ą╝čÅčéąĖ ąŠą▒čŖąĄą║čéą░ String, čģčĆą░ąĮčÅčēąĄą│ąŠ ąĘąĮą░č湥ąĮąĖąĄ "hello", ą┐čĆąĖą▓čÅąĘą░ąĮąĮąŠąĄ ą║ s1.
ąŚąĮą░č湥ąĮąĖąĄ length čŹč鹊 čüą║ąŠą╗čīą║ąŠ ą┐ą░ą╝čÅčéąĖ ą▓ ą▒ą░ą╣čéą░čģ ąĖčüą┐ąŠą╗čīąĘčāąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ String ą▓ ąĮą░čüč鹊čÅčēąĖą╣ ą╝ąŠą╝ąĄąĮčé. ąŚąĮą░č湥ąĮąĖąĄ capacity čŹč鹊 ąŠą▒čēąĖą╣ ąŠą▒čŖąĄą╝ ą┐ą░ą╝čÅčéąĖ ą▓ ą▒ą░ą╣čéą░čģ, ą║ąŠč鹊čĆąŠąĄ ąŠą▒čŖąĄą║čé String ą┐ąŠą╗čāčćąĖą╗ ąŠčé čĆą░čüą┐čĆąĄą┤ąĄą╗ąĖč鹥ą╗čÅ ą┐ą░ą╝čÅčéąĖ. ąĀą░ąĘąĮąĖčåą░ ą╝ąĄąČą┤čā length ąĖ capacity ąĖą╝ąĄąĄčé ąĘąĮą░č湥ąĮąĖąĄ, ąĮąŠ ąĮąĄ ą▓ čŹč鹊ą╝ ą║ąŠąĮč鹥ą║čüč鹥, ą┐ąŠčŹč鹊ą╝čā čüąĄą╣čćą░čü ą╝ąŠąČąĮąŠ ąĖą│ąĮąŠčĆąĖčĆąŠą▓ą░čéčī capacity.
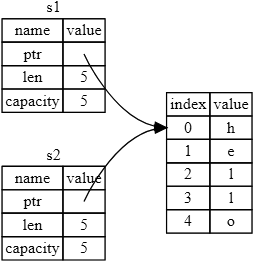
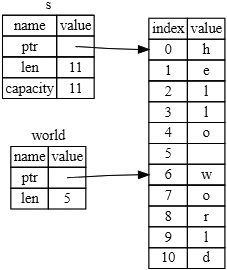
ąÜąŠą│ą┤ą░ ą╝čŗ ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĄą╝ s2 = s1, ą┤ą░ąĮąĮčŗąĄ String ą║ąŠą┐ąĖčĆčāčÄčéčüčÅ, čé. ąĄ. ą║ąŠą┐ąĖčĆčāąĄčéčüčÅ čāą║ą░ąĘą░č鹥ą╗čī (ptr), ą┤ą╗ąĖąĮą░ (length) ąĖ ąŠą▒čŖąĄą╝ (capacity), ą║ąŠč鹊čĆčŗąĄ ąĮą░čģąŠą┤čÅčéčüčÅ ą▓ čüč鹥ą║ąĄ. ą£čŗ ą┐čĆąĖ čŹč鹊ą╝ ąĮąĄ ą║ąŠą┐ąĖčĆčāąĄą╝ ą┤ą░ąĮąĮčŗąĄ ą▓ ą║čāč湥, ąĮą░ ą║ąŠč鹊čĆčŗą╣ čāą║ą░ąĘčŗą▓ą░čÄčé ąĘąĮą░č湥ąĮąĖčÅ ptr. ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ ą▓ ą┐ą░ą╝čÅčéąĖ ą▒čāą┤ąĄčé, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮą░ čĆąĖčü. 4-2.
ąĀąĖčü. 4-2. ą¤čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ ą▓ ą┐ą░ą╝čÅčéąĖ, ą║ąŠą│ą┤ą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ s1 ą║ąŠą┐ąĖčĆčāąĄčéčüčÅ ą▓ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ s2: ą║ąŠą┐ąĖčĆčāčÄčéčüčÅ č鹊ą╗čīą║ąŠ čāą║ą░ąĘą░č鹥ą╗čī, ą┤ą╗ąĖąĮą░ ąĖ ąĄą╝ą║ąŠčüčéčī s1.
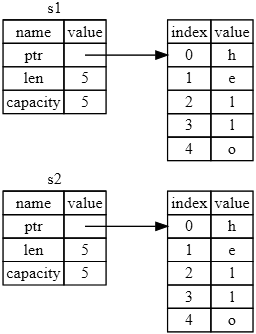
ą¤čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ čĆąĖčü. 4-2 ąĮąĄ ą┐ąŠčģąŠąČąĄ ąĮą░ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ čĆąĖčü. 4-3, ą░ ąĖą╝ąĄąĮąĮąŠ ą║ą░ą║ ą▓čŗą│ą╗čÅą┤ąĄą╗ą░ ą▒čŗ ą┐ą░ą╝čÅčéčī, ąĄčüą╗ąĖ ą▒čŗ Rust ą║ąŠą┐ąĖčĆąŠą▓ą░ą╗ čéą░ą║ąČąĄ ąĖ ą┐ą░ą╝čÅčéčī ą║čāčćąĖ. ąĢčüą╗ąĖ ą▒čŗ Rust čüą┤ąĄą╗ą░ą╗ čŹč鹊, č鹊 ąŠą┐ąĄčĆą░čåąĖčÅ s2 = s1 ą▒čŗą╗ą░ ą▒čŗ ąŠč湥ąĮčī ąĘą░čéčĆą░čéąĮą░ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ, ąŠčüąŠą▒ąĄąĮąĮąŠ ą║ąŠą│ą┤ą░ čĆą░ąĘą╝ąĄčĆ ą┤ą░ąĮąĮčŗčģ ą║čāčćąĖ ą▒čŗą╗ ą▒čŗ ą▒ąŠą╗čīčłąĖą╝.
ąĀąĖčü. 4-3. ąöčĆčāą│ąŠą╣ ą▓ąŠąĘą╝ąŠąČąĮčŗą╣ ą▓ą░čĆąĖą░ąĮčé ąŠą┐ąĄčĆą░čåąĖąĖ s2 = s1, ąĄčüą╗ąĖ Rust ą║ąŠą┐ąĖčĆčāąĄčé čéą░ą║ąČąĄ ą┤ą░ąĮąĮčŗąĄ ąĖ ą║čāčćąĖ.
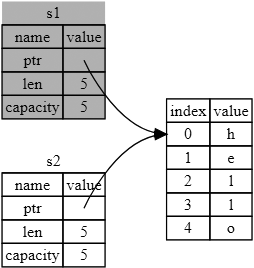
ą£čŗ čāąČąĄ ą│ąŠą▓ąŠčĆąĖą╗ąĖ čĆą░ąĮąĄąĄ, čćč鹊 ą║ąŠą│ą┤ą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ ą▓čŗčģąŠą┤ąĖčé ąĘą░ čüą▓ąŠčÄ ąŠą▒ą╗ą░čüčéčī ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ, Rust ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą▓čŗąĘčŗą▓ą░ąĄčé čäčāąĮą║čåąĖčÄ drop ąĖ ąŠčćąĖčēą░ąĄčé ą┐ą░ą╝čÅčéčī ą║čāčćąĖ ą┤ą╗čÅ čŹč鹊ą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣. ą×ą┤ąĮą░ą║ąŠ čĆąĖčü. 4-2 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ąŠą▒ą░ čāą║ą░ąĘą░č鹥ą╗čÅ ąĮą░ ą┤ą░ąĮąĮčŗąĄ čüčüčŗą╗ą░čÄčéčüčÅ ąĮą░ ąŠą┤ąĮčā ąĖ čéčā ąČąĄ ąŠą▒ą╗ą░čüčéčī. ąŁč鹊 čüąŠąĘą┤ą░ąĄčé ą┐čĆąŠą▒ą╗ąĄą╝čā: ą║ąŠą│ą┤ą░ s2 ąĖ s1 ą▓čŗčģąŠą┤čÅčé ąĘą░ čüą▓ąŠčÄ ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ, ąŠąĮąĖ ąŠą▒ąĄ ą┐ąŠą┐čŗčéą░čÄčéčüčÅ ąŠčüą▓ąŠą▒ąŠą┤ąĖčéčī ąŠą┤ąĮčā ąĖ čéčā ąČąĄ ą┐ą░ą╝čÅčéčī. ąŁč鹊 ąĖąĘą▓ąĄčüčéąĮą░čÅ ą┐čĆąŠą▒ą╗ąĄą╝ą░ ą┤ą▓ąŠą╣ąĮąŠą│ąŠ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ ąŠą┤ąĮąŠą╣ ąĖ č鹊ą╣ ąČąĄ ąŠą▒ą╗ą░čüčéčī ą┐ą░ą╝čÅčéąĖ (double free error), ąĖ čŹč鹊 ąŠą┤ąĖąĮ ąĖąĘ ą▒ą░ą│ąŠą▓ ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéąĖ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗąĄ ą╝čŗ ąŠą▒čüčāąČą┤ą░ą╗ąĖ ą▓čŗčłąĄ. ą¤ąŠą┐čŗčéą║ą░ ą┤ą▓ąŠą╣ąĮąŠą│ąŠ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĄčæ ą┐ąŠą▓čĆąĄąČą┤ąĄąĮąĖčÄ, ąĖ ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ čāčÅąĘą▓ąĖą╝ąŠčüčéąĖ čüąĖčüč鹥ą╝čŗ ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéąĖ.
ąöą╗čÅ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖčÅ ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéąĖ ą┐ą░ą╝čÅčéąĖ ą┐ąŠčüą╗ąĄ čüčéčĆąŠą║ąĖ let s2 = s1; Rust čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ąĄčé s1 ą║ą░ą║ ą▒ąŠą╗ąĄąĄ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčāčÄ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, č鹥ą┐ąĄčĆčī ą┤ą╗čÅ Rust ąĮąĄ ąĮą░ą┤ąŠ ąŠčüą▓ąŠą▒ąŠąČą┤ą░čéčī s1, ą║ąŠą│ą┤ą░ čā ąĮąĄčæ ąĘą░ą║ą░ąĮčćąĖą▓ą░ąĄčéčüčÅ ąŠą▒ą╗ą░čüčéčī ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ. ąöą░ą▓ą░ą╣č鹥 ą┐čĆąŠą▓ąĄčĆąĖą╝, čćč鹊 ą┐ąŠą╗čāčćąĖčéčüčÅ, ą║ąŠą│ą┤ą░ ą▓čŗ ą┐ąŠą┐čŗčéą░ąĄč鹥čüčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī s1 ą┐ąŠčüą╗ąĄ čüąŠąĘą┤ą░ąĮąĖčÅ s2; čŹč鹊 ąĮąĄ čüčĆą░ą▒ąŠčéą░ąĄčé:
let s1 = String:: from("hello" );
let s2 = s1;! ("{s1}, world!" );
ą¤čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąŠčłąĖą▒ą║ą░, ą┐ąŠč鹊ą╝čā čćč鹊 Rust ąĮąĄ ą┐ąŠąĘą▓ąŠą╗ąĖčé ą▓ą░ą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĮąĄą┤ąŠą┐čāčüčéąĖą╝čŗą╣ čāą║ą░ąĘą░č鹥ą╗čī:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:5:28
|
2 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{}, world!", s1);
| ^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion
of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
3 | let s2 = s1.clone();
| ++++++++
ąĢčüą╗ąĖ ą▓čŗ ą▓čüčéčĆąĄčćą░ą╗ąĖčüčī čü č鹥čĆą╝ąĖąĮą░ą╝ąĖ shallow copy (ąĮąĄą│ą╗čāą▒ąŠą║ą░čÅ ą║ąŠą┐ąĖčÅ) ąĖ deep copy (ą│ą╗čāą▒ąŠą║ą░čÅ ą║ąŠą┐ąĖčÅ) ą┐čĆąĖ čĆą░ą▒ąŠč鹥 čü ą┤čĆčāą│ąĖą╝ąĖ čÅąĘčŗą║ą░ą╝ąĖ, č鹊 ą║ąŠąĮčåąĄą┐čåąĖčÅ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ čāą║ą░ąĘą░č鹥ą╗čÅ, ą┤ą╗ąĖąĮčŗ ąĖ ąĄą╝ą║ąŠčüčéąĖ ą▒ąĄąĘ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ ą▓ąŠąĘą╝ąŠąČąĮąŠ ą▒čāą┤ąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī ą║ą░ą║ shallow copy. ą×ą┤ąĮą░ą║ąŠ ąĖąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 Rust čéą░ą║ąČąĄ ą┤ąĄą╗ą░ąĄčé ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą╣ ą┐ąĄčĆą▓čāčÄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ ą▓ą╝ąĄčüč鹊 ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĮąĄą│ą╗čāą▒ąŠą║ąŠą╣ ą║ąŠą┐ąĖąĖ, čŹčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ ąĖąĘą▓ąĄčüčéąĮą░ ą║ą░ą║ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ (move). ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą▓čŗ ą│ąŠą▓ąŠčĆąĖą╝, čćč鹊 s1 ą▒čŗą╗ą░ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮą░ ą▓ s2. ąóą░ą║ čćč鹊 čäą░ą║čéąĖč湥čüą║ąĖ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé č鹊, čćč鹊 ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮą░ čĆąĖčü. 4-4.
ąĀąĖčü. 4-4. ą¤čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ s1 ą▒čŗą╗ą░ čüą┤ąĄą╗ą░ąĮą░ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą╣.
ąŁč鹊 čĆąĄčłą░ąĄčé ą┐čĆąŠą▒ą╗ąĄą╝čā! ąĢčüą╗ąĖ ą┤ąŠčüč鹊ą▓ąĄčĆąĮą░ č鹊ą╗čīą║ąŠ čüčéčĆąŠą║ą░ s2, č鹊 ą║ąŠą│ą┤ą░ ąŠąĮą░ ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ, č鹊 ąŠąĮą░ ąŠčüčéą░ąĄčéčüčÅ ąŠą┤ąĮą░ ą┐čĆąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĖ ą┐ą░ą╝čÅčéąĖ, ąĖ ą┐čĆąŠą▒ą╗ąĄą╝ą░ ą┤ą▓ąŠą╣ąĮąŠą│ąŠ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ čĆąĄčłąĄąĮą░.
ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, čüčāčēąĄčüčéą▓čāąĄčé ą▓čŗą▒ąŠčĆ ą┤ąĖąĘą░ą╣ąĮą░, ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄą╝čŗą╣ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄą╝ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░: Rust ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą▒čāą┤ąĄčé ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą┤ąĄą╗ą░čéčī deep-ą║ąŠą┐ąĖąĖ ą▓ą░čłąĖčģ ą┤ą░ąĮąĮčŗčģ. ą¤ąŠčŹč鹊ą╝čā ą╗čÄą▒ąŠąĄ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąŠąĄ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ ą╝ąŠąČąĮąŠ čüčćąĖčéą░čéčī ąĮąĄą┤ąŠčĆąŠą│ąĖą╝ čü č鹊čćą║ąĖ ąĘčĆąĄąĮąĖčÅ runtime ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ.
ą¤ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ ąĖ ą┤ą░ąĮąĮčŗąĄ, ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓čāčÄčēąĖąĄ čü ą║ą╗ąŠąĮąĖčĆąŠą▓ą░ąĮąĖąĄą╝ . ąĢčüą╗ąĖ ą╝čŗ čüą┤ąĄą╗ą░čéčī deep-ą║ąŠą┐ąĖčÄ ą┤ą░ąĮąĮčŗčģ ą║čāčćąĖ ąŠą▒čŖąĄą║čéą░ String, ąĮąĄ ą┐čĆąŠčüč鹊 ą┤ą░ąĮąĮčŗčģ čüč鹥ą║ą░, č鹊 ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąŠą▒čēąĖą╣ ą╝ąĄč鹊ą┤ clone. ą£čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ čüąĖąĮčéą░ą║čüąĖčü čŹč鹊ą│ąŠ ą╝ąĄč鹊ą┤ą░ ą▓ ą│ą╗ą░ą▓ąĄ 5, ąŠą┤ąĮą░ą║ąŠ ą┐ąŠčüą║ąŠą╗čīą║čā ą╝ąĄč鹊ą┤čŗ čŹč鹊 ąŠą▒čēą░čÅ ąŠčüąŠą▒ąĄąĮąĮąŠčüčéčī ą╝ąĮąŠą│ąĖčģ čÅąĘčŗą║ąŠą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ, č鹊 ą▓ąŠąĘą╝ąŠąČąĮąŠ ą▓čŗ čāąČąĄ čüčéą░ą╗ą║ąĖą▓ą░ą╗ąĖčüčī čü čŹčéąĖą╝ čĆą░ąĮčīčłąĄ.
ą¤čĆąĖą╝ąĄčĆ čĆą░ą▒ąŠčéčŗ ą╝ąĄč鹊ą┤ą░ clone:
let s1 = String:: from("hello" );
let s2 = s1.clone();! ("s1 = {s1}, s2 = {s2}" );
ąŁč鹊 čüčĆą░ą▒ąŠčéą░ąĄčé ąĮąŠčĆą╝ą░ą╗čīąĮąŠ ąĖ čÅą▓ąĮąŠ čüą│ąĄąĮąĄčĆąĖčĆčāąĄčé ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ, ą┐ąŠą║ą░ąĘą░ąĮąĮąŠąĄ ąĮą░ čĆąĖčü. 4-3, ą│ą┤ąĄ ą║ąŠą┐ąĖčĆąŠą▓ą░ą╗ąĖčüčī ą┤ą░ąĮąĮčŗąĄ ą║čāčćąĖ.
ąÜąŠą│ą┤ą░ ą▓čŗ ą▓ąĖą┤ąĖč鹥 ą▓čŗąĘąŠą▓ clone, č鹊 ą┤ąŠą╗ąČąĮčŗ ąĘąĮą░čéčī, čćč鹊 ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ čéą░ą║ąČąĄ ąĮąĄą║ąĖą╣ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗą╣ ą║ąŠą┤, ąĖ čŹč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░čéčĆą░čéąĮčŗą╝ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ. ąŁč鹊 ą▓ąĖąĘčāą░ą╗čīąĮčŗą╣ ąĖąĮą┤ąĖą║ą░č鹊čĆ č鹊ą│ąŠ, čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĮąĄčćč鹊 ąŠčüąŠą▒ąĄąĮąĮąŠąĄ.
Stack-Only Data: Copy . ąĢčüčéčī ąĄčēąĄ ą║ąŠąĄ-čćč鹊, ąŠ č湥ą╝ ą╝čŗ ąĮąĄ ą│ąŠą▓ąŠčĆąĖą╗ąĖ. ąÜąŠą┤ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ čåąĄą╗čŗčģ čćąĖčüąĄą╗ ąĖąĘ ą╗ąĖčüčéąĖąĮą│ą░ 4-2 čĆą░ą▒ąŠčéą░ąĄčé, ąĖ ąŠąĮ ą┤ąŠą┐čāčüčéąĖą╝:
let x = 5 ;
let y = x;! ("x = {x}, y = {y}" );
ąŁč鹊čé ą║ąŠą┤ ą▓čŗą│ą╗čÅą┤ąĖčé ą┐čĆąŠčéąĖą▓ąŠčĆąĄčćąĖąĄą╝ č鹊ą╝čā, čćč鹊 ą╝čŗ č鹊ą╗čīą║ąŠ čćč鹊 ąĖąĘčāčćąĖą╗ąĖ: clone ąĮąĄ ą▓čŗąĘčŗą▓ą░ąĄčéčüčÅ, ąŠą┤ąĮą░ą║ąŠ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ x ąŠčüčéą░ąĄčéčüčÅ ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą╣ ąĖ ąĮąĄ ą┐ąĄčĆąĄą╝ąĄčēą░ąĄčéčüčÅ ą▓ y.
ą¤čĆąĖčćąĖąĮą░ ą▓ č鹊ą╝, čćč鹊 čéąĖą┐čŗ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ čåąĄą╗čŗčģ čćąĖčüąĄą╗ ąĖą╝ąĄčÄčé ąĖąĘą▓ąĄčüčéąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ ą▓ ą╝ąŠą╝ąĄąĮčé ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ, ąĖ ą┐ąŠą╗ąĮąŠčüčéčīčÄ čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ ą▓ čüč鹥ą║ąĄ, čéą░ą║ čćč鹊 ą║ąŠą┐ąĖąĖ čĆąĄą░ą╗čīąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣ ąŠčüčāčēąĄčüčéą▓ą╗čÅčÄčéčüčÅ ą▒čŗčüčéčĆąŠ. ąŁč鹊 ąĘąĮą░čćąĖčé, čćč鹊 ąĮąĄčé ą┐čĆąĖčćąĖąĮ ą┤ąĄą╗ą░čéčī ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ x ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą╣, ą║ąŠą│ą┤ą░ ą╝čŗ čüąŠąĘą┤ą░ąĄą╝ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ y. ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ąĘą┤ąĄčüčī ąĮąĄčé čĆą░ąĘą╗ąĖčćąĖą╣ ą╝ąĄąČą┤čā deep ąĖ shallow ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄą╝, čéą░ą║ čćč鹊 ą▓čŗąĘąŠą▓ clone ąĮąĄ čüą┤ąĄą╗ą░ąĄčé ąĮąĖč湥ą│ąŠ, čćč鹊ą▒čŗ ąŠčéą╗ąĖčćą░ą╗ąŠčüčī ąŠčé ąŠą▒čŗčćąĮąŠą│ąŠ shallow-ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ, čéą░ą║ čćč鹊 ąĘą┤ąĄčüčī čŹč鹊 ą╝ąŠąČąĮąŠ ąŠą┐čāčüčéąĖčéčī.
ąÆ Rust ąĄčüčéčī čüą┐ąĄčåąĖą░ą╗čīąĮą░čÅ ą░ąĮąĮąŠčéą░čåąĖčÅ Copy čéčĆąĄą╣čé, ą║ąŠč鹊čĆčāčÄ ą╝čŗ ą╝ąŠąČąĄą╝ čĆą░ąĘą╝ąĄčüčéąĖčéčī ą▓ čéąĖą┐ą░čģ, čģčĆą░ąĮčÅčēąĖčģčüčÅ ą▓ čüč鹥ą║ąĄ, ą║ą░ą║ ąĖ čåąĄą╗čŗąĄ čćąĖčüą╗ą░ (ą▒ąŠą╗ąĄąĄ ą┐ąŠą┤čĆąŠą▒ąĮąŠ ą┐čĆąŠ čéčĆąĄą╣čéčŗ ą╝čŗ ą┐ąŠą│ąŠą▓ąŠčĆąĖą╝ ą▓ ą│ą╗ą░ą▓ąĄ 10). ąĢčüą╗ąĖ ą▓ čéąĖą┐ąĄ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮ čéčĆąĄą╣čé Copy, č鹊 ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ, ąĄą│ąŠ ąĖčüą┐ąŠą╗čīąĘčāčÄčēąĖąĄ, ąĮąĄ ą┐ąĄčĆąĄą╝ąĄčēą░čÄčéčüčÅ, ąĖ ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ čéčĆąĖą▓ąĖą░ą╗čīąĮąŠ ą║ąŠą┐ąĖčĆčāčÄčéčüčÅ, č鹥ą╝ čüą░ą╝čŗą╝ ąŠąĮąĖ ąŠčüčéą░čÄčéčüčÅ ą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝ąĖ ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ą▒čŗą╗ąĖ ą┐čĆąĖčüą▓ąŠąĄąĮčŗ ą┤čĆčāą│ąŠą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣.
Rust ąĮąĄ ą┐ąŠąĘą▓ąŠą╗ąĖčé ąĮą░ą╝ ą░ąĮąĮąŠčéąĖčĆąŠą▓ą░čéčī čéąĖą┐ čü Copy, ąĄčüą╗ąĖ čüą░ą╝ čéąĖą┐ ąĖą╗ąĖ ą╗čÄą▒ą░čÅ ąĄą│ąŠ čćą░čüčéčī čĆąĄą░ą╗ąĖąĘčāąĄčé čéčĆąĄą╣čé Drop. ąĢčüą╗ąĖ čéąĖą┐čā ąĮčāąČąĮąŠ čćč鹊-č鹊 ąŠčüąŠą▒ąĄąĮąĮąŠąĄ, čćč鹊 ą┤ąŠą╗ąČąĮąŠ ą┐čĆąŠąĖąĘąŠą╣čéąĖ, ą║ąŠą│ą┤ą░ ąĄą│ąŠ ąĘąĮą░č湥ąĮąĖąĄ ą▓čŗčģąŠą┤ąĖčé ąĘą░ ąŠą▒ą╗ą░čüčéčī ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ, ąĖ ą╝čŗ ą┤ąŠą▒ą░ą▓ąĖą╝ ą░ąĮąĮąŠčéą░čåąĖčÄ Copy ą┤ą╗čÅ čŹč鹊ą│ąŠ čéąĖą┐ą░, č鹊 ą┐ąŠą╗čāčćąĖą╝ ąŠčłąĖą▒ą║čā ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ. ąĪą▓ąĄą┤ąĄąĮąĖčÅ ąŠ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĖ ą░ąĮąĮąŠčéą░čåąĖąĖ Copy ą║ ą▓ą░čłąĄą╝čā čéąĖą┐čā ą┤ą╗čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čéčĆąĄą╣čéą░ čüą╝. ą▓ čĆą░ąĘą┤ąĄą╗ "Derivable Traits" ą▓ Appendix C.
ąśčéą░ą║, ą║ą░ą║ąĖąĄ čéąĖą┐čŗ čĆąĄą░ą╗ąĖąĘčāčÄčé čéčĆąĄą╣čé Copy? ąÆčŗ ą╝ąŠąČąĄč鹥 čüą▓ąĄčĆąĖčéčīčüčÅ čü ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĄą╣ ą┐ąŠ ą║ąŠąĮą║čĆąĄčéąĮąŠą╝čā čéąĖą┐čā, ąŠą┤ąĮą░ą║ąŠ ą║ą░ą║ ąŠą▒čēąĄąĄ ą┐čĆą░ą▓ąĖą╗ąŠ, ą╗čÄą▒ą░čÅ ą│čĆčāą┐ą┐ą░ čüą║ą░ą╗čÅčĆąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣ ą╝ąŠąČąĄčé čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī Copy, ąĖ ąĮąĖčćč鹊, čéčĆąĄą▒čāčÄčēąĄąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ąĖą╗ąĖ ą║ą░ą║ąŠą╣-č鹊 č乊čĆą╝čŗ čĆąĄčüčāčĆčüą░ ąĮąĄ ą╝ąŠąČąĄčé čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī Copy. ąÆąŠčé ąĮąĄą║ąŠč鹊čĆčŗąĄ čéąĖą┐čŗ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī Copy:
ŌĆó ąÆčüąĄ čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮčŗąĄ čéąĖą┐čŗ, čéą░ą║ąĖąĄ ą║ą░ą║ u32.
[Ownership ąĖ čäčāąĮą║čåąĖąĖ ]
ą£ąĄčģą░ąĮąĖąĘą╝ ą┐ąĄčĆąĄą┤ą░čćąĖ ąĘąĮą░č湥ąĮąĖčÅ ą▓ čäčāąĮą║čåąĖčÄ ą┐ąŠą┤ąŠą▒ąĄąĮ ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĮąĖčÄ ąĘąĮą░č湥ąĮąĖčÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣. ą¤ąĄčĆąĄą┤ą░čćą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ą▓ čäčāąĮą║čåąĖčÄ ą┐čĆąŠąĖąĘą▓ąĄą┤ąĄčé ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ (move ) ąĖą╗ąĖ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ (copy ) ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣, č鹊čćąĮąŠ čéą░ą║ ąČąĄ, ą║ą░ą║ čŹč鹊 ą┤ąĄą╗ą░ąĄčé ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĮąĖąĄ let. ąøąĖčüčéąĖąĮą│ 4-3 ą┤ą░ąĄčé ą┐čĆąĖą╝ąĄčĆ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┐ąŠčÅčüąĮąĄąĮąĖčÅą╝ąĖ, ą│ą┤ąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ ą▓čģąŠą┤ąĖčé ą▓ ąŠą▒ą╗ą░čüčéčī ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ, ąĖ ą│ą┤ąĄ ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ.
fn main() {
let s = String:: from("hello" ); // s ą▓čģąŠą┤ąĖčé ą▓ ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ // ąĘąĮą░č湥ąĮąĖąĄ s ą┐ąĄčĆąĄą╝ąĄčēą░ąĄčéčüčÅ ą▓ čäčāąĮą║čåąĖčÄ...
// ... ąĖ ą▓ čŹč鹊ą╝ ą╝ąĄčüč鹥 s ą▒ąŠą╗čīčłąĄ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮą░ let x = 5 ; // x ą▓čģąŠą┤ąĖčé ą▓ ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ // x ą┐ąĄčĆąĄą╝ąĄčüčéąĖčéčüčÅ ą▓ čäčāąĮą║čåąĖčÄ,
// ąŠą┤ąĮą░ą║ąŠ čā i32 ąĄčüčéčī Copy, čéą░ą║ čćč鹊 ą▓čüąĄ ąĄčēąĄ
// ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī x ą┐ąŠčüą╗ąĄ ą▓čŗąĘąŠą▓ą░ čäčāąĮą║čåąĖąĖ // ąŚą┤ąĄčüčī x ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ. ą¤ąŠčüą║ąŠą╗čīą║čā ąĘąĮą░č湥ąĮąĖąĄ s ą▒čŗą╗ąŠ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąŠ,
// ąĮąĖč湥ą│ąŠ čüą┐ąĄčåąĖą░ą╗čīąĮąŠą│ąŠ ąĮąĄ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé. fn takes_ownership(some_string: String) { // some_string ą▓čģąŠą┤ąĖčé ą▓ ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ
println! ("{some_string}" );
} // ąŚą┤ąĄčüčī some_string ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ, ąĖ ą▒čāą┤ąĄčé ą▓čŗąĘą▓ą░ąĮ drop.
// ą¤ą░ą╝čÅčéčī, ą▓čŗą┤ąĄą╗ąĄąĮąĮą░čÅ ą┐ąŠą┤ č鹥ą║čüčé some_string, ąŠčüą▓ąŠą▒ąŠąČą┤ą░ąĄčéčüčÅ. fn makes_copy(some_integer: i32 ) { // some_integer ą▓čģąŠą┤ąĖčé ą▓ ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ
println! ("{some_integer}" );
} // ąŚą┤ąĄčüčī some_integer ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ. ą¤ąŠčüą║ąŠą╗čīą║čā ąŠąĮą░ čüąŠčģčĆą░ąĮčÅą╗ą░čüčī
// ą▓ čüč鹥ą║ąĄ, č鹊 ąĮąĖč湥ą│ąŠ čüą┐ąĄčåąĖą░ą╗čīąĮąŠą│ąŠ ąĮąĄ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé.
ąøąĖčüčéąĖąĮą│ 4-3. ążčāąĮą║čåąĖąĖ čü ownership, ą│ą┤ąĄ ą┐ąŠą╝ąĄč湥ąĮčŗ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ.
ąĢčüą╗ąĖ ą┐ąŠą┐čŗčéą░čéčīčüčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī s ą┐ąŠčüą╗ąĄ ą▓čŗąĘąŠą▓ą░ takes_ownership, č鹊 Rust ą▓čŗą┤ą░čüčé ąŠčłąĖą▒ą║čā ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ. ąŁčéąĖ čüčéą░čéąĖč湥čüą║ąĖąĄ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąĘą░čēąĖčēą░čÄčé ąĮą░čü ąŠčé ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüą╗ąŠąČąĮčŗčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ. ą¤ąŠą┐čĆąŠą▒čāą╣č鹥 ą┤ąŠą▒ą░ą▓ąĖčéčī ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄčé s ąĖ x, čćč鹊ą▒čŗ čāą▓ąĖą┤ąĄčéčī, ą│ą┤ąĄ ą▓čŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĖčģ, ą│ą┤ąĄ ą┐čĆą░ą▓ąĖą╗ą░ ownership ąĮąĄ ą┤ą░ą┤čāčé ą▓ą░ą╝ čŹč鹊 čüą┤ąĄą╗ą░čéčī.
[ąÆąŠąĘą▓čĆą░čēą░ąĄą╝čŗąĄ ąĘąĮą░č湥ąĮąĖčÅ ąĖ ąŠą▒ą╗ą░čüčéčī ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ ]
ąÆąŠąĘą▓čĆą░čé ąĘąĮą░č湥ąĮąĖą╣ čéą░ą║ąČąĄ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą┐ąĄčĆąĄą┤ą░č湥 ą▓ą╗ą░ą┤ąĄąĮąĖčÅ (transfer ownership). ąøąĖčüčéąĖąĮą│ 4-4 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┐čĆąĖą╝ąĄčĆ čäčāąĮą║čåąĖąĖ, ą║ąŠč鹊čĆą░čÅ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ąĮąĄą║ąŠč鹊čĆąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, čü ą┐ąŠčÅčüąĮąĄąĮąĖčÅą╝ąĖ, ą┐ąŠą┤ąŠą▒ąĮčŗą╝ąĖ č鹥ą╝, čćč鹊 ą▒čŗą╗ąĖ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 4-3.
fn main() {
let s1 = gives_ownership(); // gives_ownership ą┐ąĄčĆąĄą╝ąĄčēą░ąĄčé čüą▓ąŠąĄ ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝ąŠąĄ
// ąĘąĮą░č湥ąĮąĖąĄ ą▓ s1 let s2 = String:: from("hello" ); // s2 ą▓čģąŠą┤ąĖčé ą▓ ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ let s3 = takes_and_gives_back(s2); // s2 ą┐ąĄčĆąĄą╝ąĄčēą░ąĄčéčüčÅ ą▓ takes_and_gives_back,
// ą║ąŠč鹊čĆą░čÅ čéą░ą║ąČąĄ ą┐ąĄčĆąĄą╝ąĄčēą░ąĄčé čüą▓ąŠąĄ ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝ąŠąĄ
// ąĘąĮą░č湥ąĮąĖąĄ ą▓ s3
} // ąŚą┤ąĄčüčī s3 ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ ąĖ ąŠčéą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ. s2 ą▒čŗą╗ą░ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮą░,
// čéą░ą║ čćč鹊 ąĮąĖč湥ą│ąŠ ąĮąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé. s1 ą▓čŗčłą╗ą░ ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ ąĖ ą▒čŗą╗ą░ ą▓čŗą▒čĆąŠčłąĄąĮą░. fn gives_ownership() -> String { // gives_ownership ą┐ąĄčĆąĄą╝ąĄčüčéąĖčé čüą▓ąŠąĄ
// ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą▓ čäčāąĮą║čåąĖčÄ,
// ą║ąŠč鹊čĆą░čÅ ąĄčæ ą▓čŗąĘą▓ą░ą╗ą░ let some_string = String:: from("yours" ); // some_string 2 ą▓čģąŠą┤ąĖčé ą▓ ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ // some_string ą▓ąŠąĘą▓čĆą░čēą░ąĄčéčüčÅ, ąĖ ą┐ąĄčĆąĄą╝ąĄčēą░ąĄčéčüčÅ
// ą▓ ą▓čŗąĘą▓ą░ą▓čłčāčÄ čäčāąĮą║čåąĖčÄ
}// ąŁčéą░ čäčāąĮą║čåąĖčÅ ą┐čĆąĖąĮąĖą╝ą░ąĄčé String ąĖ ąĄčæ ąČąĄ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé fn takes_and_gives_back(a_string: String) -> String { // a_string ą▓čģąŠą┤ąĖčé ą▓ ąŠą▒ą╗ą░čüčéčī
// ą┤ąĄą╣čüčéą▓ąĖčÅ // a_string ą▓ąŠąĘą▓čĆą░čēą░ąĄčéčüčÅ, ąĖ ą┐ąĄčĆąĄą╝ąĄčēą░ąĄčéčüčÅ ą▓ ą▓čŗąĘą▓ą░ą▓čłčāčÄ čäčāąĮą║čåąĖčÄ
}
ąøąĖčüčéąĖąĮą│ 4-4. ąöąĄą╝ąŠąĮčüčéčĆą░čåąĖčÅ ą┐ąĄčĆąĄą┤ą░čćąĖ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ (transfer ownership) ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝čŗčģ ąĘąĮą░č湥ąĮąĖą╣.
ąÆą╗ą░ą┤ąĄąĮąĖąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ą║ą░ąČą┤čŗą╣ čĆą░ąĘ čüą╗ąĄą┤čāąĄčé ąŠą┤ąĮąŠą╝čā ąĖ č鹊ą╝čā ąČąĄ čłą░ą▒ą╗ąŠąĮčā: ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĮąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ ą┤čĆčāą│ąŠą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčé ąĄą│ąŠ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ. ąÜąŠą│ą┤ą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ, ą║ąŠč鹊čĆą░čÅ ą▓ą║ą╗čÄčćą░ąĄčé ą▓ čüąĄą▒ąĄ ą┤ą░ąĮąĮčŗąĄ ą║čāčćąĖ, ą▓čŗčģąŠą┤ąĖčé ąĖąĘ čüą▓ąŠąĄą╣ ąŠą▒ą╗ą░čüčéąĖ ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ, ąĄčæ ąĘąĮą░č湥ąĮąĖąĄ ą▒čāą┤ąĄčé ąŠčćąĖčēąĄąĮąŠ ą▓čŗąĘąŠą▓ąŠą╝ drop, ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ čüąĖčéčāą░čåąĖąĖ, ą║ąŠą│ą┤ą░ ą▓ą╗ą░ą┤ąĄąĮąĖąĄ ąĄčæ ą┤ą░ąĮąĮčŗą╝ąĖ ą┐ąĄčĆąĄą╝ąĄčēą░ąĄčéčüčÅ ą▓ ą┤čĆčāą│čāčÄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ.
ą¤ąŠą║ą░ čŹč鹊 čĆą░ą▒ąŠčéą░ąĄčé, ą┐čĆąĖąĮčÅčéąĖąĄ ą▓ąŠ ą▓ą╗ą░ą┤ąĄąĮąĖąĄ ąĖ ąĘą░č鹥ą╝ ą▓ąŠąĘą▓čĆą░čé ą▓ą╗ą░ą┤ąĄąĮąĖčÅ čü ą║ą░ąČą┤ąŠą╣ čäčāąĮą║čåąĖąĄą╣ čüčéą░ąĮąŠą▓ąĖčéčüčÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ čāč鹊ą╝ąĖč鹥ą╗čīąĮčŗą╝. ą¦č鹊 ąĄčüą╗ąĖ ą╝čŗ čģąŠčéąĖą╝ ą┐ąŠąĘą▓ąŠą╗ąĖčéčī čäčāąĮą║čåąĖąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĘąĮą░č湥ąĮąĖąĄ, ąĮąŠ ąĮąĄ ą┐čĆąĖąĮąĖą╝ą░čéčī ąĮąĄ čüąĄą▒čÅ ą▓ą╗ą░ą┤ąĄąĮąĖąĄą╝ ąĖą╝? ąØąĄčüą║ąŠą╗čīą║ąŠ čĆą░ąĘą┤čĆą░ąČą░ąĄčé, čćč鹊 ą▓čüąĄ, čćč鹊 ą╝čŗ ą┐ąĄčĆąĄą┤ą░ąĄą╝ ąĮčāąČąĮąŠ ą┐ąĄčĆąĄą┤ą░čéčī ąŠą▒čĆą░čéąĮąŠ, ąĄčüą╗ąĖ ą╝čŗ čģąŠčéąĖą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹč鹊 čüąĮąŠą▓ą░, ą▓ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ ą╗čÄą▒čŗą╝ ą┤ą░ąĮąĮčŗą╝, ą┐ąŠą╗čāč湥ąĮąĮčŗą╝ ąĖąĘ č鹥ą╗ą░ čäčāąĮą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ą╝čŗ ą▓ąŠąĘą╝ąŠąČąĮąŠ ąĘą░čģąŠčéąĖą╝ čéą░ą║ąČąĄ ą▓ąĄčĆąĮčāčéčī.
Rust ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĮą░ą╝ ą▓ąŠąĘą▓čĆą░čéąĖčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĘąĮą░č湥ąĮąĖą╣ ą┐ąŠą╝ąŠčēčīčÄ ą║ąŠčĆč鹥ąČą░ (tuple ), ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 4-5.
fn main() {
let s1 = String:: from("hello" );let (s2, len) = calculate_length(s1);! ("ąöą╗ąĖąĮą░ '{s2}' čĆą░ą▓ąĮą░ {len}." );
}fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() ą▓ąŠąĘą▓čĆą░čéąĖčé ą┤ą╗ąĖąĮčā String
ąøąĖčüčéąĖąĮą│ 4-5. ąÆąŠąĘą▓čĆą░čé ownership ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓.
ą×ą┤ąĮą░ą║ąŠ čŹč鹊 ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ čüą╗ąĖčłą║ąŠą╝ ą▒ąŠą╗čīčłąĖą╝ čåąĄčĆąĄą╝ąŠąĮąĖčÅą╝, ąĖ ą┐čĆąĖčģąŠą┤ąĖčéčüčÅ ą┤ąĄą╗ą░čéčī ą╝ąĮąŠą│ąŠ čĆą░ą▒ąŠčéčŗ ą┤ą╗čÅ ą║ąŠąĮčåąĄą┐čåąĖąĖ, ą║ąŠč鹊čĆą░čÅ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ąŠą▒čēąĄą╣. ąÜ čüčćą░čüčéčīčÄ ą┤ą╗čÅ ąĮą░čü, čā Rust ąĄčüčéčī čäčāąĮą║čåąĖčÅ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ ą▒ąĄąĘ ą┐ąĄčĆąĄą┤ą░čćąĖ ownership, ąĮą░ąĘčŗą▓ą░ąĄą╝ą░čÅ čüčüčŗą╗ą║ą░ą╝ąĖ (references).
[ąĪčüčŗą╗ą║ąĖ ąĖ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ ]
ą¤čĆąŠą▒ą╗ąĄą╝ą░ ą║ąŠą┤ą░ čü ą║ąŠčĆč鹥ąČąĄą╝ (tuple) ą╗ąĖčüčéąĖąĮą│ą░ 4-5 ą▓ č鹊ą╝, čćč鹊 ą╝čŗ ą┤ąŠą╗ąČąĮčŗ ą▓ąŠąĘą▓čĆą░čéąĖčéčī String ą▓ ą▓čŗąĘčŗą▓ą░čÄčēčāčÄ čäčāąĮą║čåąĖčÄ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊ą▒čŗ ą▓čüąĄ ąĄčēąĄ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī String ą┐ąŠčüą╗ąĄ ą▓čŗąĘąŠą▓ą░ calculate_length, ą┐ąŠč鹊ą╝čā čćč鹊 String ą▒čŗą╗ą░ ą┐ąĄčĆąĄąĮąĄčüąĄąĮą░ ą▓ calculate_length. ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą╝čŗ ą╝ąŠąČąĄą╝ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī čüčüčŗą╗ą║čā (reference) ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ String. ąĪčüčŗą╗ą║ą░ ą┐ąŠčģąŠąČą░ ąĮą░ čāą║ą░ąĘą░č鹥ą╗čī (pointer) ą▓ č鹊ą╝, čćč鹊 čŹč鹊 ą░ą┤čĆąĄčü, ą┐ąŠ ą║ąŠč鹊čĆąŠą╝čā ą╝čŗ ą╝ąŠąČąĄą╝ ąŠą▒čĆą░čéąĖčéčīčüčÅ ą║ ą┤ą░ąĮąĮčŗą╝, ą║ąŠč鹊čĆčŗąĄ čüąŠčģčĆą░ąĮąĄąĮčŗ ą┐ąŠ čŹč鹊ą╝čā ą░ą┤čĆąĄčüčā; čŹčéąĖ ą┤ą░ąĮąĮčŗąĄ ą┐čĆąĖąĮą░ą┤ą╗ąĄąČą░čéčī ą║ą░ą║ąŠą╣-č鹊 ą┤čĆčāą│ąŠą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣. ąÆ ąŠčéą╗ąĖčćąĖąĄ ąŠčé čāą║ą░ąĘą░č鹥ą╗čÅ, čüčüčŗą╗ą║ą░ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░ąĮąĮąŠ čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ čéąĖą┐ą░ ą▓ č鹥č湥ąĮąĖąĄ ą▓čüąĄą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ąČąĖąĘąĮąĖ čŹč鹊ą╣ čüčüčŗą╗ą║ąĖ.
ąØąĖąČąĄ ą┐ąŠą║ą░ąĘą░ąĮąŠ, ą║ą░ą║ ą╝ąŠąČąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čäčāąĮą║čåąĖčÄ calculate_length, ą║ąŠč鹊čĆą░čÅ ąĖą╝ąĄąĄčé čüčüčŗą╗ą║čā ąĮą░ ąŠą▒čŖąĄą║čé ą▓ ą║ą░č湥čüčéą▓ąĄ ą┐ą░čĆą░ą╝ąĄčéčĆą░, ą▓ą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćą░čéčī ąĘąĮą░č湥ąĮąĖąĄ ąĖ ownership ąĮą░ čŹč鹊 ąĘąĮą░č湥ąĮąĖąĄ:
fn main() {
let s1 = String:: from("hello" );let len = calculate_length(& s1);! ("The length of '{s1}' is {len}." );
}fn calculate_length(s: & String) -> usize {
s.len()
}
ąÆąŠ-ą┐ąĄčĆą▓čŗčģ, ąŠą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čāą▒čĆą░ąĮ ą▓ąĄčüčī ą║ąŠą┤ ą║ąŠčĆč鹥ąČą░ ą▓ ą┤ąĄą║ą╗ą░čĆą░čåąĖąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣, ąĖ čäčāąĮą║čåąĖčÅ calculate_length ą▒ąŠą╗čīčłąĄ ąĮąĖč湥ą│ąŠ ąĮąĄ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé. ąÆąŠ-ą▓č鹊čĆčŗčģ, ą╝čŗ ą┐ąĄčĆąĄą┤ą░ąĄą╝ &s1 ą▓ calculate_length ąĖ, ą▓ ąĄčæ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĖ ą╝čŗ ą▒ąĄčĆąĄą╝ &String ą▓ą╝ąĄčüč鹊 String. ąÉą╝ą┐ąĄčĆčüą░ąĮą┤čŗ & ąŠą▒ąŠąĘąĮą░čćą░čÄčé ąĘą┤ąĄčüčī čüčüčŗą╗ą║ąĖ, ąĖ ąŠąĮąĖ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ą▓ą░ą╝ čüčüčŗą╗ą░čéčīčüčÅ ąĮą░ ą║ą░ą║ąŠąĄ-č鹊 ąĘąĮą░č湥ąĮąĖąĄ ą▒ąĄąĘ ą▓ąĘčÅčéąĖčÅ ąĮą░ą┤ ąĮąĖą╝ ownership. ąĀąĖčü. 4-5 ąĖą╗ą╗čÄčüčéčĆąĖčĆčāąĄčé čŹčéčā ą║ąŠąĮčåąĄą┐čåąĖčÄ.
ąĀąĖčü. 4-5. ąöąĖą░ą│čĆą░ą╝ą╝ą░ &String s, čāą║ą░ąĘčŗą▓ą░čÄčēąĄą╣ ąĮą░ String s1.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą┐čĆąŠčéąĖą▓ąŠą┐ąŠą╗ąŠąČąĮąŠčüčéčīčÄ čüčüčŗą╗ą║ąĖ (referencing) čü ą┐ąŠą╝ąŠčēčīčÄ & čÅą▓ą╗čÅąĄčéčüčÅ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖąĄ (dereferencing), ą║ąŠč鹊čĆąŠąĄ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ąŠą┐ąĄčĆą░č鹊čĆąŠą╝ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖčÅ *. ą£čŗ čāą▓ąĖą┤ąĖą╝ ąĮąĄą║ąŠč鹊čĆčŗąĄ ą▓ą░čĆąĖą░ąĮčéčŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąŠą┐ąĄčĆą░č鹊čĆą░ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖčÅ ą▓ ą│ą╗ą░ą▓ąĄ 8, ąĖ ąŠą▒čüčāą┤ąĖą╝ ą┤ąĄčéą░ą╗ąĖ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖčÅ ą▓ ą│ą╗ą░ą▓ąĄ 15.
ąöą░ą▓ą░ą╣č鹥 ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ą▓čŗąĘąŠą▓ čäčāąĮą║čåąĖąĖ ą▓ čŹč鹊ą╝ ą║ąŠą┤ąĄ:
let s1 = String:: from("hello" );
let len = calculate_length(& s1);
ąĪąĖąĮčéą░ą║čüąĖčü &s1 ą┐ąŠąĘą▓ąŠą╗ąĖčé ąĮą░ą╝ čüąŠąĘą┤ą░čéčī čüčüčŗą╗ą║čā (reference), ą║ąŠč鹊čĆą░čÅ čüčüčŗą╗ą░ąĄčéčüčÅ ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ s1, ąĮąŠ ąĮąĄ ą▓čüčéčāą┐ą░ąĄčé ą▓ąŠ ą▓ą╗ą░ą┤ąĄąĮąĖąĄ s1. ąśąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 ąĮąĄčé ą▓čüčéčāą┐ą╗ąĄąĮąĖčÅ ą▓ąŠ ą▓ą╗ą░ą┤ąĄąĮąĖąĄ, ąĘąĮą░č湥ąĮąĖąĄ s1 ąĮąĄ ą▓čŗą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ, ą║ąŠą│ą┤ą░ ą┐čĆąĄą║čĆą░čēą░ąĄčéčüčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüčüčŗą╗ą║ąĖ (ąŠčéą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ č鹊ą╗čīą║ąŠ čüą░ą╝ą░ čüčüčŗą╗ą║ą░).
ą¤ąŠą┤ąŠą▒ąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝ čüąĖą│ąĮą░čéčāčĆą░ čäčāąĮą║čåąĖąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčé &, čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī, čćč鹊 čéąĖą┐ ą┐ą░čĆą░ą╝ąĄčéčĆą░ s čÅą▓ą╗čÅąĄčéčüčÅ čüčüčŗą╗ą║ąŠą╣. ąöą░ą▓ą░ą╣č鹥 ą┤ąŠą▒ą░ą▓ąĖą╝ ąĮąĄą║ąŠč鹊čĆčŗąĄ ą┐ąŠčÅčüąĮčÅčÄčēąĖąĄ ą░ąĮąĮąŠčéą░čåąĖąĖ:
fn calculate_length(s: & String) -> usize { // s čŹč鹊 čüčüčŗą╗ą║ą░ ąĮą░ String
s.len()
} // ąŚą┤ąĄčüčī s ąĘą░ą║ą░ąĮčćąĖą▓ą░ąĄčé čüą▓ąŠčÄ ąŠą▒ą╗ą░čüčéčī ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ ąĖ ąŠčéą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ. ą×ą┤ąĮą░ą║ąŠ ą┐ąŠčüą║ąŠą╗čīą║čā
// ąĮąĄ ą▒čŗą╗ąŠ ą▓ąĘčÅč鹊 ą▓ą╗ą░ą┤ąĄąĮąĖąĄ (ownership) ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ č鹊ą│ąŠ, ąĮą░ čćč鹊 čāą║ą░ąĘčŗą▓ą░ą╗ą░ čüčüčŗą╗ą║ą░ s,
// čüą░ą╝ąŠ ąĘąĮą░č湥ąĮąĖąĄ ąĮąĄ ą▓čŗą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ.
ą×ą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ, ą▓ ą║ąŠč鹊čĆąŠą╝ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ s ą┤ąŠčüč鹊ą▓ąĄčĆąĮą░, ą▒čāą┤ąĄčé čéą░ą║ąŠą╣ ąČąĄ, ą║ą░ą║ ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ ą╗čÄą▒ąŠą│ąŠ ą┐ą░čĆą░ą╝ąĄčéčĆą░ čäčāąĮą║čåąĖąĖ, ąŠą┤ąĮą░ą║ąŠ ąĘąĮą░č湥ąĮąĖąĄ, ąĮą░ ą║ąŠč鹊čĆąŠąĄ čāą║ą░ąĘčŗą▓ą░ąĄčé ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ s, ąĮąĄ ąŠčéą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ, ą║ąŠą│ą┤ą░ ą┐čĆąĄą║čĆą░čēą░ąĄčéčüčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ s, ą┐ąŠč鹊ą╝čā čćč鹊 ą║ s ąĮąĄ ą┐čĆąĖą║čĆąĄą┐ą╗čÅąĄčéčüčÅ ą▓ą╗ą░ą┤ąĄąĮąĖąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣, ąĮą░ ą║ąŠč鹊čĆčāčÄ ąŠąĮą░ čüčüčŗą╗ą░ąĄčéčüčÅ. ąÜąŠą│ą┤ą░ čā čäčāąĮą║čåąĖąĖ ąĄčüčéčī čüčüčŗą╗ą║ąĖ ą▓ ą║ą░č湥čüčéą▓ąĄ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ ą▓ą╝ąĄčüč鹊 čĆąĄą░ą╗čīąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣, ąĮą░ą╝ ąĮąĄčé ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ ą▓ąŠąĘą▓čĆą░čēą░čéčī čŹč鹊 ąĘąĮą░č湥ąĮąĖąĄ, čćč鹊ą▒čŗ ą▓ąĘčÅčéčī ąŠą▒čĆą░čéąĮąŠ ą▓ą╗ą░ą┤ąĄąĮąĖąĄ ąĮą░ą┤ ąĮąĖą╝, ą┐ąŠč鹊ą╝čā čćč鹊 ą┐čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ čüčüčŗą╗ą║ąĖ ą╝čŗ ąĮąĄ ą┐ąŠą╗čāčćą░ą╗ąĖ ą▓ą╗ą░ą┤ąĄąĮąĖąĄ.
ąöąĄą╣čüčéą▓ąĖąĄ ą┐ąŠ čüąŠąĘą┤ą░ąĮąĖčÄ čüčüčŗą╗ą║ąĖ ą╝čŗ ąĮą░ąĘčŗą▓ą░ąĄą╝ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖąĄą╝ (borrowing). ąÜą░ą║ ąĖ ą▓ čĆąĄą░ą╗čīąĮąŠą╣ ąČąĖąĘąĮąĖ, ąĄčüą╗ąĖ ą║ą░ą║ą░čÅ-č鹊 ą┐ąĄčĆčüąŠąĮą░ č湥ą╝-č鹊 ą▓ą╗ą░ą┤ąĄąĄčé, č鹊 čŹč鹊 čā ąĮąĄčæ ą╝ąŠąČąĮąŠ ąŠą┤ąŠą╗ąČąĖčéčī. ąÜąŠą│ą┤ą░ ą▓čŗ ąĘą░ą▓ąĄčĆčłąĖą╗ąĖ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖąĄ, č鹊 ą▓ąŠąĘą▓čĆą░čēą░ąĄč鹥 ą▓čüąĄ ąŠą▒čĆą░čéąĮąŠ. ąÆčŗ ąĮąĄ ą▓čüčéčāą┐ą░ąĄč鹥 ą▓ąŠ ą▓ą╗ą░ą┤ąĄąĮąĖąĄ.
ąóą░ą║ čćč鹊 ąČąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé, ąĄčüą╗ąĖ ą╝čŗ ą┐ąŠą┐čŗčéą░ąĄą╝čüčÅ ąĖąĘą╝ąĄąĮąĖčéčī č鹊, čćč鹊 ąĘą░ąĖą╝čüčéą▓čāąĄą╝? ą¤ąŠą┐čĆąŠą▒čāą╣č鹥 ą║ąŠą┤ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 4-6. ąÆčŗ čāą▓ąĖą┤ąĖč鹥, čćč鹊 ąĮąĖč湥ą│ąŠ ąĮąĄ ą┐ąŠą╗čāčćąĖčéčüčÅ!
fn main() {
let s = String:: from("hello" );& s);
}fn change(some_string: & String) {
some_string.push_str(", world" );
}
ąøąĖčüčéąĖąĮą│ 4-6. ąöąĄą╝ąŠąĮčüčéčĆą░čåąĖčÅ ą┐ąŠą┐čŗčéą║ąĖ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ borrowed-ąĘąĮą░č湥ąĮąĖčÅ.
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0596]: cannot borrow `*some_string` as mutable, as it is behind a `&` reference
--> src/main.rs:8:5
|
8 | some_string.push_str(", world");
| ^^^^^^^^^^^ `some_string` is a `&` reference, so the data it refers to cannot
| be borrowed as mutable
|
help: consider changing this to be a mutable reference
|
7 | fn change(some_string: &mut String) {
| +++
ąóąŠ, čćč鹊 ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĮąĄąĖąĘą╝ąĄąĮčÅąĄą╝čŗ, ąŠčéąĮąŠčüąĖčéčüčÅ ąĖ ą║ čüčüčŗą╗ą║ą░ą╝. ąØą░ą╝ ąĮąĄ čĆą░ąĘčĆąĄčłą░ąĄčéčüčÅ ąĖąĘą╝ąĄąĮčÅčéčī č鹊, ąĮą░ čćč鹊 čā ąĮą░čü ąĄčüčéčī čüčüčŗą╗ą║ą░.
ą£čāčéąĖčĆčāąĄą╝čŗąĄ čüčüčŗą╗ą║ąĖ . ą£čŗ ą╝ąŠąČąĄą╝ ąĖčüą┐čĆą░ą▓ąĖčéčī ą║ąŠą┤ ą╗ąĖčüčéąĖąĮą│ą░ 4-6, čćč鹊ą▒čŗ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ąĖąĘą╝ąĄąĮčÅčéčī ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, ą┐čāč鹥ą╝ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ ą╝čāčéąĖčĆčāąĄą╝ąŠą╣ čüčüčŗą╗ą║ąĖ (mutable reference):
fn main() {
let mut s = String:: from("hello" );& mut s);
}fn change(some_string: & mut String) {
some_string.push_str(", world" );
}
ąĪąĮą░čćą░ą╗ą░ ą╝čŗ ą┐ąŠą╝ąĄąĮčÅą╗ąĖ s ą╝ąŠą┤ąĖčäąĖą║ą░č鹊čĆąŠą╝ mut. ąŚą░č鹥ą╝ ą╝čŗ čüąŠąĘą┤ą░ą╗ąĖ ą╝čāčéąĖčĆčāąĄą╝čāčÄ čüčüčŗą╗ą║čā ą┐ąĄčĆąĄą┤ą░č湥ą╣ &mut s ą▓ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ čäčāąĮą║čåąĖąĖ change, ąĖ ąŠą▒ąĮąŠą▓ąĖą╗ąĖ čüąĖą│ąĮą░čéčāčĆčā čäčāąĮą║čåąĖąĖ, čćč鹊ą▒čŗ ąŠąĮą░ ą┐čĆąĖąĮąĖą╝ą░ą╗ą░ ą╝čāčéąĖčĆčāąĄą╝čāčÄ čüčüčŗą╗ą║čā č湥čĆąĄąĘ some_string: &mut String. ąŁč鹊 ąŠč湥ąĮčī čÅčüąĮąŠ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čäčāąĮą║čåąĖčÅ ą▒čāą┤ąĄčé ąĖąĘą╝ąĄąĮčÅčéčī ąĘąĮą░č湥ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ąŠąĮą░ ąĘą░ąĖą╝čüčéą▓čāąĄčé.
ą£čāčéąĖčĆčāąĄą╝čŗąĄ čüčüčŗą╗ą║ąĖ ąĖą╝ąĄčÄčé ąŠą┤ąĮąŠ ą▒ąŠą╗čīčłąŠąĄ ąŠą│čĆą░ąĮąĖč湥ąĮąĖąĄ: ąĄčüą╗ąĖ čā ą▓ą░čü ą┐čĆąĖą╝ąĄąĮąĄąĮą░ ą╝čāčéąĖčĆčāąĄą╝ą░čÅ čüčüčŗą╗ą║ą░ ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ, č鹊 ą▓čŗ ąĮąĄ ą╝ąŠąČąĄč鹥 ąĖą╝ąĄčéčī ąĮąĖą║ą░ą║ąĖąĄ ą┤čĆčāą│ąĖąĄ čüčüčŗą╗ą║ąĖ ąĮą░ čŹč鹊 ąĘąĮą░č湥ąĮąĖąĄ. ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠą┐čŗčéą░ąĄčéčüčÅ čüąŠąĘą┤ą░čéčī ą┤ą▓ąĄ ą╝čāčéąĖčĆčāąĄą╝čŗąĄ čüčüčŗą╗ą║ąĖ ąĮą░ s, ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąŠčłąĖą▒ą║ąĄ:
let mut s = String:: from("hello" );let r1 = & mut s;
let r2 = & mut s;! ("{}, {}" , r1, r2);
ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą┐ąŠą║ą░ąČąĄčé ąŠčłąĖą▒ą║čā:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src/main.rs:5:14
|
4 | let r1 = &mut s;
| ------ first mutable borrow occurs here
5 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
6 |
7 | println!("{}, {}", r1, r2);
| -- first borrow later used here
ąŁčéą░ ąŠčłąĖą▒ą║ą░ čüąŠąŠą▒čēą░ąĄčé ąŠ č鹊ą╝, čćč鹊 ą║ąŠą┤ ąĮąĄą┤ąŠą┐čāčüčéąĖą╝čŗą╣, ą┐ąŠč鹊ą╝čā čćč鹊 ąĮąĄą╗čīąĘčÅ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░čéčī s ą║ą░ą║ ą╝čāčéąĖčĆčāąĄą╝ąŠą╣ ą▒ąŠą╗ąĄąĄ ąŠą┤ąĮąŠą│ąŠ čĆą░ąĘą░ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ. ą¤ąĄčĆą▓ąŠąĄ ą╝čāčéąĖčĆčāąĄą╝ąŠąĄ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖąĄ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ r1, ąĖ ąŠąĮąŠ ą┤ąŠą╗ąČąĮąŠ ą┐čĆąŠą┤ąŠą╗ąČą░čéčīčüčÅ ą┤ąŠ č鹥čģ ą┐ąŠčĆ, ą┐ąŠą║ą░ ąĮąĄ ą▒čāą┤ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąŠ ą▓ println!, ąŠą┤ąĮą░ą║ąŠ ą╝ąĄąČą┤čā čüąŠąĘą┤ą░ąĮąĖąĄą╝ ą╝čāčéąĖčĆčāąĄą╝ąŠą│ąŠ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ r1 ąĖ ąĄą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą╝čŗ čéą░ą║ąČąĄ ą┐čŗčéą░ąĄą╝čüčÅ čüąŠąĘą┤ą░čéčī ą┤čĆčāą│ąŠąĄ ą╝čāčéąĖčĆčāąĄą╝ąŠąĄ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖąĄ r2, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░čéčī č鹥 ąČąĄ ą┤ą░ąĮąĮčŗąĄ, čćč鹊 ąĖ r1.
ą×ą│čĆą░ąĮąĖč湥ąĮąĖąĄ ąĮą░ ąĖčüą║ą╗čÄčćąĖč鹥ą╗čīąĮąŠ ąŠą┤ąĖąĮą░čĆąĮąŠąĄ ą╝čāčéąĖčĆčāąĄą╝ąŠąĄ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖąĄ ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé ąĮą░ą╝ ąŠč湥ąĮčī čģąŠčĆąŠčłąŠ čāą┐čĆą░ą▓ą╗čÅąĄą╝ąŠąĄ ą╝čāčéąĖčĆąŠą▓ą░ąĮąĖąĄ. ąŁč鹊 ą║ą░ą║ čĆą░ąĘ č鹊, čü č湥ą╝ ą┐čĆąĖčģąŠą┤ąĖčéčüčÅ ą▒ąŠčĆąŠčéčīčüčÅ ąĮąŠą▓ąĖčćą║ą░ą╝ ą▓ Rust, ą┐ąŠč鹊ą╝čā čćč鹊 ą┤čĆčāą│ąĖąĄ čÅąĘčŗą║ąĖ čćą░čüčéčī ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ą╝čāčéąĖčĆąŠą▓ą░čéčī čćč鹊 ąĮąĖ ą┐ąŠą┐ą░ą┤čÅ ąĖ ą║ą░ą║ ą┐ąŠą┐ą░ą╗ąŠ. ąÆčŗą│ąŠą┤ą░ čŹč鹊ą│ąŠ ąŠą│čĆą░ąĮąĖč湥ąĮąĖčÅ ą▓ č鹊ą╝, čćč鹊 Rust ą╝ąŠąČąĄčé ąĘą░čēąĖčéąĖčéčī ąŠčé ą║ąŠąĮą║čāčĆąĄąĮčéąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą║ ą┤ą░ąĮąĮčŗą╝ ąĮą░ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÄ (data races, čĆąĄą╣čüąĖąĮą│, ąĖą╗ąĖ "ą│ąŠąĮą║ą░ ą┤ą░ąĮąĮčŗčģ") čāąČąĄ ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ. ąōąŠąĮą║ą░ ą┤ą░ąĮąĮčŗčģ čŹč鹊 čüąĖčéčāą░čåąĖąĖ, ą▓ ą║ąŠč鹊čĆčŗčģ ą╝ąŠą│čāčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ čéčĆąĖ ą▓ą░čĆąĖą░ąĮčéą░ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ ą║ąŠą┤ą░:
ŌĆó ąöą▓ą░ ąĖą╗ąĖ ą▒ąŠą╗čīčłąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ąŠą▒čĆą░čēą░čÄčéčüčÅ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą║ ąŠą┤ąĮąĖą╝ ąĖ č鹥ą╝ ąČąĄ ą┤ą░ąĮąĮčŗą╝.
ąōąŠąĮą║ą░ ą┤ą░ąĮąĮčŗčģ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ąĮąĄąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╝čā ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÄ ą║ąŠą┤ą░, ąĖ čŹč鹊 ąŠč湥ąĮčī čüą╗ąŠąČąĮčŗą╣ ą┤ą╗čÅ ąŠčéą╗ą░ą┤ą║ąĖ ąĖ ąĖčüą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą▒ą░ą│, ą║ąŠą│ą┤ą░ ą▓čŗ ą┐čŗčéą░ąĄč鹥čüčī ą▓čŗčÅą▓ąĖčéčī ą┐čĆąĖčćąĖąĮčā ąŠčłąĖą▒ą║ąĖ runtime; Rust ą▓ ą║ąŠčĆąĮąĄ ą┐čĆąĄą┤ąŠčéą▓čĆą░čēą░ąĄčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą▓ąŠąĘąĮąĖą║ąĮąŠą▓ąĄąĮąĖčÅ čéą░ą║ąŠą╣ ą┐čĆąŠą▒ą╗ąĄą╝čŗ, ąĮąĄ ą┐ąŠąĘą▓ąŠą╗čÅčÅ ą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░čéčī ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ ą▒ąŠą╗ąĄąĮ čĆąĄą╣čüąĖąĮą│ąŠą╝!
ąÜą░ą║ ąĖ ą▓čüąĄą│ą┤ą░, ą╝čŗ ą╝ąŠąČąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čäąĖą│čāčĆąĮčŗąĄ čüą║ąŠą▒ą║ąĖ ą┤ą╗čÅ čüąŠąĘą┤ą░ąĮąĖčÅ ąĮąŠą▓ąŠą╣ ąŠą▒ą╗ą░čüčéąĖ ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ, čćč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čüąŠąĘą┤ą░ą▓ą░čéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą╝čāčéąĖčĆčāąĄą╝čŗčģ čüčüčŗą╗ąŠą║, ąĮąŠ čü čüąŠą▒ą╗čÄą┤ąĄąĮąĖąĄą╝ ąŠą│čĆą░ąĮąĖč湥ąĮąĖčÅ ąĮą░ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗąĄ ą╝čāčéąĖčĆčāąĄą╝čŗąĄ čüčüčŗą╗ą║ąĖ:
let mut s = String:: from("hello" );let r1 = & mut s;
} // ąÆ čŹč鹊ą╝ ą╝ąĄčüč鹥 r1 ą▓čŗčģąŠą┤ąĖčé ąĘą░ ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ, ą┐ąŠčŹč鹊ą╝čā ą╝čŗ ą╝ąŠąČąĄą╝
// ą▒ąĄąĘ ą┐čĆąŠą▒ą╗ąĄą╝ čüąŠąĘą┤ą░ą▓ą░čéčī ąĮąŠą▓čŗąĄ ą╝čāčéąĖčĆčāąĄą╝čŗąĄ čüčüčŗą╗ą║ąĖ. let r2 = & mut s;
Rust ą┐čĆąĖą╝ąĄąĮčÅąĄčé ą░ąĮą░ą╗ąŠą│ąĖčćąĮąŠąĄ ą┐čĆą░ą▓ąĖą╗ąŠ ą┤ą╗čÅ ą║ąŠą╝ą▒ąĖąĮąĖčĆąŠą▓ą░ąĮąĖčÅ ą╝čāčéąĖčĆčāąĄą╝čŗčģ ąĖ ąĮąĄ ą╝čāčéąĖčĆčāąĄą╝čŗčģ čüčüčŗą╗ąŠą║. ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąŠčłąĖą▒ą║ąĄ:
let mut s = String:: from("hello" );let r1 = & s; // ąĮąĄčé ą┐čĆąŠą▒ą╗ąĄą╝
let r2 = & s; // ąĮąĄčé ą┐čĆąŠą▒ą╗ąĄą╝
let r3 = & mut s; // ąæą×ąøą¼ą©ąÉą» ą¤ąĀą×ąæąøąĢą£ąÉ ! ("{}, {}, and {}" , r1, r2, r3);
ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą┐ąŠą║ą░ąČąĄčé ąŠčłąĖą▒ą║čā:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:6:14
|
4 | let r1 = &s; // no problem
| -- immutable borrow occurs here
5 | let r2 = &s; // no problem
6 | let r3 = &mut s; // BIG PROBLEM
| ^^^^^^ mutable borrow occurs here
7 |
8 | println!("{}, {}, and {}", r1, r2, r3);
| -- immutable borrow later used here
ąØčā ąĖ ąĮčā! ą£čŗ čéą░ą║ąČąĄ ąĮąĄ ą╝ąŠąČąĄą╝ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ čüąŠąĘą┤ą░čéčī ą╝čāčéąĖčĆčāąĄą╝čāčÄ čüčüčŗą╗ą║čā ąĮą░ ąŠą▒čŖąĄą║čé, ą┤ą╗čÅ ą║ąŠč鹊čĆąŠą│ąŠ čāąČąĄ ąĄčüčéčī ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗąĄ čüčüčŗą╗ą║ąĖ.
ą¤čĆąĖčćąĖąĮą░ čéą░ą║ąŠą│ąŠ ąĘą░ą┐čĆąĄčéą░ ą┐ąŠąĮčÅčéąĮą░: ą▓ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠą╣ čüčĆąĄą┤ąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĖ ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗčģ čüčüčŗą╗ąŠą║ ą╝ąŠą│čāčé ąĮąĄ ąŠąČąĖą┤ą░čéčī, čćč鹊 ąĖčģ ąĘąĮą░č湥ąĮąĖąĄ ą▓ą┤čĆčāą│ ąĮąĄąŠąČąĖą┤ą░ąĮąĮąŠ ą┐ąŠą╝ąĄąĮčÅą╗ąŠčüčī! ą×ą┤ąĮą░ą║ąŠ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗčģ čüčüčŗą╗ąŠą║ ą┐čĆąĖą╝ąĄąĮčÅčéčī čĆą░ąĘčĆąĄčłąĄąĮąŠ, ą┐ąŠč鹊ą╝čā čćč鹊 ąĮąĖ ąŠą┤ąĮą░ ąĖąĘ ąĮąĖčģ ąĮąĄ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ čüą╗čāčćą░ą╣ąĮąŠą╝čā ąĖąĘą╝ąĄąĮąĄąĮąĖčÄ čåąĄą╗ąĄą▓ąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ.
ąĪą╗ąĄą┤čāąĄčé ąŠčéą╝ąĄčéąĖčéčī, čćč鹊 ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ čüčüčŗą╗ą║ąĖ ąĮą░čćąĖąĮą░ąĄčéčüčÅ čü ą╝ąĄčüčéą░, ą│ą┤ąĄ ąŠąĮą░ ą▒čŗą╗ą░ ą▓ą▓ąĄą┤ąĄąĮą░, ąĖ ą┐čĆąŠą┤ąŠą╗ąČą░ąĄčéčüčÅ ą┤ąŠ ą┐ąŠčüą╗ąĄą┤ąĮąĄą│ąŠ ą╝ąĄčüčéą░, ą│ą┤ąĄ ąŠąĮą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ą░čüčī. ąØą░ą┐čĆąĖą╝ąĄčĆ, čüą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤ ą▒čāą┤ąĄčé ąĮąŠčĆą╝ą░ą╗čīąĮąŠ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░ąĮ, ą┐ąŠč鹊ą╝čā čćč鹊 ą┐ąŠčüą╗ąĄą┤ąĮąĄąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąĮąĄą╝čāčéąĖčĆčāąĄą╝ąŠą╣ čüčüčŗą╗ą║ąĖ ą▒čŗą╗ąŠ ą▓ println!, čćč鹊 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ ą┐ąĄčĆąĄą┤ ą▓ą▓ąĄą┤ąĄąĮąĖąĄą╝ ą╝čāčéąĖčĆčāąĄą╝ąŠą╣ čüčüčŗą╗ą║ąĖ ąĮą░ č鹊čé ąČąĄ čüą░ą╝čŗą╣ ąŠą▒čŖąĄą║čé:
let mut s = String:: from("hello" );let r1 = & s; // ąĮąĄčé ą┐čĆąŠą▒ą╗ąĄą╝
let r2 = & s; // ąĮąĄčé ą┐čĆąŠą▒ą╗ąĄą╝
println! ("{r1} and {r2}" );
// ą▓ čŹč鹊ą╣ č鹊čćą║ąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ r1 ąĖ r2 ą▒ąŠą╗čīčłąĄ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ let r3 = & mut s; // ąĮąĄčé ą┐čĆąŠą▒ą╗ąĄą╝
println! ("{r3}" );
ą×ą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗčģ čüčüčŗą╗ąŠą║ r1 ąĖ r2 ąĘą░ą║ą░ąĮčćąĖą▓ą░ąĄčéčüčÅ ą┐ąŠčüą╗ąĄ println!, ą│ą┤ąĄ ąŠąĮąĖ ą┐ąŠčüą╗ąĄą┤ąĮąĖą╣ čĆą░ąĘ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ąĖčüčī, čćč鹊 ą▒čŗą╗ąŠ ą┐ąĄčĆąĄą┤ čüąŠąĘą┤ą░ąĮąĖąĄą╝ ą╝čāčéąĖčĆčāąĄą╝ąŠą╣ čüčüčŗą╗ą║ąĖ r3. ą×ą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ r1, r2 ąĮąĄ ą┐ąĄčĆąĄčüąĄą║ą░čÄčéčüčÅ čü ąŠą▒ą╗ą░čüčéčīčÄ ą┤ąĄą╣čüčéą▓ąĖčÅ r3, čéą░ą║ čćč鹊 čŹč鹊čé ą║ąŠą┤ ą┤ąŠą┐čāčüčéąĖą╝.
ąØąĄčüą╝ąŠčéčĆčÅ ąĮą░ č鹊, čćč鹊 ąŠčłąĖą▒ą║ąĖ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ ą╝ąŠą│čāčé ąĖąĮąŠą│ą┤ą░ ą▓ą▓ąŠą┤ąĖčéčī ą▓ ąĮąĄą┤ąŠčāą╝ąĄąĮąĖąĄ, čüą╗ąĄą┤čāąĄčé čĆą░ą┤ąŠą▓ą░čéčīčüčÅ č鹊ą╝čā, čćč鹊 ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ Rust ąĮą░ čĆą░ąĮąĮąĄą╣ čüčéą░ą┤ąĖąĖ (čāąČąĄ ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ, ą░ ąĮąĄ runtime) čāą║ą░ąČąĄčé ąĮą░ ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮčŗą╣ ą▒ą░ą│, ąĖ č鹊čćąĮąŠ ą┐ąŠą┤čüą║ą░ąČąĄčé, ą│ą┤ąĄ ą┐čĆąŠą▒ą╗ąĄą╝ą░. ąóąŠą│ą┤ą░ ą▓ą░ą╝ ąĮąĄ ąĮčāąČąĮąŠ ą▒čāą┤ąĄčé ą╗ąŠą╝ą░čéčī ą│ąŠą╗ąŠą▓čā ąĮą░ą┤ č鹥ą╝, ą┐ąŠč湥ą╝čā ą▓ą░čłąĖ ą┤ą░ąĮąĮčŗąĄ ąĮąĄ č鹥, ą║ąŠč鹊čĆčŗąĄ ąŠąČąĖą┤ą░ą╗ąĖčüčī.
ąÆąĖčüčÅčēąĖąĄ čüčüčŗą╗ą║ąĖ . ąÆ čÅąĘčŗą║ą░čģ, ą│ą┤ąĄ ą┐čĆąĖą╝ąĄąĮčÅčÄčéčüčÅ čāą║ą░ąĘą░č鹥ą╗ąĖ, ąŠč湥ąĮčī ą╗ąĄą│ą║ąŠ čüąŠąĘą┤ą░čéčī "ą▓ąĖčüčÅčēąĖą╣" čāą║ą░ąĘą░č鹥ą╗čī (dangling pointer) - ą║ąŠą│ą┤ą░ čāą║ą░ąĘą░č鹥ą╗čī ą▓ąŠąĘą╝ąŠąČąĮąŠ ą▒čŗą╗ ą┐ąĄčĆąĄą┤ą░ąĮ ą║ąŠą╝čā-č鹊 ą┤čĆčāą│ąŠą╝čā, ąĖ ąŠąĮ ąŠčüą▓ąŠą▒ąŠą┤ąĖą╗ čŹčéčā ą┐ą░ą╝čÅčéčī, ą░ ąĘąĮą░č湥ąĮąĖąĄ čāą║ą░ąĘą░č鹥ą╗čÅ čüąŠčģčĆą░ąĮąĖą╗ąŠčüčī. ąó. ąĄ. ąĄčüčéčī ąĘąĮą░č湥ąĮąĖąĄ čāą║ą░ąĘą░č鹥ą╗čÅ, ą░ č鹊, ąĮą░ čćč鹊 ąŠąĮ čāą║ą░ąĘčŗą▓ą░ąĄčé, čāąČąĄ ąĮąĄ čüčāčēąĄčüčéą▓čāąĄčé. ąØą░ą┐čĆąŠčéąĖą▓, ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ Rust ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 čüčüčŗą╗ą║ąĖ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą▒čāą┤čāčé ąĘą░ą▓ąĖčüčłąĖą╝ąĖ (dangling references): ąĄčüą╗ąĖ čā ą▓ą░čü ąĄčüčéčī čüčüčŗą╗ą║ą░ ąĮą░ ą║ą░ą║ąĖąĄ-č鹊 ą┤ą░ąĮąĮčŗąĄ, č鹊 ą╝ąŠąČąĮąŠ ą▒čŗčéčī čāą▓ąĄčĆąĄąĮąĮčŗą╝, čćč鹊 ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ čŹčéąĖčģ ą┤ą░ąĮąĮčŗčģ ą▓čüąĄ ąĄčēąĄ ą░ą║čéąĖą▓ąĮą░.
ąöą░ą▓ą░ą╣č鹥 ą┐ąŠą┐čĆąŠą▒čāąĄą╝ čüąŠąĘą┤ą░čéčī ą▓ąĖčüčÅčēčāčÄ čüčüčŗą╗ą║čā, čćč鹊ą▒čŗ ą┐čĆąŠą▓ąĄčĆąĖčéčī, ą║ą░ą║ Rust čĆą░ąĘą▒ąĄčĆąĄčéčüčÅ čü čŹč鹊ą╣ ą┐čĆąŠą▒ą╗ąĄą╝ąŠą╣:
fn main() {
let reference_to_nothing = dangle();
}fn dangle() -> & String {
let s = String:: from("hello" );& s
}
ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 ą┐ąŠą╗čāčćąĖčéčüčÅ ąŠčłąĖą▒ą║ą░ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0106]: missing lifetime specifier
--> src/main.rs:5:16
|
5 | fn dangle() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is
| no value for it to be borrowed from
help: consider using the `'static` lifetime, but this is uncommon unless you're
| returning a borrowed value from a `const` or a `static`
|
5 | fn dangle() -> &'static String {
| +++++++
help: instead, you are more likely to want to return an owned value
|
5 - fn dangle() -> &String {
5 + fn dangle() -> String {
|
ąŚą┤ąĄčüčī čāą┐ąŠą╝ąĖąĮą░ąĄčéčüčÅ čäąĖčćą░, ą║ąŠč鹊čĆčāčÄ ą╝čŗ ą┐ąŠą║ą░ ąĮąĄ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ą╗ąĖ: ą▓čĆąĄą╝ąĄąĮą░ ąČąĖąĘąĮąĖ. ąæąŠą╗ąĄąĄ ą┐ąŠą┤čĆąŠą▒ąĮąŠ čŹč鹊čé č鹥čĆą╝ąĖąĮ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ąĄčéčüčÅ ą▓ ą│ą╗ą░ą▓ąĄ 10. ą×ą┤ąĮą░ą║ąŠ ąĄčüą╗ąĖ ą▓čŗ ąĮąĄ ąŠą▒čĆą░čēą░ąĄč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ ąĮą░ ą▓čĆąĄą╝čÅ ąČąĖąĘąĮąĖ, č鹊 čüąŠąŠą▒čēąĄąĮąĖąĄ čüąŠą┤ąĄčƹȹĖčé ą║ą╗čÄčć ą║ č鹊ą╝čā, čćč鹊 čŹč鹊čé ą║ąŠą┤ čÅą▓ą╗čÅąĄčéčüčÅ ą┐čĆąŠą▒ą╗ąĄą╝ąŠą╣:
this function's return type contains a borrowed value, but there is no value
for it to be borrowed from
ąöą░ą▓ą░ą╣č鹥 ą▓ąĮąĖą╝ą░č鹥ą╗čīąĮąĄą╣ ą┐ąŠčüą╝ąŠčéčĆąĖą╝ ąĮą░ č鹊, čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĮą░ ą║ą░ąČą┤ąŠą╝ čłą░ą│ąĄ ąĮą░čłąĄą│ąŠ ą║ąŠą┤ą░, ą│ą┤ąĄ ąŠą▒ąĮą░čĆčāąČąĄąĮą░ ą┐čĆąŠą▒ą╗ąĄą╝ą░ ą▓ąĖčüčÅčēąĄą╣ čüčüčŗą╗ą║ąĖ:
fn dangle() -> & String { // dangle ą▓ąŠąĘą▓čĆą░čéąĖčé čüčüčŗą╗ą║čā ąĮą░ String let s = String:: from("hello" ); // s čŹč鹊 ąĮąŠą▓čŗą╣ ąŠą▒čŖąĄą║čé String & s // ą╝čŗ ą▓ąŠąĘą▓čĆą░čéąĖą╗ąĖ čüčüčŗą╗ą║čā ąĮą░ s
} // ąÆ čŹč鹊ą╝ ą╝ąĄčüč鹥 ą┤ą╗čÅ s ąĘą░ą║ą░ąĮčćąĖą▓ą░ąĄčéčüčÅ ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ, ąĖ ąŠąĮą░ ąŠčéą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ.
// ą¤ą░ą╝čÅčéčī, ąĮą░ ą║ąŠč鹊čĆčāčÄ ąŠąĮą░ čüčüčŗą╗ą░ą╗ą░čüčī, ą▒ąŠą╗čīčłąĄ ąĮąĄ čüčāčēąĄčüčéą▓čāąĄčé.
// ą×ą┐ą░čüąĮąŠčüčéčī!
ą¤ąŠčüą║ąŠą╗čīą║čā s čüąŠąĘą┤ą░ąĄčéčüčÅ ą▓ąĮčāčéčĆąĖ čäčāąĮą║čåąĖąĖ dangle, č鹊 ą║ąŠą│ą┤ą░ ą║ąŠą┤ dangle ąĘą░ą║ą░ąĮčćąĖą▓ą░ąĄčéčüčÅ, ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ čüčüčŗą╗ą░ą╗ą░čüčī s, ąŠčüą▓ąŠą▒ąŠąČą┤ą░ąĄčéčüčÅ. ąØąŠ ą╝čŗ ą┐ąŠą┐čŗčéą░ą╗ąĖčüčī ą▓ąŠąĘą▓čĆą░čéąĖčéčī čüčüčŗą╗ą║čā, čāą║ą░ąĘčŗą▓ą░čÄčēčāčÄ ąĮą░ čŹčéčā ą▓čŗą▒čĆąŠčłąĄąĮąĮčāčÄ ą┐ą░ą╝čÅčéčī. ąŁč鹊 ąĘąĮą░čćąĖčé, čćč鹊 s ą▒čāą┤ąĄčé čāą║ą░ąĘčŗą▓ą░čéčī ąĮą░ ąĮąĄčüčāčēąĄčüčéą▓čāčÄčēąĖą╣ ąŠą▒čŖąĄą║čé String. ąÆ čŹč鹊ą╝ ąĮąĖč湥ą│ąŠ čģąŠčĆąŠčłąĄą│ąŠ ąĮąĄčé! ąś Rust ąĮąĄ ą┐ąŠąĘą▓ąŠą╗ąĖčé ąĮą░ą╝ ą┤ąĄą╣čüčéą▓ąŠą▓ą░čéčī ą┐ąŠą┤ąŠą▒ąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝.
ąĀąĄčłąĄąĮąĖąĄ čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, čćč鹊ą▒čŗ ąĮą░ą┐čĆčÅą╝čāčÄ ą▓ąŠąĘą▓čĆą░čéąĖčéčī ąŠą▒čŖąĄą║čé s, ą░ ąĮąĄ čüčüčŗą╗ą║čā ąĮą░ ąĮąĄą│ąŠ. ąóąŠą│ą┤ą░ ąĮą░ ą▓čŗčģąŠą┤ąĄ ąĖąĘ čäčāąĮą║čåąĖąĖ ą┐ą░ą╝čÅčéčī ąŠą▒čŖąĄą║čéą░ s ąĮąĄ ą▒čāą┤ąĄčé ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮą░, ąĖ ąŠąĮ čüąŠčģčĆą░ąĮąĖčéčüčÅ:
fn no_dangle() -> String {
let s = String:: from("hello" );
ąŁč鹊čé ą║ąŠą┤ čüčĆą░ą▒ąŠčéą░ąĄčé ą▒ąĄąĘ ą┐čĆąŠą▒ą╗ąĄą╝. ąÆą╗ą░ą┤ąĄąĮąĖąĄ ąŠą▒čŖąĄą║č鹊ą╝ ą┐ąĄčĆąĄą┤ą░ąĄčéčüčÅ ą▓ą╝ąĄčüč鹥 čü ąĮąĖą╝ ąĖąĘ čäčāąĮą║čåąĖąĖ, ąĖ ą┐ą░ą╝čÅčéčī ą┤ą╗čÅ ąĮąĄą│ąŠ ąĮąĄ ąŠčüą▓ąŠą▒ąŠąČą┤ą░ąĄčéčüčÅ.
ą¤čĆą░ą▓ąĖą╗ą░ čüčüčŗą╗ąŠą║ . ąöą░ą▓ą░ą╣č鹥 čĆąĄąĘčÄą╝ąĖčĆčāąĄą╝, čćč鹊 ą╝čŗ ąŠą▒čüčāąČą┤ą░ą╗ąĖ ąŠ čüčüčŗą╗ą║ą░čģ:
ŌĆó ąÆ ą╗čÄą▒ąŠą╣ ą╝ąŠą╝ąĄąĮčé ą▓čĆąĄą╝ąĄąĮąĖ čā ą▓ą░čü ą╝ąŠąČąĄčé ą▒čŗčéčī ą╗ąĖą▒ąŠ ąŠą┤ąĮą░ ą╝čāčéąĖčĆčāąĄą╝ą░čÅ čüčüčŗą╗ą║ą░, ą╗ąĖą▒ąŠ ą╗čÄą▒ąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĮąĄ ą╝čāčéąĖčĆčāąĄą╝čŗčģ čüčüčŗą╗ąŠą║ ąĮą░ ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ ąŠą▒čŖąĄą║čé (ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ).
ąöą░ą╗ąĄąĄ ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ą┤čĆčāą│ąŠą╣ čéąĖą┐ čüčüčŗą╗ą║ąĖ: čüą╗ą░ą╣čü (slice).
[ąóąĖą┐ Slice ]
Slice (čäčĆą░ą│ą╝ąĄąĮčé, čüčĆąĄąĘ, čüą╗ą░ą╣čü) ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą▓ą░ą╝ čüčüčŗą╗ą░čéčīčüčÅ ąĮą░ čüą╝ąĄąČąĮčāčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ ą▓ą╝ąĄčüč鹊 čŹč鹊ą╣ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ čåąĄą╗ąĖą║ąŠą╝. ąĪą╗ą░ą╣čü čÅą▓ą╗čÅąĄčéčüčÅ čüą▓ąŠąĄą│ąŠ čĆąŠą┤ą░ čüčüčŗą╗ą║ąŠą╣, ą┐ąŠčŹč鹊ą╝čā čā ąĮąĄą│ąŠ ąĮąĄčé ownership.
ąÆąŠčé ąĮąĄą▒ąŠą╗čīčłą░čÅ ą┐čĆąŠą▒ą╗ąĄą╝ą░, ą║ąŠč鹊čĆčāčÄ ąĮčāąČąĮąŠ čĆąĄčłąĖčéčī ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčéčā: ąĮą░ą┤ąŠ ąĮą░ą┐ąĖčüą░čéčī čäčāąĮą║čåąĖčÄ, ą║ąŠč鹊čĆą░čÅ ą┐čĆąĖąĮąĖą╝ą░ąĄčé čüčéčĆąŠą║čā čüą╗ąŠą▓, čĆą░ąĘą┤ąĄą╗ąĄąĮąĮčŗčģ ą┐čĆąŠą▒ąĄą╗ą░ą╝ąĖ, ąĖ ąŠąĮą░ ą┤ąŠą╗ąČąĮą░ ą▓ąŠąĘą▓čĆą░čēą░čéčī ą┐ąĄčĆą▓ąŠąĄ ąĮą░ą╣ą┤ąĄąĮąĮąŠąĄ ą▓ čŹč鹊ą╣ čüčéčĆąŠą║ąĄ čüą╗ąŠą▓ąŠ. ąĢčüą╗ąĖ čäčāąĮą║čåąĖčÅ ąĮąĄ ąĮą░ą╣ą┤ąĄčé ą┐čĆąŠą▒ąĄą╗ ą▓ąŠ ą▓čģąŠą┤ąĮąŠą╣ čüčéčĆąŠą║ąĄ, č鹊 čŹč鹊 ąĘąĮą░čćąĖčé čćč鹊 ą▓čüčÅ čüčéčĆąŠą║ą░ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ąĖčüą║ąŠą╝ąŠą╝čā čüą╗ąŠą▓čā, čéą░ą║ čćč鹊 ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ą▓ąŠąĘą▓čĆą░čēąĄąĮą░ čüčéčĆąŠą║ą░ čåąĄą╗ąĖą║ąŠą╝.
ąöą░ą▓ą░ą╣č鹥 ą┐ąŠą┤čāą╝ą░ąĄą╝, ą║ą░ą║ ą▒čŗ ą╝čŗ čüąŠąĘą┤ą░ą╗ąĖ čüąĖą│ąĮą░čéčāčĆčā ą┤ą╗čÅ čŹč鹊ą╣ čäčāąĮą║čåąĖąĖ ą▒ąĄąĘ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüą╗ą░ą╣čüąŠą▓, čćč鹊ą▒čŗ ą┐ąŠąĮčÅčéčī ą┐čĆąŠą▒ą╗ąĄą╝čā, ą║ąŠč鹊čĆčāčÄ čĆąĄčłą░čÄčé čüą╗ą░ą╣čüčŗ:
fn first_word(s: & String) -> ?
ążčāąĮą║čåąĖčÅ first_word ą┐čĆąĖąĮąĖą╝ą░ąĄčé &String ą▓ ą║ą░č湥čüčéą▓ąĄ ą┐ą░čĆą░ą╝ąĄčéčĆą░. ą£čŗ ąĮąĄ čģąŠčéąĖą╝ ą┐čĆąĖąĮąĖą╝ą░čéčī ą▓ąŠ ą▓ą╗ą░ą┤ąĄąĮąĖąĄ ą┐ą░čĆą░ą╝ąĄčéčĆ, čéą░ą║ čćč鹊 čŹč鹊 ąĮąŠčĆą╝ą░ą╗čīąĮąŠ. ąØąŠ čćč鹊 ą╝čŗ ą┤ąŠą╗ąČąĮčŗ ą▓ąŠąĘą▓čĆą░čéąĖčéčī? ąŻ ąĮą░čü ąĮąĄčé čüą┐ąŠčüąŠą▒ą░ ą│ąŠą▓ąŠčĆąĖčéčī ąŠ ą▓ąŠąĘą▓čĆą░č鹥 čćą░čüčéąĖ čüčéčĆąŠą║ąĖ. ą×ą┤ąĮą░ą║ąŠ ą╝čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ ą▓ąĄčĆąĮčāčéčī ąĖąĮą┤ąĄą║čü ą║ąŠąĮčåą░ čüą╗ąŠą▓ą░, ąŠą▒ąŠąĘąĮą░č湥ąĮąĮąŠą│ąŠ ą┐čĆąŠą▒ąĄą╗ąŠą╝. ąöą░ą▓ą░ą╣č鹥 ą┐ąŠą┐čĆąŠą▒čāąĄą╝ ą┐ąŠčüčéčāą┐ąĖčéčī čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 4-7.
fn first_word(s: & String) -> usize {
let bytes = s.as_bytes();for (i, & item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
ąøąĖčüčéąĖąĮą│ 4-7. ążčāąĮą║čåąĖčÅ first_word, ą▓ąŠąĘą▓čĆą░čēą░čÄčēą░čÅ ąĘąĮą░č湥ąĮąĖąĄ ąĖąĮą┤ąĄą║čüą░ ą▒ą░ą╣čéą░ ą▓ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ String.
ą¤ąŠčüą║ąŠą╗čīą║čā ąĮą░ą╝ ąĮčāąČąĮąŠ ą┐čĆąŠčüą╝ąŠčéčĆąĄčéčī String ą┐ąŠ ą║ą░ąČą┤ąŠą╝čā ąĄčæ 菹╗ąĄą╝ąĄąĮčéčā, čćč鹊ą▒čŗ ąĮą░ą╣čéąĖ ą▓ ąĮąĄą╣ ą┐čĆąŠą▒ąĄą╗, ą╝čŗ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ą╗ąĖ ąĮą░čłčā čüčéčĆąŠą║čā String ą▓ ą╝ą░čüčüąĖą▓ ą▒ą░ą╣čé čü ą┐ąŠą╝ąŠčēčīčÄ ą╝ąĄč鹊ą┤ą░ as_bytes.
let bytes = s.as_bytes();
ąöą░ą╗ąĄąĄ ą╝čŗ čüąŠąĘą┤ą░ą╗ąĖ ąĖč鹥čĆą░č鹊čĆ ą┐ąŠ ą╝ą░čüčüąĖą▓čā ą▒ą░ą╣čé čü ą┐ąŠą╝ąŠčēčīčÄ ą╝ąĄč鹊ą┤ą░ iter:
for (i, & item) in bytes.iter().enumerate() {
ąśč鹥čĆą░č鹊čĆčŗ ą▒čāą┤čāčé ą▒ąŠą╗ąĄąĄ ą┐ąŠą┤čĆąŠą▒ąĮąŠ ąŠą▒čüčāąČą┤ą░čéčīčüčÅ ą▓ ą│ą╗ą░ą▓ąĄ 13. ą¤ąŠą║ą░ ą▓čüąĄ, čćč鹊 ąĮą░ą┤ąŠ ąĘąĮą░čéčī - iter čŹč鹊 ą╝ąĄč鹊ą┤, ą║ąŠč鹊čĆčŗą╣ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ą║ą░ąČą┤čŗą╣ 菹╗ąĄą╝ąĄąĮčé ą▓ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ, ą░ enumerate ąŠą▒ąŠčĆą░čćąĖą▓ą░ąĄčé čĆąĄąĘčāą╗čīčéą░čé iter ąĖ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą║ą░ąČą┤čŗą╣ 菹╗ąĄą╝ąĄąĮčé ą║ą░ą║ čćą░čüčéčī ą║ąŠčĆč鹥ąČą░. ą¤ąĄčĆą▓čŗą╣ 菹╗ąĄą╝ąĄąĮčé ą║ąŠčĆč鹥ąČą░, ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝čŗą╣ ąĖąĘ enumerate, čŹč鹊 ąĖąĮą┤ąĄą║čü, ąĖ ą▓č鹊čĆąŠą╣ 菹╗ąĄą╝ąĄąĮčé čŹč鹊 čüčüčŗą╗ą║ą░ ąĮą░ 菹╗ąĄą╝ąĄąĮčé. ąŁč鹊 ąĮąĄčüą║ąŠą╗čīą║ąŠ čāą┤ąŠą▒ąĮąĄąĄ, č湥ą╝ ą▓čŗčćąĖčüą╗čÅčéčī ąĖąĮą┤ąĄą║čü čüą░ą╝ąŠą╝čā.
ą¤ąŠčüą║ąŠą╗čīą║čā ą╝ąĄč鹊ą┤ enumerate ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ą║ąŠčĆč鹥ąČ, ą╝čŗ ą╝ąŠąČąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čłą░ą▒ą╗ąŠąĮčŗ ą┤ą╗čÅ ą┤ąĄčüčéčĆčāą║čéčāčĆąĖčĆąŠą▓ą░ąĮąĖčÅ čŹč鹊ą│ąŠ ą║ąŠčĆč鹥ąČą░. ąæąŠą╗ąĄąĄ ą┐ąŠą┤čĆąŠą▒ąĮąŠ čłą░ą▒ą╗ąŠąĮčŗ ą▒čāą┤čāčé ąŠą▒čüčāąČą┤ą░čéčīčüčÅ ą▓ ą│ą╗ą░ą▓ąĄ 6. ąÆ čåąĖą║ą╗ąĄ for ą╝čŗ čāą║ą░ąĘčŗą▓ą░ąĄą╝ čłą░ą▒ą╗ąŠąĮ, ą║ąŠč鹊čĆčŗą╣ ąĖą╝ąĄąĄčé i ą┤ą╗čÅ ąĖąĮą┤ąĄą║čüą░ ą▓ ą║ąŠčĆč鹥ąČąĄ ąĖ &item ą┤ą╗čÅ ą┐ąĄčĆą▓ąŠą│ąŠ ą▒ą░ą╣čéą░ ą▓ ą║ąŠčĆč鹥ąČąĄ. ą¤ąŠčüą║ąŠą╗čīą║čā ą╝čŗ ą┐ąŠą╗čāčćą░ąĄą╝ čüčüčŗą╗ą║čā ąĮą░ 菹╗ąĄą╝ąĄąĮčé ąĖąĘ .iter().enumerate(), č鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ & ą▓ čłą░ą▒ą╗ąŠąĮąĄ.
ąÆąĮčāčéčĆąĖ čåąĖą║ą╗ą░ for ą╝čŗ ąĖčēąĄą╝ ą▒ą░ą╣čé, ą║ąŠč鹊čĆčŗą╣ čĆą░ą▓ąĄąĮ ą║ąŠą┤čā ą┐čĆąŠą▒ąĄą╗ą░, ąĖčüą┐ąŠą╗čīąĘčāčÅ čüąĖąĮčéą░ą║čüąĖčü ą╗ąĖč鹥čĆą░ą╗ą░ ą▒ą░ą╣čéą░. ąĢčüą╗ąĖ ą┐čĆąŠą▒ąĄą╗ ą▒čŗą╗ ąĮą░ą╣ą┤ąĄąĮ, č鹊 ą╝čŗ ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝ ąĄą│ąŠ ą┐ąŠąĘąĖčåąĖčÄ. ąśąĮą░č湥 ą╝čŗ ą▓ąŠąĘą▓čĆą░čéąĖą╝ ą┤ą╗ąĖąĮčā čüčéčĆąŠą║ąĖ, ąĖčüą┐ąŠą╗čīąĘčāčÅ s.len().
if item == b' ' {
return i;
}
}
ąóąĄą┐ąĄčĆčī čā ąĮą░čü ąĄčüčéčī čüą┐ąŠčüąŠą▒ ąĮą░ą╣čéąĖ ąĖąĮą┤ąĄą║čü ąŠą║ąŠąĮčćą░ąĮąĖčÅ ą┐ąĄčĆą▓ąŠą│ąŠ čüą╗ąŠą▓ą░ ą▓ čüčéčĆąŠą║ąĄ, ąŠą┤ąĮą░ą║ąŠ ąĘą┤ąĄčüčī ąĄčüčéčī ą┐čĆąŠą▒ą╗ąĄą╝ą░. ą£čŗ čüą░ą╝ąĖ ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝ čéąĖą┐ usize , ąĮąŠ ąĄą│ąŠ ąĘąĮą░č湥ąĮąĖąĄ ąĖą╝ąĄąĄčé čüą╝čŗčüą╗ č鹊ą╗čīą║ąŠ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 &String. ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ą┐ąŠčüą║ąŠą╗čīą║čā čŹč鹊 ąĘąĮą░č湥ąĮąĖąĄ, ąŠčéą┤ąĄą╗čīąĮąŠąĄ ąŠčé String, ąĮąĄčé ąĮąĖą║ą░ą║ąŠą╣ ą│ą░čĆą░ąĮčéąĖąĖ, čćč鹊 ąŠąĮąŠ ąŠčüčéą░ąĮąĄčéčüčÅ ą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝ ą▓ ą▒čāą┤čāčēąĄą╝. ąĀą░čüčüą╝ąŠčéčĆąĖą╝ ą┐čĆąŠą│čĆą░ą╝ą╝čā ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 4-8, ą║ąŠč鹊čĆą░čÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčé čäčāąĮą║čåąĖčÄ first_word ąĖąĘ ą╗ąĖčüčéąĖąĮą│ą░ 4-7.
fn main() {
let mut s = String:: from("hello world" );let word = first_word(& s); // ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ word ą┐ąŠą╗čāčćąĖčé ąĘąĮą░č湥ąĮąĖąĄ 5 // čŹč鹊 ą┤ąĄą╣čüčéą▓ąĖąĄ ąŠą┐čāčüč鹊賹Ėčé String, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ąŠąĮą░ čĆą░ą▓ąĮą░ "" // ą▓ čŹč鹊ą╝ ą╝ąĄčüč鹥 word ą▓čüąĄ ąĄčēąĄ čĆą░ą▓ąĮą░ 5, ąŠą┤ąĮą░ą║ąŠ č鹥ą┐ąĄčĆčī ąĮąĄ čüčāčēąĄčüčéą▓čāąĄčé
// ą▒ąŠą╗čīčłąĄ čüčéčĆąŠą║ą░, ą┤ą╗ąĖąĮą░ ą║ąŠč鹊čĆąŠą╣ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ąĘąĮą░č湥ąĮąĖčÄ 5.
// ąŚąĮą░č湥ąĮąĖąĄ word ą┐ąŠą╗čāčćą░ąĄčéčüčÅ ą▓ąŠąŠą▒čēąĄ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮčŗą╝!
}
ąøąĖčüčéąĖąĮą│ 4-8. ąĪąŠčģčĆą░ąĮąĄąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░ ą▓čŗąĘąŠą▓ą░ čäčāąĮą║čåąĖąĖ first_word ąĖ ą┐ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ąĖąĘą╝ąĄąĮąĄąĮąĖąĄ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ String.
ąŁčéą░ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ ą▒ąĄąĘ ą║ą░ą║ąŠą╣-ą╗ąĖą▒ąŠ ąŠčłąĖą▒ą║ąĖ, ąĮąŠ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąĮąĄčüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĄ čĆąĄą░ą╗čīąĮąŠčüčéąĖ, ąĄčüą╗ąĖ ą╝čŗ ą▒čāą┤ąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ word ą┐ąŠčüą╗ąĄ ą▓čŗąĘąŠą▓ą░ s.clear(). ą¤ąŠčüą║ąŠą╗čīą║čā ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ word ąĮąĖą║ą░ą║ ąĮąĄ čüą▓čÅąĘą░ąĮą░ čü čüąŠčüč鹊čÅąĮąĖąĄą╝ s, word ą▓čüąĄ ąĄčēąĄ čüąŠą┤ąĄčƹȹĖčé ąĘąĮą░č湥ąĮąĖąĄ 5. ą£čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ ą┐ąŠą┐čŗčéą░čéčīčüčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĘąĮą░č湥ąĮąĖąĄ 5 ą▓ą╝ąĄčüč鹥 čü ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ s, čćč鹊ą▒čŗ ą┐ąŠą┐čŗčéą░čéčīčüčÅ ąĖąĘą▓ą╗ąĄčćčī ą┐ąĄčĆą▓ąŠąĄ čüą╗ąŠą▓ąŠ, ąĮąŠ čŹč鹊 ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąŠčłąĖą▒ą║ąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ s ą┐ąŠą╝ąĄąĮčÅą╗ąŠčüčī ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ 5 ą▒čŗą╗ąŠ čüąŠčģčĆą░ąĮąĄąĮąŠ ą▓ word.
ąØąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ą║ą░ą║-č鹊 ą┐ąŠą▒ąĄčüą┐ąŠą║ąŠąĖčéčīčüčÅ ąŠ č鹊ą╝, čćč鹊ą▒čŗ ąĖąĮą┤ąĄą║čü ą▓ word čüąĖąĮčģčĆąŠąĮąĖąĘąĖčĆąŠą▓ą░ą╗čüčÅ čü ą┤ą░ąĮąĮčŗą╝ąĖ ą▓ s, čćč鹊 ą▓ąĄčüčīą╝ą░ čāč鹊ą╝ąĖč鹥ą╗čīąĮąŠ ąĖ ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąŠą┤ąĖčéčī ą║ ą╝ąĮąŠą│ąĖą╝ ąŠčłąĖą▒ą║ą░ą╝. ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čŹčéąĖą╝ąĖ ąĖąĮą┤ąĄą║čüą░ą╝ąĖ čüčéą░ąĮąĄčé ąĄčēąĄ ą▒ąŠą╗ąĄąĄ ą┐čĆąŠą▒ą╗ąĄą╝ąĮčŗą╝, ąĄčüą╗ąĖ ą╝čŗ ąĮą░ą┐ąĖčłąĄą╝ čäčāąĮą║čåąĖčÄ second_word ą┤ą╗čÅ ą┐ąŠąĖčüą║ą░ ą▓č鹊čĆąŠą│ąŠ čüą╗ąŠą▓ą░. ąĪąĖą│ąĮą░čéčāčĆą░ čŹč鹊ą╣ čäčāąĮą║čåąĖąĖ ą▓čŗą│ą╗čÅą┤ąĄą╗ą░ ą▒čŗ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
fn second_word(s: & String) -> (usize, usize) {
ąóąĄą┐ąĄčĆčī ą╝čŗ ąŠčéčüą╗ąĄąČąĖą▓ą░ąĄą╝ ąĮą░čćą░ą╗čīąĮčŗą╣ ąĖ ą║ąŠąĮąĄčćąĮčŗą╣ ąĖąĮą┤ąĄą║čüčŗ, ą▓ąŠąĘą▓čĆą░čēą░čÅ ąĖčģ ą▓ ą▓ąĖą┤ąĄ ą║ąŠčĆč鹥ąČą░, ąĖ čā ąĮą░čü čāąČąĄ ą▒ąŠą╗čīčłąĄ ąĘąĮą░č湥ąĮąĖą╣, ą▓čŗčćąĖčüą╗ąĄąĮąĮčŗčģ ą┐ąŠ ą┤ą░ąĮąĮčŗą╝ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ čüąŠčüč鹊čÅąĮąĖčÅ, ąĮąŠ čŹčéąĖ ą┤ą░ąĮąĮčŗąĄ ąĮąĖą║ą░ą║ ąĮąĄ ą┐čĆąĖą▓čÅąĘą░ąĮčŗ ą║ ą▓čŗčćąĖčüą╗ąĄąĮąĮčŗą╝ ąĖąĮą┤ąĄą║čüą░ą╝. ą¤ąŠą╗čāčćą░čÄčéčüčÅ 3 ąĮąĄ čüą▓čÅąĘą░ąĮąĮčŗąĄ ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ, ą║ąŠč鹊čĆčŗąĄ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ čüąĖąĮčģčĆąŠąĮąĖąĘąĖčĆąŠą▓ą░čéčī.
ąÜ čüčćą░čüčéčīčÄ, ą▓ Rust ąĄčüčéčī čĆąĄčłąĄąĮąĖąĄ ą┤ą╗čÅ čéą░ą║ąŠą╣ ą┐čĆąŠą▒ą╗ąĄą╝čŗ: čüčĆąĄąĘčŗ čüčéčĆąŠą║ (string slices).
String Slices . ąĪčĆąĄąĘ čüčéčĆąŠą║ąĖ čŹč鹊 čüčüčŗą╗ą║ą░ ąĮą░ čćą░čüčéčī čüčéčĆąŠą║ąĖ, ąĖ ąŠąĮ ą▓čŗą│ą╗čÅą┤ąĖčé ą┐čĆąĖą╝ąĄčĆąĮąŠ čéą░ą║:
let s = String:: from("hello world" );let hello = & s[0. .5 ];
let world = & s[6. .11 ];
ąÆą╝ąĄčüč鹊 čüčüčŗą╗ą║ąĖ ąĮą░ čüčéčĆąŠą║čā String čåąĄą╗ąĖą║ąŠą╝ ąĘą┤ąĄčüčī hello čŹč鹊 čüčüčŗą╗ą║ą░ ąĮą░ čćą░čüčéčī String, čāą║ą░ąĘą░ąĮąĮąŠąĄ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ [0..5]. ą£čŗ čüąŠąĘą┤ą░ąĄą╝ čüčĆąĄąĘ ąĖčüą┐ąŠą╗čīąĘčāčÅ ą┤ąĖą░ą┐ą░ąĘąŠąĮ (range), ą║ąŠč鹊čĆčŗą╣ čāą║ą░ąĘčŗą▓ą░ąĄčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ čüąĖąĮčéą░ą║čüąĖčüą░ [ąĮą░čćą░ą╗čīąĮčŗą╣_ąĖąĮą┤ąĄą║čü..ą║ąŠąĮąĄčćąĮčŗą╣_ąĖąĮą┤ąĄą║čü], ą│ą┤ąĄ ąĮą░čćą░ą╗čīąĮčŗą╣_ąĖąĮą┤ąĄą║čü čŹč鹊 ą┐ąĄčĆą▓ą░čÅ ą┐ąŠąĘąĖčåąĖčÅ ą▓ čüčĆąĄąĘąĄ, ą░ ą║ąŠąĮąĄčćąĮčŗą╣_ąĖąĮą┤ąĄą║čü čŹč鹊 ąĮą░ ąĄą┤ąĖąĮąĖčåčā ą▒ąŠą╗čīčłąĄ ą┐ąŠčüą╗ąĄą┤ąĮąĄą╣ ą┐ąŠąĘąĖčåąĖąĖ ą▓ čüčĆąĄąĘąĄ. ąÆąĮčāčéčĆąĖ čüčĆąĄąĘą░ ąĄą│ąŠ čüčéčĆčāą║čéčāčĆą░ ą┤ą░ąĮąĮčŗčģ čüąŠčģčĆą░ąĮčÅąĄčé ąĮą░čćą░ą╗čīąĮčāčÄ ą┐ąŠąĘąĖčåąĖčÄ ąĖ ą┤ą╗ąĖąĮčā čüčĆąĄąĘą░, ą║ąŠč鹊čĆą░čÅ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ąĘąĮą░č湥ąĮąĖčÄ (ą║ąŠąĮąĄčćąĮčŗą╣_ąĖąĮą┤ąĄą║čü - ąĮą░čćą░ą╗čīąĮčŗą╣_ąĖąĮą┤ąĄą║čü). ąó. ąĄ. ą┤ą╗čÅ čüą╗čāčćą░čÅ let world = &s[6..11]; čüčĆąĄąĘ world ą▒čāą┤ąĄčé čüąŠą┤ąĄčƹȹ░čéčī čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ą▒ą░ą╣čé ą┐ąŠ ąĖąĮą┤ąĄą║čüčā 6 čüčéčĆąŠą║ąĖ s, čüąŠ ąĘąĮą░č湥ąĮąĖąĄą╝ ą┤ą╗ąĖąĮčŗ 5.
ąĀąĖčü. 4-6 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čŹč鹊 čüąŠčüč鹊čÅąĮąĖąĄ ąĮą░ ą┤ąĖą░ą│čĆą░ą╝ą╝ąĄ.
ąĀąĖčü. 4-6. ąĪčĆąĄąĘ String, čüčüčŗą╗ą░čÄčēąĖą╣čüčÅ ąĮą░ čćą░čüčéčī čüčéčĆąŠą║ąĖ String.
ąĪ ą┐ąŠą╝ąŠčēčīčÄ čüąĖąĮčéą░ą║čüąĖčüą░ ą┤ąĖą░ą┐ą░ąĘąŠąĮą░ Rust (..), ąĄčüą╗ąĖ ą▓čŗ ąĘą░čģąŠčéąĖč鹥 ąĮą░čćą░čéčī čü ąĖąĮą┤ąĄą║čüą░ 0, č鹊 ą▓čŗ ą╝ąŠąČąĄč鹥 ąŠčéą▒čĆąŠčüąĖčéčī ąĘąĮą░č湥ąĮąĖąĄ ą┐ąĄčĆąĄą┤ ą┤ą▓čāą╝čÅ č鹊čćą║ą░ą╝ąĖ. ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐ąĄčĆą░č鹊čĆčŗ let ą┤ą░čÄčé ąŠą┤ąĖąĮą░ą║ąŠą▓čŗą╣ čĆąĄąĘčāą╗čīčéą░čé:
let s = String:: from("hello" );let slice = & s[0. .2 ];let slice = & s[..2 ];
ąÉąĮą░ą╗ąŠą│ąĖčćąĮąŠ, ąĄčüą╗ąĖ ą▓ą░čł čüčĆąĄąĘ ą▓ą║ą╗čÄčćą░ąĄčé ą┐ąŠčüą╗ąĄą┤ąĮąĖą╣ ą▒ą░ą╣čé String, č鹊 ą▓čŗ ą╝ąŠąČąĄč鹥 ąŠą┐čāčüčéąĖčéčī ąĘą░ą▓ąĄčĆčłą░čÄčēąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┤ąĖą░ą┐ą░ąĘąŠąĮą░. ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐ąĄčĆą░č鹊čĆčŗ let ą┤ą░čÄčé ąŠą┤ąĖąĮą░ą║ąŠą▓čŗą╣ čĆąĄąĘčāą╗čīčéą░čé:
let s = String:: from("hello" );let len = s.len();let slice = & s[3. .len];let slice = & s[3. .];
ąś čéą░ą║ąČąĄ ą▓čŗ ą╝ąŠąČąĄč鹥 ąŠčéą▒čĆąŠčüąĖčéčī ąŠą▒ą░ ą│čĆą░ąĮąĖčćąĮčŗčģ ąĘąĮą░č湥ąĮąĖčÅ ą┤ąĖą░ą┐ą░ąĘąŠąĮą░, ąĄčüą╗ąĖ čüčĆąĄąĘ čüąŠą┤ąĄčƹȹĖčé čüčéčĆąŠą║čā čåąĄą╗ąĖą║ąŠą╝. ąĪą╗ąĄą┤čāčÄčēąĖąĄ ą┐ąŠčüą╗ąĄą┤ąĮąĖąĄ ą┤ą▓ą░ ąŠą┐ąĄčĆą░č鹊čĆą░ let 菹║ą▓ąĖą▓ą░ą╗ąĄąĮčéąĮčŗ:
let s = String:: from("hello" );let len = s.len();let slice = & s[0. .len];let slice = & s[..];
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ąĖąĮą┤ąĄą║čüčŗ ą┤ąĖą░ą┐ą░ąĘąŠąĮą░ String ą┤ąŠą╗ąČąĮčŗ ą▓ą║ą╗čÄčćą░čéčī ą║ąŠčĆčĆąĄą║čéąĮčŗąĄ ą│čĆą░ąĮąĖčåčŗ čüąĖą╝ą▓ąŠą╗ąŠą▓ UTF-8. ąĢčüą╗ąĖ ą▓čŗ ą┐ąŠą┐čŗčéą░ąĄč鹥čüčī čüąŠąĘą┤ą░čéčī čüčĆąĄąĘ čüčéčĆąŠą║ąĖ ą┐ąŠčüąĄčĆąĄą┤ąĖąĮąĄ ą╝ąĮąŠą│ąŠą▒ą░ą╣čéąĮąŠą│ąŠ čüąĖą╝ą▓ąŠą╗ą░, č鹊 ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą▓čŗčģąŠą┤ ąĖąĘ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ čü čüąŠąŠą▒čēąĄąĮąĖąĄą╝ ąŠą▒ ąŠčłąĖą▒ą║ąĄ. ąÆ čŹč鹊ą╣ čüąĄą║čåąĖąĖ čü čåąĄą╗čīčÄ ąĘąĮą░ą║ąŠą╝čüčéą▓ą░ čüąŠ čüčĆąĄąĘą░ą╝ąĖ čüčéčĆąŠą║ ą╝čŗ ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄą╝, čćč鹊 ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ č鹊ą╗čīą║ąŠ čüąĖą╝ą▓ąŠą╗čŗ ASCII (ą▓ čŹčéąĖčģ ą┐čĆąĖą╝ąĄčĆą░čģ ąĮąĄą╗čīąĘčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ čüčéčĆąŠą║ čĆčāčüčüą║ąĖąĄ ą▒čāą║ą▓čŗ). ąæąŠą╗ąĄąĄ ą┐ąŠą┤čĆąŠą▒ąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ čĆą░ą▒ąŠčéčŗ čü ą║ąŠą┤ąĖčĆąŠą▓ą║ąŠą╣ UTF-8 ą┐čĆąĖą▓ąĄą┤ąĄąĮąŠ ą▓ čüąĄą║čåąĖąĖ "Storing UTF-8 Encoded Text with Strings" ą│ą╗ą░ą▓čŗ 8.
ąöą░ą▓ą░ą╣č鹥 ą┐ąĄčĆąĄą┐ąĖčłąĄą╝ first_word čü čāč湥č鹊ą╝ čŹč鹊ą│ąŠ ąĮąŠą▓ąŠą│ąŠ čäčāąĮą║čåąĖąŠąĮą░ą╗ą░. ąóąĖą┐, ąŠą▒ąŠąĘąĮą░čćą░čÄčēąĖą╣ "string slice", ąĘą░ą┐ąĖčüą░ąĮ ą║ą░ą║ &str :
fn first_word(s: & String) -> & str {
let bytes = s.as_bytes();for (i, & item) in bytes.iter().enumerate() {
if item == b' ' {
return & s[0. .i];
}
}& s[..]
}
ą£čŗ ą┐ąŠą╗čāčćą░ąĄą╝ ąĖąĮą┤ąĄą║čü ą║ąŠąĮčåą░ čüą╗ąŠą▓ą░ čéą░ą║ąĖą╝ ąČąĄ čüą┐ąŠčüąŠą▒ąŠą╝, ą║ą░ą║ ą┤ąĄą╗ą░ą╗ąĖ čŹč鹊 ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 4-7, ą┐čāč鹥ą╝ ą┐ąŠąĖčüą║ą░ ą┐ąĄčĆą▓ąŠą│ąŠ ą┐čĆąŠą▒ąĄą╗ą░ ą▓ čüčéčĆąŠą║ąĄ. ąÜąŠą│ą┤ą░ ąĮą░čłą╗ąĖ ą┐čĆąŠą▒ąĄą╗, ą╝čŗ ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝ čüčĆąĄąĘ čüčéčĆąŠą║ąĖ (string slice), ąĖčüą┐ąŠą╗čīąĘčāčÅ ąĮą░čćą░ą╗ąŠ čüčéčĆąŠą║ąĖ ąĖ ąĖąĮą┤ąĄą║čü ą┐čĆąŠą▒ąĄą╗ą░ ą▓ ą║ą░č湥čüčéą▓ąĄ ąĮą░čćą░ą╗čīąĮąŠą│ąŠ ąĖ ą║ąŠąĮąĄčćąĮąŠą│ąŠ ąĖąĮą┤ąĄą║čüąŠą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮą░.
ąóąĄą┐ąĄčĆčī ą┐čĆąĖ ą▓čŗąĘąŠą▓ąĄ first_word, ą╝čŗ ą┐ąŠą╗čāčćąĖą╝ ąŠą▒čĆą░čéąĮąŠ ąŠą┤ąĮąŠ ąĘąĮą░č湥ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ą┐čĆąĖą▓čÅąĘą░ąĮąŠ ą║ ąĮąĖąČąĄą╗ąĄąČą░čēąĖą╝ ą┤ą░ąĮąĮčŗą╝. ąŁč鹊 ąĘąĮą░č湥ąĮąĖąĄ čüąŠčüčéą░ą▓ą╗ąĄąĮąŠ ąĖąĘ čüčüčŗą╗ą║ąĖ ąĮą░ ąĮą░čćą░ą╗čīąĮčāčÄ č鹊čćą║čā čüčĆąĄąĘą░ ąĖ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą▓ čüčĆąĄąĘąĄ.
ąÆąŠąĘą▓čĆą░čé čüčĆąĄąĘą░ čéą░ą║ąČąĄ čĆą░ą▒ąŠčéą░ąĄčé ąĖ ą┤ą╗čÅ čäčāąĮą║čåąĖąĖ second_word:
fn second_word(s: & String) -> & str {
ąóąĄą┐ąĄčĆčī čā ąĮą░čü ąĄčüčéčī ą┐čĆąŠčüčéčŗąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗąĄ čäčāąĮą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ čüą╗ąŠąČąĮąĄąĄ ąĖčüą┐ąŠčĆčéąĖčéčī, ą┐ąŠč鹊ą╝čā čćč鹊 ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 čüčüčŗą╗ą║ąĖ ąĮą░ String ąŠčüčéą░čÄčéčüčÅ ą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝ąĖ. ą¤ąŠą╝ąĮąĖč鹥 ą┐čĆąŠ ą▒ą░ą│ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ą╗ąĖčüčéąĖąĮą│ą░ 4-8, ą║ąŠą│ą┤ą░ ą╝čŗ ą┐ąŠą╗čāčćąĖą╗ąĖ ąĖąĮą┤ąĄą║čü ą║ąŠąĮčåą░ ą┐ąĄčĆą▓ąŠą│ąŠ čüą╗ąŠą▓ą░, ąĮąŠ ąĘą░č鹥ą╝ ąŠčćąĖčüčéąĖą╗ąĖ ąŠčĆąĖą│ąĖąĮą░ą╗ čüčéčĆąŠą║ąĖ, ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 č湥ą│ąŠ čŹč鹊čé ąĖąĮą┤ąĄą║čü čüčéą░ą╗ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝? ąŁč鹊čé ą║ąŠą┤ ą▒čŗą╗ ą╗ąŠą│ąĖč湥čüą║ąĖ ąĮąĄą║ąŠčĆčĆąĄą║č鹥ąĮ, ąĮąŠ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąĮąĄ ą╝ąŠą│ č鹊ą│ą┤ą░ ąŠą▒ąĮą░čĆčāąČąĖčéčī ąŠčłąĖą▒ą║čā, ąĖ ą┐čĆąŠą▒ą╗ąĄą╝čŗ ą┐ąŠą╗čāčćą░čéčüčÅ ą┐ąŠąĘąČąĄ, ą┐čĆąĖ čĆą░ą▒ąŠč鹥 ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ą║ąŠą│ą┤ą░ ą╝čŗ ą┐ąŠą┐čŗčéą░ąĄą╝čüčÅ ąĖąĘą╝ąĄąĮąĖčéčī čüčéčĆąŠą║čā. ąĪąŠ čüą╗ą░ą╣čüą░ą╝ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą▒čāą┤ąĄčé ą▓ąŠąŠčĆčāąČąĄąĮ, ąĖ ąĮąĄ ą┤ą░čüčé čüąŠąĘą┤ą░čéčī čéą░ą║čāčÄ ą╗ąŠą│ąĖč湥čüą║čāčÄ ąŠčłąĖą▒ą║čā, čüčĆą░ąĘčā ą▓čŗčÅą▓ąĖą▓ ą┐čĆąŠą▒ą╗ąĄą╝čā ąĮą░ čüčéą░ą┤ąĖąĖ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ:
fn main() {
let mut s = String:: from("hello world" );let word = first_word(& s);// ąŠčłąĖą▒ą║ą░! ! ("the first word is: {word}" );
}
ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą▓čŗą┤ą░čüčé ąŠčłąĖą▒ą║čā ąĮą░ čéą░ą║ąŠą╣ ą║ąŠą┤, ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čüčĆąĄąĘ čüčéčĆąŠą║ąĖ:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let word = first_word(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("the first word is: {}", word);
| ---- immutable borrow later used here
ąÆčüą┐ąŠą╝ąĮąĖč鹥 ą┐čĆą░ą▓ąĖą╗ą░ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ (borrowing rules): ąĄčüą╗ąĖ čā ąĮą░čü ąĄčüčéčī ąĮąĄą╝čāčéąĖčĆčāąĄą╝ą░čÅ čüčüčŗą╗ą║ą░ ąĮą░ čćč鹊-ąĮąĖą▒čāą┤čī, č鹊 ą╝čŗ čéą░ą║ąČąĄ ąĮąĄ ą╝ąŠąČąĄą╝ čüąŠąĘą┤ą░čéčī ąĮą░ čŹč鹊 čćč鹊-č鹊 ąĮąĄą╝čāčéąĖčĆčāąĄą╝čāčÄ čüčüčŗą╗ą║čā. ą¤ąŠčüą║ąŠą╗čīą║čā ą╝ąĄč鹊ą┤ clear ą┤ąŠą╗ąČąĄąĮ ąŠą▒čĆąĄąĘą░čéčī String, ąĄą╝čā ąĮčāąČąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ą╝čāčéąĖčĆčāąĄą╝čāčÄ čüčüčŗą╗ą║čā. ąÆčŗąĘąŠą▓ println! ą┐ąŠčüą╗ąĄ ą▓čŗąĘąŠą▓ą░ clear ąĖčüą┐ąŠą╗čīąĘčāąĄčé čüčüčŗą╗ą║čā ą▓ word, čéą░ą║ čćč鹊 ą▓ čŹč鹊ą╝ ą╝ąĄčüč鹥 ą▓čüąĄ ąĄčēąĄ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ą░ą║čéąĖą▓ąĮą░ ąĮąĄą╝čāčéąĖčĆčāąĄą╝ą░čÅ čüčüčŗą╗ą║ą░. Rust ąĮąĄ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą╝čāčéąĖčĆčāąĄą╝čāčÄ čüčüčŗą╗ą║čā ą▓ clear ąĖ ą╝čāčéąĖčĆčāąĄą╝čāčÄ čüčüčŗą╗ą║čā ą▓ word, čćč鹊ą▒čŗ ąŠąĮąĖ čüčāčēąĄčüčéą▓ąŠą▓ą░ą╗ąĖ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ, ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 č湥ą│ąŠ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖčÄ ąĘą░ą▓ąĄčĆčłą░ąĄčéčüčÅ ąĮąĄčāą┤ą░č湥ą╣. ąóą░ą║ čćč鹊 čü ą┐ąŠą╝ąŠčēčīčÄ čüą╗ą░ą╣čüąŠą▓ Rast ąĮą░čł ą║ąŠą┤ čüčéą░ą╗ ąĮąĄ č鹊ą╗čīą║ąŠ ą┐čĆąŠčēąĄ, ąĮąŠ ąĖ ąĄčēąĄ ą▒ąŠą╗ąĄąĄ ą▒ąĄąĘąŠą┐ą░čüąĮčŗą╝, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓ąŠąĘą╝ąŠąČąĮą░čÅ ą╗ąŠą│ąĖč湥čüą║ą░čÅ ąŠčłąĖą▒ą║ą░ ą▒čŗą╗ą░ ąŠčéą╗ąŠą▓ą╗ąĄąĮą░ čāąČąĄ ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ!
ąøąĖč鹥čĆą░ą╗čŗ String ą▓ ą║ą░č湥čüčéą▓ąĄ Slice . ąÆčüą┐ąŠą╝ąĮąĖą╝, čćč鹊 ą╝čŗ ą│ąŠą▓ąŠčĆąĖą╗ąĖ ą┐čĆąŠ čüčéčĆąŠą║ąŠą▓čŗąĄ ą╗ąĖč鹥čĆą░ą╗čŗ, ą║ąŠč鹊čĆčŗąĄ čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ ą▓ąĮčāčéčĆąĖ ą┤ą▓ąŠąĖčćąĮąŠą│ąŠ ąĖčüą┐ąŠą╗ąĮčÅąĄą╝ąŠą│ąŠ ą║ąŠą┤ą░. ąóąĄą┐ąĄčĆčī, ą║ąŠą│ą┤ą░ ą╝čŗ ąĘąĮą░ąĄą╝ ą┐čĆąŠ čüą╗ą░ą╣čüčŗ, ą╝ąŠąČąĮąŠ ą┐čĆą░ą▓ąĖą╗čīąĮąŠ ą┐ąŠąĮąĖą╝ą░čéčī čüčéčĆąŠą║ąŠą▓čŗąĄ ą╗ąĖč鹥čĆą░ą╗čŗ:
ąŚą┤ąĄčüčī čéąĖą┐ s čŹč鹊 &str: čé. ąĄ. čŹč鹊 čüą╗ą░ą╣čü, čāą║ą░ąĘčŗą▓ą░čÄčēąĖą╣ ąĮą░ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčāčÄ č鹊čćą║čā ą▓ ą▒ąĖąĮą░čĆąĮąĖą║ąĄ. ąŁč鹊 čéą░ą║ąČąĄ ą┐čĆąĖčćąĖąĮą░, ą┐ąŠč湥ą╝čā čüčéčĆąŠą║ąŠą▓čŗąĄ ą╗ąĖč鹥čĆą░ą╗čŗ ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗąĄ; &str čŹč鹊 ąĮąĄą╝čāčéąĖčĆčāąĄą╝ą░čÅ čüčüčŗą╗ą║ą░.
ąĪą╗ą░ą╣čüčŗ String ą▓ ą║ą░č湥čüčéą▓ąĄ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ . ąŚąĮą░ąĮąĖąĄ č鹊ą│ąŠ, čćč鹊 ą▓čŗ ą╝ąŠąČąĄč鹥 ą▓ąĘčÅčéčī čüą╗ą░ą╣čüčŗ ą╗ąĖč鹥čĆą░ą╗ąŠą▓ ąĖ ąĘąĮą░č湥ąĮąĖą╣ String, ą┐čĆąĖą▓ąŠą┤ąĖčé ąĮą░čü ą║ ąĄčēąĄ ąŠą┤ąĮąŠą╝čā čāą╗čāčćčłąĄąĮąĖčÄ čäčāąĮą║čåąĖąĖ first_word, ąĖ ą▓ąŠčé ąĄčæ čüąĖą│ąĮą░čéčāčĆą░:
fn first_word(s: & String) -> & str {
ąæąŠą╗ąĄąĄ ą┐čĆąŠą┤ą▓ąĖąĮčāčéčŗą╣ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčé ąĮą░ą┐ąĖčüą░ą╗ ą▒čŗ čŹčéčā čüąĖą│ąĮą░čéčāčĆčā čéą░ą║, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 4-9, ą┐ąŠč鹊ą╝čā čćč鹊 čŹč鹊 ą┐ąŠąĘą▓ąŠą╗ąĖą╗ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąŠą┤ąĮčā ąĖ čéčā ąČąĄ čäčāąĮą║čåąĖčÄ ą║ą░ą║ ą┤ą╗čÅ ąĘąĮą░č湥ąĮąĖą╣ &String, čéą░ą║ ąĖ ą┤ą╗čÅ ąĘąĮą░č湥ąĮąĖą╣ &str.
fn first_word(s: & str ) -> & str {
ąøąĖčüčéąĖąĮą│ 4-9. ąŻą╗čāčćčłąĄąĮąĖąĄ čäčāąĮą║čåąĖąĖ first_word ąĮą░ ąŠčüąĮąŠą▓ąĄ čüą╗ą░ą╣čüą░ čüčéčĆąŠą║ąĖ ą┤ą╗čÅ čéąĖą┐ą░ ąĄčæ ą┐ą░čĆą░ą╝ąĄčéčĆą░ s.
ąĢčüą╗ąĖ čā ąĮą░čü ąĄčüčéčī čüą╗ą░ą╣čü čüčéčĆąŠą║ąĖ, č鹊 ą╝čŗ ą╝ąŠąČąĄą╝ ąĮą░ą┐čĆčÅą╝čāčÄ ą┐ąĄčĆąĄą┤ą░čéčī ąĄą│ąŠ ą▓ čäčāąĮą║čåąĖčÄ. ąĢčüą╗ąĖ čā ąĮą░čü ąĄčüčéčī String, č鹊 ą╝čŗ ą╝ąŠąČąĄą╝ ą┐ąĄčĆąĄą┤ą░čéčī čüą╗ą░ą╣čü String ąĖą╗ąĖ čüčüčŗą╗ą║čā ąĮą░ String. ąŁčéą░ ą│ąĖą▒ą║ąŠčüčéčī ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐čĆąĖą╝ąĄąĮąĖčéčī ą┤ąŠčüč鹊ąĖąĮčüčéą▓ą░ deref coercions, čŹč鹊čé čäčāąĮą║čåąĖąŠąĮą░ą╗ ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ą▓ čüąĄą║čåąĖąĖ "Implicit Deref Coercions with Functions and Methods" ą│ą╗ą░ą▓čŗ 15.
ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čäčāąĮą║čåąĖąĖ ą┤ą╗čÅ ą▓ąĘčÅčéąĖčÅ čüčéčĆąŠą║ąŠą▓ąŠą│ąŠ čüčĆąĄąĘą░ ą▓ą╝ąĄčüč鹊 čüčüčŗą╗ą║ąĖ ąĮą░ String ą┤ąĄą╗ą░ąĄčé ąĮą░čł API ą▒ąŠą╗ąĄąĄ ąŠą▒čēąĖą╝ ąĖ ą┐ąŠą╗ąĄąĘąĮčŗą╝ ą▒ąĄąĘ ą┐ąŠč鹥čĆąĖ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéąĖ:
fn main() {
let my_string = String:: from("hello world" );// `first_word` čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ čüą╗ą░ą╣čüą░čģ čüčéčĆąŠą║ String, ą╗ąĖą▒ąŠ ąŠčé ąĖčģ čćą░čüčéąĖ,
// ą╗ąĖą▒ąŠ ąŠčé ąŠčé čüčéčĆąŠą║ąĖ čåąĄą╗ąĖą║ąŠą╝:
let word = first_word(& my_string[0. .6 ]);
let word = first_word(& my_string[..]);
// `first_word` čéą░ą║ąČąĄ čĆą░ą▒ąŠčéą░ąĄčé ąĖ čüąŠ čüčüčŗą╗ą║ą░ą╝ąĖ ąĮą░ čüčéčĆąŠą║ąĖ String,
// ą║ąŠč鹊čĆčŗąĄ 菹║ą▓ąĖą▓ą░ą╗ąĄąĮčéąĮčŗ čåąĄą╗čŗą╝ čüčĆąĄąĘą░ą╝ čüčéčĆąŠą║ String:
let word = first_word(& my_string);let my_string_literal = "hello world" ;// `first_word` čĆą░ą▒ąŠčéą░ąĄčé ąĖ ąĮą░ čüčĆąĄąĘą░čģ čüčéčĆąŠą║ąŠą▓čŗčģ ą╗ąĖč鹥čĆą░ą╗ąŠą▓,
// ą║ą░ą║ ąŠčé ąĖčģ čćą░čüčéąĖ, čéą░ą║ ąĖ ąŠčé ą╗ąĖč鹥čĆą░ą╗ą░ čåąĄą╗ąĖą║ąŠą╝:
let word = first_word(& my_string_literal[0. .6 ]);
let word = first_word(& my_string_literal[..]);// ą¤ąŠčüą║ąŠą╗čīą║čā čüčéčĆąŠą║ąŠą▓čŗąĄ ą╗ąĖč鹥čĆą░ą╗čŗ *čāąČąĄ* čüą╗ą░ą╣čüčŗ, č鹊 čüą╗ąĄą┤čāčÄčēąĖą╣
// ą║ąŠą┤ čéą░ą║ąČąĄ čĆą░ą▒ąŠčéą░ąĄčé, ą▒ąĄąĘ čüąĖąĮčéą░ą║čüąĖčüą░ čüą╗ą░ą╣čüą░!
let word = first_word(my_string_literal);
}
ąöčĆčāą│ąĖąĄ čüą╗ą░ą╣čüčŗ . ąĪčĆąĄąĘčŗ String, ą║ą░ą║ ą▓čŗ ą╝ąŠąČąĄč鹥 čüąĄą▒ąĄ ą┐čĆąĄą┤čüčéą░ą▓ąĖčéčī, čüą┐ąĄčåąĖčäąĖčćąĮčŗ ą┤ą╗čÅ čüčéčĆąŠą║. ąØąŠ ąĄčüčéčī čéą░ą║ąČąĄ ąĖ ą▒ąŠą╗ąĄąĄ ąŠą▒čēąĖą╣ čéąĖą┐ čüą╗ą░ą╣čüą░. ąĀą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗ąĄą┤čāčÄčēąĖą╣ ą╝ą░čüčüąĖą▓:
ąóą░ą║ ąČąĄ, ą║ą░ą║ ą╝čŗ čüčüčŗą╗ą░ą╗ąĖčüčī ąĮą░ čćą░čüčéčī čüč鹊ą║ąĖ, ą╝ąŠąČąĮąŠ čüčüčŗą╗ą░čéčīčüčÅ ąĮą░ čćą░čüčéčī ą╝ą░čüčüąĖą▓ą░:
let a = [1 , 2 , 3 , 4 , 5 ];let slice = & a[1. .3 ];! (slice, & [2 , 3 ]);
ąŻ čŹč鹊ą│ąŠ čüą╗ą░ą╣čüą░ čéąĖą┐ &[i32]. ąŁč鹊 čĆą░ą▒ąŠčéą░ąĄčé čéą░ą║ ąČąĄ, ą║ą░ą║ čĆą░ą▒ąŠčéą░čÄčé čüą╗ą░ą╣čüčŗ čüčéčĆąŠą║ąĖ, ą┐čāč鹥ą╝ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čüčüčŗą╗ą║ąĖ ąĮą░ ą┐ąĄčĆą▓čŗą╣ 菹╗ąĄą╝ąĄąĮčé ąĖ ą┤ą╗ąĖąĮčŗ. ąÆčŗ ą▒čāą┤ąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹč鹊čé čéąĖą┐ čüą╗ą░ą╣čüą░ ą┤ą╗čÅ ą▓čüąĄčģ ą▓ąĖą┤ąŠą▓ ą┤čĆčāą│ąĖčģ ą║ąŠą╗ą╗ąĄą║čåąĖą╣. ą£čŗ ąŠą▒čüčāą┤ąĖą╝ čŹčéąĖ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ ą▒ąŠą╗ąĄąĄ ą┐ąŠą┤čĆąŠą▒ąĮąŠ, ą║ąŠą│ą┤ą░ ą┐ąŠą│ąŠą▓ąŠčĆąĖą╝ ąŠ ą▓ąĄą║č鹊čĆą░čģ ą▓ ą│ą╗ą░ą▓ąĄ 8.
[ą×ą▒čēąĖąĄ ą▓čŗą▓ąŠą┤čŗ ]
ąÜąŠąĮčåąĄą┐čåąĖąĖ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ (ownership), ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ (borrowing) ąĖ čüčĆąĄąĘąŠą▓ (slices) ąŠą▒ąĄčüą┐ąĄčćąĖą▓ą░čÄčé ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéčī ą┐ą░ą╝čÅčéąĖ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ą░čģ Rust, ą▓čŗčÅą▓ą╗čÅčÅ ą▒ą░ą│ąĖ ąĮą░ čüčéą░ą┤ąĖąĖ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ. ą»ąĘčŗą║ Rust ą┤ą░ąĄčé ą▓ą░ą╝ ą║ąŠąĮčéčĆąŠą╗čī ąĮą░ą┤ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą┐ą░ą╝čÅčéąĖ čéą░ą║ąĖą╝ ąČąĄ čüą┐ąŠčüąŠą▒ąŠą╝, ą║ą░ą║ ąĖ ą┤čĆčāą│ąĖąĄ čüąĖčüč鹥ą╝ąĮčŗąĄ čÅąĘčŗą║ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ, ąĮąŠ č鹊čé čäą░ą║čé, čćč鹊 ą▓ą╗ą░ą┤ąĄą╗ąĄčå ą┤ą░ąĮąĮčŗčģ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ąŠčćąĖčēą░ąĄčé čŹčéąĖ ą┤ą░ąĮąĮčŗąĄ, ą║ąŠą│ą┤ą░ ąŠąĮąĖ ą▓čŗčģąŠą┤čÅčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ, ąŠąĘąĮą░čćą░ąĄčé ąŠčéčüčāčéčüčéą▓ąĖąĄ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ ą┐ąĖčüą░čéčī ąĖ ąŠčéą╗ą░ąČąĖą▓ą░čéčī ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗą╣ ą║ąŠą┤ ą┤ą╗čÅ ą┤ąŠčüčéąĖąČąĄąĮąĖčÅ čéą░ą║ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ ą║ąŠąĮčéčĆąŠą╗čÅ.
Ownership ą▓ą╗ąĖčÅąĄčé ąĮą░ č鹊, ą║ą░ą║ čĆą░ą▒ąŠčéą░čÄčé ą╝ąĮąŠą│ąŠ ą┤čĆčāą│ąŠą│ąŠ čäčāąĮą║čåąĖąŠąĮą░ą╗ą░ Rust, čéą░ą║ čćč鹊 ą╝čŗ ą▒ąŠą╗ąĄąĄ ą│ą╗čāą▒ąŠą║ąŠ ą┐ąŠą│ąŠą▓ąŠčĆąĖą╝ ą┐čĆąŠ čŹčéąĖ ą║ąŠąĮčåąĄą┐čåąĖąĖ ą▓ ąŠčüčéą░ą╗čīąĮąŠą╣ čćą░čüčéąĖ ą║ąĮąĖą│ąĖ [1]. ąöą░ą▓ą░ą╣č鹥 ą┐ąĄčĆąĄą╣ą┤ąĄą╝ ą║ ą│ą╗ą░ą▓ąĄ 5 (čüą╝. [4]), ąĖ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ą│čĆčāą┐ą┐ąĖčĆąŠą▓ą║čā čäčĆą░ą│ą╝ąĄąĮč鹊ą▓ ą┤ą░ąĮąĮčŗčģ ą▓ čüčéčĆčāą║čéčāčĆąĄ (struct).
[ąĪčüčŗą╗ą║ąĖ ]
1 . Rust Understanding Ownership site:rust-lang.org.2 . ą»ąĘčŗą║ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ Rust .3 . Rust: ąŠą▒čēą░čÅ ą║ąŠąĮčåąĄą┐čåąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ .4 . Rust: ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüčéčĆčāą║čéčāčĆčŗ ą┤ą╗čÅ ą▓ąĘą░ąĖą╝ąŠčüą▓čÅąĘą░ąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ .