ążčāąĮą║čåąĖąĖ ą▓čŗą▓ąŠą┤ą░ ą▓ ą╗ąŠą│ Zephyr (logging API) ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ąŠą▒čēąĖą╣ ąĖąĮč鹥čĆč乥ą╣čü ą┤ą╗čÅ ą▓čŗą▓ąŠą┤ą░ ąŠčéą╗ą░ą┤ąŠčćąĮčŗčģ čüąŠąŠą▒čēąĄąĮąĖą╣, ą║ąŠč鹊čĆčŗąĄ ąŠčüčéą░ą▓ąĖą╗ąĖ ą▓ ą║ąŠą┤ąĄ čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ąĖ. ąĪąŠąŠą▒čēąĄąĮąĖčÅ ą┐ąĄčĆąĄą┤ą░čÄčéčüčÅ č湥čĆąĄąĘ frontend, ąĖ ąĘą░č鹥ą╝ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ą░ą║čéąĖą▓ąĮčŗą╝ąĖ ą▒菹║ąĄąĮą┤ą░ą╝ąĖ. ą¤čĆąĖ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ čüą░ą╝ąŠą┤ąĄą╗čīąĮčŗą╣ čäčĆąŠąĮč鹥ąĮą┤ ąĖ čüą░ą╝ąŠą┤ąĄą╗čīąĮčŗąĄ ą▒菹║ąĄąĮą┤čŗ.
ążčĆąŠąĮč鹥ąĮą┤ (frontend). ą¤ąĄčĆą▓ąĖčćąĮą░čÅ čüąĖčüč鹥ą╝ą░ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čüąŠąŠą▒čēąĄąĮąĖą╣. ą×čéą▓ąĄčćą░ąĄčé ąĘą░ ąĖčģ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖ ą┐ąŠčüčéą░ąĮąŠą▓ą║čā ą▓ ąŠč湥čĆąĄą┤čī.
ąæ菹║ąĄąĮą┤ (backend). ąØąĖąĘą║ąŠčāčĆąŠą▓ąĮąĄą▓ą░čÅ čüąĖčüč鹥ą╝ą░ ą▓čŗą▓ąŠą┤ą░ čüąĖą╝ą▓ąŠą╗čīąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ą╗ąŠą│ą░ ąĮą░čĆčāąČčā. ą¦ą░čēąĄ ą▓čüąĄą│ąŠ čŹč鹊 UART0.
ąÆąŠčé ą║čĆą░čéą║ą░čÅ čüą▓ąŠą┤ą║ą░ ą▓ąŠąĘą╝ąŠąČąĮąŠčüč鹥ą╣ čüąĖčüč鹥ą╝čŗ ą╗ąŠą│ą░ Zephyr:
ŌĆó ą×čéą╗ąŠąČąĄąĮąĮčŗą╣ ą▓čŗą▓ąŠą┤ ą▓ ą╗ąŠą│ (deferred logging) čāą╝ąĄąĮčīčłą░ąĄčé ą▓čĆąĄą╝čÅ, ą║ąŠč鹊čĆąŠąĄ čéčĆą░čéąĖčéčüčÅ ąĮą░ ą▓čŗą▓ąŠą┤ čüąŠąŠą▒čēąĄąĮąĖą╣. ąŁč鹊 čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮąŠ ąĘą░ čüč湥čé ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ ąĘą░čéčĆą░čéąĮčŗčģ ą┐ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą╝čā ą▓čĆąĄą╝ąĄąĮąĖ ąŠą┐ąĄčĆą░čåąĖą╣ ą╗ąŠą│ą░ ą▓ ąĮąĄą║čĆąĖčéąĖčćąĮčŗą╣, ą║ąŠąĮčéčĆąŠą╗ąĖčĆčāąĄą╝čŗą╣ (ąĮąĖąĘą║ąŠą┐čĆąĖąŠčĆąĖč鹥čéąĮčŗą╣) ą║ąŠąĮč鹥ą║čüčé ą▓ą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ čüčĆą░ąĘčā ą▓čŗą┐ąŠą╗ąĮčÅčéčī ąŠą▒čĆą░ą▒ąŠčéą║čā ą┐ąŠ ą╝ąĄčüčéčā ą▓čŗąĘąŠą▓ą░ čüąŠąŠą▒čēąĄąĮąĖčÅ.
Logging API ąĖą╝ąĄąĄčé čłąĖčĆąŠą║ąĖąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ą┐ąŠ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖčÄ ą║ą░ą║ ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ (compile time), čéą░ą║ ąĖ ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░ (run time). ąĪ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ąŠą┐čåąĖą╣ Kconfig (čüą╝. ą┤ą░ą╗ąĄąĄ "ąōą╗ąŠą▒ą░ą╗čīąĮčŗąĄ ąŠą┐čåąĖąĖ Kconfig") ą╗ąŠą│ąĖ ą╝ąŠąČąĮąŠ ą┐ąŠčüč鹥ą┐ąĄąĮąĮąŠ čāą┤ą░ą╗ąĖčéčī ąĖąĘ čĆąĄąĘčāą╗čīčéą░čéą░ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ, ą║ąŠą│ą┤ą░ ąŠąĮąĖ ąĮąĄ ąĮčāąČąĮčŗ, čćč鹊ą▒čŗ čāą╝ąĄąĮčīčłąĖčéčī čĆą░ąĘą╝ąĄčĆ ą▓čŗčģąŠą┤ąĮąŠą│ąŠ ąŠą▒čĆą░ąĘą░ ąĖ čāčüą║ąŠčĆąĖčéčī čĆą░ą▒ąŠčéčā ą║ąŠą┤ą░. ąÆąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ą╗ąŠą│ąĖ ą╝ąŠą│čāčé čäąĖą╗čīčéčĆąŠą▓ą░čéčīčüčÅ ąĮą░ ą▒ą░ąĘąĄ ą╝ąŠą┤čāą╗čÅ ąĖ čāčĆąŠą▓ąĮčÅ ą┐ąŠą┤čĆąŠą▒ąĮąŠčüčéąĖ (severity level).
ąóą░ą║ąČąĄ ą╗ąŠą│ąĖ ą╝ąŠą│čāčé ą▒čŗčéčī čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░ąĮčŗ, ąĮąŠ ąŠčéčäąĖą╗čīčéčĆąŠą▓ą░ąĮčŗ run time čü ą┐ąŠą╝ąŠčēčīčÄ čüą┐ąĄčåąĖą░ą╗čīąĮčŗčģ ą▓čŗąĘąŠą▓ąŠą▓ API. Run time čäąĖą╗čīčéčĆą░čåąĖčÅ ąĮąĄąĘą░ą▓ąĖčüąĖą╝ą░ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą▒菹║ąĄąĮą┤ą░ ąĖ ą║ą░ąČą┤ąŠą│ąŠ ąĖčüč鹊čćąĮąĖą║ą░ čüąŠąŠą▒čēąĄąĮąĖą╣ ą╗ąŠą│ą░. ąśčüč鹊čćąĮąĖą║ąŠą╝ čüąŠąŠą▒čēąĄąĮąĖą╣ ą╗ąŠą│ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ą╝ąŠą┤čāą╗čī, ąĖą╗ąĖ ąČąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╣ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą╝ąŠą┤čāą╗čÅ.
ąÆ čüąĖčüč鹥ą╝ąĄ ąĖą╝ąĄąĄčéčüčÅ 4 severity-čāčĆąŠą▓ąĮčÅ čüąŠąŠą▒čēąĄąĮąĖą╣ ą╗ąŠą│ą░: error, warning, info ąĖ debug. ąöą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ severity čüčāčēąĄčüčéą▓čāąĄčé čüą▓ąŠąĄ logging API (čüą╝. include/zephyr/logging/log.h ), čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮąĮąŠąĄ ą▓ ą▓ąĖą┤ąĄ ąĮą░ą▒ąŠčĆą░ čüą┐ąĄčåąĖą░ą╗čīąĮčŗčģ ą╝ą░ą║čĆąŠčüąŠą▓. ąóą░ą║ąČąĄ ąĄčüčéčī ą╝ą░ą║čĆąŠčüčŗ ą┤ą╗čÅ ą╗ąŠą│ą░ ą┤ą░ąĮąĮčŗčģ.
// ąŻčĆąŠą▓ąĮąĖ ą╗ąŠą│ą░, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ ą▓ include/zephyr/logging/log_core.h #define LOG_LEVEL_NONE 0U #define LOG_LEVEL_ERR 1U #define LOG_LEVEL_WRN 2U #define LOG_LEVEL_INF 3U #define LOG_LEVEL_DBG 4U
ą¤čĆąĖą╝ąĄčĆ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖčÅ ą╗ąŠą│ą░ ą▓ ąĖčüčģąŠą┤ąĮąŠą╝ ą║ąŠą┤ąĄ main.c :
LOG_MODULE_REGISTER(main, LOG_LEVEL_DBG);
...
int main(void )
{
for (;;)
{
LOG_ERR("ERR %d" , LOG_LEVEL_ERR);
LOG_WRN("WRN %d" , LOG_LEVEL_WRN);
LOG_INF("INF %d" , LOG_LEVEL_INF);
LOG_DBG("DBG %d" , LOG_LEVEL_DBG);
ąæčāą┤čāčé ą▓čŗą▓ąŠą┤ąĖčéčüčÅ č鹥 čüąŠąŠą▒čēąĄąĮąĖčÅ, čāčĆąŠą▓ąĄąĮčī ą║ąŠč鹊čĆčŗčģ ą╝ąĄąĮčīčłąĄ ąĖą╗ąĖ čĆą░ą▓ąĄąĮ čāčĆąŠą▓ąĮčÄ, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╝čā LOG_MODULE_REGISTER .
ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą▓ LOG_MODULE_REGISTER čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╣ čāčĆąŠą▓ąĄąĮčī:
LOG_LEVEL_DBG : ą▒čāą┤čāčé ą▓čŗą▓ąŠą┤ąĖčéčīčüčÅ čüąŠąŠą▒čēąĄąĮąĖčÅ ą▓čüąĄčģ čāčĆąŠą▓ąĮąĄą╣ severity, čé. ąĄ. LOG_ERR, LOG_WRN, LOG_INF, LOG_DBG.
LOG_LEVEL_INF : ą▒čāą┤čāčé ą▓čŗą▓ąŠą┤ąĖčéčīčüčÅ čüąŠąŠą▒čēąĄąĮąĖčÅ LOG_ERR, LOG_WRN, LOG_INF. ąĪąŠąŠą▒čēąĄąĮąĖčÅ LOG_DBG ą▓čŗą▓ąŠą┤ąĖčéčīčüčÅ ąĮąĄ ą▒čāą┤čāčé.
LOG_LEVEL_WRN : ą▒čāą┤čāčé ą▓čŗą▓ąŠą┤ąĖčéčīčüčÅ čüąŠąŠą▒čēąĄąĮąĖčÅ LOG_ERR, LOG_WRN. ąĪąŠąŠą▒čēąĄąĮąĖčÅ LOG_INF, LOG_DBG ą▓čŗą▓ąŠą┤ąĖčéčīčüčÅ ąĮąĄ ą▒čāą┤čāčé.
LOG_LEVEL_ERR : ą▒čāą┤čāčé ą▓čŗą▓ąŠą┤ąĖčéčīčüčÅ č鹊ą╗čīą║ąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ LOG_ERR. ąĪąŠąŠą▒čēąĄąĮąĖčÅ LOG_WRN, LOG_INF, LOG_DBG ą▓čŗą▓ąŠą┤ąĖčéčīčüčÅ ąĮąĄ ą▒čāą┤čāčé.
ąĢčüą╗ąĖ ą▓ LOG_MODULE_REGISTER ąĮąĖč湥ą│ąŠ ąĮąĄ čāą║ą░ąĘčŗą▓ą░čéčī (ąĮą░ą┐čĆąĖą╝ąĄčĆ čéą░ą║: LOG_MODULE_REGISTER(main)), č鹊 č鹊ą│ą┤ą░ ą▒čāą┤čāčé ą▓čŗą▓ąŠą┤ąĖčéčīčüčÅ LOG_ERR, LOG_WRN, LOG_INF, ą░ čüąŠąŠą▒čēąĄąĮąĖčÅ LOG_DBG ą▓čŗą▓ąŠą┤ąĖčéčīčüčÅ ąĮąĄ ą▒čāą┤čāčé. ąó. ąĄ. ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░ LOG_LEVEL_INF.
ąöą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ ą┤ąŠčüčéčāą┐ąĄąĮ čüą╗ąĄą┤čāčÄčēąĖą╣ ąĮą░ą▒ąŠčĆ ą╝ą░ą║čĆąŠčüąŠą▓:
ŌĆó LOG_X ą┤ą╗čÅ čüčéą░ąĮą┤ą░čĆčéąĮčŗčģ čüąŠąŠą▒čēąĄąĮąĖą╣, čĆą░ą▒ąŠčéą░čÄčēąĖčģ ą║ą░ą║ printf, ąĮą░ą┐čĆąĖą╝ąĄčĆ LOG_ERR.
ąĪčāčēąĄčüčéą▓čāąĄčé 2 ą║ą░č鹥ą│ąŠčĆąĖąĖ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ: ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÅ ą┤ą╗čÅ ą╝ąŠą┤čāą╗čÅ ąĖ ą│ą╗ąŠą▒ą░ą╗čīąĮą░čÅ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÅ. ąÜąŠą│ą┤ą░ ą╗ąŠą│ čĆą░ąĘčĆąĄčłąĄąĮ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠ, čŹč鹊 čĆą░ą▒ąŠčéą░ąĄčé ą┤ą╗čÅ ą╝ąŠą┤čāą╗ąĄą╣. ą×ą┤ąĮą░ą║ąŠ ą╝ąŠą┤čāą╗čÅą╝ ą╝ąŠąČąĮąŠ ą╗ąŠą║ą░ą╗čīąĮąŠ ąĘą░ą┐čĆąĄčéąĖčéčī ą▓čŗą▓ąŠą┤ ą▓ ą╗ąŠą│. ąÜą░ąČą┤ąŠą╝čā ą╝ąŠą┤čāą╗čÄ ą╝ąŠąČąĮąŠ čāą║ą░ąĘą░čéčī čüą▓ąŠą╣ čüąŠą▒čüčéą▓ąĄąĮąĮčŗą╣ čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░. ą£ąŠą┤čāą╗čī ą┤ąŠą╗ąČąĄąĮ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą╝ą░ą║čĆąŠčü LOG_LEVEL ą┐ąĄčĆąĄą┤ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ API ą╗ąŠą│ą░. ąĢčüą╗ąĖ ąĮąĄ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠąĄ ą┐ąĄčĆąĄąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ, č鹊 ą▒čāą┤ąĄčé čüąŠą▒ą╗čÄą┤ą░čéčīčüčÅ čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ ą╝ąŠą┤čāą╗čÅ. ąōą╗ąŠą▒ą░ą╗čīąĮąŠąĄ ą┐ąĄčĆąĄąĮą░ąĘąĮą░č湥ąĮąĖąĄ ą╝ąŠąČąĄčé č鹊ą╗čīą║ąŠ ą┐ąŠą▓čŗčüąĖčéčī čāčĆąŠą▓ąĄąĮčī ą┐ąŠą┤čĆąŠą▒ąĮąŠčüčéąĖ ą╗ąŠą│ą░. ąĢą│ąŠ ąĮąĄą╗čīąĘčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ čüąĮąĖąČąĄąĮąĖčÅ čāčĆąŠą▓ąĮąĄą╣ ą╗ąŠą│ą░ ą╝ąŠą┤čāą╗ąĄą╣, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ čĆą░ąĮąĄąĄ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮčŗ ąĮą░ ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąĖą╣ čāčĆąŠą▓ąĄąĮčī. ąóą░ą║ąČąĄ ą╝ąŠąČąĮąŠ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠ ąŠą│čĆą░ąĮąĖčćąĖčéčī ą╗ąŠą│ąĖ ą┐čāč鹥ą╝ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĖčÅ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą│ąŠ čāčĆąŠą▓ąĮčÅ severity, ą┐čĆąĖčüčāčéčüčéą▓čāčÄčēąĄą│ąŠ ą▓ čüąĖčüč鹥ą╝ąĄ, ą│ą┤ąĄ "ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčŗą╣" ąŠąĘąĮą░čćą░ąĄčé ąĮą░ąĖą╝ąĄąĮčīčłčāčÄ čüąĄčĆčīąĄąĘąĮąŠčüčéčī (čé. ąĄ. ąĄčüą╗ąĖ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčŗą╣ čāčĆąŠą▓ąĄąĮčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą▓ info, č鹊 čŹč鹊 ąĘąĮą░čćąĖčé, čćč鹊 čāčĆąŠą▓ąĮąĖ čüąŠąŠą▒čēąĄąĮąĖą╣ ąŠčłąĖą▒ąŠą║, ą┐čĆąĄą┤čāą┐čĆąĄąČą┤ąĄąĮąĖą╣ ąĖ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą▒čāą┤čāčé ą┐čĆąĖčüčāčéčüčéą▓ąŠą▓ą░čéčī, ąĮąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ debug ą▒čāą┤čāčé ąĖčüą║ą╗čÄč湥ąĮčŗ).
ąÜą░ąČą┤čŗą╣ ą╝ąŠą┤čāą╗čī, ą║ąŠč鹊čĆčŗą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą▓čŗą▓ąŠą┤ ą▓ ą╗ąŠą│, ą┤ąŠą╗ąČąĄąĮ čāą║ą░ąĘą░čéčī čüą▓ąŠąĄ čāąĮąĖą║ą░ą╗čīąĮąŠąĄ ąĖą╝čÅ ąĖ ąĘą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░čéčī čüą░ą╝ąŠą│ąŠ čüąĄą▒čÅ ą┤ą╗čÅ čüąĖčüč鹥ą╝čŗ ą╗ąŠą│ą░. ąĢčüą╗ąĖ ą╝ąŠą┤čāą╗čī čüąŠčüč鹊ąĖčé ąĖąĘ ą▒ąŠą╗ąĄąĄ č湥ą╝ ąŠą┤ąĮąŠą│ąŠ čäą░ą╣ą╗ą░, č鹊 čĆąĄą│ąĖčüčéčĆą░čåąĖčÅ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą▓ ąŠą┤ąĮąŠą╝ ąĖąĘ ąĮąĖčģ, ąĮąŠ ą║ą░ąČą┤čŗą╣ čäą░ą╣ą╗ ą┤ąŠą╗ąČąĄąĮ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ąĖą╝čÅ ą╝ąŠą┤čāą╗čÅ.
ążčĆąŠąĮč鹥ąĮą┤ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ čüąĖčüč鹥ą╝čŗ ą╗ąŠą│ą░ čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮ čü čāč湥č鹊ą╝ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖčÅ ą▒ąĄąĘąŠą┐ą░čüąĮąŠą╣ čĆą░ą▒ąŠčéčŗ ą▓ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠą╝ ąŠą║čĆčāąČąĄąĮąĖąĖ (thread safe) ąĖ ą╝ąĖąĮąĖą╝ąĖąĘą░čåąĖąĖ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ, ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠą│ąŠ ą┤ą╗čÅ ą▓čŗą▓ąŠą┤ą░ ą▓ ą╗ąŠą│ čüąŠąŠą▒čēąĄąĮąĖčÅ. ą×ą┐ąĄčĆą░č鹊čĆčŗ, ąĘą░čéčĆą░čéąĮčŗąĄ ą┐ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ, ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖčÅ čüčéčĆąŠą║ ąĖą╗ąĖ ą┤ąŠčüčéčāą┐ą░ ą║ čéčĆą░ąĮčüą┐ąŠčĆčéčā, ąĮąĄ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĮąĄ ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓čŗąĘąŠą▓ą░ logging API. ąÜąŠą│ą┤ą░ ą▓čŗąĘčŗą▓ą░ąĄčéčüčÅ čäčāąĮą║čåąĖčÅ logging API, čüąŠąŠą▒čēąĄąĮąĖąĄ čüąŠąĘą┤ą░ąĄčéčüčÅ ąĖ ą┤ąŠą▒ą░ą▓ą╗čÅąĄčéčüčÅ ą▓ čüą┐ąĖčüąŠą║. ą¤čĆąĖ čŹč鹊ą╝ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗą╣, ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄą╝čŗą╣ ą▒čāč乥čĆ ą┤ą╗čÅ ą┐čāą╗ą░ ą╗ąŠą│ą░ čüąŠąŠą▒čēąĄąĮąĖą╣. ąĪčāčēąĄčüčéą▓čāąĄčé 2 čéąĖą┐ą░ čüąŠąŠą▒čēąĄąĮąĖą╣: standard ąĖ hexdump. ąÜą░ąČą┤ąŠąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ čüąŠą┤ąĄčƹȹĖčé ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ąĖčüč鹊čćąĮąĖą║ą░ (source ID, ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāčÄčēąĖą╣ ą╝ąŠą┤čāą╗čī) ąĖą╗ąĖ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ą╝ąŠą┤čāą╗čÅ ąĖą╗ąĖ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ (module ID ąĖą╗ąĖ instance ID) ąĖ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ą┤ąŠą╝ąĄąĮą░ (domain ID, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮ ą┤ą╗čÅ ą╝ąĮąŠą│ąŠą┐čĆąŠčåąĄčüčüąŠčĆąĮčŗčģ čüąĖčüč鹥ą╝), ą╝ąĄčéą║čā ą▓čĆąĄą╝ąĄąĮąĖ ąĖ severity-čāčĆąŠą▓ąĄąĮčī. ąĪąŠąŠą▒čēąĄąĮąĖąĄ standard čüąŠą┤ąĄčƹȹĖčé čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ čüčéčĆąŠą║čā ąĖ ą░čĆą│čāą╝ąĄąĮčéčŗ. ąĪąŠąŠą▒čēąĄąĮąĖąĄ hexdump čüąŠą┤ąĄčƹȹĖčé čüą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ąĖ čüčéčĆąŠą║čā.
[ąōą╗ąŠą▒ą░ą╗čīąĮčŗąĄ ąŠą┐čåąĖąĖ Kconfig ]
ąŁčéąĖ ąŠą┐čåąĖąĖ ą╝ąŠąČąĮąŠ ąĮą░ą╣čéąĖ ą▓ subsys/logging/Kconfig .
CONFIG_LOG : ą│ą╗ąŠą▒ą░ą╗čīąĮčŗą╣ ą║ą╗čÄčć, ą▓ą║ą╗čÄčćą░ąĄčé ąĖą╗ąĖ ą▓čŗą║ą╗čÄčćą░ąĄčé ą▓čŗą▓ąŠą┤ ą▓ ą╗ąŠą│.
ąĀąĄąČąĖą╝čŗ čĆą░ą▒ąŠčéčŗ:
CONFIG_LOG_MODE_DEFERRED : čĆąĄąČąĖą╝ ąŠčéą╗ąŠąČąĄąĮąĮąŠą│ąŠ ą▓čŗą▓ąŠą┤ą░.CONFIG_LOG_MODE_IMMEDIATE : čĆąĄąČąĖą╝ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠą│ąŠ (čüąĖąĮčģčĆąŠąĮąĮąŠą│ąŠ) ą▓čŗą▓ąŠą┤ą░.CONFIG_LOG_MODE_MINIMAL : čĆąĄąČąĖą╝ ą╝ąĖąĮąĖą╝ą░ą╗čīąĮčŗčģ ąĘą░čéčĆą░čé ą┐ą░ą╝čÅčéąĖ ą║ąŠą┤ą░.
ą×ą┐čåąĖąĖ čäąĖą╗čīčéčĆą░čåąĖąĖ:
CONFIG_LOG_RUNTIME_FILTERING : čĆą░ąĘčĆąĄčłą░ąĄčé runtime-ą┐ąĄčĆąĄą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ ą┤ą╗čÅ čäąĖą╗čīčéčĆą░čåąĖąĖ.CONFIG_LOG_DEFAULT_LEVEL : čāčĆąŠą▓ąĄąĮčī ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ, čāčüčéą░ąĮąŠą▓ąĖčé čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą╝ąŠą┤čāą╗čÅą╝ąĖ, ą║ąŠč鹊čĆčŗąĄ ąĮąĄ čāčüčéą░ąĮąŠą▓ąĖą╗ąĖ čüą▓ąŠą╣ čüąŠą▒čüčéą▓ąĄąĮąĮčŗą╣ čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░.CONFIG_LOG_OVERRIDE_LEVEL : ą┐ąĄčĆąĄąĮą░ąĘąĮą░čćą░ąĄčé čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░ ą╝ąŠą┤čāą╗čÅ, ą║ąŠą│ą┤ą░ ąŠąĮ ąĮąĄ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ, ąĖą╗ąĖ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ąĮą░ čāčĆąŠą▓ąĄąĮčī ąĮąĖąČąĄ, č湥ą╝ ąĘąĮą░č湥ąĮąĖąĄ ą┐ąĄčĆąĄąĮą░ąĘąĮą░č湥ąĮąĖčÅ.CONFIG_LOG_MAX_LEVEL : ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčŗą╣ (čüą░ą╝ą░čÅ ąĮąĖąĘą║ą░čÅ ą▓ą░ąČąĮąŠčüčéčī severity) čāčĆąŠą▓ąĄąĮčī, ą║ąŠč鹊čĆčŗą╣ ą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ.
ą×ą┐čåąĖąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ:
CONFIG_LOG_MODE_OVERFLOW : ą║ąŠą│ą┤ą░ ąĮąŠą▓ąŠąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┤ąĄą╗ąĄąĮąŠ, ą▒ąŠą╗ąĄąĄ čüčéą░čĆąŠąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ ąŠčéą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ.CONFIG_LOG_BLOCK_IN_THREAD : ąĄčüą╗ąĖ čĆą░ąĘčĆąĄčłąĄąĮąŠ, ąĖ ąĮąŠą▓ąŠąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┤ąĄą╗ąĄąĮąŠ, č鹊 ą║ąŠąĮč鹥ą║čüčé ą┐ąŠč鹊ą║ą░ ąĘą░ą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ ąĮą░ CONFIG_LOG_BLOCK_IN_THREAD_TIMEOUT_MS, ąĖą╗ąĖ ą┤ąŠ č鹥čģ ą┐ąŠčĆ, ą┐ąŠą║ą░ ąĮąĄ ą▒čāą┤ąĄčé ą▓čŗą┤ąĄą╗ąĄąĮąŠ čüąŠąŠą▒čēąĄąĮąĖąĄ ą╗ąŠą│ą░.CONFIG_LOG_PRINTK : ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą▓čŗąĘąŠą▓ąŠą▓ printk ą▓ čüąĖčüč鹥ą╝čā ą╗ąŠą│ą░.CONFIG_LOG_PROCESS_TRIGGER_THRESHOLD : ą║ąŠą│ą┤ą░ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒čāč乥čĆąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗčģ čüąŠąŠą▒čēąĄąĮąĖą╣ ą╗ąŠą│ą░ ą┤ąŠčüčéąĖą│ą░ąĄčé ą┐ąŠčĆąŠą│ąŠą▓ąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ, ą┐čĆąŠą▒čāąČą┤ą░ąĄčéčüčÅ ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗą╣ ą┐ąŠč鹊ą║ (čüą╝. log_thread_set()). ąĢčüą╗ąĖ čĆą░ąĘčĆąĄčłąĄąĮąŠ CONFIG_LOG_PROCESS_THREAD, č鹊 čŹč鹊čé ą┐ąŠčĆąŠą│ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą▓ąĮčāčéčĆąĄąĮąĮąĖą╝ ą┐ąŠč鹊ą║ąŠą╝.CONFIG_LOG_PROCESS_THREAD : ą║ąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮąŠ, čüąŠąĘą┤ą░ąĄčéčüčÅ ą┐ąŠč鹊ą║ čüąĖčüč鹥ą╝čŗ ą╗ąŠą│ą░, ąĮą░ ą║ąŠč鹊čĆčŗą╣ ą▓ąŠąĘą╗ą░ą│ą░ąĄčéčüčÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ą╗ąŠą│ą░.CONFIG_LOG_PROCESS_THREAD_STARTUP_DELAY_MS : ąĘą░ą┤ąĄčƹȹ║ą░ ą▓ ą╝ąĖą╗ą╗ąĖčüąĄą║čāąĮą┤ą░čģ, ą┐ąŠčüą╗ąĄ ą║ąŠč鹊čĆąŠą╣ ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ ą┐ąŠč鹊ą║ ą╗ąŠą│ą░.CONFIG_LOG_BUFFER_SIZE : ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ą░ą╣čé, ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗčģ ą┤ą╗čÅ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ ą┐ą░ą║ąĄčéą░.CONFIG_LOG_FRONTEND : ąĮą░ą┐čĆą░ą▓ą╗čÅąĄčé ą╗ąŠą│ąĖ ą▓ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖą╣ čäčĆąŠąĮč鹥ąĮą┤.CONFIG_LOG_FRONTEND_ONLY : ą║ąŠą│ą┤ą░ čüąŠąŠą▒čēąĄąĮąĖčÅ ą┤ąŠčüčéąĖą│ą░čÄčé čäčĆąŠąĮč鹥ąĮą┤ą░, ąĮąĖą║ą░ą║ąĖąĄ ą▒菹║ąĄąĮą┤čŗ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ.CONFIG_LOG_CUSTOM_HEADER : ą▓čüčéą░ą▓ą╗čÅąĄčé ą▓ log.h ąĘą░ą│ąŠą╗ąŠą▓ąŠą║, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗą╣ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄą╝.CONFIG_LOG_TIMESTAMP_64BIT : ą╝ąĄčéą║ą░ ą▓čĆąĄą╝ąĄąĮąĖ ąĖą╝ąĄąĄčé čĆą░ąĘčĆčÅą┤ąĮąŠčüčéčī 64 ą▒ąĖčéą░.
ą×ą┐čåąĖąĖ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖčÅ:
CONFIG_LOG_FUNC_NAME_PREFIX_ERR : ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé ąĖą╝čÅ čäčāąĮą║čåąĖąĖ ą║ čüčéą░ąĮą┤ą░čĆčéąĮčŗą╝ (standard) čüąŠąŠą▒čēąĄąĮąĖčÅą╝ ERROR ą╗ąŠą│ą░.CONFIG_LOG_FUNC_NAME_PREFIX_WRN : ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé ąĖą╝čÅ čäčāąĮą║čåąĖąĖ ą║ čüčéą░ąĮą┤ą░čĆčéąĮčŗą╝ (standard) čüąŠąŠą▒čēąĄąĮąĖčÅą╝ WARNING ą╗ąŠą│ą░. ąÜ čüąŠąŠą▒čēąĄąĮąĖčÅą╝ ą┤ą░ą╝ą┐ą░ (hexdump) ąĖą╝čÅ čäčāąĮą║čåąĖąĖ ąĮąĄ ą┤ąŠą▒ą░ą▓ą╗čÅąĄčéčüčÅ.CONFIG_LOG_FUNC_NAME_PREFIX_INF : ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé ąĖą╝čÅ čäčāąĮą║čåąĖąĖ ą║ čüčéą░ąĮą┤ą░čĆčéąĮčŗą╝ (standard) čüąŠąŠą▒čēąĄąĮąĖčÅą╝ INFO ą╗ąŠą│ą░. ąÜ čüąŠąŠą▒čēąĄąĮąĖčÅą╝ ą┤ą░ą╝ą┐ą░ (hexdump) ąĖą╝čÅ čäčāąĮą║čåąĖąĖ ąĮąĄ ą┤ąŠą▒ą░ą▓ą╗čÅąĄčéčüčÅ.CONFIG_LOG_FUNC_NAME_PREFIX_DBG : ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé ąĖą╝čÅ čäčāąĮą║čåąĖąĖ ą║ čüčéą░ąĮą┤ą░čĆčéąĮčŗą╝ (standard) čüąŠąŠą▒čēąĄąĮąĖčÅą╝ DEBUG ą╗ąŠą│ą░. ąÜ čüąŠąŠą▒čēąĄąĮąĖčÅą╝ ą┤ą░ą╝ą┐ą░ (hexdump) ąĖą╝čÅ čäčāąĮą║čåąĖąĖ ąĮąĄ ą┤ąŠą▒ą░ą▓ą╗čÅąĄčéčüčÅ.CONFIG_LOG_BACKEND_SHOW_COLOR : čĆą░ąĘčĆąĄčłą░ąĄčé čĆą░čüą║čĆą░čüą║čā čåą▓ąĄč鹊ą╝ čüąŠąŠą▒čēąĄąĮąĖą╣ ąŠčłąĖą▒ąŠą║ (red, ą║čĆą░čüąĮčŗą╣) ąĖ ą┐čĆąĄą┤čāą┐čĆąĄąČą┤ąĄąĮąĖą╣ (yellow, ąČąĄą╗čéčŗą╣).CONFIG_LOG_BACKEND_FORMAT_TIMESTAMP : ąĄčüą╗ąĖ čĆą░ąĘčĆąĄčłąĄąĮąŠ, č鹊 ą╝ąĄčéą║ąĖ ą▓čĆąĄą╝ąĄąĮąĖ č乊čĆą╝ą░čéąĖčĆčāčÄčéčüčÅ ą▓ ą▓ąĖą┤ąĄ hh:mm:ss:mmm,uuu. ąśąĮą░č湥 ą╝ąĄčéą║ą░ ą┐ąĄčćą░čéą░ąĄčéčüčÅ ą▓ čüčŗčĆąŠą╝ ą▓ąĖą┤ąĄ.
ą×ą┐čåąĖąĖ ą▒菹║ąĄąĮą┤ą░:
CONFIG_LOG_BACKEND_UART : čĆą░ąĘčĆąĄčłą░ąĄčé ą▓čüčéčĆąŠąĄąĮąĮčŗą╣ UART backend.
[ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ]
ąøąŠą│ą│ąĖąĮą│ ą▓ ą╝ąŠą┤čāą╗ąĄ . ą¦č鹊ą▒čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą╗ąŠą│ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ą╝ąŠą┤čāą╗čÅ, čŹč鹊čé ą╝ąŠą┤čāą╗čī ą┤ąŠą╗ąČąĄąĮ čāą║ą░ąĘą░čéčī čāąĮąĖą║ą░ą╗čīąĮąŠąĄ ąĖą╝čÅ, ąĖ čü čŹčéąĖą╝ ąĖą╝ąĄąĮąĄą╝ ą╝ąŠą┤čāą╗čī ą┤ąŠą╗ąČąĄąĮ ąĘą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░čéčī čüąĄą▒čÅ ą╝ą░ą║čĆąŠčüąŠą╝ LOG_MODULE_REGISTER . ą×ą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ąĮą░ čŹčéą░ą┐ąĄ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ą▓ąŠ ą▓č鹊čĆąŠą╝ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ čŹč鹊ą│ąŠ ą╝ą░ą║čĆąŠčüą░ ą╝ąŠąČąĄčé ą▒čŗčéčī čāą║ą░ąĘą░ąĮ čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░ ą┤ą╗čÅ ą╝ąŠą┤čāą╗čÅ. ąĢčüą╗ąĖ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖą╣ čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░ ąĮąĄ čāą║ą░ąĘą░ąĮ, č鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ (CONFIG_LOG_DEFAULT_LEVEL).
#include < zephyr/logging/log.h>
LOG_MODULE_REGISTER(foo, CONFIG_FOO_LOG_LEVEL);
ąĢčüą╗ąĖ ą╝ąŠą┤čāą╗čī čüąŠčüč鹊ąĖčé ąĖąĘ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čäą░ą╣ą╗ąŠą▓, č鹊 LOG_MODULE_REGISTER() ą┤ąŠą╗ąČąĄąĮ ą┐ąŠčÅą▓ąĖčéčīčüčÅ č鹊ą╗čīą║ąŠ ą▓ ąŠą┤ąĮąŠą╝ ąĖąĘ čŹčéąĖčģ čäą░ą╣ą╗ąŠą▓. ąÜą░ąČą┤čŗą╣ ą┤čĆčāą│ąŠą╣ čäą░ą╣ą╗ ą┤ąŠą╗ąČąĄąĮ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą╝ą░ą║čĆąŠčü LOG_MODULE_DECLARE, čćč鹊ą▒čŗ ą┤ąĄą║ą╗ą░čĆąĖčĆąŠą▓ą░čéčī čüą▓ąŠąĄ čćą╗ąĄąĮčüčéą▓ąŠ ą▓ ą╝ąŠą┤čāą╗ąĄ. ą×ą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą▓ąŠ ą▓č鹊čĆąŠą╝ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮą░ čŹčéą░ą┐ąĄ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī čāą║ą░ąĘą░ąĮ čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░ ą┤ą╗čÅ čäą░ą╣ą╗ą░ ą╝ąŠą┤čāą╗čÅ. ąĢčüą╗ąĖ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖą╣ čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░ ąĮąĄ čāą║ą░ąĘą░ąĮ, č鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ (CONFIG_LOG_DEFAULT_LEVEL).
#include < zephyr/logging/log.h>
/* ąÆąŠ ą▓čüąĄčģ čäą░ą╣ą╗ą░čģ, čüąŠčüčéą░ą▓ą╗čÅčÄčēąĖčģ ą╝ąŠą┤čāą╗čī, ą║čĆąŠą╝ąĄ ąŠą┤ąĮąŠą│ąŠ */
LOG_MODULE_DECLARE(foo, CONFIG_FOO_LOG_LEVEL);
ą¦č鹊ą▒čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī logging API ą▓ č鹥ą╗ąĄ čäčāąĮą║čåąĖąĖ, ą║ąŠč鹊čĆą░čÅ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮą░ ą▓ ąĘą░ą│ąŠą╗ąŠą▓ąŠčćąĮąŠą╝ čäą░ą╣ą╗ąĄ, ą╝ą░ą║čĆąŠčü LOG_MODULE_DECLARE ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓čüčéą░ą▓ą╗ąĄąĮ ą▓ č鹥ą╗ąŠ čŹč鹊ą╣ čäčāąĮą║čåąĖąĖ ą┐ąĄčĆąĄą┤ ą▓čŗąĘąŠą▓ąŠą╝ logging API. ą×ą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą▓ąŠ ą▓č鹊čĆąŠą╝ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮą░ čŹčéą░ą┐ąĄ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī čāą║ą░ąĘą░ąĮ čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░ ą┤ą╗čÅ ą╝ąŠą┤čāą╗čÅ. ąĢčüą╗ąĖ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖą╣ čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░ ąĮąĄ čāą║ą░ąĘą░ąĮ, č鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ (CONFIG_LOG_DEFAULT_LEVEL).
#include < zephyr/logging/log.h>
static inline void foo (void )
{
LOG_MODULE_DECLARE(foo, CONFIG_FOO_LOG_LEVEL);
LOG_INF("foo" );
}
ą£ąŠąČąĄčé ą▒čŗčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮ ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗą╣ čłą░ą▒ą╗ąŠąĮ Kconfig (subsys/logging/Kconfig.template.log_config ), čćč鹊ą▒čŗ čüąŠąĘą┤ą░čéčī ą╗ąŠą║ą░ą╗čīąĮčāčÄ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÄ čāčĆąŠą▓ąĮčÅ ą╗ąŠą│ą░.
ą¤čĆąĖą╝ąĄčĆ ąĮąĖąČąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čŹč鹊ą│ąŠ čłą░ą▒ą╗ąŠąĮą░. ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 ą▒čāą┤ąĄčé čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮ CONFIG_FOO_LOG_LEVEL:
module = FOO
module-str = foo
source "subsys/logging/Kconfig.template.log_config"
ąøąŠą│ą│ąĖąĮą│ ą▓ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąĄ ą╝ąŠą┤čāą╗čÅ . ąÆ čüą╗čāčćą░ąĄ, ą║ąŠą│ą┤ą░ ą╝ąŠą┤čāą╗ąĖ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮčŗ ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ą╝ąĖ ąĖ čłąĖčĆąŠą║ąŠ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ, čĆą░ąĘčĆąĄčłąĄąĮąĖąĄ ą╗ąŠą│ą░ ą▓ ąĮąĖčģ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ą╗ą░ą▓ąĖąĮąĮąŠą╝čā ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÄ ą▒čāč乥čĆą░ čüąĖčüč鹥ą╝čŗ ą╗ąŠą│ą░. ąøąŠą│ą│ąĄčĆ ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé ąĖąĮčüčéčĆčāą╝ąĄąĮčé, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ čäąĖą╗čīčéčĆą░čåąĖąĖ ą┐ąŠ čāčĆąŠą▓ąĮčÄ čŹą║ąĘąĄą╝ą┐ą╗čÅčĆą░ ą▓ą╝ąĄčüč鹊 čäąĖą╗čīčéčĆą░čåąĖąĖ ąĮą░ čāčĆąŠą▓ąĮąĄ ą╝ąŠą┤čāą╗čÅ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą╗ąŠą│ ą╝ąŠąČąĄčé ą▒čŗčéčī čĆą░ąĘčĆąĄčłąĄąĮ ą┤ą╗čÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░.
ą¦č鹊ą▒čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čäąĖą╗čīčéčĆą░čåąĖčÄ ą┐ąŠ čāčĆąŠą▓ąĮčÄ čŹą║ąĘąĄą╝ą┐ą╗čÅčĆą░, ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ čüą╗ąĄą┤čāčÄčēąĖąĄ čłą░ą│ąĖ:
ŌĆó ąÆ čüčéčĆčāą║čéčāčĆąĄ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ ą┤ąĄą║ą╗ą░čĆąĖčĆčāąĄčéčüčÅ čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ čüą┐ąĄčåąĖą░ą╗čīąĮčāčÄ čüčéčĆčāą║čéčāčĆčā ą╗ąŠą│ą│ąĖąĮą│ą░. ąöą╗čÅ čŹč鹊ą│ąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą╝ą░ą║čĆąŠčü LOG_INSTANCE_PTR_DECLARE .
#include < zephyr/logging/log_instance.h>
struct foo_object {
LOG_INSTANCE_PTR_DECLARE(log);
uint32_t id;
}
ŌĆó ąöą╗čÅ ąĖąĮčüčéą░ąĮčåąĖčĆąŠą▓ą░ąĮąĖčÅ ą╝ąŠą┤čāą╗čī ą┤ąŠą╗ąČąĄąĮ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī ą╝ą░ą║čĆąŠčü. ąÆ čŹč鹊ą╝ ą╝ą░ą║čĆąŠčüąĄ čĆąĄą│ąĖčüčéčĆąĖčĆčāąĄčéčüčÅ čŹą║ąĘąĄą╝ą┐ą╗čÅčĆ ą╗ąŠą│ą│ąĖąĮą│ą░, ąĖ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāąĄčéčüčÅ čāą║ą░ąĘą░č鹥ą╗čī 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ ą╗ąŠą│ą░ ą▓ čüčéčĆčāą║čéčāčĆąĄ ąŠą▒čŖąĄą║čéą░.
#define FOO_OBJECT_DEFINE(_name) \ LOG_INSTANCE_REGISTER(foo, _name, CONFIG_FOO_LOG_LEVEL) \ struct foo_object _name = { \ LOG_INSTANCE_PTR_INIT(log, foo, _name) \ }
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą║ąŠą│ą┤ą░ ą╗ąŠą│ą│ąĖąĮą│ ąĘą░ą┐čĆąĄčēąĄąĮ, 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą╗ąŠą│ą│ąĖąĮą│ą░ ąĖ čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ čŹč鹊čé 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ąĮąĄ čüąŠąĘą┤ą░ąĄčéčüčÅ.
ą¦č鹊ą▒čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓ čäą░ą╣ą╗ąĄ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░ logging API 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░, čü ą┐ąŠą╝ąŠčēčīčÄ ą╝ą░ą║čĆąŠčüą░ LOG_LEVEL_SET ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čāą║ą░ąĘą░ąĮ čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░.
LOG_LEVEL_SET(CONFIG_FOO_LOG_LEVEL);
void foo_init (foo_object * f)
{
LOG_INST_INF(f-> log, "Initialized." );
}
ą¦č鹊ą▒čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī logging API 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ ą▓ ąĘą░ą│ąŠą╗ąŠą▓ąŠčćąĮąŠą╝ čäą░ą╣ą╗ąĄ, čü ą┐ąŠą╝ąŠčēčīčÄ ą╝ą░ą║čĆąŠčüą░ LOG_LEVEL_SET ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čāą║ą░ąĘą░ąĮ čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░.
static inline void foo_init (foo_object * f)
{
LOG_LEVEL_SET(CONFIG_FOO_LOG_LEVEL);
LOG_INST_INF(f-> log, "Initialized." );
}
ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą▓čŗą▓ąŠą┤ąŠą╝ ą▓ ą╗ąŠą│ . ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ą╗ąŠą│ą░ ą▓ čĆąĄąČąĖą╝ąĄ ąĘą░ą┤ąĄčƹȹ░ąĮąĮąŠą│ąŠ ą▓čŗą▓ąŠą┤ą░ (deferred mode) ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą▓ąĮčāčéčĆąĄąĮąĮąĄ čü ą┐ąŠą╝ąŠčēčīčÄ ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą╣ ąĘą░ą┤ą░čćąĖ, ą║ąŠč鹊čĆą░čÅ ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ. ą×ą┤ąĮą░ą║ąŠ čŹč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮąĄą┤ąŠčüčéčāą┐ąĮąŠ, ąĄčüą╗ąĖ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠčüčéčī ąĘą░ą┐čĆąĄčēąĄąĮą░. ąŁč鹊 čéą░ą║ąČąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ą┐čĆąĄčēąĄąĮąŠ ą┐čāč鹥ą╝ ąĮąĄ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮąŠą╣ ąŠą┐čåąĖąĖ CONFIG_LOG_PROCESS_TRIGGER_THRESHOLD . ąÆ čéą░ą║ąŠą╝ čüą╗čāčćą░ąĄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą╗ąŠą│ąŠą╝ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ API, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╝ ą▓ ąĘą░ą│ąŠą╗ąŠą▓ąŠčćąĮąŠą╝ čäą░ą╣ą╗ąĄ include/zephyr/logging/log_ctrl.h . ą¤ąĄčĆąĄą┤ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą╗ąŠą│ą│ąĖąĮą│ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮ. ą×ą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą╝ąŠąČąĄčé ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī čäčāąĮą║čåąĖčÄ, ą║ąŠč鹊čĆą░čÅ ą▓ąŠąĘą▓čĆą░čéąĖčé ąĘąĮą░č湥ąĮąĖąĄ ą╝ąĄčéą║ąĖ ą▓čĆąĄą╝ąĄąĮąĖ. ąĢčüą╗ąĖ čŹčéą░ čäčāąĮą║čåąĖčÅ ąĮąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮą░, č鹊 ą┤ą╗čÅ ą╝ąĄč鹊ą║ ą▓čĆąĄą╝ąĄąĮąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ k_cycle_get ąĖą╗ąĖ k_cycle_get_32. ążčāąĮą║čåąĖčÅ log_process() ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ąĘą░ą┐čāčüą║ą░ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąŠą┤ąĮąŠą│ąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░ (ąĄčüą╗ąĖ ąŠąĮąŠ ąŠąČąĖą┤ą░ąĄčé ą▓ ą▒čāč乥čĆąĄ). ąŁčéą░ čäčāąĮą║čåąĖčÅ ą▓ąĄčĆąĮąĄčé true, ąĄčüą╗ąĖ ą▓ ą▒čāč乥čĆąĄ ąĄčüčéčī ąĄčēąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ, ąŠąČąĖą┤ą░čÄčēąĖąĄ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ. ą×ą┤ąĮą░ą║ąŠ čĆąĄą║ąŠą╝ąĄąĮą┤čāąĄčéčüčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą╝ą░ą║čĆąŠčüčŗ ąŠą▒ąĄčĆčéą║ąĖ (LOG_INIT ąĖ LOG_PROCESS ), ą║ąŠč鹊čĆčŗąĄ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčé čüą╗čāčćą░ąĖ, ą║ąŠą│ą┤ą░ ą╗ąŠą│ą│ąĖąĮą│ ąĘą░ą┐čĆąĄčēąĄąĮ.
ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą║čāčüąŠą║ ą║ąŠą┤ą░ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, ą║ą░ą║ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠą▒čĆą░ą▒ąŠčéą░ąĮ ą╗ąŠą│ą│ąĖąĮą│ ą▓ ą┐čĆąŠčüč鹊ą╝ ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠą╝ čåąĖą║ą╗ąĄ.
#include < zephyr/log_ctrl.h>
int main (void )
{
LOG_INIT();
/* ąĢčüą╗ąĖ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠčüčéčī čĆą░ąĘčĆąĄčłąĄąĮą░, č鹊 ą┤ą╗čÅ ą╗ąŠą│ą│ąĖąĮą│ą░ ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčéčüčÅ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ą┐ąŠč鹊ą║ą░. */
log_thread_set(k_current_get());
while (1 )
{
if (LOG_PROCESS() == false )
{
/* ąŚą░ą┤ąĄčƹȹ║ą░ vTaskDelay ąĖą╗ąĖ ą║ą░ą║ąĖąĄ-ąĮąĖą▒čāą┤čī č乊ąĮąŠą▓čŗąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ */
}
}
}
ąĢčüą╗ąĖ ą╗ąŠą│ąĖ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ąĖąĘ ą┐ąŠč鹊ą║ą░ (ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąŠą│ąŠ ąĖą╗ąĖ ą▓ąĮčāčéčĆąĄąĮąĮąĄą│ąŠ), č鹊 ą╝ąŠąČąĮąŠ čĆą░ąĘčĆąĄčłąĖčéčī čäąĖčćčā, ą║ąŠč鹊čĆą░čÅ ą▒čāą┤ąĄčé ą▓čŗą▓ąŠą┤ąĖčéčī ąĖąĘ čüąĮą░ ą┐ąŠč鹊ą║ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą╗ąŠą│ą░, ą║ąŠą│ą┤ą░ ą▓ ą▒čāč乥čĆąĄ ą╗ąŠą│ą░ ąŠą║ą░ąČąĄčéčüčÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čüąŠąŠą▒čēąĄąĮąĖą╣ (čüą╝. CONFIG_LOG_PROCESS_TRIGGER_THRESHOLD).
ąøąŠą│ ą┐ą░ąĮąĖą║ąĖ . ąÆ čüą╗čāčćą░ąĄ ą║čĆąĖčéąĖčćąĮąŠą╣ ąŠčłąĖą▒ą║ąĖ čüąĖčüč鹥ą╝ą░ ąŠą▒čŗčćąĮąŠ ąĮąĄ ą╝ąŠąČąĄčé ą▒ąŠą╗čīčłąĄ ą┐ąŠą╗ą░ą│ą░čéčīčüčÅ ąĮą░ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ ąĖą╗ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ. ąÆ čéą░ą║ąŠą╣ čüąĖčéčāą░čåąĖąĖ ąĮąĄą╗čīąĘčÅ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī ą▓čŗą▓ąŠą┤ ą▓ ą╗ąŠą│ ą┐ąŠ ą┐čĆąĖąĮčåąĖą┐čā ąŠčéą║ą╗ą░ą┤čŗą▓ą░ąĮąĖčÅ ą▓čŗą▓ąŠą┤ą░ ąĮą░ čüą▓ąŠą▒ąŠą┤ąĮąŠąĄ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠąĄ ą▓čĆąĄą╝čÅ (deferred log). ążčāąĮą║čåąĖąĖ API ą╗ąŠą│ą│ąĄčĆą░ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé čäčāąĮą║čåąĖčÄ ą┤ą╗čÅ ą▓čģąŠą┤ą░ ą▓ čĆąĄąČąĖą╝ ą┐ą░ąĮąĖą║ąĖ (log_panic() ), ą║ąŠč鹊čĆą░čÅ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ą▓čŗąĘą▓ą░ąĮą░ ą┤ą╗čÅ čéą░ą║ąŠą╣ čüąĖčéčāą░čåąĖąĖ.
ąÜąŠą│ą┤ą░ ą▓čŗąĘą▓ą░ąĮą░ čäčāąĮą║čåąĖčÅ log_panic(), ąŠą┐ąŠą▓ąĄčēąĄąĮąĖąĄ _panic_ ą┐ąŠčüčŗą╗ą░ąĄčéčüčÅ ą▓ąŠ ą▓čüąĄ ą░ą║čéąĖą▓ąĮčŗąĄ ą▒菹║ąĄąĮą┤čŗ. ąÜą░ą║ č鹊ą╗čīą║ąŠ ą▓čüąĄ ą▒菹║ąĄąĮą┤čŗ ą▒čŗą╗ąĖ ąŠą┐ąŠą▓ąĄčēąĄąĮčŗ, ą▓čüąĄ ą▒čāč乥čĆąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ čüą╗ąĖą▓ą░čÄčéčüčÅ (flushed). ąØą░čćąĖąĮą░čÅ čü čŹč鹊ą│ąŠ ą╝ąŠą╝ąĄąĮčéą░ ą▓čüąĄ ą╗ąŠą│ąĖ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ą▓ čüąĖąĮčģčĆąŠąĮąĮąŠą╝ čĆąĄąČąĖą╝ąĄ (čü ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąŠą╣).
printk . ą×ą▒čŗčćąĮąŠ čüąĖčüč鹥ą╝ą░ ą╗ąŠą│ą░ ąĖ čäčāąĮą║čåąĖčÅ printk() ąĖčüą┐ąŠą╗čīąĘčāčÄčé ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ ą▓čŗą▓ąŠą┤, ąĘą░ ą║ąŠč鹊čĆčŗą╣ ąŠąĮąĖ ąĖ ą║ąŠąĮą║čāčĆąĖčĆčāčÄčé. ąŁč鹊 ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą┐čĆąŠą▒ą╗ąĄą╝ą░ą╝, ąĄčüą╗ąĖ ą▓čŗą▓ąŠą┤ ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą▓čŗč鹥čüąĮąĄąĮąĖąĄ, ąĖ čéą░ą║ąČąĄ ą▓čŗą▓ąŠą┤ąĖą╝čŗąĄ ą┤ą░ąĮąĮčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ąĖčüą║ą░ąČąĄąĮčŗ, ą┐ąŠčüą║ąŠą╗čīą║čā ą┤ą░ąĮąĮčŗąĄ ą╗ąŠą│ą░ ąĖ ą┤ą░ąĮąĮčŗąĄ printk ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ ą╝ąŠą│čāčé č湥čĆąĄą┤ąŠą▓ą░čéčīčüčÅ. ą×ą┤ąĮą░ą║ąŠ ąĄčüčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ąĖčéčī čüąŠąŠą▒čēąĄąĮąĖčÅ printk ą▓ ą┐ąŠą┤čüąĖčüč鹥ą╝čā ą╗ąŠą│ą░ ą┐čāč鹥ą╝ čĆą░ąĘčĆąĄčłąĄąĮąĖčÅ ąŠą┐čåąĖąĖ CONFIG_LOG_PRINTK . ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą▓čŗąĘąŠą▓čŗ printk ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ą║ą░ą║ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░ čü čāčĆąŠą▓ąĮąĄą╝ 0 (čé. ąĄ. ąŠąĮąĖ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ąĘą░ą┐čĆąĄčēąĄąĮčŗ). ąÜąŠą│ą┤ą░ čŹč鹊 čĆą░ąĘčĆąĄčłąĄąĮąŠ, čüąĖčüč鹥ą╝ą░ ą╗ąŠą│ą░ čāą┐čĆą░ą▓ą╗čÅąĄčé ą▓čŗą▓ąŠą┤ąŠą╝ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊ą▒čŗ ą▓ ąŠč鹊ą▒čĆą░ąČą░ąĄą╝ąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ąĮąĄ ą▒čŗą╗ąŠ č湥čĆąĄą┤ąŠą▓ą░ąĮąĖčÅ čćą░čüč鹥ą╣ čüąŠąŠą▒čēąĄąĮąĖą╣. ą×ą┤ąĮą░ą║ąŠ ą▓ deferred mode čŹč鹊 ą┐ąŠą╝ąĄąĮčÅąĄčé ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ printk, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓čŗą▓ąŠą┤ ą▒čāą┤ąĄčé ąĘą░ą┤ąĄčƹȹĖą▓ą░čéčīčüčÅ ą┤ąŠ ą╝ąŠą╝ąĄąĮčéą░, ą║ąŠą│ą┤ą░ ą┐ąŠč鹊ą║ ą╗ąŠą│ą░ ą┐čĆąĖčüčéčāą┐ąĖčé ą║ ąŠą▒čĆą░ą▒ąŠčéą║ąĄ ą┤ą░ąĮąĮčŗčģ. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąŠą┐čåąĖčÅ CONFIG_LOG_PRINTK čĆą░ąĘčĆąĄčłąĄąĮą░.
[ąÉčĆčģąĖč鹥ą║čéčāčĆą░ ]
ą¤ąŠą┤čüąĖčüč鹥ą╝ą░ ą╗ąŠą│ą░ čüąŠčüč鹊ąĖčé ąĖąĘ 3 ąŠčüąĮąŠą▓ąĮčŗčģ čćą░čüč鹥ą╣:
Frontend
ąĪąŠąŠą▒čēąĄąĮąĖąĄ ą╗ąŠą│ą░ ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ąĖčüč鹊čćąĮąĖą║ąŠą╝, ą║ąŠč鹊čĆčŗą╝ ą╝ąŠąČąĄčé ą▒čŗčéčī ą╝ąŠą┤čāą╗čī ąĖą╗ąĖ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą╝ąŠą┤čāą╗čÅ.
Default Frontend . ążčĆąŠąĮč鹥ąĮą┤ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą▓čüčéčāą┐ą░ąĄčé ą▓ ą┤ąĄą╣čüčéą▓ąĖąĄ, ą║ąŠą│ą┤ą░ čäčāąĮą║čåąĖčÅ logging API ą▓čŗąĘčŗą▓ą░ąĄčéčüčÅ ą▓ ąĖčüč鹊čćąĮąĖą║ąĄ ą╗ąŠą│ą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, čüąŠąŠą▒čēąĄąĮąĖąĄ ą╗ąŠą│ą░ ą▓čŗą▓ąŠą┤ąĖčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ ą╝ą░ą║čĆąŠčüą░ LOG_INF). ążčĆąŠąĮč鹥ąĮą┤ ąŠčéą▓ąĄčćą░ąĄčé ąĘą░ čäąĖą╗čīčéčĆą░čåąĖčÄ čüąŠąŠą▒čēąĄąĮąĖčÅ (ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ąĖ ą▓ąŠ ą▓čĆąĄą╝čÅ ą░ą║čéčāą░ą╗čīąĮąŠą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░), ąĘą░ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ą▒čāč乥čĆą░ ą┤ą╗čÅ čüąŠąŠą▒čēąĄąĮąĖčÅ, ąĘą░ čüąŠąĘą┤ą░ąĮąĖąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ ąĖ ąĘą░ čäąĖą║čüą░čåąĖčÄ čŹč鹊ą│ąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ. ą¤ąŠčüą║ąŠą╗čīą║čā logging API ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗąĘą▓ą░ąĮąŠ ą▓ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĖ, čäčĆąŠąĮč鹥ąĮą┤ ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░ąĮ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊ą▒čŗ ą╗ąŠą│ čüąŠąŠą▒čēąĄąĮąĖčÅ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą▒čŗčüčéčĆąŠ, ą║ą░ą║ čŹč鹊 ą▓ąŠąĘą╝ąŠąČąĮąŠ.
ąĪąŠąŠą▒čēąĄąĮąĖąĄ ą╗ąŠą│ą░ . ąĪąŠąŠą▒čēąĄąĮąĖąĄ, ą▓čŗą▓ąŠą┤ąĖą╝ąŠąĄ ą▓ ą╗ąŠą│, čüąŠą┤ąĄčƹȹĖčé ą┤ąĄčüą║čĆąĖą┐č鹊čĆ (ąĖčüč鹊čćąĮąĖą║ source, ą┤ąŠą╝ąĄąĮ domain ąĖ čāčĆąŠą▓ąĄąĮčī level), ą╝ąĄčéą║čā ą▓čĆąĄą╝ąĄąĮąĖ (timestamp), čüą▓ąĄą┤ąĄąĮąĖčÅ ąŠ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖąĖ čüčéčĆąŠą║ąĖ (čüą╝. čĆą░ąĘą┤ąĄą╗ "Cbprintf Packaging" ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ [3]) ąĖ ąŠą┐čåąĖąŠąĮą░ą╗čīąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ. ąĪąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░ čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ ą▓ ąĮąĄą┐čĆąĄčĆčŗą▓ąĮąŠą╝ ą▒ą╗ąŠą║ąĄ ą┐ą░ą╝čÅčéąĖ. ą¤ą░ą╝čÅčéčī ą▓čŗą┤ąĄą╗čÅąĄčéčüčÅ ąĖąĘ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ ą┐ą░ą║ąĄč鹊ą▓ (circular packet buffer, čüą╝. [4]. ąÜą░ą║ čüą╗ąĄą┤čüčéą▓ąĖąĄ:
ŌĆó ąÜą░ąČą┤ąŠąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ čŹč鹊 čüą░ą╝ąŠą┤ąŠčüčéą░č鹊čćąĮčŗą╣, ąĮąĄą┐čĆąĄčĆčŗą▓ąĮčŗą╣ ą▒ą╗ąŠą║ ą┐ą░ą╝čÅčéąĖ, čéą░ą║ čćč鹊 ąŠąĮ čģąŠčĆąŠčłąŠ ą┐ąŠą┤čģąŠą┤ąĖčé ą┤ą╗čÅ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ čüąŠąŠą▒čēąĄąĮąĖčÅ (ąĮą░ą┐čĆąĖą╝ąĄčĆ ą┤ą╗čÅ ąŠčäčäą╗ą░ą╣ąĮ-ąŠą▒čĆą░ą▒ąŠčéą║ąĖ).
ąĪąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░ ąĖą╝ąĄčÄčé čüą╗ąĄą┤čāčÄčēąĖą╣ č乊čĆą╝ą░čé:
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║ čüąŠąŠą▒čēąĄąĮąĖčÅ
2 ą▒ąĖčéą░: ąĘą░ą│ąŠą╗ąŠą▓ąŠą║ ą┐ą░ą║ąĄčéą░ ą▒čāč乥čĆą░ MPSC
1 ą▒ąĖčé: čäą╗ą░ą│ trace/log čüąŠąŠą▒čēąĄąĮąĖčÅ
3 ą▒ąĖčéą░: Domain ID
3 ą▒ąĖčéą░: Level
10 ą▒ąĖčé: Cbprintf Package Length
12 ą▒ąĖčé: ą┤ą╗ąĖąĮą░ ą┤ą░ąĮąĮčŗčģ
1 ą▒ąĖčé: ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąŠ
pointer: čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ ą┤ąĄčüą║čĆąĖą┐č鹊čĆ ąĖčüč鹊čćąĮąĖą║ą░(1)
32 ąĖą╗ąĖ 64 ą▒ąĖčéą░: ą╝ąĄčéą║ą░ ą▓čĆąĄą╝ąĄąĮąĖ(1)
ąŠą┐čåąĖąŠąĮą░ą╗čīąĮčŗąĄ ą▒ą░ą╣čéčŗ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ(2)
Cbprintf Package (ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ)
ąŚą░ą│ąŠą╗ąŠą▓ąŠą║
ąÉčĆą│čāą╝ąĄąĮčéčŗ
ąöąŠą▒ą░ą▓ą╗ąĄąĮąĮčŗąĄ čāčüčéą░ąĮąŠą▓ą║ąĖ
ąöą░ąĮąĮčŗąĄ Hexdump (ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ)
ą×ą┐čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ
ą¤čĆąĖą╝ąĄčćą░ąĮąĖčÅ:
(1) ąÆ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą┐ą╗ą░čéč乊čĆą╝čŗ ąĖ čĆą░ąĘą╝ąĄčĆą░ ą╝ąĄčéą║ąĖ ą▓čĆąĄą╝ąĄąĮąĖ ą┐ąŠą╗čÅ ą╝ąŠą│čāčé ą▒čŗčéčī ą┐ąŠą╝ąĄąĮčÅąĮčŗ ą╝ąĄčüčéą░ą╝ąĖ. (2) ąŁč鹊 ą╝ąŠąČąĄčé ą┐ąŠčéčĆąĄą▒ąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ ą┐ą░ą║ąĄčéą░ cbprintf.
ąÆčŗą┤ąĄą╗ąĄąĮąĖąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░ . ą£ąŠąČąĄčé ą▓ąŠąĘąĮąĖą║ąĮčāčéčī čüąĖčéčāą░čåąĖčÅ, ą║ąŠą│ą┤ą░ čäčĆąŠąĮč鹥ąĮą┤ ąĮąĄ ą╝ąŠąČąĄčé čĆą░ąĘą╝ąĄčüčéąĖčéčī čüąŠąŠą▒čēąĄąĮąĖąĄ ą▓ ą▒čāč乥čĆąĄ. ąŁč鹊 ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé, ąĄčüą╗ąĖ čüąĖčüč鹥ą╝ą░ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĮą░čüč鹊ą╗čīą║ąŠ ą╝ąĮąŠą│ąŠ čüąŠąŠą▒čēąĄąĮąĖą╣, čćč鹊 ąŠąĮąĖ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ąŠą▒čĆą░ą▒ąŠčéą░ąĮčŗ ąĘą░ ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠąĄ ą▓čĆąĄą╝čÅ. ąöą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čŹč鹊ą│ąŠ čüą╗čāčćą░čÅ ą╝ąŠą│čāčé ą▒čŗčéčī ą┐čĆąĖą╝ąĄąĮąĄąĮčŗ 2 čüčéčĆą░č鹥ą│ąĖąĖ:
ŌĆó ąæąĄąĘ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ ąŠč湥čĆąĄą┤ąĖ - ąĮąŠą▓čŗąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░ ąŠčéą▒čĆą░čüčŗą▓ą░čÄčéčüčÅ, ąĄčüą╗ąĖ ą╝ąĄčüč鹊 ą┐ąŠą┤ ąĮąĖčģ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┤ąĄą╗ąĄąĮąŠ.
Run-time čäąĖą╗čīčéčĆą░čåąĖčÅ . ąĢčüą╗ąĖ čĆą░ąĘčĆąĄčłąĄąĮą░ čäąĖą╗čīčéčĆą░čåąĖčÅ ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░ (run-time), č鹊 ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ąĖčüč鹊čćąĮąĖą║ą░ ą╗ąŠą│ą░ ą┤ąĄą║ą╗ą░čĆąĖčĆčāąĄčéčüčÅ čüčéčĆčāą║čéčāčĆą░ ą▓ RAM. ąóą░ą║ąŠą╣ čäąĖą╗čīčéčĆ ąĖčüą┐ąŠą╗čīąĘčāąĄčé 32 ą▒ąĖčéą░, ą┐ąŠą┤ąĄą╗ąĄąĮąĮčŗąĄ ąĮą░ ą┤ąĄčüčÅčéčī 3-čĆą░ąĘčĆčÅą┤ąĮčŗčģ čüą╗ąŠč鹊ą▓ ą▒ąĖčé. ąÜčĆąŠą╝ąĄ čüą╗ąŠčéą░ 0, ą║ą░ąČą┤čŗą╣ čüą╗ąŠą╣ čģčĆą░ąĮąĖčé č鹥ą║čāčēąĖą╣ čäąĖą╗čīčéčĆ ą┤ą╗čÅ ąŠą┤ąĮąŠą│ąŠ ą▒菹║ąĄąĮą┤ą░ ą▓ čüąĖčüč鹥ą╝ąĄ. ąĪą╗ąŠčé 0 (ą▒ąĖčéčŗ 0-2) ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą░ą│čĆąĄą│ą░čåąĖąĖ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ ąĮą░čüčéčĆąŠą╣ą║ąĖ čäąĖą╗čīčéčĆą░ ą▓ ąĖą╝ąĄčÄčēąĄą╝čüčÅ ąĖčüč鹊čćąĮąĖą║ąĄ ą╗ąŠą│ą░. ą×ą▒čēąĖą╣ ą░ą│čĆąĄą│ą░čéąĮčŗą╣ čüą╗ąŠčé 0 ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé, čüąŠąĘą┤ą░ąĄčéčüčÅ ą╗ąĖ čüąŠąŠą▒čēąĄąĮąĖąĄ ą╗ąŠą│ą░ ą┤ą╗čÅ čāą║ą░ąĘą░ąĮąĮąŠą╣ ąĘą░ą┐ąĖčüąĖ, ą┐ąŠčüą║ąŠą╗čīą║čā ąŠąĮ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čüčāčēąĄčüčéą▓čāąĄčé ą╗ąĖ čģąŠčéčÅ ą▒čŗ ąŠą┤ąĖąĮ ą▒菹║ąĄąĮą┤, ąŠąČąĖą┤ą░čÄčēąĖą╣ čŹčéčā ąĘą░ą┐ąĖčüčī ą╗ąŠą│ą░. ąĪą╗ąŠčéčŗ ą▒菹║ąĄąĮą┤ą░ ą┐čĆąŠą▓ąĄčĆčÅčÄčéčüčÅ, ą║ąŠą│ą┤ą░ čüąŠąŠą▒čēąĄąĮąĖąĄ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ čÅą┤čĆąŠą╝ čüąĖčüč鹥ą╝čŗ ą╗ąŠą│ą░, čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, ą┤ąŠą┐čāčüčéąĖą╝ąŠ ą╗ąĖ čüąŠąŠą▒čēąĄąĮąĖąĄ ą┤ą╗čÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ą▒菹║ąĄąĮą┤ą░. ąÆ ąŠčéą╗ąĖčćąĖąĄ ąŠčé čäąĖą╗čīčéčĆą░čåąĖąĖ ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ, čĆą░ąĘą╝ąĄčĆ ą║ąŠą┤ą░ ą┤ą╗čÅ ą╗ąŠą│ą░ čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčéčüčÅ.
ąÆ ą┐čĆąĖą╝ąĄčĆąĄ ąĮąĖąČąĄ ą▒菹║ąĄąĮą┤ 1 čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą┤ą╗čÅ ą┐čĆąĖąĄą╝ą░ ąŠčłąĖą▒ąŠą║ ERR (čüą╗ąŠčé 1), ąĖ ą▒菹║ąĄąĮą┤ 2 ą┤ą╗čÅ ą┐čĆąĖąĄą╝ą░ ąĖąĮč乊čĆą╝ą░čåąĖąŠąĮąĮčŗčģ čüąŠąŠą▒čēąĄąĮąĖą╣ INF (čüą╗ąŠčé 2). ąĪą╗ąŠčéčŗ 3-9 ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ (OFF). ąÉą│čĆąĄą│ą░čéąĮčŗą╣ čäąĖą╗čīčéčĆ (čüą╗ąŠčé 0) čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą┤ą╗čÅ čāčĆąŠą▓ąĮčÅ INF, ąĖ ą┤ąŠ čŹč鹊ą│ąŠ čāčĆąŠą▓ąĮčÅ čüąŠąŠą▒čēąĄąĮąĖąĄ ąŠčé ą┤ą░ąĮąĮąŠą│ąŠ čćą░čüčéąĮąŠą│ąŠ ąĖčüč鹊čćąĮąĖą║ą░ ą▒čāą┤ąĄčé ą▒čāč乥čĆąĖąĘąĖčĆąŠą▓ą░ąĮąŠ.
slot 0
slot 1
slot 2
slot 3
...
slot 9
INF
ERR
INF
OFF
...
OFF
ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖą╣ čäčĆąŠąĮč鹥ąĮą┤ . ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖą╣ (custom) čäčĆąŠąĮč鹥ąĮą┤ čĆą░ąĘčĆąĄčłą░ąĄčéčüčÅ ąŠą┐čåąĖąĄą╣ CONFIG_LOG_FRONTEND. ąøąŠą│ąĖ č鹊ą│ą┤ą░ ąĮą░ą┐čĆą░ą▓ą╗čÅčÄčéčüčÅ ą▓ čäčāąĮą║čåąĖąĖ, ą┤ąĄą║ą╗ą░čĆąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ą▓ include/zephyr/logging/log_frontend.h . ąĢčüą╗ąĖ čĆą░ąĘčĆąĄčłąĄąĮą░ ąŠą┐čåąĖčÅ CONFIG_LOG_FRONTEND_ONLY, č鹊 čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░ ąĮąĄ čüąŠąĘą┤ą░čÄčéčüčÅ, ąĖ ąĮąĖą║ą░ą║ąŠą╣ ą▒菹║ąĄąĮą┤ ąĮąĄ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčéčüčÅ. ąÆ ą┐čĆąŠčéąĖą▓ąĮąŠą╝ čüą╗čāčćą░ąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖą╣ čäčĆąŠąĮč鹥ąĮą┤ ą╝ąŠąČąĄčé čüąŠčüčāčēąĄčüčéą▓ąŠą▓ą░čéčī čü ą▒菹║ąĄąĮą┤ą░ą╝ąĖ.
ąÆ ąĮąĄą║ąŠč鹊čĆčŗčģ čüą╗čāčćą░čÅčģ ą╗ąŠą│ąĖ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗ąĄąĮčŗ ąĮą░ čāčĆąŠą▓ąĄąĮčī ą╝ą░ą║čĆąŠčüąŠą▓. ąöą╗čÅ čéą░ą║ąĖčģ čüą╗čāčćą░ąĄą▓ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ CONFIG_LOG_CUSTOM_HEADER ą┤ą╗čÅ ą▓čüčéą░ą▓ą║ąĖ ąĘą░ą│ąŠą╗ąŠą▓ą║ą░, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮąŠą│ąŠ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄą╝. ąŁč鹊čé ąĘą░ą│ąŠą╗ąŠą▓ąŠą║ ą┤ąŠą╗ąČąĄąĮ ąĖą╝ąĄčéčī ąĖą╝čÅ zephyr_custom_log.h , ąĖ ą┐ąŠą┤ą║ą╗čÄčćą░čéčīčüčÅ ą▓ ą║ąŠąĮčåąĄ include/zephyr/logging/log.h .
ąÆčŗą▓ąŠą┤ ą▓ ą╗ąŠą│ čüčéčĆąŠą║ . ąĪčéčĆąŠą║ąŠą▓čŗąĄ ą░čĆą│čāą╝ąĄąĮčéčŗ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ą▓ Cbprintf Packaging [3]. ąĪą╝. ą▓ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ [3] ąŠą│čĆą░ąĮąĖč湥ąĮąĖčÅ ą┐ąŠ ą┐čĆąĖą╝ąĄąĮąĖą╝ąŠčüčéąĖ ąĖ čĆąĄą║ąŠą╝ąĄąĮą┤ą░čåąĖąĖ ą┐ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÄ (čüąĄą║čåąĖčÅ "Limitations and recommendations").
ąæąŠą╗ąĄąĄ čüą╗ąŠąČąĮčŗąĄ čüąĖčüč鹥ą╝čŗ ą╝ąŠą│čāčé čüąŠčüč鹊čÅčéčī ąĖąĘ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą┤ąŠą╝ąĄąĮąŠą▓ (čäąĖąĘąĖč湥čüą║ąĖčģ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓), ą│ą┤ąĄ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą┤ąŠą╝ąĄąĮą░ ąĖą╝ąĄąĄčéčüčÅ ąŠčéą┤ąĄą╗čīąĮčŗą╣ ą▒ąĖąĮą░čĆąĮąĖą║. ą¤čĆąĖą╝ąĄčĆą░ą╝ąĖ ą┤ąŠą╝ąĄąĮąŠą▓ ą╝ąŠą│čāčé čüą╗čāąČąĖčéčī ą╝ąĮąŠą│ąŠčÅą┤ąĄčĆąĮčŗąĄ SoC, ąĖą╗ąĖ ąŠą┤ąĖąĮ ąĖąĘ ą▒ąĖąĮą░čĆąĮąĖą║ąŠą▓ (Secure ąĖą╗ąĖ Nonsecure) ąĮą░ čÅą┤čĆąĄ ARM TrustZone.
ąóčĆą░čüčüąĖčĆąŠą▓ą║ą░ ąĖ ąŠčéą╗ą░ą┤ą║ą░ ą▓ ą╝čāą╗čīčéąĖą┤ąŠą╝ąĄąĮąĮąŠą╣ čüąĖčüč鹥ą╝ąĄ ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮą░, ąĖ čéčĆąĄą▒čāąĄčé ąĮą░ą╗ąĖčćąĖčÅ čŹčäč乥ą║čéąĖą▓ąĮąŠą╣ čüąĖčüč鹥ą╝čŗ ą╗ąŠą│ą░. ąöą╗čÅ čüčéčĆčāą║čéčāčĆąĖčĆąŠą▓ą░ąĮąĖčÅ čŹč鹊ą╣ čüąĖčüč鹥ą╝čŗ čĆąĄą│ąĖčüčéčĆą░čåąĖąĖ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą▓ą░ ą┐ąŠą┤čģąŠą┤ą░:
ŌĆó ąØąĄąĘą░ą▓ąĖčüąĖą╝čŗą╣ ą╗ąŠą│ ą▓ ą║ą░ąČą┤ąŠą╝ ą┤ąŠą╝ąĄąĮąĄ. ąŁčéą░ ąŠą┐čåąĖčÅ ąĮąĄ ą▓čüąĄą│ą┤ą░ ą▓ąŠąĘą╝ąŠąČąĮą░, ą┐ąŠčüą║ąŠą╗čīą║čā čŹč鹊 čéčĆąĄą▒čāąĄčé, čćč鹊ą▒čŗ ą▓ ą║ą░ąČą┤ąŠą╝ ą┤ąŠą╝ąĄąĮąĄ ą▒čŗą╗ ą┤ąŠčüčéčāą┐ąĄąĮ ą▒菹║ąĄąĮą┤ (ąĮą░ą┐čĆąĖą╝ąĄčĆ UART). ąŁč鹊čé ą┐ąŠą┤čģąŠą┤ čéą░ą║ąČąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī čéčĆčāą┤ąĮčŗą╝ ą▓ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ąĖ ąĮąĄ ą┐ąŠą┤ą┤ą░čÄčēąĖą╝čüčÅ ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖčÄ, ą┐ąŠčüą║ąŠą╗čīą║čā ą╗ąŠą│ąĖ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮčŗ ąĮą░ ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗčģ ą▓čŗčģąŠą┤ą░čģ.
ąÆ ą┐ąŠčüą╗ąĄą┤ąĮąĄą╝ ą▓ą░čĆąĖą░ąĮč鹥 čüąŠąĄą┤ąĖąĮąĄąĮąĖąĄ ą╗ąŠą│ą░ ąŠčéą▓ąĄčćą░ąĄčé ąĘą░ čüą▓čÅąĘčī ą╝ąĄąČą┤čā ą┤ąŠą╝ąĄąĮą░ą╝ąĖ. ąĪąŠąĄą┤ąĖąĮąĄąĮąĖąĄ ąŠčéą▓ąĄčćą░ąĄčé ąĘą░ ą┐čĆąĖąĄą╝ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░ ąĖąĘ ą╗čÄą▒ąŠą│ąŠ ą┤ąŠą╝ąĄąĮą░, čüąŠąĘą┤ą░ąĮąĖąĄ ą║ąŠą┐ąĖąĖ ąĖ ą┐ąŠą╝ąĄčēąĄąĮąĖąĄ ą╗ąŠą║ą░ą╗čīąĮąŠą╣ ą║ąŠą┐ąĖąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ (ą▓ą║ą╗čÄčćą░čÅ ą┤ą░ąĮąĮčŗąĄ ąĮą░ ą┐čĆąŠčéąĖą▓ąŠą┐ąŠą╗ąŠąČąĮąŠą╝ ą║ąŠąĮčåąĄ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ) ą▓ ąŠč湥čĆąĄą┤čī čüąŠąŠą▒čēąĄąĮąĖą╣. ąŁčéą░ čüą┐ąĄčåąĖą░ą╗čīąĮą░čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ ą║ą░ąĮą░ą╗ą░ čĆąĄą│ąĖčüčéčĆą░čåąĖąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ą║ąŠą╝ą┐ą╗ąĄą╝ąĄąĮčéą░čĆąĮąŠą╣ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą▒菹║ąĄąĮą┤ą░, čćč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąŠą▒ą╝ąĄąĮąĖą▓ą░čéčīčüčÅ čüąŠąŠą▒čēąĄąĮąĖčÅą╝ąĖ ą╗ąŠą│ą░ ąĖ čāą┐čĆą░ą▓ą╗čÅčéčī ąĖą╝ąĖ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĮą░čüčéčĆą░ąĖą▓ą░čéčī čäąĖą╗čīčéčĆą░čåąĖčÄ, ą┐ąŠą╗čāčćą░čéčī ąĖą╝ąĄąĮą░ ąĖčüč鹊čćąĮąĖą║ąŠą▓ ą╗ąŠą│ą░ ąĖ čé.ą┤.
ąÆ ą╝ąĮąŠą│ąŠą┤ąŠą╝ąĄąĮąĮąŠą╣ čüąĖčüč鹥ą╝ąĄ čüčāčēąĄčüčéą▓čāąĄčé 3 čéąĖą┐ą░ ą┤ąŠą╝ąĄąĮąŠą▓:
ŌĆó ąÜąŠąĮąĄčćąĮčŗą╣ ą┤ąŠą╝ąĄąĮ (end domain), čüąŠą┤ąĄčƹȹ░čēąĖą╣ čĆąĄą░ą╗ąĖąĘą░čåąĖčÄ čÅą┤čĆą░ ą╗ąŠą│ą░ ąĖ ą▒菹║ąĄąĮą┤, ąŠčéą▓ąĄčćą░čÄčēąĖą╣ ąĘą░ ąŠą▒ą╝ąĄąĮ ą╝ąĄąČą┤čā ą┤ąŠą╝ąĄąĮą░ą╝ąĖ (cross-domain backend). ą¤ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čā ąĮąĄą│ąŠ ą╝ąŠą│čāčé ą▒čŗčéčī ą┤čĆčāą│ąĖąĄ ą┤ąŠą╝ąĄąĮčŗ ą▒菹║ąĄąĮą┤čŗ.
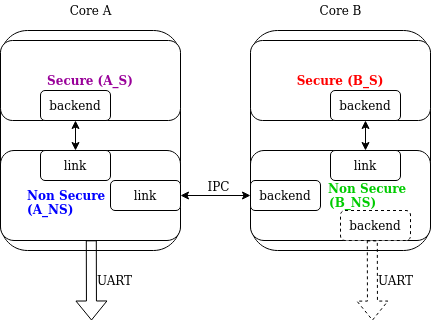
ąØą░ čüą╗ąĄą┤čāčÄčēąĄą╝ čĆąĖčüčāąĮą║ąĄ ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąĖą╝ąĄčĆ ąĮą░čüčéčĆąŠą╣ą║ąĖ multi-domain ą╗ąŠą│ą░:
ąĀąĖčü. 1. ą¤čĆąĖą╝ąĄčĆ ą╝čāą╗čīčéąĖą┤ąŠą╝ąĄąĮąĮąŠą│ąŠ ą╗ąŠą│ą░.
ąÆ čŹč鹊ą╣ ą░čĆčģąĖč鹥ą║čéčāčĆąĄ ą╗ąĖąĮą║ ą╝ąŠąČąĄčé ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┤ąŠą╝ąĄąĮąŠą▓. ąöą╗čÅ ą┐čĆąĖą╝ąĄčĆą░ čĆą░čüčüą╝ąŠčéčĆąĖą╝ SoC čü ą┤ą▓čāą╝čÅ čÅą┤čĆą░ą╝ąĖ ARM Cortex-M33 čü TrustZone: čÅą┤čĆąŠ A ąĖ čÅą┤čĆąŠ B (čüą╝. čĆąĖčü. 1). ąÆ čüąĖčüč鹥ą╝ąĄ ąĖą╝ąĄąĄčéčüčÅ 4 ą┤ąŠą╝ąĄąĮą░, ą┐ąŠčüą║ąŠą╗čīą║čā ą▓ ą║ą░ąČą┤ąŠą╝ čÅą┤čĆąĄ ąĄčüčéčī ą┤ąŠą╝ąĄąĮčŗ Secure ąĖ Nonsecure domain. ąĢčüą╗ąĖ čÅą┤čĆąŠ A nonsecure (A_NS) čŹč鹊 ą║ąŠčĆąĮąĄą▓ąŠą╣ ą┤ąŠą╝ąĄąĮ, č鹊 čā ąĮąĄą│ąŠ 2 ą╗ąĖąĮą║ą░: ąŠą┤ąĖąĮ ą┤ąŠ čÅą┤čĆą░ A secure (A_NS-A_S), ąĖ ąŠą┤ąĖąĮ ą┤ąŠ čÅą┤čĆą░ B nonsecure (A_NS-B_NS). ąŻ ą┤ąŠą╝ąĄąĮą░ B_NS ąĄčüčéčī ąŠą┤ąĖąĮ ą╗ąĖąĮą║ ą┤ąŠ čÅą┤čĆą░ B secure (B_NS-B_S), ąĖ ą▒菹║ąĄąĮą┤ ą┤ą╗čÅ A_NS.
ą¤ąŠčüą║ąŠą╗čīą║čā ą▓ąŠ ą▓čüąĄčģ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░čģ čüčāčēąĄčüčéą▓čāąĄčé čüčéą░ąĮą┤ą░čĆčéąĮą░čÅ ą┐ąŠą┤čüąĖčüč鹥ą╝ą░ ą╗ąŠą│ą░, ą▓čüąĄą│ą┤ą░ ą╝ąŠąČąĮąŠ ąĖą╝ąĄčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▒菹║ąĄąĮą┤ąŠą▓ ąĖ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą▓čŗą▓ąŠą┤ąĖčéčī ąĮą░ ąĮąĖčģ čüąŠąŠą▒čēąĄąĮąĖčÅ. ą¤čĆąĖą╝ąĄčĆ čŹč鹊ą│ąŠ ą┐ąŠą║ą░ąĘą░ąĮ ąĮą░ čĆąĖčü. 1 ą║ą░ą║ ąŠą▒ąŠąĘąĮą░č湥ąĮąĮčŗą╣ ą┐čāąĮą║čéąĖčĆąŠą╝ UART ą▒菹║ąĄąĮą┤ ą▓ ą┤ąŠą╝ąĄąĮąĄ B_NS.
Domain ID . ąśčüč鹊čćąĮąĖą║ ą▓ ą║ą░ąČą┤ąŠą╝ čüąŠąŠą▒čēąĄąĮąĖąĖ ą╗ąŠą│ą░ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāąĄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĖą╝ąĖ ą┐ąŠą╗čÅą╝ąĖ ą▓ ąĘą░ą│ąŠą╗ąŠą▓ą║ąĄ: source_id ąĖ domain_id.
ąŚąĮą░č湥ąĮąĖąĄ, ąĮą░ąĘąĮą░č湥ąĮąĮąŠąĄ ą┤ą╗čÅ domain_id, ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠąĄ. ąÜą░ąČą┤čŗą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ą┤ąŠą╝ąĄąĮ čüąŠąĘą┤ą░ąĄčé čüąŠąŠą▒čēąĄąĮąĖąĄ ą╗ąŠą│ą░, ąŠąĮ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé čüą▓ąŠą╣ domain_id ą▓ 0. ąÜąŠą│ą┤ą░ čüąŠąŠą▒čēąĄąĮąĖąĄ ą┐ąĄčĆąĄčüąĄą║ą░ąĄčé ą┤ąŠą╝ąĄąĮ, č鹊 domain_id ą╝ąĄąĮčÅąĄčéčüčÅ, ą┐ąŠčüą║ąŠą╗čīą║čā čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčéčüčÅ ąĮą░ čüą╝ąĄčēąĄąĮąĖąĄ ą╗ąĖąĮą║ą░. ąĪą╝ąĄčēąĄąĮąĖąĄ ą╗ąĖąĮą║ą░ ąĮą░ąĘąĮą░čćą░ąĄčéčüčÅ ą┐čĆąĖ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ, ą│ą┤ąĄ čÅą┤čĆąŠ ą╗ąŠą│ą│ąĄčĆą░ ą┐čĆąŠčüą╝ą░čéčĆąĖą▓ą░ąĄčé ą▓čüąĄ ąĘą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ą╗ąĖąĮą║ąĖ ąĖ ąĮą░ąĘąĮą░č湥ąĮąĮčŗąĄ ąĖą╝ čüą╝ąĄčēąĄąĮąĖčÅ.
ąŻ ą┐ąĄčĆą▓ąŠą│ąŠ ą╗ąĖąĮą║ą░ čüą╝ąĄčēąĄąĮąĖąĄ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ ą▓ 1. ąĪą╗ąĄą┤čāčÄčēąĄąĄ čüą╝ąĄčēąĄąĮąĖąĄ čĆą░ą▓ąĮąŠ čüą╝ąĄčēąĄąĮąĖčÄ ą┐čĆąĄą┤čŗą┤čāčēąĄą│ąŠ ą╗ąĖąĮą║ą░ ą┐ą╗čÄčü ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┤ąŠą╝ąĄąĮąŠą▓ ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĄą╝ ą╗ąĖąĮą║ąĄ.
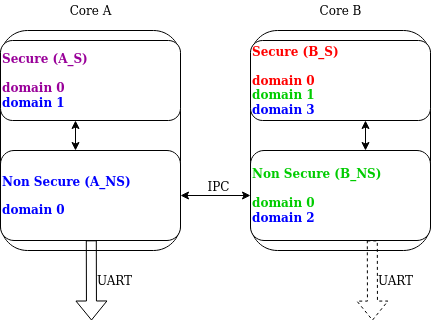
ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ, ą┐ąŠą║ą░ąĘą░ąĮąĮčŗą╣ ąĮą░ ą║ą░čĆčéąĖąĮą║ąĄ ąĮąĖąČąĄ, ą│ą┤ąĄ ąĮą░ąĘąĮą░č湥ąĮąĮčŗąĄ domain_id ą┐ąŠą║ą░ąĘą░ąĮčŗ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą┤ąŠą╝ąĄąĮą░:
ąĀąĖčü. 2. ą¤čĆąĖą╝ąĄčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆąŠą▓ ą┤ąŠą╝ąĄąĮą░ (Domain ID).
ąĀą░čüčüą╝ąŠčéčĆąĖą╝ čüąŠąŠą▒čēąĄąĮąĖąĄ ą╗ąŠą│ą░, čüąŠąĘą┤ą░ąĮąĮąŠąĄ ą▓ ą┤ąŠą╝ąĄąĮąĄ B_S:
1 . ąśąĘąĮą░čćą░ą╗čīąĮąŠ čā ąĮąĄą│ąŠ domain_id, čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮčŗą╣ ą▓ 0.2 . ąÜąŠą│ą┤ą░ ą╗ąĖąĮą║ B_NS-B_S ą┐čĆąĖąĮąĖą╝ą░ąĄčé čüąŠąŠą▒čēąĄąĮąĖąĄ, ąŠąĮ čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčé domain_id ąĮą░ 1 ą┐čāč鹥ą╝ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ čüą╝ąĄčēąĄąĮąĖčÅ B_NS-B_S.3 . ąĪąŠąŠą▒čēąĄąĮąĖąĄ ą┐ąĄčĆąĄčģąŠą┤ąĖčé ą║ A_NS.4 . ąÜąŠą│ą┤ą░ ą╗ąĖąĮą║ A_NS-B_NS ą┐čĆąĖąĮąĖą╝ą░ąĄčé čüąŠąŠą▒čēąĄąĮąĖąĄ, ąŠąĮ ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé čüą╝ąĄčēąĄąĮąĖąĄ (2) ą║ domain_id. ąÆ ą║ąŠąĮčåąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ domain_id ą▓ 3, čćč鹊 čāąĮąĖą║ą░ą╗čīąĮąŠ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāąĄčé ąŠčéą┐čĆą░ą▓ąĖč鹥ą╗čÅ čüąŠąŠą▒čēąĄąĮąĖčÅ.
ąĪąŠąŠą▒čēąĄąĮąĖąĄ, ą┐ąĄčĆąĄą┤ą░ą▓ą░ąĄą╝ąŠąĄ ą╝ąĄąČą┤čā ą┤ąŠą╝ąĄąĮą░ą╝ąĖ (Cross-domain log message). ąÆ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ čüą╗čāčćą░ąĄą▓ ą░ą┤čĆąĄčüąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ą▓ ą║ą░ąČą┤ąŠą╝ ą┤ąŠą╝ąĄąĮąĄ čāąĮąĖą║ą░ą╗čīąĮąŠ, ąĖ ąŠą┤ąĖąĮ ą┤ąŠą╝ąĄąĮ ąĮąĄ ą╝ąŠąČąĄčé ąĮą░ą┐čĆčÅą╝čāčÄ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ ą┤ą░ąĮąĮčŗą╝ ą▓ ą┤čĆčāą│ąŠą╝ ą┤ąŠą╝ąĄąĮąĄ. ą¤ąŠ čŹč鹊ą╣ ą┐čĆąĖčćąĖąĮąĄ ą▒菹║ąĄąĮą┤ ą╝ąŠąČąĄčé čćą░čüčéąĖčćąĮąŠ ąŠą▒čĆą░ą▒ąŠčéą░čéčī čüąŠąŠą▒čēąĄąĮąĖąĄ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ą┐ąĄčĆąĄą┤ą░čéčī ąĄą│ąŠ ą▓ ą┤čĆčāą│ąŠą╣ ą┤ąŠą╝ąĄąĮ. ą¦ą░čüčéąĖčćąĮą░čÅ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ą╝ąŠąČąĄčé ą▓ą║ą╗čÄčćą░čéčī ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ ą┐ą░ą║ąĄčéą░ čüčéčĆąŠą║ąĖ ą▓ ą┐ąŠą╗ąĮčāčÄ čüą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮčāčÄ ą▓ąĄčĆčüąĖčÄ (ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ čüčéčĆąŠą║, ą┤ąŠčüčéčāą┐ąĮčŗčģ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ, ą▓ č鹥ą╗ąŠ ą┐ą░ą║ąĄčéą░).
ąŻ ą║ą░ąČą┤ąŠą│ąŠ ą┤ąŠą╝ąĄąĮą░ ą╝ąŠąČąĄčé ą▒čŗčéčī čüą▓ąŠą╣, ąŠčéą┤ąĄą╗čīąĮčŗą╣ ąĖčüč鹊čćąĮąĖą║ ą╝ąĄčéą║ąĖ ą▓čĆąĄą╝ąĄąĮąĖ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 čćą░čüč鹊čéčŗ ąĖ čüą╝ąĄčēąĄąĮąĖčÅ. ąĪąĖčüč鹥ą╝ą░ ą╗ąŠą│ą░ ąĮąĄ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ ą╝ąĄčéą║ąĖ ą▓čĆąĄą╝ąĄąĮąĖ.
Runtime-čäąĖą╗čīčéčĆą░čåąĖčÅ . ąÆ čüą╗čāčćą░ąĄ ąŠą┤ąĮąŠą│ąŠ ą┤ąŠą╝ąĄąĮą░ ą║ą░ąČą┤čŗą╣ ąĖčüč鹊čćąĮąĖą║ ą╗ąŠą│ą░ ąĖą╝ąĄąĄčé ą▓čŗą┤ąĄą╗ąĄąĮąĮčāčÄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ čü runtime-čäąĖą╗čīčéčĆą░čåąĖąĄą╣ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą▒菹║ąĄąĮą┤ą░ ą▓ čüąĖčüč鹥ą╝ąĄ. ąÆ čüą╗čāčćą░ąĄ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą┤ąŠą╝ąĄąĮąŠą▓ ąĖąĮąĖčåąĖą░č鹊čĆ čüąŠąŠą▒čēąĄąĮąĖčÅ ąĮąĄ ąĘąĮą░ąĄčé ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ąĄ ą▒菹║ąĄąĮą┤ąŠą▓ ą▓ ą║ąŠčĆąĮąĄą▓ąŠą╝ ą┤ąŠą╝ąĄąĮąĄ.
ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą┤ą╗čÅ čäąĖą╗čīčéčĆą░čåąĖąĖ ą▓ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą┤ąŠą╝ąĄąĮą░čģ ąĖčüč鹊čćąĮąĖą║ čéčĆąĄą▒čāąĄčé čāčüčéą░ąĮąŠą▓ą║ąĖ runtime-čäąĖą╗čīčéčĆą░čåąĖąĖ ą▓ ą║ą░ąČą┤ąŠą╝ ą┤ąŠą╝ąĄąĮąĄ ąĮą░ ą┐čāčéąĖ ą▓ ą║ąŠčĆąĮąĄą▓ąŠą╣ ą┤ąŠą╝ąĄąĮ. ą¤ąŠčüą║ąŠą╗čīą║čā ą▓ ą╝ąŠą╝ąĄąĮčé ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĖčüč鹊čćąĮąĖą║ąŠą▓ ą▓ ą┤čĆčāą│ąĖčģ ą┤ąŠą╝ąĄąĮą░čģ ąĮąĄąĖąĘą▓ąĄčüčéąĮąŠ, runtime-čäąĖą╗čīčéčĆą░čåąĖčÅ ą┤ą░ą╗čīąĮąĖčģ ąĖčüč鹊čćąĮąĖą║ąŠą▓ ą┤ąŠą╗ąČąĮą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąĖ ą▓čŗą┤ąĄą╗čÅąĄą╝čāčÄ ą┐ą░ą╝čÅčéčī (ąŠą┤ąĮąŠ čüą╗ąŠą▓ąŠ ąĮą░ ąĖčüč鹊čćąĮąĖą║). ąÜąŠą│ą┤ą░ ą▒菹║ąĄąĮą┤ ą▓ ą║ąŠčĆąĮąĄą▓ąŠą╝ ą┤ąŠą╝ąĄąĮąĄ ą╝ąĄąĮčÅąĄčé čäąĖą╗čīčéčĆą░čåąĖčÄ ą╝ąŠą┤čāą╗čÅ ąĖąĘ ą┤ą░ą╗čīąĮąĄą│ąŠ ą┤ąŠą╝ąĄąĮą░, ą╗ąŠą║ą░ą╗čīąĮčŗą╣ čäąĖą╗čīčéčĆ ąŠą▒ąĮąŠą▓ą╗čÅąĄčéčüčÅ. ą¤ąŠčüą╗ąĄ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ ą┐čĆąŠą▓ąĄčĆčÅąĄčéčüčÅ ąŠą▒čēąĖą╣ čäąĖą╗čīčéčĆ (ą╝ą░ą║čüąĖą╝čāą╝ ąĖąĘ ą▓čüąĄčģ ą╗ąŠą║ą░ą╗čīąĮčŗčģ ą▒菹║ąĄąĮą┤ąŠą▓), ąĖ ąĄčüą╗ąĖ ą▒čŗą╗ąŠ ąĖąĘą╝ąĄąĮąĄąĮąĖąĄ, č鹊 ą┤ą░ą╗čīąĮąĖą╣ ą┤ąŠą╝ąĄąĮ ąĖąĮč乊čĆą╝ąĖčĆčāąĄčéčüčÅ ąŠą▒ čŹč鹊ą╝ ąĖąĘą╝ąĄąĮąĄąĮąĖąĖ. ą¤čĆąĖ čéą░ą║ąŠą╝ ą┐ąŠą┤čģąŠą┤ąĄ runtime-čäąĖą╗čīčéčĆą░čåąĖčÅ čĆą░ą▒ąŠčéą░ąĄčé ąĖą┤ąĄąĮčéąĖčćąĮąŠ ą║ą░ą║ ą▓ čüčåąĄąĮą░čĆąĖąĖ čü ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ ą┤ąŠą╝ąĄąĮą░ą╝ąĖ, čéą░ą║ ąĖ čü ąŠą┤ąĮąĖą╝ ą┤ąŠą╝ąĄąĮąŠą╝.
ąŻą┐ąŠčĆčÅą┤ąŠčćąĖą▓ą░ąĮąĖąĄ čüąŠąŠą▒čēąĄąĮąĖą╣ . ąĪąĖčüč鹥ą╝ą░ ą╗ąŠą│ą░ ąĮąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą╝ąĄčģą░ąĮąĖąĘą╝ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ ą╝ąĄč鹊ą║ ą▓čĆąĄą╝ąĄąĮąĖ ą▓ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą┤ąŠą╝ąĄąĮą░čģ:
ŌĆó ąĢčüą╗ąĖ čā ą┤ąŠą╝ąĄąĮąŠą▓ ąŠčéą┤ąĄą╗čīąĮčŗąĄ ąĖčüč鹊čćąĮąĖą║ąĖ ą╝ąĄč鹊ą║ ą▓čĆąĄą╝ąĄąĮąĖ, č鹊 čüąŠąŠą▒čēąĄąĮąĖčÅ ą▒čāą┤čāčé ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčīčüčÅ ą▓ č鹊ą╝ ą┐ąŠčĆčÅą┤ą║ąĄ, ą▓ ą║ą░ą║ąŠą╝ ąŠąĮąĖ ą┤ąŠčüčéąĖą│ą╗ąĖ ą▒čāč乥čĆą░ ą▓ ą║ąŠčĆąĮąĄą▓ąŠą╝ ą┤ąŠą╝ąĄąĮąĄ.
ŌĆó ąĢčüą╗ąĖ čā ą┤ąŠą╝ąĄąĮąŠą▓ ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ ąĖčüč鹊čćąĮąĖą║ ą╝ąĄčéą║ąĖ ą▓čĆąĄą╝ąĄąĮąĖ, ąĖą╗ąĖ ąĄčüą╗ąĖ čüčāčēąĄčüčéą▓čāąĄčé ą╝ąĄčģą░ąĮąĖąĘą╝ ą┐ąĄčĆąĄčüč湥čéą░ ą╝ąĄč鹊ą║ ą▓čĆąĄą╝ąĄąĮąĖ, č鹊 ą▓ąŠąĘą╝ąŠąČąĮčŗ 2 ą▓ą░čĆąĖą░ąĮčéą░:
- ąĪąŠąŠą▒čēąĄąĮąĖčÅ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ą┐ąŠ ą╝ąĄčĆąĄ ą┐ąŠčüčéčāą┐ą╗ąĄąĮąĖčÅ ą▓ ą▒čāč乥čĆ ą║ąŠčĆąĮąĄą▓ąŠą│ąŠ ą┤ąŠą╝ąĄąĮą░. ąĪąŠąŠą▒čēąĄąĮąĖčÅ ąĮąĄ čāą┐ąŠčĆčÅą┤ąŠčćąĖą▓ą░čÄčéčüčÅ, ąĮąŠ ąŠąĮąĖ ą╝ąŠą│čāčé čüąŠčĆčéąĖčĆąŠą▓ą░čéčīčüčÅ čģąŠčüč鹊ą╝, ą┐ąŠčüą║ąŠą╗čīą║čā ą╝ąĄčéą║ą░ ą▓čĆąĄą╝ąĄąĮąĖ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, ą║ąŠą│ą┤ą░ čüąŠąŠą▒čēąĄąĮąĖąĄ ą▒čŗą╗ąŠ čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąŠ.
ą¤čĆąĖ čéą░ą║ąŠą╝ ą┐ąŠą┤čģąŠą┤ąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čéčī ą┐ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ čüąŠąŠą▒čēąĄąĮąĖą╣ čåąĄąĮąŠą╣ ąĮąĄ ąŠč湥ąĮčī ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ (ą┐ąŠčüą║ąŠą╗čīą║čā ąĮąĄčé ąŠą▒čēąĄą│ąŠ ą▒čāč乥čĆą░) ąĖ čāą▓ąĄą╗ąĖč湥ąĮąĮąŠą╣ ą╗ą░č鹥ąĮčéąĮąŠčüčéąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ (čüą╝. [5]).
[ą▒菹║ąĄąĮą┤čŗ čüąĖčüč鹥ą╝čŗ ą╗ąŠą│ą░ ]
ą▒菹║ąĄąĮą┤čŗ ą╗ąŠą│ą░ čĆąĄą│ąĖčüčéčĆąĖčĆčāčÄčéčüčÅ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ LOG_BACKEND_DEFINE. ąŁč鹊čé ą╝ą░ą║čĆąŠčü čüąŠąĘą┤ą░ąĄčé 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▓ ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą╣ čüąĄą║čåąĖąĖ ą┐ą░ą╝čÅčéąĖ. ą▒菹║ąĄąĮą┤čŗ ą╝ąŠą│čāčé ą▒čŗčéčī ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąĖ čĆą░ąĘčĆąĄčłąĄąĮčŗ (log_backend_enable()) ąĖ ąĘą░ą┐čĆąĄčēąĄąĮčŗ. ąÜąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮą░ run-time čäąĖą╗čīčéčĆą░čåąĖčÅ, ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ log_filter_set() ą┤ą╗čÅ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą│ąŠ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ čäąĖą╗čīčéčĆą░čåąĖąĖ ą╗ąŠą│ąŠą▓ ą╝ąŠą┤čāą╗čÅ ą┤ą╗čÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ą▒菹║ąĄąĮą┤ą░. ą£ąŠą┤čāą╗čī ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆąŠą▓ą░ąĮ ą┐ąŠ source ID ąĖ domain ID. Source ID ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠą╗čāč湥ąĮ, ąĄčüą╗ąĖ ąĖąĘą▓ąĄčüčéąĮąŠ ąĖą╝čÅ ąĖčüč鹊čćąĮąĖą║ą░, ą┐čāč鹥ą╝ ą┐čĆąŠčüą╝ąŠčéčĆą░ ą▓čüąĄčģ ąĘą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮąĮčŗčģ ąĖčüč鹊čćąĮąĖą║ąŠą▓.
ąĪąĖčüč鹥ą╝ą░ ą╗ąŠą│ą░ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą┤ąŠ 9 ą║ąŠąĮą║čāčĆąĄąĮčéąĮčŗčģ ą▒菹║ąĄąĮą┤ąŠą▓. ąĪąŠąŠą▒čēąĄąĮąĖąĄ ą╗ąŠą│ą░ ą┐ąĄčĆąĄą┤ą░ąĄčéčüčÅ ą▓ ą║ą░ąČą┤čŗą╣ ą▒菹║ąĄąĮą┤ ąĮą░ čäą░ąĘąĄ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ. ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ ą▒菹║ąĄąĮą┤ ąŠą┐ąŠą▓ąĄčēą░ąĄčéčüčÅ, ą║ąŠą│ą┤ą░ čüąĖčüč鹥ą╝ą░ ą╗ąŠą│ą░ ą▓čģąŠą┤ąĖčé ą▓ čĆąĄąČąĖą╝ ą┐ą░ąĮąĖą║ąĖ, čü ą┐ąŠą╝ąŠčēčīčÄ log_backend_panic(). ąÆ čŹč鹊čé ą╝ąŠą╝ąĄąĮčé ą▒菹║ąĄąĮą┤ ą┤ąŠą╗ąČąĄąĮ ą┐ąĄčĆąĄą║ą╗čÄčćąĖčéčīčüčÅ ą▓ čüąĖąĮčģčĆąŠąĮąĮčŗą╣, ą▒ąĄąĘ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ čĆąĄąČąĖą╝ čĆą░ą▒ąŠčéčŗ, ąĖą╗ąĖ ąŠčüčéą░ąĮąŠą▓ąĖčéčī čüą░ą╝ąŠą│ąŠ čüąĄą▒čÅ, ąĄčüą╗ąĖ čŹč鹊 ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ. ąśąĮąŠą│ą┤ą░ čüąĖčüč鹥ą╝ą░ ą╗ąŠą│ą│ąĖąĮą│ą░ ą╝ąŠąČąĄčé ąĖąĮč乊čĆą╝ąĖčĆąŠą▓ą░čéčī ą▒菹║ąĄąĮą┤ ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ąĄ ąŠčéą▒čĆąŠčłąĄąĮąĮčŗčģ čüąŠąŠą▒čēąĄąĮąĖą╣ čü ą┐ąŠą╝ąŠčēčīčÄ log_backend_dropped(). API-čäčāąĮą║čåąĖąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čüąŠąŠą▒čēąĄąĮąĖą╣ ąĘą░ą▓ąĖčüčÅčé ąŠčé ą▓ąĄčĆčüąĖąĖ.
ąöą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ log_backend_msg2_process(). ąŁč鹊 ąŠą▒čēąĖą╣ ą╝ąĄč鹊ą┤ ą┤ą╗čÅ čüąŠąŠą▒čēąĄąĮąĖą╣ standard ąĖ hexdump, ą┐ąŠč鹊ą╝čā čćč鹊 čüąŠąŠą▒čēąĄąĮąĖąĄ ą╗ąŠą│ą░ čģčĆą░ąĮąĖčé čüčéčĆąŠą║čā čü ą░čĆą│čāą╝ąĄąĮčéą░ą╝ąĖ ąĖ ą┤ą░ąĮąĮčŗą╝ąĖ. ąŁč鹊 čéą░ą║ąČąĄ ąŠą▒čēąĖą╣ ą╝ąĄč鹊ą┤ ą┤ą╗čÅ ąŠčéą╗ąŠąČąĄąĮąĮąŠą│ąŠ (deferred) ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠą│ąŠ ą╗ąŠą│ą│ąĖąĮą│ą░.
ążąŠčĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ . ąøąŠą│ą│ąĖąĮą│ ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé ąĮą░ą▒ąŠčĆ čäčāąĮą║čåąĖą╣, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą▒菹║ąĄąĮą┤ąŠą╝ ą┤ą╗čÅ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖčÅ čüąŠąŠą▒čēąĄąĮąĖčÅ. ąÆčüą┐ąŠą╝ąŠą│ą░č鹥ą╗čīąĮčŗąĄ čäčāąĮą║čåąĖąĖ ą┤ąŠčüčéčāą┐ąĮčŗ ą▓ include/zephyr/logging/log_output.h .
ą¤čĆąĖą╝ąĄčĆ ąŠčéč乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ čü ą┐ąŠą╝ąŠčēčīčÄ log_output_msg2_process():
[00:00:00.000,274] sample_instance.inst1: logging message
ąøąŠą│ą│ąĖąĮą│ ąĮą░ ą▒ą░ąĘąĄ čüą╗ąŠą▓ą░čĆčÅ, ą▓ ąŠčéą╗ąĖčćąĖąĄ ąŠčé čāą┤ąŠą▒ąĮąŠą│ąŠ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ č鹥ą║čüčéą░, ą▓čŗą▓ąŠą┤ąĖčé čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░ ą▓ ą┤ą▓ąŠąĖčćąĮąŠą╝ č乊čĆą╝ą░č鹥. ąŁč鹊čé ą┤ą▓ąŠąĖčćąĮčŗą╣ č乊čĆą╝ą░čé ą║ąŠą┤ąĖčĆčāąĄčé ą░čĆą│čāą╝ąĄąĮčéčŗ ą┤ą╗čÅ čüčéčĆąŠą║ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖčÅ ą▓ čüą▓ąŠąĖ čéčĆą░ą┤ąĖčåąĖąŠąĮąĮčŗąĄ č乊čĆą╝ą░čéčŗ čģčĆą░ąĮąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą▒ąŠą╗ąĄąĄ ą║ąŠą╝ą┐ą░ą║čéąĮčŗąĄ, č湥ą╝ ąĖčģ č鹥ą║čüč鹊ą▓čŗąĄ 菹║ą▓ąĖą▓ą░ą╗ąĄąĮčéčŗ. ąöą╗čÅ čüčéčĆąŠą║, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ čüčéą░čéąĖč湥čüą║ąĖ (ą▓ą║ą╗čÄčćą░čÅ čüčéčĆąŠą║ąĖ č乊čĆą╝ą░čéą░ ąĖ ą╗čÄą▒čŗąĄ čüčéčĆąŠą║ąŠą▓čŗąĄ ą░čĆą│čāą╝ąĄąĮčéčŗ), ą▓ ELF-čäą░ą╣ą╗ ą║ąŠą┤ąĖčĆčāčÄčéčüčÅ čüčüčŗą╗ą║ąĖ ąĮą░ ąĮąĖčģ ą▓ą╝ąĄčüč鹊 ą▓čüąĄą╣ čüčéčĆąŠą║ąĖ. ąĪą╗ąŠą▓ą░čĆčī, čüąŠąĘą┤ą░ąĮąĮčŗą╣ ą▓ąŠ ą▓čĆąĄą╝čÅ čüą▒ąŠčĆą║ąĖ, čüąŠą┤ąĄčƹȹĖčé ąŠč鹊ą▒čĆą░ąČąĄąĮąĖčÅ čŹčéąĖčģ čüčüčŗą╗ąŠą║ ąĮą░ čĆąĄą░ą╗čīąĮčŗąĄ čüčéčĆąŠą║ąĖ. ąŁč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąŠčäčäą╗ą░ą╣ąĮ-ą┐ą░čĆčüąĄčĆčā ą┐ąŠą╗čāčćąĖčéčī čüčéčĆąŠą║ąĖ ąĖąĘ čüą╗ąŠą▓ą░čĆčÅ ą┤ą╗čÅ ą┤ąĄčłąĖčäčĆąŠą▓ą║ąĖ čüąŠąŠą▒čēąĄąĮąĖą╣ ą╗ąŠą│ą░. ąóą░ą║ąŠą╣ ą┤ą▓ąŠąĖčćąĮčŗą╣ č乊čĆą╝ą░čé čģčĆą░ąĮąĄąĮąĖčÅ ą╗ąŠą│ą░ ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ čüčåąĄąĮą░čĆąĖčÅčģ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą▒ąŠą╗ąĄąĄ ą║ąŠą╝ą┐ą░ą║čéąĮąŠ ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅčéčī čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░. ą×ą┤ąĮą░ą║ąŠ čŹč鹊 čéčĆąĄą▒čāąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąŠčäčäą╗ą░ą╣ąĮ-ą┐ą░čĆčüąĄčĆą░ ąĖ ąĮąĄ ąĮą░čüč鹊ą╗čīą║ąŠ ąĖąĮčéčāąĖčéąĖą▓ąĮąŠ ąĖ čāą┤ąŠą▒ąĮąŠ, ą║ą░ą║ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░ ąĮą░ ąŠčüąĮąŠą▓ąĄ č鹥ą║čüčéą░.
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 long double ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ ą╝ąŠą┤čāą╗ąĄą╝ struct čÅąĘčŗą║ą░ Python. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čüąŠąŠą▒čēąĄąĮąĖčÅ čü long double ąĮąĄ ą▒čāą┤čāčé ą║ąŠčĆčĆąĄą║čéąĮąŠ ąŠč鹊ą▒čĆą░ąČą░čéčī ąĘąĮą░č湥ąĮąĖčÅ.
ąÜąŠąĮčäąĖą│čāčĆą░čåąĖčÅ . ąĪą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čåąĖąĖ kconfig ąŠčéąĮąŠčüčÅčéčüčÅ ą║ dictionary-based logging:
ŌĆó CONFIG_LOG_DICTIONARY_SUPPORT čĆą░ąĘčĆąĄčłą░ąĄčé ą┐ąŠą┤ą┤ąĄčƹȹ║čā ą╗ąŠą│ą░ ąĮą░ ąŠčüąĮąŠą▓ąĄ čüą╗ąŠą▓ą░čĆčÅ. ąöąŠą╗ąČąĮąŠ ą▒čŗčéčī ą▓čŗą▒čĆą░ąĮąŠ ą▒菹║ąĄąĮą┤ą░ą╝ąĖ, ą║ąŠč鹊čĆčŗą╝ čŹč鹊 ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ.
ŌĆó UART-ą▒菹║ąĄąĮą┤ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą╗ąŠą│ą│ąĖąĮą│ ąĮą░ ąŠčüąĮąŠą▓ąĄ čüą╗ąŠą▓ą░čĆčÅ. ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮą░čÅ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÅ ą┤ą╗čÅ čéą░ą║ąŠą│ąŠ čüą╗čāčćą░čÅ:
- CONFIG_LOG_BACKEND_UART_OUTPUT_DICTIONARY_HEX ą│ąŠą▓ąŠčĆąĖčé UART-ą▒菹║ąĄąĮą┤čā ą▓čŗą▓ąŠą┤ąĖčéčī čłąĄčüčéąĮą░ą┤čåą░č鹥čĆąĖčćąĮčŗąĄ čüąĖą╝ą▓ąŠą╗čŗ ą┤ą╗čÅ ą╗ąŠą│ą░ ąĮą░ ąŠčüąĮąŠą▓ąĄ čüą╗ąŠą▓ą░čĆčÅ. ąŁč鹊 ą┐ąŠą╗ąĄąĘąĮąŠ, ą║ąŠą│ą┤ą░ ą┤ą░ąĮąĮčŗąĄ ą╗ąŠą│ą░ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąĘą░čģą▓ą░č湥ąĮčŗ ą▓čĆčāčćąĮčāčÄ č湥čĆąĄąĘ č鹥čĆą╝ąĖąĮą░ą╗čŗ ąĖ ą║ąŠąĮčüąŠą╗ąĖ.CONFIG_LOG_BACKEND_UART_OUTPUT_DICTIONARY_BIN ą│ąŠą▓ąŠčĆąĖčé UART-ą▒菹║ąĄąĮą┤čā ą▓čŗą▓ąŠą┤ąĖčéčī ą┤ą▓ąŠąĖčćąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ.
ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ . ąÜąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮ ą╗ąŠą│ą│ąĖąĮą│ ąĮą░ ąŠčüąĮąŠą▓ąĄ čüą╗ąŠą▓ą░čĆčÅ č湥čĆąĄąĘ čĆą░ąĘčĆąĄčłąĄąĮąĮčŗąĄ čüą▓čÅąĘą░ąĮąĮčŗąĄ ą▒菹║ąĄąĮą┤čŗ ą╗ąŠą│ą░, ą▓ ą┤ąĖčĆąĄą║č鹊čĆąĖąĖ build ą▒čāą┤ąĄčé čüąŠąĘą┤ą░ąĮ čäą░ą╣ą╗ ą▒ą░ąĘčŗ ą┤ą░ąĮąĮčŗčģ JSON čü ąĖą╝ąĄąĮąĄą╝ log_dictionary.json . ąŁč鹊čé čäą░ą╣ą╗ ą▒ą░ąĘčŗ ą┤ą░ąĮąĮčŗčģ čüąŠą┤ąĄčƹȹĖčé ąĖąĮč乊čĆą╝ą░čåąĖčÄ ą┤ą╗čÅ ą┐ą░čĆčüąĄčĆą░, čćč鹊ą▒čŗ ą║ąŠčĆčĆąĄą║čéąĮąŠ ąŠą▒čĆą░ą▒ąŠčéą░čéčī ą┤ą░ąĮąĮčŗąĄ ą╗ąŠą│ą░. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čŹčéą░ ą▒ą░ąĘą░ ą┤ą░ąĮąĮčŗčģ čĆą░ą▒ąŠčéą░ąĄčé č鹊ą╗čīą║ąŠ ą▓ ą┐čĆąĄą┤ąĄą╗ą░čģ ąŠą┤ąĮąŠą╣ ąĖ č鹊ą╣ ąČąĄ čüą▒ąŠčĆą║ąĖ, ąĖ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮ ą┤ą╗čÅ ą┤čĆčāą│ąĖčģ čüą▒ąŠčĆąŠą║.
ąöą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┐ą░čĆčüąĄčĆą░ ą╗ąŠą│ą░:
$ ./scripts/logging/dictionary/log_parser.py /log_dictionary.json
ą¤ą░čĆčüąĄčĆ ą┐čĆąĖąĮąĖą╝ą░ąĄčé 2 ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗčģ ą░čĆą│čāą╝ąĄąĮčéą░, ą│ą┤ąĄ ą┐ąĄčĆą▓čŗą╣ ąĖąĘ ąĮąĖčģ čŹč鹊 ą┐ąŠą╗ąĮčŗą╣ ą┐čāčéčī ą┤ąŠ čäą░ą╣ą╗ą░ ą▒ą░ąĘčŗ ą┤ą░ąĮąĮčŗčģ JSON, ąĖ ą▓č鹊čĆąŠą╣ čŹč鹊 čäą░ą╣ą╗, čüąŠą┤ąĄčƹȹ░čēąĖą╣ ą┤ą░ąĮąĮčŗąĄ ą╗ąŠą│ą░. ąöąŠą▒ą░ą▓čīč鹥 ąŠą┐čåąĖąŠąĮą░ą╗čīąĮčŗą╣ ą░čĆą│čāą╝ąĄąĮčéą░ --hex ą▓ ą║ąŠąĮčåąĄ, ąĄčüą╗ąĖ čäą░ą╣ą╗ ą┤ą░ąĮąĮčŗčģ ą╗ąŠą│ą░ čüąŠą┤ąĄčƹȹĖčé hex-čüąĖą╝ą▓ąŠą╗čŗ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ąŠą│ą┤ą░ CONFIG_LOG_BACKEND_UART_OUTPUT_DICTIONARY_HEX=y). ąŁč鹊 čāą║ą░ąČąĄčé ą┐ą░čĆčüąĄčĆčā, čćč鹊 ąĮą░ą┤ąŠ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░čéčī čłąĄčüčéąĮą░ą┤čåą░č鹥čĆąĖčćąĮčŗąĄ čüąĖą╝ą▓ąŠą╗čŗ ą▓ ą┤ą▓ąŠąĖčćąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą┐ąĄčĆąĄą┤ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄą╝ ą┐ą░čĆčüąĖąĮą│ą░.
ąÜą░ą║ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┐ą░čĆčüąĄčĆ ą╗ąŠą│ą░, čüą╝. ą┐čĆąĖą╝ąĄčĆ [6].
[ąĀąĄą║ąŠą╝ąĄąĮą┤ą░čåąĖąĖ ]
ŌĆó ąĀą░ąĘčĆąĄčłąĖč鹥 CONFIG_LOG_SPEED, čćč鹊ą▒čŗ ąĮąĄčüą║ąŠą╗čīą║ąŠ čāčüą║ąŠčĆąĖčéčī ąŠčéą╗ąŠąČąĄąĮąĮčŗą╣ (deferred) ą╗ąŠą│ą│ąĖąĮą│ čåąĄąĮąŠą╣ ąĮąĄą║ąŠč鹊čĆąŠą│ąŠ ą┐ąŠą▓čŗčłąĄąĮąĮąŠą│ąŠ čĆą░čüčģąŠą┤ą░ ą┐ą░ą╝čÅčéąĖ.
LOG_WRN("%s" , str);
LOG_WRN("%p" , (void * )str);
ąØą░ 菹╝čāą╗čÅč鹊čĆąĄ qemu_x86 ą▒čŗą╗ąŠ ą┐čĆąŠą▓ąĄą┤ąĄąĮąŠ ąĮąĄčüą║ąŠą╗čīą║ąŠ č鹥čüč鹊ą▓ ąĖąĘ tests/subsys/logging/log_benchmark. ąŁč鹊 ą┤ą░ąĄčé ą│čĆčāą▒ąŠąĄ čüčĆą░ą▓ąĮąĄąĮąĖąĄ, ą┐ąŠąĘą▓ąŠą╗čÅčÄčēąĄąĄ ą┐ąŠą╗čāčćąĖčéčī ąŠą▒čēąĖą╣ ąŠą▒ąĘąŠčĆ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ.
ążčāąĮą║čåąĖčÅ ąŚąĮą░č湥ąĮąĖąĄ
ąøąŠą│ čÅą┤čĆą░ (kernel logging)
7 ą╝ą║čü(3) /11 ą╝ą║čü
ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖą╣ ą╗ąŠą│ (user logging)
13 ą╝ą║čü
ąøąŠą│ čÅą┤čĆą░ čü ą┐ąĄčĆąĄąĘą░ą┐ąĖčüčīčÄ
10 ą╝ą║čü(3) / 15 ą╝ą║čü
ąÆčŗą▓ąŠą┤ ą▓ ą╗ąŠą│ ąĖąĘą╝ąĄąĮčÅčÄčēąĖčģčüčÅ čüčéčĆąŠą║
43 ą╝ą║čü
ąÆčŗą▓ąŠą┤ ą▓ ą╗ąŠą│ ąĖąĘą╝ąĄąĮčÅčÄčēąĖčģčüčÅ čüčéčĆąŠą║ ąĖąĘ ą║ąŠą┤ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ
50 ą╝ą║čü
ąŚą░čéčĆą░čéčŗ ą┐ą░ą╝čÅčéąĖ(4)
518 ą▒ą░ą╣čé
ą£ąĄčüč鹊 ą┐ąŠą┤ ą║ąŠą┤ (test)(5)
2 ą║ąĖą╗ąŠą▒ą░ą╣čéą░
ą£ąĄčüč鹊 ą┐ąŠą┤ ą║ąŠą┤ (ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ)(6)
3.5 ą║ąĖą╗ąŠą▒ą░ą╣čéą░
ą£ąĄčüč鹊 ą┐ąŠą┤ ą║ąŠą┤(7)
47(3) / 32 ą▒ą░ą╣čéą░
ą¤čĆąĖą╝ąĄčćą░ąĮąĖčÅ:
(1, 2, 3) ąĀą░ąĘčĆąĄčłąĄąĮą░ ąŠą┐čåąĖčÅ CONFIG_LOG_SPEED. (4) ąÜąŠą╗ąĖč湥čüčéą▓ąŠ čüąŠąŠą▒čēąĄąĮąĖą╣ ą╗ąŠą│ą░ čü čĆą░ąĘą╗ąĖčćąĮčŗą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąŠą╝ ą░čĆą│čāą╝ąĄąĮč鹊ą▓, ą║ąŠč鹊čĆąŠąĄ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé 2048 ą▒ą░ą╣čéą░ą╝, ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗą╝ ą┤ą╗čÅ ą▓ąĄą┤ąĄąĮąĖčÅ ą╗ąŠą│ą░. (5) ąŚą░čéčĆą░čéčŗ ą┐ą░ą╝čÅčéąĖ ąĮą░ ą┐ąŠą┤čüąĖčüč鹥ą╝čā ą╗ąŠą│ą░ ą▓ tests/subsys/logging/log_benchmark , ą║ąŠą│ą┤ą░ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čäąĖą╗čīčéčĆą░čåąĖčÅ ąĖ čäčāąĮą║čåąĖąĖ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖčÅ. (6) ąŚą░čéčĆą░čéčŗ ą┐ą░ą╝čÅčéąĖ ąĮą░ ą┐ąŠą┤čüąĖčüč鹥ą╝čā ą╗ąŠą│ą░ ą▓ samples/subsys/logging/logger . (7) ąĪčĆąĄą┤ąĮąĖą╣ čĆą░ąĘą╝ąĄčĆ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░ (ąĖčüą║ą╗čÄčćą░čÅ čüčéčĆąŠą║čā) čü ą┤ą▓čāą╝čÅ ą░čĆą│čāą╝ąĄąĮčéą░ą╝ąĖ ąĮą░ Cortex M3.
ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüč鹥ą║ą░ . ąÜąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮ ą╗ąŠą│ą│ąĖąĮą│, čŹč鹊 ą▓ą╗ąĖčÅąĄčé ąĮą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüč鹥ą║ą░ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ, ą│ą┤ąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ logging API. ąĢčüą╗ąĖ čüč鹥ą║ ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░ąĮ, č鹊 čŹč鹊 ą╝ąŠąČąĄčé ą▓čŗąĘą▓ą░čéčī ąĄą│ąŠ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ. ąŻčéąĖą╗ąĖąĘą░čåąĖčÅ čüč鹥ą║ą░ ąĘą░ą▓ąĖčüąĖčé ąŠčé čĆąĄąČąĖą╝ą░ ąĖ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░. ąŁč鹊 čéą░ą║ąČąĄ ą╝ąŠąČąĄčé ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠ ą╝ąĄąĮčÅčéčīčüčÅ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą┐ą╗ą░čéč乊čĆą╝čŗ. ąÆ ąŠą▒čēąĄą╝, ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ CONFIG_LOG_MODE_DEFERRED, čĆą░čüčģąŠą┤ čüč鹥ą║ą░ ą╝ąĄąĮčīčłąĄ, ą┐ąŠčüą║ąŠą╗čīą║čā ą╗ąŠą│ą│ąĖąĮą│ ąŠą│čĆą░ąĮąĖčćąĖą▓ą░ąĄčéčüčÅ čüąŠąĘą┤ą░ąĮąĖąĄą╝ ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖąĄą╝ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░. ąĢčüą╗ąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ CONFIG_LOG_MODE_IMMEDIATE, č鹊 čüąŠąŠą▒čēąĄąĮąĖąĄ ą╗ąŠą│ą░ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčéčüčÅ ą▒菹║ąĄąĮą┤ąŠą╝, čćč鹊 ą▓ą║ą╗čÄčćą░ąĄčé č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖąĄ čüčéčĆąŠą║ąĖ. ąÆ čéą░ą║ąŠą╝ čüą╗čāčćą░ąĄ čāčéąĖą╗ąĖąĘą░čåąĖčÅ čüč鹥ą║ą░ ąĘą░ą▓ąĖčüąĖčé ąŠčé č鹊ą│ąŠ, ą║ą░ą║ąŠą╣ ą▒菹║ąĄąĮą┤ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ.
ąóąĄčüčé tests/subsys/logging/log_stack ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüč鹥ą║ą░ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čĆąĄąČąĖą╝ą░, ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ ąĖ ą┐ą╗ą░čéč乊čĆą╝čŗ. ąóąĄčüčé ąĖčüą┐ąŠą╗čīąĘčāąĄčé č鹊ą╗čīą║ąŠ ą▒菹║ąĄąĮą┤ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ.
ąĀąĄąĘčāą╗čīčéą░čéčŗ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ ąĮąĄą║ąŠč鹊čĆčŗčģ ą┐ą╗ą░čéč乊čĆą╝ ą┤ą╗čÅ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░ čü ą┤ą▓čāą╝čÅ čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮčŗą╝ąĖ ą░čĆą│čāą╝ąĄąĮčéą░ą╝ąĖ:
ą¤ą╗ą░čéč乊čĆą╝ą░ Deferred Immediate
ąĪ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĄą╣ ąæąĄąĘ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ ąĪ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĄą╣ ąæąĄąĘ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ
ARM Cortex-M3
40
152
412
783
x86
12
224
388
796
riscv32
24
208
456
844
xtensa
72
336
504
944
x86_64
32
528
1088
1440
ą©ą░ą│ 1 . ąÆ čäą░ą╣ą╗ąĄ prj.conf ą┐čĆąŠąĄą║čéą░ ąŠą┐čĆąĄą┤ąĄą╗ąĖč鹥 čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čåąĖąĖ:
# Config logger
CONFIG_LOG=y
CONFIG_USE_SEGGER_RTT=y
CONFIG_LOG_BACKEND_RTT=y
CONFIG_LOG_BACKEND_UART=n
CONFIG_LOG_PRINTK=y
ą©ą░ą│ 2 . ąÆ ą╝ąŠą┤čāą╗ąĄ (ąĖą╗ąĖ ą▓ čäą░ą╣ą╗ąĄ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░), ą│ą┤ąĄ ąĮčāąČąĄąĮ ą▓čŗą▓ąŠą┤ ą▓ ą╗ąŠą│ čü ą┐ąŠą╝ąŠčēčīčÄ ą╝ą░ą║čĆąŠčüąŠą▓ LOG_XXX, ąĘą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░čéčī čüąĖčüč鹥ą╝čā ą╗ąŠą│ą░:
LOG_MODULE_REGISTER(ąĖą╝čÅ_ą╝ąŠą┤čāą╗čÅ);
ąŚą┤ąĄčüčī ą▓ą╝ąĄčüč鹊 "ąĖą╝čÅ_ą╝ąŠą┤čāą╗čÅ" ą╗čāčćčłąĄ čāą║ą░ąĘą░čéčī ą║ąŠčĆąŠčéą║ąŠąĄ, ą┐ąŠąĮčÅčéąĮąŠąĄ ąĖą╝čÅ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą┤ą╗čÅ čäą░ą╣ą╗ą░ main.c čŹč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓ąŠčé čéą░ą║:
LOG_MODULE_REGISTER(main);
ąśą╗ąĖ čéą░ą║, ąĘą┤ąĄčüčī ą▓ąŠ ą▓č鹊čĆąŠą╝ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ čāą║ą░ąĘčŗą▓ą░ąĄčéčüčÅ ąŠą│čĆą░ąĮąĖč湥ąĮąĖąĄ čāčĆąŠą▓ąĮčÅ ą▓čŗą▓ąŠą┤ą░ (ą╝ąŠąČąĄčé ą▒čŗčéčī LOG_LEVEL_ERR, LOG_LEVEL_WRN ąĖą╗ąĖ, ąĄčüą╗ąĖ čģąŠčéąĖč鹥 ą▓ąĖą┤ąĄčéčī ą▓čüąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ, č鹊 LOG_LEVEL_DBG):
LOG_MODULE_REGISTER(main, LOG_LEVEL_XXX);
ą©ą░ą│ 3 . ąŚą░ą║ąŠą╝ą╝ąĄąĮčéąĖčĆčāą╣č鹥 ą▓ ą╝ąŠą┤čāą╗ąĄ ą╝ą░ą║čĆąŠčü LOCK_SWD.
ąØą░ čŹč鹊ą╝ ą▓čüąĄ! ąóąĄą┐ąĄčĆčī ą╝ąŠąČąĮąŠ ą▓čŗą▓ąŠą┤ąĖčéčī ąŠčéą╗ą░ą┤ąŠčćąĮčŗąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ čü ą┐ąŠą╝ąŠčēčīčÄ ą╝ą░ą║čĆąŠčüąŠą▓ LOG_ERR, LOG_WRN, LOG_INF, LOG_DBG ąĖ čäčāąĮą║čåąĖąĖ printk.
ąÜą░ą║ ą┐čĆąŠčüą╝ą░čéčĆąĖą▓ą░čéčī čüąŠąŠą▒čēąĄąĮąĖčÅ . ą¤čĆąĖą╝ąĄčĆ č鹥čüč鹊ą▓ąŠą│ąŠ ą▓čŗą▓ąŠą┤ą░ ą▓ ą╗ąŠą│:
#include "main.h" // #define LOCK_SWD
LOG_MODULE_REGISTER(main, LOG_LEVEL_DBG);
void approtect (void );
int main (void )
{
log_init();#ifdef LOCK_SWD
approtect();#endif
ota_uart_gpio_init();
dk_leds_init();
for (;;)
{
printk("--------------- \n " );
LOG_ERR("ERR %d" , LOG_LEVEL_ERR);
LOG_WRN("WRN %d" , LOG_LEVEL_WRN);
LOG_INF("INF %d" , LOG_LEVEL_INF);
LOG_DBG("DBG %d" , LOG_LEVEL_DBG);
uart_update_state = ota_uart_handle();
...
ąŚą░ą┐čāčüčéąĖč鹥 JLinkRTTViewer , ą▓čŗą▒ąĄčĆąĖč鹥 ą▓ ą╝ąĄąĮčÄ File -> Connect (F2), ą▓ą▓ąĄą┤ąĖč鹥 čüąĄčĆąĖą╣ąĮčŗą╣ ąĮąŠą╝ąĄčĆ J-Link, ą║ą╗ąĖą║ąĮąĖč鹥 OK.
ą¤ąŠčüą╗ąĄ ąĘą░ą┐čāčüą║ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĖ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖčÅ ą║ ąŠčéą╗ą░ą┤čćąĖą║čā ą▓ ąŠą║ąĮąĄ JLinkRTTViewer ą╝ąŠąČąĮąŠ čāą▓ąĖą┤ąĄčéčī ą┐čĆąĖą╝ąĄčĆąĮąŠ čüą╗ąĄą┤čāčÄčēąĄąĄ:
[ąĪą┐čĆą░ą▓ąŠčćąĮąĖą║ ą┐ąŠ API čüąĖčüč鹥ą╝čŗ ą╗ąŠą│ą░ Zephyr ]
ąÆčüąĄ ąĘą░ą│ąŠą╗ąŠą▓ąŠčćąĮčŗą╣ čäą░ą╣ą╗čŗ čüąĖčüč鹥ą╝čŗ ą╗ąŠą│ą░ ąĮą░čģąŠą┤čÅčéčüčÅ ą▓ ą║ą░čéą░ą╗ąŠą│ąĄ include\zephyr\logging\ .
ąōčĆčāą┐ą┐ą░ log_api . ą×ą┐čĆąĄą┤ąĄą╗čÅąĄčé ą╝ą░ą║čĆąŠčüčŗ ą▓čŗą▓ąŠą┤ą░ čüąŠąŠą▒čēąĄąĮąĖą╣ čĆą░ąĘą╗ąĖčćąĮąŠą│ąŠ čāčĆąŠą▓ąĮčÅ. ą¤ą░čĆą░ą╝ąĄčéčĆ (...) čŹč鹊 čüčéčĆąŠą║ą░, ą║ąŠč鹊čĆą░čÅ ąŠą┐čåąĖąŠąĮą░ą╗čīąĮąŠ ą╝ąŠąČąĄčé čüąŠą┤ąĄčƹȹ░čéčī čüą┐ąĄčåąĖčäąĖą║ą░č鹊čĆčŗ č乊čĆą╝ą░čéą░ ą▓ čüčéąĖą╗ąĄ printf, ąĘą░ ą║ąŠč鹊čĆąŠą╣ ą╝ąŠą│čāčé ąĖą┤čéąĖ ą░čĆą│čāą╝ąĄąĮčéčŗ.
ąŚą░ą│ąŠą╗ąŠą▓ąŠčćąĮčŗą╣ čäą░ą╣ą╗ log.h .
LOG_ERR(...)
ąÆčŗą▓ąŠą┤ čüąŠąŠą▒čēąĄąĮąĖčÅ čāčĆąŠą▓ąĮčÅ ERROR. ąŁč鹊čé ą╝ą░ą║čĆąŠčü ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮ ą┤ą╗čÅ čüąŠąŠą▒čēąĄąĮąĖčÅ ąŠ čüąĄčĆčīąĄąĘąĮčŗčģ ąŠčłąĖą▒ą║ą░čģ, ąĖąĘ ą║ąŠč鹊čĆčŗčģ čüąĖčüč鹥ą╝ą░ ąĮąĄ ą╝ąŠąČąĄčé ą▓ąŠčüčüčéą░ąĮąŠą▓ąĖčéčīčüčÅ. ą¤čĆąĖ ą▓ą║ą╗čÄč湥ąĮąĖąĖ ą┐ąŠą┤ą║čĆą░čüą║ąĖ čüąŠąŠą▒čēąĄąĮąĖąĄ ERROR ą▓čŗą┤ąĄą╗čÅąĄčéčüčÅ ą║čĆą░čüąĮčŗą╝ čåą▓ąĄč鹊ą╝.
LOG_WRN(...)
ąÆčŗą▓ąŠą┤ čüąŠąŠą▒čēąĄąĮąĖčÅ čāčĆąŠą▓ąĮčÅ WARNING. ą¤čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąŠ ą┤ą╗čÅ čĆąĄą│ąĖčüčéčĆą░čåąĖąĖ ąĮąĄąŠą▒čŗčćąĮčŗčģ čüąĖčéčāą░čåąĖą╣, ą║ąŠč鹊čĆčŗąĄ ąĮąĄąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ čüą▓čÅąĘą░ąĮčŗ čü ąŠčłąĖą▒ą║ą░ą╝ąĖ. ą¤čĆąĖ ą▓ą║ą╗čÄč湥ąĮąĖąĖ ą┐ąŠą┤ą║čĆą░čüą║ąĖ čüąŠąŠą▒čēąĄąĮąĖąĄ WARNING ą▓čŗą┤ąĄą╗čÅąĄčéčüčÅ ąČąĄą╗čéčŗą╝ čåą▓ąĄč鹊ą╝.
LOG_INF(...)
ąÆčŗą▓ąŠą┤ čüąŠąŠą▒čēąĄąĮąĖčÅ čāčĆąŠą▓ąĮčÅ INFO. ąŁč鹊 ąŠą▒čŗčćąĮčŗąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖąĄ ąĖąĮč乊čĆą╝ą░čåąĖąŠąĮąĮčŗąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ. ą¤čĆąĖ ą▓ą║ą╗čÄč湥ąĮąĖąĖ ą┐ąŠą┤ą║čĆą░čüą║ąĖ čüąŠąŠą▒čēąĄąĮąĖąĄ INFO ą▓čŗą┤ąĄą╗čÅąĄčéčüčÅ ąĘąĄą╗ąĄąĮčŗą╝ čåą▓ąĄč鹊ą╝.
LOG_DBG(...)
ąÆčŗą▓ąŠą┤ čüąŠąŠą▒čēąĄąĮąĖčÅ čāčĆąŠą▓ąĮčÅ DEBUG. ąŁč鹊 ąŠą▒ąŠąĘąĮą░čćą░ąĄčé ąĖąĮč乊čĆą╝ą░čåąĖąŠąĮąĮąŠąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ, ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĮąŠąĄ ą┤ą╗čÅ čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ą░.
LOG_PRINTK(...)
ąæąĄąĘčāčüą╗ąŠą▓ąĮąŠ ą▓čŗą▓ąŠą┤ąĖčé ą▓ ą╗ąŠą│ čüąŠąŠą▒čēąĄąĮąĖąĄ, ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ ąŠčé ą░ą║čéąĖą▓ąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ čāčĆąŠą▓ąĮčÅ ą╗ąŠą│ą░. ąĀąĄąĘčāą╗čīčéą░čé čŹč鹊ą│ąŠ ą╝ą░ą║čĆąŠčüą░ č鹊čé ąČąĄ čüą░ą╝čŗą╣, ą║ą░ą║ ąĄčüą╗ąĖ ą▒čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ą░čüčī čäčāąĮą║čåąĖčÅ printk. ą×čéą╗ąĖčćąĖąĄ č鹊ą╗čīą║ąŠ ą▓ č鹊ą╝, čćč鹊 ą▓čŗą▓ąŠą┤ čüąŠąŠą▒čēąĄąĮąĖčÅ ą▓ ą╗ąŠą│ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé č湥čĆąĄąĘ ąĖąĮčäčĆą░čüčéčĆčāą║čéčāčĆčā ą╗ąŠą│ą│ąĖąĮą│ą░, čé. ąĄ. ąĄą│ąŠ ą▓čŗą▓ąŠą┤ ąĘą░ą▓ąĖčüąĖčé ąŠčé čĆąĄąČąĖą╝ą░ ą╗ąŠą│ą░, ąĮą░ą┐čĆąĖą╝ąĄčĆ čŹč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī deferred mode ą┤ą╗čÅ ą╗ąŠą│ą░.
LOG_RAW(...)
ąæąĄąĘčāčüą╗ąŠą▓ąĮąŠ ą▓čŗą▓ąŠą┤ąĖčé ą▓ ą╗ąŠą│ čüąŠąŠą▒čēąĄąĮąĖąĄ, ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ ąŠčé ą░ą║čéąĖą▓ąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ čāčĆąŠą▓ąĮčÅ ą╗ąŠą│ą░ (čéą░ą║ ąČąĄ, ą║ą░ą║ ąĖ LOG_PRINTK). ąĪčéčĆąŠą║ą░ ą▓čŗą▓ąŠą┤ąĖčéčüčÅ čéą░ą║, ą║ą░ą║ ą▒čŗą╗ą░ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮą░, ą▒ąĄąĘ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ čüą┐ąĄčåąĖą░ą╗čīąĮčŗčģ čüąĖą╝ą▓ąŠą╗ąŠą▓ (čé. ąĄ. ą▒ąĄąĘ ESC-ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüč鹥ą╣ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čåą▓ąĄč鹊ą╝ ąĖą╗ąĖ čüąĖą╝ą▓ąŠą╗ąŠą▓ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ).
LOG_INST_ERR(_log_inst, ...)
ąÆčŗą▓ąŠą┤ čüąŠąŠą▒čēąĄąĮąĖčÅ čāčĆąŠą▓ąĮčÅ ERROR, čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ čü 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą╝ ą╝ąŠą┤čāą╗čÅ.
ąĪąŠąŠą▒čēąĄąĮąĖąĄ ąŠčłąĖą▒ą║ąĖ, čüą▓čÅąĘą░ąĮąĮąŠąĄ čü ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╝ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą╝ ą╝ąŠą┤čāą╗čÅ, čā ą║ąŠč鹊čĆąŠą│ąŠ ąĄčüčéčī ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗąĄ ąĮą░čüčéčĆąŠą╣ą║ąĖ čäąĖą╗čīčéčĆą░čåąĖąĖ (ąĄčüą╗ąĖ runtime-čäąĖą╗čīčéčĆą░čåąĖčÅ čĆą░ąĘčĆąĄčłąĄąĮą░) ąĖ ą┐čĆąĄčäąĖą║čü čüąŠąŠą▒čēąĄąĮąĖčÅ (.).
ą¤ą░čĆą░ą╝ąĄčéčĆ _log_inst ŌĆō čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ čüčéčĆčāą║čéčāčĆčā ą╗ąŠą│ą░, čüą▓čÅąĘą░ąĮąĮčāčÄ čü 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą╝ ą╝ąŠą┤čāą╗čÅ.
LOG_INST_WRN(_log_inst, ...)
ąÆčŗą▓ąŠą┤ čüąŠąŠą▒čēąĄąĮąĖčÅ čāčĆąŠą▓ąĮčÅ WARNING, čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ čü 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą╝ ą╝ąŠą┤čāą╗čÅ.
LOG_INST_INF(_log_inst, ...)
ąÆčŗą▓ąŠą┤ čüąŠąŠą▒čēąĄąĮąĖčÅ čāčĆąŠą▓ąĮčÅ INFO, čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ čü 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą╝ ą╝ąŠą┤čāą╗čÅ.
LOG_INST_DBG(_log_inst, ...)
ąÆčŗą▓ąŠą┤ čüąŠąŠą▒čēąĄąĮąĖčÅ čāčĆąŠą▓ąĮčÅ DEBUG, čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ čü 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą╝ ą╝ąŠą┤čāą╗čÅ.
LOG_HEXDUMP_ERR(_data, _length, _str)
ąÆčŗą▓ąŠą┤ hexdump-čüąŠąŠą▒čēąĄąĮąĖčÅ čāčĆąŠą▓ąĮčÅ ERROR. ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
_data ŌĆō čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ą┤ą░ąĮąĮčŗąĄ, ą║ąŠč鹊čĆčŗąĄ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą▓čŗą▓ąĄą┤ąĄąĮčŗ ą▓ ą╗ąŠą│.
LOG_HEXDUMP_WRN(_data, _length, _str)
ąÆčŗą▓ąŠą┤ hexdump-čüąŠąŠą▒čēąĄąĮąĖčÅ čāčĆąŠą▓ąĮčÅ WARNING.
LOG_HEXDUMP_INF(_data, _length, _str)
ąÆčŗą▓ąŠą┤ hexdump-čüąŠąŠą▒čēąĄąĮąĖčÅ čāčĆąŠą▓ąĮčÅ INFO.
LOG_HEXDUMP_DBG(_data, _length, _str)
ąÆčŗą▓ąŠą┤ hexdump-čüąŠąŠą▒čēąĄąĮąĖčÅ čāčĆąŠą▓ąĮčÅ DEBUG.
LOG_INST_HEXDUMP_ERR(_log_inst, _data, _length, _str)
ąÆčŗą▓ąŠą┤ hexdump-čüąŠąŠą▒čēąĄąĮąĖčÅ čāčĆąŠą▓ąĮčÅ ERROR, čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ čü 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą╝ ą╝ąŠą┤čāą╗čÅ.
LOG_INST_HEXDUMP_WRN(_log_inst, _data, _length, _str)
ąÆčŗą▓ąŠą┤ hexdump-čüąŠąŠą▒čēąĄąĮąĖčÅ čāčĆąŠą▓ąĮčÅ WARNING, čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ čü 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą╝ ą╝ąŠą┤čāą╗čÅ.
LOG_INST_HEXDUMP_INF(_log_inst, _data, _length, _str)
ąÆčŗą▓ąŠą┤ hexdump-čüąŠąŠą▒čēąĄąĮąĖčÅ čāčĆąŠą▓ąĮčÅ INFO, čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ čü 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą╝ ą╝ąŠą┤čāą╗čÅ.
LOG_INST_HEXDUMP_DBG(_log_inst, _data, _length, _str)
ąÆčŗą▓ąŠą┤ hexdump-čüąŠąŠą▒čēąĄąĮąĖčÅ čāčĆąŠą▓ąĮčÅ DEBUG, čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ čü 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą╝ ą╝ąŠą┤čāą╗čÅ.
LOG_MODULE_REGISTER(...)
ąĪąŠąĘą┤ą░ąĄčé čüą┐ąĄčåąĖčäąĖčćąĮąŠąĄ ą┤ą╗čÅ ą╝ąŠą┤čāą╗čÅ čüąŠčüč鹊čÅąĮąĖąĄ ąĖ čĆąĄą│ąĖčüčéčĆąĖčĆčāąĄčé ą╝ąŠą┤čāą╗čī ą┤ą╗čÅ ą╗ąŠą│ą│ąĄčĆą░. ąŁč鹊čé ą╝ą░ą║čĆąŠčü ą┤ąŠą╗ąČąĄąĮ ąŠą▒čŗčćąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮ ą┐ąŠčüą╗ąĄ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖčÅ ąĘą░ą│ąŠą╗ąŠą▓ą║ą░ , čćč鹊ą▒čŗ ąĘą░ą▓ąĄčĆčłąĖčéčī ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÄ ą╝ąŠą┤čāą╗čÅ.
ąĀąĄą│ąĖčüčéčĆą░čåąĖčÅ ą╝ąŠą┤čāą╗čÅ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠą┐čāčēąĄąĮą░ ą▓ ą┤ą▓čāčģ čüą╗čāčćą░čÅčģ:
ŌĆó ą£ąŠą┤čāą╗čī čüąŠčüč鹊ąĖčé ą▒ąŠą╗čīčłąĄ č湥ą╝ ąŠą┤ąĮąŠą│ąŠ čäą░ą╣ą╗ą░, ąĖ ą┤čĆčāą│ąŠą╣ čäą░ą╣ą╗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ čŹč鹊čé ą╝ą░ą║čĆąŠčü (LOG_MODULE_DECLARE() ą┤ąŠą╗ąČąĄąĮ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą▓ą╝ąĄčüč鹊 ąĮąĄą│ąŠ ąŠą▓ąŠ ą▓čüąĄčģ ą┤čĆčāą│ąĖčģ čäą░ą╣ą╗ą░čģ čŹč鹊ą│ąŠ ą╝ąŠą┤čāą╗čÅ).
ą£ą░ą║čĆąŠčü ą┐čĆąĖąĮąĖą╝ą░ąĄčé ąŠą┤ąĖąĮ ąĖą╗ąĖ ą┤ą▓ą░ ą┐ą░čĆą░ą╝ąĄčéčĆą░:
ŌĆó ąśą╝čÅ ą╝ąŠą┤čāą╗čÅ.
ą¤čĆąĖą╝ąĄčĆčŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ:
ŌĆó LOG_MODULE_REGISTER(foo, CONFIG_FOO_LOG_LEVEL)
ąĪą╝. čéą░ą║ąČąĄ LOG_MODULE_DECLARE.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ čüąŠčüč鹊čÅąĮąĖąĄ ą╝ąŠą┤čāą╗čÅ ąĖ čĆąĄą│ąĖčüčéčĆąĖčĆčāąĄčéčüčÅ ą╝ąŠą┤čāą╗čī č鹊ą╗čīą║ąŠ ąĄčüą╗ąĖ LOG_LEVEL ą┤ą╗čÅ č鹥ą║čāčēąĄą│ąŠ ąĖčüčģąŠą┤ąĮąŠą│ąŠ čäą░ą╣ą╗ą░ ąĮąĄąĮčāą╗ąĄą▓ąŠą╣ ąĖą╗ąĖ ąĮąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ, ąĖ ąĘąĮą░č湥ąĮąĖąĄ CONFIG_LOG_DEFAULT_LEVEL ąĮąĄąĮčāą╗ąĄą▓ąŠąĄ. ąÆ ą┤čĆčāą│ąĖčģ čüą╗čāčćą░čÅčģ čŹč鹊čé ą╝ą░ą║čĆąŠčü ąĮąĄ ą┤ą░ąĄčé čŹčäč乥ą║čéą░.
LOG_MODULE_DECLARE(...)
ą£ą░ą║čĆąŠčü ą┤ą╗čÅ ą┤ąĄą║ą╗ą░čĆą░čåąĖąĖ ą╗ąŠą│ą░ ą╝ąŠą┤čāą╗čÅ (ą▒ąĄąĘ ąĄą│ąŠ čĆąĄą│ąĖčüčéčĆą░čåąĖąĖ). ą£ąŠą┤čāą╗ąĖ, ą║ąŠč鹊čĆčŗąĄ čĆą░ąĘą┤ąĄą╗ąĄąĮčŗ ąĮą░ ąĮąĄčüą║ąŠą╗čīą║ąŠ čäą░ą╣ą╗ąŠą▓, ą┤ąŠą╗ąČąĮčŗ ąĖą╝ąĄčéčī č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ čäą░ą╣ą╗, ą│ą┤ąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ LOG_MODULE_REGISTER(), čćč鹊ą▒čŗ čüąŠąĘą┤ą░čéčī čüą┐ąĄčåąĖčäąĖčćąĮąŠąĄ ą┤ą╗čÅ ą╝ąŠą┤čāą╗čÅ čüąŠčüč鹊čÅąĮąĖčÅ ąĖ ąĘą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░čéčī ą╝ąŠą┤čāą╗čī ą┤ą╗čÅ čÅą┤čĆą░ čüąĖčüč鹥ą╝čŗ ą╗ąŠą│ą░.
ąöčĆčāą│ąĖąĄ čäą░ą╣ą╗čŗ ą▓ ą╝ąŠą┤čāą╗ąĄ ą┤ąŠą╗ąČąĮčŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹč鹊čé ą╝ą░ą║čĆąŠčü ą▓ą╝ąĄčüč鹊 ą┤ąĄą║ą╗ą░čĆąĖčĆąŠą▓ą░ąĮąĖčÅ č鹊ą│ąŠ ąČąĄ čüą░ą╝ąŠą│ąŠ čüąŠčüč鹊čÅąĮąĖčÅ (ąĖąĮą░č湥 LOG_INF() ąĖ ą┐ąŠą┤ąŠą▒ąĮčŗąĄ ą╝ą░ą║čĆąŠčüčŗ ąĮąĄ ą╝ąŠą│čāčé čüčüčŗą╗ą░čéčīčüčÅ ąĮą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ čüąŠčüč鹊čÅąĮąĖčÅ ą║ąŠąĮą║čĆąĄčéąĮąŠą│ąŠ ą╝ąŠą┤čāą╗čÅ).
ą£ą░ą║čĆąŠčü ą┐čĆąĖąĮąĖą╝ą░ąĄčé ąŠą┤ąĖąĮ ąĖą╗ąĖ ą┤ą▓ą░ ą┐ą░čĆą░ą╝ąĄčéčĆą░:
ŌĆó ąśą╝čÅ ą╝ąŠą┤čāą╗čÅ.
ą¤čĆąĖą╝ąĄčĆčŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ:
ŌĆó LOG_MODULE_DECLARE(foo, CONFIG_FOO_LOG_LEVEL)
ąĪą╝. čéą░ą║ąČąĄ LOG_MODULE_REGISTER.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: čüąŠčüč鹊čÅąĮąĖąĄ ą╝ąŠą┤čāą╗čÅ ą┤ąĄą║ą╗ą░čĆąĖčĆčāąĄčéčüčÅ č鹊ą╗čīą║ąŠ ąĄčüą╗ąĖ LOG_LEVEL ą┤ą╗čÅ č鹥ą║čāčēąĄą│ąŠ ąĖčüčģąŠą┤ąĮąŠą│ąŠ čäą░ą╣ą╗ą░ ąĮąĄąĮčāą╗ąĄą▓ąŠą╣ ąĖą╗ąĖ ąĮąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ, ąĖ CONFIG_LOG_DEFAULT_LEVEL ąĮąĄąĮčāą╗ąĄą▓ąŠą╣. ąÆ ą┤čĆčāą│ąĖčģ čüą╗čāčćą░čÅčģ čŹč鹊čé ą╝ą░ą║čĆąŠčü ąĮąĄ ą┤ą░ąĄčé čŹčäč乥ą║čéą░.
LOG_LEVEL_SET(level)
ą£ą░ą║čĆąŠčü ą┤ą╗čÅ čāčüčéą░ąĮąŠą▓ą║ąĖ čāčĆąŠą▓ąĮčÅ ą╗ąŠą│ą░ ą▓ čäą░ą╣ą╗ąĄ ąĖą╗ąĖ čäčāąĮą║čåąĖąĖ, ą│ą┤ąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗čüčÅ logging API.
ąōčĆčāą┐ą┐ą░ log_ctrl , API ą┤ą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą╗ąŠą│ą│ąĄčĆąŠą╝.
ąŚą░ą│ąŠą╗ąŠą▓ąŠčćąĮčŗą╣ čäą░ą╣ą╗ log_ctrl.h .
ą£ą░ą║čĆąŠčüčŗ:
LOG_CORE_INIT() LOG_INIT() LOG_PANIC() LOG_PROCESS()
ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čéąĖą┐ą░:
typedef log_timestamp_t (*log_timestamp_get_t)(void)
ążčāąĮą║čåąĖąĖ:
void log_core_init(void)
ąĪąĖčüč鹥ą╝ąĮą░čÅ čäčāąĮą║čåąĖčÅ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ ą╗ąŠą│ą│ąĄčĆą░. ąŁčéą░ čäčāąĮą║čåąĖčÅ ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ ą▓ąŠ ą▓čĆąĄą╝čÅ ąĘą░ą┐čāčüą║ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ (start up), čćč鹊ą▒čŗ ą┐ąŠąĘą▓ąŠą╗ąĖčéčī ą▓čŗą▓ąŠą┤ ą▓ ą╗ąŠą│ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą╝ąŠąČąĄčé čÅą▓ąĮąŠ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī ą╗ąŠą│ą│ąĄčĆ.
void log_init(void)
ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ą░čÅ čäčāąĮą║čåąĖčÅ ą┤ą╗čÅ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ ą╗ąŠą│ą│ąĄčĆą░.
void log_thread_set(k_tid_t process_tid)
ążčāąĮą║čåąĖčÅ, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčēą░čÅ ą┐ąŠč鹊ą║, ą║ąŠč鹊čĆčŗą╣ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé ą╗ąŠą│ąĖ. ąĪą╝. CONFIG_LOG_PROCESS_TRIGGER_THRESHOLD.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: čäčāąĮą║čåąĖčÅ ąĖą╝ąĄąĄčé ą▓čŗąĘąŠą▓ assert ąĖ ąĮąĄ ą┤ą░ąĄčé čŹčäč乥ą║čéą░, ą║ąŠą│ą┤ą░ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮą░ ąŠą┐čåąĖčÅ CONFIG_LOG_PROCESS_THREAD.
ą¤ą░čĆą░ą╝ąĄčéčĆ process_tid ąĘą░ą┤ą░ąĄčé ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčēąĄą│ąŠ ą┐ąŠč鹊ą║ą░. ąśčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą┐čĆąŠą▒čāąČą┤ąĄąĮąĖčÅ ą┐ąŠč鹊ą║ą░.
int log_set_timestamp_func(log_timestamp_get_t timestamp_getter, uint32_t freq)
ążčāąĮą║čåąĖčÅ ą┤ą╗čÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĖčÅ ą╝ąĄčéą║ąĖ ą▓čĆąĄą╝ąĄąĮąĖ.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
timestamp_getter ŌĆō čäčāąĮą║čåąĖčÅ ą╝ąĄčéą║ąĖ ą▓čĆąĄą╝ąĄąĮąĖ.
ąÆąŠąĘą▓čĆą░čēą░ąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ: 0 ą┐čĆąĖ čāčüą┐ąĄčģąĄ ąĖą╗ąĖ ąĮąĄąĮčāą╗ąĄą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą▓ čüą╗čāčćą░ąĄ ąŠčłąĖą▒ą║ąĖ.
void log_panic(void)
ą¤ąĄčĆąĄą║ą╗čÄčćą░ąĄčé ą┐ąŠą┤čüąĖčüč鹥ą╝čā ą╗ąŠą│ą░ ą▓ čĆąĄąČąĖą╝ ą┐ą░ąĮąĖą║ąĖ. ąÆčŗą┐ąŠą╗ąĮąĖčé ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮčŗą╣ ą▓ąŠąĘą▓čĆą░čé, ąĄčüą╗ąĖ ą╗ąŠą│ą│ąĄčĆ čāąČąĄ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ panic mode.
ą¤čĆąĖ ą┐ą░ąĮąĖą║ąĄ ą┐ąŠą┤čüąĖčüč鹥ą╝ą░ ą╗ąŠą│ą│ąĄčĆą░ ąĖąĮč乊čĆą╝ąĖčĆčāąĄčé ą▓čüąĄ ą▒菹║ąĄąĮą┤čŗ ąŠ panic mode. ą▒菹║ąĄąĮą┤čŗ ą┤ąŠą╗ąČąĮčŗ ą┐ąĄčĆąĄą║ą╗čÄčćąĖčéčīčüčÅ ą▓ ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĖą╣ čĆąĄąČąĖą╝, ąĖą╗ąĖ ąŠčüčéą░ąĮąŠą▓ąĖčéčīčüčÅ (halt). ą¤ąŠčüą╗ąĄ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ ą▓ čĆąĄąČąĖą╝ ą┐ą░ąĮąĖą║ąĖ ą▓čüąĄ ąŠąČąĖą┤ą░čÄčēąĖąĄ ą▓čŗą▓ąŠą┤ ą╗ąŠą│ąĖ čüą▒čĆą░čüčŗą▓ą░čÄčéčüčÅ (flushed). ąÆ čĆąĄąČąĖą╝ąĄ ą┐ą░ąĮąĖą║ąĖ ą▓čüąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąŠą▒čĆą░ą▒ąŠčéą░ąĮčŗ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 čüą▓ąŠąĄą│ąŠ ą▓čŗąĘąŠą▓ą░.
bool log_process(void)
ą×ą▒čĆą░ą▒ąŠčéą░ąĄčé ąŠą┤ąĮąŠ ąŠąČąĖą┤ą░čÄčēąĄąĄ ą▓čŗą▓ąŠą┤ą░ čüąŠąŠą▒čēąĄąĮąĖąĄ ą╗ąŠą│ą░.
ąÆąŠąĘą▓čĆą░čēą░ąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ:
true ŌĆō ąĄčüčéčī ąĄčēąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ, ąŠąČąĖą┤ą░čÄčēąĖąĄ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ.
uint32_t log_buffered_cnt(void)
ąÆąŠąĘą▓čĆą░čéąĖčé č鹥ą║čāčēąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĘą░ą▒čāč乥čĆąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗčģ čüąŠąŠą▒čēąĄąĮąĖą╣ ą╗ąŠą│ą░.
uint32_t log_src_cnt_get(uint32_t domain_id)
ąÆąŠąĘą▓čĆą░čéąĖčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗčģ ąĖčüč鹊čćąĮąĖą║ąŠą▓ ą╗ąŠą│ą│ąĄčĆą░ (ą╝ąŠą┤čāą╗ąĄą╣ ąĖ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąŠą▓).
ą¤ą░čĆą░ą╝ąĄčéčĆ domain_id ŌĆō čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ą┤ąŠą╝ąĄąĮą░ (Domain ID).
const char *log_source_name_get(uint32_t domain_id, uint32_t source_id)
ąśąĘą▓ą╗ąĄą║ą░ąĄčé ąĖą╝čÅ ąĖčüč鹊čćąĮąĖą║ą░ (ą╝ąŠą┤čāą╗čÅ ąĖą╗ąĖ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░).
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
domain_id ŌĆō Domain ID.
ąÆąŠąĘą▓čĆą░čéąĖčé ąĖą╝čÅ ąĖčüč鹊čćąĮąĖą║ą░ ąĖą╗ąĖ NULL, ąĄčüą╗ąĖ čāą║ą░ąĘą░ąĮčŗ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮčŗąĄ ą░čĆą│čāą╝ąĄąĮčéčŗ.
static inline uint8_t log_domains_count(void)
ąÆąŠąĘą▓čĆą░čéąĖčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┤ąŠą╝ąĄąĮąŠą▓, ąĖą╝ąĄčÄčēąĖčģčüčÅ ą▓ čüąĖčüč鹥ą╝ąĄ. ąöąŠą╗ąČąĄąĮ ą▒čŗčéčī ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝ 1 ą╗ąŠą║ą░ą╗čīąĮčŗą╣ ą┤ąŠą╝ąĄąĮ.
const char *log_domain_name_get(uint32_t domain_id)
ąÆąŠąĘą▓čĆą░čéąĖčé ąĖą╝čÅ ą┤ąŠą╝ąĄąĮą░ ą┐ąŠ ąĄą│ąŠ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆčā domain_id.
int log_source_id_get(const char *name)
ążčāąĮą║čåąĖčÅ ąĮą░ą╣ą┤ąĄčé ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ąĖčüč鹊čćąĮąĖą║ą░ ą┐ąŠ ąĄą│ąŠ ąĖą╝ąĄąĮąĖ. ąÆąŠąĘą▓čĆą░čéąĖčé Source ID ąĖą╗ąĖ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠąĄ čćąĖčüą╗ąŠ, ąĄčüą╗ąĖ ąĖčüč鹊čćąĮąĖą║ ąĮąĄ ąĮą░ą╣ą┤ąĄąĮ.
uint32_t log_filter_get(struct log_backend const *const backend, uint32_t domain_id, int16_t source_id, bool runtime)
ąśąĘą▓ą╗ąĄą║ą░ąĄčé čäąĖą╗čīčéčĆ ąĖčüč鹊čćąĮąĖą║ą░ ą┤ą╗čÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮąŠą│ąŠ ą▒菹║ąĄąĮą┤ą░.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
backend ŌĆō 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▒菹║ąĄąĮą┤ą░.
ąÆąŠąĘą▓čĆą░čēą░ąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ: severity level (čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░).
uint32_t log_filter_set(struct log_backend const *const backend, uint32_t domain_id, int16_t source_id, uint32_t level)
ąŻčüčéą░ąĮąŠą▓ąĖčé čäąĖą╗čīčéčĆ ąĮą░ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╝ ąĖčüč鹊čćąĮąĖą║ąĄ ą┤ą╗čÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮąŠą│ąŠ ą▒菹║ąĄąĮą┤ą░.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
backend ŌĆō 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▒菹║ąĄąĮą┤ą░.
ąÆąŠąĘą▓čĆą░čéąĖčé ą░ą║čéčāą░ą╗čīąĮčŗą╣ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮčŗą╣ čāčĆąŠą▓ąĄąĮčī, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠą│čĆą░ąĮąĖč湥ąĮ čāčĆąŠą▓ąĮąĄą╝, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╝ ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ. ąĢčüą╗ąĖ čäąĖą╗čīčéčĆ ą▒čŗą╗ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą┤ą╗čÅ ą▓čüąĄčģ ą▒菹║ąĄąĮą┤ąŠą▓, č鹊 ą▒čāą┤ąĄčé ą▓ąŠąĘą▓čĆą░čēąĄąĮ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčŗą╣ čāčĆąŠą▓ąĄąĮčī, ą║ąŠč鹊čĆčŗą╣ ą▒čŗą╗ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ.
void log_backend_enable(struct log_backend const *const backend, void *ctx, uint32_t level)
ąĀą░ąĘčĆąĄčłąĖčé ą▒菹║ąĄąĮą┤ čü ąĮą░čćą░ą╗čīąĮčŗą╝ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčŗą╝ čāčĆąŠą▓ąĮąĄą╝ čäąĖą╗čīčéčĆą░čåąĖąĖ.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
backend ŌĆō 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▒菹║ąĄąĮą┤ą░.
void log_backend_disable(struct log_backend const *const backend)
ąŚą░ą┐čĆąĄčéąĖčé ą▒菹║ąĄąĮą┤.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
backend ŌĆō 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▒菹║ąĄąĮą┤ą░.
const struct log_backend *log_backend_get_by_name(const char *backend_name)┬Č
ąśąĘą▓ą╗ąĄą║ą░ąĄčé ą▒菹║ąĄąĮą┤ ą┐ąŠ ąĖą╝ąĄąĮąĖ.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
backend_name ŌĆō [in] ąĖą╝čÅ ą▒菹║ąĄąĮą┤ą░, ą║ą░ą║ čŹč鹊 ą▒čŗą╗ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąŠ ą╝ą░ą║čĆąŠčüąŠą╝ LOG_BACKEND_DEFINE.
ąÆąŠąĘą▓čĆą░čēą░ąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ: čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ąĮą░ą╣ą┤ąĄąĮąĮčŗą╣ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▒菹║ąĄąĮą┤ą░, ąĖą╗ąĖ NULL ąĄčüą╗ąĖ ą▒菹║ąĄąĮą┤ ąĮąĄ ąĮą░ą╣ą┤ąĄąĮ.
const struct log_backend *log_format_set_all_active_backends(size_t log_type)
ąŻčüčéą░ąĮąŠą▓ąĖčé č乊čĆą╝ą░čé ą╗ąŠą│ą│ąĖąĮą│ą░ ą┤ą╗čÅ ą▓čüąĄčģ ą░ą║čéąĖą▓ąĮčŗčģ ą▒菹║ąĄąĮą┤ąŠą▓.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
log_type ŌĆō č乊čĆą╝ą░čé ą╗ąŠą│ą░.
ąÆąŠąĘą▓čĆą░čēą░ąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ: čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ą┐ąŠčüą╗ąĄą┤ąĮąĖą╣ ą▒菹║ąĄąĮą┤, ąĮą░ ą║ąŠč鹊čĆąŠą╝ čāčüčéą░ąĮąŠą▓ą║ą░ č乊čĆą╝ą░čéą░ ą▒čŗą╗ą░ ąĮąĄčāą┤ą░čćąĮąŠą╣, ąĖą╗ąĖ NULL ą┤ą╗čÅ čāčüą┐ąĄčģą░.
static inline bool log_data_pending(void)
ą¤čĆąŠą▓ąĄčĆčÅąĄčé, ąĄčüčéčī ą╗ąĖ ąŠąČąĖą┤ą░čÄčēąĖąĄ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┤ą░ąĮąĮčŗąĄ ą╗ąŠą│ą░. ążčāąĮą║čåąĖčÅ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ č鹊ą│ąŠ, čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, ą▓čüąĄ ą╗ąĖ ą╗ąŠą│ąĖ ą▒čŗą╗ąĖ čüą╗ąĖčéčŗ (flushed). ążčāąĮą║čåąĖčÅ ą▓ąĄčĆąĮąĄčé false, ą║ąŠą│ą┤ą░ deferred mode ąĮąĄ čĆą░ąĘčĆąĄčłąĄąĮ.
ąÆąŠąĘą▓čĆą░čéąĖčé true, ąĄčüą╗ąĖ ąĄčüčéčī ą┤ą░ąĮąĮčŗąĄ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ, ąĖą╗ąĖ false ąĄčüą╗ąĖ ąĮąĄčé ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ.
int log_set_tag(const char *tag)
ąÜąŠąĮčäąĖą│čāčĆąĖčĆčāąĄčé č鹥ą│, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą┤ą╗čÅ ą┐čĆąĄčäąĖą║čüą░ ą║ą░ąČą┤ąŠą│ąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
tag ŌĆō Tag.
ąÆąŠąĘą▓čĆą░čēą░ąĄą╝čŗąĄ ąĘąĮą░č湥ąĮąĖčÅ:
0 ŌĆō čāčüą┐ąĄčģ ąŠą┐ąĄčĆą░čåąĖąĖ.
int log_mem_get_usage(uint32_t *buf_size, uint32_t *usage)
ąśąĘą▓ą╗ąĄą║ą░ąĄčé ąĖąĮč乊čĆą╝ą░čåąĖčÄ ą┐ąŠ č鹥ą║čāčēąĄą╝čā ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÄ ą┐ą░ą╝čÅčéąĖ.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
buf_size ŌĆō [out] ąĄą╝ą║ąŠčüčéčī ą▒čāč乥čĆą░, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą│ąŠ ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čüąŠąŠą▒čēąĄąĮąĖą╣ ą╗ąŠą│ą░.
ąÆąŠąĘą▓čĆą░čēą░ąĄą╝čŗąĄ ąĘąĮą░č湥ąĮąĖčÅ:
-EINVAL ŌĆō ąĄčüą╗ąĖ čĆąĄąČąĖą╝ ą╗ąŠą│ą│ąĖąĮą│ą░ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą▒čāč乥čĆ.
int log_mem_get_max_usage(uint32_t *max)
ąśąĘą▓ą╗ąĄč湥čé ąĖąĮč乊čĆą╝ą░čåąĖčÄ ą┐ąŠ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╝čā ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÄ ą┐ą░ą╝čÅčéąĖ. ąóčĆąĄą▒čāąĄčé ąŠą┐čåąĖąĖ CONFIG_LOG_MEM_UTILIZATION.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
max ŌĆō [out] ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ą░ą╣čé, ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą▓čłąĖčģčüčÅ ą┤ą╗čÅ čüąŠąŠą▒čēąĄąĮąĖą╣, ąŠąČąĖą┤ą░čÄčēąĖčģ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ.
ąÆąŠąĘą▓čĆą░čēą░ąĄą╝čŗąĄ ąĘąĮą░č湥ąĮąĖčÅ:
-EINVAL ŌĆō ąĄčüą╗ąĖ čĆąĄąČąĖą╝ ą╗ąŠą│ą│ąĖąĮą│ą░ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą▒čāč乥čĆ.
ąōčĆčāą┐ą┐ą░ log_msg , API-čäčāąĮą║čåąĖąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░.
ąŚą░ą│ąŠą╗ąŠą▓ąŠčćąĮčŗą╣ čäą░ą╣ą╗ log_msg.h .
ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ:
LOG_MSG_GENERIC_HDR
ąóąĖą┐čŗ ą┤ą░ąĮąĮčŗčģ:
struct log_msg_desc union log_msg_source struct log_msg_hdr struct log_msg struct log_msg_generic_hdr union log_msg_generic union mpsc_pbuf_generic buf
ążčāąĮą║čåąĖąĖ:
static inline uint32_t log_msg_get_total_wlen(const struct log_msg_desc desc)
ąśąĘą▓ą╗ąĄą║ą░ąĄčé ąŠą▒čēčāčÄ ą┤ą╗ąĖąĮčā (ą▓ 32-čĆą░ąĘčĆčÅą┤ąĮčŗčģ čüą╗ąŠą▓ą░čģ) čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
desc ŌĆō ą┤ąĄčüą║čĆąĖą┐č鹊čĆ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░.
static inline uint32_t log_msg_generic_get_wlen(const union mpsc_pbuf_generic *item)
ąśąĘą▓ą╗ąĄą║ą░ąĄčé ą┤ą╗ąĖąĮčā 菹╗ąĄą╝ąĄąĮčéą░ ą╗ąŠą│ą░ ą▓ 32-ą▒ąĖčéąĮčŗčģ čüą╗ąŠą▓ą░čģ.
static inline uint8_t log_msg_get_domain(struct log_msg *msg)
ąśąĘą▓ą╗ąĄą║ą░ąĄčé ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ą┤ąŠą╝ąĄąĮą░ (domain ID) čüąŠąŠą▒čēąĄąĮąĖčÅ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░.
static inline uint8_t log_msg_get_level(struct log_msg *msg)
ąśąĘą▓ą╗ąĄą║ą░ąĄčé čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░ ą┤ą╗čÅ čüąŠąŠą▒čēąĄąĮąĖčÅ.
static inline const void *log_msg_get_source(struct log_msg *msg)
ąśąĘą▓ą╗ąĄą║ą░ąĄčé ąĖčüč鹊čćąĮąĖą║ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░. ąÆąŠąĘą▓čĆą░čéąĖčé čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ąĖčüč鹊čćąĮąĖą║ ą┤ą░ąĮąĮčŗčģ.
static inline log_timestamp_t log_msg_get_timestamp(struct log_msg *msg)
ąśąĘą▓ą╗ąĄą║ą░ąĄčé ą╝ąĄčéą║čā ą▓čĆąĄą╝ąĄąĮąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░.
static inline void *log_msg_get_tid(struct log_msg *msg)
ąśąĘą▓ą╗ąĄą║ą░ąĄčé ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ą┐ąŠč鹊ą║ą░ (Thread ID) čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░.
static inline uint8_t *log_msg_get_data(struct log_msg *msg, size_t *len)
ąÆąŠąĘą▓čĆą░čéąĖčé čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ą▒čāč乥čĆ ą┤ą░ąĮąĮčŗčģ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
msg ŌĆō čüąŠąŠą▒čēąĄąĮąĖąĄ ą╗ąŠą│ą░.
static inline uint8_t *log_msg_get_package(struct log_msg *msg, size_t *len)
ąÆąŠąĘą▓čĆą░čéąĖčé čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ą┐ą░ą║ąĄčé čüčéčĆąŠą║ąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
msg ŌĆō čüąŠąŠą▒čēąĄąĮąĖąĄ ą╗ąŠą│ą░.
ąōčĆčāą┐ą┐ą░ log_backend , ąĖąĮč鹥čĆč乥ą╣čü ą▒菹║ąĄąĮą┤ą░ ą╗ąŠą│ą│ąĄčĆą░.
ąŚą░ą│ąŠą╗ąŠą▓ąŠčćąĮčŗą╣ čäą░ą╣ą╗ log_backend.h .
ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ:
LOG_BACKEND_DEFINE(_name, _api, _autostart, ...)
ą£ą░ą║čĆąŠčü ą┤ą╗čÅ čüąŠąĘą┤ą░ąĮąĖčÅ čŹą║ąĘąĄą╝ą┐ą╗čÅčĆą░ ą▒菹║ąĄąĮą┤ą░ ą╗ąŠą│ą│ąĄčĆą░.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
_name ŌĆō ąĖą╝čÅ čŹą║ąĘąĄą╝ą┐ą╗čÅčĆą░ ą▒菹║ąĄąĮą┤ą░.
ą¤ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖčÅ:
enum log_backend_evt
ąĪąŠą▒čŗčéąĖčÅ ą▒菹║ąĄąĮą┤ą░.
ąŚąĮą░č湥ąĮąĖčÅ:
enum LOG_BACKEND_EVT_PROCESS_THREAD_DONE
ąĪąŠą▒čŗčéąĖąĄ, ą║ąŠą│ą┤ą░ ą┐ąŠč鹊ą║ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą╗ąŠą│ą░ ąĘą░ą▓ąĄčĆčłą░ąĄčé ąŠą▒čĆą░ą▒ąŠčéą║čā. ąŁč鹊 čüąŠą▒čŗčéąĖąĄ ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ, ą║ąŠą│ą┤ą░ ą┐ąŠč鹊ą║ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĘą░ą▓ąĄčĆčłąĖą╗ ąŠą▒čĆą░ą▒ąŠčéą║čā ąŠąČąĖą┤ą░čÄčēąĖčģ čüąŠąŠą▒čēąĄąĮąĖą╣ ą╗ąŠą│ą░.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: čŹč鹊 čüąŠą▒čŗčéąĖąĄ ąĮąĄ ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ą┐čĆąĖ ąŠčéčüčāčéčüčéą▓ąĖąĖ ąŠąČąĖą┤ą░čÄčēąĖčģ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čüąŠąŠą▒čēąĄąĮąĖą╣ ą╗ąŠą│ą░. ą¤čĆąĖą╝ąĄąĮąĖą╝ąŠ č鹊ą╗čīą║ąŠ ą║ deferred mode.
enum LOG_BACKEND_EVT_MAX
ą£ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čüąŠą▒čŗčéąĖą╣ ą▒菹║ąĄąĮą┤ą░.
ążčāąĮą║čåąĖąĖ:
static inline void log_backend_init(const struct log_backend *const backend)
ąśąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāąĄčé ąĖą╗ąĖ ąĖąĮąĖčåąĖąĖčĆčāąĄčé ą▒菹║ąĄąĮą┤ ą╗ąŠą│ą│ąĖąĮą│ą░.
ąÆ čüą╗čāčćą░ąĄ, ą║ąŠą│ą┤ą░ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ ą▓ąĮčāčéčĆąĄąĮąĮąĄą│ąŠ ą▒菹║ąĄąĮą┤ą░ ąĘą░ąĮąĖą╝ą░ąĄčé ą▒ąŠą╗čīčłąĄ ą▓čĆąĄą╝ąĄąĮąĖ, čŹč鹊 ą╝ąŠąČąĄčé ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░čéčī ą┐ąŠč鹊ą║ ą╗ąŠą│ą░, ąĄčüą╗ąĖ ą▒菹║ąĄąĮą┤ ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ. ą¤čĆąĖčćąĖąĮą░ ą▓ č鹊ą╝, čćč鹊 ą▓čüąĄ ą▒菹║ąĄąĮą┤čŗ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāčÄčéčüčÅ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ą┐ąŠč鹊ą║ą░ ą╗ąŠą│ą░. ąÆ čéą░ą║ąŠą╝ čüą╗čāčćą░ąĄ ą▒菹║ąĄąĮą┤ ą┤ąŠą╗ąČąĄąĮ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī čäčāąĮą║čåąĖčÄ ą┤ą╗čÅ ąŠą┐čĆąŠčüą░ ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ (log_backend_is_ready).
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
static inline int log_backend_is_ready(const struct log_backend *const backend)
ą×ą┐čĆą░čłąĖą▓ą░ąĄčé ą│ąŠč鹊ą▓ąĮąŠčüčéčī ą▒菹║ąĄąĮą┤ą░. ąĢčüą╗ąĖ ą▒菹║ąĄąĮą┤ ą┐čĆąĖčģąŠą┤ąĖčé ą▓ ą│ąŠč鹊ą▓ąĮąŠčüčé čüčĆą░ąĘčā ą┐ąŠčüą╗ąĄ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ, č鹊 č鹊ą│ą┤ą░ ą▒菹║ąĄąĮą┤ ą╝ąŠąČąĄčé ąĮąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčéčī čŹčéčā čäčāąĮą║čåąĖčÄ.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
backend ŌĆō [in] čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▒菹║ąĄąĮą┤ą░.
ąÆąŠąĘą▓čĆą░čēą░ąĄą╝čŗąĄ ąĘąĮą░č湥ąĮąĖčÅ:
0 ŌĆō ąĄčüą╗ąĖ ą▒菹║ąĄąĮą┤ ą▓ ą│ąŠč鹊ą▓ąĮąŠčüčéąĖ.
static inline void log_backend_msg_process(const struct log_backend *const backend, union log_msg_generic *msg)
ą×ą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé čüąŠąŠą▒čēąĄąĮąĖąĄ. ąŁčéą░ čäčāąĮą║čåąĖčÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą▓ čĆąĄąČąĖą╝ą░čģ deferred ąĖ immediate. ą¤čĆąĖ ą▓ąŠąĘą▓čĆą░č鹥 čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčéčüčÅ ą▒菹║ąĄąĮą┤ąŠą╝ ąĖ ą┐ą░ą╝čÅčéčī ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮą░.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
backend ŌĆō [in] čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▒菹║ąĄąĮą┤ą░.
static inline void log_backend_dropped(const struct log_backend *const backend, uint32_t cnt)
ą×ą┐ąŠą▓ąĄčēą░ąĄčé ą▒菹║ąĄąĮą┤ ą┐ąŠ ą┐ąŠą▓ąŠą┤čā ąŠčéą▒čĆąŠčłąĄąĮąĮčŗčģ čüąŠąŠą▒čēąĄąĮąĖą╣ ą╗ąŠą│ą░. ąŁčéą░ čäčāąĮą║čåąĖčÅ ąŠą┐čåąĖąŠąĮą░ą╗čīąĮą░.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
backend ŌĆō [in] čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▒菹║ąĄąĮą┤ą░.
static inline void log_backend_panic(const struct log_backend *const backend)
ą¤ąĄčĆąĄą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄčé ą▒菹║ąĄąĮą┤ ą▓ čĆąĄąČąĖą╝ ą┐ą░ąĮąĖą║ąĖ.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
backend ŌĆō [in] čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▒菹║ąĄąĮą┤ą░.
static inline void log_backend_id_set(const struct log_backend *const backend, uint8_t id)
ąŻčüčéą░ąĮąŠą▓ąĖčé ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ą▒菹║ąĄąĮą┤ą░. ąŁčéą░ čäčāąĮą║čåąĖčÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą▓ąĮčāčéčĆąĄąĮąĮąĄ ą▓ ą╗ąŠą│ą│ąĄčĆąĄ.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
backend ŌĆō [in] čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▒菹║ąĄąĮą┤ą░.
static inline uint8_t log_backend_id_get(const struct log_backend *const backend)
ąÆąŠąĘą▓čĆą░čéąĖčé ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ą▒菹║ąĄąĮą┤ą░. ąŁčéą░ čäčāąĮą║čåąĖčÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą▓ąĮčāčéčĆąĄąĮąĮąĄ ą▓ ą╗ąŠą│ą│ąĄčĆąĄ.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
backend ŌĆō [in] čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▒菹║ąĄąĮą┤ą░.
static inline const struct log_backend *log_backend_get(uint32_t idx)
ąÆąŠąĘą▓čĆą░čéąĖčé ą▒菹║ąĄąĮą┤ (čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▒菹║ąĄąĮą┤ą░).
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
backend ŌĆō [in] čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▒菹║ąĄąĮą┤ą░.
static inline int log_backend_count_get(void)
ąÆąŠąĘą▓čĆą░čéąĖčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒菹║ąĄąĮą┤ąŠą▓.
static inline void log_backend_activate(const struct log_backend *const backend, void *ctx)
ąÉą║čéąĖą▓ąĖčĆčāąĄčé ą▒菹║ąĄąĮą┤.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
backend ŌĆō [in] čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▒菹║ąĄąĮą┤ą░.
static inline void log_backend_deactivate(const struct log_backend *const backend)
ąöąĄą░ą║čéąĖą▓ąĖčĆčāąĄčé ą▒菹║ąĄąĮą┤.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
backend ŌĆō [in] čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▒菹║ąĄąĮą┤ą░.
static inline bool log_backend_is_active(const struct log_backend *const backend)
ą¤čĆąŠą▓ąĄčĆąĖčé čüąŠčüč鹊čÅąĮąĖąĄ ą▒菹║ąĄąĮą┤ą░.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
backend ŌĆō [in] čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▒菹║ąĄąĮą┤ą░.
ąÆąŠąĘą▓čĆą░čēą░ąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ: ąĄčüą╗ąĖ ą▒菹║ąĄąĮą┤ ą░ą║čéąĖą▓ąĄąĮ, č鹊 ą▓ąĄčĆąĮąĄčé true, ąĖąĮą░č湥 ą▓ąĄčĆąĮąĄčé false.
static inline int log_backend_format_set(const struct log_backend *backend, uint32_t log_type)
ąŻčüčéą░ąĮąŠą▓ąĖčé č乊čĆą╝ą░čé ą╗ąŠą│ą│ąĖąĮą│ą░.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
backend ŌĆō [in] čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▒菹║ąĄąĮą┤ą░.
ąÆąŠąĘą▓čĆą░čēą░ąĄą╝čŗąĄ ąĘąĮą░č湥ąĮąĖčÅ:
-ENOTSUP ŌĆō ąĄčüą╗ąĖ ą▒菹║ąĄąĮą┤ ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ąĖąĘą╝ąĄąĮąĄąĮąĖąĄ čéąĖą┐ąŠą▓ č乊čĆą╝ą░čéą░.
static inline void log_backend_notify(const struct log_backend *const backend, enum log_backend_evt event, union log_backend_evt_arg *arg)
ą×ą┐ąŠą▓ąĄčēą░ąĄčé ą▒菹║ąĄąĮą┤ ąŠ čüąŠą▒čŗčéąĖąĖ.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
backend ŌĆō [in] čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▒菹║ąĄąĮą┤ą░.
ąōčĆčāą┐ą┐ą░ log_output , API ą▓čŗą▓ąŠą┤ą░ ą╗ąŠą│ą░.
ąŚą░ą│ąŠą╗ąŠą▓ąŠčćąĮčŗąĄ čäą░ą╣ą╗čŗ log_output.h , log_output_custom.h .
void log_custom_output_msg_process(const struct log_output *log_output, struct log_msg *msg, uint32_t flags)
ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąŠąĄ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖąĄ ą▓čŗą▓ąŠą┤ą░ ą╗ąŠą│ą░. ąĪąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ą▓ąĮąĄčłąĮąĄą╣ čäčāąĮą║čåąĖąĄą╣, čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮąŠą╣ log_custom_output_msg_set. ążčāąĮą║čåąĖčÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗą╣ ą║ąŠąĮč鹥ą║čüčé čü ą▒čāč乥čĆąŠą╝ ąĖ čäčāąĮą║čåąĖčÄ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čüčéčĆąŠą║ąĖ č乊čĆą╝ą░čéą░ ąĖ ą▓čŗą▓ąŠą┤ą░ ą┤ą░ąĮąĮčŗčģ.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
log_output ŌĆō čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▓čŗą▓ąŠą┤ą░ ą╗ąŠą│ą░.
ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ:
LOG_OUTPUT_TEXT
ą¤ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄą╝čŗ ą▒菹║ąĄąĮą┤ąŠą╝ čéąĖą┐čŗ č乊čĆą╝ą░čéą░ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ log_format_set() API, čćč鹊ą▒čŗ ą┐ąĄčĆąĄą║ą╗čÄčćą░čéčī č乊čĆą╝ą░čé ą╗ąŠą│ą░ runtime.
LOG_OUTPUT_SYST LOG_OUTPUT_DICT LOG_OUTPUT_CUSTOM
LOG_OUTPUT_DEFINE(_name, _func, _buf, _size)
ąĪąŠąĘą┤ą░ąĄčé 菹║ąĘąĄą╝ą┐ą╗čÅčĆ log_output.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
_name ŌĆō ąĖą╝čÅ čŹą║ąĘąĄą╝ą┐ą╗čÅčĆą░.
ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ čéąĖą┐ąŠą▓:
typedef int (*log_output_func_t)(uint8_t *buf, size_t size, void *ctx)
ą¤čĆąŠč鹊čéąĖą┐ čäčāąĮą║čåąĖąĖ, ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčēąĄą╣ ą▓čŗą▓ąŠą┤ąĖą╝čŗąĄ ą┤ą░ąĮąĮčŗąĄ.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąĄčüą╗ąĖ čäčāąĮą║čåąĖčÅ ą▓čŗą▓ąŠą┤ą░ ą╗ąŠą│ą░ ąĮąĄ ą╝ąŠąČąĄčé ąŠą▒čĆą░ą▒ąŠčéą░čéčī ą▓čüąĄ ą┤ą░ąĮąĮčŗąĄ, č鹊 ąŠąĮą░ ąŠčéą▓ąĄčćą░ąĄčé ąĘą░ č鹊, čćč鹊ą▒čŗ ą┐ąŠą╝ąĄčéąĖčéčī ąĖčģ ą║ą░ą║ ąŠčéą▒čĆąŠčłąĄąĮąĮčŗąĄ ą┐čāč鹥ą╝ ą▓ąŠąĘą▓čĆą░čéą░ ą▓ ą▓čŗąĘčŗą▓ą░čÄčēąĖą╣ ą║ąŠą┤ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ą░ą╣čé, ą║ąŠč鹊čĆąŠąĄ ą▒čŗą╗ąŠ ą▓čŗą║ąĖąĮčāč鹊.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
buf - ą▒čāč乥čĆ ą┤ą░ąĮąĮčŗčģ.
ąÆąŠąĘą▓čĆą░čéąĖčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąŠą▒čĆą░ą▒ąŠčéą░ąĮąĮčŗčģ ąĖą╗ąĖ ąŠčéą▒čĆąŠčłąĄąĮąĮčŗčģ ą▒ą░ą╣čé.
typedef void (*log_format_func_t)(const struct log_output *output, struct log_msg *msg, uint32_t flags)
ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ čāą║ą░ąĘą░č鹥ą╗čÅ ąĮą░ čéą░ą▒ą╗ąĖčåčā čäčāąĮą║čåąĖą╣ "format_table".
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
output - čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ čüčéčĆčāą║čéčāčĆčā log_output.
ąÆąŠąĘą▓čĆą░čēą░ąĄčé čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ čäčāąĮą║čåąĖčÄ ąĮą░ ąŠčüąĮąŠą▓ąĄ Kconfig, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ ą┤ą╗čÅ ą▒菹║ąĄąĮą┤ąŠą▓.
ążčāąĮą║čåąĖąĖ:
log_format_func_t log_format_func_t_get(uint32_t log_type)
ąöąĄą║ą╗ą░čĆą░čåąĖčÅ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ get ą┤ą╗čÅ čéą░ą▒ą╗ąĖčåčŗ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ąĮą░ čäčāąĮą║čåąĖčÄ format_table.
void log_output_msg_process(const struct log_output *log_output, struct log_msg *msg, uint32_t flags)
ą×ą▒čĆą░ą▒ąŠčéą║ą░ čüąŠąŠą▒čēąĄąĮąĖą╣ ą╗ąŠą│ą░ v2 ą┤ą╗čÅ čćąĖčéą░ąĄą╝čŗčģ čüčéčĆąŠą║.
ążčāąĮą║čåąĖčÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗą╣ ą║ąŠąĮč鹥ą║čüčé čü ą▒čāč乥čĆąŠą╝ ąĖ čäčāąĮą║čåąĖčÄ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čüčéčĆąŠą║ąĖ č乊čĆą╝ą░čéą░ ąĖ ą▓čŗą▓ąŠą┤ą░ ą┤ą░ąĮąĮčŗčģ.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
log_output ŌĆō čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą╗ąŠą│ą░ ą▓čŗą▓ąŠą┤ą░.
void log_output_process(const struct log_output *log_output, log_timestamp_t timestamp, const char *domain, const char *source, const k_tid_t tid, uint8_t level, const uint8_t *package, const uint8_t *data, size_t data_len, uint32_t flags)
ą×ą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé ą▓čģąŠą┤ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▓ čćąĖčéą░ąĄą╝čāčÄ čüčéčĆąŠą║čā.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
log_output ŌĆō čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą╗ąŠą│ą░ ą▓čŗą▓ąŠą┤ą░.
void log_output_msg_syst_process(const struct log_output *log_output, struct log_msg *msg, uint32_t flags)
ą×ą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░ v2 čü ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄą╝ ą▓ č乊čĆą╝ą░čé SYS-T. ążčāąĮą║čåąĖčÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗą╣ ą║ąŠąĮč鹥ą║čüčé čü ą▒čāč乥čĆąŠą╝ ąĖ čäčāąĮą║čåąĖąĄą╣ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čüčéčĆąŠą║ąĖ č乊čĆą╝ą░čéą░ ąĖ ą▓čŗą▓ąŠą┤ą░ ą┤ą░ąĮąĮčŗčģ ą▓ č乊čĆą╝ą░č鹥 ą╗ąŠą│ą░ sys-t.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
log_output ŌĆō čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▓čŗą▓ąŠą┤ą░ ą╗ąŠą│ą░.
void log_output_dropped_process(const struct log_output *output, uint32_t cnt)
ą×ą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé ąĖąĮą┤ąĖą║ą░čåąĖčÄ ąŠčéą▒čĆąŠčłąĄąĮąĮčŗčģ čüąŠąŠą▒čēąĄąĮąĖą╣. ążčāąĮą║čåąĖčÅ ą┐ąĄčćą░čéą░ąĄčé čüąŠąŠą▒čēąĄąĮąĖąĄ ąŠčłąĖą▒ą║ąĖ, ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčēąĄąĄ ą┐ąŠč鹥čĆčÄ čüąŠąŠą▒čēąĄąĮąĖą╣ ą╗ąŠą│ą░.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
output ŌĆō čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▓čŗą▓ąŠą┤ą░ ą╗ąŠą│ą░.
void log_output_flush(const struct log_output *output)
ąĪą╗ąĖą▓ą░ąĄčé ą▒čāč乥čĆ ą▓čŗą▓ąŠą┤ą░.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
output ŌĆō čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▓čŗą▓ąŠą┤ą░ ą╗ąŠą│ą░.
static inline void log_output_ctx_set(const struct log_output *output, void *ctx)
ążčāąĮą║čåąĖčÅ ą┤ą╗čÅ čāčüčéą░ąĮąŠą▓ą║ąĖ ą║ąŠąĮč鹥ą║čüčéą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ, ą┐ąĄčĆąĄą┤ą░ą▓ą░ąĄą╝ąŠą│ąŠ ą▓ čäčāąĮą║čåąĖčÄ ą▓čŗą▓ąŠą┤ą░.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
output ŌĆō čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▓čŗą▓ąŠą┤ą░ ą╗ąŠą│ą░.
static inline void log_output_hostname_set(const struct log_output *output, const char *hostname)
ążčāąĮą║čåąĖčÅ ą┤ą╗čÅ čāčüčéą░ąĮąŠą▓ą║ąĖ ąĖą╝ąĄąĮąĖ čģąŠčüčéą░ čŹč鹊ą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
output ŌĆō čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą▓čŗą▓ąŠą┤ą░ ą╗ąŠą│ą░.
void log_output_timestamp_freq_set(uint32_t freq)
ąŻčüčéą░ąĮąŠą▓ąĖčé čćą░čüč鹊čéčā ą╝ąĄč鹊ą║ ą▓čĆąĄą╝ąĄąĮąĖ.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
freq ŌĆō čćą░čüč鹊čéą░ ą▓ ąōčå.
uint64_t log_output_timestamp_to_us(log_timestamp_t timestamp)
ą¤čĆąĄąŠą▒čĆą░ąĘčāąĄčé ą╝ąĄčéą║čā ą▓čĆąĄą╝ąĄąĮąĖ ą▓ čüąŠąŠą▒čēąĄąĮąĖčÅ ą▓ ą╝ąĖą║čĆąŠčüąĄą║čāąĮą┤čŗ. ąÆąŠąĘą▓čĆą░čéąĖčé ąĘąĮą░č湥ąĮąĖąĄ ą╝ąĄčéą║ąĖ ą▓čĆąĄą╝ąĄąĮąĖ ą▓ ąĄą┤ąĖąĮąĖčåą░čģ ą╝ąĖą║čĆąŠčüąĄą║čāąĮą┤.
ą¤ą░čĆą░ą╝ąĄčéčĆčŗ:
timestamp ŌĆō ą╝ąĄčéą║ą░ ą▓čĆąĄą╝ąĄąĮąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ.
ąóąĖą┐čŗ ą┤ą░ąĮąĮčŗčģ:
struct log_output_control_block struct log_output
[ąĪčüčŗą╗ą║ąĖ ]
1 . Zephyr Logging site:docs.zephyrproject.org.2 . ą×čéą╗ą░ą┤ą║ą░ ą▓ Zephyr čü ą┐ąŠą╝ąŠčēčīčÄ printk ąĖ ą╝ą░ą║čĆąŠčüąŠą▓ ą▓čŗą▓ąŠą┤ą░ ą▓ ą╗ąŠą│.3 . Formatted Output Cbprintf Packaging site:docs.zephyrproject.org.4 . Multi Producer Single Consumer Packet Buffer site:docs.zephyrproject.org.5 . CONFIG_LOG_PROCESSING_LATENCY_US site:docs.zephyrproject.org.6 . Dictionary-based Logging Sample site:docs.zephyrproject.org.7 . Enabling the Logging service in Zephyr site:studiofuga.com.