ąŁč鹊čé ą┤ąŠą║čāą╝ąĄąĮčé (PEP 263 [1]) ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé čüąĖąĮčéą░ą║čüąĖčü ą┤ą╗čÅ ą┤ąĄą║ą╗ą░čĆą░čåąĖąĖ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ č鹥ą║čüčéą░ ą▓ čäą░ą╣ą╗ąĄ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░ ąĮą░ čÅąĘčŗą║ąĄ Python. ąśąĮč乊čĆą╝ą░čåąĖčÅ ąŠ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĄ ąĘą░č鹥ą╝ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┐ą░čĆčüąĄčĆąŠą╝ Python ą┤ą╗čÅ ąĖąĮč鹥čĆą┐čĆąĄčéą░čåąĖąĖ čäą░ą╣ą╗ą░ ąĮą░ čāą║ą░ąĘą░ąĮąĮąŠą╣ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĄ. ą¤čĆąĄąČą┤ąĄ ą▓čüąĄą│ąŠ čŹč鹊 čāą╗čāčćčłą░ąĄčé ąĖąĮč鹥čĆą┐čĆąĄčéą░čåąĖčÄ ą╗ąĖč鹥čĆą░ą╗ąŠą▓ Unicode ą▓ ąĖčüčģąŠą┤ąĮąŠą╝ ą║ąŠą┤ąĄ, ąĖ ą┤ąĄą╗ą░ąĄčé ą▓ąŠąĘą╝ąŠąČąĮčŗą╝ ą┐ąĖčüą░čéčī ą▓ ą╗ąĖč鹥čĆą░ą╗ą░čģ Unicode čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ąĮą░ą┐čĆąĖą╝ąĄčĆ UTF-8 ąĮą░ą┐čĆčÅą╝čāčÄ ą▓ čĆąĄą┤ą░ą║č鹊čĆąĄ, ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčēąĄą╝ Unicode.
ą×ą┐ąĖčüčŗą▓ą░ąĄą╝čŗą╣ ąĮąĖąČąĄ ą╝ąĄč鹊ą┤ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĖąĘą▒ąĄąČą░čéčī ąŠčłąĖą▒ąŠą║ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ:
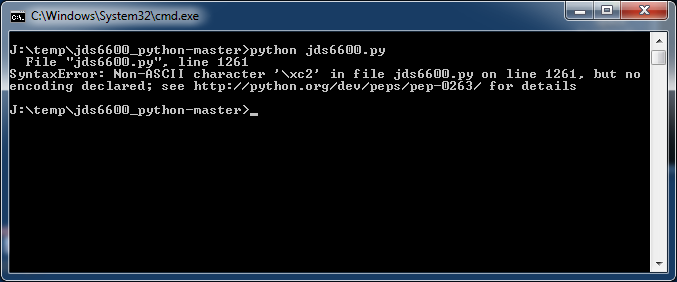
SyntaxError: Non-ASCII character '\xc2' in file ąĖą╝čÅ_ą╝ąŠą┤čāą╗čÅ.py on line 1261, but no
encoding declared; see http://python.org/dev/peps/pep-0263/ for details
ąśčüč鹊čćąĮąĖą║ ą┐čĆąŠą▒ą╗ąĄą╝čŗ . ąÆ Python 2.1 ą╗ąĖč鹥čĆą░ą╗čŗ Unicode ą╝ąŠą│čāčé ą▒čŗčéčī ąĮą░ą┐ąĖčüą░ąĮčŗ č鹊ą╗čīą║ąŠ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ ąĮą░ ąŠčüąĮąŠą▓ąĄ Latin-1 ("unicode-escape"). ąŁč鹊 ą┤ąĄą╗ą░ąĄčé čĆą░ą▒ąŠč湥ąĄ ąŠą║čĆčāąČąĄąĮąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčéą░ ąĮąĄ ą┤čĆčāąČąĄčüčéą▓ąĄąĮąĮčŗą╝ ą┤ą╗čÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╣ Python, ą║č鹊 ąČąĖą▓ąĄčé ąĖ čĆą░ą▒ąŠčéą░ąĄčé ą▓ čüčéčĆą░ąĮą░čģ, ą│ą┤ąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ąĮąĄ-Latin-1 ą╗ąŠą║ą░ą╗čī, ą║ą░ą║ ąĮą░ą┐čĆąĖą╝ąĄčĆ ą╝ąĮąŠą│ąĖąĄ ąĖąĘ čüčéčĆą░ąĮ ąÉąĘąĖąĖ. ą¤čĆąŠą│čĆą░ą╝ą╝ąĖčüčéčŗ ą╝ąŠą│čāčé ą┐ąĖčüą░čéčī čüą▓ąŠąĖ č鹥ą║čüčéčŗ čüą▓ąŠąĖą╝ąĖ 8-ą▒ąĖčéąĮčŗą╝ąĖ čüčéčĆąŠą║ą░ą╝ąĖ ą▓ ą╗čÄą▒ąĖą╝ąŠą╣ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĄ, ąĮąŠ ąŠą│čĆą░ąĮąĖč湥ąĮčŗ ą║ąŠą┤ąĖčĆąŠą▓ą║ąŠą╣ "unicode-escape" ą┤ą╗čÅ ą╗ąĖč鹥čĆą░ą╗ąŠą▓ Unicode.
ą¦ą░čēąĄ ą▓čüąĄą│ąŠ ąŠčłąĖą▒ą║ą░ "SyntaxError: Non-ASCII character" ą▓ąŠąĘąĮąĖą║ą░ąĄčé ąĖąĘ-ąĘą░ ą┐ąŠą┐čŗčéą║ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čĆčāčüčüą║ąŠčÅąĘčŗčćąĮčŗąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖąĖ ą▓ čäą░ą╣ą╗ąĄ, ą║ąŠą┤ąĖčĆąŠą▓ą║ą░ ą║ąŠč鹊čĆąŠą│ąŠ ąĮąĄ UTF-8. ą¦č鹊ą▒čŗ ą▒čŗčüčéčĆąŠ ąĖčüą┐čĆą░ą▓ąĖčéčī ą┐čĆąŠą▒ą╗ąĄą╝čā, ąĮčāąČąĮąŠ čüąŠčģčĆą░ąĮąĖčéčī č鹥ą║čüčé ą┐čĆąŠą▒ą╗ąĄą╝ąĮąŠą│ąŠ ą╝ąŠą┤čāą╗čÅ *.py ą▓ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĄ UTF-8, ąĖ čüąŠąŠą▒čēąĖčéčī ąŠą▒ čŹč鹊ą╝ ąĖąĮč鹥čĆą┐čĆąĄčéą░č鹊čĆčā Python.
ą¤čĆąŠčåąĄčüčü ą┐ąŠ čłą░ą│ą░ą╝:
1 . ą¤čĆąŠą▓ąĄčĆčīč鹥, čćč鹊 č鹥ą║čüčé ą╝ąŠą┤čāą╗čÅ Python čüąŠčģčĆą░ąĮąĄąĮ ą▓ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĄ UTF-8. ąÆ čĆąĄą┤ą░ą║č鹊čĆąĄ Notepad2 čŹč鹊 ą┤ąĄą╗ą░ąĄčéčüčÅ č湥čĆąĄąĘ ą╝ąĄąĮčÄ File -> Encoding. ąŁč鹊čé ąČąĄ ą┐čāąĮą║čé ą╝ąĄąĮčÄ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐ąĄčĆąĄą║ąŠą┤ąĖčĆąŠą▓ą░čéčī čäą░ą╣ą╗ ą▓ ą║ąŠą┤ąĖčĆąŠą▓ą║čā UTF-8.
2 . ąöąŠą▒ą░ą▓čīč鹥 ą▓ ąĮą░čćą░ą╗ąŠ ą╝ąŠą┤čāą╗čÅ čüčéčĆąŠą║čā:
ą¤ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ąŠčłąĖą▒ą║ą░ ąĖčüč湥ąĘąĮąĄčé.
ąĀąĄą║ąŠą╝ąĄąĮą┤čāąĄą╝ąŠąĄ čĆąĄčłąĄąĮąĖąĄ . ąĀąĄą║ąŠą╝ąĄąĮą┤čāąĄčéčüčÅ čüą┤ąĄą╗ą░čéčī ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░ Python ą║ą░ą║ ą▓ąĖą┤ąĖą╝čŗą╝, čéą░ą║ ąĖ ąĖąĘą╝ąĄąĮčÅąĄą╝čŗą╝ ąĮą░ čāčĆąŠą▓ąĮąĄ ąĖčüčģąŠą┤ąĮąŠą│ąŠ čäą░ą╣ą╗ą░, ą┐čĆąĖą╝ąĄąĮčÅčÅ ą▓ ą║ą░ąČą┤ąŠą╝ ą╝ąŠą┤čāą╗ąĄ čäą░ą╣ą╗ą░ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░ čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ ą▓ ąĮą░čćą░ą╗ąĄ čäą░ą╣ą╗ą░, čćč鹊ą▒čŗ ą┤ąĄą║ą╗ą░čĆąĖčĆąŠą▓ą░čéčī ą▓ ąĮąĄą╝ ą║ąŠą┤ąĖčĆąŠą▓ą║čā.
ą¦č鹊ą▒čŗ ąĮą░čüčéčĆąŠąĖčéčī Python ą┤ą╗čÅ čĆą░čüą┐ąŠąĘąĮą░ą▓ą░ąĮąĖčÅ čŹč鹊ą╣ ą┤ąĄą║ą╗ą░čĆą░čåąĖąĖ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ, ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ąŠąĘąĮą░ą║ąŠą╝ąĖčéčīčüčÅ ąŠ ą┐čĆąĖąĮčåąĖą┐ą░čģ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┤ą░ąĮąĮčŗčģ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░ Python.
[ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ ]
ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ Python ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčé, čćč鹊 ą▓ čäą░ą╣ą╗ąĄ ą┐čĆąĖąĮčÅčé čüčéą░ąĮą┤ą░čĆčé ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖčÅ ASCII, ąĄčüą╗ąĖ ąĮąĄ ą┤ą░ąĮąŠ ąĮąĖą║ą░ą║ąĖčģ ą┤čĆčāą│ąĖčģ ą┐ąŠą┤čüą║ą░ąĘčŗą▓ą░čÄčēąĖčģ čāą║ą░ąĘą░ąĮąĖą╣. ą¦č鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą║ąŠą┤ąĖčĆąŠą▓ą║čā ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░, ą▓ąŠ ą▓čüąĄ ąĖčüčģąŠą┤ąĮčŗąĄ čäą░ą╣ą╗čŗ ąĮčāąČąĮąŠ ą┤ąŠą▒ą░ą▓ąĖčéčī "ą╝ą░ą│ąĖč湥čüą║ąĖą╣" ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ ą▓ ą┐ąĄčĆą▓ąŠą╣ ąĖą╗ąĖ ą▓č鹊čĆąŠą╣ čüčéčĆąŠą║ąĄ ąĖčüčģąŠą┤ąĮąŠą│ąŠ čäą░ą╣ą╗ą░:
# coding=< ąĖą╝čÅ_ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ>
ąĖą╗ąĖ (ąĖčüą┐ąŠą╗čīąĘčāčÅ č乊čĆą╝ą░čéčŗ, čĆą░čüą┐ąŠąĘąĮą░ą▓ą░ąĄą╝čŗąĄ ą┐ąŠą┐čāą╗čÅčĆąĮčŗą╝ąĖ čĆąĄą┤ą░ą║č鹊čĆą░ą╝ąĖ):
#!/usr/bin/python # -*- coding: < ąĖą╝čÅ_ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ> -*-
ąĖą╗ąĖ:
#!/usr/bin/python # vim: set fileencoding=< ąĖą╝čÅ_ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ> :
ąĢčüą╗ąĖ ą▒čŗčéčī ą▒ąŠą╗ąĄąĄ č鹊čćąĮčŗą╝, č鹊 ą┐ąĄčĆą▓ą░čÅ ąĖą╗ąĖ ą▓č鹊čĆą░čÅ čüčéčĆąŠą║ą░ ą┤ąŠą╗ąČąĮą░ ą┐ąŠą┐ą░ą┤ą░čéčī ą┐ąŠą┤ čäąĖą╗čīčéčĆ čüą╗ąĄą┤čāčÄčēąĄą│ąŠ čĆąĄą│čāą╗čÅčĆąĮąŠą│ąŠ ą▓čŗčĆą░ąČąĄąĮąĖčÅ:
^[ \t\v]*#.*?coding[:=][ \t]*([-_.a-zA-Z0-9]+)
ą¤ąĄčĆą▓ą░čÅ ą│čĆčāą┐ą┐ą░ čŹč鹊ą│ąŠ ą▓čŗčĆą░ąČąĄąĮąĖčÅ ąĖąĮč鹥čĆą┐čĆąĄčéąĖčĆčāąĄčéčüčÅ ą║ą░ą║ ąĖą╝čÅ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ. ąĢčüą╗ąĖ čŹčéą░ ą║ąŠą┤ąĖčĆąŠą▓ą║ą░ ąĮąĄ ąĖąĘą▓ąĄčüčéąĮą░ ą┤ą╗čÅ Python, č鹊 ą▓ąŠ ą▓čĆąĄą╝čÅ ą┐ąŠą┐čŗčéą║ąĖ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąŠčłąĖą▒ą║ą░. ąØąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ąĮąĖą║ą░ą║ąŠą│ąŠ ą╗čÄą▒ąŠą│ąŠ ąŠą┐ąĄčĆą░č鹊čĆą░ Python ą▓ čüčéčĆąŠą║ąĄ, ą▓ čŹč鹊ą╣ čüčéčĆąŠą║ąĄ, ą│ą┤ąĄ čüąŠą┤ąĄčƹȹĖčéčüčÅ ą┤ąĄą║ą╗ą░čĆą░čåąĖčÅ ąŠ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĄ. ąĢčüą╗ąĖ ąĮą░ ą┐ąĄčĆą▓čāčÄ čüčéčĆąŠą║čā čĆąĄą│čāą╗čÅčĆąĮąŠąĄ ą▓čŗčĆą░ąČąĄąĮąĖąĄ čüčĆą░ą▒ąŠčéą░ąĄčé, č鹊 ą▓č鹊čĆą░čÅ čüčéčĆąŠą║ą░ ąĮą░ ą┐čĆąĄą┤ą╝ąĄčé ą┐ąŠąĖčüą║ą░ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ ąĖą│ąĮąŠčĆąĖčĆčāąĄčéčüčÅ.
ą¦č鹊ą▒čŗ ąŠą▒čĆą░ą▒ąŠčéą░čéčī čéą░ą║ąĖąĄ ą┐ą╗ą░čéč乊čĆą╝čŗ, ą║ą░ą║ Windows, ą║ąŠč鹊čĆčŗąĄ ą┤ąŠą▒ą░ą▓ą╗čÅčÄčé ą╝ą░čĆą║ąĄčĆčŗ Unicode BOM ą▓ ąĮą░čćą░ą╗ąŠ čäą░ą╣ą╗ą░ Unicode, UTF-8 čüąĖą│ąĮą░čéčāčĆą░ \xef\xbb\xbf ą▒čāą┤ąĄčé čéą░ą║ąČąĄ ąĖąĮč鹥čĆą┐čĆąĄčéąĖčĆąŠą▓ą░čéčīčüčÅ ą║ą░ą║ ą║ąŠą┤ąĖčĆąŠą▓ą║ą░ 'utf-8' (ą┤ą░ąČąĄ ąĄčüą╗ąĖ ą▓ čäą░ą╣ą╗ ąĮąĄ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮ ąŠą┐ąĖčüą░ąĮąĮčŗą╣ ą╝ą░ą│ąĖč湥čüą║ąĖą╣ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣).
ąĢčüą╗ąĖ ąĖčüčģąŠą┤ąĮčŗą╣ čäą░ą╣ą╗ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ čüąĖą│ąĮą░čéčāčĆčā ą╝ą░čĆą║ąĄčĆą░ UTF-8 BOM, ąĖ ą╝ą░ą│ąĖč湥čüą║ąĖą╣ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣, č鹊 čĆą░ąĘčĆąĄčłąĄąĮąĮąŠą╣ ą║ąŠą┤ąĖčĆąŠą▓ą║ąŠą╣ ą┤ą╗čÅ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖčÅ ą▒čāą┤ąĄčé č鹊ą╗čīą║ąŠ 'utf-8'. ąøčÄą▒ą░čÅ ą┤čĆčāą│ą░čÅ ą║ąŠą┤ąĖčĆąŠą▓ą║ą░ ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąŠčłąĖą▒ą║ąĄ.
[ą¤čĆąĖą╝ąĄčĆčŗ ]
ąØąĖąČąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮąŠ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐čĆąĖą╝ąĄčĆąŠą▓, ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčēąĖčģ čĆą░ąĘąĮčŗąĄ čüčéąĖą╗ąĖ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░ ą▓ ąĮą░čćą░ą╗ąĄ čäą░ą╣ą╗ą░ Python.
1 . ąöą▓ąŠąĖčćąĮčŗą╣ ąĖąĮč鹥čĆą┐čĆąĄčéą░č鹊čĆ ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čäą░ą╣ą╗ą░ čüčéąĖą╗čÅ Emacs:
#!/usr/bin/python # -*- coding: latin-1 -*- import os , sys ...
#!/usr/bin/python # -*- coding: iso-8859-15 -*- import os , sys ...
#!/usr/bin/python # -*- coding: ascii -*- import os , sys ...
2 . ąæąĄąĘ čüčéčĆąŠą║ąĖ ąĖąĮč鹥čĆą┐čĆąĄčéą░č鹊čĆą░, ąĖčüą┐ąŠą╗čīąĘčāčÅ čćąĖčüčéčŗą╣ č鹥ą║čüčé:
# This Python file uses the following encoding: utf-8 import os , sys ...
3 . ąóąĄą║čüč鹊ą▓čŗąĄ čĆąĄą┤ą░ą║č鹊čĆčŗ ą╝ąŠą│čāčé ąĖą╝ąĄčéčī čĆą░ąĘąĮčŗąĄ čüą┐ąŠčüąŠą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ čäą░ą╣ą╗ą░, ąĮą░ą┐čĆąĖą╝ąĄčĆ:
#!/usr/local/bin/python # coding: latin-1 import os , sys ...
4 . ąæąĄąĘ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖčÅ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ ą┐ą░čĆčüąĄčĆ Python ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčé, čćč鹊 čŹč鹊 č鹥ą║čüčé ASCII:
#!/usr/local/bin/python import os , sys ...
[ą¤ą╗ąŠčģąĖąĄ ą┐čĆąĖą╝ąĄčĆčŗ ]
ąØąĖąČąĄ ą┤ą╗čÅ ą┐ąŠą╗ąĮąŠčéčŗ ą┐čĆąĖą▓ąĄą┤ąĄąĮčŗ ąŠčłąĖą▒ąŠčćąĮčŗąĄ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖąĖ ą┤ą╗čÅ čāą║ą░ąĘą░ąĮąĖčÅ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ, ą║ąŠč鹊čĆčŗąĄ ąĮąĄ ą▒čāą┤čāčé čĆą░ą▒ąŠčéą░čéčī.
A . ą¤čĆąŠą┐čāčēąĄąĮąĮčŗą╣ ą┐čĆąĄčäąĖą║čü "coding:":
#!/usr/local/bin/python # latin-1 import os , sys ...
B . ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ ąĮąĄ ąĮą░čģąŠą┤ąĖčéčüčÅ ąĮą░ čüčéčĆąŠą║ąĄ 1 ąĖą╗ąĖ 2:
#!/usr/local/bin/python # # -*- coding: latin-1 -*- import os , sys ...
C . ąØąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄą╝ą░čÅ ą║ąŠą┤ąĖčĆąŠą▓ą║ą░:
#!/usr/local/bin/python # -*- coding: utf-42 -*- import os , sys ...
PEP [1] ąŠčüąĮąŠą▓čŗą▓ą░ąĄčéčüčÅ ąĮą░ čüą╗ąĄą┤čāčÄčēąĖčģ ą║ąŠąĮčåąĄą┐čåąĖčÅčģ, ą║ąŠč鹊čĆčŗąĄ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮčŗ, čćč鹊ą▒čŗ ą▓ą║ą╗čÄčćąĖčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čéą░ą║ąŠą│ąŠ "ą╝ą░ą│ąĖč湥čüą║ąŠą│ąŠ" ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖčÅ:
1 . ąÆąŠ ą▓čüąĄą╝ ąĖčüčģąŠą┤ąĮąŠą╝ čäą░ą╣ą╗ąĄ Python ą┤ąŠą╗ąČąĮą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ąŠą┤ąĖąĮą░ą║ąŠą▓ą░čÅ ą║ąŠą┤ąĖčĆąŠą▓ą║ą░. ąÆčüčéčĆą░ąĖą▓ą░ąĮąĖąĄ ą┐ąŠ-ą┤čĆčāą│ąŠą╝čā ąĘą░ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąŠčłąĖą▒ą║ąĄ ą┤ąĄą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖčÅ ąĮą░ čŹčéą░ą┐ąĄ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ąĖčüčģąŠą┤ąĮąŠą│ąŠ čäą░ą╣ą╗ą░ ą║ąŠą┤ą░ Python.
ą£ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓ ąĖčüčģąŠą┤ąĮąŠą╝ ą║ąŠą┤ąĄ ą╗čÄą▒ąŠąĄ ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąŠą▒čĆą░ą▒ąŠčéą░čéčī ą┤ą▓ąĄ ą┐ąĄčĆą▓čŗąĄ čüčéčĆąŠą║ąĖ čüą┐ąŠčüąŠą▒ąŠą╝, ą┐ąŠą║ą░ąĘą░ąĮąĮčŗą╝ ą▓čŗčłąĄ, ą▓ą║ą╗čÄčćą░čÅ ASCII-čüąŠą▓ą╝ąĄčüčéąĖą╝ąŠąĄ ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖąĄ, ą░ čéą░ą║ąČąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ ą╝ąĮąŠą│ąŠą▒ą░ą╣č鹊ą▓čŗąĄ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ, čéą░ą║ąĖąĄ ą║ą░ą║ Shift_JIS. ąŁč鹊 ąĮąĄ ą▓ą║ą╗čÄčćą░ąĄčé ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ UTF-16, ą║ąŠč鹊čĆčŗąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą┤ą▓ą░ ąĖą╗ąĖ ą▒ąŠą╗čīčłąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ą░ą╣č鹊ą▓ ą┤ą╗čÅ ą▓čüąĄčģ čüąĖą╝ą▓ąŠą╗ąŠą▓. ą¤čĆąĖčćąĖąĮą░ ą▓ č鹊ą╝, čćč鹊 čéčĆąĄą▒čāąĄčéčüčÅ čüąŠčģčĆą░ąĮčÅčéčī ą┐čĆąŠčüčéčŗą╝ ą░ą╗ą│ąŠčĆąĖčéą╝ ą┤ąĄą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖčÅ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ ą▓ ą┐ą░čĆčüąĄčĆąĄ ą║ą╗čÄč湥ą▓čŗčģ čüą╗ąŠą▓ (č鹊ą║ąĄąĮąĖąĘą░č鹊čĆ).
2 . ą×ą▒čĆą░ą▒ąŠčéą║ą░ escape-ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüč鹥ą╣ ą┤ąŠą╗ąČąĮą░ ą┐čĆąŠą┤ąŠą╗ąČą░čéčī čĆą░ą▒ąŠčéą░čéčī, ą║ą░ą║ ąŠąĮą░ čŹč鹊 čāąČąĄ ą┤ąĄą╗ą░ąĄčé, ąĮąŠ čüąŠ ą▓čüąĄą╝ąĖ ą▓ąŠąĘą╝ąŠąČąĮčŗą╝ąĖ ą║ąŠą┤ąĖčĆąŠą▓ą║ą░ą╝ąĖ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░, čÅą▓ą╗čÅčÄčēąĖą╝ąĖčüčÅ čüčéą░ąĮą┤ą░čĆčéąĮčŗą╝ąĖ čüčéčĆąŠą║ąŠą▓čŗą╝ąĖ ą╗ąĖč鹥čĆą░ą╗ą░ą╝ąĖ (ą║ą░ą║ 8-ą▒ąĖčéąĮčŗą╝ąĖ, čéą░ą║ ąĖ Unicode). ąĀą░čüčłąĖčĆąĄąĮąĖąĄ escape-ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüč鹥ą╣ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé č鹊ą╗čīą║ąŠ ąŠč湥ąĮčī ą╝ą░ą╗ąŠąĄ ą┐ąŠą┤ą╝ąĮąŠąČąĄčüčéą▓ąŠ ą▓ąŠąĘą╝ąŠąČąĮčŗčģ ą▓ą░čĆąĖą░ąĮč鹊ą▓.
3 . ąÜąŠą╝ą▒ąĖąĮą░čåąĖčÅ č鹊ą║ąĄąĮąĖąĘą░č鹊čĆ/ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ Python ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ąŠą▒ąĮąŠą▓ą╗ąĄąĮą░, čćč鹊ą▒čŗ čĆą░ą▒ąŠčéą░čéčī čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
A . ą¦č鹥ąĮąĖąĄ čäą░ą╣ą╗ą░.B . ąöąĄą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖąĄ č鹥ą║čüčéą░ čäą░ą╣ą╗ą░ ą▓ Unicode, ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░čÅ čäąĖą║čüą░čåąĖčÄ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ ąĮą░ ą▓ąĄčüčī čäą░ą╣ą╗. ąó. ąĄ. čäą░ą╣ą╗ąĄ ą┤ąŠą╗ąČąĮą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ąĄą┤ąĖąĮą░čÅ, ąĮąĄ ąĖąĘą╝ąĄąĮčÅąĄą╝ą░čÅ ą▓ ą┐čĆąĄą┤ąĄą╗ą░čģ čäą░ą╣ą╗ą░ ą║ąŠą┤ąĖčĆąŠą▓ą║ą░ (čĆą░ąĘąĮčŗąĄ čäą░ą╣ą╗čŗ ą╝ąŠą│čāčé ąĖą╝ąĄčéčī čĆą░ąĘąĮčŗąĄ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ).C . ą¤čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ č鹥ą║čüčéą░ ą▓ ą▒ą░ą╣č鹊ą▓čāčÄ čüčéčĆąŠą║čā UTF-8.D . ąĀą░ąĘą▒ąĖčéąĖąĄ ąĮą░ ą║ą╗čÄč湥ą▓čŗąĄ čüą╗ąŠą▓ą░ (č鹊ą║ąĄąĮąĖąĘą░čåąĖčÅ) čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ UTF-8.E . ąÜąŠą╝ą┐ąĖą╗čÅčåąĖčÅ ą║ąŠą┤ą░, čüąŠąĘą┤ą░ąĮąĖąĄ Unicode-ąŠą▒čŖąĄą║č鹊ą▓ ąĖąĘ ą┤ą░ąĮąĮčŗčģ Unicode ąĖ čüąŠąĘą┤ą░ąĮąĖąĄ čüčéčĆąŠą║ąŠą▓čŗčģ ąŠą▒čŖąĄą║č鹊ą▓ ąĖąĘ ą╗ąĖč鹥čĆą░ą╗čīąĮčŗčģ ą┤ą░ąĮąĮčŗčģ Unicode. ą¤čĆąĖ čŹč鹊ą╝ čüąĮą░čćą░ą╗ą░ ą┐ąĄčĆąĄą║ąŠą┤ąĖčĆčāčÄčéčüčÅ ą┤ą░ąĮąĮčŗčģ UTF-8 ą▓ 8-ą▒ąĖčéąĮčŗąĄ čüčéčĆąŠą║ąŠą▓čŗąĄ ą┤ą░ąĮąĮčŗąĄ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ąĖą╝ąĄčÄčēąĄą╣čüčÅ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ čäą░ą╣ą╗ą░.
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆčŗ Python ąŠą│čĆą░ąĮąĖč湥ąĮčŗ ą┐ąŠą┤ą╝ąĮąŠąČąĄčüčéą▓ąŠą╝ ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖčÅ ASCII, čéą░ą║ čćč鹊 ą┤čĆčāą│ąĖčģ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖą╣ ąĮąĄ ą┐ąŠčéčĆąĄą▒čāąĄčéčüčÅ.
ąöą╗čÅ ąŠą▒čĆą░čéąĮąŠą╣ čüąŠą▓ą╝ąĄčüčéąĖą╝ąŠčüčéąĖ čü čüčāčēąĄčüčéą▓čāčÄčēąĖą╝ ą║ąŠą┤ąŠą╝, ą║ąŠč鹊čĆčŗą╣ ą▓ ąĮąĄčüč鹊čÅčēąĄąĄ ą▓čĆąĄą╝čÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąĮąĄ-ASCII ą║ąŠą┤ąĖčĆąŠą▓ą║čā ą▓ čüčéčĆąŠą║ąŠą▓čŗčģ ą╗ąĖč鹥čĆą░ą╗ą░čģ ą▒ąĄąĘ ą┤ąĄą║ą╗ą░čĆą░čåąĖąĖ ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖčÅ, čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ ą▒čāą┤ąĄčé ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮą░ ą┤ą▓čāą╝čÅ čäčĆą░ąĘą░ą╝ąĖ:
1 . ąĀą░ąĘčĆąĄčłą░ąĄčéčüčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąĮąĄ-ASCII ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ ą▓ čüčéčĆąŠą║ąŠą▓čŗčģ ą╗ąĖč鹥čĆą░ą╗ą░čģ ąĖ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖčÅčģ, ą┐čĆąĖ čŹč鹊ą╝ ą▓ąĮčāčéčĆąĄąĮąĮąĄ ą▒čāą┤ąĄčé čĆą░čüčüą╝ą░čéčĆąĖą▓ą░čéčīčüčÅ ąŠčéčüčāčéčüčéą▓ąĖąĄ ąŠą▒čŖčÅą▓ą╗ąĄąĮąĖąĄ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ ą║ą░ą║ ą┤ąĄą║ą╗ą░čĆą░čåąĖčÅ "iso-8859-1". ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮą░čÅ čüčéčĆąŠą║ą░ ą▒ą░ą╣čé ą▒čāą┤ąĄčé ą║ąŠčĆčĆąĄą║čéąĮąŠ ąŠą▒čĆą░ą▒ąŠčéą░ąĮą░ čü ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĖąĄą╝ čüąŠą▓ą╝ąĄčüčéąĖą╝ąŠčüčéąĖ čü Python 2.2 ą┤ą╗čÅ ą╗ąĖč鹥čĆą░ą╗ąŠą▓ Unicode, ą║ąŠč鹊čĆčŗąĄ čüąŠą┤ąĄčƹȹ░čé ą▒ą░ą╣čéčŗ, ąĮąĄ ą┐ąŠą┐ą░ą┤ą░čÄčēąĖąĄ ą▓ ą║ąŠą┤ąĖčĆąŠą▓ą║čā ASCII.
ąæčāą┤čāčé ą▓čŗą┤ą░ą▓ą░čéčīčüčÅ ą┐čĆąĄą┤čāą┐čĆąĄąČą┤ąĄąĮąĖčÅ ą┐ąŠ ą╝ąĄčĆąĄ ą┐ąŠčÅą▓ą╗ąĄąĮąĖčÅ non-ASCII ą▒ą░ą╣č鹊ą▓ ąĮą░ ą▓čģąŠą┤ąĄ, ąŠą┤ąĖąĮ čĆą░ąĘ ąĮą░ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠ ąĘą░ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą▓čģąŠą┤ąĮąŠą╣ čäą░ą╣ą╗.
2 . ąŻą┤ą░ą╗ąĄąĮąĖąĄ ą┐čĆąĄą┤čāą┐čĆąĄąČą┤ąĄąĮąĖčÅ, ąĖ ąĖąĘą╝ąĄąĮąĄąĮąĖąĄ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĮą░ "ascii".
ąÆčüčéčĆąŠąĄąĮąĮąŠąĄ compile() API ą▒čāą┤ąĄčé čĆą░čüčłąĖčĆąĄąĮąŠ, čćč鹊ą▒čŗ ą┐čĆąĖąĮąĖą╝ą░čéčī ąĮą░ ą▓čģąŠą┤ąĄ Unicode. 8-ą▒ąĖčéąĮčŗąĄ ą▓čģąŠą┤ąĮčŗąĄ čüčéčĆąŠą║ąĖ čÅą▓ą╗čÅčÄčéčüčÅ čüčāą▒čŖąĄą║čéą░ą╝ąĖ čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą┐čĆąŠčåąĄą┤čāčĆčŗ ą┤ąĄč鹥ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ, ą║ą░ą║ čŹč鹊 ąŠą┐ąĖčüą░ąĮąŠ ą▓čŗčłąĄ.
ąĢčüą╗ąĖ čüčéčĆąŠą║ą░ Unicode čü ą┤ąĄą║ą╗ą░čĆą░čåąĖąĄą╣ ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖčÅ ą▒čāą┤ąĄčé ą┐ąĄčĆąĄą┤ą░ąĮą░ ą▓ compile(), ą▒čāą┤ąĄčé čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąŠ čüąŠą▒čŗčéąĖąĄ SyntaxError.
[ąĪčüčŗą╗ą║ąĖ ]
1 . PEP 263 -- Defining Python Source Code Encodings site:python.org.