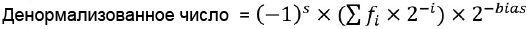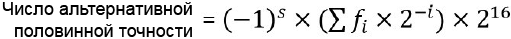| STM32: блок вычислений с плавающей точкой |
|
| Добавил(а) microsin | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Этот апноут (перевод AN4044 [1]) показывает, как использовать блоки плавающей точки (floating-point unit, сокращенно FPU), которые есть у микроконтроллеров семейств STM32 Cortex®-M4 и STM32 Cortex®-M7. Также дан краткий обзор арифметики с плавающей точкой. Разработано демонстрационное приложение (firmware) X-CUBE-FPUDEMO, где представлена работа FPU с вычислениями плавающей точки с двойной точностью (double precision), и демонстрируются улучшения от использования аппаратной обработки плавающей точки (в конце статьи приведены два примера использования FPU). [Арифметика с плавающей точкой] Числа с плавающей точкой используются для представления не целых чисел. Они состоят из 3 полей: • Знак числа. Такое представление позволяет кодировать очень широкий диапазон значений, что делает числа с плавающей запятой самым лучшим способом работать с реальными числами. Вычисления с плавающей точкой могут быть ускорены блоком FPU, встроенным в процессор. Различия фиксированной точки и плавающей точки. Одна из альтернатив для чисел с плавающей точкой - числа с фиксированной точкой, где размер поля экспоненты фиксирован. Скорость вычисления с числами фиксированной точки эквивалентна скорости вычисления с целыми числами той же разрядности. Однако если фиксированная точка дает высокое быстродействие на процессорах, где нет блока FPU, диапазон чисел с фиксированной точкой и их динамика низкие. Как следствие разработчик, который использует технику фиксированной точки, должен тщательно проверять рабочие диапазоны чисел и решать проблемы масштабирования/насыщения в применяемом алгоритме. Таблица 1. Динамический диапазон целых чисел.
Язык C предоставляет типы float и double для операций плавающей точки. Инструменты моделирования верхнего уровня, такие как MATLAB или Scilab, обычно генерирует C-код, использующий float или double. Отсутствие поддержки плавающей точки означает модификацию сгенерированного кода, чтобы адаптировать его к фиксированной точке. И все операции с фиксированной точкой должны быть жестко закодированы разработчиком. Таблица 2. Динамический диапазон чисел с плавающей точкой.
При традиционном использовании в коде операции с плавающей точкой снижают время разработки проекта. И это наиболее эффективный способ реализовать любой математический алгоритм. FPU. Вычисления с плавающей точкой требуют некоторых ресурсов для любых операций между двумя числами. Например, нам нужно: • Выравнивание двух чисел (они должны иметь одинаковую экспоненту). На процессоре без блока FPU все эти операции реализуются программно через библиотеку компилятора C, и они невидимы для программиста; однако производительность получается очень низкой. На процессорах, у которых на борту есть FPU, все операции полностью выполняются аппаратно, для большинства инструкций за 1 такт ядра. Компилятор C не использует свою собственную библиотеку плавающий точки, напрямую генерируя вместо этого инструкции FPU. Когда реализуется математический алгоритм на микропроцессоре, у которого есть FPU, программисту уже не надо выбирать между высокой производительностью и малым временем разработки. FPU привносит надежность, позволяя напрямую использовать код, сгенерированный высокоуровневыми инструментами (MATLAB или Scilab), с самым высоким уровнем производительности. [IEEE 754 - стандарт для арифметики с плавающей точкой] Использование арифметики плавающей точки всегда было востребовано в области компьютерных вычислений, даже на самых ранних этапах развития вычислительной техники. В конце 30-х годов, когда Konrad Zuse в Германии разработал Z-серию вычислителей, в них уже была реализована плавающая точка. Однако сложность внедрения аппаратной поддержки арифметики с плавающей точкой заставляла отказываться от её использования на протяжении десятилетий. В середине 50-х годов фирма IBM с компьютером 704 показала FPU в мэйнфреймах; и в 70-х появились различные платформы, где поддерживались операции с плавающей точкой, однако в них использовались индивидуальные техники кодирования чисел. Унификация произошла в 1985 году, когда IEEE опубликовала стандарт 754, где определила общие методы поддержки вычислений с плавающей точкой. Различные типы реализаций плавающей точки, разработанные за все годы, заставили IEEE стандартизировать следующие элементы: • Форматы чисел. Форматы чисел. Все значения построены из трех битовых полей: • Знак числа: s. • Смещенная экспонента: • Дробная часть, фракция (или мантисса): f. Значения могут кодироваться следующими длинами бит: • 16 бит: формат половинной точности (half precision).
Рис. 1. Кодирование чисел плавающей точки одинарной и двойной точности по стандарту IEEE.754. Также IEEE определила 5 классов чисел: • Нормализованные числа. Различные классы чисел идентифицируются специальными значениями в этих полях. [Нормализованные числа] Нормализованное число это "стандартное" число с плавающей точкой. Его значение дает следующая формула (i > 0):
У bias значение фиксировано для каждой разрядности (точности) числа с плавающей точкой (8 бит, 16 бит, 32 бита и 64 бита). Таблица 3. Диапазон нормализованных чисел.
Пример кодирования числа -7 с одинарной точностью (single-precision): • Бит знака s = 1 [Денормализованные числа] Денормализованное число используется для представления значений, которые используются для представления значений, которые слишком маленькие для нормализации (когда экспонента равна 0). Значение денормализованного числа определяется по формуле (i > 0):
Таблица 4. Диапазон денормализованных чисел.
[Нули] Значение Zero имеет знак, чтобы показать насыщение (положительное или отрицательное). И экспонента, и фракция равны нулю. [Бесконечности] Значение Infinite также имеет знак, чтобы показать +∞ или -∞. Значения Infinite получаются в результате переполнения или деления на 0. Экспонента устанавливается на свое максимальное значение, в то время как мантисса равна нулю. [NaN (Not-a-Number)] NaN используется как неопределенный результат операции, например 0/0 или квадратный корень от отрицательного числа. Экспонента устанавливается на свое максимальное значение, в то время как мантисса не нулевая. MSB мантиссы показывает, является ли это Quiet NaN (которое может распространиться на следующую операцию) или Signaling NaN (что генерирует ошибку). Таблица 5. Диапазон значений для форматов числа IEEE.754.
[Режимы округления] Определено 4 главных режима округления: • Округление к ближайшему значению. Округление к ближайшему значению это режим округления по умолчанию (используется чаще всего). Если два ближайших значения одинаково близки, то выбирается из них то значение, у которого LSB равен 0. Режим округления очень важен, поскольку он влияет на результат арифметической операции. Режим округления может быть изменен настройкой регистра конфигурации FPU. [Арифметические операции] Стандарт IEEE.754 определяет 6 арифметических операций: • Сложение (Add) [Преобразования чисел] Также стандарт IEEE определяет операции преобразования некоторых форматов и операции их сравнения: • Преобразование чисел с плавающей точкой и целых чисел. [Исключение и его обработка] Поддерживается 5 исключений (exception): • Недопустимая операция: результат операции NaN. Исключение может быть обработано двумя способами: • Генерация ловушки (trap). Обработчик trap вернет значение, используемое вместо результата, вызвавшего исключение. Стандарт IEEE.754 определяет, как числа с плавающей запятой кодируются, и как они обрабатываются. FPU, реализованный аппаратно, ускоряет вычисления с плавающей точкой по стандарту IEEE 754. Таким образом, он может реализовать либо весь стандарт IEEE целиком, либо его подмножество. Соответствующая программная библиотека реализует не поддерживаемые аппаратным ускорением функции. Для "базового" использования поддержка плавающей точки прозрачна для пользователя, как при использовании типа float в коде языка C. Для более продвинутых приложений могут обрабатываться исключения через ловушки или прерывания. [STM32 Cortex®-M floating-point unit (FPU)] В таблице 6 показаны варианты реализации FPU для STM32 Cortex®-M4 и Cortex®-M7. Таблица 6. Реализация FPU в STM32 Cortex®-M4/-M7.
Cortex® M4 FPU. Реализация Cortex® M4 FPU содержит ARM® FPv4-SP (блок плавающей запятой одинарной точности). Здесь имеется собственный набор из 32-битных single precision регистров (S0-S31) для обработки операций и хранения результатов. Эти регистры можно рассматривать как 16 регистров двойных слов (D0-15) для операций загрузки/сохранения (load/store). Регистр состояния и конфигурации (Status & Configuration Register) хранит настройки FPU (режим округления и специальные настройки), биты описания результата операции (negative, zero, carry и overflow) и флаги исключений (exception flags). Некоторые операции стандарта IEEE.754 не поддерживаются аппаратно, и реализуются программно: • Remainder. Исключения обрабатываются через прерывания (ловушки не поддерживаются). Cortex® M7 FPU. Блок плавающей точки Cortex®-M7 это реализация ARM® FPv5. Здесь полностью поддерживаются вычисления одинарной и двойной точности, а также преобразования между формами плавающей точки и фиксированной точки, и есть инструкции констант с плавающей точкой. FPU поддерживает IEEE754-совместимые 32-битные операции одинарной точности (single-precision) и 64-битные значения двойной точности (double-precision). Имеется расширенный файл регистров, содержащий 32 регистра одинарной точности. Они могут рассматриваться следующим образом: • Шестнадцать 64-битных регистров двойного слова (D0-D15), которые такие же, как в версии FPv4 без дополнительных регистров. FPv5 предоставляет аппаратную поддержку для денормализованных чисел и все режимы округления стандарта IEEE 754-2008. Специальные рабочие режимы. Cortex®M4 FPU полностью совместим со спецификациями IEEE.754. Однако могут быть активированы некоторые нестандартные режимы: • Альтернативный формат половинной точности (Alternative Half-precision, включается битом управления AHP). Это специальный 16-битный режим без значения экспоненты и без поддержки денормализованных чисел.
• Режим Flush-to-zero (бит управления FZ). Все денормализованные числа обрабатываются как нули. Имеется флаг, связанный со сбросом (flush) входа и выхода. • Режим NaN по умолчанию (бит управления DN). Любая операция с NaN на входе, или которая генерирует NaN, вернет default NaN (Quiet NaN). Floating-point status and control register (FPSCR). Регистр FPSCR хранит состояние FPU - биты условия (condition bits) и флаги исключения (exception flags), а также его конфигурацию (режимы округления и альтернативные режимы). Как следствие этот регистр можно сохранять в стек, когда меняется контекст выполнения кода. К FPSCR осуществляется доступ специальными инструкциями: • Чтение (Read): VMRS Rx, FPSCR Регистр FPSCR и его биты:
N, Z, C, V. Это биты условия (condition bits), они устанавливаются после операции сравнения. AHP, DN, FZ, RM. Это биты режима, они конфигурируют альтернативные режимы (AHP, DN, FZ) и режим округления (RM). Флаги исключения (exception flags). Они устанавливаются при возникновении исключения (exception) в случае: • Flush to zero, сброс к нулю (IDC). Примечание: флаги исключения не сбрасываются следующей инструкцией. Исключения не могут быть перехвачены ловушкой (trap). Они обслуживаются контроллером прерывания. Сигнал от 5 флагов исключений (IDC, UFC, OFC, DZC, IOC) объединяется по ИЛИ и поступает на контроллер прерываний. Нет никакой индивидуальной маски и разрешения/запрета прерывания FPU на уровне контроллера прерываний. Флаг IXC не соединен с контроллером прерывания, и не может генерировать прерывание, так как частота его появления очень велика. Если необходимо, он может обслуживаться путем опроса программой. Когда FPU разрешен, его контекст может быть сохранен в стеке CPU с использованием одного из трех методов: • Регистры плавающей точки не сохраняются. Фрейм стека состоит из 17 элементов: • FPSCR [Модель программирования] Когда MCU выходит из сброса, блок FPU должен быть разрешен указанием уровня доступа кода, использующего FPU (запрещено, привилегированный или полный доступ) в регистре Coprocessor Access Control Register (CPACR). FPSCR может быть сконфигурирован для определения альтернативных режимов или для режима округления. У FPU имеется 5 системных регистров: • FPCCR (FP Context Control Register), показывающий контекст, когда выделен фрейм стека FP, вместе с настройкой сохранения контекста. [Инструкции FPU] Поддерживаются инструкции арифметических операций, сравнения, преобразования и загрузки/сохранения. Арифметические инструкции. FPU предоставляет арифметические инструкции для: • Получение абсолютного значения (Absolute value), выполняется за 1 такт. Таблица 8 показывает некоторые инструкции обработки данных плавающей точки одинарной точности. Таблица 8. Инструкции обработки данных floating-point, single-precision.
Таблица 9 показывает некоторые инструкции обработки данных плавающей точки двойной точности. Таблица 9. Инструкции обработки данных floating-point, double-precision.
Все MAC-операции могут быть стандартные или типа fused (округление делается по окончании MAC для повышенной точности). Инструкции сравнения и преобразования. Имеются инструкции сравнения (выполняются за 1 такт) и преобразования (также выполняются за 1 такт). Преобразование может быть между целым числом, числом с фиксированной точкой, числом half precision и числом float. Инструкции load/store. FPU следует стандартной архитектуре загрузки/сохранения: • Загрузка (load) и сохранение (store) нескольких значений double, нескольких float, одиночных double или одиночных float. [Примеры приложений] Следующие два примера показывают выгоду от использования STM32 FPU. В первом примере вычисляется множество Жюлиа (Julia set), где сравнивается производительность аппаратного FPU и традиционных вычислений. Второй пример вычисляет множество Мандельброта (Mandelbrot set), где показаны различия в производительности аппаратных вычислений double precision FPU и аппаратных вычислений single precision FPU. MCU вычисляет простой математический фрактал: множество Жюлиа. Алгоритм генерации этого математического объекта довольно простой: для каждой точки комплексного плана мы оцениваем скорость расхождения (divergence speed) определяемой последовательности. Выражение для последовательности множества Жюлиа: zn+1 = zn2 + c Для каждой точки x + i.y комплексного плана мы вычисляем последовательность со значением c = cx + i.cy: xn+1 + i.yn+1 = xn2 - yn2 + 2.i.xn.yn + cx + i.cy Как только результирующее комплексное значение выходит из заданной окружности (величина числа больше радиуса окружности), последовательность расходится, и количество итераций, сделанных для достижения этого предела, ассоциируется с точкой. Это значение преобразуется в цвет, чтобы графически показать скорость дивергенции точек комплексного плана. Для имеющегося количества итераций, если результирующее комплексное значение остается внутри окружности, вычисление останавливается с учетом, что последовательность не расходится: void GenerateJulia_fpu (uint16_t size_x, uint16_t size_y, uint16_t offset_x, uint16_t offset_y, uint16_t zoom, uint8_t * buffer) { float tmp1, tmp2; float num_real, num_img; float radius; uint8_t i; uint16_t x,y; for (y=0; y < size_y; y++) { for (x=0; x < size_x; x++) { num_real = y - offset_y; num_real = num_real / zoom; num_img = x - offset_x; num_img = num_img / zoom; i=0; radius = 0; while ((i < ITERATION-1) && (radius < 4)) { tmp1 = num_real * num_real; tmp2 = num_img * num_img; num_img = 2*num_real*num_img + IMG_CONSTANT; num_real = tmp1 - tmp2 + REAL_CONSTANT; radius = tmp1 + tmp2; i++; } /* Сохранение значения в буфер: */ buffer[x+y*size_x] = i; } } } Этот алгоритм очень эффективен для демонстрации выгод использования FPU: не требуется никакой модификации кода, просто нужно активировать FPU, просто он должен быть активирован или не активирован на фазе компиляции. Для обслуживания не требуется дополнительный код FPU, поскольку он используется в режиме по умолчанию. На рисунке голубым цветом показано отображение множества Жюлиа, 8 бит на точку (c=0.285+i.0.01):
[Реализация на STM32F4] Чтобы лучше показать картинку на экране RGB565 оценочной платы разработчика STM3240G-EVAL, мы используем специальную палитру для кодирования цветовых значений. Максимальное значение итерации установлено на 128. Как следствие цветовая палитра имеет 128 элементов. Радиус круга установлен на 2. Функция main вызывает все подпрограммы инициализации платы, чтобы настроить дисплей и кнопки управления. • Кнопка WAKUP выполняет переключение из автоматического режима (приближение и удаление картинки) в ручной и обратно. Весь проект скомпилирован с разрешенным FPU, кроме модуля GenerateJulia_noFPU.c, для компиляции которого принудительно выключен FPU. Отображение множества Жюлиа с палитрой RGB565 (c=0.285+i.0.01):
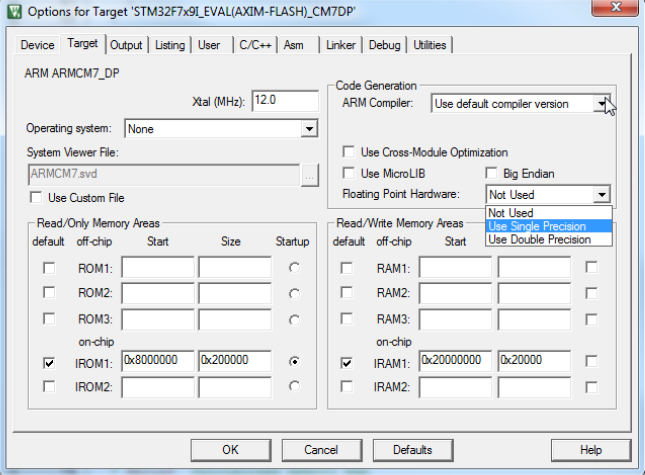
[Реализация на STM32F7] Тот же самый алгоритм реализован на оценочной плате разработчика STM32F769i-Eval. Микроконтроллер работает на частоте 216 МГц, в следующих двух конфигурациях: разрешен FPU single precision, и разрешен FPU double precision. Это сделано в среде разработки RealView Microcontroller Development Kit (MDK-ARM™) tool-chain V5.17. Опции конфигурирования FPU показаны на рисунке:
Для STM32F7 реализован только ручной режим. При определении касания к тачскрину запускается другой вариант вычислений. Также был изменен алгоритм: void GenerateJulia_fpu (uint16_t size_x, uint16_t size_y, uint16_t offset_x, uint16_t offset_y, uint16_t zoom, uint8_t * buffer) { double tmp1, tmp2; double num_real, num_img; double radius; uint8_t i; uint16_t x,y; for (y=0; y < size_y; y++) { for (x=0; x < size_x; x++) { num_real = y - offset_y; num_real = num_real / zoom; num_img = x - offset_x; num_img = num_img / zoom; i=0; radius = 0; while ((i < ITERATION-1) && (radius < 4)) { tmp1 = num_real * num_real; tmp2 = num_img * num_img; num_img = 2*num_real*num_img + IMG_CONSTANT; num_real = tmp1 - tmp2 + REAL_CONSTANT; radius = tmp1 + tmp2; i++; } /* Сохранение значения в буфер: */ buffer[x+y*size_x] = i; } } } [Результаты] Таблица 10 показывает время, затраченное Cortex®-M4 STM32F4 на вычисление множества Жюлиа для нескольких коэффициентов приближения, как показано в демонстрационном firmware. Использовалась среда разработки MDK-ARM™ tool-chain V5.17. Таблица 10. Сравнение производительности аппаратных вычислений одинарной точности Cortex®-M4 (HW SP FPU) и программной реализации тех же вычислений.
Таблица 11 показывает время, затраченное Cortex®-M7 STM32F7 на вычисление множества Жюлиа с теми же алгоритмами, которые были реализованы на Cortex®-M4 STM32F4, с одинарной точностью, для нескольких коэффициентов приближения, как показано в демонстрационном firmware. Использовалась среда разработки MDK-ARM™ tool-chain V5.17. Таблица 11. Сравнение производительности аппаратных вычислений одинарной точности Cortex®-M7 (HW SP FPU) и программной реализации тех же вычислений.
Таблица 12 показывает время, затраченное Cortex®-M7 STM32F7 на вычисление множества Жюлиа с теми же алгоритмами для нескольких коэффициентов приближения с двойной точностью, как показано в демонстрационном firmware. Использовалась среда разработки MDK-ARM™ tool-chain V5.17. Таблица 12. Сравнение производительности аппаратных вычислений двойной точности и программной реализации.
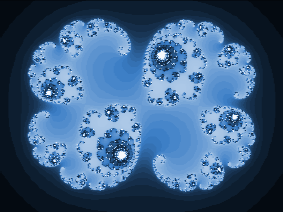
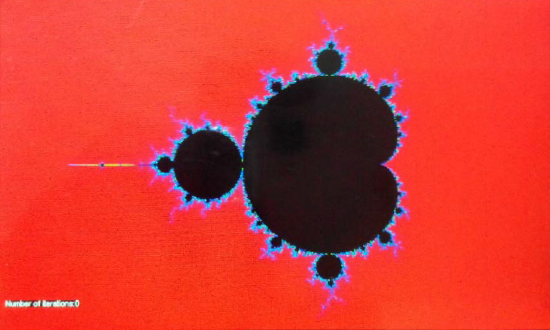
Можно увидеть, что соотношение производительности аппаратных вычислений одинарной точности и программной реализации намного выше, чем соотношение производительности аппаратной реализации двойной точности и программной реализации, поэтому пользователю следует применять двойную точность только в случае, когда необходимо получить повышенную точность вычислений. Однако если пользователь нуждается в повышенной производительности и меньшем расходе RAM, он должен использовать числа float. Для генерации множества Мандельброта используется та же самая итеративная функция, что и для множества Жюлиа, где переменная c будет представлять позицию, если точка и z будут находится в начальном положении (x=0, y=0). void drawMandelbrot_Double (float centre_X, float centre_Y, float Zoom, uint16_t IterationMax) { double X_Min = centre_X - 1.0/Zoom; double X_Max = centre_X + 1.0/Zoom; double Y_Min = centre_Y - (YSIZE_PHYS-CONTROL_SIZE_Y) / (XSIZE_PHYS * Zoom); double Y_Max = centre_Y + (YSIZE_PHYS-CONTROL_SIZE_Y) / (XSIZE_PHYS * Zoom); double dx = (X_Max - X_Min) / XSIZE_PHYS; double dy = (Y_Max - Y_Min) / (YSIZE_PHYS-CONTROL_SIZE_Y) ; double y = Y_Min; double c; for (uint16_t j = 0; j < (YSIZE_PHYS-CONTROL_SIZE_Y); j++) { double x = X_Min; for (uint16_t i = 0; i < XSIZE_PHYS; i++) { double Zx = x; double Zy = y; int n = 0; while (n < IterationMax) { double Zx2 = Zx * Zx; double Zy2 = Zy * Zy; double Zxy = 2.0 * Zx * Zy; Zx = Zx2 - Zy2 + x; Zy = Zxy + y; if(Zx2 + Zy2 > 16.0) break; n++; } x += dx; } y += dy; } } Картинка множества Мандельброта, сгенерированная с zoom=1.
Каждый раз при касании тачскрина картинка будет приближаться в 4 раза. На следующем рисунке показана картинка с большим приближением, ограниченным достигнутым числовым пределом 64-бит floating point. Картинка начинает выглядеть тупой после кратности увеличения в 48 раз:
Тот же алгоритм был вычислен на single precision FPU. Картинка начинает выглядеть тупой после кратности увеличения в 32 раза:
При использовании аппаратных вычислений плавающей точки double precision, FPU не только позволяет нам достичь времени вычисления, которое мы уже видели с множеством Жюлиа, но также дает выигрыш в точности. Аппаратные вычисления FPU ускоряют алгоритм множества Жюлиа в 12.5 раз при использовании float, и в 7.2 раза при использовании double. Не требуется никакой модификации кода, FPU активируется опциями компилятора. Также FPU позволяет расширить диапазон точности. Таким образом, STM32 FPU реализует очень быстрые вычисления для чисел float и double, что очень важно для точных систем регулирования, обработки звука, декодирования звука или цифровой фильтрации. Разработка приложений ускоряется и результат становится безопаснее, потому что проще применять высокоуровневые средства генерации кода. [Ссылки] 1. AN4044 Floating point unit demonstration on STM32 microcontrollers site:st.com. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||