|
ąÆ čŹč鹊ą╣ čüčéą░čéčīąĄ (ą┐ąĄčĆąĄą▓ąŠą┤ ą░ą┐ąĮąŠčāčéą░ AN4031 [1]) ąŠą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ ą┐čĆčÅą╝ąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ (direct memory access, DMA), ą┤ąŠčüčéčāą┐ąĮąŠą│ąŠ ą▓ ą╝ąĖą║čĆąŠą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░čģ čüąĄčĆąĖą╣ STM32F2, STM32F4 ąĖ STM32F7 Series. ążčāąĮą║čåąĖąĖ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ DMA, ą░čĆčģąĖč鹥ą║čéčāčĆą░ čüąĖčüč鹥ą╝čŗ, ą╝ąĮąŠą│ąŠčüą╗ąŠą╣ąĮą░čÅ ą╝ą░čéčĆąĖčåą░ čłąĖąĮčŗ ąĖ čüąĖčüč鹥ą╝ą░ ą┐ą░ą╝čÅčéąĖ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé čłąĖčĆąŠą║ąŠą┐ąŠą╗ąŠčüąĮčāčÄ čüąĖčüč鹥ą╝čā ąŠą▒ą╝ąĄąĮą░ ą┤ą░ąĮąĮčŗą╝ąĖ ą╝ąĄąČą┤čā ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗą╝ąĖ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ąĖ ąĖ ąŠą▒ą╗ą░čüčéčÅą╝ąĖ ą┐ą░ą╝čÅčéąĖ, čü ą╝ą░ą╗čŗą╝ąĖ ąĘą░ą┤ąĄčƹȹ║ą░ą╝ąĖ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą╝ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖąĖ čüąĖčüč鹥ą╝čŗ.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą▓ čŹč鹊ą╝ ą┤ąŠą║čāą╝ąĄąĮč鹥 STM32F2, STM32F4 ąĖ STM32F7 ą┤ą╗čÅ ą║čĆą░čéą║ąŠčüčéąĖ ąŠą▒ąŠąĘąĮą░čćą░čÄčéčüčÅ ą║ą░ą║ "MCU" ąĖą╗ąĖ "ą╝ąĖą║čĆąŠą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ", ąĖ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ DMA ąŠą▒ąŠąĘąĮą░čćą░ąĄčéčüčÅ ą┐čĆąŠčüč鹊 ą║ą░ą║ "DMA". ąÆ ą║ą░č湥čüčéą▓ąĄ ą┐čĆąĖą╝ąĄčĆą░ ą┤ą╗čÅ ąĖą╗ą╗čÄčüčéčĆą░čåąĖąĖ ą▓čŗą▒čĆą░ąĮą░ ą┐ą╗ą░čéč乊čĆą╝ą░ STM32F4. ą¤ąŠą▓ąĄą┤ąĄąĮąĖąĄ DMA ą┤ą╗čÅ čüąĄčĆąĖą╣ STM32F2, STM32F4 ąĖ STM32F7 ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠąĄ, ąĄčüą╗ąĖ ąĮąĄ čāą║ą░ąĘą░ąĮąŠ ąĮąĄčćč鹊 ą┤čĆčāą│ąŠąĄ. ą¤ąĄčĆąĄą╝ąĄčēąĄąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ ą┐ąŠą┤ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄą╝ DMA ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĄą╣ ąĖą╗ąĖ ą┐ąĄčĆąĄą┤ą░č湥ą╣. ąÆčüąĄ ąĮąĄą┐ąŠąĮčÅčéąĮčŗąĄ č鹥čĆą╝ąĖąĮčŗ ąĖ čüąŠą║čĆą░čēąĄąĮąĖčÅ čüą╝. ą▓ ąĪą╗ąŠą▓ą░čĆąĖą║ąĄ čüčéą░čéčīąĖ [3].
ą¤čĆąĖ ąĖąĘčāč湥ąĮąĖąĖ čŹč鹊ą╣ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ čüą╗ąĄą┤čāąĄčé čéą░ą║ąČąĄ ąŠą▒čĆą░čēą░čéčīčüčÅ ą║ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ą░ą╝ MCU:
ŌĆó STM32F205/215 and STM32F207/217 reference manual (RM0033)
ŌĆó STM32F405/415, STM32F407/417, STM32F427/437 and STM32F429/439 reference manual (RM0090)
ŌĆó STM32F401xB/C and STM32F401xD/E reference manual (RM0368)
ŌĆó STM32F410 reference manual (RM0401)
ŌĆó STM32F411xC/E reference manual (RM0383)
ŌĆó STM32F412 reference manual (RM0402)
ŌĆó STM32F446xx reference manual (RM0390)
ŌĆó STM32F469xx and STM32F479xx reference manual (RM0386)
ŌĆó STM32F75xxx and STM32F74xxx reference manual (RM0385)
ŌĆó STM32F76xxx and STM32F77xxx reference manual (RM0410)
DMA ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé čüąŠą▒ąŠą╣ ą╝ąŠą┤čāą╗čī AMBA ą▓čŗčüąŠą║ąŠą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠą╣ čłąĖąĮčŗ (advanced high-performance bus, AHB), ą║ąŠč鹊čĆčŗą╣ čĆą░ą▒ąŠčéą░ąĄčé č湥čĆąĄąĘ 3 ą┐ąŠčĆčéą░ AHB: slave-ą┐ąŠčĆčé ą┤ą╗čÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ DMA, ąĖ ą┤ą▓ą░ master-ą┐ąŠčĆčéą░ (ą┐ąŠčĆčéčŗ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ąĖ ą┐ą░ą╝čÅčéąĖ), ą║ąŠč鹊čĆčŗąĄ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé DMA ąĖąĮąĖčåąĖąĖčĆąŠą▓ą░čéčī čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą╝ąĄąČą┤čā čĆą░ąĘą╗ąĖčćąĮčŗą╝ąĖ ą┐ąŠą┤čćąĖąĮąĄąĮąĮčŗą╝ąĖ ą╝ąŠą┤čāą╗čÅą╝ąĖ (ą┐ąĄčĆąĄą┤ą░čćąĖ ą┐ą░ą╝čÅčéčī-ą┐ą░ą╝čÅčéčī, ą┐ą░ą╝čÅčéčī-čāčüčéčĆąŠą╣čüčéą▓ąŠ ąĖ čāčüčéčĆąŠą╣čüčéą▓ąŠ-ą┐ą░ą╝čÅčéčī).
DMA ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąŠčüčāčēąĄčüčéą▓ą╗čÅčéčī čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą▓ č乊ąĮąŠą▓ąŠą╝ čĆąĄąČąĖą╝ąĄ, ą▒ąĄąĘ ą▓ą╝ąĄčłą░č鹥ą╗čīčüčéą▓ą░ čüąŠ čüč鹊čĆąŠąĮčŗ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Cortex-Mx (CPU). ąÆąŠ ą▓čĆąĄą╝čÅ čŹč鹊ą╣ ąŠą┐ąĄčĆą░čåąĖąĖ ąŠčüąĮąŠą▓ąĮąŠą╣ CPU ą╝ąŠąČąĄčé ą▓čŗą┐ąŠą╗ąĮčÅčéčī ą┤čĆčāą│ąĖąĄ ąĘą░ą┤ą░čćąĖ, ą┐čĆąĄčĆčŗą▓ą░čÅčüčī č鹊ą╗čīą║ąŠ ą▓ č鹊ą╝ čüą╗čāčćą░ąĄ, ą║ąŠą│ą┤ą░ čéčĆą░ąĮąĘą░ą║čåąĖčÅ ąĘą░ą║ąŠąĮčćąĖą╗ą░čüčī ąĖ ąĮąŠą▓čŗą╣ ą▒ą╗ąŠą║ ą┤ą░ąĮąĮčŗčģ čåąĄą╗ąĖą║ąŠą╝ ą┤ąŠčüčéčāą┐ąĄąĮ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ. ąæąŠą╗čīčłąĖąĄ ąŠą▒čŖąĄą╝čŗ ą┤ą░ąĮąĮčŗčģ ą╝ąŠą│čāčé ą▒čŗčéčī ą┐ąĄčĆąĄą┤ą░ąĮčŗ ą▒ąĄąĘ ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠą│ąŠ čāčģčāą┤čłąĄąĮąĖčÅ ąŠą▒čēąĄą╣ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ čüąĖčüč鹥ą╝čŗ. DMA ą▓ ąŠčüąĮąŠą▓ąĮąŠą╝ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ čåąĄąĮčéčĆą░ą╗čīąĮąŠą│ąŠ ą▒čāč乥čĆąĖąĘąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ čģčĆą░ąĮąĖą╗ąĖčēą░ (ąŠą▒čŗčćąĮąŠ ą▓ system SRAM) ą┤ą╗čÅ čĆą░ąĘą╗ąĖčćąĮčŗčģ ą╝ąŠą┤čāą╗ąĄą╣ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓. ąŁč鹊 čĆąĄčłąĄąĮąĖąĄ ą╝ąĄąĮąĄąĄ ą┤ąŠčĆąŠą│ąŠąĄ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą╝ąĖą║čĆąŠčüčģąĄą╝ ąĖ ą┐ąŠčéčĆąĄą▒ą╗ąĄąĮąĖčÅ čŹąĮąĄčĆą│ąĖąĖ ą▓ čüčĆą░ą▓ąĮąĄąĮąĖąĖ čü ą┤čĆčāą│ąĖą╝ąĖ čĆą░čüą┐čĆąŠčüčéčĆą░ąĮąĄąĮąĮčŗą╝ąĖ čĆąĄčłąĄąĮąĖčÅą╝ąĖ, ą│ą┤ąĄ ą║ą░ąČą┤ąŠąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ čéčĆąĄą▒čāąĄčé čüąŠąĘą┤ą░ąĮąĖčÅ čüąŠą▒čüčéą▓ąĄąĮąĮąŠą│ąŠ ą╗ąŠą║ą░ą╗čīąĮąŠą│ąŠ čģčĆą░ąĮąĖą╗ąĖčēą░ ą┤ą░ąĮąĮčŗčģ.
ąĪą▓ąŠą╣čüčéą▓ą░ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA. ą¤ąĄčĆąĄą┤ą░čćą░ DMA čģą░čĆą░ą║č鹥čĆąĖąĘčāąĄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĖą╝ąĖ ą┐ą░čĆą░ą╝ąĄčéčĆą░ą╝ąĖ:
ŌĆó ą¤ąŠč鹊ą║/ą║ą░ąĮą░ą╗ DMA (stream/channel).
ŌĆó ą¤čĆąĖąŠčĆąĖč鹥čé ą┐ąŠč鹊ą║ą░.
ŌĆó ąÉą┤čĆąĄčüą░ ąĖčüč鹊čćąĮąĖą║ą░ ąĖ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ŌĆó ąĀąĄąČąĖą╝ ą┐ąĄčĆąĄą┤ą░čćąĖ (transfer mode).
ŌĆó ąĀą░ąĘą╝ąĄčĆ ą┐ąĄčĆąĄą┤ą░čćąĖ (č鹊ą╗čīą║ąŠ ą║ąŠą│ą┤ą░ DMA čāą┐čĆą░ą▓ą╗čÅąĄčé ą┐ąŠč鹊ą║ąŠą╝).
ŌĆó ąÉą┤čĆąĄčü ąĖčüč鹊čćąĮąĖą║ą░/ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ąĖąĮą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄčéčüčÅ ąĖą╗ąĖ ąĮąĄ ąĖąĮą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄčéčüčÅ.
ŌĆó ą©ąĖčĆąĖąĮą░ ą┤ą░ąĮąĮčŗčģ ąĖčüč鹊čćąĮąĖą║ą░ ąĖ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ŌĆó ąóąĖą┐ čéčĆą░ąĮąĘą░ą║čåąĖąĖ.
ŌĆó ąĀąĄąČąĖą╝ FIFO.
ŌĆó ąĀą░ąĘą╝ąĄčĆ ą┐ą░ą║ąĄčéą░ ąĖčüč鹊čćąĮąĖą║ą░/ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ŌĆó ąĀąĄąČąĖą╝ ą┤ą▓ąŠą╣ąĮąŠą╣ ą▒čāč乥čĆąĖąĘą░čåąĖąĖ.
ŌĆó ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąŠč鹊ą║ąŠą╝.
ąÆ MCU ą▓čüčéčĆąŠąĄąĮąŠ ą┤ą▓ą░ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ DMA (DMA1 ąĖ DMA2), ąĖ čā ą║ą░ąČą┤ąŠą│ąŠ ąĖąĘ ąĮąĖčģ ąĄčüčéčī ą┤ą▓ą░ ą┐ąŠčĆčéą░ - ąŠą┤ąĖąĮ ą┐ąŠčĆčé ą┤ą╗čÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ąĖ ąŠą┤ąĖąĮ ą┐ąŠčĆčé ą┤ą╗čÅ ą┐ą░ą╝čÅčéąĖ. ą×ą▒ą░ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ ą╝ąŠą│čāčé čĆą░ą▒ąŠčéą░čéčī ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ. ąØą░ čĆąĖčü. 1 ą┐ąŠą║ą░ąĘą░ąĮą░ ą▒ą╗ąŠą║-čüčģąĄą╝ą░ DMA.
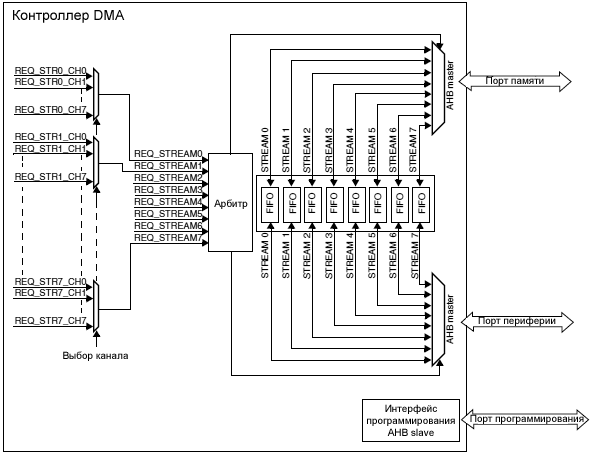
ąĀąĖčü. 1. ąĪčģąĄą╝ą░ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ DMA.
ą¤ąŠč鹊ą║ąĖ/ą║ą░ąĮą░ą╗čŗ DMA. ąÆ ą║ą░ąČą┤ąŠą╝ ąĖąĘ ą┤ą▓čāčģ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą▓ DMA ąĖą╝ąĄąĄčéčüčÅ ą┐ąŠ 8 ą┐ąŠč鹊ą║ąŠą▓ (stream), ą▓čüąĄą│ąŠ ą▓ čüčāą╝ą╝ąĄ ą┐ąŠą╗čāčćą░ąĄčéčüčÅ 16. ąÜą░ąČą┤čŗą╣ ąĖąĘ ą┐ąŠč鹊ą║ąŠą▓ ą▓čŗą┤ąĄą╗čÅąĄčéčüčÅ ą┤ą╗čÅ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÅ ąĘą░ą┐čĆąŠčüąŠą▓ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ ąŠą┤ąĮąŠą│ąŠ ąĖą╗ąĖ ą▒ąŠą╗čīčłąĄą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓.
ąÜą░ąČą┤čŗą╣ ąĖąĘ ą┐ąŠč鹊ą║ąŠą▓ ąĖą╝ąĄąĄčé ą▓čüąĄą│ąŠ ą┤ąŠ 8 ą▓čŗą▒ąĖčĆą░ąĄą╝čŗčģ ą║ą░ąĮą░ą╗ąŠą▓ (ąĘą░ą┐čĆąŠčüąŠą▓). ąŁč鹊čé ą▓čŗą▒ąŠčĆ ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄčéčüčÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ, čćč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗą╝ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ ąĖąĮąĖčåąĖąĖčĆąŠą▓ą░čéčī ąĘą░ą┐čĆąŠčüčŗ DMA. ąĀąĖčü. 2 ąŠą┐ąĖčüčŗą▓ą░ąĄčé ą▓čŗą▒ąŠčĆ ą║ą░ąĮą░ą╗ą░ (channel) ą┤ą╗čÅ ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ą┐ąŠč鹊ą║ą░ (stream).
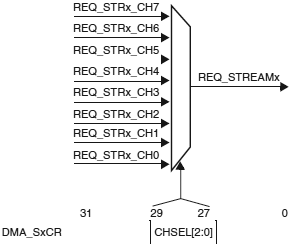
ąĀąĖčü. 2. ąÆčŗą▒ąŠčĆ ą║ą░ąĮą░ą╗ą░.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąĮą░ ą┐ąŠč鹊ą║ąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą░ą║čéąĖą▓ąĄąĮ č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ ą║ą░ąĮą░ą╗/ąĘą░ą┐čĆąŠčü. ąæąŠą╗čīčłąĄ ąŠą┤ąĮąŠą│ąŠ čĆą░ąĘčĆąĄčłąĄąĮąĮąŠą│ąŠ ą┐ąŠč鹊ą║ą░ ąĮąĄ ą┤ąŠą╗ąČąĮąŠ ąŠą▒čüą╗čāąČąĖą▓ą░čéčī ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ ąĘą░ą┐čĆąŠčü ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░.
ąóą░ą▒ą╗ąĖčåčŗ 1 ąĖ 2 ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčé ąŠč鹊ą▒čĆą░ąČąĄąĮąĖąĄ DMA1/DMA2 ąĘą░ą┐čĆąŠčüąŠą▓ STM32F427/STM32F437 ąĖ STM32F429/STM32F439. ąŁčéąĖ čéą░ą▒ą╗ąĖčåčŗ ą┤ą░čÄčé ą┤ąŠčüčéčāą┐ąĮčāčÄ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÄ ą┐ąŠč鹊ą║ąŠą▓/ą║ą░ąĮą░ą╗ąŠą▓ DMA ą┐čĆąŠčéąĖą▓ ąĘą░ą┐čĆąŠčüąŠą▓ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓.
ąóą░ą▒ą╗ąĖčåą░ 1. ą¤čĆąĖą▓čÅąĘą║ą░ ąĘą░ą┐čĆąŠčüąŠą▓ DMA1 ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ STM32F427/437 ąĖ STM32F429/439.
| REQ |
Stream0 |
Stream1 |
Stream2 |
Stream3 |
Stream4 |
Stream5 |
Stream6 |
Stream7 |
| Channel0 |
SPI3_RX |
- |
SPI3_RX |
SPI2_RX |
SPI2_TX |
SPI3_TX |
- |
SPI3_TX |
| Channel1 |
I2C1_RX |
- |
TIM7_UP |
- |
TIM7_UP |
I2C1_RX |
I2C1_TX |
I2C1_TX |
| Channel2 |
TIM4_CH1 |
- |
I2S3_EXT_RX |
TIM4_CH2 |
I2S2_EXT_TX |
I2S3_EXT_TX |
TIM4_UP |
TIM4_CH3 |
| Channel3 |
I2S3_EXT_RX |
TIM2_UP
TIM2_CH3 |
I2C3_RX |
I2S2_EXT_RX |
I2C3_TX |
TIM2_CH1 |
TIM2_CH2
TIM2_CH4 |
TIM2_UP
TIM2_CH4 |
| Channel4 |
UART5_RX |
USART3_RX |
UART4_RX |
USART3_TX |
UART4_TX |
USART2_RX |
USART2_TX |
UART5_TX |
| Channel5 |
UART8_TX |
UART7_TX |
TIM3_CH4
TIM3_UP |
UART7_RX |
TIM3_CH1
TIM3_TRIG |
TIM3_CH2 |
UART8_RX |
TIM3_CH3 |
| Channel6 |
TIM5_CH3
TIM5_UP |
TIM5_CH4
TIM5_TRIG |
TIM5_CH1 |
TIM5_CH4
TIM5_TRIG |
TIM5_CH2 |
- |
TIM5_UP |
- |
| Channel7 |
- |
TIM6_UP |
I2C2_RX |
I2C2_RX |
USART3_TX |
DAC1 |
DAC2 |
I2C2_TX |
ąóą░ą▒ą╗ąĖčåą░ 2. ą¤čĆąĖą▓čÅąĘą║ą░ ąĘą░ą┐čĆąŠčüąŠą▓ DMA2 ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ STM32F427/437 ąĖ STM32F429/439.
| REQ |
Stream0 |
Stream1 |
Stream2 |
Stream3 |
Stream4 |
Stream5 |
Stream6 |
Stream7 |
| Channel0 |
ADC1 |
SAI1_A |
TIM8_CH1
TIM8_CH2
TIM8_CH3 |
SAI1_A |
ADC1 |
SAI1_B |
TIM1_CH1
TIM1_CH2
TIM1_CH3 |
- |
| Channel1 |
- |
DCMI |
ADC2 |
ADC2 |
SAI1_B |
SPI6_TX |
SPI6_RX |
DCMI |
| Channel2 |
ADC3 |
ADC3 |
- |
SPI5_RX |
SPI5_TX |
CRYP_OUT |
CRYP_IN |
HASH_IN |
| Channel3 |
SPI1_RX |
- |
SPI1_RX |
SPI1_TX |
- |
SPI1_TX |
- |
- |
| Channel4 |
SPI4_RX |
SPI4_TX |
USART1_RX |
SDIO |
- |
USART1_RX |
SDIO |
UART1_TX |
| Channel5 |
- |
UART6_RX |
USART6_RX |
SPI4_RX |
SPI4_TX |
- |
USART6_TX |
USART6_TX |
| Channel6 |
TIM1_TRIG |
TIM1_CH1 |
TIM1_CH2 |
TIM1_CH1 |
TIM1_CH4
TIM1_TRIG
TIM1_COM |
TIM1_UP |
TIM1_CH3 |
- |
| Channel7 |
- |
TIM8_UP |
TIM8_CH1 |
TIM8_CH2 |
TIM8_CH3 |
SPI5_RX |
SPI5_TX |
TIM8_CH4
TIM8_TRIG
TIM8_COM |
ą×č鹊ą▒čĆą░ąČąĄąĮąĖąĄ ąĘą░ą┐čĆąŠčüąŠą▓ STM32F2/F4/F7 DMA čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮąŠ čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čćč鹊 ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÄ ą┤ą░ąĄčéčüčÅ ą▒ąŠą╗čīčłąĄ ą│ąĖą▒ą║ąŠčüčéąĖ ą┤ą╗čÅ ą┐čĆąĖą▓čÅąĘą║ąĖ ą║ą░ąČą┤ąŠą│ąŠ ąĘą░ą┐čĆąŠčüą░ DMA ą┤ą╗čÅ čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ ąĘą░ą┐čĆąŠčüą░ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ąŠ, ąĖ ą▒ąŠą╗čīčłą░čÅ čćą░čüčéčī čüčåąĄąĮą░čĆąĖąĄą▓ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą┐ąŠą║čĆčŗą▓ą░ąĄčéčüčÅ ą╝čāą╗čīčéąĖą┐ą╗ąĄą║čüąĖčĆąŠą▓ą░ąĮąĖąĄą╝ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖčģ ą┐ąŠč鹊ą║ąŠą▓ DMA ąĖ ą║ą░ąĮą░ą╗ąŠą▓. ąĪą╝. čéą░ą▒ą╗ąĖčåčŗ ąŠč鹊ą▒čĆą░ąČąĄąĮąĖčÅ DMA1/DMA2 ą▓ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ą░čģ ą┐ąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╝ MCU (ą▓čĆąĄąĘą║ą░ ą▓čŗčłąĄ "ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮą░čÅ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖčÅ").
ą¤čĆąĖąŠčĆąĖč鹥čé ą┐ąŠč鹊ą║ą░. ąŻ ą║ą░ąČą┤ąŠą│ąŠ ą┐ąŠčĆčéą░ DMA ąĖą╝ąĄąĄčéčüčÅ ą░čĆą▒ąĖčéčĆ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓ ą╝ąĄąČą┤čā čĆą░ąĘąĮčŗą╝ąĖ ą┐ąŠč鹊ą║ą░ą╝ąĖ DMA. ą¤čĆąĖąŠčĆąĖč鹥čé ą┐ąŠč鹊ą║ą░ ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄčéčüčÅ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ (ą▓čüąĄą│ąŠ ąĖą╝ąĄąĄčéčüčÅ 4 čāčĆąŠą▓ąĮčÅ ą┐čĆąĖąŠčĆąĖč鹥čéą░). ąĢčüą╗ąĖ 2 ąĖą╗ąĖ ą▒ąŠą╗čīčłąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąŠč鹊ą║ąŠą▓ DMA ąĖą╝ąĄčÄčé ąŠą┤ąĖąĮą░ą║ąŠą▓čŗą╣ čāčĆąŠą▓ąĄąĮčī ą┐čĆąĖąŠčĆąĖč鹥čéą░, č鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą░ą┐ą┐ą░čĆą░čéąĮčŗą╣ ą┐čĆąĖąŠčĆąĖč鹥čé (ą┐ąŠč鹊ą║ 0 ąĖą╝ąĄąĄčé ą┐čĆąĖąŠčĆąĖč鹥čé ąĮą░ą┤ ą┐ąŠč鹊ą║ąŠą╝ 1, ąĖ čé. ą┐.).
ąÉą┤čĆąĄčüą░ ąĖčüč鹊čćąĮąĖą║ą░ ąĖ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ąóčĆą░ąĮąĘą░ą║čåąĖčÅ DMA ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ ą░ą┤čĆąĄčüąŠą╝ ąĖčüč鹊čćąĮąĖą║ą░ ąĖ ą░ą┤čĆąĄčüąŠą╝ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ą×ą▒ą░ čŹčéąĖčģ ą░ą┤čĆąĄčüą░ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą▓ ą┐čĆąĄą┤ąĄą╗ą░čģ ą┤ąĖą░ą┐ą░ąĘąŠąĮąŠą▓ čłąĖąĮ AHB ąĖ APB, ąĖ ą░ą┤čĆąĄčü ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓čŗčĆąŠą▓ąĮąĄąĮ ąĮą░ čĆą░ąĘą╝ąĄčĆ čéčĆą░ąĮąĘą░ą║čåąĖąĖ.
ąĀąĄąČąĖą╝ čéčĆą░ąĮąĘą░ą║čåąĖąĖ. DMA ą╝ąŠąČąĄčé ąŠčüčāčēąĄčüčéą▓ą╗čÅčéčī 3 čĆą░ąĘąĮčŗčģ čĆąĄąČąĖą╝ą░ ą┐ąĄčĆąĄą┤ą░čćąĖ:
ŌĆó ąśąĘ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ą▓ ą┐ą░ą╝čÅčéčī.
ŌĆó ąśąĘ ą┐ą░ą╝čÅčéąĖ ą▓ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ.
ŌĆó ąśąĘ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ ą▓ ą┤čĆčāą│čāčÄ ąŠą▒ą╗ą░čüčéčī ą┐ą░ą╝čÅčéąĖ (čéą░ą║ąŠą╣ čĆąĄąČąĖą╝ ą┐ąĄčĆąĄą┤ą░čćąĖ ą╝ąŠąČąĄčé čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī č鹊ą╗čīą║ąŠ DMA2, ąĖ ą▓ ąĮąĄą╝ ąĮąĄ ą┤ąŠąĘą▓ąŠą╗čÅčÄčéčüčÅ čĆąĄąČąĖą╝čŗ circular ąĖ direct).
ąĀą░ąĘą╝ąĄčĆ čéčĆą░ąĮąĘą░ą║čåąĖąĖ. ąöąŠą╗ąČąĄąĮ ą▒čŗčéčī ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąŠ ąĘąĮą░č湥ąĮąĖąĄ čĆą░ąĘą╝ąĄčĆą░ čéčĆą░ąĮąĘą░ą║čåąĖąĖ, ą║ąŠą│ą┤ą░ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą╝ ą┐ąŠč鹊ą║ą░ čÅą▓ą╗čÅąĄčéčüčÅ DMA. ążą░ą║čéąĖč湥čüą║ąĖ čŹč鹊 ąĘąĮą░č湥ąĮąĖąĄ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ąŠą▒čŖąĄą╝ ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗąĄ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą┐ąĄčĆąĄą╝ąĄčēąĄąĮčŗ ąĖąĘ ąĖčüč鹊čćąĮąĖą║ą░ (source) ą▓ ą╝ąĄčüč鹊 ąĮą░ąĘąĮą░č湥ąĮąĖčÅ (destination).
ąĀą░ąĘą╝ąĄčĆ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ ąĘąĮą░č湥ąĮąĖąĄą╝ ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_SxNDTR ąĖ čłąĖčĆąĖąĮąŠą╣ ą┤ą░ąĮąĮčŗčģ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░. ąÆ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą┐čĆąĖąĮčÅč鹊ą│ąŠ ąĘą░ą┐čĆąŠčüą░ (burst ąĖą╗ąĖ single), ąĘąĮą░č湥ąĮąĖąĄ čĆą░ąĘą╝ąĄčĆą░ čéčĆą░ąĮąĘą░ą║čåąĖąĖ čāą╝ąĄąĮčīčłą░ąĄčéčüčÅ ąĮą░ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąĄčĆąĄą┤ą░ąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ.
ąśąĮą║čĆąĄą╝ąĄąĮčé ą░ą┤čĆąĄčüą░ ąĖčüč鹊čćąĮąĖą║ą░/ą╝ąĄčüčéą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ą£ąŠąČąĮąŠ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░čéčī DMA čéą░ą║, čćč鹊 ą▓ ą║ą░ąČą┤ąŠą╣ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą┤ą░ąĮąĮčŗčģ ą▒čāą┤ąĄčé ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ąĖąĮą║čĆąĄą╝ąĄąĮčéąĖčĆąŠą▓ą░čéčīčüčÅ ą░ą┤čĆąĄčü ąĖčüč鹊čćąĮąĖą║ą░ ąĖ/ąĖą╗ąĖ ą╝ąĄčüčéą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ (source address, destination address).
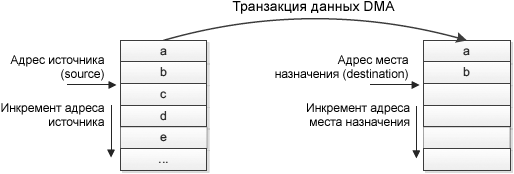
ąĀąĖčü. 3. ąśąĮą║čĆąĄą╝ąĄąĮčé ą░ą┤čĆąĄčüą░ source ąĖ destination čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA.
ą©ąĖčĆąĖąĮą░ ą┤ą░ąĮąĮčŗčģ ąĖčüč鹊čćąĮąĖą║ą░ ąĖ ą╝ąĄčüčéą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ą©ąĖčĆąĖąĮą░ (čĆą░ąĘčĆčÅą┤ąĮąŠčüčéčī) ą┤ą░ąĮąĮčŗčģ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮą░ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ŌĆó Byte (ą▒ą░ą╣čé, 8 ą▒ąĖčé).
ŌĆó Half-word (ą┐ąŠą╗ąŠą▓ąĖąĮą░ čüą╗ąŠą▓ą░, 16 ą▒ąĖčé).
ŌĆó Word (čüą╗ąŠą▓ąŠ, 32 ą▒ąĖčéą░).
ąóąĖą┐čŗ čéčĆą░ąĮąĘą░ą║čåąĖą╣. ąĪčāčēąĄčüčéą▓čāčÄčé čüą╗ąĄą┤čāčÄčēąĖąĄ čéąĖą┐čŗ (čĆąĄąČąĖą╝čŗ) ą┐ąĄčĆąĄą┤ą░čć DMA:
Circular mode: ą▓ čŹč鹊ą╝ čĆąĄąČąĖą╝ąĄ ą┤ąŠčüčéčāą┐ąĮą░ ąŠą▒čĆą░ą▒ąŠčéą║ą░ ą║ąŠą╗čīčåąĄą▓čŗčģ ą▒čāč乥čĆąŠą▓ ąĖ ąĮąĄą┐čĆąĄčĆčŗą▓ąĮčŗčģ ą┐ąŠč鹊ą║ąŠą▓ ą┤ą░ąĮąĮčŗčģ (č鹊ą│ą┤ą░ čĆąĄą│ąĖčüčéčĆ DMA_SxNDTR ą┐ąĄčĆąĄąĘą░ą│čĆčāąČą░ąĄčéčüčÅ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ čĆą░ąĮąĄąĄ ąĘą░ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĮčŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝).
Normal mode: ą║ą░ą║ č鹊ą╗čīą║ąŠ ąĘąĮą░č湥ąĮąĖąĄ čĆąĄą│ąĖčüčéčĆą░ DMA_SxNDTR ą┤ąŠčüčéąĖą│ąĮąĄčé 0, ą┐ąŠč鹊ą║ ąĘą░ą┐čĆąĄčēą░ąĄčéčüčÅ (ą▒ąĖčé EN ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_SxCR čüčéą░ąĮąŠą▓ąĖčéčüčÅ čĆą░ą▓ąĮčŗą╝ 0).
ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ DMA ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ ą┤ą╗čÅ ą┐čĆąŠąĖą│čĆčŗą▓ą░ąĮąĖčÅ č湥čĆąĄąĘ DAC ąĮąĄą▒ąŠą╗čīčłąŠą│ąŠ ą▒čāč乥čĆą░ aEscalator8bit ą▓ čåąĖą║ą╗ąĖč湥čüą║ąŠą╝ (Circular) čĆąĄąČąĖą╝ąĄ. ą¤ąŠčüą╗ąĄ ą▓čŗąĘąŠą▓ą░ čäčāąĮą║čåąĖąĖ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ MX_DAC_Init čüąĖą│ąĮą░ą╗ ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ąĮą░ ą▓čŗčģąŠą┤ąĄ ą║ą░ąĮą░ą╗ą░ 1 DAC ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ, ą▒ąĄąĘ čāčćą░čüčéąĖčÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
DAC_HandleTypeDef hdac;
DMA_HandleTypeDef hdma_dac1;
const uint8_t aEscalator8bit[6] = {0x0, 0x33, 0x66, 0x99, 0xCC, 0xFF};
// ąÜąŠąĮčäąĖą│čāčĆąĖčĆčāąĄčé ą┤ą╗čÅ ą”ąÉą¤ čéą░ą║čéąĖčĆąŠą▓ą░ąĮąĖąĄ, ą┐ąŠč鹊ą║
// ąĖ ą║ą░ąĮą░ą╗ DMA, ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ, ąĮąŠąČą║čā ą┐ąŠčĆčéą░
// ą┤ą╗čÅ ą▓čŗą▓ąŠą┤ą░ ąĘą▓čāą║ą░, ąĘą░ą┐čāčüą║ą░ąĄčé DMA.
void MX_DAC_Init(void)
{
DAC_ChannelConfTypeDef sConfig = {0};
GPIO_InitTypeDef GPIO_InitStruct = {0};
// ąÜąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ čéą░ą╣ą╝ąĄčĆą░, ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖąĄ ą║ąŠč鹊čĆąŠą│ąŠ čüą╗čāąČąĖčé
// čüąĖą│ąĮą░ą╗ąŠą╝ čéčĆąĖą│ą│ąĄčĆą░ ą┤ą╗čÅ DMA, čćč鹊ą▒čŗ ą┐ąĄčĆąĄą┤ą░čéčī ąŠč湥čĆąĄą┤ąĮčāčÄ
// ą▓čŗą▒ąŠčĆą║čā čüąĖą│ąĮą░ą╗ą░ ąĖąĘ ą▒čāč乥čĆą░:
TIM7_Config();
// ą×ą▒čēą░čÅ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ ą”ąÉą¤:
hdac.Instance = DAC;
// ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ čéą░ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ DAC ąĖ GPIOA:
__HAL_RCC_DAC_CLK_ENABLE();
__HAL_RCC_GPIOA_CLK_ENABLE();
/** ąÜąŠąĮčäąĖą│čāčĆą░čåąĖčÅ ą▓čŗčģąŠą┤ą░ DAC GPIO
PA4 ------> DAC_OUT1 */
GPIO_InitStruct.Pin = TRC_OUT_Pin;
GPIO_InitStruct.Mode = GPIO_MODE_ANALOG;
GPIO_InitStruct.Pull = GPIO_NOPULL;
HAL_GPIO_Init(TRC_OUT_GPIO_Port, &GPIO_InitStruct);
// ąśąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ DAC DMA:
hdma_dac1.Instance = DMA1_Stream5;
hdma_dac1.Init.Channel = DMA_CHANNEL_7;
hdma_dac1.Init.Direction = DMA_MEMORY_TO_PERIPH;
hdma_dac1.Init.PeriphInc = DMA_PINC_DISABLE;
hdma_dac1.Init.MemInc = DMA_MINC_ENABLE;
//hdma_dac1.Init.PeriphDataAlignment = DMA_PDATAALIGN_HALFWORD;
//hdma_dac1.Init.MemDataAlignment = DMA_MDATAALIGN_HALFWORD;
hdma_dac1.Init.PeriphDataAlignment = DMA_PDATAALIGN_BYTE;
hdma_dac1.Init.MemDataAlignment = DMA_MDATAALIGN_BYTE;
// ąÆčŗą▒ąŠčĆ čĆąĄąČąĖą╝ą░ DMA_NORMAL ąĘą░ą┐čāčüčéąĖčé ąŠą┤ąĮąŠą║čĆą░čéąĮčāčÄ čéčĆą░ąĮąĘą░ą║čåąĖčÄ, ą┐ąŠčüą╗ąĄ
// ą║ąŠč鹊čĆąŠą╣ č乊čĆą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ čüąĖą│ąĮą░ą╗ą░ ąŠčüčéą░ąĮąŠą▓ąĖčéčüčÅ:
//hdma_dac1.Init.Mode = DMA_NORMAL;
// ąÆčŗą▒ąŠčĆ čĆąĄąČąĖą╝ą░ DMA_CIRCULAR ąĘą░ą┐čāčüčéąĖčé ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠ ą┐ąŠą▓č鹊čĆčÅčÄčēąĖąĄčüčÅ
// čéčĆą░ąĮąĘą░ą║čåąĖąĖ. ąŁč鹊 čĆą░ą▒ąŠčéą░ąĄčé ą┐ąŠ ą┐čĆąĖąĮčåąĖą┐čā "ąĘą░ą┐čāčüčéąĖą╗ ąĖ ąĘą░ą▒čŗą╗",
// ą▒ąŠą╗čīčłąĄ čāčćą░čüčéąĖąĄ ą┐čĆąŠčåąĄčüčüąŠčĆąĄ ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ. ąöą░ąČąĄ ąŠčüčéą░ąĮąŠą▓ą║ą░
// ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą▓ ąŠčéą╗ą░ą┤čćąĖąĄ ąĮąĄ ąŠčüčéą░ąĮąŠą▓ąĖčé č乊čĆą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ čüąĖą│ąĮą░ą╗ą░:
hdma_dac1.Init.Mode = DMA_CIRCULAR;
hdma_dac1.Init.Priority = DMA_PRIORITY_VERY_HIGH;
hdma_dac1.Init.FIFOMode = DMA_FIFOMODE_DISABLE;
hdma_dac1.Init.FIFOThreshold = DMA_FIFO_THRESHOLD_HALFFULL;
hdma_dac1.Init.MemBurst = DMA_MBURST_SINGLE;
hdma_dac1.Init.PeriphBurst = DMA_PBURST_SINGLE;
if (HAL_DMA_Init(&hdma_dac1) != HAL_OK)
{
Error_Handler();
}
// ą¤čĆąĖą▓čÅąĘą║ą░ DMA ą║ ą║ą░ąĮą░ą╗čā DAC:
__HAL_LINKDMA(hdac, DMA_Handle1, hdma_dac1);
// ąÜąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ ą▓čŗčģąŠą┤ą░ OUT1 ąĖ čéčĆąĖą│ą│ąĄčĆą░ ą┤ą╗čÅ ą”ąÉą¤:
sConfig.DAC_Trigger = DAC_TRIGGER_T7_TRGO;
sConfig.DAC_OutputBuffer = DAC_OUTPUTBUFFER_ENABLE;
if (HAL_DAC_ConfigChannel(&hdac, &sConfig, DAC_CHANNEL_1) != HAL_OK)
{
Error_Handler();
}
// ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ DAC Channel1 ąĖ čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ čü ąĮąĖą╝ DMA:
if(HAL_DAC_Start_DMA(&hdac,
DAC_CHANNEL_1,
(uint32_t*)aEscalator8bit,
6, // sizeof(aEscalator8bit)
DAC_ALIGN_8B_R) != HAL_OK)
{
// ą×čłąĖą▒ą║ą░ ąĘą░ą┐čāčüą║ą░ DMA
Error_Handler();
}
}
ąĀąĄąČąĖą╝ DMA FIFO. ąŻ ą║ą░ąČą┤ąŠą│ąŠ ą┐ąŠč鹊ą║ą░ ąĄčüčéčī ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗą╣ FIFO ąĖąĘ 4 čüą╗ąŠą▓ (4 * 32 ą▒ąĖčéą░) ąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄą╝čŗą╣ čāčĆąŠą▓ąĄąĮčī ą┐ąŠčĆąŠą│ą░ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ: 1/4, 1/2, 3/4 ąĖą╗ąĖ full. ąŁč鹊čé FIFO ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą▓čĆąĄą╝ąĄąĮąĮąŠą│ąŠ čģčĆą░ąĮąĄąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ, ą┐ąŠčüčéčāą┐ą░čÄčēąĖčģ ąŠčé ąĖčüč鹊čćąĮąĖą║ą░ (source), ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ąŠąĮąĖ ą┐ąĄčĆąĄą┤ą░čÄčéčüčÅ ą▓ ą╝ąĄčüč鹊 ąĮą░ąĘąĮą░č湥ąĮąĖčÅ (destination).
DMA FIFO ą╝ąŠąČąĄčé ą▒čŗčéčī čĆą░ąĘčĆąĄčłąĄąĮ ąĖą╗ąĖ ąĘą░ą┐čĆąĄčēąĄąĮ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ. ąĢčüą╗ąĖ FIFO ąĘą░ą┐čĆąĄčēąĄąĮ, ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čĆąĄąČąĖą╝ Direct. ąĢčüą╗ąĖ FIFO čĆą░ąĘčĆąĄčłąĄąĮ, ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ čĆąĄąČąĖą╝ čāą┐ą░ą║ąŠą▓ą║ąĖ/čĆą░čüą┐ą░ą║ąŠą▓ą║ąĖ ą┤ą░ąĮąĮčŗčģ (data packing/unpacking) ąĖ/ąĖą╗ąĖ ą┐ą░ą║ąĄčéąĮčŗą╣ (burst) čĆąĄąČąĖą╝. ąÜąŠąĮčäąĖą│čāčĆąĖčĆčāąĄą╝čŗą╣ ą┐ąŠčĆąŠą│ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ DMA FIFO ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ą▓čĆąĄą╝čÅ ąĘą░ą┐čĆąŠčüą░ ą┐ąŠčĆčéą░ ą┐ą░ą╝čÅčéąĖ DMA.
ąöąŠčüč鹊ąĖąĮčüčéą▓ą░ DMA FIFO čüą╗ąĄą┤čāčÄčēąĖąĄ:
ŌĆó ąŻą╝ąĄąĮčīčłą░ąĄčéčüčÅ ą┤ąŠčüčéčāą┐ ą║ SRAM, čćč鹊 ą┤ą░ąĄčé ą▒ąŠą╗čīčłąĄ ą▓čĆąĄą╝ąĄąĮąĖ ą┤čĆčāą│ąĖą╝ ą╝ą░čüč鹥čĆą░ą╝ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą╝ą░čéčĆąĖčåąĄ čłąĖąĮčŗ, ą▒ąĄąĘ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ą║ąŠąĮą║čāčĆąĄąĮčåąĖąĖ.
ŌĆó ą¤čĆąŠą│čĆą░ą╝ą╝ąĄ ą┤ąŠąĘą▓ąŠą╗ąĄąĮąŠ ą▓čŗą┐ąŠą╗ąĮčÅčéčī ą┐ą░ą║ąĄčéąĮčŗąĄ (burst) čéčĆą░ąĮąĘą░ą║čåąĖąĖ, ą║ąŠč鹊čĆčŗąĄ ąŠą┐čéąĖą╝ąĖąĘąĖčĆčāčÄčé ą┐ąŠą╗ąŠčüčā ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ ą┐ąĄčĆąĄą┤ą░čćąĖ.
ŌĆó ą£ąŠąČąĮąŠ čāą┐ą░ą║ąŠą▓čŗą▓ą░čéčī/čĆą░čüą┐ą░ą║ąŠą▓čŗą▓ą░čéčī ą┤ą░ąĮąĮčŗąĄ, čćč鹊ą▒čŗ čüąŠą│ą╗ą░čüąŠą▓ą░čéčī čłąĖčĆąĖąĮčā ą┤ą░ąĮąĮčŗčģ ąĖčüč鹊čćąĮąĖą║ą░ ąĖ ą╝ąĄčüčéą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą▒ąĄąĘ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ DMA.
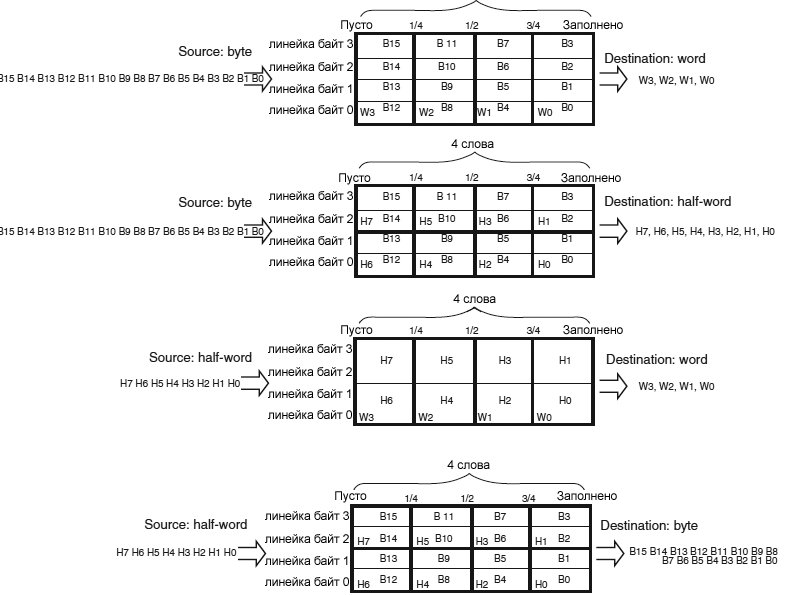
ąĀąĖčü. 4. ąĪčéčĆčāą║čéčāčĆą░ FIFO.
ąĀą░ąĘą╝ąĄčĆ ą┐ą░ą║ąĄčéą░ ąĖčüč鹊čćąĮąĖą║ą░ ąĖ ą╝ąĄčüčéą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ą¤ą░ą║ąĄčéąĮčŗąĄ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą│ą░čĆą░ąĮčéąĖčĆčāčÄčéčüčÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĄą╣ čüč鹥ą║ąŠą▓ DMA FIFO.
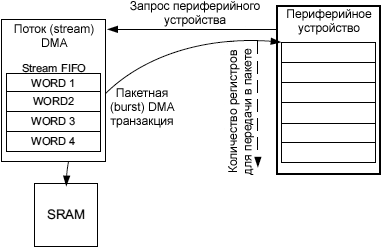
ąĀąĖčü. 5. ą¤ą░ą║ąĄčéąĮą░čÅ čéčĆą░ąĮąĘą░ą║čåąĖčÅ DMA (burst transfer).
ąÆ ąŠčéą▓ąĄčé ąĮą░ ąĘą░ą┐čĆąŠčü ą┐ą░ą║ąĄčéą░ (burst request) ąŠčé ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ DMA čüčćąĖčéčŗą▓ą░ąĄčé ąĖą╗ąĖ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé ąĮąĄą║ąŠč鹊čĆąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą┤ą░ąĮąĮčŗčģ (菹╗ąĄą╝ąĄąĮč鹊ą╝ ą┤ą░ąĮąĮčŗčģ ą╝ąŠąČąĄčé ą▒čŗčéčī čüą╗ąŠą▓ąŠ, ą┐ąŠą╗ąŠą▓ąĖąĮą░ čüą╗ąŠą▓ą░ ąĖą╗ąĖ ą▒ą░ą╣čé). ąŁč鹊 ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆčāąĄčéčüčÅ čĆą░ąĘą╝ąĄčĆąŠą╝ ą┐ą░ą║ąĄčéą░ (burst size 4x, 8x ąĖą╗ąĖ 16x 菹╗ąĄą╝ąĄąĮčéą░ ą┤ą░ąĮąĮčŗčģ). Burst size ąĮą░ ą┐ąŠčĆčéčā DMA ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗą╝ąĖ čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅą╝ąĖ ąĖą╗ąĖ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčÅą╝ąĖ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░.
DMA burst size ąĮą░ ą┐ąŠčĆčéčā ą┐ą░ą╝čÅčéąĖ ąĖ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÅ ą┐ąŠčĆąŠą│ą░ FIFO ą┤ąŠą╗ąČąĮčŗ čüąŠąŠčéą▓ąĄčéčüčéą▓ąŠą▓ą░čéčī ą┤čĆčāą│ ą┤čĆčāą│čā. ąŁč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐ąŠč鹊ą║čā DMA ąĖą╝ąĄčéčī ą┤ąŠčüčéą░č鹊čćąĮąŠ ą┤ą░ąĮąĮčŗčģ ą▓ FIFO, ą║ąŠą│ą┤ą░ ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ ą┐ą░ą║ąĄčéąĮą░čÅ ą┐ąĄčĆąĄą┤ą░čćą░ ąĮą░ ą┐ąŠčĆčéčā ą┐ą░ą╝čÅčéąĖ. ąóą░ą▒ą╗ąĖčåą░ 3 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą▓ąŠąĘą╝ąŠąČąĮčŗąĄ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ burst size ą┐ą░ą╝čÅčéąĖ, ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ ą┐ąŠčĆąŠą│ą░ FIFO ąĖ čĆą░ąĘą╝ąĄčĆą░ ą┤ą░ąĮąĮčŗčģ.
ąöą╗čÅ ą│ą░čĆą░ąĮčéąĖąĖ ą║ąŠą│ąĄčĆąĄąĮčéąĮąŠčüčéąĖ ą║ą░ąČą┤ą░čÅ ą│čĆčāą┐ą┐ą░ ą┐ąĄčĆąĄą┤ą░čć, ą║ąŠč鹊čĆą░čÅ č乊čĆą╝ąĖčĆčāąĄčé ą┐ą░ą║ąĄčé, ąĮąĄą┤ąĄą╗ąĖą╝ą░čÅ: čéčĆą░ąĮąĘą░ą║čåąĖčÅ AHB ą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ ąĖ ą░čĆą▒ąĖčéčĆ ą╝ą░čéčĆąĖčåčŗ čłąĖąĮčŗ AHB ąĮąĄ čāą┤ą░ą╗čÅąĄčé ą┐čĆą░ą▓ą░ ą╝ą░čüč鹥čĆą░ DMA ą▓ąŠ ą▓čĆąĄą╝čÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą┐ą░ą║ąĄčéą░ (burst transfer sequence).
ąóą░ą▒ą╗ąĖčåą░ 3. ąÆąŠąĘą╝ąŠąČąĮčŗąĄ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ ą┐ą░ą║ąĄčéąĮąŠą╣ (burst) čéčĆą░ąĮąĘą░ą║čåąĖąĖ.
| MSIZE |
ąŻčĆąŠą▓ąĄąĮčī
ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ
FIFO |
MBURST = INCR4 |
MBURST = INCR8 |
MBURST = INCR16 |
| Byte |
1/4 |
1 ą┐ą░ą║ąĄčé ąĖąĘ 4 ą▒ą░ą╣čé |
ąŚą░ą┐čĆąĄčēąĄąĮąŠ |
ąŚą░ą┐čĆąĄčēąĄąĮąŠ |
| 1/2 |
2 ą┐ą░ą║ąĄčéą░ ąĖąĘ 4 ą▒ą░ą╣čé |
1 ą┐ą░ą║ąĄčé ąĖąĘ 8 ą▒ą░ą╣čé |
| 3/4 |
3 ą┐ą░ą║ąĄčéą░ ąĖąĘ 4 ą▒ą░ą╣čé |
ąŚą░ą┐čĆąĄčēąĄąĮąŠ |
| Full |
4 ą┐ą░ą║ąĄčéą░ ąĖąĘ 4 ą▒ą░ą╣čé |
2 ą┐ą░ą║ąĄčéą░ ąĖąĘ 8 ą▒ą░ą╣čé |
1 ą┐ą░ą║ąĄčé ąĖąĘ 16 ą▒ą░ą╣čé |
| Half-word |
1/4 |
ąŚą░ą┐čĆąĄčēąĄąĮąŠ |
ąŚą░ą┐čĆąĄčēąĄąĮąŠ |
ąŚą░ą┐čĆąĄčēąĄąĮąŠ |
| 1/2 |
1 ą┐ą░ą║ąĄčé ąĖąĘ 4 ą┐ąŠą╗čāčüą╗ąŠą▓ |
| 3/4 |
ąŚą░ą┐čĆąĄčēąĄąĮąŠ |
| Full |
2 ą┐ą░ą║ąĄčéą░ ąĖąĘ 4 ą┐ąŠą╗čāčüą╗ąŠą▓ |
1 ą┐ą░ą║ąĄčé ąĖąĘ 8 ą┐ąŠą╗čāčüą╗ąŠą▓ |
| Word |
1/4 |
ąŚą░ą┐čĆąĄčēąĄąĮąŠ |
ąŚą░ą┐čĆąĄčēąĄąĮąŠ |
| 1/2 |
| 3/4 |
| Full |
1 ą┐ą░ą║ąĄčé ąĖąĘ 4 čüą╗ąŠą▓ |
ąĀąĄąČąĖą╝ ą┤ą▓ąŠą╣ąĮąŠą╣ ą▒čāč乥čĆąĖąĘą░čåąĖąĖ. ą¤ąŠč鹊ą║ čü ą┤ą▓ąŠą╣ąĮčŗą╝ ą▒čāč乥čĆąŠą╝ čĆą░ą▒ąŠčéą░ąĄčé čéą░ą║ ąČąĄ, ą║ą░ą║ ąĖ čü ąŠą┤ąĮąĖą╝ ą▒čāč乥čĆąŠą╝, ąĮąŠ čü č鹥ą╝ ąŠčéą╗ąĖčćąĖąĄą╝, čćč鹊 čü ą┤ą▓ąŠą╣ąĮąŠą╣ ą▒čāč乥čĆąĖąĘą░čåąĖąĄą╣ ąĄčüčéčī 2 čāą║ą░ąĘą░č鹥ą╗čÅ ąĮą░ ą┐ą░ą╝čÅčéčī. ąÜąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮ čĆąĄąČąĖą╝ ą┤ą▓ąŠą╣ąĮąŠą╣ ą▒čāč乥čĆąĖąĘą░čåąĖąĖ, ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ čĆą░ąĘčĆąĄčłą░ąĄčéčüčÅ ą║ąŠą╗čīčåąĄą▓ąŠą╣ čĆąĄąČąĖą╝ (Circular mode), ąĖ ąĮą░ ą║ą░ąČą┤ąŠą╝ ąŠą║ąŠąĮčćą░ąĮąĖąĖ čéčĆą░ąĮąĘą░ą║čåąĖąĖ (ą║ąŠą│ą┤ą░ čĆąĄą│ąĖčüčéčĆ DMA_SxNDTR ą┤ąŠčüčéąĖą│ą░ąĄčé 0) čāą║ą░ąĘą░č鹥ą╗ąĖ ąĮą░ ą┐ą░ą╝čÅčéčī ą┐ąĄčĆąĄą║ą╗čÄčćą░čÄčéčüčÅ. ąŁč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ čĆą░ą▒ąŠčéą░čéčī čü ąŠą┤ąĮąĖą╝ ą▒čāč乥čĆąŠą╝, ą┐ąŠą║ą░ ą▓č鹊čĆąŠą╣ ą▒čāč乥čĆ ąĘą░ą┐ąŠą╗ąĮčÅąĄčéčüčÅ ąĖą╗ąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĄą╣ DMA.
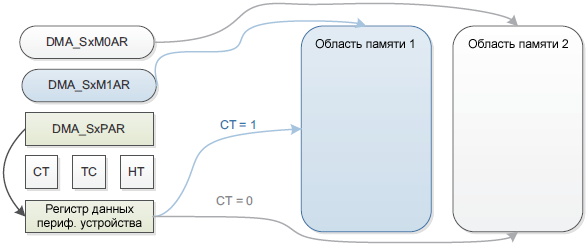
ąĀąĖčü. 6. ąĀąĄąČąĖą╝ ą┤ą▓ąŠą╣ąĮąŠą╣ ą▒čāč乥čĆąĖąĘą░čåąĖąĖ.
ąÆ čĆąĄąČąĖą╝ąĄ ą┤ą▓ąŠą╣ąĮąŠą╣ ą▒čāč乥čĆąĖąĘą░čåąĖąĖ ąĄčüčéčī ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ąŠą▒ąĮąŠą▓ą╗čÅčéčī ą▒ą░ąĘąŠą▓čŗą╣ ą░ą┤čĆąĄčü ą┤ą╗čÅ ą┐ąŠčĆčéą░ ą┐ą░ą╝čÅčéąĖ AHB ąĮą░ ą╗ąĄčéčā (DMA_SxM0AR ąĖą╗ąĖ DMA_SxM1AR), ą║ąŠą│ą┤ą░ ą┐ąŠč鹊ą║ čĆą░ąĘčĆąĄčłąĄąĮ:
ŌĆó ąÜąŠą│ą┤ą░ ą▒ąĖčé CT (Current Target) ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_SxCR čĆą░ą▓ąĄąĮ 0, č鹥ą║čāčēąĖą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ DMA čåąĄą╗ąĄą▓ąŠą╣ ą▒čāč乥čĆ ą┐ą░ą╝čÅčéąĖ 0, ą┐ąŠčŹč鹊ą╝čā ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠą▒ąĮąŠą▓ą╗ąĄąĮ ą░ą┤čĆąĄčü DMA ą▒čāč乥čĆą░ ą┐ą░ą╝čÅčéąĖ 1 (DMA_SxM1AR).
ŌĆó ąÜąŠą│ą┤ą░ ą▒ąĖčé CT (Current Target) ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_SxCR čĆą░ą▓ąĄąĮ 1, č鹥ą║čāčēąĖą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ DMA čåąĄą╗ąĄą▓ąŠą╣ ą▒čāč乥čĆ ą┐ą░ą╝čÅčéąĖ 1, ą┐ąŠčŹč鹊ą╝čā ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠą▒ąĮąŠą▓ą╗ąĄąĮ ą░ą┤čĆąĄčü DMA ą▒čāč乥čĆą░ ą┐ą░ą╝čÅčéąĖ 0 (DMA_SxM0AR).
ąŁč鹊čé ą┐čĆąĖą╝ąĄčĆ čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ ą┐ą╗ą░č鹥 STM32F4DISCOVERY (ą╝ąĖą║čĆąŠą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ STM32F407) ą┐ąŠą┤ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄą╝ FreeRTOS. ą×ą▒čĆą░ą▒ąŠčéčćąĖą║ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA1_Stream5_IRQHandler ą▓čŗą▓ąŠą┤ąĖčé ąĖąĘ čüą┐čÅčćą║ąĖ ąĘą░ą┤ą░čćčā DACtask, ą║ąŠč鹊čĆą░čÅ ąĘą░ąĮąĖą╝ą░ąĄčéčüčÅ čüąĖąĮč鹥ąĘąŠą╝ ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ čüą▓ąŠą▒ąŠą┤ąĮąŠą│ąŠ ąĮą░ ą┤ą░ąĮąĮčŗą╣ ą╝ąŠą╝ąĄąĮčé ą▒čāč乥čĆą░. ą¤ąŠ ą╝ąĄč鹊ą┤čā ą┐čĆčÅą╝ąŠą│ąŠ čüąĖąĮč鹥ąĘą░ (DDS) čüąŠąĘą┤ą░čÄčéčüčÅ ą┤ą░ąĮąĮčŗąĄ čüąĖąĮčāčüąŠąĖą┤čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╣ čćą░čüč鹊čéčŗ, ą║ąŠč鹊čĆčŗąĄ ą┐ąŠč鹊ą╝ ą┐čĆąŠąĖą│čĆčŗą▓ą░čÄčéčüčÅ ą▓ DAC čü ą┐ąŠą╝ąŠčēčīčÄ čéčĆą░ąĮąĘą░ą║čåąĖą╣ DMA. ąĪąĖą│ąĮą░ą╗ č乊čĆą╝ąĖčĆčāąĄčéčüčÅ ąĮą░ ą▓čŗčģąŠą┤ąĄ ą┐ąĄčĆą▓ąŠą│ąŠ ą║ą░ąĮą░ą╗ą░ DAC (ąĮąŠąČą║ą░ ą┐ąŠčĆčéą░ PA4). ąÜąŠą╝ą░ąĮą┤ą░ freq ą║ąŠąĮčüąŠą╗ąĖ USART2 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĘą░ą┤ą░čéčī ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮčāčÄ čćą░čüč鹊čéčā ą│ąĄąĮąĄčĆą░čåąĖąĖ ą▓ ą┤ąĖą░ą┐ą░ąĘąŠąĮąĄ ąŠčé 0 ą┤ąŠ 22049 ąōčå.
ąśąĮč鹥čĆąĄčüąĮąŠ, čćč鹊 ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąŠąĄ č乊čĆą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ čüąĖą│ąĮą░ą╗ą░ ąĮą░ ą▓čŗčģąŠą┤ąĄ DAC ąĮąĄ ą┐čĆąĄą║čĆą░čēą░ąĄčéčüčÅ, ą┤ą░ąČąĄ ą║ąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ ą▓ ąŠčéą╗ą░ą┤čćąĖą║ąĄ. ąØąĖąČąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮčŗ ąŠčüąĮąŠą▓ąĮčŗąĄ čćą░čüčéąĖ ą║ąŠą┤ą░, ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāčÄčēąĖąĄ čĆą░ą▒ąŠčéčā čü DMA. ąÆąĄčüčī ą┐čĆąŠąĄą║čé čåąĄą╗ąĖą║ąŠą╝ ą┤ą╗čÅ IAR ą▓ąĄčĆčüąĖąĖ 8.30 ą╝ąŠąČąĮąŠ čüą║ą░čćą░čéčī ą┐ąŠ čüčüčŗą╗ą║ąĄ [5].
[ą£ąŠą┤čāą╗čī dac.c]
ąÆ čŹč鹊ą╝ ą╝ąŠą┤čāą╗ąĄ ąĮą░čģąŠą┤čÅčéčüčÅ čäčāąĮą║čåąĖąĖ ąĖ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗąĄ, ąŠčéąĮąŠčüčÅčēąĖąĄčüčÅ ą║ ą”ąÉą¤ ąĖ čüąĖąĮč鹥ąĘčā č乊čĆą╝čŗ čüąĖą│ąĮą░ą╗ą░ ąĘą░ą┤ą░ąĮąĮąŠą╣ čćą░čüč鹊čéčŗ.
#include "dac.h"
#include "sinus.h"
#include "dma.h"
#include "errors.h"
#include "pins.h"
DAC_HandleTypeDef vhdac; // ąöąĄčüą║čĆąĖą┐č鹊čĆ ą┤ą╗čÅ ą”ąÉą¤
TaskHandle_t hDACtask; // ąöąĄčüą║čĆąĖą┐č鹊čĆ ąĘą░ą┤ą░čćąĖ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ ą▒čāč乥čĆąŠą▓ DDS
// ąæčāč乥čĆčŗ ą┤ą╗čÅ ą┤ą▓ąŠą╣ąĮąŠą╣ ą▒čāč乥čĆąĖąĘą░čåąĖąĖ:
uint16_t data_arr1[4096];
uint16_t data_arr2[4096];
// ąŻą║ą░ąĘą░č鹥ą╗čī ąĮą░ čüą▓ąŠą▒ąŠą┤ąĮčŗą╣ ą▒čāč乥čĆ, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĮąŠ ąĘą░ą┐ąŠą╗ąĮčÅčéčī:
uint16_t *data_arr_free = NULL;
uint16_t freq = 0; // ąōąĄąĮąĄčĆąĖčĆčāąĄą╝ą░čÅ čćą░čüč鹊čéą░ čüąĖąĮčāčüą░
static float phase; // ąóąĄą║čāčēą░čÅ čäą░ąĘą░ DDS
static float phaseincrement; // ąśąĮą║čĆąĄą╝ąĄąĮčé čäą░ąĘčŗ
/**
* @brief ąÜąŠąĮčäąĖą│čāčĆą░čåąĖčÅ čéą░ą╣ą╝ąĄčĆą░ TIM7, ą║ąŠč鹊čĆčŗą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ
* ą░ą┐ą┐ą░čĆą░čéąĮąŠą╣ ąĖąĮąĖčåąĖą░čåąĖąĖ ą┐ąĄčĆąĄą┤ą░čćąĖ ą▓čŗą▒ąŠčĆą║ąĖ ą▓ DAC ą┐ąŠą┤
* čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄą╝ DMA.
* @note ąÜąŠąĮčäąĖą│čāčĆą░čåąĖčÅ TIM7 ąŠčüąĮąŠą▓čŗą▓ą░ąĄčéčüčÅ ąĮą░ čćą░čüč鹊č鹥 čłąĖąĮčŗ APB1.
* ąÆ čŹč鹊ą╝ ą┐čĆąŠąĄą║č鹥 čéą░ą║č鹊ą▓ą░čÅ čćą░čüč鹊čéą░ čÅą┤čĆą░ 168 ą£ąōčå,
* čćą░čüč鹊čéą░ čłąĖąĮčŗ fAPB1 48 ą£ąōčå, ą░ čćą░čüč鹊čéą░ čéą░ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ
* čéą░ą╣ą╝ąĄčĆą░ (ą┤ąŠ ą┐čĆąĄčüą║ą░ą╗ąĄčĆą░) čĆą░ą▓ąĮą░ fAPB1 * 2 = 84 ą£ąōčå.
* @note TIM7 ąĪąŠą▒čŗčéąĖąĄ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé čü ą┐ąĄčĆąĖąŠą┤ąŠą╝,
* ąĘą░ą▓ąĖčüčÅčēąĖą╝ ąŠčé samplerate ąĖ ą║ąŠčŹčäčäąĖčåąĖąĄąĮčéą░ ą┤ąĄą╗ąĄąĮąĖčÅ
* ą┐čĆąĄčüą║ą░ą╗ąĄčĆą░ (100).
*/
static void TIM7_Config(uint32_t samplerate)
{
static TIM_HandleTypeDef htim;
TIM_MasterConfigTypeDef sMasterConfig;
uint32_t uwTimclock = 0;
htim.Instance = TIM7;
uwTimclock = 2*HAL_RCC_GetPCLK1Freq(); // čéą░ą║č鹊ą▓ą░čÅ čćą░čüč鹊čéą░ TIM7 (84 ą£ąōčå)
htim.Init.Prescaler = 99;
htim.Init.Period = (uwTimclock / (samplerate * (htim.Init.Prescaler+1))) - 1;;
htim.Init.ClockDivision = 0;
htim.Init.CounterMode = TIM_COUNTERMODE_UP;
HAL_TIM_Base_Init(&htim);
// ąÆčŗą▒ąŠčĆ čüąĖą│ąĮą░ą╗ą░ čéčĆąĖą│ą│ąĄčĆą░ (TRGO) TIM7:
sMasterConfig.MasterOutputTrigger = TIM_TRGO_UPDATE;
sMasterConfig.MasterSlaveMode = TIM_MASTERSLAVEMODE_DISABLE;
HAL_TIMEx_MasterConfigSynchronization(&htim, &sMasterConfig);
// ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ čéą░ą╣ą╝ąĄčĆą░:
HAL_TIM_Base_Start(&htim);
}
// ążčāąĮą║čåąĖčÅ ąĘą░ą┐čāčüą║ą░ DMA ą▓ čĆąĄąČąĖą╝ąĄ ą┤ą▓ąŠą╣ąĮąŠą│ąŠ ą▒čāč乥čĆą░. ąØą░ąĘąĮą░č湥ąĮąĖąĄ
// ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ čäčāąĮą║čåąĖąĖ ą┐ąŠąĮčÅčéąĮąŠ ąĖąĘ ąĖčģ ąĮą░ąĘą▓ą░ąĮąĖą╣.
// hdac čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ą┤ąĄčüą║čĆąĖą┐č鹊čĆ ą”ąÉą¤
// hdma čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ą┤ąĄčüą║čĆąĖą┐č鹊čĆ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ DMA
// Alignment č乊čĆą╝ą░čé ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ DAC (ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ)
// pSrc1 čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ą┐ąĄčĆą▓čŗą╣ ą▒čāč乥čĆ
// pSrc2 čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ą▓č鹊čĆąŠą╣ ą▒čāč乥čĆ
// Length ą┤ą╗ąĖąĮą░ ąŠą┤ąĮąŠą│ąŠ ą▒čāč乥čĆą░ (ą▒čāč乥čĆčŗ 1 ąĖ 2 ąĖą╝ąĄčÄčé ąŠą┤ąĖąĮą░ą║ąŠą▓čāčÄ ą┤ą╗ąĖąĮčā)
HAL_StatusTypeDef DAC_Channel1_startDMA(DAC_HandleTypeDef *hdac,
DMA_HandleTypeDef *hdma,
uint32_t Alignment,
uint32_t* pSrc1,
uint32_t* pSrc2,
uint32_t Length)
{
uint32_t tmpreg = 0U;
HAL_StatusTypeDef status = HAL_OK;
assert_param(IS_DAC_ALIGN(Alignment));
__HAL_LOCK(hdac); // ąŚą░čēąĖčéąĮą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░
hdac->State = HAL_DAC_STATE_BUSY;
// ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ ąĘą░ą┐čĆąŠčüą░ DMA ą┤ą╗čÅ ą║ą░ąĮą░ą╗ą░ 1 ą┤ą╗čÅ DAC:
hdac->Instance->CR |= DAC_CR_DMAEN1;
// ąÆčŗčćąĖčüą╗ąĄąĮąĖąĄ ą░ą┤čĆąĄčüą░ ą╝ąĄčüčéą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą┤ą╗čÅ DMA
// ą▓ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ tmpreg. ąĀąĄą│ąĖčüčéčĆ ą┤ą░ąĮąĮčŗčģ DMA ąĘą░ą▓ąĖčüąĖčé
// ąŠčé č乊čĆą╝ą░čéą░ ą┤ą░ąĮąĮčŗčģ ąĖ ą║ą░ąĮą░ą╗ą░ DAC.
// ąÆ čüą╗čāčćą░ąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą║ą░ąĮą░ą╗ą░ channel 1 ą┤ą╗čÅ DAC:
switch(Alignment)
{
case DAC_ALIGN_12B_R:
tmpreg = (uint32_t)&hdac->Instance->DHR12R1;
break;
case DAC_ALIGN_12B_L:
tmpreg = (uint32_t)&hdac->Instance->DHR12L1;
break;
case DAC_ALIGN_8B_R:
tmpreg = (uint32_t)&hdac->Instance->DHR8R1;
break;
}
// ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąĮąĄą┤ąŠą│čĆčāąĘą║ąĖ DAC DMA:
__HAL_DAC_ENABLE_IT(hdac, DAC_IT_DMAUDR1);
// ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ ą┐ąŠč鹊ą║ą░ DMA:
__HAL_LOCK(hdma); // ąŚą░čēąĖčéąĮą░čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░
if(HAL_DMA_STATE_READY == hdma->State)
{
hdma->State = HAL_DMA_STATE_BUSY;
hdma->ErrorCode = HAL_DMA_ERROR_NONE;
// ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ čĆąĄąČąĖą╝ą░ ą┤ą▓ąŠą╣ąĮąŠą╣ ą▒čāč乥čĆąĖąĘą░čåąĖąĖ:
hdma->Instance->CR |= (uint32_t)DMA_SxCR_DBM;
// ąÜąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ ą░ą┤čĆąĄčüąŠą▓ ąĖčüč鹊čćąĮąĖą║ąŠą▓ ąĖ ą┤ą╗ąĖąĮčŗ ąŠą┤ąĮąŠą│ąŠ
// ą▒čāč乥čĆą░:
hdma->Instance->M1AR = (uint32_t)pSrc2; // ą░ą┤čĆąĄčü ą▓č鹊čĆąŠą│ąŠ ą▒čāč乥čĆą░
hdma->Instance->NDTR = Length; // ą┤ą╗ąĖąĮą░ ą┤ą░ąĮąĮčŗčģ ą▓ ą▒čāč乥čĆąĄ
hdma->Instance->PAR = tmpreg; // ą░ą┤čĆąĄčü ąĮą░ąĘąĮą░č湥ąĮąĖčÅ (DAC)
hdma->Instance->M0AR = (uint32_t)pSrc1; // ą░ą┤čĆąĄčü ą┐ąĄčĆą▓ąŠą│ąŠ ą▒čāč乥čĆą░
// ą×čćąĖčüčéą║ą░ ą▓čüąĄčģ čäą╗ą░ą│ąŠą▓:
__HAL_DMA_CLEAR_FLAG (hdma, __HAL_DMA_GET_TC_FLAG_INDEX(hdma));
__HAL_DMA_CLEAR_FLAG (hdma, __HAL_DMA_GET_HT_FLAG_INDEX(hdma));
__HAL_DMA_CLEAR_FLAG (hdma, __HAL_DMA_GET_TE_FLAG_INDEX(hdma));
__HAL_DMA_CLEAR_FLAG (hdma, __HAL_DMA_GET_DME_FLAG_INDEX(hdma));
__HAL_DMA_CLEAR_FLAG (hdma, __HAL_DMA_GET_FE_FLAG_INDEX(hdma));
// ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ ąŠą▒čēąĖčģ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣:
hdma->Instance->CR |= DMA_IT_TC | DMA_IT_TE | DMA_IT_DME;
hdma->Instance->FCR |= DMA_IT_FE;
hdma->Instance->CR |= DMA_IT_HT;
// ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ DMA
__HAL_DMA_ENABLE(hdma);
}
else
{
__HAL_UNLOCK(hdma); // ąĪąĮčÅčéąĖąĄ ąĘą░čēąĖčéąĮąŠą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ
status = HAL_BUSY; // ąÆąŠąĘą▓čĆą░čé čüąŠčüč鹊čÅąĮąĖčÅ ąŠčłąĖą▒ą║ąĖ
}
// ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ą”ąÉą¤ ąĮą░ ą▓čŗą▒čĆą░ąĮąĮąŠą╝ ą║ą░ąĮą░ą╗ąĄ:
__HAL_DAC_ENABLE(hdac, DAC_CHANNEL);
__HAL_UNLOCK(hdac); // ąĪąĮčÅčéąĖąĄ ąĘą░čēąĖčéąĮąŠą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ
return status;
}
// ążčāąĮą║čåąĖčÅ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ ą”ąÉą¤
void MX_DAC_Init(void)
{
DAC_ChannelConfTypeDef sConfig = {0};
// ąÜąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ čéą░ą╣ą╝ąĄčĆą░, ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖąĄ ą║ąŠč鹊čĆąŠą│ąŠ čüą╗čāąČąĖčé
// čüąĖą│ąĮą░ą╗ąŠą╝ čéčĆąĖą│ą│ąĄčĆą░ ą┤ą╗čÅ DMA, čćč鹊ą▒čŗ ą┐ąĄčĆąĄą┤ą░čéčī ąŠč湥čĆąĄą┤ąĮčāčÄ
// ą▓čŗą▒ąŠčĆą║čā čüąĖą│ąĮą░ą╗ą░ ąĖąĘ ą▒čāč乥čĆą░:
TIM7_Config(DAC_SAMPLE_RATE);
// ą×ą▒čēą░čÅ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ ą”ąÉą¤:
vhdac.Instance = DAC;
if (HAL_DAC_Init(&vhdac) != HAL_OK)
{
Error_Handler();
}
// ąÜąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ ą▓čŗčģąŠą┤ą░ OUT1 ąĖ čéčĆąĖą│ą│ąĄčĆą░ ą┤ą╗čÅ ą”ąÉą¤:
sConfig.DAC_Trigger = DAC_TRIGGER_T7_TRGO;
sConfig.DAC_OutputBuffer = DAC_OUTPUTBUFFER_ENABLE;
if (HAL_DAC_ConfigChannel(&vhdac, &sConfig, DAC_CHANNEL) != HAL_OK)
{
Error_Handler();
}
// ąŻčüčéą░ąĮąŠą▓ą║ą░ ą│ąĄąĮąĄčĆąĖčĆčāąĄą╝ąŠą╣ čćą░čüč鹊čéčŗ 1000 ąōčå ą┐čĆąĖ čüčéą░čĆč鹥 ą┐čĆąŠą│čĆą░ą╝ą╝čŗ:
freq = 1000;
GenerateDAC(freq);
// ąŚą░ą┐čāčüą║ DMA ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ ą│ąĄąĮąĄčĆą░čåąĖąĖ čüąĖą│ąĮą░ą╗ą░ čü ą┐ąŠą╝ąŠčēčīčÄ DAC:
if (DAC_Channel1_startDMA(&vhdac, &vhdma_DAC1,
DAC_ALIGN_12B_R,
(uint32_t*)data_arr1,(uint32_t*)data_arr2,
4096) != HAL_OK)
{
// ą×čłąĖą▒ą║ą░ ąĘą░ą┐čāčüą║ą░ DMA.
Error_Handler();
}
}
// ąÜąŠąĮčäąĖą│čāčĆąĖčĆčāąĄčé ą┤ą╗čÅ ą”ąÉą¤ čéą░ą║čéąĖčĆąŠą▓ą░ąĮąĖąĄ, ą┐ąŠč鹊ą║ ąĖ ą║ą░ąĮą░ą╗ DMA,
// ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ, ąĮąŠąČą║čā ą┐ąŠčĆčéą░ ą┤ą╗čÅ ą▓čŗą▓ąŠą┤ą░, čĆą░ąĘčĆąĄčłą░ąĄčé
// ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ DMA.
void HAL_DAC_MspInit(DAC_HandleTypeDef* dacHandle)
{
GPIO_InitTypeDef GPIO_InitStruct = {0};
// ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ čéą░ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ DAC ąĖ GPIOA:
__HAL_RCC_DAC_CLK_ENABLE();
__HAL_RCC_GPIOA_CLK_ENABLE();
/** ąÜąŠąĮčäąĖą│čāčĆą░čåąĖčÅ ą▓čŗčģąŠą┤ą░ DAC GPIO
PA4 ------> DAC_OUT1
*/
GPIO_InitStruct.Pin = TRC_OUT_Pin;
GPIO_InitStruct.Mode = GPIO_MODE_ANALOG;
GPIO_InitStruct.Pull = GPIO_NOPULL;
HAL_GPIO_Init(TRC_OUT_GPIO_Port, &GPIO_InitStruct);
// ąśąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ ą┐ą░čĆą░ą╝ąĄčéčĆąŠą▓ DAC DMA:
vhdma_DAC1.Instance = DMA1_Stream5;
vhdma_DAC1.Init.Channel = DMA_CHANNEL_7;
vhdma_DAC1.Init.Direction = DMA_MEMORY_TO_PERIPH;
vhdma_DAC1.Init.PeriphInc = DMA_PINC_DISABLE;
vhdma_DAC1.Init.MemInc = DMA_MINC_ENABLE;
vhdma_DAC1.Init.PeriphDataAlignment = DMA_PDATAALIGN_HALFWORD;
vhdma_DAC1.Init.MemDataAlignment = DMA_MDATAALIGN_HALFWORD;
vhdma_DAC1.Init.Priority = DMA_PRIORITY_VERY_HIGH;
vhdma_DAC1.Init.FIFOMode = DMA_FIFOMODE_DISABLE;
vhdma_DAC1.Init.FIFOThreshold = DMA_FIFO_THRESHOLD_HALFFULL;
vhdma_DAC1.Init.MemBurst = DMA_MBURST_SINGLE;
vhdma_DAC1.Init.PeriphBurst = DMA_PBURST_SINGLE;
__HAL_RCC_DMA1_CLK_ENABLE();
if (HAL_DMA_Init(&vhdma_DAC1) != HAL_OK)
{
Error_Handler();
}
// ą¤čĆąĖą▓čÅąĘą║ą░ DMA ą║ ą”ąÉą¤:
__HAL_LINKDMA(dacHandle,DMA_Handle1,vhdma_DAC1);
// ąÜąŠąĮčäąĖą│čāčĆą░čåąĖčÅ ą┐čĆąĖąŠčĆąĖč鹥čéą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ DMA1_Stream5_IRQn:
HAL_NVIC_SetPriority(DMA1_Stream5_IRQn, DAC_DMA_INTERRUPT_PRIORITY, 0);
// ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ą║ą░ąĮą░ą╗ą░ DMA1 Stream5 IRQ:
HAL_NVIC_EnableIRQ(DMA1_Stream5_IRQn);
}
// ąŚą░ą┤ą░čćą░ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ ą▒čāč乥čĆąŠą▓ ąĮąŠą▓čŗą╝ąĖ ą┤ą░ąĮąĮčŗą╝ąĖ, DDS-čüąĖąĮč鹥ąĘ čüąĖąĮčāčüąŠąĖą┤čŗ
// čü ą┤ą▓ąŠą╣ąĮčŗą╝ ą▒čāč乥čĆąŠą╝.
void DACtask(void const * argument)
{
while(1)
{
const TickType_t xBlockTime = pdMS_TO_TICKS( 500 );
uint32_t ulNotifiedValue;
for( ;; )
{
ulNotifiedValue = ulTaskNotifyTake( pdFALSE,
xBlockTime );
if( ulNotifiedValue > 0 )
{
if (1 != ulNotifiedValue)
{
umsg("ąŚą░ą┤ą░čćą░ DACtask ą▓čŗąĘą▓ą░ąĮą░ čü ąŠą┐ąŠąĘą┤ą░ąĮąĖąĄą╝! (%u)\n", ulNotifiedValue);
continue;
}
if (NULL != data_arr_free)
{
for (int i=0; i < 4096; i++)
{
data_arr_free[i] = SinusTable[(uint8_t)phase]*16 + 2048;
phase += phaseincrement;
if (phase >= 256)
phase = phase - 256;
}
}
}
else
{
// ąØąĄ ą▒čŗą╗ąŠ ą┐ąŠą╗čāč湥ąĮąŠ ąŠą┐ąŠą▓ąĄčēąĄąĮąĖąĄ ą▓ ą┐čĆąĄą┤ąĄą╗ą░čģ ąŠąČąĖą┤ą░ąĄą╝ąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ.
umsg("ą×čłąĖą▒ą║ą░ DMA ISR\n");
}
}
}
}
// ążčāąĮą║čåąĖčÅ ąĘą░ą┐čāčüą║ą░ ą│ąĄąĮąĄčĆą░čåąĖąĖ čāą║ą░ąĘą░ąĮąĮąŠą╣ čćą░čüč鹊čéčŗ ą▓ ąōčå
void GenerateDAC (uint16_t vfreqHz)
{
// ąÆčŗčćąĖčüą╗ąĄąĮąĖąĄ ąĖąĮą║čĆąĄą╝ąĄąĮčéą░ čäą░ąĘčŗ. ąŚą┤ąĄčüčī 256 čŹč鹊 čĆą░ąĘą╝ąĄčĆ čéą░ą▒ą╗ąĖčåčŗ
// čüąĖąĮčāčüą░ SinusTable, DAC_SAMPLE_RATE_REAL čŹč鹊 čĆąĄą░ą╗čīąĮą░čÅ
// čćą░čüč鹊čéą░ ą┤ąĖčüą║čĆąĄčéąĖąĘą░čåąĖąĖ (ą▒ą╗ąĖąĘą║ą░čÅ ą║ 44100 ą┤ą╗čÅ čŹč鹊ą│ąŠ ą┐čĆąŠąĄą║čéą░).
phaseincrement = 256.0*(float)vfreqHz/DAC_SAMPLE_RATE_REAL;
}
[ą£ąŠą┤čāą╗čī dma.c]
ąÆ čŹč鹊ą╝ ą╝ąŠą┤čāą╗ąĄ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮ ą║ąŠą┤ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ DMA.
#include "dma.h"
#include "dac.h"
#include "pins.h"
#include "cmsis_os.h"
// ąöąĄčüą║čĆąĖą┐č鹊čĆ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ DMA, ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĮčŗą╣ ą┤ą╗čÅ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÅ
// ąĘą░ą┐čĆąŠčüąŠą▓ ą”ąÉą¤.
DMA_HandleTypeDef vhdma_DAC1;
// ą×ą▒čĆą░ą▒ąŠčéčćąĖą║ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ DMA. ąÆ ąĮąĄą╝ ą┐ąŠ ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĖ ą┐ąĄčĆąĄą┤ą░čćąĖ ąŠą┤ąĮąŠą│ąŠ ą▒čāč乥čĆą░
// čĆą░ąĘą▒ą╗ąŠą║ąĖčĆčāąĄčéčüčÅ ą┐ąŠč鹊ą║ hDACtask, ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĖąĘą▓ą░ąĮ ąĘą░ą┐ąŠą╗ąĮąĖčéčī čŹč鹊čé ą▒čāč乥čĆ,
// ą┐ąŠą║ą░ ą┐ąĄčĆąĄą┤ą░ąĄčéčüčÅ ą┤čĆčāą│ąŠą╣ (ą┤ą▓ąŠą╣ąĮą░čÅ ą▒čāč乥čĆąĖąĘą░čåąĖčÅ).
void DMA1_Stream5_IRQHandler(void)
{
DMA_Base_Registers *regs = (DMA_Base_Registers *)vhdma_DAC1.StreamBaseAddress;
uint32_t flags = regs->ISR;
uint32_t crreg = vhdma_DAC1.Instance->CR;
// ąÆ čŹč鹊ą╝ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ č鹊ą╗čīą║ąŠ čäą╗ą░ą│ąĖ
// TCIF5 (Transaction Complete) ąĖ HTIF5 (Half Transaction).
// ąÆčüąĄ ą┤čĆčāą│ąĖąĄ čäą╗ą░ą│ąĖ ą┤ą╗čÅ čāą┐čĆąŠčēąĄąĮąĖčÅ ąĮąĄ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ.
if (flags & DMA_HISR_TCIF5_Msk)
{
// ą¤čĆąĄčĆčŗą▓ą░ąĮąĖąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą┐ąĄčĆąĄą┤ą░čćąĖ ą▒čāč乥čĆą░. ąĪąĖą│ąĮą░ą╗ąĖąĘąĖčĆčāąĄčé
// ąŠ č鹊ą╝, čćč鹊 ąŠą┤ąĖąĮ ąĖąĘ ą▒čāč乥čĆąŠą▓ ą┐ąĄčĆąĄą┤ą░ąĮ, ąĖ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ąĮą░čćą░ą╗ą░čüčī
// ą┐ąĄčĆąĄą┤ą░čćą░ ą▓č鹊čĆąŠą│ąŠ ą▒čāč乥čĆą░.
TOGGLE_BLUE(); // ąöą╗čÅ ąĖąĮą┤ąĖą║ą░čåąĖąĖ
BaseType_t xHigherPriorityTaskWoken;
xHigherPriorityTaskWoken = pdFALSE;
// ąÆčŗčćąĖčüą╗ąĄąĮąĖąĄ ą░ą┤čĆąĄčüą░ ąŠčüą▓ąŠą▒ąŠą┤ąĖą▓čłąĄą│ąŠčüčÅ ą▒čāč乥čĆą░, ą║ąŠč鹊čĆčŗą╣
// ą╝ąŠąČąĄčé ąĘą░ą┐ąŠą╗ąĮąĖčéčī hDACtask:
if (crreg & DMA_SxCR_CT)
data_arr_free = (uint16_t*)vhdma_DAC1.Instance->M0AR;
else
data_arr_free = (uint16_t*)vhdma_DAC1.Instance->M1AR;
// ąĀą░ąĘą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ąĘą░ą┤ą░čćąĖ DDS:
vTaskNotifyGiveFromISR( hDACtask, &xHigherPriorityTaskWoken );
portYIELD_FROM_ISR( xHigherPriorityTaskWoken );
}
if (flags & DMA_HISR_HTIF5_Msk)
{
// ą¤čĆąĄčĆčŗą▓ą░ąĮąĖąĄ, čüąĖą│ąĮą░ą╗ąĖąĘąĖčĆčāčÄčēąĄąĄ ąŠ ą┐ąĄčĆąĄą┤ą░č湥 ą┐ąŠą╗ąŠą▓ąĖąĮčŗ ą▒čāč乥čĆą░
// ą▓ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA.
TOGGLE_RED(); // ąöą╗čÅ ąĖąĮą┤ąĖą║ą░čåąĖąĖ
}
// ą×čćąĖčüčéą║ą░ ą▓čüąĄčģ čäą╗ą░ą│ąŠą▓ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣.
regs->IFCR = flags;
}
[ą£ąŠą┤čāą╗čī main.c]
ą×čüąĮąŠą▓ąĮąŠą╣ ą╝ąŠą┤čāą╗čī ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. ąŚą┤ąĄčüčī ą┤ą╗čÅ čāą┐čĆąŠčēąĄąĮąĖčÅ ąŠčüčéą░ą▓ą╗ąĄąĮčŗ č鹊ą╗čīą║ąŠ ą┤ąĄą╣čüčéą▓ąĖčÅ, ą║ą░čüą░čÄčēąĖąĄčüčÅ ąĘą░ą┐čāčüą║ą░ ą┐ąŠč鹊ą║ąŠą▓ ąĖ ą│ąĄąĮąĄčĆą░čåąĖąĖ čćą░čüč鹊čéčŗ.
// ąØą░ąČą░čéąĖąĄ čüąĖąĮąĄą╣ ą║ąĮąŠą┐ą║ąĖ ąĮą░ ą┐ą╗ą░č鹥 STM32F4DISCOVERY (User B1)
// čåąĖą║ą╗ąĖč湥čüą║ąĖ ą┐ąĄčĆąĄą║ą╗čÄčćą░ąĄčé ą│ąĄąĮąĄčĆąĖčĆčāąĄą╝čŗąĄ čćą░čüč鹊čéčŗ 10, 1476 ąĖ 10000 ąōčå.
static void BtnShortPress (void)
{
static uint8_t action = 0;
switch(action)
{
case 0:
GenerateDAC(10);
action++;
break;
case 1:
GenerateDAC(1476);
action++;
break;
case 2:
GenerateDAC(10000);
action = 0;
break;
}
}
int main(void)
{
HAL_Init();
SystemClock_Config();
...
MX_DAC_Init();
MX_FREERTOS_Init();
// ąĪąŠąĘą┤ą░ąĮąĖąĄ ą┐ąŠč鹊ą║ąŠą▓:
osThreadDef(usartthread, USARTtask, osPriorityAboveNormal, 0, 512);
osThreadCreate(osThread(usartthread), NULL);
osThreadDef(commonthread, commontask, osPriorityNormal, 0, 512);
osThreadCreate(osThread(commonthread), NULL);
osThreadDef(dacthread, DACtask, osPriorityNormal, 0, 512);
hDACtask = osThreadCreate(osThread(dacthread), NULL);
// ąŚą░ą┐čāčüą║ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ą░ FreeRTOS:
osKernelStart();
// ąÆ čŹč鹊ą╝ ą╝ąĄčüč鹊 ą╝čŗ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą┐ąŠą┐ą░ą┤ąĄą╝, ą▓čüąĄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ
// ą▓ąĘčÅą╗ ąĮą░ čüąĄą▒čÅ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║:
while (1)
{
}
}
// ąÜąŠąĮčäąĖą│čāčĆą░čåąĖčÅ čéą░ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ čüąĖčüč鹥ą╝čŗ:
void SystemClock_Config(void)
{
RCC_OscInitTypeDef RCC_OscInitStruct = {0};
RCC_ClkInitTypeDef RCC_ClkInitStruct = {0};
// ąÜąŠąĮčäąĖą│čāčĆą░čåąĖčÅ ąŠčüąĮąŠą▓ąĮąŠą│ąŠ ą▓ąĮčāčéčĆąĄąĮąĮąĄą│ąŠ čĆąĄą│čāą╗čÅč鹊čĆą░ ąĮą░ą┐čĆčÅąČąĄąĮąĖčÅ:
__HAL_RCC_PWR_CLK_ENABLE();
__HAL_PWR_VOLTAGESCALING_CONFIG(PWR_REGULATOR_VOLTAGE_SCALE1);
// ąśąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖčÅ čéą░ą║č鹊ą▓ CPU, čłąĖąĮ AHB ąĖ APB. ąśčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ
// ą║ą▓ą░čĆčå ąĮą░ 8 ą£ąōčå, ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą┐ąŠą╗čāčćą░ąĄčéčüčÅ čćą░čüč鹊čéčŗ:
// SYSCLK (CPU) = 168 ą£ąōčå
// PCLK1 (APB1) = 42 ą£ąōčå
// PCLK2 (APB2) = 84 ą£ąōčå
RCC_OscInitStruct.OscillatorType = RCC_OSCILLATORTYPE_HSE;
RCC_OscInitStruct.HSEState = RCC_HSE_ON;
RCC_OscInitStruct.PLL.PLLState = RCC_PLL_ON;
RCC_OscInitStruct.PLL.PLLSource = RCC_PLLSOURCE_HSE;
RCC_OscInitStruct.PLL.PLLM = 8;
RCC_OscInitStruct.PLL.PLLN = 336;
RCC_OscInitStruct.PLL.PLLP = RCC_PLLP_DIV2;
RCC_OscInitStruct.PLL.PLLQ = 7;
if (HAL_RCC_OscConfig(&RCC_OscInitStruct) != HAL_OK)
{
Error_Handler();
}
RCC_ClkInitStruct.ClockType = RCC_CLOCKTYPE_HCLK|RCC_CLOCKTYPE_SYSCLK
|RCC_CLOCKTYPE_PCLK1|RCC_CLOCKTYPE_PCLK2;
RCC_ClkInitStruct.SYSCLKSource = RCC_SYSCLKSOURCE_PLLCLK;
RCC_ClkInitStruct.AHBCLKDivider = RCC_SYSCLK_DIV1;
RCC_ClkInitStruct.APB1CLKDivider = RCC_HCLK_DIV4;
RCC_ClkInitStruct.APB2CLKDivider = RCC_HCLK_DIV2;
if (HAL_RCC_ClockConfig(&RCC_ClkInitStruct, FLASH_LATENCY_5) != HAL_OK)
{
Error_Handler();
}
}
ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąŠč鹊ą║ąŠą╝. ąÜąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą┐ąŠč鹊ą║ą░ (flow controller) čŹč鹊 ą▒ą╗ąŠą║, ą║ąŠč鹊čĆčŗą╣ čāą┐čĆą░ą▓ą╗čÅąĄčé ą┤ą╗ąĖąĮąŠą╣ ą┐ąĄčĆąĄą┤ą░čćąĖ ą┤ą░ąĮąĮčŗčģ, ąĖ ą║ąŠč鹊čĆčŗą╣ ąŠčéą▓ąĄčćą░ąĄčé ąĘą░ ąŠčüčéą░ąĮąŠą▓ą║čā ą┐ąĄčĆąĄą┤ą░čćąĖ DMA. ąÜąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą╝ ą┐ąŠč鹊ą║ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ą╗ąĖą▒ąŠ DMA, ą╗ąĖą▒ąŠ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ.
ąĢčüą╗ąĖ ą║ąŠąĮčéčĆąŠą╗ąĄčĆąŠą╝ ą┐ąŠč鹊ą║ą░ čÅą▓ą╗čÅąĄčéčüčÅ DMA, č鹊 ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ąĘąĮą░č湥ąĮąĖąĄ čĆą░ąĘą╝ąĄčĆą░ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_SxNDTR ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ čĆą░ąĘčĆąĄčłą░ąĄčéčüčÅ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╣ ą┐ąŠč鹊ą║ DMA. ąÜąŠą│ą┤ą░ ąŠą▒čüą╗čāąČąĖą▓ą░ąĄčéčüčÅ ąĘą░ą┐čĆąŠčü DMA ąĘąĮą░č湥ąĮąĖąĄ čĆą░ąĘą╝ąĄčĆą░ čéčĆą░ąĮąĘą░ą║čåąĖąĖ čāą╝ąĄąĮčīčłą░ąĄčéčüčÅ ąĮą░ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąĄčĆąĄą┤ą░ąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ (ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čéąĖą┐ą░ ąĘą░ą┐čĆąŠčüą░: ą┐ą░ą║ąĄčéąĮčŗą╣ burst ąĖą╗ąĖ ąŠą┤ąĖąĮąŠčćąĮčŗą╣ single). ąÜąŠą│ą┤ą░ ąĘąĮą░č湥ąĮąĖąĄ čĆą░ąĘą╝ąĄčĆą░ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą┤ąŠčüčéąĖą│ą░ąĄčé 0, čéčĆą░ąĮąĘą░ą║čåąĖčÅ DMA ąĘą░ą▓ąĄčĆčłą░ąĄčéčüčÅ ąĖ ą┐ąŠč鹊ą║ DMA ąĘą░ą┐čĆąĄčēą░ąĄčéčüčÅ.
ąĢčüą╗ąĖ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą╝ ą┐ąŠč鹊ą║ą░ čÅą▓ą╗čÅąĄčéčüčÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ, č鹊 ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąĄčĆąĄą┤ą░ą▓ą░ąĄą╝čŗčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą┤ą░ąĮąĮčŗčģ ąĮąĄąĖąĘą▓ąĄčüčéąĮąŠ. ą¤ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ą░ą┐ą┐ą░čĆą░čéąĮąŠ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ą╗čÅ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ DMA, ą║ąŠą│ą┤ą░ ą┐ąĄčĆąĄą┤ą░ąĮčŗ ą┐ąŠčüą╗ąĄą┤ąĮąĖąĄ ą┤ą░ąĮąĮčŗąĄ. ąŁč鹊čé čĆąĄąČąĖą╝ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé č鹊ą╗čīą║ąŠ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ SD/MMC ąĖ JPEG.
[ąØą░čüčéčĆąŠą╣ą║ą░ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA]
ąöą╗čÅ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐ąŠč鹊ą║ą░ x DMA (ąĘą┤ąĄčüčī x čŹč鹊 ąĮąŠą╝ąĄčĆ ą┐ąŠč鹊ą║ą░) ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮą░ čüą╗ąĄą┤čāčÄčēą░čÅ ą┐čĆąŠčåąĄą┤čāčĆą░:
1. ąĢčüą╗ąĖ ą┐ąŠč鹊ą║ čĆą░ąĘčĆąĄčłąĄąĮ, č鹊 ąŠąĮ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ąĘą░ą┐čĆąĄčēąĄąĮ čüą▒čĆąŠčüąŠą╝ ą▒ąĖčéą░ EN ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_SxCR. ąŚą░č鹥ą╝ čŹč鹊čé ą▒ąĖčé ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą┐čĆąŠčćąĖčéą░ąĮ čćč鹊ą▒čŗ čāą┤ąŠčüč鹊ą▓ąĄčĆąĖčéčīčüčÅ, čćč鹊 ąĮąĄ ą░ą║čéąĖą▓ąĮą░ ąŠą┐ąĄčĆą░čåąĖčÅ ą┐ąŠč鹊ą║ą░. ąŚą░ą┐ąĖčüčī ą▓ čŹč鹊čé ą▒ąĖčé ą╗ąŠą│. 0 ąĮąĄ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠą╣ ąŠčüčéą░ąĮąŠą▓ą║ąĄ ą┐ąŠč鹊ą║ą░ (ą▒ąĖčé ąĮąĄ čüčéą░ąĮąĄčé čüčĆą░ąĘčā ą╗ąŠą│. 0), ą┐ąŠą║ą░ ą▓čüąĄ č鹥ą║čāčēąĖąĄ ą┐ąĄčĆąĄą┤ą░čćąĖ ąĮąĄ ąĘą░ą▓ąĄčĆčłą░čéčüčÅ. ąÜąŠą│ą┤ą░ čćč鹥ąĮąĖąĄ ą▒ąĖčéą░ EN ą┐ąŠą║ą░ąČąĄčé 0, čŹč鹊 ą▒čāą┤ąĄčé ąŠąĘąĮą░čćą░čéčī, čćč鹊 ą┐ąŠč鹊ą║ ąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮ ąĖ ą│ąŠč鹊ą▓ ą║ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖčÄ. ą¤ąŠčŹč鹊ą╝čā ąĮčāąČąĮąŠ ą┐ąŠą┤ąŠąČą┤ą░čéčī, ą┐ąŠą║ą░ ąĮąĄ ąŠčćąĖčüčéąĖčéčüčÅ ą▒ąĖčé EN, čćč鹊ą▒čŗ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ąĮą░čćą░čéčī ą╗čÄą▒ąŠąĄ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐ąŠč鹊ą║ą░. ąÆąĄčüčī ąĮą░ą▒ąŠčĆ ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗčģ ą┤ą╗čÅ ą┐ąŠč鹊ą║ą░ ą▒ąĖčé ą▓ čĆąĄą│ąĖčüčéčĆąĄ čüčéą░čéčāčüą░ (DMA_LISR ąĖ DMA_HISR) ąŠčé ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą▒ą╗ąŠą║ą░ ą┤ą░ąĮąĮčŗčģ DMA ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ąŠčćąĖčēąĄąĮ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ą┐ąŠč鹊ą║ ą╝ąŠąČąĄčé ą▒čŗčéčī čüąĮąŠą▓ą░ čĆą░ąĘčĆąĄčłąĄąĮ.
2. ąŻčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ čĆąĄą│ąĖčüčéčĆ ą░ą┤čĆąĄčüą░ ą┐ąŠčĆčéą░ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_SxPAR. ąöą░ąĮąĮčŗąĄ ą▒čāą┤čāčé ą┐ąĄčĆąĄą╝ąĄčēą░čéčīčüčÅ ąĖąĘ čŹč鹊ą│ąŠ ą░ą┤čĆąĄčüą░ ąĖą╗ąĖ ą▓ čŹč鹊čé ą░ą┤čĆąĄčü ą▓/ąĖąĘ ą┐ąŠčĆčéą░ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ą┐ąŠčüą╗ąĄ ą▓ąŠąĘąĮąĖą║ąĮąŠą▓ąĄąĮąĖčÅ čüąŠą▒čŗčéąĖčÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░.
3. ąŻčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ą░ą┤čĆąĄčü ą┐ą░ą╝čÅčéąĖ ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_SxMA0R (ąĖ ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_SxMA1R, ąĄčüą╗ąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čĆąĄąČąĖą╝ ą┤ą▓ąŠą╣ąĮąŠą╣ ą▒čāč乥čĆąĖąĘą░čåąĖąĖ). ąöą░ąĮąĮčŗąĄ ą▒čāą┤čāčé ąĘą░ą┐ąĖčüčŗą▓ą░čéčīčüčÅ ą┐ąŠ čŹč鹊ą╝čā ą░ą┤čĆąĄčüčā ąĖą╗ąĖ čüčćąĖčéčŗą▓ą░čéčīčüčÅ ąŠčéčéčāą┤ą░ ą┐ąŠčüą╗ąĄ ą▓ąŠąĘąĮąĖą║ąĮąŠą▓ąĄąĮąĖčÅ čüąŠą▒čŗčéąĖčÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░.
4. ąÆ čĆąĄą│ąĖčüčéčĆąĄ DMA_SxNDTR ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄčéčüčÅ ąŠą▒čēąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ ą┐ąĄčĆąĄą┤ą░čćąĖ. ą¤ąŠčüą╗ąĄ ą║ą░ąČą┤ąŠą│ąŠ čüąŠą▒čŗčéąĖčÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ąĖą╗ąĖ ą┐ąŠčüą╗ąĄ ą║ą░ąČą┤ąŠą│ąŠ ą┐ą░ą║ąĄčéą░ čŹč鹊 ąĘąĮą░č湥ąĮąĖąĄ ą┤ąĄą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄčéčüčÅ.
5. ąæąĖčéą░ą╝ąĖ CHSEL[2:0] čĆąĄą│ąĖčüčéčĆą░ DMA_SxCR ąÆčŗą▒ąĖčĆą░ąĄčéčüčÅ ą║ą░ąĮą░ą╗ (ąĘą░ą┐čĆąŠčü) DMA.
6. ąĢčüą╗ąĖ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą╝ ą┐ąŠč鹊ą║ą░, ąĖ ąĄčüą╗ąĖ ąŠąĮąŠ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé čŹčéčā ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī (ą┤ąŠčüčéčāą┐ąĮąŠ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ SD/MMC ąĖ JPEG), č鹊 čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ą▒ąĖčé PFCTRL ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_SxCR.
7. ąÜąŠąĮčäąĖą│čāčĆąĖčĆčāąĄčéčüčÅ ą┐čĆąĖąŠčĆąĖč鹥čé ą┐ąŠč鹊ą║ą░ ą▒ąĖčéą░ą╝ąĖ PL[1:0] ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_SxCR.
8. ąÜąŠąĮčäąĖą│čāčĆąĖčĆčāąĄčéčüčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ FIFO (čĆą░ąĘčĆąĄčłąĄąĮąŠ ąĖą╗ąĖ ąĘą░ą┐čĆąĄčēąĄąĮąŠ, ą┐ąŠčĆąŠą│ ą▓ ą┐ąĄčĆąĄą┤ą░čćąĖ ąĖ ą┐čĆąĖąĄą╝ąĄ).
9. ąÆ čĆąĄą│ąĖčüčéčĆąĄ DMA_SxCR register ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄčéčüčÅ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąŠč鹊ą║ą░ ą┤ą░ąĮąĮčŗčģ, čĆąĄąČąĖą╝ ąĖąĮą║čĆąĄą╝ąĄąĮčéą░ ąĖą╗ąĖ čäąĖą║čüą░čåąĖąĖ ą░ą┤čĆąĄčüą░ ą┤ą╗čÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ąĖ ą┐ą░ą╝čÅčéąĖ, čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą▒čāą┤čāčé ąŠą┤ąĖąĮąŠčćąĮčŗąĄ (single) ąĖą╗ąĖ ą┐ą░ą║ąĄčéąĮčŗąĄ (burst), čłąĖčĆąĖąĮčŗ ą┤ą░ąĮąĮčŗčģ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ąĖ ą┐ą░ą╝čÅčéąĖ, ą║ąŠą╗čīčåąĄą▓ąŠą╣ čĆąĄąČąĖą╝ ąĖą╗ąĖ čĆąĄąČąĖą╝ ą┤ą▓ąŠą╣ąĮąŠą╣ ą▒čāč乥čĆąĖąĘą░čåąĖąĖ, ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ą┐ąŠčüą╗ąĄ ą┐ąŠą╗ąŠą▓ąĖąĮčŗ ąĖą╗ąĖ ą┐ąŠą╗ąĮąŠą╣ ą┐ąĄčĆąĄą┤ą░čćąĖ ąĖ/ąĖą╗ąĖ ą┐čĆąĖ ąŠčłąĖą▒ą║ąĄ.
10. ą¤ąŠč鹊ą║ ą░ą║čéąĖą▓ąĖčĆčāąĄčéčüčÅ čāčüčéą░ąĮąŠą▓ą║ąŠą╣ ą▒ąĖčéą░ EN ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_SxCR.
ąÜą░ą║ č鹊ą╗čīą║ąŠ ą┐ąŠč鹊ą║ čĆą░ąĘčĆąĄčłąĄąĮ, ąŠąĮ ą╝ąŠąČąĄčé ąŠą▒čüą╗čāąČąĖčéčī ą╗čÄą▒ąŠą╣ ąĘą░ą┐čĆąŠčü DMA ąŠčé ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░, čüąŠąĄą┤ąĖąĮąĄąĮąĮąŠą│ąŠ čü ą┐ąŠč鹊ą║ąŠą╝.
[ą¤čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī čüąĖčüč鹥ą╝čŗ]
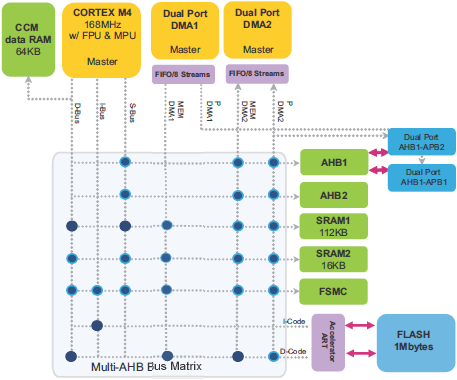
ąÆ MCU STM32F2/F4/F7 ą▓čüčéčĆąŠąĄąĮą░ ą░čĆčģąĖč鹥ą║čéčāčĆą░ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą│ą╗ą░ą▓ąĮčŗčģ ąĖ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą┐ąŠą┤čćąĖąĮąĄąĮąĮčŗčģ ą▒ą╗ąŠą║ąŠą▓ (multi-masters/multi-slaves):
ŌĆó ąØąĄčüą║ąŠą╗čīą║ąŠ čāčüčéčĆąŠą╣čüčéą▓ master:
ŌĆō ą©ąĖąĮčŗ AHB čÅą┤čĆą░ Cortex┬«-Mx
ŌĆō ą©ąĖąĮą░ ą┐ą░ą╝čÅčéąĖ DMA1
ŌĆō ą©ąĖąĮą░ ą┐ą░ą╝čÅčéąĖ DMA2
ŌĆō ą©ąĖąĮą░ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ DMA2
ŌĆō ą©ąĖąĮą░ Ethernet DMA
ŌĆō ą©ąĖąĮą░ USB high-speed DMA
ŌĆō ą©ąĖąĮą░ Chrom-ART Accelerator
ŌĆō ą©ąĖąĮą░ LCD-TFT
ŌĆó ąØąĄčüą║ąŠą╗čīą║ąŠ čāčüčéčĆąŠą╣čüčéą▓ slave:
ŌĆō ąÆąĮčāčéčĆąĄąĮąĮąĖąĄ ąĖąĮč鹥čĆč乥ą╣čüčŗ Flash, ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĮčŗąĄ ą║ ą╝ąĮąŠą│ąŠčüą╗ąŠą╣ąĮąŠą╣ ą╝ą░čéčĆąĖčåąĄ čłąĖąĮčŗ.
ŌĆō ą×čüąĮąŠą▓ąĮą░čÅ ą▓ąĮčāčéčĆąĄąĮąĮčÅčÅ ą┐ą░ą╝čÅčéčī SRAM1 ąĖ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ (Auxiliary) ą▓ąĮčāčéčĆąĄąĮąĮąĖąĄ SRAM (SRAM2, SRAM3, ą║ąŠą│ą┤ą░ ąŠąĮąĖ ąĖą╝ąĄčÄčéčüčÅ ą▓ MCU).
ŌĆō ą¤ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ AHB1, ą▓ą║ą╗čÄčćą░čÅ ą╝ąŠčüčéčŗ AHB-APB ąĖ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ APB.
ŌĆō ą¤ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ AHB2.
ŌĆō ą¤ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ AHB3 (čéą░ą║ąĖąĄ ą║ą░ą║ FMC, Quad-SPI, ą║ąŠą│ą┤ą░ čŹč鹊 ąĖą╝ąĄąĄčéčüčÅ ąĮą░ ą╗ąĖąĮąĄą╣ą║ąĄ ą┐čĆąŠą┤čāą║č鹊ą▓ MCU).
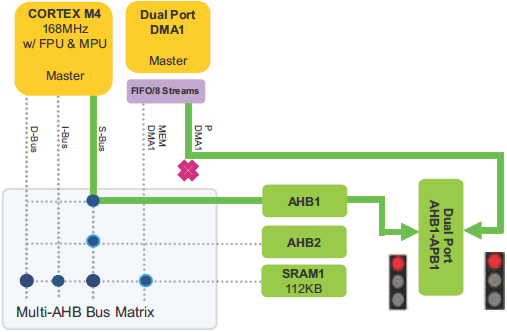
ąŻčüčéčĆąŠą╣čüčéą▓ą░ master ąĖ slave čüąŠąĄą┤ąĖąĮąĄąĮčŗ č湥čĆąĄąĘ ą╝ąĮąŠą│ąŠčüą╗ąŠą╣ąĮčāčÄ ą╝ą░čéčĆąĖčåčā čłąĖąĮčŗ, ą│ą░čĆą░ąĮčéąĖčĆčāčÄčēčāčÄ ą║ąŠąĮą║čāčĆąĄąĮčéąĮčŗą╣ ą┤ąŠčüčéčāą┐ ąĄą│ąŠ čŹčäč乥ą║čéąĖą▓ąĮąŠąĄ čäčāąĮą║čåąĖąŠąĮąĖčĆąŠą▓ą░ąĮąĖąĄ, ą┤ą░ąČąĄ ą║ąŠą│ą┤ą░ ą▓čŗčüąŠą║ąŠčüą║ąŠčĆąŠčüčéąĮčŗąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ čĆą░ą▒ąŠčéą░čÄčé ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ. ąŁčéą░ ą░čĆčģąĖč鹥ą║čéčāčĆą░ ą┤ą╗čÅ ą┐čĆąĖą╝ąĄčĆą░ ą┐ąŠą║ą░ąĘą░ąĮą░ ąĮą░ čüą╗ąĄą┤čāčÄčēąĄą╝ čĆąĖčüčāąĮą║ąĄ ą┤ą╗čÅ čüą╗čāčćą░čÅ čüąĄčĆąĖą╣ STM32F405/STM32F415 ąĖ STM32F407/STM32F417.
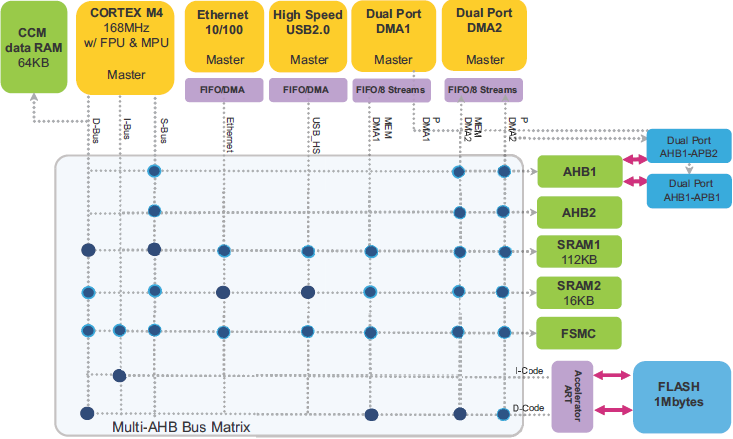
ąĀąĖčü. 7. ąÉčĆčģąĖč鹥ą║čéčāčĆą░ čüąĖčüč鹥ą╝čŗ STM32F405/STM32F415 ąĖ STM32F407/STM32F417.
ą£ąĮąŠą│ąŠčüą╗ąŠą╣ąĮą░čÅ ą╝ą░čéčĆąĖčåą░ čłąĖąĮčŗ. Multi-layer bus matrix ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ master ą║ąŠąĮą║čāčĆąĄąĮčéąĮąŠ/ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą▓čŗą┐ąŠą╗ąĮčÅčéčī ą┐ąĄčĆąĄą┤ą░čćąĖ ą┤ą░ąĮąĮčŗčģ, ą┐ąŠą║ą░ ąŠąĮąĖ ą░ą┤čĆąĄčüčāčÄčé čĆą░ąĘąĮčŗąĄ ą╝ąŠą┤čāą╗ąĖ slave. ąæą░ąĘąĖčĆčāčÅčüčī ąĮą░ ą░čĆčģąĖč鹥ą║čéčāčĆąĄ Cortex-Mx ą┤ą▓ąŠą╣ąĮčŗčģ ą┐ąŠčĆč鹊ą▓ AHB DMA, čŹčéą░ čüčéčĆčāą║čéčāčĆą░ čāą╗čāčćčłą░ąĄčé ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ čéčĆą░ąĮąĘą░ą║čåąĖą╣ ą┤ą░ąĮąĮčŗčģ, čćč鹊 čüąĮąĖąČą░ąĄčé ąĘą░čéčĆą░čéčŗ ąĮą░ ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ, ą┐ąŠą▓čŗčłą░ąĄčé čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéčī DMA ąĖ čüąĮąĖąČą░ąĄčé ą┐ąŠčéčĆąĄą▒ą╗ąĄąĮąĖąĄ 菹ĮąĄčĆą│ąĖąĖ.
ąÆ ą║ąŠąĮč鹥ą║čüč鹥 čĆą░čüčüą╝ąŠčéčĆąĄąĮąĖčÅ ą╝ą░čéčĆąĖčåčŗ čłąĖąĮčŗ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ:
AHB master: ą│ą╗ą░ą▓ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ čłąĖąĮčŗ, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ąĖąĮąĖčåąĖąĖčĆąŠą▓ą░čéčī ąŠą┐ąĄčĆą░čåąĖąĖ čćč鹥ąĮąĖčÅ ąĖ ąĘą░ą┐ąĖčüąĖ. ąŚą░ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╣ ą┐ąĄčĆąĖąŠą┤ ą▓čĆąĄą╝ąĄąĮąĖ č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ master ą╝ąŠąČąĄčé ą▓čŗąĖą│čĆą░čéčī ą▓ą╗ą░ą┤ąĄąĮąĖąĄ čłąĖąĮąŠą╣.
AHB slave: ą┐ąŠą┤čćąĖąĮąĄąĮąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ čłąĖąĮčŗ ąŠčéą▓ąĄčćą░ąĄčé ąĮą░ ąŠą┐ąĄčĆą░čåąĖąĖ čćč鹥ąĮąĖčÅ ąĖą╗ąĖ ąĘą░ą┐ąĖčüąĖ čāčüčéčĆąŠą╣čüčéą▓ą░ master. ąŻčüčéčĆąŠą╣čüčéą▓ąŠ slave čłąĖąĮčŗ čüąĖą│ąĮą░ą╗ąĖąĘąĖčĆčāąĄčé čāčüčéčĆąŠą╣čüčéą▓čā master ąŠ čüąŠčüč鹊čÅąĮąĖčÅčģ čāčüą┐ąĄčģą░ (success), ąŠčéą║ą░ąĘą░ (failure) ąĖą╗ąĖ ąŠąČąĖą┤ą░ąĮąĖčÅ.
AHB arbiter: ą░čĆą▒ąĖčéčĆ čłąĖąĮčŗ ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ master ą╝ąŠąČąĄčé ąĖąĮąĖčåąĖąĖčĆąŠą▓ą░čéčī čćč鹥ąĮąĖąĄ ąĖą╗ąĖ ąĘą░ą┐ąĖčüčī ą▓ ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ ą╝ąŠą╝ąĄąĮčé ą▓čĆąĄą╝ąĄąĮąĖ.
AHB bus matrix: ą╝ąĮąŠą│ąŠčüą╗ąŠą╣ąĮą░čÅ ą╝ą░čéčĆąĖčåą░ čłąĖąĮčŗ AHB, ą║ąŠč鹊čĆą░čÅ čüąŠąĄą┤ąĖąĮčÅąĄčé ą┤čĆčāą│ čü ą┤čĆčāą│ąŠą╝ čāčüčéčĆąŠą╣čüčéą▓ą░ AHB master ąĖ AHB slave, čü ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗą╝ ą░čĆą▒ąĖčéčĆąŠą╝ AHB ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ čüą╗ąŠčÅ. ąÉčĆą▒ąĖčéčĆą░ąČ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą░ą╗ą│ąŠčĆąĖčéą╝ round-robin (čåąĖą║ą╗ąĖč湥čüą║ąĖą╣ ą░ą╗ą│ąŠčĆąĖčéą╝ [2]).
ąĪčģąĄą╝ą░ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓ round-robin. ąØą░ čāčĆąŠą▓ąĮąĄ ą╝ą░čéčĆąĖčåčŗ čłąĖąĮ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮą░ čåąĖą║ą╗ąĖč湥čüą║ą░čÅ (round-robin) čüčģąĄą╝ą░ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓ ą┤ą╗čÅ ą│ą░čĆą░ąĮčéąĖąĖ, čćč鹊 ą║ą░ąČą┤čŗą╣ master ą╝ąŠą│ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ ą╗čÄą▒ąŠą╝čā slave čü ąŠč湥ąĮčī ąĮąĖąĘą║ąŠą╣ ą╗ą░č鹥ąĮčéąĮąŠčüčéčīčÄ:
ŌĆó ą¤ąŠą╗ąĖčéąĖą║ą░ ą░čĆą▒ąĖčéčĆą░ąČą░ round-robin ąŠą▒ąĄčüą┐ąĄčćąĖą▓ą░ąĄčé čüą┐čĆą░ą▓ąĄą┤ą╗ąĖą▓ąŠąĄ čĆą░čüą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą┐ąŠą╗ąŠčüčŗ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ čłąĖąĮčŗ.
ŌĆó ą£ą░ą║čüąĖą╝ą░ą╗čīąĮą░čÅ ąĘą░ą┤ąĄčƹȹ║ą░ ąŠą│čĆą░ąĮąĖč湥ąĮą░.
ŌĆó ąÜą▓ą░ąĮč鹊ą╝ round-robin čÅą▓ą╗čÅąĄčéčüčÅ 1x čéčĆą░ąĮąĘą░ą║čåąĖčÅ.
ąÉčĆą▒ąĖčéčĆčŗ ą╝ą░čéčĆąĖčåčŗ čłąĖąĮčŗ ą▓ą╝ąĄčłąĖą▓ą░čÄčéčüčÅ ą┤ą╗čÅ čĆąĄčłąĄąĮąĖčÅ ą║ąŠąĮčäą╗ąĖą║č鹊ą▓ ą┤ąŠčüčéčāą┐ą░, ą║ąŠą│ą┤ą░ ąĮąĄčüą║ąŠą╗čīą║ąŠ master-čāčüčéčĆąŠą╣čüčéą▓ AHB ą┐čŗčéą░čÄčéčüčÅ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ ąŠą┤ąĮąŠą╝čā slave-čāčüčéčĆąŠą╣čüčéą▓čā AHB.
ąÆ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ (čĆąĖčü. 8) čüčĆą░ąĘčā ą┤ą▓ą░ čāčüčéčĆąŠą╣čüčéą▓ą░ CPU ąĖ DMA1 ą┐čŗčéą░čÄčéčüčÅ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ SRAM1 ą┤ą╗čÅ čćč鹥ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ.
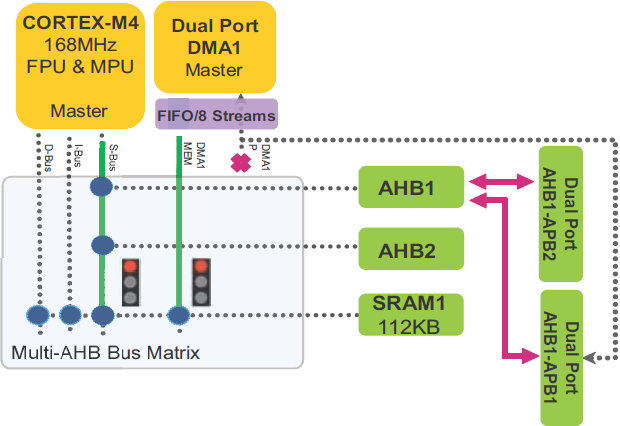
ąĀąĖčü. 8. ąŚą░ą┐čĆąŠčü CPU ąĖ DMA1 ąĮą░ ą┤ąŠčüčéčāą┐ ą║ SRAM1.
ąÆ čüą╗čāčćą░ąĄ ą║ąŠąĮą║čāčĆąĄąĮčéąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ čłąĖąĮčŗ, ą║ą░ą║ ą▓ ą┐čĆąĖą╝ąĄčĆąĄ čĆąĖčü. 8, čéčĆąĄą▒čāąĄčéčüčÅ ą░čĆą▒ąĖčéčĆą░ąČ ą╝ą░čéčĆąĖčåčŗ čłąĖąĮčŗ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ą┐ąŠą╗ąĖčéąĖą║ą░ round-robin, čćč鹊ą▒čŗ čĆąĄčłąĖčéčī ą┐čĆąŠą▒ą╗ąĄą╝čā ą┤ąŠčüčéčāą┐ą░: ąĄčüą╗ąĖ ą┐ąŠčüą╗ąĄą┤ąĮąĖą╣ ą▓čŗąĖą│čĆą░ą▓čłąĖą╣ master čłąĖąĮčŗ ą▒čŗą╗ CPU, č鹊 ą┐čĆąĖ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┤ąŠčüčéčāą┐ąĄ ą▓čŗąĖą│čĆą░ąĄčé ą┤ąŠčüčéčāą┐ DMA1, ąĖ ą┐ąĄčĆą▓čŗą╝ ą┐ąŠą╗čāčćąĖčé ą┤ąŠčüčéčāą┐ ą║ SRAM1. ąŚą░č鹥ą╝ ą┐čĆą░ą▓ą░ ą┤ąŠčüčéčāą┐ą░ ą║ SRAM1 ą┐ąŠą╗čāčćąĖčé CPU.
ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 ąĘą░ą┤ąĄčƹȹ║ą░ čéčĆą░ąĮąĘą░ą║čåąĖąĖ, čüą▓čÅąĘą░ąĮąĮą░čÅ čü ąŠą┤ąĮąĖą╝ master, ąĘą░ą▓ąĖčüąĖčé ąŠčé ą║ąŠą╗ąĖč湥čüčéą▓ą░ ąŠąČąĖą┤ą░čÄčēąĖčģ ąĘą░ą┐čĆąŠčüąŠą▓ ą║ č鹊ą╝čā ąČąĄ čüą░ą╝ąŠą╝čā čāčüčéčĆąŠą╣čüčéą▓čā AHB slave ąŠčé ą┤čĆčāą│ąĖčģ čāčüčéčĆąŠą╣čüčéą▓ master. ąÆ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┐čĆąĖą╝ąĄčĆąĄ (čĆąĖčü. 9) ą┐ąŠą║ą░ąĘą░ąĮą░ čüąĖčéčāą░čåąĖčÅ, ą║ąŠą│ą┤ą░ čüčĆą░ąĘčā 5 čāčüčéčĆąŠą╣čüčéą▓ master ą┐čŗčéą░čÄčéčüčÅ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ SRAM1.

ąĀąĖčü. 9. ą¤čÅčéčī ąĘą░ą┐čĆąŠčüąŠą▓ čāčüčéčĆąŠą╣čüčéą▓ master ąĮą░ ą┤ąŠčüčéčāą┐ ą║ SRAM.
ąøą░č鹥ąĮčéąĮąŠčüčéčī, čüą▓čÅąĘą░ąĮąĮą░čÅ čü DMA1 ą┤ą╗čÅ ą┐ąŠą▓č鹊čĆąĮąŠą│ąŠ ą▓čŗąĖą│čĆčŗčłą░ čłąĖąĮčŗ ąĖ ą┤ąŠčüčéčāą┐ą░ ą║ SRAM1 (ą┤ą╗čÅ ą┐čĆąĖą╝ąĄčĆą░ čĆąĖčü. 9) čĆą░ą▓ąĮą░ ą▓čĆąĄą╝ąĄąĮąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą▓čüąĄčģ ąŠąČąĖą┤ą░čÄčēąĖčģ ąĘą░ą┐čĆąŠčüąŠą▓ ąŠčé ą┤čĆčāą│ąĖčģ čāčüčéčĆąŠą╣čüčéą▓ master.
ąŚą░ą┤ąĄčƹȹ║ą░ (latency) ąĮą░ą▒ą╗čÄą┤ą░ąĄą╝ą░čÅ ą┐ąŠčĆč鹊ą╝ DMA master ą▓ ąŠą┤ąĮąŠą╣ čéčĆą░ąĮąĘą░ą║čåąĖąĖ, ąĘą░ą▓ąĖčüąĖčé ąŠčé čéąĖą┐ąŠą▓ ąĖ ą┤ą╗ąĖąĮ čéčĆą░ąĮąĘą░ą║čåąĖą╣ ą┤čĆčāą│ąĖčģ master.
ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą╝čŗ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ąĄą╝ ą┐čĆąĄą┤čŗą┤čāčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ DMA1 ąĖ CPU (čĆąĖčü. 8) čü ą║ąŠąĮą║čāčĆąĄąĮčéąĮčŗą╝ ą┤ąŠčüčéčāą┐ąŠą╝ ą║ SRAM, č鹊 ąĘą░ą┤ąĄčƹȹ║ą░ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA ą╝ąĄąĮčÅąĄčéčüčÅ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą┤ą╗ąĖąĮčŗ čéčĆą░ąĮąĘą░ą║čåąĖąĖ CPU.
ąĢčüą╗ąĖ ą┤ąŠčüčéčāą┐ ą║ čłąĖąĮąĄ čüąĮą░čćą░ą╗ą░ ą▒čŗą╗ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮ CPU, ąĖ CPU ąĮąĄ ą▓čŗą┐ąŠą╗ąĮčÅąĄčé ąŠą┤ąĖąĮąŠčćąĮčāčÄ ąŠą┐ąĄčĆą░čåąĖčÄ ąĘą░ą│čĆčāąĘą║ąĖ/čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ (load/store), č鹊 ą▓čĆąĄą╝čÅ ąŠąČąĖą┤ą░ąĮąĖčÅ DMA ą┤ą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ą┤ąŠčüčéčāą┐ą░ ą║ SRAM ą╝ąŠąČąĄčé čĆą░čüčłąĖčĆąĖčéčīčüčÅ ąŠčé ąŠą┤ąĮąŠą│ąŠ čåąĖą║ą╗ą░ AHB ą┤ą╗čÅ ąŠą┤ąĖąĮąŠčćąĮąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ load/store ą┤ąŠ N čåąĖą║ą╗ąŠą▓ AHB, ą│ą┤ąĄ N čŹč鹊 ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čüą╗ąŠą▓ ą┤ą░ąĮąĮčŗčģ ą▓ čéčĆą░ąĮąĘą░ą║čåąĖąĖ CPU.
CPU ą▒ą╗ąŠą║ąĖčĆčāąĄčé čłąĖąĮčā AHB, čćč鹊ą▒čŗ čüąŠčģčĆą░ąĮąĖčéčī ą▓ą╗ą░ą┤ąĄąĮąĖąĄ ąĄčæ ąĖ čüąĮąĖąĘąĖčéčī ą╗ą░č鹥ąĮčéąĮąŠčüčéčī ą▓ąŠ ą▓čĆąĄą╝čÅ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ąŠą┐ąĄčĆą░čåąĖą╣ load/store ąĖ ą▓čģąŠą┤ąĄ ą▓ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ. ąŁč鹊 čāą╗čāčćčłą░ąĄčé ąŠčéąĘčŗą▓čćąĖą▓ąŠčüčéčī firmware, ąĮąŠ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ąĘą░ą┤ąĄčƹȹ║ą░ą╝ ąĮą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA.
ąŚą░ą┤ąĄčƹȹ║ą░ ąĮą░ ą┤ąŠčüčéčāą┐ DMA1 SRAM, ą║ąŠą│ą┤ą░ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą║ąŠąĮą║čāčĆąĄąĮčåąĖčÅ čü CPU, ąĘą░ą▓ąĖčüąĖčé ąŠčé čéąĖą┐ą░ čéčĆą░ąĮąĘą░ą║čåąĖąĖ:
ŌĆó ąóčĆą░ąĮąĘą░ą║čåąĖčÅ CPU ą▓čŗą┤ą░ąĄčéčüčÅ ą┐ąŠ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÄ (čüąŠčģčĆą░ąĮąĄąĮąĖąĄ ą║ąŠąĮč鹥ą║čüčéą░): 8 čåąĖą║ą╗ąŠą▓ AHB.
ŌĆó ąóčĆą░ąĮąĘą░ą║čåąĖčÅ CPU ą▓čŗą┤ą░ąĄčéčüčÅ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą╝ ą║čŹčłą░ (256-ą▒ąĖčéąĮąŠąĄ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ/ąĘą░ą╝ąĄčēąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░): 8 čåąĖą║ą╗ąŠą▓ AHB(a).
ŌĆó ąóčĆą░ąĮąĘą░ą║čåąĖčÅ CPU ą▓čŗą┤ą░ąĄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ LDM/STM: 14 čéą░ą║č鹊ą▓ AHB(b).
ŌĆō ą¤ąĄčĆąĄą┤ą░čćą░ ą┤ąŠ 14 čĆąĄą│ąĖčüčéčĆąŠą▓ ąĖąĘ ą┐ą░ą╝čÅčéąĖ ąĖą╗ąĖ ą▓ ą┐ą░ą╝čÅčéčī.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖčÅ:
(a) ąóąŠą╗čīą║ąŠ ą┤ą╗čÅ STM32F7xx.
(b) ąøą░č鹥ąĮčéąĮąŠčüčéčī ąĖąĘ-ąĘą░ čéčĆą░ąĮąĘą░ą║čåąĖą╣, ą▓čŗąĘą▓ą░ąĮąĮčŗčģ ąĖąĮčüčéčĆčāą║čåąĖčÅą╝ąĖ LDM/STM, ą╝ąŠąČąĮąŠ čāą╝ąĄąĮčīčłąĖčéčī, ąĄčüą╗ąĖ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░čéčī ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆ ą┤ą╗čÅ ą┤ąĄą╗ąĄąĮąĖčÅ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ąĖąĮčüčéčĆčāą║čåąĖą╣ load/store ą▓ ąŠčéą┤ąĄą╗čīąĮčŗąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ load/store.
ąØą░ čĆąĖčü. 10 ą┐ąŠą┤čĆąŠą▒ąĮąŠ ą┐ąŠą║ą░ąĘą░ąĮ čüą╗čāčćą░ą╣ ąĘą░ą┤ąĄčƹȹ║ąĖ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA ąĖąĘ-ąĘą░ ą╝ąĮąŠą│ąŠčåąĖą║ą╗ąŠą▓ąŠą╣ čéčĆą░ąĮąĘą░ą║čåąĖąĖ CPU, ą▓čŗąĘą▓ą░ąĮąĮąŠą╣ ą▓čģąŠą┤ąŠą╝ ą▓ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ. ą¤ąŠčĆčé ą┐ą░ą╝čÅčéąĖ DMA ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ. ą¤ąŠčüą╗ąĄ ą░čĆą▒ąĖčéčĆą░ąČą░ čłąĖąĮą░ AHB ąĮąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčéčüčÅ ą┐ąŠčĆčéčā ą┐ą░ą╝čÅčéąĖ DMA1, ą┐ąŠč鹊ą╝čā čćč鹊 ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčéčüčÅ ą┤ą╗čÅ CPU. ąØą░ą▒ą╗čÄą┤ą░ąĄčéčüčÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮą░čÅ ąĘą░ą┤ąĄčƹȹ║ą░ ą┤ą╗čÅ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÅ ąĘą░ą┐čĆąŠčüą░ DMA, ąŠąĮą░ čüąŠčüčéą░ą▓ą╗čÅąĄčé 8 čéą░ą║č鹊ą▓ AHB ą┤ą╗čÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ CPU, ą▓čŗąĘą▓ą░ąĮąĮąŠą╣ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄą╝.
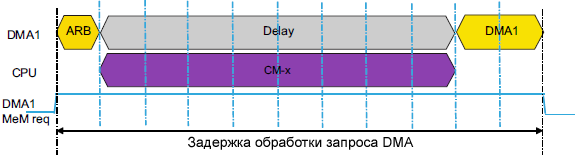
ąĀąĖčü. 10. ąŚą░ą┤ąĄčƹȹ║ą░ ąĘą░ą┐čāčüą║ą░ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ąĖąĘ-ąĘą░ čéčĆą░ąĮąĘą░ą║čåąĖąĖ CPU, ąĘą░ą┐čāčēąĄąĮąĮąŠą╣ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄą╝.
ąóąŠ ąČąĄ čüą░ą╝ąŠąĄ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ąĮą░ą▒ą╗čÄą┤ą░ąĄčéčüčÅ ąĖ ą┤ą╗čÅ ą┤čĆčāą│ąĖčģ čāčüčéčĆąŠą╣čüčéą▓ master (čéąĖą┐ą░ DMA2, USB_HS, Ethernet, ...), ą║ąŠą│ą┤ą░ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą░ą┤čĆąĄčüčāąĄčéčüčÅ ąŠą┤ąĮąŠ ąĖ č鹊 ąČąĄ slave-čāčüčéčĆąŠą╣čüčéą▓ąŠ čü ą┤ą╗ąĖąĮąŠą╣ čéčĆą░ąĮąĘą░ą║čåąĖąĖ, ąŠčéą╗ąĖčćą░čÄčēąĄą╣čüčÅ ąŠčé ąŠą┤ąĮąŠą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░ ą┤ą░ąĮąĮčŗčģ.
ą¦č鹊ą▒čŗ čāą╗čāčćčłąĖčéčī ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ą┤ąŠčüčéčāą┐ą░ DMA ąĮą░ ą╝ą░čéčĆąĖčåąĄ čłąĖąĮčŗ, čĆąĄą║ąŠą╝ąĄąĮą┤čāąĄčéčüčÅ ąĖąĘą▒ąĄą│ą░čéčī ą║ąŠąĮą║čāčĆąĄąĮčåąĖąĖ ąĘą░ čłąĖąĮčā.
[ą¤čāčéąĖ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA]
ąöą▓ąŠą╣ąĮąŠą╣ ą┐ąŠčĆčé DMA. ąÆ MCU STM32F2/F4/F7 ą▓čüčéčĆąŠąĄąĮąŠ ą┤ą▓ą░ ą▒ą╗ąŠą║ą░ DMA. ąŻ ą║ą░ąČą┤ąŠą│ąŠ DMA ąĄčüčéčī 2 ą┐ąŠčĆčéą░, ą┐ąŠčĆčé ą┐ą░ą╝čÅčéąĖ ąĖ ą┐ąŠčĆčé ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé čĆą░ą▒ąŠčéą░čéčī ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ, ąĮąĄ č鹊ą╗čīą║ąŠ ąĮą░ čāčĆąŠą▓ąĮąĄ DMA, ąĮąŠ čéą░ą║ąČąĄ čü ą┤čĆčāą│ąĖą╝ąĖ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ąĖ master čüąĖčüč鹥ą╝čŗ, ąĖčüą┐ąŠą╗čīąĘčāčÅ ą▓ąĮąĄčłąĮčÄčÄ ą╝ą░čéčĆąĖčåčā čłąĖąĮčŗ ąĖ ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗąĄ ą┐čāčéąĖ DMA.
ą×ą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░čéčī čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéčī čĆą░ą▒ąŠčéčŗ DMA ąĖ čüąĮąĖąĘąĖčéčī ą▓čĆąĄą╝čÅ ąŠčéą║ą╗ąĖą║ą░ (ą▓čĆąĄą╝čÅ ąŠąČąĖą┤ą░ąĮąĖčÅ ą╝ąĄąČą┤čā ąĘą░ą┐čĆąŠčüąŠą╝ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ąĖ ą┐ąĄčĆąĄą┤ą░č湥ą╣ ą┤ą░ąĮąĮčŗčģ čéčĆą░ąĮąĘą░ą║čåąĖąĖ).
ąĀąĖčü. 11. ąöą▓ąŠą╣ąĮąŠą╣ ą┐ąŠčĆčé DMA.
ąöą╗čÅ DMA2:
ŌĆó MEM (ą┐ąŠčĆčé ą┐ą░ą╝čÅčéąĖ) ą╝ąŠąČąĄčé ąŠą▒čĆą░čēą░čéčīčüčÅ ą║ AHB1, AHB2, AHB3 (ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, FSMC), ąŠą▒ą╗ą░čüčéčÅą╝ SRAM, ąĖ ą║ ą┐ą░ą╝čÅčéąĖ Flash č湥čĆąĄąĘ ą╝ą░čéčĆąĖčåčā čłąĖąĮčŗ.
ŌĆó Periph (ą┐ąŠčĆčé ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓) ą╝ąŠąČąĄčé ąŠą▒čĆą░čēą░čéčīčüčÅ:
ŌĆō ąÜ AHB1, AHB2, AHB3 (ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, FSMC), ąŠą▒ą╗ą░čüčéčÅą╝ SRAM, ąĖ ą║ ą┐ą░ą╝čÅčéąĖ Flash č湥čĆąĄąĘ ą╝ą░čéčĆąĖčåčā čłąĖąĮčŗ.
ŌĆō ąÜ ą╝ąŠčüčéčā AHB-APB2 ąĮą░ą┐čĆčÅą╝čāčÄ (ą▒ąĄąĘ ą┐ąĄčĆąĄčüąĄč湥ąĮąĖčÅ čü ą╝ą░čéčĆąĖčåąĄą╣ čłąĖąĮčŗ).
ąöą╗čÅ DMA1:
ŌĆó MEM (ą┐ąŠčĆčé ą┐ą░ą╝čÅčéąĖ) ą╝ąŠąČąĄčé ąŠą▒čĆą░čēą░čéčīčüčÅ ą║ AHB3 (ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, FSMC), ąŠą▒ą╗ą░čüčéčÅą╝ SRAM, ąĖ ą║ ą┐ą░ą╝čÅčéąĖ Flash č湥čĆąĄąĘ ą╝ą░čéčĆąĖčåčā čłąĖąĮčŗ.
ŌĆó Periph (ą┐ąŠčĆčé ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓) ą╝ąŠąČąĄčé ąŠą▒čĆą░čēą░čéčīčüčÅ č鹊ą╗čīą║ąŠ ą║ ą╝ąŠčüčéčā AHB-APB1 ąĮą░ą┐čĆčÅą╝čāčÄ (ą▒ąĄąĘ ą┐ąĄčĆąĄčüąĄč湥ąĮąĖčÅ čü ą╝ą░čéčĆąĖčåąĄą╣ čłąĖąĮčŗ).
ąĪąŠčüč鹊čÅąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA. ąÆ čŹč鹊ą╣ čüąĄą║čåąĖąĖ ąŠą▒čŖčÅčüąĮčÅčÄčéčüčÅ čłą░ą│ąĖ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA ąĮą░ čāčĆąŠą▓ąĮąĄ ą┐ąŠčĆčéą░ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░, ąĖ čéą░ą║ąČąĄ ąĮą░ čāčĆąŠą▓ąĮąĄ ą┐ąŠčĆčéą░ ą┐ą░ą╝čÅčéąĖ.
ŌĆó ąöą╗čÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ąŠčé ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ą▓ ą┐ą░ą╝čÅčéčī (čüą╝. čĆąĖčü. 12): ą▓ čŹč鹊ą╝ čĆąĄąČąĖą╝ąĄ DMA ąĘą░ą┐čĆą░čłąĖą▓ą░ąĄčé ą┤ą▓ą░ ą┤ąŠčüčéčāą┐ą░ ą║ čłąĖąĮąĄ ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ.
ŌĆō ą×ą┤ąĖąĮ ą┤ąŠčüčéčāą┐ č湥čĆąĄąĘ ą┐ąŠčĆčé ą┐ąĄčĆąĖč乥čĆąĖąĖ, čŹč鹊čé ą┤ąŠčüčéčāą┐ ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ ąĘą░ą┐čĆąŠčüąŠą╝ ąŠčé ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░.
ŌĆō ąöčĆčāą│ąŠą╣ ą┤ąŠčüčéčāą┐ č湥čĆąĄąĘ ą┐ąŠčĆčé ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ą┐čāčēąĄąĮ ą╗ąĖą▒ąŠ ą┐ąŠ ą┐ąŠčĆąŠą│čā FIFO (ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čĆąĄąČąĖą╝ FIFO), ą╗ąĖą▒ąŠ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ ą┐ąŠčüą╗ąĄ čćč鹥ąĮąĖčÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ (ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čĆąĄąČąĖą╝ Direct).
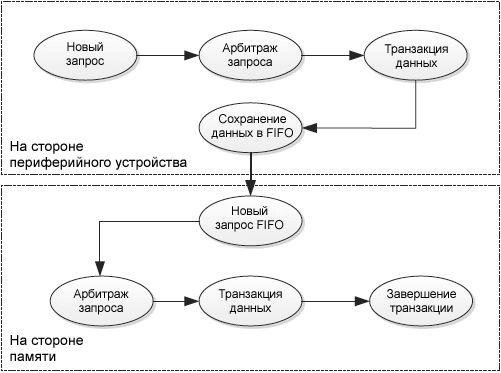
ąĀąĖčü. 12. ąĪąŠčüč鹊čÅąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą┐ąĄčĆąĖč乥čĆąĖčÅ -> ą┐ą░ą╝čÅčéčī.
ŌĆó ąöą╗čÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ąŠčé ą┐ą░ą╝čÅčéąĖ ą▓ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ (čüą╝. čĆąĖčü. 13): ą▓ čŹč鹊ą╝ čĆąĄąČąĖą╝ąĄ DMA ąĘą░ą┐čĆą░čłąĖą▓ą░ąĄčé ą┤ą▓ą░ ą┤ąŠčüčéčāą┐ą░ ą║ čłąĖąĮąĄ ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ.
ŌĆō DMA ąŠąČąĖą┤ą░ąĄčé ą┤ąŠčüčéčāą┐ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░, čüčćąĖčéčŗą▓ą░ąĄčé ą┤ą░ąĮąĮčŗąĄ ąĖąĘ ą┐ą░ą╝čÅčéąĖ ąĖ čüąŠčģčĆą░ąĮčÅąĄčé ąĖčģ ą▓ FIFO ą┤ą╗čÅ ą│ą░čĆą░ąĮčéąĖąĖ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠą╣ ą┐ąĄčĆąĄą┤ą░čćąĖ ą┤ą░ąĮąĮčŗčģ, ą║ą░ą║ č鹊ą╗čīą║ąŠ čüčĆą░ą▒ąŠčéą░ąĄčé ąĘą░ą┐čĆąŠčü DMA ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░.
ŌĆō ąÜąŠą│ą┤ą░ čüčĆą░ą▒ąŠčéą░ą╗ ąĘą░ą┐čĆąŠčü ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░, ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ čéčĆą░ąĮąĘą░ą║čåąĖčÅ ąĮą░ ą┐ąŠčĆčéčā DMA ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░.
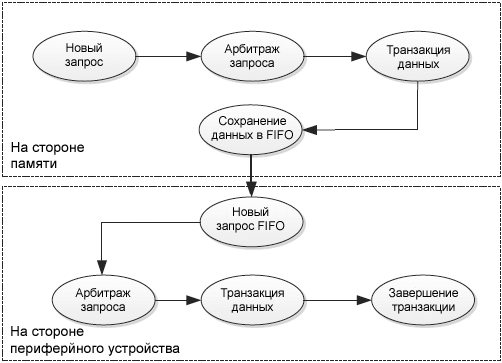
ąĀąĖčü. 13. ąĪąŠčüč鹊čÅąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą┐ą░ą╝čÅčéčī -> ą┐ąĄčĆąĖč乥čĆąĖčÅ.
ąÉčĆą▒ąĖčéčĆą░ąČ ąĘą░ą┐čĆąŠčüą░ DMA. ąÜą░ą║ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ą╗ąŠčüčī ą▓čŗčłąĄ ą▓ čüąĄą║čåąĖąĖ "ą¤čĆąĖąŠčĆąĖč鹥čé ą┐ąŠč鹊ą║ą░", ą▓ MCU STM32F2/F4/F7 DMA ą▓čüčéčĆąŠąĄąĮ ą░čĆą▒ąĖčéčĆ, ą║ąŠč鹊čĆčŗą╣ čāą┐čĆą░ą▓ą╗čÅąĄčé ąĘą░ą┐čĆąŠčüą░ą╝ąĖ ą▓ąŠčüčīą╝ąĖ ą┐ąŠč鹊ą║ąŠą▓ DMA ąĮą░ ąŠčüąĮąŠą▓ąĄ ąĖčģ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ąĖąĘ ą┤ą▓čāčģ ą┐ąŠčĆč鹊ą▓ AHB master (ą┐ąŠčĆčé ą┐ą░ą╝čÅčéąĖ ąĖ ą┐ąŠčĆčé ą┐ąĄčĆąĖč乥čĆąĖąĖ). ą¤ąŠ čŹčéąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥čéą░ą╝ ą░čĆą▒ąĖčéčĆ ąĘą░ą┐čāčüą║ą░ąĄčé ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ąĄčĆąĖč乥čĆąĖąĖ/ą┐ą░ą╝čÅčéąĖ.
ąÜąŠą│ą┤ą░ ą░ą║čéąĖą▓ąĮąŠ ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą│ąŠ ąĘą░ą┐čĆąŠčüą░ DMA, ą┤ą╗čÅ DMA ąĮčāąČąĄąĮ ą▓ąĮčāčéčĆąĄąĮąĮąĖą╣ ą░čĆą▒ąĖčéčĆ ą╝ąĄąČą┤čā ą░ą║čéąĖą▓ąĮčŗą╝ąĖ ąĘą░ą┐čĆąŠčüą░ą╝ąĖ, čćč鹊ą▒čŗ ą┐čĆąĖąĮčÅčéčī čĆąĄčłąĄąĮąĖąĄ, ą║ą░ą║ąŠą╣ ąĘą░ą┐čĆąŠčü ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ąŠą▒čĆą░ą▒ąŠčéą░ąĮ ą┐ąĄčĆą▓čŗą╝.
ąØą░ čĆąĖčü. 14 ą┐ąŠą║ą░ąĘą░ąĮčŗ ą┤ą▓ą░ ą║ąŠą╗čīčåąĄą▓čŗčģ (circular) ąĘą░ą┐čĆąŠčüą░ DMA, čüčĆą░ą▒ąŠčéą░ą▓čłąĖčģ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ąŠčé ą┐ąŠč鹊ą║ą░ DMA "request 1" ąĖ ą┐ąŠč鹊ą║ą░ DMA "request 2" (ąĘą░ą┐čĆąŠčüčŗ 1 ąĖ 2 ą╝ąŠą│čāčé ą▒čŗčéčī ą╗čÄą▒čŗą╝ ąĘą░ą┐čĆąŠčüąŠą╝ ą┐ąĄčĆąĖč乥čĆąĖąĖ DMA). ąØą░ čüą╗ąĄą┤čāčÄčēąĄą╝ čåąĖą║ą╗ąĄ čéą░ą║č鹊ą▓ AHB ą░čĆą▒ąĖčéčĆ DMA ą┐čĆąŠą▓ąĄčĆčÅąĄčé ą░ą║čéąĖą▓ąĮčŗąĄ ąŠąČąĖą┤ą░čÄčēąĖąĄ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĘą░ą┐čĆąŠčüčŗ, ąĖ ą┤ą░ąĄčé ą┤ąŠčüčéčāą┐ ą┤ą╗čÅ ą┐ąŠč鹊ą║ą░ "request 1", ą║ąŠč鹊čĆčŗą╣ ąŠą▒ą╗ą░ą┤ą░ąĄčé čüą░ą╝čŗą╝ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝.
ąĪą╗ąĄą┤čāčÄčēąĖą╣ čåąĖą║ą╗ ą░čĆą▒ąĖčéčĆą░ąČą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą▓ąŠ ą▓čĆąĄą╝čÅ ą┐ąŠčüą╗ąĄą┤ąĮąĄą│ąŠ čåąĖą║ą╗ą░ ą┤ą░ąĮąĮčŗčģ ą┐ąŠč鹊ą║ą░ "request 1". ąÆ čŹč鹊čé ą╝ąŠą╝ąĄąĮčé "request 1" ą╝ą░čüą║ąĖčĆčāąĄčéčüčÅ, ąĖ ą░čĆą▒ąĖčéčĆ ą▓ąĖą┤ąĖčé ą░ą║čéąĖą▓ąĮčŗą╝ č鹊ą╗čīą║ąŠ "request 2", ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 č湥ą│ąŠ ąĮą░ čŹč鹊čé čĆą░ąĘ ą┤ąŠčüčéčāą┐ čĆąĄąĘąĄčĆą▓ąĖčĆčāąĄčéčüčÅ ą┤ą╗čÅ "request 2", ąĖ čéą░ą║ ą┤ą░ą╗ąĄąĄ.

ąĀąĖčü. 14. ąÉčĆą▒ąĖčéčĆą░ąČ ąĘą░ą┐čĆąŠčüą░ DMA.
ą×čüąĮąŠą▓ąĮčŗąĄ čĆąĄą║ąŠą╝ąĄąĮą┤ą░čåąĖąĖ:
ŌĆó ąÆčŗčüąŠą║ąŠčüą║ąŠčĆąŠčüčéąĮčŗąĄ (high-speed) / čłąĖčĆąŠą║ąŠą┐ąŠą╗ąŠčüąĮčŗąĄ (high-bandwidth) ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ ą┤ąŠą╗ąČąĮčŗ ąĖą╝ąĄčéčī čüą░ą╝čŗąĄ ą▓čŗčüąŠą║ąĖąĄ ą┐čĆąĖąŠčĆąĖč鹥čéčŗ DMA. ąŁč鹊 ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮą░čÅ ąĘą░ą┤ąĄčƹȹ║ą░ ą┤ą░ąĮąĮčŗčģ, ąŠąČąĖą┤ą░ąĄą╝ą░čÅ ą┤ą╗čÅ čŹčéąĖčģ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓, ąĮąĄ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÄ (overrun) ąĖą╗ąĖ ąĮąĄą┤ąŠą│čĆčāąĘą║ąĄ (underrun) ą▓ ą┐ąŠč鹊ą║ąĄ ą┤ą░ąĮąĮčŗčģ.
ŌĆó ąÆ čüą╗čāčćą░ąĄ ąŠą┤ąĖąĮą░ą║ąŠą▓čŗčģ čéčĆąĄą▒ąŠą▓ą░ąĮąĖą╣ ą║ ą┐ąŠą╗ąŠčüąĄ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ, čĆąĄą║ąŠą╝ąĄąĮą┤čāąĄčéčüčÅ ąĮą░ąĘąĮą░čćąĖčéčī ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąĖą╣ ą┐čĆąĖąŠčĆąĖč鹥čé ą┤ą╗čÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓, čĆą░ą▒ąŠčéą░čÄčēąĖčģ ą▓ čĆąĄąČąĖą╝ąĄ Slave (ą║ąŠč鹊čĆčŗąĄ ąĮąĄ čāą┐čĆą░ą▓ą╗čÅčÄčé čüą║ąŠčĆąŠčüčéčīčÄ ą┐ąĄčĆąĄą┤ą░čćąĖ ą┤ą░ąĮąĮčŗčģ). ą£ąĄąĮčīčłąĖą╣ ą┐čĆąĖąŠčĆąĖč鹥čé ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ąĮą░ąĘąĮą░čćą░ąĄčéčüčÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗą╝ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝, ą║ąŠč鹊čĆčŗąĄ čĆą░ą▒ąŠčéą░čÄčé ą▓ čĆąĄąČąĖą╝ąĄ Master (ą╝ąŠą│čāčé čāą┐čĆą░ą▓ą╗čÅčéčī ą┐ąŠč鹊ą║ąŠą╝ ą┤ą░ąĮąĮčŗčģ).
ŌĆó ą¤ąŠčüą║ąŠą╗čīą║čā ą┤ą▓ą░ ą▒ą╗ąŠą║ą░ DMA ą╝ąŠą│čāčé čĆą░ą▒ąŠčéą░čéčī ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ ąĮą░ ą▒ą░ąĘąĄ ą╝ąĮąŠą│ąŠčüą╗ąŠą╣ąĮąŠą╣ čüčéčĆčāą║čéčāčĆčŗ ą╝ą░čéčĆąĖčåčŗ čłąĖąĮčŗ, ąĘą░ą┐čĆąŠčüčŗ ą▓čŗčüąŠą║ąŠčüą║ąŠčĆąŠčüčéąĮčŗčģ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ą╝ąŠą│čāčé ą▒čŗčéčī čüą▒ą░ą╗ą░ąĮčüąĖčĆąŠą▓ą░ąĮčŗ ą╝ąĄąČą┤čā ą┤ą▓čāą╝čÅ DMA, ą║ąŠą│ą┤ą░ čŹč鹊 ą▓ąŠąĘą╝ąŠąČąĮąŠ.
[ą£ąŠčüčé AHB-APB]
ąÆ MCU STM32F2/F4/F7 ą▓čüčéčĆąŠąĄąĮąŠ ą┤ą▓ą░ ą╝ąŠčüčéą░ AHB-APB (APB1 ąĖ APB2), ą║ ą║ąŠč鹊čĆčŗą╝ ą┐ąŠą┤ą║ą╗čÄč湥ąĮčŗ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░.
ąöą▓ąŠą╣ąĮąŠą╣ ą┐ąŠčĆčé AHB-APB. ą£ąŠčüčé AHB-APB ąĖą╝ąĄąĄčé ą┤ą▓čāčģą┐ąŠčĆč鹊ą▓čāčÄ ą░čĆčģąĖč鹥ą║čéčāčĆčā, ą║ąŠč鹊čĆą░čÅ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąŠčüčāčēąĄčüčéą▓ą╗čÅčéčī ą┤ąŠčüčéčāą┐ ą┤ą▓čāą╝čÅ čĆą░ąĘąĮčŗą╝ąĖ ą┐čāčéčÅą╝ąĖ:
ŌĆó ą¤čĆčÅą╝ąŠą╣ ą┐čāčéčī (ą▒ąĄąĘ ą┐ąĄčĆąĄčüąĄč湥ąĮąĖčÅ čü ą╝ą░čéčĆąĖčåąĄą╣ čłąĖąĮčŗ), ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ą▒čŗčéčī čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮ ąŠčé DMA1 ą║ APB1 ąĖą╗ąĖ ąŠčé DMA2 ą║ APB2. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą┤ąŠčüčéčāą┐ ąĮąĄ ą┐ąŠą╗čāčćą░ąĄčé ą┐ąĄąĮą░ą╗čīčéąĖ ąŠčé ą░čĆą▒ąĖčéčĆą░ ą╝ą░čéčĆąĖčåčŗ čłąĖąĮčŗ.
ŌĆó ą×ą▒čēąĖą╣ ą┐čāčéčī (č湥čĆąĄąĘ ą╝ą░čéčĆąĖčåčā čłąĖąĮčŗ), ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ą▒čŗčéčī čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮ ąŠčé CPU ąĖą╗ąĖ ąŠčé DMA2, ą┐čĆąĖ čŹč鹊ą╝ ąĮčāąČąĄąĮ ą░čĆą▒ąĖčéčĆą░ąČ ą╝ą░čéčĆąĖčåčŗ čłąĖąĮčŗ, čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą┐ąŠą▒ąĄą┤ąĖč鹥ą╗čÅ ą┤ąŠčüčéčāą┐ą░.
ąÉčĆą▒ąĖčéčĆą░ąČ ą╝ąŠčüčéą░ AHB-APB. ąśąĘ-ąĘą░ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą┐čĆčÅą╝ąŠą│ąŠ ą┐čāčéąĖ DMA čéą░ą║ąČąĄ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮ ą░čĆą▒ąĖčéčĆ ąĮą░ čāčĆąŠą▓ąĮąĄ ą╝ąŠčüčéą░ AHB-APB, čćč鹊ą▒čŗ čĆą░ąĘčĆąĄčłąĖčéčī ą║ąŠąĮą║čāčĆąĄąĮčéąĮčŗąĄ ąĘą░ą┐čĆąŠčüčŗ ą┤ąŠčüčéčāą┐ą░.
ąØą░ čĆąĖčü. 15 ąĖą╗ą╗čÄčüčéčĆąĖčĆčāąĄčéčüčÅ ą║ąŠąĮą║čāčĆąĄąĮčéąĮčŗą╣ ąĘą░ą┐čĆąŠčü ą┤ąŠčüčéčāą┐ą░ ąĮą░ čłąĖąĮąĄ AHB-APB1, ą│ąĄąĮąĄčĆąĖčĆčāąĄą╝čŗą╣ CPU (ą║ąŠč鹊čĆčŗą╣ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčé ą┤ąŠčüčéčāą┐ č湥čĆąĄąĘ ą╝ą░čéčĆąĖčåčā čłąĖąĮčŗ) ąĖ DMA1 (ą║ąŠč鹊čĆčŗą╣ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčé ą┤ąŠčüčéčāą┐ ąĮą░ą┐čĆčÅą╝čāčÄ).
ąĀąĖčü. 15. ąÜąŠąĮą║čāčĆąĄąĮčéąĮčŗą╣ ąĘą░ą┐čĆąŠčü ąĮą░ ą┤ąŠčüčéčāą┐ ą╝ąŠčüčéą░ AHB-APB1 ąŠčé CPU ąĖ DMA1.
ąöą╗čÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĖčÅ ą┤ąŠčüčéčāą┐ą░ ą║ čłąĖąĮąĄ ą╝ąŠčüčé AHB-APB ą┐čĆąĖą╝ąĄąĮčÅąĄčé ą┐ąŠą╗ąĖčéąĖą║čā round-robin:
ŌĆó ąÜą▓ą░ąĮčé round-robin čĆą░ą▓ąĄąĮ 1x čéčĆą░ąĮąĘą░ą║čåąĖąĖ APB.
ŌĆó ą£ą░ą║čüąĖą╝ą░ą╗čīąĮą░čÅ ą╗ą░č鹥ąĮčéąĮąŠčüčéčī ąĮą░ ą┐ąŠčĆčéčā ą┐ąĄčĆąĖč乥čĆąĖąĖ DMA ąŠą│čĆą░ąĮąĖč湥ąĮą░ (1 čéčĆą░ąĮąĘą░ą║čåąĖčÅ APB).
ąóąŠą╗čīą║ąŠ CPU ąĖ ą▒ą╗ąŠą║ąĖ DMA ą╝ąŠą│čāčé ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ą║ąŠąĮą║čāčĆąĄąĮčéąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ čłąĖąĮą░ą╝ APB1 ąĖ APB2:
ŌĆó ąöą╗čÅ APB1 ą║ąŠąĮą║čāčĆąĄąĮčéąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą╝ąŠąČąĄčé ą▒čŗčéčī čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮ, ąĄčüą╗ąĖ CPU, DMA1 ąĖ/ąĖą╗ąĖ DMA2 ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ąĘą░ą┐čĆąŠčüąĖą╗ąĖ ą┤ąŠčüčéčāą┐.
ŌĆó ąöą╗čÅ APB2 ą║ąŠąĮą║čāčĆąĄąĮčéąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą╝ąŠąČąĄčé ą▒čŗčéčī čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮ, ąĄčüą╗ąĖ CPU ąĖ DMA2 ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ąĘą░ą┐čĆąŠčüąĖą╗ąĖ ą┤ąŠčüčéčāą┐.
[ąÜą░ą║ ą┐čĆąĄą┤čüą║ą░ąĘą░čéčī ą╗ą░č鹥ąĮčéąĮąŠčüčéčī DMA]
ą¤čĆąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĄ firmware ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĮą░ ąŠčüąĮąŠą▓ąĄ MCU ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą┤ąŠą╗ąČąĄąĮ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ąĮąĄ ą▒čāą┤čāčé ą┐čĆąŠąĖčüčģąŠą┤ąĖčéčī čüąĖčéčāą░čåąĖąĖ ąĮąĄą┤ąŠą│čĆčāąĘą║ąĖ/ą┐ąĄčĆąĄą┐ąŠą╗ąĮąĄąĮąĖčÅ (underrun/overrun). ą¤ąŠ čŹč鹊ą╣ ą┐čĆąĖčćąĖąĮąĄ ą▓ą░ąČąĮąŠ ąĘąĮą░čéčī č鹊čćąĮčāčÄ ąĘą░ą┤ąĄčƹȹ║čā (latency) DMA ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ čéčĆą░ąĮąĘą░ą║čåąĖąĖ, čćč鹊ą▒čŗ ą┐čĆąŠą▓ąĄčĆąĖčéčī, ą╝ąŠąČąĄčé ą╗ąĖ ą▓ąĮčāčéčĆąĄąĮąĮčÅčÅ čüąĖčüč鹥ą╝ą░ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čéčī ąŠą▒čēčāčÄ ą┐ąŠą╗ąŠčüčā ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ, čéčĆąĄą▒čāąĄą╝čāčÄ ą┤ą╗čÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ.
ąÆčĆąĄą╝čÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ. ąÜą░ą║ ąŠą┐ąĖčüčŗą▓ą░ą╗ąŠčüčī ą▓čŗčłąĄ ą▓ čüąĄą║čåąĖąĖ "ąĪąŠčüč鹊čÅąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA", ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA ąĖąĘ ą┐ąĄčĆąĖč乥čĆąĖąĖ ą▓ ą┐ą░ą╝čÅčéčī čéčĆąĄą▒čāąĄčéčüčÅ ą┤ą▓ą░ ą┤ąŠčüčéčāą┐ą░ ą║ čłąĖąĮąĄ:
ŌĆó ą×ą┤ąĖąĮ ą┤ąŠčüčéčāą┐ č湥čĆąĄąĘ ą┐ąŠčĆčé ą┐ąĄčĆąĖč乥čĆąĖąĖ, ą║ąŠč鹊čĆčŗą╣ ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ ąĘą░ą┐čĆąŠčüąŠą╝ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░. ąŁčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ čéčĆąĄą▒čāąĄčé:
ŌĆō ąÉčĆą▒ąĖčéčĆą░ąČą░ ąĘą░ą┐čĆąŠčüą░ ą┐ąŠčĆčéą░ ą┐ąĄčĆąĖč乥čĆąĖąĖ DMA.
ŌĆō ąÆčŗčćąĖčüą╗ąĄąĮąĖčÅ ą░ą┤čĆąĄčüą░ ą┐ąĄčĆąĖč乥čĆąĖąĖ.
ŌĆō ą¦č鹥ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ ąĖąĘ ą┐ąĄčĆąĖč乥čĆąĖąĖ ą▓ DMA FIFO (source, ąĖčüč鹊čćąĮąĖą║ DMA).
ŌĆó ąöčĆčāą│ąŠą╣ ą┤ąŠčüčéčāą┐ č湥čĆąĄąĘ ą┐ąŠčĆčé ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ą┐čāčēąĄąĮ ą┐ąŠčĆąŠą│ąŠą╝ FIFO (ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čĆąĄąČąĖą╝ FIFO) ąĖą╗ąĖ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ ą┐ąŠčüą╗ąĄ čćč鹥ąĮąĖčÅ ą┐ąĄčĆąĖč乥čĆąĖąĖ (ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čĆąĄąČąĖą╝ Direct). ąŁčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ čéčĆąĄą▒čāąĄčé:
ŌĆō ąÉčĆą▒ąĖčéčĆą░ąČą░ ąĘą░ą┐čĆąŠčüą░ ą┐ąŠčĆčéą░ ą┐ą░ą╝čÅčéąĖ DMA.
ŌĆō ąÆčŗčćąĖčüą╗ąĄąĮąĖčÅ ą░ą┤čĆąĄčüą░ ą┐ą░ą╝čÅčéąĖ.
ŌĆō ąŚą░ą┐ąĖčüąĖ ąĘą░ą│čĆčāąČąĄąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ą▓ SRAM (destination, ą╝ąĄčüč鹊 ąĮą░ąĘąĮą░č湥ąĮąĖčÅ DMA).
ąÜąŠą│ą┤ą░ ą┤ą░ąĮąĮčŗąĄ ą┐ąĄčĆąĄą╝ąĄčēą░čÄčéčüčÅ ąĖąĘ ą┐ą░ą╝čÅčéąĖ ą▓ ą┐ąĄčĆąĖč乥čĆąĖčÄ, čéą░ą║ąČąĄ čéčĆąĄą▒čāąĄčéčüčÅ ą┤ą▓ą░ ą┤ąŠčüčéčāą┐ą░, ą║ą░ą║ ąŠą┐ąĖčüčŗą▓ą░ą╗ąŠčüčī ą▓čŗčłąĄ ą▓ čüąĄą║čåąĖąĖ "ąĪąŠčüč鹊čÅąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA":
ŌĆó ą¤ąĄčĆą▓čŗą╣ ą┤ąŠčüčéčāą┐: DMA ąŠąČąĖą┤ą░ąĄčé ą┤ąŠčüčéčāą┐ą░ ą┐ąĄčĆąĖč乥čĆąĖąĖ, čüčćąĖčéčŗą▓ą░ąĄčé ą┤ą░ąĮąĮčŗąĄ ąĖąĘ ą┐ą░ą╝čÅčéąĖ ąĖ čüąŠčģčĆą░ąĮčÅąĄčé ąĖčģ ą▓ FIFO, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮčāčÄ ą┐ąĄčĆąĄą┤ą░čćčā ą┤ą░ąĮąĮčŗčģ, ą║ą░ą║ č鹊ą╗čīą║ąŠ ą▒čŗą╗ ąĘą░ą┐čāčēąĄąĮ ąĘą░ą┐čĆąŠčü DMA ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░. ąŁčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ čéčĆąĄą▒čāąĄčé:
ŌĆō ąÉčĆą▒ąĖčéčĆą░ąČą░ ąĘą░ą┐čĆąŠčüą░ ą┐ąŠčĆčéą░ ą┐ą░ą╝čÅčéąĖ DMA.
ŌĆō ąÆčŗčćąĖčüą╗ąĄąĮąĖčÅ ą░ą┤čĆąĄčüą░ ą┐ą░ą╝čÅčéąĖ.
ŌĆō ą¦č鹥ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ ąĖąĘ ą┐ą░ą╝čÅčéąĖ ą▓ DMA FIFO (source, ąĖčüč鹊čćąĮąĖą║ DMA).
ŌĆó ąÆč鹊čĆąŠą╣ ą┤ąŠčüčéčāą┐: ą║ąŠą│ą┤ą░ čüčĆą░ą▒ąŠčéą░ą╗ ąĘą░ą┐čĆąŠčü ą┐ąĄčĆąĖč乥čĆąĖąĖ, ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ čéčĆą░ąĮąĘą░ą║čåąĖčÅ ąĮą░ ą┐ąŠčĆčéčā ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ DMA. ąŁčéą░ ąŠą┐ąĄčĆą░čåąĖčÅ čéčĆąĄą▒čāąĄčé:
ŌĆō ąÉčĆą▒ąĖčéčĆą░ąČą░ ąĘą░ą┐čĆąŠčüą░ ą┐ąŠčĆčéą░ ą┐ąĄčĆąĖč乥čĆąĖąĖ DMA.
ŌĆō ąÆčŗčćąĖčüą╗ąĄąĮąĖčÅ ą░ą┤čĆąĄčüą░ ą┐ąĄčĆąĖč乥čĆąĖąĖ.
ŌĆō ąŚą░ą┐ąĖčüąĖ ąĘą░ą│čĆčāąČąĄąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ą┐ąŠ ą░ą┤čĆąĄčüčā ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ (destination, ą╝ąĄčüč鹊 ąĮą░ąĘąĮą░č湥ąĮąĖčÅ DMA).
ąÜą░ą║ ąŠčüąĮąŠą▓ąĮąŠąĄ ą┐čĆą░ą▓ąĖą╗ąŠ, ąŠą▒čēąĄąĄ ą▓čĆąĄą╝čÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą┐ąŠč鹊ą║ą░ DMA TS čĆą░ą▓ąĮąŠ:
TS = TSP (ą▓čĆąĄą╝čÅ ą┤ąŠčüčéčāą┐ą░/čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą┐ąĄčĆąĖč乥čĆąĖąĖ) + TSM (ą▓čĆąĄą╝čÅ ą┤ąŠčüčéčāą┐ą░/čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą┐ą░ą╝čÅčéąĖ)
ąŚą┤ąĄčüčī TSP čŹč鹊 ąŠą▒čēąĄąĄ ą▓čĆąĄą╝čÅ ą┤ą╗čÅ ą┐ąŠčĆčéą░ ą┐ąĄčĆąĖč乥čĆąĖąĖ ąĖ čéčĆą░ąĮąĘą░ą║čåąĖąĖ, ą║ąŠč鹊čĆąŠąĄ čĆą░ą▓ąĮąŠ (ąĘąĮą░č湥ąĮąĖčÅ tPA, tPAC, tBMA, tEDT, tBS ą┐čĆąĖą▓ąĄą┤ąĄąĮčŗ ą▓ čéą░ą▒ą╗ąĖčåąĄ 4):
TSP = tPA + tPAC + tBMA + tEDT + tBS
ąóą░ą▒ą╗ąĖčåą░ 4. ąśąĮč鹥čĆą▓ą░ą╗čŗ ą▓čĆąĄą╝ąĄąĮąĖ ą┤ąŠčüčéčāą┐ą░/čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą┐ąŠčĆčéą░ ą┐ąĄčĆąĖč乥čĆąĖąĖ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą│ąŠ ą┐čāčéąĖ DMA.
ą×ą┐ąĖčüą░ąĮąĖąĄ
|
ą¦ąĄčĆąĄąĘ ą╝ą░čéčĆąĖčåčā čłąĖąĮčŗ |
ą¤čĆčÅą╝ąŠą╣ ą┐čāčéčī DMA |
| ąÜ ą┐ąĄčĆąĖč乥čĆąĖąĖ AHB |
ąÜ ą┐ąĄčĆąĖč乥čĆąĖąĖ APB |
| tPA: ą░čĆą▒ąĖčéčĆą░ąČ ą┐ąŠčĆčéą░ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ DMA |
1 čéą░ą║čé AHB |
| tPAC: ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ ą░ą┤čĆąĄčüą░ ą┐ąĄčĆąĖč乥čĆąĖąĖ |
1 čéą░ą║čé AHB |
| tBMA: ą░čĆą▒ąĖčéčĆą░ąČ ą╝ą░čéčĆąĖčåčŗ čłąĖąĮčŗ (ą║ąŠą│ą┤ą░ ąĮąĄčé ą║ąŠąĮą║čāčĆąĄąĮčåąĖąĖ ą┤ąŠčüčéčāą┐ą░)(1) |
1 čéą░ą║čé AHB |
ąØąĄą┤ąŠčüčéčāą┐ąĮąŠ |
| tEDT: čŹčäč乥ą║čéąĖą▓ąĮą░čÅ čéčĆą░ąĮąĘą░ą║čåąĖčÅ ą┤ą░ąĮąĮčŗčģ |
1 čéą░ą║čé AHB(2)(3) |
2 čéą░ą║čéą░ APB |
| tBS: čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÅ čłąĖąĮčŗ |
ąØąĄą┤ąŠčüčéčāą┐ąĮąŠ |
1 čéą░ą║čé AHB |
ą¤čĆąĖą╝ąĄčćą░ąĮąĖčÅ:
(1) ąÆ čüą╗čāčćą░ąĄ ą╗ąĖąĮąĄąĄą║ čüąĄčĆąĖą╣ STM32F401/STM32F410/STM32F411/STM32F412 ąĖąĮč鹥čĆą▓ą░ą╗ tBMA čĆą░ą▓ąĄąĮ 0.
(2) ąöą╗čÅ FMC ą╝ąŠą│čāčé ą▒čŗčéčī ą┤ąŠą▒ą░ą▓ą╗ąĄąĮčŗ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ čéą░ą║čéčŗ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą╣ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ. ąÜąŠą╗ąĖč湥čüčéą▓ąŠ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĮčŗčģ čéą░ą║č鹊ą▓ AHB ąĘą░ą▓ąĖčüąĖčé ąŠčé čéą░ą╣ą╝ąĖąĮą│ąŠą▓ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ.
(3) ąÆ čüą╗čāčćą░ąĄ ą┐ą░ą║ąĄčéąĮąŠą╣ ą┐ąĄčĆąĄą┤ą░čć (burst), čŹčäč乥ą║čéąĖą▓ąĮąŠąĄ ą▓čĆąĄą╝čÅ ą┐ąĄčĆąĄą┤ą░čćąĖ ą┤ą░ąĮąĮčŗčģ ąĘą░ą▓ąĖčüąĖčé ąŠčé ą┤ą╗ąĖąĮčŗ ą┐ą░ą║ąĄčéą░ (burst length, INC4 tEDT = 4 čåąĖą║ą╗ą░ AHB).
TSM čŹč鹊 ąŠą▒čēąĄąĄ ą▓čĆąĄą╝čÅ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ąĖ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą┐ąŠčĆčéą░ ą┐ą░ą╝čÅčéąĖ DMA, ąŠąĮąŠ čĆą░ą▓ąĮąŠ (ąĘąĮą░č湥ąĮąĖčÅ tMA, tMAC, tBMA, tSRAM čüą╝. ą▓ čéą░ą▒ą╗ąĖčåąĄ 5):
TSM = tMA+ tMAC + tBMA + tSRAM
ąóą░ą▒ą╗ąĖčåą░ 5. ąśąĮč鹥čĆą▓ą░ą╗čŗ ą▓čĆąĄą╝ąĄąĮąĖ ą┤ąŠčüčéčāą┐ą░/čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą┐ą░ą╝čÅčéąĖ.
| ą×ą┐ąĖčüą░ąĮąĖąĄ |
ąŚą░ą┤ąĄčƹȹ║ą░ (ą╗ą░č鹥ąĮčéąĮąŠčüčéčī) |
| tMA: ą░čĆą▒ąĖčéčĆą░ąČ ą┐ąŠčĆčéą░ ą┐ą░ą╝čÅčéąĖ DMA |
1 čéą░ą║čé AHB |
| tMAC: ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ ą░ą┤čĆąĄčüą░ ą┐ą░ą╝čÅčéąĖ |
1 čéą░ą║čé AHB |
| tBMA: ą░čĆą▒ąĖčéčĆą░ąČ ą╝ą░čéčĆąĖčåčŗ čłąĖąĮčŗ (ą║ąŠą│ą┤ą░ ąĮąĄčé ą║ąŠąĮą║čāčĆąĄąĮčåąĖąĖ)(1) |
1 čéą░ą║čé AHB(2) |
| tSRAM: ą┤ąŠčüčéčāą┐ ą║ SRAM ąĮą░ čćč鹥ąĮąĖąĄ ąĖą╗ąĖ ąĘą░ą┐ąĖčüčī |
1 čéą░ą║čé AHB |
ą¤čĆąĖą╝ąĄčćą░ąĮąĖčÅ:
(1) ąÆ čüą╗čāčćą░ąĄ ą╗ąĖąĮąĄąĄą║ čüąĄčĆąĖą╣ STM32F401/STM32F410/STM32F411/STM32F412 ąĖąĮč鹥čĆą▓ą░ą╗ tBMA čĆą░ą▓ąĄąĮ 0.
(2) ąĪą╗ąĄą┤čāčÄčēąĖčģ ą┤čĆčāą│ ąĘą░ ą┤čĆčāą│ąŠą╝ ą┤ąŠčüčéčāą┐ąŠą▓ ą║ SRAM (ą║ąŠą│ą┤ą░ ąĮąĖ ąŠą┤ąĖąĮ ąĖąĘ čāčüčéčĆąŠą╣čüčéą▓ master ąĮąĄ ąŠą▒čĆą░čēą░ąĄčéčüčÅ ą║ č鹊ą╝čā ąČąĄ čüą░ą╝ąŠą╝čā SRAM ą╝ąĄąČą┤čā ą┤ąŠčüčéčāą┐ą░ą╝ąĖ), tBMA = 0 čåąĖą║ą╗ąŠą▓.
ąÆčĆąĄą╝čÅ ą┐ąĄčĆąĄą┤ą░čćąĖ DMA ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą║ąŠąĮą║čāčĆąĄąĮčéąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░. ą£ąŠąČąĄčé ą▒čŗčéčī ą┤ąŠą▒ą░ą▓ą╗ąĄąĮą░ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮą░čÅ ąĘą░ą┤ąĄčƹȹ║ą░ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÅ DMA ą┐ąŠ čéą░ą╣ą╝ąĖąĮą│ą░ą╝, ąŠą┐ąĖčüą░ąĮąĮčŗą╝ ą▓ ą┐čĆąĄą┤čŗą┤čāčēąĄą╣ čüąĄą║čåąĖąĖ, ą║ąŠą│ą┤ą░ ąĮąĄčüą║ąŠą╗čīą║ąŠ čāčüčéčĆąŠą╣čüčéą▓ master ą┐čŗčéą░čÄčéčüčÅ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ ąŠą┤ąĮąŠą╝čā ąĖ č鹊ą╝čā ąČąĄ čāčüčéčĆąŠą╣čüčéą▓čā slave.
ąöą╗čÅ čüą░ą╝ąŠą│ąŠ čģčāą┤čłąĄą│ąŠ čüą╗čāčćą░čÅ ą▓čĆąĄą╝ąĄąĮąĖ ą┤ąŠčüčéčāą┐ą░ ą┤ą╗čÅ ą┐ąĄčĆąĖč乥čĆąĖąĖ ąĖ ą┐ą░ą╝čÅčéąĖ čüą╗ąĄą┤čāčÄčēąĖąĄ čäą░ą║č鹊čĆčŗ ą▓ą╗ąĖčÅčÄčé ąĮą░ ąŠą▒čēąĄąĄ ą▓čĆąĄą╝čÅ ąĘą░ą┤ąĄčƹȹ║ąĖ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÅ ą┐ąŠč鹊ą║ą░ DMA:
ŌĆó ąÜąŠą│ą┤ą░ ąĮąĄčüą║ąŠą╗čīą║ąŠ čāčüčéčĆąŠą╣čüčéą▓ master ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ąŠą▒čĆą░čēą░čÄčéčüčÅ ą║ ąŠą┤ąĮąŠą╝čā ąĖ č鹊ą╝čā ąČąĄ ą╝ąĄčüčéčā ąĮą░ąĘąĮą░č湥ąĮąĖčÅ AHB, čŹč鹊 ą▓ą╗ąĖčÅąĄčé ąĮą░ ąĘą░ą┤ąĄčƹȹ║čā DMA. ąóčĆą░ąĮąĘą░ą║čåąĖčÅ DMA ąĮąĄ ą╝ąŠąČąĄčé ąĘą░ą┐čāčüčéąĖčéčīčüčÅ, ą┐ąŠą║ą░ ą░čĆą▒ąĖčéčĆ ą╝ą░čéčĆąĖčåčŗ čłąĖąĮčŗ ąĮąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčé ą┤ąŠčüčéčāą┐ ą┤ą╗čÅ DMA, ą║ą░ą║ ąŠą┐ąĖčüčŗą▓ą░ą╗ąŠčüčī ą▓čŗčłąĄ ą▓ čüąĄą║čåąĖąĖ "ąĪčģąĄą╝ą░ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓ round-robin".
ŌĆó ąÜąŠą│ą┤ą░ ąĮąĄčüą║ąŠą╗čīą║ąŠ čāčüčéčĆąŠą╣čüčéą▓ master (DMA ąĖ CPU) ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ąŠą▒čĆą░čēą░čÄčéčüčÅ ą║ ą╝ąŠčüčéčā AHB-APB, ą▓čĆąĄą╝čÅ ąĘą░ą┐čāčüą║ą░ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA ąĘą░ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ ąĖąĘ-ąĘą░ ą░čĆą▒ąĖčéčĆą░ąČą░ ą╝ąŠčüčéą░, ą║ą░ą║ ąŠą┐ąĖčüčŗą▓ą░ą╗ąŠčüčī ą▓čŗčłąĄ ą▓ čüąĄą║čåąĖąĖ "ąÉčĆą▒ąĖčéčĆą░ąČ ą╝ąŠčüčéą░ AHB-APB".
ąØąĖąČąĄ ą┐čĆąĖą▓ąĄą┤ąĄąĮčŗ ą┐čĆąĖą╝ąĄčĆčŗ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖąĖ čéčĆą░ąĮąĘą░ą║čåąĖą╣ DMA.
ąŁč鹊čé ą┐čĆąĖą╝ąĄčĆ ą┐čĆąĖą╝ąĄąĮąĖą╝ ą║ MCU ą╗ąĖąĮąĄąĄą║ STM32F2, STM32F405/STM32F415, STM32F407/STM32F417, STM32F427/STM32F437 ąĖ STM32F429/STM32F439.
ADC čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮ ą▓ čĆąĄąČąĖą╝ąĄ triple Interleaved. ąÆ čŹč鹊ą╝ čĆąĄąČąĖą╝ąĄ ąŠčåąĖčäčĆąŠą▓ą║ą░ čüąĖą│ąĮą░ą╗ą░ ąŠą┤ąĮąŠą│ąŠ ą░ąĮą░ą╗ąŠą│ąŠą▓ąŠą│ąŠ ą║ą░ąĮą░ą╗ą░ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ąĮą░ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ čüą║ąŠčĆąŠčüčéąĖ (36 ą£ąōčå). ą¤čĆąĄčüą║ą░ą╗ąĄčĆ ADC čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ąĮą░ 2, ą▓čĆąĄą╝čÅ ą▓čŗą▒ąŠčĆą║ąĖ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ ąĮą░ 1.5 čéą░ą║čéą░, ąĖ ąĘą░ą┤ąĄčƹȹ║ą░ ą╝ąĄąČą┤čā ą┤ą▓čāą╝čÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗą╝ąĖ ą▓čŗą▒ąŠčĆą║ą░ą╝ąĖ ADC čĆąĄąČąĖą╝ą░ Interleaved čāčüčéą░ąĮąŠą▓ą╗ąĄąĮą░ ąĮą░ 5 čéą░ą║č鹊ą▓.
DMA2 stream0 ą┐ąĄčĆąĄą┤ą░ąĄčé ą┐čĆąĄąŠą▒čĆą░ąĘąŠą▓ą░ąĮąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ADC ą▓ ą▒čāč乥čĆ SRAM. ąöąŠčüčéčāą┐ DMA2 ą║ ADC ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ąĮą░ą┐čĆčÅą╝čāčÄ, ą▒ąĄąĘ ą╝ą░čéčĆąĖčåčŗ čłąĖąĮčŗ; ąŠą┤ąĮą░ą║ąŠ ą┤ąŠčüčéčāą┐ DMA ą║ SRAM ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ č湥čĆąĄąĘ ą╝ą░čéčĆąĖčåčā čłąĖąĮčŗ.
ąóą░ą▒ą╗ąĖčåą░ 6. ąøą░č鹥ąĮčéąĮąŠčüčéčī čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA ą┐ąŠčĆčéą░ ą┐ąĄčĆąĖč乥čĆąĖąĖ (ADC).
| ą¦ą░čüč鹊čéą░ AHB/APB2 |
FAHB = 72 ą£ąōčå/
FAPB2 = 72 ą£ąōčå
AHB/APB = 1 |
FAHB = 144 ą£ąōčå/
FAPB2 = 72 ą£ąōčå
AHB/APB = 2 |
| ąÆčĆąĄą╝čÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ |
| tPA: ą░čĆą▒ąĖčéčĆą░ąČ ą┐ąŠčĆčéą░ DMA ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ |
1 čéą░ą║čé AHB |
| tPAC: ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ ą░ą┤čĆąĄčüą░ ą┐ąĄčĆąĖč乥čĆąĖąĖ |
1 čéą░ą║čé AHB |
| tBMA: ą░čĆą▒ąĖčéčĆą░ąČ ą╝ą░čéčĆąĖčåčŗ čłąĖąĮčŗ |
ąØąĄą┤ąŠčüčéčāą┐ąĮąŠ(1) |
| tEDT: čŹčäč乥ą║čéąĖą▓ąĮą░čÅ čéčĆą░ąĮąĘą░ą║čåąĖčÅ ą┤ą░ąĮąĮčŗčģ |
2 čéą░ą║čéą░ AHB |
4 čéą░ą║čéą░ AHB |
| tBS: čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÅ čłąĖąĮčŗ |
1 čéą░ą║čé AHB |
| TSP: ąŠą▒čēąĄąĄ ą▓čĆąĄą╝čÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA ą┤ą╗čÅ ą┐ąŠčĆčéą░ ą┐ąĄčĆąĖč乥čĆąĖąĖ |
5 čéą░ą║č鹊ą▓ AHB |
7 čéą░ą║č鹊ą▓ AHB |
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ (1): DMA2 ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčé ą┤ąŠčüčéčāą┐ ą║ ADC ąĮą░ą┐čĆčÅą╝čāčÄ, ą▒ąĄąĘ ą░čĆą▒ąĖčéčĆą░ąČą░ ą╝ą░čéčĆąĖčåčŗ čłąĖąĮčŗ.
ąóą░ą▒ą╗ąĖčåą░ 7. ąøą░č鹥ąĮčéąĮąŠčüčéčī čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA ą┐ąŠčĆčéą░ ą┐ą░ą╝čÅčéąĖ (SRAM).
| ą¦ą░čüč鹊čéą░ CPU/APB2 |
FAHB = 72 ą£ąōčå/
FAPB2 = 72 ą£ąōčå
AHB/APB = 1 |
FAHB = 144 ą£ąōčå/
FAPB2 = 72 ą£ąōčå
AHB/APB = 2 |
| ąÆčĆąĄą╝čÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ |
| tMA: ą░čĆą▒ąĖčéčĆą░ąČ ą┐ąŠčĆčéą░ DMA ą┐ą░ą╝čÅčéąĖ |
1 čéą░ą║čé AHB |
| tMAC: ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ ą░ą┤čĆąĄčüą░ ą┐ą░ą╝čÅčéąĖ |
1 čéą░ą║čé AHB |
| tBMA: ą░čĆą▒ąĖčéčĆą░ąČ ą╝ą░čéčĆąĖčåčŗ čłąĖąĮčŗ |
1 čéą░ą║čé AHB(1) |
| tSRAM: ą┤ąŠčüčéčāą┐ ąĮą░ ąĘą░ą┐ąĖčüčī ą▓ SRAM |
1 čéą░ą║čé AHB |
| TSM: ąŠą▒čēąĄąĄ ą▓čĆąĄą╝čÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA ą┤ą╗čÅ ą┐ąŠčĆčéą░ ą┐ą░ą╝čÅčéąĖ |
4 čéą░ą║čéą░ AHB |
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ (1): ą▓ čüą╗čāčćą░ąĄ ą╝ąĮąŠąČąĄčüčéą▓ąĄąĮąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ DMA ą║ SRAM, ą░čĆą▒ąĖčéčĆą░ąČ ą╝ą░čéčĆąĖčåčŗ čłąĖąĮčŗ čĆą░ą▓ąĄąĮ 0 čåąĖą║ą╗ąŠą▓, ąĄčüą╗ąĖ ą▓ ą┐čĆąŠą╝ąĄąČčāčéą║ąĄ ąĮąĄčé ąŠą▒čĆą░čēąĄąĮąĖą╣ ą║ ąŠčé ą┤čĆčāą│ąĖčģ master.
ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ąŠą▒čēą░čÅ ąĘą░ą┤ąĄčƹȹ║ą░ DMA ąŠčé ą╝ąŠą╝ąĄąĮčéą░ čüčĆą░ą▒ą░čéčŗą▓ą░ąĮąĖčÅ čéčĆąĖą│ą│ąĄčĆą░ ADC DMA (ADC EOC) ą┤ąŠ ąĘą░ą┐ąĖčüąĖ ąĘąĮą░č湥ąĮąĖčÅ ADC ą▓ SRAM čĆą░ą▓ąĮą░ 9 čéą░ą║č鹊ą▓ AHB ą┤ą╗čÅ ą┐čĆąĄčüą║ą░ą╗ąĄčĆą░ AHB/APB, čĆą░ą▓ąĮąŠą│ąŠ 1, ąĖ 11 čéą░ą║č鹊ą▓ AHB ą┤ą╗čÅ ą┐čĆąĄčüą║ą░ą╗ąĄčĆą░ AHB/APB, čĆą░ą▓ąĮąŠą│ąŠ 2.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ FIFO, ą┤ąŠčüčéčāą┐ ą║ ą┐ąŠčĆčéčā ą┐ą░ą╝čÅčéąĖ DMA ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ čĆąĄąČąĄ, ą┐ąŠ ą╝ąĄčĆąĄ ą┤ąŠčüčéąĖąČąĄąĮąĖčÅ čāčĆąŠą▓ąĮčÅ ą┐ąŠčĆąŠą│ą░ FIFO, čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝.
ąŁč鹊čé ą┐čĆąĖą╝ąĄčĆ ą┐čĆąĖą╝ąĄąĮąĖą╝ ą┤ą╗čÅ MCU ą╗ąĖąĮąĄąĄą║ STM32F2, STM32F405/STM32F415, STM32F407/STM32F417, STM32F427/STM32F437 ąĖ STM32F429/STM32F439. ą¤čĆąĖą╝ąĄčĆ ąŠčüąĮąŠą▓ą░ąĮ ąĮą░ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą╝ čāčüčéčĆąŠą╣čüčéą▓ąĄ SPI1.
ąÜąŠąĮčäąĖą│čāčĆąĖčĆčāčÄčéčüčÅ 2 ąĘą░ą┐čĆąŠčüą░ DMA:
ŌĆó DMA2_Stream2 ą┤ą╗čÅ SPI1_RX: čŹč鹊čé ą┐ąŠč鹊ą║ ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄčéčüčÅ ąĮą░ čüą░ą╝čŗą╣ ą▓čŗčüąŠą║ąĖą╣ ą┐čĆąĖąŠčĆąĖč鹥čé, čćč鹊ą▒čŗ čüą▓ąŠąĄą▓čĆąĄą╝ąĄąĮąĮąŠ ąŠą▒čüą╗čāąČąĖčéčī ą┐čĆąĖąĮčÅčéčŗąĄ ą┤ą░ąĮąĮčŗąĄ SPI1, ąĖ ą┐ąĄčĆąĄą┤ą░čéčī ąĖčģ ąĖąĘ čĆąĄą│ąĖčüčéčĆą░ SPI1_DR ą▓ ą▒čāč乥čĆ SRAM.
ŌĆó DMA2_Stream3 ą┤ą╗čÅ SPI1_TX: čŹč鹊čé ą┐ąŠč鹊ą║ ą┐ąĄčĆąĄą┤ą░ąĄčé ą┤ą░ąĮąĮčŗąĄ ąĖąĘ ą▒čāč乥čĆą░ SRAM ą▓ čĆąĄą│ąĖčüčéčĆ SPI1_DR.
ą¦ą░čüč鹊čéą░ AHB čĆą░ą▓ąĮą░ čćą░čüč鹊č鹥 čłąĖąĮčŗ APB2 (84 ą£ąōčå), ąĖ SPI1 ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄčéčüčÅ ąĮą░ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčāčÄ čüą║ąŠčĆąŠčüčéčī (42 ą£ąōčå). ą¤ąŠč鹊ą║ DMA2_Stream2 (SPI1_RX) čüčĆą░ą▒ą░čéčŗą▓ą░ąĄčé ą┐ąĄčĆąĄą┤ ą┐ąŠč鹊ą║ąŠą╝ DMA2_Stream3 (SPI1_TX), ą║ąŠč鹊čĆčŗą╣ ą▒čāą┤ąĄčé ąĘą░ą┐čāčēąĄąĮ ąĮą░ 2 čéą░ą║čéą░ AHB ą┐ąŠąĘąČąĄ.
ąÆ čŹč鹊ą╣ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ CPU ą▓ ą▒ąĄčüą║ąŠąĮąĄčćąĮąŠą╝ čåąĖą║ą╗ąĄ ąŠą┐čĆą░čłąĖą▓ą░ąĄčé čĆąĄą│ąĖčüčéčĆ I2C1_DR. ą£čŗ ąĘąĮą░ąĄą╝, čćč鹊 ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ąŠč鹊ą▒čĆą░ąČąĄąĮąŠ ąĮą░ čłąĖąĮčā APB1, ąĖ čćč鹊 ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ SPI1 ąŠč鹊ą▒čĆą░ąČąĄąĮąŠ ąĮą░ čłąĖąĮčā APB2, ą┐čāčéąĖ ą┤ą░ąĮąĮčŗčģ ą▓ čüąĖčüč鹥ą╝ąĄ ą┐ąŠą╗čāčćą░čéčüčÅ čüą╗ąĄą┤čāčÄčēąĖąĄ:
ŌĆó ą¤čĆčÅą╝ąŠą╣ ą┐čāčéčī ą┤ą╗čÅ DMA2 ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ APB2 (ąĮąĄ č湥čĆąĄąĘ ą╝ą░čéčĆąĖčåčā čłąĖąĮčŗ).
ŌĆó ąöąŠčüčéčāą┐ CPU ą║ APB1 č湥čĆąĄąĘ ą╝ą░čéčĆąĖčåčā čłąĖąĮčŗ.
ą”ąĄą╗čī ą┐čĆąĖą╝ąĄčĆą░ čüąŠčüč鹊ąĖčé ą▓ ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąĖ čäą░ą║čéą░, čćč鹊 čéą░ą╣ą╝ąĖąĮą│ąĖ DMA ąĮąĄ ą▓ą╗ąĖčÅčÄčé ąĮą░ ąŠą┐čĆąŠčü CPU čłąĖąĮčŗ APB1. ąØą░ čĆąĖčü. 16 ą┐ąŠą║ą░ąĘą░ąĮčŗ čéą░ą╣ą╝ąĖąĮą│ąĖ DMA ą┤ą╗čÅ čĆąĄąČąĖą╝ąŠą▓ ą┐ąĄčĆąĄą┤ą░čćąĖ ąĖ ą┐čĆąĖąĄą╝ą░, ą░ čéą░ą║ąČąĄ ą▓čĆąĄą╝čÅ ą┐ą╗ą░ąĮąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ.
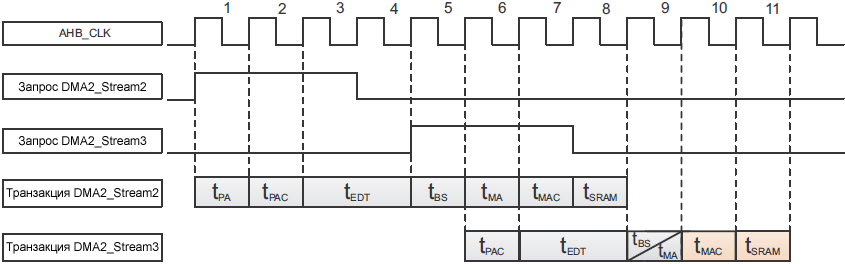
ąĀąĖčü. 16. ąÆčĆąĄą╝čÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ SPI full duplex DMA.
ąśąĘ čĆąĖčü. 16 ą▓ąĖą┤ąĮąŠ čüą╗ąĄą┤čāčÄčēąĄąĄ:
ŌĆó ą×ą┐čĆąŠčü CPU ą┐ąŠ čłąĖąĮąĄ APB1 ąĮąĄ ą▓ą╗ąĖčÅąĄčé ąĮą░ ą╗ą░č鹥ąĮčéąĮąŠčüčéčī ą┐ąĄčĆąĄą┤ą░čćąĖ DMA ą┐ąŠ čłąĖąĮąĄ APB2.
ŌĆó ąöą╗čÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą┐ąŠč鹊ą║ą░ DMA2_Stream2 (SPI1_RX) ąĮą░ ą▓ąŠčüčīą╝ąŠą╝ čéą░ą║č鹥 AHB ąĮąĄčé ą░čĆą▒ąĖčéčĆą░ąČą░ ą╝ą░čéčĆąĖčåčŗ čłąĖąĮčŗ, ą┐ąŠčüą║ąŠą╗čīą║čā ą┐čĆąĄą┤ą┐ąŠą╗ą░ą│ą░ąĄčéčüčÅ, čćč鹊 ą┐ąŠčüą╗ąĄą┤ąĮąĖą╣ master, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠą╗čāčćąĖą╗ ą┤ąŠčüčéčāą┐ ą║ SRAM, ą▒čŗą╗ DMA2 (ą┐ąŠčŹč鹊ą╝čā ą┐ąŠą▓č鹊čĆąĮčŗą╣ ą░čĆą▒ąĖčéčĆą░ąČ ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ).
ŌĆó ąöą╗čÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą┐ąŠč鹊ą║ą░ DMA2_Stream3 (SPI1_TX) čŹč鹊čé ą┐ąŠč鹊ą║ ąŠąČąĖą┤ą░ąĄčé čćč鹥ąĮąĖčÅ ąĖąĘ SRAM, ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé ą┤ą░ąĮąĮčŗąĄ ą▓ FIFO ąĖ ąĘą░č鹥ą╝, ą║ąŠą│ą┤ą░ ą┐čĆąŠąĖąĘąŠčłąĄą╗ ąĘą░ą┐čāčüą║, ą┐ąŠčĆčé ą┐ąĄčĆąĖč乥čĆąĖąĖ DMA (destination, ą╝ąĄčüč鹊 ąĮą░ąĘąĮą░č湥ąĮąĖčÅ SPI1) ąĮą░čćąĖąĮą░ąĄčéčüčÅ čéčĆą░ąĮąĘą░ą║čåąĖčÅ.
ŌĆó ąöą╗čÅ ą┐ąŠč鹊ą║ą░ DMA2_Stream3 ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ čäą░ąĘą░ ą░čĆą▒ąĖčéčĆą░ąČą░ DMA ą┐ąĄčĆąĖč乥čĆąĖąĖ (1 čéą░ą║čé AHB) ą▓ąŠ ą▓čĆąĄą╝čÅ čåąĖą║ą╗ą░ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ čłąĖąĮčŗ DMA2_Stream2.
ąŁčéą░ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖčÅ ą▓čüąĄą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą░ąĮą░ą╗ąŠą│ąĖčćąĮąŠ, ą║ąŠą│ą┤ą░ ąĘą░ą┐čĆąŠčü DMA čüčĆą░ą▒ąŠčéą░ą╗ ą┐ąĄčĆąĄą┤ ąŠą║ąŠąĮčćą░ąĮąĖąĄą╝ č鹥ą║čāčēąĄą╣ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ąĘą░ą┐čĆąŠčüą░ DMA.
[ąĪąŠą▓ąĄčéčŗ ąĖ ą┐čĆąĄą┤čāą┐čĆąĄąČą┤ąĄąĮąĖčÅ ą┐čĆąĖ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĖ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ DMA]
ą¤ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ąĘą░ą┐čĆąĄčéą░ DMA. ą¦č鹊ą▒čŗ ąŠčéą║ą╗čÄčćąĖčéčī ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ, čüąŠąĄą┤ąĖąĮąĄąĮąĮąŠąĄ čü ąĘą░ą┐čĆąŠčüąŠą╝ ą║ ą┐ąŠč鹊ą║čā DMA, ą▓ą░ąČąĮąŠ ą▓čŗą┐ąŠą╗ąĮąĖčéčī čüą╗ąĄą┤čāčÄčēąĄąĄ:
1. ąÆčŗą║ą╗čÄčćąĖčéčī ą┐ąŠč鹊ą║ DMA, ą║ ą║ąŠč鹊čĆąŠą╝čā ą┐ąŠą┤ą║ą╗čÄč湥ąĮąŠ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ.
2. ą¤ąŠą┤ąŠąČą┤ą░čéčī, ą┐ąŠą║ą░ ąĮąĄ čüą▒čĆąŠčüąĖčéčüčÅ ą▓ ą╗ąŠą│. 0 ą▒ąĖčé EN ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_SxCR.
ąóąŠą╗čīą║ąŠ ą┐ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ą╝ąŠąČąĮąŠ ą▒ąĄąĘąŠą┐ą░čüąĮąŠ ąĘą░ą┐čĆąĄčéąĖčéčī ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ. ąæąĖčé čĆą░ąĘčĆąĄčłąĄąĮąĖčÅ ąĘą░ą┐čĆąŠčüą░ DMA ą▓ čĆąĄą│ąĖčüčéčĆąĄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čüą▒čĆąŠčłąĄąĮ ą▓ ą╗ąŠą│. 0, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ąŠčćąĖčēąĄąĮ ą╗čÄą▒ąŠą╣ ąŠąČąĖą┤ą░čÄčēąĖą╣ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĘą░ą┐čĆąŠčü ąŠčé ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą▓ ąŠą▒ąŠąĖčģ čüą╗čāčćą░čÅčģ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ čäą╗ą░ą│ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ (Transfer Complete Interrupt Flag, TCIF) ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_LISR ąĖą╗ąĖ DMA_HISR), čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī ąĘą░ą▓ąĄčĆčłąĄąĮąĖąĄ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ąĖąĘ-ąĘą░ ąĘą░ą┐čĆąĄčéą░ ą┐ąŠč鹊ą║ą░.
ą×ą▒čüą╗čāąČąĖą▓ą░ąĮąĖąĄ čäą╗ą░ą│ą░ DMA ą┐ąĄčĆąĄą┤ čĆą░ąĘčĆąĄčłąĄąĮąĖąĄą╝ ąĮąŠą▓ąŠą╣ čéčĆą░ąĮąĘą░ą║čåąĖąĖ. ą¤ąĄčĆąĄą┤ čĆą░ąĘčĆąĄčłąĄąĮąĖąĄą╝ ąĮąŠą▓ąŠą╣ ą┐ąĄčĆąĄą┤ą░čćąĖ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą┤ąŠą╗ąČąĄąĮ čāą▒ąĄą┤ąĖčéčīčüčÅ, čćč鹊 ąŠčćąĖčēąĄąĮ čäą╗ą░ą│ Transfer Complete Interrupt Flag (TCIF) ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_LISR ąĖą╗ąĖ DMA_HISR. ąÆ ą║ą░č湥čüčéą▓ąĄ ąŠą▒čēąĄą╣ čĆąĄą║ąŠą╝ąĄąĮą┤ą░čåąĖąĖ ą╗čāčćčłąĄ ąŠčćąĖčüčéąĖčéčī ą▓čüąĄ čäą╗ą░ą│ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓ DMA_LIFCR ą┐ąĄčĆąĄą┤ DMA_HIFCR ąĘą░ą┐čāčüą║ąŠą╝ ąĮąŠą▓ąŠą╣ ą┐ąĄčĆąĄą┤ą░čćąĖ.
ą¤ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī čĆą░ąĘčĆąĄčłąĄąĮąĖčÅ DMA. ą¤čĆąĖ čĆą░ąĘčĆąĄčłąĄąĮąĖąĖ DMA ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čüą╗ąĄą┤čāčÄčēą░čÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ą┤ąĄą╣čüčéą▓ąĖą╣:
1. ąÜąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐ąŠą┤čģąŠą┤čÅčēąĄą│ąŠ ą┐ąŠč鹊ą║ą░ DMA.
2. ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą│ąŠ ą┐ąŠč鹊ą║ą░ DMA (čāčüčéą░ąĮąŠą▓ą║ą░ ą▒ąĖčéą░ EN ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_SxCR).
3. ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą│ąŠ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░. ąæąĖčé čĆą░ąĘčĆąĄčłąĄąĮąĖčÅ ąĘą░ą┐čĆąŠčüą░ DMA ą▓ čĆąĄą│ąĖčüčéčĆąĄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗą╝ čāčüčéčĆąŠą╣čüčéą▓ąŠą╝ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą▓ ą╗ąŠą│. 1.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąĄčüą╗ąĖ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī čĆą░ąĘčĆąĄčłą░ąĄčé ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ą┐ąĄčĆąĄą┤ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╝ ą┐ąŠč鹊ą║ąŠą╝ DMA, č鹊 ą╝ąŠąČąĄčé čāčüčéą░ąĮąŠą▓ąĖčéčīčüčÅ čäą╗ą░ą│ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąŠčłąĖą▒ą║ąĖ FEIF (FIFO Error Interrupt Flag), ą┐ąŠč鹊ą╝čā čćč鹊 DMA čäą░ą║čéąĖč湥čüą║ąĖ ąĮąĄ ą│ąŠč鹊ą▓ąŠ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī ą┐ąĄčĆą▓čŗąĄ ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗąĄ ą┤ą░ąĮąĮčŗąĄ ą┤ą╗čÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ (ą▓ čüą╗čāčćą░ąĄ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ąĖąĘ ą┐ą░ą╝čÅčéąĖ ą▓ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ).
ąóčĆą░ąĮąĘą░ą║čåąĖčÅ ą┐ą░ą╝čÅčéčī-ą┐ą░ą╝čÅčéčī ą┐čĆąĖ NDTR=0. ąÜąŠą│ą┤ą░ ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄčéčüčÅ ą┐ąŠč鹊ą║ DMA ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐ąĄčĆąĄą┤ą░čćąĖ ąĖąĘ ą┐ą░ą╝čÅčéąĖ ą▓ ą┐ą░ą╝čÅčéčī ą▓ ąĮąŠčĆą╝ą░ą╗čīąĮąŠą╝ čĆąĄąČąĖą╝ąĄ (normal mode), č鹊 ą║ą░ą║ č鹊ą╗čīą║ąŠ NDTR ą┤ąŠčüčéąĖą│ą░ąĄčé 0, čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ čäą╗ą░ą│ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ (Transfer Complete). ąÆ čŹč鹊čé ą╝ąŠą╝ąĄąĮčé, ąĄčüą╗ąĖ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī čāčüčéą░ąĮąŠą▓ąĖą╗ čäą╗ą░ą│ čĆą░ąĘčĆąĄčłąĄąĮąĖčÅ čŹč鹊ą│ąŠ ą┐ąŠč鹊ą║ą░ (ą▒ąĖčé EN ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_SxCR), čéčĆą░ąĮąĘą░ą║čåąĖčÅ ą┐ą░ą╝čÅčéčī-ą┐ą░ą╝čÅčéčī ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ąĘą░ą┐čāčüčéąĖčéčüčÅ ą┐ąŠą▓č鹊čĆąĮąŠ čü ą┐ąŠčüą╗ąĄą┤ąĮąĖą╝ ąĘąĮą░č湥ąĮąĖąĄą╝ NDTR.
ą¤ą░ą║ąĄčéąĮą░čÅ ą┐ąĄčĆąĄą┤ą░čćą░ DMA ą┐čĆąĖ PINC/MINC=0. ążčāąĮą║čåąĖčÅ ą┐ą░ą║ąĄčéąĮąŠą╣ ą┐ąĄčĆąĄą┤ą░čćąĖ DMA (Burst) čü ąĘą░ą┐čĆąĄč鹊ą╝ ąĖąĮą║čĆąĄą╝ąĄąĮčéą░ ą░ą┤čĆąĄčüą░ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ (PINC) ąĖą╗ąĖ ąĖąĮą║čĆąĄą╝ąĄąĮčéą░ ą░ą┤čĆąĄčüą░ ą┐ą░ą╝čÅčéąĖ (MINC) ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą░ą┤čĆąĄčüąŠą▓ą░čéčī ą▓ąĮčāčéčĆąĄąĮąĮąĖąĄ ąĖą╗ąĖ ą▓ąĮąĄčłąĮąĖąĄ (FSMC) ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░, ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčēąĖąĄ Burst (ąĖą╝ąĄčÄčēąĖąĄ ą▓čüčéčĆąŠąĄąĮąĮčŗąĄ FIFO). ąŁč鹊čé čĆąĄąČąĖą╝ ą│ą░čĆą░ąĮčéąĖčĆčāąĄčé, čćč鹊 čŹč鹊čé ą┐ąŠč鹊ą║ DMA ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĄčĆą▓ą░ąĮ ą┤čĆčāą│ąĖą╝ąĖ ą┐ąŠč鹊ą║ą░ą╝ąĖ DMA ą▓ąŠ ą▓čĆąĄą╝čÅ ąĖčģ čéčĆą░ąĮąĘą░ą║čåąĖą╣.
ąŚą░ą┐čĆąŠčüčŗ DMA čü ą┤ą▓ąŠą╣ąĮčŗą╝ ąŠč鹊ą▒čĆą░ąČąĄąĮąĖąĄą╝. ąÜąŠą│ą┤ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄčé ą┤ą▓ą░ (ąĖą╗ąĖ ą▒ąŠą╗čīčłąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ) ą┐ąŠč鹊ą║ąŠą▓ DMA ą┤ą╗čÅ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÅ ąĘą░ą┐čĆąŠčüą░ ąŠą┤ąĮąŠą│ąŠ ąĖ č鹊ą│ąŠ ąČąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░, ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą┤ąŠą╗ąČąĮą░ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 č鹥ą║čāčēąĖą╣ ą┐ąŠč鹊ą║ DMA ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąĘą░ą┐čĆąĄčēąĄąĮ (ą┐čāč鹥ą╝ ąŠą┐čĆąŠčüą░ ą▒ąĖčéą░ EN ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_SxCR) ą┐ąĄčĆąĄą┤ čĆą░ąĘčĆąĄčłąĄąĮąĖąĄą╝ ąĮąŠą▓ąŠą│ąŠ ą┐ąŠč鹊ą║ą░ DMA.
ąØą░ąĖą╗čāčćčłą░čÅ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÅ DMA ą┐ąŠ ą┐čĆąŠą┐čāčüą║ąĮąŠą╣ čüą┐ąŠčüąŠą▒ąĮąŠčüčéąĖ. ą¤čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ STM32F4xx čü ą┐ąŠąĮąĖąČąĄąĮąĮąŠą╣ čćą░čüč鹊č鹊ą╣ AHB, ą║ąŠą│ą┤ą░ DMA ąŠą▒čüą╗čāąČąĖą▓ą░ąĄčé ą▓čŗčüąŠą║ąŠčüą║ąŠčĆąŠčüčéąĮąŠąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ, čĆąĄą║ąŠą╝ąĄąĮą┤čāąĄčéčüčÅ ą┐ąŠą╝ąĄčüčéąĖčéčī čüč鹥ą║ ąĖ ą║čāčćčā ą▓ ą┐ą░ą╝čÅčéčī CCM (Core Coupled Memory, ą║ąŠč鹊čĆą░čÅ ą╝ąŠąČąĄčé ą▒čŗčéčī ą░ą┤čĆąĄčüąŠą▓ą░ąĮą░ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ CPU č湥čĆąĄąĘ D-čłąĖąĮčā) ą▓ą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ ą┐ąŠą╝ąĄčēą░čéčī ąĖčģ ą▓ SRAM. ąŁč鹊 čüąŠąĘą┤ą░čüčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗą╣ ą┐ą░čĆą░ą╗ą╗ąĄą╗ąĖąĘą╝ čĆą░ą▒ąŠčéčŗ CPU ąĖ DMA, ąŠčüčāčēąĄčüčéą▓ą╗čÅčÄčēąĖą╝ąĖ ą┤ąŠčüčéčāą┐ ą║ ąŠą┐ąĄčĆą░čéąĖą▓ąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ.
ą¤čĆąĖąŠčüčéą░ąĮąŠą▓ą║ą░ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA. ąÆ ą╗čÄą▒ąŠą╣ ą╝ąŠą╝ąĄąĮčé ą▓čĆąĄą╝ąĄąĮąĖ ą┐ąĄčĆąĄą┤ą░čćą░ DMA ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮą░ ą┤ąŠ ąŠą║ąŠąĮčćą░ąĮąĖčÅ, čćč鹊ą▒čŗ ą▒čŗčéčī ą┐ąĄčĆąĄąĘą░ą┐čāčēąĄąĮąĮąŠą╣ ą┐ąŠąĘąČąĄ, ąĖą╗ąĖ ąČąĄ ą▒čŗčéčī ąĘą░ą┐čĆąĄčēąĄąĮąĮąŠą╣ ą┐ąŠą╗ąĮąŠčüčéčīčÄ.
ąŚą┤ąĄčüčī ą╝ąŠą│čāčé ą▒čŗčéčī 2 čüą╗čāčćą░čÅ:
ŌĆó ą¤ąŠč鹊ą║ ąĘą░ą┐čĆąĄčēą░ąĄčé ą┐ąĄčĆąĄą┤ą░čćčā ą▒ąĄąĘ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĄą│ąŠ ą▓ąŠąĘąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ ą┐ąĄčĆąĄą┤ą░čćąĖ čü č鹊ą╣ č鹊čćą║ąĖ, ą│ą┤ąĄ ą┐ąĄčĆąĄą┤ą░čćą░ ą▒čŗą╗ą░ ąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮą░. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ ąĮąĖą║ą░ą║ąĖčģ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ ą┤ąĄą╣čüčéą▓ąĖą╣, ą║čĆąŠą╝ąĄ ą║ą░ą║ ąŠčćąĖčüčéą║ą░ ą▒ąĖčéą░ EN ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_SxCR ą┤ą╗čÅ ąĘą░ą┐čĆąĄčéą░ ą┐ąŠč鹊ą║ą░ ąĖ ąŠąČąĖą┤ą░ąĮąĖčÅ čüą▒čĆąŠčüą░ ą▓ ąĮąŠą╗čī ą▒ąĖčéą░ EN. ąÜą░ą║ čüą╗ąĄą┤čüčéą▓ąĖąĄ:
ŌĆō ąĀąĄą│ąĖčüčéčĆ DMA_SxNDTR čüąŠą┤ąĄčƹȹĖčé ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ąŠčüčéą░ą▓čłąĖčģčüčÅ čŹą╗ąĄą╝ąĄąĮč鹊ą▓ ą┤ą░ąĮąĮčŗčģ ąĮą░ ą╝ąŠą╝ąĄąĮčé, ą║ąŠą│ą┤ą░ ą┐ąĄčĆąĄą┤ą░čćą░ ą▒čŗą╗ą░ ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮą░, čéą░ą║ čćč鹊 ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą╝ąŠąČąĄčé ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, čüą║ąŠą╗čīą║ąŠ ą┤ą░ąĮąĮčŗčģ ą▒čŗą╗ąŠ ą┐ąĄčĆąĄą┤ą░ąĮąŠ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ čĆą░ą▒ąŠčéą░ ą┐ąŠč鹊ą║ą░ ą▒čŗą╗ą░ ą┐čĆąĄčĆą▓ą░ąĮą░.
ŌĆó ą¤ąŠč鹊ą║ ą┐čĆąĖąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé čéčĆą░ąĮąĘą░ą║čåąĖčÄ, čćč鹊ą▒čŗ ą┐ąŠč鹊ą╝ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ąĄčæ ą▓ąŠąĘąŠą▒ąĮąŠą▓ąĖčéčī: ą┤ą╗čÅ ą┐ąĄčĆąĄąĘą░ą┐čāčüą║ą░ ąŠčé č鹊čćą║ąĖ, ą│ą┤ąĄ ą▒čŗą╗ą░ ąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮą░ čéčĆą░ąĮąĘą░ą║čåąĖčÅ, ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą┤ąŠą╗ąČąĮą░ ą┐čĆąŠčćąĖčéą░čéčī čĆąĄą│ąĖčüčéčĆ DMA_SxNDTR ą┐ąŠčüą╗ąĄ ąĘą░ą┐čĆąĄčéą░ ą┐ąŠč鹊ą║ą░ (ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ą▒ąĖčé EN ą┐ąĄčĆąĄą╣ą┤ąĄčé ą▓ ą╗ąŠą│. ), čćč鹊ą▒čŗ čāąĘąĮą░čéčī, čüą║ąŠą╗čīą║ąŠ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą┤ą░ąĮąĮčŗčģ čāąČąĄ ą▒čŗą╗ąŠ čüąŠą▒čĆą░ąĮąŠ. ąŚą░č鹥ą╝:
ŌĆō ąÉą┤čĆąĄčüą░ ą┐ąĄčĆąĖč乥čĆąĖąĖ ąĖ/ąĖą╗ąĖ ą┐ą░ą╝čÅčéąĖ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąŠą▒ąĮąŠą▓ą╗ąĄąĮčŗ, čćč鹊ą▒čŗ čāą║ą░ąĘą░č鹥ą╗ąĖ ą▒čŗą╗ąĖ ą░ą║čéčāą░ą╗čīąĮąŠ ą┐ąŠą┤čüčéčĆąŠąĄąĮčŗ.
ŌĆō ąĀąĄą│ąĖčüčéčĆ SxNDTR ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ąŠą▒ąĮąŠą▓ą╗ąĄąĮ ąŠčüčéą░ą▓čłąĖą╝čüčÅ ą║ąŠą╗ąĖč湥čüčéą▓ąŠą╝ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗąĄ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą┐ąĄčĆąĄą┤ą░ąĮčŗ (ą┐čĆąŠčćąĖčéą░ąĮąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, ą║ąŠą│ą┤ą░ ą┐ąŠč鹊ą║ ą▒čŗą╗ ąĘą░ą┐čĆąĄčēąĄąĮ).
ŌĆō ą¤ąŠč鹊ą║ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ąĮąŠą▓ąŠ čĆą░ąĘčĆąĄčłąĄąĮ ą┤ą╗čÅ ą┐ąĄčĆąĄąĘą░ą┐čāčüą║ą░ čéčĆą░ąĮąĘą░ą║čåąĖąĖ čü č鹊ą╣ č鹊čćą║ąĖ, ą│ą┤ąĄ ąŠąĮą░ ą▒čŗą╗ą░ ąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮą░.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą▓ ąŠą▒ąŠąĖčģ čüą╗čāčćą░čÅčģ čāčüčéą░ąĮąŠą▓ąĖčéčüčÅ čäą╗ą░ą│ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ Transfer Complete Interrupt Flag (ą▒ąĖčé TCIF ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMA_LISR ąĖą╗ąĖ DMA_HISR), čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī ąŠą║ąŠąĮčćą░ąĮąĖąĄ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ąĖąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 čĆą░ą▒ąŠčéą░ ą┐ąŠč鹊ą║ą░ ą┐čĆąĄčĆą▓ą░ąĮą░.
ą¤čĆąĄąĖą╝čāčēąĄčüčéą▓ą░ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ DMA2 ąĖ ą│ąĖą▒ą║ąŠčüčéčī ą░čĆčģąĖč鹥ą║čéčāčĆčŗ čüąĖčüč鹥ą╝čŗ. ąÆ čŹč鹊ą╣ čüąĄą║čåąĖąĖ ąŠąĘą▓čāč湥ąĮą░ ąĖą┤ąĄčÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ą▓čŗą│ąŠą┤čŗ ąŠčé ą│ąĖą▒ą║ąŠčüčéąĖ, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄą╝ąŠą╣ ą░čĆčģąĖč鹥ą║čéčāčĆąŠą╣ STM32 ąĖ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą╝ DMA. ąÆ ą║ą░č湥čüčéą▓ąĄ ąĖą╗ą╗čÄčüčéčĆą░čåąĖąĖ ą╝čŗ ą┐ąŠą║ą░ąČąĄą╝, ą║ą░ą║ ąĖąĮą▓ąĄčĆčéąĖčĆąŠą▓ą░čéčī ą┐ąŠčĆčéčŗ ą┐ąĄčĆąĖč乥čĆąĖąĖ DMA2 AHB ąĖ ą┐ą░ą╝čÅčéąĖ, ąĖ čüąŠčģčĆą░ąĮąĖčéčī ą┐čĆą░ą▓ąĖą╗čīąĮąŠąĄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąĄčĆąĄą┤ą░č湥ą╣ ą┤ą░ąĮąĮčŗčģ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓. ą¦č鹊ą▒čŗ ą┤ąŠčüčéąĖčćčī čŹč鹊ą│ąŠ ąĖ ą▓ąĘčÅčéčī čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ąĮą░ą┤ ąŠą▒čŗčćąĮčŗą╝ ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄą╝ DMA2, ąĮčāąČąĮąŠ čĆą░čüčüą╝ąŠčéčĆąĄčéčī čĆą░ą▒ąŠčćčāčÄ ą╝ąŠą┤ąĄą╗čī DMA2.
ą¤ąŠčüą║ąŠą╗čīą║čā ąŠą▒ą░ ą┐ąŠčĆčéą░ DMA2 čüąŠąĄą┤ąĖąĮąĄąĮčŗ čü ą╝ą░čéčĆąĖčåąĄą╣ čłąĖąĮčŗ AHB, ąĖ ąĖą╝ąĄčÄčé čüąĖą╝ą╝ąĄčéčĆąĖčćąĮąŠąĄ čüąŠąĄą┤ąĖąĮąĄąĮąĖąĄ čü slave-čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ąĖ AHB, čŹčéą░ ą░čĆčģąĖč鹥ą║čéčāčĆą░ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐čĆąŠč鹥ą║ą░čéčī čéčĆą░čäąĖą║čā ą▓ ąŠą┤ąĮąŠ ąĖą╗ąĖ ą┤čĆčāą│ąŠą╝ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĖ č湥čĆąĄąĘ ą┐ąŠčĆčéčŗ ą┐ąĄčĆąĖč乥čĆąĖąĖ ąĖ ą┐ą░ą╝čÅčéąĖ, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą╣ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ.
ą¤ą× ąŠą▒ą╗ą░ą┤ą░ąĄčé ą│ąĖą▒ą║ąŠčüčéčīčÄ ą┤ą╗čÅ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ą┐ąŠč鹊ą║ą░ DMA2 ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čüąŠ čüą▓ąŠąĖą╝ąĖ ą┐ąŠčéčĆąĄą▒ąĮąŠčüčéčÅą╝ąĖ. ąÆ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čŹč鹊ą╣ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ ąŠą┤ąĖąĮ ą┐ąŠčĆčé DMA2 AHB ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆčāąĄčéčüčÅ ą▓ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĖ čćč鹥ąĮąĖčÅ, ą┤čĆčāą│ąŠą╣ ą▓ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĖ ąĘą░ą┐ąĖčüąĖ. ąóą░ą▒ą╗ąĖčåą░ 8 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąŠčĆčéą░ DMA AHB ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ čĆąĄąČąĖą╝ą░ čéčĆą░ąĮąĘą░ą║čåąĖąĖ.
ąóą░ą▒ą╗ąĖčåą░ 8. ąØą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąŠčĆčéą░ DMA AHB ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ čĆąĄąČąĖą╝ą░ čéčĆą░ąĮąĘą░ą║čåąĖąĖ.
| ąĀąĄąČąĖą╝ čéčĆą░ąĮąĘą░ą║čåąĖąĖ |
ą¤ąŠčĆčé ą┐ą░ą╝čÅčéąĖ DMA2 AHB |
ą¤ąŠčĆčé ą┐ąĄčĆąĖč乥čĆąĖąĖ DMA2 AHB |
| ąśąĘ ą┐ą░ą╝čÅčéąĖ ą▓ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ |
ąØą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čćč鹥ąĮąĖčÅ (Read) |
ąØą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ąĘą░ą┐ąĖčüąĖ (Write) |
| ąśąĘ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ą▓ ą┐ą░ą╝čÅčéčī |
ąØą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ąĘą░ą┐ąĖčüąĖ (Write) |
ąØą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čćč鹥ąĮąĖčÅ (Read) |
| ąśąĘ ą┐ą░ą╝čÅčéąĖ ą▓ ą┐ą░ą╝čÅčéčī |
ąóąĄą┐ąĄčĆčī čĆą░čüčüą╝ąŠčéčĆąĖą╝ ą┐ąŠč鹊ą║ čéčĆą░čäąĖą║ą░ (čüą╝. ą▓čŗčłąĄ čüąĄą║čåąĖčÄ "ąĪąŠčüč鹊čÅąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA") čéčĆą░ąĮąĘą░ą║čåąĖą╣ ąĮą░ ą┐ąŠčĆčéčā ą┐ąĄčĆąĖč乥čĆąĖąĖ, ąĘą░ą┐čāčüą║ą░ąĄą╝čŗčģ ąĘą░ą┐čĆąŠčüą░ą╝ąĖ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░, čéčĆą░ąĮąĘą░ą║čåąĖą╣ ąĮą░ ą┐ąŠčĆčéčā ą┐ą░ą╝čÅčéąĖ, ąĘą░ą┐čāčüą║ą░ąĄą╝čŗčģ ą╗ąĖą▒ąŠ ą┐ąŠ ą┐ąŠčĆąŠą│čā FIFO (ą┐čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ čĆąĄąČąĖą╝ą░ FIFO) ąĖą╗ąĖ ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮąŠ ą┐ąŠčüą╗ąĄ čćč鹥ąĮąĖčÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ (ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čĆąĄąČąĖą╝ Direct).
ąÜąŠą│ą┤ą░ ąŠą▒čüą╗čāąČąĖą▓ą░čÄčéčüčÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ čü ą┐ąŠčĆč鹊ą╝ ą┐ą░ą╝čÅčéąĖ DMA2 ąĮą░ą╝ ąĮčāąČąĮąŠ ą┐ąŠąĘą░ą▒ąŠčéąĖčéčīčüčÅ ąŠ ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮąŠ ąĘą░ą┐čāčüą║ą░ąĄą╝čŗčģ čéčĆą░ąĮąĘą░ą║čåąĖčÅčģ (čüą╝. ą┤ą░ą╗ąĄąĄ "ą¤čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮąŠ ąĘą░ą┐čāčēąĄąĮąĮą░čÅ čéčĆą░ąĮąĘą░ą║čåąĖčÅ"), ąĖ ąŠą▒ ąŠą▒čĆą░ą▒ąŠčéą║ąĄ ą┐ąŠčüą╗ąĄą┤ąĮąĖčģ ą┤ą░ąĮąĮčŗčģ (čüą╝. ą┤ą░ą╗ąĄąĄ "ą×ą▒čüą╗čāąČąĖą▓ą░ąĮąĖąĄ ą┐ąŠčüą╗ąĄą┤ąĮąĄą│ąŠ čćč鹥ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ").
ą¤čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮąŠ ąĘą░ą┐čāčēąĄąĮąĮą░čÅ čéčĆą░ąĮąĘą░ą║čåąĖčÅ. ąÜą░ą║ ą▒čŗą╗ąŠ ąŠą┐ąĖčüą░ąĮąŠ čĆą░ąĮąĄąĄ ą▓ čüąĄą║čåąĖąĖ "ąĪąŠčüč鹊čÅąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA", ą║ąŠą│ą┤ą░ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮ čĆąĄąČąĖą╝ ą┐ąĄčĆąĄą┤ą░čćąĖ ąĖąĘ ą┐ą░ą╝čÅčéąĖ ą▓ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ (čćč鹥ąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ č湥čĆąĄąĘ ą┐ąŠčĆčé ą┐ą░ą╝čÅčéąĖ) DMA ąŠąČąĖą┤ą░ąĄčé ą┤ąŠčüčéčāą┐ą░ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ąĖ čüčćąĖčéčŗą▓ą░ąĄčé ą┤ą░ąĮąĮčŗąĄ, ą║ą░ą║ č鹊ą╗čīą║ąŠ ą┐ąŠč鹊ą║ DMA ą▒čŗą╗ čĆą░ąĘčĆąĄčłąĄąĮ. ą×ą┤ąĖąĮ 菹╗ąĄą╝ąĄąĮčé ą┤ą░ąĮąĮčŗčģ ą▒čāč乥čĆąĖčĆčāąĄčéčüčÅ ą▓ čĆąĄąČąĖą╝ąĄ Direct, ąĖ ą┤ąŠ 4 x 32-čĆą░ąĘčĆčÅą┤ąĮčŗčģ čüą╗ąŠą▓, ą║ąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮ DMA FIFO.
ąÜąŠą│ą┤ą░ ąŠą▒čüą╗čāąČąĖą▓ą░čÄčéčüčÅ čćč鹥ąĮąĖčÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ č湥čĆąĄąĘ ą┐ąŠčĆčé ą┐ą░ą╝čÅčéąĖ DMA2, ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą┤ąŠą╗ąČąĮą░ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ čĆą░ąĘčĆąĄčłąĄąĮąŠ ą┐ąĄčĆąĄą┤ čĆą░ąĘčĆąĄčłąĄąĮąĖąĄą╝ DMA, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ą┐čĆą░ą▓ąĖą╗čīąĮąŠčüčéčī ą┐ąĄčĆą▓ąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ DMA.
ąĀąĖčü. 17 ąĖą╗ą╗čÄčüčéčĆąĖčĆčāąĄčé ą┤ąŠčüčéčāą┐čŗ DMA ąĮą░ ą┐ąŠčĆčéą░čģ ą┐ą░ą╝čÅčéąĖ ąĖ ą┐ąĄčĆąĖč乥čĆąĖąĖ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čéčĆąĖą│ą│ąĄčĆąŠą▓ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░.
ąĀąĖčü. 17. DMA ą▓ čĆąĄąČąĖą╝ąĄ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ąĖąĘ ą┐ą░ą╝čÅčéąĖ ą▓ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ.
ą×ą▒čüą╗čāąČąĖą▓ą░ąĮąĖąĄ ą┐ąŠčüą╗ąĄą┤ąĮąĄą│ąŠ čćč鹥ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ. ąÜąŠąĮčéčĆąŠą╗ą╗ąĄčĆ DMA ąŠą▒ą╗ą░ą┤ą░ąĄčé čäčāąĮą║čåąĖąĄą╣ 4 x 32-čĆą░ąĘčĆčÅą┤ąĮčŗčģ čüą╗ąŠą▓ FIFO ąĮą░ ą┐ąŠč鹊ą║, čćč鹊 ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ą▒čāč乥čĆąĖąĘą░čåąĖąĖ ą┤ą░ąĮąĮčŗčģ ą╝ąĄąČą┤čā ą┐ąŠčĆčéą░ą╝ąĖ AHB. ąÜąŠą│ą┤ą░ ąŠą▒čüą╗čāąČąĖą▓ą░čÄčéčüčÅ čćč鹥ąĮąĖčÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ č湥čĆąĄąĘ ą┐ąŠčĆčé ą┐ą░ą╝čÅčéąĖ DMA, ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą┤ąŠą╗ąČąĮą░ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 4x ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ čüą╗ąŠą▓ą░ ą┐čĆąŠčćąĖčéą░ąĮčŗ ąĖąĘ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░. ąŁč鹊 ą┤ą░čüčé ą│ą░čĆą░ąĮčéąĖčÄ, čćč鹊 ą┐ąŠčüą╗ąĄą┤ąĮąĖąĄ ą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▒čāą┤čāčé ą┐ąĄčĆąĄą┤ą░ąĮčŗ ąĖąĘ DMA FIFO.
ąæčāč乥čĆąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗąĄ čéčĆą░ąĮąĘą░ą║čåąĖąĖ, ą║ąŠą│ą┤ą░ ąĘą░ą┐čĆąĄčēąĄąĮ čĆąĄąČąĖą╝ Direct. ąÜąŠą│ą┤ą░ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ ą┤ą░ąĮąĮčŗąĄ č湥čĆąĄąĘ ą┐ąŠčĆčé ą┐ą░ą╝čÅčéąĖ ą▓ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ, ą║ąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮ čĆąĄąČąĖą╝ FIFO, ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ąĮčāąČąĮąŠ ą┐ąŠąĘą░ą▒ąŠčéąĖčéčīčüčÅ ąŠ č鹊ą╝, čćč鹊 ą┤ąŠčüčéčāą┐ č湥čĆąĄąĘ čŹč鹊čé ą┐ąŠčĆčé čüčĆą░ą▒ą░čéčŗą▓ą░ąĄčé ą┐ąŠ ąĘą░ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĮąŠą╝čā ą┐ąŠčĆąŠą│čā FIFO. ąÜąŠą│ą┤ą░ ą┤ąŠčüčéąĖą│ąĮčāčé ą┐ąŠčĆąŠą│ ą┤ą░ąĮąĮčŗčģ, ą┤ą░ąĮąĮčŗąĄ ą┐ąĄčĆąĄą┤ą░čÄčéčüčÅ ąĖąĘ FIFO ą▓ ą╝ąĄčüč鹊 ąĮą░ąĘąĮą░č湥ąĮąĖčÅ č湥čĆąĄąĘ ą┐ąŠčĆčé ą┐ą░ą╝čÅčéąĖ.
ąÜąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĘą░ą┐ąĖčüčī ą▓ čĆąĄą│ąĖčüčéčĆ (ąĮą░ą┐čĆąĖą╝ąĄčĆ čā GPIO ąĮąĄčé FIFO), ą┤ą░ąĮąĮčŗąĄ ąĖąĘ DMA FIFO ą▒čāą┤čāčé čāčüą┐ąĄčłąĮąŠ ąĘą░ą┐ąĖčüą░ąĮčŗ ą▓ ą╝ąĄčüč鹊 ąĮą░ąĘąĮą░č湥ąĮąĖčÅ.
ąś ą┐ąŠčüą╗ąĄą┤ąĮąĄąĄ, ąĮąŠ ąĮąĄ ą╝ąĄąĮąĄąĄ ą▓ą░ąČąĮąŠąĄ: ą║ąŠą│ą┤ą░ ą┐ąĄčĆąĄą║ą╗čÄčćą░ąĄčéčüčÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąĄčĆąĖč乥čĆąĖąĄą╣ čü ą┐ąŠčĆčéą░ ą┐ąĄčĆąĖč乥čĆąĖąĖ ąĮą░ ą┐ąŠčĆčé ą┐ą░ą╝čÅčéąĖ, ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ ąĮčāąČąĮąŠ ą┐ąĄčĆąĄčüą╝ąŠčéčĆąĄčéčī čĆą░ąĘą╝ąĄčĆ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ąĖ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÄ ąĖąĮą║čĆąĄą╝ąĄąĮčéą░ ą░ą┤čĆąĄčüą░.
ąÜą░ą║ ąŠą┐ąĖčüą░ąĮąŠ ą▓čŗčłąĄ ą▓ čüąĄą║čåąĖąĖ "ąĀą░ąĘą╝ąĄčĆ čéčĆą░ąĮąĘą░ą║čåąĖąĖ", čĆą░ąĘą╝ąĄčĆ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ čłąĖčĆąĖąĮąŠą╣ čéčĆą░ąĮąĘą░ą║čåąĖąĖ ąĮą░ čüč鹊čĆąŠąĮąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ (byte, half-word, word) ąĖ ą║ąŠą╗ąĖč湥čüčéą▓ąŠą╝ ą┐ąĄčĆąĄą┤ą░ą▓ą░ąĄą╝čŗčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą┤ą░ąĮąĮčŗčģ (ąĘąĮą░č湥ąĮąĖąĄ, ąĘą░ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĮąŠąĄ ą▓ čĆąĄą│ąĖčüčéčĆ DMA_SxNTDR). ąÆ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü ąĮąŠą▓ąŠą╣ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĄą╣ DMA, ą║ąŠą│ą┤ą░ ąĘą░ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąŠ ąĖąĮą▓ąĄčĆčéąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐ąŠčĆč鹊ą▓, ą╝ąŠąČąĄčé ą┐ąŠąĮą░ą┤ąŠą▒ąĖčéčīčüčÅ ą┐ąŠą┤čüčéčĆąŠąĖčéčī ąĘąĮą░č湥ąĮąĖąĄ čĆąĄą│ąĖčüčéčĆą░ DMA_SxNTDR.
ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ DMA_S7M0AR ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆčāąĄčéčüčÅ ą░ą┤čĆąĄčüąŠą╝ čĆąĄą│ąĖčüčéčĆą░ Quad-SPI Data, DMA_S7PAR ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆčāąĄčéčüčÅ ą░ą┤čĆąĄčüąŠą╝ ą▒čāč乥čĆą░ ą┤ą░ąĮąĮčŗčģ (ą▒čāč乥čĆ, ą║ąŠč鹊čĆčŗą╣ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ SRAM). ąÆ čĆąĄą│ąĖčüčéčĆąĄ DMA_S7CR ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąŠ ąĮą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąŠč鹊ą║ą░ DMA2 ą▓ čĆąĄąČąĖą╝ąĄ ąŠčé ą┐ąĄčĆąĖč乥čĆąĖąĖ ą▓ ą┐ą░ą╝čÅčéčī, ą║ąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĘą░ą┐ąĖčüčī ą▓ Quad-SPI. ąØą░ą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąŠč鹊ą║ą░ DMA2 ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąŠ ą▓ čĆąĄąČąĖą╝ąĄ ąĖąĘ ą┐ą░ą╝čÅčéąĖ ą▓ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ, ą║ąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé čćč鹥ąĮąĖąĄ ąĖąĘ Quad-SPI.
4x ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ čüą╗ąŠą▓ą░ (32-čĆą░ąĘčĆčÅą┤ąĮčŗčģ) ąĮčāąČąĮčŗ ą┤ą╗čÅ ąŠą┐ąĄčĆą░čåąĖąĖ čćč鹥ąĮąĖčÅ, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ą┐ąŠčüą╗ąĄą┤ąĮąĖąĄ ą┤ą░ąĮąĮčŗąĄ ą▒čŗą╗ąĖ ą┐ąĄčĆąĄą┤ą░ąĮčŗ ąĮą░čĆčāąČčā ąĖąĘ DMA FIFO ą▓ SRAM.
ąÜčāčüąŠą║ ą║ąŠą┤ą░ ą┤ą╗čÅ ąŠą┐ąĄčĆą░čåąĖąĖ čćč鹥ąĮąĖčÅ:
/* ą¤čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ M0AR ą░ą┤čĆąĄčüąŠą╝ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ QUADSPI */
DMA2_Stream7->M0AR = (uint32_t)&QUADSPI->DR;
/* ą¤čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ PAR ą░ą┤čĆąĄčüąŠą╝ ą▒čāč乥čĆą░ */
DMA2_Stream7->PAR = (uint32_t)&u32Buffer[0];
/* ąŚą░ą┐ąĖčüčī ą║ąŠą╗ąĖč湥čüčéą▓ą░ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ ą┐ąĄčĆąĄą┤ą░čćąĖ */
DMA2_Stream7->NDTR = 0x100;
/* ąÜąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ DMA: MSIZE=PSIZE=0x02 (čüą╗ąŠą▓ąŠ),
CHSEL=0x03 (QUADSPI), PINC=1, DIR=0x00 */
DMA2_Stream7->CR = DMA_SxCR_PSIZE_1
| DMA_SxCR_MSIZE_1
| 3ul << 25
| DMA_SxCR_PINC;
/* ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ ą│ąĄąĮąĄčĆą░čåąĖąĖ ąĘą░ą┐čĆąŠčüą░ DMA */
QUADSPI->CR |= QUADSPI_CR_DMAEN;
/* ąŚą░ą┐ąĖčüčī ą▓ čĆąĄą│ąĖčüčéčĆ DLR */
QUADSPI->DLR = (0x100*4)-1;
/* ąŚą░ą┐ąĖčüčī ą▓ QUADSPI DCR */
QUADSPI->CCR = QUADSPI_CCR_IMODE_0
| QUADSPI_CCR_ADMODE_0
| QUADSPI_CCR_DMODE
| QUADSPI_CCR_ADSIZE
| QUAD_IN_FAST_PROG_CMD;
/* ąĘą░ą┐ąĖčüčī ą▓ čĆąĄą│ąĖčüčéčĆ AR */
QUADSPI->AR = 0x00ul;
/* ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ ą▓čŗą▒čĆą░ąĮąĮąŠą│ąŠ ą┐ąŠč鹊ą║ą░ DMA2_Stream7 čāčüčéą░ąĮąŠą▓ą║ąŠą╣ ą▒ąĖčéą░ EN */
DMA2_Stream7->CR |= (uint32_t)DMA_SxCR_EN;
/* ą×ąČąĖą┤ą░ąĮąĖąĄ ąŠą║ąŠąĮčćą░ąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ */
while((QUADSPI->SR & QUADSPI_SR_TCF) != QUADSPI_SR_TCF);
ąÜčāčüąŠą║ ą║ąŠą┤ą░ ą┤ą╗čÅ ąŠą┐ąĄčĆą░čåąĖąĖ ąĘą░ą┐ąĖčüąĖ:
/* ą¤čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ M0AR ą░ą┤čĆąĄčüąŠą╝ čĆąĄą│ąĖčüčéčĆą░ ą┤ą░ąĮąĮčŗčģ QUADSPI */
DMA2_Stream7->M0AR = (uint32_t)&QUADSPI->DR;
/* ą¤čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖąĄ PAR ą░ą┤čĆąĄčüąŠą╝ ą▒čāč乥čĆą░ */
DMA2_Stream7->PAR = (uint32_t)&u32Buffer[0];
/* ąŚą░ą┐ąĖčüčī ą║ąŠą╗ąĖč湥čüčéą▓ą░ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ ą┐ąĄčĆąĄą┤ą░čćąĖ */
DMA2_Stream7->NDTR = 0x100;
/* ąÜąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ DMA : MSIZE=PSIZE=0x02 (Word),
CHSEL=0x03 (QUADSPI), PINC=1, DIR=0x01 */
DMA2_Stream7->CR = DMA_SxCR_PSIZE_1
| DMA_SxCR_MSIZE_1
| 3ul << 25
| DMA_SxCR_PINC
| DMA_SxCR_DIR_0;
/* ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ ą│ąĄąĮąĄčĆą░čåąĖąĖ ąĘą░ą┐čĆąŠčüą░ DMA */
QUADSPI->CR |= QUADSPI_CR_DMAEN;
/* ąŚą░ą┐ąĖčüčī ą▓ čĆąĄą│ąĖčüčéčĆ DLR */
QUADSPI->DLR = ((0x100+4)*4)-1;
/* ąŚą░ą┐ąĖčüčī ą▓ QUADSPI DCR */
QUADSPI->CCR = QUADSPI_CCR_IMODE_0
| QUADSPI_CCR_ADMODE_0
| QUADSPI_CCR_DMODE
| QUADSPI_CCR_ADSIZE
| QUADSPI_CCR_FMODE_0
| QUAD_OUT_FAST_READ_CMD;
/* ąĘą░ą┐ąĖčüčī ą▓ čĆąĄą│ąĖčüčéčĆ AR */
QUADSPI->AR = 0x00ul;
/* ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ ą▓čŗą▒čĆą░ąĮąĮąŠą│ąŠ ą┐ąŠč鹊ą║ą░ DMA2_Stream7 čāčüčéą░ąĮąŠą▓ą║ąŠą╣ ą▒ąĖčéą░ EN */
DMA2_Stream7->CR |= (uint32_t)DMA_SxCR_EN;
/* ą×ąČąĖą┤ą░ąĮąĖąĄ ąŠą║ąŠąĮčćą░ąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ */
while((DMA2_Stream7->CR & DMA_SxCR_EN) == DMA_SxCR_EN);
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąŠą│čĆą░ąĮąĖč湥ąĮąĖąĄ ą┐ąŠą▓čĆąĄąČą┤ąĄąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ, ą║ąŠą│ą┤ą░ DMA2 ąŠą▒čüą╗čāąČąĖą▓ą░ąĄčéčüčÅ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čü čéčĆą░ąĮąĘą░ą║čåąĖčÅą╝ąĖ AHB ąĖ APB2 (čüą╝. čüąŠąŠą▒čēąĄąĮąĖčÅ ąŠą▒ ąŠčłąĖą▒ą║ą░čģ ą║čĆąĖčüčéą░ą╗ą╗ą░ errata, čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, ą▓ ą║ą░ą║ąĖčģ STM32F2/F4 MCU čŹč鹊 ą┐čĆąĖčüčāčéčüčéą▓čāąĄčé) ą╝ąŠąČąĮąŠ ąŠą▒ąŠą╣čéąĖ ą┐čāč鹥ą╝ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ ą┐ąŠčĆč鹊ą▓ ą┐ąĄčĆąĖč乥čĆąĖąĖ ąĖ ą┐ą░ą╝čÅčéąĖ DMA2, ą║ą░ą║ ąŠą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą▓ čŹč鹊ą╣ čüąĄą║čåąĖąĖ.
ąóčĆą░ąĮąĘą░ą║čåąĖčÅ STM32F7 DMA ąĖ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖąĄ ą║čŹčłą░, čćč鹊ą▒čŗ ąĖąĘą▒ąĄąČą░čéčī ąĮąĄą║ąŠą│ąĄčĆąĄąĮčéąĮąŠčüčéąĖ ą┤ą░ąĮąĮčŗčģ. ąÜąŠą│ą┤ą░ ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąĮąĄ ą║čŹčłąĖčĆčāąĄą╝čŗąĄ čĆąĄą│ąĖąŠąĮčŗ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ ą▒čāč乥čĆąŠą▓ ąĖčüč鹊čćąĮąĖą║ą░ / ą╝ąĄčüčéą░ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ DMA, ą┤ą╗čÅ ąĮąĖčģ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠ ąĘą░ą┐čāčüčéąĖčéčī ąŠčćąĖčüčéą║čā ą║čŹčłą░, ą┐ąĄčĆąĄą┤ ąĘą░ą┐čāčüą║ąŠą╝ čĆą░ą▒ąŠčéčŗ DMA, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ą▓čüąĄ ą┤ą░ąĮąĮčŗąĄ ą▒čŗą╗ąĖ ąĘą░čäąĖą║čüąĖčĆąŠą▓ą░ąĮčŗ ą┐ąŠą┤čüąĖčüč鹥ą╝ąŠą╣ ą┐ą░ą╝čÅčéąĖ. ą¤čĆąĖ čćč鹥ąĮąĖąĖ ą┤ą░ąĮąĮčŗčģ ąĖąĘ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ą┐ąŠčüą╗ąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA, ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą┤ąŠą╗ąČąĮą░ ą▓čŗą┐ąŠą╗ąĮąĖčéčī čüą▒čĆąŠčü ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéąĖ ą║čŹčłą░ (cache invalidate) ą┐ąĄčĆąĄą┤ čćč鹥ąĮąĖąĄą╝ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĮąŠą│ąŠ čĆąĄą│ąĖąŠąĮą░ ą┐ą░ą╝čÅčéąĖ.
ąöą╗čÅ ą▒čāč乥čĆąŠą▓ DMA ąČąĄą╗ą░č鹥ą╗čīąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąĮąĄ ą║čŹčłąĖčĆčāąĄą╝čŗąĄ čĆąĄą│ąĖąŠąĮčŗ ą┐ą░ą╝čÅčéąĖ. ą¤čĆąŠą│čĆą░ą╝ą╝ą░ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī MPU, čćč鹊ą▒čŗ ąĮą░čüčéčĆąŠąĖčéčī ąĮąĄ ą║čŹčłąĖčĆčāąĄą╝čŗą╣ ą▒ą╗ąŠą║ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą▓ ą▓ąĖą┤ąĄ ąŠą▒čēąĄą╣ ą┐ą░ą╝čÅčéąĖ ą╝ąĄąČą┤čā CPU ąĖ DMA.
[ą×ą▒čēąĖąĄ ą▓čŗą▓ąŠą┤čŗ]
ąÜąŠąĮčéčĆąŠą╗ą╗ąĄčĆ DMA čĆą░ąĘčĆą░ą▒ąŠčéą░ąĮ ą┤ą╗čÅ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÅ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ą░ čüą╗čāčćą░ąĄą▓ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą▓ąŠ ą▓čüčéčĆą░ąĖą▓ą░ąĄą╝čŗčģ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅčģ, čüąŠ čüą╗ąĄą┤čāčÄčēąĖą╝ąĖ ąŠčüąĮąŠą▓ąĮčŗą╝ąĖ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčÅą╝ąĖ:
ŌĆó ą¤čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčéčüčÅ ą│ąĖą▒ą║ąŠčüčéčī ą▓čŗą▒ąŠčĆą░ ą┐ąŠą┤čģąŠą┤čÅčēąĄą╣ ą║ąŠą╝ą▒ąĖąĮą░čåąĖąĖ ą╝ąĄąČą┤čā 16 ą┐ąŠč鹊ą║ą░ą╝ąĖ X (ą┐ąŠ 8 ą┐ąŠč鹊ą║ąŠą▓ ąĮą░ ą║ą░ąČą┤čŗą╣ DMA).
ŌĆó ąĪąĮąĖąČą░ąĄčéčüčÅ ąŠą▒čēąĄąĄ ą▓čĆąĄą╝čÅ ąĘą░ą┤ąĄčƹȹ║ąĖ ą┤ą╗čÅ čéčĆą░ąĮąĘą░ą║čåąĖąĖ DMA ą▒ą╗ą░ą│ąŠą┤ą░čĆčÅ ą┤ą▓čāčģą┐ąŠčĆč鹊ą▓ąŠą╣ ą░čĆčģąĖč鹥ą║čéčāčĆąĄ AHB ąĖ ą┐čĆčÅą╝ąŠą╝čā ą┐čāčéąĖ ą┤ąŠčüčéčāą┐ą░ ą║ ą╝ąŠčüčéą░ą╝ APB, čćč鹊 čāčüčéčĆą░ąĮčÅąĄčé ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą║ąĖ CPU ąĮą░ ą┤ąŠčüčéčāą┐ąĄ ą║ AHB1, ą║ąŠą│ą┤ą░ DMA ąŠą▒čüą╗čāąČąĖą▓ą░ąĄčé ąĮąĖąĘą║ąŠčüą║ąŠčĆąŠčüčéąĮčŗąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ APB.
ŌĆó ąĀąĄą░ą╗ąĖąĘą░čåąĖčÅ čüč鹥ą║ąŠą▓ FIFO ąĮą░ DMA ą┤ą░ąĄčé ą▒ąŠą╗čīčłąĄ ą│ąĖą▒ą║ąŠčüčéąĖ ą┤ą╗čÅ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖčÅ čĆą░ąĘąĮčŗčģ čĆą░ąĘą╝ąĄčĆąŠą▓ ą┤ą░ąĮąĮčŗčģ ą╝ąĄąČą┤čā ąĖčüč鹊čćąĮąĖą║ąŠą╝ ąĖ ą╝ąĄčüč鹊ą╝ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ, ąĖ čāčüą║ąŠčĆčÅąĄčé ą┐ąĄčĆąĄą┤ą░čćąĖ, ą║ąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čĆąĄąČąĖą╝ ą┐ą░ą║ąĄčéąĮąŠą╣ ą┐ąĄčĆąĄą┤ą░čćąĖ čü ąĖąĮą║čĆąĄą╝ąĄąĮč鹊ą╝ (incremental burst transfer).
[ąĪčüčŗą╗ą║ąĖ]
1. AN4031 Using the STM32F2, STM32F4 and STM32F7 Series DMA controller site:st.com.
2. Round-robin (ą░ą╗ą│ąŠčĆąĖčéą╝) site:wikipedia.org.
3. STM32: ą░ą▒ą▒čĆąĄą▓ąĖą░čéčāčĆčŗ ąĖ č鹥čĆą╝ąĖąĮčŗ.
4. STM32F429: ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ DMA.
5. 210122133736DAC-DMA-STM32F407.zip - ą┐čĆąĖą╝ąĄčĆ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą┤ą╗čÅ čĆą░ą▒ąŠčéčŗ ą┤ą▓ąŠą╣ąĮąŠą│ąŠ ą▒čāč乥čĆą░ DMA. |




ąÜąŠą╝ą╝ąĄąĮčéą░čĆąĖąĖ
RSS ą╗ąĄąĮčéą░ ą║ąŠą╝ą╝ąĄąĮčéą░čĆąĖąĄą▓ čŹč鹊ą╣ ąĘą░ą┐ąĖčüąĖ