ąÆ čŹč鹊ą╣ čüčéą░čéčīąĄ (ą┐ąĄčĆąĄą▓ąŠą┤ [1, 4]) ą┤ąĄą╗ą░ąĄčéčüčÅ ą┐ąŠą┐čŗčéą║ą░ ąĮą░ ą┐ą░ą╗čīčåą░čģ ąŠą▒čŖčÅčüąĮąĖčéčī ąĮą░ąĘąĮą░č湥ąĮąĖąĄ čłąĄčüčéąĖ (ą▓ąŠąĘą╝ąŠąČąĮąŠ čüą░ą╝čŗčģ ą▓ą░ąČąĮčŗčģ) ą║ąŠąĮčåąĄą┐čåąĖą╣ .NET: čüč鹥ą║ (stack), ą║čāčćą░ (heap), čéąĖą┐ ąĘąĮą░č湥ąĮąĖčÅ (value type), čéąĖą┐ čüčüčŗą╗ą║ąĖ (reference type), ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ-čāą┐ą░ą║ąŠą▓ą║ą░ (boxing), ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ-čĆą░čüą┐ą░ą║ąŠą▓ą║ą░ (unboxing). ąæčāą┤ąĄčé ą┐ąŠą║ą░ąĘą░ąĮąŠ, čćč鹊 ąĮą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ, ą║ąŠą│ą┤ą░ ąÆčŗ ą┤ąĄą║ą╗ą░čĆąĖčĆčāąĄč鹥 ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ, ą║ą░ą║ čĆą░ą▒ąŠčéą░čÄčé čüč鹥ą║ ąĖ ą║čāčćą░, ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ čüčüčŗą╗ą║ąĖ ąĮą░ ąŠą▒čŖąĄą║čéčŗ, ąĖ ą║ąŠą│ą┤ą░ ąŠą▒čŖąĄą║čéčŗ čĆą░ą▒ąŠčéą░čÄčé ą║ą░ą║ ąĘąĮą░č湥ąĮąĖčÅ, čćč鹊 čéą░ą║ąŠąĄ čāą┐ą░ą║ąŠą▓ą║ą░ ąĖ čĆą░čüą┐ą░ą║ąŠą▓ą║ą░, ąĖ ą║ą░ą║ čŹčéąĖ ąŠą┐ąĄčĆą░čåąĖąĖ ą▓ą╗ąĖčÅčÄčé ąĮą░ čüą║ąŠčĆąŠčüčéčī čĆą░ą▒ąŠčéčŗ ą║ąŠą┤ą░.
[ą¦č鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐čĆąĖ ą┤ąĄą║ą╗ą░čĆą░čåąĖąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ]
ąÜąŠą│ą┤ą░ ąÆčŗ ą┤ąĄą║ą╗ą░čĆąĖčĆčāąĄč鹥 ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ .NET (C#, C++ ąĖą╗ąĖ Visual Basic), č鹊 ąŠąĮą░ ąĘą░ąĮąĖą╝ą░ąĄčé ąĮąĄą║ąŠč鹊čĆčŗą╣ ą║čāčüąŠč湥ą║ ąŠą┐ąĄčĆą░čéąĖą▓ąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ (RAM). ąĪ čŹč鹊ą╣ ą┐ą░ą╝čÅčéčīčÄ čüą▓čÅąĘą░ąĮčŗ 3 ą┐ąŠąĮčÅčéąĖčÅ: ąĖą╝čÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣, čéąĖą┐ ą┤ą░ąĮąĮčŗčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ (ąŠčé čéąĖą┐ą░ ąĘą░ą▓ąĖčüąĖčé čĆą░ąĘą╝ąĄčĆ ą║čāčüą║ą░ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗą╣ ąĘą░ąĮąĖą╝ą░ąĄčé ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ) ąĖ ąĘąĮą░č湥ąĮąĖąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣. ąØą░ čĆąĖčüčāąĮą║ąĄ ąĮąĖąČąĄ ą┐ąŠą║ą░ąĘą░ąĮ čüą╗čāčćą░ą╣ ą┐čĆąŠčüč鹊ą│ąŠ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ąĖąĘ čüč鹥ą║ą░ ą┐ąŠą┤ ą╗ąŠą║ą░ą╗čīąĮčāčÄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ ą▒ą░ąĘąŠą▓ąŠą│ąŠ čéąĖą┐ą░.
ąĢčüčéčī 2 čéąĖą┐ą░ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ - ąĖąĘ ą┐ą░ą╝čÅčéąĖ čüč鹥ą║ą░ ąĖ ąĖąĘ ą┐ą░ą╝čÅčéąĖ ą║čāčćąĖ.
[ąĪč鹥ą║ ąĖ ą║čāčćą░ ]
ą£ąĮąŠą│ąĖąĄ ąĮąĄ ąĖą╝ąĄčÄčé čÅčüąĮąŠą│ąŠ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖčÅ, ą▓ č湥ą╝ čĆą░ąĘąĮąĖčåą░ ą╝ąĄąČą┤čā čüč鹥ą║ąŠą╝ ąĖ ą║čāč湥ą╣. ą×ą▒ą░ čŹčéąĖčģ čģčĆą░ąĮąĖą╗ąĖčēą░ ąĮą░čģąŠą┤čÅčéčüčÅ ą▓ ąŠą┐ąĄčĆą░čéąĖą▓ąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ čüąĖčüč鹥ą╝čŗ (Random Access Memory, RAM), ąĮąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ-ą░ą┐ą┐ą░čĆą░čéąĮčŗą╣ ą║ąŠą╝ą┐ą╗ąĄą║čü (ą┐čĆąŠčåąĄčüčüąŠčĆ + ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮą░čÅ čüąĖčüč鹥ą╝ą░ + ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ .NET) čĆą░ą▒ąŠčéą░čÄčé čü čŹčéąĖą╝ąĖ ąŠą▒ą╗ą░čüčéčÅą╝ąĖ ą┐ą░ą╝čÅčéąĖ ą┐ąŠ-čĆą░ąĘąĮąŠą╝čā.
ą¦č鹊ą▒čŗ ą┐ąŠąĮčÅčéčī čüą╝čŗčüą╗ čüč鹥ą║ą░ ąĖ ą║čāčćąĖ, ą┤ą░ą▓ą░ą╣č鹥 ą┐ąŠčüą╝ąŠčéčĆąĖą╝, čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą║ąŠą┤ą░.
public void Method1 ()
{
// ąĪčéčĆąŠą║ą░ 1:
int i=4 ;
// ąĪčéčĆąŠą║ą░ 2:
int y=2 ;
//ąĪčéčĆąŠą║ą░ 3:
class1 cls1 = new class1();
}
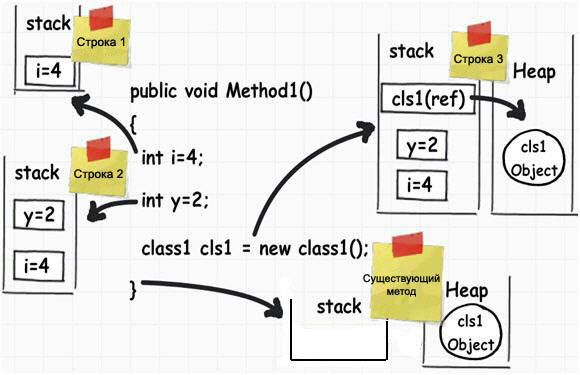
ąĪčéčĆąŠą║ą░ 1 : ą║ąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą║ąŠą┤ ą▓ čŹč鹊ą╣ čüčéčĆąŠą║ąĄ, ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą▓čŗą┤ąĄą╗čÅąĄčé ą╝ą░ą╗ąĄąĮčīą║ąĖą╣ čāčćą░čüč鹊ą║ ą┐ą░ą╝čÅčéąĖ ą▓ čüč鹥ą║ąĄ ą┤ą╗čÅ čģčĆą░ąĮąĄąĮąĖčÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ i, ą║čāą┤ą░ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ąĘąĮą░č湥ąĮąĖąĄ 4. ąĪč鹥ą║ ąŠčéą▓ąĄčćą░ąĄčé ąĘą░ ą▓čĆąĄą╝ąĄąĮąĮąŠąĄ čģčĆą░ąĮąĄąĮąĖąĄ ąĘąĮą░č湥ąĮąĖą╣ ą╗ąŠą║ą░ą╗čīąĮčŗčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ čäčāąĮą║čåąĖąĖ, čćč鹊 čéčĆąĄą▒čāąĄčéčüčÅ ą┤ą╗čÅ čĆą░ą▒ąŠčéčŗ ąÆą░čłąĄą│ąŠ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ.
ąĪčéčĆąŠą║ą░ 2 : č鹥ą┐ąĄčĆčī ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐ąĄčĆąĄčģąŠą┤ąĖčé ą║ čüą╗ąĄą┤čāčÄčēąĄą╝čā čłą░ą│čā. ąÆ č鹊čćąĮąŠą╝ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü ąĮą░ąĘą▓ą░ąĮąĖąĄą╝ č鹥čĆą╝ąĖąĮą░ "čüč鹥ą║", ąĘą┤ąĄčüčī ą┐ą░ą╝čÅčéčī ą┤ą╗čÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ y ą▓čŗą┤ąĄą╗čÅąĄčéčüčÅ čüą▓ąĄčĆčģčā ą┐ąĄčĆą▓ąŠą│ąŠ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ, ą▓ čüč鹊čĆąŠąĮčā čāą╝ąĄąĮčīčłąĄąĮąĖčÅ ą░ą┤čĆąĄčüą░. ą£ąŠąČąĮąŠ ą┐čĆąĄą┤čüčéą░ą▓ąĖčéčī čĆą░ąĘą╝ąĄčēąĄąĮąĖąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ ą▓ čüč鹥ą║ąĄ ą║ą░ą║ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ąĮą░ą│čĆąŠą╝ąŠąČą┤ąĄąĮąĮčŗčģ ą┤čĆčāą│ ąĮą░ ą┤čĆčāą│ą░ ą║ąŠčĆąŠą▒ąŠą║. ąĪą░ą╝ą░čÅ ą┐ąĄčĆą▓ą░čÅ ą▓čŗą┤ąĄą╗ąĄąĮąĮą░čÅ ą║ąŠčĆąŠą▒ą║ą░ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ąĮąĖąĘčā (ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ i), ąĮą░ ąĮąĄčæ čüčéą░ą▓ąĖčéčüčÅ ąĄčēąĄ ą║ąŠčĆąŠą▒ą║ą░ (ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ y), ąĖ čéą░ą║ ą┤ą░ą╗ąĄąĄ.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąĄčüą╗ąĖ ą▒čŗčéčī ą░ą▒čüąŠą╗čÄčéąĮąŠ č鹊čćąĮčŗą╝, č鹊 ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ i ąĖ y ą▓ čüčéčĆąŠą║ą░čģ 1 ąĖ 2 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓ ą╝ąŠą╝ąĄąĮčé ą▓čŗąĘąŠą▓ą░ ą┐čĆąŠčåąĄą┤čāčĆčŗ Method1.
ąÆčŗą┤ąĄą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą▓ čüč鹥ą║ąĄ ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄąĄ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ čŹč鹊ą╣ ą┐ą░ą╝čÅčéąĖ ą▓ čüč鹥ą║ąĄ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐ąŠ ą┐čĆąĖąĮčåąĖą┐čā LIFO (Last In First Out), "ą┐ąŠčüą╗ąĄą┤ąĮąĖą╝ ą┐čĆąĖčłąĄą╗ ą┐ąĄčĆą▓čŗą╝ ą▓čŗčłąĄą╗". ąó. ąĄ. ąŠą┐ąĄčĆą░čåąĖąĖ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ ą┐čĆąŠąĖčüčģąŠą┤čÅčé č鹊ą╗čīą║ąŠ ą▓ čüčéčĆąŠą│ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╝ ą╝ąĄčüč鹥 ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆą░čÅ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ "ą▓ąĄčĆčłąĖąĮą░ čüč鹥ą║ą░".
ąĪčéčĆąŠą║ą░ 3 : ąĘą┤ąĄčüčī ą╝čŗ čüąŠąĘą┤ą░ąĄą╝ ąŠą▒čŖąĄą║čé. ąÜąŠą│ą┤ą░ čŹčéą░ čüčéčĆąŠą║ą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ, č鹊 ą▓ čüč鹥ą║ąĄ čüąŠąĘą┤ą░ąĄčéčüčÅ čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ čĆąĄą░ą╗čīąĮčŗą╣ ąŠą▒čŖąĄą║čé, ą║ąŠč鹊čĆčŗą╣ čüąŠčģčĆą░ąĮąĄąĮ ą▓ ą┤čĆčāą│ąŠą╝ čéąĖą┐ąĄ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆą░čÅ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ "ą║čāč湥ą╣". ąÜčāčćą░ čŹč鹊 ą┐čĆąŠčüč鹊 čģčĆą░ąĮąĖą╗ąĖčēąĄ ą┤ą╗čÅ ąĮą░ą│čĆąŠą╝ąŠąČą┤ąĄąĮąĖčÅ čĆą░ąĘą╗ąĖčćąĮčŗčģ ąŠą▒čŖąĄą║č鹊ą▓, ą║ ą║ąŠč鹊čĆčŗą╝ ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ ąŠą▒čĆą░čēąĄąĮąĖąĄ ą▓ ą╗čÄą▒ąŠą╣ ą╝ąŠą╝ąĄąĮčé ą▓čĆąĄą╝ąĄąĮąĖ. ąÜčāčćą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ (čŹčéąĖą╝ ąĘą░ąĮąĖą╝ą░ąĄčéčüčÅ čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ ą╝ąĄąĮąĄą┤ąČąĄčĆ ą┐ą░ą╝čÅčéąĖ ąĖ čüą▒ąŠčĆčēąĖą║ ą╝čāčüąŠčĆą░).
ąÆą░ąČąĮčŗą╣ ą╝ąŠą╝ąĄąĮčé - ą▓ čüčéčĆąŠą║ąĄ 3 ąĘą░ą┤ąĄą╣čüčéą▓ąŠą▓ą░ąĮąŠ ą┤ą▓ą░ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ - ąŠą┤ąĮąŠ ą▓ čüč鹥ą║ąĄ ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čāą║ą░ąĘą░č鹥ą╗čÅ cls1, ąĖ ą▓č鹊čĆąŠąĄ ą▓ ą║čāč湥, ą│ą┤ąĄ čĆąĄą░ą╗čīąĮąŠ čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ ą┤ą░ąĮąĮčŗąĄ ąŠą▒čŖąĄą║čéą░. ą×ą┐ąĄčĆą░č鹊čĆ Class1 cls1 ąĮąĄ ą▓čŗą┤ąĄą╗čÅąĄčé ą┐ą░ą╝čÅčéčī ą┤ą╗čÅ čŹą║ąĘąĄą╝ą┐ą╗čÅčĆą░ ą║ą╗ą░čüčüą░ Class1, ąŠąĮ č鹊ą╗čīą║ąŠ ą╗ąĖčłčī ą▓čŗą┤ąĄą╗čÅąĄčé ą▓ čüč鹥ą║ąĄ ą╝ąĄčüč鹊 ą┐ąŠą┤ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ čāą║ą░ąĘą░č鹥ą╗čÅ cls1 (ąĖ ąĮąĄčÅą▓ąĮąŠ ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĄčé ąĄą╣ ąĘąĮą░č湥ąĮąĖąĄ null). ąÜąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┤ąŠčüčéąĖą│ą░ąĄčé ą┤ąŠ ą║ą╗čÄč湥ą▓ąŠą│ąŠ čüą╗ąŠą▓ą░ new, č鹊ą│ą┤ą░ ą┐ą░ą╝čÅčéčī ą▓čŗą┤ąĄą╗čÅąĄčéčüčÅ ąĖąĘ ą║čāčćąĖ, ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāąĄčéčüčÅ čŹą║ąĘąĄą╝ą┐ą╗čÅčĆ ąŠą▒čŖąĄą║čéą░ Class1, ąĖ ąĄą│ąŠ ą░ą┤čĆąĄčü ą▓ ą║čāč湥 ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĄčéčüčÅ čāą║ą░ąĘą░č鹥ą╗čÄ cls1.
ą¤čĆąĖ ą▓čŗčģąŠą┤ąĄ ąĖąĘ ą┐čĆąŠčåąĄą┤čāčĆčŗ Metod1 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé čüą╗ąĄą┤čāčÄčēąĄąĄ: ą▓čüąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ, čĆą░ąĘą╝ąĄčēąĄąĮąĮčŗąĄ ą▓ čüč鹥ą║ąĄ (i, y, cls1), ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ čāąĮąĖčćč鹊ąČą░čÄčéčüčÅ. ą×čüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓ ąŠą▒čĆą░čéąĮąŠą╝ ą┐ąŠčĆčÅą┤ą║ąĄ, ą┐ąŠ ą┐čĆąĖąĮčåąĖą┐čā LIFO, ąŠą┤ąĮą░ą║ąŠ čŹč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąŠč湥ąĮčī ą▒čŗčüčéčĆąŠ, ąĘą░ ąŠą┤ąĮčā ąĖąĮčüčéčĆčāą║čåąĖčÄ ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░, ą┐čāč鹥ą╝ ą┐čĆąŠčüč鹊ą│ąŠ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ ą▓ąĄčĆčłąĖąĮčŗ čüč鹥ą║ą░.
ąĢčēąĄ ąŠą┤ąĖąĮ ą▓ą░ąČąĮčŗą╣ ą╝ąŠą╝ąĄąĮčé - ąĘą┤ąĄčüčī ąĮąĄ ąŠčüą▓ąŠą▒ąŠąČą┤ą░ąĄčéčüčÅ ą┐ą░ą╝čÅčéčī ą▓ ą║čāč湥. ąÆ čüą╗čāčćą░ąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ C++ čŹč鹊 ąŠčłąĖą▒ą║ą░, ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé čāč鹥čćą║ą░ ą┐ą░ą╝čÅčéąĖ. ąöą╗čÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĮą░ Java ąĖą╗ąĖ C# ąŠčłąĖą▒ą║ąĖ čéčāčé ąĮąĄčé, ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą║čāčćąĖ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ čü ą┐ąŠą╝ąŠčēčīčÄ čüą▒ąŠčĆčēąĖą║ą░ ą╝čāčüąŠčĆą░, ą▒ąĄąĘ ą▓ą╝ąĄčłą░č鹥ą╗čīčüčéą▓ą░ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčéą░ - ą▓ č乊ąĮąŠą▓ąŠą╝ ą┐čĆąŠčåąĄčüčüąĄ, ą║ąŠą│ą┤ą░ čā ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ ą┐ąŠčÅą▓čÅčéčüčÅ ą┤ą╗čÅ čŹč鹊ą│ąŠ čĆąĄčüčāčĆčüčŗ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
ą¤ąŠč湥ą╝čā čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ąĖ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ą╗ąĖ čéą░ą║čāčÄ čüą╗ąŠąČąĮčāčÄ čüąĖčüč鹥ą╝čā ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ, čĆą░ąĘą▓ąĄ ąĮąĄą╗čīąĘčÅ ą▒čŗą╗ąŠ ąŠčüčéą░ą▓ąĖčéčī ą┐ą░ą╝čÅčéčī č鹊ą╗čīą║ąŠ ąŠą┤ąĮąŠą│ąŠ čéąĖą┐ą░?
ą¤čĆąĖčćąĖąĮą░ ą▓ č鹊ą╝, čćč鹊 čéąĖą┐čŗ ąŠą▒čŖąĄą║č鹊ą▓ ą▒čŗą▓ą░čÄčé čĆą░ąĘąĮąŠą╣ čüą╗ąŠąČąĮąŠčüčéąĖ, ąĖ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čüą╗ąŠąČąĮąŠčüčéąĖ ąŠą▒čŖąĄą║čéą░ čāą┤ąŠą▒ąĮčŗ čĆą░ąĘą╗ąĖčćąĮčŗąĄ čüą┐ąŠčüąŠą▒čŗ ą╝ą░ąĮąĖą┐čāą╗čÅčåąĖąĖ ąĮą░ą┤ ą┤ą░ąĮąĮčŗą╝ąĖ. ąĪą░ą╝čŗąĄ ą┐čĆąŠčüčéčŗąĄ čŹč鹊 čéąĖą┐čŗ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ int, ąŠąĮąĖ ąĘą░ąĮąĖą╝ą░čÄčé ąŠą▒ą╗ą░čüčéčī ą┐ą░ą╝čÅčéąĖ ąĖąĘ 4 ą▒ą░ą╣čé. ąóą░ą║ąĖąĄ ą┤ą░ąĮąĮčŗąĄ ą┐čĆąĖ ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĮąĖąĖ ą╝ąŠąČąĮąŠ ą┐čĆąŠčüč鹊 ą║ąŠą┐ąĖčĆąŠą▓ą░čéčī, čŹč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▒čŗčüčéčĆąŠ, ą▒ąĄąĘ ą╗ąĖčłąĮąĖčģ ąĮą░ą║ą╗ą░ą┤ąĮčŗčģ čĆą░čüčģąŠą┤ąŠą▓ (ąŠą┤ąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣ ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░). ąöą░ąĮąĮčŗąĄ ąŠą▒čŖąĄą║čéąĮčŗčģ čéąĖą┐ąŠą▓ ą╝ąŠą│čāčé ą▒čŗčéčī ąŠč湥ąĮčī čüą╗ąŠąČąĮčŗą╝ąĖ, ąŠąĮąĖ ą╝ąŠą│čāčé čüčüčŗą╗ą░čéčīčüčÅ ąĮą░ ą┤čĆčāą│ąĖąĄ ąŠą▒čŖąĄą║čéčŗ ąĖą╗ąĖ ą┤čĆčāą│ąĖąĄ ą┐čĆąĖą╝ąĖčéąĖą▓ąĮčŗąĄ čéąĖą┐čŗ ą┤ą░ąĮąĮčŗčģ. ą¤čĆčÅą╝ąŠąĄ ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĮąĖąĄ čéą░ą║ąĖčģ ąŠą▒čŖąĄą║č鹊ą▓ ą╝ąĄč鹊ą┤ąŠą╝ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ ą╝ąŠąČąĄčé ąĘą░ąĮąĖą╝ą░čéčī čüą╗ąĖčłą║ąŠą╝ ą╝ąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ, ą┐ąŠčŹč鹊ą╝čā ąĘą┤ąĄčüčī ą┐čĆąĖą╝ąĄąĮčÅčÄčéčüčÅ čüčüčŗą╗ą║ąĖ. ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ ąŠą▒čŖąĄą║čéą░ čüąŠą┤ąĄčƹȹ░čé čüčüčŗą╗ą║ąĖ ąĮą░ ą╝ąĮąŠą│ąĖąĄ ą┤čĆčāą│ąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ, ą║ą░ąČą┤ąŠąĄ ąĖąĘ ą║ąŠč鹊čĆčŗčģ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čüąŠčģčĆą░ąĮąĄąĮąŠ ą│ą┤ąĄ-č鹊 ą▓ ą┐ą░ą╝čÅčéąĖ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąŠą▒čŖąĄą║čéąĮčŗąĄ čéąĖą┐čŗ ąĮčāąČą┤ą░čÄčéčüčÅ ą▓ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą╣ ą┐ą░ą╝čÅčéąĖ (čŹč鹊 ą║čāčćą░), ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ą┐čĆąŠčüčéčŗąĄ čéąĖą┐čŗ čéčĆąĄą▒čāčÄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüčéą░čéąĖč湥čüą║ąŠą╣ ą┐ą░ą╝čÅčéąĖ (čüč鹥ą║).
ąÆ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠą╝ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ čā ą║ą░ąČą┤ąŠą│ąŠ ą┐ąŠč鹊ą║ą░ ąĖą╝ąĄąĄčéčüčÅ čüą▓ąŠą╣ ąŠčéą┤ąĄą╗čīąĮčŗą╣ čüč鹥ą║. ą×ą┤ąĮą░ą║ąŠ ą▓čüąĄ ą┐ąŠč鹊ą║ąĖ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ąŠą┤ąĮčā ąĖ čéčā ąČąĄ ą║čāčćčā. ąśąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 čĆą░ąĘąĮčŗąĄ ą┐ąŠč鹊ą║ąĖ ą▓ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠą╝ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ąŠą▒čēčāčÄ ą║čāčćčā, čéčĆąĄą▒čāąĄčéčüčÅ ąĮąĄą║ą░čÅ ą║ąŠąŠčĆą┤ąĖąĮą░čåąĖčÅ ą╝ąĄąČą┤čā ą┐ąŠč鹊ą║ą░ą╝ąĖ, čćč鹊ą▒čŗ ąŠąĮąĖ ąĮąĄ ą╝ą░ąĮąĖą┐čāą╗ąĖčĆąŠą▓ą░ą╗ąĖ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ąŠą┤ąĮąŠą╣ ąĖ č鹊ą╣ ąČąĄ ąŠą▒ą╗ą░čüčéčīčÄ (ąĖą╗ąĖ ąŠą▒ą╗ą░čüčéčÅą╝ąĖ) ą┐ą░ą╝čÅčéąĖ ą▓ ą║čāč湥.
ąŁč鹊 čüčéą░ąĮą┤ą░čĆčéąĮą░čÅ ą┐čĆąŠą▒ą╗ąĄą╝ą░ ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéąĖ ą┐ąŠč鹊ą║ąŠą▓, čéčĆą░ą┤ąĖčåąĖąŠąĮąĮąŠ ą▓ąŠąĘąĮąĖą║ą░čÄčēą░čÅ čü ą│ą╗ąŠą▒ą░ą╗čīąĮčŗą╝ąĖ ą┤ą░ąĮąĮčŗą╝ąĖ. ą×ąĮą░ čĆąĄčłą░ąĄčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║, ąŠč湥čĆąĄą┤ąĄą╣, čüąĄą╝ą░č乊čĆąŠą▓ ąĖ ą┤čĆčāą│ąĖčģ ą║ąŠąĮčüčéčĆčāą║čåąĖą╣ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ.
ąöą░, ąŠą▒čŖąĄą║čé ą╝ąŠąČąĄčé ą▒čŗčéčī čüąŠčģčĆą░ąĮąĄąĮ ą▓ čüč鹥ą║ąĄ. ąĢčüą╗ąĖ ąÆčŗ čüąŠąĘą┤ą░ąĄč鹥 ąŠą▒čŖąĄą║čé ą▓ąĮčāčéčĆąĖ čäčāąĮą║čåąĖąĖ ą▒ąĄąĘ ąŠą┐ąĄčĆą░č鹊čĆą░ "new", č鹊 čŹč鹊 čüąŠąĘą┤ą░čüčé ąĖ čüąŠčģčĆą░ąĮąĖčé ąŠą▒čŖąĄą║čé ą▓ čüč鹥ą║ąĄ, ą░ ąĮąĄ ą▓ ą║čāč湥. ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 čā ąĮą░čü ąĄčüčéčī C++ ą║ą╗ą░čüčü Member, ą┤ą╗čÅ ą║ąŠč鹊čĆąŠą│ąŠ ą╝čŗ čģąŠčéąĖą╝ čüąŠąĘą┤ą░čéčī ąŠą▒čŖąĄą║čé. ąóą░ą║ąČąĄ čā ąĮą░čü ąĄčüčéčī čäčāąĮą║čåąĖčÅ somefunction( ). ąÆąŠčé čéą░ą║ ą╝ąŠąČąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī ą║ąŠą┤, ą║ąŠą│ą┤ą░ ąŠą▒čŖąĄą║čé čüąŠąĘą┤ą░ąĄčéčüčÅ ą▓ čüč鹥ą║ąĄ:
void somefunction ()
{
/* ąĪąŠąĘą┤ą░ąĮąĖąĄ ąŠą▒čŖąĄą║čéą░ "m" ą║ą╗ą░čüčüą░ Member ą┐ąŠą╝ąĄčüčéąĖčé ąĄą│ąŠ ą▓ čüč鹥ą║, ą┐ąŠč鹊ą╝čā čćč鹊 ąĘą┤ąĄčüčī ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą║ą╗čÄč湥ą▓ąŠąĄ čüą╗ąŠą▓ąŠ "new", ąĖ ąŠą▒čŖąĄą║čé čüąŠąĘą┤ą░ąĄčéčüčÅ ą▓ąĮčāčéčĆąĖ čäčāąĮą║čåąĖąĖ. */
Member m;
} // ą×ą▒čŖąĄą║čé "m" čāąĮąĖčćč鹊ąČą░ąĄčéčüčÅ ą┐čĆąĖ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĖ čäčāąĮą║čåąĖąĖ.
ąśčéą░ą║, ąŠą▒čŖąĄą║čé "m" ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ čāąĮąĖčćč鹊ąČą░ąĄčéčüčÅ, ą║ąŠą│ą┤ą░ čäčāąĮą║čåąĖčÅ ą┤ąŠčģąŠą┤ąĖčé ą┤ąŠ č鹊čćą║ąĖ čüą▓ąŠąĄą│ąŠ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ, ąĖą╗ąĖ, ą┤čĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ą║ąŠą│ą┤ą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ąĖčüą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ąŠą┐ąĄčĆą░č鹊čĆąŠą▓ ą▓ ą║ąŠą┤ąĄ ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąŠą▒ą╗ą░čüčéąĖ ą┤ąĄą╣čüčéą▓ąĖčÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ m ("out of scope"). ąØąĖą║ą░ą║ąĖčģ čüą┐ąĄčåąĖą░ą╗čīąĮčŗčģ ą┤ąĄą╣čüčéą▓ąĖą╣ ą┐ąŠ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÄ ą┐ą░ą╝čÅčéąĖ ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ.
ąĢčüą╗ąĖ ą╝čŗ čģąŠčéąĖą╝ ą▓ąĮčāčéčĆąĖ čäčāąĮą║čåąĖąĖ čüąŠąĘą┤ą░čéčī ąŠą▒čŖąĄą║čé ą▓ ą║čāč湥, č鹊 ą║ąŠą┤ ą▒čāą┤ąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
void somefunction ()
{
/* ąĪąŠąĘą┤ą░ąĮąĖąĄ ąŠą▒čŖąĄą║čéą░ "m" ą║ą░ą║ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ ą║ą╗ą░čüčüą░ Member ą┐čĆąŠąĖąĘą▓ąĄą┤ąĄčé ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ą┤ą╗čÅ ąĮąĄą│ąŠ ą┐ą░ą╝čÅčéąĖ ą▓ ą║čāč湥, ą┐ąŠč鹊ą╝čā čćč鹊 ąĘą┤ąĄčüčī ą╝čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ąĖ ą║ą╗čÄč湥ą▓ąŠąĄ čüą╗ąŠą▓ąŠ "new", ąĖ čüąŠąĘą┤ą░ą╗ąĖ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ąŠą▒čŖąĄą║čéą░ ą▓ąĮčāčéčĆąĖ čäčāąĮą║čåąĖąĖ. */
Member* m = new Member();
/* ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čüą░ą╝ą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ m ąĘą┤ąĄčüčī čÅą▓ą╗čÅąĄčéčüčÅ čāą║ą░ąĘą░č鹥ą╗ąĄą╝, ąĖ ą┐ą░ą╝čÅčéčī ą┤ą╗čÅ čŹč鹊ą│ąŠ čāą║ą░ąĘą░č鹥ą╗čÅ ą▓čŗą┤ąĄą╗čÅąĄčéčüčÅ ąĮąĄ ą▓ ą║čāč湥, ą░ ą▓ čüč鹥ą║ąĄ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą▓ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą┤ą╗čÅ čüąŠąĘą┤ą░ąĮąĖčÅ ąŠą▒čŖąĄą║čéą░ ąĘą░ą┤ąĄą╣čüčéą▓ąŠą▓ą░ąĮąŠ ą┤ą▓ą░ ą▓ąĖą┤ą░ ą┐ą░ą╝čÅčéąĖ - čüč鹥ą║ (ą┤ą╗čÅ čģčĆą░ąĮąĄąĮąĖčÅ čāą║ą░ąĘą░č鹥ą╗čÅ ą║ą░ą║ ą╗ąŠą║ą░ą╗čīąĮąŠą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ čäčāąĮą║čåąĖąĖ) ąĖ ą║čāčćą░ (ą┤ą╗čÅ čģčĆą░ąĮąĄąĮąĖčÅ čĆąĄą░ą╗čīąĮčŗčģ ą┤ą░ąĮąĮčŗčģ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ ąŠą▒čŖąĄą║čéą░).
/* ąöą░ąĮąĮčŗąĄ ąŠą▒čŖąĄą║čéą░ "m" ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čÅą▓ąĮąŠ čāą┤ą░ą╗ąĄąĮčŗ, ąĖąĮą░č湥 ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé čāč鹥čćą║ą░ ą┐ą░ą╝čÅčéąĖ. ą¤ą░ą╝čÅčéčī, ą▓čŗą┤ąĄą╗ąĄąĮąĮčāčÄ ą▓ čüč鹥ą║ąĄ ą┐ąŠą┤ čāą║ą░ąĘą░č鹥ą╗čī m, ąŠčüą▓ąŠą▒ąŠąČą┤ą░čéčī ąĮąĄ ąĮčāąČąĮąŠ. */
delete m;
}
ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą║ąŠą┤ą░ ą╝ąŠąČąĮąŠ čāą▓ąĖą┤ąĄčéčī, čćč鹊 ąŠą▒čŖąĄą║čé "m" ą▒čŗą╗ čüąŠąĘą┤ą░ąĮ čü ą┐ąŠą╝ąŠčēčīčÄ ą║ą╗čÄč湥ą▓ąŠą│ąŠ čüą╗ąŠą▓ą░ "new". ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą┤ą░ąĮąĮčŗąĄ ą┤ą╗čÅ ąŠą▒čŖąĄą║čéą░ "m" ą▒čāą┤čāčé čüąŠąĘą┤ą░ąĮčŗ ą▓ ą║čāč湥.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: čŹč鹊 ą┐čĆąĖą╝ąĄčĆ ą║ąŠą┤ą░ C++, ą▓ ąĮąĄą╝ ą▓čüąĄą│ą┤ą░ ą▓ą░ąČąĮąŠ ą┐ą░čĆąĮąŠ ą▓čŗąĘčŗą▓ą░čéčī ąŠą┐ąĄčĆą░č鹊čĆčŗ new ąĖ delete. ąŻą┐čĆą░ą▓ą╗čÅąĄą╝čŗą╣ ą║ąŠą┤ C# čüą▓ąŠą▒ąŠą┤ąĄąĮ ąŠčé čéą░ą║ąŠą│ąŠ "ąĮąĄą┤ąŠčüčéą░čéą║ą░" - ąŠą▒čŖąĄą║čéčŗ, ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗąĄ ąŠą┐ąĄčĆą░č鹊čĆąŠą╝ new, ąŠčüą▓ąŠą▒ąŠąČą┤ą░čÄčéčüčÅ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ čüą▒ąŠčĆčēąĖą║ąŠą╝ ą╝čāčüąŠčĆą░, ą║ąŠą│ą┤ą░ ą▓ ąĮąĖčģ ąŠčéą┐ą░ą┤ą░ąĄčé ąĮą░ą┤ąŠą▒ąĮąŠčüčéčī.
ąÜą░ą║ č鹊ą╗čīą║ąŠ čäčāąĮą║čåąĖčÅ ąĘą░ą▓ąĄčĆčłąĖą╗ą░ čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ, ą╗čÄą▒čŗąĄ ą╗ąŠą║ą░ą╗čīąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ čäčāąĮą║čåąĖąĖ (ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗąĄ ą▓ čüč鹥ą║ąĄ), ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ ąŠčüą▓ąŠą▒ąŠąČą┤ą░čÄčéčüčÅ. ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ ą║ą░čüą░ąĄčéčüčÅ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ čäčāąĮą║čåąĖąĖ, čŹč鹊 č鹥 ąČąĄ čüą░ą╝čŗąĄ ą╗ąŠą║ą░ą╗čīąĮčŗąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ, čģčĆą░ąĮčÅčēąĖąĄčüčÅ ą▓ čüč鹥ą║ąĄ ą▓ ą╝ąŠą╝ąĄąĮčé ą▓čŗąĘąŠą▓ą░ čäčāąĮą║čåąĖąĖ. ą¤čĆąĖ ą▓čŗčģąŠą┤ąĄ ąĖąĘ čäčāąĮą║čåąĖąĖ ą▓čüąĄ ą╗ąŠą║ą░ą╗čīąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ąĖ ą┐ą░čĆą░ą╝ąĄčéčĆčŗ čäčāąĮą║čåąĖąĖ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ č鹥čĆčÅčÄčé čüą▓ąŠčÄ ą░ą║čéčāą░ą╗čīąĮąŠčüčéčī (čüčćąĖčéą░čÄčéčüčÅ čāąĮąĖčćč鹊ąČąĄąĮąĮčŗą╝ąĖ).
ąøčÄą▒čŗąĄ ą┤ą░ąĮąĮčŗąĄ, ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗąĄ ą▓ ą║čāč湥 ąŠą┐ąĄčĆą░č鹊čĆąŠą╝ new (ą╗ąĖą▒ąŠ čäčāąĮą║čåąĖčÅą╝ąĖ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą│ąŠ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ), ąĮčāąČą┤ą░čÄčéčüčÅ ą▓ čÅą▓ąĮąŠą╝ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĖ ą║ąŠą┤ąŠą╝, ąĮą░ą┐ąĖčüą░ąĮąĮčŗą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüč鹊ą╝ (čŹč鹊 ą║ą░čüą░ąĄčéčüčÅ č鹊ą╗čīą║ąŠ čÅąĘčŗą║ą░ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ C++, ąŠą▒čŖąĄą║čéčŗ čÅąĘčŗą║ą░ C# čāąĮąĖčćč鹊ąČą░čÄčéčüčÅ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ čüą▒ąŠčĆčēąĖą║ąŠą╝ ą╝čāčüąŠčĆą░).
ąĀą░ąĘą╝ąĄčĆ čüč鹥ą║ą░ čäąĖą║čüąĖčĆąŠą▓ą░ąĮ, ąĖ ą┐ąŠčüą╗ąĄ čüąŠąĘą┤ą░ąĮąĖčÅ čüč鹥ą║ą░ ąĄą│ąŠ čĆą░ąĘą╝ąĄčĆ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖąĘą╝ąĄąĮąĄąĮ (čģąŠčéčÅ ąĮąĄą║ąŠč鹊čĆčŗąĄ čÅąĘčŗą║ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ąĖą╝ąĄčÄčé čĆą░čüčłąĖčĆąĄąĮąĖčÅ ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čéą░ą║ąŠą╣ čäčāąĮą║čåąĖąĖ, čćč鹊 ąŠč湥ąĮčī čĆąĄą┤ą║ąĖą╣ čüą╗čāčćą░ą╣). ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąĄčüą╗ąĖ ą▓ čüč鹥ą║ąĄ ą▓čŗą┤ąĄą╗ąĄąĮąŠ ąĮąĄą┤ąŠčüčéą░č鹊čćąĮąŠ ą╝ąĄčüčéą░, č鹊 ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ čüč鹥ą║ą░ ąĖ ą║ą░ą║ čĆąĄąĘčāą╗čīčéą░čé čüą▒ąŠą╣ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĖą╗ąĖ čüąĖčüč鹥ą╝čŗ. ąóą░ą║ąŠąĄ čćą░čüč鹊 ą▓čüčéčĆąĄčćą░ąĄčéčüčÅ ąĖąĘ ąĘą░ ą▒ąŠą╗čīčłąŠą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą▓čŗąĘąŠą▓ąŠą▓ ą▓ą╗ąŠąČąĄąĮąĮčŗčģ čäčāąĮą║čåąĖą╣, ąĖą╗ąĖ ąĖąĘ-ąĘą░ ą▒ąĄčüą║ąŠąĮąĄčćąĮčŗčģ čĆąĄą║čāčĆčüąĖą▓ąĮčŗčģ ą▓čŗąĘąŠą▓ąŠą▓.
ąĢčüą╗ąĖ č鹥ą║čāčēąĖą╣ čĆą░ąĘą╝ąĄčĆ ą║čāčćąĖ čüą╗ąĖčłą║ąŠą╝ ą╝ą░ą╗, čćč鹊ą▒čŗ čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆąĖčéčī čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅą╝ čĆą░ą▒ąŠč湥ą│ąŠ ąŠą║čĆčāąČąĄąĮąĖčÅ, č鹊 čéčĆąĄą▒čāąĄčéčüčÅ čāą▓ąĄą╗ąĖč湥ąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą║čāčćąĖ. ąÜą░ą║ čŹč鹊 čĆąĄą░ą╗čīąĮąŠ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé - ąĘą░ą▓ąĖčüąĖčé ąŠčé č鹥ą║čāčēąĖčģ čāčüą╗ąŠą▓ąĖą╣. ąĢčüą╗ąĖ ą║čāč湥ą╣ čāą┐čĆą░ą▓ą╗čÅąĄčé ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮą░čÅ čüąĖčüč鹥ą╝ą░, č鹊 ąŠąĮą░ čüą░ą╝ą░ ą╝ąĄąĮčÅąĄčé čĆą░ąĘą╝ąĄčĆ ą║čāčćąĖ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čéčĆąĄą▒ąŠą▓ą░ąĮąĖą╣ ąĘą░ą┐čāčüą║ą░ąĄą╝čŗčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣. ąĢčüą╗ąĖ ą┐čĆąŠąĄą║čéąĖčĆčāąĄčéčüčÅ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝ą░čÅ čüąĖčüč鹥ą╝ą░, č鹊 čĆą░ąĘą╝ąĄčĆ ą║čāčćąĖ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą▓ ą╝ąŠą╝ąĄąĮčé ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ (čü ą┐ąŠą╝ąŠčēčīčÄ ąĮą░čüčéčĆąŠą╣ą║ąĖ ą║ą░čĆčéčŗ ą┐ą░ą╝čÅčéąĖ ąĖ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║).
ąÆ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠčüčéąĖ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ ąĘą░ą▓ąĖčüąĖčé ąŠčé čÅąĘčŗą║ą░ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ, ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░, ąĮą░ ą║ąŠč鹊čĆąŠą╝ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą║ąŠą┤ ą▓ čĆąĄą░ą╗čīąĮąŠą╝ ą▓čĆąĄą╝ąĄąĮąĖ. ąØąŠ čćą░čēąĄ ą▓čüąĄą│ąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ąŠą┤ąĮą░ ąĖ čéą░ ąČąĄ ą░ąĮą░ą╗ąŠą│ąĖčćąĮą░čÅ čüčģąĄą╝ą░ - čāą║ą░ąĘą░č鹥ą╗čī čüč鹥ą║ą░ ą┐čĆąĖ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĖ ą▓ ąĮąĄą╝ ą┐ą░ą╝čÅčéąĖ čüą╝ąĄčēą░ąĄčéčüčÅ ą▓ čüč鹊čĆąŠąĮčā čāą╝ąĄąĮčīčłąĄąĮąĖčÅ ą░ą┤čĆąĄčüąŠą▓ (ą┤ąĄą║čĆąĄą╝ąĄąĮč鹊ą╝ čĆąĄą│ąĖčüčéčĆą░ čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░), ą░ ą║čāčćą░ čĆąĄą░ą╗ąĖąĘčāąĄčéčüčÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ čüčĆąĄą┤čüčéą▓ą░ą╝ąĖ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ ąĖą╗ąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║.
ąÜąŠąĮąĄčćąĮąŠ, čüč鹥ą║ ąĮą░ą╝ąĮąŠą│ąŠ ą▒čŗčüčéčĆąĄąĄ ą║čāčćąĖ. ą¤čĆąĖčćąĖąĮą░ ą▓ č鹊ą╝, ą║ą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ą▓čŗą┤ąĄą╗čÅąĄčéčüčÅ čüč鹥ą║ - ą┐čĆąŠčüčéčŗą╝ ąĮą░ąĘąĮą░č湥ąĮąĖąĄą╝ čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░ (ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮą░čÅ ą║ąŠą╝ą░ąĮą┤ą░ ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░). ąÆ ąŠčéą╗ąĖčćąĖąĄ ąŠčé čüč鹥ą║ą░ ą║čāčćą░ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄčéčüčÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ, čü ą┐ąŠą╝ąŠčēčīčÄ čüą┐ąĄčåąĖą░ą╗čīąĮčŗčģ ą▓čŗąĘąŠą▓ąŠą▓ API ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ ąĖą╗ąĖ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ą┐čĆąĖ ąĖąĮč鹥ąĮčüąĖą▓ąĮąŠą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ą║čāčćąĖ ąĮąĄą║ąŠč鹊čĆčŗąĄ čÅąĘčŗą║ąĖ, ąĖčüą┐ąŠą╗čīąĘčāčÄčēąĖąĄ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖą╣ čüą▒ąŠčĆ ą╝čāčüąŠčĆą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, Java, C# .NET), ą╝ąŠą│čāčé ą▓ą▓ąŠą┤ąĖčéčī ąĮąĄ ą┐čĆąŠą│ąĮąŠąĘąĖčĆčāąĄą╝čŗąĄ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ąĘą░ą┤ąĄčƹȹ║ąĖ ą┐čĆąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ ą║ąŠą┤ą░ ą▓ čĆąĄą░ą╗čīąĮąŠą╝ ą▓čĆąĄą╝ąĄąĮąĖ.
ąöą░ąĮąĮčŗąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ą▓ čüč鹥ą║ąĄ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ą░čÄčéčüčÅ, ą║ąŠą│ą┤ą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ č鹥čĆčÅąĄčé ąŠą▒ą╗ą░čüčéčī čüą▓ąŠąĄą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ (go out of scope). ą×ą┤ąĮą░ą║ąŠ ąĮą░ čÅąĘčŗą║ą░čģ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ C ąĖ C++ ą┤ą░ąĮąĮčŗąĄ, čüąŠčģčĆą░ąĮąĄąĮąĮčŗąĄ ą▓ ą║čāč湥, ąĮčāąČą┤ą░čÄčéčüčÅ ą▓ čÅą▓ąĮąŠą╝ čĆčāčćąĮąŠą╝ čāą┤ą░ą╗ąĄąĮąĖąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüč鹊ą╝ (čü ą┐ąŠą╝ąŠčēčīčÄ ą║ą╗čÄč湥ą▓čŗčģ čüą╗ąŠą▓ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ free, delete ąĖą╗ąĖ delete[]).
ąöčĆčāą│ąĖąĄ čÅąĘčŗą║ąĖ, ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ Java ąĖ C# .NET ąĖčüą┐ąŠą╗čīąĘčāčÄčé čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ čĆą░ą▒ąŠčéą░čÄčēąĖą╣ čüą▒ąŠčĆčēąĖą║ ą╝čāčüąŠčĆą░, ą║ąŠč鹊čĆčŗą╣ čüą░ą╝ ąĘą░ą▒ąŠčéąĖčéčüčÅ ąŠą▒ čāą┤ą░ą╗ąĄąĮąĖąĖ ąĮąĄąĮčāąČąĮčŗčģ ąŠą▒čŖąĄą║č鹊ą▓ ąĖąĘ ą║čāčćąĖ (ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčéčā ą┤ą╗čÅ čŹč鹊ą│ąŠ ąĮąĖč湥ą│ąŠ ą┤ąĄą╗ą░čéčī ąĮąĄ ąĮčāąČąĮąŠ). ąŁč鹊 ą▒ąŠą╗čīčłąŠąĄ čāą┤ąŠą▒čüčéą▓ąŠ, ąĘą░ ą║ąŠč鹊čĆąŠąĄ ą┐čĆąĖčģąŠą┤ąĖčéčüčÅ čĆą░čüą┐ą╗ą░čćąĖą▓ą░čéčīčüčÅ ąĘą░ą╝ąĄą┤ą╗ąĄąĮąĖąĄą╝ čĆą░ą▒ąŠčéčŗ ą║ąŠą┤ą░ ą▓ ąĮąĄą║ąŠč鹊čĆčŗčģ ąŠčüąŠą▒ąŠ ąĮąĄ ą▒ą╗ą░ą│ąŠą┐čĆąĖčÅčéąĮčŗčģ čüą╗čāčćą░čÅčģ.
ąĢčüą╗ąĖ ąĘą░ą║ąŠąĮčćąĖčéčüčÅ ą┐ą░ą╝čÅčéčī, ąŠčéą▓ąĄą┤ąĄąĮąĮą░čÅ ą┐ąŠą┤ čüč鹥ą║, č鹊 čŹč鹊 ą▓čŗąĘąŠą▓ąĄčé ąĮąĄą┐čĆąĄą┤čüą║ą░ąĘčāąĄą╝ąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĖ čćą░čēąĄ ą▓čüąĄą│ąŠ ąĘą░ą║ąŠąĮčćąĖčéčüčÅ ąĄčæ ą┐ą░ą┤ąĄąĮąĖąĄą╝. ą¤ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĖ ą┐ąŠčĆčćą░ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ čüč鹥ą║ą░ čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čģą░ą║ąĄčĆą░ą╝ąĖ ą┤ą╗čÅ ą▓ąĘą╗ąŠą╝ą░ ą┐čĆąŠą│čĆą░ą╝ą╝ ąĖ ą┐ąŠą▓čŗčłąĄąĮąĖčÅ ą┐čĆąĖą▓ąĖą╗ąĄą│ąĖą╣ ą▓ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčŗčģ čüąĖčüč鹥ą╝ą░čģ, ąĄčüą╗ąĖ ą▓ ąĮąĖčģ ąĖą╝ąĄąĄčéčüčÅ ąĖąĘą▓ąĄčüčéąĮą░čÅ čāčÅąĘą▓ąĖą╝ąŠčüčéčī, čüą▓čÅąĘą░ąĮąĮą░čÅ čü ąŠčłąĖą▒ą║ąŠą╣ ą▓ ą║ąŠą┤ąĄ.
ąĪą▒ąŠą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ čéą░ą║ąČąĄ ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ ąĖ čü ąĖčüč湥čĆą┐ą░ąĮąĖąĄą╝ ą┐ą░ą╝čÅčéąĖ ą▓ ą║čāč湥, ąĄčüą╗ąĖ ąĮąĄčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ čāą▓ąĄą╗ąĖčćąĖčéčī ąĄčæ čĆą░ąĘą╝ąĄčĆ. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ą┐čĆąĖ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠą╝ ąŠą▒čĆą░čēąĄąĮąĖąĖ ą║ ą┤ą░ąĮąĮčŗą╝ ą║čāčćąĖ ąĄčüčéčī ąŠą┐ą░čüąĮąŠčüčéčī ą┐ąŠą▓čĆąĄą┤ąĖčéčī čćčāąČąĖąĄ ą┤ą░ąĮąĮčŗąĄ. ąóą░ą║ąČąĄ ąĄčüą╗ąĖ ą┤ą░ąĮąĮčŗąĄ ą║čāčćąĖ čüąŠą▓ą╝ąĄčüčéąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ čĆą░ąĘąĮčŗą╝ąĖ ą┐ąŠč鹊ą║ą░ą╝ąĖ ą▓ąŠąĘąĮąĖą║ą░ąĄčé ą┐čĆąŠą▒ą╗ąĄą╝ą░ čåąĄą╗ąŠčüčéąĮąŠčüčéąĖ ą┤ą░ąĮąĮčŗčģ (ą┐čĆąŠą▒ą╗ąĄą╝ą░ ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéąĖ ą┐ąŠč鹊ą║ąŠą▓, ą┐čĆąŠą▒ą╗ąĄą╝ą░ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ).
ąŻ ą║čāčćąĖ čüčāčēąĄčüčéą▓čāąĄčé ą┐čĆąŠą▒ą╗ąĄą╝ą░ čäčĆą░ą│ą╝ąĄąĮčéą░čåąĖąĖ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆą░čÅ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐čĆąĖ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĖ ą▒ą╗ąŠą║ąŠą▓ ą┐ą░ą╝čÅčéąĖ čüą╗čāčćą░ą╣ąĮąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░, ą║ąŠą│ą┤ą░ ąŠąĮąĖ ąŠą▒čĆą░ąĘčāčÄčéčüčÅ ą▓ ąĮąĄ čüą╝ąĄąČąĮčŗčģ ąŠą▒ą╗ą░čüčéčÅčģ ą┐ą░ą╝čÅčéąĖ. ąÆ čéą░ą║ąŠą╣ čüąĖčéčāą░čåąĖąĖ čĆą░ą▒ąŠčéą░ čüą▒ąŠčĆčēąĖą║ą░ ą╝čāčüąŠčĆą░ čāčüą╗ąŠąČąĮčÅąĄčéčüčÅ, ą┐ąŠč鹊ą╝čā čćč鹊 ą┐ąĄčĆąĄą┤ ąĮąĖą╝ ą▓čüčéą░ąĄčé ąĘą░ą┤ą░čćą░ ąŠą▒ąĮą░čĆčāąČąĄąĮąĖčÅ "ą┤čŗčĆąŠą║" ą▓ ą┐ą░ą╝čÅčéąĖ ąĖ ą┐ąŠ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ąĖčģ čāčüčéčĆą░ąĮąĄąĮąĖčÅ (čŹč鹊 ąĘą░ą▓ąĖčüąĖčé ąŠčé čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čüąĖčüč鹥ą╝čŗ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą╣ ą┐ą░ą╝čÅčéąĖ). ąÜąŠą│ą┤ą░ ą┐ą░ą╝čÅčéčī čćčĆąĄąĘą╝ąĄčĆąĮąŠ čäčĆą░ą│ą╝ąĄąĮčéąĖčĆąŠą▓ą░ąĮą░, čüčéą░ąĮąŠą▓ąĖčéčüčÅ ąĮąĄą▓ąŠąĘą╝ąŠąČąĮčŗą╝ ą▓čŗą┤ąĄą╗ąĖčéčī ą▒ąŠą╗čīčłąŠą╣ ą║čāčüąŠą║ ąĮąĄą┐čĆąĄčĆčŗą▓ąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ.
ąöą╗čÅ ąĮąŠą▓ąĖčćą║ąŠą▓ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĖ čüą║ąŠčĆąĄąĄ ą▓čüąĄą│ąŠ čģąŠčĆąŠčłąĄą╣ ąĖą┤ąĄąĄą╣ ą▒čāą┤ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čüč鹥ą║, ą┐ąŠč鹊ą╝čā čćč鹊 čŹč鹊 ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝ ą┐čĆąŠčēąĄ ąĖ čĆą░ą▒ąŠčéą░ąĄčé ą▒čŗčüčéčĆąĄąĄ.
ą¦ą░čēąĄ ą▓čüąĄą│ąŠ čüč鹥ą║ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ąĮąĄą▒ąŠą╗čīčłąŠą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą▓čŗą┤ąĄą╗čÅąĄą╝čŗčģ ą┤ą░ąĮąĮčŗčģ. ą¤čĆąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĄ ą▒ąŠą╗čīčłąŠą│ąŠ ąŠą▒čŖąĄą╝ą░ ą┤ą░ąĮąĮčŗčģ, ąĖą╗ąĖ ą║ąŠą│ą┤ą░ ąŠą▒čŖąĄą╝ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄą╝čŗčģ ą┤ą░ąĮąĮčŗčģ ą╝ąĄąĮčÅąĄčéčüčÅ (ąÆčŗ ąĮąĄ ąĘąĮą░ąĄč鹥 ąĘą░čĆą░ąĮąĄąĄ, ą║ą░ą║ąŠą╣ ą▒čāą┤ąĄčé ąŠą▒čŖąĄą╝ ą┤ą░ąĮąĮčŗčģ), ą╝ąŠąČąĄčé ą┐ąŠčéčĆąĄą▒ąŠą▓ą░čéčīčüčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą║čāčćčā.
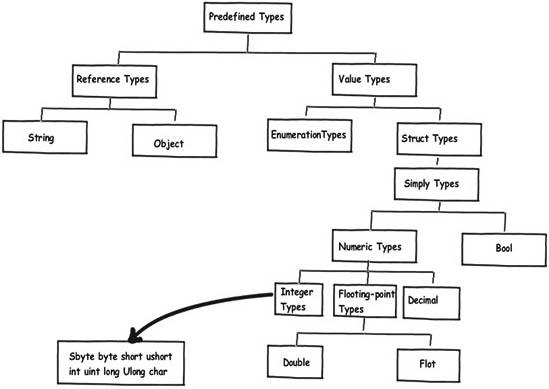
[ąóąĖą┐čŗ-ąĘąĮą░č湥ąĮąĖčÅ ąĖ čéąĖą┐čŗ-čüčüčŗą╗ą║ąĖ ]
ąÜąŠą│ą┤ą░ ą╝čŗ čĆą░ąĘąŠą▒čĆą░ą╗ąĖčüčī čü ąŠą▒čēąĄą╣ ą║ąŠąĮčåąĄą┐čåąĖąĄą╣ čüč鹥ą║ą░ ąĖ ą║čāčćąĖ, ąĮą░čüčéą░ą╗ąŠ ą▓čĆąĄą╝čÅ ą┐ąŠąĮčÅčéčī ą║ąŠąĮčåąĄą┐čåąĖčÄ čéąĖą┐ąŠą▓ ąĘąĮą░č湥ąĮąĖą╣ ąĖ čüčüčŗą╗ąŠčćąĮčŗčģ čéąĖą┐ąŠą▓. ąóąĖą┐čŗ ąĘąĮą░č湥ąĮąĖą╣ čŹč鹊 čéą░ą║ąĖąĄ čéąĖą┐čŗ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣, ą║ąŠč鹊čĆčŗąĄ čģčĆą░ąĮčÅčé ą┤ą░ąĮąĮčŗąĄ ąŠ čüąĄą▒ąĄ č鹊ą╗čīą║ąŠ ą▓ ąŠą┤ąĮąŠą╝ ą╝ąĄčüč鹥. ąĪčüčŗą╗ąŠčćąĮčŗą╣ čéąĖą┐ čüąŠčüč鹊ąĖčé ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝ ąĖąĘ čāą║ą░ąĘą░č鹥ą╗čÅ ąĮą░ ąŠą▒čŖąĄą║čé, ą║ąŠą│ą┤ą░ ąŠąĮ čĆą░ą▓ąĄąĮ null, ąĖ čéą░ą║ąČąĄ ąĖąĘ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą│ąŠ čģčĆą░ąĮąĖą╗ąĖčēą░, ąĮą░ ą║ąŠč鹊čĆąŠąĄ čüčüčŗą╗ą░ąĄčéčüčÅ čŹč鹊čé čāą║ą░ąĘą░č鹥ą╗čī. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čĆą░ą▒ąŠčćąĖą╣ čüčüčŗą╗ąŠčćąĮčŗą╣ čéąĖą┐ ąĖčüą┐ąŠą╗čīąĘčāąĄčé 2 ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ - ą╝ąĄčüč鹊 ą┤ą╗čÅ čģčĆą░ąĮąĄąĮąĖčÅ čāą║ą░ąĘą░č鹥ą╗čÅ (čŹč鹊 čüč鹥ą║) ąĖ ą╝ąĄčüč鹊, ą│ą┤ąĄ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ čüąŠą┤ąĄčƹȹ░čéčüčÅ ą┤ą░ąĮąĮčŗąĄ ąŠą▒čŖąĄą║čéą░ (čŹč鹊 ą║čāčćą░), ąĮą░ ą║ąŠč鹊čĆčŗą╣ čüčüčŗą╗ą░ąĄčéčüčÅ čāą║ą░ąĘą░č鹥ą╗čī.
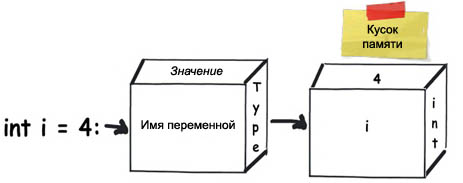
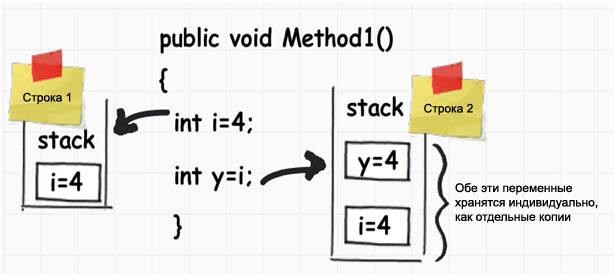
ąØąĖąČąĄ ą┐ąŠą║ą░ąĘą░ąĮą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮąŠą│ąŠ čéąĖą┐ą░ ą┤ą░ąĮąĮčŗčģ čü ąĖą╝ąĄąĮąĄą╝ i, ąĘąĮą░č湥ąĮąĖąĄ ą║ąŠč鹊čĆąŠą│ąŠ ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĄčéčüčÅ ą┤čĆčāą│ąŠą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ čü ąĖą╝ąĄąĮąĄą╝ j. ą×ą▒ąĄ čŹčéąĖčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ čéąĖą┐ą░ ąĘąĮą░č湥ąĮąĖčÅ, ąĖ ąŠąĮąĖ ąŠą▒ąĄ ą▓čŗą┤ąĄą╗čÅčÄčéčüčÅ ą▓ čüč鹥ą║ąĄ.
ąÜąŠą│ą┤ą░ ą╝čŗ ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĄą╝ ąĘąĮą░č湥ąĮąĖąĄ čéąĖą┐ą░ int ą┤čĆčāą│ąŠą╝čā ąĘąĮą░č湥ąĮąĖčÄ čéąĖą┐ą░ int, č鹊 čŹč鹊 čüąŠąĘą┤ą░ąĄčé ąŠčéą┤ąĄą╗čīąĮčāčÄ ą║ąŠą┐ąĖčÄ ą┤ą░ąĮąĮčŗčģ ąŠą┤ąĮąŠą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ą▓ ą╝ąĄčüč鹥 čĆą░ąĘą╝ąĄčēąĄąĮąĖčÅ ą┤čĆčāą│ąŠą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ (ą┤ą░ąĮąĮčŗąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ čäąĖąĘąĖč湥čüą║ąĖ ą║ąŠą┐ąĖčĆčāčÄčéčüčÅ). ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ąĄčüą╗ąĖ ąÆčŗ ą┐ąŠą╝ąĄąĮčÅąĄč鹥 ąŠą┤ąĮčā ąĖąĘ čŹčéąĖčģ ą┤ą▓čāčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ, č鹊 ą▓ ą┤čĆčāą│ąŠą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ąĘąĮą░č湥ąĮąĖąĄ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅąĄčéčüčÅ. ąöą░ąĮąĮčŗąĄ čéą░ą║ąŠą│ąŠ ą▓ąĖą┤ą░ ąĮą░ąĘčŗą▓ą░čÄčéčüčÅ "čéąĖą┐ą░ą╝ąĖ ąĘąĮą░č湥ąĮąĖą╣".
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą║ čéąĖą┐ą░ą╝ ąĘąĮą░č湥ąĮąĖą╣ ąĮą░ C# čéą░ą║ąČąĄ ąŠčéąĮąŠčüčÅčéčüčÅ čüčéčĆčāą║čéčāčĆčŗ.
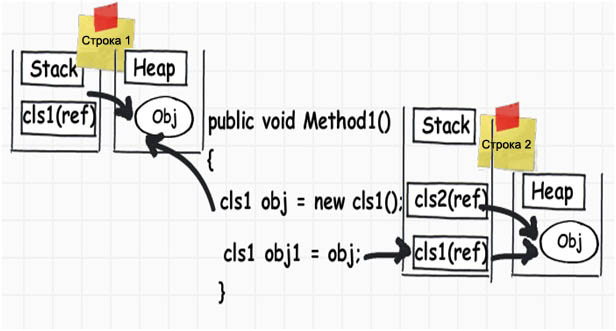
ąÜąŠą│ą┤ą░ ą╝čŗ čüąŠąĘą┤ą░ąĄą╝ ąŠą▒čŖąĄą║čé, ąĖ ą║ąŠą│ą┤ą░ ą╝čŗ ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĄą╝ ąŠą┤ąĖąĮ ąŠą▒čŖąĄą║čé ą┤čĆčāą│ąŠą╝čā, ąŠąĮąĖ ąŠą▒ą░ ą▒čāą┤čāčé čüčüčŗą╗ą░čéčīčüčÅ ąĮą░ ąŠą┤ąĮčā ąĖ čéčā ąČąĄ ąŠą▒ą╗ą░čüčéčī ą┐ą░ą╝čÅčéąĖ, ą║ą░ą║ čŹč鹊 ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą║ąŠą┤ąĄ ąĮąĖąČąĄ. ąÜąŠą│ą┤ą░ ą╝čŗ ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĄą╝ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ obj ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ obj1, č鹊 ąŠą▒ąĄ čŹčéąĖčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ ąĖą╝ąĄčÄčé čéąĖą┐ čāą║ą░ąĘą░č鹥ą╗čÅ, ąĖ ąŠą▒ąĄ ąŠąĮąĖ čüčüčŗą╗ą░čÄčéčüčÅ ąĮą░ ąŠą┤ąĮčā ąĖ čéčā ąČąĄ ąŠą▒ą╗ą░čüčéčī ą▓ ą┐ą░ą╝čÅčéąĖ (ą▓ ą║čāč湥).
ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ąĄčüą╗ąĖ ą╝čŗ ą┐ąŠą╝ąĄąĮčÅąĄą╝ ą┤ą░ąĮąĮčŗąĄ ąŠą┤ąĮąŠą│ąŠ ąĖąĘ ąŠą▒čŖąĄą║č鹊ą▓ (ąĮą░ą┐čĆąĖą╝ąĄčĆ obj), č鹊 čŹč鹊 ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ ąŠčéčĆą░ąĘąĖčéčüčÅ ąĮą░ ąĘąĮą░č湥ąĮąĖčÅčģ ą┤čĆčāą│ąŠą│ąŠ ąŠą▒čŖąĄą║čéą░ (obj1). ąóą░ą║ąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąŠą▒ąŠąĘąĮą░čćą░ąĄčéčüčÅ č鹥čĆą╝ąĖąĮąŠą╝ "čüčüčŗą╗ąŠčćąĮčŗąĄ čéąĖą┐čŗ" (ref).
ąÜą░ą║ąĖą╝ ąŠą▒čŖąĄą║čéą░ą╝ ąŠčéąĮąŠčüčÅčéčüčÅ čüčüčŗą╗ąŠčćąĮčŗąĄ čéąĖą┐čŗ, ąĖ ą║ ą║ą░ą║ąĖą╝ čéąĖą┐čŗ ąĘąĮą░č湥ąĮąĖą╣? .NET ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čéąĖą┐ą░ ą┤ą░ąĮąĮčŗčģ ąĮą░ąĘąĮą░čćą░ąĄčé ą╝ąĄčüč鹊 ą┤ą╗čÅ čģčĆą░ąĮąĄąĮąĖčÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ą╗ąĖą▒ąŠ ą▓ čüč鹥ą║ąĄ, ą╗ąĖą▒ąŠ ą▓ ą║čāč湥. ą×ą▒čŖąĄą║čéčŗ čüčéčĆąŠą║ (String) ąĖ ą┐ąŠčćčéąĖ ą▓čüąĄ ą┤čĆčāą│ąĖąĄ ą▒ąŠą╗ąĄąĄ-ą╝ąĄąĮąĄąĄ čüą╗ąŠąČąĮčŗąĄ ą▒ąĖą▒ą╗ąĖąŠč鹥čćąĮčŗąĄ ąŠą▒čŖąĄą║čéčŗ ąĖą╝ąĄčÄčé čüčüčŗą╗ąŠčćąĮčŗą╣ čéąĖą┐ (čĆąĄą░ą╗čīąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ čģčĆą░ąĮčÅčéčüčÅ ą▓ ą║čāč湥, čüčüčŗą╗ą║ąĖ ąĮą░ ąĮąĖčģ ą▓ čüč鹥ą║ąĄ), ąĖ ą┐ąŠą┤ ą╗čÄą▒čŗąĄ ą┤čĆčāą│ąĖąĄ ą┐čĆąĖą╝ąĖčéąĖą▓ąĮčŗąĄ čéąĖą┐čŗ ą┤ą░ąĮąĮčŗčģ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čüč鹥ą║ (čŹč鹊 čéąĖą┐čŗ ąĘąĮą░č湥ąĮąĖą╣). ąØą░ čĆąĖčüčāąĮą║ąĄ ąĮąĖąČąĄ č鹊 ąČąĄ čüą░ą╝ąŠąĄ ąŠą▒čŖčÅčüąĮčÅąĄčéčüčÅ ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ.
[Boxing ąĖ unboxing ]
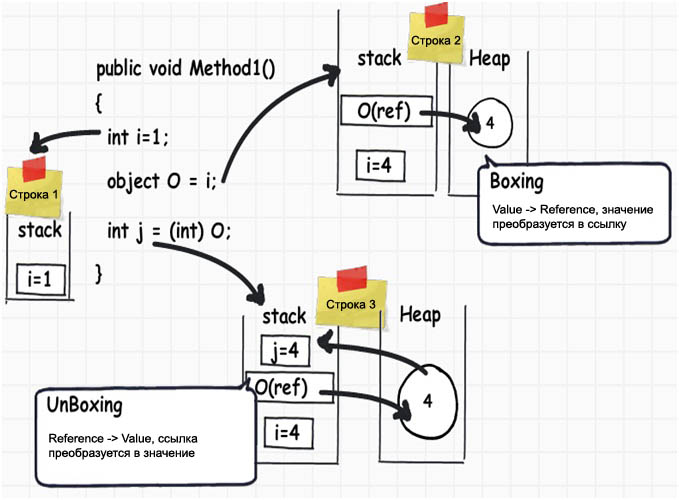
ą×ą│ąŠ, č鹥ą┐ąĄčĆčī ą╝čŗ ąĘąĮą░ąĄą╝ ą╝ąĮąŠą│ąŠ č鹊ąĮą║ąŠčüč鹥ą╣ ąŠ č鹊ą╝, ą║ą░ą║ ą▓čüąĄ čāčüčéčĆąŠąĄąĮąŠ, ąĮąŠ ą║ą░ą║ąŠą╣ ą┐čĆąŠą║ ąŠčé čŹč鹊ą│ąŠ ą▓ čĆąĄą░ą╗čīąĮąŠą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĖ? ąĪą░ą╝ąŠąĄ ą╗čāčćčłąĄąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ čŹčéąĖčģ ąĘąĮą░ąĮąĖą╣ - č湥čéą║ąŠąĄ ą┐ąŠąĮąĖą╝ą░ąĮąĖąĄ č鹊ą│ąŠ, ą║ą░ą║ čģčĆą░ąĮąĄąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ ą▓ą╗ąĖčÅąĄčé ąĮą░ ąĄą│ąŠ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī, ąĖ ą║ą░ą║ čāčģčāą┤čłą░ąĄčéčüčÅ čüą║ąŠčĆąŠčüčéčī čĆą░ą▒ąŠčéčŗ ą┐čĆąĖ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĖ ą┤ą░ąĮąĮčŗčģ ąĖąĘ čüč鹥ą║ą░ ą▓ ą║čāčćčā ąĖ ąĮą░ąŠą▒ąŠčĆąŠčé.
ąĀą░čüčüą╝ąŠčéčĆąĖą╝ ąĮąĄą▒ąŠą╗čīčłąŠą╣ ą┐čĆąĖą╝ąĄčĆ ą║ąŠą┤ą░. ąÜąŠą│ą┤ą░ ą╝čŗ ą┐ąĄčĆąĄą╝ąĄčēą░ąĄą╝ čéąĖą┐ ąĘąĮą░č湥ąĮąĖčÅ ą▓ čüčüčŗą╗ąŠčćąĮčŗą╣ čéąĖą┐, ą┤ą░ąĮąĮčŗąĄ ą┐ąĄčĆąĄą╝ąĄčēą░čÄčéčüčÅ (ą║ąŠą┐ąĖčĆčāčÄčéčüčÅ) ąĖąĘ čüč鹥ą║ą░ ą▓ ą║čāčćčā. ąÜąŠą│ą┤ą░ ą╝čŗ ą┐ąĄčĆąĄą╝ąĄčēą░ąĄą╝ čüčüčŗą╗ąŠčćąĮčŗą╣ čéąĖą┐ ą▓ čéąĖą┐ ąĘąĮą░č湥ąĮąĖčÅ, č鹊 ą┤ą░ąĮąĮčŗąĄ ą┐ąĄčĆąĄą╝ąĄčēą░čÄčéčüčÅ (ą║ąŠą┐ąĖčĆčāčÄčéčüčÅ) ąĖąĘ ą║čāčćąĖ ą▓ čüč鹥ą║.
ąóą░ą║ąĖąĄ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ ąĮąĄą│ą░čéąĖą▓ąĮąŠ čüą║ą░ąĘčŗą▓ą░čÄčéčüčÅ ąĮą░ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą║ąŠą┤ą░ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
ą¤čĆąĖ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĖ ą┤ą░ąĮąĮčŗčģ ąĖąĘ čéąĖą┐ąŠą▓ ąĘąĮą░č湥ąĮąĖčÅ ą▓ čüčüčŗą╗ąŠčćąĮčŗąĄ čéąĖą┐čŗ (čé. ąĄ. čüč鹥ą║ -> ą║čāčćą░) čéą░ą║ąŠąĄ ą┤ąĄą╣čüčéą▓ąĖąĄ ąŠą▒ąŠąĘąĮą░čćą░ąĄčéčüčÅ č鹥čĆą╝ąĖąĮąŠą╝ "Boxing" (ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ-čāą┐ą░ą║ąŠą▓ą║ą░), ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ ąŠą▒čĆą░čéąĮąŠąĄ ą┤ąĄą╣čüčéą▓ąĖąĄ (ąĖąĘ čüčüčŗą╗ąŠčćąĮčŗčģ čéąĖą┐ąŠą▓ ą▓ čéąĖą┐ ąĘąĮą░č湥ąĮąĖčÅ, ą║čāčćą░ -> čüč鹥ą║) ąŠą▒ąŠąĘąĮą░čćą░ąĄčéčüčÅ "UnBoxing" (ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ-čĆą░čüą┐ą░ą║ąŠą▓ą║ą░).
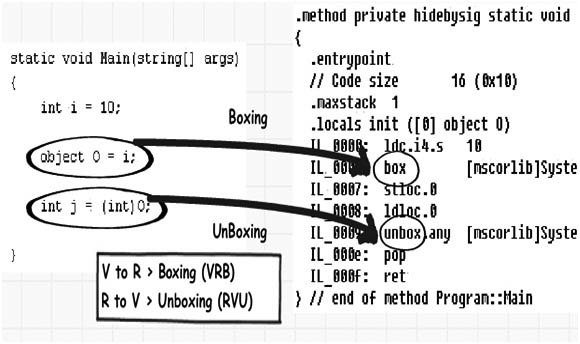
ąĢčüą╗ąĖ ąÆčŗ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄč鹥 čŹč鹊čé ą║ąŠą┤ ąĖ ą┐čĆąŠčüą╝ąŠčéčĆąĖč鹥 čĆąĄąĘčāą╗čīčéą░čé ą▓ ILDASM, č鹊 ą╝ąŠąČąĄč鹥 čāą▓ąĖą┤ąĄčéčī ą▓ ą║ąŠą┤ąĄ IL čüą╗ąŠą▓ąĄčćą║ąĖ box ąĖ unbox.
ą¦č鹊ą▒čŗ ą┐ąŠąĮčÅčéčī, ąĮą░čüą║ąŠą╗čīą║ąŠ čāčģčāą┤čłą░ąĄčéčüčÅ čüą║ąŠčĆąŠčüčéčī čĆą░ą▒ąŠčéčŗ, ą╝čŗ ąĘą░ą┐čāčüčéąĖą╗ąĖ ą┤ą▓ąĄ ą┐ąŠą║ą░ąĘą░ąĮąĮčŗąĄ ąĮąĖąČąĄ čäčāąĮą║čåąĖąĖ 10000 čĆą░ąĘ. ąÆ čäčāąĮą║čåąĖąĖ čüą╗ąĄą▓ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ boxing, ąĖ ą▓ čäčāąĮą║čåąĖąĖ čüą┐čĆą░ą▓ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┐čĆąŠčüč鹊ąĄ ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĮąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ.
Boxing-čäčāąĮą║čåąĖčÅ ą▓čŗą┐ąŠą╗ąĮąĖą╗ą░čüčī ąĘą░ 3542 ą╝čü, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ čäčāąĮą║čåąĖčÅ ą▒ąĄąĘ boxing ą▓čŗą┐ąŠą╗ąĮąĖą╗ą░čüčī ąĘą░ 2477 ą╝čü. ąÆčŗą▓ąŠą┤: čüčéą░čĆą░ą╣č鹥čüčī ąĖąĘą▒ąĄą│ą░čéčī ąŠą┐ąĄčĆą░čåąĖą╣ boxing ąĖ unboxing, ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ąĖčģ ą▓ ą┐čĆąŠąĄą║č鹥 č鹊ą╗čīą║ąŠ č鹊ą│ą┤ą░, ą║ąŠą│ą┤ą░ ą░ą▒čüąŠą╗čÄčéąĮąŠ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ, ąŠčüąŠą▒ąĄąĮąĮąŠ čŹč鹊 ą║ą░čüą░ąĄčéčüčÅ ą┤ąŠą╗ą│ąŠ čĆą░ą▒ąŠčéą░čÄčēąĖčģ, ą╝ąĮąŠą│ąŠčćąĖčüą╗ąĄąĮąĮčŗčģ ą┐ąŠą▓č鹊čĆąĄąĮąĖą╣ čåąĖą║ą╗ąŠą▓.
ąöąĄą╝ąŠąĮčüčéčĆą░čåąĖąŠąĮąĮčŗą╣ ą║ąŠą┤ čŹč鹊ą│ąŠ ą┐čĆąĖą╝ąĄčĆą░ ą╝ąŠąČąĮąŠ čüą║ą░čćą░čéčī ą┐ąŠ čüčüčŗą╗ą║ąĄ [2].
[ąĪčüčŗą╗ą║ąĖ ]
1 . Six important .NET concepts: Stack, heap, value types, reference types, boxing, and unboxing site:codeproject.com.2 . source_code.zip - ąĖčüčģąŠą┤ąĮčŗą╣ ą║ąŠą┤ ą┐čĆąĖą╝ąĄčĆąŠą▓ ąĖąĘ čüčéą░čéčīąĖ.3 . ąśąĮč鹥čĆąĄčüąĮčŗąĄ ą╝ąŠą╝ąĄąĮčéčŗ ą▓ C# (boxing unboxing) site:habrahabr.ru.4 . WhatŌĆÖs the difference between a stack and a heap? site:programmerinterview.com.





ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖąĖ
microsin: čćč鹊ą▒čŗ ą▒čŗą╗ąŠ ą▓ąŠąĘą╝ąŠąČąĮąŠ, ąĮčāąČąĮąŠ ąĘą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░čé čīčüčÅ ąĮą░ čüą░ą╣č鹥 codeproject.com.
RSS ą╗ąĄąĮčéą░ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖąĄą▓ čŹč鹊ą╣ ąĘą░ą┐ąĖčüąĖ