| Zephyr: вывод в лог информационных сообщений |
|
| Добавил(а) microsin | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Функции вывода в лог Zephyr (logging API) предоставляют общий интерфейс для вывода отладочных сообщений, которые оставили в коде разработчики. Сообщения передаются через frontend, и затем обрабатываются активными бэкендами. При необходимости могут использоваться самодельный фронтенд и самодельные бэкенды. Фронтенд (frontend). Первичная система обработки сообщений. Отвечает за их форматирование и постановку в очередь. Бэкенд (backend). Низкоуровневая система вывода символьных данных лога наружу. Чаще всего это UART0. Вот краткая сводка возможностей системы лога Zephyr: • Отложенный вывод в лог (deferred logging) уменьшает время, которое тратится на вывод сообщений. Это реализовано за счет перемещения затратных по процессорному времени операций лога в некритичный, контролируемый (низкоприоритетный) контекст вместо того, чтобы сразу выполнять обработку по месту вызова сообщения. Logging API имеет широкие возможности по конфигурированию как во время компиляции (compile time), так и во время выполнения кода (run time). С использованием опций Kconfig (см. далее "Глобальные опции Kconfig") логи можно постепенно удалить из результата компиляции, когда они не нужны, чтобы уменьшить размер выходного образа и ускорить работу кода. Во время компиляции логи могут фильтроваться на базе модуля и уровня подробности (severity level). Также логи могут быть скомпилированы, но отфильтрованы run time с помощью специальных вызовов API. Run time фильтрация независима для каждого бэкенда и каждого источника сообщений лога. Источником сообщений лога может быть модуль, или же определенный экземпляр модуля. В системе имеется 4 severity-уровня сообщений лога: error, warning, info и debug. Для каждого уровня severity существует свое logging API (см. include/zephyr/logging/log.h), реализованное в виде набора специальных макросов. Также есть макросы для лога данных. // Уровни лога, определенные в include/zephyr/logging/log_core.h
#define LOG_LEVEL_NONE 0U
#define LOG_LEVEL_ERR 1U
#define LOG_LEVEL_WRN 2U
#define LOG_LEVEL_INF 3U
#define LOG_LEVEL_DBG 4U
Пример конфигурирования лога в исходном коде main.c: LOG_MODULE_REGISTER(main, LOG_LEVEL_DBG); ... int main(void) { for (;;) { LOG_ERR("ERR %d", LOG_LEVEL_ERR); LOG_WRN("WRN %d", LOG_LEVEL_WRN); LOG_INF("INF %d", LOG_LEVEL_INF); LOG_DBG("DBG %d", LOG_LEVEL_DBG); Будут выводится те сообщения, уровень которых меньше или равен уровню, определенному LOG_MODULE_REGISTER. Например, если определить в LOG_MODULE_REGISTER соответствующий уровень: LOG_LEVEL_DBG: будут выводиться сообщения всех уровней severity, т. е. LOG_ERR, LOG_WRN, LOG_INF, LOG_DBG. LOG_LEVEL_INF: будут выводиться сообщения LOG_ERR, LOG_WRN, LOG_INF. Сообщения LOG_DBG выводиться не будут. LOG_LEVEL_WRN: будут выводиться сообщения LOG_ERR, LOG_WRN. Сообщения LOG_INF, LOG_DBG выводиться не будут. LOG_LEVEL_ERR: будут выводиться только сообщения LOG_ERR. Сообщения LOG_WRN, LOG_INF, LOG_DBG выводиться не будут. Если в LOG_MODULE_REGISTER ничего не указывать (например так: LOG_MODULE_REGISTER(main)), то тогда будут выводиться LOG_ERR, LOG_WRN, LOG_INF, а сообщения LOG_DBG выводиться не будут. Т. е. по умолчанию определен уровень лога LOG_LEVEL_INF. Для каждого уровня доступен следующий набор макросов: • LOG_X для стандартных сообщений, работающих как printf, например LOG_ERR. Существует 2 категории конфигурации: конфигурация для модуля и глобальная конфигурация. Когда лог разрешен глобально, это работает для модулей. Однако модулям можно локально запретить вывод в лог. Каждому модулю можно указать свой собственный уровень лога. Модуль должен определить макрос LOG_LEVEL перед использованием API лога. Если не установлено глобальное переопределение, то будет соблюдаться уровень лога конфигурации модуля. Глобальное переназначение может только повысить уровень подробности лога. Его нельзя использовать для снижения уровней лога модулей, которые были ранее установлены на более высокий уровень. Также можно глобально ограничить логи путем предоставления максимального уровня severity, присутствующего в системе, где "максимальный" означает наименьшую серьезность (т. е. если максимальный уровень установлен в info, то это значит, что уровни сообщений ошибок, предупреждений и информации будут присутствовать, но сообщения debug будут исключены). Каждый модуль, который использует вывод в лог, должен указать свое уникальное имя и зарегистрировать самого себя для системы лога. Если модуль состоит из более чем одного файла, то регистрация выполняется в одном из них, но каждый файл должен определить имя модуля. Фронтенд по умолчанию системы лога разработан с учетом обеспечения безопасной работы в многопоточном окружении (thread safe) и минимизации процессорного времени, необходимого для вывода в лог сообщения. Операторы, затратные по времени выполнения, наподобие форматирования строк или доступа к транспорту, не по умолчанию не выполняются во время вызова logging API. Когда вызывается функция logging API, сообщение создается и добавляется в список. При этом используется выделенный, конфигурируемый буфер для пула лога сообщений. Существует 2 типа сообщений: standard и hexdump. Каждое сообщение содержит идентификатор источника (source ID, идентифицирующий модуль) или идентификатор модуля или экземпляра (module ID или instance ID) и идентификатор домена (domain ID, который может быть использован для многопроцессорных систем), метку времени и severity-уровень. Сообщение standard содержит указатель на строку и аргументы. Сообщение hexdump содержит скопированные данные и строку. [Глобальные опции Kconfig] Эти опции можно найти в subsys/logging/Kconfig. CONFIG_LOG: глобальный ключ, включает или выключает вывод в лог. Режимы работы: CONFIG_LOG_MODE_DEFERRED: режим отложенного вывода. Опции фильтрации: CONFIG_LOG_RUNTIME_FILTERING: разрешает runtime-переконфигурирование для фильтрации. Опции обработки: CONFIG_LOG_MODE_OVERFLOW: когда новое сообщение не может быть выделено, более старое сообщение отбрасывается. Опции форматирования: CONFIG_LOG_FUNC_NAME_PREFIX_ERR: добавляет имя функции к стандартным (standard) сообщениям ERROR лога. Опции бэкенда: CONFIG_LOG_BACKEND_UART: разрешает встроенный UART backend. [Использование] Логгинг в модуле. Чтобы использовать лог в контексте модуля, этот модуль должен указать уникальное имя, и с этим именем модуль должен зарегистрировать себя макросом LOG_MODULE_REGISTER. Опционально на этапе компиляции во втором параметре этого макроса может быть указан уровень лога для модуля. Если пользовательский уровень лога не указан, то используется уровень лога по умолчанию (CONFIG_LOG_DEFAULT_LEVEL). #include < zephyr/logging/log.h>
LOG_MODULE_REGISTER(foo, CONFIG_FOO_LOG_LEVEL); Если модуль состоит из нескольких файлов, то LOG_MODULE_REGISTER() должен появиться только в одном из этих файлов. Каждый другой файл должен использовать макрос LOG_MODULE_DECLARE, чтобы декларировать свое членство в модуле. Опционально во втором параметре может быть на этапе компиляции может быть указан уровень лога для файла модуля. Если пользовательский уровень лога не указан, то используется уровень лога по умолчанию (CONFIG_LOG_DEFAULT_LEVEL). #include < zephyr/logging/log.h>
/* Во всех файлах, составляющих модуль, кроме одного */
LOG_MODULE_DECLARE(foo, CONFIG_FOO_LOG_LEVEL);
Чтобы использовать logging API в теле функции, которая реализована в заголовочном файле, макрос LOG_MODULE_DECLARE должен быть вставлен в тело этой функции перед вызовом logging API. Опционально во втором параметре может быть на этапе компиляции может быть указан уровень лога для модуля. Если пользовательский уровень лога не указан, то используется уровень лога по умолчанию (CONFIG_LOG_DEFAULT_LEVEL). #include < zephyr/logging/log.h>
static inline void foo(void) { LOG_MODULE_DECLARE(foo, CONFIG_FOO_LOG_LEVEL); LOG_INF("foo"); } Может быть использован выделенный шаблон Kconfig (subsys/logging/Kconfig.template.log_config), чтобы создать локальную конфигурацию уровня лога. Пример ниже представляет использование этого шаблона. В результате будет сгенерирован CONFIG_FOO_LOG_LEVEL: module = FOO module-str = foo source "subsys/logging/Kconfig.template.log_config" Логгинг в экземпляре модуля. В случае, когда модули представлены несколькими экземплярами и широко используются, разрешение лога в них приведет к лавинному заполнению буфера системы лога. Логгер представляет инструмент, который может использоваться для фильтрации по уровню экземпляра вместо фильтрации на уровне модуля. В этом случае лог может быть разрешен для определенного экземпляра. Чтобы использовать фильтрацию по уровню экземпляра, должны быть выполнены следующие шаги: • В структуре экземпляра декларируется указатель на специальную структуру логгинга. Для этого используется макрос LOG_INSTANCE_PTR_DECLARE. #include < zephyr/logging/log_instance.h>
struct foo_object { LOG_INSTANCE_PTR_DECLARE(log); uint32_t id; } • Для инстанцирования модуль должен предоставить макрос. В этом макросе регистрируется экземпляр логгинга, и инициализируется указатель экземпляра лога в структуре объекта. #define FOO_OBJECT_DEFINE(_name) \
LOG_INSTANCE_REGISTER(foo, _name, CONFIG_FOO_LOG_LEVEL) \
struct foo_object _name = { \
LOG_INSTANCE_PTR_INIT(log, foo, _name) \
}
Обратите внимание, что когда логгинг запрещен, экземпляр логгинга и указатель на этот экземпляр не создается. Чтобы использовать в файле исходного кода logging API экземпляра, с помощью макроса LOG_LEVEL_SET во время компиляции должен быть указан уровень лога. LOG_LEVEL_SET(CONFIG_FOO_LOG_LEVEL); void foo_init(foo_object *f) { LOG_INST_INF(f->log, "Initialized."); } Чтобы использовать logging API экземпляра в заголовочном файле, с помощью макроса LOG_LEVEL_SET во время компиляции должен быть указан уровень лога. static inline void foo_init(foo_object *f) { LOG_LEVEL_SET(CONFIG_FOO_LOG_LEVEL); LOG_INST_INF(f->log, "Initialized."); } Управление выводом в лог. По умолчанию обработка лога в режиме задержанного вывода (deferred mode) осуществляется внутренне с помощью выделенной задачи, которая запускается автоматически. Однако это может быть недоступно, если многопоточность запрещена. Это также может быть запрещено путем не установленной опции CONFIG_LOG_PROCESS_TRIGGER_THRESHOLD. В таком случае управление логом осуществляется с помощью API, определенном в заголовочном файле include/zephyr/logging/log_ctrl.h. Перед использованием логгинг должен быть инициализирован. Опционально пользователь может предоставить функцию, которая возвратит значение метки времени. Если эта функция не предоставлена, то для меток времени используется k_cycle_get или k_cycle_get_32. Функция log_process() используется для запуска обработки одного сообщения лога (если оно ожидает в буфере). Эта функция вернет true, если в буфере есть еще сообщения, ожидающие обработки. Однако рекомендуется использовать макросы обертки (LOG_INIT и LOG_PROCESS), которые обрабатывают случаи, когда логгинг запрещен. Следующий кусок кода показывает, как может быть обработан логгинг в простом бесконечном цикле. #include < zephyr/log_ctrl.h>
int main(void) { LOG_INIT(); /* Если многопоточность разрешена, то для логгинга представляется идентификатор потока. */
log_thread_set(k_current_get());
while (1) { if (LOG_PROCESS() == false) { /* Задержка vTaskDelay или какие-нибудь фоновые действия */ } } } Если логи обрабатываются из потока (пользовательского или внутреннего), то можно разрешить фичу, которая будет выводить из сна поток обработки лога, когда в буфере лога окажется определенное количество сообщений (см. CONFIG_LOG_PROCESS_TRIGGER_THRESHOLD). Лог паники. В случае критичной ошибки система обычно не может больше полагаться на планировщик или прерывания. В такой ситуации нельзя обрабатывать вывод в лог по принципу откладывания вывода на свободное процессорное время (deferred log). Функции API логгера предоставляют функцию для входа в режим паники (log_panic()), которая должна быть вызвана для такой ситуации. Когда вызвана функция log_panic(), оповещение _panic_ посылается во все активные бэкенды. Как только все бэкенды были оповещены, все буферизированные сообщения сливаются (flushed). Начиная с этого момента все логи обрабатываются в синхронном режиме (с блокировкой). printk. Обычно система лога и функция printk() используют один и тот же вывод, за который они и конкурируют. Это может привести к проблемам, если вывод не поддерживает вытеснение, и также выводимые данные могут быть искажены, поскольку данные лога и данные printk потенциально могут чередоваться. Однако есть возможность перенаправить сообщения printk в подсистему лога путем разрешения опции CONFIG_LOG_PRINTK. В этом случае вызовы printk обрабатываются как сообщения лога с уровнем 0 (т. е. они не могут быть запрещены). Когда это разрешено, система лога управляет выводом таким образом, чтобы в отображаемой информации не было чередования частей сообщений. Однако в deferred mode это поменяет поведение printk, потому что вывод будет задерживаться до момента, когда поток лога приступит к обработке данных. По умолчанию опция CONFIG_LOG_PRINTK разрешена. [Архитектура] Подсистема лога состоит из 3 основных частей: Frontend Сообщение лога генерируется источником, которым может быть модуль или экземпляр модуля. Default Frontend. Фронтенд по умолчанию вступает в действие, когда функция logging API вызывается в источнике лога (например, сообщение лога выводится с помощью макроса LOG_INF). Фронтенд отвечает за фильтрацию сообщения (во время компиляции и во время актуального выполнения кода), за выделение буфера для сообщения, за создание сообщения и за фиксацию этого сообщения. Поскольку logging API может быть вызвано в прерывании, фронтенд оптимизирован таким образом, чтобы лог сообщения происходит максимально быстро, как это возможно. Сообщение лога. Сообщение, выводимое в лог, содержит дескриптор (источник source, домен domain и уровень level), метку времени (timestamp), сведения о форматировании строки (см. раздел "Cbprintf Packaging" документации [3]) и опциональные данные. Сообщения лога сохраняются в непрерывном блоке памяти. Память выделяется из кольцевого буфера пакетов (circular packet buffer, см. [4]. Как следствие: • Каждое сообщение это самодостаточный, непрерывный блок памяти, так что он хорошо подходит для копирования сообщения (например для оффлайн-обработки). Сообщения лога имеют следующий формат:
Примечания: (1) В зависимости от платформы и размера метки времени поля могут быть поменяны местами. Выделение сообщения лога. Может возникнуть ситуация, когда фронтенд не может разместить сообщение в буфере. Это произойдет, если система генерирует настолько много сообщений, что они не могут быть обработаны за выделенное время. Для обработки этого случая могут быть применены 2 стратегии: • Без переполнения очереди - новые сообщения лога отбрасываются, если место под них не может быть выделено. Run-time фильтрация. Если разрешена фильтрация во время выполнения кода (run-time), то для каждого источника лога декларируется структура в RAM. Такой фильтр использует 32 бита, поделенные на десять 3-разрядных слотов бит. Кроме слота 0, каждый слой хранит текущий фильтр для одного бэкенда в системе. Слот 0 (биты 0-2) используется для агрегации максимальной настройки фильтра в имеющемся источнике лога. Общий агрегатный слот 0 определяет, создается ли сообщение лога для указанной записи, поскольку он показывает, существует ли хотя бы один бэкенд, ожидающий эту запись лога. Слоты бэкенда проверяются, когда сообщение обрабатываются ядром системы лога, чтобы определить, допустимо ли сообщение для определенного бэкенда. В отличие от фильтрации во время компиляции, размер кода для лога увеличивается. В примере ниже бэкенд 1 установлен для приема ошибок ERR (слот 1), и бэкенд 2 для приема информационных сообщений INF (слот 2). Слоты 3-9 не используются (OFF). Агрегатный фильтр (слот 0) установлен для уровня INF, и до этого уровня сообщение от данного частного источника будет буферизировано.
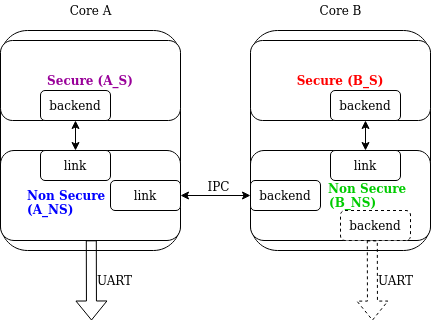
Пользовательский фронтенд. Пользовательский (custom) фронтенд разрешается опцией CONFIG_LOG_FRONTEND. Логи тогда направляются в функции, декларированные в include/zephyr/logging/log_frontend.h. Если разрешена опция CONFIG_LOG_FRONTEND_ONLY, то сообщения лога не создаются, и никакой бэкенд не обрабатывается. В противном случае пользовательский фронтенд может сосуществовать с бэкендами. В некоторых случаях логи должны быть перенаправлены на уровень макросов. Для таких случаев может использоваться CONFIG_LOG_CUSTOM_HEADER для вставки заголовка, предоставленного приложением. Этот заголовок должен иметь имя zephyr_custom_log.h, и подключаться в конце include/zephyr/logging/log.h. Вывод в лог строк. Строковые аргументы обрабатываются в Cbprintf Packaging [3]. См. в документации [3] ограничения по применимости и рекомендации по использованию (секция "Limitations and recommendations"). Более сложные системы могут состоять из нескольких доменов (физических процессоров), где для каждого домена имеется отдельный бинарник. Примерами доменов могут служить многоядерные SoC, или один из бинарников (Secure или Nonsecure) на ядре ARM TrustZone. Трассировка и отладка в мультидоменной системе более сложна, и требует наличия эффективной системы лога. Для структурирования этой системы регистрации можно использовать два подхода: • Независимый лог в каждом домене. Эта опция не всегда возможна, поскольку это требует, чтобы в каждом домене был доступен бэкенд (например UART). Этот подход также может быть трудным в использовании и не поддающимся масштабированию, поскольку логи представлены на независимых выходах. В последнем варианте соединение лога отвечает за связь между доменами. Соединение отвечает за прием сообщения лога из любого домена, создание копии и помещение локальной копии сообщения (включая данные на противоположном конце соединения) в очередь сообщений. Эта специальная реализация канала регистрации соответствует комплементарной реализации бэкенда, что позволяет обмениваться сообщениями лога и управлять ими. Например, настраивать фильтрацию, получать имена источников лога и т.д. В многодоменной системе существует 3 типа доменов: • Конечный домен (end domain), содержащий реализацию ядра лога и бэкенд, отвечающий за обмен между доменами (cross-domain backend). Параллельно у него могут быть другие домены бэкенды. На следующем рисунке показан пример настройки multi-domain лога:
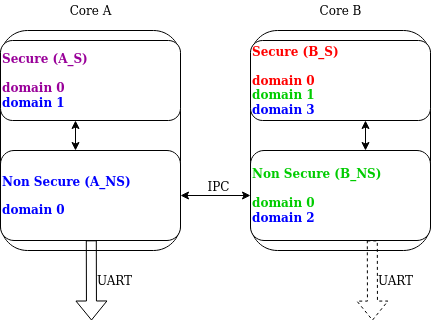
Рис. 1. Пример мультидоменного лога. В этой архитектуре линк может обрабатывать несколько доменов. Для примера рассмотрим SoC с двумя ядрами ARM Cortex-M33 с TrustZone: ядро A и ядро B (см. рис. 1). В системе имеется 4 домена, поскольку в каждом ядре есть домены Secure и Nonsecure domain. Если ядро A nonsecure (A_NS) это корневой домен, то у него 2 линка: один до ядра A secure (A_NS-A_S), и один до ядра B nonsecure (A_NS-B_NS). У домена B_NS есть один линк до ядра B secure (B_NS-B_S), и бэкенд для A_NS. Поскольку во всех экземплярах существует стандартная подсистема лога, всегда можно иметь несколько бэкендов и одновременно выводить на них сообщения. Пример этого показан на рис. 1 как обозначенный пунктиром UART бэкенд в домене B_NS. Domain ID. Источник в каждом сообщении лога идентифицируется следующими полями в заголовке: source_id и domain_id. Значение, назначенное для domain_id, относительное. Каждый раз, когда домен создает сообщение лога, он устанавливает свой domain_id в 0. Когда сообщение пересекает домен, то domain_id меняется, поскольку увеличивается на смещение линка. Смещение линка назначается при инициализации, где ядро логгера просматривает все зарегистрированные линки и назначенные им смещения. У первого линка смещение установлено в 1. Следующее смещение равно смещению предыдущего линка плюс количество доменов в предыдущем линке. Следующий пример, показанный на картинке ниже, где назначенные domain_id показаны для каждого домена:
Рис. 2. Пример назначения идентификаторов домена (Domain ID). Рассмотрим сообщение лога, созданное в домене B_S: 1. Изначально у него domain_id, установленный в 0. Сообщение, передаваемое между доменами (Cross-domain log message). В большинстве случаев адресное пространство в каждом домене уникально, и один домен не может напрямую получить доступ к данным в другом домене. По этой причине бэкенд может частично обработать сообщение перед тем, как передать его в другой домен. Частичная обработка может включать преобразование пакета строки в полную самостоятельную версию (копирование строк, доступных только для чтения, в тело пакета). У каждого домена может быть свой, отдельный источник метки времени в контексте частоты и смещения. Система лога не выполняет преобразование метки времени. Runtime-фильтрация. В случае одного домена каждый источник лога имеет выделенную переменную с runtime-фильтрацией для каждого бэкенда в системе. В случае нескольких доменов инициатор сообщения не знает о количестве бэкендов в корневом домене. Таким образом, для фильтрации в нескольких доменах источник требует установки runtime-фильтрации в каждом домене на пути в корневой домен. Поскольку в момент компиляции количество источников в других доменах неизвестно, runtime-фильтрация дальних источников должна использовать динамически выделяемую память (одно слово на источник). Когда бэкенд в корневом домене меняет фильтрацию модуля из дальнего домена, локальный фильтр обновляется. После обновления проверяется общий фильтр (максимум из всех локальных бэкендов), и если было изменение, то дальний домен информируется об этом изменении. При таком подходе runtime-фильтрация работает идентично как в сценарии с несколькими доменами, так и с одним доменом. Упорядочивание сообщений. Система лога не предоставляет механизм синхронизации меток времени в нескольких доменах: • Если у доменов отдельные источники меток времени, то сообщения будут обрабатываться в том порядке, в каком они достигли буфера в корневом домене. • Если у доменов один и тот же источник метки времени, или если существует механизм пересчета меток времени, то возможны 2 варианта: - Сообщения обрабатываются по мере поступления в буфер корневого домена. Сообщения не упорядочиваются, но они могут сортироваться хостом, поскольку метка времени показывает, когда сообщение было сгенерировано. При таком подходе возможно поддерживать порядок следования сообщений ценой не очень оптимального использования памяти (поскольку нет общего буфера) и увеличенной латентности обработки (см. [5]). [бэкенды системы лога] бэкенды лога регистрируются с использованием LOG_BACKEND_DEFINE. Этот макрос создает экземпляр в выделенной секции памяти. бэкенды могут быть динамически разрешены (log_backend_enable()) и запрещены. Когда разрешена run-time фильтрация, может использоваться log_filter_set() для динамического изменения фильтрации логов модуля для определенного бэкенда. Модуль может быть идентифицирован по source ID и domain ID. Source ID может быть получен, если известно имя источника, путем просмотра всех зарегистрированных источников. Система лога поддерживает до 9 конкурентных бэкендов. Сообщение лога передается в каждый бэкенд на фазе обработки. Дополнительно бэкенд оповещается, когда система лога входит в режим паники, с помощью log_backend_panic(). В этот момент бэкенд должен переключиться в синхронный, без прерываний режим работы, или остановить самого себя, если это не поддерживается. Иногда система логгинга может информировать бэкенд о количестве отброшенных сообщений с помощью log_backend_dropped(). API-функции обработки сообщений зависят от версии. Для обработки сообщения используется log_backend_msg2_process(). Это общий метод для сообщений standard и hexdump, потому что сообщение лога хранит строку с аргументами и данными. Это также общий метод для отложенного (deferred) непосредственного логгинга. Форматирование сообщения. Логгинг представляет набор функций, которые могут использоваться бэкендом для форматирования сообщения. Вспомогательные функции доступны в include/zephyr/logging/log_output.h. Пример отформатированного сообщения с помощью log_output_msg2_process(): [00:00:00.000,274] sample_instance.inst1: logging message Логгинг на базе словаря, в отличие от удобного для чтения текста, выводит сообщения лога в двоичном формате. Этот двоичный формат кодирует аргументы для строк форматирования в свои традиционные форматы хранения, которые более компактные, чем их текстовые эквиваленты. Для строк, определенных статически (включая строки формата и любые строковые аргументы), в ELF-файл кодируются ссылки на них вместо всей строки. Словарь, созданный во время сборки, содержит отображения этих ссылок на реальные строки. Это позволяет оффлайн-парсеру получить строки из словаря для дешифровки сообщений лога. Такой двоичный формат хранения лога в определенных сценариях позволяет более компактно представлять сообщения лога. Однако это требует использование оффлайн-парсера и не настолько интуитивно и удобно, как сообщения лога на основе текста. Обратите внимание, что long double не поддерживается модулем struct языка Python. Таким образом, сообщения с long double не будут корректно отображать значения. Конфигурация. Следующие опции kconfig относятся к dictionary-based logging: • CONFIG_LOG_DICTIONARY_SUPPORT разрешает поддержку лога на основе словаря. Должно быть выбрано бэкендами, которым это необходимо. • UART-бэкенд может использовать логгинг на основе словаря. Дополнительная конфигурация для такого случая: - CONFIG_LOG_BACKEND_UART_OUTPUT_DICTIONARY_HEX говорит UART-бэкенду выводить шестнадцатеричные символы для лога на основе словаря. Это полезно, когда данные лога должны быть захвачены вручную через терминалы и консоли. Использование. Когда разрешен логгинг на основе словаря через разрешенные связанные бэкенды лога, в директории build будет создан файл базы данных JSON с именем log_dictionary.json. Этот файл базы данных содержит информацию для парсера, чтобы корректно обработать данные лога. Обратите внимание, что эта база данных работает только в пределах одной и той же сборки, и не может быть использован для других сборок. Для использования парсера лога: $ ./scripts/logging/dictionary/log_parser.py /log_dictionary.json
Парсер принимает 2 необходимых аргумента, где первый из них это полный путь до файла базы данных JSON, и второй это файл, содержащий данные лога. Добавьте опциональный аргумента --hex в конце, если файл данных лога содержит hex-символы (например, когда CONFIG_LOG_BACKEND_UART_OUTPUT_DICTIONARY_HEX=y). Это укажет парсеру, что надо преобразовать шестнадцатеричные символы в двоичные данные перед применением парсинга. Как использовать парсер лога, см. пример [6]. [Рекомендации] • Разрешите CONFIG_LOG_SPEED, чтобы несколько ускорить отложенный (deferred) логгинг ценой некоторого повышенного расхода памяти. LOG_WRN("%s", str); LOG_WRN("%p", (void *)str); На эмуляторе qemu_x86 было проведено несколько тестов из tests/subsys/logging/log_benchmark. Это дает грубое сравнение, позволяющее получить общий обзор производительности.
Примечания: (1, 2, 3) Разрешена опция CONFIG_LOG_SPEED. Использование стека. Когда разрешен логгинг, это влияет на использование стека в контексте выполнения, где используется logging API. Если стек оптимизирован, то это может вызвать его переполнение. Утилизация стека зависит от режима и оптимизации компилятора. Это также может значительно меняться в зависимости от платформы. В общем, когда используется CONFIG_LOG_MODE_DEFERRED, расход стека меньше, поскольку логгинг ограничивается созданием и сохранением сообщения лога. Если используется CONFIG_LOG_MODE_IMMEDIATE, то сообщение лога обрабатывается бэкендом, что включает форматирование строки. В таком случае утилизация стека зависит от того, какой бэкенд используется. Тест tests/subsys/logging/log_stack используется для проверки использования стека в зависимости от режима, оптимизации и платформы. Тест использует только бэкенд по умолчанию. Результаты тестирования некоторых платформ для сообщения лога с двумя целочисленными аргументами:
Шаг 1. В файле prj.conf проекта определите следующие опции: # Config logger
CONFIG_LOG=y
CONFIG_USE_SEGGER_RTT=y
CONFIG_LOG_BACKEND_RTT=y
CONFIG_LOG_BACKEND_UART=n
CONFIG_LOG_PRINTK=y
Шаг 2. В модуле (или в файле исходного кода), где нужен вывод в лог с помощью макросов LOG_XXX, зарегистрировать систему лога: LOG_MODULE_REGISTER(имя_модуля); Здесь вместо "имя_модуля" лучше указать короткое, понятное имя. Например, для файла main.c это может быть вот так: LOG_MODULE_REGISTER(main); Или так, здесь во втором параметре указывается ограничение уровня вывода (может быть LOG_LEVEL_ERR, LOG_LEVEL_WRN или, если хотите видеть все сообщения, то LOG_LEVEL_DBG): LOG_MODULE_REGISTER(main, LOG_LEVEL_XXX); Шаг 3. Закомментируйте в модуле макрос LOCK_SWD. На этом все! Теперь можно выводить отладочные сообщения с помощью макросов LOG_ERR, LOG_WRN, LOG_INF, LOG_DBG и функции printk. Как просматривать сообщения. Пример тестового вывода в лог: #include "main.h"
// #define LOCK_SWD
LOG_MODULE_REGISTER(main, LOG_LEVEL_DBG); void approtect(void); int main(void) { log_init(); #ifdef LOCK_SWD
approtect();
#endif
ota_uart_gpio_init();
dk_leds_init();
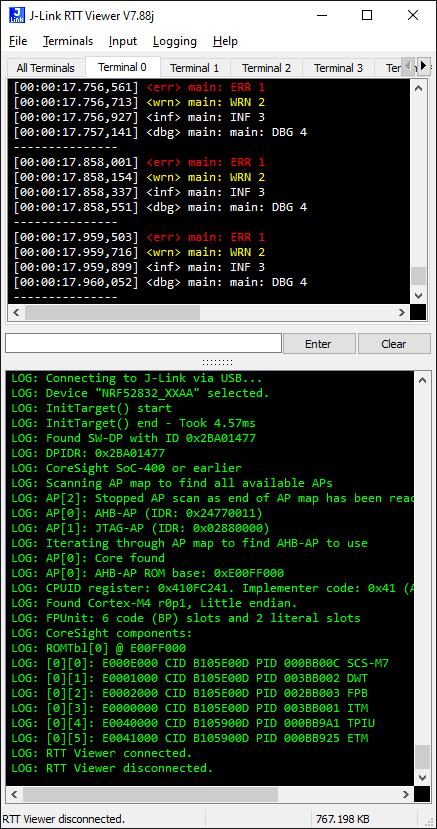
for (;;) { printk("---------------\n"); LOG_ERR("ERR %d", LOG_LEVEL_ERR); LOG_WRN("WRN %d", LOG_LEVEL_WRN); LOG_INF("INF %d", LOG_LEVEL_INF); LOG_DBG("DBG %d", LOG_LEVEL_DBG); uart_update_state = ota_uart_handle(); ... Запустите JLinkRTTViewer, выберите в меню File -> Connect (F2), введите серийный номер J-Link, кликните OK.
После запуска приложения и подключения к отладчику в окне JLinkRTTViewer можно увидеть примерно следующее:
[Справочник по API системы лога Zephyr] Все заголовочный файлы системы лога находятся в каталоге include\zephyr\logging\. Группа log_api. Определяет макросы вывода сообщений различного уровня. Параметр (...) это строка, которая опционально может содержать спецификаторы формата в стиле printf, за которой могут идти аргументы. Заголовочный файл log.h. LOG_ERR(...) Вывод сообщения уровня ERROR. Этот макрос предназначен для сообщения о серьезных ошибках, из которых система не может восстановиться. При включении подкраски сообщение ERROR выделяется красным цветом. LOG_WRN(...) Вывод сообщения уровня WARNING. Предназначено для регистрации необычных ситуаций, которые необязательно связаны с ошибками. При включении подкраски сообщение WARNING выделяется желтым цветом. LOG_INF(...) Вывод сообщения уровня INFO. Это обычные пользовательские информационные сообщения. При включении подкраски сообщение INFO выделяется зеленым цветом. LOG_DBG(...) Вывод сообщения уровня DEBUG. Это обозначает информационное сообщение, предназначенное для разработчика. LOG_PRINTK(...) Безусловно выводит в лог сообщение, независимо от активированного уровня лога. Результат этого макроса тот же самый, как если бы использовалась функция printk. Отличие только в том, что вывод сообщения в лог происходит через инфраструктуру логгинга, т. е. его вывод зависит от режима лога, например это может быть deferred mode для лога. LOG_RAW(...) Безусловно выводит в лог сообщение, независимо от активированного уровня лога (так же, как и LOG_PRINTK). Строка выводится так, как была предоставлена, без добавления специальных символов (т. е. без ESC-последовательностей управления цветом или символов новой строки). LOG_INST_ERR(_log_inst, ...) Вывод сообщения уровня ERROR, связанного с экземпляром модуля. Сообщение ошибки, связанное с определенным экземпляром модуля, у которого есть независимые настройки фильтрации (если runtime-фильтрация разрешена) и префикс сообщения (.). Параметр _log_inst – указатель на структуру лога, связанную с экземпляром модуля. LOG_INST_WRN(_log_inst, ...) Вывод сообщения уровня WARNING, связанного с экземпляром модуля. LOG_INST_INF(_log_inst, ...) Вывод сообщения уровня INFO, связанного с экземпляром модуля. LOG_INST_DBG(_log_inst, ...) Вывод сообщения уровня DEBUG, связанного с экземпляром модуля. LOG_HEXDUMP_ERR(_data, _length, _str) Вывод hexdump-сообщения уровня ERROR. Параметры: _data – указатель на данные, которые должны быть выведены в лог. LOG_HEXDUMP_WRN(_data, _length, _str) Вывод hexdump-сообщения уровня WARNING. LOG_HEXDUMP_INF(_data, _length, _str) Вывод hexdump-сообщения уровня INFO. LOG_HEXDUMP_DBG(_data, _length, _str) Вывод hexdump-сообщения уровня DEBUG. LOG_INST_HEXDUMP_ERR(_log_inst, _data, _length, _str) Вывод hexdump-сообщения уровня ERROR, связанного с экземпляром модуля. LOG_INST_HEXDUMP_WRN(_log_inst, _data, _length, _str) Вывод hexdump-сообщения уровня WARNING, связанного с экземпляром модуля. LOG_INST_HEXDUMP_INF(_log_inst, _data, _length, _str) Вывод hexdump-сообщения уровня INFO, связанного с экземпляром модуля. LOG_INST_HEXDUMP_DBG(_log_inst, _data, _length, _str) Вывод hexdump-сообщения уровня DEBUG, связанного с экземпляром модуля. LOG_MODULE_REGISTER(...) Создает специфичное для модуля состояние и регистрирует модуль для логгера. Этот макрос должен обычным образом использован после подключения заголовка , чтобы завершить инициализацию модуля. Регистрация модуля может быть опущена в двух случаях: • Модуль состоит больше чем одного файла, и другой файл использовал этот макрос (LOG_MODULE_DECLARE() должен использоваться вместо него ово всех других файлах этого модуля). Макрос принимает один или два параметра: • Имя модуля. Примеры использования: • LOG_MODULE_REGISTER(foo, CONFIG_FOO_LOG_LEVEL) См. также LOG_MODULE_DECLARE. Примечание: определяется состояние модуля и регистрируется модуль только если LOG_LEVEL для текущего исходного файла ненулевой или не определен, и значение CONFIG_LOG_DEFAULT_LEVEL ненулевое. В других случаях этот макрос не дает эффекта. LOG_MODULE_DECLARE(...) Макрос для декларации лога модуля (без его регистрации). Модули, которые разделены на несколько файлов, должны иметь только один файл, где используется LOG_MODULE_REGISTER(), чтобы создать специфичное для модуля состояния и зарегистрировать модуль для ядра системы лога. Другие файлы в модуле должны использовать этот макрос вместо декларирования того же самого состояния (иначе LOG_INF() и подобные макросы не могут ссылаться на переменные состояния конкретного модуля). Макрос принимает один или два параметра: • Имя модуля. Примеры использования: • LOG_MODULE_DECLARE(foo, CONFIG_FOO_LOG_LEVEL) См. также LOG_MODULE_REGISTER. Примечание: состояние модуля декларируется только если LOG_LEVEL для текущего исходного файла ненулевой или не определен, и CONFIG_LOG_DEFAULT_LEVEL ненулевой. В других случаях этот макрос не дает эффекта. LOG_LEVEL_SET(level) Макрос для установки уровня лога в файле или функции, где использовался logging API. Группа log_ctrl, API для управления логгером. Заголовочный файл log_ctrl.h. Макросы: LOG_CORE_INIT() Определение типа: typedef log_timestamp_t (*log_timestamp_get_t)(void) Функции: void log_core_init(void) Системная функция инициализации логгера. Эта функция запускается во время запуска приложения (start up), чтобы позволить вывод в лог до того, как пользователь может явно инициализировать логгер. void log_init(void) Пользовательская функция для инициализации логгера. void log_thread_set(k_tid_t process_tid) Функция, предоставляющая поток, который обрабатывает логи. См. CONFIG_LOG_PROCESS_TRIGGER_THRESHOLD. Примечание: функция имеет вызов assert и не дает эффекта, когда установлена опция CONFIG_LOG_PROCESS_THREAD. Параметр process_tid задает идентификатор обрабатывающего потока. Используется для пробуждения потока. int log_set_timestamp_func(log_timestamp_get_t timestamp_getter, uint32_t freq) Функция для предоставления метки времени. Параметры: timestamp_getter – функция метки времени. Возвращаемое значение: 0 при успехе или ненулевое значение в случае ошибки. void log_panic(void) Переключает подсистему лога в режим паники. Выполнит немедленный возврат, если логгер уже находится в panic mode. При панике подсистема логгера информирует все бэкенды о panic mode. бэкенды должны переключиться в блокирующий режим, или остановиться (halt). После переключения в режим паники все ожидающие вывод логи сбрасываются (flushed). В режиме паники все сообщения лога должны быть обработаны в контексте своего вызова. bool log_process(void) Обработает одно ожидающее вывода сообщение лога. Возвращаемое значение: true – есть еще сообщения, ожидающие обработки. uint32_t log_buffered_cnt(void) Возвратит текущее количество забуферизированных сообщений лога. uint32_t log_src_cnt_get(uint32_t domain_id) Возвратит количество независимых источников логгера (модулей и экземпляров). Параметр domain_id – указывает на идентификатор домена (Domain ID). const char *log_source_name_get(uint32_t domain_id, uint32_t source_id) Извлекает имя источника (модуля или экземпляра). Параметры: domain_id – Domain ID. Возвратит имя источника или NULL, если указаны неправильные аргументы. static inline uint8_t log_domains_count(void) Возвратит количество доменов, имеющихся в системе. Должен быть как минимум 1 локальный домен. const char *log_domain_name_get(uint32_t domain_id) Возвратит имя домена по его идентификатору domain_id. int log_source_id_get(const char *name) Функция найдет идентификатор источника по его имени. Возвратит Source ID или отрицательное число, если источник не найден. uint32_t log_filter_get(struct log_backend const *const backend, Извлекает фильтр источника для предоставленного бэкенда. Параметры: backend – экземпляр бэкенда. Возвращаемое значение: severity level (уровень лога). uint32_t log_filter_set(struct log_backend const *const backend, Установит фильтр на определенном источнике для предоставленного бэкенда. Параметры: backend – экземпляр бэкенда. Возвратит актуальный установленный уровень, который может быть ограничен уровнем, определенным во время компиляции. Если фильтр был установлен для всех бэкендов, то будет возвращен максимальный уровень, который был установлен. void log_backend_enable(struct log_backend const *const backend, Разрешит бэкенд с начальным максимальным уровнем фильтрации. Параметры: backend – экземпляр бэкенда. void log_backend_disable(struct log_backend const *const backend) Запретит бэкенд. Параметры: backend – экземпляр бэкенда. const struct log_backend *log_backend_get_by_name(const char *backend_name)¶ Извлекает бэкенд по имени. Параметры: backend_name – [in] имя бэкенда, как это было определено макросом LOG_BACKEND_DEFINE. Возвращаемое значение: указатель на найденный экземпляр бэкенда, или NULL если бэкенд не найден. const struct log_backend *log_format_set_all_active_backends(size_t log_type) Установит формат логгинга для всех активных бэкендов. Параметры: log_type – формат лога. Возвращаемое значение: указатель на последний бэкенд, на котором установка формата была неудачной, или NULL для успеха. static inline bool log_data_pending(void) Проверяет, есть ли ожидающие обработки данные лога. Функция может использоваться для того, чтобы определить, все ли логи были слиты (flushed). Функция вернет false, когда deferred mode не разрешен. Возвратит true, если есть данные для обработки, или false если нет данных для обработки. int log_set_tag(const char *tag) Конфигурирует тег, используемый для префикса каждого сообщения. Параметры: tag – Tag. Возвращаемые значения: 0 – успех операции. int log_mem_get_usage(uint32_t *buf_size, uint32_t *usage) Извлекает информацию по текущему использованию памяти. Параметры: buf_size – [out] емкость буфера, используемого для сохранения сообщений лога. Возвращаемые значения: -EINVAL – если режим логгинга не использует буфер. int log_mem_get_max_usage(uint32_t *max) Извлечет информацию по максимальному использованию памяти. Требует опции CONFIG_LOG_MEM_UTILIZATION. Параметры: max – [out] максимальное количество байт, использовавшихся для сообщений, ожидающих обработки. Возвращаемые значения: -EINVAL – если режим логгинга не использует буфер. Группа log_msg, API-функции сообщения лога. Заголовочный файл log_msg.h. Определения: LOG_MSG_GENERIC_HDR Типы данных: struct log_msg_desc Функции: static inline uint32_t log_msg_get_total_wlen(const struct log_msg_desc desc) Извлекает общую длину (в 32-разрядных словах) сообщения лога. Параметры: desc – дескриптор сообщения лога. static inline uint32_t log_msg_generic_get_wlen(const union mpsc_pbuf_generic *item) Извлекает длину элемента лога в 32-битных словах. static inline uint8_t log_msg_get_domain(struct log_msg *msg) Извлекает идентификатор домена (domain ID) сообщения сообщения лога. static inline uint8_t log_msg_get_level(struct log_msg *msg) Извлекает уровень лога для сообщения. static inline const void *log_msg_get_source(struct log_msg *msg) Извлекает источник сообщения лога. Возвратит указатель на источник данных. static inline log_timestamp_t log_msg_get_timestamp(struct log_msg *msg) Извлекает метку времени сообщения лога. static inline void *log_msg_get_tid(struct log_msg *msg) Извлекает идентификатор потока (Thread ID) сообщения лога. static inline uint8_t *log_msg_get_data(struct log_msg *msg, size_t *len) Возвратит указатель на буфер данных сообщения лога. Параметры: msg – сообщение лога. static inline uint8_t *log_msg_get_package(struct log_msg *msg, size_t *len) Возвратит указатель на пакет строки сообщения лога. Параметры: msg – сообщение лога. Группа log_backend, интерфейс бэкенда логгера. Заголовочный файл log_backend.h. Определения: LOG_BACKEND_DEFINE(_name, _api, _autostart, ...) Макрос для создания экземпляра бэкенда логгера. Параметры: _name – имя экземпляра бэкенда. Перечисления: enum log_backend_evt События бэкенда. Значения: enum LOG_BACKEND_EVT_PROCESS_THREAD_DONE Событие, когда поток обработки лога завершает обработку. Это событие генерируется, когда поток обработки завершил обработку ожидающих сообщений лога. Примечание: это событие не генерируется при отсутствии ожидающих обработки сообщений лога. Применимо только к deferred mode. enum LOG_BACKEND_EVT_MAX Максимальное количество событий бэкенда. Функции: static inline void log_backend_init(const struct log_backend *const backend) Инициализирует или инициирует бэкенд логгинга. В случае, когда инициализация внутреннего бэкенда занимает больше времени, это может заблокировать поток лога, если бэкенд запускается автоматически. Причина в том, что все бэкенды инициализируются в контексте потока лога. В таком случае бэкенд должен предоставить функцию для опроса готовности (log_backend_is_ready). Параметры: static inline int log_backend_is_ready(const struct log_backend *const backend) Опрашивает готовность бэкенда. Если бэкенд приходит в готовност сразу после инициализации, то тогда бэкенд может не предоставлять эту функцию. Параметры: backend – [in] указатель на экземпляр бэкенда. Возвращаемые значения: 0 – если бэкенд в готовности. static inline void log_backend_msg_process(const struct log_backend *const backend, Обрабатывает сообщение. Эта функция используется в режимах deferred и immediate. При возврате содержимое сообщения обрабатывается бэкендом и память может быть освобождена. Параметры: backend – [in] указатель на экземпляр бэкенда. static inline void log_backend_dropped(const struct log_backend *const backend, uint32_t cnt) Оповещает бэкенд по поводу отброшенных сообщений лога. Эта функция опциональна. Параметры: backend – [in] указатель на экземпляр бэкенда. static inline void log_backend_panic(const struct log_backend *const backend) Переконфигурирует бэкенд в режим паники. Параметры: backend – [in] указатель на экземпляр бэкенда. static inline void log_backend_id_set(const struct log_backend *const backend, uint8_t id) Установит идентификатор бэкенда. Эта функция используется внутренне в логгере. Параметры: backend – [in] указатель на экземпляр бэкенда. static inline uint8_t log_backend_id_get(const struct log_backend *const backend) Возвратит идентификатор бэкенда. Эта функция используется внутренне в логгере. Параметры: backend – [in] указатель на экземпляр бэкенда. static inline const struct log_backend *log_backend_get(uint32_t idx) Возвратит бэкенд (указатель на экземпляр бэкенда). Параметры: backend – [in] указатель на экземпляр бэкенда. static inline int log_backend_count_get(void) Возвратит количество бэкендов. static inline void log_backend_activate(const struct log_backend *const backend, void *ctx) Активирует бэкенд. Параметры: backend – [in] указатель на экземпляр бэкенда. static inline void log_backend_deactivate(const struct log_backend *const backend) Деактивирует бэкенд. Параметры: backend – [in] указатель на экземпляр бэкенда. static inline bool log_backend_is_active(const struct log_backend *const backend) Проверит состояние бэкенда. Параметры: backend – [in] указатель на экземпляр бэкенда. Возвращаемое значение: если бэкенд активен, то вернет true, иначе вернет false. static inline int log_backend_format_set(const struct log_backend *backend, Установит формат логгинга. Параметры: backend – [in] указатель на экземпляр бэкенда. Возвращаемые значения: -ENOTSUP – если бэкенд не поддерживает изменение типов формата. static inline void log_backend_notify(const struct log_backend *const backend, Оповещает бэкенд о событии. Параметры: backend – [in] указатель на экземпляр бэкенда. Группа log_output, API вывода лога. Заголовочные файлы log_output.h, log_output_custom.h. void log_custom_output_msg_process(const struct log_output *log_output, Пользовательское форматирование вывода лога. Сообщения лога обрабатываются внешней функцией, установленной log_custom_output_msg_set. Функция использует предоставленный контекст с буфером и функцию для обработки строки формата и вывода данных. Параметры: log_output – указатель на экземпляр вывода лога. Определения: LOG_OUTPUT_TEXT Поддерживаемы бэкендом типы формата для использования log_format_set() API, чтобы переключать формат лога runtime. LOG_OUTPUT_SYST LOG_OUTPUT_DEFINE(_name, _func, _buf, _size) Создает экземпляр log_output. Параметры: _name – имя экземпляра. Определения типов: typedef int (*log_output_func_t)(uint8_t *buf, size_t size, void *ctx) Прототип функции, обрабатывающей выводимые данные. Примечание: если функция вывода лога не может обработать все данные, то она отвечает за то, чтобы пометить их как отброшенные путем возврата в вызывающий код соответствующее количество байт, которое было выкинуто. Параметры: buf - буфер данных. Возвратит количество обработанных или отброшенных байт. typedef void (*log_format_func_t)(const struct log_output *output, Определение указателя на таблицу функций "format_table". Параметры: output - указатель на структуру log_output. Возвращает указатель на функцию на основе Kconfig, определенных для бэкендов. Функции: log_format_func_t log_format_func_t_get(uint32_t log_type) Декларация подпрограммы get для таблицы указателей на функцию format_table. void log_output_msg_process(const struct log_output *log_output, Обработка сообщений лога v2 для читаемых строк. Функция использует предоставленный контекст с буфером и функцию для обработки строки формата и вывода данных. Параметры: log_output – указатель на экземпляр лога вывода. void log_output_process(const struct log_output *log_output, Обрабатывает входные данные в читаемую строку. Параметры: log_output – указатель на экземпляр лога вывода. void log_output_msg_syst_process(const struct log_output *log_output, Обрабатывает сообщения лога v2 с преобразованием в формат SYS-T. Функция использует предоставленный контекст с буфером и функцией для обработки строки формата и вывода данных в формате лога sys-t. Параметры: log_output – указатель на экземпляр вывода лога. void log_output_dropped_process(const struct log_output *output, uint32_t cnt) Обрабатывает индикацию отброшенных сообщений. Функция печатает сообщение ошибки, показывающее потерю сообщений лога. Параметры: output – указатель на экземпляр вывода лога. void log_output_flush(const struct log_output *output) Сливает буфер вывода. Параметры: output – указатель на экземпляр вывода лога. static inline void log_output_ctx_set(const struct log_output *output, void *ctx) Функция для установки контекста пользователя, передаваемого в функцию вывода. Параметры: output – указатель на экземпляр вывода лога. static inline void log_output_hostname_set(const struct log_output *output, Функция для установки имени хоста этого устройства. Параметры: output – указатель на экземпляр вывода лога. void log_output_timestamp_freq_set(uint32_t freq) Установит частоту меток времени. Параметры: freq – частота в Гц. uint64_t log_output_timestamp_to_us(log_timestamp_t timestamp) Преобразует метку времени в сообщения в микросекунды. Возвратит значение метки времени в единицах микросекунд. Параметры: timestamp – метка времени сообщения. Типы данных: struct log_output_control_block [Ссылки] 1. Zephyr Logging site:docs.zephyrproject.org. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||