| Определение кодировки исходного кода Python |
|
| Добавил(а) microsin |
|
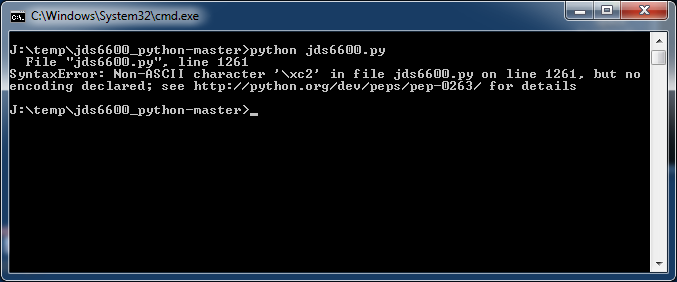
Этот документ (PEP 263 [1]) представляет синтаксис для декларации кодировки текста в файле исходного кода на языке Python. Информация о кодировке затем используется парсером Python для интерпретации файла на указанной кодировке. Прежде всего это улучшает интерпретацию литералов Unicode в исходном коде, и делает возможным писать в литералах Unicode с использованием например UTF-8 напрямую в редакторе, поддерживающем Unicode. Описываемый ниже метод позволяет избежать ошибок наподобие: SyntaxError: Non-ASCII character '\xc2' in file имя_модуля.py on line 1261, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
Источник проблемы. В Python 2.1 литералы Unicode могут быть написаны только с использованием кодировки на основе Latin-1 ("unicode-escape"). Это делает рабочее окружение программиста не дружественным для пользователей Python, кто живет и работает в странах, где используется не-Latin-1 локаль, как например многие из стран Азии. Программисты могут писать свои тексты своими 8-битными строками в любимой кодировке, но ограничены кодировкой "unicode-escape" для литералов Unicode. Чаще всего ошибка "SyntaxError: Non-ASCII character" возникает из-за попытки использовать русскоязычные комментарии в файле, кодировка которого не UTF-8. Чтобы быстро исправить проблему, нужно сохранить текст проблемного модуля *.py в кодировке UTF-8, и сообщить об этом интерпретатору Python. Процесс по шагам: 1. Проверьте, что текст модуля Python сохранен в кодировке UTF-8. В редакторе Notepad2 это делается через меню File -> Encoding. Этот же пункт меню позволяет перекодировать файл в кодировку UTF-8. 2. Добавьте в начало модуля строку: # -*- coding: utf-8 -*-
После этого ошибка исчезнет. Рекомендуемое решение. Рекомендуется сделать кодирование исходного кода Python как видимым, так и изменяемым на уровне исходного файла, применяя в каждом модуле файла исходного кода специальный комментарий в начале файла, чтобы декларировать в нем кодировку. Чтобы настроить Python для распознавания этой декларации кодировки, необходимо ознакомиться о принципах обработки данных исходного кода Python. [Определение кодировки] По умолчанию Python подразумевает, что в файле принят стандарт кодирования ASCII, если не дано никаких других подсказывающих указаний. Чтобы определить кодировку исходного кода, во все исходные файлы нужно добавить "магический" комментарий в первой или второй строке исходного файла: # coding=< имя_кодировки>
или (используя форматы, распознаваемые популярными редакторами): #!/usr/bin/python
# -*- coding: < имя_кодировки> -*-
или: #!/usr/bin/python
# vim: set fileencoding=< имя_кодировки> :
Если быть более точным, то первая или вторая строка должна попадать под фильтр следующего регулярного выражения: ^[ \t\v]*#.*?coding[:=][ \t]*([-_.a-zA-Z0-9]+) Первая группа этого выражения интерпретируется как имя кодировки. Если эта кодировка не известна для Python, то во время попытки компиляции произойдет ошибка. Не должно быть никакого любого оператора Python в строке, в этой строке, где содержится декларация о кодировке. Если на первую строку регулярное выражение сработает, то вторая строка на предмет поиска кодировки игнорируется. Чтобы обработать такие платформы, как Windows, которые добавляют маркеры Unicode BOM в начало файла Unicode, UTF-8 сигнатура \xef\xbb\xbf будет также интерпретироваться как кодировка 'utf-8' (даже если в файл не добавлен описанный магический комментарий). Если исходный файл использует одновременно сигнатуру маркера UTF-8 BOM, и магический комментарий, то разрешенной кодировкой для комментария будет только 'utf-8'. Любая другая кодировка в этом случае приведет к ошибке. [Примеры] Ниже приведено несколько примеров, показывающих разные стили определения кодировки исходного кода в начале файла Python. 1. Двоичный интерпретатор и использование файла стиля Emacs: #!/usr/bin/python
# -*- coding: latin-1 -*-
import os, sys ...
#!/usr/bin/python
# -*- coding: iso-8859-15 -*-
import os, sys ...
#!/usr/bin/python
# -*- coding: ascii -*-
import os, sys ...
2. Без строки интерпретатора, используя чистый текст: # This Python file uses the following encoding: utf-8
import os, sys ...
3. Текстовые редакторы могут иметь разные способы определения кодировки файла, например: #!/usr/local/bin/python
# coding: latin-1
import os, sys ...
4. Без комментария кодировки парсер Python подразумевает, что это текст ASCII: #!/usr/local/bin/python
import os, sys ...
[Плохие примеры] Ниже для полноты приведены ошибочные комментарии для указания кодировки, которые не будут работать. A. Пропущенный префикс "coding:": #!/usr/local/bin/python
# latin-1
import os, sys ...
B. Комментарий кодировки не находится на строке 1 или 2: #!/usr/local/bin/python
#
# -*- coding: latin-1 -*-
import os, sys ...
C. Не поддерживаемая кодировка: #!/usr/local/bin/python
# -*- coding: utf-42 -*-
import os, sys ...
PEP [1] основывается на следующих концепциях, которые должны быть реализованы, чтобы включить использование такого "магического" комментария: 1. Во всем исходном файле Python должна использоваться одинаковая кодировка. Встраивание по-другому закодированных данных приведет к ошибке декодирования на этапе компиляции исходного файла кода Python. Можно использовать в исходном коде любое кодирование, которое позволяет обработать две первые строки способом, показанным выше, включая ASCII-совместимое кодирование, а также определенные многобайтовые кодировки, такие как Shift_JIS. Это не включает кодировки наподобие UTF-16, которые используют два или большее количество байтов для всех символов. Причина в том, что требуется сохранять простым алгоритм декодирования кодировки в парсере ключевых слов (токенизатор). 2. Обработка escape-последовательностей должна продолжать работать, как она это уже делает, но со всеми возможными кодировками исходного кода, являющимися стандартными строковыми литералами (как 8-битными, так и Unicode). Расширение escape-последовательностей поддерживает только очень малое подмножество возможных вариантов. 3. Комбинация токенизатор/компилятор Python должна быть обновлена, чтобы работать следующим образом: A. Чтение файла. Обратите внимание, что идентификаторы Python ограничены подмножеством кодирования ASCII, так что других преобразований не потребуется. Для обратной совместимости с существующим кодом, который в нестоящее время использует не-ASCII кодировку в строковых литералах без декларации кодирования, реализация будет представлена двумя фразами: 1. Разрешается использование не-ASCII кодировки в строковых литералах и комментариях, при этом внутренне будет рассматриваться отсутствие объявление кодировки как декларация "iso-8859-1". В результате произвольная строка байт будет корректно обработана с предоставлением совместимости с Python 2.2 для литералов Unicode, которые содержат байты, не попадающие в кодировку ASCII. Будут выдаваться предупреждения по мере появления non-ASCII байтов на входе, один раз на неправильно закодированный входной файл. 2. Удаление предупреждения, и изменение кодировки по умолчанию на "ascii". Встроенное compile() API будет расширено, чтобы принимать на входе Unicode. 8-битные входные строки являются субъектами стандартной процедуры детектирования кодировки, как это описано выше. Если строка Unicode с декларацией кодирования будет передана в compile(), будет сгенерировано событие SyntaxError. [Ссылки] 1. PEP 263 -- Defining Python Source Code Encodings site:python.org. |