|
ąÆ čŹč鹊ą╝ ą┤ąŠą║čāą╝ąĄąĮč鹥 ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮčŗ ąĮąĄą║ąŠč鹊čĆčŗąĄ ą┐ąŠą╗ąĄąĘąĮčŗąĄ ą╝ąĄč鹊ą┤ąĖą║ąĖ ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ąĮą░ąĖą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠą│ąŠ ąĖ ą▒čŗčüčéčĆąŠą│ąŠ ą║ąŠą┤ą░ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ čüąĄą╝ąĄą╣čüčéą▓ą░ Blackfin┬«, ą┐čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ čÅąĘčŗą║ą░ C/C++ ąĖąĘ čüčĆąĄą┤čŗ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ VisualDSP++Ōäó (ą┐ąĄčĆąĄą▓ąŠą┤ ą┤ąŠą║čāą╝ąĄąĮčéą░ EE-149 [1] ą║ąŠą╝ą┐ą░ąĮąĖąĖ Analog Devices).
ąśčüą┐ąŠą╗čīąĘčāą╣č鹥 ąŠą┐čéąĖą╝ąĖąĘą░č鹊čĆ ą║ąŠą┤ą░. ąĢčüčéčī ąĘąĮą░čćąĖč鹥ą╗čīąĮčŗąĄ ąŠčéą╗ąĖčćąĖčÅ ą▓ čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéąĖ ą║ąŠą┤ą░ C, ą║ąŠą│ą┤ą░ ąŠąĮ ą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄčéčüčÅ čü ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĄą╣ ąĖą╗ąĖ ą▒ąĄąĘ ąĮąĄčæ. ąÆ ąĮąĄą║ąŠč鹊čĆčŗčģ čüą╗čāčćą░čÅčģ ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą║ąŠą┤ ą╝ąŠąČąĄčé čĆą░ą▒ąŠčéą░čéčī ą▓ 10..12 čĆą░ąĘ ą▒čŗčüčéčĆąĄąĄ. ąÆčüąĄą│ą┤ą░ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī čüą┤ąĄą╗ą░ąĮą░ ą┐ąŠą┐čŗčéą║ą░ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ ą┐ąĄčĆąĄą┤ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ą┐čĆąŠą▓ąĄčĆą║ąĖ čüą║ąŠčĆąŠčüčéąĖ čĆą░ą▒ąŠčéčŗ ą║ąŠą┤ą░ ąĖą╗ąĖ ą┐ąĄčĆąĄą┤ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄą╝ ą║ąŠą┤ą░ ą▓ ą│ąŠč鹊ą▓čŗą╣ ą┐čĆąŠą┤čāą║čé. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĮą░čüčéčĆąŠą╣ą║ą░ ą┐čĆąŠąĄą║čéą░ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ čĆą░čüčüčćąĖčéą░ąĮą░ ąĮą░ ąĮąĄ ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░ąĮąĮčāčÄ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖčÄ, ą┐ąŠč鹊ą╝čā čćč鹊 ąĮąĄ ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą▓ą░čĆąĖą░ąĮčé ą║ąŠą┤ą░ ą▒ąŠą╗čīčłąĄ ą┐ąŠą┤čģąŠą┤ąĖčé ą┤ą╗čÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüč鹊ą▓ ą▓ ą┐ąŠąĖčüą║ąĄ ąŠčłąĖą▒ąŠą║ ąĖ čāčüčéčĆą░ąĮąĄąĮąĖąĖ ą┐čĆąŠą▒ą╗ąĄą╝ ą┐čĆąĖ ąĮą░čćą░ą╗čīąĮčŗčģ čüčéą░ą┤ąĖčÅčģ ą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖčÅ.
ą¤čĆąĖą╝. ą┐ąĄčĆąĄą▓ąŠą┤čćąĖą║ą░: ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ ą┐čĆąŠąĄą║čéą░ ąĖąĘ ąĮą░čüčéčĆąŠąĄą║ Debug ą▓ ąĮą░čüčéčĆąŠą╣ą║ąĖ Release ąĖ ąŠą▒čĆą░čéąĮąŠ ąŠč湥ąĮčī ą┐ąŠą╝ąŠą│ą░ąĄčé ą┐čĆąĖ ą┐ąŠąĖčüą║ąĄ ą▒ą░ą│ąŠą▓ ąĖ ąĮąĄ ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠ ąĮą░ą┐ąĖčüą░ąĮąĮčŗčģ ą║čāčüą║ąŠą▓ ą║ąŠą┤ą░. ąźąŠčĆąŠčłąŠ ąĮą░ą┐ąĖčüą░ąĮąĮčŗą╣ ą║ąŠą┤ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čĆą░ą▒ąŠč鹊čüą┐ąŠčüąŠą▒ąĄąĮ ą▓ ąŠą▒ąŠąĖčģ ą▓ą░čĆąĖą░ąĮčéą░čģ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ, ąĖ ą▓ Debug, ąĖ ą▓ Release. ąĢčüą╗ąĖ ą▓ą┤čĆčāą│ ąŠą▒ąĮą░čĆčāąČąĖą╗ąŠčüčī, čćč鹊 ąŠą┤ąĮąŠą╝ ąĖąĘ ą▓ą░čĆąĖą░ąĮč鹊ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ąĮąĄ čĆą░ą▒ąŠčéą░ąĄčé, č鹊 ąĮą░ą▓ąĄčĆąĮčÅą║ą░ ąĄčüčéčī ą║ą░ą║ąŠą╣-č鹊 ąĮąĄčģąŠčĆąŠčłąĖą╣ ą║ąŠčüčÅą║.
ą×ą┐čéąĖą╝ąĖąĘą░č鹊čĆ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ čÅąĘčŗą║ą░ C ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮ ą┤ą╗čÅ ą│ąĄąĮąĄčĆą░čåąĖąĖ čŹčäč乥ą║čéąĖą▓ąĮąŠą│ąŠ ą┐ąŠ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖčÄ ą┤ą▓ąŠąĖčćąĮąŠą│ąŠ ą║ąŠą┤ą░, ą║ąŠč鹊čĆčŗą╣ ąĮą░ą┐ąĖčüą░ąĮ ą▓ ą┐čĆąŠčüč鹊ą╝, ą╗ąĖąĮąĄą╣ąĮąŠą╝ čüčéąĖą╗ąĄ. ąæą░ąĘąŠą▓ą░čÅ čüčéčĆą░č鹥ą│ąĖčÅ ą┐čĆąĖ ą░ą╗ą│ąŠčĆąĖčéą╝ąĖč湥čüą║ąŠą╣ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ - ą┐čĆąĄą┤čüčéą░ą▓ąĖčéčī ą░ą╗ą│ąŠčĆąĖčéą╝ čéą░ą║ąĖą╝ čüą┐ąŠčüąŠą▒ąŠą╝, ą║ąŠč鹊čĆčŗą╣ ą┤ą░čüčé ąŠą┐čéąĖą╝ąĖąĘą░č鹊čĆčā ąŠčéą╗ąĖčćąĮčāčÄ ą▓ąĖą┤ąĖą╝ąŠčüčéčī ąŠą┐ąĄčĆą░ąĮą┤ąŠą▓ ąĖ ą┤ą░ąĮąĮčŗčģ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ąĖ čüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ ą┤ą░čüčé ą▒ąŠą╗čīčłčāčÄ čüą▓ąŠą▒ąŠą┤čā ą▒ąĄąĘąŠą┐ą░čüąĮąŠ ą╝ą░ąĮąĖą┐čāą╗ąĖčĆąŠą▓ą░čéčī ą║ąŠą┤ąŠą╝ (KISS. ąÜąŠčĆąŠč湥 ą│ąŠą▓ąŠčĆčÅ, čüąĖą╗čīąĮąŠ čāą╝ąĮąĖčćą░čéčī ą▓ ąĮą░ą┐ąĖčüą░ąĮąĖąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĮąĄ čüč鹊ąĖčé). ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą▒čāą┤čāčēąĖąĄ čĆąĄą╗ąĖąĘčŗ ą▒čāą┤čāčé čāą╗čāčćčłą░čéčī ąŠą┐čéąĖą╝ąĖąĘą░č鹊čĆ, ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ ą░ą╗ą│ąŠčĆąĖčéą╝ą░ ą▓ ą▒ąŠą╗ąĄąĄ ą┐čĆąŠčüč鹊ą╝ ą▓ąĖą┤ąĄ ą┤ą░čüčé ą▒ąŠą╗čīčłąĄ ą▓čŗą│ąŠą┤čŗ ą┐čĆąĖ ą▓ąĮąĄą┤čĆąĄąĮąĖąĖ čéą░ą║ąĖčģ čāą╗čāčćčłąĄąĮąĖą╣.
ąśčüą┐ąŠą╗čīąĘčāą╣č鹥 čüčéą░čéąĖčüčéąĖč湥čüą║ąĖą╣ ą┐čĆąŠčäą░ą╣ą╗ąĄčĆ. ąØą░čüčéčĆąŠą╣ą║ą░ ą║ąŠą┤ą░ ąĮą░čćąĖąĮą░ąĄčéčüčÅ čü ą┐ąŠąĮąĖą╝ą░ąĮąĖčÅ, ą║ą░ą║ąĖąĄ ą╝ąĄčüčéą░ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ čÅą▓ą╗čÅčÄčéčüčÅ ąĮą░ąĖą▒ąŠą╗ąĄąĄ čāąĘą║ąĖą╝ ą╝ąĄčüč鹊ą╝, čé. ąĄ. ąĮą░ ą║ą░ą║ąĖąĄ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ ą┐čĆąŠčåąĄčüčüąŠčĆ ąĘą░čéčĆą░čćąĖą▓ą░ąĄčé ą▒ąŠą╗čīčłąĄ ą▓čüąĄą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ, ąĖ ą║ą░ą║ąĖąĄ ą╝ąĄčüčéą░ ą▓ ą║ąŠą┤ąĄ ąĮą░ąĖą▒ąŠą╗ąĄąĄ ą║čĆąĖčéąĖčćąĮčŗ ą║ ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ. ąĪčéą░čéąĖčüčéąĖč湥čüą║ąĖą╣ ą┐čĆąŠčäą░ą╣ą╗ąĖąĮą│, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗą╣ čüčĆąĄą┤ąŠą╣ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ VisualDSP++ čÅą▓ą╗čÅčÄčéčüčÅ ą┐čĆąĄą▓ąŠčüčģąŠą┤ąĮčŗą╝ ąĖąĮčüčéčĆčāą╝ąĄąĮč鹊ą╝ ą┤ą╗čÅ ąĮą░čģąŠąČą┤ąĄąĮąĖčÅ čŹčéąĖčģ ą│ąŠčĆčÅčćąĖčģ ą╝ąĄčüčé.
ąĢčüą╗ąĖ ąÆčŗ ąĮąĄ ąĘąĮą░ą║ąŠą╝čŗ čü ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄą╝, č鹊 čüą║ąŠą╝ą┐ąĖą╗ąĖčĆčāą╣č鹥 ąĄą│ąŠ čü ą▓ą║ą╗čÄč湥ąĮąĮčŗą╝ ą▓čŗą▓ąŠą┤ąŠą╝ ą┤ąĖą░ą│ąĮąŠčüčéąĖą║ąĖ, ąĖ ą▓ ąĮąĄ ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░ąĮąĮąŠą╝ ą▓ą░čĆąĖą░ąĮč鹥. ąŁč鹊 ą┤ą░čüčé ąÆą░ą╝ čĆąĄąĘčāą╗čīčéą░čéčŗ, ą║ąŠč鹊čĆčŗąĄ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčé ąĖčüčģąŠą┤ąĮąŠą╝čā ą║ąŠą┤čā ąĮą░ čÅąĘčŗą║ąĄ C. ąÆčŗ ą┐ąŠą╗čāčćąĖč鹥 ą▒ąŠą╗ąĄąĄ č鹊čćąĮąŠąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĖąĄ čüą▓ąŠąĄą│ąŠ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą┐ąŠ čüčĆą░ą▓ąĮąĄąĮąĖčÄ čü ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗą╝ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄą╝, ąĖ ą┐ąŠą╗čāčćąĖč鹥 čüčéą░čéąĖčüčéąĖč湥čüą║ąĖąĄ ą┤ą░ąĮąĮčŗąĄ, ą║ąŠč鹊čĆčŗąĄ ąŠčéąĮąŠčüčÅčéčüčÅ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ ą║ ą║ąŠą┤čā ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░. ąĢą┤ąĖąĮčüčéą▓ąĄąĮąĮą░čÅ ą┐čĆąŠą▒ą╗ąĄą╝ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓ čüąŠąŠčéąĮąŠčłąĄąĮąĖąĖ čüčéčĆąŠą║ ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░ ąĖ čüčéčĆąŠą║ ą▓ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮąŠą╝ ąĖčüčģąŠą┤ąĮąŠą╝ ą║ąŠą┤ąĄ. ąØąĄ čāą┤ą░ą╗čÅą╣č鹥 ąĖą╝ąĄąĮą░ čäčāąĮą║čåąĖą╣ ąĖąĘ ąŠą▒čŖąĄą║čéąĮąŠą│ąŠ ą║ąŠą┤ą░ ą┐čĆąĖ ą╗ąĖąĮą║ąŠą▓ą║ąĄ. ąĢčüą╗ąĖ ą▒čāą┤čāčé ąĖą╝ąĄąĮą░ čäčāąĮą║čåąĖą╣, č鹊 ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐čĆąŠą║čĆčāčéąĖčéčī ąŠą║ąĮąŠ ą║ąŠą┤ą░ ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░ ą▓ ąŠčéą╗ą░ą┤čćąĖą║ąĄ ąĖ ą┐ąŠ ąĖą╝ąĄąĮą░ą╝ čäčāąĮą║čåąĖą╣ ąĮą░ą╣čéąĖ ą│ąŠčĆčÅčćąĖąĄ ą╝ąĄčüčéą░ ą▓ ą║ąŠą┤ąĄ. ąÆ ąŠč湥ąĮčī čüą╗ąŠąČąĮąŠą╝ ą║ąŠą┤ąĄ ąÆčŗ ą╝ąŠąČąĄč鹥 č鹊čćąĮąŠ ąĮą░ą╣čéąĖ čüčéčĆąŠą║ąĖ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░ ą┐čāč鹥ą╝ ą┐ąŠą┤čüč湥čéą░ čåąĖą║ą╗ąŠą▓ ŌĆō ąĄčüą╗ąĖ ąŠąĮąĖ ąĮąĄ čĆą░ąĘą▓ąĄčĆąĮčāčéčŗ. ąÆ .s čäą░ą╣ą╗ą░čģ ąĄčüčéčī ąĮąŠą╝ąĄčĆą░ čüčéčĆąŠą║, ąĖčģ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī. ąśą╝ąĄą╣č鹥 ą▓ ą▓ąĖą┤čā, čćč鹊 ąŠą┐čéąĖą╝ąĖąĘą░č鹊čĆ ą╝ąŠąČąĄčé ą┐ąĄčĆąĄą╝ąĄčēą░čéčī ą║ąŠą┤.
ąóąĖą┐čŗ ą┤ą░ąĮąĮčŗčģ. ąöą╗čÅ čŹčäč乥ą║čéąĖą▓ąĮąŠą╣ čĆą░ą▒ąŠčéčŗ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą▓ą░ąČąĮąŠ ą┐čĆą░ą▓ąĖą╗čīąĮąŠ ą▓čŗą▒čĆą░čéčī ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ čéąĖą┐ ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ.
ąóą░ą▒ą╗ąĖčåą░ 1. ąóąĖą┐čŗ ą┤ą░ąĮąĮčŗčģ čü čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą╣ č鹊čćą║ąŠą╣, čéčĆą░ą┤ąĖčåąĖąŠąĮąĮą░čÅ (Native) ą░čĆąĖčäą╝ąĄčéąĖą║ą░.
| char |
8-ą▒ąĖčéąĮąŠąĄ čåąĄą╗ąŠąĄ čüąŠ ąĘąĮą░ą║ąŠą╝ |
| unsigned char |
8-ą▒ąĖčéąĮąŠąĄ čåąĄą╗ąŠąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░ |
| short |
16-ą▒ąĖčéąĮąŠąĄ čåąĄą╗ąŠąĄ čüąŠ ąĘąĮą░ą║ąŠą╝ |
| unsigned short |
16-ą▒ąĖčéąĮąŠąĄ čåąĄą╗ąŠąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░ |
| int |
32-ą▒ąĖčéąĮąŠąĄ čåąĄą╗ąŠąĄ čüąŠ ąĘąĮą░ą║ąŠą╝ |
| unsigned int |
32-ą▒ąĖčéąĮąŠąĄ čåąĄą╗ąŠąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░ |
| long |
32-ą▒ąĖčéąĮąŠąĄ čåąĄą╗ąŠąĄ čüąŠ ąĘąĮą░ą║ąŠą╝ |
| unsigned long |
32-ą▒ąĖčéąĮąŠąĄ čåąĄą╗ąŠąĄ ą▒ąĄąĘ ąĘąĮą░ą║ą░ |
ą¤ąŠą┤ čéčĆą░ą┤ąĖčåąĖąŠąĮąĮąŠą╣ ą░čĆąĖčäą╝ąĄčéąĖą║ąŠą╣ ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčéčüčÅ, čćč鹊 ą┐čĆąŠčåąĄčüčüąŠčĆ ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąĮą░ą┐čĆčÅą╝čāčÄ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą░ą┐ą┐ą░čĆą░čéąĮčŗąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░, ąĖ čŹčéąĖ čéąĖą┐čŗ ą┤ą░ąĮąĮčŗčģ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ąĮą░ąĖą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠ. ąóąĖą┐ double ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin 菹║ą▓ąĖą▓ą░ą╗ąĄąĮč鹥ąĮ čéąĖą┐čā float. 64-ą▒ąĖčéąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ ąĖ čéąĖą┐čŗ ą┤ą░ąĮąĮčŗčģ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣ ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčéčüčÅ ą░ą┐ą┐ą░čĆą░čéąĮąŠ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą╝ Blackfin, ą┐ąŠčŹč鹊ą╝čā ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą┤ą╗čÅ ąĖčģ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ ą║ąŠą┤, čćč鹊 čüąĮąĖąČą░ąĄčé ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ čĆą░ą▒ąŠčéčŗ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
ąóą░ą▒ą╗ąĖčåą░ 2. ąóąĖą┐čŗ ą┤ą░ąĮąĮčŗčģ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣, ą░čĆąĖčäą╝ąĄčéąĖą║ą░ čü 菹╝čāą╗čÅčåąĖąĄą╣ ąŠą┐ąĄčĆą░čåąĖą╣.
| float |
32-ą▒ąĖčéąĮąŠąĄ čćąĖčüą╗ąŠ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ ąĘą░ą┐čÅč鹊ą╣ (floating point) |
| double |
32-ą▒ąĖčéąĮąŠąĄ čćąĖčüą╗ąŠ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ ąĘą░ą┐čÅč鹊ą╣ (floating point) |
ąöčĆąŠą▒ąĮčŗąĄ čéąĖą┐čŗ ą┤ą░ąĮąĮčŗčģ čü čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą╣ č鹊čćą║ąŠą╣ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮčŗ ą╗ąĖą▒ąŠ ą║ą░ą║ short, ą╗ąĖą▒ąŠ ą║ą░ą║ int [2]. ą×ą┐ąĄčĆą░čåąĖąĖ čü čŹčéąĖą╝ąĖ čéąĖą┐ą░ą╝ąĖ ą╗čāčćčłąĄ ą▓čüąĄą│ąŠ ąŠčüčāčēąĄčüčéą▓ą╗čÅčéčī čü ą┐ąŠą╝ąŠčēčīčÄ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ čäčāąĮą║čåąĖą╣ ąĖ ą╝ą░ą║čĆąŠčüąŠą▓ (intrinsics), čćč鹊 ą▒čāą┤ąĄčé ąŠą┐ąĖčüą░ąĮąŠ ą▓ čüą╗ąĄą┤čāčÄčēąĖčģ čüąĄą║čåąĖčÅčģ.
ąśąĘą▒ąĄą│ą░ą╣č鹥 ą░čĆąĖčäą╝ąĄčéąĖą║ąĖ čü čéąĖą┐ą░ą╝ąĖ float ąĖ double. ąÉčĆąĖčäą╝ąĄčéąĖą║ą░ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣ čĆąĄą░ą╗ąĖąĘčāąĄčé ąŠą┐ąĄčĆą░čåąĖąĖ č湥čĆąĄąĘ ą▓čŗąĘąŠą▓čŗ ą▒ąĖą▒ą╗ąĖąŠč鹥čćąĮčŗčģ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝, ąĖ čüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ, čéą░ą║ąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ ą▒čāą┤čāčé ąĮą░ą╝ąĮąŠą│ąŠ ą╝ąĄą┤ą╗ąĄąĮąĮąĄąĄ čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮčŗčģ. ąÉčĆąĖčäą╝ąĄčéąĖą║ą░ floating-point ą▓ č鹥ą╗ąĄ čåąĖą║ą╗ą░ ąĮąĄ ą┤ą░čüčé ąŠą┐čéąĖą╝ąĖąĘą░č鹊čĆčā ą┐čĆąĖą╝ąĄąĮąĖčéčī ą░ą┐ą┐ą░čĆą░čéąĮčŗą╣ čåąĖą║ą╗.
ąśąĘą▒ąĄą│ą░ą╣č鹥 ą▓ č鹥ą╗ąĄ čåąĖą║ą╗ą░ ąŠą┐ąĄčĆą░čåąĖą╣ čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮąŠą│ąŠ ą┤ąĄą╗ąĄąĮąĖčÅ. ąÉą┐ą┐ą░čĆą░čéčāčĆą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĮąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┐čĆčÅą╝čāčÄ ą┐ąŠą┤ą┤ąĄčƹȹ║čā 32-ą▒ąĖčéąĮąŠą│ąŠ čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮąŠą│ąŠ ą┤ąĄą╗ąĄąĮąĖčÅ, čéą░ą║ čćč鹊 ąŠą┐ąĄčĆą░čåąĖąĖ ą┤ąĄą╗ąĄąĮąĖčÅ ąĖ ąŠą┐ąĄčĆą░čåąĖąĖ modulus ą┤ą╗čÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ int ą▒čāą┤čāčé ą╝ąĮąŠą│ąŠčåąĖą║ą╗ąŠą▓čŗą╝ąĖ ąŠą┐ąĄčĆą░čåąĖčÅą╝ąĖ. ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą┐čĆąĄąŠą▒čĆą░ąĘčāąĄčé čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮąŠąĄ ą┤ąĄą╗ąĄąĮąĖąĄ ą▓ ąŠą┐ąĄčĆą░čåąĖąĖ čüą┤ą▓ąĖą│ą░ ą▓ą┐čĆą░ą▓ąŠ, ąĄčüą╗ąĖ ąĄą╝čā ąĖąĘą▓ąĄčüčéąĮąŠ ąĘąĮą░č湥ąĮąĖąĄ ą┤ąĄą╗ąĖč鹥ą╗čÅ.
ąĢčüą╗ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąĖčüą┐čŗčéčŗą▓ą░ąĄčé ąĘą░čéčĆčāą┤ąĮąĄąĮąĖčÅ ą▓ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą┐ąŠą╗ąĮąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ ą┤ąĄą╗ąĄąĮąĖčÅ, č鹊 ąŠąĮ ą▓čŗąĘąŠą▓ąĄčé ą┤ą╗čÅ čŹč鹊ą│ąŠ ą▒ąĖą▒ą╗ąĖąŠč鹥čćąĮčāčÄ čäčāąĮą║čåąĖčÄ. ąÆ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÄ ą╝ąĮąŠą│ąŠčåąĖą║ą╗ąŠą▓čŗčģ ą║ąŠą╝ą░ąĮą┤ čäčāąĮą║čåąĖąĖ, čŹč鹊 ąĮąĄ ą┤ą░čüčé ąŠą┐čéąĖą╝ąĖąĘą░č鹊čĆčā ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą┐čĆąĖą╝ąĄąĮąĖčéčī ą░ą┐ą┐ą░čĆą░čéąĮčŗą╣ čåąĖą║ą╗ ą┤ą╗čÅ ą╗čÄą▒čŗčģ čåąĖą║ą╗ąŠą▓, ą▓ č鹥ą╗ąĄ ą║ąŠč鹊čĆčŗčģ ąĄčüčéčī ą┤ąĄą╗ąĄąĮąĖąĄ. ąÆčüąĄą│ą┤ą░, ą║ąŠą│ą┤ą░ čŹč鹊 ą▓ąŠąĘą╝ąŠąČąĮąŠ, ąĖąĘą▒ąĄą│ą░ą╣č鹥 ąŠą┐ąĄčĆą░čåąĖą╣ ą┤ąĄą╗ąĄąĮąĖčÅ ąĖ modulus ą▓ąĮčāčéčĆąĖ čåąĖą║ą╗ą░.
ąÆčŗą▒ąŠčĆ čüą┐ąŠčüąŠą▒ą░ ą┤ąŠčüčéčāą┐ą░ ą║ 菹╗ąĄą╝ąĄąĮčéą░ą╝ ą╝ą░čüčüąĖą▓ą░. ą¦č鹊 ą╗čāčćčłąĄ - ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĖąĄ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą╝ą░čüčüąĖą▓ą░ ąĖą╗ąĖ čāą║ą░ąĘą░č鹥ą╗ąĖ? ą»ąĘčŗą║ C ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąÆą░ą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░čéčī ą┤ąŠčüčéčāą┐ ą║ ą┤ą░ąĮąĮčŗčģ ą╝ą░čüčüąĖą▓ąŠą▓ ą┤ą▓čāą╝čÅ ą╝ąĄč鹊ą┤ą░ą╝ąĖ: ą╗ąĖą▒ąŠ ą┐ąŠ ąĖąĮą┤ąĄą║čüčā ąŠčé ąĖąĮą▓ą░čĆąĖą░ąĮčéąĮąŠą│ąŠ ą▒ą░ąĘąŠą▓ąŠą│ąŠ čāą║ą░ąĘą░č鹥ą╗čÅ, ą╗ąĖą▒ąŠ ą┐ąŠ ąĖąĮą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄą╝ąŠą╝čā čāą║ą░ąĘą░č鹥ą╗čÄ. ą¤čĆąĖą▓ąĄą┤ąĄąĮąĮčŗąĄ ąĮąĖąČąĄ 2 ą▓ąĄčĆčüąĖąĖ ą▓ąĄą║č鹊čĆąĮąŠą│ąŠ čüą╗ąŠąČąĄąĮąĖčÅ ąĖą╗ą╗čÄčüčéčĆąĖčĆčāčÄčé čŹčéąĖ ą┤ą▓ą░ čüčéąĖą╗čÅ ą┤ąŠčüčéčāą┐ą░:
void va_ind (short a[], short b[], short out[], int n)
{
int i;
for (i = 0; i < n; ++i)
out[i] = a[i] + b[i];
}
ąøąĖčüčéąĖąĮą│ 1. ąöąŠčüčéčāą┐ ą║ ą╝ą░čüčüąĖą▓čā ą┐ąŠ ąĖąĮą┤ąĄą║čüčā.
void va_ptr ( short a[], short b[], short out[], int n)
{
int i;
short *pout = out, *pa = a, *pb = b;
for (i = 0; i < n; ++i)
*pout++ = *pa++ + *pb++;
}
ąøąĖčüčéąĖąĮą│ 2. ąöąŠčüčéčāą┐ ą║ ą╝ą░čüčüąĖą▓čā ą┐ąŠ čāą║ą░ąĘą░č鹥ą╗čÄ.
ą£ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą▒čŗ ą┐ąŠą┤čāą╝ą░čéčī, čćč鹊 ąŠą▒ą░ čüčéąĖą╗čÅ ąĮąĖą║ą░ą║ ąĮąĄ ą┤ąŠą╗ąČąĮčŗ ąŠčéą╗ąĖčćą░čéčīčüčÅ ą┐ąŠ čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąĮąŠą╝čā ą║ąŠą┤čā, ąĮąŠ ąĖąĮąŠą│ą┤ą░ ąŠčéą╗ąĖčćąĖčÅ ą▓čüąĄ ąČąĄ ąĄčüčéčī. ą¦ą░čüč鹊 ąŠą┤ąĮą░ ąĖąĘ ą▓ąĄčĆčüąĖą╣ ą░ą╗ą│ąŠčĆąĖčéą╝ą░ ą┤ą░ąĄčé ą╗čāčćčłčāčÄ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖčÄ ą║ąŠą┤ą░, č湥ą╝ ą┤čĆčāą│ą░čÅ, ąĮąŠ ąĮąĄ ą▓čüąĄą│ą┤ą░ ą╗čāčćčłąĄ ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ čüčéąĖą╗čī. ąØą░ ą│ąĄąĮąĄčĆą░čåąĖčÄ ą║ąŠą┤ą░ ą▓ą╗ąĖčÅąĄčé ąŠą║čĆčāąČą░čÄčēąĖą╣ ą║ąŠą┤, ąŠčé ą║ąŠč鹊čĆąŠą│ąŠ ąĘą░ą▓ąĖčüąĖčé, ą┐ąŠč湥ą╝čā ą┐ąŠčÅą▓ą╗čÅčÄčéčüčÅ ąŠčéą╗ąĖčćąĖčÅ. ąĪčéąĖą╗čī čü čāą║ą░ąĘą░č鹥ą╗ąĄą╝ ą▓ą▓ąŠą┤ąĖčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ, ą║ąŠč鹊čĆčŗąĄ ą║ąŠąĮą║čāčĆąĖčĆčāčÄčé čü ąŠą║čĆčāąČą░čÄčēąĖą╝ ą║ąŠą┤ąŠą╝ ą┐čĆąĖ ą░ąĮą░ą╗ąĖąĘąĄ ąŠą┐čéąĖą╝ąĖąĘą░č鹊čĆąŠą╝. ąĪ ą┤čĆčāą│ąŠą╣ čüč鹊čĆąŠąĮčŗ, ą┤ąŠčüčéčāą┐ č湥čĆąĄąĘ ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĖąĄ ą╝ą░čüčüąĖą▓ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆąŠą╝ ą▓ ą┤ąŠčüčéčāą┐ č湥čĆąĄąĘ čāą║ą░ąĘą░č鹥ą╗ąĖ, ąĖ čéą░ą║ čćč鹊 ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąĖąĮąŠą│ą┤ą░ ąĮąĄ ą┤ąĄą╗ą░ąĄčé č鹊, čćč鹊 ąÆčŗ ą▓čŗą┐ąŠą╗ąĮąĖą╗ąĖ ą▓čĆčāčćąĮčāčÄ.
ąøčāčćčłą░čÅ čüčéčĆą░č鹥ą│ąĖčÅ - ąĮą░čćą░čéčī čü ą┤ąŠčüčéčāą┐ą░ č湥čĆąĄąĘ ąĖąĮą┤ąĄą║čü ą╝ą░čüčüąĖą▓ą░. ąĢčüą╗ąĖ čĆąĄąĘčāą╗čīčéą░čé ą┐ąŠą╗čāčćąĖą╗čüčÅ ąĮąĄčāą┤ąŠą▓ą╗ąĄčéą▓ąŠčĆąĖč鹥ą╗čīąĮčŗą╝, ą┐ąŠą┐čĆąŠą▒čāą╣č鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čāą║ą░ąĘą░č鹥ą╗ąĖ. ąŚą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ ąŠčüąŠą▒ąŠ ą▓ą░ąČąĮčŗčģ čåąĖą║ą╗ąŠą▓ ą▓čüąĄą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ąĖąĮą┤ąĄą║čüąĖčĆąŠą▓ą░ąĮąĮčŗą╣ čüčéąĖą╗čī, ą┐ąŠčüą║ąŠą╗čīą║čā ąŠąĮ ą┐čĆąŠčēąĄ ą┤ą╗čÅ ą┐ąŠąĮąĖą╝ą░ąĮąĖčÅ.
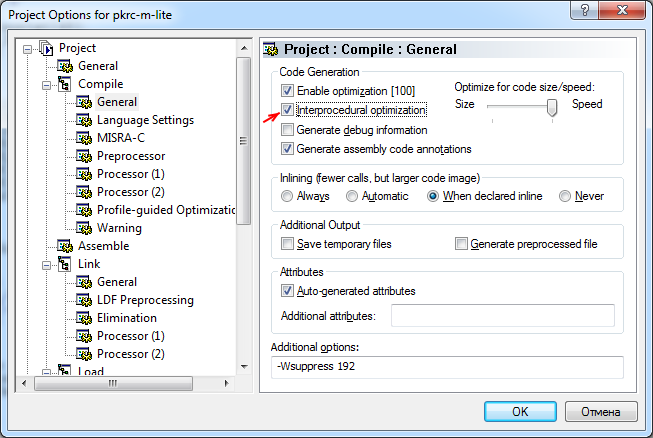
ąśčüą┐ąŠą╗čīąĘčāą╣č鹥 ąŠą┐čåąĖčÄ -ipa ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░. ą¦č鹊ą▒čŗ ąŠą▒ąĄčüą┐ąĄčćąĖčéčī ąĮą░ąĖą╗čāčćčłčāčÄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī, ąŠą┐čéąĖą╝ąĖąĘą░č鹊čĆ čćą░čüč鹊 ąĮčāąČą┤ą░ąĄčéčüčÅ ą▓ ąĖąĮč乊čĆą╝ą░čåąĖąĖ, ą║ąŠč鹊čĆčāčÄ ą╝ąŠąČąĮąŠ ą┐ąŠą╗čāčćąĖčéčī č鹊ą╗čīą║ąŠ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░čÅ ąŠą║čĆčāąČą░čÄčēąĖą╣ ąŠą┐čéąĖą╝ąĖąĘąĖčĆčāąĄą╝čāčÄ čäčāąĮą║čåąĖčÄ ą║ąŠą┤. ąÆ čćą░čüčéąĮąŠčüčéąĖ, čŹč鹊 ą┐ąŠą╝ąŠąČąĄčé čāąĘąĮą░čéčī ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ, ąĘąĮą░č湥ąĮąĖąĄ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ čāą║ą░ąĘą░č鹥ą╗čÅ ąĖ ąĘąĮą░č湥ąĮąĖąĄ ą│čĆą░ąĮąĖčå čåąĖą║ą╗ą░. ąÜą╗čÄčć ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąĖ -ipa čĆą░ąĘčĆąĄčłą░ąĄčé ą╝ąĄąČą┐čĆąŠčåąĄą┤čāčĆąĮčŗą╣ ą░ąĮą░ą╗ąĖąĘ (inter-procedural analysis, IPA), ą║ąŠč鹊čĆčŗą╣ ą┤ąĄą╗ą░ąĄčé čŹčéčā ąĖąĮč乊čĆą╝ą░čåąĖčÄ ą┤ąŠčüčéčāą┐ąĮąŠą╣. ąÆ čüčĆąĄą┤ąĄ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ VisualDSP čŹč鹊 ą╝ąŠąČąĮąŠ ą▓ą║ą╗čÄčćąĖčéčī ą│ą░ą╗ąŠčćą║ąŠą╣ "Interprocedural optimization" čĆą░ąĘą┤ąĄą╗ą░ Compile ą┤ąĖą░ą╗ąŠą│ą░ čüą▓ąŠą╣čüčéą▓ ą┐čĆąŠąĄą║čéą░ (ą╝ąĄąĮčÄ Project -> Project Options).
ąÜąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čŹčéą░ ąŠą┐čåąĖčÅ, č鹊 ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą▒čāą┤ąĄčé ąĘą░ą┐čāčēąĄąĮ ą┐ąŠą▓č鹊čĆąĮąŠ ąĮą░ čäą░ąĘąĄ ą╗ąĖąĮą║ąŠą▓ą║ąĖ, čćč鹊ą▒čŗ ą┐ąĄčĆąĄą║ąŠą╝ą┐ąĖą╗ąĖčĆąŠą▓ą░čéčī ą┐čĆąŠą│čĆą░ą╝ą╝čā ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ, ą┐ąŠą╗čāč湥ąĮąĮąŠą╣ ąĮą░ ą┐čĆąĄą┤čŗą┤čāčēąĄą╝ čŹčéą░ą┐ąĄ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąĖąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 čŹč鹊 čĆą░ą▒ąŠčéą░ąĄčé č鹊ą╗čīą║ąŠ ą▓ąŠ ą▓čĆąĄą╝čÅ ą╗ąĖąĮą║ąŠą▓ą║ąĖ, č鹊 čŹčäč乥ą║čéčŗ ąŠčé ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ ąŠą┐čåąĖąĖ -ipa ąĮąĄ ą▒čāą┤čāčé ą▓ąĖą┤ąĮčŗ ą┐čĆąĖ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ čü ąŠą┐čåąĖąĄą╣ -S (ąŠą┐čåąĖčÄ -S ąĖčüą┐ąŠą╗čīąĘčāčÄčé, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ą░čüčüąĄą╝ą▒ą╗ąĄčĆąĮčŗą╣ ą╗ąĖčüčéąĖąĮą│ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ). ą¦č鹊ą▒čŗ ą┐čĆąŠčüą╝ąŠčéčĆąĄčéčī čäą░ą╣ą╗ ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░, ą┤ąŠą▒ą░ą▓čīč鹥 ąŠą┐čåąĖčÄ -save-temps ą▓ ą┐ąŠą╗ąĄ ą▓ą▓ąŠą┤ą░ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ąŠą┐čåąĖą╣ (Additional Options) ą▓ ą┤ąĖą░ą╗ąŠą│ąĄ ąĮą░čüčéčĆąŠą╣ą║ąĖ čüą▓ąŠą╣čüčéą▓ ą┐čĆąŠąĄą║čéą░, čĆą░ąĘą┤ąĄą╗ Compile, ąĖ ą┐čĆąŠčüą╝ąŠčéčĆąĖč鹥 čäą░ą╣ą╗ .s, ą║ąŠč鹊čĆčŗą╣ ą▒čāą┤ąĄčé čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮ ą┐čĆąĖ čüą▒ąŠčĆą║ąĄ.
ąæąŠą╗čīčłą░čÅ čćą░čüčéčī čüą╗ąĄą┤čāčÄčēąĖčģ čüąŠą▓ąĄč鹊ą▓ ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą║ą╗čÄčćą░ -ipa ą▓ ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąĄ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░.
ąśąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāą╣č鹥 ą║ąŠąĮčüčéą░ąĮčéčŗ čüčéą░čéąĖč湥čüą║ąĖ. ą£ąĄąČą┐čĆąŠčåąĄą┤čāčĆąĮčŗą╣ ą░ąĮą░ą╗ąĖąĘ (IPA) čéą░ą║ąČąĄ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāąĄčé ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ, čā ą║ąŠč鹊čĆčŗčģ ąĄčüčéčī č鹊ą╗čīą║ąŠ ąŠą┤ąĮąŠ ąĘąĮą░č湥ąĮąĖąĄ, ąĖ ąĘą░ą╝ąĄąĮčÅąĄčé ąĖčģ ąĮą░ ą║ąŠąĮčüčéą░ąĮčéčŗ, čćč鹊 ą╝ąŠąČąĄčé ą┤ą░čéčī čāą╗čāčćčłąĄąĮąĖąĄ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ. ą¦č鹊ą▒čŗ čŹč鹊 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ, ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ ą┤ąŠą╗ąČąĮą░ ąĖą╝ąĄčéčī ąŠą┤ąĮąŠ ąĘąĮą░č湥ąĮąĖąĄ ąĮą░ ą▓čüąĄ ą▓čĆąĄą╝čÅ ąČąĖąĘąĮąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ.
#include < stdio.h >
static int val = 3; // ąĄą┤ąĖąĮčüčéą▓ąĄąĮąĮą░čÅ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ
void init() {
}
void func() {
printf("val %d",val);
}
int main() {
init();
func();
}
ąøąĖčüčéąĖąĮą│ 3: ą×ą┐čéąĖą╝ą░ą╗čīąĮą░čÅ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ (IPA ąĘąĮą░ąĄčé, čćč鹊 ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ val čĆą░ą▓ąĮą░ 3).
ąĢčüą╗ąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ čüčéą░čéąĖč湥čüą║ąĖ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮą░ ą▓ 0, ą║ą░ą║ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ąĄą╗ą░ąĄčéčüčÅ čüąŠ ą▓čüąĄą╝ąĖ ą│ą╗ąŠą▒ą░ą╗čīąĮčŗą╝ąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝ąĖ, ąĖ ą┐ąŠč鹊ą╝ ąĄą╣ ąĮą░ąĘąĮą░čćą░ąĄčéčüčÅ ą║ą░ą║ąŠąĄ-č鹊 ąĖąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą▓ ą┤čĆčāą│ąŠą╝ ą╝ąĄčüč鹥 ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, č鹊 ą░ąĮą░ą╗ąĖąĘ čāą▓ąĖą┤ąĖčé 2 ąĘąĮą░č湥ąĮąĖčÅ ąĖ ąĮąĄ ą▒čāą┤ąĄčé čüčćąĖčéą░čéčī ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ ą║ąŠąĮčüčéą░ąĮč鹊ą╣.
#include < stdio.h >
static int val; // ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮą░ ąĮčāą╗ąĄą╝
void init() {
val = 3; // ą┐ąŠą▓č鹊čĆąĮą░čÅ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ
}
void func() {
printf("val %d",val);
}
int main() {
init();
func();
}
ąøąĖčüčéąĖąĮą│ 4: ąĮąĄ ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠ (IPA ąĮąĄ ą╝ąŠąČąĄčé čāą▓ąĖą┤ąĄčéčī, čćč鹊 val ą║ąŠąĮčüčéą░ąĮčéą░).
ąÆčŗčĆą░ą▓ąĮąĖą▓ą░ą╣č鹥 čüą▓ąŠąĖ ą┤ą░ąĮąĮčŗąĄ ąĮą░ čĆą░ąĘą╝ąĄčĆ čüą╗ąŠą▓ą░. ą¦č鹊ą▒čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą░ą┐ą┐ą░čĆą░čéčāčĆčā ąĮą░ąĖą╗čāčćčłąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą┤ą╗čÅ ąĮąĄčæ ąĮčāąČąĮąŠ čŹčäč乥ą║čéąĖą▓ąĮąŠ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčéčī ą┤ą░ąĮąĮčŗąĄ. ąÆąŠ ą╝ąĮąŠą│ąĖčģ ą░ą╗ą│ąŠčĆąĖčéą╝ą░čģ ą▒ą░ą╗ą░ąĮčü ą┤ąŠčüčéčāą┐ą░ ą┤ą░ąĮąĮčŗčģ ąĖ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ čü ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąĘą░ą┤ąĄą╣čüčéą▓ąŠą▓ą░ąĮąĮąŠą╣ ą░ą┐ą┐ą░čĆą░čéčāčĆąŠą╣ ą▒čāą┤ąĄčé č鹊ą│ą┤ą░, ą║ąŠą│ą┤ą░ ą┤ą░ąĮąĮčŗąĄ ą┐ąĄčĆąĄą╝ąĄčēą░čÄčéčüčÅ ąĖąĘ ą┐ą░ą╝čÅčéąĖ ą▓ čĆąĄą│ąĖčüčéčĆčŗ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĖ ąŠą▒čĆą░čéąĮąŠ 32-ą▒ąĖčéąĮčŗą╝ąĖ ą┐ąŠčĆčåąĖčÅą╝ąĖ.
ąźąŠčéčÅ ą░čĆčģąĖč鹥ą║čéčāčĆą░ Blackfin ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ąĖ ą┐ąŠą▒ą░ą╣čéąĮčāčÄ ą░ą┤čĆąĄčüą░čåąĖčÄ, ą░ą┐ą┐ą░čĆą░čéčāčĆą░ čéčĆąĄą▒čāąĄčé ąŠą▒čĆą░čēąĄąĮąĖčÅ ą║ ą┐ą░ą╝čÅčéąĖ čü čéčĆą░ą┤ąĖčåąĖąŠąĮąĮčŗą╝ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄą╝. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, 16-ą▒ąĖčéąĮąŠąĄ ąŠą▒čĆą░čēąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą┐ąŠ č湥čéąĮčŗą╝ ą░ą┤čĆąĄčüą░ą╝ čÅč湥ąĄą║ ą┐ą░ą╝čÅčéąĖ (ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą░ą┤čĆąĄčüą░ ąĮą░ čĆą░ąĘą╝ąĄčĆ ą┐ąŠą╗čāčüą╗ąŠą▓ą░), ąĖ ą┤ą╗čÅ 32-ą▒ąĖčéąĮčŗčģ ąŠą▒čĆą░čēąĄąĮąĖą╣ ą░ą┤čĆąĄčü ą┤ąŠą╗ąČąĄąĮ ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░ 4 (ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą░ą┤čĆąĄčüą░ ąĮą░ čüą╗ąŠą▓ąŠ). ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖą╗čüčÅ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ čŹčäč乥ą║čéąĖą▓ąĮčŗą╣ ą║ąŠą┤, ąÆą░ą╝ ąĮčāąČąĮąŠ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ą▓čüąĄ ą┤ą░ąĮąĮčŗąĄ ą▓čŗčĆąŠą▓ąĮąĄąĮčŗ ą▓ ą┐ą░ą╝čÅčéąĖ ąĮą░ čĆą░ąĘą╝ąĄčĆ čüą╗ąŠą▓ą░ (4 ą▒ą░ą╣čéą░, ą░ą┤čĆąĄčü ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖčéčüčÅ ąĮą░ 4).
ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą┐ąŠą╝ąŠą│ą░ąĄčé ą┤ąŠą▒ąĖčéčīčüčÅ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ ą╝ą░čüčüąĖą▓ą░. ą×ą║ąĮą░ čüč鹥ą║ą░ čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ ą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗą╝ąĖ ąĮą░ čüą╗ąŠą▓ąŠ. ą£ą░čüčüąĖą▓čŗ ą▓ąĄčĆčģąĮąĄą│ąŠ čāčĆąŠą▓ąĮčÅ čĆą░ąĘą╝ąĄčēą░čÄčéčüčÅ ą┐ąŠ ąĮą░čćą░ą╗čīąĮąŠą╝čā ą░ą┤čĆąĄčüčā, ą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą╝čā ąĮą░ čüą╗ąŠą▓ąŠ, ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ ąŠčé čéąĖą┐ą░ ąĮą░čģąŠą┤čÅčēąĖčģčüčÅ ą▓ ą╝ą░čüčüąĖą▓ąĄ ą┤ą░ąĮąĮčŗčģ.
ąĢčüą╗ąĖ ąÆčŗ ą┐ąĖčłąĄč鹥 ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ą║ąŠč鹊čĆčŗąĄ ą┐ąĄčĆąĄą┤ą░čÄčé č鹊ą╗čīą║ąŠ ą░ą┤čĆąĄčü ą┐ąĄčĆą▓ąŠą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░ ą▓ ą╝ą░čüčüąĖą▓ąĄ ą║ą░ą║ ą┐ą░čĆą░ą╝ąĄčéčĆ, ąĖ ąĄčüčéčī čåąĖą║ą╗čŗ, ą║ąŠč鹊čĆčŗąĄ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčé ą▓čģąŠą┤ąĮčŗąĄ ą╝ą░čüčüąĖą▓čŗ ą┐ąŠ ąŠą┤ąĮąŠą╝čā 菹╗ąĄą╝ąĄąĮčéčā ąĘą░ ąĖč鹥čĆą░čåąĖčÄ, ąĮą░čćąĮąĖč鹥 čü 菹╗ąĄą╝ąĄąĮčéą░ 0 ą╝ą░čüčüąĖą▓ą░, č鹊ą│ą┤ą░ IPA ą▒čāą┤ąĄčé ą▓ čüąŠčüč鹊čÅąĮąĖąĖ ą▓čŗčÅčüąĮąĖčéčī, čćč鹊 ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą┐ąŠą┤čģąŠą┤ąĖčé ą┤ą╗čÅ 32-ą▒ąĖčéąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░.
ąóą░ą╝, ą│ą┤ąĄ ą▓ąĮčāčéčĆąĄąĮąĮąĖą╣ čåąĖą║ą╗ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé ą┐ąŠčüčéčĆąŠčćąĮąŠ ą╝ąĮąŠą│ąŠą╝ąĄčĆąĮčŗą╣ ą╝ą░čüčüąĖą▓, čāą┤ąŠčüč鹊ą▓ąĄčĆčīč鹥čüčī, čćč鹊 ą║ą░ąČą┤ą░čÅ čüčéčĆąŠą║ą░ ąĮą░čćąĖąĮą░ąĄčéčüčÅ ąĮą░ ą░ą┤čĆąĄčüąĄ, ą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą╝ ąĮą░ čüą╗ąŠą▓ąŠ. ąŁč鹊 ą╝ąŠąČąĮąŠ čüą┤ąĄą╗ą░čéčī, ą┤ąŠą▒ą░ą▓ą╗čÅčÅ ą▓ ą╝ą░čüčüąĖą▓ ąĖą╗ąĖ čüčéčĆčāą║čéčāčĆčā ą┐čāčüčéčŗąĄ 菹╗ąĄą╝ąĄąĮčéčŗ.
[ąĪąŠą▓ąĄčéčŗ ą┐ąŠ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖąĖ čåąĖą║ą╗ąŠą▓]
ąÆ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ A ą┤ą░ąĮ ąŠą▒ąĘąŠčĆ č鹊ą│ąŠ, ą║ą░ą║ ąŠą┐čéąĖą╝ąĖąĘą░č鹊čĆ ą┐čĆąĄąŠą▒čĆą░ąĘčāąĄčé čåąĖą║ą╗ ą┤ą╗čÅ ą│ąĄąĮąĄčĆą░čåąĖąĖ ą▓čŗčüąŠą║ąŠčŹčäč乥ą║čéąĖą▓ąĮąŠą│ąŠ ą║ąŠą┤ą░. ąŁč鹊 ąŠą┐ąĖčüą░ąĮąŠ č鹥čģąĮąĖą║ąŠą╣ "čĆą░ąĘą▓ąŠčĆą░čćąĖą▓ą░ąĮąĖąĄ čåąĖą║ą╗ą░" (loop unrolling).
ąØąĄ čĆą░ąĘą▓ąŠčĆą░čćąĖą▓ą░ą╣č鹥 čåąĖą║ą╗čŗ čüą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮąŠ (KISS, ąĮąĄ ąĮą░ą┤ąŠ čāą╝ąĮąĖčćą░čéčī!). ąĀą░ąĘą▓ąŠčĆąŠčé čåąĖą║ą╗ą░ ąĮąĄ č鹊ą╗čīą║ąŠ ą┤ąĄą╗ą░ąĄčé ą┐čĆąŠą│čĆą░ą╝ą╝čā čéčĆčāą┤ąĮąŠą╣ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ, ąĮąŠ ąĖ ąĮąĄ ą┤ą░ąĄčé ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆčā ą┐čĆąĖą╝ąĄąĮąĖčéčī ąŠą┐čéąĖą╝ąĖąĘą░čåąĖčÄ. ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą┤ąŠą╗ąČąĄąĮ čĆą░ąĘą▓ąĄčĆąĮčāčéčī čåąĖą║ą╗ čüą░ą╝, čćč鹊ą▒čŗ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čłąĖčĆąŠą║ąĖąĄ ąĘą░ą│čĆčāąĘą║ąĖ ąĖ ąŠą▒ą░ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆą░.
void va1 (short a[], short b[], short c[], int n)
{
int i;
for (i = 0; i < n; ++i)
{
c[i] = b[i] + a[i];
}
}
ąøąĖčüčéąĖąĮą│ 5: ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠ (ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ čĆą░ąĘą▓ąĄčĆąĮąĄčé ąĖ ą▒čāą┤ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąŠą▒ą░ ą▒ą╗ąŠą║ą░ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ).
void va2 (short a[], short b[], short c[], int n)
{
short xa, xb, xc, ya, yb, yc;
int i;
for (i = 0; i < n; i+=2)
{
xb = b[i]; yb = b[i+1];
xa = a[i]; ya = a[i+1];
xc = xa + xb; yc = ya + yb;
c[i] = xc; c[i+1] = yc;
}
}
ąøąĖčüčéąĖąĮą│ 6: ąĮąĄ ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠ (ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąŠčüčéą░ą▓ąĖčé 16-ą▒ąĖčéąĮčŗąĄ ąĘą░ą│čĆčāąĘą║ąĖ).
ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą┐ąĄčĆą▓ą░čÅ ą▓ąĄčĆčüąĖčÅ čåąĖą║ą╗ą░ čĆą░ą▒ąŠčéą░ąĄčé ą┐čĆąĖą╝ąĄčĆąĮąŠ ą▓ 3 čĆą░ąĘą░ ą▒čŗčüčéčĆąĄąĄ, č湥ą╝ ą▓č鹊čĆą░čÅ - ą▓ č鹥čģ čüą╗čāčćą░čÅčģ, ą║ąŠą│ą┤ą░ IPA ą╝ąŠąČąĄčé ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, čćč鹊 ąĮą░čćą░ą╗čīąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ a, b ąĖ c ą▓čŗčĆąŠą▓ąĮąĄąĮčŗ ąĮą░ 32-ą▒ąĖčéąĮčŗąĄ ą│čĆą░ąĮąĖčåčŗ ą░ą┤čĆąĄčüą░, ąĖ n ą║čĆą░čéąĮąŠ ą┤ą▓čāą╝.
ąśąĘą▒ąĄą│ą░ą╣č鹥 ąĘą░ą▓ąĖčüąĖą╝ąŠčüč鹥ą╣ ą▓ č鹥ą╗ąĄ čåąĖą║ą╗ą░. ąŚą░ą▓ąĖčüąĖą╝ąŠčüčéčī ą▓ čåąĖą║ą╗ąĄ (loop-carried dependency) čŹč鹊 čüą╗čāčćą░ą╣, ą║ąŠą│ą┤ą░ ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ č鹥ą║čāčēąĄą╣ ąĖč鹥čĆą░čåąĖąĖ čåąĖą║ą╗ą░ ąĮąĄą╗čīąĘčÅ ąŠčüčāčēąĄčüčéą▓ąĖčéčī ą▒ąĄąĘ ąĘąĮą░ąĮąĖčÅ ąĘąĮą░č湥ąĮąĖą╣, ą║ąŠč鹊čĆčŗąĄ ą▓čŗčćąĖčüą╗čÅčÄčéčüčÅ ąĮą░ ą┐čĆąĄą┤čŗą┤čāčēąĖčģ ąĖč鹥čĆą░čåąĖčÅčģ. ąÜąŠą│ą┤ą░ ą▓ čåąĖą║ą╗ąĄ ąĄčüčéčī čéą░ą║ąĖąĄ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ, ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąĮąĄ ą╝ąŠąČąĄčé ą┐ąĄčĆąĄą║čĆčŗčéčī ąĖč鹥čĆą░čåąĖąĖ čåąĖą║ą╗ą░.
ąØąĄą║ąŠč鹊čĆčŗąĄ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ą┐ąŠą╗čāčćą░čÄčéčüčÅ ąŠčé čüą║ą░ą╗čÅčĆąĮčŗčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ąŠąĮąĖ ą▒čāą┤čāčé ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮčŗ ą▓ ąŠą┤ąĮąŠą╣ ąĖč鹥čĆą░čåąĖąĖ.
for (i = 0; i < n; ++i)
x = a[i] - x;
ąøąĖčüčéąĖąĮą│ 7: ąĮąĄ ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠ (čüą║ą░ą╗čÅčĆąĮą░čÅ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéčī).
ą×ą┐čéąĖą╝ąĖąĘą░č鹊čĆ ą╝ąŠąČąĄčé ą┐ąĄčĆąĄčāą┐ąŠčĆčÅą┤ąŠčćąĖčéčī ąĖč鹥čĆą░čåąĖąĖ ą▓ ą┐čĆąĖčüčāčéčüčéą▓ąĖąĖ ą║ą╗ą░čüčüą░ čüą║ą░ą╗čÅčĆąĮčŗčģ ąĘą░ą▓ąĖčüąĖą╝ąŠčüč鹥ą╣, ąĖąĘą▓ąĄčüčéąĮčŗčģ ą║ą░ą║ čĆąĄą┤čāą║čåąĖąĖ (reduction). ąŁč鹊 čåąĖą║ą╗čŗ, ą║ąŠč鹊čĆčŗąĄ čāą╝ąĄąĮčīčłą░čÄčé ąĘąĮą░č湥ąĮąĖčÅ ą▓ąĄą║č鹊čĆą░ ą║ čüą║ą░ą╗čÅčĆąĮąŠą╣ ą▓ąĄą╗ąĖčćąĖąĮąĄ, ąĖčüą┐ąŠą╗čīąĘčāčÅ ą░čüčüąŠčåąĖą░čéąĖą▓ąĮčŗą╣ ąĖą╗ąĖ ą║ąŠą╝ą╝čāčéą░čéąĖą▓ąĮčŗą╣ ąŠą┐ąĄčĆą░č鹊čĆ. ąØąĖąČąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮ čüą░ą╝čŗą╣ ąŠą▒čēąĖą╣ ą┐čĆąĖą╝ąĄčĆ čāą╝ąĮąŠąČąĄąĮąĖčÅ čü ąĮą░ą║ąŠą┐ą╗ąĄąĮąĖąĄą╝ (multiply and accumulate, MAC).
for (i = 0; i < n; ++i)
x = x + a[i] * b[i];
ąøąĖčüčéąĖąĮą│ 8: ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠ (čĆąĄą┤čāą║čåąĖčÅ).
ąÆ ą┐ąĄčĆą▓ąŠą╝ čüą╗čāčćą░ąĄ čüą║ą░ą╗čÅčĆąĮą░čÅ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéčī čŹč鹊 ąŠą┐ąĄčĆą░čåąĖčÅ ą▓čŗčćąĖčéą░ąĮąĖčÅ; ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ x ąĖąĘą╝ąĄąĮčÅąĄčéčüčÅ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą║ąŠč鹊čĆčŗą╣ ą┤ą░čüčé čĆą░ąĘą╗ąĖčćąĮčŗąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ, ąĄčüą╗ąĖ ąĖč鹥čĆą░čåąĖąĖ ą▒čāą┤čāčé ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ąĮąĄ ą▓ č鹊ą╝ ą┐ąŠčĆčÅą┤ą║ąĄ. ąÆč鹊čĆąŠą╣ čüą╗čāčćą░ą╣, ą▓ ąŠčéą╗ąĖčćąĖąĄ ąŠčé ą┐ąĄčĆą▓ąŠą│ąŠ, ą│ą┤ąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ąŠą┐ąĄčĆą░č鹊čĆ čüą╗ąŠąČąĄąĮąĖčÅ, ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆčā ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąŠą┐ąĄčĆą░čåąĖąĖ ą▓ ą╗čÄą▒ąŠą╝ ą┐ąŠčĆčÅą┤ą║ąĄ, čü ą┐ąŠą╗čāč湥ąĮąĖąĄą╝ ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠą│ąŠ čĆąĄąĘčāą╗čīčéą░čéą░.
ąØąĄ ą┐ąĄčĆąĄą▓ąŠčĆą░čćąĖą▓ą░ą╣č鹥 čåąĖą║ą╗čŗ ą▓čĆčāčćąĮčāčÄ. ą”ąĖą║ą╗čŗ ą▓ ą║ąŠą┤ąĄ DSP čćą░čüč鹊 "ą┐ąŠą▓ąĄčĆąĮčāčéčŗ" ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüč鹊ą╝ ą▓čĆčāčćąĮčāčÄ, ą▓ ą┐ąŠą┐čŗčéą║ąĄ čüą┤ąĄą╗ą░čéčī ąĘą░ą│čĆčāąĘą║ąĖ (load) ąĖ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ (store) čĆą░ąĮčīčłąĄ ąĖ ą▒čāą┤čāčēąĖąĄ ąĖč鹥čĆą░čåąĖąĖ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ čü č鹥ą║čāčēąĄą╣ ąĖč鹥čĆą░čåąĖąĄą╣. ąŁčéą░ č鹥čģąĮąĖą║ą░ ą▓ą▓ąŠą┤ąĖčé ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéčī ą▓ čåąĖą║ą╗ (loop-carried dependence), ą║ąŠč鹊čĆą░čÅ ąĮąĄ ą┤ą░ąĄčé ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆčā čŹčäč乥ą║čéąĖą▓ąĮąŠ ą┐ąĄčĆąĄąŠčĆą│ą░ąĮąĖąĘąŠą▓ą░čéčī ą║ąŠą┤. ąøčāčćčłąĄ ą┤ą░čéčī ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆčā "ąĮąŠčĆą╝ą░ą╗ąĖąĘąŠą▓ą░ąĮąĮčāčÄ" ą▓ąĄčĆčüąĖčÄ, ąĖ ąŠčüčéą░ą▓ąĖčéčī ą┐ąŠą▓ąŠčĆąŠčéčŗ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆčā.
int ss (short *a, short *b, int n)
{
short ta, tb;
int sum = 0;
int i = 0;
ta = a[i]; tb = b[i];
for (i = 1; i < n; i++)
{
sum += ta + tb;
ta = a[i]; tb = b[i];
}
sum += ta + tb;
return sum;
}
ąøąĖčüčéąĖąĮą│ 9: ąĮąĄ ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠ (ą┐ąŠą▓ąĄčĆąĮčāč鹊 ą▓čĆčāčćąĮčāčÄ).
ą¤čĆąĖ ą┐ąŠą▓ąŠčĆąŠč鹥 čåąĖą║ą╗ą░ ą▒čŗą╗ąĖ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮčŗ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ ta ąĖ tb, ą║ąŠč鹊čĆčŗąĄ ą▓ą▓ąĄą╗ąĖ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéčī ą▓ čåąĖą║ą╗, čćč鹊 ąĮąĄ ą┤ą░ąĄčé ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆčā ą▓čŗčćąĖčüą╗čÅčéčī ąĖč鹥čĆą░čåąĖąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ. ą×ą┐čéąĖą╝ąĖąĘą░č鹊čĆ ą╝ąŠąČąĄčé ą┤ąĄą╗ą░čéčī čĆąŠčéą░čåąĖąĖ čéą░ą║ąŠą│ąŠ čĆąŠą┤ą░ čüą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮąŠ.
int ss (short *a, short *b, int n)
{
short sum = 0;
int i;
for (i = 0; i < n; i++)
{
sum += a[i] + b[i];
}
return sum;
}
ąøąĖčüčéąĖąĮą│ 10: ąŠą┐čéąĖą╝ą░ą╗čīąĮą░čÅ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖčÅ čåąĖą║ą╗ą░ (čĆąŠčéą░čåąĖčÅ ą┤ąĄą╗ą░ąĄčéčüčÅ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆąŠą╝).
ąśąĘą▒ąĄą│ą░ą╣č鹥 ąĘą░ą┐ąĖčüąĄą╣ ą▓ ą╝ą░čüčüąĖą▓ ą▓ čåąĖą║ą╗ąĄ. ąöčĆčāą│ąĖąĄ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ą╝ąŠą│čāčé ą┐ąŠą╗čāčćąĖčéčīčüčÅ ą┐čĆąĖ ąĘą░ą┐ąĖčüąĖ ą▓ 菹╗ąĄą╝ąĄąĮčéčŗ ą╝ą░čüčüąĖą▓ą░. ąÆ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ čåąĖą║ą╗ą░ ąŠą┐čéąĖą╝ąĖąĘą░č鹊čĆ ąĮąĄ ą╝ąŠąČąĄčé ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, ą▒čŗą╗ą░ ą╗ąĖ ąĘą░ą│čĆčāąĘą║ą░ ąŠčé čćč鹥ąĮąĖčÅ ąĘąĮą░č湥ąĮąĖčÅ, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮą░čÅ ąĮą░ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ ąĖč鹥čĆą░čåąĖąĖ, ąĖą╗ąĖ ąŠąĮą░ ą▒čāą┤ąĄčé ą┐ąĄčĆąĄąĘą░ą┐ąĖčüą░ąĮą░ ą▓ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĄą╣ ąĖč鹥čĆą░čåąĖąĖ.
for (i = 0; i < n; ++i)
a[i] = b[i] * a[c[i]];
ąøąĖčüčéąĖąĮą│ 11: ąĮąĄ ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠ (ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéčī ąĖąĘ-ąĘą░ ą╝ą░čüčüąĖą▓ą░).
for (i = 0; i < n; ++i)
a[i+4] = b[i] * a[i];
ąøąĖčüčéąĖąĮą│ 12: ą×ą┐čéąĖą╝ą░ą╗čīąĮąŠ (ąĖąĮą┤čāą║čåąĖąŠąĮąĮčŗąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ).
ą×ą┐čéąĖą╝ąĖąĘą░č鹊čĆ ą╝ąŠąČąĄčé čĆą░ąĘčĆąĄčłąĖčéčī čüčģąĄą╝čŗ ą┤ąŠčüčéčāą┐ą░, ą│ą┤ąĄ ą░ą┤čĆąĄčüą░ - ą▓čŗčĆą░ąČąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą▓ą░čĆčīąĖčĆčāčÄčéčüčÅ ąĮą░ čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐čĆąĖ ą║ą░ąČą┤ąŠą╣ ąĖč鹥čĆą░čåąĖąĖ. ąŁčéą░ čüčģąĄą╝ą░ ąĖąĘą▓ąĄčüčéąĮą░ ą║ą░ą║ "ąĖąĮą┤čāą║čåąĖąŠąĮąĮčŗąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ" (induction variables).
ąśąĘą▒ąĄą│ą░ą╣č鹥 ą┐čüąĄą▓ą┤ąŠąĮąĖą╝ąŠą▓ (aliases). ą”ąĖą║ą╗ ą╝ąŠąČąĄčé ą▓čŗą│ą╗ą░ą┤ąĖčéčī ą║ą░ą║ ąĮąĄ čüąŠą┤ąĄčƹȹ░čēąĖą╣ ąĘą░ą▓ąĖčüąĖą╝ąŠčüč鹥ą╣, ąĮąŠ a ąĖ b ąŠą▒ą░ ą┐ą░čĆą░ą╝ąĄčéčĆčŗ, ąĖ, čģąŠčéčÅ ąŠąĮąĖ ą┤ąĄą║ą╗ą░čĆąĖčĆąŠą▓ą░ąĮčŗ čü ą║ą▓ą░ą┤čĆą░čéąĮčŗą╝ąĖ čüą║ąŠą▒ą║ą░ą╝ąĖ [ ], ąŠąĮąĖ čäą░ą║čéąĖč湥čüą║ąĖ čāą║ą░ąĘą░č鹥ą╗ąĖ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé čāą║ą░ąĘčŗą▓ą░čéčī ąĮą░ č鹊čé ąČąĄ ą╝ą░čüčüąĖą▓. ąÜąŠą│ą┤ą░ ą║ č鹥ą╝ ąČąĄ čüą░ą╝čŗą╝ ą┤ą░ąĮąĮčŗą╝ ą╝ąŠąČąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ č湥čĆąĄąĘ 2 čāą║ą░ąĘą░č鹥ą╗čÅ, ą╝čŗ ą│ąŠą▓ąŠčĆąĖą╝, čćč鹊 ąŠąĮąĖ ą╝ąŠą│čāčé čÅą▓ą╗čÅčéčīčüčÅ ą┐čüąĄą▓ą┤ąŠąĮąĖą╝ą░ą╝ąĖ ą┤čĆčāą│ ą┤čĆčāą│ą░.
void fn (short a[], short b[], int n)
{
for (i = 0; i < n; ++i)
a[i] = b[i];
}
ąøąĖčüčéąĖąĮą│ 13: ąĮąĄ ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠ (ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮčŗą╣ ą░ą╗ąĖą░čüąĖąĮą│).
ąĢčüą╗ąĖ ą┐čĆąĖą╝ąĄąĮąĄąĮ ą║ą╗čÄčć ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąĖ -ipa, ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą╝ąŠąČąĄčé ą┐čĆąŠčüą╝ąŠčéčĆąĄčéčī ą╝ąĄčüčéą░ ą▓čŗąĘąŠą▓ąŠą▓ fn, ąĖ ą▓ąŠąĘą╝ąŠąČąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, čāą║ą░ąĘčŗą▓ą░čÄčé ą╗ąĖ ąŠąĮąĖ ą║ąŠą│ą┤ą░-ąĮąĖą▒čāą┤čī ąĮą░ č鹊čé ąČąĄ čüą░ą╝čŗą╣ ą╝ą░čüčüąĖą▓.
ąöą░ąČąĄ čü ąŠą┐čåąĖąĄą╣ -ipa ą┤ąŠą▓ąŠą╗čīąĮąŠ ą┐čĆąŠčüč鹊 čüąŠąĘą┤ą░čéčī ąŠč湥ą▓ąĖą┤ąĮčŗąĄ ą┐čüąĄą▓ą┤ąŠąĮąĖą╝čŗ. IPA čĆą░ą▒ąŠčéą░ąĄčé, čüą▓čÅąĘčŗą▓ą░čÅ čāą║ą░ąĘą░č鹥ą╗ąĖ čü ąĮą░ą▒ąŠčĆąŠą╝ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ, ą║ ą║ąŠč鹊čĆčŗą╝ ąŠąĮąĖ ą╝ąŠą│čāčé ąŠą▒čĆą░čéąĖčéčīčüčÅ ą▓ ąĮąĄą║ąŠč鹊čĆąŠą╣ č鹊čćą║ąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ąöą╗čÅ čāą┐čĆąŠčēąĄąĮąĖčÅ ą░ąĮą░ą╗ąĖąĘą░ ąĮąĄ čāčćąĖčéčŗą▓ą░ąĄčéčüčÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąŠč鹊ą║ąŠą╝ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣, ąĖ ąĄčüą╗ąĖ ąĮą░ą▒ąŠčĆ ą┤ą╗čÅ ą┤ą▓čāčģ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ąĮą░ą╣ą┤ąĄąĮ ą┐ąĄčĆąĄčüąĄą║ą░čÄčēąĖą╝čüčÅ, č鹊 ąŠą▒ą░ čāą║ą░ąĘą░č鹥ą╗čÅ ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░čÄčéčüčÅ ą║ą░ą║ čāą║ą░ąĘčŗą▓ą░čÄčēąĖąĄ ąĮą░ ąŠą▒čŖąĄą┤ąĖąĮąĄąĮąĖąĄ (union) ą┤ą▓čāčģ ąĮą░ą▒ąŠčĆąŠą▓.
ąĢčüą╗ąĖ ą▓čŗčłąĄą┐čĆąĖą▓ąĄą┤ąĄąĮąĮą░čÅ čäčāąĮą║čåąĖčÅ fn ą▒čŗą╗ą░ ą▓čŗąĘą▓ą░ąĮą░ ą▓ 2 ą╝ąĄčüčéą░čģ ą║ąŠą┤ą░ čü ą│ą╗ąŠą▒ą░ą╗čīąĮčŗą╝ąĖ ą╝ą░čüčüąĖą▓ą░ą╝ąĖ ą▓ ą║ą░č湥čüčéą▓ąĄ ą░čĆą│čāą╝ąĄąĮč鹊ą▓, č鹊 IPA ą┐ąŠą║ą░ąČąĄčé čüą╗ąĄą┤čāčÄčēąĖąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ ą┤ą╗čÅ čĆą░ąĘąĮčŗčģ čüą╗čāčćą░ąĄą▓:
ąĪą╗čāčćą░ą╣ 1:
fn(glob1, glob2, N); ąĮą░ą▒ąŠčĆčŗ ąĮąĄ ą┐ąĄčĆąĄčüąĄą║ą░čÄčéčüčÅ: a ąĖ b
fn(glob1, glob2, N); ąĮąĄčé ą┐čüąĄą▓ą┤ąŠąĮąĖą╝ąŠą▓ (ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠ)
ąĪą╗čāčćą░ą╣ 2:
fn(glob1, glob2, N); ąĮą░ą▒ąŠčĆčŗ ąĮąĄ ą┐ąĄčĆąĄčüąĄą║ą░čÄčéčüčÅ: a ąĖ b
fn(glob3, glob4, N); ąĮąĄčé ą┐čüąĄą▓ą┤ąŠąĮąĖą╝ąŠą▓ (ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠ)
ąĪą╗čāčćą░ą╣ 3:
fn(glob1, glob2, N); ąĮą░ą▒ąŠčĆčŗ ą┐ąĄčĆąĄčüąĄą║ą░čÄčéčüčÅ: a ąĖ b
fn(glob3, glob1, N); ą╝ąŠą│čāčé ą▒čŗčéčī ą▓ąĘą░ąĖą╝ąĮčŗąĄ čüčüčŗą╗ą║ąĖ (ą░ą╗ąĖą░čüčŗ, ąĮąĄ ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠ)
ąóčĆąĄčéąĖą╣ čüą╗čāčćą░ą╣ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 IPA čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ąĄčé ąŠą▒čŖąĄą┤ąĖąĮąĄąĮąĖąĄ ą┤ą╗čÅ ą▓čüąĄčģ ą▓čŗąĘąŠą▓ąŠą▓ čüčĆą░ąĘčā, ą▓ą╝ąĄčüč鹊 čĆą░čüčüą╝ąŠčéčĆąĄąĮąĖčÅ ą║ą░ąČą┤ąŠą│ąŠ ą▓čŗąĘąŠą▓ą░ ąĖąĮą┤ąĖą▓ąĖą┤čāą░ą╗čīąĮąŠ, ą║ąŠą│ą┤ą░ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé, ąĄčüčéčī ą╗ąĖ čĆąĖčüą║ ą░ą╗ąĖą░čüąĖąĮą│ą░. ąĢčüą╗ąĖ ą▒čŗ ą║ą░ąČą┤čŗą╣ ą▓čŗąĘąŠą▓ ą▒čŗą╗ čĆą░čüčüą╝ąŠčéčĆąĄąĮ ąĖąĮą┤ąĖą▓ąĖą┤čāą░ą╗čīąĮąŠ, č鹊 IPA ą┤ąŠą╗ąČąĄąĮ čāč湥čüčéčī čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąŠč鹊ą║ąŠą╝, ąĖ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąĄčĆąĄčüčéą░ąĮąŠą▓ąŠą║ čüą┤ąĄą╗ą░ą╗ąŠ ą▒čŗ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ąĮąĄą┤ąŠą┐čāčüčéąĖą╝ąŠ ą┤ąŠą╗ą│ąĖą╝.
ą×čüąŠą▒ąĄąĮąĮąŠ čéčēą░č鹥ą╗čīąĮąŠ ą┐čĆąŠąĄą║čéąĖčĆčāą╣č鹥 ą▓ąĮčāčéčĆąĄąĮąĮąĖą╣ čåąĖą║ą╗. ą×ą┐čéąĖą╝ąĖąĘą░č鹊čĆ č乊ą║čāčüąĖčĆčāąĄčéčüčÅ ąĮą░ ą▓ąĮčāčéčĆąĄąĮąĮąĖčģ čåąĖą║ą╗ą░čģ, ą┐ąŠč鹊ą╝čā čćč鹊 ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą▒ąŠą╗čīčłąĄ ą▓čüąĄą│ąŠ čéčĆą░čéčÅčé ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ąĮą░ ą┐čĆąŠčģąŠąČą┤ąĄąĮąĖąĄ ąĖą╝ąĄąĮąĮąŠ ą▓ąĮčāčéčĆąĄąĮąĮąĖčģ čåąĖą║ą╗ąŠą▓. ąĪčćąĖčéą░ąĄčéčüčÅ čģąŠčĆąŠčłąĖą╝ ą║ąŠą╝ą┐čĆąŠą╝ąĖčüčüąŠą╝ ą┤ą╗čÅ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ ąĘą░ą╝ąĄą┤ą╗ąĖčéčī ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ ą┤ąŠ ąĖ ą┐ąŠčüą╗ąĄ čåąĖą║ą╗ą░, ąĄčüą╗ąĖ čŹč鹊 ą┐ąŠą╝ąŠąČąĄčé ą▓čŗą┐ąŠą╗ąĮąĖčéčī č鹥ą╗ąŠ čåąĖą║ą╗ą░ ą▒čŗčüčéčĆąĄąĄ. ąóą░ą║ čćč鹊 čāą┤ąŠčüč鹊ą▓ąĄčĆčīč鹥čüčī čćč鹊 ąÆą░čł ą░ą╗ą│ąŠčĆąĖčéą╝ ą┐čĆąŠą▓ąŠą┤ąĖčé ą▒ąŠą╗čīčłčāčÄ čćą░čüčéčī čüą▓ąŠąĄą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą▓ąŠ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╝ čåąĖą║ą╗ąĄ. ąśąĮą░č湥 ą▓ąŠąĘą╝ąŠąČąĮąŠ, čćč鹊 čäą░ą║čéąĖč湥čüą║ąĖ ą┐ąŠčüą╗ąĄ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ ąŠąĮ ą▒čāą┤ąĄčé čĆą░ą▒ąŠčéą░čéčī ą╝ąĄą┤ą╗ąĄąĮąĮąĄąĄ.
ą¤ąŠą╗ąĄąĘąĮą░ čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝ą░čÅ č鹥čģąĮąĖą║ą░ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ čåąĖą║ą╗ą░ (loop switching). ąĢčüą╗ąĖ čā ąÆą░čü ąĄčüčéčī ą▓ą╗ąŠąČąĄąĮąĮčŗąĄ čåąĖą║ą╗čŗ, ą│ą┤ąĄ ą▓ąĮąĄčłąĮąĖą╣ čåąĖą║ą╗ čĆą░ą▒ąŠčéą░ąĄčé ą╝ąĮąŠą│ąŠ čĆą░ąĘ, ąĖ ą▓ąĮčāčéčĆąĄąĮąĮąĖą╣ čåąĖą║ą╗ čĆą░ą▒ąŠčéą░ąĄčé ą╝ąĄąĮčīčłąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čĆą░ąĘ, č鹊 ą╝ąŠąČąĮąŠ ą┐ąĄčĆąĄą┐ąĖčüą░čéčī čåąĖą║ą╗čŗ čéą░ą║, čćč鹊ą▒čŗ ą▓ąĮąĄčłąĮąĖą╣ čåąĖą║ą╗ ą┤ąĄą╗ą░ą╗ ą╝ąĄąĮčīčłąĄ ąĖč鹥čĆą░čåąĖą╣.
ąśąĘą▒ąĄą│ą░ą╣č鹥 čāčüą╗ąŠą▓ąĮčŗčģ ą▓ąĄčéą▓ą╗ąĄąĮąĖą╣ ą▓ąĮčāčéčĆąĖ čåąĖą║ą╗ąŠą▓. ąĢčüą╗ąĖ čåąĖą║ą╗ čüąŠą┤ąĄčƹȹĖčé ą║ąŠą┤ čü ą┐čĆąŠą▓ąĄčĆą║ą░ą╝ąĖ čāčüą╗ąŠą▓ąĖą╣, č鹊 ą╝ąŠą│čāčé ą▒čŗčéčī čüą╗ąĖčłą║ąŠą╝ ą▒ąŠą╗čīčłąĖąĄ ą┐ąŠč鹥čĆąĖ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ, ąĄčüą╗ąĖ čĆąĄčłąĄąĮąĖąĄ ą▒čāą┤ąĄčé čćą░čüč鹊 ą┤ą░ą▓ą░čéčī ą┐ąĄčĆąĄčģąŠą┤čŗ, ąĮąĄ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖąĄ ą┐čĆąŠą│ąĮąŠąĘčā ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░. ąÆ ąĮąĄą║ąŠč鹊čĆčŗčģ čüą╗čāčćą░čÅčģ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ čüą╝ąŠąČąĄčé ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░čéčī ą║ąŠąĮčüčéčĆčāą║čåąĖąĖ if-else ąĖ ?: ą▓ čāčüą╗ąŠą▓ąĮčŗąĄ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ. ąÆ ą┤čĆčāą│ąĖčģ čüą╗čāčćą░čÅčģ ąŠąĮ čüą╝ąŠąČąĄčé ą┐ąŠą╗ąĮąŠčüčéčīčÄ ą▓čŗčéą░čēąĖčéčī ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ ą▓čŗčĆą░ąČąĄąĮąĖčÅ ąĖąĘ č鹥ą╗ą░ čåąĖą║ą╗ą░. ą×ą┤ąĮą░ą║ąŠ ą┤ą╗čÅ ą║čĆąĖčéąĖčćąĮčŗčģ čåąĖą║ą╗ąŠą▓ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ąĮą░ą┐ąĖčüą░ąĮ ą╗ąĖąĮąĄą╣ąĮčŗą╣ ą║ąŠą┤, ą▒ąĄąĘ ą▓ąĄčéą▓ą╗ąĄąĮąĖą╣.
ąöąĄą╗ą░ą╣č鹥 čåąĖą║ą╗čŗ ą║ąŠčĆąŠč湥. ą¦č鹊ą▒čŗ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ čĆą░ą▒ąŠčéą░ą╗ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ čŹčäč乥ą║čéąĖą▓ąĮąŠ, čåąĖą║ą╗čŗ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą║ą░ą║ ą╝ąŠąČąĮąŠ ą╝ąĄąĮčīčłąĄ. ąæąŠą╗čīčłąĖąĄ ą┐ąŠ čĆą░ąĘą╝ąĄčĆčā č鹥ą╗ą░ čåąĖą║ą╗ą░ ąŠą▒čŗčćąĮąŠ ąĮą░ą╝ąĮąŠą│ąŠ čüą╗ąŠąČąĮąĄąĄ ą┤ą╗čÅ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ. ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ ą╝ąŠąČąĄčé ą┐ąŠčéčĆąĄą▒ąŠą▓ą░čéčīčüčÅ čüąŠčģčĆą░ąĮčÅčéčī ą┤ą░ąĮąĮčŗąĄ ąĖąĘ čĆąĄą│ąĖčüčéčĆąŠą▓ ą▓ ą┐ą░ą╝čÅčéčī. ąŁč鹊 ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ čüąĮąĖąČąĄąĮąĖčÄ ą┐ą╗ąŠčéąĮąŠčüčéąĖ ą║ąŠą┤ą░ ąĖ čüą║ąŠčĆąŠčüčéąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ.
ąØąĄ ą▓čüčéą░ą▓ą╗čÅą╣č鹥 ą▓čŗąĘąŠą▓čŗ čäčāąĮą║čåąĖą╣ ą▓ č鹥ą╗ąŠ čåąĖą║ą╗ąŠą▓. ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąĮąĄ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ą░ą┐ą┐ą░čĆą░čéąĮčŗčģ čåąĖą║ą╗ąŠą▓, ąĄčüą╗ąĖ ą▓ čåąĖą║ą╗ąĄ čüąŠą┤ąĄčƹȹĖčéčüčÅ ą▓čŗąĘąŠą▓ čäčāąĮą║čåąĖąĖ, ą┐ąŠč鹊ą╝čā čćč鹊 čüą╗ąĖčłą║ąŠą╝ ąĘą░čéčĆą░čéąĮąŠ čüąŠčģčĆą░ąĮčÅčéčī ąĖ ą▓ąŠčüčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čéčī ą║ąŠąĮč鹥ą║čüčé ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ čåąĖą║ą╗ą░ ą┐čĆąĖ ą▓čŗąĘąŠą▓ąĄ čäčāąĮą║čåąĖąĖ. ąÆ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ ąŠč湥ą▓ąĖą┤ąĮčŗą╝ ą▓čŗąĘąŠą▓ą░ą╝ čäčāąĮą║čåąĖą╣, čéą░ą║ąĖčģ ą║ą░ą║ printf(), ą│ąĄąĮąĄčĆą░čåąĖčÅ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ čåąĖą║ą╗ą░ ą▒čāą┤ąĄčé ąĘą░ą┐čĆąĄčēąĄąĮą░ čüą╗ąĄą┤čāčÄčēąĖą╝ąĖ ąŠą┐ąĄčĆą░čåąĖčÅą╝ąĖ: modulus ąĖ čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮąŠąĄ ą┤ąĄą╗ąĄąĮąĖąĄ, ą░čĆąĖčäą╝ąĄčéąĖą║ą░ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣, ąĖ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ ą╝ąĄąČą┤čā čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮčŗą╝ąĖ ą┤ą░ąĮąĮčŗą╝ąĖ ąĖ ą┤ą░ąĮąĮčŗą╝ąĖ čü ą┐ą╗ą░ą▓ą░čÄčēąĄą╣ č鹊čćą║ąŠą╣. ąŁčéąĖ ąŠą┐ąĄčĆą░čåąĖąĖ ą╝ąŠą│čāčé ąĮąĄčÅą▓ąĮąŠ ą┐ąŠčéčĆąĄą▒ąŠą▓ą░čéčī ą▓čŗąĘąŠą▓ąŠą▓ ą▒ąĖą▒ą╗ąĖąŠč鹥čćąĮčŗčģ čäčāąĮą║čåąĖą╣.
ąśčüą┐ąŠą╗čīąĘčāą╣č鹥 int ą┤ą╗čÅ čāą┐čĆą░ą▓ą╗čÅčÄčēąĖčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ čåąĖą║ą╗ą░ ąĖ ą┤ą╗čÅ ąĖąĮą┤ąĄą║čüąŠą▓ ą╝ą░čüčüąĖą▓ą░. ąÆčüąĄą│ą┤ą░ ą╗čāčćčłąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ čŹčéąĖčģ čüą╗čāčćą░ąĄą▓ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ čåąĄą╗ąŠą│ąŠ čéąĖą┐ą░ int, č湥ą╝ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ čéąĖą┐ą░ short. ąĪčéą░ąĮą┤ą░čĆčé C čāčéą▓ąĄčƹȹ┤ą░ąĄčé, čćč鹊 short ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čĆą░čüčłąĖčĆąĄąĮ ą┤ąŠ čĆą░ąĘą╝ąĄčĆą░ int ą┐ąĄčĆąĄą┤ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ, ąĖ ąĘą░č鹥ą╝ ąŠą▒čĆą░čéąĮąŠ ąŠą▒čĆąĄąĘą░ąĮ ą┤ąŠ čĆą░ąĘą╝ąĄčĆą░ short.
ą¦ą░čüč鹊 ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą▓ čüąŠčüč鹊čÅąĮąĖąĖ čĆą░ą▒ąŠčéą░čéčī čüąŠ čüč湥čéčćąĖą║ą░ą╝ąĖ čåąĖą║ą╗ą░ short, ąĖ ą▓čüąĄ ąĄčēąĄ ąŠą┐čĆąĄą┤ąĄą╗čÅčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą░ą┐ą┐ą░čĆą░čéąĮčŗąĄ čåąĖą║ą╗čŗ (zero-overhead loops) ąĖ ąĖąĮą┤čāą║čåąĖąŠąĮąĮčŗąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ (induction variables). ą×ą┤ąĮą░ą║ąŠ čŹč鹊 čāčüą╗ąŠąČąĮčÅąĄčé ąČąĖąĘąĮčī ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆčā, ąĖ ąĖąĮąŠą│ą┤ą░ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą╝ąĄąĮąĄąĄ ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░ąĮąĮąŠą╝čā ą║ąŠą┤čā.
ą¤čĆą░ą│ą╝čŗ ą┤ą╗čÅ čåąĖą║ą╗ą░: ą║ą░ą║ ąĖąĘą▒ąĄąČą░čéčī ą▓ąĄą║č鹊čĆąĖąĘą░čåąĖąĖ. ą¤čĆąĖą╝ąĄčĆ:
void copy (short *a, short *b)
{
int i;
for (i=0; i < 100; i++)
a[i] = b[i];
}
ąøąĖčüčéąĖąĮą│ 14: ąĮąĄ ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠ (ą▒ąĄąĘ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ pragma).
ąĢčüą╗ąĖ ą╝čŗ ą┤ą▓ą░ąČą┤čŗ ą▓čŗąĘąŠą▓ąĄą╝ čäčāąĮą║čåąĖčÄ copy ąĖąĘ ą╗ąĖčüčéąĖąĮą│ą░ 14, čüą║ą░ąČąĄą╝ čüąĮą░čćą░ą╗ą░ copy(x, y) ąĖ ąĘą░č鹥ą╝ copy(y, z), č鹊 IPA ąĮąĄ čüą╝ąŠąČąĄčé čüą║ą░ąĘą░čéčī, čćč鹊 a ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą▒čāą┤ąĄčé ą░ą╗ąĖą░čüąŠą╝ b, ą║ą░ą║ čŹč鹊 ąŠą┐ąĖčüą░ąĮąŠ ą▓čŗčłąĄ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čåąĖą║ą╗ čüąŠą┤ąĄčƹȹĖčé ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéčī, ąĖ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓ąĄą║č鹊čĆąĖąĘąĖčĆąŠą▓ą░ąĮ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ čüąŠą▓ąĄčéčāčÄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┐čĆą░ą│ą╝čā vector_for. ą×ąĮą░ čüą║ą░ąČąĄčé ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆčā, čćč鹊 ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ ą▓ ąŠą┤ąĮąŠą╣ ąĖč鹥čĆą░čåąĖąĖ čåąĖą║ą╗ą░ ąĮąĄ ąĘą░ą▓ąĖčüąĖčé ąŠčé ą┤ą░ąĮąĮčŗčģ, ą▓čŗčćąĖčüą╗ąĄąĮąĮčŗčģ ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ ąĖč鹥čĆą░čåąĖąĖ.
ąÆ čüą╗ąĄą┤čāčÄčēąĄą╝ ą║ąŠą┤ąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┐čĆą░ą│ą╝ą░ vector_for, čćč鹊ą▒čŗ ą┐ąŠąĘą▓ąŠą╗ąĖčéčī čåąĖą║ą╗čā ą▓čŗą┐ąŠą╗ąĮčÅčéčī ą┤ą▓ąĄ ąĖč鹥čĆą░čåąĖąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ.
void copy (short *a, short *b)
{
int i;
#pragma vector_for
for (i=0; i < 100; i++)
a[i] = b[i];
}
ąøąĖčüčéąĖąĮą│ 15: ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠ (ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ pragma).
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čŹčéą░ ą┐čĆą░ą│ą╝ą░ ąĮąĄ ą┐čĆąĖąĮčāąČą┤ą░ąĄčé ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą┤ąĄą╗ą░čéčī ą▓ąĄą║č鹊čĆąĖąĘą░čåąĖčÄ čåąĖą║ą╗ą░; ąŠą┐čéąĖą╝ąĖąĘą░č鹊čĆ ą┐čĆąŠą▓ąĄčĆąĖčé čĆą░ąĘą╗ąĖčćąĮčŗąĄ čüą▓ąŠą╣čüčéą▓ą░ čåąĖą║ą╗ą░ ąĖ ąĮąĄ ą▒čāą┤ąĄčé ą┤ąĄą╗ą░čéčī ąĄą│ąŠ čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖą▓ą░ąĮąĖąĄ, ąĄčüą╗ąĖ ą┐ąŠčüčćąĖčéą░ąĄčé ąĄą│ąŠ ąĮąĄą▒ąĄąĘąŠą┐ą░čüąĮčŗą╝, ąĖą╗ąĖ ąĄčüą╗ąĖ ąĄčüą╗ąĖ ąĮąĄ čüą╝ąŠąČąĄčé ą▓čŗą▓ąĄčüčéąĖ čĆą░ąĘą╗ąĖčćąĮčŗąĄ ą┐ą░čĆą░ą╝ąĄčéčĆčŗ, ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗąĄ ą┤ą╗čÅ ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖčÅ ą▓ąĄą║č鹊čĆąĖąĘą░čåąĖąĖ. ą¤čĆą░ą│ą╝ą░ ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆčā, čćč鹊 čéčāčé ąĮąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ą▓ čåąĖą║ą╗ąĄ, ąŠą┤ąĮą░ą║ąŠ ą┤čĆčāą│ąĖąĄ čüą▓ąŠą╣čüčéą▓ą░ čåąĖą║ą╗ą░ ą▓čüąĄ ąČąĄ ą╝ąŠą│čāčé ąĮąĄ ą┤ą░čéčī ą┐čĆąĖą╝ąĄąĮąĖčéčī ą▓ąĄą║č鹊čĆąĖąĘą░čåąĖčÄ.
ąÆ čüą╗čāčćą░čÅčģ, ą║ąŠą│ą┤ą░ ą▓ąĄą║č鹊čĆąĖąĘą░čåąĖčÅ ąĮąĄą▓ąŠąĘą╝ąŠąČąĮą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą╝ą░čüčüąĖą▓ a ą▓čŗčĆąŠą▓ąĮąĄąĮ ąĮą░ čĆą░ąĘą╝ąĄčĆ čüą╗ąŠą▓ą░, ąĮąŠ ą╝ą░čüčüąĖą▓ b ąĮąĄ ą▓čŗčĆąŠą▓ąĮąĄąĮ), č鹊 ąĖąĮč乊čĆą╝ą░čåąĖčÅ, ą║ąŠč鹊čĆčāčÄ ą┤ą░ąĄčé čāčüčéą░ąĮąŠą▓ą║ą░ vector_for, ą▓čüąĄ ąĄčēąĄ ą╝ąŠąČąĄčé čģąŠčĆąŠčłąŠ ą┐ąŠą╝ąŠčćčī ą┤ą╗čÅ ą┤čĆčāą│ąĖčģ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖą╣.
[ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ]
ąÜąŠąĮčüčéą░ąĮčéčŗ. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą┐čĆąĄą┤ą┐ąŠą╗ą░ą│ą░ąĄčé, čćč鹊 ąĮąĄ ą▒čāą┤čāčé ąĖąĘą╝ąĄąĮčÅčéčīčüčÅ č鹥 ą┤ą░ąĮąĮčŗąĄ, ąĮą░ ą║ąŠč鹊čĆčŗąĄ čüčüčŗą╗ą░ąĄčéčüčÅ čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ą┤ą░ąĮąĮčŗąĄ const. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ąĄčüčéčī ą┤čĆčāą│ąŠą╣ čüą┐ąŠčüąŠą▒, ą║ąŠč鹊čĆčŗąĄ čüą║ą░ąČąĄčé ąŠ ą┤ą▓čāčģ ą╝ą░čüčüąĖą▓ą░čģ, čćč鹊 ąŠąĮąĖ ąĮąĄ ą┐ąĄčĆąĄą║čĆčŗą▓ą░čÄčéčüčÅ - ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą║ą╗čÄč湥ą▓ąŠąĄ čüą╗ąŠą▓ąŠ const.
ą¤čĆąĖą╝ąĄčĆ ą▓ ą╗ąĖčüčéąĖąĮą│ąĄ 16 ą▒čāą┤ąĄčé ąĖą╝ąĄčéčī čŹčäč乥ą║čé, ą┐ąŠą┤ąŠą▒ąĮčŗą╣ ą┐čĆą░ą│ą╝ąĄ vector_for. ążą░ą║čéąĖč湥čüą║ąĖ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ čü const ą╗čāčćčłąĄ, ą┐ąŠčüą║ąŠą╗čīą║čā ąŠąĮą░ čéą░ą║ąČąĄ ą┐ąŠąĘą▓ąŠą╗ąĖčé ąŠą┐čéąĖą╝ąĖąĘą░č鹊čĆčā, ą┐ąŠčüą╗ąĄ ą▓ąĄą║č鹊čĆąĖąĘą░čåąĖąĖ, ą┐ąŠą▓ąĄčĆąĮčāčéčī čåąĖą║ą╗, čćč鹊 čéčĆąĄą▒čāąĄčé ąĮąĄ č鹊ą╗čīą║ąŠ ąĘąĮą░ąĮąĖą╣ ąŠ č鹊ą╝, čćč鹊 ąĮąĄčé ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠą┤ąĮąŠą╣ ą┐čĆąŠą║čĆčāčéą║ąĖ čåąĖą║ą╗ą░ ąŠčé ą┤čĆčāą│ąŠą╣, ąĮąŠ ąĖ čéą░ą║ąČąĄ ąŠ č鹊ą╝, čćč鹊 ąĖč鹥čĆą░čåąĖąĖ ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ą▓ ą▒čāą┤čāčēąĄą╝ ąŠą▒ąŠčüąŠą▒ą╗ąĄąĮąĮąŠ.
void copy (short *a, const short *b)
{
int i;
for (i=0; i < 100; i++)
a[i] = b[i];
}
ąøąĖčüčéąĖąĮą│ 16: ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą║ą╗čÄč湥ą▓ąŠą│ąŠ čüą╗ąŠą▓ą░ const.
ąØą░ čÅąĘčŗą║ąĄ C ą┤ąŠą┐čāčüčéąĖą╝ąŠ (čģąŠčéčÅ ąĖ čüčćąĖčéą░ąĄčéčüčÅ ą┐ą╗ąŠčģąŠą╣ ą┐čĆą░ą║čéąĖą║ąŠą╣ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĖ) ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┐čĆąĖą▓ąĄą┤ąĄąĮąĖčÅ čéąĖą┐ąŠą▓ (cast), čćč鹊ą▒čŗ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą╝ąĄąĮčÅčéčī ą┤ą░ąĮąĮčŗąĄ, ąĮą░ ą║ąŠč鹊čĆčŗąĄ čāą║ą░ąĘčŗą▓ą░ąĄčé čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ą┤ą░ąĮąĮčŗąĄ const. ąŁč鹊ą│ąŠ ąĮčāąČąĮąŠ ąĖąĘą▒ąĄą│ą░čéčī, ą┐ąŠč鹊ą╝čā čćč鹊, ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ, ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą▒čāą┤ąĄčé ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčé, čćč鹊 ą┤ą░ąĮąĮčŗąĄ const ąĮąĄ ą╝ąĄąĮčÅčÄčéčüčÅ. ą×ą┤ąĮą░ą║ąŠ, ąĄčüą╗ąĖ čā ąÆą░čü ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāąĄčé ą┤ą░ąĮąĮčŗąĄ const, ąĖčüą┐ąŠą╗čīąĘčāčÅ čāą║ą░ąĘą░č鹥ą╗čī, ąÆčŗ ą╝ąŠąČąĄč鹥 ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ą║ąŠčĆčĆąĄą║čéąĮčŗą╣ ą║ąŠą┤, ąĖčüą┐ąŠą╗čīąĘčāčÅ čäą╗ą░ą│ ą▓čĆąĄą╝ąĄąĮąĖ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ -const-read-write.
ąöčĆąŠą▒ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ (Fractional Data). ąöčĆąŠą▒čÅą╝ąĖ, ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĮčŗą╝ąĖ ą║ą░ą║ 16-ą▒ąĖčéąĮčŗąĄ ąĖą╗ąĖ 32-ą▒ąĖčéąĮčŗąĄ čåąĄą╗čŗąĄ čćąĖčüą╗ą░, ą╝ąŠąČąĮąŠ ą╝ą░ąĮąĖą┐čāą╗ąĖčĆąŠą▓ą░čéčī ą┤ą▓čāą╝čÅ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ. ąĀąĄą║ąŠą╝ąĄąĮą┤čāąĄą╝čŗą╣ čüą┐ąŠčüąŠą▒, ą║ąŠč鹊čĆčŗą╣ ą┤ą░ąĄčé ąÆą░ą╝ ą▒ąŠą╗čīčłąĄ ą║ąŠąĮčéčĆąŠą╗čÅ ąĮą░ą┤ ą┤ą░ąĮąĮčŗą╝ąĖ - ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝čŗąĄ ą▓čüčéčĆąŠąĄąĮąĮčŗąĄ ąŠą▒čŖąĄą║čéčŗ (intrinsics). ąöą░ą▓ą░ą╣č鹥 čĆą░čüčüą╝ąŠčéčĆąĖą╝ ą┤čĆąŠą▒ąĮąŠąĄ čüą║ą░ą╗čÅčĆąĮąŠąĄ ą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖąĄ. ąĢą│ąŠ ą║ąŠą┤ ą╝ąŠąČąĮąŠ ąĘą░ą┐ąĖčüą░čéčī čéą░ą║:
int sp (short *a, short *b)
{
int i;
int sum=0;
for (i=0; i < 100; i++)
{
sum += ((a[i]*b[i]) >> 15);
}
return sum;
}
ąøąĖčüčéąĖąĮą│ 17: ąĮąĄ ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠ (ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ čüą┤ą▓ąĖą│ąĖ).
ą×ą┤ąĮą░ą║ąŠ čŹč鹊čé ą║ąŠą┤ ą┤ąŠčüčéą░ą▓ąĖčé ąĮąĄą║ąŠč鹊čĆčŗąĄ ą┐čĆąŠą▒ą╗ąĄą╝čŗ ąŠą┐čéąĖą╝ąĖąĘą░č鹊čĆčā. ą×ą▒čŗčćąĮąŠ čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ąĘą┤ąĄčüčī ą║ąŠą┤ ą▒čŗą╗ ą▒čŗ čāą╝ąĮąŠąČąĄąĮąĖąĄą╝, ąĘą░ ą║ąŠč鹊čĆčŗą╝ ąĖą┤ąĄčé čüą┤ą▓ąĖą│, čüąŠą┐čĆąŠą▓ąŠąČą┤ą░ąĄą╝čŗą╣ ąĮą░ą║ąŠą┐ą╗ąĄąĮąĖąĄą╝. ą×ą┤ąĮą░ą║ąŠ čā ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin ąĄčüčéčī ąĖąĮčüčéčĆčāą║čåąĖčÅ MAC (multiply accumulate), ą║ąŠč鹊čĆą░čÅ ą┤ąĄą╗ą░ąĄčé ą▓ ąŠą┤ąĮąŠą╝ čåąĖą║ą╗ąĄ čāą╝ąĮąŠąČąĄąĮąĖąĄ ą┤čĆąŠą▒ąĮąŠą│ąŠ čćąĖčüą╗ą░ čü ąĮą░ą║ąŠą┐ą╗ąĄąĮąĖąĄą╝. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ą┐čĆąŠčåąĄčüčüąŠčĆ ą╝ąŠąČąĄčé ą▓čŗą┐ąŠą╗ąĮąĖčéčī 2 čéą░ą║ąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ.
ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆ čĆą░čüą┐ąŠąĘąĮą░ąĄčé čŹčéčā ąĖą┤ąĖąŠą╝čā ąĖ ą┐ąŠą┤čéą▓ąĄčĆą┤ąĖčé, čćč鹊 ą▓ ą╝ąĖčĆąĄ DSP-ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐čĆąĄą┤ą┐ąŠčćč鹥ąĮąĖąĄ ąŠčéą┤ą░ąĄčéčüčÅ ą░čĆąĖčäą╝ąĄčéąĖą║ąĄ čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝ (saturating arithmetic). ąŻą╝ąĮąŠąČąĄąĮąĖąĄ / čüą┤ą▓ąĖą│ ąĘą░ą╝ąĄąĮčÅąĄčéčüčÅ čāą╝ąĮąŠąČąĄąĮąĖąĄą╝ ą┤čĆąŠą▒ąĮąŠą│ąŠ čćąĖčüą╗ą░ čü ąĮą░čüčŗčēąĄąĮąĖąĄą╝. ąŁč鹊 ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĖąĄ ą╝ąŠąČąĮąŠ ąĘą░ą┐čĆąĄčéąĖčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą║ą╗čÄčćą░ ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąĖ -no_int_to_fract ą▓ č鹊ą╝ čüą╗čāčćą░ąĄ, ąĄčüą╗ąĖ ąĮą░čüčŗčēąĄąĮąĖąĄ ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ.
ą×ą┤ąĮą░ą║ąŠ čŹč鹊 ą▒čŗą╗ ą┐čĆąŠčüč鹊ą╣ čüą╗čāčćą░ą╣. ąÆ ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮčŗčģ čüąĖčéčāą░čåąĖčÅčģ, ą│ą┤ąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠ čćč鹊 ą▓ ą▒čāą┤čāčēąĄą╝ čāą╝ąĮąŠąČąĄąĮąĖąĄ ąŠčéą┤ąĄą╗ąĄąĮąŠ ąŠčé čüą┤ą▓ąĖą│ą░, ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą╝ąŠąČąĄčé ąĮąĄ ąŠą▒ąĮą░čĆčāąČąĖčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤čĆąŠą▒ąĮąŠąĄ čāą╝ąĮąŠąČąĄąĮąĖąĄ. ąóą░ą║ čćč鹊 čĆąĄą║ąŠą╝ąĄąĮą┤čāąĄą╝čŗą╣ čüčéąĖą╗čī ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ - ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī intrinsics. ąÆ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ add_fr1x32() ąĖ mult_fr1x32 ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ ą┤ą╗čÅ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ ąĖ ą┤ą╗čÅ čāą╝ąĮąŠąČąĄąĮąĖčÅ ą┤čĆąŠą▒ąĮčŗčģ 32-ą▒ąĖčéąĮčŗčģ ą┤ą░ąĮąĮčŗčģ.
#include < fract.h >
fract32 sp (fract16 *a, fract16 *b)
{
int i;
fract32 sum=0;
for (i=0; i < 100; i++)
{
sum = add_fr1x32(sum,
mult_fr1x32(a[i],b[i]));
}
return sum;
}
ąøąĖčüčéąĖąĮą│ 18: ąŠą┐čéąĖą╝ą░ą╗čīąĮąŠ (ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą▓čüčéčĆąŠąĄąĮąĮčŗąĄ čäčāąĮą║čåąĖąĖ, intrinsics).
ą¤ąŠą╗ąĮčŗą╣ čüą┐ąĖčüąŠą║ ą┤čĆąŠą▒ąĮčŗčģ ąŠą┐ąĄčĆą░čåąĖą╣ ą╝ąŠąČąĮąŠ ąĮą░ą╣čéąĖ ą▓ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąĄ ą┐ąŠ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆčā ą┐čĆąŠčåąĄčüčüąŠčĆą░ (Blackfin processor C/C++ Compiler manual), čüąŠą▓ą╝ąĄčüčéąĮąŠ čü ąŠą┐ąĖčüą░ąĮąĖąĄą╝ ą┤čĆčāą│ąĖčģ ą┤ąŠčüčéčāą┐ąĮčŗčģ intrinsic. ążčāąĮą║čåąĖąĖ intrinsic ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ąŠą┐ąĄčĆą░čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ą│ą╗ą░ą▓ąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝ čĆą░ą▒ąŠčéą░čÄčé čü 16- ąĖą╗ąĖ 32-ą▒ąĖčéąĮčŗą╝ąĖ ą▓ąĄą╗ąĖčćąĖąĮą░ą╝ąĖ; ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą▒čāą┤ąĄčé čĆą░čüą┐ąŠąĘąĮą░ą▓ą░čéčī čüąĖčéčāą░čåąĖąĖ, ą║ąŠą│ą┤ą░ čåąĖą║ą╗ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓ąĄą║č鹊čĆąĖąĘąŠą▓ą░ąĮ ąĖ ą▒čāą┤ąĄčé ą▓ čéą░ą║ąĖčģ ąŠą▒čüč鹊čÅč鹥ą╗čīčüčéą▓ą░čģ ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ą┤ą▓ąŠą╣ąĮčŗąĄ 16-ą▒ąĖčéąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ (ą┐ą░čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ, čĆą░čüą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖą▓ą░ąĮąĖąĄ). ąóąŠčćąĮąŠ čéą░ą║ ąČąĄ, ą║ą░ą║ ą╗čāčćčłąĄ ąŠčüčéą░ą▓ąĖčéčī ą┐ąŠą▓ąŠčĆąŠčé čåąĖą║ą╗ą░ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆčā, intrinsic-čäčāąĮą║čåąĖąĖ čéą░ą║ąČąĄ ąŠčüčéą░ą▓ą╗čÅčÄčé ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆčā ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ą┐ą░čĆąĮčŗąĄ ąŠą┐ąĄčĆą░čåąĖąĖ.
ą¤ąŠą╝ąĄčēą░ą╣č鹥 ą╝ą░čüčüąĖą▓čŗ ą▓ čĆą░ąĘąĮčŗąĄ čüąĄą║čåąĖąĖ ą┐ą░ą╝čÅčéąĖ. ąĢčüčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą┐ąŠą╝ąĄčüčéąĖčéčī ą╝ą░čüčüąĖą▓čŗ ą▓ čĆą░ąĘąĮčŗąĄ čüąĄą║čåąĖąĖ ą┐ą░ą╝čÅčéąĖ. ą¤čĆąŠčåąĄčüčüąŠčĆ Blackfin ą╝ąŠąČąĄčé ą┐ąŠą┤ą┤ąĄčƹȹ░čéčī 2 ąŠą┐ąĄčĆą░čåąĖąĖ ąĮą░ą┤ ą┐ą░ą╝čÅčéčīčÄ ą▓ ąŠą┤ąĮąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ą×ą┤ąĮą░ą║ąŠ čŹč鹊 ą▒čāą┤ąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąŠ ą▓ ąŠą┤ąĮąŠą╝ čåąĖą║ą╗ąĄ ąĄčüą╗ąĖ 2 ą░ą┤čĆąĄčüą░ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčé čĆą░ąĘąĮčŗą╝ ą▒ą╗ąŠą║ą░ą╝ ą┐ą░ą╝čÅčéąĖ; ąĄčüą╗ąĖ ą┤ąŠčüčéčāą┐ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą▓ č鹊čé ąČąĄ čüą░ą╝čŗą╣ ą▒ą╗ąŠą║, č鹊 ą▒čāą┤ąĄčé ą▓čüčéą░ą▓ą╗ąĄąĮą░ ąĘą░ą┤ąĄčƹȹ║ą░. ąÆąŠąĘčīą╝ąĄą╝ ą▓ ą║ą░č湥čüčéą▓ąĄ ą┐čĆąĖą╝ąĄčĆą░ čüą║ą░ą╗čÅčĆąĮąŠąĄ ą┐čĆąŠąĖąĘą▓ąĄą┤ąĄąĮąĖąĄ (ą║ą░ą║ ą▒čŗą╗ąŠ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ čüąĄą║čåąĖąĖ).
ą¤ąŠčüą║ąŠą╗čīą║čā ą┤ą░ąĮąĮčŗąĄ ąĘą░ą│čĆčāąČą░čÄčéčüčÅ ąĖąĘ ą╝ą░čüčüąĖą▓ąŠą▓ a ąĖ b ą┐ąŠ ą║ą░ąČą┤ąŠą╝čā čåąĖą║ą╗čā, ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠą╗ąĄąĘąĮąŠ čāą▒ąĄą┤ąĖčéčīčüčÅ, čćč鹊 čŹčéąĖ ą╝ą░čüčüąĖą▓čŗ ą┐čĆąĖąĮą░ą┤ą╗ąĄąČą░čé čĆą░ąĘąĮčŗą╝ čäąĖąĘąĖč湥čüą║ąĖą╝ ą▒ą╗ąŠą║ą░ą╝ ą┐ą░ą╝čÅčéąĖ. ąØą░ą┐čĆąĖą╝ąĄčĆ, čĆą░čüčüą╝ąŠčéčĆąĖą╝ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ 2 ą▒ą░ąĮą║ąŠą▓ ą▓ čĆą░ąĘą┤ąĄą╗ąĄ MEMORY ąĮą░čüčéčĆąŠąĄą║ .LDF-čäą░ą╣ą╗ą░.
MEMORY {
BANK_A1 {
TYPE(RAM) WIDTH(8)
START(0xFF900000) END(0xFF900FFF)
}
BANK_A2 {
TYPE(RAM) WIDTH(8)
START(0xFF901000) END(0xFF901FFF)
}
}
ąøąĖčüčéąĖąĮą│ 19: ą║ą░čĆčéą░ ąŠą┐ąĄčĆą░čéąĖą▓ąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ ąĖąĘ čäą░ą╣ą╗ą░ LDF.
ąŚą░č鹥ą╝ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆčāą╣č鹥 čĆą░ąĘą┤ąĄą╗ SECTIONS, čćč鹊ą▒čŗ čāą║ą░ąĘą░čéčī ą╗ąĖąĮą║ąĄčĆčā čĆą░ąĘą╝ąĄčüčéąĖčéčī čüąĄą║čåąĖąĖ ą┤ą░ąĮąĮčŗčģ ą┐ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╝ ą▒ą░ąĮą║ą░ą╝ ą┐ą░ą╝čÅčéąĖ, ą║ą░ą║ čŹč鹊 ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮąĖąČąĄ.
SECTIONS {
bank_a1 {
INPUT_SECTION_ALIGN(2)
INPUT_SECTIONS( $OBJECTS(bank_a1))
} >BANK_A1
bank_a2 {
INPUT_SECTION_ALIGN(2)
INPUT_SECTIONS( $OBJECTS(bank_a2))
} >BANK_A2
}
ąøąĖčüčéąĖąĮą│ 20: ąĮą░ąĘąĮą░č湥ąĮąĖąĄ čüąĄą║čåąĖąĖ ą▓ čäą░ą╣ą╗ąĄ LDF.
ąÆ ąĖčüčģąŠą┤ąĮąŠą╝ ą║ąŠą┤ąĄ ąĮą░ čÅąĘčŗą║ąĄ C/C++ čüąĄą║čåąĖąĖ ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčéčüčÅ ą║ąŠąĮčüčéčĆčāą║čåąĖąĄą╣ section("section_name"), ą║ąŠč鹊čĆą░čÅ ą┐čĆąĄą┤čłąĄčüčéą▓čāąĄčé ą┤ąĄą║ą╗ą░čĆą░čåąĖąĖ ą▒čāč乥čĆą░.
section("bank_a1") short a[100];
section("bank_a2") short b[100];
ąøąĖčüčéąĖąĮą│ 21: ąØą░ąĘąĮą░č湥ąĮąĖąĄ čüąĄą║čåąĖą╣ ą▓ ąĖčüčģąŠą┤ąĮąŠą╝ ą║ąŠą┤ąĄ C.
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čÅą▓ąĮąŠąĄ čĆą░ąĘą╝ąĄčēąĄąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ ą▓ čüąĄą║čåąĖčÅčģ ą╝ąŠąČąĮąŠ ąŠčüčāčēąĄčüčéą▓ąĖčéčī č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą│ą╗ąŠą▒ą░ą╗čīąĮčŗčģ ą┤ą░ąĮąĮčŗčģ. ąŚą░ ą┐ąŠą┤čĆąŠą▒ąĮąŠčüčéčÅą╝ąĖ ą┐ąŠąČą░ą╗čāą╣čüčéą░ ąŠą▒čĆą░čéąĖč鹥čüčī ą║ čĆčāą║ąŠą▓ąŠą┤čüčéą▓čā ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ą╗ąĖąĮą║ąĄčĆą░ ąĖ čāčéąĖą╗ąĖčé VisualDSP (VisualDSP++ 5.0 C/C++ Compiler and Library Manual for Blackfin┬« Processors).
[ą¤čĆąĖą╗ąŠąČąĄąĮąĖąĄ A: ą║ą░ą║ čĆą░ą▒ąŠčéą░ąĄčé ąŠą┐čéąĖą╝ąĖąĘą░č鹊čĆ]
ą£čŗ ą▒čāą┤ąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čüą╗ąĄą┤čāčÄčēąĖą╣ čåąĖą║ą╗ čüą║ą░ą╗čÅčĆąĮąŠą│ąŠ čāą╝ąĮąŠąČąĄąĮąĖčÅ ą┤čĆąŠą▒ąĮčŗčģ čćąĖčüąĄą╗, čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī čĆą░ą▒ąŠčéčā ąŠą┐čéąĖą╝ąĖąĘą░č鹊čĆą░.
#include < fract.h >
fract32 sp(fract16 *a, fract16 *b) {
int i;
fract32 sum=0;
for (i=0; i < 100; i++) {
sum = add_fr1x32(sum,
mult_fr1x32(a[i],b[i]));
}
return sum;
}
ąøąĖčüčéąĖąĮą│ 22: ąĪą║ą░ą╗čÅčĆąĮąŠąĄ čāą╝ąĮąŠąČąĄąĮąĖąĄ ą┤čĆąŠą▒ąĮčŗčģ čćąĖčüąĄą╗.
ą¤ąŠčüą╗ąĄ ą│ąĄąĮąĄčĆą░čåąĖąĖ ą║ąŠą┤ą░ ąĖ čüčéą░ąĮą┤ą░čĆčéąĮąŠą╣ čüą║ą░ą╗čÅčĆąĮąŠą╣ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ ą┐ąŠą╗čāčćąĖčéčüčÅ ą┐čĆąĖą╝ąĄčĆąĮąŠ čéą░ą║ąŠą╣ ą┤ą▓ąŠąĖčćąĮčŗą╣ ą║ąŠą┤ čåąĖą║ą╗ą░:
P2 = 100;
LSETUP(.P1L3, .P1L4 ŌĆō 2) LC0 = P2;
.P1L3:
R0 = W[P0++] (X);
R2 = W[P1++] (X);
A0 += R0.L * R2.L;
.P1L4:
R0 = A0.w;
ąøąĖčüčéąĖąĮą│ 23: ą║ąŠą┤ ąĮą░ ą▓čŗčģąŠą┤ąĄ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░.
ą¤čĆąŠą▓ąĄčĆą║ą░ ąĮą░ ą▓čŗčģąŠą┤ ąĖąĘ čåąĖą║ą╗ą░ ą▒čŗą╗ą░ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮą░ ą▓ ą║ąŠąĮąĄčå čåąĖą║ą╗ą░, ąĖ čĆą░ą▒ąŠčéą░ čüč湥čéčćąĖą║ą░ čåąĖą║ą╗ą░ ą┐ąĄčĆąĄą┐ąĖčüą░ąĮą░ čéą░ą║, čćč鹊 ąŠąĮ čüčćąĖčéą░ąĄčé ą▓ąĮąĖąĘ ą┤ąŠ ąĮčāą╗čÅ. ąĪčāą╝ą╝ą░ ąĮą░ą║ą░ą┐ą╗ąĖą▓ą░ąĄčéčüčÅ ą▓ ą░ą║ą║čāą╝čāą╗čÅč鹊čĆąĄ A0. ąĀąĄą│ąĖčüčéčĆčŗ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ P0 ąĖ P1 čüąŠą┤ąĄčƹȹ░čé čāą║ą░ąĘą░č鹥ą╗ąĖ, ą║ąŠč鹊čĆčŗąĄ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮčŗ ą┐ą░čĆą░ą╝ąĄčéčĆą░ą╝ąĖ A ąĖ B čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ, ąĖ ąŠąĮąĖ ąĖąĮą║čĆąĄą╝ąĄąĮčéąĖčĆčāčÄčéčüčÅ ąĮą░ ą║ą░ąČą┤ąŠą╣ ąĖč鹥čĆą░čåąĖąĖ čåąĖą║ą╗ą░. ą¦č鹊ą▒čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī 32-ą▒ąĖčéąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ, ąŠą┐čéąĖą╝ąĖąĘą░č鹊čĆ čĆą░ąĘą▓ąĄčĆąĮčāą╗ čåąĖą║ą╗ ą┤ą╗čÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠą│ąŠ ąĘą░ą┐čāčüą║ą░ ą┤ą▓čāčģ ąĖč鹥čĆą░čåąĖą╣. ą¤ąŠą╗ąŠą▓ąĖąĮą║ąĖ čüčāą╝ą╝čŗ č鹥ą┐ąĄčĆčī ą░ą║ą║čāą╝čāą╗ąĖčĆčāčÄčéčüčÅ ą▓ A0 ąĖ A1, ąĖ ąŠąĮąĖ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čüą╗ąŠąČąĄąĮčŗ ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝ ąĮą░ ą▓čŗčģąŠą┤ąĄ ą┐ąŠčüą╗ąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ čåąĖą║ą╗ą░, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ą║ąŠąĮąĄčćąĮčŗą╣ čĆąĄąĘčāą╗čīčéą░čé. ą¦č鹊ą▒čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĘą░ą│čĆčāąĘą║ąĖ čüą╗ąŠą▓ą░, ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąĘąĮą░ąĄčé ąŠ č鹊ą╝, čćč鹊 ąĮą░čćą░ą╗čīąĮčŗąĄ ąĘąĮą░č湥ąĮąĖčÅ ą▓ P0 ąĖ P1 ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗čÅčéčüčÅ ąĮą░ 4 (ą░ą┤čĆąĄčüą░ ą▓čŗčĆąŠą▓ąĮąĄąĮčŗ ąĮą░ čĆą░ąĘą╝ąĄčĆ čüą╗ąŠą▓ą░). ąóą░ą║ąČąĄ ąŠą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąĘąĮą░ąĄčé ąŠ č鹊ą╝, čćč鹊 ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮčŗą╣ čåąĖą║ą╗ ą▓ ąĖčüčģąŠą┤ąĮąŠą╝ ą║ąŠą┤ąĄ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ č湥čéąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čĆą░ąĘ, čéą░ą║ čćč鹊 ą▓čŗą┐ąŠą╗ąĮąĄąĮąĮą░čÅ ą┐ąŠ čāčüą╗ąŠą▓ąĖčÄ ąĮąĄč湥čéąĮą░čÅ ąĖč鹥čĆą░čåąĖčÅ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ą▓čüčéą░ą▓ą╗ąĄąĮą░ ą▓ąĮąĄ č鹥ą╗ą░ čåąĖą║ą╗ą░.
P2 = 50;
A1 = A0 = 0;
LSETUP(.P1L3, .P1L4 ŌĆō 4) LC0 = P2;
.P1L3:
R0 = [P0++];
R2 = [P1++];
A1+=R0.H*R2.H, A0+=R0.L*R2.L;
.P1L4:
R0 = (A0+=A1);
ąøąĖčüčéąĖąĮą│ 24: ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮą░čÅ ąĮąĄč湥čéąĮą░čÅ ąĖč鹥čĆą░čåąĖčÅ.
ąś ąĮą░ą║ąŠąĮąĄčå ąŠą┐čéąĖą╝ąĖąĘą░č鹊čĆ ą┐ąŠą▓ąŠčĆą░čćąĖą▓ą░ąĄčé čåąĖą║ą╗, čĆą░ąĘą▓ąŠčĆą░čćąĖą▓ą░čÅ ąĖ ą┐ąĄčĆąĄą║čĆčŗą▓ą░čÅ ąĖč鹥čĆą░čåąĖąĖ, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮčŗčģ ą▒ą╗ąŠą║ąŠą▓. ąÆ ąĘą░ą║ą╗čÄč湥ąĮąĖąĄ ą▒čāą┤ąĄčé čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮ čüą╗ąĄą┤čāčÄčēąĖą╣ ą║ąŠą┤:
A1=A0=0 || R0 = [P0++] || NOP;
R2 = [I1++];P2 = 49;
LSETUP(.P1L3,.P1L4-8) LC0 = P2;
.P1L3:
A1+=R0.H*R2.H, A0+=R0.L*R2.L || R0 =[P0++] || R2 = [I1++];
.P1L4:
A1+=R0.H*R2.H, A0+=R0.L*R2.L;
R0 = (A0+=A1);
ąøąĖčüčéąĖąĮą│ 25: ąÜąŠą┤ ąĮą░ ą▓čŗčģąŠą┤ąĄ ąŠą┐čéąĖą╝ąĖąĘą░č鹊čĆą░.
[ą¤čĆąĖą╗ąŠąČąĄąĮąĖąĄ B: ą║ą╗čÄčćąĖ ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░]
ąÜą╗čÄčćąĖ ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░, ą║ą░čüą░čÄčēąĖąĄčüčÅ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ, ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮčŗ ą▓ čéą░ą▒ą╗ąĖčåąĄ 3.
ąóą░ą▒ą╗ąĖčåą░ 3: ą×ą┐čåąĖąĖ ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░, ąŠčéąĮąŠčüčÅčēąĖąĄčüčÅ ą║ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ.
| -O |
ą×ą┐čéąĖą╝ąĖąĘą░čåąĖčÅ ą┐ąŠ čüą║ąŠčĆąŠčüčéąĖ |
| -Os |
ą×ą┐čéąĖą╝ąĖąĘą░čåąĖčÅ ą┐ąŠ čĆą░ąĘą╝ąĄčĆčā |
| -Ox |
ąŚąĮą░č湥ąĮąĖčÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ čéąĖą┐ą░ short ąŠčüčéą░čÄčéčüčÅ ą▓ 16-ą▒ąĖčéąĮąŠą╝ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ |
| -Ofp |
ąśąĘą╝ąĄąĮąĖčéčī čüą╝ąĄčēąĄąĮąĖčÅ čāą║ą░ąĘą░č鹥ą╗čÅ čäčĆąĄą╣ą╝ą░ FP čéą░ą║, čćč鹊ą▒čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĖąĮčüčéčĆčāą║čåąĖąĖ ą║ąŠčĆąŠč湥. |
| -ipa |
ąÆčŗą┐ąŠą╗ąĮčÅčéčī ą╝ąĄąČą┐ąŠąŠčåąĄą┤čāčĆąĮčŗą╣ ą░ąĮą░ą╗ąĖąĘ ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēčāčÄ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖčÄ |
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą┐ąŠą╗ąĮčŗą╣ čüą┐ąĖčüąŠą║ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄą╝čŗčģ ąŠą┐čåąĖą╣ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ čüą╝. ą▓ [3], ąĖą╗ąĖ ąŠą▒čĆą░čéąĖč鹥čüčī ą║ čĆčāą║ąŠą▓ąŠą┤čüčéą▓čā ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ą╗ąĖąĮą║ąĄčĆą░ ąĖ čāčéąĖą╗ąĖčé VisualDSP (VisualDSP++ 5.0 C/C++ Compiler and Library Manual for Blackfin┬« Processors).
[ąĪčüčŗą╗ą║ąĖ]
1. EE-149: Tuning C Source Code for the Blackfin® Processor site:analog.com.
2. ą¤ąŠą┤ą┤ąĄčƹȹ║ą░ čéčĆą░ą┤ąĖčåąĖąŠąĮąĮčŗčģ čéąĖą┐ąŠą▓ čü čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą╣ č鹊čćą║ąŠą╣ ą▓ VisualDSP++.
3. ą×ą┐čåąĖąĖ ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ Blackfin. |



