|
ąÆ čŹč鹊ą╝ ą░ą┐ąĮąŠčāč鹥 ąŠą▒čüčāąČą┤ą░ąĄčéčüčÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéčīčÄ ą║čŹčłą░ ą┤ą╗čÅ čüąĄą╝ąĄą╣čüčéą▓ą░ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin┬« ą║ąŠą╝ą┐ą░ąĮąĖąĖ Analog Devices (ą┐ąĄčĆąĄą▓ąŠą┤ ą┤ą░čéą░čłąĖčéą░ EE-271 [1]). ą¤čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮčŗ ą┐ąŠą┐čāą╗čÅčĆąĮčŗąĄ čüčģąĄą╝čŗ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ, ąĖ ą┐ąŠą┤čĆąŠą▒ąĮąŠ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ąĄčéčüčÅ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ. ą×ą┐ąĖčüą░ąĮąĮčŗąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ą┤ąŠčüčéčāą┐ąĮčŗ ąĮą░ ą▓čüąĄčģ ą╝ąŠą┤ąĄą╗čÅčģ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin. ąÆą╝ąĄčüč鹥 čü čŹčéąĖą╝ ą░ą┐ąĮąŠčāč鹊ą╝ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮčŗ ą┐čĆąĖą╝ąĄčĆčŗ ą║ąŠą┤ą░ [7], ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāčÄčēąĖąĄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ą┐ą░ą╝čÅčéąĖ. ą¤čĆąĖą╝ąĄčĆčŗ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ ą▓čüąĄčģ ą╝ąŠą┤ąĄą╗ąĄą╣ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ čüąĄą╝ąĄą╣čüčéą▓ą░ Blackfin.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąĮą░ąĘą▓ą░ąĮąĖčÅ ąĮąĄą║ąŠč鹊čĆčŗčģ č鹥čĆą╝ąĖąĮąŠą▓ ą┤ą╗čÅ ą▒ąŠą╗ąĄąĄ čÅčüąĮąŠą│ąŠ ą┐ąŠąĮąĖą╝ą░ąĮąĖčÅ čüą╝čŗčüą╗ą░ ąŠčüčéą░ą▓ą╗ąĄąĮčŗ ą▓ č鹥ą║čüč鹥 ą▒ąĄąĘ ą┐ąĄčĆąĄą▓ąŠą┤ą░. ą×ą▒čŖčÅčüąĮąĄąĮąĖąĄ č鹥čĆą╝ąĖąĮąŠą▓ č鹥čģąĮąŠą╗ąŠą│ąĖąĖ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ ąĄčüčéčī ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "ą×ą▒čēą░čÅ ą║ąŠąĮčåąĄą┐čåąĖčÅ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ -> ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ ą║čŹčłą░". ąóą░ą║ąČąĄ ąĮąĄąĘąĮą░ą║ąŠą╝čŗąĄ č鹥čĆą╝ąĖąĮčŗ ąĖ čüąŠą║čĆą░čēąĄąĮąĖčÅ čüą╝. ą▓ čĆą░ąĘą┤ąĄą╗ąĄ ąĪą╗ąŠą▓ą░čĆąĖą║ čŹč鹊ą╣ čüčéą░čéčīąĖ ąĖ čüčéą░čéčīąĖ [2].
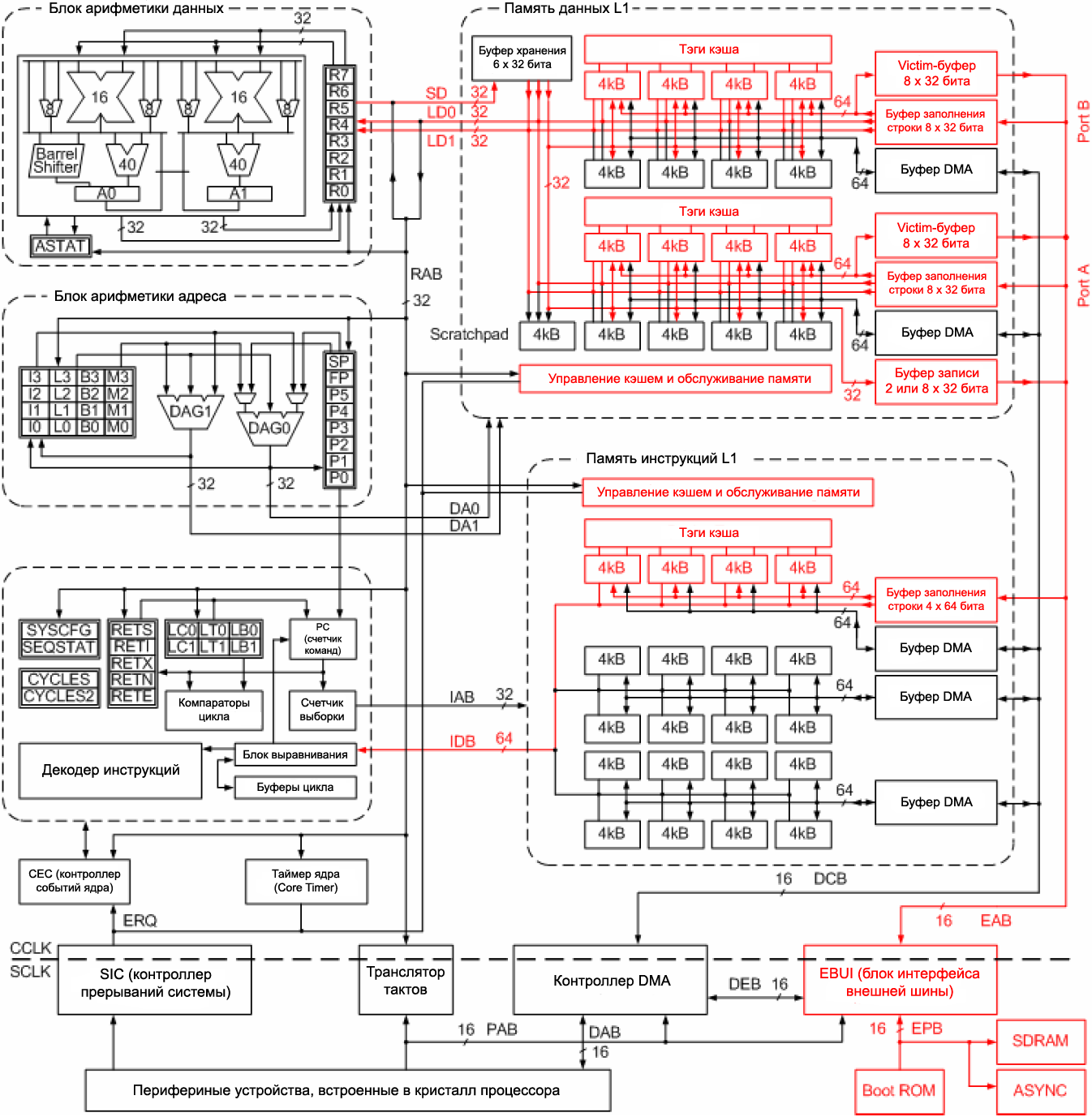
ąĀąĖčü. 1. ąæą╗ąŠą║-ą┤ąĖą░ą│čĆą░ą╝ą╝ą░ ą▓ąĮčāčéčĆąĄąĮąĮąĄą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ADSP-BF533.
Barrel Shifter, ASTAT, A1, A0, ... ą░ą┐ą┐ą░čĆą░čéąĮčŗąĄ čāąĘą╗čŗ čÅą┤čĆą░, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ ą▓ čüąĖčüč鹥ą╝ąĄ ą║ąŠą╝ą░ąĮą┤ (čāąĘąĄą╗ čüą┤ą▓ąĖą│ą░ ąĮą░ čāą║ą░ąĘą░ąĮąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ąĖčé ąĘą░ 1 čéą░ą║čé, čĆąĄą│ąĖčüčéčĆ čüąŠčüč鹊čÅąĮąĖčÅ, ą░ą║ą║čāą╝čāą╗čÅč鹊čĆčŗ, ...).
CEC Core Event Controller.
DAG1, DAG0 Data Address Generator.
SIC System Interrupt Controller.
SD, LD0, LD1, RAB, DA0, DA1, IAB, IDB, PAB, DAB, DEB, EAB, EPB, DCB ą▓ąĮčāčéčĆąĄąĮąĮąĖąĄ čłąĖąĮčŗ ą░ą┤čĆąĄčüą░ ąĖ ą┤ą░ąĮąĮčŗčģ.
Scratchpad čüą┐ąĄčåąĖą░ą╗čīąĮą░čÅ ą┐ą░ą╝čÅčéčī ą┤ą╗čÅ ą▓čĆąĄą╝ąĄąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ.
SDRAM, ASYNC čłąĖąĮčŗ ą┤ą╗čÅ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖčÅ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ - ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą╣ ąĖ ą░čüąĖąĮčģčĆąŠąĮąĮąŠą╣.
ąÆ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ ąŠą┐ąĖčüčŗą▓ą░čÄčéčüčÅ ąŠą▒čēąĖąĄ ą┐čĆąĖąĮčåąĖą┐čŗ ąĖ č鹥čĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ, ą┐čĆąĖą╝ąĄąĮčÅąĄą╝čŗąĄ ą▓ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĖ ą║ąŠą┤ą░ ąĖ ą┤ą░ąĮąĮčŗčģ.
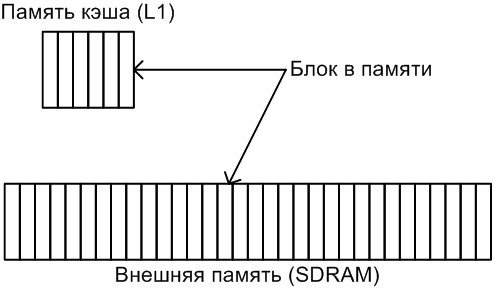
ąÜąŠąĮčäąĖą│čāčĆą░čåąĖčÅ ą┐ą░ą╝čÅčéąĖ. ąĪąĖčüč鹥ą╝čŗ, ą║ąŠč鹊čĆčŗąĄ čéčĆąĄą▒čāčÄčé ą▒ąŠą╗čīčłąŠą╣ ąŠą▒čŖąĄą╝ ą┐ą░ą╝čÅčéąĖ, ąŠą▒čŗčćąĮąŠ čĆą░čüą┐čĆąĄą┤ąĄą╗čÅčÄčé ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čāčÄ ą┐ą░ą╝čÅčéčī ą┐ąŠ ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ čāčĆąŠą▓ąĮčÅą╝. ą¤ą░ą╝čÅčéčī čüą░ą╝ąŠą│ąŠ ą▓ąĄčĆčģąĮąĄą│ąŠ čāčĆąŠą▓ąĮčÅ (ą░ą┐ą┐ą░čĆą░čéąĮąŠ ąĮą░čģąŠą┤čÅčēą░čÅčüčÅ ą▒ą╗ąĖąČąĄ ą▓čüąĄą│ąŠ ą║ čÅą┤čĆčā ą┐čĆąŠčåąĄčüčüąŠčĆą░, čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝ą░čÅ ą▓ąĮčāčéčĆąĄąĮąĮčÅčÅ ą┐ą░ą╝čÅčéčī L1) ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čüą░ą╝čŗą╣ ą▓čŗčüąŠą║ąĖą╣ čāčĆąŠą▓ąĄąĮčī ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖčÅ, ąĖ čŹčéą░ ą┐ą░ą╝čÅčéčī čüą░ą╝ą░čÅ ą┤ąŠčĆąŠą│ą░čÅ. ą¤ą░ą╝čÅčéčī ą▒ąŠą╗ąĄąĄ ąĮąĖąĘą║ąĖčģ čāčĆąŠą▓ąĮąĄą╣ čéčĆąĄą▒čāčÄčé ąĮąĄčüą║ąŠą╗čīą║ąŠ čåąĖą║ą╗ąŠą▓ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ čÅč湥ą╣ą║ą░ą╝, ąĮąŠ čüč鹊ąĖčé ą┤ąĄčłąĄą▓ą╗ąĄ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ čéą░ą║ąŠą╣ ą┐ą░ą╝čÅčéąĖ ąŠčéąĮąŠčüąĖčéčüčÅ ą▓ąĮąĄčłąĮčÅčÅ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ą░čÅ ą┐ą░ą╝čÅčéčī SDRAM).
ą¤ą░ą╝čÅčéčī ą║čŹčłą░ - čŹč鹊 čüą┐ąĄčåąĖą░ą╗čīąĮąŠ ą▓čŗą┤ąĄą╗ąĄąĮąĮą░čÅ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą╝ ą║čŹčłą░ ą┐ą░ą╝čÅčéčī ą▓čŗčüąŠą║ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ (L1). ą×ąĮą░ ąĘą░čēąĖčēąĄąĮą░ ąŠčé ą┐čĆčÅą╝ąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą║ą░ą║ čüąŠ čüč鹊čĆąŠąĮčŗ čÅą┤čĆą░, čéą░ą║ ąĖ čüąŠ čüč鹊čĆąŠąĮčŗ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓. ą¤čĆąĖą╝ąĄąĮąĄąĮąĖąĄ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ ą║čŹčłą░ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ąĮą░čģąŠą┤ąĖčéčīčüčÅ čüąĄą║čåąĖčÅą╝ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ ą┤ą░ąĮąĮčŗčģ ąĮą░čģąŠą┤ąĖčéčīčüčÅ ą▓ ą┐ą░ą╝čÅčéąĖ ąĮąĖąĘą║ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ (ąŠą▒čŗčćąĮąŠ SDRAM), čéą░ą║ čćč鹊 ąĮą░ąĖą▒ąŠą╗ąĄąĄ čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ ą┤ą░ąĮąĮčŗąĄ ąĖ/ąĖą╗ąĖ ą║ąŠą┤ (ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé č鹊ą│ąŠ, ą║ą░ą║ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮ ą║čŹčł) ą║ąŠą┐ąĖčĆčāąĄčéčüčÅ ą▓ ą┐ą░ą╝čÅčéčī ą║čŹčłą░ čü ą┐ąŠą╝ąŠčēčīčÄ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ ą║čŹčłą░. ąöąŠčüč鹊ą▓ąĄčĆąĮą░čÅ ą║ąŠą┐ąĖčÅ ą▓ ą║čŹčłąĄ čĆą░ą▒ąŠčéą░ąĄčé ąĮą░ą╝ąĮąŠą│ąŠ ą▒čŗčüčéčĆąĄąĄ, č湥ą╝ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮą░čÅ ą╝ąĄą┤ą╗ąĄąĮąĮą░čÅ ą┐ą░ą╝čÅčéčī (ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖ ą┤ą░ąĮąĮčŗąĄ ą┤ąŠčüčéčāą┐ąĮčŗ ą┤ą╗čÅ ą▓čŗą▒ąŠčĆą║ąĖ ąĘą░ 1 čåąĖą║ą╗ čÅą┤čĆą░), ą┐ąŠčüą║ąŠą╗čīą║čā čŹč鹊 čüą░ą╝ą░čÅ ą▒čŗčüčéčĆą░čÅ ą┐ą░ą╝čÅčéčī L1. ąÉčĆčģąĖč鹥ą║čéčāčĆą░ ą║čŹčłą░ ąŠčüąĮąŠą▓ą░ąĮą░ ąĮą░ ą┐čĆąĖąĮčåąĖą┐ąĄ, čćč鹊 ą░ą┤čĆąĄčüąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ą┐ą░ą╝čÅčéąĖ ą┤ąĄą╗ąĖčéčüčÅ ąĮą░ ą▒ą╗ąŠą║ąĖ čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░ (ą║ąŠč鹊čĆčŗąĄ ą▓ č鹥čĆą╝ąĖąĮąŠą╗ąŠą│ąĖąĖ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ ąĮą░ąĘčŗą▓ą░čÄčéčüčÅ čüčéčĆąŠą║ą░ą╝ąĖ ą║čŹčłą░). ąĪčéčĆąŠą║ąĖ ą║čŹčłą░ čüčćąĖčéą░čÄčéčüčÅ čüą░ą╝čŗą╝ąĖ ą╝ą░ą╗ąĄąĮčīą║ąĖą╝ąĖ ą║čāčüąŠčćą║ą░ą╝ąĖ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠąČąĮąŠ ą┐ąĄčĆąĄą┤ą░čéčī ą║ą░ą║ ą║ąŠą┐ąĖčÄ ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ (ą╝ąĄą┤ą╗ąĄąĮąĮąŠą╣) ą┐ą░ą╝čÅčéąĖ ą▓ąŠ ą▓ąĮčāčéčĆąĄąĮąĮčÄčÄ ą┐ą░ą╝čÅčéčī ą║čŹčłą░ L1, ąĄčüą╗ąĖ ą▒čŗą╗ ąĘą░čäąĖą║čüąĖčĆąŠą▓ą░ąĮ ą┐čĆąŠą╝ą░čģ ą║čŹčłą░.
ą×ą▒čĆą░čēąĄąĮąĖąĄ ą║ ą┐ą░ą╝čÅčéąĖ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāąĄčéčüčÅ ą║ą░ą║ čüčüčŗą╗ą║ą░ ąĮą░ ąĮąĄą║ąĖą╣ ąŠčéą┤ąĄą╗čīąĮčŗą╣ ą▒ą╗ąŠą║ ą┐ą░ą╝čÅčéąĖ. ąØą░ čĆąĖčü. 2 ą┐ąŠą║ą░ąĘą░ąĮą░ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÅ, ą▓ ą║ąŠč鹊čĆąŠą╣ ąŠą▒ą╗ą░čüčéčī ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ą┐ąŠą┤ąĄą╗ąĄąĮą░ ąĮą░ 24 ą▒ą╗ąŠą║ą░ ą┐ą░ą╝čÅčéąĖ, ąĖ ą┐ą░ą╝čÅčéčī ą║čŹčłą░ ą┐ąŠą┤ąĄą╗ąĄąĮą░ ąĮą░ 6 ą▒ą╗ąŠą║ąŠą▓ (čŹč鹊 ą┐čĆąĖą╝ąĄčĆ ąŠčüąĮąŠą▓ąĮąŠą╣ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ ą┐ą░ą╝čÅčéąĖ. ąÜąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ą╗ąŠą║ąŠą▓ ą┐ą░ą╝čÅčéąĖ ą╝ąŠąČąĄčé ą▓ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠčüčéąĖ ąŠčéą╗ąĖčćą░čéčīčüčÅ ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą╝ąŠą┤ąĄą╗ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin). ąĀą░ąĘą╝ąĄčĆ ą▒ą╗ąŠą║ą░ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ąĖ ą▒ą╗ąŠą║ą░ ą┐ą░ą╝čÅčéąĖ ą║čŹčłą░ ąŠą┤ąĖąĮą░ą║ąŠą▓čŗą╣. ą¤ąŠčüą║ąŠą╗čīą║čā ą▓čüąĄą│ą┤ą░ ą┐ą░ą╝čÅčéčī ą║čŹčłą░ ą┐ąŠ čĆą░ąĘą╝ąĄčĆčā čüąŠčüč鹊ąĖčé ąĖąĘ 6 ą▒ą╗ąŠą║ąŠą▓ (ą║ą░ą║ ą▓ čŹč鹊ą╝ čćą░čüčéąĮąŠą╝ ą┐čĆąĖą╝ąĄčĆąĄ), č鹊 ą╝ąŠąČąĄčé ą▒čŗčéčī č鹊ą╗čīą║ąŠ 6 ą▒ą╗ąŠą║ąŠą▓ ą┤ą░ąĮąĮčŗčģ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗąĄ ą▒čāą┤čāčé ą┤ąŠčüčéčāą┐ąĮčŗ ą║ą░ą║ ą║čŹčłąĖčĆčāąĄą╝ą░čÅ ą║ąŠą┐ąĖčÅ.
ąĀąĖčü. 2. ą¤čĆąĖ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĖ ąŠą▒ą╗ą░čüčéčī ą┐ą░ą╝čÅčéąĖ ą┐ąŠą┤ąĄą╗ąĄąĮą░ ąĮą░ ą▒ą╗ąŠą║ąĖ čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░.
ąóąĄčĆą╝ąĖąĮąŠą╗ąŠą│ąĖčÅ ą║čŹčłą░
ŌĆó Way, ą┐čāčéčī: ą╝ą░čüčüąĖą▓ čüčéčĆąŠą║ čģčĆą░ąĮąĖą╗ąĖčēą░ ą▓ m-way ą║čŹčłąĄ.
ŌĆó Locked way, ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą┐čāčéčī: ąĄčüą╗ąĖ way ą▓ čüąŠčüč鹊čÅąĮąĖąĖ locked (ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮ), č鹊 ąŠąĮ ąĮąĄ čāčćą░čüčéą▓čāąĄčé ą▓ ą┐ąŠą╗ąĖčéąĖą║ąĄ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ ą║čŹčłą░ "čüą░ą╝čŗą╣ ą┐ąŠčüą╗ąĄą┤ąĮąĖą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣" (least-recently used, LRU).
ŌĆó Set, ąĮą░ą▒ąŠčĆ: ą│čĆčāą┐ą┐ą░ ąŠą▒ą╗ą░čüč鹥ą╣ čģčĆą░ąĮąĄąĮąĖčÅ m-way ą▓ ą┐čāčéąĖ (way) ą║čŹčłą░ m-way. ą×čéą┤ąĄą╗čīąĮčŗą╣ ą▒ą╗ąŠą║ ą┐ą░ą╝čÅčéąĖ ą┐čĆąĖą▓čÅąĘą░ąĮ ą║ čüą┐ąĄčåąĖčäąĖčćąĮąŠą╝čā ąĮą░ą▒ąŠčĆčā. ąÜąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą║čŹčłą░ ą▓čŗą▒ąĖčĆą░ąĄčé way ą▓ąĮčāčéčĆąĖ ąĮą░ą▒ąŠčĆą░ set.
ŌĆó ąĪčéčĆąŠą║ą░ ą║čŹčłą░, cache-line: 32-ą▒ą░ą╣čéąĮčŗą╣ ąĮąĄą┐čĆąĄčĆčŗą▓ąĮčŗą╣ ą▒ą╗ąŠą║ ą┐ą░ą╝čÅčéąĖ ą║ąŠč鹊čĆčŗą╣ ą▒čŗą╗ ą┐ąĄčĆąĄą┤ą░ąĮ ą║ą░ą║ ą║ąŠą┐ąĖčÅ ąĖąĘ/ą▓ ą┐ą░ą╝čÅčéčī ą▓čŗčüąŠą║ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ ą▓/ąĖąĘ ą║čŹčłą░.
ŌĆó Dirty/clean, ą│čĆčÅąĘąĮą░čÅ/čćąĖčüčéą░čÅ): čüąŠčüč鹊čÅąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░, ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčēą░čÅ ąĮą░ą╗ąĖčćąĖąĄ ąĖą╗ąĖ ąŠčéčüčāčéčüčéą▓ąĖąĄ čĆą░čüčģąŠąČą┤ąĄąĮąĖą╣ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮąŠą│ąŠ ąĘąĮą░č湥ąĮąĖčÅ ą▓ąŠ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą╣ ąĄą╝čā ą║ąŠą┐ąĖąĖ ą▓ čüčéčĆąŠą║ąĄ ą║čŹčłą░. ąĢčüą╗ąĖ čĆą░ąĘą╗ąĖčćąĖčÅ ąĄčüčéčī, čé. ąĄ. ąĮąĄčé čüąĖąĮčģčĆąŠąĮąĮąŠčüčéąĖ ą╝ąĄąČą┤čā ą║čŹčłąĄą╝ ąĖ ą║čŹčłąĖčĆčāąĄą╝ąŠą╣ ą┐ą░ą╝čÅčéčīčÄ, č鹊 čüčéčĆąŠą║ą░ ą│čĆčÅąĘąĮą░čÅ, ąĄčüą╗ąĖ ą┤ą░ąĮąĮčŗąĄ ą▓ ąŠčĆąĖą│ąĖąĮą░ą╗ąĄ ąĖą╗ąĖ ą║čŹčłąĄ ąĮąĄ ą▒čŗą╗ąĖ ą┐ąŠą╝ąĄąĮčÅąĮčŗ, č鹊 čüčéčĆąŠą║ą░ čćąĖčüčéą░čÅ.
ŌĆó Cache hit, ą┐ąŠą┐ą░ą┤ą░ąĮąĖąĄ ą▓ ą║čŹčł: ą┐čĆąŠčåąĄčüčüąŠčĆ ąŠą▒čĆą░ą╗čüčÅ ą║ ą▒ą╗ąŠą║čā ą┐ą░ą╝čÅčéąĖ (ąĮą░čģąŠą┤čÅčēąĄą╝čāčüčÅ ą▓ ąŠčüąĮąŠą▓ąĮąŠą╣, ą╝ąĄą┤ą╗ąĄąĮąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ), ą║ąŠč鹊čĆą░čÅ čāąČąĄ ąĖą╝ąĄąĄčé ą┤ąŠčüč鹊ą▓ąĄčĆąĮčāčÄ ą║ąŠą┐ąĖčÄ ą▓ ą║čŹčłąĄ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą┐čĆąŠčåąĄčüčüąŠčĆ čüčĆą░ąĘčā ą┐ąŠą╗čāčćąĖčé ą┤ą░ąĮąĮčŗąĄ ąĖąĘ ą║čŹčłą░, čü ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠą╣ ąĘą░ą┤ąĄčƹȹ║ąŠą╣.
ŌĆó Cache miss, ą┐čĆąŠą╝ą░čģ ą║čŹčłą░: ą┐čĆąŠčåąĄčüčüąŠčĆ ąŠą▒čĆą░čéąĖą╗čüčÅ ą║ ą▒ą╗ąŠą║čā ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠą║ą░ ąĮąĄ ą┤ąŠčüčéčāą┐ąĄąĮ ą▓ ą║čŹčłąĄ. ąÜąŠą│ą┤ą░ ą┐čĆąŠąĖąĘąŠčłąĄą╗ ą┐čĆąŠą╝ą░čģ ą║čŹčłą░, ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą║čŹčłą░ ą┤ąĄą╗ą░ąĄčé ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ ą▒ą╗ąŠą║ą░ ą▓ ą┐ą░ą╝čÅčéčī ą║čŹčłą░ ąĖąĘ ąĮąĖąĘą║ąŠčāčĆąŠą▓ąĮąĄą▓ąŠą╣ ą┐ą░ą╝čÅčéąĖ.
ŌĆó Victim, "ąČąĄčĆčéą▓ą░": ą│čĆčÅąĘąĮą░čÅ čüčéčĆąŠą║ą░ ą║čŹčłą░ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ąĘą░ą┐ąĖčüą░ąĮą░ ą▓ ąĮąĖąĘą║ąŠčāčĆąŠą▓ąĮąĄą▓čāčÄ ą┐ą░ą╝čÅčéčī ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ą╝ąŠąČąĮąŠ ą▒čāą┤ąĄčé ąĄčæ ąŠčüą▓ąŠą▒ąŠą┤ąĖčéčī ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ ą▓ ą║čŹčł ąĮąŠą▓čŗčģ ą┤ą░ąĮąĮčŗčģ (čüą╝. victim buffer ąĮą░ čĆąĖčü. 1).
ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ą┐ąŠą┤čĆąŠą▒ąĮąŠčüčéąĖ ą┐ąŠ č鹥čĆą╝ąĖąĮąŠą╗ąŠą│ąĖąĖ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ ą╝ąŠąČąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ąĖąĘ čĆą░ąĘą┤ąĄą╗ą░ "Memory" ą┤ą░čéą░čłąĖčéą░ "Blackfin Processor Programming Reference".
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą▓ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĄą╝ ąĖąĘą╗ąŠąČąĄąĮąĖąĖ ą▒čāą┤čāčé ą▓ąĘą░ąĖą╝ąŠąĘą░ą╝ąĄąĮčÅąĄą╝ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ čüą╗ąŠą▓ą░ line (čüčéčĆąŠą║ą░), cache-line (čüčéčĆąŠą║ą░ ą║čŹčłą░) ąĖ cache-block (ą▒ą╗ąŠą║ ą║čŹčłą░). ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą▒ą╗ąŠą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé ąŠą▒ą╗ą░čüčéčī čéą░ą║ąŠą│ąŠ ąČąĄ čĆą░ąĘą╝ąĄčĆą░, ą║ą░ą║ čüčéčĆąŠą║ą░ ą║čŹčłą░.
[ąĀą░ąĘą╝ąĄčēąĄąĮąĖąĄ ą▒ą╗ąŠą║ą░]
ąśčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ 3 ąŠčüąĮąŠą▓ąĮčŗąĄ čüčģąĄą╝čŗ ą▓ąŠ ą▓čĆąĄą╝čÅ ą┐čĆąĖąĮčÅčéąĖčÅ čĆąĄčłąĄąĮąĖčÅ, ą│ą┤ąĄ čĆą░ąĘą╝ąĄčüčéąĖčéčī ą┐čĆąĖčģąŠą┤čÅčēąĖą╣ ą▒ą╗ąŠą║ ą▓ ą┐ą░ą╝čÅčéąĖ ą║čŹčłą░.
ą║čŹčł čü ą┐čĆčÅą╝ąŠą╣ ą┐čĆąĖą▓čÅąĘą║ąŠą╣ (Direct Mapped Cache). ąÆ čŹč鹊ą╣ čüčģąĄą╝ąĄ ą║ą░ąČą┤čŗą╣ ą▒ą╗ąŠą║ ą┐ą░ą╝čÅčéąĖ ąĮąĖąĘą║ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ ąĖą╝ąĄąĄčé č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą▒ą╗ąŠą║ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą▓ ą║čŹčłąĄ. ąŚą┤ąĄčüčī ą┐čĆąĖčüčāčéčüčéą▓čāąĄčé ą┐čĆąĖą▓čÅąĘą║ą░ ąŠą┤ąĖąĮ-ą║-ąŠą┤ąĮąŠą╝čā ąŠčé ąĮąĖąĘą║ąŠčāčĆąŠą▓ąĮąĄą▓ąŠą╣ ą┐ą░ą╝čÅčéąĖ ą║ ą┐ą░ą╝čÅčéąĖ ą║čŹčłą░. ą¤čĆąĖą▓čÅąĘą║ą░ ąŠčüąĮąŠą▓čŗą▓ą░ąĄčéčüčÅ ąĮą░ ą░ą┤čĆąĄčüąĄ ą▒ą╗ąŠą║ą░ ą▓ ą┐ą░ą╝čÅčéąĖ ąĮąĖąĘą║ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ. ąŁčéą░ čüčģąĄą╝ą░ ąĮą░ąĖą▒ąŠą╗ąĄąĄ ą┐čĆąŠčüčéą░, ąĖ ąĖą╝ąĄąĄčé čüą░ą╝čāčÄ ąĮąĖąĘą║čāčÄ ą│ąĖą▒ą║ąŠčüčéčī ą▓ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ.
ą¤ąŠą╗ąĮąŠ-ą░čüčüąŠčåąĖą░čéąĖą▓ąĮčŗą╣ ą║čŹčł (Fully Associative Cache). ą¤ąŠ čŹč鹊ą╣ čüčģąĄą╝ąĄ ą▒ą╗ąŠą║ ą▓ ąŠčüąĮąŠą▓ąĮąŠą╣ (ą╝ąĄą┤ą╗ąĄąĮąĮąŠą╣) ą┐ą░ą╝čÅčéąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ą╝ąĄąĮąĄąĮ ąĮą░ ą▒ą╗ąŠą║ ą▓ ą┐ą░ą╝čÅčéąĖ ą║čŹčłą░. ą¤čĆąĖą▓čÅąĘą║ą░ ą▒ą╗ąŠą║ąŠą▓ ą┐ąŠą╗ąĮąŠčüčéčīčÄ čüą╗čāčćą░ą╣ąĮą░. ąŁčéą░ čüčéčĆą░č鹥ą│ąĖčÅ ąĖą╝ąĄąĄčé čüą░ą╝čāčÄ čüą╗ąŠąČąĮąŠčüčéčī ą▓ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĖ, ąĮąŠ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čüą░ą╝čāčÄ ą▓čŗčüąŠą║čāčÄ ą│ąĖą▒ą║ąŠčüčéčī ą▓ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ.
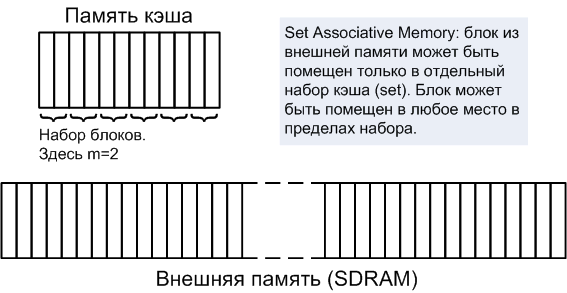
ąØą░ą▒ąŠčĆ ą░čüčüąŠčåąĖą░čéąĖą▓ąĮąŠą│ąŠ ą║čŹčłą░ (Set Associative Cache). ą¤ą░ą╝čÅčéčī ą║čŹčłą░ čĆą░ąĘą▒ąĖčéą░ ąĮą░ ąĮą░ą▒ąŠčĆčŗ. ąØą░ą▒ąŠčĆ (set) čüąŠčüč鹊ąĖčé ąĖąĘ ąĮąĄą║ąŠč鹊čĆąŠą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą▒ą╗ąŠą║ąŠą▓. ąøčÄą▒ąŠą╣ ą▒ą╗ąŠą║ ą▓ ą┐ą░ą╝čÅčéąĖ ąĮąĖąĘą║ąŠą│ąŠ čāčĆąŠą▓ąĮčÅ ąĖą╝ąĄąĄčé čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ąĮą░ą▒ąŠčĆ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą▓ ą║čŹčłąĄ (ą║čāą┤ą░ ąŠąĮ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠą╝ąĄčēąĄąĮ). ą¤ąŠčüčéčāą┐ą░čÄčēąĖą╣ ą▒ą╗ąŠą║ ą╝ąŠąČąĄčé ąĘą░ą╝ąĄąĮąĖčéčī ą╗čÄą▒čŗąĄ ą▒ą╗ąŠą║ąĖ ą▓ąĮčāčéčĆąĖ ą┐čĆąĖą▓čÅąĘą░ąĮąĮąŠą│ąŠ ąĮą░ą▒ąŠčĆą░. ąĢčüą╗ąĖ ą▓ ąĮą░ą▒ąŠčĆąĄ ąĄčüčéčī m ą▒ą╗ąŠą║ąŠą▓, č鹊 ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÅ ą║čŹčłą░ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ m-way set associative. ąŁč鹊čé ą╝ąĄč鹊ą┤ čĆą░ąĘą╝ąĄčēąĄąĮąĖčÅ ą▒ą╗ąŠą║ą░ čÅą▓ą╗čÅąĄčéčüčÅ ą║ąŠą╝ą┐čĆąŠą╝ąĖčüčüąĮčŗą╝ ą┐ąŠ čüą╗ąŠąČąĮąŠčüčéąĖ ąĖ ą│ąĖą▒ą║ąŠčüčéąĖ. ąĀąĖčü. 3 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┐ą░ą╝čÅčéčī 2-way set associate.
ąĀąĖčü. 3. ąÜąŠąĮčäąĖą│čāčĆą░čåąĖčÅ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ 2-way set associative cache.
ą¤ąĄčĆą▓čŗąĄ 2 čüčģąĄą╝čŗ čÅą▓ą╗čÅčÄčéčüčÅ čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╝ąĖ čüą╗čāčćą░čÅą╝ąĖ set associative cache (direct mapped ą┤ą╗čÅ m = 1, ąĖ fully associative ą┤ą╗čÅ m = ą║ąŠą╗ąĖč湥čüčéą▓čā čüčéčĆąŠą║ ą║čŹčłą░).
[ąŚą░ą╝ąĄąĮą░ ą▒ą╗ąŠą║ą░]
ąØą░ čĆąĖčü. 4 ą┐ąŠą║ą░ąĘą░ąĮąŠ čüčĆą░ą▓ąĮąĄąĮąĖąĄ ąĘą░ą╝ąĄąĮčŗ ą▒ą╗ąŠą║ą░ ą┤ą╗čÅ 1-way ąĖ 4-way set associative cache. ąĀą░čüčüą╝ąŠčéčĆąĖą╝ ą╗ąĖąĮąĄą╣ąĮčŗą╣ ą┐ąŠč鹊ą║ č湥čĆąĄąĘ ą▒ąŠą╗čīčłąŠą╣ čåąĖą║ą╗ ą▓ ą┐čĆąŠą│čĆą░ą╝ą╝ąĄ, čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĮčŗą╣ ą▓ąŠ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ. ąÜąŠą│ą┤ą░ čÅč湥ą╣ą║ąĖ ą║čŹčłą░ ą▒čŗą╗ąĖ ą┐ąĄčĆąĄąĘą░ą┐ąĖčüą░ąĮčŗ ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ąŠąĮąĖ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ, ą║čŹčł čüčćąĖčéą░ąĄčéčüčÅ "ą┐ąŠą▓čĆąĄąČą┤ąĄąĮąĮčŗą╝". ąæąŠą╗ąĄąĄ ą▓ąĄčĆąŠčÅčéąĮąŠ ąĮą░ą╗ąĖčćąĖąĄ čéčĆąĄą▒čāąĄą╝ąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┤ą╗čÅ ą┐ąŠą▓č鹊čĆąĮąŠą│ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą▓ 4-way ą║čŹčłąĄ, č湥ą╝ ą▓ 1-way ą║čŹčłąĄ. ąÜąŠą┤ ą┤ąŠą╗ąČąĄąĮ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐ąŠą▓č鹊čĆąĮąŠ, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ą┐čĆąĄąĖą╝čāčēąĄčüčéą▓ąŠ ą▓ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ą║čŹčłą░.

ąĀąĖčü. 4. ą¤čĆąĖą╝ąĄčĆčŗ čĆą░ąĘą╝ąĄčēąĄąĮąĖčÅ ą▒ą╗ąŠą║ą░.
ąÆ ą║čŹčłąĄ čü ą┐čĆčÅą╝ąŠą╣ ą┐čĆąĖą▓čÅąĘą║ąŠą╣ (direct mapped cache), ą▓čüąĄą│ą┤ą░ ą╝ąĄčüč鹊 ą▓ąĮčāčéčĆąĖ ą║čŹčłą░ čäąĖą║čüąĖčĆąŠą▓ą░ąĮąŠ, ą▓ ą║ąŠč鹊čĆąŠą╝ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠą╝ąĄčēąĄąĮą░ ą║čŹčłąĖčĆčāąĄą╝ą░čÅ (ą▓ąĮąĄčłąĮčÅčÅ) ą┐ą░ą╝čÅčéčī. ą×ą┤ąĮą░ą║ąŠ, ą▓ čĆą░ąĘą╝ąĄčēąĄąĮąĖąĖ ą▒ą╗ąŠą║ą░ čü ą┐ąŠą╗ąĮąŠ-čüą▓čÅąĘą░ąĮąĮčŗą╝ ą║čŹčłąĄą╝ (fully associative) ąĖą╗ąĖ čü ąĮą░ą▒ąŠčĆąŠą╝ čüą▓čÅąĘą░ąĮąĮąŠą│ąŠ ą║čŹčłą░ (set-associative), ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą▒čĆą░ąĮąŠ ąĮąĄčüą║ąŠą╗čīą║ąŠ ą╝ąĄčüčé ą┐čĆąĖ čüąŠą▒čŗčéąĖąĖ ą┐čĆąŠą╝ą░čģą░ ą║čŹčłą░. ąæą╗ąŠą║ąĖ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ąĘą░ą╝ąĄąĮąĄąĮčŗ, ąĮą░ąĘčŗą▓ą░čÄčéčüčÅ "čāčćą░čüčéą▓čāčÄčēąĖą╝ąĖ" ą▒ą╗ąŠą║ą░ą╝ąĖ. ąÆąŠčé ąĮąĄą║ąŠč鹊čĆčŗąĄ čüčéčĆą░č鹥ą│ąĖąĖ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ čćą░čēąĄ ą▓čüąĄą│ąŠ ą▓ ą▓čŗą▒ąŠčĆąĄ ą▒ą╗ąŠą║ą░ ą║čŹčłą░ ą┤ą╗čÅ ąĘą░ą╝ąĄąĮčŗ:
ŌĆó ąĪą╗čāčćą░ą╣ąĮą░čÅ ąĘą░ą╝ąĄąĮą░: ą▒ą╗ąŠą║ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ čüą╗čāčćą░ą╣ąĮąŠ ąĖąĘ čāčćą░čüčéą▓čāčÄčēąĖčģ ą▒ą╗ąŠą║ąŠą▓. ą£ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą│ąĄąĮąĄčĆą░č鹊čĆ ą┐čüąĄą▓ą┤ąŠčüą╗čāčćą░ą╣ąĮčŗčģ čćąĖčüąĄą╗, čćč鹊ą▒čŗ ą▓čŗą▒čĆą░čéčī ą▒ą╗ąŠą║ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ. ąŁč鹊 čüą░ą╝čŗą╣ ą┐čĆąŠčüčéą░čÅ, ąĮąŠ ąĮą░ąĖą╝ąĄąĮąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮą░čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖčÅ.
ŌĆó ąŚą░ą╝ąĄąĮą░ ą┐ąŠ ą┐čĆąĖąĮčåąĖą┐čā FIFO (First in first out, FIFO; ą┐čĆąĖąĮčåąĖą┐ ą┐ąĄčĆą▓čŗą╝ ąĘą░čłąĄą╗, ą┐ąĄčĆą▓čŗą╝ ą▓čŗčłąĄą╗): ą▓čģąŠą┤čÅčēąĖą╣ ą▒ą╗ąŠą║ ąĘą░ą╝ąĄąĮčÅąĄčé čüą░ą╝čŗą╣ čüčéą░čĆčŗą╣ ąĖąĘ čāčćą░čüčéą▓čāčÄčēąĖčģ ą▒ą╗ąŠą║ąŠą▓.
ŌĆó ąŚą░ą╝ąĄąĮą░ LRU (Least-recently used, LRU; ą┐ąŠčüą╗ąĄą┤ąĮąĖą╣ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣, čé. ąĄ. ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą┤ą░ą▓ąĮąŠ): ą┐ąŠ čŹč鹊ą╣ čüčģąĄą╝ąĄ ą▓čüąĄ ą┤ąŠčüčéčāą┐čŗ ą║ ą▒ą╗ąŠą║ą░ą╝ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ. ąæčāą┤ąĄčé ą▓čŗą▒čĆą░ąĮ č鹊čé ą▒ą╗ąŠą║ ą┤ą╗čÅ ąĘą░ą╝ąĄąĮčŗ, ą║ ą║ąŠč鹊čĆąŠą╝čā ąĮąĄ ą▒čŗą╗ąŠ ą┐ąŠčüą╗ąĄą┤ąĮąĄą│ąŠ ąŠą▒čĆą░čēąĄąĮąĖčÅ čüą░ą╝ąŠąĄ ą┤ą╗ąĖč鹥ą╗čīąĮąŠąĄ ą▓čĆąĄą╝čÅ. LRU ą┐ąŠą╗ą░ą│ą░ąĄčéčüčÅ ąĮą░ ą╝ąĄčüčéąĮčŗąĄ čāčüą╗ąŠą▓ąĖčÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ: ąĄčüą╗ąĖ č鹊ą╗čīą║ąŠ čćč鹊 ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĮčŗąĄ ą▒ą╗ąŠą║ąĖ čüą║ąŠčĆąĄąĄ ą▓čüąĄą│ąŠ ąŠą┐čÅčéčī ą▓ ą▒ą╗ąĖąČą░ą╣čłąĄąĄ ą▓čĆąĄą╝čÅ ą┐ąŠąĮą░ą┤ąŠą▒čÅčéčüčÅ, č鹊 čģąŠčĆąŠčłąĖą╝ ą║ą░ąĮą┤ąĖą┤ą░č鹊ą╝ ą┤ą╗čÅ ąĘą░ą╝ąĄąĮčŗ ą▒čāą┤ąĄčé ą▒ą╗ąŠą║, ą║ąŠč鹊čĆčŗą╣ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗čüčÅ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą┤ą░ą▓ąĮąŠ.
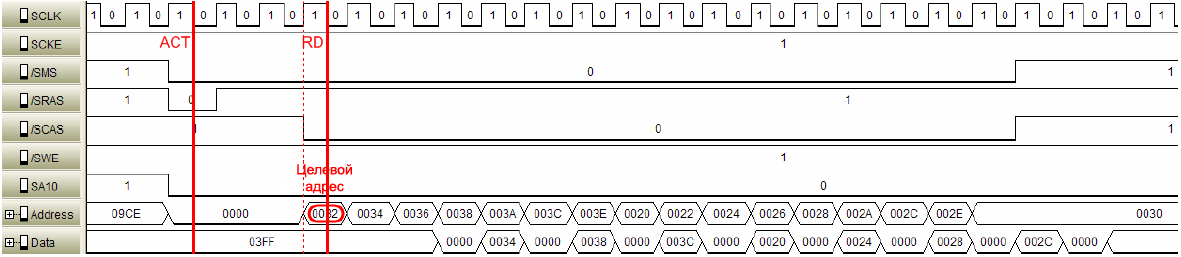
ŌĆó ą£ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą┐čĆąĖąĮčåąĖą┐ ąĘą░ą╝ąĄąĮčŗ LRU: "ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮčŗą╣" ą▓ čüą╗čāčćą░ąĄ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą▒ąĖčé 8 (CPLB_LRUPRIO) ą▓ čĆąĄą│ąĖčüčéčĆą░čģ ą┤ą░ąĮąĮčŗčģ CPLB čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ąĖą╗ąĖ ąŠčćąĖčēąĄąĮ (čüą╝. čĆąĖčü. 17 ąĖ 18). ąŻ čŹč鹊ą│ąŠ ą▒ąĖčéą░ ą┐čĆąĖąŠčĆąĖč鹥čé ą▓čŗčłąĄ, č湥ą╝ čā ą┐ąŠą╗ąĖčéąĖą║ąĖ ąĘą░ą╝ąĄąĮčŗ LRU. ąĪąŠą│ą╗ą░čüąĮąŠ čüčģąĄą╝ąĄ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ LRU, ą▒ą╗ąŠą║čā ą┐čĆąĖčüą▓ą░ąĖą▓ą░ąĄčéčüčÅ ąĮąĖąĘą║ąĖą╣ ą┐čĆąĖąŠčĆąĖč鹥čé ąĖą╗ąĖ ą▓čŗčüąŠą║ąĖą╣ ą┐čĆąĖąŠčĆąĖč鹥čé.
ąĢčüą╗ąĖ ą┐ąŠčüčéčāą┐ą░čÄčēąĖą╣ ą▒ą╗ąŠą║ ąĖą╝ąĄąĄčé ąĮąĖąĘą║ąĖą╣ ą┐čĆąĖąŠčĆąĖč鹥čé, č鹊 č鹊ą╗čīą║ąŠ ą▒ą╗ąŠą║ąĖ čü ąĮąĖąĘą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ ą╝ąŠą│čāčé čāčćą░čüčéą▓ąŠą▓ą░čéčī ą▓ ąĘą░ą╝ąĄąĮąĄ ą║čŹčłą░.
ąĢčüą╗ąĖ ą┐ąŠčüčéčāą┐ą░čÄčēąĖą╣ ą▒ą╗ąŠą║ ąĖą╝ąĄąĄčé ą▓čŗčüąŠą║ąĖą╣ ą┐čĆąĖąŠčĆąĖč鹥čé, č鹊 ą▓čüąĄ ąĮąĖąĘą║ąŠ-ą┐čĆąĖąŠčĆąĖč鹥čéąĮčŗąĄ ą▒ą╗ąŠą║ąĖ ą▒čāą┤čāčé čāčćą░čüčéą▓ąŠą▓ą░čéčī ą▓ ąĘą░ą╝ąĄąĮąĄ ą║čŹčłą░. ąĢčüą╗ąĖ ąĮąĄčé ąĮąĖąĘą║ąŠą┐čĆąĖąŠčĆąĖč鹥čéąĮčŗčģ ą▒ą╗ąŠą║ąŠą▓, č鹊 ą▓čŗčüąŠą║ąŠą┐čĆąĖąŠčĆąĖč鹥čéąĮčŗąĄ ą▒ą╗ąŠą║ąĖ ą╝ąŠą│čāčé čāčćą░čüčéą▓ąŠą▓ą░čéčī ą▓ ą┐ąŠą╗ąĖčéąĖą║ąĄ ąĘą░ą╝ąĄąĮčŗ. ą¤ąŠą╗ąĖčéąĖą║ą░ LRU ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą▓čŗą▒ąŠčĆą░ ą▒ą╗ąŠą║ą░-ąČąĄčĆčéą▓čŗ ą┤ą╗čÅ ąĘą░ą╝ąĄąĮčŗ čüčĆąĄą┤ąĖ čāčćą░čüčéą▓čāčÄčēąĖčģ ą▒ą╗ąŠą║ąŠą▓.
ąØąĄ ą▓čüąĄ ą▒ą╗ąŠą║ąĖ ą╝ąŠą│čāčé čüąŠą┤ąĄčƹȹ░čéčī ą▓ čüąĄą▒ąĄ ą┤ąŠčüč鹊ą▓ąĄčĆąĮčāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ. ąØą░ą┐čĆąĖą╝ąĄčĆ, ą▓ ą╝ąŠą╝ąĄąĮčé čüčéą░čĆčéą░ čüąĖčüč鹥ą╝čŗ ą▓ ą║čŹčłąĄ ąĮąĄ čüąŠą┤ąĄčƹȹĖčéčüčÅ ą▓ąŠąŠą▒čēąĄ ąĮąĖą║ą░ą║ąĖčģ ą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗčģ ą┤ą░ąĮąĮčŗčģ. ąæą╗ąŠą║ąĖ ą║čŹčłą░ ą▒čāą┤čāčé ąĘą░ą┐ąŠą╗ąĮčÅčéčīčüčÅ ą▓čüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ą▒čāą┤čāčé ą┐čĆąŠąĖčüčģąŠą┤ąĖčéčī ąŠą▒čĆą░čēąĄąĮąĖčÅ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ čü ą┐čĆąŠą╝ą░čģą░ą╝ąĖ ą╝ąĖą╝ąŠ ą║čŹčłą░. ą£ąĄčģą░ąĮąĖąĘą╝ ą┤ąŠą╗ąČąĄąĮ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆąŠą▓ą░čéčī, čüąŠą┤ąĄčƹȹĖčéčüčÅ ą╗ąĖ ą▓ ą▒ą╗ąŠą║ąĄ ą║čŹčłą░ ą┤ąŠčüč鹊ą▓ąĄčĆąĮą░čÅ ąĖąĮč乊čĆą╝ą░čåąĖčÅ. ą¦č鹊ą▒čŗ ą┐čĆąŠą▓ąĄčĆąĖčéčī čŹč鹊, čü ą║ą░ąČą┤čŗą╝ ą▒ą╗ąŠą║ąŠą╝ ą║čŹčłą░ čüą▓čÅąĘčŗą▓ą░ąĄčéčüčÅ čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝čŗą╣ ą▒ąĖčé ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéąĖ, "valid" ą▒ąĖčé. ąÜąŠą│ą┤ą░ ą▓ ą║čŹčłąĄ ąĮą░čģąŠą┤čÅčéčüčÅ ą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ, čüąŠą▓ą┐ą░ą┤ą░čÄčēąĖąĄ čü čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╝ ą▒ą╗ąŠą║ąŠą╝ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, č鹊 valid-ą▒ąĖčé ą┤ą╗čÅ čŹč鹊ą│ąŠ ą▒ą╗ąŠą║ą░ ą║čŹčłą░ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ.
ąÆ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ valid-ą▒ąĖčéčā, ą║ą░ąČą┤čŗą╣ ą▒ą╗ąŠą║ ą▓ ą║čŹčłąĄ čéą░ą║ąČąĄ ąĖą╝ąĄąĄčé ą┐čĆąĖą▓čÅąĘą░ąĮąĮčŗą╣ ą║ ąĮąĄą╝čā čé菹│ ą░ą┤čĆąĄčüą░. ąŁč鹊čé ą░ą┤čĆąĄčü ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čäąĖąĘąĖč湥čüą║ąĖą╣ ą░ą┤čĆąĄčü ą║čŹčłąĖčĆčāąĄą╝ąŠą│ąŠ ą▒ą╗ąŠą║ą░ ą▓ąŠ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ. ąÜąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąŠą▒čĆą░čēąĄąĮąĖąĄ ą║ ą▒ą╗ąŠą║čā ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą║čŹčłą░ čüčĆą░ą▓ąĮąĖą▓ą░ąĄčé ą▓ąĮąĄčłąĮąĖą╣ ą░ą┤čĆąĄčü čü čé菹│ą░ą╝ąĖ ą░ą┤čĆąĄčüą░ ą║čŹčłą░ (čā ą▒ą╗ąŠą║ąŠą▓, ą║ąŠč鹊čĆčŗąĄ ąĖą╝ąĄčÄčé čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮčŗą╝ valid-ą▒ąĖčé), čćč鹊ą▒čŗ ąĮą░ą╣čéąĖ ąĮą░ą▒ąŠčĆ ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé čüąŠą┤ąĄčƹȹ░čéčī čŹč鹊čé ą▒ą╗ąŠą║. ąĢčüą╗ąĖ ą░ą┤čĆąĄčü ą▒ą╗ąŠą║ą░ čüąŠą▓ą┐ą░ą┤ą░ąĄčé čü ąŠą┤ąĮąĖą╝ ąĖąĘ č鹥ą│ąŠą▓ ą░ą┤čĆąĄčüą░ ą║čŹčłą░, č鹊 ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐ąŠą┐ą░ą┤ą░ąĮąĖąĄ ą▓ ą║čŹčł (čé. ąĄ. ą▓ ą║čŹčłąĄ ąĮą░ą╣ą┤ąĄąĮą░ ąĖąĮč乊čĆą╝ą░čåąĖčÅ, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēą░čÅ ąĘą░ą┐čĆą░čłąĖą▓ą░ąĄą╝ąŠą╝čā ą▒ą╗ąŠą║čā ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ).
ąÆ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąĖ set-associative cache ą║ą░ąČą┤čŗą╣ ą░ą┤čĆąĄčü ą┐ą░ą╝čÅčéąĖ ą╝ąŠąČąĄčé čĆą░čüčüą╝ą░čéčĆąĖą▓ą░čéčīčüčÅ ą║ą░ą║ ą║ąŠą╝ą▒ąĖąĮą░čåąĖčÅ čéčĆąĄčģ ą┐ąŠą╗ąĄą╣ (čüą╝. čéą░ą▒ą╗ąĖčåčā 1). ą¤ąĄčĆą▓ąŠąĄ ą┤ąĄą╗ąĄąĮąĖąĄ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą╝ąĄąČą┤čā ą░ą┤čĆąĄčüąŠą╝ ą▒ą╗ąŠą║ą░ ąĖ čüą╝ąĄčēąĄąĮąĖąĄą╝ ą▒ą╗ąŠą║ą░. ą¤ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ą░ą┤čĆąĄčü ą▒ą╗ąŠą║ą░ (čäčĆąĄą╣ą╝) ą╝ąŠąČąĄčé ą▒čŗčéčī čéą░ą║ąČąĄ ą┐ąŠą┤ąĄą╗ąĄąĮ ąĮą░ ą┐ąŠą╗ąĄ čé菹│ą░ ąĖ ą┐ąŠą╗ąĄ ąĖąĮą┤ąĄą║čüą░.
ąóą░ą▒ą╗ąĖčåą░ 1. ąĀą░ąĘą▒ąĖąĄąĮąĖąĄ ą░ą┤čĆąĄčüą░.
ąÉą┤čĆąĄčü ą▒ą╗ąŠą║ą░
|
ąĪą╝ąĄčēąĄąĮąĖąĄ ą▒ą╗ąŠą║ą░
|
| ą¤ąŠą╗ąĄ čé菹│ą░ |
ą¤ąŠą╗ąĄ ąĖąĮą┤ąĄą║čüą░ |
| ąśčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą╝ ą║čŹčłą░, čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą┐ąŠą┐ą░ą┤ą░ąĮąĖąĄ ąĖą╗ąĖ ą┐čĆąŠą╝ą░čģ ą║čŹčłą░ |
ąśčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą┐čĆąĖą▓čÅąĘą║ąĖ čāą║ą░ąĘą░ąĮąĮąŠą│ąŠ ą▒ą╗ąŠą║ą░ ą║ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╝čā ąĮą░ą▒ąŠčĆčā (set) |
ąśčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą▓čŗą▒ąŠčĆą░ čüą╗ąŠą▓ą░ ą▓ ą┐čĆąĄą┤ąĄą╗ą░čģ čāą║ą░ąĘą░ąĮąĮąŠą│ąŠ ą▒ą╗ąŠą║ą░ |
ą¤ąŠą╗ąĄ čüą╝ąĄčēąĄąĮąĖčÅ ą▒ą╗ąŠą║ą░ ą▓čŗą▒ąĖčĆą░ąĄčé ąĮčāąČąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ąĖąĘ ą▒ą╗ąŠą║ą░. ą¤ąŠą╗ąĄ ąĖąĮą┤ąĄą║čüą░ ą▓čŗą▒ąĖčĆą░ąĄčé ąĮą░ą▒ąŠčĆ, ąĖ ą┐ąŠą╗ąĄ čé菹│ą░ čüčĆą░ą▓ąĮąĖą▓ą░ąĄčéčüčÅ čü čŹčéąĖą╝, čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą┐ąŠą┐ą░ą┤ą░ąĮąĖąĄ ą▓ ą║čŹčł.
[ąĪčéčĆą░č鹥ą│ąĖčÅ ąĘą░ą┐ąĖčüąĖ]
ąŚą┤ąĄčüčī čĆą░čüčüą╝ą░čéčĆąĖą▓ą░čÄčéčüčÅ ą┤ą▓ąĄ čĆą░ąĘąĮčŗąĄ ą┐čĆąŠą▒ą╗ąĄą╝čŗ, ą▓ąŠąĘąĮąĖą║ą░čÄčēąĖąĄ ą┐čĆąĖ ąŠą┐ąĄčĆą░čåąĖąĖ ąĘą░ą┐ąĖčüąĖ ą▓ ą┐ą░ą╝čÅčéčī, čüą▓čÅąĘą░ąĮąĮąŠą╣ čü ą┤ą░ąĮąĮčŗą╝ąĖ ą║čŹčłą░.
ą×ą┐ąĄčĆą░čåąĖčÅ ąĘą░ą┐ąĖčüąĖ ą▓ čüą╗čāčćą░ąĄ ą┐ąŠą┐ą░ą┤ą░ąĮąĖčÅ ą▓ ą║čŹčł. ąŚą┤ąĄčüčī ąĖą╝ąĄąĄčéčüčÅ 2 ąŠčüąĮąŠą▓ąĮčŗąĄ ąŠą┐čåąĖąĖ ą┐čĆąĖ ąĘą░ą┐ąĖčüąĖ ą┤ą░ąĮąĮčŗčģ ąŠą▒čĆą░čéąĮąŠ ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī:
ŌĆó Write-through (WT), čüą║ą▓ąŠąĘąĮą░čÅ ąĘą░ą┐ąĖčüčī: ąĖąĮč乊čĆą╝ą░čåąĖčÅ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą║ą░ą║ ą▓ ą▒ą╗ąŠą║ ą║čŹčłą░, čéą░ą║ ąĖ ą▓ ą▒ą╗ąŠą║ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮąŠą╣ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą╣ ą▒ą╗ąŠą║čā ą║čŹčłą░. ą¤ąŠą▓ąĄą┤ąĄąĮąĖąĄ/čüą║ąŠčĆąŠčüčéčī čĆą░ą▒ąŠčéčŗ čŹč鹊ą╣ čüčģąĄą╝čŗ ą┐ąŠą┤ąŠą▒ąĮčŗ ą┐čĆąŠčüč鹊ą╣ ąĘą░ą┐ąĖčüąĖ ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī, ą║ąŠą│ą┤ą░ ą║čŹčł ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ.
ŌĆó Write-back (WB), ąŠą▒čĆą░čéąĮą░čÅ ąĘą░ą┐ąĖčüčī: ąĖąĮč乊čĆą╝ą░čåąĖčÅ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ č鹊ą╗čīą║ąŠ ą▓ ą▒ą╗ąŠą║ ą║čŹčłą░. ą¤čĆąĖ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖąĖ ąĖąĘą╝ąĄąĮąĄąĮąĮą░čÅ čüčéčĆąŠą║ą░ ą║čŹčłą░ (victim cache-line) ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī č鹊ą╗čīą║ąŠ ą║ąŠą│ą┤ą░ čŹč鹊čé ą▒ą╗ąŠą║ ą║čŹčłą░ ąĘą░ą╝ąĄąĮčÅąĄčéčüčÅ.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąŠą┐ąĄčĆą░čåąĖčÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ (store), ąŠčüąŠą▒ąĄąĮąĮąŠ ą▓ čĆąĄąČąĖą╝ąĄ čĆą░ą▒ąŠčéčŗ WT, ą▒čāą┤ąĄčé ąŠą▒ąĮąŠą▓ą╗čÅčéčī č鹊ą╗čīą║ąŠ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ. ąØąĄ ą▒čāą┤ąĄčé ąŠčüčāčēąĄčüčéą▓ą╗čÅčéčīčüčÅ čåąĄą╗ąŠą╣ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī, ąĄčüą╗ąĖ čŹč鹊 ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ.
ą¦č鹊ą▒čŗ čāą╝ąĄąĮčīčłąĖčéčī čćą░čüč鹊čéčā ąŠą▒čĆą░čéąĮąŠą╣ ąĘą░ą┐ąĖčüąĖ ą▒ą╗ąŠą║ąŠą▓ ą┐čĆąĖ ąĘą░ą╝ąĄąĮąĄ, ąŠą▒čŗčćąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čäąĖčćą░, ąĮą░ąĘčŗą▓ą░ąĄą╝ą░čÅ "ą│čĆčÅąĘąĮčŗą╣ ą▒ąĖčé", dirty-ą▒ąĖčé. ąŁč鹊 ą▒ąĖčé čüąŠčüč鹊čÅąĮąĖčÅ, ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčēąĖą╣ ą│čĆčÅąĘąĮčŗą╣ ą▒ą╗ąŠą║ ą▓ ą║čŹčłąĄ ąĖą╗ąĖ ąĮąĄčé (ą┐ąŠą┤ "ą│čĆčÅąĘąĮčŗą╝" ą▒ą╗ąŠą║ąŠą╝ ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčéčüčÅ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮčŗą╣ ą▒ą╗ąŠą║; ąĄčüą╗ąĖ ą▒ą╗ąŠą║ ą║čŹčłą░ ąĮąĄ ą▒čŗą╗ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮ, č鹊 ąŠąĮ čüčćąĖčéą░ąĄčéčüčÅ "čćąĖčüčéčŗą╝"). ą¦ąĖčüčéčŗą╣ ą▒ą╗ąŠą║ ąĮąĄ ą▒čāą┤ąĄčé ąĘą░ą┐ąĖčüą░ąĮ ąŠą▒čĆą░čéąĮąŠ ą┐čĆąĖ ąĘą░ą╝ąĄąĮąĄ čŹč鹊ą│ąŠ ą▒ą╗ąŠą║ą░. ąźąŠčéčÅ ą╝ąĮąŠą│ąŠąĄ ąĘą░ą▓ąĖčüąĖčé ąŠčé ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, ąĮąŠ čĆąĄąČąĖą╝ WB čĆą░ą▒ąŠčéą░ąĄčé čŹčäč乥ą║čéąĖą▓ąĮąĄąĄ ą┐čĆąĖą╝ąĄčĆąĮąŠ ąĮą░ 10..15%, č湥ą╝ čĆąĄąČąĖą╝ WT. ąĀąĄąČąĖą╝ WT ą╗čāčćčłąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī, ą║ąŠą│ą┤ą░ ą┤ąŠą╗ąČąĮą░ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čéčīčüčÅ ą║ąŠą│ąĄčĆąĄąĮčéąĮąŠčüčéčī ą╝ąĄąČą┤čā ą┤ą▓čāą╝čÅ ąĖą╗ąĖ ą▒ąŠą╗čīčłąĖą╝ ą║ąŠą╗ąĖč湥čüčéą▓ąŠą╝ čĆąĄčüčāčĆčüąŠą▓ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, DMA ąĖ čÅą┤čĆąŠ).
ą×ą┐ąĄčĆą░čåąĖąĖ ąĘą░ą┐ąĖčüąĖ čü ą┐čĆąŠą╝ą░čģą░ą╝ąĖ ą║čŹčłą░. ą¤ąŠčüą║ąŠą╗čīą║čā ą┤ą░ąĮąĮčŗąĄ ąĮąĄ ą▒čŗą╗ąĖ ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗ ą┐čĆąĖ ąĘą░ą┐ąĖčüąĖ, ąĘą┤ąĄčüčī ąĄčüčéčī ą┤ą▓ąĄ ąŠą┐čåąĖąĖ ą┐čĆąĖ ą┐čĆąŠą╝ą░čģąĄ ą║čŹčłą░ ąĮą░ ąĘą░ą┐ąĖčüąĖ:
ŌĆó Write allocate, ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ą▒ą╗ąŠą║ą░ ą┐čĆąĖ ąĘą░ą┐ąĖčüąĖ: ą┐čĆąĖ ą┐čĆąŠą╝ą░čģąĄ ą║čŹčłą░ ą▓čŗą┤ąĄą╗čÅąĄčéčüčÅ ą▒ą╗ąŠą║, ąĘą░ ą║ąŠč鹊čĆčŗą╝ ą┐čĆąŠąĖčüčģąŠą┤čÅčé ą┤ąĄą╣čüčéą▓ąĖčÅ, ą║ą░ą║ ą┐čĆąĖ ą┐ąŠą┐ą░ą┤ą░ąĮąĖąĖ ą▓ ą║čŹčł, ąŠą┐ąĖčüą░ąĮąĮčŗąĄ ą▓čŗčłąĄ. ą¤ąŠ čéą░ą║ąŠą╣ čüčģąĄą╝ąĄ ą┐čĆąŠą╝ą░čģ ą╝ąĖą╝ąŠ ą║čŹčłą░ ą┐čĆąĖ ąĘą░ą┐ąĖčüąĖ čĆą░ą▒ąŠčéą░ąĄčé čéą░ą║ ąČąĄ, ą║ą░ą║ ą┐čĆąŠą╝ą░čģ ą╝ąĖą╝ąŠ ą║čŹčłą░ ą┐čĆąĖ čćč鹥ąĮąĖąĖ. ąĪąĮą░čćą░ą╗ą░ čüčéčĆąŠą║ą░ ą║čŹčłą░ ąĘą░čģą▓ą░čéčŗą▓ą░ąĄčéčüčÅ ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, ą┐ąĄčĆąĄą┤ č鹥ą╝ ą║ą░ą║ ąŠą▒ąĮąŠą▓ąĖčéčī ą║ą░ą║ ą▓ąĮčāčéčĆąĄąĮąĮąĖą╣ ą║čŹčł, čéą░ą║ ąĖ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī.
ŌĆó No-write allocate, ą▒ąĄąĘ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ą▒ą╗ąŠą║ą░ ą┐čĆąĖ ąĘą░ą┐ąĖčüąĖ: ą┐čĆąĖ čŹč鹊ą╣ čüčģąĄą╝ąĄ ą┐čĆąŠą╝ą░čģąĖ ą║čŹčłą░ ą┐čĆąĖ ąĘą░ą┐ąĖčüąĖ ąĮąĖą║ą░ą║ ąĮąĄ ą▓ą╗ąĖčÅčÄčé ąĮą░ čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ ą║čŹčłą░. ąæą╗ąŠą║ ą▒čāą┤ąĄčé ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮ č鹊ą╗čīą║ąŠ ą▓ąŠ ą▓ąĮąĄčłąĮąĄą╣ ąĮąĖąĘą║ąŠčāčĆąŠą▓ąĮąĄą▓ąŠą╣ (ą╝ąĄą┤ą╗ąĄąĮąĮąŠą╣) ą┐ą░ą╝čÅčéąĖ, ąĖ ąĮąĄ ą▒čāą┤ąĄčé ą║čŹčłąĖčĆąŠą▓ą░čéčīčüčÅ.
[ą£ąŠą┤ąĄą╗čī ą║čŹčłą░, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ą░čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą╝ Blackfin]
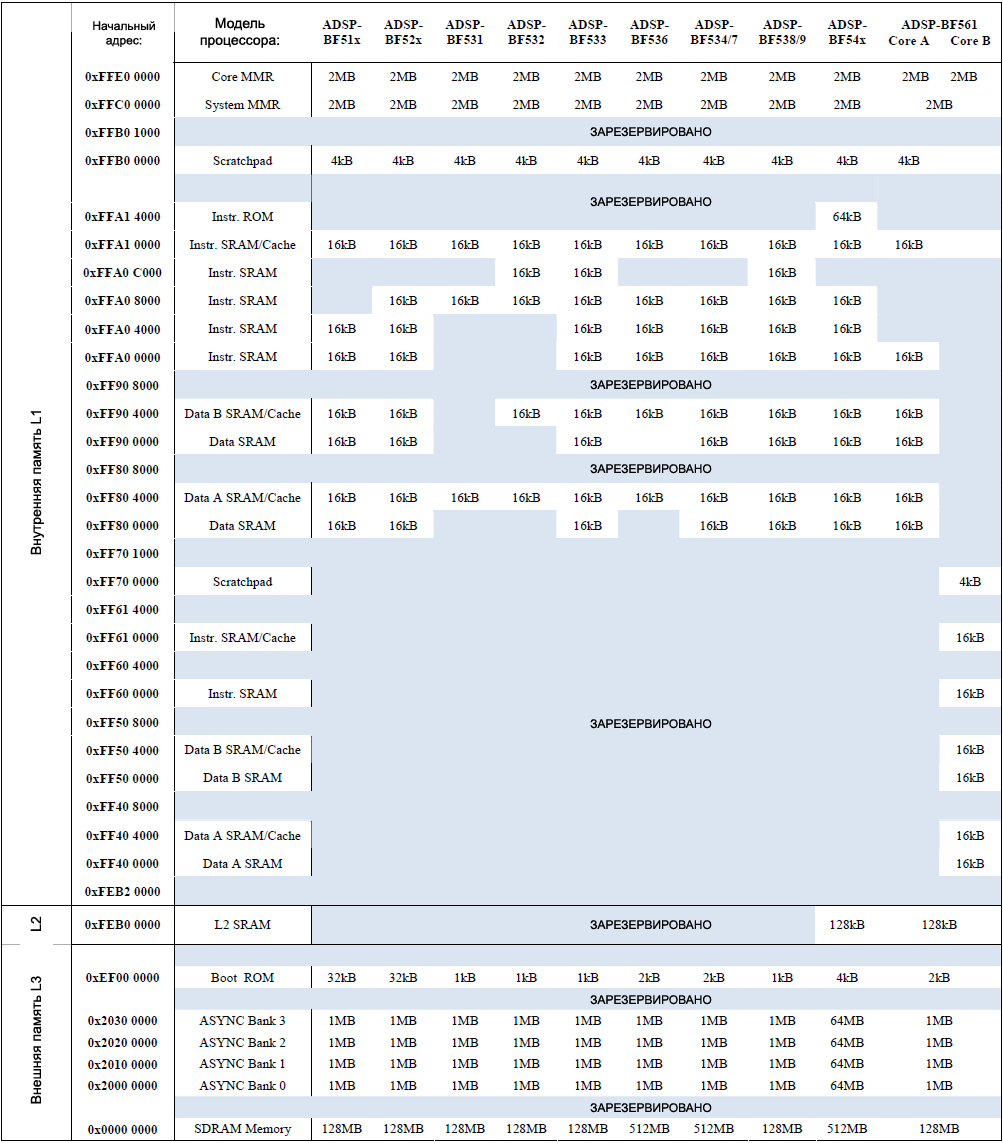
ąŻ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin ąĄčüčéčī ą┤ąŠ 3 čāčĆąŠą▓ąĮąĄą╣ ąĖąĄčĆą░čĆčģąĖąĖ ą┐ą░ą╝čÅčéąĖ - L1, L2, L3 - čćč鹊ą▒čŗ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī ąĮąĄą║ąĖą╣ ą║ąŠą╝ą┐čĆąŠą╝ąĖčüčü ą╝ąĄąČą┤čā ąŠą▒čŖąĄą╝ąŠą╝ ą┐ą░ą╝čÅčéąĖ ąĖ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄą╝ (ą┐ą░ą╝čÅčéčī L2 ąĄčüčéčī č鹊ą╗čīą║ąŠ čā ą┤ą▓čāčģčÅą┤ąĄčĆąĮąŠą│ąŠ ADSP-BF561). ą¤ą░ą╝čÅčéčī L1 ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čüą░ą╝ąŠąĄ ą▓čŗčüąŠą║ąŠąĄ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ ą┐čĆąĖ čüą░ą╝ąŠą╣ ą╝ą░ą╗ąŠą╣ ąĄą╝ą║ąŠčüčéąĖ. ąóąĖą┐čŗ ą┐ą░ą╝čÅčéąĖ L2 ąĖ L3 ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ąŠą▒čŖąĄą╝čŗ ą▒ąŠą╗čīčłąĄ, č湥ą╝ L1, ąŠą┤ąĮą░ą║ąŠ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ąĮąĖą╝ ąŠą▒čŗčćąĮąŠ čéčĆąĄą▒čāąĄčéčüčÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ čéą░ą║č鹊ą▓.
ąŻ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin ąĄčüčéčī ą▒ą░ąĮą║ąĖ ą┐ą░ą╝čÅčéąĖ L1 ą┤ą░ąĮąĮčŗčģ ąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠąČąĮąŠ ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░čéčī ą║ą░ą║ SRAM ąĖą╗ąĖ ą║ą░ą║ ą║čŹčł. ąÜąŠą│ą┤ą░ ą┐ą░ą╝čÅčéčī čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮą░ ą║ą░ą║ ą║čŹčł, č鹊 ą║ ąĮąĄą╣ ąĮąĄ ąĖą╝ąĄčÄčé ą┐čĆčÅą╝ąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ąĮąĖ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ DMA, ąĮąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĘą░ą│čĆčāąĘą║ąĖ/čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čÅą┤čĆą░. ąŻ ą▓čüąĄčģ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÅ ą║čŹčłą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐ąŠčćčéąĖ ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠ (čüą╝. čéą░ą▒ą╗ąĖčåčā 2), ąĮąŠ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĄąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ą▒čāą┤ąĄčé ąŠčüąĮąŠą▓ą░ąĮą░ ąĮą░ ą┐čĆąĖą╝ąĄčĆąĄ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF533.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą▓ąĮčāčéčĆąĄąĮąĮčÅčÅ ą┐ą░ą╝čÅčéčī L1 ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin ą┐ąŠą┤ą║ą╗čÄč湥ąĮą░ č湥čĆąĄąĘ čłąĖąĮčā External Access Bus (EAB) ą║ ą▒ą╗ąŠą║čā ą▓ąĮąĄčłąĮąĄą╣ čłąĖąĮčŗ External Bus Interface Unit (EBIU), ą║ąŠč鹊čĆčŗą╣ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░ąĄčé ą┤ąŠčüčéčāą┐čŗ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ (ąĮą░ą┐čĆąĖą╝ąĄčĆ ą║ ą┐ą░ą╝čÅčéąĖ SDRAM). ąøčÄą▒ą░čÅ č鹥ą║čāčēą░čÅ ą░ą║čéąĖą▓ąĮąŠčüčéčī EAB ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĄčĆą▓ą░ąĮą░, ąĮą░čćą░č鹊ąĄ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ ąĘą░ą║ąŠąĮčćąĖčéčüčÅ.
ąóą░ą▒ą╗ąĖčåą░ 2. ąÜą░čĆčéą░ ą┐ą░ą╝čÅčéąĖ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin.
[ąÜąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ Blackfin]
ą×čĆą│ą░ąĮąĖąĘą░čåąĖčÅ ą║čŹčłą░. ąŻ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ADSP-BF533 ąĖą╝ąĄąĄčéčüčÅ 80 ą║ąĖą╗ąŠą▒ą░ą╣čé ą▓čüčéčĆąŠąĄąĮąĮąŠą╣ ą▓ ą║čĆąĖčüčéą░ą╗ą╗ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣. 64 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą┤ąŠčüčéčāą┐ąĮčŗ ą║ą░ą║ SRAM ąĖąĮčüčéčĆčāą║čåąĖą╣. ą×čüčéą░ą╗čīąĮčŗąĄ 16 ą║ąĖą╗ąŠą▒ą░ą╣čé ą┐ą░ą╝čÅčéąĖ ą╝ąŠąČąĮąŠ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░čéčī ą║ą░ą║ ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣, ą╗ąĖą▒ąŠ ą╝ąŠąČąĮąŠ ąĖčģ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą║ą░ą║ SRAM ąĖąĮčüčéčĆčāą║čåąĖą╣. ąÆ čéą░ą▒ą╗ąĖčåąĄ 2 ą┐ąŠą║ą░ąĘą░ąĮą░ ą║ąŠą╝ą▒ąĖąĮąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą║ą░čĆčéą░ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ ą▓čüąĄčģ ą┤ąŠčüčéčāą┐ąĮčŗčģ ą▓ ąĮą░čüč鹊čÅčēąĄąĄ ą▓čĆąĄą╝čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ čüąĄą╝ąĄą╣čüčéą▓ą░ Blackfin.
ąŻ ą▓čüąĄčģ ą╝ąŠą┤ąĄą╗ąĄą╣ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčéčüčÅ ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣, ą║ąŠč鹊čĆąŠąĄ ą╝ąŠąČąĮąŠ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░čéčī ą╗ąĖą▒ąŠ ą║ą░ą║ ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣, ą╗ąĖą▒ąŠ ą║ą░ą║ SRAM. ąØą░čćą░ą╗čīąĮčŗą╣ ą░ą┤čĆąĄčü ą▓ ą║ą░čĆč鹥 ą┐ą░ą╝čÅčéąĖ ą▓čüąĄą│ą┤ą░ ąŠą┤ąĖąĮą░ą║ąŠą▓čŗą╣.
ąÜąŠą│ą┤ą░ čŹčéą░ ą┐ą░ą╝čÅčéčī čĆą░ąĘčĆąĄčłąĄąĮą░ ą┤ą╗čÅ ą║čŹčłą░, ą┐ą░ą╝čÅčéčī ąĖąĮčüčéčĆčāą║čåąĖą╣ čĆą░ą▒ąŠčéą░ąĄčé ą║ą░ą║ 4-way set associative memory. ąÜą░ąČą┤čŗą╣ ąĖąĘ 4 ą┐čāč鹥ą╣ ą╝ąŠąČąĮąŠ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░čéčī ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ. ąÜąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą╝ąŠąČąĮąŠ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░čéčī ą┤ą╗čÅ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮąŠą╣ ą┐ąŠą╗ąĖčéąĖą║ąĖ LRU (čüą╝. ą▓čĆąĄąĘą║čā "ą×ą▒čēą░čÅ ą║ąŠąĮčåąĄą┐čåąĖčÅ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ"), ąĖą╗ąĖ ą┐čĆąŠčüčéčāčÄ ą┐ąŠą╗ąĖčéąĖą║čā LRU ą┤ą╗čÅ ą┐čĆąĖąĮčÅčéąĖčÅ čĆąĄčłąĄąĮąĖčÅ ą┐ąŠ ąĘą░ą╝ąĄąĮąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░.
ŌĆó 16 ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗą╣ ą║čŹčł ąŠčĆą│ą░ąĮąĖąĘąŠą▓ą░ąĮ ą║ą░ą║ 4 ą┐ąŠą┤ą▒ą░ąĮą║ą░ ą┐ąŠ 4 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ ą║ą░ąČą┤čŗą╣. ą¤ąŠą┤ą▒ą░ąĮą║ ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ą▒ąĖčéą░ą╝ąĖ ą░ą┤čĆąĄčüą░ ą┐ą░ą╝čÅčéąĖ [13:12].
ŌĆó ąÜą░ąČą┤čŗą╣ 4 ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗą╣ ą┐ąŠą┤ą▒ą░ąĮą║ čüąŠčüč鹊ąĖčé ąĖąĘ 32 ąĮą░ą▒ąŠčĆąŠą▓. ąØą░ą▒ąŠčĆ ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ą▒ąĖčéą░ą╝ąĖ ą░ą┤čĆąĄčüą░ ą┐ą░ą╝čÅčéąĖ [9:5].
ŌĆó ąÜą░ąČą┤čŗą╣ ąĮą░ą▒ąŠčĆ čüąŠčüč鹊ąĖčé ąĖąĘ 4 ą┐čāč鹥ą╣ (way). ą¤čāčéčī ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą╝ ą║čŹčłą░ ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü ą┐ąŠą╗ąĖčéąĖą║ąŠą╣ čĆą░ąĘą╝ąĄčēąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ ą║čŹčłą░. ą¤čāčéąĖ ą╝ąŠąČąĮąŠ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆąŠą▓ą░čéčī ą▒ąĖčéą░ą╝ąĖ ą░ą┤čĆąĄčüą░ [11:10] ą▓ SRAM.
ŌĆó ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ąĮą░ą▒ąŠčĆ 0 (set-0) ą┐čĆąĄą┤čüčéą░ą▓ą╗čÅąĄčé č湥čéčŗčĆąĄ ą┐čāčéąĖ ą┤ą╗čÅ čüčéčĆąŠą║ąĖ 0 (line-0).
ŌĆó ąĀą░ąĘą╝ąĄčĆ čüčéčĆąŠą║ąĖ ą║čŹčłą░ (ą┤ą╗čÅ čćč鹥ąĮąĖčÅ ą▓ čüą╗čāčćą░ąĄ ą┐čĆąŠą╝ą░čģą░ ą║čŹčłą░) čĆą░ą▓ąĄąĮ 32 ą▒ą░ą╣čéą░.
ąÆąĮąĄčłąĮąĖą╣ ą┐ąŠčĆčé čćč鹥ąĮąĖčÅ ą┤ą░ąĮąĮčŗčģ (ą┤ą╗čÅ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆą░ ą║čŹčłą░) ąĖą╝ąĄąĄčé čłąĖčĆąĖąĮčā 64 ą▒ąĖčéą░ (8 ą▒ą░ą╣čé). ąĪą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ, ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą║čŹčłą░ čćąĖčéą░ąĄčé ą▓čüčÄ čüčéčĆąŠą║čā ą║čŹčłą░ ą║ą░ą║ ą┐ą░čćą║čā ąĖąĘ č湥čéčŗčĆąĄčģ 8-ą▒ą░ą╣čéąĮčŗčģ ą║čāčüą║ąŠą▓ ą┤ą░ąĮąĮčŗčģ.
ąŻ ą║ą░ąČą┤ąŠą╣ čüčéčĆąŠą║ąĖ ąĄčüčéčī čé菹│, čüą▓čÅąĘą░ąĮąĮčŗą╣ čü ąĮąĄą╣. ąó菹│ čüąŠčüč鹊ąĖčé ąĖąĘ čüą╗ąĄą┤čāčÄčēąĖčģ 4 čćą░čüč鹥ą╣:
ŌĆó 20-ą▒ąĖčéąĮčŗą╣ č鹥ą│ ą░ą┤čĆąĄčüą░: čüčĆą░ą▓ąĮąĖą▓ą░ąĄčéčüčÅ čü ą░ą┤čĆąĄčüąŠą╝ ą┐ą░ą╝čÅčéąĖ, čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą┐ąŠą┐ą░ą┤ą░ąĮąĖąĄ ą▓ ą║čŹčł ąĖą╗ąĖ ą┐čĆąŠą╝ą░čģ ą║čŹčłą░.
ŌĆó LRU Priority: ą┐čĆąĖąŠčĆąĖč鹥čé ą┤ą╗čÅ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮąŠą╣ ą┐ąŠą╗ąĖčéąĖą║ąĖ LRU.
ŌĆó LRU State: čüąŠčüč鹊čÅąĮąĖąĄ LRU, ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą╝ ą║čŹčłą░ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┐ąŠą╗ąĖčéąĖą║ąĖ LRU.
ŌĆó Valid-ą▒ąĖčé: ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéčī ą┤ą░ąĮąĮčŗčģ čüčéčĆąŠą║ąĖ.
32-ą▒ąĖčéąĮą░čÅ ąŠą▒ą╗ą░čüčéčī ą░ą┤čĆąĄčüą░ ą┐čĆąĖą▓čÅąĘą░ąĮą░ ą║ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ ą║čŹčłą░ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
ŌĆó ąÆčŗą▒ąŠčĆ ą┐ąŠą┤ą▒ą░ąĮą║ą░ (Subbank Select): ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ąŠčéą┤ąĄą╗čīąĮčŗą╣ 4 ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗą╣ ą┐ąŠą┤ą▒ą░ąĮą║.
ŌĆó ąÆčŗą▒ąŠčĆ ąĮą░ą▒ąŠčĆą░ (Set Select): ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ąĮą░ą▒ąŠčĆ ąĖąĘ 32 ąĮą░ą▒ąŠčĆąŠą▓ ą║čŹčłą░.
ŌĆó ąÆčŗą▒ąŠčĆ ą▒ą░ą╣čéą░ (Byte Select): ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ą▒ą░ą╣čé ąĖąĘ ą┤ą░ąĮąĮąŠą╣ čüčéčĆąŠą║ąĖ.
ąØą░ čĆąĖčü. 5 ą┐ąŠą║ą░ąĘą░ąĮąŠ, ą║ą░ą║ ąŠčĆą│ą░ąĮąĖąĘąŠą▓ą░ąĮ 4 ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗą╣ ą┐ąŠą┤ą▒ą░ąĮą║ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣. ąÜą░ąČą┤čŗą╣ 4 ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗą╣ ą┐ąŠą┤ą▒ą░ąĮą║ąĖ ąĖą╝ąĄąĄčé ąŠą┤ąĖąĮą░ą║ąŠą▓čāčÄ čüčéčĆčāą║čéčāčĆčā.
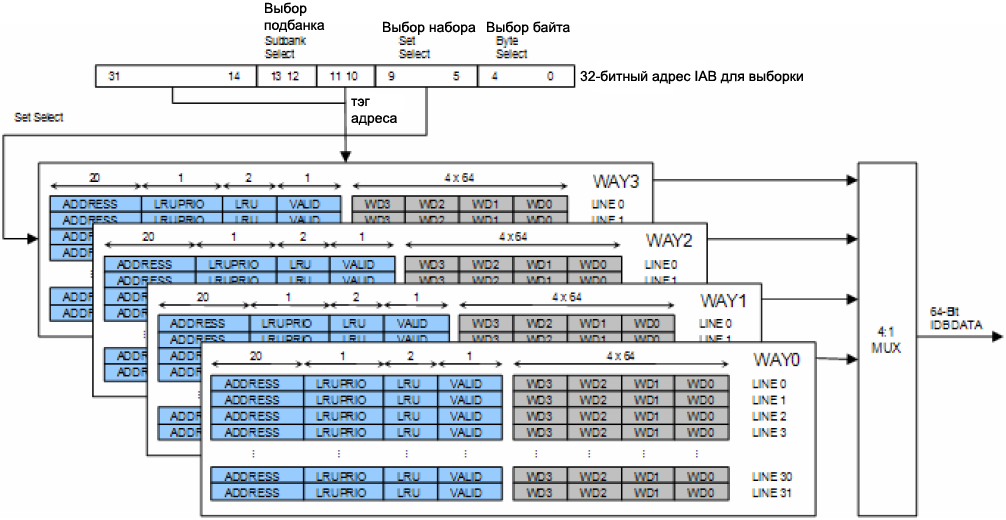
ąĀąĖčü. 5. ąÜąŠąĮčäąĖą│čāčĆą░čåąĖčÅ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą┤ą╗čÅ ąŠą┤ąĮąŠą│ąŠ ą┐ąŠą┤ą▒ą░ąĮą║ą░, ą┐čĆąĖą╝ąĄąĮąĄąĮą░ ąŠčĆą│ą░ąĮąĖąĘą░čåąĖčÅ ą║čŹčłą░ 4-way set associative.
ąóą░ą▒ą╗ąĖčåą░ 3. ą¤ąŠą╗ąĖčéąĖą║ą░ ąĘą░ą╝ąĄąĮčŗ ą┤ą╗čÅ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ Blackfin.
ąĪąĖčéčāą░čåąĖčÅ
|
ąĪčéčĆą░č鹥ą│ąĖčÅ |
| ąóąŠą╗čīą║ąŠ ąŠą┤ąĖąĮ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╣ way ą▓ ąĮą░ą▒ąŠčĆąĄ (set) |
ą¤čĆąĖčģąŠą┤čÅčēąĖą╣ ą▒ą╗ąŠą║ ąĘą░ą╝ąĄąĮąĖčé čŹč鹊čé ą▒ą╗ąŠą║ |
| ąæąŠą╗čīčłąĄ ąŠą┤ąĮąŠą│ąŠ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą│ąŠ way ą▓ ą║čŹčłąĄ |
ąØąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╣ way ą▒čāą┤ąĄčé ąĘą░ą╝ąĄąĮąĄąĮ ą▓ čéą░ą║ąŠą╝ ą┐ąŠčĆčÅą┤ą║ąĄ: ą┐ąĄčĆą▓čŗą╝ way0, ąĘą░č鹥ą╝ way1, way2, ąĖ ą▓ ą║ąŠąĮčåąĄ way3. |
| ąÆ ą║čŹčłąĄ ąĮąĄčé ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗčģ way |
ąæčāą┤ąĄčé ąĘą░ą╝ąĄąĮąĄąĮ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╣ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą┤ą░ą▓ąĮąŠ way (Last-recently used, LRU). ąöą╗čÅ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮąŠą╣ ą┐ąŠą╗ąĖčéąĖą║ąĖ LRU: way čü ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ ąĮąĄ ą▒čāą┤ąĄčé ąĘą░ą╝ąĄąĮąĄąĮ, ąĄčüą╗ąĖ ąĖą╝ąĄąĄčéčüčÅ ą▓ čŹč鹊ą╝ ąĮą░ą▒ąŠčĆąĄ way čü ąĮąĖąĘą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝. ąØąĖąĘą║ąŠą┐čĆąĖąŠčĆąĖč鹥čéąĮčŗą╣ ą▒ą╗ąŠą║ ąĮąĄ ą╝ąŠąČąĄčé ąĘą░ą╝ąĄąĮąĖčéčī ą▓čŗčüąŠą║ąŠą┐čĆąĖąŠčĆąĖč鹥čéąĮčŗą╣. ąĢčüą╗ąĖ čā ą▓čüąĄčģ way ą▓čŗčüąŠą║ąĖą╣ ą┐čĆąĖąŠčĆąĖč鹥čé, č鹊 way čü ąĮąĖąĘą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ ąĮąĄ ą╝ąŠąČąĄčé ą║čŹčłąĖčĆąŠą▓ą░čéčīčüčÅ. |
ą¤ąŠą┐ą░ą┤ą░ąĮąĖčÅ/ą┐čĆąŠą╝ą░čģąĖ ą║čŹčłą░ ąĖ ąĘą░ą╝ąĄąĮą░ čüčéčĆąŠą║ąĖ ą║čŹčłą░. ą¤ąŠą┐ą░ą┤ą░ąĮąĖąĄ ą▓ ą║čŹčł ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčéčüčÅ ą┐čāč鹥ą╝ čüčĆą░ą▓ąĮąĄąĮąĖčÅ čüčéą░čĆčłąĖčģ 18 ą▒ąĖčé ąĖ ą▒ąĖč鹊ą▓ 11 ąĖ 10 ą░ą┤čĆąĄčüą░ ą▓čŗą▒ąŠčĆą║ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čü č鹥ą│ąŠą╝ ą░ą┤čĆąĄčüą░ ą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗčģ čüčéčĆąŠą║, ąĮą░čģąŠą┤čÅčēąĖčģčüčÅ ą▓ ą┤ą░ąĮąĮčŗą╣ ą╝ąŠą╝ąĄąĮčé ą▓ ąĮą░ą▒ąŠčĆąĄ ą║čŹčłą░. ąĢčüą╗ąĖ čüčĆą░ą▓ąĮąĄąĮąĖąĄ čü č鹥ą│ąŠą╝ ą░ą┤čĆąĄčüą░ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čüąŠą▓ą┐ą░ą┤ąĄąĮąĖąĄ, č鹊 ą┐ąŠą╗čāčćą░ąĄčéčüčÅ ą┐ąŠą┐ą░ą┤ą░ąĮąĖąĄ ą▓ ą║čŹčł. ąĢčüą╗ąĖ čüčĆą░ą▓ąĮąĄąĮąĖąĄ ąĮąĄ ą┤ą░ą╗ąŠ ą┐ąŠą╗ąŠąČąĖč鹥ą╗čīąĮąŠą│ąŠ čĆąĄąĘčāą╗čīčéą░čéą░, č鹊 ą┐ąŠą╗čāčćą░ąĄčéčüčÅ ą┐čĆąŠą╝ą░čģ ą╝ąĖą╝ąŠ ą║čŹčłą░.
ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ą┐čĆąŠąĖąĘąŠčłąĄą╗ ą┤ąŠčüčéčāą┐ ą┐ąŠ ą░ą┤čĆąĄčüčā 0x10374956. ąŁč鹊čé ą░ą┤čĆąĄčü ą┐čĆąĖą▓čÅąĘą░ąĮ ą║ set-10 ą┐ąŠą┤ą▒ą░ąĮą║ą░ 0. ąĪčéą░čĆčłąĖąĄ 18 ą▒ąĖčé ąĖ ą▒ąĖčéčŗ 11-10 čŹč鹊ą│ąŠ ą░ą┤čĆąĄčüą░ (č乊čĆą╝ąĖčĆčāčÄčé čüą╗ąŠą▓ąŠ čé菹│ą░) ą▒čāą┤čāčé čüčĆą░ą▓ąĮąĖą▓ą░čéčīčüčÅ čüąŠ ą▓čüąĄą╝ąĖ ą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝ąĖ čé菹│ą░ą╝ąĖ (čā ą║ąŠč鹊čĆčŗčģ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ valid-ą▒ąĖčé) ą▓ ąĮą░ą▒ąŠčĆąĄ set-10.
ą¤čĆąĖ ą┐čĆąŠą╝ą░čģąĄ ą║čŹčłą░ ą▒ą╗ąŠą║ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ą┤ąŠčüčéčāą┐ ąĮą░ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░, čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī ąĮąĄą┤ąŠčüčéą░čÄčēčāčÄ čüčéčĆąŠą║čā ą║čŹčłą░ ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ. ą»ą┤čĆąŠ ą┐čĆąĖąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé čĆą░ą▒ąŠčéčā, ą┐ąŠą║ą░ ąĮąĄ ą▒čāą┤ąĄčé ą▓ąŠąĘą▓čĆą░čēąĄąĮąŠ čåąĄą╗ąĄą▓ąŠąĄ čüą╗ąŠą▓ąŠ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ.
ąÉą┤čĆąĄčü ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ čÅą▓ą╗čÅąĄčéčüčÅ ą░ą┤čĆąĄčüąŠą╝ čåąĄą╗ąĄą▓ąŠą│ąŠ čüą╗ąŠą▓ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąæą╗ąŠą║ ąĘą░ą╝ąĄąĮčŗ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą▒ąĖčéčŗ Valid ąĖ LRU (ąĮą░ čĆą░ąĘą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĮčŗčģ ą┐čāčéčÅčģ, unlocked ways), čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī, ą║ą░ą║ąŠą╣ ą▒ą╗ąŠą║ (ąĖąĘ ąĖą╝ąĄčÄčēąĖčģčüčÅ ą▒ą╗ąŠą║ąŠą▓ ą▓ ąĮą░ą▒ąŠčĆąĄ) ą▒čāą┤ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ ą║čŹčłą░. ąÆ čéą░ą▒ą╗ąĖčåąĄ 3 ą┐ąŠą║ą░ąĘą░ąĮąŠ, ą║ą░ą║ ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ą┐ąŠą╗ąĖčéąĖą║ą░ ąĘą░ą╝ąĄąĮčŗ čüčéčĆąŠą║ąĖ ą║čŹčłą░.
ąŚą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ čüąŠčüč鹊ąĖčé ąĖąĘ ąĘą░čģą▓ą░čéą░ 32 ą▒ą░ą╣čé (ąŠą┤ąĖąĮ ą▒ą╗ąŠą║) ą┤ą░ąĮąĮčŗčģ ąĖąĘ ą┐ą░ą╝čÅčéąĖ. ąÉą┤čĆąĄčü ą┤ą╗čÅ ą┐ąĄčĆąĄą┤ą░čćąĖ čćč鹥ąĮąĖčÅ čÅą▓ą╗čÅąĄčéčüčÅ ą░ą┤čĆąĄčüąŠą╝ čåąĄą╗ąĄą▓ąŠą│ąŠ čüą╗ąŠą▓ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ą¤čĆąĖ ąŠčéą▓ąĄč鹥 ąĮą░ ąĘą░ą┐čĆąŠčü čćč鹥ąĮąĖčÅ čüčéčĆąŠą║ąĖ ąŠčé ą▒ą╗ąŠą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą┐ą░ą╝čÅčéąĖ ą▓ąĮąĄčłąĮčÅčÅ ą┐ą░ą╝čÅčéčī ą▓ąĄčĆąĮąĄčé čüąĮą░čćą░ą╗ą░ 64-ą▒ąĖčéąĮąŠąĄ čüą╗ąŠą▓ąŠ čåąĄą╗ąĄą▓ąŠą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąĪą╗ąĄą┤čāčÄčēąĖąĄ 3 čüą╗ąŠą▓ą░ ą▒čāą┤čāčé ąĘą░čģą▓ą░čéčŗą▓ą░čéčīčüčÅ ą┤čĆčāą│ ąĘą░ ą┤čĆčāą│ąŠą╝ ą▓ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗčģ ą░ą┤čĆąĄčüą░čģ, ą║ą░ą║ čŹč鹊 ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ čéą░ą▒ą╗ąĖčåąĄ 4.
ąóą░ą▒ą╗ąĖčåą░ 4. ą¤ąŠčĆčÅą┤ąŠą║ ą▓čŗą▒ąŠčĆą║ąĖ čüą╗ąŠą▓ą░ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣.
ą”ąĄą╗ąĄą▓ąŠąĄ čüą╗ąŠą▓ąŠ
|
ą¤ąŠčĆčÅą┤ąŠą║ ą▓čŗą▒ąŠčĆą║ąĖ ą┤ą╗čÅ čüą╗ąĄą┤čāčÄčēąĖčģ čéčĆąĄčģ čüą╗ąŠą▓ |
| WD0 |
WD0, WD1, WD2, WD3 |
| WD1 |
WD1, WD2, WD3, WD0 |
| WD2 |
WD2, WD3, WD0, WD1 |
| WD3 |
WD3, WD0, WD1, WD2 |
ąÜąŠą│ą┤ą░ ą▒ą╗ąŠą║ ą║čŹčłą░ ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, ą║ą░ąČą┤ąŠąĄ 64-ą▒ąĖčéąĮąŠąĄ čüą╗ąŠą▓ąŠ ą▒čāč乥čĆąĖąĘąĖčĆčāąĄčéčüčÅ ą▓ 4-čÅč湥ąĄčćąĮąŠą╝ ą▒čāč乥čĆąĄ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ, ą┐ąĄčĆąĄą┤ č鹥ą╝ ą║ą░ą║ ąŠąĮąŠ ą▒čāą┤ąĄčé ąĘą░ą┐ąĖčüą░ąĮąŠ ą▓ 4 ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗą╣ ą▒ą░ąĮą║ ą┐ą░ą╝čÅčéąĖ. ąæčāč乥čĆ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čÅą┤čĆčā ą┐ąŠą╗čāčćąĖčéčī ą┤ą░ąĮąĮčŗąĄ ąĖąĘ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ą▓ąŠ ą▓čĆąĄą╝čÅ, ą║ąŠą│ą┤ą░ čüčéčĆąŠą║ą░ ą┐ąĄčĆąĄą┤ą░ąĄčéčüčÅ ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, ą▒ąĄąĘ ąŠąČąĖą┤ą░ąĮąĖčÅ, ą┐ąŠą║ą░ ą▓čüčÅ čüčéčĆąŠą║ą░ ą▒čāą┤ąĄčé ąĘą░ą┐ąĖčüą░ąĮą░ ą▓ ą║čŹčł.
ŌĆó ą║čŹčł ą▓čŗą║ą╗čÄč湥ąĮ: ą┤ąĄą╗ą░ąĄčéčüčÅ ą▓čŗą▒ąŠčĆą║ą░ 64 ą▒ąĖčé / 8 ą▒ą░ą╣čé
ŌĆó ą║čŹčł ą▓ą║ą╗čÄč湥ąĮ: ą▓čüąĄą│ą┤ą░ ą┤ąĄą╗ą░ąĄčéčüčÅ ą▓čŗą▒ąŠčĆą║ą░ 256 ą▒ąĖčé / 32 ą▒ą░ą╣čé (čāčüą║ąŠčĆąĄąĮąĮąŠąĄ ą┐ą░ą║ąĄčéąĮąŠąĄ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ)
ŌĆó ą¤ąŠčüą║ąŠą╗čīą║čā ąĖąĮč鹥čĆč乥ą╣čü ą║ SDRAM (ą▓ąĮąĄčłąĮčÅčÅ ą┐ą░ą╝čÅčéčī) ąĮą░ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin ąĖą╝ąĄąĄčé čłąĖčĆąĖąĮčā 16 ą▒ąĖčé, č鹊 ą║ą░ąČą┤ą░čÅ ą▓čŗą▒ąŠčĆą║ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ čüąŠčüč鹊ąĖčé ąĖąĘ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéąĖ 16-ą▒ąĖčéąĮčŗčģ ą┤ąŠčüčéčāą┐ąŠą▓ ą║ ą┐ą░ą╝čÅčéąĖ.
ąØą░ čĆąĖčü. 6 ą┐ąŠą║ą░ąĘą░ąĮą░ ą▓čŗą▒ąŠčĆą║ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ SDRAM (čåąĄą╗ąĄą▓ąŠą╣ ą░ą┤čĆąĄčü 0x000Ah), ą║ąŠą│ą┤ą░ ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣ ą▓čŗą║ą╗čÄč湥ąĮ. ą¤čĆąĖ čŹč鹊ą╝ ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ 64-ą▒ąĖčéąĮčŗą╣ ą▒ą╗ąŠą║ (ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮ ą║ą░ą║ WDx). ąØą░čćą░ą╗čīąĮčŗą╣ ą░ą┤čĆąĄčü ą▒ą╗ąŠą║ą░ 0x0008h, ą┐ąŠčüą║ąŠą╗čīą║čā ą┤ąŠčüčéčāą┐ (ą▓čŗą▒ąŠčĆą║ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ) ą▓čŗčĆąŠą▓ąĮąĄąĮ ąĮą░ ą│čĆą░ąĮąĖčåčā ą▓ 64 ą▒ąĖčéą░.
ąĀąĖčü. 7 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé č鹊čé ąČąĄ čüą░ą╝čŗą╣ ą┤ąŠčüčéčāą┐, ą║ąŠą│ą┤ą░ ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣ ą▓ą║ą╗čÄč湥ąĮ. ąØą░čćą░ą╗čīąĮčŗą╣ ą░ą┤čĆąĄčü ąŠčüčéą░ą╗čüčÅ čĆą░ą▓ąĮčŗą╝ 0x0008h. ąŁč鹊 ąĮą░čćą░ą╗ąŠ WD1. WD2 ąĮą░čćąĖąĮą░ąĄčéčüčÅ čü ą░ą┤čĆąĄčüą░ 0x0010h, ąĖ WD3 ąĮą░čćąĖąĮą░ąĄčéčüčÅ čü ą░ą┤čĆąĄčüą░ 0x0018h. WD0 čü ą░ą┤čĆąĄčüąŠą╝ 0x0000h čÅą▓ą╗čÅąĄčéčüčÅ ą┐ąŠčüą╗ąĄą┤ąĮąĄą╣ čćą░čüčéčīčÄ ą┐ąĄčĆąĄą┤ą░ą▓ą░ąĄą╝ąŠą│ąŠ ą▒ą╗ąŠą║ą░ ą║čŹčłą░.
ąĀąĖčü. 8 ąĖ 9 ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčé ąĘą░ą┤ąĄčƹȹ║ąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┤ą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖą╣, čüąŠčģčĆą░ąĮąĄąĮąĮčŗčģ ą▓ąŠ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ (ąĮą░čćą░ą╗čīąĮčŗą╣ ą░ą┤čĆąĄčü 0x00000). ąĪąĖą│ąĮą░ą╗ "GPIO" ą┐ąĄčĆąĄą║ą╗čÄčćąĖčéčüčÅ ąĖąĘ 1 ą▓ 0 čäčāąĮą║čåąĖąĄą╣, čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĮąŠą╣ ą▓ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ. ąŁčéą░ čäčāąĮą║čåąĖčÅ ą▒čāą┤ąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī ą┐čĆąĖą╝ąĄčĆąĮąŠ čéą░ą║, ą║ą░ą║ ąĮą░ čŹč鹊ą╝ ą╗ąĖčüčéąĖąĮą│ąĄ:
[--SP] = (R7:7,P5:5);
P5.H = hi(FIO_FLAG_C);
P5.L = hi(FIO_FLAG_C);
R7 = 0x20 (z);
w[P5] = R7;
ssync;
(R7:7,P5:5) = [SP++];
rts;
ąöą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ SDRAM ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąŠą┐ąĄčĆą░čåąĖą╣ ą┐čĆąĖ čäą░ą║čéąĖč湥čüą║ąŠą╝ čćč鹥ąĮąĖąĖ ą┐ą░ą╝čÅčéąĖ (RD: ąŠąĘąĮą░čćą░ąĄčé ą║ąŠą╝ą░ąĮą┤čā čćč鹥ąĮąĖčÅ). ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ SDRAM čüą╝. čĆą░ąĘą┤ąĄą╗ "ąĪąŠąŠą▒čĆą░ąČąĄąĮąĖčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ".
ąĀąĖčü. 8 ąĖ 9 ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčé ą┤ąŠčüčéčāą┐ ą║ čüą┐ąĄčåąĖčäąĖčćąĮąŠą╝čā ą▒ą░ąĮą║čā ą▓ ą┐ą░ą╝čÅčéąĖ SDRAM. ąĪąĮą░čćą░ą╗ą░ čåąĄą╗ąĄą▓ą░čÅ čüčéčĆąŠą║ą░ (row, ąĖą╝ąĄąĄčéčüčÅ ą▓ ą▓ąĖą┤čā ąĮąĄ čüčéčĆąŠą║ą░ ą║čŹčłą░, ą░ čüčéčĆąŠą║ą░ SDRAM) ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ąŠčéą║čĆčŗčéą░ ą▓ ąŠčéą┤ąĄą╗čīąĮąŠą╝ ą▒ą░ąĮą║ąĄ (ACT: ą║ąŠą╝ą░ąĮą┤ą░ Active).
ą¤ąŠčüą╗ąĄ ąĘą░ą┤ąĄčƹȹ║ąĖ ACTIVE-to-READ-or-WRITE (tRCD, ąĘą┤ąĄčüčī čŹč鹊 3 čéą░ą║čéą░ SCLK), ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠčéą┐čĆą░ą▓ą╗ąĄąĮą░ ą║ąŠą╝ą░ąĮą┤ą░ čćč鹥ąĮąĖčÅ. ą¤ąŠčüą╗ąĄ ąĘą░ą┤ąĄčƹȹ║ąĖ ą▓čŗčüčéą░ą▓ą╗ąĄąĮąĖčÅ čüąĖą│ąĮą░ą╗ą░ čüč鹊ą╗ą▒čåą░ CAS (CL, ąĘą┤ąĄčüčī čŹč鹊 3 čéą░ą║čéą░ SCLK), čüčéą░ąĮąŠą▓ąĖčéčüčÅ ą┤ąŠčüčéčāą┐ąĮąŠą╣ ą┐ąĄčĆą▓ą░čÅ ą┐ąŠčĆčåąĖčÅ ą┤ą░ąĮąĮčŗčģ.
ąöąŠ ąĮą░čüč鹊čÅčēąĄą│ąŠ ą╝ąŠą╝ąĄąĮčéą░ ąĘą░ą┤ąĄčƹȹ║ą░ ą┤ąŠčüčéčāą┐ą░ čü ą▓ą║ą╗čÄč湥ąĮąĮčŗą╝ ą║čŹčłąĄą╝ ąĖ čü ą▓čŗą║ą╗čÄč湥ąĮąĮčŗą╝ ą║čŹčłąĄą╝ ą┐ąŠą║ą░ ąŠą┤ąĖąĮą░ą║ąŠą▓ą░čÅ. ąöą╗čÅ ą┐ąĄčĆą▓ąŠą│ąŠ 64-ą▒ąĖčéąĮąŠą│ąŠ ą▒ą╗ąŠą║ą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĮąĄčé ąĮąĖą║ą░ą║ąĖčģ ąŠčéą╗ąĖčćąĖą╣, ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ąŠą┤ąĖąĮą░ą║ąŠą▓ąŠąĄ. ą¤ąŠčüą╗ąĄ ą┐čĆąĖą╝ąĄčĆąĮąŠ 10 čéą░ą║č鹊ą▓ SCLK ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą┐ąĄčĆą▓ą░čÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ.
ąöąŠčüč鹊ąĖąĮčüčéą▓ąŠ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą┐čĆąŠčÅą▓ą╗čÅąĄčéčüčÅ ą┤ą╗čÅ čüą╗ąĄą┤čāčÄčēąĄą╣ ą┐ąŠčĆčåąĖąĖ ą║ąŠą┤ą░ ŌĆō ąĖ ąŠą▒čŗčćąĮąŠ ą┐čĆąŠčåąĄčüčü ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ ą╗ąĖąĮąĄąĄąĮ ŌĆō ą║ąŠč鹊čĆčŗą╣ ą▓čŗčćąĖčéčŗą▓ą░ąĄčéčüčÅ ą┐ąŠčüą╗ąĄ ą┐ąĄčĆą▓ąŠą│ąŠ 64-ą▒ąĖčéąĮąŠą│ąŠ ą▒ą╗ąŠą║ą░. ąÆ čüčĆą░ą▓ąĮąĄąĮąĖąĖ čüąŠ čüčéčĆąŠą║ąŠą╣ ą║čŹčłą░ ą▓ 256 ą▒ąĖčé, čŹč鹊 ąĘą░ą╣ą╝ąĄčé ąŠą║ąŠą╗ąŠ 4x11 (ą┐ą╗čÄčü ACT) čéą░ą║č鹊ą▓ SCLK, ą┐ąŠą║ą░ ą┐ąŠčüą╗ąĄą┤ąĮčÅčÅ ą┐ąŠčĆčåąĖčÅ ą┤ą░ąĮąĮčŗčģ ąĮąĄ ą▒čāą┤ąĄčé ą┤ąŠčüčéčāą┐ąĮą░ ąĮą░ EAB, ą║ąŠą│ą┤ą░ ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĮąĄ čĆą░ąĘčĆąĄčłąĄąĮ.
ąÜąŠą│ą┤ą░ ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣ čĆą░ąĘčĆąĄčłąĄąĮ, čéą░ ąČąĄ čüą░ą╝ą░čÅ ąŠą┐ąĄčĆą░čåąĖčÅ ą▓čŗą┐ąŠą╗ąĮąĖčéčüčÅ ąĘą░ 21 čéą░ą║čé SCLK (ą▓ą║ą╗čÄčćą░čÅ ACT).

ąĀąĖčü. 6. ąÆčŗą▒ąŠčĆą║ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠą│ą┤ą░ ą║čŹčł ąŠčéą║ą╗čÄč湥ąĮ.

ąĀąĖčü. 7. ąÆčŗą▒ąŠčĆą║ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ąŠą│ą┤ą░ ą║čŹčł ą▓ą║ą╗čÄč湥ąĮ.

ąĀąĖčü. 8. ąŚą░ą┤ąĄčƹȹ║ą░ čü ąĖąĮčüčéčĆčāą║čåąĖąĄą╣, ą║ąŠą│ą┤ą░ ą║čŹčł ąŠčéą║ą╗čÄč湥ąĮ.
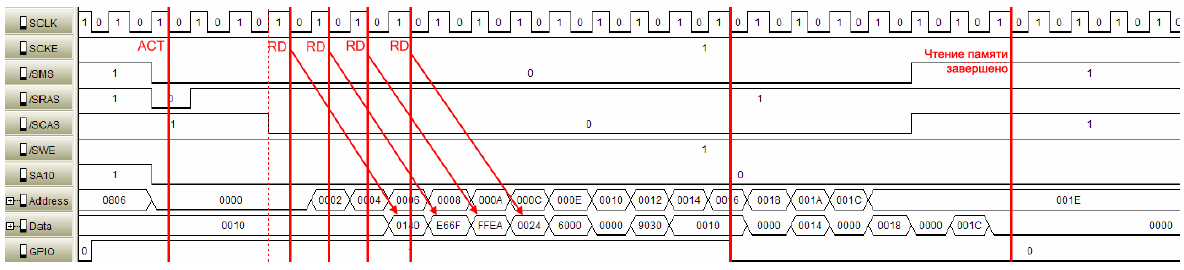
ąĀąĖčü. 9. ąŚą░ą┤ąĄčƹȹ║ą░ čü ąĖąĮčüčéčĆčāą║čåąĖąĄą╣, ą║ąŠą│ą┤ą░ ą║čŹčł ą▓ą║ą╗čÄč湥ąĮ.
[ąÜąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ Blackfin]
ą×čĆą│ą░ąĮąĖąĘą░čåąĖčÅ ą║čŹčłą░. ąŻ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ADSP-BF533 ąĖą╝ąĄąĄčéčüčÅ 64 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ ą▓čüčéčĆąŠąĄąĮąĮąŠą╣ ą▓ ą║čĆąĖčüčéą░ą╗ą╗ ą┐ą░ą╝čÅčéąĖ ą┤ą░ąĮąĮčŗčģ. 32 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ ą┐ą░ą╝čÅčéąĖ ą┤ą░ąĮąĮčŗčģ ą┤ąŠčüčéčāą┐ąĮčŗ ą║ą░ą║ SRAM ą┤ą░ąĮąĮčŗčģ. ą×čüčéą░ą╗čīąĮą░čÅ čćą░čüčéčī - ąĄčēąĄ 32 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ ą┐ą░ą╝čÅčéąĖ - ą┤ąŠčüčéčāą┐ąĮą░ ą║ą░ą║ 2 ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗčģ ą▒ą░ąĮą║ą░ ą┐ą░ą╝čÅčéąĖ ą┐ąŠ 16 ą║ąĖą╗ąŠą▒ą░ą╣čé, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠąČąĮąŠ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░čéčī ą╗ąĖą▒ąŠ ą║ą░ą║ ą║čŹčł ą┤ą░ąĮąĮčŗčģ, ą╗ąĖą▒ąŠ ą║ą░ą║ SRAM ą┤ą░ąĮąĮčŗčģ.
ąØąĄą║ąŠč鹊čĆčŗąĄ ą╝ąŠą┤ąĄą╗ąĖ čüąĄą╝ąĄą╣čüčéą▓ą░ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ ą▒ą░ąĮą║ ą┐ą░ą╝čÅčéąĖ ą┤ą░ąĮąĮčŗčģ, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĮąŠ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░čéčī ą╗ąĖą▒ąŠ ą║ą░ą║ ą║čŹčł ą┤ą░ąĮąĮčŗčģ, ą╗ąĖą▒ąŠ ą║ą░ą║ SRAM. ą¤ąŠą┤čĆąŠą▒ąĮąŠčüčéąĖ čüą╝. ą▓ čéą░ą▒ą╗ąĖčåąĄ 2.
ąÜąŠą│ą┤ą░ ą║čŹčł ą┤ą░ąĮąĮčŗčģ čĆą░ąĘčĆąĄčłąĄąĮ, č鹊 ąŠąĮ čĆą░ą▒ąŠčéą░ąĄčé ą║ą░ą║ ą┐ą░ą╝čÅčéčī 2-way set associative. ąÜąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą┐ąŠą╗ąĖčéąĖą║čā LRU ą┤ą╗čÅ ąĘą░ą╝ąĄąĮčŗ čüčéčĆąŠą║ąĖ ą║čŹčłą░ (ąŠąĮ ąĮąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮčāčÄ ą┐ąŠą╗ąĖčéąĖą║čā LRU, ą║ą░ą║ čŹč鹊 ąĖą╝ąĄąĄčé ą╝ąĄčüč鹊 čü ą║čŹčłąĄą╝ ąĖąĮčüčéčĆčāą║čåąĖą╣).
ŌĆó ąÆ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą▒ą░ąĮą║ąŠą▓, čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĮčŗčģ ą║ą░ą║ ą║čŹčł, ą║čŹčł ą┤ą░ąĮąĮčŗčģ ą╝ąŠąČąĄčé ąĘą░ąĮąĖą╝ą░čéčī ą╗ąĖą▒ąŠ 16 ą║ąĖą╗ąŠą▒ą░ą╣čé (ąŠą┤ąĖąĮ ą▒ą░ąĮą║), ą╗ąĖą▒ąŠ 32 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ (ą┤ą▓ą░ ą▒ą░ąĮą║ą░).
ŌĆó ąÜą░ąČą┤čŗą╣ 16 ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗą╣ ą▒ą░ąĮą║ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ ąŠčĆą│ą░ąĮąĖąĘąŠą▓ą░ąĮ ą║ą░ą║ č湥čéčŗčĆąĄ 4-ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗčģ ą┐ąŠą▒ą░ąĮą║ą░. ą¤ąŠą┤ą▒ą░ąĮą║ ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ą┐ąŠ ą▒ąĖčéą░ą╝ ą░ą┤čĆąĄčüą░ ą┐ą░ą╝čÅčéąĖ [13:12].
ŌĆó ąÜą░ąČą┤čŗą╣ 4-ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗą╣ ą┐ąŠą┤ą▒ą░ąĮą║ čüąŠčüč鹊ąĖčé ąĖąĘ 64 ąĮą░ą▒ąŠčĆąŠą▓ (set). ąØą░ą▒ąŠčĆ ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ą▒ąĖčéą░ą╝ąĖ ą░ą┤čĆąĄčüą░ ą┐ą░ą╝čÅčéąĖ [10:5].
ŌĆó ąÜą░ąČą┤čŗą╣ ąĮą░ą▒ąŠčĆ čüąŠčüč鹊ąĖčé ąĖąĘ 2 ą┐čāč鹥ą╣ (way). ą¤čāčéčī ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą╝ ą║čŹčłą░ ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü ą┐ąŠą╗ąĖčéąĖą║ąŠą╣ čĆą░ąĘą╝ąĄčēąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ ą║čŹčłą░. ą¤čāčéąĖ ą╝ąŠąČąĮąŠ ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆąŠą▓ą░čéčī ą┐ąŠ ą▒ąĖčéčā ą░ą┤čĆąĄčüą░ [11] ą▓ SRAM.
ŌĆó ąöčĆčāą│ąĖą╝ąĖ čüą╗ąŠą▓ą░ą╝ąĖ, ąĮą░ą▒ąŠčĆ set-0 ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮ ą┤ą▓čāą╝čÅ ą┐čāčéčÅą╝ąĖ čüčéčĆąŠą║ąĖ line-0.
ŌĆó ąĀą░ąĘą╝ąĄčĆ čüčéčĆąŠą║ąĖ ą║čŹčłą░ (ą║ąŠč鹊čĆą░čÅ ą┐ąŠą┤ą╗ąĄąČąĖčé čćč鹥ąĮąĖčÄ ą┐čĆąĖ ą┐čĆąŠą╝ą░čģąĄ ą╝ąĖą╝ąŠ ą║čŹčłą░) čüąŠčüčéą░ą▓ą╗čÅąĄčé 32 ą▒ą░ą╣čéą░.
ą¤ąŠą┤ąŠą▒ąĮąŠ ą║čŹčłčā ąĖąĮčüčéčĆčāą║čåąĖąĖ, ą║ą░ąČą┤ą░čÅ čüčéčĆąŠą║ą░ ą║čŹčłą░ ąĖą╝ąĄąĄčé čüą▓čÅąĘą░ąĮąĮčāčÄ čü ąĮąĄą╣ ą┐ąŠčĆčåąĖčÄ č鹥ą│ą░ (čüą╝. čĆąĖčü. 10):
ŌĆó 19-ą▒ąĖčéąĮčŗą╣ č鹥ą│ ą░ą┤čĆąĄčüą░: čüčĆą░ą▓ąĮąĖą▓ą░ąĄčéčüčÅ čü ą░ą┤čĆąĄčüąŠą╝ ą┐ą░ą╝čÅčéąĖ, čćč鹊ą▒čŗ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ą┐ąŠą┐ą░ą┤ą░ąĮąĖąĄ ą▓ ą║čŹčł ąĖą╗ąĖ ą┐čĆąŠą╝ą░čģ ą╝ąĖą╝ąŠ ą║čŹčłą░.
ŌĆó Dirty-ą▒ąĖčé: čŹč鹊čé ą▒ąĖčé ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 čüčéčĆąŠą║ą░ ą║čŹčłą░ ą▒čŗą╗ą░ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮą░.
ŌĆó LRU state: ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą╝ ą║čŹčłą░ ą┤ą╗čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą┐ąŠą╗ąĖčéąĖą║ąĖ LRU.
ŌĆó Valid-ą▒ąĖčé: ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéčī ą┤ą░ąĮąĮčŗčģ čüčéčĆąŠą║ąĖ ą║čŹčłą░.
32-ą▒ąĖčéąĮąŠąĄ ą░ą┤čĆąĄčüąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ą┐čĆąĖą▓čÅąĘą░ąĮąŠ ą║ ą┐ą░ą╝čÅčéąĖ ą║čŹčłą░ čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ (čüą╝. čĆąĖčü. 10):
ŌĆó Subbank select (ą▓čŗą▒ąŠčĆ ą┐ąŠą┤ą▒ą░ąĮą║ą░): ą▓čŗą▒ąĖčĆą░ąĄčé ąŠčéą┤ąĄą╗čīąĮčŗą╣ 4-ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗą╣ ą┐ąŠą┤ą▒ą░ąĮą║.
ŌĆó Set select (ą▓čŗą▒ąŠčĆ ąĮą░ą▒ąŠčĆą░): ą▓čŗą▒ąĖčĆą░ąĄčé ąĮą░ą▒ąŠčĆ (set) ąĖąĘ 64 ąĮą░ą▒ąŠčĆąŠą▓ ą║čŹčłą░.
ŌĆó Byte select (ą▓čŗą▒ąŠčĆ ą▒ą░ą╣čéą░): ą▓čŗą▒ąĖčĆą░ąĄčé ą▒ą░ą╣čé ąĖąĘ ąĖą╝ąĄčÄčēąĄą╣čüčÅ čüčéčĆąŠą║ąĖ.
ąØą░ čĆąĖčü. 10 ą┐ąŠą║ą░ąĘą░ąĮąŠ, ą║ą░ą║ ąŠčĆą│ą░ąĮąĖąĘąŠą▓ą░ąĮ 4-ą║ąĖą╗ąŠą▒ą░ą╣ąĮčéąĮčŗą╣ ą┐ąŠą┤ą▒ą░ąĮą║ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ. ąÜąŠą│ą┤ą░ ąŠą▒ą░ ą▒ą░ąĮą║ą░ ą┤ą░ąĮąĮčŗčģ čĆą░ąĘčĆąĄčłąĄąĮčŗ ą┤ą╗čÅ ą║čŹčłą░, č鹊 ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čüąŠčüč鹊čÅąĮąĖčÅ ą▒ąĖčéą░ DCBS ą╗ąĖą▒ąŠ ą▒ąĖčé 14 (ą║ą░ąČą┤čŗąĄ 16 ą║ąĖą╗ąŠą▒ą░ą╣čé) ąĖą╗ąĖ ą▒ąĖčé 23 (ą║ą░ąČą┤čŗąĄ 8 ą╝ąĄą│ą░ą▒ą░ą╣čé) ą░ą┤čĆąĄčüąĮąŠą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą▓čŗą▒ąŠčĆą░ ąŠą┤ąĮąŠą│ąŠ ąĖąĘ 16-ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗčģ ą▒ą░ąĮą║ąŠą▓ ą┤ą░ąĮąĮčŗčģ (čüą╝. čĆąĖčü. 11).
ąöąŠčüčéčāą┐ ąĮą░ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ čüąŠčüč鹊ąĖčé ąĖąĘ ąĘą░čģą▓ą░čéą░ 32 ą▒ą░ą╣čé ą┤ą░ąĮąĮčŗčģ ąĖąĘ ą┐ą░ą╝čÅčéąĖ. ąÉą┤čĆąĄčü ą┤ą╗čÅ čéčĆą░ąĮčüč乥čĆą░ čćč鹥ąĮąĖčÅ čŹč鹊 ą░ą┤čĆąĄčü čåąĄą╗ąĄą▓ąŠą│ąŠ čüą╗ąŠą▓ą░ ą┤ą░ąĮąĮčŗčģ. ą¤čĆąĄą┤ą┐ąŠą╗ąŠąČąĖą╝, čćč鹊 ąĖą╝ąĄą╗ ą╝ąĄčüč鹊 ą┤ąŠčüčéčāą┐ I/O ąĮą░ čćč鹥ąĮąĖąĄ 16-ą▒ąĖčéąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ, ą║ąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąŠčéą▓ąĄčé ąĮą░ ąĘą░ą┐čĆąŠčü čćč鹥ąĮąĖčÅ čüčéčĆąŠą║ąĖ ąŠčé ą▒ą╗ąŠą║ą░ čćč鹥ąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ, ą▓ąĮąĄčłąĮčÅčÅ ą┐ą░ą╝čÅčéčī ą▓ąŠąĘą▓čĆą░čéąĖčé čüąĮą░čćą░ą╗ą░ 16-ą▒ąĖčéąĮąŠąĄ čåąĄą╗ąĄą▓ąŠąĄ čüą╗ąŠą▓ąŠ ą┤ą░ąĮąĮčŗčģ. ąĪą╗ąĄą┤čāčÄčēąĖąĄ 15 čüą╗ąŠą▓ ą▒čāą┤čāčé ąĘą░čģą▓ą░č湥ąĮčŗ ą┤čĆčāą│ ąĘą░ ą┤čĆčāą│ąŠą╝ ą▓ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗčģ ą░ą┤čĆąĄčüą░čģ, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ čéą░ą▒ą╗ąĖčåąĄ 5.
ąóą░ą▒ą╗ąĖčåą░ 5. ą¤ąŠčĆčÅą┤ąŠą║ ą▓čŗą▒ąŠčĆą║ąĖ čüą╗ąŠą▓ą░ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ.
ą”ąĄą╗ąĄą▓ąŠąĄ čüą╗ąŠą▓ąŠ
|
ą¤ąŠčĆčÅą┤ąŠą║ ą▓čŗą▒ąŠčĆą║ąĖ ą┤ą╗čÅ čüą╗ąĄą┤čāčÄčēąĖčģ 15 čüą╗ąŠą▓ |
| WD0 |
WD0, ..., WD15 |
| WD1 |
WD1, ..., WD15, WD0 |
| WD2 |
WD2, ..., WD15, WD0, WD1 |
| WD15 |
WD15, WD0, ..., WD14 |
ąÜąŠą│ą┤ą░ čüčéčĆąŠą║ą░ ą║čŹčłą░ ąĘą░ą▒ąĖčĆą░ąĄčéčüčÅ ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, ą║ą░ąČą┤ąŠąĄ 32-ą▒ąĖčéąĮąŠąĄ čüą╗ąŠą▓ąŠ ą▒čāč乥čĆąĖąĘčāąĄčéčüčÅ ą▓ 8-čÅč湥ąĄčćąĮąŠą╝ ą▒čāč乥čĆąĄ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ (line fill buffer), ą┐ąĄčĆąĄą┤ ąĘą░ą┐ąĖčüčīčÄ ą▓ 4-ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗą╣ ą▒ą░ąĮą║ ą┐ą░ą╝čÅčéąĖ. ąæčāč乥čĆ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čÅą┤čĆčā ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ ą┤ą░ąĮąĮčŗą╝ ąĖąĘ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ą║ą░ą║ ą║ čüčéčĆąŠą║ąĄ, ą┐ąŠą╗čāčćą░ąĄą╝ąŠą╣ ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, ą▒ąĄąĘ ąŠąČąĖą┤ą░ąĮąĖčÅ, ą┐ąŠą║ą░ čüčéčĆąŠą║ą░ ą▒čāą┤ąĄčé ąĘą░ą┐ąĖčüą░ąĮą░ ą▓ ą║čŹčł.
ąÆ ąŠčéą╗ąĖčćąĖąĄ ąŠčé ąĖąĮčüčéčĆčāą║čåąĖą╣, ą┤ą░ąĮąĮčŗąĄ ąŠą▒čŗčćąĮąŠ ą╝ąŠą┤ąĖčäąĖčåąĖčĆčāčÄčéčüčÅ ąĖ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ ąŠą▒čĆą░čéąĮąŠ ą▓ąŠ (ą▓ąĮąĄčłąĮčÄčÄ) ą┐ą░ą╝čÅčéčī. ąøčÄą▒ą░čÅ ą║čŹčłąĖčĆčāąĄą╝ą░čÅ ąŠą┤ąĖąĮąŠčćąĮą░čÅ (ąĮąĄ ą┐ą░ą║ąĄčéąĮą░čÅ) ąĘą░ą┐ąĖčüčī čÅą┤čĆą░ ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī ą┐čĆąŠąĖčüčģąŠą┤ąĖčé č湥čĆąĄąĘ ą▒čāč乥čĆ ąĘą░ą┐ąĖčüąĖ. ąōą╗čāą▒ąĖąĮą░ čŹč鹊ą│ąŠ ą▒čāč乥čĆą░ ą╝ąŠąČąĄčé ąĖąĘą╝ąĄąĮčÅčéčīčüčÅ ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü ąĮą░čüčéčĆąŠą╣ą║ą░ą╝ąĖ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ą┐čĆąĖąŠčĆąĖč鹥čéą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ (interrupt priority register, IPRIO).
ąóčĆąĄčéąĖą╣ ą▒čāč乥čĆ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ ą│čĆčÅąĘąĮąŠą╣ čüčéčĆąŠą║ąĖ ą║čŹčłą░, ą║ąŠč鹊čĆą░čÅ čüą▒čĆą░čüčŗą▓ą░ąĄčéčüčÅ (flush) ąĖą╗ąĖ ąĘą░ą╝ąĄąĮčÅąĄčéčüčÅ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄą╝ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ąĖ ąĘą░č鹥ą╝ ą┤ą╗čÅ ąĖąĮąĖčåąĖą░ą╗ąĖąĘą░čåąĖąĖ ą┐ą░ą║ąĄčéąĮąŠą╣ ąŠą┐ąĄčĆą░čåąĖąĖ ąĘą░ą┐ąĖčüąĖ ąĮą░ čłąĖąĮąĄ, čćč鹊ą▒čŗ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąŠą▒čĆą░čéąĮąŠąĄ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ čüčéčĆąŠą║ąĖ ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī. ąŁč鹊čé ą▒čāč乥čĆ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ "ą▒čāč乥čĆąŠą╝ ąČąĄčĆčéą▓čŗ", victim-ą▒čāč乥čĆ. ą×ąĮ čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ ą▒čāč乥čĆą░ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ, ą║ą░ą║ FIFO ą│ą╗čāą▒ąĖąĮąŠą╣ 8 čÅč湥ąĄą║, čā ą║ą░ąČą┤ąŠą╣ čłąĖčĆąĖąĮą░ 32 ą▒ąĖčéą░ (čüą╝. čĆąĖčü. 1).
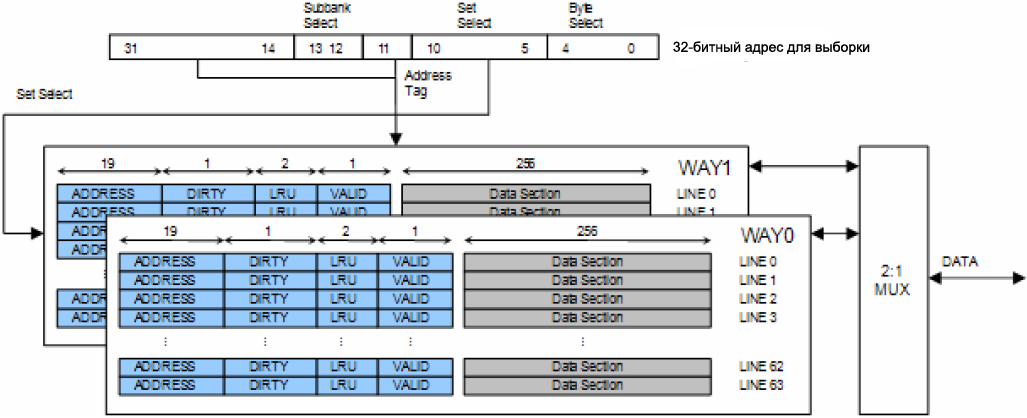
ąĀąĖčü. 10. ąÜąŠąĮčäąĖą│čāčĆą░čåąĖčÅ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ ąŠą┤ąĮąŠą│ąŠ ą┐ąŠą┤ą▒ą░ąĮą║ą░ ŌĆō 2-way set associative.

ąĀąĖčü. 11. ą¤čĆąĖą▓čÅąĘą║ą░ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü ą▒ąĖč鹊ą╝ DCBS.
ąĀąĖčü. 12. ąÆčŗą▒ąŠčĆą║ą░ ą┤ą░ąĮąĮčŗčģ, ą║ąŠą│ą┤ą░ ą║čŹčł ą▓čŗą║ą╗čÄč湥ąĮą░.
ąĀąĖčü. 13. ąÆčŗą▒ąŠčĆą║ą░ ą┤ą░ąĮąĮčŗčģ, ą║ąŠą│ą┤ą░ ą║čŹčł ą▓ą║ą╗čÄč湥ąĮą░.
ąÆčŗą▒ąŠčĆą║ą░ ą┤ą░ąĮąĮčŗčģ ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ
ŌĆó ą║čŹčł ą▓čŗą║ą╗čÄč湥ąĮą░: ą┤ąŠčüčéčāą┐ čłąĖčĆąĖąĮąŠą╣ 1 ą▒ą░ą╣čé, 2 ą▒ą░ą╣čéą░ ąĖą╗ąĖ 4 ą▒ą░ą╣čéą░
ŌĆó ą║čŹčł ą▓ą║ą╗čÄč湥ąĮą░: ą▓čüąĄą│ą┤ą░ ą┤ąĄą╗ą░ąĄčéčüčÅ ą▓čŗą▒ąŠčĆą║ą░ 256 ą▒ąĖčé / 32 ą▒ą░ą╣čéą░ (ą┐ą░ą║ąĄčéąĮąŠąĄ čāčüą║ąŠčĆąĄąĮąĮąŠąĄ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ)
ŌĆó ą¤ąŠčüą║ąŠą╗čīą║čā ąĖąĮč鹥čĆč乥ą╣čü SDRAM ąĮą░ ą▒ąŠą╗čīčłąĖąĮčüčéą▓ąĄ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin 16-ą▒ąĖčéąĮčŗą╣, č鹊 ą║ą░ąČą┤čŗą╣ ą┤ąŠčüčéčāą┐ ą▒čāą┤ąĄčé čłąĖčĆąĖąĮąŠą╣ 16 ą▒ąĖčé. ą¤čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ ą▒ą░ą╣čéčā ą╝ą╗ą░ą┤čłąĖą╣ ąĖą╗ąĖ čüčéą░čĆčłąĖą╣ ą▒ą░ą╣čé ą╝ą░čüą║ąĖčĆčāąĄčéčüčÅ čüąĖą│ąĮą░ą╗ąŠą╝ SDQM.
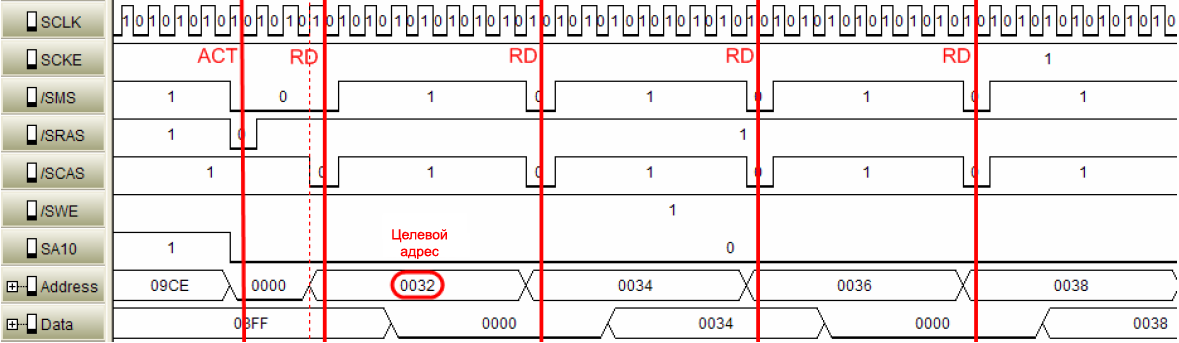
ąĀąĖčü. 12 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┤ąŠčüčéčāą┐ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ąĮą░ čćč鹥ąĮąĖąĄ 16-ą▒ąĖčéąĮčŗčģ ą┤ą░ąĮąĮčŗčģ (čåąĄą╗ąĄą▓ąŠą╣ ą░ą┤čĆąĄčü 0x0032h). ą║čŹčł ą┤ą░ąĮąĮčŗčģ ą▓čŗą║ą╗čÄč湥ąĮ. ąöą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą▓čŗą▒ąĖčĆą░ąĄčéčüčÅ ąŠą┤ąĮąŠ 16-ą▒ąĖčéąĮąŠąĄ čüą╗ąŠą▓ąŠ.
ąĀąĖčü. 13 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé č鹊čé ąČąĄ čüą░ą╝čŗą╣ ą┤ąŠčüčéčāą┐, ąĮąŠ čü ą▓ą║ą╗čÄč湥ąĮąĮčŗą╝ ą║čŹčłąĄą╝ ą┤ą░ąĮąĮčŗčģ. ąŚą┤ąĄčüčī ąĮą░čćą░ą╗čīąĮčŗą╣ ą░ą┤čĆąĄčü 0x0032h. ąöčĆčāą│ąĖąĄ ą┤ą░ąĮąĮčŗąĄ, ą┐čĆąĖąĮą░ą┤ą╗ąĄąČą░čēąĖąĄ čŹč鹊ą╣ ą║čŹčłąĖčĆčāąĄą╝ąŠą╣ čüčéčĆąŠą║ąĄ ą▒čāą┤čāčé ą▓čŗą▒čĆą░ąĮčŗ čéą░ą║, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ čéą░ą▒ą╗ąĖčåąĄ 5.
ą£ąĄč鹊ą┤čŗ ąĘą░ą┐ąĖčüąĖ ą║čŹčłą░. ąÆąĮąĄčłąĮčÅčÅ ą┐ą░ą╝čÅčéčī ą┐ąŠą┤ąĄą╗ąĄąĮą░ ąĮą░ čĆą░ąĘąĮčŗąĄ čüčéčĆą░ąĮąĖčåčŗ (ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗąĄ č湥čĆąĄąĘ čĆąĄą│ąĖčüčéčĆčŗ ąĘą░čēąĖčéčŗ ą▒čāč乥čĆąŠą▓ ą┤ą░ąĮąĮčŗčģ ą║čŹčłą░ - data cache protection lookaside buffers, čĆąĄą│ąĖčüčéčĆčŗ DCPLB). ąÉčéčĆąĖą▒čāčéčŗ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ čüčéčĆą░ąĮąĖčåčŗ ą╝ąŠąČąĮąŠ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░čéčī ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ. ąÜą░ą║ ą▒čāą┤ąĄčé ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╣ čüąĄą║čåąĖąĖ, čüčéčĆą░ąĮąĖčåčŗ ą┐ą░ą╝čÅčéąĖ ą╝ąŠą│čāčé ą▒čŗčéčī:
ŌĆó ąĪą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮčŗ ą╗ąĖą▒ąŠ ą▓ čĆąĄąČąĖą╝ąĄ ąĘą░ą┐ąĖčüąĖ write-back WB, ą╗ąĖą▒ąŠ ą▓ čĆąĄąČąĖą╝ąĄ ąĘą░ą┐ąĖčüąĖ write-through WT (ą▒ąĖčé CPLB_WT).
ŌĆó ąĪą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮčŗ ą┤ą╗čÅ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ čüčéčĆąŠą║ ą║čŹčłą░ ą╗ąĖą▒ąŠ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ, ą╗ąĖą▒ąŠ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ ąĖ ąĘą░ą┐ąĖčüąĖ (ą▒ąĖčé CPLB_L1_AOW).
ąóą░ą▒ą╗ąĖčåą░ 6. ą¤ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą▓ čüą┐ąĄčåąĖčäąĖč湥čüą║ąŠą╣ čüąĖčéčāą░čåąĖąĖ ąĘą░ą┐ąĖčüąĖ.
|
ąĪčéčĆąŠą║ą░ ą║čŹčłą░ ą┤ąŠčüč鹊ą▓ąĄčĆąĮą░čÅ (valid) |
ąĪčéčĆąŠą║ą░ ą║čŹčłą░ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮą░čÅ (invalid) |
WT
AOW=0 |
ą×ą▒ąĮąŠą▓ą╗ąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ąĖ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ |
ą×ą▒ąĮąŠą▓ą╗ąĄąĮąĖąĄ č鹊ą╗čīą║ąŠ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ |
WT
AOW=1 |
ą×ą▒ąĮąŠą▓ą╗ąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ąĖ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ |
ąÆčŗą▒ąŠčĆą║ą░ čüčéčĆąŠą║ąĖ ą║čŹčłą░
ą×ą▒ąĮąŠą▓ą╗ąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░
ą×ą▒ąĮąŠą▓ą╗ąĄąĮąĖąĄ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ |
| WB |
ą×ą▒ąĮąŠą▓ą╗ąĄąĮąĖąĄ č鹊ą╗čīą║ąŠ čüčéčĆąŠą║ąĖ ą║čŹčłą░ |
ąÆčŗą▒ąŠčĆą║ą░ čüčéčĆąŠą║ąĖ ą║čŹčłą░
ą×ą▒ąĮąŠą▓ą╗ąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ |
ąóą░ą▒ą╗ąĖčåą░ 6 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┐ąŠą▓ąĄą┤ąĄąĮąĖąĄ ą▓ čĆą░ąĘą╗ąĖčćąĮčŗčģ ą╝ąĄč鹊ą┤ą░čģ ąĘą░ą┐ąĖčüąĖ ą║čŹčłą░. ąĀąĖčü. 14 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čüąĖčéčāą░čåąĖčÄ, ą║ąŠą│ą┤ą░ ą║čŹčł ą┤ą░ąĮąĮčŗčģ čĆą░ąĘčĆąĄčłąĄąĮ ą▓ čĆąĄąČąĖą╝ąĄ write-through (WT), ąĖ čü čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮčŗą╝ ą▒ąĖč鹊ą╝ CPLB_L1_AOW. ąśąĮąĖčåąĖąĖčĆčāąĄčéčüčÅ ą┤ąŠčüčéčāą┐ ąĮą░ ąĘą░ą┐ąĖčüčī ą┐ąŠ ą░ą┤čĆąĄčüčā 0x0040h. ąĪąĮą░čćą░ą╗ą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░, ąĘą░č鹥ą╝ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĘą░ą┐ąĖčüčī ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī.

ąĀąĖčü. 14. ąÆčŗą▒ąŠčĆą║ą░ ą┤ą░ąĮąĮčŗčģ čü ą▓ą║ą╗čÄč湥ąĮąĮčŗą╝ ą║čŹčłąĄą╝, ą║ąŠą│ą┤ą░ ą▓ą║ą╗čÄč湥ąĮ čĆąĄąČąĖą╝ ąĘą░ą┐ąĖčüąĖ write-through ąĖ čĆą░ąĘčĆąĄčłąĄąĮ AOW.
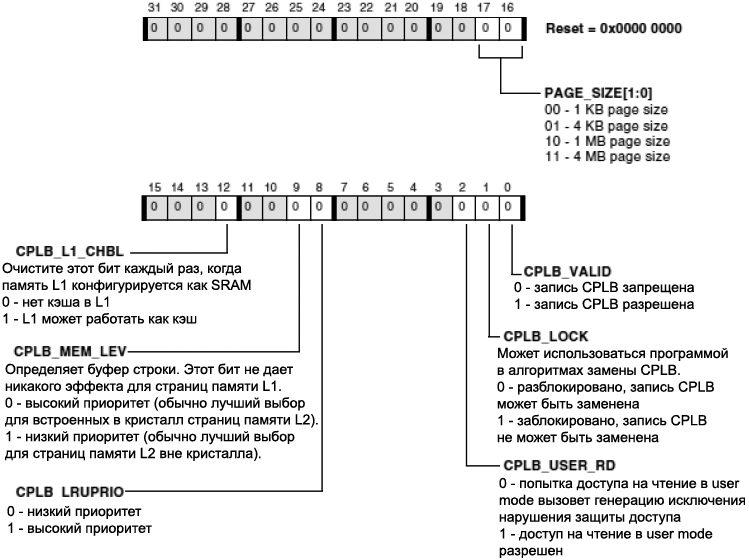
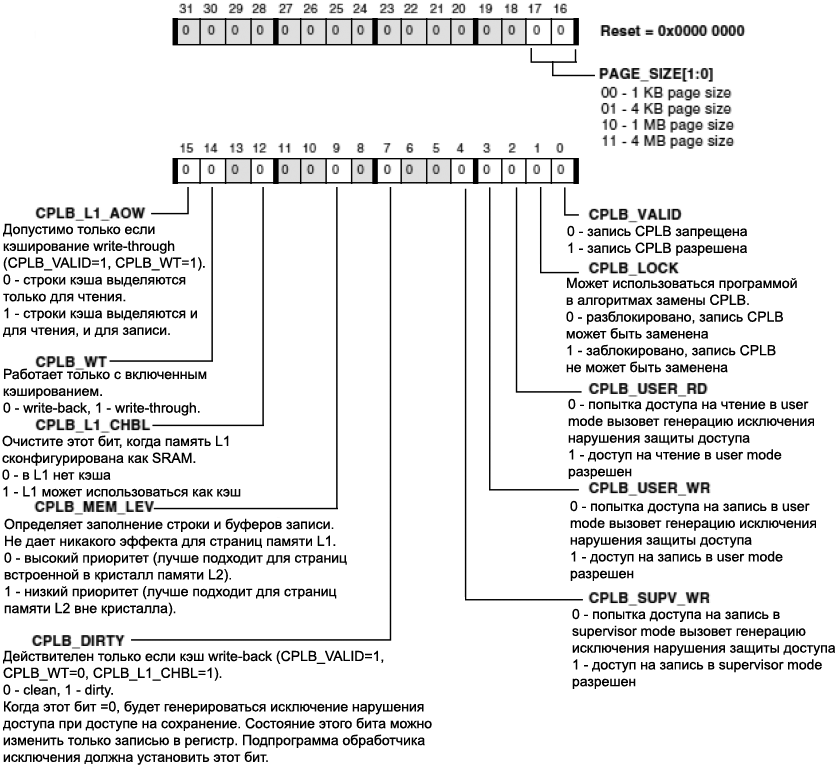
ąæą╗ąŠą║ ąĘą░čēąĖčéčŗ ą┐ą░ą╝čÅčéąĖ ąĖ ą║čŹčłą░ (Memory Protection and Cache Unit). ą¤čĆąŠčåąĄčüčüąŠčĆ Blackfin čüąŠą┤ąĄčƹȹĖčé ąŠčüąĮąŠą▓ą░ąĮąĮčŗą╣ ąĮą░ čüčéčĆą░ąĮąĖčåą░čģ ą▒ą╗ąŠą║ ąĘą░čēąĖčéčŗ ą┐ą░ą╝čÅčéąĖ Memory Protection and Cache Unit (MPCU), ą║ąŠč鹊čĆčŗą╣ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą║ąŠąĮčéčĆąŠą╗čī ąĮą░ą┤ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ą┤ąĖą░ą┐ą░ąĘąŠąĮąŠą▓ ą┐ą░ą╝čÅčéąĖ ąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą░čéčĆąĖą▒čāčéą░ą╝ąĖ ąĘą░čēąĖčéčŗ ąĮą░ čāčĆąŠą▓ąĮąĄ čüčéčĆą░ąĮąĖčåčŗ. MPCU čĆąĄą░ą╗ąĖąĘąŠą▓ą░ąĮ ą║ą░ą║ ą▒ą╗ąŠą║ąĖ 16-čÅč湥ąĄčćąĮąŠą╣, ą░ą┤čĆąĄčüčāąĄą╝ąŠą╣ ą┐ąŠ čüąŠą┤ąĄčƹȹĖą╝ąŠą╝čā ą┐ą░ą╝čÅčéąĖ (content addressable memory, CAM). ąÜą░ąČą┤ą░čÅ čÅč湥ą╣ą║ą░ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą╝ cacheability protection lookaside buffer (CPLB). ążčāąĮą║čåąĖąŠąĮą░ą╗ MPCU ą▓ą║ą╗čÄčćą░ąĄčé:
ŌĆó ąæčāč乥čĆčŗ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ ąĖ ąĘą░čēąĖčéčŗ (Caching and protection lookaside buffers, CPLB)
ŌĆó ąĪą▓ąŠą╣čüčéą▓ą░ ą║čŹčłą░/ąĘą░čēąĖčéčŗ, ąŠą┐čĆąĄą┤ąĄą╗čÅąĄą╝čŗąĄ ąĮą░ ą▒ą░ąĘąĄ čüčéčĆą░ąĮąĖčåčŗ ą┐ą░ą╝čÅčéąĖ (čĆą░ąĘą╝ąĄčĆą░ą╝ąĖ 1 ą║ąĖą╗ąŠą▒ą░ą╣čé, 4 ą║ąĖą╗ąŠą▒ą░ą╣čéą░, 1 ą╝ąĄą│ą░ą▒ą░ą╣čé ąĖ 4 ą╝ąĄą│ą░ą▒ą░ą╣čéą░)
ŌĆó ąŚą░čēąĖčéą░ ą┤ąŠčüčéčāą┐ą░ čĆąĄąČąĖą╝ąŠą▓ User/supervisor, ąĖ ąĘą░čēąĖčéą░ ąĘą░ą┤ą░čćą░/ąĘą░ą┤ą░čćą░
ąŚą░čēąĖčéą░ ą▒čāč乥čĆąŠą▓ ą║čŹčłą░ (Cacheability Protection Lookaside Buffers, CPLB). ąÜą░ąČą┤ą░čÅ ąĘą░ą┐ąĖčüčī ą▓ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░čģ CPLB ąĘą░ą┤ą░ąĄčé ą░čéčĆąĖą▒čāčéčŗ ą║čŹčłąĖčĆčāąĄą╝ąŠčüčéąĖ ąĖ ąĘą░čēąĖčéčŗ ą┤ą╗čÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╣ čüčéčĆą░ąĮąĖčåčŗ ą┐ą░ą╝čÅčéąĖ. ąŚą░ą┐ąĖčüąĖ CPLB ą┐ąŠą┤ąĄą╗ąĄąĮčŗ ą╝ąĄąČą┤čā CPLB ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ ą┤ą░ąĮąĮčŗčģ. 16 ąĘą░ą┐ąĖčüąĄą╣ CPLB (ąĮą░ąĘčŗą▓ą░ąĄą╝čŗčģ ICPLB) ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ ąĘą░ą┐čĆąŠčüąŠą▓ ą▓čŗą▒ąŠčĆą║ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąöčĆčāą│ąĖąĄ 16 ąĘą░ą┐ąĖčüąĄą╣ CPLB (ąĮą░ąĘčŗą▓ą░ąĄą╝čŗčģ DCPLB) ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ čéčĆą░ąĮąĘą░ą║čåąĖą╣ ą┤ą░ąĮąĮčŗčģ. ąŻčüčéą░ąĮąŠą▓ą║ą░ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖčģ ą▒ąĖčé ą▓ čĆąĄą│ąĖčüčéčĆą░čģ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéčīčÄ ąĖąĮčüčéčĆčāą║čåąĖą╣ (IMEM_CONTROL) ąĖ čĆąĄą│ąĖčüčéčĆą░čģ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéčīčÄ ą┤ą░ąĮąĮčŗčģ (DMEM_CONTROL) čĆą░ąĘčĆąĄčłą░čÄčé čĆą░ą▒ąŠčéčā ICPLB ąĖ DCPLB. ąÜą░ąČą┤ą░čÅ ąĘą░ą┐ąĖčüčī CPLB čüąŠčüč鹊ąĖčé ąĖąĘ ą┐ą░čĆčŗ 32-ą▒ąĖčéąĮčŗčģ ąĘąĮą░č湥ąĮąĖą╣. ą¤ąĄčĆąĄą┤ ąĘą░ą│čĆčāąĘą║ąŠą╣ ą┤ą░ąĮąĮčŗčģ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ ą▓ ą╗čÄą▒ąŠą╣ CPLB čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēą░čÅ ą│čĆčāą┐ą┐ą░ ąĖąĘ 16 CPLB ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ąĘą░ą┐čĆąĄčēąĄąĮą░ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą▒ąĖč鹊ą▓ ENICPLB ąĖą╗ąĖ ENDCPLB ą▓ čĆąĄą│ąĖčüčéčĆąĄ IMEM_CONTROL ąĖą╗ąĖ DMEM_CONTROL čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ.
ąöą╗čÅ ą▓čŗą▒ąŠčĆąŠą║ ąĖąĮčüčéčĆčāą║čåąĖą╣: ICPLB_ADDR[n] ąĘą░ą┤ą░ąĄčé ąĮą░čćą░ą╗čīąĮčŗą╣ ą░ą┤čĆąĄčü čüčéčĆą░ąĮąĖčåčŗ, ąŠą┐ąĖčüą░ąĮąĮąŠą╣ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą╝ CPLB. ICPLB_DATA[n] ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé čüą▓ąŠą╣čüčéą▓ą░ čüčéčĆą░ąĮąĖčåčŗ, ąŠą┐ąĖčüą░ąĮąĮąŠą╣ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą╝ CPLB. ąØą░ čĆąĖčü. 15 ą┐ąŠą║ą░ąĘą░ąĮčŗ čĆą░ąĘą╗ąĖčćąĮčŗąĄ ą▒ąĖč鹊ą▓čŗąĄ ą┐ąŠą╗čÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ ICPLB_DATA ąĖ ąĖčģ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčī.
ąöą╗čÅ ąŠą┐ąĄčĆą░čåąĖą╣ čü ą┤ą░ąĮąĮčŗą╝ąĖ: DCPLB_ADDR[m] ąĘą░ą┤ą░ąĄčé ąĮą░čćą░ą╗čīąĮčŗą╣ ą░ą┤čĆąĄčü čüčéčĆą░ąĮąĖčåčŗ, ąŠą┐ąĖčüą░ąĮąĮąŠą╣ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą╝ CPLB. DCPLB_DATA[m] ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé čüą▓ąŠą╣čüčéą▓ą░ čüčéčĆą░ąĮąĖčåčŗ, ąŠą┐ąĖčüą░ąĮąĮąŠą╣ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą╝ CPLB. ąĀąĖčü. 16 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čĆą░ąĘą╗ąĖčćąĮčŗąĄ ą▒ąĖč鹊ą▓čŗąĄ ą┐ąŠą╗čÅ ą▓ čĆąĄą│ąĖčüčéčĆąĄ DCPLB_DATA ąĖ ąĖčģ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčī.
ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ CPLB
ŌĆó ąĢčüą╗ąĖ ą║čŹčł čĆą░ąĘčĆąĄčłąĄąĮą░: CPLB ą┤ąŠą╗ąČąĮčŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ čüą▓ąŠą╣čüčéą▓ ą║čŹčłą░.
ŌĆó ąĢčüą╗ąĖ ą║čŹčł ąĘą░ą┐čĆąĄčēąĄąĮą░: CPLB ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ąĘą░čēąĖčéčŗ čüčéčĆą░ąĮąĖčå ą┐ą░ą╝čÅčéąĖ.
ŌĆó ąĢčüą╗ąĖ CPLB ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ, č鹊 ą┤ąŠą╗ąČąĮą░ čüčāčēąĄčüčéą▓ąŠą▓ą░čéčī ą┐čĆą░ą▓ąĖą╗čīąĮąŠ ąĮą░čüčéčĆąŠąĄąĮąĮą░čÅ ąĘą░ą┐ąĖčüčī CPLB ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ą▒čāą┤ąĄčé čüą┤ąĄą╗ą░ąĮą░ ą┐ąŠą┐čŗčéą║ą░ ą┤ąŠčüčéčāą┐ą░ ą║ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╣ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ. ąśąĮą░č湥 ą▒čāą┤ąĄčé čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąŠ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ.
ŌĆó ąĢčüčéčī ą┤ą▓ą░ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ CPLB ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ - ą┤ą╗čÅ ą┐ą░ą╝čÅčéąĖ ą┤ą░ąĮąĮčŗčģ scratchpad ąĖ ą┤ą╗čÅ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ą░ą┤čĆąĄčüąŠą▓ MMR čüąĖčüč鹥ą╝čŗ ąĖ čÅą┤čĆą░. ąŁčéąĖ ą┤ąĄčüą║čĆąĖą┐č鹊čĆčŗ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąŠą┐čĆąĄą┤ąĄą╗čÅčÄčé ą▓čŗčłąĄčāą║ą░ąĘą░ąĮąĮčŗąĄ ąŠą▒ą╗ą░čüčéąĖ ą║ą░ą║ ąĮąĄ ą║čŹčłąĖčĆčāąĄą╝čŗąĄ, čéą░ą║ čćč鹊 ąĮąĄ ąĮčāąČąĮčŗ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ CPLB ą┤ą╗čÅ ąĮą░čüčéčĆąŠą╣ą║ąĖ čŹčéąĖčģ čĆąĄą│ąĖąŠąĮąŠą▓ ą┐ą░ą╝čÅčéąĖ.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąĄčüą╗ąĖ ą┤ą╗čÅ čŹč鹊ą╣ ąŠą▒ą╗ą░čüčéąĖ ąĮą░čüčéčĆąŠąĄąĮčŗ ą┐čĆą░ą▓ąĖą╗čīąĮčŗąĄ CPLB, č鹊 CPLB ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą▒čāą┤čāčé ąĖą│ąĮąŠčĆąĖčĆąŠą▓ą░ąĮčŗ. ąØą░ ąĮąŠą▓čŗčģ čćą╗ąĄąĮą░čģ čüąĄą╝ąĄą╣čüčéą▓ą░ Blackfin, čéą░ą║ąĖčģ ą║ą░ą║ ADSP-BF51x, ADSP-BF52x ąĖ ADSP-BF54x, ą▓čüčéčĆąŠąĄąĮąĮą░čÅ ą▓ ą║čĆąĖčüčéą░ą╗ą╗ ą┐ą░ą╝čÅčéčī ą┐čĆąŠą│čĆą░ą╝ą╝ boot ROM (ą┐ą░ą╝čÅčéčī č鹊ą╗čīą║ąŠ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ) ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čäčāąĮą║čåąĖąĖ (SysControl()) ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ čĆąĄą│ąĖčüčéčĆą░ą╝ PLL ąĖ čĆąĄą│ąĖčüčéčĆą░ą╝ čĆąĄą│čāą╗čÅč鹊čĆą░ ąĮą░ą┐čĆčÅąČąĄąĮąĖčÅ. ąóą░ą║ąČąĄ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ ą┤ąŠčüčéčāą┐ąĮčŗ ą▓ąĮčāčéčĆąĄąĮąĮąĖąĄ L1 ROM ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ/ąĖą╗ąĖ L2 SRAM. ąöą╗čÅ ą▓čüąĄčģ čŹčéąĖčģ čüą╗čāčćą░ąĄą▓ čéčĆąĄą▒čāąĄčéčüčÅ ą┐čĆą░ą▓ąĖą╗čīąĮąŠ ąĮą░čüčéčĆąŠąĄąĮąĮčŗą╣ ą┤ąĄčüą║čĆąĖą┐č鹊čĆ CPLB (ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ ą┤ą░ąĮąĮčŗčģ). ąĪą╝. ą┤ą░čéą░čłąĖčé ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆ ąĖą╗ąĖ čéą░ą▒ą╗ąĖčåčā 2 ą┤ą╗čÅ ą┐ąŠą┤čĆąŠą▒ąĮąŠčüč鹥ą╣ ąŠ č鹊ą╝, ą║ą░ą║ąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ą░ą╝čÅčéąĖ ąĖą╝ąĄąĄčéčüčÅ ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░ čüąĄą╝ąĄą╣čüčéą▓ą░ Blackfin.
ąĀąĖčü. 15. ąæąĖč鹊ą▓čŗąĄ ą┐ąŠą╗čÅ ąĖ ąĖčģ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąĮą░ąĘąĮą░č湥ąĮąĖąĄ ą┤ą╗čÅ čĆąĄą│ąĖčüčéčĆąŠą▓ ICPLB_DATA.
ąĀąĖčü. 16. ąæąĖč鹊ą▓čŗąĄ ą┐ąŠą╗čÅ ąĖ ąĖčģ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠąĄ ąĮą░ąĘąĮą░č湥ąĮąĖąĄ ą┤ą╗čÅ čĆąĄą│ąĖčüčéčĆąŠą▓ DCPLB_DATA.
[ąĪčéčĆą░ąĮąĖčåčŗ ą┐ą░ą╝čÅčéąĖ ąĖ ą░čéčĆąĖą▒čāčéčŗ čüčéčĆą░ąĮąĖčåčŗ]
ąÜą░ąČą┤ą░čÅ ąĘą░ą┐ąĖčüčī CPLB čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ą┤ąŠą┐čāčüčéąĖą╝ąŠą╣ čüčéčĆą░ąĮąĖčåąĄ ą┐ą░ą╝čÅčéąĖ. ąÜą░ąČą┤čŗą╣ ą░ą┤čĆąĄčü ą▓ ą┐čĆąĄą┤ąĄą╗ą░čģ čüčéčĆą░ąĮąĖčåčŗ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ąŠą┤ąĮąĖ ąĖ č鹥 ąČąĄ ąŠą▒čēąĖąĄ ą░čéčĆąĖą▒čāčéčŗ, ąĘą░ą┤ą░ąĮąĮčŗąĄ ą┤ą╗čÅ čŹč鹊ą╣ čüčéčĆą░ąĮąĖčåčŗ. ąöąĄčüą║čĆąĖą┐č鹊čĆ ą░ą┤čĆąĄčüą░ xCPLB_ADDR[n] ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą▒ą░ąĘąŠą▓čŗą╣ ą░ą┤čĆąĄčü ą┐ąŠą╗ąŠąČąĄąĮąĖčÅ čüčéčĆą░ąĮąĖčåčŗ ą▓ ą┐ą░ą╝čÅčéąĖ. ąĪą╗ąŠą▓ąŠ čüą▓ąŠą╣čüčéą▓ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ xCPLB_DATA[n] ąĘą░ą┤ą░ąĄčé čĆą░ąĘą╝ąĄčĆ ąĖ ą░čéčĆąĖą▒čāčéčŗ ą┤ą╗čÅ čŹč鹊ą╣ čüčéčĆą░ąĮąĖčåčŗ. ąĀąĖčü. 15 ąĖ čĆąĖčü. 16 ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčé čĆą░ąĘą╗ąĖčćąĮčŗąĄ ą▒ąĖč鹊ą▓čŗąĄ ą┐ąŠą╗čÅ ąĖ ąĖčģ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčī ą▓ čĆąĄą│ąĖčüčéčĆą░čģ ICPLB_DATAx ąĖ DCPLB_DATAx čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ. ąØąĖąČąĄ ą┤ą░ąĮąŠ ą║ąŠčĆąŠčéą║ąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ ą┐ąŠą╗ąĄą╣ ą▒ąĖčé.
Page Size (čĆą░ąĘą╝ąĄčĆ čüčéčĆą░ąĮąĖčåčŗ). ąÉčĆčģąĖč鹥ą║čéčāčĆą░ ą┐ą░ą╝čÅčéąĖ Blackfin ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé 4 čĆą░ąĘą╗ąĖčćąĮčŗąĄ čĆą░ąĘą╝ąĄčĆą░ čüčéčĆą░ąĮąĖčåčŗ: 1 ą║ąĖą╗ąŠą▒ą░ą╣čé, 4 ą║ąĖą╗ąŠą▒ą░ą╣čé, 1 ą╝ąĄą│ą░ą▒ą░ą╣čé ąĖą╗ąĖ 4 ą╝ąĄą│ą░ą▒ą░ą╣čéą░. ąĪčéčĆą░ąĮąĖčåčŗ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą▓čŗčĆąŠą▓ąĮąĄąĮčŗ ą┐ąŠ ą│čĆą░ąĮąĖčåą░ą╝ čüčéčĆą░ąĮąĖčå, ą░ą┤čĆąĄčü ą║ąŠč鹊čĆčŗčģ ą┤ąŠą╗ąČąĄąĮ ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░ čĆą░ąĘą╝ąĄčĆ čüčéčĆą░ąĮąĖčåčŗ.
Cache-Line Allocation (ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░). ąĀą░ąĘčĆąĄčłąĄąĮą░ ą║čŹčł čéąĖą┐ą░ write-through, čćč鹊 ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąŠ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą┐ą░ą╝čÅčéąĖ ą┤ą░ąĮąĮčŗčģ. ąæąĖčé CPLB_L1_AOW ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé, ąĖąĮąĖčåąĖąĖčĆąŠą▓ą░ąĮąŠ ą╗ąĖ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ čćč鹥ąĮąĖčÅ ąĖą╗ąĖ čéą░ą║ąČąĄ ąĖ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ. ąöą╗čÅ ąĘą░ą┐ąĖčüąĄą╣, čü ą║ąŠč鹊čĆčŗą╝ąĖ ą▒ąĖčé CPLB_L1_AOW ąĮąĄ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ, ą║čŹčł ą▓ąĄą┤ąĄčé čüąĄą▒čÅ čéą░ą║, ą║ą░ą║ ą▒čāą┤č鹊 ąĄčæ ąĮąĄčé. ąĢčüą╗ąĖ čŹč鹊čé ą▒ąĖčé čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ, č鹊 ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║čŹčłą░ čüčĆą░ą▒ą░čéčŗą▓ą░ąĄčé ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ąĖą┤ąĄčé ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖąĄ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ ąĖą╗ąĖ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ.
Write-Through/Write-Back Flag (čäą╗ą░ą│ čéąĖą┐ą░ ą║čŹčłą░). ąŁč鹊čé čäą╗ą░ą│ ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą┐ą░ą╝čÅčéąĖ ą┤ą░ąĮąĮčŗčģ. ą×ąĮ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ą░čéčĆąĖą▒čāčéčā (ą▒ąĖčé CPLB_WT), čĆą░ąĘčĆąĄčłą░čÄčēąĄą╝čā čĆąĄąČąĖą╝ write-through ą┤ą╗čÅ ą┤ą░ąĮąĮčŗčģ, ą║ąŠą│ą┤ą░ ą▒ąĖčé čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ (CPLB_WT = 0) ą░ą║čéąĖą▓ąĄąĮ čĆąĄąČąĖą╝ write-back.
Cacheable/Non-cacheable Flag (čäą╗ą░ą│ ą║čŹčłąĖčĆąŠą▓ą░čéčī/ąĮąĄ ą║čŹčłąĖčĆąŠą▓ą░čéčī). ąĢčüą╗ąĖ čüčéčĆą░ąĮąĖčåą░ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮą░ ą║ą░ą║ ąĮąĄ ą║čŹčłąĖčĆčāąĄą╝ą░čÅ (CPLB_L1_CHBL = 0), č鹊 ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ čŹč鹊ą╣ čüčéčĆą░ąĮąĖčåąĄ ą║čŹčł ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ. ąĪčéčĆą░ąĮąĖčåčŗ ą┐ą░ą╝čÅčéąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ąĮą░ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮčŗ ą║ą░ą║ ą║čŹčłąĖčĆčāąĄą╝čŗąĄ, ą║ąŠą│ą┤ą░:
ŌĆó ąŻčüčéčĆąŠą╣čüčéą▓ąŠ ą▓ą▓ąŠą┤ą░/ą▓čŗą▓ąŠą┤ą░ (I/O) ąŠč鹊ą▒čĆą░ąČąĄąĮąŠ ąĮą░ ą░ą┤čĆąĄčü ą┐ą░ą╝čÅčéąĖ.
ŌĆó ąÜąŠą┤, ąĮą░čģąŠą┤čÅčēąĖą╣čüčÅ ą▓ čŹč鹊ą╣ čüčéčĆą░ąĮąĖčåąĄ, ą▓čŗąĘčŗą▓ą░ąĄčéčüčÅ ąĮąĄčćą░čüč鹊 (ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čī ą╝ąŠąČąĄčé ąĮąĄ ąČąĄą╗ą░čéčī ąĄą│ąŠ ą║čŹčłąĖčĆąŠą▓ą░čéčī).
ŌĆó ąÜąŠą┤ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ 菹║čüčéčĆąĄą╝ą░ą╗čīąĮąŠ ąĮąĄą╗ąĖąĮąĄą╣ąĮčŗą╣.
LRU Priority (ą┐čĆąĖąŠčĆąĖč鹥čé LRU). ąŁč鹊čé ą░čéčĆąĖą▒čāčé (CPLB_LRUPRIO) ą┤ąŠčüčéčāą┐ąĄąĮ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ CPLB ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣. ą×ąĮ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé ą┐čĆąĖąŠčĆąĖč鹥čé LRU (low/high, ąĮąĖąĘą║ąĖą╣/ą▓čŗčüąŠą║ąĖą╣) ą┤ą╗čÅ čāą║ą░ąĘą░ąĮąĮąŠą╣ čüčéčĆą░ąĮąĖčåčŗ. ąŁč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮąŠą╣ ą┐ąŠą╗ąĖčéąĖą║ąĖ LRU (čüą╝. čĆą░ąĘą┤ąĄą╗čŗ "ąĀą░ąĘą╝ąĄčēąĄąĮąĖąĄ ą▒ą╗ąŠą║ą░", "ąŚą░ą╝ąĄąĮą░ ą▒ą╗ąŠą║ą░").
Dirty/Modified Flag (čäą╗ą░ą│ ą░ą║čéčāą░ą╗čīąĮąŠą│ąŠ čüąŠčüč鹊čÅąĮąĖčÅ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮąŠčüčéąĖ ą║čŹčłą░). ąæąĖčé CPLB_DIRTY ą┤ą░ąĄčé ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčéčā ą▓čŗą▒ąŠčĆ ą┤ą╗čÅ čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖąĖ ąŠ č鹊ą╝, čćč鹊 ą┐čĆąŠąĖąĘąŠčłąĄą╗ (ą┐ąĄčĆą▓čŗą╣) ą┤ąŠčüčéčāą┐ ąĮą░ ąĘą░ą┐ąĖčüčī ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī. ą¤čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĮčŗą╣ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą┐ą░ą╝čÅčéąĖ ą┤ą░ąĮąĮčŗčģ, čŹč鹊čé ą░čéčĆąĖą▒čāčé ą┤ąŠčüč鹊ą▓ąĄčĆąĄąĮ č鹊ą╗čīą║ąŠ ą║ąŠą│ą┤ą░ čüčéčĆą░ąĮąĖčåą░ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮą░ ą║ą░ą║ ą║čŹčłąĖčĆčāąĄą╝ą░čÅ ą▓ čĆąĄąČąĖą╝ąĄ write-back. ąŁč鹊čé ą▒ąĖčé ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą┤ąŠčüčéčāą┐ąŠą▓ ą║ čŹč鹊ą╣ čüčéčĆą░ąĮąĖčåąĄ. ąÜąŠą│ą┤ą░ čŹč鹊čé ą▒ąĖčé ąŠčćąĖčēąĄąĮ, čéąĖąŠ ą┤ąŠčüčéčāą┐ ą║ čŹč鹊ą╣ čüčéčĆą░ąĮąĖčåąĄ ą▓čŗąĘčŗą▓ą░ąĄčé ąĖčüą║ą╗čÄč湥ąĮąĖąĄ (EXCAUSE 0x23). ą×ą▒čĆą░ą▒ąŠčéčćąĖą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą┤ąŠą╗ąČąĄąĮ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čéčī čŹč鹊čé ą▒ąĖčé, čćč鹊ą▒čŗ ą┐ąŠą╝ąĄčéąĖčéčī čüčéčĆą░ąĮąĖčåčā ą║ą░ą║ ą│čĆčÅąĘąĮčāčÄ.
Write Access Permission Flags (čäą╗ą░ą│ąĖ čĆą░ąĘčĆąĄčłąĄąĮąĖčÅ ąĮą░ ą╝ąŠą┤ąĖčäąĖą║ą░čåąĖčÄ ą┐ą░ą╝čÅčéąĖ). CPLB ą┤ą╗čÅ ą┐ą░ą╝čÅčéąĖ ą┤ą░ąĮąĮčŗčģ ąĖą╝ąĄčÄčé 2 čäą╗ą░ą│ą░, ą║ąŠč鹊čĆčŗąĄ čĆą░ąĘčĆąĄčłą░čÄčé/ąĘą░ą┐čĆąĄčēą░čÄčé ą┤ąŠčüčéčāą┐ ąĮą░ ąĘą░ą┐ąĖčüčī ą▓ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēčāčÄ čüčéčĆą░ąĮąĖčåčā ąĖąĮą┤ąĖą▓ąĖą┤čāą░ą╗čīąĮąŠ ą┤ą╗čÅ čĆąĄąČąĖą╝ą░ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (CPLB_SUPV_WR) ąĖ ą┤ą╗čÅ čĆąĄąČąĖą╝ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (CPLB_USER_WR).
User Read Access Permission Flag (čäą╗ą░ą│ čĆą░ąĘčĆąĄčłąĄąĮąĖčÅ ą┤ąŠčüčéčāą┐ą░ ąĮą░ čćč鹥ąĮąĖąĄ ą┤ą╗čÅ čĆąĄąČąĖą╝ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ). ąŁč鹊čé ą░čéčĆąĖą▒čāčé (CPLB_USER_RD) čĆą░ąĘčĆąĄčłą░ąĄčé/ąĘą░ą┐čĆąĄčēą░ąĄčé čćč鹥ąĮąĖčÅ čŹč鹊ą╣ čüčéčĆą░ąĮąĖčåčŗ ą║ąŠą┤ąŠą╝, čĆą░ą▒ąŠčéą░čÄčēąĄą╝ ą▓ user mode.
Lock Flag (čäą╗ą░ą│ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ). ąÜąŠą│ą┤ą░ ą▒ąĖčé CPLB_LOCK, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēą░čÅ ąĘą░ą┐ąĖčüčī CPLB ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮą░. ąŁč鹊čé ą░čéčĆąĖą▒čāčé ą┐ąŠą╗ąĄąĘąĄąĮ ą┤ą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą╣ ą┐ą░ą╝čÅčéčīčÄ. ąÜąŠą│ą┤ą░ ąĘą░ą┐ąĖčüčī CPLB ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮą░, ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą┐čĆąŠą╝ą░čģą░ CPLB ąĮąĄ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ąĄčé čŹč鹊čé ą▒ą╗ąŠą║ ą┤ą╗čÅ ąĘą░ą╝ąĄąĮčŗ.
ąÉčéčĆąĖą▒čāčéčŗ čüčéčĆą░ąĮąĖčåčŗ, čüą▓čÅąĘą░ąĮąĮčŗąĄ čü čĆą░ąĘčĆąĄčłąĄąĮąĖąĄą╝ čćč鹥ąĮąĖčÅ/ąĘą░ą┐ąĖčüąĖ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ąĘą░čēąĖčéčā ą┐ą░ą╝čÅčéąĖ. ąŁč鹊 ą╝ąŠąČąĄčé ą┐ąŠčéčĆąĄą▒ąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ą┐čĆąĖą╗ąŠąČąĄąĮąĖą╣ čĆąĄą░ą╗čīąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ, ą▓ ą║ąŠč鹊čĆčŗčģ ą▓čüąĄ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ čĆą░ąĘą┤ąĄą╗ąĄąĮąŠ ąĮą░ ą║ąŠą┤ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ąĖ ą║ąŠą┤ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ. ąÜąŠą┤ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ą╝ąŠąČąĄčé ąĖą╝ąĄčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ čĆą░ąĘąĮčŗčģ ą┐ąŠč鹊ą║ąŠą▓, ą┐čĆąĖč湥ą╝ ą║ą░ąČą┤čŗą╣ ą┐ąŠč鹊ą║ ąĖą╝ąĄąĄčé čüąŠą▒čüčéą▓ąĄąĮąĮčŗąĄ čĆąĄčüčāčĆčüčŗ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆčŗąĄ ąĮąĄą┤ąŠčüčéčāą┐ąĮčŗ ą┤ą╗čÅ ą┤čĆčāą│ąĖčģ ą┐ąŠč鹊ą║ąŠą▓. ą×ą┤ąĮą░ą║ąŠ čÅą┤čĆąŠ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ ą╝ąŠąČąĄčé ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą║ąŠ ą▓čüąĄą╝ čĆąĄčüčāčĆčüą░ą╝ ą┐ą░ą╝čÅčéąĖ. ąŁčéą░ ąĘą░ą┤ą░čćą░ ą╝ąŠąČąĄčé ą▒čŗčéčī čĆąĄčłąĄąĮą░ ąĮą░čüčéčĆąŠą╣ą║ąŠą╣ čĆą░ąĘąĮčŗčģ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖą╣ CPLB ą▓ čĆą░ąĘąĮčŗčģ ą┐ąŠč鹊ą║ą░čģ.
ąÜąŠą│ą┤ą░ CPLB čĆą░ąĘčĆąĄčłąĄąĮčŗ, ą┤ąŠą╗ąČąĮą░ čüčāčēąĄčüčéą▓ąŠą▓ą░čéčī ą┤ąŠą┐čāčüčéąĖą╝ą░čÅ ąĘą░ą┐ąĖčüčī CPLB ą░ čéą░ą▒ą╗ąĖčåąĄ CPLB ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ ą░ą┤čĆąĄčüą░, ą▓ ą║ąŠč鹊čĆčŗą╣ ą┤ąĄą╗ą░ąĄčéčüčÅ ą┤ąŠčüčéčāą┐. ąĢčüą╗ąĖ ąĮąĄčé ą┤ąŠą┐čāčüčéąĖą╝čŗčģ ąĘą░ą┐ąĖčüąĄą╣ ą┤ą╗čÅ čüčéčĆą░ąĮąĖčå, ą║ ą║ąŠč鹊čĆčŗą╝ ą┐čĆąŠąĖąĘąŠčłą╗ąŠ ąŠą▒čĆą░čēąĄąĮąĖąĄ, č鹊 ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ CPLB.
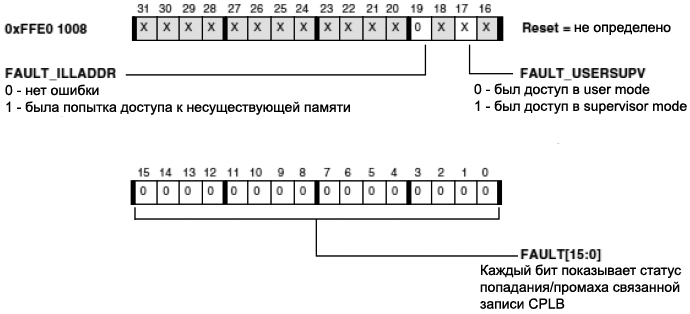
[ąĀąĄą│ąĖčüčéčĆčŗ čüąŠčüč鹊čÅąĮąĖčÅ CPLB (CPLB Status Registers)]
MPCU ąĖą╝ąĄąĄčé 2 ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗčģ čĆąĄą│ąĖčüčéčĆą░ čüąŠčüč鹊čÅąĮąĖčÅ: ąŠą┤ąĖąĮ ą┤ą╗čÅ čüčéą░čéčāčüą░ ICPLB (čĆąĖčü. 17), ąĖ ąŠą┤ąĖąĮ ą┤ą╗čÅ čüčéą░čéčāčüą░ DCPLB (čĆąĖčü. 18).
FAULT_ILLADDR. ą¤čĆąŠąĖąĘąŠčłą╗ą░ ą┐ąŠą┐čŗčéą║ą░ ąĘą░ą┐ąĖčüąĖ ą▓ ą┐ą░ą╝čÅčéčī, ą║ąŠč鹊čĆą░čÅ ąĮąĄ čüčāčēąĄčüčéą▓čāąĄčé.
FAULT_DAG. ąŁč鹊čé ą▒ąĖčé ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 DAG0 ąĖą╗ąĖ DAG1 ą┐čĆąĖą▓ąĄą╗ ą║ ąĮąĄą┐čĆą░ą▓ąĖą╗čīąĮąŠą╝čā ą┤ąŠčüčéčāą┐čā ą║ ą┤ą░ąĮąĮčŗą╝ (č鹊ą╗čīą║ąŠ DCPLB).
FAULT_USERSUPV. ąöąŠčüčéčāą┐ ą▒čŗą╗ čüą┤ąĄą╗ą░ąĮ ą╗ąĖą▒ąŠ ą▓ čĆąĄąČąĖą╝ąĄ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (user mode), ą╗ąĖą▒ąŠ ą▓ čĆąĄąČąĖą╝ąĄ čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (supervisor mode).
FAULT_RW. ąöąŠčüčéčāą┐ ą║ ą┤ą░ąĮąĮčŗą╝ ą▒čŗą╗ ą╗ąĖą▒ąŠ ąĮą░ čćč鹥ąĮąĖąĄ, ą╗ąĖą▒ąŠ ąĮą░ ąĘą░ą┐ąĖčüčī (č鹊ą╗čīą║ąŠ DCPLB).
FAULT. ąĪąŠčüč鹊čÅąĮąĖąĄ ą┐ąŠą┐ą░ą┤ą░ąĮąĖčÅ/ą┐čĆąŠą╝ą░čģą░ (hit/miss) čüą▓čÅąĘą░ąĮąĮąŠą╣ ąĘą░ą┐ąĖčüąĖ CPLB.
ąĀąĖčü. 17. ąæąĖč鹊ą▓čŗąĄ ą┐ąŠą╗čÅ ąĖ ąĖčģ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčī ą┤ą╗čÅ čĆąĄą│ąĖčüčéčĆą░ čüąŠčüč鹊čÅąĮąĖčÅ ICPLB.

ąĀąĖčü. 18. ąæąĖč鹊ą▓čŗąĄ ą┐ąŠą╗čÅ ąĖ ąĖčģ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčī ą┤ą╗čÅ čĆąĄą│ąĖčüčéčĆą░ čüąŠčüč鹊čÅąĮąĖčÅ DCPLB.
Table 7. ąĪąŠą▒čŗčéąĖčÅ CPLB, ą║ąŠč鹊čĆčŗąĄ ą▓čŗąĘčŗą▓ą░čÄčé ąĖčüą║ą╗čÄč湥ąĮąĖčÅ [6].
| ąśčüą║ą╗čÄč湥ąĮąĖąĄ (Exception) |
EXCAUSE [5:0] |
ą¤čĆąĖą╝ąĄčćą░ąĮąĖčÅ/ą┐čĆąĖą╝ąĄčĆčŗ |
| ąØą░čĆčāčłąĄąĮąĖąĄ ąĘą░čēąĖčéčŗ ą┤ąŠčüčéčāą┐ą░ CPLB ą║ ą┤ą░ąĮąĮčŗą╝ |
0x23 |
ąĪą┤ąĄą╗ą░ąĮą░ ą┐ąŠą┐čŗčéą║ą░ ą┤ąŠčüčéčāą┐ą░ ą║ čĆąĄčüčāčĆčüčā čüčāą┐ąĄčĆą▓ąĖąĘąŠčĆą░ (čüą╝. [6]), ą╗ąĖą▒ąŠ ąĮąĄą┤ąŠą┐čāčüčéąĖą╝čŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ. ąŁčéą░ ąĘą░ą┐ąĖčüčī ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖąĖ ąŠ ąĮą░čĆčāčłąĄąĮąĖąĖ ąĘą░čēąĖčéčŗ, ą║ ą║ąŠč鹊čĆąŠą╝čā ą┐čĆąĖą▓ąĄą╗ ąĮąĄ čĆą░ąĘčĆąĄčłąĄąĮąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ, ąĖ čŹč鹊 ąĘą░ą┤ą░ąĮąŠ ą▒ą╗ąŠą║ąŠą╝ MPCU ąĖ CPLB. |
| ąØą░čĆčāčłąĄąĮąĖąĄ ą┤ąŠčüčéčāą┐ą░ ą║ ą┤ą░ąĮąĮčŗą╝, čüą▓čÅąĘą░ąĮąĮąŠąĄ čü ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗą╝ ą░ą┤čĆąĄčüąŠą╝ |
0x24 |
ąæčŗą╗ą░ ą┐ąŠą┐čŗčéą║ą░ ąĮąĄą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą║ ą┤ą░ąĮąĮčŗą╝ ą┐ą░ą╝čÅčéąĖ ąĖą╗ąĖ ą┤ą░ąĮąĮčŗą╝ ą║čŹčłą░. |
| ą¤čĆąŠą╝ą░čģ CPLB ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ ą┤ą░ąĮąĮčŗą╝ |
0x26 |
ąśčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ MPCU ą┤ą╗čÅ čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖąĖ ąŠ ą┐čĆąŠą╝ą░čģąĄ CPLB ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ ą┤ą░ąĮąĮčŗą╝. |
| ą£ąĮąŠąČąĄčüčéą▓ąĄąĮąĮąŠąĄ ą┐ąŠą┐ą░ą┤ą░ąĮąĖąĄ CPLB ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ ą┤ą░ąĮąĮčŗą╝ |
0x27 |
ąÉą┤čĆąĄčüčā ą▓čŗą▒ąŠčĆą║ąĖ ą┤ą░ąĮąĮčŗčģ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą╣ ąĘą░ą┐ąĖčüąĖ CPLB. |
| ąØą░čĆčāčłąĄąĮąĖąĄ ąĘą░čēąĖčéčŗ CPLB ą┐čĆąĖ ą▓čŗą▒ąŠčĆą║ąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ |
0x2B |
ąØąĄą┤ąŠą┐čāčüčéąĖą╝čŗą╣ ą┤ąŠčüčéčāą┐ ą▓čŗą▒ąŠčĆą║ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ (ąĮą░čĆčāčłąĄąĮąĖąĄ ąĘą░čēąĖčéčŗ ą┐ą░ą╝čÅčéąĖ). |
| ą¤čĆąŠą╝ą░čģ CPLB ą┐čĆąĖ ą▓čŗą▒ąŠčĆą║ąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ |
0x2C |
ą¤čĆąŠą╝ą░čģ CPLB ą┐čĆąĖ ą▓čŗą▒ąŠčĆą║ąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ. |
| ą£ąĮąŠąČąĄčüčéą▓ąĄąĮąĮąŠąĄ ą┐ąŠą┐ą░ą┤ą░ąĮąĖąĄ CPLB ą┐čĆąĖ ą▓čŗą▒ąŠčĆą║ąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ |
0x2D |
ąÉą┤čĆąĄčüčā ą▓čŗą▒ąŠčĆą║ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ą▒ąŠą╗čīčłąĄ ąŠą┤ąĮąŠą╣ ąĘą░ą┐ąĖčüąĖ CPLB. |
[ąśčüą║ą╗čÄč湥ąĮąĖčÅ čüąĄą║ą▓ąĄąĮčüąŠčĆą░, čüą▓čÅąĘą░ąĮąĮčŗąĄ čü CPLB]
ąÆ čĆąĄą│ąĖčüčéčĆą░čģ ICPLB_DATAx ąĖ DCPLB_DATAx ąĮąĄą║ąŠč鹊čĆčŗąĄ ą┐ąŠą╗ąĖčéąĖą║ąĖ ą┤ąŠčüčéčāą┐ą░ (čćč鹥ąĮąĖąĄ/ąĘą░ą┐ąĖčüčī ą▓ user mode ąĖ supervisor mode) ą╝ąŠą│čāčé ą▒čŗčéčī ąĘą░ą┤ą░ąĮčŗ ą┤ą╗čÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ ąŠą▒ą╗ą░čüč鹥ą╣ ą┐ą░ą╝čÅčéąĖ. ąØą░čĆčāčłąĄąĮąĖąĄ ą┐čĆą░ą▓ąĖą╗ ą┤ąŠčüčéčāą┐ą░ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÅą╝ čüąĄą║ą▓ąĄąĮčüąŠčĆą░.
ą¤čĆąĖčćąĖąĮąŠą╣ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą╝ąŠąČąĄčé ą▒čŗčéčī čćč鹥ąĮąĖąĄ ąĖąĘ ą┐ąŠą╗čÅ ą▒ąĖčé EXCAUSE čĆąĄą│ąĖčüčéčĆą░ čüąŠčüč鹊čÅąĮąĖčÅ čüąĄą║ą▓ąĄąĮčüąŠčĆą░ (sequencer status register, SEQSTAT). ąÆ čéą░ą▒ą╗ąĖčåąĄ 7 ą┐ąŠą║ą░ąĘą░ąĮ čüą┐ąĖčüąŠą║ ą▓čüąĄčģ ąĖčüą║ą╗čÄč湥ąĮąĖą╣, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą┐ąŠčüčéčāą┐ą░čéčī ąŠčé CPLB.
[ąóą░ą▒ą╗ąĖčåą░ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ čüčéčĆą░ąĮąĖčåčŗ (Page Descriptor Table)]
ą×ą▒čŗčćąĮąŠ ąŠčüąĮąŠą▓ą░ąĮąĮą░čÅ ąĮą░ ą┐ą░ą╝čÅčéąĖ čüčéčĆčāą║čéčāčĆą░ ą┤ą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ CPLB ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ page descriptor table (čéą░ą▒ą╗ąĖčåą░ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ čüčéčĆą░ąĮąĖčå, PDT). ąÆčüąĄ ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ ąĮąĄąŠą▒čģąŠą┤ąĖą╝čŗąĄ ąĘą░ą┐ąĖčüąĖ CPLB ą╝ąŠą│čāčé ą▒čŗčéčī čüąŠčģčĆą░ąĮąĄąĮčŗ ą▓ PDT (ą║ąŠč鹊čĆą░čÅ ąŠą▒čŗčćąĮąŠ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ąŠ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ SRAM). ąÜąŠą│ą┤ą░ ąĮčāąČąĮąŠ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░čéčī CPLB, ą║ąŠą┤ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ą╝ąŠąČąĄčé ą▓ąĘčÅčéčī ąĘą░ą┐ąĖčüąĖ CPLB ąĖąĘ PDT ąĖ ąĘą░ą┐ąŠą╗ąĮąĖčéčī ąĖčģ ą▓ čĆąĄą│ąĖčüčéčĆčŗ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ CPLB.
ąöą╗čÅ ą╝ą░ą╗ąŠą╣/ą┐čĆąŠčüč鹊ą╣ ą╝ąŠą┤ąĄą╗ąĖ ą┐ą░ą╝čÅčéąĖ ąĖąĮąŠą│ą┤ą░ ą╝ąŠąČąĮąŠ ąŠą┐čĆąĄą┤ąĄą╗ąĖčéčī ąĮą░ą▒ąŠčĆ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ CPLB, ą║ąŠč鹊čĆčŗą╣ ą┐ąŠą╝ąĄčüčéąĖčéčüčÅ ą▓ 32 ąĘą░ą┐ąĖčüąĖ CPLB (16 ICPLB ąĖ 16 DCPLB). ąŁč鹊čé čéąĖą┐ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖčÅ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ ą║ą░ą║ čüčéą░čéąĖč湥čüą║ą░čÅ ą╝ąŠą┤ąĄą╗čī čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ. ą¤čĆąĖą╝ąĄčĆ Example1 (1) ąĖčüą┐ąŠą╗čīąĘčāąĄčé čüčéą░čéąĖč湥čüą║čāčÄ ą╝ąŠą┤ąĄą╗čī čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ.
ąöą╗čÅ čüą╗ąŠąČąĮčŗčģ ą╝ąŠą┤ąĄą╗ąĄą╣ ą┐ą░ą╝čÅčéąĖ ą▓ PDT ą╝ąŠą│čāčé ą▒čŗčéčī ąĘą░ą┐ąĖčüąĖ CPLB, ą║ąŠč鹊čĆčŗąĄ ąĮąĄ čāą║ą╗ą░ą┤čŗą▓ą░čÄčéčüčÅ ą▓ ą┤ąŠčüčéčāą┐ąĮčŗąĄ 16 čĆąĄą│ąĖčüčéčĆąŠą▓ CPLB. ąöą╗čÅ čŹčéąĖčģ čāčüą╗ąŠą▓ąĖą╣ CPLB ą╝ąŠąČąĄčé ą▒čŗčéčī čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮ čüąĮą░čćą░ą╗ą░ čü čŹčéąĖą╝ąĖ ą╗čÄą▒čŗą╝ąĖ 16 ąĘą░ą┐ąĖčüčÅą╝ąĖ. ąÜąŠą│ą┤ą░ ą┐čĆąŠčåąĄčüčüąŠčĆ ąŠą▒čĆą░čēą░ąĄčéčüčÅ ą║ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╝čā ą╝ąĄčüčéčā ą▓ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆą░čÅ ąĮąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮą░ č湥čĆąĄąĘ ąĘą░ą┐ąĖčüąĖ CPLB, ą│ąĄąĮąĄčĆąĖčĆčāąĄčéčüčÅ ąĖčüą║ą╗čÄč湥ąĮąĖąĄ, ąĖ ą░ą┤čĆąĄčü ą▓čŗąĘą▓ą░ą▓čłąĄą╣ ąŠčłąĖą▒ą║čā ą┐ą░ą╝čÅčéąĖ čüąŠčģčĆą░ąĮčÅąĄčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆ ąŠčłąĖą▒ą║ąĖ ą░ą┤čĆąĄčüą░ (Fault Address register, xCPLB_FAULT_ADDR). ą×ą▒čĆą░ą▒ąŠčéčćąĖą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čŹč鹊čé ą░ą┤čĆąĄčü ą┤ą╗čÅ ą┐ąŠąĖčüą║ą░ ąĮčāąČąĮąŠą╣ ąĘą░ą┐ąĖčüąĖ CPLB ą▓ PDT. ą×ą┤ąĮą░ ąĖąĘ čüčāčēąĄčüčéą▓čāčÄčēąĖčģ ąĘą░ą┐ąĖčüąĄą╣ CPLB ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ą╝ąĄąĮąĄąĮą░ čŹč鹊ą╣ ąĮąŠą▓ąŠą╣ ąĮą░ą╣ą┤ąĄąĮąĮąŠą╣ ąĘą░ą┐ąĖčüčīčÄ CPLB, ą▓ąĘčÅč鹊ą╣ ąĖąĘ PDT.
ą¤ąŠą╗ąĖčéąĖą║ą░ ąĘą░ą╝ąĄąĮą░ CPLB ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąŠčüč鹊ą╣ ąĖą╗ąĖ čüą╗ąŠąČąĮąŠą╣, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čéčĆąĄą▒ąŠą▓ą░ąĮąĖą╣ čüąĖčüč鹥ą╝čŗ. ą£ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ čéą░ą║, čćč鹊 ą▒ąŠą╗čīčłąĄ č湥ą╝ ąŠą┤ąĮąŠ ąŠą▒čĆą░čēąĄąĮąĖąĄ ą║ ą┐ą░ą╝čÅčéąĖ, ą┤ą╗čÅ ą║ąŠč鹊čĆąŠą╣ ąĮąĄčé ąĘą░ą┐ąĖčüąĖ ą▓ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░čģ. ąÆ čéą░ą║ąĖčģ čāčüą╗ąŠą▓ąĖčÅčģ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą┐čĆąĖąŠčĆąĖč鹥ąĘąĖčĆčāčÄčéčüčÅ ąĖ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčéčüčÅ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╝ ą┐ąŠčĆčÅą┤ą║ąĄ:
1. ą¤čĆąŠą╝ą░čģąĖ čüčéčĆą░ąĮąĖčåčŗ ą┤ą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖą╣.
2. ą¤čĆąŠą╝ą░čģąĖ čüčéčĆą░ąĮąĖčåčŗ ąĮą░ DAG0.
3. ą¤čĆąŠą╝ą░čģąĖ čüčéčĆą░ąĮąĖčåčŗ ąĮą░ DAG1.
ą¤čĆąĖą╝ąĄčĆ ą║ąŠą┤ą░ ą▓ Example2 (2) ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ąĖčüą║ą╗čÄč湥ąĮąĖą╣ ą┤ą╗čÅ ą┐čĆąŠą╝ą░čģąŠą▓ DCPLB (čüą╝. čéą░ą▒ą╗ąĖčåčā 7: EXCAUSE 0x26). ą×ąĮ ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą║ą░čĆčāčüąĄą╗čīąĮčŗą╣ ą╝ąĄč鹊ą┤ čłąĄą┤čāą╗ąĖąĮą│ą░ (round-robin) ą┤ą╗čÅ ąĘą░ą╝ąĄąĮčŗ DCPLB.
[ąĪąŠąŠą▒čĆą░ąČąĄąĮąĖčÅ, ą║ą░čüą░čÄčēąĖąĄčüčÅ ą║ąŠą│ąĄčĆąĄąĮčéąĮąŠčüčéąĖ ą║čŹčłą░]
ąĢčüą╗ąĖ ą▓ąĮąĄčłąĮąĖą╣ ąĖčüč鹊čćąĮąĖą║ (ąĮą░ą┐čĆąĖą╝ąĄčĆ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ DMA) ąŠą▒čĆą░čēą░ąĄčéčüčÅ ą║ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆą░čÅ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮą░ ą║ą░ą║ ą║čŹčłąĖčĆčāąĄą╝ą░čÅ, ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčé ą┤ąŠą╗ąČąĄąĮ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī ą║ąŠą│ąĄčĆąĄąĮčéąĮąŠčüčéčī ą┐ą░ą╝čÅčéąĖ. ąÜąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą║čŹčłą░ ąĮąĄ ąĘąĮą░ąĄčé ąĮąĖ ąŠ ą║ą░ą║ąĖčģ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅčģ, ą║ąŠč鹊čĆčŗąĄ ą▒čŗą╗ąĖ čüą┤ąĄą╗ą░ąĮčŗ ąĮąĄ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą╝. ą¤čĆąŠčüč鹊ą╣ ąŠą┐čĆąŠčü ą┐ą░ą╝čÅčéąĖ čĆą░ą▒ąŠčéą░čéčī ąĮąĄ ą▒čāą┤ąĄčé.
ą¤čĆąĖą╝ąĄčĆ ą┤ą╗čÅ čéą░ą║ąŠą╣ čüąĖčéčāą░čåąĖąĖ - ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ, ą║ąŠč鹊čĆčŗą╣ čģčĆą░ąĮąĖčéčüčÅ ą▓ąŠ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ. ąöą░ąĮąĮčŗąĄ ą┐ąĄčĆąĄą┤ą░čÄčéčüčÅ ą╝ąĄąČą┤čā čŹčéąĖą╝ ą▒čāč乥čĆąŠą╝ ąĖ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗą╝ ąĖąĮč鹥čĆč乥ą╣čüąŠą╝ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą║ą░ą║ąŠą╣-č鹊 ą┐ąŠč鹊ą║ ą░čāą┤ąĖąŠą┤ą░ąĮąĮčŗčģ). ą»ą┤čĆąŠ ą┤ąŠą╗ąČąĮąŠ čüą┤ąĄą╗ą░čéčī ąĮąĄą║ąŠč鹊čĆčŗąĄ ą▓čŗčćąĖčüą╗ąĄąĮąĖčÅ ąĖ ąĘą░ą┐ąĖčüą░čéčī ą┤ą░ąĮąĮčŗąĄ ąŠą▒čĆą░čéąĮąŠ ą▓ ą▒čāč乥čĆ, ąŠčéą║čāą┤ą░ ą┤ą░ąĮąĮčŗąĄ ą┐ąĄčĆąĄą┤ą░čÄčéčüčÅ ąŠą▒čĆą░čéąĮąŠ ą▓ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗą╣ ąĖąĮč鹥čĆč乥ą╣čü. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ąČąĄą╗ą░č鹥ą╗čīąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī čüčéčĆą░č鹥ą│ąĖčÄ write-through (čüą║ą▓ąŠąĘąĮą░čÅ ąĘą░ą┐ąĖčüčī). ąÆ čéą░ą▒ą╗ąĖčåąĄ 8 ą┐ąŠą║ą░ąĘą░ąĮčŗ čüčéą░ą┤ąĖąĖ ą║ąŠąĮą▓ąĄą╣ąĄčĆą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin.
ąóą░ą▒ą╗ąĖčåą░ 8. ąĪčéą░ą┤ąĖąĖ ą║ąŠąĮą▓ąĄą╣ąĄčĆą░ ąĖąĮčüčéčĆčāą║čåąĖą╣.
| Instr Fetch 1 (ą▓čŗą▒ąŠčĆą║ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ 1) |
| Instr Fetch 2 (ą▓čŗą▒ąŠčĆą║ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ 2) |
| Instr Fetch 3 (ą▓čŗą▒ąŠčĆą║ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ 3) |
| Instr Dec (ą┤ąĄą║ąŠą┤ąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ) |
| Addr Calc (ą▓čŗčćąĖčüą╗ąĄąĮąĖąĄ ą░ą┤čĆąĄčüą░) |
| Data Fetch 1 (ą▓čŗą▒ąŠčĆą║ą░ ą┤ą░ąĮąĮčŗčģ 1) |
| Data Fetch 2 (ą▓čŗą▒ąŠčĆą║ą░ ą┤ą░ąĮąĮčŗčģ 2) |
| Ex 1 |
| Ex 2 |
| Write-Back |
ąØą░ čüčéą░ą┤ąĖąĖ 1 (IF1) ą░ą┤čĆąĄčü ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓čŗą┤ą░ąĄčéčüčÅ ąĮą░ čłąĖąĮčā ą┤ąŠčüčéčāą┐ą░ ą║ ąĖąĮčüčéčĆčāą║čåąĖąĖ (Instruction Access Bus, IAB). ąÆ čŹč鹊ą╣ čäą░ąĘąĄ ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ čüčĆą░ą▓ąĮąĄąĮąĖąĄ čé菹│ąŠą▓ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
ąØą░ čüčéą░ą┤ąĖąĖ 6 (DF1) ą░ą┤čĆąĄčü ą┤ą░ąĮąĮčŗčģ ą▓čŗą┤ą░ąĄčéčüčÅ ąĮą░ čłąĖąĮčā ą┤ąŠčüčéčāą┐ą░ ą║ ą┤ą░ąĮąĮčŗą╝ (Data Access Buses, DA0 ąĖ DA1). ąÆ čŹč鹊ą╣ čäą░ąĘąĄ ąĘą░ą┐čāčüą║ą░ąĄčéčüčÅ čüčĆą░ą▓ąĮąĄąĮąĖąĄ čé菹│ąŠą▓ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ ą║ąŠąĮą▓ąĄą╣ąĄčĆ ąĖąĮčüčéčĆčāą║čåąĖą╣ čüą╝. čĆą░ąĘą┤ąĄą╗ "Program Sequencer" ą▓ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąĄ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin [3].
[ą×ą▒čĆą░ą▒ąŠčéą║ą░ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖ ą┤ą░ąĮąĮčŗčģ]
ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ ą║čŹčłą░. ą║čŹčłąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖ ą┤ą░ąĮąĮčŗčģ ą╝ąŠą│čāčé ą▒čŗčéčī čĆą░ąĘčĆąĄčłąĄąĮčŗ ąĖą╗ąĖ ąĘą░ą┐čĆąĄčēąĄąĮčŗ ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ ą┤čĆčāą│ ąŠčé ą┤čĆčāą│ą░ ą┐čāč鹥ą╝ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖčÅ čĆąĄą│ąĖčüčéčĆąŠą▓ IMEM_CONTROL ąĖ DMEM_CONTROL čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ. ą¤čĆąĖą╝ąĄčĆ ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄčé, ą║ą░ą║ ą╝ąŠąČąĮąŠ čĆą░ąĘčĆąĄčłąĖčéčī ą║čŹčłąĖ ą┤ą░ąĮąĮčŗčģ/ąĖąĮčüčéčĆčāą║čåąĖąĖ:
ŌĆó ą¤ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ čĆą░ąĘčĆąĄčłąĖčéčī ą║čŹčł, ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąĮą░čüčéčĆąŠąĄąĮčŗ ąĖ čĆą░ąĘčĆąĄčłąĄąĮčŗ ą║ąŠčĆčĆąĄą║čéąĮčŗąĄ ą┤ąĄčüą║čĆąĖą┐č鹊čĆčŗ CPLB.
ŌĆó ąÜąŠą│ą┤ą░ ą┐ą░ą╝čÅčéčī čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮą░ ą║ą░ą║ ą║čŹčł, ą║ ąĮąĄą╣ ąĮąĄą╗čīąĘčÅ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ąĮą░ą┐čĆčÅą╝čāčÄ (ąĮąĖ čüąŠ čüč鹊čĆąŠąĮčŗ čÅą┤čĆą░, ąĮąĖ č湥čĆąĄąĘ DMA).
Instruction Memory Control Register (IMEM_CONTROL). ąĀąĖčü. 19 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čĆą░ąĘą╗ąĖčćąĮčŗąĄ ą▒ąĖč鹊ą▓čŗąĄ ą┐ąŠą╗čÅ ąĖ ąĖčģ čäčāąĮą║čåąĖąŠąĮą░ą╗ čĆąĄą│ąĖčüčéčĆą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéčīčÄ ąĖąĮčüčéčĆčāą║čåąĖą╣ IMEM_CONTROL.
LRU Priority Reset (čüą▒čĆąŠčü ą┐čĆąĖąŠčĆąĖč鹥čéą░ LRU). ąæąĖčé LRUPRIORST ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ čüą▒čĆąŠčüą░ ą▓čüąĄčģ ą▒ąĖč鹊ą▓ ą┐čĆąĖąŠčĆąĖč鹥čéą░ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ LRU.
Instruction Cache Locking by Way (čüą┐ąŠčüąŠą▒ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖą╣). ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖą╝ąĄąĄčé 4 ąĮąĄąĘą░ą▓ąĖčüąĖą╝čŗčģ ą▒ąĖčéą░ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ (čŹčéąĖ ą▒ąĖčéčŗ ą┤ąŠčüčéčāą┐ąĮčŗ ą▓ čĆąĄą│ąĖčüčéčĆąĄ IMEM_CONTROL), ą║ąŠč鹊čĆčŗąĄ ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ č湥čéčŗčĆąĄčģ ą┐čāč鹥ą╣.
ąÜąŠą│ą┤ą░ ąŠčéą┤ąĄą╗čīąĮčŗą╣ ą┐čāčéčī ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮ (čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╣ ą▒ąĖčé ILOC ą▓ čĆąĄą│ąĖčüčéčĆąĄ IMEM_CONTROL), ąŠąĮ ąĮąĄ čāčćą░čüčéą▓čāąĄčé ą▓ ą┐ąŠą╗ąĖčéąĖą║ąĄ ąĘą░ą╝ąĄąĮčŗ čüčéčĆąŠą║ąĖ ą║čŹčłą░. ąśąĮčüčéčĆčāą║čåąĖąĖ, ą║čŹčłąĖčĆąŠą▓ą░ąĮąĮčŗąĄ ąĖąĘ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ ą┐čāčéąĖ, ą╝ąŠąČąĮąŠ čāą┤ą░ą╗ąĖčéčī č鹊ą╗čīą║ąŠ čü ą┐ąŠą╝ąŠčēčīčÄ ąĖąĮčüčéčĆčāą║čåąĖąĖ IFLUSH.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą║čŹčłą░ ą┐čĆąĄą┤ąŠčéą▓čĆą░čēą░ąĄčé ąŠčé ą▓čŗą▒ąŠčĆą░ ą┤ą╗čÅ ąĘą░ą╝ąĄąĮčŗ č鹊ą╗čīą║ąŠ ą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░. ąØąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░, čüąŠčģčĆą░ąĮąĄąĮąĮčŗąĄ ą▓ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĮąŠą╝ ą┐čāčéąĖ, ą▓čüąĄ ąĄčēąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą▒čĆą░ąĮčŗ ą┤ą╗čÅ ąĘą░ą╝ąĄąĮčŗ. ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą┐čĆąŠą╝ą░čģąĖ ą║čŹčłą░ ą▓ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčāčÄ ąĘą░ą┐ąĖčüčī ą┐čĆąĖą▓ąĄą┤čāčé ą║ č鹊ą╝čā, čćč鹊 čŹčéą░ ąĘą░ą┐ąĖčüčī ą▒čāą┤ąĄčé ą▓čŗą▒čĆą░ąĮą░ ą┤ą╗čÅ ąĘą░ą╝ąĄąĮčŗ ąĮąŠą▓ąŠą╣ čüčéčĆąŠą║ąŠą╣ ą║čŹčłą░.
ą¤čĆąĖą╝ąĄčĆ Example3 (3) (čüą╝. ą┐čĆąĖą║čĆąĄą┐ą╗ąĄąĮąĮčŗą╣ ZIP-čäą░ą╣ą╗ [7]) ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄčé, ą║ą░ą║ ą▒ąŠą╗ąĄąĄ čćą░čüč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ čäčāąĮą║čåąĖąĖ (ą▓ąŠ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ) ą╝ąŠą│čāčé ą▒čŗčéčī ąĘą░ą║čŹčłąĖčĆąŠą▓ą░ąĮčŗ ąĖ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮčŗ, čéą░ą║ čćč鹊 ąŠąĮąĖ ąĮąĄ ą▒čāą┤čāčé ąĘą░ą╝ąĄąĮčŗ ą▓ ą║čŹčłąĄ. ąŁčéą░ čüčģąĄą╝ą░ čüąŠčüč鹊ąĖčé ąĖąĘ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą┐čāč鹥ą╣ Way1, Way2, Way3 (ą┐čāčéčī Way0 čĆą░ąĘą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮ), ąĖ ą┤ąĄą╗ą░ąĄčéčüčÅ ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąŠąĮąĮčŗą╣ ą▓čŗąĘąŠą▓ ąĖąĮč鹥čĆąĄčüčāčÄčēąĖčģ čäčāąĮą║čåąĖą╣. ążčāąĮą║čåąĖąĖ ą▒čāą┤čāčé ą║čŹčłąĖčĆąŠą▓ą░ąĮčŗ ą▓ Way0 (ą┐ąŠčüą║ąŠą╗čīą║čā ą▓čüąĄ ą┤čĆčāą│ąĖąĄ ą┐čāčéąĖ ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮčŗ). ąóąĄą┐ąĄčĆčī Way0 ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮ (ąĖ Way1, Way2, Way3 ą╝ąŠą│čāčé ą▒čŗčéčī čĆą░ąĘą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮčŗ). ąøčÄą▒čŗąĄ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖąĄ ą┐čĆąŠą╝ą░čģąĖ ą║čŹčłą░ ą╝ąŠą│čāčé ąĘą░ą╝ąĄąĮąĖčéčī čüčéčĆąŠą║ąĖ č鹊ą╗čīą║ąŠ čĆą░ąĘą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮąĮčŗčģ ą┐čāč鹥ą╣ Way1..Way3 (ą┐čāčéčī Way0 ąĘą░ą▒ą╗ąŠą║ąĖčĆąŠą▓ą░ąĮ).
ąæą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ą▓čüąĄčģ 4 ą┐čāč鹥ą╣ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ąĮąĄ čĆąĄą║ąŠą╝ąĄąĮą┤čāąĄčéčüčÅ.
ąÜąŠąĮčäąĖą│čāčĆą░čåąĖčÅ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ L1. ąæąĖčé IMC čāą┐čĆą░ą▓ą╗čÅąĄčé, čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮ ą╗ąĖ ą▓ąĄčĆčģąĮąĖą╣ 16 ą║ąĖą╗ąŠą▒ą░ą╣čéąĮčŗą╣ ą▒ą░ąĮą║ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą║ą░ą║ ą║čŹčł. ąæąĖčé ENICPLB ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓ 1, ą║ąŠą│ą┤ą░ ą┐ąŠą┤ą┤ąĄčƹȹ║ą░ ą║čŹčłą░ čĆą░ąĘčĆąĄčłąĄąĮą░.
ąĀą░ąĘčĆąĄčłąĄąĮąĖąĄ CPLB ąĖąĮčüčéčĆčāą║čåąĖą╣. ąĪ ą▒ąĖč鹊ą╝ ENICPLB ą╝ąŠąČąĮąŠ čĆą░ąĘčĆąĄčłąĖčéčī/ąĘą░ą┐čĆąĄčéąĖčéčī CPLB ąĖąĮčüčéčĆčāą║čåąĖą╣. ą¤ąĄčĆąĄą┤ ąĘą░ą│čĆčāąĘą║ąŠą╣ ąĮąŠą▓čŗčģ ą┤ą░ąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ ą▓ ą╗čÄą▒ąŠą╣ CPLB, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēą░čÅ ą│čĆčāą┐ą┐ą░ ąĖąĘ 16 CPLB ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ąĘą░ą┐čĆąĄčēąĄąĮą░ čü ą┐ąŠą╝ąŠčēčīčÄ ą▒ąĖčéą░ ENICPLB.
Data Memory Control Register (DMEM_CONTROL). ąĀąĖčü. 20 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čĆą░ąĘą╗ąĖčćąĮčŗąĄ ą▒ąĖč鹊ą▓čŗąĄ ą┐ąŠą╗čÅ ąĖ ąĖčģ čäčāąĮą║čåąĖąŠąĮą░ą╗ ą┤ą╗čÅ čĆąĄą│ąĖčüčéčĆą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéčīčÄ ą┤ą░ąĮąĮčŗčģ DMEM_CONTROL.
DAG Port Preference. ąĪ ą┤ą▓čāą╝čÅ ą▒ąĖčéą░ą╝ąĖ PORT_PREFx ąĮąĄ ą║čŹčłąĖčĆčāąĄą╝čŗąĄ ą▓čŗą▒ąŠčĆą║ąĖ ą┤ą░ąĮąĮčŗčģ ŌĆō ą║ąŠč鹊čĆčŗąĄ ąĖčüčģąŠą┤čÅčé ąĖąĘ ą│ąĄąĮąĄčĆą░č鹊čĆąŠą▓ ą░ą┤čĆąĄčüą░ ą┤ą░ąĮąĮčŗčģ (Data Address Generators, DAG0 ąĖ DAG1) ŌĆō ą╝ąŠą│čāčé ą▒čŗčéčī ą┐čĆąĖą▓čÅąĘą░ąĮčŗ ą║ ąŠą┤ąĮąŠą╝čā ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą╝čā ą┐ąŠčĆčéčā DAG (Port A ąĖą╗ąĖ Port B, čüą╝. čĆąĖčü. 1).
L1 Data Cache Bank Select. ąæąĖčé DCBS čāą┐čĆą░ą▓ą╗čÅąĄčé, ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą╗ąĖ ą▒ąĖčé 14 ąĖą╗ąĖ ą▒ąĖčé 23 ą░ą┤čĆąĄčüą░ ą┤ą╗čÅ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ ą╝ąĄąČą┤čā ą▒ą░ąĮą║ą░ą╝ąĖ Bank A ąĖ Bank B ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║čŹčłą░ (čüą╝. čĆąĖčü. 20).
ąÜąŠąĮčäąĖą│čāčĆą░čåąĖčÅ ą┐ą░ą╝čÅčéąĖ ą┤ą░ąĮąĮčŗčģ L1. ąæąĖčéčŗ DMC čĆą░ąĘčĆąĄčłą░čÄčé/ąĘą░ą┐čĆąĄčēą░čÄčé ą┐ąŠą┤ą┤ąĄčƹȹ║čā ą║čŹčłą░ ą┤ą╗čÅ ą▒ą░ąĮą║ąŠą▓ ą┐ą░ą╝čÅčéąĖ ą┤ą░ąĮąĮčŗčģ L1. ąæąĖčé DMC[1] čāą┐čĆą░ą▓ą╗čÅąĄčé Bank A, ąĖ DMC[0] čāą┐čĆą░ą▓ą╗čÅąĄčé Bank B. ą¤ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ Bank A ąĖą╗ąĖ Bank A + Bank B ą▓ ą║ą░č湥čüčéą▓ąĄ ą║čŹčłą░. ąóąŠą╗čīą║ąŠ Bank B ąĮąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮ ą║ą░ą║ ą┤ąŠčüčéčāą┐ąĮčŗą╣ ą║ą░ą║ ą┐ą░ą╝čÅčéčī ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ L1. ąæąĖčé ENDCPLB ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓ 1, ą║ąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮą░ ą┐ąŠą┤ą┤ąĄčƹȹ║ą░ ą║čŹčłą░.
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąĮąĄą║ąŠč鹊čĆčŗąĄ ą┐čĆąŠčåąĄčüčüąŠčĆčŗ Blackfin ąĮąĄ ąĖą╝ąĄčÄčé 2 ą▒ą░ąĮą║ą░ ą┤ą░ąĮąĮčŗčģ, čéą░ą║ čćč鹊 ąĮąĄ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé ą▒ąĖčéčŗ DCBS ąĖ DMC[0] (čüą╝. čéą░ą▒ą╗ąĖčåčā 2).
Data CPLB Enable. ąĪ ą▒ąĖč鹊ą╝ ENDCPLB ą╝ąŠą│čāčé ą▒čŗčéčī čĆą░ąĘčĆąĄčłąĄąĮčŗ/ąĘą░ą┐čĆąĄčēąĄąĮčŗ CPLB ą┤ą░ąĮąĮčŗčģ. ą¤ąĄčĆąĄą┤ ąĘą░ą│čĆčāąĘą║ąŠą╣ ąĮąŠą▓čŗčģ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ ą┤ą░ąĮąĮčŗčģ ą▓ ą╗čÄą▒ąŠą╣ CPLB, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēą░čÅ ą│čĆčāą┐ą┐ą░ ąĖąĘ 16 CPLB ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ąĘą░ą┐čĆąĄčēąĄąĮą░ čü ą┐ąŠą╝ąŠčēčīčÄ ą▒ąĖčéą░ ENDCPLB.
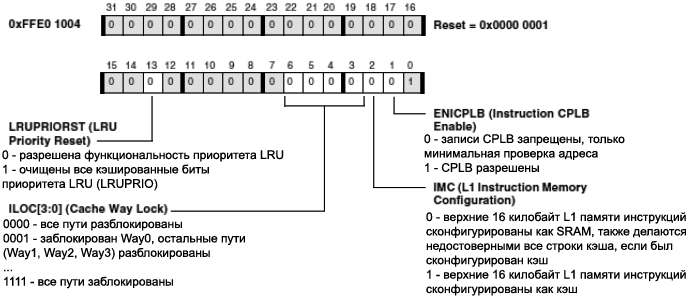
ąĀąĖčü. 19. ąæąĖč鹊ą▓čŗąĄ ą┐ąŠą╗čÅ ąĖ ąĖčģ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčī ą┤ą╗čÅ čĆąĄą│ąĖčüčéčĆą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ IMEM_CONTROL.
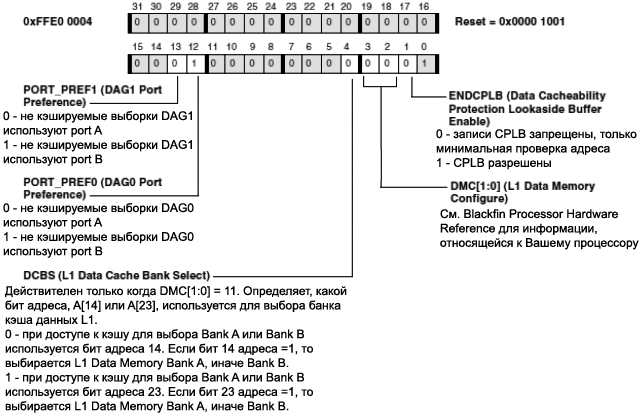
ąĀąĖčü. 20. ąæąĖč鹊ą▓čŗąĄ ą┐ąŠą╗čÅ ąĖ ąĖčģ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčī ą┤ą╗čÅ čĆąĄą│ąĖčüčéčĆą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ DMEM_CONTROL.
[ąśąĮčüčéčĆčāą║čåąĖąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą║čŹčłąĄą╝]
Instruction Cache Invalidation (ą┐ąĄčĆąĄą▓ąŠą┤ ą║čŹčłą░ ą▓ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ). ą¤čāč鹥ą╝ ą▓čŗą▓ąŠą┤ą░ ąĖąĘ ą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéąĖ čüčéčĆąŠą║ ą║čŹčłą░, čüą▓čÅąĘą░ąĮąĮčŗčģ ą▓ ą▒čāč乥čĆąŠą╝, ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčéčüčÅ "ą║ąŠą│ąĄčĆąĄąĮčéąĮąŠčüčéčī" (čüąĖąĮčģčĆąŠąĮąĮąŠčüčéčī) ą╝ąĄąČą┤čā čüąŠą┤ąĄčƹȹĖą╝čŗą╝, ą║ąŠč鹊čĆąŠąĄ čģčĆą░ąĮąĖčéčüčÅ ą▓ ą║čŹčłąĄ, ąĖ ą░ą║čéčāą░ą╗čīąĮčŗą╝ čüąŠą┤ąĄčƹȹĖą╝čŗą╝ ąĖčüčģąŠą┤ąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆą░čÅ ą║čŹčłąĖčĆčāąĄčéčüčÅ. ąĢčüčéčī 3 čüčģąĄą╝čŗ ą┤ą╗čÅ ą┐ąĄčĆąĄą▓ąŠą┤ą░ ą▓ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠčüčéčī ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣:
ŌĆó ąśąĮčüčéčĆčāą║čåąĖčÅ IFLUSH ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ą┐ąĄčĆąĄą▓ąŠą┤ą░ ą▓ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ą░ą┤čĆąĄčüą░ ą▓ ą║ą░čĆč鹥 ą┐ą░ą╝čÅčéąĖ. ąÜąŠą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ IFLUSH [P2];, ąĄčüą╗ąĖ ą░ą┤čĆąĄčü ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčŗą╣ čāą║ą░ąĘčŗą▓ą░ąĄčé P2, ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ą║čŹčłąĄ, č鹊 čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēą░čÅ čüčéčĆąŠą║ą░ ą║čŹčłą░ ą▒čāą┤ąĄčé čüą┤ąĄą╗ą░ąĮą░ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠą╣ ą┐ąŠčüą╗ąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą▓čŗčłąĄčāą┐ąŠą╝čÅąĮčāč鹊ą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ąÜąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĮą░ą┐ąŠą┤ąŠą▒ąĖąĄ IFLUSH [P2++];, čāą║ą░ąĘą░č鹥ą╗čī ąĖąĮą║čĆąĄą╝ąĄąĮčéąĖčĆčāąĄčéčüčÅ ąĮą░ čĆą░ąĘą╝ąĄčĆ čüčéčĆąŠą║ąĖ ą║čŹčłą░.
ŌĆó ąæąĖčé VALID čüąĄą║čåąĖąĖ čé菹│ą░ ą┤ą╗čÅ ą╗čÄą▒ąŠą╣ čüčéčĆąŠą║ąĖ ą▓ ą║čŹčłąĄ ą╝ąŠąČąĄčé ą▒čŗčéčī čÅą▓ąĮąŠ ąŠčćąĖčēąĄąĮ ąĘą░ą┐ąĖčüčīčÄ ą╗ąŠą│. 1 ą▓ čüąĄą║čåąĖčÄ čé菹│ą░. ąŚąĮą░č湥ąĮąĖąĄ ą▓ čé菹│ čüąĄą║čåąĖąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĘą░ą┐ąĖčüą░ąĮąŠ čü ą┐ąŠą╝ąŠčēčīčÄ čĆąĄą│ąĖčüčéčĆą░ ITEST_COMMAND. ąŁč鹊 ą┐ąŠą┤čĆąŠą▒ąĮąŠ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ąĄčéčüčÅ ą▓ čüą╗ąĄą┤čāčÄčēąĄą╝ čĆą░ąĘą┤ąĄą╗ąĄ.
ŌĆó ą¦č鹊ą▒čŗ čüą┤ąĄą╗ą░čéčī ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗą╝ ą▓ąĄčüčī ą║čŹčł, ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠčćąĖčēąĄąĮ ą▒ąĖčé IMC ą▓ čĆąĄą│ąĖčüčéčĆąĄ IMEM_CONTROL. ąŁč鹊čé ą▒ąĖčé ąŠčćąĖčēą░ąĄčé ą▒ąĖčé VALID ą┤ą╗čÅ ą▓čüąĄčģ čüąĄą║čåąĖą╣ čé菹│ą░ ą║čŹčłą░. ąæąĖčé IMC ą╝ąŠąČąĮąŠ čāčüčéą░ąĮąŠą▓ąĖčéčī, čćč鹊ą▒čŗ čüąĮąŠą▓ą░ čĆą░ąĘčĆąĄčłąĖčéčī ą║čŹčł.
ąśąĮčüčéčĆčāą║čåąĖąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą║čŹčłąĄą╝ ą┤ą░ąĮąĮčŗčģ
ŌĆó ą£ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ąĖąĮčüčéčĆčāą║čåąĖčÅ PREFETCH ą┤ą╗čÅ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ ą▓ ą║čŹčłąĄ L1.
ŌĆó ąśąĮčüčéčĆčāą║čåąĖčÅ FLUSH ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ (čüą▒čĆąŠčüčā) ą┤ą░ąĮąĮčŗčģ ą║čŹčłą░, čćč鹊ą▒čŗ čāą║ą░ąĘą░ąĮąĮą░čÅ čüčéčĆąŠą║ą░ ą║čŹčłą░ čüąŠą▓ą┐ą░ą┤ą░ą╗ą░ ą┐ąŠ čüąŠą┤ąĄčƹȹĖą╝ąŠą╝čā čü ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮčŗą╝ąĖ ą┤ą░ąĮąĮčŗą╝ąĖ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ. ąĢčüą╗ąĖ čüčéčĆąŠą║ą░ ą║čŹčłą░ ą│čĆčÅąĘąĮą░čÅ, ąĖąĮčüčéčĆčāą║čåąĖčÅ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé čüčéčĆąŠą║čā ąŠą▒čĆą░čéąĮąŠ ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī, ąĖ ą┐ąŠą╝ąĄčćą░ąĄčé čŹčéčā čüčéčĆąŠą║čā ą▓ ą║čŹčłąĄ ą┤ą░ąĮąĮčŗčģ ą║ą░ą║ čćąĖčüčéčāčÄ.
ŌĆó ąśąĮčüčéčĆčāą║čåąĖčÅ FLUSHINV ą┤ąĄą╗ą░ąĄčé čü ą║čŹčłąĄą╝ ą┤ą░ąĮąĮčŗčģ č鹊 ąČąĄ čüą░ą╝ąŠąĄ, čćč鹊 ąĖ ąĖąĮčüčéčĆčāą║čåąĖčÅ FLUSH, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ą┐ąĄčĆąĄą▓ąŠą┤ąĖ ą▓ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ čāą║ą░ąĘą░ąĮąĮčāčÄ čüčéčĆąŠą║čā ą▓ ą║čŹčłąĄ. ąĢčüą╗ąĖ čüčéčĆąŠą║ą░ ąĮąĄ ą│čĆčÅąĘąĮą░čÅ, č鹊 čüą▒čĆąŠčüą░ ą┤ą░ąĮąĮčŗčģ ą║čŹčłą░ ąĮąĄ ą▒čāą┤ąĄčé. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé č鹊ą╗čīą║ąŠ čłą░ą│ ą┐ąĄčĆąĄą▓ąŠą┤ą░ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ą▓ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮąŠąĄ čüąŠčüč鹊čÅąĮąĖąĄ.
[ą¤ąŠą╗čāč湥ąĮąĖąĄ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ ą║čŹčłą░]
ąÜąŠą│ą┤ą░ ą▒ą░ąĮą║ ą┐ą░ą╝čÅčéčī L1 čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮ ą║ą░ą║ ą║čŹčł, ą║ ąĮąĄą╝čā ąĮąĄ ą╝ąŠą│čāčé ąĮą░ą┐čĆčÅą╝čāčÄ ąŠą▒čĆą░čéąĖčéčīčüčÅ čÅą┤čĆąŠ ąĖą╗ąĖ DMA. ą×ą┐ąĄčĆą░čåąĖąĖ čćč鹥ąĮąĖčÅ/ąĘą░ą┐ąĖčüąĖ ąĮą░ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąĄ ą║čŹčłą░ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ čĆąĄą│ąĖčüčéčĆąŠą▓ ITEST_COMMAND ąĖ DTEST_COMMAND. ąĀąĄą│ąĖčüčéčĆ DTEST_COMMAND čéą░ą║ąČąĄ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą▒ą░ąĮą║ą░ą╝ SRAM ąĖąĮčüčéčĆčāą║čåąĖą╣. ąĀąĖčü. 21 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą▒ąĖč鹊ą▓čŗąĄ ą┐ąŠą╗čÅ čĆąĄą│ąĖčüčéčĆą░ ITEST_COMMAND, čĆąĖčü. 22 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą▒ąĖč鹊ą▓čŗąĄ ą┐ąŠą╗čÅ čĆąĄą│ąĖčüčéčĆą░ DTEST_COMMAND.
ąöąŠčüčéčāą┐ ą║ ą║čŹčłčā ąĖąĮčüčéčĆčāą║čåąĖą╣. ąĀąĄą│ąĖčüčéčĆ ITEST_COMMAND ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą┤ą░ąĮąĮčŗą╝ ąĖą╗ąĖ čüąĄą║čåąĖčÅą╝ č鹥ą│ą░ čüčéčĆąŠą║ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣.
ąĪčéčĆąŠą║ą░ ą║čŹčłą░ ą┐ąŠą┤ąĄą╗ąĄąĮą░ ąĮą░ č湥čéčŗčĆąĄ 64-ą▒ąĖčéąĮčŗčģ čüą╗ąŠą▓ą░. ąöą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą▒čĆą░ąĮąŠ ą╗čÄą▒ąŠąĄ ąĖąĘ čŹčéąĖčģ 4 čüą╗ąŠą▓. ą¤čĆąĖ čćč鹥ąĮąĖąĖ ą║čŹčłą░ ąĘąĮą░č湥ąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ čćąĖčéą░ąĄčéčüčÅ ą▓ ąĮą░ą▒ąŠčĆąĄ čĆąĄą│ąĖčüčéčĆąŠą▓ ITEST_DATA[1:0]. ą¤čĆąĖ ąĘą░ą┐ąĖčüąĖ ą║čŹčłą░ ąĘąĮą░č湥ąĮąĖąĄ ąĖąĘ ąĮą░ą▒ąŠčĆą░ čĆąĄą│ąĖčüčéčĆąŠą▓ ITEST_DATA[1:0] ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą▓ ą║čŹčł.
ąÜąŠą│ą┤ą░ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ ą║ čüąĄą║čåąĖąĖ čé菹│ą░, č鹊 32-ą▒ąĖčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖčÅ čé菹│ą░ ą┐ąĄčĆąĄą┤ą░ąĄčéčüčÅ č湥čĆąĄąĘ (ą▓/ąĖąĘ) čĆąĄą│ąĖčüčéčĆ ITEST_DATA0.
ąĀą░čüčüą╝ąŠčéčĆąĖą╝ ą┐čĆąĖą╝ąĄčĆ, ą│ą┤ąĄ ąĘąĮą░č湥ąĮąĖąĄ 0x0C010360 ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą▓ čĆąĄą│ąĖčüčéčĆ ITEST_COMMAND. ąŁčéą░ ąĖąĮčüčéčĆčāą║čåąĖčÅ ą▒čāą┤ąĄčé čćąĖčéą░čéčī čüąĄą║čåąĖčÄ čé菹│ą░ ąĖąĘ way-3, set-27, subbank-1 ąĖ ą┐ąĄčĆąĄą┤ą░ą▓ą░čéčī čŹč鹊 ą▓ čĆąĄą│ąĖčüčéčĆ ITEST_DATA0. ą¤ąŠą┤ąŠą▒ąĮčŗą╝ ąŠą▒čĆą░ąĘąŠą╝ ąĘą░ą┐ąĖčüčī 0x0C010362 ą┐ąĄčĆąĄą┤ą░ąĄčé čüąŠą┤ąĄčƹȹĖą╝ąŠąĄ čĆąĄą│ąĖčüčéčĆą░ ITEST_DATA0 ą▓ čüąĄą║čåąĖčÄ č鹥ą│ą░ čüčéčĆąŠą║ąĖ, čĆą░ąĘą╝ąĄčēąĄąĮąĮąŠą╣ ą▓ way-3, set-27, subbank-1. ą¤čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ čüąĄą║čåąĖąĖ čé菹│ą░ (čćč鹥ąĮąĖąĄ ąĖą╗ąĖ ąĘą░ą┐ąĖčüčī), ą▒ąĖčéčŗ 3 ąĖ 4 čĆąĄą│ąĖčüčéčĆą░ ITEST_COMMAND ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮčŗ.
ąŚą░ą┐ąĖčüčī ąĘąĮą░č湥ąĮąĖčÅ 0x0C010374 ą▒čāą┤ąĄčé čćąĖčéą░čéčī ą▓č鹊čĆąŠąĄ čüą╗ąŠą▓ąŠ čüčéčĆąŠą║ąĖ ą║čŹčłą░, čĆą░ąĘą╝ąĄčēąĄąĮąĮąŠą╣ ą▓ way-3, set-27, subbank-1 ąĖ ą┐ąĄčĆąĄą┤ą░ą▓ą░čéčī čŹč鹊 ą▓ ąĮą░ą▒ąŠčĆ čĆąĄą│ąĖčüčéčĆąŠą▓ ITEST_DATA[1:0]. ąŚą░ą┐ąĖčüčī ąĘąĮą░č湥ąĮąĖčÅ 0x0C010366 ą▓ čĆąĄą│ąĖčüčéčĆ ITEST_COMMAND ą┐ąĄčĆąĄą┤ą░ąĄčé ąĘąĮą░č湥ąĮąĖąĄ ąĮą░ą▒ąŠčĆą░ čĆąĄą│ąĖčüčéčĆąŠą▓ ITEST_DATA[1:0] ą▓ word-0 čüčéčĆąŠą║ąĖ ą║čŹčłą░ way-3, set-27, subbank-1 ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣. ą¤čĆąĖ ąĘą░ą┐ąĖčüąĖ ą║čŹčłą░ čĆąĄą│ąĖčüčéčĆ ITEST_DATA[1:0] ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ąĘą░ą│čĆčāąČąĄąĮ ą┐ąĄčĆąĄą┤ ąĘą░ą┐ąĖčüčīčÄ čĆąĄą│ąĖčüčéčĆą░ ITEST_COMMAND.
ąöąŠčüčéčāą┐ ą║ SRAM ąĖąĮčüčéčĆčāą║čåąĖą╣. ąÜąŠą│ą┤ą░ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą▒ąĖčé 24 ą▓ čĆąĄą│ąĖčüčéčĆąĄ DTEST_COMMAND, čĆąĄą│ąĖčüčéčĆ DTEST_COMMAND ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ instruction SRAM. 64-ą▒ąĖčéąĮąŠąĄ čüą╗ąŠą▓ąŠ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąĄčĆąĄą┤ą░ąĮąŠ č湥čĆąĄąĘ ąĮą░ą▒ąŠčĆ čĆąĄą│ąĖčüčéčĆąŠą▓ (ą▓/ąĖąĘ) DTEST_DATA[1:0] ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ/čćč鹥ąĮąĖčÅ instruction SRAM. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą║ ą┐ą░ą╝čÅčéąĖ ą╝ąŠąČąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ą┤ąŠčüčéčāą┐ ą┐ąŠčĆčåąĖčÅą╝ąĖ ą┐ąŠ 8 ą▒ą░ą╣čé ąĘą░ čĆą░ąĘ.
ąæąĖčé 2 čĆąĄą│ąĖčüčéčĆą░ DTEST_COMMAND ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą┐čĆąĖ čĆą░ą▒ąŠč鹥 ą▓ čŹč鹊ą╝ čĆąĄąČąĖą╝ąĄ. ąæąĖčéčŗ 3-10 ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąĮą░ąĘąĮą░č湥ąĮčŗ čü ą▒ąĖčéą░ą╝ąĖ ą░ą┤čĆąĄčüą░, ą║čāą┤ą░ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐. ąĀą░čüčüą╝ąŠčéčĆąĖą╝ čüą╗čāčćą░ą╣, ą║ąŠą│ą┤ą░ ą▒ą░ą╣čé ą┐ąŠ ą░ą┤čĆąĄčüčā 0xFFA07935 čćąĖčéą░ąĄčéčüčÅ ąĖąĘ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣. ąŁč鹊čé ą░ą┤čĆąĄčü ą╗ąĄąČąĖčé ą▓ ą▒ą░ąĮą║ąĄ bank-1. ą¤čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ ą▓čŗčłąĄčāą║ą░ąĘą░ąĮąĮąŠą╝čā ą▒ą░ą╣čéčā ą▒čāą┤ąĄčé ąŠčüčāčēąĄčüčéą▓ą╗ąĄąĮ ą┤ąŠčüčéčāą┐ čüčĆą░ąĘčā ą║ čåąĄą╗ąŠą╝čā ą▒ą╗ąŠą║čā ą▒ą░ą╣čé (0xFFA07930 ŌĆō 0xFFA07937). ąŻą┐čĆą░ą▓ą╗čÅčÄčēąĄąĄ ąĘąĮą░č湥ąĮąĖąĄ, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ąĘą░ą│čĆčāąČąĄąĮąŠ ą▓ čĆąĄą│ąĖčüčéčĆ DTEST_COMMAND ą▒čāą┤ąĄčé 0x05034134.
ąöąŠčüčéčāą┐ ą║ ą║čŹčłčā ą┤ą░ąĮąĮčŗčģ. ąÜąŠą│ą┤ą░ ąŠčćąĖčēąĄąĮ ą▒ąĖčé 24 čĆąĄą│ąĖčüčéčĆą░ DTEST_COMMAND, čĆąĄą│ąĖčüčéčĆ DTEST_COMMAND ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ą┤ąŠčüčéčāą┐ą░ ą║ ą┤ą░ąĮąĮčŗą╝ ąĖą╗ąĖ čüąĄą║čåąĖčÅą╝ čé菹│ą░ čüčéčĆąŠą║ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ. ąĪą╗ąŠą▓ąŠ ąĖąĘ čüąĄą║čåąĖąĖ ą┤ą░ąĮąĮčŗčģ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąĄčĆąĄą┤ą░ąĮąŠ č湥čĆąĄąĘ (ą▓/ąĖąĘ) ąĮą░ą▒ąŠčĆ čĆąĄą│ąĖčüčéčĆąŠą▓ DTEST_DATA[1:0].
ą¤čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ čüąĄą║čåąĖąĖ č鹥ą│ą░ 32-ą▒ąĖčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ čé菹│ą░ ą┐ąĄčĆąĄą┤ą░ąĄčéčüčÅ č湥čĆąĄąĘ (ą▓/ąĖąĘ) čĆąĄą│ąĖčüčéčĆ DTEST_DATA0.
ąĀą░čüčüą╝ąŠčéčĆąĖą╝ ą┐čĆąĖą╝ąĄčĆ, ą│ą┤ąĄ ąĘąĮą░č湥ąĮąĖčÅ ąĮą░ą▒ąŠčĆą░ čĆąĄą│ąĖčüčéčĆąŠą▓ DTEST_DATA[1:0] ąĮčāąČąĮąŠ ąĘą░ą┐ąĖčüą░čéčī ą▓ word-0 čüčéčĆąŠą║ąĖ ą║čŹčłą░ way-1, set-39, subbank-0, ą▒ą░ąĮą║ ą┤ą░ąĮąĮčŗčģ ą║čŹčłą░ bank-A. ąóąŠą│ą┤ą░ ą▓ čĆąĄą│ąĖčüčéčĆ DTEST_COMMAND ą╝ąŠąČąĮąŠ ąĘą░ą┐ąĖčüą░čéčī ąĘąĮą░č湥ąĮąĖąĄ 0x040004E5. ąØą░ą▒ąŠčĆ čĆąĄą│ąĖčüčéčĆąŠą▓ DTEST_DATA[1:0] ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ąĘą░ą│čĆčāąČąĄąĮ ą┐ąĄčĆąĄą┤ ąĘą░ą┐ąĖčüčīčÄ ą▓ čĆąĄą│ąĖčüčéčĆ DTEST_COMMAND. ąæąĖčé 14 čĆąĄą│ąĖčüčéčĆą░ DTEST_COMMAND ąĘą░čĆąĄąĘąĄčĆą▓ąĖčĆąŠą▓ą░ąĮ ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓čā ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ (ą▒ąĖčé 24 = 0).

ąĀąĖčü. 21. ąæąĖč鹊ą▓čŗąĄ ą┐ąŠą╗čÅ ąĖ ąĖčģ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčī ą┤ą╗čÅ čĆąĄą│ąĖčüčéčĆą░ ITEST_COMMAND.
ąĀąĖčü. 22. ąæąĖč鹊ą▓čŗąĄ ą┐ąŠą╗čÅ ąĖ ąĖčģ čäčāąĮą║čåąĖąŠąĮą░ą╗čīąĮąŠčüčéčī ą┤ą╗čÅ čĆąĄą│ąĖčüčéčĆą░ DTEST_COMMAND.
[ąĪąŠąŠą▒čĆą░ąČąĄąĮąĖčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ]
ąÆ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ čĆą░čüčüą╝ąŠčéčĆąĄąĮčŗ čĆąĄąĘčāą╗čīčéą░čéčŗ čüčĆą░ą▓ąĮąĄąĮąĖčÅ ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖčÅ čĆą░ą▒ąŠčéčŗ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą║čŹčłą░ ąĖ ą▒ąĄąĘ ąĮąĄą│ąŠ. ąŁčéąĖ ą┐čĆąĖą╝ąĄčĆčŗ ą┐čĆąĖą╝ąĄąĮčÅčÄčéčüčÅ ą║ čüą┐ąĄčåąĖą░ą╗čīąĮčŗą╝ čüčåąĄąĮą░čĆąĖčÅą╝, ąĖ ą┤ą░čÄčé ąĖą┤ąĄąĖ, ą║ą░ą║ ą┐ąŠą╗čāčćąĖčéčī ą╗čāčćčłčāčÄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ą▓ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗčģ čĆą░ą▒ąŠčćąĖčģ čāčüą╗ąŠą▓ąĖčÅčģ.
ąöą╗čÅ čŹčéąĖčģ čćą░čüčéąĮčŗčģ ą┐čĆąĖą╝ąĄčĆąŠą▓ ąĮą░ ąŠčåąĄąĮąŠčćąĮąŠą╣ ą┐ą╗ą░č鹥 čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ą░ (ADSPBF533 EZ-KIT Lite┬« evaluation board) ą▒ą╗ąŠą║ PLL čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮ ąĮą░ čćą░čüč鹊čéčā čÅą┤čĆą░ 270 ą£ąōčå (CCLK) ąĖ čćą░čüč鹊čéčā čüąĖčüč鹥ą╝ąĮąŠą╣ čłąĖąĮčŗ 54 ą£ąōčå (SCLK) čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ (CLKIN = 27 ą£ąōčå).
ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖąĖ: ąŠą┐čéąĖą╝ąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗąĄ čāčüą╗ąŠą▓ąĖčÅ. ąöą╗čÅ ą╗ąĖąĮąĄą╣ąĮąŠą│ąŠ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░ ą▓ąŠ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ą╝ąŠąČąĮąŠ čāą▓ąĄą╗ąĖčćąĖčéčī čü ą▓čŗąĖą│čĆčŗčłąĄą╝ ą┤ąŠ 13% (čüą╝. ą▓čĆąĄąĘą║čā "ąŚą░ą┤ąĄčƹȹ║ą░ ą┐čĆąĖ ą▓čŗą▒ąŠčĆą║ąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ, čüčĆą░ą▓ąĮąĄąĮąĖąĄ čĆą░ą▒ąŠčéčŗ čü ą║čŹčłąĄą╝ ąĖ ą▒ąĄąĘ ą║čŹčłą░") ą▓ čüčĆą░ą▓ąĮąĄąĮąĖąĖ čü ą║ąŠą┤ąŠą╝, ą║ąŠč鹊čĆčŗą╣ ąĮąĄ čüąŠčģčĆą░ąĮąĄąĮ ą▓ ą║čŹčłąĄ. ąĢčüą╗ąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ čāąČąĄ čüą║ąŠą┐ąĖčĆąŠą▓ą░ąĮčŗ ą▓ ą║čŹčł, ąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮčŗ ą║ą░ą║ ą╝ąĖąĮąĖą╝čāą╝ ą┤ą▓ą░ąČą┤čŗ, ą▓ąŠąĘą╝ąŠąČąĮąŠ čāčüą║ąŠčĆąĄąĮąĖąĄ ą▒ąŠą╗čīčłąĄ 50%. ąÆ čéą░ą▒ą╗ąĖčåąĄ 9 ą┐ąŠą║ą░ąĘą░ąĮąŠ čüčĆą░ą▓ąĮąĄąĮąĖąĄ (ą▓čĆąĄą╝čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ čāą║ą░ąĘą░ąĮąŠ ą▓ čéą░ą║čéą░čģ čÅą┤čĆą░), ą║ąŠą│ą┤ą░ čäčāąĮą║čåąĖąĖ ą▓čŗą┐ąŠą╗ąĮčÅčÄčéčüčÅ ąŠčé 1x ą┤ąŠ 1000x čĆą░ąĘ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą▓ ą░ą╗ą│ąŠčĆąĖčéą╝ąĄ čäąĖą╗čīčéčĆą░) ąĖ ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓čŗą║ą╗čÄčćą░ąĄčéčüčÅ ąĖ ą▓ą║ą╗čÄčćą░ąĄčéčüčÅ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ. ą¦ąĖčüą╗ą░ ŌĆō ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčēąĖąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čéą░ą║č鹊ą▓ čÅą┤čĆą░ ŌĆō ą┐ąŠą╗čāč湥ąĮčŗ ąĖąĘ ą║ąŠą┤ą░ Example6 (6). ąĪč鹊ą╗ą▒ąĄčå "ąÆčŗąĖą│čĆčŗčł" ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé 菹║ąŠąĮąŠą╝ąĖčÄ čåąĖą║ą╗ąŠą▓ čÅą┤čĆą░ (ą▓ ą┐čĆąŠčåąĄąĮčéą░čģ). ą¦ąĖčüą╗ą░ ą╝ąŠą│čāčé ą╝ąĄąĮčÅčéčīčüčÅ ┬▒100 čåąĖą║ą╗ąŠą▓ ą┐čĆąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĖ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą┐čĆąŠą│ąŠąĮąŠą▓ č鹥čüčéą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą┐čĆąĖ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖąĖ SDRAM).
ąóą░ą▒ą╗ąĖčåą░ 9. ą¤čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą▓ čģąŠčĆąŠčłąĖčģ čāčüą╗ąŠą▓ąĖčÅčģ.
| ąÜąŠą╗ąĖčć. ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖą╣ |
ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣ ąÆą½ąÜąø |
ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣ ąÆąÜąø |
ąÆčŗąĖą│čĆčŗčł |
| 1x |
1430 |
1245 |
12.9% |
| 2x |
2480 |
1329 |
46.4% |
| 4x |
4580 |
1469 |
67.9% |
| 8x |
8740 |
1973 |
77.4% |
| 10x |
10814 |
2173 |
79.9% |
| 100x |
104620 |
11850 |
88.7% |
| 1000x |
1042950 |
109050 |
89.5% |
ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖąĖ: ą┐ą╗ąŠčģą░čÅ ą║ąŠąĮčåąĄą┐čåąĖčÅ. ąóą░ą▒ą╗ąĖčåą░ 10 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čćąĖčüą╗ą░, ą┐ąŠą┤ąŠą▒ąĮčŗąĄ čćąĖčüą╗ą░ą╝ ąĖąĘ ą┐čĆąĄą┤čŗą┤čāčēąĄą│ąŠ ą┐čĆąĖą╝ąĄčĆą░. ąØąŠ č鹥ą┐ąĄčĆčī ą║ąŠą┤ ąĮąĄ ą▓čŗą┐ąŠą╗ąĮčÅąĄčéčüčÅ ą╗ąĖąĮąĄą╣ąĮąŠ (ą▓ ą║ą░ąČą┤ąŠą╣ čäčāąĮą║čåąĖąĖ čüąŠą┤ąĄčƹȹĖčéčüčÅ ą┐čĆąŠčüč鹊 ąĖąĮčüčéčĆčāą║čåąĖčÅ ą┐ąĄčĆąĄčģąŠą┤ą░ jump), ąĖ ą▒čāą┤ąĄčé ą┐čĆąŠąĖčüčģąŠą┤ąĖčéčī ą╝ąĮąŠąČąĄčüčéą▓ąŠ ą┐čĆąŠą╝ą░čģąŠą▓ ą║čŹčłą░ ąĖ ąĘą░ą╝ąĄąĮ čüčéčĆąŠą║ ą║čŹčłą░. ąÜą░ąČą┤čŗą╣ ą┐čĆąŠą╝ą░čģ ą║čŹčłą░ ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ąŠą┐ąĄčĆą░čåąĖąĖ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ ą║čŹčłą░. ąĢčüą╗ąĖ čäčāąĮą║čåąĖčÅ ą┐čĆąŠčüč鹊 čüąŠą┤ąĄčƹȹĖčé ąĖąĮčüčéčĆčāą║čåąĖčÄ ą┐ąĄčĆąĄčģąŠą┤ą░, ąĖ č鹥ą┐ąĄčĆčī ą▒ąŠą╗čīčłąĄ ąĮąĄčé ą┐čĆąĄąĖą╝čāčēąĄčüčéą▓ą░ ą╗ąĖąĮąĄą╣ąĮąŠą│ąŠ ą║ąŠą┤ą░, ą║ąŠą│ą┤ą░ ą▓ ą║čŹčłąĄ čāąČąĄ ąĄčüčéčī ąĮčāąČąĮčŗą╣ ą║ąŠą┤, č鹊 ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ą▓čŗą▒ąŠčĆą║ąĖ ą║ąŠą┤ą░ ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ąĖ ąĘą░ą│čĆčāąĘą║ąĖ ąĄą│ąŠ ą▓ ą║čŹčł čéčĆąĄą▒čāčÄčé ąĘą░čéčĆą░čé ą▓čĆąĄą╝ąĄąĮąĖ.
ąóą░ą▒ą╗ąĖčåą░ 10. ą¤čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ čü ą┐ą╗ąŠčģąŠą╣ ą║ąŠąĮčåąĄą┐čåąĖąĄą╣ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░.
| ąÜąŠą╗ąĖčć. ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖą╣ |
ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣ ąÆą½ąÜąø |
ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣ ąÆąÜąø |
ą¤čĆąŠąĖą│čĆčŗčł |
| 1x |
1031 |
1164 |
-12.9% |
| 2x |
1924 |
2394 |
-24.4% |
| 4x |
3747 |
4654 |
-24.2% |
| 8x |
7462 |
8918 |
-19.5% |
| 10x |
9314 |
11100 |
-19.2% |
| 100x |
91643 |
109201 |
-19.2% |
| 1000x |
915488 |
1090127 |
-19.1% |
ą║čŹčł ą┤ą░ąĮąĮčŗčģ. ąĀą░ąĘą╝ąĄčĆ čüčéčĆą░ąĮąĖčåčŗ čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą▓ The 1 ą║ąĖą╗ąŠą▒ą░ą╣čé. ąĪąĮą░čćą░ą╗ą░ čÅą┤čĆąŠ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčé 15 ą║ąĖą╗ąŠą▒ą░ą╣čé ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī ąĖ ąĘą░č鹥ą╝ čćąĖčéą░ąĄčé ą┤ą░ąĮąĮčŗąĄ ąŠą▒čĆą░čéąĮąŠ; 32-ą▒ąĖčéąĮčŗą╣ ą┤ąŠčüčéčāą┐ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą▓ ąŠą┤ąĖąĮ ąĖ č鹊čé ąČąĄ ą▓ąĮčāčéčĆąĄąĮąĮąĖą╣ ą▒ą░ąĮą║. ąĪ čéą░ą║ąŠą╣ ąĮą░čüčéčĆąŠą╣ą║ąŠą╣ ąĮąĄ ą▒čāą┤čāčé čüčĆą░ą▒ą░čéčŗą▓ą░čéčī ąĘą░ą╝ąĄąĮčŗ CPLB. ąæąĖčé DCBS ąĮąĄ ąŠčéąĮąŠčüąĖčéčüčÅ ą║ čŹč鹊ą╝čā čüą╗čāčćą░čÄ, ą┤ą╗čÅ ą║čŹčłą░ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ č鹊ą╗čīą║ąŠ L1 Data Bank A, ąĖ ą▓čüąĄ ą┤ą░ąĮąĮčŗąĄ ą╝ąŠąČąĮąŠ čģčĆą░ąĮąĖčéčī ą▒ąĄąĘ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ ąĘą░ą╝ąĄąĮčŗ ą┤ą░ąĮąĮčŗčģ ą▓ ą║čŹčłąĄ (ą▓ čĆąĄą░ą╗čīąĮąŠčüčéąĖ ą┐ąŠą┤ąŠą▒ąĮąŠąĄ, čāą▓čŗ, ą▓čüčéčĆąĄčćą░ąĄčéčüčÅ čĆąĄą┤ą║ąŠ).
ąŚą░ą╝ąĄąĮą░ CPLB ą╝ąŠąČąĄčé čüč鹊ąĖčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ čüąŠč鹥ąĮ čéą░ą║č鹊ą▓ (ąŠą▒čĆą░ą▒ąŠčéą║ą░ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ą░ą╗ą│ąŠčĆąĖčéą╝ ąĘą░ą╝ąĄąĮčŗ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ąĖ čé. ą┤.). ąÆą░ąČąĮą░ čģąŠčĆąŠčłą░čÅ čüčéčĆą░č鹥ą│ąĖčÅ ą┤ą╗čÅ ąĮą░čüčéčĆąŠą╣ą║ąĖ čéą░ą▒ą╗ąĖčåčŗ CPLB.
ąóą░ą▒ą╗ąĖčåą░ 11. ąæčŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ.
|
ąŚą░ą┐ąĖčüčī ą┐ą░ą╝čÅčéąĖ |
ą¦č鹥ąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ |
| ąæąĄąĘ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ |
23039 |
55248 |
| ą║čŹčł Write-Back |
10572 |
3866 |
| ą║čŹčł Write-Through, AOW=0 |
23039 |
10583 |
| ą║čŹčł Write-through, AOW=1 |
32154 |
3866 |
ąÆ čéą░ą▒ą╗ąĖčåąĄ 11 ą┐ąŠą║ą░ąĘą░ąĮčŗ čĆąĄąĘčāą╗čīčéą░čéčŗ, ą┐čĆąĄą┤čüčéą░ą▓ą╗ąĄąĮąĮčŗąĄ ą▓ ąĘą░čéčĆą░č湥ąĮąĮčŗčģ čéą░ą║čéą░čģ čÅą┤čĆą░:
ŌĆó ąŚą░ą┐ąĖčüčī ą▓ ą┐ą░ą╝čÅčéčī ą▒ąĄąĘ čĆą░ąĘčĆąĄčłąĄąĮąĮąŠą│ąŠ ą║čŹčłą░ ąĖ ą║čŹčłąĄą╝ čüčéčĆą░č鹥ą│ąĖąĖ čéąĖą┐ą░ write-through (ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ č鹊ą╗čīą║ąŠ ąĮą░ čćč鹥ąĮąĖąĄ) ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčé ąŠčéčüčāčéčüčéą▓ąĖąĄ ąŠčéą╗ąĖčćąĖą╣.
ŌĆó ą×ą┐ąĄčĆą░čåąĖčÅ ąĘą░ą┐ąĖčüąĖ ą▓ ą┐ą░ą╝čÅčéčī čüąŠ čüčéčĆą░č鹥ą│ąĖąĄą╣ write-back čéčĆąĄą▒čāąĄčé ą▒ąŠą╗čīčłąĄ čéą░ą║č鹊ą▓ ąĮą░ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ ą║čŹčłą░.
ŌĆó ąŚą░ą┐ąĖčüčī ą▓ ą┐ą░ą╝čÅčéčī, ą║ąŠą│ą┤ą░ ą▒ąĖčé AOW čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ, ą║čŹčł čüčéčĆą░č鹥ą│ąĖąĖ write-through ąĖą╝ąĄąĄčé ą▒čŗčüčéčĆąŠą┤ąĄą╣čüčéą▓ąĖąĄ čģčāąČąĄ, č湥ą╝ ą║ąŠą│ą┤ą░ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ ą▓ąŠ ą▓ąĮąĄčłąĮčÄčÄ ą┐ą░ą╝čÅčéčī ą▓ ą┐ąĄčĆą▓čŗą╣ čĆą░ąĘ (ą▓čüąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ąĮąĄą┤ąŠčüč鹊ą▓ąĄčĆąĮčŗ).
ŌĆó ą¦č鹥ąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą▓ čĆąĄąČąĖą╝ąĄ ą║čŹčłą░ write-back mode ąĖ write-through čü čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮčŗą╝ ą▒ąĖč鹊ą╝ AOW ą┤ą░čÄčé ą╗čāčćčłčāčÄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī, ą║ąŠą│ą┤ą░ ą┤ą░ąĮąĮčŗąĄ čāąČąĄ čüąŠčģčĆą░ąĮąĄąĮčŗ ą▓ ą┐ą░ą╝čÅčéčī ą║čŹčłą░.
ŌĆó ą¦č鹥ąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą▓ čĆąĄąČąĖą╝ąĄ ą║čŹčłą░ write-through čü čāčüčéą░ąĮąŠą▓ą╗ąĄąĮąĮčŗą╝ ą▒ąĖč鹊ą╝ AOW ąĮąĄ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą▓čŗą│ąŠą┤čā ąĖąĘ ą┐ą░ą║ąĄčéąĮąŠą│ąŠ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ ą║čŹčłą░ (cache-line burst fill).
ŌĆó ą¦č鹥ąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ą▒ąĄąĘ čĆą░ąĘčĆąĄčłąĄąĮąĮąŠą│ąŠ ą║čŹčłą░ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čüą░ą╝čāčÄ čģčāą┤čłčāčÄ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ą▓ čüčĆą░ą▓ąĮąĄąĮąĖąĖ čü ąŠčüčéą░ą╗čīąĮčŗą╝ąĖ čüčåąĄąĮą░čĆąĖčÅą╝ąĖ.
ą¦ą░čüč鹊čéą░ čÅą┤čĆą░ (CCLK) ą┐čĆąŠčéąĖą▓ čćą░čüč鹊čéčŗ čüąĖčüč鹥ą╝ąĮąŠą╣ čłąĖąĮčŗ (SCLK). ąĪ ąĮąĄčĆą░čåąĖąŠąĮą░ą╗čīąĮčŗą╝ąĖ čüąŠąŠčéąĮąŠčłąĄąĮąĖčÅą╝ąĖ ą╝ąĄąČą┤čā čćą░čüč鹊čéą░ą╝ąĖ CCLK ąĖ SCLK ą╝ąŠąČąĄčé ąĮą░ą▒ą╗čÄą┤ą░čéčīčüčÅ ą┐ąŠč鹥čĆčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ. ąĀąĖčü. 23 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą▓čŗą▒ąŠčĆą║čā ąĖąĮčüčéčĆčāą║čåąĖąĖ, ąĮą░čćąĖąĮą░čÅ čü ą░ą┤čĆąĄčüą░ shows 0x00h, ą║ąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮ ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣. ąĪąŠąŠčéąĮąŠčłąĄąĮąĖąĄ CCLK:SCLK = 3:1 ąĖą╗ąĖ ą▒ąŠą╗čīčłąĄ ą┤ąŠą╗ąČąĮąŠ ą┐čĆąĄą┤ą┐ąŠčćčéąĖč鹥ą╗čīąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ, ą║ąŠą│ą┤ą░ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ą║čŹčł. ąŁč鹊 čéčĆąĄą▒čāąĄčé 22 čéą░ą║čéą░ SCLK.
ąĪąŠąŠčéąĮąŠčłąĄąĮąĖąĄ ą╝ąĄąČą┤čā čćą░čüč鹊č鹊ą╣ čÅą┤čĆą░ ąĖ čćą░čüč鹊č鹊ą╣ čłąĖąĮčŗ 2:1. ąØą░ ą║ą░ąČą┤ąŠąĄ ą▓č鹊čĆąŠąĄ čüą╗ąŠą▓ąŠ ą▓čüčéą░ą▓ą╗čÅąĄčéčüčÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗą╣ čéą░ą║čé SCLK. ą×ą║ąŠą╗ąŠ 28 čéą░ą║č鹊ą▓ SCLK čéčĆąĄą▒čāąĄčéčüčÅ ą┤ą╗čÅ ą▓čŗą▒ąŠčĆą║ąĖ čåąĄą╗ąŠą╣ čüčéčĆąŠą║ąĖ ą║čŹčłą░ (ą▓ą║ą╗čÄčćą░čÅ ą║ąŠą╝ą░ąĮą┤čā ą░ą║čéąĖą▓ą░čåąĖąĖ).
ąĪąŠąŠčéąĮąŠčłąĄąĮąĖąĄ 1:1 čüąĮąĖąČą░ąĄčé ą┐ąŠą╗ąŠčüčā ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ čéčĆąĄą▒čāąĄčéčüčÅ ą▓čüčéą░ą▓ą║ą░ 2 ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ čéą░ą║č鹊ą▓ SCLK čü ą║ą░ąČą┤čŗą╝ ą▓č鹊čĆčŗą╝ čüą╗ąŠą▓ąŠą╝ (čüą╝. čĆąĖčü. 24). ąóčĆąĄą▒čāąĄčéčüčÅ ąŠą║ąŠą╗ąŠ 36 čéą░ą║č鹊ą▓ SCLK.
ąŁčéąĖ ąŠčéą╗ąĖčćąĖčÅ ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčé ą▓čĆąĄą╝čÅ, ą║ąŠč鹊čĆąŠąĄ čÅą┤čĆąŠ čéčĆąĄą▒čāąĄčé ąĮą░ čüčĆą░ą▓ąĮąĄąĮąĖąĄ čé菹│ąŠą▓ ą║čŹčłą░, ąĮą░ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą▓ ą▒ą╗ąŠą║ąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ, ąĖ ąĮą░ą║ąŠąĮąĄčå ąĮą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ.
[ą×ą▒ąĮąŠą▓ą╗ąĄąĮąĖąĄ SDRAM]
ąĀąĖčü. 25 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čüąĖčéčāą░čåąĖčÄ, ą│ą┤ąĄ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ ą┐čĆąĄčĆą▓ą░ąĮąŠ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖąĄą╝ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą╣ ą┐ą░ą╝čÅčéąĖ. ą¤ąĄčĆąĄą┤ą░čćą░ ąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ, ąĖ ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ ą┐ą░ą╝čÅčéąĖ (ą▓ čĆąĄąČąĖą╝ąĄ ą░ą▓č鹊ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ, autorefresh) ą▓čŗą┤ą░ąĄčé ą║ąŠą╝ą░ąĮą┤čā precharge (ąĘą░ą║čĆčŗą▓ą░ąĄčé čüčéčĆąŠą║čā/čüčéčĆą░ąĮąĖčåčā) ąĖ ą║ąŠą╝ą░ąĮą┤čā refresh. ą¤ąŠčüą╗ąĄ ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ ą┐ąĄčĆąĄą┤ą░čćą░ ą┐čĆąŠą┤ąŠą╗ąČą░ąĄčéčüčÅ čüąŠ čüą╗ąĄą┤čāčÄčēąĄą│ąŠ ąĖąĮą║čĆąĄą╝ąĄąĮčéą░ ą┐ąŠčüą╗ąĄą┤ąĮąĄą│ąŠ ą░ą┤čĆąĄčüą░.
ąÜąŠą│ą┤ą░ SDRAM ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ čĆąĄąČąĖą╝ąĄ čüą░ą╝ąŠąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ (self-refresh mode), ą┐čĆąŠčåąĄčüčüąŠčĆ ą▓čüąĄ ąĄčēąĄ ąŠą▒čĆą░čēą░ąĄčéčüčÅ ą║ ą┐ą░ą╝čÅčéąĖ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ SDC ąŠčüčéą░ą▓ą╗čÅąĄčé čĆąĄąČąĖą╝ self-refresh ą║ ą╗ąĖą▒ąŠ ą▓čĆąĄą╝ąĄąĮąĮąŠą╝čā auto-refresh ąĖą╗ąĖ ą┐čĆąŠčüč鹊ą╝čā auto-refresh, ą▓ ąĘą░ą▓ąĖčüąĖą╝ąŠčüčéąĖ ąŠčé čüąŠčüč鹊čÅąĮąĖčÅ ą▒ąĖčéą░ SRFS ą▓ čĆąĄą│ąĖčüčéčĆąĄ EBIU_SDGCTL.
[ą¤čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī SDRAM]
ąæąŠą╗čīčłąĄ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą┐ąŠ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéąĖ SDRAM čü ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆąŠą╝ SDC ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin ą╝ąŠąČąĮąŠ ąĮą░ą╣čéąĖ ą▓ čĆą░ąĘą┤ąĄą╗ąĄ "External Bus Interface Unit" čĆčāą║ąŠą▓ąŠą┤čüčéą▓ą░ ADSP-BF537 Blackfin Processor Hardware Reference (ąĖą╗ąĖ čüą╝. [4] ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ADSP-BF538). ąöąŠčüčéčāą┐ ąĮą░ čćč鹥ąĮąĖąĄ/ąĘą░ą┐ąĖčüčī čüąŠ čüč鹊čĆąŠąĮčŗ DAG čéčĆąĄą▒čāąĄčé čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ 8/1 čéą░ą║č鹊ą▓ SCLK ąĮą░ 16-ą▒ąĖčéąĮąŠąĄ čüą╗ąŠą▓ąŠ. ąÆčŗą▒ąŠčĆą║ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ ąĖ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖąĄ čüčéčĆąŠą║ąĖ ą║čŹčłą░ čéčĆąĄą▒čāčÄčé ąŠą║ąŠą╗ąŠ 1.1 čéą░ą║č鹊ą▓ SCLK ąĮą░ 16-ą▒ąĖčéąĮąŠąĄ čüą╗ąŠą▓ąŠ.
ąÆčŗą▓ąŠą┤čŗ:
ŌĆó ąÜąŠą┤ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ąĮą░ą┐ąĖčüą░ąĮ ą╗ąĖąĮąĄą╣ąĮąŠ, čćč鹊ą▒čŗ čāčéąĖą╗ąĖąĘąĖčĆąŠą▓ą░čéčī ą┤ąŠčüč鹊ąĖąĮčüčéą▓ą░ ą┐ą░ą║ąĄčéąĮąŠą│ąŠ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĖčÅ čüčéčĆąŠą║ąĖ ą║čŹčłą░ (cache-line burst fill, pre-fetch).
ŌĆó ąÜąŠą┤ ąĮčāąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┐ąŠą▓č鹊čĆąĮąŠ, čćč鹊ą▒čŗ čüą┤ąĄą╗ą░čéčī ą║čŹčł ą┐čĆąĖą▓ą╗ąĄą║ą░č鹥ą╗čīąĮąĄąĄ.

ąĀąĖčü. 23. ąÆčŗą▒ąŠčĆą║ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐čĆąĖ ą▓ą║ą╗čÄč湥ąĮąĮąŠą╝ ą║čŹčłąĄ (CCLK:SCLK = 2:1).

ąĀąĖčü. 24. ąÆčŗą▒ąŠčĆą║ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐čĆąĖ ą▓ą║ą╗čÄč湥ąĮąĮąŠą╝ ą║čŹčłąĄ (CCLK:SCLK = 1:1).

ąĀąĖčü. 25. ąÆčŗą▒ąŠčĆą║ą░ ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐čĆąĖ ą▓ą║ą╗čÄč湥ąĮąĮąŠą╝ ą║čŹčłąĄ (ą┐čĆąĄčĆą▓ą░ąĮąĮą░čÅ ąŠą┐ąĄčĆą░čåąĖąĄą╣ auto-refresh).
ąśąĮčüčéčĆčāą╝ąĄąĮčéą░čĆąĖą╣ VisualDSP++┬« ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĄą╝ ą┐ą░ą╝čÅčéąĖ. ąØąĖąČąĄ čĆą░čüčüą╝ąŠčéčĆąĄąĮčŗ ąĄą│ąŠ ąĮąĄą║ąŠč鹊čĆčŗąĄ čäčāąĮą║čåąĖąĖ. ą¤ąŠą┤čĆąŠą▒ąĮčāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ą╝ąŠąČąĮąŠ ąĮą░ą╣čéąĖ ą▓ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ąĄ VisualDSP++ C/C++ Compiler and Library Manual for Blackfin Processors [5]. ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĄ ą┤ą╗čÅ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ ą┤ą╗čÅ ą┤ą░ąĮąĮčŗčģ ą╝ąŠąČąĮąŠ čĆą░ąĘčĆąĄčłąĖčéčī ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ąĖą╗ąĖ ą┐ąŠ ąŠčéą┤ąĄą╗čīąĮąŠčüčéąĖ, ąĖ ą╝ąŠąČąĮąŠ ąĖąĮą┤ąĖą▓ąĖą┤čāą░ą╗čīąĮąŠ čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░čéčī ą┤ą╗čÅ ąĮąĖčģ ą╝ąĄčüč鹊 ą▓ ą┐ą░ą╝čÅčéąĖ ą┐ąŠą┤ ą║čŹčł.
ążą░ą╣ą╗čŗ ąĘą░ą│ąŠą╗ąŠą▓ą║ąŠą▓. ążą░ą╣ą╗čŗ čģąĄą┤ąĄčĆąŠą▓ VisualDSP++ def_LPBlackfin.h ąĖ cplb.h ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ą┤čĆčāąČąĄčüčéą▓ąĄąĮąĮčŗąĄ ą┤ą╗čÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ ą╝ą░ą║čĆąŠčüčŗ ąĖ ą╝ą░čüą║ąĖ ą┤ą╗čÅ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖčÅ CPLB ąĖ ą┤čĆčāą│ąĖąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ. ąŚąĮą░č湥ąĮąĖąĄ 0x0C010366 ą▓ ąŠą┤ąĮąŠą╝ ąĖąĘ ą┐čĆąĄą┤čŗą┤čāčēąĖčģ ą┐čĆąĖą╝ąĄčĆąŠą▓ ą╝ąŠąČąĄčé ą▓čŗą│ą╗čÅą┤ąĄčéčī čüą╗ąĄą┤čāčÄčēąĖą╝ ąŠą▒čĆą░ąĘąŠą╝:
TEST_WAY3|TEST_MB1|TEST_SET(27)|TEST_DW0|TEST_DATA|TEST_WRITE
ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ CPLB. ą¤ąŠą┤ą┤ąĄčƹȹ║ą░ CPLB čāą┐čĆą░ą▓ą╗čÅąĄčéčüčÅ č湥čĆąĄąĘ ą│ą╗ąŠą▒ą░ą╗čīąĮčāčÄ čåąĄą╗ąŠčćąĖčüą╗ąĄąĮąĮčāčÄ ą┐ąĄčĆąĄą╝ąĄąĮąĮčāčÄ ___cplb_ctrl. ąŁč鹊 čüčéą░ąĮą┤ą░čĆčéąĮąŠąĄ ąĖą╝čÅ čÅąĘčŗą║ą░ C ąĖą╝ąĄąĄčé 2 ąĮą░čćą░ą╗čīąĮčŗčģ čüąĖą╝ą▓ąŠą╗ą░ ą┐ąŠą┤č湥čĆą║ąĖą▓ą░ąĮąĖčÅ, ąĖ ąĄą│ąŠ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄąĄ ąĖą╝čÅ ąĮą░ čÅąĘčŗą║ąĄ ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░ ąĖą╝ąĄąĄčé 2 ąĮą░čćą░ą╗čīąĮčŗčģ čüąĖą╝ą▓ąŠą╗ą░ ą┐ąŠą┤č湥čĆą║ąĖą▓ą░ąĮąĖčÅ. ąŚąĮą░č湥ąĮąĖąĄ čŹč鹊ą╣ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ąŠą┐čĆąĄą┤ąĄą╗čÅąĄčé, čĆą░ąĘčĆąĄčłą░ąĄčé ą╗ąĖ ą║ąŠą┤ ą┐ąĄčĆą▓ąŠąĮą░čćą░ą╗čīąĮąŠą╣ ąĮą░čüčéčĆąŠą╣ą║ąĖ (startup code) čüąĖčüč鹥ą╝čā CPLB. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ ąĖą╝ąĄąĄčé ąĮčāą╗ąĄą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, čŹč鹊 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 CPLB ąĮąĄ čĆą░ąĘčĆąĄčłąĄąĮčŗ. ąöąŠą╗ąČąĮą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┐čĆą░ą│ą╝ą░ pragma retain_name ą▓ą╝ąĄčüč鹥 čü __cplb_ctrl, čćč鹊ą▒čŗ čŹčéą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ ąĮąĄ ą▒čŗą╗ą░ čāąĮąĖčćč鹊ąČąĄąĮą░ ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆąŠą╝, ą║ąŠą│ą┤ą░ čĆą░ąĘčĆąĄčłąĄąĮą░ ąŠą┐čéąĖą╝ąĖąĘą░čåąĖčÅ.
ąŚąĮą░č湥ąĮąĖąĄ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ___cplb_ctrl ą╝ąŠąČąĮąŠ ą┐ąŠą╝ąĄąĮčÅčéčī čüą╗ąĄą┤čāčÄčēąĖą╝ąĖ ą╝ąĄč鹊ą┤ą░ą╝ąĖ:
ŌĆó ąŁčéą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮą░ ą║ą░ą║ ąĮąŠą▓ą░čÅ ą│ą╗ąŠą▒ą░ą╗čīąĮą░čÅ čü ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝. ąŁč鹊 ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ ą┐ąĄčĆąĄąĮą░ąĘąĮą░čćą░ąĄčé ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖąĄ, ąĘą░ą┤ą░ąĮąĮąŠąĄ ą▓ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĄ.
ŌĆó ąĪą╗ąĖąĮą║ąŠą▓ą░ąĮąĮą░čÅ ą▓ąĄčĆčüąĖčÅ ą┐ąĄčĆąĄą╝ąĄąĮąĮąŠą╣ ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖąĘą╝ąĄąĮąĄąĮą░ ą▓ ąŠčéą╗ą░ą┤čćąĖą║ąĄ, ą┐ąŠčüą╗ąĄ ąĘą░ą│čĆčāąĘą║ąĖ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ ąĮąŠ ą┐ąĄčĆąĄą┤ ąĄą│ąŠ ąĘą░ą┐čāčüą║ąŠą╝, čćč鹊ą▒čŗ ą║ąŠą┤ ą┐ąĄčĆą▓ąŠąĮą░čćą░ą╗čīąĮąŠą╣ ąĮą░čüčéčĆąŠą╣ą║ąĖ (startup code) čāą▓ąĖą┤ąĄą╗ ąĮąŠą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ. ąöą╗čÅ ą┐ąŠčüą╗ąĄą┤ąĮąĄą│ąŠ ą▓ą░čĆąĖą░ąĮčéą░ ąĮčāąČąĮą░ čĆčāčćąĮą░čÅ ą┐čĆą░ą▓ą║ą░ startup code.
ąÜąŠą│ą┤ą░ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖąĄ čĆą░ąĘčĆąĄčłąĄąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ___cplb_ctrl, čéą░ą║ąČąĄ čāą║ą░ąĘčŗą▓ą░ąĄčéčüčÅ ąĖą╝ą┐ąĄčĆą░čéąĖą▓ USE_CACHE.
ąśąĮčüčéą░ą╗ą╗čÅčåąĖčÅ CPLB. ąÜąŠą│ą┤ą░ ą┐ąĄčĆąĄą╝ąĄąĮąĮą░čÅ ___cplb_ctrl ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 CPLB čĆą░ąĘčĆąĄčłąĄąĮčŗ, č鹊 startup code ą▓čŗąĘčŗą▓ą░ąĄčé ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čā _cplb_init. ąŁčéą░ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ąĮą░čüčéčĆą░ąĖą▓ą░ąĄčé CPLB ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ ą┤ą░ąĮąĮčŗčģ ąĖąĘ čéą░ą▒ą╗ąĖčåčŗ, ąĖ čĆą░ąĘčĆąĄčłą░ąĄčé čĆą░ą▒ąŠčéčā ą░ą┐ą┐ą░čĆą░čéčāčĆčŗ ąĘą░čēąĖčéčŗ ą┐ą░ą╝čÅčéąĖ. ąÜąŠąĮčäąĖą│čāčĆą░čåąĖąŠąĮąĮčŗąĄ čéą░ą▒ą╗ąĖčåčŗ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮčŗ ą▓ čäą░ą╣ą╗ą░čģ čü ąĖą╝ąĄąĮąĄą╝ cplbtabn.s, ą║ąŠč鹊čĆčŗąĄ ąĮą░čģąŠą┤čÅčéčüčÅ ą║ ą║ą░čéą░ą╗ąŠą│ąĄ VisualDSP\Blackfin\lib\src\libc\crt, ą│ą┤ąĄ n čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé ą╝ąŠą┤ąĄą╗ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin.
ąÜąŠą│ą┤ą░ ą║čŹčł čĆą░ąĘčĆąĄčłąĄąĮą░, ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÅ ąĖąĮčüčéą░ą╗ą╗ąĖčĆčāąĄčéčüčÅ CPLB ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ, ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮą░čÅ ą▓ ą▓čŗčłąĄčāą║ą░ąĘą░ąĮąĮąŠą╝ čäą░ą╣ą╗ąĄ. ąØąŠ ąÆčŗ ą╝ąŠąČąĄč鹥 ąĖąĘą╝ąĄąĮąĖčéčī čāą║ą░ąĘą░ąĮąĮčŗąĄ čäą░ą╣ą╗čŗ, čćč鹊ą▒čŗ ąĘą░ą┤ą░čéčī čüą▓ąŠčÄ čüąŠą▒čüčéą▓ąĄąĮąĮčāčÄ ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÄ CPLB. ą¤čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗą╣ čäą░ą╣ą╗ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą┐ąŠą┤ą║ą╗čÄč湥ąĮ ą▓ ą┐čĆąŠąĄą║čé, čćč鹊ą▒čŗ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą▓čüčéčāą┐ąĖą╗ąĖ ą▓ čüąĖą╗čā. ąÆ ą┐čĆąŠąĄą║č鹥 Example5 (5) ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄčéčüčÅ, ą║ą░ą║ ą╝ąŠąČąĮąŠ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░čéčī ą║ąŠąĮčäąĖą│čāčĆą░čåąĖąŠąĮąĮčāčÄ čéą░ą▒ą╗ąĖčåčā CPLB.
ą×ą▒čĆą░ą▒ąŠčéą║ą░ ąĖčüą║ą╗čÄč湥ąĮąĖą╣. ąÜą░ą║ čāąČąĄ ąŠą▒čüčāąČą┤ą░ą╗ąŠčüčī čĆą░ąĮčīčłąĄ, ą▓ čüą╗ąŠąČąĮąŠą╣ ą╝ąŠą┤ąĄą╗ąĖ ą┐ą░ą╝čÅčéąĖ ą╝ąŠąČąĄčé ą┐ąŠąĮą░ą┤ąŠą▒ąĖčéčīčüčÅ ą▒ąŠą╗čīčłąĄąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ CPLB, č湥ą╝ ą╝ąŠąČąĄčé ą▒čŗčéčī ą░ą║čéąĖą▓ąĮąŠ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ. ąÆ čéą░ą║ąĖčģ čüąĖčüč鹥ą╝ą░čģ ą▒čāą┤čāčé ą▓čĆąĄą╝čÅ ąŠčé ą▓čĆąĄą╝ąĄąĮąĖ ą┐čĆąŠąĖčüčģąŠą┤ąĖčéčī čüąĖčéčāą░čåąĖąĖ, ą║ąŠą│ą┤ą░ ą┐čĆąĖą╗ąŠąČąĄąĮąĖąĄ ą┐ąŠčéčĆąĄą▒čāąĄčé ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ, ą║ąŠč鹊čĆą░čÅ ą┐ąŠą║ą░ ąĮąĄ ą┐ąŠą║čĆčŗą▓ą░ąĄčéčüčÅ ą░ą║čéąĖą▓ąĮčŗą╝ąĖ CPLB. ąóą░ą║ąĖąĄ čüąĖčéčāą░čåąĖąĖ ą▒čāą┤čāčé ą▓čŗąĘčŗą▓ą░čéčī ąĖčüą║ą╗čÄč湥ąĮąĖąĄ ą┐čĆąŠą╝ą░čģą░ ą║čŹčłą░ (CPLB miss exception).
ąæąĖą▒ą╗ąĖąŠč鹥ą║ą░ VisualDSP++ ą▓ą║ą╗čÄčćą░ąĄčé ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝čā ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ą┤ą╗čÅ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖčÅ ąĖčüą║ą╗čÄč湥ąĮąĖą╣ CPLB čéą░ą║ąĖčģ čüąĖčéčāą░čåąĖą╣, _cplb_mgr. ąŁčéą░ ą┐ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ą░ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ą▓čŗąĘą▓ą░ąĮą░ ąĖąĘ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ, ą║ąŠč鹊čĆčŗą╣ ąŠą┐čĆąĄą┤ąĄą╗ąĖą╗ čüąŠą▒čŗčéąĖąĄ ą┐čĆąŠą╝ą░čģą░ CPLB, ąĮąĄąĘą░ą▓ąĖčüąĖą╝ąŠ ąŠčé č鹊ą│ąŠ, ą▒čŗą╗ ą╗ąĖ čŹč鹊 ą┐čĆąŠą╝ą░čģ ą┤ą░ąĮąĮčŗčģ ąĖą╗ąĖ ą┐čĆąŠą╝ą░čģ ąĖąĮčüčéčĆčāą║čåąĖąĖ. ą¤ąŠą┤ą┐čĆąŠą│čĆą░ą╝ą╝ą░ _cplb_mgr ąĖą┤ąĄąĮčéąĖčäąĖčåąĖčĆčāąĄčé ąĮąĄą░ą║čéąĖą▓ąĮčŗą╣ CPLB, ą║ąŠč鹊čĆčŗą╣ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ čćč鹊ą▒čŗ čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ą┤ąŠčüčéčāą┐ č湥čĆąĄąĘ ą║čŹčł, ąĖ ąĘą░ą╝ąĄąĮąĖčéčī čŹč鹊ą╣ ąĘą░ą┐ąĖčüčīčÄ CPLB ąŠą┤ąĮčā ąĖąĘ č鹥ą║čāčēąĖčģ ą░ą║čéąĖą▓ąĮčŗčģ ąĘą░ą┐ąĖčüąĄą╣ CPLB. ąĢčüą╗ąĖ CPLB čĆą░ąĘčĆąĄčłąĄąĮčŗ, č鹊 ą║ąŠą┤ ąĘą░ą┐čāčüą║ą░ (startup code) ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą▓ą║ą╗čÄč湥ąĮąŠ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ, ą║ąŠč鹊čĆčŗą╣ ąĮą░ąĘčŗą▓ą░ąĄčéčüčÅ called _cplb_hdr; ąŠąĮ ąĮąĖč湥ą│ąŠ ąĮąĄ ą┤ąĄą╗ą░ąĄčé ą║čĆąŠą╝ąĄ ą┐čĆąŠą▓ąĄčĆą║ąĖ čüąŠą▒čŗčéąĖčÅ ą┐čĆąŠą╝ą░čģą░ CPLB, ą║ąŠč鹊čĆąŠąĄ ą┤ąĄą╗ąĄą│ąĖčĆčāąĄčéčüčÅ ą▓ _cplb_mgr. ą¤ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčéčüčÅ, čćč鹊 čā ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╣ ąĄčüčéčī čüą▓ąŠąĖ čüąŠą▒čüčéą▓ąĄąĮąĮčŗąĄ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗčģ čüąŠą▒čŗčéąĖą╣ [6].
ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ Project Wizard. ą£ą░čüč鹥čĆ ą┐čĆąŠąĄą║čéą░ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī čüąŠąĘą┤ą░ąĮąĖčÅ ą┐čĆąŠąĄą║čéą░, ą▓ą║ą╗čÄčćą░čÄčēąĄą│ąŠ ą┐ąŠą┤ą┤ąĄčƹȹ║čā ąĘą░čēąĖčéčŗ ą┐ą░ą╝čÅčéąĖ ąĖ ą║čŹčłą░ ą║ą░ą║ ą┤ą╗čÅ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣, čéą░ą║ ąĖ ą┤ą░ąĮąĮčŗčģ. ąĀąĖčü. 26..30 ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ ąĮčāąČąĮčŗąĄ ą┤ąĄą╣čüčéą▓ąĖčÅ:
1. ąöąŠą╗ąČąĮčŗ ą▒čŗčéčī ą┤ąŠą▒ą░ą▓ą╗ąĄąĮčŗ čäą░ą╣ą╗čŗ .LDF ąĖ startup code (čĆąĖčü. 26).
ąĀąĖčü. 26. Project Wizard: ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ ą║ąŠą┤ą░ ą┐ąĄčĆą▓ąŠąĮą░čćą░ą╗čīąĮąŠą│ąŠ ąĘą░ą┐čāčüą║ą░ / čäą░ą╣ą╗ą░ ąĮą░čüčéčĆąŠą╣ą║ąĖ ą╗ąĖąĮą║ąĄčĆą░ (Add Startup Code/LDF).
2. ąöąŠą╗ąČąĮą░ ą▒čŗčéčī ą┤ąŠą▒ą░ą▓ą╗ąĄąĮą░ ą┐ąŠą┤ą┤ąĄčƹȹ║ą░ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ (SDRAM) ąĖ ą▓čŗą▒čĆą░ąĮ čĆą░ąĘą╝ąĄčĆ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą╣ ą┐ą░ą╝čÅčéąĖ (čĆąĖčü. 27).
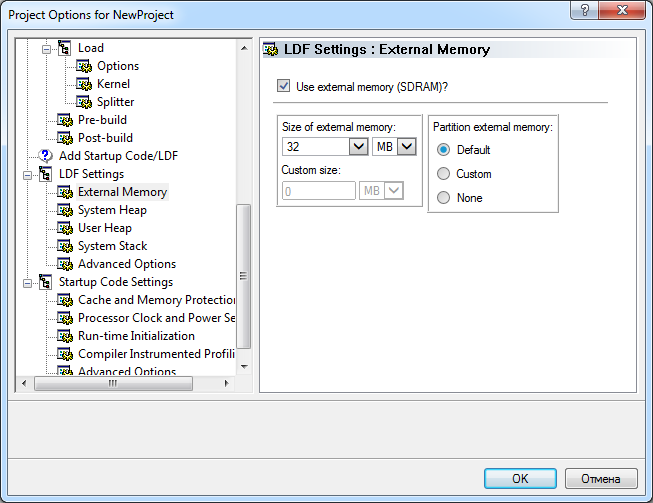
ąĀąĖčü. 27. Project Wizard: ąĮą░čüčéčĆąŠą╣ą║ąĖ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ą┤ą╗čÅ LDF.
3. ąÆ čĆą░ąĘą┤ąĄą╗ąĄ ąĮą░čüčéčĆąŠąĄą║ "Cache and Memory Protection" ą╝ąŠąČąĄčé ą▒čŗčéčī ą┤ąŠą▒ą░ą▓ą╗ąĄąĮą░ ą┐ąŠą┤ą┤ąĄčƹȹ║ą░ ą┤ą╗čÅ ąĘą░čēąĖčéčŗ ą┐ą░ą╝čÅčéąĖ ąĖ ą┐ąŠą┤ą┤ąĄčƹȹ║ą░ ą┤ą╗čÅ ą║čŹčłą░ ą║ą░ą║ ą┤ą╗čÅ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣, čéą░ą║ ąĖ ą┐ą░ą╝čÅčéąĖ ą┤ą░ąĮąĮčŗčģ (čĆąĖčü. 28). ą£ąŠą│čāčé ą▒čŗčéčī čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮčŗ ąĮą░čüčéčĆą░ąĖą▓ą░ąĄą╝čŗąĄ čéą░ą▒ą╗ąĖčåčŗ CPLB, ąĖ ąÆčŗ ą╝ąŠąČąĄč鹥 ą▓čŗą▒čĆą░čéčī čüčéčĆą░č鹥ą│ąĖčÄ čĆą░ą▒ąŠčéčŗ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ ą╝ąĄąČą┤čā write-through ąĖą╗ąĖ write-back. ą×ą┐čåąĖčÅ "Cache mapping set size" čāą┐čĆą░ą▓ą╗čÅąĄčé ą▒ąĖč鹊ą╝ DCBS ą▓ čĆąĄą│ąĖčüčéčĆąĄ DMEM_CONTROL.
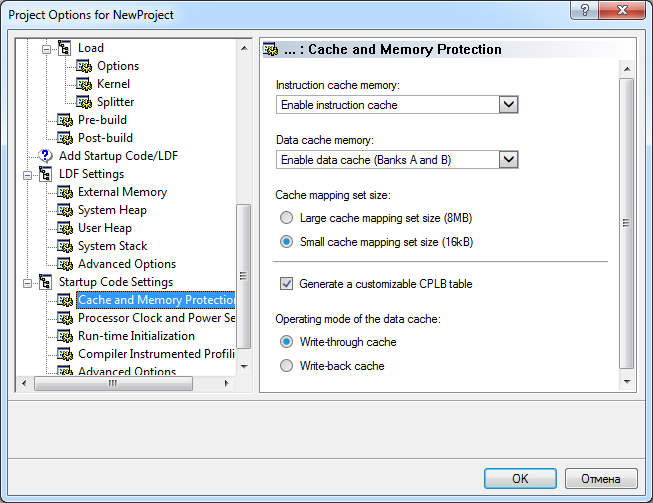
ąĀąĖčü. 28. Project Wizard: ąĮą░čüčéčĆąŠą╣ą║ą░ ą║ąŠą┤ą░ ąĘą░ą┐čāčüą║ą░, čāčüčéą░ąĮąŠą▓ą║ą░ ą║čŹčłą░ ąĖ ąĘą░čēąĖčéčŗ ą┐ą░ą╝čÅčéąĖ (Startup Code Settings: Cache and Memory Protection).
4. ąÆčüąĄ ąĮą░čüčéčĆąŠą╣ą║ąĖ ą╝ąŠąČąĮąŠ ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░čéčī ą▓ ą┤ąĖą░ą╗ąŠą│ąŠą▓ąŠą╝ ąŠą║ąĮąĄ Project Options. ą¤ąŠčüą╗ąĄ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ąĮą░čüčéčĆąŠąĄą║ ąĖ ą┐ąĄčĆąĄą┤ ą┐ąĄčĆąĄą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĄą╣ čäą░ą╣ą╗čŗ ą║ąŠą┤ą░ ąĘą░ą┐čāčüą║ą░ ąĖ ąĮą░čüčéčĆąŠąĄą║ ą╗ąĖąĮą║ąĄčĆą░ ą┐ąĄčĆąĄą│ąĄąĮąĄčĆąĖčĆčāčÄčéčüčÅ ąĘą░ąĮąŠą▓ąŠ (čĆąĖčü. 29).
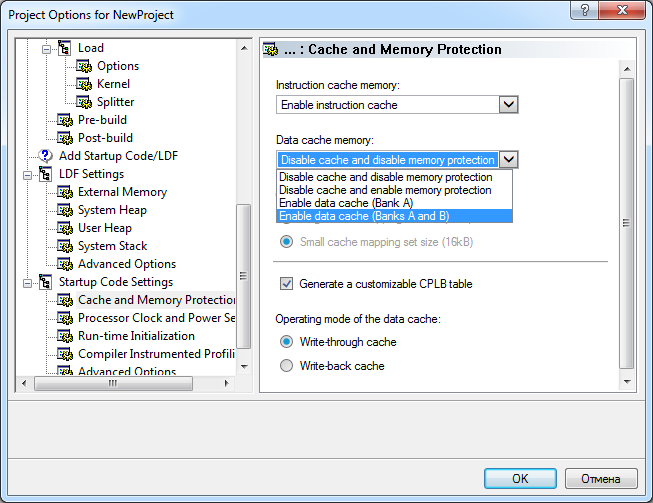
ąĀąĖčü. 29. Project Options: Startup Code Settings: Cache and Memory Protection.
ą¤ąŠčüą╗ąĄ ąŠą║ąŠąĮčćą░ąĮąĖčÅ ąĮą░čüčéčĆąŠą╣ą║ąĖ ą┐čĆąŠąĄą║čéą░ ą▒čāą┤čāčé čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮ ą┐ąŠą┤ą║ą╗čÄčćą░ąĄą╝čŗą╣ čäą░ą╣ą╗ ą┤ą╗čÅ ą┐čĆąŠąĄą║čéą░, ą║ąŠč鹊čĆčŗą╣ ą▒čāą┤ąĄčé ąĮą░ąĘčŗą▓ą░čéčīčüčÅ ąĖą╝čÅą┐čĆąŠąĄą║čéą░_cplbtab.c (Generated Files -> Startup). ąŁč鹊čé čäą░ą╣ą╗ čüąŠą┤ąĄčƹȹĖčé ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄą╝čāčÄ čéą░ą▒ą╗ąĖčåčā CPLB (čĆąĖčü. 30).
ąĀąĖčü. 30. VisualDSP++: čüą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąĮą░čÅ čéą░ą▒ą╗ąĖčåą░ CPLB.
[ą×ą▒ąĘąŠčĆ MMR]
ąöą╗čÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéčīčÄ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĖąĄ ąŠč鹊ą▒čĆą░ąČąĄąĮąĮčŗąĄ ąĮą░ ą┐ą░ą╝čÅčéčī čĆąĄą│ąĖčüčéčĆčŗ (memory-map registers, MMR):
Table 12. ąĀąĄą│ąĖčüčéčĆčŗ MMR ą┤ą╗čÅ ąĮą░čüčéčĆąŠą╣ą║ąĖ CPLB.
| IMEM_CONTROL |
DMEM_CONTROL |
| ITEST_COMMAND |
DTEST_COMMAND |
| ITEST_DATA [1:0] |
DTEST_DATA [1:0] |
| ICPLB_DATA [15:0] |
DCPLB_DATA [15:0] |
| ICPLB_ADDR [15:0] |
DCPLB_ADDR [15:0] |
| ICPLB_STATUS |
DCPLB_STATUS |
| ICPLB_FAULT_ADDR |
DCPLB_FAULT_ADDR |
[ąÜąŠąĮčäąĖą│čāčĆą░čåąĖčÅ ą║čŹčłą░ ą┤ą╗čÅ čĆą░ąĘą╗ąĖčćąĮčŗčģ ą╝ąŠą┤ąĄą╗ąĄą╣ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin]
ąŚą┤ąĄčüčī ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆąŠą▓ą░ą╗ą░čüčī ą║ąŠąĮčäąĖą│čāčĆą░čåąĖčÅ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą║čŹčłąĄą╝ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF533. ąÆčüąĄ, čćč鹊 čéą░ą╝ ą▒čŗą╗ąŠ čĆą░čüčüą╝ąŠčéčĆąĄąĮąŠ, ą╝ąŠąČąĮąŠ ą┐čĆąĖą╝ąĄąĮąĖčéčī ąĖ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF531 ąĖ ADSP-BF532. ąÜąŠą┤ ą┐čĆąĖą╝ąĄčĆąŠą▓ (1)..(5) ą╝ąŠąČąĮąŠ čéą░ą║ąČąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ ADSP-BF531 ąĖ ADSP-BF532. ą¤čĆąĖą╝ąĄčĆčŗ ą║ąŠą┤ą░ (6) ąĖ (7), ą┐ąŠčüčéą░ą▓ą╗čÅąĄą╝čŗąĄ čü čŹčéąĖą╝ ą░ą┐ąĮąŠčāč鹊ą╝, ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┤ą╗čÅ ą▓čüąĄčģ ąŠą┤ąĮąŠčÅą┤ąĄčĆąĮčŗčģ ą╝ąŠą┤ąĄą╗ąĄą╣ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin. ąĀą░ąĘą╝ąĄčĆ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣, ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄą╝ąŠą╣ ą┐ąŠą┤ ą║čŹčł, ą▓ ąĮą░čüč鹊čÅčēąĄąĄ ą▓čĆąĄą╝čÅ ą┤ą╗čÅ ą▓čüąĄčģ ąŠą┤ąĮąŠčÅą┤ąĄčĆąĮčŗčģ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin ąŠą┤ąĖąĮą░ą║ąŠą▓čŗą╣ (16 ą║ąĖą╗ąŠą▒ą░ą╣čé).
ąæąŠą╗čīčłąĖąĮčüčéą▓ąŠ ąŠą┤ąĮąŠčÅą┤ąĄčĆąĮčŗčģ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čÄčé ą┤ą▓ą░ ą▒ą░ąĮą║ą░ ą┤ą░ąĮąĮčŗčģ L1, ą║ąŠąĮčäąĖą│čāčĆąĖčĆčāąĄą╝čŗčģ ą║ą░ą║ ą║čŹčł, ą║ą░ąČą┤čŗą╣ čĆą░ąĘą╝ąĄčĆąŠą╝ 16 ą║ąĖą╗ąŠą▒ą░ą╣čé. ąŻ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ADSP-BF531 ąĄčüčéčī č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ ą▒ą░ąĮą║ ą┤ą░ąĮąĮčŗčģ.
ąŻ ą┤ą▓čāčģčÅą┤ąĄčĆąĮąŠą│ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ADSP-BF561 ąŠą▒čŖąĄą╝ ą║čŹčłą░ ą▓ą┤ą▓ąŠąĄ ą▒ąŠą╗čīčłąĄ, č湥ą╝ čā ą┐čĆąŠčåąĄčüčüąŠčĆą░ ADSP-BF533.
[ąŚą░ą║ą╗čÄč湥ąĮąĖąĄ]
ąÆ čŹč鹊ą╝ ą┤ąŠą║čāą╝ąĄąĮč鹥 čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ą╗ąŠčüčī ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin. ąóą░ą║ąČąĄ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░ą╗ą░čüčī ą┐čĆąĖą▓čÅąĘą║ą░ čüčéčĆąŠą║ ą║čŹčłą░ ą║ ą░ą┤čĆąĄčüą░ą╝ ą┐ą░ą╝čÅčéąĖ. ą¤čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮąĮčŗąĄ ą┐čĆąĖą╝ąĄčĆčŗ ą║ąŠą┤ą░ (1)..(8) [7] ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāčÄčé, ą║ą░ą║ ąĮą░čüčéčĆąŠąĖčéčī ą┤ąĄčüą║čĆąĖą┐č鹊čĆčŗ CPLB ą┤ą╗čÅ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ ąĖ ą┤ą░ąĮąĮčŗčģ, ą║ą░ą║ čĆą░ąĘčĆąĄčłąĖčéčī/ąĘą░ą┐čĆąĄčéąĖčéčī ą║čŹčł ąĖąĮčüčéčĆčāą║čåąĖą╣/ą┤ą░ąĮąĮčŗčģ, ąĖ ą║ą░ą║ ąŠą▒čĆą░ą▒ąŠčéą░čéčī ąĖčüą║ą╗čÄč湥ąĮąĖčÅ CPLB ąĖ čüą┤ąĄą╗ą░čéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą┐ąŠ ą┐čāčéąĖ (way). ąóą░ą║ąČąĄ čĆą░čüčüą╝ąŠčéčĆąĄąĮ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣/ą┤ą░ąĮąĮčŗčģ čüąŠ čüč鹊čĆąŠąĮčŗ čÅą┤čĆą░ č湥čĆąĄąĘ ą║ąŠą╝ą░ąĮą┤čŗ ITEST_COMMAND ąĖ DTEST_COMMAND.
ąÆą╝ąĄčüč鹥 čü čŹčéąĖą╝ ą░ą┐ąĮąŠčāč鹊ą╝ Analog Devices ą┐ąŠčüčéą░ą▓ą╗čÅąĄčé ZIP-čäą░ą╣ą╗ [7], ą▓ ą║ąŠč鹊čĆąŠą╝ ąĮą░čģąŠą┤čÅčéčüčÅ ą┐čĆąĖą╝ąĄčĆčŗ ą║ąŠą┤ą░. ą×ąĮ čüąŠą┤ąĄčƹȹĖčé čüą╗ąĄą┤čāčÄčēąĖąĄ ą┐čĆąĖą╝ąĄčĆčŗ:
(1) Example1, ą║ąŠą┤ ą┤ą╗čÅ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ CPLB ąĖ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣/ą┤ą░ąĮąĮčŗčģ (čÅąĘčŗą║ C).
(2) Example2, ą║ąŠą┤ ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ CPLB (čÅąĘčŗą║ C).
(3) Example3, ą║ąŠą┤ ą┤ą╗čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ ą┐ąŠ ą┐čāčéąĖ (čÅąĘčŗą║ C).
(4) Example4, ą║ąŠą┤ ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąĖ ąĖąĮčüčéčĆčāą║čåąĖą╣ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą║čŹčłąĄą╝ ą┤ą░ąĮąĮčŗčģ (čÅąĘčŗą║ C).
(5) Example5, ą║ąŠą┤ ą┤ąĄą╝ąŠąĮčüčéčĆą░čåąĖąĖ ą┐ąŠą┤ą┤ąĄčƹȹ║čā ą║ąŠą╝ą┐ąĖą╗čÅč鹊čĆą░ VisualDSP++ ą┤ą╗čÅ ą║čŹčłą░ Blackfin (čÅąĘčŗą║ C).
(6) Example6, ą║ąŠą┤ ą┤ą╗čÅ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ ICPLB ąĖ ą║čŹčłą░ ąĖąĮčüčéčĆčāą║čåąĖą╣ (čÅąĘčŗą║ ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░ Blackfin).
(7) Example7, ą║ąŠą┤ ą┤ą╗čÅ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ąĄčüą║čĆąĖą┐č鹊čĆąŠą▓ DCPLB ąĖ ą║čŹčłą░ ą┤ą░ąĮąĮčŗčģ (čÅąĘčŗą║ ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░ Blackfin).
(8) Example8, ą║ąŠą┤ ą┤ą╗čÅ ą┐ą╗ąŠčģąŠą╣ ą║ąŠąĮčåąĄą┐čåąĖąĖ ą┐ąŠčüčéčĆąŠąĄąĮąĖčÅ ą║ąŠą┤ą░ čü č鹊čćą║ąĖ ąĘčĆąĄąĮąĖčÅ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ ąĖąĮčüčéčĆčāą║čåąĖą╣ (čÅąĘčŗą║ ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░ Blackfin).
[1] ADSP-BF533 Blackfin Processor Hardware Reference. Rev 3.6, February 2013. Analog Devices, Inc.
[2] Computes Architecture A Quantitative Approach. Second Edition, 2000 David A. Patterson and John L. Hennessy.
ąÆčüčÄ čāą┐ąŠą╝čÅąĮčāčéčāčÄ ą▓ čüčéą░čéčīąĄ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖčÄ ąĖ ą┐čĆąĖą╝ąĄčĆčŗ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░ ą╝ąŠąČąĮąŠ čüą║ą░čćą░čéčī čü čüą░ą╣čéą░ ą║ąŠą╝ą┐ą░ąĮąĖąĖ Analog Devices, ąĖą╗ąĖ ą┐ąŠ čüčüčŗą╗ą║ąĄ [7].
[ąĪą╗ąŠą▓ą░čĆąĖą║]
CCLK čéą░ą║č鹊ą▓ą░čÅ čćą░čüč鹊čéą░ čÅą┤čĆą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
CLKIN ą▓čģąŠą┤ąĮą░čÅ čćą░čüč鹊čéą░ ą║čĆąĖčüčéą░ą╗ą╗ą░, ą║ąŠč鹊čĆą░čÅ ą┐čĆąŠčģąŠą┤ąĖčé č湥čĆąĄąĘ ą▓ąĮčāčéčĆąĄąĮąĮąĄąĄ čāą╝ąĮąŠąČąĄąĮąĖąĄ ąĖ ą┤ąĄą╗ąĄąĮąĖąĄ, ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ą┐ąŠą╗čāčćą░čÄčéčüčÅ čćą░čüč鹊čéčŗ čÅą┤čĆą░ (CCLK) ąĖ čłąĖąĮčŗ (SCLK).
MMR Memory-Mapped Register - čĆąĄą│ąĖčüčéčĆ, ąŠč鹊ą▒čĆą░ąČąĄąĮąĮčŗą╣ ąĮą░ ą░ą┤čĆąĄčüąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin. ą×ą▒čŗčćąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ ąŠą▒ą╝ąĄąĮą░ ą┤ą░ąĮąĮčŗą╝ąĖ čü čĆą░ąĘą╗ąĖčćąĮčŗą╝ąĖ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗą╝ąĖ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ąĖ ą║čĆąĖčüčéą░ą╗ą╗ą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░.
MPCU Memory Protection and Cache Unit, ą▒ą╗ąŠą║ ąĘą░čēąĖčéčŗ ą┐ą░ą╝čÅčéąĖ ąĖ ą║čŹčłąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin.
PLL Phase Locked Loop, ą┐ąĄčéą╗čÅ čäą░ąĘąŠą▓ąŠą╣ ą┐ąŠą┤čüčéčĆąŠą╣ą║ąĖ čćą░čüč鹊čéčŗ, ążąÉą¤ą¦. ą¤čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ą┤ą╗čÅ čüąĖąĮč鹥ąĘą░ ą▓ąĮčāčéčĆąĄąĮąĮąĖčģ čéą░ą║č鹊ą▓čŗčģ čćą░čüč鹊čé ą┐čĆąŠčåąĄčüčüąŠčĆą░ (CCLK, SCLK).
SCLK čéą░ą║č鹊ą▓ą░čÅ čćą░čüč鹊čéą░ čłąĖąĮčŗ ą┐čĆąŠčåąĄčüčüąŠčĆą░, ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ ą┤ą╗čÅ čéą░ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ ą▓čüąĄčģ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓. ąæą╗ą░ą│ąŠą┤ą░čĆčÅ čŹč鹊ą╝čā ą▓čüąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗąĄ čāčüčéčĆąŠą╣čüčéą▓ą░ (čéą░ą╣ą╝ąĄčĆčŗ, ąĖąĮč鹥čĆč乥ą╣čüčŗ) čĆą░ą▒ąŠčéą░čÄčé čüąĖąĮčģčĆąŠąĮąĮąŠ ąĖ ąŠčéą┤ąĄą╗čīąĮąŠ ąŠčé ą┐ąŠč鹊ą║ą░ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą║ąŠą┤ą░ čÅą┤čĆą░.
SDC ą║ąŠąĮčéčĆąŠą╗ą╗ąĄčĆ čüąĖąĮčģčĆąŠąĮąĮąŠą╣ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą╣ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ.
[ąĪčüčŗą╗ą║ąĖ]
1. Using Cache Memory on Blackfin® Processors (EE-271) site:analog.com.
2. Blackfin ADSP-BF538.
3. Blackfin Processor Programming Reference. Rev. 2.2, February 2013. Analog Devices, Inc.
4. ADSP-BF538: ą▒ą╗ąŠą║ ąĖąĮč鹥čĆč乥ą╣čüą░ ą▓ąĮąĄčłąĮąĄą╣ čłąĖąĮčŗ.
5. VisualDSP++ C/C++ Compiler and Library Manual for Blackfin Processors. Rev. 5.4, January 2011. Analog Devices, Inc.
6. ADSP-BF538: ąŠą▒čĆą░ą▒ąŠčéą║ą░ čüąŠą▒čŗčéąĖą╣ (ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ, ąĖčüą║ą╗čÄč湥ąĮąĖčÅ).
7. 160211EE271v02.zip - ą┐čĆąĖą╝ąĄčĆčŗ ąĖčüčģąŠą┤ąĮąŠą│ąŠ ą║ąŠą┤ą░ (1..8), ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖčÅ. |



