|
ą¤ąŠąĮčÅčéąĖčÅ čüč鹥ą║ą░ (stack) ąĖ ą║čāčćąĖ (heap) čäčāąĮą┤ą░ą╝ąĄąĮčéą░ą╗čīąĮčŗ ą┤ą╗čÅ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝ąŠą╣ čüąĖčüč鹥ą╝čŗ. ąśčģ ąĮą░čüčéčĆąŠą╣ą║ą░ ąŠč湥ąĮčī ą▓ą░ąČąĮą░ ą┤ą╗čÅ čüčéą░ą▒ąĖą╗čīąĮąŠą╣ ąĖ ąĮą░ą┤ąĄąČąĮąŠą╣ čĆą░ą▒ąŠčéčŗ čüąĖčüč鹥ą╝čŗ. ąØąĄą║ąŠčĆčĆąĄą║čéąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ č鹊ą╝čā, čćč鹊 ąÆą░čłąĄ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝ąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ąĮą░ ą╝ąĖą║čĆąŠą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąĄ ą▒čāą┤ąĄčé ą│ą╗čÄčćąĖčéčī čüą░ą╝čŗą╝ ąĮąĄą┐čĆąĄą┤čüą║ą░ąĘčāąĄą╝čŗą╝ ąŠą▒čĆą░ąĘąŠą╝.
ą¤čĆąŠą│čĆą░ą╝ą╝ąĖčüčé ą┤ąŠą╗ąČąĄąĮ čüčéą░čéąĖč湥čüą║ąĖ ą▓čŗą▒čĆą░čéčī ą▓ ą┐ą░ą╝čÅčéąĖ ą╝ąĄčüč鹊 čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĖčÅ ąĖ čĆą░ąĘą╝ąĄčĆ ą║ą░ą║ ą┤ą╗čÅ čüč鹥ą║ą░, čéą░ą║ ąĖ ą┤ą╗čÅ ą║čāčćąĖ. ąÆčŗčćąĖčüą╗ąĖčéčī čĆą░ąĘą╝ąĄčĆ čüč鹥ą║ą░ čćą░čēąĄ ą▓čüąĄą│ąŠ ąŠč湥ąĮčī čéčĆčāą┤ąĮąŠ, ąĘą░ ąĖčüą║ą╗čÄč湥ąĮąĖąĄą╝ čüąŠą▓čüąĄą╝ čāąČ ą╝ą░ą╗ąĄąĮčīą║ąĖčģ ąĖ ą┐čĆąŠčüčéčŗčģ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ čüąĖčüč鹥ą╝, ąĖ ąĮąĄą┤ąŠąŠčåąĄąĮą║ą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüč鹥ą║ą░ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ čüąĄčĆčīąĄąĘąĮčŗą╝ ąŠčłąĖą▒ą║ą░ą╝ ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą▓ą░ąĄčé čéčĆčāą┤ąĮąŠ ąĮą░ą╣čéąĖ. ąĪ ą┤čĆčāą│ąŠą╣ čüč鹊čĆąŠąĮčŗ, ą┐ąĄčĆąĄąŠčåąĄąĮą║ą░ ą╝ąĄčüčéą░ ą┤ą╗čÅ čüč鹥ą║ą░ ąŠąĘąĮą░čćą░ąĄčé ą▒ąĄčüą┐ąŠą╗ąĄąĘąĮčāčÄ čéčĆą░čéčā čåąĄąĮąĮąŠą│ąŠ čĆąĄčüčāčĆčüą░ ą┐ą░ą╝čÅčéąĖ. ąśąĮč乊čĆą╝ą░čåąĖčÅ ą┤ą╗čÅ čüą░ą╝ąŠą│ąŠ čģčāą┤čłąĄą│ąŠ čüą╗čāčćą░čÅ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ ą│ą╗čāą▒ąĖąĮčŗ čüč鹥ą║ą░ ąŠč湥ąĮčī ą┐ąŠą╗ąĄąĘąĮą░ ą┤ą╗čÅ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ą░ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ ą┐čĆąŠąĄą║č鹊ą▓, čéą░ą║ ą║ą░ą║ čŹč鹊 ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠ čāą┐čĆąŠčēą░ąĄčé ąŠčåąĄąĮą║čā, čüą║ąŠą╗čīą║ąŠ ą╝ąĄčüčéą░ ą┐ąŠą┤ čüč鹥ą║ ąĮčāąČąĮąŠ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÄ. ą¤ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ą║čāčćąĖ ą┐čĆąŠąĖčüčģąŠą┤čÅčé ą║ąŠčĆčĆąĄą║čéąĮąŠ, ąĮąŠ čéą░ą║ąĖąĄ čüą╗čāčćą░ąĖ ą▓čüąĄ čĆą░ą▓ąĮąŠ ąĮąĄčāą┤ąŠą▒ąĮčŗ, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠč湥ąĮčī ą╝ą░ą╗ąŠ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ ą╝ąŠą│čāčé ą▓ąŠčüčüčéą░ąĮąŠą▓ąĖčéčī čĆą░ą▒ąŠč鹊čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī ą▓ čéą░ą║ąĖčģ 菹║čüčéčĆąĄą╝ą░ą╗čīąĮčŗčģ čāčüą╗ąŠą▓ąĖčÅčģ ąĮąĄčģą▓ą░čéą║ąĖ ą┐ą░ą╝čÅčéąĖ.
[ąÜčĆą░čéą║ąŠąĄ ą▓ą▓ąĄą┤ąĄąĮąĖąĄ ą▓ čüč鹥ą║ ąĖ ą║čāčćčā]
ą×ą┐ąĖčüą░ąĮąĖąĄ ą▓ čŹč鹊ą╣ čüčéą░čéčīąĄ čüąŠčüčĆąĄą┤ąŠč鹊č湥ąĮąŠ ąĮą░ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĄ ąĮą░ą┤ąĄąČąĮąŠą│ąŠ čüč鹥ą║ą░ ąĖ ą║čāčćąĖ: ą║ą░ą║ ą╝ąĖąĮąĖą╝ąĖąĘąĖčĆąŠą▓ą░čéčī čüč鹥ą║ ąĖ ą║čāčćčā ą▒ąĄąĘąŠą┐ą░čüąĮčŗą╝ čüą┐ąŠčüąŠą▒ąŠą╝.
ąØą░čüč鹊ą╗čīąĮčŗąĄ ą║ąŠą╝ą┐čīčÄč鹥čĆąĮčŗąĄ čüąĖčüč鹥ą╝čŗ (ą║ąŠą╝ą┐čīčÄč鹥čĆčŗ PC) ąĖ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗąĄ čüąĖčüč鹥ą╝čŗ ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠ čüčéčĆą░ą┤ą░čÄčé ąŠčé ąŠą▒čēąĖčģ ąŠčłąĖą▒ąŠą║ ą▓ ą┤ąĖąĘą░ą╣ąĮąĄ čüč鹥ą║ą░ ąĖ ą║čāčćąĖ, ąŠą┤ąĮą░ą║ąŠ ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąŠčéą╗ąĖčćą░čÄčéčüčÅ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ ą▓ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą╝ąĮąŠą│ąĖčģ ą┤čĆčāą│ąĖčģ ą░čüą┐ąĄą║č鹊ą▓. ą×ą┤ąĖąĮ ą┐čĆąĖą╝ąĄčĆ čĆą░ąĘą╗ąĖčćąĖą╣ ą▓ čŹčéąĖčģ čĆą░ą▒ąŠčćąĖčģ čāčüą╗ąŠą▓ąĖčÅčģ - čĆą░ąĘą╝ąĄčĆ ą┤ąŠčüčéčāą┐ąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ. Windows ąĖ Linux ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąĖčüą┐ąŠą╗čīąĘčāčÄčé 1 ąĖ 8 ą╝ąĄą│ą░ą▒ą░ą╣čé ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ą┐ąŠą┤ čüč鹥ą║; čŹč鹊čé čĆą░ąĘą╝ąĄčĆ ą┤ą░ąČąĄ ą╝ąŠąČąĄčé čāą▓ąĄą╗ąĖčćąĖą▓ą░čéčīčüčÅ. ąĀą░ąĘą╝ąĄčĆ ą║čāčćąĖ ąŠą│čĆą░ąĮąĖč湥ąĮ č鹊ą╗čīą║ąŠ ą┤ąŠčüčéčāą┐ąĮąŠą╣ čäąĖąĘąĖč湥čüą║ąŠą╣ ą┐ą░ą╝čÅčéčīčÄ ąĖ/ąĖą╗ąĖ čĆą░ąĘą╝ąĄčĆąŠą╝ čäą░ą╣ą╗ą░ ą┐ąŠą┤ą║ą░čćą║ąĖ. ąÆčüčéčĆą░ąĖą▓ą░ąĄą╝čŗąĄ čüąĖčüč鹥ą╝čŗ, čü ą┤čĆčāą│ąŠą╣ čüč鹊čĆąŠąĮčŗ, ąĖą╝ąĄčÄčé ąŠč湥ąĮčī ąŠą│čĆą░ąĮąĖč湥ąĮąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ ą┐ąŠ čĆąĄčüčāčĆčüą░ą╝ ą┐ą░ą╝čÅčéąĖ, ąŠčüąŠą▒ąĄąĮąĮąŠ ą║ąŠą│ą┤ą░ čŹč鹊 ą┐ą░ą╝čÅčéčī RAM. ąØąĄčüąŠą╝ąĮąĄąĮąĮąŠ ąĘą┤ąĄčüčī čéčĆąĄą▒čāąĄčéčüčÅ ą╝ąĖąĮąĖą╝ąĖąĘąĖčĆąŠą▓ą░čéčī čüč鹥ą║ ąĖ ą║čāčćčā, čćč鹊ą▒čŗ čāą╗ąŠąČąĖčéčīčüčÅ ą▓ ąŠą│čĆą░ąĮąĖč湥ąĮąĖčÅ ą┐ąŠ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ čŹč鹊ą│ąŠ čĆą░ą▒ąŠč湥ą│ąŠ ąŠą║čĆčāąČąĄąĮąĖčÅ. ąæąŠą╗čīčłąĖąĮčüčéą▓ąŠ ą╝ą░ą╗čŗčģ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ čüąĖčüč鹥ą╝ ąĮąĄ ąĖą╝ąĄčÄčé ą╝ąĄčģą░ąĮąĖąĘą╝ą░ ą▓ąĖčĆčéčāą░ą╗čīąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ; ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ čüč鹥ą║ą░, ą║čāčćąĖ ąĖ ą│ą╗ąŠą▒ą░ą╗čīąĮčŗčģ ą┤ą░ąĮąĮčŗčģ (čé. ąĄ. ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ, ą▒čāč乥čĆąŠą▓ TCP/IP, USB ąĖ čé. ą┤.) čüčéą░čéąĖč湥čüą║ąĖąĄ, ąĖ čŹč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓ ą╝ąŠą╝ąĄąĮčé čüą▒ąŠčĆą║ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ.
ą£čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ čüą┐ąĄčåąĖą░ą╗čīąĮčŗąĄ ą┐čĆąŠą▒ą╗ąĄą╝čŗ, ą║ąŠč鹊čĆčŗąĄ ą▓ąŠąĘąĮąĖą║ą░čÄčé ą▓ąŠ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ čüąĖčüč鹥ą╝ą░čģ, ąĮąĄ ą║ą░čüą░čÅčüčī č鹊ą│ąŠ, ą║ą░ą║ ąĘą░čēąĖčēą░čéčī čüč鹥ą║ ąĖ ą║čāčćčā ąŠčé čüą┐ąĄčåąĖą░ą╗čīąĮąŠ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĮčŗčģ ą░čéą░ą║. ą×ą┐ąĖčüą░ąĮąĖąĄ ą┐ąŠą║ą░ ąĮąĄ ą║ą░čüą░ąĄčéčüčÅ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ąĮą░ ą┤ąĄčüą║č鹊ą┐-čüąĖčüč鹥ą╝ą░čģ ąĖ ą╝ąŠą▒ąĖą╗čīąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ą░čģ (č鹥ą╗ąĄč乊ąĮčŗ, čüą╝ą░čĆčéč乊ąĮčŗ).
ą¤čĆąĄą▓čŗčłąĄąĮąĖąĄ ą╗ąĖą╝ąĖčéą░. ą¤čĆąĄą▓čŗčłąĄąĮąĖąĄ ą┐čĆąĄą┤ąĄą╗ąŠą▓ ąŠą│čĆą░ąĮąĖč湥ąĮąĖą╣ ą▓ čĆąĄą░ą╗čīąĮąŠą╣ ąČąĖąĘąĮąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖąĮąŠą│ą┤ą░ ą┐ąŠą╗ąĄąĘąĮčŗą╝, ąĮąŠ ąĖąĮąŠą│ą┤ą░ ą╝ąŠąČąĄčé čüąŠąĘą┤ą░čéčī ą┤ą╗čÅ ąÆą░čü ą┐čĆąŠą▒ą╗ąĄą╝čā. ą¤čĆąĄą▓čŗčłąĄąĮąĖąĄ ą┐čĆąĄą┤ąĄą╗ąŠą▓ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĖ, ą║ąŠą│ą┤ą░ čŹč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé čü ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄą╝ ą┤ą░ąĮąĮčŗčģ, ąŠą┤ąĮąŠąĘąĮą░čćąĮąŠ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ą┐čĆąŠą▒ą╗ąĄą╝ąĄ. ąÆ čüčćą░čüčéą╗ąĖą▓ąŠą╝ čüą╗čāčćą░ąĄ ą┐čĆąŠą▒ą╗ąĄą╝ą░ ą╝ąŠąČąĄčé ą▓ąŠąĘąĮąĖą║ąĮčāčéčī čüčĆą░ąĘčā ąĖą╗ąĖ ą▓ąŠ ą▓čĆąĄą╝čÅ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ čüąĖčüč鹥ą╝čŗ, ąĮąŠ ą╝ąŠąČąĄčé čéą░ą║ąČąĄ čüą╗čāčćąĖčéčīčüčÅ ąĖ čüą╗ąĖčłą║ąŠą╝ ą┐ąŠąĘą┤ąĮąŠ, ą║ąŠą│ą┤ą░ ą┐čĆąŠą┤čāą║čé ą┐ąŠą┐ą░ą╗ ą║ čéčŗčüčÅčćą░ą╝ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╣ ąĖą╗ąĖ ą▒čŗą╗ čĆą░ąĘą▓ąĄčĆąĮčāčé ą▓ čāą┤ą░ą╗ąĄąĮąĮąŠą╝ ąŠą║čĆčāąČąĄąĮąĖąĖ.
ą¤ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ ą▓ čéčĆąĄčģ ąŠą▒ą╗ą░čüčéčÅčģ čģčĆą░ąĮąĄąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ; ą│ą╗ąŠą▒ą░ą╗čīąĮčŗąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ (global), čüč鹥ą║ (stack) ąĖ ą║čāčćą░ (heap). ąŚą░ą┐ąĖčüčī ą▓ ą╝ą░čüčüąĖą▓čŗ čü ą┐čĆąĄą▓čŗčłąĄąĮąĖąĄą╝ ąĖąĮą┤ąĄą║čüą░ ąĖą╗ąĖ ąĘą░ą┐ąĖčüčī ą┐ąŠ ą░ą┤čĆąĄčüčā ą▓ čāą║ą░ąĘą░č鹥ą╗ąĄ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą▓čŗčģąŠą┤čā ąĘą░ ą┐čĆąĄą┤ąĄą╗čŗ ą┐ą░ą╝čÅčéąĖ, ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą╣ ą┤ą╗čÅ ąŠą▒čŖąĄą║čéą░ (ą▓ čéą░ą║ąŠą╝ čüą╗čāčćą░ąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ąĖčüą┐ąŠčĆč湥ąĮčŗ ą┤čĆčāą│ąĖąĄ ą▓ą░ąČąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ). ąØąĄą║ąŠč鹊čĆčŗąĄ ą┐ąŠą┐čŗčéą║ąĖ ą┤ąŠčüčéčāą┐ą░ ą║ ą╝ą░čüčüąĖą▓čā ą╝ąŠą│čāčé ą▒čŗčéčī ą┐čĆąŠą▓ąĄčĆąĄąĮčŗ čüčéą░čéąĖč湥čüą║ąĖą╝ ą░ąĮą░ą╗ąĖąĘąŠą╝, ąĮą░ą┐čĆąĖą╝ąĄčĆ čüą░ą╝ąĖą╝ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆąŠą╝ ąĖą╗ąĖ č湥ą║ąĄčĆąŠą╝ MISRA C:
int array[32];
array[35] = 0x1234;
ąÜąŠą│ą┤ą░ ąĖąĮą┤ąĄą║čü ą▓čŗčćąĖčüą╗čÅąĄčéčüčÅ ą▓ ą▓čŗčĆą░ąČąĄąĮąĖąĖ, čüčéą░čéąĖč湥čüą║ąĖą╣ ą░ąĮą░ą╗ąĖąĘ ąĮąĄ čüą╝ąŠąČąĄčé ą▒ąŠą╗čīčłąĄ ąĖčüą║ą░čéčī ą┐ąŠą┤ąŠą▒ąĮčŗąĄ ą┐čĆąŠą▒ą╗ąĄą╝čŗ. ą×ą▒čĆą░čēąĄąĮąĖčÅ ą┐ąŠ čāą║ą░ąĘą░č鹥ą╗čÅą╝ čéą░ą║ąČąĄ čüą╗ąŠąČąĮčŗ ą┤ą╗čÅ čéčĆą░čüčüąĖčĆąŠą▓ą║ąĖ čüčéą░čéąĖč湥čüą║ąĖą╝ ą░ąĮą░ą╗ąĖąĘąŠą╝:
int* p = malloc(32 * sizeof(int));
p += 35;
*p = 0x1234;
ąöąŠą╗ą│ąŠąĄ ą▓čĆąĄą╝čÅ ą╝ąĄč鹊ą┤čŗ ą┐ąĄčĆąĄčģą▓ą░čéą░ ąŠčłąĖą▒ąŠą║ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ ąŠą▒čŖąĄą║č鹊ą▓ ą▒čŗą╗ąĖ ą┤ąŠčüčéčāą┐ąĮčŗ ą┤ą╗čÅ ą┤ąĄčüą║č鹊ą┐-čüąĖčüč鹥ą╝ (ą╝ąŠąČąĮąŠ ąĮą░ąĘą▓ą░čéčī ąĮąĄą║ąŠč鹊čĆčŗąĄ ąĖąĘ ąĮąĖčģ: Purify, Insure++, Valgrind). ąŁčéąĖ čüčĆąĄą┤čüčéą▓ą░ ą▓čüčéčĆą░ąĖą▓ą░ą╗ąĖ ą▓ ą║ąŠą┤ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ čüą┐ąĄčåąĖą░ą╗čīąĮčŗąĄ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąŠą▒čĆą░čēąĄąĮąĖą╣ ą║ ą┐ą░ą╝čÅčéąĖ ą▓ąŠ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ąŁč鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé čåąĄąĮąŠą╣ čüąĮąĖąČąĄąĮąĖčÅ čüą║ąŠčĆąŠčüčéąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĖ čāą▓ąĄą╗ąĖč湥ąĮąĖčÅ čĆą░ąĘą╝ąĄčĆą░ ą║ąŠą┤ą░, čéą░ą║ čćč鹊 čéą░ą║ąŠą╣ ą╝ąĄč鹊ą┤ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠą╗ąĄąĘąĮčŗą╝ ą┤ą╗čÅ ą╝ą░ą╗čŗčģ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ čüąĖčüč鹥ą╝.
Stack. ąĪč鹥ą║ čŹč鹊 ąŠą▒ą╗ą░čüčéčī ą┐ą░ą╝čÅčéąĖ, ą│ą┤ąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ čüąŠčģčĆą░ąĮčÅąĄčé, ą║ ą┐čĆąĖą╝ąĄčĆčā, čüą╗ąĄą┤čāčÄčēąĖąĄ ą┤ą░ąĮąĮčŗąĄ:
ŌĆó ąøąŠą║ą░ą╗čīąĮčŗąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ
ŌĆó ąÉą┤čĆąĄčüą░ ą▓ąŠąĘą▓čĆą░čéą░ ąĖąĘ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝
ŌĆó ąÉčĆą│čāą╝ąĄąĮčéčŗ čäčāąĮą║čåąĖąĖ
ŌĆó ąÆčĆąĄą╝ąĄąĮąĮčŗąĄ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆąŠą╝
ŌĆó ąÜąŠąĮč鹥ą║čüčé ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣
ąÆčĆąĄą╝čÅ ąČąĖąĘąĮąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ ą▓ čüč鹥ą║ąĄ ąŠą│čĆą░ąĮąĖč湥ąĮąŠ ą┤ą╗ąĖč鹥ą╗čīąĮąŠčüčéčīčÄ čĆą░ą▒ąŠčéčŗ čäčāąĮą║čåąĖąĖ (ąĖą╗ąĖ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ), ą║ąŠč鹊čĆąŠą╣ ąŠąĮąĖ ą┐čĆąĖąĮą░ą┤ą╗ąĄąČą░čé. ąÜą░ą║ č鹊ą╗čīą║ąŠ čäčāąĮą║čåąĖčÅ ą▓čŗą┐ąŠą╗ąĮąĖą╗ą░ ą▓ąŠąĘą▓čĆą░čé ą▓ ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ ąĄčæ ą▓čŗąĘą▓ą░ą╗, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ą░čÅ ąĄą╣ ą┐ą░ą╝čÅčéčī čüč鹥ą║ą░ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ ąŠčüą▓ąŠą▒ąŠąČą┤ą░ąĄčéčüčÅ ą┤ą╗čÅ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖčģ ą▓čŗąĘąŠą▓ąŠą▓ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝.
ą¤ą░ą╝čÅčéčī čüč鹥ą║ą░ ą▓čŗą┤ąĄą╗čÅąĄčéčüčÅ čüčéą░čéąĖč湥čüą║ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüč鹊ą╝ ą▓ ą┐čĆąŠčåąĄčüčüąĄ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. ąĪč鹥ą║ ąŠą▒čŗčćąĮąŠ čĆą░čüč鹥čé ą▓ąĮąĖąĘ (ą▓ čüč鹊čĆąŠąĮčā čāą╝ąĄąĮčīčłąĄąĮąĖčÅ ą░ą┤čĆąĄčüą░ ą▓ ą┐ą░ą╝čÅčéąĖ), ąĖ ąĄčüą╗ąĖ ąŠą▒ą╗ą░čüčéčī ą┐ą░ą╝čÅčéąĖ, ą▓čŗą┤ąĄą╗ąĄąĮąĮą░čÅ ą┐ąŠą┤ čüč鹥ą║, ąĮąĄą┤ąŠčüčéą░č鹊čćąĮąŠ ą▓ąĄą╗ąĖą║ą░, č鹊 ą▓čŗą┐ąŠą╗ąĮčÅčÄčēąĖą╣čüčÅ ą║ąŠą┤ ą┐ąĄčĆąĄąĘą░ą┐ąĖčłąĄčé ąŠą▒ą╗ą░čüčéčī ą┐ą░ą╝čÅčéąĖ, ą╗ąĄąČą░čēčāčÄ ąĮąĖąČąĄ čüč鹥ą║ą░, ąĖ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ čüč鹥ą║ą░ (čüą╝. čĆąĖčü. 1).
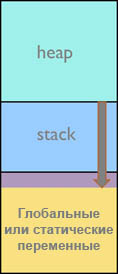
ąĀąĖčü. 1. ąĪąĖčéčāą░čåąĖčÅ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ čüč鹥ą║ą░.
ąŚą░ą┐ąĖčüčŗą▓ą░ąĄą╝ą░čÅ ą┐čĆąĖ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĖ čüč鹥ą║ą░ ąŠą▒ą╗ą░čüčéčī čŹč鹊 č鹊 ą╝ąĄčüč鹊, ą│ą┤ąĄ ąĮą░čģąŠą┤čÅčéčüčÅ ą│ą╗ąŠą▒ą░ą╗čīąĮčŗąĄ ąĖ čüčéą░čéąĖč湥čüą║ąĖąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąĮąĄą┤ąŠąŠčåąĄąĮą║ą░ ą╝ąĄčüčéą░ ą┐ąŠą┤ čüč鹥ą║ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ čüąĄčĆčīąĄąĘąĮčŗą╝ ąŠčłąĖą▒ą║ą░ą╝ ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ, čéą░ą║ąĖą╝ ą║ą░ą║ ą┐ąĄčĆąĄąĘą░ą┐ąĖčüčī ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ, ą┤ąĖą║ąĖąĄ čāą║ą░ąĘą░č鹥ą╗ąĖ ąĖ ąĖčüą┐ąŠčĆč湥ąĮąĮčŗąĄ ą░ą┤čĆąĄčüą░ ą▓ąŠąĘą▓čĆą░čéą░. ąÆčüąĄ čŹčéąĖ ąŠčłąĖą▒ą║ąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī čéčĆčāą┤ąĮčŗ ą┤ą╗čÅ ąŠą▒ąĮą░čĆčāąČąĄąĮąĖčÅ. ąĪ ą┤čĆčāą│ąŠą╣ čüč鹊čĆąŠąĮčŗ, ą┐ąĄčĆąĄąŠčåąĄąĮą║ą░ ą╝ąĄčüčéą░ ą┐ąŠą┤ čüč鹥ą║ ąŠąĘąĮą░čćą░ąĄčé čéčĆą░čéčā čĆąĄčüčāčĆčüąŠą▓ ąŠą┐ąĄčĆą░čéąĖą▓ąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ.
ą£čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ąĮąĄą║ąŠč鹊čĆčŗąĄ ą╝ąĄč鹊ą┤čŗ ą┤ą╗čÅ ąĮą░ą┤ąĄąČąĮąŠą│ąŠ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ čéčĆąĄą▒čāąĄą╝ąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░ čüč鹥ą║ą░ ąĖ ą┤ąĄč鹥ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐čĆąŠą▒ą╗ąĄą╝, čüą▓čÅąĘą░ąĮąĮčŗčģ čüąŠ čüč鹥ą║ąŠą╝.
Heap. ąÜčāčćą░ čŹč鹊 č鹊 ą╝ąĄčüč鹊, ą│ą┤ąĄ čĆą░ąĘą╝ąĄčēąĄąĮą░ ą┐ąŠą┤čüąĖčüč鹥ą╝ą░ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą│ąŠ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ (ąĮąĄ ą┐čāčéą░ą╣č鹥 ą▓ ą┤ą░ąĮąĮąŠą╝ ą║ąŠąĮč鹥ą║čüč鹥 ą┤ąĖąĮą░ą╝ąĖč湥čüą║čāčÄ ą┐ą░ą╝čÅčéčī čü DRAM ąĖ SDRAM!). ąöąĖąĮą░ą╝ąĖč湥čüą║ą░čÅ ą┐ą░ą╝čÅčéčī ąĖ ą║čāčćą░ ą╝ąŠąČąĄčé ą▓ąŠ ą╝ąĮąŠą│ąĖčģ čüą╗čāčćą░čÅčģ ą▒čŗčéčī ąĮąĄąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠą╣ ą┤ą╗čÅ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ ą▓ąŠ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ čüąĖčüč鹥ą╝ą░čģ (ą╝ąŠąČąĄčé čĆą░čüčüą╝ą░čéčĆąĖą▓ą░čéčīčüčÅ ą║ą░ą║ ąŠą┐čåąĖčÅ). ąöąĖąĮą░ą╝ąĖč湥čüą║ą░čÅ ą┐ą░ą╝čÅčéčī ą┤ąĄą╗ą░ąĄčé ą▓ąŠąĘą╝ąŠąČąĮčŗą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąŠą┤ąĮąŠą╣ ąĖ č鹊ą╣ ąČąĄ ą┐ą░ą╝čÅčéąĖ čüąŠą▓ą╝ąĄčüčéąĮąŠ čĆą░ąĘąĮčŗą╝ąĖ čćą░čüčéčÅą╝ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ (ąĖą╝ąĄąĄčéčüčÅ ą▓ ą▓ąĖą┤čā ąĮąĄ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ). ąÜąŠą│ą┤ą░ ąŠą┤ąĖąĮ ą╝ąŠą┤čāą╗čī ą▒ąŠą╗čīčłąĄ ąĮąĄ ąĮčāąČą┤ą░ąĄčéčüčÅ ą▓ čüą▓ąŠąĄą╣ ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ, ąŠąĮ ą┐čĆąŠčüč鹊 ą▓ąŠąĘą▓čĆą░čēą░ąĄčé ąĄčæ ą▓ ąŠą▒čēąĖą╣ ą┐čāą╗ ą║čāčćąĖ, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ąŠąĮą░ ą╝ąŠąČąĄčé ą┐ąŠą▓č鹊čĆąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą║ą░ą║ąĖą╝-č鹊 ą┤čĆčāą│ąĖą╝ ą╝ąŠą┤čāą╗ąĄą╝. ą×ą┐ąĄčĆą░čåąĖčÅą╝ąĖ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ąĘą░ą▓ąĄą┤čāąĄčé čüą┐ąĄčåąĖą░ą╗čīąĮą░čÅ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą╣ ą┐ą░ą╝čÅčéąĖ, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčēą░čÅ čäčāąĮą║čåąĖąĖ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ malloc, calloc, realloc ąĖ free [] ąĮą░ čÅąĘčŗą║ąĄ C. ą»ąĘčŗą║ C++ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą▒ąĖą▒ą╗ąĖąŠč鹥ą║čā ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą╣ ą┐ą░ą╝čÅčéąĖ ą▓ ąŠą┐ąĄčĆą░č鹊čĆą░čģ new ąĖ delete. ąÜčāčćčā čéą░ą║ąČąĄ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čüč鹊čĆąŠąĮąĮąĖąĄ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ą║ąŠą┤ą░ ąĖ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮčŗąĄ čüąĖčüč鹥ą╝čŗ čĆąĄą░ą╗čīąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ (RTOS []). ą×ą▒čŗčćąĮąŠ ą║čāčćą░ ąŠą┤ąĮą░, ąĮąŠ ąĖčģ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖ ąĮąĄčüą║ąŠą╗čīą║ąŠ. ąØąĄą║ąŠč鹊čĆčŗąĄ ąŠčüąŠą▒ąŠ ą┐čĆąŠą┤ą▓ąĖąĮčāčéčŗąĄ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ą┤ą░ąČąĄ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čüą▓ąŠąĖ čäčāąĮą║čåąĖąĖ ą┤ą╗čÅ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÅ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą╣ ą┐ą░ą╝čÅčéąĖ.
ąóąĖą┐ąĖčćąĮčŗąĄ ą┐čĆąĖą╝ąĄčĆčŗ ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗąĄ čĆą░ąĘą╝ąĄčēą░čÄčéčüčÅ ą▓ ą║čāč湥:
ŌĆó ą×ą▒čŖąĄą║čéčŗ č鹥ą║čāčēąĖčģ ą┤ą░ąĮąĮčŗčģ
ŌĆó ą×ą▒čŖąĄą║čéčŗ C++, ą▓čĆąĄą╝čÅ ąČąĖąĘąĮąĖ ą║ąŠč鹊čĆčŗčģ čāą┐čĆą░ą▓ą╗čÅčÄčéčüčÅ ąŠą┐ąĄčĆą░č鹊čĆą░ą╝ąĖ new/delete
ŌĆó ąÜąŠąĮč鹥ą╣ąĮąĄčĆčŗ STL C++
ŌĆó ąśčüą║ą╗čÄč湥ąĮąĖčÅ C++
ąÆčŗčćąĖčüą╗ąĄąĮąĖąĄ čĆą░ąĘą╝ąĄčĆą░ ą║čāčćąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī ą║ą░ą║ ąŠč湥ąĮčī čéčĆčāą┤ąĮąŠ, čéą░ą║ ąĖ ą▓ąŠą▓čüąĄ ąĮąĄą▓ąŠąĘą╝ąŠąČąĮąŠ ą┤ą╗čÅ ą▒ąŠą╗čīčłąĖčģ čüąĖčüč鹥ą╝ - ąĖąĘ-ąĘą░ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą│ąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ą░ą╝čÅčéąĖ ą▓ ą║čāč湥, ą║ąŠč鹊čĆčāčÄ ą╝ąŠąČąĄčé ą┐ąŠčéčĆąĄą▒ąŠą▓ą░čéčī ą┤ą╗čÅ čüąĄą▒čÅ ą▓ąĄą▒-čüąĄčĆą▓ąĄčĆ, ą╝ąŠąČąĄčé ąĘą░ą▓ąĖčüąĄčéčī ąŠčé ą║ąŠą╗ąĖč湥čüčéą▓ą░ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗčģ čüąĄč鹥ą▓čŗčģ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖą╣. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ą┤ąŠą▓ąŠą╗čīąĮąŠ ą╝ą░ą╗ąŠ ąĖąĮčüčéčĆčāą╝ąĄąĮč鹊ą▓ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ ąĖąĘą╝ąĄčĆąĄąĮąĖčÅ čāčéąĖą╗ąĖąĘą░čåąĖąĖ čüč鹥ą║ą░ ą▓ ą╝ąĖčĆąĄ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣, ąĮąŠ ąĮąĄą║ąŠč鹊čĆčŗąĄ ą╝ąĄč鹊ą┤čŗ ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝.
ąÆą░ąČąĮąŠ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čéčī čåąĄą╗ąŠčüčéąĮąŠčüčéčī ą║čāčćąĖ. ąÆčŗą┤ąĄą╗ąĄąĮąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ą┤ą░ąĮąĮčŗčģ čéąĖą┐ąĖčćąĮąŠ čüąŠą┐čĆąŠą▓ąŠąČą┤ą░ąĄčéčüčÅ ą║čĆąĖčéąĖčćąĮčŗą╝ąĖ ą┤ą░ąĮąĮčŗą╝ąĖ ą┐ąŠ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÄ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ą▓čŗą┤ąĄą╗ąĄąĮąĖą╣ ą┐ą░ą╝čÅčéąĖ. ąØąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ą▓čŗą┤ąĄą╗čÅąĄą╝čŗčģ ą┤ą░ąĮąĮčŗčģ ąĮąĄ č鹊ą╗čīą║ąŠ ą▓ą▓ąŠą┤ąĖčé čĆąĖčüą║ ą┐ąŠą▓čĆąĄąČą┤ąĄąĮąĖčÅ ą┤čĆčāą│ąĖčģ ą┤ą░ąĮąĮčŗčģ, č鹊 čéą░ą║ąČąĄ ą╝ąŠąČąĄčé ą┐ąŠą▓čĆąĄą┤ąĖčéčī čüą╗čāąČąĄą▒ąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ą▓čŗą┤ąĄą╗ąĄąĮąĖą╣ ą┐ą░ą╝čÅčéąĖ, čćč鹊 čüą║ąŠčĆąĄąĄ ą▓čüąĄą│ąŠ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ą┐ąŠą╗ąĮąŠą╝čā ą║čĆą░čģčā ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. ą£čŗ ąŠą▒čüčāą┤ąĖą╝ ąĮąĄą║ąŠč鹊čĆčŗąĄ ą╝ąĄč鹊ą┤čŗ, ą┐ąŠą╝ąŠą│ą░čÄčēąĖąĄ ą┐čĆąŠą▓ąĄčĆąĖčéčī čåąĄą╗ąŠčüčéąĮąŠčüčéčī ą║čāčćąĖ.
ąöčĆčāą│ąŠą╣ ą░čüą┐ąĄą║čé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą║čāčćąĖ ą▓ č鹊ą╝, čćč鹊 ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ą║ąŠą┤ą░ čĆąĄą░ą╗čīąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ čü ą┤ą░ąĮąĮčŗą╝ąĖ ą▓ ą║čāč湥 čüčéą░ąĮąŠą▓ąĖčéčüčÅ ąĮąĄąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╝. ąÆčĆąĄą╝čÅ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ąĘą░ą▓ąĖčüąĖčé ąŠčé čéą░ą║ąĖčģ čäą░ą║č鹊čĆąŠą▓, ą║ą░ą║ ą┐čĆąĄą┤čŗą┤čāčēąĖąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ, ąĮą░ą╗ąĖčćąĖąĄ ą▓ ą║čāč湥 "ą┤čŗčĆąŠą║" ąĖ ąŠčé čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéąĖ čāą▒ąŠčĆčēąĖą║ą░ ą╝čāčüąŠčĆą░. ąÜąŠą│ą┤ą░ čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ čāčćąĖčéčŗą▓ą░ąĄčé ą║ą░ąČą┤čŗą╣ čåąĖą║ą╗ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░ ą┤ą╗čÅ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖčÅ ą┐čĆąŠą│ąĮąŠąĘąĖčĆčāąĄą╝ąŠą│ąŠ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ ą▓ čĆąĄą░ą╗čīąĮąŠą╝ ą▓čĆąĄą╝ąĄąĮąĖ, ąĖąĮč鹥ąĮčüąĖą▓ąĮčŗąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ/ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ą╝ąŠą│čāčé čüčéą░čéčī ąĮąĄą┤ąŠą┐čāčüčéąĖą╝čŗą╝ąĖ.
ą×ą▒čēąĖąĄ čĆąĄą║ąŠą╝ąĄąĮą┤ą░čåąĖąĖ ą▓ čŹč鹊ą╣ čüčéą░čéčīąĄ ą║ą░čüą░čÄčéčüčÅ ą▓ ąŠčüąĮąŠą▓ąĮąŠą╝ ą╝ąĖąĮąĖą╝ąĖąĘą░čåąĖąĖ čĆą░ąĘą╝ąĄčĆą░ ą║čāčćąĖ ą▓ ą╝ą░ą╗čŗčģ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ čüąĖčüč鹥ą╝ą░čģ.
[ąĀą░ąĘčĆą░ą▒ąŠčéą║ą░ ąĮą░ą┤ąĄąČąĮąŠą│ąŠ čüč鹥ą║ą░]
ąĢčüčéčī ą╝ąĮąŠą│ąŠ čäą░ą║č鹊čĆąŠą▓, ą┤ąŠą▒ą░ą▓ą╗čÅčÄčēąĖčģ čüą╗ąŠąČąĮąŠčüčéąĖ ą▓ ą▓čŗčćąĖčüą╗ąĄąĮąĖąĖ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüč鹥ą║ą░. ą£ąĮąŠą│ąĖąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ čüą╗ąŠąČąĮčŗ ąĖ čĆąĄą░ą│ąĖčĆčāčÄčé ąĮą░ ą▓ąĮąĄčłąĮąĖąĄ čüąŠą▒čŗčéąĖčÅ (event driven), ą▓ ąĮąĖčģ ąĄčüčéčī čüąŠčéąĮąĖ čäčāąĮą║čåąĖčÅ ąĖ ą╝ąĮąŠąČąĄčüčéą▓ąŠ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣. ąĢčüčéčī ą▓ąĄčĆąŠčÅčéąĮąŠčüčéčī, čćč鹊 čäčāąĮą║čåąĖąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ (ISR) ą╝ąŠą│čāčé ąĘą░ą┐čāčüčéąĖčéčīčüčÅ ą▓ ą╗čÄą▒ąŠą╣ ą╝ąŠą╝ąĄąĮčé ą▓čĆąĄą╝ąĄąĮąĖ, ąĖ ąĄčüą╗ąĖ čĆą░ąĘčĆąĄčłąĄąĮąŠ ą▓ą╗ąŠąČąĄąĮąĖąĄ ą▓čŗąĘąŠą▓ąŠą▓ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ ą┤čĆčāą│ ą▓ ą┤čĆčāą│ą░, č鹊 čüąĖčéčāą░čåąĖčÅ čüčéą░ąĮąŠą▓ąĖčéčüčÅ ąĄčēąĄ ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮąŠą╣ ą┤ą╗čÅ ąŠčåąĄąĮą║ąĖ. ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ąŠčéčüčāčéčüčéą▓čāąĄčé ą╗ąĄą│ą║ąŠ čüąŠą┐čĆąŠą▓ąŠąČą┤ą░ąĄą╝čŗą╣ ą┐ąŠč鹊ą║ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░. ą£ąŠą│čāčé ą┐čĆąĖčüčāčéčüčéą▓ąŠą▓ą░čéčī ą║ąŠčüą▓ąĄąĮąĮčŗąĄ ą▓čŗąĘąŠą▓čŗ (indirect calls) čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ąĮą░ čäčāąĮą║čåąĖąĖ, ą│ą┤ąĄ č鹊čćą║ą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą▓čŗąĘąŠą▓ą░ ą╝ąŠąČąĄčé ąĘą░ą▓ąĖčüąĄčéčī ąŠčé čĆą░ąĘąĮčŗčģ čäčāąĮą║čåąĖą╣. ąĀąĄą║čāčĆčüąĖčÅ ąĖ ąĮąĄ čüąĮą░ą▒ąČąĄąĮąĮčŗąĄ ą┐ąŠą┤čĆąŠą▒ąĮčŗą╝ąĖ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖčÅą╝ąĖ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĮą░ ą░čüčüąĄą╝ą▒ą╗ąĄčĆąĄ čéą░ą║ąČąĄ ą▒čāą┤čāčé čüąŠąĘą┤ą░ą▓ą░čéčī ą┐čĆąŠą▒ą╗ąĄą╝čŗ ą┤ą╗čÅ č鹥čģ, ą║č鹊 ą║ąŠč湥čé ą▓čŗčćąĖčüą╗ąĖčéčī ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüč鹥ą║ą░ ą┐ąŠ ą║ąŠą┤čā ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ.
ą£ąĮąŠą│ąĖąĄ ą╝ąĖą║čĆąŠą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆčŗ čĆąĄą░ą╗ąĖąĘčāčÄčé ąĮąĄčüą║ąŠą╗čīą║ąŠ ą░ą┐ą┐ą░čĆą░čéąĮčŗčģ čüč鹥ą║ąŠą▓, ąĮą░ą┐čĆąĖą╝ąĄčĆ čüąĖčüč鹥ą╝ąĮčŗą╣ čüč鹥ą║ (system stack) ąĖ čüč鹥ą║ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (user stack). ąØąĄčüą║ąŠą╗čīą║ąŠ čüč鹥ą║ąŠą▓ čéą░ą║ąČąĄ čĆąĄą░ą╗čīąĮčŗ, ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗąĄ RTOS ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ ┬ĄC/OS, ThreadX ąĖ ą┤čĆčāą│ąĖąĄ, ą│ą┤ąĄ ą║ą░ąČą┤ą░čÅ ąĘą░ą┤ą░čćą░ ą┐ąŠą╗čāčćą░ąĄčé čüą▓ąŠčÄ čüąŠą▒čüčéą▓ąĄąĮąĮčāčÄ ąŠą▒ą╗ą░čüčéčī čüč鹥ą║ą░. Runtime-ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ąĖ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ čüč鹊čĆąŠąĮąĮąĖčģ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗ąĄą╣ - ąĄčēąĄ ąŠą┤ąĖąĮ čäą░ą║č鹊čĆ čāčüą╗ąŠąČąĮąĄąĮąĖčÅ čĆą░čüč湥čéą░ čüč鹥ą║ą░, ą┐ąŠčüą║ąŠą╗čīą║čā ąĖčüčģąŠą┤ąĮčŗą╣ ą║ąŠą┤ čŹčéąĖčģ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ ąĖ RTOS ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮąĄą┤ąŠčüčéčāą┐ąĄąĮ. ąóą░ą║ąČąĄ ą▓ą░ąČąĮąŠ ą┐ąŠą╝ąĮąĖčéčī, čćč鹊 ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą║ąŠą┤ą░ ąĖ ą┐ą╗ą░ąĮąĖčĆąŠą▓ą║ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą╝ąŠą│čāčé čüąĖą╗čīąĮąŠ ą┐ąŠą▓ą╗ąĖčÅčéčī ąĮą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüč鹥ą║ą░. ąĀą░ąĘąĮčŗąĄ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆčŗ ąĖ čĆą░ąĘąĮčŗąĄ čāčĆąŠą▓ąĮąĖ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖąĖ čéą░ą║ąČąĄ ą│ąĄąĮąĄčĆąĖčĆčāčÄčé čĆą░ąĘąĮčŗą╣ ą║ąŠą┤, ą║ąŠč鹊čĆčŗą╣ čéą░ą║ąČąĄ ą▒čāą┤ąĄčé ą┐ąŠ-čĆą░ąĘąĮąŠą╝čā ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čüč鹥ą║. ąÆ ąĖč鹊ą│ąĄ ą┐ąŠą╗čāčćą░ąĄčéčüčÅ, čćč鹊 ą▓ą░ąČąĮąŠ ą┐ąŠčüč鹊čÅąĮąĮąŠ ąŠčéčüą╗ąĄąČąĖą▓ą░čéčī ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčŗąĄ čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅ ą║ čĆą░ąĘą╝ąĄčĆčā čüč鹥ą║ą░.
ąÜą░ą║ čāčüčéą░ąĮąŠą▓ąĖčéčī čĆą░ąĘą╝ąĄčĆ čüč鹥ą║ą░. ąÜąŠą│ą┤ą░ čĆą░ąĘčĆą░ą▒ą░čéčŗą▓ą░ąĄčéčüčÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ, čĆą░ąĘą╝ąĄčĆ čüč鹥ą║ą░ čŹč鹊 ąŠą┤ąĖąĮ ąĖąĘ ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗčģ čāčćąĖčéčŗą▓ą░ąĄą╝čŗčģ čäą░ą║č鹊čĆąŠą▓, ąĖ ąĮčāąČąĄąĮ ą║ą░ą║ąŠą╣-č鹊 ą╝ąĄč鹊ą┤ ą┤ą╗čÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ čĆą░ąĘą╝ąĄčĆą░ čüč鹥ą║ą░, ą║ąŠč鹊čĆčŗą╣ ąÆą░ą╝ ąĮąĄąŠą▒čģąŠą┤ąĖą╝. ąöą░ąČąĄ ąĄčüą╗ąĖ ąÆčŗ ą▓čŗą┤ąĄą╗ąĖč鹥 ą▓čüčÄ ąŠčüčéą░ą▓čłčāčÄčüčÅ ą┐ą░ą╝čÅčéčī RAM ą┐ąŠą┤ ąŠą▒ą╗ą░čüčéčī čüč鹥ą║ą░, ą▓čüąĄ ąĄčēąĄ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ čāą▒ąĄą┤ąĖčéčīčüčÅ, čćč鹊 ą╝ąĄčüčéą░ ą┤ą╗čÅ čüč鹥ą║ą░ ą┤ąŠčüčéą░č鹊čćąĮąŠ. ą×ą┤ąĖąĮ ąŠč湥ą▓ąĖą┤ąĮčŗą╣ ą╝ąĄč鹊ą┤ ą┐čĆąŠą▓ąĄčĆą║ąĖ čüąĖčüč鹥ą╝čŗ - ą┐ąŠą╝ąĄčüčéąĖčéčī ąĄčæ ą▓ čāčüą╗ąŠą▓ąĖčÅ čģčāą┤čłąĄą│ąŠ čüą╗čāčćą░čÅ, ą║ąŠą│ą┤ą░ ą┤ąŠą╗ąČąĮąŠ ąĮą░ą▒ą╗čÄą┤ą░čéčīčüčÅ čüą░ą╝ąŠąĄ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ čüč鹥ą║ą░. ąÆąŠ ą▓čĆąĄą╝čÅ čŹč鹊ą│ąŠ č鹥čüčéą░ ąĮčāąČąĄąĮ ą╝ąĄč鹊ą┤ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ, čüą║ąŠą╗čīą║ąŠ čĆąĄą░ą╗čīąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ąŠčüčī ą╝ąĄčüčéą░ ą▓ čüč鹥ą║ąĄ. ąŁč鹊 ą╝ąŠąČąĮąŠ čüą┤ąĄą╗ą░čéčī ą▓ ąŠčüąĮąŠą▓ąĮąŠą╝ ą┤ą▓čāą╝čÅ čüą┐ąŠčüąŠą▒ą░ą╝ąĖ: ąĖąĘ čĆą░čüą┐ąĄčćą░č鹊ą║ č鹥ą║čāčēąĄą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüč鹥ą║ą░, ąĖą╗ąĖ ą┐čāč鹥ą╝ čüąŠąĘą┤ą░ąĮąĖčÅ ą▓ ą┐ą░ą╝čÅčéąĖ ąŠčéč湥čéą░ čéčĆą░čüčüąĖčĆąŠą▓ą║ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüč鹥ą║ą░ ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ą▒čŗą╗ ąĘą░ą▓ąĄčĆčłąĄąĮ ą┐čĆąŠą│ąŠąĮ č鹥čüčéą░. ąØąŠ, ą║ą░ą║ čāąČąĄ čāą┐ąŠą╝ąĖąĮą░ą╗ąŠčüčī ą▓čŗčłąĄ, ą▓ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ čüą╗ąŠąČąĮčŗčģ čüąĖčüč鹥ą╝ čāčüą╗ąŠą▓ąĖčÅ čüą░ą╝ąŠą│ąŠ čģčāą┤čłąĄą│ąŠ čüą╗čāčćą░čÅ čüąŠąĘą┤ą░čéčī ąŠč湥ąĮčī čéčĆčāą┤ąĮąŠ. ążčāąĮą┤ą░ą╝ąĄąĮčéą░ą╗čīąĮą░čÅ ą┐čĆąŠą▒ą╗ąĄą╝ą░ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ čĆąĄą░ą│ąĖčĆčāčÄčēąĄą╣ ąĮą░ čüąŠą▒čŗčéąĖčÅ čüąĖčüč鹥ą╝čŗ čü ą╝ąĮąŠą│ąĖą╝ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅą╝ąĖ - ą▒ąŠą╗čīčłą░čÅ ą▓ąĄčĆąŠčÅčéąĮąŠčüčéčī, čćč鹊 ąĮąĄą║ąŠč鹊čĆčŗąĄ ą┐čāčéąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą▓čüąĄ-čéą░ą║ąĖ ąĮąĄ ą▒čāą┤čāčé ą┐ąŠą║čĆčŗčéčŗ č鹥čüč鹊ą╝.
ąöčĆčāą│ąŠą╣ ą┐ąŠą┤čģąŠą┤ ą┤ąŠą╗ąČąĄąĮ ą▒čŗą╗ ą▒čŗ ą▓čŗčćąĖčüą╗ąĖčéčī č鹥ąŠčĆąĄčéąĖč湥čüą║ąĖąĄ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčŗąĄ čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅ ą║ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓čā čüč鹥ą║ą░. ą×č湥ąĮčī ą┐čĆąŠčüč鹊 ą┐ąŠąĮčÅčéčī, čćč鹊 ąĮąĄą▓ąŠąĘą╝ąŠąČąĮąŠ ą▓čŗčćąĖčüą╗ąĖčéčī ą▓čĆčāčćąĮčāčÄ ą┐ąŠčéčĆąĄą▒ą╗ąĄąĮąĖąĄ čüč鹥ą║ą░ ą┐ąŠą╗ąĮąŠą╣ čüąĖčüč鹥ą╝čŗ. ąŁč鹊 ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ ą┐ąŠčéčĆąĄą▒čāąĄčé ąĖąĮčüčéčĆčāą╝ąĄąĮčé, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ą┐čĆąŠą░ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī ą▓čüčÄ čüąĖčüč鹥ą╝čā. ąŁč鹊čé ąĖąĮčüčéčĆčāą╝ąĄąĮčé ą┤ąŠą╗ąČąĄąĮ čĆą░ą▒ąŠčéą░čéčī ą╗ąĖą▒ąŠ čü ą┤ą▓ąŠąĖčćąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝ ąĖčüą┐ąŠą╗ąĮčÅąĄą╝ąŠą│ąŠ ą║ąŠą┤ą░, ą╗ąĖą▒ąŠ čü ąĖčüčģąŠą┤ąĮčŗą╝ ą║ąŠą┤ąŠą╝. ąöą▓ąŠąĖčćąĮčŗą╣ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░čĆąĖą╣ čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ čāčĆąŠą▓ąĮąĄ ą╝ą░čłąĖąĮąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖą╣, čćč鹊ą▒čŗ ąĮą░ą╣čéąĖ ą▓čüąĄ ą▓ąŠąĘą╝ąŠąČąĮčŗąĄ ą┐ąĄčĆąĄą╝ąĄčēąĄąĮąĖčÅ čüč湥čéčćąĖą║ą░ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą▓ ą║ąŠą┤ąĄ ąĖ ąŠą▒ąĮą░čĆčāąČąĖčéčī čüą░ą╝čŗąĄ čģčāą┤čłąĖąĄ čüą╗čāčćą░ąĖ ą┐čāčéąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ. ąŻčéąĖą╗ąĖčéą░ čüčéą░čéąĖč湥čüą║ąŠą│ąŠ ą░ąĮą░ą╗ąĖąĘą░ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░ ą▒čāą┤ąĄčé čćąĖčéą░čéčī ą▓čüąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ 菹╗ąĄą╝ąĄąĮčéčŗ ą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄą╝ąŠą│ąŠ ą║ąŠą┤ą░. ąÆ ąŠą▒ąŠąĖčģ čüą╗čāčćą░čÅčģ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░čĆąĖą╣ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓ čüąŠčüč鹊čÅąĮąĖąĖ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą▓ ą║ą░ąČą┤ąŠą╝ 菹╗ąĄą╝ąĄąĮč鹥 ą║ąŠą╝ą┐ąĖą╗ąĖčĆčāąĄą╝ąŠą│ąŠ ą║ąŠą┤ą░ ą┐čĆčÅą╝čŗąĄ ąĖ ą║ąŠčüą▓ąĄąĮąĮčŗąĄ ą▓čŗąĘąŠą▓čŗ čäčāąĮą║čåąĖąĖ č湥čĆąĄąĘ čāą║ą░ąĘą░č鹥ą╗ąĖ, ą▓čŗčćąĖčüą╗čÅčÅ ą┐čĆąŠčäąĖą╗čī ą║ąŠąĮčüąĄčĆą▓ą░čéąĖą▓ąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüč鹥ą║ą░ č湥čĆąĄąĘ ą▓čüčÄ čüąĖčüč鹥ą╝čā ą┤ą╗čÅ ą▓čüąĄčģ ą┤ąĄčĆąĄą▓čīąĄą▓ ą▓čŗąĘąŠą▓ąŠą▓. ąśąĮčüčéčĆčāą╝ąĄąĮčéčā ą░ąĮą░ą╗ąĖąĘą░ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░ čéą░ą║ąČąĄ čéčĆąĄą▒čāąĄčéčüčÅ ąĘąĮą░čéčī, ą║čāą┤ą░ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą┐ąŠą╝ąĄčēą░ąĄčé čüč鹥ą║, ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ čÅč湥ąĄą║ ą┐ą░ą╝čÅčéąĖ ąĖ ą▓čĆąĄą╝ąĄąĮąĮčŗąĄ čÅč湥ą╣ą║ąĖ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░.
ąĪą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮąŠąĄ ąĮą░ą┐ąĖčüą░ąĮąĖąĄ ą┐ąŠą┤ąŠą▒ąĮčŗčģ ąĖąĮčüčéčĆčāą╝ąĄąĮč鹊ą▓ čüą╗ąŠąČąĮąŠąĄ ąĘą░ąĮčÅčéąĖąĄ, ąŠą┤ąĮą░ą║ąŠ ąĄčüčéčī ą║ąŠą╝ą╝ąĄčĆč湥čüą║ąĖąĄ ą░ą╗čīč鹥čĆąĮą░čéąĖą▓čŗ, ą╗ąĖą▒ąŠ ąŠčéą┤ąĄą╗čīąĮčŗąĄ ąĖąĮčüčéčĆčāą╝ąĄąĮčéčŗ čüčéą░čéąĖč湥čüą║ąŠą│ąŠ ąŠą▒čüč湥čéą░ čüč鹥ą║ą░, ą╗ąĖą▒ąŠ ąĖąĮčüčéčĆčāą╝ąĄąĮčéčŗ, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄą╝čŗąĄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗ąĄą╝ čĆąĄčłąĄąĮąĖčÅ ą┤ą╗čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ. ąØą░ą┐čĆąĖą╝ąĄčĆ, čāčéąĖą╗ąĖčéą░ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ čüč鹥ą║ą░ ą┤ąŠčüčéčāą┐ąĮą░ ą┤ą╗čÅ ThreadX RTOS ąŠčé Express Logic.
ąöčĆčāą│ąĖąĄ čéąĖą┐čŗ ąĖąĮčüčéčĆčāą╝ąĄąĮč鹊ą▓, čā ą║ąŠč鹊čĆčŗčģ ąĄčüčéčī ąĮąĄąŠą▒čģąŠą┤ąĖą╝ą░čÅ ąĖąĮč乊čĆą╝ą░čåąĖčÅ ą┤ą╗čÅ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą│ąŠ čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅ ą║ čüč鹥ą║čā, čŹč鹊 ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąĖ ą╗ąĖąĮą║ąĄčĆ. ąŁčéą░ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčī ą┤ąŠčüčéčāą┐ąĮą░ ą┤ą╗čÅ čüčĆąĄą┤čŗ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ IAR Embedded Workbench for ARM. ą£čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ąĮąĄą║ąŠč鹊čĆčŗąĄ ą╝ąĄč鹊ą┤čŗ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ ąŠčåąĄąĮą║ąĖ čéčĆąĄą▒ąŠą▓ą░ąĮąĖą╣ ą║ čĆą░ąĘą╝ąĄčĆčā čüč鹥ą║ą░.
ąĀą░ąĘą╗ąĖčćąĮčŗąĄ ą╝ąĄč鹊ą┤čŗ čāčüčéą░ąĮąŠą▓ą║ąĖ čĆą░ąĘą╝ąĄčĆą░ čüč鹥ą║ą░. ą×ą┤ąĖąĮ ąĖąĘ čüą┐ąŠčüąŠą▒ąŠą▓ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ ą│ą╗čāą▒ąĖąĮčŗ čüč鹥ą║ą░ - ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą░ą┤čĆąĄčüą░ č鹥ą║čāčēąĄą│ąŠ čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░. ąŁč鹊 ą╝ąŠąČąĮąŠ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ą┐ąŠą╗čāč湥ąĮąĖąĄą╝ ą░ą┤čĆąĄčüą░ ą░čĆą│čāą╝ąĄąĮčéą░ čäčāąĮą║čåąĖąĖ ąĖą╗ąĖ ąĄčæ ą╗ąŠą║ą░ą╗čīąĮąŠą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣. ąĢčüą╗ąĖ čŹč鹊 čüą┤ąĄą╗ą░čéčī ą▓ ąĮą░čćą░ą╗ąĄ čäčāąĮą║čåąĖąĖ main ąĖ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ąĖąĘ čäčāąĮą║čåąĖą╣, ąĮą░ ą║ąŠč鹊čĆčāčÄ čā ąÆą░čü ąĄčüčéčī ą┐ąŠą┤ąŠąĘčĆąĄąĮąĖąĄ ą░ ą▒ąŠą╗čīčłąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüč鹥ą║ą░, č鹊 ąÆčŗ ą╝ąŠąČąĄč鹥 ą▓čŗčćąĖčüą╗ąĖčéčī čĆą░ąĘą╝ąĄčĆ čüč鹥ą║ą░, ą║ąŠč鹊čĆčŗą╣ ąĮčāąČąĄąĮ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÄ. ąØąĖąČąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮ ą┐čĆąĖą╝ąĄčĆ, ą│ą┤ąĄ ą╝čŗ ą┐čĆąĄą┤ą┐ąŠą╗ą░ą│ą░ąĄą╝, čćč鹊 čüč鹥ą║ čĆą░čüč鹥čé ąŠčé čüčéą░čĆčłąĖčģ ą░ą┤čĆąĄčüąŠą▓ ą┐ą░ą╝čÅčéąĖ ą║ ą╝ą╗ą░ą┤čłąĖą╝ (čéą░ą║ ąŠčĆą│ą░ąĮąĖąĘąŠą▓ą░ąĮ čüč鹥ą║ čā ą▒ąŠą╗čīčłąĖąĮčüčéą▓ą░ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓, ą▓ č鹊ą╝ čćąĖčüą╗ąĄ MCS51, ARM, 8080):
char *highStack, *lowStack;
int main(int argc, char *argv[])
{
highStack = (char *)&argc;
// ...
printf("ąóąĄą║čāčēąĄąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüč鹥ą║ą░ (ą│ą╗čāą▒ąĖąĮą░): %d\n", highStack - lowStack);
}
// ąĪą░ą╝ą░čÅ "ą┐ąŠą┤ąŠąĘčĆąĖč鹥ą╗čīąĮą░čÅ" čäčāąĮą║čåąĖčÅ ąĮą░ ą┐čĆąĄą┤ą╝ąĄčé čāą│ą╗čāą▒ą╗ąĄąĮąĖčÅ ą▓ čüč鹥ą║:
void deepest_stack_path_function(void)
{
int a;
lowStack = (char *)&a;
// ...
}
ąŁč鹊čé ą╝ąĄč鹊ą┤ ą╝ąŠąČąĄčé ą┤ą░čéčī ą┤ąŠą▓ąŠą╗čīąĮąŠ čģąŠčĆąŠčłąĖąĄ čĆąĄąĘčāą╗čīčéą░čéčŗ ą▓ ąĮąĄą▒ąŠą╗čīčłąĖčģ čüąĖčüč鹥ą╝ą░čģ čü ą┤ąĄč鹥čĆą╝ąĖąĮąĖčüčéčüą║ąĖą╝ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄą╝, ąĮąŠ ą┤ą╗čÅ ą╝ąĮąŠą│ąĖčģ čüąĖčüč鹥ą╝ ą╝ąŠąČąĄčé ą▒čŗčéčī čüą╗ąŠąČąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī čüą░ą╝ąŠąĄ ą│ą╗čāą▒ąŠą║ąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüč鹥ą║ą░ ą┐čĆąĖ ą▓ą╗ąŠąČąĄąĮąĮčŗčģ ą▓čŗąĘąŠą▓ą░čģ čäčāąĮą║čåąĖą╣ ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣, čćč鹊ą▒čŗ ą┤ąŠą▒ąĖčéčīčüčÅ čüąĖčéčāą░čåąĖąĖ čüą░ą╝ąŠą│ąŠ ą┐ą╗ąŠčģąŠą│ąŠ čüą╗čāčćą░čÅ.
ąĪč鹊ąĖčé ąĘą░ą╝ąĄčéąĖčéčī, čćč鹊 čĆąĄąĘčāą╗čīčéą░čéčŗ, ą┐ąŠą╗čāč湥ąĮąĮčŗąĄ čŹčéąĖą╝ ą╝ąĄč鹊ą┤ąŠą╝, ąĮąĄ čāčćąĖčéčŗą▓ą░čÄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüč鹥ą║ą░ čäčāąĮą║čåąĖčÅą╝ąĖ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąŠą▓ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣.
ąĢčüčéčī ą▓ą░čĆąĖą░ąĮčé čŹč鹊ą│ąŠ ą╝ąĄč鹊ą┤ą░ - ą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║ąĖ ą┤ąĄą╗ą░čéčī ą▓čŗą▒ąŠčĆą║čā ąĘąĮą░č湥ąĮąĖčÅ čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░ ą▓ąĮčāčéčĆąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ čéą░ą╣ą╝ąĄčĆą░, čüčĆą░ą▒ą░čéčŗą▓ą░čÄčēąĄą│ąŠ čü ą┤ąŠčüčéą░č鹊čćąĮąŠ ą▓čŗčüąŠą║ąŠą╣ čćą░čüč鹊č鹊ą╣. ą¦ą░čüč鹊čéą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ čéą░ą╣ą╝ąĄčĆą░ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą▓ąŠąĘą╝ąŠąČąĮąŠą╣, ą┐ąŠą║ą░ ąŠąĮą░ ąĮąĄ ąĮą░čćąĖąĮą░ąĄčé ą▓ą╗ąĖčÅčéčī ąĮą░ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī čĆąĄą░ą╗čīąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. ąóąĖą┐ąĖčćąĮčŗąĄ čćą░čüč鹊čéčŗ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 10..250 ą║ąōčå. ąöąŠčüč鹊ąĖąĮčüčéą▓ąŠ čŹč鹊ą│ąŠ ą╝ąĄč鹊ą┤ą░ - ąĮąĄ ąĮčāąČąĮąŠ ą▓čĆčāčćąĮčāčÄ ąĖčüą║ą░čéčī čäčāąĮą║čåąĖčÄ čü čüą░ą╝čŗą╝ ą│ą╗čāą▒ąŠą║ąĖą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ čüč鹥ą║ą░. ąóą░ą║ąČąĄ ą╝ąŠąČąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗čÅčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüč鹥ą║ą░ čäčāąĮą║čåąĖčÅą╝ąĖ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ (ISR), ąĄčüą╗ąĖ čŹčéą░ čäčāąĮą║čåąĖčÅ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ą╝ąŠąČąĄčé ą▓čŗč鹥čüąĮčÅčéčī ą┤čĆčāą│ąĖąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ. ą×ą┤ąĮą░ą║ąŠ čüą╗ąĄą┤čāąĄčé čāčćąĖčéčŗą▓ą░čéčī, čćč鹊 čäčāąĮą║čåąĖąĖ ISR ąŠą▒čŗčćąĮąŠ ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ąŠč湥ąĮčī ą▒čŗčüčéčĆąŠ, ąĖ ą░ąĮą░ą╗ąĖąĘąĖčĆčāčÄčēą░čÅ čäčāąĮą║čåąĖčÅ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ą╝ąŠąČąĄčé ą┐čĆąŠą┐čāčüčéąĖčéčī ą║ąŠčĆąŠčéą║ąĖą╣ ą▓čŗąĘąŠą▓ ąŠą┤ąĮąŠą│ąŠ ąĖąĘ ą┤čĆčāą│ąĖčģ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣.
void sampling_timer_interrupt_handler(void)
{
char* currentStack;
int a;
currentStack = (char *)&a;
if (currentStack < lowStack) lowStack = currentStack;
}
ąŚą░čēąĖčéąĮą░čÅ ąĘąŠąĮą░ čüč鹥ą║ą░ (stack guard zone). ąŚą░čēąĖčéąĮą░čÅ ąĘąŠąĮą░ čüč鹥ą║ą░ čŹč鹊 ąŠą▒ą╗ą░čüčéčī ą┐ą░ą╝čÅčéąĖ, čĆą░ąĘą╝ąĄčēąĄąĮąĮą░čÅ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ ąĮąĖąČąĄ čüč鹥ą║ą░, ą│ą┤ąĄ čüč鹥ą║ ąŠčüčéą░ą▓ą╗čÅąĄčé čüą╗ąĄą┤čŗ, ąĄčüą╗ąĖ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĄą│ąŠ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ. ąŁč鹊čé ą╝ąĄč鹊ą┤ ą▓čüąĄą│ą┤ą░ čĆąĄą░ą╗ąĖąĘčāąĄčéčüčÅ ą▓ ąĮą░čüč鹊ą╗čīąĮčŗčģ (ą▒ąŠą╗čīčłąĖčģ) čüąĖčüč鹥ą╝ą░čģ, ą│ą┤ąĄ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮą░čÅ čüąĖčüč鹥ą╝ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠčüč鹊 ąĮą░čüčéčĆąŠąĄąĮą░ ą┤ą╗čÅ ą┤ąĄč鹥ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ ąŠčłąĖą▒ąŠą║ ąĘą░čēąĖčéčŗ ą┐ą░ą╝čÅčéąĖ ą▓ čüąĖčéčāą░čåąĖčÅčģ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ čüč鹥ą║ą░. ąØą░ ą╝ą░ą╗čŗčģ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ čüąĖčüč鹥ą╝ą░čģ ą▒ąĄąĘ ą▒ą╗ąŠą║ą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéčīčÄ (Memory Management Unit, MMU) ąĘą░čēąĖčéąĮą░čÅ ąĘąŠąĮą░ ą▓čüąĄ ąĄčēąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠčĆą│ą░ąĮąĖąĘąŠą▓ą░ąĮą░ čéą░ą║ąĖą╝ ąČąĄ čüą┐ąŠčüąŠą▒ąŠą╝, ąĖ čŹč鹊 ą▒čāą┤ąĄčé ą┤ąŠą▓ąŠą╗čīąĮąŠ ą┐ąŠą╗ąĄąĘąĮąŠ. ą¦č鹊ą▒čŗ čéą░ą║ą░čÅ ąĘąŠąĮą░ ą▒čŗą╗ą░ ą┤ąŠčüčéą░č鹊čćąĮąŠ čŹčäč乥ą║čéąĖą▓ąĮąŠą╣, ąŠąĮą░ ą┤ąŠą╗ąČąĮą░ ąĖą╝ąĄčéčī ą┐ąŠą┤čģąŠą┤čÅčēąĖą╣ čĆą░ąĘą╝ąĄčĆ, čćč鹊ą▒čŗ ą┐ąŠą╣ą╝ą░čéčī ąĘą░ą┐ąĖčüąĖ ą▓ čŹčéčā ąĘą░čēąĖčéąĮčāčÄ ąĘąŠąĮčā.
ą¤ąŠčüč鹊čÅąĮąĮčŗąĄ ą┐čĆąŠą▓ąĄčĆą║ąĖ čüąŠą┤ąĄčƹȹĖą╝ąŠą│ąŠ ąĘą░čēąĖčéąĮąŠą╣ ąĘąŠąĮčŗ ą╝ąŠą│čāčé ą▒čŗčéčī čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮčŗ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ, čćč鹊ą▒čŗ firmware ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ąŠą┐čĆąĄą┤ąĄą╗čÅą╗ąŠ, čćč鹊 čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čŹč鹊ą╣ ąĘą░čēąĖčéąĮąŠą╣ ąĘąŠąĮčŗ ą▒čŗą╗ąŠ ąĮąĄčéčĆąŠąĮčāč鹊.
ąĪą░ą╝čŗą╣ ą╗čāčćčłąĖą╣ ą╝ąĄč鹊ą┤ ąĘą░čēąĖčéąĮąŠą╣ ąĘąŠąĮčŗ ą╝ąŠąČąĄčé ą▒čŗčéčī čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮ, ąĄčüą╗ąĖ MCU ąŠą▒ąŠčĆčāą┤ąŠą▓ą░ąĮ (ą░ą┐ą┐ą░čĆą░čéąĮčŗą╝) ą▒ą╗ąŠą║ąŠą╝ ąĘą░čēąĖčéčŗ ą┐ą░ą╝čÅčéąĖ (memory protection unit, MPU ąĖą╗ąĖ MMU). ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ MPU ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮą░čüčéčĆąŠąĄąĮ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊ą▒čŗ ąŠąĮ čüčĆą░ą▒ą░čéčŗą▓ą░ą╗ ąĮą░ ąĘą░ą┐ąĖčüąĖ ą▓ ąĘą░čēąĖčéąĮčāčÄ ąĘąŠąĮčā. ąĢčüą╗ąĖ ą┐čĆąŠąĖąĘąŠčłąĄą╗ čéą░ą║ąŠą│ąŠ čĆąŠą┤ą░ ąĮąĄą┤ąŠą┐čāčüčéąĖą╝čŗą╣ ą┤ąŠčüčéčāą┐, ą▒čāą┤ąĄčé čüčĆą░ą▒ą░čéčŗą▓ą░čéčī ąĖčüą║ą╗čÄč湥ąĮąĖąĄ (exception), ąĖ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą╝ąŠąČąĄčé ąĘą░ą┐ąĖčüą░čéčī ąĖą╗ąĖ ą▓čŗą▓ąĄčüčéąĖ ą▓ ą╗ąŠą│ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠ č鹊ą╝, čćč鹊 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ. ąŁčéčā ąĖąĮč乊čĆą╝ą░čåąĖčÄ ą╝ąŠąČąĮąŠ ą▒čāą┤ąĄčé ą▓ą┐ąŠčüą╗ąĄą┤čüčéą▓ąĖąĖ ą┐čĆąŠą░ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī.
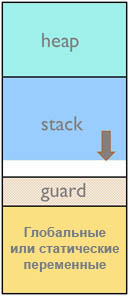
ąĀąĖčü. 2. ąĪč鹥ą║ čü ąĘą░čēąĖčéąĮąŠą╣ (guard) ąĘąŠąĮąŠą╣.
ąŚą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ ąŠą▒ą╗ą░čüčéąĖ čüč鹥ą║ą░ ąĖąĘą▓ąĄčüčéąĮčŗą╝ąĖ ą┤ą░ąĮąĮčŗą╝ąĖ. ą×ą┤ąĮą░ ąĖąĘ č鹥čģąĮąĖą║ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ čüč鹥ą║ą░ - ąĘą░ą┐ąŠą╗ąĮąĖčéčī ą▓čüąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ čüč鹥ą║ą░ ąĘą░čĆą░ąĮąĄąĄ ąĖąĘą▓ąĄčüčéąĮąŠą╣ ą╝ą░čüą║ąŠą╣, ąĮą░ą┐čĆąĖą╝ąĄčĆ ą▒ą░ą╣čéą░ą╝ąĖ 0xCD, ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ąĮą░čćąĮąĄčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ. ąÆčüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, čü ą┐ąŠą╝ąŠčēčīčÄ ąŠčéą╗ą░ą┤čćąĖą║ą░), ąŠą▒ą╗ą░čüčéčī ą┐ą░ą╝čÅčéąĖ čüč鹥ą║ą░ ą╝ąŠąČąĮąŠ ą┐čĆąŠčüą╝ąŠčéčĆąĄčéčī ą▓ ąŠą▒ą╗ą░čüčéąĖ ąĄą│ąŠ ą║ąŠąĮčåą░. ąÆ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą╣ ąŠą▒ą╗ą░čüčéąĖ čüč鹥ą║ą░ 0xCD ąĮąĄ ą┐čĆąĖčüčāčéčüčéą▓čāąĄčé, ą┐ąŠč鹊ą╝čā čćč鹊 čéčāą┤ą░ ąĘą░ą┐ąĖčüčŗą▓ą░ą╗ąĖčüčī ą░ą┤čĆąĄčüą░ ą▓ąŠąĘą▓čĆą░čéą░ ąĖ ąĘąĮą░č湥ąĮąĖčÅ čĆą░ąĘą╗ąĖčćąĮčŗčģ ą╗ąŠą║ą░ą╗čīąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗčģ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ. ąĢčüą╗ąĖ ą▓ ąŠą▒ą╗ą░čüčéąĖ čüč鹥ą║ą░ ąĮąĄ ąĮą░ą╣ą┤ąĄąĮąŠ ąĘąĮą░č湥ąĮąĖą╣ ą╝ą░čüą║ąĖ (0xCD), č鹊 čŹč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 čüč鹥ą║ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĖą╗čüčÅ.
ąźąŠčéčÅ čŹč鹊čé čüą┐ąŠčüąŠą▒ ą┤ąĄč鹥ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ čüč鹥ą║ą░ ą┤ąŠčüčéą░č鹊čćąĮąŠ ąĮą░ą┤ąĄąČąĄąĮ, ą▓čüąĄ čĆą░ą▓ąĮąŠ ąĮąĄčé ą│ą░čĆą░ąĮčéąĖąĖ, čćč鹊 ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ čüč鹥ą║ą░ ą▒čāą┤ąĄčé ąŠą▒ąĮą░čĆčāąČąĄąĮąŠ. ąØą░ą┐čĆąĖą╝ąĄčĆ, čüč鹥ą║ ą╝ąŠąČąĄčé ąĮąĄą║ąŠčĆčĆąĄą║čéąĮąŠ ą▓čŗčĆą░čüčéąĖ, ą┐ąĄčĆąĄčģąŠą┤čÅ č湥čĆąĄąĘ čüą▓ąŠąĖ ą│čĆą░ąĮąĖčåčŗ, ąĖ ą┤ą░ąČąĄ ąĖąĘą╝ąĄąĮąĖčéčī ą┐ą░ą╝čÅčéčī ą▓ąĮąĄ ąŠą▒ą╗ą░čüčéąĖ čüč鹥ą║ą░, ą┐čĆąĖč湥ą╝ ą▒ąĄąĘ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖąĖ ą║ą░ą║ąĖčģ-ą╗ąĖą▒ąŠ ą▒ą░ą╣čé ą▓ ąŠą▒ą╗ą░čüčéąĖ čüč鹥ą║ą░. ąóą░ą║ąČąĄ čüč鹥ą║ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠą▓čĆąĄąČą┤ąĄąĮ ą▓ ąĄą│ąŠ čĆą░ą▒ąŠč湥ą╣ ąŠą▒ą╗ą░čüčéąĖ. ąŁč鹊 ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ, ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą▓ čüą╗čāčćą░ąĄ ą│čĆčāą▒ąŠą╣ ąŠčłąĖą▒ą║ąĖ, ą║ąŠą│ą┤ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ąŠčłąĖą▒ąŠčćąĮąŠ ąĖąĘą╝ąĄąĮčÅąĄčé ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ (ą▓ č鹊ą╝ čćąĖčüą╗ąĄ ąĖ čüč鹥ą║ą░), ą║ą░ą║ąĖąĄ ąŠąĮąŠ ąĖąĘą╝ąĄąĮčÅčéčī ąĮąĄ ą┤ąŠą╗ąČąĮąŠ.
ąŁč鹊čé ą╝ąĄč鹊ą┤ ą╝ąŠąĮąĖč鹊čĆąĖąĮą│ą░ čüč鹥ą║ą░ čłąĖčĆąŠą║ąŠ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ąŠčéą╗ą░ą┤čćąĖą║ąĖ. ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ąŠčéą╗ą░ą┤čćąĖą║ ą╝ąŠąČąĄčé ąŠč鹊ą▒čĆą░ąĘąĖčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüč鹥ą║ą░ ą┐ąŠą┤ąŠą▒ąĮąŠ č鹊ą╝čā, ą║ą░ą║ čŹč鹊 ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮą░ čĆąĖčü. 3. ą×ą▒čŗčćąĮąŠ ąŠčéą╗ą░ą┤čćąĖą║ ąĮąĄ ąŠą▒ąĮą░čĆčāąČąĖą▓ą░ąĄčé ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ čüč鹥ą║ą░, ą║ąŠą│ą┤ą░ čŹč鹊 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ, ąŠąĮ ą╝ąŠąČąĄčé č鹊ą╗čīą║ąŠ ą┐ąŠą║ą░ąĘą░čéčī čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą┐ą░ą╝čÅčéąĖ čüč鹥ą║ą░, ą│ą┤ąĄ ą▒čāą┤ąĄčé ą▓ąĖą┤ąĮąŠ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┤ą░ąĮąĮčŗą╝ąĖ.

ąĀąĖčü. 3. ą×ą║ąĮąŠ čüč鹥ą║ą░ ą▓ čüčĆąĄą┤ąĄ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ IAR Embedded Workbench.
ąÆčŗčćąĖčüą╗ąĄąĮąĮąŠąĄ ą╗ąĖąĮą║ąĄčĆąŠą╝ čéčĆąĄą▒ąŠą▓ą░ąĮąĖąĄ ą║ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╝čā čĆą░ąĘą╝ąĄčĆčā čüč鹥ą║ą░. ąöą░ą▓ą░ą╣č鹥 č鹥ą┐ąĄčĆčī ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ čĆą░čüčüą╝ąŠčéčĆąĖą╝, ą║ą░ą║ čāčéąĖą╗ąĖčéčŗ čüą▒ąŠčĆą║ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ ąĖ ą╗ąĖąĮą║ąĄčĆą░ ą╝ąŠą│čāčé ą▓čŗčćąĖčüą╗ąĖčéčī ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗą╣ čĆą░ąĘą╝ąĄčĆ čüč鹥ą║ą░. ąÆ ą║ą░č湥čüčéą▓ąĄ ą┐čĆąĖą╝ąĄčĆą░ ą╝čŗ ą▒čāą┤ąĄą╝ ąĘą┤ąĄčüčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąĖ ą╗ąĖąĮą║ąĄčĆ IAR. ąÜąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĮąĄąŠą▒čģąŠą┤ąĖą╝čāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ, ąĖ ą┐čĆąĖ ą┐čĆą░ą▓ąĖą╗čīąĮčŗčģ ąŠą▒čüč鹊čÅč鹥ą╗čīčüčéą▓ą░čģ (ą║ąŠą│ą┤ą░ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ čĆą░ą▒ąŠčéą░ąĄčé ąŠąČąĖą┤ą░ąĄą╝ąŠ ą┤ą╗čÅ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░čĆąĖčÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ) ą╗ąĖąĮą║ąĄčĆ č鹊čćąĮąŠ ą╝ąŠąČąĄčé ą▓čŗčćąĖčüą╗ąĖčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüč鹥ą║ą░ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą║ąŠčĆąĮčÅ ą│čĆą░čäą░ ą▓čŗąĘąŠą▓ąŠą▓ (ąŠčé ą║ą░ąČą┤ąŠą╣ čäčāąĮą║čåąĖąĖ, ą║ąŠč鹊čĆą░čÅ ąĮąĄ ą▓čŗąĘčŗą▓ą░ąĄčéčüčÅ ąĖąĘ ą┤čĆčāą│ąŠą╣ čäčāąĮą║čåąĖąĖ, ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ ąĘą░ą┐čāčüą║ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ). ąŁč鹊 ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ čĆą░ąĘą╝ąĄčĆą░ čüč鹥ą║ą░ ą▒čāą┤ąĄčé č鹊čćąĮčŗą╝ č鹊ą╗čīą║ąŠ ą▓ č鹊ą╝ čüą╗čāčćą░ąĄ, ą║ąŠą│ą┤ą░ ą┐čĆąĖčüčāčéčüčéą▓čāąĄčé č鹊čćąĮą░čÅ ąĖąĮč乊čĆą╝ą░čåąĖčÅ ą┐ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÄ čüč鹥ą║ą░ ą║ą░ąČą┤ąŠą╣ čäčāąĮą║čåąĖąĄą╣ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ.
ą×ą▒čŗčćąĮąŠ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą▒čāą┤ąĄčé ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī čŹčéčā ąĖąĮč乊čĆą╝ą░čåąĖčÄ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ čäčāąĮą║čåąĖąĖ čÅąĘčŗą║ą░ C, ąĮąŠ ą▓ ąĮąĄą║ąŠč鹊čĆčŗčģ čüąĖčéčāą░čåąĖčÅčģ ąÆčŗ ą┤ąŠą╗ąČąĮčŗ čüą░ą╝ąĖ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī ą┤ą╗čÅ čüąĖčüč鹥ą╝čŗ ąĖąĮč乊čĆą╝ą░čåąĖčÄ, ąŠčéąĮąŠčüčÅčēčāčÄčüčÅ ą║ čüč鹥ą║čā. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ ą┐čĆąĖčüčāčéčüčéą▓čāčÄčé ą║ąŠčüą▓ąĄąĮąĮčŗąĄ ą▓čŗąĘąŠą▓čŗ čäčāąĮą║čåąĖą╣, indirect call (čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ąĮą░ čäčāąĮą║čåąĖąĖ), č鹊 ąÆčŗ ą┤ąŠą╗ąČąĮčŗ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī čüą┐ąĖčüąŠą║ ą▓ąŠąĘą╝ąŠąČąĮčŗčģ čäčāąĮą║čåąĖą╣, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗąĘą▓ą░ąĮčŗ ąĖąĘ ą║ą░ąČą┤ąŠą╣ ą▓čŗąĘčŗą▓ą░ąĄą╝ąŠą╣ čäčāąĮą║čåąĖąĖ. ąÆčŗ ą╝ąŠąČąĄč鹥 čüą┤ąĄą╗ą░čéčī čŹč鹊 čü ą┐ąŠą╝ąŠčēčīčÄ ą┤ąĖčĆąĄą║čéąĖą▓ pragma ą▓ čäą░ą╣ą╗ąĄ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░, ąĖą╗ąĖ čü ą┐ąŠą╝ąŠčēčīčÄ ąŠčéą┤ąĄą╗čīąĮąŠą│ąŠ čäą░ą╣ą╗ą░ ą┤ą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüč鹥ą║ą░ (stack usage control file) ą▓ ą┐čĆąŠčåąĄčüčüąĄ ą╗ąĖąĮą║ąŠą▓ą║ąĖ.
void foo(int i)
{
#pragma calls = fun1, fun2, fun3
func_arr[i]();
}
ąĢčüą╗ąĖ ąÆčŗ ąĖčüą┐ąŠą╗čīąĘčāąĄč鹥 čäą░ą╣ą╗ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüč鹥ą║ą░, č鹊 ą╝ąŠąČąĄč鹥 čéą░ą║ąČąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī ąĖąĮč乊čĆą╝ą░čåąĖčÄ ą┐ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÄ čüč鹥ą║ą░ ą┤ą╗čÅ čäčāąĮą║čåąĖą╣ ą▓ ą╝ąŠą┤čāą╗čÅčģ, čā ą║ąŠč鹊čĆčŗčģ ąĮąĄčé ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą┐ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÄ čüč鹥ą║ą░. ąóąŠą│ą┤ą░ ą▒čāą┤ąĄčé ą▓ čüąŠčüč鹊čÅąĮąĖąĖ ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ą┐čĆąĄą┤čāą┐čĆąĄąČą┤ąĄąĮąĖčÅ, čéą░ą║ąČąĄ ąĄčüą╗ąĖ ąŠčéčüčāčéčüčéą▓čāąĄčé ąĮąĄąŠą▒čģąŠą┤ąĖą╝ą░čÅ ąĖąĮč乊čĆą╝ą░čåąĖčÅ, ąĮą░ą┐čĆąĖą╝ąĄčĆ ą▓ čüą╗ąĄą┤čāčÄčēąĖčģ čāčüą╗ąŠą▓ąĖčÅčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ:
ŌĆó ąśą╝ąĄąĄčéčüčÅ ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝ ąŠą┤ąĮą░ čäčāąĮą║čåąĖčÅ ą▒ąĄąĘ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą┐ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÄ čüč鹥ą║ą░.
ŌĆó ąśą╝ąĄąĄčéčüčÅ ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝ ąŠą┤ąĖąĮ ą║ąŠčüą▓ąĄąĮąĮčŗą╣ ą▓čŗąĘąŠą▓, ą┤ą╗čÅ ą║ąŠč鹊čĆąŠą│ąŠ ąĮąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮ čüą┐ąĖčüąŠą║ ą▓ąŠąĘą╝ąŠąČąĮčŗčģ ą▓čŗąĘčŗą▓ą░ąĄą╝čŗčģ čäčāąĮą║čåąĖą╣.
ŌĆó ąØąĄčé ąĖąĘą▓ąĄčüčéąĮčŗčģ ą║ąŠčüą▓ąĄąĮąĮčŗčģ ą▓čŗąĘąŠą▓ąŠą▓, ąŠą┤ąĮą░ą║ąŠ ąĄčüčéčī ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝ ąŠą┤ąĮą░ ąĮąĖ ąŠčéą║čāą┤ą░ ąĮąĄ ą▓čŗąĘčŗą▓ą░ąĄą╝ą░čÅ čäčāąĮą║čåąĖčÅ, ą║ąŠč鹊čĆą░čÅ, ą║ą░ą║ ąĖąĘą▓ąĄčüčéąĮąŠ, ąĮąĄ čÅą▓ą╗čÅąĄčéčüčÅ ą║ąŠčĆąĮąĄą╝ ą│čĆą░čäą░ ą▓čŗąĘąŠą▓ąŠą▓.
ŌĆó ą¤čĆąĖą╗ąŠąČąĄąĮąĖąĄ čüąŠą┤ąĄčƹȹĖčé čĆąĄą║čāčĆčüąĖčÄ (čåąĖą║ą╗ ą▓ ą│čĆą░č乥 ą▓čŗąĘąŠą▓ąŠą▓).
ŌĆó ąśą╝ąĄčÄčéčüčÅ ą▓čŗąĘąŠą▓čŗ čäčāąĮą║čåąĖąĖ, ą║ąŠč鹊čĆą░čÅ ą┤ąĄą║ą╗ą░čĆąĖčĆąŠą▓ą░ąĮą░ ą║ą░ą║ ą║ąŠčĆąĄąĮčī ą│čĆą░čäą░ ą▓čŗąĘąŠą▓ąŠą▓.
ąÜąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮ ą░ąĮą░ą╗ąĖąĘ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüč鹥ą║ą░, ą▓ ą│ąĄąĮąĄčĆąĖčĆčāąĄą╝čŗą╣ map-čäą░ą╣ą╗ ą╗ąĖąĮą║ąĄčĆą░ ą▒čāą┤ąĄčé ą┤ąŠą▒ą░ą▓ą╗ąĄąĮą░ čüąĄą║čåąĖčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ (usage), ą│ą┤ąĄ ą┐ąĄčĆąĄčćąĖčüą╗čÅąĄčéčüčÅ ą║ą░ąČą┤čŗą╣ ą│čĆą░čä ą▓čŗąĘąŠą▓ąŠą▓ ąŠčé ą║ąŠčĆąĮčÅ ą▓ ą▓ąĖą┤ąĄ čåąĄą┐ąŠčćą║ąĖ ą▓čŗąĘąŠą▓ąŠą▓ ą┤ąŠ čüą░ą╝ąŠą│ąŠ ą│ą╗čāą▒ąŠą║ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüč鹥ą║ą░.

ąĀąĖčü. 4. ąĀąĄąĘčāą╗čīčéą░čé ą▓čŗčćąĖčüą╗ąĄąĮąĮąŠą│ąŠ ą╗ąĖąĮą║ąĄčĆąŠą╝ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čüč鹥ą║ą░.
[ąØą░ą┤ąĄąČąĮčŗą╣ ą┤ąĖąĘą░ą╣ąĮ ą║čāčćąĖ]
ąōą┤ąĄ čéčāčé ą╝ąŠąČąĮąŠ čüą┤ąĄą╗ą░čéčī ąŠčłąĖą▒ą║čā? ąØąĄą┤ąŠąŠčåąĄąĮą║ą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą║čāčćąĖ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ąŠčłąĖą▒ą║ąĄ ą┐čĆąĖ ą▓čŗąĘąŠą▓ąĄ malloc(), čé. ąĄ. čéčĆąĄą▒čāąĄą╝ą░čÅ ąŠą▒ą╗ą░čüčéčī ą┐ą░ą╝čÅčéąĖ ąĮąĄ ą▒čāą┤ąĄčé ą▓čŗą┤ąĄą╗ąĄąĮą░. ąŁčéčā čüąĖčéčāą░čåąĖčÄ ą╝ąŠąČąĮąŠ ąŠč湥ąĮčī ą┐čĆąŠčüč鹊 ąŠčéčüą╗ąĄą┤ąĖčéčī ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ, ą┐čĆąŠą▓ąĄčĆčÅčÅ čĆąĄąĘčāą╗čīčéą░čé ą▓čŗąĘąŠą▓ą░ čäčāąĮą║čåąĖąĖ malloc(). ąĢčüą╗ąĖ ąŠąĮą░ ą▓ąĄčĆąĮąĄčé NULL, č鹊 ąĘąĮą░čćąĖčé ą┐ą░ą╝čÅčéčī ąĮąĄ ą▒čŗą╗ą░ ą▓čŗą┤ąĄą╗ąĄąĮą░, ąĮąŠ č鹊ą│ą┤ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī čüą╗ąĖčłą║ąŠą╝ ą┐ąŠąĘą┤ąĮąŠ (ąĄčüą╗ąĖ čŹč鹊 ą┐čĆąŠąĖąĘąŠčłą╗ąŠ ą▓ čĆą░ą▒ąŠč湥ą╝ ąĖąĘą┤ąĄą╗ąĖąĖ čā ąĘą░ą║ą░ąĘčćąĖą║ą░). ąŁč鹊 čüąĄčĆčīąĄąĘąĮą░čÅ čüąĖčéčāą░čåąĖčÅ, ą┐ąŠčüą║ąŠą╗čīą║čā ą▓ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ čüąĖčüč鹥ą╝ ąĮąĄčé ą┐ąŠą┤čģąŠą┤čÅčēąĄą│ąŠ čüą┐ąŠčüąŠą▒ą░ ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖčÅ ąĖąĘ ąŠčłąĖą▒ą║ąĖ ą┐ąŠ ąĮąĄčģą▓ą░čéą║ąĄ ą┐ą░ą╝čÅčéąĖ ą▓ ą║čāč湥; ąĄčüčéčī č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ ą┤ąŠčüčéčāą┐ąĮčŗą╣ ą┐ąŠą┤čģąŠą┤čÅčēąĖą╣ čüą┐ąŠčüąŠą▒ - ą┐ąĄčĆąĄąĘą░ą┐čāčüčéąĖčéčī ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ. ą¤ąĄčĆąĄąŠčåąĄąĮą║ą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą║čāčćąĖ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ą░ ąĖąĘ-ąĘą░ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą╣ ą┐čĆąĖčĆąŠą┤čŗ čĆą░ą▒ąŠčéčŗ ą║čāčćąĖ, ąŠą┤ąĮą░ą║ąŠ čüą╗ąĖčłą║ąŠą╝ ą▒ąŠą╗čīčłąŠąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ ą║čāčćąĖ č鹊ą╗čīą║ąŠ ą▓ą┐čāčüčéčāčÄ ą┐ąŠčéčĆą░čéąĖčé čåąĄąĮąĮčŗąĄ čĆąĄčüčāčĆčüčŗ ą┐ą░ą╝čÅčéąĖ.
ą¤čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ą║čāčćąĖ ą╝ąŠą│čāčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ ą┤ą▓ąĄ ą┤čĆčāą│ąĖąĄ ąŠčłąĖą▒ą║ąĖ:
ŌĆó ą¤ąĄčĆąĄąĘą░ą┐ąĖčüčī ą┤ą░ąĮąĮčŗčģ ą║čāčćąĖ (ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ ąĖ čāą║ą░ąĘą░č鹥ą╗ąĖ).
ŌĆó ą¤ąŠą▓čĆąĄąČą┤ąĄąĮąĖąĄ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ ąĖąĮč乊čĆą╝ą░čåąĖąŠąĮąĮąŠą╣ čüčéčĆčāą║čéčāčĆčŗ ą║čāčćąĖ.
ą¤ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ą┐čĆąŠą┤ąŠą╗ąČąĖčéčī, ą┤ą░ą▓ą░ą╣č鹥 ą▓čüą┐ąŠą╝ąĮąĖą╝ API ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą╣ ą┐ą░ą╝čÅčéąĖ.
void* malloc(size_t size);
ążčāąĮą║čåąĖčÅ malloc ą┤ąĄą╗ą░ąĄčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
ŌĆó ąÆčŗą┤ąĄą╗čÅąĄčé ąĮąĄą┐čĆąĄčĆčŗą▓ąĮčŗą╣ ą▒ą╗ąŠą║ ą┐ą░ą╝čÅčéąĖ čĆą░ąĘą╝ąĄčĆą░ size ą▒ą░ą╣čé.
ŌĆó ąÆąŠąĘą▓čĆą░čēą░ąĄčé čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ąĮą░čćą░ą╗ąŠ čŹč鹊ą│ąŠ ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ą▒ą╗ąŠą║ą░.
ŌĆó ąØąĄ ą┤ąĄą╗ą░ąĄčé ąĮąĖą║ą░ą║čāčÄ ąŠčćąĖčüčéą║čā ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ą▒ą╗ąŠą║ą░ ą┐ą░ą╝čÅčéąĖ.
ŌĆó ąÆąĄčĆąĮąĄčé NULL, ąĄčüą╗ąĖ ą▓ ą║čāč湥 ąĮąĄ ąŠčüčéą░ą╗ąŠčüčī ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą┐ą░ą╝čÅčéąĖ.
ą×ą┐ąĖčüą░ąĮąĖąĄ čĆą░ą▒ąŠčéčŗ čäčāąĮą║čåąĖąĖ free:
ŌĆó ą×čüą▓ąŠą▒ąŠąČą┤ą░ąĄčé ąŠą▒ą╗ą░čüčéčī ą┐ą░ą╝čÅčéąĖ (čĆą░ąĮąĄąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗą╣ ą▒ą╗ąŠą║), ąĮą░ ą║ąŠč鹊čĆčāčÄ čāą║ą░ąĘčŗą▓ą░ąĄčé ą░čĆą│čāą╝ąĄąĮčé p.
ŌĆó ąóčĆąĄą▒čāąĄčé ą▓ ą║ą░č湥čüčéą▓ąĄ ą░čĆą│čāą╝ąĄąĮčéą░ ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ čāą║ą░ąĘą░č鹥ą╗čÅ p, ą║ąŠč鹊čĆąŠąĄ ą▒čŗą╗ąŠ čĆą░ąĮąĄąĄ ą┐ąŠą╗čāč湥ąĮąŠ ąĖąĘ ą▓čŗąĘąŠą▓ą░ malloc(), calloc() ąĖą╗ąĖ realloc().
ŌĆó ąĪą╗ąĄą┤čāąĄčé ąĖąĘą▒ąĄą│ą░čéčī ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą▓čŗąĘąŠą▓ąŠą▓ free(p) ą┤ą╗čÅ ąŠą┤ąĮąŠą│ąŠ ąĖ č鹊ą│ąŠ ąČąĄ ąĘąĮą░č湥ąĮąĖčÅ p (ą┐ąŠčüą╗ąĄ ą┐ąĄčĆą▓ąŠą│ąŠ ą▓čŗąĘąŠą▓ą░ free čāą║ą░ąĘą░č鹥ą╗čī p čüčéą░ąĮąŠą▓ąĖčéčüčÅ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝).
void* calloc(size_t nelem, size_t elsize);
ążčāąĮą║čåąĖčÅ calloc čĆą░ą▒ąŠčéą░ąĄčé ą┐ąŠą┤ąŠą▒ąĮąŠ malloc(), ąĮąŠ čü č鹥ą╝ ąŠčéą╗ąĖčćąĖąĄą╝, čćč鹊 ąŠčćąĖčēą░ąĄčé ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗą╣ ą▒ą╗ąŠą║ ą┐ą░ą╝čÅčéąĖ.
void* realloc(void* p, size_t size);
ą×ą┐ąĖčüą░ąĮąĖąĄ čĆą░ą▒ąŠčéčŗ čäčāąĮą║čåąĖąĖ realloc:
ŌĆó ąĀą░ą▒ąŠčéą░ąĄčé ą┐ąŠą┤ąŠą▒ąĮąŠ malloc().
ŌĆó ąŻą▓ąĄą╗ąĖčćąĖą▓ą░ąĄčé ąĖą╗ąĖ čāą╝ąĄąĮčīčłą░ąĄčé (ą╝ąĄąĮčÅąĄčé čĆą░ąĘą╝ąĄčĆ) čĆą░ąĮąĄąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ą▒ą╗ąŠą║ą░.
ŌĆó ąÆąŠąĘą▓čĆą░čēąĄąĮąĮčŗą╣ ą▒ą╗ąŠą║ ą╝ąŠąČąĄčé ąĖą╝ąĄčéčī ąĮąŠą▓čŗą╣ ą░ą┤čĆąĄčü.
ąÆ C++ čüą╗ąĄą┤čāčÄčēąĖąĄ ą▓čüčéčĆąŠąĄąĮąĮčŗąĄ ąŠą┐ąĄčĆą░č鹊čĆčŗ čÅąĘčŗą║ą░ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą┤ąĖąĮą░ą╝ąĖč湥čüą║čāčÄ ą┐ą░ą╝čÅčéčī ą║čāčćąĖ:
ŌĆó ą×ą┐ąĄčĆą░č鹊čĆ new, čĆą░ą▒ąŠčéą░čÄčēąĖą╣ ą┐ąŠą┤ąŠą▒ąĮąŠ malloc().
ŌĆó new[].
ŌĆó ą×ą┐ąĄčĆą░č鹊čĆ delete, čĆą░ą▒ąŠčéą░čÄčēąĖą╣ ą┐ąŠą┤ąŠą▒ąĮąŠ free().
ŌĆó delete[].
ąśą╝ąĄąĄčéčüčÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▓ą░čĆąĖą░ąĮč鹊ą▓ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą░ą╗ą╗ąŠą║ą░č鹊čĆą░ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą╣ ą┐ą░ą╝čÅčéąĖ. ąØą░ąĖą▒ąŠą╗ąĄąĄ čćą░čüč鹊 čüąĄą│ąŠą┤ąĮčÅ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ Dlmalloc (Doug LeaŌĆÖs Memory Allocator). Dlmalloc ą╝ąŠąČąĮąŠ ąĮą░ą╣čéąĖ ą▓ Linux, ą░ čéą░ą║ąČąĄ ą▓ąŠ ą╝ąĮąŠą│ąĖčģ ąĖąĮčüčéčĆčāą╝ąĄąĮčéą░čģ (ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░čģ) čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ą┤ą╗čÅ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ čüąĖčüč鹥ą╝. Dlmalloc čüą▓ąŠą▒ąŠą┤ąĮąŠ ą┤ąŠčüčéčāą┐ąĮą░ ą┤ą╗čÅ ą▒ąĄčüą┐ą╗ą░čéąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ (ą┐ąŠą╝ąĄčēąĄąĮą░ ą▓ public domain).
ąÆąĮčāčéčĆąĄąĮąĮčÅčÅ čüčéčĆčāą║čéčāčĆą░ ą║čāčćąĖ ą▓ą║čĆą░ą┐ą╗čÅąĄčéčüčÅ ą┤ą░ąĮąĮčŗą╝ąĖ, ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗą╝ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄą╝. ąĢčüą╗ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ąĘą░ą┐ąĖčłąĄčé ą┐ą░ą╝čÅčéčī ą▓ąĮąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ, č鹊 ąŠąĮąŠ ą╝ąŠąČąĄčé ą╗ąĄą│ą║ąŠ ąĮą░čĆčāčłąĖčéčī ą▓ąĮčāčéčĆąĄąĮąĮčÄčÄ čüą▓čÅąĘą░ąĮąĮčāčÄ čüčéčĆčāą║čéčāčĆčā ą║čāčćąĖ.
ąĀąĖčü. 5 ą┤ą░ąĄčé ąĮąĄą║ąĖą╣ čāą┐čĆąŠčēąĄąĮąĮčŗą╣ ą▓ąĖą┤ ąĮą░ č鹊, ą║ą░ą║ čĆą░ąĘą╗ąĖčćąĮčŗąĄ čüčéčĆčāą║čéčāčĆčŗ ą┤ą░ąĮąĮčŗčģ ąŠą║čĆčāąČą░čÄčé ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖąĄ ą┤ą░ąĮąĮčŗąĄ (user data). ąĪčéą░ąĮąŠą▓ąĖčéčüčÅ ąŠč湥ą▓ąĖą┤ąĮčŗą╝, čćč鹊 ą╗čÄą▒ą░čÅ ąĘą░ą┐ąĖčüčī ą▓ ąŠą▒ą╗ą░čüčéčī ą▓ąĮąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖčģ ą┤ą░ąĮąĮčŗčģ čüąĄčĆčīąĄąĘąĮąŠ ą┐ąŠą▓čĆąĄą┤ąĖčé ą║čāčćčā.

ąĀąĖčü. 5. ą×ą║čĆčāąČąĄąĮąĖąĄ čüą╗čāąČąĄą▒ąĮčŗą╝ąĖ ą┤ą░ąĮąĮčŗą╝ąĖ ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ąĖąĘ ą║čāčćąĖ ą▒ą╗ąŠą║ą░ ą┤ą╗čÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖčģ ą┤ą░ąĮąĮčŗčģ.
ąÆčŗčćąĖčüą╗ąĄąĮąĖąĄ čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅ ą║ čĆą░ąĘą╝ąĄčĆčā ą║čāčćąĖ čÅą▓ą╗čÅąĄčéčüčÅ ąĮąĄčéčĆąĖą▓ąĖą░ą╗čīąĮąŠą╣ ąĘą░ą┤ą░č湥ą╣, ąĄčüą╗ąĖ ą║čāčćą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą░ą║čéąĖą▓ąĮąŠ, čé. ąĄ. ą║ąŠą│ą┤ą░ ą▓ ą┐čĆąŠčåąĄčüčüąĄ čĆą░ą▒ąŠčéčŗ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą╝ąĮąŠąČąĄčüčéą▓ąŠ čåąĖą║ą╗ąŠą▓ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ ą▒ą╗ąŠą║ąŠą▓ ą┐ą░ą╝čÅčéąĖ (ąŠą▒čŗčćąĮąŠ čŹč鹊 čéą░ą║ ąĖ ąĄčüčéčī, ąĖąĮą░č湥 ą║čāčćą░ ą▒čŗą╗ą░ ą▒čŗ ąĮąĄ ąĮčāąČąĮą░). ąæąŠą╗čīčłąĖąĮčüčéą▓ąŠ čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ąŠą▓ ą┤ą╗čÅ ą▓čŗą▒ąŠčĆą░ čĆą░ąĘą╝ąĄčĆą░ ą║čāčćąĖ ą┐čĆąĖą▒ąĄą│ą░čÄčé ą║ ą╝ąĄč鹊ą┤čā ą┐čĆąŠą▒ ąĖ ąŠčłąĖą▒ąŠą║, ą┐ąŠč鹊ą╝čā čćč鹊 ą┤čĆčāą│ąĖąĄ ą░ą╗čīč鹥čĆąĮą░čéąĖą▓čŗ čüą╗ąĖčłą║ąŠą╝ čāč鹊ą╝ąĖč鹥ą╗čīąĮčŗ. ąóąĖą┐ąĖčćąĮčŗą╣ ą░ą╗ą│ąŠčĆąĖčéą╝ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ čĆą░ąĘą╝ąĄčĆą░ ą║čāčćąĖ: ąĮą░ą╣čéąĖ čüą░ą╝čŗą╣ ą╝ą░ą╗čŗą╣ čĆą░ąĘą╝ąĄčĆ ą║čāčćąĖ, ą┐čĆąĖ ą║ąŠč鹊čĆąŠą╝ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ą▓čüąĄ ąĄčēąĄ čĆą░ą▒ąŠčéą░ąĄčé, ąĘą░č鹥ą╝ ą║ ą┐ąŠą╗čāč湥ąĮąĮąŠą╝čā čĆą░ąĘą╝ąĄčĆčā ą┤ąŠą▒ą░ą▓ą╗čÅčÄčé 50% čüą▓ąĄčĆčģčā.
ą¤čĆąĄą┤ąŠčéą▓čĆą░čēąĄąĮąĖąĄ ąŠčłąĖą▒ąŠą║ ą║čāčćąĖ. ąĢčüčéčī ąĮąĄą║ąĖą╣ ąĮą░ą▒ąŠčĆ ąŠą▒čēąĖčģ ąŠčłąĖą▒ąŠą║, ą┤ąŠą┐čāčüą║ą░ąĄą╝čŗčģ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčéą░ą╝ąĖ ąĖ č鹥čüčéąĖčĆąŠą▓čēąĖą║ą░ą╝ąĖ ą║ąŠą┤ą░, ą║ąŠč鹊čĆčŗčģ čüą╗ąĄą┤čāąĄčé ąĖąĘąĮą░čćą░ą╗čīąĮąŠ ąĖąĘą▒ąĄą│ą░čéčī, čćč鹊ą▒čŗ čüąĮąĖąĘąĖčéčī čĆąĖčüą║ ą▓čŗą┐čāčüą║ą░ ą┐čĆąŠą┤čāą║čåąĖąĖ, ą│ą┤ąĄ ąĄčüčéčī ąŠčłąĖą▒ą║ąĖ ą║čāčćąĖ.
ŌĆó ą×čłąĖą▒ą║ąĖ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ
ąØąĄ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ą│ą╗ąŠą▒ą░ą╗čīąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▓čüąĄą│ą┤ą░ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāčÄčéčüčÅ ąĮčāą╗čÅą╝ąĖ. ąźąŠčĆąŠčłąŠ ąĖąĘą▓ąĄčüčéąĮčŗą╣ čäą░ą║čé, čćč鹊 ą╝ąŠąČąĮąŠ ą╗ąĄą│ą║ąŠ ąĘą░ą▒čŗčéčī ąŠ č鹊ą╝, čćč鹊 ą▓čŗąĘąŠą▓čŗ malloc(), realloc() ąĖ ąŠą┐ąĄčĆą░č鹊čĆ new čÅąĘčŗą║ą░ C++ ąĮąĖč湥ą│ąŠ ą┐ąŠą┤ąŠą▒ąĮąŠą│ąŠ ąĮąĄ ą┤ąĄą╗ą░čÄčé, čé. ąĄ. ą▓čŗą┤ąĄą╗ąĄąĮąĮą░čÅ ąŠą▒ą╗ą░čüčéčī ą┤ą░ąĮąĮčŗčģ ąĘą░ą┐ąŠą╗ąĮąĄąĮą░ ą╝čāčüąŠčĆąŠą╝. ą×ą┤ąĮą░ą║ąŠ ąĄčüčéčī čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ ą▓ą░čĆąĖą░ąĮčé malloc(), ąĮąŠčüčÅčēąĖą╣ ąĖą╝čÅ calloc(), ą║ąŠč鹊čĆčŗą╣ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆčāąĄčé ąĮčāą╗čÅą╝ąĖ ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗą╣ ą▒ą╗ąŠą║ ą┤ą╗čÅ ą┤ą░ąĮąĮčŗčģ. ą×ą┐ąĄčĆą░č鹊čĆ C++ new ą▓čŗąĘąŠą▓ąĄčé čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╣ ą║ąŠąĮčüčéčĆčāą║č鹊čĆ, ą│ą┤ąĄ čüą╗ąĄą┤čāąĄčé ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ą▓čüąĄ 菹╗ąĄą╝ąĄąĮčéčŗ ą┤ą░ąĮąĮčŗčģ čüą║ąŠąĮčüčéčĆčāąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ (ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ąĖąĘ ą║čāčćąĖ) ąŠą▒čŖąĄą║čéą░ ą▒čāą┤čāčé ą┐čĆą░ą▓ąĖą╗čīąĮąŠ ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮčŗ.
ŌĆó ąØąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠąĄ čĆą░ąĘą┤ąĄą╗ąĄąĮąĖąĄ čüą║ą░ą╗čÅčĆąŠą▓ ąĖ ą╝ą░čüčüąĖą▓ąŠą▓
ąØą░ čÅąĘčŗą║ąĄ C++ ąĄčüčéčī čĆą░ąĘąĮčŗąĄ ąŠą┐ąĄčĆą░č鹊čĆčŗ ą┤ą╗čÅ čüą║ą░ą╗čÅčĆąŠą▓ ąĖ ą╝ą░čüčüąĖą▓ąŠą▓: new ąĖ delete ą┐čĆąĖą╝ąĄąĮčÅčÄčéčüčÅ ą┤ą╗čÅ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ čüą║ą░ą╗čÅčĆąŠą▓, ąĖ new[] ąĖ delete[] ą┐čĆąĖą╝ąĄąĮčÅčÄčéčüčÅ ą┤ą╗čÅ ą╝ą░čüčüąĖą▓ąŠą▓.
ŌĆó ąŚą░ą┐ąĖčüčī ą▓ čāąČąĄ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĮčāčÄ ą┐ą░ą╝čÅčéčī
ąŁč鹊 ą╗ąĖą▒ąŠ ą┐ąŠą▓čĆąĄą┤ąĖčé ą▓ąĮčāčéčĆąĄąĮąĮąĖąĄ čüčéčĆčāą║čéčāčĆčŗ ą┤ą░ąĮąĮčŗčģ ą░ą╗ą╗ąŠą║ą░č鹊čĆą░, ą╗ąĖą▒ąŠ čŹčéąĖ ą┤ą░ąĮąĮčŗąĄ ą▒čāą┤čāčé ą┐ąĄčĆąĄąĘą░ą┐ąĖčüą░ąĮčŗ ą┐ąŠąĘąČąĄ ą▓ ą┐čĆąŠčåąĄčüčüąĄ ą╗ąĄą│ą░ą╗čīąĮąŠą│ąŠ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ąĮąŠą▓ąŠą│ąŠ ą▒ą╗ąŠą║ą░ ą┐ą░ą╝čÅčéąĖ. ąÆ ą╗čÄą▒ąŠą╝ čüą╗čāčćą░ąĄ čŹč鹊 ą│čĆčāą▒ą░čÅ ąŠčłąĖą▒ą║ą░, ąĖ ą┐ąŠą┤ąŠą▒ąĮčŗąĄ ąŠčłąĖą▒ą║ąĖ čĆąĄą░ą╗čīąĮąŠ čéčĆčāą┤ąĮąŠ ą┐ąĄčĆąĄčģą▓ą░čéąĖčéčī ąĖ ąĖčüą┐čĆą░ą▓ąĖčéčī.
ŌĆó ą×čéčüčāčéčüčéą▓ąĖąĄ ą┐čĆąŠą▓ąĄčĆą║ąĖ ą▓ąŠąĘą▓čĆą░čēąĄąĮąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣
ąÆčüąĄ ą▓čŗąĘąŠą▓čŗ malloc(), realloc() ąĖ calloc() ą▓ąŠąĘą▓čĆą░čéčÅčé čāą║ą░ąĘą░č鹥ą╗čī NULL, čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī ąŠčéčüčāčéčüčéą▓ąĖąĄ čüą▓ąŠą▒ąŠą┤ąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ (ąĮąĄčāą┤ą░čćąĮąŠąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ą▒ą╗ąŠą║ą░ ą┐ą░ą╝čÅčéąĖ, out of memory). ąØą░čüč鹊ą╗čīąĮčŗąĄ čüąĖčüč鹥ą╝čŗ čüą│ąĄąĮąĄčĆąĖčĆčāčÄčé čüąŠą▒čŗčéąĖčÅ ąŠčéą║ą░ąĘą░ ą┐ą░ą╝čÅčéąĖ (memory fault) ąĖ ąĮąĄčģą▓ą░čéą║ąĖ ą┐ą░ą╝čÅčéąĖ (out-of-memory), čéą░ą║ čćč鹊 čŹčéąĖ čüąĖčéčāą░čåąĖąĖ ą┐čĆąŠčüč鹊 ąŠčéčüą╗ąĄą┤ąĖčéčī ąĄčēąĄ ą▓ ą┐čĆąŠčåąĄčüčüąĄ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ. ąÆčüčéčĆą░ąĖą▓ą░ąĄą╝čŗąĄ čüąĖčüč鹥ą╝čŗ ą╝ąŠą│čāčé ą▒čŗčéčī čāčüčéčĆąŠąĄąĮčŗ ą┐ąŠ-ą┤čĆčāą│ąŠą╝čā: ą┐ąŠ ą░ą┤čĆąĄčüčā 0 čā ąĮąĖčģ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ą░ą╝čÅčéčī ą┐čĆąŠą│čĆą░ą╝ą╝ FLASH, ąĖ ą▓ ąĮąĖčģ ą╝ąŠą│čāčé ą┐čĆąŠąĖčüčģąŠą┤ąĖčéčī ą▒ąŠą╗čīčłąĄ ą┤čĆčāą│ąĖčģ č鹊ąĮą║ąĖčģ ąŠčłąĖą▒ąŠą║. ąĢčüą╗ąĖ ą▓ ąÆą░čłąĄą╝ MCU ąĄčüčéčī ą▒ą╗ąŠą║ ąĘą░čēąĖčéčŗ ą┐ą░ą╝čÅčéąĖ (memory protection unit, MPU), č鹊 čüą╗ąĄą┤čāąĄčé čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░čéčī ąĄą│ąŠ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊ą▒čŗ ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ą╗ąĖčüčī ąŠčłąĖą▒ą║ąĖ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ ą┐čĆąĖ ą┐ąŠą┐čŗčéą║ąĄ ą┤ąŠčüčéčāą┐ą░ ą▓ąŠ FLASH ąĖ ą┤čĆčāą│ąĖąĄ ą║čĆąĖčéąĖč湥čüą║ąĖąĄ ąŠą▒ą╗ą░čüčéąĖ (ą×ąŚąŻ, ą│ą┤ąĄ ąĮą░čģąŠą┤ąĖčéčüčÅ ąĖčüą┐ąŠą╗ąĮčÅąĄą╝čŗą╣ ą║ąŠą┤, ąĘą░čēąĖčéąĮą░čÅ ąŠą▒ą╗ą░čüčéčī čüč鹥ą║ą░ ąĖ čé. ą┐.).
ŌĆó ą×čüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ąĮąĄčüą║ąŠą╗čīą║ąŠ čĆą░ąĘ ąŠą┤ąĮąŠą│ąŠ ąĖ č鹊ą│ąŠ ąČąĄ ą▒ą╗ąŠą║ą░ ą┐ą░ą╝čÅčéąĖ
ąŁč鹊 čüą║ąŠčĆąĄąĄ ą▓čüąĄą│ąŠ ą┐ąŠą▓čĆąĄą┤ąĖčé ą▓ąĮčāčéčĆąĄąĮąĮąĖąĄ čüčéčĆčāą║čéčāčĆčŗ ą░ą╗ą╗ąŠą║ą░č鹊čĆą░ ą┐ą░ą╝čÅčéąĖ, ąĖ čéą░ą║čāčÄ čüąĖčéčāą░čåąĖčÄ čüą╗ąŠąČąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ąĖ ąĖčüą┐čĆą░ą▓ąĖčéčī.
ŌĆó ąŚą░ą┐ąĖčüčī ą▓ąĮąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą╣ ąŠą▒ą╗ą░čüčéąĖ
ąŁč鹊 čéą░ą║ąČąĄ ą┐ąŠą▓čĆąĄą┤ąĖčé ą▓ąĮčāčéčĆąĄąĮąĮąĖąĄ čüčéčĆčāą║čéčāčĆčŗ ą░ą╗ą╗ąŠą║ą░č鹊čĆą░ ą┐ą░ą╝čÅčéąĖ, ąĖ čéą░ą║čāčÄ čüąĖčéčāą░čåąĖčÄ čüą╗ąŠąČąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ąĖ ąĖčüą┐čĆą░ą▓ąĖčéčī.
ą¤ąŠčüą╗ąĄą┤ąĮąĖąĄ čéčĆąĖ ą▓ąĖą┤ą░ ąŠčłąĖą▒ąŠą║ ą┐čĆąŠčēąĄ ąŠą▒ąĮą░čĆčāąČąĖčéčī, ąĄčüą╗ąĖ ąÆčŗ ąĮą░ą┐ąĖčłąĄč鹥 ąŠą▒ąĄčĆčéą║ąĖ ą▓ąŠą║čĆčāą│ čüčéą░ąĮą┤ą░čĆčéąĮčŗčģ čäčāąĮą║čåąĖą╣ malloc(), free() ąĖ čüą▓čÅąĘą░ąĮąĮčŗčģ čü ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄą╝ ą┐ą░ą╝čÅčéąĖ čäčāąĮą║čåąĖą╣. ąŁčéąĖ ąŠą▒ąĄčĆčéą║ąĖ ą┤ąŠą╗ąČąĮčŗ ą▓čŗą┤ąĄą╗čÅčéčī ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ą▒ą░ą╣čéčŗ ą┐ą░ą╝čÅčéąĖ, ą│ą┤ąĄ ą┤ąŠą╗ąČąĮą░ čĆą░ąĘą╝ąĄčēą░čéčīčüčÅ ąĖąĮč乊čĆą╝ą░čåąĖčÅ, ąĮąĄąŠą▒čģąŠą┤ąĖą╝ą░čÅ ą┤ą╗čÅ ą┐čĆąŠą▓ąĄčĆąŠą║ čåąĄą╗ąŠčüčéąĮąŠčüčéąĖ. ą¤čĆąĖą╝ąĄčĆ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖąĖ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ ą┤ą░ąĮąĮčŗčģ čéą░ą║ąŠą╣ ąŠą▒ąĄčĆčéą║ąĖ ą┐ąŠą║ą░ąĘą░ąĮą░ ąĮą░ čĆąĖčü. 6.
ąĀąĖčü. 6. ąÆčŗą┤ąĄą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ č鹥čüč鹊ą▓ąŠą╣ ąŠą▒ąĄčĆčéą║ąŠą╣ MyMalloc.
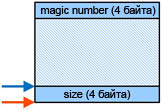
ąŚą┤ąĄčüčī ą┐ąŠą╗ąĄ "magic number" ą┐ąĄčĆąĄą┤ ą┤ą░ąĮąĮčŗą╝ąĖ (user data) ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą┤ąĄč鹥ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐ąŠą▓čĆąĄąČą┤ąĄąĮąĖčÅ ąĖ ą▒čāą┤ąĄčé ą┐čĆąŠą▓ąĄčĆąĄąĮ, ą║ąŠą│ą┤ą░ ą┐ą░ą╝čÅčéčī ą▒čāą┤ąĄčé ąŠčüą▓ąŠą▒ąŠąČą┤ą░čéčīčüčÅ. ą¤ąŠą╗ąĄ size, ąĮą░čģąŠą┤čÅčēąĄąĄčüčÅ ąĮąĖąČąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖčģ ą┤ą░ąĮąĮčŗčģ, ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ąŠą▒ąĄčĆčéą║ąŠą╣ ą┤ą╗čÅ free() (čäčāąĮą║čåąĖčÅ MyFree), čćč鹊ą▒čŗ ąĮą░ą╣čéąĖ "magic number". ą¤čĆąĖą╝ąĄčĆ ąŠą▒ąĄčĆč鹊ą║, ą┐ąŠą║ą░ąĘą░ąĮąĮčŗą╣ ąĮąĖąČąĄ, ąĖčüą┐ąŠą╗čīąĘčāąĄčé 8 ą▒ą░ą╣čé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĮą░ą│čĆčāąĘą║ąĖ ąĮą░ ąŠą┤ąĮąŠ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ, čćč鹊 ą▓ą┐ąŠą╗ąĮąĄ ą┤ąŠą┐čāčüčéąĖą╝ąŠ ą┤ą╗čÅ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣. ąŁč鹊čé ą┐čĆąĖą╝ąĄčĆ čéą░ą║ąČąĄ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, ą║ą░ą║ ą│ą╗ąŠą▒ą░ą╗čīąĮąŠ ą┐ąĄčĆąĄąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī (override) ąŠą┐ąĄčĆą░č鹊čĆčŗ new ąĖ delete čÅąĘčŗą║ą░ C++. ą¤čĆąĖą╝ąĄčĆ ą┐ąĄčĆąĄčģą▓ą░čéąĖčé č鹊ą╗čīą║ąŠ ąŠčłąĖą▒ą║ąĖ čéą░ą║ąŠą│ąŠ čĆąŠą┤ą░, čćč鹊 ą▓čüčÅ ą▓čŗą┤ąĄą╗ąĄąĮąĮą░čÅ ą┐ą░ą╝čÅčéčī ąĮąĄ ą▒čŗą╗ą░ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮą░ ą▓ ą║ą░ą║ąŠą╣-č鹊 ą╝ąŠą╝ąĄąĮčé ą▓čĆąĄą╝ąĄąĮąĖ. ąöą╗čÅ ąĮąĄą║ąŠč鹊čĆčŗčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ čéą░ą║ą░čÅ ą┐čĆąŠą▓ąĄčĆą║ą░ ą╝ąŠąČąĄčé ąĮąĄ ą┐ąŠčéčĆąĄą▒ąŠą▓ą░čéčīčüčÅ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ąŠą▒ąĄčĆčéą║ą░ ą┤ąŠą╗ąČąĮą░ ą▓ąĄčüčéąĖ čüą┐ąĖčüąŠą║ ą▓čüąĄčģ ą▓čŗą┤ąĄą╗ąĄąĮąĖą╣ ą┐ą░ą╝čÅčéąĖ, ąĖ ą┐ąĄčĆąĖąŠą┤ąĖč湥čüą║ąĖ ą┐čĆąŠą▓ąĄčĆčÅčéčī ą▓čüąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ, ąĘą░ą┐ąĖčüą░ąĮąĮčŗąĄ ą▓ čŹč鹊ą╝ čüą┐ąĖčüą║ąĄ. ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮą░čÅ ąĮą░ą│čĆčāąĘą║ą░ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čŹč鹊ą│ąŠ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĮąĄ čéą░ą║ą░čÅ ą▒ąŠą╗čīčłą░čÅ, ą║ą░ą║ čŹč鹊 ą╝ąŠąČąĄčé ą┐ąŠą║ą░ąĘą░čéčīčüčÅ ąĮą░ ą┐ąĄčĆą▓čŗą╣ ą▓ąĘą│ą╗čÅą┤, ą┐ąŠčüą║ąŠą╗čīą║čā ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗąĄ čüąĖčüč鹥ą╝čŗ ąŠą▒čŗčćąĮąŠ ąĮąĄ ąŠč湥ąĮčī ąĖąĮč鹥ąĮčüąĖą▓ąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāčÄčé ą┤ąĖąĮą░ą╝ąĖč湥čüą║čāčÄ ą┐ą░ą╝čÅčéčī, čüąŠčģčĆą░ąĮčÅčÅ čĆą░ąĘą╝ąĄčĆ čüą┐ąĖčüą║ą░ ą▓čŗą┤ąĄą╗ąĄąĮąĖą╣ ą▓ čĆą░ąĘčāą╝ąĮčŗčģ ą┐čĆąĄą┤ąĄą╗ą░čģ.
#include < stdint.h>
#include < stdlib.h>
#define MAGIC_NUMBER 0xefdcba98
uint32_t myMallocMaxMem;
void* MyMalloc(size_t bytes)
{
uint8_t *p, *p_end;
static uint8_t* mLow = (uint8_t*)0xffffffff; /* čüą░ą╝čŗą╣ ą╝ą░ą╗čŗą╣ ą░ą┤čĆąĄčü, ą▓ąŠąĘą▓čĆą░čēąĄąĮąĮčŗą╣
ą▓čŗąĘąŠą▓ąŠą╝ malloc() */
static uint8_t* mHigh; /* čüą░ą╝čŗą╣ ą▒ąŠą╗čīčłąŠą╣ ą░ą┤čĆąĄčü + data, ą▓ąŠąĘą▓čĆą░čēąĄąĮąĮčŗą╣ malloc() */
bytes = (bytes + 3) & ~3; /* ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą┤ą╗čÅ magic number */
p = (uint8_t*)malloc(bytes + 8); /* čāč湥čé ąŠą▒ą╗ą░čüčéąĖ 2x32-ą▒ąĖčé ą┤ą╗čÅ size ąĖ magic number */
if (p == NULL)
{
abort(); /* ąŠčłąĖą▒ą║ą░ ąĮąĄčģą▓ą░čéą║ąĖ ą┐ą░ą╝čÅčéąĖ, out of memory */
}
*((uint32_t*)p) = bytes; /* ąĘą░ą┐ąŠą╝ąĮąĖčéčī čĆą░ąĘą╝ąĄčĆ size */
*((uint32_t*)(p + 4 + bytes)) = MAGIC_NUMBER; /* ąĘą░ą┐ąĖčüą░čéčī magic number ą┐ąŠčüą╗ąĄ
ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąŠą│ąŠ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ */
/* ąōčĆčāą▒čŗą╣ ą╝ąĄč鹊ą┤ ąŠčåąĄąĮą║ąĖ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░
čü ą╝ąŠą╝ąĄąĮčéą░ ąĘą░ą┐čāčüą║ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ. */
if (p < mLow) mLow = p;
p_end = p + bytes + 8;
if (p_end > mHigh) mHigh = p_end;
myMallocMaxMem = mHigh - mLow;
return p + 4; /* ą▓čŗą┤ąĄą╗čÅąĄą╝ą░čÅ ąŠą▒ą╗ą░čüčéčī ąĮą░čćąĖąĮą░ąĄčéčüčÅ ą┐ąŠčüą╗ąĄ size */
}
void MyFree(void* vp)
{
uint8_t* p = (uint8_t*)vp - 4;
int bytes = *((uint32_t*)p);
/* ą¤čĆąŠą▓ąĄčĆą║ą░, čćč鹊 magic number ąĮąĄ ą▒čŗą╗ ą┐ąŠą▓čĆąĄąČą┤ąĄąĮ: */
if (*((uint32_t*)(p + 4 + bytes)) != MAGIC_NUMBER)
{
abort(); /* ą×čłąĖą▒ą║ą░: ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ ąĖą╗ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ą▒ą╗ąŠą║ą░
ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗą╣ čāąČąĄ ą▒čŗą╗ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮ */
}
*((uint32_t*)(p + 4 + bytes)) = 0; /* čāą┤ą░ą╗ąĄąĮąĖąĄ magic number, čćč鹊ą▒čŗ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ
ąŠą▒ąĮą░čĆčāąČąĖčéčī ąŠčłąĖą▒ąŠčćąĮąŠ-ą┐ąŠą▓č鹊čĆąĮąŠąĄ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ
ą▒ą╗ąŠą║ą░ ą┐ą░ą╝čÅčéąĖ */
free(p);
}
#ifdef __cplusplus
// ąōą╗ąŠą▒ą░ą╗čīąĮąŠąĄ ą┐ąĄčĆąĄąĮą░ąĘąĮą░č湥ąĮąĖąĄ ąŠą┐ąĄčĆą░č鹊čĆąŠą▓ new, delete, new[] ąĖ delete[].
void* operator new (size_t bytes) { return MyMalloc(bytes); }
void operator delete (void *p) { MyFree(p); }
#endif
ąÜą░ą║ čāčüčéą░ąĮąŠą▓ąĖčéčī čĆą░ąĘą╝ąĄčĆ ą║čāčćąĖ. ąśčéą░ą║, ą║ą░ą║ ą╝ąŠąČąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī čéčĆąĄą▒čāąĄą╝čŗą╣ ą╝ąĖąĮąĖą╝ą░ą╗čīąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ ą║čāčćąĖ ą┤ą╗čÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ? ąśąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ čäčĆą░ą│ą╝ąĄąĮčéą░čåąĖčÅ ą┐ą░ą╝čÅčéąĖ ą▓ ą┐čĆąŠčåąĄčüčüąĄ ą┐ąŠą▓č鹊čĆčÅčÄčēąĖčģčüčÅ čåąĖą║ą╗ąŠą▓ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ ąĖ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ, ąŠčéą▓ąĄčé ąĮą░ čŹč鹊čé ą▓ąŠą┐čĆąŠčü ąĮąĄčéčĆąĖą▓ąĖą░ą╗ąĄąĮ. ąĀąĄą║ąŠą╝ąĄąĮą┤čāąĄčéčüčÅ ąĘą░ą┐čāčüčéąĖčéčī č鹥čüčé čüąĖčüč鹥ą╝čŗ ą┐čĆąĖ čāčüą╗ąŠą▓ąĖčÅčģ, ą║ąŠą│ą┤ą░ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ą░čÅ ą┐ą░ą╝čÅčéčī ą▒čāą┤ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ąŠ ą╝ą░ą║čüąĖą╝čāą╝čā. ąÆą░ąČąĮąŠ ą▓čŗą┐ąŠą╗ąĮąĖčéčī čŹč鹊čé č鹥čüčé ąĮąĄčüą║ąŠą╗čīą║ąŠ čĆą░ąĘ, čćč鹊ą▒čŗ ą┐čĆąŠą░ąĮą░ą╗ąĖąĘąĖčĆąŠą▓ą░čéčī ą┐ąĄčĆąĄčģąŠą┤ ąŠčé ą╝ą░ą╗ąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ą║čāčćąĖ ą║ ąĖąĮč鹥ąĮčüąĖą▓ąĮąŠą╝čā, ąĖ ąŠčåąĄąĮąĖčéčī ąĄčæ ą▓ąŠąĘą╝ąŠąČąĮčāčÄ čäčĆą░ą│ą╝ąĄąĮčéą░čåąĖčÄ. ąÜąŠą│ą┤ą░ č鹥čüčéčŗ ą▒čāą┤čāčé ąĘą░ą▓ąĄčĆčłąĄąĮčŗ, ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčŗą╣ čāčĆąŠą▓ąĄąĮčī ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ ą▓ ą║čāč湥 čüčĆą░ą▓ąĮąĖą▓ą░čÄčé čü čĆąĄą░ą╗čīąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╝ čĆą░ąĘą╝ąĄčĆąŠą╝ ą║čāčćąĖ. ąĀąĄą░ą╗čīąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ ą║čāčćąĖ ą▓čŗčüčéą░ą▓ą╗čÅčÄčé, ą┤ąŠą▒ą░ą▓ą╗čÅčÅ ąŠčé 25% ą┤ąŠ 100% ą║ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╝čā ąĘą░ą┤ąĄą╣čüčéą▓ąŠą▓ą░ąĮąĮąŠą╝čā čĆą░ąĘą╝ąĄčĆčā ą║čāčćąĖ, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé č鹊ą│ąŠ, ą║ą░ą║ čāčüčéčĆąŠąĄąĮąŠ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ.
ąöą╗čÅ čüąĖčüč鹥ą╝, ą║ąŠč鹊čĆčŗąĄ č鹥čüčéąĖčĆčāčÄčéčüčÅ ąĮą░ ą┤ąĄčüč鹊ą┐ąĮčŗčģ čüąĖčüč鹥ą╝ą░čģ ą┐čāč鹥ą╝ 菹╝čāą╗čÅčåąĖąĖ sbrk(), ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą║čāčćąĖ ą╝ąŠąČąĮąŠ čāąĘąĮą░čéčī č湥čĆąĄąĘ bymalloc_max_footprint().
ąöą╗čÅ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ čüąĖčüč鹥ą╝, ą║ąŠč鹊čĆčŗąĄ ąĮąĄ 菹╝čāą╗ąĖčĆčāčÄčé sbrk() (ą░ čüčĆąĄą┤ą░ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ IAR Embedded Workbench ą║ą░ą║ čĆą░ąĘ ąŠčéąĮąŠčüąĖčéčüčÅ ą║ čéą░ą║ąĖą╝ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗą╝ čüąĖčüč鹥ą╝ą░ą╝), ąŠą▒čŗčćąĮąŠ ą┤ą╗čÅ ą░ą╗ą╗ąŠą║ą░č鹊čĆą░ ą┐ą░ą╝čÅčéąĖ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ą┐ą░ą╝čÅčéčī ą║čāčćąĖ ąŠą┤ąĮąĖą╝ ą║čāčüą║ąŠą╝. ąÆ čéą░ą║ąŠą╝ čüą╗čāčćą░ąĄ ą▓čŗąĘąŠą▓ malloc_max_footprint() čüčéą░ąĮąŠą▓ąĖčéčüčÅ ą▒ąĄčüą┐ąŠą╗ąĄąĘąĮčŗą╝; ąŠąĮ ą┐čĆąŠčüč鹊 ą▓ąĄčĆąĮąĄčé čĆą░ąĘą╝ąĄčĆ ą▓čüąĄą╣ ą║čāčćąĖ. ą×ą┤ąĮąĖą╝ ąĖąĘ čĆąĄčłąĄąĮąĖą╣ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗąĘąŠą▓ mallinfo() ą┐ąŠčüą╗ąĄ ą║ą░ąČą┤ąŠą│ąŠ ą▓čŗąĘąŠą▓ą░ malloc(), ąĮą░ą┐čĆąĖą╝ąĄčĆ ą▓ ąŠą▒ąĄčĆčéą║ąĄ čäčāąĮą║čåąĖąĖ, ąŠą┐ąĖčüą░ąĮąĮąŠą╣ čĆą░ąĮąĮąĄąĄ, ąĖ ą┐ąŠą╗čāčćąĖčéčī ąŠą▒ąĘąŠčĆ ąŠą▒čēąĄą│ąŠ ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ (mallinfo->uordblks). ążčāąĮą║čåąĖčÅ mallinfo() ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ą┤ąŠą▓ąŠą╗čīąĮąŠ ąĖąĮč鹥ąĮčüąĖą▓ąĮčŗąĄ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ, čéą░ą║ čćč鹊 ąĄčæ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą╝ąŠąČąĄčé ą┐ąŠą▓ą╗ąĖčÅčéčī ąĮą░ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī čüąĖčüč鹥ą╝čŗ. ąøčāčćčłąĖą╣ ą╝ąĄč鹊ą┤ - ąĘą░ą┐ąĖčüčŗą▓ą░čéčī ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčŗąĄ čĆą░čüčüč鹊čÅąĮąĖčÅ ą╝ąĄąČą┤čā ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗą╝ąĖ ąŠą▒ą╗ą░čüčéčÅą╝ąĖ ą┐ą░ą╝čÅčéąĖ. ąŁč鹊 ą┐čĆąŠčüč鹊 ąŠčüčāčēąĄčüčéą▓ąĖčéčī, ąĖ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą┐čĆąĖą╝ąĄčĆąĄ ąŠą▒ąĄčĆčéą║ąĖ; ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą▓ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ myMallocMaxMem. ąŁč鹊čé ą╝ąĄč鹊ą┤ ą▒čāą┤ąĄčé čĆą░ą▒ąŠčéą░čéčī, ą║ąŠą│ą┤ą░ ą║čāčćą░ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮą░ ą▓ ąŠą┤ąĮąŠą╝ ąĮąĄą┐čĆąĄčĆčŗą▓ąĮąŠą╣ (ąĮąĄ čüąŠčüč鹊čÅčēąĄą╣ ąĖąĘ ąŠčéą┤ąĄą╗čīąĮčŗčģ ą║čāčüą║ąŠą▓) ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ.
[ąĪč鹥ą║ ąĖ ą║čāčćą░ ą▓ IAR 4.41]
ąÆ čŹč鹊ą╣ čüčéą░čĆąŠą╣ ą▓ąĄčĆčüąĖąĖ IAR čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ąĘą░ą┤ą░ąĄčéčüčÅ ą▓ čäą░ą╣ą╗ąĄ *.xcl, ą║ąŠč鹊čĆčŗą╣ ąĮą░čüčéčĆą░ąĖą▓ą░ąĄčéčüčÅ ą▓ ąŠą┐čåąĖčÅčģ ą┐čĆąŠąĄą║čéą░ (Options... -> Linker -> ąĘą░ą║ą╗ą░ą┤ą║ą░ Config -> Linker command file). ąĪč鹥ą║ ąĮą░čćąĖąĮą░ąĄčéčüčÅ ąŠčé čüčéą░čĆčłąĖčģ (čüą░ą╝čŗčģ ą▒ąŠą╗čīčłąĖčģ) ą░ą┤čĆąĄčüąŠą▓ ą┐ą░ą╝čÅčéąĖ ąĖ čĆą░čüč鹥čé ą║ ąĮąĖąČąĮąĖą╝ (čüą░ą╝čŗą╝ ą╝ą░ą╗čŗą╝ ą░ą┤čĆąĄčüą░ą╝), ąĮą░ą▓čüčéčĆąĄčćčā ą║ čäčāąĮą║čåąĖčÅą╝ __ramfunc ąĖ ą│ą╗ąŠą▒ą░ą╗čīąĮčŗą╝ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝. ąÆąŠčé ą┐čĆąĖą╝ąĄčĆ ąĮą░čüčéčĆąŠą╣ą║ąĖ ą▓ XCL-čäą░ą╣ą╗ąĄ, ą║ąŠą│ą┤ą░ ą║čāčćąĖ ąĮąĄčé, ąĖ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ č鹊ą╗čīą║ąŠ čüč鹥ą║ čĆą░ąĘą╝ąĄčĆą░ 400 ą▒ą░ą╣čé:
//*************************************************************************
// ąĪąĄą│ą╝ąĄąĮčéčŗ čüč鹥ą║ą░ ąĖ ą║čāčćąĖ.
//*************************************************************************
-D_CSTACK_SIZE=(100*4)
-D_IRQ_STACK_SIZE=(3*8*4)
-D_HEAP_SIZE=0
ąĢčüą╗ąĖ ą▓ ą┐čĆąŠąĄą║č鹥 ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮą░ ą║čāčćą░, č鹊 ąŠąĮą░ ąĮą░čģąŠą┤ąĖčéčüčÅ čüčĆą░ąĘčā ąĘą░ ą╗ąŠą║ą░ą╗čīąĮčŗą╝ąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝ąĖ, ąĖ čĆą░čüč鹥čé ąĮą░ą▓čüčéčĆąĄčćčā čüč鹥ą║čā. ąÆąŠčé ą┤čĆčāą│ąŠą╣ ą┐čĆąĖą╝ąĄčĆ, ą│ą┤ąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮą░ ą║čāčćą░ čĆą░ąĘą╝ąĄčĆą░ 0x3C50 ąĖ čüč鹥ą║ čĆą░ąĘą╝ąĄčĆą░ 0x1D00:
-D_CSTACK_SIZE=(1D00)
-D_IRQ_STACK_SIZE=(3*8*4)
-D_HEAP_SIZE=3C50
ąÆąŠčé čéą░ą║ ą╝ąŠąČąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī ą║ą░čĆčéą░ ą┐ą░ą╝čÅčéąĖ RAM ą╝ąĖą║čĆąŠą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ AT91SAM7X256 ą┤ą╗čÅ ą▓č鹊čĆąŠą│ąŠ ą┐čĆąĖą╝ąĄčĆą░:

ą×ą┐čĆąĄą┤ąĄą╗ąĖčéčī, ąĮą░čüą║ąŠą╗čīą║ąŠ ą║ąŠčĆčĆąĄą║čéąĮąŠ ąĘą░ą┤ą░ąĮčŗ čĆą░ąĘą╝ąĄčĆ ą║čāčćąĖ ąĖ čĆą░ąĘą╝ąĄčĆ čüč鹥ą║ą░, ą╝ąŠąČąĮąŠ čü ą┐ąŠą╝ąŠčēčīčÄ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ ąŠą▒ą╗ą░čüčéąĖ ą║čāčćąĖ ąĖ čüč鹥ą║ą░ ąĘą░čĆą░ąĮąĄąĄ ąĖąĘą▓ąĄčüčéąĮčŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝ ą▒ą░ą╣čéą░. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą▓čüčÄ ą┐ą░ą╝čÅčéčī ą║čāčćąĖ ą╝ąŠąČąĮąŠ ąĘą░ą┐ąŠą╗ąĮąĖčéčī ą▒ą░ą╣č鹊ą╝ 0xaa, ą░ ą▓čüčÄ čüą▓ąŠą▒ąŠą┤ąĮčāčÄ ą┐ą░ą╝čÅčéčī čüč鹥ą║ą░ ą╝ąŠąČąĮąŠ ąĘą░ą┐ąŠą╗ąĮąĖčéčī ą▒ą░ą╣č鹊ą╝ 0xbb. ąŁč鹊 čåąĄą╗ąĄčüąŠąŠą▒čĆą░ąĘąĮąŠ ą┤ąĄą╗ą░čéčī ą▓ čäčāąĮą║čåąĖąĖ void AT91F_LowLevelInit(void), ą║ąŠč鹊čĆą░čÅ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą╝ąŠą┤čāą╗ąĄ Cstartup_SAM7.c. ą¤čĆąĖą╝ąĄčĆ čéą░ą║ąŠą│ąŠ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ:
void AT91F_LowLevelInit(void)
{
...
//ąŚą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║čāčćąĖ ąĖąĘą▓ąĄčüčéąĮčŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝ 0xAA:
#define HEAP_BEGIN 0x0020A344 //ą▓ąĘčÅč鹊 ąĖąĘ map-čäą░ą╣ą╗ą░ PImain.map
#define HEAP_SIZE 0x3C50 //ą▓ąĘčÅč鹊 ąĖąĘ map-čäą░ą╣ą╗ą░ PImain.map
memset((void*)HEAP_BEGIN, 0xAA, HEAP_SIZE);
//ąŚą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ čüč鹥ą║ą░ ąĖąĘą▓ąĄčüčéąĮčŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝ 0xBB:
#define STACK_BEGIN (HEAP_BEGIN+HEAP_SIZE) //čüč鹥ą║ ąĮą░čćąĖąĮą░ąĄčéčüčÅ čüčĆą░ąĘčā ąĘą░ ą║čāč湥ą╣
#define STACK_SIZE 0x1D00-0x0100) //ą▓ąĘčÅč鹊 ąĖąĘ čäą░ą╣ą╗ą░ at91SAM7X256_FLASH.xcl
//čü ąŠčéčüčéčāą┐ąŠą╝ 0x0100 ą▒ą░ą╣čé ąŠčé ą║ąŠąĮčåą░ ą┐ą░ą╝čÅčéąĖ
memset((void*)STACK_BEGIN, 0xBB, STACK_SIZE);
}
ąÜą░ą║ čāąĘąĮą░čéčī ąĘąĮą░č湥ąĮąĖčÅ HEAP_BEGIN, HEAP_SIZE, STACK_BEGIN, STACK_SIZE. HEAP_BEGIN ąĘą░ą┤ą░ąĄčé čüą░ą╝čŗą╣ ą╝ą╗ą░ą┤čłąĖą╣ ą░ą┤čĆąĄčü ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ ą║čāčćąĖ, ą░ ą║ąŠąĮčüčéą░ąĮčéą░ HEAP_SIZE ąĘą░ą┤ą░ąĄčé čĆą░ąĘą╝ąĄčĆ ąĘą░ą┐ąŠą╗ąĮčÅąĄą╝ąŠą╣ ąŠą▒ą╗ą░čüčéąĖ. ąŚąĮą░č湥ąĮąĖąĄ HEAP_BEGIN ą╝ąŠąČąĮąŠ čāąĘąĮą░čéčī ąŠą┐čŗčéąĮčŗą╝ ą┐čāč鹥ą╝ ą▓ ąŠčéą╗ą░ą┤čćąĖą║ąĄ ą┐ąŠ ą░ą┤čĆąĄčüčā ą┐ąĄčĆą▓ąŠą│ąŠ ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ą▒ą╗ąŠą║ą░ (č湥čĆąĄąĘ malloc ąĖą╗ąĖ new), ąĖą╗ąĖ ąĄčüą╗ąĖ ąĘą░ą│ą╗čÅąĮčāčéčī ą▓ ą║ąŠąĮąĄčå map-čäą░ą╣ą╗ą░, čĆą░ąĘą┤ąĄą╗ "SEGMENTS IN ADDRESS ORDER", čéą░ą╝ ą▒čāą┤ąĄčé čāą║ą░ąĘą░ąĮčŗ ąĮą░čćą░ą╗ąŠ ąĖ ą║ąŠąĮąĄčå ą║čāčćąĖ, ą┐čĆąĖą╝ąĄčĆ (ą┐ą░čĆą░ą╝ąĄčéčĆčŗ ą║čāčćąĖ ą▓čŗą┤ąĄą╗ąĄąĮčŗ ąČąĖčĆąĮčŗą╝ čłčĆąĖčäč鹊ą╝):
****************************************
* *
* SEGMENTS IN ADDRESS ORDER *
* *
****************************************
SEGMENT SPACE START ADDRESS END ADDRESS SIZE TYPE ALIGN
======= ===== ============= =========== ==== ==== =====
ICODE 00001000 - 0000111B 11C rel 2
CODE 0000111C - 0000C5C7 B4AC rel 2
INITTAB 0000C5C8 - 0000C5EB 24 rel 2
DATA_ID 0000C5EC - 00014B6F 8584 rel 2
DATA_C 00014B70 - 0001651F 19B0 rel 2
CODE_ID 00016520 - 000169A7 488 rel 2
?FILL1 000169A8 - 0003FFFF 29658 rel 0
CODE_I 00200050 - 002004D7 488 rel 2
DATA_I 002004D8 - 00208A5B 8584 rel 2
DATA_Z 00208A5C - 0020A33D 18E2 rel 2
DATA_N 0020A340 - 0020A343 4 rel 2
HEAP 0020A344 - 0020DF93 3C50 rel 2
INTRAMEND_REMAP 00210000 rel 2
HEAP_SIZE ą╝ąŠąČąĮąŠ čāąĘąĮą░čéčī ąĖąĘ čäą░ą╣ą╗ą░ XCL ą▓ ą┐ą░čĆą░ą╝ąĄčéčĆąĄ HEAP_SIZE, ąĖą╗ąĖ ąĖąĘ č鹊ą│ąŠ ąČąĄ map-čäą░ą╣ą╗ą░, čüą╝. ą┐ą░čĆą░ą╝ąĄčéčĆ SIZE čéą░ą▒ą╗ąĖčåčŗ ą▓čŗčłąĄ.
STACK_BEGIN ąĘą░ą┤ą░ąĄčé čüą░ą╝čŗą╣ ą╝ą╗ą░ą┤čłąĖą╣ ą░ą┤čĆąĄčü ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ čüč鹥ą║ą░, ą░ STACK_SIZE ąĘą░ą┤ą░ąĄčé čĆą░ąĘą╝ąĄčĆ ąĘą░ą┐ąŠą╗ąĮčÅąĄą╝ąŠą╣ ąŠą▒ą╗ą░čüčéąĖ. ąŚąĮą░č湥ąĮąĖąĄ STACK_BEGIN čĆą░ą▓ąĮąŠ čüą╗ąĄą┤čāčÄčēąĄą╝čā ąĘą░ ą║čāč湥ą╣ ą░ą┤čĆąĄčüčā, ą░ STACK_SIZE ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊ą▒čŗ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą▒ą░ą╣č鹊ą╝ 0xBB ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░ąĮąĮąŠ ąĮąĄ ą┐ąĄčĆąĄą║čĆčŗą╗ąŠ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čüč鹥ą║ą░, ą┤ąĄą╣čüčéą▓čāčÄčēąĄąĄ ą▓ ąĮą░čüč鹊čÅčēąĖą╣ ą╝ąŠą╝ąĄąĮčé.
ą¤ąŠčüą╗ąĄ ąĘą░ą┐čāčüą║ą░ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą▓ čĆą░ą▒ąŠčćąĖą╣ čĆąĄąČąĖą╝ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čÄčé čāčüą╗ąŠą▓ąĖčÅ, ą┐čĆąĖ ą║ąŠč鹊čĆąŠą╝ ą┤ąŠą╗ąČąĮąŠ ąĮą░ą▒ą╗čÄą┤ą░čéčīčüčÅ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüč鹥ą║ą░ ąĖ ą║čāčćąĖ. ąöą░čÄčé ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ąĮąĄą║ąŠč鹊čĆąŠąĄ ą▓čĆąĄą╝čÅ ą┐ąŠčĆą░ą▒ąŠčéą░čéčī, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čÄčé ąŠčéą╗ą░ą┤čćąĖą║, ąĖ ą┐ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ą▓ ą┤ą░ą╝ą┐ąĄ ą┐ą░ą╝čÅčéąĖ ą╝ąŠąČąĮąŠ čāą▓ąĖą┤ąĄčéčī, ąĮą░čüą║ąŠą╗čīą║ąŠ ą┤ą░ą╗ąĄą║ąŠ ą┐čĆąŠą┤ą▓ąĖąĮčāą╗ąŠčüčī ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ čüč鹥ą║ą░ ąĖ ą║čāčćąĖ. ąóąĄ ą╝ąĄčüčéą░, ą║ąŠč鹊čĆčŗąĄ ąĄčēąĄ čüą▓ąŠą▒ąŠą┤ąĮčŗ, ą▒čāą┤čāčé ąĘą░ą┐ąŠą╗ąĮąĄąĮčŗ ą▒ą░ą╣čéą░ą╝ąĖ 0xAA ąĖ 0xBB ą┤ą╗čÅ ą║čāčćąĖ ąĖ čüč鹥ą║ą░ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ. ąØąĖąČąĄ ąĮą░ čüą║čĆąĖąĮčłąŠč鹥 ą┐ąŠą║ą░ąĘą░ąĮąŠ, ą║ą░ą║ ą╝ąŠąČąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī ą┐ą░ą╝čÅčéčī ą║čāčćąĖ ąĖ čüč鹥ą║ą░. ąÆąĖą┤ąĮąŠ, čćč鹊 ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą▓ ą║čāč湥 ą┐ąŠą┤ąŠčłą╗ąŠ ą║ čüą▓ąŠąĄą╝čā ą┐čĆąĄą┤ąĄą╗čā, ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą▓ ą║čāč湥 ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą┐ąĄčĆąĄčģąŠą┤čā ąĮą░ ąŠą▒ą╗ą░čüčéčī čüč鹥ą║ą░:

[ąĪčüčŗą╗ą║ąĖ]
1. Mastering stack and heap for system reliability site:iar.com.
2. Nigel Jones, blog posts at embeddedgurus.com, 2007 and 2009.
3. John Regehr "Say no to stack overflow", EE Times Design, 2004.
4. Carnegie Mellon University, "Secure Coding in C and C++, Module 4, Dynamic Memory Management", 2010.
5. FreeRTOS: ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüč鹥ą║ą░ ąĖ ą┐čĆąŠą▓ąĄčĆą║ą░ čüč鹥ą║ą░ ąĮą░ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĄ.
6. FreeRTOS: ą┐čĆą░ą║čéąĖč湥čüą║ąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ, čćą░čüčéčī 6 (čāčüčéčĆą░ąĮąĄąĮąĖąĄ ą┐čĆąŠą▒ą╗ąĄą╝).
7. FreeRTOS, STM32: ąŠčéą╗ą░ą┤ą║ą░ ąŠčłąĖą▒ąŠą║ ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖą╣.
8. IAR C-SPY: ą┐čĆąĄą┤čāą┐čĆąĄąČą┤ąĄąĮąĖąĄ ąŠ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖąĖ čüč鹥ą║ą░.
9. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ čüč鹥ą║ą░ ą▓ IAR ąĖ čäą░ą╣ą╗čŗ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ čüč鹥ą║ąŠą╝.
10. Cortex: ąŠčéą┤ąĄą╗čīąĮčŗą╣ čüč鹥ą║ ą┤ą╗čÅ ISR. |




ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖąĖ
microsin: ąĮąĄ ąĘąĮą░čÄ čüą┐ąŠčüąŠą▒ą░, ą║ą░ą║ čŹč鹊 čüą┤ąĄą╗ą░čéčī, ąĖ ą▒čāą┤čā čĆą░ą┤, ąĄčüą╗ąĖ ą┐ąŠą┤ąĄą╗ąĖč鹥čüčī ąĖąĮč乊čĆą╝ą░čåąĖąĄą╣. ąś ąĄčēąĄ ą▓čŗąĘčŗą▓ą░ąĄčé ąĖąĮč鹥čĆąĄčü čüą╗ąĄą┤čāčÄčēąĄąĄ: ąŚąÉą¦ąĢą£ ą╝ąŠąČąĄčé ą┐ąŠąĮą░ą┤ąŠą▒ąĖčéčīčüčÅ ą┤ąĄą╗ą░čéčī ąŠčéą┤ąĄą╗čīąĮčŗą╣ čüč鹥ą║ ą║ąŠą┤ą░ main ąĖ ąŠčéą┤ąĄą╗čīąĮčŗą╣ čüč鹥ą║ ą┤ą╗čÅ ISR?
ąÆ Cortex-M4 ąĘąĮą░č湥ąĮąĖąĄ ą┤ą╗čÅ ą▓ąĄčĆčģčāčłą║ąĖ čüč鹥ą║ą░ ą┤ą╗čÅ čäčāąĮą║čåąĖąĖ main (MSP) ą▒ąĄčĆąĄčéčüčÅ ąĖąĘ Vector Table (čäą░ą║čéąĖč湥čüą║ąĖ ąĖąĘ Flash ą┐ą░ą╝čÅčéąĖ) ą┐ąĄčĆą▓ąŠą╣ ASM čüčéčĆąŠčćą║ąŠą╣ ą┐čĆąŠčłąĖą▓ą║ąĖ ąĖąĘ ą░ą┤čĆąĄčüą░ 0x00000000.
ąÉ ąŠčéą║čāą┤ą░ č鹊ą│ą┤ą░ ą▒čĆą░čéčī ą┤čĆčāą│ąŠąĄ (ąŠčéą╗ąĖčćąĮąŠąĄ ąŠčé MSP) ąĘąĮą░č湥ąĮąĖąĄ ą▓ąĄčĆčģčāčłą║ąĖ čüč鹥ą║ą░ ą┤ą╗čÅ čāą║ą░ąĘą░č鹥ą╗čÅ čüč鹥ą║ą░ ą┤ą╗čÅ ą╗ąŠą║ą░ą╗čīąĮčŗčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ (PSP)?
microsin: PSP ą▓čĆąŠą┤ąĄ ąĮąĖ čĆą░ąĘčā ąĮąĄ čüč鹥ą║ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ. ąŁč鹊 čüč鹥ą║ ą┐čĆąŠąŠčåąĄčüčüą░, čé. ąĄ. ąĘą░ą┤ą░čćąĖ.
microsin: čéčāčé ą╝ąŠą│čāčé ą▒čŗčéčī 2 ą▓ą░čĆąĖą░ąĮčéą░. ąĢčüą╗ąĖ čŹč鹊 ąŠą▒čŗčćąĮąŠąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ (ąĮąĄ RTOS), č鹊 čüč鹥ą║ ąŠą▒čēąĖą╣ ą║ą░ą║ ą┤ą╗čÅ ąŠčüąĮąŠą▓ąĮąŠą│ąŠ ą║ąŠą┤ą░, čéą░ą║ ąĖ ą┤ą╗čÅ ą╗čÄą▒ąŠą│ąŠ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ (ISR). ąĢčüą╗ąĖ ąČąĄ čŹč鹊 ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮą░čÅ čüąĖčüč鹥ą╝ą░, č鹊 ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ RTOS ąĮąĄ čāą┐čĆą░ą▓ą╗čÅąĄčé ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖąĄą╝ ą║ąŠąĮč鹥ą║čüčéą░ ą┤ą╗čÅ ISR. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄčé ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ąĘą░ą┤ą░čćąĖ (ą┐ąŠč鹊ą║ą░) ąŠą▒ąĄčüą┐ąĄčćąĖą▓ą░ąĄčéčüčÅ ąĖąĮą┤ąĖą▓ąĖą┤čāą░ą╗čīąĮčŗą╣ čüč鹥ą║, ą░ čā ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ą░ ąĖ ą▓čüąĄčģ ISR čüą▓ąŠą╣ čüč鹥ą║. ą¤ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ RTOS ą┐ąŠ čüčāčéąĖ čŹč鹊 č鹊ąČąĄ ISR, ąŠą▒čŗčćąĮąŠ čéą░ą╣ą╝ąĄčĆą░.
RSS ą╗ąĄąĮčéą░ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖąĄą▓ čŹč鹊ą╣ ąĘą░ą┐ąĖčüąĖ