ą¤čĆąŠčüą╗čāčłą░ą╗ ą║čāčĆčü ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ [1]. ąØą░ ą╝ąŠą╣ ą▓ąĘą│ą╗čÅą┤, ąŠč湥ąĮčī ą┐ąŠą╗ąĄąĘąĮčŗą╣ ą║čāčĆčü, ąŠčüąŠą▒ąĄąĮąĮąŠ ą┤ą╗čÅ ąĮąŠą▓ąĖčćą║ąŠą▓. ąøąĄą║čåąĖąĖ ą║ąŠčĆąŠčéą║ąĖąĄ ąĖ ąŠč湥ąĮčī ą┐ąŠąĮčÅčéąĮčŗąĄ. ąÜąŠąĮąĄčćąĮąŠ, ą╝ąĮąŠą│ąŠąĄ ąĖąĘ č鹊ą│ąŠ, čćč鹊 čĆą░čüčüą║ą░ąĘą░ąĮąŠ ą▓ ą╗ąĄą║čåąĖčÅčģ, čÅ čāąČąĄ ąĖ čéą░ą║ ąĘąĮą░ą╗, ąĮąŠ ą▓čüąĄ čĆą░ą▓ąĮąŠ ą┐čĆąŠčüą╗čāčłą░ą╗ ą║čāčĆčü čü čāą┤ąŠą▓ąŠą╗čīčüčéą▓ąĖąĄą╝. ą×čüąŠą▒ąĄąĮąĮąŠ ą╝ąĮąŠą│ąŠ ą┐ąŠą╗ąĄąĘąĮąŠą│ąŠ ą┤ą╗čÅ čüąĄą▒čÅ čāąĘąĮą░ą╗ ą▓ čāčĆąŠą║ą░čģ, ą┐ąŠčüą▓čÅčēąĄąĮąĮčŗčģ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖčÅą╝ ąĖ čłą░ą▒ą╗ąŠąĮą░ą╝ čäčāąĮą║čåąĖą╣.
ąĪą░ą╝čŗą╝ ą╝čāčéąĮčŗą╝ąĖ, ąĮą░ ą╝ąŠą╣ ą▓ąĘą│ą╗čÅą┤, čÅą▓ą╗čÅčÄčéčüčÅ č鹥ą╝čŗ ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ (inheritance), ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ąĖ (overloading, overriding, hiding), ą┐ąŠą╗ąĖą╝ąŠčĆčäąĖąĘą╝ą░, čāčĆąĄąĘą░ąĮąĖčÅ ą║ąŠą┐ąĖąĖ ą┤ąŠč湥čĆąĮąĄą│ąŠ ą║ą╗ą░čüčüą░ (slicing), ą░ą▒čüčéčĆą░ą║čéąĮčŗąĄ ą║ą╗ą░čüčüčŗ, ą▓ąĖčĆčéčāą░ą╗čīąĮčŗąĄ čäčāąĮą║čåąĖąĖ, ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ, čłą░ą▒ą╗ąŠąĮčŗ čäčāąĮą║čåąĖąĖ, ą▓ąŠą┐čĆąŠčüčŗ ą┤ąŠčüčéčāą┐ą░ ą║ 菹╗ąĄą╝ąĄąĮčéą░ą╝ ą║ą╗ą░čüčüą░ ą┐čĆąĖ ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖąĖ. ąĪą╗ąŠą▓ąŠ "ą╝čāčéąĮčŗą╣" čÅ ą┐čĆąĖą╝ąĄąĮąĖą╗ ą▓ č鹊ą╝ čüą╝čŗčüą╗ąĄ, čćč鹊 ą▓čĆčÅą┤ ą╗ąĖ ą┤ą╗čÅ ą╝ąĄąĮčÅ ąĄčüčéčī čüą╝čŗčüą╗ ą┐čĆą░ą║čéąĖč湥čüą║ąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą▓čüąĄčģ čŹčéąĖčģ čäąĖčć ą┤ą╗čÅ čĆą░ą▒ąŠčéčŗ, ą┐ąŠč鹊ą╝čā čćč鹊 ąĖčģ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ąśą£ąźą× č鹊ą╗čīą║ąŠ ąĘą░ą┐čāčéą░ąĄčé ą║ąŠą┤ ąĖ ąĄą│ąŠ ą┐ąŠąĮąĖą╝ą░ąĮąĖąĄ. ą×ą┤ąĮą░ą║ąŠ ąŚąØąÉąóą¼ ąŠ ą▓čüąĄčģ čŹčéąĖčģ čłčéčāą║ą░čģ ąĖ ąĖą╝ąĄčéčī ąŠ ąĮąĖčģ čģąŠčéčÅ ą▒čŗ ąŠą▒čēąĄąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ ą▓ ąĮą░čüč鹊čÅčēąĄąĄ ą▓čĆąĄą╝čÅ ąØąĢą×ąæąźą×ąöąśą£ą×.
ąŚą┤ąĄčüčī ą▓čŗą┐ąĖčüą░ą╗ ą┤ą╗čÅ čüąĄą▒čÅ ąŠčüąĮąŠą▓ąĮčŗąĄ č鹥ąĘąĖčüčŗ, č湥ą│ąŠ čĆą░ąĮčīčłąĄ ąĮąĄ ąĘąĮą░ą╗, ąĖą╗ąĖ ąĘąĮą░ą╗ ąĮąŠ ąĘą░ą▒čŗą╗, ąĖą╗ąĖ č鹊, čćč鹊 ą╝ąŠąČąĄčé ąŠą║ą░ąĘą░čéčīčüčÅ ąĖąĮč鹥čĆąĄčüąĮčŗą╝ ąĖ ą┐ąŠą╗ąĄąĘąĮčŗą╝.
1 . ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆčŗ, ą║ąŠč鹊čĆčŗąĄ ąĮčāąČąĮąŠ čāčüčéą░ąĮąŠą▓ąĖčéčī ą▓ Linux: GCC, Clang llvm.
ąŻčüčéą░ąĮąŠą▓ą║ą░ ąĮą░ Ubuntu:
$ sudo apt install gcc
$ sudo apt install clang
ąÜąŠą╝ą░ąĮą┤čŗ g++ --version ąĖ clang++ --version ą┐ąŠą║ą░ąČčāčé ą▓ąĄčĆčüąĖąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆąŠą▓ GCC ąĖ Clang:
$ g++ --version
g++ (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
Copyright (C) 2021 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
$ clang++ --version
Ubuntu clang version 14.0.0-1ubuntu1.1
Target: x86_64-pc-linux-gnu
Thread model: posix
InstalledDir: /usr/bin
ąÜąŠą╝ą░ąĮą┤ą░ gdb --version ą┐ąŠą║ą░ąČąĄčé ą▓ąĄčĆčüąĖčÄ ąŠčéą╗ą░ą┤čćąĖą║ą░:
$ gdb --version
GNU gdb (Ubuntu 12.1-0ubuntu1~22.04) 12.1
Copyright (C) 2022 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later < http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
ą¤ąŠčüą╗ąĄą┤ąĮčÄčÄ ą▓ąĄčĆčüąĖčÄ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ gcc čéą░ą║ąČąĄ ą╝ąŠąČąĮąŠ čāčüčéą░ąĮąŠą▓ąĖčéčī čü ą┐ąŠą╝ąŠčēčīčÄ ą║ąŠą╝ą░ąĮą┤čŗ brew [9].
2 . ążąĖčćąĖ, ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄą╝čŗąĄ čĆą░ąĘą╗ąĖčćąĮčŗą╝ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ą╝ąĖ, ą╝ąŠąČąĮąŠ ą┐ąŠčüą╝ąŠčéčĆąĄčéčī ąĮą░ čüčéčĆą░ąĮąĖčćą║ąĄ [2].
3 . Visual Studio Code (VSCode) - čāą┤ąŠą▒ąĮą░čÅ ąĖ ą┐ąŠą┐čāą╗čÅčĆąĮą░čÅ čüčĆąĄą┤ą░ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ. ąŻčüčéą░ąĮąŠą▓ą║ą░ ą┐ąŠą┤ Ubuntu:
$ sudo apt install code
4 . ąŻčüčéą░ąĮąŠą▓ą║ą░ čĆą░čüčłąĖčĆąĄąĮąĖą╣ ą┤ą╗čÅ VSCode ą┤ąŠčüčéčāą┐ąĮą░ ąĮą░ ą╗ąĄą▓ąŠą╣ ą┐ą░ąĮąĄą╗ąĖ, ą┐ąŠ ą║ąĮąŠą┐ą║ąĄ Extensions (Ctrl+Shift+X):
ąĀą░čüčłąĖčĆąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ čüč鹊ąĖčé čāčüčéą░ąĮąŠą▓ąĖčéčī, ąĄčüą╗ąĖ ąŠąĮąĖ ąĄčēąĄ ąĮąĄ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮčŗ:
C/C++ for Visual Studio Code
ąŻą┤ąŠą▒ąĮčŗą╣ čüą┐ąŠčüąŠą▒ ąĘą░ą┐čāčüčéąĖčéčī VSCode ą▓ č鹥ą║čāčēąĄą╣ ą┐ą░ą┐ą║ąĄ:
$ code .
ą¤ąŠą╗ąĮčāčÄ ąĖąĮčüčéčĆčāą║čåąĖčÄ ąĮą░ ą▓čüąĄ čüą╗čāčćą░ąĖ ąČąĖąĘąĮąĖ ą╝ąŠąČąĮąŠ ą┐ąŠčüą╝ąŠčéčĆąĄčéčī ąĮą░ čüčéčĆą░ąĮąĖčćą║ąĄ [3].
5 . ąÜą░ą║ čüą║ą░čćą░čéčī čāčĆąŠą║ąĖ:
- ą¤ąĄčĆąĄą╣ą┤ąĖč鹥 ą▓ ą┐ą░ą┐ą║čā, ą│ą┤ąĄ ą▓čŗ čģąŠč鹥ą╗ąĖ ą▒čŗ čüąŠčģčĆą░ąĮąĖčéčī čāčĆąŠą║ąĖ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ~/MyProjects .
ą¤ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ą▓ ą┐ą░ą┐ą║ąĄ ~/MyProjects ą┐ąŠčÅą▓ąĖčéčüčÅ ą┐ą░ą┐ą║ą░ The-C-20-Masterclass-Source-Code čü čäą░ą╣ą╗ą░ą╝ąĖ čāčĆąŠą║ąŠą▓.
02.EnvironmentSetup
ąØą░čüčéčĆąŠą╣ą║ą░ čüčĆąĄą┤čŗ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ą▓ čüčĆąĄą┤ąĄ Windows ąĖ Linux ą┤ą╗čÅ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆąŠą▓ GCC, MSVC, Clang. ąōąŠč鹊ą▓čŗąĄ čłą░ą▒ą╗ąŠąĮčŗ ąĘą░ą┤ą░čć ą┤ą╗čÅ čüčĆąĄą┤čŗ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ VScode (task.json).
03.FirstSteps
3.2FirstCppProgram: čćč鹊 čéą░ą║ąŠąĄ #include < iostream>, std::endl, ą┐čĆąŠčüč鹥ą╣čłąĖą╣ ą┐čĆąĖą╝ąĄčĆ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą▓čŗą▓ąŠą┤ą░ ą▓ ą║ąŠąĮčüąŠą╗čī.
04.VariablesAndDatatypes
4.2NumberSystems: ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ čćąĖčüąĄą╗ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ą▓ čĆą░ąĘą╗ąĖčćąĮčŗčģ čüąĖčüč鹥ą╝ą░čģ čüčćąĖčüą╗ąĄąĮąĖčÅ: ą┤ą▓ąŠąĖčćąĮą░čÅ, ą┤ąĄčüčÅčéąĖčćąĮą░čÅ, ą▓ąŠčüčīą╝ąĄčĆąĖčćąĮą░čÅ, čłąĄčüčéąĮą░ą┤čåą░č鹥čĆąĖčćąĮą░čÅ, čüąĖą╝ą▓ąŠą╗čīąĮą░čÅ.
05.OperationsOnData
5.2.BasicOperations: ąŠą▒ąĘąŠčĆ ą▒ą░ąĘąŠą▓čŗčģ ą╝ą░č鹥ą╝ą░čéąĖč湥čüą║ąĖčģ ąŠą┐ąĄčĆą░čåąĖą╣.
06.LiteralsAndConstants
07.ConversionsOverflowAndUnderflow
08.BitwiseOperators
09.VariableLifetimeAndScope
10.FlowControl , čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąŠč鹊ą║ąŠą╝ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣.
10.2IfStatements: ąŠą┐ąĄčĆą░č鹊čĆčŗ čāčüą╗ąŠą▓ąĮąŠą│ąŠ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ ą┐ąŠč鹊ą║ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ.
11.Loops , čåąĖą║ą╗čŗ.
11.2ForLoop: čåąĖą║ą╗ for.
12.Arrays , ą╝ą░čüčüąĖą▓čŗ.
12.2DeclaringAndUsingArrays: ą┤ąĄą║ą╗ą░čĆąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą╝ą░čüčüąĖą▓ąŠą▓.
13.Pointers , čāą║ą░ąĘą░č鹥ą╗ąĖ.
13.2DeclaringAndUsingPointers: ą┤ąĄą║ą╗ą░čĆąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čāą║ą░ąĘą░č鹥ą╗ąĄą╣.
14.References , čĆą░ą▒ąŠčéą░ čüąŠ čüčüčŗą╗ą║ą░ą╝ąĖ.
14.2.DeclaringAndUsingReferences: ą┐čĆąĖą╝ąĄčĆčŗ ą┤ąĄą║ą╗ą░čĆąĖčĆąŠą▓ą░ąĮąĖčÅ ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüčüčŗą╗ąŠą║.
15.CharacterManipulationAndStrings , čüčéčĆąŠą║ąĖ, ąŠą┐ąĄčĆą░čåąĖąĖ ąĮą░ą┤ čüčéčĆąŠą║ą░ą╝ąĖ.
15.2CharacterManipulation: ą┐čĆąŠą▓ąĄčĆą║ąĖ čüąĖą╝ą▓ąŠą╗ąŠą▓ ąĮą░ čĆąĄą│ąĖčüčéčĆ, čÅą▓ą╗čÅąĄčéčüčÅ ą╗ąĖ ąŠąĮąĖ ą░ą╗čäą░ą▓ąĖčéąĮąŠ-čåąĖčäčĆąŠą▓čŗą╝ąĖ, ą┐ąŠą┤čüč湥čé ą┐čĆąŠą▒ąĄą╗ąŠą▓ ą▓ čüčéčĆąŠą║ąĄ ąĖ čé. ą┐.
16.Functions , čĆą░ą▒ąŠčéą░ čü čäčāąĮą║čåąĖčÅą╝ąĖ.
16.2FirstHandOnCppFunctions: ą┐ąĄčĆą▓ąŠąĄ ąĘąĮą░ą║ąŠą╝čüčéą▓ąŠ čü čäčāąĮą║čåąĖčÅą╝ąĖ C++.
17.EnumsAndTypeAliases
18.ArgumentsToTheMainFunction
19.GettingThingsOutOfFuntions , ą╝ąĄč鹊ą┤čŗ čĆą░ą▒ąŠčéčŗ čü čäčāąĮą║čåąĖčÅą╝ąĖ.
19.2InputAndOutputParameters: čüą┐ąŠčüąŠą▒čŗ ą▓čŗą▓ąŠą┤ą░ ą┤ą░ąĮąĮčŗčģ ąĖąĘ čäčāąĮą║čåąĖąĖ čü ą┐ąŠą╝ąŠčēčīčÄ čüčüčŗą╗ąŠą║ ąĖ čāą║ą░ąĘą░č鹥ą╗ąĄą╣.
20.FunctionOverloading , ąŠą▒ąĘąŠčĆ ą┐ąĄčĆąĄą│čĆčāąĘą║ąĖ čäčāąĮą║čåąĖąĖ.
20.2OverloadingWithDifferentParameters: ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖčÅ ą┐ąĄčĆąĄą│čĆčāąĘą║ąĖ čäčāąĮą║čåąĖąĖ ą┐čāč鹥ą╝ čĆą░ąĘą╗ąĖčćąĖą╣ ą▓ ą┐ą░čĆą░ą╝ąĄčéčĆą░čģ.
21.LambdaFunctions , ąĘąĮą░ą║ąŠą╝čüčéą▓ąŠ čü ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖčÅą╝ąĖ.
21.2DeclaringAndUsingLambdas: ą┐čĆąŠčüčéčŗąĄ ą┐čĆąĖą╝ąĄčĆčŗ ą┤ąĄą║ą╗ą░čĆąĖčĆąŠą▓ą░ąĮąĖčÅ ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖą╣.
22.FunctionsTheMisfits
23.FunctionCallStackD_ebugging
24.FunctionTemplates , ą▓ą▓ąĄą┤ąĄąĮąĖąĄ ą▓ čłą░ą▒ą╗ąŠąĮčŗ čäčāąĮą║čåąĖąĖ.
24.2TryingOutFunctionTemplates: ą┐ąĄčĆą▓ąŠąĄ ąĘąĮą░ą║ąŠą╝čüčéą▓ąŠ čü čłą░ą▒ą╗ąŠąĮąŠą╝ čäčāąĮą║čåąĖąĖ. ąÆ čāčĆąŠą║ąĄ ąŠą▒čüčāąČą┤ą░čÄčéčüčÅ ą┐čĆąŠą▒ą╗ąĄą╝čŗ, čüą▓čÅąĘą░ąĮąĮčŗąĄ čü ąĮąĄčüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĄą╝ čéąĖą┐ąŠą▓ ą┐ąĄčĆąĄą┤ą░ą▓ą░ąĄą╝čŗčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ čéąĖą┐ą░ą╝ čłą░ą▒ą╗ąŠąĮą░, ą░ čéą░ą║ąČąĄ čüą╗čāčćą░čÅą╝ ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄą╝čŗčģ ą▓ č鹥ą╗ąĄ čłą░ą▒ą╗ąŠąĮą░ ąŠą┐ąĄčĆą░č鹊čĆąŠą▓ ą┤ą╗čÅ ą┐ąĄčĆąĄą┤ą░ąĮąĮčŗčģ ą▓ čłą░ą▒ą╗ąŠąĮ čéąĖą┐ąŠą▓ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓. ą¤ąŠą║ą░ąĘą░ąĮą░ ąŠčéą╗ą░ą┤ą║ą░ ą║ąŠą┤ą░ čłą░ą▒ą╗ąŠąĮą░ ą▓ čüčĆąĄą┤ąĄ VSCode.
25.Concepts , ą▓ą▓ąĄą┤ąĄąĮąĖąĄ ą▓ ą║ąŠąĮčåąĄą┐čåąĖąĖ čłą░ą▒ą╗ąŠąĮą░ čäčāąĮą║čåąĖąĖ.
25.02UsingConcepts: ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą║ąŠąĮčåąĄą┐čåąĖą╣.
26.Classes , ąĘąĮą░ą║ąŠą╝čüčéą▓ąŠ čü ą║ą╗ą░čüčüą░ą╝ąĖ.
26.2YourFirstClass: ą▓ą░čł ą┐ąĄčĆą▓čŗą╣ ą║ą╗ą░čüčü ąĮą░ C++.
27.ZoomingInOnClassObjects
28.DivingDeepIntoConstructorsAndInitialization
29.Friends
30.ConstAndStaticMembers
31.Namespaces
32.ProgramsWithMultipleFiles
32.5OneDefinitionRule: ąŠą▒čŖčÅčüąĮąĄąĮąĖąĄ čĆą░ą▒ąŠčéčŗ "ą┐čĆą░ą▓ąĖą╗ą░ ąŠą┤ąĮąŠą│ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ".
33.SmartPointers
34.OperatorOverloading
35.LogicalOperatorsAndThreeWayComparison
36.Inheritance , ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖąĄ.
36.2FirstTryOnInheritance: ą┐ąĄčĆą▓ąŠąĄ ąĘąĮą░ą║ąŠą╝čüčéą▓ąŠ čü ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖąĄą╝.
37.Polymorphism , ąŠą▒čŖčÅčüąĮąĄąĮąĖąĄ ą┐ąŠą╗ąĖą╝ąŠčĆčäąĖąĘą╝ą░.
37.2StaticBindingWithInheritance: ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖčÅ čüčéą░čéąĖč湥čüą║ąŠą╣ ą┐čĆąĖą▓čÅąĘą║ąĖ ąŠą┤ąĮąŠąĖą╝ąĄąĮąĮčŗčģ ą╝ąĄč鹊ą┤ąŠą▓ ą║ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮąŠą╝čā ą║ą╗ą░čüčüčā ą▓ ą┐ąŠą╗ąĖą╝ąŠčĆčäąĖąĘą╝ąĄ.
38.Exceptions
39.Practice-BoxContainerType
40.ClassTemplates
41.MoveSemantics
42.FunctionLikeEntities
43.StlContainersAndIterators
44.ZoomingOnSTLContainers
45.StlAlgorithms
46.RangesLibraryInCpp20
47.BuildingIteratorsForCustomContainers
48.Coroutines
49.Modules
6 . ąśąĮč鹥ą│čĆą░čåąĖčÅ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ ą▓ čüčĆąĄą┤čā čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ VSCode.
ąÆ ą┐ą░ą┐ą║ą░čģ, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ čüą║ą░čćą░ąĮčŗ ąĮą░ čłą░ą│ąĄ 5, ąĮą░čģąŠą┤ąĖčéčüčÅ čłą░ą▒ą╗ąŠąĮ ą┐čĆąŠąĄą║čéą░, ąĮą░ ąŠčüąĮąŠą▓ąĄ ą║ąŠč鹊čĆąŠą│ąŠ ą▒čāą┤čāčé čüąŠąĘą┤ą░ą▓ą░čéčīčüčÅ ą▓čüąĄ ą┐čĆąŠąĄą║čéčŗ čāčĆąŠą║ąŠą▓ (ąŠą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą┐čĆąŠą▒ąĄą╗čŗ ą▓ ą┐čāčéąĖ ą┐ą░ą┐ą║ąĖ 菹║čĆą░ąĮąĖčĆčāčÄčéčüčÅ čüąĖą╝ą▓ąŠą╗ąŠą╝ ąŠą▒čĆą░čéąĮąŠą│ąŠ čüą╗ąĄčłą░ \):
~/The-C-20-Masterclass-Source-Code/02.EnvironmentSetup/1.Windows/8.C++20\ Template\ Project_all_compilers/
ąØą░ą┐čĆąĖą╝ąĄčĆ, čćč鹊ą▒čŗ ąĮą░čćą░čéčī čĆą░ąĘčĆą░ą▒ą░čéčŗą▓ą░čéčī ąĮąŠą▓čŗą╣ čāčĆąŠą║ (ą┐čĆąŠąĄą║čé ą┐čĆąŠą│čĆą░ą╝ą╝čŗ), čüą┤ąĄą╗ą░ą╣č鹥 ą║ąŠą┐ąĖčÄ ą┐ą░ą┐ą║ąĖ "8.C++20 Template Project_all_compilers" ą┐ąŠą┤ ąĮąŠą▓čŗą╝ ąĖą╝ąĄąĮąĄą╝. ą¤ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ą║ą╗ąĖą║ąĮąĖč鹥 ą┐čĆą░ą▓ąŠą╣ ą║ąĮąŠą┐ą║ąŠą╣ ąĮą░ ą║ąŠą┐ąĖčÄ čŹč鹊ą╣ ą┐ą░ą┐ą║ąĖ, ąĖ ą▓čŗą▒ąĄčĆąĖč鹥 "ą×čéą║čĆčŗčéčī čü ą┐ąŠą╝ąŠčēčīčÄ -> Visual Studio Code". ąŚą░ą┐čāčüčéąĖčéčüčÅ čüčĆąĄą┤ą░ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ VSCode, ą│ą┤ąĄ ą▓ ą┤ąĄčĆąĄą▓ąĄ ą┐čĆąŠčüą╝ąŠčéčĆą░ ą┐čĆąŠąĄą║čéą░ (EXPLORER) ą▒čāą┤čāčé ą▓ąĖą┤ąĮčŗ čäą░ą╣ą╗čŗ čłą░ą▒ą╗ąŠąĮą░ c_cpp_properties.json , main.cpp ąĖ tasks.json .
ą¤ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ąĖąĘą╝ąĄąĮčÅą╣č鹥 ą║ąŠą┤ main.cpp ąĖ ą┤ąŠą▒ą░ą▓ą╗čÅą╣č鹥 ąĮąŠą▓čŗąĄ ą╝ąŠą┤čāą╗ąĖ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░.
1 . ąĪąŠąĘą┤ą░ą╣č鹥 ą┐čāčüčéčāčÄ ą┐ą░ą┐ą║čā ą┤ą╗čÅ ą┐čĆąŠąĄą║čéą░, ą┤ą░ą╣č鹥 ąĄą╣ ą┐ąŠąĮčÅčéąĮąŠąĄ ąĖą╝čÅ, čģą░čĆą░ą║č鹥čĆąĖąĘčāčÄčēąĄąĄ ą▓čŗą┐ąŠą╗ąĮčÅąĄą╝čāčÄ ąĘą░ą┤ą░čćčā. ąöą╗čÅ ą┐čĆąĖą╝ąĄčĆą░ ąĮą░ąĘąŠą▓ąĄą╝ ą┐ą░ą┐ą║čā MyFirstCppProgram .
2 . ąÜą╗ąĖą║ąĮąĖč鹥 ą┐čĆą░ą▓ąŠą╣ ą║ąĮąŠą┐ą║ąŠą╣ ąĮą░ ą┐ą░ą┐ą║ąĄ MyFirstCppProgram , ąĖ ą▓čŗą▒ąĄčĆąĖč鹥 "ą×čéą║čĆčŗčéčī čü ą┐ąŠą╝ąŠčēčīčÄ -> Visual Studio Code". ąŚą░ą┐čāčüčéąĖčéčüčÅ čüčĆąĄą┤ą░ VSCode, ąĖ ąŠčéą║čĆąŠąĄčéčüčÅ ąŠą║ąĮąŠ Welcome.
3 . ąĪąŠąĘą┤ą░ą╣č鹥 ąĮąŠą▓čŗą╣ čäą░ą╣ą╗ main.cpp (ą╝ąĄąĮčÄ File -> New File... -> ą▓ą▓ąĄą┤ąĖč鹥 ąĖą╝čÅ main.cpp ). ąÆ čĆąĄą┤ą░ą║č鹊čĆąĄ čäą░ą╣ą╗ą░ main.cpp ą▓ą▓ąĄą┤ąĖč鹥 čüą╗ąĄą┤čāčÄčēąĖą╣ č鹥ą║čüčé:
#include < iostream> int main ()
{
auto result = (10 < => 20 ) > 0 ;
std ::cout << result << std ::endl ;
}ąÆ čŹč鹊ą╝ ą║ąŠą┤ąĄ ą╝čŗ ą┐čĆąŠą▓ąĄčĆčÅąĄą╝, čćč鹊 čĆąĄą░ą╗čīąĮąŠ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčéčüčÅ čäąĖčćąĖ C++ ą▓ąĄčĆčüąĖąĖ 2.0. ąöą╗čÅ čŹč鹊ą│ąŠ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ąŠą┐ąĄčĆą░č鹊čĆ '< => ' [11], ą║ąŠč鹊čĆčŗą╣ ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ čüčéą░čĆčŗą╝ąĖ ą▓ą░čĆąĖą░ąĮčéą░ą╝ąĖ čüčéą░ąĮą┤ą░čĆčéą░ C++. ąöą╗čÅ ąĄą│ąŠ čāčüą┐ąĄčłąĮąŠą╣ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ą┐čĆąĖą╝ąĄąĮąĖčéčī ąŠą┐čåąĖčÄ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ -std=c++20 . ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ąĘą░ą┐čāčüčéąĖčéčī ą║ąŠą╝ą┐ąĖą╗čÅčåąĖčÄ ą║ąŠą╝ą░ąĮą┤ąŠą╣ g++ main.cpp , č鹊 ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąŠčłąĖą▒ą║ą░:
$ g++ main.cpp
main.cpp: In function ŌĆśint main()ŌĆÖ:
main.cpp:5:25: error: expected primary-expression before ŌĆś>ŌĆÖ token
5 | auto result = (10 < => 20) > 0;
ąØąŠ ąĄčüą╗ąĖ ą┤ąŠą▒ą░ą▓ąĖčéčī ąŠą┐čåąĖčÄ -std=c++20, č鹊 ą║ąŠą╝ą┐ąĖą╗čÅčåąĖčÅ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ čāčüą┐ąĄčłąĮąŠ:
$ g++ -std=c++20 main.cpp
ą¤ąŠą╗čāčćąĖčéčüčÅ ąĖčüą┐ąŠą╗ąĮčÅąĄą╝čŗą╣ čäą░ą╣ą╗ a.out , ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĮąŠ ąĘą░ą┐čāčüčéąĖčéčī ąĖ ą┐ąŠą╗čāčćąĖčéčī ąŠąČąĖą┤ą░ąĄą╝čŗą╣ čĆąĄąĘčāą╗čīčéą░čé 0:
$ ./a.out
0
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąĘą░ą┐čāčüą║ą░čéčī ą║ąŠą╝ą░ąĮą┤čŗ ą┤ą╗čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ą╝ąŠąČąĮąŠ ą▓ ąŠčéą┤ąĄą╗čīąĮąŠą╝ ąŠą║ąĮąĄ č鹥čĆą╝ąĖąĮą░ą╗ą░, ąŠčéą║čĆčŗą▓ č鹥ą║čāčēčāčÄ ą┐ą░ą┐ą║čā ą┐čĆąŠąĄą║čéą░ ą║ąŠą╝ą░ąĮą┤ą░ą╝ąĖ cd, ą╗ąĖą▒ąŠ ą╝ąŠąČąĮąŠ ąŠčéą║čĆčŗčéčī ą┐ą░ąĮąĄą╗čī č鹥čĆą╝ąĖąĮą░ą╗ą░ ą┐čĆčÅą╝ąŠ čā čüčĆąĄą┤ąĄ VSCode ą▓čŗą▒ąŠčĆąŠą╝ ą▓ ą╝ąĄąĮčÄ Terminal -> New Terminal:
ąÆ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ ą▓čĆąĄąĘą║ąĄ ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĄą╗ąĖ ą┐čĆąĖą╝ąĄčĆ ą┐čĆąŠčüč鹥ą╣čłąĄą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĖ ąĄčæ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ čü ą┐ąŠą╝ąŠčēčīčÄ ą┐čĆčÅą╝ąŠą│ąŠ ą▓čŗąĘąŠą▓ą░ ą▓ ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąĄ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ g++ . ą×ą┤ąĮą░ą║ąŠ ą╝ąŠąČąĮąŠ ąĮą░čüčéčĆąŠąĖčéčī ąĖ ą░ą▓č鹊ą╝ą░čéąĖąĘąĖčĆąŠą▓ą░čéčī čŹč鹊čé ą┐čĆąŠčåąĄčüčü, čüą┤ąĄą╗ą░ą▓ ąĄą│ąŠ ą▒ąŠą╗ąĄąĄ čāą┤ąŠą▒ąĮčŗą╝, čü ą┐ąŠą╝ąŠčēčīčÄ ąĘą░ą┤ą░čć VSCode (Tasks).
1 . ąÆčŗą▒ąĄčĆąĖč鹥 ą▓ ą╝ąĄąĮčÄ Terminal -> Configure Tasks..., čüčĆąĄą┤ą░ VSCode ąĮą░ą╣ą┤ąĄčé ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆčŗ, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮčŗ ąĮą░ čłą░ą│ąĄ "ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆčŗ, ą║ąŠč鹊čĆčŗąĄ ąĮčāąČąĮąŠ čāčüčéą░ąĮąŠą▓ąĖčéčī ą▓ Linux: GCC, Clang llvm".
ą¦č鹊ą▒čŗ čüąŠąĘą┤ą░čéčī ąĘą░ą┤ą░čćčā ą┤ą╗čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ č鹥ą║čāčēąĄą│ąŠ čäą░ą╣ą╗ą░ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆąŠą╝ GCC (g++), ą▓čŗą▒ąĄčĆąĖč鹥 ą▓ ą▓čŗą┐ą░ą▓čłąĄą╝ čüą┐ąĖčüą║ąĄ ą┐čāąĮą║čé "C/C++: g++ build active file". ąÆ ą┐ą░ą┐ą║ąĄ ą┐čĆąŠąĄą║čéą░ ą▒čāą┤ąĄčé ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ čüąŠąĘą┤ą░ąĮą░ ą┐ą░ą┐ą║ą░ ą┤ą╗čÅ ąĮą░čüčéčĆąŠąĄą║ .vscode tasks.json
{
"version" : "2.0.0" ,
"tasks" : [
{
"type" : "cppbuild" ,
"label" : "C/C++: g++ build active file" ,
"command" : "/usr/bin/g++" ,
"args" : [
"-fdiagnostics-color=always" ,
"-g" ,
"${file}" ,
"-o" ,
"${fileDirname}/${fileBasenameNoExtension}"
] ,
"options" : {
"cwd" : "${fileDirname}"
} ,
"problemMatcher" : [
"$gcc"
] ,
"group" : "build" ,
"detail" : "compiler: /usr/bin/g++"
}
] } 2 . ąŁč鹊čé čäą░ą╣ą╗ ąĮą░čüčéčĆąŠąĄą║ ą╝ąŠąČąĮąŠ ąĖ ąĮčāąČąĮąŠ ą┐ąŠą┐čĆą░ą▓ąĖčéčī, čćč鹊ą▒čŗ ąŠąĮ čüčéą░ą╗ ą▒ąŠą╗ąĄąĄ čāąĮąĖą▓ąĄčĆčüą░ą╗čīąĮčŗą╝.
label . ą¤čāąĮą║čé ąĮą░čüčéčĆąŠąĄą║ label ąĘą░ą┤ą░ąĄčé č鹥ą║čüč鹊ą▓čāčÄ ą╝ąĄčéą║čā, ą║ąŠč鹊čĆą░čÅ ą▒čāą┤ąĄčé ąŠč鹊ą▒čĆą░ąČą░čéčīčüčÅ ą▓ ą╝ąĄąĮčÄ ąĘą░ą┤ą░čć Terminal -> Run Task..., ąĄčæ ą╝ąŠąČąĮąŠ ą┐ąŠą╝ąĄąĮčÅčéčī ąĮą░ ą╗čÄą▒ąŠą╣ č鹥ą║čüčé ą┐ąŠ ą▓ą░čłąĄą╝čā čāčüą╝ąŠčéčĆąĄąĮąĖčÄ. ąØą░ą┐čĆąĖą╝ąĄčĆ, čāą║ą░ąČąĄą╝ ą▓ ą╝ąĄčéą║ąĄ, čćč鹊 čā ąĮą░čü ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čüčéą░ąĮą┤ą░čĆčé C++ v20:
"label" : "C/C++: g++ build std=c++20" ,
args . ąŁč鹊čé ą┐čāąĮą║čé ąĮą░čüčéčĆąŠąĄą║ ąĘą░ą┤ą░ąĄčé ąŠą┐čåąĖąĖ, ą┐ąĄčĆąĄą┤ą░ą▓ą░ąĄą╝čŗąĄ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆčā ą▓ ąĄą│ąŠ ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąĄ. ąŚą┤ąĄčüčī ąĖą╝ąĄąĄčé čüą╝čŗčüą╗ ą┐ąŠą╝ąĄąĮčÅčéčī ąŠą┐čåąĖčÄ "${file}", ą║ąŠč鹊čĆą░čÅ ą▒čāą┤ąĄčé ą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░čéčī č鹊ą╗čīą║ąŠ č鹥ą║čāčēąĖą╣ čäą░ą╣ą╗, ąĖ ąĮą░ą┤ąŠ ą▒čāą┤ąĄčé čéą░ą║ąČąĄ ą┤ąŠą▒ą░ą▓ąĖčéčī ąŠą┐čåąĖčÄ -std=c++20. ąóą░ą║ąČąĄ ą╝ąŠąČąĮąŠ ą┐ąŠą╝ąĄąĮčÅčéčī ąĮą░ąĘą▓ą░ąĮąĖąĄ čĆąĄąĘčāą╗čīčéą░čéą░ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ, ąĄčüą╗ąĖ ąĖąĘą╝ąĄąĮąĖčéčī ąŠą┐čåąĖčÄ "${fileDirname}/${fileBasenameNoExtension}". ąĪą┤ąĄą╗ą░ąĮąĮčŗąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą▓čŗą┤ąĄą╗ąĄąĮčŗ ąČąĖčĆąĮčŗą╝ čłčĆąĖčäč鹊ą╝:
"args" : [
"-fdiagnostics-color=always" ,
"-g" ,
"${workspaceFolder}/*.cpp" ,
"-std=c++20" ,
"-o" ,
"${fileDirname}/myprogram"
] ,
ą¤ąŠčüą╗ąĄ ą▓ąĮąĄčüąĄąĮąĮčŗčģ ąĖąĘą╝ąĄąĮąĄąĮąĖą╣ ą▒čāą┤čāčé ą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░čéčīčüčÅ ą▓čüąĄ ą╝ąŠą┤čāą╗ąĖ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░, ąĮą░čģąŠą┤čÅčēąĖąĄčüčÅ ą▓ ą┐ą░ą┐ą║ąĄ ą┐čĆąŠąĄą║čéą░, ąĮąĄ č鹊ą╗čīą║ąŠ č鹥ą║čāčēąĖą╣ ąŠčéą║čĆčŗčéčŗą╣ čäą░ą╣ą╗ ("${workspaceFolder}/*.cpp"), ą▒čāą┤čāčé ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čéčīčüčÅ čäąĖčćąĖ C++ 20 ("-std=c++20"), ąĖ ą┐ąŠą╝ąĄąĮčÅąĄčéčüčÅ ąĖą╝čÅ čĆąĄąĘčāą╗čīčéą░čéą░ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ąĮą░ myprogram.
ąÆčŗą┐ąŠą╗ąĮąĖč鹥 ą▓čüąĄ č鹥 ąČąĄ čüą░ą╝čŗąĄ čłą░ą│ąĖ, čćč鹊 ą▒čŗą╗ąĖ čüą┤ąĄą╗ą░ąĮčŗ ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ ą▓čĆąĄąĘą║ąĄ ą┤ą╗čÅ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ g++, č鹊ą╗čīą║ąŠ ą▓ ą╝ąĄąĮčÄ čüąŠąĘą┤ą░ąĮąĖčÅ ąĮąŠą▓ąŠą╣ ąĘą░ą┤ą░čćąĖ Terminal -> Configure Tasks... ą▓čŗą▒ąĄčĆąĖč鹥 ą▓ ą▓čŗą┐ą░ą▓čłąĄą╝ čüą┐ąĖčüą║ąĄ ą┐čāąĮą║čé "C/C++: clang++ build active file". ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 čäą░ą╣ą╗ ąĮą░čüčéčĆąŠąĄą║ ąĘą░ą┤ą░čć tasks.json ą┐čĆąĖą╝ąĄčé ą┐čĆąĖą╝ąĄčĆąĮąŠ čéą░ą║ąŠą╣ ą▓ąĖą┤ (ą▓ąĮąĄčüąĄąĮąĮčŗąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą▓čŗą┤ąĄą╗ąĄąĮčŗ ąČąĖčĆąĮčŗą╝ čłčĆąĖčäč鹊ą╝):
{
"version" : "2.0.0" ,
"tasks" : [
{
"type" : "cppbuild" ,
"label" : "C/C++: g++ build std=c++20" ,
"command" : "/usr/bin/g++" ,
"args" : [
"-fdiagnostics-color=always" ,
"-g" ,
"${workspaceFolder}/*.cpp" ,
"-std=c++20" ,
"-o" ,
"${fileDirname}/myprogram"
] ,
"options" : {
"cwd" : "${fileDirname}"
} ,
"problemMatcher" : [
"$gcc"
] ,
"group" : "build" ,
"detail" : "compiler: /usr/bin/g++"
} ,
{
"type" : "cppbuild" ,
"label" : "C/C++: clang++ build std=c++20" ,
"command" : "/usr/bin/clang++" ,
"args" : [
"-fcolor-diagnostics" ,
"-fansi-escape-codes" ,
"-g" ,
"${workspaceFolder}/*.cpp" ,
"-std=c++20" ,
"-o" ,
"${fileDirname}/myprogram"
] ,
"options" : {
"cwd" : "${fileDirname}"
} ,
"problemMatcher" : [
"$gcc"
] ,
"group" : "build" ,
"detail" : "compiler: /usr/bin/clang++"
}
] }
ąØą░ Windows ąĖąĮč鹥ą│čĆą░čåąĖčÅ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆąŠą▓ g++.exe ąĖ clang++.exe ą░ąĮą░ą╗ąŠą│ąĖčćąĮą░ č鹊ą╝čā, ą║ą░ą║ čŹč鹊 ą┤ąĄą╗ą░ąĄčéčüčÅ ąĮą░ Linux (čüą╝. ą┐čĆąĄą┤čŗą┤čāčēąĖąĄ ą┤ą▓ąĄ ą▓čĆąĄąĘą║ąĖ), ąĄčüčéčī č鹊ą╗čīą║ąŠ ąĮąĄąĘąĮą░čćąĖč鹥ą╗čīąĮčŗąĄ ąŠčéą╗ąĖčćąĖčÅ ą▓ čüčéąĖą╗ąĄ čāą║ą░ąĘą░ąĮąĖčÅ ą┐čāčéąĖ ą║ čäą░ą╣ą╗čā (čĆą░ąĘą┤ąĄą╗ąĖč鹥ą╗čī ą┐čāčéąĖ / ąĘą░ą╝ąĄąĮčÅąĄčéčüčÅ ąĮą░ \\). ąōąŠč鹊ą▓čŗą╣ čäą░ą╣ą╗ ąĮą░čüčéčĆąŠąĄą║ tasks.json ą┤ą╗čÅ Windows ą╝ąŠąČąĮąŠ ąĮą░ą╣čéąĖ ą▓ ą┐ą░ą┐ą║ąĄ "8.C++20 Template Project_all_compilers " čüčĆąĄą┤ąĖ čüą║ą░čćą░ąĮąĮčŗčģ čāčĆąŠą║ąŠą▓ [2] (čüą╝. ą▓čŗčłąĄ "ąÜą░ą║ čüą║ą░čćą░čéčī čāčĆąŠą║ąĖ"). ąÆąŠčé ąĄą│ąŠ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ:
{
"version" : "2.0.0" ,
"tasks" : [
{
"type" : "cppbuild" ,
"label" : "Build GCC" ,
"command" : "C:\\mingw64\\bin\\g++.exe" ,
"args" : [
"-g" ,
"-std=c++20" ,
"${workspaceFolder}\\*.cpp" ,
"-o" ,
"${fileDirname}\\rooster.exe"
] ,
"options" : {
"cwd" : "${fileDirname}"
} ,
"problemMatcher" : [
"$gcc"
] ,
"group" : "build" ,
"detail" : "compiler: C:\\mingw64\\bin\\g++.exe"
} ,
{
"type" : "cppbuild" ,
"label" : "Build with MSVC" ,
"command" : "cl.exe" ,
"args" : [
"/Zi" ,
"/std:c++latest" ,
"/EHsc" ,
"/Fe:" ,
"${fileDirname}\\rooster.exe" ,
"${workspaceFolder}\\*.cpp"
] ,
"options" : {
"cwd" : "${fileDirname}"
} ,
"problemMatcher" : [
"$msCompile"
] ,
"group" : "build" ,
"detail" : "compiler: cl.exe"
} ,
{
"type" : "cppbuild" ,
"label" : "Build with Clang" ,
"command" : "C:\\mingw64\\bin\\clang++.exe" ,
"args" : [
"-g" ,
"-std=c++20" ,
"${workspaceFolder}\\*.cpp" ,
"-o" ,
"${fileDirname}\\rooster.exe"
] ,
"options" : {
"cwd" : "${fileDirname}"
} ,
"problemMatcher" : [
"$gcc"
] ,
"group" : "build" ,
"detail" : "compiler: C:\\mingw64\\bin\\clang++.exe"
}
] } ąŁč鹊čé čäą░ą╣ą╗ ą╝ąŠąČąĮąŠ ą▓ąĘčÅčéčī ą║ą░ą║ ą▒ą░ąĘąŠą▓čŗą╣ ą┐čĆąĖą╝ąĄčĆ ą┤ą╗čÅ ąĮą░čüčéčĆąŠąĄą║, ąĮčāąČąĮąŠ ą▓ ąĮąĄą╝ ą┐čĆąŠčüč鹊 ą┐ąŠą┐čĆą░ą▓ąĖčéčī ą░ą▒čüąŠą╗čÄčéąĮčŗąĄ ą┐čāčéąĖ ą┤ąŠ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆąŠą▓ "command".
ąĪčāčēąĄčüčéą▓čāąĄčé ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐ąŠą┐čāą╗čÅčĆąĮčŗčģ ąŠąĮą╗ą░ą╣ąĮ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆąŠą▓:
ŌĆó OnlineGDB
ą×ąĮąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą┐ąŠą╗ąĄąĘąĮčŗ ą┤ą╗čÅ ą▒čŗčüčéčĆąŠą│ąŠ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ ą║ą░ą║ąĖčģ-ąĮąĖą▒čāą┤čī ą░ą╗ą│ąŠčĆąĖčéą╝ąŠą▓, ą║ąŠą│ą┤ą░ ąĮąĄčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ą▓ąŠčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ąŠą╗ąĮąŠčåąĄąĮąĮąŠą╣ ąŠčäčäą╗ą░ą╣ąĮ-čüčĆąĄą┤ąŠą╣ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ.
7 . ą×ą┐ąĄčĆą░č鹊čĆ std::endl ąŠąĘąĮą░čćą░ąĄčé č鹊 ąČąĄ čüą░ą╝ąŠąĄ, čćč鹊 ąĖ '\n', ąŠą▒ąĄ ąŠąĘąĮą░čćą░čÄčé čüąĖą╝ą▓ąŠą╗ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ. ąØą░ą┐čĆąĖą╝ąĄčĆ, čüą╗ąĄą┤čāčÄčēąĖąĄ ą┤ą▓ąĄ čüčéčĆąŠą║ąĖ 菹║ą▓ąĖą▓ą░ą╗ąĄąĮčéąĮčŗ:
std ::cout << "Number1" << std ::endl ;
std ::cout << "Number1" << '\n' ;
ąĪą╗ąĄą┤čāčÄčēąĖąĄ čäąĖčćąĖ čéčĆąĄą▒čāčÄčé ąŠą┐čåąĖąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ -std=c++20 (čüą╝. ą▓čŗčłąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ čäą░ą╣ą╗ą░ ąĮą░čüčéčĆąŠąĄą║ tasks.json ą┤ą╗čÅ VSCode):
1 . ą×ą┐ąĄčĆą░č鹊čĆ < => , čüą╝. [11].
2 . ąĪą┐ąĄčåąĖčäąĖą║ą░č鹊čĆ consteval (čüą╝. consteval specifier site:cppreference.com). ą×ąĮ ą┤ąĄą║ą╗ą░čĆąĖčĆčāąĄčé čäčāąĮą║čåąĖčÄ ąĖą╗ąĖ čłą░ą▒ą╗ąŠąĮ čäčāąĮą║čåąĖąĖ, čćč鹊ą▒čŗ ąŠąĮą░ ą▒čŗą╗ą░ "ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠą╣" (immediate function). ąó. ąĄ. ą║ą░ąČą┤čŗą╣ ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮčŗą╣ ą▓čŗąĘąŠą▓ čŹč鹊ą╣ čäčāąĮą║čåąĖąĖ ą┤ąŠą╗ąČąĄąĮ (ąĮą░ą┐čĆčÅą╝čāčÄ ąĖą╗ąĖ ą║ąŠčüą▓ąĄąĮąĮąŠ) ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ą║ąŠąĮčüčéą░ąĮčéąĮąŠąĄ ą▓čŗčĆą░ąČąĄąĮąĖąĄ.
ąØąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮą░čÅ (immediate) čäčāąĮą║čåąĖčÅ čŹč鹊 constexpr čäčāąĮą║čåąĖčÅ, čü čāč湥č鹊ą╝ ąĄčæ čéčĆąĄą▒ąŠą▓ą░ąĮąĖą╣ ąĖ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ąŠą▒čüč鹊čÅč鹥ą╗čīčüčéą▓. ąóą░ą║ ąČąĄ, ą║ą░ą║ ąĖ čüą┐ąĄčåąĖčäąĖą║ą░č鹊čĆ constexpr, čüą┐ąĄčåąĖčäąĖą║ą░č鹊čĆ consteval ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčé inline. ą×ą┤ąĮą░ą║ąŠ consteval ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĖą╝ąĄąĮąĄąĮ ą║ ą┤ąĄčüčéčĆčāą║č鹊čĆą░ą╝, čäčāąĮą║čåąĖčÅą╝ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ąĖą╗ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ (allocation, deallocation functions).
ą×ą▒čŖčÅą▓ą╗ąĄąĮąĖąĄ čäčāąĮą║čåąĖąĖ ąĖą╗ąĖ čłą░ą▒ą╗ąŠąĮą░ čäčāąĮą║čåąĖąĖ, čāą║ą░ąĘčŗą▓ą░čÄčēąĄąĄ consteval, ą╝ąŠąČąĄčé čéą░ą║ąČąĄ ąĮąĄ čāą║ą░ąĘčŗą▓ą░čéčī constexpr , ąĖ ą╗čÄą▒čŗąĄ ą┐ąŠą▓č鹊čĆąĮčŗąĄ ąŠą▒čŖčÅą▓ą╗ąĄąĮąĖčÅ čŹč鹊ą╣ čäčāąĮą║čåąĖąĖ ąĖą╗ąĖ čłą░ą▒ą╗ąŠąĮą░ čäčāąĮą║čåąĖąĖ čéą░ą║ąČąĄ ą┤ąŠą╗ąČąĮčŗ čāą║ą░ąĘčŗą▓ą░čéčī consteval.
ą¤ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ ą▓čŗčćąĖčüą╗čÅąĄą╝čŗą╣ ą▓čŗąĘąŠą▓ immediate-čäčāąĮą║čåąĖąĖ, čüą░ą╝ą░čÅ ą▓ąĮčāčéčĆąĄąĮąĮčÅčÅ ąĮąĄ ą▒ą╗ąŠčćąĮą░čÅ ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ ą║ąŠč鹊čĆąŠą╣ ąĮąĄ čÅą▓ą╗čÅąĄčéčüčÅ ąŠą▒ą╗ą░čüčéčīčÄ ą┤ąĄą╣čüčéą▓ąĖčÅ ą┐ą░čĆą░ą╝ąĄčéčĆą░ čäčāąĮą║čåąĖąĖ immediate-čäčāąĮą║čåąĖąĖ ąĖą╗ąĖ ąĖčüčéąĖąĮąĮąŠą╣ ą▓ąĄčéą▓čīčÄ ąŠą┐ąĄčĆą░č鹊čĆą░ consteval if (ąĮą░čćąĖąĮą░čÅ ąŠčé C++ 23), ą┤ąŠą╗ąČąĄąĮ čüąŠąĘą┤ą░ą▓ą░čéčī ą║ąŠąĮčüčéą░ąĮčéąĮąŠąĄ ą▓čŗčĆą░ąČąĄąĮąĖąĄ; čéą░ą║ąŠą╣ ą▓čŗąĘąŠą▓ ąĖąĘą▓ąĄčüč鹥ąĮ ą║ą░ą║ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮčŗą╣ ą▓čŗąĘąŠą▓ (immediate invocation).
8 . ąÜąŠą┤ ą▓ąŠąĘą▓čĆą░čéą░ ąĖąĘ čäčāąĮą║čåąĖąĖ main. ą×ą▒čēąĄą┐čĆąĖąĮčÅč鹊ąĄ čāčüč鹊čÅą▓čłąĄąĄčüčÅ čüąŠą│ą╗ą░čłąĄąĮąĖąĄ ą┤ą╗čÅ ą┐čĆąŠą│čĆą░ą╝ą╝, ą║ą░ą║ ą▓ Linux, čéą░ą║ ąĖ ą▓ Windows, čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, čćč鹊 ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ 0 ąĖąĘ čäčāąĮą║čåąĖąĖ main ąŠąĘąĮą░čćą░ąĄčé čāčüą┐ąĄčłąĮąŠąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ąøčÄą▒ąŠąĄ ą┤čĆčāą│ąŠąĄ ą▓ąŠąĘą▓čĆą░čēąĄąĮąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ąŠąĘąĮą░čćą░ąĄčé ąŠčłąĖą▒ą║čā, ąĖ ąŠąĮąŠ čĆą░ąĘą╗ąĖčćąĮčŗąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ ą╝ąŠą│čāčé ą║ąŠą┤ąĖčĆąŠą▓ą░čéčī čéąĖą┐ čŹč鹊ą╣ ąŠčłąĖą▒ą║ąĖ.
9 . ąśąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ ą╝ąŠąČąĮąŠ čüąŠąĘą┤ą░ą▓ą░čéčī čĆą░ąĘąĮčŗą╝ąĖ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ:
Braced Initialization, ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ čü ą┐ąŠą╝ąŠčēčīčÄ čäąĖą│čāčĆąĮčŗčģ čüą║ąŠą▒ąŠą║ {}.
ą¤čĆąĖą╝ąĄčĆčŗ:
int myValue1 = 7 ; // ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ąĘąĮą░č湥ąĮąĖąĄą╝ 7 int myValue2 {8 }; // ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ąĘąĮą░č湥ąĮąĖąĄą╝ 8 int myValue3 {}; // ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ąĮčāą╗ąĄą╝ int myValue4 (9 ) ; // ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ąĘąĮą░č湥ąĮąĖąĄą╝ 9 ąÆ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░č鹊čĆąĄ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓čŗčĆą░ąČąĄąĮąĖąĄ:
int A = 2 ;int B = 3 ;int sum {A + B};ąśąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ čüąŠ čüą║ąŠą▒ą║ą░ą╝ąĖ () ąĖ {} ąĖą╝ąĄčÄčé ąŠčüąŠą▒ąĄąĮąĮąŠčüčéąĖ, ąĘą░ą║ą╗čÄčćą░čÄčēąĖąĄčüčÅ ą▓ ąĮąĄčÅą▓ąĮąŠą╝ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĖ ą┤ą░ąĮąĮčŗčģ. ąØą░ą┐čĆąĖą╝ąĄčĆ:
// ąĪą╗ąĄą┤čāčÄčēąĄąĄ ąŠą▒čŖčÅą▓ą╗ąĄąĮąĖąĄ čüąŠąĘą┤ą░čüčé ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ narrowing_conversion_functional, // ąĖ ąĮąĄčÅą▓ąĮąŠ ą┐čĆąĖčüą▓ąŠąĖčé ąĄą╣ ąĘąĮą░č湥ąĮąĖąĄ 2, ąŠčéą▒čĆąŠčüąĖą▓ ą┤čĆąŠą▒ąĮčāčÄ čćą░čüčéčī. ąŁč鹊čé čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝ąŠąĄ // "čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ" ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ, ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą┐čĆąĖ čŹč鹊ą╝ ąĮąĄ ą▓čŗą┤ą░čüčé ąĮąĖą║ą░ą║ąĖčģ // čüąŠąŠą▒čēąĄąĮąĖą╣. ąÆąĄčĆąŠčÅčéąĮąŠ čŹč鹊 ąĮąĄ č鹊, čćč鹊 ą▓čŗ čģąŠč鹥ą╗ąĖ ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī: int narrowing_conversion_functional (2.9 ) ;// ąæąŠą╗ąĄąĄ ą▒ąĄąĘąŠą┐ą░čüąĮčŗą╣ ą▓ą░čĆąĖą░ąĮčé čüą┤ąĄą╗ą░čéčī č鹊 ąČąĄ čüą░ą╝ąŠąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ // ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą▓čŗą┤ą░čüčé čüąŠąŠą▒čēąĄąĮąĖąĄ ąŠą▒ ąŠčłąĖą▒ą║ąĄ int.ERROR ąĖą╗ąĖ WARNING: int narrowing_conversion (2.9 ) ;10 . ąöą╗čÅ ą▓čŗą▓ąŠą┤ą░ ą▓ ą║ąŠąĮčüąŠą╗čī ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ std::cout , ą░ ą┤ą╗čÅ ą▓ą▓ąŠą┤ą░ std::cin . ąóą░ą║ąČąĄ čüčāčēąĄčüčéą▓čāčÄčé ą┐ąŠč鹊ą║ąĖ std::cerr ą┤ą╗čÅ ą▓čŗą▓ąŠą┤ą░ ą▓ ą║ąŠąĮčüąŠą╗čī čüąŠąŠą▒čēąĄąĮąĖą╣ ąŠą▒ ąŠčłąĖą▒ą║ą░čģ ąĖ std::clog ą┤ą╗čÅ ą▓čŗą▓ąŠą┤ą░ ą▓ ą║ąŠąĮčüąŠą╗čī čüąŠąŠą▒čēąĄąĮąĖą╣ ą╗ąŠą│ą░.
11 . ąØąĄą╝ąĮąŠą│ąŠ ąŠčüąĮąŠą▓ąĮąŠą╣ č鹥čĆą╝ąĖąĮąŠą╗ąŠą│ąĖąĖ.
Core features . ąŁč鹊 ąŠčüąĮąŠą▓ąĮčŗąĄ čäąĖčćąĖ, ą║ ą║ąŠč鹊čĆčŗą╝ ąŠčéąĮąŠčüčÅčéčüčÅ ą┐čĆą░ą▓ąĖą╗ą░ čüąĖąĮčéą░ą║čüąĖčüą░ čÅąĘčŗą║ą░ C++, ą▒ą░ąĘąŠą▓čŗąĄ čéąĖą┐čŗ ąĖ ąŠą┐ąĄčĆą░č鹊čĆčŗ.
Standard library . ąØą░ą▒ąŠčĆ ą│ąŠč鹊ą▓čŗčģ ą║ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÄ čüą┐ąĄčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗčģ ą║ąŠą╝ą┐ąŠąĮąĄąĮč鹊ą▓, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ąĮą░ C++. ąĪčéą░ąĮą┤ą░čĆčéąĮčŗąĄ ą▒ąĖą▒ą╗ąĖąŠč鹥čćąĮčŗąĄ čäčāąĮą║čåąĖąĖ ą┐ąŠą┤ą║ą╗čÄčćą░čÄčéčüčÅ ą║ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ąŠą┐ąĄčĆą░č鹊čĆą░ą╝ąĖ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ #include < iostream>, #include < string>.
STL . Standard Template Library, čćą░čüčéčī čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ C++, ąĮąŠ ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé čüąŠą▒ąŠą╣ ąĮą░ą▒ąŠčĆ čéąĖą┐ąŠą▓ ą║ąŠąĮč鹥ą╣ąĮąĄčĆąŠą▓. ąśčģ ą╝ąŠąČąĮąŠ ą┐čĆąĄą┤čüčéą░ą▓ąĖčéčī čüąĄą▒ąĄ ą║ą░ą║ ąĮą░ą▒ąŠčĆčŗ ą║ą░ą║ąĖčģ-č鹊 čüčāčēąĮąŠčüč鹥ą╣ (ąŠą▒čŖąĄą║č鹊ą▓), ąĖąĘ ą║ąŠč鹊čĆčŗčģ ą╝ąŠąČąĮąŠ čüąŠčüčéą░ą▓ą╗čÅčéčī ą║ąŠą╗ą╗ąĄą║čåąĖąĖ. ąĪčāčēąĄčüčéą▓čāčÄčé čüą┐ąĄčåąĖą░ą╗čīąĮčŗąĄ ąĖč鹥čĆą░č鹊čĆčŗ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą┐čĆąŠčüą╝ą░čéčĆąĖą▓ą░čéčī čŹčéąĖ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ čüčāčēąĮąŠčüč鹥ą╣, čü ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ąĘą░ą┤ą░ą▓ą░ąĄą╝ąŠą│ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüč鹊ą╝ ą░ą╗ą│ąŠčĆąĖčéą╝ą░ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ.
int main() {} . ą×čüąĮąŠą▓ąĮą░čÅ čäčāąĮą║čåąĖčÅ, ą│ą┤ąĄ ąŠą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą▓ąĄčüčī ą░ą╗ą│ąŠčĆąĖčéą╝ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ C++.
Entry Point . ąóąŠčćą║ą░ ą▓čģąŠą┤ą░ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝čā, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēą░čÅ ąĮą░čćą░ą╗čā č鹥ą╗ą░ čäčāąĮą║čåąĖąĖ main.
Statement . ą×ą┐ąĄčĆą░č鹊čĆ čÅąĘčŗą║ą░, ą╝ąĖąĮąĖą╝ą░ą╗čīąĮą░čÅ ąĄą┤ąĖąĮąĖčåą░ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčēą░čÅ ą║ą░ą║ąŠąĄ-č鹊 ą┤ąĄą╣čüčéą▓ąĖąĄ.
Function . ążčāąĮą║čåąĖčÅ, ąŠą▒čŖąĄą┤ąĖąĮąĄąĮąĮčŗą╣ ąĮą░ą▒ąŠčĆ ą┤ąĄą╣čüčéą▓ąĖą╣ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ. ążčāąĮą║čåąĖčÅ ąĮą░ ą▓čģąŠą┤ąĄ ą╝ąŠąČąĄčé ą┐čĆąĖąĮąĖą╝ą░čéčī ą▓čģąŠą┤ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ (ą┐ą░čĆą░ą╝ąĄčéčĆčŗ čäčāąĮą║čåąĖąĖ) ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ čéąĖą┐ąŠą▓, ąĖ ąĮą░ ą▓čŗčģąŠą┤ąĄ ą╝ąŠąČąĄčé ą▓ąŠąĘą▓čĆą░čēą░čéčī ą║ą░ą║ąŠąĄ-ą╗ąĖą▒ąŠ ąĘąĮą░č湥ąĮąĖąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ čéąĖą┐ą░.
Error, Warning . ą×čłąĖą▒ą║ą░, ą┐čĆąĄą┤čāą┐čĆąĄąČą┤ąĄąĮąĖąĄ. ąĀą░ąĘą┤ąĄą╗čÅčÄčé ąŠčłąĖą▒ą║ąĖ ą▓čĆąĄą╝ąĄąĮąĖ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ (compile time error, čüąŠąŠą▒čēąĄąĮąĖąĄ ąŠą▒ čŹč鹊ą╣ ąŠčłąĖą▒ą║ąĄ ą▓čŗą▓ąŠą┤ąĖčé ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ, ąĄčüą╗ąĖ ąŠąĮ ąŠą▒ąĮą░čĆčāąČąĖčé ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮčŗą╣ čüąĖąĮčéą░ą║čüąĖčü) ąĖ ąŠčłąĖą▒ą║ąĖ ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ (runtime error, čŹčéčā ąŠčłąĖą▒ą║čā ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąĮąĄ ąĘą░ą╝ąĄčéąĖčé, ąĮąŠ ąŠąĮą░ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠą╣ čĆą░ą▒ąŠč鹥 ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĖą╗ąĖ ą┤ą░ąČąĄ ą║ ąĘą░ą▓ąĖčüą░ąĮąĖčÄ ąĖą╗ąĖ ą░ą▓ą░čĆąĖą╣ąĮąŠą╝čā ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ). ąóą░ą║ąČąĄ ą▒čŗą▓ą░čÄčé ą┐čĆąĄą┤čāą┐čĆąĄąČą┤ąĄąĮąĖčÅ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ (warning), ą║ąŠą│ą┤ą░ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąŠą▒ąĮą░čĆčāąČąĖą╗ ą┐ąŠą┤ąŠąĘčĆąĖč鹥ą╗čīąĮąŠąĄ ą╝ąĄčüč鹊, ą│ą┤ąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠ čüąŠą┤ąĄčƹȹĖčéčüčÅ ąŠčłąĖą▒ą║ą░. ą¤čĆąĄą┤čāą┐čĆąĄąČą┤ąĄąĮąĖčÅ ąŠą▒čŗčćąĮąŠ ąĮąĄ ą┐čĆąĖą▓ąŠą┤čÅčé ą║ ąŠčłąĖą▒ą║ąĄ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ, ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą▓čüąĄ čĆą░ą▓ąĮąŠ ą▒čāą┤ąĄčé čāčüą┐ąĄčłąĮąŠ čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░ąĮą░.
Input, Output . ąÆą▓ąŠą┤ ąĖ ą▓čŗą▓ąŠą┤ - čüąĖčüč鹥ą╝ą░, čü ą┐ąŠą╝ąŠčēčīčÄ ą║ąŠč鹊čĆąŠą╣ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą╝ąŠąČąĄčé ąŠą▒čēą░čéčīčüčÅ čü ą▓ąĮąĄčłąĮąĖą╝ ą╝ąĖčĆąŠą╝ (ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ).
Comment . ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖą╣: ą┐ąŠčÅčüąĮčÅčÄčēąĖą╣ č鹥ą║čüčé ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ, ą║ąŠč鹊čĆčŗą╣ ąĮąĄ ą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ ą▓ ą┤ą▓ąŠąĖčćąĮčŗą╣ ą║ąŠą┤.
Dev Workflow . ąĀą░ą▒ąŠčćąĖą╣ ą┐čĆąŠčåąĄčüčü čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
Memory Model . ą£ąŠą┤ąĄą╗čī ąŠčĆą│ą░ąĮąĖąĘą░čåąĖąĖ ą┐ą░ą╝čÅčéąĖ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ.
Execution Model . ą£ąŠą┤ąĄą╗čī ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
Base Types . ą¤čĆąĄą┤ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ ą▒ą░ąĘąŠą▓čŗąĄ čéąĖą┐čŗ ą┤ą░ąĮąĮčŗčģ, ąĮą░ą┐čĆąĖą╝ąĄčĆ int, double, float, char, bool, void, auto ąĖ čé. ą┤.
12 . ą¤čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ čćąĖčüąĄą╗ ą▓ čĆą░ąĘą╗ąĖčćąĮčŗčģ čüąĖčüč鹥ą╝ą░čģ čüčćąĖčüą╗ąĄąĮąĖčÅ ąĖ č乊čĆą╝ą░čģ:
int number1 = 15 ; // Decimal (ą┤ąĄčüčÅčéąĖčćąĮą░čÅ)
int number2 = 017 ; // Octal (ą▓ąŠčüčīą╝ąĄčĆąĖčćąĮą░čÅ)
int number3 = 0x0F ; // Hexadecimal (čłąĄčüčéąĮą░ą┤čåą░č鹥čĆąĖčćąĮą░čÅ)
int number4 = 0b00001111 ; // Binary (ą┤ą▓ąŠąĖčćąĮą░čÅ)
char number5 = 'A' ; // Symbolic (čüąĖą╝ą▓ąŠą╗čīąĮą░čÅ)
13 . ą¦ąĖčüą╗ą░ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣:
ąóąĖą┐ ąĀą░ąĘą╝ąĄčĆ ą▓ ą▒ą░ą╣čéą░čģ ąóąŠčćąĮąŠčüčéčī, ą▒ąĖčé ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ
float
4
7
double
8
15
ąĀąĄą║ąŠą╝ąĄąĮą┤čāąĄą╝čŗą╣ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čéąĖą┐.
long double
12
> double
// ą¤čĆąĖą╝ąĄčĆčŗ ą┤ąĄą║ą╗ą░čĆą░čåąĖąĖ ąĖ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąĖ.
// ąÆ ą┐čĆąĖą╝ąĄčĆąĄ čéąĖą┐ą░ float ąĖąĘ-ąĘą░ č鹊čćąĮąŠčüčéąĖ 7 ąĮąĄ ą▒čāą┤čāčé čüąŠčģčĆą░ąĮąĄąĮčŗ ą▓čüąĄ
// ąĘąĮą░čćą░čēąĖąĄ čåąĖčäčĆčŗ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░č鹊čĆą░:
float number1 {1.12345678901234567890f }; // Precision : 7
double number2 {1.12345678901234567890 }; // Precision : 15
long double number3 {1.12345678901234567890L };
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ ąĮą░ čüčāčäčäąĖą║čüčŗ f L
ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ąŠč鹊ą▒čĆą░ąČąĄąĮąĖąĄą╝ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ č鹊čćąĮąŠčüčéąĖ ą┐čĆąĖ ą▓čŗą▓ąŠą┤ąĄ čćąĖčüąĄą╗ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣ (ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąŠ ą▓ ąĘą░ą│ąŠą╗ąŠą▓ąŠčćąĮąŠą╝ čäą░ą╣ą╗ąĄ < iomanip>):
std ::cout << std ::setprecision(20 );ą¦ąĖčüą╗ą░ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ ąĘą░ą┐čÅč鹊ą╣ ą╝ąŠąČąĮąŠ ą┤ąĄą╗ąĖčéčī ąĮą░ 0, ą▓ ąŠčéą╗ąĖčćąĖąĄ ąŠčé čåąĄą╗čŗčģ čćąĖčüąĄą╗. ąØą░ą┐čĆąĖą╝ąĄčĆ:
n (čćąĖčüą╗ąŠ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣) / 0 = Infinity(+/-) (ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠčüčéčī)
0.0 / 0.0 = NaN (Not A Number, ąĮąĄ čćąĖčüą╗ąŠ. ą¦ąĖčüą╗ąŠ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣ ą▒ąĄąĘ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖčÅ)
14 . ąŚąĮą░č湥ąĮąĖčÅ čéąĖą┐ą░ bool ąĘą░ąĮąĖą╝ą░čÄčé ą▓ ą┐ą░ą╝čÅčéąĖ 8 ą▒ąĖčé. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┐čĆąĖ ą▓čŗą▓ąŠą┤ąĄ ąĮą░ ą┐ąĄčćą░čéčī ąĘąĮą░č湥ąĮąĖąĄ true ą▒čāą┤ąĄčé ą▓čŗą▓ąĄą┤ąĄąĮąŠ ą║ą░ą║ 1, false ą║ą░ą║ 0. ąŁč鹊 ą╝ąŠąČąĮąŠ ą┐ąŠą╝ąĄąĮčÅčéčī čü ą┐ąŠą╝ąŠčēčīčÄ ąŠą┐ąĄčĆą░č鹊čĆą░ std::boolalpha , č鹊ą│ą┤ą░ ą┐čĆąĖ ą▓čŗą▓ąŠą┤ąĄ ąĮą░ ą┐ąĄčćą░čéčī ąŠąĮąĖ ą▒čāą┤čāčé ą▓čŗą▓ąŠą┤ąĖčéčīčüčÅ ą║ą░ą║ true ąĖ false.
15 . ąØą░ čÅąĘčŗą║ąĄ C čÅą▓ąĮąŠąĄ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ čéąĖą┐ą░ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ ą┐čĆąĄčäąĖą║čüą░ ą▓ ą║čĆčāą│ą╗čŗčģ čüą║ąŠą▒ą║ą░čģ (čéąĖą┐). ąØą░ C++ ą┤ą╗čÅ č鹊ą╣ ąČąĄ čåąĄą╗ąĖ ą┐čĆąĖąĮčÅč鹊 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąŠą┐ąĄčĆą░č鹊čĆ static_cast< čéąĖą┐> , čģąŠčéčÅ ą▓ą░čĆąĖą░ąĮčé čÅąĘčŗą║ą░ C č鹊ąČąĄ čĆą░ą▒ąŠčéą░ąĄčé. ąØą░ą┐čĆąĖą╝ąĄčĆ:
char chA = 'A' ;int intA = (int )chA; // čéą░ą║ ąĮą░ čÅąĘčŗą║ąĄ C int intB = static_cast< int >(chA); // čéą░ą║ ąĮą░ čÅąĘčŗą║ąĄ C++ 16 . ąóąĖą┐ auto . ą¤čĆąĖ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ čéąĖą┐ą░ auto ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ čüą░ą╝ ąĘą░ą┤ą░čüčé ą┐ąŠą┤čģąŠą┤čÅčēąĖą╣ ą▓čüčéčĆąŠąĄąĮąĮčŗą╣ čéąĖą┐ ą┤ą╗čÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣, ąŠčĆąĖąĄąĮčéąĖčĆčāčÅčüčī ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░č鹊čĆą░.
17 . ążąŠčĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖąĄ ą▓čŗą▓ąŠą┤ą░ std::cout . ąÆ čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĄ C++ (#include < ios>, #include < iomanip>) čüčāčēąĄčüčéą▓čāčÄčé ą▒ąŠą│ą░čéčŗąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ą┐ąŠ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÄ ą▓čŗą▓ąŠą┤ąŠą╝ ąĖąĮč乊čĆą╝ą░čåąĖąĖ. ąÆąŠčé ąĖčģ čüą┐ąĖčüąŠą║ (ąĮąĄą┐ąŠą╗ąĮčŗą╣) čü ą║čĆą░čéą║ąĖą╝ ąŠą┐ąĖčüą░ąĮąĖąĄą╝:
std::endl ąÜąŠąĮąĄčå čüčéčĆąŠą║ąĖ.
std::flush ąĪą▒čĆąŠčü ąĮą░ą║ąŠą┐ą╗ąĄąĮąĮąŠą│ąŠ čüąĖą╝ą▓ąŠą╗čīąĮąŠą│ąŠ ą▒čāč乥čĆą░ ąĮą░ čüąĖčüč鹥ą╝čā ą▓čŗą▓ąŠą┤ą░ (菹║čĆą░ąĮ č鹥čĆą╝ąĖąĮą░ą╗ą░).
std::left , std::right , std::internal ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąŠąĘąĖčåąĖąŠąĮąĖčĆąŠą▓ą░ąĮąĖąĄą╝ čü čüąĖą╝ą▓ąŠą╗ą░ą╝ąĖ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ [12].
std::boolalpha ąÉą║čéąĖą▓ą░čåąĖčÅ č鹥ą║čüč鹊ą▓ąŠą│ąŠ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖčÅ ą▒čāą╗ąĄą▓čŗčģ ąĘąĮą░č湥ąĮąĖą╣ (true, false).
std::showpoint , std::noshowpoint ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čĆą░ąĘčĆąĄčłąĄąĮąĖąĄą╝ ąĖą╗ąĖ ąĘą░ą┐čĆąĄč鹊ą╝ ą▒ąĄąĘčāčüą╗ąŠą▓ąĮąŠą│ąŠ ą▓ą║ą╗čÄč湥ąĮąĖčÅ ą┤ąĄčüčÅčéąĖčćąĮąŠą╣ č鹊čćą║ąĖ ą┐čĆąĖ ą▓čŗą▓ąŠą┤ąĄ čćąĖčüąĄą╗ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ ąĘą░ą┐čÅč鹊ą╣. ąĀą░ą▒ąŠčéą░ąĄčé č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą▓čŗą▓ąŠą┤ą░.
std::setfill() ąŻčüčéą░ąĮąŠą▓ąĖčé čüąĖą╝ą▓ąŠą╗ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┤ą╗čÅ ą┐ąŠč鹊ą║ą░ ą▓čŗą▓ąŠą┤ą░ [12].
std::setw() ąŻčüčéą░ąĮąŠą▓ąĖčé čłąĖčĆąĖąĮčā ą▓čŗą▓ąŠą┤ą░ ą┐čĆąĖ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĖ ą┤ą╗čÅ ą┐ąŠč鹊ą║ą░ ą▓čŗą▓ąŠą┤ą░.
std::dec , std::hex , std::oct ą£ąŠą┤ąĖčäąĖčåąĖčĆčāąĄčé ąŠčüąĮąŠą▓ą░ąĮąĖąĄ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą╗čÅ čćąĖčüąĄą╗ ą┐čĆąĖ ą▓ą▓ąŠą┤ąĄ/ą▓čŗą▓ąŠą┤ąĄ.
std::fixed , std::scientific , std::hexfloat , std::defaultfloat ą£ąŠą┤ąĖčäąĖčåąĖčĆčāąĄčé č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą╗čÅ ą▓čŗą▓ąŠą┤ą░ čćąĖčüąĄą╗ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ ąĘą░ą┐čÅč鹊ą╣.
std::setprecision() ąŻčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čüąĖą╝ą▓ąŠą╗ąŠą▓ ą┐ąŠčüą╗ąĄ ą┤ąĄčüčÅčéąĖčćąĮąŠą╣ č鹊čćą║ąĖ (č鹊čćąĮąŠčüčéčī) ą┐čĆąĖ ą▓čŗą▓ąŠą┤ąĄ čćąĖčüąĄą╗ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣.
std::showbase , std::noshowbase ąŻą┐čĆą░ą▓ą╗čÅąĄčé, ą┐ąŠą║ą░ąĘčŗą▓ą░čéčī ąĖą╗ąĖ ąĮąĄ ą┐ąŠą║ą░ąĘčŗą▓ą░čéčī ą┐čĆąĖ ą▓čŗą▓ąŠą┤ąĄ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ą▒ą░ąĘčŗ čćąĖčüą╗ą░ (čéą░ą║ąŠą╣ ą║ą░ą║ 0x).
std::uppercase , std::nouppercase ąŻą┐čĆą░ą▓ą╗čÅąĄčé ą┐ąĄčĆąĄą▓ąŠą┤ąŠą╝ ą▓ ą▓ąĄčĆčģąĮąĖą╣ ąĖą╗ąĖ ąĮąĖąČąĮąĖą╣ čĆąĄą│ąĖčüčéčĆ čüąĖą╝ą▓ąŠą╗ąŠą▓ ą┐čĆąĖ ą▓čŗą▓ąŠą┤ąĄ čłąĄčüčéąĮą░ą┤čåą░č鹥čĆąĖčćąĮąŠą│ąŠ ąĖą╗ąĖ ąĮą░čāčćąĮąŠą│ąŠ č乊čĆą╝ą░čéą░ čćąĖčüąĄą╗.
std::showpos , std::noshowpos ąŻą┐čĆą░ą▓ą╗čÅąĄčé, ą┐ąŠą║ą░ąĘčŗą▓ą░čéčī ąĖą╗ąĖ ąĮąĄ ą┐ąŠą║ą░ąĘčŗą▓ą░čéčī ąĘąĮą░ą║ ą┐ą╗čÄčüą░ ą┐čĆąĖ ą▓čŗą▓ąŠą┤ąĄ čćąĖčüąĄą╗.
18 . ą£ą░č鹥ą╝ą░čéąĖč湥čüą║ąĖąĄ čäčāąĮą║čåąĖąĖ . ą¤ąŠą┤ą║ą╗čÄčćą░čÄčéčüčÅ čüčéčĆąŠčćą║ąŠą╣ #include < cmath>.
std::floor() , std::floorf() , std::floorl() ą×ą║čĆčāą│ą╗ąĄąĮąĖąĄ čćąĖčüą╗ą░ ą▓ąĮąĖąĘ (ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖąĄą╝ ą┤čĆąŠą▒ąĮąŠą╣ čćą░čüčéąĖ).
std::ceil() , std::ceilf() , std::ceill() ą×ą║čĆčāą│ą╗ąĄąĮąĖąĄ čćąĖčüą╗ą░ ą▓ą▓ąĄčĆčģ.
std::abs() ąÉą▒čüąŠą╗čÄčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ čćąĖčüą╗ą░.
std::sin() , std::cos() , std::tan() ąóčĆąĖą│ąŠąĮąŠą╝ąĄčéčĆąĖč湥čüą║ąĖąĄ čäčāąĮą║čåąĖąĖ: čüąĖąĮčāčü, ą║ąŠčüąĖąĮčāčü, čéą░ąĮą│ąĄąĮčü.
std::exp() ąŁą║čüą┐ąŠąĮąĄąĮčéą░.
std::log() ąøąŠą│ą░čĆąĖčäą╝.
std::pow() ąÆąŠąĘą▓ąĄą┤ąĄąĮąĖąĄ ą▓ čüč鹥ą┐ąĄąĮčī.
std::sqrt() ąÜą▓ą░ą┤čĆą░čéąĮčŗą╣ ą║ąŠčĆąĄąĮčī.
std::round ą×ą║čĆčāą│ą╗ąĄąĮąĖąĄ čćąĖčüą╗ą░.
19 . ąöą╗čÅ čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮčŗčģ čéąĖą┐ąŠą▓, čĆą░ąĘą╝ąĄčĆ ą║ąŠč鹊čĆčŗčģ ą╝ąĄąĮčīčłąĄ 4 ą▒ą░ą╣čé (char, short int), ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčéčüčÅ ą░ą┐ą┐ą░čĆą░čéąĮąŠ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą║ąŠą│ą┤ą░ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ąĮą░ą┤ ąĮąĖą╝ąĖ ą┐čĆąŠąĖąĘą▓ąŠą┤čÅčéčüčÅ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ, ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą┐ąĄčĆąĄą▓ąŠą┤ąĖčé ąĖčģ ą▓ čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮčŗąĄ 4-ą▒ą░ą╣čéąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ.
20 . size_t . ąŁč鹊 čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮčŗą╣ čéąĖą┐ ą▒ąĄąĘ ąĘąĮą░ą║ą░, čā ą║ąŠč鹊čĆąŠą│ąŠ ą╝ąŠąČąĄčé ą▒čŗčéčī čĆą░ąĘą╗ąĖčćąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą╣ čüąĖčüč鹥ą╝čŗ. ąØą░ą┐čĆąĖą╝ąĄčĆ ąĮą░ 64-ą▒ąĖčéąĮčŗčģ čüąĖčüč鹥ą╝ą░čģ ąĄą│ąŠ čĆą░ąĘą╝ąĄčĆ čüąŠčüčéą░ą▓ą╗čÅąĄčé 8 ą▒ą░ą╣čé.
21 . std:size(ąĖą╝čÅ_ą╝ą░čüčüąĖą▓ą░) . ą×ą┐ąĄčĆą░č鹊čĆ std:size ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĘą░ą┐čĆąŠčüąĖčéčī čĆą░ąĘą╝ąĄčĆ ą╝ą░čüčüąĖą▓ą░ ą▓ 菹╗ąĄą╝ąĄąĮčéą░čģ, ąĮąĄ ą▓ ą▒ą░ą╣čéą░čģ, ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ.
22 . ą”ąĖą║ą╗ ąĮą░ ąŠčüąĮąŠą▓ąĄ ą┤ąĖą░ą┐ą░ąĘąŠąĮą░ :
for (auto i: ąĖą╝čÅ_ą╝ą░čüčüąĖą▓ą░)
{
č鹥ą╗ąŠ čåąĖą║ą╗ą░
}23 . nullptr . ąŁč鹊 ą░ąĮą░ą╗ąŠą│ NULL ąĮą░ čÅąĘčŗą║ąĄ C, ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░č鹊čĆąŠą▓ čāą║ą░ąĘą░č鹥ą╗ąĄą╣:
int *pNum{nullptr }; // č鹊 ąČąĄ čüą░ą╝ąŠąĄ, čćč鹊 ąĖ int *pNum = NULL; 24 . ąÆąĖčĆčéčāą░ą╗čīąĮą░čÅ ą┐ą░ą╝čÅčéčī . ąÜą░ąČą┤ąŠą╣ ąĘą░ą┐čāčēąĄąĮąĮąŠą╣ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮą░čÅ čüąĖčüč鹥ą╝ą░ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą▓ąĖčĆčéčāą░ą╗čīąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ą┐ą░ą╝čÅčéąĖ čĆą░ąĘą╝ąĄčĆąŠą╝ ą▓ 2^N ą▒ą░ą╣čé (čü ą░ą┤čĆąĄčüą░ą╝ąĖ ąŠčé 0 ą┤ąŠ (2^N)-1). ąŚą┤ąĄčüčī N=32 ą┤ą╗čÅ 32-ą▒ąĖčéąĮčŗčģ čüąĖčüč鹥ą╝, ąĖ N=64 ą┤ą╗čÅ 64-ą▒ąĖčéąĮčŗčģ čüąĖčüč鹥ą╝. ąŁč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▒ą╗ą░ą│ąŠą┤ą░čĆčÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ-ą░ą┐ą┐ą░čĆą░čéąĮąŠą╝čā ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąĖčÄ ą╝ąĄąČą┤čā ą┐čĆąŠčåąĄčüčüąŠčĆąŠą╝ (CPU) ąĖ ą▒ą╗ąŠą║ąŠą╝ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéčīčÄ (Memory Management Unut, MMU), ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĄąŠą▒čĆą░ąĘčāąĄčé čäąĖąĘąĖč湥čüą║čāčÄ ą┐ą░ą╝čÅčéčī (ąŠą┐ąĄčĆą░čéąĖą▓ąĮą░čÅ ą┐ą░ą╝čÅčéčī ąĖ ą┤ąĖčüą║ąŠą▓čŗą╣ čäą░ą╣ą╗ ą┐ąŠą┤ą║ą░čćą║ąĖ) ą▓ ą▓ąĖčĆčéčāą░ą╗čīąĮčāčÄ ą┐ą░ą╝čÅčéčī ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
25 . ąĪč鹥ą║ ąĖ ą║čāčćą░ . ą¤ąŠąĮčÅčéąĖčÅ čüč鹥ą║ą░ (stack) ąĖ ą║čāčćą░ (heap) ąŠčéąĮąŠčüčÅčéčüčÅ ą║ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą╣ ą┐ą░ą╝čÅčéąĖ. ąöąĖąĮą░ą╝ąĖč湥čüą║ą░čÅ ą┐ą░ą╝čÅčéčī ąŠčéą╗ąĖčćą░ąĄčéčüčÅ ąŠčé čüčéą░čéąĖč湥čüą║ąŠą╣ ą┐ą░ą╝čÅčéąĖ (ąŠą┐ąĄčĆą░čéąĖą▓ąĮą░čÅ ą┐ą░ą╝čÅčéčī data ąĖ ą┐ą░ą╝čÅčéčī ą┐čĆąŠą│čĆą░ą╝ą╝ text) č鹥ą╝, ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ čŹčéą░ ą┐ą░ą╝čÅčéčī ą╝ąŠąČąĄčé ą┐ąŠčÅą▓ą╗čÅčéčīčüčÅ ąĖ ąĖčüč湥ąĘą░čéčī, čé. ąĄ. ą▒čāą┤ąĄčé ą▓čŗą┤ąĄą╗čÅčéčīčüčÅ ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ą░čéčīčüčÅ.
ą×ą┤ąĮą░ą║ąŠ ąĖ čā čüč鹥ą║ą░ ąĖ ą║čāčćąĖ ąĄčüčéčī ąŠčéą╗ąĖčćąĖčÅ ą▓ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĖ ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ. ąÆ čüč鹥ą║ąĄ čģčĆą░ąĮąĖčéčüčÅ ąĖąĮč乊čĆą╝ą░čåąĖčÅ ąŠ ą╗ąŠą║ą░ą╗čīąĮčŗčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ čäčāąĮą║čåąĖąĖ ąĖ ąŠ ą┐ąĄčĆąĄą┤ą░ą▓ą░ąĄą╝čŗčģ ą▓ ąĮąĄčæ ą┐ą░čĆą░ą╝ąĄčéčĆą░čģ. ąóą░ą║ąČąĄ ą╗ąŠą║ą░ą╗čīąĮčŗąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ ą▒čŗčéčī ą▓ąĮčāčéčĆąĖ ą▒ą╗ąŠą║ą░ ąĖąĘ čäąĖą│čāčĆąĮčŗčģ čüą║ąŠą▒ąŠą║. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą╗ąŠą║ą░ą╗čīąĮčŗčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ, ą▓čŗą┤ąĄą╗čÅąĄą╝čŗčģ ą▓ čüč鹥ą║ąĄ, ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąŠą│čĆą░ąĮąĖčćąĖą▓ą░ąĄčéčüčÅ ąŠą▒ą╗ą░čüčéčīčÄ ą┤ąĄą╣čüčéą▓ąĖčÅ ą╗ąŠą║ą░ą╗čīąĮčŗčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ, ąĖ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ąŠą▒ą╗ą░čüč鹥ą╣ čüč鹥ą║ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ, ą▒ąĄąĘ ą┐čĆčÅą╝ąŠą│ąŠ čāčćą░čüčéąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčéą░. ą¤čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ą║čāčćąĖ čüąĖčéčāą░čåąĖčÅ ąŠą▒čĆą░čéąĮą░čÅ, ąĘą┤ąĄčüčī ąĖą╝ąĄąĮąĮąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčé ąŠčéą▓ąĄčćą░ąĄčé ąĘą░ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ (ąŠą┐ąĄčĆą░č鹊čĆ new , ą▓čŗąĘąŠą▓ ą║ąŠąĮčüčéčĆčāą║č鹊čĆąŠą▓ ą║ą╗ą░čüčüą░) ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ (ąŠą┐ąĄčĆą░č鹊čĆ delete , ą▓čŗąĘąŠą▓ ą┤ąĄčüčéčĆčāą║č鹊čĆąŠą▓ ą║ą╗ą░čüčüą░).
26 . ąŻą║ą░ąĘą░č鹥ą╗ąĖ ą╝ąŠąČąĮąŠ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī čü ą┐ąŠą╝ąŠčēčīčÄ ąŠą┐ąĄčĆą░č鹊čĆą░ new ą▓ąŠčé čéą░ą║:
int *p1 {new int }; // ąÆčŗą┤ąĄą╗ąĄąĮąĖąĄ ą▓ ą║čāč湥 ą┐ą░ą╝čÅčéąĖ ą┐ąŠą┤ čćąĖčüą╗ąŠ int
// ąĖ ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĮąĖąĄ p1 ą░ą┤čĆąĄčüą░ čŹč鹊ą│ąŠ čćąĖčüą╗ą░. int *p2 {new int {12 }}; // ąÆčŗą┤ąĄą╗ąĄąĮąĖąĄ ą▓ ą║čāč湥 ą┐ą░ą╝čÅčéąĖ ą┐ąŠą┤ 12 čćąĖčüąĄą╗ int
// ąĖ ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĮąĖąĄ p2 ą░ą┤čĆąĄčüą░ ą┐ąĄčĆą▓ąŠą│ąŠ ąĖąĘ ąĮąĖčģ. 27 . ą¤čĆąĖą╝ąĄčĆ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą╝ą░čüčüąĖą▓ąŠą▓ čü ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄą╝ ą┐ą░ą╝čÅčéąĖ ąĖąĘ ą║čāčćąĖ:
#include < iostream> int main ()
const size_t size{10 };
// ąĀą░ąĘą╗ąĖčćąĮčŗąĄ čüą┐ąŠčüąŠą▒čŗ, čü ą┐ąŠą╝ąŠčēčīčÄ ą║ąŠč鹊čĆčŗčģ ą▓čŗ ą╝ąŠąČąĄč鹥 ą┤ąĄą║ą╗ą░čĆąĖčĆąŠą▓ą░čéčī
// ą╝ą░čüčüąĖą▓čŗ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąĖ, ąĖ ą║ą░ą║ ąŠąĮąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮčŗ.
// ąÆ ą╝ą░čüčüąĖą▓ąĄ salaries ą▒čāą┤čāčé čüąŠą┤ąĄčƹȹ░čéčīčüčÅ ąĮąĄąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ,
// čé. ąĄ. čŹč鹊čé ą╝ą░čüčüąĖą▓ ą┐čĆąĖ čüąŠąĘą┤ą░ąĮąĖąĖ ąĮąĄ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāąĄčéčüčÅ:
double *p_salaries { new double [size]};
// ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą▓čüąĄ ąĘąĮą░č湥ąĮąĖčÅ ą╝ą░čüčüąĖą▓ą░ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāčÄčéčüčÅ ą▓ 0.
// ąśčüą║ą╗čÄč湥ąĮąĖčÅ ą┐čĆąĖ čĆą░ą▒ąŠč鹥 čü ą╝ą░čüčüąĖą▓ąŠą╝ ąŠčéą║ą╗čÄčćą░čÄčéčüčÅ:
int *p_students { new (std::nothrow) int [size]{} };
// ąÆčŗą┤ąĄą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą┐ąŠą┤ ą╝ą░čüčüąĖą▓ ąĖąĘ size 菹╗ąĄą╝ąĄąĮč鹊ą▓ (čé. ąĄ. 10).
// ą¤ąĄčĆą▓čŗąĄ ą┐čÅčéčī 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą╝ą░čüčüąĖą▓ą░ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāąĄčéčüčÅ ąĘąĮą░č湥ąĮąĖčÅą╝ąĖ
// 1, 2, 3, 4, 5, ą░ ąŠčüčéą░ą╗čīąĮčŗąĄ 菹╗ąĄą╝ąĄąĮčéčŗ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāčÄčéčüčÅ
// ąĮčāą╗čÅą╝ąĖ:
double *p_scores { new (std::nothrow) double [size]{1 ,2 ,3 ,4 ,5 }};
// ą¤čĆąŠą▓ąĄčĆą║ą░ ąĮą░ nullptr: ą║ąŠčĆčĆąĄą║čéąĮąŠ ą╗ąĖ ą▒čŗą╗ą░ ą▓čŗą┤ąĄą╗ąĄąĮą░ ą┐ą░ą╝čÅčéčī ą┐ąŠą┤ ą╝ą░čüčüąĖą▓.
if (p_scores)
{
std::cout << "size of scores (it's a regular pointer) : " \
<< sizeof (p_scores) << std::endl;
std::cout << "Successfully allocated memory for scores." \
<< std::endl;
// ą¤ąĄčćą░čéčī 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą╝ą░čüčüąĖą▓ą░. ą£ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą║ą░ą║ čéčĆą░ą┤ąĖčåąĖąŠąĮąĮčāčÄ
// ąĮąŠčéą░čåąĖčÄ ąŠą▒čĆą░čēąĄąĮąĖčÅ ą║ 菹╗ąĄą╝ąĄąĮčéą░ą╝ ą╝ą░čüčüąĖą▓ą░, čéą░ą║ ąĖ ą░čĆąĖčäą╝ąĄčéąĖą║čā čāą║ą░ąĘą░č鹥ą╗ąĄą╣:
for ( size_t i{}; i < size ; ++i)
{
std::cout << "value : " << p_scores[i] << " : " << \
*(p_scores + i) << std::endl;
}
}delete [] p_salaries;
p_salaries = nullptr ;delete [] p_students;
p_students = nullptr ;delete [] p_scores;
p_scores = nullptr ;return 0 ;
}ąÆą░ąČąĮąŠąĄ ąĘą░ą╝ąĄčćą░ąĮąĖąĄ : ą╝ą░čüčüąĖą▓čŗ, ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗąĄ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąĖ, čüąĖą╗čīąĮąŠ ąŠčéą╗ąĖčćą░čÄčéčüčÅ ąŠčé ą╝ą░čüčüąĖą▓ąŠą▓, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ čüčéą░čéąĖč湥čüą║ąĖ ąĖą╗ąĖ ą╗ąŠą║ą░ą╗čīąĮąŠ ą▓ čüč鹥ą║ąĄ. ąØą░ą┐čĆąĖą╝ąĄčĆ ą┐ąŠ ą╝ą░čüčüąĖą▓ą░ą╝, ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗą╝ ą▓ ą║čāč湥, ąĮąĄą╗čīąĘčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĖč鹥čĆą░čåąĖčÄ ą┐ąŠ ą┤ąĖą░ą┐ą░ąĘąŠąĮčā (for(auto i: ąĖą╝čÅ_ą╝ą░čüčüąĖą▓ą░){}), ąĖ ą┤ą╗čÅ ąĮąĖčģ ąĮąĄ čĆą░ą▒ąŠčéą░ąĄčé ąŠą┐ąĄčĆą░č鹊čĆ std::size .
// ąĪčĆą░ą▓ąĮąĄąĮąĖąĄ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąĖčģ ą╝ą░čüčüąĖą▓ąŠą▓ čü ą╝ą░čüčüąĖą▓ą░ą╝ąĖ ą▓ čüč鹥ą║ąĄ:
std::cout << "=====================================" << std::endl;// ąŁč鹊čé ą╝ą░čüčüąĖą▓ ą▓čŗą┤ąĄą╗čÅąĄčéčüčÅ ąĖąĘ čüč鹥ą║ą░, ąĖ ąĮą░ ąĮąĄą╝ ą▒čāą┤ąĄčé ąĮąŠčĆą╝ą░ą╗čīąĮąŠ čĆą░ą▒ąŠčéą░čéčī ą║ąŠą┤
// čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ std::size ąĖ for( auto s : scores):
int scores[10 ] {1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 ,10 };
std::cout << "scores size : " << std::size (scores) << std::endl;
for ( auto s : scores)
{
std::cout << "value : " << s << std::endl;
}// ąŁč鹊čé ą╝ą░čüčüąĖą▓ ą▓čŗą┤ąĄą╗čÅąĄčéčüčÅ ąĖąĘ ą║čāčćąĖ, ąĖ ąĮą░ ąĮąĄą╝ ąĮąĄą╗čīąĘčÅ ą▒čāą┤ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī
// std::size ąĖ for( auto s : p_scores1):
int * p_scores1 = new int [10 ] {1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 ,10 };
// std::cout << "p_scores1 size : " << std::size(p_scores1) << std::endl;
/*
for( auto s : p_scores1)
{
std::cout << "value : " << s << std::endl;
}
*/
28 . ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čüčüčŗą╗ąŠą║ ąĮą░ C++ ą╝ąŠąČąĄčé ą▒čŗčéčī čüą┤ąĄą╗ą░ąĮąŠ ą┐ąŠ-ą┤čĆčāą│ąŠą╝čā:
// ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ int_data ąĖ double_data:
int int_data{33 };
double double_data{55 };// ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ref_int_data ąĖ ref_double_data,
// ąĖ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ ąĖčģ ą░ą┤čĆąĄčüą░ą╝ąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ int_data ąĖ double_data:
int & ref_int_data{int_data};
double & ref_double_data{double_data};
ąĪč鹊ąĖčé ąŠčéą╝ąĄčéąĖčéčī, čćč鹊 č鹊ą╗čīą║ąŠ čéą░ą║ ąČąĄ, ą║ą░ą║ ąĖ ąĮą░ čÅąĘčŗą║ąĄ C, čüčüčŗą╗ą║ąĖ ąĮą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ čĆą░ą▒ąŠčéą░čÄčé č鹊čćąĮąŠ čéą░ą║ ąČąĄ, ą║ą░ą║ ąĖ ąĖą╝ąĄąĮą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ. ąó. ąĄ. ą┤ą╗čÅ ą┐čĆąĄą┤čŗą┤čāčēąĄą│ąŠ ą┐čĆąĖą╝ąĄčĆą░ &int_data ąĖ &ref_int_data ą┤ą░ą┤čāčé ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ ą░ą┤čĆąĄčü.
29 . ąĪčüčŗą╗ą║ąĖ ąĖ čāą║ą░ąĘą░č鹥ą╗ąĖ . ąÆ ą┐čĆąĖąĮčåąĖą┐ąĄ ąĖ čüčüčŗą╗ą║ąĖ, ąĖ čāą║ą░ąĘą░č鹥ą╗ąĖ ą┤ąĄą╗ą░čÄčé ąŠą┤ąĮąŠ ąĖ č鹊 ąČąĄ, ąĮąŠ ą▓čüąĄ ąČąĄ ąĖčģ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĖ čĆą░ą▒ąŠčéą░ čü ąĮąĖą╝ąĖ ąŠčéą╗ąĖčćą░ąĄčéčüčÅ.
ąĪčüčŗą╗ą║ąĖ (references) :
- ąØąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čĆą░ąĘąĖą╝ąĄąĮąŠą▓ą░ąĮąĖąĄ (*) ą┤ą╗čÅ čćč鹥ąĮąĖčÅ ąĖ ąĘą░ą┐ąĖčüąĖ ą┐ąŠ čüčüčŗą╗ą║ąĄ. ąĪčüčŗą╗ą║ą░ čāą║ą░ąĘčŗą▓ą░ąĄčéčüčÅ ą▓ ą║ąŠą┤ąĄ č鹊čćąĮąŠ čéą░ą║ ąČąĄ, ą║ą░ą║ ąĖčüčģąŠą┤ąĮą░čÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ.
ąŻą║ą░ąĘą░č鹥ą╗ąĖ (pointers) :
- ą¤čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ ąĘąĮą░č湥ąĮąĖčÄ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ ąĖ ąĘą░ą┐ąĖčüąĖ ą┐ąŠ čāą║ą░ąĘą░č鹥ą╗čÄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čĆą░ąĘąĖą╝ąĄąĮąŠą▓ą░ąĮąĖąĄ (*).
ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą║ąŠą┤ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ čüčüčŗą╗ąŠą║ ą▒ąŠą╗ąĄąĄ ą▒ąĄąĘąŠą┐ą░čüąĄąĮ ąĖ ą┐čĆąŠčüčé. ąŻą║ą░ąĘą░č鹥ą╗ąĖ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮąŠ ą╝ą░ąĮąĖą┐čāą╗ąĖčĆąŠą▓ą░čéčī ą┤ą░ąĮąĮčŗą╝ąĖ.
int age {58 }; // ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ
int & ref_age{age}; // ąŠą▒čŗčćąĮą░čÅ čüčüčŗą╗ą║ą░ ąĮą░ age,
ref_age++; // ą┐ąŠąĘą▓ąŠą╗čÅčÄčēą░čÅ ąĄčæ ąĖąĘą╝ąĄąĮčÅčéčī // ąĪčüčŗą╗ą║ą░ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąĄčĆąĄąĮą░čüčéčĆąŠąĄąĮą░ ąĮą░ ą┤čĆčāą│čāčÄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ.
// ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ ą╝ąŠąČąĮąŠ ą┐čĆąŠą┤ąĄą╗ą░čéčī čü čāą║ą░ąĘą░č鹥ą╗ąĄą╝, ąĄčüą╗ąĖ ąŠą▒čŖčÅą▓ąĖčéčī
// ąĄą│ąŠ čü ą╝ąŠą┤ąĖčäąĖą║ą░č鹊čĆąŠą╝ const:
int * const pnt_age{&age};
pnt_age = nullptr ; // ąĮą░ čŹčéčā čüčéčĆąŠą║čā ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą▓čŗą┤ą░čüčé ąŠčłąĖą▒ą║čā
const-čüčüčŗą╗ą║ą░ . ąĪčüčŗą╗ą║čā ą╝ąŠąČąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī čéą░ą║, čćč鹊 č湥čĆąĄąĘ ąĮąĄčæ ąĮąĄą▓ąŠąĘą╝ąŠąČąĮąŠ ą▒čāą┤ąĄčé ąĖąĘą╝ąĄąĮąĖčéčī ąĄčæ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ:
const int & const_ref_age{age};
// ąóąĄą┐ąĄčĆčī ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ age ąĮąĄą╗čīąĘčÅ ą┐ąŠą╝ąĄąĮčÅčéčī č湥čĆąĄąĘ čŹčéčā čüčüčŗą╗ą║čā:
const_ref_age = 59 ; // ąĮą░ čŹčéčā čüčéčĆąŠą║čā ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą▓čŗą┤ą░čüčé ąŠčłąĖą▒ą║čā
// ąÉąĮą░ą╗ąŠą│ const-čüčüčŗą╗ą║ąĖ ą╝ąŠąČąĮąŠ čüą┤ąĄą╗ą░čéčī čü ą┐ąŠą╝ąŠčēčīčÄ čāą║ą░ąĘą░č鹥ą╗čÅ:
const int * const const_ptr_to_const_age{&age};
const_ptr_to_const_age = 59 ; // ąĮą░ čŹčéčā čüčéčĆąŠą║čā ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą▓čŗą┤ą░čüčé ąŠčłąĖą▒ą║čā
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĮąĄ ą▒čŗą▓ą░ąĄčé const-čüčüčŗą╗ąŠą║ ąĮą░ ąĮąĄ ąĖąĘą╝ąĄąĮčÅąĄą╝čāčÄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ, čŹč鹊 ąĮąĄ ąĖą╝ąĄąĄčé čüą╝čŗčüą╗ą░. ą¤ąŠčŹč鹊ą╝čā ąĮą░ čüą╗ąĄą┤čāčÄčēąĄąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą▓čŗą┤ą░čüčé ąŠčłąĖą▒ą║čā:
const int & const weird_ref_age{age}; // ąŠčłąĖą▒ą║ą░, čŹč鹊 ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą▒ąĄčüčüą╝čŗčüą╗ąĄąĮąĮąŠąĄ!
30 . ąØą░ čÅąĘčŗą║ąĄ C++ ą╝ąŠąČąĮąŠ čĆą░ą▒ąŠčéą░čéčī čü čéčĆą░ą┤ąĖčåąĖąŠąĮąĮčŗą╝ąĖ čüčéčĆąŠą║ą░ą╝ąĖ čÅąĘčŗą║ą░ C, čé. ąĄ. ASCIIZ-čüčéčĆąŠą║ą░ą╝ąĖ (ą╝ą░čüčüąĖą▓ čüąĖą╝ą▓ąŠą╗ąŠą▓ char, ąĘą░ą║ą░ąĮčćąĖą▓ą░čÄčēąĖą╣čüčÅ 0). ą×ą┤ąĮą░ą║ąŠ čĆą░ą▒ąŠčéą░čéčī čü čéą░ą║ąĖą╝ąĖ čüčéčĆąŠą║ą░ą╝ąĖ ąĮąĄ ąŠč湥ąĮčī čāą┤ąŠą▒ąĮąŠ, ą┐ąŠčüą║ąŠą╗čīą║čā ąĮčāąČąĮąŠ čüą╗ąĄą┤ąĖčéčī ąĘą░ ą▒čāč乥čĆąŠą╝ ą▓ ą┐ą░ą╝čÅčéąĖ, ą│ą┤ąĄ ą┐ąŠą╝ąĄčēą░ąĄčéčüčÅ čéą░ą║ą░čÅ čüčéčĆąŠą║ą░, čé. ąĄ. ąĮčāąČąĮąŠ čüą╗ąĄą┤ąĖčéčī ąĘą░ čĆą░ąĘą╝ąĄčĆąŠą╝ čüčéčĆąŠą║ąĖ ą▓ ą┐ą░ą╝čÅčéąĖ. ą¤ąŠ čŹč鹊ą╣ ą┐čĆąĖčćąĖąĮąĄ ą▓ C++ ą┐ąŠčÅą▓ąĖą╗čüčÅ ąĄčēąĄ ąŠą┤ąĖąĮ čéąĖą┐ std::string (ą┐ąŠą┤ą║ą╗čÄčćą░ąĄčéčüčÅ #include < string>), ą║ąŠč鹊čĆčŗą╣ ą┤ą░ąĄčé ą▒ąŠą╗ąĄąĄ ą┐čĆąŠčüč鹊ą╣ ąĖąĮč鹥čĆč乥ą╣čü ą┤ą╗čÅ čĆą░ą▒ąŠčéčŗ čüąŠ čüčéčĆąŠą║ą░ą╝ąĖ, č湥ą╝ čüčéą░ąĮą┤ą░čĆčéąĮą░čÅ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░ < string.h> čÅąĘčŗą║ą░ C. ąĪ čéąĖą┐ąŠą╝ std::string ą╝ąŠąČąĮąŠ ą░ą▒čüčéčĆą░ą│ąĖčĆąŠą▓ą░čéčīčüčÅ ąŠčé čĆą░ąĘą╝ąĄčĆąŠą▓ čüčéčĆąŠą║, ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ ąĘą░ą▓ąĄčĆčłą░čéčī ąĖčģ ąĮčāą╗ąĄą╝ ('\0') ąĖ ąŠčéčüą╗ąĄąČąĖą▓ą░čéčī ą│čĆą░ąĮąĖčåčŗ ą╝ą░čüčüąĖą▓ą░ čüčéčĆąŠą║ąĖ.
cctype . ą×čüąĮąŠą▓ąĮčŗąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ą╝ą░ąĮąĖą┐čāą╗čÅčåąĖąĖ ąĮą░ą┤ čüąĖą╝ą▓ąŠą╗ą░ą╝ąĖ ąĪ++ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ < cctype> [14] (čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčé C-ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĄ < ctype.h>):
isalnum . ą¤čĆąŠą▓ąĄčĆą║ą░, čÅą▓ą╗čÅąĄčéčüčÅ ą╗ąĖ čüąĖą╝ą▓ąŠą╗ ą░ą╗čäą░ą▓ąĖčéąĮąŠ-čåąĖčäčĆąŠą▓čŗą╝.isalpha . ą¤čĆąŠą▓ąĄčĆą║ą░, čÅą▓ą╗čÅąĄčéčüčÅ ą╗ąĖ čüąĖą╝ą▓ąŠą╗ ą░ą╗čäą░ą▓ąĖčéąĮčŗą╝.isdigit . ą¤čĆąŠą▓ąĄčĆą║ą░, čÅą▓ą╗čÅąĄčéčüčÅ ą╗ąĖ čüąĖą╝ą▓ąŠą╗ čåąĖčäčĆąŠą╣ (0 .. 9).isxdigit . ą¤čĆąŠą▓ąĄčĆą║ą░, čÅą▓ą╗čÅąĄčéčüčÅ ą╗ąĖ čüąĖą╝ą▓ąŠą╗ čłąĄčüčéąĮą░ą┤čåą░č鹥čĆąĖčćąĮąŠą╣ čåąĖčäčĆąŠą╣ (0 .. 9, a .. f, A .. F).isblank . ą¤čĆąŠą▓ąĄčĆą║ą░, čÅą▓ą╗čÅąĄčéčüčÅ ą╗ąĖ čüąĖą╝ą▓ąŠą╗ ą┐čāčüčéčŗą╝, čé. ąĄ. ą┐čĆąŠą▒ąĄą╗ąŠą╝ (ąĮą░čćąĖąĮą░čÅ čü C++11).islower , isupper . ą¤čĆąŠą▓ąĄčĆą║ą░, ąĮą░čģąŠą┤ąĖčéčüčÅ ą╗ąĖ čüąĖą╝ą▓ąŠą╗ ą▓ ąĮąĖąČąĮąĄą╝ čĆąĄą│ąĖčüčéčĆąĄ ąĖą╗ąĖ ą▓ ą▓ąĄčĆčģąĮąĄą╝ čĆąĄą│ąĖčüčéčĆąĄ.std::tolower , std::toupper . ą¤čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ čüąĖą╝ą▓ąŠą╗ąŠą▓ ą║ ąĮąĖąČąĮąĄą╝čā ąĖą╗ąĖ ą▓ąĄčĆčģąĮąĄą╝čā čĆąĄą│ąĖčüčéčĆčā.
cstring . ąóą░ą║ąČąĄ čüčāčēąĄčüčéą▓čāčÄčé std::-ą░ąĮą░ą╗ąŠą│ąĖ C-čäčāąĮą║čåąĖą╣ < string.h>, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ ą▓ ąĘą░ą│ąŠą╗ąŠą▓ąŠčćąĮąŠą╝ čäą░ą╣ą╗ąĄ < cstring>.
31 . ą¤čĆąĖą╝ąĄčĆčŗ ą┤ąĄą║ą╗ą░čĆą░čåąĖąĖ čüčéčĆąŠą║ čéąĖą┐ą░ std::string :
#include < iostream> #include < string> // ą¤čāčüčéą░čÅ čüčéčĆąŠą║ą░:
std::string full_name;
// ąśąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ čüčéčĆąŠą║ąĖ ą╗ąĖč鹥čĆą░ą╗ąŠą╝:
std::string planet {"Earth. Where the sky is blue" };
// ąśąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ čüčéčĆąŠą║ąĖ čüčāčēąĄčüčéą▓čāčÄčēąĄą╣ čüčéčĆąŠą║ąŠą╣:
std::string prefered_planet{planet};
// ąśąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ čüčéčĆąŠą║ąĖ čćą░čüčéčīčÄ čüčéčĆąŠą║ąŠą▓ąŠą│ąŠ ą╗ąĖč鹥čĆą░ą╗ą░ ("Hello"):
std::string message {"Hello there" ,5 };
// ąśąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ ą║ąŠą┐ąĖčÅą╝ąĖ čüąĖą╝ą▓ąŠą╗ą░ (ą▒čāą┤ąĄčé čüąŠą┤ąĄčƹȹ░čéčī "eeee"):
std::string weird_message (4 ,'e' ) ;"Hello World" };
// ąśąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ čćą░čüčéčīčÄ čüčāčēąĄčüčéą▓čāčÄčēąĄą╣ čüčéčĆąŠą║ąĖ, ąĮą░čćąĖąĮą░čÅ čü ąĖąĮą┤ąĄą║čüą░ 6
// ą▓ ą║ąŠą╗ąĖč湥čüčéą▓ąĄ 5 čüąĖą╝ą▓ąŠą╗ąŠą▓ (ą▒čāą┤ąĄčé čüąŠą┤ąĄčƹȹ░čéčī "World"):
std::string saying_hello{ greeting,6 ,5 };32 . One Definition Rule (ODR) . ą¤čĆą░ą▓ąĖą╗ąŠ ąŠą┤ąĮąŠą│ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą│ą╗ą░čüąĖčé: "ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ąĮąĄ ą╝ąŠą│čāčé ą┐ąŠčÅą▓ą╗čÅčéčīčüčÅ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ąĖą╗ąĖ ąĄą┤ąĖąĮąĖčåą░čģ čéčĆą░ąĮčüą╗čÅčåąĖąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą│ąŠ čĆą░ąĘą░". ąŁč鹊 ąŠčéąĮąŠčüąĖčéčüčÅ ą║ ą│ą╗ąŠą▒ą░ą╗čīąĮčŗą╝ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝, ąĖą╝ąĄąĮą░ą╝ čäčāąĮą║čåąĖą╣. ą¤ąŠą┤ "ąĄą┤ąĖąĮąĖčåąĄą╣ čéčĆą░ąĮčüą╗čÅčåąĖąĖ" ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčéčüčÅ ą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄą╝čŗą╣ čäą░ą╣ą╗ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░ C++.
ąśčüą║ą╗čÄč湥ąĮąĖąĄ ąĖąĘ čŹč鹊ą│ąŠ ą┐čĆą░ą▓ąĖą╗ą░ ąŠčéąĮąŠčüąĖčéčüčÅ č鹊ą╗čīą║ąŠ ą║ ą║ą╗ą░čüčüą░ą╝: ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ č鹊ą│ąŠ ąĖą╗ąĖ ąĖąĮąŠą│ąŠ ą║ą╗ą░čüčüą░ ą╝ąŠąČąĄčé čüąŠą┤ąĄčƹȹ░čéčīčüčÅ ą▓ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ąĄą┤ąĖąĮąĖčåą░čģ čéčĆą░ąĮčüą╗čÅčåąĖąĖ, ąĮąŠ ą▓ ąŠą┤ąĮąŠą╣ ąĄą┤ąĖąĮąĖčåąĄ čéčĆą░ąĮčüą╗čÅčåąĖąĖ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ąŠą┤ąĮąŠąĖą╝ąĄąĮąĮčŗčģ ą║ą╗ą░čüčüąŠą▓. ą¤čĆąĖčćąĖąĮą░ čŹč鹊ą│ąŠ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą▓ č鹊ą╝, čćč鹊 ąĮą░ą╝ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ čüąŠąĘą┤ą░ą▓ą░čéčī ąŠą▒čŖąĄą║čéčŗ čŹčéąĖčģ ą║ą╗ą░čüčüąŠą▓, čéą░ą║ čćč鹊 ą║ą░ąČą┤ą░čÅ ąĄą┤ąĖąĮąĖčåą░ čéčĆą░ąĮčüą╗čÅčåąĖąĖ ą┤ąŠą╗ąČąĮą░ ą▓ąĖą┤ąĄčéčī ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čüą▓ąŠąĄą│ąŠ ą║ą╗ą░čüčüą░. ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čüą▓ąŠąĄą│ąŠ ą║ą╗ą░čüčüą░ ą┐ąŠą┤ą║ą╗čÄčćą░ąĄčéčüčÅ ą║ ąĖčüčģąŠą┤ąĮąŠą╝čā ą║ąŠą┤čā C++ čäą░ą╣ą╗ą░ą╝ąĖ *.h (ąĖą╗ąĖ *.hpp) čü ą┐ąŠą╝ąŠčēčīčÄ ą┤ąĖčĆąĄą║čéąĖą▓čŗ #include.
ąĪąĖą│ąĮą░čéčāčĆą░ čäčāąĮą║čåąĖąĖ . ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 "ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ" ą┤ą╗čÅ čäčāąĮą║čåąĖąĖ ąĮą░ čÅąĘčŗą║ąĄ C++ ąŠąĘąĮą░čćą░ąĄčé ąĮąĄ č鹊ą╗čīą║ąŠ ąĖą╝čÅ čäčāąĮą║čåąĖąĖ, ąĮąŠ čéą░ą║ąČąĄ ąĖ čāąĮąĖą║ą░ą╗čīąĮčŗą╣ ą┐ąŠ čéąĖą┐čā ąĮą░ą▒ąŠčĆ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓. ąŁč鹊 ąĮą░ąĘčŗą▓ą░čÄčé čüąĖą│ąĮą░čéčāčĆąŠą╣ čäčāąĮą║čåąĖąĖ. ąÜą░ą║ ąĮąĖ čüčéčĆą░ąĮąĮąŠ, ąĮą░ C++ ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝čŗą╣ čéąĖą┐ ą║ čüąĖą│ąĮą░čéčāčĆąĄ čäčāąĮą║čåąĖąĖ ąĮąĄ ąŠčéąĮąŠčüąĖčéčüčÅ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą▓ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠą╝ ą║ąŠąĮč鹥ą║čüč鹥 ąĖą╝ąĄąĮąĮąŠ čüąĖą│ąĮą░čéčāčĆą░ čäčāąĮą║čåąĖąĖ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī čāąĮąĖą║ą░ą╗čīąĮąŠą╣. ąó. ąĄ. ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą┤ą▓ą░ ąŠą┤ąĖąĮą░ą║ąŠą▓čŗčģ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ čäčāąĮą║čåąĖąĖ, ąŠą┤ąĮą░ą║ąŠ ą╝ąŠą│čāčé ą▒čŗčéčī čäčāąĮą║čåąĖąĖ čü ąŠą┤ąĖąĮą░ą║ąŠą▓čŗą╝ąĖ ąĖą╝ąĄąĮą░ą╝ąĖ, ąĮąŠ čü čĆą░ąĘąĮčŗą╝ąĖ čüąĖą│ąĮą░čéčāčĆą░ą╝ąĖ: čü čĆą░ąĘąĮčŗą╝ąĖ ąĮą░ą▒ąŠčĆą░ą╝ąĖ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ (čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝ą░čÅ ą┐ąĄčĆąĄą│čĆčāąĘą║ą░ čäčāąĮą║čåąĖąĖ, function overloading).
ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ (definition) ąĖ ą┤ąĄą║ą╗ą░čĆą░čåąĖčÅ (declaration) čäčāąĮą║čåąĖąĖ . ąśąĮąŠą│ą┤ą░ ą▒ąŠą╗ąĄąĄ ą│ąĖą▒ą║ąĖą╝ ą▒čāą┤ąĄčé čĆą░ąĘą╝ąĄčüčéąĖčéčī ąĘą░ą│ąŠą╗ąŠą▓ąŠą║ čäčāąĮą║čåąĖąĖ (ą┤ąĄą║ą╗ą░čĆą░čåąĖčÄ) ą▓ ąŠčéą┤ąĄą╗čīąĮąŠą╝ čäą░ą╣ą╗ąĄ. ąóą░ą║ąĖąĄ čäą░ą╣ą╗čŗ ąĮą░ąĘčŗą▓ą░čÄčé ąĘą░ą│ąŠą╗ąŠą▓ąŠčćąĮčŗą╝ąĖ (header files), ąĖ ąŠąĮąĖ ą┐ąŠą╗čāčćą░čÄčé čĆą░čüčłąĖčĆąĄąĮąĖąĄ *.h ąĖą╗ąĖ *.hpp. ąĪą░ą╝ ą║ąŠą┤ č鹥ą╗ą░ čäčāąĮą║čåąĖąĖ, čé. ąĄ. ąĄčæ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ (ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ) ą▒čāą┤ąĄčé ą┐čĆąĖ čŹč鹊ą╝ čĆą░ąĘą╝ąĄčēą░čéčīčüčÅ ą▓ ą╝ąŠą┤čāą╗ąĄ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░, ą▓ čäą░ą╣ą╗ąĄ čü čĆą░čüčłąĖčĆąĄąĮąĖąĄą╝ *.cpp. ąöąĄą║ą╗ą░čĆą░čåąĖąĖ čäčāąĮą║čåąĖą╣ čéą░ą║ąČąĄ ą╝ąŠą│čāčé čĆą░ąĘą╝ąĄčēą░čéčīčüčÅ ąĖ ą▓ ąĮą░čćą░ą╗ąĄ ą╝ąŠą┤čāą╗čÅ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░, ąĮąĄ ąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ ą▓ ąĘą░ą│ąŠą╗ąŠą▓ąŠčćąĮčŗčģ čäą░ą╣ą╗ą░čģ. ąöąĄą║ą╗ą░čĆą░čåąĖčÄ čäčāąĮą║čåąĖąĖ čéą░ą║ąČąĄ ąĖąĮąŠą│ą┤ą░ ąĮą░ąĘčŗą▓ą░čÄčé ą┐čĆąŠč鹊čéąĖą┐ąŠą╝ čäčāąĮą║čåąĖąĖ.
33 . ąśąĘ čäčāąĮą║čåąĖąĖ ą╝ąŠąČąĮąŠ ą▓čŗą▓ąŠą┤ąĖčéčī ą┤ą░ąĮąĮčŗąĄ čüą╗ąĄą┤čāčÄčēąĖą╝ąĖ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ, ą▓ ą┐ąŠčĆčÅą┤ą║ąĄ čāą▒čŗą▓ą░ąĮąĖčÅ ą┐čĆąĄą┤ą┐ąŠčćč鹥ąĮąĖčÅ:
- ą¦ąĄčĆąĄąĘ ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
ą¤čĆąĖ ą▓ąŠąĘą▓čĆą░č鹥 ą┐ąŠ ąĘąĮą░č湥ąĮąĖčÄ čüą╗ąĄą┤čāąĄčé ąĖą╝ąĄčéčī ą▓ ą▓ąĖą┤čā, čćč鹊 ą▓ čüąŠą▓čĆąĄą╝ąĄąĮąĮčŗčģ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░čģ ą▓ąŠąĘą▓čĆą░čé ą┐ąŠ ąĘąĮą░č湥ąĮąĖčÄ ąŠą▒čŗčćąĮąŠ ąŠą┐čéąĖą╝ąĖąĘąĖčĆčāąĄčéčüčÅ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆąŠą╝, ą║ąŠą│ą┤ą░ čŹč鹊 ą▓ąŠąĘą╝ąŠąČąĮąŠ, ąĖ čäčāąĮą║čåąĖčÅ ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāąĄčéčüčÅ ąĘą░ ą▓ą░čłąĄą╣ čüą┐ąĖąĮąŠą╣ ą┤ą╗čÅ ą▓ąŠąĘą▓čĆą░čéą░ ą┐ąŠ čüčüčŗą╗ą║ąĄ, ąĖąĘą▒ąĄą│ą░čÅ ąĮąĄąĮčāąČąĮčŗčģ ą║ąŠą┐ąĖą╣!
34 . ą¤ąĄčĆąĄą│čĆčāąĘą║ą░ čäčāąĮą║čåąĖąĖ . ąÆ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ C++ ą╝ąŠąČąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ čüąŠą▓ąĄčĆčłąĄąĮąĮąŠ čĆą░ąĘąĮčŗčģ čäčāąĮą║čåąĖą╣ čü ąŠą┤ąĖąĮą░ą║ąŠą▓čŗą╝ąĖ ąĖą╝ąĄąĮą░ą╝ąĖ, ąĮąŠ čü čĆą░ąĘąĮčŗą╝ąĖ čüąĖą│ąĮą░čéčāčĆą░ą╝ąĖ (čé. ąĄ. čĆą░ąĘąĮčŗą╝ąĖ ąĮą░ą▒ąŠčĆą░ą╝ąĖ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓). ąŁč鹊 ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ ą┐ąĄčĆąĄą│čĆčāąĘą║ą░ čäčāąĮą║čåąĖąĖ.
ą¦č鹊ą▒čŗ ą┐ąĄčĆąĄą│čĆčāąĘą║ą░ čĆą░ą▒ąŠčéą░ą╗ą░ ą┐čĆą░ą▓ąĖą╗čīąĮąŠ, ą┐ą░čĆą░ą╝ąĄčéčĆčŗ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ą┐ąĄčĆąĄą│čĆčāąĘą║ąĖ ą╝ąŠą│čāčé ąŠčéą╗ąĖčćą░čéčīčüčÅ čüą╗ąĄą┤čāčÄčēąĖą╝:
- ąóąĖą┐ą░ą╝ąĖ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓.
ą¤čĆąĖą╝ąĄčĆ ą┐ąĄčĆąĄą│čĆčāąĘą║ąĖ čäčāąĮą║čåąĖąĖ max:
int max (int a, int b)
"int overload called" << std::endl;
return (a>b)? a : b;
}double max (double a, double b)
"double overload called" << std::endl;
return (a>b)? a : b;
}double max (int a, double b)
"(int,double) overload called" << std::endl;
return (a>b)? a : b;
}double max (double a, int b)
"(double,int) overload called" << std::endl;
return (a>b)? a : b;
}double max (double a, int b,int c)
"(double,int,int) overload called" << std::endl;
return a;
}std::string_view max (std::string_view a, std::string_view b)
{
std::cout << "(string_view,string_view) overload called" << std::endl;
return (a>b)? a : b;
}ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą▓čŗą▒ąĄčĆąĄčé ą┐čĆą░ą▓ąĖą╗čīąĮčāčÄ ą┐ąĄčĆąĄą│čĆčāąĘą║čā čäčāąĮą║čåąĖąĖ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čéąĖą┐ą░, ą║ąŠą╗ąĖč湥čüčéą▓ą░ ąĖ ą┐ąŠčĆčÅą┤ą║ą░ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ čéąĖą┐ąŠą▓ ą┐ąĄčĆąĄą┤ą░ą▓ą░ąĄą╝čŗčģ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓.
ąĪą╗ąĄą┤čāąĄčé ą┐ąŠą╝ąĮąĖčéčī, čćč鹊 čéąĖą┐ ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝ąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ ąĮąĄ ąŠčéąĮąŠčüąĖčéčüčÅ ą║ čüąĖą│ąĮą░čéčāčĆąĄ čäčāąĮą║čåąĖąĖ, ą┐ąŠčŹč鹊ą╝čā ąĮąĄą╗čīąĘčÅ ąĮą░ ąŠčüąĮąŠą▓ąĄ čŹč鹊ą│ąŠ ąŠą┐čĆąĄą┤ąĄą╗čÅčéčī ą┐ąĄčĆąĄą│čĆčāąĘą║čā. ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆ čüąŠąŠą▒čēąĖčé ąŠą▒ ąŠčłąĖą▒ą║ąĄ, ąĄčüą╗ąĖ ą▓čŗ ą┐ąŠą┐čŗčéą░ąĄč鹥čüčī čüą┤ąĄą╗ą░čéčī čćč鹊-č鹊 ą┐ąŠą┤ąŠą▒ąĮąŠąĄ.
35 . ąøčÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ . ąŁč鹊 ą╝ąĄčģą░ąĮąĖąĘą╝ ąĮą░čüčéčĆąŠą╣ą║ąĖ ą░ąĮąŠąĮąĖą╝ąĮčŗčģ čäčāąĮą║čåąĖą╣ (ą▒ąĄąĘčŗą╝čÅąĮąĮčŗčģ čäčāąĮą║čåąĖą╣). ąÜą░ą║ č鹊ą╗čīą║ąŠ ąŠąĮąĖ ąĮą░čüčéčĆąŠąĄąĮčŗ, ą╝čŗ ą╝ąŠąČąĄą╝ ą╗ąĖą▒ąŠ ą┤ą░čéčī ąĖą╝ ąĖą╝ąĄąĮą░, čćč鹊ą▒čŗ ą┐ąŠč鹊ą╝ ą▓čŗąĘčŗą▓ą░čéčī ąĖčģ, ą╗ąĖą▒ąŠ ą╝čŗ ą┤ą░ąČąĄ ą╝ąŠąČąĄą╝ ąĘą░čüčéą░ą▓ąĖčéčī ąĖčģ ą┤ąĄą╗ą░čéčī čćč鹊-č鹊 ąĮą░ą┐čĆčÅą╝čāčÄ, ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāčÅ ąĖą╝ąĄąĮąĖ.
ą×čüąŠą▒ąĄąĮąĮąŠčüčéčī ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ ą▓ č鹊ą╝, čćč鹊 ą▓ ąĄčæ č鹥ą╗ąĄ ąĮąĄčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ą┤ąŠčüčéčāą┐ą░ ą║ ą▓ąĮąĄčłąĮąĄą╝čā ą║ąŠąĮč鹥ą║čüčéčā (ą▓ąĮąĄčłąĮąĖą╝ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝ ąĖ čäčāąĮą║čåąĖčÅą╝), ąĄčüą╗ąĖ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čüą┐ąĄčåąĖą░ą╗čīąĮąŠ ą┐čĆąĄą┤čāčüą╝ąŠčéčĆąĄąĮąĮčŗą╣ ą┤ą╗čÅ čŹč鹊ą│ąŠ čüą┐ąĖčüąŠą║ ąĘą░čģą▓ą░čéą░ (capture list). ąÆąĄčĆąŠčÅčéąĮąŠ čŹč鹊 ąĄčēąĄ ąŠą┤ąĖąĮ čłą░ą│ ą▓ čüč鹊čĆąŠąĮčā čāčüąĖą╗ąĄąĮąĖčÅ ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐čāč鹥ą╝ čĆą░ąĘą┤ąĄą╗ąĄąĮąĖčÅ ą┤ąŠčüčéčāą┐ą░.
ąĪąĖą│ąĮą░čéčāčĆą░ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ:
[capture list] (parameters)->return type
{
ąóąĄą╗ąŠ čäčāąĮą║čåąĖąĖ
};
[capture list] čüą┐ąĖčüąŠą║ ąĘą░čģą▓ą░čéą░ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ.(parameters) ą┐ą░čĆą░ą╝ąĄčéčĆčŗ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ.-> return type ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝čŗą╣ čéąĖą┐ ąĘąĮą░č湥ąĮąĖčÅ. ąŁč鹊 čāą║ą░ąĘčŗą▓ą░čéčī ąĮąĄąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ, ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ čüą░ą╝ ą▓čŗą▒ąĄčĆąĄčé ą┐ąŠą┤čģąŠą┤čÅčēąĖą╣ čéąĖą┐.; ą┐čĆąĖąĘąĮą░ą║ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ, ą║ąŠč鹊čĆčŗą╣ ą┤ąĄą╗ą░ąĄčé čŹč鹊 čāčéą▓ąĄčƹȹ┤ąĄąĮąĖąĄ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮčŗą╝.
ą¤čĆąĖą╝ąĄčĆ ą▓čŗąĘąŠą▓ą░ ą╗čÅą╝ą▒ą┤ą░ čäčāąĮą║čåąĖąĖ čü ą┐ąŠą╝ąŠčēčīčÄ ą┐čĆąĖčüą▓ąŠąĄąĮąĖčÅ ąĖą╝ąĄąĮąĖ:
auto mylambda = []()
{
std::cout << "Hello World!" << std:endl;
};ąÆčŗąĘąŠą▓ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ ą┐ąŠ ą┐čĆąĖčüą▓ąŠąĄąĮąĮąŠą╝čā ąĖą╝ąĄąĮąĖ:
mylambda ();ąóą░ą║ąČąĄ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖčÄ ą╝ąŠąČąĮąŠ ą▓čŗąĘą▓ą░čéčī ą▒ąĄąĘ čāą║ą░ąĘą░ąĮąĖčÅ ąĖą╝ąĄąĮąĖ:
[]()
{
std::cout << "Hello World!" << std:endl;
}();
ąĢčēąĄ ą┐čĆąĖą╝ąĄčĆ ą▒ąĄąĘčŗą╝čÅąĮąĮąŠą│ąŠ ą▓čŗąĘąŠą▓ą░ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ čü ą┐ąĄčĆąĄą┤ą░č湥ą╣ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓:
[](double a, double b) { std::cout << "a + b : " << (a + b) << std:endl; }(12.1 , 5.7 );
ą¤čĆąĖą╝ąĄčĆ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ, ą║ąŠč鹊čĆą░čÅ ą▓ąŠąĘą▓čĆą░čéąĖčé ąĘąĮą░č湥ąĮąĖąĄ:
auto result = [](double a, double b)
{
return (a + b);
}(12.1 , 5.7 );"result : " << result << std:endl;ąóą░ą║ąČąĄ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖčÄ ą╝ąŠąČąĮąŠ ą┐ąŠą╝ąĄčüčéąĖčéčī ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ ą▓ ąŠą┐ąĄčĆą░č鹊čĆ ą▓čŗą▓ąŠą┤ą░:
std::cout << "result : " << [](double a, double b)
{
return (a + b);
}(12.1 , 5.7 ) << std:endl;
ąóąĖą┐ ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝ąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ ą╝ąŠąČąĮąŠ čāą║ą░ąĘą░čéčī čÅą▓ąĮąŠ čüą╗ąĄą┤čāčÄčēąĖą╝ čüą┐ąŠčüąŠą▒ąŠą╝:
auto result = [](double a, double b)->double
{
return (a + b);
}(12.1 , 5.7 );"result : " << result << std:endl;Capture list . ąĪą┐ąĖčüąŠą║ ąĘą░čģą▓ą░čéą░ - čŹč鹊 č鹊, čćč鹊 čā ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą┐čĆčÅą╝ąŠčāą│ąŠą╗čīąĮčŗčģ čüą║ąŠą▒ą║ą░čģ. ąĪą┐ąĖčüąŠą║ ąĘą░čģą▓ą░čéą░ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐ąŠą╗čāčćąĖčéčī ą▓ąĮčāčéčĆąĖ č鹥ą╗ą░ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ ą┤ąŠčüčéčāą┐ ą║ ą▓ąĮąĄčłąĮąĖą╝ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝ ąĖ čäčāąĮą║čåąĖčÅą╝. ąöą╗čÅ čŹč鹊ą│ąŠ ąĖčģ ąĖą╝ąĄąĮą░ ą┐ąĄčĆąĄčćąĖčüą╗čÅčÄčéčüčÅ ą▓ąĮčāčéčĆąĖ ą║ą▓ą░ą┤čĆą░čéąĮčŗčģ čüą║ąŠą▒ąŠą║ č湥čĆąĄąĘ ąĘą░ą┐čÅčéčāčÄ. ą¤čĆąĖą╝ąĄčĆ:
double a{10 };
double b{20 };
// ąĪą┐ąĖčüąŠą║ ąĘą░čģą▓ą░čéą░ ąĖąĘ ą┤ą▓čāčģ ą▓ąĮąĄčłąĮąĖčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ, ą┐ąĄčĆąĄą┤ą░čćą░ ą┐ąŠ ąĘąĮą░č湥ąĮąĖčÄ:
auto func = [a,b](){
std::cout << "a + b : " << a + b << std::endl;
};
func ();// ąöąĄą╝ąŠąĮčüčéčĆą░čåąĖčÅ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĘą░čģą▓ą░čéą░ ą┐ąŠ ąĘąĮą░č湥ąĮąĖčÄ. ąśąĘą╝ąĄąĮąĄąĮąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ ą▓ąĮąĄčłąĮąĄą╣
// ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ąĮąĖą║ą░ą║ ąĮąĄ ąŠčéčĆą░ąČą░ąĄčéčüčÅ ą▓ąĮčāčéčĆąĖ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ. ąÉą┤čĆąĄčüą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ
// čĆą░ąĘąĮčŗąĄ.
int c{42 };
auto func = [c](){
std::cout << "ąÆąĮčāčéčĆąĄąĮąĮąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ : " << c << " &inner : " << &c << std::endl;
};
for (size_t i{} ; i < 5 ;++i){
std::cout << "ąÆąĮąĄčłąĮąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ : " << c << " &outer : " << &c << std::endl;
func ();
++c;
}// ąöąĄą╝ąŠąĮčüčéčĆą░čåąĖčÅ ąĘą░čģą▓ą░čéą░ ą┐ąŠ čüčüčŗą╗ą║ąĄ. ąśąĘą╝ąĄąĮąĄąĮąĖąĄ ą▓ąĮąĄčłąĮąĄą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ąŠčéčĆą░ąČą░ąĄčéčüčÅ
// ą▓ąĮčāčéčĆąĖ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ, ą░ą┤čĆąĄčüą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ čüąŠą▓ą┐ą░ą┤ą░čÄčé.
int c{42 };
auto func = [&c](){
std::cout << "Inner value : " << c << " &inner : " << &c << std::endl;
};
for (size_t i{} ; i < 5 ;++i){
std::cout << "Outer value : " << c << " &outer : " << &c << std::endl;
func ();
++c;
}
ą¤ąŠą╗ąĮčŗą╣ ąĘą░čģą▓ą░čé ą▓ąĮąĄčłąĮąĄą│ąŠ ą║ąŠąĮč鹥ą║čüčéą░ . ą£ąŠąČąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ąŠ ą▓čüąĄą╝ ą▓ąĮąĄčłąĮąĖą╝ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝ ąĖ čäčāąĮą║čåąĖčÅą╝ ą▓ąĮčāčéčĆąĖ č鹥ą╗ą░ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ:
[=] ąŚą░čģą▓ą░čé ą┐ąŠ ąĘąĮą░č湥ąĮąĖčÄ. ąÆ č鹥ą╗ąŠ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ ą▒čāą┤ąĄčé ą┐ąĄčĆąĄą┤ą░ąĮą░ ą║ąŠą┐ąĖčÅ ą▓ąĮąĄčłąĮąĖčģ ąŠą▒čŖąĄą║č鹊ą▓.
[&] ąŚą░čģą▓ą░čé ą┐ąŠ čüčüčŗą╗ą║ąĄ. ąÆ č鹥ą╗ąŠ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ ą▒čāą┤ąĄčé ą┐ąĄčĆąĄą┤ą░ąĮą░ čüčüčŗą╗ą║ą░ ąĮą░ ą▓ąĮąĄčłąĮąĖą╣ ąŠą▒čŖąĄą║čé. ąöąŠą▓ąŠą╗čīąĮąŠ ąŠą┐ą░čüąĮčŗą╣ ą▓čŗą▒ąŠčĆ, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓čüąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ ąĮą░ą┤ ąŠą▒čŖąĄą║čéą░ą╝ąĖ ą▓ąĮčāčéčĆąĖ ą╗čÅą╝ą▒ą┤ą░ čäčāąĮą║čåąĖąĖ ą▒čāą┤čāčé ąŠčéčĆą░ąČą░čéčīčüčÅ čüąĮą░čĆčāąČąĖ, ąĖ ąĮą░ąŠą▒ąŠčĆąŠčé, ą▓čüąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ čüąĮą░čĆčāąČąĖ ąĮą░ą┤ ąŠą▒čŖąĄą║čéą░ą╝ąĖ ą▒čāą┤čāčé ąŠčéčĆą░ąČą░čéčīčüčÅ ąĖ ą▓ąĮčāčéčĆąĖ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ.
// ąŚą░čģą▓ą░čé ą┐ąŠ ąĘąĮą░č湥ąĮąĖčÄ, ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ čüąĮą░čĆčāąČąĖ ąĮąĄ ąŠčéčĆą░ąČą░čÄčéčüčÅ
// ą▓ąĮčāčéčĆąĖ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ:
int c{42 };
auto func = [=](){
std::cout << "ąÆąĮčāčéčĆąĄąĮąĮąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ : " << c << std::endl;
};
for (size_t i{} ; i < 5 ;++i){
std::cout << "ąÆąĮąĄčłąĮąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ : " << c << std::endl;
func ();
++c;
}
// ąŚą░čģą▓ą░čé ą┐ąŠ čüčüčŗą╗ą║ąĄ. ąśąĘą╝ąĄąĮąĄąĮąĖčÅ čüąĮą░čĆčāąČąĖ ąŠčéčĆą░ąČą░čÄčéčüčÅ ą▓ąĮčāčéčĆąĖ
// ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖąĖ. ąøčāčćčłąĄ čéą░ą║ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą┤ąĄą╗ą░čéčī.
int c{42 };
int d{5 };
auto func = [&](){
std::cout << "ąÆąĮčāčéčĆąĄąĮąĮąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ : " << c << std::endl;
std::cout << "ąÆąĮčāčéčĆąĄąĮąĮąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ (d) : " << d << std::endl;
};
for (size_t i{} ; i < 5 ;++i){
std::cout << "ąÆąĮąĄčłąĮąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ : " << c << std::endl;
func ();
++c;
}
36 . ą©ą░ą▒ą╗ąŠąĮčŗ čäčāąĮą║čåąĖąĖ . ą¤čĆąŠčüčéčŗą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ čŹč鹊 ą╝ąŠąČąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą║ą░ą║ ąŠą▒čēčāčÄ ą╝ąŠą┤ąĄą╗čī ą┤ą╗čÅ ąĮą░ą▒ąŠčĆą░ čüąŠą│ą╗ą░čüąŠą▓ą░ąĮąĮčŗčģ ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝ čäčāąĮą║čåąĖą╣, čāą┐čĆą░ą▓ą╗čÅąĄą╝čŗčģ čüčĆą░ąĘčā ą▓ ąŠą┤ąĮąŠą╣ č鹊čćą║ąĄ - ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĖ čłą░ą▒ą╗ąŠąĮą░. ą©ą░ą▒ą╗ąŠąĮ čäčāąĮą║čåąĖąĖ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮ ą┤ą╗čÅ čāčüčéčĆą░ąĮąĄąĮąĖčÅ ą┤čāą▒ą╗ąĖčĆąŠą▓ą░ąĮąĖčÅ ą║ąŠą┤ą░, ą║ąŠą│ą┤ą░ ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ ą░ą╗ą│ąŠčĆąĖčéą╝ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĮčāąČąĮąŠ ą┐čĆąĖą╝ąĄąĮčÅčéčī ą║ čĆą░ąĘą╗ąĖčćąĮčŗą╝ čéąĖą┐ą░ą╝ ą┤ą░ąĮąĮčŗčģ. ąØą░ąĘąĮą░č湥ąĮąĖąĄ čłą░ą▒ą╗ąŠąĮąŠą▓ ą┐čĆąŠčēąĄ ą┐ąŠąĮčÅčéčī, ąĄčüą╗ąĖ čüčĆą░ą▓ąĮąĖčéčī ąĖčģ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čü ą╝ą░ą║čĆąŠčüą░ą╝ąĖ [15]. ą©ą░ą▒ą╗ąŠąĮčŗ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé čüą┤ąĄą╗ą░čéčī ą║ąŠą┤ ą▒ąŠą╗ąĄąĄ ą╗ą░ą║ąŠąĮąĖčćąĮčŗą╝ ąĖ čĆąĄčłąĖčéčī ą┐čĆąŠą▒ą╗ąĄą╝čŗ, čüą▓čÅąĘą░ąĮąĮčŗąĄ čü ą┐ąĄčĆąĄą│čĆčāąĘą║ąŠą╣ čäčāąĮą║čåąĖąĖ. ąÆ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą╝čŗ ą▓ąĖą┤ąĖą╝ čéčĆąĖ čĆą░ąĘą╗ąĖčćąĮčŗąĄ ą┐ąĄčĆąĄą│čĆčāąĘą║ąĖ čäčāąĮą║čåąĖąĖ max, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠ čüčāčéąĖ ą┤ąĄą╗ą░čÄčé ąŠą┤ąĮąŠ ąĖ č鹊 ąČąĄ.
int max (int a, int b)
return (a > b) ? a : b;
}double max (double a, double b)
return (a > b) ? a : b;
}std::string_view max (std::string_view a, std::string_view b)
{
return (a > b) ? a : b;
}ąĢčüą╗ąĖ ą┐čĆąĄą┤ą┐ąŠą╗ąŠąČąĖčéčī, čćč鹊 ą┐ąŠąĮą░ą┤ąŠą▒čÅčéčüčÅ ąĄčēąĄ čłčéčāą║ 10 ą┐ąĄčĆąĄą│čĆčāąĘąŠą║, č鹊 čüčéą░ąĮąŠą▓ąĖčéčüčÅ ąŠč湥ą▓ąĖą┤ąĮąŠ, čćč鹊 ą║ąŠą┤ čüčéą░ąĮąŠą▓ąĖčéčüčÅ čćčĆąĄąĘą╝ąĄčĆąĮąŠ ą│čĆąŠą╝ąŠąĘą┤ą║ąĖą╝. ąóą░ą║ąŠąĄ ą┐ąŠą▓č鹊čĆąĄąĮąĖąĄ ą║ąŠą┤ą░ čŹč鹊 ąŠč湥ąĮčī ą┐ą╗ąŠčģąŠ, ą┐ąŠč鹊ą╝čā čćč鹊 ą┐čĆąĖ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ čüą┤ąĄą╗ą░čéčī ąĖąĘą╝ąĄąĮąĄąĮąĖąĄ ą░ą╗ą│ąŠčĆąĖčéą╝ą░ ą┐čĆąĖą┤ąĄčéčüčÅ ą▓ąĮąŠčüąĖčéčī ą┐čĆą░ą▓ą║ąĖ ą▓ ą║ą░ąČą┤čāčÄ ąĖąĘ ą┐ąĄčĆąĄą│čĆčāąĘąŠą║. ąŁč鹊 ąĮąĄčāą┤ąŠą▒ąĮąŠ ąĖ čćčĆąĄą▓ą░č鹊 čéčĆčāą┤ąĮąŠ ąŠą▒ąĮą░čĆčāąČąĖą▓ą░ąĄą╝čŗą╝ąĖ ąŠčłąĖą▒ą║ą░ą╝ąĖ. ąöą╗čÅ ą┐čĆąĄąŠą┤ąŠą╗ąĄąĮąĖčÅ čŹč鹊ą╣ ą┐čĆąŠą▒ą╗ąĄą╝čŗ ą║ą░ą║ čĆą░ąĘ ąĖ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮčŗ čłą░ą▒ą╗ąŠąĮčŗ čäčāąĮą║čåąĖąĖ.
ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ čłą░ą▒ą╗ąŠąĮą░ ąĘą░ą╝ąĄąĮąĖčé ą▓čüąĄ ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ąĖ čäčāąĮą║čåąĖąĖ max, ą┐ąŠą║ą░ąĘą░ąĮąĮčŗąĄ ą▓čŗčłąĄ.
template < typename T> T maximum (T a , T b)
{
return (a > b)? a : b;
}ą¤čĆąĖą╝ąĄčĆ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čŹč鹊ą│ąŠ čłą░ą▒ą╗ąŠąĮą░ čäčāąĮą║čåąĖąĖ:
int main ()
int x{5 };
int y{7 };int * p_x {&x};
int * p_y {&y};auto result = maximum (p_x,p_y);
std::cout << "result : " << *result << std::endl;
return 0 ;
}ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čéąĖą┐ T ą▓ čłą░ą▒ą╗ąŠąĮąĄ ą┤ąŠą╗ąČąĄąĮ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čéčī ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą▓ č鹥ą╗ąĄ čäčāąĮą║čåąĖąĖ ąŠą┐ąĄčĆą░č鹊čĆ >, ąĖąĮą░č湥 ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą▓čŗą┤ą░čüčé ąŠčłąĖą▒ą║čā. ąśčéą░ą║, čłą░ą▒ą╗ąŠąĮ čäčāąĮą║čåąĖąĖ čŹč鹊 ąĮąĄ ąĮą░čüč鹊čÅčēąĖą╣ ą▓čŗą┐ąŠą╗ąĮčÅąĄą╝čŗą╣ ą║ąŠą┤, čŹč鹊 ą▓čüąĄą│ąŠ ą╗ąĖčłčī čłą░ą▒ą╗ąŠąĮ, ą┐ąŠ ą║ąŠč鹊čĆąŠą╝čā ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ą┐ąĄčĆąĄą│čĆčāąĘą║ąĖ čäčāąĮą║čåąĖąĖ, ąŠčüąĮąŠą▓čŗą▓ą░čÅčüčī ąĮą░ čéąĖą┐ą░čģ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ čäčāąĮą║čåąĖąĖ.
37 . ąöąĄą┤čāą║čåąĖčÅ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ ą┐čĆąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĄ čéąĖą┐ąŠą▓ ą▓ čłą░ą▒ą╗ąŠąĮąĄ, ąĖ čÅą▓ąĮčŗąĄ ą░čĆą│čāą╝ąĄąĮčéčŗ . ąŚą┤ąĄčüčī ą┐ąŠą┤ ą┤ąĄą┤čāą║čåąĖąĄą╣ ą┐ąŠąĮąĖą╝ą░ąĄčéčüčÅ ą░ą╗ą│ąŠčĆąĖčéą╝, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĖą╝ąĄąĮčÅąĄčé ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą┐čĆąĖ ą│ąĄąĮąĄčĆą░čåąĖąĖ čĆąĄą░ą╗čīąĮąŠą│ąŠ ą║ąŠą┤ą░ ąĮą░ ąŠčüąĮąŠą▓ąĄ čłą░ą▒ą╗ąŠąĮą░ čäčāąĮą║čåąĖąĖ, ą║ąŠą│ą┤ą░ ąŠąĮ ą░ąĮą░ą╗ąĖąĘąĖčĆčāąĄčé ą░čĆą│čāą╝ąĄąĮčéčŗ, ą┐ąĄčĆąĄą┤ą░ąĮąĮčŗąĄ ą▓ čłą░ą▒ą╗ąŠąĮ čäčāąĮą║čåąĖąĖ.
#include < iostream> #include < string> template < typename T> T maximum (T a, T b) {
return (a > b) ? a : b;
}main ()
int a{10 };
int b{23 };
double c{34.7 };
double d{23.4 };
std::string e{"hello" };
std::string f{"world" };// ąōąĄąĮąĄčĆą░čåąĖčÅ ą║ąŠą┤ą░ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆąŠą╝ čü ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄą╝ ą┤ąĄą┤čāą║čåąĖąĖ:
maximum (a, b); // ą│ąĄąĮąĄčĆą░čåąĖčÅ ą║ąŠą┤ą░ ą┤ą╗čÅ čéąĖą┐ą░ int
maximum (c, d); // ą│ąĄąĮąĄčĆą░čåąĖčÅ ą║ąŠą┤ą░ ą┤ą╗čÅ čéąĖą┐ą░ double
maximum (e, f); // ą│ąĄąĮąĄčĆą░čåąĖčÅ ą║ąŠą┤ą░ ą┤ą╗čÅ čéąĖą┐ą░ string ą×ą┤ąĮą░ą║ąŠ ą┤ąĄą┤čāą║čåąĖčÅ ą▓ ąĮąĄą║ąŠč鹊čĆčŗčģ čüą╗čāčćą░čÅčģ, ą╝ąŠąČąĄčé ą▓čŗąĘą▓ą░čéčī ą┐čĆąŠą▒ą╗ąĄą╝čŗ, ą║ąŠą│ą┤ą░ ą▓ čłą░ą▒ą╗ąŠąĮ čäčāąĮą║čåąĖąĖ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ą┐ąĄčĆąĄą┤ą░čéčī čĆą░ąĘąĮčŗąĄ, ąĮąĄ ąŠą┤ąĖąĮą░ą║ąŠą▓čŗąĄ čéąĖą┐čŗ, ą┐ąŠčüą║ąŠą╗čīą║čā ą▒ąĄąĘ čÅą▓ąĮčŗčģ ą░čĆą│čāą╝ąĄąĮč鹊ą▓ ą▒čāą┤ąĄčé čéčĆąĄą▒ąŠą▓ą░čéčīčüčÅ, čćč鹊ą▒čŗ čā ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ ąĖ ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝ąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ ą▒čŗą╗ ąŠą┤ąĖąĮą░ą║ąŠą▓čŗą╣ čéąĖą┐ T.
ąÆ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ čÅą▓ąĮčŗčģ ą░čĆą│čāą╝ąĄąĮč鹊ą▓, ą║ąŠč鹊čĆąŠąĄ ą▓ čŹč鹊ą╣ čüąĖčéčāą░čåąĖąĖ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐ąĄčĆąĄą┤ą░ą▓ą░čéčī ą▓ čłą░ą▒ą╗ąŠąĮ ą░čĆą│čāą╝ąĄąĮčéčŗ čĆą░ąĘąĮąŠą│ąŠ čéąĖą┐ą░.
// ą¤čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠąĄ čāą║ą░ąĘą░ąĮąĖąĄ čéąĖą┐ą░ double ą┤ą╗čÅ ą░čĆą│čāą╝ąĄąĮč鹊ą▓
// čłą░ą▒ą╗ąŠąĮą░ čäčāąĮą║čåąĖąĖ (čÅą▓ąĮčŗąĄ ą░čĆą│čāą╝ąĄąĮčéčŗ):
maximum < double >(c, d); // ą»ą▓ąĮąŠąĄ čāą║ą░ąĘą░ąĮąĖąĄ, čćč鹊 ą╝čŗ čģąŠčéąĖą╝ double.
// ąĢčüą╗ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╣ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ čäčāąĮą║čåąĖąĖ
// ą┐ąŠą║ą░ ąĮąĄ čüčāčēąĄčüčéą▓čāąĄčé, č鹊 ąŠąĮ ą▒čāą┤ąĄčé čüąŠąĘą┤ą░ąĮ.
maximum < double >(a, c); // ąĪčĆą░ą▒ąŠčéą░ąĄčé, ą┤ą░ąČąĄ ąĄčüą╗ąĖ čā ą░čĆą│čāą╝ąĄąĮč鹊ą▓ čĆą░ąĘąĮčŗąĄ čéąĖą┐čŗ.
// ąöą╗čÅ ą┐ąĄčĆą▓ąŠą│ąŠ ą┐ą░čĆą░ą╝ąĄčéčĆą░ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąĮąĄčÅą▓ąĮąŠąĄ
// ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ čéąĖą┐ą░ ą║ čāą║ą░ąĘą░ąĮąĮąŠą╝čā double.
maximum < double >(a, e); // ą¤čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąŠčłąĖą▒ą║ą░ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ąĖąĘ-ąĘą░ ąĮąĄą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ
// ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅ čéąĖą┐ą░ std::string ą▓ čéąĖą┐ double.
ą¤ąĄčĆąĄą┤ą░čćą░ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ ą▓ čłą░ą▒ą╗ąŠąĮ ą┐ąŠ čüčüčŗą╗ą║ąĄ . ąĪ ą┐ąŠą╝ąŠčēčīčÄ čüąĖą╝ą▓ąŠą╗ą░ & ą╝ąŠąČąĮąŠ čāą║ą░ąĘą░čéčī, čćč鹊 ąĘąĮą░č湥ąĮąĖčÅ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ čéąĖą┐ąŠą▓ čłą░ą▒ą╗ąŠąĮą░ čäčāąĮą║čåąĖąĖ ą▒čāą┤čāčé ą┐ąĄčĆąĄą┤ą░ą▓ą░čéčīčüčÅ ą▓ ąĄą│ąŠ č鹥ą╗ąŠ ą┐ąŠ čüčüčŗą╗ą║ąĄ, ąĮą░ą┐čĆąĖą╝ąĄčĆ:
template < typename T> const T& maximum (const T& a, const T& b) return (a > b) ? a : b;
}ą¤čĆąĖ čŹč鹊ą╝ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą┐ąĄčĆąĄą┤ą░ąĮąĮčŗčģ ą┐ąŠ čüčüčŗą╗ą║ąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ ą▓ąĮčāčéčĆąĖ čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąĮąŠą╣ čäčāąĮą║čåąĖąĖ ą▒čāą┤čāčé ąŠčéčĆą░ąČą░čéčīčüčÅ čüąĮą░čĆčāąČąĖ. ąÜą╗čÄč湥ą▓ąŠąĄ čüą╗ąŠą▓ąŠ const ąĘą┤ąĄčüčī ą┐čĆąĖą╝ąĄąĮąĄąĮąŠ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą║ą░ąĮąŠąĮąĖčćąĮąŠčüčéąĖ, čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī, čćč鹊 ą▓ ą┤ą░ąĮąĮąŠą╝ ą┐čĆąĖą╝ąĄčĆąĄ čłą░ą▒ą╗ąŠąĮą░ čäčāąĮą║čåąĖąĖ ąĮąĄčé ąĮąĖą║ą░ą║ąĖčģ ąĮą░ą╝ąĄčĆąĄąĮąĖą╣ ąĖąĘą╝ąĄąĮčÅčéčī ą┐ąĄčĆąĄą┤ą░ąĮąĮčŗąĄ ą┐ą░čĆą░ą╝ąĄčéčĆčŗ ą▓ č鹥ą╗ąĄ čäčāąĮą║čåąĖąĖ.
ąĪą┐ąĄčåąĖą░ą╗ąĖąĘą░čåąĖčÅ čłą░ą▒ą╗ąŠąĮą░ čäčāąĮą║čåąĖąĖ . ąĪą┐ąĄčåąĖą░ą╗ąĖąĘą░čåąĖčÅ čłą░ą▒ą╗ąŠąĮą░ čŹč鹊 ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮą░čÅ ąĄą│ąŠ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ ą┤ą╗čÅ čćą░čüčéąĮąŠą│ąŠ čüą╗čāčćą░čÅ čéąĖą┐ąŠą▓ ą░čĆą│čāą╝ąĄąĮč鹊ą▓, ą║ąŠą│ą┤ą░ ą┤ą╗čÅ čŹč鹊ą│ąŠ čüą╗čāčćą░čÅ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ąŠčéą┤ąĄą╗čīąĮąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ čäčāąĮą║čåąĖąĖ. ąĪą┐ąĄčåąĖą░ą╗ąĖąĘą░čåąĖčÅ čĆąĄą░ą╗ąĖąĘčāąĄčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ ą┐ąŠą▓č鹊čĆąĄąĮąĖčÅ ąĖą╝ąĄąĮąĖ čäčāąĮą║čåąĖąĖ čłą░ą▒ą╗ąŠąĮą░ ąĖ ą┐čāčüčéčŗčģ čāą│ą╗ąŠą▓čŗčģ čüą║ąŠą▒ąŠą║. ą¤čĆąĖą╝ąĄčĆ:
// ąśčüčģąŠą┤ąĮčŗą╣ čłą░ą▒ą╗ąŠąĮ čäčāąĮą║čåąĖąĖ: template < typename T> T maximum (T a,T b) {
return (a > b) ? a : b ;
}// ąĪą┐ąĄčåąĖą░ą╗ąĖąĘą░čåąĖčÅ čŹč鹊ą│ąŠ čłą░ą▒ą╗ąŠąĮą░ ą┤ą╗čÅ čéąĖą┐ą░ const char *: template < > const char * maximum < const char *> (const char * a, const char * b){
return (std::strcmp (a,b) > 0 ) ? a : b;
}ąØą░ąĘąĮą░č湥ąĮąĖąĄ 菹╗ąĄą╝ąĄąĮč鹊ą▓ čŹč鹊ą╣ čüą┐ąĄčåąĖą░ą╗ąĖąĘą░čåąĖąĖ, ą┐ąŠ ą┐ąŠčĆčÅą┤ą║čā:
template < > . ą×ą▒ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 čŹč鹊 čüą┐ąĄčåąĖą░ą╗ąĖąĘą░čåąĖčÅ ą║ą░ą║ąŠą│ąŠ-č鹊 čāąČąĄ čüčāčēąĄčüčéą▓čāčÄčēąĄą│ąŠ čłą░ą▒ą╗ąŠąĮą░. ąŻ čüą┐ąĄčåąĖą░ą╗ąĖąĘą░čåąĖąĖ ą┤ąŠą╗ąČąĮąŠ čüąŠą▓ą┐ą░ą┤ą░čéčī ąĖą╝čÅ čäčāąĮą║čåąĖąĖ čü ąĖą╝ąĄąĮąĄą╝ čäčāąĮą║čåąĖąĖ ąĖčüčģąŠą┤ąĮąŠą│ąŠ čłą░ą▒ą╗ąŠąĮą░ (ą▓ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ maximum).
const char * maximum . ą×ą▒ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 čüą┐ąĄčåąĖą░ą╗ąĖąĘą░čåąĖčÅ ą▒čāą┤ąĄčé ą▓ąŠąĘą▓čĆą░čēą░čéčī čéąĖą┐ const char *.
< const char*> . ą×ą▒ąŠąĘąĮą░čćą░ąĄčé čéąĖą┐čŗ ą░čĆą│čāą╝ąĄąĮč鹊ą▓ čüą┐ąĄčåąĖą░ą╗ąĖąĘą░čåąĖąĖ.
(const char* a, const char* b) . ąĪą┐ąĖčüąŠą║ ą░čĆą│čāą╝ąĄąĮč鹊ą▓ čüą┐ąĄčåąĖą░ą╗ąĖąĘą░čåąĖąĖ.
ąÜą░ą║ ą▓ąĖą┤ąĮąŠ, ą▓ č鹥ą╗ąĄ čüą┐ąĄčåąĖą░ą╗ąĖąĘą░čåąĖąĖ čłą░ą▒ą╗ąŠąĮą░ ą┐čĆąĖą▓ąĄą┤ąĄąĮ ąŠčéą┤ąĄą╗čīąĮčŗą╣, ąŠčéą╗ąĖčćą░čÄčēąĖą╣čüčÅ ą░ą╗ą│ąŠčĆąĖčéą╝ čüčĆą░ą▓ąĮąĄąĮąĖčÅ čüčéčĆąŠą║, ą║ąŠč鹊čĆčŗą╣ ąĘą░ą┤ąĄą╣čüčéą▓čāąĄčé ą▒ąĖą▒ą╗ąĖąŠč鹥čćąĮčāčÄ čäčāąĮą║čåąĖčÄ std::strcmp. ą¤čĆąĖą╝ąĄčĆ čĆą░ą▒ąŠčéčŗ čłą░ą▒ą╗ąŠąĮą░ ą▒ąĄąĘ čüą┐ąĄčåąĖą░ą╗ąĖąĘą░čåąĖąĖ ąĖ čüąŠ čüą┐ąĄčåąĖą░ą╗ąĖąĘą░čåąĖąĄą╣:
#include < iostream> #include < cstring> int main ()
// ą×ą▒čŗčćąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čłą░ą▒ą╗ąŠąĮą░ čäčāąĮą║čåąĖąĖ:
int a{10 };
int b{23 };
double c{34.7 };
double d{23.4 };
std::string e{"hello" };
std::string f{"world" };auto max_int = maximum (a,b); // čäčāąĮą║čåąĖčÅ maximum() čüą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ą┤ą╗čÅ čéąĖą┐ą░ int
auto max_double = maximum (c,d); // čäčāąĮą║čåąĖčÅ maximum() čüą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ą┤ą╗čÅ čéąĖą┐ą░ double
auto max_str = maximum (e,f); // čäčāąĮą║čåąĖčÅ maximum() čüą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ą┤ą╗čÅ čéąĖą┐ą░ string "max_int : " << max_int << std::endl;
std::cout << "max_double : " << max_double << std::endl;
std::cout << "max_str : " << max_str << std::endl;// ąÉ ąĘą┤ąĄčüčī ą░ą║čéąĖą▓ąĖčĆčāąĄčéčüčÅ ąŠčéą┤ąĄą╗čīąĮą░čÅ čüą┐ąĄčåąĖą░ą╗ąĖąĘą░čåąĖčÅ čłą░ą▒ą╗ąŠąĮą░:
const char * g{"wild" };
const char * h{"animal" };const char * result = maximum (g,h);
std::cout << "max(const char*) : " << result << std::endl;
return 0 ;
}ąĪčéą░ąĮą┤ą░čĆčéąĮčŗąĄ ą║ąŠąĮčåąĄą┐čåąĖąĖ čłą░ą▒ą╗ąŠąĮą░ čäčāąĮą║čåąĖąĖ . ąÜąŠąĮčåąĄą┐čåąĖčÅ čłą░ą▒ą╗ąŠąĮą░ čÅą▓ą╗čÅąĄčéčüčÅ ąŠą┤ąĮąŠą╣ ąĖąĘ č湥čéčŗčĆąĄčģ ąŠčüąĮąŠą▓ąĮčŗčģ ąĮąŠą▓ąŠą▓ą▓ąĄą┤ąĄąĮąĖą╣ čüčéą░ąĮą┤ą░čĆčéą░ C++ 20. ąŁč鹊 čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ ą╝ąĄčģą░ąĮąĖąĘą╝ ąĮą░ą╗ąŠąČąĄąĮąĖčÅ ąŠą│čĆą░ąĮąĖč湥ąĮąĖą╣ ąĮą░ čéąĖą┐čŗ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ čłą░ą▒ą╗ąŠąĮą░. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą╝čŗ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ą╝ąŠąČąĄą╝ ąĮą░ą╗ąŠąČąĖčéčī ąŠą│čĆą░ąĮąĖč湥ąĮąĖąĄ, čćč鹊ą▒čŗ ąĮą░čłą░ čäčāąĮą║čåąĖčÅ ą▓čŗąĘčŗą▓ą░ą╗ą░čüčī č鹊ą╗čīą║ąŠ čü čćąĖčüą╗ą░ą╝ąĖ čéąĖą┐ą░ int. ąś ąĄčüą╗ąĖ ą▓čŗ ą▓čŗąĘąŠą▓ąĄč鹥 ąĄčæ čü č湥ą╝-č鹊, čćč鹊 ąĮąĄ čÅą▓ą╗čÅąĄčéčüčÅ čåąĄą╗čŗą╝ čćąĖčüą╗ąŠą╝, č鹊 ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ čüąŠąŠą▒čēąĖčé ą▓ą░ą╝ ąŠą▒ čŹč鹊ą╝.
ąĪą╗ąĄą┤čāąĄčé ąĘą░ą╝ąĄčéąĖčéčī, čćč鹊 ąŠą│čĆą░ąĮąĖč湥ąĮąĖąĄ ą▓ ą▓ąĖą┤ąĄ čÅą▓ąĮąŠą╣ ą┐čĆąŠą▓ąĄčĆą║ąĖ čéąĖą┐ąŠą▓ ą╝ąŠąČąĮąŠ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ąĖ ą░ą╗čīč鹥čĆąĮą░čéąĖą▓ąĮčŗą╝ąĖ ą╝ąĄč鹊ą┤ą░ą╝ąĖ, ąĮą░ą┐čĆąĖą╝ąĄčĆ čü ą┐ąŠą╝ąŠčēčīčÄ assert, ąŠą┤ąĮą░ą║ąŠ ą║ąŠąĮčåąĄą┐čåąĖčÅ čłą░ą▒ą╗ąŠąĮą░ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čŹč鹊 čüą┤ąĄą╗ą░čéčī ą▒ąŠą╗ąĄąĄ čāą┤ąŠą▒ąĮąŠ ąĖ čüąĖąĮčéą░ą║čüąĖč湥čüą║ąĖ ą║čĆą░čüąĖą▓ąŠ. ąØąĖąČąĄ ą┐ąŠą║ą░ąĘą░ąĮ ą░ą╗čīč鹥čĆąĮą░čéąĖą▓ąĮčŗą╣ čüą┐ąŠčüąŠą▒ ąŠą│čĆą░ąĮąĖč湥ąĮąĖčÅ ąĮą░ čéąĖą┐ ą┤ą░ąĮąĮčŗčģ, čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮąĮčŗą╣ čü ą┐ąŠą╝ąŠčēčīčÄ static_assert .
template < typename T> void print_number (T n)
static_assert (std::is_integral_v< T> ,"print_number() ą╝ąŠąČąĮąŠ ą▓čŗąĘą▓ą░čéčī \
č鹊ą╗čīą║ąŠ čü čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮčŗą╝ąĖ čéąĖą┐ą░ą╝ąĖ" );
std::cout << "number : " << n << std::endl;
}ąĪčāčēąĄčüčéą▓čāčÄčé 2 ą▓ą░čĆąĖą░ąĮčéą░ ą║ąŠąĮčåąĄą┐čåąĖąĖ čłą░ą▒ą╗ąŠąĮą░ čäčāąĮą║čåąĖąĖ. ą¤ąĄčĆą▓čŗą╣ čŹč鹊 ą▓čüčéčĆąŠąĄąĮąĮčŗąĄ čüčéą░ąĮą┤ą░čĆčéąĮčŗąĄ ą║ąŠąĮčåąĄą┐čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠčüčéą░ą▓ą╗čÅčÄčéčüčÅ ą▓ą╝ąĄčüč鹥 čü čÅąĘčŗą║ąŠą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ C++ ą▓ ą▓ąĖą┤ąĄ ą│ąŠč鹊ą▓ąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ (ą┐ąŠą┤ą║ą╗čÄčćą░čÄčéčüčÅ ąĘą░ą│ąŠą╗ąŠą▓ą║ąŠą╝ < concepts>). ąĢčüą╗ąĖ ą┐ąŠ ą║ą░ą║ąŠą╣-č鹊 ą┐čĆąĖčćąĖąĮąĄ čŹč鹊ą│ąŠ ąŠą║ą░ąČąĄčéčüčÅ ąĮąĄą┤ąŠčüčéą░č鹊čćąĮąŠ, č鹊 ą╝ąŠąČąĮąŠ čüąŠąĘą┤ą░čéčī čüą▓ąŠčÄ čüąŠą▒čüčéą▓ąĄąĮąĮčāčÄ ą║ąŠąĮčåąĄą┐čåąĖčÄ, ąĖ čŹč鹊 ą▓č鹊čĆąŠą╣ ą▓ą░čĆąĖą░ąĮčé - ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ą░čÅ ą║ąŠąĮčåąĄą┐čåąĖčÅ čłą░ą▒ą╗ąŠąĮą░ čäčāąĮą║čåąĖąĖ. ą¤čĆąĖ ą┐ąŠą┐čŗčéą║ąĄ ą▓čŗąĘąŠą▓ą░ čłą░ą▒ą╗ąŠąĮą░ čäčāąĮą║čåąĖąĖ, ą║ąŠč鹊čĆčŗą╣ ąĮą░čĆčāčłą░ąĄčé ą║ąŠąĮčåąĄą┐čåąĖčÄ, ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąŠčłąĖą▒ą║ą░ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ.
ąÆąŠčé ąŠčüąĮąŠą▓ąĮąŠą╣ čüą┐ąĖčüąŠą║ ą║ąŠąĮčåąĄą┐čåąĖą╣ čłą░ą▒ą╗ąŠąĮą░ čäčāąĮą║čåąĖąĖ C++20, ą║ąŠč鹊čĆčŗąĄ ą▓čŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓ C++ (ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮčŗ ą▓ ąĘą░ą│ąŠą╗ąŠą▓ąŠčćąĮąŠą╝ čäą░ą╣ą╗ąĄ < concepts>, čüą╝. čéą░ą║ąČąĄ [16]):
same_as . ąŻą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čéąĖą┐ čéą░ą║ąŠą╣ ąČąĄ, ą║ą░ą║ ąĖ ą┤čĆčāą│ąŠą╣ čéąĖą┐.derived_from . ąŻą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čéąĖą┐ čÅą▓ą╗čÅąĄčéčüčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮčŗą╝ ąŠčé ą┤čĆčāą│ąŠą│ąŠ čéąĖą┐ą░.convertible_to . ąŻą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čā čŹč鹊ą│ąŠ čéąĖą┐ą░ čüčāčēąĄčüčéą▓čāąĄčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ąĮąĄčÅą▓ąĮąŠą│ąŠ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅ ą▓ ą┤čĆčāą│ąŠą╣ čéąĖą┐.common_reference_with . ąŻą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ą┤ą▓ą░ čéąĖą┐ą░ čĆą░ąĘą┤ąĄą╗čÅčÄčé ąŠą▒čēąĖą╣ čüčüčŗą╗ąŠčćąĮčŗą╣ čéąĖą┐.common_with . ąŻą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ą┤ą▓ą░ čéąĖą┐ą░ čĆą░ąĘą┤ąĄą╗čÅčÄčé ąŠą▒čēąĖą╣ čéąĖą┐.integral . ąŻą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čŹč鹊čé čéąĖą┐ čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮčŗą╣.signed_integral . ąŻą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čŹč鹊čé čéąĖą┐ čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮčŗą╣, ąĖ ąĖą╝ąĄąĄčé ąĘąĮą░ą║.unsigned_integral . ąŻą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čŹč鹊čé čéąĖą┐ čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮčŗą╣ ąĖ ą▒ąĄąĘąĘąĮą░ą║ąŠą▓čŗą╣.floating_point . ąŻą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čŹč鹊čé čéąĖą┐ ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąĖ.assignable_from . ąŻą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čŹč鹊čé čéąĖą┐ ą╝ąŠąČąĮąŠ ąĮą░ąĘąĮą░čćąĖčéčī ąĘąĮą░č湥ąĮąĖąĄą╝ ą┤čĆčāą│ąŠą│ąŠ čéąĖą┐ą░.swappable , swappable_with . ąŻą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čŹč鹊čé čéąĖą┐ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ą╝ąĄąĮąĄąĮ, ąĖą╗ąĖ čćč鹊 ą┤ą▓ą░ čéąĖą┐ą░ ą╝ąŠąČąĮąŠ ą┐ąŠą╝ąĄąĮčÅčéčī ą╝ąĄčüčéą░ą╝ąĖ.destructible . ąŻą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ąŠą▒čŖąĄą║čé čŹč鹊ą│ąŠ čéąĖą┐ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī čāąĮąĖčćč鹊ąČąĄąĮ.constructible_from . ąŻą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ čŹč鹊ą│ąŠ čéąĖą┐ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠčüčéčĆąŠąĄąĮą░ ąĖąĘ ąĮą░ą▒ąŠčĆą░ čéąĖą┐ąŠą▓ ą░čĆą│čāą╝ąĄąĮč鹊ą▓.default_initializable . ąŻą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ąŠą▒čŖąĄą║čé čŹč鹊ą│ąŠ čéąĖą┐ą░ ą╝ąŠąČąĄčé ąĖą╝ąĄčéčī ą║ąŠąĮčüčéčĆčāą║č鹊čĆ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ.move_constructible . ąŻą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ąŠą▒čŖąĄą║čé čŹč鹊ą│ąŠ čéąĖą┐ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī čüą║ąŠąĮčüčéčĆčāąĖčĆąŠą▓ą░ąĮ ą┐ąŠ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÄ.copy_constructible . ąŻą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ąŠą▒čŖąĄą║čé čŹč鹊ą│ąŠ čéąĖą┐ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī čüą║ąŠąĮčüčéčĆčāąĖčĆąŠą▓ą░ąĮ ą┐ąŠ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖčÄ ąĖ ą┐ąŠ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÄ.
ąÆą░čĆąĖą░ąĮčé 1, ą║ąŠą│ą┤ą░ čüąĖąĮčéą░ą║čüąĖčü ą║ąŠąĮčåąĄą┐čåąĖąĖ čłą░ą▒ą╗ąŠąĮą░ ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą║ą╗čÄč湥ą▓ąŠą│ąŠ čüą╗ąŠą▓ą░ requires, ąĮą░ą┐čĆąĖą╝ąĄčĆ:
template < typename T> void print_number (T n)
static_assert (std::is_integral_v< T> ,"print_number() ą╝ąŠąČąĮąŠ ą▓čŗąĘą▓ą░čéčī \
č鹊ą╗čīą║ąŠ čü čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮčŗą╝ąĖ čéąĖą┐ą░ą╝ąĖ" );
std::cout << "number : " << n << std::endl;
}ąŚą┤ąĄčüčī ą║ąŠąĮčåąĄą┐čåąĖąĄą╣ čÅą▓ą╗čÅąĄčéčüčÅ ą║ąŠąĮčüčéčĆčāą║čåąĖčÅ requires std::integral< T>. ąĪ čéą░ą║ąŠą╣ ą║ąŠąĮčåąĄą┐čåąĖąĄą╣ čłą░ą▒ą╗ąŠąĮ ą▒čāą┤ąĄčé čĆą░ą▒ąŠčéą░čéčī č鹊ą╗čīą║ąŠ ą▓ č鹊ą╝ čüą╗čāčćą░ąĄ, ąĄčüą╗ąĖ ą┐čĆąĖ ą▓čŗąĘąŠą▓ąĄ čłą░ą▒ą╗ąŠąĮą░ ą║ąŠąĮčåąĄą┐čåąĖčÅ ą▒čāą┤ąĄčé čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆąĄąĮą░. ąöą╗čÅ čŹč鹊ą│ąŠ ą┐čĆąĖą╝ąĄčĆą░ ą║ąŠąĮčåąĄą┐čåąĖčÅ čéčĆąĄą▒čāąĄčé, čćč鹊ą▒čŗ čéąĖą┐čŗ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ ą▒čŗą╗ąĖ čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮčŗąĄ (std::integral).
ąÆą░čĆąĖą░ąĮčé 2, ą║ąŠąĮčåąĄą┐čåąĖčÅ čłą░ą▒ą╗ąŠąĮą░ ą▒ąĄąĘ requires. ą£ąŠąČąĮąŠ čéą░ą║ąČąĄ čāčüčéą░ąĮąŠą▓ąĖčéčī ą║ąŠąĮčåąĄą┐čåąĖčÄ čłą░ą▒ą╗ąŠąĮą░, ąĄčüą╗ąĖ ą▓ą╝ąĄčüč鹊 typename čāą║ą░ąĘą░čéčī ą║ąŠąĮą║čĆąĄčéąĮčŗą╣ čéąĖą┐. ąØą░ą┐čĆąĖą╝ąĄčĆ:
template < std::integral T> T add (T a, T b) {
return a + b;
}ąÆą░čĆąĖą░ąĮčé 3, čāą║ą░ąĘą░ąĮąĖąĄ ą║ąŠąĮčåąĄą┐čåąĖąĖ ą▓ą╝ąĄčüč鹥 čü ą┐ą░čĆą░ą╝ąĄčéčĆą░ą╝ąĖ čłą░ą▒ą╗ąŠąĮą░.
auto add (std::integral auto a, std::integral auto b) return a + b;
}ąÆą░čĆąĖą░ąĮčé 4.
template < typename T> T add (T a, T b) requires std::integral< T> {
return a + b;
}ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖąĄ ą║ąŠąĮčåąĄą┐čåąĖąĖ čłą░ą▒ą╗ąŠąĮą░ čäčāąĮą║čåąĖąĖ . ą£ąŠąČąĮąŠ čüąŠąĘą┤ą░ą▓ą░čéčī čüą▓ąŠąĖ ą║ąŠąĮčåąĄą┐čåąĖąĖ, ąŠą│čĆą░ąĮąĖčćąĖą▓ą░čÄčēąĖąĄ ą┐čĆąĖą╝ąĄąĮčÅąĄą╝čŗąĄ ą▓ čłą░ą▒ą╗ąŠąĮąĄ čéąĖą┐čŗ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓. ąŁč鹊 ą┤ąĄą╗ą░ąĄčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ ą║ą╗čÄč湥ą▓ąŠą│ąŠ čüą╗ąŠą▓ą░ concept.
ąÆą░čĆąĖą░ąĮčé 1 čüąĖąĮčéą░ą║čüąĖčüą░. ą¤čĆąĖą╝ąĄčĆ čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅ, čćč鹊ą▒čŗ ą┐ą░čĆą░ą╝ąĄčéčĆ čłą░ą▒ą╗ąŠąĮą░ ą▒čŗą╗ čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮčŗą╝:
template < typename T> concept MyIntegral = std::is_integral_v< T>;ąŚą┤ąĄčüčī MyIntegral čŹč鹊 ąĖą╝čÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąŠą╣ ą║ąŠąĮčåąĄą┐čåąĖąĖ. ąÆąŠčé čéą░ą║ čŹčéą░ ą║ąŠąĮčåąĄą┐čåąĖčÅ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ:
template < typename T> requires MyIntegral < T> T add_1 (T a, T b) {
return a + b;
};ąøąĖą▒ąŠ ą╝ąŠąČąĮąŠ ą▓ąŠčé čéą░ą║:
template < MyIntegral T> T add_2 (T a, T b) {
return a + b;
};ą£ąŠąČąĮąŠ ąĄčēąĄ ąĖ čéą░ą║:
auto add_3 (MyIntegral auto a, MyIntegral auto b) return a + b;
};ąÆą░čĆąĖą░ąĮčé 2 čüąĖąĮčéą░ą║čüąĖčüą░. ąŚą┤ąĄčüčī čéčĆąĄą▒čāąĄčéčüčÅ, čćč鹊ą▒čŗ ąŠą▒ą░ ą┐ą░čĆą░ą╝ąĄčéčĆą░ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ą╗ąĖ čāą╝ąĮąŠąČąĄąĮąĖąĄ:
template < typename T> concept Multipliable = requires (T a, T b){
a * b; // ąÜąŠą┤, ą║ąŠč鹊čĆąŠą╝čā ą┤ąŠą╗ąČąĮą░ čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆčÅčéčī ą║ąŠąĮčåąĄą┐čåąĖčÅ Multipliable
};ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą▓ą╝ąĄčüč鹊 a ąĖ b ą┐ąĄčĆąĄą┤ą░čéčī čüčéčĆąŠą║ąĖ, č鹊 ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąŠčłąĖą▒ą║ą░ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 čéąĖą┐ čüčéčĆąŠą║ąĖ ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé čāą╝ąĮąŠąČąĄąĮąĖąĄ (ąĮąĄ ąĖą╝ąĄąĄčé čüą╝čŗčüą╗ą░ čāą╝ąĮąŠąČą░čéčī čüčéčĆąŠą║ąĖ).
ąÆą░čĆąĖą░ąĮčé 3 čüąĖąĮčéą░ą║čüąĖčüą░. ąŚą┤ąĄčüčī čéčĆąĄą▒čāąĄčéčüčÅ, čćč鹊ą▒čŗ ą┐ą░čĆą░ą╝ąĄčéčĆ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ąĖąĮą║čĆąĄą╝ąĄąĮčéąĖčĆąŠą▓ą░čéčī:
template < typename T> concept Incrementable = requires (T a){
a += 1 ;
++a;
a++;
};
ąĪčāčēąĄčüčéą▓čāąĄčé 4 ą▓ąĖą┤ą░ čéčĆąĄą▒ąŠą▓ą░ąĮąĖą╣ ą▓ ą║ąŠąĮčåąĄą┐čåąĖčÅčģ čłą░ą▒ą╗ąŠąĮą░ čäčāąĮą║čåąĖąĖ:
ŌĆó ą¤čĆąŠčüčéčŗąĄ čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅ (simple requirements).
[ą¤čĆąŠčüčéčŗąĄ čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅ ]
ąÆ ą┐čĆąĖąĮčåąĖą┐ąĄ čŹč鹊 ą▓čüąĄ č鹊, čćč鹊 čāąČąĄ ą▒čŗą╗ąŠ čĆą░čüčüą╝ąŠčéčĆąĄąĮąŠ ą▓čŗčłąĄ. ąĢčēąĄ ą┐čĆąĖą╝ąĄčĆ:
template < typename T> concept TinyType = requires (T t){
// ą¤čĆąŠčüč鹊ąĄ čéčĆąĄą▒ąŠą▓ą░ąĮąĖąĄ: ą▓čŗčĆą░ąČąĄąĮąĖąĄ č鹊ą╗čīą║ąŠ ą╗ąĖčłčī ą┐čĆąŠą▓ąĄčĆčÅąĄčéčüčÅ ąĮą░ ą┤ąŠą┐čāčüčéąĖą╝čŗą╣ čüąĖąĮčéą░ą║čüąĖčü:
sizeof (T) < = 4 ;
};[ąÆą╗ąŠąČąĄąĮąĮčŗąĄ čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅ ]
ą¤čĆąĖą╝ąĄčĆ:
template < typename T> concept TinyType = requires (T t){
// ą¤čĆąŠčüč鹊ąĄ čéčĆąĄą▒ąŠą▓ą░ąĮąĖąĄ: ą▓čŗčĆą░ąČąĄąĮąĖąĄ č鹊ą╗čīą║ąŠ ą╗ąĖčłčī ą┐čĆąŠą▓ąĄčĆčÅąĄčéčüčÅ ąĮą░ ą┤ąŠą┐čāčüčéąĖą╝čŗą╣ čüąĖąĮčéą░ą║čüąĖčü:
sizeof (T) < = 4 ;
// ąÆą╗ąŠąČąĄąĮąĮąŠąĄ čéčĆąĄą▒ąŠą▓ą░ąĮąĖąĄ: ą┐čĆąŠą▓ąĄčĆą║ą░ ąĮą░ č鹊, čćč鹊ą▒čŗ ą▓čŗčĆą░ąČąĄąĮąĖąĄ ą▒čŗą╗ąŠ true:
requires sizeof (T) < 4 ;
};[ąĪąŠčüčéą░ą▓ąĮąŠąĄ čéčĆąĄą▒ąŠą▓ą░ąĮąĖąĄ ]
ą¤čĆąĖą╝ąĄčĆ:
template < typename T> concept Addable = requires (T a, T b){
// ąĪąŠčüčéą░ą▓ąĮąŠąĄ čéčĆąĄą▒ąŠą▓ą░ąĮąĖąĄ (ąĘą┤ąĄčüčī noexcept ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĮąĄąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ):
{a + b} noexcept -> std::convertible_to< int >;
};ąÆ čŹč鹊ą╝ čüąŠčüčéą░ą▓ąĮąŠą╝ čéčĆąĄą▒ąŠą▓ą░ąĮąĖąĖ ą┤ąĄą╗ą░ąĄčéčüčÅ ą┐čĆąŠą▓ąĄčĆą║ą░, čćč鹊 a + b čŹč鹊 čüąŠą▓ą╝ąĄčüčéąĖą╝čŗą╣ čüąĖąĮčéą░ą║čüąĖčü, čü ą┐ąŠą╝ąŠčēčīčÄ noexcept ąŠčéą║ą╗čÄčćą░čÄčéčüčÅ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ (čŹč鹊 ąĮąĄ ąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ), ąĖ ąĄčēąĄ ą┤ąĄą╗ą░ąĄčéčüčÅ ą┐čĆąŠą▓ąĄčĆą║ą░, čćč鹊 čĆąĄąĘčāą╗čīčéą░čé ą╝ąŠąČąĮąŠ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░čéčī ą▓ int (čéą░ą║ąČąĄ ąĮąĄ ąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ).
ąøąŠą│ąĖč湥čüą║ąĖąĄ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ ą║ąŠąĮčåąĄą┐čåąĖą╣ . ąÜąŠąĮčåąĄą┐čåąĖąĖ čéą░ą║ąČąĄ ą╝ąŠąČąĮąŠ ąŠą▒čŖąĄą┤ąĖąĮčÅčéčī ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝, čü ą┐ąŠą╝ąŠčēčīčÄ ąŠą┐ąĄčĆą░č鹊čĆąŠą▓ && ąĖ ||.
#include < iostream> #include < concepts> template < typename T> concept TinyType = requires ( T t){
sizeof (T) < =4 ; // ą┐čĆąŠčüč鹊ąĄ čéčĆąĄą▒ąŠą▓ą░ąĮąĖąĄ
requires sizeof (T) < 4 ; // ą▓ą╗ąŠąČąĄąĮąĮąŠąĄ čéčĆąĄą▒ąŠą▓ą░ąĮąĖąĄ
};typename T>//requires std::integral< T> || std::floating_point< T> // ąŠą┐ąĄčĆą░č鹊čĆ OR //requires std::integral< T> && TinyType< T> // ąŠą┐ąĄčĆą░č鹊čĆą░ AND requires std::integral< T> && requires (T t) sizeof (T) < =4 ; // ą┐čĆąŠčüč鹊ąĄ čéčĆąĄą▒ąŠą▓ą░ąĮąĖąĄ
requires sizeof (T) < 4 ; // ą▓ą╗ąŠąČąĄąĮąĮąŠąĄ čéčĆąĄą▒ąŠą▓ą░ąĮąĖąĄ
}T add (T a, T b) {
return a + b;
}main ()
long long int x{7 };
long long int y{5 };add (x,y);
return 0 ;
}ąÜąŠąĮčåąĄą┐čåąĖąĖ ąĖ auto . ąÜąŠąĮčåąĄą┐čåąĖąĖ čéą░ą║ąČąĄ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ ąŠą▒čŖčÅą▓ą╗ąĄąĮąĖčÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣, ą┤ą╗čÅ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ ąĖ ą┤ą╗čÅ ą▓ąŠąĘą▓čĆą░čēą░ąĄą╝ąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ čäčāąĮą║čåąĖąĖ.
#include < iostream> #include < concepts> // ąŁč鹊čé čüąĖąĮčéą░ą║čüąĖčü ąŠą│čĆą░ąĮąĖčćąĖą▓ą░ąĄčé ą┐ą░čĆą░ą╝ąĄčéčĆčŗ auto, ą║ąŠč鹊čĆčŗąĄ ą▓čŗ ą┐ąĄčĆąĄą┤ą░ąĄč鹥 // ą▓ čäčāąĮą║čåąĖčÄ, čćč鹊ą▒čŗ ąŠąĮąĖ čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆčÅą╗ąĖ ą║ąŠąĮčåąĄą┐čåąĖąĖ std::integral: std::integral auto add (std::integral auto a,std::integral auto b) {
return a + b;
}int main () // ąÉ ąĘą┤ąĄčüčī ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąĖą╝ąĄčĆ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ ą║ąŠąĮčåąĄą┐čåąĖąĖ ą┤ą╗čÅ ąŠą▒čŖčÅą▓ą╗ąĄąĮąĖčÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣:
std::floating_point auto x = add (5 ,8 );
return 0 ;
}38 . ąÜą╗ą░čüčüčŗ . ąØą░ čÅąĘčŗą║ąĄ C++ ą║ą╗ą░čüčüčŗ (class) čŹč鹊 ą┐čĆąŠčüč鹊 čüčĆąĄą┤čüčéą▓ąŠ ą┤ą╗čÅ čüąŠąĘą┤ą░ąĮąĖčÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖčģ čéąĖą┐ąŠą▓ (ą║čüčéą░čéąĖ, čüčéčĆčāą║čéčāčĆčŗ ąĮą░ C++ čéą░ą║ąČąĄ ąĮąĄčÅą▓ąĮąŠ čÅą▓ą╗čÅčÄčéčüčÅ ą║ą╗ą░čüčüą░ą╝ąĖ). ą¤čĆąĖą╝ąĄčĆ ą║ą╗ą░čüčüą░:
const double PI {3.1415926535897932384626433832795 };class Cylinder
{
public :
// ążčāąĮą║čåąĖąĖ (ą╝ąĄč鹊ą┤čŗ) ą║ą╗ą░čüčüą░:
double volume ()
return PI * base_radius * base_radius * height;
}public :
// ą¤ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ čćą╗ąĄąĮčŗ ą║ą╗ą░čüčüą░ (čüą▓ąŠą╣čüčéą▓ą░):
double base_radius{1 };
double height{1 };
};ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ čćą╗ąĄąĮčŗ ą║ą╗ą░čüčüą░ (čüą▓ąŠą╣čüčéą▓ą░ ąĖ ą╝ąĄč鹊ą┤čŗ) ą┐ąŠą╝ąĄč湥ąĮčŗ čüą┐ąĄčåąĖčäąĖą║ą░č鹊čĆąŠą╝ ą┤ąŠčüčéčāą┐ą░ public. ąŁč鹊 ąĘąĮą░čćąĖčé, čćč鹊 čŹčéąĖ čćą╗ąĄąĮčŗ ą║ą╗ą░čüčüą░ ąŠą▒čēąĄą┤ąŠčüčéčāą┐ąĮčŗ. ąó. ąĄ. ą╝ąĄč鹊ą┤ volume ą╝ąŠąČąĮąŠ ą▓čŗąĘą▓ą░čéčī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąĄ ą║ą╗ą░čüčüą░, ąĖ čüą▓ąŠą╣čüčéą▓ą░ base_radius ąĖ ą▒čāą┤čāčé ą┤ąŠčüčéčāą┐ąĮčŗ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ ąĖ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ (ąĄčüą╗ąĖ ąĮąĄ čāą║ą░ąĘą░čéčī public_ čćą╗ąĄąĮčŗ ą║ą╗ą░čüčüą░ ą┐ąŠą╗čāčćą░čÄčé ą┤ąŠčüčéčāą┐ private, čé. ąĄ. ąŠąĮąĖ ą▒čāą┤čāčé ąĮąĄą┤ąŠčüčéčāą┐ąĮčŗ ąĘą░ ą┐čĆąĄą┤ąĄą╗ą░ą╝ąĖ ą║ą╗ą░čüčüą░. ą£ąĄč鹊ą┤čŗ ą║ą╗ą░čüčüą░ ą▓čüąĄą│ą┤ą░ ąĖą╝ąĄčÄčé ą┤ąŠčüčéčāą┐ ą║ čüą▓ąŠą╣čüčéą▓ą░ą╝ ą║ą╗ą░čüčüą░ ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ ąŠčé č鹊ą│ąŠ, čÅą▓ą╗čÅčÄčéčüčÅ ą╗ąĖ ąŠąĮąĖ private ąĖą╗ąĖ public.
ąĪą▓ąŠą╣čüčéą▓ą░ ą║ą╗ą░čüčüą░ ą╝ąŠą│čāčé ą▒čŗčéčī ą╗ąĖą▒ąŠ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝ąĖ, ą╗ąĖą▒ąŠ čāą║ą░ąĘą░č鹥ą╗čÅą╝ąĖ, ąĮąŠ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī čüčüčŗą╗ą║ą░ą╝ąĖ. ą¤čĆąĖčćąĖąĮą░ ą▓ č鹊ą╝, čćč鹊 čüčüčŗą╗ą║ąĖ ą▓čüąĄą│ą┤ą░ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮčŗ, ą░ ą┤ą╗čÅ čüą▓ąŠą╣čüčéą▓ ą║ą╗ą░čüčüą░ ą▓ą░ąČąĮąŠ ąĖą╝ąĄčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą▒čŗčéčī ąĮąĄ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗą╝ąĖ.
39 . ąÜąŠąĮčüčéčĆčāą║č鹊čĆčŗ . ąŁč鹊 čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ ą╝ąĄč鹊ą┤ ą║ą╗ą░čüčüą░, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮ ą▓čŗą┐ąŠą╗ąĮčÅčéčī ą║ą░ą║ąĖąĄ-č鹊 ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąŠąĮąĮčŗąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ. ą×ąĮąĖ ą▓čŗąĘčŗą▓ą░čÄčéčüčÅ ą▓ ą╝ąŠą╝ąĄąĮčé čüąŠąĘą┤ą░ąĮąĖčÅ čŹą║ąĘąĄą╝ą┐ą╗čÅčĆą░ ą║ą╗ą░čüčüą░. ąÆ ą┐čĆąĄą┤čŗą┤čāčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ čā ą║ą╗ą░čüčüą░ Cylinder ąĮąĄ ą▒čŗą╗ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ ą║ąŠąĮčüčéčĆčāą║č鹊čĆ. ąöą╗čÅ čéą░ą║ąŠą│ąŠ čüą╗čāčćą░čÅ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ čüą│ąĄąĮąĄčĆąĖčĆčāąĄčé ą┐čāčüč鹊ą╣ ą║ąŠąĮčüčéčĆčāą║č鹊čĆ. ąŻ ąĮąĄą│ąŠ ąĮąĄ ą▒čāą┤ąĄčé ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓, ąĖ ą▓ ąĄą│ąŠ č鹥ą╗ąĄ ąĮąĄ ą▒čāą┤ąĄčé ąĮąĖą║ą░ą║ąĖčģ ą┤ąĄą╣čüčéą▓ąĖą╣.
ą×čüąŠą▒ąĄąĮąĮąŠčüčéąĖ ą║ąŠąĮčüčéčĆčāą║č鹊čĆąŠą▓:
ŌĆó ąÜąŠąĮčüčéčĆčāą║č鹊čĆčŗ ąĮąĄ ą▓ąŠąĘą▓čĆą░čēą░čÄčé ą║ą░ą║ąŠą╣-ą╗ąĖą▒ąŠ čéąĖą┐.
ą¤čĆąĖą╝ąĄčĆ ą║ą╗ą░čüčüą░ Cylinder čü ą║ąŠąĮčüčéčĆčāą║č鹊čĆą░ą╝ąĖ:
class Cylinder
{
public :
// ąÜąŠąĮčüčéčĆčāą║č鹊čĆčŗ ą║ą╗ą░čüčüą░:
Cylinder (){
base_radius = 2.0 ;
height = 2.0 ;
}Cylinder (double rad_param, double height_param){
base_radius = rad_param;
height = height_param;
}
// ążčāąĮą║čåąĖąĖ (ą╝ąĄč鹊ą┤čŗ) ą║ą╗ą░čüčüą░:
double volume () return PI * base_radius * base_radius * height;
}private :
// ąĪą▓ąŠą╣čüčéą▓ą░ ą║ą╗ą░čüčüą░:
double base_radius{1 };
double height{1 };
};ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 č鹥ą┐ąĄčĆčī čüą▓ąŠą╣čüčéą▓ą░ base_radius ąĖ double height čüčéą░ą╗ąĖ ą┐čĆąĖą▓ą░čéąĮčŗą╝ąĖ, čé. ąĄ. č鹥ą┐ąĄčĆčī ą║ ąĮąĖą╝ čüąĮą░čĆčāąČąĖ ąĮąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ (ąĖčģ ąĮąĄą╗čīąĘčÅ ą┐čĆąŠčćąĖčéą░čéčī ąĖą╗ąĖ ąĘą░ą┐ąĖčüą░čéčī). ąŁčéąĖ čüą▓ąŠą╣čüčéą▓ą░ ą╝ąŠą│čāčé ą▒čŗčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮčŗ č鹊ą╗čīą║ąŠ ą┐čĆąĖ čüąŠąĘą┤ą░ąĮąĖąĖ ąŠą▒čŖąĄą║čéą░ ą║ą╗ą░čüčüą░: ą╗ąĖą▒ąŠ ąĘąĮą░č湥ąĮąĖčÅą╝ąĖ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ, ąĄčüą╗ąĖ ą▓čŗąĘą▓ą░čéčī ą║ąŠąĮčüčéčĆčāą║č鹊čĆ ą▒ąĄąĘ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓, ą╗ąĖą▒ąŠ čāą║ą░ąĘą░ąĮąĮčŗą╝ąĖ ąĘąĮą░č湥ąĮąĖčÅą╝ąĖ, ąĄčüą╗ąĖ ą▓čŗąĘą▓ą░čéčī ą▓č鹊čĆąŠą╣ ą▓ą░čĆąĖą░ąĮčé ą║ąŠąĮčüčéčĆčāą║č鹊čĆą░, čā ą║ąŠč鹊čĆąŠą│ąŠ ąĄčüčéčī ą┐ą░čĆą░ą╝ąĄčéčĆčŗ.
ąÜąŠąĮčüčéčĆčāą║č鹊čĆ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ . ąĪąĖąĮčéą░ą║čüąĖčü ą║ąŠąĮčüčéčĆčāą║č鹊čĆą░ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ (ąĖąĮąŠą│ą┤ą░ ąĄą│ąŠ ąĮą░ąĘčŗą▓ą░čÄčé ą┐čāčüčéčŗą╝ ą║ąŠąĮčüčéčĆčāą║č鹊čĆąŠą╝):
#include < iostream> const double PI {3.1415926535897932384626433832795 };class Cylinder
{
public :
// ąÜąŠąĮčüčéčĆčāą║č鹊čĆčŗ ą║ą╗ą░čüčüą░:
Cylinder () = default ; // ą║ąŠąĮčüčéčĆčāą║č鹊čĆ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ
Cylinder (double rad_param,double height_param)
{
base_radius = rad_param;
height = height_param;
}
// ążčāąĮą║čåąĖąĖ (ą╝ąĄč鹊ą┤čŗ) ą║ą╗ą░čüčüą░:
double volume () return PI * base_radius * base_radius * height;
}private :
// ą¤ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ - čćą╗ąĄąĮčŗ ą║ą╗ą░čüčüą░:
double base_radius{1 };
double height{1 };
};main ()
"volume : " << cylinder1.volume () << std::endl;
return 0 ;
}ąÜąŠąĮčüčéčĆčāą║č鹊čĆ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĮčāąČąĄąĮ ą▓ č鹊ą╝ čüą╗čāčćą░ąĄ, ąĄčüą╗ąĖ ą▓čŗ čģąŠčéąĖč鹥 čüąŠčģčĆą░ąĮąĖčéčī ąĄą│ąŠ ąĮą░ą╗ąĖčćąĖąĄ. ąöąĄą╗ąŠ ą▓ č鹊ą╝, čćč鹊 ąĄčüą╗ąĖ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī čüąŠąĘą┤ą░ą╗ čüą▓ąŠą╣ ą║ąŠąĮčüčéčĆčāą║č鹊čĆ, č鹊 ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąĮąĄ ą▒čāą┤ąĄčé ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ą┐čāčüč鹊ą╣ ą║ąŠąĮčüčéčĆčāą║č鹊čĆ. ąĢčüą╗ąĖ ą▓čŗ ą┐ąŠ ą║ą░ą║ąŠą╣-č鹊 ą┐čĆąĖčćąĖąĮąĄ čģąŠčéąĖč鹥 ąŠčéą╝ąĄąĮąĖčéčī čŹč鹊 ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ, č鹊 čü ą┐ąŠą╝ąŠčēčīčÄ čüą╗ąĄą┤čāčÄčēąĄą│ąŠ čüąĖąĮčéą░ą║čüąĖčüą░ ą╝ąŠąČąĮąŠ čüąŠčģčĆą░ąĮąĖčéčī ą┐čāčüč鹊ą╣ ą║ąŠąĮčüčéčĆčāą║č鹊čĆ (ąĮą░ ą┐čĆąĖą╝ąĄčĆąĄ ą║ą╗ą░čüčüą░ Cylinder):
Cylinder () = default ;
ąĪąĄčéč鹥čĆčŗ (set) ąĖ ą│ąĄčéč鹥čĆčŗ (get) . ąÜąŠą│ą┤ą░ ą╝čŗ ą┤ąĄą╗ą░ąĄą╝ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ - čćą╗ąĄąĮčŗ ą║ą╗ą░čüčüą░ ą┐čĆąĖą▓ą░čéąĮčŗą╝ąĖ (private), č鹊 ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ąĮąĖą╝ ąĮčāąČąĮąŠ čüąŠąĘą┤ą░čéčī ą┐čāą▒ą╗ąĖčćąĮčŗąĄ čäčāąĮą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ąĮą░ąĘčŗą▓ą░čÄčé čüąĄčéč鹥čĆą░ą╝ąĖ (ąŠčé čüą╗ąŠą▓ą░ set, čé. ąĄ. "čāčüčéą░ąĮąŠą▓ąĖčéčī ąĘąĮą░č湥ąĮąĖąĄ") ąĖ ą│ąĄčéč鹥čĆą░ą╝ąĖ (ąŠčé čüą╗ąŠą▓ą░ get, čé. ąĄ. "ą┐ąŠą╗čāčćąĖčéčī ąĘąĮą░č湥ąĮąĖąĄ"). ąĪąĄčéč鹥čĆčŗ ąĖ ą│ąĄčéč鹥čĆčŗ ą┤ąŠą╗ąČąĮčŗ ąŠą┐čĆąĄą┤ąĄą╗čÅčéčīčüčÅ čüąŠ čüą┐ąĄčåąĖčäąĖą║ą░č鹊čĆąŠą╝ ą┤ąŠčüčéčāą┐ą░ public.
ąĀą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą║ą╗ą░čüčüą░ ą┐ąŠ ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ čäą░ą╣ą╗ą░ą╝ . ąÆ ą┐čĆąĄą┤čŗą┤čāčēąĖčģ ą┐čĆąĖą╝ąĄčĆą░čģ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą║ą╗ą░čüčüą░ Cylinder ą┐čĆąĖčüčāčéčüčéą▓ąŠą▓ą░ą╗ą░ ą║ąŠąĮčüčéą░ąĮčéą░ PI. ąĢčæ čåąĄą╗ąĄčüąŠąŠą▒čĆą░ąĘąĮąŠ ą▓čŗąĮąĄčüčéąĖ ą▓ ąŠčéą┤ąĄą╗čīąĮčŗą╣ čäą░ą╣ą╗, ąĮą░ą┐čĆąĖą╝ąĄčĆ constants.h , čćč鹊 ą┐ąŠąĘą▓ąŠą╗ąĖčé ą┐ąŠą┤ą║ą╗čÄčćąĖčéčī ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čŹč鹊ą╣ ą║ąŠąĮčüčéą░ąĮčéčŗ ą▓ ą┤čĆčāą│ąĖčģ čĆą░ąĘąĮčŗčģ ą╝ąŠą┤čāą╗čÅčģ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░ ą▓ą░čłąĄą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ąŁč鹊 ą┤ąĄą╗ą░ąĄčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ ą┤ąĖčĆąĄą║čéąĖą▓čŗ #include:
#include "constants" ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĖą╝čÅ ą┐ąŠą┤ą║ą╗čÄčćą░ąĄą╝ąŠą│ąŠ čäą░ą╣ą╗ą░ ą┤ąŠą┐čāčüą║ą░ąĄčéčüčÅ čāą║ą░ąĘčŗą▓ą░čéčī ą▒ąĄąĘ čĆą░čüčłąĖčĆąĄąĮąĖčÅ ".h".
ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą║ą╗ą░čüčüą░ Cylinder čéą░ą║ąČąĄ ą╝ąŠąČąĮąŠ ą┐ąĄčĆąĄą╝ąĄčüčéąĖčéčī ą▓ ąŠčéą┤ąĄą╗čīąĮčŗą╣ ąĘą░ą│ąŠą╗ąŠą▓ąŠčćąĮčŗą╣ čäą░ą╣ą╗, ąĮą░ą┐čĆąĖą╝ąĄčĆ cylinder.h . ąØąŠ ą╝ąŠąČąĮąŠ ą┐ąŠą╣čéąĖ ąĄčēąĄ ą┤ą░ą╗čīčłąĄ: ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ąŠčéą┤ąĄą╗čīąĮčŗą╣ ą╝ąŠą┤čāą╗čī cylinder.cpp , čćč鹊ą▒čŗ ą▓ ąĮąĄą╝ ąĮą░čģąŠą┤ąĖą╗ą░čüčī čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ ą╝ąĄč鹊ą┤ąŠą▓ ą║ą╗ą░čüčüą░. ąóą░ą║ą░čÅ ą╝ąĄč鹊ą┤ąĖą║ą░ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čĆą░ąĘą┤ąĄą╗ąĖčéčī ą╗ąŠą│ąĖą║čā ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĮą░ ą┐čĆąŠčüčéčŗąĄ, ą╗ąĄą│ą║ąŠ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄą╝čŗąĄ čāčĆąŠą▓ąĮąĖ, ą│ą┤ąĄ ą║ą░ąČą┤ą░čÅ čćą░čüčéčī č湥čéą║ąŠ ąŠčéą▓ąĄčćą░ąĄčé ąĘą░ ą║ą░ą║ąĖąĄ-č鹊 ą║ąŠąĮą║čĆąĄčéąĮčŗąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ. ąØąĖąČąĄ ąĮą░ ą┐čĆąĖą╝ąĄčĆąĄ ą║ą╗ą░čüčüą░ Cylinder ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąĖąĮčåąĖą┐ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą╝ąŠą┤čāą╗čīąĮąŠčüčéąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
ąŚą░ą│ąŠą╗ąŠą▓ąŠčćąĮčŗą╣ čäą░ą╣ą╗ constants.h :
#pragma once const double PI {3.1415926535897932384626433832795 };ąŚą░ą│ąŠą╗ąŠą▓ąŠčćąĮčŗą╣ čäą░ą╣ą╗ cylinder.h :
#pragma once #include "constants.h" class Cylinder
{public :
// ąÜąŠąĮčüčéčĆčāą║č鹊čĆčŗ:
Cylinder () = default ;
Cylinder (double rad_param,double height_param);
// ą¤čāą▒ą╗ąĖčćąĮčŗą╣ ą╝ąĄč鹊ą┤:
double volume () // ąōąĄčéč鹥čĆčŗ ąĖ čüąĄčéč鹥čĆčŗ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐čĆąĖą▓ą░čéąĮčŗą╝ čćą╗ąĄąĮą░ą╝ ą║ą╗ą░čüčüą░:
double get_base_radius () double get_height () void set_base_radius (double rad_param) void set_height (double height_param) double base_radius{1 };
double height{1 };
};ą£ąŠą┤čāą╗čī cylinder.cpp , ą│ą┤ąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮą░ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ ą╝ąĄč鹊ą┤ąŠą▓ ą║ą╗ą░čüčüą░:
#include "cylinder.h" Cylinder (double rad_param, double height_param)
{
base_radius = rad_param;
height = height_param;
}Cylinder::volume ()
return PI * base_radius * base_radius * height;
}Cylinder::get_base_radius ()
return base_radius;
}double Cylinder::get_height ()
return height;
}void Cylinder::set_base_radius (double rad_param)
Cylinder::set_height (double height_param)
ą£ąŠą┤čāą╗čī main.cpp , ą│ą┤ąĄ ąĮą░čģąŠą┤ąĖčéčüčÅ ą╗ąŠą│ąĖą║ą░ ą▓ąĄčĆčģąĮąĄą│ąŠ čāčĆąŠą▓ąĮčÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ:
#include < iostream> #include "cylinder.h" int main ()
Cylinder cylinder1 (10 ,10 ) ;
std::cout << "volume : " << cylinder1.volume () << std::endl;
return 0 ;
}ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą┤ą╗čÅ čéą░ą║ąŠą╣ ą╝ąĄč鹊ą┤ąĖą║ąĖ ą▓ ąĘą░ą│ąŠą╗ąŠą▓ąŠčćąĮąŠą╝ čäą░ą╣ą╗ąĄ ą║ą╗ą░čüčüą░ (ą▓ ą┤ą░ąĮąĮąŠą╝ ą┐čĆąĖą╝ąĄčĆąĄ čŹč鹊 cylinder.h ) ąĮąĄ ą┤ąŠą╗ąČąĮąŠ ąŠčüčéą░ą▓ą░čéčīčüčÅ ąĮąĖą║ą░ą║ąĖčģ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖą╣ ą╝ąĄč鹊ą┤ąŠą▓ ą║ą╗ą░čüčüą░, ą▓čüąĄ čŹčéąĖ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą┐ąĄčĆąĄąĮąĄčüąĄąĮčŗ ą▓ ąŠčéą┤ąĄą╗čīąĮčŗą╣ ą╝ąŠą┤čāą╗čī, ąĖ čüąĮą░ą▒ąČąĄąĮčŗ ą┐čĆąĄčäąĖą║čüąŠą╝ ąĖąĘ ąĖą╝ąĄąĮąĖ ą║ą╗ą░čüčüą░ ąĖ ą┤ą▓ąŠą╣ąĮąŠą│ąŠ ą┤ą▓ąŠąĄč鹊čćąĖčÅ (ą▓ ąĮą░čłąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ čŹč鹊 Cylinder::).
ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ąŠą▒čŖąĄą║čéą░ą╝ąĖ ą║ą╗ą░čüčüą░ čü ą┐ąŠą╝ąŠčēčīčÄ čāą║ą░ąĘą░č鹥ą╗ąĄą╣. ą×ą▒čŖąĄą║čéčŗ ą║ą╗ą░čüčüą░ ą╝ąŠą│čāčé ą▒čŗčéčī čüąŠąĘą┤ą░ąĮčŗ ą▓ čüč鹥ą║ąĄ ą╗ąĖą▒ąŠ ą▓ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ, ąĖ č鹊ą│ą┤ą░ ą║ čćą╗ąĄąĮą░ą╝ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ ą║ą╗ą░čüčüą░ ą┤ąŠčüčéčāą┐ ą▒čāą┤ąĄčé ąŠčüčāčēąĄčüčéą▓ą╗čÅčéčīčüčÅ č湥čĆąĄąĘ č鹊čćą║čā. ąóą░ą║ąČąĄ ąŠą▒čŖąĄą║čéčŗ ą╝ąŠą│čāčé ą▒čŗčéčī čüąŠąĘą┤ą░ąĮčŗ ą▓ ą║čāč湥 čü ą┐ąŠą╝ąŠčēčīčÄ ąŠą┐ąĄčĆą░č鹊čĆą░ new, ą┤ąŠčüčéčāą┐ ą║ čéą░ą║ąĖą╝ ąŠą▒čŖąĄą║čéą░ą╝ ą▒čāą┤ąĄčé ąŠčüčāčēąĄčüčéą▓ą╗čÅčéčīčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ čāą║ą░ąĘą░č鹥ą╗čÅ ąĖ ->. ą¤čĆąĖą╝ąĄčĆčŗ:
#include < iostream> #include "cylinder.h" // ąĪąŠąĘą┤ą░ąĮąĖąĄ ąŠą▒čŖąĄą║čéą░ ą▓ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ:
Cylinder cylinder1;int main ()
// ąĪąŠąĘą┤ą░ąĮąĖąĄ ąŠą▒čŖąĄą║čéą░ ą▓ čüč鹥ą║ąĄ:
Cylinder cylinder2 (10 ,10 ) ;volume ();
cylinder2.volume ();// ąĪąŠąĘą┤ą░ąĮąĖąĄ ąŠą▒čŖąĄą║čéą░ ą▓ ą║čāč湥 (heap) ąĖ ą┐ąŠą╗čāč湥ąĮąĖąĄ čāą║ą░ąĘą░č鹥ą╗čÅ ąĮą░ ąĮąĄą│ąŠ:
Cylinder* p_cylinder3 = new Cylinder (11 , 20 );// ą×ą▒čĆą░čēąĄąĮąĖąĄ ą║ ąŠą▒čŖąĄą║čéčā čü ą┐ąŠą╝ąŠčēčīčÄ čāą║ą░ąĘą░č鹥ą╗ąĄą╣:
Cylinder* p_cylinder1 = &cylinder1;
Cylinder* p_cylinder2 = &cylinder2;"volume 1: " << (*p_cylinder1).volume () << std::endl;
std::cout << "volume 2: " << p_cylinder2->volume () << std::endl;
std::cout << "volume 3: " << p_cylinder3->volume () << std::endl;
std::cout << "base_rad(cylinder2): " << p_cylinder2->get_base_radius () << std::endl;delete p_cylinder3;
return 0 ;
}40 . ąöąĄčüčéčĆčāą║č鹊čĆčŗ . ąŁč鹊 čüą┐ąĄčåąĖą░ą╗čīąĮčŗąĄ ą╝ąĄč鹊ą┤čŗ ą║ą╗ą░čüčüą░, ą║ąŠč鹊čĆčŗąĄ ą▓čŗąĘčŗą▓ą░čÄčéčüčÅ ą▓ ą╝ąŠą╝ąĄąĮčé čāą┤ą░ą╗ąĄąĮąĖčÅ ąŠą▒čŖąĄą║čéą░ ą║ą╗ą░čüčüą░. ąŁčéąĖ ą╝ąĄč鹊ą┤čŗ ą╝ąŠą│čāčé ą┐ąŠąĮą░ą┤ąŠą▒ąĖčéčīčüčÅ ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ą┤ąĄą╣čüčéą▓ąĖą╣, čüą▓čÅąĘą░ąĮąĮčŗčģ čü čāą┤ą░ą╗ąĄąĮąĖąĄą╝ ąŠą▒čŖąĄą║čéą░, ąĮą░ą┐čĆąĖą╝ąĄčĆ ą┤ą╗čÅ čāą┤ą░ą╗ąĄąĮąĖčÅ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ąĖąĘ ą║čāčćąĖ, ąĖą╗ąĖ ą┤čĆčāą│ąĖčģ ąŠą┐ąĄčĆą░čåąĖą╣ ąŠčćąĖčüčéą║ąĖ (čéą░ą║ąĖčģ ą║ą░ą║ ą┐ąĄčĆąĄąĮą░čüčéčĆąŠą╣ą║ą░ ą║ą░ą║ąŠą│ąŠ-ą╗ąĖą▒ąŠ ąŠą▒ąŠčĆčāą┤ąŠą▓ą░ąĮąĖčÅ). ą¤čĆąĖą╝ąĄčĆ:
#include < iostream> #include < string_view> class Dog
{public :
// ąöąĄą║ą╗ą░čĆą░čåąĖčÅ ą║ąŠąĮčüčéčĆčāą║č鹊čĆąŠą▓:
Dog () = default ;
Dog (std::string_view name_param, std::string_view breed_param, int age_param);
// ąöąĄą║ą╗ą░čĆą░čåąĖčÅ ą┤ąĄčüčéčĆčāą║č鹊čĆą░:
~Dog ();private :
std::string name;
std::string breed;
int * p_age{nullptr };
};Dog (std::string_view name_param, std::string_view breed_param, int age_param)
{
name = name_param;
breed = breed_param;
p_age = new int ;
*p_age = age_param;
std::cout << "Dog constructor called for " << name << std::endl;
}// ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąŠą│ąŠ ą┤ąĄčüčéčĆčāą║č鹊čĆą░:
Dog::~Dog ()
{
delete p_age;
std::cout << "Dog destructor called for : " << name << std::endl;
}some_func ()
new Dog ("Fluffy" , "Shepherd" , 2 );
delete p_dog; // čŹč鹊 ą▓čŗąĘąŠą▓ąĄčé ą┤ąĄčüčéčĆčāą║č鹊čĆ ą║ą╗ą░čüčüą░ Dog
}int main ()
some_func ();
std::cout << "Done!" << std::endl;
return 0 ;
}ą×č湥ą▓ąĖą┤ąĮčŗąĄ čüą╗čāčćą░ąĖ ą▓čŗąĘąŠą▓ą░ ą┤ąĄčüčéčĆčāą║č鹊čĆą░:
ŌĆó ąÜąŠą│ą┤ą░ ąĘą░ą║ą░ąĮčćąĖą▓ą░ąĄčéčüčÅ ą╗ąŠą║ą░ą╗čīąĮą░čÅ ąŠą▒ą╗ą░čüčéčī ą┤ąĄą╣čüčéą▓ąĖčÅ ąŠą▒čŖąĄą║čéą░ (čé. ąĄ. ąŠą▒čŖąĄą║čé ą▒čŗą╗ ą▓čŗą┤ąĄą╗ąĄąĮ ą▓ čüč鹥ą║ąĄ, ąĮą░ą┐čĆąĖą╝ąĄčĆ ą▓ąĮčāčéčĆąĖ č鹥ą╗ą░ čäčāąĮą║čåąĖąĖ).
ą×ą┤ąĮą░ą║ąŠ čéą░ą║ąČąĄ čüčāčēąĄčüčéą▓čāčÄčé čüą╗čāčćą░ąĖ ą║ąŠčüą▓ąĄąĮąĮąŠą│ąŠ ą▓čŗąĘąŠą▓ą░ ą┤ąĄčüčéčĆčāą║č鹊čĆąŠą▓. ąöąĄčüčéčĆčāą║č鹊čĆčŗ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗąĘą▓ą░ąĮčŗ ą▓ ąĮąĄ ąŠč湥ą▓ąĖą┤ąĮčŗčģ ą╝ąĄčüčéą░čģ, č湥ą│ąŠ čüą╗ąĄą┤čāąĄčé ąĖąĘą▒ąĄą│ą░čéčī:
ŌĆó ąÜąŠą│ą┤ą░ ąŠą▒čŖąĄą║čé ą║ą╗ą░čüčüą░ ą▒čŗą╗ ą┐ąĄčĆąĄą┤ą░ąĮ ą▓ čäčāąĮą║čåąĖčÄ ą┐ąŠ ąĘąĮą░č湥ąĮąĖčÄ.
ą¤ąŠčĆčÅą┤ąŠą║ ą▓čŗąĘąŠą▓ą░ ą║ąŠąĮčüčéčĆčāą║č鹊čĆąŠą▓ ąĖ ą┤ąĄčüčéčĆčāą║č鹊čĆąŠą▓. ąöąĄčüčéčĆčāą║č鹊čĆčŗ ą▓čŗąĘčŗą▓ą░čÄčéčüčÅ ą▓ ąŠą▒čĆą░čéąĮąŠą╝ ą┐ąŠčĆčÅą┤ą║ąĄ ą▓čŗąĘąŠą▓čā ą║ąŠąĮčüčéčĆčāą║č鹊čĆąŠą▓.
41 . ąŻą║ą░ąĘą░č鹥ą╗čī this . ąŁč鹊 čüą┐ąĄčåąĖą░ą╗čīąĮąŠąĄ ą║ą╗čÄč湥ą▓ąŠąĄ čüą╗ąŠą▓ąŠ, ą║ąŠč鹊čĆąŠąĄ ą▓ąĮčāčéčĆąĖ ą╝ąĄč鹊ą┤ąŠą▓, ą║ąŠąĮčüčéčĆčāą║č鹊čĆąŠą▓ ąĖ ą┤ąĄčüčéčĆčāą║č鹊čĆąŠą▓ ąŠą▒čŖąĄą║čéą░ ą║ą╗ą░čüčüą░ čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĄ ą┐ą░ą╝čÅčéčī, ąĘą░ąĮąĖą╝ą░ąĄą╝čāčÄ čŹčéąĖą╝ ąŠą▒čŖąĄą║č鹊ą╝. ąÜą╗čÄč湥ą▓ąŠąĄ čüą╗ąŠą▓ąŠ this ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ, ą║ąŠą│ą┤ą░ ą┐ą░čĆą░ą╝ąĄčéčĆ ą╝ąĄč鹊ą┤ą░ ąĖ čüą▓ąŠą╣čüčéą▓ąŠ ą║ą╗ą░čüčüą░ ąĖą╝ąĄčÄčé ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠąĄ ąĖą╝čÅ:
class Dog
{public :
...
Dog* set_dog_name (std::string_view name)
{
this ->name = name;
return this ;
}private :
std::string name;
std::string breed;
int * p_age{nullptr };
};ąĢčüą╗ąĖ ą╝ąĄč鹊ą┤ ą▒čāą┤ąĄčé ą▓ąŠąĘą▓čĆą░čēą░čéčī čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ąŠą▒čŖąĄą║čé, č鹊 ą┐ąŠčÅą▓ąĖčéčüčÅ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą▓čŗąĘčŗą▓ą░čéčī ą╝ąĄč鹊ą┤čŗ čåąĄą┐ąŠčćą║ąŠą╣ ą▓ ąŠą┤ąĮąŠą╣ čüčéčĆąŠą║ąĄ:
dog1.set_dog_name ("Pumba" )->set_dog_breed ("Wire Fox Terrier" )->set_dog_age (4 );
ąóą░ą║ąČąĄ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī this ą▓ą╝ąĄčüč鹥 čüąŠ čüčüčŗą╗ą║ą░ą╝ąĖ, ąĮąŠ čüąĖąĮčéą░ą║čüąĖčü ą▒čāą┤ąĄčé ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┤čĆčāą│ąŠą╣.
Dog& set_dog_name (std::string_view name)
{
this ->name = name;
return *this ;
}
ą£ąĄč鹊ą┤čŗ ąŠą▒čŖąĄą║čéą░ č鹥ą┐ąĄčĆčī ą▓čŗąĘčŗą▓ą░čÄčéčüčÅ č湥čĆąĄąĘ č鹊čćą║čā:
dog1.set_dog_name ("Pumba" )->set_dog_breed ("Wire Fox Terrier" )->set_dog_age (4 );
42 . ą×čéą╗ąĖčćąĖčÅ ą▓ čüąŠąĘą┤ą░ąĮąĖąĖ ą║ą╗ą░čüčüą░ č湥čĆąĄąĘ class ąĖ č湥čĆąĄąĘ struct . ąÜą╗ą░čüčüčŗ ą╝ąŠąČąĮąŠ čüąŠąĘą┤ą░ą▓ą░čéčī ą║ą░ą║ čü ą┐ąŠą╝ąŠčēčīčÄ ą║ą╗čÄč湥ą▓ąŠą│ąŠ čüą╗ąŠą▓ą░ class, čéą░ą║ ąĖ čü ą┐ąŠą╝ąŠčēčīčÄ ą║ą╗čÄč湥ą▓ąŠą│ąŠ čüą╗ąŠą▓ą░ struct:
class Dog
{
std::string m_name;
};struct Cat
{
std::string m_name;
};ąĢčüčéčī ą▓ą░ąČąĮąŠąĄ ąŠčéą╗ąĖčćąĖąĄ čüąŠąĘą┤ą░ąĮąĖčÅ ą║ą╗ą░čüčüą░ č湥čĆąĄąĘ struct, ąĖ čŹč鹊 ąŠčéą╗ąĖčćąĖąĄ ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮąŠąĄ: ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą╗čÅ class ą┐ąŠą╗čÅ ą║ą╗ą░čüčüą░ ą┐ąŠą╗čāčćą░čÄčé čāčĆąŠą▓ąĄąĮčī ą┤ąŠčüčéčāą┐ą░ private, ą░ ą┤ą╗čÅ ą║ą╗ą░čüčüą░, čüąŠąĘą┤ą░ąĮąĮąŠą│ąŠ č湥čĆąĄąĘ struct, ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┐ąŠą╗čÅ ą║ą╗ą░čüčüą░ ą┐ąŠą╗čāčćą░čÄčé čāčĆąŠą▓ąĄąĮčī ą┤ąŠčüčéčāą┐ą░ public.
ą£čŗ ą╝ąŠąČąĄą╝ ąĖąĘą╝ąĄąĮąĖčéčī čŹč鹊 ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ, ąĖčüą┐ąŠą╗čīąĘčāčÅ ą┤ą╗čÅ ą║ą╗ą░čüčüą░ class ą╝ąŠą┤ąĖčäąĖą║ą░č鹊čĆ ą┤ąŠčüčéčāą┐ą░ public, ą░ ą┤ą╗čÅ ą║ą╗ą░čüčüą░ struct ą╝ąŠą┤ąĖčäąĖą║ą░č鹊čĆ ą┤ąŠčüčéčāą┐ą░ private.
43 . ąĀą░ąĘą╝ąĄčĆ ąŠą▒čŖąĄą║čéą░ ą║ą╗ą░čüčüą░ . ą¤ąŠą┐čĆąŠą▒čāąĄą╝ ą┐čĆąŠą░ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī čĆą░ąĘą╝ąĄčĆ ąŠą▒čŖąĄą║čéą░ čüą╗ąĄą┤čāčÄčēąĄą│ąŠ ą║ą╗ą░čüčüą░:
#include < stdint.h> #include < iostream> class SomeClass
{public :
void do_some ()
void print_info ()
"name: " << m_name << std::endl;
std::cout << "size_of(m_name): " << sizeof (m_name) << std::endl;
std::cout << "size_of(this): " << sizeof (this ) << std::endl;
}
char m8{};
short m16{};
int m32{};
size_t m64{};
std::string m_name{"I am center of Universe" };
};int main ()
"sizeof(char): " << sizeof (sc.m8) << std::endl;
std::cout << "sizeof(short): " << sizeof (sc.m16) << std::endl;
std::cout << "sizeof(int): " << sizeof (sc.m32) << std::endl;
std::cout << "sizeof(size_t): " << sizeof (sc.m64) << std::endl;
std::cout << "sizeof(std::string): " << sizeof (std::string) << std::endl;
std::cout << "sizeof(SomeClass): " << sizeof (SomeClass) << std::endl;
std::cout << "sizeof(sc): " << sizeof (sc) << std::endl;
sc.print_info ();
return 0 ;
}ąĢčüą╗ąĖ ąĘą░ą┐čāčüčéąĖčéčī čŹčéčā ą┐čĆąŠą│čĆą░ą╝ą╝čā, č鹊 ą▒čāą┤ąĄčé ą▓čŗą▓ąĄą┤ąĄąĮąŠ čüą╗ąĄą┤čāčÄčēąĄąĄ:
sizeof(char): 1
sizeof(short): 2
sizeof(int): 4
sizeof(size_t): 8
sizeof(std::string): 32
sizeof(SomeClass): 48
sizeof(sc): 48
name: I am center of Universe
size_of(m_name): 32
size_of(this): 8
ążčāąĮą║čåąĖąĖ do_some ąĖ print_info ąĘą░ąĮąĖą╝ą░čÄčé ą║ą░ą║ąŠąĄ-č鹊 ą╝ąĄčüč鹊 ą▓ ą┐ą░ą╝čÅčéąĖ ą┐čĆąŠą│čĆą░ą╝ą╝, ąĖ čÅą▓ą╗čÅčÄčéčüčÅ ąŠą▒čēąĖą╝ąĖ ą┤ą╗čÅ ą▓čüąĄčģ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą▓ ą║ą╗ą░čüčüą░. ąÆ čĆą░ąĘą╝ąĄčĆąĄ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ ą║ą╗ą░čüčüą░ ąŠąĮąĖ ąĮąĖą║ą░ą║ ąĮąĄ čāčćąĖčéčŗą▓ą░čÄčéčüčÅ.
ą¤ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ m8, m16, m32 ąĖ m64 ą▒čāą┤čāčé ąĘą░ąĮąĖą╝ą░čéčī ą▓ ą┐ą░ą╝čÅčéąĖ 1, 2, 4 ąĖ 8 ą▒ą░ą╣čé čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ. ą£ąŠąČąĄčé ą┐ąŠą║ą░ąĘą░čéčīčüčÅ, čćč鹊 čĆą░ąĘą╝ąĄčĆ čŹą║ąĘąĄą╝ą┐ą╗čÅčĆą░ ąŠą▒čŖąĄą║čéą░ ą▒čāą┤ąĄčé čĆą░ą▓ąĄąĮ čüčāą╝ą╝ąĄ čĆą░ąĘą╝ąĄčĆąŠą▓ ąĄą│ąŠ čćą╗ąĄąĮąŠą▓ (čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ąĮą░ ą╝ąĄč鹊ą┤čŗ, ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ, čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ąĮą░ ą┤ąŠč湥čĆąĮąĖąĄ ąŠą▒čŖąĄą║čéčŗ). ą×ą┤ąĮą░ą║ąŠ čŹč鹊 ąĮąĄ ą▓ąĄčĆąĮąŠ, ą┐ąŠčüą║ąŠą╗čīą║čā čüčāčēąĄčüčéą▓čāąĄčé ąĄčēąĄ ąĖ čéą░ą║ą░čÅ ą▓ąĄčēčī, ą║ą░ą║ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ čĆą░ąĘą╝ąĄčēąĄąĮąĖčÅ ąŠą▒čŖąĄą║č鹊ą▓ ą▓ ą┐ą░ą╝čÅčéąĖ (boundary alignment). ą¤ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ ą▒čāą┤čāčé čģčĆą░ąĮąĖčéčīčüčÅ ą▓ ą▒ą░ą╣č鹊ą▓čŗčģ ą│čĆčāą┐ą┐ą░čģ ą┐ą░ą╝čÅčéąĖ, ąĮą░čćą░ą╗čīąĮčŗąĄ ą░ą┤čĆąĄčüą░ ą║ąŠč鹊čĆčŗčģ ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗čÅčéčüčÅ ąĮą░ 4. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąĄčüą╗ąĖ čā ąĮą░čü ąĄčüčéčī ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ čĆą░ąĘą╝ąĄčĆąŠą╝ ą╝ąĄąĮčīčłąĄ 4 ą▒ą░ą╣čé, č鹊 ą▓ ą┐ą░ą╝čÅčéąĖ ą╝ąŠą│čāčé ąŠą▒čĆą░ąĘąŠą▓čŗą▓ą░čéčīčüčÅ ą┐čāčüčéčŗąĄ ą╝ąĄčüčéą░. ą¤ąŠčŹč鹊ą╝čā čĆą░ąĘą╝ąĄčĆ ąŠą▒čŖąĄą║čéą░ ą║ą╗ą░čüčüą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▒ąŠą╗čīčłąĄ, č湥ą╝ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą▒čŗ ąŠąČąĖą┤ą░čéčī ą┐čĆąĖ čüčāą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĖ čĆą░ąĘą╝ąĄčĆąŠą▓ čćą╗ąĄąĮąŠą▓ ą║ą╗ą░čüčüą░. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čŹčéąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ ą▒čāą┤čāčé ąĘą░ąĮąĖą╝ą░čéčī ą▓ ą┐ą░ą╝čÅčéąĖ 20 ą▒ą░ą╣čé: 4 + 4 + 4 + 8.
ą¤ąĄčĆąĄą╝ąĄąĮąĮą░čÅ m_name ą▓ąĮčāčéčĆąĄąĮąĮąĄ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮą░ ą║ą░ą║ ą║ą╗ą░čüčü, ąĖ ąĘą┤ąĄčüčī čģčĆą░ąĮąĖčéčüčÅ čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ čŹč鹊ą│ąŠ ą║ą╗ą░čüčüą░. ąó. ąĄ. čĆą░ąĘą╝ąĄčĆ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ m_name ą▒čāą┤ąĄčé čĆą░ą▓ąĄąĮ čĆą░ąĘą╝ąĄčĆčā 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ ą║ą╗ą░čüčüą░, ą░ čüčéčĆąŠą║ą░, ą║ąŠč鹊čĆą░čÅ čģčĆą░ąĮąĖčéčüčÅ ą▓ ąĮąĄą╣, ą▒čāą┤ąĄčé ąĮą░čģąŠą┤ąĖčéčīčüčÅ ą▓ ąŠčéą┤ąĄą╗čīąĮąŠ ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ.
ąÜą╗čÄč湥ą▓ąŠąĄ čüą╗ąŠą▓ąŠ this ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé čüąŠą▒ąŠą╣ čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ąŠą▒čŖąĄą║čé ą║ą╗ą░čüčüą░, ą┐ąŠčŹč鹊ą╝čā ąĄą│ąŠ čĆą░ąĘą╝ąĄčĆ čĆą░ą▓ąĄąĮ 8 ą▒ą░ą╣čé.
44 . ąØą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖąĄ . ąŁč鹊 čüą┐ąŠčüąŠą▒ čüąŠąĘą┤ą░ąĮąĖčÅ ąĖąĄčĆą░čĆčģąĖąĖ ą║ą╗ą░čüčüąŠą▓, ą║ąŠą│ą┤ą░ ąĮąŠą▓čŗą╣ ą║ą╗ą░čüčü čüąŠąĘą┤ą░ąĄčéčüčÅ ąĮą░ ąŠčüąĮąŠą▓ąĄ čĆąŠą┤ąĖč鹥ą╗čīčüą║ąŠą│ąŠ ą║ą╗ą░čüčüą░. ąØąŠą▓čŗąĄ čéąĖą┐čŗ ą┤ą░ąĮąĮčŗčģ čüąŠąĘą┤ą░čÄčéčüčÅ ąĮą░ ąŠčüąĮąŠą▓ąĄ ą┤čĆčāą│ąĖčģ čéąĖą┐ąŠą▓, ąĖ ąĮąŠą▓čŗąĄ čéąĖą┐čŗ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą╝ąĄč鹊ą┤čŗ ąĖ čüą▓ąŠą╣čüčéą▓ą░ čĆąŠą┤ąĖč鹥ą╗čīčüą║ąĖčģ čéąĖą┐ąŠą▓, ą░ čéą░ą║ąČąĄ čüą╝ąŠą│čāčé ą┤ąŠą▒ą░ą▓ą╗čÅčéčī čüą▓ąŠąĖ čüąŠą▒čüčéą▓ąĄąĮąĮčŗąĄ ą╝ąĄč鹊ą┤čŗ ąĖ čüą▓ąŠą╣čüčéą▓ą░. ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 čüąŠąĘą┤ą░ąĄčéčüčÅ ą┤ąĄčĆąĄą▓ąŠ ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ, ą║ąŠč鹊čĆąŠąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą╝ąĮąŠą│ąŠčāčĆąŠą▓ąĮąĄą▓čŗą╝, ąĮą░čćąĖąĮą░čÅ ąŠčé čüą░ą╝ąŠą│ąŠ ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░, ą║ąŠąĮčćą░čÅ ą║ąŠąĮąĄčćąĮčŗą╝ąĖ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮčŗą╝ąĖ ą║ą╗ą░čüčüą░ą╝ąĖ. ąŁč鹊 ą▓čĆąŠą┤ąĄ ą║ą░ą║ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čāą╗čāčćčłąĖčéčī ą┐ąŠą▓č鹊čĆąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą║ąŠą┤ą░. ą¤čĆąĖą╝ąĄčĆ ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ, ą║ą╗ą░čüčü Player ąĮą░čüą╗ąĄą┤čāąĄčéčüčÅ ąŠčé Person:
ąæą░ąĘąŠą▓čŗą╣ ą║ą╗ą░čüčü Person, čäą░ą╣ą╗ person.h :
#ifndef PERSON_H #define PERSON_H include < string> #include < iostream> class Person
{
friend std::ostream& operator << (std::ostream& out, const Person& person);public :
Person ();
Person (std::string& first_name_param, std::string& last_name_param);
~Person ();
// Getters
std::string get_first_name () const {
return first_name;
}
std::string get_last_name () const {
return last_name;
}// Setters
void set_first_name (std::string_view fn) void set_last_name (std::string_view ln) private :
std::string first_name{"Mysterious" };
std::string last_name{"Person" };
};#endif // PERSON_H ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░, čäą░ą╣ą╗ person.cpp :
#include "person.h" Person (){
}Person (std::string& first_name_param, std::string& last_name_param)
: first_name (first_name_param), last_name (last_name_param)
{
}operator << (std::ostream& out, const Person& person)
{
out << "Person [" << person.first_name << " " << person.last_name << "]" ;
return out;
}Person ()
{
}ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░, čäą░ą╣ą╗ player.h :
#ifndef PLAYER_H #define PLAYER_H include < string> #include < iostream> #include < string_view> #include "person.h" class Player : public Person
{
friend std::ostream& operator << (std::ostream& out, const Player& player);public :
Player () = default ;
Player (std::string_view game_param);
private :
std::string m_game{"None" };
};endif // PLAYER_H ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░, čäą░ą╣ą╗ player.cpp :
#include "person.h" #include "player.h" Player (std::string_view game_param)
: m_game (game_param)
{
//first_name = "John"; Compiler errors
//last_name = "Snow";
}operator << (std::ostream& out, const Player& player)
{
out << "Player : [ game : " << player.m_game
<< " names : " << player.get_first_name ()
<< " " << player.get_last_name () << "]" ;
return out;
}ą¤čĆąĖą╝ąĄčĆ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ, čäą░ą╣ą╗ main.cpp :
#include < iostream> #include "player.h" int main ()
Player p1 ("Basketball" ) ;
p1.set_first_name ("John" );
p1.set_last_name ("Snow" );
std::cout << "player : " << p1 << std::endl;
return 0 ;
}ąĪ public-ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖąĄą╝ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮčŗąĄ ą║ą╗ą░čüčüčŗ ą╝ąŠą│čāčé ą┐ąŠą╗čāčćą░čéčī ą┤ąŠčüčéčāą┐ ą║ public čćą╗ąĄąĮą░ą╝ ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░, ąĮąŠ ąĮąĄ ą╝ąŠąČąĄčé ąŠą▒čĆą░čēą░čéčīčüčÅ ą║ private čćą╗ąĄąĮą░ą╝ ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░. ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ ąŠčéąĮąŠčüąĖčéčüčÅ ąĖ ą║ friend ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░. ą×ąĮąĖ ą╝ąŠą│čāčé ąŠą▒čĆą░čēą░čéčīčüčÅ ą║ private čćą╗ąĄąĮą░ą╝ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░, ąĮąŠ ąĮąĄ ą╝ąŠą│čāčé ąŠą▒čĆą░čēą░čéčīčüčÅ ą║ private čćą╗ąĄąĮą░ą╝ ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░.
ąĪčāčēąĄčüčéą▓čāąĄčé čéą░ą║ąČąĄ ą║čĆąŠą╝ąĄ ą╝ąŠą┤ąĖčäąĖą║ą░č鹊čĆąŠą▓ ą┤ąŠčüčéčāą┐ą░ public ąĖ private čüčāčēąĄčüčéą▓čāąĄčé čéą░ą║ąČąĄ ąĖ ą╝ąŠą┤ąĖčäąĖą║ą░č鹊čĆ protected. ą×ąĮ ą┤ą░ąĄčé ą┤ąŠčüčéčāą┐ ąĮą░ čćč鹥ąĮąĖąĄ ąĖ ąĘą░ą┐ąĖčüčī ą║ čćą╗ąĄąĮą░ą╝ ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░ ąĖąĘ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░, ąĮąŠ ąĮąĄ ą┤ą░ąĄčé ą┤ąŠčüčéčāą┐ ą║ ąĮąĖą╝ ąĖąĘą▓ąĮąĄ.
ąĪą┐ąĄčåąĖčäąĖą║ą░č鹊čĆ ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ protected . ąÆ ą┐čĆąĖą╝ąĄčĆąĄ ą▓čŗčłąĄ ą┤ą╗čÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗čüčÅ ą╝ąŠą┤ąĖčäąĖą║ą░č鹊čĆ ą┤ąŠčüčéčāą┐ą░ public :
class Player : public Person
{
...ąĪąŠ čüą┐ąĄčåąĖčäąĖą║ą░č鹊čĆąŠą╝ ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ public ą┤ą╗čÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░ ą▒čāą┤ąĄčé č鹊čćąĮąŠ čéą░ą║ąŠą╣ ąČąĄ ą┤ąŠčüčéčāą┐ ą║ čćą╗ąĄąĮą░ą╝ ą║ą╗ą░čüčüą░, ą║ą░ą║ ąĖ ą┤ąŠčüčéčāą┐ čüąĮą░čĆčāąČąĖ ą║ čćą╗ąĄąĮą░ą╝ ą┤ą╗čÅ ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░. ąŁč鹊 ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ąŠą▒ą╗ąĄą│č湥ąĮąĮčŗą╣ čüą┐ąŠčüąŠą▒ ą┤ąŠčüčéčāą┐ą░ ą║ 菹╗ąĄą╝ąĄąĮčéą░ą╝ ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░ ąĖąĘ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░:
[ąæą░ąĘąŠą▓čŗą╣ ą║ą╗ą░čüčü] --> [ą¤čĆąŠąĖąĘą▓ąŠą┤ąĮčŗą╣ ą║ą╗ą░čüčü]
public --> public protected --> protected private --> private
ąĪąŠ čüą┐ąĄčåąĖčäąĖą║ą░č鹊čĆąŠą╝ ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ protected ą┤ą╗čÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░ ą┤ąŠčüčéčāą┐ ą║ čćą╗ąĄąĮą░ą╝ ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░ ą▒čāą┤ąĄčé čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
class Player : protected Person
{
...[ąæą░ąĘąŠą▓čŗą╣ ą║ą╗ą░čüčü] --> [ą¤čĆąŠąĖąĘą▓ąŠą┤ąĮčŗą╣ ą║ą╗ą░čüčü]
public --> protected protected --> protected private --> private
ąóą░ą║ąČąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠ ąĄčēąĄ ąĖ private ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖąĄ. ąĪ čŹčéąĖą╝ čéąĖą┐ąŠą╝ ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą┤ąŠčüčéčāą┐ ą║ čćą╗ąĄąĮą░ą╝ ą║ą╗ą░čüčüą░ čüąŠ čüč鹊čĆąŠąĮčŗ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░ ą▒čāą┤ąĄčé ąĘą░ą║čĆčŗčé. ąŁč鹊 čüą░ą╝čŗą╣ ąĘą░čēąĖčēąĄąĮąĮčŗą╣ ą▓ą░čĆąĖą░ąĮčé ą┤ą╗čÅ ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░:
class Player : private Person
{
...[ąæą░ąĘąŠą▓čŗą╣ ą║ą╗ą░čüčü] --> [ą¤čĆąŠąĖąĘą▓ąŠą┤ąĮčŗą╣ ą║ą╗ą░čüčü]
public --> private protected --> private private --> private
ąŚą░ą║čĆčŗčéąĖąĄ ą┤ąŠčüčéčāą┐ą░ ą┐ąŠčüą╗ąĄ private-ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ . ą¦ą░čüčéąĮąŠąĄ (private) ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖąĄ ąĮąĄ ą┐ąŠąĘą▓ąŠą╗ąĖčé čćą╗ąĄąĮą░ą╝ čŹč鹊ą│ąŠ ą║ą╗ą░čüčüą░ ą▒čŗčéčī čāąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĮčŗą╝ąĖ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┤ąŠč湥čĆąĮąĄą╝ ą║ą╗ą░čüčüąĄ, ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ ąŠčé ąĄą│ąŠ čéąĖą┐ą░ ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ (ąŠą▒čŖčÅčüąĮąĄąĮąĖąĄ čŹč鹊ą│ąŠ čü ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąŠąĮąĮčŗą╝ ą┐čĆąĖą╝ąĄčĆąŠą╝ čüą╝. ą▓ čćą░čüčéąĖ 3 čāčĆąŠą║ąŠą▓ [1], č鹥ą╝ą░ "Closing in on private inheritance" čü ą┐ąŠąĘąĖčåąĖąĖ 30 ą╝ąĖąĮčāčé 55 čüąĄą║čāąĮą┤. ą¤čĆąĖą╝ąĄčĆ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą┐ą░ą┐ą║ąĄ 36.Inheritance/36.6ClosingInOnPrivateInheritance).
ąÆąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖąĄ ą┤ąŠčüčéčāą┐ą░ ą┐ąŠčüą╗ąĄ private-ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ . ąŁč鹊 ą╝ąŠąČąĮąŠ čüą┤ąĄą╗ą░čéčī čü ą┐ąŠą╝ąŠčēčīčÄ ą║ą╗čÄč湥ą▓ąŠą│ąŠ čüą╗ąŠą▓ą░ using (ąŠą▒čŖčÅčüąĮąĄąĮąĖąĄ čŹč鹊ą│ąŠ čü ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąŠąĮąĮčŗą╝ ą┐čĆąĖą╝ąĄčĆąŠą╝ čüą╝. ą▓ čćą░čüčéąĖ 3 čāčĆąŠą║ąŠą▓ [1], č鹥ą╝ą░ "Resurrecting members back in scope" čü ą┐ąŠąĘąĖčåąĖąĖ 49 ą╝ąĖąĮčāčé 47 čüąĄą║čāąĮą┤. ą¤čĆąĖą╝ąĄčĆ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą┐ą░ą┐ą║ąĄ 36.Inheritance/36.7ResurectingMembersBackInContext).
45 . ą¤ąŠą╗ąĖą╝ąŠčĆčäąĖąĘą╝ . ąĪčāčēąĮąŠčüčéčī ą┐ąŠą╗ąĖą╝ąŠčĆčäąĖąĘą╝ą░ ąĘą░ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ č鹊ą╝, čćč鹊 ą╝ąŠąČąĮąŠ čāą┐čĆą░ą▓ą╗čÅčéčī ąŠą▒čŖąĄą║čéą░ą╝ąĖ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮčŗčģ ą║ą╗ą░čüčüąŠą▓ č湥čĆąĄąĘ čāą║ą░ąĘą░č鹥ą╗ąĖ ąĮą░ ąŠą▒čŖąĄą║čé ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░, ąĖ ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą┐ąŠą╗čāčćą░čéčī ą┐čĆą░ą▓ąĖą╗čīąĮčŗą╣ ą╝ąĄč鹊ą┤, ą▓čŗąĘčŗą▓ą░ąĄą╝čŗą╣ ą┐ąŠ čāą║ą░ąĘą░č鹥ą╗čÄ ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░. ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ ąŠčéąĮąŠčüąĖčéčüčÅ ąĖ čüčüčŗą╗ą║ą░ą╝ ąĮą░ ąŠą▒čŖąĄą║čé ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░.
- ąŻą║ą░ąĘą░č鹥ą╗čī ąĮą░ ą▒ą░ąĘąŠą▓čŗą╣ ą║ą╗ą░čüčü ą╝ąŠąČąĄčé ą┐čĆąĖąĮąĖą╝ą░čéčī ą░ą┤čĆąĄčü ąĮą░ ąŠą▒čŖąĄą║čé ą╗čÄą▒ąŠą│ąŠ ąĖąĘ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮčŗčģ ą║ą╗ą░čüčüąŠą▓. ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ ąŠčéąĮąŠčüąĖčéčüčÅ ąĖ ą║ čüčüčŗą╗ą║ą░ą╝ ąĮą░ ą▒ą░ąĘąŠą▓čŗą╣ ą║ą╗ą░čüčü.
ą¤ąŠą╗ąĖą╝ąŠčĆčäąĖąĘą╝ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé:
1 . ą¤čĆąĖčüą▓ąŠąĖčéčī čāą║ą░ąĘą░č鹥ą╗čÄ ąĮą░ ą▒ą░ąĘąŠą▓čŗą╣ ą║ą╗ą░čüčü ą░ą┤čĆąĄčü ąŠą▒čŖąĄą║čéą░ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░ (čüąŠąĘą┤ą░ąĮąĮąŠą│ąŠ čü ą┐ąŠą╝ąŠčēčīčÄ new).
Shape * shape1 = new Circle;
Shape * shape2 = new Rectangle;
Shape * shape3 = new Oval;
2 . ąĪąŠąĘą┤ą░ą▓ą░čéčī čüčüčŗą╗ą║ąĖ ąĮą░ ąŠą▒čŖąĄą║čéčŗ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░ č湥čĆąĄąĘ čŹčéąĖ čāą║ą░ąĘą░č鹥ą╗ąĖ.
Shape& ref1 {&shape1};
Shape& ref2 {&shape2};
Shape& ref3 {&shape3};
3 . ąÆčŗąĘčŗą▓ą░čéčī č湥čĆąĄąĘ čāą║ą░ąĘą░č鹥ą╗ąĖ (ąĖą╗ąĖ čüčüčŗą╗ą║ąĖ) ą╝ąĄč鹊ą┤čŗ ą║ą░ą║ ą▒ą░ąĘąŠą▓ąŠą│ąŠ, čéą░ą║ ąĖ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░.
4 . ą£ąŠąČąĮąŠ čüąŠąĘą┤ą░čéčī čäčāąĮą║čåąĖčÄ, ąŠą▒čēčāčÄ ą┤ą╗čÅ ą▓čüąĄčģ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮčŗčģ ą║ą╗ą░čüčüąŠą▓, ą║ąŠč鹊čĆą░čÅ ą▒čāą┤ąĄčé ą▓ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ ą┐čĆąĖąĮąĖą╝ą░čéčī čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ą▒ą░ąĘąŠą▓čŗą╣ ą║ą╗ą░čüčü. ąÆ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé č鹊ą│ąŠ, čćč鹊 ą┐ąĄčĆąĄą┤ą░ąĮąŠ ą▓ čŹč鹊ą╝ čāą║ą░ąĘą░č鹥ą╗ąĄ (ą░ą┤čĆąĄčü ą║ą░ą║ąŠą│ąŠ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░ ąŠą▒čŖąĄą║čé) ą╝ąŠą│čāčé ą▒čŗčéčī ą┐čĆąĄą┤ą┐čĆąĖąĮčÅčéčŗ čĆą░ąĘąĮčŗąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ.
void dtaw_shape (const Shape& shape)
// ąæčāą┤ąĄčé ą▓čŗąĘą▓ą░ąĮ ą┐čĆą░ą▓ąĖą╗čīąĮčŗą╣ ą╝ąĄč鹊ą┤ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░,
// ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé č鹊ą│ąŠ, ą░ą┤čĆąĄčü ą║ą░ą║ąŠą│ąŠ ąŠą▒čŖąĄą║čéą░ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮąŠą│ąŠ
// ą║ą╗ą░čüčüą░ ą▒čŗą╗ ą┐ąĄčĆąĄą┤ą░ąĮ ą▓ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ shape:
shape->draw ();
}5 . ąĢčēąĄ ąŠą┤ąĮąŠ ą┐čĆąĄąĖą╝čāčēąĄčüčéą▓ąŠ ą┐ąŠą╗ąĖą╝ąŠčĆčäąĖąĘą╝ą░ - ą╝ąŠąČąĮąŠ čģčĆą░ąĮąĖčéčī čāą║ą░ąĘą░č鹥ą╗ąĖ ąĮą░ ąŠą▒čŖąĄą║čéčŗ čĆą░ąĘą╗ąĖčćąĮčŗčģ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮčŗčģ čéąĖą┐ąŠą▓ ą▓ ąŠą┤ąĮąŠą╣ ą║ąŠą╗ą╗ąĄą║čåąĖąĖ (ą╝ą░čüčüąĖą▓ąĄ), ąĖ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī ąĖčģ ąŠą┤ąĮąŠąŠą▒čĆą░ąĘąĮąŠ, ą▓ ąŠą┤ąĮąŠą╝ čåąĖą║ą╗ąĄ. ąöą╗čÅ čŹč鹊ą│ąŠ ąĮčāąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą╝ą░čüčüąĖą▓ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ąĮą░ ąŠą▒čŖąĄą║čéčŗ ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░.
ąÆąĮąĖą╝ą░ąĮąĖąĄ: ąĄčüą╗ąĖ ąĘą░ąĮąŠą▓ąŠ ą┐čĆąĖčüą▓ąŠąĖčéčī čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ąŠą▒čŖąĄą║čé ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░ ą░ą┤čĆąĄčüąŠą╝ ą┤čĆčāą│ąŠą│ąŠ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░, č鹊 ą▓čüąĄ čĆą░ą▓ąĮąŠ ą▒čāą┤ąĄčé ą▓čŗąĘą▓ą░ąĮ ą╝ąĄč鹊ą┤ ą┐čĆąĄą┤čŗą┤čāčēąĄą│ąŠ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮąŠą│ąŠ ą║ą╗ą░čüčüą░. ą¤čĆąĖčćąĖąĮą░ ą▓ č鹊ą╝, čćč鹊 ą▒čŗą╗ą░ čüą┤ąĄą╗ą░ąĮą░ čüčéą░čéąĖč湥čüą║ą░čÅ ą┐čĆąĖą▓čÅąĘą║ą░ ą▓ ą╝ąŠą╝ąĄąĮčé ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ąśąĘą▒ąĄąČą░čéčī čéą░ą║ąŠą│ąŠ ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮąŠą│ąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ ą╝ąŠąČąĮąŠ čü ą┐ąŠą╝ąŠčēčīčÄ ą║ą╗čÄč湥ą▓ąŠą│ąŠ čüą╗ąŠą▓ą░ virtual, ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅčÄčēąĄą│ąŠ ą┤ąĖąĮą░ą╝ąĖč湥čüą║čāčÄ ą┐čĆąĖą▓čÅąĘą║čā ą╝ąĄč鹊ą┤ąŠą▓. ąÜą╗čÄč湥ą▓ąŠąĄ čüą╗ąŠą▓ąŠ virtual ą┤ąŠą▒ą░ą▓ą╗čÅąĄčéčüčÅ ą┐ąĄčĆąĄą┤ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄą╝ ąĖ ą┤ąĄą║ą╗ą░čĆą░čåąĖąĄą╣ ą╝ąĄč鹊ą┤ąŠą▓ ą║ą╗ą░čüčüą░.
ą¤čĆąĖ ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖąĖ: ą▒ąĄąĘ ą║ą╗čÄč湥ą▓ąŠą│ąŠ čüą╗ąŠą▓ą░ virtual ą┐ąĄčĆąĄą┤ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄą╝ ą╝ąĄč鹊ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĄą│ąŠ čüčéą░čéąĖč湥čüą║ąŠąĄ čüą▓čÅąĘčŗą▓ą░ąĮąĖąĄ, ą░ čü ą║ą╗čÄč湥ą▓čŗą╝ čüą╗ąŠą▓ąŠą╝ virtial - ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠąĄ. ąó. ąĄ. čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ virtual čĆą░ąĘą╝ąĄčĆčŗ ąŠą▒čŖąĄą║č鹊ą▓ ą▒čāą┤čāčé ą▒ąŠą╗čīčłąĄ.
ąĪčéą░čéąĖč湥čüą║ąŠąĄ čüą▓čÅąĘčŗą▓ą░ąĮąĖąĄ:
ąöąĖąĮą░ą╝ąĖč湥čüą║ąŠąĄ čüą▓čÅąĘčŗą▓ą░ąĮąĖąĄ:
ą¤čĆąĖ čüčéą░čéąĖč湥čüą║ąŠą╝ čüą▓čÅąĘčŗą▓ą░ąĮąĖąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą▒čāą┤ąĄčé ą▓čŗąĘčŗą▓ą░čéčī ą╝ąĄč鹊ą┤čŗ ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░ ą┐ąŠ čāą║ą░ąĘą░č鹥ą╗čÄ ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░, ą║ąŠč鹊čĆąŠą╝čā ą┐čĆąĖčüą▓ąŠąĄąĮ ą░ą┤čĆąĄčü ąŠą▒čŖąĄą║čéą░ ą┤ąŠč湥čĆąĮąĄą│ąŠ ą║ą╗ą░čüčüą░. ą¤čĆąĖ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą╝ čüą▓čÅąĘčŗą▓ą░ąĮąĖąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ čāą╝ąĮąĄąĄ - ąŠąĮ ą╝ąŠąČąĄčé ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą▓čŗąĘčŗą▓ą░čéčī ą╝ąĄč鹊ą┤čŗ ąŠą▒čŖąĄą║čéą░ ą┤ąŠč湥čĆąĮąĄą│ąŠ ą║ą╗ą░čüčüą░.
46 . ąĀą░ąĘą╝ąĄčĆ ą┐ąŠą╗ąĖą╝ąŠčĆčäąĮčŗčģ ąŠą▒čŖąĄą║č鹊ą▓, ąĖą╗ąĖ ąŠą▒čŖąĄą║č鹊ą▓, ąĖčüą┐ąŠą╗čīąĘčāčÄčēąĖčģ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠąĄ čüą▓čÅąĘčŗą▓ą░ąĮąĖąĄ.
ąöąĖąĮą░ą╝ąĖč湥čüą║ąŠąĄ čüą▓čÅąĘčŗą▓ą░ąĮąĖąĄ ąĮąĄ čÅą▓ą╗čÅąĄčéčüčÅ ą▒ąĄčüą┐ą╗ą░čéąĮčŗą╝, čŹč鹊 ą┤ąŠčüčéąĖą│ą░ąĄčéčüčÅ čåąĄąĮąŠą╣ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą│ąŠ čĆą░čüčģąŠą┤ą░ ą┐ą░ą╝čÅčéąĖ.
47 . ąĪą╗ą░ą╣čüąĖąĮą│, čüčĆąĄąĘ (slicing). ąĢčüą╗ąĖ ą┐čĆąĖčüą▓ąŠąĖčéčī ąŠą▒čŖąĄą║čéčā ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░ ąŠą▒čŖąĄą║čé ą┤ąŠč湥čĆąĮąĄą│ąŠ ą║ą╗ą░čüčüą░, č鹊 ąĖąĘ ą┤ąŠč湥čĆąĮąĄą│ąŠ ą║ą╗ą░čüčüą░ ą▒čāą┤ąĄčé ą▓ąĘčÅč鹊 č鹊ą╗čīą║ąŠ č鹊, čćč鹊 ąŠčéąĮąŠčüąĖčéčüčÅ ą║ ą▒ą░ąĘąŠą▓ąŠą╝čā ą║ą╗ą░čüčüčā.
48 . Override (ą┐ąĄčĆąĄąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ). ąÜą╗čÄč湥ą▓ąŠąĄ čüą╗ąŠą▓ąŠ override ą▓čüčéą░ą▓ą╗čÅąĄčéčüčÅ ą┐ąŠčüą╗ąĄ ąĖą╝ąĄąĮąĖ ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĖ ą╝ąĄč鹊ą┤ą░, ą┐ąĄčĆąĄą┤ ąŠčéą║čĆčŗą▓ą░čÄčēąĄą╣ čäąĖą│čāčĆąĮąŠą╣ čüą║ąŠą▒ą║ąŠą╣:
virtual void draw () const override
"Oval::draw() called. Drawing " << m_description <<
" with m_x_radius : " << m_x_radius << " and m_y_radius : " << m_y_radius
<< std::endl;
}Override čāą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ąĘą┤ąĄčüčī ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐ąĄčĆąĄąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čüčāčēąĄčüčéą▓čāčÄčēąĄą│ąŠ ą╝ąĄč鹊ą┤ą░ ą▓ ą▒ą░ąĘąŠą▓ąŠą╝ ą║ą╗ą░čüčüąĄ. ąśčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ čüą┐ąĄčåąĖčäąĖčćąĮąŠą╣ ąĮą░čüčéčĆąŠą╣ą║ąĖ ą╝ąĄč鹊ą┤ąŠą▓ ą▓ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĮčŗčģ ą║ą╗ą░čüčüą░čģ.
49 . Overloading , overriding , hiding . Overloading: čŹč鹊 ą║ąŠą│ą┤ą░ čüčāčēąĄčüčéą▓čāąĄčé 2 čäčāąĮą║čåąĖąĖ (ą╝ąĄč鹊ą┤ą░) čü ąŠą┤ąĖąĮą░ą║ąŠą▓čŗą╝ ąĖą╝ąĄąĮąĄą╝, ąĮąŠ čĆą░ąĘąĮčŗą╝ ąĮą░ą▒ąŠčĆąŠą╝ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓. Hiding: ąĄčüą╗ąĖ čüą┤ąĄą╗ą░čéčī ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║čā ą▓ ą┤ąŠč湥čĆąĮąĄą╝ ą║ą╗ą░čüčüąĄ čü ą║ą╗čÄč湥ą▓čŗą╝ čüą╗ąŠą▓ąŠą╝ override, č鹊 č鹊ą│ą┤ą░ ą▓čüąĄ ą╝ąĄč鹊ą┤čŗ ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░ čü čéą░ą║ąĖą╝ ąČąĄ ąĖą╝ąĄąĮąĄą╝ (ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ąĖ) čüčéą░ąĮčāčé ąĮąĄą┤ąŠčüčéčāą┐ąĮčŗ.
50 . Final . ą£ąĄč鹊ą┤ čü ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĮąŠą╣ čüą┐ąĄčåąĖčäąĖą║ą░čåąĖąĄą╣ final ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąĄčĆąĄąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┤ąŠč湥čĆąĮąĄą╝ ą║ą╗ą░čüčüąĄ. ąĢčüą╗ąĖ ą┐čĆąĖą╝ąĄąĮąĖčéčī final ąĮą░ čāčĆąŠą▓ąĮąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą║ą╗ą░čüčüą░, č鹊 čŹč鹊 ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąĘą░ą┐čĆąĄčēą░ąĄčé ąĄą│ąŠ ą┤ą░ą╗čīąĮąĄą╣čłąĄąĄ ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖąĄ.
51 . ąÉčĆą│čāą╝ąĄąĮčéčŗ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĖ ą┐ąŠą╗ąĖą╝ąŠčĆčäąĖąĘą╝ virtual . ąĪą╗ąĄą┤čāąĄčé ąĖą╝ąĄčéčī ą▓ ą▓ąĖą┤čā ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ C++, ą║ą░čüą░čÄčēąĄąĄčüčÅ ą░čĆą│čāą╝ąĄąĮč鹊ą▓ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą╝ąĄč鹊ą┤ą░ ą▓ ą▒ą░ąĘąŠą▓ąŠą╝ ą║ą╗ą░čüčüąĄ ąĖ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą│ąŠ ą┐ąĄčĆąĄąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ čŹč鹊ą│ąŠ ą╝ąĄč鹊ą┤ą░ ą▓ ą┤ąŠč湥čĆąĮąĄą╝ ą║ą╗ą░čüčüąĄ čü ą┐ąŠą╝ąŠčēčīčÄ virtual ąĖ override :
ŌĆó ąÉčĆą│čāą╝ąĄąĮčéčŗ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ą▓ ą╝ąŠą╝ąĄąĮčé ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ, čé. ąĄ. čüčéą░čéąĖč湥čüą║ąĖ.
ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą▓ ą┐ąŠą╗ąĖą╝ąŠčĆčäąĮąŠą╣ čäčāąĮą║čåąĖąĖ ą┤ąŠč湥čĆąĮąĄą│ąŠ ą║ą╗ą░čüčüą░ (ąĮąĄąŠąČąĖą┤ą░ąĮąĮąŠ) ą▒čāą┤čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą░čĆą│čāą╝ąĄąĮčéčŗ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĖąĘ ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░. ąó. ąĄ. ą┐čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ą┐ąŠą╗ąĖą╝ąŠčĆčäąĖąĘą╝ą░ čüą╗ąĄą┤čāąĄčé ąĖąĘą▒ąĄą│ą░čéčī ą░čĆą│čāą╝ąĄąĮč鹊ą▓ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą╗čÅ čäčāąĮą║čåąĖą╣.
52 . ąÆąĖčĆčéčāą░ą╗čīąĮčŗą╣ ą┤ąĄčüčéčĆčāą║č鹊čĆ . ąĢčüą╗ąĖ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą┤ąĄčüčéčĆčāą║č鹊čĆ č湥čĆąĄąĘ virtual, č鹊 čŹč鹊 ą┐ąŠąĘą▓ąŠą╗ąĖčé ąĖąĘą▒ąĄąČą░čéčī ą┐čĆąŠą▒ą╗ąĄą╝čŗ čāą┤ą░ą╗ąĄąĮąĖčÅ ą┤ąŠč湥čĆąĮąĖčģ ąŠą▒čŖąĄą║č鹊ą▓ ą┐ąŠ čāą║ą░ąĘą░č鹥ą╗čÄ, čā ą║ąŠč鹊čĆąŠą│ąŠ čéąĖą┐ čāą║ą░ąĘą░č鹥ą╗čÅ ąĮą░ ą▒ą░ąĘąŠą▓čŗą╣ ąŠą▒čŖąĄą║čé.
53 . dynamic_cast < >() . ąŁč鹊 ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠąĄ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ čéąĖą┐ą░ ąŠą▒čŖąĄą║čéą░, ą║ąŠč鹊čĆąŠąĄ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čüą┤ąĄą╗ą░čéčī čüą╗ąĄą┤čāčÄčēąĄąĄ:
ŌĆó ąÆčŗą┐ąŠą╗ąĮąĖčéčī runtime-čéčĆą░ąĮčüč乊čĆą╝ą░čåąĖčÄ ą┤ą░ąĮąĮčŗčģ ąĖąĘ čāą║ą░ąĘą░č鹥ą╗čÅ ąĖą╗ąĖ čüčüčŗą╗ą║ąĖ ąĮą░ ąŠą▒čŖąĄą║čé ą▒ą░ąĘąŠą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░ ą▓ ąŠą▒čŖąĄą║čé ą┤ąŠč湥čĆąĮąĄą│ąŠ ą║ą╗ą░čüčüą░.
54 . ąÜąŠąĮčüčéčĆčāą║č鹊čĆčŗ, ą┤ąĄčüčéčĆčāą║č鹊čĆčŗ ąĖ ą▓ąĖčĆčéčāą░ą╗čīąĮčŗąĄ čäčāąĮą║čåąĖąĖ . ąØąĖ ą▓ ą║ąŠąĄą╝ čüą╗čāčćą░ąĄ ąĮąĄ čüą╗ąĄą┤čāąĄčé ą┐čŗčéą░čéčīčüčÅ ą▓čŗąĘčŗą▓ą░čéčī ą▓ąĖčĆčéčāą░ą╗čīąĮčŗąĄ čäčāąĮą║čåąĖąĖ ąĖąĘ č鹥ą╗ą░ ą║ąŠąĮčüčéčĆčāą║č鹊čĆąŠą▓ ąĖą╗ąĖ ą┤ąĄčüčéčĆčāą║č鹊čĆąŠą▓:
ŌĆó ąÆčŗąĘąŠą▓ ą┐ąŠą╗ąĖą╝ąŠčĆčäąĮąŠą╣ čäčāąĮą║čåąĖąĖ ąĖąĘ ą║ąŠąĮčüčéčĆčāą║č鹊čĆą░ ąĖą╗ąĖ ą┤ąĄčüčéčĆčāą║č鹊čĆą░ ąĮąĄ ą┤ą░čüčé čŹčäč乥ą║čéą░ ą┐ąŠą╗ąĖą╝ąŠčĆčäąĖąĘą╝ą░.
55 . ą¦ąĖčüč鹊 ą▓ąĖčĆčéčāą░ą╗čīąĮčŗąĄ ą╝ąĄč鹊ą┤čŗ, ą░ą▒čüčéčĆą░ą║čéąĮčŗą╣ ą║ą╗ą░čüčü . ąÉą▒čüčéčĆą░ą║čéąĮčŗą╣ ą║ą╗ą░čüčü čŹč鹊 čéą░ą║ąŠą╣ ą║ą╗ą░čüčü, ą│ą┤ąĄ ąĮąĄčé čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą▓ąĖčĆčéčāą░ą╗čīąĮčŗčģ ą╝ąĄč鹊ą┤ąŠą▓, čé. ąĄ. ąŠąĮąĖ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮčŗ ą▓ ą┤ąŠč湥čĆąĮąĖčģ ą║ą╗ą░čüčüą░čģ. ą¤ąŠą▒ąŠčćąĮčŗą╣ čŹčäč乥ą║čé - ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąĘą░ą┐čĆąĄčéąĖčé čüąŠąĘą┤ą░ą▓ą░čéčī ąŠą▒čŖąĄą║čéčŗ čéą░ą║ąŠą│ąŠ ą║ą╗ą░čüčüą░.
ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čćąĖčüč鹊 ą▓ąĖčĆčéčāą░ą╗čīąĮąŠą│ąŠ ą║ą╗ą░čüčüą░ ą▓čŗą│ą╗čÅą┤ąĖčé ą┤ąŠą▓ąŠą╗čīąĮąŠ ąĮąĄą┐čĆąĖą▓čŗčćąĮąŠ. ąŻ čéą░ą║ąŠą│ąŠ ą║ą╗ą░čüčüą░ ąĄčüčéčī pure virtual (čćąĖčüč鹊 ą▓ąĖčĆčéčāą░ą╗čīąĮčŗąĄ) ą╝ąĄč鹊ą┤čŗ, č鹥ą╗ąŠ ą║ąŠč鹊čĆčŗčģ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąŠ ą║ą░ą║ "const = 0;". ą¤čĆąĖą╝ąĄčĆ:
class Shape
{protected :
Shape () = default ;
Shape (std::string_view description);public :
virtual ~Shape () = default ; // ąĢčüą╗ąĖ ą┤ąĄčüčéčĆčāą║č鹊čĆ ąĮąĄ public, č鹊 ąĮąĄą╗čīąĘčÅ čāą┤ą░ą╗čÅčéčī
// ąŠą▒čŖąĄą║čéčŗ ą┐ąŠ čāą║ą░ąĘą░č鹥ą╗čÄ ąĮą░ ą▒ą░ąĘąŠą▓čŗą╣ ą║ą╗ą░čüčü.
// Pure virtual čäčāąĮą║čåąĖąĖ:
virtual double perimeter () const 0 ;
virtual double surface () const 0 ;private :
std::string m_description;
};ą¤ąŠą╗čāčćą░ąĄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĄąĄ:
ŌĆó ąĢčüą╗ąĖ ą▓ ą║ą╗ą░čüčüąĄ ąĄčüčéčī čģąŠčéčÅ ą▒čŗ ąŠą┤ąĮą░ čćąĖčüč鹊 ą▓ąĖčĆčéčāą░ą╗čīąĮą░čÅ (pure virtual) čäčāąĮą║čåąĖčÅ, č鹊 ąŠąĮ čüčéą░ąĮąŠą▓ąĖčéčüčÅ ą░ą▒čüčéčĆą░ą║čéąĮčŗą╝ ą║ą╗ą░čüčüąŠą╝.
56 . ą£ąŠą┤ąĄą╗ąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖąĮč鹥čĆč乥ą╣čüąŠą▓ čü ą┐ąŠą╝ąŠčēčīčÄ ą░ą▒čüčéčĆą░ą║čéąĮčŗčģ ą║ą╗ą░čüčüąŠą▓.
ŌĆó ąÉą▒čüčéčĆą░ą║čéąĮčŗą╣ ą║ą╗ą░čüčü, ą│ą┤ąĄ ąĄčüčéčī č鹊ą╗čīą║ąŠ čćąĖčüč鹊 ą▓ąĖčĆčéčāą░ą╗čīąĮčŗąĄ čäčāąĮą║čåąĖąĖ, ąĖ ąŠčéčüčāčéčüčéą▓čāčÄčé ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ čćą╗ąĄąĮčŗ ą║ą╗ą░čüčüą░, ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą║ą░ą║ ą╝ąŠą┤ąĄą╗čī, ą║ąŠč鹊čĆą░čÅ ą▓ ą×ą×ą¤ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ ąĖąĮč鹥čĆč乥ą╣čüąŠą╝.
[ąĪčüčŗą╗ą║ąĖ ]
1 . ąÜčāčĆčü ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ąĮą░ C++ ąŠčé ąĮąŠą▓ąĖčćą║ą░ ą┤ąŠ ą┐čĆąŠą┤ą▓ąĖąĮčāč鹊ą│ąŠ / ą╝ą░čłąĖąĮąĮčŗą╣ ą┐ąĄčĆąĄą▓ąŠą┤ site:youtube.com.2 . rutura / The-C-20-Masterclass-Source-Code site:github.com.3 . C++ compiler support site:cppreference.com.4 . Visual Studio Code on Linux site:code.visualstudio.com.5 . VSCode FAQ .6 . VSCode: ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čäą░ą╣ą╗ą░ ąĮą░čüčéčĆąŠąĄą║ c_cpp_properties.json .7 . ąśąĮč鹥čĆč乥ą╣čü ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąĖ Visual Studio Code .8 . VScode: ą║ą░ą║ ą┤ąŠą▒ą░ą▓ąĖčéčī ą┐čāčéčī ą┐ąŠąĖčüą║ą░ ą┐ąŠą┤ą║ą╗čÄčćą░ąĄą╝čŗčģ čäą░ą╣ą╗ąŠą▓ .9 . Homebrew on Linux site:docs.brew.sh.10 . C++ Operator Precedence site:cppreference.com.11 . Three-way comparison site:cppreference.com.12 . std::left, std::right, std::internal site:cppreference.com.13 . ą×čéą╗ą░ą┤ą║ą░ ą║ąŠąĮčüąŠą╗čīąĮčŗčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ Linux .14 . Standard library header cctype site:cppreference.com.15 . ą¤čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ čłą░ą▒ą╗ąŠąĮąŠą▓ C++ ą┤ą╗čÅ ąĖą┤ąĖąŠč鹊ą▓, čćą░čüčéčī 1 .16 . Concepts library Core language concepts site:cppreference.com.



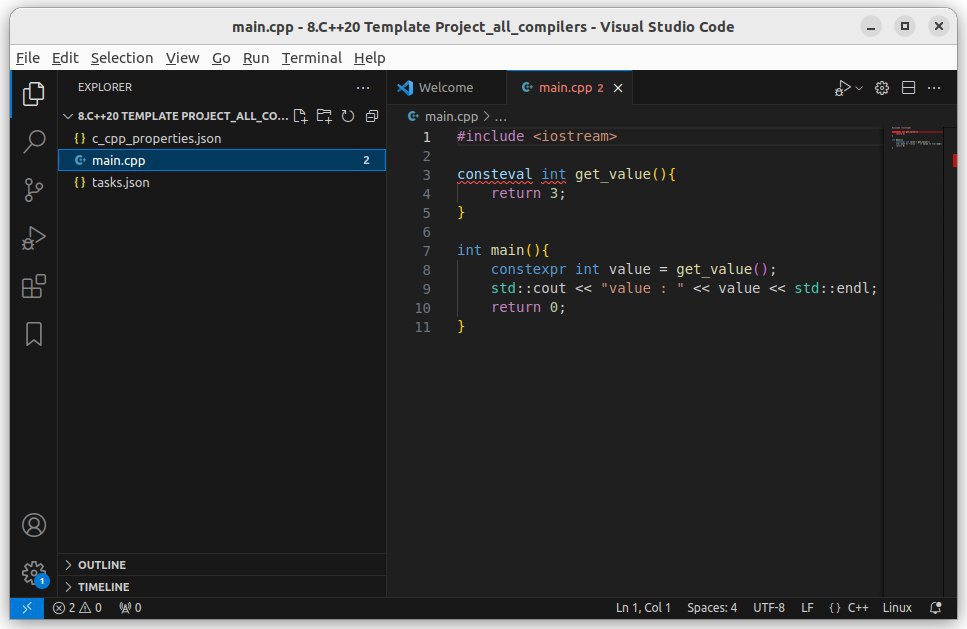
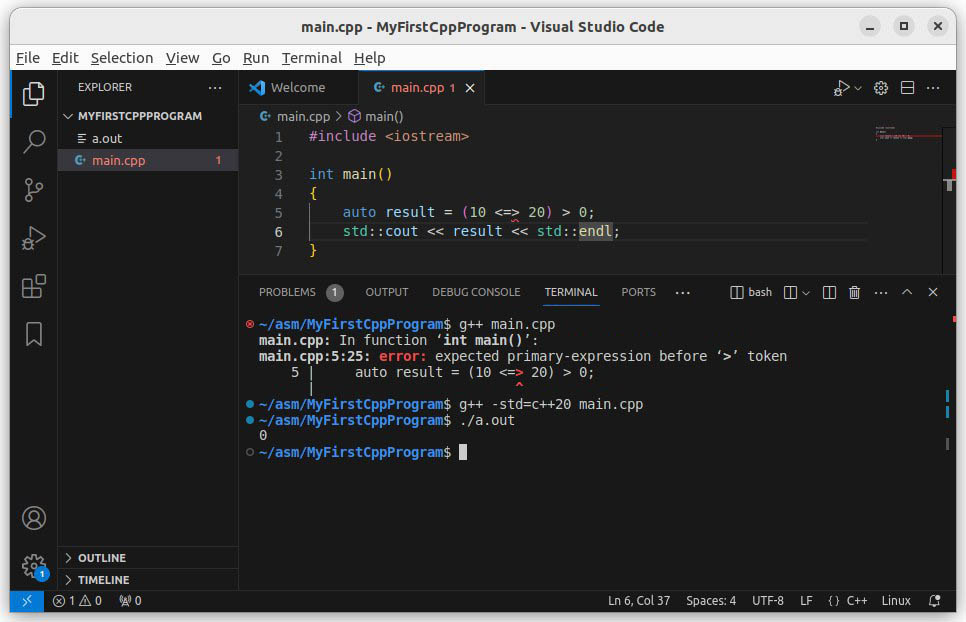
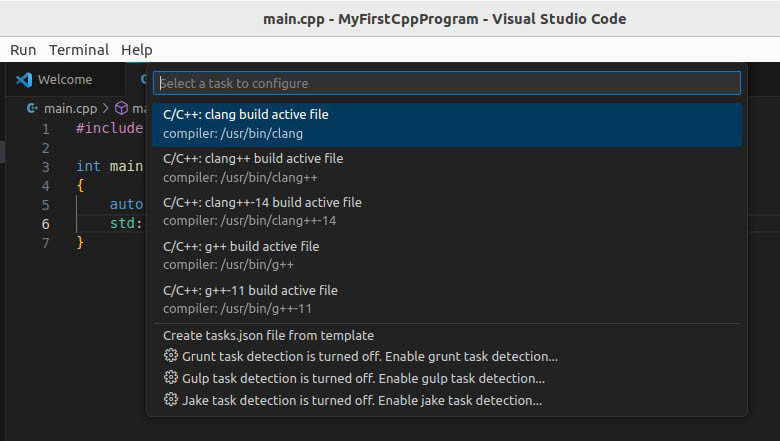

ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖąĖ
RSS ą╗ąĄąĮčéą░ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖąĄą▓ čŹč鹊ą╣ ąĘą░ą┐ąĖčüąĖ