|
ą¤ąŠą┤ą║ą╗čÄčćąĖčéčī LCD-ąĖąĮą┤ąĖą║ą░č鹊čĆ ąĮą░ ąŠčüąĮąŠą▓ąĄ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ Hitachi 44780 ą║ ą╝ąĖą║čĆąŠą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆčā čüąĄą╣čćą░čü ąĮąĄ čüąŠčüčéą░ą▓ą╗čÅąĄčé ą┐čĆąŠą▒ą╗ąĄą╝čŗ, ą┐ąŠčüą║ąŠą╗čīą║čā ąĖą╝ąĄąĄčéčüčÅ ą╝ąĮąŠąČąĄčüčéą▓ąŠ ą│ąŠč鹊ą▓čŗčģ ą┐čĆąĖą╝ąĄčĆąŠą▓ ą║ąŠą┤ą░ ąĖ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ ą┤ą╗čÅ čĆą░ąĘąĮčŗčģ ą┐ą╗ą░čéč乊čĆą╝. ą×ą┤ąĮą░ą║ąŠ ą┐ąŠą┤ą║ą╗čÄčćąĖčéčī ąĖąĮą┤ąĖą║ą░č鹊čĆ ąĖ ąĘą░čüčéą░ą▓ąĖčéčī ąĄą│ąŠ čĆą░ą▒ąŠčéą░čéčī čŹč鹊 č鹊ą╗čīą║ąŠ ą┐ąŠą╗ąŠą▓ąĖąĮą░ čĆąĄčłąĄąĮąĖčÅ ą┐čĆąŠą▒ą╗ąĄą╝čŗ, ąĄčüą╗ąĖ ąÆą░ą╝ ąĮčāąČąĮąŠ ąŠčĆą│ą░ąĮąĖąĘąŠą▓ą░čéčī ą▓čŗą▓ąŠą┤ čĆčāčüčüą║ąŠą│ąŠ č鹥ą║čüčéą░, ąĮąŠ ą║ąŠą┤ąĖčĆąŠą▓ą║ą░ čüąĖą╝ą▓ąŠą╗ąŠą▓ ąĖąĮą┤ąĖą║ą░č鹊čĆą░ ąĮąĄ čüąŠą▓ą┐ą░ą┤ą░ąĄčé čü ą║ąŠą┤ąĖčĆąŠą▓ą║ąŠą╣, ą║ąŠč鹊čĆčāčÄ ą▓čŗą▓ąŠą┤ąĖčé ąĮą░ 菹║čĆą░ąĮ ąÆą░čł ą║ąŠą┤. ąó. ąĄ. ą▓ą╝ąĄčüč鹊 ą▓čŗą▓ąŠą┤ą░ ąĮą░ 菹║čĆą░ąĮ čĆčāčüčüą║ąŠą│ąŠ č鹥ą║čüčéą░ ąÆčŗ ą▓ąĖą┤ąĖč鹥 ą╗ąĖą▒ąŠ ą║čĆą░ą║ąŠąĘčÅą▒čĆčŗ, ą╗ąĖą▒ąŠ ą┐čāčüčéčŗąĄ ąĘąĮą░ą║ąŠą╝ąĄčüčéą░.
ą¤ąŠą┤ "čĆčāčüąĖčäąĖą║ą░čåąĖąĄą╣" ąĖąĮą┤ąĖą║ą░č鹊čĆą░ ąŠą▒čŗčćąĮąŠ ą┐ąŠąĮąĖą╝ą░čÄčé ą▓čŗą▓ąŠą┤ čĆčāčüčüą║ąŠčÅąĘčŗčćąĮąŠą│ąŠ č鹥ą║čüčéą░ ąĮą░ 菹║čĆą░ąĮąĄ ąĖąĮą┤ąĖą║ą░č鹊čĆą░, ą║ąŠą│ą┤ą░ čĆčāčüčüą║ąĖą╣ č鹥ą║čüčé čüčéčĆąŠą║ ą▓ č鹥ą║čüč鹥 ą┐čĆąŠą│čĆą░ą╝ą╝ ą░ą┤ąĄą║ą▓ą░čéąĮąŠ ąŠč鹊ą▒čĆą░ąČą░ąĄčéčüčÅ ąĮą░ 菹║čĆą░ąĮąĄ. ą¤čĆąĖ čŹč鹊ą╝ ąĮčāąČąĮąŠ čĆąĄčłąĖčéčī 3 ąŠčüąĮąŠą▓ąĮčŗąĄ ą┐čĆąŠą▒ą╗ąĄą╝čŗ:
1. ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čüąĖą╝ą▓ąŠą╗čīąĮąŠą╣ čéą░ą▒ą╗ąĖčåčŗ ąĖąĮą┤ąĖą║ą░č鹊čĆą░. ąØąĄąŠą▒čģąŠą┤ąĖą╝ąŠ čāąĘąĮą░čéčī, ą║ą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ą║ą░ąČą┤čŗą╣ ą║ąŠą┤ čüąĖą╝ą▓ąŠą╗ą░, ąĘą░ą┐ąĖčüčŗą▓ą░ąĄą╝čŗą╣ ą▓ ąĖąĮą┤ąĖą║ą░č鹊čĆ, ąŠč鹊ą▒čĆą░ąČą░ąĄčéčüčÅ ąĮą░ ąĄą│ąŠ 菹║čĆą░ąĮąĄ.
2. ą¤ąŠąĖčüą║/čüąŠąĘą┤ą░ąĮąĖąĄ čĆčāčüčüą║ąĖčģ ą▒čāą║ą▓. ąØąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ąĮą░ą╣čéąĖ čüą┐ąŠčüąŠą▒ ą▓čŗą▓ąŠą┤ą░ ąĮą░ 菹║čĆą░ąĮ čĆčāčüčüą║ąŠčÅąĘčŗčćąĮčŗčģ čüąĖą╝ą▓ąŠą╗ąŠą▓.
3. ą¤ąĄčĆąĄą║ąŠą┤ąĖčĆąŠą▓ą║ą░ ą▓čŗą▓ąŠą┤ąĖą╝ąŠą│ąŠ č鹥ą║čüčéą░. ąØąĄąŠą▒čģąŠą┤ąĖą╝ąŠ čüąŠčüčéą░ą▓ąĖčéčī čéą░ą▒ą╗ąĖčåčā ą┐ąĄčĆąĄą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊ą▒čŗ ą║ąŠą┤ąĖčĆąŠą▓ą║ą░ ą▓čüąĄčģ čüąĖą╝ą▓ąŠą╗ąŠą▓ čüčéčĆąŠą║ ą▓ č鹥ą║čüč鹥 ą┐čĆąŠą│čĆą░ą╝ą╝čŗ čüąŠąŠčéą▓ąĄčéčüčéą▓ąŠą▓ą░ą╗ą░ ą▓ąĮąĄčłąĮąĄą╝čā ą▓ąĖą┤čā čüąĖą╝ą▓ąŠą╗ąŠą▓ ąĮą░ 菹║čĆą░ąĮąĄ ąĖąĮą┤ąĖą║ą░č鹊čĆą░.
[ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čüąĖą╝ą▓ąŠą╗čīąĮąŠą╣ čéą░ą▒ą╗ąĖčåčŗ ąĖąĮą┤ąĖą║ą░č鹊čĆą░]
ą¤ąŠą┤ "ą║ąŠą┤ąĖčĆąŠą▓ą║ąŠą╣" ąĖąĮą┤ąĖą║ą░č鹊čĆą░ ą┐ąŠąĮąĖą╝ą░čÄčé čéą░ą▒ą╗ąĖčåčā, ą│ą┤ąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮąŠ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĄ 8-ą▒ąĖčéąĮąŠą│ąŠ ą║ąŠą┤ą░ čüąĖą╝ą▓ąŠą╗ą░ (ą║ąŠą┤ ASCII ąĖą╗ąĖ ANSI) ąĮą░č湥čĆčéą░ąĮąĖčÄ čüąĖą╝ą▓ąŠą╗ąŠą▓ ąĮą░ 菹║čĆą░ąĮąĄ ąĖąĮą┤ąĖą║ą░č鹊čĆą░. ąØąĖąČąĄ ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąĖą╝ąĄčĆ čéą░ą║ąŠą╣ čéą░ą▒ą╗ąĖčåčŗ, ą║ąŠč鹊čĆčāčÄ ąŠą▒čŗčćąĮąŠ ą╝ąŠąČąĮąŠ ąĮą░ą╣čéąĖ ą▓ ą┤ą░čéą░čłąĖč鹥 ąĮą░ ąĖąĮą┤ąĖą║ą░č鹊čĆ LCD-016N001A-NFG-ET. ąÆ ąĘą░ą│ąŠą╗ąŠą▓ą║ąĄ čüč鹊ą╗ą▒čåąŠą▓ čāą║ą░ąĘą░ąĮą░ čüčéą░čĆčłą░čÅ č鹥čéčĆą░ą┤ą░ ą▒ą░ą╣čéą░ ą║ąŠą┤ą░ čüąĖą╝ą▓ąŠą╗ą░, ą░ ą▓ ąĘą░ą│ąŠą╗ąŠą▓ą║ąĄ čüčéčĆąŠą║ ą╝ą╗ą░ą┤čłą░čÅ. ąÜąŠą┤ čüąĖą╝ą▓ąŠą╗ą░ ą┐ąŠą╗čāčćą░ąĄčéčüčÅ ą║ąŠąĮą║ą░č鹥ąĮą░čåąĖąĄą╣ (čüą║ą╗ąĄąĖą▓ą░ąĮąĖąĄą╝) ą▒ąĖčé č鹥čéčĆą░ą┤, ą░ ą▓ ą┐ąĄčĆąĄčüąĄč湥ąĮąĖąĖ čüčéčĆąŠą║ąĖ ąĖ čüč鹊ą╗ą▒čåą░ ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮą░č湥čĆčéą░ąĮąĖąĄ čüąĖą╝ą▓ąŠą╗ą░.

ąĀąĖčü. 1. ąØą░č湥čĆčéą░ąĮąĖąĄ ąĮą░ą▒ąŠčĆą░ čüąĖą╝ą▓ąŠą╗ąŠą▓ ąĖąĮą┤ąĖą║ą░č鹊čĆą░ LCD-016N001A-NFG-ET.
ą×č湥ą▓ąĖą┤ąĮąŠ, čćč鹊 ą▓ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĄ čŹč鹊ą│ąŠ ąĖąĮą┤ąĖą║ą░č鹊čĆą░ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąŠčéčüčāčéčüčéą▓čāčÄčé čĆčāčüčüą║ąĖąĄ ą▒čāą║ą▓čŗ. ąÜą░ą║ ą▓ čéą░ą║ąŠą╝ čüą╗čāčćą░ąĄ ąĄą│ąŠ ą╝ąŠąČąĮąŠ čĆčāčüąĖčäąĖčåąĖčĆąŠą▓ą░čéčī?
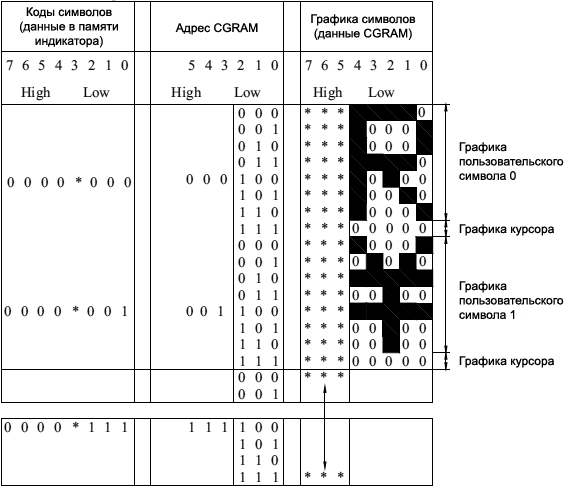
ąÆąŠ-ą┐ąĄčĆą▓čŗčģ, ąĮąĄą║ąŠč鹊čĆčŗąĄ ą▒čāą║ą▓čŗ ą░ąĮą│ą╗ąĖą╣čüą║ąŠą│ąŠ ą░ą╗čäą░ą▓ąĖčéą░ čüąŠą▓ą┐ą░ą┤ą░čÄčé ą┐ąŠ ąĮą░č湥čĆčéą░ąĮąĖčÄ čü čĆčāčüčüą║ąĖą╝ąĖ. ąÆąŠ-ą▓č鹊čĆčŗčģ, čā ąĖąĮą┤ąĖą║ą░č鹊čĆą░ ąĄčüčéčī čüą┐ąĄčåąĖą░ą╗čīąĮą░čÅ ąŠą▒ą╗ą░čüčéčī ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąŠą╣ ą│čĆą░čäąĖą║ąĖ (CG RAM), ą║čāą┤ą░ ą╝ąŠąČąĮąŠ ąĘą░ą│čĆčāąĘąĖčéčī ą│čĆą░čäąĖą║čā čĆčāčüčüą║ąĖčģ čüąĖą╝ą▓ąŠą╗ąŠą▓, ąĖ ą▓čŗą▓ąŠą┤ąĖčéčī čŹčéąĖ čüąĖą╝ą▓ąŠą╗čŗ č湥čĆąĄąĘ ą║ąŠą┤čŗ 00h..0Fh.
ąĢčüą╗ąĖ ą▓ ąĘąĮą░ą║ąŠą│ąĄąĮąĄčĆą░č鹊čĆąĄ ą▓ąŠąŠą▒čēąĄ ąĮąĄčé čĆčāčüčüą║ąĖčģ čüąĖą╝ą▓ąŠą╗ąŠą▓, č鹊 čüą╗ąĄą┤čāąĄčé ą┐čĆąĖąĮčÅčéčī čĆąĄčłąĄąĮąĖąĄ ąĘą░ą│čĆčāąĘąĖčéčī ą│čĆą░čäąĖą║čā čĆčāčüčüą║ąĖčģ ą▒čāą║ą▓, ąĮą░č湥čĆčéą░ąĮąĖąĄ ą║ąŠč鹊čĆčŗčģ ąŠčéčüčāčéčüčéą▓čāąĄčé ą▓ ą░ąĮą│ą╗ąĖą╣čüą║ąŠą╝ ą░ą╗čäą░ą▓ąĖč鹥, ąĖ čéą░ą║ąČąĄ čüąŠčüčéą░ą▓ąĖčéčī čéą░ą▒ą╗ąĖčåčā ą┐ąĄčĆąĄą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ, čćč鹊ą▒čŗ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą░ąĮą│ą╗ąĖą╣čüą║ąĖą╝ąĖ čüąĖą╝ą▓ąŠą╗ą░ą╝ąĖ ąĖ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗą╝ąĖ ąĘą░ą│čĆčāąČąĄąĮąĮčŗą╝ąĖ čĆčāčüčüą║ąĖą╝ąĖ čüąĖą╝ą▓ąŠą╗ą░ą╝ąĖ čüąĖąĮč鹥ąĘąĖčĆąŠą▓ą░čéčī ą▓čŗą▓ąŠą┤ čĆčāčüčüą║ąŠą│ąŠ č鹥ą║čüčéą░.
ą×ą┤ąĮą░ą║ąŠ čüą╗ąĄą┤čāąĄčé ąĖą╝ąĄčéčī ą▓ ą▓ąĖą┤čā, čćč鹊 ą│ą╗ąŠą▒ą░ą╗čīąĮąŠ čü ą┐ąŠą╝ąŠčēčīčÄ 8 ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖčģ čüąĖą╝ą▓ąŠą╗ąŠą▓ čĆčāčüąĖčäąĖčåąĖčĆąŠą▓ą░čéčī čéą░ą║ąŠą╣ ąĖąĮą┤ąĖą║ą░č鹊čĆ, ą║ąŠą┤ąĖčĆąŠą▓ą║ą░ ą║ąŠč鹊čĆąŠą│ąŠ ą┐ąŠą║ą░ąĘą░ąĮą░ ąĮą░ čĆąĖčü. 1, ąĮąĄ ą┐ąŠą╗čāčćąĖčéčüčÅ. ą¤čĆąĖą┤ąĄčéčüčÅ ą╗ąĖą▒ąŠ ąŠą│čĆą░ąĮąĖčćąĖčéčī čĆčāčüąĖčäąĖą║ą░čåąĖčÄ čĆąĄą░ą╗ąĖąĘą░čåąĖąĄą╣ č鹊ą╗čīą║ąŠ č鹥čģ čüąĖą╝ą▓ąŠą╗ąŠą▓, ą║ąŠč鹊čĆčŗąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ, ą╗ąĖą▒ąŠ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąĖ ą┐ąŠą┤ą│čĆčāąČą░čéčī ąĮčāąČąĮčŗąĄ čĆčāčüčüą║ąĖąĄ čüąĖą╝ą▓ąŠą╗čŗ, ą║ąŠą│ą┤ą░ ąŠąĮąĖ ą┐ąŠčÅą▓ą╗čÅčÄčéčüčÅ ąĮą░ 菹║čĆą░ąĮąĄ.
[Character Generator RAM (CGRAM)]
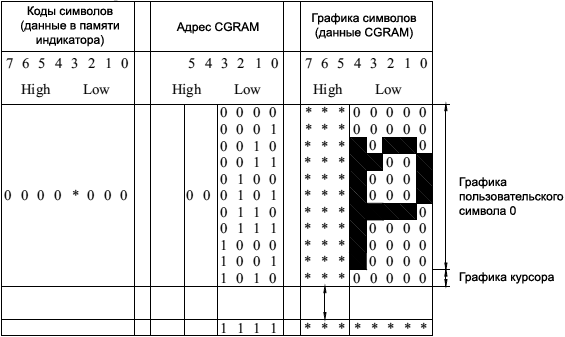
ąÆ CGRAM ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą╝ąŠąČąĄčé ą┐ąĄčĆąĄąĘą░ą┐ąĖčüą░čéčī čüąĖą╝ą▓ąŠą╗ čüą▓ąŠąĄą╣ ą┐čĆąŠą│čĆą░ą╝ą╝ąŠą╣. ąöą╗čÅ čĆąĄąČąĖą╝ą░ 5x8 č鹊č湥ą║ ą╝ąŠąČąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī 8 čüąĖą╝ą▓ąŠą╗ąŠą▓, ąĖ ą┤ą╗čÅ čĆąĄąČąĖą╝ą░ 5x10 č鹊č湥ą║ ą╝ąŠąČąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī 4 čüąĖą╝ą▓ąŠą╗ą░.
ąŚą░ą┐ąĖčłąĖč鹥 ą┐ą░ą╝čÅčéčī ąĖąĮą┤ąĖą║ą░č鹊čĆą░ ą║ąŠą┤ čüąĖą╝ą▓ąŠą╗ą░ ą┐ąŠ ą░ą┤čĆąĄčüčā, ą┐ąŠą║ą░ąĘą░ąĮąĮąŠą╝čā ą▓ ą╗ąĄą▓ąŠą╝ čüč鹊ą╗ą▒čåąĄ čéą░ą▒ą╗ąĖčåčŗ 1, čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī ą│čĆą░čäąĖą║čā, čüąŠčģčĆą░ąĮąĄąĮąĮčāčÄ ą▓ CGRAM. ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖąĄ čüąĖą╝ą▓ąŠą╗čŗ ąŠčüčéą░čÄčéčüčÅ ą▓ ą┐ą░ą╝čÅčéąĖ ąĖąĮą┤ąĖą║ą░č鹊čĆą░ ą┤ąŠ ą▓čŗą║ą╗čÄč湥ąĮąĖčÅ ąĄą│ąŠ ą┐ąĖčéą░ąĮąĖčÅ.
ąóą░ą▒ą╗ąĖčåą░ 1. ąÜą░ą║ čģčĆą░ąĮąĖčéčüčÅ ą│čĆą░čäąĖą║ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖčģ čüąĖą╝ą▓ąŠą╗ąŠą▓ ą▓ CGRAM.
ąöą╗čÅ čĆąĄąČąĖą╝ą░ 5x8:
ąÜą░ąČą┤čŗą╣ čüąĖą╝ą▓ąŠą╗ LCD ą┐ąŠčüčéčĆąŠąĄąĮ ą║ą░ą║ ą╝ą░čéčĆąĖčåą░ ą│čĆą░čäąĖą║ąĖ ąĖąĘ 8 čüčéčĆąŠą║ ąĖ 5 čüč鹊ą╗ą▒čåąŠą▓ (5x8). ą¦č鹊ą▒čŗ čüąŠąĘą┤ą░čéčī čüą▓ąŠą╣ čüąĖą╝ą▓ąŠą╗, ąĮčāąČąĮąŠ ą┐ąŠčüą╗ą░čéčī ą▓ ąĖąĮą┤ąĖą║ą░č鹊čĆ ą╝ą░čüčüąĖą▓ ąĖąĘ 8 ą▒ą░ą╣čé. ąÜą░ąČą┤čŗą╣ ą▒ą░ą╣čé ą▓ ąĮąĄą╝ ą▒čāą┤ąĄčé ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅčéčī ą┤ą░ąĮąĮčŗąĄ ą│čĆą░čäąĖą║ąĖ čüčéčĆąŠą║ąĖ 5-čÄ ą╝ą╗ą░ą┤čłąĖą╝ąĖ ą▒ąĖčéą░ą╝ąĖ. ąĢčüą╗ąĖ ą▒ąĖčé čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ, č鹊 ąĮą░ čŹč鹊ą╝ ą╝ąĄčüč鹥 ą▒čāą┤ąĄčé ąŠč鹊ą▒čĆą░ąČą░čéčīčüčÅ č鹊čćą║ą░, ąĄčüą╗ąĖ ąĮąĄ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ, č鹊 č鹊čćą║ą░ ąŠč鹊ą▒čĆą░ąČąĄąĮą░ ąĮąĄ ą▒čāą┤ąĄčé.
ąöą╗čÅ čĆąĄąČąĖą╝ą░ 5x10:
[LCD Custom Char Builder]
ąÆčŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┐čĆąŠą│čĆą░ą╝ą╝čā LCD Custom Char Builder Software [2], čćč鹊ą▒čŗ ą▒čŗčüčéčĆąŠ ąĖ ą┐čĆąŠčüč鹊 čüąŠąĘą┤ą░čéčī ą│čĆą░čäąĖą║čā ą┤ą╗čÅ čüą▓ąŠąĖčģ čüąĖą╝ą▓ąŠą╗ąŠą▓ ą┤ą╗čÅ čüąĖą╝ą▓ąŠą╗čīąĮčŗčģ LCD-ąĖąĮą┤ąĖą║ą░č鹊čĆąŠą▓.
ąĪčéą░ąĮą┤ą░čĆčéąĮčŗąĄ ą░ą╗čäą░ą▓ąĖčéąĮąŠ-čåąĖčäčĆąŠą▓čŗąĄ LCD ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé 4 ąĖą╗ąĖ 8 ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖčģ čüąĖą╝ą▓ąŠą╗ąŠą▓ (ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čéąĖą┐ą░ ąĖąĮą┤ąĖą║ą░č鹊čĆą░ ąĖ ą▓čŗą▒čĆą░ąĮąĮąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░ ąĘąĮą░ą║ąŠą╝ąĄčüčéą░). ąĪ ą┐ąŠą╝ąŠčēčīčÄ čŹč鹊ą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą╝ąŠąČąĮąŠ čüąŠąĘą┤ą░čéčī 8 čüąĖą╝ą▓ąŠą╗ąŠą▓ ą▓ čü ąĖą╝ąĄąĮą░ą╝ąĖ ąŠčé Char0 ą┤ąŠ Char7. ąÆčŗ ą╝ąŠąČąĄč鹥 ą▓čŗą▒čĆą░čéčī ą╗čÄą▒ąŠą╣ ąĖąĘ čŹčéąĖčģ čüąĖą╝ą▓ąŠą╗ąŠą▓ ąĖ ąŠčéčĆąĄą┤ą░ą║čéąĖčĆąŠą▓ą░čéčī ąĄą│ąŠ ą│čĆą░čäąĖą║čā.
ąĪ ą┐ąŠą╝ąŠčēčīčÄ ą╗ąĄą▓ąŠą╣ ą║ąĮąŠą┐ą║ąĖ ą╝čŗčłąĖ ą╝ąŠąČąĮąŠ čĆąĖčüąŠą▓ą░čéčī čüąĖą╝ą▓ąŠą╗. ąŻą┤ąĄčƹȹĖą▓ą░ąĮąĖąĄ ą┐čĆą░ą▓ąŠą╣ ą║ąĮąŠą┐ą║ąĖ ą╝čŗčłąĖ čüčéąĖčĆą░ąĄčé č鹊čćą║čā.
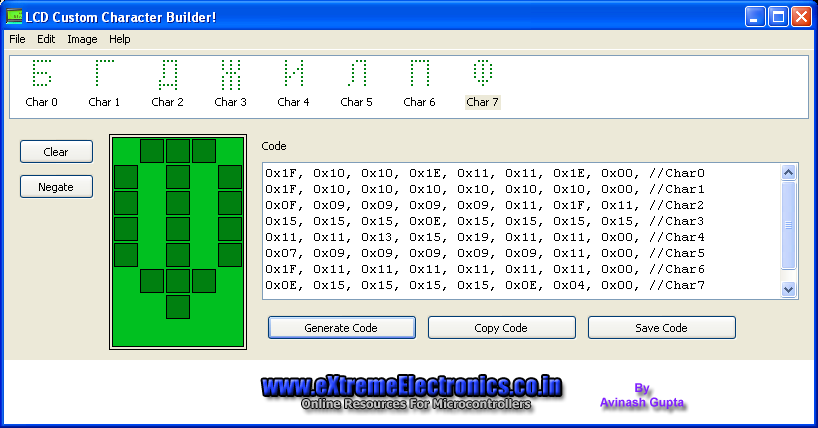
ąØą░čĆąĖčüčāą╣č鹥 ą▓čüąĄ 8 čüąĖą╝ą▓ąŠą╗ąŠą▓. ą¤ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ą║ą╗ąĖą║ąĮąĖč鹥 ąĮą░ ą║ąĮąŠą┐ą║ąĄ Save code, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī čäą░ą╣ą╗ custom_char.h file. ąŁč鹊čé ąĘą░ą│ąŠą╗ąŠą▓ąŠčćąĮčŗą╣ čäą░ą╣ą╗ čüąŠą▓ą╝ąĄčüčéąĖą╝ čü ą┐ąŠą┐čāą╗čÅčĆąĮąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąŠą╣ [3]. ąÆ čäą░ą╣ą╗ąĄ čüąŠą┤ąĄčƹȹ░čéčüčÅ ą┤ą░ąĮąĮčŗąĄ ą│čĆą░čäąĖą║ąĖ ąĮą░čĆąĖčüąŠą▓ą░ąĮąĮčŗčģ čüąĖą╝ą▓ąŠą╗ąŠą▓, ą║ąŠč鹊čĆčŗąĄ ąÆčŗ ą╝ąŠąČąĄč鹥 ąĘą░ą│čĆčāąĘąĖčéčī ą▓ CGRAM ąĖąĮą┤ąĖą║ą░č鹊čĆą░.
ąæąĖą▒ą╗ąĖąŠč鹥ą║ą░ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąŠč湥ąĮčī ą┐čĆąŠčüč鹊 ą▓čŗą▓ąŠą┤ąĖčéčī ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖąĄ čüąĖą╝ą▓ąŠą╗čŗ čü ą┐ąŠą╝ąŠčēčīčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ %n, ą│ą┤ąĄ n - ąĮąŠą╝ąĄčĆ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąŠą│ąŠ čüąĖą╝ą▓ąŠą╗ą░. ą¤čĆąĖą╝ąĄčĆ ą▓čŗą▓ąŠą┤ą░ čüąĖą╝ą▓ąŠą╗ą░ Char2:
LCDWriteString("I %2 AVR");
ąöą╗ą░ čĆąĖčüąŠą▓ą░ąĮąĖčÅ ą│čĆą░čäąĖą║ąĖ čüąĖą╝ą▓ąŠą╗ąŠą▓ 5x8 ą╝ąŠąČąĮąŠ čéą░ą║ąČąĄ ą▓ąŠčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ čāą┤ąŠą▒ąĮčŗą╝ ąŠąĮą╗ą░ą╣ąĮ-čĆąĄą┤ą░ą║č鹊čĆąŠą╝ [4].
[ą¤čĆąĖą╝ąĄčĆ ąĘą░ą│čĆčāąĘą║ąĖ ą▓ CGRAM ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖčģ čüąĖą╝ą▓ąŠą╗ąŠą▓]
/////////////////////////////////////////////////////////////
// ąĪą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąĮčŗą╣ čäą░ą╣ą╗ custom_char.h:
#ifndef __CUSTOMCHAR_H
#define __CUSTOMCHAR_H
unsigned char __cgram[]=
{
0x1F, 0x10, 0x10, 0x1E, 0x11, 0x11, 0x1E, 0x00, //Char0 'ąæ'
0x1F, 0x10, 0x10, 0x10, 0x10, 0x10, 0x10, 0x00, //Char1 'ąō'
0x07, 0x09, 0x09, 0x09, 0x09, 0x11, 0x1F, 0x11, //Char2 'ąö'
0x15, 0x15, 0x15, 0x0E, 0x15, 0x15, 0x15, 0x00, //Char3 'ą¢'
0x11, 0x11, 0x13, 0x15, 0x19, 0x11, 0x11, 0x00, //Char4 'ąś'
0x07, 0x09, 0x09, 0x09, 0x09, 0x09, 0x11, 0x00, //Char5 'ąø'
0x1F, 0x11, 0x11, 0x11, 0x11, 0x11, 0x11, 0x00, //Char6 'ą¤'
0x0E, 0x15, 0x15, 0x15, 0x15, 0x0E, 0x04, 0x00, //Char7 'ąż'
};
#endif
/////////////////////////////////////////////////////////////
// ąóąĄčüčé-ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą┤ą╗čÅ ą▓čŗą▓ąŠą┤ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖčģ čüąĖą╝ą▓ąŠą╗ąŠą▓
// ąĖąĘ ą╝ą░čüčüąĖą▓ą░ __cgram[] čäą░ą╣ą╗ą░ custom_char.h.
/////////////////////////////////////////////////////////////
#include < stdlib.h >
#include < string.h >
#include < stdio.h >
#include < avr/io.h >
#include < util/delay.h >
#include "lcd.h"
#include "custom_char.h"
int main(void)
{
/* ąśąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ LCD BC1601A1 */
lcd_init();
/* ąŚą░ą┐ąĖčüčī ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖčģ čüąĖą╝ą▓ąŠą╗ąŠą▓ ą▓ ą┐ą░ą╝čÅčéčī ąĖąĮą┤ąĖą║ą░č鹊čĆą░ */
for (u8 i=0; i < 8; i++)
{
lcd_create_char(i, &__cgram[i*8]);
}
lcd_on(); // ąÆą║ą╗čÄč湥ąĮąĖąĄ ąĖąĮą┤ąĖą║ą░č鹊čĆą░.
lcd_clear(); // ą×čćąĖčüčéą║ą░ ą┤ąĖčüą┐ą╗ąĄčÅ.
lcd_disable_cursor(); // ąÆčŗą║ą╗čÄčćąĖčéčī ą║čāčĆčüąŠčĆ.
/* ąÆčŗą▓ąŠą┤ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖčģ čüąĖą╝ą▓ąŠą╗ąŠą▓ ąĮą░ 菹║čĆą░ąĮ */
lcd_set_cursor(0, 0);
char tmpstr[9];
for (u8 i=0; i < 8; i++)
{
tmpstr[i] = i+8;
}
tmpstr[8] = 0;
//ąØą░ 菹║čĆą░ąĮ ą▓čŗą▓ąĄą┤čāčéčüčÅ čüąĖą╝ą▓ąŠą╗čŗ "ąæąōąöą¢ąśąøąĀąż":
lcd_printf("%s", tmpstr);
while (1)
{
}
}
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čüąĖą╝ą▓ąŠą╗čŗ "ąæąōąöą¢ąśąøąĀąż" ąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ ą▓ čüčéčĆąŠą║čā tmpstr ą║ą░ą║ ą║ąŠą┤čŗ ąŠčé 8 ą┤ąŠ 15. ąöąĄą╗ąŠ ą▓ č鹊ą╝, čćč鹊 ą▓ ą┐ą░ą╝čÅčéąĖ CGRAM ą│čĆą░čäąĖą║ą░ ą┤ą╗čÅ ą║ąŠą┤ąŠą▓ čüąĖą╝ą▓ąŠą╗ąŠą▓ 0..7 ąĖ 8..15 ą┤čāą▒ą╗ąĖčĆčāąĄčéčüčÅ, ąŠą┤ąĮą░ą║ąŠ čüąĖą╝ą▓ąŠą╗ čü ą║ąŠą┤ąŠą╝ 0 ą▓čüąĄą│ą┤ą░ ą▓čŗą▓ąŠą┤ąĖčéčüčÅ ą║ą░ą║ ą┐čĆąŠą▒ąĄą╗. ą¤ąŠčŹč鹊ą╝čā ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖąĄ čüąĖą╝ą▓ąŠą╗čŗ čüą╗ąĄą┤čāąĄčé ą▓čŗą▓ąŠą┤ąĖčéčī ą║ą░ą║ ą║ąŠą┤čŗ ąŠčé 8 ą┤ąŠ 15.
ąĢčüą╗ąĖ čā ąÆą░čü ąĮąĄčé ą┤ą░čéą░čłąĖčéą░ ąĮą░ ąĖąĮą┤ąĖą║ą░č鹊čĆ, čćč鹊ą▒čŗ č鹊čćąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ąĄą│ąŠ ą║ąŠą┤ąĖčĆąŠą▓ą║čā, č鹊 ąĮą░ą┤ąŠ ąĮą░ą┐ąĖčüą░čéčī ą┐čĆąŠčüč鹊ą╣ č鹥čüč鹊ą▓čŗą╣ ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ą▓čŗą▓ąĄą┤ąĄčé ąĮą░ ąĖąĮą┤ąĖą║ą░č鹊čĆčŗ ą▓čüąĄ čüąĖą╝ą▓ąŠą╗čŗ ąĖ ąĖčģ ą║ąŠą┤čŗ. ąöą╗čÅ čāą┤ąŠą▒čüčéą▓ą░ ą║ąŠą┤ ą╝ąŠąČąĮąŠ ą▓čŗą▓ąĄčüčéąĖ ą▓ čłąĄčüčéąĮą░ą┤čåą░č鹥čĆąĖčćąĮąŠą╣ ąĖ ą┤ąĄčüčÅčéąĖčćąĮąŠą╣ č乊čĆą╝ąĄ, ąĖ čĆčÅą┤ąŠą╝ ąŠč鹊ą▒čĆą░ąĘąĖčéčī čüąĖą╝ą▓ąŠą╗ čŹč鹊ą│ąŠ ą║ąŠą┤ą░.
#include < stdlib.h >
#include < string.h >
#include < stdio.h >
#include < avr/io.h >
#include "encoder.h"
#include "lcd.h"
int main (void)
{
initialize();
lcd_on();
lcd_clear();
lcd_disable_cursor();
static u8 sym = 0;
static bool showsym = true;
u8 encstate;
while (true)
{
encstate = ENC_GetStateEncoder();
if (LEFT_SPIN == encstate)
{
sym--;
showsym = true;
}
else if (RIGHT_SPIN == encstate)
{
sym++;
showsym = true;
}
if (showsym)
{
lcd_clear();
lcd_printf("%02X %i %c", sym, sym, sym);
showsym = false;
}
}
}
ąØąĖąČąĄ ąĮą░ č乊č鹊 ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąĖą╝ąĄčĆ ą▓čŗą▓ąŠą┤ą░ ąĮą░ 菹║čĆą░ąĮ čüąĖą╝ą▓ąŠą╗ą░ čü ą║ąŠą┤ąŠą╝ A2h (162 ą┤ąĄčüčÅčéąĖčćąĮąŠąĄ).

ąĀąĖčü. 2. ą¤čĆąĖą╝ąĄčĆ čĆą░ą▒ąŠčéčŗ č鹥čüčé-ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą┤ą╗čÅ ą░ąĮą░ą╗ąĖąĘą░ ąĘąĮą░ą║ąŠą│ąĄąĮąĄčĆą░č鹊čĆą░ ąĖąĮą┤ąĖą║ą░č鹊čĆą░.
ą¤ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ąĮčāąČąĮąŠ ą┐čĆąŠčüą╝ąŠčéčĆąĄčéčī ą▓čŗą▓ąŠą┤ ą║ąŠą┤ąŠą▓ ą▓čüąĄčģ čüąĖą╝ą▓ąŠą╗ąŠą▓, ąĖ čüąŠčüčéą░ą▓ąĖčéčī čéą░ą▒ą╗ąĖčåčā ąĘąĮą░ą║ąŠą│ąĄąĮąĄčĆą░č鹊čĆą░ ąĖąĮą┤ąĖą║ą░č鹊čĆą░.
[ą¤ąŠąĖčüą║ čĆčāčüčüą║ąĖčģ ą▒čāą║ą▓]
ą£ąĮąĄ ąĮčāąČąĮąŠ ą▒čŗą╗ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą║ąŠą┤ąĖčĆąŠą▓ą║čā ąĖąĮą┤ąĖą║ą░č鹊čĆą░ BC1601AGPLCWs, ąĖ čü ą┐ąŠą╝ąŠčēčīčÄ čŹč鹊ą╣ č鹥čüčé-ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą╝ąĮąĄ čāą┤ą░ą╗ąŠčüčī čüąŠčüčéą░ą▓ąĖčéčī ą▓ąŠčé čéą░ą║čāčÄ čéą░ą▒ą╗ąĖčåčā:
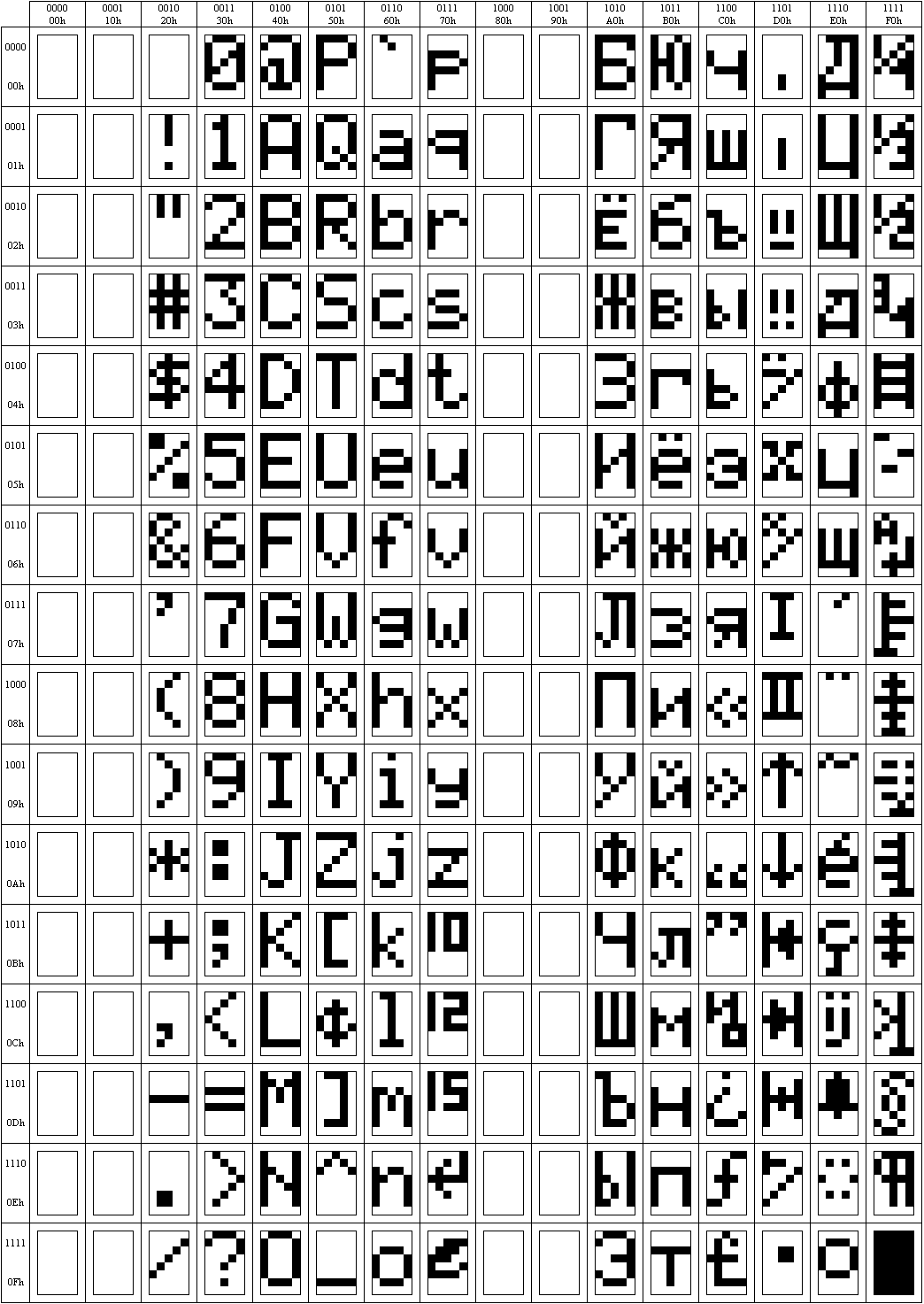
ąĀąĖčü. 3. ąØą░č湥čĆčéą░ąĮąĖąĄ ąĮą░ą▒ąŠčĆą░ čüąĖą╝ą▓ąŠą╗ąŠą▓ ąĖąĮą┤ąĖą║ą░č鹊čĆą░ BC1601AGPLCWs.
ąĪąĖą╝ą▓ąŠą╗čŗ čĆčāčüčüą║ąĖčģ ą▒čāą║ą▓ čéčāčé ą┐čĆąĖčüčāčéčüčéą▓čāčÄčé, ąĮąŠ ą║ąŠą┤ąĖčĆąŠą▓ą║ą░ čüąĖą╝ą▓ąŠą╗ąŠą▓ ąĮąĄ čüąŠą▓ą┐ą░ą┤ą░ąĄčé ąĮąĖ čü ASCII, ąĮąĖ čü ANSI, ą┐ąŠčŹč鹊ą╝čā ą┤ą╗čÅ ąĮąŠčĆą╝ą░ą╗čīąĮąŠą│ąŠ ąŠč鹊ą▒čĆą░ąČąĄąĮąĖčÅ č鹥ą║čüčéą░ čéčĆąĄą▒čāąĄčéčüčÅ čéą░ą▒ą╗ąĖčåą░ ą┐ąĄčĆąĄą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ.
[ąĪąŠąĘą┤ą░ąĮąĖąĄ čéą░ą▒ą╗ąĖčåčŗ ą┐ąĄčĆąĄą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ]
ąĢčüą╗ąĖ ąÆčŗ čüąŠąĘą┤ą░ąĄč鹥 č鹥ą║čüčé ą┐čĆąŠą│čĆą░ą╝ą╝čŗ čü ą┐ąŠą╝ąŠčēčīčÄ ąŠą▒čŗčćąĮąŠą│ąŠ č鹥ą║čüč鹊ą▓ąŠą│ąŠ čĆąĄą┤ą░ą║č鹊čĆą░, ąĮą░ą┐čĆąĖą╝ąĄčĆ ą▓ čüčĆąĄą┤ąĄ Atmel Studio, č鹊 ąĮą░ą▓ąĄčĆąĮčÅą║ą░ ą┤ą╗čÅ č鹥ą║čüčéą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ 8-ą▒ąĖčéąĮą░čÅ ą║ąŠą┤ąĖčĆąŠą▓ą║ą░ ANSI CP1251 [1], ą▓ ą║ąŠč鹊čĆąŠą╣ ąĖą╝ąĄčÄčéčüčÅ čĆčāčüčüą║ąĖąĄ ą▒čāą║ą▓čŗ.
ąöą╗čÅ ą┐čĆąŠčüč鹊ą╣ ą┐ąĄčĆąĄą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ ąĮčāąČąĮąŠ čüąŠąĘą┤ą░čéčī čéą░ą▒ą╗ąĖčåčā č鹊ą╗čīą║ąŠ ą┤ą╗čÅ čüąĖą╝ą▓ąŠą╗ąŠą▓ čü ą║ąŠą┤ą░ą╝ąĖ 0xC0..0xFF. ąöą╗čÅ čĆą░čüčłąĖčĆąĄąĮąĮąŠą╣ ą┐ąĄčĆąĄą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ, ąĄčüą╗ąĖ ąĄčüčéčī čüą▓ąŠą▒ąŠą┤ąĮą░čÅ ą┐ą░ą╝čÅčéčī, ą╝ąŠąČąĮąŠ čüą┤ąĄą╗ą░čéčī čéą░ą▒ą╗ąĖčåčā ą┐ąĄčĆąĄą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ ą┤ą╗čÅ čüąĖą╝ą▓ąŠą╗ąŠą▓ čü ą║ąŠą┤ą░ą╝ąĖ 0xA0..0xFF, ąĖą╗ąĖ ą┤ą░ąČąĄ 0x80..0xFF.
ąÆąŠčé čéą░ą▒ą╗ąĖčåą░ ą┐ąĄčĆąĄą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ ANSI CP1251 ą┤ą╗čÅ ą┤ąĖą░ą┐ą░ąĘąŠąĮą░ ą║ąŠą┤ąŠą▓ 0xC0..0xFF, ąĄčüą╗ąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ąĘąĮą░ą║ąŠą│ąĄąĮąĄčĆą░č鹊čĆ ą┐čĆąĖą╝ąĄčĆą░ ąĮą░ čĆąĖčü. 3:
char ANSI1251_CO_FF [] =
{
0x41, //ą║ąŠą┤ 0xC0, čüąĖą╝ą▓ąŠą╗ 'ąÉ'
0xA0, //ą║ąŠą┤ 0xC1, čüąĖą╝ą▓ąŠą╗ 'ąæ'
0x42, //ą║ąŠą┤ 0xC2, čüąĖą╝ą▓ąŠą╗ 'ąÆ'
0xA1, //ą║ąŠą┤ 0xC3, čüąĖą╝ą▓ąŠą╗ 'ąō'
0xE0, //ą║ąŠą┤ 0xC4, čüąĖą╝ą▓ąŠą╗ 'ąö'
0x45, //ą║ąŠą┤ 0xC5, čüąĖą╝ą▓ąŠą╗ 'ąĢ'
0xA3, //ą║ąŠą┤ 0xC6, čüąĖą╝ą▓ąŠą╗ 'ą¢'
0xA4, //ą║ąŠą┤ 0xC7, čüąĖą╝ą▓ąŠą╗ 'ąŚ'
0xA5, //ą║ąŠą┤ 0xC8, čüąĖą╝ą▓ąŠą╗ 'ąś'
0xA6, //ą║ąŠą┤ 0xC9, čüąĖą╝ą▓ąŠą╗ 'ąÖ'
0x4B, //ą║ąŠą┤ 0xCA, čüąĖą╝ą▓ąŠą╗ 'ąÜ'
0xA7, //ą║ąŠą┤ 0xCB, čüąĖą╝ą▓ąŠą╗ 'ąø'
0x4D, //ą║ąŠą┤ 0xCC, čüąĖą╝ą▓ąŠą╗ 'ą£'
0x48, //ą║ąŠą┤ 0xCD, čüąĖą╝ą▓ąŠą╗ 'ąØ'
0x4F, //ą║ąŠą┤ 0xCE, čüąĖą╝ą▓ąŠą╗ 'ą×'
0xA8, //ą║ąŠą┤ 0xCF, čüąĖą╝ą▓ąŠą╗ 'ą¤'
0x50, //ą║ąŠą┤ 0xD0, čüąĖą╝ą▓ąŠą╗ 'ąĀ'
0x43, //ą║ąŠą┤ 0xD1, čüąĖą╝ą▓ąŠą╗ 'ąĪ'
0x54, //ą║ąŠą┤ 0xD2, čüąĖą╝ą▓ąŠą╗ 'ąó'
0xA9, //ą║ąŠą┤ 0xD3, čüąĖą╝ą▓ąŠą╗ 'ąŻ'
0xAA, //ą║ąŠą┤ 0xD4, čüąĖą╝ą▓ąŠą╗ 'ąż'
0x58, //ą║ąŠą┤ 0xD5, čüąĖą╝ą▓ąŠą╗ 'ąź'
0xE1, //ą║ąŠą┤ 0xD6, čüąĖą╝ą▓ąŠą╗ 'ą”'
0xAB, //ą║ąŠą┤ 0xD7, čüąĖą╝ą▓ąŠą╗ 'ą¦'
0xAC, //ą║ąŠą┤ 0xD8, čüąĖą╝ą▓ąŠą╗ 'ą©'
0xE2, //ą║ąŠą┤ 0xD9, čüąĖą╝ą▓ąŠą╗ 'ą®'
0xAD, //ą║ąŠą┤ 0xDA, čüąĖą╝ą▓ąŠą╗ 'ą¬'
0xAE, //ą║ąŠą┤ 0xDB, čüąĖą╝ą▓ąŠą╗ 'ą½'
0x62, //ą║ąŠą┤ 0xDC, čüąĖą╝ą▓ąŠą╗ 'ą¼'
0xAF, //ą║ąŠą┤ 0xDD, čüąĖą╝ą▓ąŠą╗ 'ąŁ'
0xB0, //ą║ąŠą┤ 0xDE, čüąĖą╝ą▓ąŠą╗ 'ą«'
0xB1, //ą║ąŠą┤ 0xDF, čüąĖą╝ą▓ąŠą╗ 'ą»'
0x61, //ą║ąŠą┤ 0xE0, čüąĖą╝ą▓ąŠą╗ 'ą░'
0xB2, //ą║ąŠą┤ 0xE1, čüąĖą╝ą▓ąŠą╗ 'ą▒'
0xB3, //ą║ąŠą┤ 0xE2, čüąĖą╝ą▓ąŠą╗ 'ą▓'
0xB4, //ą║ąŠą┤ 0xE3, čüąĖą╝ą▓ąŠą╗ 'ą│'
0xE3, //ą║ąŠą┤ 0xE4, čüąĖą╝ą▓ąŠą╗ 'ą┤'
0x65, //ą║ąŠą┤ 0xE5, čüąĖą╝ą▓ąŠą╗ 'ąĄ'
0xB6, //ą║ąŠą┤ 0xE6, čüąĖą╝ą▓ąŠą╗ 'ąČ'
0xB7, //ą║ąŠą┤ 0xE7, čüąĖą╝ą▓ąŠą╗ 'ąĘ'
0xB8, //ą║ąŠą┤ 0xE8, čüąĖą╝ą▓ąŠą╗ 'ąĖ'
0xB9, //ą║ąŠą┤ 0xE9, čüąĖą╝ą▓ąŠą╗ 'ą╣'
0xBA, //ą║ąŠą┤ 0xEA, čüąĖą╝ą▓ąŠą╗ 'ą║'
0xBB, //ą║ąŠą┤ 0xEB, čüąĖą╝ą▓ąŠą╗ 'ą╗'
0xBC, //ą║ąŠą┤ 0xEC, čüąĖą╝ą▓ąŠą╗ 'ą╝'
0xBD, //ą║ąŠą┤ 0xED, čüąĖą╝ą▓ąŠą╗ 'ąĮ'
0x6F, //ą║ąŠą┤ 0xEE, čüąĖą╝ą▓ąŠą╗ 'ąŠ'
0xBE, //ą║ąŠą┤ 0xEF, čüąĖą╝ą▓ąŠą╗ 'ą┐'
0x70, //ą║ąŠą┤ 0xF0, čüąĖą╝ą▓ąŠą╗ 'čĆ'
0x63, //ą║ąŠą┤ 0xF1, čüąĖą╝ą▓ąŠą╗ 'čü'
0xBF, //ą║ąŠą┤ 0xF2, čüąĖą╝ą▓ąŠą╗ 'čé'
0x79, //ą║ąŠą┤ 0xF3, čüąĖą╝ą▓ąŠą╗ 'čā'
0xE4, //ą║ąŠą┤ 0xF4, čüąĖą╝ą▓ąŠą╗ 'čä'
0x78, //ą║ąŠą┤ 0xF5, čüąĖą╝ą▓ąŠą╗ 'čģ'
0xE5, //ą║ąŠą┤ 0xF6, čüąĖą╝ą▓ąŠą╗ 'čå'
0xC0, //ą║ąŠą┤ 0xF7, čüąĖą╝ą▓ąŠą╗ 'čć'
0xC1, //ą║ąŠą┤ 0xF8, čüąĖą╝ą▓ąŠą╗ 'čł'
0xE6, //ą║ąŠą┤ 0xF9, čüąĖą╝ą▓ąŠą╗ 'čē'
0xC2, //ą║ąŠą┤ 0xFA, čüąĖą╝ą▓ąŠą╗ 'čŖ'
0xC3, //ą║ąŠą┤ 0xFB, čüąĖą╝ą▓ąŠą╗ 'čŗ'
0xC4, //ą║ąŠą┤ 0xFC, čüąĖą╝ą▓ąŠą╗ 'čī'
0xC5, //ą║ąŠą┤ 0xFD, čüąĖą╝ą▓ąŠą╗ 'čŹ'
0xC6, //ą║ąŠą┤ 0xFE, čüąĖą╝ą▓ąŠą╗ 'čÄ'
0xC7 //ą║ąŠą┤ 0xFF, čüąĖą╝ą▓ąŠą╗ 'čÅ'
};
ą£ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ą░ lcd_puts, ąĖčüą┐ąŠą╗ąĘčāčÄčēą░čÅ čéą░ą▒ą╗ąĖčåčā ą┐ąĄčĆąĄą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ ANSI1251_C0_FF:
void lcd_puts(char *string)
{
for (char *it = string; *it; it++)
{
//ąĪčéą░čĆčŗą╣ ą║ąŠą┤, ą▓čŗą▓ąŠą┤ ą▒ąĄąĘ ą┐ąĄčĆąĄą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ:
//lcd_write(*it);
//ąÆčŗą▓ąŠą┤ čü ą┐ąĄčĆąĄą║ąŠą┤ąĖčĆąŠą▓ą║ąŠą╣:
if (*it < 0xC0)
{
lcd_write(*it);
}
else
{
lcd_write(ANSI1251_CO_FF[(unsigned char)(*it)-0xC0]);
}
}
}
[ąĪčüčŗą╗ą║ąĖ]
1. ąóą░ą▒ą╗ąĖčåą░ čüąĖą╝ą▓ąŠą╗ąŠą▓ ANSI.
2. Displaying Custom Characters on Alphanumeric LCDs site:extremeelectronics.co.in.
3. Using LCD Module with AVRs site:extremeelectronics.co.in.
4. ą×ąĮą╗ą░ą╣ąĮ-ą│ąĄąĮąĄčĆą░č鹊čĆ ą│čĆą░čäąĖą║ąĖ ą┤ą╗čÅ LCD-ąĖąĮą┤ąĖą║ą░č鹊čĆąŠą▓.
5. ą¤ąĄčĆąĄą║ąŠą┤ąĖčĆąŠą▓ą║ą░ čĆčāčüčüą║ąŠą│ąŠ č鹥ą║čüčéą░ ąĖąĘ UTF-8 ą▓ CP1251. |




ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖąĖ
ąÆ čüą▓ąŠčæ ą▓čĆąĄą╝čÅ čéą░ą║ąĖą╝ ąČąĄ ąŠą▒čĆą░ąĘąŠą╝ ą▓čŗčćąĖčüą╗ąĖą╗ ą║ąŠą┤čŗ ą▓čüąĄčģ čüąĖą╝ą▓ąŠą╗ąŠą▓, ą░ čüąĄą╣čćą░čü, ą║ąŠą│ą┤ą░ čüąĮąŠą▓ą░ ą┐ąŠąĮą░ą┤ąŠą▒ąĖą╗ąŠčüčī, ąĮąĄ čüą╝ąŠą│ čā čüąĄą▒čÅ ą▓ ą║ąŠą╝ą┐ąĄ ąĮą░ą╣čéąĖ čŹčéčā ąĖąĮč乊čĆą╝ą░čåąĖčÄ.
ąÆą░čłą░ čüčéą░čéčīčÅ ą▓čŗčĆčāčćąĖą╗ą░.
microsin: ą▓ąĄčĆąŠčÅčéąĮąŠ ą┤čĆčāą│ą░čÅ ą▓ąĄčĆčüąĖčÅ ą┐čĆąŠčłąĖą▓ą║ąĖ ąĖąĮą┤ąĖą║ą░č鹊čĆą░. ąØčāąČąĮąŠ ąŠą┐čŗčéąĮčŗą╝ ą┐čāč鹥ą╝ ą┐čĆąŠą▓ąĄčĆčÅčéčī, ą║ą░ą║ąĖąĄ čüąĖą╝ą▓ąŠą╗čŗ ąŠąĮ ąŠč鹊ą▒čĆą░ąČą░ąĄčé ą▓ ąŠčéą▓ąĄčé ąĮą░ ą║ą░ą║ąŠą╣ ą║ąŠą┤ čüąĖą╝ą▓ąŠą╗ą░, ąĖ čāąČąĄ ą┐ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ąĖčüą┐čĆą░ą▓ą╗čÅčéčī čéą░ą▒ą╗ąĖčåčā ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čā ą┐ąĄčĆąĄą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ.
RSS ą╗ąĄąĮčéą░ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖąĄą▓ čŹč鹊ą╣ ąĘą░ą┐ąĖčüąĖ