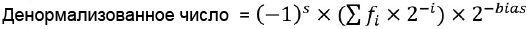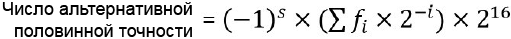ąŁč鹊čé ą░ą┐ąĮąŠčāčé (ą┐ąĄčĆąĄą▓ąŠą┤ AN4044 [1]) ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, ą║ą░ą║ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▒ą╗ąŠą║ąĖ ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąĖ (floating-point unit, čüąŠą║čĆą░čēąĄąĮąĮąŠ FPU), ą║ąŠč鹊čĆčŗąĄ ąĄčüčéčī čā ą╝ąĖą║čĆąŠą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą▓ čüąĄą╝ąĄą╣čüčéą▓ STM32 Cortex┬« -M4 ąĖ STM32 Cortex┬« -M7. ąóą░ą║ąČąĄ ą┤ą░ąĮ ą║čĆą░čéą║ąĖą╣ ąŠą▒ąĘąŠčĆ ą░čĆąĖčäą╝ąĄčéąĖą║ąĖ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣.
ąĀą░ąĘčĆą░ą▒ąŠčéą░ąĮąŠ ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąŠąĮąĮąŠąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ (firmware) X-CUBE-FPUDEMO, ą│ą┤ąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮą░ čĆą░ą▒ąŠčéą░ FPU čü ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅą╝ąĖ ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąĖ čü ą┤ą▓ąŠą╣ąĮąŠą╣ č鹊čćąĮąŠčüčéčīčÄ (double precision), ąĖ ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāčÄčéčüčÅ čāą╗čāčćčłąĄąĮąĖčÅ ąŠčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą░ą┐ą┐ą░čĆą░čéąĮąŠą╣ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąĖ (ą▓ ą║ąŠąĮčåąĄ čüčéą░čéčīąĖ ą┐čĆąĖą▓ąĄą┤ąĄąĮčŗ ą┤ą▓ą░ ą┐čĆąĖą╝ąĄčĆą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ FPU).
[ąÉčĆąĖčäą╝ąĄčéąĖą║ą░ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣ ]
ą¦ąĖčüą╗ą░ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖčÅ ąĮąĄ čåąĄą╗čŗčģ čćąĖčüąĄą╗. ą×ąĮąĖ čüąŠčüč鹊čÅčé ąĖąĘ 3 ą┐ąŠą╗ąĄą╣:
ŌĆó ąŚąĮą░ą║ čćąĖčüą╗ą░.
ąóą░ą║ąŠąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą║ąŠą┤ąĖčĆąŠą▓ą░čéčī ąŠč湥ąĮčī čłąĖčĆąŠą║ąĖą╣ ą┤ąĖą░ą┐ą░ąĘąŠąĮ ąĘąĮą░č湥ąĮąĖą╣, čćč鹊 ą┤ąĄą╗ą░ąĄčé čćąĖčüą╗ą░ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ ąĘą░ą┐čÅč鹊ą╣ čüą░ą╝čŗą╝ ą╗čāčćčłąĖą╝ čüą┐ąŠčüąŠą▒ąŠą╝ čĆą░ą▒ąŠčéą░čéčī čü čĆąĄą░ą╗čīąĮčŗą╝ąĖ čćąĖčüą╗ą░ą╝ąĖ. ąÆčŗčćąĖčüą╗ąĄąĮąĖčÅ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣ ą╝ąŠą│čāčé ą▒čŗčéčī čāčüą║ąŠčĆąĄąĮčŗ ą▒ą╗ąŠą║ąŠą╝ FPU, ą▓čüčéčĆąŠąĄąĮąĮčŗą╝ ą▓ ą┐čĆąŠčåąĄčüčüąŠčĆ.
ąĀą░ąĘą╗ąĖčćąĖčÅ čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą╣ č鹊čćą║ąĖ ąĖ ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąĖ . ą×ą┤ąĮą░ ąĖąĘ ą░ą╗čīč鹥čĆąĮą░čéąĖą▓ ą┤ą╗čÅ čćąĖčüąĄą╗ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣ - čćąĖčüą╗ą░ čü čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą╣ č鹊čćą║ąŠą╣, ą│ą┤ąĄ čĆą░ąĘą╝ąĄčĆ ą┐ąŠą╗čÅ čŹą║čüą┐ąŠąĮąĄąĮčéčŗ čäąĖą║čüąĖčĆąŠą▓ą░ąĮ. ąĪą║ąŠčĆąŠčüčéčī ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ čü čćąĖčüą╗ą░ą╝ąĖ čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą╣ č鹊čćą║ąĖ 菹║ą▓ąĖą▓ą░ą╗ąĄąĮčéąĮą░ čüą║ąŠčĆąŠčüčéąĖ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ čü čåąĄą╗čŗą╝ąĖ čćąĖčüą╗ą░ą╝ąĖ č鹊ą╣ ąČąĄ čĆą░ąĘčĆčÅą┤ąĮąŠčüčéąĖ. ą×ą┤ąĮą░ą║ąŠ ąĄčüą╗ąĖ čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ č鹊čćą║ą░ ą┤ą░ąĄčé ą▓čŗčüąŠą║ąŠąĄ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ, ą│ą┤ąĄ ąĮąĄčé ą▒ą╗ąŠą║ą░ FPU, ą┤ąĖą░ą┐ą░ąĘąŠąĮ čćąĖčüąĄą╗ čü čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą╣ č鹊čćą║ąŠą╣ ąĖ ąĖčģ ą┤ąĖąĮą░ą╝ąĖą║ą░ ąĮąĖąĘą║ąĖąĄ. ąÜą░ą║ čüą╗ąĄą┤čüčéą▓ąĖąĄ čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║, ą║ąŠč鹊čĆčŗą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄčé č鹥čģąĮąĖą║čā čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą╣ č鹊čćą║ąĖ, ą┤ąŠą╗ąČąĄąĮ čéčēą░č鹥ą╗čīąĮąŠ ą┐čĆąŠą▓ąĄčĆčÅčéčī čĆą░ą▒ąŠčćąĖąĄ ą┤ąĖą░ą┐ą░ąĘąŠąĮčŗ čćąĖčüąĄą╗ ąĖ čĆąĄčłą░čéčī ą┐čĆąŠą▒ą╗ąĄą╝čŗ ą╝ą░čüčłčéą░ą▒ąĖčĆąŠą▓ą░ąĮąĖčÅ/ąĮą░čüčŗčēąĄąĮąĖčÅ ą▓ ą┐čĆąĖą╝ąĄąĮčÅąĄą╝ąŠą╝ ą░ą╗ą│ąŠčĆąĖčéą╝ąĄ.
ąóą░ą▒ą╗ąĖčåą░ 1. ąöąĖąĮą░ą╝ąĖč湥čüą║ąĖą╣ ą┤ąĖą░ą┐ą░ąĘąŠąĮ čåąĄą╗čŗčģ čćąĖčüąĄą╗.
ąÜąŠą┤ąĖčĆąŠą▓ą░ąĮąĖąĄ čćąĖčüą╗ą░ (čĆą░ąĘčĆčÅą┤ąĮąŠčüčéčī) ąöąĖąĮą░ą╝ąĖą║ą░
Int8
48 dB
Int16
96 dB
Int32
192 dB
Int64
385 dB
ą»ąĘčŗą║ C ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čéąĖą┐čŗ float ąĖ double ą┤ą╗čÅ ąŠą┐ąĄčĆą░čåąĖą╣ ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąĖ. ąśąĮčüčéčĆčāą╝ąĄąĮčéčŗ ą╝ąŠą┤ąĄą╗ąĖčĆąŠą▓ą░ąĮąĖčÅ ą▓ąĄčĆčģąĮąĄą│ąŠ čāčĆąŠą▓ąĮčÅ, čéą░ą║ąĖąĄ ą║ą░ą║ MATLAB ąĖą╗ąĖ Scilab, ąŠą▒čŗčćąĮąŠ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé C-ą║ąŠą┤, ąĖčüą┐ąŠą╗čīąĘčāčÄčēąĖą╣ float ąĖą╗ąĖ double. ą×čéčüčāčéčüčéą▓ąĖąĄ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąĖ ąŠąĘąĮą░čćą░ąĄčé ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÄ čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ ą║ąŠą┤ą░, čćč鹊ą▒čŗ ą░ą┤ą░ą┐čéąĖčĆąŠą▓ą░čéčī ąĄą│ąŠ ą║ čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą╣ č鹊čćą║ąĄ. ąś ą▓čüąĄ ąŠą┐ąĄčĆą░čåąĖąĖ čü čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą╣ č鹊čćą║ąŠą╣ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąČąĄčüčéą║ąŠ ąĘą░ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮčŗ čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ąŠą╝.
ąóą░ą▒ą╗ąĖčåą░ 2. ąöąĖąĮą░ą╝ąĖč湥čüą║ąĖą╣ ą┤ąĖą░ą┐ą░ąĘąŠąĮ čćąĖčüąĄą╗ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣.
ąÜąŠą┤ąĖčĆąŠą▓ą░ąĮąĖąĄ čćąĖčüą╗ą░ (čĆą░ąĘčĆčÅą┤ąĮąŠčüčéčī) ąöąĖąĮą░ą╝ąĖą║ą░
Half precision (ą┐ąŠą╗ąŠą▓ąĖąĮąĮą░čÅ č鹊čćąĮąŠčüčéčī, 16 ą▒ąĖčé)
180 dB
Single precision (ąŠą┤ąĖąĮą░čĆąĮą░čÅ č鹊čćąĮąŠčüčéčī, 32 ą▒ąĖčéą░)
1529 dB
Double precision (ą┤ą▓ąŠą╣ąĮą░čÅ č鹊čćąĮąŠčüčéčī, 64 ą▒ąĖčéą░)
12318 dB
ą¤čĆąĖ čéčĆą░ą┤ąĖčåąĖąŠąĮąĮąŠą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ą▓ ą║ąŠą┤ąĄ ąŠą┐ąĄčĆą░čåąĖąĖ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣ čüąĮąĖąČą░čÄčé ą▓čĆąĄą╝čÅ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ą┐čĆąŠąĄą║čéą░. ąś čŹč鹊 ąĮą░ąĖą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮčŗą╣ čüą┐ąŠčüąŠą▒ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ą╗čÄą▒ąŠą╣ ą╝ą░č鹥ą╝ą░čéąĖč湥čüą║ąĖą╣ ą░ą╗ą│ąŠčĆąĖčéą╝.
FPU . ąÆčŗčćąĖčüą╗ąĄąĮąĖčÅ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣ čéčĆąĄą▒čāčÄčé ąĮąĄą║ąŠč鹊čĆčŗčģ čĆąĄčüčāčĆčüąŠą▓ ą┤ą╗čÅ ą╗čÄą▒čŗčģ ąŠą┐ąĄčĆą░čåąĖą╣ ą╝ąĄąČą┤čā ą┤ą▓čāą╝čÅ čćąĖčüą╗ą░ą╝ąĖ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĮą░ą╝ ąĮčāąČąĮąŠ:
ŌĆó ąÆčŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą┤ą▓čāčģ čćąĖčüąĄą╗ (ąŠąĮąĖ ą┤ąŠą╗ąČąĮčŗ ąĖą╝ąĄčéčī ąŠą┤ąĖąĮą░ą║ąŠą▓čāčÄ čŹą║čüą┐ąŠąĮąĄąĮčéčā).
ąØą░ ą┐čĆąŠčåąĄčüčüąŠčĆąĄ ą▒ąĄąĘ ą▒ą╗ąŠą║ą░ FPU ą▓čüąĄ čŹčéąĖ ąŠą┐ąĄčĆą░čåąĖąĖ čĆąĄą░ą╗ąĖąĘčāčÄčéčüčÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ č湥čĆąĄąĘ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║čā ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ C, ąĖ ąŠąĮąĖ ąĮąĄą▓ąĖą┤ąĖą╝čŗ ą┤ą╗čÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčéą░; ąŠą┤ąĮą░ą║ąŠ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ą┐ąŠą╗čāčćą░ąĄčéčüčÅ ąŠč湥ąĮčī ąĮąĖąĘą║ąŠą╣.
ąØą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ, čā ą║ąŠč鹊čĆčŗčģ ąĮą░ ą▒ąŠčĆčéčā ąĄčüčéčī FPU, ą▓čüąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ą░ą┐ą┐ą░čĆą░čéąĮąŠ, ą┤ą╗čÅ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĘą░ 1 čéą░ą║čé čÅą┤čĆą░. ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆ C ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčé čüą▓ąŠčÄ čüąŠą▒čüčéą▓ąĄąĮąĮčāčÄ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║čā ą┐ą╗ą░ą▓ą░čÄčēąĖą╣ č鹊čćą║ąĖ, ąĮą░ą┐čĆčÅą╝čāčÄ ą│ąĄąĮąĄčĆąĖčĆčāčÅ ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ąĖąĮčüčéčĆčāą║čåąĖąĖ FPU.
ąÜąŠą│ą┤ą░ čĆąĄą░ą╗ąĖąĘčāąĄčéčüčÅ ą╝ą░č鹥ą╝ą░čéąĖč湥čüą║ąĖą╣ ą░ą╗ą│ąŠčĆąĖčéą╝ ąĮą░ ą╝ąĖą║čĆąŠą┐čĆąŠčåąĄčüčüąŠčĆąĄ, čā ą║ąŠč鹊čĆąŠą│ąŠ ąĄčüčéčī FPU, ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčéčā čāąČąĄ ąĮąĄ ąĮą░ą┤ąŠ ą▓čŗą▒ąĖčĆą░čéčī ą╝ąĄąČą┤čā ą▓čŗčüąŠą║ąŠą╣ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčīčÄ ąĖ ą╝ą░ą╗čŗą╝ ą▓čĆąĄą╝ąĄąĮąĄą╝ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ. FPU ą┐čĆąĖą▓ąĮąŠčüąĖčé ąĮą░ą┤ąĄąČąĮąŠčüčéčī, ą┐ąŠąĘą▓ąŠą╗čÅčÅ ąĮą░ą┐čĆčÅą╝čāčÄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą║ąŠą┤, čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą▓čŗčüąŠą║ąŠčāčĆąŠą▓ąĮąĄą▓čŗą╝ąĖ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░ą╝ąĖ (MATLAB ąĖą╗ąĖ Scilab), čü čüą░ą╝čŗą╝ ą▓čŗčüąŠą║ąĖą╝ čāčĆąŠą▓ąĮąĄą╝ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ.
[IEEE 754 - čüčéą░ąĮą┤ą░čĆčé ą┤ą╗čÅ ą░čĆąĖčäą╝ąĄčéąĖą║ąĖ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣ ]
ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą░čĆąĖčäą╝ąĄčéąĖą║ąĖ ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąĖ ą▓čüąĄą│ą┤ą░ ą▒čŗą╗ąŠ ą▓ąŠčüčéčĆąĄą▒ąŠą▓ą░ąĮąŠ ą▓ ąŠą▒ą╗ą░čüčéąĖ ą║ąŠą╝ą┐čīčÄč鹥čĆąĮčŗčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣, ą┤ą░ąČąĄ ąĮą░ čüą░ą╝čŗčģ čĆą░ąĮąĮąĖčģ čŹčéą░ą┐ą░čģ čĆą░ąĘą▓ąĖčéąĖčÅ ą▓čŗčćąĖčüą╗ąĖč鹥ą╗čīąĮąŠą╣ č鹥čģąĮąĖą║ąĖ. ąÆ ą║ąŠąĮčåąĄ 30-čģ ą│ąŠą┤ąŠą▓, ą║ąŠą│ą┤ą░ Konrad Zuse ą▓ ąōąĄčĆą╝ą░ąĮąĖąĖ čĆą░ąĘčĆą░ą▒ąŠčéą░ą╗ Z-čüąĄčĆąĖčÄ ą▓čŗčćąĖčüą╗ąĖč鹥ą╗ąĄą╣, ą▓ ąĮąĖčģ čāąČąĄ ą▒čŗą╗ą░ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮą░ ą┐ą╗ą░ą▓ą░čÄčēą░čÅ č鹊čćą║ą░. ą×ą┤ąĮą░ą║ąŠ čüą╗ąŠąČąĮąŠčüčéčī ą▓ąĮąĄą┤čĆąĄąĮąĖčÅ ą░ą┐ą┐ą░čĆą░čéąĮąŠą╣ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ ą░čĆąĖčäą╝ąĄčéąĖą║ąĖ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣ ąĘą░čüčéą░ą▓ą╗čÅą╗ą░ ąŠčéą║ą░ąĘčŗą▓ą░čéčīčüčÅ ąŠčé ąĄčæ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąĮą░ ą┐čĆąŠčéčÅąČąĄąĮąĖąĖ ą┤ąĄčüčÅčéąĖą╗ąĄčéąĖą╣.
ąÆ čüąĄčĆąĄą┤ąĖąĮąĄ 50-čģ ą│ąŠą┤ąŠą▓ čäąĖčĆą╝ą░ IBM čü ą║ąŠą╝ą┐čīčÄč鹥čĆąŠą╝ 704 ą┐ąŠą║ą░ąĘą░ą╗ą░ FPU ą▓ ą╝菹╣ąĮčäčĆąĄą╣ą╝ą░čģ; ąĖ ą▓ 70-čģ ą┐ąŠčÅą▓ąĖą╗ąĖčüčī čĆą░ąĘą╗ąĖčćąĮčŗąĄ ą┐ą╗ą░čéč乊čĆą╝čŗ, ą│ą┤ąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ą╗ąĖčüčī ąŠą┐ąĄčĆą░čåąĖąĖ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣, ąŠą┤ąĮą░ą║ąŠ ą▓ ąĮąĖčģ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ąĖčüčī ąĖąĮą┤ąĖą▓ąĖą┤čāą░ą╗čīąĮčŗąĄ č鹥čģąĮąĖą║ąĖ ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖčÅ čćąĖčüąĄą╗.
ąŻąĮąĖčäąĖą║ą░čåąĖčÅ ą┐čĆąŠąĖąĘąŠčłą╗ą░ ą▓ 1985 ą│ąŠą┤čā, ą║ąŠą│ą┤ą░ IEEE ąŠą┐čāą▒ą╗ąĖą║ąŠą▓ą░ą╗ą░ čüčéą░ąĮą┤ą░čĆčé 754, ą│ą┤ąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĖą╗ą░ ąŠą▒čēąĖąĄ ą╝ąĄč鹊ą┤čŗ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣.
ąĀą░ąĘą╗ąĖčćąĮčŗąĄ čéąĖą┐čŗ čĆąĄą░ą╗ąĖąĘą░čåąĖą╣ ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąĖ, čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮąĮčŗąĄ ąĘą░ ą▓čüąĄ ą│ąŠą┤čŗ, ąĘą░čüčéą░ą▓ąĖą╗ąĖ IEEE čüčéą░ąĮą┤ą░čĆčéąĖąĘąĖčĆąŠą▓ą░čéčī čüą╗ąĄą┤čāčÄčēąĖąĄ 菹╗ąĄą╝ąĄąĮčéčŗ:
ŌĆó ążąŠčĆą╝ą░čéčŗ čćąĖčüąĄą╗.
ążąŠčĆą╝ą░čéčŗ čćąĖčüąĄą╗ . ąÆčüąĄ ąĘąĮą░č湥ąĮąĖčÅ ą┐ąŠčüčéčĆąŠąĄąĮčŗ ąĖąĘ čéčĆąĄčģ ą▒ąĖč鹊ą▓čŗčģ ą┐ąŠą╗ąĄą╣:
ŌĆó ąŚąĮą░ą║ čćąĖčüą╗ą░: s.
ŌĆó ąĪą╝ąĄčēąĄąĮąĮą░čÅ čŹą║čüą┐ąŠąĮąĄąĮčéą░:
ŌĆó ąöčĆąŠą▒ąĮą░čÅ čćą░čüčéčī, čäčĆą░ą║čåąĖčÅ (ąĖą╗ąĖ ą╝ą░ąĮčéąĖčüčüą░): f.
ąŚąĮą░č湥ąĮąĖčÅ ą╝ąŠą│čāčé ą║ąŠą┤ąĖčĆąŠą▓ą░čéčīčüčÅ čüą╗ąĄą┤čāčÄčēąĖą╝ąĖ ą┤ą╗ąĖąĮą░ą╝ąĖ ą▒ąĖčé:
ŌĆó 16 ą▒ąĖčé: č乊čĆą╝ą░čé ą┐ąŠą╗ąŠą▓ąĖąĮąĮąŠą╣ č鹊čćąĮąŠčüčéąĖ (half precision).
ąĀąĖčü. 1. ąÜąŠą┤ąĖčĆąŠą▓ą░ąĮąĖąĄ čćąĖčüąĄą╗ ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąĖ ąŠą┤ąĖąĮą░čĆąĮąŠą╣ ąĖ ą┤ą▓ąŠą╣ąĮąŠą╣ č鹊čćąĮąŠčüčéąĖ ą┐ąŠ čüčéą░ąĮą┤ą░čĆčéčā IEEE.754.
ąóą░ą║ąČąĄ IEEE ąŠą┐čĆąĄą┤ąĄą╗ąĖą╗ą░ 5 ą║ą╗ą░čüčüąŠą▓ čćąĖčüąĄą╗:
ŌĆó ąØąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮąĮčŗąĄ čćąĖčüą╗ą░.
ąĀą░ąĘą╗ąĖčćąĮčŗąĄ ą║ą╗ą░čüčüčŗ čćąĖčüąĄą╗ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāčÄčéčüčÅ čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╝ąĖ ąĘąĮą░č湥ąĮąĖčÅą╝ąĖ ą▓ čŹčéąĖčģ ą┐ąŠą╗čÅčģ.
[ąØąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮąĮčŗąĄ čćąĖčüą╗ą░ ]
ąØąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮąĮąŠąĄ čćąĖčüą╗ąŠ čŹč鹊 "čüčéą░ąĮą┤ą░čĆčéąĮąŠąĄ" čćąĖčüą╗ąŠ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣. ąĢą│ąŠ ąĘąĮą░č湥ąĮąĖąĄ ą┤ą░ąĄčé čüą╗ąĄą┤čāčÄčēą░čÅ č乊čĆą╝čāą╗ą░ (i > 0):
ąŻ bias ąĘąĮą░č湥ąĮąĖąĄ čäąĖą║čüąĖčĆąŠą▓ą░ąĮąŠ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ čĆą░ąĘčĆčÅą┤ąĮąŠčüčéąĖ (č鹊čćąĮąŠčüčéąĖ) čćąĖčüą╗ą░ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣ (8 ą▒ąĖčé, 16 ą▒ąĖčé, 32 ą▒ąĖčéą░ ąĖ 64 ą▒ąĖčéą░).
ąóą░ą▒ą╗ąĖčåą░ 3. ąöąĖą░ą┐ą░ąĘąŠąĮ ąĮąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮąĮčŗčģ čćąĖčüąĄą╗.
ąĀąĄąČąĖą╝ ąŁą║čüą┐ąŠąĮąĄąĮčéą░ Bias 菹║čüą┐ąŠąĮąĄąĮčéčŗ ąöąĖą░ą┐ą░ąĘąŠąĮ 菹║čüą┐ąŠąĮąĄąĮčéčŗ ą£ą░ąĮčéąĖčüčüą░ MIN ąĘąĮą░č湥ąĮąĖąĄ MAX ąĘąĮą░č湥ąĮąĖąĄ
Half precision (ą┐ąŠą╗ąŠą▓ąĖąĮąĮą░čÅ č鹊čćąĮąŠčüčéčī, 16 ą▒ąĖčé)
5 ą▒ąĖčé
15
-14 .. +15
10 ą▒ąĖčé
6.10x10-5
65504
Single precision (ąŠą┤ąĖąĮą░čĆąĮą░čÅ č鹊čćąĮąŠčüčéčī, 32 ą▒ąĖčéą░)
8 ą▒ąĖčé
127
-126 .. +127
23 ą▒ąĖčéą░
1.18x10-38
3.40x1038
Double precision (ą┤ą▓ąŠą╣ąĮą░čÅ č鹊čćąĮąŠčüčéčī, 64 ą▒ąĖčéą░)
11 ą▒ąĖčé
1023
-1022 .. +1023
52 ą▒ąĖčéą░
2.23x10-308
1.8x10308
ą¤čĆąĖą╝ąĄčĆ ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖčÅ čćąĖčüą╗ą░ -7 čü ąŠą┤ąĖąĮą░čĆąĮąŠą╣ č鹊čćąĮąŠčüčéčīčÄ (single-precision):
ŌĆó ąæąĖčé ąĘąĮą░ą║ą░ s = 12 -1 + 2-2 = 0b11000000000000000000000
[ąöąĄąĮąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮąĮčŗąĄ čćąĖčüą╗ą░ ]
ąöąĄąĮąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮąĮąŠąĄ čćąĖčüą╗ąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖčÅ ąĘąĮą░č湥ąĮąĖą╣, ą║ąŠč鹊čĆčŗąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖčÅ ąĘąĮą░č湥ąĮąĖą╣, ą║ąŠč鹊čĆčŗąĄ čüą╗ąĖčłą║ąŠą╝ ą╝ą░ą╗ąĄąĮčīą║ąĖąĄ ą┤ą╗čÅ ąĮąŠčĆą╝ą░ą╗ąĖąĘą░čåąĖąĖ (ą║ąŠą│ą┤ą░ 菹║čüą┐ąŠąĮąĄąĮčéą░ čĆą░ą▓ąĮą░ 0). ąŚąĮą░č湥ąĮąĖąĄ ą┤ąĄąĮąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮąĮąŠą│ąŠ čćąĖčüą╗ą░ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ ą┐ąŠ č乊čĆą╝čāą╗ąĄ (i > 0):
ąóą░ą▒ą╗ąĖčåą░ 4. ąöąĖą░ą┐ą░ąĘąŠąĮ ą┤ąĄąĮąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮąĮčŗčģ čćąĖčüąĄą╗.
ąĀąĄąČąĖą╝ MIN ąĘąĮą░č湥ąĮąĖąĄ
Half precision (ą┐ąŠą╗ąŠą▓ąĖąĮąĮą░čÅ č鹊čćąĮąŠčüčéčī, 16 ą▒ąĖčé)
5.96x10-8
Single precision (ąŠą┤ąĖąĮą░čĆąĮą░čÅ č鹊čćąĮąŠčüčéčī, 32 ą▒ąĖčéą░)
1.4x10-45
Double precision (ą┤ą▓ąŠą╣ąĮą░čÅ č鹊čćąĮąŠčüčéčī, 64 ą▒ąĖčéą░)
4.94x10-324
[ąØčāą╗ąĖ ]
ąŚąĮą░č湥ąĮąĖąĄ Zero ąĖą╝ąĄąĄčé ąĘąĮą░ą║, čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī ąĮą░čüčŗčēąĄąĮąĖąĄ (ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠąĄ ąĖą╗ąĖ ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠąĄ). ąś 菹║čüą┐ąŠąĮąĄąĮčéą░, ąĖ čäčĆą░ą║čåąĖčÅ čĆą░ą▓ąĮčŗ ąĮčāą╗čÄ.
[ąæąĄčüą║ąŠąĮąĄčćąĮąŠčüčéąĖ ]
ąŚąĮą░č湥ąĮąĖąĄ Infinite čéą░ą║ąČąĄ ąĖą╝ąĄąĄčé ąĘąĮą░ą║, čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī +Ōł× ąĖą╗ąĖ -Ōł×. ąŚąĮą░č湥ąĮąĖčÅ Infinite ą┐ąŠą╗čāčćą░čÄčéčüčÅ ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĖą╗ąĖ ą┤ąĄą╗ąĄąĮąĖčÅ ąĮą░ 0. ąŁą║čüą┐ąŠąĮąĄąĮčéą░ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ąĮą░ čüą▓ąŠąĄ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ą╝ą░ąĮčéąĖčüčüą░ čĆą░ą▓ąĮą░ ąĮčāą╗čÄ.
[NaN (Not-a-Number) ]
NaN ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą║ą░ą║ ąĮąĄąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╣ čĆąĄąĘčāą╗čīčéą░čé ąŠą┐ąĄčĆą░čåąĖąĖ, ąĮą░ą┐čĆąĖą╝ąĄčĆ 0/0 ąĖą╗ąĖ ą║ą▓ą░ą┤čĆą░čéąĮčŗą╣ ą║ąŠčĆąĄąĮčī ąŠčé ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠą│ąŠ čćąĖčüą╗ą░. ąŁą║čüą┐ąŠąĮąĄąĮčéą░ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ąĮą░ čüą▓ąŠąĄ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ą╝ą░ąĮčéąĖčüčüą░ ąĮąĄ ąĮčāą╗ąĄą▓ą░čÅ. MSB ą╝ą░ąĮčéąĖčüčüčŗ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čÅą▓ą╗čÅąĄčéčüčÅ ą╗ąĖ čŹč鹊 Quiet NaN (ą║ąŠč鹊čĆąŠąĄ ą╝ąŠąČąĄčé čĆą░čüą┐čĆąŠčüčéčĆą░ąĮąĖčéčīčüčÅ ąĮą░ čüą╗ąĄą┤čāčÄčēčāčÄ ąŠą┐ąĄčĆą░čåąĖčÄ) ąĖą╗ąĖ Signaling NaN (čćč鹊 ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąŠčłąĖą▒ą║čā).
ąóą░ą▒ą╗ąĖčåą░ 5. ąöąĖą░ą┐ą░ąĘąŠąĮ ąĘąĮą░č湥ąĮąĖą╣ ą┤ą╗čÅ č乊čĆą╝ą░č鹊ą▓ čćąĖčüą╗ą░ IEEE.754.
ąŚąĮą░ą║ ąŁą║čüą┐ąŠąĮąĄąĮčéą░ ążčĆą░ą║čåąĖčÅ ą¦ąĖčüą╗ąŠ
0
0
0
+0
1
0
0
-0
0
Max
0
+Ōł×
1
Max
0
-Ōł×
[0, 1]
Max
!=0 & MSB=1
QNaN
[0, 1]
Max
!=0 & MSB=0
SNaN
[0, 1]
0
!=0
ąöąĄąĮąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮąĮąŠąĄ čćąĖčüą╗ąŠ
[0, 1]
[1, Max-1]
[0, Max]
ąØąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮąĮąŠąĄ čćąĖčüą╗ąŠ
[ąĀąĄąČąĖą╝čŗ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ]
ą×ą┐čĆąĄą┤ąĄą╗ąĄąĮąŠ 4 ą│ą╗ą░ą▓ąĮčŗčģ čĆąĄąČąĖą╝ą░ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ:
ŌĆó ą×ą║čĆčāą│ą╗ąĄąĮąĖąĄ ą║ ą▒ą╗ąĖąČą░ą╣čłąĄą╝čā ąĘąĮą░č湥ąĮąĖčÄ.
ą×ą║čĆčāą│ą╗ąĄąĮąĖąĄ ą║ ą▒ą╗ąĖąČą░ą╣čłąĄą╝čā ąĘąĮą░č湥ąĮąĖčÄ čŹč鹊 čĆąĄąČąĖą╝ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ (ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čćą░čēąĄ ą▓čüąĄą│ąŠ). ąĢčüą╗ąĖ ą┤ą▓ą░ ą▒ą╗ąĖąČą░ą╣čłąĖčģ ąĘąĮą░č湥ąĮąĖčÅ ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠ ą▒ą╗ąĖąĘą║ąĖ, č鹊 ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ąĖąĘ ąĮąĖčģ č鹊 ąĘąĮą░č湥ąĮąĖąĄ, čā ą║ąŠč鹊čĆąŠą│ąŠ LSB čĆą░ą▓ąĄąĮ 0.
ąĀąĄąČąĖą╝ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ąŠč湥ąĮčī ą▓ą░ąČąĄąĮ, ą┐ąŠčüą║ąŠą╗čīą║čā ąŠąĮ ą▓ą╗ąĖčÅąĄčé ąĮą░ čĆąĄąĘčāą╗čīčéą░čé ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ. ąĀąĄąČąĖą╝ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖąĘą╝ąĄąĮąĄąĮ ąĮą░čüčéčĆąŠą╣ą║ąŠą╣ čĆąĄą│ąĖčüčéčĆą░ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ FPU.
[ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ]
ąĪčéą░ąĮą┤ą░čĆčé IEEE.754 ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé 6 ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖčģ ąŠą┐ąĄčĆą░čåąĖą╣:
ŌĆó ąĪą╗ąŠąČąĄąĮąĖąĄ (Add)
[ą¤čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅ čćąĖčüąĄą╗ ]
ąóą░ą║ąČąĄ čüčéą░ąĮą┤ą░čĆčé IEEE ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ąŠą┐ąĄčĆą░čåąĖąĖ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅ ąĮąĄą║ąŠč鹊čĆčŗčģ č乊čĆą╝ą░č鹊ą▓ ąĖ ąŠą┐ąĄčĆą░čåąĖąĖ ąĖčģ čüčĆą░ą▓ąĮąĄąĮąĖčÅ:
ŌĆó ą¤čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ čćąĖčüąĄą╗ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣ ąĖ čåąĄą╗čŗčģ čćąĖčüąĄą╗.
[ąśčüą║ą╗čÄč湥ąĮąĖąĄ ąĖ ąĄą│ąŠ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ]
ą¤ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ 5 ąĖčüą║ą╗čÄč湥ąĮąĖą╣ (exception):
ŌĆó ąØąĄą┤ąŠą┐čāčüčéąĖą╝ą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ: čĆąĄąĘčāą╗čīčéą░čé ąŠą┐ąĄčĆą░čåąĖąĖ NaN.
ąśčüą║ą╗čÄč湥ąĮąĖąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠą▒čĆą░ą▒ąŠčéą░ąĮąŠ ą┤ą▓čāą╝čÅ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ:
ŌĆó ąōąĄąĮąĄčĆą░čåąĖčÅ ą╗ąŠą▓čāčłą║ąĖ (trap). ą×ą▒čĆą░ą▒ąŠčéčćąĖą║ trap ą▓ąĄčĆąĮąĄčé ąĘąĮą░č湥ąĮąĖąĄ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠąĄ ą▓ą╝ąĄčüč鹊 čĆąĄąĘčāą╗čīčéą░čéą░, ą▓čŗąĘą▓ą░ą▓čłąĄą│ąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ.
ąĪčéą░ąĮą┤ą░čĆčé IEEE.754 ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé, ą║ą░ą║ čćąĖčüą╗ą░ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ ąĘą░ą┐čÅč鹊ą╣ ą║ąŠą┤ąĖčĆčāčÄčéčüčÅ, ąĖ ą║ą░ą║ ąŠąĮąĖ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ. FPU, čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮąĮčŗą╣ ą░ą┐ą┐ą░čĆą░čéąĮąŠ, čāčüą║ąŠčĆčÅąĄčé ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣ ą┐ąŠ čüčéą░ąĮą┤ą░čĆčéčā IEEE 754. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąŠąĮ ą╝ąŠąČąĄčé čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ą╗ąĖą▒ąŠ ą▓ąĄčüčī čüčéą░ąĮą┤ą░čĆčé IEEE čåąĄą╗ąĖą║ąŠą╝, ą╗ąĖą▒ąŠ ąĄą│ąŠ ą┐ąŠą┤ą╝ąĮąŠąČąĄčüčéą▓ąŠ. ąĪąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēą░čÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮą░čÅ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░ čĆąĄą░ą╗ąĖąĘčāąĄčé ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄą╝čŗąĄ ą░ą┐ą┐ą░čĆą░čéąĮčŗą╝ čāčüą║ąŠčĆąĄąĮąĖąĄą╝ čäčāąĮą║čåąĖąĖ.
ąöą╗čÅ "ą▒ą░ąĘąŠą▓ąŠą│ąŠ" ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┐ąŠą┤ą┤ąĄčƹȹ║ą░ ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąĖ ą┐čĆąŠąĘčĆą░čćąĮą░ ą┤ą╗čÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ, ą║ą░ą║ ą┐čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ čéąĖą┐ą░ float ą▓ ą║ąŠą┤ąĄ čÅąĘčŗą║ą░ C. ąöą╗čÅ ą▒ąŠą╗ąĄąĄ ą┐čĆąŠą┤ą▓ąĖąĮčāčéčŗčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ ą╝ąŠą│čāčé ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčīčüčÅ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ č湥čĆąĄąĘ ą╗ąŠą▓čāčłą║ąĖ ąĖą╗ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ.
[STM32 Cortex® -M floating-point unit (FPU) ]
ąÆ čéą░ą▒ą╗ąĖčåąĄ 6 ą┐ąŠą║ą░ąĘą░ąĮčŗ ą▓ą░čĆąĖą░ąĮčéčŗ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ FPU ą┤ą╗čÅ STM32 Cortex┬« -M4 ąĖ Cortex┬« -M7.
ąóą░ą▒ą╗ąĖčåą░ 6. ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ FPU ą▓ STM32 Cortex┬« -M4/-M7.
ąÜąŠąĮčäąĖą│čāčĆąĖčĆčāąĄą╝čŗąĄ ąŠą┐čåąĖąĖ ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ STM32
STM32F3xx STM32F76x/7x
ąæąĄąĘ FPU
-
-
ąóąŠą╗čīą║ąŠ ąŠą┤ąĖąĮą░čĆąĮą░čÅ č鹊čćąĮąŠčüčéčī
ąöąÉ
-
ą×ą┤ąĖąĮą░čĆąĮą░čÅ ąĖ ą┤ą▓ąŠą╣ąĮą░čÅ č鹊čćąĮąŠčüčéčī
-
ąöąÉ
Cortex┬« M4 FPU . ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ Cortex┬« M4 FPU čüąŠą┤ąĄčƹȹĖčé ARM┬« FPv4-SP (ą▒ą╗ąŠą║ ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ ąĘą░ą┐čÅč鹊ą╣ ąŠą┤ąĖąĮą░čĆąĮąŠą╣ č鹊čćąĮąŠčüčéąĖ). ąŚą┤ąĄčüčī ąĖą╝ąĄąĄčéčüčÅ čüąŠą▒čüčéą▓ąĄąĮąĮčŗą╣ ąĮą░ą▒ąŠčĆ ąĖąĘ 32-ą▒ąĖčéąĮčŗčģ single precision čĆąĄą│ąĖčüčéčĆąŠą▓ (S0-S31) ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąŠą┐ąĄčĆą░čåąĖą╣ ąĖ čģčĆą░ąĮąĄąĮąĖčÅ čĆąĄąĘčāą╗čīčéą░č鹊ą▓. ąŁčéąĖ čĆąĄą│ąĖčüčéčĆčŗ ą╝ąŠąČąĮąŠ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░čéčī ą║ą░ą║ 16 čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ą▓ąŠą╣ąĮčŗčģ čüą╗ąŠą▓ (D0-15) ą┤ą╗čÅ ąŠą┐ąĄčĆą░čåąĖą╣ ąĘą░ą│čĆčāąĘą║ąĖ/čüąŠčģčĆą░ąĮąĄąĮąĖčÅ (load/store).
ąĀąĄą│ąĖčüčéčĆ čüąŠčüč鹊čÅąĮąĖčÅ ąĖ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ (Status & Configuration Register) čģčĆą░ąĮąĖčé ąĮą░čüčéčĆąŠą╣ą║ąĖ FPU (čĆąĄąČąĖą╝ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ąĖ čüą┐ąĄčåąĖą░ą╗čīąĮčŗąĄ ąĮą░čüčéčĆąŠą╣ą║ąĖ), ą▒ąĖčéčŗ ąŠą┐ąĖčüą░ąĮąĖčÅ čĆąĄąĘčāą╗čīčéą░čéą░ ąŠą┐ąĄčĆą░čåąĖąĖ (negative, zero, carry ąĖ overflow) ąĖ čäą╗ą░ą│ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖą╣ (exception flags).
ąØąĄą║ąŠč鹊čĆčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ čüčéą░ąĮą┤ą░čĆčéą░ IEEE.754 ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčéčüčÅ ą░ą┐ą┐ą░čĆą░čéąĮąŠ, ąĖ čĆąĄą░ą╗ąĖąĘčāčÄčéčüčÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ:
ŌĆó Remainder.
ąśčüą║ą╗čÄč湥ąĮąĖčÅ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ č湥čĆąĄąĘ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ (ą╗ąŠą▓čāčłą║ąĖ ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčéčüčÅ).
Cortex┬« M7 FPU . ąæą╗ąŠą║ ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąĖ Cortex┬« -M7 čŹč鹊 čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ ARM┬« FPv5. ąŚą┤ąĄčüčī ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčéčüčÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ ąŠą┤ąĖąĮą░čĆąĮąŠą╣ ąĖ ą┤ą▓ąŠą╣ąĮąŠą╣ č鹊čćąĮąŠčüčéąĖ, ą░ čéą░ą║ąČąĄ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅ ą╝ąĄąČą┤čā č乊čĆą╝ą░ą╝ąĖ ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąĖ ąĖ čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą╣ č鹊čćą║ąĖ, ąĖ ąĄčüčéčī ąĖąĮčüčéčĆčāą║čåąĖąĖ ą║ąŠąĮčüčéą░ąĮčé čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣.
FPU ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé IEEE754-čüąŠą▓ą╝ąĄčüčéąĖą╝čŗąĄ 32-ą▒ąĖčéąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ąŠą┤ąĖąĮą░čĆąĮąŠą╣ č鹊čćąĮąŠčüčéąĖ (single-precision) ąĖ 64-ą▒ąĖčéąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ ą┤ą▓ąŠą╣ąĮąŠą╣ č鹊čćąĮąŠčüčéąĖ (double-precision). ąśą╝ąĄąĄčéčüčÅ čĆą░čüčłąĖčĆąĄąĮąĮčŗą╣ čäą░ą╣ą╗ čĆąĄą│ąĖčüčéčĆąŠą▓, čüąŠą┤ąĄčƹȹ░čēąĖą╣ 32 čĆąĄą│ąĖčüčéčĆą░ ąŠą┤ąĖąĮą░čĆąĮąŠą╣ č鹊čćąĮąŠčüčéąĖ. ą×ąĮąĖ ą╝ąŠą│čāčé čĆą░čüčüą╝ą░čéčĆąĖą▓ą░čéčīčüčÅ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ŌĆó ą©ąĄčüčéąĮą░ą┤čåą░čéčī 64-ą▒ąĖčéąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ą┤ą▓ąŠą╣ąĮąŠą│ąŠ čüą╗ąŠą▓ą░ (D0-D15), ą║ąŠč鹊čĆčŗąĄ čéą░ą║ąĖąĄ ąČąĄ, ą║ą░ą║ ą▓ ą▓ąĄčĆčüąĖąĖ FPv4 ą▒ąĄąĘ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓.
FPv5 ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą░ą┐ą┐ą░čĆą░čéąĮčāčÄ ą┐ąŠą┤ą┤ąĄčƹȹ║čā ą┤ą╗čÅ ą┤ąĄąĮąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮąĮčŗčģ čćąĖčüąĄą╗ ąĖ ą▓čüąĄ čĆąĄąČąĖą╝čŗ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ čüčéą░ąĮą┤ą░čĆčéą░ IEEE 754-2008.
ąĪą┐ąĄčåąĖą░ą╗čīąĮčŗąĄ čĆą░ą▒ąŠčćąĖąĄ čĆąĄąČąĖą╝čŗ . Cortex┬« M4 FPU ą┐ąŠą╗ąĮąŠčüčéčīčÄ čüąŠą▓ą╝ąĄčüčéąĖą╝ čüąŠ čüą┐ąĄčåąĖčäąĖą║ą░čåąĖčÅą╝ąĖ IEEE.754. ą×ą┤ąĮą░ą║ąŠ ą╝ąŠą│čāčé ą▒čŗčéčī ą░ą║čéąĖą▓ąĖčĆąŠą▓ą░ąĮčŗ ąĮąĄą║ąŠč鹊čĆčŗąĄ ąĮąĄčüčéą░ąĮą┤ą░čĆčéąĮčŗąĄ čĆąĄąČąĖą╝čŗ:
ŌĆó ąÉą╗čīč鹥čĆąĮą░čéąĖą▓ąĮčŗą╣ č乊čĆą╝ą░čé ą┐ąŠą╗ąŠą▓ąĖąĮąĮąŠą╣ č鹊čćąĮąŠčüčéąĖ (Alternative Half-precision, ą▓ą║ą╗čÄčćą░ąĄčéčüčÅ ą▒ąĖč鹊ą╝ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ AHP). ąŁč鹊 čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ 16-ą▒ąĖčéąĮčŗą╣ čĆąĄąČąĖą╝ ą▒ąĄąĘ ąĘąĮą░č湥ąĮąĖčÅ čŹą║čüą┐ąŠąĮąĄąĮčéčŗ ąĖ ą▒ąĄąĘ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ ą┤ąĄąĮąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮąĮčŗčģ čćąĖčüąĄą╗.
ŌĆó ąĀąĄąČąĖą╝ Flush-to-zero (ą▒ąĖčé čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ FZ). ąÆčüąĄ ą┤ąĄąĮąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮąĮčŗąĄ čćąĖčüą╗ą░ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ą║ą░ą║ ąĮčāą╗ąĖ. ąśą╝ąĄąĄčéčüčÅ čäą╗ą░ą│, čüą▓čÅąĘą░ąĮąĮčŗą╣ čüąŠ čüą▒čĆąŠčüąŠą╝ (flush) ą▓čģąŠą┤ą░ ąĖ ą▓čŗčģąŠą┤ą░.
ŌĆó ąĀąĄąČąĖą╝ NaN ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ (ą▒ąĖčé čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ DN). ąøčÄą▒ą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ čü NaN ąĮą░ ą▓čģąŠą┤ąĄ, ąĖą╗ąĖ ą║ąŠč鹊čĆą░čÅ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé NaN, ą▓ąĄčĆąĮąĄčé default NaN (Quiet NaN).
Floating-point status and control register (FPSCR) . ąĀąĄą│ąĖčüčéčĆ FPSCR čģčĆą░ąĮąĖčé čüąŠčüč鹊čÅąĮąĖąĄ FPU - ą▒ąĖčéčŗ čāčüą╗ąŠą▓ąĖčÅ (condition bits) ąĖ čäą╗ą░ą│ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ (exception flags), ą░ čéą░ą║ąČąĄ ąĄą│ąŠ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÄ (čĆąĄąČąĖą╝čŗ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ ąĖ ą░ą╗čīč鹥čĆąĮą░čéąĖą▓ąĮčŗąĄ čĆąĄąČąĖą╝čŗ). ąÜą░ą║ čüą╗ąĄą┤čüčéą▓ąĖąĄ čŹč鹊čé čĆąĄą│ąĖčüčéčĆ ą╝ąŠąČąĮąŠ čüąŠčģčĆą░ąĮčÅčéčī ą▓ čüč鹥ą║, ą║ąŠą│ą┤ą░ ą╝ąĄąĮčÅąĄčéčüčÅ ą║ąŠąĮč鹥ą║čüčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░.
ąÜ FPSCR ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ:
ŌĆó ą¦č鹥ąĮąĖąĄ (Read): VMRS Rx, FPSCR
ąĀąĄą│ąĖčüčéčĆ FPSCR ąĖ ąĄą│ąŠ ą▒ąĖčéčŗ:
31
30
29
28
27
26
25
24
23
22
21
20
19
18
17
16
N Z C V ąĘą░čĆąĄąĘ. AHP DN FZ RM ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąŠ
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąŠ IDC ąĘą░čĆąĄąĘąĄčĆą▓. IXC rw UFC rw OFC rw DZC rw IOC rw
N Z C V
AHP DN FZ RM
ążą╗ą░ą│ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ (exception flags). ą×ąĮąĖ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čÄčéčüčÅ ą┐čĆąĖ ą▓ąŠąĘąĮąĖą║ąĮąŠą▓ąĄąĮąĖąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ (exception) ą▓ čüą╗čāčćą░ąĄ:
ŌĆó Flush to zero, čüą▒čĆąŠčü ą║ ąĮčāą╗čÄ (IDC).
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: čäą╗ą░ą│ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĮąĄ čüą▒čĆą░čüčŗą▓ą░čÄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣.
ąśčüą║ą╗čÄč湥ąĮąĖčÅ ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą┐ąĄčĆąĄčģą▓ą░č湥ąĮčŗ ą╗ąŠą▓čāčłą║ąŠą╣ (trap). ą×ąĮąĖ ąŠą▒čüą╗čāąČąĖą▓ą░čÄčéčüčÅ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą╝ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ. ąĪąĖą│ąĮą░ą╗ ąŠčé 5 čäą╗ą░ą│ąŠą▓ ąĖčüą║ą╗čÄč湥ąĮąĖą╣ (IDC, UFC, OFC, DZC, IOC) ąŠą▒čŖąĄą┤ąĖąĮčÅąĄčéčüčÅ ą┐ąŠ ąśąøąś ąĖ ą┐ąŠčüčéčāą┐ą░ąĄčé ąĮą░ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣. ąØąĄčé ąĮąĖą║ą░ą║ąŠą╣ ąĖąĮą┤ąĖą▓ąĖą┤čāą░ą╗čīąĮąŠą╣ ą╝ą░čüą║ąĖ ąĖ čĆą░ąĘčĆąĄčłąĄąĮąĖčÅ/ąĘą░ą┐čĆąĄčéą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ FPU ąĮą░ čāčĆąŠą▓ąĮąĄ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣.
ążą╗ą░ą│ IXC ąĮąĄ čüąŠąĄą┤ąĖąĮąĄąĮ čü ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą╝ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ, ąĖ ąĮąĄ ą╝ąŠąČąĄčé ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ, čéą░ą║ ą║ą░ą║ čćą░čüč鹊čéą░ ąĄą│ąŠ ą┐ąŠčÅą▓ą╗ąĄąĮąĖčÅ ąŠč湥ąĮčī ą▓ąĄą╗ąĖą║ą░. ąĢčüą╗ąĖ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ, ąŠąĮ ą╝ąŠąČąĄčé ąŠą▒čüą╗čāąČąĖą▓ą░čéčīčüčÅ ą┐čāč鹥ą╝ ąŠą┐čĆąŠčüą░ ą┐čĆąŠą│čĆą░ą╝ą╝ąŠą╣.
ąÜąŠą│ą┤ą░ FPU čĆą░ąĘčĆąĄčłąĄąĮ, ąĄą│ąŠ ą║ąŠąĮč鹥ą║čüčé ą╝ąŠąČąĄčé ą▒čŗčéčī čüąŠčģčĆą░ąĮąĄąĮ ą▓ čüč鹥ą║ąĄ CPU čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ąŠą┤ąĮąŠą│ąŠ ąĖąĘ čéčĆąĄčģ ą╝ąĄč鹊ą┤ąŠą▓:
ŌĆó ąĀąĄą│ąĖčüčéčĆčŗ ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąĖ ąĮąĄ čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ.
ążčĆąĄą╣ą╝ čüč鹥ą║ą░ čüąŠčüč鹊ąĖčé ąĖąĘ 17 菹╗ąĄą╝ąĄąĮč鹊ą▓:
ŌĆó FPSCR
[ą£ąŠą┤ąĄą╗čī ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ]
ąÜąŠą│ą┤ą░ MCU ą▓čŗčģąŠą┤ąĖčé ąĖąĘ čüą▒čĆąŠčüą░, ą▒ą╗ąŠą║ FPU ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čĆą░ąĘčĆąĄčłąĄąĮ čāą║ą░ąĘą░ąĮąĖąĄą╝ čāčĆąŠą▓ąĮčÅ ą┤ąŠčüčéčāą┐ą░ ą║ąŠą┤ą░, ąĖčüą┐ąŠą╗čīąĘčāčÄčēąĄą│ąŠ FPU (ąĘą░ą┐čĆąĄčēąĄąĮąŠ, ą┐čĆąĖą▓ąĖą╗ąĄą│ąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ąĖą╗ąĖ ą┐ąŠą╗ąĮčŗą╣ ą┤ąŠčüčéčāą┐) ą▓ čĆąĄą│ąĖčüčéčĆąĄ Coprocessor Access Control Register (CPACR). FPSCR ą╝ąŠąČąĄčé ą▒čŗčéčī čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮ ą┤ą╗čÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą░ą╗čīč鹥čĆąĮą░čéąĖą▓ąĮčŗčģ čĆąĄąČąĖą╝ąŠą▓ ąĖą╗ąĖ ą┤ą╗čÅ čĆąĄąČąĖą╝ą░ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ.
ąŻ FPU ąĖą╝ąĄąĄčéčüčÅ 5 čüąĖčüč鹥ą╝ąĮčŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓:
ŌĆó FPCCR (FP Context Control Register), ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčēąĖą╣ ą║ąŠąĮč鹥ą║čüčé, ą║ąŠą│ą┤ą░ ą▓čŗą┤ąĄą╗ąĄąĮ čäčĆąĄą╣ą╝ čüč鹥ą║ą░ FP, ą▓ą╝ąĄčüč鹥 čü ąĮą░čüčéčĆąŠą╣ą║ąŠą╣ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą║ąŠąĮč鹥ą║čüčéą░.
[ąśąĮčüčéčĆčāą║čåąĖąĖ FPU ]
ą¤ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖčģ ąŠą┐ąĄčĆą░čåąĖą╣, čüčĆą░ą▓ąĮąĄąĮąĖčÅ, ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅ ąĖ ąĘą░ą│čĆčāąĘą║ąĖ/čüąŠčģčĆą░ąĮąĄąĮąĖčÅ.
ąÉčĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ . FPU ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą░čĆąĖčäą╝ąĄčéąĖč湥čüą║ąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ą╗čÅ:
ŌĆó ą¤ąŠą╗čāč湥ąĮąĖąĄ ą░ą▒čüąŠą╗čÄčéąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ (Absolute value), ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ąĘą░ 1 čéą░ą║čé.
ąóą░ą▒ą╗ąĖčåą░ 8 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĄą║ąŠč鹊čĆčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┤ą░ąĮąĮčŗčģ ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąĖ ąŠą┤ąĖąĮą░čĆąĮąŠą╣ č鹊čćąĮąŠčüčéąĖ.
ąóą░ą▒ą╗ąĖčåą░ 8. ąśąĮčüčéčĆčāą║čåąĖąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┤ą░ąĮąĮčŗčģ floating-point, single-precision.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą×ą┐ąĖčüą░ąĮąĖąĄ ąÆčĆąĄą╝čÅ ą▓ čéą░ą║čéą░čģ
VABS.F32 ąÉą▒čüąŠą╗čÄčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ
1
VADD.F32 ąĪą╗ąŠąČąĄąĮąĖąĄ
1
VSUB.F32 ąÆčŗčćąĖčéą░ąĮąĖąĄ
1
VMUL.F32 ąŻą╝ąĮąŠąČąĄąĮąĖąĄ
1
VDIV.F32 ąöąĄą╗ąĄąĮąĖąĄ
14
VCVT.F32 ą¤čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ čåąĄą╗ąŠąĄ/čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ č鹊čćą║ą░ ąĖ ąŠą▒čĆą░čéąĮąŠ
1
VSQRT.F32 ąÜą▓ą░ą┤čĆą░čéąĮčŗą╣ ą║ąŠčĆąĄąĮčī
14
ąóą░ą▒ą╗ąĖčåą░ 9 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮąĄą║ąŠč鹊čĆčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┤ą░ąĮąĮčŗčģ ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąĖ ą┤ą▓ąŠą╣ąĮąŠą╣ č鹊čćąĮąŠčüčéąĖ.
ąóą░ą▒ą╗ąĖčåą░ 9. ąśąĮčüčéčĆčāą║čåąĖąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┤ą░ąĮąĮčŗčģ floating-point, double-precision.
ąśąĮčüčéčĆčāą║čåąĖčÅ ą×ą┐ąĖčüą░ąĮąĖąĄ ąÆčĆąĄą╝čÅ ą▓ čéą░ą║čéą░čģ
VADD.F64 ąĪą╗ąŠąČąĄąĮąĖąĄ
3
VSUB.F64 ąÆčŗčćąĖčéą░ąĮąĖąĄ
3
VCVT.F< 32|64> ą¤čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ čåąĄą╗ąŠąĄ/čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮą░čÅ č鹊čćą║ą░ ąĖ ąŠą▒čĆą░čéąĮąŠ
3
ąÆčüąĄ MAC-ąŠą┐ąĄčĆą░čåąĖąĖ ą╝ąŠą│čāčé ą▒čŗčéčī čüčéą░ąĮą┤ą░čĆčéąĮčŗąĄ ąĖą╗ąĖ čéąĖą┐ą░ fused (ąŠą║čĆčāą│ą╗ąĄąĮąĖąĄ ą┤ąĄą╗ą░ąĄčéčüčÅ ą┐ąŠ ąŠą║ąŠąĮčćą░ąĮąĖąĖ MAC ą┤ą╗čÅ ą┐ąŠą▓čŗčłąĄąĮąĮąŠą╣ č鹊čćąĮąŠčüčéąĖ).
ąśąĮčüčéčĆčāą║čåąĖąĖ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ąĖ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅ. ąśą╝ąĄčÄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖąĖ čüčĆą░ą▓ąĮąĄąĮąĖčÅ (ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ąĘą░ 1 čéą░ą║čé) ąĖ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅ (čéą░ą║ąČąĄ ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ąĘą░ 1 čéą░ą║čé). ą¤čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą╝ąĄąČą┤čā čåąĄą╗čŗą╝ čćąĖčüą╗ąŠą╝, čćąĖčüą╗ąŠą╝ čü čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą╣ č鹊čćą║ąŠą╣, čćąĖčüą╗ąŠą╝ half precision ąĖ čćąĖčüą╗ąŠą╝ float.
ąśąĮčüčéčĆčāą║čåąĖąĖ load/store . FPU čüą╗ąĄą┤čāąĄčé čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą░čĆčģąĖč鹥ą║čéčāčĆąĄ ąĘą░ą│čĆčāąĘą║ąĖ/čüąŠčģčĆą░ąĮąĄąĮąĖčÅ:
ŌĆó ąŚą░ą│čĆčāąĘą║ą░ (load) ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖąĄ (store) ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ąĘąĮą░č湥ąĮąĖą╣ double, ąĮąĄčüą║ąŠą╗čīą║ąĖčģ float, ąŠą┤ąĖąĮąŠčćąĮčŗčģ double ąĖą╗ąĖ ąŠą┤ąĖąĮąŠčćąĮčŗčģ float.
[ą¤čĆąĖą╝ąĄčĆčŗ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ ]
ąĪą╗ąĄą┤čāčÄčēąĖąĄ ą┤ą▓ą░ ą┐čĆąĖą╝ąĄčĆą░ ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčé ą▓čŗą│ąŠą┤čā ąŠčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ STM32 FPU. ąÆ ą┐ąĄčĆą▓ąŠą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą▓čŗčćąĖčüą╗čÅąĄčéčüčÅ ą╝ąĮąŠąČąĄčüčéą▓ąŠ ą¢čÄą╗ąĖą░ (Julia set), ą│ą┤ąĄ čüčĆą░ą▓ąĮąĖą▓ą░ąĄčéčüčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ FPU ąĖ čéčĆą░ą┤ąĖčåąĖąŠąĮąĮčŗčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣.
ąÆč鹊čĆąŠą╣ ą┐čĆąĖą╝ąĄčĆ ą▓čŗčćąĖčüą╗čÅąĄčé ą╝ąĮąŠąČąĄčüčéą▓ąŠ ą£ą░ąĮą┤ąĄą╗čīą▒čĆąŠčéą░ (Mandelbrot set), ą│ą┤ąĄ ą┐ąŠą║ą░ąĘą░ąĮčŗ čĆą░ąĘą╗ąĖčćąĖčÅ ą▓ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą░ą┐ą┐ą░čĆą░čéąĮčŗčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ double precision FPU ąĖ ą░ą┐ą┐ą░čĆą░čéąĮčŗčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ single precision FPU.
MCU ą▓čŗčćąĖčüą╗čÅąĄčé ą┐čĆąŠčüč鹊ą╣ ą╝ą░č鹥ą╝ą░čéąĖč湥čüą║ąĖą╣ čäčĆą░ą║čéą░ą╗: ą╝ąĮąŠąČąĄčüčéą▓ąŠ ą¢čÄą╗ąĖą░. ąÉą╗ą│ąŠčĆąĖčéą╝ ą│ąĄąĮąĄčĆą░čåąĖąĖ čŹč鹊ą│ąŠ ą╝ą░č鹥ą╝ą░čéąĖč湥čüą║ąŠą│ąŠ ąŠą▒čŖąĄą║čéą░ ą┤ąŠą▓ąŠą╗čīąĮąŠ ą┐čĆąŠčüč鹊ą╣: ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ č鹊čćą║ąĖ ą║ąŠą╝ą┐ą╗ąĄą║čüąĮąŠą│ąŠ ą┐ą╗ą░ąĮą░ ą╝čŗ ąŠčåąĄąĮąĖą▓ą░ąĄą╝ čüą║ąŠčĆąŠčüčéčī čĆą░čüčģąŠąČą┤ąĄąĮąĖčÅ (divergence speed) ąŠą┐čĆąĄą┤ąĄą╗čÅąĄą╝ąŠą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ. ąÆčŗčĆą░ąČąĄąĮąĖąĄ ą┤ą╗čÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ ą╝ąĮąŠąČąĄčüčéą▓ą░ ą¢čÄą╗ąĖą░:
zn+1 = zn 2 + c
ąöą╗čÅ ą║ą░ąČą┤ąŠą╣ č鹊čćą║ąĖ x + i.y ą║ąŠą╝ą┐ą╗ąĄą║čüąĮąŠą│ąŠ ą┐ą╗ą░ąĮą░ ą╝čŗ ą▓čŗčćąĖčüą╗čÅąĄą╝ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī čüąŠ ąĘąĮą░č湥ąĮąĖąĄą╝ c = cx + i.cy :
xn+1 + i.yn+1 = xn 2 - yn 2 + 2.i.xn .yn + cx + i.cy n+1 = xn 2 - yn 2 + cx and yn+1 = 2.xn .yn + cy
ąÜą░ą║ č鹊ą╗čīą║ąŠ čĆąĄąĘčāą╗čīčéąĖčĆčāčÄčēąĄąĄ ą║ąŠą╝ą┐ą╗ąĄą║čüąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą▓čŗčģąŠą┤ąĖčé ąĖąĘ ąĘą░ą┤ą░ąĮąĮąŠą╣ ąŠą║čĆčāąČąĮąŠčüčéąĖ (ą▓ąĄą╗ąĖčćąĖąĮą░ čćąĖčüą╗ą░ ą▒ąŠą╗čīčłąĄ čĆą░ą┤ąĖčāčüą░ ąŠą║čĆčāąČąĮąŠčüčéąĖ), ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī čĆą░čüčģąŠą┤ąĖčéčüčÅ, ąĖ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąĖč鹥čĆą░čåąĖą╣, čüą┤ąĄą╗ą░ąĮąĮčŗčģ ą┤ą╗čÅ ą┤ąŠčüčéąĖąČąĄąĮąĖčÅ čŹč鹊ą│ąŠ ą┐čĆąĄą┤ąĄą╗ą░, ą░čüčüąŠčåąĖąĖčĆčāąĄčéčüčÅ čü č鹊čćą║ąŠą╣. ąŁč鹊 ąĘąĮą░č湥ąĮąĖąĄ ą┐čĆąĄąŠą▒čĆą░ąĘčāąĄčéčüčÅ ą▓ čåą▓ąĄčé, čćč鹊ą▒čŗ ą│čĆą░čäąĖč湥čüą║ąĖ ą┐ąŠą║ą░ąĘą░čéčī čüą║ąŠčĆąŠčüčéčī ą┤ąĖą▓ąĄčĆą│ąĄąĮčåąĖąĖ č鹊č湥ą║ ą║ąŠą╝ą┐ą╗ąĄą║čüąĮąŠą│ąŠ ą┐ą╗ą░ąĮą░.
ąöą╗čÅ ąĖą╝ąĄčÄčēąĄą│ąŠčüčÅ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ąĖč鹥čĆą░čåąĖą╣, ąĄčüą╗ąĖ čĆąĄąĘčāą╗čīčéąĖčĆčāčÄčēąĄąĄ ą║ąŠą╝ą┐ą╗ąĄą║čüąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ąŠčüčéą░ąĄčéčüčÅ ą▓ąĮčāčéčĆąĖ ąŠą║čĆčāąČąĮąŠčüčéąĖ, ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ ąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ čü čāč湥č鹊ą╝, čćč鹊 ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ąĮąĄ čĆą░čüčģąŠą┤ąĖčéčüčÅ:
void GenerateJulia_fpu (uint16_t size_x,
uint16_t size_y,
uint16_t offset_x,
uint16_t offset_y,
uint16_t zoom,
uint8_t * buffer)
{
float tmp1, tmp2;
float num_real, num_img;
float radius;
uint8_t i;
uint16_t x,y;
for (y= 0 ; y < size_y; y++ )
{
for (x= 0 ; x < size_x; x++ )
{
num_real = y - offset_y;
num_real = num_real / zoom;
num_img = x - offset_x;
num_img = num_img / zoom;
i= 0 ;
radius = 0 ;
while ((i < ITERATION- 1 ) && (radius < 4 ))
{
tmp1 = num_real * num_real;
tmp2 = num_img * num_img;
num_img = 2 * num_real* num_img + IMG_CONSTANT;
num_real = tmp1 - tmp2 + REAL_CONSTANT;
radius = tmp1 + tmp2;
i++ ;
}
/* ąĪąŠčģčĆą░ąĮąĄąĮąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ ą▓ ą▒čāč乥čĆ: */
buffer[x+ y* size_x] = i;
}
}
}
ąŁč鹊čé ą░ą╗ą│ąŠčĆąĖčéą╝ ąŠč湥ąĮčī čŹčäč乥ą║čéąĖą▓ąĄąĮ ą┤ą╗čÅ ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąĖ ą▓čŗą│ąŠą┤ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ FPU: ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ ąĮąĖą║ą░ą║ąŠą╣ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖąĖ ą║ąŠą┤ą░, ą┐čĆąŠčüč鹊 ąĮčāąČąĮąŠ ą░ą║čéąĖą▓ąĖčĆąŠą▓ą░čéčī FPU, ą┐čĆąŠčüč鹊 ąŠąĮ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą░ą║čéąĖą▓ąĖčĆąŠą▓ą░ąĮ ąĖą╗ąĖ ąĮąĄ ą░ą║čéąĖą▓ąĖčĆąŠą▓ą░ąĮ ąĮą░ čäą░ąĘąĄ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ. ąöą╗čÅ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÅ ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗą╣ ą║ąŠą┤ FPU, ą┐ąŠčüą║ąŠą╗čīą║čā ąŠąĮ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą▓ čĆąĄąČąĖą╝ąĄ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ.
ąØą░ čĆąĖčüčāąĮą║ąĄ ą│ąŠą╗čāą▒čŗą╝ čåą▓ąĄč鹊ą╝ ą┐ąŠą║ą░ąĘą░ąĮąŠ ąŠč鹊ą▒čĆą░ąČąĄąĮąĖąĄ ą╝ąĮąŠąČąĄčüčéą▓ą░ ą¢čÄą╗ąĖą░, 8 ą▒ąĖčé ąĮą░ č鹊čćą║čā (c=0.285+i.0.01):
[ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ ąĮą░ STM32F4 ]
ą¦č鹊ą▒čŗ ą╗čāčćčłąĄ ą┐ąŠą║ą░ąĘą░čéčī ą║ą░čĆčéąĖąĮą║čā ąĮą░ 菹║čĆą░ąĮąĄ RGB565 ąŠčåąĄąĮąŠčćąĮąŠą╣ ą┐ą╗ą░čéčŗ čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ą░ STM3240G-EVAL, ą╝čŗ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ čüą┐ąĄčåąĖą░ą╗čīąĮčāčÄ ą┐ą░ą╗ąĖčéčĆčā ą┤ą╗čÅ ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖčÅ čåą▓ąĄč鹊ą▓čŗčģ ąĘąĮą░č湥ąĮąĖą╣.
ą£ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ąĖč鹥čĆą░čåąĖąĖ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ ąĮą░ 128. ąÜą░ą║ čüą╗ąĄą┤čüčéą▓ąĖąĄ čåą▓ąĄč鹊ą▓ą░čÅ ą┐ą░ą╗ąĖčéčĆą░ ąĖą╝ąĄąĄčé 128 菹╗ąĄą╝ąĄąĮč鹊ą▓. ąĀą░ą┤ąĖčāčü ą║čĆčāą│ą░ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ąĮą░ 2.
ążčāąĮą║čåąĖčÅ main ą▓čŗąĘčŗą▓ą░ąĄčé ą▓čüąĄ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ ą┐ą╗ą░čéčŗ, čćč鹊ą▒čŗ ąĮą░čüčéčĆąŠąĖčéčī ą┤ąĖčüą┐ą╗ąĄą╣ ąĖ ą║ąĮąŠą┐ą║ąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ.
ŌĆó ąÜąĮąŠą┐ą║ą░ WAKUP ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ąĖąĘ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąŠą│ąŠ čĆąĄąČąĖą╝ą░ (ą┐čĆąĖą▒ą╗ąĖąČąĄąĮąĖąĄ ąĖ čāą┤ą░ą╗ąĄąĮąĖąĄ ą║ą░čĆčéąĖąĮą║ąĖ) ą▓ čĆčāčćąĮąŠą╣ ąĖ ąŠą▒čĆą░čéąĮąŠ.
ąÆąĄčüčī ą┐čĆąŠąĄą║čé čüą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░ąĮ čü čĆą░ąĘčĆąĄčłąĄąĮąĮčŗą╝ FPU, ą║čĆąŠą╝ąĄ ą╝ąŠą┤čāą╗čÅ GenerateJulia_noFPU.c, ą┤ą╗čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ą║ąŠč鹊čĆąŠą│ąŠ ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ ą▓čŗą║ą╗čÄč湥ąĮ FPU.
ą×č鹊ą▒čĆą░ąČąĄąĮąĖąĄ ą╝ąĮąŠąČąĄčüčéą▓ą░ ą¢čÄą╗ąĖą░ čü ą┐ą░ą╗ąĖčéčĆąŠą╣ RGB565 (c=0.285+i.0.01):
[ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ ąĮą░ STM32F7 ]
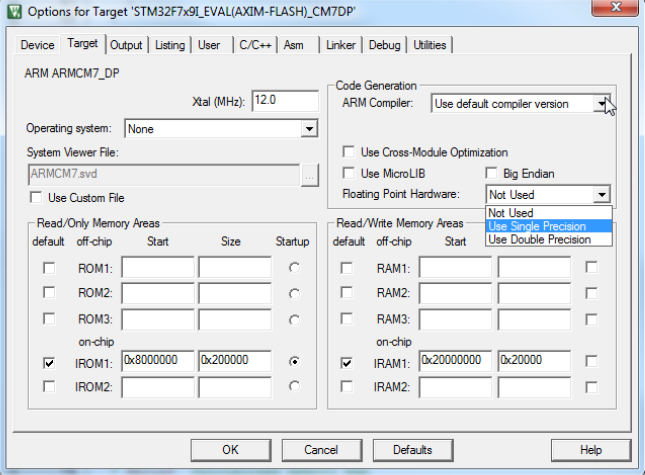
ąóąŠčé ąČąĄ čüą░ą╝čŗą╣ ą░ą╗ą│ąŠčĆąĖčéą╝ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮ ąĮą░ ąŠčåąĄąĮąŠčćąĮąŠą╣ ą┐ą╗ą░č鹥 čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ą░ STM32F769i-Eval. ą£ąĖą║čĆąŠą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ čćą░čüč鹊č鹥 216 ą£ąōčå, ą▓ čüą╗ąĄą┤čāčÄčēąĖčģ ą┤ą▓čāčģ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÅčģ: čĆą░ąĘčĆąĄčłąĄąĮ FPU single precision, ąĖ čĆą░ąĘčĆąĄčłąĄąĮ FPU double precision. ąŁč鹊 čüą┤ąĄą╗ą░ąĮąŠ ą▓ čüčĆąĄą┤ąĄ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ RealView Microcontroller Development Kit (MDK-ARMŌäó) tool-chain V5.17. ą×ą┐čåąĖąĖ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖčÅ FPU ą┐ąŠą║ą░ąĘą░ąĮčŗ ąĮą░ čĆąĖčüčāąĮą║ąĄ:
ąöą╗čÅ STM32F7 čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮ č鹊ą╗čīą║ąŠ čĆčāčćąĮąŠą╣ čĆąĄąČąĖą╝. ą¤čĆąĖ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĖ ą║ą░čüą░ąĮąĖčÅ ą║ čéą░čćčüą║čĆąĖąĮčā ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ ą┤čĆčāą│ąŠą╣ ą▓ą░čĆąĖą░ąĮčé ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣.
ąóą░ą║ąČąĄ ą▒čŗą╗ ąĖąĘą╝ąĄąĮąĄąĮ ą░ą╗ą│ąŠčĆąĖčéą╝:
void GenerateJulia_fpu (uint16_t size_x,
uint16_t size_y,
uint16_t offset_x,
uint16_t offset_y,
uint16_t zoom,
uint8_t * buffer)
{
double tmp1, tmp2;
double num_real, num_img;
double radius;
uint8_t i;
uint16_t x,y;
for (y= 0 ; y < size_y; y++ )
{
for (x= 0 ; x < size_x; x++ )
{
num_real = y - offset_y;
num_real = num_real / zoom;
num_img = x - offset_x;
num_img = num_img / zoom;
i= 0 ;
radius = 0 ;
while ((i < ITERATION- 1 ) && (radius < 4 ))
{
tmp1 = num_real * num_real;
tmp2 = num_img * num_img;
num_img = 2 * num_real* num_img + IMG_CONSTANT;
num_real = tmp1 - tmp2 + REAL_CONSTANT;
radius = tmp1 + tmp2;
i++ ;
}
/* ąĪąŠčģčĆą░ąĮąĄąĮąĖąĄ ąĘąĮą░č湥ąĮąĖčÅ ą▓ ą▒čāč乥čĆ: */
buffer[x+ y* size_x] = i;
}
}
}
[ąĀąĄąĘčāą╗čīčéą░čéčŗ ]
ąóą░ą▒ą╗ąĖčåą░ 10 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą▓čĆąĄą╝čÅ, ąĘą░čéčĆą░č湥ąĮąĮąŠąĄ Cortex┬« -M4 STM32F4 ąĮą░ ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ ą╝ąĮąŠąČąĄčüčéą▓ą░ ą¢čÄą╗ąĖą░ ą┤ą╗čÅ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą║ąŠčŹčäčäąĖčåąĖąĄąĮč鹊ą▓ ą┐čĆąĖą▒ą╗ąĖąČąĄąĮąĖčÅ, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąŠąĮąĮąŠą╝ firmware. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ą░čüčī čüčĆąĄą┤ą░ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ MDK-ARMŌäó tool-chain V5.17.
ąóą░ą▒ą╗ąĖčåą░ 10. ąĪčĆą░ą▓ąĮąĄąĮąĖąĄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą░ą┐ą┐ą░čĆą░čéąĮčŗčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ ąŠą┤ąĖąĮą░čĆąĮąŠą╣ č鹊čćąĮąŠčüčéąĖ Cortex┬« -M4 (HW SP FPU) ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą╣ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ č鹥čģ ąČąĄ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣.
ążčĆąĄą╣ą╝ Zoom ąöą╗ąĖč鹥ą╗čīąĮąŠčüčéčī ąöą╗ąĖč鹥ą╗čīąĮąŠčüčéčī SW ąÆčŗąĖą│čĆčŗčł
0
120
195
2426
12.44
1
110
170
2097
12.34
2
100
146
1782
12.21
3
150
262
3323
12.68
4
200
275
3494
12.71
5
275
261
3307
12.67
6
350
250
3165
12.66
7
450
254
3221
12.68
8
600
240
3038
12.66
9
800
235
2965
12.62
10
1000
230
2896
12.59
11
1200
224
2824
12.61
12
1500
213
2672
12.54
13
2000
184
2293
12.46
14
1500
213
2672
12.54
15
1200
224
2824
12.61
16
1000
230
2896
12.59
17
800
235
2965
12.62
18
600
240
3038
12.66
19
450
254
3221
12.68
20
350
250
3165
12.66
21
275
261
3307
12.67
22
200
275
3494
12.71
23
150
262
3323
12.68
24
100
146
1781
12.20
25
110
170
2097
12.34
ąóą░ą▒ą╗ąĖčåą░ 11 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą▓čĆąĄą╝čÅ, ąĘą░čéčĆą░č湥ąĮąĮąŠąĄ Cortex┬« -M7 STM32F7 ąĮą░ ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ ą╝ąĮąŠąČąĄčüčéą▓ą░ ą¢čÄą╗ąĖą░ čü č鹥ą╝ąĖ ąČąĄ ą░ą╗ą│ąŠčĆąĖčéą╝ą░ą╝ąĖ, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮčŗ ąĮą░ Cortex┬« -M4 STM32F4, čü ąŠą┤ąĖąĮą░čĆąĮąŠą╣ č鹊čćąĮąŠčüčéčīčÄ, ą┤ą╗čÅ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą║ąŠčŹčäčäąĖčåąĖąĄąĮč鹊ą▓ ą┐čĆąĖą▒ą╗ąĖąČąĄąĮąĖčÅ, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąŠąĮąĮąŠą╝ firmware. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ą░čüčī čüčĆąĄą┤ą░ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ MDK-ARMŌäó tool-chain V5.17.
ąóą░ą▒ą╗ąĖčåą░ 11. ąĪčĆą░ą▓ąĮąĄąĮąĖąĄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą░ą┐ą┐ą░čĆą░čéąĮčŗčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ ąŠą┤ąĖąĮą░čĆąĮąŠą╣ č鹊čćąĮąŠčüčéąĖ Cortex┬« -M7 (HW SP FPU) ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą╣ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ č鹥čģ ąČąĄ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣.
ążčĆąĄą╣ą╝ Zoom ąöą╗ąĖč鹥ą╗čīąĮąŠčüčéčī ąöą╗ąĖč鹥ą╗čīąĮąŠčüčéčī SW ąÆčŗąĖą│čĆčŗčł
0
120
134
1759
13.13
1
110
118
1519
12.87
2
100
102
1291
12.66
3
150
179
2407
13.45
4
200
187
2529
13.52
5
275
178
2396
13.46
6
350
171
2294
13.42
7
450
174
2335
13.42
8
600
165
2204
13.36
9
800
161
2150
13.35
10
1000
157
2101
13.38
11
1200
154
2048
13.30
12
1500
146
1936
13.26
13
2000
127
1661
13.08
14
1500
146
1936
13.26
15
1200
154
2048
13.30
16
1000
157
2101
13.38
17
800
161
2150
13.35
18
600
165
2204
13.36
19
450
174
2335
13.42
20
350
171
2294
13.42
21
275
178
2396
13.46
22
200
187
2529
13.52
23
150
179
2407
13.45
24
100
102
1291
12.66
25
110
118
1519
12.87
ąóą░ą▒ą╗ąĖčåą░ 12 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą▓čĆąĄą╝čÅ, ąĘą░čéčĆą░č湥ąĮąĮąŠąĄ Cortex┬« -M7 STM32F7 ąĮą░ ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ ą╝ąĮąŠąČąĄčüčéą▓ą░ ą¢čÄą╗ąĖą░ čü č鹥ą╝ąĖ ąČąĄ ą░ą╗ą│ąŠčĆąĖčéą╝ą░ą╝ąĖ ą┤ą╗čÅ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą║ąŠčŹčäčäąĖčåąĖąĄąĮč鹊ą▓ ą┐čĆąĖą▒ą╗ąĖąČąĄąĮąĖčÅ čü ą┤ą▓ąŠą╣ąĮąŠą╣ č鹊čćąĮąŠčüčéčīčÄ, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąŠąĮąĮąŠą╝ firmware. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ą░čüčī čüčĆąĄą┤ą░ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ MDK-ARMŌäó tool-chain V5.17.
ąóą░ą▒ą╗ąĖčåą░ 12. ąĪčĆą░ą▓ąĮąĄąĮąĖąĄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą░ą┐ą┐ą░čĆą░čéąĮčŗčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ ą┤ą▓ąŠą╣ąĮąŠą╣ č鹊čćąĮąŠčüčéąĖ ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą╣ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ.
ążčĆąĄą╣ą╝ Zoom ąöą╗ąĖč鹥ą╗čīąĮąŠčüčéčī ąöą╗ąĖč鹥ą╗čīąĮąŠčüčéčī SW ąÆčŗąĖą│čĆčŗčł
0
120
408
2920
7.16
1
110
355
2523
7.11
2
100
305
2145
7.03
3
150
550
3995
7.26
4
200
577
4197
7.27
5
275
547
3971
7.26
6
350
524
3799
7.25
7
450
533
3866
7.25
8
600
504
3643
7.23
9
800
492
3557
7.23
10
1000
481
3476
7.23
11
1200
470
3390
7.21
12
1500
446
3206
7.19
13
2000
386
2752
7.13
14
1500
446
3206
7.19
15
1200
470
3390
7.21
16
1000
481
3476
7.23
17
800
492
3557
7.23
18
600
504
3643
7.23
19
450
533
3866
7.25
20
350
524
3799
7.25
21
275
547
3971
7.26
22
200
577
4197
7.27
23
150
550
3995
7.26
24
100
305
2145
7.03
25
110
355
2523
7.11
ą£ąŠąČąĮąŠ čāą▓ąĖą┤ąĄčéčī, čćč鹊 čüąŠąŠčéąĮąŠčłąĄąĮąĖąĄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą░ą┐ą┐ą░čĆą░čéąĮčŗčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ ąŠą┤ąĖąĮą░čĆąĮąŠą╣ č鹊čćąĮąŠčüčéąĖ ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą╣ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ąĮą░ą╝ąĮąŠą│ąŠ ą▓čŗčłąĄ, č湥ą╝ čüąŠąŠčéąĮąŠčłąĄąĮąĖąĄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ ą░ą┐ą┐ą░čĆą░čéąĮąŠą╣ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą┤ą▓ąŠą╣ąĮąŠą╣ č鹊čćąĮąŠčüčéąĖ ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą╣ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ, ą┐ąŠčŹč鹊ą╝čā ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÄ čüą╗ąĄą┤čāąĄčé ą┐čĆąĖą╝ąĄąĮčÅčéčī ą┤ą▓ąŠą╣ąĮčāčÄ č鹊čćąĮąŠčüčéčī č鹊ą╗čīą║ąŠ ą▓ čüą╗čāčćą░ąĄ, ą║ąŠą│ą┤ą░ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ą┐ąŠą╗čāčćąĖčéčī ą┐ąŠą▓čŗčłąĄąĮąĮčāčÄ č鹊čćąĮąŠčüčéčī ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣. ą×ą┤ąĮą░ą║ąŠ ąĄčüą╗ąĖ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ąĮčāąČą┤ą░ąĄčéčüčÅ ą▓ ą┐ąŠą▓čŗčłąĄąĮąĮąŠą╣ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ ąĖ ą╝ąĄąĮčīčłąĄą╝ čĆą░čüčģąŠą┤ąĄ RAM, ąŠąĮ ą┤ąŠą╗ąČąĄąĮ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čćąĖčüą╗ą░ float.
ąöą╗čÅ ą│ąĄąĮąĄčĆą░čåąĖąĖ ą╝ąĮąŠąČąĄčüčéą▓ą░ ą£ą░ąĮą┤ąĄą╗čīą▒čĆąŠčéą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čéą░ ąČąĄ čüą░ą╝ą░čÅ ąĖč鹥čĆą░čéąĖą▓ąĮą░čÅ čäčāąĮą║čåąĖčÅ, čćč鹊 ąĖ ą┤ą╗čÅ ą╝ąĮąŠąČąĄčüčéą▓ą░ ą¢čÄą╗ąĖą░, ą│ą┤ąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ c ą▒čāą┤ąĄčé ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅčéčī ą┐ąŠąĘąĖčåąĖčÄ, ąĄčüą╗ąĖ č鹊čćą║ą░ ąĖ z ą▒čāą┤čāčé ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ąĮą░čćą░ą╗čīąĮąŠą╝ ą┐ąŠą╗ąŠąČąĄąĮąĖąĖ (x=0, y=0).
void drawMandelbrot_Double (float centre_X,
float centre_Y,
float Zoom,
uint16_t IterationMax)
{
double X_Min = centre_X - 1.0 / Zoom;
double X_Max = centre_X + 1.0 / Zoom;
double Y_Min = centre_Y - (YSIZE_PHYS- CONTROL_SIZE_Y) / (XSIZE_PHYS * Zoom);
double Y_Max = centre_Y + (YSIZE_PHYS- CONTROL_SIZE_Y) / (XSIZE_PHYS * Zoom);
double dx = (X_Max - X_Min) / XSIZE_PHYS;
double dy = (Y_Max - Y_Min) / (YSIZE_PHYS- CONTROL_SIZE_Y) ;
double y = Y_Min;
double c;
for (uint16_t j = 0 ; j < (YSIZE_PHYS- CONTROL_SIZE_Y); j++ )
{
double x = X_Min;
for (uint16_t i = 0 ; i < XSIZE_PHYS; i++ )
{
double Zx = x;
double Zy = y;
int n = 0 ;
while (n < IterationMax)
{
double Zx2 = Zx * Zx;
double Zy2 = Zy * Zy;
double Zxy = 2.0 * Zx * Zy;
Zx = Zx2 - Zy2 + x;
Zy = Zxy + y;
if (Zx2 + Zy2 > 16.0 )
break ;
n++ ;
}
x += dx;
}
y += dy;
}
}
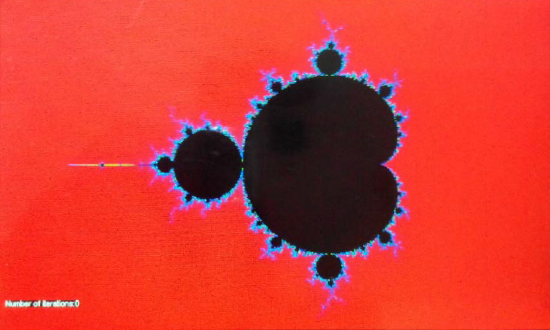
ąÜą░čĆčéąĖąĮą║ą░ ą╝ąĮąŠąČąĄčüčéą▓ą░ ą£ą░ąĮą┤ąĄą╗čīą▒čĆąŠčéą░, čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąĮą░čÅ čü zoom=1.
ąÜą░ąČą┤čŗą╣ čĆą░ąĘ ą┐čĆąĖ ą║ą░čüą░ąĮąĖąĖ čéą░čćčüą║čĆąĖąĮą░ ą║ą░čĆčéąĖąĮą║ą░ ą▒čāą┤ąĄčé ą┐čĆąĖą▒ą╗ąĖąČą░čéčīčüčÅ ą▓ 4 čĆą░ąĘą░.
ąØą░ čüą╗ąĄą┤čāčÄčēąĄą╝ čĆąĖčüčāąĮą║ąĄ ą┐ąŠą║ą░ąĘą░ąĮą░ ą║ą░čĆčéąĖąĮą║ą░ čü ą▒ąŠą╗čīčłąĖą╝ ą┐čĆąĖą▒ą╗ąĖąČąĄąĮąĖąĄą╝, ąŠą│čĆą░ąĮąĖč湥ąĮąĮčŗą╝ ą┤ąŠčüčéąĖą│ąĮčāčéčŗą╝ čćąĖčüą╗ąŠą▓čŗą╝ ą┐čĆąĄą┤ąĄą╗ąŠą╝ 64-ą▒ąĖčé floating point. ąÜą░čĆčéąĖąĮą║ą░ ąĮą░čćąĖąĮą░ąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī čéčāą┐ąŠą╣ ą┐ąŠčüą╗ąĄ ą║čĆą░čéąĮąŠčüčéąĖ čāą▓ąĄą╗ąĖč湥ąĮąĖčÅ ą▓ 48 čĆą░ąĘ:
ąóąŠčé ąČąĄ ą░ą╗ą│ąŠčĆąĖčéą╝ ą▒čŗą╗ ą▓čŗčćąĖčüą╗ąĄąĮ ąĮą░ single precision FPU. ąÜą░čĆčéąĖąĮą║ą░ ąĮą░čćąĖąĮą░ąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī čéčāą┐ąŠą╣ ą┐ąŠčüą╗ąĄ ą║čĆą░čéąĮąŠčüčéąĖ čāą▓ąĄą╗ąĖč湥ąĮąĖčÅ ą▓ 32 čĆą░ąĘą░:
ą¤čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ą░ą┐ą┐ą░čĆą░čéąĮčŗčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąĖ double precision, FPU ąĮąĄ č鹊ą╗čīą║ąŠ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĮą░ą╝ ą┤ąŠčüčéąĖčćčī ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ, ą║ąŠč鹊čĆąŠąĄ ą╝čŗ čāąČąĄ ą▓ąĖą┤ąĄą╗ąĖ čü ą╝ąĮąŠąČąĄčüčéą▓ąŠą╝ ą¢čÄą╗ąĖą░, ąĮąŠ čéą░ą║ąČąĄ ą┤ą░ąĄčé ą▓čŗąĖą│čĆčŗčł ą▓ č鹊čćąĮąŠčüčéąĖ.
ąÉą┐ą┐ą░čĆą░čéąĮčŗąĄ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ FPU čāčüą║ąŠčĆčÅčÄčé ą░ą╗ą│ąŠčĆąĖčéą╝ ą╝ąĮąŠąČąĄčüčéą▓ą░ ą¢čÄą╗ąĖą░ ą▓ 12.5 čĆą░ąĘ ą┐čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ float, ąĖ ą▓ 7.2 čĆą░ąĘą░ ą┐čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ double. ąØąĄ čéčĆąĄą▒čāąĄčéčüčÅ ąĮąĖą║ą░ą║ąŠą╣ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖąĖ ą║ąŠą┤ą░, FPU ą░ą║čéąĖą▓ąĖčĆčāąĄčéčüčÅ ąŠą┐čåąĖčÅą╝ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░. ąóą░ą║ąČąĄ FPU ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čĆą░čüčłąĖčĆąĖčéčī ą┤ąĖą░ą┐ą░ąĘąŠąĮ č鹊čćąĮąŠčüčéąĖ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, STM32 FPU čĆąĄą░ą╗ąĖąĘčāąĄčé ąŠč湥ąĮčī ą▒čŗčüčéčĆčŗąĄ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ ą┤ą╗čÅ čćąĖčüąĄą╗ float ąĖ double, čćč鹊 ąŠč湥ąĮčī ą▓ą░ąČąĮąŠ ą┤ą╗čÅ č鹊čćąĮčŗčģ čüąĖčüč鹥ą╝ čĆąĄą│čāą╗ąĖčĆąŠą▓ą░ąĮąĖčÅ, ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĘą▓čāą║ą░, ą┤ąĄą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖčÅ ąĘą▓čāą║ą░ ąĖą╗ąĖ čåąĖčäčĆąŠą▓ąŠą╣ čäąĖą╗čīčéčĆą░čåąĖąĖ. ąĀą░ąĘčĆą░ą▒ąŠčéą║ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ čāčüą║ąŠčĆčÅąĄčéčüčÅ ąĖ čĆąĄąĘčāą╗čīčéą░čé čüčéą░ąĮąŠą▓ąĖčéčüčÅ ą▒ąĄąĘąŠą┐ą░čüąĮąĄąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 ą┐čĆąŠčēąĄ ą┐čĆąĖą╝ąĄąĮčÅčéčī ą▓čŗčüąŠą║ąŠčāčĆąŠą▓ąĮąĄą▓čŗąĄ čüčĆąĄą┤čüčéą▓ą░ ą│ąĄąĮąĄčĆą░čåąĖąĖ ą║ąŠą┤ą░.
[ąĪčüčŗą╗ą║ąĖ ]
1 . AN4044 Floating point unit demonstration on STM32 microcontrollers site:st.com.2 . PM0214 STM32 Cortex® -M4 MCUs and MPUs programming manual site:st.com.