| ESP32: функции поддержки FreeRTOS |
|
| Добавил(а) microsin | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
ESP-IDF [2] использует модифицированную версию FreeRTOS v10.4.3, содержащую значительные изменения для SMP-совместимости (см. [3]). Однако, в дополнение к ESP-IDF FreeRTOS, система разработки ESP-IDF предоставляет различные возможности в дополнение к функциям, предлагаемым традиционной FreeRTOS. Этот документ описывает такие функции поддержки FreeRTOS, добавляемые системой разработки ESP-IDF (перевод документации [1]). Незнакомые термины и сокращения см. в разделе Словарик, в конце статьи. Модифицированная версия ESP-IDF FreeRTOS основана на порте Xtensa FreeRTOS v10.4.3, в который были введены значительные изменения для обеспечения SMP-совместимости. Добавлены следующие новые функции, специфичные для ESP-IDF FreeRTOS: Кольцевые буферы (ring buffer). Эта функция предоставляет буфер FIFO, который может принимать в себя элементы произвольной длины. Обработчики тиков и состояния ожидания (ESP-IDF Tick и Idle Hooks). ESP-IDF предоставляет несколько пользовательских перехватчиков прерываний тика (tick interrupt hooks) и перехватчиков задачи ожидания (idle task hooks), которые намного богаче по возможностям и гибкости в сравнении с традиционными для FreeRTOS обработчиками тика и состояния idle. Callback-функции удаления TLSP (Thread Local Storage Pointer). Это функции обратного вызова, которые запустятся автоматически при удалении задачи, что позволит реализовать автоматическую очистку памяти (освобождение выделенных ресурсов). Поддержка свойств компонента. Предусмотрена поддержка свойств, специфичных для компонента. В настоящее время это пока только ORIG_INCLUDE_PATH. [Кольцевые буферы] Кольцевой буфер ESP-IDF FreeRTOS, строго работающий по принципу FIFO, поддерживает элементы (ячейки) буфера произвольного размера. Такой буфер дает практически тот же функционал, что и традиционные очереди FreeRTOS, однако кольцевой буфер ESP-IDF более эффективен, чем очереди FreeRTOS, в тех случаях, когда размер элементов буфера изменяемый. Емкость кольцевого буфера не измеряется в количестве элементов, который он может хранить, а в количестве памяти, используемой для хранения элементов. Кольцевой буфер предоставляет API-функции для отправки элемента в буфер, или для выделения пространства для элемента в кольцевом буфере, которое должно быть заполнено пользователем вручную. По соображениям эффективности элементы буфера всегда извлекаются из кольцевого буфера по указателю. В результате все излеченные элементы должны быть также возвращены в кольцевой буфер с помощью vRingbufferReturnItem() или vRingbufferReturnItemFromISR(), чтобы они были полностью удалены из буфера. Кольцевые буферы делятся на следующие 3 типа: No-Split. Эти буферы гарантируют, что элемент сохранен в непрерывной области памяти, т. е. в любых условиях никогда не будет попыток сохранить элемент кусками. Только этот тип буфера позволит Вам получить адрес элемента буфера и выполнить запись в элемент самостоятельно. Подробнее см. xRingbufferSendAcquire() и xRingbufferSendComplete(). Allow-Split. Этот тип буферов допускает разделить элемент буфера на 2 части, когда был достигнут конец области памяти буфера (случай, когда памяти буфера не хватило, и начало элемента будет записано в конец буфера, а хвост элемента в начало буфера). Буферы Allow-Split более эффективны, чем буферы No-Split, однако при извлечении элемента могут возвратить его двумя кусками. Байтовый буфер. Все данные сохраняются в памяти как последовательность байт, и каждый раз в буфер может быть отправлено любое количество элементов, и извлечено любое количество элементов. Используйте байтовые буферы, когда не требуется поддержка отдельных элементов разного размера (например поток байт, byte stream). Важные замечания: 1. Буферы No-Split и Allow-Split будут всегда сохранять элементы по байтовому адресу, выровненному на 32 бита (адрес нацело делится на 4). Таким образом для извлечения элемента из буфера, будет предоставлен указатель на 32-битное слово. Это особенно полезно, когда нужно отправить некоторые данные через DMA. Следующий пример демонстрирует использование xRingbufferCreate() и xRingbufferSend() для создания кольцевого буфера и последующей отправки в него элемента. #include "freertos/ringbuf.h"
static char tx_item[] = "test_item"; ... // Создание кольцевого буфера: RingbufHandle_t buf_handle; buf_handle = xRingbufferCreate(1028, RINGBUF_TYPE_NOSPLIT); if (buf_handle == NULL) { printf("Failed to create ring buffer\n"); } // Отправка элемента: UBaseType_t res = xRingbufferSend(buf_handle, tx_item, sizeof(tx_item), pdMS_TO_TICKS(1000)); if (res != pdTRUE) { printf("Failed to send item\n"); } Следующий пример показывает использование xRingbufferSendAcquire() и xRingbufferSendComplete() вместо xRingbufferSend(), чтобы выделить память на кольцевом буфере (типа RINGBUF_TYPE_NOSPLIT), и затем отправить в него элемент. Эта процедура включает один дополнительный шаг, однако позволяет получить адрес памяти, чтобы можно было в эту память сделать запись самостоятельно. #include "freertos/ringbuf.h"
#include "soc/lldesc.h"
typedef struct { lldesc_t dma_desc; uint8_t buf[1]; }dma_item_t; #define DMA_ITEM_SIZE(N) (sizeof(lldesc_t)+(((N)+3)&(~3)))
... // Получение пространства для дескриптора DMA и соответствующего // буфера данных. Это должно быть сделано через SendAcquire, // или адрес может отличаться, когда мы делаем копирование. dma_item_t item; UBaseType_t res = xRingbufferSendAcquire(buf_handle, &item, DMA_ITEM_SIZE(buffer_size), pdMS_TO_TICKS(1000)); if (res != pdTRUE) { printf("Failed to acquire memory for item\n"); } item->dma_desc = (lldesc_t) { .size = buffer_size, .length = buffer_size, .eof = 0, .owner = 1, .buf = &item->buf, }; // Здесь происходит реальная отправка в кольцевой буфер: res = xRingbufferSendComplete(buf_handle, &item); if (res != pdTRUE) { printf("Failed to send item\n"); } Следующий пример демонстрирует запрос и получение элемента из кольцевого буфера типа No-Split с использованием xRingbufferReceive() и vRingbufferReturnItem(). ... // Получение элемента: size_t item_size; char *item = (char *)xRingbufferReceive(buf_handle, &item_size, pdMS_TO_TICKS(1000)); // Проверка, получен ли элемент: if (item != NULL) { // Печать элемента: for (int i = 0; i < item_size; i++) { printf("%c", item[i]); } printf("\n"); // Возврат элемента: vRingbufferReturnItem(buf_handle, (void *)item); } else { // Не получилось получить элемент printf("Failed to receive item\n"); } Следующий пример демонстрирует получение и возврат элемента из кольцевого буфера Allow-Split с помощью xRingbufferReceiveSplit() и vRingbufferReturnItem(). ... // Получение элемента: size_t item_size1, item_size2; char *item1, *item2; BaseType_t ret = xRingbufferReceiveSplit(buf_handle, (void **)&item1, (void **)&item2, &item_size1, &item_size2, pdMS_TO_TICKS(1000)); // Проверка, получен ли элемент: if (ret == pdTRUE && item1 != NULL) { for (int i = 0; i < item_size1; i++) { printf("%c", item1[i]); } vRingbufferReturnItem(buf_handle, (void *)item1); // Проверка, получен ли элемент целиком, или был поделен на части: if (item2 != NULL) { // Имеется также и вторая часть: for (int i = 0; i < item_size2; i++) { printf("%c", item2[i]); } vRingbufferReturnItem(buf_handle, (void *)item2); } printf("\n"); } else { // Не получилось получить элемент printf("Failed to receive item\n"); } Следующий пример демонстрирует получение и возврать байтового буфера с помощью xRingbufferReceiveUpTo() и vRingbufferReturnItem(). ... // Прием данных из байтового буфера: size_t item_size; char *item = (char *)xRingbufferReceiveUpTo(buf_handle, &item_size, pdMS_TO_TICKS(1000), sizeof(tx_item)); // Проверка принятых данных: if (item != NULL) { // Печать принятой порции данных: for (int i = 0; i < item_size; i++) { printf("%c", item[i]); } printf("\n"); // Возврат данных: vRingbufferReturnItem(buf_handle, (void *)item); } else { // Не получилось получить данные из буфера printf("Failed to receive item\n"); } Для безопасного вызова из обработчика прерывания (ISR safe функции) используйте аналогичные функции с суффиксом ISR: xRingbufferSendFromISR(), xRingbufferReceiveFromISR(), xRingbufferReceiveSplitFromISR(), xRingbufferReceiveUpToFromISR() и vRingbufferReturnItemFromISR(). Если байты элемента переходят из конца в начало кольцевого буфера, то требуется 2 вызова RingbufferReceive[UpTo][FromISR](). Отправка в кольцевой буфер. Следующие диаграммы на рис. 1 показывает различия между буферами No-Split и Allow-Split в сравнении с байтовыми буферами в контексте отправки в буфер элементов/данных. Диаграммы подразумевают, что были отправлены 3 элемента по 18, 3 и 27 байт соответственно в буфер размером 128 байт.
Рис. 1. Отправка элементов в в кольцевые буферы No-Split или Allow-Split. Как видно из диаграммы рис. 1, для буферов No-Split и Allow-Split каждому элементу предшествует заголовок из 8 байт. Кроме того, для каждого элемента выделяется количество байт, округленное вверх так, чтобы оно делилось нацело на 4 (32-bit aligned, т. е. размеры 18, 3 и 27 байт округляются на 20, 4 и 28). Это обеспечивает 32-битное выравнивание данных в памяти. Однако в заголовок будет записан реальный размер элементов данных, чтобы этот размер мог быть получен при выемке данных из буфера. Байтовые буферы обрабатывают данные как последовательность байт, и при этом нет лишних расходов на заголовок и 32-битное выравнивание данных в памяти. В результате все элементы данных, отправленные в байтовый буфер, непосредственно примыкают друг к другу, формируя один элемент данных (см. рис. 2).
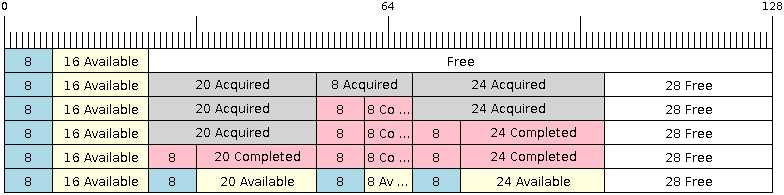
Рис. 2. Отправка элементов в байтовый буфер. На диаграмме рис. 2 видно, что отправленные элементы из 18, 3 и 27 байт последовательно записываются в память байтового буфера, объединяясь в один элемент из 48 байт. Использование SendAcquire и SendComplete. Элементы в буферах No-Split извлекаются (вызовом SendAcquire) в строгом порядке FIFO, и должны быть отправлены в буфер вызовом SendComplete, чтобы данные стали доступны их потребителю. Могут быть отправлены или извлечены несколько элементов без вызова SendComplete, и элементы не обязательно должны быть заполнены в том же порядке, в котором были извлечены. Однако получение элементов данных должно осуществляться в порядке FIFO, поэтому не вызывайте SendComplete для самого раннего извлеченного элемента, что предотвратило бы получение последующих элементов. Следующая диаграмма на рис. 3. показывает, что произойдет, когда SendAcquire и SendComplete вызываются в одном и том же порядке. В самом начале в буфере уже имеются отправленный элемент данных из 16 байт. Затем вызывается SendAcquire, чтобы выделить пространство из 20, 8, 24 байт в кольцевом буфере.
Рис. 3. SendAcquire/SendComplete для элементов в кольцевом буфере типа No-Split. После этого мы заполним (используем) выделенные области, и отправим их в кольцевой буфер вызовом в порядке 8, 24, 20. Когда будут отправлены 8 байт и 24 байта данных, получатель все еще может получить 16 байт предыдущего элемента данных. Следовательно, если SendComplete не будет вызвана для 20 байт, эти 16 байт не будут доступны, как и данные элементов, следующих за элементом из 20 байт. Когда элемент 20 байт завершен окончательно (через SendComplete), тогда могут быть получены все 3 элемента данных в порядке 20, 8, 24, сразу после элемента 16 байт, который находится в начале буфера. Буферы Allow-Split и байтовые буфера не пользволяют использовать SendAcquire или SendComplete, поскольку выделенные области в буфере требуют завершения (без перехода в начало кольцевого буфера). Переход из конца в начало. Следующие диаграммы на рис. 4, 5 и 6 показывают различия между буферами No-Split, Allow-Split и байтовыми буферами, когда отправленные элементы данных требуют перескока из конца кольцевого буфера в его начало. Показанные диаграммы подразумевают, что буфер имеет размер 128 со свободным пространством из 56 байт, перетекащим из конца в начало, и отправляемый элемент имеет размер 28 байт.
Рис. 4. Перескок в начало для буфера No-Split. Буферы типа No-Split могут сохранять элементы только в непрерывных областях памяти, и ни при каких обстоятельствах сохраняемые элементы данных не будут поделены на куски. Когда свободное пространство в конце кольцевого буфера недостаточно, чтобы полностью сохранить элемент и его заголовок, то это свободное пространство в конце помечается как пустые данных (dummy data). Тогда происходит перескок в начало, и для сохранения элемента будет использоваться свободная область от начала кольцевого буфера. Как видно из рис. 4, свободное пространство из 16 байт в хвосте буфера недостаточно, чтобы сохранить 28 элемент размером 28 байт. Таким образом эти 16 байт помечаются как dummy data, и элемент с заголовком запишется в свободную область в начале буфера.
Рис. 5. Перескок в начало для буфера Allow-Split. Буферы типа Allow-Split будут пытаться поделить элемент на 2 куска, если свободное место в конце буфера не хватит места для размещения элемента и его заголовка. Оба куска разделенного элемента в этом случае получат свой заголовок (таким образом на заголовки будет потрачено 16 байт вместо 8 байт, когда элемент не делится на куски). Из диаграммы на рис. 5 видно, что свободное пространство 16 байт в хвосте буфера недостаточно, чтобы сохранить элемент из 28 байт. Таким образом, элемент делится на 2 куска (по 8 и 20 байт), и эти куски записываются в буфер. Важное замечание: буферы Allow-Split обрабатывают оба этих куска как два отдельные элемета, таким образом вызывайте xRingbufferReceiveSplit() вместо xRingbufferReceive(), чтобы безопасно (thread safe) извлечь оба куска разделенного элемента.
Рис. 6. Перескок в начало для байтового буфера. Байтовые буферы будут сохранять максимально возможное количество байт данных в свободное пространство хвоста буфера. Остальные данные будут записаны в свободную область, находящуюся в начале буфера. При этом не будет никаких лишних расходов при перескоке из конца в начало байтового буфера. Как видно из рис. 6, здесь 16 байт хвоста буфера не хватит, чтобы полностью разместить элемент из 28 байт. Таким образом, эти 16 байт свободного пространства будут полностью заполненны данными элемента, и остальные 12 будут записаны в свободное место, находящееся в начале буфера. Теперь буфер содержит данные элемента в двух отдельных непрерывных кусках, каждый из кусков будут обрабатываться байтовым буфером как одельный элемент данных. Получение/возврат элементов. Диаграммы ниже покажут раличия буферов No-Split и Allow-Split в сравнении с байтовыми буферами, когда данные запрашиваются и возвращаются для потребителя.
Рис. 7. Запрос/возврат элементов для кольцевых буферов No-Split и Allow-Split. Элементы из буферов No-Split и Allow-Split извлекаются в строгом порядке FIFO, и должны быть возвращены для освобождения пространства, занимаемого элементами. Несколько элементов могут быть запрошены перед их возвратом, и элементы необязательно должны быть возвращены в том же порядке, в котором были запрошены. Однако возвращение пространства должно происходить в порядке FIFO, поэтому возврат самого раннего запрошенного элемента предотвратит от освобождения пространства последующих элементов. На диаграмме рис. 7 видно, что элементы из 16, 20 и 8 байт запрашиваются в порядке FIFO. Однако не возвращаются в том порядке, в котором они были запрошены. Сначала возвращается элемент из 20 байт, за тем элемент 8 байт, и затем элемент из 16 байт. Простраство не освобождается, пока не будет возвращен первый элемент, т. е. элемент из 16 байт.
Рис. 8. Запрос/возврат данных в байтовых буферах. Байтовые буферы не позволяют производить несколько запросов перед возвратом (за каждым запросом обязательно должен последовать возврат, перед тем как может быть разрешен другой запрос). Когда используются xRingbufferReceive() или xRingbufferReceiveFromISR(), будут запрошены все непрерывно сохраненные данные. xRingbufferReceiveUpTo() или xRingbufferReceiveUpToFromISR() могут использоваться для ограничения максимального количества запрашиваемых байт. Поскольку каждый запрос должен сопровождаться возвратом, пространство будет освобождено, как только данные были возвращены. Как видно из диаграммы рис. 8, непрерывно сохраненные 38 байт в хвосте буфера запрашиваются, возвращаются и освобождаются. Последующий вызов xRingbufferReceive() или xRingbufferReceiveFromISR() затем приведет к перескоку к началу буфера и делает то же самого с 30 байтами непрерывно сохраненных данных в начале буфера. Кольцевые буферы и наборы очередей. Кольцевые буферы могут быть добавлены в наборы очередей FreeRTOS (queue sets) с использованием xRingbufferAddToQueueSetRead(), так что кажды раз, когда кольцевой буфер принимает элемент или данные, об этом событии будет оповещен queue set. Когда было добавление к queue set, каждая попытка получить элемент из кольцевого буфера должна сопровождаться предварительным вызовом xQueueSelectFromSet(). Для проверки, является ли выбранный член queue set кольцевым буфером, вызовите xRingbufferCanRead(). Следующий пример демонстрирует использование queue set вместе с кольцевыми буферами. #include "freertos/queue.h"
#include "freertos/ringbuf.h"
... // Создание кольцевого буфера и queue set: RingbufHandle_t buf_handle = xRingbufferCreate(1028, RINGBUF_TYPE_NOSPLIT); QueueSetHandle_t queue_set = xQueueCreateSet(3); // Добавление кольцевого буфера к queue set: if (xRingbufferAddToQueueSetRead(buf_handle, queue_set) != pdTRUE) { printf("Failed to add to queue set\n"); } ... // Блокировка на queue set: QueueSetMemberHandle_t member = xQueueSelectFromSet(queue_set, pdMS_TO_TICKS(1000)); // Проверка, является ли элемент из queue set кольцевым буфером: if (member != NULL && xRingbufferCanRead(buf_handle, member) == pdTRUE) { // Это кольцевой буфер, запрос элемента из кольцевого буфера: size_t item_size; char *item = (char *)xRingbufferReceive(buf_handle, &item_size, 0); // Обработка элемента: ... } else { ... } Кольцевые буферы и статическое выделение памяти. Может использоваться xRingbufferCreateStatic() для создания кольцевого буфера со специфическими требованиями к памяти, как например кольцевой буфер, находящийся во внешнем ОЗУ (external RAM). Все блоки памяти, используемые кольцевым буфером, должны быть выделены вручную заранее, и затем переданы в xRingbufferCreateStatic(), чтобы быть инициализированными как кольцевой буфер. Эти блоки включают следующее: • Структура данных кольцевого буфера типа StaticRingbuffer_t. Способ, которым выделяются эти блоки, будет зависеть от требований пользователя (например все блоки декларируются статически, или выделяются динамически, с учетом специальных особенностей, таких как external RAM). Важное замечание: когда уделяется кольцевой буфер, созданный через xRingbufferCreateStatic(), функция vRingbufferDelete() не освободит никакие блоки памяти. Это освобождение должно быть выполнено вручную после вызова vRingbufferDelete(). Следующий кусок кода демонстрирует кольцевой буфер, полностью размещенный в external RAM. #include "freertos/ringbuf.h"
#include "freertos/semphr.h"
#include "esp_heap_caps.h"
#define BUFFER_SIZE 400 // размер, выровненный на 32 бита #define BUFFER_TYPE RINGBUF_TYPE_NOSPLIT
...
// Выделение структуры кольцевого буфера и области хранения в external RAM: StaticRingbuffer_t *buffer_struct = (StaticRingbuffer_t*)heap_caps_malloc(sizeof(StaticRingbuffer_t), MALLOC_CAP_SPIRAM); uint8_t *buffer_storage = (uint8_t*)heap_caps_malloc(sizeof(uint8_t)*BUFFER_SIZE, MALLOC_CAP_SPIRAM); // Создание кольцевого буфера с вручную выделенной памятью: RingbufHandle_t handle = xRingbufferCreateStatic(BUFFER_SIZE, BUFFER_TYPE, buffer_storage, buffer_struct); ... // Удаление кольцевого буфера после использования:
vRingbufferDelete(handle);
// Освобождение всех блоков памяти вручную:
free(buffer_struct);
free(buffer_storage);
Инверсия приоритета. В идеале кольцевые буферы могут использоваться с несколькими задачами в среде SMP, когда задача с самым высоким приоритетом будет всегда обслуживаться первой. Однако из-за использования бинарных семафоров в нижележащей реализации кольцевого буфера инверсия приоритета может произойти при очень специфических обстоятельствах. Кольцевой буфер управляет отправкой с помощью двоичного семафора, который выдается всякий раз, когда освобождается пространство в кольцевом буфере. Задача с наивысшим приоритетом, ожидающая отправки, будет неоднократно брать семафор до тех пор, пока не станет доступно достаточное количество свободного места, или пока не истечет таймаут. В идеале это должно предотвратить обслуживание любых задач низкого приоритета, поскольку семафор всегда должен быть отдан задаче с самым высоким приоритетом. Однако в промежутках между итерациями получения семафора есть зазор в критической секции, который может позволить другой задаче (на другом ядре, или с еще более высоким приоритетом) освободить некоторое место в кольцевом буфере, и в результате может быть выдан семафор. Поэтому семафор будет предоставлен до того, как задача с самым высоким приоритетом сможет повторно получить семафор. Это приведет к тому, что семафор будет захвачен задачей второго уровня по приоритету, которая ожидает отправки, и это вызовет инверсию приоритета. Этот побочный эффект не приведет значительно на производительность кольцевого буфера, если число задач, одновременно использующих кольцевой буфер, невелико, и кольцевой буфер не работает вблизи максимальной емкости. [Перехватчики ESP-IDF для тика и для состояния ожидания] FreeRTOS позволяет приложениям предоставить обработчик тика (tick hook) и обработчик состояния ожидания (idle hook) во время компиляции: • FreeRTOS tick hook может быть разрешен опцией CONFIG_FREERTOS_USE_TICK_HOOK. Приложение должно предоставить для обработчика callback-функцию void vApplicationTickHook (void). Однако обработчики FreeRTOS имеют следующие недостатки: • Обработчики FreeRTOS регистрируются во время компиляции. ESP-IDF предоставляет свои обработчики тика и idle для поддержки FreeRTOS-функций перехвата тика и idle. Обработчики ESP-IDF имеют следующие возможности: • Обработчики могут регистрироваться и может отменяться их регистрация во время работы приложения (run-time). Обработчики ESP-IDF могут быть зарегистрированы и дерегистрированы следующими вызовами API-функций: Tick hook. Обработчики регисрируются вызовом esp_register_freertos_tick_hook() или esp_register_freertos_tick_hook_for_cpu(). Дерегистрация производится вызовом esp_deregister_freertos_tick_hook() или esp_deregister_freertos_tick_hook_for_cpu(). Idle hook. Обработчики регисрируются вызовом esp_register_freertos_idle_hook() или esp_register_freertos_idle_hook_for_cpu(). Дерегистрация производится вызовом esp_deregister_freertos_idle_hook() или esp_deregister_freertos_idle_hook_for_cpu(). Важное замечание: прерывание тика остается активным, когда кэш отключен, поэтому любые функции tick hook (FreeRTOS или ESP-IDF) должны быть размещены во внутреннем ОЗУ (internal RAM). Подробности см. в документации по SPI flash API [4], раздел "IRAM-Safe Interrupt Handlers". [Callback-функции удаления TLSP] Vanilla FreeRTOS предоставляет функцию указателей на хранилище задачи (Thread Local Storage Pointers, TLSP). Эти указатели сохраняются непосредственно в блоке управления задачей (Task Control Block, TCB) для каждой отдельной задачи. TLSP позволяет каждой задаче иметь свой собственный уникальный набор указателей на структуры данных. Vanilla FreeRTOS ожидает от пользователей следующее: • Установку TLSP указателей для задачи путем вызова vTaskSetThreadLocalStoragePointer() после того, как задача была создана. Однако могут быть ситуации, когда пользователям нужно получить автоматическое освобождение памяти TLSP. Поэтому ESP-IDF FreeRTOS предоставляет дополнительную возможность в виде callback-функций удаления TLSP. Эти callback-функции подготавливаются пользователем, и они вызываются автоматически в момент удаления задачи. Таким образом, память TLSP может быть очищена без необходимости добавления в каждую задачу кода логики очистки память. Callback-функции удаления TLSP устанавливаются аналогично самими TLSP. • vTaskSetThreadLocalStoragePointerAndDelCallback() устанавливает оба определенный TLSP и связанный с ним callback. Когда реализуются callback-функции TLSP, пользователи должны иметь в виду следующее: • Callback никогда не должен пытаться делать блокировку или выполнять уступать контекст (yield), и критические секции должны быть настолько короткими, насколько это возможно. [Свойства, специфичные для компонента] Помимо стандартных переменных компонента, которые доступны с базовыми свойствами сборки cmake, компонент FreeRTOS также предоставляет аргументы (пока только один) для упрощения интеграции с другими модулями: ORIG_INCLUDE_PATH - содержит абсолютный путь до корня папки подключаемых заголовков FreeRTOS. Таким образом, вместо #include "freertos/FreeRTOS.h" можно просто подключать заголовки напрямую: #include "FreeRTOS.h". [Справочник API] Подробное описание функций, структур и определений типа см. в [1].
[Словарик] FIFO First Input First Output, принцип сохранения информации в буфер и извлечения информации из него - первым пришел, первым вышел. ISR Interrupt Service Routine, обработчик прерывания. SMP Symmetric MultiProcessing, симметричное выполнение кода с использованием нескольких процессорных ядер. TCB Task Control Block, блок управления задачей. TLSP Thread Local Storage Pointer, указатель на локальное хранилище информации потока. [Ссылки] 1. FreeRTOS Supplemental Features site:docs.espressif.com. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||