|
ąÆ čŹč鹊ą╣ ą│ą╗ą░ą▓ąĄ (ą┐ąĄčĆąĄą▓ąŠą┤ [1]) ą╝čŗ ą┐čĆąŠą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄą╝ ąĮąĄą║ąŠč鹊čĆčŗąĄ ą║ąŠąĮčåąĄą┐čåąĖąĖ, ą║ąŠč鹊čĆčŗą╣ ą▒čŗą╗ąĖ čĆą░čüčüą╝ąŠčéčĆąĄąĮčŗ ą▓ ą┐ąŠčüą╗ąĄą┤ąĮąĖčģ ą│ą╗ą░ą▓ą░čģ ąŠą▒čāčćą░čÄčēąĄą│ąŠ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ą░ Rust ąĖ ąĮąĄą║ąŠč鹊čĆčŗčģ ą▒ąŠą╗ąĄąĄ čĆą░ąĮąĮąĖčģ ą╗ąĄą║čåąĖčÅčģ. ąÆ ą║ą░č湥čüčéą▓ąĄ ą║ąŠąĮąĄčćąĮąŠą│ąŠ ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąŠąĮąĮąŠą│ąŠ ą┐čĆąŠąĄą║čéą░ ą╝čŗ čüąŠąĘą┤ą░ą┤ąĖą╝ ą▓ąĄą▒-čüąĄčĆą▓ąĄčĆ, ą║ąŠč鹊čĆčŗą╣ ąŠč鹊ą▒čĆą░ąĘąĖčé ą▓ ą▒čĆą░čāąĘąĄčĆąĄ čüčéčĆą░ąĮąĖčćą║čā čü č鹥ą║čüč鹊ą╝ "hello", ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮą░ čĆąĖčü. 20-1.
ąĀąĖčü. 20-1. ąöąŠą╝ą░čłąĮčÅčÅ čüčéčĆą░ąĮąĖčćą║ą░ ą▓ąĄą▒-čüąĄčĆą▓ąĄčĆą░, ąĮą░ą┐ąĖčüą░ąĮąĮąŠą│ąŠ ąĮą░ Rust.
ąØą░čł ą▓ąĄą▒-čüąĄčĆą▓ąĄčĆ ą╝čŗ ą▒čāą┤ąĄą╝ čüąŠąĘą┤ą░ą▓ą░čéčī ą┐ąŠ čüą╗ąĄą┤čāčÄčēąĄą╝čā ą┐ą╗ą░ąĮčā:
1. ąÆčüą┐ąŠą╝ąĮąĖą╝ ą║ąŠąĄ-čćč鹊 ą┐čĆąŠ ą┐čĆąŠč鹊ą║ąŠą╗čŗ TCP ąĖ HTTP.
2. ąŚą░ą┐čāčüčéąĖą╝ ą┐čĆąŠčüą╗čāčłąĖą▓ą░ąĮąĖąĄ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖą╣ TCP ąĮą░ čüąŠą║ąĄč鹥.
3. ąĀąĄą░ą╗ąĖąĘčāąĄą╝ ą┐ą░čĆčüąĖąĮą│ ąĮąĄą║ąŠč鹊čĆčŗčģ ąĘą░ą┐čĆąŠčüąŠą▓ HTTP.
4. ąĪąŠąĘą┤ą░ą┤ąĖą╝ ą║ąŠčĆčĆąĄą║čéąĮčŗą╣ ąŠčéą▓ąĄčé HTTP.
5. ąŻą╗čāčćčłąĖą╝ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ąĮą░čłąĄą│ąŠ čüąĄčĆą▓ąĄčĆą░ čü ą┐ąŠą╝ąŠčēčīčÄ ą┐čāą╗ą░ ą┐ąŠč鹊ą║ąŠą▓.
ą¤ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ą┐čĆąŠą┤ąŠą╗ąČąĖčéčī, čüą╗ąĄą┤čāąĄčé čāą┐ąŠą╝čÅąĮčāčéčī ąŠą┤ąĮčā ą┤ąĄčéą░ą╗čī: ą╝čŗ ą▒čāą┤ąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĮąĄ čüą░ą╝čŗą╣ ą╗čāčćčłąĖą╣ ą╝ąĄč鹊ą┤ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ web-čüąĄčĆą▓ąĄčĆą░ ąĮą░ Rust. ąÆ čüąŠąŠą▒čēąĄčüčéą▓ąĄ Rust ąĮą░ ą║čĆąĄą╣čéą░čģ crates.io ąŠą┐čāą▒ą╗ąĖą║ąŠą▓ą░ąĮąŠ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą│ąŠč鹊ą▓čŗčģ, ą▒ąŠą╗ąĄąĄ ą┐ąŠą╗ąĮąŠčåąĄąĮąĮčŗčģ čĆąĄą░ą╗ąĖąĘą░čåąĖą╣ web-čüąĄčĆą▓ąĄčĆą░ ąĖ ą┐čāą╗ą░ ą┐ąŠč鹊ą║ąŠą▓. ą×ą┤ąĮą░ą║ąŠ ąĮą░čłąĄ ąĮą░ą╝ąĄčĆąĄąĮąĖąĄ čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, čćč鹊ą▒čŗ ą┐ąŠą╝ąŠčćčī ą▓ą░ą╝ čāčćąĖčéčīčüčÅ, ą░ ąĮąĄ ąĖą┤čéąĖ ą╗ąĄą│ą║ąĖą╝ ą┐čāč鹥ą╝. ą¤ąŠčüą║ąŠą╗čīą║čā Rust - čŹč鹊 čÅąĘčŗą║ čüąĖčüč鹥ą╝ąĮąŠą│ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ, ą╝čŗ ą╝ąŠąČąĄą╝ ą▓čŗą▒čĆą░čéčī čéą░ą║ąŠą╣ čāčĆąŠą▓ąĄąĮčī ą░ą▒čüčéčĆą░ą║čåąĖąĖ, čü ą║ąŠč鹊čĆčŗą╝ ą╝čŗ čģąŠčéąĖą╝ čĆą░ą▒ąŠčéą░čéčī, ąĖ ą╝ąŠąČąĄą╝ ą┐ąĄčĆąĄą╣čéąĖ ąĮą░ ą▒ąŠą╗ąĄąĄ ąĮąĖąĘą║ąĖą╣ čāčĆąŠą▓ąĄąĮčī, č湥ą╝ čŹč鹊 ą▓ąŠąĘą╝ąŠąČąĮąŠ ąĖą╗ąĖ ą┐čĆą░ą║čéąĖčćąĮąŠ ą▓ ą┤čĆčāą│ąĖčģ čÅąĘčŗą║ą░čģ. ą¤ąŠčŹč鹊ą╝čā ą╝čŗ ąĮą░ą┐ąĖčłąĄą╝ ą▒ą░ąĘąŠą▓čŗą╣ HTTP-čüąĄčĆą▓ąĄčĆ ąĖ ą┐čāą╗ ą┐ąŠč鹊ą║ąŠą▓ ą▓čĆčāčćąĮčāčÄ, čćč鹊ą▒čŗ ą▓čŗ ą╝ąŠą│ą╗ąĖ ąĖąĘčāčćąĖčéčī ąŠą▒čēąĖąĄ ąĖą┤ąĄąĖ ąĖ ą╝ąĄč鹊ą┤čŗ, ą╗ąĄąČą░čēąĖąĄ ą▓ ąŠčüąĮąŠą▓ąĄ ą║čĆąĄą╣č鹊ą▓, ą║ąŠč鹊čĆčŗąĄ ą▓čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓ ą▒čāą┤čāčēąĄą╝.
[ą¤ąŠčüčéčĆąŠąĄąĮąĖąĄ ąŠą┤ąĮąŠą┐ąŠč鹊čćąĮąŠą│ąŠ web-čüąĄčĆą▓ąĄčĆą░]
ą£čŗ ąĮą░čćąĮąĄą╝ čü ąĘą░ą┐čāčüą║ą░ ąŠą┤ąĮąŠą┐ąŠč鹊čćąĮąŠą│ąŠ ą▓ąĄą▒-čüąĄčĆą▓ąĄčĆą░, ąĖ ą┐ąĄčĆąĄą┤ čŹčéąĖą╝ ąĮąĄą╝ąĮąŠą│ąŠ ąŠą▒čüčāą┤ąĖą╝ ą┐čĆąŠč鹊ą║ąŠą╗čŗ, ą║ąŠč鹊čĆčŗąĄ ą▓ ąĮąĄą╝ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ: Hypertext Transfer Protocol (HTTP) ąĖ Transmission Control Protocol (TCP). ą×ą▒ą░ čŹčéąĖčģ ą┐čĆąŠč鹊ą║ąŠą╗ą░ čĆą░ą▒ąŠčéą░čÄčé ą┐ąŠ ą┐čĆąĖąĮčåąĖą┐čā ąĘą░ą┐čĆąŠčü-ąŠčéą▓ąĄčé (request-response), čé. ąĄ. ą║ą╗ąĖąĄąĮčé ąĖąĮąĖčåąĖąĖčĆčāąĄčé ąĘą░ą┐čĆąŠčü, ą░ čüąĄčĆą▓ąĄčĆ ąŠąČąĖą┤ą░ąĄčé čŹčéąĖ ąĘą░ą┐čĆąŠčüčŗ ąĖ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄčé ąĖčģ, ą▓čŗą┤ą░ą▓ą░čÅ ą║ą╗ąĖąĄąĮčéčā ąŠčéą▓ąĄčéčŗ ąĮą░ ąĄą│ąŠ ąĘą░ą┐čĆąŠčüčŗ. ąĪąŠą┤ąĄčƹȹĖą╝ąŠąĄ čŹčéąĖčģ ąĘą░ą┐čĆąŠčüąŠą▓ ąĖ ąŠčéą▓ąĄč鹊ą▓ ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčéčüčÅ ą┐čĆąŠč鹊ą║ąŠą╗ą░ą╝ąĖ.
TCP čŹč鹊 ąĮąĖąĘą║ąŠčāčĆąŠą▓ąĮąĄą▓čŗą╣ ą┐čĆąŠč鹊ą║ąŠą╗, ą║ąŠč鹊čĆčŗą╣ ąŠą┐ąĖčüčŗą▓ą░ąĄčé, ą║ą░ą║ ąĖąĮč乊čĆą╝ą░čåąĖčÅ ą┐ąĄčĆąĄą┤ą░ąĄčéčüčÅ ąŠčé ąŠą┤ąĮąŠą│ąŠ čģąŠčüčéą░ ą║ ą┤čĆčāą│ąŠą╝čā. ą¤čĆąĖ čŹč鹊ą╝ ąĮąĄ ąĖą╝ąĄąĄčé ąĘąĮą░č湥ąĮąĖąĄ, ą║ą░ą║ą░čÅ čŹč鹊 ąĖąĮč乊čĆą╝ą░čåąĖčÅ. HTTP čĆą░ą▒ąŠčéą░ąĄčé ą┐ąŠą▓ąĄčĆčģ TCP, ąĖ HTTP ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé č乊čĆą╝ą░čé ąĘą░ą┐čĆąŠčüąŠą▓ ą║ą╗ąĖąĄąĮčéą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ ą▒čĆą░čāąĘąĄčĆą░) ąĖ ąŠčéą▓ąĄč鹊ą▓ web-čüąĄčĆą▓ąĄčĆą░. ąóąĄčģąĮąĖč湥čüą║ąĖ ą▓ąŠąĘą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī HTTP čü ą┤čĆčāą│ąĖą╝ąĖ ą┐čĆąŠč鹊ą║ąŠą╗ą░ą╝ąĖ, ąĮąŠ ą▓ ą┐ąŠą┤ą░ą▓ą╗čÅčÄčēąĄą╝ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ čüą╗čāčćą░ąĄą▓ HTTP ąŠčéą┐čĆą░ą▓ą╗čÅąĄčé čüą▓ąŠąĖ ą┤ą░ąĮąĮčŗąĄ ą┐ąŠ TCP. ą£čŗ ą▒čāą┤ąĄą╝ čĆą░ą▒ąŠčéą░čéčī čü ąĮąĄąŠą▒čĆą░ą▒ąŠčéą░ąĮąĮčŗą╝ąĖ ą▒ą░ą╣čéą░ą╝ąĖ TCP ąĖ HTTP ąĘą░ą┐čĆąŠčüąŠą▓ ąĖ ąŠčéą▓ąĄč鹊ą▓.
ą×ąČąĖą┤ą░ąĮąĖąĄ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ TCP. ąØą░čł web-čüąĄčĆą▓ąĄčĆ ą┤ąŠą╗ąČąĄąĮ ąŠčéą║čĆčŗčéčī ą┐čĆąŠčüą╗čāčłąĖą▓ą░ąĮąĖąĄ čüąŠą║ąĄčéą░ ą▓ ąŠąČąĖą┤ą░ąĮąĖąĖ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ TCP ąŠčé ą║ą╗ąĖąĄąĮčéą░, čéą░ą║ čćč鹊 čŹč鹊 ą┐ąĄčĆą▓ąŠąĄ, č湥ą╝ ą╝čŗ ąĘą░ą╣ą╝ąĄą╝čüčÅ. ąĪčéą░ąĮą┤ą░čĆčéąĮą░čÅ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą╝ąŠą┤čāą╗čī std::net, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĮą░ą╝ čŹč鹊 čüą┤ąĄą╗ą░čéčī. ąöą░ą▓ą░ą╣č鹥 čüąŠąĘą┤ą░ą┤ąĖą╝ ąĮąŠą▓čŗą╣ ą┐čĆąŠąĄą║čé, ą║ą░ą║ ąŠą▒čŗčćąĮąŠ:
$ cargo new hello
Created binary (application) `hello` project
$ cd hello
ąóąĄą┐ąĄčĆčī ą▓ą▓ąĄą┤ąĄą╝ ą║ąŠą┤ ą╗ąĖčüčéąĖąĮą│ 20-1 ą▓ čäą░ą╣ą╗ src/main.rs. ąŁč鹊čé ą║ąŠą┤ ą┐čĆąŠčüą╗čāčłąĖą▓ą░ąĄčé ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖąĄ ąĮą░ ą╗ąŠą║ą░ą╗čīąĮąŠą╝ ą░ą┤čĆąĄčüąĄ ąĖ ą┐ąŠčĆčéčā 127.0.0.1:7878 ąĮą░ ą┐čĆąĄą┤ą╝ąĄčé ą┐ąŠą╗čāč湥ąĮąĖčÅ ą▓čģąŠą┤čÅčēąĖčģ čüąŠąĄą┤ąĖąĮąĄąĮąĖą╣ TCP. ąÜąŠą│ą┤ą░ ą║ąŠą┤ ą┐ąŠą╗čāčćąĖčé ą▓čģąŠą┤čÅčēąĖą╣ ą┐ąŠč鹊ą║ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ, ąŠąĮ ąĮą░ą┐ąĄčćą░čéą░ąĄčé "Connection established!".
use std::net::TcpListener;
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
println!("Connection established!");
}
}
ąøąĖčüčéąĖąĮą│ 20-1. ą¤čĆąŠčüą╗čāčłąĖą▓ą░ąĮąĖąĄ ą▓čģąŠą┤čÅčēąĖčģ čüąŠąĄą┤ąĖąĮąĄąĮąĖą╣ TCP ąĖ ą┐ąĄčćą░čéčī čüąŠąŠą▒čēąĄąĮąĖčÅ ąŠ č鹊ą╝, čćč鹊 ą┐ąŠą╗čāč湥ąĮ ą┐ąŠč鹊ą║ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ stream (čäą░ą╣ą╗ src/main.rs).
ąśčüą┐ąŠą╗čīąĘčāčÅ TcpListener, ą╝čŗ ą╝ąŠąČąĄą╝ ą┐čĆąŠčüą╗čāčłąĖą▓ą░čéčī čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ TCP ąĮą░ ą░ą┤čĆąĄčüąĄ 127.0.0.1:7878. ąÆ čŹč鹊ą╝ ą░ą┤čĆąĄčüąĄ ą┐ąĄčĆąĄą┤ ą┤ą▓ąŠąĄč鹊čćąĖąĄą╝ čüč鹊ąĖčé IP-ą░ą┤čĆąĄčü, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĖčüčāčéčüčéą▓čāąĄčé ąĮą░ ą╗čÄą▒ąŠą╝ ą║ąŠą╝ą┐čīčÄč鹥čĆąĄ (čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝čŗą╣ ą░ą┤čĆąĄčü loopback, ąĖą╗ąĖ localhost), ą░ 7878 čŹč鹊 ąĮąŠą╝ąĄčĆ ą┐čĆąŠčüą╗čāčłąĖą▓ą░ąĄą╝ąŠą│ąŠ ą┐ąŠčĆčéą░. ą×ą▒čŗčćąĮąŠ HTTP čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ ą┐ąŠčĆčéčā 80, ąĮąŠ ą╝čŗ ą▓čŗą▒čĆą░ą╗ąĖ ąĘą┤ąĄčüčī ą┐ąŠčĆčé 7878, čćč鹊ą▒čŗ ąŠąĮ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░ąĮąĮąŠ ąĮąĄ ą║ąŠąĮčäą╗ąĖą║č鹊ą▓ą░ą╗ čü ą┤čĆčāą│ąĖą╝ ą▓ąĄą▒-čüąĄčĆą▓ąĄčĆąŠą╝, ą║ąŠč鹊čĆčŗą╣ ą▓ąŠąĘą╝ąŠąČąĮąŠ čāąČąĄ čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ ą▓ą░čłąĄą╣ ą╝ą░čłąĖąĮąĄ.
ążčāąĮą║čåąĖčÅ bind ą▓ čŹč鹊ą╝ čüčåąĄąĮą░čĆąĖąĖ čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ čäčāąĮą║čåąĖąĖ new, ąĖ ąŠąĮą░ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ąĮąŠą▓čŗą╣ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ TcpListener. ążčāąĮą║čåąĖčÅ ąĮą░ąĘą▓ą░ąĮą░ bind ą┐ąŠč鹊ą╝čā, čćč鹊 ą▓ č鹥čĆą╝ąĖąĮąŠą╗ąŠą│ąĖąĖ čüąĄč鹥ą╣ čüąŠąĄą┤ąĖąĮąĄąĮąĖąĄ ąĮą░ ą┐čĆąŠčüą╗čāčłąĖą▓ą░ąĄą╝ąŠą╝ ą┐ąŠčĆčéčā ąĖąĘą▓ąĄčüčéąĮąŠ ą║ą░ą║ "ą┐čĆąĖą▓čÅąĘą║ą░" (binding) ą║ ą┐ąŠčĆčéčā.
ążčāąĮą║čåąĖčÅ bind ą▓ąŠąĘą▓čĆą░čéąĖčé Result< T, E>, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čāčüą┐ąĄčłąĮąŠą╣ ą╗ąĖ ą▒čŗą╗ą░ ą┐čĆąĖą▓čÅąĘą║ą░ ą║ ą┐ąŠčĆčéčā, ąĖą╗ąĖ ąĮąĄčé. ąØą░ą┐čĆąĖą╝ąĄčĆ, čĆą░ąĘčĆąĄčłąĄąĮąĖąĄ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖčÅ ą║ ą┐ąŠčĆčéčā 80 čéčĆąĄą▒čāąĄčé ą┐čĆą░ą▓ ą░ą┤ą╝ąĖąĮąĖčüčéčĆą░č鹊čĆą░ (ąĮąĄ ą░ą┤ą╝ąĖąĮąĖčüčéčĆą░č鹊čĆčŗ ą╝ąŠą│čāčé ąĘą░ą┐čāčüčéąĖčéčī ą┐čĆąŠčüą╗čāčłąĖą▓ą░ąĮąĖčÅ č鹊ą╗čīą║ąŠ ąĮą░ ą┐ąŠčĆčéą░čģ ą▒ąŠą╗čīčłąĄ 1023), čéą░ą║ čćč鹊 ąĄčüą╗ąĖ ą╝čŗ ą┐ąŠą┐čŗčéą░ąĄą╝čüčÅ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī čüąŠąĄą┤ąĖąĮąĄąĮąĖąĄ čü ą┐ąŠčĆč鹊ą╝ 80 ą▒ąĄąĘ ą┐čĆąĖą▓ąĖą╗ąĄą│ąĖą╣ ą░ą┤ą╝ąĖąĮąĖčüčéčĆą░č鹊čĆą░, č鹊 ą┐čĆąĖą▓čÅąĘą║ą░ ą║ ą┐ąŠčĆčéčā ąĮąĄ čüčĆą░ą▒ąŠčéą░ąĄčé. ą¤čĆąĖą▓čÅąĘą║ą░ čéą░ą║ąČąĄ ąĮąĄ čüčĆą░ą▒ąŠčéą░ąĄčé, ąĮą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą▒čāą┤čāčé ąĘą░ą┐čāčēąĄąĮčŗ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą┤ą▓ąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ą┐čĆąŠčüą╗čāčłąĖą▓ą░čÄčēąĖąĄ ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ ą┐ąŠčĆčé. ą¤ąŠčüą║ąŠą╗čīą║čā ą╝čŗ ą┐ąĖčłąĄą╝ ą▒ą░ąĘąŠą▓čŗą╣ čüąĄčĆą▓ąĄčĆ č鹊ą╗čīą║ąŠ čü čåąĄą╗čīčÄ ąŠą▒čāč湥ąĮąĖčÅ, č鹊 ąĘą┤ąĄčüčī ą╝čŗ ąĮąĄ ą▒čāą┤ąĄą╝ ąĘą░ą▒ąŠčéąĖčéčīčüčÅ ąŠą▒čĆą░ą▒ąŠčéą║ąŠą╣ ą┐ąŠą┤ąŠą▒ąĮčŗčģ ąŠčłąĖą▒ąŠą║; ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą╝čŗ ą┐čĆąŠčüč鹊 ą▓čŗąĘčŗą▓ą░ąĄą╝ unwrap ą┤ą╗čÅ ąŠčüčéą░ąĮąŠą▓ą║ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ąĄčüą╗ąĖ ą┐čĆąŠąĖąĘąŠą╣ą┤čāčé ąŠčłąĖą▒ą║ąĖ.
ą£ąĄč鹊ą┤ incoming ąĮą░ TcpListener ą▓ąŠąĘą▓čĆą░čéąĖčé ąĖč鹥čĆą░č鹊čĆ, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ąĮą░ą╝ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ą┐ąŠč鹊ą║ąŠą▓ (ą░ ąĖą╝ąĄąĮąĮąŠ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą▓ stream čéąĖą┐ą░ TcpStream). ą×ą┤ąĖąĮ stream ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé ąŠčéą║čĆčŗč鹊ąĄ čüąŠąĄą┤ąĖąĮąĄąĮąĖąĄ ą╝ąĄąČą┤čā ą║ą╗ąĖąĄąĮč鹊ą╝ ąĖ čüąĄčĆą▓ąĄčĆąŠą╝r. ąĪąŠąĄą┤ąĖąĮąĄąĮąĖąĄ čŹč鹊 ąĖą╝čÅ ą┐ąŠą╗ąĮąŠą│ąŠ ą┐čĆąŠčåąĄčüčüą░ ąĘą░ą┐čĆąŠčüą░ ąĖ ąŠčéą▓ąĄčéą░, ą║ąŠą│ą┤ą░ ą║ą╗ąĖąĄąĮčé ą┐ąŠą┤ą║ą╗čÄčćą░ąĄčéčüčÅ ą║ čüąĄčĆą▓ąĄčĆčā, čüąĄčĆą▓ąĄčĆ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąŠčéą▓ąĄčé ąĖ ąĘą░ą║čĆčŗą▓ą░ąĄčé čüąŠąĄą┤ąĖąĮąĄąĮąĖąĄ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą╝čŗ ą▒čāą┤ąĄą╝ čćąĖčéą░čéčī ąĖąĘ TcpStream, čćč鹊ą▒čŗ čāą▓ąĖą┤ąĄčéčī, čćč鹊 ąŠčéą┐čĆą░ą▓ąĖą╗ ą║ą╗ąĖąĄąĮčé, ą░ ąĘą░č鹥ą╝ ąĘą░ą┐ąĖčłąĄą╝ ąĮą░čł ąŠčéą▓ąĄčé ą▓ ą┐ąŠč鹊ą║ (stream), čćč鹊ą▒čŗ ąŠčéą┐čĆą░ą▓ąĖčéčī ą┤ą░ąĮąĮčŗąĄ ąŠą▒čĆą░čéąĮąŠ ą║ą╗ąĖąĄąĮčéčā. ąÆ čåąĄą╗ąŠą╝ čŹč鹊čé čåąĖą║ą╗ for ą▒čāą┤ąĄčé ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī ą║ą░ąČą┤ąŠąĄ čüąŠąĄą┤ąĖąĮąĄąĮąĖąĄ ą┐ąŠ ąŠč湥čĆąĄą┤ąĖ, ąĖ čüąŠąĘą┤ą░ą▓ą░čéčī ąĮą░ą╝ čüąĄčĆąĖčÄ ą┐ąŠč鹊ą║ąŠą▓ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ.
ąĪąĄą╣čćą░čü ąĮą░čłą░ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĘą░ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ ą▓čŗąĘąŠą▓ąĄ unwrap ą┤ą╗čÅ ąŠčüčéą░ąĮąŠą▓ą║ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ąĄčüą╗ąĖ ą┐čĆąŠąĖąĘąŠčłą╗ą░ ą║ą░ą║ą░čÅ-ą╗ąĖą▒ąŠ ąŠčłąĖą▒ą║ą░; ąĄčüą╗ąĖ ąĮąĖ ąŠą┤ąĮąŠą╣ ąŠčłąĖą▒ą║ąĖ ąĮąĄ ą▒čŗą╗ąŠ, č鹊 ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ąĮą░ą┐ąĄčćą░čéą░ąĄčé čüąŠąŠą▒čēąĄąĮąĖąĄ. ą£čŗ ą┤ąŠą▒ą░ą▓ąĖą╝ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╝ ą╗ąĖčüčéąĖąĮą│ąĄ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗą╣ čäčāąĮą║čåąĖąŠąĮą░ą╗ ą┤ą╗čÅ čüą╗čāčćą░čÅ čāčüą┐ąĄčģą░. ą¤čĆąĖčćąĖąĮą░, ą┐ąŠ ą║ąŠč鹊čĆčŗą╣ ą╝ąĄč鹊ą┤ incoming ą╝ąŠąČąĄčé ą▓ąĄčĆąĮčāčéčī ąŠčłąĖą▒ą║čā, ą╝ąŠąČąĄčé ąĘą░ą║ą╗čÄčćą░čéčīčüčÅ ą▓ č鹊ą╝, čćč鹊 ą╝čŗ čäą░ą║čéąĖč湥čüą║ąĖ ąĮąĄ ą▓čŗą┐ąŠą╗ąĮčÅąĄą╝ ąĖč鹥čĆą░čåąĖčÄ ą┐ąŠ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅą╝. ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą╝čŗ ą┐čĆąŠą▓ąŠą┤ąĖą╝ ąĖč鹥čĆą░čåąĖąĖ ą┐ąŠ ą┐ąŠą┐čŗčéą║ą░ą╝ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ. ąĪąŠąĄą┤ąĖąĮąĄąĮąĖąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮąĄčāą┤ą░čćąĮčŗą╝ ą┐ąŠ čĆą░ąĘąĮčŗą╝ ą┐čĆąĖčćąĖąĮą░ą╝, ą╝ąĮąŠą│ąĖąĄ ąĖąĘ ą║ąŠč鹊čĆčŗčģ čüą┐ąĄčåąĖčäąĖčćąĮčŗ ą┤ą╗čÅ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ. ąØą░ą┐čĆąĖą╝ąĄčĆ ą╝ąĮąŠą│ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčŗąĄ čüąĖčüč鹥ą╝čŗ ąŠą│čĆą░ąĮąĖčćąĖą▓ą░čÄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ąŠčéą║čĆčŗčéčŗčģ čüąŠąĄą┤ąĖąĮąĄąĮąĖą╣, ą║ąŠč鹊čĆčŗąĄ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮą░čÅ čüąĖčüč鹥ą╝ą░ ą╝ąŠąČąĄčé ą┐ąŠą┤ą┤ąĄčƹȹ░čéčī; ąĮąŠą▓čŗąĄ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ, ą║ąŠą│ą┤ą░ ą┐čĆąĄą▓čŗčłąĄąĮąŠ ą┤ąŠą┐čāčüčéąĖą╝ąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čüąŠąĄą┤ąĖąĮąĄąĮąĖą╣, ą▒čāą┤čāčé ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ąŠčłąĖą▒ą║čā, ą┐ąŠą║ą░ ąŠčéą║čĆčŗčéčŗąĄ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ ąĮąĄ ąĘą░ą║čĆąŠčÄčéčüčÅ.
ąöą░ą▓ą░ą╣č鹥 ą┐ąŠą┐čĆąŠą▒čāąĄą╝ ąĘą░ą┐čāčüčéąĖčéčī čŹč鹊čé ą║ąŠą┤ ą║ąŠą╝ą░ąĮą┤ąŠą╣ cargo run ą▓ č鹥čĆą╝ąĖąĮą░ą╗ąĄ, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ąŠčéą║čĆąŠą╣č鹥 ą░ą┤čĆąĄčü 127.0.0.1:7878 ą▓ web-ą▒čĆą░čāąĘąĄčĆąĄ. ąæčĆą░čāąĘąĄčĆ ą┤ąŠą╗ąČąĄąĮ ą┐ąŠą║ą░ąĘą░čéčī čüąŠąŠą▒čēąĄąĮąĖąĄ ąŠą▒ ąŠčłąĖą▒ą║ąĄ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ "Connection reset", ą┐ąŠč鹊ą╝čā čćč鹊 ąĮą░čł čüąĄčĆą▓ąĄčĆ ą┐ąŠą║ą░ ąĮąĄ ąŠčéą┐čĆą░ą▓ą╗čÅąĄčé ąŠą▒čĆą░čéąĮąŠ ąĮąĖą║ą░ą║ąĖąĄ ą┤ą░ąĮąĮčŗąĄ. ą×ą┤ąĮą░ą║ąŠ ą▓ č鹥čĆą╝ąĖąĮą░ą╗ąĄ ą╝čŗ čāą▓ąĖą┤ąĖą╝ ąĮąĄčüą║ąŠą╗čīą║ąŠ čüąŠąŠą▒čēąĄąĮąĖą╣, ą║ąŠą│ą┤ą░ ą▒čĆą░čāąĘąĄčĆ ą┐ąŠą┤ą║ą╗čÄčćą░ąĄčéčüčÅ ą║ čüąĄčĆą▓ąĄčĆčā.
Running `target/debug/hello`
Connection established!
Connection established!
Connection established!
ąśąĮąŠą│ą┤ą░ ą▓ ąŠčéą▓ąĄčé ąĮą░ ąŠą┤ąĮąŠ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖąĄ ą▒čĆą░čāąĘąĄčĆą░ čüąŠąŠą▒čēąĄąĮąĖą╣ "Connection established!" ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ; čŹč鹊 ą╝ąŠąČąĄčé ą┐čĆąŠąĖčüčģąŠą┤ąĖčéčī ąĖąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 ą▒čĆą░čāąĘąĄčĆ ą┤ąĄą╗ą░ąĄčé ąĘą░ą┐čĆąŠčü ąŠč鹊ą▒čĆą░ąČąĄąĮąĖčÅ čüčéčĆą░ąĮąĖčåčŗ ą┤ą╗čÅ ą┤čĆčāą│ąĖčģ čĆąĄčüčāčĆčüąŠą▓, čéą░ą║ąĖčģ ą║ą░ą║ ąĖą║ąŠąĮą║ąĖ favicon.ico, ą║ąŠč鹊čĆą░čÅ ą┐ąŠčÅą▓ą╗čÅąĄčéčüčÅ ąĮą░ ąĘą░ą║ą╗ą░ą┤ą║ąĄ ą▒čĆą░čāąĘąĄčĆą░. ąóą░ą║ąČąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī, čćč鹊 ą▒čĆą░čāąĘąĄčĆ ą┐ąŠą┐čŗčéą░ąĄčéčüčÅ ą┐ąŠą┤ą║ą╗čÄčćąĖčéčīčüčÅ ą║ čüąĄčĆą▓ąĄčĆčā ąĮąĄčüą║ąŠą╗čīą║ąŠ čĆą░ąĘ, ą┐ąŠč鹊ą╝čā čćč鹊 čüąĄčĆą▓ąĄčĆ ąĮąĄ ąŠčéą▓ąĄčćą░ąĄčé ąŠčéą┐čĆą░ą▓ą║ąŠą╣ ą┤ą░ąĮąĮčŗčģ. ąÜąŠą│ą┤ą░ stream ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ, ąĖ ąŠčéą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ ą▓ ą║ąŠąĮčåąĄ čåąĖą║ą╗ą░, čüąŠąĄą┤ąĖąĮąĄąĮąĖąĄ ąĘą░ą║čĆčŗą▓ą░ąĄčéčüčÅ ą║ą░ą║ čćą░čüčéčī čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ drop. ąæčĆą░čāąĘąĄčĆčŗ ąĖąĮąŠą│ą┤ą░ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčé ąĘą░ą║čĆčŗčéčŗąĄ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ ą┐ąŠą▓č鹊čĆąĮčŗą╝ąĖ ą┐ąŠą┐čŗčéą║ą░ą╝ąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 ą┐čĆąŠą▒ą╗ąĄą╝ą░ čüąĄčéąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čĆąĄą╝ąĄąĮąĮą░čÅ.
ą¤ąŠą╝ąĮąĖč鹥, čćč鹊 ąŠčüčéą░ąĮąŠą▓ąĖčéčī ą┐čĆąŠą│čĆą░ą╝ą╝čā ą╝ąŠąČąĮąŠ ąĮą░ąČą░čéąĖąĄą╝ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ ą║ą╗ą░ą▓ąĖčł Ctrl+C, ą║ąŠą│ą┤ą░ ą▓čŗ čģąŠčéąĖč鹥 ą┐čĆąĄą║čĆą░čéąĖčéčī čĆą░ą▒ąŠčéčā ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╣ ą▓ąĄčĆčüąĖąĖ ą║ąŠą┤ą░. ąŚą░č鹥ą╝ ą╝ąŠąČąĮąŠ ą┐ąĄčĆąĄąĘą░ą┐čāčüčéąĖčéčī ą┐čĆąŠą│čĆą░ą╝ą╝čā ą║ąŠą╝ą░ąĮą┤ąŠą╣ cargo run ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ą▓čŗ čüą┤ąĄą╗ą░ąĄč鹥 ąĖąĘą╝ąĄąĮąĄąĮąĖąĄ ąĖ ąĘą░ą┐čāčüčéąĖč鹥 ąĮąŠą▓čāčÄ ą▓ąĄčĆčüąĖčÄ ą║ąŠą┤ą░.
ą¦č鹥ąĮąĖąĄ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ ąĘą░ą┐čĆąŠčüą░. ą¦č鹊ą▒čŗ čĆą░ąĘą┤ąĄą╗ąĖčéčī ą┐čĆąŠą▒ą╗ąĄą╝čŗ ą┐ąŠą╗čāč湥ąĮąĖčÅ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ ąĖ ą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖčÅ ąĮąĄą║ąŠč鹊čĆčŗčģ ą┤ąĄą╣čüčéą▓ąĖą╣ čü čüąŠąĄą┤ąĖąĮąĄąĮąĖąĄą╝, ą╝čŗ čüąŠąĘą┤ą░ą┤ąĖą╝ ąĮąŠą▓čāčÄ čäčāąĮą║čåąĖčÄ handle_connection, ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčēčāčÄ čüąŠąĄą┤ąĖąĮąĄąĮąĖąĄ. ąÆ č鹥ą╗ąĄ čŹč鹊ą╣ čäčāąĮą║čåąĖąĖ ą╝čŗ ą▒čāą┤ąĄą╝ čüčćąĖčéčŗą▓ą░čéčī ą┤ą░ąĮąĮčŗąĄ ąĖąĘ TCP stream ąĖ ą┐ąĄčćą░čéą░čéčī ąĖčģ, čćč鹊ą▒čŗ čāą▓ąĖą┤ąĄčéčī, ą║ą░ą║ąĖąĄ ą┤ą░ąĮąĮčŗąĄ ą┐ąŠčüčŗą╗ą░ąĄčé ą▒čĆą░čāąĘąĄčĆ. ą¤ąŠą╝ąĄąĮčÅą╣č鹥 ą║ąŠą┤, ą║ą░ą║ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 20-2.
use std::{
io::{prelude::*, BufReader},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&mut stream);
let http_request: Vec< _> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
println!("Request: {http_request:#?}");
}
ąøąĖčüčéąĖąĮą│ 20-2: Reading from the TcpStream and printing the data (čäą░ą╣ą╗ src/main.rs).
ą£čŗ ą┐čĆąĖą▓ąĄą╗ąĖ std::io::prelude ąĖ std::io::BufReader ą▓ ąŠą▒ą╗ą░čüčéčī ą▓ąĖą┤ąĖą╝ąŠčüčéąĖ, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ čéčĆąĄą╣čéą░ą╝ ąĖ čéąĖą┐ą░ą╝, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ą▓čŗą┐ąŠą╗ąĮčÅčéčī čü ą┐ąŠč鹊ą║ąŠą╝ TCP ąŠą┐ąĄčĆą░čåąĖąĖ čćč鹥ąĮąĖčÅ ąĖ ąĘą░ą┐ąĖčüąĖ. ąÆ čåąĖą║ą╗ąĄ for čäčāąĮą║čåąĖąĖ main ą▓ą╝ąĄčüč鹊 ą┐ąĄčćą░čéąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ, ą║ąŠč鹊čĆąŠąĄ ą│ąŠą▓ąŠčĆąĖčé ąĮą░ą╝ ąŠ čüąŠąĘą┤ą░ąĮąĖąĖ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ, ą╝čŗ č鹥ą┐ąĄčĆčī ą▒čāą┤ąĄą╝ ą▓čŗąĘčŗą▓ą░čéčī čäčāąĮą║čåąĖčÄ handle_connection ąĖ ą┐ąĄčĆąĄą┤ą░ą▓ą░čéčī ą▓ ąĮąĄčæ ą┐ąŠč鹊ą║ stream.
ąÆ čäčāąĮą║čåąĖąĖ handle_connection ą╝čŗ čüąŠąĘą┤ą░ąĄą╝ ąĮąŠą▓čŗą╣ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ BufReader, ą║ąŠč鹊čĆčŗą╣ ąŠą▒ąĄčĆčéčŗą▓ą░ąĄčé ą║ąŠč鹊čĆčŗą╣ ąŠą▒čĆą░čēą░ąĄčéčüčÅ ą║ stream č湥čĆąĄąĘ ą╝čāčéąĖčĆčāąĄą╝čāčÄ čüčüčŗą╗ą║čā. BufReader ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé ą▒čāč乥čĆąĖąĘą░čåąĖčÄ ą┤ą╗čÅ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÅ ą▓čŗąĘąŠą▓ąŠą▓ ą╝ąĄč鹊ą┤ąŠą▓ std::io::Read čéčĆąĄą╣čéą░.
ą£čŗ čüąŠąĘą┤ą░ą╗ąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ http_request, čćč鹊ą▒čŗ čüąŠą▒čĆą░čéčī čüčéčĆąŠą║ąĖ ąĘą░ą┐čĆąŠčüą░, ą║ąŠč鹊čĆčŗąĄ ą▒čĆą░čāąĘąĄčĆ ą┐ąŠčüčŗą╗ą░ąĄčé čüąĄčĆą▓ąĄčĆčā. ą£čŗ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄą╝, čćč鹊 čģąŠčéąĖą╝ čüąŠą▒čĆą░čéčī čŹčéąĖ čüčéčĆąŠą║ąĖ ą▓ ą▓ąĄą║č鹊čĆ ą┐čāč鹥ą╝ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ ą░ąĮąĮąŠčéą░čåąĖąĖ čéąĖą┐ą░ Vec< _>.
BufReader čĆąĄą░ą╗ąĖąĘčāąĄčé čéčĆąĄą╣čé std::io::BufRead, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą╝ąĄč鹊ą┤ lines. ą£ąĄč鹊ą┤ lines ą▓ąŠąĘą▓čĆą░čéąĖčé ąĖč鹥čĆą░č鹊čĆ Result< String, std::io::Error> ą┐čāč鹥ą╝ čĆą░ąĘą┤ąĄą╗ąĄąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ stream ąĮą░ ą┐ąŠčĆčåąĖąĖ, ą║ąŠą│ą┤ą░ ą▓ ą┐ąŠč鹊ą║ąĄ ą▓čüčéčĆąĄčćą░ąĄčéčüčÅ ą▒ą░ą╣čé ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ. ą¦č鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ą║ą░ąČą┤čāčÄ čüčéčĆąŠą║čā String, ą╝čŗ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄą╝ ą║ą░ąČą┤čŗą╣ Result č湥čĆąĄąĘ map ąĖ unwrap. Result ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠčłąĖą▒ą║ąŠą╣, ąĄčüą╗ąĖ ą┤ą░ąĮąĮčŗąĄ čüąŠą┤ąĄčƹȹ░čé ąĮąĄą┤ąŠą┐čāčüčéąĖą╝čŗąĄ ą┤ą╗čÅ UTF-8 ą┤ą░ąĮąĮčŗąĄ, ąĖą╗ąĖ ąĄčüą╗ąĖ ąĄčüčéčī ą┐čĆąŠą▒ą╗ąĄą╝ą░ čü čćč鹥ąĮąĖąĄą╝ ąĖąĘ stream. ą×ą┐čÅčéčī-čéą░ą║ąĖ, čĆąĄą░ą╗čīąĮą░čÅ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą┤ąŠą╗ąČąĮą░ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī čŹčéąĖ ąŠčłąĖą▒ą║ąĖ ą▒ąŠą╗ąĄąĄ ą┐čĆą░ą▓ąĖą╗čīąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝, ąŠą┤ąĮą░ą║ąŠ ąĘą┤ąĄčüčī ą┤ą╗čÅ ą┤ąĄą╝ąŠąĮčüčéčĆą░čéąĖą▓ąĮąŠą│ąŠ čāą┐čĆąŠčēąĄąĮąĖčÅ ą╝čŗ ą▓čŗą▒čĆą░ą╗ąĖ ąŠčüčéą░ąĮąŠą▓čā ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą▓ čüą╗čāčćą░ąĄ ąŠčłąĖą▒ą║ąĖ.
ąæčĆą░čāąĘąĄčĆ čüąĖą│ąĮą░ą╗ąĖąĘąĖčĆčāąĄčé ąŠ ą║ąŠąĮčåąĄ ąĘą░ą┐čĆąŠčüą░ HTTP ąŠčéą┐čĆą░ą▓ą║ąŠą╣ ą┤ą▓čāčģ čüąĖą╝ą▓ąŠą╗ąŠą▓ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ, ą┐ąŠčŹč鹊ą╝čā ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ąŠą┤ąĮąŠą│ąŠ ąĘą░ą┐čĆąŠčüą░ ąĖąĘ stream ą╝čŗ ąĖąĘą▓ą╗ąĄą║ą░ąĄą╝ čüčéčĆąŠą║ąĖ, ą┐ąŠą║ą░ ą┐ąŠą╗čāčćąĖą╝ čüčéčĆąŠą║čā, ą║ąŠč鹊čĆą░čÅ čÅą▓ą╗čÅąĄčéčüčÅ ą┐čāčüč鹊ą╣ čüčéčĆąŠą║ąŠą╣. ąÜą░ą║ č鹊ą╗čīą║ąŠ ą╝čŗ čüąŠą▒čĆą░ą╗ąĖ čüčéčĆąŠą║ąĖ ą▓ ą▓ąĄą║č鹊čĆ, ą╝čŗ čĆą░čüą┐ąĄčćą░čéčŗą▓ą░ąĄą╝ ąĖčģ, ąĖčüą┐ąŠą╗čīąĘčāčÅ ąŠčéą╗ą░ą┤ąŠčćąĮąŠąĄ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖąĄ, čćč鹊ą▒čŗ ąĖąĘčāčćąĖčéčī ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▒čĆą░čāąĘąĄčĆą░, ąŠčéą┐čĆą░ą▓ą╗čÅąĄą╝čŗąĄ ąĮą░čłąĄą╝čā čüąĄčĆą▓ąĄčĆčā.
ąöą░ą▓ą░ą╣č鹥 ą┐ąŠą┐čĆąŠą▒čāąĄą╝ čŹč鹊čé ą║ąŠą┤, ą┤ą╗čÅ č湥ą│ąŠ ąĘą░ą┐čāčüčéąĖč鹥 ą┐čĆąŠą│čĆą░ą╝ą╝čā ąĖ čüąĮąŠą▓ą░ ą▓čŗą┐ąŠą╗ąĮąĖč鹥 ąĘą░ą┐čĆąŠčü ą▓ ą▒čĆą░čāąĘąĄčĆąĄ ą┐ąŠ ą░ą┤čĆąĄčüčā 127.0.0.1:7878. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą▒čĆą░čāąĘąĄčĆ ą▓čüąĄ ąĄčēąĄ čüąŠąŠą▒čēą░ąĄčé ąŠą▒ ąŠčłąĖą▒ą║ąĄ, ąĮąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą▓čŗą▓ąĄą┤ąĄčé ą┐čĆąĖą╝ąĄčĆąĮąŠ čéą░ą║ąĖąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished dev [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/hello`
Request: [
"GET / HTTP/1.1",
"Host: 127.0.0.1:7878",
"User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:99.0)
Gecko/20100101 Firefox/99.0",
"Accept: text/html,application/xhtml+xml,application/xml;q=0.9,
image/avif,image/webp,*/*;q=0.8",
"Accept-Language: en-US,en;q=0.5",
"Accept-Encoding: gzip, deflate, br",
"DNT: 1",
"Connection: keep-alive",
"Upgrade-Insecure-Requests: 1",
"Sec-Fetch-Dest: document",
"Sec-Fetch-Mode: navigate",
"Sec-Fetch-Site: none",
"Sec-Fetch-User: ?1",
"Cache-Control: max-age=0",
]
ąÆ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą▓ą░čłąĄą│ąŠ ą▒čĆą░čāąĘąĄčĆą░ čŹčéąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╝ąŠą│čāčé ąĮąĄčüą║ąŠą╗čīą║ąŠ ąŠčéą╗ąĖčćą░čéčīčüčÅ. ąóąĄą┐ąĄčĆčī, ą║ąŠą│ą┤ą░ ą╝čŗ ąĮą░ą┐ąĄčćą░čéą░ą╗ąĖ ą┤ą░ąĮąĮčŗąĄ ąĘą░ą┐čĆąŠčüą░, ą╝čŗ ą╝ąŠąČąĄą╝ čāą▓ąĖą┤ąĄčéčī ą┐čĆąĖčćąĖąĮčā, ą┐ąŠč湥ą╝čā ą┐ąŠą╗čāčćą░ą╗ąĖ ąĮąĄčüą║ąŠą╗čīą║ąŠ čüąŠąĄą┤ąĖąĮąĄąĮąĖą╣ ą▓ ąŠą┤ąĮąŠą╝ ąĘą░ą┐čĆąŠčüąĄ ą▒čĆą░čāąĘąĄčĆą░, ą┐ąŠčüą╝ąŠčéčĆąĄą▓ ą┐čāčéčī ą┐ąŠčüą╗ąĄ GET ą▓ ą┐ąĄčĆą▓ąŠą╣ čüčéčĆąŠą║ąĄ ąĘą░ą┐čĆąŠčüą░. ąĢčüą╗ąĖ ą▓čüąĄ ą┐ąŠą▓č鹊čĆčÅčÄčēąĖąĄčüčÅ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ ąĘą░ą┐čĆą░čłąĖą▓ą░čÄčé /, č鹊 ą╝čŗ ąĘąĮą░ąĄą╝, čćč鹊 ą▒čĆą░čāąĘąĄčĆ ą┐čŗčéą░ąĄčéčüčÅ ąĖąĘą▓ą╗ąĄčćčī / ą┐ąŠą▓č鹊čĆąĮąŠ, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąĮ ąĮąĄ ą┐ąŠą╗čāčćą░ąĄčé ąŠčéą▓ąĄčéą░ ąŠčé ąĮą░čłąĄą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
ąöą░ą▓ą░ą╣č鹥 čĆą░ąĘą▒ąĄčĆąĄą╝ čŹčéąĖ ą┤ą░ąĮąĮčŗąĄ ąĘą░ą┐čĆąŠčüą░, čćč鹊ą▒čŗ ą┐ąŠąĮčÅčéčī, čćč鹊 ą▒čĆą░čāąĘąĄčĆ ąĘą░ą┐čĆą░čłąĖą▓ą░ąĄčé ąŠčé ąĮą░čłąĄą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
ąśąĘ č湥ą│ąŠ čüąŠčüč鹊ąĖčé ąĘą░ą┐čĆąŠčü HTTP. ą¤čĆąŠč鹊ą║ąŠą╗ HTTP č鹥ą║čüč鹊ą▓čŗą╣, ąĖ ąĄą│ąŠ ąĘą░ą┐čĆąŠčü ąŠč乊čĆą╝ą╗ąĄąĮ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
Method Request-URI HTTP-Version CRLF
headers CRLF
message-body
ą¤ąĄčĆą▓ą░čÅ čüčéčĆąŠą║ą░ ąĘą░ą┐čĆąŠčüą░ čüąŠą┤ąĄčƹȹĖčé ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠ ą║ą╗ąĖąĄąĮč鹥, ą║ąŠč鹊čĆčŗą╣ ą▓čŗą┐ąŠą╗ąĮąĖą╗ ąĘą░ą┐čĆąŠčü. ą┐ąĄčĆą▓ą░čÅ čćą░čüčéčī čüčéčĆąŠą║ąĖ ąĘą░ą┐čĆąŠčüą░ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą╝ąĄč鹊ą┤ ąĘą░ą┐čĆąŠčüą░, čéą░ą║ąŠą╣ ą║ą░ą║ GET ąĖą╗ąĖ POST, čćč鹊 ąŠą┐ąĖčüčŗą▓ą░ąĄčé ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąĄčĆąĄą┤ą░čćąĖ ą┤ą░ąĮąĮčŗčģ ą╝ąĄąČą┤čā ą║ą╗ąĖąĄąĮč鹊ą╝ ąĖ čüąĄčĆą▓ąĄčĆąŠą╝. ąØą░čł ą║ą╗ąĖąĄąĮčé ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąĘą░ą┐čĆąŠčü GET, čćč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ąŠąĮ ąĘą░ą┐čĆą░čłąĖą▓ą░ąĄčé ąĖąĮč乊čĆą╝ą░čåąĖčÄ.
ąĪą╗ąĄą┤čāčÄčēą░čÅ čćą░čüčéčī ąĘą░ą┐čĆąŠčüą░ čŹč鹊 /, čćč鹊 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé Uniform Resource Identifier (URI), ąĘą░ą┐čĆą░čłąĖą▓ą░ąĄą╝čŗą╣ ą║ą╗ąĖąĄąĮč鹊ą╝: URI ą┐ąŠčćčéąĖ, ąĮąŠ ąĮąĄ čüąŠą▓čüąĄą╝, čéą░ą║ąŠą╣ ąČąĄ, ą║ą░ą║ Uniform Resource Locator (URL). ąĀą░ąĘą╗ąĖčćąĖąĄ ą╝ąĄąČą┤čā URI ąĖ URL ą┤ą╗čÅ ąĮą░čłąĖčģ čåąĄą╗ąĄą╣ ąĮąĄ ąĖą╝ąĄąĄčé ąĘąĮą░č湥ąĮąĖčÅ, ąĮąŠ čüą┐ąĄčåąĖčäąĖą║ą░čåąĖčÅ HTTP ąĖčüą┐ąŠą╗čīąĘčāąĄčé č鹥čĆą╝ąĖąĮ URI, čéą░ą║ čćč鹊 ą╝čŗ ąĘą┤ąĄčüčī ą╝ąŠąČąĄą╝ ą┐čĆąŠčüč鹊 ą╝čŗčüą╗ąĄąĮąĮąŠ ąĘą░ą╝ąĄąĮąĖčéčī URI ąĮą░ URL.
ą¤ąŠčüą╗ąĄą┤ąĮčÅčÅ čćą░čüčéčī čŹč鹊 ą▓ąĄčĆčüąĖčÅ HTTP, ą║ąŠč鹊čĆčāčÄ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą║ą╗ąĖąĄąĮčé, ąĖ ąĘą░č鹥ą╝ čüčéčĆąŠą║ą░ ąĘą░ą┐čĆąŠčüą░ ąĘą░ą║ą░ąĮčćąĖą▓ą░ąĄčéčüčÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčīčÄ CRLF. CRLF čŹč鹊 čüąŠą║čĆą░čēąĄąĮąĖąĄ ąŠčé carriage return ąĖ line feed, čŹčéąĖ č鹥čĆą╝ąĖąĮčŗ ą┐čĆąĖčłą╗ąĖ čüąŠ ą▓čĆąĄą╝ąĄąĮ ą┐ąĄčćą░čéąĮąŠą╣ ą╝ą░čłąĖąĮą║ąĖ, ąĖ ąŠą▒ąŠąĘąĮą░čćą░čÄčé ą▒ą░ą╣čéčŗ ą▓ąŠąĘą▓čĆą░čéą░ ą║ą░čĆąĄčéą║ąĖ ąĖ ą┐ąĄčĆąĄą▓ąŠą┤ą░ čüčéčĆąŠą║ąĖ. ą¤ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī CRLF čéą░ą║ąČąĄ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčé ą║ą░ą║ \r\n, ą│ą┤ąĄ \r čŹč鹊 ą▓ąŠąĘą▓čĆą░čé ą║ą░čĆąĄčéą║ąĖ (ą▒ą░ą╣čé 0x0D), ą░ \n čŹč鹊 ą┐ąĄčĆąĄą▓ąŠą┤ čüčéčĆąŠą║ąĖ (ą▒ą░ą╣čé 0x0A). ą¤ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ą▒ą░ą╣čé CRLF ąŠčéą┤ąĄą╗čÅąĄčé čüčéčĆąŠą║čā ąĘą░ą┐čĆąŠčüą░ ąŠčé ąŠčüčéą░ą╗čīąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ąĘą░ą┐čĆąŠčüą░. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 CRLF ą┐ąĄčćą░čéą░ąĄčéčüčÅ, čéą░ą║ čćč鹊 ą╝čŗ ą▓ąĖą┤ąĖą╝ ąĮą░čćą░ą╗ąŠ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ ą▓ą╝ąĄčüč鹊 \r\n.
ąōą╗čÅą┤čÅ ąĮą░ ą┤ą░ąĮąĮčŗąĄ čüčéčĆąŠą║ąĖ ąĘą░ą┐čĆąŠčüą░, ą┐ąŠą╗čāč湥ąĮąĮčŗąĄ ąĖąĘ ąĘą░ą┐čāčüą║ą░ ąĮą░čłąĄą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ą╝čŗ ą▓ąĖą┤ąĖą╝, čćč鹊 GET čŹč鹊 ą╝ąĄč鹊ą┤, / čŹč鹊 URI ąĘą░ą┐čĆąŠčüą░, ąĖ HTTP/1.1 ą▓ąĄčĆčüąĖčÅ ą┐čĆąŠč鹊ą║ąŠą╗ą░.
ą¤ąŠčüą╗ąĄ čüčéčĆąŠą║ąĖ ąĘą░ą┐čĆąŠčüą░ ąŠčüčéą░ą╗čīąĮčŗąĄ čüčéčĆąŠą║ąĖ čÅą▓ą╗čÅčÄčéčüčÅ ąĘą░ą│ąŠą╗ąŠą▓ą║ą░ą╝ąĖ, ąĮą░čćąĖąĮą░čÅ čü Host: ąĖ ą┤ą░ą╗ąĄąĄ. ąŚą░ą┐čĆąŠčüčŗ GET ąĮąĄ ąĖą╝ąĄčÄčé č鹥ą╗ą░.
ą¤ąŠą┐čĆąŠą▒čāą╣č鹥 ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąĘą░ą┐čĆąŠčü ąĖąĘ ą┤čĆčāą│ąŠą│ąŠ ą▒čĆą░čāąĘąĄčĆą░, ąĖą╗ąĖ ąĘą░ą┐čĆąŠčüąĖą▓ ą┤čĆčāą│ąŠą╣ ą░ą┤čĆąĄčü, čéą░ą║ąŠą╣ ą║ą░ą║ 127.0.0.1:7878/test, čćč鹊ą▒čŗ čāą▓ąĖą┤ąĄčéčī, ą║ą░ą║ ą┐ąŠą╝ąĄąĮčÅčÄčéčüčÅ ą┤ą░ąĮąĮčŗąĄ ąĘą░ą┐čĆąŠčüą░.
ąóąĄą┐ąĄčĆčī, ą║ąŠą│ą┤ą░ ą╝čŗ ąĘąĮą░ąĄą╝, ą║ą░ą║ ą▓čŗą┤ą░ąĄčé ąĘą░ą┐čĆąŠčü ą▒čĆą░čāąĘąĄčĆ, ą╝čŗ ąŠčéą┐čĆą░ą▓ąĖą╝ ą┤ą░ąĮąĮčŗąĄ ąĄą╝čā ąŠą▒čĆą░čéąĮąŠ!
ą×čéą▓ąĄčé ąĮą░ ąĘą░ą┐čĆąŠčü HTTP. ą£čŗ čüąŠą▒ąĖčĆą░ąĄą╝čüčÅ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ąŠčéą┐čĆą░ą▓ą║čā ą┤ą░ąĮąĮčŗčģ ą▓ ąŠčéą▓ąĄčé ąĮą░ ąĘą░ą┐čĆąŠčü ą║ą╗ąĖąĄąĮčéą░. ą×čéą▓ąĄčéčŗ ą┤ąŠą╗ąČąĮčŗ ąĖą╝ąĄčéčī čüą╗ąĄą┤čāčÄčēąĖą╣ č乊čĆą╝ą░čé:
HTTP-Version Status-Code Reason-Phrase CRLF
headers CRLF
message-body
ą¤ąĄčĆą▓ą░čÅ čüčéčĆąŠą║ą░ čŹč鹊 čüčéčĆąŠą║ą░ čüąŠčüč鹊čÅąĮąĖčÅ, ą║ąŠč鹊čĆą░čÅ čüąŠą┤ąĄčƹȹĖčé ą▓ąĄčĆčüąĖčÄ HTTP (HTTP-Version), ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čāčÄ ą▓ ąŠčéą▓ąĄč鹥, čćąĖčüą╗ąŠą▓ąŠą╣ ą║ąŠą┤ čüčéą░čéčāčüą░, ąŠčåąĄąĮąĖą▓ą░čÄčēąĖą╣ čĆąĄąĘčāą╗čīčéą░čé ąĘą░ą┐čĆąŠčüą░ (Status-Code), ąĖ č鹥ą║čüčé ąŠą┐ąĖčüčŗą▓ą░čÄčēąĖą╣ ą║ąŠą┤ čüčéą░čéčāčüą░ (Reason-Phrase). ąöą░ą╗ąĄąĄ ąĖą┤čāčé ąĘą░ą│ąŠą╗ąŠą▓ą║ąĖ (headers) ąĖ č鹥ą╗ąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ (message-body). ąŁčéąĖ 3 čćą░čüčéąĖ ąŠčéą▓ąĄčéą░ ąŠčéą┤ąĄą╗ąĄąĮčŗ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčīčÄ CRLF.
ąÆąŠčé ą┐čĆąĖą╝ąĄčĆ ąŠčéą▓ąĄčéą░, ą║ąŠč鹊čĆčŗą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄčé HTTP ą▓ąĄčĆčüąĖąĖ 1.1, ą║ąŠą┤ čüčéą░čéčāčüą░ 200, ąĖ OK reason phrase, ą▒ąĄąĘ ąĘą░ą│ąŠą╗ąŠą▓ą║ąŠą▓ ąĖ ą▒ąĄąĘ č鹥ą╗ą░ ąŠčéą▓ąĄčéą░:
HTTP/1.1 200 OK\r\n\r\n
ąÜąŠą┤ čüčéą░čéčāčüą░ 200 čŹč鹊 čüčéą░ąĮą┤ą░čĆčéąĮčŗą╣ ą║ąŠą┤ čāčüą┐ąĄčłąĮąŠą│ąŠ ąŠčéą▓ąĄčéą░. ąŁč鹊 ą╝ąĖąĮąĖą╝ą░ą╗čīąĮčŗą╣ č鹥ą║čüčé čāčüą┐ąĄčłąĮąŠą│ąŠ ąŠčéą▓ąĄčéą░ čüąĄčĆą▓ąĄčĆą░. ąöą░ą▓ą░ą╣č鹥 ąĘą░ą┐ąĖčłąĄą╝ ąĄą│ąŠ ą▓ ą┐ąŠč鹊ą║, čćč鹊ą▒čŗ čüč乊čĆą╝ąĖčĆąŠą▓ą░čéčī čāčüą┐ąĄčłąĮčŗą╣ ąŠčéą▓ąĄčé. ąśąĘ čäčāąĮą║čåąĖąĖ ą╝čŗ čāą┤ą░ą╗ąĖą╝ println!, ą║ąŠč鹊čĆčŗą╣ ą┐ąĄčćą░čéą░ą╗ ą┤ą░ąĮąĮčŗąĄ, ąĖ ąĘą░ą╝ąĄąĮąĖą╝ ą║ąŠą┤ąŠą╝ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 20-3.
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&mut stream);
let http_request: Vec< _> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
let response = "HTTP/1.1 200 OK\r\n\r\n";
stream.write_all(response.as_bytes()).unwrap();
}
ąøąĖčüčéąĖąĮą│ 20-3. ążąŠčĆą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠą│ąŠ čāčüą┐ąĄčłąĮąŠą│ąŠ HTTP-ąŠčéą▓ąĄčéą░ ą┐čāč鹥ą╝ ąĘą░ą┐ąĖčüąĖ ą▓ ą┐ąŠč鹊ą║ stream (čäą░ą╣ą╗ src/main.rs).
ą¤ąĄčĆą▓ą░čÅ ąĮąŠą▓ą░čÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ ąŠčéą▓ąĄčéą░, ą║ąŠč鹊čĆą░čÅ čģčĆą░ąĮąĖčé ą┤ą░ąĮąĮčŗąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ čāčüą┐ąĄčģą░. ąŚą░č鹥ą╝ ą╝čŗ ą▓čŗąĘčŗą▓ą░ąĄą╝ as_bytes ąĮą░ ąĮą░čłąĄą╝ ąŠčéą▓ąĄč鹥, čćč鹊ą▒čŗ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░čéčī ą┤ą░ąĮąĮčŗąĄ čüčéčĆąŠą║ąĖ ą▓ ą▒ą░ą╣čéčŗ. ą£ąĄč鹊ą┤ write_all ąĮą░ stream ą┐čĆąĖąĮąĖą╝ą░ąĄčé &[u8] ąĖ ąŠčéą┐čĆą░ą▓ą╗čÅąĄčé čŹčéąĖ ą▒ą░ą╣čéčŗ ąĮą░ą┐čĆčÅą╝čāčÄ č湥čĆąĄąĘ čüąŠąĄą┤ąĖąĮąĄąĮąĖąĄ. ą¤ąŠčüą║ąŠą╗čīą║čā ąŠą┐ąĄčĆą░čåąĖčÅ write_all ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮąĄčāą┤ą░čćąĮąŠą╣, ą╝čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ unwrap ąĮą░ ą╗čÄą▒ąŠą╝ čĆąĄąĘčāą╗čīčéą░č鹥 ąŠčłąĖą▒ą║ąĖ, ą║ą░ą║ ą┤ąĄą╗ą░ą╗ąĖ čĆą░ąĮčīčłąĄ. ąś ąŠą┐čÅčéčī, ą▓ čĆąĄą░ą╗čīąĮąŠą╝ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ ąĘą┤ąĄčüčī ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąŠčłąĖą▒ą║ąĖ, ą░ ąĮąĄ ą┐čĆąŠčüč鹊ąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
ąĪ čŹčéąĖą╝ąĖ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅą╝ąĖ ąĘą░ą┐čāčüčéąĖč鹥 ą║ąŠą┤ ąĖ čüą┤ąĄą╗ą░ą╣č鹥 ąĘą░ą┐čĆąŠčü ą▓ ą▒čĆą░čāąĘąĄčĆąĄ. ąÆ č鹥čĆą╝ąĖąĮą░ą╗ąĄ ą▒ąŠą╗čīčłąĄ ąĮąĄ ą▒čāą┤čāčé ą┐ąĄčćą░čéą░čéčīčüčÅ ąĮąĖą║ą░ą║ąĖąĄ ą┤ą░ąĮąĮčŗąĄ, čéą░ą║ čćč鹊 ą▓čŗ ąĮąĄ čāą▓ąĖą┤ąĖč鹥 ąĮąĖą║ą░ą║ąŠą╣ ą▓čŗą▓ąŠą┤, ą║čĆąŠą╝ąĄ Cargo. ąÜąŠą│ą┤ą░ ą▓čŗ ąĘą░ą│čĆčāąĘąĖč鹥 čüčüčŗą╗ą║čā 127.0.0.1:7878 ą▓ ą▓ąĄą▒-ą▒čĆą░čāąĘąĄčĆąĄ, č鹊 ą┤ąŠą╗ąČąĮčŗ ą┐ąŠą╗čāčćąĖčéčī ą┐čāčüč鹊ą╣ 菹║čĆą░ąĮ ą▓ą╝ąĄčüč鹊 ąŠčłąĖą▒ą║ąĖ. ąÆčŗ čüą╝ąŠą│ą╗ąĖ ąĘą░čģą░čĆą┤ą║ąŠą┤ąĖčéčī ą┐čĆąĖąĄą╝ ąĘą░ą┐čĆąŠčüą░ HTTP ąĖ ą┐ąŠčüą╗ą░čéčī ąĮą░ ąĮąĄą│ąŠ ąŠčéą▓ąĄčé!
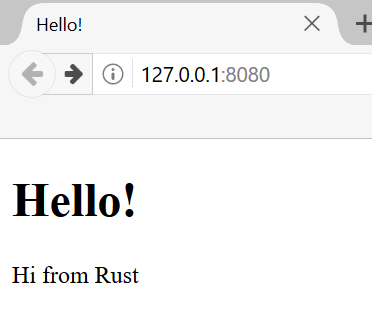
ąÆąŠąĘą▓čĆą░čé čĆąĄą░ą╗čīąĮąŠą│ąŠ HTML. ąöą░ą▓ą░ą╣č鹥 čĆąĄą░ą╗ąĖąĘčāąĄą╝ ą║ą░ą║ąŠą╣-ąĮąĖą▒čāą┤čī čäčāąĮą║čåąĖąŠąĮą░ą╗, ą▒ąŠą╗čīčłąĖą╣, č湥ą╝ ą┐čāčüčéą░čÅ čüčéčĆą░ąĮąĖčćą║ą░. ąĪąŠąĘą┤ą░ą╣č鹥 ąĮąŠą▓čŗą╣ čäą░ą╣ą╗ hello.html ą▓ ą║ąŠčĆąĮąĄą▓ąŠą╣ ą┤ąĖčĆąĄą║č鹊čĆąĖąĖ ą▓ą░čłąĄą│ąŠ ą┐čĆąŠąĄą║čéą░, ąĮąŠ ąĮąĄ ą▓ ą┤ąĖčĆąĄą║č鹊čĆąĖąĖ src. ąÆčŗ ą╝ąŠąČąĄč鹥 ą▓ą▓ąĄčüčéąĖ ą╗čÄą▒ąŠą╣ HTML, ą║ą░ą║ąŠą╣ ąĘą░čģąŠčéąĖč鹥; ą╗ąĖčüčéąĖąĮą│ 20-4 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąŠą┤ąĖąĮ ąĖąĘ ą▓ą░čĆąĖą░ąĮč鹊ą▓.
< !DOCTYPE html>
< html lang="en">
< head>
< meta charset="utf-8">
< title>Hello!< /title>
< /head>
< body>
< h1>Hello!< /h1>
< p>Hi from Rust< /p>
< /body>
< /html>
ąøąĖčüčéąĖąĮą│ 20-4. ą¤čĆąĖą╝ąĄčĆ HTML-čäą░ą╣ą╗ą░ ą┤ą╗čÅ č乊čĆą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ąŠčéą▓ąĄčéą░ čüąĄčĆą▓ąĄčĆą░ (čäą░ą╣ą╗ hello.html).
ąŁč鹊 ą╝ąĖąĮąĖą╝ą░ą╗čīąĮčŗą╣ HTML5 ą┤ąŠą║čāą╝ąĄąĮčé, čü ąĘą░ą│ąŠą╗ąŠą▓ą║ąŠą╝ ąĖ ąĮąĄą║ąŠč鹊čĆčŗą╝ č鹥ą║čüč鹊ą╝. ąöą╗čÅ ą▓ąŠąĘą▓čĆą░čéą░ ąĄą│ąŠ čüąĄčĆą▓ąĄčĆąŠą╝, ą║ąŠą│ą┤ą░ ą┐čĆąĖąĮčÅčé ąĘą░ą┐čĆąŠčü, ą╝čŗ ąĖąĘą╝ąĄąĮąĖą╝ handle_connection, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 20-5, čćč鹊ą▒čŗ ą┐čĆąŠčćąĖčéą░čéčī HTML-čäą░ą╣ą╗, ą┤ąŠą▒ą░ą▓ąĖčéčī ąĄą│ąŠ ą▓ ą║ą░č湥čüčéą▓ąĄ č鹥ą╗ą░ ąŠčéą▓ąĄčéą░, ąĖ ąŠčéą┐čĆą░ą▓ąĖčéčī.
use std::{
fs,
io::{prelude::*, BufReader},
net::{TcpListener, TcpStream},
};
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&mut stream);
let http_request: Vec< _> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}
ąøąĖčüčéąĖąĮą│ 20-5. ą×čéą┐čĆą░ą▓ą║ą░ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ čäą░ą╣ą╗ą░ hello.html ą▓ ą║ą░č湥čüčéą▓ąĄ č鹥ą╗ą░ ąŠčéą▓ąĄčéą░ (čäą░ą╣ą╗ src/main.rs).
ą£čŗ ą┤ąŠą▒ą░ą▓ąĖą╗ąĖ fs ą▓ ąŠą┐ąĄčĆą░č鹊čĆ use, čćč鹊ą▒čŗ ą┐čĆąĖą▓ąĄčüčéąĖ čäą░ą╣ą╗ąŠą▓čāčÄ čüąĖčüč鹥ą╝čā čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ą▓ ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ. ąÜąŠą┤ čćč鹥ąĮąĖčÅ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ čäą░ą╣ą╗ą░ ą▓ čüčéčĆąŠą║ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą┤ą╗čÅ ą▓ą░čü ąĘąĮą░ą║ąŠą╝čŗą╝; ą╝čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ąĖ čŹč鹊 ą▓ ą│ą╗ą░ą▓ąĄ 12 [2], ą║ąŠą│ą┤ą░ čćąĖčéą░ą╗ąĖ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čäą░ą╣ą╗ą░ ą┤ą╗čÅ ą┐čĆąŠąĄą║čéą░ ą▓ą▓ąŠą┤ą░/ą▓čŗą▓ąŠą┤ą░ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 12-4.
ąöą░ą╗ąĄąĄ ą╝čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ format! ą┤ą╗čÅ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ čäą░ą╣ą╗ą░ ą▓ ą║ą░č湥čüčéą▓ąĄ č鹥ą╗ą░ čāčüą┐ąĄčłąĮąŠą│ąŠ ąŠčéą▓ąĄčéą░. ą¦č鹊ą▒čŗ ąŠą▒ąĄčüą┐ąĄčćąĖčéčī ą║ąŠčĆčĆąĄą║čéąĮčŗą╣ HTTP-ąŠčéą▓ąĄčé, ą╝čŗ ą┤ąŠą▒ą░ą▓ąĖą╗ąĖ ąĘą░ą│ąŠą╗ąŠą▓ąŠą║ Content-Length, ą║ąŠč鹊čĆčŗą╣ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą▓ čĆą░ąĘą╝ąĄčĆ ąĮą░čłąĄą│ąŠ č鹥ą╗ą░ ąŠčéą▓ąĄčéą░, čé. ąĄ. ą▓ ąĮą░čłąĄą╝ čüą╗čāčćą░ąĄ čŹč鹊 čĆą░ąĘą╝ąĄčĆ hello.html.
ąŚą░ą┐čāčüčéąĖč鹥 čŹč鹊čé ą║ąŠą┤ ą║ąŠą╝ą░ąĮą┤ąŠą╣ cargo run ąĖ ąĘą░ą┐čāčüčéąĖč鹥 ąĘą░ą┐čĆąŠčü 127.0.0.1:7878 ą▓ ą▒čĆą░čāąĘąĄčĆąĄ; ą▓čŗ ą┤ąŠą╗ąČąĮčŗ čāą▓ąĖą┤ąĄčéčī ą▓ą░čł ąŠčéčĆąĖčüąŠą▓ą░ąĮąĮčŗą╣ HTML!
ąÆ ąĮą░čüč鹊čÅčēąĖą╣ ą╝ąŠą╝ąĄąĮčé ą╝čŗ ąĖą│ąĮąŠčĆąĖčĆčāąĄą╝ ą┤ą░ąĮąĮčŗąĄ ąĘą░ą┐čĆąŠčüą░ ą▓ http_request, ąĖ ą┐čĆąŠčüč鹊, ą▒ąĄąĘčāčüą╗ąŠą▓ąĮąŠ ąŠčéą┐čĆą░ą▓ą╗čÅąĄą╝ ą▓ ąŠčéą▓ąĄčé ąĮą░ ąĘą░ą┐čĆąŠčü čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ HTML-čäą░ą╣ą╗ą░. ąó. ąĄ. ąĄčüą╗ąĖ ą▓čŗ ą┐ąŠą┐čŗčéą░ąĄč鹥čüčī ą▓ ą▒čĆą░čāąĘąĄčĆąĄ čüą┤ąĄą╗ą░čéčī ą╗čÄą▒ąŠą╣ ą┤čĆčāą│ąŠą╣ ąĘą░ą┐čĆąŠčü ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ 127.0.0.1:7878/something-else, č鹊 ą▓čüąĄ ąĄčēąĄ ą┐ąŠą╗čāčćąĖč鹥 č鹊čé ąČąĄ čüą░ą╝čŗą╣ HTML-ąŠčéą▓ąĄčé. ą¤ąŠą║ą░ čćč鹊 ąĮą░čł čüąĄčĆą▓ąĄčĆ ąŠč湥ąĮčī ąŠą│čĆą░ąĮąĖč湥ąĮ ąĖ ąĮąĄ ą┤ąĄą╗ą░ąĄčé ą▓čüąĄ č鹊, čćč鹊 ą▓čŗą┐ąŠą╗ąĮčÅčÄčé ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąŠ ą▓ąĄą▒-čüąĄčĆą▓ąĄčĆąŠą▓. ą£čŗ čģąŠčéąĖą╝ ą┤ąŠčĆą░ą▒ąŠčéą░čéčī čŹč鹊čé čäčāąĮą║čåąĖąŠąĮą░ą╗, čćč鹊ą▒čŗ ąĮą░čł ąŠčéą▓ąĄčé ą╝ąĄąĮčÅą╗čüčÅ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ąĘą░ą┐čĆąŠčüą░, čü ąŠčéą┐čĆą░ą▓ą║ąŠą╣ ąŠą▒čĆą░čéąĮąŠ HTML-čäą░ą╣ą╗ą░ ą║ą░ą║ čĆąĄą░ą║čåąĖčÄ ąĮą░ ą┐čĆą░ą▓ąĖą╗čīąĮąŠ čüč乊čĆą╝ąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ąĘą░ą┐čĆąŠčü ą║ /.
ą¤čĆąŠą▓ąĄčĆą║ą░ ąĘą░ą┐čĆąŠčüą░ ąĖ čüąĄą╗ąĄą║čéąĖą▓ąĮčŗą╣ ąŠčéą▓ąĄčé ąĮą░ ąĮąĄą│ąŠ. ąĪąĄą╣čćą░čü ąĮą░čł web-čüąĄčĆą▓ąĄčĆ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé HTML ąĖąĘ čäą░ą╣ą╗ą░, ąĮąĄ ąŠą▒čĆą░čēą░čÅ ą▓ąĮąĖą╝ą░ąĮąĖčÅ ąĮą░ č鹊, čćč鹊 ąĘą░ą┐čĆąŠčüąĖą╗ ą║ą╗ąĖąĄąĮčé. ąöą░ą▓ą░ą╣č鹥 ą┤ąŠą▒ą░ą▓ąĖą╝ ą┐čĆąŠą▓ąĄčĆą║čā, čćč鹊 ą▒čĆą░čāąĘąĄčĆ ąĘą░ą┐čĆą░čłąĖą▓ą░ąĄčé ą║ąŠčĆąĮąĄą▓ąŠą╣ ą║ą░čéą░ą╗ąŠą│ / ą┐ąĄčĆąĄą┤ ąŠčéą┐čĆą░ą▓ą║ąŠą╣ HTML-čäą░ą╣ą╗ą░, ąĖ ą▓ąŠąĘą▓čĆą░čéąĖą╝ ąŠčłąĖą▒ą║čā, ąĄčüą╗ąĖ ą▒čĆą░čāąĘąĄčĆ ąĘą░ą┐čĆą░čłąĖą▓ą░ąĄčé čćč鹊-č鹊 ą┤čĆčāą│ąŠąĄ. ąöą╗čÅ čŹč鹊ą│ąŠ ąĮą░ą╝ ąĮčāąČąĮąŠ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░čéčī ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ handle_connection, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 20-6. ąŁč鹊čé ąĮąŠą▓čŗą╣ ą║ąŠą┤ ą┐čĆąŠą▓ąĄčĆčÅąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą┐ąŠą╗čāč湥ąĮąĮąŠą│ąŠ ąĘą░ą┐čĆąŠčüą░ ąĮą░ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĄ ąŠąČąĖą┤ą░ąĄą╝ąŠą╝čā /, ąĖ ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé ą▒ą╗ąŠą║ąĖ if ąĖ else ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čĆą░ąĘąĮčŗčģ ąĘą░ą┐čĆąŠčüąŠą▓ ą┐ąŠ-čĆą░ąĘąĮąŠą╝čā.
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&mut stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
if request_line == "GET / HTTP/1.1" {
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
} else {
// ąÜą░ą║ąŠą╣-č鹊 ą┤čĆčāą│ąŠą╣ ąĘą░ą┐čĆąŠčü
}
}
ąøąĖčüčéąĖąĮą│ 20-6. ą×ą▒čĆą░ą▒ąŠčéą║ą░ ąĘą░ą┐čĆąŠčüąŠą▓ ą┤ą╗čÅ / ą┐ąŠ-ą┤čĆčāą│ąŠą╝čā ą▓ ąŠčéą╗ąĖčćąĖąĄ ąŠčé ą┐čĆąŠčćąĖčģ ąĘą░ą┐čĆąŠčüąŠą▓ (čäą░ą╣ą╗ src/main.rs).
ą£čŗ ą▒čāą┤ąĄą╝ čüą╝ąŠčéčĆąĄčéčī č鹊ą╗čīą║ąŠ ąĮą░ ą┐ąĄčĆą▓čāčÄ čüčéčĆąŠą║čā HTTP-ąĘą░ą┐čĆąŠčüą░, ą┐ąŠčŹč鹊ą╝čā ą▓ą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ čüčćąĖčéčŗą▓ą░čéčī ą▓ąĄčüčī ąĘą░ą┐čĆąŠčü ą▓ ą▓ąĄą║č鹊čĆ, ą╝čŗ ą▓čŗąĘčŗą▓ą░ąĄą╝ next, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ą┐ąĄčĆą▓čŗą╣ 菹╗ąĄą╝ąĄąĮčé ąĖąĘ ąĖč鹥čĆą░č鹊čĆą░. ą¤ąĄčĆą▓čŗą╣ unwrap ąĘą░ą▒ąŠčéąĖčéčüčÅ ąŠą▒ Option, ąĖ ąŠčüčéą░ąĮąŠą▓ąĖčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ, ąĄčüą╗ąĖ ą▓ ąĖč鹥čĆą░č鹊čĆąĄ ąĮąĄ ąŠą║ą░ąČąĄčéčüčÅ čŹą╗ąĄą╝ąĄąĮč鹊ą▓. ąÆč鹊čĆąŠą╣ unwrap ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé Result, ąĖ ą┤ą░ąĄčé č鹊čé ąČąĄ čŹčäč乥ą║čé, čćč鹊 ąĖ map, ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĮčŗą╣ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 20-2.
ąöą░ą╗ąĄąĄ ą╝čŗ ą┐čĆąŠą▓ąĄčĆčÅąĄą╝ request_line, čćč鹊ą▒čŗ čāą▓ąĖą┤ąĄčéčī, čćč鹊 ą▓ ąĮąĄą╣ ąĮą░čģąŠą┤ąĖčéčüčÅ GET-ąĘą░ą┐čĆąŠčü ą┤ą╗čÅ ą┐čāčéąĖ /. ąĢčüą╗ąĖ čŹč鹊 čéą░ą║, č鹊 ą▒ą╗ąŠą║ if ą▓ąŠąĘą▓čĆą░čéąĖčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ąĮą░čłąĄą│ąŠ čäą░ą╣ą╗ą░ HTML.
ąĢčüą╗ąĖ ąČąĄ request_line ąĮąĄ čĆą░ą▓ąĮą░ čüčéčĆąŠą║ąĄ ąĘą░ą┐čĆąŠčüą░ ą┤ą╗čÅ ą┐čāčéąĖ /, č鹊 čŹč鹊 ąŠąĘąĮą░čćą░ąĄčé ą║ą░ą║ąŠą╣-č鹊 ą┤čĆčāą│ąŠą╣ ąĘą░ą┐čĆąŠčü. ąöą░ą▓ą░ą╣č鹥 ą┤ąŠą▒ą░ą▓ąĖą╝ ą║ąŠą┤ ą▒ą╗ąŠą║ą░ else, ą║ąŠč鹊čĆčŗą╣ ą▒čāą┤ąĄčé ąŠčéą▓ąĄčćą░čéčī ąĮą░ ą▓čüąĄ ą┤čĆčāą│ąĖąĄ ąĘą░ą┐čĆąŠčüčŗ.
ąŚą░ą┐čāčüčéąĖč鹥 čŹč鹊čé ą║ąŠą┤ ąĖ ą▓čŗą┐ąŠą╗ąĮąĖč鹥 ą▓ ą▒čĆą░čāąĘąĄčĆąĄ ąĘą░ą┐čĆąŠčü 127.0.0.1:7878; ą▓čŗ ą┤ąŠą╗ąČąĮčŗ ą┐ąŠą╗čāčćąĖčéčī HTML ą▓ čäą░ą╣ą╗ąĄ hello.html. ąĢčüą╗ąĖ ą▓čŗ čüą┤ąĄą╗ą░ąĄč鹥 ą╗čÄą▒ąŠą╣ ą┤čĆčāą│ąŠą╣ ąĘą░ą┐čĆąŠčü, ąĮą░ą┐čĆąĖą╝ąĄčĆ 127.0.0.1:7878/something-else, č鹊 ą┐ąŠą╗čāčćąĖč鹥 ąŠčłąĖą▒ą║čā čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ, ą║ąŠč鹊čĆčāčÄ ą▓čŗ ą▓ąĖą┤ąĄą╗ąĖ, ą║ąŠą│ą┤ą░ ąĘą░ą┐čāčüą║ą░ą╗ąĖ ą║ąŠą┤ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 20-1 ąĖ ą╗ąĖčüčéąĖąĮą│ąĄ 20-2.
ąóąĄą┐ąĄčĆčī ą┤ąŠą▒ą░ą▓čīč鹥 ą║ąŠą┤ ą╗ąĖčüčéąĖąĮą│ą░ 20-7 ą▓ ą▒ą╗ąŠą║ else, čćč鹊ą▒čŗ ąŠčéą┐čĆą░ą▓ą╗čÅą╗čüčÅ ąŠčéą▓ąĄčé čü ą║ąŠą┤ąŠą╝ čüčéą░čéčāčüą░ 404, čćč鹊 čüąĖą│ąĮą░ą╗ąĖąĘąĖčĆčāąĄčé ą▒čĆą░čāąĘąĄčĆčā ąŠ č鹊ą╝, čćč鹊 čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą┤ą╗čÅ ąĘą░ą┐čĆąŠčüą░ ąĮąĄ ą▒čŗą╗ąŠ ąĮą░ą╣ą┤ąĄąĮąŠ. ą£čŗ čéą░ą║ąČąĄ ą▓ąŠąĘą▓čĆą░čéąĖą╝ ąĮąĄą║ąŠč鹊čĆčŗą╣ HTML ą┤ą╗čÅ čüčéčĆą░ąĮąĖčćą║ąĖ, ą║ąŠč鹊čĆą░čÅ ą▒čāą┤ąĄčé ąŠč鹊ą▒čĆą░ąČą░čéčīčüčÅ ą▓ ą▒čĆą░čāąĘąĄčĆąĄ ą┤ą╗čÅ ą║ąŠąĮąĄčćąĮąŠą│ąŠ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ.
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
} else {
let status_line = "HTTP/1.1 404 NOT FOUND";
let contents = fs::read_to_string("404.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
}
ąøąĖčüčéąĖąĮą│ 20-7. ą×čéą▓ąĄčé ą║ąŠą┤ąŠą╝ čüčéą░čéčāčüą░ 404 ąĖ čüčéčĆą░ąĮąĖčćą║ąŠą╣ čü ąŠą┐ąĖčüą░ąĮąĖąĄą╝ ąŠčłąĖą▒ą║ąĖ, ąĄčüą╗ąĖ ą▒čŗą╗ąŠ ąĘą░ą┐čĆąŠčłąĄąĮąŠ čćč鹊-č鹊 ą┤čĆčāą│ąŠąĄ, ąŠčéą╗ąĖčćą░čÄčēąĄąĄčüčÅ ąŠčé ą║ąŠčĆąĮąĄą▓ąŠą│ąŠ ą║ą░čéą░ą╗ąŠą│ą░ / čüąĄčĆą▓ąĄčĆą░ (čäą░ą╣ą╗ src/main.rs).
ąŚą┤ąĄčüčī ą▓ ąĮą░čłąĄą╝ ąŠčéą▓ąĄč鹥 čüčéčĆąŠą║ą░ čüąŠčüč鹊čÅąĮąĖčÅ ąĖą╝ąĄąĄčé ą║ąŠą┤ čüčéą░čéčāčüą░ 404 ąĖ reason-čäčĆą░ąĘčā NOT FOUND. ąóąĄą╗ąŠ ąŠčéą▓ąĄčéą░ ą▒čāą┤ąĄčé ą▓ HTML-čäą░ą╣ą╗ąĄ 404.html. ąöą╗čÅ čüčéčĆą░ąĮąĖčćą║ąĖ ąŠčłąĖą▒ą║ąĖ ą▓ą░ą╝ ą┐ąŠąĮą░ą┤ąŠą▒ąĖčéčüčÅ čüąŠąĘą┤ą░čéčī čäą░ą╣ą╗ 404.html čĆčÅą┤ąŠą╝ čü čäą░ą╣ą╗ąŠą╝ hello.html; ąĮąĄ ąŠą┐ą░čüą░ą╣č鹥čüčī 菹║čüą┐ąĄčĆąĖą╝ąĄąĮčéąĖčĆąŠą▓ą░čéčī, čüąŠąĘą┤ą░ą╣č鹥 ą╗čÄą▒ąŠą╣ HTML, ąŠčüąĮąŠą▓čŗą▓ą░čÅčüčī ąĮą░ ą┐čĆąĖą╝ąĄčĆąĄ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 20-8.
< !DOCTYPE html>
< html lang="en">
< head>
< meta charset="utf-8">
< title>Hello!< /title>
< /head>
< body>
< h1>Oops!< /h1>
< p>Sorry, I don't know what you're asking for.< /p>
< /body>
< /html>
ąøąĖčüčéąĖąĮą│ 20-8. ąĪąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą┐čĆąĖą╝ąĄčĆą░ čüčéčĆą░ąĮąĖčćą║ąĖ, ąŠčéą┐čĆą░ą▓ą╗čÅąĄą╝ąŠą╣ ą▓ ą╗čÄą▒ąŠą╝ ąŠčéą▓ąĄč鹥 404 (čäą░ą╣ą╗ 404.html).
ąĪ čŹčéąĖą╝ąĖ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅą╝ąĖ čüąĮąŠą▓ą░ ąĘą░ą┐čāčüčéąĖč鹥 čüąĄčĆą▓ąĄčĆ. ąŚą░ą┐čĆąŠčü 127.0.0.1:7878 ą┤ąŠą╗ąČąĄąĮ ą┐ąŠą╗čāčćą░čéčī ą▓ ąŠčéą▓ąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ hello.html, ąĖ ą╗čÄą▒ąŠą╣ ą┤čĆčāą│ąŠą╣ ąĘą░ą┐čĆąŠčü, ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ 127.0.0.1:7878/foo, ą┤ąŠą╗ąČąĄąĮ ą┐ąŠą╗čāčćą░čéčī čüąŠąŠą▒čēąĄąĮąĖąĄ ąŠą▒ ąŠčłąĖą▒ą║ąĄ ąĖąĘ HTML-čäą░ą╣ą╗ą░ 404.html.
ąØą░čćą░ą╗ąŠ čĆąĄčäą░ą║č鹊čĆąĖąĮą│ą░. ąĪąĄą╣čćą░čü ą▒ą╗ąŠą║ąĖ if ąĖ else čüąŠą┤ąĄčƹȹ░čé ą┐ąŠą▓č鹊čĆčÅčÄčēąĖą╣čüčÅ ą║ąŠą┤: ąŠąĮąĖ ąŠą▒ą░ čćąĖčéą░čÄčé čäą░ą╣ą╗čŗ ąĖ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčé ąĖčģ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą▓ stream. ąĢą┤ąĖąĮčüčéą▓ąĄąĮąĮąŠąĄ ąŠčéą╗ąĖčćąĖąĄ ą▓ ąĮąĖčģ čŹč鹊 čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čüčéčĆąŠą║ąĖ čüčéą░čéčāčüą░ (ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ status_line) ąĖą╝čÅ ąŠčéą┐čĆą░ą▓ą╗čÅąĄą╝ąŠą│ąŠ čäą░ą╣ą╗ą░ (ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ filename). ąöą░ą▓ą░ą╣č鹥 čüą┤ąĄą╗ą░ąĄą╝ ą║ąŠą┤ ą▒ąŠą╗ąĄąĄ ą╗ą░ą║ąŠąĮąĖčćąĮčŗą╝, ą┐ąĄčĆąĄą╝ąĄčüčéąĖą▓ čŹčéąĖ čĆą░ąĘą╗ąĖčćąĖčÅ ą▓ ąŠčéą┤ąĄą╗čīąĮčŗąĄ čüčéčĆąŠą║ąĖ if ąĖ else, ą║ąŠč鹊čĆčŗąĄ ą▒čāą┤čāčé čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čéčī čŹčéąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ; ąĘą░č鹥ą╝ ą╝čŗ ą╝ąŠąČąĄą╝ ą▒ąĄąĘčāčüą╗ąŠą▓ąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹčéąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ čäą░ą╣ą╗ą░ ąĖ ąĘą░ą┐ąĖčüąĖ ąŠčéą▓ąĄčéą░ ą▓ ą┐ąŠč鹊ą║. ąøąĖčüčéąĖąĮą│ 20-9 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čĆąĄąĘčāą╗čīčéąĖčĆčāčÄčēąĖą╣ ą║ąŠą┤ ą┐ąŠčüą╗ąĄ ąĘą░ą╝ąĄąĮčŗ ą▒ąŠą╗čīčłąĖčģ ą▒ą╗ąŠą║ąŠą▓ if ąĖ else.
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
fn handle_connection(mut stream: TcpStream) {
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
let (status_line, filename) = if request_line == "GET / HTTP/1.1" {
("HTTP/1.1 200 OK", "hello.html")
} else {
("HTTP/1.1 404 NOT FOUND", "404.html")
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}
ąøąĖčüčéąĖąĮą│ 20-9. ąĀąĄčäą░ą║č鹊čĆąĖąĮą│ ą▒ą╗ąŠą║ąŠą▓ if ąĖ else, čćč鹊ą▒čŗ ąŠąĮąĖ čüąŠą┤ąĄčƹȹ░ą╗ąĖ č鹊ą╗čīą║ąŠ ąŠčéą╗ąĖčćąĖčÅ ą┤ą▓čāčģ čüą╗čāčćą░ąĄą▓ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ (čäą░ą╣ą╗ src/main.rs).
ąóąĄą┐ąĄčĆčī ą▒ą╗ąŠą║ąĖ if ąĖ else ą▓ąŠąĘą▓čĆą░čéčÅčé ą▓ ą║ąŠčĆč鹥ąČąĄ č鹊ą╗čīą║ąŠ ą┐ąŠą┤čģąŠą┤čÅčēąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ ą┤ą╗čÅ čüčéčĆąŠą║ąĖ čüčéą░čéčāčüą░ ąĖ ąĖą╝ąĄąĮąĖ čäą░ą╣ą╗ą░; ąĘą░č鹥ą╝ ą╝čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ ą┤ąĄčüčéčĆčāą║čéčāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ ą║ąŠčĆč鹥ąČą░, čćč鹊ą▒čŗ ą┐čĆąĖčüą▓ąŠąĖčéčī ąĖąĘ ąĮąĄą│ąŠ ą┤ą▓ą░ ąĘąĮą░č湥ąĮąĖčÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝ status_line ąĖ filename čü ą┐ąŠą╝ąŠčēčīčÄ ą┐ą░čéč鹥čĆąĮą░, ą║ą░ą║ ąŠą▒čüčāąČą┤ą░ą╗ąŠčüčī ą▓ ą│ą╗ą░ą▓ąĄ 18 [3].
ąÜąŠą┤ ą┐ąŠą╗čāčćąĖą╗čüčÅ ą▒ąŠą╗ąĄąĄ ą┐čĆąŠčüč鹊ą╣, ąĖ ąŠąĮ č鹥ą┐ąĄčĆčī ą╗čāčćčłąĄ ąŠčéčĆą░ąČą░ąĄčé čĆą░ąĘąĮąĖčåčā ą╝ąĄąČą┤čā ą┤ą▓čāą╝čÅ čüą╗čāčćą░čÅą╝ąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĘą░ą┐čĆąŠčüą░. ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 čā ąĮą░čü ąĄčüčéčī č鹊ą╗čīą║ąŠ ąŠą┤ąĮąŠ ą╝ąĄčüč鹊 ą┤ą╗čÅ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ ą║ąŠą┤ą░, ąĄčüą╗ąĖ ą╝čŗ ąĘą░čģąŠčéąĖą╝ ąĖąĘą╝ąĄąĮąĖčéčī čüą┐ąŠčüąŠą▒ čćč鹥ąĮąĖčÅ čäą░ą╣ą╗ąŠą▓ ąĖ ąŠčéą┐čĆą░ą▓ą║ąĖ ąŠčéą▓ąĄč鹊ą▓. ą¤ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą║ąŠą┤ą░ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 20-9 ą▒čāą┤ąĄčé čéą░ą║ąĖą╝ ąČąĄ, ą║ą░ą║ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 20-7.
ą×čéą╗ąĖčćąĮąŠ! ąØą░čł ą┐čĆąŠčüč鹥ą╣čłąĖą╣ web-čüąĄčĆą▓ąĄčĆ ąĮą░ą┐ąĖčüą░ąĮ ą┐čĆąĖą╝ąĄčĆąĮąŠ 40 čüčéčĆąŠą║ą░ą╝ąĖ ą║ąŠą┤ą░ Rust, ąĖ ąŠąĮ ą╝ąŠąČąĄčé ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī ąĘą░ą┐čĆąŠčü ą║ąŠčĆąĮąĄą▓ąŠą│ąŠ ą║ą░čéą░ą╗ąŠą│ą░ čüąĄčĆą▓ąĄčĆą░ ąŠčéą┐čĆą░ą▓ą║ąŠą╣ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ čäą░ą╣ą╗ą░ hello.html, ąĖ ą▓ ąŠčéą▓ąĄčé ąĮą░ ą▓čüąĄ ą┤čĆčāą│ąĖąĄ ąĘą░ą┐čĆąŠčüčŗ ą┐ąŠčüčŗą╗ą░čéčī ąŠčéą▓ąĄčé 404.
ąĪąĄą╣čćą░čü ąĮą░čł čüąĄčĆą▓ąĄčĆ ąŠą┤ąĮąŠą┐ąŠč鹊čćąĮčŗą╣, čé. ąĄ. ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ąŠąĮ ą╝ąŠąČąĄčé ąŠą▒čĆą░ą▒ąŠčéą░čéčī ąĘą░ą┐čĆąŠčü č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ ąĘą░ą┐čĆąŠčü. ąöą░ą▓ą░ą╣č鹥 čāą▒ąĄą┤ąĖą╝čüčÅ, čćč鹊 čŹč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠą▒ą╗ąĄą╝ąŠą╣, čüąĖą╝čāą╗ąĖčĆčāčÅ ąĮąĄą║ąŠč鹊čĆčŗąĄ ą╝ąĄą┤ą╗ąĄąĮąĮčŗąĄ ąĘą░ą┐čĆąŠčüčŗ. ąŚą░č鹥ą╝ ą╝čŗ ąĖčüą┐čĆą░ą▓ąĖą╝ ąĮą░čł čüąĄčĆą▓ąĄčĆ, čćč鹊ą▒čŗ ąŠąĮ ą╝ąŠą│ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĘą░ą┐čĆąŠčüąŠą▓ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ.
[ą¤ąĄčĆąĄą┤ąĄą╗ą║ą░ ąŠą┤ąĮąŠą┐ąŠč鹊čćąĮąŠą│ąŠ čüąĄčĆą▓ąĄčĆą░ ą▓ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮčŗą╣]
ąĪąĄą╣čćą░čü ąĮą░čł čüąĄčĆą▓ąĄčĆ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé ą║ą░ąČą┤čŗą╣ ąĘą░ą┐čĆąŠčü ą┐ąŠ ąŠč湥čĆąĄą┤ąĖ. ąŁč鹊 ąĘąĮą░čćąĖčé, čćč鹊 ąŠąĮ ąĮąĄ ą▒čāą┤ąĄčé ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī ą▓č鹊čĆąŠąĄ čüąŠąĄą┤ąĖąĮąĄąĮąĖąĄ, ą┐ąŠą║ą░ ąĮąĄ ąĘą░ą▓ąĄčĆčłąĖčé ąŠą▒čĆą░ą▒ąŠčéą║čā ą┐ąĄčĆą▓ąŠą│ąŠ. ąĢčüą╗ąĖ čüąĄčĆą▓ąĄčĆ ą┐ąŠą╗čāčćąĖčé ąĄčēąĄ ąĖ ąĄčēąĄ ąĘą░ą┐čĆąŠčüčŗ, č鹊 čŹč鹊 ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ čüčéą░ąĮąĄčé ą▓čüąĄ ą╝ąĄąĮąĄąĄ ąĖ ą╝ąĄąĮąĄąĄ ąŠą┐čéąĖą╝ą░ą╗čīąĮčŗą╝. ąĢčüą╗ąĖ čüąĄčĆą▓ąĄčĆ ą┐ąŠą╗čāčćąĖčé ąĘą░ą┐čĆąŠčü, ą║ąŠč鹊čĆčŗą╣ ąĘą░ąĮąĖą╝ą░ąĄčé ą╝ąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ, č鹊 ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖąĄ ąĘą░ą┐čĆąŠčüčŗ ą┤ąŠą╗ąČąĮčŗ ą▒čāą┤čāčé ąŠąČąĖą┤ą░čéčī, ą┐ąŠą║ą░ ąĮąĄ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ ą┤ąŠą╗ą│ąĖą╣ ąĘą░ą┐čĆąŠčü, ą┤ą░ąČąĄ ąĄčüą╗ąĖ ąĮąŠą▓čŗąĄ ąĘą░ą┐čĆąŠčüčŗ ą╝ąŠą│čāčé ą▒čŗčéčī ąŠą▒čĆą░ą▒ąŠčéą░ąĮčŗ ą▒čŗčüčéčĆąŠ. ąØą░ą╝ čŹč鹊 ąĮą░ą┤ąŠ ąĖčüą┐čĆą░ą▓ąĖčéčī, ąĮąŠ čüąĮą░čćą░ą╗ą░ ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ čŹčéčā ą┐čĆąŠą▒ą╗ąĄą╝čā ą▓ ą┤ąĄą╣čüčéą▓ąĖąĖ.
ąĪąĖą╝čāą╗čÅčåąĖčÅ ą╝ąĄą┤ą╗ąĄąĮąĮąŠą│ąŠ ąĘą░ą┐čĆąŠčüą░ ą▓ č鹥ą║čāčēąĄą╣ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čüąĄčĆą▓ąĄčĆą░. ąöą░ą▓ą░ą╣č鹥 ą┐čĆąŠą▓ąĄčĆąĖą╝, ą║ą░ą║ ąĘą░ą┐čĆąŠčü čü ą╝ąĄą┤ą╗ąĄąĮąĮąŠą╣ ąŠą▒čĆą░ą▒ąŠčéą║ąŠą╣ ą╝ąŠąČąĄčé ą┐ąŠą▓ą╗ąĖčÅčéčī ąĮą░ ą┤čĆčāą│ąĖąĄ ąĘą░ą┐čĆąŠčüčŗ čü ąĮą░čłąĄą╣ č鹥ą║čāčēąĄą╣ čĆąĄą░ą╗ąĖąĘą░čåąĖąĄą╣ čüąĄčĆą▓ąĄčĆą░. ąøąĖčüčéąĖąĮą│ 20-10 čĆąĄą░ą╗ąĖąĘčāąĄčé ąŠą▒čĆą░ą▒ąŠčéą║čā ąĘą░ą┐čĆąŠčüą░ /sleep čü čüąĖą╝čāą╗ąĖčĆčāąĄą╝čŗą╝ ą╝ąĄą┤ą╗ąĄąĮąĮčŗą╝ ąŠčéą▓ąĄč鹊ą╝, ą║ąŠč鹊čĆčŗą╣ ąĘą░čüčéą░ą▓ąĖčé čüąĄčĆą▓ąĄčĆ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ąĖčéčī čĆą░ą▒ąŠčéčā (sleep) ąĮą░ 5 čüąĄą║čāąĮą┤ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ąŠąĮ ą┐ąŠčłą╗ąĄčé ąŠčéą▓ąĄčé.
use std::{
fs,
io::{prelude::*, BufReader},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
fn handle_connection(mut stream: TcpStream) {
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
}
ąøąĖčüčéąĖąĮą│ 20-10. ąĪąĖą╝čāą╗čÅčåąĖčÅ ą╝ąĄą┤ą╗ąĄąĮąĮąŠą│ąŠ ąŠčéą▓ąĄčéą░ ąĮą░ ąĘą░ą┐čĆąŠčü čü ąĘą░ą┤ąĄčƹȹ║ąŠą╣ 5 čüąĄą║čāąĮą┤ (čäą░ą╣ą╗ src/main.rs).
ą£čŗ ą┐ąŠą╝ąĄąĮčÅą╗ąĖ ąŠą┐ąĄčĆą░č鹊čĆ if ąĮą░ match, ą▓ ą║ąŠč鹊čĆąŠą╝ č鹥ą┐ąĄčĆčī 3 ą▓ąĄčéą║ąĖ. ąØą░ą╝ ąĮčāąČąĮąŠ čüą┤ąĄą╗ą░čéčī čÅą▓ąĮąŠąĄ čüąŠą┐ąŠčüčéą░ą▓ą╗ąĄąĮąĖąĄ čüą╗ą░ą╣čüą░ request_line čü ą┐ą░čéč鹥čĆąĮąŠą╝ ąĮą░ čüąŠą▓ą┐ą░ą┤ąĄąĮąĖąĄ čüąŠ ąĘąĮą░č湥ąĮąĖčÅą╝ąĖ čüčéčĆąŠą║ąŠą▓čŗčģ ą╗ąĖč鹥čĆą░ą╗ąŠą▓; ąŠą┐ąĄčĆą░č鹊čĆ match, ą▓ ąŠčéą╗ąĖčćąĖąĄ ąŠčé if, ąĮąĄ ą┤ąĄą╗ą░ąĄčé ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąŠąĄ ąŠą▒čĆą░čēąĄąĮąĖąĄ ą┐ąŠ čüčüčŗą╗ą║ą░ą╝ ąĖ čĆą░ąĘčŗą╝ąĄąĮąŠą▓ą░ąĮąĖąĄ čüčüčŗą╗ąŠą║.
ą¤ąĄčĆą▓ą░čÅ ą▓ąĄčéą║ą░ match čéą░ą║ą░čÅ ąČąĄ, ą║ą░ą║ ą▒čŗą╗ ą▒ą╗ąŠą║ if ą╗ąĖčüčéąĖąĮą│ą░ 20-9. ąÆč鹊čĆą░čÅ ą▓ąĄčéą║ą░ ą┐čĆąŠą▓ąĄčĆčÅąĄčé ąĮą░ čüąŠą▓ą┐ą░ą┤ąĄąĮąĖąĄ ąĘą░ą┐čĆąŠčüą░ čüąŠ /sleep. ąÜąŠą│ą┤ą░ čŹč鹊čé ąĘą░ą┐čĆąŠčü ą┐čĆąĖąĮčÅčé, čüąĄčĆą▓ąĄčĆ ąĘą░čüąĮąĄčé ąĮą░ 5 čüąĄą║čāąĮą┤ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ čāčüą┐ąĄčłąĮąŠ ąŠčéčĆąĖčüąŠą▓ą░čéčī HTML-čüčéčĆą░ąĮąĖčćą║čā. ąóčĆąĄčéčīčÅ ą▓ąĄčéą║ą░ čéą░ą║ą░čÅ ąČąĄ, ą║ą░ą║ ą▒ą╗ąŠą║ else ą╗ąĖčüčéąĖąĮą│ą░ 20-9.
ąóąĄą┐ąĄčĆčī ą▓čŗ čāą▓ąĖą┤ąĖč鹥, ąĮą░čüą║ąŠą╗čīą║ąŠ ą┐čĆąĖą╝ąĖčéąĖą▓ąĄąĮ ąĮą░čł čüąĄčĆą▓ąĄčĆ: čĆąĄą░ą╗čīąĮčŗąĄ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ą▒čāą┤čāčé ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī čĆą░čüą┐ąŠąĘąĮą░ą▓ą░ąĮąĖąĄ ą╝ąĮąŠąČąĄčüčéą▓ąĄąĮąĮčŗčģ ąĘą░ą┐čĆąŠčüąŠą▓ ą│ąŠčĆą░ąĘą┤ąŠ ą╝ąĄąĮąĄąĄ ą╝ąĮąŠą│ąŠčüą╗ąŠą▓ąĮčŗą╝ čüą┐ąŠčüąŠą▒ąŠą╝!
ąŚą░ą┐čāčüčéąĖč鹥 čüąĄčĆą▓ąĄčĆ ą║ąŠą╝ą░ąĮą┤ąŠą╣ cargo run. ąŚą░č鹥ą╝ ąŠčéą║čĆąŠą╣č鹥 ą┤ą▓ą░ ąŠą║ąĮą░ ą▒čĆą░čāąĘąĄčĆą░: ąŠą┤ąĮąŠ ą┤ą╗čÅ http://127.0.0.1:7878/, ąĖ ą┤čĆčāą│ąŠąĄ ą┤ą╗čÅ http://127.0.0.1:7878/sleep. ąĢčüą╗ąĖ ą▓čŗ ą▓ą▓ąĄą┤ąĄč鹥 / URI ąĮąĄčüą║ąŠą╗čīą║ąŠ čĆą░ąĘ, ą║ą░ą║ čĆą░ąĮčīčłąĄ, č鹊 ą┐ąŠą╗čāčćąĖč鹥 ą▒čŗčüčéčĆčŗą╣ ąŠčéą▓ąĄčé. ą×ą┤ąĮą░ą║ąŠ ąĄčüą╗ąĖ ą▓čŗ ą▓ą▓ąĄą┤ąĄč鹥 ąĘą░ą┐čĆąŠčü /sleep ąĖ ąĘą░č鹥ą╝ ąĘą░ą│čĆčāąĘąĖč鹥 ąĘą░ą┐čĆąŠčü /, č鹊 čāą▓ąĖą┤ąĖč鹥, čćč鹊 / ąČą┤ąĄčé, ą┐ąŠą║ą░ ąĮąĄ ąĘą░ą║ąŠąĮčćąĖčéčüčÅ ąĘą░ą┤ąĄčƹȹ║ą░ sleep 5 čüąĄą║čāąĮą┤.
ąĪčāčēąĄčüčéą▓čāąĄčé ąĮąĄčüą║ąŠą╗čīą║ąŠ č鹥čģąĮąĖą║, čü ą┐ąŠą╝ąŠčēčīčÄ ą║ąŠč鹊čĆčŗčģ ą╝čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ ąĖąĘą▒ąĄąČą░čéčī ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą║čā ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĖąĘ-ąĘą░ ą╝ąĄą┤ą╗ąĄąĮąĮčŗčģ ąĘą░ą┐čĆąŠčüąŠą▓; ąŠą┤ąĮą░ ąĖąĘ ąĮąĖčģ, ą║ąŠč鹊čĆčāčÄ ą╝čŗ čĆąĄą░ą╗ąĖąĘčāąĄą╝, čŹč鹊 ą┐čāą╗ ą┐ąŠč鹊ą║ąŠą▓ (thread pool).
ąŻą▓ąĄą╗ąĖč湥ąĮąĖąĄ ą┐čĆąŠą┐čāčüą║ąĮąŠą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ čüąĄčĆą▓ąĄčĆą░ čü ą┐ąŠą╝ąŠčēčīčÄ ą┐čāą╗ą░ ą┐ąŠč鹊ą║ąŠą▓. Thread pool čŹč鹊 ą│čĆčāą┐ą┐ą░ ą┐ąŠčĆąŠąČą┤ąĄąĮąĮčŗčģ ą┐ąŠč鹊ą║ąŠą▓, ą║ąŠč鹊čĆčŗąĄ ąĮą░čģąŠą┤čÅčéčüčÅ ą▓ ąŠąČąĖą┤ą░ąĮąĖąĖ ąĖ ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ ą║ ąŠą▒čĆą░ą▒ąŠčéą║ąĄ ąĘą░ą┤ą░čćąĖ. ąÜąŠą│ą┤ą░ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą┐ąŠą╗čāčćą░ąĄčé ąĮąŠą▓čāčÄ ąĘą░ą┤ą░čćčā, ąŠąĮą░ ąĮą░ąĘąĮą░čćą░ąĄčé ąĄčæ ąŠą┤ąĮąŠą╝čā ąĖąĘ ą┐ąŠč鹊ą║ąŠą▓ ą┐čāą╗ą░, ąĖ čŹč鹊čé ą┐ąŠč鹊ą║ ą▒čāą┤ąĄčé ąĘą░ą┤ą░čćčā ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī. ą×čüčéą░ą╗čīąĮčŗąĄ ą┐ąŠč鹊ą║ąĖ ą▓ ą┐čāą╗ąĄ ą┤ąŠčüčéčāą┐ąĮčŗ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą╗čÄą▒čŗčģ ą┤čĆčāą│ąĖčģ ąĘą░ą┤ą░čć, ą┐ąŠčüčéčāą┐ą░čÄčēąĖčģ ą┐čĆąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĄ ą┐ąĄčĆą▓ąŠą╣ ąĘą░ą┤ą░čćąĖ. ąÜąŠą│ą┤ą░ ą┐ąĄčĆą▓čŗą╣ ą┐ąŠč鹊ą║ ąĘą░ą║ąŠąĮčćąĖčé ąŠą▒čĆą░ą▒ąŠčéą║čā čüą▓ąŠąĄą╣ ąĘą░ą┤ą░čćąĖ, ąŠąĮ ą▓ąŠąĘą▓čĆą░čēą░ąĄčéčüčÅ ą▓ ą┐čāą╗ ąŠąČąĖą┤ą░čÄčēąĖčģ ą┐ąŠč鹊ą║ąŠą▓, ą│ąŠč鹊ą▓čŗą╣ ą║ ą┐čĆąĖąĄą╝čā ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĮąŠą▓ąŠą╣ ąĘą░ą┤ą░čćąĖ. ą¤čāą╗ ą┐ąŠč鹊ą║ąŠą▓ ą┐ąŠąĘą▓ąŠą╗ąĖčé ą▓ą░ą╝ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ, ą┐ąŠą▓čŗčłą░čÅ č鹥ą╝ čüą░ą╝čŗą╝ ą┐čĆąŠą┐čāčüą║ąĮčāčÄ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī čüąĄčĆą▓ąĄčĆą░.
ą£čŗ ąŠą│čĆą░ąĮąĖčćąĖą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠč鹊ą║ąŠą▓ ą▓ ą┐čāą╗ąĄ, čćč鹊ą▒čŗ ąĘą░čēąĖčéąĖčéčīčüčÅ ąŠčé ą░čéą░ą║ čéąĖą┐ą░ "ą×čéą║ą░ąĘ ą▓ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖąĖ" (Denial of Service, DoS); ąĄčüą╗ąĖ ą▒čŗ ąĮą░čłą░ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ čüąŠąĘą┤ą░ą▓ą░ą╗ą░ ąĮąŠą▓čŗą╣ ą┐ąŠč鹊ą║ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą┐ąŠčüčéčāą┐ąĖą▓čłąĄą│ąŠ ąĘą░ą┐čĆąŠčüą░, č鹊 ąĄčüą╗ąĖ ą║č鹊-č鹊 ąĘą░ą┐čāčüčéąĖčé ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ 10 ą╝ąĖą╗ą╗ąĖąŠąĮąŠą▓ ąĘą░ą┐čĆąŠčüąŠą▓ ą┤ą╗čÅ ąĮą░čłąĄą│ąŠ čüąĄčĆą▓ąĄčĆą░, č鹊 čüąŠąĘą┤ą░čüčé čģą░ąŠčü, ą┐čĆąĖ ą║ąŠč鹊čĆčŗą╝ ą▒čāą┤čāčé ąĘą░ąĮčÅčéčŗ ą▓čüąĄ čĆąĄčüčāčĆčüčŗ ąĮą░čłąĄą│ąŠ čüąĄčĆą▓ąĄčĆą░, ąĖ ą▓čüąĄ ąĘą░ą┐čĆąŠčüčŗ ąĘą░ą▓ąĖčüąĮčāčé.
ąÆą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ ą┐ąŠčĆąŠąČą┤ą░čéčī ąĮąĄąŠą│čĆą░ąĮąĖč湥ąĮąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠč鹊ą║ąŠą▓, čā ąĮą░čü ą▒čāą┤ąĄčé ąŠą│čĆą░ąĮąĖč湥ąĮąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠč鹊ą║ąŠą▓, ąŠąČąĖą┤ą░čÄčēąĖčģ ą▓ ą┐čāą╗ąĄ. ą¤čāą╗ ą▒čāą┤ąĄčé ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čéčī ąŠč湥čĆąĄą┤čī ą▓čģąŠą┤čÅčēąĖčģ ąĘą░ą┐čĆąŠčüąŠą▓. ąÜą░ąČą┤čŗą╣ ąĖąĘ ą┐ąŠč鹊ą║ąŠą▓ ą▓ ą┐čāą╗ąĄ ą▒čāą┤ąĄčé ąĖąĘą▓ą╗ąĄą║ą░čéčī ąĘą░ą┐čĆąŠčü ąĖąĘ čŹč鹊ą╣ ąŠč湥čĆąĄą┤ąĖ, ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī ąĄą│ąŠ, ąĖ ąĘą░č鹥ą╝ ąĘą░ą┐čĆą░čłąĖą▓ą░čéčī ąŠč湥čĆąĄą┤čī ąĮą░ ą┐ąŠą╗čāč湥ąĮąĖąĄ ąĮąŠą▓ąŠą│ąŠ ąĘą░ą┐čĆąŠčüą░ (čŹč鹊 čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝ą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą┐ąŠč鹊ą║ą░ ąĮą░ ąŠč湥čĆąĄą┤ąĖ). ąĪ čéą░ą║ąĖą╝ ą┤ąĖąĘą░ą╣ąĮąŠą╝ ą╝čŗ ą╝ąŠąČąĄą╝ ąŠą▒čĆą░ą▒ąŠčéą░čéčī ą┤ąŠ N ąĘą░ą┐čĆąŠčüąŠą▓ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ, ą│ą┤ąĄ N čŹč鹊 ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠč鹊ą║ąŠą▓. ąĢčüą╗ąĖ ą║ą░ąČą┤čŗą╣ ą┐ąŠč鹊ą║ ąŠčéą▓ąĄčćą░ąĄčé ąĮą░ ą┤ąŠą╗ą│ąŠ čĆą░ą▒ąŠčéą░čÄčēąĖą╣ ąĘą░ą┐čĆąŠčü, č鹊 ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖąĄ ąĘą░ą┐čĆąŠčüčŗ ą▓čüąĄ ąĄčēąĄ ą╝ąŠą│čāčé čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░čéčīčüčÅ ą▓ ąŠč湥čĆąĄą┤ąĖ, ąĮąŠ ą╝čŗ čāą▓ąĄą╗ąĖčćąĖą╗ąĖ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐čĆąŠą┤ąŠą╗ąČąĖč鹥ą╗čīąĮąŠ ą▓čŗą┐ąŠą╗ąĮčÅčÄčēąĖčģčüčÅ ąĘą░ą┐čĆąŠčüąŠą▓, ą║ąŠč鹊čĆčŗąĄ ą╝čŗ ą╝ąŠąČąĄą╝ ąŠą▒čĆą░ą▒ąŠčéą░čéčī, ą┐ąŠą║ą░ ąĮąĄ ą┤ąŠčüčéąĖą│ąĮąĄą╝ ą║ąŠą╗ąĖč湥čüčéą▓ą░ N ą┐ąŠč鹊ą║ąŠą▓.
ąŁčéą░ č鹥čģąĮąĖą║ą░ ą▓čüąĄą│ąŠ ą╗ąĖčłčī ąŠą┤ąĮą░ ąĖąĘ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čüą┐ąŠčüąŠą▒ąŠą▓ ą┐ąŠą▓čŗčüąĖčéčī ą┐čĆąŠą┐čāčüą║ąĮčāčÄ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī web-čüąĄčĆą▓ąĄčĆą░. ąöčĆčāą│ąĖąĄ ąŠą┐čåąĖąĖ ą╝ąŠą│čāčé 菹║čüą┐ą╗čāą░čéąĖčĆąŠą▓ą░čéčī ą╝ąŠą┤ąĄą╗čī fork/join, ą╝ąŠą┤ąĄą╗čī ąŠą┤ąĮąŠą┐ąŠč鹊čćąĮąŠą│ąŠ ą░čüąĖąĮčģčĆąŠąĮąĮąŠą│ąŠ ą▓ą▓ąŠą┤ą░/ą▓čŗą▓ąŠą┤ą░ (single-threaded async I/O), ąĖą╗ąĖ ą╝ąŠą┤ąĄą╗čī ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠą│ąŠ ą░čüąĖąĮčģčĆąŠąĮąĮąŠą│ąŠ ą▓ą▓ąŠą┤ą░/ą▓čŗą▓ąŠą┤ą░ (multi-threaded async I/O). ąĢčüą╗ąĖ ą▓ą░čü ąĖąĮč鹥čĆąĄčüčāąĄčé čŹčéą░ č鹥ą╝ą░, č鹊 ąŠąĘąĮą░ą║ąŠą╝čīč鹥čüčī čü čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą╣ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĄą╣ ą┐ąŠ ą┤čĆčāą│ąĖą╝ čĆąĄčłąĄąĮąĖčÅą╝ ąĖ ą┐ąŠą┐čĆąŠą▒čāą╣č鹥 ąĖčģ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī; čü čéą░ą║ąĖą╝ ąĮąĖąĘą║ąŠčāčĆąŠą▓ąĮąĄą▓čŗą╝ čÅąĘčŗą║ąŠą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ, ą║ą░ą║ Rust, ą▓ąŠąĘą╝ąŠąČąĮčŗ ą▓čüąĄ čŹčéąĖ ąŠą┐čåąĖąĖ.
ą¤ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ą╝čŗ ąĮą░čćąĮąĄą╝ čĆąĄą░ą╗ąĖąĘąŠą▓čŗą▓ą░čéčī ą┐čāą╗ ą┐ąŠč鹊ą║ąŠą▓, ąĮąĄą╝ąĮąŠą│ąŠ ą┐ąŠą│ąŠą▓ąŠčĆąĖą╝ ą┐čĆąŠ č鹊, ą║ą░ą║ ą┤ąŠą╗ąČąĮąŠ ą▓čŗą│ą╗čÅą┤ąĄčéčī ąĄą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ. ąÜąŠą│ą┤ą░ ą▓čŗ ą┐čŗčéą░ąĄč鹥čüčī čĆą░ąĘčĆą░ą▒ąŠčéą░čéčī ą║ąŠą┤, č鹊 ą╝ąŠąČąĄčé ą┐ąŠą╝ąŠčćčī ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮąŠąĄ ąĮą░ą┐ąĖčüą░ąĮąĖąĄ ą║ą╗ąĖąĄąĮčéčüą║ąŠą│ąŠ ąĖąĮč鹥čĆč乥ą╣čüą░. ąØą░ą┐ąĖčłąĖč鹥 API ą║ąŠą┤ą░ čéą░ą║, ą║ą░ą║ ą▓čŗ čģąŠč鹥ą╗ąĖ ą▒čŗ ąĄą│ąŠ ą▓čŗąĘčŗą▓ą░čéčī; ąĘą░č鹥ą╝ čĆąĄą░ą╗ąĖąĘčāą╣č鹥 čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčī ą▓ čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮąĮąŠą╣ čüčéčĆčāą║čéčāčĆąĄ, ą▓ą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ čüąĮą░čćą░ą╗ą░ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī čäčāąĮą║čåąĖąŠąĮą░ą╗, ą░ čāąČąĄ ą┐ąŠč鹊ą╝ ą┐čĆąĖą║čĆčāčćąĖą▓ą░čéčī ą║ ąĮąĄą╝čā ą┐čāą▒ą╗ąĖčćąĮčŗą╣ API.
ą¤ąŠą┤ąŠą▒ąĮąŠ č鹊ą╝čā, ą║ą░ą║ ą╝čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║čā ąĮą░ ąŠčüąĮąŠą▓ąĄ č鹥čüč鹊ą▓ ą▓ ą┐čĆąŠąĄą║č鹥 ą│ą╗ą░ą▓čŗ 12 [2], ąĘą┤ąĄčüčī ą╝čŗ ą▒čāą┤ąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čĆą░ąĘčĆą░ą▒ąŠčéą║čā ąĮą░ ąŠčüąĮąŠą▓ąĄ ą┐ąŠą╝ąŠčēąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░. ąó. ąĄ. ąĮą░ą┐ąĖčłąĄą╝ ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ą▓čŗąĘčŗą▓ą░ąĄčé ąĮčāąČąĮčāčÄ ąĮą░ą╝ čäčāąĮą║čåąĖčÄ, ąĖ ąĘą░č鹥ą╝ ą┐ąŠčüą╝ąŠčéčĆąĖą╝ ąĮą░ čüąŠąŠą▒čēąĄąĮąĖčÅ ąŠčłąĖą▒ą║ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░, čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, čćč鹊 ąĮą░ą┤ąŠ ą┐ąŠą╝ąĄąĮčÅčéčī, čćč鹊ą▒čŗ ą║ąŠą┤ čĆą░ą▒ąŠčéą░ą╗. ą×ą┤ąĮą░ą║ąŠ ą┐ąĄčĆąĄą┤ čŹčéąĖą╝ ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ č鹥čģąĮąĖą║čā, ą║ąŠč鹊čĆčāčÄ ąĮąĄ čüąŠą▒ąĖčĆą░ąĄą╝čüčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓ ą║ą░č湥čüčéą▓ąĄ ąŠčéą┐čĆą░ą▓ąĮąŠą╣ č鹊čćą║ąĖ.
ą¤ąŠčĆąŠąČą┤ąĄąĮąĖąĄ ą┐ąŠč鹊ą║ą░ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ąĘą░ą┐čĆąŠčüą░. ąĪąĮą░čćą░ą╗ą░ ą┤ą░ą▓ą░ą╣č鹥 čĆą░čüčüą╝ąŠčéčĆąĖą╝, ą║ą░ą║ ą╝ąŠą│ ą▒čŗ ą▓čŗą│ą╗čÅą┤ąĄčéčī ąĮą░čł ą║ąŠą┤, ąĄčüą╗ąĖ ą▒čŗ ą╝čŗ čüąŠąĘą┤ą░ą▓ą░ą╗ąĖ ą┐ąŠč鹊ą║ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ. ąÜą░ą║ čāą┐ąŠą╝ąĖąĮą░ą╗ąŠčüčī čĆą░ąĮąĄąĄ, čŹč鹊 ąĮąĄ ąĮą░čł ą║ąŠąĮąĄčćąĮčŗą╣ ą┐ą╗ą░ąĮ ąĖąĘ-ąĘą░ ą▓ąŠąĘą╝ąŠąČąĮčŗčģ ą┐čĆąŠą▒ą╗ąĄą╝ ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠą│ąŠ ą┐ąŠčĆąŠąČą┤ąĄąĮąĖčÅ ąĮąĄąŠą│čĆą░ąĮąĖč湥ąĮąĮąŠą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą┐ąŠč鹊ą║ąŠą▓, ąŠą┤ąĮą░ą║ąŠ čŹč鹊 čüčéą░čĆč鹊ą▓ą░čÅ č鹊čćą║ą░ ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ čüąĮą░čćą░ą╗ą░ čĆą░ą▒ąŠč湥ą│ąŠ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠą│ąŠ čüąĄčĆą▓ąĄčĆą░. ąŚą░č鹥ą╝ ą║ą░ą║ čāą╗čāčćčłąĄąĮąĖąĄ ą╝čŗ ą┤ąŠą▒ą░ą▓ąĖą╝ ą┐čāą╗ ą┐ąŠč鹊ą║ąŠą▓, ąĖ čĆą░ąĘą╗ąĖčćąĖąĄ ą╝ąĄąČą┤čā ą┤ą▓čāą╝čÅ čŹčéąĖą╝ąĖ čĆąĄčłąĄąĮąĖčÅą╝ąĖ ą▒čāą┤ąĄčé ą┐ąŠąĮčÅčéąĮąĄąĄ. ąøąĖčüčéąĖąĮą│ 20-11 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ čäčāąĮą║čåąĖąĖ main, čćč鹊ą▒čŗ ą┐ąŠčĆąŠąČą┤ą░čéčī ąĮąŠą▓čŗą╣ ą┐ąŠč鹊ą║ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą║ą░ąČą┤ąŠą│ąŠ ą┐ąŠč鹊ą║ą░ stream ą▓ čåąĖą║ą╗ąĄ for.
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
thread::spawn(|| {
handle_connection(stream);
});
}
}
ąøąĖčüčéąĖąĮą│ 20-11. ą¤ąŠčĆąŠąČą┤ąĄąĮąĖąĄ ąĮąŠą▓ąŠą│ąŠ ą┐ąŠč鹊ą║ą░ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ stream (čäą░ą╣ą╗ src/main.rs).
ąÜą░ą║ ą▓čŗ čāąČąĄ ąĘąĮą░ąĄč鹥 ąĖąĘ ą│ą╗ą░ą▓čŗ 16 [4], thread::spawn čüąŠąĘą┤ą░čüčé ąĮąŠą▓čŗą╣ ą┐ąŠč鹊ą║ ąĖ ąĘą░ą┐čāčüčéąĖčé ą║ąŠą┤ ąĖąĘ ą▒ą╗ąŠą║ą░ ąĘą░ą╝čŗą║ą░ąĮąĖčÅ ą▓ ąĮąŠą▓ąŠą╝ ą┐ąŠč鹊ą║ąĄ. ąĢčüą╗ąĖ ą▓čŗ ąĘą░ą┐čāčüčéąĖč鹥 čŹč鹊čé ą║ąŠą┤ ąĖ ąĘą░ą│čĆčāąĘąĖč鹥 ąĘą░ą┐čĆąŠčü /sleep ą▓ čüą▓ąŠąĄą╝ ą▒čĆą░čāąĘąĄčĆąĄ, ąĘą░č鹥ą╝ / ą▓ ą┤ą▓čāčģ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ąĘą░ą║ą╗ą░ą┤ą║ą░čģ ą▒čĆą░čāąĘąĄčĆą░, č鹊 čāą▓ąĖą┤ąĖč鹥, čćč鹊 ąĘą░ą┐čĆąŠčüčŗ / ą▒ąŠą╗čīčłąĄ ąĮąĄ ąČą┤čāčé, ą║ąŠą│ą┤ą░ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ /sleep. ą×ą┤ąĮą░ą║ąŠ, ą║ą░ą║ ą╝čŗ čāąČąĄ čāą┐ąŠą╝ąĖąĮą░ą╗ąĖ, čŹč鹊 ą╝ąŠąČąĄčé ąĖąĮąŠą│ą┤ą░ ą┐ąĄčĆąĄą│čĆčāąĘąĖčéčī čüąĖčüč鹥ą╝čā, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓čŗ čüąŠąĘą┤ą░ąĄč鹥 ą┐ąŠč鹊ą║ąĖ ą▒ąĄąĘ ą║ą░ą║ąŠą│ąŠ-ą╗ąĖą▒ąŠ ąŠą│čĆą░ąĮąĖč湥ąĮąĖčÅ.
ąĪąŠąĘą┤ą░ąĮąĖąĄ ą║ąŠąĮąĄčćąĮąŠą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą┐ąŠč鹊ą║ąŠą▓. ą£čŗ čģąŠčéąĖą╝, čćč鹊ą▒čŗ ąĮą░čł ą┐čāą╗ ą┐ąŠč鹊ą║ąŠą▓ čĆą░ą▒ąŠčéą░ą╗ ą░ąĮą░ą╗ąŠą│ąĖčćąĮčŗą╝, ą┐čĆąĖą▓čŗčćąĮčŗą╝ čüą┐ąŠčüąŠą▒ąŠą╝, ą┐ąŠčŹč鹊ą╝čā ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ąĮą░ ą┐čāą╗ ą┐ąŠč鹊ą║ąŠą▓ ąĮąĄ ą┐ąŠčéčĆąĄą▒čāąĄčé ą▒ąŠą╗čīčłąĖčģ ąĖąĘą╝ąĄąĮąĄąĮąĖą╣ ą▓ ą║ąŠą┤ąĄ, ą║ąŠč鹊čĆčŗą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąĮą░čł API. ąøąĖčüčéąĖąĮą│ 20-12 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą│ąĖą┐ąŠč鹥čéąĖč湥čüą║ąĖą╣ ąĖąĮč鹥čĆč乥ą╣čü ą┤ą╗čÅ čüčéčĆčāą║čéčāčĆčŗ ThreadPool, ą║ąŠč鹊čĆčŗą╣ ą╝čŗ čģąŠčéąĖą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓ą╝ąĄčüč鹊 thread::spawn.
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
ąøąĖčüčéąĖąĮą│ 20-12. ąØą░čł ąĖą┤ąĄą░ą╗čīąĮčŗą╣ ąĖąĮč鹥čĆč乥ą╣čü ThreadPool (čäą░ą╣ą╗ src/main.rs, čŹč鹊čé ą║ąŠą┤ ąĮąĄ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ).
ą£čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ ThreadPool::new, čćč鹊ą▒čŗ čüąŠąĘą┤ą░čéčī ąĮąŠą▓čŗą╣ ą┐čāą╗ ą┐ąŠč鹊ą║ąŠą▓ čü ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄą╝čŗą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąŠą╝ ą┐ąŠč鹊ą║ąŠą▓, ą▓ ąĮą░čłąĄą╝ čüą╗čāčćą░ąĄ 4. ąŚą░č鹥ą╝ ą▓ čåąĖą║ą╗ąĄ for ą▓čŗąĘąŠą▓ pool.execute ąĖą╝ąĄąĄčé ą░ąĮą░ą╗ąŠą│ąĖčćąĮčŗą╣ ąĖąĮč鹥čĆč乥ą╣čü, ą║ą░ą║ čā thread::spawn, ą▓ ą║ąŠč鹊čĆąŠą╝ ąĮą░ ą▓čģąŠą┤ąĄ ąĘą░ą╝čŗą║ą░ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ą┐čāą╗ ą┤ąŠą╗ąČąĄąĮ ąĘą░ą┐čāčüą║ą░čéčī ą▓ ą║ą░ąČą┤ąŠą╝ ą┐ąŠč鹊ą║ąĄ. ąØą░ą╝ ąĮčāąČąĮąŠ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī pool.execute čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊ą▒čŗ ąŠąĮ ą┐čĆąĖąĮąĖą╝ą░ą╗ ąĘą░ą╝čŗą║ą░ąĮąĖąĄ, ąĖ ą┐ąĄčĆąĄą┤ą░ą▓ą░ą╗ ąĄą│ąŠ ą▓ ą┐ąŠč鹊ą║ ą┐čāą╗ą░ ą┤ą╗čÅ ąĘą░ą┐čāčüą║ą░. ąŁč鹊čé ą║ąŠą┤ ą┐ąŠą║ą░ čćč鹊 ąĮąĄ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ, ąĮąŠ ą╝čŗ ą┐ąŠą┐čĆąŠą▒čāąĄą╝ ąĄą│ąŠ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░čéčī, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī čāą║ą░ąĘą░ąĮąĖčÅ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░, čćč鹊 ąĮčāąČąĮąŠ čüą┤ąĄą╗ą░čéčī ą┤ą╗čÅ ąĖčüą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąŠčłąĖą▒ą║ąĖ.
ąĪą▒ąŠčĆą║ą░ ThreadPool ą┐ąŠą┤ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄą╝ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░. ąĪą┤ąĄą╗ą░ą╣č鹥 ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą▓ src/main.rs čüąŠą│ą╗ą░čüąĮąŠ ą╗ąĖčüčéąĖąĮą│čā 20-12, ąĖ ąĘą░č鹥ą╝ ąĘą░ą┐čāčüčéąĖč鹥 ą║ąŠą╝ą░ąĮą┤čā cargo check, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī čāą║ą░ąĘą░ąĮąĖčÅ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░, čćč鹊 ą┤ąĄą╗ą░čéčī ą┤ą░ą╗čīčłąĄ. ąÆąŠčé ą┐ąĄčĆą▓ą░čÅ ąŠčłąĖą▒ą║ą░, ą║ąŠč鹊čĆčāčÄ ą╝čŗ ą┐ąŠą╗čāčćąĖą╝:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0433]: failed to resolve: use of undeclared type `ThreadPool`
--> src/main.rs:11:16
|
11 | let pool = ThreadPool::new(4);
| ^^^^^^^^^^ use of undeclared type `ThreadPool`
For more information about this error, try `rustc --explain E0433`.
error: could not compile `hello` (bin "hello") due to 1 previous error
ą×čéą╗ąĖčćąĮąŠ! ąŁčéą░ ąŠčłąĖą▒ą║ą░ ą│ąŠą▓ąŠčĆąĖčé ąĮą░ą╝, čćč鹊 ąĮą░ą╝ ąĮčāąČąĄąĮ čéąĖą┐ ThreadPool ąĖą╗ąĖ ą╝ąŠą┤čāą╗čī, čéą░ą║ čćč鹊 ą╝čŗ ąĄą│ąŠ čüąĄą╣čćą░čü čüąŠąĘą┤ą░ą┤ąĖą╝. ąØą░čłą░ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ ThreadPool ąĮąĄ ą▒čāą┤ąĄčé ąĘą░ą▓ąĖčüąĄčéčī ąŠčé č鹊ą│ąŠ, ą║ą░ą║čāčÄ čĆą░ą▒ąŠčéčā ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ąĮą░čł ą▓ąĄą▒-čüąĄčĆą▓ąĄčĆ. ąśčéą░ą║, ą┤ą░ą▓ą░ą╣č鹥 ą┐ąŠą╝ąĄąĮčÅąĄą╝ ą║čĆąĄą╣čé hello čü ą┤ą▓ąŠąĖčćąĮąŠą│ąŠ ąĮą░ ą▒ąĖą▒ą╗ąĖąŠč鹥čćąĮčŗą╣, čćč鹊ą▒čŗ ą▓ ąĮąĄą╝ ą▒čŗą╗ą░ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ ąĮą░čłąĄą│ąŠ ThreadPool. ą¤ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ą╝čŗ čüą╝ąŠąČąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąŠčéą┤ąĄą╗čīąĮčāčÄ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║čā ą┐čāą╗ą░ ą┐ąŠč鹊ą║ąŠą▓ ą┤ą╗čÅ ą╗čÄą▒ąŠą╣ čĆą░ą▒ąŠčéčŗ, ą║ą░ą║čāčÄ ą╝čŗ čģąŠčéąĖą╝ ą▓čŗą┐ąŠą╗ąĮčÅčéčī čü ą┐ąŠą╝ąŠčēčīčÄ ą┐čāą╗ą░ ą┐ąŠč鹊ą║ąŠą▓, ąĮąĄ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ web-ąĘą░ą┐čĆąŠčüąŠą▓.
ąĪąŠąĘą┤ą░ą╣č鹥 čäą░ą╣ą╗ src/lib.rs, čüąŠą┤ąĄčƹȹ░čēąĖą╣ čüą╗ąĄą┤čāčÄčēąĄąĄ, ą┐čĆąŠčüč鹥ą╣čłąĄąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čüčéčĆčāą║čéčāčĆčŗ ThreadPool, ą║ąŠč鹊čĆąŠąĄ ą╝čŗ ą╝ąŠąČąĄą╝ ąĖą╝ąĄčéčī ą▓ ąĮą░čüč鹊čÅčēąĖą╣ ą╝ąŠą╝ąĄąĮčé (čäą░ą╣ą╗ src/lib.rs):
pub struct ThreadPool;
ąŚą░č鹥ą╝ ąŠčéčĆąĄą┤ą░ą║čéąĖčĆčāą╣č鹥 čäą░ą╣ą╗ main.rs, čćč鹊ą▒čŗ ą┐čĆąĖą▓ąĄčüčéąĖ ThreadPool ą▓ ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ ąĖąĘ ą▒ąĖą▒ą╗ąĖąŠč鹥čćąĮąŠą│ąŠ ą║čĆąĄą╣čéą░ ą┐čāč鹥ą╝ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ čüą╗ąĄą┤čāčÄčēąĄą╣ čüčéčĆąŠą║ąĖ ą▓ ąĮą░čćą░ą╗ąŠ src/main.rs:
use hello::ThreadPool;
ąŁč鹊čé ą║ąŠą┤ ą▓čüąĄ ąĄčēąĄ ąĮąĄ ą▒čāą┤ąĄčé čĆą░ą▒ąŠčéą░čéčī, ą┤ą░ą▓ą░ą╣č鹥 ąĄą│ąŠ čüąĮąŠą▓ą░ ą┐čĆąŠą▓ąĄčĆąĖą╝ ąĮą░ ą┐ąŠą╗čāč湥ąĮąĖąĄ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ąŠ čüą╗ąĄą┤čāčÄčēąĄą╣ ąŠčłąĖą▒ą║ąĄ, ą║ąŠč鹊čĆčāčÄ ą┐čĆąĄą┤čüč鹊ąĖčé ąĖčüą┐čĆą░ą▓ąĖčéčī:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no function or associated item named `new` found for struct
`ThreadPool` in the current scope
--> src/main.rs:12:28
|
12 | let pool = ThreadPool::new(4);
| ^^^ function or associated item not found
in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` (bin "hello") due to 1 previous error
ąŁčéą░ ąŠčłąĖą▒ą║ą░ ą│ąŠą▓ąŠčĆąĖčé ąŠ č鹊ą╝, čćč鹊 ą┤ą░ą╗ąĄąĄ ąĮą░ą╝ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ čüąŠąĘą┤ą░čéčī čüą▓čÅąĘą░ąĮąĮčāčÄ čäčāąĮą║čåąĖčÄ new ą┤ą╗čÅ ThreadPool. ą£čŗ čéą░ą║ąČąĄ ąĘąĮą░ąĄą╝, čćč鹊 new ą┤ąŠą╗ąČąĮą░ ąĖą╝ąĄčéčī ąŠą┤ąĖąĮ ą┐ą░čĆą░ą╝ąĄčéčĆ, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ą┐čĆąĖąĮčÅčéčī 4 ą▓ ą║ą░č湥čüčéą▓ąĄ ą░čĆą│čāą╝ąĄąĮčéą░, ąĖ ą┤ąŠą╗ąČąĮą░ ą▓ąŠąĘą▓čĆą░čéąĖčéčī 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ThreadPool. ąöą░ą▓ą░ą╣č鹥 čĆąĄą░ą╗ąĖąĘčāąĄą╝ ą┐čĆąŠčüč鹥ą╣čłčāčÄ čäčāąĮą║čåąĖčÄ new čü čéą░ą║ąĖą╝ąĖ čģą░čĆą░ą║č鹥čĆąĖčüčéąĖą║ą░ą╝ąĖ (čäą░ą╣ą╗ src/lib.rs):
pub struct ThreadPool;
impl ThreadPool {
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
}
ą£čŗ ą▓čŗą▒čĆą░ą╗ąĖ usize ą▓ ą║ą░č湥čüčéą▓ąĄ čéąĖą┐ą░ ą┤ą╗čÅ ą┐ą░čĆą░ą╝ąĄčéčĆą░ size, ą┐ąŠč鹊ą╝čā čćč鹊 ą╝čŗ ąĘąĮą░ąĄą╝, čćč鹊 ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠč鹊ą║ąŠą╗ąŠą▓ ąĮąĄ ąĖą╝ąĄąĄčé čüą╝čŗčüą╗ą░. ą£čŗ čéą░ą║ąČąĄ ąĘąĮą░ąĄą╝, čćč鹊 ą▒čāą┤ąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī 4 ą▓ ą║ą░č湥čüčéą▓ąĄ ą║ąŠą╗ąĖč湥čüčéą▓ą░ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą▓ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ ą┐ąŠč鹊ą║ąŠą▓, ą┤ą╗čÅ č湥ą│ąŠ ąĖ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮ čéąĖą┐ usize (čüą╝. čüąĄą║čåąĖčÄ "ą”ąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮčŗąĄ čéąĖą┐čŗ" ą│ą╗ą░ą▓čŗ 3 [5].
ąĢčēąĄ čĆą░ąĘ ą┐čĆąŠą▓ąĄčĆąĖą╝ ą║ąŠą┤:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no method named `execute` found for struct `ThreadPool`
in the current scope
--> src/main.rs:17:14
|
17 | pool.execute(|| {
| -----^^^^^^^ method not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` (bin "hello") due to 1 previous error
ąóąĄą┐ąĄčĆčī ąŠčłąĖą▒ą║ą░ ą┐čĆąŠąĖąĘąŠčłą╗ą░ ąĖąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 čā ąĮą░čü ąĮąĄčé ą╝ąĄč鹊ą┤ą░ execute ąĮą░ ThreadPool. ąÆčüą┐ąŠą╝ąĮąĖą╝ ąĖąĘ čüąĄą║čåąĖąĖ "ąĪąŠąĘą┤ą░ąĮąĖąĄ ą║ąŠąĮąĄčćąĮąŠą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą┐ąŠč鹊ą║ąŠą▓", čćč鹊 ąĮą░čł ą┐čāą╗ ą┐ąŠč鹊ą║ąŠą▓ ą┤ąŠą╗ąČąĄąĮ ąĖą╝ąĄčéčī ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗą╣ ąĖąĮč鹥čĆč乥ą╣čü, ą┐ąŠą┤ąŠą▒ąĮčŗą╣ thread::spawn. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ą╝čŗ čĆąĄą░ą╗ąĖąĘčāąĄą╝ čäčāąĮą║čåąĖčÄ execute, čćč鹊ą▒čŗ ąŠąĮą░ ą┐čĆąĖąĮąĖą╝ą░ą╗ą░ ąĘą░ą╝čŗą║ą░ąĮąĖąĄ ąĖ ą┐ąĄčĆąĄą┤ą░ą▓ą░ą╗ą░ ąĄą│ąŠ ą▓ ąŠąČąĖą┤ą░čÄčēąĖą╣ ą┐ąŠč鹊ą║ ąĮą░ ą┐čāą╗ąĄ ą┤ą╗čÅ ąĘą░ą┐čāčüą║ą░.
ąöą░ą▓ą░ą╣č鹥 ąŠą┐čĆąĄą┤ąĄą╗ąĖą╝ ą╝ąĄč鹊ą┤ execute ąĮą░ ThreadPool, čćč鹊ą▒čŗ ąŠąĮ ą┐čĆąĖąĮąĖą╝ą░ą╗ ąĘą░ą╝čŗą║ą░ąĮąĖąĄ ą▓ ą║ą░č湥čüčéą▓ąĄ ą┐ą░čĆą░ą╝ąĄčéčĆą░. ąÆčüą┐ąŠą╝ąĮąĖą╝ ąĖąĘ čüąĄą║čåąĖąĖ "ą¤ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ ąĘą░čģą▓ą░č湥ąĮąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣ ąĖąĘ ąĘą░ą╝čŗą║ą░ąĮąĖą╣ ąĖ Fn-čéčĆąĄą╣čéčŗ" ą│ą╗ą░ą▓čŗ 13 [6], čćč鹊 ą╝čŗ ą╝ąŠąČąĄą╝ ą┐čĆąĖąĮčÅčéčī ąĘą░ą╝čŗą║ą░ąĮąĖčÅ ą▓ ą║ą░č湥čüčéą▓ąĄ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ čü čéčĆąĄą╝čÅ čĆą░ąĘą╗ąĖčćąĮčŗą╝ąĖ čéčĆąĄą╣čéą░ą╝ąĖ: Fn, FnMut ąĖ FnOnce. ąØą░ą╝ ąĮčāąČąĮąŠ čĆąĄčłąĖčéčī, ą║ą░ą║ąŠą╣ ą▓ąĖą┤ ąĘą░ą╝čŗą║ą░ąĮąĖčÅ ąĘą┤ąĄčüčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī. ą£čŗ ąĘąĮą░ąĄą╝, čćč鹊 ą▓ ą║ąŠąĮąĄčćąĮąŠą╝ ąĖč鹊ą│ąĄ čüą┤ąĄą╗ą░ąĄą╝ čćč鹊-č鹊 ą┐ąŠčģąŠąČąĄąĄ ąĮą░ čüčéą░ąĮą┤ą░čĆčéąĮčāčÄ čĆąĄą░ą╗ąĖąĘą░čåąĖčÄ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ thread::spawn, ą┐ąŠčŹč鹊ą╝čā ą╝čŗ ą╝ąŠąČąĄą╝ ą┐ąŠčüą╝ąŠčéčĆąĄčéčī ąĮą░ trait bound ą┐ą░čĆą░ą╝ąĄčéčĆą░ ą▓ čüąĖą│ąĮą░čéčāčĆąĄ thread::spawn. ąöąŠą║čāą╝ąĄąĮčéą░čåąĖčÅ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ą╝ čüą╗ąĄą┤čāčÄčēąĄąĄ:
pub fn spawn< F, T>(f: F) -> JoinHandle< T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,
ą¤ą░čĆą░ą╝ąĄčéčĆ čéąĖą┐ą░ F čŹč鹊 č鹊, čćč鹊 ąĮą░čü ąĘą┤ąĄčüčī ąĖąĮč鹥čĆąĄčüčāąĄčé; ą┐ą░čĆą░ą╝ąĄčéčĆ čéąĖą┐ą░ T čüą▓čÅąĘą░ąĮ čü ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝čŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝, ąĖ ąĮą░čü čŹč鹊 ąĮąĄ ą║ą░čüą░ąĄčéčüčÅ. ą£čŗ ą╝ąŠąČąĄą╝ ą▓ąĖą┤ąĄčéčī, čćč鹊 spawn ąĖčüą┐ąŠą╗čīąĘčāąĄčé FnOnce ą║ą░ą║ trait bound ąĮą░ F. ąŁč鹊 ą▓ąĄčĆąŠčÅčéąĮąŠ č鹊, čćč鹊 ą╝čŗ čéą░ą║ąČąĄ čģąŠčéąĖą╝, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓ ą║ąŠąĮąĄčćąĮąŠą╝ ąĖč鹊ą│ąĄ ą┐ąĄčĆąĄą┤ą░ąĄą╝ ą░čĆą│čāą╝ąĄąĮčé, ą║ąŠč鹊čĆčŗą╣ čģąŠčéąĖą╝ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą┤ą╗čÅ spawn. ą£čŗ čéą░ą║ąČąĄ ą╝ąŠąČąĄą╝ ą▒čŗčéčī čāą▓ąĄčĆąĄąĮčŗ, čćč鹊 FnOnce čŹč鹊 čéčĆąĄą╣čé, ą║ąŠč鹊čĆčŗą╣ ą╝čŗ čģąŠčéąĖą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī, ą┐ąŠč鹊ą╝čā čćč鹊 ą┐ąŠč鹊ą║ ą┤ą╗čÅ ąĘą░ą┐čāčüą║ą░ ąĘą░ą┐čĆąŠčüą░ ą▒čāą┤ąĄčé ą▓čŗą┐ąŠą╗ąĮčÅčéčī ąĘą░ą╝čŗą║ą░ąĮąĖąĄ ąĘą░ą┐čĆąŠčüą░ ąŠą┤ąĮąŠą║čĆą░čéąĮąŠ, čćč鹊 čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé Once ą▓ FnOnce.
ą¤ą░čĆą░ą╝ąĄčéčĆ čéąĖą┐ą░ F čéą░ą║ąČąĄ ąĖą╝ąĄąĄčé trait bound Send ąĖ lifetime bound 'static, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠą╗ąĄąĘąĮčŗ ą▓ ąĮą░čłąĄą╣ čüąĖčéčāą░čåąĖąĖ: ąĮą░ą╝ ąĮčāąČąĄąĮ Send ą┤ą╗čÅ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ ąĘą░ą╝čŗą║ą░ąĮąĖčÅ ąĖąĘ ąŠą┤ąĮąŠą│ąŠ ą┐ąŠč鹊ą║ą░ ą▓ ą┤čĆčāą│ąŠą╣, ąĖ 'static, ą┐ąŠč鹊ą╝čā čćč鹊 ą╝čŗ ąĮąĄ ąĘąĮą░ąĄą╝, čüą║ąŠą╗čīą║ąŠ ą┐ąŠčéčĆąĄą▒čāąĄčéčüčÅ ą▓čĆąĄą╝ąĄąĮąĖ ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐ąŠč鹊ą║ą░. ąöą░ą▓ą░ą╣č鹥 čüąŠąĘą┤ą░ą┤ąĖą╝ ą╝ąĄč鹊ą┤ execute ąĮą░ ThreadPool, ą║ąŠč鹊čĆčŗą╣ ą▒čāą┤ąĄčé ą┐čĆąĖąĮąĖą╝ą░čéčī generic-ą┐ą░čĆą░ą╝ąĄčéčĆ čéąĖą┐ą░ F čü čŹčéąĖą╝ąĖ bounds (čäą░ą╣ą╗ src/lib.rs):
impl ThreadPool {
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
pub fn execute< F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
ą£čŗ ą▓čüąĄ ąĄčēąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ () ą┐ąŠčüą╗ąĄ FnOnce, ą┐ąŠč鹊ą╝čā čćč鹊 čŹč鹊čé FnOnce ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé ąĘą░ą╝čŗą║ą░ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ąĮąĄ ą┐čĆąĖąĮąĖą╝ą░ąĄčé ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓, ąĖ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé unit-čéąĖą┐ (). ąÜą░ą║ ąĖ ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅčģ čäčāąĮą║čåąĖą╣, ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝čŗą╣ čéąĖą┐ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠą┐čāčēąĄąĮ ąĖąĘ čüąĖą│ąĮą░čéčāčĆčŗ, ąŠą┤ąĮą░ą║ąŠ ą┤ą░ąČąĄ ąĄčüą╗ąĖ čā ąĮą░čü ąĮąĄčé ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓, čüą║ąŠą▒ą║ąĖ ą▓čüąĄ čĆą░ą▓ąĮąŠ ąĮčāąČąĮčŗ.
ąś čüąĮąŠą▓ą░, ąĘą┤ąĄčüčī ą┐ąŠą║ą░ čćč鹊 ą┐čĆąŠčüč鹥ą╣čłą░čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ ą╝ąĄč鹊ą┤ą░ execute: ąŠąĮą░ ąĮąĖč湥ą│ąŠ ąĮąĄ ą┤ąĄą╗ą░ąĄčé, ąĮąŠ ą╝čŗ ą┐čĆąŠą▓ąĄčĆąĖą╝, čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ ą╗ąĖ čŹč鹊čé ą║ąŠą┤:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.24s
ąÜąŠą┤ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░ą╗čüčÅ! ą×ą┤ąĮą░ą║ąŠ ąĖą╝ąĄą╣č鹥 ą▓ ą▓ąĖą┤čā, čćč鹊 ąĄčüą╗ąĖ ą▓čŗ ą┐ąŠą┐čĆąŠą▒čāąĄč鹥 ą▓čŗą┐ąŠą╗ąĮąĖčéčī cargo run ąĖ čüą┤ąĄą╗ą░ąĄč鹥 ąĘą░ą┐čĆąŠčü ą▓ ą▒čĆą░čāąĘąĄčĆąĄ, č鹊 ą▒čĆą░čāąĘąĄčĆ ą┐ąŠą║ą░ąČąĄčé ąŠčłąĖą▒ą║čā, ą║ąŠč鹊čĆčāčÄ ą╝čŗ ą▓ąĖą┤ąĄą╗ąĖ ą▓ ąĮą░čćą░ą╗ąĄ čŹč鹊ą╣ ą│ą╗ą░ą▓čŗ. ąØą░čłą░ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░ ą┐ąŠą║ą░ ąĮąĄ ąĘą░ą┐čāčüą║ą░ąĄčé ąĘą░ą╝čŗą║ą░ąĮąĖąĄ, ą┐ąĄčĆąĄą┤ą░ąĮąĮąŠąĄ ą▓ execute!
ąÆąĄčĆąŠčÅčéąĮąŠ ą▓čŗ čüą╗čŗčłą░ą╗ąĖ ą┐ąŠą│ąŠą▓ąŠčĆą║čā, čüą▓čÅąĘą░ąĮąĮčŗąĄ čüąŠ čüčéčĆąŠą│ąĖą╝ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ą╝ąĖ, čéą░ą║ąĖą╝ąĖ ą║ą░ą║ Haskell ąĖ Rust: "ąĄčüą╗ąĖ ą║ąŠą┤ ą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ, č鹊 ąŠąĮ čĆą░ą▒ąŠčéą░ąĄčé". ą×ą┤ąĮą░ą║ąŠ čŹč鹊 ą▓čŗčüą║ą░ąĘčŗą▓ą░ąĮąĖąĄ ąĮąĄ čāąĮąĖą▓ąĄčĆčüą░ą╗čīąĮąŠ ą▓ąĄčĆąĮąŠąĄ. ąØą░čł ą┐čĆąŠąĄą║čé ą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ, ąĮąŠ ąŠąĮ ą░ą▒čüąŠą╗čÄčéąĮąŠ ąĮąĖč湥ą│ąŠ ąĮąĄ ą┤ąĄą╗ą░ąĄčé! ąĢčüą╗ąĖ ą▒čŗ ą╝čŗ čüčéčĆąŠąĖą╗ąĖ čĆąĄą░ą╗čīąĮčŗą╣, ą┐ąŠą╗ąĮčŗą╣ ą┐čĆąŠąĄą║čé, č鹊 čŹč鹊 ą▒čŗą╗ ą▒čŗ čģąŠčĆąŠčłąĖą╣ ą╝ąŠą╝ąĄąĮčé ą┤ą╗čÅ ąĮą░ą┐ąĖčüą░ąĮąĖčÅ unit-č鹥čüč鹊ą▓, čćč鹊ą▒čŗ ą┐čĆąŠą▓ąĄčĆąĖčéčī, čćč鹊 čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą║ąŠą┤ ą┤ąĄą╗ą░ąĄčé ąĖą╝ąĄąĮąĮąŠ č鹊, čćč鹊 ą╝čŗ čģąŠč鹥ą╗ąĖ.
ą¤čĆąŠą▓ąĄčĆą║ą░ ą▓ new ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą┐ąŠč鹊ą║ąŠą▓. ą£čŗ ąĮąĖč湥ą│ąŠ ąĮąĄ ą┤ąĄą╗ą░ąĄą╝ čü ą┐ą░čĆą░ą╝ąĄčéčĆą░ą╝ąĖ ą┤ą╗čÅ new ąĖ execute. ąöą░ą▓ą░ą╣č鹥 čĆąĄą░ą╗ąĖąĘčāąĄą╝ č鹥ą╗ą░ čŹčéąĖčģ čäčāąĮą║čåąĖą╣ čü ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄą╝, ą║ąŠč鹊čĆąŠąĄ ąĮą░ą╝ ąĮčāąČąĮąŠ. ąĪąĮą░čćą░ą╗ą░ ą┐ąŠą┤čāą╝ą░ąĄą╝ ąĮą░ą┤ new. ąĀą░ąĮąĄąĄ ą╝čŗ ą▓čŗą▒čĆą░ą╗ąĖ unsigned-čéąĖą┐ ą┤ą╗čÅ ą┐ą░čĆą░ą╝ąĄčéčĆą░ size, ą┐ąŠč鹊ą╝čā čćč鹊 ą┐čāą╗ čü ąŠčéčĆąĖčåą░č鹥ą╗čīąĮčŗą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąŠą╝ ą┐ąŠč鹊ą║ąŠą▓ ąĮąĄ ąĖą╝ąĄąĄčé čüą╝čŗčüą╗ą░. ą×ą┤ąĮą░ą║ąŠ ąĮąĄ ąĖą╝ąĄąĄčé čéą░ą║ąČąĄ čüą╝čŗčüą╗ ą┐čāą╗ čü ąĮčāą╗ąĄą▓čŗą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąŠą╝ ą┐ąŠč鹊ą║ąŠą▓, č鹥ą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ 0 čŹč鹊 ą░ą▒čüąŠą╗čÄčéąĮąŠ ą┤ąŠą┐čāčüčéąĖą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┤ą╗čÅ čéąĖą┐ą░ usize. ą£čŗ ą┤ąŠą▒ą░ą▓ąĖą╝ ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąŠą▓ąĄčĆąĖčé, čćč鹊 ą┐ą░čĆą░ą╝ąĄčéčĆ size ą▒ąŠą╗čīčłąĄ ąĮčāą╗čÅ, ą┐ąĄčĆąĄą┤ č鹥ą╝ ą║ą░ą║ ą▓ąŠąĘą▓čĆą░čéąĖą╝ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ThreadPool, ąĖ ą▒čāą┤ąĄą╝ ą▓čŗąĘčŗą▓ą░čéčī ą┐ą░ąĮąĖą║čā ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ąĄčüą╗ąĖ new ą┐ąŠą╗čāčćąĖčé ąĮčāą╗ąĄą▓ąŠą╣ ą┐ą░čĆą░ą╝ąĄčéčĆ, ąĖčüą┐ąŠą╗čīąĘčāčÅ ą╝ą░ą║čĆąŠčü assert!, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 20-13.
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
ThreadPool
}
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
}
ąøąĖčüčéąĖąĮą│ 20-13. ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ ThreadPool::new ą┤ą╗čÅ panic, ąĄčüą╗ąĖ size čĆą░ą▓ąĄąĮ 0 (čäą░ą╣ą╗ src/lib.rs).
ą£čŗ čéą░ą║ąČąĄ ą┤ąŠą▒ą░ą▓ąĖą╗ąĖ ąĮąĄą║ąŠč鹊čĆčāčÄ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖčÄ ą┤ą╗čÅ ąĮą░čłąĄą│ąŠ ThreadPool čü ą┐ąŠą╝ąŠčēčīčÄ čüąĖąĮčéą░ą║čüąĖčüą░ doc comments. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą╝čŗ čüą╗ąĄą┤ąŠą▓ą░ą╗ąĖ čģąŠčĆąŠčłąĄą╣ ą┐čĆą░ą║čéąĖą║ąĄ ąŠč乊čĆą╝ą╗ąĄąĮąĖčÅ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ, ą║ąŠą│ą┤ą░ ąŠą┐ąĖčüčŗą▓ą░čÄčéčüčÅ čüąĖčéčāą░čåąĖąĖ, ą▓ ą║ąŠč鹊čĆčŗčģ ąĮą░čłą░ čäčāąĮą║čåąĖčÅ ą╝ąŠąČąĄčé ą▓čŗąĘą▓ą░čéčī ą┐ą░ąĮąĖą║čā, čćč鹊 ąŠą▒čüčāąČą┤ą░ą╗ąŠčüčī ą▓ ą│ą╗ą░ą▓ąĄ 14 [7]. ą¤ąŠą┐čĆąŠą▒čāą╣č鹥 ąĘą░ą┐čāčüčéąĖčéčī cargo doc --open ąĖ ą║ą╗ąĖą║ąĮąĖč鹥 ąĮą░ čüčéčĆčāą║čéčāčĆčā ThreadPool, čćč鹊ą▒čŗ čāą▓ąĖą┤ąĄčéčī, ą║ą░ą║ ą▓čŗą│ą╗čÅą┤ąĖčé čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖčÅ.
ąÆą╝ąĄčüč鹊 ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ ą╝ą░ą║čĆąŠčüą░ assert!, ą║ą░ą║ čüą┤ąĄą╗ą░ąĮąŠ ąĘą┤ąĄčüčī, ą╝čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ ą┐ąŠą╝ąĄąĮčÅčéčī new ąĮą░ build ąĖ ą▓ąŠąĘą▓čĆą░čéąĖčéčī Result ą║ą░ą║ ą╝čŗ ą┤ąĄą╗ą░ą╗ąĖ čü Config::build ą▓ ą┐čĆąŠąĄą║č鹥 I/O, čüą╝. ą╗ąĖčüčéąĖąĮą│ 12-9 [2]. ą×ą┤ąĮą░ą║ąŠ ą┤ą╗čÅ čŹč鹊ą│ąŠ čüą╗čāčćą░čÅ ą╝čŗ čĆąĄčłąĖą╗ąĖ, čćč鹊 ą┐ąŠą┐čŗčéą║ą░ čüąŠąĘą┤ą░ąĮąĖčÅ ą┐čāą╗ą░ ą┐ąŠč鹊ą║ąŠą▓ ą▓ąŠąŠą▒čēąĄ ą▒ąĄąĘ ą┐ąŠč鹊ą║ąŠą▓ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ąĮąĄčāčüčéčĆą░ąĮąĖą╝ąŠą╣ ąŠčłąĖą▒ą║ąŠą╣. ąĢčüą╗ąĖ ą▓čŗ čćčāą▓čüčéą▓čāąĄč鹥 čüąĄą▒čÅ čāą▓ąĄčĆąĄąĮąĮčŗą╝, č鹊 ą┐ąŠą┐čĆąŠą▒čāą╣č鹥 ąĮą░ą┐ąĖčüą░čéčī čäčāąĮą║čåąĖčÄ build čüąŠ čüą╗ąĄą┤čāčÄčēąĄą╣ čüąĖą│ąĮą░čéčāčĆąŠą╣, čćč鹊ą▒čŗ čüčĆą░ą▓ąĮąĖčéčī ąĄčæ čü čäčāąĮą║čåąĖąĄą╣ new:
pub fn build(size: usize) -> Result< ThreadPool, PoolCreationError> {
ąÆčŗą┤ąĄą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą┐ąŠč鹊ą║ąŠą▓. ąóąĄą┐ąĄčĆčī čā ąĮą░čü ąĄčüčéčī čüą┐ąŠčüąŠą▒ čāąĘąĮą░čéčī, čćč鹊 ąĖą╝ąĄąĄčéčüčÅ ą┤ąŠą┐čāčüčéąĖą╝ąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠč鹊ą║ąŠą▓ ą┤ą╗čÅ čģčĆą░ąĮąĄąĮąĖčÅ ą▓ ą┐čāą╗ąĄ, ą╝čŗ ą╝ąŠąČąĄą╝ čüąŠąĘą┤ą░čéčī čŹčéąĖ ą┐ąŠč鹊ą║ąĖ ąĖ čüąŠčģčĆą░ąĮąĖčéčī ąĖčģ ą▓ čüčéčĆčāą║čéčāčĆąĄ ThreadPool ą┐ąĄčĆąĄą┤ ą▓ąŠąĘą▓čĆą░č鹊ą╝ čüčéčĆčāą║čéčāčĆčŗ. ąØąŠ ą║ą░ą║ ą╝čŗ ą╝ąŠąČąĄą╝ "čüąŠčģčĆą░ąĮąĖčéčī" ą┐ąŠč鹊ą║? ąöą░ą▓ą░ą╣č鹥 ąĄčēąĄ čĆą░ąĘ ą┐ąŠčüą╝ąŠčéčĆąĖą╝ ąĮą░ čüąĖą│ąĮą░čéčāčĆčā thread::spawn:
pub fn spawn< F, T>(f: F) -> JoinHandle< T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,
ążčāąĮą║čåąĖčÅ spawn ą▓ąŠąĘą▓čĆą░čēą░ąĄčé JoinHandle< T>, ą│ą┤ąĄ T čŹč鹊 čéąĖą┐, ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝čŗą╣ ąĘą░ą╝čŗą║ą░ąĮąĖąĄą╝. ąöą░ą▓ą░ą╣č鹥 č鹊ąČąĄ ą┐ąŠą┐čĆąŠą▒čāąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī JoinHandle ąĖ ą┐ąŠčüą╝ąŠčéčĆąĖą╝, čćč鹊 ą┐ąŠą╗čāčćąĖčéčüčÅ. ąÆ ąĮą░čłąĄą╝ čüą╗čāčćą░ąĄ ąĘą░ą╝čŗą║ą░ąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą╝čŗ ą┐ąĄčĆąĄą┤ą░ąĄą╝ ą▓ ą┐čāą╗ ą┐ąŠč鹊ą║ąŠą▓, ą▒čāą┤čāčé ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ ąĖ ą▓ąŠąĘą▓čĆą░čēą░čéčī čćč鹊-č鹊, čéą░ą║ čćč鹊 T ą▒čāą┤ąĄčé unit-čéąĖą┐ąŠą╝ ().
ąÜąŠą┤ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 20-14 ą▒čāą┤ąĄčé ą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░čéčīčüčÅ, ąŠą┤ąĮą░ą║ąŠ ą┐ąŠą║ą░ ąĮąĄ čüąŠąĘą┤ą░ąĄčé ąĮąĖą║ą░ą║ąĖąĄ ą┐ąŠč鹊ą║ąĖ. ą£čŗ ąĖąĘą╝ąĄąĮąĖą╗ąĖ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ThreadPool, čćč鹊ą▒čŗ ąŠąĮ čüąŠą┤ąĄčƹȹ░ą╗ ą▓ąĄą║č鹊čĆ čŹą║ąĘąĄą╝ą┐ą╗čÅčĆąŠą▓ thread::JoinHandle< ()>, ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ą╗ ą▓ąĄą║č鹊čĆ čĆą░ąĘą╝ąĄčĆąŠą╝ size, ąĮą░čüčéčĆąŠąĖą╗ čåąĖą║ą╗ for, ą║ąŠč鹊čĆčŗą╣ ą▒čāą┤ąĄčé ąĘą░ą┐čāčüą║ą░čéčī ąĮąĄą║ąŠč鹊čĆčŗą╣ ą║ąŠą┤ ą┤ą╗čÅ čüąŠąĘą┤ą░ąĮąĖčÅ ą┐ąŠč鹊ą║ąŠą▓, ąĖ ą▓ąĄčĆąĮčāą╗ čüąŠą┤ąĄčƹȹ░čēąĖą╣ ąĖčģ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ThreadPool.
use std::thread;
pub struct ThreadPool {
threads: Vec< thread::JoinHandle< ()>>,
}
impl ThreadPool {
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut threads = Vec::with_capacity(size);
for _ in 0..size {
// čüąŠąĘą┤ą░ąĮąĖąĄ ąĮąĄą║ąĖčģ ą┐ąŠč鹊ą║ąŠą▓ ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖąĄ ąĖčģ ą▓ ą▓ąĄą║č鹊čĆ
}
ThreadPool { threads }
}
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
}
ąøąĖčüčéąĖąĮą│ 20-14. ąĪąŠąĘą┤ą░ąĮąĖąĄ ą▓ąĄą║č鹊čĆą░ ą┤ą╗čÅ ThreadPool, čćč鹊ą▒čŗ ą▓ ąĮąĄą╝ čģčĆą░ąĮąĖą╗ąĖčüčī ą┐ąŠč鹊ą║ąĖ (čäą░ą╣ą╗ src/lib.rs, čŹč鹊čé ą║ąŠą┤ ą┐ąŠą║ą░ ąĮąĄ ąŠą▒ąĄčüą┐ąĄčćąĖą▓ą░ąĄčé ąČąĄą╗ą░ąĄą╝ąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ).
ą£čŗ ą┐čĆąĖą▓ąĄą╗ąĖ std::thread ą▓ ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ ą▒ąĖą▒ą╗ąĖąŠč鹥čćąĮąŠą│ąŠ ą║čĆąĄą╣čéą░, ą┐ąŠč鹊ą╝čā čćč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ thread::JoinHandle ą║ą░ą║ čéąĖą┐ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą▓ ą▓ąĄą║č鹊čĆą░ ą▓ ThreadPool.
ąÜą░ą║ č鹊ą╗čīą║ąŠ ą┐ąŠą╗čāč湥ąĮ ą┤ąŠą┐čāčüčéąĖą╝čŗą╣ čĆą░ąĘą╝ąĄčĆ, ąĮą░čł ThreadPool čüąŠąĘą┤ą░ąĄčé ąĮąŠą▓čŗą╣ ą▓ąĄą║č鹊čĆ, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé čģčĆą░ąĮąĖčéčī size 菹╗ąĄą╝ąĄąĮč鹊ą▓. ążčāąĮą║čåąĖčÅ with_capacity ą▓čŗą┐ąŠą╗ąĮčÅąĄčé čéčā ąČąĄ ąĘą░ą┤ą░čćčā, čćč鹊 ąĖ Vec::new, ąĮąŠ čü ą▓ą░ąČąĮčŗą╝ ąŠčéą╗ąĖčćąĖąĄą╝: ąŠąĮą░ ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮąŠ ą▓čŗą┤ąĄą╗čÅąĄčé ą┐ą░ą╝čÅčéčī ą▓ ą▓ąĄą║č鹊čĆąĄ. ą¤ąŠčüą║ąŠą╗čīą║čā ą╝čŗ ąĘąĮą░ąĄą╝, čćč鹊 ąĮčāąČąĮąŠ čüąŠčģčĆą░ąĮąĖčéčī size 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą▓ ą▓ąĄą║č鹊čĆąĄ, č鹊 čŹč鹊 ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮąŠąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠ, č湥ą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ Vec::new čü čüą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮčŗą╝ ąĖąĘą╝ąĄąĮąĄąĮąĖąĄą╝ čĆą░ąĘą╝ąĄčĆą░ ą┐ąŠ ą╝ąĄčĆąĄ ą▓čüčéą░ą▓ą║ąĖ 菹╗ąĄą╝ąĄąĮč鹊ą▓.
ąÜąŠą│ą┤ą░ ą▓čŗ čüąĮąŠą▓ą░ ąĘą░ą┐čāčüčéąĖč鹥 cargo check, č鹊 čĆąĄąĘčāą╗čīčéą░čé ą▒čāą┤ąĄčé čāčüą┐ąĄčłąĮčŗą╝.
ąĪčéčĆčāą║čéčāčĆą░ Worker, ąŠčéą▓ąĄčćą░čÄčēą░čÅ ąĘą░ ąŠčéą┐čĆą░ą▓ą║čā ą║ąŠą┤ą░ ąĖąĘ ThreadPool ą▓ Thread. ą£čŗ ąŠčüčéą░ą▓ąĖą╗ąĖ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ ą▓ čåąĖą║ą╗ąĄ for ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 20-14, ąŠčéąĮąŠčüčÅčēąĖą╣čüčÅ ą║ čüąŠąĘą┤ą░ąĮąĖčÄ ą┐ąŠč鹊ą║ąŠą▓. ąŚą┤ąĄčüčī ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝, ą║ą░ą║ čĆąĄą░ą╗čīąĮąŠ čüąŠąĘą┤ą░ą▓ą░čéčī ą┐ąŠč鹊ą║ąĖ. ąĪčéą░ąĮą┤ą░čĆčéąĮą░čÅ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé thread::spawn ą║ą░ą║ čüą┐ąŠčüąŠą▒ ą┤ą╗čÅ čüąŠąĘą┤ą░ąĮąĖčÅ ą┐ąŠč鹊ą║ąŠą▓, ąĖ thread::spawn ąŠąČąĖą┤ą░ąĄčé ąĮą░ ą▓čģąŠą┤ąĄ ąĮąĄą║ąŠč鹊čĆčŗą╣ ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠč鹊ą║ ą┤ąŠą╗ąČąĄąĮ ąĘą░ą┐čāčüčéąĖčéčī ą┐čĆąĖ ąĄą│ąŠ čüąŠąĘą┤ą░ąĮąĖąĖ. ą×ą┤ąĮą░ą║ąŠ ą▓ ąĮą░čłąĄą╝ čüą╗čāčćą░ąĄ ą╝čŗ čģąŠčéąĖą╝ čüąŠąĘą┤ą░čéčī ą┐ąŠč鹊ą║ąĖ, čćč鹊ą▒čŗ ąŠąĮąĖ ąČą┤ą░ą╗ąĖ ą║ąŠą┤ą░, ą║ąŠč鹊čĆčŗą╣ ą╝čŗ ąŠčéą┐čĆą░ą▓ąĖą╝ ą┐ąŠąĘąČąĄ. ąĪčéą░ąĮą┤ą░čĆčéąĮą░čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ąĮąĄ ą▓ą║ą╗čÄčćą░ąĄčé ąĮąĖč湥ą│ąŠ ą┐ąŠą┤ąŠą▒ąĮąŠą│ąŠ, čéą░ą║ čćč鹊 ąĮą░ą╝ ą┐čĆąĖą┤ąĄčéčüčÅ čŹč鹊 ą┤ąĄą╗ą░čéčī ą▓čĆčāčćąĮčāčÄ.
ąöą░ą▓ą░ą╣č鹥 čĆąĄą░ą╗ąĖąĘčāąĄą╝ čŹč鹊 ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐čāč鹥ą╝ ą▓ą▓ąĄą┤ąĄąĮąĖčÅ ąĮąŠą▓ąŠą╣ čüčéčĆčāą║čéčāčĆčŗ ą┤ą░ąĮąĮčŗčģ ą╝ąĄąČą┤čā ThreadPool ąĖ ą┐ąŠč鹊ą║ą░ą╝ąĖ, ą║ąŠč鹊čĆą░čÅ ą▒čāą┤ąĄčé ąŠą▒čüą╗čāąČąĖą▓ą░čéčī čŹč鹊 ąĮąŠą▓ąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ. ąØą░ąĘąŠą▓ąĄą╝ čŹčéčā čüčéčĆčāą║čéčāčĆčā Worker, ąŠą▒čēąĖą╝ č鹥čĆą╝ąĖąĮąŠą╝ pooling-čĆąĄą░ą╗ąĖąĘą░čåąĖą╣. Worker ą▒ąĄčĆąĄčé ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ąĘą░ą┐čāčēąĄąĮ, ąĖ ąĘą░ą┐čāčüą║ą░ąĄčé ąĄą│ąŠ ą▓ ą┐ąŠč鹊ą║ąĄ Worker. ąŁč鹊 ą╝ąŠąČąĮąŠ ą┐čĆąĄą┤čüčéą░ą▓ąĖčéčī čüąĄą▒ąĄ ą║ą░ą║ č湥ą╗ąŠą▓ąĄą║ą░, čĆą░ą▒ąŠčéą░čÄčēąĄą│ąŠ ąĮą░ ą║čāčģąĮąĄ ą▓ čĆąĄčüč鹊čĆą░ąĮąĄ: čĆą░ą▒ąŠčéąĮąĖą║ (worker) ąČą┤ąĄčé, ą║ąŠą│ą┤ą░ ą┐ąŠčüčéčāą┐ąĖčé ąĘą░ą║ą░ąĘ ąŠčé ą║ą╗ąĖąĄąĮč鹊ą▓, ą░ ąĘą░č鹥ą╝ ąŠčéą▓ąĄčćą░čÄčé ąĘą░ ą┐čĆąĖąĄą╝ čŹčéąĖčģ ąĘą░ą║ą░ąĘąŠą▓ ąĖ ąĖčģ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ.
ąÆą╝ąĄčüč鹊 čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą▓ąĄą║č鹊čĆą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą▓ JoinHandle< ()> ą▓ ą┐čāą╗ąĄ ą┐ąŠč鹊ą║ąŠą▓, ą╝čŗ ą▒čāą┤ąĄą╝ čüąŠčģčĆą░ąĮčÅčéčī 菹║ąĘąĄą╝ą┐ą╗čÅčĆčŗ čüčéčĆčāą║čéčāčĆ Worker. ąÜą░ąČą┤čŗą╣ Worker čüąŠčģčĆą░ąĮąĖčé ąŠą┤ąĖąĮ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ JoinHandle< ()>. ąŚą░č鹥ą╝ ą╝čŗ čĆąĄą░ą╗ąĖąĘčāąĄą╝ ą╝ąĄč鹊ą┤ ąĮą░ Worker, ą║ąŠč鹊čĆčŗą╣ ą▒ąĄčĆąĄčé ąĘą░ą╝čŗą║ą░ąĮąĖąĄ čü ą║ąŠą┤ąŠą╝ ą┤ą╗čÅ ąĘą░ą┐čāčüą║ą░, ąĖ ą┐ąŠčłą╗ąĄčé ąĄą│ąŠ ą▓ čāąČąĄ ąĘą░ą┐čāčēąĄąĮąĮčŗą╣ ą┐ąŠč鹊ą║ ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ. ą£čŗ čéą░ą║ąČąĄ ą┤ą░ą┤ąĖą╝ ą║ą░ąČą┤ąŠą╝čā worker ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ (id), čćč鹊ą▒čŗ ą╝čŗ ą╝ąŠą│ą╗ąĖ ąŠčéą╗ąĖčćą░čéčī ą║ą░ąČą┤ąŠą│ąŠ worker ą▓ ą┐čāą╗ąĄ, ą║ąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą▓čŗą▓ąŠą┤ ą▓ ą╗ąŠą│ ąĖą╗ąĖ ąŠčéą╗ą░ą┤ą║ą░.
ąŚą┤ąĄčüčī ą┐čĆąĖą▓ąĄą┤ąĄąĮąŠ ąŠą┐ąĖčüą░ąĮąĖąĄ ąĮąŠą▓ąŠą│ąŠ ą┐čĆąŠčåąĄčüčüą░, ą║ąŠč鹊čĆčŗą╣ ą▒čāą┤ąĄčé ą┐čĆąŠąĖčüčģąŠą┤ąĖčéčī, ą║ąŠą│ą┤ą░ ą╝čŗ čüąŠąĘą┤ą░ąĄą╝ ThreadPool. ą£čŗ čĆąĄą░ą╗ąĖąĘčāąĄą╝ ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ąŠčéą┐čĆą░ą▓ą╗čÅąĄčé ąĘą░ą╝čŗą║ą░ąĮąĖąĄ ą▓ ą┐ąŠč鹊ą║ ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ą╝čŗ ąĮą░čüčéčĆąŠąĖą╝ Worker čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
1. ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čüčéčĆčāą║čéčāčĆčŗ Worker, ą║ąŠč鹊čĆą░čÅ čüąŠą┤ąĄčƹȹĖčé id ąĖ JoinHandle< ()>.
2. ą¤ąŠą╝ąĄąĮčÅąĄą╝ ThreadPool, čćč鹊ą▒čŗ ą▓ ąĮąĄą╝ čüąŠą┤ąĄčƹȹ░ą╗čüčÅ ą▓ąĄą║č鹊čĆ čŹą║ąĘąĄą╝ą┐ą╗čÅčĆąŠą▓ Worker.
3. ą×ą┐čĆąĄą┤ąĄą╗ąĖą╝ čäčāąĮą║čåąĖčÄ Worker::new, ą║ąŠč鹊čĆą░čÅ ą┐čĆąĖąĮąĖą╝ą░ąĄčé ąĮąŠą╝ąĄčĆ id ąĖ ą▓ąŠąĘą▓čĆą░čéąĖčé 菹║ąĘąĄą╝ą┐ą╗čÅčĆ Worker, ą│ą┤ąĄ čģčĆą░ąĮąĖčéčüčÅ id ąĖ ą┐ąŠčĆąŠąČą┤ąĄąĮąĮčŗą╣ ą┐ąŠč鹊ą║ čü ą┐čāčüčéčŗą╝ ąĘą░ą╝čŗą║ą░ąĮąĖąĄą╝.
4. ąÆ ThreadPool::new ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ čåąĖą║ą╗ for čüąŠ čüč湥čéčćąĖą║ąŠą╝, čćč鹊ą▒čŗ ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī id, čüąŠąĘą┤ą░ąĮąĖčÅ ąĮąŠą▓ąŠą│ąŠ Worker čü čŹčéąĖą╝ id, ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ worker-ą░ ą▓ ą▓ąĄą║č鹊čĆ.
ąĢčüą╗ąĖ ą▓čŗ ą┤ąŠčüčéą░č鹊čćąĮąŠ ą┐čĆąŠą┤ą▓ąĖąĮčāą╗ąĖčüčī, ą┐ąŠą┐čĆąŠą▒čāą╣č鹥 čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ą▓čüąĄ čŹč鹊 čüą░ą╝ąĖ, ą┐ąĄčĆąĄą┤ č鹥ą╝ ą║ą░ą║ ą┐ąŠčüą╝ąŠčéčĆąĄčéčī ąĮą░ ą╗ąĖčüčéąĖąĮą│ 20-15.
ąōąŠč鹊ą▓čŗ? ąÆąŠčé ą╗ąĖčüčéąĖąĮą│ 20-15 čü ąŠą┤ąĮąĖą╝ ąĖąĘ ą▓ą░čĆąĖą░ąĮč鹊ą▓ ą▓ą▓ąĄą┤ąĄąĮąĖčÅ ą▓čŗčłąĄąŠą┐ąĖčüą░ąĮąĮčŗčģ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖą╣ (čäą░ą╣ą╗ src/lib.rs):
use std::thread;
pub struct ThreadPool {
workers: Vec< Worker>,
}
impl ThreadPool {
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers }
}
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
}
struct Worker {
id: usize,
thread: thread::JoinHandle< ()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}
ąøąĖčüčéąĖąĮą│ 20-15. ą£ąŠą┤ąĖčäąĖą║ą░čåąĖčÅ ThreadPool, čćč鹊ą▒čŗ čģčĆą░ąĮąĖčéčī 菹║ąĘąĄą╝ą┐ą╗čÅčĆčŗ Worker ą▓ą╝ąĄčüč鹊 ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠą│ąŠ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą┐ąŠč鹊ą║ąŠą▓.
ą£čŗ ą┐ąŠą╝ąĄąĮčÅą╗ąĖ ąĖą╝čÅ ą┐ąŠą╗čÅ ą▓ ThreadPool čü threads ąĮą░ workers, ą┐ąŠč鹊ą╝čā čćč鹊 č鹥ą┐ąĄčĆčī ąŠąĮąŠ čģčĆą░ąĮąĖčé 菹║ąĘąĄą╝ą┐ą╗čÅčĆčŗ Worker ą▓ą╝ąĄčüč鹊 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą▓ JoinHandle< ()>. ą£čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ čüč湥čéčćąĖą║ ą▓ čåąĖą║ą╗ąĄ for ą▓ ą║ą░č湥čüčéą▓ąĄ ą░čĆą│čāą╝ąĄąĮčéą░ ą┤ą╗čÅ Worker::new, ąĖ čüąŠčģčĆą░ąĮčÅąĄą╝ ą║ą░ąČą┤čŗą╣ ąĮąŠą▓čŗą╣ Worker ą▓ ą▓ąĄą║č鹊čĆąĄ workers.
ąÆąĮąĄčłąĮąĖą╣ ą║ąŠą┤ (ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ ąĮą░čłąĄą│ąŠ čüąĄčĆą▓ąĄčĆą░ ą▓ src/main.rs) ąĮąĄ ą┤ąŠą╗ąČąĄąĮ ąĘąĮą░čéčī ą┐ąŠą┤čĆąŠą▒ąĮąŠčüčéąĖ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ, ąŠčéąĮąŠčüčÅčēąĖąĄčüčÅ ą║ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÄ čüčéčĆčāą║čéčāčĆčŗ Worker ą▓ąĮčāčéčĆąĖ ThreadPool, čéą░ą║ čćč鹊 ą╝čŗ čüą┤ąĄą╗ą░ą╗ąĖ ą┐čĆąĖą▓ą░čéąĮąŠą╣ čüčéčĆčāą║čéčāčĆčā Worker ąĖ ąĄčæ čäčāąĮą║čåąĖčÄ new. ążčāąĮą║čåąĖčÅ Worker::new ąĖčüą┐ąŠą╗čīąĘčāąĄčé id, ą║ąŠč鹊čĆčŗą╣ ą╝čŗ ąĄą╣ ą┐ąĄčĆąĄą┤ą░ąĄą╝, ąĖ čüąŠčģčĆą░ąĮčÅąĄčé 菹║ąĘąĄą╝ą┐ą╗čÅčĆ JoinHandle< ()>, ą║ąŠč鹊čĆčŗą╣ čüąŠąĘą┤ą░ąĄčéčüčÅ ą┐čāč鹥ą╝ ą┐ąŠčĆąŠąČą┤ąĄąĮąĖčÅ ąĮąŠą▓ąŠą│ąŠ ą┐ąŠč鹊ą║ą░ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą┐čāčüč鹊ą│ąŠ ąĘą░ą╝čŗą║ą░ąĮąĖčÅ.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ąĄčüą╗ąĖ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮą░čÅ čüąĖčüč鹥ą╝ą░ ąĮąĄ ą╝ąŠąČąĄčé čüąŠąĘą┤ą░čéčī ą┐ąŠč鹊ą║ ąĖąĘ-ąĘą░ ąĮąĄčģą▓ą░čéą║ąĖ čüąĖčüč鹥ą╝ąĮčŗčģ čĆąĄčüčāčĆčüąŠą▓, č鹊 ą▓čŗąĘąŠą▓ thread::spawn ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ą┐ą░ąĮąĖą║ąĄ. ąŁč鹊 ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ č鹊ą╝čā, čćč鹊 ą▒čāą┤ąĄčé ą┐ą░ąĮąĖą║ąŠą▓ą░čéčī ą▓ąĄčüčī čüąĄčĆą▓ąĄčĆ, ąĮąĄčüą╝ąŠčéčĆčÅ ąĮą░ č鹊, čćč鹊 ąĮąĄą║ąŠč鹊čĆčŗąĄ ą┐ąŠč鹊ą║ąĖ ą╝ąŠą│ą╗ąĖ čüąŠąĘą┤ą░čéčīčüčÅ čāčüą┐ąĄčłąĮąŠ. ąöą╗čÅ čāą┐čĆąŠčēąĄąĮąĖčÅ čŹč鹊 ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┤ąŠą┐čāčüčéąĖą╝ąŠ, ąŠą┤ąĮą░ą║ąŠ ą▓ čĆąĄą░ą╗čīąĮąŠą╝ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ čüąĄčĆą▓ąĄčĆą░ čü čĆąĄą░ą╗ąĖąĘą░čåąĖąĄą╣ ą┐čāą╗ą░ ą┐ąŠč鹊ą║ąŠą▓ ą▒čŗą╗ąŠ ą▒čŗ ą╗čāčćčłąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī std::thread::Builder ąĖ ąĄą│ąŠ ą╝ąĄč鹊ą┤ spawn, ą║ąŠč鹊čĆčŗą╣ ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé Result.
ąŁč鹊čé ą║ąŠą┤ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ ąĖ ą▒čāą┤ąĄčé čüąŠčģčĆą░ąĮčÅčéčī ą║ąŠą╗ąĖč湥čüčéą▓ąŠ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą▓ Worker, čāą║ą░ąĘą░ąĮąĮąŠąĄ ą║ą░ą║ ą░čĆą│čāą╝ąĄąĮčé ą┤ą╗čÅ ThreadPool::new. ąØąŠ ą╝čŗ ą▓čüąĄ ąĄčēąĄ ąĮąĄ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄą╝ ąĘą░ą╝čŗą║ą░ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ą┐ąŠą╗čāčćą░ąĄą╝ ą▓ execute. ąöą░ą▓ą░ą╣č鹥 ą┤ą░ą╗čīčłąĄ čĆą░čüčüą╝ąŠčéčĆąĖą╝, ą║ą░ą║ čŹč鹊 čüą┤ąĄą╗ą░čéčī.
ą×čéą┐čĆą░ą▓ą║ą░ ąĘą░ą┐čĆąŠčüąŠą▓ ą▓ ą┐ąŠč鹊ą║ąĖ č湥čĆąĄąĘ ą║ą░ąĮą░ą╗čŗ. ąĪą╗ąĄą┤čāčÄčēą░čÅ ą┐čĆąŠą▒ą╗ąĄą╝ą░, ą║ąŠč鹊čĆčāčÄ ą╝čŗ ą▒čāą┤ąĄą╝ čĆąĄčłą░čéčī, ąĘą░ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ č鹊ą╝, čćč鹊 ąĘą░ą╝čŗą║ą░ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ą┐ąĄčĆąĄą┤ą░ąĮąŠ ą▓ thread::spawn, ą░ą▒čüąŠą╗čÄčéąĮąŠ ąĮąĖč湥ą│ąŠ ąĮąĄ ą┤ąĄą╗ą░ąĄčé. ąÆ ąĮą░čüč鹊čÅčēąĖą╣ ą╝ąŠą╝ąĄąĮčé ą╝čŗ ą┐ąŠą╗čāčćą░ąĄą╝ ąĘą░ą╝čŗą║ą░ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ čģąŠčéąĖą╝ ą▓čŗą┐ąŠą╗ąĮčÅčéčī ą▓ ą╝ąĄč鹊ą┤ąĄ execute. ą×ą┤ąĮą░ą║ąŠ ąĮą░ą╝ ąĮčāąČąĮąŠ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī thread::spawn ąĘą░ą╝čŗą║ą░ąĮąĖąĄ ą┤ą╗čÅ ąĘą░ą┐čāčüą║ą░, ą║ąŠą│ą┤ą░ čüąŠąĘą┤ą░ąĄą╝ ą║ą░ąČą┤čŗą╣ Worker ą┐čĆąĖ čüąŠąĘą┤ą░ąĮąĖąĖ ThreadPool.
ą£čŗ čģąŠčéąĖą╝, čćč鹊ą▒čŗ čüčéčĆčāą║čéčāčĆčŗ Worker, ą║ąŠč鹊čĆčŗąĄ ą╝čŗ č鹊ą╗čīą║ąŠ čćč鹊 čüąŠąĘą┤ą░ą╗ąĖ, ąĖąĘą▓ą╗ąĄą║ą░ą╗ąĖ ą║ąŠą┤ ą┤ą╗čÅ ąĘą░ą┐čāčüą║ą░ ąĖčģ ąŠč湥čĆąĄą┤ąĖ, čüąŠą┤ąĄčƹȹ░čēąĄą╣čüčÅ ą▓ ThreadPool, ąĖ ąŠčéą┐čĆą░ą▓ą╗čÅą╗ąĖ čŹč鹊čé ą║ąŠą┤ ą▓ ąĄą│ąŠ ą┐ąŠč鹊ą║ ą┤ą╗čÅ ąĘą░ą┐čāčüą║ą░.
ąÜą░ąĮą░ą╗čŗ, ą║ąŠč鹊čĆčŗąĄ ą╝čŗ ąĖąĘčāčćąĖą╗ąĖ ą▓ ą│ą╗ą░ą▓ąĄ 16 [4], ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ą┐čĆąŠčüč鹊ą╣ čüą┐ąŠčüąŠą▒ ą║ąŠą╝ą╝čāąĮąĖą║ą░čåąĖą╣ ą╝ąĄąČą┤čā ą┐ąŠč鹊ą║ą░ą╝ąĖ, ąĖ ąŠąĮąĖ ą┤ą╗čÅ ąĮą░čłąĄą│ąŠ čüą╗čāčćą░čÅ ąŠčéą╗ąĖčćąĮąŠ ą┐ąŠą┤ąŠą╣ą┤čāčé. ą£čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ ą║ą░ąĮą░ą╗ ą┤ą╗čÅ čäčāąĮą║čåąĖąĖ ą║ą░ą║ ąŠč湥čĆąĄą┤čī ąĘą░ą┤ą░ąĮąĖą╣, ąĖ ą╝ąĄč鹊ą┤ execute ą▒čāą┤ąĄčé ą┐ąŠčüčŗą╗ą░čéčī ąĘą░ą┤ą░ąĮąĖąĄ ąĖąĘ ThreadPool ą▓ 菹║ąĘąĄą╝ą┐ą╗čÅčĆčŗ Worker, ą║ąŠč鹊čĆčŗąĄ ą▒čāą┤čāčé ą┐ąŠčüčŗą╗ą░čéčī ąĘą░ą┤ą░ąĮąĖąĄ ą▓ čüą▓ąŠą╣ ą┐ąŠč鹊ą║. ą¤ą╗ą░ąĮ ą▒čāą┤ąĄčé čéą░ą║ąŠą╣:
1. ThreadPool čüąŠąĘą┤ą░čüčé ą║ą░ąĮą░ą╗ ąĖ ą▒čāą┤ąĄčé čāą┤ąĄčƹȹĖą▓ą░čéčī ąŠčéą┐čĆą░ą▓ąĖč鹥ą╗čÅ (sender).
2. ąÜą░ąČą┤čŗą╣ Worker ą▒čāą┤ąĄčé čāą┤ąĄčƹȹĖą▓ą░čéčī ą┐ąŠą╗čāčćą░č鹥ą╗čÅ (receiver).
3. ą£čŗ čüąŠąĘą┤ą░ą┤ąĖą╝ ąĮąŠą▓čāčÄ čüčéčĆčāą║čéčāčĆčā ąĘą░ą┤ą░ąĮąĖčÅ Job, ą║ąŠč鹊čĆą░čÅ ą▒čāą┤ąĄčé čģčĆą░ąĮąĖčéčī ąĘą░ą╝čŗą║ą░ąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą╝čŗ čģąŠčéąĖą╝ ą┐ąŠčüą╗ą░čéčī č湥čĆąĄąĘ ą║ą░ąĮą░ą╗.
4. ą£ąĄč鹊ą┤ execute ą┐ąŠčłą╗ąĄčé ąĘą░ą┤ą░ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ąŠąĮ čģąŠč湥čé ą▓čŗą┐ąŠą╗ąĮąĖčéčī, č湥čĆąĄąĘ ąŠčéą┐čĆą░ą▓ąĖč鹥ą╗čÅ.
5. ąÆ čüą▓ąŠąĄą╝ ą┐ąŠč鹊ą║ąĄ Worker ą▒čāą┤ąĄčé ąĘą░čåąĖą║ą╗ąĄąĮ ąĮą░ čüą▓ąŠąĄą╝ ą┐ąŠą╗čāčćą░č鹥ą╗ąĄ, ąĖ ą▓čŗą┐ąŠą╗ąĮčÅčéčī ąĘą░ą╝čŗą║ą░ąĮąĖčÅ ą╗čÄą▒čŗčģ ąĘą░ą┤ą░ąĮąĖą╣, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠą╗čāčćąĖčé.
ąØą░čćąĮąĄą╝ čü čüąŠąĘą┤ą░ąĮąĖčÅ ą║ą░ąĮą░ą╗ą░ ą▓ ThreadPool::new ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖąĖ ąŠčéą┐čĆą░ą▓ąĖč鹥ą╗čÅ ą▓ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąĄ ThreadPool, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 20-16. ąĪčéčĆčāą║čéčāčĆą░ Job ą┐ąŠą║ą░ ąĮąĖč湥ą│ąŠ ąĮąĄ čüąŠą┤ąĄčƹȹĖčé, ąĮąŠ ą▒čāą┤ąĄčé 菹╗ąĄą╝ąĄąĮč鹊ą╝ čéąĖą┐ą░, ą║ąŠč鹊čĆčŗą╣ ą╝čŗ ą┐ąŠčüčŗą╗ą░ąĄą╝ ą┐ąŠ ą║ą░ąĮą░ą╗čā.
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec< Worker>,
sender: mpsc::Sender< Job>,
}
struct Job;
impl ThreadPool {
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers, sender }
}
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
}
ąøąĖčüčéąĖąĮą│ 20-16. ą£ąŠą┤ąĖčäąĖą║ą░čåąĖčÅ ThreadPool ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ sender ą║ą░ąĮą░ą╗ą░, ą┐ąŠ ą║ąŠč鹊čĆąŠą╝čā ą┐ąĄčĆąĄą┤ą░čÄčéčüčÅ čŹą║ąĘąĄą╝ą┐ą╗čÅčĆčŗ ąĘą░ą┤ą░ąĮąĖčÅ Job (čäą░ą╣ą╗ src/lib.rs).
ąÆ ThreadPool::new ą╝čŗ čüąŠąĘą┤ą░ąĄą╝ ąĮą░čł ąĮąŠą▓čŗą╣ ą║ą░ąĮą░ą╗ ąĖ ąĘą░čüčéą░ą▓ą╗čÅąĄą╝ ą┐čāą╗ čāą┤ąĄčƹȹĖą▓ą░čéčī sender. ąŁč鹊 čāčüą┐ąĄčłąĮąŠ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ.
ąöą░ą▓ą░ą╣č鹥 ą┐ąŠą┐čĆąŠą▒čāąĄą╝ ą┐ąĄčĆąĄą┤ą░čéčī ą┐ąŠą╗čāčćą░č鹥ą╗čÅ (receiver) ą║ą░ąČą┤ąŠą╝čā worker, ą║ąŠą│ą┤ą░ ą┐čāą╗ ą┐ąŠč鹊ą║ąŠą▓ čüąŠąĘą┤ą░ąĄčé ą║ą░ąĮą░ą╗. ą£čŗ ąĘąĮą░ąĄą╝, čćč鹊 čģąŠčéąĖą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī receiver ą▓ ą┐ąŠč鹊ą║ąĄ, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠčĆąŠąČą┤ą░čÄčé worker-čŗ, ą┐ąŠčŹč鹊ą╝čā ą╝čŗ ą▒čāą┤ąĄą╝ čüčüčŗą╗ą░čéčīčüčÅ ąĮą░ ą┐ą░čĆą░ą╝ąĄčéčĆ receiver ą▓ ąĘą░ą╝čŗą║ą░ąĮąĖąĖ. ąÜąŠą┤ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 20-17 ą┐ąŠą║ą░ čćč鹊 ąĮąĄ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ.
impl ThreadPool {
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, receiver));
}
ThreadPool { workers, sender }
}
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
}
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
impl Worker {
fn new(id: usize, receiver: mpsc::Receiver< Job>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}
ąøąĖčüčéąĖąĮą│ 20-17. ą¤ąĄčĆąĄą┤ą░čćą░ receiver ą▓ worker-čŗ (čäą░ą╣ą╗ src/lib.rs, čŹč鹊čé ą║ąŠą┤ ąĮąĄ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ).
ą£čŗ čüą┤ąĄą╗ą░ą╗ąĖ ąĮąĄą║ąŠč鹊čĆčŗąĄ ąĮąĄą▒ąŠą╗čīčłąĖąĄ ąĖ ąŠč湥ą▓ąĖą┤ąĮčŗąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ: ą┐ąĄčĆąĄą┤ą░ą╗ąĖ receiver ą▓ Worker::new, ąĖ ąĘą░č鹥ą╝ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ čŹč鹊 ą▓ ąĘą░ą╝čŗą║ą░ąĮąĖąĖ.
ąÜąŠą│ą┤ą░ ą╝čŗ ą┐ąŠą┐čĆąŠą▒čāąĄą╝ ą┐čĆąŠą▓ąĄčĆąĖčéčī čŹč鹊čé ą║ąŠą┤, č鹊 ą┐ąŠą╗čāčćąĖą╝ ąŠčłąĖą▒ą║čā:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0382]: use of moved value: `receiver`
--> src/lib.rs:26:42
|
21 | let (sender, receiver) = mpsc::channel();
| -------- move occurs because `receiver` has type
| `std::sync::mpsc::Receiver< Job>`,
| which does not implement the `Copy` trait
...
25 | for id in 0..size {
| ----------------- inside of this loop
26 | workers.push(Worker::new(id, receiver));
| ^^^^^^^^ value moved here,
| in previous iteration of loop
|
note: consider changing this parameter type in method `new` to borrow
instead if owning the value isn't necessary
--> src/lib.rs:47:33
|
47 | fn new(id: usize, receiver: mpsc::Receiver< Job>) -> Worker {
| --- in this method ^^^^^^^^^^^^^^^^^^^ this parameter
takes ownership of the value
help: consider moving the expression out of the loop so it is only moved once
|
25 ~ let mut value = Worker::new(id, receiver);
26 ~ for id in 0..size {
27 ~ workers.push(value);
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `hello` (lib) due to 1 previous error
ąÜąŠą┤ ą┐čŗčéą░ąĄčéčüčÅ ą┐ąĄčĆąĄą┤ą░čéčī receiver ą▓ ąĮąĄčüą║ąŠą╗čīą║ąŠ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą▓ Worker. ąŁč鹊 ąĮąĄ čüčĆą░ą▒ąŠčéą░ąĄčé ą┐ąŠ ą┐čĆąĖčćąĖąĮąĄ, ą║ąŠč鹊čĆą░čÅ ąŠą┐ąĖčüą░ąĮą░ ą▓ ą│ą╗ą░ą▓ąĄ 16 [4]: čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ ą║ą░ąĮą░ą╗ą░, ą║ąŠč鹊čĆčāčÄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé Rust, ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčé ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą│ąĄąĮąĄčĆą░č鹊čĆąŠą▓ (producer) ąĖ ąŠą┤ąĮąŠą│ąŠ ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗čÅ (consumer). ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą╝čŗ ąĮąĄ ą╝ąŠąČąĄą╝ ą┐čĆąŠčüč鹊 ą║ą╗ąŠąĮąĖčĆąŠą▓ą░čéčī ą┐ąŠčéčĆąĄą▒ą╗čÅčÄčēąĖą╣ ą║ąŠąĮąĄčå ą║ą░ąĮą░ą╗ą░, čćč鹊ą▒čŗ ąĖčüą┐čĆą░ą▓ąĖčéčī čŹč鹊čé ą║ąŠą┤. ą£čŗ čéą░ą║ąČąĄ ąĮąĄ čģąŠčéąĖą╝ ąŠčéą┐čĆą░ą▓ą╗čÅčéčī čüąŠąŠą▒čēąĄąĮąĖąĄ ąĮąĄčüą║ąŠą╗čīą║ąŠ čĆą░ąĘ ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗čÅą╝; ąĮą░ą╝ ąĮčāąČąĄąĮ ąŠą┤ąĖąĮ čüą┐ąĖčüąŠą║ čüąŠąŠą▒čēąĄąĮąĖą╣ čü ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ worker-ą░ą╝ąĖ, čćč鹊ą▒čŗ ą║ą░ąČą┤ąŠąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ą╗ąŠčüčī ąŠą┤ąĖąĮ čĆą░ąĘ.
ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, čüąĮčÅčéąĖąĄ ąĘą░ą┤ą░čćąĖ čü ąŠč湥čĆąĄą┤ąĖ ą║ą░ąĮą░ą╗ą░ ą▓ą║ą╗čÄčćą░ąĄčé ą▓ čüąĄą▒čÅ ą╝čāčéą░čåąĖčÄ receiver, ą┐ąŠčŹč鹊ą╝čā ą┐ąŠč鹊ą║ą░ą╝ ąĮčāąČąĄąĮ ą▒ąĄąĘąŠą┐ą░čüąĮčŗą╣ čüą┐ąŠčüąŠą▒ čüąŠą▓ą╝ąĄčüčéąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąĖ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖąĖ receiver; ąĖąĮą░č湥 ą╝čŗ ą╝ąŠąČąĄą╝ ą┐ąŠą╗čāčćąĖčéčī čāčüą╗ąŠą▓ąĖčÅ ą│ąŠąĮą║ąĖ (race conditions, čćč鹊 čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ą╗ąŠčüčī ą▓ ą│ą╗ą░ą▓ąĄ 16 [4]).
ąÆčüą┐ąŠą╝ąĮąĖą╝ ą┐ąŠč鹊ą║ąŠ-ą▒ąĄąĘąŠą┐ą░čüąĮčŗąĄ čāą╝ąĮčŗąĄ čāą║ą░ąĘą░č鹥ą╗ąĖ (thread-safe smart pointers), ą║ąŠč鹊čĆčŗąĄ ąŠą▒čüčāąČą┤ą░ą╗ąĖčüčī ą▓ ą│ą╗ą░ą▓ąĄ 16 [4]: čćč鹊ą▒čŗ čüąŠą▓ą╝ąĄčüčéąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐ąŠč鹊ą║ąŠą▓ (share ownership) ąĖ ą┐ąŠąĘą▓ąŠą╗ąĖčéčī ą┐ąŠč鹊ą║ą░ą╝ ą╝čāčéąĖčĆąŠą▓ą░čéčī ąĘąĮą░č湥ąĮąĖąĄ, ąĮą░ą╝ ąĮčāąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī Arc< Mutex< T>>. ąóąĖą┐ Arc ą┐ąŠąĘą▓ąŠą╗ąĖčé ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ worker-ą░ą╝ ą▓ą╗ą░ą┤ąĄčéčī receiver, ąĖ Mutex ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ ą┐ąŠč鹊ą║ ą┐ąŠą╗čāčćąĖčé ąĘą░ą┤ą░ąĮąĖąĄ job ąĖąĘ receiver ą▓ ą╗čÄą▒ąŠą╣ ą╝ąŠą╝ąĄąĮčé ą▓čĆąĄą╝ąĄąĮąĖ. ąøąĖčüčéąĖąĮą│ 20-18 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ąĮą░ą╝ ąĮčāąČąĮąŠ čüą┤ąĄą╗ą░čéčī.
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
impl ThreadPool {
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
}
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
impl Worker {
fn new(id: usize, receiver: Arc< Mutex< mpsc::Receiver< Job>>>) -> Worker {
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
}
}
ąøąĖčüčéąĖąĮą│ 20-18. ąĪąŠą▓ą╝ąĄčüčéąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ receiver ą╝ąĄąČą┤čā worker-ą░ą╝ąĖ čü ą┐ąŠą╝ąŠčēčīčÄ Arc ąĖ Mutex (čäą░ą╣ą╗ src/lib.rs).
ąÆ ThreadPool::new, ą╝čŗ ą┐ąŠą╝ąĄčēą░ąĄą╝ receiver ą▓ Arc ąĖ Mutex. ąöą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ąĮąŠą▓ąŠą│ąŠ worker ą╝čŗ ą║ą╗ąŠąĮąĖčĆčāąĄą╝ we clone the Arc, čćč鹊ą▒čŗ čāą▓ąĄą╗ąĖčćąĖčéčī čüč湥čéčćąĖą║ čüčüčŗą╗ąŠą║, ą▒ą╗ą░ą│ąŠą┤ą░čĆčÅ č湥ą╝čā worker-čŗ ą╝ąŠą│čāčé čüąŠą▓ą╝ąĄčüčéąĮąŠ ą▓ą╗ą░ą┤ąĄčéčī receiver.
ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ ą╝ąĄč鹊ą┤ą░ Method. ąöą░ą▓ą░ą╣č鹥 ąĮą░ą║ąŠąĮąĄčå-č鹊 čĆąĄą░ą╗ąĖąĘčāąĄą╝ ą╝ąĄč鹊ą┤ execute ąĮą░ ThreadPool. ą£čŗ čéą░ą║ąČąĄ ą┐ąŠą╝ąĄąĮčÅąĄą╝ Job čüąŠ čüčéčĆčāą║čéčāčĆčŗ ąĮą░ čéąĖą┐ ą░ą╗ąĖą░čüą░ ą┤ą╗čÅ ąŠą▒čŖąĄą║čéą░ čéčĆąĄą╣čéą░, ą║ąŠč鹊čĆčŗą╣ čģčĆą░ąĮąĖčé čéąĖą┐ ąĘą░ą╝čŗą║ą░ąĮąĖčÅ, ą┐ąŠą╗čāčćą░ąĄą╝čŗą╣ execute. ąÜą░ą║ ąŠą▒čüčāąČą┤ą░ą╗ąŠčüčī ą▓ čüąĄą║čåąĖąĖ "ąĪąŠąĘą┤ą░ąĮąĖąĄ čüąĖąĮąŠąĮąĖą╝ąŠą▓ čéąĖą┐ąŠą▓ čü ą░ą╗ąĖą░čüą░ą╝ąĖ čéąĖą┐ąŠą▓" ą│ą╗ą░ą▓čŗ 19 [8], čéąĖą┐ ą░ą╗ąĖą░čüąŠą▓ ą┐ąŠąĘą▓ąŠą╗ąĖčé ąĮą░ą╝ čüą┤ąĄą╗ą░čéčī ą┤ą╗ąĖąĮąĮčŗąĄ čéąĖą┐čŗ ą║ąŠčĆąŠč湥, čćč鹊ą▒čŗ ąĖčģ ą▒čŗą╗ąŠ ą┐čĆąŠčēąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī. ąÆąĘą│ą╗čÅąĮąĖč鹥 ąĮą░ ą╗ąĖčüčéąĖąĮą│ 20-19.
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
type Job = Box< dyn FnOnce() + Send + 'static>;
impl ThreadPool {
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
pub fn execute< F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
ąøąĖčüčéąĖąĮą│ 20-19. ąĪąŠąĘą┤ą░ąĮąĖąĄ ą░ą╗ąĖą░čüą░ čéąĖą┐ą░ Job ą┤ą╗čÅ Box, ą║ąŠč鹊čĆčŗą╣ čüąŠą┤ąĄčƹȹĖčé ą║ą░ąČą┤ąŠąĄ ąĘą░ą╝čŗą║ą░ąĮąĖąĄ ąĖ ąĘą░č鹥ą╝ ą┐ąŠčüčŗą╗ą░ąĄčé ąĘą░ą┤ą░ąĮąĖąĄ job č湥čĆąĄąĘ ą║ą░ąĮą░ą╗ (čäą░ą╣ą╗ src/lib.rs).
ą¤ąŠčüą╗ąĄ čüąŠąĘą┤ą░ąĮąĖčÅ ąĮąŠą▓ąŠą│ąŠ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ Job čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ąĘą░ą╝čŗą║ą░ąĮąĖčÅ, ą║ąŠč鹊čĆąŠąĄ ą╝čŗ ą┐ąŠą╗čāčćą░ąĄą╝ ą▓ execute, ą╝čŗ ą┐ąŠčüčŗą╗ą░ąĄą╝ čŹč鹊 ąĘą░ą┤ą░ąĮąĖąĄ job ąĮą░ ąŠčéą┐čĆą░ą▓ą╗čÅčÄčēąĖą╣ ą║ąŠąĮąĄčå ą║ą░ąĮą░ą╗ą░. ą£čŗ ą▓čŗąĘčŗą▓ą░ąĄą╝ unwrap ąĮą░ send ą┤ą╗čÅ čüą╗čāčćą░čÅ, ą║ąŠą│ą┤ą░ ąŠčéą┐čĆą░ą▓ą║ą░ ąŠą║ą░ąĘą░ą╗ą░čüčī ąĮąĄčāą┤ą░čćąĮąŠą╣. ąŁč鹊 ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ, ąĮą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą╝čŗ ąŠčüčéą░ąĮąŠą▓ąĖą╝ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą▓čüąĄčģ ąĮą░čłąĖčģ ą┐ąŠč鹊ą║ąŠą▓, čé. ąĄ. ą┐čĆąĖąĮąĖą╝ą░čÄčēą░čÅ čüč鹊čĆąŠąĮą░ ą║ą░ąĮą░ą╗ą░ ą┐čĆąĄą║čĆą░čéąĖą╗ą░ ą┐ąŠą╗čāčćą░čéčī ąĮąŠą▓čŗąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ. ąØą░ ą┤ą░ąĮąĮčŗą╣ ą╝ąŠą╝ąĄąĮčé ą╝čŗ ąĮąĄ ą╝ąŠąČąĄą╝ ąŠčüčéą░ąĮąŠą▓ąĖčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĮą░čłąĖčģ ą┐ąŠč鹊ą║ąŠą▓: ąĮą░čłąĖ ą┐ąŠč鹊ą║ąĖ ą┐čĆąŠą┤ąŠą╗ąČą░čé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ, ą┐ąŠą║ą░ čüčāčēąĄčüčéą▓čāąĄčé ą┐čāą╗. ą¤čĆąĖčćąĖąĮą░, ą┐ąŠ ą║ąŠč鹊čĆąŠą╣ ą╝čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ unwrap, ąĘą░ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ č鹊ą╝, čćč鹊 ą╝čŗ ąĘąĮą░ąĄą╝, čćč鹊 čüą╗čāčćą░ą╣ čüą▒ąŠčÅ ąĮąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé, ąĮąŠ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ čŹč鹊ą│ąŠ ąĮąĄ ąĘąĮą░ąĄčé.
ąØąŠ čŹč鹊 ąĄčēąĄ ąĮąĄ ą▓čüąĄ! ąÆ worker ąĮą░čłąĄ ąĘą░ą╝čŗą║ą░ąĮąĖąĄ, ą┐ąĄčĆąĄą┤ą░ąĮąĮąŠąĄ ą▓ thread::spawn, ą▓čüąĄ ąĄčēąĄ č鹊ą╗čīą║ąŠ čüčüčŗą╗ą░ąĄčéčüčÅ ąĮą░ ą┐čĆąĖąĮąĖą╝ą░čÄčēąĖą╣ ą║ąŠąĮąĄčå ą║ą░ąĮą░ą╗ą░. ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ąĮą░ą╝ ąĮčāąČąĮąŠ, čćč鹊ą▒čŗ ąĘą░ą╝čŗą║ą░ąĮąĖąĄ čĆą░ą▒ąŠčéą░ą╗ąŠ ą▓ ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠą╝ čåąĖą║ą╗ąĄ, ąĘą░ą┐čĆą░čłąĖą▓ą░čÅ ą┐čĆąĖąĮąĖą╝ą░čÄčēąĖą╣ ą║ąŠąĮąĄčå ą║ą░ąĮą░ą╗ą░ ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ąĘą░ą┤ą░ąĮąĖčÅ job ąĖ ąĘą░ą┐čāčüą║ą░ ąĘą░ą┤ą░ąĮąĖčÅ ą┐čĆąĖ ąĄą│ąŠ ą┐ąŠą╗čāč湥ąĮąĖąĖ. ąöą░ą▓ą░ą╣č鹥 čüą┤ąĄą╗ą░ąĄą╝ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą┤ą╗čÅ Worker::new, ą┐ąŠą║ą░ąĘą░ąĮąĮčŗąĄ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 20-20.
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
impl Worker {
fn new(id: usize, receiver: Arc< Mutex< mpsc::Receiver< Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker { id, thread }
}
}
ąøąĖčüčéąĖąĮą│ 20-20. ą¤ąŠą╗čāč湥ąĮąĖąĄ ąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĘą░ą┤ą░ąĮąĖą╣ ą▓ ą┐ąŠč鹊ą║ąĄ worker-ą░ (čäą░ą╣ą╗ src/lib.rs).
ąŚą┤ąĄčüčī ą╝čŗ čüąĮą░čćą░ą╗ą░ ą▒ą╗ąŠą║ąĖčĆčāąĄą╝čüčÅ ąĮą░ receiver ą┤ą╗čÅ ąĘą░čģą▓ą░čéą░ ą╝čīčÄč鹥ą║čüą░, ąĖ ąĘą░č鹥ą╝ ą▓čŗąĘčŗą▓ą░ąĄą╝ unwrap ą┤ą╗čÅ ą┐ą░ąĮąĖą║ąĖ ą┐čĆąĖ ą╗čÄą▒ąŠą╣ ąŠčłąĖą▒ą║ąĄ. ą¤ąŠą╗čāč湥ąĮąĖąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą╝ąŠąČąĄčé ąĘą░ą▓ąĄčĆčłąĖčéčīčüčÅ ąĮąĄčāą┤ą░č湥ą╣, ąĄčüą╗ąĖ ą╝čīčÄč鹥ą║čü ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ poisoned-čüąŠčüč鹊čÅąĮąĖąĖ, ą║ąŠč鹊čĆąŠąĄ ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ, ąĄčüą╗ąĖ ą║ą░ą║ąŠą╣-č鹊 ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║ ąĘą░ą┐ą░ąĮąĖą║ąŠą▓ą░ą╗ ą┐čĆąĖ čāą┤ąĄčƹȹ░ąĮąĖąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą▓ą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ ąŠčüą▓ąŠą▒ąŠą┤ąĖčéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā. ąÆ čŹč鹊ą╣ čüąĖčéčāą░čåąĖąĖ ą▓čŗąĘąŠą▓ unwrap ą┤ą░čüčé čŹč鹊ą╝čā ą┐ąŠč鹊ą║čā ą┐ą░ąĮąĖą║čā ą║ą░ą║ ą║ąŠčĆčĆąĄą║čéąĮąŠąĄ ą┐čĆąĄą┤ą┐čĆąĖąĮąĖą╝ą░ąĄą╝ąŠąĄ ą┤ąĄą╣čüčéą▓ąĖąĄ. ąØąĄ čüč鹥čüąĮčÅą╣č鹥čüčī ą┐ąŠą╝ąĄąĮčÅčéčī čŹč鹊čé unwrap ąĮą░ expect čü čüąŠąŠą▒čēąĄąĮąĖąĄą╝ ąŠą▒ ąŠčłąĖą▒ą║ąĄ, ą║ąŠč鹊čĆąŠąĄ ą▒čāą┤ąĄčé ą┤ą╗čÅ ą▓ą░čü ąŠčüą╝čŗčüą╗ąĄąĮąĮčŗą╝.
ąĢčüą╗ąĖ ą▓čŗ ą┐ąŠą╗čāčćąĖą╗ąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ąĮą░ ą╝čīčÄč鹥ą║čüąĄ, č鹊 ą▓čŗąĘąŠą▓ąĄą╝ recv ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ Job ąĖąĘ ą║ą░ąĮą░ą╗ą░. ą¤ąŠčüą╗ąĄą┤ąĮąĖą╣ unwrap čéą░ą║ąČąĄ ąŠą▒čĆą░ą▒ąŠčéą░ąĄčé ąĘą┤ąĄčüčī ą╗čÄą▒čŗąĄ ąŠčłąĖą▒ą║ąĖ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ, ąĄčüą╗ąĖ ą┐ąŠč鹊ą║, čāą┤ąĄčƹȹĖą▓ą░čÄčēąĖą╣ sender, ąĘą░ą║čĆčŗą╗čüčÅ, ą┐ąŠą┤ąŠą▒ąĮąŠ č鹊ą╝čā, ą║ą░ą║ ą╝ąĄč鹊ą┤ send ą▓ąŠąĘą▓čĆą░čéąĖą╗ Err, ąĄčüą╗ąĖ ąĘą░ą║čĆčŗą╗čüčÅ receiver.
ąÆčŗąĘąŠą▓ recv ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĖą╣, čéą░ą║ čćč鹊 ąĄčüą╗ąĖ ą┐ąŠą║ą░ ąĮąĄčé ąĘą░ą┤ą░ąĮąĖčÅ job, č鹥ą║čāčēąĖą╣ ą┐ąŠč鹊ą║ ą▒čāą┤ąĄčé ąČą┤ą░čéčī, ą┐ąŠą║ą░ ąĮąĄ ą▒čāą┤ąĄčé ą┤ąŠčüčéčāą┐ąĮąŠ ąĘą░ą┤ą░ąĮąĖąĄ. Mutex< T> ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ ą┐ąŠč鹊ą║ Worker ą▓ ą╗čÄą▒ąŠą╣ ą╝ąŠą╝ąĄąĮčé ą▓čĆąĄą╝ąĄąĮąĖ ą┐čŗčéą░ąĄčéčüčÅ ąĘą░ą┐čĆąŠčüąĖčéčī ąĘą░ą┤ą░ąĮąĖąĄ.
ąØą░čł ą┐čāą╗ ą┐ąŠč鹊ą║ąŠą▓ č鹥ą┐ąĄčĆčī ą▓ čĆą░ą▒ąŠč湥ą╝ čüąŠčüč鹊čÅąĮąĖąĖ! ąŚą░ą┐čāčüčéąĖč鹥 cargo run, ąĖ čüą┤ąĄą╗ą░ą╣č鹥 ą┤ą╗čÅ čüąĄčĆą▓ąĄčĆą░ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĘą░ą┐čĆąŠčüąŠą▓:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
warning: field is never read: `workers`
--> src/lib.rs:7:5
|
7 | workers: Vec< Worker>,
| ^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(dead_code)]` on by default
warning: field is never read: `id`
--> src/lib.rs:48:5
|
48 | id: usize,
| ^^^^^^^^^
warning: field is never read: `thread`
--> src/lib.rs:49:5
|
49 | thread: thread::JoinHandle< ()>,
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
warning: `hello` (lib) generated 3 warnings
Finished dev [unoptimized + debuginfo] target(s) in 1.40s
Running `target/debug/hello`
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
ąŁč鹊 čāčüą┐ąĄčģ! ąŻ ąĮą░čü ąĄčüčéčī ą┐čāą╗ ą┐ąŠč鹊ą║ąŠą▓, ą║ąŠč鹊čĆčŗąĄ ą░čüąĖąĮčģčĆąŠąĮąĮąŠ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčé čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ. ąØąĖą║ąŠą│ą┤ą░ ąĮąĄ čüąŠąĘą┤ą░ąĄčéčüčÅ ą▒ąŠą╗čīčłąĄ 4 ą┐ąŠč鹊ą║ąŠą▓, čéą░ą║ čćč鹊 ąĮą░čłą░ čüąĖčüč鹥ą╝ą░ ąĮąĄ ąŠą║ą░ąČąĄčéčüčÅ ą┐ąĄčĆąĄą│čĆčāąČąĄąĮąĮąŠą╣, ąĄčüą╗ąĖ čüąĄčĆą▓ąĄčĆ ą┐ąŠą╗čāčćąĖčé čüą╗ąĖčłą║ąŠą╝ ą╝ąĮąŠą│ąŠ ąĘą░ą┐čĆąŠčüąŠą▓. ąĢčüą╗ąĖ ą╝čŗ ą┐ąŠą╗čāčćąĖą╝ ąĘą░ą┐čĆąŠčü /sleep, č鹊 čüąĄčĆą▓ąĄčĆ čüą╝ąŠąČąĄčé ąĄą│ąŠ ąŠą▒čĆą░ą▒ąŠčéą░čéčī ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ čü ąŠą▒čĆą░ą▒ąŠčéą║ąŠą╣ ą┐ąŠčüčéčāą┐ąĖą▓čłąĖčģ ą┤čĆčāą│ąĖčģ ąĘą░ą┐čĆąŠčüąŠą▓, ąĘą░ą┐čāčüčéąĖą▓ ąĖčģ ą▓ ą┤čĆčāą│ąŠą╝ ą┐ąŠč鹊ą║ąĄ.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ąĄčüą╗ąĖ ą▓čŗ ąŠčéą║čĆąŠąĄč鹥 ąĘą░ą┐čĆąŠčü /sleep ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą▓ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ąŠą║ąĮą░čģ ą▒čĆą░čāąĘąĄčĆą░, č鹊 ąŠąĮąĖ ą╝ąŠą│čāčé ąĘą░ą│čĆčāąČą░čéčīčüčÅ ą┐ąŠ ąŠą┤ąĮąŠą╝čā 5-čüąĄą║čāąĮą┤ąĮčŗčģ ąĖąĮč鹥čĆą▓ą░ą╗ą░čģ. ąØąĄą║ąŠč鹊čĆčŗąĄ web-ą▒čĆą░čāąĘąĄčĆčŗ ą▓čŗą┐ąŠą╗ąĮčÅčÄčé ąĮąĄčüą║ąŠą╗čīą║ąŠ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą▓ ąŠą┤ąĮąŠą│ąŠ ąĖ č鹊ą│ąŠ ąČąĄ ąĘą░ą┐čĆąŠčüą░ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ ą┐ąŠ čüąŠąŠą▒čĆą░ąČąĄąĮąĖčÅą╝ ą║ąĄčłąĖčĆąŠą▓ą░ąĮąĖčÅ. ąŁč鹊 ąŠą│čĆą░ąĮąĖč湥ąĮąĖąĄ ąĮąĄ ą▓čŗąĘą▓ą░ąĮąŠ ąĮą░čłąĖą╝ web-čüąĄčĆą▓ąĄčĆąŠą╝.
ą¤ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ą▓čŗ ą┐ąŠąĘąĮą░ą║ąŠą╝ąĖą╗ąĖčüčī čü čåąĖą║ą╗ąŠą╝ while let ą▓ ą│ą╗ą░ą▓ąĄ 18, čā ą▓ą░čü ą╝ąŠąČąĄčé ą▓ąŠąĘąĮąĖą║ąĮčāčéčī ą▓ąŠą┐čĆąŠčü, ą┐ąŠč湥ą╝čā ą║ąŠą┤ ąĮąĄ ą▒čŗą╗ ąĮą░ą┐ąĖčüą░ąĮ čéą░ą║, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 20-21.
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
impl Worker {
fn new(id: usize, receiver: Arc< Mutex< mpsc::Receiver< Job>>>) -> Worker {
let thread = thread::spawn(move || {
while let Ok(job) = receiver.lock().unwrap().recv() {
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}
ąøąĖčüčéąĖąĮą│ 20-21. ąÉą╗čīč鹥čĆąĮą░čéąĖą▓ąĮą░čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ Worker::new čü ą┐ąŠą╝ąŠčēčīčÄ čåąĖą║ą╗ą░ while let (čäą░ą╣ą╗ src/lib.rs, čŹč鹊čé ą║ąŠą┤ ą┐ąŠą║ą░ ąĮąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ąČąĄą╗ą░ąĄą╝ąŠą│ąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ).
ąŁč鹊čé ą║ąŠą┤ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ ąĖ ąĘą░ą┐čāčüčéąĖčéčüčÅ, ąĮąŠ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ąČąĄą╗ą░ąĄą╝ąŠą╝čā ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÄ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠčüčéąĖ: ą╝ąĄą┤ą╗ąĄąĮąĮčŗą╣ ąĘą░ą┐čĆąŠčü ą┐ąŠ-ą┐čĆąĄąČąĮąĄą╝čā ą▒čāą┤ąĄčé ąĘą░čüčéą░ą▓ą╗čÅčéčī ą┤čĆčāą│ąĖąĄ ą┐ąŠč鹊ą║ąĖ ąŠąČąĖą┤ą░čéčī ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ. ą¤čĆąĖčćąĖąĮą░ ą┤ąŠą▓ąŠą╗čīąĮąŠ č鹊ąĮą║ą░: čüčéčĆčāą║čéčāčĆą░ Mutex ąĮąĄ ąĖą╝ąĄąĄčé ą┐čāą▒ą╗ąĖčćąĮąŠą│ąŠ ą╝ąĄč鹊ą┤ą░ unlock, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓ą╗ą░ą┤ąĄąĮąĖąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąŠą╣ ąŠčüąĮąŠą▓ą░ąĮąŠ ąĮą░ ą▓čĆąĄą╝ąĄąĮąĖ ąČąĖąĘąĮąĖ MutexGuard< T> ą▓ąĮčāčéčĆąĖ LockResult< MutexGuard< T>>, ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝ąŠą│ąŠ ą╝ąĄč鹊ą┤ąŠą╝ lock. ąÆąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ čüąĖčüč鹥ą╝ą░ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖčÅ (borrow checker) ą╝ąŠąČąĄčé ąĘą░č鹥ą╝ ą┐čĆąĖą╝ąĄąĮąĖčéčī ą┐čĆą░ą▓ąĖą╗ąŠ, čćč鹊 čĆąĄčüčāčĆčü, ąĘą░čēąĖčēą░ąĄą╝čŗą╣ Mutex ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┤ąŠčüčéčāą┐ąĄąĮ, ąĄčüą╗ąĖ ą╝čŗ ąĮąĄ čāą┤ąĄčƹȹĖą▓ą░ąĄą╝ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā. ą×ą┤ąĮą░ą║ąŠ čŹčéą░ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ čéą░ą║ąČąĄ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ č鹊ą╝čā, čćč鹊 ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą▒čāą┤ąĄčé čāą┤ąĄčƹȹĖą▓ą░čéčīčüčÅ ą┤ąŠą╗čīčłąĄ, č湥ą╝ ą┐čĆąĄą┤ą┐ąŠą╗ą░ą│ą░ą╗ąŠčüčī, ąĄčüą╗ąĖ ą╝čŗ ąĮąĄ ą▒čāą┤ąĄą╝ ą┐ąŠą╝ąĮąĖčéčī ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ąČąĖąĘąĮąĖ MutexGuard< T>.
ąÜąŠą┤ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 20-20, ą║ąŠč鹊čĆčŗą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄčé let job = receiver.lock().unwrap().recv().unwrap(); čĆą░ą▒ąŠčéą░ąĄčé, ą┐ąŠč鹊ą╝čā čćč鹊 čü let ą╗čÄą▒čŗąĄ ą▓čĆąĄą╝ąĄąĮąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ ą▓ ą▓čŗčĆą░ąČąĄąĮąĖąĖ ąĮą░ ą┐čĆą░ą▓ąŠą╣ čüč鹊čĆąŠąĮąĄ ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĮąĖčÅ, ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ čāą┤ą░ą╗čÅčÄčéčüčÅ ą┐čĆąĖ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĖ ąŠą┐ąĄčĆą░č鹊čĆą░ let. ą×ą┤ąĮą░ą║ąŠ while let (ąĖ if let, ąĖ match) ąĮąĄ ąŠčéą▒čĆą░čüčŗą▓ą░čÄčé ą▓čĆąĄą╝ąĄąĮąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ, ą┐ąŠą║ą░ ąĮąĄ ąĘą░ą║ąŠąĮčćąĖčéčüčÅ čüą▓čÅąĘą░ąĮąĮčŗą╣ ą▒ą╗ąŠą║. ąÆ ą╗ąĖčüčéąĖąĮą│ąĄ 20-21 ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ąŠčüčéą░ąĄčéčüčÅ čāą┤ąĄčƹȹĖą▓ą░ąĄą╝ąŠą╣ ąĮą░ ą▓čĆąĄą╝čÅ ą▓čŗąĘąŠą▓ą░ job(), čé. ąĄ. ą┤čĆčāą│ąĖąĄ worker-čŗ ąĮąĄ čüą╝ąŠą│čāčé ą┐ąŠą╗čāčćąĖčéčī ąĘą░ą┤ą░ąĮąĖčÅ.
[ąÜąŠčĆčĆąĄą║čéąĮąŠąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄ ąĖ ąŠčćąĖčüčéą║ą░]
ąÜąŠą┤ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 20-20 ąŠčéą▓ąĄčćą░ąĄčé ąĘą░ ą░čüąĖąĮčģčĆąŠąĮąĮąŠ ą┐čĆąĖčģąŠą┤čÅčēąĖąĄ ąĘą░ą┐čĆąŠčüčŗ čü ą┐ąŠą╝ąŠčēčīčÄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┐čāą╗ą░ ą┐ąŠč鹊ą║ąŠą▓, čéą░ą║ ą║ą░ą║ ą╝čŗ ąĖ čģąŠč鹥ą╗ąĖ. ą£čŗ ą┐ąŠą╗čāčćąĖą╗ąĖ ąĮąĄą║ąŠč鹊čĆčŗąĄ ą┐čĆąĄą┤čāą┐čĆąĄąČą┤ąĄąĮąĖčÅ (warnings) ą┐ąŠ ą┐ąŠą▓ąŠą┤čā ą┐ąŠą╗ąĄą╣ worker, id ąĖ thread, ą║ąŠč鹊čĆčŗąĄ ą╝čŗ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ ąĮą░ą┐čĆčÅą╝čāčÄ, čćč鹊 ąĮą░ą┐ąŠą╝ąĖąĮą░ąĄčé ąĮą░ą╝, čćč鹊 ą╝čŗ ąĮąĄ ą┤ąĄą╗ą░ąĄą╝ ąĮąĖą║ą░ą║čāčÄ ąŠčćąĖčüčéą║čā. ąÜąŠą│ą┤ą░ ą╝čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ ąĮąĄ ąŠč湥ąĮčī ą║čĆą░čüąĖą▓čŗą╣ ą╝ąĄč鹊ą┤ Ctrl+C ą┤ą╗čÅ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ą┐ąŠč鹊ą║ą░ main, ą▓čüąĄ ą┤čĆčāą│ąĖąĄ ą┐ąŠč鹊ą║ąĖ čéą░ą║ąČąĄ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ ąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čÄčéčüčÅ, ą┤ą░ąČąĄ ąĄčüą╗ąĖ ąŠąĮąĖ ąĮą░čģąŠą┤čÅčéčüčÅ ą▓ ą┐čĆąŠčåąĄčüčüą░ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĘą░ą┐čĆąŠčüą░.
ąŚą░č鹥ą╝ ą╝čŗ čĆąĄą░ą╗ąĖąĘčāąĄą╝ čéčĆąĄą╣čé Drop ą┤ą╗čÅ ą▓čŗąĘąŠą▓ą░ join ąĮą░ ą║ą░ąČą┤ąŠą╝ ą┐ąŠč鹊ą║ąĄ ą▓ ą┐čāą╗ąĄ, čéą░ą║ čćč鹊ą▒čŗ ąŠąĮąĖ ą╝ąŠą│ą╗ąĖ ąĘą░ą▓ąĄčĆčłąĖčéčī ąĘą░ą┐čĆąŠčüčŗ, ąĮą░ą┤ ą║ąŠč鹊čĆčŗą╝ čĆą░ą▒ąŠčéą░čÄčé, ą┐ąĄčĆąĄą┤ ąĘą░ą║čĆčŗčéąĖąĄą╝. ąŚą░č鹥ą╝ ą╝čŗ čĆąĄą░ą╗ąĖąĘčāąĄą╝ čüą┐ąŠčüąŠą▒ čāą║ą░ąĘą░čéčī ą┐ąŠč鹊ą║ą░ą╝, čćč鹊 ąŠąĮąĖ ą┤ąŠą╗ąČąĮčŗ ą┐čĆąĄą║čĆą░čéąĖčéčī ą┐čĆąĖąĮąĖą╝ą░čéčī ąĮąŠą▓čŗąĄ ąĘą░ą┐čĆąŠčüčŗ ąĖ ąĘą░ą▓ąĄčĆčłąĖčéčī čĆą░ą▒ąŠčéčā. ą¦č鹊ą▒čŗ čāą▓ąĖą┤ąĄčéčī čŹč鹊čé ą║ąŠą┤ ą▓ ą┤ąĄą╣čüčéą▓ąĖąĖ, ą╝čŗ ąĖąĘą╝ąĄąĮąĖą╝ ąĮą░čł čüąĄčĆą▓ąĄčĆ, čćč鹊ą▒čŗ ąŠąĮ ą┐čĆąĖąĮąĖą╝ą░ą╗ č鹊ą╗čīą║ąŠ ą┤ą▓ą░ ąĘą░ą┐čĆąŠčüą░, ą┐čĆąĄąČą┤ąĄ č湥ą╝ ą║čĆą░čüąĖą▓ąŠ ąĘą░ą║čĆčŗčéčī ąĄą│ąŠ ą┐čāą╗ ą┐ąŠč鹊ą║ąŠą▓.
ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ čéčĆąĄą╣čéą░ Drop ąĮą░ ThreadPool. ąöą░ą▓ą░ą╣č鹥 ąĮą░čćąĮąĄą╝ čü čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ Drop ąĮą░ ąĮą░čłąĄą╝ ą┐čāą╗ąĄ ą┐ąŠč鹊ą║ąŠą▓. ąÜąŠą│ą┤ą░ ą┐čāą╗ ąŠčéą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ, ą▓čüąĄ ąĮą░čłąĖ ą┐ąŠč鹊ą║ąĖ ą┤ąŠą╗ąČąĮčŗ ąŠą▒čŖąĄą┤ąĖąĮąĖčéčīčüčÅ, čćč鹊ą▒čŗ ąŠąĮąĖ ąĘą░ą║ąŠąĮčćąĖą╗ąĖ čüą▓ąŠčÄ čĆą░ą▒ąŠčéčā. ąøąĖčüčéąĖąĮą│ 20-22 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┐ąĄčĆą▓čāčÄ ą┐ąŠą┐čŗčéą║čā čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ Drop; čŹč鹊čé ą║ąŠą┤ ą┐ąŠą║ą░ čćč鹊 ąĮąĄ čĆą░ą▒ąŠčéą░ąĄčé.
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
ąøąĖčüčéąĖąĮą│ 20-22. ą¤čĆąĖčüąŠąĄą┤ąĖąĮąĄąĮąĖąĄ ą║ ą║ą░ąČą┤ąŠą╝čā ą┐ąŠč鹊ą║čā, ą║ąŠą│ą┤ą░ ą┐ąŠą╗ ą┐ąŠč鹊ą║ąŠą▓ ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ (čäą░ą╣ą╗ src/lib.rs, čŹč鹊čé ą║ąŠą┤ ąĮąĄ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ).
ąĪąĮą░čćą░ą╗ą░ ą╝čŗ ą▓ čåąĖą║ą╗ąĄ ą┐čĆąŠčģąŠą┤ąĖą╝ ą┐ąŠ ą║ą░ąČą┤ąŠą╝čā worker-čā ą▓ ą┐čāą╗ąĄ ą┐ąŠč鹊ą║ąŠą▓. ą£čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ ą┤ą╗čÅ čŹč鹊ą│ąŠ &mut, ą┐ąŠč鹊ą╝čā čćč鹊 self ą╝čāčéąĖčĆčāąĄą╝ą░čÅ čüčüčŗą╗ą║ą░, ąĖ ą╝čŗ ą┤ąŠą╗ąČąĮčŗ čéą░ą║ąČąĄ ą▒čŗčéčī ą▓ čüąŠčüč鹊čÅąĮąĖąĖ ą╝čāčéąĖčĆąŠą▓ą░čéčī worker. ąöą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ worker ą╝čŗ ą┐ąĄčćą░čéą░ąĄą╝ čüąŠąŠą▒čēąĄąĮąĖąĄ ąŠ č鹊ą╝, čćč鹊 ą║ąŠąĮą║čĆąĄčéąĮčŗą╣ worker ąĘą░ą▓ąĄčĆčłą░ąĄčé čĆą░ą▒ąŠčéčā, ą░ ąĘą░č鹥ą╝ ą▓čŗąĘčŗą▓ą░ąĄą╝ join ą▓ ą┐ąŠč鹊ą║ąĄ čŹč鹊ą│ąŠ worker-ą░. ąĢčüą╗ąĖ ą▓čŗąĘąŠą▓ join ą┐ąŠč鹥čĆą┐ąĄą╗ ąĮąĄčāą┤ą░čćčā, č鹊 ą╝čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ unwrap, čćč鹊ą▒čŗ Rust ą▓čŗąĘčŗą▓ą░ą╗ ą┐ą░ąĮąĖą║čā ąĖ ą┐ąĄčĆąĄčłąĄą╗ ą▓ ą░ą▓ą░čĆąĖą╣ąĮąŠąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
ąÜąŠą│ą┤ą░ ą╝čŗ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄą╝ čŹč鹊čé ą║ąŠą┤, ą┐ąŠą╗čāčćąĖčéčüčÅ ąŠčłąĖą▒ą║ą░:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0507]: cannot move out of `worker.thread` which is behind a mutable reference
--> src/lib.rs:52:13
|
52 | worker.thread.join().unwrap();
| ^^^^^^^^^^^^^ ------ `worker.thread` moved due to this method call
| |
| move occurs because `worker.thread` has type `JoinHandle< ()>`,
| which does not implement the `Copy` trait
|
note: `JoinHandle::< T>::join` takes ownership of the receiver `self`,
which moves `worker.thread`
--> /rustc/129f3b9964af4d4a709d1383930ade12dfe7c081/library/std/src/thread/mod.rs:1718:17
For more information about this error, try `rustc --explain E0507`.
error: could not compile `hello` (lib) due to 1 previous error
ą×čłąĖą▒ą║ą░ ą│ąŠą▓ąŠčĆąĖčé ąĮą░ą╝, čćč鹊 ą╝čŗ ąĮąĄ ą╝ąŠąČąĄą╝ ą▓čŗąĘą▓ą░čéčī join, ą┐ąŠč鹊ą╝čā čćč鹊 čā ąĮą░čü ąĄčüčéčī č鹊ą╗čīą║ąŠ ą╝čāčéąĖčĆčāąĄą╝ąŠąĄ ąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮąĖąĄ ą║ą░ąČą┤ąŠą│ąŠ worker, ą░ join ą┐čĆąĖąĮąĖą╝ą░ąĄčé ą▓ąŠ ą▓ą╗ą░ą┤ąĄąĮąĖąĄ čüą▓ąŠą╣ ą░čĆą│čāą╝ąĄąĮčé. ą¦č鹊ą▒čŗ čĆąĄčłąĖčéčī čŹčéčā ą┐čĆąŠą▒ą╗ąĄą╝čā, ąĮą░ą╝ ąĮčāąČąĮąŠ ą┐ąĄčĆąĄą╝ąĄčüčéąĖčéčī thread ąĮą░čĆčāąČčā ąĖąĘ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ Worker, ą║ąŠč鹊čĆčŗą╣ ą▓ą╗ą░ą┤ąĄąĄčé thread, čćč鹊ą▒čŗ join ą╝ąŠą│ ą┐ąŠčéčĆąĄą▒ąĖčéčī thread. ą£čŗ čüą┤ąĄą╗ą░ą╗ čŹč鹊 ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 17-15 (čüą╝. čüąĄą║čåąĖčÄ "ąŚą░ą┐čĆąŠčü čĆąĄą▓čīčÄ ą┐ąŠčüčéą░, ą╝ąĄąĮčÅčÄčēąĖą╣ ąĄą│ąŠ čüąŠčüč鹊čÅąĮąĖąĄ" ą│ą╗ą░ą▓čŗ 17): ąĄčüą╗ąĖ Worker ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ čüąŠą┤ąĄčƹȹĖčé Option< thread::JoinHandle< ()>>, č鹊 ą╝čŗ ą╝ąŠąČąĄą╝ ą▓čŗąĘčŗą▓ą░čéčī ą╝ąĄč鹊ą┤ take ąĮą░ Option, čćč鹊ą▒čŗ ą┐ąĄčĆąĄą╝ąĄčüčéąĖčéčī ąĘąĮą░č湥ąĮąĖąĄ ąĮą░čĆčāąČčā ąĖąĘ ą▓ą░čĆąĖą░ąĮčéą░ Some, ąĖ ąŠčüčéą░ą▓ąĖčéčī ą▓ą░čĆąĖą░ąĮčé None ąĮą░ čüą▓ąŠąĄą╝ ą╝ąĄčüč鹥. ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, čĆą░ą▒ąŠčéą░čÄčēąĖą╣ Worker ą▒čāą┤ąĄčé ąĖą╝ąĄčéčī ą▓ą░čĆąĖą░ąĮčé Some ą▓ ą┐ąŠč鹊ą║ąĄ, ąĖ ą║ąŠą│ą┤ą░ ą╝čŗ čģąŠčéąĖą╝ ąŠčćąĖčüčéąĖčéčī Worker, ą╝čŗ ąĘą░ą╝ąĄąĮąĖą╝ Some ąĮą░ None, čćč鹊ą▒čŗ čā Worker ąĮąĄ ą▒čŗą╗ąŠ ą┐ąŠč鹊ą║ą░ ą┤ą╗čÅ ąĘą░ą┐čāčüą║ą░.
ąśčéą░ą║, ą╝čŗ ąĘąĮą░ąĄą╝, čćč鹊 čģąŠčéąĖą╝ ąŠą▒ąĮąŠą▓ąĖčéčī ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ Worker ą┐čĆąĖą╝ąĄčĆąĮąŠ čéą░ą║ (čäą░ą╣ą╗ src/lib.rs, čŹč鹊čé ą║ąŠą┤ ąĮąĄ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ):
struct Worker {
id: usize,
thread: Option< thread::JoinHandle< ()>>,
}
ąöą░ą▓ą░ą╣č鹥 č鹥ą┐ąĄčĆčī čüąĮąŠą▓ą░ ąŠą▒čĆą░čéąĖą╝čüčÅ ą║ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆčā, čćč鹊ą▒čŗ ąŠąĮ ą┐ąŠą┤čüą║ą░ąĘą░ą╗, čćč鹊 ąĄčēąĄ čéčĆąĄą▒čāąĄčé ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ. ą¤čĆąŠą▓ąĄčĆą║ą░ čŹč鹊ą│ąŠ ą║ąŠą┤ą░ ą┐ąŠą║ą░ąČąĄčé ąĮą░ą╝ ąĄčēąĄ 2 ąŠčłąĖą▒ą║ąĖ:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no method named `join` found for enum `Option` in the current scope
--> src/lib.rs:52:27
|
52 | worker.thread.join().unwrap();
| ^^^^ method not found in `Option< JoinHandle< ()>>`
|
note: the method `join` exists on the type `JoinHandle< ()>`
--> /rustc/129f3b9964af4d4a709d1383930ade12dfe7c081/library/std/src/thread/mod.rs:1718:5
help: consider using `Option::expect` to unwrap the `JoinHandle< ()>` value, panicking if
| the value is an `Option::None`
|
52 | worker.thread.expect("REASON").join().unwrap();
| +++++++++++++++++
error[E0308]: mismatched types
--> src/lib.rs:72:22
|
72 | Worker { id, thread }
| ^^^^^^ expected `Option< JoinHandle< ()>>`, found `JoinHandle< _>`
|
= note: expected enum `Option< JoinHandle< ()>>`
found struct `JoinHandle< _>`
help: try wrapping the expression in `Some`
|
72 | Worker { id, thread: Some(thread) }
| +++++++++++++ +
Some errors have detailed explanations: E0308, E0599.
For more information about an error, try `rustc --explain E0308`.
error: could not compile `hello` (lib) due to 2 previous errors
ąöą░ą▓ą░ą╣č鹥 ąĖčüą┐čĆą░ą▓ąĖą╝ ą▓č鹊čĆčāčÄ ąŠčłąĖą▒ą║čā, ą║ąŠč鹊čĆą░čÅ čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ ą║ąŠą┤ ą▓ ą║ąŠąĮčåąĄ Worker::new;, ąĮą░ą╝ ąĮčāąČąĮąŠ ąŠą▒ąĄčĆąĮčāčéčī ąĘąĮą░č湥ąĮąĖąĄ thread ą▓ Some, ą║ąŠą│ą┤ą░ čüąŠąĘą┤ą░ąĄą╝ ąĮąŠą▓čŗą╣ Worker. ąĪą┤ąĄą╗ą░ą╣č鹥 čüą╗ąĄą┤čāčÄčēąĖąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ, čćč鹊ą▒čŗ ąĖčüą┐čĆą░ą▓ąĖčéčī čŹčéčā ąŠčłąĖą▒ą║čā (čäą░ą╣ą╗ src/lib.rs, čŹč鹊čé ą║ąŠą┤ ąĮąĄ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ):
impl Worker {
fn new(id: usize, receiver: Arc< Mutex< mpsc::Receiver< Job>>>) -> Worker {
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
Worker {
id,
thread: Some(thread),
}
}
}
ą¤ąĄčĆą▓ą░čÅ ąŠčłąĖą▒ą║ą░ ąŠčéąĮąŠčüąĖčéčüčÅ ą║ ąĮą░čłąĄą╣ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ Drop. ąÜą░ą║ čāą┐ąŠą╝ąĖąĮą░ą╗ąŠčüčī čĆą░ąĮąĄąĄ, ą╝čŗ ąĮą░ą╝ąĄčĆąĄą▓ą░ąĄą╝čüčÅ ą▓čŗąĘą▓ą░čéčī take ąĮą░ ąĘąĮą░č湥ąĮąĖąĖ Option, čćč鹊ą▒čŗ ą┐ąĄčĆąĄą╝ąĄčüčéąĖčéčī thread ąĮą░čĆčāąČčā ąĖąĘ worker. ąĪą╗ąĄą┤čāčÄčēąĖąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ čüą┤ąĄą╗ą░čÄčé čŹč鹊 (čäą░ą╣ą╗ src/lib.rs, čŹč鹊čé ą║ąŠą┤ ąĮąĄ ą┤ą░čüčé ąČąĄą╗ą░ąĄą╝ąŠą│ąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ):
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
ąÜą░ą║ ąŠą▒čüčāąČą┤ą░ą╗ąŠčüčī ą▓ ą│ą╗ą░ą▓ąĄ 17 [9], ą╝ąĄč鹊ą┤ take ąĮą░ Option ąĖąĘą▓ą╗ąĄą║ą░ąĄčé ąĮą░čĆčāąČčā ą▓ą░čĆąĖą░ąĮčé Some ąĖ ąŠčüčéą░ą▓ą╗čÅąĄčé None ąĮą░ čüą▓ąŠąĄą╝ ą╝ąĄčüč鹥. ą£čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ if let ą┤ą╗čÅ ą┤ąĄčüčéčĆčāą║čéčāčĆąĖčĆąŠą▓ą░ąĮąĖčÅ Some ąĖ ą┐ąŠą╗čāč湥ąĮąĖčÅ ą┐ąŠč鹊ą║ą░ thread; ąĘą░č鹥ą╝ ą╝čŗ ą▓čŗąĘčŗą▓ą░ąĄą╝ join ąĮą░ thread. ąĢčüą╗ąĖ ą┐ąŠč鹊ą║ worker-ą░ čāąČąĄ None, č鹊 ą╝čŗ ąĘąĮą░ąĄą╝, čćč鹊 čā worker-ą░ čāąČąĄ ąĄą│ąŠ thread ąŠčćąĖčēąĄąĮ, ąĖ ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ąĮąĖč湥ą│ąŠ ąĮąĄ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé.
ąĪąĖą│ąĮą░ą╗ Threads ąŠčüčéą░ąĮąŠą▓ąĖčéčī ą┐čĆąŠčüą╗čāčłąĖą▓ą░ąĮąĖąĄ ą┤ą╗čÅ Jobs. ąĪąŠ ą▓čüąĄą╝ąĖ čüą┤ąĄą╗ą░ąĮąĮčŗą╝ąĖ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅą╝ąĖ ąĮą░čł ą║ąŠą┤ ą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ ą▒ąĄąĘ ą║ą░ą║ąĖčģ-ą╗ąĖą▒ąŠ warning-ąŠą▓. ą×ą┤ąĮą░ą║ąŠ ą┐ą╗ąŠčģą░čÅ ąĮąŠą▓ąŠčüčéčī ąĘą░ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ č鹊ą╝, čćč鹊 čŹč鹊čé ą║ąŠą┤ ą▓čüąĄ ąĄčēąĄ ąĮąĄ čĆą░ą▒ąŠčéą░ąĄčé čéą░ą║, ą║ą░ą║ ą╝čŗ čģąŠčéąĖą╝. ąÜą╗čÄč湊ą╝ čÅą▓ą╗čÅąĄčéčüčÅ ą╗ąŠą│ąĖą║ą░ ą▓ ąĘą░ą╝čŗą║ą░ąĮąĖčÅčģ, ąĘą░ą┐čāčüą║ą░ąĄą╝ą░čÅ ą┐ąŠč鹊ą║ą░ą╝ąĖ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą▓ Worker: ą▓ ąĮą░čüč鹊čÅčēąĖą╣ ą╝ąŠą╝ąĄąĮčé ą╝čŗ ą▓čŗąĘčŗą▓ą░ąĄą╝ join, ąĮąŠ čŹč鹊 ąĮąĄ ąĘą░ą║čĆąŠąĄčé ą┐ąŠč鹊ą║ąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 ą▒ąĄčüą║ąŠąĮąĄčćąĮčŗą╣ čåąĖą║ą╗ ąČą┤ąĄčé ą┐ąŠčüčéčāą┐ą╗ąĄąĮąĖčÅ ąĘą░ą┤ą░ąĮąĖą╣. ąĢčüą╗ąĖ ą╝čŗ ą┐ąŠą┐čŗčéą░ąĄą╝čüčÅ ąŠčéą▒čĆąŠčüąĖčéčī ąĮą░čł ThreadPool čü ąĮą░čłąĄą╣ č鹥ą║čāčēąĄą╣ čĆąĄą░ą╗ąĖąĘą░čåąĖąĄą╣ drop, č鹊 ą┐ąŠč鹊ą║ main ąĘą░ą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ ąĮą░ą▓čüąĄą│ą┤ą░, ąŠąČąĖą┤ą░čÅ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ą┐ąĄčĆą▓ąŠą│ąŠ ą┐ąŠč鹊ą║ą░.
ą¦č鹊ą▒čŗ ąĖčüą┐čĆą░ą▓ąĖčéčī čŹčéčā ą┐čĆąŠą▒ą╗ąĄą╝čā, ąĮą░ą╝ ąĮčāąČąĮąŠ ąĖąĘą╝ąĄąĮąĖčéčī čĆąĄą░ą╗ąĖąĘą░čåąĖčÄ drop ą▓ ThreadPool, ąĖ ąĘą░č鹥ą╝ ą┐ąŠą╝ąĄąĮčÅčéčī čåąĖą║ą╗ ą▓ Worker.
ąĪąĮą░čćą░ą╗ą░ ą╝čŗ ą┐ąŠą╝ąĄąĮčÅąĄą╝ čĆąĄą░ą╗ąĖąĘą░čåąĖčÄ drop ą▓ ThreadPool ą┤ą╗čÅ čÅą▓ąĮąŠą│ąŠ ą▓čŗą▒čĆą░čüčŗą▓ą░ąĮąĖčÅ sender ą┐ąĄčĆąĄą┤ ąŠąČąĖą┤ą░ąĮąĖąĄą╝ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ čĆą░ą▒ąŠčéčŗ ą┐ąŠč鹊ą║ąŠą▓. ąøąĖčüčéąĖąĮą│ 20-23 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą┤ą╗čÅ ThreadPool, čćč鹊ą▒čŗ čÅą▓ąĮąŠ ą▓čŗą▒čĆą░čüčŗą▓ą░čéčī sender. ą£čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ čéčā ąČąĄ čüą░ą╝čāčÄ č鹥čģąĮąĖą║čā čü Option ąĖ take, ą║ą░ą║ ą╝čŗ ą┤ąĄą╗ą░ą╗ąĖ čü thread, čćč鹊ą▒čŗ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą┐ąĄčĆąĄą╝ąĄčüčéąĖčéčī sender ąĖąĘąĮčāčéčĆąĖ ThreadPool (čäą░ą╣ą╗ src/lib.rs, čŹč鹊čé ą║ąŠą┤ ąĮąĄ ą┤ą░čüčé ąČąĄą╗ą░ąĄą╝ąŠą│ąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ):
pub struct ThreadPool {
workers: Vec< Worker>,
sender: Option< mpsc::Sender< Job>>,
}
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
impl ThreadPool {
pub fn new(size: usize) -> ThreadPool {
// -- ą▓čŗčĆąĄąĘą░ąĮąŠ --
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute< F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
ąøąĖčüčéąĖąĮą│ 20-23. ą»ą▓ąĮąŠąĄ ą▓čŗą▒čĆą░čüčŗą▓ą░ąĮąĖąĄ sender ą┐ąĄčĆąĄą┤ ą┐čĆąĖčüąŠąĄą┤ąĖąĮąĄąĮąĖąĄą╝ ą┐ąŠč鹊ą║ąŠą▓ worker.
ąÆčŗą▒čĆą░čüčŗą▓ą░ąĮąĖąĄ sender ąĘą░ą║čĆąŠąĄčé ą║ą░ąĮą░ą╗, čćč鹊 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ą▒ąŠą╗čīčłąĄ ąĮąĄ ą╝ąŠą│čāčé ą┐ąĄčĆąĄą┤ą░ą▓ą░čéčīčüčÅ čüąŠąŠą▒čēąĄąĮąĖčÅ. ąÜąŠą│ą┤ą░ čŹč鹊 ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé, ą▓čüąĄ ą▓čŗąĘąŠą▓čŗ recv, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ čüą┤ąĄą╗ą░ąĮčŗ ą▓ ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠą╝ čåąĖą║ą╗ąĄ, ą▓ąŠąĘą▓čĆą░čéčÅčé ąŠčłąĖą▒ą║čā. ąÆ ą╗ąĖčüčéąĖąĮą│ąĄ 20-24 ą╝čŗ ą┐ąŠą╝ąĄąĮčÅą╗ąĖ čåąĖą║ą╗ Worker ą┤ą╗čÅ ą║ąŠčĆčĆąĄą║čéąĮąŠą│ąŠ ą▓čŗčģąŠą┤ą░ ąĖąĘ čåąĖą║ą╗ą░ ą┤ą╗čÅ čéą░ą║ąŠą│ąŠ čüą╗čāčćą░čÅ, čé. ąĄ. ą┐ąŠč鹊ą║ąĖ ąĘą░ą▓ąĄčĆčłą░čéčüčÅ, ą║ąŠą│ą┤ą░ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ drop ą▓ ThreadPool ą▓čŗąĘąŠą▓ąĄčé ąĮą░ ąĮąĖčģ join.
impl Worker {
fn new(id: usize, receiver: Arc< Mutex< mpsc::Receiver< Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}
ąøąĖčüčéąĖąĮą│ 20-24. ą»ą▓ąĮčŗą╣ ą▓čŗčģąŠą┤ ąĖąĘ čåąĖą║ą╗ą░, ą║ąŠą│ą┤ą░ recv ą▓ąŠąĘą▓čĆą░čéąĖą╗ ąŠčłąĖą▒ą║čā (čäą░ą╣ą╗ src/lib.rs).
ą¦č鹊ą▒čŗ čāą▓ąĖą┤ąĄčéčī čŹč鹊čé ą║ąŠą┤ ą▓ ą┤ąĄą╣čüčéą▓ąĖąĖ, ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāą╣č鹥 main, čćč鹊ą▒čŗ ą┐čĆąĖąĮčÅčéčī č鹊ą╗čīą║ąŠ 2 ąĘą░ą┐čĆąŠčüą░ ą┐ąĄčĆąĄą┤ ą║ąŠčĆčĆąĄą║čéąĮčŗą╝ ąĘą░ą║čĆčŗčéąĖąĄą╝ čüąĄčĆą▓ąĄčĆą░, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 20-25.
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
ąøąĖčüčéąĖąĮą│ 20-25. ą×čüčéą░ąĮąŠą▓ą║ą░ čüąĄčĆą▓ąĄčĆą░ ą┐ąŠčüą╗ąĄ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÅ ą┤ą▓čāčģ ąĘą░ą┐čĆąŠčüąŠą▓ ą┐čāč鹥ą╝ ą▓čŗčģąŠą┤ą░ ąĖąĘ čåąĖą║ą╗ą░ (čäą░ą╣ą╗ src/main.rs).
ąÆčŗ ąĮąĄ ąĘą░čģąŠčéąĖč鹥 ąĖą╝ąĄčéčī čĆąĄą░ą╗čīąĮčŗą╣ web-čüąĄčĆą▓ąĄčĆ, čćč鹊ą▒čŗ ąŠąĮ ąĘą░ą▓ąĄčĆčłą░ą╗čüčÅ ą┐ąŠčüą╗ąĄ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ č鹊ą╗čīą║ąŠ ą┤ą▓čāčģ ąĘą░ą┐čĆąŠčüąŠą▓. ąŁč鹊čé ą║ąŠą┤ ą┐čĆąŠčüč鹊 ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄčé, čćč鹊 ąĖąĘčÅčēąĮąŠąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄ ąĖ ąŠčćąĖčüčéą║ą░ čĆą░ą▒ąŠčéą░čÄčé ą║ąŠčĆčĆąĄą║čéąĮąŠ.
ą£ąĄč鹊ą┤ take ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ ą▓ čéčĆąĄą╣č鹥 Iterator, ąĖ ąŠą│čĆą░ąĮąĖčćąĖą▓ą░ąĄčé ąĖč鹥čĆą░čåąĖčÄ ą╝ą░ą║čüąĖą╝čāą╝ ą┐ąĄčĆą▓čŗą╝ąĖ ą┤ą▓čāą╝čÅ čŹą╗ąĄą╝ąĄąĮčéą░ą╝ąĖ. ThreadPool ą▓čŗą╣ą┤ąĄčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ ą┐ąŠ ąŠą║ąŠąĮčćą░ąĮąĖčÄ main, ąĖ ąĘą░ą┐čāčüčéąĖčéčüčÅ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ drop.
ąŚą░ą┐čāčüčéąĖč鹥 čüąĄčĆą▓ąĄčĆ ą║ąŠą╝ą░ąĮą┤ąŠą╣ cargo run, ąĖ čüą┤ąĄą╗ą░ą╣č鹥 čéčĆąĖ ąĘą░ą┐čĆąŠčüą░. ąóčĆąĄčéąĖą╣ ąĘą░ą┐čĆąŠčü ą┤ąŠą╗ąČąĄąĮ ą▓ąŠąĘą▓čĆą░čéąĖčéčī ąŠčłąĖą▒ą║čā, ąĖ ą▓ ą▓ą░čłąĄą╝ č鹥čĆą╝ąĖąĮą░ą╗ąĄ ą▓čŗ ą┤ąŠą╗ąČąĮčŗ čāą▓ąĖą┤ąĄčéčī ąĮąĄčćč鹊 ą┐ąŠą┤ąŠą▒ąĮąŠąĄ:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished dev [unoptimized + debuginfo] target(s) in 1.0s
Running `target/debug/hello`
Worker 0 got a job; executing.
Shutting down.
Shutting down worker 0
Worker 3 got a job; executing.
Worker 1 disconnected; shutting down.
Worker 2 disconnected; shutting down.
Worker 3 disconnected; shutting down.
Worker 0 disconnected; shutting down.
Shutting down worker 1
Shutting down worker 2
Shutting down worker 3
ąŻ ą▓ą░čü ą╝ąŠąČąĄčé ą▒čŗčéčī ą┤čĆčāą│ąŠą╣ ą┐ąŠčĆčÅą┤ąŠą║ worker-ąŠą▓ ą▓ ą┐ąĄčćą░čéą░ąĄą╝čŗčģ čüąŠąŠą▒čēąĄąĮąĖčÅčģ. ą£čŗ ą╝ąŠąČąĄą╝ ą▓ąĖą┤ąĄčéčī ąĖąĘ čüąŠąŠą▒čēąĄąĮąĖą╣, ą║ą░ą║ čŹč鹊čé ą║ąŠą┤ čĆą░ą▒ąŠčéą░ąĄčé: worker-čŗ 0 ąĖ 3 ą┐ąŠą╗čāčćąĖą╗ąĖ ą┐ąĄčĆą▓čŗąĄ ą┤ą▓ą░ ąĘą░ą┐čĆąŠčüą░. ąĪąĄčĆą▓ąĄčĆ ąŠčüčéą░ąĮąŠą▓ąĖą╗ ą┐čĆąĖąĄą╝ čüąŠąŠą▒čēąĄąĮąĖą╣ ą┐ąŠčüą╗ąĄ ą▓č鹊čĆąŠą│ąŠ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ, ąĖ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ Drop ąĮą░ ThreadPool ąĮą░čćą░ą╗ą░ ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ ąĄčēąĄ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ worker 3 ąĮą░čćą░ą╗ ą▓čŗą┐ąŠą╗ąĮčÅčéčī čüą▓ąŠąĄ ąĘą░ą┤ą░ąĮąĖąĄ job. ą×čéą▒čĆą░čüčŗą▓ą░ąĮąĖąĄ sender ąŠčéą║ą╗čÄčćą░ąĄčé ą▓čüąĄ worker-čŗ ąĖ ą│ąŠą▓ąŠčĆąĖčé ąĖą╝ ąĘą░ą▓ąĄčĆčłąĖčéčī čĆą░ą▒ąŠčéčā. ąÜą░ąČą┤čŗą╣ worker ą┐ąĄčćą░čéą░ąĄčé čüąŠąŠą▒čēąĄąĮąĖąĄ, ą║ąŠą│ą┤ą░ ąŠčéą║ą╗čÄčćą░ąĄčéčüčÅ, ąĖ ąĘą░č鹥ą╝ ą┐čāą╗ ą┐ąŠč鹊ą║ąŠą▓ ą▓čŗąĘčŗą▓ą░ąĄčé join ą┤ą╗čÅ ąŠąČąĖą┤ą░ąĮąĖčÅ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ą║ą░ąČą┤ąŠą│ąŠ ą┐ąŠč鹊ą║ą░ worker.
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ ąĮą░ ąŠą┤ąĖąĮ ąĖąĮč鹥čĆąĄčüąĮčŗą╣ ą░čüą┐ąĄą║čé ą▓ čŹč鹊ą╝ ą║ąŠąĮą║čĆąĄčéąĮąŠą╝ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ: ThreadPool ąŠčéą▒čĆąŠčüąĖą╗ sender, ąĖ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ą╗čÄą▒ąŠą╣ worker ą┐ąŠą╗čāčćąĖą╗ ąŠčłąĖą▒ą║čā, ą╝čŗ ą┐čŗčéą░ąĄą╝čüčÅ čüą┤ąĄą╗ą░čéčī join ą┤ą╗čÅ worker 0. Worker 0 ąĄčēąĄ ąĮąĄ ą┐ąŠą╗čāčćąĖą╗ ąŠčłąĖą▒ą║čā ąŠčé recv, čéą░ą║ čćč鹊 ą┐ąŠč鹊ą║ main ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ą╗čüčÅ ą▓ ąŠąČąĖą┤ą░ąĮąĖąĖ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ worker 0. ąóąĄą╝ ą▓čĆąĄą╝ąĄąĮąĄą╝ worker 3 ą┐ąŠą╗čāčćąĖą╗ job, ąĖ ąĘą░č鹥ą╝ ą▓čüąĄ ą┐ąŠč鹊ą║ąĖ ą┐ąŠą╗čāčćąĖą╗ąĖ ąŠčłąĖą▒ą║čā. ąÜąŠą│ą┤ą░ worker 0 ąĘą░ą▓ąĄčĆčłąĖą╗čüčÅ, ą┐ąŠč鹊ą║ main ąČą┤ą░ą╗ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąŠčüčéą░ą╗čīąĮčŗčģ worker-ąŠą▓. ąÆ čŹč鹊čé ą╝ąŠą╝ąĄąĮčé ąŠąĮąĖ ą▓čüąĄ ą▓čŗčłą╗ąĖ ąĖąĘ čüą▓ąŠąĖčģ čåąĖą║ą╗ąŠą▓ ąĖ ąŠčüčéą░ąĮąŠą▓ąĖą╗ąĖčüčī.
ą¤ąŠąĘą┤čĆą░ą▓ą╗čÅąĄą╝! ąÆčŗ ąĘą░ą▓ąĄčĆčłąĖą╗ąĖ ą┐čĆąŠąĄą║čé, ą┐ąŠą╗čāčćąĖą╗čüčÅ web-čüąĄčĆą▓ąĄčĆ, ą║ąŠč鹊čĆčŗą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą┐čāą╗ ą┐ąŠč鹊ą║ąŠą▓ ą┤ą╗čÅ ą░čüąĖąĮčģčĆąŠąĮąĮąŠą╣ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĘą░ą┐čĆąŠčüąŠą▓. ą£čŗ ą╝ąŠąČąĄą╝ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą║ąŠčĆčĆąĄą║čéąĮąŠąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄ čĆą░ą▒ąŠčéčŗ čüąĄčĆą▓ąĄčĆą░, ą║ąŠč鹊čĆąŠąĄ ąŠčćąĖčēą░ąĄčé ą▓čüąĄ ą┐ąŠč鹊ą║ąĖ ą▓ ą┐čāą╗ąĄ.
ąÆąŠčé ą┐ąŠą╗ąĮčŗą╣ ą║ąŠą┤ čüąĄčĆą▓ąĄčĆą░, čäą░ą╣ą╗ src/main.rs:
use hello::ThreadPool;
use std::{
fs,
io::{prelude::*, BufReader},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&mut stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}
ążą░ą╣ą╗ src/lib.rs:
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec< Worker>,
sender: Option< mpsc::Sender< Job>>,
}
type Job = Box< dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute< F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option< thread::JoinHandle< ()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc< Mutex< mpsc::Receiver< Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}
ąŚą┤ąĄčüčī ą▓čŗ ą╝ąŠąČąĄč鹥 čüą┤ąĄą╗ą░čéčī ą║ąŠąĄ-čćč鹊 ąĄčēąĄ, ąĄčüą╗ąĖ ąĘą░čģąŠčéąĖč鹥 čāą╗čāčćčłąĖčéčī ą┐čĆąŠąĄą║čé. ąÆąŠčé ąĮąĄą║ąŠč鹊čĆčŗąĄ ąĖą┤ąĄąĖ:
ŌĆó ąöąŠą▒ą░ą▓čīč鹥 ą▒ąŠą╗čīčłąĄ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ ą┤ą╗čÅ ThreadPool ąĖ ąĄą│ąŠ ą┐čāą▒ą╗ąĖčćąĮčŗčģ ą╝ąĄč鹊ą┤ąŠą▓.
ŌĆó ąöąŠą▒ą░ą▓čīč鹥 č鹥čüčéčŗ čäčāąĮą║čåąĖąŠąĮą░ą╗ą░ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ (čüą╝. [10]).
ŌĆó ą¤ąŠą╝ąĄąĮčÅą╣č鹥 ą▓čŗąĘąŠą▓čŗ unwrap ą┤ą╗čÅ ą▒ąŠą╗ąĄąĄ ąĮą░ą┤ąĄąČąĮąŠą╣ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąŠčłąĖą▒ąŠą║.
ŌĆó ąśčüą┐ąŠą╗čīąĘčāą╣č鹥 ThreadPool ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ą░ą║ąŠą╣-ąĮąĖą▒čāą┤čī ąĘą░ą┤ą░čćąĖ, ą║čĆąŠą╝ąĄ ą║ą░ą║ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ web-ąĘą░ą┐čĆąŠčüąŠą▓.
ŌĆó ąØą░ą╣ą┤ąĖč鹥 ą║čĆąĄą╣čé ą┐čāą╗ą░ ą┐ąŠč鹊ą║ąŠą▓ ąĮą░ crates.io, ąĖ čĆąĄą░ą╗ąĖąĘčāą╣č鹥 ą┐ąŠą┤ąŠą▒ąĮčŗą╣ web-čüąĄčĆą▓ąĄčĆ, ąĖčüą┐ąŠą╗čīąĘčāčÅ čŹč鹊čé ą║čĆąĄą╣čé. ąŚą░č鹥ą╝ čüčĆą░ą▓ąĮąĖč鹥 ąĄą│ąŠ API ąĖ ąĮą░ą┤ąĄąČąĮąŠčüčéčī čü ą┐čāą╗ąŠą╝ ą┐ąŠč鹊ą║ąŠą▓, ą║ąŠč鹊čĆčŗą╣ ą╝čŗ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ą╗ąĖ.
[ą×ą▒čēąĖąĄ ą▓čŗą▓ąŠą┤čŗ]
ąóąĄą┐ąĄčĆčī ą▓čŗ ą│ąŠč鹊ą▓čŗ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī čüą▓ąŠąĖ čüąŠą▒čüčéą▓ąĄąĮąĮčŗąĄ ą┐čĆąŠąĄą║čéčŗ Rust ąĖ ą┐ąŠą╝ąŠčćčī čü ą┐čĆąŠąĄą║čéą░ą╝ąĖ ą┤čĆčāą│ąĖčģ ą╗čÄą┤ąĄą╣. ąśą╝ąĄą╣č鹥 ą▓ ą▓ąĖą┤čā, čćč鹊 čüčāčēąĄčüčéą▓čāąĄčé ą│ąŠčüč鹥ą┐čĆąĖąĖą╝ąĮąŠąĄ čüąŠąŠą▒čēąĄčüčéą▓ąŠ ą┤čĆčāą│ąĖčģ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╣ Rust, ą║ąŠč鹊čĆčŗąĄ čģąŠč鹥ą╗ąĖ ą▒čŗ ą┐ąŠą╝ąŠčćčī ą▓ą░ą╝ čü ą╗čÄą▒čŗą╝ąĖ ą┐čĆąŠą▒ą╗ąĄą╝ą░ą╝ąĖ.
[ąĪčüčŗą╗ą║ąĖ]
1. Rust Final Project Building a Multithreaded Web Server site:rust-lang.org.
2. Rust: ą┐čĆąĖą╝ąĄčĆ ą║ąŠąĮčüąŠą╗čīąĮąŠą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą▓ą▓ąŠą┤ą░/ą▓čŗą▓ąŠą┤ą░.
3. Rust: ą┐ą░čéč鹥čĆąĮčŗ ąĖ ą▓čŗčĆą░ąČąĄąĮąĖąĄ match.
4. Rust: ą▒ąĄąĘąŠą┐ą░čüąĮą░čÅ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠčüčéčī.
5. Rust: ąŠą▒čēą░čÅ ą║ąŠąĮčåąĄą┐čåąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ.
6. Rust: ąĖč鹥čĆą░č鹊čĆčŗ ąĖ ąĘą░ą╝čŗą║ą░ąĮąĖčÅ.
7. Rust: ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮą░čÅ ąĖąĮč乊čĆą╝ą░čåąĖčÅ ą┐čĆąŠ Cargo ąĖ Crates.io.
8. Rust: ą┐čĆąŠą┤ą▓ąĖąĮčāčéčŗąĄ čäčāąĮą║čåąĖąĖ.
9. Rust: ąŠą▒čŖąĄą║čéąĮąŠ-ąŠčĆąĖąĄąĮčéąĖčĆąŠą▓ą░ąĮąĮąŠąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ.
10. Rust: ąĮą░ą┐ąĖčüą░ąĮąĖąĄ ą░ą▓č鹊ą╝ą░čéąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗčģ č鹥čüč鹊ą▓. |



