| STM32: использование контроллера DMA |
|
| Добавил(а) microsin | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
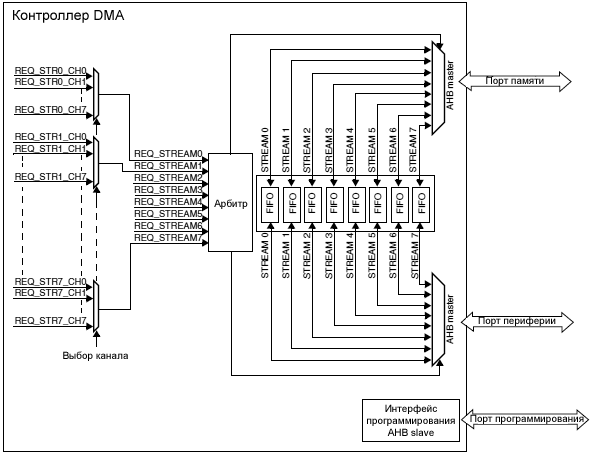
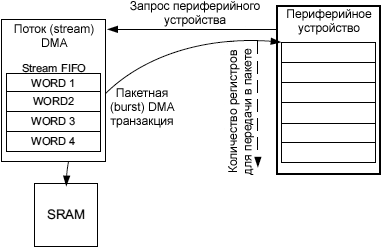
В этой статье (перевод апноута AN4031 [1]) описывается применение контроллера прямого доступа к памяти (direct memory access, DMA), доступного в микроконтроллерах серий STM32F2, STM32F4 и STM32F7 Series. Функции контроллера DMA, архитектура системы, многослойная матрица шины и система памяти предоставляют широкополосную систему обмена данными между периферийными устройствами и областями памяти, с малыми задержками для использования в программном обеспечении системы. Примечание: в этом документе STM32F2, STM32F4 и STM32F7 для краткости обозначаются как "MCU" или "микроконтроллер", и контроллер DMA обозначается просто как "DMA". В качестве примера для иллюстрации выбрана платформа STM32F4. Поведение DMA для серий STM32F2, STM32F4 и STM32F7 одинаковое, если не указано нечто другое. Перемещение данных под управлением DMA называется транзакцией или передачей. Все непонятные термины и сокращения см. в Словарике статьи [3]. При изучении этой документации следует также обращаться к руководствам MCU: • STM32F205/215 and STM32F207/217 reference manual (RM0033) DMA представляет собой модуль AMBA высокопроизводительной шины (advanced high-performance bus, AHB), который работает через 3 порта AHB: slave-порт для программирования DMA, и два master-порта (порты периферийных устройств и памяти), которые позволяют DMA инициировать транзакции между различными подчиненными модулями (передачи память-память, память-устройство и устройство-память). DMA позволяет осуществлять транзакции в фоновом режиме, без вмешательства со стороны процессора Cortex-Mx (CPU). Во время этой операции основной CPU может выполнять другие задачи, прерываясь только в том случае, когда транзакция закончилась и новый блок данных целиком доступен для обработки. Большие объемы данных могут быть переданы без значительного ухудшения общей производительности системы. DMA в основном используется для реализации центрального буферизированного хранилища (обычно в system SRAM) для различных модулей периферийных устройств. Это решение менее дорогое в контексте использования микросхем и потребления энергии в сравнении с другими распространенными решениями, где каждое периферийное устройство требует создания собственного локального хранилища данных. Свойства транзакции DMA. Передача DMA характеризуется следующими параметрами: • Поток/канал DMA (stream/channel). В MCU встроено два контроллера DMA (DMA1 и DMA2), и у каждого из них есть два порта - один порт для периферийных устройств и один порт для памяти. Оба контроллера могут работать одновременно. На рис. 1 показана блок-схема DMA.
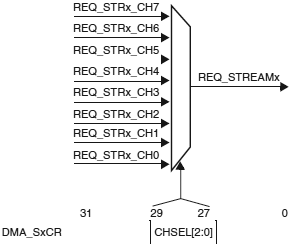
Рис. 1. Схема контроллера DMA. Потоки/каналы DMA. В каждом из двух контроллеров DMA имеется по 8 потоков (stream), всего в сумме получается 16. Каждый из потоков выделяется для обслуживания запросов доступа к памяти одного или большего количества периферийных устройств. Каждый из потоков имеет всего до 8 выбираемых каналов (запросов). Этот выбор конфигурируется программно, что позволяет нескольким периферийным устройствам инициировать запросы DMA. Рис. 2 описывает выбор канала (channel) для выделенного потока (stream).
Рис. 2. Выбор канала. Примечание: на потоке может быть одновременно активен только один канал/запрос. Больше одного разрешенного потока не должно обслуживать один и тот же запрос периферийного устройства. Таблицы 1 и 2 показывают отображение DMA1/DMA2 запросов STM32F427/STM32F437 и STM32F429/STM32F439. Эти таблицы дают доступную конфигурацию потоков/каналов DMA против запросов периферийных устройств. Таблица 1. Привязка запросов DMA1 периферийных устройств STM32F427/437 и STM32F429/439.
Таблица 2. Привязка запросов DMA2 периферийных устройств STM32F427/437 и STM32F429/439.
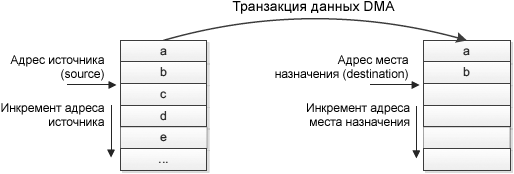
Отображение запросов STM32F2/F4/F7 DMA разработано таким образом, что приложению дается больше гибкости для привязки каждого запроса DMA для связанного запроса периферийного устройство, и большая часть сценариев приложения покрывается мультиплексированием соответствующих потоков DMA и каналов. См. таблицы отображения DMA1/DMA2 в руководствах по используемым MCU (врезка выше "Дополнительная документация"). Приоритет потока. У каждого порта DMA имеется арбитр для обработки приоритетов между разными потоками DMA. Приоритет потока конфигурируется программно (всего имеется 4 уровня приоритета). Если 2 или большее количество потоков DMA имеют одинаковый уровень приоритета, то используется аппаратный приоритет (поток 0 имеет приоритет над потоком 1, и т. п.). Адреса источника и назначения. Транзакция DMA определяется адресом источника и адресом назначения. Оба этих адреса должны быть в пределах диапазонов шин AHB и APB, и адрес должен быть выровнен на размер транзакции. Режим транзакции. DMA может осуществлять 3 разных режима передачи: • Из периферийного устройства в память. Размер транзакции. Должен быть определено значение размера транзакции, когда контроллером потока является DMA. Фактически это значение определяет объем данных, которые должны быть перемещены из источника (source) в место назначения (destination). Размер транзакции определяется значением в регистре DMA_SxNDTR и шириной данных периферийного устройства. В зависимости от принятого запроса (burst или single), значение размера транзакции уменьшается на количество переданных данных. Инкремент адреса источника/места назначения. Можно сконфигурировать DMA так, что в каждой транзакции данных будет автоматически инкрементироваться адрес источника и/или места назначения (source address, destination address).
Рис. 3. Инкремент адреса source и destination транзакции DMA. Ширина данных источника и места назначения. Ширина (разрядность) данных может быть определена следующим образом: • Byte (байт, 8 бит). Типы транзакций. Существуют следующие типы (режимы) передач DMA: Circular mode: в этом режиме доступна обработка кольцевых буферов и непрерывных потоков данных (тогда регистр DMA_SxNDTR перезагружается автоматически ранее запрограммированным значением). В этом примере DMA запускается для проигрывания через DAC небольшого буфера aEscalator8bit в циклическом (Circular) режиме. После вызова функции инициализации MX_DAC_Init сигнал генерируется на выходе канала 1 DAC автоматически, без участия процессора. DAC_HandleTypeDef hdac; DMA_HandleTypeDef hdma_dac1; const uint8_t aEscalator8bit[6] = {0x0, 0x33, 0x66, 0x99, 0xCC, 0xFF}; // Конфигурирует для ЦАП тактирование, поток
// и канал DMA, выравнивание данных, ножку порта
// для вывода звука, запускает DMA.
void MX_DAC_Init(void) { DAC_ChannelConfTypeDef sConfig = {0}; GPIO_InitTypeDef GPIO_InitStruct = {0}; // Конфигурирование таймера, обновление которого служит // сигналом триггера для DMA, чтобы передать очередную // выборку сигнала из буфера: TIM7_Config(); // Общая инициализация ЦАП: hdac.Instance = DAC; // Разрешение тактирования DAC и GPIOA: __HAL_RCC_DAC_CLK_ENABLE(); __HAL_RCC_GPIOA_CLK_ENABLE(); /** Конфигурация выхода DAC GPIO PA4 ------> DAC_OUT1 */ GPIO_InitStruct.Pin = TRC_OUT_Pin; GPIO_InitStruct.Mode = GPIO_MODE_ANALOG; GPIO_InitStruct.Pull = GPIO_NOPULL; HAL_GPIO_Init(TRC_OUT_GPIO_Port, &GPIO_InitStruct); // Инициализация параметров DAC DMA: hdma_dac1.Instance = DMA1_Stream5; hdma_dac1.Init.Channel = DMA_CHANNEL_7; hdma_dac1.Init.Direction = DMA_MEMORY_TO_PERIPH; hdma_dac1.Init.PeriphInc = DMA_PINC_DISABLE; hdma_dac1.Init.MemInc = DMA_MINC_ENABLE; //hdma_dac1.Init.PeriphDataAlignment = DMA_PDATAALIGN_HALFWORD; //hdma_dac1.Init.MemDataAlignment = DMA_MDATAALIGN_HALFWORD; hdma_dac1.Init.PeriphDataAlignment = DMA_PDATAALIGN_BYTE; hdma_dac1.Init.MemDataAlignment = DMA_MDATAALIGN_BYTE; // Выбор режима DMA_NORMAL запустит однократную транзакцию, после // которой формирование сигнала остановится: //hdma_dac1.Init.Mode = DMA_NORMAL; // Выбор режима DMA_CIRCULAR запустит бесконечно повторяющиеся // транзакции. Это работает по принципу "запустил и забыл", // больше участие процессоре не требуется. Даже остановка // программы в отладчие не остановит формирование сигнала: hdma_dac1.Init.Mode = DMA_CIRCULAR; hdma_dac1.Init.Priority = DMA_PRIORITY_VERY_HIGH; hdma_dac1.Init.FIFOMode = DMA_FIFOMODE_DISABLE; hdma_dac1.Init.FIFOThreshold = DMA_FIFO_THRESHOLD_HALFFULL; hdma_dac1.Init.MemBurst = DMA_MBURST_SINGLE; hdma_dac1.Init.PeriphBurst = DMA_PBURST_SINGLE; if (HAL_DMA_Init(&hdma_dac1) != HAL_OK) { Error_Handler(); } // Привязка DMA к каналу DAC:
__HAL_LINKDMA(hdac, DMA_Handle1, hdma_dac1);
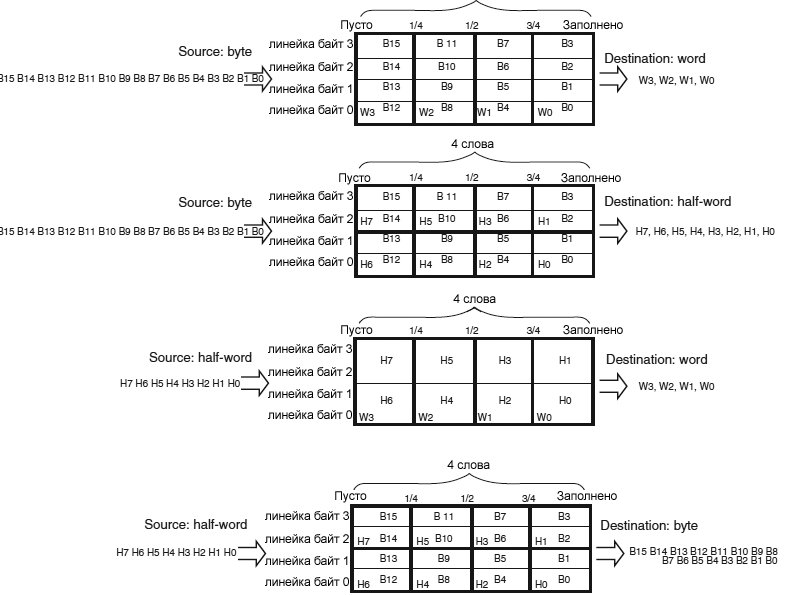
// Конфигурирование выхода OUT1 и триггера для ЦАП: sConfig.DAC_Trigger = DAC_TRIGGER_T7_TRGO; sConfig.DAC_OutputBuffer = DAC_OUTPUTBUFFER_ENABLE; if (HAL_DAC_ConfigChannel(&hdac, &sConfig, DAC_CHANNEL_1) != HAL_OK) { Error_Handler(); } // Разрешение DAC Channel1 и связанного с ним DMA: if(HAL_DAC_Start_DMA(&hdac, DAC_CHANNEL_1, (uint32_t*)aEscalator8bit, 6, // sizeof(aEscalator8bit) DAC_ALIGN_8B_R) != HAL_OK) { // Ошибка запуска DMA Error_Handler(); } } Режим DMA FIFO. У каждого потока есть независимый FIFO из 4 слов (4 * 32 бита) и программно конфигурируемый уровень порога заполнения: 1/4, 1/2, 3/4 или full. Этот FIFO используется для временного хранения данных, поступающих от источника (source), перед тем, как они передаются в место назначения (destination). DMA FIFO может быть разрешен или запрещен программно. Если FIFO запрещен, используется режим Direct. Если FIFO разрешен, может использоваться режим упаковки/распаковки данных (data packing/unpacking) и/или пакетный (burst) режим. Конфигурируемый порог заполнения DMA FIFO определяет время запроса порта памяти DMA. Достоинства DMA FIFO следующие: • Уменьшается доступ к SRAM, что дает больше времени другим мастерам для доступа к матрице шины, без дополнительной конкуренции.
Рис. 4. Структура FIFO. Размер пакета источника и места назначения. Пакетные транзакции гарантируются реализацией стеков DMA FIFO.
Рис. 5. Пакетная транзакция DMA (burst transfer). В ответ на запрос пакета (burst request) от периферийного устройства DMA считывает или записывает некоторое количество элементов данных (элементом данных может быть слово, половина слова или байт). Это количество программируется размером пакета (burst size 4x, 8x или 16x элемента данных). Burst size на порту DMA периферийного устройства должно быть установлено в соответствии с необходимыми требованиями или возможностями периферийного устройства. DMA burst size на порту памяти и конфигурация порога FIFO должны соответствовать друг другу. Это позволяет потоку DMA иметь достаточно данных в FIFO, когда запускается пакетная передача на порту памяти. Таблица 3 показывает возможные комбинации burst size памяти, конфигурации порога FIFO и размера данных. Для гарантии когерентности каждая группа передач, которая формирует пакет, неделимая: транзакция AHB блокируется и арбитр матрицы шины AHB не удаляет права мастера DMA во время последовательности транзакции пакета (burst transfer sequence). Таблица 3. Возможные конфигурации пакетной (burst) транзакции.
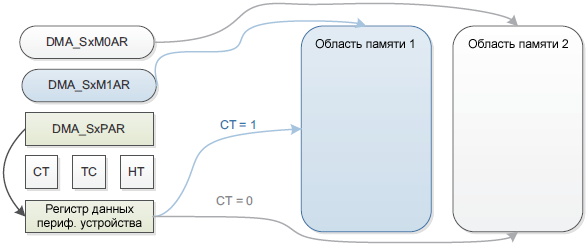
Режим двойной буферизации. Поток с двойным буфером работает так же, как и с одним буфером, но с тем отличием, что с двойной буферизацией есть 2 указателя на память. Когда разрешен режим двойной буферизации, автоматически разрешается кольцевой режим (Circular mode), и на каждом окончании транзакции (когда регистр DMA_SxNDTR достигает 0) указатели на память переключаются. Это позволяет программе работать с одним буфером, пока второй буфер заполняется или используется транзакцией DMA.
Рис. 6. Режим двойной буферизации. В режиме двойной буферизации есть возможность обновлять базовый адрес для порта памяти AHB на лету (DMA_SxM0AR или DMA_SxM1AR), когда поток разрешен: • Когда бит CT (Current Target) в регистре DMA_SxCR равен 0, текущий используемый DMA целевой буфер памяти 0, поэтому может быть обновлен адрес DMA буфера памяти 1 (DMA_SxM1AR). Этот пример работает на плате STM32F4DISCOVERY (микроконтроллер STM32F407) под управлением FreeRTOS. Обработчик прерывания завершения транзакции DMA1_Stream5_IRQHandler выводит из спячки задачу DACtask, которая занимается синтезом данных для свободного на данный момент буфера. По методу прямого синтеза (DDS) создаются данные синусоиды определенной частоты, которые потом проигрываются в DAC с помощью транзакций DMA. Сигнал формируется на выходе первого канала DAC (ножка порта PA4). Команда freq консоли USART2 позволяет задать произвольную частоту генерации в диапазоне от 0 до 22049 Гц. Интересно, что автоматическое формирование сигнала на выходе DAC не прекращается, даже когда выполнение программы остановлено в отладчике. Ниже приведены основные части кода, демонстрирующие работу с DMA. Весь проект целиком для IAR версии 8.30 можно скачать по ссылке [5]. [Модуль dac.c] В этом модуле находятся функции и переменные, относящиеся к ЦАП и синтезу формы сигнала заданной частоты. #include "dac.h"
#include "sinus.h"
#include "dma.h"
#include "errors.h"
#include "pins.h"
DAC_HandleTypeDef vhdac; // Дескриптор для ЦАП TaskHandle_t hDACtask; // Дескриптор задачи заполнения буферов DDS // Буферы для двойной буферизации:
uint16_t data_arr1[4096]; uint16_t data_arr2[4096]; // Указатель на свободный буфер, который можно заполнять:
uint16_t *data_arr_free = NULL; uint16_t freq = 0; // Генерируемая частота синуса static float phase; // Текущая фаза DDS static float phaseincrement; // Инкремент фазы /**
* @brief Конфигурация таймера TIM7, который используется для
* аппаратной инициации передачи выборки в DAC под
* управлением DMA.
* @note Конфигурация TIM7 основывается на частоте шины APB1.
* В этом проекте тактовая частота ядра 168 МГц,
* частота шины fAPB1 48 МГц, а частота тактирования
* таймера (до прескалера) равна fAPB1 * 2 = 84 МГц.
* @note TIM7 Событие обновления происходит с периодом,
* зависящим от samplerate и коэффициента деления
* прескалера (100).
*/
static void TIM7_Config(uint32_t samplerate) { static TIM_HandleTypeDef htim; TIM_MasterConfigTypeDef sMasterConfig; uint32_t uwTimclock = 0; htim.Instance = TIM7; uwTimclock = 2*HAL_RCC_GetPCLK1Freq(); // тактовая частота TIM7 (84 МГц) htim.Init.Prescaler = 99; htim.Init.Period = (uwTimclock / (samplerate * (htim.Init.Prescaler+1))) - 1;; htim.Init.ClockDivision = 0; htim.Init.CounterMode = TIM_COUNTERMODE_UP; HAL_TIM_Base_Init(&htim); // Выбор сигнала триггера (TRGO) TIM7: sMasterConfig.MasterOutputTrigger = TIM_TRGO_UPDATE; sMasterConfig.MasterSlaveMode = TIM_MASTERSLAVEMODE_DISABLE; HAL_TIMEx_MasterConfigSynchronization(&htim, &sMasterConfig); // Разрешение периферийного устройства таймера: HAL_TIM_Base_Start(&htim); } // Функция запуска DMA в режиме двойного буфера. Назначение
// параметров функции понятно из их названий.
// hdac указатель на дескриптор ЦАП
// hdma указатель на дескриптор контроллера DMA
// Alignment формат данных для DAC (выравнивание)
// pSrc1 указатель на первый буфер
// pSrc2 указатель на второй буфер
// Length длина одного буфера (буферы 1 и 2 имеют одинаковую длину) HAL_StatusTypeDef DAC_Channel1_startDMA(DAC_HandleTypeDef *hdac, DMA_HandleTypeDef *hdma, uint32_t Alignment, uint32_t* pSrc1, uint32_t* pSrc2, uint32_t Length) { uint32_t tmpreg = 0U; HAL_StatusTypeDef status = HAL_OK; assert_param(IS_DAC_ALIGN(Alignment)); __HAL_LOCK(hdac); // Защитная блокировка hdac->State = HAL_DAC_STATE_BUSY; // Разрешение запроса DMA для канала 1 для DAC: hdac->Instance->CR |= DAC_CR_DMAEN1; // Вычисление адреса места назначения для DMA // в переменной tmpreg. Регистр данных DMA зависит // от формата данных и канала DAC. // В случае использования канала channel 1 для DAC: switch(Alignment) { case DAC_ALIGN_12B_R: tmpreg = (uint32_t)&hdac->Instance->DHR12R1; break; case DAC_ALIGN_12B_L: tmpreg = (uint32_t)&hdac->Instance->DHR12L1; break; case DAC_ALIGN_8B_R: tmpreg = (uint32_t)&hdac->Instance->DHR8R1; break; } // Разрешение прерывания недогрузки DAC DMA: __HAL_DAC_ENABLE_IT(hdac, DAC_IT_DMAUDR1); // Разрешение потока DMA: __HAL_LOCK(hdma); // Защитная блокировка if(HAL_DMA_STATE_READY == hdma->State) { hdma->State = HAL_DMA_STATE_BUSY; hdma->ErrorCode = HAL_DMA_ERROR_NONE; // Разрешение режима двойной буферизации: hdma->Instance->CR |= (uint32_t)DMA_SxCR_DBM; // Конфигурирование адресов источников и длины одного // буфера: hdma->Instance->M1AR = (uint32_t)pSrc2; // адрес второго буфера hdma->Instance->NDTR = Length; // длина данных в буфере hdma->Instance->PAR = tmpreg; // адрес назначения (DAC) hdma->Instance->M0AR = (uint32_t)pSrc1; // адрес первого буфера // Очистка всех флагов: __HAL_DMA_CLEAR_FLAG (hdma, __HAL_DMA_GET_TC_FLAG_INDEX(hdma)); __HAL_DMA_CLEAR_FLAG (hdma, __HAL_DMA_GET_HT_FLAG_INDEX(hdma)); __HAL_DMA_CLEAR_FLAG (hdma, __HAL_DMA_GET_TE_FLAG_INDEX(hdma)); __HAL_DMA_CLEAR_FLAG (hdma, __HAL_DMA_GET_DME_FLAG_INDEX(hdma)); __HAL_DMA_CLEAR_FLAG (hdma, __HAL_DMA_GET_FE_FLAG_INDEX(hdma)); // Разрешение общих прерываний: hdma->Instance->CR |= DMA_IT_TC | DMA_IT_TE | DMA_IT_DME; hdma->Instance->FCR |= DMA_IT_FE; hdma->Instance->CR |= DMA_IT_HT; // Разрешение периферийного устройства DMA __HAL_DMA_ENABLE(hdma); } else { __HAL_UNLOCK(hdma); // Снятие защитной блокировки status = HAL_BUSY; // Возврат состояния ошибки } // Разрешение периферийного устройства ЦАП на выбранном канале: __HAL_DAC_ENABLE(hdac, DAC_CHANNEL); __HAL_UNLOCK(hdac); // Снятие защитной блокировки return status; } // Функция инициализации ЦАП
void MX_DAC_Init(void) { DAC_ChannelConfTypeDef sConfig = {0}; // Конфигурирование таймера, обновление которого служит // сигналом триггера для DMA, чтобы передать очередную // выборку сигнала из буфера: TIM7_Config(DAC_SAMPLE_RATE); // Общая инициализация ЦАП: vhdac.Instance = DAC; if (HAL_DAC_Init(&vhdac) != HAL_OK) { Error_Handler(); } // Конфигурирование выхода OUT1 и триггера для ЦАП: sConfig.DAC_Trigger = DAC_TRIGGER_T7_TRGO; sConfig.DAC_OutputBuffer = DAC_OUTPUTBUFFER_ENABLE; if (HAL_DAC_ConfigChannel(&vhdac, &sConfig, DAC_CHANNEL) != HAL_OK) { Error_Handler(); } // Установка генерируемой частоты 1000 Гц при старте программы: freq = 1000; GenerateDAC(freq); // Запуск DMA и соответственно генерации сигнала с помощью DAC: if (DAC_Channel1_startDMA(&vhdac, &vhdma_DAC1, DAC_ALIGN_12B_R, (uint32_t*)data_arr1,(uint32_t*)data_arr2, 4096) != HAL_OK) { // Ошибка запуска DMA. Error_Handler(); } } // Конфигурирует для ЦАП тактирование, поток и канал DMA,
// выравнивание данных, ножку порта для вывода, разрешает
// прерывание DMA.
void HAL_DAC_MspInit(DAC_HandleTypeDef* dacHandle) { GPIO_InitTypeDef GPIO_InitStruct = {0}; // Разрешение тактирования DAC и GPIOA: __HAL_RCC_DAC_CLK_ENABLE(); __HAL_RCC_GPIOA_CLK_ENABLE(); /** Конфигурация выхода DAC GPIO PA4 ------> DAC_OUT1
*/ GPIO_InitStruct.Pin = TRC_OUT_Pin; GPIO_InitStruct.Mode = GPIO_MODE_ANALOG; GPIO_InitStruct.Pull = GPIO_NOPULL; HAL_GPIO_Init(TRC_OUT_GPIO_Port, &GPIO_InitStruct); // Инициализация параметров DAC DMA: vhdma_DAC1.Instance = DMA1_Stream5; vhdma_DAC1.Init.Channel = DMA_CHANNEL_7; vhdma_DAC1.Init.Direction = DMA_MEMORY_TO_PERIPH; vhdma_DAC1.Init.PeriphInc = DMA_PINC_DISABLE; vhdma_DAC1.Init.MemInc = DMA_MINC_ENABLE; vhdma_DAC1.Init.PeriphDataAlignment = DMA_PDATAALIGN_HALFWORD; vhdma_DAC1.Init.MemDataAlignment = DMA_MDATAALIGN_HALFWORD; vhdma_DAC1.Init.Priority = DMA_PRIORITY_VERY_HIGH; vhdma_DAC1.Init.FIFOMode = DMA_FIFOMODE_DISABLE; vhdma_DAC1.Init.FIFOThreshold = DMA_FIFO_THRESHOLD_HALFFULL; vhdma_DAC1.Init.MemBurst = DMA_MBURST_SINGLE; vhdma_DAC1.Init.PeriphBurst = DMA_PBURST_SINGLE; __HAL_RCC_DMA1_CLK_ENABLE(); if (HAL_DMA_Init(&vhdma_DAC1) != HAL_OK) { Error_Handler(); } // Привязка DMA к ЦАП:
__HAL_LINKDMA(dacHandle,DMA_Handle1,vhdma_DAC1);
// Конфигурация приоритета прерывания DMA1_Stream5_IRQn: HAL_NVIC_SetPriority(DMA1_Stream5_IRQn, DAC_DMA_INTERRUPT_PRIORITY, 0); // Разрешение прерывания канала DMA1 Stream5 IRQ: HAL_NVIC_EnableIRQ(DMA1_Stream5_IRQn); } // Задача заполнения буферов новыми данными, DDS-синтез синусоиды
// с двойным буфером.
void DACtask(void const * argument) { while(1) { const TickType_t xBlockTime = pdMS_TO_TICKS( 500 ); uint32_t ulNotifiedValue; for( ;; ) { ulNotifiedValue = ulTaskNotifyTake( pdFALSE, xBlockTime ); if( ulNotifiedValue > 0 ) { if (1 != ulNotifiedValue) { umsg("Задача DACtask вызвана с опозданием! (%u)\n", ulNotifiedValue); continue; } if (NULL != data_arr_free) { for (int i=0; i < 4096; i++) { data_arr_free[i] = SinusTable[(uint8_t)phase]*16 + 2048; phase += phaseincrement; if (phase >= 256) phase = phase - 256; } } } else { // Не было получено оповещение в пределах ожидаемого времени. umsg("Ошибка DMA ISR\n"); } } } } // Функция запуска генерации указанной частоты в Гц
void GenerateDAC (uint16_t vfreqHz) { // Вычисление инкремента фазы. Здесь 256 это размер таблицы // синуса SinusTable, DAC_SAMPLE_RATE_REAL это реальная // частота дискретизации (близкая к 44100 для этого проекта). phaseincrement = 256.0*(float)vfreqHz/DAC_SAMPLE_RATE_REAL; } [Модуль dma.c] В этом модуле представлен код обработчика прерывания DMA. #include "dma.h"
#include "dac.h"
#include "pins.h"
#include "cmsis_os.h"
// Дескриптор контроллера DMA, предназначенный для обслуживания
// запросов ЦАП.
DMA_HandleTypeDef vhdma_DAC1;
// Обработчик прерывания DMA. В нем по завершении передачи одного буфера
// разблокируется поток hDACtask, который призван заполнить этот буфер,
// пока передается другой (двойная буферизация).
void DMA1_Stream5_IRQHandler(void) { DMA_Base_Registers *regs = (DMA_Base_Registers *)vhdma_DAC1.StreamBaseAddress; uint32_t flags = regs->ISR; uint32_t crreg = vhdma_DAC1.Instance->CR; // В этом обработчике прерывания обрабатываются только флаги // TCIF5 (Transaction Complete) и HTIF5 (Half Transaction). // Все другие флаги для упрощения не обрабатываются. if (flags & DMA_HISR_TCIF5_Msk) { // Прерывание завершения транзакции передачи буфера. Сигнализирует // о том, что один из буферов передан, и автоматически началась // передача второго буфера. TOGGLE_BLUE(); // Для индикации BaseType_t xHigherPriorityTaskWoken;
xHigherPriorityTaskWoken = pdFALSE;
// Вычисление адреса освободившегося буфера, который
// может заполнить hDACtask:
if (crreg & DMA_SxCR_CT)
data_arr_free = (uint16_t*)vhdma_DAC1.Instance->M0AR;
else
data_arr_free = (uint16_t*)vhdma_DAC1.Instance->M1AR;
// Разблокировка задачи DDS:
vTaskNotifyGiveFromISR( hDACtask, &xHigherPriorityTaskWoken );
portYIELD_FROM_ISR( xHigherPriorityTaskWoken );
}
if (flags & DMA_HISR_HTIF5_Msk)
{
// Прерывание, сигнализирующее о передаче половины буфера
// в транзакции DMA.
TOGGLE_RED(); // Для индикации
}
// Очистка всех флагов прерываний.
regs->IFCR = flags;
}
[Модуль main.c] Основной модуль программы. Здесь для упрощения оставлены только действия, касающиеся запуска потоков и генерации частоты. // Нажатие синей кнопки на плате STM32F4DISCOVERY (User B1)
// циклически переключает генерируемые частоты 10, 1476 и 10000 Гц.
static void BtnShortPress (void) { static uint8_t action = 0; switch(action) { case 0: GenerateDAC(10); action++; break; case 1: GenerateDAC(1476); action++; break; case 2: GenerateDAC(10000); action = 0; break; } } int main(void) { HAL_Init(); SystemClock_Config(); ... MX_DAC_Init(); MX_FREERTOS_Init(); // Создание потоков: osThreadDef(usartthread, USARTtask, osPriorityAboveNormal, 0, 512); osThreadCreate(osThread(usartthread), NULL); osThreadDef(commonthread, commontask, osPriorityNormal, 0, 512); osThreadCreate(osThread(commonthread), NULL); osThreadDef(dacthread, DACtask, osPriorityNormal, 0, 512); hDACtask = osThreadCreate(osThread(dacthread), NULL); // Запуск планировщика FreeRTOS: osKernelStart(); // В этом место мы никогда не попадем, все управление // взял на себя планировщик: while (1) { } } // Конфигурация тактирования системы:
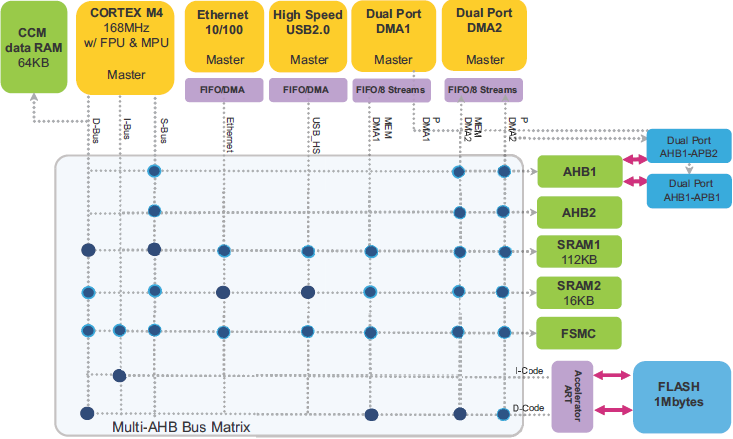
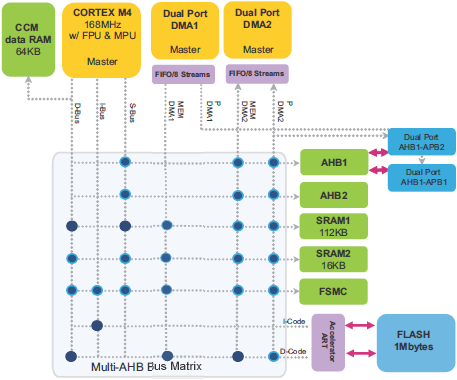
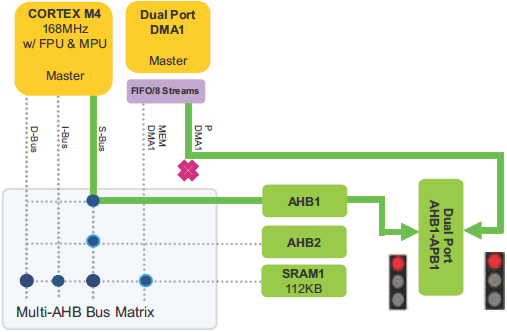
void SystemClock_Config(void) { RCC_OscInitTypeDef RCC_OscInitStruct = {0}; RCC_ClkInitTypeDef RCC_ClkInitStruct = {0}; // Конфигурация основного внутреннего регулятора напряжения: __HAL_RCC_PWR_CLK_ENABLE(); __HAL_PWR_VOLTAGESCALING_CONFIG(PWR_REGULATOR_VOLTAGE_SCALE1); // Инициализация тактов CPU, шин AHB и APB. Используется // кварц на 8 МГц, в результате получается частоты: // SYSCLK (CPU) = 168 МГц // PCLK1 (APB1) = 42 МГц // PCLK2 (APB2) = 84 МГц RCC_OscInitStruct.OscillatorType = RCC_OSCILLATORTYPE_HSE; RCC_OscInitStruct.HSEState = RCC_HSE_ON; RCC_OscInitStruct.PLL.PLLState = RCC_PLL_ON; RCC_OscInitStruct.PLL.PLLSource = RCC_PLLSOURCE_HSE; RCC_OscInitStruct.PLL.PLLM = 8; RCC_OscInitStruct.PLL.PLLN = 336; RCC_OscInitStruct.PLL.PLLP = RCC_PLLP_DIV2; RCC_OscInitStruct.PLL.PLLQ = 7; if (HAL_RCC_OscConfig(&RCC_OscInitStruct) != HAL_OK) { Error_Handler(); } RCC_ClkInitStruct.ClockType = RCC_CLOCKTYPE_HCLK|RCC_CLOCKTYPE_SYSCLK |RCC_CLOCKTYPE_PCLK1|RCC_CLOCKTYPE_PCLK2; RCC_ClkInitStruct.SYSCLKSource = RCC_SYSCLKSOURCE_PLLCLK; RCC_ClkInitStruct.AHBCLKDivider = RCC_SYSCLK_DIV1; RCC_ClkInitStruct.APB1CLKDivider = RCC_HCLK_DIV4; RCC_ClkInitStruct.APB2CLKDivider = RCC_HCLK_DIV2; if (HAL_RCC_ClockConfig(&RCC_ClkInitStruct, FLASH_LATENCY_5) != HAL_OK) { Error_Handler(); } } Управление потоком. Контроллер потока (flow controller) это блок, который управляет длиной передачи данных, и который отвечает за остановку передачи DMA. Контроллером потока может быть либо DMA, либо периферийное устройство. Если контролером потока является DMA, то необходимо определить значение размера транзакции в регистре DMA_SxNDTR перед тем, как разрешается соответствующий поток DMA. Когда обслуживается запрос DMA значение размера транзакции уменьшается на количество переданных данных (в зависимости от типа запроса: пакетный burst или одиночный single). Когда значение размера транзакции достигает 0, транзакция DMA завершается и поток DMA запрещается. Если контроллером потока является периферийное устройство, то количество передаваемых элементов данных неизвестно. Периферийное устройство аппаратно показывает для контроллера DMA, когда переданы последние данные. Этот режим поддерживают только периферийные устройства SD/MMC и JPEG. [Настройка транзакции DMA] Для конфигурирования потока x DMA (здесь x это номер потока) должна быть выполнена следующая процедура: 1. Если поток разрешен, то он должен быть запрещен сбросом бита EN в регистре DMA_SxCR. Затем этот бит должен быть прочитан чтобы удостовериться, что не активна операция потока. Запись в этот бит лог. 0 не приведет к немедленной остановке потока (бит не станет сразу лог. 0), пока все текущие передачи не завершатся. Когда чтение бита EN покажет 0, это будет означать, что поток остановлен и готов к конфигурированию. Поэтому нужно подождать, пока не очистится бит EN, чтобы можно было начать любое конфигурирование потока. Весь набор выделенных для потока бит в регистре статуса (DMA_LISR и DMA_HISR) от предыдущей транзакции блока данных DMA должен быть очищен до того, как поток может быть снова разрешен. 2. Устанавливается регистр адреса порта периферийного устройства в регистре DMA_SxPAR. Данные будут перемещаться из этого адреса или в этот адрес в/из порта периферийного устройства после возникновения события периферийного устройства. 3. Устанавливается адрес памяти в регистре DMA_SxMA0R (и в регистре DMA_SxMA1R, если используется режим двойной буферизации). Данные будут записываться по этому адресу или считываться оттуда после возникновения события периферийного устройства. 4. В регистре DMA_SxNDTR конфигурируется общее количество элементов данных для передачи. После каждого события периферийного устройства или после каждого пакета это значение декрементируется. 5. Битами CHSEL[2:0] регистра DMA_SxCR Выбирается канал (запрос) DMA. 6. Если периферийное устройство должно быть контроллером потока, и если оно поддерживает эту возможность (доступно только для периферийных устройств SD/MMC и JPEG), то устанавливается бит PFCTRL в регистре DMA_SxCR. 7. Конфигурируется приоритет потока битами PL[1:0] в регистре DMA_SxCR. 8. Конфигурируется использование FIFO (разрешено или запрещено, порог в передачи и приеме). 9. В регистре DMA_SxCR register конфигурируется направление потока данных, режим инкремента или фиксации адреса для периферийного устройства и памяти, транзакции будут одиночные (single) или пакетные (burst), ширины данных периферийного устройства и памяти, кольцевой режим или режим двойной буферизации, и прерывания после половины или полной передачи и/или при ошибке. 10. Поток активируется установкой бита EN в регистре DMA_SxCR. Как только поток разрешен, он может обслужить любой запрос DMA от периферийного устройства, соединенного с потоком. [Производительность системы] В MCU STM32F2/F4/F7 встроена архитектура нескольких главных и нескольких подчиненных блоков (multi-masters/multi-slaves): • Несколько устройств master: – Шины AHB ядра Cortex®-Mx • Несколько устройств slave: – Внутренние интерфейсы Flash, подключенные к многослойной матрице шины. Устройства master и slave соединены через многослойную матрицу шины, гарантирующую конкурентный доступ его эффективное функционирование, даже когда высокоскоростные периферийные устройства работают одновременно. Эта архитектура для примера показана на следующем рисунке для случая серий STM32F405/STM32F415 и STM32F407/STM32F417.
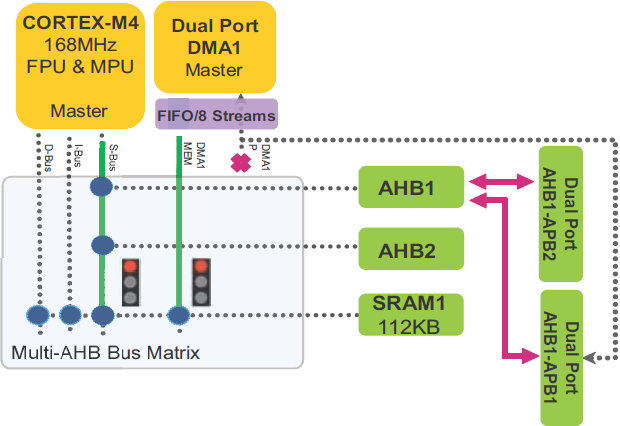
Рис. 7. Архитектура системы STM32F405/STM32F415 и STM32F407/STM32F417. Многослойная матрица шины. Multi-layer bus matrix позволяет устройствам master конкурентно/одновременно выполнять передачи данных, пока они адресуют разные модули slave. Базируясь на архитектуре Cortex-Mx двойных портов AHB DMA, эта структура улучшает параллелизм транзакций данных, что снижает затраты на время выполнения, повышает эффективность DMA и снижает потребление энергии. В контексте рассмотрения матрицы шины используются следующие определения: AHB master: главное устройство шины, который может инициировать операции чтения и записи. За определенный период времени только один master может выиграть владение шиной. Схема приоритетов round-robin. На уровне матрицы шин реализована циклическая (round-robin) схема обработки приоритетов для гарантии, что каждый master мог получить доступ к любому slave с очень низкой латентностью: • Политика арбитража round-robin обеспечивает справедливое распределение полосы пропускания шины. Арбитры матрицы шины вмешиваются для решения конфликтов доступа, когда несколько master-устройств AHB пытаются одновременно получить доступ к одному slave-устройству AHB. В следующем примере (рис. 8) сразу два устройства CPU и DMA1 пытаются получить доступ к SRAM1 для чтения данных.
Рис. 8. Запрос CPU и DMA1 на доступ к SRAM1. В случае конкурентного доступа шины, как в примере рис. 8, требуется арбитраж матрицы шины. В этом случае применяется политика round-robin, чтобы решить проблему доступа: если последний выигравший master шины был CPU, то при следующем доступе выиграет доступ DMA1, и первым получит доступ к SRAM1. Затем права доступа к SRAM1 получит CPU. В результате задержка транзакции, связанная с одним master, зависит от количества ожидающих запросов к тому же самому устройству AHB slave от других устройств master. В следующем примере (рис. 9) показана ситуация, когда сразу 5 устройств master пытаются одновременно получить доступ к SRAM1.
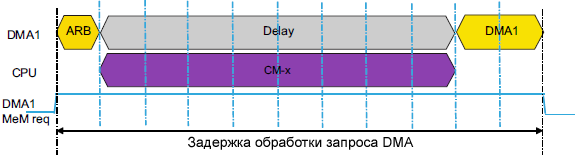
Рис. 9. Пять запросов устройств master на доступ к SRAM. Латентность, связанная с DMA1 для повторного выигрыша шины и доступа к SRAM1 (для примера рис. 9) равна времени выполнения всех ожидающих запросов от других устройств master. Задержка (latency) наблюдаемая портом DMA master в одной транзакции, зависит от типов и длин транзакций других master. Например, если мы рассматриваем предыдущий пример DMA1 и CPU (рис. 8) с конкурентным доступом к SRAM, то задержка транзакции DMA меняется в зависимости от длины транзакции CPU. Если доступ к шине сначала был предоставлен CPU, и CPU не выполняет одиночную операцию загрузки/сохранения данных (load/store), то время ожидания DMA для получения доступа к SRAM может расшириться от одного цикла AHB для одиночной операции load/store до N циклов AHB, где N это количество слов данных в транзакции CPU. CPU блокирует шину AHB, чтобы сохранить владение её и снизить латентность во время нескольких операций load/store и входе в прерывания. Это улучшает отзывчивость firmware, но может привести к задержкам на выполнение транзакции DMA. Задержка на доступ DMA1 SRAM, когда осуществляется конкуренция с CPU, зависит от типа транзакции: • Транзакция CPU выдается по прерыванию (сохранение контекста): 8 циклов AHB. Примечания: (a) Только для STM32F7xx. На рис. 10 подробно показан случай задержки транзакции DMA из-за многоцикловой транзакции CPU, вызванной входом в обработчик прерывания. Порт памяти DMA запускается для доступа к памяти. После арбитража шина AHB не предоставляется порту памяти DMA1, потому что предоставляется для CPU. Наблюдается дополнительная задержка для обслуживания запроса DMA, она составляет 8 тактов AHB для транзакции CPU, вызванной прерыванием.
Рис. 10. Задержка запуска транзакции из-за транзакции CPU, запущенной прерыванием. То же самое поведение наблюдается и для других устройств master (типа DMA2, USB_HS, Ethernet, ...), когда одновременно адресуется одно и то же slave-устройство с длиной транзакции, отличающейся от одного элемента данных. Чтобы улучшить производительность доступа DMA на матрице шины, рекомендуется избегать конкуренции за шину. [Пути транзакции DMA] Двойной порт DMA. В MCU STM32F2/F4/F7 встроено два блока DMA. У каждого DMA есть 2 порта, порт памяти и порт периферийного устройства, которые могут работать одновременно, не только на уровне DMA, но также с другими устройствами master системы, используя внешнюю матрицу шины и выделенные пути DMA. Одновременная операция позволяет оптимизировать эффективность работы DMA и снизить время отклика (время ожидания между запросом транзакции и передачей данных транзакции).
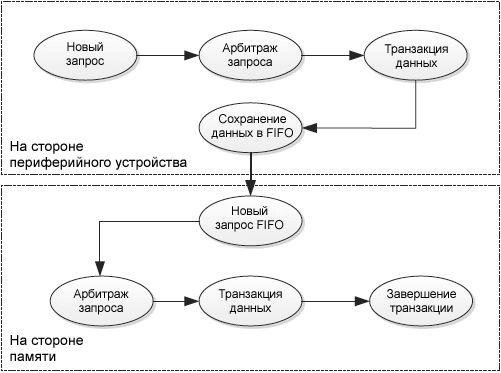
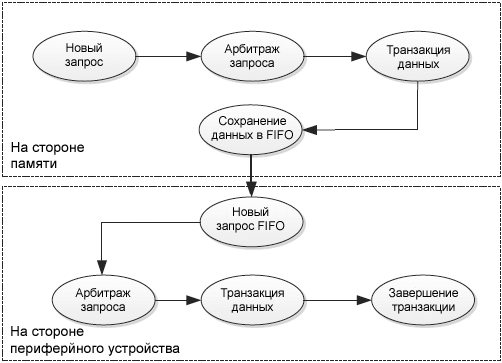
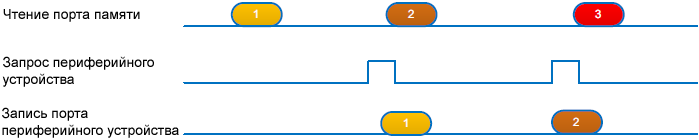
Рис. 11. Двойной порт DMA. Для DMA2: • MEM (порт памяти) может обращаться к AHB1, AHB2, AHB3 (контроллер внешней памяти, FSMC), областям SRAM, и к памяти Flash через матрицу шины. • Periph (порт периферийных устройств) может обращаться: – К AHB1, AHB2, AHB3 (контроллер внешней памяти, FSMC), областям SRAM, и к памяти Flash через матрицу шины. Для DMA1: • MEM (порт памяти) может обращаться к AHB3 (контроллер внешней памяти, FSMC), областям SRAM, и к памяти Flash через матрицу шины. • Periph (порт периферийных устройств) может обращаться только к мосту AHB-APB1 напрямую (без пересечения с матрицей шины). Состояния транзакции DMA. В этой секции объясняются шаги транзакции DMA на уровне порта периферийного устройства, и также на уровне порта памяти. • Для транзакции от периферийного устройства в память (см. рис. 12): в этом режиме DMA запрашивает два доступа к шине для выполнения транзакции. – Один доступ через порт периферии, этот доступ запускается запросом от периферийного устройства.
Рис. 12. Состояния транзакции периферия -> память. • Для транзакции от памяти в периферийное устройство (см. рис. 13): в этом режиме DMA запрашивает два доступа к шине для выполнения транзакции. – DMA ожидает доступ периферийного устройства, считывает данные из памяти и сохраняет их в FIFO для гарантии немедленной передачи данных, как только сработает запрос DMA периферийного устройства.
Рис. 13. Состояния транзакции память -> периферия. Арбитраж запроса DMA. Как рассматривалось выше в секции "Приоритет потока", в MCU STM32F2/F4/F7 DMA встроен арбитр, который управляет запросами восьми потоков DMA на основе их приоритетов для каждого из двух портов AHB master (порт памяти и порт периферии). По этим приоритетам арбитр запускает последовательности доступа к периферии/памяти. Когда активно больше одного запроса DMA, для DMA нужен внутренний арбитр между активными запросами, чтобы принять решение, какой запрос должен быть обработан первым. На рис. 14 показаны два кольцевых (circular) запроса DMA, сработавших одновременно от потока DMA "request 1" и потока DMA "request 2" (запросы 1 и 2 могут быть любым запросом периферии DMA). На следующем цикле тактов AHB арбитр DMA проверяет активные ожидающие обработки запросы, и дает доступ для потока "request 1", который обладает самым высоким приоритетом. Следующий цикл арбитража происходит во время последнего цикла данных потока "request 1". В этот момент "request 1" маскируется, и арбитр видит активным только "request 2", в результате чего на этот раз доступ резервируется для "request 2", и так далее.
Рис. 14. Арбитраж запроса DMA. Основные рекомендации: • Высокоскоростные (high-speed) / широкополосные (high-bandwidth) периферийные устройства должны иметь самые высокие приоритеты DMA. Это гарантирует, что максимальная задержка данных, ожидаемая для этих периферийных устройств, не приведет к переполнению (overrun) или недогрузке (underrun) в потоке данных. [Мост AHB-APB] В MCU STM32F2/F4/F7 встроено два моста AHB-APB (APB1 и APB2), к которым подключены периферийные устройства. Двойной порт AHB-APB. Мост AHB-APB имеет двухпортовую архитектуру, которая позволяет осуществлять доступ двумя разными путями: • Прямой путь (без пересечения с матрицей шины), который может быть сгенерирован от DMA1 к APB1 или от DMA2 к APB2. В этом случае доступ не получает пенальти от арбитра матрицы шины. Арбитраж моста AHB-APB. Из-за реализации прямого пути DMA также реализован арбитр на уровне моста AHB-APB, чтобы разрешить конкурентные запросы доступа. На рис. 15 иллюстрируется конкурентный запрос доступа на шине AHB-APB1, генерируемый CPU (который осуществляет доступ через матрицу шины) и DMA1 (который осуществляет доступ напрямую).
Рис. 15. Конкурентный запрос на доступ моста AHB-APB1 от CPU и DMA1. Для предоставления доступа к шине мост AHB-APB применяет политику round-robin: • Квант round-robin равен 1x транзакции APB. Только CPU и блоки DMA могут генерировать конкурентный доступ к шинам APB1 и APB2: • Для APB1 конкурентный доступ может быть сгенерирован, если CPU, DMA1 и/или DMA2 одновременно запросили доступ. [Как предсказать латентность DMA] При разработке firmware приложения на основе MCU пользователь должен гарантировать, что не будут происходить ситуации недогрузки/переполнения (underrun/overrun). По этой причине важно знать точную задержку (latency) DMA для каждой транзакции, чтобы проверить, может ли внутренняя система поддерживать общую полосу пропускания, требуемую для приложения. Время транзакции DMA по умолчанию. Как описывалось выше в секции "Состояния транзакции DMA", для выполнения транзакции DMA из периферии в память требуется два доступа к шине: • Один доступ через порт периферии, который запускается запросом периферийного устройства. Эта операция требует: – Арбитража запроса порта периферии DMA. • Другой доступ через порт памяти, который может быть запущен порогом FIFO (когда используется режим FIFO) или немедленно после чтения периферии (когда используется режим Direct). Эта операция требует: – Арбитража запроса порта памяти DMA. Когда данные перемещаются из памяти в периферию, также требуется два доступа, как описывалось выше в секции "Состояния транзакции DMA": • Первый доступ: DMA ожидает доступа периферии, считывает данные из памяти и сохраняет их в FIFO, чтобы гарантировать немедленную передачу данных, как только был запущен запрос DMA периферийного устройства. Эта операция требует: – Арбитража запроса порта памяти DMA. • Второй доступ: когда сработал запрос периферии, генерируется транзакция на порту периферийного устройства DMA. Эта операция требует: – Арбитража запроса порта периферии DMA. Как основное правило, общее время транзакции потока DMA TS равно: TS = TSP (время доступа/транзакции периферии) + TSM (время доступа/транзакции памяти) Здесь TSP это общее время для порта периферии и транзакции, которое равно (значения tPA, tPAC, tBMA, tEDT, tBS приведены в таблице 4): TSP = tPA + tPAC + tBMA + tEDT + tBS Таблица 4. Интервалы времени доступа/транзакции порта периферии в зависимости от используемого пути DMA.
Примечания: (1) В случае линеек серий STM32F401/STM32F410/STM32F411/STM32F412 интервал tBMA равен 0. TSM это общее время для доступа и транзакции порта памяти DMA, оно равно (значения tMA, tMAC, tBMA, tSRAM см. в таблице 5): TSM = tMA+ tMAC + tBMA + tSRAM Таблица 5. Интервалы времени доступа/транзакции памяти.
Примечания: (1) В случае линеек серий STM32F401/STM32F410/STM32F411/STM32F412 интервал tBMA равен 0. Время передачи DMA в зависимости от конкурентного доступа. Может быть добавлена дополнительная задержка обслуживания DMA по таймингам, описанным в предыдущей секции, когда несколько устройств master пытаются одновременно получить доступ к одному и тому же устройству slave. Для самого худшего случая времени доступа для периферии и памяти следующие факторы влияют на общее время задержки обслуживания потока DMA: • Когда несколько устройств master одновременно обращаются к одному и тому же месту назначения AHB, это влияет на задержку DMA. Транзакция DMA не может запуститься, пока арбитр матрицы шины не предоставит доступ для DMA, как описывалось выше в секции "Схема приоритетов round-robin". Ниже приведены примеры организации транзакций DMA. Этот пример применим к MCU линеек STM32F2, STM32F405/STM32F415, STM32F407/STM32F417, STM32F427/STM32F437 и STM32F429/STM32F439. ADC сконфигурирован в режиме triple Interleaved. В этом режиме оцифровка сигнала одного аналогового канала осуществляется на максимальной скорости (36 МГц). Прескалер ADC установлен на 2, время выборки установлено на 1.5 такта, и задержка между двумя последовательными выборками ADC режима Interleaved установлена на 5 тактов. DMA2 stream0 передает преобразованное значение ADC в буфер SRAM. Доступ DMA2 к ADC осуществляется напрямую, без матрицы шины; однако доступ DMA к SRAM осуществляется через матрицу шины. Таблица 6. Латентность транзакции DMA порта периферии (ADC).
Примечание (1): DMA2 осуществляет доступ к ADC напрямую, без арбитража матрицы шины. Таблица 7. Латентность транзакции DMA порта памяти (SRAM).
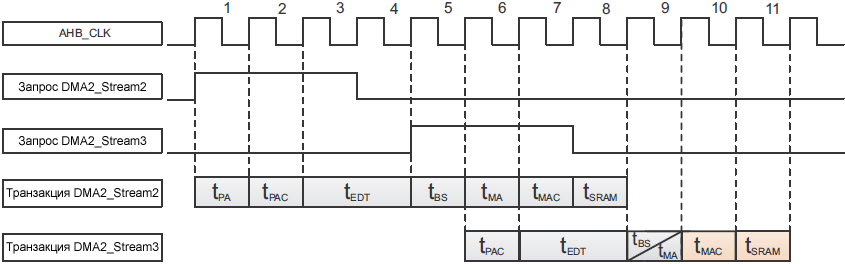
Примечание (1): в случае множественного доступа DMA к SRAM, арбитраж матрицы шины равен 0 циклов, если в промежутке нет обращений к от других master. В этом примере общая задержка DMA от момента срабатывания триггера ADC DMA (ADC EOC) до записи значения ADC в SRAM равна 9 тактов AHB для прескалера AHB/APB, равного 1, и 11 тактов AHB для прескалера AHB/APB, равного 2. Примечание: когда используется FIFO, доступ к порту памяти DMA осуществляется реже, по мере достижения уровня порога FIFO, сконфигурированного пользователем. Этот пример применим для MCU линеек STM32F2, STM32F405/STM32F415, STM32F407/STM32F417, STM32F427/STM32F437 и STM32F429/STM32F439. Пример основан на периферийном устройстве SPI1. Конфигурируются 2 запроса DMA: • DMA2_Stream2 для SPI1_RX: этот поток конфигурируется на самый высокий приоритет, чтобы своевременно обслужить принятые данные SPI1, и передать их из регистра SPI1_DR в буфер SRAM. Частота AHB равна частоте шины APB2 (84 МГц), и SPI1 конфигурируется на максимальную скорость (42 МГц). Поток DMA2_Stream2 (SPI1_RX) срабатывает перед потоком DMA2_Stream3 (SPI1_TX), который будет запущен на 2 такта AHB позже. В этой конфигурации CPU в бесконечном цикле опрашивает регистр I2C1_DR. Мы знаем, что периферийное устройство отображено на шину APB1, и что периферийное устройство SPI1 отображено на шину APB2, пути данных в системе получатся следующие: • Прямой путь для DMA2 при доступе к APB2 (не через матрицу шины). Цель примера состоит в демонстрации факта, что тайминги DMA не влияют на опрос CPU шины APB1. На рис. 16 показаны тайминги DMA для режимов передачи и приема, а также время планирования для каждой операции.
Рис. 16. Время транзакции SPI full duplex DMA. Из рис. 16 видно следующее: • Опрос CPU по шине APB1 не влияет на латентность передачи DMA по шине APB2. Эта оптимизация всегда выполняется аналогично, когда запрос DMA сработал перед окончанием текущей транзакции запроса DMA. [Советы и предупреждения при программировании контроллера DMA] Последовательность запрета DMA. Чтобы отключить периферийное устройство, соединенное с запросом к потоку DMA, важно выполнить следующее: 1. Выключить поток DMA, к которому подключено периферийное устройство. Только после этого можно безопасно запретить периферийное устройство. Бит разрешения запроса DMA в регистре управления периферийного устройства должен быть сброшен в лог. 0, чтобы гарантировать, что очищен любой ожидающий обработки запрос от периферийного устройства. Примечание: в обоих случаях установится флаг прерывания завершения транзакции (Transfer Complete Interrupt Flag, TCIF) в регистре DMA_LISR или DMA_HISR), чтобы показать завершение транзакции из-за запрета потока. Обслуживание флага DMA перед разрешением новой транзакции. Перед разрешением новой передачи пользователь должен убедиться, что очищен флаг Transfer Complete Interrupt Flag (TCIF) в регистре DMA_LISR или DMA_HISR. В качестве общей рекомендации лучше очистить все флаги регистров DMA_LIFCR перед DMA_HIFCR запуском новой передачи. Последовательность разрешения DMA. При разрешении DMA используется следующая последовательность действий: 1. Конфигурирование подходящего потока DMA. Примечание: если пользователь разрешает используемое периферийное устройство перед соответствующим потоком DMA, то может установиться флаг прерывания ошибки FEIF (FIFO Error Interrupt Flag), потому что DMA фактически не готово предоставить первые необходимые данные для периферийного устройства (в случае транзакции из памяти в периферийное устройство). Транзакция память-память при NDTR=0. Когда конфигурируется поток DMA для выполнения передачи из памяти в память в нормальном режиме (normal mode), то как только NDTR достигает 0, установится флаг завершения транзакции (Transfer Complete). В этот момент, если пользователь установил флаг разрешения этого потока (бит EN в регистре DMA_SxCR), транзакция память-память автоматически запустится повторно с последним значением NDTR. Пакетная передача DMA при PINC/MINC=0. Функция пакетной передачи DMA (Burst) с запретом инкремента адреса периферийного устройства (PINC) или инкремента адреса памяти (MINC) позволяет адресовать внутренние или внешние (FSMC) периферийные устройства, поддерживающие Burst (имеющие встроенные FIFO). Этот режим гарантирует, что этот поток DMA не может быть прерван другими потоками DMA во время их транзакций. Запросы DMA с двойным отображением. Когда пользователь конфигурирует два (или большее количество) потоков DMA для обслуживания запроса одного и того же периферийного устройства, программа должна гарантировать, что текущий поток DMA полностью запрещен (путем опроса бита EN в регистре DMA_SxCR) перед разрешением нового потока DMA. Наилучшая конфигурация DMA по пропускной способности. При использовании STM32F4xx с пониженной частотой AHB, когда DMA обслуживает высокоскоростное периферийное устройство, рекомендуется поместить стек и кучу в память CCM (Core Coupled Memory, которая может быть адресована непосредственно CPU через D-шину) вместо того, чтобы помещать их в SRAM. Это создаст дополнительный параллелизм работы CPU и DMA, осуществляющими доступ к оперативной памяти. Приостановка транзакции DMA. В любой момент времени передача DMA может быть приостановлена до окончания, чтобы быть перезапущенной позже, или же быть запрещенной полностью. Здесь могут быть 2 случая: • Поток запрещает передачу без последующего возобновления передачи с той точки, где передача была остановлена. В этом случае не требуется никаких дополнительных действий, кроме как очистка бита EN в регистре DMA_SxCR для запрета потока и ожидания сброса в ноль бита EN. Как следствие: – Регистр DMA_SxNDTR содержит количество оставшихся элементов данных на момент, когда передача была приостановлена, так что программа может определить, сколько данных было передано до того, как работа потока была прервана. • Поток приостанавливает транзакцию, чтобы потом можно было её возобновить: для перезапуска от точки, где была остановлена транзакция, программа должна прочитать регистр DMA_SxNDTR после запрета потока (после того, как бит EN перейдет в лог. ), чтобы узнать, сколько элементов данных уже было собрано. Затем: – Адреса периферии и/или памяти должны быть обновлены, чтобы указатели были актуально подстроены. Примечание: в обоих случаях установится флаг завершения транзакции Transfer Complete Interrupt Flag (бит TCIF в регистре DMA_LISR или DMA_HISR), чтобы показать окончание транзакции из-за того, что работа потока прервана. Преимущества контроллера DMA2 и гибкость архитектуры системы. В этой секции озвучена идея получения выгоды от гибкости, предоставляемой архитектурой STM32 и контроллером DMA. В качестве иллюстрации мы покажем, как инвертировать порты периферии DMA2 AHB и памяти, и сохранить правильное управление передачей данных периферийных устройств. Чтобы достичь этого и взять управление над обычным поведением DMA2, нужно рассмотреть рабочую модель DMA2. Поскольку оба порта DMA2 соединены с матрицей шины AHB, и имеют симметричное соединение с slave-устройствами AHB, эта архитектура позволяет протекать трафику в одно или другом направлении через порты периферии и памяти, в зависимости от программной конфигурации. ПО обладает гибкостью для конфигурации транзакции потока DMA2 в соответствии со своими потребностями. В зависимости от этой конфигурации один порт DMA2 AHB программируется в направлении чтения, другой в направлении записи. Таблица 8 показывает направление порта DMA AHB в зависимости от конфигурации режима транзакции. Таблица 8. Направление порта DMA AHB в зависимости от конфигурации режима транзакции.
Теперь рассмотрим поток трафика (см. выше секцию "Состояния транзакции DMA") транзакций на порту периферии, запускаемых запросами периферийного устройства, транзакций на порту памяти, запускаемых либо по порогу FIFO (при использовании режима FIFO) или немедленно после чтения периферийного устройства (когда используется режим Direct). Когда обслуживаются периферийные устройства с портом памяти DMA2 нам нужно позаботиться о предварительно запускаемых транзакциях (см. далее "Предварительно запущенная транзакция"), и об обработке последних данных (см. далее "Обслуживание последнего чтения данных"). Предварительно запущенная транзакция. Как было описано ранее в секции "Состояния транзакции DMA", когда сконфигурирован режим передачи из памяти в периферийное устройство (чтение данных через порт памяти) DMA ожидает доступа периферийного устройства и считывает данные, как только поток DMA был разрешен. Один элемент данных буферируется в режиме Direct, и до 4 x 32-разрядных слов, когда разрешен DMA FIFO. Когда обслуживаются чтения периферийного устройства через порт памяти DMA2, программа должна гарантировать, что периферийное устройство разрешено перед разрешением DMA, чтобы гарантировать правильность первого доступа DMA. Рис. 17 иллюстрирует доступы DMA на портах памяти и периферии в зависимости от триггеров периферийного устройства.
Рис. 17. DMA в режиме транзакции из памяти в периферийное устройство. Обслуживание последнего чтения данных. Контроллер DMA обладает функцией 4 x 32-разрядных слов FIFO на поток, что может использоваться для буферизации данных между портами AHB. Когда обслуживаются чтения периферийных устройств через порт памяти DMA, программа должна гарантировать, что 4x дополнительные слова прочитаны из периферийного устройства. Это даст гарантию, что последние достоверные данные будут переданы из DMA FIFO. Буферизированные транзакции, когда запрещен режим Direct. Когда записываются данные через порт памяти в периферийное устройство, когда разрешен режим FIFO, программе нужно позаботиться о том, что доступ через этот порт срабатывает по запрограммированному порогу FIFO. Когда достигнут порог данных, данные передаются из FIFO в место назначения через порт памяти. Когда происходит запись в регистр (например у GPIO нет FIFO), данные из DMA FIFO будут успешно записаны в место назначения. И последнее, но не менее важное: когда переключается управление периферией с порта периферии на порт памяти, программе нужно пересмотреть размер транзакции и конфигурацию инкремента адреса. Как описано выше в секции "Размер транзакции", размер транзакции определяется шириной транзакции на стороне периферийного устройства (byte, half-word, word) и количеством передаваемых элементов данных (значение, запрограммированное в регистр DMA_SxNTDR). В соответствии с новой конфигурацией DMA, когда запрограммировано инвертирование портов, может понадобиться подстроить значение регистра DMA_SxNTDR. В этом примере DMA_S7M0AR программируется адресом регистра Quad-SPI Data, DMA_S7PAR программируется адресом буфера данных (буфер, который находится в SRAM). В регистре DMA_S7CR должно быть сконфигурировано направление потока DMA2 в режиме от периферии в память, когда происходит запись в Quad-SPI. Направление потока DMA2 должно быть сконфигурировано в режиме из памяти в периферийное устройство, когда происходит чтение из Quad-SPI. 4x дополнительных слова (32-разрядных) нужны для операции чтения, чтобы гарантировать, что последние данные были переданы наружу из DMA FIFO в SRAM. Кусок кода для операции чтения: /* Программирование M0AR адресом регистра данных QUADSPI */ DMA2_Stream7->M0AR = (uint32_t)&QUADSPI->DR; /* Программирование PAR адресом буфера */ DMA2_Stream7->PAR = (uint32_t)&u32Buffer[0]; /* Запись количества элементов данных для передачи */ DMA2_Stream7->NDTR = 0x100; /* Конфигурирование DMA: MSIZE=PSIZE=0x02 (слово),
CHSEL=0x03 (QUADSPI), PINC=1, DIR=0x00 */ DMA2_Stream7->CR = DMA_SxCR_PSIZE_1 | DMA_SxCR_MSIZE_1 | 3ul << 25 | DMA_SxCR_PINC; /* Разрешение генерации запроса DMA */ QUADSPI->CR |= QUADSPI_CR_DMAEN; /* Запись в регистр DLR */ QUADSPI->DLR = (0x100*4)-1; /* Запись в QUADSPI DCR */ QUADSPI->CCR = QUADSPI_CCR_IMODE_0 | QUADSPI_CCR_ADMODE_0 | QUADSPI_CCR_DMODE | QUADSPI_CCR_ADSIZE | QUAD_IN_FAST_PROG_CMD; /* запись в регистр AR */ QUADSPI->AR = 0x00ul; /* Разрешение выбранного потока DMA2_Stream7 установкой бита EN */ DMA2_Stream7->CR |= (uint32_t)DMA_SxCR_EN; /* Ожидание окончания транзакции */
while((QUADSPI->SR & QUADSPI_SR_TCF) != QUADSPI_SR_TCF); Кусок кода для операции записи: /* Программирование M0AR адресом регистра данных QUADSPI */ DMA2_Stream7->M0AR = (uint32_t)&QUADSPI->DR; /* Программирование PAR адресом буфера */ DMA2_Stream7->PAR = (uint32_t)&u32Buffer[0]; /* Запись количества элементов данных для передачи */ DMA2_Stream7->NDTR = 0x100; /* Конфигурирование DMA : MSIZE=PSIZE=0x02 (Word),
CHSEL=0x03 (QUADSPI), PINC=1, DIR=0x01 */ DMA2_Stream7->CR = DMA_SxCR_PSIZE_1 | DMA_SxCR_MSIZE_1 | 3ul << 25 | DMA_SxCR_PINC | DMA_SxCR_DIR_0; /* Разрешение генерации запроса DMA */ QUADSPI->CR |= QUADSPI_CR_DMAEN; /* Запись в регистр DLR */ QUADSPI->DLR = ((0x100+4)*4)-1; /* Запись в QUADSPI DCR */ QUADSPI->CCR = QUADSPI_CCR_IMODE_0 | QUADSPI_CCR_ADMODE_0 | QUADSPI_CCR_DMODE | QUADSPI_CCR_ADSIZE | QUADSPI_CCR_FMODE_0 | QUAD_OUT_FAST_READ_CMD; /* запись в регистр AR */ QUADSPI->AR = 0x00ul; /* Разрешение выбранного потока DMA2_Stream7 установкой бита EN */ DMA2_Stream7->CR |= (uint32_t)DMA_SxCR_EN; /* Ожидание окончания транзакции */
while((DMA2_Stream7->CR & DMA_SxCR_EN) == DMA_SxCR_EN); Примечание: ограничение повреждения данных, когда DMA2 обслуживается параллельно с транзакциями AHB и APB2 (см. сообщения об ошибках кристалла errata, чтобы определить, в каких STM32F2/F4 MCU это присутствует) можно обойти путем переключения портов периферии и памяти DMA2, как описывается в этой секции. Транзакция STM32F7 DMA и обслуживание кэша, чтобы избежать некогерентности данных. Когда программа использует не кэшируемые регионы памяти для буферов источника / места назначения DMA, для них необходимо запустить очистку кэша, перед запуском работы DMA, чтобы гарантировать, что все данные были зафиксированы подсистемой памяти. При чтении данных из периферийного устройства после завершения транзакции DMA, программа должна выполнить сброс достоверности кэша (cache invalidate) перед чтением обновленного региона памяти. Для буферов DMA желательно использовать не кэшируемые регионы памяти. Программа может использовать MPU, чтобы настроить не кэшируемый блок памяти для использования в виде общей памяти между CPU и DMA. [Общие выводы] Контроллер DMA разработан для обслуживания большинства случаев использования во встраиваемых приложениях, со следующими основными возможностями: • Предоставляется гибкость выбора подходящей комбинации между 16 потоками X (по 8 потоков на каждый DMA). [Ссылки] 1. AN4031 Using the STM32F2, STM32F4 and STM32F7 Series DMA controller site:st.com. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||