|
ąÜąŠą╝ą┐ą░ąĮąĖčÅ Analog Devices ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┐ąŠčĆčé ąŠą▒ą╗ąĄą│č湥ąĮąĮąŠą│ąŠ čüč鹥ą║ą░ TCP/IP (light-weight TCP/IP, LwIP) ą┤ą╗čÅ čüąĄą╝ąĄą╣čüčéą▓ą░ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin┬«. ąĪč鹥ą║ LwIP ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ Blackfin ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ čüąĄč鹥ą▓čŗčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ ą▓ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ čü ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅą╝ąĖ ą┤ą╗čÅ ąĘą▓čāą║ą░/ą▓ąĖą┤ąĄąŠ ąĖą╗ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅą╝ąĖ ą┤ą╗čÅ ąĖąĮą┤čāčüčéčĆąĖą░ą╗čīąĮąŠą╣ ą░ą▓č鹊ą╝ą░čéąĖąĘą░čåąĖąĖ ąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ. LwIP čŹč鹊 ą┐čĆąĖą▓ą╗ąĄą║ą░č鹥ą╗čīąĮčŗą╣ ąĖąĮčüčéčĆčāą╝ąĄąĮčé ą┤ą╗čÅ ą▒čŗčüčéčĆąŠą│ąŠ ą┐ąŠčĆčéąĖčĆąŠą▓ą░ąĮąĖčÅ ąŠčéą┤ąĄą╗čīąĮčŗčģ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ ą▓ąŠ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗąĄ čüąĄč鹥ą▓čŗąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ.
ąśąĮč鹥ą│čĆą░čåąĖčÅ ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗčģ ą║ąŠą╝ą┐ąŠąĮąĄąĮč鹊ą▓ ą▓ ąŠą┤ąĮąŠ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ čÅą▓ą╗čÅąĄčéčüčÅ čüą╗ąŠąČąĮąŠą╣ ąĘą░ą┤ą░č湥ą╣. ąÜąŠą│ą┤ą░ ąÆčŗ ąĖčüą┐ąŠą╗čīąĘčāąĄč鹥 ą╝ąĮąŠą│ąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗąĄ ą║ąŠą╝ą┐ąŠąĮąĄąĮčéčŗ, čüą╗ąŠąČąĮąŠčüčéčī čüąĖčüč鹥ą╝čŗ čĆą░čüč鹥čé ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ą░ąĮą░ą╗ąĖąĘą░ čāčéąĖą╗ąĖąĘą░čåąĖąĖ čĆąĄčüčāčĆčüąŠą▓ čüąĖčüč鹥ą╝čŗ, čéčĆąĄą▒ąŠą▓ą░ąĮąĖą╣ ą║ ą┐čĆąŠą┐čāčüą║ąĮąŠą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ, čĆą░ąĘčĆąĄčłąĄąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗčģ ąĖ ą░ą┐ą┐ą░čĆą░čéąĮčŗčģ ą║ąŠąĮčäą╗ąĖą║č鹊ą▓, ąŠčéą╗ą░ą┤ą║ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, ąĖ čé. ą┤. ąöą╗čÅ ą┐ąŠčüčéčĆąŠąĄąĮąĖčÅ čŹčäč乥ą║čéąĖą▓ąĮčŗčģ ąĖ ąĮą░ą┤ąĄąČąĮčŗčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ ą┐čĆąĖ ąĖąĮč鹥ą│čĆąĖčĆąŠą▓ą░ąĮąĖąĖ LwIP ąĮčāąČąĮąŠ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ čłą░ą│ąŠą▓. ąŁč鹊čé ą┤ąŠą║čāą╝ąĄąĮčé (ą┐ąĄčĆąĄą▓ąŠą┤ čüčéą░čéčīąĖ ąĪčüčŗą╗ą║ąĖ/[1]) ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąŠ ą┐ąŠ ąĖąĮč鹥ą│čĆą░čåąĖąĖ LwIP ą▓ ą┤čĆčāą│ąĖąĄ čüąĖčüč鹥ą╝čŗ ąĖą╗ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. ą×čüąĮąŠą▓ąĮą░čÅ čåąĄą╗čī čĆčāą║ąŠą▓ąŠą┤čüčéą▓ą░ - ą╝ąĖąĮąĖą╝ąĖąĘąĖčĆąŠą▓ą░čéčī čĆą░čüą┐čĆąŠčüčéčĆą░ąĮąĄąĮąĮčŗąĄ ąŠčłąĖą▒ą║ąĖ ą┐čĆąĖ čüąŠąĘą┤ą░ąĮąĖąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ ąĮą░ ąŠčüąĮąŠą▓ąĄ čüč鹥ą║ą░ LwIP ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ Blackfin. ąŁč鹊čé ą┤ąŠą║čāą╝ąĄąĮčé čéą░ą║ąČąĄ ąŠą▒čüčāąČą┤ą░ąĄčé č鹥čģąĮąĖą║ąĖ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ čüąĖčüč鹥ą╝čŗ, ą║ąŠč鹊čĆčŗąĄ ą┤ąĄą╗ą░čÄčé ą▓ąŠąĘą╝ąŠąČąĮčŗą╝ ą┤ąŠčüčéąĖąČąĄąĮąĖąĄ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą│ąŠ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖčÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ Blackfin ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ąĖąĮč鹥ą│čĆą░čåąĖąĖ čüč鹥ą║ą░ LwIP. ąóą░ą║ąČąĄ ąŠą┐ąĖčüą░ąĮčŗ ą┐čĆąŠčåąĄčüčüąŠčĆąĮčŗąĄ čĆąĄčüčāčĆčüčŗ, ą║ąŠč鹊čĆčŗąĄ ąĘą░ą┤ąĄą╣čüčéą▓ąŠą▓ą░ąĮčŗ ą┤ą╗čÅ ą┐ąŠčĆčéą░ LwIP, čćč鹊ą▒čŗ ą┐ąŠą╝ąŠčćčī ąÆą░ą╝ čĆą░ąĘčĆą░ą▒ąŠčéą░čéčī čŹčäč乥ą║čéąĖą▓ąĮčāčÄ čüąĖčüč鹥ą╝čā.
[ą×ą▒ąĘąŠčĆ LwIP ąĖ ą▓čŗą│ąŠą┤čŗ ąŠčé ąĄą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ]
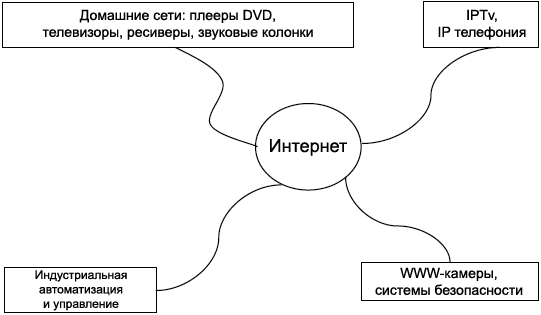
ąÆčüčéčĆą░ąĖą▓ą░ąĄą╝čŗąĄ čüąĄč鹥ą▓čŗąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ čüąĄą╣čćą░čü ą▓čüąĄ čćą░čēąĄ ą┐čĆąĖčüą┐ąŠčüą░ą▒ą╗ąĖą▓ą░čÄčéčüčÅ ą║ ą┐ąĄčĆąĄą┤ą░č湥 ą╝čāą╗čīčéąĖą╝ąĄą┤ąĖą╣ąĮąŠą│ąŠ ą║ąŠąĮč鹥ąĮčéą░ (ąĘą▓čāą║, ą▓ąĖą┤ąĄąŠ ąĖ čé. ą┐.) č湥čĆąĄąĘ ą┐čĆąŠą▓ąŠą┤ąĮčŗąĄ ąĖ ą▒ąĄčüą┐čĆąŠą▓ąŠą┤ąĮčŗąĄ čüąĄčéąĖ. ąśąĮą┤čāčüčéčĆąĖą░ą╗čīąĮčŗąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą░ą▓č鹊ą╝ą░čéąĖąĘą░čåąĖąĖ ąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ - ą┤čĆčāą│ą░čÅ ąŠą▒ą╗ą░čüčéčī, ą║ąŠč鹊čĆą░čÅ ąĮčāąČą┤ą░ąĄčéčüčÅ ą▓ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖčÅ ą║ čüąĄčéąĖ. ąØą░ čĆąĖčü. 1 ą┐ąŠą║ą░ąĘą░ąĮčŗ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, ą▓ ą║ąŠč鹊čĆčŗčģ čéčĆąĄą▒čāąĄčéčüčÅ ąĮą░ą╗ąĖčćąĖąĄ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖčÅ ą║ ąśąĮč鹥čĆąĮąĄčé.
ąÜąŠą╝ą┐ą░ąĮąĖčÅ Analog Devices ą┐čĆąĄą┤ą╗ą░ą│ą░ąĄčé čüą▓ąŠą▒ąŠą┤ąĮčŗąĄ ąŠčé ą▓čŗą┐ą╗ą░čé (ą┐čĆąĖ čāčüą╗ąŠą▓ąĖąĖ čüąŠą▒ą╗čÄą┤ąĄąĮąĖčÅ ą╗ąĖčåąĄąĮąĘąĖąŠąĮąĮąŠą│ąŠ čüąŠą│ą╗ą░čłąĄąĮąĖčÅ) ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗąĄ ą▒ą╗ąŠą║ąĖ, ą┐ąŠąĘą▓ąŠą╗čÅčÄčēąĖąĄ ą▒čŗčüčéčĆčāčÄ čĆą░ąĘčĆą░ą▒ąŠčéą║čā čüą╗ąŠąČąĮčŗčģ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ čüąĄč鹥ą▓čŗčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣. ąØąĖąČąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮ čüą┐ąĖčüąŠą║ ąŠčüąĮąŠą▓ąĮčŗčģ ąĖ ą▒ą░ąĘąŠą▓čŗčģ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗčģ ą║ąŠą╝ą┐ąŠąĮąĄąĮč鹊ą▓, ą║ąŠč鹊čĆčŗąĄ ą┤ąŠčüčéčāą┐ąĮčŗ ą▓ą╝ąĄčüč鹥 čüąŠ čüčĆąĄą┤čüčéą▓ą░ą╝ąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Analog Devices VisualDSP++┬« 4.5 ąĖ ą▒ąŠą╗ąĄąĄ čüą▓ąĄąČąĄą╣ ą▓ąĄčĆčüąĖąĖ:
ŌĆó LwIP ŌĆō ąŠą▒ą╗ąĄą│č湥ąĮąĮčŗą╣ čüč鹥ą║ TCP/IP (čüą╝. ąĪą┐ąĖčüąŠą║ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ą╗ąĖč鹥čĆą░čéčāčĆčŗ/[1]), ą║ąŠč鹊čĆčŗą╣ ą▒čŗą╗ ą┐ąŠčĆčéąĖčĆąŠą▓ą░ąĮ ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆčŗ ADSP-BF52x, ADSP-BF54x, ADSP-BF53x ąĖ ADSP-BF56x1.
ŌĆó ąöčĆą░ą╣ą▓ąĄčĆčŗ čāčüčéčĆąŠą╣čüčéą▓ ąĖ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ čüąĖčüč鹥ą╝ąĮčŗčģ čüąĄčĆą▓ąĖčüąŠą▓ (SSL) ŌĆō čäčāąĮą║čåąĖąĖ API ą┤ą╗čÅ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖčÅ ąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čüąĖčüč鹥ą╝ąĮčŗą╝ąĖ čĆąĄčüčāčĆčüą░ą╝ąĖ ąĖ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗą╝ąĖ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ąĖ (čüą╝. ąĪčüčŗą╗ą║ąĖ/[2]).
ŌĆó VisualDSP++ Kernel (VDK) (ąĪčüčŗą╗ą║ąĖ/[3]) ŌĆō čÅą┤čĆąŠ čĆąĄą░ą╗čīąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ (RTOS). ąśčüą┐ąŠą╗čīąĘčāą╣č鹥 čŹč鹊 ąĮąĄ čéčĆąĄą▒ąŠą▓ą░č鹥ą╗čīąĮąŠąĄ ą║ čĆąĄčüčāčĆčüą░ą╝ čÅą┤čĆąŠ ą┤ą╗čÅ čŹčäč乥ą║čéąĖą▓ąĮąŠą│ąŠ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čüąĖčüč鹥ą╝ąĮčŗą╝ąĖ čĆąĄčüčāčĆčüą░ą╝ąĖ ą▓ ą╝ąĮąŠą│ąŠąĘą░ą┤ą░čćąĮąŠą╝ čĆą░ą▒ąŠč湥ą╝ ąŠą║čĆčāąČąĄąĮąĖąĖ ą┤ą╗čÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ.
ŌĆó MM SDK ŌĆō Multimedia Software Development Kit (čüą╝. ąĪą┐ąĖčüąŠą║ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ą╗ąĖč鹥čĆą░čéčāčĆčŗ/[16]). ą×čé ą▓ą║ą╗čÄčćą░ąĄčé ą┐čĆąĖą╝ąĄčĆčŗ ą║ąŠą┤ą░ ąŠą▒čēąĖčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣, ą▓čüčéčĆąĄčćą░čÄčēąĖčģčüčÅ ą▓ čĆąĄą░ą╗čīąĮąŠą╝ ą╝ąĖčĆąĄ ą╝čāą╗čīčéąĖą╝ąĄą┤ąĖą░.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ 1: čüč鹥ą║ LwIP ąĮąĄą┤ąŠčüčéčāą┐ąĄąĮ ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ ADSP-BF535 Blackfin.
ąĀąĖčü. 1. ąóąĖą┐ąĖčćąĮąŠąĄ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝ąŠąĄ čüąĄč鹥ą▓ąŠąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ.
ąĀąĄą░ą╗čīąĮčŗąĄ čüąĄč鹥ą▓čŗąĄ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą╝ąŠą│čāčé ąĖąĮč鹥ą│čĆąĖčĆąŠą▓ą░čéčīčüčÅ čü čŹčéąĖą╝ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗą╝ąĖ ą▒ą╗ąŠą║ą░ą╝ąĖ, čćč鹊ą▒čŗ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī čüąĖčüč鹥ą╝čā čü ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗą╝ąĖ čäčāąĮą║čåąĖčÅą╝ąĖ. ąśąĮč鹥ą│čĆą░čåąĖčÅ čĆą░ąĘą╗ąĖčćąĮčŗčģ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗčģ ą║ąŠą╝ą┐ąŠąĮąĄąĮč鹊ą▓ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ čĆą░ąĘą╗ąĖčćąĮčŗą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗą╝ ąĖ ą░ą┐ą┐ą░čĆą░čéąĮčŗą╝ ą║ąŠąĮčäą╗ąĖą║čéą░ą╝. ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗčģ ą║ąŠą╝ą┐ąŠąĮąĄąĮč鹊ą▓ čü ą┐ąŠą┤ąŠą▒ąĮčŗą╝ ą▓čŗčüąŠą║ąĖą╝ čāčĆąŠą▓ąĮąĄą╝ ą░ą▒čüčéčĆą░ą║čåąĖąĖ ą▓ čāčüą╗ąŠą▓ąĖčÅčģ ąĖąĘąĮą░čćą░ą╗čīąĮąŠ ąŠą│čĆą░ąĮąĖč湥ąĮąĮčŗčģ čĆąĄčüčāčĆčüąŠą▓ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝ąŠą╣ ą┐ą╗ą░čéč乊čĆą╝čŗ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ čćčĆąĄąĘą╝ąĄčĆąĮčŗą╝ ąĘą░čéčĆą░čéą░ą╝ čĆąĄčüčāčĆčüąŠą▓ čüąĖčüč鹥ą╝čŗ ąĖ ąŠčłąĖą▒ą║ą░ą╝ ą▓ ąĖčģ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĖ.
ąŁč鹊čé EE-Note čüą┐ąĄčåąĖą░ą╗čīąĮąŠ ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮ čĆą░čüą║čĆčŗčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą░čüą┐ąĄą║č鹊ą▓ ąĖąĮč鹥ą│čĆą░čåąĖąĖ LwIP ą▓ą╝ąĄčüč鹥 čü ą▓čŗčłąĄąŠą┐ąĖčüą░ąĮąĮčŗą╝ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗą╝ąĖ ą║ąŠą╝ą┐ąŠąĮąĄąĮčéą░ą╝ąĖ. ąĪą╗ąĄą┤čāčÄčēąĖąĄ ą┐čĆąŠčåąĄą┤čāčĆčŗ, ąŠą┐ąĖčüą░ąĮąĮčŗąĄ ą▓ čŹč鹊ą╝ ą┤ąŠą║čāą╝ąĄąĮč鹥, ą┐ąŠą╝ąŠą│čāčé ąÆą░ą╝ ą▒čŗčüčéčĆąĄąĄ čĆą░ąĘčĆą░ą▒ąŠčéą░čéčī ąŠčüąĮąŠą▓ą░ąĮąĮčŗąĄ ąĮą░ LwIP ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ Blackfin. ą×čüčéą░ą╗čīąĮą░čÅ čćą░čüčéčī ą┤ąŠą║čāą╝ąĄąĮčéą░ ąŠčĆą│ą░ąĮąĖąĘąŠą▓ą░ąĮą░ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ŌĆó ą×ą▒ąĘąŠčĆ LwIP.
ŌĆó ąæąĄąĮčćą╝ą░čĆą║ąĖ, ąĘą░čéčĆą░čéčŗ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ LwIP čü ą┐čĆąŠčåąĄčüčüąŠčĆą░ą╝ąĖ Blackfin.
ŌĆó ąĀčāą║ąŠą▓ąŠą┤čüčéą▓ą░ ą┐ąŠ ąĖąĮč鹥ą│čĆą░čåąĖąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗčģ ąĖ ą░ą┐ą┐ą░čĆą░čéąĮčŗčģ ą║ąŠą╝ą┐ąŠąĮąĄąĮč鹊ą▓ ą▓ą╝ąĄčüč鹥 čü LwIP ąĖ ą┤čĆčāą│ąĖą╝ąĖ čćą░čüčéčÅą╝ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ.
ŌĆó ąóąĄčģąĮąĖą║ąĖ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ ąĮą░ ą┐ą╗ą░čéč乊čĆą╝ąĄ Blackfin, čćč鹊ą▒čŗ ą┐ąŠą╝ąŠčćčī čāą▓ąĄą╗ąĖčćąĖčéčī ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ čüąĖčüč鹥ą╝čŗ ąĖ čÅą┤čĆą░.
ąŁč鹊čé EE-Note ąĮąĄ ąĘą░ą╝ąĄąĮčÅąĄčé čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąŠ LwIP, čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąŠ VDK ąĖ čüąĖčüč鹥ą╝ąĮčŗčģ čüą╗čāąČą▒ (SSL) ą┤čĆčāą│čāčÄ čüą▓čÅąĘą░ąĮąĮčāčÄ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖčÄ (čüą╝. ąĪą┐ąĖčüąŠą║ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ą╗ąĖč鹥čĆą░čéčāčĆčŗ/[1, 2, 3, 4, 5, 6, 7, 8]).
LwIP čŹč鹊 ąŠą▒ą╗ąĄą│č湥ąĮąĮą░čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ čüč鹥ą║ą░ ą┐čĆąŠč鹊ą║ąŠą╗ąŠą▓ TCP/IP (ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░). ą×ąĮą░ ą▒ąĄčüą┐ą╗ą░čéąĮą░, čü ąŠčéą║čĆčŗčéčŗą╝ ąĖčüčģąŠą┤ąĮčŗą╝ ą║ąŠą┤ąŠą╝, ą┤ąŠčüčéčāą┐ąĮą░ ą┤ą╗čÅ ąĘą░ą│čĆčāąĘą║ąĖ ą┐ąŠ čüčüčŗą╗ą║ąĄ [4]. ąśąĘ-ąĘą░ ąĮąĖąĘą║ąĖčģ čéčĆąĄą▒ąŠą▓ą░ąĮąĖą╣ ą║ ąŠą▒čŖąĄą╝čā ą┐ą░ą╝čÅčéąĖ, LwIP čģąŠčĆąŠčłąŠ ą┐ąŠą┤čģąŠą┤ąĖčé ą┤ą╗čÅ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣.
ąæąĖą▒ą╗ąĖąŠč鹥ą║ą░ LwIP ą▒čŗą╗ą░ ą┐ąŠčĆčéąĖčĆąŠą▓ą░ąĮą░ ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆčŗ ADSP-BF52x, ADSP-BF53x, ADSP-B54x ąĖ ADSP-BF56x, ąĖ čŹč鹊čé ą┐ąŠčĆčé ą┤ąŠčüčéčāą┐ąĄąĮ ą▓ą╝ąĄčüč鹥 čü čüąĖčüč鹥ą╝ąŠą╣ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ VisualDSP++. ąöą╗čÅ ąĮą░čćą░ą╗ą░ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ TCP/IP ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ Blackfin ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąŠčåąĄąĮąŠčćąĮčŗąĄ ą┐ą╗ą░čéčŗ ADSP-BF537 EZ-KIT Lite┬«, ADSP-BF548 EZ-KIT Lite, ADSP-BF527 EZ-KIT Lite, ąĖą╗ąĖ ADSP-BF526 EZ-KIT Lite, ąĮą░ ą║ąŠč鹊čĆčŗčģ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ąĖąĮč鹥čĆč乥ą╣čü Ethernet. ąöą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF533/BF532/BF531 ąĖ ADSP-BF561 ą╝ąŠąČąĄč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą║ą░čĆčéčā čĆą░čüčłąĖčĆąĖč鹥ą╗čÅ čüąĄč鹥ą▓ąŠą│ąŠ ąĖąĮč鹥čĆč乥ą╣čüą░ (USBLAN extender card). ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ č鹊, ą║ą░ą║ ąĮą░čćą░čéčī čĆą░ąĘčĆą░ą▒ą░čéčŗą▓ą░čéčī ą┐čĆąŠąĄą║čé TCP/IP, čüą╝. LwIP User Guide (ąĪą┐ąĖčüąŠą║ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ą╗ąĖč鹥čĆą░čéčāčĆčŗ/[1]). ą¤ąŠčĆčé LwIP ą┤ą╗čÅ Blackfin ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą▒ąĖą▒ą╗ąĖąŠč鹥ą║čā čÅą┤čĆą░ RTOS (VisualDSP kernel, VDK), ą┤čĆą░ą╣ą▓ąĄčĆąŠą▓ čāčüčéčĆąŠą╣čüčéą▓ (Device Drivers) ąĖ čüąĖčüč鹥ą╝ąĮčŗčģ čüą╗čāąČą▒ (system services libraries, SSL). ą×ą▒čĆą░čéąĖč鹥čüčī ą║ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ ą┐ąŠ VDK (ąĪčüčŗą╗ą║ąĖ/[3]) ąĖ SSL (ąĪčüčŗą╗ą║ąĖ/[2]) ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ.
ążčāąĮą║čåąĖąĖ, ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄą╝čŗąĄ LwIP. ąĪą┐ąĖčüąŠą║ č鹥ą║čāčēąĖčģ ą┤ąŠčüčéčāą┐ąĮčŗčģ ą▓ąŠąĘą╝ąŠąČąĮąŠčüč鹥ą╣ LwIP ą┤ą╗čÅ čĆąĄą╗ąĖąĘą░, ąŠčéąĮąŠčüčÅčēąĄą│ąŠčüčÅ ą║ čŹč鹊ą╝čā EE-Note, čüą╝. ą▓ ą┐čĆąĖą╗ą░ą│ą░ąĄą╝ąŠą╝ .ZIP čäą░ą╣ą╗ąĄ (ąĪčüčŗą╗ą║ąĖ/[5]).
[ąĀąĄčüčāčĆčüčŗ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ ą┤ą╗čÅ LwIP]
ąÆ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ čüčéą░čéčīąĖ ąŠą▒čüčāąČą┤ą░ąĄčéčüčÅ ą┐čĆąŠą┐čāčüą║ąĮą░čÅ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī, čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅ ą║ ą┐ą░ą╝čÅčéąĖ ąĖ čüąĖčüč鹥ą╝ąĮčŗąĄ čĆąĄčüčāčĆčüčŗ, ąĘą░ą┤ąĄą╣čüčéą▓ąŠą▓ą░ąĮąĮčŗąĄ ą┐čĆąĖ ąĘą░ą┐čāčüą║ąĄ ą▓ čĆą░ą▒ąŠčéčā LwIP ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ Blackfin.
ą¤čĆąŠą┐čāčüą║ąĮą░čÅ čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī LwIP ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ Blackfin ą▒čŗą╗ą░ ąĖąĘą╝ąĄčĆąĄąĮą░ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░ ADI-TTCP, ą░ą┤ą░ą┐čéąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ ą║ čüą▓ąŠą▒ąŠą┤ąĮąŠ ą┤ąŠčüčéčāą┐ąĮąŠą╝čā ąĖąĮčüčéčĆčāą╝ąĄąĮčéčā PCATTCP. ą¤ąŠą┤čĆąŠą▒ąĮąŠčüčéąĖ ąŠ č鹊ą╝, ą║ą░ą║ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹč鹊čé ąĖąĮčüčéčĆčāą╝ąĄąĮčé, ąĖ čāčüą╗ąŠą▓ąĖčÅ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ PCAUSA ąŠą┐ąĖčüą░ąĮčŗ ą▓ ą┐čĆąĖą╗ą░ą│ą░ąĄą╝ąŠą╝ čäą░ą╣ą╗ąĄ .ZIP (ąĪčüčŗą╗ą║ąĖ/[5]). ąĀąĖčü. 2 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┐ąĖą║ąŠą▓čāčÄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī LwIP ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čĆą░ąĘą╝ąĄčĆą░ ą▒čāč乥čĆą░ ąĮą░ ą┐ą╗ą░čéč乊čĆą╝ąĄ ADSP-BF537. ąśą╝ąĄą╣č鹥 ą▓ ą▓ąĖą┤čā, čćč鹊 ą┐ąŠą║ą░ąĘą░ąĮąĮčŗą╣ čĆąĄąĘčāą╗čīčéą░čé ą╝ąŠąČąĄčé ą╝ąĄąĮčÅčéčīčüčÅ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ąĘą░ą│čĆčāąČąĄąĮąĮąŠčüčéąĖ (ąĖą╝ąĄčÄčēąĄą│ąŠčüčÅ čéčĆą░čäąĖą║ą░) čüąĄčéąĖ ąĖ ąĄčæ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄą╝ąŠą╣ ą┐čĆąŠą┐čāčüą║ąĮąŠą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ. ąÜą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮą░ čĆąĖčü. 2, čüč鹥ą║ LwIP ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą┤ąŠ 11 ą╝ąĄą│ą░ą▒ąĖčé/čüąĄą║ ą┤ą╗čÅ čüč鹥ą║ą░ ą┐čĆąŠč鹊ą║ąŠą╗ąŠą▓ TCP ąĖ UDP.

ąĀąĖčü. 2. ąÆąĘą░ąĖą╝ąŠčüą▓čÅąĘčī čĆą░ąĘą╝ąĄčĆą░ ą▒čāč乥čĆą░ ąĖ ą┐ąĖą║ąŠą▓ąŠą╣ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ.
ą×ą▒čŖąĄą╝ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą╣ ą┐ą░ą╝čÅčéąĖ LwIP ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ BF53x. ąÜą░ą║ čāąČąĄ čāą┐ąŠą╝ąĖąĮą░ą╗ąŠčüčī ą▓čŗčłąĄ, ą┐ąŠčĆčé LwIP ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ VDK ąĖ SSL. ąŚą░čéčĆą░čćąĖą▓ą░ąĄą╝čŗąĄ čĆąĄčüčāčĆčüčŗ ą┐ą░ą╝čÅčéąĖ ą┐ąŠą┤ąĄą╗ąĄąĮčŗ ąĮą░ ąŠčéą┤ąĄą╗čīąĮčŗąĄ čćą░čüčéąĖ, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖąĄ čŹčéąĖą╝ ą║ąŠą╝ą┐ąŠąĮąĄąĮčéą░ą╝ - čćč鹊ą▒čŗ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą╗čāčćčłąĄ ąŠčåąĄąĮąĖčéčī ąĘą░čéčĆą░čéčŗ ą┤ą╗čÅ čüąĖčüč鹥ą╝, ą│ą┤ąĄ VDK ąĖ SSL čāąČąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą▓čüčéčĆąŠąĄąĮąĮčŗą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗą╝ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖąĄą╝. ą¤ąŠą║ą░ąĘą░ąĮąĮčŗąĄ ą▓ čéą░ą▒ą╗ąĖčåąĄ ąĘąĮą░č湥ąĮąĖčÅ čÅą▓ą╗čÅčÄčéčüčÅ ą┐čĆąĖą▒ą╗ąĖąĘąĖč鹥ą╗čīąĮčŗą╝ąĖ, ąĖ ąŠąĮąĖ ą▒čŗą╗ąĖ ą┐ąŠą╗čāč湥ąĮčŗ ą┤ą╗čÅ ą┐čĆąŠčüč鹊ą╣ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ LwIP, ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ "Hello world".
ąóą░ą▒ą╗ąĖčåą░ 1. ą×ą▒čŖąĄą╝čŗ ą┐ą░ą╝čÅčéąĖ, ąĘą░ą┤ąĄą╣čüčéą▓ąŠą▓ą░ąĮąĮčŗąĄ ą┤ą╗čÅ LwIP-ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ.
| ą¤čĆąŠą│čĆą░ą╝ą╝ąĮčŗą╣ ą║ąŠą╝ą┐ąŠąĮąĄąĮčé/ą┐čĆąŠč鹊ą║ąŠą╗ |
UDP (ą║ąŠą┤) |
TCP (ą║ąŠą┤) |
UDP (ą┤ą░ąĮąĮčŗąĄ) |
TCP (ą┤ą░ąĮąĮčŗąĄ) |
| ąĪč鹥ą║ LwIP |
35 ą║ąĖą╗ąŠą▒ą░ą╣čé |
52 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ |
10 ą║ąĖą╗ąŠą▒ą░ą╣čé |
12 ą║ąĖą╗ąŠą▒ą░ą╣čé |
| ąæąĖą▒ą╗ąĖąŠč鹥ą║ą░ čüąĖčüč鹥ą╝ąĮčŗčģ čüą╗čāąČą▒ (SSL) |
15 ą║ąĖą╗ąŠą▒ą░ą╣čé |
15 ą║ąĖą╗ąŠą▒ą░ą╣čé |
1.2 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ |
1.2 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ |
| ąæąĖą▒ą╗ąĖąŠč鹥ą║ą░ VDK ąĖ ą┤čĆčāą│ąŠąĄ |
28 ą║ąĖą╗ąŠą▒ą░ą╣čé |
28 ą║ąĖą╗ąŠą▒ą░ą╣čé |
43 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ |
43 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ |
| ąÆčüąĄą│ąŠ |
78 ą║ąĖą╗ąŠą▒ą░ą╣čé |
95 ą║ąĖą╗ąŠą▒ą░ą╣čé |
54.2 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ |
56.2 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ |
ąóą░ą▒ą╗ąĖčåą░ 2. ą×ą▒ą╗ą░čüčéčī ą║čāčćąĖ, ąĮąĄąŠą▒čģąŠą┤ąĖą╝ą░čÅ ą┤ą╗čÅ LwIP.
| ąóąĖą┐ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ |
ąæčāč乥čĆčŗ ą┤čĆą░ą╣ą▓ąĄčĆą░ |
ąÜčāčćą░ |
ą¤čāą╗ ą┐ą░ą╝čÅčéąĖ |
ąæčāč乥čĆčŗ ą┐ą░ą║ąĄčéą░ |
ąÆčüąĄą│ąŠ |
| ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ |
Rx=8*1560
Tx=2*1548
~16 ą║ąĖą╗ąŠą▒ą░ą╣čé |
~64 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ |
~7 ą║ąĖą╗ąŠą▒ą░ą╣čé |
~64 ą║ąĖą╗ąŠą▒ą░ą╣čé |
~151 ą║ąĖą╗ąŠą▒ą░ą╣čé |
| ąÉčāą┤ąĖąŠ/ą▓ąĖą┤ąĄąŠ (ą▒ąŠą╗čīčłąŠą╣ čĆą░ąĘą╝ąĄčĆ ą┐ą░ą║ąĄčéą░) |
Rx=16*1560
Tx=8*1560
~50 ą║ąĖą╗ąŠą▒ą░ą╣čé |
~128 ą║ąĖą╗ąŠą▒ą░ą╣čé |
~7 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ |
~128 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ |
~313 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ |
| ą£ą░ą╗ąĄąĮčīą║ąĖąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ (ą╝ą░ą╗čŗą╣ čĆą░ąĘą╝ąĄčĆ ą┐ą░ą║ąĄčéą░) |
Rx=8*256
Tx=8*256
~4 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ |
~8 ą║ąĖą╗ąŠą▒ą░ą╣čé |
~7 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ |
~8 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ |
~27 ą║ąĖą╗ąŠą▒ą░ą╣čé |
ą¤čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąĖ DMA. ąÜąŠą│ą┤ą░ LwIP ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░čģ ADSP-BF537, ADSP-BF527 ąĖ ADSP-BF526, ą┤čĆą░ą╣ą▓ąĄčĆčŗ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ąĖčģ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ Ethernet. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ Ethernet DMA ą┐čĆąĖą▓čÅąĘą░ąĮ ąĮą░ ą│čĆčāą┐ą┐čā ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ IVG11, ąĖ ą┤ą╗čÅ ąĮąĄą│ąŠ ąĖą╝ąĄąĄčéčüčÅ čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ ą║ą░ąĮą░ą╗ DMA.
ąöą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF533, ADSP-BF532, ADSP-BF531, ADSP-BF54x ąĖ ADSP-BF561 čüč鹥ą║ LwIP ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą┤ą╗čÅ čüąĄč鹥ą▓ąŠą│ąŠ ąĖąĮč鹥čĆč乥ą╣čüą░ USB-LAN extender card. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤čĆą░ą╣ą▓ąĄčĆ čāčüčéčĆąŠą╣čüčéą▓ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąŠą┤ąĖąĮ čāčĆąŠą▓ąĄąĮčī ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ ą┤ą╗čÅ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ą┐čĆąĖąĄą╝ą░ ąĖ ą┐ąĄčĆąĄą┤ą░čćąĖ čäčĆąĄą╣ą╝ą░. IVG8 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ą╝ąĖ ADSP-BF533 ą║ą░ą║ čāčĆąŠą▓ąĄąĮčī ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ čģąŠčüčéą░, ąĖ IVG11 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ą╝ąĖ ADSP-BF561. ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ą┐ąŠ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĄ ą┤čĆą░ą╣ą▓ąĄčĆą░ čāčüčéčĆąŠą╣čüčéą▓ą░ čüą╝. ąĪą┐ąĖčüąŠą║ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ą╗ąĖč鹥čĆą░čéčāčĆčŗ/[3] ąĖ ąĪčüčŗą╗ą║ąĖ/[2, 6].
[ąŻą║ą░ąĘą░ąĮąĖčÅ ą┐ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą╝čā ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖčÄ ąĖ ą░ą┐ą┐ą░čĆą░čéčāčĆąĄ]
ą¤čĆąŠą│čĆą░ą╝ą╝ąĮąŠąĄ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖąĄ. LwIP ą▒čŗą╗ ą┐ąŠčĆčéąĖčĆąŠą▓ą░ąĮ ąĮą░ Blackfin čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą┐ą╗ą░čéč乊čĆą╝čŗ VDK. ą×ąČąĖą┤ą░ąĄčéčüčÅ, čćč鹊 ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĖ LwIP ąĘąĮą░ą║ąŠą╝čŗ čü ąŠą▒čēąĄą╣ ą║ąŠąĮčåąĄą┐čåąĖąĄą╣ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ čĆąĄą░ą╗čīąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ (real-time operating system, RTOS), ą║ą░ą║ąŠą╣ čÅą▓ą╗čÅąĄčéčüčÅ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░ VDK. ą¤ąŠą┤čĆąŠą▒ąĮąŠąĄ ąŠą▒čüčāąČą┤ąĄąĮąĖąĄ ą║ąŠąĮčåąĄą┐čåąĖąĖ RTOS ą▓čŗčģąŠą┤ąĖčé ąĘą░ čĆą░ą╝ą║ąĖ čŹč鹊ą│ąŠ ą┤ąŠą║čāą╝ąĄąĮčéą░, ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. ąĪą┐ąĖčüąŠą║ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ą╗ąĖč鹥čĆą░čéčāčĆčŗ/[22].
ąÆ čŹč鹊ą╣ čüąĄą║čåąĖąĖ ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮčŗ ąĖ ąŠą┐ąĖčüą░ąĮčŗ ąŠą▒čēąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗąĄ ą║ąŠąĮčäą╗ąĖą║čéčŗ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▓ąŠąĘąĮąĖą║ąĮčāčéčī ą┐čĆąĖ ąĖąĮč鹥ą│čĆą░čåąĖąĖ LwIP čü ą┤čĆčāą│ąĖą╝ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗą╝ąĖ ą║ąŠą╝ą┐ąŠąĮąĄąĮčéą░ą╝ąĖ ąĖą╗ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅą╝ąĖ.
ŌĆó ąøčÄą▒ąŠą╣ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗą╣ ą║ąŠą╝ą┐ąŠąĮąĄąĮčé, ą║ąŠč鹊čĆčŗą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą▒ąĖą▒ą╗ąĖąŠč鹥ą║čā SSL (ą░ VDK ąĖčüą┐ąŠą╗čīąĘčāąĄčé), ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝ ą┐ąŠčéčĆąĄą▒čāąĄčé ąĘą░ą┤ąĄą╣čüčéą▓ąŠą▓ą░ąĮąĖčÅ ą£ąĄąĮąĄą┤ąČąĄčĆą░ ą¤čĆąĄčĆčŗą▓ą░ąĮąĖą╣ (ąĪčüčŗą╗ą║ąĖ/[7]) ąĖ ą£ąĄąĮąĄą┤ąČąĄčĆą░ DMA (ąĪčüčŗą╗ą║ąĖ/[8]) (čŹč鹊 ąŠčéą┤ąĄą╗čīąĮčŗąĄ čüą╗čāąČą▒čŗ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ SSL). ąśąĮč鹥ą│čĆąĖčĆąŠą▓ą░ąĮąĖąĄ ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝ ą┤ą▓čāčģ ąĖą╗ąĖ ą▒ąŠą╗čīčłąĄą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą┐čĆąŠąĄą║č鹊ą▓, ą║ąŠč鹊čĆčŗąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ SSL, ą┐ąŠčéčĆąĄą▒čāąĄčé č鹊ą╗čīą║ąŠ ąŠą┤ąĮąŠą│ąŠ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ ą£ąĄąĮąĄą┤ąČąĄčĆą░ ą¤čĆąĄčĆčŗą▓ą░ąĮąĖą╣ ąĖ ąŠą┤ąĮąŠą│ąŠ 菹║ąĘąĄą╝ą┐ą╗čÅčĆą░ ą£ąĄąĮąĄą┤ąČąĄčĆą░ DMA ą┤ą╗čÅ ą▓čüąĄą│ąŠ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ čüą┐čĆą░ą▓ąĄą┤ą╗ąĖą▓ąŠ ąĖ ą┤ą╗čÅ ą£ąĄąĮąĄą┤ąČąĄčĆą░ ąŻčüčéčĆąŠą╣čüčéą▓ (ąĪčüčŗą╗ą║ąĖ/[6]), ąĖ ą┤ą╗čÅ ą£ąĄąĮąĄą┤ąČąĄčĆą░ DCB (ąĪčüčŗą╗ą║ąĖ/[9]), ąĖ ą▓čüąĄčģ ą┤čĆčāą│ąĖčģ čüą╗čāąČą▒, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ą▓ čüąĖčüč鹥ą╝ąĄ.
ŌĆó ąśąĮč鹥ą│čĆąĖčĆąŠą▓ą░ąĮąĖąĄ ą▒ąŠą╗čīčłąĄą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ čāčüčéčĆąŠą╣čüčéą▓ ąĖą╗ąĖ čĆąĄčüčāčĆčüąŠą▓ ą▓ čüąĖčüč鹥ą╝čā ą┐ąŠčéčĆąĄą▒čāąĄčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą│ąŠ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ ą£ąĄąĮąĄą┤ąČąĄčĆą░ ąŻčüčéčĆąŠą╣čüčéą▓ ąĖ ą£ąĄąĮąĄą┤ąČąĄčĆą░ ą¤čĆąĄčĆčŗą▓ą░ąĮąĖą╣. ąĪą╗ąĄą┤čāčÄčēąĖąĄ ą╗ąĖčüčéąĖąĮą│ąĖ ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčé ą╝ą░ą║čĆąŠčüčŗ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ ą┤ą╗čÅ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ą║ą░ąĮą░ą╗ą░ą╝ DMA ąĖ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝. ąśčüą┐ąŠą╗čīąĘčāą╣č鹥 ą┐ąŠčģąŠą┤čÅčēąĖą╣ ą║ąŠčŹčäčäąĖčåąĖąĄąĮčé čāą╝ąĮąŠąČąĄąĮąĖčÅ, ąŠčüąĮąŠą▓ą░ąĮąĮčŗą╣ ąĮą░ ą║ąŠą╗ąĖč湥čüčéą▓ąĄ ąĘą░ą┤ąĄą╣čüčéą▓ąŠą▓ą░ąĮąĮčŗčģ ą▓ čüąĖčüč鹥ą╝ąĄ ą║ą░ąĮą░ą╗ąŠą▓/čāčüčéčĆąŠą╣čüčéą▓.
// ąöą░ąĮąĮčŗąĄ ą£ąĄąĮąĄą┤ąČąĄčĆą░ DMA (ą▒ą░ąĘąŠą▓ą░čÅ ą┐ą░ą╝čÅčéčī + ą┐ą░ą╝čÅčéčī ą┤ą╗čÅ 2 ą║ą░ąĮą░ą╗ąŠą▓ DMA):
static u8 DMAmgr_storage[ADI_DMA_BASE_MEMORY + (ADI_DMA_CHANNEL_MEMORY * 2)];
// ąöą░ąĮąĮčŗąĄ ą£ąĄąĮąĄą┤ąČąĄčĆą░ ąŻčüčéčĆąŠą╣čüčéą▓ (ą▒ą░ąĘąŠą▓ą░čÅ ą┐ą░ą╝čÅčéčī + ą┐ą░ą╝čÅčéčī ą┤ą╗čÅ 2 čāčüčéčĆąŠą╣čüčéą▓):
static u8 devmgr_storage[ADI_DEV_BASE_MEMORY + (ADI_DEV_DEVICE_MEMORY * 2)];
ŌĆó ąÜą░ąČą┤čŗą╣ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗą╣ ą║ąŠą╝ą┐ąŠąĮąĄąĮčé ą╝ąŠąČąĄčé ąĖą╝ąĄčéčī čüą▓ąŠąĖ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą┤ą╗čÅ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▓čŗąĘą▓ą░čéčī ą║ąŠąĮčäą╗ąĖą║čé ą▓ ą┐čĆąŠčåąĄčüčüąĄ ąĖąĮč鹥ą│čĆą░čåąĖąĖ. ą×ą▒čēąĖąĄ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ ą▓ą║ą╗čÄčćą░čÄčé ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣, čāčüčéčĆąŠą╣čüčéą▓, ąĮą░čüčéčĆąŠąĄą║ čéą░ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ ąĖ čüąĖčüč鹥ą╝ąĮąŠą│ąŠ ą┐ąĖčéą░ąĮąĖčÅ, ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, ą┐ą░ą╝čÅčéąĖ ą║čāčćąĖ ąĖ čé. ą┤. ąĪą╗ąĄą┤čāčÄčēąĖąĄ ą╗ąĖčüčéąĖąĮą│ąĖ ą║ąŠą┤ą░ ą▓ąĘčÅčéčŗ ąĖąĘ čäčāąĮą║čåąĖąĖ sys_init() ą┐čĆąŠąĄą║čéą░ VisualDSP++ LwIP.
/* ąśąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ ą£ąĄąĮąĄą┤ąČąĄčĆą░ ą¤čĆąĄčĆčŗą▓ą░ąĮąĖą╣ */
adi_int_Init (intmgr_storage, sizeof(intmgr_storage), &response_count,
&critical_reg);
/* ąśąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ ą£ąĄąĮąĄą┤ąČąĄčĆą░ ąŻčüčéčĆąŠą╣čüčéą▓ */
adi_dev_Init (devmgr_storage, sizeof(devmgr_storage), &response_count,
&devmgr_handle, &imask_storage);
ąÉą┐ą┐ą░čĆą░čéčāčĆą░. ą¤čĆąŠą▒ą╗ąĄą╝ą░, ą║ąŠč鹊čĆą░čÅ čćą░čüč鹊 ąĮąĄ ą┤ą░ąĄčé ąŠčéą┤ąĄą╗čīąĮąŠą╣ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠą╣ čüąĖčüč鹥ą╝ąĄ čĆą░ą▒ąŠčéą░čéčī čü ą┤čĆčāą│ąĖą╝ąĖ ą║ąŠą╝ą┐ąŠąĮąĄąĮčéą░ą╝ąĖ, ąĘą░ą║ą╗čÄčćą░ąĄčéčüčÅ ą▓ ąŠą│čĆą░ąĮąĖč湥ąĮąĮąŠą╣ ą┐čĆąŠą┐čāčüą║ąĮąŠą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝ąŠą╣ ą┐ą╗ą░čéč乊čĆą╝čŗ. ą¤čĆąŠčåąĄčüčüąŠčĆčŗ Blackfin ąĖą╝ąĄčÄčé ą▓ąĮčāčéčĆąĄąĮąĮąĖąĄ čłąĖąĮčŗ čü čĆą░ąĘąĮąŠą╣ čłąĖčĆąĖąĮąŠą╣ (ADSP-BF53x ąĖ ADSP-BF52x ąĖą╝ąĄčÄčé 16-ą▒ąĖčéąĮčāčÄ čłąĖąĮčŗ, ąĖ ADSP-BF54x ąĖ ADSP-BF561 ąĖą╝ąĄčÄčé 32-ą▒ąĖčéąĮčāčÄ čłąĖąĮčā). ąÜą░ąČą┤ą░čÅ čłąĖąĮą░ ą╝ąŠąČąĄčé čĆą░ą▒ąŠčéą░čéčī čü ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ čćą░čüč鹊č鹊ą╣ 133 ą£ąōčå, čćč鹊 ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčé ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčāčÄ čüą║ąŠčĆąŠčüčéčī ą┤ą░ąĮąĮčŗčģ 266 ąĖą╗ąĖ 532 ą╝ąĄą│ą░ą▒ą░ą╣čéą░/čüąĄą║, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čłąĖčĆąĖąĮčŗ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ čłąĖąĮčŗ. ąØąĄčüą║ąŠą╗čīą║ąŠ čäą░ą║č鹊čĆąŠą▓ ą╝ąŠą│čāčé čüąĮąĖąĘąĖčéčī ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą┤ąŠčüčéčāą┐ąĮčāčÄ ą┐ąŠą╗ąŠčüčā, čéą░ą║ąĖąĄ ą║ą░ą║ ą▓čĆąĄą╝čÅ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄ čüąĖčüč鹥ą╝ąĮąŠą╣ čłąĖąĮčŗ ą╝ąĄąČą┤čā čćč鹥ąĮąĖąĄą╝ ąĖ ąĘą░ą┐ąĖčüčīčÄ, ą║ąŠąĮčäą╗ąĖą║čéčŗ ą▒ą░ąĮą║ąŠą▓, ąĘą░ą┤ąĄčƹȹ║ąĖ ąĖąĘ-ąĘą░ ą╗ąŠą│ąĖą║ąĖ ą░čĆą▒ąĖčéčĆą░ąČą░, ą║ąŠąĮčäą╗ąĖą║čéčŗ čÅą┤čĆą░ ąĖ DMA, ąĖ čéą░ą║ ą┤ą░ą╗ąĄąĄ. ąŁčéąĖ čäą░ą║č鹊čĆčŗ čüą┐ąĄčåąĖčäąĖčćąĮčŗ ą┤ą╗čÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, ąĖ ąĘą░ą▓ąĖčüčÅčé ąŠčé ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąĖčÅ ą▓ čĆąĄą░ą╗čīąĮąŠą╝ ą▓čĆąĄą╝ąĄąĮąĖ ą╝ąĄąČą┤čā ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄą╝ ą┤ą░ąĮąĮčŗčģ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ąĖ ą┤ąŠčüčéčāą┐ąŠą╝ ą║ ą┤ą░ąĮąĮčŗą╝ čüąŠ čüč鹊čĆąŠąĮčŗ čÅą┤čĆą░. ąÆ čĆą░ąĘą┤ąĄą╗ąĄ "ą×ą┐čéąĖą╝ąĖąĘą░čåąĖčÅ čüąĖčüč鹥ą╝čŗ" ąŠą▒čüčāąČą┤ą░čÄčéčüčÅ č鹥čģąĮąĖą║ąĖ, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠą╝ąŠą│čāčé ą╝ąĖąĮąĖą╝ąĖąĘąĖčĆąŠą▓ą░čéčī ą┤ąĄą╣čüčéą▓ąĖąĄ čäą░ą║č鹊čĆąŠą▓, ą▓ą╗ąĖčÅčÄčēąĖčģ ąĮą░ čüąĮąĖąČąĄąĮąĖąĄ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ čüąĖčüč鹥ą╝čŗ, ą║ąŠč鹊čĆčŗąĄ ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą┤ą░čÄčé ą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čĆąĄčüčāčĆčüąŠą▓ čüąĖčüč鹥ą╝čŗ.
ą×ą▒čüą╗čāąČąĖą▓ą░ąĮąĖąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣. ąØąĄčüą║ąŠą╗čīą║ąŠ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ą╝ąŠą│čāčé ą▒čŗčéčī ą┐čĆąĖą▓čÅąĘą░ąĮčŗ ą║ ąŠą┤ąĮąŠą╝čā čāčĆąŠą▓ąĮčÄ IVG, ąĖ ąĮąĄą║ąŠč鹊čĆčŗąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗąĄ ą║ąŠą╝ą┐ąŠąĮąĄąĮčéčŗ ą╝ąŠą│čāčé ą┐čĆąĖąĮčÅčéčī čüą▓ąŠą╣ ISR ą║ą░ą║ ą┐ąĄčĆą▓ąĖčćąĮčŗą╣ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ą┤ą╗čÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ čāčĆąŠą▓ąĮčÅ IVG (č鹥čĆą╝ąĖąĮčŗ "ą┐ąĄčĆą▓ąĖčćąĮčŗą╣" ąĖ "ą▓č鹊čĆąĖčćąĮčŗą╣" ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ąŠčéąĮąŠčüčÅčéčüčÅ ą║ čåąĄą┐ąŠčćą║ąĄ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąŠą▓ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣, ą║ą░ą║ ąŠą▒ąĄčüą┐ąĄčćąĖą▓ą░ąĄčé ą£ąĄąĮąĄą┤ąČąĄčĆ ą¤čĆąĄčĆčŗą▓ą░ąĮąĖą╣, čüą╝. ąĪčüčŗą╗ą║ąĖ/[7]). ą¤čĆąĖ ąĖąĮč鹥ą│čĆą░čåąĖąĖ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąŠčé ąŠą┤ąĮąŠą│ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ ą║ąŠą╝ą┐ąŠąĮąĄąĮčéą░ ą▒čāą┤ąĄčé ąĘą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ ą▓ čéą░ą▒ą╗ąĖčåąĄ ą▓ąĄą║č鹊čĆąŠą▓ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ (event vector table, EVT), ą┐ąĄčĆąĄąĘą░ą┐ąĖčüčŗą▓ą░čÅ ą╗čÄą▒ąŠą╣ ISR, ą┐čĆąĖą▓čÅąĘą░ąĮąĮčŗą╣ ąĮą░ čŹč鹊čé čāčĆąŠą▓ąĄąĮčī IVG. ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, čāą▒ąĄą┤ąĖč鹥čüčī, čćč鹊 ąÆčŗ ą┐čĆąĖą▓čÅąĘą░ą╗ąĖ č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ ą┐ąĄčĆą▓ąĖčćąĮčŗą╣ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ ąĮą░ ąŠą┤ąĖąĮ čāčĆąŠą▓ąĄąĮčī IVG čü ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗą╝ąĖ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ą╝ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓, ą┐čĆąĖą▓čÅąĘą░ąĮąĮčŗąĄ ą║ą░ą║ ą▓č鹊čĆąĖčćąĮčŗąĄ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ ąĮą░ ąŠą┤ąĖąĮ čāčĆąŠą▓ąĄąĮčī IVG. ą¦č鹊ą▒čŗ ąĖąĘą▒ąĄąČą░čéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą▓č鹊čĆąĖčćąĮčŗčģ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąŠą▓, čĆą░čüą┐čĆąĄą┤ąĄą╗ąĖč鹥 ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ ą┐ąŠ čĆą░ąĘąĮčŗą╝ ą┐čĆąĖąŠčĆąĖč鹥čéą░ą╝ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÅ, ąĖ ą┐čĆąĖą▓čÅąČąĖč鹥 ąĖčģ ąĮą░ čĆą░ąĘą╗ąĖčćąĮčŗąĄ čāčĆąŠą▓ąĮąĖ IVG, ąĄčüą╗ąĖ čŹč鹊 ą▓ąŠąĘą╝ąŠąČąĮąŠ.
ąĀą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą║ąŠą┤ą░/ą┤ą░ąĮąĮčŗčģ ą┐ąŠ ąŠą▒ą╗ą░čüčéčÅą╝ ą┐ą░ą╝čÅčéąĖ. ąøčÄą▒čŗąĄ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ, čüą▓čÅąĘą░ąĮąĮčŗąĄ čü ą┐čĆąĖą▓čÅąĘą║ąŠą╣ ą║ ą┐ą░ą╝čÅčéąĖ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĖąĄ ą║čĆąĖčéąĖč湥čüą║ąĖčģ ąĖ ąĮą░ąĖą▒ąŠą╗ąĄąĄ čćą░čüč鹊 ąĘą░ą┐čāčüą║ą░čÄčēąĖčģčüčÅ čāčćą░čüčéą║ąŠą▓ ą║ąŠą┤ą░ ąĖą╗ąĖ čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ ą┤ą░ąĮąĮčŗčģ ą▓ ą▒čŗčüčéčĆąŠą╣ ą┐ą░ą╝čÅčéąĖ L1), ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą┐ąŠą▓č鹊čĆąĮąŠ ą┐čĆąŠą░ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮčŗ ą┐čĆąĖ ąĖąĮč鹥ą│čĆą░čåąĖąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗčģ ą║ąŠą╝ą┐ąŠąĮąĄąĮč鹊ą▓. ą¦ą░čüč鹊 čŹč鹊 ąĖą│ąĮąŠčĆąĖčĆčāąĄčéčüčÅ, ą║ąŠą│ą┤ą░ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗąĄ ą║ąŠą╝ą┐ąŠąĮąĄąĮčéčŗ ą▒čŗą╗ąĖ ą┐ąŠą╗čāč湥ąĮčŗ ąĖąĘ čĆą░ąĘąĮčŗčģ ąĖčüč鹊čćąĮąĖą║ąŠą▓, ą║ąŠč鹊čĆčŗąĄ ąĖą╝ąĄą╗ąĖ čüą▓ąŠčÄ ą┐čĆąĖą▓čÅąĘą║čā ą║ čüąĄą║čåąĖčÅą╝ ą┐ą░ą╝čÅčéąĖ, ąĮą░čüčéčĆąŠąĄąĮąĮčāčÄ ą┐ąŠą┤ čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą│ąŠ čĆą░ąĮąĄąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖčÅ. ą¤ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ (ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ą┐čĆąŠčåąĄąĮčéąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą┤ą╗čÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ čüąĄą║čåąĖą╣ ą║ąŠą┤ą░/ą┤ą░ąĮąĮčŗčģ) ą╝ąŠąČąĄčé ą┐ąŠą╝ąĄąĮčÅčéčīčüčÅ ą▓ ąĮąŠą▓ąŠą╝ ąĖąĮč鹥ą│čĆąĖčĆąŠą▓ą░ąĮąĮąŠą╝ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ, čćč鹊 ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą┐ąŠą▓čŗčłąĄąĮąĮčŗą╝ ąĘą░ą┤ąĄčƹȹ║ą░ą╝ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ ą▓ čüčĆą░ą▓ąĮąĄąĮąĖąĖ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗčģ ą║ąŠą╝ą┐ąŠąĮąĄąĮč鹊ą▓ ą┐ąŠ ąŠčéą┤ąĄą╗čīąĮąŠčüčéąĖ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ, ą│ą┤ąĄ ą┐ąŠ-ąĮąŠą▓ąŠą╝čā ąĖąĮč鹥ą│čĆąĖčĆčāčÄčéčüčÅ čĆą░ąĘąĮčŗąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗąĄ ą║ąŠą╝ą┐ąŠąĮąĄąĮčéčŗ, ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ą┐ąŠą▓č鹊čĆąĮąŠ ą┐čĆąŠą░ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī (ąĖ ą▓ąŠąĘą╝ąŠąČąĮąŠ ą┐ąŠą┤čüčéčĆąŠąĖčéčī) ą┐čĆąĖą▓čÅąĘą║čā ą║ ą┐ą░ą╝čÅčéąĖ ą║ąŠą┤ą░ ąĖ ą┤ą░ąĮąĮčŗčģ.
ą×ą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖą╣ ąĖ ąŠčłąĖą▒ąŠą║ ą░ą┐ą┐ą░čĆą░čéčāčĆčŗ (Exception, Hardware Error Handlers). VDK ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖčÅ čüą╗čāąČą▒ ą┤ą╗čÅ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÅ ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąĖčÅ ąĘą░ą┐čāčüą║ą░ ąĘą░ą┤ą░čć ąĖ ą┤čĆčāą│ąĖčģ ą░ą║čéąĖą▓ąĮąŠčüč鹥ą╣ čÅą┤čĆą░. ąŁč鹊 ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčé ą┐čĆąĖą▓čÅąĘą║čā ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą║ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ą▓ ą║ąŠą┤ąĄ čÅą┤čĆą░. ą¤čĆąĖą▓čÅąĘą║ą░ ą┐ąĄčĆąĄą┤ą░ąĄčé ą▓čüąĄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąŠčłąĖą▒ąŠą║ ą║ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖą╣ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ, ą║ąŠč鹊čĆą░čÅ čüąŠąĘą┤ą░ąĄčéčüčÅ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ. ąöą╗čÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, ą║ąŠč鹊čĆąŠąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčé č鹊ą╗čīą║ąŠ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ SSL, čā ąÆą░čü ąĖą╝ąĄąĄčéčüčÅ ą┐čĆąĖą▓čÅąĘą║ą░ čéą░ą║ąŠą│ąŠ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ąĖčüą║ą╗čÄč湥ąĮąĖą╣. ą×ą┤ąĮą░ą║ąŠ, ą║ąŠą│ą┤ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ čü ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąŠą╣ SSL ąĖąĮč鹥ą│čĆąĖčĆčāąĄčéčüčÅ ą▓ ą┐čĆąŠąĄą║čé VDK, čŹč鹊čé ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ąĖčüą║ą╗čÄč湥ąĮąĖą╣ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĖą▓čÅąĘą░ąĮ ąŠčéą┤ąĄą╗čīąĮąŠ, ąĖ ą▓čüąĄ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąŠą▒čĆą░ą▒ąŠčéą░ąĮčŗ ą▓ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖą╣ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ, ą║ąŠč鹊čĆą░čÅ čüąŠąĘą┤ą░ąĄčéčüčÅ ą▓ VDK-ą┐čĆąŠąĄą║č鹥. ąøąĖčüčéąĖąĮą│ ąĮąĖąČąĄ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą╗čÅ ąĖčüą║ą╗čÄč湥ąĮąĖą╣, čüąŠąĘą┤ą░ą▓ą░ąĄą╝čŗą╣ ą▓ ą┐čĆąŠąĄą║č鹥 VDK.
/* UserExceptionHandler */
/* ąóąŠčćą║ą░ ą▓čģąŠą┤ą░ ą▓ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ąĖčüą║ą╗čÄč湥ąĮąĖą╣ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ */
.GLOBAL UserExceptionHandler;
UserExceptionHandler:
/**
* ąŚą┤ąĄčüčī ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ...
*
* ą¤ąŠą╝ąĮąĖč鹥, čćč鹊 VDK čĆąĄąĘąĄčĆą▓ąĖčĆčāąĄčé exception 0 ą┤ą╗čÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ,
* ą║ ą║ąŠč鹊čĆąŠą╝čā ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ čüą╗ąĄą┤čāčÄčēąĄą╣ ąĖąĮčüčéčĆčāą║čåąĖąĄą╣:
*
* EXCPT 0;
*
* ąøčÄą▒ąŠąĄ ą┤čĆčāą│ąŠąĄ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ (ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ąĖą╗ąĖ čüąĖčüč鹥ą╝čŗ), ą┤ąŠą╗ąČąĮąŠ
* ą▒čŗčéčī ąŠą▒čĆą░ą▒ąŠčéą░ąĮąŠ ąÆą░ą╝ąĖ ą▓ čŹč鹊ą╝ ą╝ąĄčüč鹥. */
RTX;
.UserExceptionHandler.end:
ą¤čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąŠčłąĖą▒ąŠą║ (Error Interrupts). ąæąŠą╗čīčłąĖąĮčüčéą▓ąŠ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ ąŠčłąĖą▒ąŠą║ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ą┐čĆąĖą▓čÅąĘčŗą▓ą░čÄčéčüčÅ ą║ IVG7. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą┤ą╗čÅ čŹčäč乥ą║čéąĖą▓ąĮąŠą╣ ąŠčéą╗ą░ą┤ą║ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą▓ą░ąČąĮąŠ čÅą▓ąĮąŠ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ąŠą▒čĆą░ą▒ąŠčéą║čā čĆą░ąĘą╗ąĖčćąĮčŗčģ ąŠčłąĖą▒ąŠą║ DMA ąĖą╗ąĖ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ ąŠčłąĖą▒ą║ąĖ ą▓ ąÆą░čłąĄą╣ čüąĖčüč鹥ą╝ąĄ - čüą░ą╝čŗą╣ ą╗čāčćčłąĖą╣ čüą┐ąŠčüąŠą▒ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, ą║ąŠą│ą┤ą░ ą▓ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą╝ čāčüčéčĆąŠą╣čüčéą▓ąĄ ą┐čĆąŠąĖąĘąŠčłą╗ąĖ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĖą╗ąĖ ąĮąĄą┤ąŠą│čĆčāąĘą║ą░ ą┤ą░ąĮąĮčŗčģ (overrun ąĖą╗ąĖ underrun). ąØą░ą┐čĆąĖą╝ąĄčĆ, čĆąĄčüčāčĆčü čü ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ ąĮąĄ ą┤ą░ąĄčé ą┤ą╗čÅ čĆąĄčüčāčĆčüą░ čü ą╝ąĄąĮčīčłąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ ą▓ąŠą▓čĆąĄą╝čÅ ąŠą▒čĆą░čéąĖčéčīčüčÅ ą║ ą┐ą░ą╝čÅčéąĖ, ą▓ ą║ąŠč鹊čĆąŠą╝ ą╝ąŠą│čāčé ąĮą░čģąŠą┤ąĖčéčīčüčÅ ą┤ą░ąĮąĮčŗąĄ ąĖą╗ąĖ ą┤ą░ąČąĄ ą┤ąĄčüą║čĆąĖą┐č鹊čĆ DMA.
[ą×ą┐čéąĖą╝ąĖąĘą░čåąĖčÅ čüąĖčüč鹥ą╝čŗ]
ąÆ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮčŗ ąĮąĄčüą║ąŠą╗čīą║ąŠ č鹥čģąĮąĖą║ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ, čüą▓čÅąĘą░ąĮąĮčŗčģ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖčÅ ąĖ ą░ą┐ą┐ą░čĆą░čéčāčĆčŗ, čćč鹊 ą┐ąŠą╝ąŠąČąĄčé ąÆą░ą╝ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ąŠčüč鹊ąĖąĮčüčéą▓ą░ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ Blackfin. ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĖ, ą║ąŠč鹊čĆčŗąĄ čģąŠčĆąŠčłąŠ ąĘąĮą░ą║ąŠą╝čŗ čü ą┐ą╗ą░čéč乊čĆą╝ąŠą╣ Blackfin ąĖ čüąĖčüč鹥ą╝ąŠą╣ ąŠčéą╗ą░ą┤ą║ąĖ VisualDSP++, ą╝ąŠą│čāčé ą┐čĆąŠą┐čāčüčéąĖčéčī čćč鹥ąĮąĖąĄ čŹč鹊ą│ąŠ čĆą░ąĘą┤ąĄą╗ą░.
ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą░ą┐ą┐ą░čĆą░čéčāčĆčŗ. ąØąĄčüą╝ąŠčéčĆčÅ ąĮą░ č鹊, čćč鹊 ą╝ąŠą│čāčé ą▒čŗčéčī ą┐čĆąĖą╝ąĄąĮąĄąĮčŗ čĆą░ąĘą╗ąĖčćąĮčŗąĄ č鹥čģąĮąĖą║ąĖ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ čüąĖčüč鹥ą╝čŗ, čĆąĄą║ąŠą╝ąĄąĮą┤čāąĄčéčüčÅ ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čüą╗ąĄą┤čāčÄčēąĄąĄ:
ŌĆó 16/32-ą▒ąĖčéąĮčŗąĄ ą┐ąĄčĆąĄą┤ą░čćąĖ: ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčāčÄ ą┐ąŠą╗ąŠčüčā čłąĖąĮčŗ ą┤ą╗čÅ ą▓čüąĄčģ ą┐ąĄčĆąĄą┤ą░čć DMA ąŠčé ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ (PDMA) ąĖ ą▓čüąĄčģ ą┐ąĄčĆąĄčüčŗą╗ąŠą║ DMA ą┐ąŠ ą┐ą░ą╝čÅčéąĖ (MDMA). ąśąĮąĖčåąĖąĖčĆčāą╣č鹥 16-ą▒ąĖčéąĮčŗąĄ ą┐ąĄčĆąĄą┤ą░čćąĖ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF53x ąĖ ADSP-BF52x, ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ ąĖąĮąĖčåąĖąĖčĆčāą╣č鹥 32-ą▒ąĖčéąĮčŗąĄ ą┐ąĄčĆąĄą┤ą░čćąĖ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF561 ąĖ ADSP-BF54x.
ŌĆó ąŁčäč乥ą║čéąĖą▓ąĮąŠąĄ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą║ą░ąĮą░ą╗ąŠą▓ DMA: ąĮąĄ ą┐čĆąĖą╝ąĄąĮčÅą╣č鹥 ą┤ą▓ąĄ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗąĄ ą┐ąĄčĆąĄą┤ą░čćąĖ DMA ąĮą░ ąŠą┤ąĮąŠą╝ ąĖ č鹊ą╝ ąČąĄ ą║ą░ąĮą░ą╗ąĄ DMA.
ŌĆó ąæą░ąĮą║ąĖ ą┐ą░ą╝čÅčéąĖ SDRAM: čĆą░ąĘą▒ąĄą╣č鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ SDRAM ą┐ąŠ 4 ą▒ą░ąĮą║ą░ą╝, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ ą▒čāč乥čĆą░ą╝ ą┤ą░ąĮąĮčŗčģ ąĖ ą╝ąĖąĮąĖą╝ąĖąĘąĖčĆąŠą▓ą░čéčī ą▓čĆąĄą╝čÅ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ ą┤ąŠčüčéčāą┐ą░. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĮą░ ą┐ą╗ą░č鹥 čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ą░ ADSP-BF561 EZ-KIT Lite ąĖą╝ąĄąĄčéčüčÅ 64 ą╝ąĄą│ą░ą▒ą░ą╣čéą░ SDRAM, ą║ąŠč鹊čĆčāčÄ ą╝ąŠąČąĮąŠ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░čéčī ą║ą░ą║ č湥čéčŗčĆąĄ ą▒ą░ąĮą║ą░ ą┐ą░ą╝čÅčéąĖ ą┐ąŠ 16 ą╝ąĄą│ą░ą▒ą░ą╣čé. ą¦č鹊ą▒čŗ ąĘą░ą┤ąĄą╣čüčéą▓ąŠą▓ą░čéčī ą┐ąŠą╗čīąĘčā ąŠčé čĆą░ąĘą▒ąĖąĄąĮąĖčÅ ąĮą░ ą▒ą░ąĮą║ąĖ, ąĮąĄ čĆą░ąĘą╝ąĄčēą░ą╣č鹥 ą▓ ąŠą┤ąĮąŠą╝ ą▒ą░ąĮą║ąĄ SDRAM ą┤ą▓ą░ ą▒čāč乥čĆą░ ą┤ą░ąĮąĮčŗčģ, ą║ ą║ąŠč鹊čĆčŗą╝ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗą╣ ą┤ąŠčüčéčāą┐.
ŌĆó ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čéčĆą░čäąĖą║ąŠą╝ DMA: ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 čĆąĄą│ąĖčüčéčĆčŗ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čéčĆą░čäąĖą║ąŠą╝ DMA (čüą╝. ąĪčüčŗą╗ą║ąĖ/[10], "ą¤čĆąĖąŠčĆąĖčéąĖąĘą░čåąĖčÅ ąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čéčĆą░čäąĖą║ąŠą╝") ą┤ą╗čÅ čŹčäč乥ą║čéąĖą▓ąĮąŠą╣ čāčéąĖą╗ąĖąĘą░čåąĖąĖ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ čüąĖčüč鹥ą╝čŗ. ąĀąĄą│ąĖčüčéčĆčŗ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čéčĆą░čäąĖą║ąŠą╝ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé čüą┐ąŠčüąŠą▒ ą▓ą╗ąĖčÅčéčī ąĮą░ č鹊, ą║ą░ą║ čćą░čüč鹊čé ą╝ąŠąČąĄčé ą╝ąĄąĮčÅčéčīčüčÅ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąĄčĆąĄą┤ą░čćąĖ ąĮą░ čłąĖąĮą░čģ ą┤ą░ąĮąĮčŗčģ, ą┐čāč鹥ą╝ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąŠą│ąŠ ą│čĆčāą┐ą┐ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐ąĄčĆąĄą┤ą░čć ą▓ ąŠą┤ąĮąŠą╝ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĖ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. ąĪčüčŗą╗ą║ąĖ/[11, 12], ą│ą┤ąĄ ąŠą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖčÅ čĆą░ą▒ąŠčéčŗ DMA.
ŌĆó ą£ąĖąĮąĖą╝ąĖąĘą░čåąĖčÅ ą║ąŠąĮčäą╗ąĖą║č鹊ą▓ DMA ąĖ čÅą┤čĆą░. ąśąĘą▒ąĄą│ą░ą╣č鹥 ą┤ąŠčüčéčāą┐ą░ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ čüąŠ čüč鹊čĆąŠąĮčŗ čÅą┤čĆą░. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ čā čÅą┤čĆą░ ąĖą╝ąĄąĄčéčüčÅ ą┐čĆąĖąŠčĆąĖč鹥čé ą┐ąŠ ą┤ąŠčüčéčāą┐čā ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ą┐ąĄčĆąĄą┤ DMA, ąĮąŠ čŹč鹊 ą╝ąŠąČąĮąŠ ą┐ąŠą╝ąĄąĮčÅčéčī ą┐čāč鹥ą╝ čāčüčéą░ąĮąŠą▓ą║ąĖ ą▒ąĖčéą░ CDPRIO ą▓ čĆąĄą│ąĖčüčéčĆąĄ EBIU_AMGCTL. ąĢčüą╗ąĖ ą┤ą░čéčī DMA ą┐čĆąĖąŠčĆąĖč鹥čé ą▓čŗčłąĄ, č湥ą╝ čā čÅą┤čĆą░, č鹊 ą▓čģąŠą┤čÅčēąĖąĄ ąĖą╗ąĖ ąĖčüčģąŠą┤čÅčēąĖąĄ ą┐ąĄčĆąĄą┤ą░čćąĖ čéčĆą░čäąĖą║ą░ ą┤ą░ąĮąĮčŗčģ ąŠčé ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ąĮąĄ ą▒čāą┤čāčé ą┐čĆąĖąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čéčīčüčÅ, ą║ąŠą│ą┤ą░ čÅą┤čĆąŠ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčé ą┤ąŠčüčéčāą┐ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ.
ŌĆó ąÜčŹčłąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ ą┤ą░ąĮąĮčŗčģ: čĆą░ąĘčĆąĄčłąĄąĮąĖąĄ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ ą┤ą░ąĮąĮčŗčģ ą╝ąŠąČąĄčé ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠ ą┐ąŠą▓čŗčüąĖčéčī ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. ąĢčüą╗ąĖ čĆą░ąĘą╝ąĄčĆ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą▓ąĄą╗ąĖą║, čćč鹊 ąŠą▒čŗčćąĮąŠ čéą░ą║ ąĖ ąĄčüčéčī ą▓ čüą╗čāčćą░ąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ LwIP/VDK, č鹊 ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĄ ą╝ąŠąČąĄčé ą┐ąŠą╝ąŠčćčī čāą▓ąĄą╗ąĖčćąĖčéčī ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ č鹥čģąĮąĖą║ąĖ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ čĆą░čüčüą╝ąŠčéčĆąĄąĮčŗ ą▓ čüčéą░čéčīčÅčģ ąĪčüčŗą╗ą║ąĖ/[11], ąĖ ąĪą┐ąĖčüąŠą║ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ą╗ąĖč鹥čĆą░čéčāčĆčŗ/[8, 13].
ą¤čĆąŠą│čĆą░ą╝ą╝ąĮąŠąĄ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖąĄ - ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ISR. ąśąĘą▒ąĄą│ą░ą╣č鹥 ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┤ą░ąĮąĮčŗčģ ą▓ ISR ąĖą╗ąĖ čäčāąĮą║čåąĖčÅčģ ąŠą▒čĆą░čéąĮąŠą│ąŠ ą▓čŗąĘąŠą▓ą░ (callback). ą×ą▒čĆą░ą▒ą░čéčŗą▓ą░ą╣č鹥 ą▒čāč乥čĆčŗ ą┤ą░ąĮąĮčŗčģ ą▓ ą┐ąŠč鹊ą║ą░čģ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ. ą¤čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąĘą░ą┐čāčüą║ą░čÄčéčüčÅ čü ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝, č湥ą╝ ą┐ąŠč鹊ą║ąĖ, ąŠą┐čĆąĄą┤ąĄą╗čÅąĄą╝čŗąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝. ą¤ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖąĄ ą┐ąŠč鹊ą║ąĖ ą▓čüąĄą│ą┤ą░ čĆą░ą▒ąŠčéą░čÄčé ąĮą░ čāčĆąŠą▓ąĮąĄ IVG15 (čé. ąĄ. čü čüą░ą╝čŗą╝ ąĮąĖąĘą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝), ąĖ ISR-čŗ ąĖ callbacks-ąĖ (ąĪčüčŗą╗ą║ąĖ/[9]) ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ąĮą░ čüą▓ąŠąĄą╝ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą╝ čāčĆąŠą▓ąĮąĄ ą┐čĆąĖąŠčĆąĖč鹥čéą░ IVG. ąśčüą┐ąŠą╗čīąĘčāą╣č鹥 ąŠčéą╗ąŠąČąĄąĮąĮčŗąĄ čäčāąĮą║čåąĖąĖ ąŠą▒čĆą░čéąĮąŠą│ąŠ ą▓čŗąĘąŠą▓ą░ (deferred callbacks, DCB) čćč鹊ą▒čŗ ą┐ąŠąĮąĖąĘąĖčéčī ą┐čĆąĖąŠčĆąĖč鹥čé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąĮąĄą║ąŠč鹊čĆčŗčģ čāčćą░čüčéą║ąŠą▓ ą║ąŠą┤ą░ ą┐ąŠ čüčĆą░ą▓ąĮąĄąĮąĖčÄ čü ISR, ą┐ąŠąĘą▓ąŠą╗čÅčÅ ą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĖčéčī ą▓čĆąĄą╝čÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
ISR čü ą╝ąĄąĮąĄąĄ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ ąĮąĄ ą┤ą░čüčé ąĘą░ą┐čāčüčéąĖčéčīčüčÅ ą▒ąŠą╗ąĄąĄ ą┐čĆąĖąŠčĆąĖč鹥čéąĮąŠą╝čā ISR, ą║ąŠą│ą┤ą░ ąĮąĄ čĆą░ąĘčĆąĄčłąĄąĮąŠ ą▓ą╗ąŠąČąĄąĮąĖąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ ą┤čĆčāą│ ą▓ ą┤čĆčāą│ą░ ą┤ą╗čÅ čŹč鹊ą│ąŠ ąĮąĖąĘą║ąŠą┐čĆąĖąŠčĆąĖč鹥čéąĮąŠą│ąŠ ISR. ą¤čĆąŠčåąĄčüčüąŠčĆčŗ Blackfin ą╝ąŠą│čāčé ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī ą▓ą╗ąŠąČąĄąĮąĮąŠčüčéčī ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ ą┤čĆčāą│ ą▓ ą┤čĆčāą│ą░, čćč鹊 ą┐ąŠąĘą▓ąŠą╗ąĖčé ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąŠą┐čĆąĖąŠčĆąĖč鹥čéąĮčŗą╝ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗą╝ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ ą┐čĆąĄčĆčŗą▓ą░čéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąŠą▓ ą╝ąĄąĮąĄąĄ ą┐čĆąĖąŠčĆąĖč鹥čéąĮčŗčģ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣.
ąŁčäč乥ą║čéąĖą▓ąĮą░čÅ čüčģąĄą╝ą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą▒čāč乥čĆą░ą╝ąĖ. ąśčüą┐ąŠą╗čīąĘčāą╣č鹥 čüčģąĄą╝čā ą┤ą▓ąŠą╣ąĮąŠą╣ ą▒čāč乥čĆąĖąĘą░čåąĖąĖ, čćč鹊ą▒čŗ ąĖąĘą▒ąĄąČą░čéčī ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ąŠą║ ą┐čĆąŠčåąĄčüčüąŠčĆą░. ąöą▓ąŠą╣ąĮą░čÅ ą▒čāč乥čĆąĖąĘą░čåąĖčÅ ąĖą╗ąĖ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▒čāč乥čĆąŠą▓ ą│ą░čĆą░ąĮčéąĖčĆčāčÄčé, čćč鹊 ą┐čĆąŠčåąĄčüčüąŠčĆ ą╝ąŠąČąĄčé ąŠą▒čĆą░ą▒ąŠčéą░čéčī č鹥ą║čāčēąĖą╣ ą▒čāč乥čĆ, ą┐ąŠą║ą░ ą┤čĆčāą│ąĖąĄ ą▒čāč乥čĆčŗ ąĘą░ą┐ąŠą╗ąĮčÅčÄčéčüčÅ č湥čĆąĄąĘ DMA ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░. ąĀąĖčü. 4 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┐čĆąŠčüčéčāčÄ ą┤ąĖą░ą│čĆą░ą╝ą╝čā ą┐ąŠč鹊ą║ą░ ą┤ą░ąĮąĮčŗčģ ą▓ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čü ą┤ą▓ąŠą╣ąĮčŗą╝ ą▒čāč乥čĆąŠą╝. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. ąĪčüčŗą╗ą║ąĖ/[11], ą│ą┤ąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮąŠ ą▒ąŠą╗čīčłąĄ ą┤ąĖą░ą│čĆą░ą╝ą╝ ą┐ąŠč鹊ą║ąŠą▓ ą┤ą░ąĮąĮčŗčģ, ąĖ ą┤ą░ąĮčŗ čĆąĄą║ąŠą╝ąĄąĮą┤ą░čåąĖąĖ ą┐ąŠ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÄ ą┤ą▓ąŠą╣ąĮąŠą╣ ą▒čāč乥čĆąĖąĘą░čåąĖąĖ ąĖ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÄ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą▒čāč乥čĆąŠą▓ ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ.

ąĀąĖčü. 4. ąöąĖą░ą│čĆą░ą╝ą╝ą░ ą┐ąŠč鹊ą║ą░ ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ čüčģąĄą╝čŗ čü ą┤ą▓ąŠą╣ąĮąŠą╣ ą▒čāč乥čĆąĖąĘą░čåąĖąĄą╣.
ą×ą┐čéąĖą╝ąĖąĘą░čåąĖąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░. ąöą╗čÅ čāą▓ąĄą╗ąĖč湥ąĮąĖčÅ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖčÅ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ąĮąĄą║ąŠč鹊čĆčŗąĄ ąŠą┐čåąĖąĖ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░. ą×ą▒čŗčćąĮąŠ ą╗čāčćčłąĖą╣ čŹčäč乥ą║čé ą┤ą░čÄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąŠą┐čåąĖą╣ ŌĆōO ąĖ ŌĆōipa (čüą╝. ąĪčüčŗą╗ą║ąĖ/[13]). ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ, čāą┐čĆą░ą▓ą╗čÅąĄą╝ąŠą╣ ą┐čĆąŠčäąĖą╗ąĄą╝ (profile-guided optimization, PGO ąĪčüčŗą╗ą║ąĖ/[11]) čéą░ą║ąČąĄ ą┐ąŠą╝ąŠą│ą░ąĄčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ čāą▓ąĄą╗ąĖčćąĖčéčī ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ č鹥čģąĮąĖą║ąĖ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ čüą╝. ą│ą╗ą░ą▓čā "Achieving Optimal Performance from C/C++ Sources" ą▓ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąĄ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ (čüą╝. ąĪą┐ąĖčüąŠą║ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ą╗ąĖč鹥čĆą░čéčāčĆčŗ/[18]). ąØąĄą║ąŠč鹊čĆčŗąĄ ISR ąĖ čäčāąĮą║čåąĖąĖ ą║čĆąĖčéąĖč湥čüą║ąĖčģ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣ ą╝ąŠą│čāčé ą▒čŗčéčī ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░ąĮčŗ ą▓čĆčāčćąĮčāčÄ ąĮą░ą┐ąĖčüą░ąĮąĖąĄą╝ ąĮą░ ą░čüčüąĄą╝ą▒ą╗ąĄčĆąĄ, čćč鹊ą▒čŗ čāą▓ąĄą╗ąĖčćąĖčéčī ąĖčģ čüą║ąŠčĆąŠčüčéčī čĆą░ą▒ąŠčéčŗ.
ą×ą┐čéąĖą╝ąĖąĘą░čåąĖąĖ ą╗ąĖąĮą║ąĄčĆą░. ąØą░ ą║čĆąĖčüčéą░ą╗ą╗ąĄ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin ąĖą╝ąĄąĄčéčüčÅ ą▒čŗčüčéčĆą░čÅ ą┐ą░ą╝čÅčéčī L1 SRAM, ą║ąŠč鹊čĆą░čÅ čćą░čüč鹊 ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čŹčäč乥ą║čéąĖą▓ąĮąŠ. ą¤čĆąĖą▓čÅąĘą║ą░ ą║čĆąĖčéąĖč湥čüą║ąŠą╣ ą┐ą░ą╝čÅčéąĖ ąĖ ąĮą░ąĖą▒ąŠą╗ąĄąĄ čćą░čüč鹊 ą▓čŗą┐ąŠą╗ąĮčÅąĄą╝ąŠą│ąŠ ą║ąŠą┤ą░ ą║ L1 SRAM ą╝ąŠąČąĄčé čāčüčéčĆą░ąĮąĖčéčī ą┐čĆąŠą┐čāčüą║ čåąĖą║ą╗ąŠą▓ ąŠąČąĖą┤ą░ąĮąĖčÅ ąĖąĘ-ąĘą░ ą┐čĆąŠą╝ą░čģąŠą▓ ą║čŹčłą░. ąśčüą┐ąŠą╗čīąĘčāą╣č鹥 čüčéą░čéąĖčüčéąĖč湥čüą║ąĖą╣ ą┐čĆąŠčäą░ą╣ą╗ąĄčĆ (Tools -> Statistical profiler), čćč鹊ą▒čŗ ąŠą▒ąĮą░čĆčāąČąĖčéčī ąĮą░ąĖą▒ąŠą╗ąĄąĄ čćą░čüč鹊 ą▓čŗą┐ąŠą╗ąĮčÅąĄą╝čŗą╣ ą║ąŠą┤, ąĖ ą┐čĆąĖą▓čÅąĘą░čéčī čŹčéąĖ čäčāąĮą║čåąĖąĖ ą║ ą┐ą░ą╝čÅčéąĖ L1 SRAM. ąóą░ą║ąČąĄ ą┤ąĄą╗ą░ą╣č鹥 ą┐čĆąĖą▓čÅąĘą║čā ą║čĆąĖčéąĖč湥čüą║ąĖčģ ISR ą║ ą┐ą░ą╝čÅčéąĖ L1 SRAM, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠąĄ ą▓čĆąĄą╝čÅ ą┤ąŠčüčéčāą┐ą░. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą┐čĆąĖą▓čÅąĘą║čā ą║ąŠą┤ą░ ą║ čĆą░ąĘą╗ąĖčćąĮčŗą╝ ąŠą▒ą╗ą░čüčéčÅą╝ ą┐ą░ą╝čÅčéąĖ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin čüą╝. ąĪčüčŗą╗ą║ąĖ/[11].
[ą×čüąĮąŠą▓ąĮčŗąĄ čüąŠą▓ąĄčéčŗ ą┐ąŠ ąŠčéą╗ą░ą┤ą║ąĄ]
ąÜčĆąŠą╝ąĄ ąŠą▒čŗčćąĮčŗčģ ą▓ąŠąĘą╝ąŠąČąĮąŠčüč鹥ą╣ ąŠčéą╗ą░ą┤ą║ąĖ, čéą░ą║ąĖčģ ą║ą░ą║ č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░, (breakpoints) ąĖ ąŠą║ąĮąŠ ą┐čĆąŠčüą╝ąŠčéčĆą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ (ąŠą║ąĮą░ Expressions ąĖą╗ąĖ Locals), ąĮą░ą▒ąŠčĆ čĆąĄą│ąĖčüčéčĆąŠą▓ ą░čĆčģąĖč鹥ą║čéčāčĆčŗ Blackfin ąĖ čüčĆąĄą┤ą░ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ VisualDSP++ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ą▒ąŠą│ą░čéčŗą╣ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░čĆąĖą╣ ą┤ą╗čÅ ąŠčéą╗ą░ą┤ą║ąĖ čüą╗ąŠąČąĮčŗčģ čüąĖčüč鹥ą╝. ąÆąŠčé ąĮąĄą║ąŠč鹊čĆčŗąĄ ąĖąĘ čŹčéąĖčģ ą║ą╗čÄč湥ą▓čŗčģ ąĖąĮčüčéčĆčāą╝ąĄąĮč鹊ą▓ ąŠčéą╗ą░ą┤ą║ąĖ:
ą×ą║ąĮąŠ VDK History. ąśčüą┐ąŠą╗čīąĘčāą╣č鹥 ąŠą║ąĮąŠ VDK History (čüą╝. čĆąĖčü. 5), čćč鹊ą▒čŗ ąŠčéčüą╗ąĄąČąĖą▓ą░čéčī čüąŠčüč鹊čÅąĮąĖąĄ ą┐ąŠč鹊ą║ąŠą▓, čüąŠą▒čŗčéąĖą╣ ąĖ ą│ąŠąĮąŠą║ ą╝ąĄąČą┤čā ą┐ąŠč鹊ą║ą░ą╝ąĖ ąĖ čé. ą┐. ąŁč鹊 ąŠą║ąĮąŠ ą▓ čćą░čüčéąĮąŠčüčéąĖ ą┐ąŠą╗ąĄąĘąĮąŠ, ą║ąŠą│ą┤ą░ ąÆčŗ ąŠčéą╗ą░ąČąĖą▓ą░ąĄč鹥 ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą▓ąŠą▓ą╗ąĄą║ą░čÄčé ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą┐ąŠč鹊ą║ąŠą▓. ą×čéą║čĆčŗčéčī ąŠą║ąĮąŠ VDK History ą╝ąŠąČąĮąŠ ąĖąĘ ą╝ąĄąĮčÄ VisualDSP++ ą┐čāč鹥ą╝ ą▓čŗą▒ąŠčĆą░ View -> VDK windows -> History.

ąĀąĖčü. 5. ą×ą║ąĮąŠ VDK History.
ą×ą║ąĮąŠ VDK Status. ą×ą║ąĮąŠ VDK Status (čĆąĖčü. 6) ąŠč鹊ą▒čĆą░ąČą░ąĄčé čüąŠčüč鹊čÅąĮąĖąĄ (status) ą▓čüąĄčģ ą┐ąŠč鹊ą║ąŠą▓, čüąĄą╝ą░č乊čĆąŠą▓, čüąŠąŠą▒čēąĄąĮąĖą╣ ąĖ čé. ą┤., ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ ą▓ čüąĖčüč鹥ą╝ąĄ. ą×ą║ąĮąŠ VDK Status čéą░ą║ąČąĄ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą║ąŠą┤ ąŠčłąĖą▒ą║ąĖ ą▓ čüą╗čāčćą░ąĄ ą┐ą░ąĮąĖą║ąĖ čÅą┤čĆą░ (Kernel Panic). ą×ą▒čēąĖąĄ ąŠčłąĖą▒ą║ąĖ, ą║ąŠč鹊čĆčŗąĄ ą┐čĆąĖą▓ąŠą┤čÅčé ą║ ą┐ą░ąĮąĖą║ąĄ čÅą┤čĆą░, ą▓ą║ą╗čÄčćą░čÄčé ą▓čŗąĘąŠą▓ ą▓ ISR ąĘą░ą┐čĆąĄčēąĄąĮąĮčŗčģ ą┤ą╗čÅ ISR ąĖą╗ąĖ callback-ąŠą▓ čäčāąĮą║čåąĖą╣ VDK API, ąĖą╗ąĖ ą┐ąŠą┐čŗčéą║ą░ ą┤ąŠčüčéčāą┐ą░ ą║ čĆąĄčüčāčĆčüčā ą┐ąŠč鹊ą║ą░, ą║ąŠč鹊čĆčŗą╣ ą▒čŗą╗ čāąĮąĖčćč鹊ąČąĄąĮ. ą×čéą║čĆčŗčéčī ąŠą║ąĮąŠ VDK Status ą╝ąŠąČąĮąŠ ąĖąĘ ą╝ąĄąĮčÄ VisualDSP++ ą┐čāč鹥ą╝ ą▓čŗą▒ąŠčĆą░ View -> VDK windows -> Status.

ąĀąĖčü. 6. ą×ą║ąĮąŠ VDK Status.
ąæą╗ąŠą║ ąŠčéą╗ą░ą┤ą║ąĖ (Trace Unit) ąĖ čĆąĄą│ąĖčüčéčĆčŗ čüąĄą║ą▓ąĄąĮčüąŠčĆą░ (Sequencer). ą¦č鹊ą▒čŗ ąŠčéą╗ą░ą┤ąĖčéčī ąĖčüą║ą╗čÄč湥ąĮąĖąĄ (exception), čüąĮą░čćą░ą╗ą░ ąÆčŗ ą┤ąŠą╗ąČąĮčŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą┐čĆąĖčćąĖąĮčā ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą┐čāč鹥ą╝ ą░ąĮą░ą╗ąĖąĘą░ ą┐ąŠą╗čÅ EXCAUSE (čŹčéą░ ą╝ąĮąĄą╝ąŠąĮąĖą║ą░ ąŠąĘąĮą░čćą░ąĄčé EX: exception ąĖ CAUSE: ą┐čĆąĖčćąĖąĮą░) ą▓ čĆąĄą│ąĖčüčéčĆąĄ SEQSTAT (SEQ ąŠčé čüą╗ąŠą▓ą░ sequence, ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ąĖ STAT ąŠčé status, čé. ąĄ. čüąŠčüč鹊čÅąĮąĖąĄ). ąÉą┤čĆąĄčü ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠč鹊čĆą░čÅ ą┐čĆąĖą▓ąĄą╗ą░ ą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÄ, čüąŠčģčĆą░ąĮčÅąĄčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ RETX. ą¤ąŠą▓č鹊čĆąĮąŠ ąĘą░ą┐čāčüčéąĖč鹥 ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ, ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮąŠ čĆą░ąĘą╝ąĄčüčéąĖą▓ č鹊čćą║čā ąŠčüčéą░ąĮąŠą▓ą░ ą┐ąŠ ą░ą┤čĆąĄčüčā, ą│ą┤ąĄ ąŠąČąĖą┤ą░ąĄčéčüčÅ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ, ą░ čéą░ą║ąČąĄ čĆą░ąĘčĆąĄčłąĖč鹥 ą▒ą╗ąŠą║ ą▒čāč乥čĆą░ čéčĆą░čüčüąĖčĆąŠą▓ą║ąĖ (Trace Buffer Unit) ą┐čāč鹥ą╝ čāčüčéą░ąĮąŠą▓ą║ąĖ ą┤ą▓čāčģ ą▒ąĖčé ą▓ čĆąĄą│ąĖčüčéčĆąĄ TBUFCTL (Trace Buffer Control). ą¤ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐čĆąŠą░ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖąĘ Trace Buffer Unit, čćč鹊ą▒čŗ č鹊čćąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą┐čĆąĖčćąĖąĮčā ąĖčüą║ą╗čÄč湥ąĮąĖčÅ.
ąæą╗ąŠą║ ą┐čĆąŠčüą╝ąŠčéčĆą░ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ (Watchpoint Unit). ąĀąĄą│ąĖčüčéčĆ watchpoint ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čüčĆąĄą┤čüčéą▓ąŠ ą┤ą╗čÅ ąŠčéą╗ą░ą┤ą║ąĖ čüąĖčéčāą░čåąĖą╣, ą║ąŠą│ą┤ą░ ąŠčłąĖą▒ą║ą░ ą▓ąŠąĘąĮąĖą║ą░ąĄčé ąĮą░ n-ą┤ąŠčüčéčāą┐ąĄ ą║ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖą╗ąĖ ą┤ą░ąĮąĮčŗą╝. ąÆ čéą░ą║ąĖčģ čüą╗čāčćą░čÅčģ čüąŠą▒čŗčéąĖąĄ 菹╝čāą╗čÅčåąĖąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąŠ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ čĆąĄą│ąĖčüčéčĆąŠą▓ watchpoint ą┤ą╗čÅ n-1 ą┐ąŠ čüč湥čéčā ą┤ąŠčüčéčāą┐ą░ ą║ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖą╗ąĖ ą┤ą░ąĮąĮčŗą╝; ąĘą░č鹥ą╝ ąÆčŗ ą╝ąŠąČąĄč鹥 ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą┐ąŠčłą░ą│ąŠą▓čāčÄ ąŠčéą╗ą░ą┤ą║čā, čćč鹊ą▒čŗ ąĮą░ą╣čéąĖ ą┐čĆąĖčćąĖąĮčā ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ąĖą╗ąĖ ąŠčłąĖą▒ą║ąĖ.
ąĀąĄą│ąĖčüčéčĆčŗ čüąŠčüč鹊čÅąĮąĖčÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ (Peripheral Status Registers). ąĢčüą╗ąĖ ą▒čŗą╗ą░ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮą░ ąŠčłąĖą▒ą║ą░ DMA ąĖą╗ąĖ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░, ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐čĆąŠą░ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī čĆąĄą│ąĖčüčéčĆčŗ čüąŠčüč鹊čÅąĮąĖčÅ DMA/ą┐ąĄčĆąĖč乥čĆąĖąĖ, čćč鹊ą▒čŗ ąŠą▒ąĮą░čĆčāąČąĖčéčī ą┐čĆąĖčćąĖąĮčā ąŠčłąĖą▒ą║ąĖ. ąÜčĆąŠą╝ąĄ ąŠčłąĖą▒ąŠą║ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ, ąŠčłąĖą▒ą║ąĖ (čéą░ą║ąĖąĄ ą║ą░ą║ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĖą╗ąĖ ąĮąĄą┤ąŠą│čĆčāąĘą║ą░ DMA, čé. ąĄ. ąŠčłąĖą▒ą║ąĖ overrun ąĖą╗ąĖ underrun) ą┐čĆąŠąĖčüčģąŠą┤čÅčé ąĖąĘ-ąĘą░ ąĮąĄčŹčäč乥ą║čéąĖą▓ąĮąŠą│ąŠ ą┐čĆąŠąĄą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ čüąĖčüč鹥ą╝čŗ. ąÆ čŹč鹊ą╝ ą╝ąĄčüč鹥 ą╝ąŠąČąĄčé ą┐ąŠą╝ąŠčćčī ą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮąŠąĄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą▒čāč乥čĆą░ą╝ąĖ, ąĖą╗ąĖ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠąĄ ą┤ąĄą╗ąĄąĮąĖąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĮą░ ą▒ąŠą╗ąĄąĄ ą╝ąĄą╗ą║ąĖąĄ ąĘą░ą┤ą░čćąĖ.
ąóą░ą║ąČąĄ, ąĄčüą╗ąĖ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ čüąĖčüč鹥ą╝ąĮčŗčģ čüą╗čāąČą▒ (system service libraries, SSL), ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąŠ ąŠčłąĖą▒ąŠą║ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāčÄčéčüčÅ ą┐ąŠ ą║ąŠą┤ą░ą╝ ą▓ąŠąĘą▓čĆą░čéą░ ąĖąĘ ą▓čŗąĘąŠą▓ąŠą▓ čäčāąĮą║čåąĖą╣ API čüąĖčüč鹥ą╝ąĮčŗčģ čüą╗čāąČą▒, ąĖ ą║ąŠą┤ąŠą▓ čüąŠą▒čŗčéąĖą╣ ą▓ callback-čäčāąĮą║čåąĖąĖ. SSL ą┐ąŠą║čĆčŗą▓ą░čÄčé čüąŠą▒čŗčéąĖčÅ, ą┐čĆąĖčćąĖąĮąŠą╣ ą║ąŠč鹊čĆčŗčģ ą▒čŗą╗ąĖ ąŠčłąĖą▒ą║ąĖ DMA ąĖą╗ąĖ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓. ąŚą░ ą┐ąŠą┤čĆąŠą▒ąĮąŠčüčéčÅą╝ąĖ ąŠą▒čĆą░čéąĖč鹥čüčī ą║ ą┐čĆąĖą╝ąĄčĆą░ą╝, ą║ąŠč鹊čĆčŗąĄ ą▓ą║ą╗čÄč湥ąĮčŗ ą▓ Multimedia starter kit (ąĪą┐ąĖčüąŠą║ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ą╗ąĖč鹥čĆą░čéčāčĆčŗ/[16]).
ąŚą┤ąĄčüčī ą▒čŗą╗ ą┐čĆąĖą▓ąĄą┤ąĄąĮ ąŠą▒ąĘąŠčĆ ąĮą░ąĖą▒ąŠą╗ąĄąĄ čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ č鹥čģąĮąĖą║ ąŠčéą╗ą░ą┤ą║ąĖ. ąŚą░ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĄą╣ ąŠą▒čĆą░čēą░ą╣č鹥čüčī ą║ ąĪčüčŗą╗ą║ąĖ/[14].
[1] LwIP User Guide, %ProgramFiles%\Analog Devices\VisualDSP 5.0\Blackfin\lib\src\lwip\doc\, %ProgramFiles%\Analog Devices\VisualDSP 5.0\Blackfin\lib\src\lwip\contrib\ports\ADSP-Blackfin\docs\.
[2] BF537EthernetDeviceDriverDesign.doc, %ProgramFiles%\Analog Devices\VisualDSP 5.0\Blackfin\lib\src\lwip\contrib\ports\ADSP-Blackfin\docs\.
[3] SMSCLAN91C111_DeviceDriver.doc, %ProgramFiles%\Analog Devices\VisualDSP 5.0\Blackfin\lib\src\lwip\contrib\ports\ADSP-Blackfin\docs\.
[4] ADSP-BF533 Blackfin Processor Hardware Reference. Rev 3.2, July 2006. Analog Devices, Inc.
[5] ADSP-BF561 Blackfin Processor Hardware Reference. Rev 1.1, February 2007. Analog Devices, Inc.
[6] ADSP-BF537 Blackfin Processor Hardware Reference. Rev 3.0, December 2007. Analog Devices, Inc.
[7] ADSP-BF52x Blackfin Processor Hardware Reference (Volume 2 of 2). Rev 0.3, September, 2007. Analog Devices, Inc.
[8] ADSP-BF54x Blackfin Processor Hardware Reference (Volume 2 of 2). Rev 0.4, August 2008. Analog Devices, Inc.
[9] Embedded Media Processing. David Katz and Rick Gentile. Newnes Publishers., Burlington, MA, USA, 2005.
[10] Digital Video and HDTV. Charles Poynton. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 2003.
[11] Video Framework Considerations for Image Processing on Blackfin Processors (EE-276). Rev 1, September 2005. Analog Devices Inc.
[13] Video Templates for Developing Multimedia Applications on Blackfin Processors (EE-301). Rev 1, September 2006. Analog Devices Inc.
[15]/[3] VisualDSP 5.0 Kernel (VDK) Users Guide. Rev 3.0, August 2007. Analog Devices, Inc.
[16] Multimedia Starter Kit site:analog.com.
[17] VisualDSP++ 5.0 Linker and Utilities Manual, Rev 3.0, August 2007. Analog Devices Inc.
[18] VisualDSP++ 5.0 Blackfin C/C++ Compiler and Library Manual, Rev 5.0, August 2007, Analog Devices Inc.
[21] Unix Network Programming, volumes 1-2. W. Richard Stevens, Prentice Hall, USA, 1998.
[22] MicroC/OS-II. Jean J. Labrosse. CMP Books, San Francisco, CA, USA, 2002.
[23] Computer Networks, Andrew Tanenbaum, Prentice Hall, USA, 2002.
[ąĪčüčŗą╗ą║ąĖ]
1. EE-312 Building Complex VDK/LwIP Applications Using Blackfin® Processors site:analog.com.
2. VDK: ą┤čĆą░ą╣ą▓ąĄčĆčŗ čāčüčéčĆąŠą╣čüčéą▓ ąĖ čüąĖčüč鹥ą╝ąĮčŗąĄ čüą╗čāąČą▒čŗ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin.
3. ą×ą▒ąĘąŠčĆ VisualDSP++ Kernel RTOS (VDK).
4. LwIP download site:savannah.gnu.org.
5. 160516EE312v2.zip - ą┐čĆąĖą╝ąĄčĆčŗ ą║ąŠą┤ą░ ą┤ą╗čÅ EE-312.
6. VDK: ą╝ąĄąĮąĄą┤ąČąĄčĆ ą┤čĆą░ą╣ą▓ąĄčĆąŠą▓ čāčüčéčĆąŠą╣čüčéą▓.
7. VDK: ą╝ąĄąĮąĄą┤ąČąĄčĆ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣.
8. VDK: ą╝ąĄąĮąĄą┤ąČąĄčĆ DMA.
9. VDK: ą╝ąĄąĮąĄą┤ąČąĄčĆ ąŠčéą╗ąŠąČąĄąĮąĮčŗčģ čäčāąĮą║čåąĖą╣ ąŠą▒čĆą░čéąĮąŠą│ąŠ ą▓čŗąĘąŠą▓ą░.
10. ADSP-BF538: DMA.
11. PGO Linker: ąĖąĮčüčéčĆčāą╝ąĄąĮčé čĆą░ąĘą╝ąĄčēąĄąĮąĖčÅ ą║ąŠą┤ą░ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin.
12. ą×ą┐čéąĖą╝ąĖąĘą░čåąĖčÅ čüąĖčüč鹥ą╝čŗ ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆąĄ Blackfin.
13. ą×ą┐čåąĖąĖ ą║ąŠą╝ą░ąĮą┤ąĮąŠą╣ čüčéčĆąŠą║ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ Blackfin.
14. EE-307: čüąŠą▓ąĄčéčŗ ą┐ąŠ ąŠčéą╗ą░ą┤ą║ąĄ ą┤ą╗čÅ Blackfin. |



