| Руководство по сторожевым таймерам для встраиваемых систем |
|
| Добавил(а) microsin | ||||||||||||||||||||
|
Скорее всего, каждый встречался с ситуацией, когда нужно отключить и снова подключить электронное устройство, чтобы оно снова заработало! Подобные зависания системы не только расстраивают конечного пользователя, но и могут быть довольно сложными для отладки и исправления. Для некоторых классов устройств, таких как спутник на орбите, когда сброс вручную принципиально недоступен, зависание может привести к получению вместо устройства "кирпича" ценой нескольких миллионов долларов. Как разработчики firmware, мы должны уделить особое внимание в нашей системе тому, чтобы зависшая задача (или прибор целиком) всегда могли выйти из нерабочего состояния. Это лучше всего решается с помощью сторожевого таймера (watchdog). В этой статье (перевод [1]) мы обсудим последнюю линию обороны встраиваемых систем - сторожевые таймеры, watchdog. Мы также рассмотрим пошаговые примеры, как реализуется подсистема watchdog, включая как "аппаратный", так и "программный" watchdog, и изучим эффективные стратегии обнаружения причин возникновения основных проблем, приводящих к зависаниям. [Аппаратный Watchdog] Большинство производителей чипов MCU включают в состав его кристалла изолированный RTL-блок, так называемый "Watchdog Timer". Это периферийное устройство MCU состоит из счетчика, который автоматически аппаратно декрементируется с каждым тактовым циклом. Когда счетчик достиг нуля, генерируется аппаратный сброс устройства. По умолчанию эта функция обычно запрещена, и программист отвечает за конфигурирование и разрешение её в программе. Как только функция аппаратного таймера watchdog разрешена, запретить её уже нельзя, и программе необходимо с определенными периодами сбрасывать сторожевой таймер, чтобы предотвратить перезагрузку системы. Смысл этой системы в том, что если ПО не смогло вовремя сбросить счетчик таймера watchdog в исходное состояние, то значит программа работает неправильно (зависла?), система не выполняет должным образом свои функции, и необходимо вернуть её обратно в безопасное состояние. Примечание: следует заметить, что в системах, где которых контроль зависания особенно важен, применяют специальные микросхемы сторожевого таймера [2]. Для этих микросхем сброс watchdog обычно осуществляется путем дергания ножкой GPIO MCU. Почему следует использовать Watchdog? Встраиваемое устройство на MCU может зависнуть по многим причинам. Вот некоторые из самых распространенных случаев: • Повредилось содержимое памяти, и код завис в бесконечном цикле. Независимо от того, находится ли проект на стадии разработки, или уже проект вышел на рынок в свободное плавание и продается тысячами штук, встраиваемая система должна быть снабжена подсистемой самоконтроля типа watchdog. Это самый лучший способ идентифицировать зависания системы и собрать достаточно информации, чтобы идентифицировать основную проблему и устранить её. Конфигурирование аппаратного Watchdog. Когда аппаратный сторожевой таймер конфигурируются в первый раз, важно внимательно изучить даташит, чтобы понять, как это периферийное устройство работает. Работа сторожевого таймера определяется производителем и может меняться, так что даже если используете чип из того же семейства MCU (например ARM Cortex-M MCU) поведение периферии watchdog может отличаться от того, с чем Вам уже приходилось сталкиваться. Невнимательность к нюансам может позже привести к неожиданным проблемам. Давайте быстро рассмотрим основные моменты, которые стоит проверить. 1. Когда сбрасывается конфигурация watchdog? Как правило, мы сталкиваемся со следующими вариантами: • Watchdog может быть разрешен и запрещен несколько раз, и должен конфигурироваться при каждой загрузке программы firmware. 2. Как ведет себя watchdog при работе под отладчиком? Разработчики часто запрещают watchdog во время отладки, чтобы сборки debug не приводили к сбросам на платах, где активно отлаживается код. Однако это большая ошибка, что приводит к тому, что проблемы остаются незамеченными до тех пор, пока сборка не отправится в релиз. Если бы сторожевой таймер был разрешен в процессе отладки, это могло бы помочь исправить множество проблем уже на этапе написания и отладки кода. Не всем известен факт, что почти все производители MCU добавляют в процессор специальную функцию, которая останавливает сторожевой таймер, когда JTAG/SWD отладчик приостановил работу кода (например, остановка на breakpoint). Таким образом, если Вы добавили точку останова в проверяемый код, или выполняете операторы программы по шагам, можно не беспокоиться о том, что сторожевой таймер сработает и сбросит процессор. При запуске программы на постоянное выполнение под отладчиком watchdog продолжит нормальное функционирование. Однако не всякая аппаратура поддерживает такую функцию - например, установлена отдельная микросхема сторожевого таймера, которую необходимо сбрасывать выдачей импульса логического уровня. В таких особых сценариях отладчик может быть сконфигурирован для записи в регистр, что приостановит действие сторожевого таймера или будет его сбрасывать автоматически с нужными интервалами. Как это делается, мы рассмотрим позже на примере настройки отладчика GDB. Для Cortex-M доступны опции конфигурации, которые STMicroelectronics предоставляет для STM32 через компонент DBGMCU. Оттуда можно выбрать "заморозку" тактирования любого периферийного устройства, когда работа программы остановлена отладчиком. 3. Что происходит, когда истекло время таймера watchdog? Вот типовые варианты для MCU: • При истечении задержки watchdog его аппаратура немедленно сбросит MCU системы. 4. Как узнать, был ли сброс вызван таймаутом watchdog? Почти все производители/вендоры MCU предоставляют информацию о типе произошедшего сброса, которая записывается в специальный регистр. Если в MCU реализовано периферийное устройство watchdog, то один из бит в этом регистре покажет, что сброс был вызван срабатыванием watchdog. Замечание: часто эти регистры снабжены так называемыми "липкими" (sticky) битами. Т. е. после того как Вы прочитаете эти биты в момент загрузки, их нужно очистить. Иначе биты сохранят свое старое значение при следующей загрузке, пока не произойдет полный сброс от включения питания (Power-On-Reset, POR). Таблице ниже по семействам MCU перечислены мнемоники регистров некоторых производителей микроконтроллеров, где хранится информация о сбросе.
[Разрешение Hardware Watchdog в системе] После того, как мы получили базовую информацию по сторожевому таймеру, как он работает, рассмотрим на примере конфигурирование watchdog и использование его для отслеживания зависаний в реальной системе. Рассматриваемый пример приложения работает под FreeRTOS, в нем передается сообщение между двумя задачами. В примере приложения предусмотрено несколько различных способов ввода системы в зависание. Пример приложения можно скачать на страничке [3]. Выполните в консоли следующие команды: $ git clone git@github.com:memfault/interrupt.git $ cd interrupt/example/watchdog-example/ Для тестирования кода примера используются следующие инструменты и утилиты: • GNU Arm Embedded Toolchain 9-2019-q4-update [4]. Давайте откроем даташит NRF52840 [6], и взглянем на главу "6.36 WDT — Watchdog timer". 1. Конфигурирование поведения сброса Цитата из секции "6.36.3 Watchdog reset": "Перед запуском watchdog должен быть сконфигурирован. После запуска его регистры конфигурации CRV, RREN и CONFIG будут заблокированы, чтобы не допустить изменение конфигурации. ... " Важно отменить, что обычный сброс ("Soft reset") не сбрасывает сторожевой таймер. Это может привести к проблемам, например если главное приложение разрешило watchdog, но загрузчик (bootloader) не знал об этом. Если загрузчик делает какую-то долгую операцию, такую как обновление firmware, таймер watchdog будет при этом работать, и может сбросить систему посередине процесса обновления! Примечание: в случае NRF52 предоставленный bootloader в SDK сбрасывает watchdog, если он был разрешен в основном приложении. 2. Взаимодействие с отладчиком В секции "6.36.2 Temporarily pausing the watchdog" написано: "По умолчанию watchdog будет продолжать счет вниз, когда CPU находится в режиме сна, и когда его работа приостановлена отладчиком. Однако есть возможность сконфигурировать watchdog автоматически ставить счет на паузу, когда CPU спит (находится в режиме пониженного энергопотребления), а также когда он приостановлен отладчиком." Таким образом, при подключении отладчиком к процессору мы можем сконфигурировать периферийное устройство сторожевого таймера ставить на паузу его счетчик. Это позволит не беспокоиться о том, что будет генерироваться системный сброс во время срабатывания точек останова в программе. Если читать даташит дальше, что создастся впечатление, что информация в нем не совсем верна. По умолчанию watchdog запрещен, когда отладчик приостановил программу (бит 3 по умолчанию в лог. 0), так что можно просто оставить эту конфигурацию по умолчанию. 3. Что происходит по завершению счета (таймаут watchdog) Из секции "6.36.3 Watchdog reset": "Если watchdog сконфигурирован для генерации прерывания при событии TIMEOUT, сброс от watchdog будет отложен два такта 32.768 кГц после того, как сгенерировалось событие TIMEOUT. После этого всегда будет активирован watchdog reset." Таким образом, после таймаута сторожевого таймера может быть разрешено прерывание. Остается по времени только 2 периода частоты 32768 Гц до момента, как будет сгенерирован сброс. Если ядро CPU NRF52840 работает на частоте 64 МГц, то на практике у него есть только (64 МГц * 2) / 32768 = 3900 такта, чтобы выполнить очистку перед сбросом. Примечание: чтобы избежать риска сброса во время очистки, не рекомендуется использовать эту функцию. Далее в статье будут рассмотрены возможные альтернативы. 4. Как определить причину сброса (RESETREAS) Секция "5.3.7.11 RESETREAS" даташита содержит общую информацию о причинах сброса: "Если регистр RESETREAS не очищен, он будет кумулятивно накапливать информацию. Для очистки бита регистра в него записывается лог. 1. Если не установлен ни один из бит, обозначающих источник сброса, то это означает, что чип был сброшен от внутреннего генератора сброса, т. е. от сброса по включению питания (power-on-reset, POR) или от детектора сбоя питания (brownout reset)." Важно отметить, что чтение бита 1 покажет, имел ли место сброс от сторожевого таймера (watchdog reset). Нам нужно сбросить установленные биты, чтобы они не сохраняли свое значение между перезагрузками ядра. Выбор времени таймаута. Поскольку watchdog это реально последняя линия обороны, следует выбрать его таймаут значительно больше, чем время обработки большинства событий, обслуживаемых задачей RTOS или главным циклом main. Хорошее общее правило - выбор таймаута в диапазоне 5 .. 30 секунд. Для демонстрационных целей в этой статье используется таймаут 10 секунд. [Конфигурирование аппаратного Watchdog NRF52] NRF52840 watchdog представлен тремя регистрами конфигурации, которые можно установить только один раз: CRV, RREN и CONFIG. Как уже обсуждалось выше, значение по умолчанию регистра CONFIG вполне соответствует тому, что нам нужно (watchdog не работает, когда система приостановлена на breakpoint отладчика). Регистр RREN позволяет нам конфигурировать несколько регистров "запроса перезагрузки" (reload request registers, RRR), которые могут использоваться для спроса счетчику watchdog перезагрузить свое значение. Существует 8 RRR-регистров, и по умолчанию разрешен только один. Для аппаратного watchdog для сброса его счетчика необходимо только лишь сделать запись во все разрешенные RRR. Одним из вариантов использования разрешения нескольких регистров RRR - независимый мониторинг разных задач или машин состояний в системе. Для демонстрации в этом примере мы будем использовать конфигурацию по умолчанию, где разрешен только один первый регистр RRR. Код для настройки watchdog: // hardware_watchdog.c
// ...
#define HARDWARE_WATCHDOG_TIMEOUT_SECS 10
// ...
void hardware_watchdog_enable(void) { if ((WDT->RUNSTATUS & 0x1) != 0) { // Watchdog уже работает, и не может быть сконфигурирован return; } // Значение для перезагрузки счетчика - количество периодов // частоты 32.768 кГц до истечения таймаута watchdog: WDT->CRV = 32768 * HARDWARE_WATCHDOG_TIMEOUT_SECS; // Разрешение периферийного устройства watchdog: WDT->TASKS_START = 0x1; } Код для сброса watchdog: // hardware_watchdog.c
void hardware_watchdog_feed(void) { // В соответствии с секцией "6.36.4.10" даташита, если это // значение записывается в разрешенный RRR, то счетчик // watchdog сбросится, и таймаут/перезагрузка не произойдет. // // Замечание: как правило подобные "магические" константы // используются как ключ для активации перезагрузки // сторожевого таймера, чтобы до минимума снизить шанс // случайного сброса watchdog при неправильном доступе // к памяти. const uint32_t reload_magic_value = 0x6E524635; WDT->RR[0] = reload_magic_value; } Проверка причины перезагрузки. Ниже показан пример кода приложения, который проверяет и сбрасывает значение полей регистра RESETREAS. Если имел место сброс от watchdog, автоматически активируется инструкция точки останова (__asm("bkpt 10");): // main.c
static void prv_check_and_reset_reboot_reason(void) { // Сохранение информации о причине сброса: const uint32_t last_reboot_reason = *RESETREAS; // Очиcтка любых полей, которые показывают информацию сброса: *RESETREAS |= *RESETREAS; // Приостановка системы при загрузке, если произошел // Watchdog Reset: const uint32_t watchdog_reset_mask = 0x2; if ((last_reboot_reason & watchdog_reset_mask) == watchdog_reset_mask) { __asm("bkpt 10"); } } Проверка работоспособности конфигурации. Пример приложения определяет глобальную переменную g_watchdog_hang_config в модуле main.c, которую мы будем устанавливать в отладчике gdb, чтобы управлять искусственным зависанием. Код запуска (startup code) может выглядеть примерно так: //main.c
int main(void) { prv_check_and_reset_reboot_reason(); hardware_watchdog_enable(); //... // Ввод различных зависаний на основе g_watchdog_hang_config По умолчанию для зависания код просто входит в бесконечный цикл while (1) {} при загрузке. Таким образом, если все настроено правильно, то прошивки кода мы должны через 10 секунд увидеть остановку отладчика внутри prv_check_and_reset_reboot_reason(). $ cd example/watchdog-example/
$ make
$ arm-none-eabi-gdb --eval-command="target remote localhost:2331" --ex="mon reset" --ex="load"
--ex="mon reset" --se=build/nrf52.elf
(gdb) continue
[ ... ожидание примерно 10 секунд ...]
Program received signal SIGTRAP, Trace/breakpoint trap.
prv_check_and_reset_reboot_reason () at interrupt/example/watchdog-example/main.c:157
157 __asm("bkpt 10");
(gdb)
Теперь давайте попробуем вставить в цикл while(1) {} повторяющиеся вызовы hardware_watchdog_feed() (см. код выше). Это обеспечит непрерывную работу программы, без перезагрузки. (gdb) mon reset (gdb) break main (gdb) continue Continuing. Breakpoint 1, main () at interrupt/example/watchdog-example/main.c:162 162 prv_check_and_reset_reboot_reason(); (gdb) set g_watchdog_hang_config=1 (gdb) continue [... мы должны увидеть, что перезагрузки программы от таймаута watchdog больше нет ...] Мы может также приостановить работу программы и проверить её состояние, чтобы убедиться, что watchdog запущен и сконфигурирован так, как это ожидалось: (gdb) p/x *WDT
$3 = {
TASKS_START = 0x0,
RSVD = {0x0 < repeats 63 times>},
EVENTS_TIMEOUT = 0x0,
RSVD1 = {0x0 < repeats 128 times>},
INTENSET = 0x0,
INTENCLR = 0x0,
RSVD2 = {0x0 < repeats 61 times>},
RUNSTATUS = 0x1,
REQSTATUS = 0x1,
RSVD3 = {0x0 < repeats 63 times>},
CRV = 0x50000,
RREN = 0x1,
CONFIG = 0x1,
RSVD4 = {0x0 < repeats 60 times>},
RR = {0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}
}
[Базовая реализация в многопоточной среде] Основная идея состоит в создании потока с низким приоритетом, который должен сбрасывать сторожевой таймер. Если этот поток получает процессорное время для своей работы, то будет исправно сбрасывать watchdog. Если же по какой-то причине более высокоприоритетная задача зависла в бесконечном цикле, то система должна перезагрузиться, потому что низкоприритетный поток, сбрасывающий watchdog, не сможет получить процессорное время. Пример кода низкоприоритетной задачи (FreeRTOS): static void prvWatchdogTask(void *pvParameters) { while (1) { vTaskDelay(1000); hardware_watchdog_feed(); } } Зависание при опросе датчика. Общий класс зависаний может происходить из-за опроса сенсора при ожидании завершения транзакции по передаче данных, или из-за ошибки программирования памяти. Пример: // main.cvoid erase_external_flash(void) { // Здесь находится какая-нибудь логика, запускающая // стирание памяти flash. // Опрос завершения операции: while (!spi_flash_erase_complete()) { }; // В случае проблемы сюда мы уже не попадем! } Замечание по реализации: вместо опроса в бесконечном цикле здесь мы могли бы проверить время ожидания по таймауту. Однако для большинства простых устройств ожидается нормальный отклик. Проблема отказа в подобных случаях часто возникает из-за программной ошибки, такой как неправильной конфигурации прерывания или периферийного устройства. Добавление логики таймаута и попытки корректного восстановления это нечто такое, чего следует избегать, потому что потенциально маскирует возможные ошибки. Если вы вводите логику восстановления, то открываете для себя пути для получения более сложных проблем из-за дополнительных ошибок. Кроме того, маскирование нижележащей проблемы делает поиск причин ошибки еще сложнее. Зависание в том месте, где произошла ошибка, может упростить в выяснение причины отказа и уменьшить время на исправление ошибки. Посмотрим, сможет ли наша реализация watchdog перехватить этот тип зависания. (gdb) mon reset Resetting target (gdb) break main Breakpoint 1 at 0x174: file interrupt/example/watchdog-example/main.c, line 151. (gdb) continue Continuing. Breakpoint 1, main () at interrupt/example/watchdog-example/main.c:151 151 prv_check_and_reset_reboot_reason(); // Select the polling hang configuration (gdb) set g_watchdog_hang_config=2 (gdb) continue Continuing. Breakpoint 1, main () at interrupt/example/watchdog-example/main.c:151 151 prv_check_and_reset_reboot_reason(); (gdb) c Continuing. [ ... ожидание примерно 10 секунд ... ]
Program received signal SIGTRAP, Trace/breakpoint trap.
prv_check_and_reset_reboot_reason () at interrupt/example/watchdog-example/main.c:146
146 __asm("bkpt 10");
ОК, все сработало как надо. Мы увидели, что произошла перезагрузка из-за таймаута watchdog. Зависание из-за ожидания мьютекса/семафора. Рассмотрим другой класс зависания из-за того, что не освобождается mutex или не появляется семафор. int read_temp_sensor(uint32_t *temp) { xSemaphoreTake(s_temp_i2c_mutex, portMAX_DELAY); int rv = i2c_read_temp(temp); if (rv == -1) { // БАГ: в этом месте должен быть выставлен семафор! return rv; } xSemaphoreGive(s_temp_i2c_mutex); return 0; } Проверочные действия: (gdb) mon reset Resetting target (gdb) break main Breakpoint 1 at 0x174: file interrupt/example/watchdog-example/main.c, line 151. (gdb) continue Continuing. Breakpoint 1, main () at interrupt/example/watchdog-example/main.c:151 151 prv_check_and_reset_reboot_reason(); // Выбор конфигурации mutex hang: (gdb) set g_watchdog_hang_config=3 (gdb) continue Continuing. // Тут мы видим отсутствие перезагрузки Но почему перезагрузка не происходит?.. Здесь зависание более тонкое. Наш поток с более высоким приоритетом завис, потому что ожидает мьютекс. Это значит, что он освобождает процессорное время RTOS, так что низкоприоритетный поток может работать и сбрасывать watchdog. Добавление "задачи" Watchdog. Итак, мы только что обнаружили, что наша простая схема реализации watchdog имеет некоторые недостатки - она не может перехватить мертвые блокировки (deadlocks) между задачами. Вероятно, что нам нужен какой-то способ отследить, что наши циклы событий выполняются. Этой цели можно достичь реализацией системы контроля над аппаратным watchdog. Вместо того, чтобы безусловно вызывать hardware_watchdog_feed(), добавим API-задачи, которые могут определить работоспособность рабочих задач и сбрасывать hardware watchdog только если все задачи проверены. static uint32_t s_registered_tasks = 0; static uint32_t s_fed_tasks = 0; static void prv_task_watchdog_check(void) { if ((s_fed_tasks & s_registered_tasks) == s_registered_tasks) { // Все задачи в порядке, или приостановлены! hardware_watchdog_feed(); s_fed_tasks = 0; } } void task_watchdog_register_task(uint32_t task_id) { __disable_irq(); s_registered_tasks |= (1 << task_id); __enable_irq(); } void task_watchdog_unregister_task(uint32_t task_id) { __disable_irq(); s_registered_tasks &= ~(1 << task_id); s_fed_tasks &= ~(1 << task_id); prv_task_watchdog_check(); __enable_irq(); } void task_watchdog_feed_task(uint32_t task_id) { __disable_irq(); s_fed_tasks |= (1 << task_id); prv_task_watchdog_check(); __enable_irq(); } Примечание: поскольку к процедурам s_fed_tasks и s_registered_tasks осуществляется обращение из нескольких задач, в их код добавлены вызовы __disable_irq/__enable_irq, чтобы предотвратить одновременный доступ к общим данным (организуется критический регион кода [8]). Поскольку количество тактов для работы внутри критической секции весьма мало, то это не должно составить проблемы. Однако при использовании GCC можно было бы использовать встроенное API для организации атомарного доступа [9] к переменным. Псевдокод, демонстрирующий использование Task Watchdog. Все встраиваемые системы работают на основе обработки некоторого цикла событий (event loop). Ниже приведен пример, как можно использовать показанные выше API-функции в цикле, чтобы лучше понять, как они работают. static void background_service_event_loop(void) { while (1) { const int task_id = kTaskId_BackGroundWorkLoop; // Поскольку между событиями может пройти много времени, // отменяется регистрация задачи task watchdog: task_watchdog_unregister_task(task_id); wait_for_work(); // Появилась какая-то работа, поэтому регистрируем watchdog // для перехвата ситуаций, когда эта работа выполняется // слишком долго: task_watchdog_register_task(task_id); // ОПЦИОНАЛЬНО: если задача работает долго, но это ожидаемо // (например, стирается большая по объему память микросхемы // flash), можно сбрасывать task watchdog, чтобы предоставить // процессу задачи больше времени. // // Примечание: выбранный таймаут watchdog должен быть // достаточным, чтобы достаточен для каждого системного // события, поэтому используйте этот шаблон очень редко: task_watchdog_feed_task(task_id); [... выполнение работы ...]
}
}
Task Watchdog, реализованный аппаратно. Проницательный читатель может заметить, что это звучит как использование нескольких RRR в чипе NRF52, которые упоминались выше. Но нет, это слишком редко встречающаяся аппаратура, поэтому предпочтительнее заменить её программной реализацией, которую легко можно запустить и протестировать на широком спектре устройств MCU. Изменим task watchdog следующим образом. $ cd $INTERRUPT_REPO/example/watchdog-example/ $ git apply 01-patch-task-watchdog.patch $ make Это исправление использует новый task watchdog, протестируем еще раз ввод зависания. (gdb) mon reset (gdb) continue Continuing. Breakpoint 1, main () at interrupt/example/watchdog-example/main.c:162 162 prv_check_and_reset_reboot_reason(); (gdb) set g_watchdog_hang_config=3 (gdb) continue Continuing. Breakpoint 1, main () at interrupt/example/watchdog-example/main.c:160 160 prv_check_and_reset_reboot_reason(); (gdb) continue Program received signal SIGTRAP, Trace/breakpoint trap.
prv_check_and_reset_reboot_reason () at interrupt/example/watchdog-example/main.c:157
157 __asm("bkpt 10");
Отлично, все работает! [Выяснение причин срабатывания watchdog] Хорошо, что мы имеем возможность перехватывать зависания системы, но как их отлаживать? На данный момент все, что мы видим, это один бит при сбросе после того, как сработал сторожевой таймер, что не особенно полезно для выяснения причины проблемы. Мы действительно хотим иметь возможность выполнить код до того, как произойдет watchdog reset. Как уже упоминалось, у NRF52 есть прерывание, которое можно разрешить, но оно не дает нам никакого контроля над отсрочкой перезагрузки для какой-либо очистки. В этой ситуации обычно довольно легко перепрофилировать встроенный периферийный таймер для реализации программного watchdog. Добавление "программного" watchdog. Для примера будем использовать NRF52 Timer0 для реализации software watchdog. Сделаем немного меньшее время таймаута (7 секунд), чем таймаут у аппаратного watchdog (10 секунд). Для сброса software watchdog нужно просто перезапустить таймер. Если истекли 7 секунд без перезапуска таймера, сработает ISR, и система узнает об этом событии срабатывания software watchdog. Мы можем использовать это прерывание как еще один обработчик отказов, отслеживая какие-либо ошибки в коде Cortex-M. void TimerTask0_Handler(void) { __asm volatile( "tst lr, #4 \n" "ite eq \n" "mrseq r0, msp \n" "mrsne r0, psp \n" "b watchdog_fault_handler_c \n"); } // Запрет оптимизаций, чтобы компилятор не оптимизировал
// в этой функции аргумент "frame": __attribute__((optimize("O0")))void watchdog_fault_handler_c(sContextStateFrame *frame) { // И только если подключен отладчик, выполнится инструкция breakpoint, // чтобы можно было выяснить причину отказа: HALT_IF_DEBUGGING(); // Сброс аппаратного watchdog, чтобы получить время для очистки // и последующего явного сброса: hardware_watchdog_feed(); // Логика, которая обрабатывает исключение. Здесь обычно делается // следующее: // - сохраняется дамп ядра, чтобы можно было позже провести анализ // возникновения deadlock-ов или зависаний // - выполняется любая очистка и/или выключение оборудования // необходимые перед перезагрузкой // - перезагружается система. } Добавление Software Watchdog в пример приложения. Можно ввести изменения следующим образом: $ cd $INTERRUPT_REPO/example/watchdog-example/ $ git apply 02-patch-software-watchdog.patch $ make Вернемся обратно к рассмотренным ранее примерам, и посмотрим, как можно отследить причину зависания. (gdb) mon reset Resetting target (gdb) break main Breakpoint 1, main () at interrupt/example/watchdog-example/main.c:162 162 prv_check_and_reset_reboot_reason(); (gdb) set g_watchdog_hang_config=2 (gdb) continue Continuing. [... ожидание примерно 7 секунд ...] Program received signal SIGTRAP, Trace/breakpoint trap. 0x00002bbc in watchdog_fault_handler_c (frame=0x200003b8 < ucHeap+592>) at interrupt/example/watchdog-example/software_watchdog.c:81 81 HALT_IF_DEBUGGING(); (gdb) p/a *frame
$3 = {
r0 = 0x0 < g_pfnVectors>,
r1 = 0x200001bc < ucHeap+84>,
r2 = 0x20000164 < s_registered_tasks>,
r3 = 0x2 < g_pfnVectors+2>,
r12 = 0x200003e0 < ucHeap+632>,
lr = 0x10b < erase_external_flash+6>,
return_address = 0x2b8 < spi_flash_erase_complete>,
xpsr = 0x61000000
}
Отлично, мы видим, что регистры pc & lr точно указывают на цикл, где крутится зависание: void erase_external_flash(void) { // Некая логика, запускающая стирание flash. ... // Опрос завершения операции: while (!spi_flash_erase_complete()) { }; } Попробуем теперь отладить зависание из-за deadlock-а. (gdb) mon reset Resetting target (gdb) break main Breakpoint 1, main () at interrupt/example/watchdog-example/main.c:162 162 prv_check_and_reset_reboot_reason(); (gdb) set g_watchdog_hang_config=3 (gdb) continue Continuing. [... ожидание в течение нескольких секунд ...] Program received signal SIGTRAP, Trace/breakpoint trap. 0x00002bbc in watchdog_fault_handler_c (frame=0x20000b10 < ucHeap+2472>) at interrupt/example/watchdog-example/software_watchdog.c:81 81 HALT_IF_DEBUGGING(); (gdb) p/a *frame
$4 = {
r0 = 0x0 < g_pfnVectors>,
r1 = 0x0 < g_pfnVectors>,
r2 = 0x0 < g_pfnVectors>,
r3 = 0x0 < g_pfnVectors>,
r12 = 0x0 < g_pfnVectors>,
lr = 0x2741 < prvTaskExitError>,
return_address = 0x39a < prvIdleTask+14>,
xpsr = 0x61000000
}
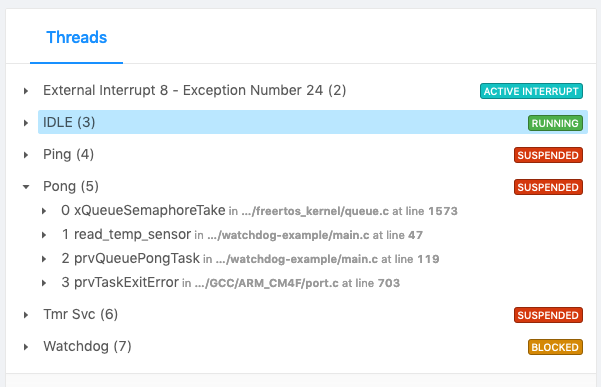
Здесь все несколько сложнее. Регистры $pc и $lr указывают на задачу FreeRTOS. Выполнение потока приостановлено, поэтому другие задачи могут выполняться. Мы можем сравнить s_registered_tasks и s_fed_tasks, чтобы найти ту задачу, которая зависла: (gdb) p/x s_registered_tasks&~s_fed_tasks $8 = 0x2 Таким образом задача Task Id 1 находится в ожидании мьютекса (зависла). Из списка Task Id мы узнаем, что это задача Pong: typedef enum { kWatchdogExampleTaskId_Ping = 0, kWatchdogExampleTaskId_Pong, kWatchdogExampleTaskId_Watchdog, }eWatchdogExampleTaskId; Если отладчик поддерживает поток FreeRTOS, то можно переключиться в этот поток, чтобы посмотреть стек вызовов (backtrace). Альтернативно можно использовать инструмент типа Memfault, чтобы вытащит данные и запустить анализ в облаке. (gdb) memfault coredump -r 0x20000000 262144 One moment please, capturing memory... [...] Are you currently at the start of an exception handler [y/n]?n [...] Cortex-M4 detected Collected MPU config Capturing RAM @ 0x20000000 (1048576 bytes)... Captured RAM @ 0x20000000 (1048576 bytes) Symbols have already been uploaded, skipping! Coredump uploaded successfully! Затем в интерфейсе Memfault Issue Detail можно просмотреть задачу Pong и увидеть, что она заблокирована на ожидании в вызове xQueueSemaphoreTake.
[Использование GDB Python для предотвращения ошибочных срабатываний Software Watchdog] К сожалению, в отличие от таймера watchdog, нет способа остановить тактирование периферийного устройства таймера, когда к NRF52 подключен отладчик. Это значит, что если мы приостановим программу отладчиком на время больше 7 секунд, то попадем в срабатывание software watchdog ISR сразу после возобновления выполнения кода. Это можно проверить: (gdb) CTRL-C [... ожидание в течение 7 секунд ...] (gdb) continue Continuing. Program received signal SIGTRAP, Trace/breakpoint trap. 0x00002bbc in watchdog_fault_handler_c (frame=0x20002a78) at interrupt/example/watchdog-example/software_watchdog.c:81 81 HALT_IF_DEBUGGING(); Это та ситуация, где может помочь Python API отладчика GDB (подробнее про GDB Python API см. [10]). Можно использовать Events API8 для приостановки периферийного устройства таймера, когда система приостанавливается, и снова запускать таймер, когда система продолжает выполнение. Пример: # gdb_resume_handlers.py
try: import gdb except ImportError: raise Exception("This script can only be run within gdb!") import struct class Nrf52Timer0: TIMER0_TASKS_START_ADDR = 0x40008000 TIMER0_TASKS_STOP_ADDR = 0x40008004 @staticmethod def _trigger_task(addr): gdb.selected_inferior().write_memory(addr, struct.pack("< I", 1)) @classmethod def start(cls): print("Resuming Software Watchdog") cls._trigger_task(cls.TIMER0_TASKS_START_ADDR) @classmethod def stop(cls): print("Pausing Software Watchdog") cls._trigger_task(cls.TIMER0_TASKS_STOP_ADDR) def nrf52_debug_stop_handler(event): Nrf52Timer0.stop() def nrf52_debug_start_handler(event): Nrf52Timer0.start() gdb.events.stop.connect(nrf52_debug_stop_handler) gdb.events.cont.connect(nrf52_debug_start_handler) Теперь когда мы обратимся к GDB, можно добавить аргумент --ex="source gdb_resume_handlers.py", и таймер будет автоматически приостанавливаться отладчиком GDB, когда он останавливает программу. $ arm-none-eabi-gdb-py --eval-command="target remote localhost:2331" \
--ex="mon reset" --ex="load" --ex="mon reset" \
--ex="source gdb_resume_handlers.py" --se=build/nrf52.elf
Program received signal SIGTRAP, Trace/breakpoint trap.
main () at interrupt/example/watchdog-example/main.c:134
134 }
Pausing Software Watchdog
(gdb) c
Continuing.
Resuming Software Watchdog
[Отладка зависаний в прерывании] Посмотрим, как будет работать система, когда зависание произойдет в теле ISR: (gdb) set g_watchdog_hang_config=4 (gdb) c Continuing. Resuming Software Watchdog (gdb) p/a *frame
$2 = {
r0 = 0x3 < g_pfnVectors+3>,
r1 = 0x200001bc < ucHeap+84>,
r2 = 0xe000e100,
r3 = 0x1 < g_pfnVectors+1>,
r12 = 0x200003e0 < ucHeap+632>,
lr = 0xfffffffd,
return_address = 0xd0 < ExternalInt0_Handler>,
xpsr = 0x21000010
}
Адрес возврата указывает на обработчик прерывания ExternalInt0_Handler. Инспекция его кода покажет, почему произошло зависание: void ExternalInt0_Handler(void) { while (1) {} } [Советы в по разработке на ARM Cortex-M] Вот общие правила реализации сторожевых таймеров на cortex-M MCU: • Убедитесь, что обработчик software watchdog handler работает с самым высоким приоритетом, который можно сконфигурировать, и что все другие прерывания имеют приоритет ниже его. Благодаря этому гарантируется, что если зависание произойдет в любом рабочем ISR, код software handler все еще будет работать, и можно будет отследить, что пошло не так. • Если архитектура поддерживает конфигурирование BASEPRI (это поддерживает любой Cortex-M, кроме Cortex-M0), используйте __set_BASEPRI для входа в критические секции и выхода из них без использования прямого управления запретом прерываний __disable/__enable_irq(). Таким способом можно гарантировать, что ISR "Software Watchdog” всегда разрешен, и сможет перехватить зависание даже тогда, когда оно произошло в критической секции. Подробнее про исключения (ARM exceptions) см. [11]. [Словарик] breakpoint точка останова, специальная метка в коде firmware, которая приводит к остановке отладчиком выполнение кода в реальном времени. ISR Interrupt Service Routine, обработчик прерывания. MCU MicroController Unit, микроконтроллер. HRM Hardware Resource Management, система управления аппаратными ресурсами. RTL-блок аббревиатура RTL переводится как Register-Transfer Level. Здесь под этим подразумевается некий электронный блок, доступный для кода firmware через чтение/запись регистров MCU. UI User Interface, интерфейс пользователя. [Ссылки] 1. A Guide to Watchdog Timers for Embedded Systems site:memfault.com. |