ąĢčüą╗ąĖ ą▓čŗ ąŠčéąĮąŠčüąĖč鹥čüčī ą║ ą▒ąŠą╗čīčłąĖąĮčüčéą▓čā ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╣ Python , č鹊 čüą║ąŠčĆąĄąĄ ą▓čüąĄą│ąŠ ąĮą░čćą░ą╗ąĖ ą┐čāč鹥賹Ąčüčéą▓ąĖąĄ ą┐ąŠ Python čüąŠ ąĘąĮą░ą║ąŠą╝čüčéą▓ą░ čü čäčāąĮą║čåąĖąĄą╣ print() . ąÆčŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĄčæ ą┤ą╗čÅ ąŠč鹊ą▒čĆą░ąČąĄąĮąĖčÅ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĮčŗčģ čüąŠąŠą▒čēąĄąĮąĖą╣ ąĮą░ 菹║čĆą░ąĮąĄ, ąĖ ą▓ąŠąĘą╝ąŠąČąĮąŠ ąĮą░ą╣čéąĖ ą║ą░ą║ąĖąĄ-č鹊 ąŠčłąĖą▒ą║ąĖ ą▓ čüą▓ąŠąĄą╣ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ. ąØąŠ ąĄčüą╗ąĖ ą▓čŗ ą┤čāą╝ą░ąĄč鹥, čćč鹊 čŹč鹊 ą▓čüąĄ, čćč鹊 ąĮčāąČąĮąŠ ąĘąĮą░čéčī ą┐čĆąŠ Python-čäčāąĮą║čåąĖčÄ print(), č鹊 ą╝ąĮąŠą│ąŠąĄ čāą┐čāčüą║ą░ąĄč鹥 (čŹč鹊 ą┐ąĄčĆąĄą▓ąŠą┤ čüčéą░čéčīąĖ [1])!
ą¤ąŠčüą╗ąĄ ąĖąĘčāč湥ąĮąĖčÅ čŹč鹊ą│ąŠ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ą░ ą▓čŗ čāąĘąĮą░ąĄč鹥, ą║ą░ą║:
ŌĆó ąśąĘą▒ąĄąČą░čéčī čĆą░čüą┐čĆąŠčüčéčĆą░ąĮąĄąĮąĮčŗčģ ąŠčłąĖą▒ąŠą║ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ print().
ąĢčüą╗ąĖ ą▓čŗ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠ ą┐ąŠą╗ąĮčŗą╣ ąĮąŠą▓ąĖč湊ą║, č鹊 čüą║ąŠčĆąĄąĄ ą▓čüąĄą│ąŠ ą▒čāą┤ąĄčé ą┐ąŠą╗ąĄąĘąĮčŗą╝ ą┐čĆąŠčćąĖčéą░čéčī ą┐ąĄčĆą▓čāčÄ čćą░čüčéčī čŹč鹊ą│ąŠ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ą░, ą│ą┤ąĄ čĆą░čüą║čĆčŗą▓ą░čÄčéčüčÅ ąŠčüąĮąŠą▓čŗ ą┐ąĄčćą░čéąĖ ą▓ Python. ąśąĮą░č湥 ą┐čĆąŠą┐čāčüą║ą░ą╣č鹥 ą▓ą▓ąĄą┤ąĄąĮąĖąĄ, ąĖ ą┐ąŠą╗čīąĘčāą╣č鹥čüčī čŹč鹊ą╣ čüčéą░čéčīąĄą╣ ą║ą░ą║ čüą┐čĆą░ą▓ąŠčćąĮąĖą║ąŠą╝ ą┐ąŠ čĆą░ąĘą╗ąĖčćąĮčŗą╝ ą▓ąŠą┐čĆąŠčüą░ą╝.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: čäčāąĮą║čåąĖčÅ print() ą┐ąŠą╗čāčćąĖą╗ą░ ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠąĄ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ ą▓ Python 3, čćč鹊 ąĘą░ą╝ąĄąĮąĖą╗ąŠ čüčéą░čĆčŗą╣ ąŠą┐ąĄčĆą░č鹊čĆ print, ą┤ąŠčüčéčāą┐ąĮčŗą╣ ą▓ Python 2. ąöą╗čÅ čŹč鹊ą│ąŠ ą▒čŗą╗ąŠ ąĮąĄą╝ą░ą╗ąŠ ą▓ąĄčüą║ąĖčģ ą┐čĆąĖčćąĖąĮ. ąźąŠčéčÅ čŹč鹊 čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąŠ č乊ą║čāčüąĖčĆčāąĄčéčüčÅ ąĮą░ Python 3, ą┤ą╗čÅ čüą┐čĆą░ą▓ą║ąĖ ą┐ąŠą║ą░ąĘą░ąĮ čéą░ą║ąČąĄ ąĖ čüčéą░čĆčŗą╣ čüą┐ąŠčüąŠą▒ ą┐ąĄčćą░čéąĖ Python 2 (čüą╝. ą▓čĆąĄąĘą║ąĖ "ąĪąĖąĮčéą░ą║čüąĖčü ą▓ Python 2").
[ą×čüąĮąŠą▓čŗ ą┐ąĄčćą░čéąĖ ą▓ Python ]
ąÆ čŹč鹊ą╣ ą│ą╗ą░ą▓ąĄ ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ čĆąĄą░ą╗čīąĮčŗąĄ ą┐čĆąĖą╝ąĄčĆčŗ ą┐ąĄčćą░čéąĖ ą▓ Python. ąŚą┤ąĄčüčī ą▓čŗ ą┐ąŠąĘąĮą░ą║ąŠą╝ąĖč鹥čüčī čü čĆą░ąĘą╗ąĖčćąĮčŗą╝ąĖ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čäčāąĮą║čåąĖąĖ print().
ąÆčŗąĘąŠą▓ print() . ąĪą░ą╝čŗą╣ ą┐čĆąŠčüč鹊ą╣ ą┐čĆąĖą╝ąĄčĆ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ print() ą┐ąĄčĆąĄą▓ąĄą┤ąĄčé ą┐ąŠąĘąĖčåąĖčÄ ą┐ąĄčćą░čéąĖ ą║ąŠąĮčüąŠą╗ąĖ ąĮą░ ąĮąŠą▓čāčÄ čüčéčĆąŠą║čā:
print ()ąŚą┤ąĄčüčī ąĮąĄ ą▓čŗ ąĮąĄ ą┐ąĄčĆąĄą┤ą░ąĄč鹥 ąĮąĖą║ą░ą║ąĖąĄ ą░čĆą│čāą╝ąĄąĮčéčŗ, ąŠą┤ąĮą░ą║ąŠ ą▓čüąĄ čĆą░ą▓ąĮąŠ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ą┐ąŠčüą╗ąĄ ąĖą╝ąĄąĮąĖ čäčāąĮą║čåąĖąĖ čāą║ą░ąĘą░čéčī ą┐ą░čĆčā ą║čĆčāą│ą╗čŗčģ čüą║ąŠą▒ąŠą║, čćč鹊ą▒čŗ Python ą▓čŗą┐ąŠą╗ąĮąĖą╗ čĆąĄą░ą╗čīąĮčŗą╣ ą▓čŗąĘąŠą▓ čäčāąĮą║čåąĖąĖ ą▓ą╝ąĄčüč鹊 čüčüčŗą╗ą║ąĖ ąĮą░ čäčāąĮą║čåąĖčÄ ą┐ąŠ ąĖą╝ąĄąĮąĖ.
ąŁč鹊čé ą┐čĆąĖą╝ąĄčĆ čüą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĮąĄą▓ąĖą┤ąĖą╝čŗą╣ čüąĖą╝ą▓ąŠą╗ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ (newline ), ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ąĮą░ ą▓ą░čłąĄą╝ 菹║čĆą░ąĮąĄ ą▒čāą┤ąĄčé ą▓čŗą▓ąĄą┤ąĄąĮą░ ą┐čāčüčéą░čÅ čüčéčĆąŠą║ą░. ąÆčŗ ą╝ąŠąČąĄč鹥 ą▓čŗąĘą▓ą░čéčī print() ąĮąĄčüą║ąŠą╗čīą║ąŠ čĆą░ąĘ, čćč鹊ą▒čŗ ą┤ąŠą▒ą░ą▓ąĖčéčī ą▓ ą▓čŗą▓ąŠą┤ ą┐čāčüčéčŗąĄ čüčéčĆąŠą║ąĖ. ąŁč鹊 ą▓čŗą│ą╗čÅą┤ąĖčé ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ ąĮą░ąČą░čéąĖčÅ ąĮą░ Enter ą▓ čĆąĄą┤ą░ą║č鹊čĆąĄ č鹥ą║čüčéą░.
ąĪąĖą╝ą▓ąŠą╗ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ (newline) čŹč鹊 čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ čāą┐čĆą░ą▓ą╗čÅčÄčēąĖą╣ čüąĖą╝ą▓ąŠą╗, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą┤ą╗čÅ ąŠą▒ąŠąĘąĮą░č湥ąĮąĖčÅ ą║ąŠąĮčåą░ čüčéčĆąŠą║ąĖ (end of line, EOL). ą×ą▒čŗčćąĮąŠ čā ąĮąĄą│ąŠ ąĮąĄčé čüą┐ąĄčåąĖą░ą╗čīąĮąŠą│ąŠ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖčÅ ąĮą░ 菹║čĆą░ąĮąĄ, ąŠą┤ąĮą░ą║ąŠ ąĮąĄą║ąŠč鹊čĆčŗąĄ č鹥ą║čüč鹊ą▓čŗąĄ čĆąĄą┤ą░ą║č鹊čĆčŗ ą╝ąŠą│čāčé ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╣ ą│čĆą░čäąĖą║ąŠą╣ ą┐ąŠą║ą░ąĘčŗą▓ą░čéčī ąĮąĄ ą┐ąĄčćą░čéą░ąĄą╝čŗąĄ čüąĖą╝ą▓ąŠą╗čŗ.
ąĪą╗ąŠą▓ąŠ "čüąĖą╝ą▓ąŠą╗" ą┤ą╗čÅ newline ą▓ ą┤ą░ąĮąĮąŠą╝ čüą╗čāčćą░ąĄ čÅą▓ą╗čÅąĄčéčüčÅ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮčŗą╝, ą┐ąŠč鹊ą╝čā čćč鹊 newline čćą░čüčéčī ąĖą╝ąĄąĄčé ą┤ą╗ąĖąĮčā ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą│ąŠ čüąĖą╝ą▓ąŠą╗ą░. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą▓ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝ąĄ Windows, ą║ą░ą║ ąĖ ą▓ ą┐čĆąŠč鹊ą║ąŠą╗ąĄ HTTP, newline ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮ ą┐ą░čĆąŠą╣ čüąĖą╝ą▓ąŠą╗ąŠą▓. ąśąĮąŠą│ą┤ą░ čüą╗ąĄą┤čāąĄčé čāčćąĖčéčŗą▓ą░čéčī čŹčéąĖ ąŠčéą╗ąĖčćąĖčÅ, čćč鹊ą▒čŗ čĆą░ąĘčĆą░ą▒ą░čéčŗą▓ą░čéčī čĆąĄą░ą╗čīąĮąŠ ą┐ąŠčĆčéąĖčĆčāąĄą╝čŗą╣ ą║ąŠą┤ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
ą¦č鹊ą▒čŗ čāąĘąĮą░čéčī, čćč鹊 ąĖą╝ąĄąĮąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ newline ą▓ ą▓ą░čłąĄą╣ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝ąĄ, ą▓ąŠčüą┐ąŠą╗čīąĘčāą╣č鹥čüčī ą╝ąŠą┤čāą╗ąĄą╝ os, ą▓čüčéčĆąŠąĄąĮąĮčŗą╝ ą▓ Python. ąŁč鹊 ą┐ąŠą║ą░ąČąĄčé ą▓ą░ą╝, čćč鹊 ąĮą░ Windows ąĖ DOS čüčāčēąĮąŠčüčéčī newline čŹč鹊 ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ąĖąĘ čüąĖą╝ą▓ąŠą╗ąŠą▓ \r \n
>>> import os>>> os.linesep'\r\n' ąØą░ Unix, Linux, FreeBSD ąĖ ą┐ąŠčüą╗ąĄą┤ąĮąĖčģ ą▓ąĄčĆčüąĖčÅčģ macOS čŹč鹊 ąŠą┤ąĖąĮ čüąĖą╝ą▓ąŠą╗ \n:
>>> import os>>> os.linesep'\n' ą×ą┤ąĮą░ą║ąŠ ą║ą╗ą░čüčüąĖč湥čüą║ą░čÅ Mac OS X, čüą╗ąĄą┤čāčÅ čüą▓ąŠąĄą╣ čäąĖą╗ąŠčüąŠčäąĖąĖ "think different", ą▓čŗą┤ą░čüčé ą┤čĆčāą│ąŠąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ:
>>> import os>>> os.linesep'\r' ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, ą║ą░ą║ čŹčéąĖ čüąĖą╝ą▓ąŠą╗čŗ ą┐ąŠčÅą▓ą╗čÅčÄčéčüčÅ ą▓ čüčéčĆąŠą║ąŠą▓čŗčģ ą╗ąĖč鹥čĆą░ą╗ą░čģ. ąŁč鹊 čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝ąŠąĄ 菹║čĆą░ąĮąĖčĆąŠą▓ą░ąĮąĖąĄ: ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ čüąĖą╝ą▓ąŠą╗ ąŠą▒čĆą░čéąĮąŠą│ąŠ čüą╗ąĄčłą░ (backslash, \), čćč鹊ą▒čŗ ąŠą▒ąŠąĘąĮą░čćąĖčéčī ąĮą░čćą░ą╗ąŠ čāą┐čĆą░ą▓ą╗čÅčÄčēąĄą╣ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ čüąĖą╝ą▓ąŠą╗ąŠą▓ (escape character sequence). ąŁč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą▓čŗčĆą░ąĘąĖčéčī čāą┐čĆą░ą▓ą╗čÅčÄčēąĖąĄ čüąĖą╝ą▓ąŠą╗čŗ, ą║ąŠč鹊čĆčŗąĄ ąĖąĮą░č湥 ą▒čŗą╗ąĖ ą▒čŗ ąĮąĄą▓ąĖą┤ąĖą╝čŗ ąĮą░ 菹║čĆą░ąĮąĄ.
ąØą░ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ čÅąĘčŗą║ąŠą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ąĖą╝ąĄąĄčéčüčÅ ą┐čĆąĄą┤ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╣ ąĮą░ą▒ąŠčĆ čüą┐ąĄčåąĖą░ą╗čīąĮčŗčģ čüąĖą╝ą▓ąŠą╗ąŠą▓, čéą░ą║ąĖčģ ą║ą░ą║:
\\ \b \t \r \n
ą¤ąŠčüą╗ąĄą┤ąĮąĖąĄ ą┤ą▓ą░ čüą┐ąĄčåąĖą░ą╗čīąĮčŗčģ čüąĖą╝ą▓ąŠą╗ą░ \r ąĖ \n ąĮą░ą┐ąŠą╝ąĖąĮą░čÄčé ąŠ čĆą░ą▒ąŠč鹥 ą╝ąĄčģą░ąĮąĖč湥čüą║ąĖčģ ą┐ąĄčćą░čéąĮčŗčģ ą╝ą░čłąĖąĮąŠą║, ą│ą┤ąĄ čéčĆąĄą▒ąŠą▓ą░ą╗ąĖčüčī čüą┐ąĄčåąĖą░ą╗čīąĮčŗąĄ ą║ąŠą╝ą░ąĮą┤čŗ ą┤ą╗čÅ č鹊ą│ąŠ, čćč鹊ą▒čŗ ąĮą░čćą░čéčī ą┐ąĄčćą░čéą░čéčī čü ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ ąĖą╗ąĖ ą▓čüčéą░ą▓ąĖčéčī ąĮąŠą▓čāčÄ čüčéčĆąŠą║čā. ąĪąĖą╝ą▓ąŠą╗ \r ąŠą▒ąŠąĘąĮą░čćą░ąĄčé ą║ąŠą╝ą░ąĮą┤čā, ą┐ąĄčĆąĄą▓ąŠą┤čÅčēčāčÄ ą║ą░čĆąĄčéą║čā ą╝ą░čłąĖąĮą║ąĖ ąŠą▒čĆą░čéąĮąŠ ąĮą░ ąĮą░čćą░ą╗ąŠ čüčéčĆąŠą║ąĖ, ą░ čüąĖą╝ą▓ąŠą╗ \n ąŠą▒ąŠąĘąĮą░čćą░ąĄčé ą┐čĆąŠą║čĆčāčéą║čā ą╗ąĖčüčéą░ ą▓ą▓ąĄčĆčģ ąĮą░ ąĖąĮč鹥čĆą▓ą░ą╗ ąŠą┤ąĮąŠą╣ čüčéčĆąŠą║ąĖ.
ąĪčĆą░ą▓ąĮąĖą▓ą░čÅ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖąĄ ą║ąŠą┤čŗ čüąĖą╝ą▓ąŠą╗ąŠą▓ ASCII, ą▓čŗ čāą▓ąĖą┤ąĖč鹥, čćč鹊 čĆą░ąĘą╝ąĄčēąĄąĮąĖąĄ ąŠą▒čĆą░čéąĮąŠą╣ ą║ąŠčüąŠą╣ č湥čĆčéčŗ ą┐ąĄčĆąĄą┤ čüąĖą╝ą▓ąŠą╗ąŠą╝ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą╝ąĄąĮčÅąĄčé ąĄą│ąŠ ąĘąĮą░č湥ąĮąĖąĄ. ą×ą┤ąĮą░ą║ąŠ ąĮąĄ ą▓čüąĄ čüąĖą╝ą▓ąŠą╗čŗ ą┤ąŠą┐čāčüą║ą░čÄčé čŹč鹊 - č鹊ą╗čīą║ąŠ čüą┐ąĄčåąĖą░ą╗čīąĮčŗąĄ.
ąöą╗čÅ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą║ąŠą┤ąŠą▓ čüąĖą╝ą▓ąŠą╗ąŠą▓ ASCII ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓čüčéčĆąŠąĄąĮąĮčāčÄ čäčāąĮą║čåąĖčÄ ord() :
>>> ord ('r' )114 >>> ord ('\r' )13 ąśą╝ąĄą╣č鹥 ą▓ ą▓ąĖą┤čā, čćč鹊ą▒čŗ čüč乊čĆą╝ąĖčĆąŠą▓ą░čéčī ą║ąŠčĆčĆąĄą║čéąĮčāčÄ esc-ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī, ąĮąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą┐čĆąŠą▒ąĄą╗ą░ ą╝ąĄąČą┤čā čüąĖą╝ą▓ąŠą╗ąŠą╝ backslash ąĖ ą▒čāą║ą▓ąŠą╣.
ąÜą░ą║ čāąČąĄ ą▒čŗą╗ąŠ čüą║ą░ąĘą░ąĮąŠ, ą▓čŗąĘąŠą▓ print() ą▒ąĄąĘ ą░čĆą│čāą╝ąĄąĮč鹊ą▓ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ čüąŠąĘą┤ą░ąĮąĖčÄ ąĖ ą▓čŗą▓ąŠą┤čā čüčéčĆąŠą║ąĖ, ą║ąŠč鹊čĆą░čÅ čüąŠčüč鹊ąĖčé č鹊ą╗čīą║ąŠ ąĖąĘ čüąĖą╝ą▓ąŠą╗ą░ newline. ąØąĄ ą┐čāčéą░ą╣č鹥 čŹč鹊 čü ą┐čāčüč鹊ą╣ čüčéčĆąŠą║ąŠą╣, ą║ąŠč鹊čĆą░čÅ ąĮąĄ čüąŠą┤ąĄčƹȹĖčé ąĮąĖą║ą░ą║ąĖčģ čüąĖą╝ą▓ąŠą╗ąŠą▓, ą┤ą░ąČąĄ newline. ąŁčéąĖ ą┤ą▓ąĄ čĆą░ąĘąĮčŗąĄ čüčéčĆąŠą║ąĖ ą╝ąŠąČąĮąŠ ą┐ąŠą║ą░ąĘą░čéčī čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
'\n' # ą┐čĆąŠą┐čāčēąĄąĮąĮą░čÅ čüčéčĆąŠą║ą░ '' # ą┐čāčüčéą░čÅ čüčéčĆąŠą║ą░
ąŻ ą┐ąĄčĆą▓ąŠą╣ čüčéčĆąŠą║ąĖ ą┤ą╗ąĖąĮą░ čĆą░ą▓ąĮą░ 1 čüąĖą╝ą▓ąŠą╗čā, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ą▓č鹊čĆą░čÅ ąĮąĖč湥ą│ąŠ ąĮąĄ čüąŠą┤ąĄčƹȹĖčé, ą▓ ąĮąĄą╣ 0 čüąĖą╝ą▓ąŠą╗ąŠą▓.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: čćč鹊ą▒čŗ čāą┤ą░ą╗ąĖčéčī čüąĖą╝ą▓ąŠą╗ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ, ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ąĄčæ ą╝ąĄč鹊ą┤ .rstrip() , ą▓ąŠčé čéą░ą║:
>>> 'ąĪčéčĆąŠą║ą░ č鹥ą║čüčéą░.\n' .rstrip()'ąĪčéčĆąŠą║ą░ č鹥ą║čüčéą░.' ą£ąĄč鹊ą┤ rstrip() ą▓čŗčĆąĄąČąĄčé ą▓čüąĄ ą┐čĆąŠą▒ąĄą╗čŗ čü ą┐čĆą░ą▓ąŠą╣ čüč鹊čĆąŠąĮčŗ čüčéčĆąŠą║ąĖ. ą¤ąŠą┤ ą┐čĆąŠą▒ąĄą╗ą░ą╝ąĖ ąĘą┤ąĄčüčī ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░čÄčéčüčÅ čéą░ą║ąĖąĄ ąĮąĄą▓ąĖą┤ąĖą╝čŗąĄ čüąĖą╝ą▓ąŠą╗čŗ, ą║ą░ą║ ' ', '\r', '\n', '\t'.
ąÆ ą▒ąŠą╗ąĄąĄ ąŠą▒čēąĄą╝ čüą╗čāčćą░ąĄ ą║ąŠąĮąĄčćąĮąŠą╝čā ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÄ ą▓čŗ ą▓ąĄčĆąŠčÅčéąĮąŠ čģąŠč鹥ą╗ąĖ ą▒čŗ ą┐ąĄčĆąĄą┤ą░čéčī ąŠčéą┤ąĄą╗čīąĮąŠąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ. ąŁč鹊 ą╝ąŠąČąĮąŠ čüą┤ąĄą╗ą░čéčī ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ.
ąÆąŠ-ą┐ąĄčĆą▓čŗčģ, ą▓čŗ ą╝ąŠąČąĄč鹥 ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ ą┐ąĄčĆąĄą┤ą░čéčī ą▓ čäčāąĮą║čåąĖčÄ print() čüčéčĆąŠą║ąŠą▓čŗą╣ ą╗ąĖč鹥čĆą░ą╗:
>>> print ('ą¤ąŠąČą░ą╗čāą╣čüčéą░, ą┐ąŠą┤ąŠąČą┤ąĖč鹥, ąĖą┤ąĄčé ąĘą░ą│čĆčāąĘą║ą░...' )ąŁč鹊 ą┤ąŠčüą╗ąŠą▓ąĮąŠ ą▓čŗą▓ąĄą┤ąĄčé č鹥ą║čüč鹊ą▓ąŠąĄ čüąŠąŠą▒čēąĄąĮąĖąĄ ąĮą░ 菹║čĆą░ąĮ.
ąĪčéčĆąŠą║ąŠą▓čŗąĄ ą╗ąĖč鹥čĆą░ą╗čŗ ą▓ Python ą╝ąŠą│čāčé ą▒čŗčéčī ąĘą░ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮčŗ čü ą┐ąŠą╝ąŠčēčīčÄ ąŠą┤ąĖąĮąŠčćąĮčŗčģ (') ąĖą╗ąĖ ą┤ą▓ąŠą╣ąĮčŗčģ ą║ą░ą▓čŗč湥ą║s ("). ąÆ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąŠą╝ ą┐ąŠ čüčéąĖą╗čÄ Python [2], ą▓čŗ ą┐čĆąŠčüč鹊 ą┤ąŠą╗ąČąĮčŗ ą▓čŗą▒čĆą░čéčī ąŠą┤ąĖąĮ ąĖąĘ čŹčéąĖčģ čüą┐ąŠčüąŠą▒ąŠą▓, ąĖ čüąŠčģčĆą░ąĮčÅčéčī čŹč鹊čé ą▓čŗą▒ąŠčĆ ą┤ą╗čÅ čåąĄą╗ąŠčüčéąĮąŠčüčéąĖ ą▓ą░čłąĄą│ąŠ ą║ąŠą┤ą░. ąØąĄčé ąĮąĖą║ą░ą║ąŠą╣ čĆą░ąĘąĮąĖčåčŗ ą╝ąĄąČą┤čā ąŠą┤ąĖąĮą░čĆąĮčŗą╝ąĖ ąĖ ą┤ą▓ąŠą╣ąĮčŗą╝ąĖ ą║ą░ą▓čŗčćą║ą░ą╝ąĖ, ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ čüą╗čāčćą░čÅ, ą║ąŠą│ą┤ą░ ąĮčāąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą║ą░ą▓čŗčćą║ąĖ ą▓ąĮčāčéčĆąĖ čüčéčĆąŠą║ąĖ.
ąØą░ą┐čĆąĖą╝ąĄčĆ, ą▓čŗ ąĮąĄ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą▓ąŠą╣ąĮčŗąĄ ą║ą░ą▓čŗčćą║ąĖ ą┤ą╗čÅ ą╗ąĖč鹥čĆą░ą╗ą░, ą║ąŠą│ą┤ą░ ą▓ ąĄą│ąŠ č鹥ą╗ąŠ čéą░ą║ąČąĄ ą▓ą║ą╗čÄč湥ąĮčŗ ą┤ą▓ąŠą╣ąĮčŗąĄ ą║ą░ą▓čŗčćą║ąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 čŹč鹊 ąĮąĄąŠą┤ąĮąŠąĘąĮą░čćąĮąŠ ą┤ą╗čÅ ąĖąĮč鹥čĆą┐čĆąĄčéą░č鹊čĆą░ Python:
"ą£ąŠčÅ ą╗čÄą▒ąĖą╝ą░čÅ ą║ąĮąĖą│ą░ čŹč鹊 " Python Tricks"" # ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠ! ąÆčüąĄ, čćč鹊 ą▓ą░ą╝ ąĮčāąČąĮąŠ ą┤ą╗čÅ ą╗ąĖč鹥čĆą░ą╗ą░, ą║ąŠą│ą┤ą░ ą▓ąĮčāčéčĆąĖ ąĮąĄą│ąŠ ąĄčüčéčī ą┤ą▓ąŠą╣ąĮčŗąĄ ą║ą░ą▓čŗčćą║ąĖ, čéą░ą║ čŹč鹊 ąĘą░ą║ą╗čÄčćąĖčéčī ąĄą│ąŠ ą▓ ąŠą┤ąĖąĮą░čĆąĮčŗąĄ ą║ą░ą▓čŗčćą║ąĖ:
'ą£ąŠčÅ ą╗čÄą▒ąĖą╝ą░čÅ ą║ąĮąĖą│ą░ čŹč鹊 "Python Tricks"' ąóąŠčé ąČąĄ čüą░ą╝čŗą╣ čéčĆčÄą║ čüčĆą░ą▒ąŠčéą░ąĄčé ąĖ ąĮą░ąŠą▒ąŠčĆąŠčé:
"ą£ąŠčÅ ą╗čÄą▒ąĖą╝ą░čÅ ą║ąĮąĖą│ą░ čŹč鹊 'Python Tricks'" ąÉą╗čīč鹥čĆąĮą░čéąĖą▓ąĮąŠ ą▓čŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čāą┐ąŠą╝čÅąĮčāčéčŗą╣ čĆą░ąĮąĄąĄ čüąĖą╝ą▓ąŠą╗ 菹║čĆą░ąĮąĖčĆąŠą▓ą░ąĮąĖčÅ, čćč鹊ą▒čŗ Python ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ą╗ čŹčéąĖ ą▓ąĮčāčéčĆąĄąĮąĮąĖąĄ ą┤ą▓ąŠą╣ąĮčŗąĄ ą║ą░ą▓čŗčćą║ąĖ ą║ą░ą║ čćą░čüčéčī čüčéčĆąŠą║ąŠą▓ąŠą│ąŠ ą╗ąĖč鹥čĆą░ą╗ą░:
"ą£ąŠčÅ ą╗čÄą▒ąĖą╝ą░čÅ ą║ąĮąĖą│ą░ čŹč鹊 \"Python Tricks\"" ąŁą║čĆą░ąĮąĖčĆąŠą▓ą░ąĮąĖąĄ čü ą┐ąŠą╝ąŠčēčīčÄ ąŠą▒čĆą░čéąĮąŠą│ąŠ čüą╗ąĄčłą░ čģąŠčĆąŠčłą░čÅ ą▓ąĄčēčī, ąĮąŠ ąĖąĮąŠą│ą┤ą░ čŹč鹊 ą╝ąŠąČąĄčé ą╝ąĄčłą░čéčī. ąÆ čćą░čüčéąĮąŠčüčéąĖ, ą║ąŠą│ą┤ą░ ą▓čŗ čģąŠčéąĖč鹥, čćč鹊ą▒čŗ čüčéčĆąŠą║ą░ ą╗ąĖč鹥čĆą░ą╗čīąĮąŠ čüąŠą┤ąĄčƹȹ░ą╗ą░ čüąĖą╝ą▓ąŠą╗čŗ backslash. ą×ą┤ąĖąĮ ąĖąĘ ą║ą╗ą░čüčüąĖč湥čüą║ąĖčģ ą┐čĆąĖą╝ąĄčĆąŠą▓: čäą░ą╣ą╗ąŠą▓čŗą╣ ą┐čāčéčī ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ Windows:
'C:\Users\jdoe' # ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠ! 'C:\\Users\\jdoe' # ą┐čĆą░ą▓ąĖą╗čīąĮąŠ
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą║ą░ąČą┤čŗą╣ čüąĖą╝ą▓ąŠą╗ backslash ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī 菹║čĆą░ąĮąĖčĆąŠą▓ą░ąĮ ąĄčēąĄ ąŠą┤ąĮąĖą╝ čüąĖą╝ą▓ąŠą╗ąŠą╝ backslash.
ąŁč鹊 ąĄčēąĄ ą▒ąŠą╗čīčłąĄ ąĘą░ą╝ąĄčéąĮąŠ čü čĆąĄą│čāą╗čÅčĆąĮčŗą╝ąĖ ą▓čŗčĆą░ąČąĄąĮąĖčÅą╝ąĖ, ą║ąŠč鹊čĆčŗąĄ ą▒čŗčüčéčĆąŠ čüčéą░ąĮąŠą▓čÅčéčüčÅ ąĘą░ą┐čāčéą░ąĮąĮčŗą╝ąĖ ąĖąĘ-ąĘą░ ąĖąĮč鹥ąĮčüąĖą▓ąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüą┐ąĄčåąĖą░ą╗čīąĮčŗčģ čüąĖą╝ą▓ąŠą╗ąŠą▓:
'^\\w:\\\\(?:(?:(?:[^\\\\]+)?|(?:[^\\\\]+)\\\\[^\\\\]+)*)$'
ąÜ čüčćą░čüčéčīčÄ, ą▓čŗ ą╝ąŠąČąĄč鹥 ą▓čŗą║ą╗čÄčćąĖčéčī 菹║čĆą░ąĮąĖčĆąŠą▓ą░ąĮąĖąĄ ą▓ąĮčāčéčĆąĖ čüčéčĆąŠą║ąŠą▓ąŠą│ąŠ ą╗ąĖč鹥čĆą░ą╗ą░, čćč鹊 ą╝ąŠąČąĄčé ą┐ąŠą╝ąŠčćčī. ą¤čĆąŠčüč鹊 ą┐ąŠą┤čüčéą░ą▓čīč鹥 r ąĖą╗ąĖ R ą┐ąĄčĆąĄą┤ ąŠčéą║čĆčŗą▓ą░čÄčēąĄą╣ ą║ą░ą▓čŗčćą║ąŠą╣:
r'C:\Users\jdoe' r'^\w:\\(?:(?:(?:[^\\]+)?|(?:[^\\]+)\\[^\\]+)*)$'
ąĪčāčēąĄčüčéą▓čāąĄčé ąĖ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┤čĆčāą│ąĖčģ ą┐čĆąĄčäąĖą║čüąŠą▓ čüčéčĆąŠą║ąŠą▓čŗčģ ą╗ąĖč鹥čĆą░ą╗ąŠą▓, ąĮąŠ ą╝čŗ ą┐ąŠą║ą░ ąĮąĄ ą▒čāą┤ąĄą╝ ą▓ čŹč鹊 čāą│ą╗čāą▒ą╗čÅčéčīčüčÅ.
ąś ąĮą░ą║ąŠąĮąĄčå, ą▓čŗ ą╝ąŠąČąĄč鹥 ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą╝ąĮąŠą│ąŠčüčéčĆąŠčćąĮčŗąĄ čüčéčĆąŠą║ąŠą▓čŗąĄ ą╗ąĖč鹥čĆą░ą╗čŗ, ąĘą░ą║ą╗čÄčćąĖą▓ ąĖčģ ą╝ąĄąČą┤čā ''' """
ąÆąŠčé ą┐čĆąĖą╝ąĄčĆ:
"""
ą¤čĆąĖą▓ąĄčé!
ąŁč鹊 ą┐čĆąĖą╝ąĄčĆ ą╝ąĮąŠą│ąŠčüčéčĆąŠčćąĮąŠą╣
čüčéčĆąŠą║ąĖ ą▓ Python.
""" ą¦č鹊ą▒čŗ ąĖąĘą▒ą░ą▓ąĖčéčīčüčÅ ąŠčé ąĮą░čćą░ą╗čīąĮąŠą│ąŠ čüąĖą╝ą▓ąŠą╗ą░ newline, ą┐čĆąŠčüč鹊 ą┐ąŠą╝ąĄčüčéąĖč鹥 č鹥ą║čüčé čüčĆą░ąĘčā ą┐ąŠčüą╗ąĄ ąŠčéą║čĆčŗą▓ą░čÄčēąĄą╣ """:
"""ą¤čĆąĖą▓ąĄčé!
ąŁč鹊 ą┐čĆąĖą╝ąĄčĆ ą╝ąĮąŠą│ąŠčüčéčĆąŠčćąĮąŠą╣
čüčéčĆąŠą║ąĖ ą▓ Python.
""" ąóą░ą║ąČąĄ ą▓čŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī backslash, čćč鹊ą▒čŗ ąĖąĘą▒ą░ą▓ąĖčéčīčüčÅ ąŠčé newline:
"""\
ą¤čĆąĖą▓ąĄčé!
ąŁč鹊 ą┐čĆąĖą╝ąĄčĆ ą╝ąĮąŠą│ąŠčüčéčĆąŠčćąĮąŠą╣
čüčéčĆąŠą║ąĖ ą▓ Python.
""" ąöą╗čÅ čāą┤ą░ą╗ąĄąĮąĖčÅ ąŠčéčüčéčāą┐ą░ ąĖąĘ ą┐čĆąŠą▒ąĄą╗ąŠą▓ ąĖąĘ ą╝ąĮąŠą│ąŠčüčéčĆąŠčćąĮąŠą╣ čüčéčĆąŠą║ąĖ ą▓čŗ ą╝ąŠąČąĄč鹥 ą▓ąŠčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ čäčāąĮą║čåąĖąŠąĮą░ą╗ąŠą╝ ą▓čüčéčĆąŠąĄąĮąĮąŠą│ąŠ ą╝ąŠą┤čāą╗čÅ textwrap :
>>> import textwrap>>> paragraph = '''
ą¤čĆąĖą▓ąĄčé!
ąŁč鹊 ą┐čĆąĖą╝ąĄčĆ ą╝ąĮąŠą│ąŠčüčéčĆąŠčćąĮąŠą╣
čüčéčĆąŠą║ąĖ ą▓ Python.
''' >>> print (paragraph)>>> print (textwrap.dedent(paragraph).strip())ąĢčüčéčī čéą░ą║ąČąĄ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┤čĆčāą│ąĖčģ ą┐ąŠą╗ąĄąĘąĮčŗčģ čäčāąĮą║čåąĖą╣ ą▓ TextWrap ą┤ą╗čÅ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ č鹥ą║čüčéą░, ą║ąŠč鹊čĆčŗąĄ ą▓čŗ ąĮą░ą╣ą┤ąĄč鹥 ą▓ ą┐čĆąŠą┤ą▓ąĖąĮčāč鹊ą╝ čĆąĄą┤ą░ą║č鹊čĆąĄ č鹥ą║čüčéą░.
ąÆąŠ-ą▓č鹊čĆčŗčģ, ą┤ą╗čÅ ą▓čŗą▓ąŠą┤ą░ čüąŠąŠą▒čēąĄąĮąĖčÅ ą▓čŗ ą╝ąŠąČąĄč鹥 ą▓ąŠčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ąŠčéą┤ąĄą╗čīąĮąŠą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣, ą║ąŠč鹊čĆąŠą╣ ą┤ą░ą┤ąĖč鹥 ąŠčüą╝čŗčüą╗ąĄąĮąĮąŠąĄ ąĖą╝čÅ, čćč鹊 ą┐ąŠčüą┐ąŠčüąŠą▒čüčéą▓čāąĄčé čćąĖčéą░ąĄą╝ąŠčüčéąĖ ą║ąŠą┤ą░ ąĖ ąĄą│ąŠ ą┐ąŠą▓č鹊čĆąĮąŠą╝čā ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÄ:
>>> message = 'ą¤ąŠąČą░ą╗čāą╣čüčéą░, ą┐ąŠą┤ąŠąČą┤ąĖč鹥, ąĖą┤ąĄčé ąĘą░ą│čĆčāąĘą║ą░...' >>> print (message)ąś ąĮą░ą║ąŠąĮąĄčå, ą▓čŗ ą╝ąŠąČąĄč鹥 ą┐ąĄčĆąĄą┤ą░čéčī ą▓ čäčāąĮą║čåąĖčÄ print() ą▓čŗčĆą░ąČąĄąĮąĖąĄ, ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ string concatenation (čé. ąĄ. čüą║ą╗ąĄą╣ą║ą░ čüčéčĆąŠą║), ą║ąŠč鹊čĆąŠąĄ ą▒čāą┤ąĄčé ą▓čŗčćąĖčüą╗ąĄąĮąŠ ą┐ąĄčĆąĄą┤ ą┐ąĄčćą░čéčīčÄ čĆąĄąĘčāą╗čīčéą░čéą░:
>>> import os>>> print ('ą¤čĆąĖą▓ąĄčé, ' + os.getlogin() + '! ąÜą░ą║ ą┤ąĄą╗ą░?' )
ą¤čĆąĖą▓ąĄčé, jdoe! ąÜą░ą║ ą┤ąĄą╗ą░?ąØą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ čüčāčēąĄčüčéą▓čāąĄčé ąĄčēąĄ čü ą┤ąĄčüčÅč鹊ą║ čüą┐ąŠčüąŠą▒ąŠą▓ č乊čĆą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ čüąŠąŠą▒čēąĄąĮąĖą╣ ąĮą░ Python. ą» čĆąĄą║ąŠą╝ąĄąĮą┤čāčÄ ą▓ą░ą╝ ą┐čĆąĖčüą╝ąŠčéčĆąĄčéčīčüčÅ ą║ f-čüčéčĆąŠą║ą░ą╝, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠčÅą▓ąĖą╗ąĖčüčī ą▓ Python 3.6, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąĮąĖ ą┐čĆąĄą┤ą╗ą░ą│ą░čÄčé čüą░ą╝čŗą╣ ą║čĆą░čéą║ąĖą╣ čüąĖąĮčéą░ą║čüąĖčü ąĖąĘ ą▓čüąĄčģ:
>>> import os>>> print (f'ą¤čĆąĖą▓ąĄčé, {os.getlogin()} ! ąÜą░ą║ ą┤ąĄą╗ą░' )ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ f-čüčéčĆąŠą║ąĖ ąĖąĘą▒ą░ą▓čÅčé ą▓ą░čü ąŠčé ąŠą▒čēąĄą╣ ąŠčłąĖą▒ą║ąĖ, ą║ąŠą│ą┤ą░ ą▓čŗ ąĘą░ą▒čŗą▓ą░ąĄč鹥 čüą┤ąĄą╗ą░čéčī ą┐čĆąĖą▓ąĄą┤ąĄąĮąĖąĄ čéąĖą┐ą░ ą┐ąĄčĆąĄą┤ čüą║ą╗ąĄą╣ą║ąŠą╣ čćą░čüč鹥ą╣ čüčéčĆąŠą║ąĖ. Python čŹč鹊 čÅąĘčŗą║ čüąŠ čüčéčĆąŠą│ąŠą╣ čéąĖą┐ąĖąĘą░čåąĖąĄą╣, ąĖ ąŠąĮ ąĮąĄ čĆą░ąĘčĆąĄčłąĖčé čćč鹊-č鹊 ą┐ąŠą┤ąŠą▒ąĮąŠąĄ:
>>> 'ą£ąĮąĄ ' + 42 + 'ą│ąŠą┤ą░'
Traceback (most recent call last):
File "< input>" , line 1 , in < module>
msg = 'ą£ąĮąĄ ' + 42 + 'ą│ąŠą┤ą░'
~~~~~~~^~~~
TypeError: can only concatenate str (not "int" ) to str ą×čłąĖą▒ą║ą░ ą┐čĆąŠąĖąĘąŠčłą╗ą░ ąĖąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 ąĮąĄą╗čīąĘčÅ čüą║ą╗ąĄąĖą▓ą░čéčī čüčéčĆąŠą║ąĖ čü čćąĖčüą╗ą░ą╝ąĖ, čŹč鹊 ąĮąĄ ąĖą╝ąĄąĄčé čüą╝čŗčüą╗ą░. ąÆą░ą╝ ąĮčāąČąĮąŠ čüąĮą░čćą░ą╗ą░ čÅą▓ąĮąŠ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░čéčī čćąĖčüą╗ąŠ ą▓ čüčéčĆąŠą║čā, čćč鹊ą▒čŗ ąĄčæ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ čüą║ą╗ąĄąĖčéčī čü ą┤čĆčāą│ąŠą╣ čüčéčĆąŠą║ąŠą╣:
>>> 'ą£ąĮąĄ ' + str (42 ) + 'ą│ąŠą┤ą░' 'ą£ąĮąĄ 42 ą│ąŠą┤ą░' ąĢčüą╗ąĖ ą▓čŗ ąĮąĄ ąŠą▒čĆą░ą▒ąŠčéą░ąĄč鹥 ą┐ąŠą┤ąŠą▒ąĮčŗąĄ ąŠčłąĖą▒ą║ąĖ čüą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮąŠ, ąĖąĮč鹥čĆą┐čĆąĄčéą░č鹊čĆ Python čüąŠąŠą▒čēąĖčé ą▓ą░ą╝ ąŠ ą┐čĆąŠą▒ą╗ąĄą╝ąĄ, ą┐ąŠą║ą░ąĘą░ą▓ ąŠą▒čĆą░čéąĮčāčÄ čüą▓čÅąĘčī.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: str() čŹč鹊 ą│ą╗ąŠą▒ą░ą╗čīąĮą░čÅ ą▓čüčéčĆąŠąĄąĮąĮą░čÅ čäčāąĮą║čåąĖčÅ, ą║ąŠč鹊čĆą░čÅ ą┐čĆąĄąŠą▒čĆą░ąĘčāąĄčé ą╗čÄą▒ąŠą╣ ąŠą▒čŖąĄą║čé ą▓ čüčéčĆąŠą║ąŠą▓ąŠąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ. ąÆčŗ ą╝ąŠąČąĄč鹥 ą▓čŗąĘčŗą▓ą░čéčī čŹčéčā čäčāąĮą║čåąĖčÄ ąĮą░ ą╗čÄą▒ąŠą╝ ąŠą▒čŖąĄą║č鹥, ąĮą░ą┐čĆąĖą╝ąĄčĆ, ąĮą░ ąŠą▒čŖąĄą║č鹥 čćąĖčüą╗ą░ float :
>>> str (3.14 )'3.14' ąÆčüčéčĆąŠąĄąĮąĮčŗąĄ čéąĖą┐čŗ ą┤ą░ąĮąĮčŗčģ ąĖą╝ąĄčÄčé ą┐čĆąĄą┤ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ čüčéčĆąŠą║ ąĖąĘ ą║ąŠčĆąŠą▒ą║ąĖ, ąĮąŠ ą┐ąŠąĘąČąĄ ą▓ čŹč鹊ą╣ čüčéą░čéčīąĄ ą▓čŗ čāąĘąĮą░ąĄč鹥, ą║ą░ą║ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī ąĄą│ąŠ ą┤ą╗čÅ ą▓ą░čłąĖčģ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖčģ ą║ą╗ą░čüčüąŠą▓.
ąÜą░ą║ ąĖ čü ą╗čÄą▒ąŠą╣ čäčāąĮą║čåąĖąĄą╣, ąĮąĄ ąĖą╝ąĄąĄčé ąĘąĮą░č湥ąĮąĖąĄ, čćč鹊 ą▓čŗ ą▓ ąĮąĄčæ ą┐ąĄčĆąĄą┤ą░ąĄč鹥 - ą╗ąĖč鹥čĆą░ą╗, ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ ąĖą╗ąĖ ą▓čŗčĆą░ąČąĄąĮąĖąĄ. ą×ą┤ąĮą░ą║ąŠ ą▓ ąŠčéą╗ąĖčćąĖąĄ ąŠčé ą╝ąĮąŠą│ąĖčģ čäčāąĮą║čåąĖą╣, print() ą┐čĆąĖą╝ąĄčé ą╗čÄą▒ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ ąŠčé ąĄą│ąŠ čéąĖą┐ą░.
ą¤ąŠą║ą░ čćč鹊 ą╝čŗ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ą╗ąĖ č鹊ą╗čīą║ąŠ čüčéčĆąŠą║ąĖ, ąĮąŠ ą║ą░ą║ ąĮą░čüč湥čé ą┤čĆčāą│ąĖčģ čéąĖą┐ąŠą▓ ą┤ą░ąĮąĮčŗčģ? ą¤ąŠą┐čĆąŠą▒čāąĄą╝ ą╗ąĖč鹥čĆą░ą╗čŗ čĆą░ąĘąĮčŗčģ ą▓čüčéčĆąŠąĄąĮąĮčŗčģ čéąĖą┐ąŠą▓ ąĖ ą┐ąŠčüą╝ąŠčéčĆąĖą╝, čćč鹊 ą┐ąŠą╗čāčćąĖčéčüčÅ:
>>> print (42 ) # < class 'int'> 42 >>> print (3.14 ) # < class 'float'> 3.14 >>> print (1 + 2j ) # < class 'complex'>
(1 +2j )>>> print (True ) # < class 'bool'> True >>> print ([1 , 2 , 3 ]) # < class 'list'>
[1 , 2 , 3 ]>>> print ((1 , 2 , 3 )) # < class 'tuple'>
(1 , 2 , 3 )>>> print ({'red' , 'green' , 'blue' }) # < class 'set'>
{'red' , 'green' , 'blue' }>>> print ({'name' : 'Alice' , 'age' : 42 }) # < class 'dict'>
{'name' : 'Alice' , 'age' : 42 }>>> print ('hello' ) # < class 'str'>
helloą×čüąŠą▒ąĄąĮąĮčŗą╣ čüą╗čāčćą░ą╣ čü ą║ąŠąĮčüčéą░ąĮč鹊ą╣ None . ąØąĄčüą╝ąŠčéčĆčÅ ąĮą░ č鹊, čćč鹊 čŹč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ čāą║ą░ąĘą░ąĮąĖčÅ ąŠčéčüčāčéčüčéą▓ąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ, ąŠąĮą░ ą▒čāą┤ąĄčé ą┐ąŠą║ą░ąĘą░ąĮą░ ą║ą░ą║ 'None', ą░ ąĮąĄ ą║ą░ą║ ą┐čāčüčéą░čÅ čüčéčĆąŠą║ą░:
>>> print (None )None ąÜą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ čäčāąĮą║čåąĖčÅ print() ąĘąĮą░ąĄčé, ą║ą░ą║ čĆą░ą▒ąŠčéą░čéčī čüąŠ ą▓čüąĄą╝ąĖ čŹčéąĖą╝ąĖ čĆą░ąĘąĮčŗą╝ąĖ čéąĖą┐ą░ą╝ąĖ? ąØą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ ąĮąĖą║ą░ą║ ąĮąĄ ąĘąĮą░ąĄčé. ą¤čĆąŠčüč鹊 ąŠąĮą░ ąĮąĄčÅą▓ąĮąŠ ą▓čŗąĘčŗą▓ą░ąĄčé str() ąĮą░ ą║ą░ąČą┤ąŠą╝ čéąĖą┐ąĄ, čćč鹊ą▒čŗ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░čéčī ą╗čÄą▒ąŠą╣ ąŠą▒čŖąĄą║čé ą▓ čüčéčĆąŠą║čā. ą¤ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ą┐ąŠą╗čāč湥ąĮąĮčŗąĄ čüčéčĆąŠą║ąĖ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ąŠą▒čŗčćąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝.
ą¤ąŠąĘąČąĄ ą▓ čŹč鹊ą╝ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąĄ ą▓čŗ čāąĘąĮą░ąĄč鹥, ą║ą░ą║ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹč鹊čé ą╝ąĄčģą░ąĮąĖąĘą╝ ą┤ą╗čÅ ą┐ąĄčćą░čéąĖ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖčģ čéąĖą┐ąŠą▓ ą┤ą░ąĮąĮčŗčģ, čéą░ą║ąĖčģ ą║ą░ą║ ą▓ą░čłąĖ čüąŠą▒čüčéą▓ąĄąĮąĮčŗąĄ ą║ą╗ą░čüčüčŗ.
ą¦č鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī čéą░ą║ąŠą╣ ąČąĄ čĆąĄąĘčāą╗čīčéą░čé ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ ą▓ąĄčĆčüąĖąĖ čÅąĘčŗą║ą░, č鹊 ą▓čŗ čüą║ąŠčĆąĄąĄ ą▓čüąĄą│ąŠ ąĘą░čģąŠčéąĖč鹥 ąŠą┐čāčüčéąĖčéčī ą║čĆčāą│ą╗čŗąĄ čüą║ąŠą▒ą║ąĖ ą▓ąŠą║čĆčāą│ ą▓čŗą▓ąŠą┤ąĖą╝ąŠą│ąŠ č鹥ą║čüčéą░:
# Python 2 print print 'ą¤ąŠąČą░ą╗čāą╣čüčéą░, ą┐ąŠą┤ąŠąČą┤ąĖč鹥...' print 'ą¤čĆąĖą▓ąĄčé, %s! ąÜą░ą║ ą┤ąĄą╗ą░?' % os.getlogin()print 'ą¤čĆąĖą▓ąĄčé, %s. ąóą▓ąŠą╣ ą▓ąŠąĘčĆą░čüčé %d ą│ąŠą┤ą░.' % (name, age)ąŁč鹊 ą┐ąŠč鹊ą╝čā čćč鹊 č鹊ą│ą┤ą░ print ą▒čŗą╗ą░ ąŠą┐ąĄčĆą░č鹊čĆąŠą╝, ą░ ąĮąĄ čäčāąĮą║čåąĖąĄą╣, ą║ą░ą║ ą╝čŗ čāą▓ąĖą┤ąĖą╝ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╣ čüąĄą║čåąĖąĖ. ą×ą┤ąĮą░ą║ąŠ čüą╗ąĄą┤čāąĄčé ąĘą░ą╝ąĄčéąĖčéčī, čćč鹊 ą┤ą░ą╗ąĄą║ąŠ ąĮąĄ ą▓čüąĄą│ą┤ą░ ą║čĆčāą│ą╗čŗąĄ čüą║ąŠą▒ą║ąĖ ą▓ Python ąŠą▒čÅąĘą░č鹥ą╗čīąĮčŗ. ąØąĄ ą▒čāą┤ąĄčé ąŠčłąĖą▒ą║ąŠą╣ ą┤ą░ąČąĄ ąĖčģ ąĖąĘą╗ąĖčłąĮąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓ ą║čĆą░ą╣ąĮąĄą╝ čüą╗čāčćą░ąĄ ąŠąĮąĖ ą▒čāą┤čāčé ą┐čĆąŠčüč鹊 ąŠčéą▒čĆąŠčłąĄąĮčŗ. ą×ąĘąĮą░čćą░ąĄčé ą╗ąĖ čŹč鹊, čćč鹊 ąŠą┐ąĄčĆą░č鹊čĆ print čüą╗ąĄą┤čāąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čéą░ą║ ąČąĄ, ą║ą░ą║ ąĄčüą╗ąĖ ą▒čŗ čŹč鹊 ą▒čŗą╗ą░ čäčāąĮą║čåąĖčÅ? ąÉą▒čüąŠą╗čÄčéąĮąŠ ąĮąĄčé!
ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĮąĄąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ ąĘą░ą║čĆčŗą▓ą░čéčī ą▓ ą║čĆčāą│ą╗čŗąĄ čüą║ąŠą▒ą║ąĖ ąŠą┤ąĖąĮąŠčćąĮąŠąĄ ą▓čŗčĆą░ąČąĄąĮąĖąĄ ąĖą╗ąĖ ą╗ąĖč鹥čĆą░ą╗. ą×ą▒ąĄ čüą╗ąĄą┤čāčÄčēąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ą░čÄčé ą▓ Python 2 ąŠą┤ąĖąĮą░ą║ąŠą▓čŗą╣ čĆąĄąĘčāą╗čīčéą░čé:
>>> # Python 2 >>> print 'ą¤ąŠąČą░ą╗čāą╣čüčéą░, ą┐ąŠą┤ąŠąČą┤ąĖč鹥...'
ą¤ąŠąČą░ą╗čāą╣čüčéą░, ą┐ąŠą┤ąŠąČą┤ąĖč鹥...>>> print ('ą¤ąŠąČą░ą╗čāą╣čüčéą░, ą┐ąŠą┤ąŠąČą┤ąĖč鹥...' )
ą¤ąŠąČą░ą╗čāą╣čüčéą░, ą┐ąŠą┤ąŠąČą┤ąĖč鹥...ąÜčĆčāą│ą╗čŗąĄ čüą║ąŠą▒ą║ąĖ čäą░ą║čéąĖč湥čüą║ąĖ čÅą▓ą╗čÅčÄčéčüčÅ čćą░čüčéčīčÄ ą▓čŗčĆą░ąČąĄąĮąĖčÅ, ą░ ąĮąĄ ąŠą┐ąĄčĆą░č鹊čĆą░ print. ąĢčüą╗ąĖ ą▓ą░čłąĄ ą▓čŗčĆą░ąČąĄąĮąĖąĄ čüąŠą┤ąĄčƹȹĖčé č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ 菹╗ąĄą╝ąĄąĮčé, č鹊 ąĮąĄ ąĖą╝ąĄąĄčé ąĘąĮą░č湥ąĮąĖąĄ, ąĘą░ą║ą╗čÄčćą░ąĄč鹥 ą╗ąĖ ą▓čŗ ąĄą│ąŠ ą▓ čüą║ąŠą▒ą║ąĖ.
ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ąĘą░ą║ą╗čÄč湥ąĮąĖąĄ ą▓ čüą║ąŠą▒ą║ąĖ ąĮąĄčüą║ąŠą╗čīą║ąŠ 菹╗ąĄą╝ąĄąĮč鹊ą▓ čüč乊čĆą╝ąĖčĆčāčÄčé ą║ąŠčĆč鹥ąČ (tuple):
>>> # Python 2 >>> print 'ą£ąĄąĮčÅ ąĘąŠą▓čāčé' , 'John'
ą£ąĄąĮčÅ ąĘąŠą▓čāčé John>>> print ('ą£ąĄąĮčÅ ąĘąŠą▓čāčé' , 'John' )
('ą£ąĄąĮčÅ ąĘąŠą▓čāčé' , 'John' )ąŁč鹊 ąĖąĘą▓ąĄčüčéąĮčŗą╣ ąĖčüč鹊čćąĮąĖą║ ą┐čāčéą░ąĮąĖčåčŗ. ążą░ą║čéąĖč湥čüą║ąĖ ą▓čŗ čéą░ą║ąČąĄ ą┐ąŠą╗čāčćąĖč鹥 ą║ąŠčĆč鹥ąČ, ą┤ąŠą▒ą░ą▓ąĖą▓ ą┐ąŠčüą╗ąĄą┤ąĮčÄčÄ ąĘą░ą┐čÅčéčāčÄ ą║ ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮąŠą╝čā 菹╗ąĄą╝ąĄąĮčéčā, ąĘą░ą║ą╗čÄč湥ąĮąĮąŠą╝čā ą▓ čüą║ąŠą▒ą║ąĖ:
>>> # Python 2 >>> print ('ą¤ąŠąČą░ą╗čāą╣čüčéą░, ą┐ąŠą┤ąŠąČą┤ąĖč鹥...' )
ą¤ąŠąČą░ą╗čāą╣čüčéą░, ą┐ąŠą┤ąŠąČą┤ąĖč鹥...>>> print (ą¤ąŠąČą░ą╗čāą╣čüčéą░, ą┐ąŠą┤ąŠąČą┤ąĖč鹥...',) # ąŠą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ ąĮą░ ąĘą░ą┐čÅčéčāčÄ
(' ą¤ąŠąČą░ą╗čāą╣čüčéą░, ą┐ąŠą┤ąŠąČą┤ąĖč鹥...',) ąĪčāčéčī ą▓ č鹊ą╝, čćč鹊 ąĮą░ ąĮąĖąČąĮąĄą╣ čüčéčĆąŠą║ąĄ ą▓ Python 2 ąĮąĄ čüč鹊ąĖčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čüą║ąŠą▒ą║ąĖ ą▓ą╝ąĄčüč鹥 čü print. ąźąŠčéčÅ, ąĄčüą╗ąĖ ą▒čŗčéčī ą┐ąŠą╗ąĮąŠčüčéčīčÄ č鹊čćąĮčŗą╝, ą▓čŗ ą╝ąŠąČąĄč鹥 ąŠą▒ąŠą╣čéąĖ čŹč鹊 čü ą┐ąŠą╝ąŠčēčīčÄ ąĖą╝ą┐ąŠčĆčéą░ __future__ , ąŠ č湥ą╝ ą╝čŗ ą┐ąŠą│ąŠą▓ąŠčĆąĖą╝ ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą╣ čüąĄą║čåąĖąĖ.
ą×ąÜ, č鹥ą┐ąĄčĆčī ą▓čŗ ą╝ąŠąČąĄč鹥 ą▓čŗąĘčŗą▓ą░čéčī print() čü ąŠą┤ąĮąĖą╝ ą░čĆą│čāą╝ąĄąĮč鹊ą╝ ąĖą╗ąĖ ą▒ąĄąĘ ą░čĆą│čāą╝ąĄąĮč鹊ą▓. ąÆčŗ ąĘąĮą░ąĄč鹥, ą║ą░ą║ ą┐ąĄčćą░čéą░čéčī ąĮą░ 菹║čĆą░ąĮąĄ čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ąĖą╗ąĖ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĮčŗąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ. ąÆ čüą╗ąĄą┤čāčÄčēąĄą╣ ą│ą╗ą░ą▓ąĄ ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖąĄ čüąŠąŠą▒čēąĄąĮąĖą╣.
[ąĀą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą░čĆą│čāą╝ąĄąĮč鹊ą▓ ]
ąÆčŗ čāąČąĄ ą▓ąĖą┤ąĄą╗ąĖ, ą║ą░ą║ print () ą▓čŗąĘčŗą▓ą░ą╗čüčÅ ą▒ąĄąĘ ą║ą░ą║ąĖčģ-ą╗ąĖą▒ąŠ ą░čĆą│čāą╝ąĄąĮč鹊ą▓ ą┤ą╗čÅ čüąŠąĘą┤ą░ąĮąĖčÅ ą┐čāčüč鹊ą╣ čüčéčĆąŠą║ąĖ, ą░ ąĘą░č鹥ą╝ ą▓čŗąĘčŗą▓ą░ą╗čüčÅ čü ąŠą┤ąĮąĖą╝ ą░čĆą│čāą╝ąĄąĮč鹊ą╝ ą┤ą╗čÅ ąŠč鹊ą▒čĆą░ąČąĄąĮąĖčÅ čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ ąĖą╗ąĖ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ.
ą×ą┤ąĮą░ą║ąŠ ą┐ąŠą╗čāčćą░ąĄčéčüčÅ, čćč鹊 čŹčéą░ čäčāąĮą║čåąĖčÅ ą╝ąŠąČąĄčé ą┐čĆąĖąĮąĖą╝ą░čéčī ą╗čÄą▒ąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠąĘąĖčåąĖąŠąĮąĮčŗčģ ą░čĆą│čāą╝ąĄąĮč鹊ą▓, ą▓ą║ą╗čÄčćą░čÅ ąĮąŠą╗čī, ąŠą┤ąĖąĮ ąĖą╗ąĖ ą▒ąŠą╗ąĄąĄ ą░čĆą│čāą╝ąĄąĮč鹊ą▓. ąŁč鹊 ąŠč湥ąĮčī čāą┤ąŠą▒ąĮąŠ ą▓ ąŠą▒čēąĄą╝ čüą╗čāčćą░ąĄ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖčÅ čüąŠąŠą▒čēąĄąĮąĖą╣, ą│ą┤ąĄ ą▓čŗ čģąŠč鹥ą╗ąĖ ą▒čŗ ąŠą▒čŖąĄą┤ąĖąĮąĖčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą▓ą╝ąĄčüč鹥.
ąÉčĆą│čāą╝ąĄąĮčéčŗ ą╝ąŠą│čāčé ą▒čŗčéčī ą┐ąĄčĆąĄą┤ą░ąĮčŗ ą▓ čäčāąĮą║čåąĖčÄ čĆą░ąĘą╗ąĖčćąĮčŗą╝ąĖ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ. ą×ą┤ąĖąĮ ąĖąĘ čüą┐ąŠčüąŠą▒ąŠą▓ - čÅą▓ąĮąŠąĄ ąĖą╝ąĄąĮąŠą▓ą░ąĮąĖąĄ ą░čĆą│čāą╝ąĄąĮč鹊ą▓ ą┐čĆąĖ ą▓čŗąĘąŠą▓ąĄ čäčāąĮą║čåąĖąĖ, ą┐čĆąĖą╝ąĄčĆąĮąŠ čéą░ą║:
>>> def div (a, b ):... return a / b
...>>> div(a=3 , b=4 )0.75 ą¤ąŠčüą║ąŠą╗čīą║čā čā ą░čĆą│čāą╝ąĄąĮč鹊ą▓ ą╝ąŠą│čāčé ą▒čŗčéčī čāąĮąĖą║ą░ą╗čīąĮčŗąĄ, ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāčÄčēąĖąĄ ąĖčģ ąĖą╝ąĄąĮą░, ąĖčģ ą┐ąŠčĆčÅą┤ąŠą║ čüą╗ąĄą┤ąŠą▓ą░ąĮąĖčÅ ą▓ ą▓čŗąĘąŠą▓ąĄ ąĮąĄ ąĖą╝ąĄąĄčé ąĘąĮą░č湥ąĮąĖčÅ. ąĢčüą╗ąĖ ąĖčģ ą┐ąĄčĆąĄčüčéą░ą▓ąĖčéčī ąĮą░ąŠą▒ąŠčĆąŠčé, č鹊 čŹč鹊 ą┤ą░čüčé čéą░ą║ąŠą╣ ąČąĄ čĆąĄąĘčāą╗čīčéą░čé:
>>> div(b=4 , a=3 )0.75 ąØąŠ ąĄčüą╗ąĖ ą┐ąĄčĆąĄą┤ą░ą▓ą░čéčī ą░čĆą│čāą╝ąĄąĮčéčŗ ą▒ąĄąĘ čāą║ą░ąĘą░ąĮąĖčÅ ąĖčģ ąĖą╝ąĄąĮąĖ, č鹊 ąŠąĮąĖ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāčÄčéčüčÅ ą┐ąŠ ąĖčģ ą┐ąŠąĘąĖčåąĖąĖ. ąÆąŠčé ą┐ąŠč湥ą╝čā ą┐ąŠąĘąĖčåąĖąŠąĮąĮčŗąĄ ą░čĆą│čāą╝ąĄąĮčéčŗ ą┤ąŠą╗ąČąĮčŗ čüčéčĆąŠą│ąŠ čüą╗ąĄą┤ąŠą▓ą░čéčī ą┐ąŠčĆčÅą┤ą║čā, ąĘą░ą┤ą░ąĮąĮąŠą╝čā čüąĖą│ąĮą░čéčāčĆąŠą╣ čäčāąĮą║čåąĖąĖ:
>>> div(3 , 4 )0.75 >>> div(4 , 3 )1.3333333333333333 ążčāąĮą║čåąĖčÅ print() ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐ąĄčĆąĄą┤ą░ą▓ą░čéčī ą▓ čüąĄą▒čÅ ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠąĘąĖčåąĖąŠąĮąĮčŗčģ ą░čĆą│čāą╝ąĄąĮč鹊ą▓ ą▒ą╗ą░ą│ąŠą┤ą░čĆčÅ ą┐ą░čĆą░ą╝ąĄčéčĆčā *args.
ąöą░ą▓ą░ą╣č鹥 ą┐ąŠčüą╝ąŠčéčĆąĖą╝ ąĮą░ čŹč鹊čé ą┐čĆąĖą╝ąĄčĆ:
>>> import os>>> print ('ą£ąĄąĮčÅ ąĘąŠą▓čāčé' , os.getlogin(), 'ąĖ ą╝ąĮąĄ' , 42 , 'ą│ąŠą┤ą░.' )
ą£ąĄąĮčÅ ąĘąŠą▓čāčé jdoe ąĖ ą╝ąĮąĄ 42 ą│ąŠą┤ą░.ążčāąĮą║čåąĖčÅ print() čüą║ą╗ąĄąĖą╗ą░ ą▓čüąĄ 5 ą┐ąĄčĆąĄą┤ą░ąĮąĮčŗčģ ą░čĆą│čāą╝ąĄąĮč鹊ą▓ ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝, ąĖ ą▓čüčéą░ą▓ąĖą╗ą░ ą┐ąŠ ąŠą┤ąĮąŠą╝čā ą┐čĆąŠą▒ąĄą╗čā ą╝ąĄąČą┤čā ąĮąĖą╝ąĖ.
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 print() čéą░ą║ąČąĄ ą┐ąŠąĘą░ą▒ąŠčéąĖą╗ą░čüčī ąŠ ą┐čĆą░ą▓ąĖą╗čīąĮąŠą╝ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĖ čéąĖą┐ą░ ą┐ąĄčĆąĄą┤ą░ąĮąĮčŗčģ ą░čĆą│čāą╝ąĄąĮč鹊ą▓ ą▒ą╗ą░ą│ąŠą┤ą░čĆčÅ ąĮąĄčÅą▓ąĮąŠ ą▓čŗąĘą▓ą░ąĮąĮąŠą╣ čäčāąĮą║čåąĖąĖ str() ąĮą░ ą║ą░ąČą┤ąŠą╝ ą░čĆą│čāą╝ąĄąĮč鹥 ą┐ąĄčĆąĄą┤ ąĖčģ čüą║ą╗ąĄąĖą▓ą░ąĮąĖąĄą╝ ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝. ąĢčüą╗ąĖ ą▓čŗ ą▓čüą┐ąŠą╝ąĮąĖč鹥 ą┐čĆąĖą╝ąĄčĆ ąĖąĘ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ čüąĄą║čåąĖąĖ, ąĮą░ąĖą▓ąĮąŠąĄ čüą║ą╗ąĄąĖą▓ą░ąĮąĖąĄ ą╗ąĄą│ą║ąŠ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ąŠčłąĖą▒ą║ąĄ ąĮąĄčüąŠą▓ą╝ąĄčüčéąĖą╝ąŠčüčéąĖ čéąĖą┐ąŠą▓:
>>> 'ą£ąĮąĄ ' + 42 + 'ą│ąŠą┤ą░'
Traceback (most recent call last):
File "< input>" , line 1 , in < module>
msg = 'ą£ąĮąĄ ' + 42 + 'ą│ąŠą┤ą░'
~~~~~~~^~~~
TypeError: can only concatenate str (not "int" ) to str ą¤ąŠą╝ąĖą╝ąŠ ą┐čĆąĖąĮčÅčéąĖčÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą┐ąŠąĘąĖčåąĖąŠąĮąĮčŗčģ ą░čĆą│čāą╝ąĄąĮč鹊ą▓, čäčāąĮą║čåąĖčÅ print() ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé 4 ąĖą╝ąĄąĮąŠą▓ą░ąĮąĮčŗčģ (ąĖą╗ąĖ ą║ą╗čÄč湥ą▓čŗčģ) ą░čĆą│čāą╝ąĄąĮčéą░ [3], ą║ąŠč鹊čĆčŗąĄ čÅą▓ą╗čÅčÄčéčüčÅ ąĮąĄąŠą▒čÅąĘą░č鹥ą╗čīąĮčŗą╝ąĖ, ą┐ąŠčüą║ąŠą╗čīą║čā čā ąĮąĖčģ čā ą▓čüąĄčģ ąĘą░ą┤ą░ąĮčŗ ąĘąĮą░č湥ąĮąĖčÅ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ. ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐čĆąŠčüą╝ąŠčéčĆąĄčéčī ąĖčģ ą║čĆą░čéą║čāčÄ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖčÄ, ąĄčüą╗ąĖ ą▓čŗąĘąŠą▓ąĖč鹥 help(print) ąĖąĘ ąĖąĮč鹥čĆą░ą║čéąĖą▓ąĮąŠą╣ ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąĖ ąĖąĮč鹥čĆą┐čĆąĄčéą░č鹊čĆą░ Python.
>>> help(print)
print(*args, sep=' ', end='\n', file=None, flush=False)
sep
end
file
flush
ąöą░ą▓ą░ą╣č鹥 čüąĄą╣čćą░čü ąŠą▒čĆą░čéąĖą╝ ą▓ąĮąĖą╝ą░ąĮąĖąĄ ąĮą░ ąĖą╝ąĄąĮąŠą▓ą░ąĮąĮčŗą╣ ą┐ą░čĆą░ą╝ąĄčéčĆ sep . ąśą╝čÅ čŹč鹊ą│ąŠ ą┐ą░čĆą░ą╝ąĄčéčĆą░ - čüąŠą║čĆą░čēąĄąĮąĖąĄ ąŠčé separator (čé. ąĄ. čĆą░ąĘą┤ąĄą╗ąĖč鹥ą╗čī). ąŁč鹊 čüčéčĆąŠą║ą░, ą║ąŠč鹊čĆčāčÄ print ą▓čüčéą░ą▓ą╗čÅąĄčé ą╝ąĄąČą┤čā ą░čĆą│čāą╝ąĄąĮčéą░ą╝ąĖ, ąĖ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĄą╣ ąĮą░ąĘąĮą░č湥ąĮ ą┐čĆąŠą▒ąĄą╗ (' ').
ąöą╗čÅ sep ą╝ąŠąČąĮąŠ čāą║ą░ąĘą░čéčī ą╗čÄą▒čāčÄ ąĮčāąČąĮčāčÄ čüčéčĆąŠą║čā, ą▓ č鹊ą╝ čćąĖčüą╗ąĄ ąĖ None, ąŠą┤ąĮą░ą║ąŠ čāą║ą░ąĘą░ąĮąĖąĄ None ą┤ą░čüčé čéą░ą║ąŠą╣ ąČąĄ čŹčäč乥ą║čé, čćč鹊 ąĖ ą┐čĆąŠą▒ąĄą╗ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ:
>>> print ('hello' , 'world' , sep=None )
hello world>>> print ('hello' , 'world' , sep=' ' )
hello world>>> print ('hello' , 'world' )
hello worldąĢčüą╗ąĖ ą▓čŗ čģąŠčéąĖč鹥 ą┐ąŠą┤ą░ą▓ąĖčéčī ą▓čüčéą░ą▓ą║čā čĆą░ąĘą┤ąĄą╗ąĖč鹥ą╗čÅ, č鹊 ą┤ąŠą╗ąČąĮčŗ ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą┐ąĄčĆąĄą┤ą░čéčī ą┐čāčüčéčāčÄ čüčéčĆąŠą║čā (''):
>>> print ('hello' , 'world' , sep='' )
helloworldąĢčüą╗ąĖ ą▓čŗ čģąŠčéąĖč鹥, čćč鹊ą▒čŗ print() ą┐ąĄčćą░čéą░ą╗ą░ čüą▓ąŠąĖ ą░čĆą│čāą╝ąĄąĮčéčŗ ą║ą░ąČą┤čŗą╣ ąĮą░ ąŠčéą┤ąĄą╗čīąĮąŠą╣ čüčéčĆąŠą║ąĄ, č鹊 ą┐čĆąŠčüč鹊 ą┐ąĄčĆąĄą┤ą░ą╣č鹥 ą┤ą╗čÅ sep čüčéčĆąŠą║čā čü čüąĖą╝ą▓ąŠą╗ąŠą╝ newline:
>>> print ('hello' , 'world' , sep='\n' )
hello
worldąĢčēąĄ ąŠą┤ąĖąĮ ą┐ąŠą╗ąĄąĘąĮčŗą╣ ą┐čĆąĖą╝ąĄčĆ - ą┐ąĄčĆąĄą┤ą░čćą░ sep čüčéčĆąŠą║ąĖ čüąŠ čüą╗ąĄčłąĄą╝, čćč鹊 ą┐ąŠąĘą▓ąŠą╗ąĖčé č乊čĆą╝ąĖčĆąŠą▓ą░čéčī čüčéčĆąŠą║ąĖ čéąĖą┐ą░ ą┐čāč鹥ą╣ ą║ čäą░ą╣ą╗čā:
>>> print ('home' , 'user' , 'documents' , sep='/' )
home/user/documentsą¤ąŠą╝ąĮąĖč鹥, čćč鹊 čĆą░ąĘą┤ąĄą╗ąĖč鹥ą╗čī ą▓čüčéą░ą▓ą╗čÅąĄčéčüčÅ č鹊ą╗čīą║ąŠ ą╝ąĄąČą┤čā ą┐ąĄčćą░čéą░ąĄą╝čŗą╝ąĖ 菹╗ąĄą╝ąĄąĮčéą░ą╝ąĖ, ąĮąŠ ąĮąĄ ą▓ąŠą║čĆčāą│ ąĮąĖčģ, ą┐ąŠčŹč鹊ą╝čā ą▓ą░ą╝ čüą╗ąĄą┤čāąĄčé čéą░ą║ ąĖą╗ąĖ ąĖąĮą░č湥 čŹč鹊 čāčćąĖčéčŗą▓ą░čéčī:
>>> print ('/home' , 'user' , 'documents' , sep='/' )
/home/user/documents>>> print ('' , 'home' , 'user' , 'documents' , sep='/' )
/home/user/documentsąÆ čćą░čüčéąĮąŠčüčéąĖ, ą▓čŗ ą╝ąŠąČąĄč鹥 ą╗ąĖą▒ąŠ ą▓čüčéą░ą▓ąĖčéčī čüąĖą╝ą▓ąŠą╗ čüą╗ąĄčłą░ (/) ą▓ ą┐ąĄčĆą▓čŗą╣ ą┐ąŠąĘąĖčåąĖąŠąĮąĮčŗą╣ ą░čĆą│čāą╝ąĄąĮčé, ą╗ąĖą▒ąŠ ą┤ąŠą▒ą░ą▓ąĖčéčī ą┐ąĄčĆą▓čŗą╣ ą░čĆą│čāą╝ąĄąĮčé ą▓ ą▓ąĖą┤ąĄ ą┐čāčüč鹊ą╣ čüčéčĆąŠą║ąĖ, čćč鹊ą▒čŗ ą▓čüčéą░ą▓ąĖą╗čüčÅ čüą╗ąĄčł čüą┐ąĄčĆąĄą┤ąĖ.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ą▒čāą┤čīč鹥 ąŠčüč鹊čĆąŠąČąĮčŗ, ą║ąŠą│ą┤ą░ čüą║ą╗ąĄąĖą▓ą░ąĄč鹥 菹╗ąĄą╝ąĄąĮčéčŗ čüą┐ąĖčüą║ą░ ąĖą╗ąĖ ą║ąŠčĆč鹥ąČą░. ąÆčŗą┐ąŠą╗ąĮąĄąĮąĖąĄ čŹč鹊ą│ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ ą▓čĆčāčćąĮčāčÄ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĖąĘą▓ąĄčüčéąĮąŠą╣ ąŠčłąĖą▒ą║ąĄ TypeError, ąĄčüą╗ąĖ čģąŠčéčÅ ą▒čŗ ąŠą┤ąĖąĮ ąĖąĘ 菹╗ąĄą╝ąĄąĮč鹊ą▓ čüą┐ąĖčüą║ą░ ąĖą╗ąĖ ą║ąŠčĆč鹥ąČą░ ąĮąĄ čÅą▓ą╗čÅąĄčéčüčÅ čüčéčĆąŠą║ąŠą╣:
>>> print (' ' .join(['jdoe' , 42 , 'ą│ąŠą┤ą░' ]))
Traceback (most recent call last):
File "< input>" , line 1 , in < module>
print (',' .join(['jdoe' , 42 , 'ą│ąŠą┤ą░' ]))
TypeError: sequence item 1 : expected str instance, int foundąæąĄąĘąŠą┐ą░čüąĮąĄąĄ ą┐čĆąŠčüč鹊 ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮąŠ čĆą░čüą┐ą░ą║ąŠą▓ą░čéčī ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī čü ą┐ąŠą╝ąŠčēčīčÄ ąŠą┐ąĄčĆą░č鹊čĆą░ ąĘą▓ąĄąĘą┤ąŠčćą║ąĖ (*), čćč鹊 ą┐ąŠąĘą▓ąŠą╗ąĖčé čäčāąĮą║čåąĖąĖ print() ą┐čĆąĖą╝ąĄąĮąĖčéčī ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ čéąĖą┐ą░ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ:
>>> print (*['jdoe' , 42 , 'ą│ąŠą┤ą░' ])
jdoe 42 ą│ąŠą┤ą░ąĀą░čüą┐ą░ą║ąŠą▓ą║ą░ čäą░ą║čéąĖč湥čüą║ąĖ ą┤ąĄą╗ą░ąĄčé č鹊 ąČąĄ čüą░ą╝ąŠąĄ, čćč鹊 ąĖ ą▓čŗąĘąŠą▓ print() čü ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮąĖąĄą╝ ąŠčéą┤ąĄą╗čīąĮčŗčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ąĖąĘ čüą┐ąĖčüą║ą░.
ąĢčēąĄ ąŠą┤ąĖąĮ ą┐ąŠą╗ąĄąĘąĮčŗą╣ ą┐čĆąĖą╝ąĄčĆ - 菹║čüą┐ąŠčĆčé ą┤ą░ąĮąĮčŗčģ ą▓ č乊čĆą╝ą░čé CSV (comma-separated values):
>>> print (1 , 'Python Tricks' , 'Dan Bader' , sep=',' )1 ,Python Tricks,Dan BaderąŁč鹊 ąĮąĄ ą▒čāą┤ąĄčé ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī čćą░čüčéąĮčŗąĄ čüą╗čāčćą░ąĖ, čéą░ą║ąĖąĄ ą║ą░ą║ ą║ąŠčĆčĆąĄą║čéąĮąŠąĄ 菹║čĆą░ąĮąĖčĆąŠą▓ą░ąĮąĖąĄ ąĘą░ą┐čÅčéčŗčģ, ąĮąŠ ą┤ą╗čÅ ą┐čĆąŠčüčéčŗčģ čüą╗čāčćą░ąĄą▓ ą▒čāą┤ąĄčé čĆą░ą▒ąŠčéą░čéčī. ą¤ąŠą║ą░ąĘą░ąĮąĮą░čÅ ą▓ ą┐čĆąĖą╝ąĄčĆąĄ ą▓čŗčłąĄ čüčéčĆąŠą║ą░ ą┐ąŠčÅą▓ąĖčéčüčÅ ą▓ ąŠą║ąĮąĄ č鹥čĆą╝ąĖąĮą░ą╗ą░. ą¦č鹊ą▒čŗ čüąŠčģčĆą░ąĮąĖčéčī ąĄčæ ą▓ čäą░ą╣ą╗, ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ąĖčéčī ą▓čŗą▓ąŠą┤. ąöą░ą╗ąĄąĄ ą▒čāą┤ąĄčé ą┐ąŠą║ą░ąĘą░ąĮąŠ, ą║ą░ą║ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī print() ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ č鹥ą║čüč鹊ą▓čŗčģ čäą░ą╣ą╗ąŠą▓ ąĮą░ą┐čĆčÅą╝čāčÄ ąĖąĘ Python.
ąś ąĮą░ą║ąŠąĮąĄčå, ą┐ą░čĆą░ą╝ąĄčéčĆ sep ąĮąĄ ąŠą│čĆą░ąĮąĖčćąĖą▓ą░ąĄčéčüčÅ č鹊ą╗čīą║ąŠ ąŠą┤ąĮąĖą╝ čüąĖą╝ą▓ąŠą╗ąŠą╝. ąÆčŗ ą╝ąŠąČąĄč鹥 čüą║ą╗ąĄąĖą▓ą░čéčī 菹╗ąĄą╝ąĄąĮčéčŗ, ą▓čüčéą░ą▓ą╗čÅčÅ ą╝ąĄąČą┤čā ąĮąĖą╝ąĖ čüčéčĆąŠą║čā ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮąŠą╣ ą┤ą╗ąĖąĮčŗ:
>>> print ('node' , 'child' , 'child' , sep=' -> ' )
node -> child -> child
ą¦č鹊ą▒čŗ ąĮą░ą┐ąĄčćą░čéą░čéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą▓ Python 2, ą▓čŗ ą┤ąŠą╗ąČąĮčŗ ąŠčéą▒čĆąŠčüąĖčéčī ą║čĆčāą│ą╗čŗąĄ čüą║ąŠą▒ą║ąĖ ą▓ąŠą║čĆčāą│ ąĮąĖčģ, čéą░ą║ ąČąĄ ą║ą░ą║ ąĖ čĆą░ąĮčīčłąĄ:
>>> # Python 2 >>> import os>>> print 'ą£ąĄąĮčÅ ąĘąŠą▓čāčé' , os.getlogin(), 'ąĖ ą╝ąĮąĄ' , 42 , 'ą│ąŠą┤ą░.'
ą£ąĄąĮčÅ ąĘąŠą▓čāčé jdoe ąĖ ą╝ąĮąĄ 42 ą│ąŠą┤ą░.ąØąŠ ąĄčüą╗ąĖ ą▓čŗ čüą║ąŠą▒ą║ąĖ ąŠčüčéą░ą▓ąĖč鹥, č鹊 ą┐ąŠą╗čāčćąĖčéčüčÅ, čćč鹊 ą▒čāą┤ąĄčé ą┐ąĄčĆąĄą┤ą░ąĮ ąŠą┤ąĖąĮ 菹╗ąĄą╝ąĄąĮčé ą║ąŠčĆč鹥ąČą░ ą▓ ąŠą┐ąĄčĆą░č鹊čĆ print:
>>> # Python 2 >>> import os>>> print ('ą£ąĄąĮčÅ ąĘąŠą▓čāčé' , os.getlogin(), 'ąĖ ą╝ąĮąĄ' , 42 , 'ą│ąŠą┤ą░' )
('ą£ąĄąĮčÅ ąĘąŠą▓čāčé' , 'jdoe' , 'ąĖ ą╝ąĮąĄ' , 42 , 'ą│ąŠą┤ą░' )ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ą▓ Python 2 ąĮąĄčé čüą┐ąŠčüąŠą▒ą░ ąĖąĘą╝ąĄąĮąĖčéčī čĆą░ąĘą┤ąĄą╗ąĖč鹥ą╗čī ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą╝ąĄąČą┤čā 菹╗ąĄą╝ąĄąĮčéą░ą╝ąĖ. ą×ą┤ąĖąĮ ąĖąĘ čüą┐ąŠčüąŠą▒ąŠą▓ čĆąĄčłąĖčéčī ą┐čĆąŠą▒ą╗ąĄą╝čā - ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĖąĮč鹥čĆą┐ąŠą╗čÅčåąĖčÄ čüčéčĆąŠą║ąĖ (č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą▓čŗą▓ąŠą┤ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ printf čÅąĘčŗą║ą░ C), ą┐čĆąĖą╝ąĄčĆąĮąŠ čéą░ą║:
>>> # Python 2 >>> import os>>> print 'ą£ąĄąĮčÅ ąĘąŠą▓čāčé %s ąĖ ą╝ąĮąĄ %d ą│ąŠą┤ą░.' % (os.getlogin(), 42 )
ą£ąĄąĮčÅ ąĘąŠą▓čāčé jdoe ąĖ ą╝ąĮąĄ 42 ą│ąŠą┤ą░.ąŁč鹊 ą▒čŗą╗ čüą┐ąŠčüąŠą▒ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖčÅ čüčéčĆąŠą║ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ, ą┐ąŠą║ą░ ą╝ąĄč鹊ą┤ .format () ąĮąĄ ą▒čŗą╗ ąŠą▒čĆą░čéąĮąŠ ą┐ąĄčĆąĄąĮąĄčüąĄąĮ ąĖąĘ Python 3.
ąÆ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖčģ čüąĄą║čåąĖčÅčģ ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ąŠčüčéą░ą╗čīąĮčŗąĄ ąĖą╝ąĄąĮąŠą▓ą░ąĮąĮčŗąĄ ą░čĆą│čāą╝ąĄąĮčéčŗ čäčāąĮą║čåąĖąĖ print().
[ą×čéą╝ąĄąĮą░ ą┐ąĄčćą░čéąĖ čüąĖą╝ą▓ąŠą╗ąŠą▓ ą║ąŠąĮčåą░ čüčéčĆąŠą║ąĖ ]
ąśąĮąŠą│ą┤ą░ ą▓ą░ą╝ ąĮčāąČąĮąŠ, čćč鹊ą▒čŗ čüąŠąŠą▒čēąĄąĮąĖąĄ ąĮąĄ ąĘą░ą║ą░ąĮčćąĖą▓ą░ą╗ąŠčüčī ąĘą░ą▓ąĄčĆčłą░čÄčēąĖą╝ newline, čćč鹊ą▒čŗ čüą╗ąĄą┤čāčÄčēąĖą╣ ą▓čŗąĘąŠą▓ print() ą┐čĆąŠą┤ąŠą╗ąČąĖą╗ ą▓čŗą▓ąŠą┤ ąĮą░ č鹊ą╣ ąČąĄ čüčéčĆąŠą║ąĄ. ąÜą╗ą░čüčüąĖč湥čüą║ąĖąĄ ą┐čĆąĖą╝ąĄčĆčŗ ą▓ą║ą╗čÄčćą░čÄčé ąĖąĮą┤ąĖą║ą░čåąĖčÄ ą┐čĆąŠą│čĆąĄčüčüą░ ą║ą░ą║ąŠą╣-č鹊 ą┤ąŠą╗ą│ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ, ąĖą╗ąĖ ąĘą░ą┐čĆąŠčü ą║ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÄ ąĮą░ ąŠąČąĖą┤ą░ąĮąĖąĖ ąĄą│ąŠ ą▓ą▓ąŠą┤ą░. ąÆ ą┐ąŠčüą╗ąĄą┤ąĮąĄą╝ čüą╗čāčćą░ąĄ ą▓čŗ ąĘą░čģąŠčéąĖč鹥, čćč鹊ą▒čŗ ąŠčéą▓ąĄčé ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ą▒čŗą╗ ąĮą░ č鹊ą╣ ąČąĄ čüčéčĆąŠą║ąĄ:
ąÆčŗ čāą▓ąĄčĆąĄąĮčŗ, čćč鹊 čģąŠčéąĖč鹥 ą┐čĆąŠą┤ąŠą╗ąČąĖčéčī? [y/n] y
ą£ąĮąŠą│ąĖąĄ čÅąĘčŗą║ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé čäčāąĮą║čåąĖąĖ, ą┐ąŠą┤ąŠą▒ąĮčŗąĄ print(), č湥čĆąĄąĘ čüą▓ąŠąĖ čüčéą░ąĮą┤ą░čĆčéąĮčŗąĄ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ, ąĮąŠ ąŠąĮąĖ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ą▓ą░ą╝ čüą░ą╝ąĖą╝ čĆąĄčłą░čéčī, ą┤ąŠą▒ą░ą▓ą╗čÅčéčī ą╗ąĖ newline, ąĖą╗ąĖ ąĮąĄčé. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĮą░ Java ąĖ C# čā ą▓ą░čü ąĄčüčéčī ą┤ą╗čÅ čŹč鹊ą│ąŠ ą┤ą▓ąĄ čĆą░ąĘąĮčŗąĄ čäčāąĮą║čåąĖąĖ, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ąĮą░ ą┤čĆčāą│ąĖčģ čÅąĘčŗą║ą░čģ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ čéčĆąĄą▒čāąĄčéčüčÅ čÅą▓ąĮąŠ čāą║ą░ąĘą░čéčī \n ą▓ ą║ąŠąĮčåąĄ čüčéčĆąŠą║ąŠą▓ąŠą│ąŠ ą╗ąĖč鹥čĆą░ą╗ą░.
ąÆąŠčé ą┐čĆąĖą╝ąĄčĆčŗ čéą░ą║ąŠą│ąŠ čüąĖąĮčéą░ą║čüąĖčüą░ ąĮą░ ąĮąĄą║ąŠč鹊čĆčŗčģ čÅąĘčŗą║ą░čģ:
ą»ąĘčŗą║ ą¤čĆąĖą╝ąĄčĆ
Perl
print "hello world\n"
C
printf ("hello world\n" );
C++
std::cout << "hello world" << std::endl;
ąÆ ąŠčéą╗ąĖčćąĖąĄ ąŠčé čŹč鹊ą│ąŠ Python-čäčāąĮą║čåąĖčÅ print() ą▓čüąĄą│ą┤ą░ ą┤ąŠą▒ą░ą▓ąĖčé \n ą▓ ą║ąŠąĮąĄčå čüčéčĆąŠą║ąĖ ą▒ąĄąĘ ą▓čüčÅą║ąŠą│ąŠ čüą┐čĆąŠčüą░, ą┐ąŠč鹊ą╝čā čćč鹊 čŹč鹊 čćą░čēąĄ ą▓čüąĄą│ąŠ ąĖą╝ąĄąĮąĮąŠ č鹊, čćč鹊 čéčĆąĄą▒čāąĄčéčüčÅ. ą¦č鹊ą▒čŗ ąĘą░ą┐čĆąĄčéąĖčéčī čŹč鹊 ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ, ą▓čŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤čĆčāą│ąŠą╣ čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ ąĖą╝ąĄąĮąŠą▓ą░ąĮąĮčŗą╣ ą░čĆą│čāą╝ąĄąĮčé end, ą║ąŠč鹊čĆčŗą╣ ąĘą░ą┤ą░ąĄčé, ą║ą░ą║ ą┤ąŠą╗ąČąĮą░ ąĘą░ą║ą░ąĮčćąĖą▓ą░čéčīčüčÅ čüčéčĆąŠą║ą░.
ąĪ č鹊čćą║ąĖ ąĘčĆąĄąĮąĖčÅ čüąĄą╝ą░ąĮčéąĖą║ąĖ ą┐ą░čĆą░ą╝ąĄčéčĆ end ą┐čĆą░ą║čéąĖč湥čüą║ąĖ ąĖą┤ąĄąĮčéąĖč湥ąĮ ą┐ą░čĆą░ą╝ąĄčéčĆčā sep, ą║ąŠč鹊čĆčŗą╣ ą▓čŗ ą▓ąĖą┤ąĄą╗ąĖ čĆą░ąĮąĄąĄ:
ŌĆó ą×ąĮ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čüčéčĆąŠą║ąŠą╣ ąĖą╗ąĖ None.
ąóąĄą┐ąĄčĆčī ą┤ą░ą▓ą░ą╣č鹥 čĆą░ąĘą▒ąĄčĆąĄą╝čüčÅ, čćč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé, ą║ąŠą│ą┤ą░ ą╝čŗ ą▓čŗąĘčŗą▓ą░ąĄą╝ print() ą▒ąĄąĘ ą░čĆą│čāą╝ąĄąĮč鹊ą▓. ą¤ąŠčüą║ąŠą╗čīą║čā ąĮąĖą║ą░ą║ąĖąĄ ą┐ąŠąĘąĖčåąĖąŠąĮąĮčŗąĄ ą░čĆą│čāą╝ąĄąĮčéčŗ ąĮąĄ ą▒čŗą╗ąĖ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮčŗ, č鹊 ąĮąĖč湥ą│ąŠ čüą║ą╗ąĄąĖą▓ą░čéčī ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝ ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ, ąĖ čĆą░ąĘą┤ąĄą╗ąĖč鹥ą╗čī ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą▓ąŠąŠą▒čēąĄ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ. ą×ą┤ąĮą░ą║ąŠ ąĘąĮą░č湥ąĮąĖąĄ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą╗čÅ end ą▓čüąĄ ąĄčēąĄ ą┐čĆąĖą╝ąĄąĮąĖą╝ąŠ, ąĖ ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą▓ ą▓čŗą▓ąŠą┤ ą▓čüčéą░ą▓ą╗čÅąĄčéčüčÅ ą┐čāčüčéą░čÅ čüčéčĆąŠą║ą░, čé. ąĄ. ą┐ąŠąĘąĖčåąĖčÅ ą▓ą▓ąŠą┤ą░ ąŠą┐čāčüą║ą░ąĄčéčüčÅ ąĮą░ ąŠą┤ąĮčā čüčéčĆąŠą║čā ą▓ąĮąĖąĘ ąĖ ą▓ ąĮą░čćą░ą╗ąŠ čüčéčĆąŠą║ąĖ.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ą▓ą░ą╝ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖąĮč鹥čĆąĄčüąĮąŠ, ą┐ąŠč湥ą╝čā ą┐ą░čĆą░ą╝ąĄčéčĆčā end ąĮą░ąĘąĮą░č湥ąĮąŠ čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ '\n', ą░ ąĮąĄ č鹊, čćč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą▓ ą▓ą░čłąĄą╣ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝ąĄ. ąÆ ąŠą▒čēąĄą╝, ą▓ą░ą╝ ąĮąĄ ąĮčāąČąĮąŠ ą▒ąĄčüą┐ąŠą║ąŠąĖčéčīčüčÅ ąŠ ą▓ą░čĆąĖą░ąĮčéą░čģ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖčÅ newline ą╝ąĄąČą┤čā čĆą░ąĘą╗ąĖčćąĮčŗą╝ąĖ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčŗą╝ąĖ čüąĖčüč鹥ą╝ą░ą╝ąĖ ą┐čĆąĖ ą┐ąĄčćą░čéąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 print() ą▒čāą┤ąĄčé ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ. ą¤čĆąŠčüč鹊 ą▓čüąĄą│ą┤ą░ ąĮąĄ ąĘą░ą▒čŗą▓ą░ą╣č鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī escape-ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī \n ą▓ čüčéčĆąŠą║ąŠą▓čŗčģ ą╗ąĖč鹥čĆą░ą╗ą░čģ.
ąÆ ąĮą░čüč鹊čÅčēąĄąĄ ą▓čĆąĄą╝čÅ čŹč鹊 ąĮą░ąĖą▒ąŠą╗ąĄąĄ ą┐ąĄčĆąĄąĮąŠčüąĖą╝čŗą╣ čüą┐ąŠčüąŠą▒ ą┐ąĄčćą░čéąĖ newline-čüąĖą╝ą▓ąŠą╗ą░ ą▓ Python:
>>> print ('čüčéčĆąŠą║ą░1\nčüčéčĆąŠą║ą░2\nčüčéčĆąŠą║ą░3' )
čüčéčĆąŠą║ą░1
čüčéčĆąŠą║ą░2
čüčéčĆąŠą║ą░3 ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą▒čŗ ą▓čŗ ą┐ąŠą┐čŗčéą░ą╗ąĖčüčī ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ ąĮą░ą┐ąĄčćą░čéą░čéčī čüą┐ąĄčåąĖčäąĖčćąĮčŗą╣ ą┤ą╗čÅ Windows čüąĖą╝ą▓ąŠą╗ newline (čé. ąĄ. \r\n) ąĮą░ ą╝ą░čłąĖąĮąĄ Linux, č鹊 ą┐ąŠą╗čāčćąĖč鹥 ą┐ąŠą╗ąŠą╝ą░ąĮąĮčŗą╣ ą▓čŗą▓ąŠą┤:
>>> print ('čüčéčĆąŠą║ą░1\r\nčüčéčĆąŠą║ą░2\r\nčüčéčĆąŠą║ą░3' )3 ąĪ ą┤čĆčāą│ąŠą╣ čüč鹊čĆąŠąĮčŗ, ą║ąŠą│ą┤ą░ ąŠčéą║čĆčŗą▓ą░ąĄč鹥 čäą░ą╣ą╗ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ čü ą┐ąŠą╝ąŠčēčīčÄ open(), ą▓ą░ą╝ čéą░ą║ąČąĄ ąĮąĄ ąĮčāąČąĮąŠ ąĘą░ą▒ąŠčéąĖčéčīčüčÅ ąŠ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĖ newline. ążčāąĮą║čåąĖčÅ ą▒čāą┤ąĄčé čéčĆą░ąĮčüą╗ąĖčĆąŠą▓ą░čéčī ą╗čÄą▒čāčÄ ąĘą░ą▓ąĖčüčÅčēčāčÄ ąŠčé čüąĖčüč鹥ą╝čŗ newline, ą║ąŠč鹊čĆą░čÅ ą▓čüčéčĆąĄčéąĖčéčüčÅ, ą▓ čāąĮąĖą▓ąĄčĆčüą░ą╗čīąĮčŗą╣ '\n'. ąÆ č鹊 ąČąĄ ą▓čĆąĄą╝čÅ čā ą▓ą░čü ąĄčüčéčī ą║ąŠąĮčéčĆąŠą╗čī ąĮą░ą┤ č鹥ą╝, ą║ą░ą║ newline ą┤ąŠą╗ąČąĮčŗ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčīčüčÅ ąĮą░ ą▓ą▓ąŠą┤ąĄ ąĖ ą▓čŗą▓ąŠą┤ąĄ, ąĄčüą╗ąĖ ą▓ą░ą╝ čŹč鹊 ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠ ąĮčāąČąĮąŠ.
ą¦č鹊ą▒čŗ ąĘą░ą┐čĆąĄčéąĖčéčī newline ą▓ ą║ąŠąĮčåąĄ čüčéčĆąŠą║ąĖ, ą▓čŗ ą┤ąŠą╗ąČąĮčŗ čÅą▓ąĮąŠ čāą║ą░ąĘą░čéčī ą┐čāčüčéčāčÄ čüčéčĆąŠą║čā ą▓ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ end:
print ('ą¤čĆąŠą▓ąĄčĆą║ą░ čåąĄą╗ąŠčüčéąĮąŠčüčéąĖ čäą░ą╣ą╗ą░...' , end='' )# (...) print ('ok' )ąŁčéąĖ ą┤ą▓ą░ ą▓čŗąĘąŠą▓ą░ ą┤ąŠą╗ąČąĮčŗ ą▓čŗąĘčŗą▓ą░čéčīčüčÅ čü ą▒ąŠą╗čīčłąĖą╝ ąĖąĮč鹥čĆą▓ą░ą╗ąŠą╝ ą┐ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą┤čĆčāą│ ąŠčéąĮąŠčüąĖč鹥ą╗čīąĮąŠ ą┤čĆčāą│ą░, ą┐ąŠč鹊ą╝čā čćč鹊 ąĮąĄąŠą▒čģąŠą┤ąĖą╝ą░ ą┐čĆąŠą▓ąĄčĆą║ą░ čäą░ą╣ą╗ą░. ą¤ąŠ čŹč鹊ą╣ ą┐čĆąĖčćąĖąĮąĄ ą┤ąŠą╗ąČąĮąŠ ąĮą░ 菹║čĆą░ąĮąĄ čüąĮą░čćą░ą╗ą░ ą┐ąŠčÅą▓ąĖčéčīčüčÅ čüąŠąŠą▒čēąĄąĮąĖąĄ:
ą¤čĆąŠą▓ąĄčĆą║ą░ čåąĄą╗ąŠčüčéąĮąŠčüčéąĖ čäą░ą╣ą╗ą░...
ą¤ąŠčüą╗ąĄ ą▓č鹊čĆąŠą│ąŠ ą▓čŗąĘąŠą▓ą░ print() ąĮą░ č鹊ą╣ ąČąĄ čüą░ą╝ąŠą╣ čüčéčĆąŠą║ąĄ ą┤ąŠą╗ąČąĮąŠ ąŠč鹊ą▒čĆą░ąČą░čéčīčüčÅ:
ą¤čĆąŠą▓ąĄčĆą║ą░ čåąĄą╗ąŠčüčéąĮąŠčüčéąĖ čäą░ą╣ą╗ą░...ok
ąÜą░ą║ ą▒čŗą╗ąŠ čü ą┐ą░čĆą░ą╝ąĄčéčĆąŠą╝ sep, ą▓čŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┐ą░čĆą░ą╝ąĄčéčĆ end ą┤ą╗čÅ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝ ąŠčéą┤ąĄą╗čīąĮčŗčģ čćą░čüč鹥ą╣ č鹥ą║čüčéą░ ą▓ ą▒ąŠą╗čīčłąŠą╣ č鹥ą║čüčé čü ąĮą░čüčéčĆąŠąĄąĮąĮčŗą╝ čĆą░ąĘą┤ąĄą╗ąĖč鹥ą╗ąĄą╝. ą×ą┤ąĮą░ą║ąŠ ą▓ą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ čüąŠąĄą┤ąĖąĮčÅčéčī čćą░čüčéąĖ č鹥ą║čüčéą░ čü ą┐ąŠą╝ąŠčēčīčÄ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą░čĆą│čāą╝ąĄąĮč鹊ą▓ ą▓ ąŠą┤ąĮąŠą╝ ą▓čŗąĘąŠą▓ąĄ print(), ą▓čŗ ą╝ąŠąČąĄč鹥 ą┤ąŠą▒ąĖčéčīčüčÅ č鹊ą│ąŠ ąČąĄ čüą░ą╝ąŠą│ąŠ čĆąĄąĘčāą╗čīčéą░čéą░, ąĖčüą┐ąŠą╗čīąĘčāčÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▓čŗąĘąŠą▓ąŠą▓ print() ąĖ ą┐ąĄčĆąĄą┤ą░čćčā ą▓ end č鹥ą║čüčéą░ čĆą░ąĘą┤ąĄą╗ąĖč鹥ą╗čÅ:
print ('ą¤ąĄčĆą▓ąŠąĄ ą┐čĆąĄą┤ą╗ąŠąČąĄąĮąĖąĄ' , end='. ' )print ('ąÆč鹊čĆąŠąĄ ą┐čĆąĄą┤ą╗ąŠąČąĄąĮąĖąĄ' , end='. ' )print ('ą¤ąŠčüą╗ąĄą┤ąĮąĄąĄ ą┐čĆąĄą┤ą╗ąŠąČąĄąĮąĖąĄ.' )ąŁčéąĖ čéčĆąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓čŗą▓ąĄą┤čāčé č鹥ą║čüčé ą▓ ąŠą┤ąĮąŠą╣ čüčéčĆąŠą║ąĄ:
ą¤ąĄčĆą▓ąŠąĄ ą┐čĆąĄą┤ą╗ąŠąČąĄąĮąĖąĄ. ąÆč鹊čĆąŠąĄ ą┐čĆąĄą┤ą╗ąŠąČąĄąĮąĖąĄ. ą¤ąŠčüą╗ąĄą┤ąĮąĄąĄ ą┐čĆąĄą┤ą╗ąŠąČąĄąĮąĖąĄ.
ąÆčŗ čéą░ą║ąČąĄ ą╝ąŠąČąĄč鹥 ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą░čĆą│čāą╝ąĄąĮčéčŗ sep ąĖ end:
print ('ą£ąĄčĆą║čāčĆąĖą╣' , 'ąÆąĄąĮąĄčĆą░' , 'ąŚąĄą╝ą╗čÅ' , sep=', ' , end=', ' )print ('ą£ą░čĆčü' , 'ą«ą┐ąĖč鹥čĆ' , 'ąĪą░čéčāčĆąĮ' , sep=', ' , end=', ' )print ('ąŻčĆą░ąĮ' , 'ąØąĄą┐čéčāąĮ' , 'ą¤ą╗čāč鹊ąĮ' , sep=', ' )ąóą░ą║ąĖą╝ čüą┐ąŠčüąŠą▒ąŠą╝ ą┐ąŠą╗čāčćąĖčéčüčÅ ąĮąĄ č鹊ą╗čīą║ąŠ ąŠą┤ąĮą░ čüčéčĆąŠą║ą░ č鹥ą║čüčéą░, ąĮąŠ ąĖ ą┐čĆąĖ čŹč鹊ą╝ ą║ą░ąČą┤čŗą╣ 菹╗ąĄą╝ąĄąĮčé čüčéčĆąŠą║ąĖ ą▒čāą┤ąĄčé ąŠčéą┤ąĄą╗ąĄąĮ ąŠčé ą┤čĆčāą│ąŠą│ąŠ ąĘą░ą┐čÅč鹊ą╣:
ą£ąĄčĆą║čāčĆąĖą╣, ąÆąĄąĮąĄčĆą░, ąŚąĄą╝ą╗čÅ, ą£ą░čĆčü, ą«ą┐ąĖč鹥čĆ, ąĪą░čéčāčĆąĮ, ąŻčĆą░ąĮ, ąØąĄą┐čéčāąĮ, ą¤ą╗čāč鹊ąĮ
ąØąĖčćč鹊 ąĮąĄ ą┐ąŠą╝ąĄčłą░ąĄčé ą▓ą░ą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čüąĖą╝ą▓ąŠą╗ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ čü ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗą╝ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ą▓ąŠą║čĆčāą│ ąĮąĄą│ąŠ:
print ('ą×čüąĮąŠą▓čŗ ą┐ąĄčćą░čéąĖ ą▓ Python' , end='\n * ' )print ('ąÆčŗąĘąŠą▓ print()' , end='\n * ' )print ('ąĀą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą░čĆą│čāą╝ąĄąĮč鹊ą▓' , end='\n * ' )print ('ą×čéą╝ąĄąĮą░ ą┐ąĄčćą░čéąĖ čüąĖą╝ą▓ąŠą╗ąŠą▓ ą║ąŠąĮčåą░ čüčéčĆąŠą║ąĖ' )ąŁč鹊 ąĮą░ą┐ąĄčćą░čéą░ąĄčé čüą╗ąĄą┤čāčÄčēčāčÄ ą┐ąŠčĆčåąĖčÄ č鹥ą║čüčéą░:
ą×čüąĮąŠą▓čŗ ą┐ąĄčćą░čéąĖ ą▓ Python * ąÆčŗąĘąŠą▓ print() * ąĀą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą░čĆą│čāą╝ąĄąĮč鹊ą▓ * ą×čéą╝ąĄąĮą░ ą┐ąĄčćą░čéąĖ čüąĖą╝ą▓ąŠą╗ąŠą▓ ą║ąŠąĮčåą░ čüčéčĆąŠą║ąĖ
ąÜą░ą║ ą▓ąĖą┤ąĖč鹥, ąĖą╝ąĄąĮąŠą▓ą░ąĮąĮčŗą╣ ą░čĆą│čāą╝ąĄąĮčé end ą┐čĆąĖąĮąĖą╝ą░ąĄčé ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮčŗąĄ čüčéčĆąŠą║ąĖ.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ą┐čĆąŠčģąŠą┤ ą▓ čåąĖą║ą╗ąĄ ą┐ąŠ čüčéčĆąŠą║ą░ ą▓ č鹥ą║čüč鹊ą▓ąŠą╝ čäą░ą╣ą╗ąĄ čüąŠčģčĆą░ąĮčÅąĄčé ąĖčģ čüąŠą▒čüčéą▓ąĄąĮąĮčŗąĄ čüąĖą╝ą▓ąŠą╗čŗ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ, čćč鹊 ą▓ čüąŠč湥čéą░ąĮąĖąĖ čü ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄą╝ čäčāąĮą║čåąĖąĖ print() ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĖąĘą▒čŗč鹊čćąĮąŠą╝čā čüąĖą╝ą▓ąŠą╗čā ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ:
>>> with open ('file.txt' ) as file_object:... for line in file_object:... print (line)
...
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmodą¤ąŠą╗čāčćąĖą╗ąŠčüčī ą┤ą▓ą░ newline ą┐ąŠčüą╗ąĄ ą║ą░ąČą┤ąŠą╣ čüčéčĆąŠą║ąĖ č鹥ą║čüčéą░. ąÆčŗ ąĘą░čģąŠčéąĖč鹥 ą▓čŗčĆąĄąĘą░čéčī ąŠą┤ąĖąĮ ąĖąĘ ąĮąĖčģ ą┐ąĄčĆąĄą┤ ą┐ąĄčćą░čéčīčÄ čüčéčĆąŠą║ąĖ, čŹč鹊 ą┤ąĄą╗ą░ąĄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
print (line.rstrip())ąÉą╗čīč鹥čĆąĮą░čéąĖą▓ąĮąŠ ą▓čŗ ą╝ąŠąČąĄč鹥 čüąŠčģčĆą░ąĮąĖčéčī newline ą▓ čüąŠą┤ąĄčƹȹĖą╝ąŠą╝ čäą░ą╣ą╗ą░, ą┐ąŠą┤ą░ą▓ąĖą▓ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąŠąĄ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ newline ą┐čĆąĖ ą▓čŗąĘąŠą▓ąĄ print(). ąöą╗čÅ čŹč鹊ą│ąŠ ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ąĖą╝ąĄąĮąŠą▓ą░ąĮąĮčŗą╣ ą░čĆą│čāą╝ąĄąĮčé end :
>>> with open ('file.txt' ) as file_object:... for line in file_object:... print (line, end='' )
...
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod
tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam,
quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodoąŚą░ą▓ąĄčĆčłąĄąĮąĖąĄ ą▓čŗą▓ąŠą┤ą░ ą┐čāčüč鹊ą╣ čüčéčĆąŠą║ąŠą╣ čŹčäč乥ą║čéąĖą▓ąĮąŠ ąĖčüą║ą╗čÄčćąĖčé ąĖąĘ ą▓čŗą▓ąŠą┤ą░ ąŠą┤ąĖąĮ ąĖąĘ čüąĖą╝ą▓ąŠą╗ąŠą▓ newline.
ą¦č鹊ą▒čŗ ą┐čĆąĄą┤ąŠčéą▓čĆą░čéąĖčéčī ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą▓ Python 2, čéčĆąĄą▒čāąĄčéčüčÅ ą┤ąŠą▒ą░ą▓ąĖčéčī ą▓ ą▓čŗčĆą░ąČąĄąĮąĖąĄ ąĘą░ą▓ąĄčĆčłą░čÄčēčāčÄ ąĘą░ą┐čÅčéčāčÄ:
print 'hello world' ,ą×ą┤ąĮą░ą║ąŠ čŹč鹊 ąĮąĄ ąĖą┤ąĄą░ą╗čīąĮąŠąĄ čĆąĄčłąĄąĮąĖąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 ą┤ąŠą▒ą░ą▓ąĖčé ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮčŗą╣ ą┐čĆąŠą▒ąĄą╗. ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐čĆąŠą▓ąĄčĆąĖčéčī čŹč鹊 čüą╗ąĄą┤čāčÄčēąĖą╝ ą║čāčüą║ąŠą╝ ą║ąŠą┤ą░:
print 'BEFORE' print 'hello' ,print 'AFTER' ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ ąĮą░ ą▓čŗą▓ąŠą┤: ą▓čüčéą░ą▓ą╗ąĄąĮ ą┐čĆąŠą▒ąĄą╗ ą╝ąĄąČą┤čā čüą╗ąŠą▓ąŠą╝ hello ąĖ AFTER:
BEFORE hello AFTER
ą¦č鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ąČąĄą╗ą░ąĄą╝čŗą╣ čĆąĄąĘčāą╗čīčéą░čé, ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ą▓ąŠčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ čéčĆčÄą║ąŠą╝, ą║ąŠč鹊čĆčŗą╣ ą▒čāą┤ąĄčé ąŠą┐ąĖčüą░ąĮ ą┤ą░ą╗ąĄąĄ. ąŁč鹊čé čéčĆčÄą║ ąĘą░ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ ąĖą╝ą┐ąŠčĆč鹥 čäčāąĮą║čåąĖąĖ print() ąĖąĘ ą▒čāą┤čāčēąĄą│ąŠ čĆąĄą╗ąĖąĘą░ Python (čäčāąĮą║čåąĖčÅ ąĖąĘ ą╝ąŠą┤čāą╗čÅ __future__), ąĖą╗ąĖ ą╝ąŠąČąĮąŠ ą▓ąĄčĆąĮčāčéčīčüčÅ ą║ ą┐ąŠą╝ąŠčēąĖ ą╝ąŠą┤čāą╗čÅ sys:
import sysprint 'BEFORE'
sys.stdout.write('hello' )print 'AFTER' ąŁč鹊 ą┤ą░čüčé ą║ąŠčĆčĆąĄą║čéąĮčŗą╣ ą▓čŗą▓ąŠą┤ ą▒ąĄąĘ ą╗ąĖčłąĮąĄą│ąŠ ą┐čĆąŠą▒ąĄą╗ą░:
BEFORE helloAFTER
ąźąŠčéčÅ ą╝ąŠą┤čāą╗čī sys ą┤ą░ąĄčé ą▓ą░ą╝ ą┐ąŠą╗ąĮčŗą╣ ą║ąŠąĮčéčĆąŠą╗čī ąĮą░ą┤ č鹥ą╝, čćč鹊 ą┐ąĄčćą░čéą░ąĄčéčüčÅ ą▓ stdout, ą║ąŠą┤ čüčéą░ąĮąŠą▓ąĖčéčüčÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▒ąŠą╗ąĄąĄ ąĘą░ą│čĆąŠą╝ąŠąČą┤ąĄąĮąĮčŗą╝.
[ą¤ąĄčćą░čéčī ą▓ čäą░ą╣ą╗ ]
ąźąŠčéąĖč鹥 ą▓ąĄčĆčīč鹥, čģąŠčéąĖč鹥 ąĮąĄčé, ąĮąŠ čäčāąĮą║čåąĖčÅ print() ąĮą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ ąĮąĖč湥ą│ąŠ ąĮąĄ ąĘąĮą░ąĄčé ąŠ č鹊ą╝, ą║ą░ą║ ą┐čĆąĄą▓čĆą░čéąĖčéčī č鹥ą║čüčé ą▓ ą┐ąŠčÅą▓ą╗ąĄąĮąĖąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ ąĮą░ 菹║čĆą░ąĮąĄ ą║ąŠąĮčüąŠą╗ąĖ, ąĖ ą┐ąŠ ą┐čĆą░ą▓ą┤ąĄ ą│ąŠą▓ąŠčĆčÅ, ąĮąĄ ąĮčāąČą┤ą░ąĄčéčüčÅ ą▓ čŹč鹊ą╝. ąŁč鹊 čĆą░ą▒ąŠčéą░ ą┤ą╗čÅ ąĮąĖąĘą║ąŠčāčĆąŠą▓ąĮąĄą▓čŗčģ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠą╗čāčćą░čÄčé ąĮą░ ą▓čģąŠą┤ąĄ ą▒ą░ą╣čéčŗ ąĖ ąĘąĮą░čÄčé, ą║ą░ą║ ąĖčģ ą┐čĆąŠą┤ą▓ąĖą│ą░čéčī ą┤ą░ą╗čīčłąĄ.
ążčāąĮą║čåąĖčÅ print() čüą╗čāąČąĖčé ą░ą▒čüčéčĆą░ą║čåąĖąĄą╣ ąĮą░ą┤ čŹčéąĖą╝ąĖ čüą╗ąŠčÅą╝ąĖ, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčēą░čÅ čāą┤ąŠą▒ąĮčŗą╣ ąĖąĮč鹥čĆč乥ą╣čü, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąŠčüč鹊 ą┤ąĄą╗ąĄą│ąĖčĆčāąĄčé čäą░ą║čéąĖč湥čüą║čāčÄ ą┐ąĄčćą░čéčī ą┐ąŠč鹊ą║ąŠą▓ąŠą╝čā ąĖą╗ąĖ čäą░ą╣ą╗ąŠą▓ąŠą╝čā ąŠą▒čŖąĄą║čéčā. ą¤ąŠč鹊ą║ąŠą╝ ą╝ąŠąČąĄčé ą▒čŗčéčī ą╗čÄą▒ąŠą╣ čäą░ą╣ą╗ ąĮą░ ą┤ąĖčüą║ąĄ, čüąĄč鹥ą▓ąŠą╣ čüąŠą║ąĄčé ąĖą╗ąĖ, ą▓ąŠąĘą╝ąŠąČąĮąŠ, ą▒čāč乥čĆ ą▓ ą┐ą░ą╝čÅčéąĖ.
ąÆ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ čŹč鹊ą╝čā čüčāčēąĄčüčéą▓čāąĄčé čéčĆąĖ čüčéą░ąĮą┤ą░čĆčéąĮčŗčģ ą┐ąŠč鹊ą║ą░, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄą╝čŗąĄ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝ąŠą╣:
stdin : čüčéą░ąĮą┤ą░čĆčéąĮčŗą╣ ą▓ą▓ąŠą┤ (standard input)stdout : čüčéą░ąĮą┤ą░čĆčéąĮčŗą╣ ą▓čŗą▓ąŠą┤ (standard output)stderr : čüčéą░ąĮą┤ą░čĆčéąĮčŗą╣ ą▓čŗą▓ąŠą┤ ąŠčłąĖą▒ąŠą║ (standard error)
ąĪčéą░ąĮą┤ą░čĆčéąĮčŗą╣ ą▓čŗą▓ąŠą┤ čŹč鹊 č鹊, čćč鹊 ą▓čŗ ą▓ąĖą┤ąĖč鹥 ą▓ č鹥čĆą╝ąĖąĮą░ą╗ąĄ, ą║ąŠą│ą┤ą░ ąĘą░ą┐čāčüą║ą░ąĄč鹥 čĆą░ąĘą╗ąĖčćąĮčŗąĄ čāčéąĖą╗ąĖčéčŗ ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąĖ. ąÜ čŹč鹊ą╝čā ąŠčéąĮąŠčüčÅčéčüčÅ ąĖ ą▓ą░čłąĖ čüąŠą▒čüčéą▓ąĄąĮąĮčŗąĄ čüą║čĆąĖą┐čéčŗ Python:
$ cat hello.py
print('ąŁč鹊 ą┤ąŠą╗ąČąĮąŠ ą┐ąŠčÅą▓ąĖčéčīčüčÅ ą▓ ą▓čŗą▓ąŠą┤ąĄ stdout')
$ python hello.py
ąŁč鹊 ą┤ąŠą╗ąČąĮąŠ ą┐ąŠčÅą▓ąĖčéčīčüčÅ ą▓ ą▓čŗą▓ąŠą┤ąĄ stdout
ąĢčüą╗ąĖ čüą┐ąĄčåąĖą░ą╗čīąĮąŠ ąĮąĄ čāą║ą░ąĘą░ąĮąŠ čćč鹊-č鹊 ąĖąĮąŠąĄ, čäčāąĮą║čåąĖčÅ print() ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┐ąĖčłąĄčé ą▓ stdout. ą×ą┤ąĮą░ą║ąŠ ą▓čŗ ą╝ąŠąČąĄč鹥 čāą║ą░ąĘą░čéčī ą▓ą░čłąĄą╣ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝ąĄ ą▓čĆąĄą╝ąĄąĮąĮąŠ ą┐ąĄčĆąĄą║ą╗čÄčćąĖčéčīčüčÅ ąĖąĘ stdout ąĮą░ ą┐ąŠč鹊ą║ čäą░ą╣ą╗ą░ (file stream), ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą╗čÄą▒ąŠą╣ ą▓čŗą▓ąŠą┤ ą┐ąŠą┐ą░ą┤ąĄčé ą▓ čäą░ą╣ą╗ ą▓ą╝ąĄčüč鹊 菹║čĆą░ąĮą░:
$ python hello.py > file.txt
$ cat file.txt
ąŁč鹊 ą┤ąŠą╗ąČąĮąŠ ą┐ąŠčÅą▓ąĖčéčīčüčÅ ą▓ ą▓čŗą▓ąŠą┤ąĄ stdout
ąŁč鹊 ąĮą░ąĘčŗą▓ą░čÄčé ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄą╝ ą┐ąŠč鹊ą║ą░ (stream redirection).
ą¤ąŠč鹊ą║ čüčéą░ąĮą┤ą░čĆčéąĮąŠą│ąŠ ą▓čŗą▓ąŠą┤ą░ ąŠčłąĖą▒ąŠą║ stderr ą┐ąŠą┤ąŠą▒ąĄąĮ stdout č鹥ą╝, čćč鹊 ąŠąĮ čéą░ą║ąČąĄ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čüąŠąŠą▒čēąĄąĮąĖčÅ ąĮą░ 菹║čĆą░ąĮąĄ. ąóąĄą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ, čŹč鹊 ą▓čüąĄ-čéą░ą║ąĖ ąŠčéą┤ąĄą╗čīąĮčŗą╣ ą┐ąŠč鹊ą║, ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĖąĄą╝ ą║ąŠč鹊čĆąŠą│ąŠ čÅą▓ą╗čÅąĄčéčüčÅ čĆąĄą│ąĖčüčéčĆą░čåąĖčÅ čüąŠąŠą▒čēąĄąĮąĖą╣ ąŠą▒ ąŠčłąĖą▒ą║ą░čģ ą┤ą╗čÅ ą┤ąĖą░ą│ąĮąŠčüčéąĖą║ąĖ. ąĪ ą┐ąŠą╝ąŠčēčīčÄ ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąŠą┤ąĮąŠą│ąŠ ąĖą╗ąĖ ąŠą▒ąŠąĖčģ čŹčéąĖčģ ą┐ąŠč鹊ą║ąŠą▓ ą▓čŗ ą╝ąŠąČąĄč鹥 ąŠą▒ąĄčüą┐ąĄčćąĖčéčī ą▒ąŠą╗ąĄąĄ čÅčüąĮąŠąĄ ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąĖąĄ čü ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą╣ ą┐čĆąŠą│čĆą░ą╝ą╝ąŠą╣.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: čćč鹊ą▒čŗ ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ąĖčéčī stderr, ą▓ą░ą╝ ąĮčāąČąĮąŠ ąĘąĮą░čéčī ą┐čĆąŠ ą┤ąĄčüą║čĆąĖą┐č鹊čĆčŗ čäą░ą╣ą╗ą░, ąĖąĘą▓ąĄčüčéąĮčŗąĄ čéą░ą║ąČąĄ ą║ą░ą║ file handle.
ąŁč鹊 ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮčŗąĄ čćąĖčüą╗ą░, čģąŠčéčÅ ąĖ ą┐ąŠčüč鹊čÅąĮąĮčŗąĄ, čüą▓čÅąĘą░ąĮąĮčŗąĄ čüąŠ čüčéą░ąĮą┤ą░čĆčéąĮčŗą╝ąĖ ą┐ąŠč鹊ą║ą░ą╝ąĖ. ąÆąŠčé čéą░ą▒ą╗ąĖčåą░ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ čäą░ą╣ą╗ą░ ą┤ą╗čÅ čüąĄą╝ąĄą╣čüčéą▓ą░ POSIX-čüąŠą▓ą╝ąĄčüčéąĖą╝čŗčģ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčŗčģ čüąĖčüč鹥ą╝:
ą¤ąŠč鹊ą║ ąöąĄčüą║čĆąĖą┐č鹊čĆ čäą░ą╣ą╗ą░
stdin
0
stdout
1
stderr
2
ąŚąĮą░čÅ čŹčéąĖ ą┤ąĄčüą║čĆąĖą┐č鹊čĆčŗ, ą▓čŗ ą╝ąŠąČąĄč鹥 ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ąĖčéčī čüčĆą░ąĘčā ąŠą┤ąĖąĮ ąĖą╗ąĖ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐ąŠč鹊ą║ąŠą▓:
ąÜąŠą╝ą░ąĮą┤ą░ ą×ą┐ąĖčüą░ąĮąĖąĄ
./program > out.txt
ą¤ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗čÅąĄčé stdout.
./program 2> err.txt
ą¤ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗čÅąĄčé stderr.
./program > out.txt 2> err.txt
ą¤ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗čÅąĄčé stdout ąĖ stderr ą▓ ąŠčéą┤ąĄą╗čīąĮčŗąĄ čäą░ą╣ą╗čŗ.
./program &> out_err.txt
ą¤ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗čÅąĄčé stdout ąĖ stderr ą▓ ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ čäą░ą╣ą╗.
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 > č鹊 ąČąĄ čüą░ą╝ąŠąĄ, čćč鹊 ąĖ 1>.
ąØąĄą║ąŠč鹊čĆčŗąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĖčüą┐ąŠą╗čīąĘčāčÄčé čĆą░ąĘąĮčŗąĄ čåą▓ąĄčéą░ č鹥ą║čüčéą░ ą┤ą╗čÅ čüąŠąŠą▒čēąĄąĮąĖą╣, ą┐ąĄčćą░čéą░ąĄą╝čŗčģ ą▓ stdout ąĖ stderr.
ąÆ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ stdout ąĖ stderr čŹč鹊 ą┐ąŠč鹊ą║ąĖ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ (write-only), ą┐ąŠč鹊ą║ čüčéą░ąĮą┤ą░čĆčéąĮąŠą│ąŠ ą▓ą▓ąŠą┤ą░ stdin čŹč鹊 ą┐ąŠč鹊ą║ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ (read-only). ąÆčŗ ą╝ąŠąČąĄč鹥 ą┤čāą╝ą░čéčī stdin ą║ą░ą║ ąŠ ą▓ą░čłąĄą╣ ą║ą╗ą░ą▓ąĖą░čéčāčĆąĄ, ąŠą┤ąĮą░ą║ąŠ ą║ą░ą║ ąĖ čü ą┤čĆčāą│ąĖą╝ąĖ ą┤ą▓čāą╝čÅ, ą▓čŗ ą╝ąŠąČąĄč鹥 ą┐ąĄčĆąĄą║ą╗čÄčćąĖčéčī ą▓ą▓ąŠą┤ stdin ąĮą░ čäą░ą╣ą╗, čćč鹊ą▒čŗ čćąĖčéą░čéčī ąĖąĘ ąĮąĄą│ąŠ ą┤ą░ąĮąĮčŗąĄ.
ąÆ Python ą▓čŗ ą╝ąŠąČąĄč鹥 ąŠą▒čĆą░čēą░čéčīčüčÅ ą║ąŠ ą▓čüąĄą╝ čüčéą░ąĮą┤ą░čĆčéąĮčŗą╝ ą┐ąŠč鹊ą║ą░ą╝ č湥čĆąĄąĘ ą▓čüčéčĆąŠąĄąĮąĮčŗą╣ ą╝ąŠą┤čāą╗čī sys :
>>> import sys>>> sys.stdin
< _io.TextIOWrapper name='< stdin>' mode='r' encoding='UTF-8' >>>> sys.stdin.fileno()0 >>> sys.stdout
< _io.TextIOWrapper name='< stdout>' mode='w' encoding='UTF-8' >>>> sys.stdout.fileno()1 >>> sys.stderr
< _io.TextIOWrapper name='< stderr>' mode='w' encoding='UTF-8' >>>> sys.stderr.fileno()2 ąÜą░ą║ ą▓čŗ ą╝ąŠąČąĄč鹥 ą▓ąĖą┤ąĄčéčī, čŹčéąĖčé ą┐čĆąĄą┤ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ ą┐ąŠčģąŠąČąĖ ąĮą░ čäą░ą╣ą╗ąŠą▓čŗąĄ ąŠą▒čŖąĄą║čéčŗ čü ą░čéčĆąĖą▒čāčéą░ą╝ąĖ mode ąĖ encoding , ą░ čéą░ą║ąČąĄ ą╝ąĄč鹊ą┤ą░ą╝ąĖ .read() ąĖ .write() čüčĆąĄą┤ąĖ ą╝ąĮąŠą│ąĖčģ ą┤čĆčāą│ąĖčģ.
ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ print() čüą▓čÅąĘą░ąĮą░ čü sys.stdout č湥čĆąĄąĘ ąĄčæ ąĖą╝ąĄąĮąŠą▓ą░ąĮąĮčŗą╣ ą░čĆą│čāą╝ąĄąĮčé file , ąĮąŠ ą▓čŗ ą╝ąŠąČąĄč鹥 čŹč鹊 ą┐ąŠą╝ąĄąĮčÅčéčī. ąśčüą┐ąŠą╗čīąĘčāą╣č鹥 ą║ą╗čÄč湥ą▓ąŠą╣ ą░čĆą│čāą╝ąĄąĮčé file, čćč鹊ą▒čŗ čāą║ą░ąĘą░čéčī čäą░ą╣ą╗, ą║ąŠč鹊čĆčŗą╣ ą▒čŗą╗ ąŠčéą║čĆčŗčé ą▓ čĆąĄąČąĖą╝ąĄ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ, čéą░ą║ čćč鹊ą▒čŗ čüąŠąŠą▒čēąĄąĮąĖčÅ ą┐ąŠą┐ą░ą┤ą░ą╗ąĖ ą┐čĆčÅą╝ąĖą║ąŠą╝ čéčāą┤ą░:
with open ('file.txt' , mode='w' ) as file_object:
print ('hello world' , file=file_object)ąŁč鹊 čüą┤ąĄą╗ą░ąĄčé ą▓ą░čł ą║ąŠą┤ ąĖą╝čāąĮąĮčŗą╝ ą║ ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖčÄ ą┐ąŠč鹊ą║ą░ ąĮą░ čāčĆąŠą▓ąĮąĄ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ, čćč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖą╗ąĖ ąĮąĄ ą▒čŗčéčī ąČąĄą╗ą░č鹥ą╗čīąĮčŗą╝.
ąöą╗čÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą┐ąŠ čĆą░ą▒ąŠč鹥 čü čäą░ą╣ą╗ą░ą╝ąĖ ą▓ Python čüą╝. čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąŠ [4].
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ąĮąĄ ą┐čŗčéą░ą╣č鹥čüčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čäčāąĮą║čåąĖčÄ print() ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ ą┤ą▓ąŠąĖčćąĮčŗčģ čäą░ą╣ą╗ąŠą▓, ą┐ąŠčüą║ąŠą╗čīą║čā ąŠąĮą░ čģąŠčĆąŠčłąŠ ą┐ąŠą┤čģąŠą┤ąĖčé č鹊ą╗čīą║ąŠ ą┤ą╗čÅ č鹥ą║čüčéą░. ą¤čĆąŠčüč鹊 ą▓čŗąĘčŗą▓ą░ą╣č鹥 ąĮą░ ą┤ą▓ąŠąĖčćąĮčŗčģ čäą░ą╣ą╗ą░čģ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ ą╝ąĄč鹊ą┤ .write() directly:
with open ('file.dat' , 'wb' ) as file_object:
file_object.write(bytes (4 ))
file_object.write(b'\xff' )ąĢčüą╗ąĖ ą▓čŗ ąĘą░čģąŠčéąĖč鹥 ąĘą░ą┐ąĖčüčŗą▓ą░čéčī čüčŗčĆčŗąĄ ą▒ą░ą╣čéčŗ ą▓ čüčéą░ąĮą┤ą░čĆčéąĮčŗą╣ ą▓čŗą▓ąŠą┤, č鹊 čŹč鹊 ąŠą║ąŠąĮčćąĖčéčüčÅ ąĮąĄčāą┤ą░č湥ą╣, ą┐ąŠč鹊ą╝čā čćč鹊 sys.stdout čŹč鹊 čüąĖą╝ą▓ąŠą╗čīąĮčŗą╣ ą┐ąŠč鹊ą║:
>>> import sys>>> sys.stdout.write(bytes (4 ))
Traceback (most recent call last):
File "< stdin>" , line 1 , in < module>
TypeError: write() argument must be str , not bytes ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą▓ą░ą╝ čüą╗ąĄą┤čāąĄčé ą║ąŠą┐ąĮčāčéčī ą│ą╗čāą▒ąČąĄ, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ą┤ąĄčüą║čĆąĖą┐č鹊čĆ ąĮąĖąČąĄą╗ąĄąČą░čēąĄą│ąŠ ą▒ą░ą╣č鹊ą▓ąŠą│ąŠ ą┐ąŠč鹊ą║ą░:
>>> import sys>>> num_bytes_written = sys.stdout.buffer.write(b'\x41\x0a' )
AąŁč鹊 ąĮą░ą┐ąĄčćą░čéą░ąĄčé ą▒čāą║ą▓čā A ą▓ ą▓ąĄčĆčģąĮąĄą╝ čĆąĄą│ąĖčüčéčĆąĄ ąĖ čüąĖą╝ą▓ąŠą╗ newline, čćč鹊 čüąŠąŠčéą▓ąĄčéčüčéčāąĄčé ASCII-ą║ąŠą┤ą░ą╝ 65 ąĖ 10. ą×ą┤ąĮą░ą║ąŠ ąĘą┤ąĄčüčī ąŠąĮąĖ ą║ąŠą┤ąĖčĆčāčÄčéčü čü ą┐ąŠą╝ąŠčēčīčÄ čłąĄčüčéąĮą░ą┤čåą░č鹥čĆąĖčćąĮąŠą╣ ąĮąŠčéą░čåąĖąĖ ą▓ ą▒ą░ą╣čéą░čģ ą╗ąĖč鹥čĆą░ą╗ą░.
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 print() ąĮąĖą║ą░ą║ ąĮąĄ čāą┐čĆą░ą▓ą╗čÅąĄčé ą║ąŠą┤ąĖčĆąŠą▓ą║ąŠą╣ čüąĖą╝ą▓ąŠą╗ąŠą▓. ą¤ąŠč鹊ą║ ąŠčéą▓ąĄčćą░ąĄčé ąĘą░ ą║ąŠčĆčĆąĄą║čéąĮąŠąĄ ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐ąŠą╗čāč湥ąĮąĮčŗčģ čüčéčĆąŠą║ Unicode ą▓ ą▒ą░ą╣čéčŗ. ąÆ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ čüą╗čāčćą░ąĄą▓ ą▓čŗ ąĮąĄ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄč鹥 ą║ąŠą┤ąĖčĆąŠą▓ą║čā čüą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮąŠ, ą┐ąŠč鹊ą╝čā čćč鹊 čāą╝ąŠą╗čćą░ąĮąĖąĄ UTF-8 čŹč鹊 č鹊, čćč鹊 ą▓ą░ą╝ ąĮčāąČąĮąŠ. ąĢčüą╗ąĖ ąČąĄ ą▓ą░ą╝ čĆąĄą░ą╗čīąĮąŠ ąĮčāąČąĮą░ čüą╝ąĄąĮą░ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĖ, ą▓ąŠąĘą╝ąŠąČąĮąŠ ą┤ą╗čÅ čāčüčéą░čĆąĄą▓čłąĖčģ čüąĖčüč鹥ą╝, č鹊 ą▓čŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą░čĆą│čāą╝ąĄąĮčé encoding ą▓ čäčāąĮą║čåąĖąĖ open():
with open ('file.txt' , mode='w' , encoding='iso-8859-1' ) as file_object:
print ('├╝ber na├»ve caf├®' , file=file_object)ąÆą╝ąĄčüč鹊 čĆąĄą░ą╗čīąĮąŠą│ąŠ čäą░ą╣ą╗ą░, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĖčüčāčéčüčéą▓čāąĄčé ą│ą┤ąĄ-č鹊 ą▓ ą▓ą░čłąĄą╣ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝ąĄ, ą▓čŗ ą╝ąŠąČąĄč鹥 ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī ą┐ąŠą┤ą┤ąĄą╗čīąĮčŗą╣ čäą░ą╣ą╗, ą║ąŠč鹊čĆčŗą╣ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą┐ą░ą╝čÅčéąĖ ą▓ą░čłąĄą│ąŠ ą║ąŠą╝ą┐čīčÄč鹥čĆą░. ą£čŗ ą┐ąŠąĘąČąĄ ą▒čāą┤ąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹčéčā mock -č鹥čģąĮąĖą║čā ą┤ą╗čÅ ą┤ą╗čÅ ą┐ąŠą┤ą╝ąĄąĮčŗ print() ą▓ unit-č鹥čüčéą░čģ:
>>> import io>>> fake_file = io.StringIO()>>> print ('hello world' , file=fake_file)>>> fake_file.getvalue()'hello world\n' ąĢčüą╗ąĖ ą▓čŗ ą┤ąŠčłą╗ąĖ ą┤ąŠ čŹč鹊ą│ąŠ ą╝ąĄčüčéą░, č鹊 ąŠčüčéą░ąĮąĄčéčüčÅ čĆą░čüčüą╝ąŠčéčĆąĄčéčī č鹊ą╗čīą║ąŠ ąĄčēąĄ ąŠą┤ąĖąĮ ąĖą╝ąĄąĮąŠą▓ą░ąĮąĮčŗą╣ ą░čĆą│čāą╝ąĄąĮčé (keyword argument) čäčāąĮą║čåąĖąĖ print(), ą║ąŠč鹊čĆčŗą╣ ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╣ čüąĄą║čåąĖąĖ. ąÆąĄčĆąŠčÅčéąĮąŠ ąŠąĮ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą╝ąĄąĮčīčłąĄ ą▓čüąĄą│ąŠ ą┐ąŠ čüčĆą░ą▓ąĮąĄąĮąĖčÄ čü ąŠčüčéą░ą╗čīąĮčŗą╝ąĖ. ąóąĄą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ ą▒čŗą▓ą░čÄčé čüą╗čāčćą░ąĖ, ą║ąŠą│ą┤ą░ čŹč鹊 ą░ą▒čüąŠą╗čÄčéąĮąŠ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ.
ąĪą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ čüąĖąĮčéą░ą║čüąĖčü Python 2 ą┤ą╗čÅ ąĘą░ą╝ąĄąĮčŗ čāą╝ąŠą╗čćą░ąĮąĖčÅ sys.stdout ąĮą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖą╣ čäą░ą╣ą╗ ą▓ ąŠą┐ąĄčĆą░č鹊čĆąĄ print:
with open ('file.txt' , mode='w' ) as file_object:
print >> file_object, 'hello world' ą¤ąŠčüą║ąŠą╗čīą║čā ą▓ Python 2 čüčéčĆąŠą║ąĖ ąĖ ą▒ą░ą╣čéčŗ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮčŗ ąŠą┤ąĮąĖą╝ ąĖ č鹥ą╝ ąČąĄ čéąĖą┐ąŠą╝ str, ąŠą┐ąĄčĆą░č鹊čĆ print ą╝ąŠąČąĄčé ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī ą┤ą▓ąŠąĖčćąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ:
with open ('file.dat' , mode='wb' ) as file_object:
print >> file_object, '\x41\x0a' ąźąŠčéčÅ ąĘą┤ąĄčüčī ąĄčüčéčī ą┐čĆąŠą▒ą╗ąĄą╝ą░ čü ą║ąŠą┤ąĖčĆąŠą▓ą║ąŠą╣ čüąĖą╝ą▓ąŠą╗ąŠą▓. ążčāąĮą║čåąĖčÅ open() ą▓ Python 2 ą╗ąĖčłąĄąĮą░ ą┐ą░čĆą░ą╝ąĄčéčĆą░ encoding, čćč鹊 čćą░čüč鹊 ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ čāąČą░čüąĮąŠą╣ ąŠčłąĖą▒ą║ąĄ UnicodeEncodeError:
>>> with open ('file.txt' , mode='w' ) as file_object:... unicode_text = u'\xfcber na\xefve caf\xe9' ... print >> file_object, unicode_text
...
Traceback (most recent call last):
File "< stdin>" , line 3 , in < module>
UnicodeEncodeError: 'ascii' codec can't encode character u' \xfc'... ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 non-Latin čüąĖą╝ą▓ąŠą╗čŗ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī 菹║čĆą░ąĮąĖčĆąŠą▓ą░ąĮčŗ ą║ą░ą║ ą▓ Unicode-ą╗ąĖč鹥čĆą░ą╗ą░čģ, čéą░ą║ ąĖ ą▓ čüčéčĆąŠą║ąŠą▓čŗčģ ą╗ąĖč鹥čĆą░ą╗ą░čģ, čćč鹊ą▒čŗ ąĖąĘą▒ąĄąČą░čéčī ąŠčłąĖą▒ą║ąĖ čüąĖąĮčéą░ą║čüąĖčüą░. ąöą╗čÅ ąĮąĄčłąĄą│ąŠ ą┐čĆąĖą╝ąĄčĆą░ čŹč鹊 ą┤ąŠą╗ąČąĮąŠ ą▓čŗą│ą╗čÅą┤ąĄčéčī čéą░ą║:
unicode_literal = u'\xfcber na\xefve caf\xe9'
string_literal = '\xc3\xbcber na\xc3\xafve caf\xc3\xa9'
ąÉą╗čīč鹥čĆąĮą░čéąĖą▓ąĮąŠ ą▓čŗ ą╝ąŠąČąĄč鹥 čāą║ą░ąĘą░čéčī ą║ąŠą┤ąĖčĆąŠą▓ą║čā ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░ ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü čĆąĄą║ąŠą╝ąĄąĮą┤ą░čåąĖąĄą╣ PEP 263 ą▓ ąĮą░čćą░ą╗ąĄ čäą░ą╣ą╗ą░, ąĮąŠ čŹč鹊 ąĮąĄ ą▒čāą┤ąĄčé ą╗čāčćčłąĄą╣ ą┐čĆą░ą║čéąĖą║ąŠą╣ ąĖąĘ-ąĘą░ ą┐čĆąŠą▒ą╗ąĄą╝ ą┐ąĄčĆąĄąĮąŠčüąĖą╝ąŠčüčéąĖ:
#!/usr/bin/env python2 # -*- coding: utf-8 -*-
unescaped_unicode_literal = u'├╝ber na├»ve caf├®'
unescaped_string_literal = '├╝ber na├»ve caf├®' ąøčāčćčłąĖą╣ ą╝ąĄč鹊ą┤ - ą┐čĆąĖą╝ąĄąĮąĖčéčī ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖąĄ čüčéčĆąŠą║ąĖ Unicode ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ ą┐ąĄčĆąĄą┤ ąĄčæ ą┐ąĄčćą░čéčīčÄ. ąÆčŗ ą╝ąŠąČąĄč鹥 čŹč鹊 čüą┤ąĄą╗ą░čéčī ą▓čĆčāčćąĮčāčÄ:
with open ('file.txt' , mode='w' ) as file_object:
unicode_text = u'\xfcber na\xefve caf\xe9'
encoded_text = unicode_text.encode('utf-8' )
print >> file_object, encoded_textą×ą┤ąĮą░ą║ąŠ ą▒ąŠą╗ąĄąĄ čāą┤ąŠą▒ąĮą░čÅ ąŠą┐čåąĖčÅ - ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓čüčéčĆąŠąĄąĮąĮčŗą╣ ą╝ąŠą┤čāą╗čī codecs:
import codecswith codecs.open ('file.txt' , 'w' , encoding='utf-8' ) as file_object:
unicode_text = u'\xfcber na\xefve caf\xe9'
print >> file_object, unicode_textąŁč鹊 ą┐ąŠąĘą░ą▒ąŠčéąĖčéčüčÅ ąŠ ą┐ąŠą┤čģąŠą┤čÅčēąĖčģ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅčģ, ą║ąŠą│ą┤ą░ ą▓čŗ čćąĖčéą░ąĄč鹥 ąĖą╗ąĖ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄč鹥 čäą░ą╣ą╗čŗ.
[ąæčāč乥čĆąĖąĘą░čåąĖčÅ ą▓čŗąĘąŠą▓ąŠą▓ print() ]
ąÆ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ čüąĄą║čåąĖąĖ ą╝čŗ ąĮą░čāčćąĖą╗ąĖčüčī, ą║ą░ą║ ą┤ąĄą╗ąĄą│ąĖčĆąŠą▓ą░čéčī ą┐ąĄčćą░čéčī print() ą▓ ąŠą▒čŖąĄą║čé ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ čäą░ą╣ą╗ą░, čéą░ą║ąŠą╣ ą║ą░ą║ sys.stdout. ą×ą┤ąĮą░ą║ąŠ ąĮąĄą║ąŠč鹊čĆčŗąĄ ą┐ąŠč鹊ą║ąĖ ą▒čāč乥čĆąĖąĘąĖčĆčāčÄčé ąŠą┐ąĄčĆą░čåąĖąĖ ą▓ą▓ąŠą┤ą░ ą▓čŗą▓ąŠą┤ą░ (I/O) ą┤ą╗čÅ ą┐ąŠą▓čŗčłąĄąĮąĖčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ, čćč鹊 ą╝ąŠąČąĄčé ą╝ąĄčłą░čéčī. ąĀą░čüčüą╝ąŠčéčĆąĖą╝ čŹč鹊 ąĮą░ ą┐čĆąĖą╝ąĄčĆąĄ.
ą¤čĆąĄą┤čüčéą░ą▓ąĖą╝ čüąĄą▒ąĄ, čćč鹊 ą╝čŗ ą┐ąĖčłąĄą╝ čéą░ą╣ą╝ąĄčĆ ąŠą▒čĆą░čéąĮąŠą│ąŠ ąŠčéčüč湥čéą░, ą║ąŠč鹊čĆčŗą╣ ą┤ąŠą╗ąČąĄąĮ ą┐ąĄčćą░čéą░čéčī ąŠčüčéą░ą▓čłąĄąĄčüčÅ ą▓čĆąĄą╝čÅ ą║ą░ąČą┤čāčÄ čüąĄą║čāąĮą┤čā ąĮą░ ąŠą┤ąĮąŠą╣ ąĖ č鹊ą╣ ąČąĄ čüčéčĆąŠą║ąĄ:
3...2...1...Go!
ąÆą░čłą░ ą┐ąĄčĆą▓ą░čÅ ą┐ąŠą┐čŗčéą║ą░ ą╝ąŠąČąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī ą┐čĆąĖą╝ąĄčĆąĮąŠ čéą░ą║:
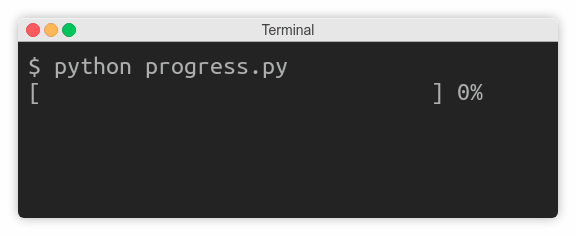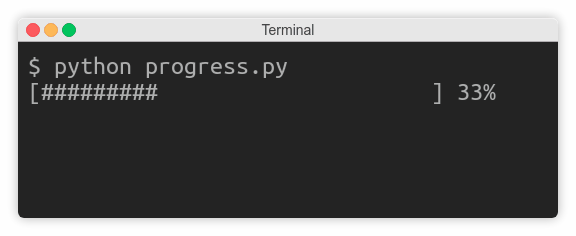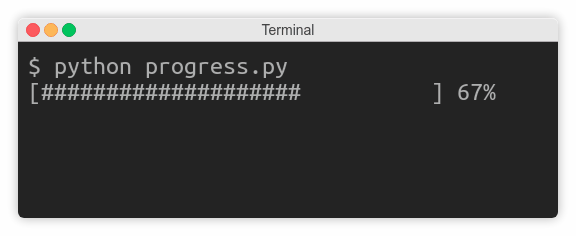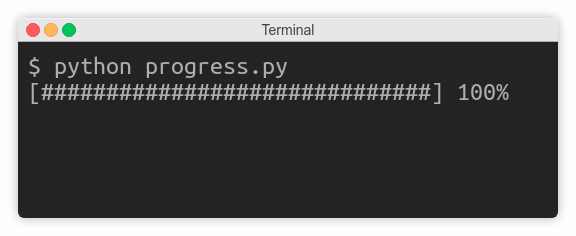
import time3 for countdown in reversed (range (num_seconds + 1 )):
if countdown > 0 :
print (countdown, end='...' )
time.sleep(1 )
else :
print ('Go!' )ą¤ąŠą║ą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ countdown ą▒ąŠą╗čīčłąĄ ąĮčāą╗čÅ, ą║ąŠą┤ ą┐čĆąŠą┤ąŠą╗ąČą░ąĄčé ą┤ąŠą▒ą░ą▓ą╗čÅčéčī č鹥ą║čüčé ą▒ąĄąĘ ąĘą░ą▓ąĄčĆčłą░čÄčēąĄą│ąŠ newline, čü ąĘą░čüčŗą┐ą░ąĮąĖąĄą╝ ąĮą░ ąŠą┤ąĮčā čüąĄą║čāąĮą┤čā. ąÆ ą║ąŠąĮčåąĄ ąŠą▒čĆą░čéąĮąŠą│ąŠ ąŠčéčüč湥čéą░ ą┐ąĄčćą░čéą░ąĄčéčüčÅ Go! ąĖ čüčéčĆąŠą║ą░ ąĘą░ą▓ąĄčĆčłą░ąĄčéčüčÅ.
ą×ą┤ąĮą░ą║ąŠ ąĮąĄąŠąČąĖą┤ą░ąĮąĮąŠ ą▓ą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ ą▓čŗą▓ąŠą┤ąĖčéčī ą┐ąĄčćą░čéčī ą║ą░ąČą┤čāčÄ čüąĄą║čāąĮą┤čā, ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ąČą┤ąĄčé čéčĆąĖ čüąĄą║čāąĮą┤čŗ ą▒ąĄąĘ ą║ą░ą║ąŠą│ąŠ-ą╗ąĖą▒ąŠ ą▓čŗą▓ąŠą┤ą░, ąĖ ą┐ąŠč鹊ą╝ ą▓ą┤čĆčāą│ ą┐ąĄčćą░čéą░ąĄčé ą▓čüčÄ čüčéčĆąŠą║čā ą┐ąŠą╗ąĮąŠčüčéčīčÄ:
ąŁč鹊 ą┐ąŠč鹊ą╝čā čćč鹊 ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮą░čÅ čüąĖčüč鹥ą╝ą░ ą┤ą╗čÅ čŹč鹊ą│ąŠ čüą╗čāčćą░čÅ ą▒čāč乥čĆąĖąĘąĖčĆčāąĄčé ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗąĄ ąĘą░ą┐ąĖčüąĖ ą▓ stdout. ąØąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ąĘąĮą░čéčī, čćč鹊 čüčāčēąĄčüčéą▓čāąĄčé čéčĆąĖ ą▓ąĖą┤ą░ ą┐ąŠč鹊ą║ąŠą▓ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ą▒čāč乥čĆąĖąĘą░čåąĖąĖ:
Unbuffered (ą▒ąĄąĘ ą▒čāč乥čĆąĖąĘą░čåąĖąĖ)Line-buffered (ą┐ąŠčüčéčĆąŠčćąĮą░čÅ ą▒čāč乥čĆąĖąĘą░čåąĖčÅ)Block-buffered (ą▒ą╗ąŠčćąĮą░čÅ ą▒čāč乥čĆąĖąĘą░čåąĖčÅ)
ą¤ąŠč鹊ą║ unbuffered - ą▒čāč乥čĆąĖąĘą░čåąĖąĖ ąĮąĄčé, ąĖ ą▓čüąĄ ąĘą░ą┐ąĖčüąĖ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ ą┤ą░čÄčé čŹčäč乥ą║čé. ą¤ąŠč鹊ą║ line-buffered ąČą┤ąĄčé, ą┐ąŠą║ą░ ą▓čŗąĘąŠą▓čŗ I/O ą┤ąŠčüčéąĖą│ąĮčāčé ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠčÅą▓ąĖčéčüčÅ ą│ą┤ąĄ-č鹊 ą▓ ą▒čāč乥čĆąĄ, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ block-buffered ą┐čĆąŠčüč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĘą░ą┐ąŠą╗ąĮčÅčéčī ą▒čāč乥čĆ ą┤ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░, ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ ąŠčé ąĄą│ąŠ čüąŠą┤ąĄčƹȹ░ąĮąĖčÅ. ąĪčéą░ąĮą┤ą░čĆčéąĮčŗą╣ ą▓čŗą▓ąŠą┤ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ line-buffered ąĖ block-buffered, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé č鹊ą│ąŠ, ą║ą░ą║ąŠąĄ čüąŠą▒čŗčéąĖąĄ ąĮą░čüčéčāą┐ąĖčé čĆą░ąĮčīčłąĄ.
ąæčāč乥čĆąĖąĘą░čåąĖčÅ ą┐ąŠą╝ąŠą│ą░ąĄčé čāą╝ąĄąĮčīčłąĖčéčī čćčĆąĄąĘą╝ąĄčĆąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▓čŗąĘąŠą▓ąŠą▓ I/O. ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐čĆąĄą┤čüčéą░ą▓ąĖčéčī čŹč鹊 ą║ą░ą║ ąŠčéą┐čĆą░ą▓ą║čā čüąŠąŠą▒čēąĄąĮąĖą╣ č湥čĆąĄąĘ čüąĄčéčī čü ą▒ąŠą╗čīčłąĖą╝ąĖ ąĘą░ą┤ąĄčƹȹ║ą░ą╝ąĖ. ąÜąŠą│ą┤ą░ ą▓čŗ čüąŠąĄą┤ąĖąĮčÅąĄč鹥čüčī čü čüąĄč鹥ą▓čŗą╝ čüąĄčĆą▓ąĄčĆąŠą╝ ą┐ąŠ ą┐čĆąŠč鹊ą║ąŠą╗čā SSH ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĮą░ ąĮąĄą╝, ą║ą░ąČą┤ąŠąĄ ą▓ą░čłąĄ ąĮą░ąČą░čéąĖąĄ ąĮą░ ą║ą╗ą░ą▓ąĖčłčā ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą│ąĄąĮąĄčĆą░čåąĖąĖ ąŠčéą┤ąĄą╗čīąĮąŠą│ąŠ ą┐ą░ą║ąĄčéą░ MTU, čĆą░ąĘą╝ąĄčĆ ą║ąŠč鹊čĆąŠą│ąŠ ąĮą░ą╝ąĮąŠą│ąŠ ą┐čĆąĄą▓čŗčłą░ąĄčé čĆą░ąĘą╝ąĄčĆ ąĄą│ąŠ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ. ą¤ąŠą╗čāčćą░ąĄčéčüčÅ ą▒ąĄčüą┐ąŠą╗ąĄąĘąĮą░čÅ ąĮą░ą│čĆčāąĘą║ą░ ąĮą░ ą╝ąĄą┤ą╗ąĄąĮąĮčŗą╣ ą║ą░ąĮą░ą╗ čüą▓čÅąĘąĖ! ąśą╝ąĄąĄčé čüą╝čŗčüą╗ ą┐ąŠą┤ąŠąČą┤ą░čéčī ą▓ą▓ąŠą┤ą░ ąĄčēąĄ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čüąĖą╝ą▓ąŠą╗ąŠą▓, čćč鹊ą▒čŗ ąŠčéą┐čĆą░ą▓ąĖčéčī ąĖčģ ą▓čüąĄ ą▓ą╝ąĄčüč鹥 ą▓ ąŠą┤ąĮąŠą╝ ą┐ą░ą║ąĄč鹥. ąÆąŠčé ą│ą┤ąĄ ą▓čüčéčāą┐ą░ąĄčé ą▓ ą┤ąĄą╗ąŠ ą▒čāč乥čĆąĖąĘą░čåąĖčÅ.
ąĪ ą┤čĆčāą│ąŠą╣ čüč鹊čĆąŠąĮčŗ, ą▒čāč乥čĆąĖąĘą░čåąĖčÅ ąĖąĮąŠą│ą┤ą░ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąŠą┤ąĖčéčī ą║ ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮčŗą╝ čŹčäč乥ą║čéą░ą╝, ą║ąŠą│ą┤ą░ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą▓ čĆąĄą░ą╗čīąĮąŠą╝ ą▓čĆąĄą╝ąĄąĮąĖ ą▓ąĄą┤ąĄčé čüąĄą▒čÅ ąĮąĄąŠąČąĖą┤ą░ąĮąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝, ą║ą░ą║ čŹč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓ ąĮą░čłąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ. ą¦č鹊ą▒čŗ ąĖčüą┐čĆą░ą▓ąĖčéčī čŹč鹊, ą▓čŗ ą╝ąŠąČąĄč鹥 ą┐čĆąŠčüč鹊 čāą║ą░ąĘą░čéčī print() ą┐čĆąĖąĮčāą┤ąĖč鹥ą╗čīąĮąŠ čüą▒čĆą░čüčŗą▓ą░čéčī ąĮą░ ą▓čŗčģąŠą┤ ą▒čāč乥čĆ ą┐ąŠč鹊ą║ą░ (flush) ą▒ąĄąĘ ąŠąČąĖą┤ą░ąĮąĖčÅ ą┐ąŠčÅą▓ą╗ąĄąĮąĖčÅ čüąĖą╝ą▓ąŠą╗ą░ newline ą▓ ą▒čāč乥čĆąĄ. ąŁč鹊 ą┤ąĄą╗ą░ąĄčéčüčÅ čāą║ą░ąĘą░ąĮąĖąĄą╝ ą┐ą░čĆą░ą╝ąĄčéčĆą░ čäą╗ą░ą│ą░ flush :
print (countdown, end='...' , flush=True )
ąØąĄčé ą┐čĆąŠčüč鹊ą│ąŠ čüą┐ąŠčüąŠą▒ą░ ą┐čĆąĖą╝ąĄąĮąĖčéčī flush ą┤ą╗čÅ ą┐ąŠč鹊ą║ą░ ą▓ Python 2, ą┐ąŠč鹊ą╝čā čćč鹊 čüą░ą╝ ąŠą┐ąĄčĆą░č鹊čĆ print čüą░ą╝ ą┐ąŠ čüąĄą▒ąĄ čŹč鹊ą│ąŠ ąĮąĄ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé. ąØčāąČąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ąĄą│ąŠ ą┤ąĄčüą║čĆąĖą┐č鹊čĆ ąĮąĖąČąĮąĄą│ąŠ čāčĆąŠą▓ąĮčÅ, ą║ąŠč鹊čĆčŗą╣ čÅą▓ą╗čÅąĄčéčüčÅ čüčéą░ąĮą┤ą░čĆčéąĮčŗą╝ ą▓čŗą▓ąŠą┤ąŠą╝, ąĖ ą▓čŗąĘą▓ą░čéčī ąĄą│ąŠ ąĮą░ą┐čĆčÅą╝čāčÄ:
import timeimport sys3 for countdown in reversed (range (num_seconds + 1 )):
if countdown > 0 :
sys.stdout.write('%s...' % countdown)
sys.stdout.flush()
time.sleep(1 )
else :
print 'Go!' ąÉą╗čīč鹥čĆąĮą░čéąĖą▓ąĮąŠ ą▓čŗ ą╝ąŠąČąĄč鹥 ąĘą░ą┐čĆąĄčéąĖčéčī ą▒čāč乥čĆąĖąĘą░čåąĖčÄ čüčéą░ąĮą┤ą░čĆčéąĮčŗčģ ą┐ąŠč鹊ą║ąŠą▓ ą┐čāč鹥ą╝ ą┐ąĄčĆąĄą┤ą░čćąĖ čäą╗ą░ą│ą░ -u ąĖąĮč鹥čĆą┐čĆąĄčéą░č鹊čĆčā Python, ąĖą╗ąĖ ą┐čāč鹥ą╝ čāčüčéą░ąĮąŠą▓ą║ąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ąŠą║čĆčāąČąĄąĮąĖčÅ PYTHONUNBUFFERED :
$ python2 -u countdown.py
$ PYTHONUNBUFFERED=1 python2 countdown.py
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 print() ą▒čŗą╗ą░ ąŠą▒čĆą░čéąĮąŠ ą┐ąŠčĆčéąĖčĆąŠą▓ą░ąĮą░ ą▓ Python 2, ąĖ ąŠąĮą░ čüčéą░ąĮąŠą▓ąĖčéčüčÅ ą┤ąŠčüčéčāą┐ąĮąŠą╣ č湥čĆąĄąĘ ąĖą╝ą┐ąŠčĆčé ą╝ąŠą┤čāą╗čÅ __future__. ąØąŠ ą║ čüąŠąČą░ą╗ąĄąĮąĖčÄ, ąŠąĮą░ ąĮąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčéčüčÅ čü ą┐ą░čĆą░ą╝ąĄčéčĆąŠą╝ flush:
>>> from __future__ import print_function>>> help (print )
Help on built-in function print in module __builtin__:print (...)
print (value, ..., sep=' ' , end='\n' , file=sys.stdout)ąŚą┤ąĄčüčī ą▓čŗ ą▓ąĖą┤ąĖč鹥 čüčéčĆąŠą║čā ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ (docstring) čäčāąĮą║čåąĖąĖ print(). ąÆčŗ ą╝ąŠąČąĄč鹥 ą░ąĮą░ą╗ąŠą│ąĖčćąĮąŠ ą┐čĆąŠčüą╝ą░čéčĆąĖą▓ą░čéčī čüčéčĆąŠą║ąĖ docstring čĆą░ąĘą╗ąĖčćąĮčŗčģ ąŠą▒čŖąĄą║č鹊ą▓ Python, ąĖčüą┐ąŠą╗čīąĘčāčÅ ą▓čüčéčĆąŠąĄąĮąĮčāčÄ čäčāąĮą║čåąĖčÄ help() .
ą×čéą╗ąĖčćąĮąŠ! ąÆčŗ ą┐ąŠąĘąĮą░ą║ąŠą╝ąĖą╗ąĖčüčī čü ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ ą┐čĆąĖą╝ąĄčĆą░ą╝ąĖ ą▓čŗąĘąŠą▓ą░ čäčāąĮą║čåąĖąĖ print(), ą│ą┤ąĄ ą┐čĆąĖą╝ąĄąĮčÅą╗ąĖčüčī ą▓čüąĄ ąĄčæ ą┐ą░čĆą░ą╝ąĄčéčĆčŗ. ąóąĄą┐ąĄčĆčī ą▓čŗ ąĘąĮą░ąĄč鹥, ą┤ą╗čÅ č湥ą│ąŠ ąŠąĮąĖ ąĮčāąČąĮčŗ, ąĖ ą╝ąŠąČąĄč鹥 ąĮą░čćą░čéčī ąĖčģ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī. ą×ą┤ąĮą░ą║ąŠ ą┐ąŠąĮąĖą╝ą░ąĮąĖąĄ čüąĖą│ąĮą░čéčāčĆčŗ čäčāąĮą║čåąĖąĖ print() čŹč鹊 č鹊ą╗čīą║ąŠ ąĮą░čćą░ą╗ąŠ. ąÆ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖčģ čüąĄą║čåąĖčÅčģ ą▓čŗ ą┐ąŠą╣ą╝ąĄč鹥 ą┐ąŠč湥ą╝čā.
[ą¤ąĄčćą░čéčī ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖčģ čéąĖą┐ąŠą▓ ą┤ą░ąĮąĮčŗčģ ]
ą¤ąŠą║ą░ ą╝čŗ ąĖą╝ąĄą╗ąĖ ą┤ąĄą╗ąŠ č鹊ą╗čīą║ąŠ čüąŠ ą▓čüčéčĆąŠąĄąĮąĮčŗą╝ąĖ čéąĖą┐ą░ą╝ąĖ ą┤ą░ąĮąĮčŗčģ, čéą░ą║ąĖą╝ąĖ ą║ą░ą║ čüčéčĆąŠą║ąĖ ąĖ čćąĖčüą╗ą░, ąĮąŠ ą▓ą░ą╝ čćą░čüč鹊 ą┐ąŠąĮą░ą┤ąŠą▒ąĖčéčüčÅ ą┐ąĄčćą░čéą░čéčī čüą▓ąŠąĖ čüąŠą▒čüčéą▓ąĄąĮąĮčŗąĄ ą░ą▒čüčéčĆą░ą║čéąĮčŗąĄ čéąĖą┐čŗ ą┤ą░ąĮąĮčŗčģ. ąöą░ą▓ą░ą╣č鹥 čĆą░čüčüą╝ąŠčéčĆąĖą╝ ąĮąĄčüą║ąŠą╗čīą║ąŠ čĆą░ąĘąĮčŗčģ čüą┐ąŠčüąŠą▒ąŠą▓ ąĖčģ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ.
ąöą╗čÅ ą┐čĆąŠčüčéčŗčģ ąŠą▒čŖąĄą║č鹊ą▓, ąĮąĄ čüąŠą┤ąĄčƹȹ░čēąĖčģ ą║ą░ą║ąŠą╣-ą╗ąĖą▒ąŠ ą╗ąŠą│ąĖą║ąĖ, ąĮą░ąĘąĮą░č湥ąĮąĖąĄ ą║ąŠč鹊čĆčŗčģ ą┐čĆąŠčüč鹊 ą┐ąĄčĆąĄąĮąŠčüąĖčéčī ą┤ą░ąĮąĮčŗąĄ, ąŠą▒čŗčćąĮąŠ ą▓čŗ ą╝ąŠąČąĄč鹥 ą┐čĆąĖą╝ąĄąĮąĖčéčī namedtuple (ąĖą╝ąĄąĮąŠą▓ą░ąĮąĮčŗą╣ ą║ąŠčĆč鹥ąČ), ą┤ąŠčüčéčāą┐ąĮčŗą╣ ą▓ čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĄ. ąśą╝ąĄąĮąŠą▓ą░ąĮąĮčŗąĄ ą║ąŠčĆč鹥ąČąĖ ąĖąĘ ą║ąŠčĆąŠą▒ą║ąĖ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ą░ą║ą║čāčĆą░čéąĮąŠąĄ č鹥ą║čüč鹊ą▓ąŠąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ čéąĖą┐ą░:
>>> from collections import namedtuple>>> Person = namedtuple('Person' , 'name age' )>>> jdoe = Person('John Doe' , 42 )>>> print (jdoe)
Person(name='John Doe' , age=42 )ąŁč鹊 čĆą░ą▒ąŠčéą░ąĄčé čģąŠčĆąŠčłąŠ, ą┐ąŠą║ą░ čģą▓ą░čéą░ąĄčé ą╝ąĄčüčéą░ ą┤ą╗čÅ čģčĆą░ąĮąĄąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ, ąĮąŠ ą┤ą╗čÅ č鹊ą│ąŠ, čćč鹊ą▒čŗ ą┤ąŠą▒ą░ą▓ąĖčéčī čäčāąĮą║čåąĖąŠąĮą░ą╗ ą┐ąŠą▓ąĄą┤ąĄąĮąĖą╣ ą▓ čéąĖą┐ Person, ą▓ą░ą╝ ą▓ ąĖč鹊ą│ąĄ ą┐ąŠčéčĆąĄą▒čāąĄčéčüčÅ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą║ą╗ą░čüčü. ąÆąĘą│ą╗čÅąĮąĖč鹥 ąĮą░ čŹč鹊čé ą┐čĆąĖą╝ąĄčĆ:
class Person :
def __init__ (self, name, age ):
self.name, self.age = name, ageąĢčüą╗ąĖ ą▓čŗ čüąĄą╣čćą░čü čüąŠąĘą┤ą░ą┤ąĖč鹥 菹║ąĘąĄą╝ą┐ą╗čÅčĆ ą║ą╗ą░čüčüą░ Person ąĖ ą┐ąŠą┐čŗčéą░ąĄč鹥čüčī ąĄą│ąŠ čĆą░čüą┐ąĄčćą░čéą░čéčī, ą▓čŗ ą┐ąŠą╗čāčćąĖč鹥 čŹč鹊čé ą┐čĆąĖčćčāą┤ą╗ąĖą▓čŗą╣ ą▓čŗą▓ąŠą┤, ą║ąŠč鹊čĆčŗą╣ čüąĖą╗čīąĮąŠ ąŠčéą╗ąĖčćą░ąĄčéčüčÅ ąŠčé 菹║ą▓ąĖą▓ą░ą╗ąĄąĮčéąĮąŠą│ąŠ namedtuple:
>>> jdoe = Person('John Doe' , 42 )>>> print (jdoe)
< __main__.Person object at 0x7fcac3fed1d0 >ąŁč鹊 ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą╗čÅ ąŠą▒čŖąĄą║č鹊ą▓, ą│ą┤ąĄ ą┐čĆąĖčüčāčéčüčéą▓čāąĄčé ąĖčģ ą░ą┤čĆąĄčü ą▓ ą┐ą░ą╝čÅčéąĖ, ąĖą╝čÅ čéąĖą┐ą░ ąŠą▒čŖąĄą║čéą░ ąĖ ą╝ąŠą┤čāą╗čī, ą▓ ą║ąŠč鹊čĆąŠą╝ ąŠą▒čŖąĄą║čé ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ. ąÆčŗ čŹč鹊 ąĮąĄą╝ąĮąŠą│ąŠ ąĖčüą┐čĆą░ą▓ąĖč鹥, ąĮąŠ ą┐čĆąŠčüč鹊 ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ, ą║ą░ą║ ą▒čŗčüčéčĆčŗą╣ ąŠą▒čģąŠą┤ąĮąŠą╣ ą┐čāčéčī, ąŠą▒čŖąĄą┤ąĖąĮąĖą▓ namedtuple ąĖ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖą╣ ą║ą╗ą░čüčü č湥čĆąĄąĘ ąĮą░čüą╗ąĄą┤ąŠą▓ą░ąĮąĖąĄ:
from collections import namedtupleclass Person (namedtuple('Person' , 'name age' )):
pass ą¤čĆąĖ čŹč鹊ą╝ ą▓ą░čł ą║ą╗ą░čüčü Person ą┐čĆąŠčüč鹊 čüčéą░ąĮąŠą▓ąĖčéčüčÅ čüą┐ąĄčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮąĮąŠą╣ čĆą░ąĘąĮąŠą▓ąĖą┤ąĮąŠčüčéčīčÄ namedtuple čü ą┤ą▓čāą╝čÅ ą░čéčĆąĖą▒čāčéą░ą╝ąĖ, ą║ąŠč鹊čĆčŗąĄ ą▓čŗ ą╝ąŠąČąĄč鹥 ąĮą░čüčéčĆą░ąĖą▓ą░čéčī.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ą▓ Python 3 ąŠą┐ąĄčĆą░č鹊čĆ pass ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ą╝ąĄąĮąĄąĮ ą╗ąĖč鹥čĆą░ą╗ąŠą╝ ą╝ąĮąŠą│ąŠč鹊čćąĖčÅ (...), čćč鹊ą▒čŗ čāą║ą░ąĘą░čéčī ą╝ąĄčüč鹊ąĘą░ą┐ąŠą╗ąĮąĖč鹥ą╗čī:
def delta (a, b, c ):
...ąŁč鹊 ą┐čĆąĄą┤ąŠčéą▓čĆą░čēą░ąĄčé ą│ąĄąĮąĄčĆą░čåąĖčÄ ąŠčłąĖą▒ą║ąĖ IndentationError ąĖąĮč鹥čĆą┐čĆąĄčéą░č鹊čĆą░ ąĖąĘ-ąĘą░ ąŠčéčüčāčéčüčéą▓ąĖąĄ ąŠčéčüčéčāą┐ą░ ą┤ą╗čÅ ą▒ą╗ąŠą║ą░ ą║ąŠą┤ą░.
ąŁč鹊 ą╗čāčćčłąĄ, č湥ą╝ čćąĖčüčéčŗą╣ namedtuple, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓čŗ ąĮąĄ ą┐čĆąŠčüč鹊 ą┐ąŠą╗čāčćą░ąĄč鹥 ą▒ąĄčüą┐ą╗ą░čéąĮąŠ ą┐ąĄčćą░čéčī, ąĮąŠ čéą░ą║ąČąĄ ą╝ąŠąČąĄč鹥 ą┤ąŠą▒ą░ą▓ąĖčéčī čüą▓ąŠąĖ čüąŠą▒čüčéą▓ąĄąĮąĮčŗąĄ ą╝ąĄč鹊ą┤čŗ ąĖ čüą▓ąŠą╣čüčéą▓ą░ ą▓ ą║ą╗ą░čüčü. ą×ą┤ąĮą░ą║ąŠ čéą░ą║ąŠąĄ čĆąĄčłąĄąĮąĖąĄ ąŠą┤ąĮąŠą╣ ą┐čĆąŠą▒ą╗ąĄą╝čŗ čüąŠąĘą┤ą░ąĄčé ą┤čĆčāą│čāčÄ ą┐čĆąŠą▒ą╗ąĄą╝čā. ą¤ąŠą╝ąĮąĖč鹥, čćč鹊 ą║ąŠčĆč鹥ąČąĖ, ą▓ą║ą╗čÄčćą░čÅ ąĖą╝ąĄąĮąŠą▓ą░ąĮąĮčŗąĄ ą║ąŠčĆč鹥ąČąĖ, čÅą▓ą╗čÅčÄčéčüčÅ ą▓ Python ąĮąĄ ąĖąĘą╝ąĄąĮčÅąĄą╝čŗą╝ąĖ, ą┐ąŠčŹč鹊ą╝čā ąŠąĮąĖ ąĮąĄ ą╝ąŠą│čāčé ąĖąĘą╝ąĄąĮčÅčéčī čüą▓ąŠąĖ ąĘąĮą░č湥ąĮąĖčÅ ą┐ąŠčüą╗ąĄ čüąŠąĘą┤ą░ąĮąĖčÅ.
ąŁč鹊 ą┐ąŠą┤čģąŠą┤ąĖčé, ą║ąŠą│ą┤ą░ čĆą░ąĘčĆą░ą▒ąŠčéą║ą░ ąĮąĄą╝čāčéąĖčĆčāąĄą╝čŗčģ čéąĖą┐ąŠą▓ ą┤ą░ąĮąĮčŗčģ čÅą▓ą╗čÅąĄčéčüčÅ ąČąĄą╗ą░č鹥ą╗čīąĮąŠą╣, ąĮąŠ ą▓ąŠ ą╝ąĮąŠą│ąĖčģ čüą╗čāčćą░čÅčģ ą▓čŗ ąĘą░čģąŠčéąĖč鹥 ą┤ąŠą┐čāčüą║ą░čéčī ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ, čéą░ą║ čćč鹊 čüąĮąŠą▓ą░ ą┐čĆąĖą┤ąĄčéčüčÅ ą▓ąĄčĆąĮčāčéčīčüčÅ ą║ ąŠą▒čŗčćąĮčŗą╝ ą║ą╗ą░čüčüą░ą╝.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: čüą╗ąĄą┤čāčÅ ą┐čĆąĖą╝ąĄčĆčā ą┤čĆčāą│ąĖčģ čÅąĘčŗą║ąŠą▓ ąĖ čĆą░ą▒ąŠčćąĖčģ čüčĆąĄą┤, Python 3.7 ą▓ą▓ąĄą╗ ą║ą╗ą░čüčüčŗ ą┤ą░ąĮąĮčŗčģ (dataclass ąĖąĘ ą╝ąŠą┤čāą╗čÅ dataclasses), ąŠ ą║ąŠč鹊čĆčŗčģ ą▓čŗ ą╝ąŠąČąĄč鹥 ą┤čāą╝ą░čéčī ą║ą░ą║ ąŠą▒ ąĖąĘą╝ąĄąĮčÅąĄą╝čŗčģ ą║ąŠčĆč鹥ąČą░čģ (mutable tuples). ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą▓čŗ ą┐ąŠą╗čāčćą░ąĄč鹥 ą╗čāčćčłąĄąĄ ąĖąĘ ąŠą▒ąŠąĖčģ ą╝ąĖčĆąŠą▓:
>>> from dataclasses import dataclass>>> @dataclass... class Person :... name: str ... age: int ... ... def celebrate_birthday (self ):... self.age += 1 ... >>> jdoe = Person('John Doe' , 42 )>>> jdoe.celebrate_birthday()>>> print (jdoe)
Person(name='John Doe' , age=43 )ąĪąĖąĮčéą░ą║čüąĖčü ą░ąĮąĮąŠčéą░čåąĖą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣, ą║ąŠč鹊čĆčŗąĄ čéčĆąĄą▒čāąĄčé čāą║ą░ąĘą░ąĮąĖčÅ ą┐ąŠą╗ąĄą╣ ą║ą╗ą░čüčüą░ čü ąĖčģ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╝ąĖ čéąĖą┐ą░ą╝ąĖ, ą▒čŗą╗ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ ą▓ Python 3.6.
ąśąĘ ą┐čĆąĄą┤čŗą┤čāčēąĖčģ čüąĄą║čåąĖą╣ ą▓čŗ čāąČąĄ ąĘąĮą░ąĄč鹥, čćč鹊 čäčāąĮą║čåąĖčÅ print() ąĮąĄčÅą▓ąĮąŠ ą▓čŗąĘčŗą▓ą░ąĄčé ą▓čüčéčĆąŠąĄąĮąĮčāčÄ čäčāąĮą║čåąĖčÄ str() čćč鹊ą▒čŗ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░čéčī ą┐ąŠąĘąĖčåąĖąŠąĮąĮčŗąĄ ą░čĆą│čāą╝ąĄąĮčéčŗ ą▓ čüčéčĆąŠą║ąĖ. ąöąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠ, ą▓čŗąĘąŠą▓ str() ą▓čĆčāčćąĮčāčÄ ą┐čĆąŠčéąĖą▓ ąŠą▒čŗčćąĮąŠą│ąŠ ą║ą╗ą░čüčüą░ Person ą┤ą░ąĄčé č鹊čé ąČąĄ čĆąĄąĘčāą╗čīčéą░čé, čćč鹊 ąĖ ąĄą│ąŠ ą┐ąĄčćą░čéčī:
>>> jdoe = Person('John Doe' , 42 )>>> str (jdoe)'< __main__.Person object at 0x7fcac3fed1d0>' ążčāąĮą║čåąĖčÅ str(), ą▓ čüą▓ąŠčÄ ąŠč湥čĆąĄą┤čī, ąĖčēąĄčé ąŠą┤ąĖąĮ ąĖąĘ ą┤ą▓čāčģ ą╝ą░ą│ąĖč湥čüą║ąĖčģ ą╝ąĄč鹊ą┤ąŠą▓ ą▓ č鹥ą╗ąĄ ą║ą╗ą░čüčüą░, ą║ąŠč鹊čĆčŗą╣ ą▓čŗ ąŠą▒čŗčćąĮąŠ čĆąĄą░ą╗ąĖąĘčāąĄč鹥. ąĢčüą╗ąĖ ą║ą░ą║ąŠą╣-č鹊 ąĖąĘ ąĮąĖčģ ąĮąĄ ąĮą░ą╣ą┤ąĄąĮ, č鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąŠčéą║ą░čé ą║ ą│čĆčāą▒ąŠą╣ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ. ąÆąŠčé čŹčéąĖ magic-ą╝ąĄč鹊ą┤čŗ, ą▓ ą┐ąŠčĆčÅą┤ą║ąĄ ą┐ąŠąĖčüą║ą░:
def __str__ (self )def __repr__ (self )ąöą╗čÅ ą┐ąĄčĆą▓ąŠą│ąŠ ąĖąĘ ąĮąĖčģ čĆąĄą║ąŠą╝ąĄąĮą┤čāąĄčéčüčÅ ą▓ąŠąĘą▓ą░čĆą░čēą░čéčī ą║ąŠčĆąŠčéą║ąĖą╣, čāą┤ąŠą▒ąŠčćąĖčéą░ąĄą╝čŗą╣ č鹥ą║čüčé, ą║ąŠč鹊čĆčŗą╣ ą▓ą║ą╗čÄčćą░ąĄčé ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąĖąĘ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ą░ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖčģ ą░čéčĆąĖą▒čāč鹊ą▓. ąÆ ą║ąŠąĮčåąĄ ą║ąŠąĮčåąŠą▓, ą▓čŗ ąĮąĄ ąĘą░čģąŠčéąĖč鹥 ą▓čŗą┤ą░ą▓ą░čéčī ą║ąŠąĮčäąĖą┤ąĄąĮčåąĖą░ą╗čīąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ, čéą░ą║ąĖąĄ ą║ą░ą║ ą┐ą░čĆąŠą╗ąĖ, ą┐čĆąĖ ą┐ąĄčćą░čéąĖ ąŠą▒čŖąĄą║č鹊ą▓.
ą×ą┤ąĮą░ą║ąŠ ą┤čĆčāą│ąŠą╣ ąĖąĘ ąĮąĖčģ ą┤ąŠą╗ąČąĄąĮ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčéčī ą┐ąŠą╗ąĮčāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠą▒ ąŠą▒čŖąĄą║č鹥, čćč鹊ą▒čŗ ą┐ąŠąĘą▓ąŠą╗ąĖčéčī ą▓ąŠčüčüčéą░ąĮąŠą▓ąĖčéčī ąĄą│ąŠ čüąŠčüč鹊čÅąĮąĖąĄ ąĖąĘ čüčéčĆąŠą║ąĖ. ąÆ ąĖą┤ąĄą░ą╗čīąĮąŠą╝ ą▓ą░čĆąĖą░ąĮč鹥 ąŠąĮ ą┤ąŠą╗ąČąĄąĮ ą▓ąŠąĘą▓čĆą░čēą░čéčī čĆą░ą▒ąŠčćąĖą╣ ą║ąŠą┤ Python, čéą░ą║ čćč鹊ą▒čŗ ąĄą│ąŠ ąĮą░ą┐čĆčÅą╝čāčÄ ą┐ąĄčĆąĄą┤ą░čéčī ą▓ eval():
>>> repr (jdoe)"Person(name='John Doe', age=42)" >>> type (eval (repr (jdoe)))
< class '__main__.Person' >ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ ąĮą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą┤čĆčāą│ąŠą╣ ą▓čüčéčĆąŠąĄąĮąĮąŠą╣ čäčāąĮą║čåąĖąĖ repr() , ą║ąŠč鹊čĆą░čÅ ą▓čüąĄą│ą┤ą░ ą┐čŗčéą░ąĄčéčüčÅ ą▓čŗąĘą▓ą░čéčī .__repr__() ą▓ ąŠą▒čŖąĄą║č鹥, ąĮąŠ ą▓ąŠąĘą▓čĆą░čēą░ąĄčéčüčÅ ą║ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ, ąĄčüą╗ąĖ ąĮąĄ ąĮą░čģąŠą┤ąĖčé čŹč鹊čé ą╝ąĄč鹊ą┤.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ąĮąĄčüą╝ąŠčéčĆčÅ ąĮą░ č鹊, čćč鹊 print() čüą░ą╝ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčé str() ą┤ą╗čÅ ą┐čĆąĖą▓ąĄą┤ąĄąĮąĖčÅ čéąĖą┐ąŠą▓ (type casting), ąĮąĄą║ąŠč鹊čĆčŗąĄ čüąŠčüčéą░ą▓ąĮčŗąĄ čéąĖą┐čŗ ą┤ą░ąĮąĮčŗčģ ą┤ąĄą╗ąĄą│ąĖčĆčāčÄčé ą▓čŗąĘąŠą▓ čäčāąĮą║čåąĖąĖ repr() čüą▓ąŠąĖą╝ čćą╗ąĄąĮą░ą╝. ąØą░ą┐čĆąĖą╝ąĄčĆ, čŹč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┤ą╗čÅ čüą┐ąĖčüą║ąŠą▓ (lists) ąĖ ą║ąŠčĆč鹥ąČąĄą╣ (tuples).
ąĀą░čüčüą╝ąŠčéčĆąĖą╝ čŹč鹊čé ą║ą╗ą░čüčü čü ąŠą▒ąŠąĖą╝ąĖ magic-ą╝ąĄč鹊ą┤ą░ą╝ąĖ, ą║ąŠč鹊čĆčŗąĄ ą▓ąŠąĘą▓čĆą░čéčÅčé ą░ą╗čīč鹥čĆąĮą░čéąĖą▓ąĮčŗąĄ čüčéčĆąŠą║ąŠą▓čŗąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖčÅ ą┤ą╗čÅ ąŠą┤ąĮąŠą│ąŠ ąĖ č鹊ą│ąŠ ąČąĄ ąŠą▒čŖąĄą║čéą░:
class User :
def __init__ (self, login, password ):
self.login = login
self.password = passworddef __str__ (self ):
return self.logindef __repr__ (self ):
return f"User('{self.login} ', '{self.password} ')" ąĢčüą╗ąĖ ą▓čŗ ą┐ąĄčćą░čéą░ąĄč鹥 ąŠą┤ąĖąĮ ąŠą▒čŖąĄą║čé ą║ą╗ą░čüčüą░ User, č鹊 ą▓čŗ ąĮąĄ čāą▓ąĖą┤ąĖč鹥 password, ą┐ąŠč鹊ą╝čā čćč鹊 print(user) ą▓čŗąĘąŠą▓ąĄčé str(user), ą║ąŠč鹊čĆą░čÅ ą▓ ą║ąŠąĮąĄčćąĮąŠą╝ ąĖč鹊ą│ąĄ ą▓čŗąĘąŠą▓ąĄčé user.__str__() :
>>> user = User('jdoe' , 's3cret' )>>> print (user)
jdoeą×ą┤ąĮą░ą║ąŠ ąĄčüą╗ąĖ ą┐ąŠą╝ąĄčüčéąĖčéčī čéčā ąČąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║čāčÄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ ą▓ąĮčāčéčĆčī čüą┐ąĖčüą║ą░, ąŠą▒ąĄčĆąĮčāą▓ ąĄčæ ą▓ ą║ą▓ą░ą┤čĆą░čéąĮčŗąĄ čüą║ąŠą▒ą║ąĖ, č鹊 ą┐ą░čĆąŠą╗čī čüčéą░ąĮąĄčé čģąŠčĆąŠčłąŠ ą▓ąĖą┤ąĄąĮ:
>>> print ([user])
[User('jdoe' , 's3cret' )]ąŁč鹊 ą┐ąŠč鹊ą╝čā, čćč鹊 ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ, čéą░ą║ąĖąĄ ą║ą░ą║ čüą┐ąĖčüą║ąĖ ąĖ ą║ąŠčĆč鹥ąČąĖ, čĆąĄą░ą╗ąĖąĘčāčÄčé ąĖčģ ą╝ąĄč鹊ą┤ .__str__() čéą░ą║, čćč鹊 ą▓čüąĄ ąĖčģ 菹╗ąĄą╝ąĄąĮčéčŗ čüąĮą░čćą░ą╗ą░ ą┐čĆąĄąŠą▒čĆą░ąĘčāčÄčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ repr().
Python ą┤ą░ąĄčé ą▓ą░ą╝ ą▒ąŠą╗čīčłčāčÄ čüą▓ąŠą▒ąŠą┤čā, ą║ąŠą│ą┤ą░ ą┤ąĄą╗ąŠ ą┤ąŠčģąŠą┤ąĖčé ą┤ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ čüąŠą▒čüčéą▓ąĄąĮąĮčŗčģ čéąĖą┐ąŠą▓ ą┤ą░ąĮąĮčŗčģ, ąĄčüą╗ąĖ ąĮąĖ ąŠą┤ąĖąĮ ąĖąĘ ą▓čüčéčĆąŠąĄąĮąĮčŗčģ čéąĖą┐ąŠą▓ ąĮąĄ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ą▓ą░čłąĖą╝ ą┐ąŠčéčĆąĄą▒ąĮąŠčüčéčÅą╝. ąØąĄą║ąŠč鹊čĆčŗąĄ ąĖąĘ ąĮąĖčģ, čéą░ą║ąĖąĄ ą║ą░ą║ ąĖą╝ąĄąĮąŠą▓ą░ąĮąĮčŗąĄ ą║ąŠčĆč鹥ąČąĖ (named tuples) ąĖ ą║ą╗ą░čüčüčŗ ą┤ą░ąĮąĮčŗčģ (data classes), ą┐čĆąĄą┤ą╗ą░ą│ą░čÄčé čüčéčĆąŠą║ąŠą▓čŗąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą▓čŗą│ą╗čÅą┤čÅčé čģąŠčĆąŠčłąŠ, ąĮąĄ čéčĆąĄą▒čāčÅ ąĮąĖą║ą░ą║ąŠą╣ čĆą░ą▒ąŠčéčŗ čü ą▓ą░čłąĄą╣ čüč鹊čĆąŠąĮčŗ. ąóąĄą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ, ą┤ą╗čÅ ą▒ąŠą╗čīčłąĄą╣ ą│ąĖą▒ą║ąŠčüčéąĖ ą▓ą░ą╝ ą┐čĆąĖą┤ąĄčéčüčÅ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą║ą╗ą░čüčü ąĖ ą┐ąĄčĆąĄąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ąĄą│ąŠ magic-ą╝ąĄč鹊ą┤čŗ, ąŠą┐ąĖčüą░ąĮąĮčŗąĄ ą▓čŗčłąĄ.
ąĪąĄą╝ą░ąĮčéąĖą║ą░ .__str__() ąĖ .__repr__() ąĮąĄ ą┐ąŠą╝ąĄąĮčÅą╗ą░čüčī čüąŠ ą▓čĆąĄą╝ąĄąĮ Python 2, ąĮąŠ ą▓čŗ ą┤ąŠą╗ąČąĮčŗ ą┐ąŠą╝ąĮąĖčéčī, čćč鹊 čüčéčĆąŠą║ąĖ ą▒čŗą╗ąĖ č鹊ą│ą┤ą░ ąĮąĄ ą▒ąŠą╗ąĄąĄ č湥ą╝ ą┐čĆąŠčüą╗ą░ą▓ą╗ąĄąĮąĮčŗą╝ąĖ ą╝ą░čüčüąĖą▓ą░ą╝ąĖ ą▒ą░ą╣čé. ą¦č鹊ą▒čŗ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░čéčī ą▓ą░čłąĖ ąŠą▒čŖąĄą║čéčŗ ą▓ ą┐čĆą░ą▓ąĖą╗čīąĮčŗą╣ Unicode, ą║ąŠč鹊čĆčŗą╣ ą▒čŗą╗ ąŠčéą┤ąĄą╗čīąĮčŗą╝ čéąĖą┐ąŠą╝ ą┤ą░ąĮąĮčŗčģ, ą▓čŗ ą┤ąŠą╗ąČąĮčŗ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī č鹊ą╗čīą║ąŠ ą┤čĆčāą│ąŠą╣ magic-ą╝ąĄč鹊ą┤: .__unicode__() .
ąÆąŠčé ą┐čĆąĖą╝ąĄčĆ č鹊ą│ąŠ ąČąĄ čüą░ą╝ąŠą│ąŠ ą║ą╗ą░čüčüą░ ąĮą░ Python 2:
class User (object ):
def __init__ (self, login, password ):
self.login = login
self.password = passworddef __unicode__ (self ):
return self.logindef __str__ (self ):
return unicode(self).encode('utf-8' )def __repr__ (self ):
user = u"User('%s', '%s')" % (self.login, self.password)
return user.encode('unicode_escape' )ąÜą░ą║ ą▓čŗ ą╝ąŠąČąĄč鹥 ą▓ąĖą┤ąĄčéčī, čŹčéą░ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ ą┤ąĄą╗ąĄą│ąĖčĆčāąĄčé ąĮąĄą║čāčÄ čĆą░ą▒ąŠčéčā, čćč鹊ą▒čŗ ąĖąĘą▒ąĄąČą░čéčī ą┤čāą▒ą╗ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐čāč鹥ą╝ ą▓čŗąĘąŠą▓ą░ ą▓čüčéčĆąŠąĄąĮąĮąŠą╣ čäčāąĮą║čåąĖąĖ unicode() ąĮą░ čüą░ą╝ąŠą╣ čüąĄą▒ąĄ.
ą×ą▒ą░ ą╝ąĄč鹊ą┤ą░ .__str__() ąĖ .__repr__() ą┤ąŠą╗ąČąĮčŗ ą▓ąŠąĘą▓čĆą░čéąĖčéčī čüčéčĆąŠą║ąĖ, čćč鹊ą▒čŗ ą║ąŠą┤ąĖčĆąŠą▓ą░čéčī čüąĖą╝ą▓ąŠą╗čŗ Unicode ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ ą▒ą░ą╣č鹊ą▓čŗąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖčÅ, ąĮą░ąĘčŗą▓ą░ąĄą╝čŗąĄ ąĮą░ą▒ąŠčĆą░ą╝ąĖ čüąĖą╝ą▓ąŠą╗ąŠą▓. UTF-8 čÅą▓ą╗čÅąĄčéčüčÅ ąĮą░ąĖą▒ąŠą╗ąĄąĄ čĆą░čüą┐čĆąŠčüčéčĆą░ąĮąĄąĮąĮąŠą╣ ąĖ ą▒ąĄąĘąŠą┐ą░čüąĮąŠą╣ ą║ąŠą┤ąĖčĆąŠą▓ą║ąŠą╣, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ unicode_escape čÅą▓ą╗čÅąĄčéčüčÅ čüą┐ąĄčåąĖą░ą╗čīąĮąŠą╣ ą║ąŠąĮčüčéą░ąĮč鹊ą╣ ą┤ą╗čÅ ą▓čŗčĆą░ąČąĄąĮąĖčÅ čüčéčĆą░ąĮąĮčŗčģ čüąĖą╝ą▓ąŠą╗ąŠą▓, čéą░ą║ąĖčģ ą║ą░ą║ ├®, ą║ą░ą║ escape-ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ ąĮą░ čćąĖčüč鹊ą╝ ą║ąŠą┤ąĄ ASCII, ą║ą░ą║ ąĮą░ą┐čĆąĖą╝ąĄčĆ \xe9.
ą×ą┐ąĄčĆą░č鹊čĆ print ąĖčēąĄčé magic-ą╝ąĄč鹊ą┤ .__str__() ą▓ ą║ą╗ą░čüčüąĄ, ą┐ąŠčŹč鹊ą╝čā ą▓čŗą▒čĆą░ąĮąĮą░čÅ ą║ąŠą┤ąĖčĆąŠą▓ą║ą░ ą┤ąŠą╗ąČąĮą░ čüąŠąŠčéą▓ąĄčéčüčéą▓ąŠą▓ą░čéčī ą║ąŠą┤ąĖčĆąŠą▓ą║ąĄ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą╣ č鹥čĆą╝ąĖąĮą░ą╗ąŠą╝. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą║ąŠą┤ąĖčĆąŠą▓ą║ą░ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą╗čÅ DOS ąĖ Windows čŹč鹊 CP 852, ą░ ąĮąĄ UTF-8, ą┐ąŠčŹč鹊ą╝čā ąĘą░ą┐čāčüą║ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ UnicodeEncodeError ąĖą╗ąĖ ą┤ą░ąČąĄ ąĖčüą║ą░ąČąĄąĮąĮąŠą╝čā ą▓čŗą▓ąŠą┤čā:
>>> user = User(u'\u043d\u0438\u043a\u0438\u0442\u0430' , u's3cret' )>>> print user
─æ┼╗─æ┼×─æŌĢæ─æ┼×─É├®─æŌ¢æą×ą┤ąĮą░ą║ąŠ ąĄčüą╗ąĖ ą▓čŗ ąĘą░ą┐čāčüčéąĖč鹥 č鹊čé ąČąĄ čüą░ą╝čŗą╣ ą║ąŠą┤ ąĮą░ čüąĖčüč鹥ą╝ąĄ čü ą║ąŠą┤ąĖčĆąŠą▓ą║ąŠą╣ UTF-8, č鹊 ą▓čŗ ą┐ąŠą╗čāčćąĖč鹥 ą┐čĆą░ą▓ąĖą╗čīąĮąŠąĄ ąĮą░ą┐ąĖčüą░ąĮąĖąĄ čĆčāčüčüą║ąŠą│ąŠ ąĖą╝ąĄąĮąĖ:
>>> user = User(u'\u043d\u0438\u043a\u0438\u0442\u0430' , u's3cret' )>>> print user
ąĮąĖą║ąĖčéą░ąĀąĄą║ąŠą╝ąĄąĮą┤čāąĄčéčüčÅ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓čŗą▓ą░čéčī čüčéčĆąŠą║ąĖ ą▓ Unicode ą║ą░ą║ ą╝ąŠąČąĮąŠ čĆą░ąĮčīčłąĄ, ąĮą░ą┐čĆąĖą╝ąĄčĆ ą┐čĆąĖ čćč鹥ąĮąĖąĖ ą┤ą░ąĮąĮčŗčģ ąĖąĘ čäą░ą╣ą╗ą░, ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĄą│ąŠ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ ą▓ąĄąĘą┤ąĄ ą▓ ą▓ą░čłąĄą╝ ą║ąŠą┤ąĄ. ą¤čĆąĖ čŹč鹊ą╝ ą║ąŠą┤ąĖčĆąŠą▓ą░čéčī Unicode ąŠą▒čĆą░čéąĮąŠ ą▓ ą▓čŗą▒čĆą░ąĮąĮčŗą╣ ąĮą░ą▒ąŠčĆ čüąĖą╝ą▓ąŠą╗ąŠą▓ čüą╗ąĄą┤čāąĄčé ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ ą┐ąĄčĆąĄą┤ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄą╝ ąĄą│ąŠ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÄ.
ąÜą░ąČąĄčéčüčÅ, čćč鹊 čā ą▓ą░čü ą▒ąŠą╗čīčłąĄ ą║ąŠąĮčéčĆąŠą╗čÅ ąĮą░ą┤ čüčéčĆąŠą║ąŠą▓čŗą╝ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄą╝ ąŠą▒čŖąĄą║č鹊ą▓ ą▓ Python 2, ą┐ąŠč鹊ą╝čā čćč鹊 ą▒ąŠą╗čīčłąĄ ąĮąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ magic-ą╝ąĄč鹊ą┤ą░ .__unicode__() ą▓ Python 3. ąÆčŗ ą╝ąŠąČąĄč鹥 čüą┐čĆąŠčüąĖčéčī čüąĄą▒čÅ, ą▓ąŠąĘą╝ąŠąČąĮąŠ ą╗ąĖ ąĮą░ Python 3 ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░čéčī ąŠą▒čŖąĄą║čé ą▓ ąĄą│ąŠ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą▒ą░ą╣čé, ą░ ąĮąĄ ą▓ čüčéčĆąŠą║čā Unicode. ąŁč鹊 ą▓ąŠąĘą╝ąŠąČąĮąŠ čü ą┐ąŠą╝ąŠčēčīčÄ čüą┐ąĄčåąĖą░ą╗čīąĮąŠą│ąŠ ą╝ąĄč鹊ą┤ą░ .__bytes__() , ą║ąŠč鹊čĆčŗą╣ ą┤ąĄą╗ą░ąĄčé ąĖą╝ąĄąĮąĮąŠ čŹč鹊:
>>> class User (object ):... def __init__ (self, login, password ):... self.login = login... self.password = password... ... def __bytes__ (self ): # Python 3 ... return self.login.encode('utf-8' )
...>>> user = User(u'\u043d\u0438\u043a\u0438\u0442\u0430' , u's3cret' )>>> bytes (user)b'\xd0\xbd\xd0\xb8\xd0\xba\xd0\xb8\xd1\x82\xd0\xb0' ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą▓čüčéčĆąŠąĄąĮąĮąŠą╣ čäčāąĮą║čåąĖąĖ bytes() ąĮą░ 菹║ąĘąĄą╝ą┐ą╗čÅčĆąĄ ą┤ąĄą╗ąĄą│ąĖčĆčāąĄčé ą▓čŗąĘąŠą▓ ąĮą░ ąĮąĄą╝ ą╝ąĄč鹊ą┤ą░ __bytes__(), ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą╝ ą║ą╗ą░čüčüąĄ.
[ą¤ąŠąĮąĖą╝ą░ąĮąĖąĄ čĆą░ą▒ąŠčéčŗ Python-čäčāąĮą║čåąĖąĖ print() ]
ąĪąĄą╣čćą░čü ą▓čŗ ą┤ąŠą▓ąŠą╗čīąĮąŠ čģąŠčĆąŠčłąŠ ąĘąĮą░ąĄč鹥, ą║ą░ą║ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čäčāąĮą║čåąĖčÄ print(), ąĮąŠ ąŠą▒ą╗ą░ą┤ą░čÅ ąĘąĮą░ąĮąĖąĄą╝, čćč鹊 ąŠąĮą░ čéą░ą║ąŠąĄ, ą▓čŗ čüą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĄčæ ąĄčēąĄ ą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠ ąĖ ąŠčüąŠąĘąĮą░ąĮąĮąŠ. ą¤ąŠčüą╗ąĄ ą┐čĆąŠčćč鹥ąĮąĖčÅ čŹč鹊ą╣ čüąĄą║čåąĖąĖ ą▓čŗ ą┐ąŠą╣ą╝ąĄč鹥, ą║ą░ą║ čü ą│ąŠą┤ą░ą╝ąĖ čāą╗čāčćčłą░ą╗ą░čüčī ą┐ąĄčćą░čéčī ą▓ Python.
ą×ą┐ąĄčĆą░č鹊čĆ print ą▓ Python 3 čüčéą░ą╗ čäčāąĮą║čåąĖąĄą╣. ąÆčŗ ą▓ąĖą┤ąĄą╗ąĖ, čćč鹊 print() čŹč鹊 čäčāąĮą║čåąĖčÅ Python 3. ąĢčüą╗ąĖ ą▒čŗčéčī č鹊čćąĮąĄąĄ, čŹč鹊 ą▓čüčéčĆąŠąĄąĮąĮą░čÅ čäčāąĮą║čåąĖčÅ, čé. ąĄ. ąĄčæ ąĮąĄ ąĮčāąČąĮąŠ ąĮąĖąŠčéą║čāą┤ą░ ąĖą╝ą┐ąŠčĆčéąĖčĆąŠą▓ą░čéčī:
>>> print
< built-in function print >ą×ąĮą░ ą▓čüąĄą│ą┤ą░ ą┤ąŠčüčéčāą┐ąĮą░ ą▓ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠą╝ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąĄ ąĖą╝ąĄąĮ, čéą░ą║ čćč鹊 ąĄčæ ą╝ąŠąČąĮąŠ ą▓čŗąĘčŗą▓ą░čéčī ąĮą░ą┐čĆčÅą╝čāčÄ, ąĮąŠ ą▓čŗ ą╝ąŠąČąĄč鹥 čéą░ą║ąČąĄ ąŠą▒čĆą░čēą░čéčīčüčÅ ą║ ąĮąĄą╣ č湥čĆąĄąĘ ą╝ąŠą┤čāą╗čī čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ:
>>> import builtins>>> builtins.print
< built-in function print >ąóą░ą║ąĖą╝ čüą┐ąŠčüąŠą▒ąŠą╝ ą╝ąŠąČąĮąŠ ąĖąĘą▒ąĄąČą░čéčī ą║ąŠąĮčäą╗ąĖą║čéą░ ąĖą╝ąĄąĮ čü ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖą╝ąĖ čäčāąĮą║čåąĖčÅą╝ąĖ. ąöąŠą┐čāčüčéąĖą╝, čćč鹊 ą▓čŗ čģąŠč鹥ą╗ąĖ ą▒čŗ ą┐ąĄčĆąĄąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī print(), čćč鹊ą▒čŗ ąŠąĮ ąĮąĄ ą┤ąŠą▒ą░ą▓ą╗čÅą╗ ą▓ ą║ąŠąĮčåąĄ newline. ą×ą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą▓čŗ čģąŠčéąĖč鹥 ą┐ąĄčĆąĄąĖą╝ąĄąĮąŠą▓ą░čéčī ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮčāčÄ čäčāąĮą║čåąĖčÄ ą▓ čćč鹊-č鹊 ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ println():
>>> import builtins>>> println = builtins.print >>> def print (*args, **kwargs ):... builtins.print (*args, **kwargs, end='' )
...>>> println('hello' )
hello>>> print ('hello\n' )
helloąóąĄą┐ąĄčĆčī čā ą▓ą░čü ą┤ą▓ąĄ ąŠčéą┤ąĄą╗čīąĮčŗąĄ čäčāąĮą║čåąĖąĖ ą┐ąĄčćą░čéąĖ, č鹊čćąĮąŠ ą║ą░ą║ ąĮą░ čÅąĘčŗą║ąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ Java. ą¤ąŠąĘąČąĄ ą▓čŗ čéą░ą║ąČąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĖč鹥 čüą▓ąŠąĖ čäčāąĮą║čåąĖąĖ print() ą▓ čüąĄą║čåąĖąĖ 菹║čüą┐ąĄčĆąĖą╝ąĄąĮč鹊ą▓. ąóą░ą║ąČąĄ ąŠą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĮąĄ čüą╝ąŠąČąĄč鹥 ą┐ąĄčĆąĄąĘą░ą┐ąĖčüą░čéčī print() ą▓ ą┐ąĄčĆą▓ąŠą╝ ą╝ąĄčüč鹥, ąĄčüą╗ąĖ čŹč鹊 ąĮąĄ čäčāąĮą║čåąĖčÅ.
ąĪ ą┤čĆčāą│ąŠą╣ čüč鹊čĆąŠąĮčŗ, print() ąĮąĄ čÅą▓ą╗čÅąĄčéčüčÅ čäčāąĮą║čåąĖąĄą╣ ą▓ ą╝ą░č鹥ą╝ą░čéąĖč湥čüą║ąŠą╝ čüą╝čŗčüą╗ąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąĮą░ ąĮąĄ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ąĮąĖč湥ą│ąŠ ąĘąĮą░čćąĖą╝ąŠą│ąŠ, ą║čĆąŠą╝ąĄ ąĮąĄčÅą▓ąĮąŠą│ąŠ None:
>>> value = print ('hello world' )
hello world>>> print (value)None ąóą░ą║ąĖąĄ čäčāąĮą║čåąĖąĖ čäą░ą║čéąĖč湥čüą║ąĖ čÅą▓ą╗čÅčÄčéčüčÅ ą┐čĆąŠčåąĄą┤čāčĆą░ą╝ąĖ ąĖą╗ąĖ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ą░ą╝ąĖ, ą║ąŠč鹊čĆčŗąĄ ą▓čŗ ą▓čŗąĘčŗą▓ą░ąĄč鹥 ą┤ą╗čÅ ą┤ąŠčüčéąĖąČąĄąĮąĖčÅ ą║ą░ą║ąŠą│ąŠ-č鹊 ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą│ąŠ čŹčäč乥ą║čéą░, ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą╝ąĄąĮčÅčÄčēąĄą│ąŠ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ. ąÆ čüą╗čāčćą░ąĄ čäčāąĮą║čåąĖąĖ print(), čŹč鹊čé čŹčäč乥ą║čé ąĘą░ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ ąŠč鹊ą▒čĆą░ąČąĄąĮąĖąĖ čüąŠąŠą▒čēąĄąĮąĖčÅ ąĮą░ čüčéą░ąĮą┤ą░čĆčéąĮąŠą╝ ą▓čŗą▓ąŠą┤ąĄ ąĖą╗ąĖ ąĮą░ ąĘą░ą┐ąĖčüąĖ ą▓ čäą░ą╣ą╗.
ą¤ąŠčüą║ąŠą╗čīą║čā print() čŹč鹊 čäčāąĮą║čåąĖčÅ, č鹊 čā ąĮąĄčæ čģąŠčĆąŠčłąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮą░čÅ čüąĖą│ąĮą░čéčāčĆą░ čü ąĖąĘą▓ąĄčüčéąĮčŗą╝ąĖ ą░čéčĆąĖą▒čāčéą░ą╝ąĖ. ąÆčŗ ą╝ąŠąČąĄč鹥 ą▒čŗčüčéčĆąŠ ąĮą░ą╣čéąĖ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖčÄ ą┐ąŠ ąĮąĄą╣ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą▓čŗą▒čĆą░ąĮąĮąŠą│ąŠ ą▓ą░ą╝ąĖ čĆąĄą┤ą░ą║č鹊čĆą░, ą▒ąĄąĘ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ ąĘą░ą┐ąŠą╝ąĖąĮą░čéčī ą║ą░ą║ąŠą╣-ąĮąĖą▒čāą┤čī čüčéčĆą░ąĮąĮčŗą╣ čüąĖąĮčéą░ą║čüąĖčü ą┐čĆąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╣ ąĘą░ą┤ą░čćąĖ.
ą¤ąŠą╝ąĖą╝ąŠ ą▓čüąĄą│ąŠ ą┐čĆąŠč湥ą│ąŠ, čäčāąĮą║čåąĖąĖ ą┐čĆąŠčēąĄ čĆą░čüčłąĖčĆąĖčéčī. ąöąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ ąĮąŠą▓ąŠą╣ čäąĖčćąĖ ą▓ čéą░ą║ ąČąĄ ą┐čĆąŠčüč鹊, ą║ą░ą║ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ ąĄčēąĄ ąŠą┤ąĮąŠą│ąŠ ąĖą╝ąĄąĮąŠą▓ą░ąĮąĮąŠą│ąŠ ą░čĆą│čāą╝ąĄąĮčéą░ (keyword argument), ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ąĖąĘą╝ąĄąĮąĄąĮąĖąĄ čÅąĘčŗą║ą░ ą┤ą╗čÅ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ ąĮąŠą▓ąŠą╣ čäąĖčćąĖ ą│ąŠčĆą░ąĘą┤ąŠ ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮąŠ ąĖ ą│čĆąŠą╝ąŠąĘą┤ą║ąŠ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą┐ąŠą┤čāą╝ą░ą╣č鹥 ąŠ ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĖ ą┐ąŠč鹊ą║ą░ ąĖą╗ąĖ čüą▒čĆąŠčüąĄ (flush) ą▒čāč乥čĆą░.
ąĢčēąĄ ąŠą┤ąĮąĖą╝ ą┐čĆąĄąĖą╝čāčēąĄčüčéą▓ąŠą╝ print() ą║ą░ą║ čäčāąĮą║čåąĖąĖ čÅą▓ą╗čÅąĄčéčüčÅ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą║ąŠą╝ą┐ąŠąĮąŠą▓ą║ąĖ. ążčāąĮą║čåąĖąĖ ą▓ Python čŹč鹊 čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝čŗąĄ ąŠą▒čŖąĄą║čéčŗ ą┐ąĄčĆą▓ąŠą│ąŠ ą║ą╗ą░čüčüą░ (first-class objects) ąĖą╗ąĖ ą│čĆą░ąČą┤ą░ąĮąĄ ą┐ąĄčĆą▓ąŠą│ąŠ čüąŠčĆčéą░ (first-class citizens), čćč鹊 čÅą▓ą╗čÅąĄčéčüčÅ ą┐čĆąĖčćčāą┤ą╗ąĖą▓čŗą╝ čüą┐ąŠčüąŠą▒ąŠą╝ ą┐ąŠą║ą░ąĘą░čéčī, čćč鹊 ąŠąĮąĖ ąĘąĮą░č湥ąĮąĖčÅ, čéą░ą║ąĖąĄ ąČąĄ ą║ą░ą║ čüčéčĆąŠą║ąĖ ąĖą╗ąĖ čćąĖčüą╗ą░. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą▓čŗ ą╝ąŠąČąĄč鹥 ąĮą░ąĘąĮą░čćąĖčéčī čäčāąĮą║čåąĖčÄ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣, ą┐ąĄčĆąĄą┤ą░čéčī ąĄčæ ą┤čĆčāą│ąŠą╣ čäčāąĮą║čåąĖąĖ, ąĖą╗ąĖ ą┤ą░ąČąĄ ą▓ąŠąĘą▓čĆą░čéąĖčéčī ąŠą┤ąĮčā čäčāąĮą║čåąĖčÄ ąĖąĘ ą┤čĆčāą│ąŠą╣. ążčāąĮą║čåąĖčÅ print() ą▓ čŹč鹊ą╝ ąŠčéąĮąŠčłąĄąĮąĖąĖ ąĮąĖč湥ą╝ ąĮąĄ ąŠčéą╗ąĖčćą░ąĄčéčüčÅ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą▓čŗ ą╝ąŠąČąĄč鹥 ą▓ąŠčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ąĄčæ ą┐čĆąĄąĖą╝čāčēąĄčüčéą▓ąŠą╝ ą┤ą╗čÅ ą▓ąĮąĄą┤čĆąĄąĮąĖčÅ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ (dependency injection):
def download (url, log=print ):
log(f'ąŚą░ą│čĆčāąĘą║ą░ {url} ' )
# ... def custom_print (*args ):
pass # ąĮąĖč湥ą│ąŠ ąĮąĄ ą┐ąĄčćą░čéą░ąĄčéčüčÅ
download('/js/app.js' , log=custom_print)ąŚą┤ąĄčüčī ą┐ą░čĆą░ą╝ąĄčéčĆ log ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą▓ą░ą╝ ą▓ąĮąĄą┤čĆąĖčéčī čäčāąĮą║čåąĖčÄ ąŠą▒čĆą░čéąĮąŠą│ąŠ ą▓čŗąĘąŠą▓ą░ (callback function), ą║ąŠč鹊čĆą░čÅ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ print(), ąĮąŠ ą╝ąŠąČąĄčé ą▒čŗčéčī ą╗čÄą▒čŗą╝ ą┤čĆčāą│ąĖą╝ ą▓čŗąĘčŗą▓ą░ąĄą╝čŗą╝ ąŠą▒čŖąĄą║č鹊ą╝. ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą┐ąĄčćą░čéčī ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąĘą░ą┐čĆąĄčēąĄąĮą░ ąĘą░ą╝ąĄąĮąŠą╣ print() ąĮą░ ą┐čāčüčéčāčÄ čäčāąĮą║čåąĖčÄ, ą║ąŠč鹊čĆą░čÅ ąĮąĖč湥ą│ąŠ ąĮąĄ ą┤ąĄą╗ą░ąĄčé.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéčī (dependency) čŹč鹊 ą╗čÄą▒ą░čÅ čćą░čüčéčī ą║ąŠą┤ą░, ą║ąŠč鹊čĆą░čÅ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ą░ ą┤ą╗čÅ ą┤čĆčāą│ąŠą╣ čćą░čüčéąĖ ą║ąŠą┤ą░.
ąśąĮąČąĄą║čéąĖčĆąŠą▓ą░ąĮąĖąĄ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ čŹč鹊 č鹥čģąĮąĖą║ą░, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ą░čÅ ą┤ą╗čÅ č鹊ą│ąŠ, čćč鹊ą▒čŗ ą║ąŠą┤ ą▒čŗą╗ąŠ ą╗ąĄą│č湥 č鹥čüčéąĖčĆąŠą▓ą░čéčī, ą┐čĆąĖą╝ąĄąĮčÅčéčī ą┐ąŠą▓č鹊čĆąĮąŠ, ąĖ čćč鹊ą▒čŗ ąŠąĮ ą▒čŗą╗ ąŠčéą║čĆčŗčé ą┤ą╗čÅ čĆą░čüčłąĖčĆąĄąĮąĖčÅ. ąÆčŗ ą╝ąŠąČąĄč鹥 ą┤ąŠčüčéąĖčćčī čŹč鹊ą│ąŠ, ą║ąŠčüą▓ąĄąĮąĮąŠ čüčüčŗą╗ą░čÅčüčī ąĮą░ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ č湥čĆąĄąĘ ą░ą▒čüčéčĆą░ą║čéąĮčŗąĄ ąĖąĮč鹥čĆč乥ą╣čüčŗ, ąĖ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÅ ąĖčģ ą▓ čĆąĄąČąĖą╝ąĄ ą┐čĆąŠčéą░ą╗ą║ąĖą▓ą░ąĮąĖčÅ (push) ą▓ą╝ąĄčüč鹊 čĆąĄąČąĖą╝ą░ ą▓čŗčéą░ą╗ą║ąĖą▓ą░ąĮąĖčÅ (pull).
ąĪčāčēąĄčüčéą▓čāąĄčé ąŠą┤ąĮąŠ ą▓ąĄčüąĄą╗ąŠąĄ ąŠą▒čŖčÅčüąĮąĄąĮąĖąĄ ą┤ą╗čÅ ąĖąĮąČąĄą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ, ą│čāą╗čÅčÄčēąĄąĄ ą┐ąŠ ąśąĮč鹥čĆąĮąĄčéčā ("Dependency injection ą┤ą╗čÅ ą┐čÅčéąĖą╗ąĄčéąĮąĖčģ ą┤ąĄč鹥ą╣", ąĖčüč鹊čćąĮąĖą║ John Munsch, 28 ąŠą║čéčÅą▒čĆčÅ 2009):
"ąÜąŠą│ą┤ą░ ą▓čŗ čćč鹊-č鹊 ą▒ąĄčĆąĄč鹥 ą┤ą╗čÅ čüąĄą▒čÅ ąĖąĘ čģąŠą╗ąŠą┤ąĖą╗čīąĮąĖą║ą░, č鹊 čŹč鹊 ą╝ąŠąČąĄčé čüąŠąĘą┤ą░ą▓ą░čéčī ą┐čĆąŠą▒ą╗ąĄą╝čŗ. ąÆčŗ ą╝ąŠąČąĄč鹥 ąŠčüčéą░ą▓ąĖčéčī ą┤ą▓ąĄčĆčåčā čģąŠą╗ąŠą┤ąĖą╗čīąĮąĖą║ą░ ąŠčéą║čĆčŗč鹊ą╣, ą▓čŗ ą╝ąŠąČąĄč鹥 ą▓ąĘčÅčéčī ąŠčéčéčāą┤ą░ čćč鹊-č鹊, čćč鹊 ą╝ą░ą╝ą░ ąĖą╗ąĖ ą┐ą░ą┐ą░ ąĘą░ą┐čĆąĄčēą░čÄčé. ąÆąŠąĘą╝ąŠąČąĮąŠ, čćč鹊 ą┤ą░ąČąĄ ą▓čŗ čéą░ą╝ ąĖčēąĄč鹥 čćč鹊-č鹊, č湥ą│ąŠ čéą░ą╝ ąĮąĄčé, ąĖą╗ąĖ čüčĆąŠą║ ą│ąŠą┤ąĮąŠčüčéąĖ ą║ąŠč鹊čĆąŠą│ąŠ ąĖčüč鹥ą║.
ąÆčüąĄ, čćč鹊 ą▓čŗ ą┤ąŠą╗ąČąĮčŗ ą┤ąĄą╗ą░čéčī - ą┐čĆąŠčüč鹊 ą▓čŗčĆą░ąĘąĖčéčī ą║ą░ą║čāčÄ-č鹊 čüą▓ąŠčÄ ą┐ąŠčéčĆąĄą▒ąĮąŠčüčéčī, čéąĖą┐ą░ "ą╝ąĮąĄ ąĮą░ą┤ąŠ č湥ą│ąŠ-ąĮąĖą▒čāą┤čī ą▓čŗą┐ąĖčéčī ą▓ąŠ ą▓čĆąĄą╝čÅ ąŠą▒ąĄą┤ą░", ą░ ąĘą░č鹥ą╝ čāąČąĄ ą╝čŗ ą┐ąŠąĘą░ą▒ąŠčéąĖą╝čüčÅ ąŠ č鹊ą╝, čćč鹊ą▒čŗ čā ą▓ą░čü čćč鹊-č鹊 ą▒čŗą╗ąŠ, ą║ąŠą│ą┤ą░ ą▓čŗ čüčÅą┤ąĄč鹥 ąĄčüčéčī. "
ąÜąŠą╝ą┐ąŠąĘąĖčåąĖčÅ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą▓ą░ą╝ ą║ą░ą║ąĖą╝-č鹊 čüą┐ąŠčüąŠą▒ąŠą╝ ą║ąŠą╝ą▒ąĖąĮąĖčĆąŠą▓ą░čéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ čäčāąĮą║čåąĖą╣ ą▓ ąĮąŠą▓čāčÄ čéą░ą║ąŠą│ąŠ ąČąĄ čĆąŠą┤ą░. ąĀą░čüčüą╝ąŠčéčĆąĖą╝ čŹč鹊 ą▓ ą┤ąĄą╣čüčéą▓ąĖąĖ, čāą║ą░ąĘą░ą▓ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║čāčÄ čäčāąĮą║čåąĖčÄ error(), ą║ąŠč鹊čĆą░čÅ ą┐ąĄčćą░čéą░ąĄčé ą▓ čüčéą░ąĮą┤ą░čĆčéąĮčŗą╣ ą┐ąŠč鹊ą║ ąŠčłąĖą▒ąŠą║ ąĖ čüąĮą░ą▒ąČą░ąĄčé ą▓čüąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ ą┐čĆąĄčäąĖą║čüąŠą╝ ąĘą░ą┤ą░ąĮąĮąŠą│ąŠ čāčĆąŠą▓ąĮčÅ ą╗ąŠą│ą░:
>>> from functools import partial>>> import sys>>> redirect = lambda function, stream: partial(function, file=stream)>>> prefix = lambda function, prefix: partial(function, prefix)>>> error = prefix(redirect(print , sys.stderr), '[ERROR]' )>>> error('ą¦č鹊-č鹊 ą┐ąŠčłą╗ąŠ ąĮąĄ čéą░ą║' )
[ERROR] ą¦č鹊-č鹊 ą┐ąŠčłą╗ąŠ ąĮąĄ čéą░ą║ąŁčéą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ą░čÅ čäčāąĮą║čåąĖčÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčé čäčāąĮą║čåąĖąĖ partial ą┤ą╗čÅ ą┤ąŠčüčéąĖąČąĄąĮąĖčÅ ąČąĄą╗ą░ąĄą╝ąŠą│ąŠ čŹčäč乥ą║čéą░. ąŁčéą░ ą┐čĆąŠą┤ą▓ąĖąĮčāčéą░čÅ ą║ąŠąĮčåąĄą┐čåąĖčÅ ą▒čŗą╗ą░ ą┐ąŠąĘą░ąĖą╝čüčéą▓ąŠą▓ą░ąĮą░ ąĖąĘ ą┐ą░čĆą░ą┤ąĖą│ą╝čŗ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠą│ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ, čéą░ą║ čćč鹊 ą┐ąŠą║ą░ ą▓ą░ą╝ ąĮąĄ ąĮčāąČąĮąŠ čāą│ą╗čāą▒ą╗čÅčéčīčüčÅ ą▓ čŹčéčā č鹥ą╝čā. ą×ą┤ąĮą░ą║ąŠ, ąĄčüą╗ąĖ ą▓ą░ą╝ čŹč鹊 ąĖąĮč鹥čĆąĄčüąĮąŠ, č鹊 čĆąĄą║ąŠą╝ąĄąĮą┤čāčÄ ąŠąĘąĮą░ą║ąŠą╝ąĖčéčīčüčÅ čü ą╝ąŠą┤čāą╗ąĄą╝ functools [5].
ąÆ ąŠčéą╗ąĖčćąĖąĄ ąŠčé ąŠą┐ąĄčĆą░č鹊čĆąŠą▓, čäčāąĮą║čåąĖąĖ čŹč鹊 ąĘąĮą░č湥ąĮąĖčÅ. ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą▓čŗ ą╝ąŠąČąĄč鹥 čüą╝ąĄčłąĖą▓ą░čéčī ąĖčģ čü ą▓čŗčĆą░ąČąĄąĮąĖčÅą╝ąĖ, ą▓ čćą░čüčéąĮąŠčüčéąĖ, čü ą╗čÅą╝ą▒ą┤ą░-ą▓čŗčĆą░ąČąĄąĮąĖčÅą╝ąĖ. ąÆą╝ąĄčüč鹊 ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą┐ąŠą╗ąĮąŠą╝ą░čüčłčéą░ą▒ąĮąŠą╣ čäčāąĮą║čåąĖąĖ ą┤ą╗čÅ ąĘą░ą╝ąĄąĮčŗ print(), ą▓čŗ ą╝ąŠąČąĄč鹥 čüąŠąĘą┤ą░čéčī ą░ąĮąŠąĮąĖą╝ąĮąŠąĄ ą╗čÅą╝ą▒ą┤ą░-ą▓čŗčĆą░ąČąĄąĮąĖąĄ, ą▓čŗąĘčŗą▓ą░čÄčēąĄąĄ ąĄčæ:
>>> download('/js/app.js' , lambda msg: print ('[INFO]' , msg))
[INFO] ąŚą░ą│čĆčāąĘą║ą░ /js/app.jsą×ą┤ąĮą░ą║ąŠ, ą┐ąŠčüą║ąŠą╗čīą║čā ą╗čÅą╝ą▒ą┤ą░-ą▓čŗčĆą░ąČąĄąĮąĖąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąŠ ąĮą░ ą╝ąĄčüč鹥, ąĮąĄčé ąĮąĖą║ą░ą║ąŠą│ąŠ čüą┐ąŠčüąŠą▒ą░ čüčüčŗą╗ą░čéčīčüčÅ ąĮą░ ąĮąĄą│ąŠ ą▓ ą┤čĆčāą│ąŠą╝ ą╝ąĄčüč鹥 ą║ąŠą┤ą░.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ą▓ Python ą▓čŗ ąĮąĄ ą╝ąŠąČąĄč鹥 ą┐ąŠą╝ąĄčüčéąĖčéčī ąŠą┐ąĄčĆą░č鹊čĆčŗ, čéą░ą║ąĖąĄ ą║ą░ą║ ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĮąĖčÅ, ąŠą┐ąĄčĆą░č鹊čĆčŗ ą┐čĆąŠą▓ąĄčĆą║ąĖ čāčüą╗ąŠą▓ąĖčÅ, čåąĖą║ą╗čŗ, ąĖ čé. ą┤., ą▓ ą░ąĮąŠąĮąĖą╝ąĮčāčÄ ą╗čÅą╝ą▒ą┤ą░-čäčāąĮą║čåąĖčÄ. ąŁč鹊 ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ąĄą┤ąĖąĮąŠąĄ ą▓čŗčĆą░ąČąĄąĮąĖąĄ!
ąöčĆčāą│ąŠą╣ ą▓ąĖą┤ ą▓čŗčĆą░ąČąĄąĮąĖčÅ - čéčĆąŠąĖčćąĮąŠąĄ (ternary) čāčüą╗ąŠą▓ąĮąŠąĄ ą▓čŗčĆą░ąČąĄąĮąĖąĄ:
>>> user = 'jdoe' >>> print ('Hi!' ) if user is None else print (f'Hi, {user} .' )
Hi, jdoe.ąÆ Python ąĄčüčéčī ą║ą░ą║ ąŠą┐ąĄčĆą░č鹊čĆčŗ ą▓ąĄčéą▓ą╗ąĄąĮąĖčÅ ą┐ąŠ čāčüą╗ąŠą▓ąĖčÄ (conditional statements), čéą░ą║ ąĖ čāčüą╗ąŠą▓ąĮčŗąĄ ą▓čŗčĆą░ąČąĄąĮąĖčÅ (conditional expressions). ą¤ąŠčüą╗ąĄą┤ąĮąĖąĄ ą▓čŗčćąĖčüą╗čÅčÄčéčüčÅ ą▓ ąŠą┤ąĮąŠ ąĘąĮą░č湥ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĖčüą▓ąŠąĄąĮąŠ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ąĖą╗ąĖ ą┐ąĄčĆąĄą┤ą░ąĮąŠ ą▓ čäčāąĮą║čåąĖčÄ. ąÆ ą┐čĆąĖą▓ąĄą┤ąĄąĮąĮąŠą╝ ą▓čŗčłąĄ ą┐čĆąĖą╝ąĄčĆąĄ ą▓ą░čü ąĖąĮč鹥čĆąĄčüčāąĄčé ą┐ąŠą▒ąŠčćąĮčŗą╣ čŹčäč乥ą║čé, ą░ ąĮąĄ ąĘąĮą░č湥ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ čĆą░ą▓ąĮąŠ None, ą┐ąŠčŹč鹊ą╝čā ą▓čŗ ą┐čĆąŠčüč鹊 ąĖą│ąĮąŠčĆąĖčĆčāąĄč鹥 ąĄą│ąŠ.
ąÜą░ą║ ą▓čŗ ą╝ąŠąČąĄč鹥 ą▓ąĖą┤ąĄčéčī, čäčāąĮą║čåąĖąĖ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé čüąŠąĘą┤ą░čéčī 菹╗ąĄą│ą░ąĮčéąĮąŠąĄ ąĖ čĆą░čüčłąĖčĆčÅąĄą╝ąŠąĄ čĆąĄčłąĄąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ čüąŠą│ą╗ą░čüčāąĄčéčüčÅ čü ąŠčüčéą░ą╗čīąĮčŗą╝ čÅąĘčŗą║ąŠą╝. ąÆ čüą╗ąĄą┤čāčÄčēąĄą╣ ą┐ąŠą┤čüąĄą║čåąĖąĖ ą▓čŗ čāąĘąĮą░ąĄč鹥, ą║ą░ą║ ąŠčéčüčāčéčüčéą▓ąĖąĄ ą┐ąĄčćą░čéąĖ ą║ą░ą║ čäčāąĮą║čåąĖąĖ print() ą▓čŗąĘčŗą▓ą░ą╗ąŠ ą╝ąĮąŠą│ąŠ ą│ąŠą╗ąŠą▓ąĮąŠą╣ ą▒ąŠą╗ąĖ.
ąÆ Python 2 print ą▒čŗą╗ ąŠą┐ąĄčĆą░č鹊čĆąŠą╝. ą×ą┐ąĄčĆą░č鹊čĆ čŹč鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ, ą║ąŠč鹊čĆą░čÅ ą╝ąŠąČąĄčé ą▓čŗąĘčŗą▓ą░čéčī ą┐ąŠą▒ąŠčćąĮčŗą╣ čŹčäč乥ą║čé ą┐čĆąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ, ąĮąŠ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą▓čŗčćąĖčüą╗čÅąĄčéčüčÅ ą║ą░ą║ ąĘąĮą░č湥ąĮąĖąĄ. ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ą▓čŗ ąĮąĄ čüą╝ąŠąČąĄč鹥 ąĮą░ą┐ąĄčćą░čéą░čéčī ąŠą┐ąĄčĆą░č鹊čĆ, ąĖą╗ąĖ ąĮą░ąĘąĮą░čćąĖčéčī ąĄą│ąŠ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣, ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ čüą╗ąĄą┤čāčÄčēąĄą│ąŠ:
result = print 'hello world'
ąØą░ Python 2 čŹč鹊 ą▓čŗąĘąŠą▓ąĄčé ąŠčłąĖą▒ą║čā čüąĖąĮčéą░ą║čüąĖčüą░.
ąÆąŠčé ąĄčēąĄ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐čĆąĖą╝ąĄčĆąŠą▓ ąŠą┐ąĄčĆą░č鹊čĆąŠą▓ Python:
ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĮąĖąĄ: = if while assert
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: Python 3.8 ą┐čĆąĖą▓ąĮąĄčü čüą┐ąŠčĆąĮčŗą╣ ąŠą┐ąĄčĆą░č鹊čĆ ą╝ąŠčƹȹ░ (:=), ą║ąŠč鹊čĆčŗą╣ čÅą▓ą╗čÅąĄčéčüčÅ ą▓čŗčĆą░ąČąĄąĮąĖąĄą╝ ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĮąĖčÅ. ąĪ ąĄą│ąŠ ą┐ąŠą╝ąŠčēčīčÄ ą▓čŗ ą╝ąŠąČąĄč鹥 ą▓čŗčćąĖčüą╗ąĖčéčī ą▓čŗčĆą░ąČąĄąĮąĖąĄ ąĖ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą┐čĆąĖčüą▓ąŠąĖčéčī ąĄą│ąŠ čĆąĄąĘčāą╗čīčéą░čé ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣, ą┤ą░ąČąĄ ą▓ąĮčāčéčĆąĖ ą┤čĆčāą│ąŠą│ąŠ ą▓čŗčĆą░ąČąĄąĮąĖčÅ!
ąöą░ą▓ą░ą╣č鹥 čĆą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗ąĄą┤čāčÄčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ, ą║ąŠč鹊čĆčŗą╣ ą▓čŗąĘčŗą▓ą░ąĄčé ą┤ąŠčĆąŠą│čāčÄ čäčāąĮą║čåąĖčÄ ąŠą┤ąĖąĮ čĆą░ąĘ, ą░ ąĘą░č鹥ą╝ ą┐ąŠą▓č鹊čĆąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąĄčæ čĆąĄąĘčāą╗čīčéą░čé ą┤ą╗čÅ ą┤ą░ą╗čīąĮąĄą╣čłąĖčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣:
# Python 3.8+
values = [y := f(x), y**2 , y**3 ]ąŁč鹊 ą┐ąŠą╗ąĄąĘąĮąŠ ą┤ą╗čÅ čāą┐čĆąŠčēąĄąĮąĖčÅ ą║ąŠą┤ą░ ą▒ąĄąĘ ą┐ąŠč鹥čĆąĖ ąĄą│ąŠ čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéąĖ. ą×ą▒čŗčćąĮąŠ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮčŗą╣ ą║ąŠą┤ ą▒čŗą╗ ą▒čŗ ą▒ąŠą╗ąĄąĄ ą┐ąŠą┤čĆąŠą▒ąĮčŗą╝:
y = f(x)
values = [y, y**2 , y**3 ]
ąŁč鹊čé ą║ąŠąĮčéčĆąŠą▓ąĄčĆčüąĖąŠąĮąĮčŗą╣ ąŠą┐ąĄčĆą░č鹊čĆ ą▓čŗąĘą▓ą░ą╗ ą╝ąĮąŠą│ąŠ ą┤ąĖčüą║čāčüčüąĖą╣. ą×ą▒ąĖą╗ąĖąĄ ąĮąĄą│ą░čéąĖą▓ąĮčŗčģ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖąĄą▓ ąĖ ąČą░čĆą║ąĖąĄ ą┤ąĄą▒ą░čéčŗ ą▓ ą║ąŠąĮąĄčćąĮąŠą╝ ąĖč鹊ą│ąĄ ą┐čĆąĖą▓ąĄą╗ąĖ ą║ č鹊ą╝čā, čćč鹊 Guido van Rossum čāčłąĄą╗ čü ą┐ąŠąĘąĖčåąĖąĖ Benevolent Dictator For Life (BDFL).
ą×ą┐ąĄčĆą░č鹊čĆčŗ ąŠą▒čŗčćąĮąŠ čüąŠčüč鹊čÅčé ąĖąĘ ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮąĮčŗčģ ą║ą╗čÄč湥ą▓čŗčģ čüą╗ąŠą▓, čéą░ą║ąĖčģ ą║ą░ą║ if, for ąĖą╗ąĖ print, ą║ąŠč鹊čĆčŗąĄ ąĖą╝ąĄčÄčé čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮčŗą╣ čüą╝čŗčüą╗ ąĮą░ čÅąĘčŗą║ąĄ. ąÆčŗ ąĮąĄ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĖčģ ą┤ą╗čÅ ąĖą╝ąĄąĮąĖ ą▓ą░čłąĖčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ ąĖą╗ąĖ ą┤čĆčāą│ąĖčģ čüąĖą╝ą▓ąŠą╗ąŠą▓. ąÆąŠčé ą┐ąŠč湥ą╝čā ą┐ąĄčĆąĄąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ, ąĖą╗ąĖ "ąĖąĘą┤ąĄą▓ą░č鹥ą╗čīčüčéą▓ąŠ" ąĮą░ą┤ ąŠą┐ąĄčĆą░č鹊čĆąŠą╝ print ąĮąĄą▓ąŠąĘą╝ąŠąČąĮąŠ ą▓ Python 2. ąÆčŗ ąĘą░čüčéčĆčÅą╗ąĖ ą▓ č鹊ą╝, čćč鹊 ą┐ąŠą╗čāčćąĖą╗ąĖ.
ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ą▓čŗ ąĮąĄ ą╝ąŠąČąĄč鹥 ą┐ąĄčćą░čéą░čéčī ąĖąĘ ą░ąĮąŠąĮąĖą╝ąĮčŗčģ čäčāąĮą║čåąĖą╣, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠą┐ąĄčĆą░č鹊čĆčŗ ąĮąĄ ą┐čĆąĖąĮąĖą╝ą░čÄčéčüčÅ ą▓ ą╗čÅą╝ą▒ą┤ą░-ą▓čŗčĆą░ąČąĄąĮąĖčÅčģ:
>>> lambda : print 'hello world'
File "< stdin>" , line 1
lambda : print 'hello world'
^
SyntaxError: invalid syntaxąĪąĖąĮčéą░ą║čüąĖčü ąŠą┐ąĄčĆą░č鹊čĆą░ print ąĮąĄąŠą┤ąĮąŠąĘąĮą░čćąĮčŗą╣. ąśąĮąŠą│ą┤ą░ ą▓čŗ ą╝ąŠąČąĄč鹥 ą┤ąŠą▒ą░ą▓ąĖčéčī ą║čĆčāą│ą╗čŗąĄ čüą║ąŠą▒ą║ąĖ ą▓ąŠą║čĆčāą│ ą▓čŗčĆą░ąČąĄąĮąĖčÅ, ą░ ąŠąĮąĖ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąĮąĄąŠą▒čÅąĘą░č鹥ą╗čīąĮčŗ:
>>> print 'Please wait...'
Please wait...>>> print ('Please wait...' )
Please wait...ąÉ ą▓ ą┤čĆčāą│ąĖčģ čüą╗čāčćą░čÅčģ ąŠąĮąĖ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą╝ąĄąĮčÅčÄčé ą▓ąĖą┤ ą┐ąĄčćą░čéą░ąĄą╝ąŠą│ąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ:
>>> print 'My name is' , 'John'
My name is John>>> print ('My name is' , 'John' )
('My name is' , 'John' )ąĪą║ą╗ąĄąĖą▓ą░ąĮąĖąĄ čüčéčĆąŠą║ (string concatenation) ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ąŠčłąĖą▒ą║ąĄ TypeError ąĖąĘ-ąĘą░ ąĮąĄčüąŠą▓ą╝ąĄčüčéąĖą╝ąŠčüčéąĖ čéąĖą┐ąŠą▓, čćč鹊 ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ąŠą▒čĆą░ą▒ąŠčéą░čéčī ą▓čĆčāčćąĮčāčÄ, ąĮą░ą┐čĆąĖą╝ąĄčĆ:
>>> values = ['jdoe' , 'is' , 42 , 'years old' ]>>> print ' ' .join(map (str , values))
jdoe is 42 years oldąĪčĆą░ą▓ąĮąĖč鹥 čŹč鹊 čü ą░ąĮą░ą╗ąŠą│ąĖčćąĮčŗą╝ ą║ąŠą┤ąŠą╝ ą▓ Python 3, ą║ąŠč鹊čĆčŗą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄčé čĆą░čüą┐ą░ą║ąŠą▓ą║čā ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ:
>>> values = ['jdoe' , 'is' , 42 , 'years old' ]>>> print (*values) # Python 3
jdoe is 42 years oldąØą░ Python 2 čā ąŠą┐ąĄčĆą░č鹊čĆą░ print ąĮąĄčé ąĖą╝ąĄąĮąŠą▓ą░ąĮąĮčŗčģ ą░čĆą│čāą╝ąĄąĮč鹊ą▓ ą┤ą╗čÅ čéą░ą║ąĖčģ ąŠą▒čēąĖčģ ąĘą░ą┤ą░čć, ą║ą░ą║ čüą▒čĆąŠčü (flush) ą▒čāč乥čĆą░ ąĖą╗ąĖ ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąŠč鹊ą║ą░. ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą▓ą░ą╝ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ą┐ąŠą╝ąĮąĖčéčī ą┐čĆąĖčćčāą┤ą╗ąĖą▓čŗą╣ čüąĖąĮčéą░ą║čüąĖčü. ąöą░ąČąĄ ą▓čüčéčĆąŠąĄąĮąĮą░čÅ čäčāąĮą║čåąĖčÅ help() ąĮąĄ ą┐ąŠą╝ąŠąČąĄčé ą┤ą╗čÅ ąŠą┐ąĄčĆą░č鹊čĆą░ print:
>>> help (print )
File "< stdin>" , line 1
help (print )
^
SyntaxError: invalid syntaxąŻą┤ą░ą╗ąĄąĮąĖąĄ newline ą▓ ą║ąŠąĮčåąĄ čüčéčĆąŠą║ąĖ čĆą░ą▒ąŠčéą░ąĄčé ąĮąĄ čüąŠą▓čüąĄą╝ ą║ąŠčĆčĆąĄą║čéąĮąŠ, ą┐ąŠč鹊ą╝čā čćč鹊 ą┤ąŠą▒ą░ą▓ą╗čÅąĄčé ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮčŗą╣ ą┐čĆąŠą▒ąĄą╗. ąÆčŗ ąĮąĄ ą╝ąŠąČąĄč鹥 čüąŠčüčéą░ą▓ąĖčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ąŠą┐ąĄčĆą░č鹊čĆąŠą▓ ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝, ąĖ ą║čĆąŠą╝ąĄ čŹč鹊ą│ąŠ, ą▓čŗ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąŠč湥ąĮčī ą▓ąĮąĖą╝ą░č鹥ą╗čīąĮčŗ ą║ ą║ąŠą┤ąĖčĆąŠą▓ą║ąĄ čüąĖą╝ą▓ąŠą╗ąŠą▓.
ąŁč鹊čé čüą┐ąĖčüąŠą║ ą┐čĆąŠą▒ą╗ąĄą╝ ą╝ąŠąČąĮąŠ ą┐čĆąŠą┤ąŠą╗ąČą░čéčī ąĖ ą┐čĆąŠą┤ąŠą╗ąČą░čéčī. ąĢčüą╗ąĖ ą▓ą░ą╝ ąĖąĮč鹥čĆąĄčüąĮąŠ, ą▓čŗ ą╝ąŠąČąĄč鹥 ą▓ąĄčĆąĮčāčéčīčüčÅ ąĮą░ąĘą░ą┤ ąĖ ą┐čĆąŠčüą╝ąŠčéčĆąĄčéčī ą┤čĆčāą│ąĖąĄ ą▓čĆąĄąĘą║ąĖ, ąŠą┐ąĖčüčŗą▓ą░čÄčēąĖąĄ ąŠčéą╗ąĖčćąĖčÅ čüąĖąĮčéą░ą║čüąĖčüą░ Python 2.
ą×ą┤ąĮą░ą║ąŠ ą▓čŗ ą╝ąŠąČąĄč鹥 čĆą░ąĘąŠą▒čĆą░čéčīčüčÅ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ąĖąĘ čŹčéąĖčģ ą┐čĆąŠą▒ą╗ąĄą╝ ą▒ąŠą╗ąĄąĄ ą┐čĆąŠčüčéčŗą╝ čüą┐ąŠčüąŠą▒ąŠą╝, č湥ą╝ ą┐ąĄčĆąĄąĮąŠčü ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĮą░ Python 3. ą×ąĮ ąĘą░ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖąĖ čäčāąĮą║čåąĖąĖ print(), ą║ąŠč鹊čĆą░čÅ ą▒čŗą╗ą░ ąŠą▒čĆą░čéąĮąŠ ą┐ąŠčĆčéąĖčĆąŠą▓ą░ąĮą░ ą┤ą╗čÅ čāą┐čĆąŠčēąĄąĮąĖčÅ ą╝ąĖą│čĆą░čåąĖąĖ ąĮą░ Python 3. ąÆčŗ ą╝ąŠąČąĄč鹥 ąĖą╝ą┐ąŠčĆčéąĖčĆąŠą▓ą░čéčī ąĄčæ ąĖąĘ čüą┐ąĄčåąĖą░ą╗čīąĮąŠą│ąŠ ą╝ąŠą┤čāą╗čÅ __future__, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą▓čŗą▒ąŠčĆ čäąĖčć čÅąĘčŗą║ą░, ą┐ąŠčÅą▓ąĖą▓čłąĖčģčüčÅ ą▓ ą▒ąŠą╗ąĄąĄ ąĮąŠą▓čŗčģ ą▓ąĄčĆčüąĖčÅčģ Python.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ą▓čŗ ą╝ąŠąČąĄč鹥 ąĖą╝ą┐ąŠčĆčéąĖčĆąŠą▓ą░čéčī ą║ą░ą║ ą▒čāą┤čāčēąĖąĄ čäčāąĮą║čåąĖąĖ, čéą░ą║ ąĖ ą▓čüčéčĆąŠąĄąĮąĮčŗąĄ čÅąĘčŗą║ąŠą▓čŗąĄ ą║ąŠąĮčüčéčĆčāą║čåąĖąĖ, čéą░ą║ąĖąĄ ą║ą░ą║ ąŠą┐ąĄčĆą░č鹊čĆ with.
ą¦č鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī čüą┐ąĖčüąŠą║ čäąĖčć, ą║ąŠč鹊čĆčŗąĄ čüčéą░ą╗ąĖ ą┤ą╗čÅ ą▓ą░čü ą┤ąŠčüčéčāą┐ąĮčŗ, ą▓čŗ ą╝ąŠąČąĄč鹥 ą┐čĆąŠąĖąĮčüą┐ąĄą║čéąĖčĆąŠą▓ą░čéčī ą╝ąŠą┤čāą╗čī:
>>> import __future__>>> __future__.all_feature_names
['nested_scopes' ,
'generators' ,
'division' ,
'absolute_import' ,
'with_statement' ,
'print_function' ,
'unicode_literals' ]ąÆčŗ čéą░ą║ąČąĄ ą╝ąŠąČąĄč鹥 ą▓čŗąĘą▓ą░čéčī dir(__future__) , ąĮąŠ čŹč鹊 ą┐ąŠą║ą░ąČąĄčé ą╝ąĮąŠąČąĄčüčéą▓ąŠ ąĮąĄ ąŠč湥ąĮčī ąĖąĮč鹥čĆąĄčüąĮčŗčģ ą▓ąĮčāčéčĆąĄąĮąĮąĖčģ ą┐ąŠą┤čĆąŠą▒ąĮąŠčüč鹥ą╣ ą╝ąŠą┤čāą╗čÅ.
ą¦č鹊ą▒čŗ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čäčāąĮą║čåąĖčÄ print() ą▓ Python 2, ą▓ą░ą╝ ąĮčāąČąĮąŠ ą┤ąŠą▒ą░ą▓ąĖčéčī čüą╗ąĄą┤čāčÄčēąĖą╣ ąŠą┐ąĄčĆą░č鹊čĆ import ą▓ ąĮą░čćą░ą╗ąŠ ą▓ą░čłąĄą│ąŠ ą║ąŠą┤ą░:
from __future__ import print_functionąØą░čćąĖąĮą░čÅ čü čŹč鹊ą│ąŠ ą╝ąĄčüčéą░ ąŠą┐ąĄčĆą░č鹊čĆ print ą▒ąŠą╗čīčłąĄ ą┐ąĄčĆąĄčüčéą░ąĮąĄčé ą▒čŗčéčī ą┤ąŠčüčéčāą┐ąĮčŗą╝, ąĮąŠ ą▓ ą▓ą░čłąĄą╝ čĆą░čüą┐ąŠčĆčÅąČąĄąĮąĖąĖ ąŠą║ą░ąČąĄčéčüčÅ čäčāąĮą║čåąĖčÅ print(). ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čŹč鹊 ąĮąĄ čéą░ ąČąĄ čüą░ą╝ą░čÅ čäčāąĮą║čåąĖčÅ, čćč鹊 ą▓ Python 3, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓ ąĮąĄą╣ ąĮąĄčé ąĖą╝ąĄąĮąŠą▓ą░ąĮąĮąŠą│ąŠ ą░čĆą│čāą╝ąĄąĮčéą░ flush, ąĮąŠ ąŠčüčéą░ą╗čīąĮčŗąĄ ą░čĆą│čāą╝ąĄąĮčéčŗ čéą░ą║ąĖąĄ ąČąĄ.
ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, čŹč鹊 ąĮąĄ ąĖąĘą▒ą░ą▓ąĖčé ą▓ą░čü ąŠčé ą┐čĆą░ą▓ąĖą╗čīąĮąŠą│ąŠ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą║ąŠą┤ąĖčĆąŠą▓ą║ą░ą╝ąĖ čüąĖą╝ą▓ąŠą╗ąŠą▓.
ąÆąŠčé ą┐čĆąĖą╝ąĄčĆ ą▓čŗąĘąŠą▓ą░ čäčāąĮą║čåąĖąĖ print() ą▓ Python 2:
>>> from __future__ import print_function>>> import sys>>> print ('ą» čäčāąĮą║čåąĖčÅ ą▓ Python' , sys.version_info.major)
ą» čäčāąĮą║čåąĖčÅ ą▓ Python 2 ąóąĄą┐ąĄčĆčī čā ą▓ą░čü ąĄčüčéčī ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ ąŠ č鹊ą╝, ą║ą░ą║ čĆą░ąĘą▓ąĖą▓ą░ą╗ą░čüčī čäčāąĮą║čåąĖčÅ ą┐ąĄčćą░čéąĖ Python, ąĖ čćč鹊 čüą░ą╝ąŠąĄ ą│ą╗ą░ą▓ąĮąŠąĄ, ą▓čŗ ą┐ąŠąĮąĖą╝ą░ąĄč鹥, ą┐ąŠč湥ą╝čā čŹčéąĖ ąŠą▒čĆą░čéąĮąŠ ąĮąĄčüąŠą▓ą╝ąĄčüčéąĖą╝čŗąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą▒čŗą╗ąĖ ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗ. ąóą░ą║ąĖąĄ ąĘąĮą░ąĮąĖčÅ ąĮą░ą▓ąĄčĆąĮčÅą║ą░ ą┐ąŠą╝ąŠą│čāčé ą▓ą░ą╝ čüčéą░čéčī ą╗čāčćčłąĖą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüč鹊ą╝ Python.
[ą¤čĆąŠą┤ą▓ąĖąĮčāčéčŗąĄ ą╝ąĄč鹊ą┤čŗ ą┐ąĄčćą░čéąĖ ]
ąÆ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ ą▓čŗ čāąĘąĮą░ąĄč鹥, ą║ą░ą║ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░čéčī čüą╗ąŠąČąĮčŗąĄ čüčéčĆčāą║čéčāčĆčŗ ą┤ą░ąĮąĮčŗčģ, ą┤ąŠą▒ą░ą▓ą╗čÅčéčī čåą▓ąĄčéą░ ąĖ ą┤čĆčāą│ąĖąĄ čāą║čĆą░čłąĄąĮąĖčÅ, čüąŠąĘą┤ą░ą▓ą░čéčī ąĖąĮč鹥čĆč乥ą╣čüčŗ, ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą░ąĮąĖą╝ą░čåąĖčÄ ąĖ ą┤ą░ąČąĄ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčéčī ąĘą▓čāą║ąĖ čü č鹥ą║čüč鹊ą╝.
Pretty-printing ą┤ą╗čÅ ą┐ąĄčćą░čéąĖ ą▓ą╗ąŠąČąĄąĮąĮčŗčģ čüčéčĆčāą║čéčāčĆ ą┤ą░ąĮąĮčŗčģ . ą»ąĘčŗą║ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐ąŠąĘą▓ąŠą╗čÅčé ą▓ą░ą╝ ą┐čĆąĄą┤čüčéą░ą▓ąĖčéčī ą▓ čüčéčĆčāą║čéčāčĆąĖčĆąŠą▓ą░ąĮąĮąŠą╝ ą▓ąĖą┤ąĄ ą║ą░ą║ ą┤ą░ąĮąĮčŗąĄ, čéą░ą║ ąĖ ąĖčüą┐ąŠą╗ąĮčÅąĄą╝čŗą╣ ą║ąŠą┤. ą×ą┤ąĮą░ą║ąŠ ą▓ ąŠčéą╗ąĖčćąĖąĄ ąŠčé Python, ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąŠ čÅąĘčŗą║ąŠą▓ ą┤ą░čÄčé ą▓ą░ą╝ ąĮąĄą║ąŠč鹊čĆčāčÄ čüą▓ąŠą▒ąŠą┤čā ą▓ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ą┐čĆąŠą▒ąĄą╗ąŠą▓ ąĖ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖčÅ. ąŁč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠą╗ąĄąĘąĮčŗą╝, ąĮą░ą┐čĆąĖą╝ąĄčĆ ą▓ ą╗ą░ą║ąŠąĮąĖčćąĮąŠčüčéąĖ, ąĮąŠ ąĖąĮąŠą│ą┤ą░ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ą╝ąĄąĮąĄąĄ čāą┤ąŠą▒ąŠčćąĖčéą░ąĄą╝ąŠą╝čā ą║ąŠą┤čā.
Pretty-printing čŹč鹊 ąŠ č鹊ą╝, čćč鹊ą▒čŗ ą┐ąŠčĆčåąĖčÅ ą┤ą░ąĮąĮčŗčģ ąĖą╗ąĖ ą║ąŠą┤ą░ ą▓čŗą│ą╗čÅą┤ąĄą╗ą░ ą║čĆą░čüąĖą▓ąŠ, ąĖ ą▒čŗą╗ą░ ą┐ąŠąĮčÅčéąĮąĄąĄ. ąŁč鹊 ą┤ąĄą╗ą░ąĄčéčüčÅ ą┐čāč鹥ą╝ ąŠčéčüčéčāą┐ą░ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ čüčéčĆąŠą║, ą▓čüčéą░ą▓ą║ąĖ ąĮąŠą▓čŗčģ čüčéčĆąŠą║, ą┐ąĄčĆąĄčāą┐ąŠčĆčÅą┤ąŠčćąĖą▓ą░ąĮąĖčÅ čŹą╗ąĄą╝ąĄąĮč鹊ą▓, ąĖ čéą░ą║ ą┤ą░ą╗ąĄąĄ.
Python ą┐ąŠčüčéą░ą▓ą╗čÅąĄčéčüčÅ čü ą╝ąŠą┤čāą╗ąĄą╝ pprint (čüąŠą║čĆą░čēąĄąĮąĖąĄ ąŠčé pretty-printing) ą▓ čüą▓ąŠąĄą╣ čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĄ, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠą╝ąŠąČąĄčé ą▓ą░ą╝ ą║ą░č湥čüčéą▓ąĄąĮąĮąŠ ąĮą░ą┐ąĄčćą░čéą░čéčī ą▒ąŠą╗čīčłąĖąĄ čüčéčĆčāą║čéčāčĆčŗ ą┤ą░ąĮąĮčŗčģ, ąĮąĄ ą┐ąŠą╝ąĄčēą░čÄčēąĖąĄčüčÅ ą▓ ąŠą┤ąĮčā čüčéčĆąŠą║čā. ą¤ąŠčüą║ąŠą╗čīą║čā ąŠąĮ ą┐ąĄčćą░čéą░ąĄčé ą▒ąŠą╗ąĄąĄ čāą┤ąŠą▒ąĮčŗą╝ ą┤ą╗čÅ č湥ą╗ąŠą▓ąĄą║ą░ čüą┐ąŠčüąŠą▒ąŠą╝, ą╝ąĮąŠą│ąĖąĄ ą┐ąŠą┐čāą╗čÅčĆąĮčŗąĄ ąĖąĮčüčéčĆčāą╝ąĄąĮčéčŗ REPL, ą▓ą║ą╗čÄčćą░čÅ JupyterLab ąĖ IPython, ąĄą│ąŠ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą▓ą╝ąĄčüč鹊 ąŠą▒čŗčćąĮąŠą╣ čäčāąĮą║čåąĖąĖ print().
Read-Eval-Print Loop, ąĖą╗ąĖ REPL , čŹč鹊 čĆą░ą▒ąŠč湥ąĄ ąŠą║čĆčāąČąĄąĮąĖąĄ ą▓ ą║ąŠą╝ą┐čīčÄč鹥čĆąĄ, ą│ą┤ąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą▓ą▓ąŠą┤ąĖčé ą▓čģąŠą┤ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą┤ą╗čÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ, ąĮą░ą┐čĆąĖą╝ąĄčĆ ą▓čŗčĆą░ąČąĄąĮąĖčÅ, ąĖ ąĘą░č鹥ą╝ ą┐ąŠą╗čāčćą░ąĄčé čĆąĄąĘčāą╗čīčéą░čé. ąĪąĖčüč鹥ą╝ą░ REPL ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ąĖąĮč鹥čĆą░ą║čéąĖą▓ąĮąŠąĄ ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąĖąĄ čü ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÅ ąĄą╝čā ąŠą┐ąĖčüą░ąĮąĖąĄ čüą▓ąŠąĖčģ ą▓ąŠąĘą╝ąŠąČąĮąŠčüč鹥ą╣ ąĖą╗ąĖ čÅąĘčŗą║ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ. ą¤čĆąĖą╝ąĄčĆą░ą╝ąĖ čéą░ą║ąĖčģ čüąĖčüč鹥ą╝ čÅą▓ą╗čÅčÄčéčüčÅ Node.js ą║ąŠąĮčüąŠą╗čī, IPython, Bash shell, ą░ čéą░ą║ąČąĄ ą║ąŠąĮčüąŠą╗čī čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ą░, ą║ąŠč鹊čĆčāčÄ ą╝ąŠąČąĮąŠ ąĮą░ą╣čéąĖ ą▓ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ web-ą▒čĆą░čāąĘąĄčĆąŠą▓.
ąöą╗čÅ ąĖą╗ą╗čÄčüčéčĆą░čåąĖąĖ, ą║ą░ą║ čĆą░ą▒ąŠčéą░ąĄčé REPL, čĆą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗ąĄą┤čāčÄčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ ą▓ ą║ąŠąĮčüąŠą╗ąĖ Bash shell ąĮą░ čüąĄčĆą▓ąĄčĆąĄ Debian. ąöą╗čÅ ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąĖčÅ čü čüąĄčĆą▓ąĄčĆąŠą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą▓ą▓ąŠą┤ąĖčé ą║ąŠą╝ą░ąĮą┤čŗ, ąĖąĮčüčéčĆčāą║čéąĖčĆčāčÅ čüąĄčĆą▓ąĄčĆ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠąĄ ą┤ąĄą╣čüčéą▓ąĖąĄ, ąĖą╗ąĖ ą▓ąŠąĘą▓čĆą░čéąĖčéčī ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą╝ąŠąČąĄčé ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą║ąŠą╝ą░ąĮą┤čā expr , ą║ąŠč鹊čĆą░čÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ ą╝ą░č鹥ą╝ą░čéąĖč湥čüą║ąĖčģ ą▓čŗčĆą░ąČąĄąĮąĖą╣. ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą║ąŠą╝ą░ąĮą┤ą░ expr ą▓čŗčćąĖčüą╗ąĖčé ą▓čŗčĆą░ąČąĄąĮąĖąĄ čüčāą╝ą╝čŗ 2 + 2:
$ expr 2 + 2
4_
ą¤ąŠčüą╗ąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čŹč鹊ą╣ ą║ąŠą╝ą░ąĮą┤čŗ ąĖ ą▓ąŠąĘą▓čĆą░čéą░ čĆąĄąĘčāą╗čīčéą░čéą░ ąŠą▒ąŠą╗ąŠčćą║ą░ Bash ą▓ąŠąĘą▓čĆą░čēą░ąĄčéčüčÅ ą▓ čĆąĄąČąĖą╝ čćč鹥ąĮąĖčÅ, ąĘą░ą╝čŗą║ą░čÅ č鹥ą╝ čüą░ą╝čŗą╝ čåąĖą║ą╗, ąĖ ą┐ąŠąĘą▓ąŠą╗čÅčÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÄ ą▓ą▓ąĄčüčéąĖ ąĮąŠą▓čāčÄ ą║ąŠą╝ą░ąĮą┤čā.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: čćč鹊ą▒čŗ ą┐ąĄčĆąĄą║ą╗čÄčćąĖčéčīčüčÅ ąĮą░ pretty printing ą▓ IPython, ą▓čŗą┤ą░ą╣č鹥 čüą╗ąĄą┤čāčÄčēčāčÄ ą║ąŠą╝ą░ąĮą┤čā:
In [1]: %pprint Pretty printing has been turned OFF In [2]: %pprint Pretty printing has been turned ON
ąŁč鹊 ą┐čĆąĖą╝ąĄčĆ ą╝ą░ą│ąĖąĖ IPython. ąĢčüčéčī ą╝ąĮąŠą│ąŠ ą▓čüčéčĆąŠąĄąĮąĮčŗčģ ą║ąŠą╝ą░ąĮą┤, ą║ąŠč鹊čĆčŗąĄ ąĮą░čćąĖąĮą░čÄčéčüčÅ čüąŠ ąĘąĮą░ą║ą░ ą┐čĆąŠčåąĄąĮčéą░ (%), ąĮąŠ ą▓čŗ ą╝ąŠąČąĄč鹥 ąĮą░ą╣čéąĖ ąĄčēąĄ ą▒ąŠą╗čīčłąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüč鹥ą╣ ąĮą░ PyPI, ąĖą╗ąĖ ą╝ąŠąČąĄč鹥 ą┤ą░ąČąĄ čüąŠąĘą┤ą░čéčī čüą▓ąŠąĖ ą▓ą░čĆąĖą░ąĮčéčŗ.
ąĢčüą╗ąĖ ą▓ą░ą╝ ąĮąĄ ąĮą░ą┤ąŠ ą▒ąĄčüą┐ąŠą║ąŠąĖčéčīčüčÅ ąŠ ą┤ąŠčüčéčāą┐ąĄ ą║ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮąŠą╣ čäčāąĮą║čåąĖąĖ print(), č鹊 ą▓čŗ ą┐čĆąŠčüč鹊 ą╝ąŠąČąĄč鹥 ąĘą░ą╝ąĄąĮąĖčéčī ąĄčæ ą▓ čüą▓ąŠąĄą╝ ą║ąŠą┤ąĄ ąĮą░ pprint() čü ą┐ąŠą╝ąŠčēčīčÄ ąĖą╝ą┐ąŠčĆčéą░ čü ą┐ąĄčĆąĄąĖą╝ąĄąĮąŠą▓ą░ąĮąĖąĄą╝:
>>> from pprint import pprint as print >>> print
< function pprint at 0x7f7a775a3510 >ą£ąĮąĄ ą╗ąĖčćąĮąŠ ąĮčĆą░ą▓ąĖčéčüčÅ ąĖą╝ąĄčéčī ą┐ąŠą┤ čĆčāą║ąŠą╣ ąŠą▒ąĄ čäčāąĮą║čåąĖąĖ, čćč鹊 ą╝ąŠąČąĮąŠ ą┤ąŠčüčéąĖą│ąĮčāčéčī ą┐ąĄčĆąĄąĖą╝ąĄąĮąŠą▓ą░ąĮąĖąĄą╝ pprint ą▓ čüąŠą║čĆą░čēąĄąĮąĮąŠąĄ ąĖą╝čÅ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ pp:
from pprint import pprint as ppąØą░ ą┐ąĄčĆą▓čŗą╣ ą▓ąĘą│ą╗čÅą┤, ą╝ąĄąČą┤čā print() ąĖ pprint() ą┐ąŠčćčéąĖ ąĮąĄčé čĆą░ąĘąĮąĖčåčŗ, ąĖ ą▓ ąĮąĄą║ąŠč鹊čĆčŗčģ čüą╗čāčćą░čÅčģ čĆą░ąĘą╗ąĖčćąĖą╣ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠ ąĮąĄčé:
>>> print (42 )42 >>> pp(42 )42 >>> print ('hello' )
hello>>> pp('hello' )'hello' # ąĘą░ą╝ąĄčéąĖą╗ąĖ čĆą░ąĘąĮąĖčåčā? ą¤čĆąĖčćąĖąĮą░ ą▓ č鹊ą╝, čćč鹊 pprint() ą▓čŗąĘčŗą▓ą░ąĄčé repr() ą▓ą╝ąĄčüč鹊 ąŠą▒čŗčćąĮąŠą╣ str() ą┤ą╗čÅ ą┐čĆąĖą▓ąĄą┤ąĄąĮąĖčÅ čéąĖą┐ąŠą▓ (type casting). ąĀą░ąĘą╗ąĖčćąĖčÅ čüčéą░ąĮčāčé ą▒ąŠą╗ąĄąĄ ąŠč湥ą▓ąĖą┤ąĮčŗą╝ąĖ ą┐ąŠčüą╗ąĄ ą▓čŗą▓ąŠą┤ą░ ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮčŗčģ čüčéčĆčāą║čéčāčĆ ą┤ą░ąĮąĮčŗčģ:
>>> data = {'powers' : [x**10 for x in range (10 )]}>>> pp(data)
{'powers' : [0 ,
1 ,
1024 ,
59049 ,
1048576 ,
9765625 ,
60466176 ,
282475249 ,
1073741824 ,
3486784401 ]}ążčāąĮą║čåąĖčÅ ą┐čĆąĖą╝ąĄąĮąĖą╗ą░ čĆą░ąĘčāą╝ąĮąŠąĄ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖąĄ ą▓čŗą▓ąŠą┤ą░ ą┤ą╗čÅ čāą╗čāčćčłąĄąĮąĖčÅ čćąĖčéą░ąĄą╝ąŠčüčéąĖ, ąĮąŠ ą▓čŗ ą╝ąŠąČąĄč鹥 ąĮą░čüčéčĆąŠąĖčéčī čŹč鹊 ąĄčēąĄ ą▒ąŠą╗čīčłąĄ čü ą┐ąŠą╝ąŠčēčīčÄ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą▓čŗ ą╝ąŠąČąĄč鹥 ąŠą│čĆą░ąĮąĖčćąĖčéčī ą▓čŗą▓ąŠą┤ ą│ą╗čāą▒ąŠą║ąŠ ą▓ą╗ąŠąČąĄąĮąĮąŠą╣ ąĖąĄčĆą░čĆčģąĖąĖ, ą┐ąŠą║ą░ąĘčŗą▓ą░čÅ ą╝ąĮąŠą│ąŠč鹊čćąĖąĄ ąĮąĖąČąĄ ąĘą░ą┤ą░ąĮąĮąŠą│ąŠ čāčĆąŠą▓ąĮčÅ:
>>> cities = {'USA' : {'Texas' : {'Dallas' : ['Irving' ]}}}>>> pp(cities, depth=3 )
{'USA' : {'Texas' : {'Dallas' : [...]}}}ą×ą▒čŗčćąĮą░čÅ čäčāąĮą║čåąĖčÅ print() čéą░ą║ąČąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą╝ąĮąŠą│ąŠč鹊čćąĖčÅ, ąĮąŠ ą┤ą╗čÅ ąŠč鹊ą▒čĆą░ąČąĄąĮąĖčÅ čĆąĄą║čāčĆčüąĖą▓ąĮčŗčģ čüčéčĆčāą║čéčāčĆ ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗąĄ č乊čĆą╝ąĖčĆčāčÄčé čåąĖą║ą╗, čćč鹊ą▒čŗ ąĖąĘą▒ąĄąČą░čéčī ąŠčłąĖą▒ą║ąĖ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ čüč鹥ą║ą░:
>>> items = [1 , 2 , 3 ]>>> items.append(items)>>> print (items)
[1 , 2 , 3 , [...]]ąóąĄą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ čäčāąĮą║čåąĖčÅ pprint() ą▒ąŠą╗ąĄąĄ čÅą▓ąĮąŠ čŹč鹊 ąŠą┐ąĖčüčŗą▓ą░ąĄčé, ą▓ą║ą╗čÄčćą░čÅ čāąĮąĖą║ą░ą╗čīąĮčŗą╣ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ąŠą▒čŖąĄą║čéą░, ą║ąŠč鹊čĆčŗą╣ čüčüčŗą╗ą░ąĄčéčüčÅ čüą░ą╝ ąĮą░ čüąĄą▒čÅ:
>>> pp(items)
[1 , 2 , 3 , < Recursion on list with id =140635757287688 >]>>> id (items)140635757287688 ą¤ąŠčüą╗ąĄą┤ąĮąĖą╣ 菹╗ąĄą╝ąĄąĮčé ą▓ čüą┐ąĖčüą║ąĄ čÅą▓ą╗čÅąĄčéčüčÅ čéą░ą║ąĖą╝ ąČąĄ ąŠą▒čŖąĄą║č鹊ą╝, ą║ą░ą║ ąĖ ą▓ąĄčüčī čüą┐ąĖčüąŠą║.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: čĆąĄą║čāčĆčüąĖą▓ąĮčŗąĄ ąĖą╗ąĖ ąŠč湥ąĮčī ą▒ąŠą╗čīčłąĖąĄ ąĮą░ą▒ąŠčĆčŗ ą┤ą░ąĮąĮčŗčģ ą╝ąŠą│čāčé ą▒čŗčéčī čéą░ą║ąČąĄ ąŠą▒čĆą░ą▒ąŠčéą░ąĮčŗ čü ą┐ąŠą╝ąŠčēčīčÄ ą╝ąŠą┤čāą╗čÅ reprlib :
>>> import reprlib>>> reprlib.repr ([x**10 for x in range (10 )])'[0, 1, 1024, 59049, 1048576, 9765625, ...]' ąŁč鹊čé ą╝ąŠą┤čāą╗čī ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąŠ ą▓čüčéčĆąŠąĄąĮąĮčŗčģ čéąĖą┐ąŠą▓, ąĖ ąĄą│ąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąŠčéą╗ą░ą┤čćąĖą║ Python.
ążčāąĮą║čåąĖčÅ pprint() ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ čüąŠčĆčéąĖčĆčāąĄčé ą┤ą╗čÅ ą▓ą░čü ą║ą╗čÄčćąĖ čüą╗ąŠą▓ą░čĆčÅ ą┐ąĄčĆąĄą┤ ą┐ąĄčćą░čéčīčÄ, čćč鹊 ąŠą▒ąĄčüą┐ąĄčćąĖą▓ą░ąĄčé ąĮąĄą┐čĆąŠčéąĖą▓ąŠčĆąĄčćąĖą▓ąŠąĄ čüčĆą░ą▓ąĮąĄąĮąĖąĄ. ąÜąŠą│ą┤ą░ ą▓čŗ čüčĆą░ą▓ąĮąĖą▓ą░ąĄč鹥 čüčéčĆąŠą║ąĖ, ą▓čŗ čćą░čüč鹊 ąĮąĄ ąĘą░ą▒ąŠčéąĖč鹥čüčī ąŠ ą║ąŠąĮą║čĆąĄčéąĮąŠą╝ ą┐ąŠčĆčÅą┤ą║ąĄ čüąĄčĆąĖą░ą╗ąĖąĘąŠą▓ą░ąĮąĮčŗčģ ą░čéčĆąĖą▒čāč鹊ą▓. ąÆ ą╗čÄą▒ąŠą╝ čüą╗čāčćą░ąĄ, ą▓čüąĄą│ą┤ą░ ą╗čāčćčłąĄ čüčĆą░ą▓ąĮąĖą▓ą░čéčī čäą░ą║čéąĖč湥čüą║ąĖąĄ čüą╗ąŠą▓ą░čĆąĖ ą┐ąĄčĆąĄą┤ čüąĄčĆąĖą░ą╗ąĖąĘą░čåąĖąĄą╣.
ąĪą╗ąŠą▓ą░čĆąĖ čćą░čüč鹊 ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮčŗ ą┤ą░ąĮąĮčŗą╝ąĖ JSON , ą║ąŠč鹊čĆčŗąĄ čłąĖčĆąŠą║ąŠ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą▓ ąśąĮč鹥čĆąĮąĄč鹥. ą¦č鹊ą▒čŗ ą┐čĆą░ą▓ąĖą╗čīąĮąŠ čüąĄčĆąĖą░ą╗ąĖąĘąŠą▓ą░čéčī čüą╗ąŠą▓ą░čĆčī ą▓ ą┤ąŠą┐čāčüčéąĖą╝čāčÄ čüčéčĆąŠą║čā č乊čĆą╝ą░čéą░ JSON, ą▓čŗ ą╝ąŠąČąĄč鹥 ą▓ąŠčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą╝ąŠą┤čāą╗ąĄą╝ json. ą×ąĮ čéą░ą║ąČąĄ ąŠą▒ą╗ą░ą┤ą░ąĄčé ąĖąĘčĆčÅą┤ąĮčŗą╝ąĖ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčÅą╝ąĖ ą┐ąĄčćą░čéąĖ:
>>> import json>>> data = {'username' : 'jdoe' , 'password' : 's3cret' }>>> ugly = json.dumps(data)>>> pretty = json.dumps(data, indent=4 , sort_keys=True )>>> print (ugly)
{"username" : "jdoe" , "password" : "s3cret" }>>> print (pretty)
{
"password" : "s3cret" ,
"username" : "jdoe"
}ą×ą┤ąĮą░ą║ąŠ ąŠą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĖąĮąŠą│ą┤ą░ ą▓ą░ą╝ ąĮčāąČąĮąŠ čüą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮąŠ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī ą┐ąĄčćą░čéą░ąĄą╝ąŠą╣ čüčéčĆąŠą║ąĖ, ą┐ąŠč鹊ą╝čā ą┐ąĄčćą░čéčī ąĮąĄ ą▓čüąĄą│ą┤ą░ č鹊, čćč鹊 ą▓čŗ čģąŠčéąĖč鹥 ą┐ąŠą╗čāčćąĖčéčī. ą¤ąŠą┤ąŠą▒ąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝ ą╝ąŠą┤čāą╗čī pprint ąĖą╝ąĄąĄčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčāčÄ čäčāąĮą║čåąĖčÄ pformat() , ą║ąŠč鹊čĆą░čÅ ą▓ąŠąĘą▓čĆą░čéąĖčé čüčéčĆąŠą║čā ą▓ čüą╗čāčćą░ąĄ, ą║ąŠą│ą┤ą░ ąĮčāąČąĮąŠ ą┤ąĄą╗ą░čéčī čćč鹊-č鹊 ą┐ąŠą╝ąĖą╝ąŠ ą┐ąĄčćą░čéąĖ.
ąŻą┤ąĖą▓ąĖč鹥ą╗čīąĮąŠ, čćč鹊 čüąĖą│ąĮą░čéčāčĆą░ pprint() ąĮąĄ ą┐ąŠčģąŠąČą░ ąĮą░ čüąĖą│ąĮą░čéčāčĆčā čäčāąĮą║čåąĖąĖ print(). ąØąĄą╗čīąĘčÅ ą┤ą░ąČąĄ ą┐ąĄčĆąĄą┤ą░čéčī ą▒ąŠą╗ąĄąĄ ąŠą┤ąĮąŠą│ąŠ ą┐ąŠąĘąĖčåąĖąŠąĮąĮąŠą│ąŠ ą░čĆą│čāą╝ąĄąĮčéą░, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, ąĮą░čüą║ąŠą╗čīą║ąŠ ąŠąĮ ąŠčĆąĄąĮčéąĖčĆąŠą▓ą░ąĮ ąĮą░ ą┐ąĄčćą░čéčī čüčéčĆčāą║čéčāčĆ ą┤ą░ąĮąĮčŗčģ.
ąöąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ čåą▓ąĄč鹊ą▓ čü ą┐ąŠą╝ąŠčēčīčÄ escape-ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüč鹥ą╣ ANSI . ą¤ąŠ ą╝ąĄčĆąĄ čüąŠą▓ąĄčĆčłąĄąĮčüčéą▓ąŠą▓ą░ąĮąĖčÅ ą┐ąĄčĆčüąŠąĮą░ą╗čīąĮčŗčģ ą║ąŠą╝ą┐čīčÄč鹥čĆąŠą▓ ąŠąĮąĖ čüčéą░ą╗ąĖ ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮčŗą╝ąĖ, ą┐ąŠą╗čāčćąĖą╗ąĖ ą┐čĆąŠą┤ą▓ąĖąĮčāčéčŗąĄ ą│čĆą░čäąĖč湥čüą║ąĖąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ąĖ ą╝ąŠą│čāčé ąŠč鹊ą▒čĆą░ąČą░čéčī ą▒ąŠą╗čīčłąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čåą▓ąĄč鹊ą▓. ą×ą┤ąĮą░ą║ąŠ čĆą░ąĘą╗ąĖčćąĮčŗąĄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗ąĖ ąĖą╝ąĄą╗ąĖ čćą░čüč鹊 čüąŠą▒čüčéą▓ąĄąĮąĮąŠąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ ąŠ ą┤ąĖąĘą░ą╣ąĮąĄ API ąĖ ąĄą│ąŠ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĖ. ąŁč鹊 ą┐ąŠą╝ąĄąĮčÅą╗ąŠčüčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┤ąĄčüčÅčéąĖą╗ąĄčéąĖą╣ ąĮą░ąĘą░ą┤, ą║ąŠą│ą┤ą░ ą▓ ą░ą╝ąĄčĆąĖą║ą░ąĮčüą║ąŠą╝ ąĖąĮčüčéąĖčéčāč鹥 ąĮą░čåąĖąŠąĮą░ą╗čīąĮčŗčģ čüčéą░ąĮą┤ą░čĆč鹊ą▓ (American National Standards Institute, ANSI) ą┐čĆąĖą┤čāą╝ą░ą╗ąĖ čüčéą░ąĮą┤ą░čĆčé čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄą╝ čåą▓ąĄčéą░, ąŠą┐čĆąĄą┤ąĄą╗ąĖą▓ escape-ą║ąŠą┤čŗ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ANSI.
ąæąŠą╗čīčłąĖąĮčüčéą▓ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ 菹╝čāą╗čÅč鹊čĆą░ č鹥čĆą╝ąĖąĮą░ą╗ą░ ą┤ąŠ ąĮąĄą║ąŠč鹊čĆąŠą╣ čüč鹥ą┐ąĄąĮąĖ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé čŹč鹊čé čüčéą░ąĮą┤ą░čĆčé. ąöąŠ ąĮąĄą┤ą░ą▓ąĮąĄą│ąŠ ą▓čĆąĄą╝ąĄąĮ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮą░čÅ čüąĖčüč鹥ą╝ą░ Windows ą▒čŗą╗ą░ ąĘą░ą╝ąĄčéąĮčŗą╝ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąĄčüą╗ąĖ ą▓čŗ čģąŠčéąĖč鹥 ą┤ąŠčüčéąĖčćčī ą╗čāčćčłąĄą╣ ą┐ąŠčĆčéąĖčĆčāąĄą╝ąŠčüčéąĖ, ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ą▓ Python ą▒ąĖą▒ą╗ąĖąŠč鹥ą║čā colorama. ą×ąĮą░ čéčĆą░ąĮčüą╗ąĖčĆčāąĄčé ANSI-ą║ąŠą┤čŗ ąĖ ąĖčģ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖąĄ ą░ąĮą░ą╗ąŠą│ąĖ Windows, čüąŠčģčĆą░ąĮčÅčÅ ą║ąŠą┤čŗ ąĮąĄąĖąĘą╝ąĄąĮąĮčŗą╝ąĖ ą▓ ą┤čĆčāą│ąĖčģ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčŗčģ čüąĖčüč鹥ą╝ą░čģ.
ą¦č鹊ą▒čŗ ą┐čĆąŠą▓ąĄčĆąĖčéčī, ą┐ąŠąĮąĖą╝ą░ąĄčé ą╗ąĖ ą▓ą░čł č鹥čĆą╝ąĖąĮą░ą╗ ą┐ąŠą┤ą╝ąĮąŠąČąĄčüčéą▓ąŠ escape-ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüč鹥ą╣ ANSI, čüą▓čÅąĘą░ąĮąĮčŗąĄ ąĮą░ą┐čĆąĖą╝ąĄčĆ čü čåą▓ąĄč鹊ą╝, ą▓čŗ ą╝ąŠąČąĄč鹥 ą┐ąŠą┐čĆąŠą▒ąŠą▓ą░čéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čüą╗ąĄą┤čāčÄčēčāčÄ ą║ąŠą╝ą░ąĮą┤čā:
$ tput colors
ą£ąŠą╣ č鹥čĆą╝ąĖąĮą░ą╗ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĮą░ Linux ą│ąŠą▓ąŠčĆąĖčé, čćč鹊 ą╝ąŠąČąĄčé ąŠč鹊ą▒čĆą░ąĘąĖčéčī 256 čĆą░ąĘą╗ąĖčćąĮčŗčģ čåą▓ąĄč鹊ą▓, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ xterm ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐ąŠą║ą░ąĘą░čéčī č鹊ą╗čīą║ąŠ 8. ąŁčéą░ ą║ąŠą╝ą░ąĮą┤ą░ ą▓ąŠąĘą▓čĆą░čéąĖčé ąŠčéčĆąĖčåą░č鹥ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, ąĄčüą╗ąĖ čåą▓ąĄčéą░ ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčéčüčÅ.
Escape-ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ ANSI čĆą░ą▒ąŠčéą░čÄčé ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ čÅąĘčŗą║ą░ čĆą░ąĘą╝ąĄčéą║ąĖ ą┤ą╗čÅ č鹥čĆą╝ąĖąĮą░ą╗ą░. ąØą░ HTML ą▓čŗ čĆą░ą▒ąŠčéą░ąĄč鹥 čü č鹥ą│ą░ą╝ąĖ, čéą░ą║ąĖą╝ąĖ ą║ą░ą║ < b> ąĖą╗ąĖ < i>, čćč鹊ą▒čŗ ąĖąĘą╝ąĄąĮąĖčéčī ą▓ąĖą┤ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą┤ąŠą║čāą╝ąĄąĮčéą░. ąŁčéąĖ č鹥ą│ąĖ ą┐čĆąĖą╝ąĄąĮčÅčÄčé ą║ čüąŠą┤ąĄčƹȹĖą╝ąŠą╝čā ą┤ąŠą║čāą╝ąĄąĮčéą░, ąĮąŠ čüą░ą╝ąĖ ąŠąĮąĖ ąĮąĄ ąŠč鹊ą▒čĆą░ąČą░čÄčéčüčÅ. ą¤ąŠą┤ąŠą▒ąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝ escape-ą║ąŠą┤čŗ ąĮąĄ ąŠč鹊ą▒čĆą░ąČą░čÄčéčüčÅ ą▓ č鹥čĆą╝ąĖąĮą░ą╗ąĄ, ą┐ąŠą║ą░ ąŠąĮ ąĖčģ čĆą░čüą┐ąŠąĘąĮą░ąĄčé. ąśąĮą░č湥 ąŠąĮąĖ ą┐ąŠčÅą▓čÅčéčüčÅ ąĮą░ 菹║čĆą░ąĮąĄ ą▓ ą╗ąĖč鹥čĆą░ą╗čīąĮąŠą╣ č乊čĆą╝ąĄ, ą║ą░ą║ ąĄčüą╗ąĖ ą▒čŗ ą▓čŗ ą┐čĆąŠčüą╝ą░čéčĆąĖą▓ą░ą╗ąĖ ąĖčüčģąŠą┤ąĮčŗą╣ ą║ąŠą┤ web-čüčéčĆą░ąĮąĖčåčŗ čüą░ą╣čéą░.
ąÜą░ą║ ą│ąŠą▓ąŠčĆąĖčé ąĮą░ąĘą▓ą░ąĮąĖąĄ, ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ą┤ąŠą╗ąČąĮą░ ąĮą░čćąĖąĮą░čéčīčüčÅ ąĮą░ ąĮąĄ ą┐ąĄčćą░čéą░ąĄą╝čŗą╣ čüąĖą╝ą▓ąŠą╗ Esc, čā ą║ąŠč鹊čĆąŠą│ąŠ ASCII-ąĘąĮą░č湥ąĮąĖąĄ ą║ąŠą┤ą░ 27. ąśąĮąŠą│ą┤ą░ čŹč鹊 ąĘąĮą░č湥ąĮąĖąĄ ą┐čĆąĄą┤čüčéą░ą╗čÅąĄčéčüčÅ ą▓ čłąĄčüčéąĮą░ą┤čåą░č鹥čĆąĖčćąĮąŠą╝ ą▓ąĖą┤ąĄ ą║ą░ą║ 0x1b, ąĖą╗ąĖ ą▓ ą▓ąŠčüčīą╝ąĄčĆąĖčćąĮąŠą╝ ą▓ąĖą┤ąĄ ą║ą░ą║ 033. ąÆčŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą╗ąĖč鹥čĆą░ą╗čŗ čćąĖčüąĄą╗ Python, čćč鹊ą▒čŗ ą▒čŗčüčéčĆąŠ ą┐čĆąŠą▓ąĄčĆąĖčéčī, čćč鹊 čŹčéąĖ ąĘąĮą░č湥ąĮąĖčÅ ąŠą┤ąĖąĮą░ą║ąŠą▓čŗąĄ:
>>> 27 == 0x1b == 0o33 True ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ąĄą│ąŠ ą╝ąŠąČąĮąŠ ą┐ąŠą╗čāčćąĖčéčī čü ą┐ąŠą╝ąŠčēčīčÄ escape-ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ \e ą▓ ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąĄ čłąĄą╗ą╗ą░:
$ echo -e "\e"
ąØą░ąĖą▒ąŠą╗ąĄąĄ čĆą░čüą┐čĆąŠčüčéčĆą░ąĮąĄąĮąĮčŗąĄ escape-ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ ANSI ąĖą╝ąĄčÄčé čüą╗ąĄą┤čāčÄčēąĖą╣ ą▓ąĖą┤:
ąŁą╗ąĄą╝ąĄąĮčé ą×ą┐ąĖčüą░ąĮąĖąĄ ą¤čĆąĖą╝ąĄčĆ
Esc
ąØąĄ ą┐ąĄčćą░čéą░ąĄą╝čŗą╣ čāą┐čĆą░ą▓ą╗čÅčÄčēąĖą╣ čüąĖą╝ą▓ąŠą╗
\033
[
ą×čéą║čĆčŗą▓ą░čÄčēą░čÅ ą║ą▓ą░ą┤čĆą░čéąĮą░čÅ čüą║ąŠą▒ą║ą░
[
čćąĖčüą╗ąŠą▓ąŠą╣ ą║ąŠą┤
ą×ą┤ąĮąŠ čćąĖčüą╗ąŠ, ąĖą╗ąĖ ąĮąĄčüą║ąŠą╗čīą║ąŠ čćąĖčüąĄą╗, čĆą░ąĘą┤ąĄą╗ąĄąĮąĮčŗčģ ;
0
čüąĖą╝ą▓ąŠą╗čīąĮčŗą╣ ą║ąŠą┤
ąæčāą║ą▓ą░ ą▓ ą▓ąĄčĆčģąĮąĄą╝ ąĖą╗ąĖ ąĮąĖąČąĮąĄą╝ čĆąĄą│ąĖčüčéčĆąĄ
m
ą¦ąĖčüą╗ąŠą▓ąŠą╣ ą║ąŠą┤ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠą┤ąĮąĖą╝ ąĖą╗ąĖ ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ čćąĖčüą╗ą░ą╝ąĖ, čĆą░ąĘą┤ąĄą╗ąĄąĮąĮčŗą╝ąĖ č鹊čćą║ąŠą╣ čü ąĘą░ą┐čÅč鹊ą╣, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ą║ąŠą┤ čüąĖą╝ą▓ąŠą╗ą░ - ą▓čüąĄą│ąŠ ąŠą┤ąĮą░ ą▒čāą║ą▓ą░. ąśčģ ą║ąŠąĮą║čĆąĄčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ čüčéą░ąĮą┤ą░čĆč鹊ą╝ ANSI. ąØą░ą┐čĆąĖą╝ąĄčĆ, čćč鹊ą▒čŗ čüą▒čĆąŠčüąĖčéčī ą▓čüąĄ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖąĄ, ą▓čŗ ą┤ąŠą╗ąČąĮčŗ ą▓ą▓ąĄčüčéąĖ ąŠą┤ąĮčā ąĖąĘ čüą╗ąĄą┤čāčÄčēąĖčģ ą║ąŠą╝ą░ąĮą┤, ą║ąŠč鹊čĆčŗąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą║ąŠą┤ ąĮąŠą╗čī ąĖ ą▒čāą║ą▓čā m:
$ echo -e "\e[0m"
$ echo -e "\x1b[0m"
$ echo -e "\033[0m"
ąØą░ ą┤čĆčāą│ąŠą╝ ą║ąŠąĮčåąĄ čüą┐ąĄą║čéčĆą░ ąĮą░čģąŠą┤čÅčéčüčÅ ąĘąĮą░č湥ąĮąĖčÅ čüąŠčüčéą░ą▓ąĮąŠą│ąŠ ą║ąŠą┤ą░. ąöą╗čÅ ąĮą░čüčéčĆąŠą╣ą║ąĖ čåą▓ąĄčéą░ ą┐ąĄčĆąĄą┤ąĮąĄą│ąŠ ą┐ą╗ą░ąĮą░ (foreground) ąĖ č乊ąĮą░ (background) čü ą║ą░ąĮą░ą╗ą░ą╝ąĖ RGB, čāčćąĖčéčŗą▓ą░čÅ, čćč鹊 ą▓ą░čł č鹥čĆą╝ąĖąĮą░ą╗ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé 24-ą▒ąĖčéąĮčāčÄ ą│ą╗čāą▒ąĖąĮčā, ą▓čŗ ą╝ąŠąČąĄč鹥 ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĮąŠą╝ąĄčĆąŠą▓:
$ echo -e "\e[38;2;0;0;0m\e[48;2;255;255;255mBlack on white\e[0m"
ąÆčŗ ą╝ąŠąČąĄč鹥 čāčüčéą░ąĮąŠą▓ąĖčéčī čü ą┐ąŠą╝ąŠčēčīčÄ escape-ą║ąŠą┤ąŠą▓ ANSI ąĮąĄ č鹊ą╗čīą║ąŠ čåą▓ąĄčé č鹥ą║čüčéą░. ąÆčŗ ą╝ąŠąČąĄč鹥, ąĮą░ą┐čĆąĖą╝ąĄčĆ, ąŠčćąĖčüčéąĖčéčī ąĖ ą┐čĆąŠą║čĆčāčéąĖčéčī ąŠą║ąĮąŠ č鹥čĆą╝ąĖąĮą░ą╗ą░, ąĖąĘą╝ąĄąĮąĖčéčī ąĄą│ąŠ č乊ąĮ, ą┐ąĄčĆąĄą╝ąĄčüčéąĖčéčī ą║čāčĆčüąŠčĆ, ąĘą░čüčéą░ą▓ąĖčéčī č鹥ą║čüčé ą╝ąĖą│ą░čéčī ąĖą╗ąĖ ą▓čŗą┤ąĄą╗ąĖčéčī ąĄą│ąŠ ą┐ąŠą┤č湥čĆą║ąĖą▓ą░ąĮąĖąĄą╝.
ąÆ Python ą▓čŗ, ą▓ąĄčĆąŠčÅčéąĮąŠ, ąĮą░ą┐ąĖčłąĄč鹥 ą▓čüą┐ąŠą╝ąŠą│ą░č鹥ą╗čīąĮčāčÄ čäčāąĮą║čåąĖčÄ, ą┐ąŠąĘą▓ąŠą╗čÅčÄčēčāčÄ čāą┐ą░ą║ąŠą▓čŗą▓ą░čéčī ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮčŗąĄ ą║ąŠą┤čŗ ą▓ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī:
>>> def esc (code ):... return f'\033[{code} m'
...>>> print (esc('31;1;4' ) + 'really' + esc(0 ) + ' important' )ąŁč鹊čé ą┤ąĄą╗ą░ąĄčé čüą╗ąŠą▓ąŠ ąĮą░ą┐ąĄčćą░čéą░ąĮąĮčŗą╝ ą║čĆą░čüąĮčŗą╝ čåą▓ąĄč鹊ą╝ (red), čłąĖčĆąŠą║ąĖą╝ čłčĆąĖčäč鹊ą╝ (bold), čü ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄą╝ ą┐ąŠą┤č湥čĆą║ąĖą▓ą░ąĮąĖčÅ (underline):
ą×ą┤ąĮą░ą║ąŠ čüčāčēąĄčüčéą▓čāčÄčé ą░ą▒čüčéčĆą░ą║čåąĖąĖ ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ ą┐ąŠ čüčĆą░ą▓ąĮąĄąĮąĖčÄ čü escape-ą║ąŠą┤ą░ą╝ąĖ ANSI, čéą░ą║ąĖąĄ ą║ą░ą║ čāąČąĄ čāą┐ąŠą╝čÅąĮčāčéą░čÅ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░ colorama, ą░ čéą░ą║ąČąĄ ąĖąĮčüčéčĆčāą╝ąĄąĮčéčŗ ą┤ą╗čÅ ą┐ąŠčüčéčĆąŠąĄąĮąĖčÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖčģ ąĖąĮč鹥čĆč乥ą╣čüąŠą▓ ą▓ ą║ąŠąĮčüąŠą╗ąĖ.
ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ ąĖąĮč鹥čĆč乥ą╣čüą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ą▓ ą║ąŠąĮčüąŠą╗ąĖ . ąźąŠčéčÅ ąĖą│čĆą░ čü escape-ą║ąŠą┤ą░ą╝ąĖ ANSI ąĘą░ąĮąĖą╝ą░č鹥ą╗čīąĮą░čÅ ą▓ąĄčēčī, ą▓ čĆąĄą░ą╗čīąĮąŠą╝ ą╝ąĖčĆąĄ ą▓čŗ čüą║ąŠčĆąĄąĄ ą▓čüąĄą│ąŠ ąĘą░čģąŠčéąĖč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▒ąŠą╗ąĄąĄ ą░ą▒čüčéčĆą░ą║čéąĮčŗąĄ čüčéčĆąŠąĖč鹥ą╗čīąĮčŗąĄ ą▒ą╗ąŠą║ąĖ, čćč鹊ą▒čŗ čüąŠą▒čĆą░čéčī ąĖąĘ ąĮąĖčģ ąĖąĮč鹥čĆč乥ą╣čü ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ. ąĪčāčēąĄčüčéą▓čāąĄčé ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ą┐ąŠą┤ąŠą▒ąĮčŗą╣ čāčĆąŠą▓ąĄąĮčī ą▓čŗčüąŠą║ąŠčāčĆąŠą▓ąĮąĄą▓ąŠą│ąŠ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ č湥čĆąĄąĘ č鹥čĆą╝ąĖąĮą░ą╗, ąŠą┤ąĮą░ą║ąŠ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░ curses ą▓čŗą│ą╗čÅą┤ąĖčé ąĮą░ąĖą▒ąŠą╗ąĄąĄ ą┐ąŠą┐čāą╗čÅčĆąĮčŗą╝ ą▓čŗą▒ąŠčĆąŠą╝.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ curses ąĮą░ Windows, ą▓ą░ą╝ ąĮčāąČąĮąŠ ą▒čāą┤ąĄčé čāčüčéą░ąĮąŠą▓ąĖčéčī čüč鹊čĆąŠąĮąĮąĖą╣ ą┐ą░ą║ąĄčé:
C:\> pip install windows-curses
ą¤čĆąĖčćąĖąĮą░ ą▓ č鹊ą╝, čćč鹊 curses ąĮąĄą┤ąŠčüčéčāą┐ąĮą░ ą▓ ą┤ąĖčüčéčĆąĖą▒čāčéąĖą▓ąĄ Python čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ Windows.
ąÆ ą┐ąĄčĆą▓čāčÄ ąŠč湥čĆąĄą┤čī čŹč鹊 ą┐ąŠąĘą▓ąŠą╗ąĖčé ą┐čĆąĖ ą┐čĆąŠąĄą║čéąĖčĆąŠą▓ą░ąĮąĖąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą╝čŗčüą╗ąĖčéčī ą▓ č鹥čĆą╝ąĖąĮą░čģ ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗčģ ą│čĆą░čäąĖč湥čüą║ąĖčģ ą│čĆą░čäąĖč湥čüą║ąĖčģ ą▓ąĖą┤ąČąĄą║č鹊ą▓ ą▓ą╝ąĄčüč鹊 ą▓čŗą▓ąŠą┤ą░ ą▒ąŠą╗čīčłąĖčģ ą▒ą╗ąŠą║ąŠą▓ č鹥ą║čüčéą░. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ą▓čŗ ą┐ąŠą╗čāčćą░ąĄč鹥 ą▒ąŠą╗čīčłąĄ čüą▓ąŠą▒ąŠą┤čŗ ą║ą░ą║ čģčāą┤ąŠąČąĮąĖą║, ą┐ąŠč鹊ą╝čā čćč鹊 ą║ą░ą║ ą▒čāą┤č鹊 čĆąĄą░ą╗čīąĮąŠ čĆą░čüą┐ąŠčĆčÅąČą░ąĄč鹥čüčī čĆąĖčüąŠą▓ą░ąĮąĖąĄą╝ ąĮą░ čćąĖčüč鹊ą╝ čģąŠą╗čüč鹥. ąæąĖą▒ą╗ąĖąŠč鹥ą║ą░ čüą║čĆčŗą▓ą░ąĄčé čüą╗ąŠąČąĮąŠčüčéąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čĆą░ąĘą╗ąĖčćąĖą╣ čĆąĄą░ą╗ąĖąĘą░čåąĖą╣ č鹥čĆą╝ąĖąĮą░ą╗ąŠą▓. ąÜčĆąŠą╝ąĄ čŹč鹊ą│ąŠ, ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░ ąĖą╝ąĄąĄčé ą▒ąŠą╗čīčłčāčÄ ą┐ąŠą┤ą┤ąĄčƹȹ║čā čüąŠą▒čŗčéąĖą╣ ą║ą╗ą░ą▓ąĖą░čéčāčĆčŗ, čćč鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠą╗ąĄąĘąĮąŠ ą┤ą╗čÅ ąĮą░ą┐ąĖčüą░ąĮąĖčÅ ą▓ąĖą┤ąĄąŠąĖą│čĆ.
ąÜą░ą║ ąĮą░čüč湥čé čüąŠąĘą┤ą░ąĮąĖčÅ čĆąĄčéčĆąŠ-ąĖą│čĆčŗ "ąĘą╝ąĄą╣ą║ą░"? ąöą░ą▓ą░ą╣č鹥 čüąŠąĘą┤ą░ą┤ąĖą╝ ąĮą░ Python čüąĖą╝čāą╗čÅč鹊čĆ ąĘą╝ąĄąĖ:
ąĪąĮą░čćą░ą╗ą░ ą▓ą░ą╝ ąĮčāąČąĮąŠ ąĖą╝ą┐ąŠčĆčéąĖčĆąŠą▓ą░čéčī ą╝ąŠą┤čāą╗čī curses . ą¤ąŠčüą║ąŠą╗čīą║čā čŹč鹊 ąĖąĘą╝ąĄąĮąĖčé čüąŠčüč鹊čÅąĮąĖąĄ čĆą░ą▒ąŠčéą░čÄčēąĄą│ąŠ č鹥čĆą╝ąĖąĮą░ą╗ą░, ą▓ą░ąČąĮąŠ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčī ąŠčłąĖą▒ą║ąĖ ąĖ ą║ąŠčĆčĆąĄą║čéąĮąŠ ą▓ąŠčüčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čéčī ą┐čĆąĄą┤čŗą┤čāčēąĄąĄ čüąŠčüč鹊čÅąĮąĖąĄ. ąÆčŗ ą╝ąŠąČąĄč鹥 čüą┤ąĄą╗ą░čéčī čŹč鹊 ą▓čĆčāčćąĮčāčÄ, ąĮąŠ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░ ą┐ąŠčüčéą░ą▓ą╗čÅąĄčéčüčÅ čü čāą┤ąŠą▒ąĮąŠą╣ ąŠą▒ąĄčĆčéą║ąŠą╣ ą┤ą╗čÅ ą▓ą░čłąĄą╣ čäčāąĮą║čåąĖąĖ main:
import cursesdef main (screen ):
pass if __name__ == '__main__' :
curses.wrapper(main)ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čäčāąĮą║čåąĖčÅ ą┤ąŠą╗ąČąĮą░ ą┐čĆąĖąĮčÅčéčī čüčüčŗą╗ą║čā ąĮą░ ąŠą▒čŖąĄą║čé screen, čéą░ą║ąČąĄ ąĖąĘą▓ąĄčüčéąĮčŗą╣ ą║ą░ą║ stdscr, ą║ąŠč鹊čĆčŗą╣ ą▓čŗ ą▒čāą┤ąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┐ąŠąĘąČąĄ ą┤ą╗čÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĮą░čüčéčĆąŠą╣ą║ąĖ.
ąĢčüą╗ąĖ ą▓čŗ čüąĄą╣čćą░čü ąĘą░ą┐čāčüčéąĖč鹥 čŹčéčā ą┐čĆąŠą│čĆą░ą╝ą╝čā, č鹊 ąĮąĄ čāą▓ąĖą┤ąĖč鹥 ąĮąĖą║ą░ą║ąŠą│ąŠ čŹčäč乥ą║čéą░, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąĮą░ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ. ą×ą┤ąĮą░ą║ąŠ ą▓čŗ ą╝ąŠąČąĄč鹥 ą┤ąŠą▒ą░ą▓ąĖčéčī ąĮąĄą▒ąŠą╗čīčłčāčÄ ąĘą░ą┤ąĄčƹȹ║čā ą┤ą╗čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą┐čĆąŠą┤ą▓ąĖąČąĄąĮąĖčÅ ąĘą╝ąĄąĖ:
import time, cursesdef main (screen ):
time.sleep(1 )if __name__ == '__main__' :
curses.wrapper(main)ąÆ č鹥č湥ąĮąĖąĄ čŹč鹊ą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ 1 čüąĄą║čāąĮą┤čŗ 菹║čĆą░ąĮ ą▒čāą┤ąĄčé ą┐ąŠą╗ąĮąŠčüčéčīčÄ č鹥ą╝ąĮčŗą╝, ą▒čāą┤ąĄčé č鹊ą╗čīą║ąŠ ą╝ąĄčĆčåą░čéčī ą║čāčĆčüąŠčĆ. ą¦č鹊ą▒čŗ ąĄą│ąŠ čüą┐čĆčÅčéą░čéčī, ą▓čŗąĘąŠą▓ąĖč鹥 čäčāąĮą║čåąĖčÄ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčāčÄ ą▓ ą╝ąŠą┤čāą╗ąĄ:
import time, cursesdef main (screen ):
curses.curs_set(0 ) # čŹč鹊 čüą┐čĆčÅč湥čé ą║čāčĆčüąŠčĆ
time.sleep(1 )if __name__ == '__main__' :
curses.wrapper(main)ąöą░ą▓ą░ą╣č鹥 ąŠą┐čĆąĄą┤ąĄą╗ąĖą╝ ąĘą╝ąĄą╣ą║čā ą║ą░ą║ čüą┐ąĖčüąŠą║ č鹊č湥ą║ ą▓ ą▓ąĖą┤ąĄ ą║ąŠąŠčĆą┤ąĖąĮą░čé ąĮą░ 菹║čĆą░ąĮąĄ:
snake = [(0 , i) for i in reversed (range (20 ))]
ąōąŠą╗ąŠą▓ą░ ąĘą╝ąĄąĖ ą▓čüąĄą│ą┤ą░ ą▒čāą┤ąĄčé ą┐ąĄčĆą▓čŗą╝ 菹╗ąĄą╝ąĄąĮč鹊ą╝ čŹč鹊ą│ąŠ čüą┐ąĖčüą║ą░, ą▓ č鹊 ą▓čĆąĄą╝čÅ čģą▓ąŠčüč鹊ą╝ ą▒čāą┤ąĄčé ą┐ąŠčüą╗ąĄą┤ąĮąĖą╣ 菹╗ąĄą╝ąĄąĮčé. ąĪąĮą░čćą░ą╗ą░ ąĘą╝ąĄčÅ ą▒čāą┤ąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī ą║ą░ą║ ą│ąŠčĆąĖąĘąŠąĮčéą░ą╗čīąĮą░čÅ ą┐ąŠą╗ąŠčüą║ą░ ąĖąĘ ąĘą▓ąĄąĘą┤ąŠč湥ą║, ąŠą▒čĆą░čēąĄąĮąĮą░čÅ ą▓ą┐čĆą░ą▓ąŠ, ąĮą░čćąĖąĮą░čÅčüčī ąŠčé ą▓ąĄčĆčģąĮąĄą│ąŠ ą╗ąĄą▓ąŠą│ąŠ čāą│ą╗ą░ 菹║čĆą░ąĮą░. ąÆ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ą║ąŠąŠčĆą┤ąĖąĮą░čéą░ y čüąŠčģčĆą░ąĮčÅąĄčéčüčÅ ąĮčāą╗ąĄą▓ąŠą╣, ą║ąŠąŠčĆą┤ąĖąĮą░čéą░ x čāą╝ąĄąĮčīčłą░č鹥čüčÅ ąŠčé ą│ąŠą╗ąŠą▓čŗ ą║ čģą▓ąŠčüčéčā.
ą¦č鹊ą▒čŗ ąĮą░čĆąĖčüąŠą▓ą░čéčī ąĘą╝ąĄčÄ, ąĮą░čćąĮąĖč鹥 čü ą│ąŠą╗ąŠą▓čŗ, ąĖ ą▓čŗą┐ąŠą╗ąĮąĖč鹥 čåąĖą║ą╗ ą┐ąŠ ąŠčüčéą░ą▓čłąĖą╝čüčÅ čüąĄą│ą╝ąĄąĮčéą░ą╝. ąÜą░ąČą┤čŗą╣ čüąĄą│ą╝ąĄąĮčé čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ą║ąŠąŠčĆą┤ąĖąĮą░čéą░ą╝ (y, x):
# ąĀąĖčüąŠą▓ą░ąĮąĖąĄ ąĘą╝ąĄąĖ:
screen.addstr(*snake[0 ], '@' )for segment in snake[1 :]:
screen.addstr(*segment, '*' )ąś ąŠą┐čÅčéčī-čéą░ą║ąĖ, ąĄčüą╗ąĖ ą▓čŗ ąĘą░ą┐čāčüčéąĖč鹥 čŹč鹊čé ą║ąŠą┤, č鹊 ąŠąĮ ąĮąĖč湥ą│ąŠ ąĮąĄ ąŠč鹊ą▒čĆą░ąĘąĖčé, ą┐ąŠč鹊ą╝čā čćč鹊 ą┐ąŠčüą╗ąĄ čåąĖą║ą╗ą░ čĆąĖčüąŠą▓ą░ąĮąĖčÅ ą▓čŗ ą┤ąŠą╗ąČąĮčŗ čÅą▓ąĮąŠ ąŠą▒ąĮąŠą▓ąĖčéčī 菹║čĆą░ąĮ:
import time, cursesdef main (screen ):
curses.curs_set(0 ) # čŹč鹊 čüą┐čĆčÅč湥čé ą║čāčĆčüąŠčĆ
snake = [(0 , i) for i in reversed (range (20 ))]# ąØą░čĆąĖčüčāąĄčé ąĘą╝ąĄą╣ą║čā
screen.addstr(*snake[0 ], '@' )
for segment in snake[1 :]:
screen.addstr(*segment, '*' )1 )if __name__ == '__main__' :
curses.wrapper(main)ąŚą╝ąĄą╣ą║ą░ ą┤ąŠą╗ąČąĮą░ ą┐ąĄčĆąĄą╝ąĄčēą░čéčīčüčÅ ą▓ ąŠą┤ąĮąŠą╝ ąĖąĘ 4 ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖą╣, ą║ąŠč鹊čĆčŗąĄ ą▓čŗ ą╝ąŠąČąĄč鹥 ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą║ą░ą║ ą▓ąĄą║č鹊čĆčŗ. ąóą░ą║ ąĖą╗ąĖ ąĖąĮą░č湥, ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ ąĘą╝ąĄąĖ ą▒čāą┤ąĄčé čüąŠąŠčéą▓ąĄčéčüč鹊ą▓ą░čéčī ą║ą░ąČą░čéąĖčÄ ą║ą╗ą░ą▓ąĖčł čüąŠ čüčéčĆąĄą╗ą║ą░ą╝ąĖ, ą┐ąŠčŹč鹊ą╝čā ą▓čŗ ą╝ąŠąČąĄč鹥 čüą▓čÅąĘą░čéčī ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čü ą║ąŠą┤ą░ą╝ąĖ ą║ąŠą┤čŗ ą║ą╗ą░ą▓ąĖčł:
directions = {
curses.KEY_UP: (-1 , 0 ),
curses.KEY_DOWN: (1 , 0 ),
curses.KEY_LEFT: (0 , -1 ),
curses.KEY_RIGHT: (0 , 1 ),
}
ąÜą░ą║ ą┤ą▓ąĖąČąĄčéčüčÅ ąĘą╝ąĄčÅ? ą¤ąŠą╗čāčćą░ąĄčéčüčÅ, čćč鹊 ą│ąŠą╗ąŠą▓ą░ ą┐ąŠčÅą▓ąĖčéčüčÅ ąĮą░ ąĮąŠą▓ąŠą╝ ą╝ąĄčüč鹥, ą┐čĆąĖ čŹč鹊ą╝ ąĄčæ ąĮą░ą┤ąŠ ąĮą░ čüčéą░čĆąŠą╝ ą╝ąĄčüč鹥 ąĘą░ą╝ąĄąĮąĖčéčī ąĘą▓ąĄąĘą┤ąŠčćą║ąŠą╣, ąĖ ą▓čüąĄ č鹥ą╗ąŠ ą┤ąŠą╗ąČąĮąŠ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░čéčī ąĘą░ ą│ąŠą╗ąŠą▓ąŠą╣, čé. ąĄ. ąĘą▓ąĄąĘą┤ąŠčćą║čā ą▓ ą┐ąŠąĘąĖčåąĖąĖ čģą▓ąŠčüčéą░ ąĮčāąČąĮąŠ čüč鹥čĆąĄčéčī. ąØą░ ą║ą░ąČą┤ąŠą╝ čłą░ą│ąĄ ą┐ąŠčćčéąĖ ą▓čüąĄ čüąĄą│ą╝ąĄąĮčéčŗ č鹥ą╗ą░ ąĘą╝ąĄąĖ ąŠčüčéą░ąĮčāčéčüčÅ ąĮą░ čüčéą░čĆąŠą╝ ą╝ąĄčüč鹥, ą╝ąĄąĮčÅčÄčéčüčÅ č鹊ą╗čīą║ąŠ ą┐ąŠąĘąĖčåąĖąĖ ą│ąŠą╗ąŠą▓čŗ ąĖ čģą▓ąŠčüčéą░. ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ąĘą╝ąĄčÅ ąĮąĄ čĆą░čüč鹥čé, č鹊ą│ą┤ą░ ą▓čŗ ą╝ąŠąČąĄč鹥 čāą┤ą░ą╗ąĖčéčī 菹╗ąĄą╝ąĄąĮčé čģą▓ąŠčüčéą░ ąĖ ą▓čüčéą░ą▓ąĖčéčī ąĮąŠą▓čāčÄ ą│ąŠą╗ąŠą▓čā ą▓ ąĮą░čćą░ą╗ąŠ čüą┐ąĖčüą║ą░:
# ą¤ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ ąĘą╝ąĄąĖ
snake.pop()
snake.insert(0 , tuple (map (sum , zip (snake[0 ], direction))))ą¦č鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ąĮąŠą▓čŗąĄ ą║ąŠąŠčĆą┤ąĖąĮą░čéčŗ ą│ąŠą╗ąŠą▓čŗ, ą▓ą░ą╝ ąĮčāąČąĮąŠ ą┤ą╗čÅ ąĮąĄčæ ą┤ąŠą▒ą░ą▓ąĖčéčī ą▓ąĄą║č鹊čĆ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ. ą×ą┤ąĮą░ą║ąŠ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ ą║ąŠčĆč鹥ąČąĄą╣ ą▓ Python ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ą▒ąŠą╗čīčłąĄą╝čā ą║ąŠčĆč鹥ąČčā ą▓ą╝ąĄčüč鹊 ą░ą╗ą│ąĄą▒čĆą░ąĖč湥čüą║ąŠą╣ čüčāą╝ą╝čŗ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖčģ ą▓ąĄą║č鹊čĆąĮčŗčģ ą║ąŠą╝ą┐ąŠąĮąĄąĮč鹊ą▓. ą×ą┤ąĖąĮ ąĖąĘ čüą┐ąŠčüąŠą▒ąŠą▓ ąĖčüą┐čĆą░ą▓ąĖčéčī čŹč鹊 - ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓čüčéčĆąŠąĄąĮąĮčŗąĄ čäčāąĮą║čåąĖąĖ zip() , sum() ąĖ map() .
ąØą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą▒čāą┤ąĄčé ą╝ąĄąĮčÅčéčīčüčÅ ą┐ąŠ ąĮą░ąČą░čéąĖčÄ ą║ą╗ą░ą▓ąĖčłąĖ, čéą░ą║ čćč鹊 ą▓ą░ą╝ ąĮčāąČąĮąŠ ą▒čāą┤ąĄčé ą▓čŗąĘą▓ą░čéčī .getch() , čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ą║ąŠą┤ ąĮą░ąČą░č鹊ą╣ ą║ą╗ą░ą▓ąĖčłąĖ. ą×ą┤ąĮą░ą║ąŠ ąĄčüą╗ąĖ ąĮą░ąČą░čéą░čÅ ą║ą╗ą░ą▓ąĖčłą░ ąĮąĄ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ą║ą╗ą░ą▓ąĖčłą░ą╝ čüąŠ čüčéčĆąĄą╗ą║ą░ą╝ąĖ, ą║ąŠč鹊čĆčŗąĄ ą╝čŗ čĆą░ąĮąĄąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĖą╗ąĖ ą▓ čüą╗ąŠą▓ą░čĆąĄ directions, č鹊 ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅąĄčéčüčÅ:
# ąśąĘą╝ąĄąĮąĄąĮąĖąĄ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ąŠ ą║ą╗ą░ą▓ąĖčłąĄ čüąŠ čüčéčĆąĄą╗ą║ąŠą╣
direction = directions.get(screen.getch(), direction)ą×ą┤ąĮą░ą║ąŠ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ .getch() čĆą░ą▒ąŠčéą░ąĄčé ą║ą░ą║ ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĖą╣ ą▓čŗąĘąŠą▓, ą║ąŠč鹊čĆčŗą╣ ąĮąĄ ą┤ą░čüčé ą┐ąĄčĆąĄą╝ąĄčüčéąĖčéčīčüčÅ ąĘą╝ąĄą╣ą║ąĄ, ą┐ąŠą║ą░ ąĮąĄ ą▒čāą┤ąĄčé ąĮą░ąČą░čéą░ ą║ą╗ą░ą▓ąĖčłą░. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą▓ą░ą╝ ąĮčāąČąĮąŠ čüą┤ąĄą╗ą░čéčī ąĮąĄ ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĖą╣ ą▓čŗąĘąŠą▓, ą┐čāč鹥ą╝ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ ąĮąĄą╝ąĮąŠą│ąŠ ą┤čĆčāą│ąŠą╣ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ:
def main (screen ):
curses.curs_set(0 ) # čŹč鹊 čüą┐čĆčÅč湥čé ą║čāčĆčüąŠčĆ
screen.nodelay(True ) # ąĮąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░čéčī ą▓čŗąĘąŠą▓čŗ I/O ąś čŹč鹊 ą┐ąŠčćčéąĖ ą▓čüąĄ, ąĮąŠ ąŠčüčéą░ą╗ąŠčüčī č鹊ą╗čīą║ąŠ ąŠą┤ąĮąŠ ą┐ąŠčüą╗ąĄą┤ąĮąĄąĄ. ąĢčüą╗ąĖ ą▓čŗ č鹥ą┐ąĄčĆčī ąĘą░čåąĖą║ą╗ąĖą▓ą░ąĄč鹥 čŹč鹊čé ą║ąŠą┤, ąĘą╝ąĄčÅ ą▒čāą┤ąĄčé čĆą░čüčéąĖ, ą░ ąĮąĄ ą┤ą▓ąĖą│ą░čéčīčüčÅ. ąŁč鹊 ą┐ąŠč鹊ą╝čā, čćč鹊 ą┐ąĄčĆąĄą┤ ą║ą░ąČą┤ąŠą╣ ąĖč鹥čĆą░čåąĖąĄą╣ ą▓čŗ ą┤ąŠą╗ąČąĮčŗ čÅą▓ąĮąŠ čüč鹥čĆąĄčéčī 菹║čĆą░ąĮ.
ąØą░ą║ąŠąĮąĄčå, ą▓ąŠčé ą┐ąŠą╗čāčćąĖą▓čłąĖą╣čüčÅ ą║ąŠą┤ ą┤ą╗čÅ ąĖą│čĆčŗ ą▓ ąĘą╝ąĄčÄ ąĮą░ Python:
import time, cursesdef main (screen ):
curses.curs_set(0 ) # čŹč鹊 čüą┐čĆčÅč湥čé ą║čāčĆčüąŠčĆ
screen.nodelay(True ) # ąĮąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░čéčī ą▓čŗąĘąŠą▓čŗ I/O
directions = {
curses.KEY_UP: (-1 , 0 ),
curses.KEY_DOWN: (1 , 0 ),
curses.KEY_LEFT: (0 , -1 ),
curses.KEY_RIGHT: (0 , 1 ),
}0 , i) for i in reversed (range (20 ))]while True :
screen.erase()# ąĀąĖčüąŠą▓ą░ąĮąĖąĄ ąĘą╝ąĄąĖ
screen.addstr(*snake[0 ], '@' )
for segment in snake[1 :]:
screen.addstr(*segment, '*' )# ą¤ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ ąĘą╝ąĄąĖ
snake.pop()
snake.insert(0 , tuple (map (sum , zip (snake[0 ], direction))))# ąśąĘą╝ąĄąĮąĄąĮąĖąĄ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ąŠ ą║ą╗ą░ą▓ąĖčłąĄ čüąŠ čüčéčĆąĄą╗ą║ąŠą╣
direction = directions.get(screen.getch(), direction)0.1 )if __name__ == '__main__' :
curses.wrapper(main)ąŁč鹊čé ą┐čĆąĖą╝ąĄčĆ č鹊ą╗čīą║ąŠ ą┐čĆąĖąŠčéą║čĆčŗą▓ą░ąĄčé čćą░čüčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüč鹥ą╣, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą╝ąŠą┤čāą╗čī curses. ąÆčŗ ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĄą│ąŠ ą┤ą╗čÅ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ąĖą│čĆ, ą┐ąŠą┤ąŠą▒ąĮčŗčģ čŹč鹊ą╣, ąĖą╗ąĖ ą▒ąŠą╗ąĄąĄ ą▒ąĖąĘąĮąĄčü-ąŠčĆąĖąĄąĮčéąĖčĆąŠą▓ą░ąĮąĮčŗčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣.
ąöąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ ą░ąĮąĖą╝ą░čåąĖą╣ . ąĢčüčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĖąĮč鹥čĆąĄčüąĮčŗčģ čüą┐ąŠčüąŠą▒ąŠą▓ ąŠąČąĖą▓ąĖčéčī ąĖąĮč鹥čĆč乥ą╣čü ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ. ąŁčéąĖą╝ ą▓čŗ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖč鹥 ąŠą▒čĆą░čéąĮčāčÄ čüą▓čÅąĘčī, čćč鹊 ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ąĮąĄ ąĘą░ą▓ąĖčüą╗ą░, ąĮą░ą┤ č湥ą╝-č鹊 čĆą░ą▒ąŠčéą░ąĄčé, ąĖ ą┐ąŠą║ą░ ąĮąĄ ą▓čĆąĄą╝čÅ ąĄčæ ąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čéčī.
ąöą╗čÅ ą░ąĮąĖą╝ą░čåąĖąĖ č鹥ą║čüčéą░ ą▓ č鹥čĆą╝ąĖąĮą░ą╗ąĄ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ąĖą╝ąĄčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī čüą▓ąŠą▒ąŠą┤ąĮąŠą│ąŠ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ ą║čāčĆčüąŠčĆą░. ąÆčŗ ą╝ąŠąČąĄč鹥 čüą┤ąĄą╗ą░čéčī čŹč鹊 čü ą┐ąŠą╝ąŠčēčīčÄ ąŠą┤ąĮąŠą│ąŠ ąĖąĘ ąĖąĮčüčéčĆčāą╝ąĄąĮč鹊ą▓, čāą┐ąŠą╝čÅąĮčāčéčŗčģ čĆą░ąĮąĄąĄ, č鹊 ąĄčüčéčī escape-ą║ąŠą┤ąŠą▓ ANSI ąĖą╗ąĖ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ curses. ąóąĄą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ ąĄčüčéčī ąĄčēąĄ ą▒ąŠą╗ąĄąĄ ą┐čĆąŠčüč鹊ą╣ čüą┐ąŠčüąŠą▒.
ąĢčüą╗ąĖ ą░ąĮąĖą╝ą░čåąĖčÅ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠą│čĆą░ąĮąĖč湥ąĮą░ ąŠą┤ąĮąŠą╣ čüčéčĆąŠą║ąŠą╣ č鹥ą║čüčéą░, č鹊 ą▓ą░čü ą╝ąŠą│čāčé ąĘą░ąĖąĮč鹥čĆąĄčüąŠą▓ą░čéčī ą┤ą▓ąĄ čüą┐ąĄčåąĖą░ą╗čīąĮčŗąĄ escape-ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ čüąĖą╝ą▓ąŠą╗ąŠą▓:
ąÆąŠąĘą▓čĆą░čé ą║ą░čĆąĄčéą║ąĖ (Carriage Return, CR): \r \b
ąÜąŠą┤ \r ą┐ąĄčĆąĄą╝ąĄčüčéąĖčé ą║čāčĆčüąŠčĆ ą▓ ąĮą░čćą░ą╗ąŠ č鹥ą║čāčēąĄą╣ čüčéčĆąŠą║ąĖ, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ \b ą┐ąĄčĆąĄą╝ąĄčüčéąĖčé ą║čāčĆčüąŠčĆ ąĮą░ ąŠą┤ąĮčā ą┐ąŠąĘčåąĖąĖčÄ ą▓ą╗ąĄą▓ąŠ. ą×ą▒ą░ čŹčéąĖčģ ą║ąŠą┤ą░ čĆą░ą▒ąŠčéą░čÄčé ąĮąĄ ą┤ąĄčüčéčĆčāą║čéąĖą▓ąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝, ą▒ąĄąĘ ą┐ąĄčĆąĄąĘą░ą┐ąĖčüąĖ č鹥ą║čüčéą░ ą▓ ą┐ąŠąĘąĖčåąĖąĖ, ą│ą┤ąĄ ąŠąĮ čāąČąĄ ą▒čŗą╗ ąĘą░ą┐ąĖčüą░ąĮ.
ąöą░ą▓ą░ą╣č鹥 čĆą░čüčüą╝ąŠčéčĆąĖą╝ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐čĆąĖą╝ąĄčĆąŠą▓.
ąÆčŗ ąĖąĮąŠą│ą┤ą░ ą▓ąĄčĆąŠčÅčéąĮąŠ ąĘą░čģąŠčéąĖč鹥 ąŠč鹊ą▒čĆą░ąĘąĖčéčī ą▓čĆą░čēą░čÄčēčāčÄčüčÅ ą┐ą░ą╗ąŠčćą║čā, čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī, čćč鹊 ąĖą┤ąĄčé ą║ą░ą║ą░čÅ-č鹊 čĆą░ą▒ąŠčéą░, ąĖ ą┐ąŠą║ą░ ąĮąĄąĖąĘą▓ąĄčüčéąĮąŠ čüą║ąŠą╗čīą║ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą┐ąŠčéčĆąĄą▒čāąĄčéčüčÅ ą┤ą╗čÅ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ:
ą£ąĮąŠą│ąĖąĄ čāčéąĖą╗ąĖčéčŗ ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąĖ ąĖčüą┐ąŠą╗čīąĘčāčÄčé čŹč鹊čé čéčĆčÄą║ ą┐čĆąĖ ąĘą░ą│čĆčāąĘą║ąĄ ą┤ą░ąĮąĮčŗčģ ą┐ąŠ čüąĄčéąĖ. ąÆčŗ ą╝ąŠąČąĄč鹥 čüą┤ąĄą╗ą░čéčī ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠ ą┐čĆąŠčüčéčāčÄ ą░ąĮąĖą╝ą░čåąĖčÄ ąĖąĘ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ čüąĖą╝ą▓ąŠą╗ąŠą▓, ą║ąŠč鹊čĆčŗąĄ ą▒čāą┤čāčé čüą╝ąĄąĮčÅčéčī ą┤čĆčāą│ ą┤čĆčāą│ą░ čåąĖą║ą╗ąĖč湥čüą║ąĖ:
from itertools import cyclefrom time import sleepfor frame in cycle(r'-\|/-\|/' ):
print ('\r' , frame, sep='' , end='' , flush=True )
sleep(0.2 )ą”ąĖą║ą╗ ą▒ąĄčĆąĄčé čüą╗ąĄą┤čāčÄčēąĖą╣ čüąĖą╝ą▓ąŠą╗ ą┤ą╗čÅ ą┐ąĄčćą░čéąĖ, ąĘą░č鹥ą╝ ą┐ąĄčĆąĄą╝ąĄčēą░ąĄčé ą║čāčĆčüąŠčĆ ą▓ ąĮą░čćą░ą╗ąŠ čüčéčĆąŠą║ąĖ, ąĖ ą┐ąĄčĆąĄąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé ą┐čĆąĄą┤čŗą┤čāčēąĖą╣ čüąĖą╝ą▓ąŠą╗ ą▓ ąŠą┤ąĮąŠą╣ ąĖ č鹊ą╣ ąČąĄ ą┐ąŠąĘąĖčåąĖąĖ, ą▒ąĄąĘ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ. ąøąĖčłąĮąĖą╣ ą┐čĆąŠą▒ąĄą╗ ą╝ąĄąČą┤čā ą┐ąŠąĘąĖčåąĖąŠąĮąĮčŗą╝ąĖ ą░čĆą│čāą╝ąĄąĮčéą░ą╝ąĖ ąĮąĄ ąĮčāąČąĄąĮ, ą┐ąŠčŹč鹊ą╝čā ą┐ą░čĆą░ą╝ąĄčéčĆ čĆą░ąĘą┤ąĄą╗ąĖč鹥ą╗čÅ sep ąĮčāąČąĮąŠ čāčüčéą░ąĮąŠą▓ąĖčéčī ą▓ ą┐čāčüčéčāčÄ čüčéčĆąŠą║čā ''. ąóą░ą║ąČąĄ ąŠą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĘą┤ąĄčüčī ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┐čĆąĄčäąĖą║čü r ą┤ą╗čÅ ąŠą▒ąŠąĘąĮą░č湥ąĮąĖčÅ čüčŗčĆąŠą╣ čüčéčĆąŠą║ąĖ ą╗ąĖč鹥čĆą░ą╗ą░ (raw), ą┐ąŠč鹊ą╝čā čćč鹊 ą▓ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ čüąĖą╝ą▓ąŠą╗ąŠą▓ ą┐čĆąĖčüčāčéčüčéą▓čāąĄčé čüąĖą╝ą▓ąŠą╗čŗ backslash.
ąÜąŠą│ą┤ą░ ą▓čŗ ąĘąĮą░ąĄč鹥, čüą║ąŠą╗čīą║ąŠ ąŠčüčéą░ą╗ąŠčüčī ą▓čĆąĄą╝ąĄąĮąĖ ą┤ąŠ ąŠą║ąŠąĮčćą░ąĮąĖčÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĘą░ą┤ą░čćąĖ, ąĖą╗ąĖ čüą║ąŠą╗čīą║ąŠ ą┐čĆąŠčåąĄąĮč鹊ą▓ čĆą░ą▒ąŠčéčŗ čāąČąĄ čüą┤ąĄą╗ą░ąĮąŠ, č鹊 ą╝ąŠąČąĄč鹥 ą┐ąŠą║ą░ąĘą░čéčī ą░ąĮąĖą╝ąĖčĆąŠą▓ą░ąĮąĮčāčÄ ą┐ąŠą╗ąŠčüčā ą┐čĆąŠą│čĆąĄčüčüą░:
ąÆąŠ-ą┐ąĄčĆą▓čŗčģ, ąĮčāąČąĮąŠ ą┐ąŠą┤čüčćąĖčéą░čéčī, čüą║ąŠą╗čīą║ąŠ čüąĖą╝ą▓ąŠą╗ąŠą▓ # ąŠč鹊ą▒čĆą░ąČą░čéčī, ąĖ čüą║ąŠą╗čīą║ąŠ ą┐čĆąŠą▒ąĄą╗ąŠą▓ ą▓čüčéą░ą▓ą╗čÅčéčī. ąöą░ą╗ąĄąĄ ą▓čŗ čüčéąĖčĆą░ąĄč鹥 čüčéčĆąŠą║čā ąĖ čüčéčĆąŠąĖč鹥 ą┐ąŠą╗ąŠčüą║čā ą┐čĆąŠą│čĆąĄčüčüą░ čü ąĮčāą╗čÅ:
from time import sleepdef progress (percent=0 , width=30 ):
left = width * percent // 100
right = width - left
print ('\r[' , '#' * left, ' ' * right, ']' ,
f' {percent:.0 f} %' ,
sep='' , end='' , flush=True )for i in range (101 ):
progress(i)
sleep(0.1 )ąÜą░ą║ ąĖ čĆą░ąĮčīčłąĄ, ą║ą░ąČą┤čŗą╣ ąĘą░ą┐čĆąŠčü ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ ą┐ąĄčĆąĄčĆąĖčüčāąĄčé ą▓čüčÄ čüčéčĆąŠą║čā.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: čüčāčēąĄčüčéą▓čāąĄčé ą╝ąĮąŠą│ąŠčäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮą░čÅ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░ progressbar2, ąĮą░čĆčÅą┤čā čü ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ ą┤čĆčāą│ąĖą╝ąĖ ą░ąĮą░ą╗ąŠą│ąĖčćąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░ą╝ąĖ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą┐ąŠą║ą░ąĘą░čéčī ą┐čĆąŠą│čĆąĄčüčü ą│ąŠčĆą░ąĘą┤ąŠ ą▒ąŠą╗ąĄąĄ ą▓čüąĄąŠą▒čŖąĄą╝ą╗čÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝.
ąŚą▓čāą║ąĖ ą▓ą╝ąĄčüč鹥 čü print() . ąĢčüą╗ąĖ ą▓čŗ ą┤ąŠčüčéą░č鹊čćąĮąŠ čüčéą░čĆčŗ, čćč鹊 ą┐ąŠą╝ąĮąĖč鹥 ą║ąŠą╝ą┐čīčÄč鹥čĆčŗ čü PC čüą┐ąĖą║ąĄčĆąŠą╝, č鹊 ą┤ąŠą╗ąČąĮčŗ čéą░ą║ąČąĄ ą┐ąŠą╝ąĮąĖčéčī ąĖčģ ąŠčéą╗ąĖčćąĖč鹥ą╗čīąĮčŗą╣ ąĘą▓čāą║ąŠą▓ąŠą╣ čüąĖą│ąĮą░ą╗, čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą┤ą╗čÅ ąĖąĮą┤ąĖą║ą░čåąĖąĖ ą░ą┐ą┐ą░čĆą░čéąĮčŗčģ ą┐čĆąŠą▒ą╗ąĄą╝. ąŁčéąĖ PC-čüą┐ąĖą║ąĄčĆčŗ čĆąĄą┤ą║ąŠ ą╝ąŠą│ą╗ąĖ čüąŠąĘą┤ą░ą▓ą░čéčī ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮčŗąĄ ąĘą▓čāą║ąĖ, ąŠą┤ąĮą░ą║ąŠ ą┤ą╗čÅ ą▓ąĖą┤ąĄąŠąĖą│čĆ ą┤ą░ąČąĄ čŹč鹊 ąĖą╝ąĄą╗ąŠ ą▒ąŠą╗čīčłąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ.
ąĪąĄą│ąŠą┤ąĮčÅ ą▓ ąĮąĄą║ąŠč鹊čĆčŗčģ čüą╗čāčćą░čÅčģ ą▓čŗ ą▓čüąĄ ąĄčēąĄ ą╝ąŠąČąĄč鹥 ą▓ąŠčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ čŹčéąĖą╝ ą╝ą░ą╗ąĄąĮčīą║ąĖą╝ ą│čĆąŠą╝ą║ąŠą│ąŠą▓ąŠčĆąĖč鹥ą╗ąĄą╝, ąĮąŠ čüą║ąŠčĆąĄąĄ ą▓čüąĄą│ąŠ ą▓ ą▓ą░čłąĄą╝ ąĮąŠčāčéą▒čāą║ąĄ ąĄą│ąŠ čāąČąĄ ąĮąĄčé. ąÆ čéą░ą║ąŠą╝ čüą╗čāčćą░ąĄ ą▓čŗ ą╝ąŠąČąĄč鹥 ą▓ą║ą╗čÄčćąĖčéčī 菹╝čāą╗čÅčåąĖčÄ ąĘą▓čāą║ąŠą▓ąŠą│ąŠ čüąĖą│ąĮą░ą╗ą░ č鹥čĆą╝ąĖąĮą░ą╗ą░ ą▓ čüą▓ąŠąĄą╝ čłąĄą╗ą╗ąĄ (terminal bell emulation), čćč鹊ą▒čŗ ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąŠą┤ąĖą╗čüčÅ čüąĖčüč鹥ą╝ąĮčŗą╣ ą┐čĆąĄą┤čāą┐čĆąĄąČą┤ą░čÄčēąĖą╣ ąĘą▓čāą║.
ąÆą▓ąĄą┤ąĖč鹥 čŹčéčā ą║ąŠą╝ą░ąĮą┤čā, čćč鹊ą▒čŗ čāą▓ąĖą┤ąĄčéčī, ą╝ąŠąČąĄčé ą╗ąĖ ą▓ą░čł č鹥čĆą╝ąĖąĮą░ą╗ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčéčī ąĘą▓čāą║:
$ echo -e "\a"
ą×ą▒čŗčćąĮąŠ čŹč鹊 ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ą┐ąĄčćą░čéąĖ č鹥ą║čüčéą░, ąĮąŠ čäą╗ą░ą│ -e ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĖąĮč鹥čĆą┐čĆąĄčéąĖčĆąŠą▓ą░čéčī esc-ą║ąŠą┤čŗ backslash. ąÜą░ą║ ą▓čŗ ą╝ąŠąČąĄč鹥 ą▓ąĖą┤ąĄčéčī, ąĘą┤ąĄčüčī ą┐čĆąĖčüčāčéčüčéą▓čāąĄčé čüą┐ąĄčåąĖą░ą╗čīąĮą░čÅ escape-ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī \a, ą║ąŠč鹊čĆą░čÅ ąŠąĘąĮą░čćą░ąĄčé "alert", čćč鹊 ą▓čŗą▓ąĄą┤ąĄčé čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ čüąĖą╝ą▓ąŠą╗ "ąĘą▓ąŠąĮą║ą░" (bell character). ąØąĄą║ąŠč鹊čĆčŗąĄ č鹥čĆą╝ąĖąĮą░ą╗čŗ č乊čĆą╝ąĖčĆčāčÄčé ąĘą▓čāą║ąŠą▓ąŠą╣ čüąĖą│ąĮą░ą╗, ą║ąŠą│ą┤ą░ ą▓čüčéčĆąĄčćą░čÄčéčüčÅ čü čéą░ą║ąĖą╝ čüąĖą╝ą▓ąŠą╗ąŠą╝.
ąÉąĮą░ą╗ąŠą│ąĖčćąĮąŠ ą╝ąŠąČąĮąŠ ąĮą░ą┐ąĄčćą░čéą░čéčī čŹč鹊čé čüąĖą╝ą▓ąŠą╗ ąĮą░ Python. ąÆąŠąĘą╝ąŠąČąĮąŠ, ą▓ čåąĖą║ą╗ąĄ čüč乊čĆą╝ąĖčĆąŠą▓ą░čéčī ą║ą░ą║čāčÄ-č鹊 ą╝ąĄą╗ąŠą┤ąĖčÄ. ąźąŠčéčÅ ą┐ąŠą╗čāčćąĖčéčüčÅ čĆąĄą░ą╗čīąĮąŠ č鹊ą╗čīą║ąŠ ąŠą┤ąĮą░ ąĮąŠčéą░, ą▓čŗ ą▓čüąĄ-čéą░ą║ąĖ ą╝ąŠąČąĄč鹥 ą╝ąĄąĮčÅčéčī ą┤ą╗ąĖč鹥ą╗čīąĮąŠčüčéčī ą┐ą░čāąĘ ą╝ąĄąČą┤čā ą┐čĆąŠąĖą│čĆčŗą▓ą░ąĮąĖąĄą╝ ąĘą▓čāą║ąŠą▓. ąŁč鹊 ą║ą░ąČąĄčéčüčÅ ąĖą┤ąĄą░ą╗čīąĮčŗą╝ ą╝ąĄč鹊ą┤ąŠą╝ ą┤ą╗čÅ ą▓ąŠčüą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖčÅ ą╝ąŠčĆąĘčÅąĮą║ąĖ!
ą¤čĆą░ą▓ąĖą╗ą░ ą║ąŠą┤ą░ ą£ąŠčƹʹĄ čüą╗ąĄą┤čāčÄčēąĖąĄ:
ŌĆó ąæčāą║ą▓čŗ ą║ąŠą┤ąĖčĆčāčÄčéčüčÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčīčÄ čüąĖą╝ą▓ąŠą╗ąŠą▓ č鹊č湥ą║ (┬Ę) ąĖ čéąĖčĆąĄ (ŌĆō).
ą¤ąŠ čŹčéąĖą╝ ą┐čĆą░ą▓ąĖą╗ą░ą╝ ą▓čŗ ą╝ąŠąČąĄč鹥 "ą┐ąĄčćą░čéą░čéčī" ą┐ąŠą▓č鹊čĆčÅčÄčēąĖą╣čüčÅ čüąĖą│ąĮą░ą╗ SOS čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
while True :
dot()
symbol_space()
dot()
symbol_space()
dot()
letter_space()
dash()
symbol_space()
dash()
symbol_space()
dash()
letter_space()
dot()
symbol_space()
dot()
symbol_space()
dot()
word_space()ąØą░ Python ą▓čŗ ą╝ąŠąČąĄč鹥 čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī čŹč鹊 ą▓čüąĄą│ąŠ ą┤ąĄčüčÅčéčīčÄ čüčéčĆąŠą║ą░ą╝ąĖ ą║ąŠą┤ą░:
from time import sleep0.1 def signal (duration, symbol ):
sleep(duration)
print (symbol, end='' , flush=True )lambda : signal(speed, '┬Ę\a' )
dash = lambda : signal(3 *speed, 'ŌłÆ\a' )
symbol_space = lambda : signal(speed, '' )
letter_space = lambda : signal(3 *speed, '' )
word_space = lambda : signal(7 *speed, ' ' )[ą¤ąŠą┤ą╝ąĄąĮą░ print() ą▓ čÄąĮąĖčé-č鹥čüčéą░čģ ]
ąÆ ąĮą░čüč鹊čÅčēąĄąĄ ą▓čĆąĄą╝čÅ ąŠąČąĖą┤ą░ąĄčéčüčÅ, čćč鹊 ą▓čŗ ą┐ąŠčüčéą░ą▓ą╗čÅąĄč鹥 ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ą▓čŗčüąŠą║ąĖą╝ čüčéą░ąĮą┤ą░čĆčéą░ą╝ ą║ą░č湥čüčéą▓ą░. ąĢčüą╗ąĖ ą▓čŗ čüčéčĆąĄą╝ąĖč鹥čüčī čüčéą░čéčī ą┐čĆąŠč乥čüčüąĖąŠąĮą░ą╗ąŠą╝, ą▓čŗ ą┤ąŠą╗ąČąĮčŗ ąĮą░čāčćąĖčéčīčüčÅ č鹥čüčéąĖčĆąŠą▓ą░čéčī čüą▓ąŠą╣ ą║ąŠą┤.
ąóąĄčüčéąĖčĆąŠą▓ą░ąĮąĖąĄ ą¤ą× ąŠčüąŠą▒ąĄąĮąĮąŠ ą▓ą░ąČąĮąŠ ą┤ą╗čÅ čÅąĘčŗą║ąŠą▓ čü ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą╣ čéąĖą┐ąĖąĘą░čåąĖąĄą╣, čéą░ą║ąĖčģ ą║ą░ą║ Python, čā ą║ąŠč鹊čĆčŗčģ ąĮąĄčé ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĄą┤čāą┐čĆąĄą┤ąĖčé ą▓ą░čü ąŠą▒ ąŠč湥ą▓ąĖą┤ąĮčŗčģ ąŠčłąĖą▒ą║ą░čģ. ąöąĄč乥ą║čéčŗ ą╝ąŠą│čāčé ą┐čĆąŠą▒čĆą░čéčīčüčÅ ą▓ ą┐čĆąŠąĖąĘą▓ąŠą┤čüčéą▓ąĄąĮąĮčāčÄ čüčĆąĄą┤čā ąĖ ąŠčüčéą░ą▓ą░čéčīčüčÅ ąĮąĄąĘą░ą╝ąĄčéąĮčŗą╝ąĖ ą┤ą╗ąĖč鹥ą╗čīąĮąŠąĄ ą▓čĆąĄą╝čÅ, č鹊 č鹊ą│ąŠ ą┤ąĮčÅ, ą║ąŠą│ą┤ą░ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēą░čÅ ą▓ąĄčéą▓čī ą║ąŠą┤ą░ ą▒čāą┤ąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮą░.
ąÜąŠąĮąĄčćąĮąŠ, čā ą▓ą░čü ąĄčüčéčī ą╗ąĖąĮč鹥čĆčŗ, č湥ą║ąĄčĆčŗ ąĖ ą┤čĆčāą│ąĖąĄ ąĖąĮčüčéčĆčāą╝ąĄąĮčéčŗ ą┤ą╗čÅ čüčéą░čéąĖč湥čüą║ąŠą│ąŠ ą░ąĮą░ą╗ąĖąĘą░ ą║ąŠą┤ą░, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠą╝ąŠą│čāčé ą▓ą░ą╝. ąØąŠ ąŠąĮąĖ ąĮąĄ čüą║ą░ąČčāčé, ą┤ąĄą╗ą░ąĄčé ą╗ąĖ ą▓ą░čłą░ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ č鹊, čćč鹊 ąŠąĮą░ ą┤ąŠą╗ąČąĮą░ ą┤ąĄą╗ą░čéčī ąĮą░ čāčĆąŠą▓ąĮąĄ ą▒ąĖąĘąĮąĄčüą░.
ąśčéą░ą║, ą▓čŗ ą┤ąŠą╗ąČąĮčŗ č鹥čüčéąĖčĆąŠą▓ą░čéčī print()? ąØąĄčé. ąÆ ą║ąŠąĮčåąĄ ą║ąŠąĮčåąŠą▓ čŹč鹊 ą▓čüčéčĆąŠąĄąĮąĮą░čÅ čäčāąĮą║čåąĖčÅ, ą║ąŠč鹊čĆą░čÅ ą▓ąĄčĆąŠčÅčéąĮąŠ čāąČąĄ ą┐čĆąŠčłą╗ą░ ą║ąŠą╝ą┐ą╗ąĄą║čüąĮčŗą╣ ąĮą░ą▒ąŠčĆ č鹥čüč鹊ą▓. ą×ą┤ąĮą░ą║ąŠ ą▓čŗ ąĘą░čģąŠčéąĖč鹥 ą┐čĆąŠą▓ąĄčĆąĖčéčī, ą▓čŗąĘčŗą▓ą░ąĄčé ą╗ąĖ ą▓ą░čł ą║ąŠą┤ print() ą▓ ąĮčāąČąĮąŠąĄ ą▓čĆąĄą╝čÅ čü ąŠąČąĖą┤ą░ąĄą╝čŗą╝ąĖ ą┐ą░čĆą░ą╝ąĄčéčĆą░ą╝ąĖ. ąŁč鹊 ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄą╝.
ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐čĆąŠč鹥čüčéąĖčĆąŠą▓ą░čéčī ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐čāč鹥ą╝ ą┐ąŠą┤ą╝ąĄąĮčŗ (mocking) čĆąĄą░ą╗čīąĮčŗčģ ąŠą▒čŖąĄą║č鹊ą▓ ąĖą╗ąĖ čäčāąĮą║čåąĖą╣. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą▓čŗ ąĘą░čģąŠčéąĖč鹥 ą┐ąŠą┤ą╝ąĄąĮąĖčéčī čäčāąĮą║čåąĖčÄ print() ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ ąĖ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąĄčæ ą▓ąŠą▓ą╗ąĄč湥ąĮąĖą╣.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ą▓ąŠąĘą╝ąŠąČąĮąŠ ą▓čŗ čüą╗čŗčłą░ą╗ąĖ čéą░ą║ąĖąĄ č鹥čĆą╝ąĖąĮčŗ: dummy, fake, stub, spy ąĖą╗ąĖ mock, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ ą▓ąĘą░ąĖą╝ąŠąĘą░ą╝ąĄąĮčÅąĄą╝čŗą╝ ąŠą▒čĆą░ąĘąŠą╝. ąØąĄą║ąŠč鹊čĆčŗąĄ ą╗čÄą┤ąĖ ą┤ąĄą╗ą░čÄčé čĆą░ąĘą╗ąĖčćąĖąĄ ą╝ąĄąČą┤čā ąĮąĖą╝ąĖ, ą░ ą┤čĆčāą│ąĖąĄ ąĮąĄčé.
Martin Fowler ąŠą▒čŖčÅčüąĮčÅąĄčé ąĖčģ čĆą░ąĘą╗ąĖčćąĖčÅ ą▓ ą║ąŠčĆąŠčéą║ąŠą╝ čüą╗ąŠą▓ą░čĆąĖą║ąĄ [6], ąĖ ąĮą░ąĘčŗą▓ą░ąĄčé ąĖčģ ą▓čüąĄ ą┤ą▓ąŠą╣ąĮčŗą╝ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖąĄą╝ (test doubles).
Mocking ą▓ Python ą╝ąŠąČąĮąŠ čüą┤ąĄą╗ą░čéčī ą┤ą▓ąŠčÅą║ąŠ. ąÆąŠ-ą┐ąĄčĆą▓čŗčģ, ą▓čŗ ą╝ąŠąČąĄč鹥 ą▓čŗą▒čĆą░čéčī čéčĆą░ą┤ąĖčåąĖąŠąĮąĮčŗą╣ ą┐čāčéčī čüčéą░čéąĖč湥čüą║ąĖ čéąĖą┐ąĖąĘąĖčĆčāąĄą╝čŗčģ čÅąĘčŗą║ąŠą▓, ąĖčüą┐ąŠą╗čīąĘčāčÅ ą▓ąĮąĄą┤čĆąĄąĮąĖąĄ ąĘą░ą▓ąĖčüąĖą╝ąŠčüč鹥ą╣ (dependency injection). ąŁč鹊 ą╝ąŠąČąĄčé ąĖąĮąŠą│ą┤ą░ ą┐ąŠčéčĆąĄą▒ąŠą▓ą░čéčī ąŠčé ą▓ą░ąĘ ą┐ąŠą╝ąĄąĮčÅčéčī č鹥čüčéąĖčĆčāąĄą╝čŗą╣ ą║ąŠą┤, čćč鹊 ąĮąĄ ą▓čüąĄą│ą┤ą░ ą▓ąŠąĘą╝ąŠąČąĮąŠ, ąĄčüą╗ąĖ čŹč鹊čé ą║ąŠą┤ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ ą▓ąŠ ą▓ąĮąĄčłąĮąĄą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĄ:
def download (url, log=print ):
log(f'ąŚą░ą│čĆčāąĘą║ą░ {url} ' )
# ... ąŁč鹊 č鹊čé ąČąĄ ą┐čĆąĖą╝ąĄčĆ, čćč鹊 ą▒čŗą╗ čĆą░ąĮąĄąĄ ą┐ąŠą║ą░ąĘą░ąĮ, ą║ąŠą│ą┤ą░ čłą╗ą░ čĆąĄčćčī ą┐čĆąŠ ą║ąŠą╝ą┐ąŠąĘąĖčåąĖčÄ čäčāąĮą║čåąĖąĖ. ąŁč鹊čé ą╝ąĄč鹊ą┤ ą▓ ąŠčüąĮąŠą▓ąĮąŠą╝ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĘą░ą╝ąĄąĮčÅčéčī print() ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąŠą╣ čäčāąĮą║čåąĖąĄą╣ čü čéą░ą║ąĖą╝ ąČąĄ ąĖąĮč鹥čĆč乥ą╣čüąŠą╝. ą¦č鹊ą▒čŗ ą┐čĆąŠą▓ąĄčĆąĖčéčī, ą┐čĆą░ą▓ąĖą╗čīąĮąŠ ą╗ąĖ ą┐ąĄčćą░čéą░ąĄčéčüčÅ čüąŠąŠą▒čēąĄąĮąĖąĄ, ą┐čĆąĖą┤ąĄčéčüčÅ ą┐ąĄčĆąĄčģą▓ą░čéąĖčéčī ąĄą│ąŠ, ą▓ąĮąĄą┤čĆąĖą▓ mocked-čäčāąĮą║čåąĖčÄ:
>>> def mock_print (message ):... mock_print.last_message = message
...>>> download('resource' , mock_print)>>> assert 'ąŚą░ą│čĆčāąĘą║ą░ čĆąĄčüčāčĆčüą░' == mock_print.last_messageąÆčŗąĘąŠą▓ čŹč鹊ą│ąŠ ą╝ą░ą║ąĄčéą░ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ čüąŠčģčĆą░ąĮąĄąĮąĖčÄ ą┐ąŠčüą╗ąĄą┤ąĮąĄą│ąŠ čüąŠąŠą▒čēąĄąĮąĖčÅ ą▓ ą░čéčĆąĖą▒čāč鹥, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĮąŠ ą┐čĆąŠą▓ąĄčĆąĖčéčī ą┐ąŠąĘąČąĄ, ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą▓ ąĖąĮčüčéčĆčāą║čåąĖąĖ assert.
ąÆ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą░ą╗čīč鹥čĆąĮą░čéąĖą▓ąĮąŠą╝ čĆąĄčłąĄąĮąĖąĖ ą▓ą╝ąĄčüč鹊 ąĘą░ą╝ąĄąĮčŗ ą▓čüąĄą╣ čäčāąĮą║čåąĖąĖ print() ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąŠą╣ ąŠą▒ąĄčĆčéą║ąŠą╣ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą▒čŗ ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ąĖčéčī čüčéą░ąĮą┤ą░čĆčéąĮčŗą╣ ą▓čŗą▓ąŠą┤ ą▓ čäą░ą╣ą╗ąŠą▓čŗą╣ ą┐ąŠč鹊ą║ čüąĖą╝ą▓ąŠą╗ąŠą▓ ą▓ ą┐ą░ą╝čÅčéąĖ:
>>> def download (url, stream=None ):... print (f'ąŚą░ą│čĆčāąĘą║ą░ {url} ' , file=stream)... # ...
...>>> import io>>> memory_buffer = io.StringIO()>>> download('app.js' , memory_buffer)>>> download('style.css' , memory_buffer)>>> memory_buffer.getvalue()'ąŚą░ą│čĆčāąĘą║ą░ app.js\nąŚą░ą│čĆčāąĘą║ą░ style.css\n' ąØą░ čŹč鹊čé čĆą░ąĘ čäčāąĮą║čåąĖčÅ čÅą▓ąĮąŠ ą▓čŗąĘčŗą▓ą░ąĄčé print(), ąŠą┤ąĮą░ą║ąŠ ą▓čŗčüčéą░ą▓ą╗čÅąĄčé čüą▓ąŠą╣ ą┐ą░čĆą░ą╝ąĄčéčĆ file ą▓ąŠ ą▓ąĮąĄčłąĮąĖą╣ ą╝ąĖčĆ.
ąóąĄą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ, ą▒ąŠą╗ąĄąĄ ą┐ąĖč鹊ąĮčüą║ąĖą╣ čüą┐ąŠčüąŠą▒ ą┐ąŠą┤ą╝ąĄąĮčŗ ąŠą▒čŖąĄą║č鹊ą▓ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą┐čĆąĄąĖą╝čāčēąĄčüčéą▓ą░ ą▓čüčéčĆąŠąĄąĮąĮąŠą│ąŠ ą╝ą░ą║ąĄčéąĮąŠą│ąŠ ą╝ąŠą┤čāą╗čÅ mock, ą║ąŠč鹊čĆčŗą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄčé č鹥čģąĮąĖą║čā, ąĮą░ąĘčŗą▓ą░ąĄą╝čāčÄ "ąŠą▒ąĄąĘčīčÅąĮčīąĖą╝ ą┐ą░čéč湥ą╝" (monkey patching). ąŁč鹊 čāąĮąĖčćąĖąČąĖč鹥ą╗čīąĮąŠąĄ ąĮą░ąĘą▓ą░ąĮąĖąĄ ą┐čĆąŠąĖčüč鹥ą║ą░ąĄčé ąĖąĘ č鹊ą│ąŠ, čćč鹊 ąŠąĮąŠ ą┐ąŠčģąŠąČąĄ ąĮą░ "ą│čĆčÅąĘąĮčŗą╣ čģą░ą║", čü ą║ąŠč鹊čĆčŗą╝ ą▓čŗ ą╝ąŠąČąĄč鹥 ą╗ąĄą│ą║ąŠ ą▓čŗčüčéčĆąĄą╗ąĖčéčī čüąĄą▒ąĄ ą▓ ąĮąŠą│čā. ąŁč鹊 ą╝ąĄąĮąĄąĄ 菹╗ąĄą│ą░ąĮčéąĮąŠ, č湥ą╝ ąĖąĮčŖąĄą║čåąĖčÅ ąĘą░ą▓ąĖčüąĖą╝ąŠčüč鹥ą╣, ąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠ ą▒čŗčüčéčĆąŠ ąĖ čāą┤ąŠą▒ąĮąŠ.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ą╝ąŠą┤čāą╗čī mock ą▒čŗą╗ ą▓čüčéčĆąŠąĄąĮ ą▓ čüčéą░ąĮą┤ą░čĆčéąĮčāčÄ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║čā Python 3, ąĮąŠ ą┤ąŠ čŹč鹊ą│ąŠ ąŠąĮ ą▒čŗą╗ čüč鹊čĆąŠąĮąĮąĖą╝ ą┐ą░ą║ąĄč鹊ą╝. ąÆčŗ ą┤ąŠą╗ąČąĮčŗ ą▒čāą┤ąĄč鹥 čāčüčéą░ąĮąŠą▓ąĖčéčī ąĄą│ąŠ ąŠčéą┤ąĄą╗čīąĮąŠ:
$ pip2 install mock
ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ą▓čŗ ą▒čāą┤ąĄč鹥 ąŠą▒čĆą░čēą░čéčīčüčÅ ą║ ąĮąĄą╝čā ą┐ąŠ ąĖą╝ąĄąĮąĖ mock, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ą▓ Python 3 ąŠąĮ čĆą░ą▒ąŠčéą░ąĄčé ą║ą░ą║ čćą░čüčéčī ą╝ąŠą┤čāą╗čÅ čÄąĮąĖčé-č鹥čüč鹊ą▓, ąĖ ą▓čŗ ą┤ąŠą╗ąČąĮčŗ ąĄą│ąŠ ąĖą╝ą┐ąŠčĆčéąĖčĆąŠą▓ą░čéčī ąĖąĘ unittest.mock.
Monkey patching ąĖčüą┐čĆą░ą▓ą╗čÅąĄčé čĆąĄą░ą╗ąĖąĘą░čåąĖčÄ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąĖ, ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░. ąóą░ą║ąŠąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖąĄ ą▓ąĖą┤ąĖčéčüčÅ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠ, ą┐ąŠčŹč鹊ą╝čā ą╝ąŠąČąĄčé ąĖą╝ąĄčéčī ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮčŗąĄ ą┐ąŠčüą╗ąĄą┤čüčéą▓ąĖčÅ. ą×ą┤ąĮą░ą║ąŠ ąĮą░ ą┐čĆą░ą║čéąĖą║ąĄ ą┐ą░čéčć ą▓ą╗ąĖčÅąĄčé ąĮą░ ą║ąŠą┤ č鹊ą╗čīą║ąŠ ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ č鹥čüčéą░.
ą¦č鹊ą▒čŗ ąĖą╝ąĖčéąĖčĆąŠą▓ą░čéčī print() ą▓ č鹥čüč鹊ą▓ąŠą╝ ą║ąĄą╣čüąĄ, ą▓čŗ ąŠą▒čŗčćąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄč鹥 ą┤ąĄą║ąŠčĆą░č鹊čĆ @patch ąĖ čāą║ą░ąĘčŗą▓ą░ąĄč鹥 čåąĄą╗čī ą┤ą╗čÅ ąĖčüą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ, čüčüčŗą╗ą░čÅčüčī ąĮą░ ąĮąĄąĄ ą┐ąŠ ą┐ąŠą╗ąĮąŠą╝čā ąĖą╝ąĄąĮąĖ, ą║ąŠč鹊čĆąŠąĄ ą▓ą║ą╗čÄčćą░ąĄčé ąĖą╝čÅ ą╝ąŠą┤čāą╗čÅ:
from unittest.mock import patch@patch('builtins.print' def test_print (mock_print ):
print ('not a real print' )
mock_print.assert_called_with('not a real print' )ąŁč鹊 ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ čüąŠąĘą┤ą░čüčé ą┤ą╗čÅ ą▓ą░čü mock ąĖ ąĖąĮąČąĄą║čéąĖčĆčāąĄčé ąĄą│ąŠ ą▓ čäčāąĮą║čåąĖčÄ č鹥čüčéą░. ą×ą┤ąĮą░ą║ąŠ ą▓ą░ą╝ ąĮčāąČąĮąŠ ą┤ąĄą║ą╗ą░čĆąĖčĆąŠą▓ą░čéčī, čćč鹊 ą▓ą░čłą░ č鹥čüčéąĖčĆčāąĄą╝ą░čÅ čäčāąĮą║čåąĖčÅ č鹥ą┐ąĄčĆčī ą┐čĆąĖąĮąĖą╝ą░ąĄčé mock. ąØąĖąČąĄą╗ąĄąČą░čēąĖą╣ mock-ąŠą▒čŖąĄą║čé ąĖą╝ąĄąĄčé ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐ąŠą╗ąĄąĘąĮčŗčģ ą╝ąĄč鹊ą┤ąŠą▓ ąĖ ą░čéčĆąĖą▒čāč鹊ą▓ ą┤ą╗čÅ ą┐čĆąŠą▓ąĄčĆą║ąĖ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ.
ąÆčŗ ąĘą░ą╝ąĄčéąĖą╗ąĖ čćč鹊-ąĮąĖą▒čāą┤čī ąŠčüąŠą▒ąĄąĮąĮąŠąĄ ą▓ čŹč鹊ą╝ čäčĆą░ą│ą╝ąĄąĮč鹥 ą║ąŠą┤ą░?
ąØąĄčüą╝ąŠčéčĆčÅ ąĮą░ ą▓ąĮąĄą┤čĆąĄąĮąĖąĄ mock ą▓ čäčāąĮą║čåąĖčÄ, ą▓čŗ ąĮąĄ ą▓čŗąĘčŗą▓ą░ąĄč鹥 ąĄąĄ ąĮą░ą┐čĆčÅą╝čāčÄ, čģąŠčéčÅ ąĖ ą╝ąŠąČąĄč鹥. ąŁč鹊čé ą▓ąĮąĄą┤čĆąĄąĮąĮčŗą╣ mock ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĄą╣ ą▓čüčéą░ą▓ą║ąĖ assert ąĖ, ą▓ąŠąĘą╝ąŠąČąĮąŠ, ą┤ą╗čÅ ą┐ąŠą┤ą│ąŠč鹊ą▓ą║ąĖ ą║ąŠąĮč鹥ą║čüčéą░ ą┐ąĄčĆąĄą┤ ąĘą░ą┐čāčüą║ąŠą╝ č鹥čüčéą░.
ąÆ čĆąĄą░ą╗čīąĮąŠą╣ ąČąĖąĘąĮąĖ č鹥čģąĮąĖą║ą░ mock ą┐ąŠą╝ąŠą│ą░ąĄčé ąĖąĘąŠą╗ąĖčĆąŠą▓ą░čéčī č鹥čüčéąĖčĆčāąĄą╝čŗą╣ ą║ąŠą┤ ą┐čāč鹥ą╝ čāčüčéčĆą░ąĮąĄąĮąĖčÅ čéą░ą║ąĖčģ ąĘą░ą▓ąĖčüąĖą╝ąŠčüč鹥ą╣, ą║ą░ą║ čüąŠąĄą┤ąĖąĮąĄąĮąĖąĄ čü ą▒ą░ąĘąŠą╣ ą┤ą░ąĮąĮčŗčģ. ąÆčŗ čĆąĄą┤ą║ąŠ ą▓čŗąĘčŗą▓ą░ąĄč鹥 mock-ąĖ ą▓ č鹥čüč鹥, ą┐ąŠč鹊ą╝čā čćč鹊 čŹč鹊 ąĮąĄ ąĖą╝ąĄąĄčé čüą╝čŗčüą╗ą░. ąĪą║ąŠčĆąĄąĄ, čŹč鹊 ą▒čāą┤ąĄčé ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓ ą┤čĆčāą│ąĖčģ čćą░čüčéčÅčģ ą║ąŠą┤ą░, ą║ąŠč鹊čĆčŗąĄ ąĮą░ąĘčŗą▓ą░čÄčé ą▓ą░čł mock ą║ąŠčüą▓ąĄąĮąĮąŠ, ąĮąĄ ąĘąĮą░čÅ ąŠą▒ čŹč鹊ą╝.
ąÆąŠčé čćč鹊 čŹč鹊 ąŠąĘąĮą░čćą░ąĄčé:
from unittest.mock import patchdef greet (name ):
print (f'Hello, {name} !' )@patch('builtins.print' def test_greet (mock_print ):
greet('John' )
mock_print.assert_called_with('Hello, John!' )ąŚą┤ąĄčüčī č鹥čüčéąĖčĆčāąĄą╝čŗą╣ ą║ąŠą┤ čŹč鹊 čäčāąĮą║čåąĖčÅ, ą║ąŠč鹊čĆą░čÅ ą┐ąĄčćą░čéą░ąĄčé ą┐čĆąĖą▓ąĄčéčüčéą▓ąĖąĄ. ąØąĄčüą╝ąŠčéčĆčÅ ąĮą░ č鹊, čćč鹊 čŹč鹊 ą┤ąŠą▓ąŠą╗čīąĮąŠ ą┐čĆąŠčüčéą░čÅ čäčāąĮą║čåąĖčÅ, ą▓čŗ ąĮąĄ ą╝ąŠąČąĄč鹥 ą╗ąĄą│ą║ąŠ ąĄąĄ ą┐čĆąŠą▓ąĄčĆąĖčéčī, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąĮą░ ąĮąĄ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ąĘąĮą░č湥ąĮąĖąĄ. ąŁč鹊 ą┐ąŠą▒ąŠčćąĮčŗą╣ čŹčäč乥ą║čé.
ą¦č鹊ą▒čŗ čāčüčéčĆą░ąĮąĖčéčī čŹč鹊čé ą┐ąŠą▒ąŠčćąĮčŗą╣ čŹčäč乥ą║čé, ą▓ą░ą╝ ąĮčāąČąĮąŠ ąĖą╝ąĖčéąĖčĆąŠą▓ą░čéčī ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéčī. ąØą░ą╗ąŠąČąĄąĮąĖąĄ ą┐ą░čéčćą░ ą┐ąŠąĘą▓ąŠą╗ąĖčé ą▓ą░ą╝ ąĖąĘą▒ąĄąČą░čéčī ą▓ąĮąĄčüąĄąĮąĖąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖą╣ ą▓ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮčāčÄ čäčāąĮą║čåąĖčÄ, ą║ąŠč鹊čĆą░čÅ ą╝ąŠąČąĄčé ąŠčüčéą░ą▓ą░čéčīčüčÅ ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠą╣ ąŠčé print(). ą×ąĮą░ ą▒čāą┤ąĄčé ą┤čāą╝ą░čéčī, čćč鹊 ą▓čŗąĘčŗą▓ą░ąĄčé print(), ąĮąŠ ąĮą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ ą▓čŗąĘąŠą▓ąĄčé mock, ą║ąŠč鹊čĆčŗą╣ ą▓čŗ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą║ąŠąĮčéčĆąŠą╗ąĖčĆčāąĄč鹥.
ąÆ Python 2 ą▓čŗ ąĮąĄ ą╝ąŠąČąĄč鹥 ąĮą░ą╗ąŠąČąĖčéčī monkey patch ąĮą░ ąŠą┐ąĄčĆą░č鹊čĆ print ąĖą╗ąĖ ą▓ąĮąĄą┤čĆąĖčéčī ąĄą│ąŠ ą║ą░ą║ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéčī. ą×ą┤ąĮą░ą║ąŠ čā ą▓ą░čü ąĄčüčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┤čĆčāą│ąĖčģ ą▓ą░čĆąĖą░ąĮč鹊ą▓:
ŌĆó ąśčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąŠč鹊ą║ą░.
ąöą░ą▓ą░ą╣č鹥 ą┐čĆąŠą▓ąĄčĆąĖą╝ čŹčéąĖ čüą┐ąŠčüąŠą▒čŗ ą┤čĆčāą│ ąĘą░ ą┤čĆčāą│ąŠą╝.
ą¤ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąŠč鹊ą║ą░ ą┐ąŠčćčéąĖ ąĖą┤ąĄąĮčéąĖč湥ąĮ ą┐čĆąĖą╝ąĄčĆčā, ą║ąŠč鹊čĆčŗą╣ ą▓čŗ ą▓ąĖą┤ąĄą╗ąĖ čĆą░ąĮčīčłąĄ:
>>> def download (url, stream=None ):... print >> stream, 'ąŚą░ą│čĆčāąĘą║ą░ %s' % url... # ...
...>>> from StringIO import StringIO>>> memory_buffer = StringIO()>>> download('app.js' , memory_buffer)>>> download('style.css' , memory_buffer)>>> memory_buffer.getvalue()'ąŚą░ą│čĆčāąĘą║ą░ app.js\nąŚą░ą│čĆčāąĘą║ą░ style.css\n' ąŚą┤ąĄčüčī č鹊ą╗čīą║ąŠ 2 ąŠčéą╗ąĖčćąĖčÅ. ą¤ąĄčĆą▓ąŠąĄ ąŠčéą╗ąĖčćąĖąĄ: čüąĖąĮčéą░ą║čüąĖčü ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ąŠč鹊ą║ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčé čłąĄą▓čĆąŠąĮ (>>) ą▓ą╝ąĄčüč鹊 ą░čĆą│čāą╝ąĄąĮčéą░ file. ąöčĆčāą│ąŠąĄ ąŠčéą╗ąĖčćąĖąĄ čéą░ą╝, ą│ą┤ąĄ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ StringIO. ąÆčŗ ą╝ąŠąČąĄč鹥 ąĖą╝ą┐ąŠčĆčéąĖčĆąŠą▓ą░čéčī ąĄą│ąŠ ąĖąĘ ą╝ąŠą┤čāą╗čÅ StringIO, ąĖą╗ąĖ ąĖąĘ cStringIO ą┤ą╗čÅ ą▒ąŠą╗ąĄąĄ ą▒čŗčüčéčĆąŠą╣ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ.
ąśčüą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čüčéą░ąĮą┤ą░čĆčéąĮąŠą│ąŠ ą▓čŗą▓ąŠą┤ą░ čŹč鹊 ąĖą╝ąĄąĮąĮąŠ č鹊, ą║ą░ą║ čŹč鹊 ąĘą▓čāčćąĖčé, ąŠą┤ąĮą░ą║ąŠ ą▓ą░ą╝ ąĮčāąČąĮąŠ ąĘąĮą░čéčī ąŠ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą┐ąŠą┤ą▓ąŠą┤ąĮčŗčģ ą║ą░ą╝ąĮčÅčģ:
from mock import patch, calldef greet (name ):
print 'Hello, %s!' % name@patch('sys.stdout' def test_greet (mock_stdout ):
greet('John' )
mock_stdout.write.assert_has_calls([
call('Hello, John!' ),
call('\n' )
])ą¤čĆąĄąČą┤ąĄ ą▓čüąĄą│ąŠ ąĮąĄ ąĘą░ą▒čāą┤čīč鹥 ąĖąĮčüčéą░ą╗ą╗ąĖčĆąŠą▓ą░čéčī ą╝ąŠą┤čāą╗čī mock, ą┐ąŠčüą║ąŠą╗čīą║čā ąŠąĮ ąĮąĄ ą▒čŗą╗ ą┤ąŠčüčéčāą┐ąĄąĮ ą▓ čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĄ Python 2.
ąÆąŠ-ą▓č鹊čĆčŗčģ, ąŠą┐ąĄčĆą░č鹊čĆ print ą▓čŗąĘčŗą▓ą░ąĄčé ąĮąĖąČąĄą╗ąĄąČą░čēąĖą╣ ą╝ąĄč鹊ą┤ .write() ąĮą░ mock-ąŠą▒čŖąĄą║č鹥 ą▓ą╝ąĄčüč鹊 ą▓čŗąĘąŠą▓ą░ čüą░ą╝ąŠą│ąŠ ąŠą▒čŖąĄą║čéą░. ąÆąŠčé ą┐ąŠč湥ą╝čā ą▓čŗ ą▒čāą┤ąĄč鹥 ąĘą░ą┐čāčüą║ą░čéčī assert-čŗ ą┐čĆąŠčéąĖą▓ mock_stdout.write.
ąś ąĮą░ą║ąŠąĮąĄčå, ąŠą┤ąĖąĮ ąŠą┐ąĄčĆą░č鹊čĆ print ąĮąĄ ą▓čüąĄą│ą┤ą░ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ąŠą┤ąĮąŠą╝čā ą▓čŗąĘąŠą▓čā sys.stdout.write(). ążą░ą║čéąĖč湥čüą║ąĖ ą▓čŗ čāą▓ąĖą┤ąĖč鹥 čüąĖą╝ą▓ąŠą╗ newline, ąĘą░ą┐ąĖčüčŗą▓ą░ąĄą╝čŗą╣ ąŠčéą┤ąĄą╗čīąĮąŠ.
ąÆ ą┐ąŠčüą╗ąĄą┤ąĮąĄą╝ ą▓ą░čĆąĖą░ąĮč鹥 ą▓čŗ ą┤ąŠą╗ąČąĮčŗ ąĖą╝ą┐ąŠčĆčéąĖčĆąŠą▓ą░čéčī čäčāąĮą║čåąĖčÄ print() ąĖąĘ ą▒čāą┤čāčēąĄą│ąŠ ąĖ ą┐čĆąĖą╝ąĄąĮąĖčéčī ąĮą░ ąĮąĄą╣ ą┐ą░čéčć:
from __future__ import print_functionfrom mock import patchdef greet (name ):
print ('Hello, %s!' % name)@patch('__builtin__.print' def test_greet (mock_print ):
greet('John' )
mock_print.assert_called_with('Hello, John!' )ąś čüąĮąŠą▓ą░, čŹč鹊 ą┤ąĄą╗ą░ąĄčéčüčÅ ą┐ąŠčćčéąĖ ąĖą┤ąĄąĮčéąĖčćąĮąŠ Python 3, ąĮąŠ čäčāąĮą║čåąĖčÅ print() ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮą░ ą▓ ą╝ąŠą┤čāą╗ąĄ __builtin__ ą▓ą╝ąĄčüč鹊 ą╝ąŠą┤čāą╗čÅ builtins .
ąĪčāčēąĄčüčéą▓čāąĄčé ą╝ąĮąŠąČąĄčüčéą▓ąŠ ą▓ąĄčüą║ąĖčģ ą┐čĆąĖčćąĖąĮ ą┤ą╗čÅ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ ą¤ą×. ą×ą┤ąĮą░ ąĖąĘ ąĮąĖčģ - ą┐ąŠąĖčüą║ ą▒ą░ą│ąŠą▓. ą¤čĆąĖ ąĮą░ą┐ąĖčüą░ąĮąĖąĖ č鹥čüč鹊ą▓ ą▓ą░ą╝ čćą░čüč鹊 ąĘą░čģąŠč湥čéčüčÅ ą┐ąŠą┤ą╝ąĄąĮąĖčéčī čäčāąĮą║čåąĖčÄ print(), ąĮą░ą┐čĆąĖą╝ąĄčĆ čü ą┐ąŠą╝ąŠčēčīčÄ č鹥čģąĮąĖą║ąĖ mock. ą×ą┤ąĮą░ą║ąŠ ą┐ą░čĆą░ą┤ąŠą║čüą░ą╗čīąĮąŠ, čćč鹊 čéą░ ąČąĄ čüą░ą╝ą░čÅ čäčāąĮą║čåąĖčÅ ą╝ąŠąČąĄčé ą┐ąŠą╝ąŠčćčī ą▓ą░ą╝ ąĮą░ą╣čéąĖ ą▒ą░ą│ąĖ, ą▓ąŠ ą▓čĆąĄą╝čÅ čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ ą┐čĆąŠčåąĄčüčüą░ ąŠčéą╗ą░ą┤ą║ąĖ, ąŠ č湥ą╝ ą▓čŗ čāąĘąĮą░ąĄč鹥 ą▓ čüą╗ąĄą┤čāčÄčēąĄą╝ čĆą░ąĘą┤ąĄą╗ąĄ.
[ą×čéą╗ą░ą┤ą║ą░ čü ą┐ąŠą╝ąŠčēčīčÄ print() ]
ąÆ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ ą▓čŗ ą┐ąŠąĘąĮą░ą║ąŠą╝ąĖč鹥čüčī čü ą┤ąŠčüčéčāą┐ąĮčŗą╝ąĖ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░ą╝ąĖ ą┤ą╗čÅ ąŠčéą╗ą░ą┤ą║ąĖ ąĮą░ Python, ąĮą░čćąĖąĮą░čÅ ąŠčé čüą║čĆąŠą╝ąĮąŠą╣ čäčāąĮą║čåąĖąĖ print(), ąĘą░č鹥ą╝ ą┐ąŠąĘąĮą░ą║ąŠą╝ąĖč鹥čüčī čü ą╝ąŠą┤čāą╗ąĄą╝ ą╗ąŠą│ą░, ąĖ ąĘą░ą║ąŠąĮčćąĖč鹥 ą┐ąŠą╗ąĮąŠčåąĄąĮąĮčŗą╝ ąŠčéą╗ą░ą┤čćąĖą║ąŠą╝. ą¤čĆąŠčćąĖčéą░ą▓ ąĄą│ąŠ, ą▓čŗ čüą╝ąŠąČąĄč鹥 ą┐čĆąĖąĮčÅčéčī ąŠą▒ąŠčüąĮąŠą▓ą░ąĮąĮąŠąĄ čĆąĄčłąĄąĮąĖąĄ ąŠ č鹊ą╝, ą║ą░ą║ąŠą╣ ąĖąĘ ąĮąĖčģ čÅą▓ą╗čÅąĄčéčüčÅ ąĮą░ąĖą▒ąŠą╗ąĄąĄ ą┐ąŠą┤čģąŠą┤čÅčēąĖą╝ ą▓ ą║ąŠąĮą║čĆąĄčéąĮąŠą╣ čüąĖčéčāą░čåąĖąĖ.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ąŠčéą╗ą░ą┤ą║ą░ čŹč鹊 ą┐čĆąŠčåąĄčüčü ą┐ąŠąĖčüą║ą░ ąŠčüąĮąŠą▓ąĮčŗčģ ą┐čĆąĖčćąĖąĮ ą▒ą░ą│ąŠą▓ ąĖą╗ąĖ ą┤ąĄč乥ą║č鹊ą▓ ą▓ ą¤ą× ą┐ąŠčüą╗ąĄ ąĖčģ ąŠą▒ąĮą░čĆčāąČąĄąĮąĖčÅ, ą░ čéą░ą║ąČąĄ ą┐čĆąĖąĮčÅčéąĖąĄ ą╝ąĄčĆ ą┐ąŠ ąĖčģ čāčüčéčĆą░ąĮąĄąĮąĖčÄ. ąóąĄčĆą╝ąĖąĮ "ą▒ą░ą│" ąĖą╝ąĄąĄčé ąĘą░ą▒ą░ą▓ąĮčāčÄ ąĖčüč鹊čĆąĖčÄ ąŠ ą┐čĆąŠąĖčüčģąŠąČą┤ąĄąĮąĖąĖ čüą▓ąŠąĄą│ąŠ ąĮą░ąĘą▓ą░ąĮąĖčÅ (čüą╝. "Debugging" ą▓ ąÆąĖą║ąĖą┐ąĄą┤ąĖąĖ).
ąóčĆą░čüčüąĖčĆąŠą▓ą║ą░ . ąŁč鹊 čéą░ą║ąČąĄ ąĖąĘą▓ąĄčüčéąĮąŠ ą║ą░ą║ ąŠčéą╗ą░ą┤ą║ą░ čü ą┐ąŠą╝ąŠčēčīčÄ ą┐ąĄčćą░čéąĖ, ąĖą╗ąĖ ą┐ąĄčēąĄčĆąĮą░čÅ ąŠčéą╗ą░ą┤ą║ą░, ąĖ čÅą▓ą╗čÅąĄčéčüčÅ čüą░ą╝ąŠą╣ ą▒ą░ąĘąŠą▓ąŠą╣ č乊čĆą╝ąŠą╣ ąŠčéą╗ą░ą┤ą║ąĖ. ąźąŠčéčÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ čüčéą░čĆąŠą╝ąŠą┤ąĮą░čÅ, ąŠąĮą░ ą▓čüąĄ ąĄčēąĄ ąŠą▒ą╗ą░ą┤ą░ąĄčé ą╝ąŠčēąĮčŗą╝ąĖ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčÅą╝ąĖ ąĖ ąĖą╝ąĄąĄčé ą┐čĆą░ą▓ąŠ ąĮą░ ąČąĖąĘąĮčī.
ąśą┤ąĄčÅ čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, čćč鹊ą▒čŗ čüą╗ąĄą┤ąŠą▓ą░čéčī ą┐ąŠ ą┐čāčéąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą░ą╗ą│ąŠčĆąĖčéą╝ą░ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ą┐ąŠą║ą░ ąŠąĮą░ čĆąĄąĘą║ąŠ ąĮąĄ ąŠčüčéą░ąĮąŠą▓ąĖčéčüčÅ ąĖą╗ąĖ ąĮąĄ ą┤ą░čüčé ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮčŗčģ čĆąĄąĘčāą╗čīčéą░č鹊ą▓, čćč鹊ą▒čŗ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆąŠą▓ą░čéčī č鹊čćąĮčāčÄ ąĖąĮčüčéčĆčāą║čåąĖčÄ čü ą┐čĆąŠą▒ą╗ąĄą╝ąŠą╣. ąŁč鹊 ą┤ąĄą╗ą░ąĄčéčüčÅ ą┐čāč鹥ą╝ čéčēą░č鹥ą╗čīąĮąŠą│ąŠ ą▓čŗą▒ąŠčĆą░ ą╝ąĄčüčé, ą▓ ą║ąŠč鹊čĆčŗąĄ ą▓čüčéą░ą▓ą╗čÅčÄčéčüčÅ ą▓čŗąĘąŠą▓čŗ ą┐ąĄčćą░čéąĖ čüąŠąŠą▒čēąĄąĮąĖą╣, čćč鹊ą▒čŗ ąĮąĄ ąĘą░ą│čĆąŠą╝ąŠąČą┤ą░čéčī ą▓čŗą▓ąŠą┤.
ąöą░ą▓ą░ą╣č鹥 čĆą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗ąĄą┤čāčÄčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ, ą▓ ą║ąŠč鹊čĆąŠą╝ ą┐čĆąŠčÅą▓ą╗čÅąĄčéčüčÅ ąŠčłąĖą▒ą║ą░ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÅ:
>>> def average (numbers ):... print ('debug1:' , numbers)... if len (numbers) > 0 :... print ('debug2:' , sum (numbers))... return sum (numbers) / len (numbers)
...>>> 0.1 == average(3 *[0.1 ])
debug1: [0.1 , 0.1 , 0.1 ]
debug2: 0.30000000000000004 False ąÜą░ą║ ą▓čŗ ą╝ąŠąČąĄč鹥 ą▓ąĖą┤ąĄčéčī, čäčāąĮą║čåąĖčÅ ąĮąĄ ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ąŠąČąĖą┤ą░ąĄą╝ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ 0.1, ąĮąŠ č鹥ą┐ąĄčĆčī ą▓čŗ ąĘąĮą░ąĄč鹥, čćč鹊 čŹč鹊 ą┐ąŠč鹊ą╝čā, čćč鹊 sum ąĮąĄą╝ąĮąŠą│ąŠ ąŠčłąĖą▒ą░ąĄčéčüčÅ. ąóčĆą░čüčüąĖčĆąŠą▓ą║ą░ čüąŠčüč鹊čÅąĮąĖčÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ąĮą░ ąŠčéą┤ąĄą╗čīąĮčŗčģ čłą░ą│ą░čģ ą░ą╗ą│ąŠčĆąĖčéą╝ą░ ą╝ąŠąČąĄčé ą┤ą░čéčī ą▓ą░ą╝ ą┐ąŠą┤čüą║ą░ąĘą║čā, ą│ą┤ąĄ ąĮą░čģąŠą┤ąĖčéčüčÅ ą┐čĆąŠą▒ą╗ąĄą╝ą░.
ąöą╗čÅ čŹč鹊ą│ąŠ čüą╗čāčćą░čÅ ą┐čĆąŠą▒ą╗ąĄą╝ą░ ąĘą░ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ č鹊ą╝, ą║ą░ą║ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮčŗ čćąĖčüą╗ą░ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ ąĘą░ą┐čÅč鹊ą╣ ą▓ ą┐ą░ą╝čÅčéąĖ ą║ąŠą╝ą┐čīčÄč鹥čĆą░. ąÆčüą┐ąŠą╝ąĮąĖč鹥, čćč鹊 čćąĖčüą╗ą░ čģčĆą░ąĮčÅčéčüčÅ ą▓ ą┤ą▓ąŠąĖčćąĮąŠą╝ ą▓ąĖą┤ąĄ. ąöąĄčüčÅčéąĖčćąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ 0.1 ą┐čĆąĄą▓čĆą░čēą░ąĄčéčüčÅ ą▓ ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠąĄ ą┤ą▓ąŠąĖčćąĮąŠąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ąŠą║čĆčāą│ą╗čÅąĄčéčüčÅ.
ąöą╗čÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą┐ąŠ ąŠą║čĆčāą│ą╗ąĄąĮąĖčÄ čćąĖčüąĄą╗ ą▓ Python čüą╝. [7].
ąŁč鹊čé ą╝ąĄč鹊ą┤ ą┐čĆąŠčüčé, ąĖąĮčéčāąĖčéąĖą▓ąĮąŠ ą┐ąŠąĮčÅč鹥ąĮ ąĖ ą▒čāą┤ąĄčé čĆą░ą▒ąŠčéą░čéčī ą┐čĆą░ą║čéąĖč湥čüą║ąĖ ąĮą░ ą╗čÄą▒ąŠą╝ čÅąĘčŗą║ąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ. ąØąĄ ą│ąŠą▓ąŠčĆčÅ čāąČąĄ ąŠ č鹊ą╝, čćč鹊 čŹč鹊 ąŠčéą╗ąĖčćąĮąŠąĄ čāą┐čĆą░ąČąĮąĄąĮąĖąĄ ą▓ ą┐čĆąŠčåąĄčüčüąĄ ąŠą▒čāč湥ąĮąĖčÅ.
ąĪ ą┤čĆčāą│ąŠą╣ čüč鹊čĆąŠąĮčŗ, ą║ąŠą│ą┤ą░ ą▓čŗ ąŠčüą▓ąŠąĖč鹥 ą▒ąŠą╗ąĄąĄ ą┐čĆąŠą┤ą▓ąĖąĮčāčéčŗąĄ č鹥čģąĮąĖą║ąĖ, čéčĆčāą┤ąĮąŠ ą▓ąĄčĆąĮčāčéčīčüčÅ ąĮą░ąĘą░ą┤, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąĮąĖ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ą▒čŗčüčéčĆąĄąĄ ąĮą░ą╣čéąĖ ąŠčłąĖą▒ą║ąĖ. ąóčĆą░čüčüąĖčĆąŠą▓ą║ą░ čŹč鹊 čéčĆčāą┤ąŠąĄą╝ą║ąĖą╣, ą▓čŗą┐ąŠą╗ąĮčÅąĄą╝čŗą╣ ą▓čĆčāčćąĮčāčÄ ą┐čĆąŠčåąĄčüčü, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ą┐čĆąŠą┐čāčüčéąĖčéčī ąĄčēąĄ ą▒ąŠą╗čīčłąĄ ąŠčłąĖą▒ąŠą║. ą”ąĖą║ą╗ čüą▒ąŠčĆą║ąĖ ąĖ ą┐čāą▒ą╗ąĖą║ą░čåąĖąĖ (ąĖą╗ąĖ ą┐ąĄčĆąĄą┐čĆąŠčłąĖą▓ą║ąĖ firmware) ąĘą░ąĮąĖą╝ą░ąĄčé ą▓čĆąĄą╝čÅ. ąś ą┐ąŠčüą╗ąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąĖčüą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąĮą░ą╣ą┤ąĄąĮąĮčŗčģ ąŠčłąĖą▒ąŠą║ ąĮčāąČąĮąŠ ą┤ąŠč鹊賹ĮąŠ čāą┤ą░ą╗ąĖčéčī ą▓čüąĄ ą▓čüčéą░ą▓ą╗ąĄąĮąĮčŗąĄ čéčĆą░čüčüąĖčĆąŠą▓ąŠčćąĮčŗąĄ ą▓čŗąĘąŠą▓čŗ print(), ąĮąĄ čāą┤ą░ą╗ąĖą▓ čüą╗čāčćą░ą╣ąĮąŠ čĆą░ą▒ąŠčćąĖąĄ ą▓čŗąĘąŠą▓čŗ.
ą¤ąŠą╝ąĖą╝ąŠ ą▓čüąĄą│ąŠ ą┐čĆąŠč湥ą│ąŠ, čéčĆą░čüčüąĖčĆąŠą▓ą║ą░ čéčĆąĄą▒čāąĄčé ą▓ąĮąĄčüąĄąĮąĖčÅ ąĖąĘą╝ąĄąĮąĄąĮąĖą╣ ą▓ ą║ąŠą┤, čćč鹊 ąĮąĄ ą▓čüąĄą│ą┤ą░ ą▓ąŠąĘą╝ąŠąČąĮąŠ. ą£ąŠą│čāčé ą▒čŗčéčī čüą╗čāčćą░ąĖ, ą║ąŠą│ą┤ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ čāą┤ą░ą╗ąĄąĮąĮąŠą╝ web-čüąĄčĆą▓ąĄčĆąĄ, ąĖą╗ąĖ ą▓čŗ čģąŠčéąĖč鹥 ąĮą░ą╣čéąĖ ą┐čĆąĖčćąĖąĮčā ą┐čĆąŠą▒ą╗ąĄą╝čŗ čāąČąĄ ą┐ąŠ čäą░ą║čéčā, ą║ąŠą│ą┤ą░ ąŠąĮą░ čāąČąĄ čüą▓ąĄčĆčłąĖą╗ą░čüčī. ąśąĮąŠą│ą┤ą░ čā ą▓ą░čü ą┐čĆąŠčüč鹊 ąĮąĄčé ą┤ąŠčüčéčāą┐ą░ ą║ čüčéą░ąĮą┤ą░čĆčéąĮąŠą╝čā ą▓čŗą▓ąŠą┤čā.
ąŁč鹊 ą║ą░ą║ čĆą░ąĘ č鹊 ą╝ąĄčüč鹊, ą│ą┤ąĄ ą┐čĆąŠčÅą▓ą╗čÅąĄčé čüą▓ąŠąĖ ą╗čāčćčłąĖąĄ ą║ą░č湥čüčéą▓ą░ ą▓čŗą▓ąŠą┤ ą▓ ą╗ąŠą│.
ąÆčŗą▓ąŠą┤ ą▓ ą╗ąŠą│ . ąöą░ą▓ą░ą╣č鹥 ą┐čĆąĄą┤čüčéą░ą▓ąĖą╝ ąĮą░ ą╝ąĖąĮčāčéčā, čćč鹊 ą▓čŗ čāą┐čĆą░ą▓ą╗čÅąĄč鹥 čüą░ą╣č鹊ą╝ 菹╗ąĄą║čéčĆąŠąĮąĮąŠą╣ ą║ąŠą╝ą╝ąĄčĆčåąĖąĖ. ą×ą┤ąĮą░ąČą┤čŗ čĆą░ąĘą│ąĮąĄą▓ą░ąĮąĮčŗą╣ ą║ą╗ąĖąĄąĮčé ąĘą▓ąŠąĮąĖčé ą┐ąŠ č鹥ą╗ąĄč乊ąĮčā čü ąČą░ą╗ąŠą▒ąŠą╣ ąĮą░ ąĮąĄčāą┤ą░čćąĮčāčÄ čéčĆą░ąĮąĘą░ą║čåąĖčÄ ąĖ ą│ąŠą▓ąŠčĆąĖčé, čćč鹊 ą┐ąŠč鹥čĆčÅą╗ čüą▓ąŠąĖ ą┤ąĄąĮčīą│ąĖ. ą×ąĮ čāčéą▓ąĄčƹȹ┤ą░ąĄčé, čćč鹊 ą┐čŗčéą░ą╗čüčÅ ą┐čĆąĖąŠą▒čĆąĄčüčéąĖ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐čĆąĄą┤ą╝ąĄč鹊ą▓, ąĮąŠ ą▓ ą║ąŠąĮčåąĄ ą║ąŠąĮčåąŠą▓ ą┐čĆąŠąĖąĘąŠčłą╗ą░ ą║ą░ą║ą░čÅ-č鹊 ąĘą░ą│ą░ą┤ąŠčćąĮą░čÅ ąŠčłąĖą▒ą║ą░, ą║ąŠč鹊čĆą░čÅ ą┐ąŠą╝ąĄčłą░ą╗ą░ ąĄą╝čā ąĘą░ą║ąŠąĮčćąĖčéčī čŹč鹊čé ąĘą░ą║ą░ąĘ. ąóąĄą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ, ą║ąŠą│ą┤ą░ ąŠąĮ ą┐čĆąŠą▓ąĄčĆąĖą╗ čüą▓ąŠą╣ ą▒ą░ąĮą║ąŠą▓čüą║ąĖą╣ čüč湥čé, ą┤ąĄąĮčīą│ąĖ ą┐čĆąŠą┐ą░ą╗ąĖ.
ąÆčŗ ąĖčüą║čĆąĄąĮąĮąĄ ąĖąĘą▓ąĖąĮčÅąĄč鹥čüčī ąĖ ą┤ąĄą╗ą░ąĄč鹥 ą▓ąŠąĘą▓čĆą░čé čüčĆąĄą┤čüčéą▓, ąĮąŠ čéą░ą║ąČąĄ ąĮąĄ čģąŠčéąĖč鹥, čćč鹊ą▒čŗ čŹč鹊 ą┐ąŠą▓č鹊čĆąĖą╗ąŠčüčī ą▓ ą▒čāą┤čāčēąĄą╝. ąÜą░ą║ ą▓čŗ čŹč鹊 ąŠčéą╗ą░ą┤ąĖč鹥? ą£ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą▒čŗ ą┐ąŠą┐čŗčéą░čéčīčüčÅ, ąĄčüą╗ąĖ ą▒čŗ čā ą▓ą░čü ą▒čŗą╗ ą║ą░ą║ąŠą╣-č鹊 čüą╗ąĄą┤ ą┐čĆąŠąĖąĘąŠčłąĄą┤čłąĄą│ąŠ, ą▓ ąĖą┤ąĄą░ą╗ąĄ ą▓ ą▓ąĖą┤ąĄ čģčĆąŠąĮąŠą╗ąŠą│ąĖč湥čüą║ąŠą│ąŠ čüą┐ąĖčüą║ą░ čüąŠą▒čŗčéąĖą╣ čü ąĖčģ ą║ąŠąĮč鹥ą║čüč鹊ą╝.
ąÆčüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ą▓čŗ ą┐čĆąŠą▓ąŠą┤ąĖč鹥 ąŠčéą╗ą░ą┤ą║čā čü ą┐ąŠą╝ąŠčēčīčÄ ą┐ąĄčćą░čéąĖ čüąŠąŠą▒čēąĄąĮąĖą╣, ą┐ąŠą┤čāą╝ą░ą╣č鹥 ąŠ č鹊ą╝, čüą╗ąĄą┤čāąĄčé ą╗ąĖ ą┐čĆąĄą▓čĆą░čéąĖčéčī čŹč鹊 ą▓ ą┐ąŠčüč鹊čÅąĮąĮčŗą╣ ą▓čŗą▓ąŠą┤ čüąŠąŠą▒čēąĄąĮąĖą╣ ą▓ ą╗ąŠą│. ąŁč鹊 ą╝ąŠąČąĄčé ą┐ąŠą╝ąŠčćčī ą▓ ą┐ąŠą┤ąŠą▒ąĮčŗčģ čüąĖčéčāą░čåąĖčÅčģ, ą║ąŠą│ą┤ą░ ą┐ąŠąĮą░ą┤ąŠą▒ąĖčéčüčÅ ą░ąĮą░ą╗ąĖąĘ ą┐čĆąŠą▒ą╗ąĄą╝čŗ ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ąŠąĮą░ ą▓ąŠąĘąĮąĖą║ą╗ą░ ą▓ čüčĆąĄą┤ąĄ, ą║čāą┤ą░ čā ą▓ą░čü ąĮąĄčé ą┤ąŠčüčéčāą┐ą░.
ąĪčāčēąĄčüčéą▓čāčÄčé čüą╗ąŠąČąĮčŗąĄ ąĖąĮčüčéčĆčāą╝ąĄąĮčéčŗ ą┤ą╗čÅ ąĮą░ą║ąŠą┐ą╗ąĄąĮąĖčÅ ą╗ąŠą│ąŠą▓ ąĖ ą┐ąŠąĖčüą║ą░ ą┐ąŠ ąĮąĖą╝, ąĮąŠ ąĮą░ čüą░ą╝ąŠą╝ ą▒ą░ąĘąŠą▓ąŠą╝ čāčĆąŠą▓ąĮąĄ ą▓čŗ ą╝ąŠąČąĄč鹥 ą┤čāą╝ą░čéčī ąŠ ą╗ąŠą│ą░čģ ą║ą░ą║ ąŠ čäą░ą╣ą╗ą░čģ čü č鹥ą║čüč鹊ą╝. ąÜą░ąČą┤ą░čÅ čüčéčĆąŠą║ą░ čäą░ą╣ą╗ą░ ą╗ąŠą│ą░ čüąŠą┤ąĄčƹȹĖčé ą┐ąŠą┤čĆąŠą▒ąĮčāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠ čüąŠą▒čŗčéąĖąĖ ą▓ ą▓ą░čłąĄą╣ čüąĖčüč鹥ą╝ąĄ. ą×ą▒čŗčćąĮąŠ ą▓ ą╗ąŠą│ąĄ ąĮąĄ čüąŠą┤ąĄčƹȹ░čéčüčÅ ą┐ąĄčĆčüąŠąĮą░ą╗čīąĮčŗąĄ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāčÄčēąĖąĄ ą┤ą░ąĮąĮčŗąĄ, čģąŠčéčÅ ą▓ ąĮąĄą║ąŠč鹊čĆčŗčģ čüą╗čāčćą░čÅčģ čŹč鹊 ą┐čĆąĄą┤ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ąĘą░ą║ąŠąĮąŠą╝.
ąÆąŠčé čéą░ą║ ą╝ąŠąČąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī čéąĖą┐ąŠą▓ą░čÅ ąĘą░ą┐ąĖčüčī ą╗ąŠą│ą░:
[2019-06-14 15:18:34,517][DEBUG][root][MainThread] Customer(id=123) logged out
ąÜą░ą║ ą▓čŗ ą▓ąĖą┤ąĖč鹥, ąĘą░ą┐ąĖčüčī ąĖą╝ąĄąĄčé čüčéčĆčāą║čéčāčĆąĖčĆąŠą▓ą░ąĮąĮčāčÄ č乊čĆą╝čā. ąÜčĆąŠą╝ąĄ ąŠą┐ąĖčüą░ąĮąĖčÅ čüąŠą▒čŗčéąĖčÅ (ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī čü ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆąŠą╝ 123 čĆą░ąĘą╗ąŠą│ąĖąĮąĖą╗čüčÅ) ą▓ ąĘą░ą┐ąĖčüąĖ čüąŠą┤ąĄčƹȹĖčéčüčÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĮą░čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ ą┐ąŠą╗ąĄą╣, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčēąĖčģ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠ ą║ąŠąĮč鹥ą║čüč鹥 čüąŠą▒čŗčéąĖčÅ. ąÆ ąĮąĖčģ ą▓čŗ ą┐ąŠą╗čāčćą░ąĄč鹥 č鹊čćąĮčāčÄ ą┤ą░čéčā ąĖ ą▓čĆąĄą╝čÅ (2019-06-14 15:18:34,517), čāčĆąŠą▓ąĄąĮčī ą╗ąŠą│ą░ (DEBUG), ąŠčé ąĖą╝ąĄąĮąĖ ą║ą░ą║ąŠą╣ čāč湥čéąĮąŠą╣ ąĘą░ą┐ąĖčüąĖ ą┐čĆąŠąĖąĘąŠčłą╗ąŠ čüąŠą▒čŗčéąĖąĄ (root), ąĖ ąĖą╝čÅ ą┐ąŠč鹊ą║ą░ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ (MainThread).
ąŻčĆąŠą▓ąĮąĖ ą╗ąŠą│ą░ ą┐ąŠąĘą▓ąŠą╗čÅčé ą▓ą░ą╝ ą▒čŗčüčéčĆąŠ ąŠčéčäąĖą╗čīčéčĆąŠą▓ą░čéčī čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░, ąĖąĘą▒ą░ą▓ąĖą▓čłąĖčüčī ąŠčé ą╗ąĖčłąĮąĄą│ąŠ čłčāą╝ą░. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą▓čŗ ąĖčēąĄč鹥 ąŠčłąĖą▒ą║čā, č鹊 ą▓ą░ą╝ ąĮąĄ ąĮą░ą┤ąŠ ą▓ąĖą┤ąĄčéčī ą▓čüąĄ ą┐čĆąĄą┤čāą┐čĆąĄąČą┤ą░čÄčēąĖąĄ (WARNING) ąĖą╗ąĖ ąŠčéą╗ą░ą┤ąŠčćąĮčŗąĄ (DEBUG) čüąŠąŠą▒čēąĄąĮąĖčÅ. ą×č湥ąĮčī ą╗ąĄą│ą║ąŠ ąĘą░ą┐čĆąĄčéąĖčéčī ąĖą╗ąĖ čĆą░ąĘčĆąĄčłąĖčéčī čüąŠąŠą▒čēąĄąĮąĖčÅ ąĮą░ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ čāčĆąŠą▓ąĮčÅčģ ą╗ąŠą│ą░ č湥čĆąĄąĘ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÄ čüąĄčĆą▓ąĖčüą░, ąĮąĄ ąĘą░čéčĆą░ą│ąĖą▓ą░čÅ ąĄą│ąŠ ą║ąŠą┤.
ąĪ ą┐ąŠą╝ąŠčēčīčÄ ą▓čŗą▓ąŠą┤ą░ ą▓ ą╗ąŠą│ ą▓čŗ ą╝ąŠąČąĄč鹥 čāą┤ąĄčƹȹĖą▓ą░čéčī čüą▓ąŠąĖ ąŠčéą╗ą░ą┤ąŠčćąĮčŗąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ ąŠčéą┤ąĄą╗čīąĮąŠ ąŠčé čüčéą░ąĮą┤ą░čĆčéąĮąŠą│ąŠ ą▓čŗą▓ąŠą┤ą░. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą▓čüąĄ čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░ ą┐ąŠčüčéčāą┐ą░čÄčé ą▓ čüčéą░ąĮą┤ą░čĆčéąĮčŗą╣ ą┐ąŠč鹊ą║ ąŠčłąĖą▒ąŠą║ (stderr), ą║ąŠč鹊čĆčŗą╣ ą┤ą╗čÅ čāą┤ąŠą▒čüčéą▓ą░ ą┐ąŠą┤čüą▓ąĄčćąĖą▓ą░ąĄčéčüčÅ ą┤čĆčāą│ąĖą╝ąĖ čåą▓ąĄčéą░ą╝ąĖ č鹥ą║čüčéą░. ą×ą┤ąĮą░ą║ąŠ ą▓čŗ ą╝ąŠąČąĄč鹥 ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ąĖčéčī čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░ ą▓ ąŠčéą┤ąĄą╗čīąĮčŗąĄ čäą░ą╣ą╗čŗ, ą┤ą░ąČąĄ ą┤ą╗čÅ ąŠčéą┤ąĄą╗čīąĮčŗčģ ą╝ąŠą┤čāą╗ąĄą╣!
ąöąŠą▓ąŠą╗čīąĮąŠ čćą░čüč鹊 ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠ ąĮą░čüčéčĆąŠąĄąĮąĮąŠąĄ ą▓ąĄą┤ąĄąĮąĖąĄ ąČčāčĆąĮą░ą╗ą░ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ąĮąĄčģą▓ą░čéą║ąĄ ą╝ąĄčüčéą░ ąĮą░ ą┤ąĖčüą║ąĄ čüąĄčĆą▓ąĄčĆą░. ą¦č鹊ą▒čŗ ą┐čĆąĄą┤ąŠčéą▓čĆą░čéąĖčéčī čŹč鹊, ą▓čŗ ą╝ąŠąČąĄč鹥 ąĮą░čüčéčĆąŠąĖčéčī čĆąŠčéą░čåąĖčÄ ąČčāčĆąĮą░ą╗ąŠą▓, ą║ąŠč鹊čĆą░čÅ ą▒čāą┤ąĄčé čģčĆą░ąĮąĖčéčī čäą░ą╣ą╗čŗ ąČčāčĆąĮą░ą╗ąŠą▓ ą▓ č鹥č湥ąĮąĖąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╣ ą┐čĆąŠą┤ąŠą╗ąČąĖč鹥ą╗čīąĮąŠčüčéąĖ, ąĮą░ą┐čĆąĖą╝ąĄčĆ, ąŠą┤ąĮąŠą╣ ąĮąĄą┤ąĄą╗ąĖ ąĖą╗ąĖ ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ąŠąĮąĖ ą┤ąŠčüčéąĖą│ąĮčāčé ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░. ąóąĄą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ, ą▓čüąĄą│ą┤ą░ ą┐ąŠą╗ąĄąĘąĮąŠ ą░čĆčģąĖą▓ąĖčĆąŠą▓ą░čéčī čüčéą░čĆčŗąĄ ąČčāčĆąĮą░ą╗čŗ. ąØąĄą║ąŠč鹊čĆčŗąĄ ą┐čĆą░ą▓ąĖą╗ą░ ą┐čĆąĄą┤ą┐ąĖčüčŗą▓ą░čÄčé čģčĆą░ąĮąĖčéčī ą┤ą░ąĮąĮčŗąĄ ąŠ ą║ą╗ąĖąĄąĮčéą░čģ ą┤ąŠ ą┐čÅčéąĖ ą╗ąĄčé!
ąÆ čüčĆą░ą▓ąĮąĄąĮąĖąĖ čü ą┤čĆčāą│ąĖą╝ąĖ čÅąĘčŗą║ą░ą╝ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ą╗ąŠą│ąĖčĆąŠą▓ą░ąĮąĖąĄ ą▓ Python čāčüčéčĆąŠąĄąĮąŠ ą┐čĆąŠčēąĄ, ą┐ąŠč鹊ą╝čā čćč鹊 ą╝ąŠą┤čāą╗čī logging [8] ą┐ąŠčüčéą░ą▓ą╗čÅąĄčéčüčÅ ą▓ čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĄ. ąÆ ą┐čĆąŠčüč鹊 ąĖą╝ą┐ąŠčĆčéąĖčĆčāąĄč鹥 ąĖ ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄč鹥 ąĄą│ąŠ ą┤ą▓čāą╝čÅ čüčéčĆąŠčćą║ą░ą╝ąĖ ą║ąŠą┤ą░:
import logging
logging.basicConfig(level=logging.DEBUG)ąÆčŗ ą╝ąŠąČąĄč鹥 ą▓čŗąĘčŗą▓ą░čéčī čäčāąĮą║čåąĖąĖ, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ ąĮą░ čāčĆąŠą▓ąĮąĄ ą╝ąŠą┤čāą╗čÅ, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠą┤ą║ą╗čÄč湥ąĮčŗ ą║ ą║ąŠčĆąĮąĄą▓ąŠą╝čā ą╗ąŠą│čā (root logger), ąĮąŠ ą▒ąŠą╗ąĄąĄ čĆą░čüą┐čĆąŠčüčéčĆą░ąĮąĄąĮąĮą░čÅ ą┐čĆą░ą║čéąĖą║ą░ - ą┐ąŠą╗čāčćąĖčéčī ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗą╣ ą╗ąŠą│ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą▓ą░čłąĄą│ąŠ ąĖčüčģąŠą┤ąĮąŠą│ąŠ čäą░ą╣ą╗ą░:
logging.debug('hello' ) # čäčāąĮą║čåąĖčÅ ąĮą░ čāčĆąŠą▓ąĮąĄ ą╝ąŠą┤čāą╗čÅ
logger = logging.getLogger(__name__)
logger.debug('hello' ) # ą▓čŗąĘąŠą▓ ą╝ąĄč鹊ą┤ą░ ą╗ąŠą│ą░
ąöąŠčüč鹊ąĖąĮčüčéą▓ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąŠčéą┤ąĄą╗čīąĮčŗčģ ąĮą░čüčéčĆąŠąĄąĮąĮčŗčģ ą╗ąŠą│ąŠą▓ ąĘą░ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ ą▒ąŠą╗ąĄąĄ č鹊ąĮą║ąŠą╝ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĖ. ą×ą▒čŗčćąĮąŠ ą╗ąŠą│ąĖ ąĮą░ąĘčŗą▓ą░čÄčéčüčÅ ą┐ąŠ ąĖą╝ąĄąĮąĖ ą╝ąŠą┤čāą╗čÅ, ą│ą┤ąĄ ą╗ąŠą│ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ, č湥čĆąĄąĘ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ __name__.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ą▓ Python ąĄčüčéčī ą╝ąŠą┤čāą╗čī warnings , ąĮąĄčüą║ąŠą╗čīą║ąŠ čüą▓čÅąĘą░ąĮąĮčŗą╣ čü ą▓čŗą▓ąŠą┤ąŠą╝ ą▓ ą╗ąŠą│, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé čéą░ą║ąČąĄ ą▓čŗą▓ąŠą┤ąĖčéčī čüąŠąŠą▒čēąĄąĮąĖčÅ ą╗ąŠą│ą░ ą▓ čüčéą░ąĮą┤ą░čĆčéąĮčŗą╣ ą┐ąŠč鹊ą║ ąŠčłąĖą▒ąŠą║. ą×ą┤ąĮą░ą║ąŠ čā ąĮąĄą│ąŠ ą▒ąŠą╗ąĄąĄ čāąĘą║ąĖą╣ čüą┐ąĄą║čéčĆ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ, ą▓ ąŠčüąĮąŠą▓ąĮąŠą╝ ą▓ ą▒ąĖą▒ą╗ąĖąŠč鹥čćąĮąŠą╝ ą║ąŠą┤ąĄ, č鹊ą│ą┤ą░ ą║ą░ą║ ą║ą╗ąĖąĄąĮčéčüą║ąĖąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą┤ąŠą╗ąČąĮčŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą╝ąŠą┤čāą╗čī logging.
ąóąĄą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ, ą▓čŗ ą╝ąŠąČąĄč鹥 ąĘą░čüčéą░ą▓ąĖčéčī ąĖčģ čĆą░ą▒ąŠčéą░čéčī čüąŠą▓ą╝ąĄčüčéąĮąŠ, ą┐čāč鹥ą╝ ą▓čŗąĘąŠą▓ą░ logging.captureWarnings(True).
ą¤ąŠčüą╗ąĄą┤ąĮčÅčÅ ą┐čĆąĖčćąĖąĮą░ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ čü čäčāąĮą║čåąĖąĖ print() ąĮą░ ą▓čŗą▓ąŠą┤ ą▓ ą╗ąŠą│ - ąĮą░ą┐ąĖčüą░ąĮąĖąĄ ą┐ąŠč鹊ą║ąŠą▒ąĄąĘąŠą┐ą░čüąĮąŠą│ąŠ ą║ąŠą┤ą░ (thread safety). ąÆ čüą╗ąĄą┤čāčÄčēąĄą╝ čĆą░ąĘą┤ąĄą╗ąĄ ą▓čŗ čāą▓ąĖą┤ąĖč鹥, čćč鹊 ą┐ąĄčĆą▓čŗą╣ print() ąĮąĄ ąŠč湥ąĮčī čģąŠčĆąŠčłąŠ čüčéčŗą║čāąĄčéčüčÅ čü ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ čĆą░ą▒ąŠčéą░čÄčēąĖą╝ąĖ ą┐ąŠč鹊ą║ą░ą╝ąĖ.
ą×čéą╗ą░ą┤ą║ą░ . ą¤čĆą░ą▓ą┤ą░ čüąŠčüč鹊ąĖčé ą▓ č鹊ą╝, čćč鹊 ąĮąĖ čéčĆą░čüčüąĖčĆąŠą▓ą║čā, ąĮąĖ ą▓čŗą▓ąŠą┤ ą▓ ą╗ąŠą│ ąĮąĄą╗čīąĘčÅ čüčćąĖčéą░čéčī ą┐ąŠą╗ąĮąŠčåąĄąĮąĮąŠą╣ ąŠčéą╗ą░ą┤ą║ąŠą╣. ą¦č鹊ą▒čŗ ą▓čŗą┐ąŠą╗ąĮąĖčéčī čĆąĄą░ą╗čīąĮčāčÄ ąŠčéą╗ą░ą┤ą║čā, ą▓ą░ą╝ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ą░ čāčéąĖą╗ąĖčéą░ ąŠčéą╗ą░ą┤čćąĖą║ą░ (debugger), ą║ąŠč鹊čĆčŗą╣ ą┐ąŠąĘą▓ąŠą╗ąĖčé ą▓ą░ą╝ ą┐ąŠą╗čāčćąĖčéčī čüą╗ąĄą┤čāčÄčēąĖąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ:
ŌĆó ą¤ąŠčłą░ą│ąŠą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐ąŠ ąĖčüčģąŠą┤ąĮąŠą╝čā ą║ąŠą┤čā.
ąĪčŗčĆąŠą╣ ąŠčéą╗ą░ą┤čćąĖą║, čĆą░ą▒ąŠčéą░čÄčēąĖą╣ ą▓ č鹥čĆą╝ąĖąĮą░ą╗ąĄ, ą║ąŠč鹊čĆčŗą╣ ąŠąČąĖą┤ą░ąĄą╝ąŠ ą┐ąŠą╗čāčćąĖą╗ ąĖą╝čÅ pdb
ą×ą┤ąĮą░ą║ąŠ ą▓ ąĮąĄą╝ ąĮąĄčé ą│čĆą░čäąĖč湥čüą║ąŠą│ąŠ ąĖąĮč鹥čĆč乥ą╣čüą░, čéą░ą║ čćč鹊 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ pdb ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ čāčüą╗ąŠąČąĮąĄąĮąŠ. ąĢčüą╗ąĖ ą▓čŗ ąĮąĄ ą╝ąŠąČąĄč鹥 čĆąĄą┤ą░ą║čéąĖčĆąŠą▓ą░čéčī ą║ąŠą┤, č鹊 ą▓čŗ ą┤ąŠą╗ąČąĮčŗ ąĘą░ą┐čāčüčéąĖčéčī ąĄą│ąŠ ą║ą░ą║ ą╝ąŠą┤čāą╗čī, ąĖ ą┐ąĄčĆąĄą┤ą░čéčī ą▓ ąĮąĄą│ąŠ ą╝ąĄčüč鹊 čĆą░ąĘą╝ąĄčēąĄąĮąĖčÅ ą▓ą░čłąĄą│ąŠ čüą║čĆąĖą┐čéą░:
$ python -m pdb my_script.py
ąÆ ą┐čĆąŠčéąĖą▓ąĮąŠą╝ čüą╗čāčćą░ąĄ ą▓čŗ ą╝ąŠąČąĄč鹥 ą▓čüčéą░ą▓ąĖčéčī breakpoint ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ ą▓ ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ąŠčüčéą░ąĮąŠą▓ąĖčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą▓ą░čłąĄą│ąŠ čüą║čĆąĖą┐čéą░ ąĖ ą▓čŗą▒čĆąŠčüąĖčé ą▓ą░čü ą▓ ąŠčéą╗ą░ą┤čćąĖą║. ąĪčéą░čĆčŗą╣ čüą┐ąŠčüąŠą▒ ą┤ą╗čÅ čŹč鹊ą│ąŠ čéčĆąĄą▒čāąĄčé ą┤ą▓čāčģ čłą░ą│ąŠą▓:
>>> import pdb>>> pdb.set_trace()
--Return--
> < stdin>(1 )< module>()->None
(Pdb)ąŁč鹊 ąŠč鹊ą▒čĆą░ąĘąĖčé ąĖąĮč鹥čĆą░ą║čéąĖą▓ąĮąŠąĄ ą┐čĆąĖą│ą╗ą░čłąĄąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ą┐ąŠąĮą░čćą░ą╗čā ą╝ąŠąČąĄčé ąĮą░ą┐čāą│ą░čéčī. ąóąĄą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ ą▓ čŹč鹊ą╝ ą╝ąĄčüč鹥 ą▓čŗ ą▓čüąĄ ąĄčēąĄ ą╝ąŠąČąĄč鹥 ą▓ą▓ąĄčüčéąĖ čĆąŠą┤ąĮąŠą╣ Python, čćč鹊ą▒čŗ ą┐čĆąŠą░ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī ąĖą╗ąĖ ąĖąĘą╝ąĄąĮąĖčéčī čüąŠčüč鹊čÅąĮąĖąĄ ą╗ąŠą║ą░ą╗čīąĮčŗčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ąĄčüčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ čüą┐ąĄčåąĖčäąĖčćąĮčŗčģ ą┤ą╗čÅ ąŠčéą╗ą░ą┤čćąĖą║ą░ ą║ąŠą╝ą░ąĮą┤, ą║ąŠč鹊čĆčŗąĄ ą▓čŗ ąĘą░čģąŠčéąĖč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ ą┐ąŠčłą░ą│ąŠą▓ąŠą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ą┤ą▓ąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ą╗čÅ ąĖąĮąČąĄą║čåąĖąĖ ąŠčéą╗ą░ą┤čćąĖą║ą░ ą┐čĆąĖąĮčÅč鹊 ą▓čüčéą░ą▓ą╗čÅčéčī ąĮą░ ąŠą┤ąĮčā čüčéčĆąŠą║čā. ąŁč鹊 čéčĆąĄą▒čāąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüąĖą╝ą▓ąŠą╗ą░ č鹊čćą║ąĖ čü ąĘą░ą┐čÅč鹊ą╣, čćč鹊 ąĖąĮąŠą│ą┤ą░ ą▓čüčéčĆąĄčćą░ąĄčéčüčÅ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ą░čģ Python:
import pdb; pdb.set_trace()ą¤ąŠčüą║ąŠą╗čīą║čā čŹč鹊čé čüčéąĖą╗čī ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠ ąĮąĄ ą┐ąĖč鹊ąĮčüą║ąĖą╣, ąŠąĮ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ ąĮą░ą┐ąŠą╝ąĖąĮą░ąĄčé ąŠ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ čāą┤ą░ą╗ąĄąĮąĖčÅ ą┐ąŠčüą╗ąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąŠčéą╗ą░ą┤ą║ąĖ.
ąØą░čćąĖąĮą░čÅ čü Python 3.7 ą▓čŗ ą╝ąŠąČąĄč鹥 čéą░ą║ąČąĄ ą▓čŗąĘą▓ą░čéčī ą▓čüčéčĆąŠąĄąĮąĮčāčÄ čäčāąĮą║čåąĖčÄ breakpoint() , ą║ąŠč鹊čĆą░čÅ ą┤ąĄą╗ą░ąĄčé č鹊 ąČąĄ čüą░ą╝ąŠąĄ, ąĮąŠ ą▒ąŠą╗ąĄąĄ ą║ąŠą╝ą┐ą░ą║čéąĮčŗą╝ čüą┐ąŠčüąŠą▒ąŠą╝ ąĖ čü ąĮąĄą║ąŠč鹊čĆčŗą╝ąĖ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗą╝ąĖ ąĮą░ą▓ąŠčĆąŠčéą░ą╝ąĖ:
def average (numbers ):
if len (numbers) > 0 :
breakpoint () # Python 3.7+
return sum (numbers) / len (numbers)ąÆčŗ ą▓ąĄčĆąŠčÅčéąĮąŠ ą┐čĆąĄą┤ą┐ąŠčćč鹥č鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓ąĖąĘčāą░ą╗čīąĮčŗą╣ ąŠčéą╗ą░ą┤čćąĖą║, ą▓ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ čüą╗čāčćą░ąĄą▓ ąĖąĮč鹥ą│čĆąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą▓ čĆąĄą┤ą░ą║č鹊čĆ ą║ąŠą┤ą░. PyCharm ąĖą╝ąĄąĄčé ąŠčéą╗ąĖčćąĮčŗą╣ ąŠčéą╗ą░ą┤čćąĖą║ čü ą┐čĆąĄą▓ąŠčüčģąŠą┤ąĮąŠą╣ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčīčÄ, ąĮąŠ ą▓čŗ ąĮą░ą╣ą┤ąĄč鹥 ą╝ąĮąŠąČąĄčüčéą▓ąŠ ą░ą╗čīč鹥čĆąĮą░čéąĖą▓ąĮčŗčģ IDE čü ąŠčéą╗ą░ą┤čćąĖą║ą░ą╝ąĖ, ą║ą░ą║ ą┐ą╗ą░čéąĮčŗčģ, čéą░ą║ ąĖ ą▒ąĄčüą┐ą╗ą░čéąĮčŗčģ.
ą×čéą╗ą░ą┤ą║čā ąĮąĄ čüč鹊ąĖčé čüčćąĖčéą░čéčī čüąĄčĆąĄą▒čĆčÅąĮąŠą╣ ą┐čāą╗ąĄą╣, čĆąĄčłą░čÄčēąĄą╣ ą▓čüąĄ ą┐čĆąŠą▒ą╗ąĄą╝čŗ. ąśąĮąŠą│ą┤ą░ ą▓čŗą▓ąŠą┤ ą▓ ą╗ąŠą│ ąĖą╗ąĖ čéčĆą░čüčüąĖčĆąŠą▓ą║ą░ ą▒čāą┤ąĄčé ą╗čāčćčłąĖą╝ čĆąĄčłąĄąĮąĖąĄą╝. ąØą░ą┐čĆąĖą╝ąĄčĆ čĆąĄą┤ą║ąŠ ą┐čĆąŠčÅą▓ą╗čÅčÄčēąĖąĄčüčÅ ą┤ąĄč乥ą║čéčŗ, čéą░ą║ąĖąĄ ą║ą░ą║ čāčüą╗ąŠą▓ąĖčÅ ą│ąŠąĮą║ąĖ (race conditions), čćą░čüč鹊 ą┐čĆąŠąĖčüčģąŠą┤čÅčé ąĖąĘ-ąĘą░ čüą╗čāčćą░ą╣ąĮąŠą╣ čüą▓čÅąĘąĖ. ąÜąŠą│ą┤ą░ ą▓čŗ ą▓čŗą┐ąŠą╗ąĮčÅąĄč鹥 ąŠčüčéą░ąĮąŠą▓ą║čā ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą▓ breakpoint, č鹊 čŹčéą░ ą╝ą░ą╗ąĄąĮčīą║ą░čÅ ą┐ą░čāąĘą░ ą▓ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą╝ą░čüą║ąĖčĆčāąĄčé ą┐čĆąŠą▒ą╗ąĄą╝čā. ąŁč鹊 ą┐ąŠčģąŠąČąĄ ąĮą░ ą┐čĆąĖąĮčåąĖą┐ ąōąĄą╣ąĘąĄąĮą▒ąĄčĆą│ą░: čü ą┐ąŠą╝ąŠčēčīčÄ ąŠčéą╗ą░ą┤ą║ąĖ ą▓čŗ ąĮąĄ ą╝ąŠąČąĄč鹥 ąĖąĘą╝ąĄčĆąĖčéčī ąĖ ąĮą░ą▒ą╗čÄą┤ą░čéčī ą▒ą░ą│ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ.
ą¤ąĄčĆąĄčćąĖčüą╗ąĄąĮąĮčŗąĄ ą╝ąĄč鹊ą┤čŗ ą┐ąŠąĖčüą║ą░ ąŠčłąĖą▒ąŠą║ ąĮąĄ čÅą▓ą╗čÅčÄčéčüčÅ ą▓ąĘą░ąĖą╝ąŠąĖčüą║ą╗čÄčćą░čÄčēąĖą╝ąĖ. ą×ąĮąĖ ą┤ąŠą┐ąŠą╗ąĮčÅčÄčé ą┤čĆčāą│ ą┤čĆčāą│ą░.
[ą¤ąŠč鹊ą║ąŠą▒ąĄąĘąŠą┐ą░čüąĮą░čÅ ą┐ąĄčćą░čéčī ]
ą» čĆą░ąĮąĄąĄ ą║čĆą░čéą║ąŠ čāą┐ąŠą╝ąĖąĮą░ą╗ ą┐čĆąŠą▒ą╗ąĄą╝čā thread safety, ą║ąŠą│ą┤ą░ čĆąĄą║ąŠą╝ąĄąĮą┤ąŠą▓ą░ą╗ ą▓čŗą▓ąŠą┤ ą▓ ą╗ąŠą│ č湥čĆąĄąĘ čäčāąĮą║čåąĖčÄ print(). ąĢčüą╗ąĖ ą▓čŗ ą┤ąŠčćąĖčéą░ą╗ąĖ ą┤ąŠ čŹč鹊ą│ąŠ ą╝ąĄčüčéą░, č鹊 čüą║ąŠčĆąĄąĄ ą▓čüąĄą│ąŠ ąĮą░čģąŠą┤ąĖč鹥 čāą┤ąŠą▒ąĮčŗą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą║ąŠąĮčåąĄą┐čåąĖąĖ ą┐ąŠč鹊ą║ąŠą▓ (threads).
Thread safety ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮą░čÅ čćą░čüčéčī ą║ąŠą┤ą░ ą╝ąŠąČąĄčé ą▒ąĄąĘąŠą┐ą░čüąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ ą┐ąŠč鹊ą║ą░ą╝ąĖ čéą░ą║, čćč鹊 ąŠąĮąĖ ąĮąĄ ąĮą░čĆčāčłą░čÄčé ąĮąŠčĆą╝ą░ą╗čīąĮčāčÄ čĆą░ą▒ąŠčéčā ą┤čĆčāą│ ą┤čĆčāą│ą░. ąĪą░ą╝ą░čÅ ą┐čĆąŠčüčéą░čÅ čüčéčĆą░č鹥ą│ąĖčÅ ąŠą▒ąĄčüą┐ąĄčćąĖčéčī thread-safety - čłą░čĆąĖąĮą│ č鹊ą╗čīą║ąŠ ąĮąĄąĖąĘą╝ąĄąĮčÅąĄą╝čŗčģ ąŠą▒čŖąĄą║č鹊ą▓. ąĢčüą╗ąĖ ą┐ąŠč鹊ą║ąĖ ąĮąĄ ą╝ąŠą│čāčé ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░čéčī čüąŠčüč鹊čÅąĮąĖąĄ ąŠą▒čēąĄą│ąŠ ąŠą▒čŖąĄą║čéą░, č鹊 ąĮąĄ ą▒čāą┤ąĄčé čĆąĖčüą║ą░ ąĮą░čĆčāčłąĄąĮąĖčÅ ąĄą│ąŠ čåąĄą╗ąŠčüčéąĮąŠčüčéąĖ.
ąöčĆčāą│ąŠą╣ ą╝ąĄč鹊ą┤ - ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą╗ąŠą║ą░ą╗čīąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ, ą║ąŠą│ą┤ą░ ą║ą░ąČą┤čŗą╣ ą┐ąŠč鹊ą║ ą┐ąŠą╗čāčćą░ąĄčé čüąŠą▒čüčéą▓ąĄąĮąĮčāčÄ ą║ąŠą┐ąĖčÄ ąŠą┤ąĮąŠą│ąŠ ąĖ č鹊ą│ąŠ ąČąĄ ąŠą▒čŖąĄą║čéą░. ąóą░ą║ąĖą╝ čüą┐ąŠčüąŠą▒ąŠą╝ ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║ ąĮąĄ ą╝ąŠąČąĄčé ą▓ąĖą┤ąĄčéčī ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ, čüą┤ąĄą╗ą░ąĮąĮčŗąĄ ą▓ č鹥ą║čāčēąĄą╝ ą┐ąŠč鹊ą║ąĄ.
ąØąŠ čŹč鹊 ąĮąĄ čĆąĄčłą░ąĄčé ą┐čĆąŠą▒ą╗ąĄą╝čā, ąĮąĄ čéą░ą║ ą╗ąĖ? ąÆčŗ čćą░čüč鹊 čģąŠčéąĖč鹥, čćč鹊ą▒čŗ ą▓ą░čłąĖ ą┐ąŠč鹊ą║ąĖ čüąŠčéčĆčāą┤ąĮąĖčćą░ą╗ąĖ, ąĖą╝ąĄčÅ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą╝čāčéąĖčĆąŠą▓ą░čéčī ąŠą▒čēąĖą╣ čĆąĄčüčāčĆčü. ąØą░ąĖą▒ąŠą╗ąĄąĄ čćą░čüčéčŗą╣ čüą┐ąŠčüąŠą▒ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ ą║ąŠąĮą║čāčĆąĄąĮčéąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą║ čéą░ą║ąŠą╝čā čĆąĄčüčāčĆčüčā čÅą▓ą╗čÅąĄčéčüčÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą▓čüąĄčģ ą║ąŠąĮą║čāčĆąĖčĆčāčÄčēąĖčģ ą┐ąŠč鹊ą║ąŠą▓, ą║čĆąŠą╝ąĄ ąŠą┤ąĮąŠą│ąŠ. ąŁč鹊 ą┤ą░ąĄčé 菹║čüą║ą╗čĹʹĖą▓ąĮčŗą╣ ą┤ąŠčüčéčāą┐ ąĮą░ ąĘą░ą┐ąĖčüčī ąŠą┤ąĮąŠą╝čā ą┐ąŠč鹊ą║čā, ąĖą╗ąĖ ąĖąĮąŠą│ą┤ą░ ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ ą┐ąŠč鹊ą║ą░ą╝ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ.
ą×ą┤ąĮą░ą║ąŠ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ čÅą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčĆąŠą│ąĖą╝ ą╝ąĄč鹊ą┤ąŠą╝, ąĖ ąŠąĮą░ čüąĮąĖąČą░ąĄčé ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮčāčÄ ą┐čĆąŠą┐čāčüą║ąĮčāčÄ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī, ą┐ąŠčŹč鹊ą╝čā ą▒čŗą╗ąĖ ąĖąĘąŠą▒čĆąĄč鹥ąĮčŗ ą┤čĆčāą│ąĖąĄ čüčĆąĄą┤čüčéą▓ą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┤ąŠčüčéčāą┐ąŠą╝, čéą░ą║ąĖąĄ ą║ą░ą║ ą░č鹊ą╝ą░čĆąĮčŗąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ ąĖą╗ąĖ ą░ą╗ą│ąŠčĆąĖčéą╝ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ąĖ ąĘą░ą╝ąĄąĮčŗ.
ą¤ąĄčćą░čéčī ą▓ Python ąĮąĄ thread-safe. ążčāąĮą║čåąĖčÅ print() čģčĆą░ąĮąĖčé čüčüčŗą╗ą║čā ąĮą░ čüčéą░ąĮą┤ą░čĆčéąĮčŗą╣ ą▓čŗą▓ąŠą┤, ą║ąŠč鹊čĆčŗą╣ čÅą▓ą╗čÅąĄčéčüčÅ ąŠą▒čēąĄą╣ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣. ąóąĄąŠčĆąĄčéąĖč湥čüą║ąĖ, ą┐ąŠčüą║ąŠą╗čīą║čā ąĮąĄčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ, ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą║ąŠąĮč鹥ą║čüčéą░ ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓čŗąĘąŠą▓ą░ sys.stdout.write(), ą┐ąĄčĆąĄą┐ą╗ąĄčéą░čÅ ą▒ą░ą╣čéčŗ č鹥ą║čüčéą░ ąĖąĘ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą▓čŗąĘąŠą▓ąŠą▓ print().
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą║ąŠąĮč鹥ą║čüčéą░ ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ąŠą┤ąĖąĮ ą┐ąŠč鹊ą║ ą┐čĆąĖąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ, ą┤ąŠą▒čĆąŠą▓ąŠą╗čīąĮąŠ ąĖą╗ąĖ ąĮąĄčé, čćč鹊ą▒čŗ ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║ ą╝ąŠą│ ą▓ąĘčÅčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ąŠą┤ą░ ąĮą░ čüąĄą▒čÅ. ąŁč鹊 ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ ą▓ ą╗čÄą▒ąŠą╣ ą╝ąŠą╝ąĄąĮčé, ą┤ą░ąČąĄ ą┐ąŠčüąĄčĆąĄą┤ąĖąĮąĄ ą▓čŗąĘąŠą▓ą░ čäčāąĮą║čåąĖąĖ.
ą×ą┤ąĮą░ą║ąŠ ąĮą░ ą┐čĆą░ą║čéąĖrąĄ čŹč鹊ą│ąŠ ąĮąĄ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé. ąÜą░ą║ ąĮąĖ čüčéą░čĆą░ą╣čüčÅ, ąĘą░ą┐ąĖčüčī ą▓ čüčéą░ąĮą┤ą░čĆčéąĮčŗą╣ ą▓čŗą▓ąŠą┤ ą▓čŗą│ą╗čÅą┤ąĖčé ą░č鹊ą╝ą░čĆąĮąŠą╣. ąĢą┤ąĖąĮčüčéą▓ąĄąĮąĮą░čÅ ą┐čĆąŠą▒ą╗ąĄą╝ą░, ą║ąŠč鹊čĆčāčÄ ą▓čŗ ą╝ąŠąČąĄč鹥 ąĖąĮąŠą│ą┤ą░ ąĮą░ą▒ą╗čÄą┤ą░čéčī čüą▓čÅąĘą░ąĮą░ čü ąĖčüą┐ąŠčĆč湥ąĮąĮčŗą╝ąĖ ą╝ąĄčüčéą░ą╝ąĖ ą┐ąŠčÅą▓ą╗ąĄąĮąĖčÅ čĆą░ąĘčĆčŗą▓ąŠą▓ čüčéčĆąŠą║ąĖ:
[Thread-3 A][Thread-2 A][Thread-1 A]
[Thread-3 B][Thread-1 B]
[Thread-1 C][Thread-3 C]
[Thread-2 B]
[Thread-2 C]
ąöą╗čÅ čüąĖą╝čāą╗čÅčåąĖąĖ čŹč鹊ą│ąŠ ą▓čŗ ą╝ąŠąČąĄčé čāą▓ąĄą╗ąĖčćąĖčéčī ą▓ąĄčĆąŠčÅčéąĮąŠčüčéčī ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ ą║ąŠąĮč鹥ą║čüčéą░, ąĘą░čüčéą░ą▓ąĖą▓ ąĮąĖąČąĄą╗ąĄąČą░čēąĖą╣ ą╝ąĄč鹊ą┤ .write() čāą╣čéąĖ ą▓ čüąŠąĮ ąĮą░ čüą╗čāčćą░ą╣ąĮąŠąĄ ą▓čĆąĄą╝čÅ. ąÜą░ą║? ą¤čĆąĖą╝ąĄąĮąĖą▓ ą┤ą╗čÅ ąĮąĄą│ąŠ mock-č鹥čģąĮąĖą║čā, čü ą║ąŠč鹊čĆąŠą╣ ą▓čŗ ą┐ąŠąĘąĮą░ą║ąŠą╝ąĖą╗ąĖčüčī ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ čüąĄą║čåąĖąĖ:
import sysfrom time import sleepfrom random import randomfrom threading import current_thread, Threadfrom unittest.mock import patchdef slow_write (text ):
sleep(random())
write(text)def task ():
thread_name = current_thread().name
for letter in 'ABC' :
print (f'[{thread_name} {letter} ]' )with patch('sys.stdout' ) as mock_stdout:
mock_stdout.write = slow_write
for _ in range (3 ):
Thread(target=task).start()ąĪąĮą░čćą░ą╗ą░ ą▓ą░ą╝ ąĮčāąČąĮąŠ čüąŠčģčĆą░ąĮąĖčéčī ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮčŗą╣ ą╝ąĄč鹊ą┤ .write() ą▓ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣, ą║ąŠč鹊čĆčāčÄ ą▓čŗ ą┤ąĄą╗ąĄą│ąĖčĆčāąĄč鹥 ą┐ąŠąĘąČąĄ. ąŚą░č鹥ą╝ ą▓čŗ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖč鹥 ą┐ąŠą┤ą┤ąĄą╗čīąĮčāčÄ čĆąĄą░ą╗ąĖąĘą░čåąĖčÄ, ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠč鹊čĆąŠą╣ ąĘą░ą╣ą╝ąĄčé ą┤ąŠ ąŠą┤ąĮąŠą╣ čüąĄą║čāąĮą┤čŗ. ąÜą░ąČą┤čŗą╣ ą┐ąŠč鹊ą║ ą▒čāą┤ąĄčé ą┤ąĄą╗ą░čéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▓čŗąĘąŠą▓ąŠą▓ print(), ąŠą▒ąŠąĘąĮą░čćą░čÅ čüąĄą▒čÅ ą┐ąŠ ąĖą╝ąĄąĮąĖ ąĖ ą▒čāą║ą▓ąĄ: A, B ąĖ C.
ąĢčüą╗ąĖ ą▓čŗ čćąĖčéą░ą╗ąĖ čĆą░ąĮąĄąĄ čüąĄą║čåąĖčÄ, ą┐ąŠčüą▓čÅčēąĄąĮąĮčāčÄ mock-č鹥čģąĮąĖą║ąĄ, č鹊 ą▓ąŠąĘą╝ąŠąČąĮąŠ čāąČąĄ ąĖą╝ąĄąĄč鹥 ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ, ą┐ąŠč湥ą╝čā ą┐ąĄčćą░čéčī čéą░ą║ čüąĄą▒čÅ ą▓ąĄą┤ąĄčé. ąóąĄą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ, čćč鹊ą▒čŗ ąŠą║ąŠąĮčćą░č鹥ą╗čīąĮąŠ ą▓čüąĄ ą┐čĆąŠčÅčüąĮąĖčéčī, ą▓čŗ ą╝ąŠąČąĄč鹥 ą┐ąĄčĆąĄčģą▓ą░čéąĖčéčī ąĘąĮą░č湥ąĮąĖčÅ, ą┐ąĄčĆąĄą┤ą░ą▓ą░ąĄą╝čŗąĄ ą▓ą░čłąĄą╣ čäčāąĮą║čåąĖąĖ slow_write(). ąÆčŗ ąĘą░ą╝ąĄčéąĖč鹥, čćč鹊 ą┐ąŠą╗čāčćą░ąĄč鹥 ą║ą░ąČą┤čŗą╣ čĆą░ąĘ ąĮąĄą╝ąĮąŠą│ąŠ ą┤čĆčāą│čāčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī:
[ '[Thread-3 A]', '[Thread-2 A]', '[Thread-1 A]', '\n', '\n', '[Thread-3 B]', (...) ]
ąØąĄčüą╝ąŠčéčĆčÅ ąĮą░ č鹊, čćč鹊 sys.stdout.write() čüą░ą╝ ą┐ąŠ čüąĄą▒ąĄ čÅą▓ą╗čÅąĄčéčüčÅ ą░č鹊ą╝ą░čĆąĮąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĄą╣, ąŠą┤ąĖąĮ ą▓čŗąĘąŠą▓ čäčāąĮą║čåąĖąĖ print() ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ ąŠą┐ąĄčĆą░čåąĖčÅą╝ ąĘą░ą┐ąĖčüąĖ. ąØą░ą┐čĆąĖą╝ąĄčĆ, čüąĖą╝ą▓ąŠą╗čŗ čĆą░ąĘčĆčŗą▓ą░ čüčéčĆąŠą║ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ ąŠčéą┤ąĄą╗čīąĮąŠ ąŠčé ąŠčüčéą░ą╗čīąĮąŠą│ąŠ č鹥ą║čüčéą░, ąĖ ą╝ąĄąČą┤čā čŹčéąĖą╝ąĖ ąĘą░ą┐ąĖčüčÅą╝ąĖ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą║ąŠąĮč鹥ą║čüčéą░.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ą░č鹊ą╝ą░čĆąĮčŗą╣ čģą░čĆą░ą║č鹥čĆ čüčéą░ąĮą┤ą░čĆčéąĮąŠą│ąŠ ą▓čŗą▓ąŠą┤ą░ ą▓ Python čÅą▓ą╗čÅąĄčéčüčÅ ą┐ąŠą▒ąŠčćąĮčŗą╝ ą┐čĆąŠą┤čāą║č鹊ą╝ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ąĖąĮč鹥čĆą┐čĆąĄčéą░č鹊čĆą░ (Global Interpreter Lock, GIL), ą║ąŠč鹊čĆą░čÅ ą┐čĆąĖą╝ąĄąĮčÅąĄčé ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ą▓ąŠą║čĆčāą│ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą▒ą░ą╣čé-ą║ąŠą┤ą░. ą×ą┤ąĮą░ą║ąŠ ąĖą╝ąĄą╣č鹥 ą▓ ą▓ąĖą┤čā, čćč鹊 ą╝ąĮąŠą│ąĖąĄ čĆą░ąĘąĮąŠą▓ąĖą┤ąĮąŠčüčéąĖ ąĖąĮč鹥čĆą┐čĆąĄčéą░č鹊čĆą░ ąĮąĄ ąĖą╝ąĄčÄčé GIL, ą│ą┤ąĄ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮą░čÅ ą┐ąĄčćą░čéčī čéčĆąĄą▒čāąĄčé čÅą▓ąĮąŠą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ.
ąÆčŗ ą╝ąŠąČąĄč鹥 čüą┤ąĄą╗ą░čéčī čüąĖą╝ą▓ąŠą╗ newline ąĖąĮč鹥ą│čĆą░ą╗čīąĮąŠą╣ čćą░čüčéčīčÄ čüąŠąŠą▒čēąĄąĮąĖčÅ, ą▓čŗą┐ąŠą╗ąĮąĖą▓ čŹč鹊 ą▓čĆčāčćąĮčāčÄ:
print (f'[{thread_name} {letter} ]\n' , end='' )ąŁč鹊 ąĖčüą┐čĆą░ą▓ąĖčé ą▓čŗą▓ąŠą┤:
[Thread-2 A] [Thread-1 A] [Thread-3 A] [Thread-1 B] [Thread-3 B] [Thread-2 B] [Thread-1 C] [Thread-2 C] [Thread-3 C]
ą×ą┤ąĮą░ą║ąŠ ąŠą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čäčāąĮą║čåąĖčÅ print() ą┐čĆąŠą┤ąŠą╗ąČą░ąĄčé ą┤ąĄą╗ą░čéčī ąŠčéą┤ąĄą╗čīąĮčŗą╣ ą▓čŗąĘąŠą▓ ą┤ą╗čÅ ą┐čāčüč鹊ą│ąŠ čüčāčäčäąĖą║čüą░, čćč鹊 čéčĆą░ąĮčüą╗ąĖčĆčāąĄčéčüčÅ ą▓ ą▒ąĄčüą┐ąŠą╗ąĄąĘąĮčāčÄ ąĖąĮčüčéčĆčāą║čåąĖčÄ sys.stdout.write(''):
[ '[Thread-2 A]\n', '[Thread-1 A]\n', '[Thread-3 A]\n', '', '', '', '[Thread-1 B]\n', (...) ]
ąĀąĄą░ą╗čīąĮąŠ thread-safe ą▓ąĄčĆčüąĖčÅ čäčāąĮą║čåąĖąĖ print() ą╝ąŠąČąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī ą┐čĆąĖą╝ąĄčĆąĮąŠ čéą░ą║:
import threadingdef thread_safe_print (*args, **kwargs ):
with lock:
print (*args, **kwargs)ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐ąŠą╝ąĄčüčéąĖčéčī čŹčéčā čäčāąĮą║čåąĖčÄ ą▓ ą╝ąŠą┤čāą╗čī, ąĖ ąĖą╝ą┐ąŠčĆčéąĖčĆąŠą▓ą░čéčī ąĄčæ ą▓ ą┤čĆčāą│ąŠą╝ ą╝ąĄčüč鹥:
from thread_safe_print import thread_safe_printdef task ():
thread_name = current_thread().name
for letter in 'ABC' :
thread_safe_print(f'[{thread_name} {letter} ]' )ąóąĄą┐ąĄčĆčī, ąĮąĄčüą╝ąŠčéčĆčÅ ąĮą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┤ą▓čāčģ ąŠą┐ąĄčĆą░čåąĖą╣ ąĘą░ą┐ąĖčüąĖ ąĮą░ ą║ą░ąČą┤čŗą╣ ąĘą░ą┐čĆąŠčü print(), č鹊ą╗čīą║ąŠ ąŠą┤ąĮąŠą╝čā ą┐ąŠč鹊ą║čā čĆą░ąĘčĆąĄčłą░ąĄčéčüčÅ ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąŠą▓ą░čéčī čü ą▓čŗą▓ąŠą┤ąŠą╝, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ąŠčüčéą░ą╗čīąĮčŗąĄ ą┤ąŠą╗ąČąĮčŗ ąČą┤ą░čéčī:
[ # ąæą╗ąŠą║ąĖčĆąŠą▓ą║ą░, ąĘą░čģą▓ą░č湥ąĮąĮą░čÅ ą┐ąŠč鹊ą║ąŠą╝ Thread-3 '[Thread-3 A]', '\n', # Thread-3 ąŠčüą▓ąŠą▒ąŠą┤ąĖą╗ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā # ąæą╗ąŠą║ąĖčĆąŠą▓ą║ą░, ąĘą░čģą▓ą░č湥ąĮąĮą░čÅ ą┐ąŠč鹊ą║ąŠą╝ Thread-1 '[Thread-1 B]', '\n', # Thread-1 ąŠčüą▓ąŠą▒ąŠą┤ąĖą╗ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā (...) ]
ąöąŠą▒ą░ą▓ą╗ąĄąĮąĮčŗąĄ ąĘą┤ąĄčüčī ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖąĖ ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčé, ą║ą░ą║ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ąŠą│čĆą░ąĮąĖčćąĖą▓ą░ąĄčé ą┤ąŠčüčéčāą┐ ą║ ąŠą▒čēąĄą╝čā čĆąĄčüčāčĆčüčā.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ą┤ą░ąČąĄ ą▓ ąŠą┤ąĮąŠą┐ąŠč鹊čćąĮąŠą╝ ą║ąŠą┤ąĄ ą▓čŗ ą╝ąŠąČąĄč鹥 čüč鹊ą╗ą║ąĮčāčéčīčüčÅ čü ą┐ąŠą┤ąŠą▒ąĮąŠą╣ čüąĖčéčāą░čåąĖąĄą╣. ąÆ čćą░čüčéąĮąŠčüčéąĖ, ą║ąŠą│ą┤ą░ ą▓čŗ ą┐ąĄčćą░čéą░ąĄč鹥 ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą▓ stdout ąĖ stderr. ąĢčüą╗ąĖ ą▓čŗ ąĮąĄ ą┐ąĄčĆąĄąĮą░ą┐čĆą░ą▓ąĖą╗ąĖ ąĖčģ ą▓ ąŠčéą┤ąĄą╗čīąĮčŗąĄ čäą░ą╣ą╗čŗ, ą▓čüąĄ ąĖčģ čüąŠąŠą▒čēąĄąĮąĖčÅ ą▒čāą┤čāčé ą┐ąŠčÅą▓ą╗čÅčéčīčüčÅ ą▓ ąŠą┤ąĮąŠą╝ ąŠą▒čēąĄą╝ ąŠą║ąĮąĄ č鹥čĆą╝ąĖąĮą░ą╗ą░.
ąś ąĮą░ąŠą▒ąŠčĆąŠčé, ą╝ąŠą┤čāą╗čī logging čÅą▓ą╗čÅąĄčéčüčÅ thread-safe ą▒ą╗ą░ą│ąŠą┤ą░čĆčÅ čüą▓ąŠąĄą╝čā ą┤ąĖąĘą░ą╣ąĮčā, čćč鹊 ąŠčéčĆą░ąČą░ąĄčéčüčÅ ą▓ ąĄą│ąŠ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ ąŠč鹊ą▒čĆą░ąČą░čéčī ąĖą╝ąĄąĮą░ ą┐ąŠč鹊ą║ąŠą▓ ą▓ ąŠčéč乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĮąŠą╝ čüąŠąŠą▒čēąĄąĮąĖąĖ:
>>> import logging>>> logging.basicConfig(format ='%(threadName)s %(message)s' )>>> logging.error('hello' )
MainThread helloąŁč鹊 ąĄčēąĄ ąŠą┤ąĮą░ ą┐čĆąĖčćąĖąĮą░, ą┐ąŠ ą║ąŠč鹊čĆąŠą╣ ą▓čŗ ą▓ąŠąĘą╝ąŠąČąĮąŠ ąĮąĄ ąĘą░čģąŠčéąĖč鹥 ą▓čüąĄ ą▓čĆąĄą╝čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čäčāąĮą║čåąĖčÄ print().
[ąÆą▓ąŠą┤ ą▓ Python ]
ąĪąĄą╣čćą░čü ą▓čŗ čāąČąĄ ą╝ąĮąŠą│ąŠąĄ ąĘąĮą░ąĄč鹥 ąĖąĘ č鹊ą│ąŠ, čćč鹊 čüą╗ąĄą┤čāąĄčé ąĘąĮą░čéčī ąŠ čäčāąĮą║čåąĖąĖ print()! ąóąĄą╝ą░ č鹥ą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ ąĮąĄ ą▒čāą┤ąĄčé ą┐ąŠą╗ąĮąŠą╣, ąĄčüą╗ąĖ ąĮąĄą╝ąĮąŠą│ąŠ ąĮąĄ čĆą░čüčüą║ą░ąĘą░čéčī ąŠ ą┐čĆąŠčéąĖą▓ąŠą┐ąŠą╗ąŠąČąĮąŠą╝ čäčāąĮą║čåąĖąŠąĮą░ą╗ąĄ. ąÆ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ print() čŹč鹊 ą▓čŗą▓ąŠą┤, čüčāčēąĄčüčéą▓čāčÄčé čäčāąĮą║čåąĖąĖ ąĖ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ą┤ą╗čÅ ą▓ą▓ąŠą┤ą░.
ąÆčüčéčĆąŠąĄąĮąĮčŗąĄ čüčĆąĄą┤čüčéą▓ą░ . Python ą┐ąŠčüčéą░ą▓ą╗čÅąĄčéčüčÅ čüąŠ ą▓čüčéčĆąŠąĄąĮąĮąŠą╣ čäčāąĮą║čåąĖąĄą╣ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą▓ą▓ąŠą┤ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ, ą║ąŠč鹊čĆą░čÅ ą┐čĆąĄą┤čüą║ą░ąĘčāąĄą╝ąŠ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ input() . ą×ąĮą░ ą┐čĆąĖąĮąĖą╝ą░ąĄčé ą┤ą░ąĮąĮčŗąĄ ąĖąĘ čüčéą░ąĮą┤ą░čĆčéąĮąŠą│ąŠ ą┐ąŠč鹊ą║ą░ ą▓ą▓ąŠą┤ą░, ą║ąŠč鹊čĆčŗą╣ ąŠą▒čŗčćąĮąŠ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ą║ą╗ą░ą▓ąĖą░čéčāčĆąĄ:
>>> name = input ('ąÆą▓ąĄą┤ąĖč鹥 ą▓ą░čłąĄ ąĖą╝čÅ: ' )
ąÆą▓ąĄą┤ąĖč鹥 ą▓ą░čłąĄ ąĖą╝čÅ: jdoe>>> print (name)
jdoeąŁčéą░ čäčāąĮą║čåąĖčÅ ą▓čüąĄą│ą┤ą░ ą▓ąŠąĘą▓čĆą░čéąĖčé čüčéčĆąŠą║čā, čéą░ą║ čćč鹊 ą▓čŗ čüą╝ąŠąČąĄč鹥 ą┐čĆąŠą░ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī ąĄčæ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
try :
age = int (input ('How old are you? ' ))except ValueError:
pass ą¤ą░čĆą░ą╝ąĄčéčĆ ą┐čĆąĖą│ą╗ą░čłąĄąĮąĖčÅ prompt čüąŠą▓čüąĄą╝ ąĮąĄ ąŠą▒čÅąĘą░č鹥ą╗ąĄąĮ ą┤ą╗čÅ čäčāąĮą║čåąĖąĖ input(), ąĖ ąĄčüą╗ąĖ ąĄą│ąŠ ąŠą┐čāčüčéąĖčéčī, č鹊 ąĮąĖą║ą░ą║ąŠą╣ č鹥ą║čüčé ąĮąĄ ą▒čāą┤ąĄčé ą▓čŗą▓ąĄą┤ąĄąĮ, ąĮąŠ čäčāąĮą║čåąĖčÅ ą▓čüąĄ ąĄčēąĄ ą▒čāą┤ąĄčé čĆą░ą▒ąŠčéą░čéčī:
>>> x = input ()
hello world>>> print (x)
hello worldąóąĄą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ ą▓čŗą▒čĆą░čüčŗą▓ą░ąĮąĖąĄ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą│ąŠ ąĘą░ą┐čĆąŠčüą░, ąŠą┐ąĖčüčŗą▓ą░čÄčēąĄą│ąŠ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠąĄ ą┤ąĄą╣čüčéą▓ąĖąĄ ą┐čĆąĖ ą▓čŗąĘąŠą▓ąĄ input(), ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą╗čāčćčłąĄ ąĖąĮč乊čĆą╝ąĖčĆąŠą▓ą░čéčī ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: čćč鹊ą▒čŗ ą┐čĆąŠčćąĖčéą░čéčī ąĖąĘ čüčéą░ąĮą┤ą░čĆčéąĮąŠą│ąŠ ą▓ą▓ąŠą┤ą░ ąĮą░ Python 2, ą▓čŗ ą┤ąŠą╗ąČąĮčŗ ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą▓čŗąĘą▓ą░čéčī raw_input() , ą║ąŠč鹊čĆą░čÅ ą┐čĆąŠčüč鹊 ą┤čĆčāą│ą░čÅ ą▓čüčéčĆąŠąĄąĮąĮą░čÅ čäčāąĮą║čåąĖčÅ. ąÜ čüąŠąČą░ą╗ąĄąĮąĖčÄ, čéą░ą║ąČąĄ čüčāčēąĄčüčéą▓čāąĄčé ąĮąĄčāą┤ą░čćąĮąŠ ąĖą╝ąĄąĮąŠą▓ą░ąĮąĮą░čÅ čäčāąĮą║čåąĖčÅ input(), ą║ąŠč鹊čĆą░čÅ ą┤ąĄą╗ą░ąĄčé ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┤čĆčāą│ąŠąĄ.
ążą░ą║čéąĖč湥čüą║ąĖ ąŠąĮą░ čéą░ą║ąČąĄ ą┐čĆąĖąĮąĖą╝ą░ąĄčé ą▓ą▓ąŠą┤ ąĖąĘ čüčéą░ąĮą┤ą░čĆčéąĮąŠą│ąŠ ą┐ąŠč鹊ą║ą░ stdin, ąĮąŠ ąĘą░č鹥ą╝ ą┐čŗčéą░ąĄčéčüčÅ ąŠą▒čĆą░ą▒ąŠčéą░čéčī ąĄą│ąŠ ą║ą░ą║ ą║ąŠą┤ Python. ąśąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 čŹčéą░ čäąĖčćą░ ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ ą┤čŗčĆčā ą▓ ą▒ąĄąĘąŠą┐ą░čüąĮąŠčüčéąĖ, ąŠąĮą░ ą▒čŗą╗ą░ ą┐ąŠą╗ąĮąŠčüčéčīčÄ čāą┤ą░ą╗ąĄąĮą░ ąĖąĘ Python 3, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ raw_input() ą▒čŗą╗ą░ ą┐ąĄčĆąĄąĖą╝ąĄąĮąŠą▓ą░ąĮą░ ą▓ input().
ąóą░ą▒ą╗ąĖčåą░ ą┤ą╗čÅ ą▒čŗčüčéčĆąŠą│ąŠ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą┤ąŠčüčéčāą┐ąĮčŗčģ ą▓čüčéčĆąŠąĄąĮąĮčŗčģ čäčāąĮą║čåąĖą╣ ą▓ą▓ąŠą┤ą░:
Python 2 Python 3
raw_input()
input()
input()
eval(input())
ąÆ Python 3 ą▓čüąĄ ąĄčēąĄ ą╝ąŠąČąĮąŠ ąĖą╝ąĖčéąĖčĆąŠą▓ą░čéčī čüčéą░čĆąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ.
ąŚą░ą┐čĆą░čłąĖą▓ą░čéčī ą▓ą▓ąŠą┤ ą┐ą░čĆąŠą╗čÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ č湥čĆąĄąĘ input() čŹč鹊 ą┐ą╗ąŠčģą░čÅ ąĖą┤ąĄčÅ, ą┐ąŠč鹊ą╝čā čćč鹊 ą▓ą▓ąŠą┤ąĖą╝čŗą╣ ą┐ą░čĆąŠą╗čī ą┐čĆąĖ ą▓ą▓ąŠą┤ąĄ ą▒čāą┤ąĄčé ąŠč鹊ą▒čĆą░ąČą░čéčīčüčÅ ą▓ ą║ąŠąĮčüąŠą╗ąĖ ąŠčéą║čĆčŗčéčŗą╝ č鹥ą║čüč鹊ą╝. ąöą╗čÅ čéą░ą║ąŠą│ąŠ čüą╗čāčćą░čÅ ą▓ą╝ąĄčüč鹊 input() ą▓čŗ ą┤ąŠą╗ąČąĮčŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čäčāąĮą║čåąĖčÄ getpass() , ą║ąŠč鹊čĆą░čÅ ą╝ą░čüą║ąĖčĆčāąĄčé ą▓ą▓ąŠą┤ąĖą╝čŗąĄ čüąĖą╝ą▓ąŠą╗čŗ. ąŁčéą░ čäčāąĮą║čåąĖčÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮą░ ą▓ ą╝ąŠą┤čāą╗ąĄ čü čéą░ą║ąĖą╝ ąČąĄ ąĖą╝ąĄąĮąĄą╝, ą║ąŠč鹊čĆčŗą╣ čéą░ą║ąČąĄ ą┤ąŠčüčéčāą┐ąĄąĮ ą▓ čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĄ:
>>> from getpass import getpass>>> password = getpass()
Password: >>> print (password)
s3cretą£ąŠą┤čāą╗čī getpass ąĖą╝ąĄąĄčé ą┤čĆčāą│čāčÄ čäčāąĮą║čåąĖčÄ ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ąĖą╝ąĄąĮąĖ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ąĖąĘ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ąŠą║čĆčāąČąĄąĮąĖčÅ:
>>> from getpass import getuser>>> getuser()'jdoe' ąÆčüčéčĆąŠąĄąĮąĮčŗąĄ čäčāąĮą║čåąĖąĖ Python ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čüčéą░ąĮą┤ą░čĆčéąĮąŠą│ąŠ ą▓ą▓ąŠą┤ą░ ą┤ąŠą▓ąŠą╗čīąĮąŠ ąŠą│čĆą░ąĮąĖč湥ąĮąĮčŗąĄ. ąÆ č鹊 ąČąĄ ą▓čĆąĄą╝čÅ čüčāčēąĄčüčéą▓čāąĄčé ą╝ąĮąŠąČąĄčüčéą▓ąŠ čüč鹊čĆąŠąĮąĮąĖčģ ą┐ą░ą║ąĄč鹊ą▓, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąĄą┤ą╗ą░ą│ą░čÄčé ąĮą░ą╝ąĮąŠą│ąŠ ą▒ąŠą╗ąĄąĄ ą┐čĆąŠą┤ą▓ąĖąĮčāčéčŗąĄ ąĖąĮčüčéčĆčāą╝ąĄąĮčéčŗ.
ąĪč鹊čĆąŠąĮąĮąĖąĄ čüčĆąĄą┤čüčéą▓ą░ . ąĪčāčēąĄčüčéą▓čāčÄčé ą▓ąĮąĄčłąĮąĖąĄ ą┐ą░ą║ąĄčéčŗ Python, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé čüčéčĆąŠąĖčéčī čüą╗ąŠąČąĮčŗąĄ ą│čĆą░čäąĖč湥čüą║ąĖąĄ ąĖąĮč鹥čĆč乥ą╣čüčŗ, čüą┐ąĄčåąĖą░ą╗čīąĮąŠ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĮčŗąĄ ą┤ą╗čÅ čüą▒ąŠčĆą░ ą┤ą░ąĮąĮčŗčģ ąŠčé ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ. ąØąĄą║ąŠč鹊čĆčŗąĄ ąĖąĘ ąĖčģ ąŠčüąŠą▒ąĄąĮąĮąŠčüč鹥ą╣ ą▓ą║ą╗čÄčćą░čÄčé ą▓ čüąĄą▒čÅ:
ŌĆó ą¤čĆąŠą┤ą▓ąĖąĮčāč鹊ąĄ č乊čĆą╝ą░čéąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖ ą┐ąŠą┤ą┤ąĄčƹȹ║čā čüčéąĖą╗ąĄą╣.
ąöąĄą╝ąŠąĮčüčéčĆą░čåąĖčÅ čéą░ą║ąĖčģ ąĖąĮčüčéčĆčāą╝ąĄąĮč鹊ą▓ ą▓čŗčģąŠą┤ąĖčé ąĘą░ čĆą░ą╝ą║ąĖ čŹč鹊ą╣ čüčéą░čéčīąĖ, ąĮąŠ ą▓čŗ ą╝ąŠąČąĄč鹥 ąĖčģ ą┐ąŠą┐čĆąŠą▒ąŠą▓ą░čéčī čüą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮąŠ. ąÉą▓č鹊čĆ čüą░ą╝ čāąĘąĮą░ą╗ ąŠ ąĮąĖčģ ąĖąĘ Python Bytes Podcast:
ŌĆó bullet
ąóąĄą╝ ąĮąĄ ą╝ąĄąĮąĄąĄ čüč鹊ąĖčé čāą┐ąŠą╝čÅąĮčāčéčī čāčéąĖą╗ąĖčéčā ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąĖ rlwrap , ą║ąŠč鹊čĆą░čÅ ą▒ąĄčüą┐ą╗ą░čéąĮąŠ ą┤ąŠą▒ą░ą▓ąĖčé ą╝ąŠčēąĮčŗąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ą┐ąŠ čĆąĄą┤ą░ą║čéąĖčĆąŠą▓ą░ąĮąĖčÄ čüčéčĆąŠą║ąĖ ą▓ ą▓ą░čłąĖ čüą║čĆąĖą┐čéčŗ Python. ąÆą░ą╝ ąĮąĖč湥ą│ąŠ ąĮąĄ ąĮą░ą┤ąŠ ą┤ąĄą╗ą░čéčī, čćč鹊ą▒čŗ čŹč鹊 čüčĆą░ą▒ąŠčéą░ą╗ąŠ!
ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ą▓čŗ ą┐ąĖčłąĄč鹥 ąĖąĮč鹥čĆč乥ą╣čü ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąĖ, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠąĮąĖą╝ą░ąĄčé čéčĆąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą▓ą║ą╗čÄčćą░čÅ ąŠą┤ąĮčā ą┤ą╗čÅ čüą╗ąŠąČąĄąĮąĖčÅ čćąĖčüąĄą╗:
print ('ąÆą▓ąĄą┤ąĖč鹥 "help", "exit", "add a [b [c ...]]"' )while True :
command, *arguments = input ('~ ' ).split(' ' )
if len (command) > 0 :
if command.lower() == 'exit' :
break
elif command.lower() == 'help' :
print ('This is help.' )
elif command.lower() == 'add' :
print (sum (map (int , arguments)))
else :
print ('ąØąĄąĖąĘą▓ąĄčüčéąĮą░čÅ ą║ąŠą╝ą░ąĮą┤ą░' )ąØą░ ą┐ąĄčĆą▓čŗą╣ ą▓ąĘą│ą╗čÅą┤, čŹč鹊 ąŠą║ą░ąČąĄčéčüčÅ ą║ąŠą╝ą░ąĮą┤ąŠą╣ čü čéąĖą┐ąĖčćąĮąŠą╣ ą┐ąŠą┤čüą║ą░ąĘą║ąŠą╣, ą║ąŠą│ą┤ą░ ą▓čŗ ąĄčæ ąĘą░ą┐čāčüčéąĖč鹥:
$ python calculator.py
ąÆą▓ąĄą┤ąĖč鹥 "help", "exit", "add a [b [c ...]]"
~ add 1 2 3 4
10
~ aad 2 3
ąØąĄąĖąĘą▓ąĄčüčéąĮą░čÅ ą║ąŠą╝ą░ąĮą┤ą░
~ exit
$
ąØąŠ ą║ąŠą│ą┤ą░ ą▓čŗ ąĘą░ą╝ąĄčéąĖč鹥 ąŠčłąĖą▒ą║čā ą▓ą▓ąŠą┤ą░, ąĖ ąĘą░čģąŠčéąĖč鹥 ąĄčæ ąĖčüą┐čĆą░ą▓ąĖčéčī, č鹊 čāą▓ąĖą┤ąĖč鹥, čćč鹊 ąĮąĖ ąŠą┤ąĮą░ ąĖąĘ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮčŗčģ ą║ą╗ą░ą▓ąĖčł ąĮąĄ čĆą░ą▒ąŠčéą░ąĄčé čéą░ą║, ą║ą░ą║ ąŠąČąĖą┤ą░ąĄčéčüčÅ. ąĢčüą╗ąĖ ąĮą░ąČą░čéčī ąĮą░ ą║ą╗ą░ą▓ąĖčłčā čüčéčĆąĄą╗ą║ąĖ ą▓ą╗ąĄą▓ąŠ, č鹊 ą▓ą╝ąĄčüč鹊 ą▓ąŠąĘą▓čĆą░čēąĄąĮąĖčÅ ą║čāčĆčüąŠčĆą░ ąŠą▒čĆą░čéąĮąŠ ą┐ąŠą╗čāčćąĖčéčüčÅ čüą╗ąĄą┤čāčÄčēąĄąĄ:
$ python calculator.py
ąÆą▓ąĄą┤ąĖč鹥 "help", "exit", "add a [b [c ...]]"
~ aad^[[D
ąóąĄą┐ąĄčĆčī ą▓čŗ ą╝ąŠąČąĄč鹥 ąŠą▒ąĄčĆąĮčāčéčī ą▓čŗąĘąŠą▓ č鹊ą│ąŠ ąČąĄ čüą║čĆąĖą┐čéą░ ą║ąŠą╝ą░ąĮą┤ąŠą╣ rlwrap. ąóąĄą┐ąĄčĆčī ąĮąĄ č鹊ą╗čīą║ąŠ ą▒čāą┤čāčé ąĮąŠčĆą╝ą░ą╗čīąĮąŠ čĆą░ą▒ąŠčéą░čéčī ą║ą╗ą░ą▓ąĖčłąĖ čüąŠ čüčéčĆąĄą╗ą║ą░ą╝ąĖ, č鹊 čéą░ą║ąČąĄ ą▓čŗ ą┐ąŠą╗čāčćąĖč鹥 ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą┐ąŠąĖčüą║ą░ ą┐ąŠ ąĖčüč鹊čĆąĖąĖ ą▓ą▓ąĄą┤ąĄąĮąĮčŗčģ čĆą░ąĮąĄąĄ ą║ąŠą╝ą░ąĮą┤, ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą░ą▓č鹊ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄ ą║ąŠą╝ą░ąĮą┤čŗ, ąĖ čĆąĄą┤ą░ą║čéąĖčĆąŠą▓ą░ąĮąĖąĄ čüčéčĆąŠą║ąĖ čü čłąŠčĆčéą║ą░čéą░ą╝ąĖ:
$ rlwrap python calculator.py
ąÆą▓ąĄą┤ąĖč鹥 "help", "exit", "add a [b [c ...]]"
(reverse-i-search)`a': add 1 2 3 4
[ąŚą░ą║ą╗čÄč湥ąĮąĖąĄ ]
ąóąĄą┐ąĄčĆčī ą▓čŗ ą▓ąŠąŠčĆčāąČąĄąĮčŗ ą║ą░ą║ ąĘąĮą░ąĮąĖčÅą╝ąĖ ą┐ąŠ čäčāąĮą║čåąĖąĖ print() ą▓ Python, čéą░ą║ ąĖ ą┐ąŠ ą╝ąĮąŠą│ąĖą╝ čüą▓čÅąĘą░ąĮąĮčŗą╝ čü ąĮąĄą╣ č鹥ą╝ą░ą╝. ąŻ ą▓ą░čü ąĄčüčéčī ą│ą╗čāą▒ąŠą║ąŠąĄ ą┐ąŠąĮąĖą╝ą░ąĮąĖąĄ, ą║ą░ą║ ąŠąĮą░ čĆą░ą▒ąŠčéą░ąĄčé, ą▓ą║ą╗čÄčćą░čÅ ą▓čüąĄ ąĄčæ ąĖą╝ąĄąĮąŠą▓ą░ąĮąĮčŗąĄ ą┐ą░čĆą░ą╝ąĄčéčĆčŗ. ą£ąĮąŠą│ąŠčćąĖčüą╗ąĄąĮąĮčŗąĄ ą┐čĆąĖą╝ąĄčĆčŗ ą┐ąŠą║ą░ąĘą░ą╗ąĖ ą▓ą░ą╝ čĆą░ąĘą▓ąĖčéąĖąĄ čäčāąĮą║čåąĖąĖ ą┐ąĄčćą░čéąĖ ąŠčé ąŠą┐ąĄčĆą░č鹊čĆą░ Python 2.
ą×ą▒ą╗ą░ą┤ą░čÅ čŹčéąĖą╝ąĖ ąĘąĮą░ąĮąĖčÅą╝ąĖ, ą▓čŗ ą╝ąŠąČąĄč鹥 čü čāčüą┐ąĄčģąŠą╝ čĆąĄą░ą╗ąĖąĘąŠą▓čŗą▓ą░čéčī ąĖąĮč鹥čĆą░ą║čéąĖą▓ąĮčŗąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ą║ąŠč鹊čĆčŗąĄ ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓čāčÄčé čü ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝ ąĖą╗ąĖ ą│ąĄąĮąĄčĆąĖčĆčāčÄčé ą┤ą░ąĮąĮčŗąĄ ą▓ ą┐ąŠą┐čāą╗čÅčĆąĮčŗčģ č乊čĆą╝ą░čéą░čģ čäą░ą╣ą╗ąŠą▓. ąÆčŗ čüą╝ąŠąČąĄč鹥 ą▒čŗčüčéčĆąŠ ą┤ąĖą░ą│ąĮąŠčüčéąĖčĆąŠą▓ą░čéčī ą┐čĆąŠą▒ą╗ąĄą╝čŗ ą▓ čüą▓ąŠąĄą╝ ą║ąŠą┤ąĄ ąĖ ąŠą▒ąĄčüą┐ąĄčćąĖčéčī ąĘą░čēąĖčéčā ąŠčé ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮčŗčģ ąŠčłąĖą▒ąŠą║.
[ąĪčüčŗą╗ą║ąĖ ]
1 . Your Guide to the Python print() Function site:realpython.com.2 . Whitespace in Expressions and Statements site:peps.python.org.3 . Python: čäčāąĮą║čåąĖąĖ .4 . Reading and Writing Files in Python site:realpython.com.5 . functools ŌĆö Tools for Manipulating Functions site:pymotw.com.6 . Test Double site:martinfowler.com.7 . How to Round Numbers in Python site:realpython.com.8 . Python: ą╝ąŠą┤čāą╗čī ą▓čŗą▓ąŠą┤ą░ ą▓ ą╗ąŠą│ .