ąĪą║ąŠčĆąĄąĄ ą▓čüąĄą│ąŠ, ą║ą░ąČą┤čŗą╣ ą▓čüčéčĆąĄčćą░ą╗čüčÅ čü čüąĖčéčāą░čåąĖąĄą╣, ą║ąŠą│ą┤ą░ ąĮčāąČąĮąŠ ąŠčéą║ą╗čÄčćąĖčéčī ąĖ čüąĮąŠą▓ą░ ą┐ąŠą┤ą║ą╗čÄčćąĖčéčī 菹╗ąĄą║čéčĆąŠąĮąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ, čćč鹊ą▒čŗ ąŠąĮąŠ čüąĮąŠą▓ą░ ąĘą░čĆą░ą▒ąŠčéą░ą╗ąŠ! ą¤ąŠą┤ąŠą▒ąĮčŗąĄ ąĘą░ą▓ąĖčüą░ąĮąĖčÅ čüąĖčüč鹥ą╝čŗ ąĮąĄ č鹊ą╗čīą║ąŠ čĆą░čüčüčéčĆą░ąĖą▓ą░čÄčé ą║ąŠąĮąĄčćąĮąŠą│ąŠ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ, ąĮąŠ ąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą┤ąŠą▓ąŠą╗čīąĮąŠ čüą╗ąŠąČąĮčŗą╝ąĖ ą┤ą╗čÅ ąŠčéą╗ą░ą┤ą║ąĖ ąĖ ąĖčüą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ.
ąöą╗čÅ ąĮąĄą║ąŠč鹊čĆčŗčģ ą║ą╗ą░čüčüąŠą▓ čāčüčéčĆąŠą╣čüčéą▓, čéą░ą║ąĖčģ ą║ą░ą║ čüą┐čāčéąĮąĖą║ ąĮą░ ąŠčĆą▒ąĖč鹥, ą║ąŠą│ą┤ą░ čüą▒čĆąŠčü ą▓čĆčāčćąĮčāčÄ ą┐čĆąĖąĮčåąĖą┐ąĖą░ą╗čīąĮąŠ ąĮąĄą┤ąŠčüčéčāą┐ąĄąĮ, ąĘą░ą▓ąĖčüą░ąĮąĖąĄ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą┐ąŠą╗čāč湥ąĮąĖčÄ ą▓ą╝ąĄčüč鹊 čāčüčéčĆąŠą╣čüčéą▓ą░ "ą║ąĖčĆą┐ąĖčćą░" čåąĄąĮąŠą╣ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą╝ąĖą╗ą╗ąĖąŠąĮąŠą▓ ą┤ąŠą╗ą╗ą░čĆąŠą▓. ąÜą░ą║ čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ąĖ firmware, ą╝čŗ ą┤ąŠą╗ąČąĮčŗ čāą┤ąĄą╗ąĖčéčī ąŠčüąŠą▒ąŠąĄ ą▓ąĮąĖą╝ą░ąĮąĖąĄ ą▓ ąĮą░čłąĄą╣ čüąĖčüč鹥ą╝ąĄ č鹊ą╝čā, čćč鹊ą▒čŗ ąĘą░ą▓ąĖčüčłą░čÅ ąĘą░ą┤ą░čćą░ (ąĖą╗ąĖ ą┐čĆąĖą▒ąŠčĆ čåąĄą╗ąĖą║ąŠą╝) ą▓čüąĄą│ą┤ą░ ą╝ąŠą│ą╗ąĖ ą▓čŗą╣čéąĖ ąĖąĘ ąĮąĄčĆą░ą▒ąŠč湥ą│ąŠ čüąŠčüč鹊čÅąĮąĖčÅ. ąŁč鹊 ą╗čāčćčłąĄ ą▓čüąĄą│ąŠ čĆąĄčłą░ąĄčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ čüč鹊čĆąŠąČąĄą▓ąŠą│ąŠ čéą░ą╣ą╝ąĄčĆą░ (watchdog).
ąÆ čŹč鹊ą╣ čüčéą░čéčīąĄ (ą┐ąĄčĆąĄą▓ąŠą┤ [1]) ą╝čŗ ąŠą▒čüčāą┤ąĖą╝ ą┐ąŠčüą╗ąĄą┤ąĮčÄčÄ ą╗ąĖąĮąĖčÄ ąŠą▒ąŠčĆąŠąĮčŗ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ čüąĖčüč鹥ą╝ - čüč鹊čĆąŠąČąĄą▓čŗąĄ čéą░ą╣ą╝ąĄčĆčŗ, watchdog . ą£čŗ čéą░ą║ąČąĄ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ą┐ąŠčłą░ą│ąŠą▓čŗąĄ ą┐čĆąĖą╝ąĄčĆčŗ, ą║ą░ą║ čĆąĄą░ą╗ąĖąĘčāąĄčéčüčÅ ą┐ąŠą┤čüąĖčüč鹥ą╝ą░ watchdog, ą▓ą║ą╗čÄčćą░čÅ ą║ą░ą║ "ą░ą┐ą┐ą░čĆą░čéąĮčŗą╣", čéą░ą║ ąĖ "ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗą╣" watchdog, ąĖ ąĖąĘčāčćąĖą╝ čŹčäč乥ą║čéąĖą▓ąĮčŗąĄ čüčéčĆą░č鹥ą│ąĖąĖ ąŠą▒ąĮą░čĆčāąČąĄąĮąĖčÅ ą┐čĆąĖčćąĖąĮ ą▓ąŠąĘąĮąĖą║ąĮąŠą▓ąĄąĮąĖčÅ ąŠčüąĮąŠą▓ąĮčŗčģ ą┐čĆąŠą▒ą╗ąĄą╝, ą┐čĆąĖą▓ąŠą┤čÅčēąĖčģ ą║ ąĘą░ą▓ąĖčüą░ąĮąĖčÅą╝.
[ąÉą┐ą┐ą░čĆą░čéąĮčŗą╣ Watchdog ]
ąæąŠą╗čīčłąĖąĮčüčéą▓ąŠ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗ąĄą╣ čćąĖą┐ąŠą▓ MCU ą▓ą║ą╗čÄčćą░čÄčé ą▓ čüąŠčüčéą░ą▓ ąĄą│ąŠ ą║čĆąĖčüčéą░ą╗ą╗ą░ ąĖąĘąŠą╗ąĖčĆąŠą▓ą░ąĮąĮčŗą╣ RTL-ą▒ą╗ąŠą║, čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝čŗą╣ "Watchdog Timer". ąŁč鹊 ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ MCU čüąŠčüč鹊ąĖčé ąĖąĘ čüč湥čéčćąĖą║ą░, ą║ąŠč鹊čĆčŗą╣ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą░ą┐ą┐ą░čĆą░čéąĮąŠ ą┤ąĄą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄčéčüčÅ čü ą║ą░ąČą┤čŗą╝ čéą░ą║č鹊ą▓čŗą╝ čåąĖą║ą╗ąŠą╝. ąÜąŠą│ą┤ą░ čüč湥čéčćąĖą║ ą┤ąŠčüčéąĖą│ ąĮčāą╗čÅ, ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ą░ą┐ą┐ą░čĆą░čéąĮčŗą╣ čüą▒čĆąŠčü čāčüčéčĆąŠą╣čüčéą▓ą░.
ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ čŹčéą░ čäčāąĮą║čåąĖčÅ ąŠą▒čŗčćąĮąŠ ąĘą░ą┐čĆąĄčēąĄąĮą░, ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčé ąŠčéą▓ąĄčćą░ąĄčé ąĘą░ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖ čĆą░ąĘčĆąĄčłąĄąĮąĖąĄ ąĄčæ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ. ąÜą░ą║ č鹊ą╗čīą║ąŠ čäčāąĮą║čåąĖčÅ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ čéą░ą╣ą╝ąĄčĆą░ watchdog čĆą░ąĘčĆąĄčłąĄąĮą░, ąĘą░ą┐čĆąĄčéąĖčéčī ąĄčæ čāąČąĄ ąĮąĄą╗čīąĘčÅ, ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ čü ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╝ąĖ ą┐ąĄčĆąĖąŠą┤ą░ą╝ąĖ čüą▒čĆą░čüčŗą▓ą░čéčī čüč鹊čĆąŠąČąĄą▓ąŠą╣ čéą░ą╣ą╝ąĄčĆ, čćč鹊ą▒čŗ ą┐čĆąĄą┤ąŠčéą▓čĆą░čéąĖčéčī ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║čā čüąĖčüč鹥ą╝čŗ. ąĪą╝čŗčüą╗ čŹč鹊ą╣ čüąĖčüč鹥ą╝čŗ ą▓ č鹊ą╝, čćč鹊 ąĄčüą╗ąĖ ą¤ą× ąĮąĄ čüą╝ąŠą│ą╗ąŠ ą▓ąŠą▓čĆąĄą╝čÅ čüą▒čĆąŠčüąĖčéčī čüč湥čéčćąĖą║ čéą░ą╣ą╝ąĄčĆą░ watchdog ą▓ ąĖčüčģąŠą┤ąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ, č鹊 ąĘąĮą░čćąĖčé ą┐čĆąŠą│čĆą░ą╝ą╝ą░ čĆą░ą▒ąŠčéą░ąĄčé ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠ (ąĘą░ą▓ąĖčüą╗ą░?), čüąĖčüč鹥ą╝ą░ ąĮąĄ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ą┤ąŠą╗ąČąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝ čüą▓ąŠąĖ čäčāąĮą║čåąĖąĖ, ąĖ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ą▓ąĄčĆąĮčāčéčī ąĄčæ ąŠą▒čĆą░čéąĮąŠ ą▓ ą▒ąĄąĘąŠą┐ą░čüąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: čüą╗ąĄą┤čāąĄčé ąĘą░ą╝ąĄčéąĖčéčī, čćč鹊 ą▓ čüąĖčüč鹥ą╝ą░čģ, ą│ą┤ąĄ ą║ąŠč鹊čĆčŗčģ ą║ąŠąĮčéčĆąŠą╗čī ąĘą░ą▓ąĖčüą░ąĮąĖčÅ ąŠčüąŠą▒ąĄąĮąĮąŠ ą▓ą░ąČąĄąĮ, ą┐čĆąĖą╝ąĄąĮčÅčÄčé čüą┐ąĄčåąĖą░ą╗čīąĮčŗąĄ ą╝ąĖą║čĆąŠčüčģąĄą╝čŗ čüč鹊čĆąŠąČąĄą▓ąŠą│ąŠ čéą░ą╣ą╝ąĄčĆą░ [2]. ąöą╗čÅ čŹčéąĖčģ ą╝ąĖą║čĆąŠčüčģąĄą╝ čüą▒čĆąŠčü watchdog ąŠą▒čŗčćąĮąŠ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┐čāč鹥ą╝ ą┤ąĄčĆą│ą░ąĮąĖčÅ ąĮąŠąČą║ąŠą╣ GPIO MCU.
ą¤ąŠč湥ą╝čā čüą╗ąĄą┤čāąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī Watchdog? ąÆčüčéčĆą░ąĖą▓ą░ąĄą╝ąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ąĮą░ MCU ą╝ąŠąČąĄčé ąĘą░ą▓ąĖčüąĮčāčéčī ą┐ąŠ ą╝ąĮąŠą│ąĖą╝ ą┐čĆąĖčćąĖąĮą░ą╝. ąÆąŠčé ąĮąĄą║ąŠč鹊čĆčŗąĄ ąĖąĘ čüą░ą╝čŗčģ čĆą░čüą┐čĆąŠčüčéčĆą░ąĮąĄąĮąĮčŗčģ čüą╗čāčćą░ąĄą▓:
ŌĆó ą¤ąŠą▓čĆąĄą┤ąĖą╗ąŠčüčī čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą┐ą░ą╝čÅčéąĖ, ąĖ ą║ąŠą┤ ąĘą░ą▓ąĖčü ą▓ ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠą╝ čåąĖą║ą╗ąĄ.
ąØąĄąĘą░ą▓ąĖčüąĖą╝ąŠ ąŠčé č鹊ą│ąŠ, ąĮą░čģąŠą┤ąĖčéčüčÅ ą╗ąĖ ą┐čĆąŠąĄą║čé ąĮą░ čüčéą░ą┤ąĖąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ, ąĖą╗ąĖ čāąČąĄ ą┐čĆąŠąĄą║čé ą▓čŗčłąĄą╗ ąĮą░ čĆčŗąĮąŠą║ ą▓ čüą▓ąŠą▒ąŠą┤ąĮąŠąĄ ą┐ą╗ą░ą▓ą░ąĮąĖąĄ ąĖ ą┐čĆąŠą┤ą░ąĄčéčüčÅ čéčŗčüčÅčćą░ą╝ąĖ čłčéčāą║, ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝ą░čÅ čüąĖčüč鹥ą╝ą░ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī čüąĮą░ą▒ąČąĄąĮą░ ą┐ąŠą┤čüąĖčüč鹥ą╝ąŠą╣ čüą░ą╝ąŠą║ąŠąĮčéčĆąŠą╗čÅ čéąĖą┐ą░ watchdog. ąŁč鹊 čüą░ą╝čŗą╣ ą╗čāčćčłąĖą╣ čüą┐ąŠčüąŠą▒ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆąŠą▓ą░čéčī ąĘą░ą▓ąĖčüą░ąĮąĖčÅ čüąĖčüč鹥ą╝čŗ ąĖ čüąŠą▒čĆą░čéčī ą┤ąŠčüčéą░č鹊čćąĮąŠ ąĖąĮč乊čĆą╝ą░čåąĖąĖ, čćč鹊ą▒čŗ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆąŠą▓ą░čéčī ąŠčüąĮąŠą▓ąĮčāčÄ ą┐čĆąŠą▒ą╗ąĄą╝čā ąĖ čāčüčéčĆą░ąĮąĖčéčī ąĄčæ.
ąÜąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ Watchdog . ąÜąŠą│ą┤ą░ ą░ą┐ą┐ą░čĆą░čéąĮčŗą╣ čüč鹊čĆąŠąČąĄą▓ąŠą╣ čéą░ą╣ą╝ąĄčĆ ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāčÄčéčüčÅ ą▓ ą┐ąĄčĆą▓čŗą╣ čĆą░ąĘ, ą▓ą░ąČąĮąŠ ą▓ąĮąĖą╝ą░č鹥ą╗čīąĮąŠ ąĖąĘčāčćąĖčéčī ą┤ą░čéą░čłąĖčé, čćč鹊ą▒čŗ ą┐ąŠąĮčÅčéčī, ą║ą░ą║ čŹč鹊 ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ čĆą░ą▒ąŠčéą░ąĄčé. ąĀą░ą▒ąŠčéą░ čüč鹊čĆąŠąČąĄą▓ąŠą│ąŠ čéą░ą╣ą╝ąĄčĆą░ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗ąĄą╝ ąĖ ą╝ąŠąČąĄčé ą╝ąĄąĮčÅčéčīčüčÅ, čéą░ą║ čćč鹊 ą┤ą░ąČąĄ ąĄčüą╗ąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄč鹥 čćąĖą┐ ąĖąĘ č鹊ą│ąŠ ąČąĄ čüąĄą╝ąĄą╣čüčéą▓ą░ MCU (ąĮą░ą┐čĆąĖą╝ąĄčĆ ARM Cortex-M MCU) ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą┐ąĄčĆąĖč乥čĆąĖąĖ watchdog ą╝ąŠąČąĄčé ąŠčéą╗ąĖčćą░čéčīčüčÅ ąŠčé č鹊ą│ąŠ, čü č湥ą╝ ąÆą░ą╝ čāąČąĄ ą┐čĆąĖčģąŠą┤ąĖą╗ąŠčüčī čüčéą░ą╗ą║ąĖą▓ą░čéčīčüčÅ. ąØąĄą▓ąĮąĖą╝ą░č鹥ą╗čīąĮąŠčüčéčī ą║ ąĮčÄą░ąĮčüą░ą╝ ą╝ąŠąČąĄčé ą┐ąŠąĘąČąĄ ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ąĮąĄąŠąČąĖą┤ą░ąĮąĮčŗą╝ ą┐čĆąŠą▒ą╗ąĄą╝ą░ą╝. ąöą░ą▓ą░ą╣č鹥 ą▒čŗčüčéčĆąŠ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ąŠčüąĮąŠą▓ąĮčŗąĄ ą╝ąŠą╝ąĄąĮčéčŗ, ą║ąŠč鹊čĆčŗąĄ čüč鹊ąĖčé ą┐čĆąŠą▓ąĄčĆąĖčéčī.
1 . ąÜąŠą│ą┤ą░ čüą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÅ watchdog?
ąÜą░ą║ ą┐čĆą░ą▓ąĖą╗ąŠ, ą╝čŗ čüčéą░ą╗ą║ąĖą▓ą░ąĄą╝čüčÅ čüąŠ čüą╗ąĄą┤čāčÄčēąĖą╝ąĖ ą▓ą░čĆąĖą░ąĮčéą░ą╝ąĖ:
ŌĆó Watchdog ą╝ąŠąČąĄčé ą▒čŗčéčī čĆą░ąĘčĆąĄčłąĄąĮ ąĖ ąĘą░ą┐čĆąĄčēąĄąĮ ąĮąĄčüą║ąŠą╗čīą║ąŠ čĆą░ąĘ, ąĖ ą┤ąŠą╗ąČąĄąĮ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░čéčīčüčÅ ą┐čĆąĖ ą║ą░ąČą┤ąŠą╣ ąĘą░ą│čĆčāąĘą║ąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ firmware.
2 . ąÜą░ą║ ą▓ąĄą┤ąĄčé čüąĄą▒čÅ watchdog ą┐čĆąĖ čĆą░ą▒ąŠč鹥 ą┐ąŠą┤ ąŠčéą╗ą░ą┤čćąĖą║ąŠą╝?
ąĀą░ąĘčĆą░ą▒ąŠčéčćąĖą║ąĖ čćą░čüč鹊 ąĘą░ą┐čĆąĄčēą░čÄčé watchdog ą▓ąŠ ą▓čĆąĄą╝čÅ ąŠčéą╗ą░ą┤ą║ąĖ, čćč鹊ą▒čŗ čüą▒ąŠčĆą║ąĖ debug ąĮąĄ ą┐čĆąĖą▓ąŠą┤ąĖą╗ąĖ ą║ čüą▒čĆąŠčüą░ą╝ ąĮą░ ą┐ą╗ą░čéą░čģ, ą│ą┤ąĄ ą░ą║čéąĖą▓ąĮąŠ ąŠčéą╗ą░ąČąĖą▓ą░ąĄčéčüčÅ ą║ąŠą┤. ą×ą┤ąĮą░ą║ąŠ čŹč鹊 ą▒ąŠą╗čīčłą░čÅ ąŠčłąĖą▒ą║ą░, čćč鹊 ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ č鹊ą╝čā, čćč鹊 ą┐čĆąŠą▒ą╗ąĄą╝čŗ ąŠčüčéą░čÄčéčüčÅ ąĮąĄąĘą░ą╝ąĄč湥ąĮąĮčŗą╝ąĖ ą┤ąŠ č鹥čģ ą┐ąŠčĆ, ą┐ąŠą║ą░ čüą▒ąŠčĆą║ą░ ąĮąĄ ąŠčéą┐čĆą░ą▓ąĖčéčüčÅ ą▓ čĆąĄą╗ąĖąĘ. ąĢčüą╗ąĖ ą▒čŗ čüč鹊čĆąŠąČąĄą▓ąŠą╣ čéą░ą╣ą╝ąĄčĆ ą▒čŗą╗ čĆą░ąĘčĆąĄčłąĄąĮ ą▓ ą┐čĆąŠčåąĄčüčüąĄ ąŠčéą╗ą░ą┤ą║ąĖ, čŹč鹊 ą╝ąŠą│ą╗ąŠ ą▒čŗ ą┐ąŠą╝ąŠčćčī ąĖčüą┐čĆą░ą▓ąĖčéčī ą╝ąĮąŠąČąĄčüčéą▓ąŠ ą┐čĆąŠą▒ą╗ąĄą╝ čāąČąĄ ąĮą░ čŹčéą░ą┐ąĄ ąĮą░ą┐ąĖčüą░ąĮąĖčÅ ąĖ ąŠčéą╗ą░ą┤ą║ąĖ ą║ąŠą┤ą░.
ąØąĄ ą▓čüąĄą╝ ąĖąĘą▓ąĄčüč鹥ąĮ čäą░ą║čé, čćč鹊 ą┐ąŠčćčéąĖ ą▓čüąĄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗ąĖ MCU ą┤ąŠą▒ą░ą▓ą╗čÅčÄčé ą▓ ą┐čĆąŠčåąĄčüčüąŠčĆ čüą┐ąĄčåąĖą░ą╗čīąĮčāčÄ čäčāąĮą║čåąĖčÄ, ą║ąŠč鹊čĆą░čÅ ąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé čüč鹊čĆąŠąČąĄą▓ąŠą╣ čéą░ą╣ą╝ąĄčĆ, ą║ąŠą│ą┤ą░ JTAG/SWD ąŠčéą╗ą░ą┤čćąĖą║ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ąĖą╗ čĆą░ą▒ąŠčéčā ą║ąŠą┤ą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ąŠčüčéą░ąĮąŠą▓ą║ą░ ąĮą░ breakpoint). ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąĄčüą╗ąĖ ąÆčŗ ą┤ąŠą▒ą░ą▓ąĖą╗ąĖ č鹊čćą║čā ąŠčüčéą░ąĮąŠą▓ą░ ą▓ ą┐čĆąŠą▓ąĄčĆčÅąĄą╝čŗą╣ ą║ąŠą┤, ąĖą╗ąĖ ą▓čŗą┐ąŠą╗ąĮčÅąĄč鹥 ąŠą┐ąĄčĆą░č鹊čĆčŗ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą┐ąŠ čłą░ą│ą░ą╝, ą╝ąŠąČąĮąŠ ąĮąĄ ą▒ąĄčüą┐ąŠą║ąŠąĖčéčīčüčÅ ąŠ č鹊ą╝, čćč鹊 čüč鹊čĆąŠąČąĄą▓ąŠą╣ čéą░ą╣ą╝ąĄčĆ čüčĆą░ą▒ąŠčéą░ąĄčé ąĖ čüą▒čĆąŠčüąĖčé ą┐čĆąŠčåąĄčüčüąŠčĆ. ą¤čĆąĖ ąĘą░ą┐čāčüą║ąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĮą░ ą┐ąŠčüč鹊čÅąĮąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐ąŠą┤ ąŠčéą╗ą░ą┤čćąĖą║ąŠą╝ watchdog ą┐čĆąŠą┤ąŠą╗ąČąĖčé ąĮąŠčĆą╝ą░ą╗čīąĮąŠąĄ čäčāąĮą║čåąĖąŠąĮąĖčĆąŠą▓ą░ąĮąĖąĄ.
ą×ą┤ąĮą░ą║ąŠ ąĮąĄ ą▓čüčÅą║ą░čÅ ą░ą┐ą┐ą░čĆą░čéčāčĆą░ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé čéą░ą║čāčÄ čäčāąĮą║čåąĖčÄ - ąĮą░ą┐čĆąĖą╝ąĄčĆ, čāčüčéą░ąĮąŠą▓ą╗ąĄąĮą░ ąŠčéą┤ąĄą╗čīąĮą░čÅ ą╝ąĖą║čĆąŠčüčģąĄą╝ą░ čüč鹊čĆąŠąČąĄą▓ąŠą│ąŠ čéą░ą╣ą╝ąĄčĆą░, ą║ąŠč鹊čĆčāčÄ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ čüą▒čĆą░čüčŗą▓ą░čéčī ą▓čŗą┤ą░č湥ą╣ ąĖą╝ą┐čāą╗čīčüą░ ą╗ąŠą│ąĖč湥čüą║ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ. ąÆ čéą░ą║ąĖčģ ąŠčüąŠą▒čŗčģ čüčåąĄąĮą░čĆąĖčÅčģ ąŠčéą╗ą░ą┤čćąĖą║ ą╝ąŠąČąĄčé ą▒čŗčéčī čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ ą▓ čĆąĄą│ąĖčüčéčĆ, čćč鹊 ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ąĖčé ą┤ąĄą╣čüčéą▓ąĖąĄ čüč鹊čĆąŠąČąĄą▓ąŠą│ąŠ čéą░ą╣ą╝ąĄčĆą░ ąĖą╗ąĖ ą▒čāą┤ąĄčé ąĄą│ąŠ čüą▒čĆą░čüčŗą▓ą░čéčī ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ čü ąĮčāąČąĮčŗą╝ąĖ ąĖąĮč鹥čĆą▓ą░ą╗ą░ą╝ąĖ. ąÜą░ą║ čŹč鹊 ą┤ąĄą╗ą░ąĄčéčüčÅ, ą╝čŗ čĆą░čüčüą╝ąŠčéčĆąĖą╝ ą┐ąŠąĘąČąĄ ąĮą░ ą┐čĆąĖą╝ąĄčĆąĄ ąĮą░čüčéčĆąŠą╣ą║ąĖ ąŠčéą╗ą░ą┤čćąĖą║ą░ GDB.
ąöą╗čÅ Cortex-M ą┤ąŠčüčéčāą┐ąĮčŗ ąŠą┐čåąĖąĖ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ STMicroelectronics ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┤ą╗čÅ STM32 č湥čĆąĄąĘ ą║ąŠą╝ą┐ąŠąĮąĄąĮčé DBGMCU. ą×čéčéčāą┤ą░ ą╝ąŠąČąĮąŠ ą▓čŗą▒čĆą░čéčī "ąĘą░ą╝ąŠčĆąŠąĘą║čā" čéą░ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ ą╗čÄą▒ąŠą│ąŠ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░, ą║ąŠą│ą┤ą░ čĆą░ą▒ąŠčéą░ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮą░ ąŠčéą╗ą░ą┤čćąĖą║ąŠą╝.
3 . ą¦č鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé, ą║ąŠą│ą┤ą░ ąĖčüč鹥ą║ą╗ąŠ ą▓čĆąĄą╝čÅ čéą░ą╣ą╝ąĄčĆą░ watchdog?
ąÆąŠčé čéąĖą┐ąŠą▓čŗąĄ ą▓ą░čĆąĖą░ąĮčéčŗ ą┤ą╗čÅ MCU:
ŌĆó ą¤čĆąĖ ąĖčüč鹥č湥ąĮąĖąĖ ąĘą░ą┤ąĄčƹȹ║ąĖ watchdog ąĄą│ąŠ ą░ą┐ą┐ą░čĆą░čéčāčĆą░ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ čüą▒čĆąŠčüąĖčé MCU čüąĖčüč鹥ą╝čŗ.
4 . ąÜą░ą║ čāąĘąĮą░čéčī, ą▒čŗą╗ ą╗ąĖ čüą▒čĆąŠčü ą▓čŗąĘą▓ą░ąĮ čéą░ą╣ą╝ą░čāč鹊ą╝ watchdog?
ą¤ąŠčćčéąĖ ą▓čüąĄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗ąĖ/ą▓ąĄąĮą┤ąŠčĆčŗ MCU ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠ čéąĖą┐ąĄ ą┐čĆąŠąĖąĘąŠčłąĄą┤čłąĄą│ąŠ čüą▒čĆąŠčüą░, ą║ąŠč鹊čĆą░čÅ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą▓ čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╣ čĆąĄą│ąĖčüčéčĆ. ąĢčüą╗ąĖ ą▓ MCU čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮąŠ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ watchdog, č鹊 ąŠą┤ąĖąĮ ąĖąĘ ą▒ąĖčé ą▓ čŹč鹊ą╝ čĆąĄą│ąĖčüčéčĆąĄ ą┐ąŠą║ą░ąČąĄčé, čćč鹊 čüą▒čĆąŠčü ą▒čŗą╗ ą▓čŗąĘą▓ą░ąĮ čüčĆą░ą▒ą░čéčŗą▓ą░ąĮąĖąĄą╝ watchdog.
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: čćą░čüč鹊 čŹčéąĖ čĆąĄą│ąĖčüčéčĆčŗ čüąĮą░ą▒ąČąĄąĮčŗ čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝čŗą╝ąĖ "ą╗ąĖą┐ą║ąĖą╝ąĖ" (sticky) ą▒ąĖčéą░ą╝ąĖ. ąó. ąĄ. ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ ą║ą░ą║ ąÆčŗ ą┐čĆąŠčćąĖčéą░ąĄč鹥 čŹčéąĖ ą▒ąĖčéčŗ ą▓ ą╝ąŠą╝ąĄąĮčé ąĘą░ą│čĆčāąĘą║ąĖ, ąĖčģ ąĮčāąČąĮąŠ ąŠčćąĖčüčéąĖčéčī. ąśąĮą░č湥 ą▒ąĖčéčŗ čüąŠčģčĆą░ąĮčÅčé čüą▓ąŠąĄ čüčéą░čĆąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┐čĆąĖ čüą╗ąĄą┤čāčÄčēąĄą╣ ąĘą░ą│čĆčāąĘą║ąĄ, ą┐ąŠą║ą░ ąĮąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą┐ąŠą╗ąĮčŗą╣ čüą▒čĆąŠčü ąŠčé ą▓ą║ą╗čÄč湥ąĮąĖčÅ ą┐ąĖčéą░ąĮąĖčÅ (Power-On-Reset, POR).
ąóą░ą▒ą╗ąĖčåąĄ ąĮąĖąČąĄ ą┐ąŠ čüąĄą╝ąĄą╣čüčéą▓ą░ą╝ MCU ą┐ąĄčĆąĄčćąĖčüą╗ąĄąĮčŗ ą╝ąĮąĄą╝ąŠąĮąĖą║ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ ąĮąĄą║ąŠč鹊čĆčŗčģ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗ąĄą╣ ą╝ąĖą║čĆąŠą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą▓, ą│ą┤ąĄ čģčĆą░ąĮąĖčéčüčÅ ąĖąĮč乊čĆą╝ą░čåąĖčÅ ąŠ čüą▒čĆąŠčüąĄ.
ą¤čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čī ąĪąĄą╝ąĄą╣čüčéą▓ąŠ MCU ąśą╝čÅ čĆąĄą│ąĖčüčéčĆą░
Espressif Systems
ESP32
RTC_CNTL_RESET_CAUSE[PROCPU/APPCPU]
Maxim Integrated
MAX32
PWRSEQ_FLAGS
NXP
LPC
AOREG1
Nordic Semiconductor
NRF52
RESETREAS
STMicroelectronics
STM32F
RCC_CSR
STM32H
RCC_RSR
[ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ Hardware Watchdog ą▓ čüąĖčüč鹥ą╝ąĄ ]
ą¤ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ą╝čŗ ą┐ąŠą╗čāčćąĖą╗ąĖ ą▒ą░ąĘąŠą▓čāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ą┐ąŠ čüč鹊čĆąŠąČąĄą▓ąŠą╝čā čéą░ą╣ą╝ąĄčĆčā, ą║ą░ą║ ąŠąĮ čĆą░ą▒ąŠčéą░ąĄčé, čĆą░čüčüą╝ąŠčéčĆąĖą╝ ąĮą░ ą┐čĆąĖą╝ąĄčĆąĄ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ watchdog ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąĄą│ąŠ ą┤ą╗čÅ ąŠčéčüą╗ąĄąČąĖą▓ą░ąĮąĖčÅ ąĘą░ą▓ąĖčüą░ąĮąĖą╣ ą▓ čĆąĄą░ą╗čīąĮąŠą╣ čüąĖčüč鹥ą╝ąĄ. ąĀą░čüčüą╝ą░čéčĆąĖą▓ą░ąĄą╝čŗą╣ ą┐čĆąĖą╝ąĄčĆ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ čĆą░ą▒ąŠčéą░ąĄčé ą┐ąŠą┤ FreeRTOS, ą▓ ąĮąĄą╝ ą┐ąĄčĆąĄą┤ą░ąĄčéčüčÅ čüąŠąŠą▒čēąĄąĮąĖąĄ ą╝ąĄąČą┤čā ą┤ą▓čāą╝čÅ ąĘą░ą┤ą░čćą░ą╝ąĖ. ąÆ ą┐čĆąĖą╝ąĄčĆąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą┐čĆąĄą┤čāčüą╝ąŠčéčĆąĄąĮąŠ ąĮąĄčüą║ąŠą╗čīą║ąŠ čĆą░ąĘą╗ąĖčćąĮčŗčģ čüą┐ąŠčüąŠą▒ąŠą▓ ą▓ą▓ąŠą┤ą░ čüąĖčüč鹥ą╝čŗ ą▓ ąĘą░ą▓ąĖčüą░ąĮąĖąĄ.
ą¤čĆąĖą╝ąĄčĆ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą╝ąŠąČąĮąŠ čüą║ą░čćą░čéčī ąĮą░ čüčéčĆą░ąĮąĖčćą║ąĄ [3]. ąÆčŗą┐ąŠą╗ąĮąĖč鹥 ą▓ ą║ąŠąĮčüąŠą╗ąĖ čüą╗ąĄą┤čāčÄčēąĖąĄ ą║ąŠą╝ą░ąĮą┤čŗ:
$ git clone git@github.com:memfault/interrupt.git
$ cd interrupt/example/watchdog-example/
ąöą╗čÅ č鹥čüčéąĖčĆąŠą▓ą░ąĮąĖčÅ ą║ąŠą┤ą░ ą┐čĆąĖą╝ąĄčĆą░ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĖąĄ ąĖąĮčüčéčĆčāą╝ąĄąĮčéčŗ ąĖ čāčéąĖą╗ąĖčéčŗ:
ŌĆó GNU Arm Embedded Toolchain 9-2019-q4-update [4].
ąöą░ą▓ą░ą╣č鹥 ąŠčéą║čĆąŠąĄą╝ ą┤ą░čéą░čłąĖčé NRF52840 [6], ąĖ ą▓ąĘą│ą╗čÅąĮąĄą╝ ąĮą░ ą│ą╗ą░ą▓čā "6.36 WDT ŌĆö Watchdog timer".
1 . ąÜąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÅ čüą▒čĆąŠčüą░
ą”ąĖčéą░čéą░ ąĖąĘ čüąĄą║čåąĖąĖ "6.36.3 Watchdog reset":
"ą¤ąĄčĆąĄą┤ ąĘą░ą┐čāčüą║ąŠą╝ watchdog ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮ. ą¤ąŠčüą╗ąĄ ąĘą░ą┐čāčüą║ą░ ąĄą│ąŠ čĆąĄą│ąĖčüčéčĆčŗ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ CRV, RREN ąĖ CONFIG ą▒čāą┤čāčé ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮčŗ, čćč鹊ą▒čŗ ąĮąĄ ą┤ąŠą┐čāčüčéąĖčéčī ąĖąĘą╝ąĄąĮąĄąĮąĖąĄ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ. ... "
ąÆą░ąČąĮąŠ ąŠčéą╝ąĄąĮąĖčéčī, čćč鹊 ąŠą▒čŗčćąĮčŗą╣ čüą▒čĆąŠčü ("Soft reset") ąĮąĄ čüą▒čĆą░čüčŗą▓ą░ąĄčé čüč鹊čĆąŠąČąĄą▓ąŠą╣ čéą░ą╣ą╝ąĄčĆ. ąŁč鹊 ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą┐čĆąŠą▒ą╗ąĄą╝ą░ą╝, ąĮą░ą┐čĆąĖą╝ąĄčĆ ąĄčüą╗ąĖ ą│ą╗ą░ą▓ąĮąŠąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ čĆą░ąĘčĆąĄčłąĖą╗ąŠ watchdog, ąĮąŠ ąĘą░ą│čĆčāąĘčćąĖą║ (bootloader) ąĮąĄ ąĘąĮą░ą╗ ąŠą▒ čŹč鹊ą╝. ąĢčüą╗ąĖ ąĘą░ą│čĆčāąĘčćąĖą║ ą┤ąĄą╗ą░ąĄčé ą║ą░ą║čāčÄ-č鹊 ą┤ąŠą╗ą│čāčÄ ąŠą┐ąĄčĆą░čåąĖčÄ, čéą░ą║čāčÄ ą║ą░ą║ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖąĄ firmware, čéą░ą╣ą╝ąĄčĆ watchdog ą▒čāą┤ąĄčé ą┐čĆąĖ čŹč鹊ą╝ čĆą░ą▒ąŠčéą░čéčī, ąĖ ą╝ąŠąČąĄčé čüą▒čĆąŠčüąĖčéčī čüąĖčüč鹥ą╝čā ą┐ąŠčüąĄčĆąĄą┤ąĖąĮąĄ ą┐čĆąŠčåąĄčüčüą░ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ!
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą▓ čüą╗čāčćą░ąĄ NRF52 ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗą╣ bootloader ą▓ SDK čüą▒čĆą░čüčŗą▓ą░ąĄčé watchdog, ąĄčüą╗ąĖ ąŠąĮ ą▒čŗą╗ čĆą░ąĘčĆąĄčłąĄąĮ ą▓ ąŠčüąĮąŠą▓ąĮąŠą╝ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĖ.
2 . ąÆąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąĖąĄ čü ąŠčéą╗ą░ą┤čćąĖą║ąŠą╝
ąÆ čüąĄą║čåąĖąĖ "6.36.2 Temporarily pausing the watchdog" ąĮą░ą┐ąĖčüą░ąĮąŠ:
"ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ watchdog ą▒čāą┤ąĄčé ą┐čĆąŠą┤ąŠą╗ąČą░čéčī čüč湥čé ą▓ąĮąĖąĘ, ą║ąŠą│ą┤ą░ CPU ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ čĆąĄąČąĖą╝ąĄ čüąĮą░, ąĖ ą║ąŠą│ą┤ą░ ąĄą│ąŠ čĆą░ą▒ąŠčéą░ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮą░ ąŠčéą╗ą░ą┤čćąĖą║ąŠą╝. ą×ą┤ąĮą░ą║ąŠ ąĄčüčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░čéčī watchdog ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ čüčéą░ą▓ąĖčéčī čüč湥čé ąĮą░ ą┐ą░čāąĘčā, ą║ąŠą│ą┤ą░ CPU čüą┐ąĖčé (ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ čĆąĄąČąĖą╝ąĄ ą┐ąŠąĮąĖąČąĄąĮąĮąŠą│ąŠ 菹ĮąĄčĆą│ąŠą┐ąŠčéčĆąĄą▒ą╗ąĄąĮąĖčÅ), ą░ čéą░ą║ąČąĄ ą║ąŠą│ą┤ą░ ąŠąĮ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮ ąŠčéą╗ą░ą┤čćąĖą║ąŠą╝. "
ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą┐čĆąĖ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖąĖ ąŠčéą╗ą░ą┤čćąĖą║ąŠą╝ ą║ ą┐čĆąŠčåąĄčüčüąŠčĆčā ą╝čŗ ą╝ąŠąČąĄą╝ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░čéčī ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ čüč鹊čĆąŠąČąĄą▓ąŠą│ąŠ čéą░ą╣ą╝ąĄčĆą░ čüčéą░ą▓ąĖčéčī ąĮą░ ą┐ą░čāąĘčā ąĄą│ąŠ čüč湥čéčćąĖą║. ąŁč鹊 ą┐ąŠąĘą▓ąŠą╗ąĖčé ąĮąĄ ą▒ąĄčüą┐ąŠą║ąŠąĖčéčīčüčÅ ąŠ č鹊ą╝, čćč鹊 ą▒čāą┤ąĄčé ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčīčüčÅ čüąĖčüč鹥ą╝ąĮčŗą╣ čüą▒čĆąŠčü ą▓ąŠ ą▓čĆąĄą╝čÅ čüčĆą░ą▒ą░čéčŗą▓ą░ąĮąĖčÅ č鹊č湥ą║ ąŠčüčéą░ąĮąŠą▓ą░ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ.
ąĢčüą╗ąĖ čćąĖčéą░čéčī ą┤ą░čéą░čłąĖčé ą┤ą░ą╗čīčłąĄ, čćč鹊 čüąŠąĘą┤ą░čüčéčüčÅ ą▓ą┐ąĄčćą░čéą╗ąĄąĮąĖąĄ, čćč鹊 ąĖąĮč乊čĆą╝ą░čåąĖčÅ ą▓ ąĮąĄą╝ ąĮąĄ čüąŠą▓čüąĄą╝ ą▓ąĄčĆąĮą░. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ watchdog ąĘą░ą┐čĆąĄčēąĄąĮ, ą║ąŠą│ą┤ą░ ąŠčéą╗ą░ą┤čćąĖą║ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ąĖą╗ ą┐čĆąŠą│čĆą░ą╝ą╝čā (ą▒ąĖčé 3 ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą▓ ą╗ąŠą│. 0), čéą░ą║ čćč鹊 ą╝ąŠąČąĮąŠ ą┐čĆąŠčüč鹊 ąŠčüčéą░ą▓ąĖčéčī čŹčéčā ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÄ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ.
3 . ą¦č鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐ąŠ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÄ čüč湥čéą░ (čéą░ą╣ą╝ą░čāčé watchdog)
ąśąĘ čüąĄą║čåąĖąĖ "6.36.3 Watchdog reset":
"ąĢčüą╗ąĖ watchdog čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮ ą┤ą╗čÅ ą│ąĄąĮąĄčĆą░čåąĖąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ą┐čĆąĖ čüąŠą▒čŗčéąĖąĖ TIMEOUT, čüą▒čĆąŠčü ąŠčé watchdog ą▒čāą┤ąĄčé ąŠčéą╗ąŠąČąĄąĮ ą┤ą▓ą░ čéą░ą║čéą░ 32.768 ą║ąōčå ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ą╗ąŠčüčī čüąŠą▒čŗčéąĖąĄ TIMEOUT. ą¤ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ą▓čüąĄą│ą┤ą░ ą▒čāą┤ąĄčé ą░ą║čéąĖą▓ąĖčĆąŠą▓ą░ąĮ watchdog reset. "
ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą┐ąŠčüą╗ąĄ čéą░ą╣ą╝ą░čāčéą░ čüč鹊čĆąŠąČąĄą▓ąŠą│ąŠ čéą░ą╣ą╝ąĄčĆą░ ą╝ąŠąČąĄčé ą▒čŗčéčī čĆą░ąĘčĆąĄčłąĄąĮąŠ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ. ą×čüčéą░ąĄčéčüčÅ ą┐ąŠ ą▓čĆąĄą╝ąĄąĮąĖ č鹊ą╗čīą║ąŠ 2 ą┐ąĄčĆąĖąŠą┤ą░ čćą░čüč鹊čéčŗ 32768 ąōčå ą┤ąŠ ą╝ąŠą╝ąĄąĮčéą░, ą║ą░ą║ ą▒čāą┤ąĄčé čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮ čüą▒čĆąŠčü. ąĢčüą╗ąĖ čÅą┤čĆąŠ CPU NRF52840 čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ čćą░čüč鹊č鹥 64 ą£ąōčå, č鹊 ąĮą░ ą┐čĆą░ą║čéąĖą║ąĄ čā ąĮąĄą│ąŠ ąĄčüčéčī č鹊ą╗čīą║ąŠ (64 ą£ąōčå * 2) / 32768 = 3900 čéą░ą║čéą░, čćč鹊ą▒čŗ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąŠčćąĖčüčéą║čā ą┐ąĄčĆąĄą┤ čüą▒čĆąŠčüąŠą╝.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: čćč鹊ą▒čŗ ąĖąĘą▒ąĄąČą░čéčī čĆąĖčüą║ą░ čüą▒čĆąŠčüą░ ą▓ąŠ ą▓čĆąĄą╝čÅ ąŠčćąĖčüčéą║ąĖ, ąĮąĄ čĆąĄą║ąŠą╝ąĄąĮą┤čāąĄčéčüčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹčéčā čäčāąĮą║čåąĖčÄ. ąöą░ą╗ąĄąĄ ą▓ čüčéą░čéčīąĄ ą▒čāą┤čāčé čĆą░čüčüą╝ąŠčéčĆąĄąĮčŗ ą▓ąŠąĘą╝ąŠąČąĮčŗąĄ ą░ą╗čīč鹥čĆąĮą░čéąĖą▓čŗ.
4 . ąÜą░ą║ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą┐čĆąĖčćąĖąĮčā čüą▒čĆąŠčüą░ (RESETREAS)
ąĪąĄą║čåąĖčÅ "5.3.7.11 RESETREAS" ą┤ą░čéą░čłąĖčéą░ čüąŠą┤ąĄčƹȹĖčé ąŠą▒čēčāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠ ą┐čĆąĖčćąĖąĮą░čģ čüą▒čĆąŠčüą░:
"ąĢčüą╗ąĖ čĆąĄą│ąĖčüčéčĆ RESETREAS ąĮąĄ ąŠčćąĖčēąĄąĮ, ąŠąĮ ą▒čāą┤ąĄčé ą║čāą╝čāą╗čÅčéąĖą▓ąĮąŠ ąĮą░ą║ą░ą┐ą╗ąĖą▓ą░čéčī ąĖąĮč乊čĆą╝ą░čåąĖčÄ. ąöą╗čÅ ąŠčćąĖčüčéą║ąĖ ą▒ąĖčéą░ čĆąĄą│ąĖčüčéčĆą░ ą▓ ąĮąĄą│ąŠ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą╗ąŠą│. 1. ąĢčüą╗ąĖ ąĮąĄ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ąĮąĖ ąŠą┤ąĖąĮ ąĖąĘ ą▒ąĖčé, ąŠą▒ąŠąĘąĮą░čćą░čÄčēąĖčģ ąĖčüč鹊čćąĮąĖą║ čüą▒čĆąŠčüą░, č鹊 čŹč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 čćąĖą┐ ą▒čŗą╗ čüą▒čĆąŠčłąĄąĮ ąŠčé ą▓ąĮčāčéčĆąĄąĮąĮąĄą│ąŠ ą│ąĄąĮąĄčĆą░č鹊čĆą░ čüą▒čĆąŠčüą░, čé. ąĄ. ąŠčé čüą▒čĆąŠčüą░ ą┐ąŠ ą▓ą║ą╗čÄč湥ąĮąĖčÄ ą┐ąĖčéą░ąĮąĖčÅ (power-on-reset, POR) ąĖą╗ąĖ ąŠčé ą┤ąĄč鹥ą║č鹊čĆą░ čüą▒ąŠčÅ ą┐ąĖčéą░ąĮąĖčÅ (brownout reset). "
ąÆą░ąČąĮąŠ ąŠčéą╝ąĄčéąĖčéčī, čćč鹊 čćč鹥ąĮąĖąĄ ą▒ąĖčéą░ 1 ą┐ąŠą║ą░ąČąĄčé, ąĖą╝ąĄą╗ ą╗ąĖ ą╝ąĄčüč鹊 čüą▒čĆąŠčü ąŠčé čüč鹊čĆąŠąČąĄą▓ąŠą│ąŠ čéą░ą╣ą╝ąĄčĆą░ (watchdog reset). ąØą░ą╝ ąĮčāąČąĮąŠ čüą▒čĆąŠčüąĖčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮčŗąĄ ą▒ąĖčéčŗ, čćč鹊ą▒čŗ ąŠąĮąĖ ąĮąĄ čüąŠčģčĆą░ąĮčÅą╗ąĖ čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą╝ąĄąČą┤čā ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ą░ą╝ąĖ čÅą┤čĆą░.
ąÆčŗą▒ąŠčĆ ą▓čĆąĄą╝ąĄąĮąĖ čéą░ą╣ą╝ą░čāčéą░ . ą¤ąŠčüą║ąŠą╗čīą║čā watchdog čŹč鹊 čĆąĄą░ą╗čīąĮąŠ ą┐ąŠčüą╗ąĄą┤ąĮčÅčÅ ą╗ąĖąĮąĖčÅ ąŠą▒ąŠčĆąŠąĮčŗ, čüą╗ąĄą┤čāąĄčé ą▓čŗą▒čĆą░čéčī ąĄą│ąŠ čéą░ą╣ą╝ą░čāčé ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠ ą▒ąŠą╗čīčłąĄ, č湥ą╝ ą▓čĆąĄą╝čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ą░ čüąŠą▒čŗčéąĖą╣, ąŠą▒čüą╗čāąČąĖą▓ą░ąĄą╝čŗčģ ąĘą░ą┤ą░č湥ą╣ RTOS ąĖą╗ąĖ ą│ą╗ą░ą▓ąĮčŗą╝ čåąĖą║ą╗ąŠą╝ main. ąźąŠčĆąŠčłąĄąĄ ąŠą▒čēąĄąĄ ą┐čĆą░ą▓ąĖą╗ąŠ - ą▓čŗą▒ąŠčĆ čéą░ą╣ą╝ą░čāčéą░ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ 5 .. 30 čüąĄą║čāąĮą┤. ąöą╗čÅ ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąŠąĮąĮčŗčģ čåąĄą╗ąĄą╣ ą▓ čŹč鹊ą╣ čüčéą░čéčīąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čéą░ą╣ą╝ą░čāčé 10 čüąĄą║čāąĮą┤.
[ąÜąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ Watchdog NRF52 ]
NRF52840 watchdog ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮ čéčĆąĄą╝čÅ čĆąĄą│ąĖčüčéčĆą░ą╝ąĖ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠąČąĮąŠ čāčüčéą░ąĮąŠą▓ąĖčéčī č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ čĆą░ąĘ: CRV, RREN ąĖ CONFIG. ąÜą░ą║ čāąČąĄ ąŠą▒čüčāąČą┤ą░ą╗ąŠčüčī ą▓čŗčłąĄ, ąĘąĮą░č湥ąĮąĖąĄ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ čĆąĄą│ąĖčüčéčĆą░ CONFIG ą▓ą┐ąŠą╗ąĮąĄ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé č鹊ą╝čā, čćč鹊 ąĮą░ą╝ ąĮčāąČąĮąŠ (watchdog ąĮąĄ čĆą░ą▒ąŠčéą░ąĄčé, ą║ąŠą│ą┤ą░ čüąĖčüč鹥ą╝ą░ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮą░ ąĮą░ breakpoint ąŠčéą╗ą░ą┤čćąĖą║ą░).
ąĀąĄą│ąĖčüčéčĆ RREN ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĮą░ą╝ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░čéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ čĆąĄą│ąĖčüčéčĆąŠą▓ "ąĘą░ą┐čĆąŠčüą░ ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ąĖ" (reload request registers, RRR), ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ čüą┐čĆąŠčüą░ čüč湥čéčćąĖą║čā watchdog ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘąĖčéčī čüą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ. ąĪčāčēąĄčüčéą▓čāąĄčé 8 RRR-čĆąĄą│ąĖčüčéčĆąŠą▓, ąĖ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ čĆą░ąĘčĆąĄčłąĄąĮ č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ. ąöą╗čÅ ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ watchdog ą┤ą╗čÅ čüą▒čĆąŠčüą░ ąĄą│ąŠ čüč湥čéčćąĖą║ą░ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ č鹊ą╗čīą║ąŠ ą╗ąĖčłčī čüą┤ąĄą╗ą░čéčī ąĘą░ą┐ąĖčüčī ą▓ąŠ ą▓čüąĄ čĆą░ąĘčĆąĄčłąĄąĮąĮčŗąĄ RRR. ą×ą┤ąĮąĖą╝ ąĖąĘ ą▓ą░čĆąĖą░ąĮč鹊ą▓ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ čĆą░ąĘčĆąĄčłąĄąĮąĖčÅ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čĆąĄą│ąĖčüčéčĆąŠą▓ RRR - ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗą╣ ą╝ąŠąĮąĖč鹊čĆąĖąĮą│ čĆą░ąĘąĮčŗčģ ąĘą░ą┤ą░čć ąĖą╗ąĖ ą╝ą░čłąĖąĮ čüąŠčüč鹊čÅąĮąĖą╣ ą▓ čüąĖčüč鹥ą╝ąĄ. ąöą╗čÅ ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąĖ ą▓ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą╝čŗ ą▒čāą┤ąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÄ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ, ą│ą┤ąĄ čĆą░ąĘčĆąĄčłąĄąĮ č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ ą┐ąĄčĆą▓čŗą╣ čĆąĄą│ąĖčüčéčĆ RRR.
ąÜąŠą┤ ą┤ą╗čÅ ąĮą░čüčéčĆąŠą╣ą║ąĖ watchdog:
// hardware_watchdog.c // ... #define HARDWARE_WATCHDOG_TIMEOUT_SECS 10 // ...
void hardware_watchdog_enable (void )
{
if ((WDT-> RUNSTATUS & 0x1 ) != 0 )
{
// Watchdog čāąČąĄ čĆą░ą▒ąŠčéą░ąĄčé, ąĖ ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮ
return ;
}
// ąŚąĮą░č湥ąĮąĖąĄ ą┤ą╗čÅ ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ąĖ čüč湥čéčćąĖą║ą░ - ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąĄčĆąĖąŠą┤ąŠą▓
// čćą░čüč鹊čéčŗ 32.768 ą║ąōčå ą┤ąŠ ąĖčüč鹥č湥ąĮąĖčÅ čéą░ą╣ą╝ą░čāčéą░ watchdog:
WDT-> CRV = 32768 * HARDWARE_WATCHDOG_TIMEOUT_SECS;
// ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ watchdog:
WDT-> TASKS_START = 0x1 ;
}
ąÜąŠą┤ ą┤ą╗čÅ čüą▒čĆąŠčüą░ watchdog:
// hardware_watchdog.c void hardware_watchdog_feed (void )
{
// ąÆ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü čüąĄą║čåąĖąĄą╣ "6.36.4.10" ą┤ą░čéą░čłąĖčéą░, ąĄčüą╗ąĖ čŹč鹊
// ąĘąĮą░č湥ąĮąĖąĄ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą▓ čĆą░ąĘčĆąĄčłąĄąĮąĮčŗą╣ RRR, č鹊 čüč湥čéčćąĖą║
// watchdog čüą▒čĆąŠčüąĖčéčüčÅ, ąĖ čéą░ą╣ą╝ą░čāčé/ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ą░ ąĮąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé.
//
// ąŚą░ą╝ąĄčćą░ąĮąĖąĄ: ą║ą░ą║ ą┐čĆą░ą▓ąĖą╗ąŠ ą┐ąŠą┤ąŠą▒ąĮčŗąĄ "ą╝ą░ą│ąĖč湥čüą║ąĖąĄ" ą║ąŠąĮčüčéą░ąĮčéčŗ
// ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą║ą░ą║ ą║ą╗čÄčć ą┤ą╗čÅ ą░ą║čéąĖą▓ą░čåąĖąĖ ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ąĖ
// čüč鹊čĆąŠąČąĄą▓ąŠą│ąŠ čéą░ą╣ą╝ąĄčĆą░, čćč鹊ą▒čŗ ą┤ąŠ ą╝ąĖąĮąĖą╝čāą╝ą░ čüąĮąĖąĘąĖčéčī čłą░ąĮčü
// čüą╗čāčćą░ą╣ąĮąŠą│ąŠ čüą▒čĆąŠčüą░ watchdog ą┐čĆąĖ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠą╝ ą┤ąŠčüčéčāą┐ąĄ
// ą║ ą┐ą░ą╝čÅčéąĖ.
const uint32_t reload_magic_value = 0x6E524635 ;
WDT-> RR[0 ] = reload_magic_value;
}
ą¤čĆąŠą▓ąĄčĆą║ą░ ą┐čĆąĖčćąĖąĮčŗ ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ąĖ . ąØąĖąČąĄ ą┐ąŠą║ą░ąĘą░ąĮ ą┐čĆąĖą╝ąĄčĆ ą║ąŠą┤ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąŠą▓ąĄčĆčÅąĄčé ąĖ čüą▒čĆą░čüčŗą▓ą░ąĄčé ąĘąĮą░č湥ąĮąĖąĄ ą┐ąŠą╗ąĄą╣ čĆąĄą│ąĖčüčéčĆą░ RESETREAS. ąĢčüą╗ąĖ ąĖą╝ąĄą╗ ą╝ąĄčüč鹊 čüą▒čĆąŠčü ąŠčé watchdog, ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą░ą║čéąĖą▓ąĖčĆčāąĄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ č鹊čćą║ąĖ ąŠčüčéą░ąĮąŠą▓ą░ (__asm
// main.c static void prv_check_and_reset_reboot_reason (void )
{
// ąĪąŠčģčĆą░ąĮąĄąĮąĖąĄ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ąŠ ą┐čĆąĖčćąĖąĮąĄ čüą▒čĆąŠčüą░:
const uint32_t last_reboot_reason = * RESETREAS;
// ą×čćąĖcčéą║ą░ ą╗čÄą▒čŗčģ ą┐ąŠą╗ąĄą╣, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčé ąĖąĮč乊čĆą╝ą░čåąĖčÄ čüą▒čĆąŠčüą░:
* RESETREAS |= * RESETREAS;
// ą¤čĆąĖąŠčüčéą░ąĮąŠą▓ą║ą░ čüąĖčüč鹥ą╝čŗ ą┐čĆąĖ ąĘą░ą│čĆčāąĘą║ąĄ, ąĄčüą╗ąĖ ą┐čĆąŠąĖąĘąŠčłąĄą╗
// Watchdog Reset:
const uint32_t watchdog_reset_mask = 0x2 ;
if ((last_reboot_reason & watchdog_reset_mask) == watchdog_reset_mask)
{
__asm ("bkpt 10" );
}
}
ą¤čĆąŠą▓ąĄčĆą║ą░ čĆą░ą▒ąŠč鹊čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ . ą¤čĆąĖą╝ąĄčĆ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ą│ą╗ąŠą▒ą░ą╗čīąĮčāčÄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ g_watchdog_hang_config ą▓ ą╝ąŠą┤čāą╗ąĄ main.c, ą║ąŠč鹊čĆčāčÄ ą╝čŗ ą▒čāą┤ąĄą╝ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čéčī ą▓ ąŠčéą╗ą░ą┤čćąĖą║ąĄ gdb, čćč鹊ą▒čŗ čāą┐čĆą░ą▓ą╗čÅčéčī ąĖčüą║čāčüčüčéą▓ąĄąĮąĮčŗą╝ ąĘą░ą▓ąĖčüą░ąĮąĖąĄą╝. ąÜąŠą┤ ąĘą░ą┐čāčüą║ą░ (startup code) ą╝ąŠąČąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī ą┐čĆąĖą╝ąĄčĆąĮąŠ čéą░ą║:
//main.c int main (void )
{
prv_check_and_reset_reboot_reason();
hardware_watchdog_enable();
//...
// ąÆą▓ąŠą┤ čĆą░ąĘą╗ąĖčćąĮčŗčģ ąĘą░ą▓ąĖčüą░ąĮąĖą╣ ąĮą░ ąŠčüąĮąŠą▓ąĄ g_watchdog_hang_config
ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┤ą╗čÅ ąĘą░ą▓ąĖčüą░ąĮąĖčÅ ą║ąŠą┤ ą┐čĆąŠčüč鹊 ą▓čģąŠą┤ąĖčé ą▓ ą▒ąĄčüą║ąŠąĮąĄčćąĮčŗą╣ čåąĖą║ą╗ while (1) {} ą┐čĆąĖ ąĘą░ą│čĆčāąĘą║ąĄ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ąĄčüą╗ąĖ ą▓čüąĄ ąĮą░čüčéčĆąŠąĄąĮąŠ ą┐čĆą░ą▓ąĖą╗čīąĮąŠ, č鹊 ą┐čĆąŠčłąĖą▓ą║ąĖ ą║ąŠą┤ą░ ą╝čŗ ą┤ąŠą╗ąČąĮčŗ č湥čĆąĄąĘ 10 čüąĄą║čāąĮą┤ čāą▓ąĖą┤ąĄčéčī ąŠčüčéą░ąĮąŠą▓ą║čā ąŠčéą╗ą░ą┤čćąĖą║ą░ ą▓ąĮčāčéčĆąĖ prv_check_and_reset_reboot_reason().
$ cd example/watchdog-example/
$ make
$ arm-none-eabi-gdb --eval-command="target remote localhost:2331" --ex="mon reset" --ex="load"
--ex="mon reset" --se=build/nrf52.elf
(gdb) continue
[ ... ąŠąČąĖą┤ą░ąĮąĖąĄ ą┐čĆąĖą╝ąĄčĆąĮąŠ 10 čüąĄą║čāąĮą┤ ...]
Program received signal SIGTRAP, Trace/breakpoint trap.
prv_check_and_reset_reboot_reason () at interrupt/example/watchdog-example/main.c:157
157 __asm("bkpt 10");
(gdb)
ąóąĄą┐ąĄčĆčī ą┤ą░ą▓ą░ą╣č鹥 ą┐ąŠą┐čĆąŠą▒čāąĄą╝ ą▓čüčéą░ą▓ąĖčéčī ą▓ čåąĖą║ą╗ while(1) {} ą┐ąŠą▓č鹊čĆčÅčÄčēąĖąĄčüčÅ ą▓čŗąĘąŠą▓čŗ hardware_watchdog_feed() (čüą╝. ą║ąŠą┤ ą▓čŗčłąĄ). ąŁč鹊 ąŠą▒ąĄčüą┐ąĄčćąĖčé ąĮąĄą┐čĆąĄčĆčŗą▓ąĮčāčÄ čĆą░ą▒ąŠčéčā ą┐čĆąŠą│čĆą░ą╝ą╝čŗ, ą▒ąĄąĘ ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ąĖ.
(gdb) mon reset
(gdb) break main
(gdb) continue
Continuing.
Breakpoint 1, main () at interrupt/example/watchdog-example/main.c:162
162 prv_check_and_reset_reboot_reason();
(gdb) set g_watchdog_hang_config=1
(gdb) continue
[... ą╝čŗ ą┤ąŠą╗ąČąĮčŗ čāą▓ąĖą┤ąĄčéčī, čćč鹊 ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąŠčé čéą░ą╣ą╝ą░čāčéą░ watchdog ą▒ąŠą╗čīčłąĄ ąĮąĄčé ...]
ą£čŗ ą╝ąŠąČąĄčé čéą░ą║ąČąĄ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ąĖčéčī čĆą░ą▒ąŠčéčā ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąĖ ą┐čĆąŠą▓ąĄčĆąĖčéčī ąĄčæ čüąŠčüč鹊čÅąĮąĖąĄ, čćč鹊ą▒čŗ čāą▒ąĄą┤ąĖčéčīčüčÅ, čćč鹊 watchdog ąĘą░ą┐čāčēąĄąĮ ąĖ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮ čéą░ą║, ą║ą░ą║ čŹč鹊 ąŠąČąĖą┤ą░ą╗ąŠčüčī:
(gdb) p/x *WDT
$3 = {
TASKS_START = 0x0,
RSVD = {0x0 < repeats 63 times>},
EVENTS_TIMEOUT = 0x0,
RSVD1 = {0x0 < repeats 128 times>},
INTENSET = 0x0,
INTENCLR = 0x0,
RSVD2 = {0x0 < repeats 61 times>},
RUNSTATUS = 0x1,
REQSTATUS = 0x1,
RSVD3 = {0x0 < repeats 63 times>},
CRV = 0x50000,
RREN = 0x1,
CONFIG = 0x1,
RSVD4 = {0x0 < repeats 60 times>},
RR = {0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}
}
[ąæą░ąĘąŠą▓ą░čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ ą▓ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮąŠą╣ čüčĆąĄą┤ąĄ ]
ą×čüąĮąŠą▓ąĮą░čÅ ąĖą┤ąĄčÅ čüąŠčüč鹊ąĖčé ą▓ čüąŠąĘą┤ą░ąĮąĖąĖ ą┐ąŠč鹊ą║ą░ čü ąĮąĖąĘą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝, ą║ąŠč鹊čĆčŗą╣ ą┤ąŠą╗ąČąĄąĮ čüą▒čĆą░čüčŗą▓ą░čéčī čüč鹊čĆąŠąČąĄą▓ąŠą╣ čéą░ą╣ą╝ąĄčĆ. ąĢčüą╗ąĖ čŹč鹊čé ą┐ąŠč鹊ą║ ą┐ąŠą╗čāčćą░ąĄčé ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠąĄ ą▓čĆąĄą╝čÅ ą┤ą╗čÅ čüą▓ąŠąĄą╣ čĆą░ą▒ąŠčéčŗ, č鹊 ą▒čāą┤ąĄčé ąĖčüą┐čĆą░ą▓ąĮąŠ čüą▒čĆą░čüčŗą▓ą░čéčī watchdog. ąĢčüą╗ąĖ ąČąĄ ą┐ąŠ ą║ą░ą║ąŠą╣-č鹊 ą┐čĆąĖčćąĖąĮąĄ ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąŠą┐čĆąĖąŠčĆąĖč鹥čéąĮą░čÅ ąĘą░ą┤ą░čćą░ ąĘą░ą▓ąĖčüą╗ą░ ą▓ ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠą╝ čåąĖą║ą╗ąĄ, č鹊 čüąĖčüč鹥ą╝ą░ ą┤ąŠą╗ąČąĮą░ ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘąĖčéčīčüčÅ, ą┐ąŠč鹊ą╝čā čćč鹊 ąĮąĖąĘą║ąŠą┐čĆąĖčĆąĖč鹥čéąĮčŗą╣ ą┐ąŠč鹊ą║, čüą▒čĆą░čüčŗą▓ą░čÄčēąĖą╣ watchdog, ąĮąĄ čüą╝ąŠąČąĄčé ą┐ąŠą╗čāčćąĖčéčī ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠąĄ ą▓čĆąĄą╝čÅ.
ą¤čĆąĖą╝ąĄčĆ ą║ąŠą┤ą░ ąĮąĖąĘą║ąŠą┐čĆąĖąŠčĆąĖč鹥čéąĮąŠą╣ ąĘą░ą┤ą░čćąĖ (FreeRTOS):
static void prvWatchdogTask (void * pvParameters)
{
while (1 )
{
vTaskDelay(1000 );
hardware_watchdog_feed();
}
}
ąŚą░ą▓ąĖčüą░ąĮąĖąĄ ą┐čĆąĖ ąŠą┐čĆąŠčüąĄ ą┤ą░čéčćąĖą║ą░ . ą×ą▒čēąĖą╣ ą║ą╗ą░čüčü ąĘą░ą▓ąĖčüą░ąĮąĖą╣ ą╝ąŠąČąĄčé ą┐čĆąŠąĖčüčģąŠą┤ąĖčéčī ąĖąĘ-ąĘą░ ąŠą┐čĆąŠčüą░ čüąĄąĮčüąŠčĆą░ ą┐čĆąĖ ąŠąČąĖą┤ą░ąĮąĖąĖ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą┐ąŠ ą┐ąĄčĆąĄą┤ą░č湥 ą┤ą░ąĮąĮčŗčģ, ąĖą╗ąĖ ąĖąĘ-ąĘą░ ąŠčłąĖą▒ą║ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ. ą¤čĆąĖą╝ąĄčĆ:
// main.c void erase_external_flash (void )
{
// ąŚą┤ąĄčüčī ąĮą░čģąŠą┤ąĖčéčüčÅ ą║ą░ą║ą░čÅ-ąĮąĖą▒čāą┤čī ą╗ąŠą│ąĖą║ą░, ąĘą░ą┐čāčüą║ą░čÄčēą░čÅ
// čüčéąĖčĆą░ąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ flash.
// ą×ą┐čĆąŠčü ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąŠą┐ąĄčĆą░čåąĖąĖ:
while (! spi_flash_erase_complete()) { };
// ąÆ čüą╗čāčćą░ąĄ ą┐čĆąŠą▒ą╗ąĄą╝čŗ čüčÄą┤ą░ ą╝čŗ čāąČąĄ ąĮąĄ ą┐ąŠą┐ą░ą┤ąĄą╝!
}
ąŚą░ą╝ąĄčćą░ąĮąĖąĄ ą┐ąŠ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ: ą▓ą╝ąĄčüč鹊 ąŠą┐čĆąŠčüą░ ą▓ ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠą╝ čåąĖą║ą╗ąĄ ąĘą┤ąĄčüčī ą╝čŗ ą╝ąŠą│ą╗ąĖ ą▒čŗ ą┐čĆąŠą▓ąĄčĆąĖčéčī ą▓čĆąĄą╝čÅ ąŠąČąĖą┤ą░ąĮąĖčÅ ą┐ąŠ čéą░ą╣ą╝ą░čāčéčā. ą×ą┤ąĮą░ą║ąŠ ą┤ą╗čÅ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ą░ ą┐čĆąŠčüčéčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ąŠąČąĖą┤ą░ąĄčéčüčÅ ąĮąŠčĆą╝ą░ą╗čīąĮčŗą╣ ąŠčéą║ą╗ąĖą║. ą¤čĆąŠą▒ą╗ąĄą╝ą░ ąŠčéą║ą░ąĘą░ ą▓ ą┐ąŠą┤ąŠą▒ąĮčŗčģ čüą╗čāčćą░čÅčģ čćą░čüč鹊 ą▓ąŠąĘąĮąĖą║ą░ąĄčé ąĖąĘ-ąĘą░ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą╣ ąŠčłąĖą▒ą║ąĖ, čéą░ą║ąŠą╣ ą║ą░ą║ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠą╣ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąĖą╗ąĖ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░. ąöąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ ą╗ąŠą│ąĖą║ąĖ čéą░ą╣ą╝ą░čāčéą░ ąĖ ą┐ąŠą┐čŗčéą║ąĖ ą║ąŠčĆčĆąĄą║čéąĮąŠą│ąŠ ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖčÅ čŹč鹊 ąĮąĄčćč鹊 čéą░ą║ąŠąĄ, č湥ą│ąŠ čüą╗ąĄą┤čāąĄčé ąĖąĘą▒ąĄą│ą░čéčī, ą┐ąŠč鹊ą╝čā čćč鹊 ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ ą╝ą░čüą║ąĖčĆčāąĄčé ą▓ąŠąĘą╝ąŠąČąĮčŗąĄ ąŠčłąĖą▒ą║ąĖ. ąĢčüą╗ąĖ ą▓čŗ ą▓ą▓ąŠą┤ąĖč鹥 ą╗ąŠą│ąĖą║čā ą▓ąŠčüčüčéą░ąĮąŠą▓ą╗ąĄąĮąĖčÅ, č鹊 ąŠčéą║čĆčŗą▓ą░ąĄč鹥 ą┤ą╗čÅ čüąĄą▒čÅ ą┐čāčéąĖ ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ą▒ąŠą╗ąĄąĄ čüą╗ąŠąČąĮčŗčģ ą┐čĆąŠą▒ą╗ąĄą╝ ąĖąĘ-ąĘą░ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ąŠčłąĖą▒ąŠą║. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ą╝ą░čüą║ąĖčĆąŠą▓ą░ąĮąĖąĄ ąĮąĖąČąĄą╗ąĄąČą░čēąĄą╣ ą┐čĆąŠą▒ą╗ąĄą╝čŗ ą┤ąĄą╗ą░ąĄčé ą┐ąŠąĖčüą║ ą┐čĆąĖčćąĖąĮ ąŠčłąĖą▒ą║ąĖ ąĄčēąĄ čüą╗ąŠąČąĮąĄąĄ. ąŚą░ą▓ąĖčüą░ąĮąĖąĄ ą▓ č鹊ą╝ ą╝ąĄčüč鹥, ą│ą┤ąĄ ą┐čĆąŠąĖąĘąŠčłą╗ą░ ąŠčłąĖą▒ą║ą░, ą╝ąŠąČąĄčé čāą┐čĆąŠčüčéąĖčéčī ą▓ ą▓čŗčÅčüąĮąĄąĮąĖąĄ ą┐čĆąĖčćąĖąĮčŗ ąŠčéą║ą░ąĘą░ ąĖ čāą╝ąĄąĮčīčłąĖčéčī ą▓čĆąĄą╝čÅ ąĮą░ ąĖčüą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ąŠčłąĖą▒ą║ąĖ.
ą¤ąŠčüą╝ąŠčéčĆąĖą╝, čüą╝ąŠąČąĄčé ą╗ąĖ ąĮą░čłą░ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ watchdog ą┐ąĄčĆąĄčģą▓ą░čéąĖčéčī čŹč鹊čé čéąĖą┐ ąĘą░ą▓ąĖčüą░ąĮąĖčÅ.
(gdb) mon reset
Resetting target
(gdb) break main
Breakpoint 1 at 0x174: file interrupt/example/watchdog-example/main.c, line 151.
(gdb) continue
Continuing.
Breakpoint 1, main () at interrupt/example/watchdog-example/main.c:151
151 prv_check_and_reset_reboot_reason();
// Select the polling hang configuration
(gdb) set g_watchdog_hang_config=2
(gdb) continue
Continuing.
Breakpoint 1, main () at interrupt/example/watchdog-example/main.c:151
151 prv_check_and_reset_reboot_reason();
(gdb) c
Continuing.
[ ... ąŠąČąĖą┤ą░ąĮąĖąĄ ą┐čĆąĖą╝ąĄčĆąĮąŠ 10 čüąĄą║čāąĮą┤ ... ]
Program received signal SIGTRAP, Trace/breakpoint trap.
prv_check_and_reset_reboot_reason () at interrupt/example/watchdog-example/main.c:146
146 __asm("bkpt 10");
ą×ąÜ, ą▓čüąĄ čüčĆą░ą▒ąŠčéą░ą╗ąŠ ą║ą░ą║ ąĮą░ą┤ąŠ. ą£čŗ čāą▓ąĖą┤ąĄą╗ąĖ, čćč鹊 ą┐čĆąŠąĖąĘąŠčłą╗ą░ ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ą░ ąĖąĘ-ąĘą░ čéą░ą╣ą╝ą░čāčéą░ watchdog.
ąŚą░ą▓ąĖčüą░ąĮąĖąĄ ąĖąĘ-ąĘą░ ąŠąČąĖą┤ą░ąĮąĖčÅ ą╝čīčÄč鹥ą║čüą░/čüąĄą╝ą░č乊čĆą░ . ąĀą░čüčüą╝ąŠčéčĆąĖą╝ ą┤čĆčāą│ąŠą╣ ą║ą╗ą░čüčü ąĘą░ą▓ąĖčüą░ąĮąĖčÅ ąĖąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 ąĮąĄ ąŠčüą▓ąŠą▒ąŠąČą┤ą░ąĄčéčüčÅ mutex ąĖą╗ąĖ ąĮąĄ ą┐ąŠčÅą▓ą╗čÅąĄčéčüčÅ čüąĄą╝ą░č乊čĆ.
int read_temp_sensor (uint32_t * temp)
{
xSemaphoreTake(s_temp_i2c_mutex, portMAX_DELAY);
int rv = i2c_read_temp(temp);
if (rv == - 1 )
{
// ąæąÉąō: ą▓ čŹč鹊ą╝ ą╝ąĄčüč鹥 ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓čŗčüčéą░ą▓ą╗ąĄąĮ čüąĄą╝ą░č乊čĆ!
return rv;
}
xSemaphoreGive(s_temp_i2c_mutex);
return 0 ;
}
ą¤čĆąŠą▓ąĄčĆąŠčćąĮčŗąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ:
(gdb) mon reset
Resetting target
(gdb) break main
Breakpoint 1 at 0x174: file interrupt/example/watchdog-example/main.c, line 151.
(gdb) continue
Continuing.
Breakpoint 1, main () at interrupt/example/watchdog-example/main.c:151
151 prv_check_and_reset_reboot_reason();
// ąÆčŗą▒ąŠčĆ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ mutex hang:
(gdb) set g_watchdog_hang_config=3
(gdb) continue
Continuing.
// ąóčāčé ą╝čŗ ą▓ąĖą┤ąĖą╝ ąŠčéčüčāčéčüčéą▓ąĖąĄ ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ąĖ
ąØąŠ ą┐ąŠč湥ą╝čā ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ą░ ąĮąĄ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé?.. ąŚą┤ąĄčüčī ąĘą░ą▓ąĖčüą░ąĮąĖąĄ ą▒ąŠą╗ąĄąĄ č鹊ąĮą║ąŠąĄ. ąØą░čł ą┐ąŠč鹊ą║ čü ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ ąĘą░ą▓ąĖčü, ą┐ąŠč鹊ą╝čā čćč鹊 ąŠąČąĖą┤ą░ąĄčé ą╝čīčÄč鹥ą║čü. ąŁč鹊 ąĘąĮą░čćąĖčé, čćč鹊 ąŠąĮ ąŠčüą▓ąŠą▒ąŠąČą┤ą░ąĄčé ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠąĄ ą▓čĆąĄą╝čÅ RTOS, čéą░ą║ čćč鹊 ąĮąĖąĘą║ąŠą┐čĆąĖąŠčĆąĖč鹥čéąĮčŗą╣ ą┐ąŠč鹊ą║ ą╝ąŠąČąĄčé čĆą░ą▒ąŠčéą░čéčī ąĖ čüą▒čĆą░čüčŗą▓ą░čéčī watchdog.
ąöąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ "ąĘą░ą┤ą░čćąĖ" Watchdog . ąśčéą░ą║, ą╝čŗ č鹊ą╗čīą║ąŠ čćč鹊 ąŠą▒ąĮą░čĆčāąČąĖą╗ąĖ, čćč鹊 ąĮą░čłą░ ą┐čĆąŠčüčéą░čÅ čüčģąĄą╝ą░ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ watchdog ąĖą╝ąĄąĄčé ąĮąĄą║ąŠč鹊čĆčŗąĄ ąĮąĄą┤ąŠčüčéą░čéą║ąĖ - ąŠąĮą░ ąĮąĄ ą╝ąŠąČąĄčé ą┐ąĄčĆąĄčģą▓ą░čéąĖčéčī ą╝ąĄčĆčéą▓čŗąĄ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ (deadlocks) ą╝ąĄąČą┤čā ąĘą░ą┤ą░čćą░ą╝ąĖ. ąÆąĄčĆąŠčÅčéąĮąŠ, čćč鹊 ąĮą░ą╝ ąĮčāąČąĄąĮ ą║ą░ą║ąŠą╣-č鹊 čüą┐ąŠčüąŠą▒ ąŠčéčüą╗ąĄą┤ąĖčéčī, čćč鹊 ąĮą░čłąĖ čåąĖą║ą╗čŗ čüąŠą▒čŗčéąĖą╣ ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ.
ąŁč鹊ą╣ čåąĄą╗ąĖ ą╝ąŠąČąĮąŠ ą┤ąŠčüčéąĖčćčī čĆąĄą░ą╗ąĖąĘą░čåąĖąĄą╣ čüąĖčüč鹥ą╝čŗ ą║ąŠąĮčéčĆąŠą╗čÅ ąĮą░ą┤ ą░ą┐ą┐ą░čĆą░čéąĮčŗą╝ watchdog. ąÆą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ ą▒ąĄąĘčāčüą╗ąŠą▓ąĮąŠ ą▓čŗąĘčŗą▓ą░čéčī hardware_watchdog_feed(), ą┤ąŠą▒ą░ą▓ąĖą╝ API-ąĘą░ą┤ą░čćąĖ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī čĆą░ą▒ąŠč鹊čüą┐ąŠčüąŠą▒ąĮąŠčüčéčī čĆą░ą▒ąŠčćąĖčģ ąĘą░ą┤ą░čć ąĖ čüą▒čĆą░čüčŗą▓ą░čéčī hardware watchdog č鹊ą╗čīą║ąŠ ąĄčüą╗ąĖ ą▓čüąĄ ąĘą░ą┤ą░čćąĖ ą┐čĆąŠą▓ąĄčĆąĄąĮčŗ.
static uint32_t s_registered_tasks = 0 ;static uint32_t s_fed_tasks = 0 ;
static void prv_task_watchdog_check (void )
{
if ((s_fed_tasks & s_registered_tasks) == s_registered_tasks)
{
// ąÆčüąĄ ąĘą░ą┤ą░čćąĖ ą▓ ą┐ąŠčĆčÅą┤ą║ąĄ, ąĖą╗ąĖ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮčŗ!
hardware_watchdog_feed();
s_fed_tasks = 0 ;
}
}
void task_watchdog_register_task (uint32_t task_id)
{
__disable_irq();
s_registered_tasks |= (1 << task_id);
__enable_irq();
}
void task_watchdog_unregister_task (uint32_t task_id)
{
__disable_irq();
s_registered_tasks &= ~ (1 << task_id);
s_fed_tasks &= ~ (1 << task_id);
prv_task_watchdog_check();
__enable_irq();
}
void task_watchdog_feed_task (uint32_t task_id)
{
__disable_irq();
s_fed_tasks |= (1 << task_id);
prv_task_watchdog_check();
__enable_irq();
}
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą┐ąŠčüą║ąŠą╗čīą║čā ą║ ą┐čĆąŠčåąĄą┤čāčĆą░ą╝ s_fed_tasks ąĖ s_registered_tasks ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ąŠą▒čĆą░čēąĄąĮąĖąĄ ąĖąĘ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ąĘą░ą┤ą░čć, ą▓ ąĖčģ ą║ąŠą┤ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮčŗ ą▓čŗąĘąŠą▓čŗ __disable_irq/__enable_irq, čćč鹊ą▒čŗ ą┐čĆąĄą┤ąŠčéą▓čĆą░čéąĖčéčī ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ąŠą▒čēąĖą╝ ą┤ą░ąĮąĮčŗą╝ (ąŠčĆą│ą░ąĮąĖąĘčāąĄčéčüčÅ ą║čĆąĖčéąĖč湥čüą║ąĖą╣ čĆąĄą│ąĖąŠąĮ ą║ąŠą┤ą░ [8]). ą¤ąŠčüą║ąŠą╗čīą║čā ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čéą░ą║č鹊ą▓ ą┤ą╗čÅ čĆą░ą▒ąŠčéčŗ ą▓ąĮčāčéčĆąĖ ą║čĆąĖčéąĖč湥čüą║ąŠą╣ čüąĄą║čåąĖąĖ ą▓ąĄčüčīą╝ą░ ą╝ą░ą╗ąŠ, č鹊 čŹč鹊 ąĮąĄ ą┤ąŠą╗ąČąĮąŠ čüąŠčüčéą░ą▓ąĖčéčī ą┐čĆąŠą▒ą╗ąĄą╝čŗ. ą×ą┤ąĮą░ą║ąŠ ą┐čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ GCC ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą▒čŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓čüčéčĆąŠąĄąĮąĮąŠąĄ API ą┤ą╗čÅ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖąĖ ą░č鹊ą╝ą░čĆąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ [9] ą║ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗą╝.
ą¤čüąĄą▓ą┤ąŠą║ąŠą┤, ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāčÄčēąĖą╣ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ Task Watchdog . ąÆčüąĄ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗąĄ čüąĖčüč鹥ą╝čŗ čĆą░ą▒ąŠčéą░čÄčé ąĮą░ ąŠčüąĮąŠą▓ąĄ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĮąĄą║ąŠč鹊čĆąŠą│ąŠ čåąĖą║ą╗ą░ čüąŠą▒čŗčéąĖą╣ (event loop). ąØąĖąČąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮ ą┐čĆąĖą╝ąĄčĆ, ą║ą░ą║ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┐ąŠą║ą░ąĘą░ąĮąĮčŗąĄ ą▓čŗčłąĄ API-čäčāąĮą║čåąĖąĖ ą▓ čåąĖą║ą╗ąĄ, čćč鹊ą▒čŗ ą╗čāčćčłąĄ ą┐ąŠąĮčÅčéčī, ą║ą░ą║ ąŠąĮąĖ čĆą░ą▒ąŠčéą░čÄčé.
static void background_service_event_loop (void )
{
while (1 )
{
const int task_id = kTaskId_BackGroundWorkLoop;
// ą¤ąŠčüą║ąŠą╗čīą║čā ą╝ąĄąČą┤čā čüąŠą▒čŗčéąĖčÅą╝ąĖ ą╝ąŠąČąĄčé ą┐čĆąŠą╣čéąĖ ą╝ąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ,
// ąŠčéą╝ąĄąĮčÅąĄčéčüčÅ čĆąĄą│ąĖčüčéčĆą░čåąĖčÅ ąĘą░ą┤ą░čćąĖ task watchdog:
task_watchdog_unregister_task(task_id);
wait_for_work();
// ą¤ąŠčÅą▓ąĖą╗ą░čüčī ą║ą░ą║ą░čÅ-č鹊 čĆą░ą▒ąŠčéą░, ą┐ąŠčŹč鹊ą╝čā čĆąĄą│ąĖčüčéčĆąĖčĆčāąĄą╝ watchdog
// ą┤ą╗čÅ ą┐ąĄčĆąĄčģą▓ą░čéą░ čüąĖčéčāą░čåąĖą╣, ą║ąŠą│ą┤ą░ čŹčéą░ čĆą░ą▒ąŠčéą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ
// čüą╗ąĖčłą║ąŠą╝ ą┤ąŠą╗ą│ąŠ:
task_watchdog_register_task(task_id);
// ą×ą¤ą”ąśą×ąØąÉąøą¼ąØą×: ąĄčüą╗ąĖ ąĘą░ą┤ą░čćą░ čĆą░ą▒ąŠčéą░ąĄčé ą┤ąŠą╗ą│ąŠ, ąĮąŠ čŹč鹊 ąŠąČąĖą┤ą░ąĄą╝ąŠ
// (ąĮą░ą┐čĆąĖą╝ąĄčĆ, čüčéąĖčĆą░ąĄčéčüčÅ ą▒ąŠą╗čīčłą░čÅ ą┐ąŠ ąŠą▒čŖąĄą╝čā ą┐ą░ą╝čÅčéčī ą╝ąĖą║čĆąŠčüčģąĄą╝čŗ
// flash), ą╝ąŠąČąĮąŠ čüą▒čĆą░čüčŗą▓ą░čéčī task watchdog, čćč鹊ą▒čŗ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī
// ą┐čĆąŠčåąĄčüčüčā ąĘą░ą┤ą░čćąĖ ą▒ąŠą╗čīčłąĄ ą▓čĆąĄą╝ąĄąĮąĖ.
//
// ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą▓čŗą▒čĆą░ąĮąĮčŗą╣ čéą░ą╣ą╝ą░čāčé watchdog ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī
// ą┤ąŠčüčéą░č鹊čćąĮčŗą╝, čćč鹊ą▒čŗ ą┤ąŠčüčéą░č鹊č湥ąĮ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ čüąĖčüč鹥ą╝ąĮąŠą│ąŠ
// čüąŠą▒čŗčéąĖčÅ, ą┐ąŠčŹč鹊ą╝čā ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 čŹč鹊čé čłą░ą▒ą╗ąŠąĮ ąŠč湥ąĮčī čĆąĄą┤ą║ąŠ:
task_watchdog_feed_task(task_id);
[... ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ čĆą░ą▒ąŠčéčŗ ...]
}
}
Task Watchdog, čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮąĮčŗą╣ ą░ą┐ą┐ą░čĆą░čéąĮąŠ . ą¤čĆąŠąĮąĖčåą░č鹥ą╗čīąĮčŗą╣ čćąĖčéą░č鹥ą╗čī ą╝ąŠąČąĄčé ąĘą░ą╝ąĄčéąĖčéčī, čćč鹊 čŹč鹊 ąĘą▓čāčćąĖčé ą║ą░ą║ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ RRR ą▓ čćąĖą┐ąĄ NRF52, ą║ąŠč鹊čĆčŗąĄ čāą┐ąŠą╝ąĖąĮą░ą╗ąĖčüčī ą▓čŗčłąĄ. ąØąŠ ąĮąĄčé, čŹč鹊 čüą╗ąĖčłą║ąŠą╝ čĆąĄą┤ą║ąŠ ą▓čüčéčĆąĄčćą░čÄčēą░čÅčüčÅ ą░ą┐ą┐ą░čĆą░čéčāčĆą░, ą┐ąŠčŹč鹊ą╝čā ą┐čĆąĄą┤ą┐ąŠčćčéąĖč鹥ą╗čīąĮąĄąĄ ąĘą░ą╝ąĄąĮąĖčéčī ąĄčæ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą╣ čĆąĄą░ą╗ąĖąĘą░čåąĖąĄą╣, ą║ąŠč鹊čĆčāčÄ ą╗ąĄą│ą║ąŠ ą╝ąŠąČąĮąŠ ąĘą░ą┐čāčüčéąĖčéčī ąĖ ą┐čĆąŠč鹥čüčéąĖčĆąŠą▓ą░čéčī ąĮą░ čłąĖčĆąŠą║ąŠą╝ čüą┐ąĄą║čéčĆąĄ čāčüčéčĆąŠą╣čüčéą▓ MCU.
ąśąĘą╝ąĄąĮąĖą╝ task watchdog čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝.
$ cd $INTERRUPT_REPO/example/watchdog-example/
$ git apply 01-patch-task-watchdog.patch
$ make
ąŁč鹊 ąĖčüą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąĮąŠą▓čŗą╣ task watchdog, ą┐čĆąŠč鹥čüčéąĖčĆčāąĄą╝ ąĄčēąĄ čĆą░ąĘ ą▓ą▓ąŠą┤ ąĘą░ą▓ąĖčüą░ąĮąĖčÅ.
(gdb) mon reset
(gdb) continue
Continuing.
Breakpoint 1, main () at interrupt/example/watchdog-example/main.c:162
162 prv_check_and_reset_reboot_reason();
(gdb) set g_watchdog_hang_config=3
(gdb) continue
Continuing.
Breakpoint 1, main () at interrupt/example/watchdog-example/main.c:160
160 prv_check_and_reset_reboot_reason();
(gdb) continue
Program received signal SIGTRAP, Trace/breakpoint trap.
prv_check_and_reset_reboot_reason () at interrupt/example/watchdog-example/main.c:157
157 __asm("bkpt 10");
ą×čéą╗ąĖčćąĮąŠ, ą▓čüąĄ čĆą░ą▒ąŠčéą░ąĄčé!
[ąÆčŗčÅčüąĮąĄąĮąĖąĄ ą┐čĆąĖčćąĖąĮ čüčĆą░ą▒ą░čéčŗą▓ą░ąĮąĖčÅ watchdog ]
ąźąŠčĆąŠčłąŠ, čćč鹊 ą╝čŗ ąĖą╝ąĄąĄą╝ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą┐ąĄčĆąĄčģą▓ą░čéčŗą▓ą░čéčī ąĘą░ą▓ąĖčüą░ąĮąĖčÅ čüąĖčüč鹥ą╝čŗ, ąĮąŠ ą║ą░ą║ ąĖčģ ąŠčéą╗ą░ąČąĖą▓ą░čéčī? ąØą░ ą┤ą░ąĮąĮčŗą╣ ą╝ąŠą╝ąĄąĮčé ą▓čüąĄ, čćč鹊 ą╝čŗ ą▓ąĖą┤ąĖą╝, čŹč鹊 ąŠą┤ąĖąĮ ą▒ąĖčé ą┐čĆąĖ čüą▒čĆąŠčüąĄ ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ čüčĆą░ą▒ąŠčéą░ą╗ čüč鹊čĆąŠąČąĄą▓ąŠą╣ čéą░ą╣ą╝ąĄčĆ, čćč鹊 ąĮąĄ ąŠčüąŠą▒ąĄąĮąĮąŠ ą┐ąŠą╗ąĄąĘąĮąŠ ą┤ą╗čÅ ą▓čŗčÅčüąĮąĄąĮąĖčÅ ą┐čĆąĖčćąĖąĮčŗ ą┐čĆąŠą▒ą╗ąĄą╝čŗ.
ą£čŗ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠ čģąŠčéąĖą╝ ąĖą╝ąĄčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą▓čŗą┐ąŠą╗ąĮąĖčéčī ą║ąŠą┤ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé watchdog reset. ąÜą░ą║ čāąČąĄ čāą┐ąŠą╝ąĖąĮą░ą╗ąŠčüčī, čā NRF52 ąĄčüčéčī ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ą╝ąŠąČąĮąŠ čĆą░ąĘčĆąĄčłąĖčéčī, ąĮąŠ ąŠąĮąŠ ąĮąĄ ą┤ą░ąĄčé ąĮą░ą╝ ąĮąĖą║ą░ą║ąŠą│ąŠ ą║ąŠąĮčéčĆąŠą╗čÅ ąĮą░ą┤ ąŠčéčüčĆąŠčćą║ąŠą╣ ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ąĖ ą┤ą╗čÅ ą║ą░ą║ąŠą╣-ą╗ąĖą▒ąŠ ąŠčćąĖčüčéą║ąĖ. ąÆ čŹč鹊ą╣ čüąĖčéčāą░čåąĖąĖ ąŠą▒čŗčćąĮąŠ ą┤ąŠą▓ąŠą╗čīąĮąŠ ą╗ąĄą│ą║ąŠ ą┐ąĄčĆąĄą┐čĆąŠčäąĖą╗ąĖčĆąŠą▓ą░čéčī ą▓čüčéčĆąŠąĄąĮąĮčŗą╣ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗą╣ čéą░ą╣ą╝ąĄčĆ ą┤ą╗čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ watchdog.
ąöąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ "ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą│ąŠ" watchdog . ąöą╗čÅ ą┐čĆąĖą╝ąĄčĆą░ ą▒čāą┤ąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī NRF52 Timer0 ą┤ą╗čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ software watchdog. ąĪą┤ąĄą╗ą░ąĄą╝ ąĮąĄą╝ąĮąŠą│ąŠ ą╝ąĄąĮčīčłąĄąĄ ą▓čĆąĄą╝čÅ čéą░ą╣ą╝ą░čāčéą░ (7 čüąĄą║čāąĮą┤), č湥ą╝ čéą░ą╣ą╝ą░čāčé čā ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ watchdog (10 čüąĄą║čāąĮą┤). ąöą╗čÅ čüą▒čĆąŠčüą░ software watchdog ąĮčāąČąĮąŠ ą┐čĆąŠčüč鹊 ą┐ąĄčĆąĄąĘą░ą┐čāčüčéąĖčéčī čéą░ą╣ą╝ąĄčĆ. ąĢčüą╗ąĖ ąĖčüč鹥ą║ą╗ąĖ 7 čüąĄą║čāąĮą┤ ą▒ąĄąĘ ą┐ąĄčĆąĄąĘą░ą┐čāčüą║ą░ čéą░ą╣ą╝ąĄčĆą░, čüčĆą░ą▒ąŠčéą░ąĄčé ISR, ąĖ čüąĖčüč鹥ą╝ą░ čāąĘąĮą░ąĄčé ąŠą▒ čŹč鹊ą╝ čüąŠą▒čŗčéąĖąĖ čüčĆą░ą▒ą░čéčŗą▓ą░ąĮąĖčÅ software watchdog. ą£čŗ ą╝ąŠąČąĄą╝ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹč鹊 ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ ą║ą░ą║ ąĄčēąĄ ąŠą┤ąĖąĮ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ąŠčéą║ą░ąĘąŠą▓, ąŠčéčüą╗ąĄąČąĖą▓ą░čÅ ą║ą░ą║ąĖąĄ-ą╗ąĖą▒ąŠ ąŠčłąĖą▒ą║ąĖ ą▓ ą║ąŠą┤ąĄ Cortex-M.
void TimerTask0_Handler (void )
{
__asm volatile (
"tst lr, #4 \n "
"ite eq \n "
"mrseq r0, msp \n "
"mrsne r0, psp \n "
"b watchdog_fault_handler_c \n " );
}
// ąŚą░ą┐čĆąĄčé ąŠą┐čéąĖą╝ąĖąĘą░čåąĖą╣, čćč鹊ą▒čŗ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ąĮąĄ ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░ą╗ // ą▓ čŹč鹊ą╣ čäčāąĮą║čåąĖąĖ ą░čĆą│čāą╝ąĄąĮčé "frame":
__attribute__((optimize("O0" )))void watchdog_fault_handler_c(sContextStateFrame * frame)
{
// ąś č鹊ą╗čīą║ąŠ ąĄčüą╗ąĖ ą┐ąŠą┤ą║ą╗čÄč湥ąĮ ąŠčéą╗ą░ą┤čćąĖą║, ą▓čŗą┐ąŠą╗ąĮąĖčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ breakpoint,
// čćč鹊ą▒čŗ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą▓čŗčÅčüąĮąĖčéčī ą┐čĆąĖčćąĖąĮčā ąŠčéą║ą░ąĘą░:
HALT_IF_DEBUGGING();
// ąĪą▒čĆąŠčü ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ watchdog, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ą▓čĆąĄą╝čÅ ą┤ą╗čÅ ąŠčćąĖčüčéą║ąĖ
// ąĖ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĄą│ąŠ čÅą▓ąĮąŠą│ąŠ čüą▒čĆąŠčüą░:
hardware_watchdog_feed();
// ąøąŠą│ąĖą║ą░, ą║ąŠč鹊čĆą░čÅ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ. ąŚą┤ąĄčüčī ąŠą▒čŗčćąĮąŠ ą┤ąĄą╗ą░ąĄčéčüčÅ
// čüą╗ąĄą┤čāčÄčēąĄąĄ:
// - čüąŠčģčĆą░ąĮčÅąĄčéčüčÅ ą┤ą░ą╝ą┐ čÅą┤čĆą░, čćč鹊ą▒čŗ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą┐ąŠąĘąČąĄ ą┐čĆąŠą▓ąĄčüčéąĖ ą░ąĮą░ą╗ąĖąĘ
// ą▓ąŠąĘąĮąĖą║ąĮąŠą▓ąĄąĮąĖčÅ deadlock-ąŠą▓ ąĖą╗ąĖ ąĘą░ą▓ąĖčüą░ąĮąĖą╣
// - ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą╗čÄą▒ą░čÅ ąŠčćąĖčüčéą║ą░ ąĖ/ąĖą╗ąĖ ą▓čŗą║ą╗čÄč湥ąĮąĖąĄ ąŠą▒ąŠčĆčāą┤ąŠą▓ą░ąĮąĖčÅ
// ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗąĄ ą┐ąĄčĆąĄą┤ ą┐ąĄčĆąĄąĘą░ą│čĆčāąĘą║ąŠą╣
// - ą┐ąĄčĆąĄąĘą░ą│čĆčāąČą░ąĄčéčüčÅ čüąĖčüč鹥ą╝ą░.
}
ąöąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ Software Watchdog ą▓ ą┐čĆąĖą╝ąĄčĆ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ . ą£ąŠąČąĮąŠ ą▓ą▓ąĄčüčéąĖ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
$ cd $INTERRUPT_REPO/example/watchdog-example/
$ git apply 02-patch-software-watchdog.patch
$ make
ąÆąĄčĆąĮąĄą╝čüčÅ ąŠą▒čĆą░čéąĮąŠ ą║ čĆą░čüčüą╝ąŠčéčĆąĄąĮąĮčŗą╝ čĆą░ąĮąĄąĄ ą┐čĆąĖą╝ąĄčĆą░ą╝, ąĖ ą┐ąŠčüą╝ąŠčéčĆąĖą╝, ą║ą░ą║ ą╝ąŠąČąĮąŠ ąŠčéčüą╗ąĄą┤ąĖčéčī ą┐čĆąĖčćąĖąĮčā ąĘą░ą▓ąĖčüą░ąĮąĖčÅ.
(gdb) mon reset
Resetting target
(gdb) break main
Breakpoint 1, main () at interrupt/example/watchdog-example/main.c:162
162 prv_check_and_reset_reboot_reason();
(gdb) set g_watchdog_hang_config=2
(gdb) continue
Continuing.
[... ąŠąČąĖą┤ą░ąĮąĖąĄ ą┐čĆąĖą╝ąĄčĆąĮąŠ 7 čüąĄą║čāąĮą┤ ...]
Program received signal SIGTRAP, Trace/breakpoint trap.
0x00002bbc in watchdog_fault_handler_c (frame=0x200003b8 < ucHeap+592>)
at interrupt/example/watchdog-example/software_watchdog.c:81
81 HALT_IF_DEBUGGING();
(gdb) p/a *frame
$3 = {
r0 = 0x0 < g_pfnVectors>,
r1 = 0x200001bc < ucHeap+84>,
r2 = 0x20000164 < s_registered_tasks>,
r3 = 0x2 < g_pfnVectors+2>,
r12 = 0x200003e0 < ucHeap+632>,
lr = 0x10b < erase_external_flash+6>,
return_address = 0x2b8 < spi_flash_erase_complete>,
xpsr = 0x61000000
}
ą×čéą╗ąĖčćąĮąŠ, ą╝čŗ ą▓ąĖą┤ąĖą╝, čćč鹊 čĆąĄą│ąĖčüčéčĆčŗ pc & lr č鹊čćąĮąŠ čāą║ą░ąĘčŗą▓ą░čÄčé ąĮą░ čåąĖą║ą╗, ą│ą┤ąĄ ą║čĆčāčéąĖčéčüčÅ ąĘą░ą▓ąĖčüą░ąĮąĖąĄ:
void erase_external_flash (void )
{
// ąØąĄą║ą░čÅ ą╗ąŠą│ąĖą║ą░, ąĘą░ą┐čāčüą║ą░čÄčēą░čÅ čüčéąĖčĆą░ąĮąĖąĄ flash.
...
// ą×ą┐čĆąŠčü ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ąŠą┐ąĄčĆą░čåąĖąĖ:
while (! spi_flash_erase_complete()) { };
}
ą¤ąŠą┐čĆąŠą▒čāąĄą╝ č鹥ą┐ąĄčĆčī ąŠčéą╗ą░ą┤ąĖčéčī ąĘą░ą▓ąĖčüą░ąĮąĖąĄ ąĖąĘ-ąĘą░ deadlock-ą░.
(gdb) mon reset
Resetting target
(gdb) break main
Breakpoint 1, main () at interrupt/example/watchdog-example/main.c:162
162 prv_check_and_reset_reboot_reason();
(gdb) set g_watchdog_hang_config=3
(gdb) continue
Continuing.
[... ąŠąČąĖą┤ą░ąĮąĖąĄ ą▓ č鹥č湥ąĮąĖąĄ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ čüąĄą║čāąĮą┤ ...]
Program received signal SIGTRAP, Trace/breakpoint trap.
0x00002bbc in watchdog_fault_handler_c (frame=0x20000b10 < ucHeap+2472>)
at interrupt/example/watchdog-example/software_watchdog.c:81
81 HALT_IF_DEBUGGING();
(gdb) p/a *frame
$4 = {
r0 = 0x0 < g_pfnVectors>,
r1 = 0x0 < g_pfnVectors>,
r2 = 0x0 < g_pfnVectors>,
r3 = 0x0 < g_pfnVectors>,
r12 = 0x0 < g_pfnVectors>,
lr = 0x2741 < prvTaskExitError>,
return_address = 0x39a < prvIdleTask+14>,
xpsr = 0x61000000
}
ąŚą┤ąĄčüčī ą▓čüąĄ ąĮąĄčüą║ąŠą╗čīą║ąŠ čüą╗ąŠąČąĮąĄąĄ. ąĀąĄą│ąĖčüčéčĆčŗ $pc ąĖ $lr čāą║ą░ąĘčŗą▓ą░čÄčé ąĮą░ ąĘą░ą┤ą░čćčā FreeRTOS. ąÆčŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐ąŠč鹊ą║ą░ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ, ą┐ąŠčŹč鹊ą╝čā ą┤čĆčāą│ąĖąĄ ąĘą░ą┤ą░čćąĖ ą╝ąŠą│čāčé ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ. ą£čŗ ą╝ąŠąČąĄą╝ čüčĆą░ą▓ąĮąĖčéčī s_registered_tasks ąĖ s_fed_tasks, čćč鹊ą▒čŗ ąĮą░ą╣čéąĖ čéčā ąĘą░ą┤ą░čćčā, ą║ąŠč鹊čĆą░čÅ ąĘą░ą▓ąĖčüą╗ą░:
(gdb) p/x s_registered_tasks&~s_fed_tasks
$8 = 0x2
ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ąĘą░ą┤ą░čćą░ Task Id 1 ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ąŠąČąĖą┤ą░ąĮąĖąĖ ą╝čīčÄč鹥ą║čüą░ (ąĘą░ą▓ąĖčüą╗ą░). ąśąĘ čüą┐ąĖčüą║ą░ Task Id ą╝čŗ čāąĘąĮą░ąĄą╝, čćč鹊 čŹč鹊 ąĘą░ą┤ą░čćą░ Pong:
typedef enum
{
kWatchdogExampleTaskId_Ping = 0 ,
kWatchdogExampleTaskId_Pong,
kWatchdogExampleTaskId_Watchdog,
}eWatchdogExampleTaskId;
ąĢčüą╗ąĖ ąŠčéą╗ą░ą┤čćąĖą║ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą┐ąŠč鹊ą║ FreeRTOS, č鹊 ą╝ąŠąČąĮąŠ ą┐ąĄčĆąĄą║ą╗čÄčćąĖčéčīčüčÅ ą▓ čŹč鹊čé ą┐ąŠč鹊ą║, čćč鹊ą▒čŗ ą┐ąŠčüą╝ąŠčéčĆąĄčéčī čüč鹥ą║ ą▓čŗąĘąŠą▓ąŠą▓ (backtrace). ąÉą╗čīč鹥čĆąĮą░čéąĖą▓ąĮąŠ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĖąĮčüčéčĆčāą╝ąĄąĮčé čéąĖą┐ą░ Memfault, čćč鹊ą▒čŗ ą▓čŗčéą░čēąĖčé ą┤ą░ąĮąĮčŗąĄ ąĖ ąĘą░ą┐čāčüčéąĖčéčī ą░ąĮą░ą╗ąĖąĘ ą▓ ąŠą▒ą╗ą░ą║ąĄ.
(gdb) memfault coredump -r 0x20000000 262144
One moment please, capturing memory...
[...]
Are you currently at the start of an exception handler [y/n]?n
[...]
Cortex-M4 detected
Collected MPU config
Capturing RAM @ 0x20000000 (1048576 bytes)...
Captured RAM @ 0x20000000 (1048576 bytes)
Symbols have already been uploaded, skipping!
Coredump uploaded successfully!
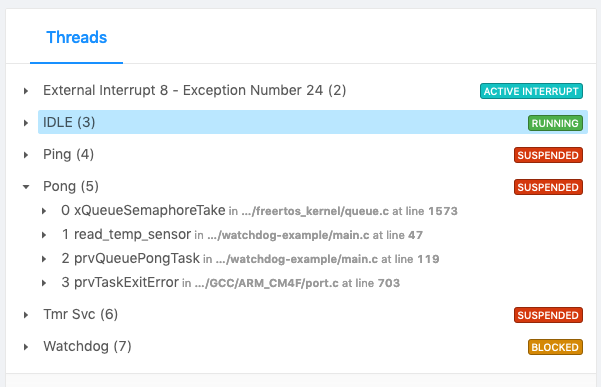
ąŚą░č鹥ą╝ ą▓ ąĖąĮč鹥čĆč乥ą╣čüąĄ Memfault Issue Detail ą╝ąŠąČąĮąŠ ą┐čĆąŠčüą╝ąŠčéčĆąĄčéčī ąĘą░ą┤ą░čćčā Pong ąĖ čāą▓ąĖą┤ąĄčéčī, čćč鹊 ąŠąĮą░ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮą░ ąĮą░ ąŠąČąĖą┤ą░ąĮąĖąĖ ą▓ ą▓čŗąĘąŠą▓ąĄ xQueueSemaphoreTake.
[ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ GDB Python ą┤ą╗čÅ ą┐čĆąĄą┤ąŠčéą▓čĆą░čēąĄąĮąĖčÅ ąŠčłąĖą▒ąŠčćąĮčŗčģ čüčĆą░ą▒ą░čéčŗą▓ą░ąĮąĖą╣ Software Watchdog ]
ąÜ čüąŠąČą░ą╗ąĄąĮąĖčÄ, ą▓ ąŠčéą╗ąĖčćąĖąĄ ąŠčé čéą░ą╣ą╝ąĄčĆą░ watchdog, ąĮąĄčé čüą┐ąŠčüąŠą▒ą░ ąŠčüčéą░ąĮąŠą▓ąĖčéčī čéą░ą║čéąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ čéą░ą╣ą╝ąĄčĆą░, ą║ąŠą│ą┤ą░ ą║ NRF52 ą┐ąŠą┤ą║ą╗čÄč湥ąĮ ąŠčéą╗ą░ą┤čćąĖą║. ąŁč鹊 ąĘąĮą░čćąĖčé, čćč鹊 ąĄčüą╗ąĖ ą╝čŗ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ąĖą╝ ą┐čĆąŠą│čĆą░ą╝ą╝čā ąŠčéą╗ą░ą┤čćąĖą║ąŠą╝ ąĮą░ ą▓čĆąĄą╝čÅ ą▒ąŠą╗čīčłąĄ 7 čüąĄą║čāąĮą┤, č鹊 ą┐ąŠą┐ą░ą┤ąĄą╝ ą▓ čüčĆą░ą▒ą░čéčŗą▓ą░ąĮąĖąĄ software watchdog ISR čüčĆą░ąĘčā ą┐ąŠčüą╗ąĄ ą▓ąŠąĘąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░. ąŁč鹊 ą╝ąŠąČąĮąŠ ą┐čĆąŠą▓ąĄčĆąĖčéčī:
(gdb) CTRL-C
[... ąŠąČąĖą┤ą░ąĮąĖąĄ ą▓ č鹥č湥ąĮąĖąĄ 7 čüąĄą║čāąĮą┤ ...]
(gdb) continue
Continuing.
Program received signal SIGTRAP, Trace/breakpoint trap.
0x00002bbc in watchdog_fault_handler_c (frame=0x20002a78) at
interrupt/example/watchdog-example/software_watchdog.c:81
81 HALT_IF_DEBUGGING();
ąŁč鹊 čéą░ čüąĖčéčāą░čåąĖčÅ, ą│ą┤ąĄ ą╝ąŠąČąĄčé ą┐ąŠą╝ąŠčćčī Python API ąŠčéą╗ą░ą┤čćąĖą║ą░ GDB (ą┐ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ GDB Python API čüą╝. [10]). ą£ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī Events API8 ą┤ą╗čÅ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą║ąĖ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ čéą░ą╣ą╝ąĄčĆą░, ą║ąŠą│ą┤ą░ čüąĖčüč鹥ą╝ą░ ą┐čĆąĖąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ, ąĖ čüąĮąŠą▓ą░ ąĘą░ą┐čāčüą║ą░čéčī čéą░ą╣ą╝ąĄčĆ, ą║ąŠą│ą┤ą░ čüąĖčüč鹥ą╝ą░ ą┐čĆąŠą┤ąŠą╗ąČą░ąĄčé ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ. ą¤čĆąĖą╝ąĄčĆ:
# gdb_resume_handlers.py try :
import gdb except ImportError :
raise Exception ("This script can only be run within gdb!" )
import struct
class Nrf52Timer0 :
TIMER0_TASKS_START_ADDR = 0x40008000
TIMER0_TASKS_STOP_ADDR = 0x40008004
@staticmethod
def _trigger_task (addr):
gdb. selected_inferior(). write_memory(addr, struct. pack("< I" , 1 ))
@classmethod
def start (cls):
print ("Resuming Software Watchdog" )
cls. _trigger_task(cls. TIMER0_TASKS_START_ADDR)
@classmethod
def stop (cls):
print ("Pausing Software Watchdog" )
cls. _trigger_task(cls. TIMER0_TASKS_STOP_ADDR)
def nrf52_debug_stop_handler (event):
Nrf52Timer0. stop()
def nrf52_debug_start_handler (event):
Nrf52Timer0. start()
gdb. events. stop. connect(nrf52_debug_stop_handler)
gdb. events. cont. connect(nrf52_debug_start_handler)
ąóąĄą┐ąĄčĆčī ą║ąŠą│ą┤ą░ ą╝čŗ ąŠą▒čĆą░čéąĖą╝čüčÅ ą║ GDB, ą╝ąŠąČąĮąŠ ą┤ąŠą▒ą░ą▓ąĖčéčī ą░čĆą│čāą╝ąĄąĮčé --ex="source gdb_resume_handlers.py", ąĖ čéą░ą╣ą╝ąĄčĆ ą▒čāą┤ąĄčé ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą┐čĆąĖąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čéčīčüčÅ ąŠčéą╗ą░ą┤čćąĖą║ąŠą╝ GDB, ą║ąŠą│ą┤ą░ ąŠąĮ ąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé ą┐čĆąŠą│čĆą░ą╝ą╝čā.
$ arm-none-eabi-gdb-py --eval-command="target remote localhost:2331" \
--ex="mon reset" --ex="load" --ex="mon reset" \
--ex="source gdb_resume_handlers.py" --se=build/nrf52.elf
Program received signal SIGTRAP, Trace/breakpoint trap.
main () at interrupt/example/watchdog-example/main.c:134
134 }
Pausing Software Watchdog
(gdb) c
Continuing.
Resuming Software Watchdog
[ą×čéą╗ą░ą┤ą║ą░ ąĘą░ą▓ąĖčüą░ąĮąĖą╣ ą▓ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĖ ]
ą¤ąŠčüą╝ąŠčéčĆąĖą╝, ą║ą░ą║ ą▒čāą┤ąĄčé čĆą░ą▒ąŠčéą░čéčī čüąĖčüč鹥ą╝ą░, ą║ąŠą│ą┤ą░ ąĘą░ą▓ąĖčüą░ąĮąĖąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą▓ č鹥ą╗ąĄ ISR:
(gdb) set g_watchdog_hang_config=4
(gdb) c
Continuing.
Resuming Software Watchdog
(gdb) p/a *frame
$2 = {
r0 = 0x3 < g_pfnVectors+3>,
r1 = 0x200001bc < ucHeap+84>,
r2 = 0xe000e100,
r3 = 0x1 < g_pfnVectors+1>,
r12 = 0x200003e0 < ucHeap+632>,
lr = 0xfffffffd,
return_address = 0xd0 < ExternalInt0_Handler>,
xpsr = 0x21000010
}
ąÉą┤čĆąĄčü ą▓ąŠąĘą▓čĆą░čéą░ čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ExternalInt0_Handler. ąśąĮčüą┐ąĄą║čåąĖčÅ ąĄą│ąŠ ą║ąŠą┤ą░ ą┐ąŠą║ą░ąČąĄčé, ą┐ąŠč湥ą╝čā ą┐čĆąŠąĖąĘąŠčłą╗ąŠ ąĘą░ą▓ąĖčüą░ąĮąĖąĄ:
void ExternalInt0_Handler (void )
{
while (1 ) {}
}
[ąĪąŠą▓ąĄčéčŗ ą▓ ą┐ąŠ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĄ ąĮą░ ARM Cortex-M ]
ąÆąŠčé ąŠą▒čēąĖąĄ ą┐čĆą░ą▓ąĖą╗ą░ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čüč鹊čĆąŠąČąĄą▓čŗčģ čéą░ą╣ą╝ąĄčĆąŠą▓ ąĮą░ cortex-M MCU:
ŌĆó ąŻą▒ąĄą┤ąĖč鹥čüčī, čćč鹊 ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ software watchdog handler čĆą░ą▒ąŠčéą░ąĄčé čü čüą░ą╝čŗą╝ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĮąŠ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░čéčī, ąĖ čćč鹊 ą▓čüąĄ ą┤čĆčāą│ąĖąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąĖą╝ąĄčÄčé ą┐čĆąĖąŠčĆąĖč鹥čé ąĮąĖąČąĄ ąĄą│ąŠ. ąæą╗ą░ą│ąŠą┤ą░čĆčÅ čŹč鹊ą╝čā ą│ą░čĆą░ąĮčéąĖčĆčāąĄčéčüčÅ, čćč鹊 ąĄčüą╗ąĖ ąĘą░ą▓ąĖčüą░ąĮąĖąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé ą▓ ą╗čÄą▒ąŠą╝ čĆą░ą▒ąŠč湥ą╝ ISR, ą║ąŠą┤ software handler ą▓čüąĄ ąĄčēąĄ ą▒čāą┤ąĄčé čĆą░ą▒ąŠčéą░čéčī, ąĖ ą╝ąŠąČąĮąŠ ą▒čāą┤ąĄčé ąŠčéčüą╗ąĄą┤ąĖčéčī, čćč鹊 ą┐ąŠčłą╗ąŠ ąĮąĄ čéą░ą║.
ŌĆó ąĢčüą╗ąĖ ą░čĆčģąĖč鹥ą║čéčāčĆą░ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ BASEPRI (čŹč鹊 ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą╗čÄą▒ąŠą╣ Cortex-M, ą║čĆąŠą╝ąĄ Cortex-M0), ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 __set_BASEPRI ą┤ą╗čÅ ą▓čģąŠą┤ą░ ą▓ ą║čĆąĖčéąĖč湥čüą║ąĖąĄ čüąĄą║čåąĖąĖ ąĖ ą▓čŗčģąŠą┤ą░ ąĖąĘ ąĮąĖčģ ą▒ąĄąĘ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą┐čĆčÅą╝ąŠą│ąŠ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąĘą░ą┐čĆąĄč鹊ą╝ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ __disable/__enable_irq(). ąóą░ą║ąĖą╝ čüą┐ąŠčüąŠą▒ąŠą╝ ą╝ąŠąČąĮąŠ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ISR "Software WatchdogŌĆØ ą▓čüąĄą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮ, ąĖ čüą╝ąŠąČąĄčé ą┐ąĄčĆąĄčģą▓ą░čéąĖčéčī ąĘą░ą▓ąĖčüą░ąĮąĖąĄ ą┤ą░ąČąĄ č鹊ą│ą┤ą░, ą║ąŠą│ą┤ą░ ąŠąĮąŠ ą┐čĆąŠąĖąĘąŠčłą╗ąŠ ą▓ ą║čĆąĖčéąĖč湥čüą║ąŠą╣ čüąĄą║čåąĖąĖ.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ (ARM exceptions) čüą╝. [11].
[ąĪą╗ąŠą▓ą░čĆąĖą║ ]
breakpoint č鹊čćą║ą░ ąŠčüčéą░ąĮąŠą▓ą░, čüą┐ąĄčåąĖą░ą╗čīąĮą░čÅ ą╝ąĄčéą║ą░ ą▓ ą║ąŠą┤ąĄ firmware, ą║ąŠč鹊čĆą░čÅ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ąŠčüčéą░ąĮąŠą▓ą║ąĄ ąŠčéą╗ą░ą┤čćąĖą║ąŠą╝ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ąŠą┤ą░ ą▓ čĆąĄą░ą╗čīąĮąŠą╝ ą▓čĆąĄą╝ąĄąĮąĖ.
ISR Interrupt Service Routine, ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ.
MCU MicroController Unit, ą╝ąĖą║čĆąŠą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ.
HRM Hardware Resource Management, čüąĖčüč鹥ą╝ą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą░ą┐ą┐ą░čĆą░čéąĮčŗą╝ąĖ čĆąĄčüčāčĆčüą░ą╝ąĖ.
RTL-ą▒ą╗ąŠą║ ą░ą▒ą▒čĆąĄą▓ąĖą░čéčāčĆą░ RTL ą┐ąĄčĆąĄą▓ąŠą┤ąĖčéčüčÅ ą║ą░ą║ Register-Transfer Level. ąŚą┤ąĄčüčī ą┐ąŠą┤ čŹčéąĖą╝ ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčéčüčÅ ąĮąĄą║ąĖą╣ 菹╗ąĄą║čéčĆąŠąĮąĮčŗą╣ ą▒ą╗ąŠą║, ą┤ąŠčüčéčāą┐ąĮčŗą╣ ą┤ą╗čÅ ą║ąŠą┤ą░ firmware č湥čĆąĄąĘ čćč鹥ąĮąĖąĄ/ąĘą░ą┐ąĖčüčī čĆąĄą│ąĖčüčéčĆąŠą▓ MCU.
UI User Interface, ąĖąĮč鹥čĆč乥ą╣čü ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ.
[ąĪčüčŗą╗ą║ąĖ ]
1 . A Guide to Watchdog Timers for Embedded Systems site:memfault.com.2 . Watchdog Timers site:maximintegrated.com.3 . memfault / interrupt site:github.com.4 . GNU Arm Embedded Toolchain Downloads site:developer.arm.com.5 . nRF52840 DK site:nordicsemi.com.6 . nRF52840 Product Specification site:nordicsemi.com.7 . J-Link GDB Server site:segger.com.8 . FreeRTOS: ą┐čĆą░ą║čéąĖč湥čüą║ąŠąĄ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ, čćą░čüčéčī 4 (čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čĆąĄčüčāčĆčüą░ą╝ąĖ) .9 . Built-in Functions for Memory Model Aware Atomic Operations site:gcc.gnu.org.10 . Automate Debugging with GDB Python API site:memfault.com.11 . A Practical guide to ARM Cortex-M Exception Handling site:memfault.com.12 . ąĪč鹊čĆąŠąČąĄą▓čŗąĄ čéą░ą╣ą╝ąĄčĆčŗ STM32F4 .