|
ąØą░ čäąĖąĘąĖč湥čüą║ąŠą╝ ą┤ąĖčüą║ąĄ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čäą░ą╣ą╗ą░ čģčĆą░ąĮąĖčéčüčÅ ą▒ą╗ąŠą║ą░ą╝ąĖ čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░ (ąĮą░ čüąŠą▓čĆąĄą╝ąĄąĮąĮčŗčģ čäą░ą╣ą╗ąŠą▓čŗčģ čüąĖčüč鹥ą╝ą░čģ čŹč鹊 ą▒ą╗ąŠą║ąĖ čĆą░ąĘą╝ąĄčĆąŠą╝ 4 KiB ąĖą╗ąĖ ą▒ąŠą╗čīčłąĄ). ąÜąŠą│ą┤ą░ ą▓čüąĄ ą▒ą░ą╣čéčŗ ą▓ čéą░ą║ąŠą╝ ą▒ą╗ąŠą║ąĄ čüąŠą┤ąĄčƹȹ░čé 0, čäą░ą╣ą╗ąŠą▓ą░čÅ čüąĖčüč鹥ą╝ą░, ą▓ ą║ąŠč鹊čĆąŠą╣ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮčŗ čĆą░ąĘčĆąĄąČąĄąĮąĮčŗąĄ čäą░ą╣ą╗čŗ (sparse files) ąĮąĄ čüąŠčģčĆą░ąĮčÅąĄčé čéą░ą║ąŠą╣ ą▒ą╗ąŠą║ ąĮą░ ą┤ąĖčüą║, ąĘą░ą┐ąĖčüčŗą▓ą░čÅ ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠ čéą░ą║ąŠą╝ ą▒ą╗ąŠą║ąĄ ą▓ ą╝ąĄčéą░ą┤ą░ąĮąĮčŗčģ čäą░ą╣ą╗ą░.
ąöąŠčüč鹊ąĖąĮčüčéą▓ą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čĆą░ąĘčĆąĄąČąĄąĮąĮčŗčģ čäą░ą╣ą╗ąŠą▓:
ŌĆó ą¤čāčüčéčŗąĄ ą▒ą╗ąŠą║ąĖ ą┤ą░ąĮąĮčŗčģ ąĮąĄ ąĘą░ąĮąĖą╝ą░čÄčé ą╝ąĄčüč鹊 ąĮą░ ą┤ąĖčüą║ąĄ; ą▓ą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą▓ ą╝ąĄčéą░ą┤ą░ąĮąĮčŗčģ čäą░ą╣ą╗ą░ čüąŠčģčĆą░ąĮčÅąĄčéčüčÅ č鹊ą╗čīą║ąŠ ąĖčģ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆčŗ (čćč鹊 čüąŠčüčéą░ą▓ą╗čÅąĄčé č鹊ą╗čīą║ąŠ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▒ą░ą╣čé). ąóą░ą║ąĖą╝ čüą┐ąŠčüąŠą▒ąŠą╝ 菹║ąŠąĮąŠą╝ąĖčéčüčÅ 4 KiB (ąĖą╗ąĖ ą▒ąŠą╗čīčłąĄ) čäąĖąĘąĖč湥čüą║ąŠą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ą┤ąĖčüą║ą░ ąĮą░ ą║ą░ąČą┤čŗą╣ ą┐čāčüč鹊ą╣ ą▒ą╗ąŠą║.
ŌĆó ą¦č鹥ąĮąĖąĄ ą┐čāčüč鹊ą│ąŠ ą▒ą╗ąŠą║ą░ ą┤ą░ąĮąĮčŗčģ ąĖąĘ čĆą░ąĘčĆąĄąČąĄąĮąĮąŠą│ąŠ čäą░ą╣ą╗ą░ ąĮąĄ ąĘą░ąĮąĖą╝ą░ąĄčé ą▓čĆąĄą╝čÅ, ą┐ąŠč鹊ą╝čā čćč鹊 ą┤ą░ąĮąĮčŗąĄ ąĮąĄ čüčćąĖčéčŗą▓ą░čÄčéčüčÅ čü ą┤ąĖčüą║ą░. ą¤ąŠčüą║ąŠą╗čīą║čā čäą░ą╣ą╗ąŠą▓ą░čÅ čüąĖčüč鹥ą╝ą░ ąĘąĮą░ąĄčé, čćč鹊 ą▓čüąĄ ą▒ą░ą╣čéčŗ ą▓ ą▒ą╗ąŠą║ąĄ čĆą░ą▓ąĮčŗ 0, ąŠąĮą░ ą┐čĆąŠčüč鹊 čāčüčéą░ąĮąŠą▓ąĖčé ą▓ 0 ą▓čüąĄ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖąĄ ą▒ą░ą╣čéčŗ ą▓ ą▒čāč乥čĆąĄ, ąĖ čŹčéąĖ ą┤ą░ąĮąĮčŗąĄ čüčĆą░ąĘčā ą│ąŠč鹊ą▓čŗ ą║ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÄ. ąØąĄčé ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ ąŠčüčāčēąĄčüčéą▓ą╗čÅčéčī ą┤ąŠčüčéčāą┐ ą║ ą╝ąĄą┤ą╗ąĄąĮąĮąŠą╝čā čāčüčéčĆąŠą╣čüčéą▓čā čģčĆą░ąĮąĄąĮąĖčÅ.
ŌĆó ąŚą░ą┐ąĖčüčī ą┐čāčüč鹊ą│ąŠ ą▒ą╗ąŠą║ą░ ą┤ą░ąĮąĮčŗčģ ą▓ čĆą░ąĘčĆąĄąČąĄąĮąĮčŗą╣ čäą░ą╣ą╗ ąĮąĄ ąĘą░ąĮąĖą╝ą░ąĄčé ą▓čĆąĄą╝čÅ. ąÆąŠ ą▓čĆąĄą╝čÅ ąĘą░ą┐ąĖčüąĖ čäą░ą╣ą╗ąŠą▓ą░čÅ čüąĖčüč鹥ą╝ą░ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé, čćč鹊 ą▒ą╗ąŠą║ ą┐čāčüč鹊ą╣ (ą▓čüąĄ ąĄą│ąŠ ą▒ą░ą╣čéčŗ čĆą░ą▓ąĮčŗ 0), ąĖ ąŠąĮą░ ą┐ąŠą╝ąĄčüčéąĖčé ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ą▒ą╗ąŠą║ą░ (block ID) ą▓ čüą┐ąĖčüąŠą║ ą┐čāčüčéčŗčģ ą▒ą╗ąŠą║ąŠą▓ (čŹč鹊čé čüą┐ąĖčüąŠą║ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą╝ąĄčéą░ą┤ą░ąĮąĮčŗčģ čäą░ą╣ą╗ą░). ą¤čĆąĖ čŹč鹊ą╝ ąĮą░ ą┤ąĖčüą║ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ąĮą░ą╝ąĮąŠą│ąŠ ą╝ąĄąĮčīčłąĄ ąĖąĮč乊čĆą╝ą░čåąĖąĖ.
ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čā ą▓čüąĄ ąĄčüčéčī čäą░ą╣ą╗, ą│ą┤ąĄ ą╝ąĮąŠą│ąŠ ą┐čāčüčéčŗčģ ą▒ą░ą╣čé \x00. ąŁčéąĖ ą┐čāčüčéčŗąĄ ą▒ą░ą╣čéčŗ ąĮą░ąĘčŗą▓ą░čÄčé ą┤čŗčĆą║ą░ą╝ąĖ (holes). ąśčģ čģčĆą░ąĮąĄąĮąĖąĄ ąĮąĄčŹčäč乥ą║čéąĖą▓ąĮąŠ, ąĖ ą╝čŗ ąĘąĮą░ąĄą╝, čüą║ąŠą╗čīą║ąŠ ąĖčģ ą▓ čäą░ą╣ą╗ąĄ, čéą░ą║ čćč鹊 ąĘą░č湥ą╝ ąĖčģ čģčĆą░ąĮąĖčéčī ąĮą░ čāčüčéčĆąŠą╣čüčéą▓ąĄ? ąÆą╝ąĄčüč鹊 čŹč鹊ą│ąŠ ą╝ąŠąČąĮąŠ čģčĆą░ąĮąĖčéčī ą╝ąĄčéą░ą┤ą░ąĮąĮčŗąĄ, ąŠą┐ąĖčüčŗą▓ą░čÄčēąĖąĄ čŹčéąĖ ąĮčāą╗ąĖ. ąÜąŠą│ą┤ą░ ą┐čĆąŠčåąĄčüčü čüčćąĖčéčŗą▓ą░ąĄčé čäą░ą╣ą╗, čŹčéąĖ ą▒ą╗ąŠą║ąĖ čü ąĮčāą╗ąĄą▓čŗą╝ąĖ ą▒ą░ą╣čéą░ą╝ąĖ ą│ąĄąĮąĄčĆąĖčĆčāčÄčéčüčÅ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąĖ ą▓ą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ čüčćąĖčéčŗą▓ą░čéčīčüčÅ čü čäąĖąĘąĖč湥čüą║ąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ čģčĆą░ąĮąĄąĮąĖčÅ (čüą╝. ąĮą░ čüą╗ąĄą┤čāčÄčēčāčÄ čüčģąĄą╝čā ąĖąĘ ąÆąĖą║ąĖą┐ąĄą┤ąĖąĖ):
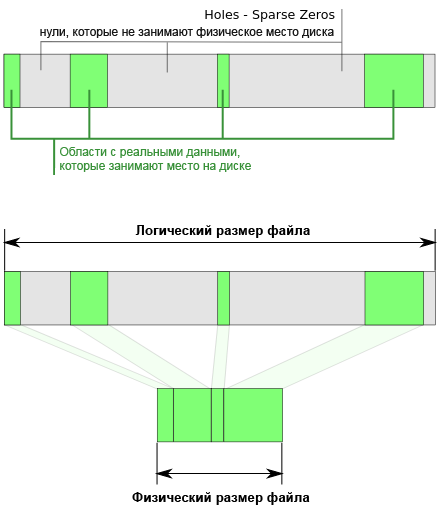
ą¤ąŠ čŹč鹊ą╣ ą┐čĆąĖčćąĖąĮąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ čĆą░ąĘčĆąĄąČąĄąĮąĮąŠą│ąŠ čäą░ą╣ą╗ą░ čŹčäč乥ą║čéąĖą▓ąĮąŠ, čéą░ą║ ą║ą░ą║ ą╝čŗ ąĮąĄ čüąŠčģčĆą░ąĮčÅąĄą╝ ąĮčāą╗ąĖ ąĮą░ ą┤ąĖčüą║, čģčĆą░ąĮčÅ č鹊ą╗čīą║ąŠ ąĮąĄą▒ąŠą╗čīčłčāčÄ ą┐ąŠčĆčåąĖčÄ ą┤ą░ąĮąĮčŗčģ, ąŠą┐ąĖčüčŗą▓ą░čÄčēčāčÄ čüą║ąŠą╗čīą║ąŠ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąŠ ąĮčāą╗ąĄą▓čŗčģ ą▒ą░ą╣čé.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ą╗ąŠą│ąĖč湥čüą║ąĖą╣ čĆą░ąĘą╝ąĄčĆ čäą░ą╣ą╗ą░ ą▒ąŠą╗čīčłąĄ, č湥ą╝ čäąĖąĘąĖč湥čüą║ąĖą╣ čĆą░ąĘą╝ąĄčĆ čĆą░ąĘčĆąĄąČąĄąĮąĮąŠą│ąŠ čäą░ą╣ą╗ą░.
[fallocate: ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖčÅ čĆą░ąĘčĆąĄąČąĄąĮąĮąŠą│ąŠ čäą░ą╣ą╗ą░]
ąĢčüą╗ąĖ ą▓čŗ ąĘą░ą┐čāčüčéąĖč鹥 ą║ąŠą╝ą░ąĮą┤čā:
$ dd if=/dev/zero of=output bs=1G count=4
ąŁčéą░ ą║ąŠą╝ą░ąĮą┤ą░ ą║ąŠą┐ąĖčĆčāąĄčé 4G ą▒ą╗ąŠą║ą░ ąĮčāą╗ąĄą▓čŗčģ ą▒ą░ą╣čé ą▓ čäą░ą╣ą╗ output. ą¦č鹊ą▒čŗ čŹč鹊 čāą▓ąĖą┤ąĄčéčī, ąĘą░ą┐čāčüčéąĖč鹥:
$ stat output
File: output
Size: 4294967296 Blocks: 8388616 IO Block: 4096 regular file
...
ąÆčŗ čāą▓ąĖą┤ąĖč鹥 čćč鹊 ą┤ą╗čÅ čŹč鹊ą│ąŠ čäą░ą╣ą╗ą░ ą▒čŗą╗ąŠ ą▓čŗą┤ąĄą╗ąĄąĮąŠ 8388616 ą▒ą╗ąŠą║ąŠą▓, ą▓ ą║ąŠč鹊čĆčŗčģ ąĮąĄčé ąĮąĖč湥ą│ąŠ, ą║čĆąŠą╝ąĄ ą┐čāčüčéčŗčģ ą▒ą░ą╣čé, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ čüą║ąŠą┐ąĖčĆąŠą▓ą░ąĮčŗ čü čāčüčéčĆąŠą╣čüčéą▓ą░ /dev/zero, ąĖ ąŠąĮąĖ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠ ą┐ąŠčÅą▓ąĖą╗ąĖčüčī ąĮą░ čäąĖąĘąĖč湥čüą║ąŠą╝ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąĄ ą┤ąĖčüą║ąĄ, čŹč鹊 "ą┤čŗčĆčŗ" (sparse zeros). ąŻčéąĖą╗ąĖčéą░ dd čüą┤ąĄą╗ą░ą╗ą░ č鹊, čćč鹊 ą▓čŗ ąĘą░ą┐čĆąŠčüąĖą╗ąĖ, čüą║ąŠą┐ąĖčĆąŠą▓ą░ą▓ ą▒ą╗ąŠą║ąĖ ą┤ą░ąĮąĮčŗčģ ąĖąĘ ąŠą┤ąĮąŠ čäą░ą╣ą╗ą░ ą▓ ą┤čĆčāą│ąŠą╣.
ąóąĄą┐ąĄčĆčī ąĘą░ą┐čāčüčéąĖč鹥 čŹčéčā ą║ąŠą╝ą░ąĮą┤čā, čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą┤čŗčĆčŗ ąĖ čüą┤ąĄą╗ą░čéčī ą┐ąŠ ą╝ąĄčüčéčā čĆą░ąĘčĆąĄąČąĄąĮąĮčŗą╣ čäą░ą╣ą╗:
$ fallocate -d output
$ stat output
File: swapfile
Size: 4294967296 Blocks: 0 IO Block: 4096 regular file
...
ąÜąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ą╗ąŠą║ąŠą▓ č鹥ą┐ąĄčĆčī čüčéą░ą╗ąŠ 0, ą┐ąŠč鹊ą╝čā ą▒ą╗ąŠą║ąĖ, ą│ą┤ąĄ čģčĆą░ąĮąĖą╗ąĖčüčī č鹊ą╗čīą║ąŠ ąĮčāą╗ąĖ, ą▒čŗą╗ąĖ ą┐ąĄčĆąĄčĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮčŗ. ą¤ąŠčüą║ąŠą╗čīą║čā ą▒ą╗ąŠą║ąĖ čäą░ą╣ą╗ą░ output ąĮąĖč湥ą│ąŠ ąĮąĄ čģčĆą░ąĮčÅčé, č鹊ą╗čīą║ąŠ ąĮčāą╗ąĖ, ą║ąŠą╝ą░ąĮą┤ą░ fallocate -d ąŠą┐čĆąĄą┤ąĄą╗ąĖą╗ą░ čŹčéąĖ ą┐čāčüč鹊čéčŗ ąĖ ąŠčéą╝ąĄąĮąĖą╗ą░ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ą┤ą╗čÅ ąĮąĖčģ čäąĖąĘąĖč湥čüą║ąŠą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░. ą¤čĆąĖ čŹč鹊ą╝ čĆą░ąĘą╝ąĄčĆ čäą░ą╣ą╗ą░ ąĮąĄ ą┐ąŠą╝ąĄąĮčÅą╗čüčÅ. ąŁč鹊 ą╗ąŠą│ąĖč湥čüą║ąĖą╣ (ą▓ąĖčĆčéčāą░ą╗čīąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ) čäą░ą╣ą╗ą░, ąĮąŠ ąĮąĄ ąĄą│ąŠ ąĘą░ąĮąĖą╝ą░ąĄą╝ąŠąĄ ą╝ąĄčüč鹊 ąĮą░ ą┤ąĖčüą║ąĄ.
ą¤ąŠą╝ąĮąĖč鹥, čćč鹊 ą║ąŠą│ą┤ą░ ą▓čŗ čćąĖčéą░ąĄč鹥 čäą░ą╣ą╗ output, ą┐čāčüčéčŗąĄ ą▒ą░ą╣čéčŗ ą│ąĄąĮąĄčĆąĖčĆčāčÄčéčüčÅ čäą░ą╣ą╗ąŠą▓ąŠą╣ čüąĖčüč鹥ą╝ąŠą╣ ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąĖ, ąŠąĮąĖ ąĮą░ čüą░ą╝ąŠą╝ ą┤ąĄą╗ąĄ čäąĖąĘąĖč湥čüą║ąĖ ąĮąĄ čģčĆą░ąĮčÅčéčüčÅ ąĮą░ ą┤ąĖčüą║ąĄ, ąĖ čĆą░ąĘą╝ąĄčĆ čäą░ą╣ą╗ą░, ą║ą░ą║ čüąŠąŠą▒čēą░ąĄčé stat, čÅą▓ą╗čÅąĄčéčüčÅ ą╗ąŠą│ąĖč湥čüą║ąĖą╝ čĆą░ąĘą╝ąĄčĆąŠą╝, ą░ čäąĖąĘąĖč湥čüą║ąĖą╣ čĆą░ąĘą╝ąĄčĆ čĆą░ą▓ąĄąĮ ąĮčāą╗čÄ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ čäą░ą╣ą╗ąŠą▓ą░čÅ čüąĖčüč鹥ą╝ą░ ą┤ąŠą╗ąČąĮą░ ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī 4G ą┐čāčüčéčŗčģ ą▒ą░ą╣č鹊ą▓, ą║ąŠą│ą┤ą░ ą┐čĆąŠčåąĄčüčü čćąĖčéą░ąĄčé čäą░ą╣ą╗.
ąöą╗čÅ ą│ąĄąĮąĄčĆą░čåąĖąĖ čĆą░ąĘčĆąĄąČąĄąĮąĮąŠą│ąŠ čäą░ą╣ą╗ą░ čü ą┐ąŠą╝ąŠčēčīčÄ dd:
$ dd if=/dev/zero of=output2 bs=1G seek=0 count=0
$ stat
stat output2
File: output2
Size: 4294967296 Blocks: 0 IO Block: 4096 regular file
GNU dd ą▓ąĮčāčéčĆąĖ čüąĄą▒čÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčé lseek ąĖ ftruncate, čüą╝. truncate(2) ąĖ lseek(2).
[ąĪčüčŗą╗ą║ąĖ]
1. What is a sparse file and why do we need it? site:stackoverflow.com. |



