|
ąÆ čŹč鹊ą╣ čüčéą░čéčīąĄ (ą┐ąĄčĆąĄą▓ąŠą┤ [1]) ąŠą▒čüčāąČą┤ą░ąĄčéčüčÅ ą║ąŠąĮčåąĄą┐čåąĖčÅ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ ą┐ąŠč鹊ą║ąŠą▓ ą┤ą╗čÅ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠą│ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ąĮą░ čÅąĘčŗą║ąĄ Python [2].
[ąĪąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÅ ą╝ąĄąČą┤čā ą┐ąŠč鹊ą║ą░ą╝ąĖ]
ąĪąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÅ ą┐ąŠč鹊ą║ąŠą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮą░ ą║ą░ą║ ą╝ąĄčģą░ąĮąĖąĘą╝, ą║ąŠč鹊čĆčŗą╣ ąŠą▒ąĄčüą┐ąĄčćąĖą▓ą░ąĄčé ąĮąĄą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą┤ą╗čÅ ą┤ą▓čāčģ ąĖą╗ąĖ ą▒ąŠą╗čīčłąĄą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą┐ąŠč鹊ą║ąŠą▓ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą▓čŗą┐ąŠą╗ąĮčÅčéčī ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ čüąĄą│ą╝ąĄąĮčé ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ąĖąĘą▓ąĄčüčéąĮčŗą╣ ą║ą░ą║ ą║čĆąĖčéąĖč湥čüą║ą░čÅ čüąĄą║čåąĖčÅ.
ąÜčĆąĖčéąĖč湥čüą║ą░čÅ čüąĄą║čåąĖčÅ ąŠčéąĮąŠčüąĖčéčüčÅ ą║ čćą░čüčéčÅą╝ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ą│ą┤ąĄ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ ą║ ąŠą▒čēąĄą╝čā čĆąĄčüčāčĆčüčā (čéą░ą║ąŠą╝čā ą║ą░ą║ čäą░ą╣ą╗ ąĖą╗ąĖ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗą╣ ą┐ąŠčĆčé).
ąØą░ ą┤ąĖą░ą│čĆą░ą╝ą╝ąĄ ąĮąĖąČąĄ ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąĖą╝ąĄčĆ, ą│ą┤ąĄ 3 ą┐ąŠč鹊ą║ą░ ą┐čŗčéą░čÄčéčüčÅ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ąŠą▒čĆą░čéąĖčéčīčüčÅ ą║ ąŠą▒čēąĄą╝čā čĆąĄčüčāčĆčüčā, ąĖą╗ąĖ ą║ ą║čĆąĖčéąĖč湥čüą║ąŠą╣ čüąĄą║čåąĖąĖ. ąŁč鹊 čéą░ą║ąČąĄ ąĮą░ąĘčŗą▓ą░čÄčé ą║ąŠąĮą║čāčĆąĄąĮčéąĮčŗą╝ ą┤ąŠčüčéčāą┐ąŠą╝ ą║ ąŠą▒čēąĄą╝čā čĆąĄčüčāčĆčüčā.
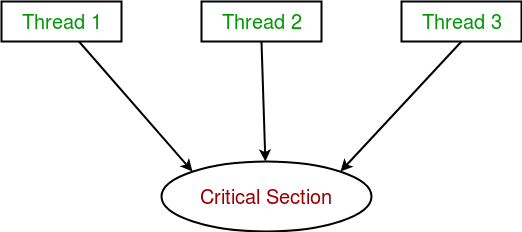
ąæąĄąĘ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ ą║ąŠąĮą║čāčĆąĄąĮčéąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ąŠą▒čēąĄą╝čā čĆąĄčüčāčĆčüčā ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą│ąŠąĮą║ąĄ ą╝ąĄąČą┤čā ą┐ąŠč鹊ą║ą░ą╝ąĖ (čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝čŗą╣ čĆąĄą╣čüąĖąĮą│, race condition, ąĖ čüąŠčüčéčÅąĘą░ąĮąĖąĄ ą┐ąŠč鹊ą║ąŠą▓), ą║ąŠą│ą┤ą░ ąĄčüčéčī čĆąĖčüą║ ą┐ąŠč鹥čĆąĖ čåąĄą╗ąŠčüčéąĮąŠčüčéąĖ ąŠą▒čēąĄą│ąŠ čĆąĄčüčāčĆčüą░.
ąĀąĄą╣čüąĖąĮą│ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé, ą║ąŠą│ą┤ą░ ą┤ą▓ą░ ąĖą╗ąĖ ą▒ąŠą╗čīčłąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠč鹊ą║ąŠą▓ ą┐čŗčéą░čÄčéčüčÅ ąŠą▒čĆą░čéąĖčéčīčüčÅ ą║ ąŠą▒čēąĄą╝čā čĆąĄčüčāčĆčüčā ąĖ ąĖąĘą╝ąĄąĮąĖčéčī ąĄą│ąŠ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ. ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 ąĘąĮą░č湥ąĮąĖčÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ ąŠą▒čēąĄą│ąŠ čĆąĄčüčāčĆčüą░ ą╝ąŠą│čāčé čüčéą░čéčī ąĮąĄą┐čĆąĄą┤čüą║ą░ąĘčāąĄą╝čŗą╝ąĖ, ąĖ ą╝ąĄąĮčÅčéčīčüčÅ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ąĖąĮč鹥čĆą▓ą░ą╗ąŠą▓ ą▓čĆąĄą╝ąĄąĮąĖ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ ą║ąŠąĮč鹥ą║čüčéą░ ą┐ąŠč鹊ą║ąŠą▓.
ąĀą░čüčüą╝ąŠčéčĆąĖą╝ ą┐čĆąŠą│čĆą░ą╝ą╝čā, ą║ąŠč鹊čĆą░čÅ ą┐ąŠą╝ąŠąČąĄčé ą┐ąŠąĮčÅčéčī ą║ąŠąĮčåąĄą┐čåąĖčÄ čĆąĄą╣čüąĖąĮą│ą░:
import threading
# ąōą╗ąŠą▒ą░ą╗čīąĮą░čÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ x:
x = 0
# ążčāąĮą║čåąĖčÅ ą┤ą╗čÅ ąĖąĮą║čĆąĄą╝ąĄąĮčéą░ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ x:
def increment():
global x
x += 1
# ąŚą░ą┤ą░čćą░ ą┐ąŠč鹊ą║ą░, ą║ąŠč鹊čĆą░čÅ ą▓čŗąĘčŗą▓ą░ąĄčé čäčāąĮą║čåąĖčÄ increment
# 100000 čĆą░ąĘ:
def thread_task():
for _ in range(100000):
increment()
def main_task():
global x
# ąŻčüčéą░ąĮąŠą▓ą║ą░ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ x ą▓ 0:
x = 0
# ąĪąŠąĘą┤ą░ąĮąĖąĄ ą┐ąŠč鹊ą║ąŠą▓:
t1 = threading.Thread(target=thread_task)
t2 = threading.Thread(target=thread_task)
# ąŚą░ą┐čāčüą║ ą┐ąŠč鹊ą║ąŠą▓:
t1.start()
t2.start()
# ą×ąČąĖą┤ą░ąĮąĖąĄ, ą║ąŠą│ą┤ą░ ą┐ąŠč鹊ą║ąĖ ąĘą░ą▓ąĄčĆčłą░čé čüą▓ąŠčÄ čĆą░ą▒ąŠčéčā:
t1.join()
t2.join()
if __name__ == "__main__":
for i in range(10):
main_task()
print("ąśč鹥čĆą░čåąĖčÅ {0}: x = {1}".format(i,x))
ąÆčŗą▓ąŠą┤ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ:
ąśč鹥čĆą░čåąĖčÅ 0: x = 175005
ąśč鹥čĆą░čåąĖčÅ 1: x = 200000
ąśč鹥čĆą░čåąĖčÅ 2: x = 200000
ąśč鹥čĆą░čåąĖčÅ 3: x = 169432
ąśč鹥čĆą░čåąĖčÅ 4: x = 153316
ąśč鹥čĆą░čåąĖčÅ 5: x = 200000
ąśč鹥čĆą░čåąĖčÅ 6: x = 167322
ąśč鹥čĆą░čåąĖčÅ 7: x = 200000
ąśč鹥čĆą░čåąĖčÅ 8: x = 169917
ąśč鹥čĆą░čåąĖčÅ 9: x = 153589
ąÆ čŹč鹊ą╣ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĖąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ:
ŌĆó ąÆ čäčāąĮą║čåąĖąĖ main_task čüąŠąĘą┤ą░čÄčéčüčÅ ą┤ą▓ą░ ą┐ąŠč鹊ą║ą░ t1 ąĖ t2, ąĖ ą│ą╗ąŠą▒ą░ą╗čīąĮą░čÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ x čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ą▓ 0.
ŌĆó ąÜą░ąČą┤čŗą╣ ą┐ąŠč鹊ą║ ąĖą╝ąĄąĄčé čåąĄą╗ąĄą▓čāčÄ čäčāąĮą║čåąĖčÄ thread_task, ą▓ ą║ąŠč鹊čĆąŠą╣ čäčāąĮą║čåąĖčÅ increment ą▓čŗąĘčŗą▓ą░ąĄčéčüčÅ 100000 čĆą░ąĘ.
ŌĆó ążčāąĮą║čåąĖčÅ increment ą▒čāą┤ąĄčé ąĖąĮą║čĆąĄą╝ąĄąĮčéąĖčĆąŠą▓ą░čéčī ąĮą░ 1 ą│ą╗ąŠą▒ą░ą╗čīąĮčāčÄ x ą▓ ą║ą░ąČą┤ąŠą╝ ą▓čŗąĘąŠą▓ąĄ.
ŌĆó ą”ąĖą║ą╗ for ąŠčüąĮąŠą▓ąĮąŠą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĘą░ą┐čāčüą║ą░ąĄčé ąŠą┐ąĖčüą░ąĮąĮčŗąĄ ą▓čŗčłąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ 10 čĆą░ąĘ.
ą×ąČąĖą┤ą░ąĄčéčüčÅ, čćč鹊 ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 čĆą░ą▒ąŠčéčŗ ąŠą▒ąŠąĖčģ ą┐ąŠč鹊ą║ąŠą▓ ąĮą░ ą║ą░ąČą┤ąŠą╣ ąĖč鹥čĆą░čåąĖąĖ čåąĖą║ą╗ą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ x ą┤ąŠą╗ąČąĮą░ ą▒čāą┤ąĄčé čüąŠą┤ąĄčƹȹ░čéčī ąĘąĮą░č湥ąĮąĖąĄ 200000. ąØąŠ ąŠč湥ą▓ąĖą┤ąĮąŠ, čćč鹊 čŹč鹊 ą┐ąŠą╗čāčćą░ąĄčéčüčÅ ą┤ą░ą╗ąĄą║ąŠ ąĮąĄ ą▓čüąĄą│ą┤ą░. ą¦č鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé?..
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąĮą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ čĆąĄąĘčāą╗čīčéą░čé ą╝ąŠąČąĄčé ąŠčéą╗ąĖčćą░čéčīčüčÅ ąŠčé ą▓ąĄčĆčüąĖąĖ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ. ą¤ąŠą║ą░ąĘą░ąĮąĮčŗą╣ ą▓čŗčłąĄ ą▓čŗą▓ąŠą┤ čü ąŠčéą╗ąĖčćą░čÄčēąĖą╝ąĖčüčÅ ąĘąĮą░č湥ąĮąĖčÅą╝ąĖ x ą▒čŗą╗ ą┤ą╗čÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ąĘą░ą┐čāčēąĄąĮąĮąŠą╣ ąĮą░ Ubuntu. ąØą░ Windows ą▓ ą║ą░ąČą┤ąŠą╣ ąĖč鹥čĆą░čåąĖąĖ ąĘąĮą░č湥ąĮąĖąĄ x ą┐ąŠą╗čāčćą░ą╗ąŠčüčī 200000.
ąØąĄ ąŠą┤ąĖąĮą░ą║ąŠą▓čŗąĄ ą▓čŗčćąĖčüą╗ąĄąĮąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ x ą┐ąŠą╗čāčćą░čÄčéčüčÅ ąĖąĘ-ąĘą░ ą║ąŠąĮą║čāčĆąĄąĮčéąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą║ ąŠą▒čēąĄą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ x. ąŁčéą░ ąĮąĄą┐čĆąĄą┤čüą║ą░ąĘčāąĄą╝ąŠčüčéčī ą▓ ąĘąĮą░č湥ąĮąĖąĖ x - ąĮąĄ čćč鹊 ąĖąĮąŠąĄ, ą║ą░ą║ čüąŠčüč鹊čÅąĮąĖąĄ ą│ąŠąĮą║ąĖ.
ąØąĖąČąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮą░ ą┤ąĖą░ą│čĆą░ą╝ą╝ą░, ą║ąŠč鹊čĆą░čÅ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, ą║ą░ą║ čüąŠčüč鹊čÅąĮąĖąĄ ą│ąŠąĮą║ąĖ ą╝ąŠąČąĄčé ą▓ąŠąĘąĮąĖą║ąĮčāčéčī ą▓ ą▓čŗčłąĄčāą║ą░ąĘą░ąĮąĮąŠą╣ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ:
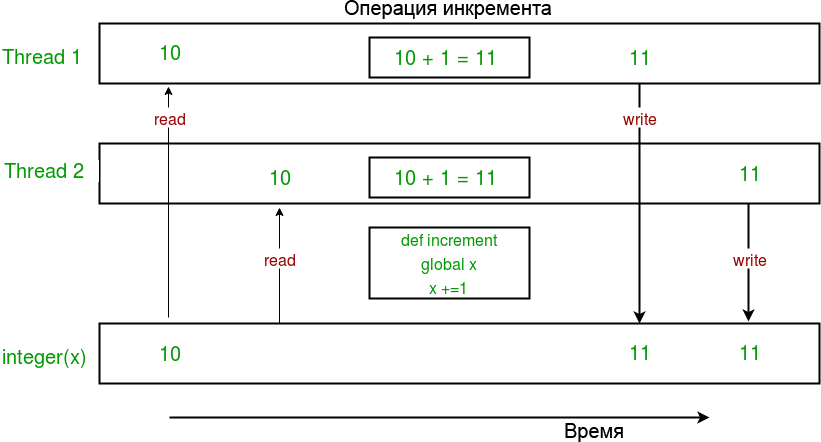
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąŠąČąĖą┤ą░ąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ x ąĮą░ ą┐čĆąĖą▓ąĄą┤ąĄąĮąĮąŠą╣ ą▓čŗčłąĄ ą┤ąĖą░ą│čĆą░ą╝ą╝ąĄ čĆą░ą▓ąĮąŠ 12, ąĮąŠ ąĖąĘ-ąĘą░ čüąŠčüč鹊čÅąĮąĖčÅ ą│ąŠąĮą║ąĖ ąŠąĮąŠ ąŠą║ą░ąĘčŗą▓ą░ąĄčéčüčÅ čĆą░ą▓ąĮčŗą╝ 11!
ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąĮą░ą╝ ąĮčāąČąĄąĮ ąĖąĮčüčéčĆčāą╝ąĄąĮčé ą┤ą╗čÅ ą┐čĆą░ą▓ąĖą╗čīąĮąŠą╣ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ ą╝ąĄąČą┤čā ą┐ąŠč鹊ą║ą░ą╝ąĖ.
[ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ ą║čĆąĖčéąĖč湥čüą║ąŠą╣ čüąĄą║čåąĖąĖ čü ą┐ąŠą╝ąŠčēčīčÄ Lock]
ą£ąŠą┤čāą╗čī threading ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą║ą╗ą░čüčü Lock, ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĮčŗą╣ ą┤ą╗čÅ čāčüčéčĆą░ąĮąĄąĮąĖčÅ ą│ąŠąĮą║ąĖ. Lock čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ąŠą▒čŖąĄą║čéą░ Semaphore, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄą╝ąŠą│ąŠ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝ąŠą╣.
ą¦č鹊 čéą░ą║ąŠąĄ čüąĄą╝ą░č乊čĆ. ąĪąĄą╝ą░č乊čĆ čŹč鹊 ąŠą▒čŖąĄą║čé čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ, ą║ąŠč鹊čĆčŗą╣ čāą┐čĆą░ą▓ą╗čÅąĄčé ą┤ąŠčüčéčāą┐ąŠą╝ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą┐čĆąŠčåąĄčüčüąŠą▓/ą┐ąŠč鹊ą║ąŠą▓ ą║ ąŠą▒čēąĄą╝čā čĆąĄčüčāčĆčüčā ą▓ čĆą░ą▒ąŠč湥ą╝ ąŠą║čĆčāąČąĄąĮąĖąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░. ąŁč鹊 ą┐čĆąŠčüč鹊 ąĘąĮą░č湥ąĮąĖąĄ ą▓ ąĮą░ąĘąĮą░č湥ąĮąĮąŠą╝ ą╝ąĄčüč鹥 ą▓ čģčĆą░ąĮąĖą╗ąĖčēą░ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ (ąĖą╗ąĖ čÅą┤čĆą░), ą║ąŠč鹊čĆąŠąĄ ą║ą░ąČą┤čŗą╣ ą┐čĆąŠčåąĄčüčü/ą┐ąŠč鹊ą║ ą╝ąŠąČąĄčé ą┐čĆąŠą▓ąĄčĆąĖčéčī, ą░ ąĘą░č鹥ą╝ ąĖąĘą╝ąĄąĮąĖčéčī. ąÆ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čŹč鹊ą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ ą┐čĆąŠčåąĄčüčü/ą┐ąŠč鹊ą║ ą╗ąĖą▒ąŠ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąŠą▒čēąĖą╣ čĆąĄčüčāčĆčü, ą╗ąĖą▒ąŠ ąŠą▒ąĮą░čĆčāąČąĖčé, čćč鹊 ąŠąĮ čāąČąĄ ą║ąĄą╝-č鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ, ąĖ ąĮčāąČąĮąŠ ą┐ąŠą┤ąŠąČą┤ą░čéčī ąĮąĄą║ąŠč鹊čĆąŠąĄ ą▓čĆąĄą╝čÅ, ą┐čĆąĄąČą┤ąĄ č湥ą╝ ą┐ąŠą▓č鹊čĆąĖčéčī ą┐ąŠą┐čŗčéą║čā ą┤ąŠčüčéčāą┐ą░. ąĪąĄą╝ą░č乊čĆčŗ ą╝ąŠą│čāčé ą▒čŗčéčī ą┤ą▓ąŠąĖčćąĮčŗą╝ąĖ (čüąŠ ąĘąĮą░č湥ąĮąĖčÅą╝ąĖ 0 ąĖą╗ąĖ 1), ą╗ąĖą▒ąŠ ą╝ąŠą│čāčé ąĖą╝ąĄčéčī ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ (čéą░ą║ąĖąĄ čüąĄą╝ą░č乊čĆčŗ ąĮą░ąĘčŗą▓ą░čÄčéčüčÅ čüąĄą╝ą░č乊čĆą░ą╝ąĖ čüąŠ čüč湥čéčćąĖą║ąŠą╝). ą×ą▒čŗčćąĮąŠ ą┐čĆąŠčåąĄčüčü/ą┐ąŠč鹊ą║, ąĖčüą┐ąŠą╗čīąĘčāčÄčēąĖą╣ čüąĄą╝ą░č乊čĆ, ą┐čĆąŠą▓ąĄčĆčÅąĄčé ąĄą│ąŠ ąĘąĮą░č湥ąĮąĖąĄ. ąĢčüą╗ąĖ čüąĄą╝ą░č乊čĆ čüąĖą│ąĮą░ą╗ąĖąĘąĖčĆčāąĄčé (== 0), čćč鹊 čĆąĄčüčāčĆčü ą▓ ąĮą░čüč鹊čÅčēąĄąĄ ą▓čĆąĄą╝čÅ čüą▓ąŠą▒ąŠą┤ąĄąĮ, č鹊 ą┐ąŠč鹊ą║ ąĖąĘą╝ąĄąĮčÅąĄčé ąĘąĮą░č湥ąĮąĖąĄ čüąĄą╝ą░č乊čĆą░ (== 1), ą┐ąŠą║ą░ąĘčŗą▓ą░čÅ č鹥ą╝ čüą░ą╝čŗą╝ ą┤čĆčāą│ąĖą╝ ą┐čĆąŠčåąĄčüčüą░ą╝/ą┐ąŠč鹊ą║ą░ą╝, čćč鹊 čĆąĄčüčāčĆčü ąĘą░ąĮčÅčé.
ąÜą╗ą░čüčü Lock ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čüą╗ąĄą┤čāčÄčēąĖąĄ ą╝ąĄč鹊ą┤čŗ:
acquire([blocking]): ąĘą░čģą▓ą░čé čüąĄą╝ą░č乊čĆą░. ąŚą░čģą▓ą░čé ą╝ąŠąČąĄčé ą▒čŗčéčī ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĖą╝ ąĖ ąĮąĄ ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĖą╝.
- ąÜąŠą│ą┤ą░ ą░čĆą│čāą╝ąĄąĮčé blocking čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą▓ True (ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ), č鹊 ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą▓čŗąĘą▓ą░ą▓čłąĄą│ąŠ ą┐ąŠč鹊ą║ą░ ą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ ą┤ąŠ č鹥čģ ą┐ąŠčĆ, ą┐ąŠą║ą░ ąĘą░čģą▓ą░čé ąĮąĄ ą▒čāą┤ąĄčé čüąĮčÅčé. ąÆ ą╝ąŠą╝ąĄąĮčé ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ čüąĄą╝ą░č乊čĆ ą┐ąĄčĆąĄą▓ąŠą┤ąĖčéčüčÅ ą▓ čüąŠčüč鹊čÅąĮąĖąĄ ąĘą░čģą▓ą░čéą░, ąĖ acquire ą▓ąŠąĘą▓čĆą░čéąĖčé True.
- ąÜąŠą│ą┤ą░ ą░čĆą│čāą╝ąĄąĮčé blocking čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą▓ False, ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą▓čŗąĘą▓ą░ą▓čłąĄą│ąŠ ą┐ąŠč鹊ą║ą░ ąĮąĄ ą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ. ąĢčüą╗ąĖ ąĘą░čģą▓ą░čé čüąĮčÅčé, č鹊 acquire ąĘą░čģą▓ą░čéąĖčé čüąĄą╝ą░č乊čĆ ąĖ ą▓ąĄčĆąĮąĄčé True, ąĖąĮą░č湥 ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ ą▓ąĄčĆąĮąĄčé False.
release(): ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ąĘą░čģą▓ą░čéą░ čüąĄą╝ą░č乊čĆą░. ąÜąŠą│ą┤ą░ čüąĄą╝ą░č乊čĆ ąĘą░čģą▓ą░č湥ąĮ, ąŠąĮ ąŠčüą▓ąŠą▒ąŠąČą┤ą░ąĄčéčüčÅ, ąĖ release ą▓čŗą┐ąŠą╗ąĮąĖčé ą▓ąŠąĘą▓čĆą░čé. ąĢčüą╗ąĖ ą┐čĆąĖ čŹč鹊ą╝ ą╗čÄą▒ąŠą╣ ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ čüąŠčüč鹊čÅąĮąĖąĖ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ, ąŠąČąĖą┤ą░čÅ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ čüąĄą╝ą░č乊čĆą░, č鹊 ąŠąĮ ą▓čŗą╣ą┤ąĄčé ąĖąĘ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ, ąĘą░čģą▓ą░čéąĖčé čüąĄą╝ą░č乊čĆ ąĖ ą┐čĆąŠą┤ąŠą╗ąČąĖčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ. ąĢčüą╗ąĖ čüąĄą╝ą░č乊čĆ čāąČąĄ ą▓ čĆą░ąĘą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĮąŠą╝ čüąŠčüč鹊čÅąĮąĖąĖ, č鹊 ą▒čāą┤ąĄčé ą▓čŗą▒čĆąŠčłąĄąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ThreadError.
ąĀą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗ąĄą┤čāčÄčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ, ąĖčüą┐čĆą░ą▓ą╗čÅčÄčēąĖą╣ ąĮąĄą┤ąŠčüčéą░č鹊ą║ ą┐čĆąĄą┤čŗą┤čāčēąĄą│ąŠ ą┐čĆąĖą╝ąĄčĆą░:
import threading
# ąōą╗ąŠą▒ą░ą╗čīąĮą░čÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ x:
x = 0
# ążčāąĮą║čåąĖčÅ ą┤ą╗čÅ ąĖąĮą║čĆąĄą╝ąĄąĮčéą░ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ x:
def increment():
global x
x += 1
# ąŚą░ą┤ą░čćą░ ą┐ąŠč鹊ą║ą░, ą║ąŠč鹊čĆą░čÅ ą▓čŗąĘčŗą▓ą░ąĄčé čäčāąĮą║čåąĖčÄ increment
# 100000 čĆą░ąĘ:
def thread_task():
for _ in range(100000):
lock.acquire()
increment() # ą║čĆąĖčéąĖč湥čüą║ą░čÅ čüąĄą║čåąĖčÅ
lock.release()
global x
# ąŻčüčéą░ąĮąŠą▓ą║ą░ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ x ą▓ 0:
x = 0
# ąĪąŠąĘą┤ą░ąĮąĖąĄ ąŠą▒čŖąĄą║čéą░ čüąĄą╝ą░č乊čĆą░ lock:
lock = threading.Lock()
# ąĪąŠąĘą┤ą░ąĮąĖąĄ ą┐ąŠč鹊ą║ąŠą▓:
t1 = threading.Thread(target=thread_task, args=(lock,))
t2 = threading.Thread(target=thread_task, args=(lock,))
# ąŚą░ą┐čāčüą║ ą┐ąŠč鹊ą║ąŠą▓:
t1.start()
t2.start()
# ą×ąČąĖą┤ą░ąĮąĖąĄ, ą║ąŠą│ą┤ą░ ą┐ąŠč鹊ą║ąĖ ąĘą░ą▓ąĄčĆčłą░čé čüą▓ąŠčÄ čĆą░ą▒ąŠčéčā:
t1.join()
t2.join()
if __name__ == "__main__":
for i in range(10):
main_task()
print("ąśč鹥čĆą░čåąĖčÅ {0}: x = {1}".format(i,x))
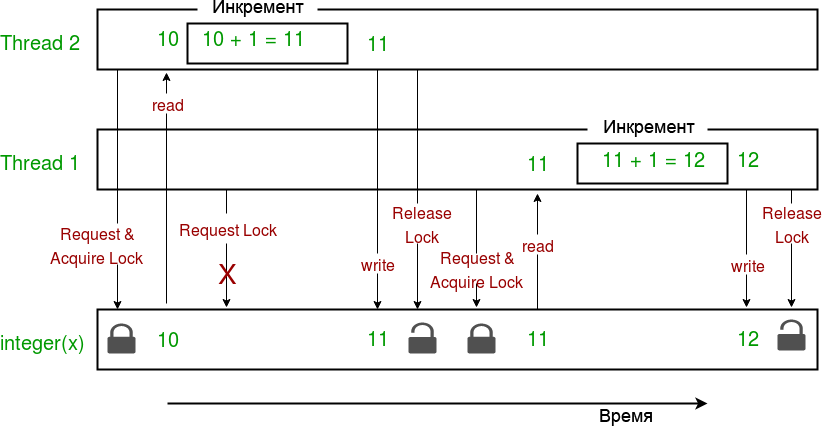
ąÜčĆąĖčéąĖč湥čüą║ą░čÅ čüąĄą║čåąĖčÅ ą▓ čŹč鹊ą╣ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ (čé. ąĄ. ą║ąŠą┤, ą▓čŗą┐ąŠą╗ąĮčÅčÄčēąĖą╣čüčÅ ąĮąĄą┐čĆąĄčĆčŗą▓ąĮąŠ ąĖ ą░č鹊ą╝ą░čĆąĮąŠ), ąĮą░čģąŠą┤ąĖčéčüčÅ ą╝ąĄąČą┤čā ą▓čŗąĘąŠą▓ą░ą╝ąĖ lock.acquire() ąĖ lock.release(). ąÆčŗą▓ąŠą┤ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ č鹥ą┐ąĄčĆčī ą┐čĆą░ą▓ąĖą╗čīąĮčŗą╣:
ąśč鹥čĆą░čåąĖčÅ 0: x = 200000
ąśč鹥čĆą░čåąĖčÅ 1: x = 200000
ąśč鹥čĆą░čåąĖčÅ 2: x = 200000
ąśč鹥čĆą░čåąĖčÅ 3: x = 200000
ąśč鹥čĆą░čåąĖčÅ 4: x = 200000
ąśč鹥čĆą░čåąĖčÅ 5: x = 200000
ąśč鹥čĆą░čåąĖčÅ 6: x = 200000
ąśč鹥čĆą░čåąĖčÅ 7: x = 200000
ąśč鹥čĆą░čåąĖčÅ 8: x = 200000
ąśč鹥čĆą░čåąĖčÅ 9: x = 200000
ąöą░ą▓ą░ą╣č鹥 čĆą░ąĘą▒ąĄčĆąĄą╝čüčÅ ą┐ąŠ čłą░ą│ą░ą╝, čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓ čŹč鹊ą╝ ą║ąŠą┤ąĄ:
ŌĆó ąĪąĮą░čćą░ą╗ą░ čüąŠąĘą┤ą░ąĄčéčüčÅ čŹą║ąĘąĄą╝ą┐ą╗čÅčĆ ąŠą▒čŖąĄą║čéą░ Lock ą▓čŗąĘąŠą▓ąŠą╝ ąĄą│ąŠ ą║ąŠąĮčüčéčĆčāą║č鹊čĆą░:
lock = threading.Lock()
ŌĆó ąŚą░č鹥ą╝ lock ą┐ąĄčĆąĄą┤ą░ąĄčéčüčÅ ą║ą░ą║ ą░čĆą│čāą╝ąĄąĮčé čäčāąĮą║čåąĖčÄ ą┐ąŠč鹊ą║ą░:
t1 = threading.Thread(target=thread_task, args=(lock,))
t2 = threading.Thread(target=thread_task, args=(lock,))
ŌĆó ąÆ ą║čĆąĖčéąĖč湥čüą║ąŠą╣ čüąĄą║čåąĖąĖ čäčāąĮą║čåąĖąĖ ą┐ąŠč鹊ą║ą░ ą╝čŗ ą┐čĆąĖą╝ąĄąĮąĖą╗ąĖ ąĘą░čģą▓ą░čé čüąĄą╝ą░č乊čĆą░ ą▓čŗąĘąŠą▓ąŠą╝ ą╝ąĄč鹊ą┤ą░ lock.acquire(). ąÜą░ą║ č鹊ą╗čīą║ąŠ ą┐čĆąŠąĖąĘąŠčłąĄą╗ ąĘą░čģą▓ą░čé čüąĄą╝ą░č乊čĆą░, ąĮąĖą║ą░ą║ąŠą╣ ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║ ąĮąĄ čüą╝ąŠąČąĄčé ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ ą║ąŠą┤čā ą║čĆąĖčéąĖč湥čüą║ąŠą╣ čüąĄą║čåąĖąĖ (ą▓ ąĮą░čłąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ čŹč鹊 čäčāąĮą║čåąĖčÅ increment) ą┐ąŠą║ą░ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ąĮąĄ ą▒čāą┤ąĄčé ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮą░ ą▓čŗąĘąŠą▓ąŠą╝ ą╝ąĄč鹊ą┤ą░ lock.release().
lock.acquire()
increment()
lock.release()
ąÜą░ą║ ą▓čŗ ą╝ąŠąČąĄč鹥 ą▓ąĖą┤ąĄčéčī ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą┤ą░ąĄčé č鹥ą┐ąĄčĆčī ą║ą░ąČą┤čŗą╣ čĆą░ąĘ ą┐čĆą░ą▓ąĖą╗čīąĮčŗą╣ čĆąĄąĘčāą╗čīčéą░čé 200000 ą┤ą╗čÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ x. ąĪą╗ąĄą┤čāčÄčēą░čÅ ą┤ąĖą░ą│čĆą░ą╝ą╝ą░ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐čĆąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ čŹč鹊ą│ąŠ ą║ąŠą┤ą░:
[ą¤čĆąĖą╝ąĄčĆ čŹčäč乥ą║čéąĖą▓ąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ background-ą┐ąŠč鹊ą║ą░]
ąÆ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┐čĆąŠčüč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ čüąŠąĘą┤ą░ąĄčéčüčÅ č乊ąĮąŠą▓čŗą╣ ą┐ąŠč鹊ą║, ą║ąŠč鹊čĆčŗą╣ čćąĖčéą░ąĄčé ąĖąĘ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠą│ąŠ ą┐ąŠčĆčéą░ ą┤ą░ąĮąĮčŗąĄ ą▓ ą│ą╗ąŠą▒ą░ą╗čīąĮčŗą╣ ą▒čāč乥čĆ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ čüąŠąĘą┤ą░ąĄčéčüčÅ ą┤ą▓čāčģą┐ąŠč鹊čćąĮąŠąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ - č乊ąĮąŠą▓čŗą╣ ą┐ąŠč鹊ą║ ąĖ ąŠčüąĮąŠą▓ąĮąŠą╣ ą┐ąŠč鹊ą║. ą×čüąĮąŠą▓ąĮąŠą╣ ą┐ąŠč鹊ą║ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ čćąĖčéą░ąĄčé ą┤ą░ąĮąĮčŗąĄ ąĖąĘ čŹč鹊ą│ąŠ ą▒čāč乥čĆą░ ąĖ ą▓čŗą▓ąŠą┤ąĖčé ąĖčģ ąĮą░ 菹║čĆą░ąĮ ą║ąŠąĮčüąŠą╗ąĖ.
import serial
import threading
import time
from queue import Queue
# ąōą╗ąŠą▒ą░ą╗čīąĮčŗą╣ ą▒čāč乥čĆ, ą│ą┤ąĄ ą┐ąŠč鹊ą║ ąĮą░ą║ą░ą┐ą╗ąĖą▓ą░ąĄčé ą┐čĆąĖąĮčÅčéčŗąĄ ą┤ą░ąĮąĮčŗąĄ:
serial_buffer = bytearray()
buffer_lock = threading.Lock()
def serial_reader():
global serial_buffer
try:
# ąØą░ Windows ą┤ą╗čÅ ą┐ą░čĆą░ą╝ąĄčéčĆą░ port ą▒čāą┤ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ąĖą╝čÅ
# ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ 'COMn', ąĮą░ Linyx čŹč鹊 ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ąĖą╝čÅ
# ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ '/dev/ttyUSB1'.
ser = serial.Serial(
port='COM1', # ą¤ąŠą┤čüčéą░ą▓čīč鹥 čéčāčé čĆąĄą░ą╗čīąĮąŠąĄ ąĖą╝čÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠą│ąŠ ą┐ąŠčĆčéą░
baudrate=9600,
timeout=1
)
while True:
if ser.in_waiting:
# ą¦č鹥ąĮąĖąĄ ą┤ąŠčüčéčāą┐ąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ą▓ąŠ ą▓čĆąĄą╝ąĄąĮąĮčŗą╣ ą▒čāč乥čĆ:
data = ser.read(ser.in_waiting)
# ąæąĄąĘąŠą┐ą░čüąĮąŠ ą┤ąŠą▒ą░ą▓ąĖą╝ ą┐čĆąĖąĮčÅčéčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▓ ą│ą╗ąŠą▒ą░ą╗čīąĮčŗą╣ ą▒čāč乥čĆ,
# ąĖčüą┐ąŠą╗čīąĘčāčÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā (lock):
with buffer_lock:
serial_buffer.extend(data)
time.sleep(0.1) # ąØąĄą▒ąŠą╗čīčłą░čÅ ąĘą░ą┤ąĄčƹȹ║ą░, čćč鹊ą▒čŗ ąĮąĄ ą┐ąĄčĆąĄą│čĆčāąČą░čéčī CPU:
except serial.SerialException as e:
print(f"ą×čłąĖą▒ą║ą░ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠą│ąŠ ą┐ąŠčĆčéą░: {e}")
return
def main():
# ąŚą░ą┐čāčüą║ background-ą┐ąŠč鹊ą║ą░, ą║ąŠč鹊čĆčŗą╣ čćąĖčéą░ąĄčé ą┤ą░ąĮąĮčŗąĄ ąĖąĘ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠą│ąŠ ą┐ąŠčĆčéą░:
reader_thread = threading.Thread(target=serial_reader, daemon=True)
reader_thread.start()
# ą×čüąĮąŠą▓ąĮąŠą╣ ą┐ąŠč鹊ą║ čćąĖčéą░ąĄčé ąĖ ą┐ąĄčćą░čéą░ąĄčé ą┐čĆąĖąĮčÅčéčŗąĄ ą┤ą░ąĮąĮčŗąĄ:
try:
while True:
# ąæąĄąĘąŠą┐ą░čüąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠą╝čā ą▒čāč乥čĆčā čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ:
with buffer_lock:
if len(serial_buffer) > 0:
# ą¤ąĄčćą░čéčī ąĖ ąŠčćąĖčüčéą║ą░ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠą│ąŠ ą▒čāč乥čĆą░:
print(serial_buffer.decode('utf-8', errors='ignore'), end='')
serial_buffer.clear()
time.sleep(0.1) # ąØąĄą▒ąŠą╗čīčłą░čÅ ąĘą░ą┤ąĄčƹȹ║ą░, čćč鹊ą▒čŗ ąĮąĄ ą┐ąĄčĆąĄą│čĆčāąČą░čéčī CPU
except KeyboardInterrupt:
# ąæčŗą╗ą░ ąĮą░ąČą░čéą░ ą║ąŠą╝ą▒ąĖąĮą░čåąĖčÅ ą║ą╗ą░ą▓ąĖčł Ctrl+C, ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄ čĆą░ą▒ąŠčéčŗ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ:
print("\nExiting...")
if __name__ == "__main__":
main()
[ąöąŠčüč鹊ąĖąĮčüčéą▓ą░ ąĖ ąĮąĄą┤ąŠčüčéą░čéą║ąĖ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠčüčéąĖ]
ąöąŠčüč鹊ąĖąĮčüčéą▓ą░:
ŌĆó ą¤ąŠąĘą▓ąŠą╗čÅąĄčé ą┐ąĖčüą░čéčī ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ą▓ ą║ąŠč鹊čĆčŗčģ ąĖąĮč鹥čĆč乥ą╣čü ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąĖčÅ čü ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝ ąĮąĄ ą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ (ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ąĮąĄ ąĘą░ą▓ąĖčüą░ąĄčé ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┤ą╗ąĖč鹥ą╗čīąĮčŗčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣). ąŁč鹊 ą┐ąŠč鹊ą╝čā, čćč鹊 ą┐ąŠč鹊ą║ąĖ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ą┐ąŠą╗čāčćą░čÄčé ąĮąĄą║ąŠč鹊čĆčāčÄ ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠčüčéčī ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░.
ŌĆó ąøčāčćčłąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ čüąĖčüč鹥ą╝ąĮčŗąĄ čĆąĄčüčāčĆčüčŗ, ą┐ąŠčüą║ąŠą╗čīą║čā ą┐ąŠč鹊ą║ąĖ ą╝ąŠą│čāčé ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ ą▓čŗą┐ąŠą╗ąĮčÅčéčī čüą▓ąŠąĖ ąĘą░ą┤ą░čćąĖ.
ŌĆó ąŻą╗čāčćčłą░ąĄčéčüčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ą╝ąĮąŠą│ąŠą┐čĆąŠčåąĄčüčüąŠčĆąĮčŗčģ čüąĖčüč鹥ą╝.
ą£ąĮąŠą│ąŠą┐ąŠč鹊čćąĮčŗąĄ čüąĄčĆą▓ąĄčĆčŗ ąĖ ąĖąĮč鹥čĆą░ą║čéąĖą▓ąĮčŗąĄ GUI ąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠčüčéčī.
ąØąĄą┤ąŠčüčéą░čéą║ąĖ:
ŌĆó ąĪ ą┐ąŠą▓čŗčłąĄąĮąĖąĄą╝ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą┐ąŠč鹊ą║ąŠą▓ čāą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčéčüčÅ čüą╗ąŠąČąĮąŠčüčéčī, ą┐ąŠą▓čŗčłą░čÄčéčüčÅ ąĮą░ą║ą╗ą░ą┤ąĮčŗąĄ čĆą░čüčģąŠą┤čŗ ąĮą░ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą║ąŠąĮč鹥ą║čüčéą░.
ŌĆó ąØąĄąŠą▒čģąŠą┤ąĖą╝ą░ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÅ ąŠą▒čēąĖčģ čĆąĄčüčāčĆčüąŠą▓ (ąŠą▒čŖąĄą║č鹊ą▓, ą┤ą░ąĮąĮčŗčģ, čäą░ą╣ą╗ąŠą▓, ąĖ čé. ą┐.).
ŌĆó ą£ąĮąŠą│ąŠą┐ąŠč鹊čćąĮčŗą╣ ą║ąŠą┤ čüą╗ąŠąČąĄąĮ ą▓ ąŠčéą╗ą░ą┤ą║ąĄ, ą┐čĆąĖ ąĮąĄą┤ąŠčüčéą░č鹊čćąĮąŠ čéčēą░č鹥ą╗čīąĮąŠą╝ ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąĖąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐ąŠč鹊ą║ąŠą▓ ą╝ąŠąČąĄčé ą┤ą░ą▓ą░čéčī ąĮąĄą┐čĆąĄą┤čüą║ą░ąĘčāąĄą╝čŗąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ.
ŌĆó ą¤ąŠč鹥ąĮčåąĖą░ą╗čīąĮčŗąĄ ą▓ąĘą░ąĖą╝ąĮčŗąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ (deadlocks) ą╝ąŠą│čāčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ č鹊ą╝čā, čćč鹊 ąĮąĄą║ąŠč鹊čĆčŗąĄ ą┐ąŠč鹊ą║ąĖ ą╝ąŠą│čāčé ą┐ąŠą╗čāčćą░čéčī čüą╗ąĖčłą║ąŠą╝ ą╝ą░ą╗ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ.
ŌĆó ąĪąŠąĘą┤ą░ąĮąĖąĄ ąĖ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÅ ą┐ąŠč鹊ą║ąŠą▓ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ą┐ąŠą▓čŗčłąĄąĮąĮąŠą╝čā čĆą░čüčģąŠą┤čā čĆąĄčüčāčĆčüąŠą▓ CPU ąĖ ą┐ą░ą╝čÅčéąĖ.
ŌĆó ą¤ąĄčĆąĄąĮąŠčüąĖą╝ąŠčüčéčī čüą╗ąŠąČąĮąŠą│ąŠ ą║ąŠą┤ą░ ą╝ąŠąČąĄčé ąĘą░ą▓ąĖčüąĄčéčī ąŠčé ą▓ąĄčĆčüąĖąĖ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ ąĖ ą┤ą░ąČąĄ ąŠčé ą▓ąĄčĆčüąĖąĖ Python.
[ąĪčüčŗą╗ą║ąĖ]
1. Multithreading in Python | Set 2 (Synchronization) site:geeksforgeeks.org.
2. Python: ą▓ą▓ąĄą┤ąĄąĮąĖąĄ ą▓ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ. |



