|
ą¤ąŠč鹊ą║ąĖ ąĖą╝ąĄčÄčé 5 čüą┐ąŠčüąŠą▒ąŠą▓ ą┤ą╗čÅ ąŠą▒ą╝ąĄąĮą░ ą┤ą░ąĮąĮčŗą╝ąĖ ąĖ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ:
ŌĆó ąĪąĄą╝ą░č乊čĆčŗ (semaphore)
ŌĆó ą£čīčÄč鹥ą║čüčŗ (mutex)
ŌĆó ąĪąŠąŠą▒čēąĄąĮąĖčÅ (message)
ŌĆó ąĪąŠą▒čŗčéąĖčÅ (event) ąĖ ą▒ąĖčéčŗ čüąŠą▒čŗčéąĖą╣ (Event Bit)
ŌĆó ążą╗ą░ą│ąĖ čāčüčéčĆąŠą╣čüčéą▓ą░ (Device Flag)
ąÆčüąĄ čŹčéąĖ čüą┐ąŠčüąŠą▒čŗ ąŠą▒ą╝ąĄąĮą░ ąĖąĮč乊čĆą╝ą░čåąĖąĄą╣ ąĮą░ąĘčŗą▓ą░čÄčéčüčÅ čüąĖą│ąĮą░ą╗ą░ą╝ąĖ.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą▓ ą┤čĆčāą│ąĖčģ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčŗčģ čüąĖčüč鹥ą╝ą░čģ čĆąĄą░ą╗čīąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ (RTOS) ą┤ą╗čÅ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ ąĖ ąŠą▒ą╝ąĄąĮą░ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ čéą░ą║ąČąĄ ąŠč湥čĆąĄą┤ąĖ, ąĮąŠ ą▓ VDK ą┐ąŠč湥ą╝čā-č鹊 ąĮąĄčé čéą░ą║ąŠą│ąŠ ą┐ąŠąĮčÅčéąĖčÅ. ąĢčüčéčī ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ ą┐ąŠč鹊ą║ąŠą▓ ąĖ ąŠč湥čĆąĄą┤čī ą┐ąĄčĆąĖąŠą┤ąĖčćąĮąŠčüčéąĖ čüąĄą╝ą░č乊čĆąŠą▓, ąĮąŠ ąŠąĮąĖ ą║ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ ąĮą░ą┐čĆčÅą╝čāčÄ ąĮąĄ ąŠčéąĮąŠčüčÅčéčüčÅ. ąĪąĖą│ąĮą░ą╗čŗ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ąŠą▒ą╝ąĄąĮą░ ąĖąĮč乊čĆą╝ą░čåąĖąĄą╣ ąĮąĄ č鹊ą╗čīą║ąŠ ą╝ąĄąČą┤čā ą┐ąŠč鹊ą║ą░ą╝ąĖ, ąĮąŠ ąĖ ą┤ą╗čÅ ąŠą▒ą╝ąĄąĮą░ ą╝ąĄąČą┤čā ISR ąĖ ą┐ąŠč鹊ą║ą░ą╝ąĖ.
ąÜą░ąČą┤čŗą╣ ąĖąĘ ą╝ąĄč鹊ą┤ąŠą▓ ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąĖčÅ ąŠčéą╗ąĖčćą░ąĄčéčüčÅ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄą╝ ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝. ą¤ąŠč鹊ą║ (thread) ąŠąČąĖą┤ą░ąĄčé (pends) ą╗čÄą▒ąŠą│ąŠ ąĖąĘ čŹčéąĖčģ ą┐čÅčéąĖ čüąĖą│ąĮą░ą╗ąŠą▓, ąĖ ąĄčüą╗ąĖ čüąĖą│ąĮą░ą╗ ą┐ąŠą║ą░ ąĮąĄą┤ąŠčüčéčāą┐ąĄąĮ, č鹊 ą┐ąŠč鹊ą║ ą▒ą╗ąŠą║ąĖčĆčāąĄčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ, ą┐ąŠą║ą░ čüąĖą│ąĮą░ą╗ ąĮąĄ ą┐ąŠčÅą▓ąĖčéčüčÅ ąĖą╗ąĖ (čćč鹊 ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ) ąĮąĄ ąĖčüč鹥č湥čé čéą░ą╣ą╝ą░čāčé ąŠąČąĖą┤ą░ąĮąĖčÅ čüąĖą│ąĮą░ą╗ą░.
[ąĪąĄą╝ą░č乊čĆčŗ]
ąĪąĄą╝ą░č乊čĆčŗ čŹč鹊 ą╝ąĄčģą░ąĮąĖąĘą╝čŗ ą┐čĆąŠč鹊ą║ąŠą╗ą░ ąŠą▒ą╝ąĄąĮą░, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄą╝čŗąĄ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąŠą╝ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčŗčģ čüąĖčüč鹥ą╝. ąĪąĄą╝ą░č乊čĆčŗ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ čüą╗ąĄą┤čāčÄčēąĖčģ čåąĄą╗ąĄą╣:
ŌĆó ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┤ąŠčüčéčāą┐ąŠą╝ ą║ ąŠą▒čēąĖą╝ čĆąĄčüčāčĆčüą░ą╝.
ŌĆó ą¦č鹊ą▒čŗ čüąĖą│ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī ąŠ č鹊ą╝, čćč鹊 ą▓ čüąĖčüč鹥ą╝ąĄ čćč鹊-č鹊 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ.
ŌĆó ą¦č鹊ą▒čŗ ą┐ąŠąĘą▓ąŠą╗ąĖčéčī ą┐ąŠč鹊ą║ą░ą╝ čüąĖąĮčģčĆąŠąĮąĖąĘąĖčĆąŠą▓ą░čéčīčüčÅ ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝.
ŌĆó ą¤ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║ąŠą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐ąŠč鹊ą║ąŠą▓.
ą£ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą░ą║čéąĖą▓ąĮčŗčģ čüąĄą╝ą░č乊čĆąŠą▓ ąĖ ąĮą░čćą░ą╗čīąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ čĆą░ąĘčĆąĄčłąĄąĮąĮčŗčģ čüąĄą╝ą░č乊čĆąŠą▓ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ ą▓ ą╝ąŠą╝ąĄąĮčé ąĘą░ą│čĆčāąĘą║ąĖ VDK-ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, ąĖ ąĮą░čüčéčĆą░ąĖą▓ą░ąĄčéčüčÅ, ą║ąŠą│ą┤ą░ ąÆčŗ čüąŠą▒ąĖčĆą░ąĄč鹥 ąĄą│ąŠ ą┐čĆąŠąĄą║čé.
ą¤ąŠą▓ąĄą┤ąĄąĮąĖąĄ čüąĄą╝ą░č乊čĆąŠą▓. ąĪąĄą╝ą░č乊čĆ čŹč鹊 ąĮąĄą║ąĖą╣ ą╝ą░čĆą║ąĄčĆ (token), ą║ąŠč鹊čĆčŗą╣ ą┐ąŠą╗čāčćą░ąĄčé ą┐ąŠč鹊ą║, čćč鹊 ąŠąĘąĮą░čćą░ąĄčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą┤ą╗čÅ čŹč鹊ą│ąŠ ą┐ąŠč鹊ą║ą░ ą┐čĆąŠą┤ąŠą╗ąČąĖčéčī čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ. ąĢčüą╗ąĖ ą┐ąŠč鹊ą║ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ąŠąČąĖą┤ą░ąĮąĖąĖ ąĮą░ čüąĄą╝ą░č乊čĆąĄ, ąĖ čüąĄą╝ą░č乊čĆ čüčéą░ąĮąŠą▓ąĖčéčüčÅ ą┤ąŠčüčéčāą┐ąĮčŗą╝, čé. ąĄ. ą┐ąĄčĆąĄčģąŠą┤ąĖčé ą▓ čüąŠčüč鹊čÅąĮąĖąĄ ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ (ąĘąĮą░č湥ąĮąĖąĄ čüč湥čéčćąĖą║ą░, čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ čü čüąĄą╝ą░č乊čĆąŠą╝, ą▒ąŠą╗čīčłąĄ ąĮčāą╗čÅ), č鹊 ą┐ąŠč鹊ą║ "ąĘą░ą▒ąĖčĆą░ąĄčé" čüąĄą╝ą░č乊čĆ, čüč湥čéčćąĖą║ čüąĄą╝ą░č乊čĆą░ ą┐čĆąĖ čŹč鹊ą╝ čāą╝ąĄąĮčīčłą░ąĄčéčüčÅ ąĮą░ 1, ąĖ ą┐ąŠč鹊ą║ ą┐čĆąŠą┤ąŠą╗ąČą░ąĄčé čüą▓ąŠąĄ ąĮąŠčĆą╝ą░ą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ. ąĢčüą╗ąĖ čüąĄą╝ą░č乊čĆ ąĮąĄą┤ąŠčüčéčāą┐ąĄąĮ (ąĖą╗ąĖ ąĮąĄ ą│ąŠč鹊ą▓, ąĄą│ąŠ čüč湥čéčćąĖą║ čĆą░ą▓ąĄąĮ 0), č鹊 ą┐ąŠč鹊ą║, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠą┐čŗčéą░ą╗čüčÅ ąĘą░ą▒čĆą░čéčī čüąĄą╝ą░č乊čĆ, ą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ ąĮą░ ąĮąĄą╝ ą▓ čüąŠčüč鹊čÅąĮąĖąĖ ąŠąČąĖą┤ą░ąĮąĖčÅ (pend on), ą┐ąŠą║ą░ čüąĄą╝ą░č乊čĆ ąĮąĄ ą┐ąĄčĆąĄą╣ą┤ąĄčé ą▓ čüąŠčüč鹊čÅąĮąĖąĄ ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ, ąĖą╗ąĖ ą┐ąŠą║ą░ ąĮąĄ ąĖčüč鹥č湥čé čéą░ą╣ą╝ą░čāčé čüąĄą╝ą░č乊čĆą░. ąĢčüą╗ąĖ čüąĄą╝ą░č乊čĆ ąĮąĄą┤ąŠčüčéčāą┐ąĄąĮ ą▓ č鹥č湥ąĮąĖąĄ čāą║ą░ąĘą░ąĮąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ, č鹊 ą┐ąŠč鹊ą║ ą┐čĆąŠą┤ąŠą╗ąČąĖčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą▓ čäčāąĮą║čåąĖąĖ ąŠčłąĖą▒ą║ąĖ.
ąĪąĄą╝ą░č乊čĆčŗ čÅą▓ą╗čÅčÄčéčüčÅ ą│ą╗ąŠą▒ą░ą╗čīąĮčŗą╝ąĖ čĆąĄčüčāčĆčüą░ą╝ąĖ, ą┤ąŠčüčéčāą┐ąĮčŗą╝ąĖ ą┤ą╗čÅ ą▓čüąĄčģ ą┐ąŠč鹊ą║ąŠą▓ ą▓ čüąĖčüč鹥ą╝ąĄ. ą¤ąŠč鹊ą║ąĖ čĆą░ąĘąĮčŗčģ čéąĖą┐ąŠą▓ ąĖ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓ ą╝ąŠą│čāčé ąŠąČąĖą┤ą░čéčī ąĮą░ čüąĄą╝ą░č乊čĆąĄ. ąÜąŠą│ą┤ą░ čüąĄą╝ą░č乊čĆ ą┐čāą▒ą╗ąĖą║čāąĄčéčüčÅ (posted), ą┐ąŠč鹊ą║ čü čüą░ą╝čŗą╝ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĖ čŹč鹊ą╝ ąČą┤ąĄčé čüąĄą╝ą░č乊čĆ ą┤ąŠą╗čīčłąĄ ą▓čüąĄą│ąŠ, ą┐ąĄčĆąĄą╝ąĄčēą░ąĄčéčüčÅ ą▓ ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ (ready queue). ąĢčüą╗ąĖ ąĮąĄčé ą┐ąŠč鹊ą║ąŠą▓, ąŠąČąĖą┤ą░čÄčēąĖčģ čüąĄą╝ą░č乊čĆą░, č鹊 ąĘąĮą░č湥ąĮąĖąĄ čüč湥čéčćąĖą║ą░ čüąĄą╝ą░č乊čĆą░ čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčéčüčÅ ąĮą░ 1. ąŚąĮą░č湥ąĮąĖąĄ čüč湥čéčćąĖą║ą░ ąŠą│čĆą░ąĮąĖč湥ąĮąŠ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ ą▓ąĄą╗ąĖčćąĖąĮąŠą╣, čāą║ą░ąĘą░ąĮąĮąŠą╣ ą┐čĆąĖ čüąŠąĘą┤ą░ąĮąĖąĖ čüąĄą╝ą░č乊čĆą░. ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ, ą▓ ąŠčéą╗ąĖčćąĖąĄ ąŠčé ą╝ąĮąŠą│ąĖčģ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčŗčģ čüąĖčüč鹥ą╝, čüąĄą╝ą░č乊čĆčŗ VDK ąĮąĖą║ąŠą╝čā ąĮąĄ ą┐čĆąĖąĮą░ą┤ą╗ąĄąČą░čé. ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ą╗čÄą▒ąŠą╣ ą┐ąŠč鹊ą║ ą╝ąŠąČąĄčé ą┐čāą▒ą╗ąĖą║ąŠą▓ą░čéčī čüąĄą╝ą░č乊čĆ (čüą┤ąĄą╗ą░čéčī ąĄą│ąŠ ą┤ąŠčüčéčāą┐ąĮčŗą╝). ąĢčüą╗ąĖ ą┐ąŠč鹊ą║ ąĘą░ą┐čĆąŠčüąĖą╗ čüąĄą╝ą░č乊čĆ (ą┐ąĄčĆąĄčłąĄą╗ ą▓ ąŠąČąĖą┤ą░ąĮąĖąĄ ąĮą░ ąĮąĄą╝) ąĖ ą▓ąĘčÅą╗ ąĄą│ąŠ, ą┐ąŠ ą┐ąŠčüą╗ąĄ č湥ą│ąŠ čŹč鹊čé ą┐ąŠč鹊ą║ ą▒čŗą╗ čāąĮąĖčćč鹊ąČąĄąĮ, č鹊 čüąĄą╝ą░č乊čĆ ąĮąĄ ą▒čāą┤ąĄčé ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą▓čŗčüčéą░ą▓ą╗ąĄąĮ čÅą┤čĆąŠą╝ VDK.
ą¤ąŠą╝ąĖą╝ąŠ čĆą░ą▒ąŠčéčŗ ą▓ ą║ą░č湥čüčéą▓ąĄ čäą╗ą░ą│ą░ ą╝ąĄąČą┤čā čüąŠą▒čŗčéąĖčÅą╝ąĖ, čüąĄą╝ą░č乊čĆ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮą░čüčéčĆąŠąĄąĮ ą║ą░ą║ ą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║ąĖą╣. ą¤ąĄčĆąĖąŠą┤ąĖč湥čüą║ąĖą╣ čüąĄą╝ą░č乊čĆ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą▓čŗčüčéą░ą▓ą╗čÅąĄčéčüčÅ čÅą┤čĆąŠą╝ ą║ą░ąČą┤čŗąĄ n čéąĖą║ąŠą▓, ą│ą┤ąĄ n čŹč鹊 ą┐ąĄčĆąĖąŠą┤ čüąĄą╝ą░č乊čĆą░. ą¤ąĄčĆąĖąŠą┤ąĖč湥čüą║ąĖąĄ čüąĄą╝ą░č乊čĆčŗ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ č鹊ą│ąŠ, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐ąŠč鹊ą║ą░ čü čĆąĄą│čāą╗čÅčĆąĮčŗą╝ąĖ ąĖąĮč鹥čĆą▓ą░ą╗ą░ą╝ąĖ.
ąÆąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąĖąĄ ą┐ąŠč鹊ą║ąŠą▓ čü čüąĄą╝ą░č乊čĆą░ą╝ąĖ. ą¤ąŠč鹊ą║ąĖ ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓čāčÄčé čü čüąĄą╝ą░č乊čĆą░ą╝ąĖ č湥čĆąĄąĘ ąĮą░ą▒ąŠčĆ ą▓čŗąĘąŠą▓ąŠą▓ API čüąĄą╝ą░č乊čĆąŠą▓ (semaphore API). ąŁčéąĖ čäčāąĮą║čåąĖąĖ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ą┐ąŠč鹊ą║čā čüąŠąĘą┤ą░čéčī čüąĄą╝ą░č乊čĆ, čāąĮąĖčćč鹊ąČąĖčéčī čüąĄą╝ą░č乊čĆ, ąĮą░čćą░čéčī ąŠąČąĖą┤ą░ąĮąĖąĄ čüąĄą╝ą░č乊čĆą░ (pend on a semaphore), ąŠą┐čāą▒ą╗ąĖą║ąŠą▓ą░čéčī (ą▓čŗčüčéą░ą▓ąĖčéčī) čüąĄą╝ą░č乊čĆ (post a semaphore), ą┐ąŠą╗čāčćąĖčéčī ąĘąĮą░č湥ąĮąĖąĄ čüąĄą╝ą░č乊čĆą░, ąĖ ą┤ąŠą▒ą░ą▓ąĖčéčī ąĖą╗ąĖ čāą┤ą░ą╗ąĖčéčī čüąĄą╝ą░č乊čĆ ąĖąĘ ą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║ąŠą╣ ąŠč湥čĆąĄą┤ąĖ (periodic queue).
ą×ąČąĖą┤ą░ąĮąĖąĄ ąĮą░ čüąĄą╝ą░č乊čĆąĄ (Pending on a Semaphore). ąØą░ čĆąĖčü. 3-3 ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąŠčåąĄčüčü ąŠąČąĖą┤ą░ąĮąĖčÅ čüąĄą╝ą░č乊čĆą░.
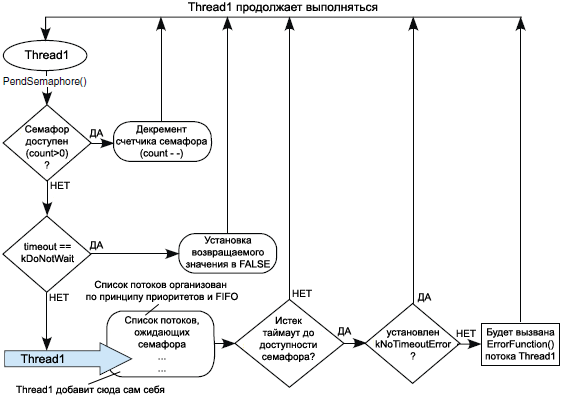
ąĀąĖčü. 3-3. ą×ąČąĖą┤ą░ąĮąĖąĄ (pending) ąĮą░ čüąĄą╝ą░č乊čĆąĄ.
ą¤ąŠč鹊ą║ąĖ ą╝ąŠą│čāčé ąĘą░ą┐čāčüčéąĖčéčī čüą▓ąŠąĄ ąŠąČąĖą┤ą░ąĮąĖąĄ ąĮą░ čüąĄą╝ą░č乊čĆąĄ ą▓čŗąĘąŠą▓ąŠą╝ PendSemaphore(). ąÜąŠą│ą┤ą░ ą┐ąŠč鹊ą║ ą▓čŗąĘą▓ą░ą╗ PendSemaphore(), ąŠąĮ ą▓čŗą┐ąŠą╗ąĮąĖčé ąŠą┤ąĮąŠ ąĖąĘ čüą╗ąĄą┤čāčÄčēąĖčģ ą┤ąĄą╣čüčéą▓ąĖą╣.
ŌĆó ą¤ąŠą╗čāčćą░ąĄčé čüąĄą╝ą░č乊čĆ, ą┤ąĄą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄčé ąĄą│ąŠ čüč湥čéčćąĖą║ ąĮą░ 1, ąĖ ą┐čĆąŠą┤ąŠą╗ąČą░ąĄčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ.
ŌĆó ąæą╗ąŠą║ąĖčĆčāąĄčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ, ą┐ąŠą║ą░ čüąĄą╝ą░č乊čĆ ąĮąĄ čüčéą░ąĮąĄčé ą┤ąŠčüčéčāą┐ąĄąĮ, ąĖą╗ąĖ ą┐ąŠą║ą░ ąĮąĄ ąĖčüč鹥č湥čé čāą║ą░ąĘą░ąĮąĮčŗą╣ čéą░ą╣ą╝ą░čāčé.
ŌĆó ąĢčüą╗ąĖ čéą░ą╣ą╝ą░čāčé čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą▓ ąĘąĮą░č湥ąĮąĖąĄ kDoNotWait, ąĖ čüąĄą╝ą░č乊čĆ ąĮąĄą┤ąŠčüčéčāą┐ąĄąĮ, č鹊 ą▓čŗąĘąŠą▓ API ą▓ąĄčĆąĮąĄčé FALSE, ąĖ ą┐ąŠč鹊ą║ ą┐čĆąŠą┤ąŠą╗ąČąĖčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ.
ąĢčüą╗ąĖ čüąĄą╝ą░č乊čĆ čüčéą░ą╗ ą┤ąŠčüčéčāą┐ąĄąĮ ą┤ąŠ ąĖčüč鹥č湥ąĮąĖčÅ čéą░ą╣ą╝ą░čāčéą░, ąĖą╗ąĖ ąĖčüč鹥ą║ čéą░ą╣ą╝ą░čāčé, ąĖ ą▓ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ čéą░ą╣ą╝ą░čāčéą░ čāą║ą░ąĘą░ąĮ ą▒ąĖčé kNoTimeoutError, č鹊 ą┐ąŠč鹊ą║ ą┐čĆąŠą┤ąŠą╗ąČąĖčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ; ąĖąĮą░č湥 ą▒čāą┤ąĄčé ą▓čŗąĘą▓ą░ąĮą░ čäčāąĮą║čåąĖčÅ ąŠčłąĖą▒ą║ąĖ ą┐ąŠč鹊ą║ą░ (thread error function), ąĖ ą┐ąŠč鹊ą║ ą┐čĆąŠą┤ąŠą╗ąČąĖčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ. ąÆčŗ ąĮąĄ ą┤ąŠą╗ąČąĮčŗ ą▓čŗąĘčŗą▓ą░čéčī PendSemaphore() ąĖąĘ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ (unscheduled) ąĖą╗ąĖ ą║čĆąĖčéąĖč湥čüą║ąŠą│ąŠ (critical) čĆąĄą│ąĖąŠąĮą░ ą║ąŠą┤ą░, ą┐ąŠč鹊ą╝čā čćč鹊 ąĄčüą╗ąĖ čüąĄą╝ą░č乊čĆ ąĮąĄą┤ąŠčüčéčāą┐ąĄąĮ, č鹊 ą┐ąŠč鹊ą║ ąĘą░ą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ. ą×ą┤ąĮą░ą║ąŠ čü ąĘą░ą┐čĆąĄčēąĄąĮąĮčŗą╝ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ąŠą╝ čüčéą░ąĮąĄčé ąĮąĄą▓ąŠąĘą╝ąŠąČąĮčŗą╝ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą║ąŠąĮč鹥ą║čüčéą░ (ą┐ąĄčĆąĄčģąŠą┤ ą║ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÄ ą┤čĆčāą│ąŠą│ąŠ ą┐ąŠč鹊ą║ą░), ą┐ąŠčŹč鹊ą╝čā čéą░ą║ ą┤ąĄą╗ą░čéčī ąĮąĄą╗čīąĘčÅ. ąŚą░ą┐čāčüą║ ąŠąČąĖą┤ą░ąĮąĖčÅ ąĮą░ čüąĄą╝ą░č乊čĆąĄ čü ąĮčāą╗ąĄą▓čŗą╝ čéą░ą╣ą╝ą░čāč鹊ą╝ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ č鹊ą╝čā, čćč鹊 ą┐ąŠčÅą▓ą╗ąĄąĮąĖąĄ čüąĄą╝ą░č乊čĆą░ ąŠąČąĖą┤ą░ąĄčéčüčÅ ą▒ąĄąĘ ąŠčéčüą╗ąĄąČąĖą▓ą░ąĮąĖčÅ čéą░ą╣ą╝ą░čāčéą░.
ą¤čāą▒ą╗ąĖą║ą░čåąĖčÅ čüąĄą╝ą░č乊čĆą░ (Posting a Semaphore). ąĪąĄą╝ą░č乊čĆ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗčüčéą░ą▓ą╗ąĄąĮ (ąŠą┐čāą▒ą╗ąĖą║ąŠą▓ą░ąĮ, posted) ąĖąĘ ą╗čÄą▒ąŠą│ąŠ ąĖąĘ ą┤ą▓čāčģ ąŠčéą╗ąĖčćą░čÄčēąĖčģčüčÅ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ ą┤ąŠą╝ąĄąĮą░ ą║ąŠą┤ą░ (ą▓ąĖą┤ ą┤ąŠą╝ąĄąĮą░ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé, ą║ą░ą║ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąĖąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░ ą▓ ą┤ąŠą╝ąĄąĮąĄ): ąĖąĘ ą┤ąŠą╝ąĄąĮą░ ą┐ąŠč鹊ą║ąŠą▓ (thread domain) ąĖ ąĖąĘ ą┤ąŠą╝ąĄąĮą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ (interrupt domain). ąĢčüą╗ąĖ ą▓ čŹč鹊čé ą╝ąŠą╝ąĄąĮčé ąĄčüčéčī ą┐ąŠč鹊ą║ąĖ, ąŠąČąĖą┤ą░čÄčēąĖąĄ čüąĄą╝ą░č乊čĆą░, č鹊 ą┐čāą▒ą╗ąĖą║ą░čåąĖčÅ čüąĄą╝ą░č乊čĆą░ ą┐ąĄčĆąĄą▓ąĄą┤ąĄčé ą┐ąŠč鹊ą║ čü čüą░ą╝čŗą╝ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ ąĖąĘ čüą┐ąĖčüą║ą░ ą┐ąŠč鹊ą║ąŠą▓, ąŠąČąĖą┤ą░čÄčēąĖčģ ąĮą░ čüąĄą╝ą░č乊čĆąĄ, ą▓ ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ. ąÆčüąĄ ą┤čĆčāą│ąĖąĄ ą┐ąŠč鹊ą║ąĖ ąŠčüčéą░ąĮčāčéčüčÅ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĮčŗą╝ąĖ ąĮą░ čüąĄą╝ą░č乊čĆąĄ, ą┐ąŠą║ą░ ąĮąĄ ąĖčüč鹥č湥čé ąĖčģ čéą░ą╣ą╝ą░čāčé, ą╗ąĖą▒ąŠ ą┐ąŠą║ą░ čüąĄą╝ą░č乊čĆ ąĮąĄ čüčéą░ąĮąĄčé ą┤ą╗čÅ ąĮąĖčģ ą┤ąŠčüčéčāą┐ąĮčŗą╝. ąĢčüą╗ąĖ ą▓ ą╝ąŠą╝ąĄąĮčé ą┐čāą▒ą╗ąĖą║ą░čåąĖąĖ čüąĄą╝ą░č乊čĆą░ ąĮąĄčé ą┐ąŠč鹊ą║ąŠą▓, ąŠąČąĖą┤ą░čÄčēąĖčģ čüąĄą╝ą░č乊čĆą░, č鹊 ą┐čāą▒ą╗ąĖą║ą░čåąĖčÅ ą┐čĆąŠčüč鹊 čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčé čüč湥čéčćąĖą║ čüąĄą╝ą░č乊čĆą░ ąĮą░ 1. ąĢčüą╗ąĖ ą┤ąŠčüčéąĖą│ąĮčāčé ą┐čĆąĄą┤ąĄą╗ čüč湥čéčćąĖą║ą░ (maximum count, čćč鹊 čāą║ą░ąĘčŗą▓ą░ąĄčéčüčÅ ą┐čĆąĖ čüąŠąĘą┤ą░ąĮąĖąĖ čüąĄą╝ą░č乊čĆą░) č鹊 ą┐čāą▒ą╗ąĖą║ą░čåąĖčÅ čüąĄą╝ą░č乊čĆą░ ąĮąĄ ą┐čĆąĖą▓ąŠą┤ąĖčé ąĮąĖ ą║ ą║ą░ą║ąŠą╝čā čŹčäč乥ą║čéčā.
ą¤čāą▒ą╗ąĖą║ą░čåąĖčÅ ąĖąĘ ą┤ąŠą╝ąĄąĮą░ ą┐ąŠč鹊ą║ąŠą▓ (Thread Domain): ąĮą░ čĆąĖčü. 3-4 ąĖ 3-5 ąĖą╗ą╗čÄčüčéčĆąĖčĆčāąĄčéčüčÅ ą┐čĆąŠčåąĄčüčü ą┐čāą▒ą╗ąĖą║ą░čåąĖąĖ čüąĄą╝ą░č乊čĆąŠą▓ ąĖąĘ ą┤ąŠą╝ąĄąĮą░ ą┐ąŠč鹊ą║ąŠą▓.
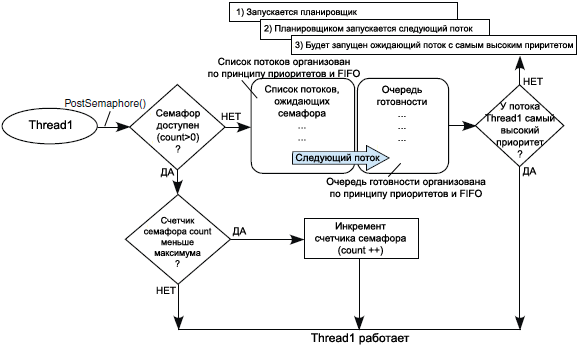
ąĀąĖčü. 3-4. ą×ą▒čüą╗čāąČąĖą▓ą░ąĄą╝ą░čÅ ąŠą▒ą╗ą░čüčéčī ą║ąŠą┤ą░ Thread Domain, ą┐čāą▒ą╗ąĖą║ą░čåąĖčÅ čüąĄą╝ą░č乊čĆą░.
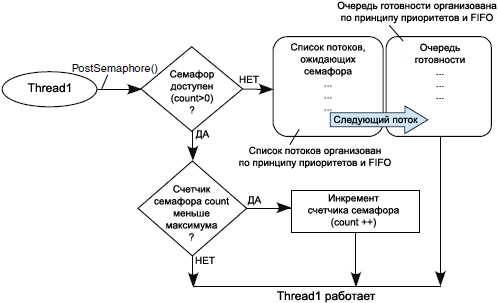
ąĀąĖčü. 3-5. ąØąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ą░čÅ ąŠą▒ą╗ą░čüčéčī ą║ąŠą┤ą░ Thread Domain, ą┐čāą▒ą╗ąĖą║ą░čåąĖčÅ čüąĄą╝ą░č乊čĆą░.
ą¤ąŠč鹊ą║ ą╝ąŠąČąĄčé ą▓čŗčüčéą░ą▓ąĖčéčī (ąŠą┐čāą▒ą╗ąĖą║ąŠą▓ą░čéčī) čüąĄą╝ą░č乊čĆ API-ą▓čŗąĘąŠą▓ąŠą╝ PostSemaphore(). ąĢčüą╗ąĖ ą┐ąŠč鹊ą║ ą▓čŗąĘą▓ą░ą╗ PostSemaphore() ąĖąĘ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ąŠą╝ čĆąĄą│ąĖąŠąĮą░ ą║ąŠą┤ą░ (čüą╝. čĆąĖčü. 3-4), ąĖ ą┐ąŠč鹊ą║ čü čüą░ą╝čŗą╝ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ ą▒čŗą╗ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮ ą▓ ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ, č鹊 ąĖąĘ ą┐ąŠč鹊ą║ą░, ą║ąŠč鹊čĆčŗą╣ ą▓čŗąĘą▓ą░ą╗ PostSemaphore(), ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ąĮą░ ą┤čĆčāą│ąŠą╣ ą║ąŠąĮč鹥ą║čüčé (ąĮą░čćąĮąĄčé ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║).
ąĢčüą╗ąĖ ą┐ąŠč鹊ą║ ą▓čŗąĘą▓ą░ą╗ PostSemaphore() ąĖąĘ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ čĆąĄą│ąĖąŠąĮą░ ą║ąŠą┤ą░, ą│ą┤ąĄ čĆą░ą▒ąŠčéą░ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ą░ ąĘą░ą┐čĆąĄčēąĄąĮą░, č鹊 ą┐ąŠč鹊ą║ čü čüą░ą╝čŗą╝ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ ą┐ąĄčĆąĄą╝ąĄčüčéąĖčéčüčÅ ą▓ ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ, ąĮąŠ ąĮąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą║ąŠąĮč鹥ą║čüčéą░ (ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮą░ čĆąĖčü. 3-5).
ą¤čāą▒ą╗ąĖą║ą░čåąĖčÅ ąĖąĘ ą┤ąŠą╝ąĄąĮą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣: ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ (ISR) čéą░ą║ąČąĄ ą╝ąŠą│čāčé ą┐čāą▒ą╗ąĖą║ąŠą▓ą░čéčī čüąĄą╝ą░č乊čĆčŗ. ąØą░ čĆąĖčü. 3-6 ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąŠčåąĄčüčü ą┐čāą▒ą╗ąĖą║ą░čåąĖąĖ čüąĄą╝ą░č乊čĆą░ ąĖąĘ ą┤ąŠą╝ąĄąĮą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣.
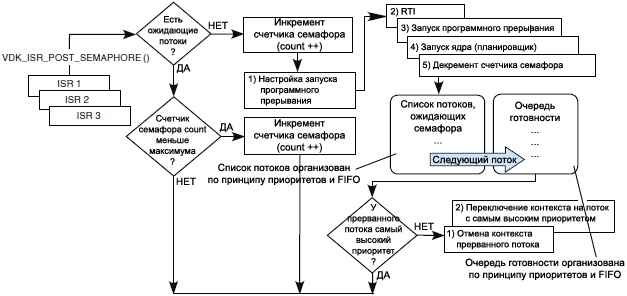
ąĀąĖčü. 3-6. Interrupt Domain, ą┐čāą▒ą╗ąĖą║ą░čåąĖčÅ čüąĄą╝ą░č乊čĆą░.
ISR ą▓čŗčüčéą░ą▓ą╗čÅąĄčé čüąĄą╝ą░č乊čĆ ą▓čŗąĘąŠą▓ąŠą╝ ą╝ą░ą║čĆąŠčüą░ VDK_ISR_POST_SEMAPHORE_(). ąŁč鹊čé ą╝ą░ą║čĆąŠčü ą┐ąĄčĆąĄą╝ąĄčēą░ąĄčé ą┐ąŠč鹊ą║ čü čüą░ą╝čŗą╝ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝, ąŠąČąĖą┤ą░čÄčēąĖą╣ ąĮą░ čüąĄą╝ą░č乊čĆąĄ, ą▓ ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ, ąĖ ąĘą░čēąĄą╗ą║ąĖą▓ą░ąĄčé ąĮąĖąĘą║ąŠą┐čĆąĖąŠčĆąĖč鹥čéąĮąŠąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ, ąĄčüą╗ąĖ čéčĆąĄą▒čāąĄčéčüčÅ ą▓čŗąĘąŠą▓ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ą░. ąÜąŠą│ą┤ą░ ISR ąĘą░ą▓ąĄčĆčłąĖčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ, ąĖ ąĘą░ą┐čāčüčéąĖčéčüčÅ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ, č鹊 ąĘą░ą┐čāčüčéąĖčéčüčÅ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║. ąĢčüą╗ąĖ ą┐čĆąĄčĆą▓ą░ąĮąĮčŗą╣ ą┐ąŠč鹊ą║ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą╝ čĆąĄą│ąĖąŠąĮąĄ, ąĖ čüčéą░ąĮąŠą▓ąĖčéčüčÅ ą│ąŠč鹊ą▓čŗą╝ ą║ ąĘą░ą┐čāčüą║čā ą┐ąŠč鹊ą║ čü ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝, č鹊 ą┐čĆąĄčĆą▓ą░ąĮąĮčŗą╣ ą┐ąŠč鹊ą║ ą┐čĆąĖąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ (switched out) ąĖ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ąĮą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┤čĆčāą│ąŠą│ąŠ ą┐ąŠč鹊ą║ą░ (switched in), čā ą║ąŠč鹊čĆąŠą│ąŠ čüąĄą╣čćą░čü čüą░ą╝čŗą╣ ą▓čŗčüąŠą║ąĖą╣ ą┐čĆąĖąŠčĆąĖč鹥čé.
ą¤ąĄčĆąĖąŠą┤ąĖč湥čüą║ąĖąĄ čüąĄą╝ą░č乊čĆčŗ (Periodic Semaphores). ąĪąĄą╝ą░č乊čĆčŗ čéą░ą║ąČąĄ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║ąŠą│ąŠ ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąĖčÅ ąĘą░ą┐čāčüą║ą░ ą┐ąŠč鹊ą║ąŠą▓. ąŁč鹊 čüąĄą╝ą░č乊čĆ, ą║ąŠč鹊čĆčŗą╣ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą▓čŗčüčéą░ą▓ą╗čÅąĄčéčüčÅ ą║ą░ąČą┤čŗąĄ n čéąĖą║ąŠą▓ čüąĖčüč鹥ą╝čŗ (ą│ą┤ąĄ n ą┐ąĄčĆąĖąŠą┤ čüąĄą╝ą░č乊čĆą░). ąóąŠą│ą┤ą░ ą┐ąŠč鹊ą║ ą╝ąŠąČąĄčé ąŠąČąĖą┤ą░čéčī čüąĄą╝ą░č乊čĆą░, ąĖ ąĄą│ąŠ ąĘą░ą┐čāčüą║ ą▒čāą┤ąĄčé ąĘą░ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮ ą▓čüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ čüąĄą╝ą░č乊čĆ ą▓čŗčüčéą░ą▓ą╗čÅąĄčéčüčÅ, čé. ąĄ. č湥čĆąĄąĘ ą┐ąĄčĆąĖąŠą┤ ą▓čĆąĄą╝ąĄąĮąĖ n čéąĖą║ąŠą▓. ą¤ąĄčĆąĖąŠą┤ąĖč湥čüą║ąĖą╣ čüąĄą╝ą░č乊čĆ ąĮąĄ ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ąŠąČąĖą┤ą░čÄčēąĖą╣ ąĮą░ čüąĄą╝ą░č乊čĆąĄ ą┐ąŠč鹊ą║ ąĖą╝ąĄąĄčé čüą░ą╝čŗą╣ ą▓čŗčüąŠą║ąĖą╣ ą┐čĆąĖąŠčĆąĖč鹥čé ą┤ą╗čÅ ąĘą░ą┐čāčüą║ą░, ąĖą╗ąĖ čćč鹊 čĆą░ąĘčĆąĄčłąĄąĮąŠ ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąĖąĄ. ąÆčüąĄ čćč鹊 ą│ą░čĆą░ąĮčéąĖčĆčāąĄčéčüčÅ - č鹊ą╗čīą║ąŠ č鹊, čćč鹊 čüąĄą╝ą░č乊čĆ ą┐čāą▒ą╗ąĖą║čāąĄčéčüčÅ, ąĖ ąŠąČąĖą┤ą░čÄčēąĖą╣ čüąĄą╝ą░č乊čĆą░ ą┐ąŠč鹊ą║ čü čüą░ą╝čŗą╝ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ ą▒čāą┤ąĄčé ą┐ąĄčĆąĄą╝ąĄčēąĄąĮ ą▓ ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ.
ą¤ąĄčĆąĖąŠą┤ąĖč湥čüą║ąĖąĄ čüąĄą╝ą░č乊čĆčŗ ą▓čŗčüčéą░ą▓ą╗čÅčÄčéčüčÅ čÅą┤čĆąŠą╝ ą┐ąŠ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÄ čéą░ą╣ą╝ąĄčĆą░, ąĮą░ ą│čĆą░ąĮąĖčåą░čģ ąĖąĮč鹥čĆą▓ą░ą╗ąŠą▓ ą▓čĆąĄą╝ąĄąĮąĖ čéąĖą║ą░. ą¤ąĄčĆąĖąŠą┤ąĖč湥čüą║ąĖąĄ čüąĄą╝ą░č乊čĆčŗ čéą░ą║ąČąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ąŠą┐čāą▒ą╗ąĖą║ąŠą▓ą░ąĮčŗ ą▓ ą╗čÄą▒ąŠą╣ ą╝ąŠą╝ąĄąĮčé ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗąĘąŠą▓ąŠą╝ PostSemaphore() ąĖą╗ąĖ VDK_ISR_POST_SEMAPHORE_(). ąÆčŗąĘąŠą▓čŗ čŹčéąĖčģ čäčāąĮą║čåąĖą╣ ąĮąĄ ą▓ą╗ąĖčÅčÄčé ąĮą░ ą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║čāčÄ ą┐čāą▒ą╗ąĖą║ą░čåąĖčÄ čŹč鹊ą│ąŠ čüąĄą╝ą░č乊čĆą░.
ąØąĖąČąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮąŠ ąŠą┐ąĖčüą░ąĮąĖąĄ ąĮą░ąĖą▒ąŠą╗ąĄąĄ čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ API-čäčāąĮą║čåąĖą╣, čĆą░ą▒ąŠčéą░čÄčēąĖčģ čü čüąĄą╝ą░č乊čĆą░ą╝ąĖ.
ą¤čĆąŠč鹊čéąĖą┐ C:
VDK_SemaphoreID VDK_CreateSemaphore (unsigned int inInitialValue,
unsigned int inMaxCount,
VDK_Ticks inInitialDelay,
VDK_Ticks inPeriod);
ą¤čĆąŠč鹊čéąĖą┐ C++:
VDK::SemaphoreID VDK::CreateSemaphore (unsigned int inInitialValue,
unsigned int inMaxCount,
VDK::Ticks inInitialDelay,
VDK::Ticks inPeriod);
ąöąĖąĮą░ą╝ąĖč湥čüą║ąĖ (ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░) čüąŠąĘą┤ą░ąĄčé ąĖ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāąĄčé čüąĄą╝ą░č乊čĆ. ąĢčüą╗ąĖ ąĘąĮą░č湥ąĮąĖąĄ inPeriod ąĮąĄ čĆą░ą▓ąĮąŠ 0, č鹊 ą▒čāą┤ąĄčé čüąŠąĘą┤ą░ąĮ ą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║ąĖą╣ čüąĄą╝ą░č乊čĆ.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: čüąŠąĘą┤ą░ąĮąĖąĄ čüąĄą╝ą░č乊čĆą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ą┤ą░ąĮąŠ čüčéą░čéąĖč湥čüą║ąĖ, ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖčÅ čüą▓ąŠą╣čüčéą▓ VDK-ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ (ą▒čĆą░čāąĘąĄčĆ ą┐čĆąŠąĄą║čéą░ VisualDSP++ -> ąĘą░ą║ą╗ą░ą┤ą║ą░ Kernel -> Semaphores).
ążčāąĮą║čåąĖčÅ CreateSemaphore ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ą░. ąÆčĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čäčāąĮą║čåąĖąĖ ąĮąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąŠ.
ąÆąŠąĘą▓čĆą░čēą░ąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ: ąĮąŠą▓čŗą╣ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ čüąĄą╝ą░č乊čĆą░ SemaphoreID ą┐čĆąĖ čāčüą┐ąĄčłąĮąŠą╝ čüąŠąĘą┤ą░ąĮąĖąĖ ąĖ UINT_MAX, ąĄčüą╗ąĖ ą┐čĆąŠąĖąĘąŠčłą╗ą░ ąŠčłąĖą▒ą║ą░.
[ą¤ą░čĆą░ą╝ąĄčéčĆčŗ]
inInitialValue ąĮą░čćą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ čüč湥čéčćąĖą║ą░ čüąĄą╝ą░č乊čĆą░ ą▓ ą╝ąŠą╝ąĄąĮčé čüąŠąĘą┤ą░ąĮąĖčÅ. ąŚąĮą░č湥ąĮąĖąĄ 0 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čüąĄą╝ą░č乊čĆ ą┐ąŠčüą╗ąĄ čüąŠąĘą┤ą░ąĮąĖčÅ ąĮąĄą┤ąŠčüčéčāą┐ąĄąĮ. ąŚąĮą░č湥ąĮąĖąĄ ą┐ą░čĆą░ą╝ąĄčéčĆą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ą╝ąĄąČą┤čā 0 ąĖ inMaxCount ą▓ą║ą╗čÄčćąĖč鹥ą╗čīąĮąŠ.
inMaxCount ąĘą░ą┤ą░ąĄčé ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ čüč湥čéčćąĖą║ą░ čüąĄą╝ą░č乊čĆą░, ą┤ąŠ ą║ąŠč鹊čĆąŠą│ąŠ čüč湥čéčćąĖą║ ą╝ąŠąČąĄčé ą┤ąŠą╣čéąĖ ą┐čĆąĖ ą┐čāą▒ą╗ąĖą║ą░čåąĖčÅčģ čüąĄą╝ą░č乊čĆą░. ąŚąĮą░č湥ąĮąĖąĄ inMaxCount == 1 čüąŠąĘą┤ą░ąĄčé ą┤ą▓ąŠąĖčćąĮčŗą╣ čüąĄą╝ą░č乊čĆ (ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĮąŠ ąŠą┐čāą▒ą╗ąĖą║ąŠą▓ą░čéčī č鹊ą╗čīą║ąŠ 1 čĆą░ąĘ).
inInitialDelay ąĘą░ą┤ą░ąĄčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čéąĖą║ąŠą▓ ą┐ąĄčĆąĄą┤ ą┐ąĄčĆą▓ąŠą╣ ą┐čāą▒ą╗ąĖą║ą░čåąĖąĄą╣ ą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║ąŠą│ąŠ čüąĄą╝ą░č乊čĆą░. ąŚąĮą░č湥ąĮąĖąĄ inInitialDelay ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čĆą░ą▓ąĮąŠ ąĖą╗ąĖ ą▒ąŠą╗čīčłąĄ 1.
inPeriod ąĘą░ą┤ą░ąĄčé čüą▓ąŠą╣čüčéą▓ąŠ ą┐ąĄčĆąĖąŠą┤ą░ čüąĄą╝ą░č乊čĆą░ ąĖ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čéąĖą║ąŠą▓ ą┤ą╗čÅ ą┐ąĄčĆąĄčģąŠą┤ą░ ą▓ čüąŠąĮ ąĮą░ ą║ą░ąČą┤ąŠą╝ čåąĖą║ą╗ąĄ ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ą┐ąĄčĆą▓čŗą╣ čĆą░ąĘ ą▒čŗą╗ ąŠą┐čāą▒ą╗ąĖą║ąŠą▓ą░ąĮ čüąĄą╝ą░č乊čĆ. ąĢčüą╗ąĖ inPeriod == 0, č鹊 ą▒čāą┤ąĄčé čüąŠąĘą┤ą░ąĮ ąĮąĄ ą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║ąĖą╣ čüąĄą╝ą░č乊čĆ.
ą¤čĆąĖą╝ąĄčĆ čüąŠąĘą┤ą░ąĮąĖčÅ ąĮąĄą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║ąŠą│ąŠ čüąĄą╝ą░č乊čĆą░ čü ąĮą░čćą░ą╗čīąĮčŗą╝ ąĮčāą╗ąĄą▓čŗą╝ čüč湥čéčćąĖą║ąŠą╝ ąĖ ą║ąŠąĮąĄčćąĮčŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝ čüč湥čéčćąĖą║ą░ 1024:
VDK::SemaphoreID semID = VDK::CreateSemaphore (0, 1024, 0, 0);
[ą×ą▒čĆą░ą▒ąŠčéą║ą░ ąŠčłąĖą▒ąŠą║]
ąŚą┤ąĄčüčī ą┐čĆąĖą▓ąĄą┤ąĄąĮą░ čĆą░čüčłąĖčäčĆąŠą▓ą║ą░ ą▓ąŠąĘą╝ąŠąČąĮčŗčģ ąŠčłąĖą▒ąŠą║ čÅą┤čĆą░ (ąŠč鹊ą▒čĆą░ąČą░čÄčéčüčÅ ą▓ ąŠą║ąĮąĄ View -> VDK Windows -> Status), ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī čĆąĄąĘčāą╗čīčéą░č鹊ą╝ ą▓čŗąĘąŠą▓ą░ čäčāąĮą║čåąĖąĖ. ą¤ąŠą┤ą┤ąĄčƹȹ║ą░ Full instrumentation:
kMaxCountExceeded ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 inInitialValue ą▒ąŠą╗čīčłąĄ, č湥ą╝ inMaxCount.
kSemaphoreCreationFailure ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čÅą┤čĆąŠ ąĮąĄ ą╝ąŠąČąĄčé ą▓čŗą┤ąĄą╗ąĖčéčī ąĖ/ąĖą╗ąĖ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī ą┐ą░ą╝čÅčéčī ą┤ą╗čÅ čüąŠąĘą┤ą░ąĮąĖčÅ čüąĄą╝ą░č乊čĆą░.
ąæąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąŠčłąĖą▒ąŠą║ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ.
ą¤čĆąŠč鹊čéąĖą┐ C:
void VDK_PostSemaphore (VDK_SemaphoreID inSemaphoreID);
ą¤čĆąŠč鹊čéąĖą┐ C++:
void VDK::PostSemaphore (VDK::SemaphoreID inSemaphoreID);
ążčāąĮą║čåąĖčÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą╝ąĄčģą░ąĮąĖąĘą╝, č湥čĆąĄąĘ ą║ąŠč鹊čĆčŗą╣ ą┐ąŠč鹊ą║ąĖ ą╝ąŠą│čāčé ą┐čāą▒ą╗ąĖą║ąŠą▓ą░čéčī čüąĄą╝ą░č乊čĆčŗ. ąÜą░ąČą┤čŗą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ čüąĄą╝ą░č乊čĆ ą┐čāą▒ą╗ąĖą║čāąĄčéčüčÅ, ąĄą│ąŠ čüč湥čéčćąĖą║ čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčéčüčÅ ąĮą░ 1, ą┐ąŠą║ą░ ąĮąĄ ą┤ąŠčüčéąĖą│ąĮąĄčé ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą│ąŠ ąĘą░ą┤ą░ąĮąĮąŠą│ąŠ ą┤ą╗čÅ čüąĄą╝ą░č乊čĆą░ ąĘąĮą░č湥ąĮąĖčÅ, ą║ąŠč鹊čĆąŠąĄ ą▒čŗą╗ąŠ čāą║ą░ąĘą░ąĮąŠ ą┐čĆąĖ čüąŠąĘą┤ą░ąĮąĖąĖ (čüą╝. ąŠą┐ąĖčüą░ąĮąĖąĄ CreateSemaphore(), ą┐ą░čĆą░ą╝ąĄčéčĆ inMaxCount). ąÆčüąĄ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖąĄ ą┐čāą▒ą╗ąĖą║ą░čåąĖąĖ čüąĄą╝ą░č乊čĆą░ ąĮąĄ ą┤ą░ą┤čāčé čŹčäč乥ą║čéą░. ąśą╝ąĄą╣č鹥 ą▓ ą▓ąĖą┤čā, čćč鹊 ą┤ą╗čÅ č鹊ą╣ ąČąĄ čäčāąĮą║čåąĖąĖ ą▓ąĮčāčéčĆąĖ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąŠą▓ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ (Interrupt Service Routines, ISR) ą┤ąŠą╗ąČąĄąĮ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤čĆčāą│ąŠą╣ čüąĖąĮčéą░ą║čüąĖčü, ą║ą░ą║ čŹč鹊 ąŠą┐ąĖčüą░ąĮąŠ ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "Assembly Macros and C/C++ ISR API" čĆčāą║ąŠą▓ąŠą┤čüčéą▓ą░ VDK (Kernel) User's Guide. ąĪą╝. čéą░ą║ąČąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ čäčāąĮą║čåąĖąĖ C_ISR_PostSemaphore() ą▓ąŠ ą▓čĆąĄąĘą║ąĄ ąĮąĖąČąĄ.
ążčāąĮą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ą░ ąĖ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÄ ą║ąŠąĮč鹥ą║čüčéą░.
ąÆčĆąĄą╝čÅ čĆą░ą▒ąŠčéčŗ čäčāąĮą║čåąĖąĖ:
ŌĆó ąĢčüą╗ąĖ ą┐ąŠč鹊ą║ ąĮąĄ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮ ąĮą░ čŹč鹊ą╝ čüąĄą╝ą░č乊čĆąĄ: ą┐ąŠčüč鹊čÅąĮąĮąŠąĄ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ.
ŌĆó ąĢčüą╗ąĖ ąĮą░ čŹč鹊ą╝ čüąĄą╝ą░č乊čĆąĄ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮ ą╝ąĄąĮąĄąĄ ą┐čĆąĖąŠčĆąĖč鹥čéąĮčŗą╣ ą┐ąŠč鹊ą║: ą┐ąŠčüč鹊čÅąĮąĮąŠąĄ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ.
ŌĆó ąĢčüą╗ąĖ ąĮą░ čŹč鹊ą╝ čüąĄą╝ą░č乊čĆąĄ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮ ą╝ąĄąĮąĄąĄ ą┐čĆąĖąŠčĆąĖč鹥čéąĮčŗą╣ ą┐ąŠč鹊ą║: ą┐ąŠčüč鹊čÅąĮąĮąŠąĄ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ, ą┐ą╗čÄčü ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą║ąŠąĮč鹥ą║čüčéą░ ąĮą░ ą▒ąŠą╗ąĄąĄ ą┐čĆąĖąŠčĆąĖč鹥čéąĮčŗą╣ ą┐ąŠč鹊ą║.
[ą¤ą░čĆą░ą╝ąĄčéčĆčŗ]
inSemaphoreID ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ čüąĄą╝ą░č乊čĆą░, ąĘąĮą░č湥ąĮąĖąĄ čéąĖą┐ą░ SemaphoreID, čāą║ą░ąĘčŗą▓ą░čÄčēąĄąĄ ąĮą░ ą┐čāą▒ą╗ąĖą║čāąĄą╝čŗą╣ čüąĄą╝ą░č乊čĆ.
[ą×ą▒čĆą░ą▒ąŠčéą║ą░ ąŠčłąĖą▒ąŠą║]
ąŚą┤ąĄčüčī ą┐čĆąĖą▓ąĄą┤ąĄąĮą░ čĆą░čüčłąĖčäčĆąŠą▓ą║ą░ ą▓ąŠąĘą╝ąŠąČąĮčŗčģ ąŠčłąĖą▒ąŠą║ čÅą┤čĆą░ (ąŠč鹊ą▒čĆą░ąČą░čÄčéčüčÅ ą▓ ąŠą║ąĮąĄ View -> VDK Windows -> Status), ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī čĆąĄąĘčāą╗čīčéą░č鹊ą╝ ą▓čŗąĘąŠą▓ą░ čäčāąĮą║čåąĖąĖ. ą¤ąŠą┤ą┤ąĄčƹȹ║ą░ Full instrumentation:
kUnknownSemaphore ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 inSemaphoreID ąĮąĄą┤ąŠą┐čāčüčéąĖą╝čŗą╣ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ čüąĄą╝ą░č乊čĆą░ SemaphoreID.
ąæąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąŠčłąĖą▒ąŠą║ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ.
ąŁčéą░ čäčāąĮą║čåąĖčÅ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮą░ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą▓ąĮčāčéčĆąĖ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ (ą║ąŠąĮč鹥ą║čüčé ISR). ąÆąŠ ą▓čüąĄą╝ ąŠčüčéą░ą╗čīąĮąŠą╝ ąŠąĮą░ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą░ąĮą░ą╗ąŠą│ąĖčćąĮą░ čäčāąĮą║čåąĖąĖ PostSemaphore, ą║ąŠč鹊čĆą░čÅ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮą░ ą┤ą╗čÅ ą▓čŗąĘąŠą▓ą░ č鹊ą╗čīą║ąŠ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ą┐ąŠč鹊ą║ą░.
ą¤čĆąŠč鹊čéąĖą┐ C:
bool VDK_PendSemaphore (VDK_SemaphoreID inSemaphoreID,
VDK_Ticks inTimeout);
ą¤čĆąŠč鹊čéąĖą┐ C++:
bool VDK::PendSemaphore (VDK::SemaphoreID inSemaphoreID,
VDK::Ticks inTimeout);
ą¤čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą╝ąĄčģą░ąĮąĖąĘą╝, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐ąŠč鹊ą║ą░ą╝ ą▓čŗą┐ąŠą╗ąĮčÅčéčī ąŠąČąĖą┤ą░ąĮąĖąĄ ą┐čāą▒ą╗ąĖą║ą░čåąĖąĖ čüąĄą╝ą░č乊čĆą░ (čüą╝. čäčāąĮą║čåąĖčÄ PostSemaphore()).
ąĢčüą╗ąĖ čāą║ą░ąĘą░ąĮąĮčŗą╣ čüąĄą╝ą░č乊čĆ ą┤ąŠčüčéčāą┐ąĄąĮ (ąĄą│ąŠ čüč湥čéčćąĖą║ ą▒ąŠą╗čīčłąĄ 0), č鹊 ą┐ąŠčüą╗ąĄ ą▓ąŠąĘą▓čĆą░čéą░ ąĖąĘ čäčāąĮą║čåąĖąĖ čüč湥čéčćąĖą║ čüąĄą╝ą░č乊čĆą░ ą▒čāą┤ąĄčé ą┤ąĄą║čĆąĄą╝ąĄąĮčéąĖčĆąŠą▓ą░ąĮ ąĮą░ 1 čü ą▓ąŠąĘą▓čĆą░č鹊ą╝ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą▓ ą▓čŗąĘą▓ą░ą▓čłąĖą╣ čäčāąĮą║čåąĖčÄ ą┐ąŠč鹊ą║. ąĢčüą╗ąĖ čüąĄą╝ą░č乊čĆ ąĮąĄ ą┤ąŠčüčéčāą┐ąĄąĮ (ąĄą│ąŠ čüč湥čéčćąĖą║ čĆą░ą▓ąĄąĮ 0), ąĖ čéą░ą╣ą╝ą░čāčé čāą║ą░ąĘą░ąĮ ą║ą░ą║ kDoNotWait (VDK_kDoNotWait ąĮą░ čÅąĘčŗą║ąĄ C ąĖą╗ąĖ VDK::kDoNotWait ąĮą░ čÅąĘčŗą║ąĄ C++), č鹊 ą▓čŗąĘąŠą▓ ą▓ąĄčĆąĮąĄčé FALSE ąĖ ą┐ąŠč鹊ą║ ą┐čĆąŠą┤ąŠą╗ąČąĖčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ.
ąĢčüą╗ąĖ čüąĄą╝ą░č乊čĆ ąĮąĄ ą┤ąŠčüčéčāą┐ąĄąĮ, ąĖ čāą║ą░ąĘą░ąĮ čéą░ą╣ą╝ą░čāčé, ąĮąĄ čĆą░ą▓ąĮčŗą╣ kDoNotWait, č鹊 ą┐ąŠč鹊ą║ ą┐čĆąĖąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┤ąŠ ą╝ąŠą╝ąĄąĮčéą░ ą┐čāą▒ą╗ąĖą║ą░čåąĖąĖ čŹč鹊ą│ąŠ čüąĄą╝ą░č乊čĆą░ ą┤čĆčāą│ąĖą╝ ą┐ąŠč鹊ą║ąŠą╝. ąĢčüą╗ąĖ ą┐ąŠč鹊ą║ ąĮąĄ ą▓ąŠąĘąŠą▒ąĮąŠą▓ąĖą╗ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĘą░ ą▓čĆąĄą╝čÅ inTimeout čéąĖą║ąŠą▓, ą┐ąŠ ą┐ąŠč鹊ą║ ą┐ąĄčĆąĄą╣ą┤ąĄčé ąĮą░ č鹊čćą║čā ą▓čģąŠą┤ą░ čüą▓ąŠąĄą│ąŠ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ąŠčłąĖą▒ą║ąĖ, ąĖ ą┐ąŠč鹊ą║ čüčéą░ąĮąĄčé ą┤ąŠčüčéčāą┐ąĮčŗą╝ ą┤ą╗čÅ ąĘą░ą┐čāčüą║ą░ (čé. ąĄ. ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ ąĘą░ą┐čāčüčéąĖčé ąĄą│ąŠ, ąĄčüą╗ąĖ ąĮąĄčé ą┤ą╗čÅ ąĘą░ą┐čāčüą║ą░ ą▒ąŠą╗ąĄąĄ ą┐čĆąĖąŠčĆąĖč鹥čéąĮčŗčģ ą┐ąŠč鹊ą║ąŠą▓). ąŁč鹊 ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖąĘą╝ąĄąĮąĄąĮąŠ, ąĄčüą╗ąĖ ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ čéą░ą╣ą╝ą░čāčéą░ ąĮą░ą╗ąŠąČąĖčéčī ąŠą┐ąĄčĆą░čåąĖąĄą╣ OR ą║ąŠąĮčüčéą░ąĮčéčā kNoTimeoutError (VDK_kNoTimeoutError ąĮą░ čÅąĘčŗą║ąĄ C ąĖą╗ąĖ VDK::kNoTimeoutError ąĮą░ čÅąĘčŗą║ąĄ C++). ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą┐čĆąĖ čéą░ą╣ą╝ą░čāč鹥 ąĮąĄ ą▒čāą┤ąĄčé ąĘą░ą┐čāčēąĄąĮą░ ą┤ąĖčüą┐ąĄčéč湥čĆąĖąĘą░čåąĖčÅ ąŠčłąĖą▒ą║ąĖ, ą▒čāą┤ąĄčé ą┐čĆąŠčüč鹊 ąŠčüčāčēąĄčüčéą▓ą╗ąĄąĮ ą▓ąŠąĘą▓čĆą░čé ąĖąĘ čäčāąĮą║čåąĖąĖ ąĖ ą┐ąŠč鹊ą║ čüčéą░ąĮąĄčé ą┤ąŠčüčéčāą┐ąĮčŗą╝ ą┤ą╗čÅ ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąĖčÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ. ąĢčüą╗ąĖ ą┐ąĄčĆąĄą┤ą░ąĮąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ čéą░ą╣ą╝ą░čāčéą░ čĆą░ą▓ąĮąŠ 0, č鹊 ą┐ąŠč鹊ą║ ą╝ąŠąČąĄčé ąČą┤ą░čéčī ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠ.
ążčāąĮą║čåąĖčÅ ąĘą░ą┐čāčüą║ą░ąĄčé ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ ąĖ ą╝ąŠąČąĄčé ą┐ąŠą▓ą╗ąĖčÅčéčī ąĮą░ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą║ąŠąĮč鹥ą║čüčéą░. ąĢčüą╗ąĖ čüąĄą╝ą░č乊čĆ ą┤ąŠčüčéčāą┐ąĄąĮ, č鹊 ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čäčāąĮą║čåąĖąĖ ą┐ąŠčüč鹊čÅąĮąĮąŠ.
[ą¤ą░čĆą░ą╝ąĄčéčĆčŗ]
inSemaphoreID ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ čüąĄą╝ą░č乊čĆą░, ąĘąĮą░č湥ąĮąĖąĄ čéąĖą┐ą░ SemaphoreID. ą¤ąŠč鹊ą║ ą▒čāą┤ąĄčé ąĮą░čģąŠą┤ąĖčéčīčüčÅ ą▓ ąŠąČąĖą┤ą░ąĮąĖąĖ ą┐čāą▒ą╗ąĖą║ą░čåąĖąĖ čŹč鹊ą│ąŠ čüąĄą╝ą░č乊čĆą░.
inTimeout ąĘąĮą░č湥ąĮąĖąĄ ą╝ąĄąĮčīčłąĄ INT_MAX, ą║ąŠč鹊čĆąŠąĄ ąĘą░ą┤ą░ąĄčé ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčāčÄ ą┤ą╗ąĖč鹥ą╗čīąĮąŠčüčéčī ą▓ čéąĖą║ą░čģ, čüą║ąŠą╗čīą║ąŠ ą┐ąŠč鹊ą║ ąČą┤ąĄčé ą┐čāą▒ą╗ąĖą║ą░čåąĖąĖ čüąĄą╝ą░č乊čĆą░. ąØą░ čŹč鹊 ąĘąĮą░č湥ąĮąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĄą╣ OR ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮą░ą╗ąŠąČąĄąĮą░ ą║ąŠąĮčüčéą░ąĮčéą░ kNoTimeoutError, ąĄčüą╗ąĖ ąĮąĄ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ą┤ąĖčüą┐ąĄčéč湥čĆąĖąĘą░čåąĖčÅ ąŠčłąĖą▒ąŠą║ čéą░ą╣ą╝ą░čāčéą░. ąŚąĮą░č湥ąĮąĖąĄ kDoNotWait čāą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ąĮąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ąĮą░ ąŠąČąĖą┤ą░ąĮąĖąĖ čüąĄą╝ą░č乊čĆą░, ąĄčüą╗ąĖ ąŠąĮ ąĮąĄ ą┤ąŠčüčéčāą┐ąĄąĮ.
[ąÆąŠąĘą▓čĆą░čēą░ąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ]
ążčāąĮą║čåąĖčÅ ą▓ąĄčĆąĮąĄčé TRUE, ąĄčüą╗ąĖ:
ŌĆó ąæčŗą╗ ą┤ąŠčüčéčāą┐ąĄąĮ (ąŠą┐čāą▒ą╗ąĖą║ąŠą▓ą░ąĮ) čüąĄą╝ą░č乊čĆ čü ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆąŠą╝ SemaphoreID.
FALSE ą▒čāą┤ąĄčé ą▓ąŠąĘą▓čĆą░čēąĄąĮąŠ, ąĄčüą╗ąĖ:
ŌĆó ą¤čĆąŠąĖąĘąŠčłąĄą╗ čéą░ą╣ą╝ą░čāčé ąĮą░ ą▓čŗąĘąŠą▓ąĄ PendSemaphore(), ąĮąŠ ą▒čŗą╗ąŠ čāą║ą░ąĘą░ąĮąŠ kNoTimeoutError.
ŌĆó ąŚąĮą░č湥ąĮąĖąĄ inTimeout ą▒čŗą╗ąŠ čāą║ą░ąĘą░ąĮąŠ ą║ą░ą║ kDoNotWait, ąĖ ąĮąĄčé ą┤ąŠčüčéčāą┐ąĮąŠą│ąŠ čüąĄą╝ą░č乊čĆą░.
[ą×ą▒čĆą░ą▒ąŠčéą║ą░ ąŠčłąĖą▒ąŠą║]
ąŚą┤ąĄčüčī ą┐čĆąĖą▓ąĄą┤ąĄąĮą░ čĆą░čüčłąĖčäčĆąŠą▓ą║ą░ ą▓ąŠąĘą╝ąŠąČąĮčŗčģ ąŠčłąĖą▒ąŠą║ čÅą┤čĆą░ (ąŠč鹊ą▒čĆą░ąČą░čÄčéčüčÅ ą▓ ąŠą║ąĮąĄ View -> VDK Windows -> Status), ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī čĆąĄąĘčāą╗čīčéą░č鹊ą╝ ą▓čŗąĘąŠą▓ą░ čäčāąĮą║čåąĖąĖ. ą¤ąŠą┤ą┤ąĄčƹȹ║ą░ Full instrumentation:
kUnknownSemaphore ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 inSemaphoreID ąĮąĄą┤ąŠą┐čāčüčéąĖą╝čŗą╣ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ čüąĄą╝ą░č乊čĆą░ SemaphoreID.
kSemaphoreTimeout ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ąĖčüč鹥ą║ą╗ąŠ ąĘąĮą░č湥ąĮąĖąĄ čéą░ą╣ą╝ą░čāčéą░ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ čüąĄą╝ą░č乊čĆ čüčéą░ą╗ ą┤ąŠčüčéčāą┐ąĄąĮ (ą▒čŗą╗ ąŠą┐čāą▒ą╗ąĖą║ąŠą▓ą░ąĮ). ąŁčéą░ ąŠčłąĖą▒ą║ą░ ąĮąĄ ą▒čāą┤ąĄčé ą┤ąĖčüą┐ąĄčéč湥čĆąĖąĘąĖčĆąŠą▓ą░ąĮą░, ąĄčüą╗ąĖ ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ čéą░ą╣ą╝ą░čāčéą░ ąŠą┐ąĄčĆą░čåąĖąĄą╣ OR ą▒čŗą╗ą░ ąĮą░ą╗ąŠąČąĄąĮą░ ą║ąŠąĮčüčéą░ąĮčéą░ kNoTimeoutError.
kUnknownSemaphore ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ą▓ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ inSemaphoreID čāą║ą░ąĘą░ąĮ ąĮąĄą┤ąŠą┐čāčüčéąĖą╝čŗą╣ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ čüąĄą╝ą░č乊čĆą░.
kBlockInInvalidRegion ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ą▓čŗąĘąŠą▓ PendSemaphore() čüą┤ąĄą╗ą░ą╗ ą┐ąŠą┐čŗčéą║čā ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą▓ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą╝ čĆąĄą│ąĖąŠąĮąĄ ą║ąŠą┤ą░, čćč鹊 ą┐čĆąĖą▓ąĄą╗ąŠ ą▒čŗ ą║ ą║ąŠąĮčäą╗ąĖą║čéčā ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąĖčÅ ąĘą░ą┐čāčüą║ą░ ąĘą░ą┤ą░čć (ą╝ąĄčĆčéą▓ą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░).
kDbgPossibleBlockInRegion ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 PendSemaphore() ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗąĘą▓ą░ąĮą░ ąĮą░ ą▓ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą╝ čĆąĄą│ąĖąŠąĮąĄ ą║ąŠą┤ą░, čćč鹊 ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą║ąŠąĮčäą╗ąĖą║čéčā ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąĖčÅ ąĘą░ą┐čāčüą║ą░ ąĘą░ą┤ą░čć (ą╝ąĄčĆčéą▓ą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░).
kInvalidTimeout ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ą▓ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ inTimeout ąĘą░ą┤ą░ąĮąŠ ą╗ąĖą▒ąŠ INT_MAX, ą╗ąĖą▒ąŠ (0 | kNoTimeoutError).
ąæąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąŠčłąĖą▒ąŠą║ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ: kSemaphoreTimeout, ą║ą░ą║ ą▒čŗą╗ąŠ čāą║ą░ąĘą░ąĮąŠ ą▓čŗčłąĄ.
ą×ą┐ąĖčüą░ąĮąĖąĄ API-čäčāąĮą║čåąĖą╣ čüąĄą╝ą░č乊čĆąŠą▓ VDK čüą╝. čéą░ą║ąČąĄ ą▓ čüčéą░čéčīąĄ [5].
[ą£čīčÄč鹥ą║čüčŗ]
ą£ąĮąŠą│ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčŗąĄ čüąĖčüč鹥ą╝čŗ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ą╝ąĄčģą░ąĮąĖąĘą╝ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ, ąĖąĘą▓ąĄčüčéąĮčŗą╣ ą║ą░ą║ ą╝čīčÄč鹥ą║čü. ąØą░ąĘą▓ą░ąĮąĖąĄ čŹč鹊ą╣ čüčāčēąĮąŠčüčéąĖ ą┐čĆąŠąĖąĘąŠčłą╗ąŠ ąŠčé čüą╗ąŠą▓ Mutual Exclusion, ąĖą╗ąĖ ą▓ąĘą░ąĖą╝ąĮąŠąĄ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ. ą£čīčÄč鹥ą║čüčŗ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ą┐ąŠč鹊ą║ą░ą╝ čüąĖąĮčģčĆąŠąĮąĖąĘąĖčĆąŠą▓ą░čéčī ą┤ąŠčüčéčāą┐ ą║ ąŠą▒čēąĄą╝čā čĆąĄčüčāčĆčüčā.
ŌĆó ą£čīčÄč鹥ą║čüčŗ VDK čŹč鹊 čćąĖčüč鹊 ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąĖąĄ ąŠą▒čŖąĄą║čéčŗ. ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ąĮąĄ čüčāčēąĄčüčéą▓čāčÄčé ą╝čīčÄč鹥ą║čüąŠą▓ ąĘą░ą│čĆčāąĘą║ąĖ (boot mutexes), ąĖ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą╝čīčÄč鹥ą║čüąŠą▓ ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ ąŠą│čĆą░ąĮąĖč湥ąĮąŠ č鹊ą╗čīą║ąŠ čĆą░ąĘą╝ąĄčĆąŠą╝ ą┤ąŠčüčéčāą┐ąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ - ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą╝čīčÄč鹥ą║čüąŠą▓ ąĮąĄ ąĮą░čüčéčĆą░ąĖą▓ą░ąĄčéčüčÅ ąĮą░ ąĘą░ą║ą╗ą░ą┤ą║ąĄ Kernel ąĮą░čüčéčĆąŠąĄą║ VDK-ą┐čĆąŠąĄą║čéą░.
ŌĆó ą£čīčÄč鹥ą║čüčŗ VDK ąĖą╝ąĄčÄčé ą▓ą╗ą░ą┤ąĄą╗čīčåą░ - č鹊ą╗čīą║ąŠ ą▓ą╗ą░ą┤ąĄą╗ąĄčå ą╝čīčÄč鹥ą║čüą░ ą╝ąŠąČąĄčé ąŠčüą▓ąŠą▒ąŠą┤ąĖčéčī (release) ą╝čīčÄč鹥ą║čü.
ŌĆó ą£čīčÄč鹥ą║čüčŗ VDK čÅą▓ą╗čÅčÄčéčüčÅ čĆąĄą║čāčĆčüąĖą▓ąĮčŗą╝ąĖ - č鹥ą║čāčēąĖą╣ ą▓ą╗ą░ą┤ąĄą╗ąĄčå ą╝ąŠąČąĄčé ą┐ąŠą╗čāčćąĖčéčī ą▓ąĘą░ąĖą╝ąĮąŠąĄ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ (ą╝čīčÄč鹥ą║čü) ą╝ąĮąŠą│ąŠą║čĆą░čéąĮąŠ, čü ą▓ą╗ąŠąČąĄąĮąĖčÅą╝ąĖ ą┤čĆčāą│ ą▓ ą┤čĆčāą│ą░.
ą¤ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą╝čīčÄč鹥ą║čüąŠą▓. ą£čīčÄč鹥ą║čü (mutex) čŹč鹊 ą╝ą░čĆą║ąĄčĆ (token), ą║ąŠč鹊čĆčŗą╣ ą┐ąŠč鹊ą║ ą┐ąŠą╗čāčćą░ąĄčé ą┤ą╗čÅ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖčÅ čüą▓ąŠąĄą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ. ąĢčüą╗ąĖ ą┐ąŠč鹊ą║ ą┐ąŠą┐čŗčéą░ą╗čüčÅ ą▓ąĘčÅčéčī ą╝čīčÄč鹥ą║čü, ąĖ ą╝čīčÄč鹥ą║čü ą┤ąŠčüčéčāą┐ąĄąĮ (čā ą╝čīčÄč鹥ą║čüą░ čüąĄą╣čćą░čü ą╗ąĖą▒ąŠ ąĮąĄčé ą▓ą╗ą░ą┤ąĄą╗čīčåą░, ąĖą╗ąĖ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą╝ čÅą▓ą╗čÅąĄčéčüčÅ č鹥ą║čāčēąĖą╣ ą┐ąŠč鹊ą║), č鹊 ą╝čīčÄč鹥ą║čü ąĘą░čģą▓ą░čéčŗą▓ą░ąĄčéčüčÅ. ąÜąŠą│ą┤ą░ ą╝čīčÄč鹥ą║čü ąĘą░čģą▓ą░č湥ąĮ, ąĄą│ąŠ ąĘąĮą░č湥ąĮąĖąĄ ą▓ąĮčāčéčĆąĄąĮąĮąĄą│ąŠ čüč湥čéčćąĖą║ą░ čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčéčüčÅ, ąĖ ą┐ąŠč鹊ą║ ą┐čĆąŠą┤ąŠą╗ąČą░ąĄčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ. ąĢčüą╗ąĖ ą╝čīčÄč鹥ą║čü ąĮąĄą┤ąŠčüčéčāą┐ąĄąĮ (ą▓ąĘčÅčé ą▓ąŠ ą▓ą╗ą░ą┤ąĄąĮąĖąĄ ą┤čĆčāą│ąĖą╝ ą┐ąŠč鹊ą║ąŠą╝), č鹊ą│ą┤ą░ ą┐ąŠč鹊ą║, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠą┐čŗčéą░ą╗čüčÅ ą▓ąĘčÅčéčī ą╝čīčÄč鹥ą║čü, ą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ, ą┐ąŠą║ą░ ą╝čīčÄč鹥ą║čü ąĮąĄ čüčéą░ąĮąĄčé ą┤ąŠčüčéčāą┐ąĮčŗą╝.
ą£čīčÄč鹥ą║čüčŗ čÅą▓ą╗čÅčÄčéčüčÅ ą│ą╗ąŠą▒ą░ą╗čīąĮčŗą╝ąĖ čĆąĄčüčāčĆčüą░ą╝ąĖ ą┤ą╗čÅ ą▓čüąĄčģ ą┐ąŠč鹊ą║ąŠą▓ ą▓ čüąĖčüč鹥ą╝ąĄ. ą¤ąŠč鹊ą║ąĖ čĆą░ąĘąĮčŗčģ čéąĖą┐ąŠą▓ ąĖ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓ ą╝ąŠą│čāčé ą┐ąŠą╗čāčćąĖčéčī ą╝čīčÄč鹥ą║čü. ąÜąŠą│ą┤ą░ ą╝čīčÄč鹥ą║čü ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮ, ą┐ąŠč鹊ą║ čü čüą░ą╝čŗą╝ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝, ąŠąČąĖą┤ą░čÄčēąĖą╣ ąĮą░ ą╝čīčÄč鹥ą║čüąĄ ą┤ąŠą╗čīčłąĄ ą▓čüąĄą│ąŠ, ą┐ąĄčĆąĄąĮąŠčüąĖčéčüčÅ ą▓ ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ. ą£čīčÄč鹥ą║čüčŗ VDK ąĖą╝ąĄčÄčé ą▓ą╗ą░ą┤ąĄą╗čīčåą░; č鹊ą╗čīą║ąŠ č鹊čé ą┐ąŠč鹊ą║ ą╝ąŠąČąĄčé ąŠčüą▓ąŠą▒ąŠą┤ąĖčéčī ą╝čīčÄč鹥ą║čü, ą║ąŠč鹊čĆčŗą╣ čÅą▓ą╗čÅąĄčéčüčÅ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą╝ ą╝čīčÄč鹥ą║čüą░. ąÆ čüą╗čāčćą░ąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░ą╗čīąĮčŗčģ (instrumented) ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ ąĖą╗ąĖ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ čü ą┐čĆąŠą▓ąĄčĆą║ąŠą╣ ąŠčłąĖą▒ąŠą║ (error-checking), ąĄčüą╗ąĖ ą▒čŗą╗ čāąĮąĖčćč鹊ąČąĄąĮ ą┐ąŠč鹊ą║, ą║ąŠč鹊čĆčŗą╣ ą▓ą╗ą░ą┤ąĄą╗ ą╝čīčÄč鹥ą║čüąŠą╝, č鹊 ą▓ čüą╗ąĄą┤čāčÄčēąĖą╣ ą╝ąŠą╝ąĄąĮčé ą┐ąŠą┐čŗčéą║ąĖ ą┐ąŠč鹊ą║ą░ ą▓ąĘčÅčéčī ą╝čīčÄč鹥ą║čü VDK ą┤ąĖčüą┐ąĄčéč湥čĆąĖąĘąĖčĆčāąĄčé ąŠčłąĖą▒ą║čā, ąĖ ą╝čīčÄč鹥ą║čü ą▒čāą┤ąĄčé ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮ čÅą┤čĆąŠą╝.
ąÆąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąĖąĄ ą┐ąŠč鹊ą║ąŠą▓ čü ą╝čīčÄč鹥ą║čüą░ą╝ąĖ. ą¤ąŠč鹊ą║ąĖ ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓čāčÄčé čü ą╝čīčÄč鹥ą║čüą░ą╝ąĖ č湥čĆąĄąĘ ąĮą░ą▒ąŠčĆ čäčāąĮą║čåąĖą╣ mutex API. ąŁč鹊čé API ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐ąŠč鹊ą║čā čüąŠąĘą┤ą░ą▓ą░čéčī ą╝čīčÄč鹥ą║čü, ąĘą░čģą▓ą░čéčŗą▓ą░čéčī ąĖą╗ąĖ ą┐ąŠą╗čāčćą░čéčī ą╝čīčÄč鹥ą║čü (acquire), ąŠčüą▓ąŠą▒ąŠąČą┤ą░čéčī ą╝čīčÄč鹥ą║čü (release) ąĖą╗ąĖ čāąĮąĖčćč鹊ąČą░čéčī ą╝čīčÄč鹥ą║čü.
ąÆąĘčÅčéąĖąĄ ą╝čīčÄč鹥ą║čüą░ (Acquiring a Mutex). ąØą░ čĆąĖčü. 3-7 ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąŠčåąĄčüčü ą┐ąŠą╗čāč湥ąĮąĖčÅ ą╝čīčÄč鹥ą║čüą░. ą¤ąŠč鹊ą║ ą╝ąŠąČąĄčé ąĘą░čģą▓ą░čéąĖčéčī ą╝čīčÄč鹥ą║čü ą▓čŗąĘąŠą▓ąŠą╝ AcquireMutex(), ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 č湥ą│ąŠ ą▒čāą┤čāčé ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ čüą╗ąĄą┤čāčÄčēąĖąĄ ą▓ąŠąĘą╝ąŠąČąĮčŗąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ.
ŌĆó ą¤ąŠč鹊ą║ čüčéą░ąĮąĄčé ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą╝ ą╝čīčÄč鹥ą║čüą░ ąĖ ą┐čĆąŠą┤ąŠą╗ąČąĖčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ.
ŌĆó ąÆąĮčāčéčĆąĄąĮąĮąĖą╣ čüč湥čéčćąĖą║ ą╝čīčÄč鹥ą║čüą░ čāą▓ąĄą╗ąĖčćąĖčéčüčÅ, ąĖ ą┐ąŠč鹊ą║ ą┐čĆąŠą┤ąŠą╗ąČąĖčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ.
ŌĆó ą¤ąŠč鹊ą║ ąĘą░ą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ ąĮą░ ą╝čīčÄč鹥ą║čüąĄ, ą┐ąŠą║ą░ ą╝čīčÄč鹥ą║čü ąĮąĄ čüčéą░ąĮąĄčé ą┤ąŠčüčéčāą┐ąĮčŗą╝, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ąĘą░čģą▓ą░čéąĖčé ą╝čīčÄč鹥ą║čü.
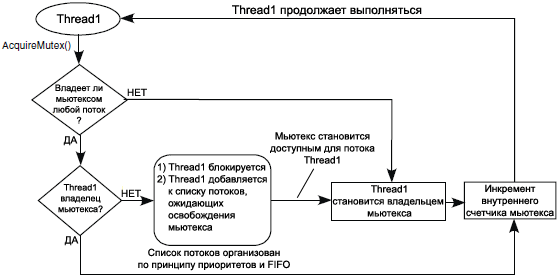
ąĀąĖčü. 3-7. ąŚą░čģą▓ą░čé ą╝čīčÄč鹥ą║čüą░.
ąØąĄ ą▓čŗąĘčŗą▓ą░ą╣č鹥 AcquireMutex() ąĖąĘ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ ąĖą╗ąĖ ą║čĆąĖčéąĖč湥čüą║ąŠą│ąŠ čĆąĄą│ąĖąŠąĮą░ ą║ąŠą┤ą░. ąĢčüą╗ąĖ ą╝čīčÄč鹥ą║čü ąĮąĄą┤ąŠčüčéčāą┐ąĄąĮ, č鹊 ą┐ąŠč鹊ą║ ą┐ąŠą┐čŗčéą░ąĄčéčüčÅ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░čéčīčüčÅ, čćč鹊 ąĮąĄą┤ąŠą┐čāčüčéąĖą╝ąŠ ą┤ą╗čÅ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ąŠą╝ čĆąĄą│ąĖąŠąĮą░.
ą×čüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ą╝čīčÄč鹥ą║čüą░ (Releasing a mutex). ą£čīčÄč鹥ą║čü ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮ č鹊ą╗čīą║ąŠ č鹥ą╝ ą┐ąŠč鹊ą║ąŠą╝, ą║ąŠč鹊čĆčŗą╣ čÅą▓ą╗čÅąĄčéčüčÅ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą╝ ą╝čīčÄč鹥ą║čüą░. ąĢčüą╗ąĖ ą┐ąŠč鹊ą║ ąĘą░čģą▓ą░čéąĖą╗ ą╝čīčÄč鹥ą║čü ąĮąĄčüą║ąŠą╗čīą║ąŠ čĆą░ąĘ, č鹊 ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ąĖą╝ ą╝čīčÄč鹥ą║čüą░ ą┤ąĄą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄčé ą▓ąĮčāčéčĆąĄąĮąĮąĖą╣ čüč湥čéčćąĖą║ ą╝čīčÄč鹥ą║čüą░, ąĖ ą┐ąŠč鹊ą║ ąŠčüčéą░ąĄčéčüčÅ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą╝ ą╝čīčÄč鹥ą║čüą░. ą£čīčÄč鹥ą║čü č鹥čĆčÅąĄčé ą▓ą╗ą░ą┤ąĄą╗čīčåą░ č鹊ą╗čīą║ąŠ ą║ąŠą│ą┤ą░ ReleaseMutex() ą▒čŗą╗ ą▓čŗąĘą▓ą░ąĮ ąŠą┤ąĖąĮ čĆą░ąĘ ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ą╝čīčÄč鹥ą║čü ą▒čŗą╗ ąĘą░čģą▓ą░č湥ąĮ, ąĖą╗ąĖ ą▓ č鹊čé ą╝ąŠą╝ąĄąĮčé, ą║ąŠą│ą┤ą░ ą▓ąĮčāčéčĆąĄąĮąĮąĖą╣ čüč湥čéčćąĖą║ ą╝čīčÄč鹥ą║čüą░ ą┤ąŠčüčéąĖą│ ąĮčāą╗čÅ. ą¤ąŠčüą╗ąĄ ą┐ąŠč鹥čĆąĖ ą▓ą╗ą░ą┤ąĄą╗čīčåą░ ą╝čīčÄč鹥ą║čü čüčéą░ąĮąŠą▓ąĖčéčüčÅ ą┤ąŠčüčéčāą┐ąĮčŗą╝ ą┤ą╗čÅ ąĘą░čģą▓ą░čéą░ ą╗čÄą▒čŗą╝ ą┤čĆčāą│ąĖą╝ ą┐ąŠč鹊ą║ąŠą╝. ąĢčüą╗ąĖ ą▓čüąĄ ą┐ąŠč鹊ą║ąĖ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮčŗ ąĮą░ ą╝čīčÄč鹥ą║čüąĄ, č鹊 ą┐ąĄčĆąĄą▓ąŠą┤ ą╝čīčÄč鹥ą║čüą░ ą▓ ą┤ąŠčüčéčāą┐ąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ ą┐ąĄčĆąĄą╝ąĄčüčéąĖčé (ąĖąĘ čüą┐ąĖčüą║ą░ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĮčŗčģ ąĮą░ ą╝čīčÄč鹥ą║čüąĄ ą┐ąŠč鹊ą║ąŠą▓) ą▓ ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ č鹊ą╗čīą║ąŠ ą┐ąŠč鹊ą║ čü čüą░ą╝čŗą╝ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝. ąĢčüą╗ąĖ ąĮąĄčé ą┐ąŠč鹊ą║ąŠą▓, ąŠąČąĖą┤ą░čÄčēąĖčģ ąĮą░ ą╝čīčÄč鹥ą║čüąĄ, ą║ąŠą│ą┤ą░ ą╝čīčÄč鹥ą║čü čüčéą░ą╗ ą┤ąŠčüčéčāą┐ąĄąĮ, č鹊 ą╝čīčÄč鹥ą║čü ąŠčüčéą░ąĮąĄčéčüčÅ ą▓ ą┤ąŠčüčéčāą┐ąĮąŠą╝ čüąŠčüč鹊čÅąĮąĖąĖ. ąØąĖą║ą░ą║ąŠą╣ ą┐ąŠč鹊ą║ ąĮąĄ ą╝ąŠąČąĄčé ąŠčüą▓ąŠą▒ąŠą┤ąĖčéčī ą╝čīčÄč鹥ą║čü, ąĄčüą╗ąĖ ąŠąĮ ąĮąĄ čÅą▓ą╗čÅąĄčéčüčÅ čüąĄą╣čćą░čü ąĄą│ąŠ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą╝.
ąØą░ čĆąĖčü. 3-8 ąĖ 3-9 ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąŠčåąĄčüčü ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ ą╝čīčÄč鹥ą║čüąŠą▓ ą▓ąŠ ą▓čĆąĄą╝čÅ ąĮąŠčĆą╝ą░ą╗čīąĮąŠą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ (ą▓ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą╝ čĆąĄą│ąĖąŠąĮąĄ ą║ąŠą┤ą░) ąĖ ą▓ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą╝ čĆąĄą│ąĖąŠąĮąĄ ą║ąŠą┤ą░.

ąĀąĖčü. 3-8. ą×čüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ą╝čīčÄč鹥ą║čüą░ ąĖąĘ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ąŠą╝ čĆąĄą│ąĖąŠąĮą░ ą║ąŠą┤ą░.
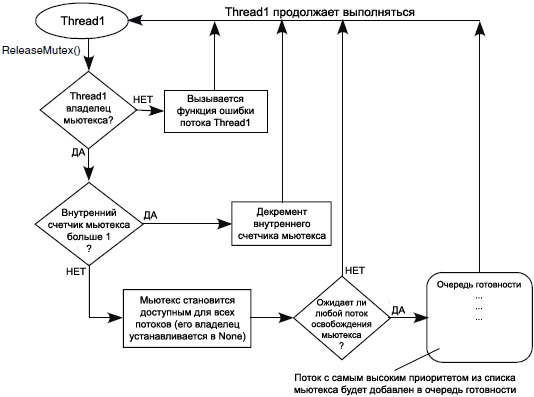
ąĀąĖčü. 3-9. ą×čüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ą╝čīčÄč鹥ą║čüą░ ąĖąĘ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ąŠą╝ čĆąĄą│ąĖąŠąĮą░ ą║ąŠą┤ą░.
ŌĆó ąĢčüą╗ąĖ ą┐ąŠč鹊ą║ ą▓čŗąĘą▓ą░ą╗ ReleaseMutex() ą▓ąŠ ą▓čĆąĄą╝čÅ ąĮąŠčĆą╝ą░ą╗čīąĮąŠą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ, ą║ąŠą│ą┤ą░ ą░ą║čéąĖą▓ąĄąĮ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ (čüą╝. čĆąĖčü. 3-8), ąĖ ą┐ąŠč鹊ą║ čü čüą░ą╝čŗą╝ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝, ąŠąČąĖą┤ą░čÄčēąĖą╣ ą╝čīčÄč鹥ą║čü, ą▒čŗą╗ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮ ą▓ ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ, č鹊 ą┐ąŠč鹊ą║, ą║ąŠč鹊čĆčŗą╣ ą▓čŗąĘą▓ą░ą╗ ReleaseMutex(), ą▒čāą┤ąĄčé ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ąŠą╝ (switched out), ąĖ ąĘą░ą┐čāčüčéąĖčéčüčÅ ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║ (ą║ąŠč鹊čĆčŗą╣ čüč鹊ąĖčé ą┐ąĄčĆą▓čŗą╝ ąĮą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą▓ ąŠč湥čĆąĄą┤ąĖ ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ).
ŌĆó ąĢčüą╗ąĖ ą┐ąŠč鹊ą║ ą▓čŗąĘą▓ą░ą╗ ReleaseMutex() ąĖąĘ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ čĆąĄą│ąĖąŠąĮą░ (čüą╝. čĆąĖčü. 3-9), čé. ąĄ. ą║ąŠą│ą┤ą░ čĆą░ą▒ąŠčéą░ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ą░ ąĘą░ą┐čĆąĄčēąĄąĮą░, č鹊 čüą░ą╝čŗą╣ ą▓čŗčüąŠą║ąŠą┐čĆąĖąŠčĆąĖč鹥čéąĮčŗą╣ ą┐ąŠč鹊ą║, ąŠąČąĖą┤ą░čÄčēąĖą╣ ą╝čīčÄč鹥ą║čü, ą▒čāą┤ąĄčé ą┐ąĄčĆąĄą╝ąĄčēąĄąĮ ą▓ ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ, ąĮąŠ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą║ąŠąĮč鹥ą║čüčéą░ ąĮąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé.
ą×ą┐ąĖčüą░ąĮąĖąĄ API-čäčāąĮą║čåąĖą╣ ą╝čīčÄč鹥ą║čüąŠą▓ VDK čüą╝. čéą░ą║ąČąĄ ą▓ čüčéą░čéčīąĄ [6].
[ąĪąŠąŠą▒čēąĄąĮąĖčÅ]
ą£ąĮąŠą│ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčŗąĄ čüąĖčüč鹥ą╝čŗ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ą╝ąĄčģą░ąĮąĖąĘą╝ ąŠą▒ą╝ąĄąĮą░ čüąŠąŠą▒čēąĄąĮąĖčÅą╝ąĖ ą╝ąĄąČą┤čā ą┐ąŠč鹊ą║ą░ą╝ąĖ, ąĖąĘą▓ąĄčüčéąĮčŗą╣ ą║ą░ą║ čüąŠąŠą▒čēąĄąĮąĖčÅ (messages). ąĪąŠąŠą▒čēąĄąĮąĖčÅ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ čüą╗ąĄą┤čāčÄčēąĖčģ čåąĄą╗ąĄą╣:
ŌĆó ąöą╗čÅ ąŠą▒ą╝ąĄąĮą░ ąĖąĮč乊čĆą╝ą░čåąĖąĄą╣ ą╝ąĄąČą┤čā ą┤ą▓čāą╝čÅ ą┐ąŠč鹊ą║ą░ą╝ąĖ.
ŌĆó ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┤ąŠčüčéčāą┐ąŠą╝ ą║ ąŠą▒čēąĄą╝čā čĆąĄčüčāčĆčüčā.
ŌĆó ąĪąĖą│ąĮą░ą╗ąĖąĘą░čåąĖąĖ ąŠą▒ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ čüąŠą▒čŗčéąĖčÅčģ ąĖ ąŠą▒ą╝ąĄąĮą░ ąĖąĮč乊čĆą╝ą░čåąĖąĄą╣, čüą▓čÅąĘą░ąĮąĮąŠą╣ čü čŹčéąĖą╝ąĖ čüąŠą▒čŗčéąĖčÅą╝ąĖ.
ŌĆó ąĪąŠąŠą▒čēąĄąĮąĖčÅ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ą┤ą▓čāą╝ ą┐ąŠč鹊ą║ą░ą╝ čüąĖąĮčģčĆąŠąĮąĖąĘąĖčĆąŠą▓ą░čéčīčüčÅ ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝.
ą£ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čüąŠąŠą▒čēąĄąĮąĖą╣, ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄą╝ąŠąĄ ą▓ čüąĖčüč鹥ą╝ąĄ, ąĮą░čüčéčĆą░ąĖą▓ą░ąĄčéčüčÅ ą▓ ą╝ąŠą╝ąĄąĮčé čüą▒ąŠčĆą║ąĖ VDK-ą┐čĆąŠąĄą║čéą░. ąÜąŠą│ą┤ą░ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čüąŠąŠą▒čēąĄąĮąĖą╣ ąĮąĄ čĆą░ą▓ąĮąŠ 0, čüąŠąĘą┤ą░ąĄčéčüčÅ čüąĖčüč鹥ą╝ąĮčŗą╣ ą┐čāą╗ ą┐ą░ą╝čÅčéąĖ, čćč鹊ą▒čŗ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čéčī čüąŠąŠą▒čēąĄąĮąĖčÅ (čŹčéąĖą╝ ą┐čāą╗ąŠą╝ ą▓ą╗ą░ą┤ąĄąĄčé čüąĖčüč鹥ą╝ą░). ąĪą▓ąŠą╣čüčéą▓ą░ čŹč鹊ą│ąŠ ą┐čāą╗ą░ ą┐ą░ą╝čÅčéąĖ ąĮąĄ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąĖąĘą╝ąĄąĮąĄąĮčŗ. ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ą┐ąŠ ą┐ąŠą▓ąŠą┤čā ą┐čāą╗ąŠą▓ čüą╝. ą▓ [2].
ąÜą░ąČą┤čŗą╣ čéąĖą┐ ą┐ąŠč鹊ą║ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮą░čüčéčĆąŠąĄąĮ ą╗ąĖą▒ąŠ ą║ą░ą║ čĆą░ąĘčĆąĄčłąĄąĮąĮčŗą╣ ą┤ą╗čÅ čüąŠąŠą▒čēąĄąĮąĖą╣ (message-enabled), ą╗ąĖą▒ąŠ ąĮąĄčé. ąŚą┤ąĄčüčī ąĄčüčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī 菹║ąŠąĮąŠą╝ąĖąĖ ą╝ąĄčüčéą░ ą▓ ą┐ą░ą╝čÅčéąĖ, ąĄčüą╗ąĖ čéąĖą┐ ą┐ąŠč鹊ą║ą░ čü ąĮąĄčĆą░ąĘčĆąĄčłąĄąĮąĮčŗą╝ąĖ čüąŠąŠą▒čēąĄąĮąĖčÅą╝ąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 č鹊ą│ą┤ą░ ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ ą┤ą╗čÅ čŹč鹊ą│ąŠ ą┐ąŠą┤ą┤ąĄčƹȹ║ą░ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ čüčéčĆčāą║čéčāčĆčŗ. ąóąĖą┐ ą┐ąŠč鹊ą║ą░, čā ą║ąŠč鹊čĆąŠą│ąŠ ąĮąĄčé ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ čüąŠąŠą▒čēąĄąĮąĖą╣ (not message-enabled), ą▓čüąĄ ąĄčēąĄ ą╝ąŠąČąĄčé ąŠčéą┐čĆą░ą▓ą╗čÅčéčī čüąŠąŠą▒čēąĄąĮąĖčÅ; ąŠą┤ąĮą░ą║ąŠ ąŠąĮ ąĮąĄ ą╝ąŠąČąĄčé ą┐čĆąĖąĮąĖą╝ą░čéčī čüąŠąŠą▒čēąĄąĮąĖčÅ.
ą¤ąŠą▓ąĄą┤ąĄąĮąĖąĄ čüąŠąŠą▒čēąĄąĮąĖą╣. ąĪąŠąŠą▒čēąĄąĮąĖčÅ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ą┤ą▓čāą╝ ą┐ąŠč鹊ą║ą░ą╝ ąŠą▒ą╝ąĄąĮąĖą▓ą░čéčīčüčÅ ąĖąĮč乊čĆą╝ą░čåąĖąĄą╣ č湥čĆąĄąĘ ą╗ąŠą│ąĖč湥čüą║ąĖ čĆą░ąĘą┤ąĄą╗ąĄąĮąĮčŗąĄ ą║ą░ąĮą░ą╗čŗ. ąĪąŠąŠą▒čēąĄąĮąĖąĄ ąŠčéą┐čĆą░ą▓ą╗čÅąĄčéčüčÅ č湥čĆąĄąĘ ąŠą┤ąĖąĮ ąĖąĘ 15 ą▓ąŠąĘą╝ąŠąČąĮčŗčģ ą║ą░ąĮą░ą╗ąŠą▓, ąŠčé kMsgChannel1 ą┤ąŠ kMsgChannel15. ąĪąŠąŠą▒čēąĄąĮąĖčÅ ą▓čŗą▒ąĖčĆą░čÄčéčüčÅ ąĖąĘ čŹčéąĖčģ ą║ą░ąĮą░ą╗ąŠą▓ ą▓ ą┐ąŠčĆčÅą┤ą║ąĄ ą┐čĆąĖąŠčĆąĖč鹥čéą░: kMsgChannel1, kMsgChannel2, ... kMsgChannel15k, ąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ, ą┐čĆąĖąĮąĖą╝ą░ąĄą╝čŗąĄ ą┐ąŠ ą║ą░ąČą┤ąŠą╝čā ą║ą░ąĮą░ą╗čā, ą┐ąŠčüčéčāą┐ą░čÄčé ą▓ ą┐ąŠčĆčÅą┤ą║ąĄ FIFO. ąÜą░ąČą┤ąŠąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ ą╝ąŠąČąĄčé ą┐ąĄčĆąĄą┤ą░čéčī čüčüčŗą╗ą║čā ąĮą░ ą▒čāč乥čĆ ą┤ą░ąĮąĮčŗčģ ą▓ ą║ą░č湥čüčéą▓ąĄ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ (message payload) ąŠčé ą┐ąĄčĆąĄą┤ą░čÄčēąĄą│ąŠ ą┐ąŠč鹊ą║ą░ ą║ ą┐čĆąĖąĮąĖą╝ą░čÄčēąĄą╝čā ą┐ąŠč鹊ą║čā.
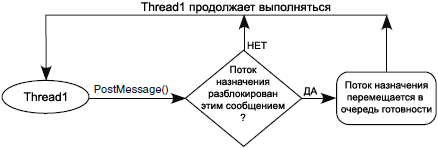
ą¤ąŠč鹊ą║ čüąŠąĘą┤ą░ąĄčé čüąŠąŠą▒čēąĄąĮąĖąĄ (ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ čüą▓čÅąĘą░ąĮąĮąŠąĄ čü ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąŠą╣) ą▓čŗąĘąŠą▓ąŠą╝ čäčāąĮą║čåąĖąĖ GreateMessage(), ąĖ ąĘą░č鹥ą╝ ą┐čĆąĖ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ ą┐čāą▒ą╗ąĖą║čāąĄčé ąĄą│ąŠ (ąŠčéą┐čĆą░ą▓ą╗čÅąĄčé) ą┤čĆčāą│ąŠą╝čā ą┐ąŠč鹊ą║čā ą▓čŗąĘąŠą▓ąŠą╝ čäčāąĮą║čåąĖąĖ PostMessage(). ą¤čāą▒ą╗ąĖą║čāčÄčēąĖą╣ čüąŠąŠą▒čēąĄąĮąĖąĄ ą┐ąŠč鹊ą║ ą┐čĆąŠą┤ąŠą╗ąČą░ąĄčé čüą▓ąŠąĄ ąĮąŠčĆą╝ą░ą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ, ąĄčüą╗ąĖ ą┐čāą▒ą╗ąĖą║ą░čåąĖčÅ čüąŠąŠą▒čēąĄąĮąĖčÅ ąĮąĄ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ č鹊ą╝čā, čćč鹊 ą░ą║čéąĖą▓ąĖąĘąĖčĆčāąĄčéčüčÅ ą┐ąŠč鹊ą║ čü ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝, ą║ąŠč鹊čĆčŗą╣ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ čüąŠčüč鹊čÅąĮąĖąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ąĮą░ ąŠąČąĖą┤ą░ąĮąĖąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ (ąŠąČąĖą┤ą░ąĮąĖąĄ ą┐čĆąĖąĄą╝ą░ čüąŠąŠą▒čēąĄąĮąĖčÅ).
ą¤ąŠč鹊ą║ ą╝ąŠąČąĄčé ąĮą░čģąŠą┤ąĖčéčīčüčÅ ą▓ čüąŠčüč鹊čÅąĮąĖąĖ ąŠąČąĖą┤ą░ąĮąĖčÅ čüąŠąŠą▒čēąĄąĮąĖčÅ ąĮą░ ąŠą┤ąĮąŠą╝ ąĖą╗ąĖ ą▒ąŠą╗čīčłąĄą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąĄ ąĄą│ąŠ ą║ą░ąĮą░ą╗ąŠą▓. ąĢčüą╗ąĖ čüąŠąŠą▒čēąĄąĮąĖąĄ čāąČąĄ ą┐ąŠčüčéčāą┐ąĖą╗ąŠ ą▓ ąŠč湥čĆąĄą┤čī čüąŠąŠą▒čēąĄąĮąĖą╣ ą┤ą╗čÅ ą┐ąŠč鹊ą║ą░, č鹊 ą┐ąŠč鹊ą║ ą┐ąŠą╗čāčćąĖčé čüąŠąŠą▒čēąĄąĮąĖąĄ ąĖ ą┐čĆąŠą┤ąŠą╗ąČąĖčé čüą▓ąŠąĄ ąĮąŠčĆą╝ą░ą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ. ąĢčüą╗ąĖ ą▓ ąŠč湥čĆąĄą┤ąĖ ąĮąĄčé ą┐ąŠą┤čģąŠą┤čÅčēąĄą│ąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ, č鹊 ą┐ąŠč鹊ą║ ą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ, ą┐ąŠą║ą░ ą┤ą╗čÅ ą┐ąŠč鹊ą║ą░ ąĮąĄ ą┐ąŠčüčéčāą┐ąĖčé ą┐ąŠą┤čģąŠą┤čÅčēąĄąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ, ąĖą╗ąĖ ą┐ąŠą║ą░ ąĮąĄ ąĖčüč鹥č湥čé ąĘą░ą┤ą░ąĮąĮčŗą╣ čéą░ą╣ą╝ą░čāčé. ąĢčüą╗ąĖ ą┐ąŠą┤čģąŠą┤čÅčēąĄąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ ąĮąĄ ą▒čŗą╗ąŠ ąŠą┐čāą▒ą╗ąĖą║ąŠą▓ą░ąĮąŠ ą┤ą╗čÅ ą┐ąŠč鹊ą║ą░ ąĘą░ čāą║ą░ąĘą░ąĮąĮąŠąĄ ą▓čĆąĄą╝čÅ, č鹊 ą┐ąŠč鹊ą║ ą┐čĆąŠą┤ąŠą╗ąČąĖčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą▓ čüą▓ąŠąĄą╣ čäčāąĮą║čåąĖąĖ ąŠčłąĖą▒ą║ąĖ (error function). ąÆą╝ąĄčüč鹊 ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠą║ čéą░ą║ąČąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą╝ąŠą┤ąĄą╗čī čü ąŠą┐čĆąŠčüąŠą╝ ąŠč湥čĆąĄą┤ąĖ čüąŠąŠą▒čēąĄąĮąĖą╣ (polling model), ą║ąŠą│ą┤ą░ ą┐ąŠč鹊ą║ ąČą┤ąĄčé ą┐ąŠčüčéčāą┐ą╗ąĄąĮąĖčÅ čüąŠąŠą▒čēąĄąĮąĖčÅ. ąöą╗čÅ čéą░ą║ąŠą╣ ą╝ąŠą┤ąĄą╗ąĖ ą┐ąŠą╗čāč湥ąĮąĖčÅ čüąŠąŠą▒čēąĄąĮąĖą╣ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮ API-ą▓čŗąĘąŠą▓ MessageAvailable().
ąÆ ąŠčéą╗ąĖčćąĖąĄ ąŠčé čüąĄą╝ą░č乊čĆąŠą▓, ą║ą░ąČą┤ąŠąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ ą▓čüąĄą│ą┤ą░, ą▓ ą╗čÄą▒ąŠą╣ ą╝ąŠą╝ąĄąĮčé ą▓čĆąĄą╝ąĄąĮąĖ ąĖą╝ąĄąĄčé ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ą▓ą╗ą░ą┤ąĄą╗čīčåą░, ąĖ č鹊ą╗čīą║ąŠ ą▓ą╗ą░ą┤ąĄčÄčēąĖą╣ čüąŠąŠą▒čēąĄąĮąĖąĄą╝ ą┐ąŠč鹊ą║ ą╝ąŠąČąĄčé ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąŠą┐ąĄčĆą░čåąĖąĖ ąĮą░ą┤ čüąŠąŠą▒čēąĄąĮąĖąĄą╝. ąÜąŠą│ą┤ą░ ą┐ąŠč鹊ą║ čüąŠąĘą┤ą░ąĄčé čüąŠąŠą▒čēąĄąĮąĖąĄ, ąŠąĮ čÅą▓ą╗čÅąĄčéčüčÅ ąĄą│ąŠ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą╝, ą┐ąŠą║ą░ čüąŠąŠą▒čēąĄąĮąĖąĄ ąĮąĄ ą▒čāą┤ąĄčé ąŠą┐čāą▒ą╗ąĖą║ąŠą▓ą░ąĮąŠ ą┤ą╗čÅ ą┤čĆčāą│ąŠą│ąŠ ą┐ąŠč鹊ą║ą░. ą¤ąŠčüą╗ąĄ ą┐čāą▒ą╗ąĖą║ą░čåąĖąĖ ą▓ą╗ą░ą┤ąĄąĮąĖąĄ čüąŠąŠą▒čēąĄąĮąĖąĄą╝ ą┐ąĄčĆąĄčģąŠą┤ąĖčé ą║ ą┐čĆąĖąĮąĖą╝ą░čÄčēąĄą╝čā ą┐ąŠč鹊ą║čā, ą║ąŠą│ą┤ą░ ąŠąĮ ąŠąČąĖą┤ą░ąĄčé ą┐ąŠčüčéčāą┐ą╗ąĄąĮąĖčÅ čüąŠąŠą▒čēąĄąĮąĖčÅ ą┐ąŠ ąŠą┤ąĮąŠą╝čā ąĖąĘ ą║ą░ąĮą░ą╗ąŠą▓ čüąŠąŠą▒čēąĄąĮąĖčÅ. ą¤čĆąĖąĮąĖą╝ą░čÄčēąĖą╣ ą┐ąŠč鹊ą║ č鹥ą┐ąĄčĆčī čÅą▓ą╗čÅąĄčéčüčÅ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą╝ čüąŠąŠą▒čēąĄąĮąĖčÅ. ąÆ čŹč鹊čé ą╝ąŠą╝ąĄąĮčé ąĮą░ą┤ čüąŠąŠą▒čēąĄąĮąĖąĄą╝ ą╝ąŠąČąĮąŠ ą▓čŗą┐ąŠą╗ąĮąĖčéčī č鹊ą╗čīą║ąŠ čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ: ąŠąČąĖą┤ą░ąĮąĖąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ (ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ąĮą░ čüąŠąŠą▒čēąĄąĮąĖąĖ), čüąŠąĘą┤ą░ąĮąĖąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ, ąĖ ą┐ąŠą╗čāč湥ąĮąĖąĄ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ ą┤ą╗čÅ ą┐čĆąĖąĮąĖą╝ą░čÄčēąĄą│ąŠ ą┐ąŠč鹊ą║ą░.
ąĪąŠąŠą▒čēąĄąĮąĖąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī čāąĮąĖčćč鹊ąČąĄąĮąŠ č鹊ą╗čīą║ąŠ ąĄą│ąŠ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą╝; čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, č鹊ą╗čīą║ąŠ č鹊čé ą┐ąŠč鹊ą║, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĖąĮąĖą╝ą░ąĄčé čüąŠąŠą▒čēąĄąĮąĖąĄ, ąŠčéą▓ąĄčćą░ąĄčé ą╗ąĖą▒ąŠ ąĘą░ ąĄą│ąŠ čāą┤ą░ą╗ąĄąĮąĖąĄ, ą╗ąĖą▒ąŠ ąĘą░ ąĄą│ąŠ ą┐ąŠą▓č鹊čĆąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ. ąÆą╗ą░ą┤ąĄąĮąĖąĄ ą┐čĆąĖą▓čÅąĘą░ąĮąĮąŠą╣ ą║ čüąŠąŠą▒čēąĄąĮąĖčÄ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąŠą╣ čéą░ą║ąČąĄ ą┐čĆąĖąĮą░ą┤ą╗ąĄąČąĖčé ą┐ąŠč鹊ą║čā, ą║ąŠč鹊čĆčŗą╣ čÅą▓ą╗čÅąĄčéčüčÅ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą╝ čüąŠąŠą▒čēąĄąĮąĖčÅ. ąÆą╗ą░ą┤ąĄą╗ąĄčå čüąŠąŠą▒čēąĄąĮąĖčÅ ąŠčéą▓ąĄčćą░ąĄčé ąĘą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéčīčÄ, čüą▓čÅąĘą░ąĮąĮąŠą╣ čü čüąŠąŠą▒čēąĄąĮąĖąĄą╝.
ąÜą░ąČą┤čŗą╣ ą┐ąŠč鹊ą║ ąŠčéą▓ąĄčćą░ąĄčé ąĘą░ čāąĮąĖčćč鹊ąČąĄąĮąĖąĄ ą╗čÄą▒čŗčģ čüąŠąŠą▒čēąĄąĮąĖą╣, ą║ąŠč鹊čĆčŗą╝ąĖ ąŠąĮ ą▓ą╗ą░ą┤ąĄąĄčé, ą┤ąŠ č鹊ą│ąŠ ą╝ąŠą╝ąĄąĮčéą░, ą║ą░ą║ ą▒čāą┤ąĄčé čāąĮąĖčćč鹊ąČąĄąĮ čüą░ą╝ ą▓ą╗ą░ą┤ąĄčÄčēąĖą╣ čüąŠąŠą▒čēąĄąĮąĖčÅą╝ąĖ ą┐ąŠč鹊ą║. ąĢčüą╗ąĖ ąĮą░ ą║ą░ąĮą░ą╗ąĄ čüąŠąŠą▒čēąĄąĮąĖą╣ ąŠčüčéą░ą╗ąĖčüčī ąĮąĄąŠą▒čĆą░ą▒ąŠčéą░ąĮąĮčŗą╝ąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ, ą║ąŠą│ą┤ą░ ą▓ą╗ą░ą┤ąĄčÄčēąĖą╣ ąĖą╝ąĖ ą┐ąŠč鹊ą║ ą▒čŗą╗ čāąĮąĖčćč鹊ąČąĄąĮ, č鹊 čüąĖčüč鹥ą╝ą░ čāąĮąĖčćč鹊ąČą░ąĄčé ą▓ą╝ąĄčüč鹥 čü ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą╝ ąĄą│ąŠ ąĮą░čģąŠą┤čÅčēąĖąĄčüčÅ ą▓ ąŠč湥čĆąĄą┤ąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ. ą¤ąŠčüą║ąŠą╗čīą║čā čā čüąĖčüč鹥ą╝čŗ ąĮąĄčé ąĘąĮą░ąĮąĖą╣ ąŠ čüąŠą┤ąĄčƹȹĖą╝ąŠą╝ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ, čüąĖčüč鹥ą╝ą░ ąĮąĄ ąŠčüą▓ąŠą▒ąŠąČą┤ą░ąĄčé ąĮąĖą║ą░ą║ąĖčģ čĆąĄčüčāčĆčüąŠą▓, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąŠą╣.
ąÆąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąĖąĄ ą┐ąŠč鹊ą║ąŠą▓ čü čüąŠąŠą▒čēąĄąĮąĖčÅą╝ąĖ. ą¤ąŠč鹊ą║ąĖ ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓čāčÄčé čü čüąŠąŠą▒čēąĄąĮąĖčÅą╝ąĖ č湥čĆąĄąĘ čäčāąĮą║čåąĖąĖ message API. ąŁčéąĖ čäčāąĮą║čåąĖąĖ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ą┐ąŠč鹊ą║čā čüąŠąĘą┤ą░ą▓ą░čéčī čüąŠąŠą▒čēąĄąĮąĖąĄ, ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░čéčīčüčÅ ąĮą░ ąŠąČąĖą┤ą░ąĮąĖąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ, ą┐čāą▒ą╗ąĖą║ąŠą▓ą░čéčī čüąŠąŠą▒čēąĄąĮąĖąĄ, ą┐ąŠą╗čāčćą░čéčī ąĖ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čéčī ąĖąĮč乊čĆą╝ą░čåąĖčÄ, čüą▓čÅąĘą░ąĮąĮčāčÄ čü čüąŠąŠą▒čēąĄąĮąĖąĄą╝, ąĖ čāą┤ą░ą╗čÅčéčī čüąŠąŠą▒čēąĄąĮąĖąĄ.
ąæą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ąĮą░ ąŠąČąĖą┤ą░ąĮąĖąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ (Pending on a Message). ąØą░ čĆąĖčü. 3-10 ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąŠčåąĄčüčü ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ąĮą░ čüąŠąŠą▒čēąĄąĮąĖąĖ.
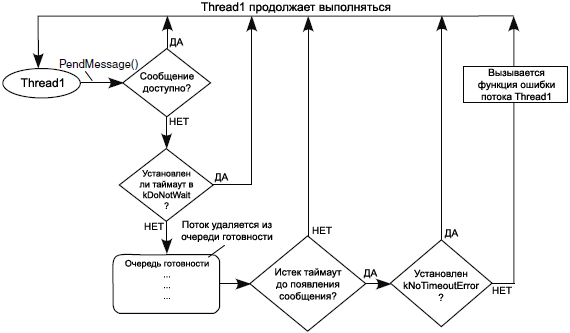
ąĀąĖčü. 3-10. ąæą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą┐ąŠč鹊ą║ą░ ąĮą░ čüąŠąŠą▒čēąĄąĮąĖąĖ.
ą¤ąŠč鹊ą║ąĖ ą╝ąŠą│čāčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░čéčīčüčÅ ąĮą░ čüąŠąŠą▒čēąĄąĮąĖąĖ ą▓čŗąĘąŠą▓ąŠą╝ PendMessage(), čü čāą║ą░ąĘą░ąĮąĖąĄą╝ ąŠą┤ąĮąŠą│ąŠ ąĖą╗ąĖ ą▒ąŠą╗čīčłąĄą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą║ą░ąĮą░ą╗ąŠą▓, ą┐ąŠ ą║ąŠč鹊čĆąŠą╝čā ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą┐čĆąĖąĮčÅč鹊 čüąŠąŠą▒čēąĄąĮąĖąĄ. ąÜąŠą│ą┤ą░ ą┐ąŠč鹊ą║ ą▓čŗąĘčŗą▓ą░ąĄčé PendMessage(), ąŠąĮ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ąŠą┤ąĮąŠ ąĖąĘ čüą╗ąĄą┤čāčÄčēąĖčģ ą┤ąĄą╣čüčéą▓ąĖą╣.
ŌĆó ą¤čĆąĖąĮąĖą╝ą░ąĄčé čüąŠąŠą▒čēąĄąĮąĖąĄ ąĖ ą┐čĆąŠą┤ąŠą╗ąČą░ąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ.
ŌĆó ąæą╗ąŠą║ąĖčĆčāąĄčéčüčÅ, ą┐ąŠą║ą░ ąĮąĄ čüčéą░ąĮąĄčé ą┤ąŠčüčéčāą┐ąĮčŗą╝ čüąŠąŠą▒čēąĄąĮąĖąĄ ąĮą░ čāą║ą░ąĘą░ąĮąĮąŠą╝ ą║ą░ąĮą░ą╗ąĄ (ą║ą░ąĮą░ą╗ą░ą╝), ąĖą╗ąĖ ąĮąĄ ąĖčüč鹥č湥čé čāą║ą░ąĘą░ąĮąĮčŗą╣ čéą░ą╣ą╝ą░čāčé.
ŌĆó ą¤čĆąŠą┤ąŠą╗ąČą░ąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ, ąĄčüą╗ąĖ čéą░ą╣ą╝ą░čāčé čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą▓ ąĘąĮą░č湥ąĮąĖąĄ kDoNotWait, ąĖ čüąŠąŠą▒čēąĄąĮąĖąĄ ąĮąĄą┤ąŠčüčéčāą┐ąĮąŠ.
ąĢčüą╗ąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ ą┐ąŠčüčéą░ą▓ą╗ąĄąĮčŗ ą▓ ąŠč湥čĆąĄą┤čī ąĮą░ čāą║ą░ąĘą░ąĮąĮčŗčģ ą║ą░ąĮą░ą╗ą░čģ ą┤ąŠ ąĖčüč鹥č湥ąĮąĖčÅ čéą░ą╣ą╝ą░čāčéą░, ąĖą╗ąĖ ąĄčüą╗ąĖ ąĖčüč鹥ą║ čéą░ą╣ą╝ą░čāčé ąĖ ą▓ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ čéą░ą╣ą╝ą░čāčéą░ čāą║ą░ąĘą░ąĮ ą▒ąĖčé kNoTimeoutError, č鹊 ą┐ąŠč鹊ą║ ą┐čĆąŠą┤ąŠą╗ąČąĖčé čüą▓ąŠąĄ ąĮąŠčĆą╝ą░ą╗čīąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ; ąĖąĮą░č湥 ą┐ąŠč鹊ą║ ą┐čĆąŠą┤ąŠą╗ąČąĖčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą▓ čüą▓ąŠąĄą╣ čäčāąĮą║čåąĖąĖ ąŠčłąĖą▒ą║ąĖ (thread error function).
ąÜą░ą║ č鹊ą╗čīą║ąŠ čüąŠąŠą▒čēąĄąĮąĖąĄ ą▒čŗą╗ąŠ ą┐čĆąĖąĮčÅč鹊, ąÆčŗ ą╝ąŠąČąĄč鹥 ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆąŠą▓ą░čéčī ąŠčéą┐čĆą░ą▓ąĖą▓čłąĖą╣ čüąŠąŠą▒čēąĄąĮąĖąĄ ą┐ąŠč鹊ą║, ąĖ ą║ą░ąĮą░ą╗, ąĮą░ ą║ąŠč鹊čĆčŗą╣ ą┐ąŠčüčéčāą┐ąĖą╗ąŠ čüąŠąŠą▒čēąĄąĮąĖąĄ, ą┐čāč鹥ą╝ ą▓čŗąĘąŠą▓ą░ GetMessageReceiveInfo(). ąÆčŗ čéą░ą║ąČąĄ ą╝ąŠąČąĄč鹥 ą┐ąŠą╗čāčćąĖčéčī ąĖąĮč乊čĆą╝ą░čåąĖčÄ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ ą▓čŗąĘąŠą▓ąŠą╝ GetMessagePayload(), ą║ąŠč鹊čĆčŗą╣ ą▓ąĄčĆąĮąĄčé čéąĖą┐ ąĖ ą┤ą╗ąĖąĮčā ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ ą▓ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ ąĄčæ ą╝ąĄčüč鹊ą┐ąŠą╗ąŠąČąĄąĮąĖčÄ. ąØąĄ ą▓čŗąĘčŗą▓ą░ą╣č鹥 PendMessage() ąĖąĘ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ ąĖą╗ąĖ ą║čĆąĖčéąĖč湥čüą║ąŠą│ąŠ čĆąĄą│ąĖąŠąĮą░, ąĄčüą╗ąĖ čüąŠąŠą▒čēąĄąĮąĖąĄ ąĮąĄą┤ąŠčüčéčāą┐ąĮąŠ, ą┐ąŠč鹊ą╝čā čćč鹊 č鹊ą│ą┤ą░ ą┐ąŠč鹊ą║ ąĘą░ą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ, ąĮąŠ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ ąŠčüčéą░ąĮąĄčéčüčÅ ąĮąĄą░ą║čéąĖą▓ąĮčŗą╝, čéą░ą║ čćč鹊 ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĮąĄ čüą╝ąŠąČąĄčé ą┐ąĄčĆąĄą║ą╗čÄčćąĖčéčīčüčÅ ąĮą░ ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║. ąŚą░ą┐čāčüą║ ąŠąČąĖą┤ą░ąĮąĖčÅ čü ąĮčāą╗ąĄą▓čŗą╝ čéą░ą╣ą╝ą░čāč鹊ą╝ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąŠąČąĖą┤ą░ąĮąĖčÄ čüąŠąŠą▒čēąĄąĮąĖčÅ ą▒ąĄąĘ čéą░ą╣ą╝ą░čāčéą░ (ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠ ą┤ąŠą╗ą│ąŠ).
ą¤čāą▒ą╗ąĖą║ą░čåąĖčÅ čüąŠąŠą▒čēąĄąĮąĖčÅ (Posting a Message). ą¤čāą▒ą╗ąĖą║ą░čåąĖčÅ čüąŠąŠą▒čēąĄąĮąĖčÅ ąŠčéą┐čĆą░ą▓ąĖčé ąĘą░ą┤ą░ąĮąĮąŠąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ ą▓ą╝ąĄčüč鹥 čüąŠ čüčüčŗą╗ą║ąŠą╣ ąĮą░ ąĄą│ąŠ ą┐ąŠą╗ąĄąĘąĮčāčÄ ąĮą░ą│čĆčāąĘą║čā čāą║ą░ąĘą░ąĮąĮąŠą╝čā ą┐ąŠč鹊ą║čā, ąĖ ą┐ąĄčĆąĄą┤ą░čüčé ą▓ą╗ą░ą┤ąĄąĮąĖąĄ čüąŠąŠą▒čēąĄąĮąĖąĄą╝ ą┐čĆąĖąĮąĖą╝ą░čÄčēąĄą╝čā ą┐ąŠč鹊ą║čā. ąĪąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ą┤ą░ąĮąŠ ą▓čŗąĘąŠą▓ąŠą╝ SetMessagePayload(), čćč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐ąŠč鹊ą║čā ą┐ąĄčĆąĄą┤ ąŠčéą┐čĆą░ą▓ą║ąŠą╣ čüąŠąŠą▒čēąĄąĮąĖčÅ čāą║ą░ąĘą░čéčī čéąĖą┐ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ, ą┤ą╗ąĖąĮčā ąĖ ąĄčæ ą╝ąĄčüč鹊 čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĖčÅ. ą¤ąŠč鹊ą║ ą╝ąŠąČąĄčé ąŠčéą┐čĆą░ą▓ąĖčéčī čüąŠąŠą▒čēąĄąĮąĖąĄ, ą║ąŠč鹊čĆčŗą╝ ąŠąĮ ą▓ ąĮą░čüč鹊čÅčēąĄąĄ ą▓čĆąĄą╝čÅ ą▓ą╗ą░ą┤ąĄąĄčé, ą┐čāč鹥ą╝ ą▓čŗąĘąŠą▓ą░ PostMessage(), čāą║ą░ąĘčŗą▓ą░čÅ ą┐čĆąĖ čŹč鹊ą╝ ą┐ąŠč鹊ą║-ą┐ąŠą╗čāčćą░č鹥ą╗čī ąĖ ą║ą░ąĮą░ą╗ ą┤ą╗čÅ čüąŠąŠą▒čēąĄąĮąĖčÅ, ą┐ąŠ ą║ąŠč鹊čĆąŠą╝čā čüąŠąŠą▒čēąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą┐ąĄčĆąĄą┤ą░ąĮąŠ. ąØą░ čĆąĖčü. 3-11 ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąŠčåąĄčüčü ą┐čāą▒ą╗ąĖą║ą░čåąĖąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ ąĖąĘ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ąŠą╝ čĆąĄą│ąĖąŠąĮą░ ą║ąŠą┤ą░.
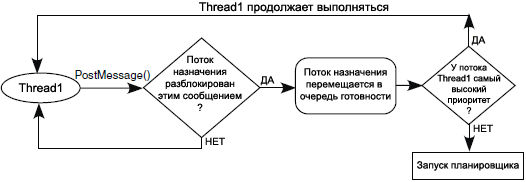
ąĀąĖčü. 3-11. ą¤čāą▒ą╗ąĖą║ą░čåąĖčÅ čüąŠąŠą▒čēąĄąĮąĖčÅ ąĖąĘ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ čĆąĄą│ąĖąŠąĮą░ ą║ąŠą┤ą░.
ąĢčüą╗ąĖ ą┐ąŠč鹊ą║ ą▓čŗąĘą▓ą░ą╗ PostMessage() ąĖąĘ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ čĆąĄą│ąĖąŠąĮą░, ąĖ ąŠąČąĖą┤ą░čÄčēąĖą╣ čŹč鹊 čüąŠąŠą▒čēąĄąĮąĖąĄ ą┐ąŠč鹊ą║ čü ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ ą▒čŗą╗ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮ ą▓ ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ, č鹊 ąŠą┐čāą▒ą╗ąĖą║ąŠą▓ą░ą▓čłąĖą╣ čüąŠąŠą▒čēąĄąĮąĖąĄ ą┐ąŠč鹊ą║ ą▒čāą┤ąĄčé ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮ (switched out), ąĖ ąĘą░ą┐čāčüčéąĖčéčüčÅ ą┐ąŠč鹊ą║, ą║ąŠč鹊čĆčŗą╣ ąĮą░čģąŠą┤ąĖčéčüčÅ ą┐ąĄčĆą▓čŗą╝ ą▓ ąŠč湥čĆąĄą┤ąĖ ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ.
ąØą░ čĆąĖčü. 3-12 ą┐ąŠą║ą░ąĘą░ąĮą░ ą┤čĆčāą│ą░čÅ čüąĖčéčāą░čåąĖčÅ - ą┐čāą▒ą╗ąĖą║ą░čåąĖčÅ čüąŠąŠą▒čēąĄąĮąĖčÅ ąĖąĘ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ąŠą╝ čĆąĄą│ąĖąŠąĮą░ ą║ąŠą┤ą░.
ąĀąĖčü. 3-12. ą¤čāą▒ą╗ąĖą║ą░čåąĖčÅ čüąŠąŠą▒čēąĄąĮąĖčÅ ąĖąĘ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ čĆąĄą│ąĖąŠąĮą░ ą║ąŠą┤ą░.
ąĢčüą╗ąĖ ą┐ąŠč鹊ą║ ą▓čŗąĘą▓ą░ą╗ PostMessage() ąĖąĘ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ čĆąĄą│ąĖąŠąĮą░, č鹊 ą┤ą░ąČąĄ ąĄčüą╗ąĖ ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąŠą┐čĆąĖąŠčĆąĖč鹥čéąĮčŗą╣ ą┐ąŠč鹊ą║ ą▒čŗą╗ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮ ą▓ ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ, č鹊 ą▓čŗąĘą▓ą░ą▓čłąĖą╣ PostMessage() ą┐ąŠč鹊ą║ ą▓čüąĄ čĆą░ą▓ąĮąŠ ą┐čĆąŠą┤ąŠą╗ąČąĖčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ (ą┤ąŠ ąŠą║ąŠąĮčćą░ąĮąĖčÅ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ čĆąĄą│ąĖąŠąĮą░ ą║ąŠą┤ą░).
ąØąĖąČąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮąŠ ąŠą┐ąĖčüą░ąĮąĖąĄ ąĮąĄčüą║ąŠą╗čīą║ąŠ čäčāąĮą║čåąĖą╣ API, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ą┤ą╗čÅ ąŠą▒ą╝ąĄąĮą░ čüąŠąŠą▒čēąĄąĮąĖčÅą╝ąĖ.
ą¤čĆąŠč鹊čéąĖą┐ C:
VDK_MessageID VDK_CreateMessage (int inPayloadType,
unsigned int inPayloadSize,
void *inPayloadAddr);
ą¤čĆąŠč鹊čéąĖą┐ C++:
VDK::MessageID VDK::CreateMessage (int inPayloadType,
unsigned int inPayloadSize,
void *inPayloadAddr);
ążčāąĮą║čåąĖčÅ čüąŠąĘą┤ą░ąĄčé ąĖ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāąĄčé ąĮąŠą▓čŗą╣ ąŠą▒čŖąĄą║čé ą┤ą╗čÅ čüąŠąŠą▒čēąĄąĮąĖčÅ. ąÆąŠąĘą▓čĆą░čēą░ąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ - ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ąĮąŠą▓ąŠą│ąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ (čüą╝. ąŠą┐ąĖčüą░ąĮąĖąĄ čéąĖą┐ą░ MessageID). ąŚąĮą░č湥ąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ ą┐ąĄčĆąĄą┤ą░ąĮčŗ ą▓ CreateMessage(), ą╝ąŠą│čāčé ą▒čŗčéčī ą┐čĆąŠčćąĖčéą░ąĮčŗ ą▓čŗąĘąŠą▓ąŠą╝ GetMessagePayload(), ąĖ ą╝ąŠą│čāčé ą▒čŗčéčī čüą▒čĆąŠčłąĄąĮčŗ ą▓čŗąĘąŠą▓ąŠą╝ FreeMessagePayload(). ą¤ąŠč鹊ą║, ą▓čŗąĘą▓ą░ą▓čłąĖą╣ čäčāąĮą║čåąĖčÄ CreateMessage(), čüčéą░ąĮąŠą▓ąĖčéčüčÅ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą╝ ąĮąŠą▓ąŠą│ąŠ čüąŠąĘą┤ą░ąĮąĮąŠą│ąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ, ąŠą┤ąĮą░ą║ąŠ ąŠąĮąŠ ą┐ąŠą║ą░ ąĮąĄ ąĮą░čģąŠą┤ąĖčéčüčÅ ąĮąĖ ą▓ ą║ą░ą║ąŠą╣ ąĖąĘ ąŠč湥čĆąĄą┤ąĄą╣ čüąŠąŠą▒čēąĄąĮąĖą╣ (ąĖąĮą┤ąĖą▓ąĖą┤čāą░ą╗čīąĮčŗąĄ ąŠč湥čĆąĄą┤ąĖ čüąŠąŠą▒čēąĄąĮąĖą╣ ąĄčüčéčī čā ą▓čüąĄčģ ą┐ąŠč鹊ą║ąŠą▓, ą┤ą╗čÅ ą║ąŠč鹊čĆčŗčģ čĆą░ąĘčĆąĄčłąĄąĮ čäčāąĮą║čåąĖąŠąĮą░ą╗ ą┐čĆąĖąĄą╝ą░ čüąŠąŠą▒čēąĄąĮąĖą╣).
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą▓ąŠąĘą╝ąŠąČąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ čüąŠąĘą┤ą░ąĮąĮčŗčģ čüąŠąŠą▒čēąĄąĮąĖą╣ ąĘą░ą▓ąĖčüąĖčé ąŠčé ąĮą░čüčéčĆąŠąĄą║ ą┐čĆąŠąĄą║čéą░ ąĮą░ ąĘą░ą║ą╗ą░ą┤ą║ąĄ Kernel, čüą╝. čĆą░ąĘą┤ąĄą╗ Messages, čüą▓ąŠą╣čüčéą▓ąŠ Maximum Messages.
ąŚą░ą┐čāčüą║ čäčāąĮą║čåąĖąĖ CreateMessage() ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ą░. ąÆčĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čäčāąĮą║čåąĖąĖ ą┐ąŠčüč鹊čÅąĮąĮąŠ.
ążčāąĮą║čåąĖčÅ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ ą▓ čĆąĄąČąĖą╝ąĄ ąŠčéą╗ą░ą┤ą║ąĖ (Full instrumentation): kErrorMallocBlock ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ąĮąĄčé čüą▓ąŠą▒ąŠą┤ąĮčŗčģ ą▒ą╗ąŠą║ąŠą▓ ą▓ čüąĖčüč鹥ą╝ąĮąŠą╝ ą┐čāą╗ąĄ ą┐ą░ą╝čÅčéąĖ, čćč鹊ą▒čŗ ąĖčģ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą▓čŗą┤ąĄą╗ąĖčéčī ą┤ą╗čÅ čüąŠąĘą┤ą░ąĮąĖčÅ čüąŠąŠą▒čēąĄąĮąĖą╣.
[ą¤ą░čĆą░ą╝ąĄčéčĆčŗ]
inPayloadType čŹč鹊 čéąĖą┐ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ, ąŠą┐čĆąĄą┤ąĄą╗čÅąĄą╝ąŠąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝ ąĘąĮą░č湥ąĮąĖąĄ (ąŠą▒čŗčćąĮąŠ čŹč鹊 ąĘąĮą░č湥ąĮąĖąĄ ąĖąĘ enum ąĖą╗ąĖ ą║ąŠąĮčüčéą░ąĮčéą░, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮą░čÅ č湥čĆąĄąĘ #define), ą║ąŠč鹊čĆąŠąĄ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī, čćč鹊ą▒čŗ ą┐ąĄčĆąĄą┤ą░čéčī ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠ čüąŠąŠą▒čēąĄąĮąĖąĖ ąĖą╗ąĖ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĄ (ąŠ ą┤ą░ąĮąĮčŗčģ čüąŠąŠą▒čēąĄąĮąĖčÅ), ą║ąŠą│ą┤ą░ čüąŠąŠą▒čēąĄąĮąĖąĄ ą┐ąĄčĆąĄą┤ą░ąĄčéčüčÅ ą┐čĆąĖąĮąĖą╝ą░čÄčēąĄą╝čā ą┐ąŠč鹊ą║čā. ąŁč鹊 ąĘąĮą░č湥ąĮąĖąĄ ąĮąĖą║ą░ą║ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ąĖ ąĮąĄ ąĖąĘą╝ąĄąĮčÅąĄčéčüčÅ čÅą┤čĆąŠą╝, ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣ ą┤ą╗čÅ čéąĖą┐ą░ ąĮą░ą│čĆčāąĘą║ąĖ, ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąĮčŗčģ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą▓ąĮčāčéčĆąĖ VDK. ą¤ąŠą╗ąŠąČąĖč鹥ą╗čīąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ ą┤ą╗čÅ čéąĖą┐ą░ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮčŗ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą║ąŠą┤ąŠą╝ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. ąĀąĄą║ąŠą╝ąĄąĮą┤čāąĄčéčüčÅ, čćč鹊ą▒čŗ ą░ą┤čĆąĄčü ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ ąĖ ąĄčæ čĆą░ąĘą╝ąĄčĆ ą▓čüąĄą│ą┤ą░ ąĖąĮč鹥čĆą┐čĆąĄčéąĖčĆąŠą▓ą░ą╗ąĖčüčī ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ąŠčéą┤ąĄą╗čīąĮąŠą│ąŠ čéąĖą┐ą░ čüąŠąŠą▒čēąĄąĮąĖčÅ.
inPayloadSize ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé čĆą░ąĘą╝ąĄčĆ ą▒čāč乥čĆą░ ą┤ą╗čÅ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ ą▓ čüą░ą╝čŗčģ ą╝ą░ą╗čŗčģ ą░ą┤čĆąĄčüčāąĄą╝čŗčģ ąĄą┤ąĖąĮąĖčåą░čģ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ ą┐čĆąŠčåąĄčüčüąŠčĆą░ (ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin čŹč鹊 ą▒čāą┤ąĄčé sizeof(char) == 1 ą▒ą░ą╣čé). ąÜąŠą│ą┤ą░ ą▓ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ inPayloadSize ą┐ąĄčĆąĄą┤ą░ąĮ 0, č鹊 čÅą┤čĆąŠ ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčé, čćč鹊 inPayloadAddr ąĮąĄ čāą║ą░ąĘą░č鹥ą╗čī, ąĖ ą▓ ąĮąĄą╝ ą╝ąŠąČąĄčé čüąŠą┤ąĄčƹȹ░čéčīčüčÅ ą╗čÄą▒ąŠąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ č鹊ą│ąŠ ąČąĄ čüą░ą╝ąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░, čćč鹊 ąĖ čāą║ą░ąĘą░č鹥ą╗čī.
inPayloadAddr čŹč鹊 čāą║ą░ąĘą░č鹥ą╗čī, ą║ąŠč鹊čĆčŗą╣ ąĘą░ą┤ą░ąĄčé ąĮą░čćą░ą╗čīąĮčŗą╣ ą░ą┤čĆąĄčü ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗąĄ ą┐ąĄčĆąĄą┤ą░čÄčéčüčÅ ą▓ čüąŠąŠą▒čēąĄąĮąĖąĖ.
[ąÆąŠąĘą▓čĆą░čēą░ąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ]
ąØąŠą▓čŗą╣ MessageID ą┐čĆąĖ čāčüą┐ąĄčłąĮąŠą╝ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĖ ąĖ ąĘąĮą░č湥ąĮąĖąĄ UINT_MAX, ąĄčüą╗ąĖ ą┐čĆąĖ čüąŠąĘą┤ą░ąĮąĖąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ ą┐čĆąŠąĖąĘąŠčłą╗ą░ ąŠčłąĖą▒ą║ą░.
ą¤čĆąŠč鹊čéąĖą┐ C:
void VDK_PostMessage (VDK_ThreadID inRecipient,
VDK_MessageID inMessageID,
VDK_MsgChannel inChannel);
ą¤čĆąŠč鹊čéąĖą┐ C++:
void VDK::PostMessage (VDK::ThreadID inRecipient,
VDK::MessageID inMessageID,
VDK::MsgChannel inChannel);
ąöąŠą▒ą░ą▓ą╗čÅąĄčé čüąŠąŠą▒čēąĄąĮąĖąĄ čü ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆąŠą╝ inMessageID ą║ ąŠč湥čĆąĄą┤ąĖ čüąŠąŠą▒čēąĄąĮąĖą╣ ą┐ąŠč鹊ą║ą░ čü ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆąŠą╝ inRecipient ąĮą░ ą║ą░ąĮą░ą╗ąĄ inChannel. ążčāąĮą║čåąĖčÅ PostMessage() čÅą▓ą╗čÅąĄčéčüčÅ ąĮąĄ ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĄą╣ - ąŠąĮą░ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ ą▓ąŠąĘą▓čĆą░čéąĖčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą▓ ą▓čŗąĘčŗą▓ą░čÄčēąĖą╣ ą║ąŠą┤ ą┐ąŠč鹊ą║ą░ ą▒ąĄąĘ ąŠąČąĖą┤ą░ąĮąĖčÅ, ą┐ąŠą║ą░ ą┐ąŠą╗čāčćą░č鹥ą╗čī ąĘą░ą┐čāčüčéąĖčéčīčüčÅ ąĖą╗ąĖ ą┐ąŠą┤čéą▓ąĄčĆą┤ąĖčé ąĮąŠą▓ąŠąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ ą▓ ąŠč湥čĆąĄą┤ąĖ. ąĪąŠąŠą▒čēąĄąĮąĖąĄ čüčćąĖčéą░ąĄčéčüčÅ ą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗą╝, ą║ąŠą│ą┤ą░ čäčāąĮą║čåąĖčÅ PostMessage() ą▓ąĄčĆąĮąĄčé čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ. ąóąŠą╗čīą║ąŠ č鹊čé ą┐ąŠč鹊ą║, ą║ąŠč鹊čĆčŗą╣ čÅą▓ą╗čÅąĄčéčüčÅ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą╝ čüąŠąŠą▒čēąĄąĮąĖčÅ inMessageID, ą╝ąŠąČąĄčé ąŠčéą┐čĆą░ą▓ąĖčéčī ąĄą│ąŠ (čé. ąĄ. ą▓čŗąĘą▓ą░čéčī ą┤ą╗čÅ ąĮąĄą│ąŠ čäčāąĮą║čåąĖčÄ PostMessage).
ąÆ ą╝ąŠą╝ąĄąĮčé ą┤ąŠčüčéą░ą▓ą║ąĖ ą▓ą╗ą░ą┤ąĄąĮąĖąĄ čüąŠąŠą▒čēąĄąĮąĖąĄą╝ ąĖ čüą▓čÅąĘą░ąĮąĮą░čÅ čü ąĮąĖą╝ ą┐ąŠą╗ąĄąĘąĮą░čÅ ąĮą░ą│čĆčāąĘą║ą░ (ą┤ą░ąĮąĮčŗąĄ) ą┐ąĄčĆąĄčģąŠą┤čÅčé ąŠčé ą┐ąŠč鹊ą║ą░-ąŠčéą┐čĆą░ą▓ąĖč鹥ą╗čÅ čüąŠąŠą▒čēąĄąĮąĖčÅ ą║ ą┐ąŠč鹊ą║čā-ą┐ąŠą╗čāčćą░č鹥ą╗čÄ čüąŠąŠą▒čēąĄąĮąĖčÅ. ąæčāą┤čāčćąĖ ą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗą╝, ą▓čüąĄ čüčüčŗą╗ą║ąĖ ąĮą░ ą┐ąŠą╗ąĄąĘąĮčāčÄ ąĮą░ą│čĆčāąĘą║čā, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠąČąĄčé čģčĆą░ąĮąĖčéčī ąŠčéą┐čĆą░ą▓ą╗čÅčÄčēąĖą╣ ą┐ąŠč鹊ą║, čüčéą░ąĮąŠą▓čÅčéčüčÅ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝ąĖ. ą¤čĆąĖą▓ąĖą╗ąĄą│ąĖąĖ ąĮą░ čćč鹥ąĮąĖąĄ ąĖ ąĘą░ą┐ąĖčüčī ą┐ą░ą╝čÅčéąĖ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ, ąĖ ąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠčüčéčī ąĘą░ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ čŹč鹊ą╣ ą┐ą░ą╝čÅčéąĖ č鹥ą┐ąĄčĆčī ą┐čĆąĖąĮą░ą┤ą╗ąĄąČą░čé ą┐ąŠč鹊ą║čā-ą┐ąŠą╗čāčćą░č鹥ą╗čÄ ą▓ą╝ąĄčüč鹥 čü ą┐čĆą░ą▓ą░ą╝ąĖ ą▓ą╗ą░ą┤ąĄąĮąĖčÅ ąĮą░ čüąŠąŠą▒čēąĄąĮąĖąĄ.
ążčāąĮą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ą░, ąĖ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÄ ą║ąŠąĮč鹥ą║čüčéą░. ąÆčĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čäčāąĮą║čåąĖąĖ ąĖąĘąĮą░čćą░ą╗čīąĮąŠ ąĮąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąŠ.
[ą¤ą░čĆą░ą╝ąĄčéčĆčŗ]
inRecipient ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ą┐ąŠč鹊ą║ą░-ą┐ąŠą╗čāčćą░č鹥ą╗čÅ čüąŠąŠą▒čēąĄąĮąĖčÅ (ąĘąĮą░č湥ąĮąĖąĄ čéąĖą┐ą░ ThreadID).
inMessageID ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ čüąŠąŠą▒čēąĄąĮąĖčÅ (ąĘąĮą░č湥ąĮąĖąĄ čéąĖą┐ą░ MessageID), ą║ąŠč鹊čĆąŠąĄ ą▒čāą┤ąĄčé ąŠčéą┐čĆą░ą▓ą╗ąĄąĮąŠ. ąĪąŠąŠą▒čēąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮąŠ čüąŠąĘą┤ą░ąĮąŠ, ą┐čĆąĄąČą┤ąĄ č湥ą╝ ąŠąĮąŠ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠčéą┐čĆą░ą▓ą╗ąĄąĮąŠ. ąŚąĮą░č湥ąĮąĖąĄ čŹč鹊ą│ąŠ ą┐ą░čĆą░ą╝ąĄčéčĆą░ ą▒čŗą╗ąŠ čĆą░ąĮąĄąĄ ą┐ąŠą╗čāč湥ąĮąŠ ą┐čĆąĖ ą▓čŗąĘąŠą▓ąĄ čäčāąĮą║čåąĖąĖ CreateMessage().
inChannel čŹč鹊 čüč鹥ą║ FIFO ą▓ ąŠč湥čĆąĄą┤ąĖ čüąŠąŠą▒čēąĄąĮąĖą╣, ą║čāą┤ą░ ą▒čŗą╗ąŠ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąŠ čüąŠąŠą▒čēąĄąĮąĖąĄ. ąŚąĮą░č湥ąĮąĖąĄ inChannel ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ kMsgChannel1 .. kMsgChannel15 (čüą╝. čéąĖą┐ MsgChannel).
[ą¤ąŠą┤ą┤ąĄčƹȹ║ą░ Full instrumentation ąĖ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąŠčłąĖą▒ąŠą║]
ąŚą┤ąĄčüčī ą┐čĆąĖą▓ąĄą┤ąĄąĮą░ čĆą░čüčłąĖčäčĆąŠą▓ą║ą░ ą▓ąŠąĘą╝ąŠąČąĮčŗčģ ąŠčłąĖą▒ąŠą║ čÅą┤čĆą░ (ąŠč鹊ą▒čĆą░ąČą░čÄčéčüčÅ ą▓ ąŠą║ąĮąĄ View -> VDK Windows -> Status), ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī čĆąĄąĘčāą╗čīčéą░č鹊ą╝ ą▓čŗąĘąŠą▓ą░ čäčāąĮą║čåąĖąĖ.
kInvalidMessageChannel ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 inChannel ąĮąĄ čÅą▓ą╗čÅąĄčéčüčÅ ąĘąĮą░č湥ąĮąĖąĄą╝ ą║ą░ąĮą░ą╗ą░ (čüą╝. MsgChannel).
kUnknownThread ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ą▓ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ inRecipient ą┐ąĄčĆąĄą┤ą░ąĮ ąĮąĄą┤ąŠą┐čāčüčéąĖą╝čŗą╣ ThreadID.
kInvalidMessageID ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ą▓ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ inMessageID ą┐ąĄčĆąĄą┤ą░ąĮ ąĮąĄą┤ąŠą┐čāčüčéąĖą╝čŗą╣ MessageID.
kInvalidMessageRecipient ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 inRecipient ąĮąĄ ąĖą╝ąĄąĄčé ąŠč湥čĆąĄą┤ąĖ čüąŠąŠą▒čēąĄąĮąĖą╣, ą┐ąŠč鹊ą╝čā čćč鹊 ą┤ą╗čÅ ąĮąĄą│ąŠ ąĮąĄ čĆą░ąĘčĆąĄčłąĄąĮ čäčāąĮą║čåąĖąŠąĮą░ą╗ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ čüąŠąŠą▒čēąĄąĮąĖą╣. ą¤ąŠą┤ą┤ąĄčƹȹ║ą░ čüąŠąŠą▒čēąĄąĮąĖą╣ ą▓ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ čüą▓ąŠą╣čüčéą▓ą░čģ čéąĖą┐ą░ ą┐ąŠč鹊ą║ą░, ąĘą░ą║ą╗ą░ą┤ą║ą░ Kernel -> Threads -> Thread Types -> čĆą░ąĘą▓ąĄčĆąĮąĖč鹥 čüą▓ąŠą╣čüčéą▓ą░ ąĮčāąČąĮąŠą│ąŠ čéąĖą┐ą░ ą┐ąŠč鹊ą║ą░ -> čüą▓ąŠą╣čüčéą▓ąŠ Message Enabled ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ ą▓ true.
kInvalidMessageOwner ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ą┐ąŠč鹊ą║ ą┐ąŠą┐čŗčéą░ą╗čüčÅ ąŠčéą┐čĆą░ą▓ąĖčéčī čüąŠąŠą▒čēąĄąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ąĄą╝čā ąĮąĄ ą┐čĆąĖąĮą░ą┤ą╗ąĄąČąĖčé. ąŚąĮą░č湥ąĮąĖąĄ ąŠčłąĖą▒ą║ąĖ (Value) ą┐ąŠą║ą░ąČąĄčé ThreadID ą▓ą╗ą░ą┤ąĄą╗čīčåą░ čüąŠąŠą▒čēąĄąĮąĖčÅ.
kMessageInQueue ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čüąŠąŠą▒čēąĄąĮąĖąĄ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąŠ ą┤ą╗čÅ ą┐ąŠč鹊ą║ą░ (ą▓ čŹč鹊čé ą╝ąŠą╝ąĄąĮčé ThreadID ąĮąĄ ąĖąĘą▓ąĄčüč鹥ąĮ), ąĖ čüąŠąŠą▒čēąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čāą┤ą░ą╗ąĄąĮąŠ ąĖąĘ ąŠč湥čĆąĄą┤ąĖ čüąŠąŠą▒čēąĄąĮąĖą╣ ą▓čŗąĘąŠą▓ąŠą╝ PendMessage().
kInvalidTargetDSP ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ą┐ąŠą╗čāčćą░č鹥ą╗čī čüąŠąŠą▒čēąĄąĮąĖčÅ čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ čÅą┤čĆąĄ, ą║ąŠč鹊čĆąŠąĄ ąĮąĄ ą▒čŗą╗ąŠ ą┤ąĄą║ą╗ą░čĆąĖčĆąŠą▓ą░ąĮąŠ ą▓ ąĮą░čüčéčĆąŠą╣ą║ą░čģ VDK-ą┐čĆąŠąĄą║čéą░ (ąĮą░ ąĘą░ą║ą╗ą░ą┤ą║ąĄ Kernel čüą▓ąŠą╣čüčéą▓ VDK-ą┐čĆąŠąĄą║čéą░). ąŁčéą░ ąŠčłąĖą▒ą║ą░ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčéčüčÅ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą╝ąĮąŠą│ąŠą┐čĆąŠčåąĄčüčüąŠčĆąĮčŗčģ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖą╣.
ąæąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąŠčłąĖą▒ąŠą║ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ.
ą¤čĆąŠč鹊čéąĖą┐ C:
VDK_MessageID VDK_PendMessage (unsigned int inMessageChannelMask,
VDK_Ticks inTimeout);
ą¤čĆąŠč鹊čéąĖą┐ C++:
VDK::MessageID VDK::PendMessage (unsigned int inMessageChannelMask,
VDK::Ticks inTimeout);
ąŚą░ą┐čĆą░čłąĖą▓ą░ąĄčé ą┐ąŠą╗čāč湥ąĮąĖąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ ąĖąĘ ąŠč湥čĆąĄą┤ąĖ čüąŠąŠą▒čēąĄąĮąĖą╣ ą┐ąŠč鹊ą║ą░. ąŚą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ čüą╗čāčćą░ąĄą▓, ą║ąŠą│ą┤ą░ čéą░ą╣ą╝ą░čāčé ąĘą░ą┤ą░ąĮ ą▓ kDoNotWait (VDK::kDoNotWait ąĮą░ čÅąĘčŗą║ąĄ C++ ąĖ VDK_kDoNotWait ąĮą░ čÅąĘčŗą║ąĄ C), čäčāąĮą║čåąĖčÅ PendMessage() čÅą▓ą╗čÅąĄčéčüčÅ ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĄą╣ ŌĆö ą║ąŠą│ą┤ą░ čāą║ą░ąĘą░ąĮąĮčŗąĄ čāčüą╗ąŠą▓ąĖčÅ ą┤ą╗čÅ ą┤ąŠą┐čāčüčéąĖą╝ąŠą│ąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ ąĮąĄ ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ, ą┐ąŠč鹊ą║, ą║ąŠč鹊čĆčŗą╣ ą▓čŗąĘą▓ą░ą╗ PendMessage(), ą▒čāą┤ąĄčé ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮ. ąĢčüą╗ąĖ čéą░ą╣ą╝ą░čāčé čāą║ą░ąĘą░ąĮ kDoNotWait, ąĖ čāčüą╗ąŠą▓ąĖąĄ ą┤ą╗čÅ ą┤ąŠą┐čāčüčéąĖą╝ąŠą│ąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ ąĮąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ, č鹊 čäčāąĮą║čåąĖčÅ ą▓ąĄčĆąĮąĄčé PendMessage() ąĘąĮą░č湥ąĮąĖąĄ UINT_MAX ąĖ ą┐ąŠč鹊ą║ ą┐čĆąŠą┤ąŠą╗ąČąĖčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ.
ą£ą░čüą║ą░ ą║ą░ąĮą░ą╗ą░ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąÆą░ą╝ čāą║ą░ąĘą░čéčī, ą║ą░ą║ąĖąĄ ą║ą░ąĮą░ą╗čŗ (ąŠčé kMsgChannel1 ą┤ąŠ kMsgChannel15) ą▒čāą┤čāčé ą┐čĆąŠą▓ąĄčĆąĄąĮčŗ ąĮą░ ą┐čĆąĖčģąŠą┤čÅčēąĖąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ. API-čäčāąĮą║čåąĖčÅ MessageAvailable() ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąĮą░ą╗ąĖčćąĖčÅ ą┤ąŠą┐čāčüčéąĖą╝čŗčģ čüąŠąŠą▒čēąĄąĮąĖą╣ ą▓ą╝ąĄčüč鹊 ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĄą│ąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ čäčāąĮą║čåąĖąĖ PendMessage().
ąÆ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ ą╝ą░čüą║ąĄ ą║ą░ąĮą░ą╗ąŠą▓ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĖčüąŠąĄą┤ąĖąĮąĄąĮ čäą╗ą░ą│ VDK::kMsgWaitForAll (ąŠą┐ąĄčĆą░čåąĖąĄą╣ OR), čćč鹊ą▒čŗ čāą║ą░ąĘą░čéčī, čćč鹊 ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝ ąŠą┤ąĮąŠ čüąŠąŠą▒čēąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮąŠ ą┐čĆąĖčüčāčéčüčéą▓ąŠą▓ą░čéčī ąĮą░ ą║ą░ąČą┤ąŠą╝ ąĖąĘ ą║ą░ąĮą░ą╗ąŠą▓, ąĘą░ą┤ą░ąĮąĮčŗčģ ą▓ ą╝ą░čüą║ąĄ. ąĪąŠąŠą▒čēąĄąĮąĖčÅ ą▒čāą┤čāčé ą▓čŗą▒čĆą░ąĮčŗ ąĖąĘ ąŠč湥čĆąĄą┤ąĖ ąĮą░čćąĖąĮą░čÅ čü ą║ą░ąĮą░ą╗ąŠą▓ čü čüą░ą╝čŗą╝ąĖ ą╝ą░ą╗ąĄąĮčīą║ąĖą╝ąĖ ąĮąŠą╝ąĄčĆą░ą╝ąĖ (čüąĮą░čćą░ą╗ą░ kMsgChannel1, ą┐ąŠč鹊ą╝ kMsgChannel2, ...). ąÜą░ą║ č鹊ą╗čīą║ąŠ MessageID ą▒čŗą╗ ą▓ąŠąĘą▓čĆą░čēąĄąĮ čäčāąĮą║čåąĖąĄą╣ PendMessage(), čüąŠąŠą▒čēąĄąĮąĖąĄ ą▒ąŠą╗čīčłąĄ ąĮąĄ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ąŠč湥čĆąĄą┤ąĖ ąĖ ą┐čĆąĖąĮą░ą┤ą╗ąĄąČąĖčé ą┐ąŠč鹊ą║čā, ą║ąŠč鹊čĆčŗą╣ ą▓čŗąĘą▓ą░ą╗ čäčāąĮą║čåąĖčÄ PendMessage(). ąĢčüą╗ąĖ ą┐ąŠč鹊ą║ ąĮąĄ ą▓ąŠąĘąŠą▒ąĮąŠą▓ąĖą╗ čĆą░ą▒ąŠčéčā ąĘą░ inTimeout čéąĖą║ąŠą▓, č鹊 čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą▒čāą┤ąĄčé ąŠą┐čÅčéčī ą┐ąĄčĆąĄą┤ą░ąĮąŠ ą┐ąŠč鹊ą║čā ą▓ ąĄą│ąŠ čäčāąĮą║čåąĖąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąŠčłąĖą▒ą║ąĖ, ąĖ ą┐ąŠč鹊ą║ čüčéą░ąĮąĄčé ą┤ąŠčüčéčāą┐ąĄąĮ ą┤ą╗čÅ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ ą║ąŠąĮč鹥ą║čüčéą░. ąŁč鹊 ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖąĘą╝ąĄąĮąĄąĮąŠ ą┐čāč鹥ą╝ ąĮą░ą╗ąŠąČąĄąĮąĖčÅ ąŠą┐ąĄčĆą░čåąĖąĄą╣ OR ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ čéą░ą╣ą╝ą░čāčéą░ ą║ąŠąĮčüčéą░ąĮčéčŗ VDK_kNoTimeoutError ąĮą░ čÅąĘčŗą║ąĄ C ąĖą╗ąĖ VDK::kNoTimeoutError ąĮą░ čÅąĘčŗą║ąĄ C++. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą┐čĆąĖ ą┤ąŠčüčéąĖąČąĄąĮąĖąĖ čéą░ą╣ą╝ą░čāčéą░ ąĮąĄ ą▒čāą┤ąĄčé ą┐ąĄčĆąĄą┤ą░ąĮąŠ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą▓ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ąŠčłąĖą▒ą║ąĖ, ąĖ API ą┐čĆąŠčüč鹊 ą▓ąĄčĆąĮąĄčé ą┐ąŠč鹊ą║čā čüąŠčüč鹊čÅąĮąĖąĄ, ą┤ąŠčüčéčāą┐ąĮąŠąĄ ą┤ą╗čÅ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ ą║ąŠąĮč鹥ą║čüčéą░. ąĢčüą╗ąĖ ąĘąĮą░č湥ąĮąĖąĄ inTimeout ą┐ąĄčĆąĄą┤ą░ąĮąŠ ą║ą░ą║ 0, č鹊 ą┐ąŠč鹊ą║ ą╝ąŠąČąĄčé ąČą┤ą░čéčī ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠ.
ąÆąŠąĘą▓čĆą░čēą░ąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ - ą▓ čüą╗čāčćą░ąĄ čāčüą┐ąĄčģą░ čŹč鹊 ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ čüąŠąŠą▒čēąĄąĮąĖčÅ, ą║ąŠč鹊čĆąŠąĄ ą┐ąŠč鹊ą║ ąŠąČąĖą┤ą░ą╗; ąĖąĮą░č湥 ą▒čāą┤ąĄčé ą▓ąŠąĘą▓čĆą░čēąĄąĮąŠ ąĘąĮą░č湥ąĮąĖąĄ UINT_MAX.
ążčāąĮą║čåąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ ąĖ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÄ ą║ąŠąĮč鹥ą║čüčéą░. ąÆčĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čäčāąĮą║čåąĖąĖ ą┐ąŠčüč鹊čÅąĮąĮąŠ, ąĄčüą╗ąĖ ąĮąĄ ąĮčāąČąĮą░ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░.
[ą¤ą░čĆą░ą╝ąĄčéčĆčŗ]
inMessageChannelMask ą╝ą░čüą║ą░ ą║ą░ąĮą░ą╗ąŠą▓, ą║ąŠč鹊čĆą░čÅ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ą║ą░ąĮą░ą╗čŗ ą┐čĆąĖąĄą╝ą░ čüąŠąŠą▒čēąĄąĮąĖčÅ. ą£ą░čüą║ą░ ąĄą┤ąĖąĮąĖčå ą▓ ą▒ąĖčéą░čģ čāą║ą░ąĘčŗą▓ą░ąĄčé čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖąĄ ą║ą░ąĮą░ą╗čŗ ą┐čĆąĖąĄą╝ą░. ą×čćąĖčēąĄąĮąĮčŗą╣ ą▒ąĖčé ą▓ ą╝ą░čüą║ąĄ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ąĖą│ąĮąŠčĆąĖčĆčāąĄą╝ąŠą╝čā ą║ą░ąĮą░ą╗čā. ą¤ą░čĆą░ą╝ąĄčéčĆ ąĮąĄ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čĆą░ą▓ąĄąĮ 0.
ąĢčüą╗ąĖ ą▓ ą╝ą░čüą║ąĄ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ kMsgWaitForAll, č鹊 ąŠą┐ąĄčĆą░čåąĖčÅ ąŠąČąĖą┤ą░ąĮąĖčÅ čĆą░ą▒ąŠčéą░ąĄčé ą┐ąŠ AND-ą╗ąŠą│ąĖą║ąĄ, ą░ ąĮąĄ ą┐ąŠ OR-ą╗ąŠą│ąĖą│ąĄ. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ čäčāąĮą║čåąĖčÅ ą▒čāą┤ąĄčé ąČą┤ą░čéčī č鹊ą╗čīą║ąŠ ąŠą┤ąĮąŠ ą╗čÄą▒ąŠąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ą┐čĆąĖą┤ąĄčé ą┐ąŠ ą╗čÄą▒ąŠą╝čā ąĖąĘ ąĘą░ą┤ą░ąĮąĮčŗčģ ą║ą░ąĮą░ą╗ąŠą▓, ą┐ąŠ ą┐ąŠą╗čāč湥ąĮąĖąĖ ą║ąŠč鹊čĆąŠą│ąŠ ą┐ąŠč鹊ą║ ą▒čāą┤ąĄčé čĆą░ąĘą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮ. ążą╗ą░ą│ kMsgWaitForAll čéčĆąĄą▒čāąĄčé, čćč鹊ą▒čŗ ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝ ąŠą┤ąĮąŠ čüąŠąŠą▒čēąĄąĮąĖąĄ ą▒čŗą╗ąŠ ą┐ąŠčüčéą░ą▓ą╗ąĄąĮąŠ ą▓ ąŠč湥čĆąĄą┤čī ąĮą░ ą║ą░ąČą┤ąŠą╝ ąĖąĘ čāą║ą░ąĘą░ąĮąĮčŗčģ ą║ą░ąĮą░ą╗ąŠą▓ ą┐čĆąĖąĄą╝ą░, čćč鹊ą▒čŗ ą┐ąŠč鹊ą║, ą▓čŗąĘą▓ą░ą▓čłąĖą╣ čäčāąĮą║čåąĖčÄ, ą▒čŗą╗ čĆą░ąĘą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮ.
inTimeout ąĘąĮą░č湥ąĮąĖąĄ, ą╝ąĄąĮčīčłąĄąĄ č湥ą╝ INT_MAX, ą║ąŠč鹊čĆąŠąĄ ąĘą░ą┤ą░ąĄčé ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ą▓čĆąĄą╝čÅ ąŠąČąĖą┤ą░ąĮąĖčÅ ą▓ čéąĖą║ą░čģ, ą▓ č鹥č湥ąĮąĖąĄ ą║ąŠč鹊čĆąŠą│ąŠ ą┐ąŠč鹊ą║ ąČą┤ąĄčé ą┐čĆąĖąĄą╝ą░ čéčĆąĄą▒čāąĄą╝ąŠą│ąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ (ąĖą╗ąĖ čüąŠąŠą▒čēąĄąĮąĖą╣). ąØą░ čŹč鹊 ąĘąĮą░č湥ąĮąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĄą╣ OR ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮą░ą╗ąŠąČąĄąĮąŠ ąĘąĮą░č湥ąĮąĖąĄ kNoTimeoutError ą┤ą╗čÅ č鹊ą│ąŠ, čćč鹊ą▒čŗ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ąĮąĄ ą▒čŗą╗ąŠ ą┐ąĄčĆąĄą┤ą░ąĮąŠ ą▓ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ąŠčłąĖą▒ąŠą║ ą┐ąŠč鹊ą║ą░ ą┐čĆąĖ ą▓ąŠąĘąĮąĖą║ąĮąŠą▓ąĄąĮąĖąĖ čéą░ą╣ą╝ą░čāčéą░. ąŚąĮą░č湥ąĮąĖąĄ kDoNotWait ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 API ąĮąĄ ą┤ąŠą╗ąČąĮąŠ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░čéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐ąŠč鹊ą║ą░, ąĄčüą╗ąĖ ąĮąĄčé ą┤ąŠčüčéčāą┐ąĮąŠą│ąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ.
[ą×ą▒čĆą░ą▒ąŠčéą║ą░ ąŠčłąĖą▒ąŠą║]
ąŚą┤ąĄčüčī ą┐čĆąĖą▓ąĄą┤ąĄąĮą░ čĆą░čüčłąĖčäčĆąŠą▓ą║ą░ ą▓ąŠąĘą╝ąŠąČąĮčŗčģ ąŠčłąĖą▒ąŠą║ čÅą┤čĆą░ (ąŠč鹊ą▒čĆą░ąČą░čÄčéčüčÅ ą▓ ąŠą║ąĮąĄ View -> VDK Windows -> Status), ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī čĆąĄąĘčāą╗čīčéą░č鹊ą╝ ą▓čŗąĘąŠą▓ą░ čäčāąĮą║čåąĖąĖ. ą¤ąŠą┤ą┤ąĄčƹȹ║ą░ Full instrumentation:
kDbgPossibleBlockInRegion ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 PendMessage() ą▒čŗą╗ą░ ą▓čŗąĘą▓ą░ąĮą░ ą▓ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą╝ čĆąĄą│ąĖąŠąĮąĄ, čćč鹊 ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ą║ąŠąĮčäą╗ąĖą║čéčā ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąĖčÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐ąŠč鹊ą║ąŠą▓ (ą│ą╗čāčģą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ čüąĖčüč鹥ą╝čŗ).
kInvalidMessageChannel ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 inMessageChannelMask ąĮąĄ ąĘą░ą┤ą░ąĄčé ą║ąŠčĆčĆąĄą║čéąĮčāčÄ ą│čĆčāą┐ą┐čā ą║ą░ąĮą░ą╗ąŠą▓.
kMessageTimeout ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ąĘąĮą░č湥ąĮąĖąĄ čéą░ą╣ą╝ą░čāčéą░ ąĖčüč鹥ą║ą╗ąŠ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ą┐ąŠč鹊ą║ čāą┤ą░ą╗ąĖą╗ čŹč鹊 čüąŠąŠą▒čēąĄąĮąĖąĄ ąĖąĘ čüą▓ąŠąĄą╣ ąŠč湥čĆąĄą┤ąĖ čüąŠąŠą▒čēąĄąĮąĖą╣. ąŁčéą░ ąŠčłąĖą▒ą║ą░ ąĮąĄ ą▒čāą┤ąĄčé ąŠą▒čĆą░ą▒ąŠčéą░ąĮą░ (čé. ąĄ. ąĮąĄ ą▒čāą┤ąĄčé čüčćąĖčéą░čéčīčüčÅ ąŠčłąĖą▒ą║ąŠą╣ ąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ąĮąĄ ą▒čāą┤ąĄčé ą┐ąĄčĆąĄą┤ą░ąĮąŠ ą▓ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ąŠčłąĖą▒ą║ąĖ ą┐ąŠč鹊ą║ą░), ąĄčüą╗ąĖ ąĮą░ čéą░ą╣ą╝ą░čāčé ąŠą┐ąĄčĆą░čåąĖąĄą╣ OR ą▒čŗą╗ą░ ąĮą░ą╗ąŠąČąĄąĮą░ ą║ąŠąĮčüčéą░ąĮčéą░ kNoTimeoutError.
kBlockInInvalidRegion ą┐ąŠą║ą░ąĘčŗą░ą▓ąĄčé, čćč鹊 PendMessage() čüą┤ąĄą╗ą░ą╗ą░ ą┐ąŠą┐čŗčéą║čā ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ąĮą░ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą╝ čĆąĄą│ąĖąŠąĮąĄ ą║ąŠą┤ą░, čćč鹊 čüąŠąĘą┤ą░ąĄčé ą║ąŠąĮčäą╗ąĖą║čé ą┤ą╗čÅ ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąĖčÅ ąĘą░ą┐čāčüą║ą░ ąĘą░ą┤ą░čć (ą│ą╗čāčģą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ čüąĖčüč鹥ą╝čŗ).
kInvalidTimeout ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 inTimeout ąĖą╗ąĖ INT_MAX, ąĖą╗ąĖ (0 | kNoTimeouterror).
kInvalidThread ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čā č鹥ą║čāčēąĄą│ąŠ ą┐ąŠč鹊ą║ą░ ąĮąĄčé ąŠč湥čĆąĄą┤ąĖ čüąŠąŠą▒čēąĄąĮąĖą╣, čé. ąĄ. ą┤ą╗čÅ ąĮąĄą│ąŠ ąĮąĄ ą▒čŗą╗ čĆą░ąĘčĆąĄčłąĄąĮ čäčāąĮą║čåąĖąŠąĮą░ą╗ ą┐čĆąĖąĄą╝ą░ čüąŠąŠą▒čēąĄąĮąĖą╣. ą¤ąŠą┤ą┤ąĄčƹȹ║ą░ čüąŠąŠą▒čēąĄąĮąĖą╣ ą▓ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ čüą▓ąŠą╣čüčéą▓ą░čģ čéąĖą┐ą░ ą┐ąŠč鹊ą║ą░, ąĘą░ą║ą╗ą░ą┤ą║ą░ Kernel -> Threads -> Thread Types -> čĆą░ąĘą▓ąĄčĆąĮąĖč鹥 čüą▓ąŠą╣čüčéą▓ą░ ąĮčāąČąĮąŠą│ąŠ čéąĖą┐ą░ ą┐ąŠč鹊ą║ą░ -> čüą▓ąŠą╣čüčéą▓ąŠ Message Enabled ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ ą▓ true.
ąØąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąŠčłąĖą▒ąŠą║: kMessageTimeout, ą║ą░ą║ čŹč鹊 ą▒čŗą╗ąŠ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓čŗčłąĄ.
ą¤čĆąŠč鹊čéąĖą┐ C:
void VDK_GetMessagePayload (VDK_MessageID inMessageID,
int *outPayloadType,
unsigned int *outPayloadSize,
void **outPayloadAddr);
ą¤čĆąŠč鹊čéąĖą┐ C++:
void VDK::GetMessagePayload (VDK::MessageID inMessageID,
int *outPayloadType,
unsigned int *outPayloadSize,
void **outPayloadAddr);
ążčāąĮą║čåąĖčÅ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ą░čéčĆąĖą▒čāčéčŗ, čüą▓čÅąĘą░ąĮąĮčŗąĄ čü ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąŠą╣ čüąŠąŠą▒čēąĄąĮąĖčÅ: čéąĖą┐, čĆą░ąĘą╝ąĄčĆ ąĖ ą░ą┤čĆąĄčü.
ąĪą╝čŗčüą╗ čŹčéąĖčģ ąĘąĮą░č湥ąĮąĖą╣ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄą╝, ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ą░čĆą│čāą╝ąĄąĮčéą░ą╝, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ čĆą░ąĮąĄąĄ ą┐ąĄčĆąĄą┤ą░ąĮčŗ ą▓ ą▓čŗąĘąŠą▓ CreateMessage(). ąóąŠą╗čīą║ąŠ č鹊čé ą┐ąŠč鹊ą║, ą║ąŠč鹊čĆčŗą╣ čÅą▓ą╗čÅąĄčéčüčÅ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą╝ čüąŠąŠą▒čēąĄąĮąĖčÅ, ą╝ąŠąČąĄčé ą┐čĆąŠą▓ąĄčĆąĖčéčī ą░čéčĆąĖą▒čāčéčŗ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ. ąĢčüą╗ąĖ ą┤čĆčāą│ąĖąĄ ą┐ąŠč鹊ą║ąĖ (ąĮąĄ ą▓ą╗ą░ą┤ąĄą╗čīčåčŗ čüąŠąŠą▒čēąĄąĮąĖčÅ) ą▓čŗąĘąŠą▓čāčé API-čäčāąĮą║čåąĖčÄ GetMessagePayload(), ą▒čāą┤ąĄčé ą┤ąĖčüą┐ąĄčéč湥čĆąĖąĘąŠą▓ą░ąĮą░ ąŠčłąĖą▒ą║ą░, ąĖ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ outPayloadType (čéąĖą┐), outPayloadSize (čĆą░ąĘą╝ąĄčĆ) ąĖ outPayloadAddr (ą░ą┤čĆąĄčü) ąŠčüčéą░ąĮčāčéčüčÅ ąĮąĄąĖąĘą╝ąĄąĮąĄąĮąĮčŗą╝ąĖ.
ążčāąĮą║čåąĖčÅ GetMessagePayload() ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ ąĘą░ą┤ą░čć. ąÆčĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čŹč鹊ą╣ čäčāąĮą║čåąĖąĖ ą▓čüąĄą│ą┤ą░ ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠąĄ.
[ą¤ą░čĆą░ą╝ąĄčéčĆčŗ]
inMessageID ąĖą╝ąĄąĄčé čéąĖą┐ MessageID (ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ čüąŠąŠą▒čēąĄąĮąĖčÅ), ąĖ ąŠąĮ ąĘą░ą┤ą░ąĄčé ąŠą┐čĆą░čłąĖą▓ą░ąĄą╝ąŠąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ.
*outPayloadType čéąĖą┐ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ. ąŻą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ ąĘąĮą░č湥ąĮąĖąĄ, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄą╝, ąĖ ąŠąĮ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ąŠą┐ąĖčüą░ąĮąĖčÅ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ. ą×čéčĆąĖčåą░č鹥ą╗čīąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ čŹč鹊ą│ąŠ ą┐ą░čĆą░ą╝ąĄčéčĆą░ ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮčŗ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą▓ąĮčāčéčĆąĖ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ VDK.
*outPayloadSize ąŠą▒čŗčćąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé čĆą░ąĘą╝ąĄčĆ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ ą▓ ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠ ą▓ąŠąĘą╝ąŠąČąĮčŗčģ ą░ą┤čĆąĄčüčāąĄą╝čŗčģ ąĄą┤ąĖąĮąĖčåą░čģ ą┐ą░ą╝čÅčéąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ (ą▓ ą▒ą░ą╣čéą░čģ, sizeof(char)).
**outPayloadAddr ą░ą┤čĆąĄčü ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ. ą×ą▒čŗčćąĮąŠ čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ ąĮą░čćą░ą╗ąŠ ą▒čāč乥čĆą░, ą│ą┤ąĄ ąĮą░čģąŠą┤čÅčéčüčÅ ą┤ą░ąĮąĮčŗąĄ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ. ą×ą┤ąĮą░ą║ąŠ, ąĄčüą╗ąĖ čĆą░ąĘą╝ąĄčĆ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ čāą║ą░ąĘą░ąĮ ą║ą░ą║ 0, č鹊 ą░ą┤čĆąĄčü ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ ą╝ąŠąČąĄčé čüąŠą┤ąĄčƹȹ░čéčī ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄą╝ ą┤ą░ąĮąĮčŗąĄ.
[ą×ą▒čĆą░ą▒ąŠčéą║ą░ ąŠčłąĖą▒ąŠą║]
ąŚą┤ąĄčüčī ą┐čĆąĖą▓ąĄą┤ąĄąĮą░ čĆą░čüčłąĖčäčĆąŠą▓ą║ą░ ą▓ąŠąĘą╝ąŠąČąĮčŗčģ ąŠčłąĖą▒ąŠą║ čÅą┤čĆą░ (ąŠč鹊ą▒čĆą░ąČą░čÄčéčüčÅ ą▓ ąŠą║ąĮąĄ View -> VDK Windows -> Status), ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī čĆąĄąĘčāą╗čīčéą░č鹊ą╝ ą▓čŗąĘąŠą▓ą░ čäčāąĮą║čåąĖąĖ. ą¤ąŠą┤ą┤ąĄčƹȹ║ą░ Full instrumentation:
kInvalidMessageOwner ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ą░čĆą│čāą╝ąĄąĮčé inMessageID ąĘą░ą┤ą░ąĄčé čüąŠąŠą▒čēąĄąĮąĖąĄ, ą║ąŠč鹊čĆčŗą╝ ąĮąĄ ą▓ą╗ą░ą┤ąĄąĄčé ą▓čŗąĘą▓ą░ą▓čłąĖą╣ čäčāąĮą║čåąĖčÄ ą┐ąŠč鹊ą║.
kInvalidMessageID ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ą░čĆą│čāą╝ąĄąĮčé inMessageID ąĮąĄ čüąŠą┤ąĄčƹȹĖčé ą┤ąŠą┐čāčüčéąĖą╝čŗą╣ MessageID.
kMessageInQueue ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čŹč鹊 čüąŠąŠą▒čēąĄąĮąĖąĄ ą▒čŗą╗ąŠ ąŠčéą┐čĆą░ą▓ą╗ąĄąĮąŠ ą┐ąŠč鹊ą║čā (čüąĄą╣čćą░čü ThreadID ąĮąĄ ąĖąĘą▓ąĄčüč鹥ąĮ), ąĖ čüąŠąŠą▒čēąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čāą┤ą░ą╗ąĄąĮąŠ ąĖąĘ ąŠč湥čĆąĄą┤ąĖ ą▓čŗąĘąŠą▓ąŠą╝ PendMessage().
ąæąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąŠčłąĖą▒ąŠą║ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ.
MessageID čŹč鹊 čéąĖą┐, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą┤ą╗čÅ čģčĆą░ąĮąĄąĮąĖčÅ čāąĮąĖą║ą░ą╗čīąĮąŠą│ąŠ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆą░ čüąŠąŠą▒čēąĄąĮąĖčÅ. ąóąĖą┐ MessageID ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ ą║ą░ą║ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖąĄ ą▓ čäą░ą╣ą╗ąĄ VDK.h.
enum MessageID
{
last_message__3VDK=-1
};
ąÜą░ą║ ąÆčŗ ą▓ąĖą┤ąĖč鹥, čŹč鹊 ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖąĄ čäą░ą║čéąĖč湥čüą║ąĖ ą┐čāčüč鹊ąĄ. ąÆčüąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ čüąŠąĘą┤ą░čÄčéčüčÅ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąĖ ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ, ą┐ąŠą╗čāčćą░čé ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ čéąĖą┐ą░ MessageID, čćč鹊 ą┐ąŠąĘą▓ąŠą╗ąĖčé ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆčā ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą┐čĆąŠą▓ąĄčĆą║čā čéąĖą┐ąŠą▓ ąĖ ą┐čĆąĄą┤ąŠčéą▓čĆą░čéąĖčéčī čüą▓čÅąĘą░ąĮąĮčŗąĄ čü čŹčéąĖą╝ ąŠčłąĖą▒ą║ąĖ.
ąØą░ čÅąĘčŗą║ąĄ C:
typedef enum MessageID VDK_MessageID;
ąØą░ čÅąĘčŗą║ąĄ C++:
typedef enum MessageID VDK::MessageID;
ąóąĖą┐ MsgChannel ą┐ąĄčĆąĄčćąĖčüą╗čÅąĄčé ą║ą░ąĮą░ą╗čŗ, ąĮą░ ą║ąŠč鹊čĆčŗčģ ą╝ąŠą│čāčé ą▒čŗčéčī ą┐ąŠą╝ąĄčēąĄąĮčŗ čüąŠąŠą▒čēąĄąĮąĖčÅ, ąĖ ąĮą░ ą║ąŠč鹊čĆčŗčģ ą║ą░ąĮą░ą╗čŗ ą╝ąŠą│čāčé ąŠąČąĖą┤ą░čéčī čüąŠąŠą▒čēąĄąĮąĖčÅ.
ąØą░ čÅąĘčŗą║ąĄ C:
enum VDK_MsgChannel
{
VDK_kMsgWaitForAll = 1 << 15,
VDK_kMsgChannel1 = 1 << 14,
VDK_kMsgChannel2 = 1 << 13,
VDK_kMsgChannel3 = 1 << 12,
VDK_kMsgChannel4 = 1 << 11,
VDK_kMsgChannel5 = 1 << 10,
VDK_kMsgChannel6 = 1 << 9,
VDK_kMsgChannel7 = 1 << 8,
VDK_kMsgChannel8 = 1 << 7,
VDK_kMsgChannel9 = 1 << 6,
VDK_kMsgChannel10 = 1 << 5,
VDK_kMsgChannel11 = 1 << 4,
VDK_kMsgChannel12 = 1 << 3,
VDK_kMsgChannel13 = 1 << 2,
VDK_kMsgChannel14 = 1 << 1,
VDK_kMsgChannel15 = 1 << 0
};
ąØą░ čÅąĘčŗą║ąĄ C++:
enum VDK::MsgChannel
{
VDK::kMsgWaitForAll = 1 << 15,
VDK::kMsgChannel1 = 1 << 14,
VDK::kMsgChannel2 = 1 << 13,
VDK::kMsgChannel3 = 1 << 12,
VDK::kMsgChannel4 = 1 << 11,
VDK::kMsgChannel5 = 1 << 10,
VDK::kMsgChannel6 = 1 << 9,
VDK::kMsgChannel7 = 1 << 8,
VDK::kMsgChannel8 = 1 << 7,
VDK::kMsgChannel9 = 1 << 6,
VDK::kMsgChannel10 = 1 << 5,
VDK::kMsgChannel11 = 1 << 4,
VDK::kMsgChannel12 = 1 << 3,
VDK::kMsgChannel13 = 1 << 2,
VDK::kMsgChannel14 = 1 << 1,
VDK::kMsgChannel15 = 1 << 0
};
ążčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčī čüąŠąŠą▒čēąĄąĮąĖą╣ VDK ą▓ VisualDSP++ 3.5 ą▒čŗą╗ą░ čĆą░čüčłąĖčĆąĄąĮą░ čéą░ą║, čćč鹊ą▒čŗ ąĖčģ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą┐čĆąĄą┤ą░ą▓ą░čéčī ą╝ąĄąČą┤čā ą┐čĆąŠčåąĄčüčüąŠčĆą░ą╝ąĖ ą▓ čüąĖčüč鹥ą╝ąĄ čü ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ą╝ąĖ. API ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ čüąŠąŠą▒čēąĄąĮąĖą╣, ąĮą░čüą║ąŠą╗čīą║ąŠ čŹč鹊 ą▒čŗą╗ąŠ ą▓ąŠąĘą╝ąŠąČąĮąŠ, ąŠčüčéą░ą▓ą╗ąĄąĮąŠ čéą░ą║ąĖą╝ ąČąĄ, ą║ą░ą║ ą┐čĆąĖ ąŠą▒ą╝ąĄąĮąĄ čüąŠąŠą▒čēąĄąĮąĖčÅą╝ąĖ ą▓ ą┐čĆąĄą┤ąĄą╗ą░čģ ąŠą┤ąĮąŠą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░, ąĮąŠ ą▒čŗą╗ąĖ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮčŗ čĆą░čüčłąĖčĆąĄąĮąĖčÅ.
ąÜą░ąČą┤čŗą╣ ą┐čĆąŠčåąĄčüčüąŠčĆ ą▓ ą╝ąĮąŠą│ąŠą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą╣ čüąĖčüč鹥ą╝ąĄ čüčćąĖčéą░ąĄčéčüčÅ ą║ą░ą║ čāąĘąĄą╗ (node), ąĖ ą║ą░ąČą┤čŗą╣ ą┐čĆąŠčåąĄčüčüąŠčĆ ą┤ąŠą╗ąČąĄąĮ ąĖą╝ąĄčéčī čüą▓ąŠą╣ čüąŠą▒čüčéą▓ąĄąĮąĮčŗą╣, ąŠčéą┤ąĄą╗čīąĮčŗą╣ ą┐čĆąŠąĄą║čé VisualDSP++. ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą║ą░ąČą┤čŗą╣ čāąĘąĄą╗ ąĘą░ą┐čāčüą║ą░ąĄčé čüą▓ąŠą╣ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ čÅą┤čĆą░ VDK, čüąŠ čüą▓ąŠąĖą╝ąĖ čüčāčēąĮąŠčüčéčÅą╝ąĖ VDK (čéą░ą║ąĖą╝ąĖ ą║ą░ą║ čüąĄą╝ą░č乊čĆčŗ, ą▒ąĖčéčŗ čüąŠą▒čŗčéąĖą╣, čüąŠą▒čŗčéąĖčÅ ąĖ čé. ą┤., ąĮąŠ ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ ą┐ąŠč鹊ą║ąŠą▓), ą┐čĆąĖą▓ą░čéąĮčŗą╝ąĖ ą┤ą╗čÅ čŹč鹊ą│ąŠ čāąĘą╗ą░. ąÜą░ąČą┤čŗą╣ čāąĘąĄą╗ ąĖą╝ąĄąĄčé čāąĮąĖą║ą░ą╗čīąĮčŗą╣ čćąĖčüą╗ąŠą▓ąŠą╣ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ (ID) čāąĘą╗ą░, ą║ąŠč鹊čĆčŗą╣ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ąĮą░ ąĘą░ą║ą╗ą░ą┤ą║ąĄ Kernel ą┐čĆąŠąĄą║čéą░ VDK.
ą¤ąŠč鹊ą║ąĖ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāčÄčéčüčÅ čāąĮąĖą║ą░ą╗čīąĮąŠ ą╝ąĄąČą┤čā ą▓čüąĄą╝ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ą╝ąĖ čüąĖčüč鹥ą╝čŗ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊 ą▓ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ą┐ąŠč鹊ą║ą░ ThreadID ą▓čüčéčĆą░ąĖą▓ą░ąĄčéčüčÅ ID čāąĘą╗ą░ ą║ą░ą║ 5-ą▒ąĖčéąĮąŠąĄ ą┐ąŠą╗ąĄ ThreadID. ąĀą░ąĘą╝ąĄčĆ čŹč鹊ą│ąŠ ą┐ąŠą╗čÅ ąŠą│čĆą░ąĮąĖč湥ąĮ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčŗą╝ ą▓ąŠąĘą╝ąŠąČąĮčŗą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąŠą╝ čāąĘą╗ąŠą▓ ą▓ čüąĖčüč鹥ą╝ąĄ 32. ą¤ąŠč鹊ą║ąĖ ą┐ąŠčüč鹊čÅąĮąĮąŠ ąĮą░čģąŠą┤čÅčéčüčÅ ąĮą░ č鹊ą╝ čāąĘą╗ąĄ, ą│ą┤ąĄ ąŠąĮąĖ ą▒čŗą╗ąĖ čüąŠąĘą┤ą░ąĮčŗ - ąĮąĄčé ąĮąĖą║ą░ą║ąŠą╣ "ą╝ąĖą│čĆą░čåąĖąĖ" ą┐ąŠč鹊ą║ąŠą▓ ą╝ąĄąČą┤čā čāąĘą╗ą░ą╝ąĖ.
ą¦č鹊ą▒čŗ ąĮą░ ą┐ąŠč鹊ą║ąĖ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ čüčüčŗą╗ą░čéčīčüčÅ ąĖąĘ ą┤čĆčāą│ąĖčģ čāąĘą╗ąŠą▓, ą║ą░ąČą┤čŗą╣ ą┐čĆąŠąĄą║čé ą▓ ą╝ąĮąŠą│ąŠą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą╣ čüąĖčüč鹥ą╝ąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčé čüą┐ąĖčüąŠą║ ąĖą╝ą┐ąŠčĆčéą░ (Import list) ąĘą░ą║ą╗ą░ą┤ą║ąĖ Kernel, čćč鹊ą▒čŗ ąĖą╝ą┐ąŠčĆčéąĖčĆąŠą▓ą░čéčī čäą░ą╣ą╗čŗ ą┐čĆąŠąĄą║čéą░ ą┤ą╗čÅ ą▓čüąĄčģ ą┤čĆčāą│ąĖčģ čāąĘą╗ąŠą▓ ą▓ čüąĖčüč鹥ą╝ąĄ. ąŁč鹊 ą┤ąĄą╗ą░ąĄčé ą▓ąĖą┤ąĖą╝čŗą╝ąĖ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆčŗ ą┐ąŠč鹊ą║ąŠą▓ ąĘą░ą│čĆčāąĘą║ąĖ (boot ThreadID) ą┤ą╗čÅ ą▓čüąĄčģ ą┐čĆąŠąĄą║č鹊ą▓ čüąĖčüč鹥ą╝čŗ, ąĖ ąĖčģ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓ ą┐čĆąĄą┤ąĄą╗ą░čģ ą▓čüąĄą╣ čüąĖčüč鹥ą╝čŗ. ą¤ąŠč鹊ą║ąĖ, čĆą░ąĘą╝ąĄčēąĄąĮąĮčŗąĄ ą▓ ą┤čĆčāą│ąĖčģ čāąĘą╗ą░čģ, ą╝ąŠą│čāčé ą▒čŗčéčī č鹊ą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮčŗ ą║ą░ą║ ą╝ąĄčüčéą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą┤ą╗čÅ čäčāąĮą║čåąĖą╣ VDK::PostMessage() ąĖ VDK::ForwardMessage(), čģąŠčéčÅ čŹč鹊 ąĄčüčéčī ąĮąĄ ą┤ą╗čÅ ą╗čÄą▒ąŠą╣ ą┤čĆčāą│ąŠą╣ čüą▓čÅąĘą░ąĮąĮąŠą╣ čü ą┐ąŠč鹊ą║ąŠą╝ čäčāąĮą║čåąĖąĖ API.
ą¤ąŠč鹊ą║ąĖ ąĘą░ą│čĆčāąĘą║ąĖ (boot threads) čüą╗čāąČą░čé č鹊čćą║ą░ą╝ąĖ ą┐čĆąĖą▓čÅąĘą║ąĖ (anchor points) ą┤ą╗čÅ ąŠą▒ą╝ąĄąĮą░ ą╝ąĄąČą┤čā čāąĘą╗ą░ą╝ąĖ, ą┐ąŠčüą║ąŠą╗čīą║čā ąĖčģ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆčŗ čāąČąĄ ąĖąĘą▓ąĄčüčéąĮčŗ ą▓ąŠ ą▓čĆąĄą╝čÅ čüą▒ąŠčĆą║ąĖ. ą¦č鹊ą▒čŗ ąŠčüčāčēąĄčüčéą▓ą╗čÅčéčī ąŠą▒ą╝ąĄąĮ čü ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąĖ čüąŠąĘą┤ą░ąĮąĮčŗą╝ąĖ ą┐ąŠč鹊ą║ą░ą╝ąĖ ą▓ ą┤čĆčāą│ąĖčģ čāąĘą╗ą░čģ, ąĮčāąČąĮąŠ ą┐ąĄčĆąĄą┤ą░čéčī ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆčŗ ThreadID ą║ą░ą║ ą┤ą░ąĮąĮčŗąĄ ą╝ąĄąČą┤čā čāąĘą╗ą░ą╝ąĖ (čé. ąĄ. ą▓ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ). ą×čéą▓ąĄčé ąĮą░ ą┐čĆąĖčłąĄą┤čłąĄąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čüąĄą│ą┤ą░ ąŠčéą┐čĆą░ą▓ą╗ąĄąĮąŠ, ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ ąŠčé ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆą░ ąŠčéą┐čĆą░ą▓ą╗čÅčÄčēąĄą│ąŠ ą┐ąŠč鹊ą║ą░, ą┐ąŠčüą║ąŠą╗čīą║čā ID ąŠčéą┐čĆą░ą▓ąĖč鹥ą╗čÅ ą┐ąĄčĆąĄąĮąŠčüąĖčéčüčÅ ą▓ čüą░ą╝ąŠą╝ čüąŠąŠą▒čēąĄąĮąĖąĖ. ąóą░ą║ čćč鹊 ą┐ąŠč鹊ą║ąĖ ąĘą░ą│čĆčāąĘą║ąĖ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĖčÅ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ąŠ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąĖ čüąŠąĘą┤ą░ąĮąĮčŗčģ ą┐ąŠč鹊ą║ą░čģ, ąĮąŠ čéą░ą║ą░čÅ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖčÅ ąĘą░ą▓ąĖčüąĖčé ąŠčé čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ ąĖ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮą░ ą║ą░ą║ čćą░čüčéčī ą┤ąĖąĘą░ą╣ąĮą░ čüąĖčüč鹥ą╝čŗ.
ą¤ąŠč鹊ą║ąĖ ą╝ą░čĆčłčĆčāčéąĖąĘą░čåąĖąĖ (Routing Threads, RThreads). ąÜąŠą│ą┤ą░ čüąŠąŠą▒čēąĄąĮąĖąĄ ą┐čāą▒ą╗ąĖą║čāąĄčéčüčÅ ą┐ąŠč鹊ą║ąŠą╝, ą┐čĆąŠą▓ąĄčĆčÅąĄčéčüčÅ ID čāąĘą╗ą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ (ą▓čüčéčĆąŠąĄąĮąĮčŗą╣ ą▓ ThreadID ą┐ąŠč鹊ą║ą░-ą┐ąŠą╗čāčćą░č鹥ą╗čÅ). ąĢčüą╗ąĖ ąŠąĮ čüąŠą▓ą┐ą░ą┤ą░ąĄčé čü ID čāąĘą╗ą░, ą▓ ą║ąŠč鹊čĆąŠą╝ ą┐ąŠč鹊ą║ čĆą░ą▒ąŠčéą░ąĄčé, č鹊 čüąŠąŠą▒čēąĄąĮąĖąĄ ąĮą░ą┐čĆčÅą╝čāčÄ ą┐ąŠą╝ąĄčēą░ąĄčéčüčÅ ą▓ ąŠč湥čĆąĄą┤čī čüąŠąŠą▒čēąĄąĮąĖą╣ ą┐ąŠč鹊ą║ą░ ą┐ąŠą╗čāčćą░č鹥ą╗čÅ, č鹊čćąĮąŠ čéą░ą║ ąČąĄ, ą║ą░ą║ čŹč鹊 ą▒čŗą╗ąŠ ą▒čŗ ą▓ ąŠą▒ą╝ąĄąĮąĄ čüąŠąŠą▒čēąĄąĮąĖčÅą╝ąĖ ąŠą┤ąĮąŠą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą╣ čüąĖčüč鹥ą╝čŗ. ąĢčüą╗ąĖ ID čāąĘą╗ą░ ąĮąĄ čüąŠą▓ą┐ą░ą┤ą░ąĄčé, č鹊 čüąŠąŠą▒čēąĄąĮąĖąĄ ą┐ąĄčĆąĄą┤ą░ąĄčéčüčÅ ąŠą┤ąĮąŠą╝čā ąĖąĘ ą╝ą░čĆčłčĆčāčéąĖąĘąĖčĆčāčÄčēąĖčģ ą┐ąŠč鹊ą║ąŠą▓ (RThreads), ą║ąŠč鹊čĆčŗąĄ ąŠčéą▓ąĄčćą░čÄčé ąĘą░ čüą╗ąĄą┤čāčÄčēčāčÄ čüčéą░ą┤ąĖčÄ ą▓ ą┐čĆąŠčåąĄčüčüąĄ ą┐ąĄčĆąĄąĮąŠčüą░ čüąŠąŠą▒čēąĄąĮąĖčÅ ą▓ ąĄą│ąŠ č鹊čćą║čā ą┤ąŠčüčéą░ą▓ą║ąĖ.
ąÜą░ąČą┤čŗą╣ ą┐ąŠč鹊ą║ RThread ą┐ąŠą╗čāčćą░ąĄčé ąŠą┤ąĮčā ąĖąĘ ą┤ą▓čāčģ čĆąŠą╗ąĄą╣, incoming (ąŠą▒čĆą░ą▒ąŠčéą║ą░ ą▓čģąŠą┤čÅčēąĖčģ čüąŠąŠą▒čēąĄąĮąĖą╣) ąĖ outgoing (ąŠą▒čĆą░ą▒ąŠčéą║ą░ ą▓čģąŠą┤čÅčēąĖčģ čüąŠąŠą▒čēąĄąĮąĖą╣), ą║ąŠč鹊čĆčŗąĄ čäąĖą║čüąĖčĆąŠą▓ą░ąĮčŗ ą┤ą╗čÅ ą┐ąŠč鹊ą║ą░ ą▓ąŠ ą▓čĆąĄą╝čÅ ąĄą│ąŠ čüąŠąĘą┤ą░ąĮąĖčÅ.
ąÜą░ąČą┤čŗą╣ RThread ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą┤čĆą░ą╣ą▓ąĄčĆ čāčüčéčĆąŠą╣čüčéą▓ą░, ą║ąŠč鹊čĆčŗą╣ čāą┐čĆą░ą▓ą╗čÅąĄčé čäąĖąĘąĖč湥čüą║ąĖą╝ąĖ ą┐ąŠą┤čĆąŠą▒ąĮąŠčüčéčÅą╝ąĖ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ čüąŠąŠą▒čēąĄąĮąĖą╣ ą╝ąĄąČą┤čā čāąĘą╗ą░ą╝ąĖ. Outgoing RThread ąĖą╝ąĄąĄčé čüą▓ąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ incoming RThread ąĖą╝ąĄąĄčé čüą▓ąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ.
ąØą░ ą┐ąŠč鹊ą║ąĖ outgoing RThread čüčüčŗą╗ą░čÄčéčüčÅ č湥čĆąĄąĘ čéą░ą▒ą╗ąĖčåčā ą╝ą░čĆčłčĆčāčéąĖąĘą░čåąĖąĖ, ą║ąŠč鹊čĆą░čÅ ą║ąŠąĮčüčéčĆčāąĖčĆčāąĄčéčüčÅ čüąĖčüč鹥ą╝ąŠą╣ VisualDSP++ ą▓ąŠ ą▓čĆąĄą╝čÅ čüą▒ąŠčĆą║ąĖ. ąÜąŠą│ą┤ą░ čüąŠąŠą▒čēąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ąŠčéą┐čĆą░ą▓ą╗ąĄąĮąŠ ą▓ ą┤čĆčāą│ąŠą╣ čāąĘąĄą╗ čüąĖčüč鹥ą╝čŗ, ID čāąĘą╗ą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą║ą░ą║ ąĖąĮą┤ąĄą║čü ą▓ čŹč鹊ą╣ čéą░ą▒ą╗ąĖčåąĄ ą┤ą╗čÅ ą▓čŗą▒ąŠčĆą░, ą║ą░ą║ąŠą╣ outgoing RThread ą▒čāą┤ąĄčé ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī ą┐ąĄčĆąĄą┤ą░čćčā čüąŠąŠą▒čēąĄąĮąĖčÅ.
ąÜą░ąČą┤čŗą╣ čāąĘąĄą╗ ą┤ąŠą╗ąČąĄąĮ čüąŠą┤ąĄčƹȹ░čéčī ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝ ąŠą┤ąĖąĮ incoming RThread ąĖ ąŠą┤ąĖąĮ outgoing RThread, ą▓ą╝ąĄčüč鹥 čüąŠ čüą▓ąŠąĖą╝ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╝ąĖ ą┤čĆą░ą╣ą▓ąĄčĆą░ą╝ąĖ čāčüčéčĆąŠą╣čüčéą▓. ą£ąŠąČąĄčé ą▒čŗčéčī ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąŠ ą▒ąŠą╗čīčłąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠč鹊ą║ąŠą▓ RThread, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą║ąŠą╗ąĖč湥čüčéą▓ą░ čäąĖąĘąĖč湥čüą║ąĖčģ čüąŠąĄą┤ąĖąĮąĄąĮąĖą╣ čü ą┤čĆčāą│ąĖą╝ąĖ čāąĘą╗ą░ą╝ąĖ. ą×ą┤ąĮą░ą║ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ outgoing RThread ą╝ąŠąČąĄčé ą▒čŗčéčī ą╝ąĄąĮčīčłąĄ, č湥ą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čāąĘą╗ąŠą▓ ą▓ čüąĖčüč鹥ą╝ąĄ, čéą░ą║ ą║ą░ą║ ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą╣ ąĘą░ą┐ąĖčüąĖ ą▓ čéą░ą▒ą╗ąĖčåąĄ ą╝ą░čĆčłčĆčāčéąĖąĘą░čåąĖąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĖą▓čÅąĘą░ąĮąŠ ą║ ąŠą┤ąĮąŠą╝čā ąĖ č鹊ą╝čā ąČąĄ ą┐ąŠč鹊ą║čā RThread. ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 č鹊ą┐ąŠą╗ąŠą│ąĖčÅ ą╝čāą╗čīčéąĖą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą╣ čüąĖčüč鹥ą╝čŗ ą╝ąŠąČąĄčé ą▒čŗčéčī čéą░ą║ąŠą╣, čćč鹊 čüąŠąŠą▒čēąĄąĮąĖčÄ ą┤ą╗čÅ ą┤ąŠčüčéąĖąČąĄąĮąĖčÅ ą╝ąĄčüčéą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą╝ąŠąČąĄčé ą┐ąŠąĮą░ą┤ąŠą▒ąĖčéčīčüčÅ ą┐čĆąŠą╣čéąĖ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐čĆąŠą╝ąĄąČčāč鹊čćąĮčŗčģ čāąĘą╗ąŠą▓.
ą¤ąŠč鹊ą║ outgoing RThread, ą║ąŠą│ą┤ą░ ąŠąĮ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ čüąŠčüč鹊čÅąĮąĖąĖ idle, ąČą┤ąĄčé čüąŠąŠą▒čēąĄąĮąĖą╣, ą║ąŠč鹊čĆčŗąĄ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą┐ąŠą╝ąĄčēąĄąĮčŗ ą▓ ą╗čÄą▒ąŠą╣ ą║ą░ąĮą░ą╗ ąĄą│ąŠ ąŠč湥čĆąĄą┤ąĖ čüąŠąŠą▒čēąĄąĮąĖą╣, ąĖ ąĘą░č鹥ą╝ ą┐ąĄčĆąĄą┤ą░ąĄčé čŹč鹊 čüąŠąŠą▒čēąĄąĮąĖąĄ (ą║ą░ą║ ą┐ą░ą║ąĄčé čüąŠąŠą▒čēąĄąĮąĖčÅ) ą┐čāč鹥ą╝ ąŠą┤ąĮąŠą│ąŠ ąĖą╗ąĖ ą▒ąŠą╗čīčłąĄą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą▓čŗąĘąŠą▓ąŠą▓ SyncWrite() čüą▓ąŠąĄą│ąŠ čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ ą┤čĆą░ą╣ą▓ąĄčĆą░ čāčüčéčĆąŠą╣čüčéą▓ą░. ąŁčéąĖ ą▓čŗąĘąŠą▓čŗ SyncWrite() ą╝ąŠą│čāčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░čéčīčüčÅ ąĮą░ ąŠąČąĖą┤ą░ąĮąĖąĖ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ą┐čĆąŠčåąĄčüčüą░ ą▓ą▓ąŠą┤ą░/ą▓čŗą▓ąŠą┤ą░ ą┤ą░ąĮąĮčŗčģ.
ą¤ąŠč鹊ą║ incoming RThread, ą║ąŠą│ą┤ą░ ąŠąĮ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ čüąŠčüč鹊čÅąĮąĖąĖ idle, ą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ ąĮą░ ą▓čŗąĘąŠą▓ąĄ SyncRead() čüą▓ąŠąĄą│ąŠ ą┤čĆą░ą╣ą▓ąĄčĆą░ čāčüčéčĆąŠą╣čüčéą▓ą░, ąŠąČąĖą┤ą░čÅ ą┐čĆąĖąĄą╝ą░ ą┐ą░ą║ąĄčéą░ čüąŠąŠą▒čēąĄąĮąĖčÅ. ąÜą░ą║ č鹊ą╗čīą║ąŠ ą┐ą░ą║ąĄčé ą▒čŗą╗ ą┐čĆąĖąĮčÅčé ąĖ čĆą░čüą┐ą░ą║ąŠą▓ą░ąĮ ą▓ ąŠą▒čŖąĄą║čé čüąŠąŠą▒čēąĄąĮąĖčÅ, RThread ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗čÅąĄčé ąĄą│ąŠ ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄąĄ ą╝ąĄčüč鹊 ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ąŁč鹊 ą╝ąŠąČąĄčé ą▓ąŠą▓ą╗ąĄčćčī ą┐ąĄčĆąĄą┤ą░čćčā čüąŠąŠą▒čēąĄąĮąĖčÅ ą▓ outgoing RThread, ąĄčüą╗ąĖ č鹥ą║čāčēąĖą╣ čāąĘąĄą╗ ąĮąĄ čüąŠą▓ą┐ą░ą┤ą░ąĄčé čü ą║ąŠąĮąĄčćąĮčŗą╝ ą┐čāąĮą║č鹊ą╝ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ čüąŠąŠą▒čēąĄąĮąĖčÅ.
ąĀąĄą░ą╗čīąĮčŗąĄ ąŠą▒čŖąĄą║čéčŗ čüąŠąŠą▒čēąĄąĮąĖą╣, ąĮą░ ą║ąŠč鹊čĆčŗąĄ čüčüčŗą╗ą░čÄčéčüčÅ ą┐ąŠ ąŠčéą┤ąĄą╗čīąĮąŠą╝čā MessageID, čÅą▓ą╗čÅčÄčéčüčÅ ą╗ąŠą║ą░ą╗čīąĮčŗą╝ąĖ ą┐ąŠ ąŠčéąĮąŠčłąĄąĮąĖčÄ ą║ ąŠčéą┤ąĄą╗čīąĮąŠą╝čā čāąĘą╗čā. ąÜąŠą│ą┤ą░ čüąŠąŠą▒čēąĄąĮąĖąĄ ą┐ąĄčĆąĄą┤ą░ąĮąŠ ą╝ąĄąČą┤čā ą┤ą▓čāą╝čÅ čāąĘą╗ą░ą╝ąĖ, ą┐ąĄčĆąĄą┤ą░ąĄčéčüčÅ č鹊ą╗čīą║ąŠ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ (ą║ą░ą║ ą┐ą░ą║ąĄčé čüąŠąŠą▒čēąĄąĮąĖčÅ).
ą×ą▒čŖąĄą║čé čüąŠąŠą▒čēąĄąĮąĖčÅ čüą░ą╝ ą┐ąŠ čüąĄą▒ąĄ čāąĮąĖčćč鹊ąČą░ąĄčéčüčÅ ąĮą░ čüč鹊čĆąŠąĮąĄ ąŠčéą┐čĆą░ą▓ą║ąĖ ąĖ ąĘą░ąĮąŠą▓ąŠ čüąŠąĘą┤ą░ąĄčéčüčÅ ąĮą░ čüč鹊čĆąŠąĮąĄ ą┐čĆąĖąĄą╝ą░ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ.
ŌĆó ąĪąŠąŠą▒čēąĄąĮąĖąĄ ąŠą▒čŗčćąĮąŠ ąĖą╝ąĄąĄčé ą┤čĆčāą│ąŠą╣ ID ąĮą░ ą┐čĆąĖąĄą╝ąĮąŠą╣ čüč鹊čĆąŠąĮąĄ, ąŠčéą╗ąĖčćą░čÄčēąĄąĄčüčÅ ąŠčé čüč鹊čĆąŠąĮčŗ ąŠčéą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ.
ŌĆó ą×ą▒čŖąĄą║čéčŗ čüąŠąŠą▒čēąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą┐ąĄčĆąĄą┤ą░ąĮčŗ ą▓ outgoing RThread, čāąĮąĖčćč鹊ąČą░čÄčéčüčÅ ą┐ąŠčüą╗ąĄ ą┐ąĄčĆąĄą┤ą░čćąĖ, ąĖ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ą▓ąŠąĘą▓čĆą░čēą░čÄčéčüčÅ ą▓ ą┐čāą╗ čüą▓ąŠą▒ąŠą┤ąĮčŗčģ čüąŠąŠą▒čēąĄąĮąĖą╣.
ŌĆó ąÜąŠą│ą┤ą░ ą┐ą░ą║ąĄčé čüąŠąŠą▒čēąĄąĮąĖčÅ ą┐čĆąĖąĮčÅčé ą▓ incoming RThread, ąŠą▒čŖąĄą║čé čüąŠąŠą▒čēąĄąĮąĖčÅ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čüąŠąĘą┤ą░ąĮ ąĖąĘ ą┐čāą╗ą░ čüą▓ąŠą▒ąŠą┤ąĮčŗčģ čüąŠąŠą▒čēąĄąĮąĖą╣.
ąĀąĖčü. 3-13 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┐čāčéčī, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąŠčģąŠą┤ąĖčé čüąŠąŠą▒čēąĄąĮąĖąĄ ą╝ąĄąČą┤čā ą┤ą▓čāą╝čÅ ą┐ąŠč鹊ą║ą░ą╝ąĖ ąĮą░ čĆą░ąĘąĮčŗčģ čāąĘą╗ą░čģ (A ąĖ B), ą│ą┤ąĄ čüčāčēąĄčüčéą▓čāąĄčé ą┐čĆčÅą╝ąŠąĄ čüąŠąĄą┤ąĖąĮąĄąĮąĖąĄ ą╝ąĄąČą┤čā ą┤ą▓čāą╝čÅ čāąĘą╗ą░ą╝ąĖ.
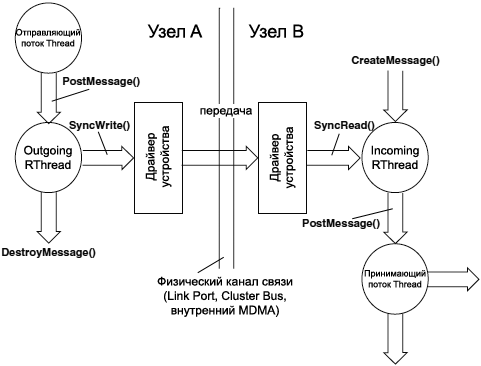
ąĀąĖčü. 3-13. ą×čéą┐čĆą░ą▓ą║ą░ čüąŠąŠą▒čēąĄąĮąĖą╣ ą╝ąĄąČą┤čā čüąŠčüąĄą┤ąĮąĖą╝ąĖ čāąĘą╗ą░ą╝ąĖ.
ąĀąĖčü. 3-14 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čüčåąĄąĮą░čĆąĖą╣, ą│ą┤ąĄ čāąĘąĄą╗ Y čüą╗čāąČąĖčé ą┐čĆąŠą╝ąĄąČčāč鹊čćąĮčŗą╝ ą┐čāąĮą║č鹊ą╝ ąĮą░ ą┐čāčéąĖ ą║ čéčĆąĄčéčīąĄą╝čā čāąĘą╗čā Z. ąĪąŠąŠą▒čēąĄąĮąĖąĄ, ą┐ąŠą┐ą░ą┤ą░čÄčēąĄąĄ ą▓ incoming RThread čāąĘą╗ą░ Y, ąĮą░ą┐čĆčÅą╝čāčÄ ąĮą░ą┐čĆą░ą▓ą╗čÅąĄčéčüčÅ ą▓ outgoing RThread čāąĘą╗ą░ Y.
ąĢčüą╗ąĖ ąĮąĄ ą┐ąŠą╗čāčćąĖą╗ąŠčüčī ą▓čŗą┤ąĄą╗ąĖčéčī čĆąĄčüčāčĆčüčŗ ą┤ą╗čÅ čüąŠąŠą▒čēąĄąĮąĖčÅ ą▓ incoming RThread, č鹊 ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ čüąĖčüč鹥ą╝ąĮą░čÅ ąŠčłąĖą▒ą║ą░ (system error) ąĖ ąĮą░ čŹč鹊ą╝ čāąĘą╗ąĄ ąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ąŠą┤ą░. ąóą░ą║ąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ą║ą░ą║ ą░ą╗čīč鹥čĆąĮą░čéąĖą▓ą░ "ąŠčéą▒čĆą░čüčŗą▓ą░ąĮąĖčÄ" čüąŠąŠą▒čēąĄąĮąĖčÅ, ą║ąŠč鹊čĆąŠąĄ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĖąĮčÅč鹊 (ą┤ąŠčüčéą░ą▓ą║ą░ čüąŠąŠą▒čēąĄąĮąĖą╣ ą▓ ą┐čĆąĄą┤ąĄą╗ą░čģ VDK ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮą░ ą║ą░ą║ ąĮą░ą┤ąĄąČąĮą░čÅ).
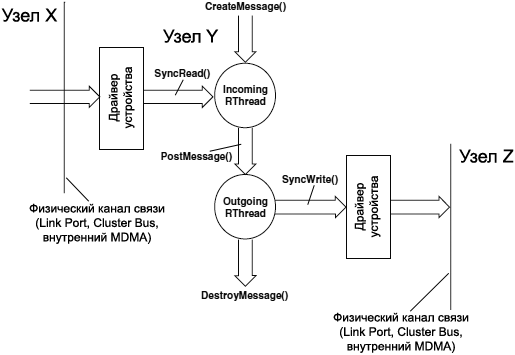
ąĀąĖčü. 3-14. ą×čéą┐čĆą░ą▓ą║ą░ čüąŠąŠą▒čēąĄąĮąĖą╣ ą╝ąĄąČą┤čā ąĮąĄ čüąŠčüąĄą┤ąĮąĖą╝ąĖ čāąĘą╗ą░ą╝ąĖ (č湥čĆąĄąĘ ą┐čĆąŠą╝ąĄąČčāč鹊čćąĮčŗą╣ čāąĘąĄą╗).
ąĢčüčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐čāč鹥ą╣ ąŠą▒ąŠą╣čéąĖ čŹčéčā ą┐čĆąŠą▒ą╗ąĄą╝čā.
1. ąÆčŗą┐ąŠą╗ąĮąĄąĮąĖąĄ čéčēą░č鹥ą╗čīąĮąŠą╣ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ą┐ąŠč鹊ą║ą░ čüąŠąŠą▒čēąĄąĮąĖą╣ ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ, ąĖ čéčēą░č鹥ą╗čīąĮčŗą╝ ą▓čŗą▒ąŠčĆąŠą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓ ą┤ą╗čÅ ą┐ąŠč鹊ą║ąŠą▓ RThread. ąÆ čŹč鹊ą╝ ą╝ąŠąČąĄčé ą┐ąŠą╝ąŠčćčī ą┐ąĄčéą╗čÅ ąŠą▒čĆą░čéąĮąŠą╣ čüą▓čÅąĘąĖ (čé. ąĄ. ą▓ąŠąĘą▓čĆą░čé čüąŠąŠą▒čēąĄąĮąĖą╣ ąŠčéą┐čĆą░ą▓ąĖč鹥ą╗čÄ ą▓ą╝ąĄčüč鹊 ąĖčģ čāąĮąĖčćč鹊ąČąĄąĮąĖčÅ).
2. ą¤čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮąŠąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ čĆąĄčüčāčĆčüąŠą▓ ą┤ą╗čÅ ą▓čüąĄčģ čüąŠąŠą▒čēąĄąĮąĖą╣ ą▓ąŠ ą▓čĆąĄą╝čÅ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ, ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą┐ąĄčéą╗ąĖ ąŠą▒čĆą░čéąĮąŠą╣ čüą▓čÅąĘąĖ čéą░ą║, čćč鹊 ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ąĮčāąČąĮąŠ čÅą▓ąĮąŠ čāąĮąĖčćč鹊ąČą░čéčī čĆąĄčüčāčĆčüčŗ čüąŠąŠą▒čēąĄąĮąĖą╣. ąŻčüčéą░ąĮąŠą▓ą║ą░ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ čüąŠąŠą▒čēąĄąĮąĖą╣ (ąĘą░ą┤ą░ą▓ą░ąĄą╝ąŠąĄ ąĮą░ ąĘą░ą║ą╗ą░ą┤ą║ąĄ Kernel ą┐čĆąŠąĄą║čéą░ VDK) ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ čāąĘą╗ą░ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ čĆą░ą▓ąĮčŗą╝ ąŠą▒čēąĄą╝čā ą║ąŠą╗ąĖč湥čüčéą▓čā čüąŠąŠą▒čēąĄąĮąĖą╣ ą▓čüąĄą╣ čüąĖčüč鹥ą╝čŗ. ąŁč鹊 ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ąĮąĄ ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ čüąĖčéčāą░čåąĖąĖ ąĮąĄą┤ąŠčüčéą░čćąĖ čĆąĄčüčāčĆčüąŠą▓ ą┤ą╗čÅ čüąŠąŠą▒čēąĄąĮąĖą╣ ą┤ą░ąČąĄ ą▓ č鹊ą╝ čüą╗čāčćą░ąĄ, ą║ąŠą│ą┤ą░ ą▓čüąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ čüčĆą░ąĘčā ą▒čāą┤čāčé ąŠčéą┐čĆą░ą▓ą╗ąĄąĮčŗ ąŠą┤ąĮąŠą╝čā čāąĘą╗čā.
3. ą£ąŠąČąĄčé ą▒čŗčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ čüąĄą╝ą░č乊čĆ ą┐ąŠą┤čüč湥čéą░, čćč鹊ą▒čŗ čĆąĄą│čāą╗ąĖčĆąŠą▓ą░čéčī ą┐ąŠč鹊ą║ čüąŠąŠą▒čēąĄąĮąĖą╣ ą▓ čāąĘąĄą╗, ąĖčüą┐ąŠą╗čīąĘčāčÅ API-čäčāąĮą║čåąĖčÄ VDK::InstallMessageControlSemaphore(). ąØą░čćą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ čüąĄą╝ą░č乊čĆą░ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ ą╝ąĄąĮčīčłąĄ ąĖą╗ąĖ čĆą░ą▓ąĮąŠ ą║ąŠą╗ąĖč湥čüčéą▓čā čüą▓ąŠą▒ąŠą┤ąĮčŗčģ čüąŠąŠą▒čēąĄąĮąĖą╣, ą║ąŠč鹊čĆąŠąĄ čĆąĄąĘąĄčĆą▓ąĖčĆčāąĄčéčüčÅ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┐ąŠč鹊ą║ą░ą╝ąĖ RThread. ąŁč鹊čé čüąĄą╝ą░č乊čĆ ąŠąČąĖą┤ą░ąĄčéčüčÅ ą┐ąŠč鹊ą║ąŠą╝ incoming RThread ą┐ąĄčĆąĄą┤ ą║ą░ąČą┤čŗą╝ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄą╝ čĆąĄčüčāčĆčüą░ čüąŠąŠą▒čēąĄąĮąĖčÅ, ąĖ ą┐čāą▒ą╗ąĖą║čāąĄčéčüčÅ ą┐ąŠčüą╗ąĄ ą║ą░ąČą┤ąŠą│ąŠ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ čĆąĄčüčāčĆčüą░ čüąŠąŠą▒čēąĄąĮąĖčÅ ą▓ ą┐ąŠč鹊ą║ąĄ outgoing RThread. ąóą░ą║ ą║ą░ą║ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗą╣ čüč湥čéčćąĖą║ čüąĄą╝ą░č乊čĆą░ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą╝ąĄąĮčīčłąĄ, č湥ą╝ čüą▓ąŠą▒ąŠą┤ąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┤ą╗čÅ čüąŠąŠą▒čēąĄąĮąĖą╣ čāąĘą╗ą░, č鹊 ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ čĆąĄčüčāčĆčüąŠą▓ ą┤ą╗čÅ čüąŠąŠą▒čēąĄąĮąĖčÅ ą▓čüąĄą│ą┤ą░ ą▒čāą┤ąĄčé čāą┤ą░čćąĮčŗą╝. ą×ą┤ąĮą░ą║ąŠ ą┐ąŠč鹊ą║ čüąŠąŠą▒čēąĄąĮąĖą╣ ą▓ čāąĘąĄą╗ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮ, ąĄčüą╗ąĖ čüč湥čéčćąĖą║ čüąĄą╝ą░č乊čĆą░ ą┐ąŠą┐ą░ą╗ ą▓ ąĘąĮą░č湥ąĮąĖąĄ 0.
ąÆą░čĆąĖą░ąĮčé 1 čéčĆąĄą▒čāąĄčé ą┐ąŠą╗ąĮąŠą│ąŠ ą┐ąŠąĮąĖą╝ą░ąĮąĖčÅ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. ąÆą░čĆąĖą░ąĮčé 2 ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ąĘąĮą░čćąĖč鹥ą╗čīąĮčŗą╝ ąĘą░čéčĆą░čéą░ą╝ ą┐ą░ą╝čÅčéąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 čéčĆąĄą▒čāąĄčéčüčÅ ą▒ąŠą╗čīčłąĄ ą╝ąĄčüčéą░ ą┐ąŠą┤ čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąĖąĄ čüąŠąŠą▒čēąĄąĮąĖą╣, č湥ą╝ čŹč鹊 čĆąĄą░ą╗čīąĮąŠ čéčĆąĄą▒čāąĄčéčüčÅ ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, ąŠą┤ąĮą░ą║ąŠ čŹč鹊 čüą░ą╝čŗą╣ ą┐čĆąŠčüč鹊ą╣ ąĖ ąĮą░ą┤ąĄąČąĮčŗą╣ čüą┐ąŠčüąŠą▒ čĆąĄčłąĄąĮąĖčÅ ą┐čĆąŠą▒ą╗ąĄą╝čŗ. ąÆą░čĆąĖą░ąĮčé 3 ą▓ą╗ąĖčÅąĄčé ąĮą░ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī čüąĖčüč鹥ą╝čŗ ąĖąĘ-ąĘą░ ąŠą┐ąĄčĆą░čåąĖą╣ ą┐ąŠ ąŠąČąĖą┤ą░ąĮąĖčÄ ąĖ ą┐čāą▒ą╗ąĖą║ą░čåąĖąĖ čüąĄą╝ą░č乊čĆą░. ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ, ąĄčüą╗ąĖ ą┐ąŠč鹊ą║ čüąŠąŠą▒čēąĄąĮąĖą╣ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮ, čćč鹊 ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ čü ą▓ą░čĆąĖą░ąĮč鹊ą╝ 3, ą╝ąŠą│čāčé ąĮą░čüčéčāą┐ąĖčéčī ą┤čĆčāą│ąĖąĄ ąĮąĄą│ą░čéąĖą▓ąĮčŗąĄ ą┐ąŠčüą╗ąĄą┤čüčéą▓ąĖčÅ ą┤ą╗čÅ čüąĖčüč鹥ą╝čŗ.
ą¤ąĄčĆąĄą┤ą░čćą░ ą┤ą░ąĮąĮčŗčģ (ą╝ą░čĆčłą░ą╗ąĖąĮą│ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ, Payload Marshalling). ą×č湥ąĮčī ą┐čĆąŠčüčéčŗąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╝ąŠą│čāčé ą▒čŗčéčī ą┐ąŠčüą╗ą░ąĮčŗ ą╝ąĄąČą┤čā čāąĘą╗ą░ą╝ąĖ ą▒ąĄąĘ ąĖąĮč鹥čĆą┐čĆąĄčéą░čåąĖąĖ; čé. ąĄ. ąĄčüą╗ąĖ ąĖąĮč乊čĆą╝ą░čåąĖčÅ ą▓ čüąŠąŠą▒čēąĄąĮąĖąĖ ą┐ąŠą╗ąĮąŠčüčéčīčÄ čāą╝ąĄčēą░ąĄčéčüčÅ ą▓ 2 čüą╗ąŠą▓ą░čģ ą┤ą░ąĮąĮčŗčģ čüąŠąŠą▒čēąĄąĮąĖčÅ (ą▓ąĮčāčéčĆąĄąĮąĮčÅčÅ ą┐ąŠą╗ąĄąĘąĮą░čÅ ąĮą░ą│čĆčāąĘą║ą░). ą×ą┤ąĮą░ą║ąŠ ąĄčüą╗ąĖ čüąŠąŠą▒čēąĄąĮąĖąĄ ą▓ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠčüčéąĖ ąĖą╝ąĄąĄčé ą▓ąĮąĄčłąĮąĖąĄ ą┐ąŠą╗ąĄąĘąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ, ąĮą░čģąŠą┤čÅčēąĖąĄčüčÅ ą│ą┤ąĄ-č鹊 ą▓ ą┐ą░ą╝čÅčéąĖ, č鹊 ą░ą┤čĆąĄčü ą▓ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĄ ąĮąĄ ą╝ąŠąČąĄčé ąĖą╝ąĄčéčī ą║ą░ą║ąŠą╣-č鹊 čüą╝čŗčüą╗ ą┤ą╗čÅ ą┤čĆčāą│ąŠą│ąŠ čāąĘą╗ą░. ąÆ čŹčéąĖčģ čüą╗čāčćą░čÅčģ ą┐ąŠą╗ąĄąĘąĮą░čÅ ąĮą░ą│čĆčāąĘą║ą░ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ą┐ąĄčĆąĄą┤ą░ąĮą░ ą▓ą╝ąĄčüč鹥 čü čüąŠąŠą▒čēąĄąĮąĖąĄą╝. ąŁč鹊 ą┤ąĄą╗ą░ąĄčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ payload marshalling.
ąøčÄą▒ąŠą╣ čéąĖą┐ čüąŠąŠą▒čēąĄąĮąĖčÅ, čā ą║ąŠč鹊čĆąŠą│ąŠ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą▒ąĖčé MSB (ą▒ąĖčé ąĘąĮą░ą║ą░, čüčéą░čĆčłąĖą╣ ą▒ąĖčé, čé. ąĄ. ą┐ąŠą╗čāčćą░ąĄčéčüčÅ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ), čüčćąĖčéą░ąĄčéčüčÅ marshalled-čéąĖą┐ąŠą╝, ąŠąĘąĮą░čćą░čÄčēąĖą╝, čćč鹊 čüąĖčüč鹥ą╝ą░ ąŠąČąĖą┤ą░ąĄčé ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąŠą│ąŠ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ, ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ ąĖ čéčĆą░ąĮčüč乥čĆą░ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ ąŠčé čāąĘą╗ą░ ą║ čāąĘą╗čā.
ą¤ąŠčüą║ąŠą╗čīą║čā ąŠčĆą│ą░ąĮąĖąĘą░čåąĖčÅ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ąŠčéą┤ąĄą╗čīąĮąŠą│ąŠ čéąĖą┐ą░ čüąŠąŠą▒čēąĄąĮąĖčÅ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąĘą░ą▓ąĖčüąĖčé č鹊ą╗čīą║ąŠ ąŠčé čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ (čŹč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī čüą▓čÅąĘą░ąĮąĮčŗą╣ čüą┐ąĖčüąŠą║, ąĖą╗ąĖ ą┤ąĄčĆąĄą▓ąŠ, ą░ ąĮąĄ ą┐čĆąŠčüč鹊 čćąĖčüčéčŗą╣ ą▒ą╗ąŠą║ ą┐ą░ą╝čÅčéąĖ), č鹊 ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ, ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ, ąĖ ą┐ąĄčĆąĄą┤ą░čćą░ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ąĘąŠąĮąĄ ąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠčüčéąĖ čäčāąĮą║čåąĖąĖ ą╝ą░čĆčłą░ą╗ąĖąĮą│ą░. ąŻą║ą░ąĘą░č鹥ą╗ąĖ ąĮą░ čŹčéąĖ čäčāąĮą║čåąĖąĖ čüąŠą┤ąĄčƹȹ░čéčüčÅ ą▓ čüčéą░čéąĖč湥čüą║ąŠą╣ čéą░ą▒ą╗ąĖčåąĄ ą╝ą░čĆčłą░ą╗ąĖąĮą│ą░, ą║ąŠč鹊čĆčŗąĄ ąĖąĮą┤ąĄą║čüąĖčĆčāčÄčéčüčÅ ą╝ą╗ą░ą┤čłąĖą╝ąĖ ą▒ąĖčéą░ą╝ąĖ čéąĖą┐ą░ čüąŠąŠą▒čēąĄąĮąĖčÅ.
ążčāąĮą║čåąĖčÅ ą╝ą░čĆčłą░ą╗ąĖąĮą│ą░ čĆąĄą░ą╗ąĖąĘčāąĄčé (ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝) čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ:
ŌĆó ąÆčŗą┤ąĄą╗ąĄąĮąĖąĄ čĆąĄčüčāčĆčüą░ ąĖ ą┐čĆąĖąĄą╝
ŌĆó ą¤ąĄčĆąĄą┤ą░čćą░ ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ čĆąĄčüčāčĆčüą░
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čäčāąĮą║čåąĖąĖ ą╝ą░čĆčłą░ą╗ąĖąĮą│ą░ ąĮąĄ ąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ ą┐ąĄčĆąĄą┤ą░ą▓ą░čéčī ą┐ąŠą╗ąĄąĘąĮčāčÄ ąĮą░ą│čĆčāąĘą║čā č湥čĆąĄąĘ ą┤čĆą░ą╣ą▓ąĄčĆ čāčüčéčĆąŠą╣čüčéą▓ą░. ąŁč鹊 ą╝ąŠąČąĄčé ą┐ąŠčéčĆąĄą▒ąŠą▓ą░čéčīčüčÅ, ąĮą░ą┐čĆąĖą╝ąĄčĆ, č鹊ą╗čīą║ąŠ ą┤ą╗čÅ čéčĆą░ąĮčüą╗ąĖčĆąŠą▓ą░ąĮąĖčÅ ą░ą┤čĆąĄčüą░ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ ąĖąĘ ą╗ąŠą║ą░ą╗čīąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ ą▓ ą░ą┤čĆąĄčü čłąĖąĮčŗ ą║ą╗ą░čüč鹥čĆą░ (ąĮą░ č鹥čģ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ, ą│ą┤ąĄ ąĄčüčéčī čäčāąĮą║čåąĖąŠąĮą░ą╗ čłąĖąĮčŗ ą║ą╗ą░čüč鹥čĆą░), čćč鹊ą▒čŗ čĆą░ąĘčĆąĄčłąĖčéčī ą┤ąŠčüčéčāą┐ ą║ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĄ ąŠčé ą┤čĆčāą│ąŠą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░. ąÜąŠą│ą┤ą░ ą┐ąŠą╗ąĄąĘąĮčŗąĄ ąĮą░ą│čĆčāąĘą║ąĖ ą┤ą╗čÅ ąŠčéą┤ąĄą╗čīąĮąŠą│ąŠ čéąĖą┐ą░ čüąŠąŠą▒čēąĄąĮąĖčÅ ą▓čüąĄą│ą┤ą░ čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ ą▓ ą┐ą░ą╝čÅčéąĖ (ąĮą░ą┐čĆąĖą╝ąĄčĆ SDRAM), čćč鹊 ą▒čāą┤ąĄčé ą▓ąĖą┤ąĮąŠ ą┤ą╗čÅ ą▓čüąĄčģ čāąĘą╗ąŠą▓ ąĖ ą┐čĆąĖą▓čÅąĘą░ąĮąŠ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ čāąĘą╗ą░ ą┤ą╗čÅ č鹊ą│ąŠ ąČąĄ čüą░ą╝ąŠą│ąŠ ą┤ąĖą░ą┐ą░ąĘąŠąĮą░ ą░ą┤čĆąĄčüąŠą▓, č鹊ą│ą┤ą░ ą╝ą░čĆčłą░ą╗ąĖąĮą│ ąĮąĄ ąĮčāąČąĄąĮ. ąóąĖą┐ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╝ąŠąČąĄčé čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą▓ ąĮąĄ ą╝ą░čĆčłą░ą╗ąĖčĆčāąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ (čé. ąĄ. ą▒ąĖčé ąĘąĮą░ą║ą░ ą▒čāą┤ąĄčé čüą▒čĆąŠčłąĄąĮ ą▓ 0).
ą¤ąŠčüą║ąŠą╗čīą║čā ą╝ą░čĆčłą░ą╗ąĖčĆčāąĄą╝ą░čÅ ą┐ąŠą╗ąĄąĘąĮą░čÅ ąĮą░ą│čĆčāąĘą║ą░ čćą░čēąĄ ą▓čüąĄą│ąŠ čüą▓čÅąĘą░ąĮą░ ą╗ąĖą▒ąŠ čü ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄą╝ ą┐ą░ą╝čÅčéąĖ ą╗ąĖą▒ąŠ ąĖąĘ ą║čāčćąĖ, ą╗ąĖą▒ąŠ ąĖąĘ ą┐čāą╗ą░ ą┐ą░ą╝čÅčéąĖ VDK, ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░ VDK ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą▓čüčéčĆąŠąĄąĮąĮčŗąĄ čüčéą░ąĮą┤ą░čĆčéąĮčŗąĄ čäčāąĮą║čåąĖąĖ ą╝ą░čĆčłą░ą╗ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čŹčéąĖčģ čüą╗čāčćą░ąĄą▓ (čüą╝. ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ A "Processor-Specific Notes" ą┤ą╗čÅ ą┐ąŠą┤čĆąŠą▒ąĮąŠčüč鹥ą╣ ą┐ąŠ čĆą░ąĘą╗ąĖčćąĮčŗą╝ čüąĄą╝ąĄą╣čüčéą▓ą░ą╝ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓). ąæąŠą╗ąĄąĄ čüą╗ąŠąČąĮčŗąĄ čüą╗čāčćą░ąĖ (čüą▓čÅąĘą░ąĮąĮčŗąĄ čüčéčĆčāą║čéčāčĆčŗ ą┤ą░ąĮąĮčŗčģ, ąŠą▒čēą░čÅ ą┐ą░ą╝čÅčéčī ąĖ čé. ą┤.) čéčĆąĄą▒čāčÄčé ąĮą░ą┐ąĖčüą░ąĮąĮčŗčģ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝ čäčāąĮą║čåąĖą╣ ą╝ą░čĆčłą░ą╗ąĖčĆąŠą▓ą░ąĮąĖčÅ.
ążčāąĮą║čåąĖąĖ ą╝ą░čĆčłą░ą╗ąĖčĆąŠą▓ą░ąĮąĖčÅ ą▓čŗąĘčŗą▓ą░čÄčéčüčÅ ąĖąĘ ą┐ąŠč鹊ą║ąŠą▓ ą╝ą░čĆčłčĆčāčéąĖąĘą░čåąĖąĖ ąĖ ą▓ ąĮąĖčģ ą┐ąĄčĆąĄą┤ą░čÄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĖąĄ ą░čĆą│čāą╝ąĄąĮčéčŗ:
ŌĆó ąÜąŠą┤ ą╝ą░čĆčłą░ą╗ąĖčĆąŠą▓ą░ąĮąĖčÅ - ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, ą║ą░ą║ąĖąĄ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ąŠą┐ąĄčĆą░čåąĖąĖ.
ŌĆó ąŻą║ą░ąĘą░č鹥ą╗čī ąĮą░ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą┐ą░ą║ąĄčé čüąŠąŠą▒čēąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗą╣ ą▓ą║ą╗čÄčćą░ąĄčé ą▓ čüąĄą▒čÅ čéąĖą┐ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ, čĆą░ąĘą╝ąĄčĆ ąĖ ą░ą┤čĆąĄčü - ą┤ą╗čÅ ą▓čģąŠą┤ą░ ąĖ ą▓čŗčģąŠą┤ą░ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ.
ŌĆó ąöąĄčüą║čĆąĖą┐č鹊čĆ čāčüčéčĆąŠą╣čüčéą▓ą░ - ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāąĄčé ą┤čĆą░ą╣ą▓ąĄčĆ čāčüčéčĆąŠą╣čüčéą▓ą░ VDK ą┤ą╗čÅ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ.
ŌĆó ąśąĮą┤ąĄą║čü ą║čāčćąĖ ąĖą╗ąĖ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ą┐čāą╗ą░ ą┐ą░ą╝čÅčéąĖ PoolID - ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ čüčéą░ąĮą┤ą░čĆčéąĮąŠą│ąŠ ą╝ą░čĆčłą░ą╗ąĖčĆąŠą▓ą░ąĮąĖčÅ.
ŌĆó ąöą╗ąĖč鹥ą╗čīąĮąŠčüčéčī čéą░ą╣ą╝ą░čāčéą░ I/O (ąŠą▒čŗčćąĮąŠ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ą▓ 0 ą┤ą╗čÅ ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠą│ąŠ ąŠąČąĖą┤ą░ąĮąĖčÅ).
ąöą╗čÅ ą┐ąĄčĆąĄą┤ą░čćąĖ čäčāąĮą║čåąĖčÅ ą╝ą░čĆčłą░ą╗ąĖčĆąŠą▓ą░ąĮąĖčÅ čéą░ą║ąČąĄ ąŠčéą▓ąĄčćą░ąĄčé ąĘą░ ą┐ąĄčĆą▓čāčÄ ą┐ąĄčĆąĄą┤ą░čćčā ą┐ą░ą║ąĄčéą░ čüąŠąŠą▒čēąĄąĮąĖčÅ. ąŁč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čäčāąĮą║čåąĖąĖ ą╝ą░čĆčłą░ą╗ąĖąĮą│ą░ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░čéčī ą░čéčĆąĖą▒čāčéčŗ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ą┐ąŠąĮą░ą┤ąŠą▒ąĖčéčüčÅ ą┐ąĄčĆąĄą┤ą░čćą░. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą║ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĄ ąĮčāąČąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ č湥čĆąĄąĘ čłąĖąĮčā ą║ą╗ą░čüč鹥čĆą░ (ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ, ą│ą┤ąĄ ąĄčüčéčī čäčāąĮą║čåąĖąŠąĮą░ą╗ čłąĖąĮčŗ ą║ą╗ą░čüč鹥čĆą░), č鹊 čüą┐ąĄčåąĖčäąĖč湥čüą║ąĖą╣ ą┤ą╗čÅ čāąĘą╗ą░ ą░ą┤čĆąĄčü ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čéčĆą░ąĮčüą╗ąĖčĆąŠą▓ą░ąĮ ą▓ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠąĄ ą░ą┤čĆąĄčüąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ąĖ ąŠą▒čĆą░čéąĮąŠ.
ążčāąĮą║čåąĖčÅ ą╝ą░čĆčłą░ą╗ąĖąĮą│ą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ą┐ąŠč鹊ą║ąŠą▓ ą╝ą░čĆčłčĆčāčéąĖąĘą░čåąĖąĖ RThread. ąÆčŗąĘąŠą▓čŗ SyncRead() ąĖą╗ąĖ SyncWrite(), ą║ąŠč鹊čĆčŗąĄ ą┤ąĄą╗ą░ąĄčé čäčāąĮą║čåąĖčÅ ą╝ą░čĆčłą░ą╗ąĖčĆąŠą▓ą░ąĮąĖčÅ ą▒čāą┤čāčé (ąĖą╗ąĖ ą╝ąŠą│čāčé) ą┐ąĄčĆąĄą▓ąŠą┤ąĖčéčī ą┐ąŠč鹊ą║ąĖ ąĮą░ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĖąĄ ą▓ ąŠąČąĖą┤ą░ąĮąĖąĖ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ą▓ą▓ąŠą┤ą░/ą▓čŗą▓ąŠą┤ą░; ąŠą┤ąĮą░ą║ąŠ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮčŗą╣ ąŠčéą┐čĆą░ą▓ą╗čÅčÄčēąĖą╣ ą┐ąŠč鹊ą║ (ą┐ąŠč鹊ą║ąĖ) ąĮąĄ ą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ą┐ąŠč鹊ą║ąĖ ą╝ą░čĆčłčĆčāčéąĖąĘą░čåąĖąĖ RThreads čĆą░ą▒ąŠčéą░čÄčé ą║ą░ą║ ą▒čāč乥čĆ ą╝ąĄąČą┤čā ą╝ąĄąČą┤čā ą┐ąŠč鹊ą║ą░ą╝ąĖ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ąĖ ą╝ąĄčģą░ąĮąĖąĘą╝ąŠą╝ ą╝ąĄąČą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą╣ ą┐ąĄčĆąĄą┤ą░čćąĖ čüąŠąŠą▒čēąĄąĮąĖą╣.
ąśą╝ąĄą╣č鹥 ą▓ ą▓ąĖą┤čā, čćč鹊 ąĮąĄ ąĮčāąČąĮąŠ čüčéčĆąŠą│ąŠ ą┤ąĄą╗ą░čéčī čéą░ą║, čćč鹊ą▒čŗ čäčāąĮą║čåąĖčÅ ą╝ą░čĆčłą░ą╗ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠ ą┐ąĄčĆąĄą┤ą░ą▓ą░ą╗ą░ ą┤ą░ąĮąĮčŗąĄ. ąÆ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ ąŠą▒čüč鹊čÅč鹥ą╗čīčüčéą▓ą░čģ ą┤ą╗čÅ ąĮąĄčæ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┤ąŠčüčéą░č鹊čćąĮąŠ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ čĆąĄčüčāčĆčüąŠą▓. ą¤čĆąĖą╝ąĄčĆ, ą│ą┤ąĄ čŹč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠą╗ąĄąĘąĮąŠ - ąŠą▒čĆą░čéąĮą░čÅ čüą▓čÅąĘčī ą┐ąŠ čüąŠąŠą▒čēąĄąĮąĖčÄ (ą┐ąĄčĆąĄą┤ą░čćą░ čüąŠąŠą▒čēąĄąĮąĖčÅ ąŠą▒čĆą░čéąĮąŠ, message loopback). ąĪąŠąŠą▒čēąĄąĮąĖąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓ąŠąĘą▓čĆą░čēąĄąĮąŠ ąŠčéą┐čĆą░ą▓ąĖč鹥ą╗čÄ ą┐ąŠčüą╗ąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ąĄą│ąŠ čéąĖą┐ą░ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ čéą░ą║, čćč鹊 ąĄą│ąŠ čäčāąĮą║čåąĖčÅ ą╝ą░čĆčłą░ą╗ąĖąĮą│ą░ ą┐čĆąŠčüč鹊 ąŠčüą▓ąŠą▒ąŠąČą┤ą░ąĄčé ą┐ąŠą╗ąĄąĘąĮčāčÄ ąĮą░ą│čĆčāąĘą║čā ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ čüąŠąŠą▒čēąĄąĮąĖąĄ ą┐ąĄčĆąĄą┤ą░ąĮąŠ, ąĖ ą▓čŗą┤ąĄą╗čÅąĄčé ą┐ąŠą╗ąĄąĘąĮčāčÄ ąĮą░ą│čĆčāąĘą║čā, ą║ąŠą│ą┤ą░ čüąŠąŠą▒čēąĄąĮąĖąĄ ą┐ąŠą╗čāč湥ąĮąŠ. ąŁč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĖąĘą▒ąĄąČą░čéčī ąĘą░čéčĆą░čé čĆąĄčüčāčĆčüąŠą▓ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĮą░ ą┐ąĄčĆąĄą┤ą░čćčā ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗąĄ ą▒ąŠą╗čīčłąĄ ąĮąĄ ąĮčāąČąĮčŗ, ąŠą┤ąĮą░ą║ąŠ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĄ ą▓čüąĄ ąĄčēąĄ ą▒čŗčéčī ąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą╣ čüąĖčüč鹥ą╝ąŠą╣.
ąĢą┤ąĖąĮčüčéą▓ąĄąĮąĮą░čÅ ą┤ąŠą▒ą░ą▓ą╗čÅąĄą╝ą░čÅ čüą╗ąŠąČąĮąŠčüčéčī - ąĮčāąČąĮąŠ ąĖą╝ąĄčéčī ą┤ą▓ą░ ą╝ą░čĆčłą░ą╗ąĖčĆčāąĄą╝čŗčģ čéąĖą┐ą░ ą▓ą╝ąĄčüč鹊 ąŠą┤ąĮąŠą│ąŠ, ąĖ ą┤ą╗čÅ ą┐ąŠč鹊ą║ąŠą▓ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ąĮą░ą┤ąŠ ą╝ąĄąĮčÅčéčī čéąĖą┐ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ ąĮą░ čŹčéąĖ ą┤ą▓ą░ čéąĖą┐ą░, ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü čüąŠčüč鹊čÅąĮąĖąĄą╝ čüąŠąŠą▒čēąĄąĮąĖčÅ - ąĘą░ą┐ąŠą╗ąĮąĄąĮąĮąŠąĄ ąŠąĮąŠ ąĖą╗ąĖ ą┐čāčüč鹊ąĄ. ąöą╗čÅ čŹč鹊ą╣ čåąĄą╗ąĖ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮčŗ čüčéą░ąĮą┤ą░čĆčéąĮčŗąĄ čäčāąĮą║čåąĖąĖ ą╝ą░čĆčłą░ą╗ąĖąĮą│ą░ Empty Pool ąĖ Empty Heap.
ąÜąŠą│ą┤ą░ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ ą╝ą░čĆčłą░ą╗ąĖčĆčāąĄą╝čŗą╣ čéąĖą┐ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ ąĮą░ ąĘą░ą║ą╗ą░ą┤ą║ąĄ Kernel ą┐čĆąŠąĄą║čéą░ VDK, ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą╝ąŠąČąĄčé ą▓čŗą▒čĆą░čéčī ą╗ąĖą▒ąŠ čüčéą░ąĮą┤ą░čĆčéąĮąŠąĄ, ą╗ąĖą▒ąŠ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąŠąĄ ą╝ą░čĆčłą░ą╗ąĖčĆąŠą▓ą░ąĮąĖąĄ. ąöą╗čÅ čüčéą░ąĮą┤ą░čĆčéąĮąŠą│ąŠ ą╝ą░čĆčłą░ą╗ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī (ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝) čüą┤ąĄą╗ą░ąĮ ą▓čŗą▒ąŠčĆ ą╝ąĄąČą┤čā ą╝ą░čĆčłą░ą╗ąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ą║čāčćąĖ ąĖą╗ąĖ ą┐čāą╗ą░, ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü č鹥ą╝, ą│ą┤ąĄ ą▓čŗą┤ąĄą╗čÅąĄčéčüčÅ ą┐ą░ą╝čÅčéčī ą┤ą╗čÅ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ - ą╗ąĖą▒ąŠ ąĖąĘ ą║čāčćąĖ C/C++ heap (čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ API-čĆą░čüčłąĖčĆąĄąĮąĖą╣ VisualDSP++ ą┤ą╗čÅ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą║čāčć), ą╗ąĖą▒ąŠ ąĖąĘ ą┐čāą╗ą░ ą┐ą░ą╝čÅčéąĖ VDK [2]. ąóą░ą║ąČąĄ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čāą║ą░ąĘą░ąĮčŗ HeapID ąĖą╗ąĖ PoolID. ąöą╗čÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąŠą│ąŠ ą╝ą░čĆčłą░ą╗ąĖąĮą│ą░ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąŠ ąĖą╝čÅ čäčāąĮą║čåąĖąĖ ą╝ą░čĆčłą░ą╗ąĖąĮą│ą░, ąĖ ą▒čāą┤ąĄčé ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ čüąŠąĘą┤ą░ąĮ ą╝ąŠą┤čāą╗čī ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░, čüąŠą┤ąĄčƹȹ░čēąĖą╣ čüą║ąĄą╗ąĄčé ą▒čāą┤čāčēąĄą╣ čäčāąĮą║čåąĖąĖ ą╝ą░čĆčłą░ą╗ąĖąĮą│ą░ (ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÄ ąŠčüčéą░ąĮąĄčéčüčÅ č鹊ą╗čīą║ąŠ ąĖąĘą╝ąĄąĮąĖčéčī ąĄčæ č鹥ą╗ąŠ, čćč鹊ą▒čŗ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ čäčāąĮą║čåąĖąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓ąŠą▓ą░ą╗ąŠ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÄ). ąŚą░ą┤ą░č湥ą╣ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ čüčéą░ąĮąŠą▓ąĖčéčüčÅ ą┤ąŠą▒ą░ą▓ąĖčéčī ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ą┤ąĄą╗ą░ąĄčé ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ čĆąĄčüčāčĆčüąŠą▓, ą▓čŗą┐ąŠą╗ąĮčÅąĄčé čćč鹥ąĮąĖąĄ ąĖ ąĘą░ą┐ąĖčüčī ą┤ą╗čÅ čĆąĄą░ą╗čīąĮąŠą╣ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ.
ąöčĆą░ą╣ą▓ąĄčĆčŗ čāčüčéčĆąŠą╣čüčéą▓ą░ ą┤ą╗čÅ ąŠą▒ą╝ąĄąĮą░ čüąŠąŠą▒čēąĄąĮąĖčÅą╝ąĖ. ąöčĆą░ą╣ą▓ąĄčĆčŗ čāčüčéčĆąŠą╣čüčéą▓, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ ą▓ ą┐ąĄčĆąĄą┤ą░č湥 čüąŠąŠą▒čēąĄąĮąĖą╣, ą┤ąŠą╗ąČąĮčŗ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī čüą▓ąŠąĖ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ čüą▓ąŠą╣čüčéą▓ą░, ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄą╝čŗąĄ ą▓ ą┤ąĖąĘą░ą╣ąĮąĄ ą╝ą░čĆčłčĆčāčéąĖąĘąĖčĆčāčÄčēąĖčģ ą┐ąŠč鹊ą║ąŠą▓:
ŌĆó ąĪąĖąĮčģčĆąŠąĮąĮąŠąĄ čäčāąĮą║čåąĖąŠąĮąĖčĆąŠą▓ą░ąĮąĖąĄ - ą║ą░ą║ č鹊ą╗čīą║ąŠ ą┐čĆąŠąĖąĘąŠčłąĄą╗ ą▓ąŠąĘą▓čĆą░čé ąĖąĘ ą▓čŗąĘąŠą▓ą░ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ, ą▓čŗąĘčŗą▓ą░čÄčēąĖą╣ ą║ąŠą┤ ąĘąĮą░ąĄčé, čćč鹊 ą┤ą░ąĮąĮčŗąĄ ą▒čŗą╗ąĖ ąŠčéą┐čĆą░ą▓ą╗ąĄąĮčŗ.
ŌĆó ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąŠč鹊ą║ąŠą╝ ą┤ą░ąĮąĮčŗčģ (flow control) - ąĮąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą┐ąŠč鹥čĆčī, ąĄčüą╗ąĖ ąĘą░ą┐ąĖčüčī (čüąŠ čüč鹊čĆąŠąĮčŗ ąŠčéą┐čĆą░ą▓ąĖč鹥ą╗čÅ) ą▒čŗą╗ą░ ąĖąĮąĖčåąĖąĖčĆąŠą▓ą░ąĮą░ ą┐ąĄčĆąĄą┤ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╝ čćč鹥ąĮąĖąĄą╝ (ąĮą░ čüč鹊čĆąŠąĮąĄ ą┐čĆąĖąĄą╝ąĮąĖą║ą░).
ŌĆó ąØą░ą┤ąĄąČąĮą░čÅ ą┤ąŠčüčéą░ą▓ą║ą░ - ą▓čüąĄ ąŠčéą┐čĆą░ą▓ą╗ąĄąĮąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ (ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ ąĘą░ą┐ąĖčüą░ąĮčŗ) ą▒čāą┤čāčé ą┐čĆąĖąĮčÅčéčŗ (ą┐čĆąŠčćąĖčéą░ąĮčŗ) ąĮą░ ą┤čĆčāą│ąŠą╣ čüč鹊čĆąŠąĮąĄ.
ąÜą░ą║ čāąČąĄ čāą┐ąŠą╝ąĖąĮą░ą╗ąŠčüčī čĆą░ąĮąĄąĄ, čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čüąŠąŠą▒čēąĄąĮąĖą╣ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą▓ ą┤čĆą░ą╣ą▓ąĄčĆ čüąŠąŠą▒čēąĄąĮąĖą╣ ąĖ čćąĖčéą░ąĄčéčüčÅ ąĖąĘ ąĮąĄą│ąŠ ą║ą░ą║ ą┐ą░ą║ąĄčéčŗ čüąŠąŠą▒čēąĄąĮąĖčÅ. ąŻ čŹčéąĖčģ ą┐ą░ą║ąĄč鹊ą▓ čĆą░ąĘą╝ąĄčĆ 16 ą▒ą░ą╣čé (128 ą▒ąĖčé), ąĖ ąŠąĮąĖ ą▓čüąĄą│ą┤ą░ čćąĖčéą░čÄčéčüčÅ ąĖ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ ą║ą░ą║ ąŠą┤ąĖąĮąŠčćąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ čü ą┤ą░ąĮąĮčŗą╝ąĖ ąĖą╝ąĄąĮąĮąŠ čéą░ą║ąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░. ąöčĆą░ą╣ą▓ąĄčĆčŗ čāčüčéčĆąŠą╣čüčéą▓ą░, čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą╝ąŠą│čāčé ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░čéčī čŹčéąĖ ą┐ąĄčĆąĄą┤ą░čćąĖ, ą║ą░ą║ čŹč鹊 ą┤ąĄą╗ą░ąĄčéčüčÅ čćą░čēąĄ ą▓čüąĄą│ąŠ, čģąŠčéčÅ ą╝ąŠą│čāčé ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čéčīčüčÅ ąĖ ą┤čĆčāą│ąĖąĄ čĆą░ąĘą╝ąĄčĆčŗ.
ąÜą░ą║ ąĖ ą┐ą░ą║ąĄčéčŗ čüąŠąŠą▒čēąĄąĮąĖčÅ, ą┤čĆą░ą╣ą▓ąĄčĆ čāčüčéčĆąŠą╣čüčéą▓ą░ ą┤ąŠą╗ąČąĄąĮ ą┤ąŠą╗ąČąĄąĮ čéą░ą║ąČąĄ ą┐ąĄčĆąĄą┤ą░čéčī ą┐ąŠą╗ąĄąĘąĮčāčÄ ąĮą░ą│čĆčāąĘą║čā, ą║ąŠč鹊čĆą░čÅ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ąĖ čćąĖčéą░ąĄčéčüčÅ čäčāąĮą║čåąĖąĖ ą╝ą░čĆčłą░ą╗ąĖčĆąŠą▓ą░ąĮąĖčÅ. ąŚą░ čŹč鹊 ąŠčéą▓ąĄčćą░ąĄčé čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ą╝ą░čĆčłą░ą╗ąĖčĆčāąĄą╝čŗąĄ čäčāąĮą║čåąĖąĖ ą┤čĆą░ą╣ą▓ąĄčĆąŠą▓ čāčüčéčĆąŠą╣čüčéą▓ą░ ą▓ą╝ąĄčüč鹥 ą║ąŠčĆčĆąĄą║čéąĮąŠ čĆą░ą▒ąŠčéą░čÄčé, čé. ąĄ. ą╗čÄą▒čŗąĄ ąŠą│čĆą░ąĮąĖč湥ąĮąĖčÅ ąĮą░ čĆą░ąĘą╝ąĄčĆ ą┐ąĄčĆąĄą┤ą░čćąĖ ąĖą╗ąĖ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ, ąĮą░ą║ą╗ą░ą┤čŗą▓ą░ąĄą╝čŗąĄ ą┤čĆą░ą╣ą▓ąĄčĆą░ą╝ąĖ, čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆčÅčÄčé ą┐ąŠą╗ąĄąĘąĮčŗą╝ ąĮą░ą│čĆčāąĘą║ą░ą╝. ąŁč鹊 čéą░ą║ąČąĄ ą▓ąĄčĆąĮąŠ ą┤ą╗čÅ ą╝ą░čĆčłą░ą╗ąĖčĆčāąĄą╝čŗčģ čéąĖą┐ąŠą▓ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ čüčéą░ąĮą┤ą░čĆčéąĮąŠą│ąŠ ą╝ą░čĆčłą░ą╗ąĖąĮą│ą░ - čĆą░ąĘą╝ąĄčĆčŗ ąĖ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ ą║čāčćąĖ ąĖą╗ąĖ ą┐čāą╗ą░ ą┐ą░ą╝čÅčéąĖ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą┤ąŠą┐čāčüčéąĖą╝čŗą╝ąĖ ą┤ą╗čÅ ąŠą▒ą╝ąĄąĮą░ čüąŠąŠą▒čēąĄąĮąĖčÅą╝ąĖ ą┤čĆą░ą╣ą▓ąĄčĆąŠą▓ čāčüčéčĆąŠą╣čüčéą▓.
ąóą░ą╝, ą│ą┤ąĄ ąĄčüčéčī ą┤ą▓čāąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĮąŠąĄ ą░ą┐ą┐ą░čĆą░čéąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ (čéą░ą║ąŠąĄ ą║ą░ą║ link port, ą┐čĆąĖčüčāčéčüčéą▓čāčÄčēąĖą╣ ą┐ąŠčćčéąĖ ąĮą░ ą▓čüąĄčģ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ TigerSHARC ąĖą╗ąĖ SHARC), ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄą╝ąŠąĄ ąŠą┤ąĮąĖą╝ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą╝ ą┤čĆą░ą╣ą▓ąĄčĆą░ čāčüčéčĆąŠą╣čüčéą▓ą░ ąĮą░ ą║ą░ąČą┤ąŠą╝ ąĖąĘ ą┤ą▓čāčģ čāąĘą╗ąŠą▓, ą║ąŠč鹊čĆčŗąĄ ą┤čĆą░ą╣ą▓ąĄčĆ čüąŠąĄą┤ąĖąĮčÅąĄčé, č鹊 ą┤ą╗čÅ ą┤čĆą░ą╣ą▓ąĄčĆą░ čāčüčéčĆąŠą╣čüčéą▓ą░ čéčĆąĄą▒čāąĄčéčüčÅ čĆą░ąĘčĆąĄčłąĖčéčī čüą░ą╝ąŠą╝čā čüąĄą▒ąĄ ą▒čŗčéčī ąŠčéą║čĆčŗčéčŗą╝ ąŠą▒ąŠąĖą╝ąĖ ą┐ąŠč鹊ą║ą░ą╝ąĖ ą╝ą░čĆčłčĆčāčéąĖąĘą░čåąĖąĖ - incoming ąĖ outgoing. ą×ą▒ąŠą▒čēąĄąĮąĮą░čÅ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ąŠčéą║čĆčŗčéąĖčÅ ą╝ąĮąŠąČąĄčüčéą▓ąŠ čĆą░ąĘ ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ. ąÆą░ąČąĮą░ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠą│ąŠ ąŠčéą║čĆčŗčéąĖčÅ ąŠą┤ąĖąĮ čĆą░ąĘ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ ąĖ ąŠą┤ąĖąĮ čĆą░ąĘ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ (čćč鹊 ąĖąĮąŠą│ą┤ą░ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ čĆą░ąĘą┤ąĄą╗ąĄąĮąĮąŠąĄ ąŠčéą║čĆčŗčéąĖąĄ, split open). ąÉą╗čīč鹥čĆąĮą░čéąĖą▓ąĮąŠ ą┤ą╗čÅ ąĮąĄą║ąŠč鹊čĆčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▒ąŠą╗ąĄąĄ ą┐čĆąĄą┤ą┐ąŠčćčéąĖč鹥ą╗čīąĮčŗą╝ čüąŠąĘą┤ą░ąĮąĖąĄ ą┤ą▓čāčģ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą▓ ą┤čĆą░ą╣ą▓ąĄčĆą░ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ čāąĘą╗ą░, čéą░ą║ čćč鹊ą▒čŗ ą░ą┐ą┐ą░čĆą░čéčāčĆą░ ą▒čŗą╗ą░ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮą░ ą▓ ąŠčéą┤ąĄą╗čīąĮčŗčģ ąŠą┤ąĮąŠąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĮčŗčģ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅčģ.
ąóąŠą┐ąŠą╗ąŠą│ąĖčÅ ą╝ą░čĆčłčĆčāčéąĖąĘą░čåąĖąĖ (Routing Topology). ąĀą░ąĘčĆą░ą▒ąŠčéčćąĖą║ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą┤ąŠą╗ąČąĮčŗ ą▓čŗą▒čĆą░čéčī čüčéčĆčāą║čéčāčĆčā ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą║ąŠąĮą║čĆąĄčéąĮąŠą│ąŠ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. ąÆčŗą▒ąŠčĆ č鹥čüąĮąŠ čüą▓čÅąĘą░ąĮ čü ąŠčĆą│ą░ąĮąĖąĘą░čåąĖąĄą╣ ą░ą┐ą┐ą░čĆą░čéčāčĆčŗ čåąĄą╗ąĄą▓ąŠą╣ čüąĖčüč鹥ą╝čŗ.
ąÆ 菹║čüčéčĆąĄą╝ą░ą╗čīąĮąŠą╣, ąĖą┤ąĄą░ą╗čīąĮąŠą╣ čüąĖčéčāą░čåąĖąĖ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą┐čĆčÅą╝ąŠąĄ čüąŠąĄą┤ąĖąĮąĄąĮąĖąĄ ą╝ąĄąČą┤čā ą║ą░ąČą┤čŗą╝ čāąĘą╗ąŠą╝. ąÆ čéą░ą║ąŠą╣ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ čüą║ą▓ąŠąĘąĮą░čÅ ą╝ą░čĆčłčĆčāčéąĖąĘą░čåąĖčÅ: čé. ąĄ. ą║ą░ąČą┤ą░čÅ ą┐čāą▒ą╗ąĖą║ą░čåąĖčÅ čüąŠąŠą▒čēąĄąĮąĖą╣ čéčĆąĄą▒čāąĄčé č鹊ą╗čīą║ąŠ ąŠą┤ąĮčā čüčéą░ą┤ąĖčÄ. ąŁč鹊ą│ąŠ ą╝ąŠąČąĮąŠ ą┤ąŠčüčéąĖčćčī, ą║ąŠą│ą┤ą░ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čāąĘą╗ąŠą▓ ąĮąĄą▓ąĄą╗ąĖą║ąŠ (ąŠčé ą┤ą▓čāčģ ą┤ąŠ ą┐čÅčéąĖ). ą×ą┤ąĮą░ą║ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čüąŠąĄą┤ąĖąĮąĄąĮąĖą╣ ąŠč湥ąĮčī ą▒čŗčüčéčĆąŠ čüčéą░ąĮąŠą▓ąĖčéčüčÅ ąĮąĄą┤ąŠą┐čāčüčéąĖą╝ąŠ ą▒ąŠą╗čīčłąĖą╝ čü čĆąŠčüč鹊ą╝ ą║ąŠą╗ąĖč湥čüčéą▓ą░ čāąĘą╗ąŠą▓.
ąÆ ą┤čĆčāą│ąŠą╝ 菹║čüčéčĆąĄą╝ą░ą╗čīąĮąŠą╝ čüą╗čāčćą░ąĄ čéčĆąĄą▒čāąĄčéčüčÅ ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čüąŠąĄą┤ąĖąĮąĄąĮąĖą╣ ąĮą░ čāąĘąĄą╗ - ąŠą┤ąĮąŠ ą┤ą╗čÅ incoming, ą┤čĆčāą│ąŠąĄ ą┤ą╗čÅ outgoing. ąóą░ą║ą░čÅ čüčģąĄą╝ą░ ą┤ąŠčüčéą░č鹊čćąĮą░ ą┤ą╗čÅ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖąĖ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ čāąĘą╗ąŠą▓ ą▓ ą┐čĆąŠčüč鹊ąĄ ą║ąŠą╗čīčåąŠ. ąØąŠ ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą┐čāą▒ą╗ąĖą║ą░čåąĖčÅ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╝ąŠąČąĄčé ą┐ąŠčéčĆąĄą▒ąŠą▓ą░čéčī ą╝ąĮąŠąČąĄčüčéą▓ą░ ą┐čĆąŠą╝ąĄąČčāč鹊čćąĮčŗčģ čāąĘą╗ąŠą▓, ąĄčüą╗ąĖ ąŠčéą┐čĆą░ą▓ąĖč鹥ą╗čī ąĖ ą┐čĆąĖąĄą╝ąĮąĖą║ ąĮą░čģąŠą┤čÅčéčüčÅ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ ąĮą░ ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠą╝ čāą┤ą░ą╗ąĄąĮąĖąĖ, č湥čĆąĄąĘ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐čĆąŠą╝ąĄąČčāč鹊čćąĮčŗčģ čāąĘą╗ąŠą▓. ąĢčüą╗ąĖ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ ą┤ą▓čāąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĮčŗąĄ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, čŹč鹊 link port) ąĖ ąĮą░ ą║ą░ąČą┤ąŠą╝ čāąĘą╗ąĄ ąĄčüčéčī ą┤ą▓ą░, č鹊 ą╝ąŠąČąĮąŠ ąŠčĆą│ą░ąĮąĖąĘąŠą▓ą░čéčī ą┤ą▓čāąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĮąŠąĄ ą║ąŠą╗čīčåąŠ - ą║ąŠą│ą┤ą░ čüąŠąŠą▒čēąĄąĮąĖčÅ čåąĖčĆą║čāą╗ąĖčĆčāčÄčé ą▓ ą┤ą▓čāčģ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖčÅčģ.
ą£ąĄąČą┤čā čŹčéąĖą╝ąĖ ą┤ą▓čāą╝čÅ čŹą║čüčéčĆąĄą╝ą░ą╗čīąĮčŗą╝ąĖ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÅą╝ąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ąĖ ą┤čĆčāą│ąĖąĄ, ą▓ą║ą╗čÄčćą░čÅ čĆąĄčłąĄčéą║ąĖ, ą║čāą▒čŗ, ą│ąĖą┐ąĄčĆą║čāą▒čŗ (ąĄčüą╗ąĖ ąĖą╝ąĄąĄčéčüčÅ ą┤ąŠčüčéą░č鹊čćąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą╗ąĖąĮą║ąŠą▓ ąĮą░ ą║ą░ąČą┤ąŠą╝ čāąĘą╗ąĄ). ąóą░ą╝, ą│ą┤ąĄ čüąĖčüč鹥ą╝ą░ čü čģąŠčüč鹊ą╝ čÅą▓ą╗čÅąĄčéčüčÅ čćą░čüčéčīčÄ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ąĖ čāčćą░čüčéą▓čāąĄčé ą▓ ąŠą▒ą╝ąĄąĮąĄ čüąŠąŠą▒čēąĄąĮąĖčÅą╝ąĖ, čŹč鹊 čéą░ą║ąČąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą▓ą║ą╗čÄč湥ąĮąŠ ą▓ č鹊ą┐ąŠą╗ąŠą│ąĖčÄ ą╝ą░čĆčłčĆčāčéąĖąĘą░čåąĖąĖ.
ąĀą░ąĘčĆą░ą▒ąŠčéą║čā čüąĄčéąĖ ą╝ą░čĆčłčĆčāčéąĖąĘą░čåąĖąĖ ą╗čāčćčłąĄ ą▓čüąĄą│ąŠ ąĮą░čćąĖąĮą░čéčī "ąĮą░ ą▒čāą╝ą░ą│ąĄ", ą▓ ą▓ąĖą┤ąĄ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĮąŠą│ąŠ ą│čĆą░čäą░ ąĖąĘ čāąĘą╗ąŠą▓ ąĖ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĮčŗčģ ą╝ąĄąČą┤čā ąĮąĖą╝ąĖ čüčéčĆąĄą╗ąŠą║ čüąŠąĄą┤ąĖąĮąĄąĮąĖą╣. ąĀą░ąĘčĆą░ą▒ąŠčéčćąĖą║ ą┤ąŠą╗ąČąĄąĮ čāčćąĖčéčŗą▓ą░čéčī ąĮą░ąĘąĮą░č湥ąĮąĖąĄ ą┐ąŠč鹊ą║ąŠą▓ ąĮą░ čāąĘą╗čŗ čéą░ą║, čćč鹊ą▒čŗ ą║ą░ą║ ą╝ąŠąČąĮąŠ ą▒ąŠą╗čīčłąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čüąŠąŠą▒čēąĄąĮąĖą╣ ą┐čĆąŠčģąŠą┤ąĖą╗ąŠ č湥čĆąĄąĘ ą┐čĆčÅą╝čŗąĄ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ (ą▒ąĄąĘ ą┐čĆąŠą╝ąĄąČčāč鹊čćąĮčŗčģ čāąĘą╗ąŠą▓). ąÜą░ą║ č鹊ą╗čīą║ąŠ čüąŠčüčéą░ą▓ą╗ąĄąĮą░ č鹊ą┐ąŠą╗ąŠą│ąĖčÅ čü čāč湥č鹊ą╝ ąŠą│čĆą░ąĮąĖč湥ąĮąĖą╣ ą┐ąŠ ąĖą╝ąĄčÄčēąĄą╣čüčÅ ą░ą┐ą┐ą░čĆą░čéčāčĆąĄ, č鹊 čüąĖčüč鹥ą╝ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠą┐ąĖčüą░ąĮą░ ą▓ č鹥čĆą╝ąĖąĮą░čģ ID čāąĘą╗ąŠą▓, ą┤čĆą░ą╣ą▓ąĄčĆąŠą▓ čāčüčéčĆąŠą╣čüčéą▓ ąĖ ą┐ąŠč鹊ą║ąŠą▓ ą╝ą░čĆčłčĆčāčéąĖąĘą░čåąĖąĖ. ąŁčéą░ ąĖąĮč乊čĆą╝ą░čåąĖčÅ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓ą▓ąĄą┤ąĄąĮą░ ąĮą░ ąĘą░ą║ą╗ą░ą┤ą║ąĄ Kernel ą┐čĆąŠąĄą║čéą░ VDK ą║ą░ąČą┤ąŠą│ąŠ čāąĘą╗ą░.
ąÆą╝ąĄčüč鹥 čü čāčüčéą░ąĮąŠą▓ą║ąŠą╣ VisualDSP++ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčéčüčÅ ą┐čĆąĖą╝ąĄčĆčŗ ą┤ą╗čÅ ą┐ą╗ą░čé EZ-KIT Lite, ąĮą░ ą║ąŠč鹊čĆčŗčģ ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą│ąŠ čÅą┤čĆą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą┐čĆąŠčåąĄčüčüąŠčĆ ADSP-BF561), ąĖą╗ąĖ čā ą║ąŠč鹊čĆčŗčģ ąĄčüčéčī čüą┐ąĄčåąĖą░ą╗čīąĮąŠ čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮąĮčŗąĄ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, čŹč鹊 link port-čŗ ą╝ąĮąŠą│ąĖčģ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ TigerSHARC ąĖ SHARC). ąÆ čŹčéąĖčģ ą┐čĆąĖą╝ąĄčĆą░čģ čāąČąĄ ą┐čĆąĖčüčāčéčüčéą▓čāčÄčé ą┐ąŠą┤čģąŠą┤čÅčēąĖąĄ ą┤čĆą░ą╣ą▓ąĄčĆčŗ čāčüčéčĆąŠą╣čüčéą▓ ąĖ ą┐ąŠč鹊ą║ąĖ ą╝ą░čĆčłčĆčāčéąĖąĘą░čåąĖąĖ (ą┤ą╗čÅ č鹊ą┐ąŠą╗ąŠą│ąĖą╣ čü ąĮą░ą╗ąĖčćąĖąĄą╝ ą▓čüąĄčģ ą▓ąŠąĘą╝ąŠąČąĮčŗčģ ą┐čĆčÅą╝čŗčģ čüąŠąĄą┤ąĖąĮąĄąĮąĖą╣, ą┐ąŠčüą║ąŠą╗čīą║čā ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čāąĘą╗ąŠą▓ ą╝ą░ą╗ąŠ), čćč鹊 ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą║ą░ą║ čüčéą░čĆč鹊ą▓čāčÄ č鹊čćą║čā ą┤ą╗čÅ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ąĮąŠą▓čŗčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣.
[ąĪąŠą▒čŗčéąĖčÅ ąĖ ą▒ąĖčéčŗ čüąŠą▒čŗčéąĖą╣ (Events and Event Bits)]
ąĪąŠą▒čŗčéąĖčÅ ąĖ ą▒ąĖčéčŗ čüąŠą▒čŗčéąĖą╣ čŹč鹊 čüąĖą│ąĮą░ą╗čŗ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ ą┤ą╗čÅ čĆąĄą│čāą╗ąĖčĆąŠą▓ą░ąĮąĖčÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐ąŠč鹊ą║ąŠą▓, ą▒ą░ąĘąĖčĆčāčÅčüčī ąĮą░ čüąŠčüč鹊čÅąĮąĖąĖ čüąĖčüč鹥ą╝čŗ. ąæąĖčé čüąŠą▒čŗčéąĖčÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖąĖ ąŠ č鹊ą╝, čćč鹊 ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╣ 菹╗ąĄą╝ąĄąĮčé čüąĖčüč鹥ą╝čŗ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ čāą║ą░ąĘą░ąĮąĮąŠą╝ čüąŠčüč鹊čÅąĮąĖąĖ. ąĪąŠą▒čŗčéąĖąĄ čŹč鹊 ą┤ą▓ąŠąĖčćąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ, ą▓čŗą┐ąŠą╗ąĮčÅąĄą╝ą░čÅ ąĮą░ą┤ čüąŠčüč鹊čÅąĮąĖąĄą╝ ą▓čüąĄčģ ą▒ąĖčé čüąŠą▒čŗčéąĖą╣. ąÜąŠą│ą┤ą░ ą▒čāą╗ąĄą▓ą░ ą║ąŠą╝ą▒ąĖąĮą░čåąĖčÅ ą▒ąĖčé čüąŠą▒čŗčéąĖą╣ čéą░ą║ą░čÅ, čćč鹊 čüąŠą▒čŗčéąĖąĄ ą▓čŗčćąĖčüą╗čÅąĄčéčüčÅ ą║ą░ą║ TRUE, ą▓čüąĄ ą┐ąŠč鹊ą║ąĖ, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮčŗ ąĮą░ ąŠąČąĖą┤ą░ąĮąĖąĖ čüąŠą▒čŗčéąĖčÅ, ą┐ąĄčĆąĄčģąŠą┤čÅčé ą▓ ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ, ąĖ čüąŠą▒čŗčéąĖąĄ ąŠčüčéą░ąĄčéčüčÅ ą▓ čüąŠčüč鹊čÅąĮąĖąĖ TRUE. ąøčÄą▒ąŠą╣ ą┐ąŠč鹊ą║, ą║ąŠč鹊čĆčŗą╣ ąŠąČąĖą┤ą░ąĄčé čüąŠą▒čŗčéąĖčÅ, ą▓čŗčćąĖčüą╗ąĄąĮąĮąŠą│ąŠ ą║ą░ą║ TRUE, ąĮąĄ ą▒čāą┤ąĄčé ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮ, ąĮąŠ ą║ąŠą│ą┤ą░ čüąŠą▒čŗčéąĖčÅ ą╝ąĄąĮčÅčÄčéčüčÅ čéą░ą║, čćč鹊 čüąŠą▒čŗčéąĖąĄ ą▓čŗčćąĖčüą╗čÅąĄčéčüčÅ ą║ą░ą║ FALSE, č鹊 ą╗čÄą▒ąŠą╣ ąŠąČąĖą┤ą░čÄčēąĖą╣ čŹč鹊 čüąŠą▒čŗčéąĖąĄ ą┐ąŠč鹊ą║ ą▒čāą┤ąĄčé ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮ.
ąÜąŠą╗ąĖč湥čüčéą▓ąŠ čüąŠą▒čŗčéąĖą╣ ąĖ ą▒ąĖč鹊ą▓ čüąŠą▒čŗčéąĖą╣ ąŠą│čĆą░ąĮąĖč湥ąĮąŠ čĆą░ąĘą╝ąĄčĆąŠą╝ čüą╗ąŠą▓ą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą╝ąĖąĮčāčü 1. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ Blackfin, SHARC ąĖ TigerSHARC ą╝ąŠąČąĄčé ą▒čŗčéčī 31 čüąŠą▒čŗčéąĖąĄ ąĖ ą▒ąĖč鹊ą▓ čüąŠą▒čŗčéąĖčÅ.
ą¤ąŠą▓ąĄą┤ąĄąĮąĖąĄ čüąŠą▒čŗčéąĖą╣. ąÜą░ąČą┤ąŠąĄ čüąŠą▒čŗčéąĖąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé čüčéčĆčāą║čéčāčĆčā ą┤ą░ąĮąĮčŗčģ VDK_EventData, ą║ąŠč鹊čĆą░čÅ ąĖąĮą║ą░ą┐čüčāą╗ąĖčĆčāąĄčé ą▓ čüąĄą▒ąĄ ą▓čüčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čāčÄ ą┤ą╗čÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ čüąŠą▒čŗčéąĖčÅ:
typedef struct
{
bool matchAll;
unsigned int values;
unsigned int mask;
} VDK_EventData;
ąÜąŠą│ą┤ą░ ąĮą░čüčéčĆą░ąĖą▓ą░ąĄčéčüčÅ čüąŠą▒čŗčéąĖąĄ, ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄčéčüčÅ čäą╗ą░ą│, ąŠą┐ąĖčüčŗą▓ą░čÄčēąĖą╣, ą║ą░ą║ ąŠą▒čĆą░ą▒ąŠčéą░čéčī ą╝ą░čüą║čā ąĖ čåąĄą╗ąĄą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ:
matchAll: TRUE ą║ąŠą│ą┤ą░ čüąŠą▒čŗčéąĖąĄ ą┤ąŠą╗ąČąĮąŠ č鹊čćąĮąŠ čüąŠąŠčéą▓ąĄčéčüčéą▓ąŠą▓ą░čéčī ą▓čüąĄą╝ ą╝ą░čüą║ąĖčĆąŠą▓ą░ąĮąĮčŗą╝ ą▒ąĖčéą░ą╝. FALSE ąĄčüą╗ąĖ čüąŠą▓ą┐ą░ą┤ąĄąĮąĖąĄ čü ą╗čÄą▒čŗą╝ ą╝ą░čüą║ąĖčĆąŠą▓ą░ąĮąĮčŗą╝ ą▒ąĖč鹊ą╝ ąŠąĘąĮą░čćą░ąĄčé ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ čüąŠą▒čŗčéąĖčÅ ą║ą░ą║ TRUE.
values: čåąĄą╗ąĄą▓čŗąĄ ąĘąĮą░č湥ąĮąĖčÅ ą┤ą╗čÅ ą▒ąĖč鹊ą▓ čüąŠą▒čŗčéąĖą╣, ą╝ą░čüą║ąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ą┐ąŠą╗ąĄą╝ ą╝ą░čüą║ąĖ čüčéčĆčāą║čéčāčĆčŗVDK_EventData.
mask: ąĘą░ą┤ą░ąĄčé ą▒ąĖčéčŗ čüąŠą▒čŗčéąĖą╣, ą║ąŠč鹊čĆčŗąĄ čāčćą░čüčéą▓čāčÄčé ą▓ ą▓čŗčćąĖčüą╗ąĄąĮąĖąĖ čüąŠą▒čŗčéąĖčÅ.
ąÆ ąŠčéą╗ąĖčćąĖąĄ ąŠčé čüąĄą╝ą░č乊čĆąŠą▓, čüąŠą▒čŗčéąĖčÅ ą▓čüąĄą│ą┤ą░ TRUE, ą║ąŠą│ą┤ą░ ąĖčģ čāčüą╗ąŠą▓ąĖčÅ TRUE, ąĖ ą▓čüąĄ ą┐ąŠč鹊ą║ąĖ, ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ąĮą░ čüąŠą▒čŗčéąĖąĖ, ą┐ąĄčĆąĄčģąŠą┤čÅčé ą▓ ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ. ąĢčüą╗ąĖ ą┐ąŠč鹊ą║ ąŠąČąĖą┤ą░ąĄčé čüąŠą▒čŗčéąĖčÅ, ą║ąŠč鹊čĆąŠąĄ čāąČąĄ TRUE, č鹊 ą┐ąŠč鹊ą║ ą┐čĆąŠą┤ąŠą╗ąČąĖčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ, ąĖ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ ąĮąĄ ą▒čāą┤ąĄčé ą▓čŗąĘą▓ą░ąĮ. ąØą░ą┐ąŠą┤ąŠą▒ąĖąĄ čüąĄą╝ą░č乊čĆąŠą▓, ą┐ąŠč鹊ą║, ąŠąČąĖą┤ą░čÄčēąĖą╣ ąĮą░ čüąŠą▒čŗčéąĖąĖ, ą║ąŠč鹊čĆąŠąĄ ąĮąĄ čüčéą░ą╗ąŠ TRUE, ąŠčüčéą░ąĄčéčüčÅ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĮčŗą╝, ą┐ąŠą║ą░ čüąŠą▒čŗčéąĖąĄ ąĮąĄ čüčéą░ąĮąĄčé true, ąĖą╗ąĖ ą┐ąŠą║ą░ ąĮąĄ ąĖčüč鹥č湥čé čéą░ą╣ą╝ą░čāčé ą┐ąŠč鹊ą║ą░. ą×ąČąĖą┤ą░ąĮąĖąĄ čü čéą░ą╣ą╝ą░čāč鹊ą╝ 0 ąĮą░ čüąŠą▒čŗčéąĖąĖ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąŠąČąĖą┤ą░ąĮąĖčÄ ą▒ąĄąĘ čéą░ą╣ą╝ą░čāčéą░ (ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠ).
ąōą╗ąŠą▒ą░ą╗čīąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ ą▒ąĖčé čüąŠą▒čŗčéąĖčÅ. ąĪąŠčüč鹊čÅąĮąĖąĄ ą▓čüąĄčģ ą▒ąĖčé čüąŠą▒čŗčéąĖčÅ čüąŠčģčĆą░ąĮčÅąĄčéčüčÅ ą▓ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣. ąÜąŠą│ą┤ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé ąĖą╗ąĖ ąŠčćąĖčēą░ąĄčé ą▒ąĖčéčŗ čüąŠą▒čŗčéąĖčÅ, č鹊 ąĖąĘą╝ąĄąĮčÅąĄčéčüčÅ ąĘąĮą░č湥ąĮąĖąĄ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠą│ąŠ čüą╗ąŠą▓ą░. ąĢčüą╗ąĖ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą▒ąĖčéą░ čüąŠą▒čŗčéąĖčÅ ą▓ą╗ąĖčÅąĄčé ąĮą░ ą▓čüąĄ čüąŠą▒čŗčéąĖčÅ, č鹊 čüąŠą▒čŗčéąĖąĄ ą▓čŗčćąĖčüą╗čÅąĄčéčüčÅ ąĘą░ąĮąŠą▓ąŠ. ąŁč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓čŗąĘąŠą▓ą░ SetEventBit() ąĖą╗ąĖ ClearEventBit() (ąĄčüą╗ąĖ ą▓čŗąĘąŠą▓ čüą┤ąĄą╗ą░ąĮ ąĖąĘ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ čĆąĄą│ąĖąŠąĮą░ ą║ąŠą┤ą░), ąĖą╗ąĖ ą▓ čüą╗ąĄą┤čāčÄčēąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ ą▒čāą┤ąĄčé čĆą░ąĘčĆąĄčłąĄąĮ ą▓čŗąĘąŠą▓ąŠą╝ PopUnscheduledRegion().
ąÆčŗčćąĖčüą╗ąĄąĮąĖąĄ čüąŠą▒čŗčéąĖčÅ. ą¦č鹊ą▒čŗ ą┐ąŠąĮčÅčéčī, ą║ą░ą║ čüąŠą▒čŗčéąĖčÅ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą▒ąĖčéčŗ čüąŠą▒čŗčéąĖčÅ, čĆą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗ąĄą┤čāčÄčēąĖąĄ ą┐čĆąĖą╝ąĄčĆčŗ.
ą¤čĆąĖą╝ąĄčĆ 1: ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ ą┤ą╗čÅ ą▓čüąĄą│ąŠ čüąŠą▒čŗčéąĖčÅ (All Event).
| 4 |
3 |
2 |
1 |
0 |
ąØąŠą╝ąĄčĆą░ ą▒ąĖčé čüąŠą▒čŗčéąĖčÅ |
| 0 |
1 |
0 |
1 |
0 |
ąŚąĮą░č湥ąĮąĖąĄ ą▒ąĖčéą░ |
| 0 |
1 |
1 |
0 |
1 |
mask |
| 0 |
1 |
1 |
0 |
0 |
ą”ąĄą╗ąĄą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ |
ąĪąŠą▒čŗčéąĖąĄ FALSE, ą┐ąŠč鹊ą╝čā čćč鹊 ą│ą╗ąŠą▒ą░ą╗čīąĮčŗą╣ ą▒ąĖčé čüąŠą▒čŗčéąĖčÅ 2 ąĮąĄ čåąĄą╗ąĄą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
ą¤čĆąĖą╝ąĄčĆ 2: ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ ą┤ą╗čÅ ą▓čüąĄą│ąŠ čüąŠą▒čŗčéąĖčÅ (All Event).
| 4 |
3 |
2 |
1 |
0 |
ąØąŠą╝ąĄčĆą░ ą▒ąĖčé čüąŠą▒čŗčéąĖčÅ |
| 0 |
1 |
1 |
1 |
0 |
ąŚąĮą░č湥ąĮąĖąĄ ą▒ąĖčéą░ |
| 0 |
1 |
1 |
0 |
1 |
mask |
| 0 |
1 |
1 |
0 |
0 |
ą”ąĄą╗ąĄą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ |
ąĪąŠą▒čŗčéąĖąĄ TRUE.
ą¤čĆąĖą╝ąĄčĆ 3: ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ ą┤ą╗čÅ ą╗čÄą▒ąŠą│ąŠ čüąŠą▒čŗčéąĖčÅ (Any Event).
| 4 |
3 |
2 |
1 |
0 |
ąØąŠą╝ąĄčĆą░ ą▒ąĖčé čüąŠą▒čŗčéąĖčÅ |
| 0 |
1 |
0 |
1 |
0 |
ąŚąĮą░č湥ąĮąĖąĄ ą▒ąĖčéą░ |
| 0 |
1 |
1 |
0 |
1 |
mask |
| 0 |
1 |
1 |
0 |
0 |
ą”ąĄą╗ąĄą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ |
ąĪąŠą▒čŗčéąĖąĄ TRUE, ą┐ąŠčüą║ąŠą╗čīą║čā ą▒ąĖčéčŗ 0 ąĖ 3 čåąĄą╗ąĖ ąĖ ą│ą╗ąŠą▒ą░ą╗čīąĮčŗąĄ ą▒ąĖčéčŗ čüąŠą▓ą┐ą░ą┤ą░čÄčé.
ą¤čĆąĖą╝ąĄčĆ 4: ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ ą┤ą╗čÅ ą╗čÄą▒ąŠą│ąŠ čüąŠą▒čŗčéąĖčÅ (Any Event).
| 4 |
3 |
2 |
1 |
0 |
ąØąŠą╝ąĄčĆą░ ą▒ąĖčé čüąŠą▒čŗčéąĖčÅ |
| 0 |
1 |
0 |
1 |
1 |
ąŚąĮą░č湥ąĮąĖąĄ ą▒ąĖčéą░ |
| 0 |
1 |
1 |
0 |
1 |
mask |
| 0 |
0 |
1 |
0 |
0 |
ą”ąĄą╗ąĄą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ |
ąĪąŠą▒čŗčéąĖąĄ FALSE, ą┐ąŠč鹊ą╝čā čćč鹊 ą▒ąĖčéčŗ 0, 2 ąĖ 3 ąĮąĄ čüąŠą▓ą┐ą░ą┤ą░čÄčé.
ąÆą╗ąĖčÅąĮąĖąĄ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝čŗčģ čĆąĄą│ąĖąŠąĮąŠą▓ ąĮą░ ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ čüąŠą▒čŗčéąĖčÅ. ąÜą░ąČą┤čŗą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ąĖą╗ąĖ ąŠčćąĖčēą░ąĄčéčüčÅ ą▒ąĖčé čüąŠą▒čŗčéąĖčÅ, ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓čģąŠą┤ ą▓ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ ą┤ą╗čÅ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ ą▓čüąĄčģ ąĘą░ą▓ąĖčüąĖą╝čŗčģ ąĘąĮą░č湥ąĮąĖą╣ čüąŠą▒čŗčéąĖą╣. ąĪ ą┐ąŠą╝ąŠčēčīčÄ ą▓čģąŠą┤ą░ ą▓ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝čŗą╣ čĆąĄą│ąĖąŠąĮ ąÆčŗ ą╝ąŠąČąĄč鹥 čüčĆą░ąĘčā ą┐ąĄčĆąĄą║ą╗čÄčćąĖčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▒ąĖčé čüąŠą▒čŗčéąĖčÅ ą▒ąĄąĘ ą╗ąĖčłąĮąĖčģ ąĘą░ą┐čāčüą║ąŠą▓ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ čüąŠą▒čŗčéąĖčÅ, ąĖ č鹥ą╝ čüą░ą╝čŗą╝ ąĖąĘą▒ąĄąČą░čéčī ą▓ąŠąĘąĮąĖą║ąĮąŠą▓ąĄąĮąĖčÅ ąŠčłąĖą▒ąŠčćąĮčŗčģ čāčüą╗ąŠą▓ąĖą╣ ą▓ čüąĖčüč鹥ą╝ąĄ. ąĀą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤.
/* ąÜąŠą┤, ą║ąŠč鹊čĆčŗą╣ čüą╗čāčćą░ą╣ąĮąŠ ąĖąĮąĖčåąĖąĖčĆąŠą▓ą░ą╗ Event1 ą┐čĆąĖ ą┐ąŠą┐čŗčéą║ąĄ čāčüčéą░ąĮąŠą▓ąĖčéčī Event2.
ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ą┐čĆąĄą┤čŗą┤čāčēąĄąĄ čüąŠčüč鹊čÅąĮąĖąĄ ą▒ąĖčé = 0x00. */
VDK_EventData data1 = { true, 0x1, 0x3 };
VDK_EventData data2 = { true, 0x3, 0x3 };
VDK_LoadEvent(kEvent1, data1);
VDK_LoadEvent(kEvent2, data2);
VDK_SetEventBit(kEventBit1); /* ą▓čŗąĘąŠą▓ąĄčé čüą╗čāčćą░ą╣ąĮąŠąĄ čüčĆą░ą▒ą░čéčŗą▓ą░ąĮąĖąĄ Event1 */
VDK_SetEventBit(kEventBit2); /* Event1 == FALSE, Event2 == TRUE */
ąÆčüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ąÆčŗ ą╝ąĄąĮčÅąĄč鹥 ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▒ąĖčé čüąŠą▒čŗčéąĖčÅ, ą▓čģąŠą┤ąĖč鹥 ą▓ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝čŗą╣ čĆąĄą│ąĖąŠąĮ, čćč鹊ą▒čŗ ąĖąĘą▒ąĄąČą░čéčī ą┐ąŠą┤ąŠą▒ąĮčŗčģ ą┐čĆąŠą╝ą░čģąŠą▓. ąØą░ą┐čĆąĖą╝ąĄčĆ, čćč鹊ą▒čŗ ąĖčüą┐čĆą░ą▓ąĖčéčī čüą╗čāčćą░ą╣ąĮąŠąĄ čüčĆą░ą▒ą░čéčŗą▓ą░ąĮąĖąĄ čüąŠą▒čŗčéąĖčÅ Event1 ą▓ ą┐čĆąĖą▓ąĄą┤ąĄąĮąĮąŠą╝ ą▓čŗčłąĄ ą║ąŠą┤ąĄ, ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 čüą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤:
VDK_PushUnscheduledRegion();
VDK_SetEventBit(kEventBit1); /* Event1 ąĮąĄ čüčĆą░ą▒ąŠčéą░ą╗ąŠ */
VDK_SetEventBit(kEventBit2); /* Event1 == FALSE, Event2 == TRUE */
VDK_PopUnscheduledRegion();
ąÆąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąĖąĄ ą┐ąŠč鹊ą║ąŠą▓ čü čüąŠą▒čŗčéąĖčÅą╝ąĖ. ą¤ąŠč鹊ą║ąĖ čĆą░ą▒ąŠčéą░čÄčé čü čüąŠą▒čŗčéąĖčÅą╝ąĖ ą┐čāč鹥ą╝ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ąĮą░ čüąŠą▒čŗčéąĖčÅčģ, čāčüčéą░ąĮąŠą▓ą║ąĖ ąĖą╗ąĖ ąŠčćąĖčüčéą║ąĖ ą▒ąĖčé čüąŠą▒čŗčéąĖčÅ, ąĖ ą┐čāč鹥ą╝ ąĘą░ą│čĆčāąĘą║ąĖ ąĮąŠą▓ąŠą╣ čüčéčĆčāą║čéčāčĆčŗ VDK_EventData ą▓ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮąŠąĄ čüąŠą▒čŗčéąĖąĄ.
ą×ąČąĖą┤ą░ąĮąĖąĄ ąĮą░ čüąŠą▒čŗčéąĖąĖ. ąØą░ą┐ąŠą┤ąŠą▒ąĖąĄ čüąĄą╝ą░č乊čĆąŠą▓, ą┐ąŠč鹊ą║ąĖ ą╝ąŠą│čāčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░čéčīčüčÅ ąĮą░ čāčüą╗ąŠą▓ąĖąĖ čüąŠą▒čŗčéąĖčÅ, ą┐ąŠą║ą░ ąŠąĮąŠ ąĮąĄ čüčéą░ąĮąĄčé TRUE, čü čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮčŗą╝ čéą░ą╣ą╝ą░čāč鹊ą╝. ąØą░ čĆąĖčü. 3-15 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčéčüčÅ ą┐čĆąŠčåąĄčüčü ąŠąČąĖą┤ą░ąĮąĖčÅ ąĮą░ čüąŠą▒čŗčéąĖąĖ.

ąĀąĖčü. 3-15. ą×ąČąĖą┤ą░ąĮąĖąĄ (ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░) ą┐ąŠč鹊ą║ą░ ąĮą░ čüąŠą▒čŗčéąĖąĖ.
ą¤ąŠč鹊ą║ ą▓čŗąĘčŗą▓ą░ąĄčé PendEvent() ąĖ čāą║ą░ąĘčŗą▓ą░ąĄčé čéą░ą╣ą╝ą░čāčé. ąĢčüą╗ąĖ čüąŠą▒čŗčéąĖąĄ čüčéą░ąĮąŠą▓ąĖčéčüčÅ TRUE ą┐ąĄčĆąĄą┤ ąĖčüč鹥č湥ąĮąĖąĄą╝ čéą░ą╣ą╝ą░čāčéą░, č鹊 ą┐ąŠč鹊ą║ (ąĖ ą▓čüąĄ ą┤čĆčāą│ąĖąĄ ą┐ąŠč鹊ą║ąĖ, ąŠąČąĖą┤ą░čÄčēąĖąĄ čüąŠą▒čŗčéąĖčÅ) ą┐ąĄčĆąĄčģąŠą┤ąĖčé ą▓ ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ. ąÆčŗąĘąŠą▓ PendEvent() čü čéą░ą╣ą╝ą░čāč鹊ą╝ 0 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą┐ąŠč鹊ą║ ą▒čāą┤ąĄčé ąČą┤ą░čéčī čüąŠą▒čŗčéąĖčÅ ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠ. ąÆčŗąĘąŠą▓ PendEvent() čü čéą░ą╣ą╝ą░čāč鹊ą╝ kDoNotWait ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą┐ąŠč鹊ą║ ą┐čĆąŠą┤ąŠą╗ąČąĖčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ, ą┤ą░ąČąĄ ąĄčüą╗ąĖ čüąŠą▒čŗčéąĖąĄ ąĮąĄą┤ąŠčüčéčāą┐ąĮąŠ.
ąŻčüčéą░ąĮąŠą▓ą║ą░ ąĖ ąŠčćąĖčüčéą║ą░ ą▒ąĖčé čüąŠą▒čŗčéąĖčÅ. ąśąĘą╝ąĄąĮąĄąĮąĖąĄ čüąŠčüč鹊čÅąĮąĖčÅ ą▒ąĖčé čüąŠą▒čŗčéąĖčÅ ą╝ąŠąČąĮąŠ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą║ą░ą║ ą▓ ą┤ąŠą╝ąĄąĮąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣, čéą░ą║ ąĖ ą▓ ą┤ąŠą╝ąĄąĮąĄ ą┐ąŠč鹊ą║ąŠą▓. ą¤čĆąĖ čŹč鹊ą╝ ą▒čāą┤čāčé ą┐ąŠą╗čāč湥ąĮčŗ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąŠčéą╗ąĖčćą░čÄčēąĖąĄčüčÅ čĆąĄąĘčāą╗čīčéą░čéčŗ.
ą¤čĆąŠčåąĄčüčü ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą▒ąĖčé čüąŠą▒čŗčéąĖčÅ ąĖąĘ ą┤ąŠą╝ąĄąĮą░ ą┐ąŠč鹊ą║ąŠą▓ ą┐ąŠą║ą░ąĘą░ąĮ ąĮą░ čĆąĖčü. 3-16.

ąĀąĖčü. 3-16. ąŻčüčéą░ąĮąŠą▓ą║ą░ ąĖą╗ąĖ ąŠčćąĖčüčéą║ą░ ą▒ąĖčéą░ čüąŠą▒čŗčéąĖčÅ ąĖąĘ ą┤ąŠą╝ąĄąĮą░ ą┐ąŠč鹊ą║ąŠą▓.
ą¤ąŠč鹊ą║ ą╝ąŠąČąĄčé čāčüčéą░ąĮąŠą▓ąĖčéčī ą▒ąĖčé čüąŠą▒čŗčéąĖčÅ ą┐čāč鹥ą╝ ą▓čŗąĘąŠą▓ą░ SetEventBit(), ąĖą╗ąĖ ą╝ąŠąČąĄčé ąŠčćąĖčüčéąĖčéčī ąĄą│ąŠ ą▓čŗąĘąŠą▓ąŠą╝ ClearEventBit(). ąś č鹊čé, ąĖ ą┤čĆčāą│ąŠą╣ ą▓čŗąĘąŠą▓ ąĖąĘ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ čĆąĄą│ąĖąŠąĮą░ ą║ąŠą┤ą░ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĮąŠą▓ąŠą╝čā ą▓čŗčćąĖčüą╗ąĄąĮąĖčÄ ą▓čüąĄčģ čüąŠą▒čŗčéąĖą╣, ąĘą░ą▓ąĖčüčÅčēąĖčģ ąŠčé ąĖąĘą╝ąĄąĮąĄąĮąĮąŠą│ąŠ ą▒ąĖčéą░, ąĖ čŹč鹊 ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ č鹊ą╝čā, čćč鹊 ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą▒čāą┤ąĄčé ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąŠ ąĮą░ ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║, čā ą║ąŠč鹊čĆąŠą│ąŠ ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąĖą╣ ą┐čĆąĖąŠčĆąĖč鹥čé, ąĄčüą╗ąĖ ąŠąĮ ąŠąČąĖą┤ą░ą╗ čüąŠą▒čŗčéąĖčÅ, ą║ąŠč鹊čĆąŠąĄ ąĖąĘ-ąĘą░ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą▒ąĖčéą░ čüąŠą▒čŗčéąĖčÅ čüčéą░ą╗ąŠ TRUE.
ąØą░ čĆąĖčü. 3-17 ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąŠčåąĄčüčü ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą▒ąĖčéą░ čüąŠą▒čŗčéąĖčÅ ąĖąĘ ą┤ąŠą╝ąĄąĮą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣.

ąĀąĖčü. 3-17. ąŻčüčéą░ąĮąŠą▓ą║ą░ ąĖą╗ąĖ ąŠčćąĖčüčéą║ą░ ą▒ąĖčéą░ čüąŠą▒čŗčéąĖčÅ ąĖąĘ ą┤ąŠą╝ąĄąĮą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣.
ISR ą╝ąŠąČąĄčé ą▓čŗąĘą▓ą░čéčī VDK_ISR_SET_EVENTBIT_() ąĖ VDK_ISR_CLEAR_EVENTBIT_(), čćč鹊ą▒čŗ ą┐ąŠą╝ąĄąĮčÅčéčī ąĘąĮą░č湥ąĮąĖąĄ ą▒ąĖčéą░ čüąŠą▒čŗčéąĖčÅ, č湥ą╝ ą╝ąŠąČąĄčé ąŠčüą▓ąŠą▒ąŠą┤ąĖčéčī ąĘą░ą┐čāčüą║ ąĮąŠą▓ąŠą│ąŠ ą┐ąŠč鹊ą║ą░. ąÆčŗąĘąŠą▓ čŹčéąĖčģ ą╝ą░ą║čĆąŠčüąŠą▓ ąĮąĄ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĮąŠą▓ąŠą╝čā ą▓čŗčćąĖčüą╗ąĄąĮąĖčÄ čüąŠą▒čŗčéąĖą╣; ąŠą┤ąĮą░ą║ąŠ ą▒čāą┤ąĄčé ąĮą░čüčéčĆąŠąĄąĮ ąĘą░ą┐čāčüą║ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ čü ąĮąĖąĘą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝, čćč鹊 ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĘą░ą┐čāčüą║čā ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ą░ ąĮą░ ą▓čŗčģąŠą┤ąĄ ąĖąĘ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ. ąĢčüą╗ąĖ ą┐čĆąĄčĆą▓ą░ąĮąĮčŗą╣ ą┐ąŠč鹊ą║ ąĮą░čģąŠą┤ąĖą╗čüčÅ ą▓ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą╝ čĆąĄą│ąĖąŠąĮąĄ, č鹊 ą▓ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ąĮąŠą▓ąŠąĄ ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ čüąŠą▒čŗčéąĖą╣, čćč鹊 ą╝ąŠąČąĄčé ą▓čŗąĘą▓ą░čéčī ą┐ąĄčĆąĄčģąŠą┤ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĮą░ ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║ (ą║ąŠč鹊čĆčŗą╣ ąŠąČąĖą┤ą░ą╗ ąĮą░ čüąŠą▒čŗčéąĖąĖ, ąĄčüą╗ąĖ ąŠąĮąŠ čüčéą░ą╗ąŠ TRUE ąĖ čŹč鹊čé ąĮąŠą▓čŗą╣ ą┐ąŠč鹊ą║ ąĖą╝ąĄąĄčé ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąĖą╣ ą┐čĆąĖąŠčĆąĖč鹥čé). ąĢčüą╗ąĖ ISR čāčüčéą░ąĮąŠą▓ąĖą╗ ą▓ąĮčāčéčĆąĖ čüąĄą▒čÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▒ąĖč鹊ą▓ čüąŠą▒čŗčéąĖčÅ, č鹊 ą▓čŗąĘąŠą▓čŗ ą┤ą╗čÅ čüą╝ąĄąĮčŗ ą▒ąĖčé ąĮąĄ čéčĆąĄą▒čāčÄčé ąĘą░čēąĖčéčŗ čĆąĄą│ąĖąŠąĮąŠą╝ ąĮąĄąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ ą║ąŠą┤ą░ (ą┐ąŠčüą║ąŠą╗čīą║čā ą║ąŠą┤, čĆą░ą▒ąŠčéą░čÄčēąĖą╣ ą▓ ą┤ąŠą╝ąĄąĮąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣, ąĖąĘąĮą░čćą░ą╗čīąĮąŠ ąĘą░čēąĖčēąĄąĮ ąŠčé ą▓čŗč鹥čüąĮąĄąĮąĖčÅ ą║ąŠą┤ąŠą╝ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ą░). ą¤čĆąĖą╝ąĄčĆ:
/* ąĪą╗ąĄą┤čāčÄčēąĖąĄ ą┤ą▓ą░ ą▓čŗąĘąŠą▓ą░ ąĖąĘ ISR ąĮąĄ ąĮčāąČą┤ą░čÄčéčüčÅ ą▓ ąĘą░čēąĖč鹥: */
VDK_ISR_SET_EVENTBIT_(kEventBit1);
VDK_ISR_SET_EVENTBIT_(kEventBit2);
ąŚą░ą│čĆčāąĘą║ą░ ąĮąŠą▓čŗčģ ą┤ą░ąĮąĮčŗčģ ą▓ čüąŠą▒čŗčéąĖąĄ. ąśąĘ ą┤ąŠą╝ąĄąĮą░ ą┐ąŠč鹊ą║ąŠą▓, ą║ąŠč鹊čĆčŗą╣ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄčé ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║, ą┐ąŠč鹊ą║ ą╝ąŠąČąĄčé ą┐ąŠą╗čāčćąĖčéčī čüčéčĆčāą║čéčāčĆčā VDK_EventData, čüą▓čÅąĘą░ąĮąĮčāčÄ čü čüąŠą▒čŗčéąĖąĄą╝, ą┐čāč鹥ą╝ ą▓čŗąĘąŠą▓ą░ API-čäčāąĮą║čåąĖąĖ GetEventData(). ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ ą┐ąŠč鹊ą║ ą╝ąŠąČąĄčé ą┐ąŠą╝ąĄąĮčÅčéčī VDK_EventData ą▓čŗąĘąŠą▓ąŠą╝ API-čäčāąĮą║čåąĖąĖ LoadEvent(). ąÆčŗąĘąŠą▓ LoadEvent() ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĮąŠą▓ąŠą╝čā ą▓čŗčćąĖčüą╗ąĄąĮąĖčÄ ąĘąĮą░č湥ąĮąĖčÅ čüąŠą▒čŗčéąĖčÅ. ąĢčüą╗ąĖ ąĖąĘ-ąĘą░ ą▓čŗąĘąŠą▓ą░ ąĖąĘ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝ąŠą│ąŠ čĆąĄą│ąĖąŠąĮą░ čüčéą░ąĮąĄčé ą│ąŠč鹊ą▓čŗą╝ ą║ ąĘą░ą┐čāčüą║čā ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąŠą┐čĆąĖąŠčĆąĖč鹥čéąĮčŗą╣ ą┐ąŠč鹊ą║, č鹊 ąŠąĮ ą▒čāą┤ąĄčé ąĘą░ą┐čāčēąĄąĮ.
[ążą╗ą░ą│ąĖ čāčüčéčĆąŠą╣čüčéą▓ą░ (Device Flags)]
ąśąĘ-ąĘą░ čüą┐ąĄčåąĖą░ą╗čīąĮąŠą╣ ą┐čĆąĖčĆąŠą┤čŗ ą┤čĆą░ą╣ą▓ąĄčĆąŠą▓ čāčüčéčĆąŠą╣čüčéą▓ą░ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąŠ ąĖąĘ ąĮąĖčģ čéčĆąĄą▒čāčÄčé ą╝ąĄč鹊ą┤ąŠą▓ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ, ą┐ąŠą┤ąŠą▒ąĮčŗčģ č鹥ą╝, čćč鹊 ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮčŗ čüąŠą▒čŗčéąĖčÅą╝ąĖ ąĖ čüąĄą╝ą░č乊čĆą░ą╝ąĖ, ąĮąŠ čĆą░ą▒ąŠčéą░čÄčēąĖčģ ą┐ąŠ-ą┤čĆčāą│ąŠą╝čā. ążą╗ą░ą│ąĖ čāčüčéčĆąŠą╣čüčéą▓ą░ čüąŠąĘą┤ą░čÄčéčüčÅ ą┤ą╗čÅ čāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆąĄąĮąĖčÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ ąŠą▒čüč鹊čÅč鹥ą╗čīčüčéą▓, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│ą╗ąĖ ą▒čŗ ą┐ąŠčéčĆąĄą▒ąŠą▓ą░čéčī ą┤čĆą░ą╣ą▓ąĄčĆčŗ čāčüčéčĆąŠą╣čüčéą▓ą░. ąæąŠą╗čīčłą░čÅ čćą░čüčéčī čéą░ą║ąŠą│ąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠą▒čŖčÅčüąĮąĄąĮą░ ą▒ąĄąĘ ą▓ą▓ąĄą┤ąĄąĮąĖčÅ ą┐ąŠąĮčÅčéąĖčÅ ą┤čĆą░ą╣ą▓ąĄčĆą░ čāčüčéčĆąŠą╣čüčéą▓ą░ (čüą╝. čĆą░ąĘą┤ąĄą╗ "Device Drivers" [4]).
ą¤ąŠą▓ąĄą┤ąĄąĮąĖąĄ čäą╗ą░ą│ąŠą▓ čāčüčéčĆąŠą╣čüčéą▓. ąØą░ą┐ąŠą┤ąŠą▒ąĖąĄ čäą╗ą░ą│ąŠą▓ ąĖ čüąĄą╝ą░č乊čĆąŠą▓, ą┐ąŠč鹊ą║ ą╝ąŠąČąĄčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░čéčīčüčÅ ąĮą░ ąŠąČąĖą┤ą░ąĮąĖąĖ čäą╗ą░ą│ą░ čāčüčéčĆąŠą╣čüčéą▓ą░, ąĮąŠ ą▓ ąŠčéą╗ąĖčćąĖąĄ ąŠčé čüąĄą╝ą░č乊čĆąŠą▓ ąĖ čüąŠą▒čŗčéąĖą╣, čäą╗ą░ą│ čāčüčéčĆąŠą╣čüčéą▓ą░ ą▓čüąĄą│ą┤ą░ FALSE. ą¤ąŠč鹊ą║, ąĘą░ą┐čāčüčéąĖą▓čłąĖą╣ ąŠąČąĖą┤ą░ąĮąĖąĄ ąĮą░ čäą╗ą░ą│ąĄ čāčüčéčĆąŠą╣čüčéą▓ą░, čüčĆą░ąĘčā ą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ. ąÜąŠą│ą┤ą░ čāčüčéčĆąŠą╣čüčéą▓ąŠ ąŠą┐čāą▒ą╗ąĖą║ąŠą▓ą░ą╗ąŠ čäą╗ą░ą│, č鹊 ą▓čüąĄ ą┐ąŠč鹊ą║ąĖ, ą║ąŠč鹊čĆčŗąĄ ąČą┤ą░ą╗ąĖ čäą╗ą░ą│ą░, ą┐ąĄčĆąĄąĮąŠčüčÅčéčüčÅ ą▓ ąŠč湥čĆąĄą┤čī ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ.
ążą╗ą░ą│ąĖ čāčüčéčĆąŠą╣čüčéą▓ą░ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ ąŠą▒ą╝ąĄąĮą░ čü ą╗čÄą▒čŗą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąŠą╝ ą┐ąŠč鹊ą║ąŠą▓, ąĖ ą┐ąĄčĆąĄą┤ą░čéčī ąĖą╝ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠ č鹊ą╝, čćč鹊 čāčüčéčĆąŠą╣čüčéą▓ąŠ ą▓ąŠčłą╗ąŠ ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ. ąØą░ą┐čĆąĖą╝ąĄčĆ ą┐čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐ąŠč鹊ą║ąŠą▓ ąČą┤čāčé ą┐ąŠčüčéčāą┐ą╗ąĄąĮąĖčÅ ąĮąŠą▓čŗčģ ą┤ą░ąĮąĮčŗčģ ą▓ ą▒čāč乥čĆ ąŠčé ąÉą”ą¤. ąÆ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ąĮąĖ čüąĄą╝ą░č乊čĆ, ąĮąĖ čüąŠą▒čŗčéąĖąĄ ąĮąĄ ą╝ąŠą│čāčé ą║ąŠčĆčĆąĄą║čéąĮąŠ ą┐čĆąĄą┤čüčéą░ą▓ąĖčéčī čŹč鹊 čüąŠčüč鹊čÅąĮąĖąĄ, ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ čäą╗ą░ą│ą░ čāčüčéčĆąŠą╣čüčéą▓ą░ ą╝ąŠąČąĄčé ąĖąĮą║ą░ą┐čüčāą╗ąĖčĆąŠą▓ą░čéčī čŹč鹊 čüąŠčüč鹊čÅąĮąĖąĄ čüąĖčüč鹥ą╝čŗ.
ąÆąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąĖąĄ ą┐ąŠč鹊ą║ą░ čü čäą╗ą░ą│ą░ą╝ąĖ čāčüčéčĆąŠą╣čüčéą▓. ą¤ąŠč鹊ą║ ą┐ąŠą╗čāčćą░ąĄčé ą┤ąŠčüčéčāą┐ ą║ čäą╗ą░ą│čā čāčüčéčĆąŠą╣čüčéą▓ą░ č湥čĆąĄąĘ ą┤ą▓ąĄ API-čäčāąĮą║čåąĖąĖ: PendDeviceFlag() ąĖ PostDeviceFlag(). ąÆ ąŠčéą╗ąĖčćąĖąĄ ąŠčé ą▒ąŠą╗čīčłąĖąĮčüčéą▓ą░ API, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą┐čĆąĖą▓ąĄčüčéąĖ ą┐ąŠč鹊ą║ ą║ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĄ, PendDeviceFlag() ą┤ąŠą╗ąČąĄąĮ ą▓čŗąĘčŗą▓ą░čéčīčüčÅ ąĖąĘ ą║čĆąĖčéąĖč湥čüą║ąŠą│ąŠ čĆąĄą│ąĖąŠąĮą░ ą║ąŠą┤ą░.
PendDeviceFlag() čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ čéą░ą║ąĖą╝ čüą┐ąŠčüąŠą▒ąŠą╝ ąĖąĘ-ąĘą░ ą┐čĆąĖčĆąŠą┤čŗ ą┤čĆą░ą╣ą▓ąĄčĆąŠą▓ čāčüčéčĆąŠą╣čüčéą▓ą░. ąĪą╝. "Device Drivers" [4] ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą┐ąŠ čäą╗ą░ą│ą░ą╝ čāčüčéčĆąŠą╣čüčéą▓ą░ ąĖą╗ąĖ ą┤čĆą░ą╣ą▓ąĄčĆą░ą╝ čāčüčéčĆąŠą╣čüčéą▓ą░.
[ąĪčüčŗą╗ą║ąĖ]
1. ą×ą▒ąĘąŠčĆ VisualDSP++ Kernel RTOS (VDK).
2. VDK: ą┐čāą╗čŗ ą┐ą░ą╝čÅčéąĖ.
3. VDK: ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ (ISR).
4. VDK: ąĖąĮč鹥čĆč乥ą╣čü ą▓ą▓ąŠą┤ą░/ą▓čŗą▓ąŠą┤ą░.
5. VDK: API čüąĄą╝ą░č乊čĆąŠą▓.
6. VDK: API ą╝čīčÄč鹥ą║čüąŠą▓.
7. ą¦ąĄą╝ ąŠčéą╗ąĖčćą░ąĄčéčüčÅ ą╝čīčÄč鹥ą║čü ąŠčé čüąĄą╝ą░č乊čĆą░? |



