| Blackfin: система команд (ассемблер) - часть 2 |
|
| Добавил(а) microsin | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
В этом руководстве приведена вторая часть перевода даташита "Blackfin DSP Instruction Set Reference" [1], где описывается система команд процессоров Blackfin. В первой части руководства сначала объясняются основные понятия и термины, затем обсуждается смысл каждой отдельной команды (инструкции) ассемблера. Все непонятные термины и сокращения см. в разделе Словарик первой части перевода, а также в разделе словарик общей документации по процессору Blackfin ADSP-BF538 [2]. Первая часть перевода здесь: "Blackfin: система команд (ассемблер) - часть 1". [Арифметические операции] В этом разделе обсуждаются инструкции, которые задают арифметические операции. Пользователи могут использовать эти инструкции для сложения (add), вычитания (subtract), деления (divide) и умножения (multiply), вычисления и сохранения абсолютных значений, определять экспоненты, округлять, выполнять насыщение, возвращать количество бит знака. Инструкция вычисляет абсолютное значение. Общая форма: dest_reg = ABS src_reg Синтаксис: A0 = ABS A0; // (b)1 A0 = ABS A1; // (b) A1 = ABS A0; // (b) A1 = ABS A1; // (b) A1 = ABS A1, A0 = ABS A0; // (b) Dreg = ABS Dreg; // (b) Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: регистры R0, ..., R7. [Функциональное описание] Инструкция Absolute Value вычисляет абсолютное значение от величины в 32-битном регистре источнике (src_reg) и сохраняет его в 32-битном регистре назначения (dest_reg) в соответствии со следующими правилами: • Если входное значение положительное, или 0, то оно без изменений копируется в регистр назначения. Операция ABS также может быть выполнена с обоими аккумуляторами, причем даже в одной инструкции. [Флаги] Эта инструкция влияет на следующие флаги: • AZ установится, если результат 0, иначе очистится. В случае 2 одновременных операций AZ представит логическое ИЛИ от этих двух флагов нуля. Все остальные флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битная версия инструкции может быть выполнена параллельно с некоторыми 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] a0 = abs a0; a0 = abs a1; a1 = abs a0; a1 = abs a1; a1 = abs a1, a0 = abs a0; r3 = abs r1; См. также Vector Absolute Value (в разделе "Векторные операции"). Инструкция сложения. Общая форма: dest_reg = src_reg_1 + src_reg_2 Синтаксис для сложения регистров-указателей: Preg = Preg + Preg; // (a)1 Синтаксис для 32-битных операндов и 32-битного результата: Dreg = Dreg + Dreg; /* насыщение не поддерживается, но Dreg = Dreg + Dreg (sat_flag); /* насыщение опционально поддерживается, но Синтаксис для 16-битных операндов и 16-битного результата: Dreg_lo_hi = Dreg_lo_hi + Dreg_lo_hi (sat_flag); // (b) Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. Комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Preg: регистры P0, ..., P5, SP, FP. Dreg: регистры R0, ..., R7. Dreg_lo_hi: половинки регистров R0.L, ..., R7.L, R0.H, ..., R7.H. sat_flag: обязательный флаг управления насыщением, (S) или (NS). [Функциональное описание] Инструкция Add складывает две величины из регистров источника помещает результат в регистр назначения. Есть 2 способа сложения 32-битных данных в D-регистрах. Один с длиной инструкции 16 бит, без поддержки насыщения. Другой с длиной инструкции 32 бита, опционально поддерживает насыщение. Более длинная инструкция DSP иногда может экономить время выполнения, потому что она может быть выполнена параллельно с другими инструкциями (см. раздел "Параллельная обработка инструкций"). Инструкция для 16-битных данных использует половинки слова в регистре данных и сохраняет результат также в половинку слова регистра данных. Все инструкции для 16-битных данных имеют длину 32 бита. Опция синтаксиса: там, где появляется sat_flag, он заменяется на следующие значения: • (S) применяется насыщение результата. Подробнее про насыщение см. секцию "Saturation (насыщение)". [Флаги] Версии инструкции с D-регистрами влияют на следующие флаги: • AZ установится, если результат 0, иначе очистится. В случае 2 одновременных операций AZ представит логическое ИЛИ от этих двух флагов нуля. Все остальные флаги не поменяют свое значение. Версии инструкции с P-регистрами не влияют ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные инструкции могут быть выполнены параллельно с некоторыми 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". 16-битные версии этих инструкций не могут быть выполнены параллельно с другими инструкциями. [Примеры] r5 = r2 + r1; // инструкция сложения длиной 16 бит, без насыщения r5 = r2 + r1(ns); /* то же самое, но инструкция длиной 32 бита */ r5 = r2 + r1(s); // насыщение результата p5 = p3 + p0 ; // Если r0.l = 0x7000 и r7.l = 0x2000, то ... r4.l = r0.l + r7.l (ns); /* ... получится r4.l = 0x9000, потому что не было насыщения. */ // Если r0.l = 0x7000 и r7.h = 0x2000, то ... r4.l = r0.l + r7.h (s); /* ... получится r4.l = 0x7FFF, потому что результат получил насыщение до максимальной положительной величины */ r0.l = r2.h + r4.l(ns); r1.l = r3.h + r7.h(ns); r4.h = r0.l + r7.l (ns); r4.h = r0.l + r7.h (ns); r0.h = r2.h + r4.l(s); // насыщение результата r1.h = r3.h + r7.h(ns); См. также Modify - Increment, Round - 12-bit, Round - 20-bit, Shift with Add и Add with Shift (эти операции обе находятся в разделе "Операции сдвига и прокрутки"), Vector Add/Subtract (в разделе "Векторные операции"). Инструкция прибавления к регистру непосредственной константы (т. е. такой константы, которая указана прямо в команде). Общая форма: register += constant Синтаксис: Dreg += imm7; // Dreg = Dreg + константа (a)1 Preg += imm7; // Preg = Preg + константа (a) Ireg += 2; /* инкремент Ireg на 2, инкремент адреса Ireg += 4; // инкремент адреса указателя на слово (a) Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. [Терминология синтаксиса] Dreg: регистры данных R0, ..., R7. Preg: регистры указателей P0, ..., P5, SP, FP. Ireg: индексные регистры I0, ..., I3. imm7: 7-битное поле со знаком, в диапазоне -64 .. 63. [Функциональное описание] Инструкция Add Immediate прибавляет значение константы к значению регистра без насыщения. Примечание: чтобы вычесть непосредственные значения из I-регистров, используйте инструкцию Subtract Immediate. [Флаги] Версии инструкции с D-регистрами влияют на следующие флаги: • AZ установится, если результат 0, иначе очистится. В случае 2 одновременных операций AZ представит логическое ИЛИ от этих двух флагов нуля. Все остальные флаги не поменяют свое значение. Версии инструкции с P-регистрами и I-регистрами не влияют ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] Версии с D-регистрами и P-регистрами не могут быть выполнены параллельно с другими инструкциями. Версии инструкции с I-регистрами могут быть выполнены параллельно с некоторыми другими инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] r0 += 40; p5 += -4; // декремент путем добавления отрицательного значения i0 += 2; i1 += 4; См. также Subtract Immediate. Общая форма: DIVS ( регистр_делимого, регистр_делителя ) DIVQ ( регистр_делимого, регистр_делителя ) Синтаксис: DIVS (Dreg, Dreg); /* Инициализация для DIVQ. Устанавливает флаг AQ на базе DIVQ (Dreg, Dreg); /* Базируясь на флаге AQ либо добавляет, либо отнимает Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. [Терминология синтаксиса] Dreg: регистры данных R0, ..., R7. [Функциональное описание] Версии инструкции Divide Primitive являются основными элементами для алгоритма не восстанавливаемого условного деления методом добавления-вычитания (non-restoring conditional add-subtract division). См. "Пример" для такого алгоритма. Делимое (нумератор) представляет 32-битное значение. Делитель (деноминатор) является 16-битным значением из младшей регистра-делителя. Старшая половина регистра-делителя полностью игнорируется. Деление может быть со знаком или без знака, но делимое и делитель должны быть одного типа. Делитель не может быть отрицательным. Операция деления со знаком, когда делимое может быть отрицательным, начинает последовательность с инструкции DIVS (от слова divide-sign, деление со знаком), за которой идут повторяющиеся инструкции DIVQ (от слов divide-quotient, деление-частное). При беззнаковом делении инструкция DIVS опускается. В этом случае пользователь должен вручную очистить флаг AQ в регистре ASTAT перед запуском инструкций DIVQ. При разрешающей способности 16 бит деление со знаком может быть вычислено выдачей один раз инструкции DIVS, после чего инструкция DIVQ повторяется 15 раз. 16-битное беззнаковое частное вычисляется с пропуском DIVS, очисткой флага AQ, затем выдачей 16 раз инструкции DIVQ. Меньшая точность частного достигается выполнением меньшего количества повторений DIVQ. Результат каждого последовательного сложения или вычитания появляется в регистре делимого, с выравниванием и готовностью для следующего шага прибавления или вычитания. Эта инструкция не модифицирует содержимое регистра-делителя. Конечное частное появляется в младшей половине регистра делимого по окончании последовательности сложений/вычитаний. DIVS вычисляет бит знака частного на базе знаков делимого и делителя. DIVS инициализирует флаг AQ на базе этого знака, и инициализирует делимое для первой операции сложения или вычитания. DIVS не выполняет сложение или вычитание. DIVQ либо складывает (делимое + делитель), либо вычитает (делимое – делитель) на базе флага AQ, после чего заново инициализирует флаг AQ и делимое для следующей итерации. Если AQ в лог. 1, то выполняется сложение; если AQ в лог. 0, то выполняется вычитание. См. ниже секцию "Флаги", где говорится про условия установки и очистки флага AQ. Обе версии инструкции выравнивают делимое для следующей итерации сдвигом делимого влево на 1 бит (без переноса). Этот сдвиг влево выполняет ту же функцию, как и выравнивание делителя на 1 бит вправо, такую, как была бы выполнена при ручном двоичном делении. Формат частного для любого числового представления может быть определен по формату делимого и делителя. Позволяется... • NL представляет количество бит слева от двоичной точки, и Затем в частном будет NL – DL + 1 бит слева от двоичной точки, и NR – DR – 1 бит справа от двоичной точки. См. ниже иллюстрацию примера.
Могут потребоваться некоторые манипуляции над форматом, чтобы гарантировать допустимое значение частного. Например, если оба операнда со знаком, и полностью дробные (делимое в формате 1.31, и делитель в формате 1.15), то результат будет полностью дробным (в формате 1.15), так что старшие 16 бит частного должны иметь магнитуду меньше, чем у делителя, чтобы избежать переполнение сверх 16 бит. Если произойдет переполнение, то установится AV0. Программное обеспечение пользователя может определить переполнение, заново смасштабировать операнд, и повторить деление. Деление двух целых чисел (32.0 dividend by a 16.0 divisor) приведет к неправильному формату частного, потому что результат не уложится в 16-разрядный регистр. Для деления двух целых чисел (когда делимое в формате 32.0, и делитель в формате 16.0) и получения целого частного (в формате 16.0), перед делением нужно сдвинуть делимое на 1 бит влево (чтобы получить формат 31.1). Это требование сдвига влево ограничивает диапазон делимого 31 битами. Нарушение этого диапазона даст неверный результат операции деления. В алгоритме произойдет переполнение, если результат не может быть представлен в формате частного, как было вычислено выше, или когда делитель 0 или меньше чем старшие 16 бит магнитуды делимого (который эквивалентен умножению). [Условия ошибки] Два отдельных случая могут дать неправильный или неточный результат. Программа в состоянии перехватить и скорректировать оба случая. 1. Как уже упоминалось, инструкции Divide Primitive не поддерживают деление на отрицательный делитель. Попытки поделить на отрицательный делитель дадут в результате частное, которое в большинстве случаев будет на один бит LSB меньше, чем правильное значение. Если требуется поделить на отрицательный делитель, используйте следующее решение: • Перед выполнением деления сохраните знак делителя во временный регистр. В результате частное получит корректную магнитуду и корректный знак. 2. Инструкции Divide Primitive не поддерживают беззнаковое деление на делитель, который больше чем 0x7FFF. Если требуется провести такое деление, сделайте предварительное масштабирование обоих операндов путем сдвига на один бит вправо делимого и делителя, после чего выполняйте деление. Результирующее частное будет корректно выровнено. Конечно, предварительное масштабирование операндов снижают точность, и в результате может быть ошибка на 1 бит LSB в частном. Такая ошибка может быть детектирована следующим решением: • Сохраните оригинальные значения (до масштабирования) делимого и делителя во временные регистры. — Если error > делителя, добавьте один LSB к частному. [Флаги] Эта инструкция влияет на флаги следующим образом: • AQ равен MSB_делимого Exclusive-OR MSB_делителя, где делимое является 32-битным значением, и делитель является 16-битным значением. Все другие флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] Инструкция не может использоваться параллельно с другими инструкциями. [Пример] /* Обработка имеющихся целого со знаком делимого и делителя */ p0 = 15; // Точность вычисления частного 16 бит. r0 = 70; // Делимое, или нумератор r1 = 5; // Делитель, или деноминатор r0 <<= 1; /* Сдвиг на 1 бит влево требуется для деления целого числа */ divs (r0, r1); /* Вычисление MSB частного. Здесь инициализируется флаг AQ и делимое подготавливается для цикла инструкций DIVQ. */ loop .div_prim lc0=p0; // Выполнение 15 раз инструкции DIVQ, так как p0=15 loop_begin .div_prim; divq (r0, r1); loop_end .div_prim; r0 = r0.l (x); /* Расширение знаком 16-битного частного до 32 бит. */
/* r0 содержит частное (70/5 = 14). */
См. также Multiply (Modulo 232), Zero Overhead Loop. Общая форма: dest_reg = EXPADJ ( sample_register, exponent_register ) Синтаксис: Dreg_lo = EXPADJ (Dreg, Dreg_lo); // 32-битная выборка (b)1 Dreg_lo = EXPADJ (Dreg_lo_hi, Dreg_lo); // одна 16-битная выборка (b) Dreg_lo = EXPADJ (Dreg, Dreg_lo)(V); // две 16-битные выборки (b) Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg_lo_hi: половинки регистров R0.L, ..., R7.L, R0.H, ..., R7.H. Dreg_lo: половинки регистров R0.L, ..., R7.L. Dreg: регистры данных R0, ..., R7. [Функциональное описание] Инструкция Exponent Detection идентифицирует наибольшую магнитуду из двух или трех дробных чисел на базе их экспонент. Она сравнивает магнитуду одной или двух значений выборок по отношению к экспоненте, и возвращает самую маленькую из экспонент. Экспонента это количество бит знака минус 1. Другими словами, экспонента это количество избыточных бит числа со знаком. Экспоненты это целые числа без знака. Инструкция Exponent Detection приспосабливается под 2 специальных случая (0 и –1) и всегда возвращает самое маленькое значение экспоненты для каждого случая. Образцовая экспонента и получаемая экспонента являются 16-битными числами без знака, хранящимися в половинке регистра. Число выборки (sample) может быть либо словом (32 бита), либо полусловом (16 бит). Инструкция детектирования экспоненты не делает неявную модификацию входных значений. Однако dest_reg (регистр назначения, получаемая экспонента) и exponent_register (регистр образцовой экспоненты) могут быть одним и тем же D-регистром. В таком случае инструкция делает явную модификацию exponent_register. Допустимый диапазон для экспонент 0 .. 31, когда 31 представляет 32-битное число с самой малой магнитудой, и 15 представляет самую маленькую магнитуду 16-битного числа. Инструкция Exponent Detection поддерживает 3 типа выборок (samples): одну 32-битную, одну 16-битную (либо старшая, либо младшая половинка регистра), и две 16-битных выборки, которые занимают старшую и младшую половинки одного 32-битного регистра. Специальное применение: инструкция EXPADJ детектирует экспоненту от максимальной магнитуды числа в массиве. Детектированное значение может быть использовано для нормализации массива последующим проходом с операцией сдвига. Обычно эта функция используется для реализации блока возможностей чисел с плавающей точкой. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битная версия инструкции может быть выполнена параллельно с некоторыми 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] r5.l = expadj (r4, r2.l); /* Предположим: R4 = 0x0000 0052 и R2.L = 12. Тогда R5.L получит значение 12.
R4 = 0xFFFF 0052 и R2.L = 12. Тогда R5.L получит значение 12.
R4 = 0x0000 0052 и R2.L = 27. Тогда R5.L получит значение 24.
R4 = 0xF000 0052 и R2.L = 27. Тогда R5.L получит значение 3. */ r5.l = expadj (r4.l, r2.l); /* Предположим: R4.L = 0x0765 и R2.L = 12. Тогда R5.L получит значение 4.
R4.L = 0xC765 и R2.L = 12. Тогда R5.L получит значение 1. */ r5.l = expadj (r4.h, r2.l); /* Предположим: R4.H = 0x0765 и R2.L = 12. Тогда R5.L получит значение 4.
R4.H = 0xC765 и R2.L = 12. Тогда R5.L получит значение 1. */ r5.l = expadj (r4, r2.l)(v); /* Предположим: R4.L = 0x0765, R4.H = 0xFF74 и R2.L = 12. Тогда R5.L получит значение 4.
R4.L = 0x0765, R4.H = 0xE722 и R2.L = 12. Тогда R5.L получит значение 2. */
См. также Sign Bit для получения дополнительной информации по экспонентам. Общая форма: dest_reg = MAX ( src_reg_0, src_reg_1 ) Синтаксис: Dreg = MAX (Dreg, Dreg); // операнды 32-битные (b)1 Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: регистры данных R0, ..., R7. [Функциональное описание] Инструкция Maximum возвратит максимум, или наибольшее положительное значение из исходных регистров src_reg_1, src_reg_0. Операция вычитает src_reg_1 из src_reg_0, и выбирает результат на базе знака входных значений и флагов арифметики. Инструкция Maximum не делает неявную модификацию входных значений (src_reg_1, src_reg_0). Однако dest_reg может быть тем же D-регистром, что и один из исходных регистров, тогда инструкция явно поменяет этот исходный регистр. [Флаги] Инструкция влияет на следующие флаги: • AZ установится, если результат 0, иначе очистится. В случае 2 одновременных операций AZ представит логическое ИЛИ от этих двух флагов нуля. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битная версия инструкции может быть выполнена параллельно с некоторыми 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Пример] r5 = max (r2, r3); /* Предположим: R2 = 0x00000000 и R3 = 0x0000000F, тогда R5 = 0x0000000F.
R2 = 0x80000000 и R3 = 0x0000000F, тогда R5 = 0x0000000F.
R2 = 0xFFFFFFFF и R3 = 0x0000000F, тогда R5 = 0x0000000F. */
См. также Minimum, Maximum Value Selection and History Update, Vector Maximum, Vector Minimum (в разделе "Векторные операции", для алгоритмов декодирования Витерби). Общая форма: dest_reg = MIN ( src_reg_0, src_reg_1 ) Синтаксис: Dreg = MIN (Dreg, Dreg); // операнды 32-битные (b)1 Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: регистры данных R0, ..., R7. [Функциональное описание] Инструкция Minimum возвратит минимальное значение из исходных регистров src_reg_1, src_reg_0, и результат поместит в регистр назначения dest_reg (минимальное значение это то, которое максимально близко к -?). Операция вычитает src_reg_1 из src_reg_0, и выбирает результат на базе знака входных значений и флагов арифметики. Инструкция Minimum не делает неявную модификацию входных значений (src_reg_1, src_reg_0). Однако dest_reg может быть тем же D-регистром, что и один из исходных регистров, тогда инструкция явно поменяет этот исходный регистр. [Флаги] Инструкция влияет на следующие флаги: • AZ установится, если результат 0, иначе очистится. В случае 2 одновременных операций AZ представит логическое ИЛИ от этих двух флагов нуля. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битная версия инструкции может быть выполнена параллельно с некоторыми 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Пример] r5 = min (r2, r3); /* Предположим: R2 = 0x00000000 и R3 = 0x0000000F, тогда R5 = 0x00000000.
R2 = 0x80000000 и R3 = 0x0000000F, тогда R5 = 0x80000000.
R2 = 0xFFFFFFFF и R3 = 0x0000000F, тогда R5 = 0xFFFFFFFF. */
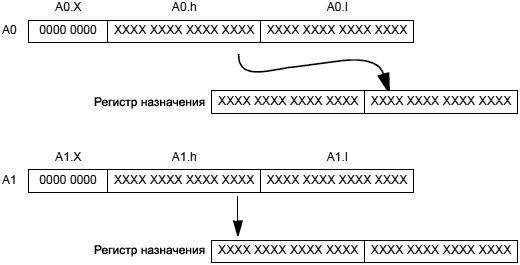
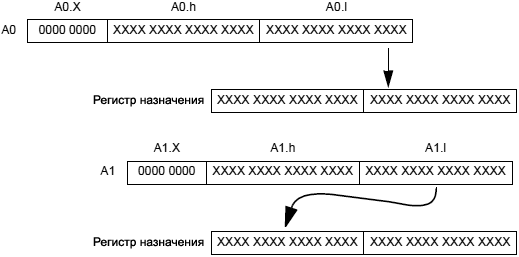
См. также Maximum, Vector Maximum, Vector Minimum. Общая форма: dest_reg -= src_reg Синтаксис для 40-разрядных аккумуляторов: A0 -= A1; /* dest_reg_new = dest_reg_old - src_reg, с насыщением A0 -= A1(W32); /* dest_reg_new = dest_reg_old - src_reg, декремент и насыщение Синтаксис для 32-разрядных регистров: Preg -= Preg; // dest_reg_new = dest_reg_old - src_reg (a) Ireg -= Mreg; // dest_reg_new = dest_reg_old - src_reg (a) Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. Комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Preg: регистры P0, ..., P5, SP, FP. Ireg: регистры I0, ..., I3. Mreg: регистры M0, ..., M3. [Функциональное описание] Инструкция Modify-Decrement декрементирует регистр на указанное пользователем значение. Подробнее про поведение насыщения см. секцию "Saturation (насыщение)". Специальное применение инструкции: обычно версии инструкции с индексным регистром (I-регистр) и регистром указателя (P-регистр) используются для декремента косвенного (indirect) адреса в указателе при операциях загрузки или сохранения. [Флаги] Версии инструкции с аккумулятором влияют на следующие флаги: • AZ установится, если результат 0, иначе очистится. Все остальные флаги не поменяют свое значение. Версии инструкции с P-регистрами и I-регистрами не влияют ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные инструкции могут быть выполнены параллельно с некоторыми 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". 16-битные версии этих инструкций не могут быть выполнены параллельно с другими инструкциями. [Примеры] a0 -= a1; a0 -= a1(w32); p3 -= p0; i1 -= m2; См. также Modify – Increment, Subtract, Shift with Add. Общая форма: dest_reg += src_reg dest_reg = ( src_reg_0 += src_reg_1 ) Синтаксис для 40-разрядных аккумуляторов: A0 += A1; /* dest_reg_new = dest_reg_old + src_reg, с насыщением A0 += A1(W32); /* dest_reg_new = dest_reg_old + src_reg, инкремент и насыщение Синтаксис для 32-разрядных регистров: Preg += Preg(BREV); // dest_reg_new = dest_reg_old + src_reg, Ireg += Mreg(opt_brev); // dest_reg_new = dest_reg_old + src_reg, Dreg = (A0 += A1); /* инкремент 40-битного A0 на A1 с насыщением Синтаксис для 16-битных половинок регистров данных: Dreg_lo_hi = (A0 += A1); /* инкремент 40-битного A0 на A1 с насыщением Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. Комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: регистры данных R0, ..., R7. Preg: регистры P0, ..., P5, SP, FP. Ireg: регистры I0, ..., I3. Mreg: регистры M0, ..., M3. opt_brev: опциональный синтаксис реверсирования бит; замените на (brev). Dreg_lo_hi: половинки регистров R0.L, ..., R7.L, R0.H, ..., R7.H. [Функциональное описание] Инструкция Modify-Decrement инкрементирует регистр на указанное пользователем значение. В некоторых версиях инструкция копирует результат в третий регистр. Версия с половинками регистра инкрементирует 40-разрядный A0 на A1 с насыщением в 40 битах, затем распаковывает результат в половинку регистра. На шаге распаковки вовлекается сначала округление 40-битного результата в позиции бита 16 (в соответствии с настройкой в бите RND_MOD регистра ASTAT), затем делается насыщение по 32 битам, и биты 31..16 переносятся в половинку регистра. Подробнее про поведение насыщения см. секцию "Saturation (насыщение)". Про округление подробнее см. раздел "Rounding, Truncating". Специальное применение инструкции: обычно версии инструкции с индексным регистром (I-регистр) и регистром указателя (P-регистр) используются для инкремента косвенного (indirect) адреса в указателе при операциях загрузки или сохранения. Опция: (BREV) - сокращение от bit reverse carry adder (сложение с обратным битом инверсии). Когда эта опция указана, бит переноса распространяется слева направо, как это показано на рис. 10-1, вместо справа налево.
Рис. 10-1. Поток сложения бит для случая (BREV). Когда используется обратный бит инверсии с версией инструкции с I-регистром, запрещена кольцевая буферизация для поддержки адресации операндов в алгоритмах FFT, DCT и DFT. Версия с P-регистром в любом случае не поддерживает кольцевую буферизацию. [Флаги] Версии инструкции с аккумулятором и D-регистрами влияют на следующие флаги: • AZ установится, если результат 0, иначе очистится. Все остальные флаги не поменяют свое значение. Версии инструкции с P-регистрами и I-регистрами, и версии с модификацией регистра не влияют ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные инструкции могут быть выполнены параллельно с некоторыми 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". 16-битные версии этих инструкций не могут быть выполнены параллельно с другими инструкциями. [Примеры] a0 += a1;
a0 += a1(w32);
p3 += p0(brev);
i1 += m1;
i0 += m0(brev); // опциональный режим carry bit reverse mode
r5 = (a0 += a1);
r2.l = (a0 += a1);
r5.h = (a0 += a1);
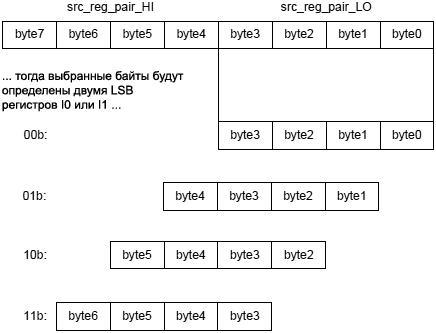
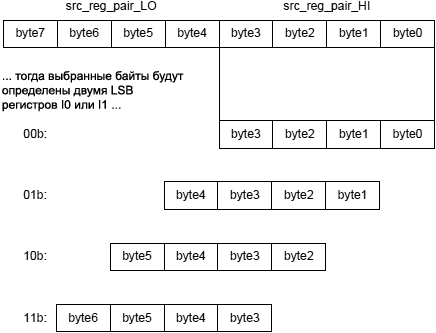
См. также Modify – Decrement, Add, Shift with Add. Общая форма: dest_reg = src_reg_0 * src_reg_1 (opt_mode) Синтаксис для MULTIPLY-AND-ACCUMULATE UNIT 0 (MAC0): Dreg_lo = Dreg_lo_hi * Dreg_lo_hi (opt_mode_1); /* 16-битный результат в младшую половинку Dreg = Dreg_lo_hi * Dreg_lo_hi (opt_mode_2); // 32-битный результат (b) Синтаксис для MULTIPLY-AND-ACCUMULATE UNIT 1 (MAC1): Dreg_hi = Dreg_lo_hi * Dreg_lo_hi (opt_mode_1); /* 16-битный результат в старшую половинку Dreg = Dreg_lo_hi * Dreg_lo_hi (opt_mode_2); // 32-битный результат (b) Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: регистры R0, ..., R7. Dreg_lo: младшая половинка регистров R0.L, ..., R7.L. Dreg_hi: старшая половинка регистров R0.H, ..., R7.H. Dreg_lo_hi: могут использоваться обе половинки регистров R0.L, ..., R7.L, R0.H, ..., R7.H. opt_mode_1: могут быть указаны по выбору опции (FU), (IS), (IU), (T), (TFU), (S2RND), (ISS2) или (IH). Опция (M) может быть использована вместе с версиями MAC1, либо по отдельности, либо совместно с любыми другими этими опциями. opt_mode_2: могут быть указаны по выбору опции (FU), (IS), (S2RND) или (ISS2). Опция (M) может быть использована вместе с версиями MAC1, либо по отдельности, либо совместно с любыми другими этими опциями. Примечание: при совместном использовании опций набор этих опций должен быть включен в круглые скобки, с разделением опций друг от друга запятой. Пример: (M, IS). [Функциональное описание] Инструкция Multiply умножает два 16-разрядных операнда и сохраняет результат напрямую в регистр назначения, с использованием насыщения. Инструкция работает наподобие инструкций Multiply-Accumulate (умножение с накоплением) с тем исключением, что Multiply не влияет на содержимое аккумуляторов. Операции, выполняемые блоком умножения с накоплением 0 (Multiply-and-Accumulate Unit 0, или сокращенно MAC0) архитектуры загружает свои результаты в младшую половину регистра назначения. Операции, выполняемые с помощью MAC1, загружают свои результаты в старшую половину регистра назначения. С синтаксисом 32-разрядного результата регистром назначения Dreg будет определен используемый блок MAC. Регистры Dreg с четными номерами (R6, R4, R2, R0) обрабатываются MAC0. Регистры Dreg с нечетными номерами (R7, R5, R3, R1) обрабатываются MAC1. Таким образом, операции с 32-разрядным результатом, которые используют опцию (M), могут быть выполнены только на регистрах назначения Dreg с нечетными номерами. С синтаксисом 16-разрядного результата половинкой регистра назначения Dreg будет определен используемый блок MAC. Младшие половинки Dreg (R0.L, ..., R7.L) будут использовать MAC0. Старшие половинки Dreg (R0.H, ..., R7.H) будут использовать MAC1. Таким образом, операции с 16-битным результатом, использующие опцию (M), могут быть выполнены только на старших половинках Dreg в качестве места назначения. На версии этой инструкции, которые генерируют 16-битный результат, влияет бит RND_MOD регистра ASTAT, когда результат копируется в 16-битный регистр назначения. RND_MOD определяет, какое будет использоваться округление - смещенное (biased) или не смещенное (unbiased). RND_MOD управляет округлением всех версий этой инструкции, которые генерируют 16-битные результаты, за исключением опций (IS), (IU) и (ISS2). Подробнее про поведение насыщения см. секцию "Saturation (насыщение)". Про округление подробнее см. раздел "Rounding, Truncating". Версии этой инструкции, которые дают 32-битные результаты, не выполняют округление и на них не влияет бит RND_MOD регистра ASTAT. [Опции] Инструкция Multiply поддерживает следующие опции. Насыщение поддерживается для каждой опции. Таблица 10-1. Опции умножения.
Для обрезки (truncate) результата операция уничтожает младшие по значимости биты, которые не укладываются в регистр назначения. В режиме дробных чисел (fractional mode), продукт самых малых представимых чисел (например, 0x8000-я часть от 0x8000) насыщается до максимально представимой положительной дробной части (0x7FFF). [Флаги] Инструкция влияет на флаги следующим образом: • V установится, если в результате произошло насыщение, иначе очистится. Все остальные флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные инструкции могут быть выполнены параллельно с некоторыми 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] r3.l=r3.h*r2.h; /* MAC0. Оба операнда имеют части со знаком. */ r3.h=r6.h*r4.l(fu); /* MAC1. Оба операнда имеют части без знака. */ См. также Multiply and Multiply-Accumulate to Accumulator, Multiply and Multiply-Accumulate to Half-Register, Multiply and Multiply-Accumulate to Data Register, Multiply (Modulo 232), Vector Multiply, Vector Multiply and Multiply-Accumulate. Общая форма: accumulator = src_reg_0 * src_reg_1 (opt_mode) accumulator += src_reg_0 * src_reg_1 (opt_mode) accumulator –= src_reg_0 * src_reg_1 (opt_mode) Синтаксис операций с MAC0: A0 = Dreg_lo_hi * Dreg_lo_hi (opt_mode); // умножение и сохранение (b)1 A0 += Dreg_lo_hi * Dreg_lo_hi (opt_mode); // умножение и добавление (b) A0 –= Dreg_lo_hi * Dreg_lo_hi (opt_mode); // умножение и вычитание (b) Синтаксис операций с MAC1: A1 = Dreg_lo_hi * Dreg_lo_hi (opt_mode); // умножение и сохранение (b) A1 += Dreg_lo_hi * Dreg_lo_hi (opt_mode); // умножение и добавление (b) A1 –= Dreg_lo_hi * Dreg_lo_hi (opt_mode); // умножение и вычитание (b) Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg_lo_hi: половинки регистров R0.L, ..., R7.L, R0.H, ..., R7.H. opt_mode: опционально может быть указано (FU), (IS) или (W32). Также опционально может использоваться (M) по отдельности или вместе с (W32). Если опции умножения указаны совместно для MAC, то опции должны отделяться друг от друга запятой, и все вместе должны быть закрыты парой круглых скобок. Пример: (M, W32) [Функциональное описание] Инструкция Multiply and Multiply-Accumulate to Accumulator умножает два 16-битных операнда, лежащих в половинках D-регистра. Также она сохраняет полученный умножением результат вместе с добавлением (или вычитанием) в назначенный аккумулятор с применением насыщения. Часть архитектуры, которая использует Multiply-and-Accumulate Unit 0 (MAC0), вовлекает аккумулятор A0. MAC1 выполняет операции с A1. По умолчанию инструкция обрабатывает оба операнда в обоих MAC-ах как дробные числа со знаком с коррекцией левым сдвигом, если это необходимо. [Опции] Инструкция Multiply and Multiply-Accumulate to Accumulator поддерживает следующие опции. Насыщение поддерживается для каждой опции. Таблица 10-2. Опции для инструкции Multiply and Multiply-Accumulate to Accumulator.
Когда опции (M) и (W32) используются вместе, оба MAC делают насыщение своих результатов в аккумуляторе по 32 битам. MAC1 умножает дробные числа со знаком на дробные числа без знака, и MAC0 умножает дробные числа со знаком. При совместном использовании опций их порядок следования друг за другом не имеет значения. В режиме дробных чисел (fractional mode), продукт самых малых представимых чисел (например, 0x8000-я часть от 0x8000) насыщается до максимально представимой положительной дробной части (0x7FFF) до момента накопления. Подробнее про поведение насыщения см. секцию "Saturation (насыщение)". Специальное применение инструкции: приложения фильтра DSP часто используют инструкцию Multiply and Multiply-Accumulate to Accumulator для вычисления результата двух векторов сигнала. [Флаги] Инструкция влияет на флаги следующим образом: • AV0 установится, если результат в аккумуляторе A0 (операция с MAC0) получил насыщение. Очистится, если результат A0 не получил насыщения. Все остальные флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные инструкции могут быть выполнены параллельно с некоторыми 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Пример] a0=r3.h*r2.h; /* Работает только MAC0, only. Оба операнда это дробные числа со знаком. Результат будет помещен в A0. */ a1+=r6.h*r4.l(fu); /* Работает только MAC1. Оба операнда это дробные числа без знака. Результат будет помещен в A1. */
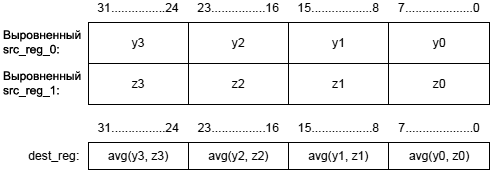
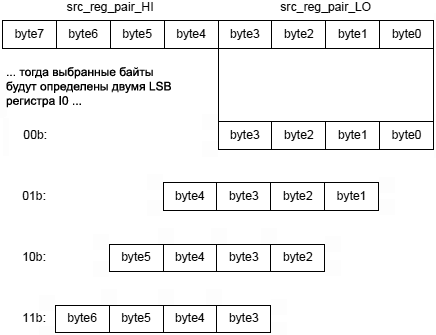
См. также инструкции Multiply, Multiply and Multiply-Accumulate to Half-Register, Multiply and Multiply-Accumulate to Data Register, Multiply (Modulo 232), Vector Multiply, Vector Multiply and Multiply-Accumulate. Общая форма: dest_reg_half = (accumulator = src_reg_0 * src_reg_1) (opt_mode) dest_reg_half = (accumulator += src_reg_0 * src_reg_1) (opt_mode) dest_reg_half = (accumulator –= src_reg_0 * src_reg_1) (opt_mode) Синтаксис операций с MAC0: Dreg_lo = (A0 = Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // умножение и сохранение (b)1 Dreg_lo = (A0 += Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // умножение и добавление (b) Dreg_lo = (A0 –= Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // умножение и вычитание (b) Синтаксис операций с MAC1: Dreg_hi = (A1 = Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // умножение и сохранение (b) Dreg_hi = (A1 += Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // умножение и добавление (b) Dreg_hi = (A1 –= Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // умножение и вычитание (b) Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg_lo_hi: половинки регистров R0.L, ..., R7.L, R0.H, ..., R7.H. Dreg_lo: младшие половинки регистров R0.L, ..., R7.L. Dreg_hi: старшие половинки регистров R0.H, ..., R7.H. opt_mode: опционально может быть указано (FU), (IS), (IU), (T), (TFU), (S2RND), (ISS2) или (IH). Также опционально может использоваться (M) в версиях с MAC1, по отдельности или вместе с любой другой опцией. Если опции умножения указаны совместно для MAC, то опции должны отделяться друг от друга запятой, и все вместе должны быть закрыты парой круглых скобок. Пример: (M, TFU). [Функциональное описание] Инструкция Multiply and Multiply-Accumulate to Half-Register умножает два 16-битных операнда размещенных в половинках регистра. Также она сохраняет полученный умножением результат вместе с добавлением (или вычитанием) в назначенный аккумулятор с применением насыщения. Затем 16 бит (с операцией насыщения по 16 битам) из аккумулятора копируются в половинку D-регистра. Версии этой инструкции, работающие с дробными числами (опции по умолчанию и (FU)) переносят результат из аккумулятора в регистр назначения в соответствии с диаграммой, показанной ниже:
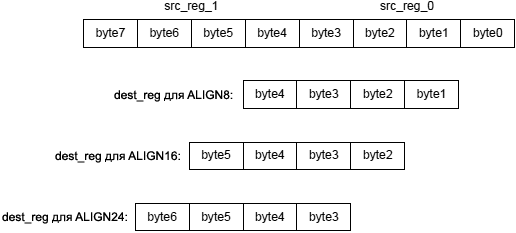
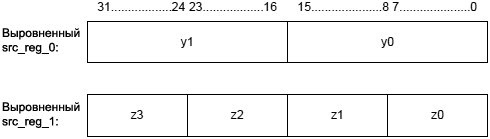
Целочисленные версии этой инструкции (опции (IS) и (IU)) переносят результат из аккумулятора в регистр назначения в соответствии с диаграммой, показанной ниже:
Операции, выполняемые блоком умножения с накоплением 0 (Multiply-and-Accumulate Unit 0, или сокращенно MAC0), вовлекают в обработку аккумулятор A0, и загружают свои результаты в младшую половину регистра назначения. Операции, выполняемые с помощью MAC1, используют аккумулятор A1 и загружают свои результаты в старшую половину регистра назначения. Все версии этой инструкции поддерживают округление (rounding), на которое оказывает влияние бит RND_MOD в регистре ASTAT, когда результаты копируются в регистр назначения. RND_MOD определяет, какое используется округление - смещенное (biased rounding) или не смещенное (unbiased rounding). Подробнее про поведение округления см. раздел "Rounding, Truncating". Специальное применение инструкции: приложения фильтра DSP часто используют инструкцию Multiply-Accumulate Half-Register для вычисления точки между двух векторов сигнала. [Опции] Инструкция Multiply and Multiply-Accumulate to Half-Register поддерживает опции операндов и копирования аккумулятора. Таблица 10-3. Опции для инструкции Multiply and Multiply-Accumulate to Half-Register. Опция Как обрабатываются операнды Форматирование при копировании аккумулятора
Чтобы сделать обрезку (truncate) результата, операция уничтожает младшие значащие биты, которые не укладываются в регистр назначения. Когда это необходимо, после округления (rounding) применяется насыщение (saturation). В режиме дробных чисел (fractional mode), продукт самых отрицательных представимых дробных чисел (например, 0x8000-я часть от 0x8000) насыщается до максимально представимой положительной дробной части (0x7FFF) до момента накопления. Если Вы хотели бы сохранить содержимое аккумуляторе не измененным, используйте простую инструкцию копирования (Move), чтобы сделать копию A.x или A.w в каком-нибудь регистре. Подробнее про поведение насыщения см. секцию "Saturation (насыщение)". [Флаги] Инструкция влияет на флаги следующим образом: • V установится, если результат, распакованный в Dreg, претерпел насыщение; очистится, если насыщения не было. Все остальные флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные инструкции могут быть выполнены параллельно с некоторыми 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Пример] r3.l=(a0=r3.h*r2.h); /* Работает только MAC0. Оба операнда - дробные числа со знаком. Результат будет записан в A0, затем
скопирован в r3.l. */ r3.h=(a1+=r6.h*r4.l)(fu); /* Работает только MAC1. Оба операнда - дробные числа без знака. Результат будет записан в A1, затем
скопирован в r3.h. */
См. также инструкции Multiply and Multiply-Accumulate to Accumulator, Multiply and Multiply-Accumulate to Data Register, Multiply (Modulo 232), Vector Multiply, Vector Multiply and Multiply-Accumulate. Общая форма: dest_reg = (accumulator = src_reg_0 * src_reg_1) (opt_mode) dest_reg = (accumulator += src_reg_0 * src_reg_1) (opt_mode) dest_reg = (accumulator –= src_reg_0 * src_reg_1) (opt_mode) Синтаксис операций с MAC0: Dreg_even = (A0 = Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // умножение и сохранение (b)1 Dreg_even = (A0 += Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // умножение и добавление (b) Dreg_even = (A0 –= Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // умножение и вычитание (b) Синтаксис операций с MAC1: Dreg_hi = (A1 = Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // умножение и сохранение (b) Dreg_hi = (A1 += Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // умножение и добавление (b) Dreg_hi = (A1 –= Dreg_lo_hi * Dreg_lo_hi) (opt_mode); // умножение и вычитание (b) Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg_lo_hi: половинки регистров R0.L, ..., R7.L, R0.H, ..., R7.H. Dreg_even: регистры с четными номерами R0, R2, R4, R6. Dreg_odd: регистры с нечетными номерами R1, R3, R5, R7. opt_mode: опционально может быть указано (FU), (IS), (S2RND) или (ISS2). Также опционально может использоваться (M) в версиях с MAC1, по отдельности или вместе с любой другой опцией. Если опции умножения указаны совместно для MAC, то опции должны отделяться друг от друга запятой, и все вместе должны быть закрыты парой круглых скобок. Пример: (M, IS). [Функциональное описание] Эта инструкция перемножает два 16-разрядных операнда, находящихся в половинках регистров. Инструкция делает операцию сохранения, добавления или вычитания результата в выбранный аккумулятор. Затем из аккумулятора копируются 32 бита в регистр данных. 32 бита насыщаются по 32 битам. Часть архитектуры, работающая с блоком Multiply-and-Accumulate Unit 0 (MAC0) вовлекают в вычисления аккумулятор A0; при этом инструкция может загрузить результат в D-регистр с четным номером. MAC1 выполняет операции с A1, и загружает результаты в D-регистры с нечетными номерами. Комбинация инструкций с MAC0 и MAC1 может быть объединена в одну инструкцию. Подробнее см. раздел "Векторные операции". Приложения DSP часто используют инструкцию Multiply and Multiply-Accumulate to Data Register или векторную версию (см. раздел "Векторные операции") для вычисления точки между двух векторов сигнала. [Опции] Инструкция Multiply and Multiply-Accumulate to Data Register поддерживает опции операндов и формата копирования аккумулятора (см. таблицу 10-4). Таблица 10-4. Опции инструкции Multiply and Multiply-Accumulate to Data Register.
Синтаксис поддерживает только округление со смещением (biased rounding). Бит RND_MOD регистра ASTAT не оказывает влияние на поведение округления для этой инструкции. Подробнее про поведение округления см. раздел "Rounding, Truncating". В режиме дробных чисел (fractional mode), продукт самых малых представимых чисел (например, 0x8000-я часть от 0x8000) насыщается до максимально представимой положительной дробной части (0x7FFF) до момента накопления. Если Вы хотели бы сохранить содержимое аккумуляторе не измененным, используйте простую инструкцию копирования (Move), чтобы сделать копию A.x или A.w в каком-нибудь регистре. Подробнее про поведение насыщения см. секцию "Saturation (насыщение)". [Флаги] Инструкция влияет на флаги следующим образом: • V установится, если результат, распакованный в Dreg, претерпел насыщение; очистится, если насыщения не было. Все остальные флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные инструкции могут быть выполнены параллельно с некоторыми 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Пример] r4=(a0=r3.h*r2.h); /* Работает только MAC0. В обоих операндах находятся дробные числа со знаком. Результат загрузится в A0,
затем в r4. */ r3=(a1+=r6.h*r4.l)(fu); /* Работает только MAC1. В обоих операндах находятся дробные числа без знака. Результат загрузится в A1,
затем в r3. */
См. также инструкции Move Register, Move Register Half, Multiply and Multiply-Accumulate to Accumulator, Multiply and Multiply-Accumulate to Half-Register, Multiply (Modulo 232), Vector Multiply, Vector Multiply and Multiply-Accumulate. Общая форма: dest_reg *= multiple_register Синтаксис: Dreg *= Dreg; // целочисленное умножение 32 x 32 (a)1 Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. [Терминология синтаксиса] Dreg: регистры R0, ..., R7. [Функциональное описание] Инструкция Multiply (Modulo 232) умножает два 32-разрядных регистра данных dest_reg и multiple_register, и сохраняет результат в dest_reg. Инструкция выглядит точно так же, как и аналогичная операция на языке C, которая выполняет действие Dreg1 = (Dreg1 * Dreg2) modulo 232. Поскольку инструкция работает с modulo 232, то результат всегда помещается в 32-разрядный регистр dest_reg, и переполнение невозможно; флаг переполнения в регистре ASTAT никогда не устанавливается. Пользователь должен позаботиться об ограничении значения входных чисел, чтобы гарантировать, что в результат не превысит разрядность 32-битного регистра dest_reg. Если требуется оповещение о переполнении, то программист должен написать собственный макрос для умножения с поддержкой такой возможности. Эта инструкция не меняет аккумуляторы A0 и A1. Инструкция Multiply (Modulo 232) не делает неявную модификацию значения в регистре multiple_register. Эта инструкция может использоваться для реализации метода конгруэнтности при генерации случайных чисел: x[n+1] = (a*x[n]) mod 2^32 Здесь x[n] начальное значение генератора (seed value), a это большое число, и x[n+1] это результат, который может быть умножен снова для продолжения псевдослучайной последовательности. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] Инструкция не может быть выполнена параллельно с другими инструкциями. [Пример] r3 *= r0;
См. также инструкции Divide Primitive, Arithmetic Shift, Shift with Add, Add with Shift. В разделе "Векторные операции" см. Vector Multiply and Multiply-Accumulate, Vector Multiply. Операция отрицания (двоичное дополнение). Общая форма: dest_reg = –src_reg dest_accumulator = –src_accumulator Синтаксис: Dreg = –Dreg; // (a)1 Dreg = –Dreg (sat_flag); // (b) A0 = –A0; // (b) A0 = –A1; // (b) A1 = –A0; // (b) A1 = –A1; // (b) A1 = –A1, A0 = –A0; // отрицание обоих аккумуляторов в одной Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. Комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: регистры данных R0, ..., R7. sat_flag: обязательный флаг управления насыщением, (S) или (NS). [Функциональное описание] Инструкция Negate (Two’s Complement) возвратит значение той же самой магнитуды, но с обратным арифметическим знаком. Версии с аккумулятором делают насыщение результата по 40 битам. Инструкция получает результат вычитанием из нуля. Версия с Dreg без опции sat_flag не делает насыщение. Будет только тогда переполнение инструкции Negate без насыщения, когда входное значение равно 0x8000 0000. Версия с насыщением вернет; версия без насыщения вернет 0x8000 0000. В синтаксисе, где появляется опция sat_flag, она заменяется одним из следующих значений: • (S) – выполняется насыщение результата. Подробнее про поведение насыщения см. секцию "Saturation (насыщение)". [Флаги] Инструкция влияет на флаги следующим образом: • AZ установится, если результат операции 0, иначе очистится. Все остальные флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные инструкции могут быть выполнены параллельно с некоторыми 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Пример] r5 = -r0; a0 = -a0; a0 = -a1; a1 = -a0; a1 = -a1; a1 = -a1, a0 = -a0; См. также инструкцию Vector Negate (Two’s Complement) в разделе "Векторные операции". Округление до половины слова. Общая форма: dest_reg = src_reg (RND) Синтаксис: Dreg_lo_hi = Dreg(RND); // округление и насыщение источника до 16 бит (b)1 Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: регистры R0, ..., R7. Dreg_lo_hi: половинки регистров R0.L, ..., R7.L, R0.H, ..., R7.H. [Функциональное описание] Инструкция Round Half-Word округляет 32-битное, нормализованное дробное число в 16-битное, нормализованное дробное число путем распаковки и насыщения бит 31:16, затем отбрасывания бит 15:0. Инструкция поддерживает только смещенное округление (biased rounding), которое добавляет половинку LSB (в этом случае, бит bit 15) перед отбрасыванием бит 15:0. ALU выполняет округление. Бит RND_MOD в регистре ASTAT не оказывает влияние на поведение округления в этой инструкции. Дробные типы данных, какие используются в этой инструкции, всегда со знаком. Подробнее про поведение насыщения см. секцию "Saturation (насыщение)". Подробнее про поведение округления см. раздел "Rounding, Truncating". [Флаги] Инструкция влияет на флаги следующим образом: • AZ установится, если результат операции 0, иначе очистится. Все остальные флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные инструкции могут быть выполнены параллельно с некоторыми 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Пример] // Если r6 = 0xFFFC FFFF, то округление до 16 бит операцией ... r1.l = r6 (rnd); // ... даст в результате r1.l = 0xFFFD
// Если r7 = 0x0001 8000, то округление до 16 бит операцией ... r1.h = r7 (rnd); // ... даст в результате r1.h = 0x0002
См. также инструкции Round – 12 Bit, Round – 20 Bit, Add. Сложение или вычитание с округлением до 12 бит слова. Общая форма: dest_reg = src_reg_0 + src_reg_1 (RND12) dest_reg = src_reg_0 - src_reg_1 (RND12) Синтаксис: Dreg_lo_hi = Dreg + Dreg (RND12); // (b)1 Dreg_lo_hi = Dreg - Dreg (RND12); // (b) Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: регистры R0, ..., R7. Dreg_lo_hi: половинки регистров R0.L, ..., R7.L, R0.H, ..., R7.H. [Функциональное описание] Инструкция Round - 12 bit складывает или вычитает два 32-битных значения, затем округляет результат по позиции бита 12. Эта инструкция сохраняет 16 бит числа распаковкой битов 27:12 с насыщением результата. Инструкция поддерживает только смещенное округление (biased rounding), которое добавляет половинку LSB (в этом случае, бит bit 11) перед отбрасыванием бит 11:0. Бит RND_MOD в регистре ASTAT не оказывает влияние на поведение округления в этой инструкции. Подробнее про поведение насыщения см. секцию "Saturation (насыщение)". Подробнее про поведение округления см. раздел "Rounding, Truncating". Специальное применение инструкции: обычно Round – 12 Bit используют для алгоритма операции 2D 8x8 inverse discrete cosine transform, совместимой со стандартом IEEE 1180. [Флаги] Инструкция влияет на флаги следующим образом: • AZ установится, если результат операции 0, иначе очистится. Все остальные флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные инструкции могут быть выполнены параллельно с некоторыми 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] r1.l = r6+r7(rnd12); r1.l = r6-r7(rnd12); r1.h = r6+r7(rnd12); r1.h = r6-r7(rnd12); См. также инструкции Round – Half-Word, Round – 20 Bit, Add. Сложение или вычитание с округлением до 20 бит слова. Общая форма: dest_reg = src_reg_0 + src_reg_1 (RND20) dest_reg = src_reg_0 - src_reg_1 (RND20) Синтаксис: Dreg_lo_hi = Dreg + Dreg (RND20); // (b)1 Dreg_lo_hi = Dreg - Dreg (RND20); // (b) Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: регистры R0, ..., R7. Dreg_lo_hi: половинки регистров R0.L, ..., R7.L, R0.H, ..., R7.H. [Функциональное описание] Инструкция Round - 20 bit складывает или вычитает два 32-битных значения, округляет результат по позиции бита 20, после чего распаковывает биты 31:20 в 16-битный регистр назначения. Инструкция поддерживает только смещенное округление (biased rounding), которое добавляет половинку LSB (в этом случае, бит bit 19) перед отбрасыванием бит 19:0. Бит RND_MOD в регистре ASTAT не оказывает влияние на поведение округления в этой инструкции. Практически эта инструкция делает правый сдвиг на 4 бита каждого входного слова, чтобы предотвратить переполнение результата, складывает или вычитает 2 слова, затем делает округление результата в позиции бита 16. Эта инструкция сохраняет старшие 16 бит числа. Подробнее про поведение округления см. раздел "Rounding, Truncating". Специальное применение инструкции: обычно Round – 20 Bit используют для алгоритма операции 2D 8x8 inverse discrete cosine transform, совместимой со стандартом IEEE 1180. [Флаги] Инструкция влияет на флаги следующим образом: • AZ установится, если результат операции 0, иначе очистится. Все остальные флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные инструкции могут быть выполнены параллельно с некоторыми 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] r1.l = r6+r7(rnd20);
r1.l = r6-r7(rnd20);
r1.h = r6+r7(rnd20);
r1.h = r6-r7(rnd20);
См. также инструкции Round – 12 Bit, Round – Half-Word, Add. Операция насыщения. Общая форма: dest_reg = src_reg (S) Синтаксис: A0 = A0 (S); // (b)1 A1 = A1 (S); // (b) A1 = A1 (S), A0 = A0 (S); // насыщение со знаком для обоих аккумуляторов Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Функциональное описание] Инструкция Saturate делает насыщение 40-разрядных аккумуляторов по 32 битам. Результирующее насыщенное значение получает расширение знаком в битах расширения аккумулятора (extension bits). Подробнее про поведение насыщения см. секцию "Saturation (насыщение)". [Флаги] Инструкция влияет на флаги следующим образом: • AZ установится, если результат операции 0, иначе очистится. В случае двух одновременных операций AZ представит результат логического ИЛИ от этих двух операций. Все остальные флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные инструкции могут быть выполнены параллельно с некоторыми 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] a0 = a0 (s); a1 = a1 (s); a1 = a1 (s), a0 = a0 (s); См. также инструкции Subtract (опции насыщения), Add (опции насыщения). Общая форма: dest_reg = SIGNBITS sample_register Синтаксис: Dreg_lo = SIGNBITS Dreg; // 32-битная выборка (b)1 Dreg_lo = SIGNBITS Dreg_lo_hi; // 16-битная выборка (b) Dreg_lo = SIGNBITS A0; // 40-битная выборка (b) Dreg_lo = SIGNBITS A1; // 40-битная выборка (b) [Терминология синтаксиса] Dreg: регистры R0, ..., R7. Dreg_lo: половинки регистров R0.L, ..., R7.L. Dreg_lo_hi: половинки регистров R0.L, ..., R7.L, R0.H, ..., R7.H. [Функциональное описание] Инструкция Sign Bit возвращает количество бит знака в числе, и может использоваться совместно со сдвигом для нормализации чисел. Инструкция может работать с входными числами 16 бит, 32 бита или 40 бит. • Для 16-битных входных чисел Sign Bit вернет количество начальных знаковых бит минус 1, в результате получится число в диапазоне 0 .. 15. Здесь не может быть специальных случаев: когда на входе все нули, то будет возвращено +15 (все биты знаковые), и когда на входе все единички, то будет также возвращено +15. • Для 32-битных входных чисел Sign Bit вернет количество начальных знаковых бит минус 1, в результате получится число в диапазоне 0 .. 31. Когда на входе все нули или все единички, инструкция возвратит +31 (все знаковые биты). • Для 40-битных аккумуляторов на входе Sign Bit вернет количество начальных знаковых бит минус 9, в результате получится число в диапазоне -8 .. 31. Отрицательное число будет возвращено, когда результат в аккумуляторе расширился на дополнительные биты (extension bits); соответствующая нормализация сдвинет результат вниз до 32-разрядов (с потерей точности). Все входные нули или все единицы вернет значение +31. Результат инструкции SIGNBITS может напрямую использоваться как аргумент инструкции ASHIFT для нормализации числа. В результате получатся числа в следующих форматах (S == биты знака, M == биты магнитуды). 16-bit: S.MMM MMMM MMMM MMMM Дополнительно результат SIGNBITS может быть напрямую вычтен для формирования новой экспоненты. Инструкция Sign Bit не производит неявную модификацию входного значения. Для 32-битных и 16-битных входных значений dest_reg и sample_register могут быть одним и тем же D-регистром, в таком случае будет произведена явная модификация sample_register. Специальное применение: Вы можете использовать экспоненту как магнитуду сдвига для нормализации массива. Вы можете выполнить нормализацию прямым использованием инструкции ASHIFT, без использования специальных инструкций нормализации, как это требуется в других архитектурах. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные инструкции могут быть выполнены параллельно с некоторыми 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] r2.l = signbits r7; r1.l = signbits r5.l; r0.l = signbits r4.h; r6.l = signbits a0; r5.l = signbits a1; См. также Exponent Detection. Вычитание. Общая форма: dest_reg = src_reg_1 - src_reg_2 Синтаксис для 32-битных операндов и 32-битного результата: Dreg = Dreg - Dreg; // нет поддержки насыщения, но инструкция короче(a)1 Dreg = Dreg - Dreg (sat_flag); // опционально поддерживается насыщение ценой Синтаксис для 16-битных операндов и 16-битного результата: Dreg_lo_hi = Dreg_lo_hi – Dreg_lo_hi (sat_flag); // (b) Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. Комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: регистры данных R0, ..., R7. Dreg_lo_hi: половинки регистров R0.L, ..., R7.L, R0.H, ..., R7.H. sat_flag: обязательный флаг управления насыщением, (S) или (NS). [Функциональное описание] Инструкция Subtract вычитает src_reg_2 из src_reg_1, и помещает результат в регистр назначения. Есть 2 способа задать вычитание 32-битных данных. Один использует инструкцию длиной 16-бит, но не поддерживает насыщение. Другая инструкция 32-битной длины может опционально поддерживать насыщение. Инструкция DSP размером больше может иногда экономить время выполнения, потому что она может выполняться параллельно с некоторыми другими инструкциями (см. "Параллельное выполнение"). Инструкции для 16-битных данных используют операнды в половинках регистра данных, и сохраняет результат в половинку регистра данных. Все инструкции для 16-битных данных имеют длину 32-бита. В синтаксисе, где появляется опция sat_flag, она заменяется одним из следующих значений: • (S) – выполняется насыщение результата. Подробнее про поведение насыщения см. секцию "Saturation (насыщение)". Инструкция Subtract не имеет эквивалента вычитания синтаксиса сложения для P-регистров. [Флаги] Инструкция влияет на флаги следующим образом: • AZ установится, если результат операции 0, иначе очистится. Все остальные флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные инструкции могут быть выполнены параллельно с некоторыми 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". 16-битные версии инструкции не могут быть выполнены вместе с другими инструкциями. [Примеры] r5 = r2 - r1; // вычитание с 16-битной длиной инструкции, без насыщения r5 = r2 - r1(ns); // тот же результат, что и выше, но с 32-битной длиной инструкции r5 = r2 - r1(s); // насыщение результата r4.l = r0.l - r7.l (ns); r4.l = r0.l - r7.h (s); // насыщение результата r0.l = r2.h - r4.l(ns); r1.l = r3.h - r7.h(ns); r4.h = r0.l - r7.l (ns); r4.h = r0.l - r7.h (ns); r0.h = r2.h - r4.l(s); // насыщение результата r1.h = r3.h - r7.h(ns); См. также инструкции Modify – Decrement, Vector Add/Subtract (в разделе "Векторные операции"). Вычитание непосредственной константы. Общая форма: register -= constant Синтаксис: Ireg -= 2; // декремент Ireg на 2, что соответствует перемещению Ireg -= 4; // декремент адреса указателя на слово (a) Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. [Терминология синтаксиса] Ireg: индексные регистры I0, ..., I3. [Функциональное описание] Инструкция Subtract Immediate вычитает значение константы из индексного регистра, без применения насыщения. Примечание: для вычитания непосредственной константы из D-регистров или P-регистров используйте отрицательную константу в инструкции Add Immediate. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] Эти 16-битные инструкции могут быть выполнены параллельно с некоторыми другими инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] i0 -= 4;
i2 -= 2;
См. также инструкции Add Immediate, Subtract. [Обработка внешних событий (External Event Management)] В этом разделе рассматриваются инструкции для управления внешними событиями. Пользователи могут использовать эти инструкции для разрешения прерываний [3], принудительно сгенерировать нужное прерывание или сброс [4], или перевести процессор в состояние ожидания (idle state). Инструкция синхронизации ядра (Core Synchronize, CSYNC) дожидается окончания всех операций, стоящих в очереди, и синхронизирует (сбрасывает, flushes) буфер хранения ядра перед началом выполнения следующей инструкции. Инструкция синхронизации системы (System Synchronize, SSYNC) принуждает к завершению все спекулятивные, переходные состояния в ядре и системе перед продолжением выполнения программы. Другие инструкции в этом разделе позволяют принудительно сгенерировать исключение отладки (emulation exception), перевести процессор в режим эмуляции/отладки (Emulation mode), проверить значение определенного, косвенно адресуемого (indirectly address) байта, или инкрементировать счетчик программ (Program Counter) без выполнения полезной работы. Синтаксис: IDLE; // (a)1 Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. [Функциональное описание] Инструкция Idle является частью последовательности, помещающей Blackfin в остановленное состояние, так чтобы внешняя система могла переключиться между тактовыми частотами ядра. Инструкция Idle запрашивает вход в состояние ожидания путем установки бита idle_req в регистре SEQSTAT. Установка бита idle_req предшествует помещению процессора Blackfin в остановленное состояние. Инструкция Idle является единственным способом установить бит idle_req в регистре SEQSTAT. Архитектура не поддерживает явные записи в SEQSTAT. Если Вы хотите поместить процессор в Idle mode, инструкция IDLE должна немедленно предшествовать инструкции SSYNC. Первая инструкция, которая идет после SSYNC, будет первой выполненной инструкцией, когда процессор выйдет из Idle mode. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Инструкция Idle работает только в режиме супервизора (Supervisor mode). Если сделать попытку её вызова в режиме пользователя (User mode), то инструкция приведет к генерации исключения неправильного использования защищенного ресурса (Illegal Use of Protected Resource exception). [Параллельное выполнение] Инструкция не может использоваться параллельно с другими инструкциями. [Пример] idle; См. также инструкцию System Synchronize. Синтаксис: CSYNC; // (a)1 Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. [Функциональное описание] Инструкция Core Synchronize (CSYNC) приводит к принудительной остановке хода выполнения программы, пока не завершатся все ожидающие операции ядра (pending core operations) и не будут засинхронизированы все буферы хранения ядра (flushing core store buffer). Т. е. следующая после CSYNC инструкция не выполнится, пока не завершатся все эти действия. Pending core operations включают любые спекулятивные состояния (например branch prediction, т. е. предсказание ветвления) или исключения (exceptions). Буфер хранения ядра (core store buffer) расположен между процессором и памятью кэш L1. CCYNC обычно используется после записи ядром MMR, чтобы избежать неточного поведения программы. Специальное применение инструкции: используйте CSYNC для принудительного четкого выполнения последовательности команд при загрузке и сохранении (работа с медленной памятью), или для того, чтобы завершить все переходные состояния ядра перед переконфигурированием режимов ядра. Например, выполните CSYNC перед конфигурированием регистров, отображенных на память (memory-mapped registers, MMRs). CSYNC должна также выдаваться после сохранения в MMR-регистры, чтобы гарантировать, что данные достигли целевого места назначения в MMR перед выборкой для выполнения следующей инструкции. Обычно процессор Blackfin выполняет все инструкции загрузки точно в том порядке, как это задано в программе. Однако из соображений производительности архитектура не гарантирует упорядоченность между операциями загрузки (load) и сохранения (store). Это обычно позволяет операциям загрузки получить доступ к памяти вне порядка следования инструкций в программе по отношению к операциям сохранения. Таким образом, это обычно позволяет спекулятивные загрузки при доступе к памяти. Спекулятивные - это означает, что действие загрузки задано теоретически, т. е. ядро может позже отменить или перезапустить спекулятивные загрузки. С помощью использования инструкций Core Synchronize или System Synchronize и правильной обработки прерываний Вы можете избежать неупорядоченного выполнения программы или спекулятивного поведения кода. Обратите внимание, что инструкции сохранения (store) никогда не делают спекулятивный доступ к памяти. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] Инструкция не может использоваться параллельно с другими инструкциями. [Пример] if cc jump away_from_here; // производит спекулятивное предсказание ветвлений csync; r0 = [p0]; // загрузка (load) В этом примере инструкция CSYNC гарантирует, что инструкция загрузки (load) не будет выполнена спекулятивно. CSYNC гарантирует, что операция условного ветвления будет обработана и любые имеющиеся данные в промежуточном буфере хранения ядра будут сброшены в их места назначения (flushed). Дополнительно будут завершены все спекулятивные состояния или исключения перед тем, как завершится выполнение CSYNC. См. также инструкцию System Synchronize. Синтаксис: SSYNC; // (a)1 Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. [Функциональное описание] Инструкция System Synchronize (CSYNC) приводит к принудительной остановке хода выполнения программы, пока не завершатся все спекулятивные, переходные состояния ядра и системы. Т. е. пока SSYNC инструкция не выполнится, никакая их следующих за этой командой инструкций не попадет в конвейер процессора. Инструкция SSYNC выполняет ту же функцию, что и инструкция Core Synchronize (CSYNC). Дополнительно SSYNC сбрасывает (flushes, другими словами, синхронизирует кэш) любые буферы записи (между памятью L1 и системным интерфейсом), и генерирует сигнал запроса синхронизации (Synch request signal) для внешней системы. Эта операция требует поступления сигнала подтверждения Synch_Ack от системы до завершения этой инструкции SSYNC. Если бит idle_req в регистре SEQSTAT установлен при выполнении SSYNC, то процессор переходит в состояние ожидания (Idle state), и выставляет внешний сигнал Idle после приема сигнала Synch_Ack signal. После выставления внешнего сигнала Idle выход из состояния Idle требует поступления внешнего сигнала пробуждения для процессора (Wakeup signal). SSYNC должна быть выполнена сразу перед и после записи в системный регистр MMR. Иначе эффект от записи в MMR может наступить в неопределенный момент времени по отношению к потоку вычислений (т. е. к времени выполнения остальных инструкций), в результате может получиться неточное поведение программы. Специальное применение инструкции: обычно SSYNC подготавливает архитектуру к прекращению тактирования или к изменению тактовой частоты. В таких случаях типичной будет следующая последовательность инструкций: инструкция... инструкция... CLI r0; // запрет прерываний idle; // разрешение состояния ожидания (Idle state) ssync; /* Завершить все спекулятивные состояния, выставить внешний сигнал Sync, после чего ждать сигнал Synch_Ack,
затем выставить внешний сигнал Idle, и оставаться
в состоянии Idle, пока не поступит сигнал Wakeup.
Во время этого состояния ожидания тактовая частота
может быть изменена. */ sti r0; /* Пришел сигнал Wakeup, восстановить прерывания. */ инструкция... инструкция... [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] Инструкция не может использоваться параллельно с другими инструкциями. [Пример] Рассмотрим следующую последовательность кода. if cc jump away_from_here; // производит спекулятивное предсказание ветвлений ssync; r0 = [p0]; // загрузка (load) В этом примере инструкция SSYNC гарантирует, что инструкция загрузки (load) не будет выполнена спекулятивно. SSYNC гарантирует, что операция условного ветвления будет обработана и любые имеющиеся данные в промежуточном буфере хранения ядра и буфере записи будут сброшены в их места назначения (flushed). Дополнительно будут завершены все состояния исключения перед тем, как завершится выполнение SSYNC. См. также инструкции Core Synchronize, Idle. Инструкция переводит процессор в режим отладки. Синтаксис: EMUEXCPT; // (a)1 Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. [Функциональное описание] Инструкция Force Emulation принудительно генерирует исключение отладки (emulation exception), что позволяет перевести процессор в состояние эмуляции (отладки). Подробнее про события и исключения см. [4]. Когда эмуляция разрешена, процессор немедленно получает исключение, и это переводит его в режим отладки (emulation mode). Когда эмуляция запрещена, EMUEXCPT генерирует исключения недопустимой инструкции (illegal instruction exception). Исключение эмуляции имеет самый высокий приоритет между всеми событиями процессора. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] Инструкция не может использоваться параллельно с другими инструкциями. [Пример] emuexcpt; См. также инструкцию Force Interrupt / Reset. Инструкция запрещает прерывания. Синтаксис: CLI Dreg; // предыдущее состояние в IMASK помещается в Dreg (a)1 Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. [Терминология синтаксиса] Dreg: регистры данных R0, ..., R7. [Функциональное описание] Инструкция Disable Interrupts глобально запрещает прерывания записью нулей во все биты IMASK. Дополнительно перед этой записью инструкция переносит все биты IMASK в регистр, указанный пользователем, чтобы сохранить текущее состояние системы прерываний. Инструкция Disable Interrupts не маскирует (не отменяет) прерывания NMI, сброса (reset), исключения (exceptions) и отладки (emulation). Специальное применение: инструкция CLI часто вставляется перед инструкцией IDLE. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Инструкция может быть выполнена только в режиме супервизора (Supervisor mode). Если попытаться выполнить инструкцию в режиме пользователя (User mode), то будет сгенерировано исключение неправильного использования защищенного ресурса (Illegal Use of Protected Resource). [Параллельное выполнение] Инструкция не может использоваться параллельно с другими инструкциями. [Пример] cli r3; См. также инструкцию Enable Interrupts. Инструкция разрешает прерывания. Синтаксис: STI Dreg; // предыдущее состояние из регистра Dreg будет восстановлено в IMASK (a)1 Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. [Терминология синтаксиса] Dreg: регистры данных R0, ..., R7. [Функциональное описание] Инструкция Enable Interrupts глобально разрешает прерывания путем восстановления предыдущего состояния системы прерываний (содержимого регистра IMASK). Специальное применение: инструкция STI часто вставляется после инструкции IDLE, чем будут восстановлены прерывания после пробуждения процессора. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Инструкция может быть выполнена только в режиме супервизора (Supervisor mode). Если попытаться выполнить инструкцию в режиме пользователя (User mode), то будет сгенерировано исключение неправильного использования защищенного ресурса (Illegal Use of Protected Resource). [Параллельное выполнение] Инструкция не может использоваться параллельно с другими инструкциями. [Пример] sti r3; См. также инструкцию Disable Interrupts. Инструкция вызывает срабатывание прерывания. Синтаксис: RAISE uimm4; // (a)1 Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. [Терминология синтаксиса] uimm4: 4-битное поле без знака, диапазон значений 0 .. 15. [Функциональное описание] Инструкция Force Interrupt / Reset вызывает принудительную генерацию указанного прерывания или сброса (см. [4]). Обычно это является методом программного вызова аппаратного события, что может применяться в целях отладки. Когда начинает выполняться инструкция RAISE, процессор устанавливает бит регистра ILAT, соответствующий вектору прерывания, указанному константой uimm4 в теле инструкции. Прерывание будет выполнено, когда его приоритет окажется достаточным для распознавания процессором. Эта инструкция приводит к генерации следующих событий (прерываний) в зависимости от значения поля uimm4 (цифры 0 .. 15 показывают значение поля). 0. Зарезервировано. Инструкция Force Interrupt / Reset не может вызывать события исключения Exception (EXC) или эмуляции Emulation (EMU); для генерации этих событий используйте инструкции EXCPT и EMUEXCPT соответственно. Инструкция RAISE не сработает, пока не завершится стадия обратной записи в конвейере. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Инструкция может быть выполнена только в режиме супервизора (Supervisor mode). Если попытаться выполнить инструкцию в режиме пользователя (User mode), то будет сгенерировано исключение неправильного использования защищенного ресурса (Illegal Use of Protected Resource). [Параллельное выполнение] Инструкция не может использоваться параллельно с другими инструкциями. [Пример] raise 1; // Сгенерировать сброс (RST) raise 6; // Сгенерировать прерывание таймера (IVTMR) См. также инструкции Force Exception (EXCPT), Force Emulation (EMUEXCPT). Инструкция вызывает срабатывание исключения. Синтаксис: EXCPT uimm4; // (a)1 Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. [Терминология синтаксиса] uimm4: 4-битное поле без знака, диапазон значений 0 .. 15. [Функциональное описание] Инструкция Force Exception вызывает принудительную генерацию указанного исключения (exception) с кодом в поле uimm4 (что такое исключение, см. [4]). Когда запускается инструкция EXCPT, секвенсер передает управление на вектор обработчика исключения, который предоставляет пользователь. Код пользователя на уровне приложения использует инструкцию Force Exception для вызова функций операционной системы. Эта инструкция не устанавливает бит EVSW (бит 3) регистра ILAT. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] Инструкция не может использоваться параллельно с другими инструкциями. [Пример] excpt 4;
Синтаксис: TESTSET (Preg); // (a)1 Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. [Терминология синтаксиса] Preg: P0, ..., P5 (SP и FP не разрешается использовать в качестве регистра для этой инструкции). [Функциональное описание] Инструкция Test and Set Byte (Atomic) загружает косвенно (indirectly) адресуемый байт, проверяет его значение на 0, после чего устанавливает в нем самый старший значащий бит (most significant bit, MSB), не меняя значение всех остальных битов. Если байт изначально был равен 0, то инструкция установит бит CC. Если же байт изначально не был равен 0, то инструкция очистит бит CC. Вся эта транзакция при обращении к памяти является атомарной. TESTSET может получить доступ ко всему логическом пространству адресов памяти, за исключением области регистров ядра MMR (Memory-Mapped Register, отображенные на адресное пространство памяти регистры). Система разработана так, что должна гарантировать атомарность доступа для всех областей памяти, для которых разрешен доступ инструкцией TESTSET. Аппаратура процессора не выполняет атомарный доступ к области памяти L1, сконфигурированной как SRAM. Таким образом, семафоры не должны находиться в памяти ядра. Архитектура памяти всегда обрабатывает атомарные операции как доступ с запрещенным кэшированием, даже если дескриптор CPLB показывает для этого адреса разрешенный доступ через кэш. Если детектировано попадание в кэш, то операция синхронизирует кэш (flushes) и делает недостоверной строку кэша перед тем, как будет разрешено выполниться инструкции TESTSET. Разработчик программного обеспечения отвечает за выполнение атомарных операций в правильном (в контексте кэширования / не кэширования) пространстве памяти. Обычно эти операции должны быть выполнены для не кэшируемой, находящейся вне ядра памяти (например, внешняя память SDRAM). В реализации чипа, которая требует жесткой привязки по времени между процессорами или процессами, разрабатываемая система должна предоставить выделенный, не кэшируемый блок памяти, который удовлетворяет требования системы по латентности (времени задержки для доступа к данным). TESTSET может быть прервана перед стадией выполнения загрузки в инструкции. Если инструкция TESTSET была прервана, то она заново выполнится при возврате из прерывания. После стадий тестирования или загрузки инструкция TESTSET завершит свое выполнение, и вся последовательность стадий TESTSET не может быть ничем прервана (будет атомарной). Например, любые исключения, связанные с просмотром CPLB как для операции загрузки (load), так и для операций сохранения (store) должны быть завершены перед завершением стадии загрузки инструкции TESTSET. Целостность операции атомарности TESTSET зависит от механизма доступа к ресурсу памяти L2. Если память L2 не поддерживает атомарный захват для области адресов, к которым Вы обращаетесь, то для Вашего программного обеспечения нет гарантии корректного поведения для семафора. См. документацию процессора по памяти L2 для получении информации по поддержке блокировки. Специальное использование: обычно используйте TESTSET в качестве метода выборки семафора для обмена данными между сопроцессорами или смежными процессами. [Флаги] Эта инструкция влияет только а один флаг следующим образом: • CC установится, если адресуемое значение равно 0, иначе очистится. Все другие флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] Инструкция не может использоваться параллельно с другими инструкциями. [Пример] testset (p1);
Перед инструкцией TESTSET может находиться инструкция CSYNC или SSYNC, чтобы гарантировать, что все предыдущие исключения или прерывания были обработаны до начала атомарной операции. См. также инструкции Core Synchronize, System Synchronize. Пустая операция. Синтаксис: NOP; // (a)1 MNOP; // (b) Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. Комментарий (b) показывает длину инструкции 32 бита. [Функциональное описание] Инструкция No Op инкрементирует PC, и не делает никаких других действий. Обычно инструкция No Op дает время для завершения выполнения предыдущих инструкций перед тем, как будет продолжено выполнение следующих инструкций. Другое использование - генерация определенных задержек в циклах или для работы в качестве аппаратного таймера и генератора скорости, когда нет больше доступных таймеров или генераторов скорости. Специальное применение: MNOP может быть использована для параллельной выдачи инструкций загрузки (load) или сохранения (store) без вовлечения в операции 32-bit MAC или ALU. Подробнее см. раздел "Параллельная обработка инструкций". [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 16-битные версии инструкции могут быть выполнены параллельно с некоторыми другими инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Пример] nop;
mnop;
[Управление кэшированием] В этом разделе обсуждаются инструкции, предназначенные для управления кэшем (cache control). Используя эти инструкции, пользователи могут делать предварительное заполнение кэша данных (prefetch) или его синхронизацию с местом хранения (flush), делать недостоверными строки кэша данных (invalidate data cache lines), или синхронизировать кэш инструкций (flush instruction cache). Инструкция делает предварительное заполнение кэша данными. Синтаксис: PREFETCH [Preg]; // индексированная адресация (a)1 PREFETCH [Preg++]; // индексированная адресация с постдекрементом (a) Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. [Терминология синтаксиса] Preg: P0, ..., P5, SP, FP. [Функциональное описание] Инструкция Data Cache Prefetch делает предварительную выборку строки кэша данных по эффективному адресу, указанному в P-регистре. Операция приводит к тому, что указанные данные будут помещены в кэш, если они там еще не находятся, и если адрес кэшируемый (т. е. если установлен бит CPLB_L1_CHBL). Если строка уже находится в кэше, или если кэш уже захватила строку, то инструкция не делает никаких действий, и ведет себя так же, как инструкция NOP. Опция: инструкция может делать постдекремент указателя на строку кэша на значение размера строки кэша. Эта инструкция не приводит к ошибкам/исключениям доступа по адресу (address exception violations). Если происходит нарушение защиты, связанной с адресом, то инструкция ведет себя как NOP, и не генерирует исключения нарушения защиты (protection violation exception). [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] Инструкция не может использоваться параллельно с другими инструкциями. [Примеры] prefetch [p2];
prefetch [p0++];
Инструкция делает синхронизацию кэша данных. Синтаксис: FLUSH [Preg]; // индексированная адресация (a)1 FLUSH [Preg++]; // индексированная адресация с постдекрементом (a) Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. [Терминология синтаксиса] Preg: P0, ..., P5, SP, FP. [Функциональное описание] Инструкция Data Cache Flush делает синхронизацию содержимого кэша с памятью более высокого уровня, которая обслуживается кэшем. Эта инструкция выбирает строку кэша, связанную с указанным эффективным адресом, указанном в P-регистре. Если данные в кэше "грязные" (т. е. они были модифицированы), то инструкция записывает данные кэша (эта операция называется flush, или синхронизация) в обслуживаемую память высокого уровня, и помечает эту строку кэша как "чистую". Если указанная (по адресу в P-регистре) строка кэша и так "чистая", или если кэш не содержит указанного адреса, то эта инструкция ничего не делает, и ведет себя так же, как инструкция NOP. Опция: инструкция может делать постдекремент указателя на строку кэша на значение размера строки кэша. Эта инструкция не приводит к ошибкам/исключениям доступа по адресу (address exception violations). Если происходит нарушение защиты, связанной с адресом, то инструкция ведет себя как NOP, и не генерирует исключения нарушения защиты (protection violation exception). [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] Инструкция не может использоваться параллельно с другими инструкциями. [Примеры] flush [p2];
flush [p0++];
Инструкция переводит строку кэша в недостоверное (или "грязное") состояние. Синтаксис: FLUSHINV [Preg]; // индексированная адресация (a)1 FLUSHINV [Preg++]; // индексированная адресация с постдекрементом (a) Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. [Терминология синтаксиса] Preg: P0, ..., P5, SP, FP. [Функциональное описание] Инструкция Data Cache Invalidate делает недостоверным содержимое определенной строки кэша. Содержимое P-регистра задает строку кэша (по адресу). Если строка данных по указанному адресу находится в кэше и является "грязной", то строка кэша записывается в обслуживаемую память высокого уровня. Если указанная (по адресу в P-регистре) строка не содержится в кэше, то эта инструкция ничего не делает, и ведет себя так же, как инструкция NOP. Опция: инструкция может делать постдекремент указателя на строку кэша на значение размера строки кэша. Эта инструкция не приводит к ошибкам/исключениям доступа по адресу (address exception violations). Если происходит нарушение защиты, связанной с адресом, то инструкция ведет себя как NOP, и не генерирует исключения нарушения защиты (protection violation exception). [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] Инструкция не может использоваться параллельно с другими инструкциями. [Примеры] flushinv [p2];
flushinv [p0++];
Инструкция делает синхронизацию кэша инструкций. Синтаксис: IFLUSH [Preg]; // индексированная адресация (a)1 IFLUSH [Preg++]; // индексированная адресация с постдекрементом (a) Примечание 1: в синтаксисе комментарий (a) показывает длину инструкции 16 бит. [Терминология синтаксиса] Preg: P0, ..., P5, SP, FP. [Функциональное описание] Инструкция Instruction Cache Flush делает недостоверной указанную строку кэша инструкций. Содержимое P-регистра задает строку, которую нужно сделать недостоверной. Кэш инструкций не содержит бит "чистоты" кэша. Соответственно, содержимое кэша инструкций никогда не сбрасывается в память более высокого уровня. Опция: инструкция может делать постдекремент указателя на строку кэша на значение размера строки кэша. Эта инструкция не приводит к ошибкам/исключениям доступа по адресу (address exception violations). Если происходит нарушение защиты, связанной с адресом, то инструкция ведет себя как NOP, и не генерирует исключения нарушения защиты (protection violation exception). [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] Инструкция не может использоваться параллельно с другими инструкциями. [Примеры] iflush [p2];
iflush [p0++];
[Операции обработки видео (Video Pixel Operations)] В этом разделе рассматриваются инструкции, позволяющие манипулировать точками изображения видео. Пользователи могут использовать эти инструкции для выравнивания данных, запрета исключений из-за неправильного по выравниванию доступа к 32-битной памяти, и могут выполнять двойные и счетверенные операции сложения, вычитания и усреднения для 8- и 16-разрядных данных. Общая форма: dest_reg = ALIGN8 ( src_reg_1, src_reg_0 ) dest_reg = ALIGN16 (src_reg_1, src_reg_0 ) dest_reg = ALIGN24 (src_reg_1, src_reg_0 ) Синтаксис: Dreg = ALIGN8 (Dreg, Dreg); // overlay 1 byte (b)1 Dreg = ALIGN16 (Dreg, Dreg); // overlay 2 bytes (b) Dreg = ALIGN24 (Dreg, Dreg); // overlay 3 bytes (b) Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: регистры данных R0, ..., R7. [Функциональное описание] Инструкция Byte Align делает копирование четырехбайтной последовательности не выровненного слова из комбинации двух регистров данных. Версия инструкции определяет, какие байты надо копировать, другими словами, определяет выравнивание байт копируемого слова. Опции выравнивания могут быть такими:
Версия ALIGN16 выполняет ту же операцию, что инструкция Vector Pack, использующая синтаксис dest_reg = PACK (Dreg_lo, Dreg_hi). Используйте инструкцию Byte Align для выравнивания байт данных для последующей одиночной инструкции, обрабатывающей несколько порций данных (multiple-data instructions, или SIMD, т. е. single instruction multiple data, одиночный поток инструкций - множественный поток данных). Входные значения не будут неявно модифицированы этой инструкцией. Однако регистр назначения может быть тем же самым D-регистром, как и один из регистров-источников. В таком случае инструкция делает явную модификацию содержимого исходного регистра. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] // Если r3 = 0xABCD 1234, и r4 = 0xBEEF DEAD, то ... r0 = align8 (r3, r4); // ... даст результат r0 = 0x34BE EFDE r0 = align16 (r3, r4); // ... даст результат r0 = 0x1234 BEEF r0 = align24 (r3, r4); // ... даст результат r0 = 0xCD12 34BE См. также инструкцию Vector Pack. Синтаксис: DISALGNEXCPT; // (b)1 Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Функциональное описание] Инструкция Disable Alignment Exception для загрузки предотвращает появление исключений, которые иначе возникли бы при операциях невыровненного доступа к 32-битным ячейкам памяти, запущенных параллельно. Эта инструкция влияет только на инструкции 32-битного доступа, производящие невыровненное обращение с использованием косвенной (indirect) адресации через I-регистр. Чтобы выполнить принудительное выравнивание по 32-битной границе, должны быть очищены 2 младших бита (LSB) адреса, перед тем как адрес будет передан аппаратуре системы. I-регистр не модифицируется инструкцией DISALIGNEXCPT. Кроме того, на любые модификации I-регистра, выполненные параллельно, инструкция DISALIGNEXCPT никак не влияет. Специальное применение: используйте инструкцию DISALGNEXCPT, когда заполняете регистры данных для инструкции Quad 8-Bit SIMD. Инструкции Quad 8-Bit SIMD требуют целых 16 восьмибитных операндов, четыре D-регистра, которые должны быть загружены в качестве операндов. Операнды 8-битные, и не обязательно они должны быть выровнены в памяти. Таким образом, используйте DISALGNEXCPT для предотвращения случайного появления исключения для таких потенциально невыровненых доступов к памяти. Во время выполнения, когда инструкции Quad 8-Bit SIMD выполняют побайтный невыровненый доступ к памяти, для них будет автоматически отменено исключение невыровненного доступа к памяти. При этом не требуется вмешательство со стороны пользователя. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] disalgnexcpt || r1 = [i0++] || r3 = [i1++]; // три инструкции параллельно disalgnexcpt || [p0 ++ p1] = r5 || r3 = [i1++]; // только для загрузки будет // отменено исключение выравнивания disalgnexcpt || r0 = [p2++] || r3 = [i1++]; // только для загрузки через I-регистр // отменено исключение выравнивания См. также инструкции Quad 8-Bit Byte Align. Общая форма: dest_reg = BYTEOP3P ( src_reg_0, src_reg_1 ) (LO) dest_reg = BYTEOP3P ( src_reg_0, src_reg_1 ) (HI) dest_reg = BYTEOP3P ( src_reg_0, src_reg_1 ) (LO, R) dest_reg = BYTEOP3P ( src_reg_0, src_reg_1 ) (HI, R) Синтаксис: // операнды с прямым порядком следования байт // операнды с обратным порядком следования байт Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: регистры данных R0, ..., R7. Dreg_pair: только пары регистров R1:0, R3:2. [Функциональное описание] Инструкция Dual 16-Bit Add / Clip добавляет два 8-битных беззнаковых значения к двум 16-битным значениям со знаком, после чего ограничивает (или обрезает, clip) результат до 8-битного диапазона без знака 0 .. 255, включительно. Это инструкция загружает результаты как байты на границах половин слов в один 32-битный регистр назначения. Один вариант синтаксиса загружает старший байт в половине слова, и другой вариант загружает младший байт, как это показано ниже. Предположим, что исходные регистры содержат следующее:
... тогда версии, которые загружают результат в младший байт (LO), приведут к следующему результату:
... и версии, которые загружают результат в старший байт (HI), приведут к следующему результату:
В любом случае не использованные байты в регистре назначения будут заполнены 0x00. 8-битное и 16-битное сложение выполняется как операция со знаком. 16-битный операнд перед сложением расширяется знаком до 32 бит. В качестве входных регистров допустимы только пары R1:0 и R3:2. Инструкция предоставляет выравнивание байт прямо в парах исходных регистров R1:0 и R3:2, базируясь на регистрах I0 и I1. • Два LSB регистра I0 определяют байтовое выравнивание для исходной пары регистров R1:0. Взаимосвязь между битами I-регистров и выравниванием байт показана ниже. В случае порядка по умолчанию для источника (например, в синтаксисе без ( – , R)), предполагается, что пара регистров источника содержит следующее:
Эта инструкция предотвращает исключения, которые иначе возникли бы при невыровненных 32-битных загрузках памяти, запущенных параллельно. Специальное применение инструкции: она предназначена для алгоритмов компенсации движения в видео (video motion compensation). Инструкция поддерживает добавление остатка к значению пикселя видео, за которым следует беззнаковое насыщение байта. [Опции] Синтаксис ( – , R) меняет на обратный порядок исходных регистров в каждой паре регистров. Обычные высокопроизводительные приложения не могут предоставить расходы процессорного времени для перезагрузки обоих регистровых пар операндов, чтобы обеспечить порядок следования байт для каждой операции вычисления. Вместо этого они чередуют и загружают только одну пару регистров каждый раз, и делают чередование между версиями инструкции с прямым и обратным порядком байт. По умолчанию байты младшего порядка поступают из младшего регистра в паре регистров. Опция ( – , R) приводит к тому, что байты младшего порядка поступают из старшего регистра. В случае с опцией реверсирования порядка (например, когда используется синтаксис ( – , R)), единственная разница состоит в том, как меняется в исходных регистрах места внутри регистровой пары в их порядке байт. Предположим, что пара исходных регистров содержит следующее:
[Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] r3 = byteop3p (r1:0, r3:2) (lo); r3 = byteop3p (r1:0, r3:2) (hi); r3 = byteop3p (r1:0, r3:2) (lo, r); r3 = byteop3p (r1:0, r3:2) (hi, r); См. также инструкцию Quad 8-Bit Add. Синтаксис: Dreg = A1.L + A1.H, Dreg = A0.L + A0.H; // (b)1 Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: регистры данных R0, ..., R7. [Функциональное описание] Инструкция Dual 16-Bit Accumulator Extraction with Addition складывает друг с другом старшие половинки слова (биты 31 .. 16) и младшие половинки слова (биты 15 .. 0) в каждом аккумуляторе и загружает каждый из результатов в 32-битный регистр назначения. Каждая 16-битная половника слова в каждом из аккумуляторов расширяется знаком перед тем, как они будут сложены друг с другом. Специальное применение: Dual 16-Bit Accumulator Extraction with Addition используются для алгоритмов оценки движения (motion estimation) совместно с инструкцией Quad 8-Bit Subtract-Absolute-Accumulate. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Пример] r4=a1.l+a1.h, r7=a0.l+a0.h; См. также инструкцию Quad 8-Bit Subtract-Absolute-Accumulate. Общая форма: ( dest_reg_1, dest_reg_0 ) = BYTEOP16P ( src_reg_0, src_reg_1 ) ( dest_reg_1, dest_reg_0 ) = BYTEOP16P ( src_reg_0, src_reg_1 ) (R) Синтаксис: // операнды с прямым порядком следования байт // операнды с обратным порядком следования байт Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: регистры данных R0, ..., R7. Dreg_pair: только пары регистров R1:0, R3:2. [Функциональное описание] Инструкция Quad 8-Bit Add складывает два набора чисел из 4 байт побайтно, с побайтным выравниванием. Байтовые результаты загружаются как 16-битные, расширенные знаком, половинки слов в два регистра назначения, как это показано ниже.
В качестве входных регистров допустимы только пары R1:0 и R3:2. Инструкция предоставляет выравнивание байт прямо в парах исходных регистров R1:0 и R3:2, базируясь на регистрах I0 и I1. • Два LSB регистра I0 определяют байтовое выравнивание для исходной пары регистров R1:0. Взаимосвязь между битами I-регистров и выравниванием байт показана ниже. В случае порядка по умолчанию для источника (например, в синтаксисе без (R)), предполагается, что пара регистров источника содержит следующее:
Эта инструкция предотвращает исключения, которые иначе возникли бы при невыровненных 32-битных загрузках памяти, запущенных параллельно. Специальное применение: эта инструкция предоставляет арифметику для упакованных данных, что типично для приложений обработки видео и изображений. [Опции] Синтаксис (R) меняет на обратный порядок исходных регистров в каждой паре регистров. Обычные высокопроизводительные приложения не могут предоставить расходы процессорного времени для перезагрузки обоих регистровых пар операндов, чтобы обеспечить порядок следования байт для каждой операции вычисления. Вместо этого они чередуют и загружают только одну пару регистров каждый раз, и делают чередование между версиями инструкции с прямым и обратным порядком байт. По умолчанию байты младшего порядка поступают из младшего регистра в паре регистров. Опция (R) приводит к тому, что байты младшего порядка поступают из старшего регистра. В случае с опцией реверсирования порядка (например, когда используется синтаксис (R)), единственная разница состоит в том, как меняется в исходных регистрах места внутри регистровой пары в их порядке байт. Предположим, что пара исходных регистров содержит следующее:
Мнемоника получила свое имя из того факта, что операнды являются байтами, результат 16-битный, и имеется арифметическая операция plus для сложения. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] (r1,r2)= byteop16p (r3:2,r1:0); (r1,r2)= byteop16p (r3:2,r1:0) (r); См. также инструкцию Quad 8-Bit Subtract. Общая форма: dest_reg = BYTEOP1P ( src_reg_0, src_reg_1 ) dest_reg = BYTEOP1P ( src_reg_0, src_reg_1 ) (T) dest_reg = BYTEOP1P ( src_reg_0, src_reg_1 ) (R) dest_reg = BYTEOP1P ( src_reg_0, src_reg_1 ) (T, R) Синтаксис: // операнды с прямым порядком байт: // операнды с обратным порядком байт: Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: регистры данных R0, ..., R7. Dreg_pair: только пары регистров R1:0, R3:2. [Функциональное описание] Инструкция Quad 8-Bit Average – Byte вычисляет арифметическое среднее от двух беззнаковых набора из 4 байт, складывая их байт за байтом, с побайтным выравниванием. Эта инструкция загружает побайтно выровненные результаты как соединенные байты в один 32-битный регистр назначения, что показано ниже.
Арифметическое среднее (или что под этим подразумевается) вычисляется сложением двух операндов, после чего происходит сдвиг вправо на 1 бит, что означает деление на 2. Имеется две опции для смещения результата - обрезка (truncation) или округление вверх (rounding up). По умолчанию архитектура округляет вверх, когда сумма нечетна. Однако синтаксис поддерживает опцию обрезки. Подробнее про поведение округления и обрезки см. раздел "Rounding, Truncating". Бит RND_MOD регистра ASTAT никак не влияет на поведение округления в этой инструкции. В качестве входных регистров допустимы только пары R1:0 и R3:2. Инструкция предоставляет выравнивание байт прямо в парах исходных регистров R1:0 и R3:2, базируясь на регистрах I0 и I1. • Два LSB регистра I0 определяют байтовое выравнивание для исходной пары регистров R1:0. Взаимосвязь между битами I-регистров и выравниванием байт показана ниже. В случае порядка по умолчанию для источника (например, в синтаксисе без (R)), предполагается, что пара регистров источника содержит следующее:
Эта инструкция предотвращает исключения, которые иначе возникли бы при невыровненных 32-битных загрузках памяти, запущенных параллельно. Специальное применение: эта инструкция поддерживает двоичную интерполяцию, используемую в алгоритмах поиска движения с плавающей запятой и алгоритмах компенсации движения. [Опции] В таблице ниже перечислены опции, поддерживаемые инструкцией. Таблица 13-1. Опции для инструкции Options for Quad 8-Bit Average – Byte.
В случае с опцией реверсирования порядка (например, когда используется синтаксис (R)), единственная разница состоит в том, как меняется в исходных регистрах места внутри регистровой пары в их порядке байт. Предположим, что пара исходных регистров содержит следующее:
Мнемоника получила свое имя из того факта, что операнды являются байтами, результатом является слово (word), и имеется арифметическая операция plus для сложения. Единственный регистр назначения показывает, что происходит усреднение. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] r3 = byteop1p (r1:0, r3:2); r3 = byteop1p (r1:0, r3:2) (r); r3 = byteop1p (r1:0, r3:2) (t); r3 = byteop1p (r1:0, r3:2) (t,r); См. также инструкцию Quad 8-Bit Add. Общая форма: dest_reg = BYTEOP2P ( src_reg_0, src_reg_1 ) (RNDL) dest_reg = BYTEOP2P ( src_reg_0, src_reg_1 ) (RNDH) dest_reg = BYTEOP2P ( src_reg_0, src_reg_1 ) (TL) dest_reg = BYTEOP2P ( src_reg_0, src_reg_1 ) (TH) dest_reg = BYTEOP2P ( src_reg_0, src_reg_1 ) (RNDL, R) dest_reg = BYTEOP2P ( src_reg_0, src_reg_1 ) (RNDH, R) dest_reg = BYTEOP2P ( src_reg_0, src_reg_1 ) (TL, R) dest_reg = BYTEOP2P ( src_reg_0, src_reg_1 ) (TH, R) Синтаксис: // операнды с прямым порядком байт: // операнды с обратным порядком байт: Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: регистры данных R0, ..., R7. Dreg_pair: только пары регистров R1:0, R3:2. [Функциональное описание] Инструкция Quad 8-Bit Average – Half-Word вычисляет арифметическое среднее от двух беззнаковых набора из 4 байт, складывая их байт за байтом, с побайтным выравниванием. Эта инструкция в результате дает среднее значение от 4 байт. Она загружает выровненные по границе слова результаты как байты в один 32-битный регистр назначения, что показано ниже. Предположим, что исходные регистры содержат ...
... тогда версии, которые загружают результат в младший байт (с опциями RNDL и TL) дадут результат ...
... тогда версии, которые загружают результат в старший байт (с опциями RNDH и TH) дадут результат ...
Арифметическое среднее (или что под этим подразумевается) вычисляется сложением двух операндов, после чего происходит сдвиг вправо на 2 бита, что означает деление на 4. Когда промежуточная сумма иногда не делится на 4, точность может быть потеряна. Имеется две опции для смещения результата - обрезка (truncation) или округление вверх (rounding up). Подробнее про поведение округления и обрезки см. раздел "Rounding, Truncating". Бит RND_MOD регистра ASTAT никак не влияет на поведение округления в этой инструкции. В качестве входных регистров допустимы только пары R1:0 и R3:2. Инструкция предоставляет выравнивание байт прямо в парах исходных регистров R1:0 и R3:2, базируясь на регистре I0. Байтовое выравнивание в обоих исходных регистрах должно быть одинаковым, поскольку лишь 1 регистр указывает выравнивание сразу для двух входных регистров. Взаимосвязь между битами I-регистров и выравниванием байт показана ниже. В случае порядка по умолчанию для источника (например, в синтаксисе без (R)), предполагается, что пара регистров источника содержит следующее:
Эта инструкция предотвращает исключения, которые иначе возникли бы при невыровненных 32-битных загрузках памяти, запущенных параллельно. Специальное применение: эта инструкция поддерживает двоичную интерполяцию, используемую в алгоритмах поиска движения с плавающей запятой и алгоритмах компенсации движения. [Опции] В таблице ниже перечислены опции, поддерживаемые инструкцией. Таблица 13-1. Опции для инструкции Options for Quad 8-Bit Average – Byte.
Когда используется несколько опций в круглых скобках (указанные через запятую), то их порядок следования друг за другом не имеет никакого значения. В случае с опцией реверсирования порядка байт (например, когда используется синтаксис (R)), единственная разница состоит в том, как меняется в исходных регистрах места внутри регистровой пары в их порядке байт. Предположим, что пара исходных регистров содержит следующее:
Мнемоника получила свое имя из того факта, что операнды являются байтами, результатом является половины слова (half word), и имеется арифметическая операция plus для сложения. Единственный регистр назначения показывает, что происходит усреднение. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] r3 = byteop2p (r1:0, r3:2) (rndl); r3 = byteop2p (r1:0, r3:2) (rndh); r3 = byteop2p (r1:0, r3:2) (tl); r3 = byteop2p (r1:0, r3:2) (th); r3 = byteop2p (r1:0, r3:2) (rndl, r); r3 = byteop2p (r1:0, r3:2) (rndh, r); r3 = byteop2p (r1:0, r3:2) (tl, r); r3 = byteop2p (r1:0, r3:2) (th, r); См. также инструкцию Quad 8-Bit Average - Byte. Общая форма: dest_reg = BYTEPACK ( src_reg_0, src_reg_1 ) Синтаксис: Dreg = BYTEPACK (Dreg, Dreg); // (b)1 Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: регистры данных R0, ..., R7. [Функциональное описание] Инструкция Quad 8-Bit Pack упаковывает в один регистр четыре 8-битных значения, выровненных на половину слова, содержащиеся в двух исходных регистрах.
Эта инструкция предотвращает исключения, которые иначе возникли бы при невыровненных 32-битных загрузках памяти, запущенных параллельно. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Пример] r2 = bytepack (r4,r5);
Предположим, что R4 = 0xFEED FACE Тогда эта инструкция вернет: R2 = 0xEFDD EDCE См. также инструкцию Quad 8-Bit Unpack. Общая форма: ( dest_reg_1, dest_reg_0 ) = BYTEOP16M ( src_reg_0, src_reg_1 ) ( dest_reg_1, dest_reg_0 ) = BYTEOP16M ( src_reg_0, src_reg_1 ) (R) Синтаксис: // операнды с прямым порядком байт: // операнды с обратным порядком байт: Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: регистры данных R0, ..., R7. Dreg_pair: только пары регистров R1:0, R3:2. [Функциональное описание] Инструкция Quad 8-Bit Subtract побайтно вычитает два беззнаковых четырехбайтных набора чисел, с побайтным выравниванием. Она загружает результаты в виде байт как расширенные знаком полуслова в два регистра назначения, что показано ниже.
В качестве входных регистров допустимы только пары R1:0 и R3:2. Инструкция предоставляет выравнивание байт прямо в парах исходных регистров R1:0 и R3:2, базируясь на регистрах I0 и I1. • Два LSB регистра I0 определяют байтовое выравнивание для исходной пары регистров R1:0. Взаимосвязь между битами I-регистров и выравниванием байт показана ниже. В случае порядка по умолчанию для источника (например, в синтаксисе без (R)), предполагается, что пара регистров источника содержит следующее:
Эта инструкция предотвращает исключения, которые иначе возникли бы при невыровненных 32-битных загрузках памяти, запущенных параллельно. Специальное применение: эта инструкция предоставляет упакованные данные для программ обработки видео и изображений. [Опции] Синтаксис (R) меняет порядок следования исходных регистров внутри каждой пары регистров. Обычные высокопроизводительные приложения не могут предоставить расходы процессорного времени для перезагрузки обоих регистровых пар операндов, чтобы обеспечить порядок следования байт для каждой операции вычисления. Вместо этого они чередуют и загружают только одну пару регистров каждый раз, и делают чередование между версиями инструкции с прямым и обратным порядком байт. По умолчанию байты младшего порядка поступают из младшего регистра в паре регистров. Опция (R) приводит к тому, что байты младшего порядка поступают из старшего регистра. В случае с опцией реверсирования порядка байт (например, когда используется синтаксис (R)), единственная разница состоит в том, как меняется в исходных регистрах места внутри регистровой пары в их порядке байт. Предположим, что пара исходных регистров содержит следующее:
Мнемоника получила свое имя из того факта, что операнды являются байтами, результат 16-битный, и имеется арифметическая операция minus для вычитания. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] (r1,r2)= byteop16m (r3:2,r1:0); (r1,r2)= byteop16m (r3:2,r1:0) (r); См. также инструкцию Quad 8-Bit Add. Общая форма: SAA ( src_reg_0, src_reg_1 ) SAA ( src_reg_0, src_reg_1 ) (R) Синтаксис: // операнды с прямым порядком байт: // операнды с обратным порядком байт: Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg_pair: только пары регистров R1:0, R3:2. [Функциональное описание] Инструкция Quad 8-Bit Subtract-Absolute-Accumulate вычитает четыре пары значений, берет абсолютное значение от каждой разницы, и накапливает каждый результат в 16-разрядную половину аккумулятора. Результаты помещаются в старшую и младшую половины аккумуляторов A0.H, A0.L, A1.H и A1.L. Для этой операции не делается насыщение. В качестве входных регистров допустимы только пары R1:0 и R3:2. Инструкция поддерживает следующую побайтную сумму вычислений абсолютной разницы (sum of absolute difference, SAD):
Типичные значения для N будут 8 и 16, что соответствует размеру видеоблока 8x8 и 16x16 точек соответственно. 16-битные регистры в аккумуляторе ограничивают область точек или размер блока до размера 32x32 точек. Поведение инструкции SAA показано ниже.
Инструкция предоставляет выравнивание байт прямо в парах исходных регистров R1:0 и R3:2, базируясь на регистрах I0 и I1. • Два LSB регистра I0 определяют байтовое выравнивание для исходной пары регистров src_reg_0. Взаимосвязь между битами I-регистров и выравниванием байт показана ниже. В случае порядка по умолчанию для источника (например, в синтаксисе без (R)), предполагается, что пара регистров источника содержит следующее:
Эта инструкция предотвращает исключения, которые иначе возникли бы при невыровненных 32-битных загрузках памяти, запущенных параллельно. Специальное применение: используйте инструкцию Quad 8-Bit Subtract-Absolute-Accumulate для алгоритмов оценки движения на видео на базе блока, применяя вычисления суммы абсолютных различий (SAD) для измерения искажения. [Опции] Синтаксис (R) меняет порядок следования исходных регистров внутри каждой пары регистров. Обычные высокопроизводительные приложения не могут предоставить расходы процессорного времени для перезагрузки обоих регистровых пар операндов, чтобы обеспечить порядок следования байт для каждой операции вычисления. Вместо этого они чередуют и загружают только одну пару регистров каждый раз, и делают чередование между версиями инструкции с прямым и обратным порядком байт. По умолчанию байты младшего порядка поступают из младшего регистра в паре регистров. Опция (R) приводит к тому, что байты младшего порядка поступают из старшего регистра. В случае с опцией реверсирования порядка байт (например, когда используется синтаксис (R)), единственная разница состоит в том, как меняется в исходных регистрах места внутри регистровой пары в их порядке байт. Предположим, что пара исходных регистров содержит следующее:
Инструкция SAA вычисляет одновременно 12 операций над точками - 3 операции subtract-absolute-accumulate параллельно на 4 парах байтовых операндов. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] saa (r1:0, r3:2) || r0 = [i0++] || r2 = [i1++]; // инструкции параллельного заполнения saa (r1:0, r3:2) (R) || r1 = [i0++] || r3 = [i1++]; // то же самое, но с обратным порядком saa (r1:0, r3:2); // последняя операция SAA в цикле, больше не требуется заполнение См. также Disable Alignment Exception for Load, Load Data Register. Общая форма: ( dest_reg_1, dest_reg_0 ) = BYTEUNPACK src_reg_pair ( dest_reg_1, dest_reg_0 ) = BYTEUNPACK src_reg_pair (R) Синтаксис: (Dreg, Dreg) = BYTEUNPACK Dreg_pair; // (b)1 (Dreg, Dreg) = BYTEUNPACK Dreg_pair (R); // обратный порядок в исходных регистрах (b) Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: регистры данных R0, ..., R7. Dreg_pair: только пары регистров R1:0, R3:2. [Функциональное описание] Инструкция Quad 8-Bit Unpack копирует 4 последовательных байта из пары исходных регистров, побайтным выравниванием. Инструкция загружает выбранные байты в 2 произвольно выбранных регистра данных с выравниванием на половину слова. В качестве входных регистров допустимы только пары R1:0 и R3:2. Два LSB бита регистра I0 определяют байтовое выравнивания в регистрах источника, как показано ниже. В случае порядка по умолчанию для источника (например, в синтаксисе без (R)), предполагается, что пара регистров источника содержит следующее:
Эта инструкция предотвращает исключения, которые иначе возникли бы при невыровненных 32-битных загрузках памяти, запущенных параллельно. [Опции] Синтаксис (R) меняет на обратный порядок исходных регистров в каждой паре регистров. Обычные высокопроизводительные приложения не могут предоставить расходы процессорного времени для перезагрузки обоих регистровых пар операндов, чтобы обеспечить порядок следования байт для каждой операции вычисления. Вместо этого они чередуют и загружают только одну пару регистров каждый раз, и делают чередование между версиями инструкции с прямым и обратным порядком байт. По умолчанию байты младшего порядка поступают из младшего регистра в паре регистров. Опция (R) приводит к тому, что байты младшего порядка поступают из старшего регистра. В случае с опцией реверсирования порядка (например, когда используется синтаксис (R)), единственная разница состоит в том, как меняется в исходных регистрах места внутри регистровой пары в их порядке байт. Предположим, что пара исходных регистров содержит следующее:
Мнемоника получила свое имя из того факта, что операнды являются байтами, результат 16-битный, и имеется арифметическая операция plus для сложения. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] (r6,r5) = byteunpack r1:0; // исходные данные с нормальным порядком данных Предположим, что R1 = 0xFEED FACE Если два бита LSB регистра I0 = 00b, то эта инструкция возвратит R6 = 0x00BE 00EF Если два бита LSB регистра I0 = 01b, то эта инструкция возвратит R6 = 0x00CE 00BE Если два бита LSB регистра I0 = 10b, то эта инструкция возвратит R6 = 0x00FA 00CE Если два бита LSB регистра I0 = 11b, то эта инструкция возвратит R6 = 0x00FA 00CE (r6,r5) = byteunpack r1:0 (R); // исходные данные с обратным порядком данных Предположим, что R1 = 0xFEED FACE Если два бита LSB регистра I0 = 00b, то эта инструкция возвратит R6 = 0x00FE 00ED Если два бита LSB регистра I0 = 01b, то эта инструкция возвратит R6 = 0x00DD 00FE Если два бита LSB регистра I0 = 10b, то эта инструкция возвратит R6 = 0x00BA 00DD Если два бита LSB регистра I0 = 11b, то эта инструкция возвратит R6 = 0x00EF 00BA См. также инструкцию Quad 8-bit Pack. [Векторные операции] В этом разделе обсуждаются векторные операции, с помощью которых можно одновременно производить умножение 16-битных значений, включая сложение, вычитание, умножение, сдвиг, отрицание, упаковку и поиск. Также в этот раздел включены операции Compare-Select и Add-On-Sign. Общая форма: dest_hi = dest_lo = SIGN ( src0_hi ) * src1_hi + SIGN ( src0_lo ) * src1_lo Синтаксис: Dreg_hi = Dreg_lo = SIGN (Dreg_hi) * Dreg_hi + SIGN (Dreg_lo) * Dreg_lo; // (b)1 Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. Есть ограничения по регистрам: регистры назначения dest_hi и dest_lo должны быть половинками одного и того же 32-битного регистра данных (D-регистр, Dreg). Подобное относится и к регистрам - источникам, src0_hi и src0_lo должны быть половинками одного регистра и src1_hi и src1_lo должны быть половинками одного регистра. [Терминология синтаксиса] Dreg_hi: R0.H, ..., R7.H. Dreg_lo: R0.L, ..., R7.L. [Функциональное описание] Инструкция Add on Sign выполняет двухшаговую функцию следующим образом: 1. Умножает арифметический знак числа, находящегося в 16-битной половинке слова в src0 на соответствующее число в половинке слова src1. Арифметический знак src0 это либо (+1), либо (–1), в зависимости от бита знака src0. Инструкция выполняет эту операцию на верхней и нижней половинках одного и того же D-регистра. Результаты этого шага подчиняются правилам умножения со знаком, которые в общем виде показаны ниже. В таблице Y это число в src0, и Z число в src1. Числа в src0 и src1 могут быть положительными или отрицательными.
Обратите внимание, что результат всегда получает амплитуду Z, и может только лишь поменять свой знак. 2. После этого складывается результат src1 с исправленным знаком в старшем полуслове и младшем полуслове, и сохраняется та же самая 16-битная сумма в старшем и младшем половинках регистра назначения, как показано на рисунке ниже. Предположим, что исходные регистры содержат...
... тогда регистр назначения будет содержать:
К сумме не будет применяться насыщение, если сложение даст результат, который не умещается в 16 бит. Специальное применение: используйте инструкцию Sum on Sign при вычислении метрики ветвления для алгоритма Viterbi Butterfly. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] r7.h=r7.l=sign(r2.h)*r3.h+sign(r2.l)*r3.l; Если ... R2.H = 2 тогда ... R7.H = 1257 (или 1234 + 23) Если ... R2.H = –2 тогда ... R7.H = 1211 (или 1234 – 23) Если ... R2.H = 2 тогда ... R7.H = –1211 (или (–1234) + 23) Если ... R2.H = –2 тогда ... R7.H = –1257 (или (–1234) – 23) Общая форма: dest_reg = VIT_MAX ( src_reg_0, src_reg_1 ) (ASL) dest_reg = VIT_MAX ( src_reg_0, src_reg_1 ) (ASR) dest_reg_lo = VIT_MAX ( src_reg ) (ASL) dest_reg_lo = VIT_MAX ( src_reg ) (ASR) Синтаксис двойной 16-битной операции: Dreg = VIT_MAX (Dreg, Dreg) (ASL); // сдвиг бит истории влево (b)1 Синтаксис одиночной 16-битной операции: Dreg_lo = VIT_MAX (Dreg, Dreg) (ASL); // сдвиг бит истории влево (b) Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: R0, ..., R7. Dreg_lo: R0.L, ..., R7.L. [Функциональное описание] Инструкция Compare-Select (VIT_MAX) выбирает максимальные значения пар 16-битных операндов, возвращая наибольшие значения в регистре назначения, и при этом последовательно записывая в A0.W источник максимального значения. Эта операция работает с учетом знака числа. Операнды сравниваются как числа в формате передачи знака в виде двоичного дополнения (two’s complements). Доступны версии для двойной и одиночной 16-битной операции. Версии двойной операции сравнивают четыре операнда и возвращают два максимума, тогда как одиночная версия операции сравнивает 2 операнда и возвращает один максимум. Биты расширения аккумулятора The (биты 39 .. 32) перед выполнением этой инструкции должны быть очищены. Ниже показано, как работает инструкция. Двойная версия инструкции. Если исходные регистры содержат:
... то регистр назначения будет содержать:
Версия ASL сдвигает A0 влево на 2 позиции бита, и добавляет два LSB, показывая источник каждого полученного максимума.
Здесь BB означает следующее:
Аналогично ASR-версия сдвигает вправо A0 на 2 позиции бит и добавляет два MSB, чтобы показать источники каждого максимума.
Здесь BB означает следующее:
Обратите внимание, что история в виде битового кода зависит от направления сдвига A0. Бит src_reg_1 всегда вдвигается в A0 первым, за ним следует бит для src_reg_0. Одиночные версии инструкции работают аналогично. Одиночная версия инструкции. Если исходные регистры содержат:
... то регистр назначения будет содержать:
Версия ASL сдвигает A0 влево на 1 позицию бита, и добавляет один LSB, показывая источник полученного максимума.
Аналогично ASR-версия сдвигает вправо A0 на 1 позицию бит и добавляет один MSB, чтобы показать источник максимума.
Здесь B означает следующее:
Разрешены метрики переполнения, и сравнение на на максимум выполняется по круговому циклу дополнения до 2 (2's complement). Такое сравнение дает лучшую индикацию относительной магнитуды двух больших чисел, когда малые числа добавляются отнимаются от обоих. Специальное применение: инструкция Compare-Select (VIT_MAX) является ключевым элементом функции Add-Compare-Select (ACS) декодеров Витерби. Её комбинируют с инструкцией Vector Add для вычисления "решетки бабочки" (trellis butterfly), используемой в функциях ACS. [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] r5 = vit_max(r3, r2)(asl); // сдвиг влево, двойная операция Предположим: R3 = 0xFFFF 0000 Тогда этот пример даст результат: R5 = 0x0000 0000 r7 = vit_max(r1, r0)(asr); // сдвиг вправо, двойная операция Предположим: R1 = 0xFEED BEEF Тогда этот пример даст результат: R7 = 0xFEED 0000 r3.l = vit_max(r1)(asl); // сдвиг влево, одиночная операция Предположим: R1 = 0xFFFF 0000 Тогда этот пример даст результат: R3.L = 0x0000 r3.l = vit_max(r1)(asr); // сдвиг вправо, одиночная операция Предположим: R1 = 0x1234 FADE Тогда этот пример даст результат: R3.L = 0x1234 См. также операцию максимума (в разделе "Арифметические операции"). Общая форма: dest_reg = ABS source_reg (V) Синтаксис: Dreg = ABS Dreg (V); // (b)1 Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: R0, ..., R7. [Функциональное описание] Инструкция Vector Absolute Value вычисляет индивидуальные абсолютные значения старшей и младшей половин одного 32-битного регистра данных. Результаты помещаются в 32-битный dest_reg, используя следующие правила: • Если входное значение положительное или 0, то оно без изменений копируется в место назначения. Например, если исходный регистр содержит:
... то регистр назначения будет содержать:
Эта инструкция делает насыщение результата. [Флаги] Инструкция влияет на следующие флаги: • AZ установится, если оба или любой из результатов равен 0; очищается, если оба результата не равны 0. Все другие флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Пример] // Если r1 = 0xFFFF 7FFF, то ... r3 = abs r1 (v); // ... даст результат 0x0001 7FFF См. также инструкцию Absolute Value (в разделе "Арифметические операции"). Общая форма: dest = src_reg_0+ |+ src_reg_1 dest = src_reg_0 –|+ src_reg_1 dest = src_reg_0 +|– src_reg_1 dest = src_reg_0 –|– src_reg_1 dest_0 = src_reg_0 +|+ src_reg_1, dest_1 = src_reg_0 –|– src_reg_1 dest_0 = src_reg_0 +|– src_reg_1, dest_1 = src_reg_0 –|+ src_reg_1 dest_0 = src_reg_0 + src_reg_1, dest_1 = src_reg_0 – src_reg_1 dest_0 = A1 + A0, dest_1 = A1 – A0 dest_0 = A0 + A1, dest_1 = A0 – A1 Синтаксис двойных 16-битных операций: Dreg = Dreg +|+ Dreg (opt_mode0); // add | add (b)1 Синтаксис счетверенных 16-битных операций: // add | add, subtract | subtract; набор исходных (source) регистров // add | subtract, subtract | add; набор исходных (source) регистров Синтаксис двойных 32-битных операций: // add, subtract; набор исходных (source) регистров Синтаксис двойных операций с 40-битными аккумуляторами: // add, subtract; при subtract происходит вычитание A0 из A1 (b): Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: R0, ..., R7 opt_mode0: опционально (S), (CO) или (SCO) opt_mode1: опционально (S) opt_mode2: опционально (ASR) или (ASL) [Функциональное описание] Инструкция Vector Add / Subtract одновременно складывает и/или вычитает две пары чисел, расположенных в регистрах. Затем она сохраняет результаты каждой операции в отдельном 32-битном регистре данных или 16-битной половинке регистра, в соответствии с используемым синтаксисом. Регистр назначения для каждой счетверенной или двойной версии операции должен быть уникальным. Специальное применение: подпрограммы FFT butterfly, где каждый из регистров рассматривается как одно комплексное число, и где часто используются инструкции сложения/вычитания вектора (Vector Add / Subtract). // Если r1 = 0x0003 0004 и r2 = 0x0001 0002, тогда ... r0 = r2 + | - r1(co); // ... даст результат r0 = 0xFFFE 0004
[Опции] Инструкция Vector Add / Subtract предоставляет три режима, настраиваемые опциями: • opt_mode0 поддерживает двойные 16-битные операции. В таблице 14.6 описаны опции, которые поддерживают 3 режима опций opt_mode. Таблица 14-1. Опции для инструкции Vector Add / Subtract.
Опции, показанные для opt_mode2, относятся к масштабированию. [Флаги] Инструкция влияет на следующие флаги: • AZ установится, если любой из результатов равен 0, иначе очистится. Все другие флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] r5=r3+|+r4; // двойные 16-битные операции, add|add r6=r0-|+r1(s); // то же самое, только subtract|add с насыщением r0=r2+|-r1(co); // add|subtract с результатами полуслов, переставленными // в регистре назначения r7=r3-|-r6(sco); // subtract|subtract с насыщением и перестановкой полуслов // результатов в регистре назначения r5=r3+|+r4, r7=r3-|-r4; // счетверенные 16-битные операции, add|add, // subtract|subtract r5=r3+|-r4, r7=r3-|+r4; // счетверенные 16-битные операции, add|subtract, // subtract|add r5=r3+|-r4, r7=r3-|+r4(asr); // счетверенные 16-битные операции, add|subtract, // subtract|add, с результатами, поделенными на 2 // (путем сдвига вправо на 1 бит) перед сохранением в // регистр назначения r5=r3+|-r4, r7=r3-|+r4(asl); // счетверенные 16-битные операции, add|subtract, // subtract|add, с результатами, умноженными на 2 // (путем сдвига влево на 1 бит) перед сохранением в // регистр назначения. r2=r0+r1, r3=r0-r1; // 32-битные операции r2=r0+r1, r3=r0-r1(s); // двойные 32-битные операции с насыщением r4=a1+a0, r6=a1-a0; // двойные 40-битные операции с участием аккумуляторов, // где из A1 вычитается A0 r4=a1+a0, r6=a1-a0(s); // двойные 40-битные операции с участием аккумуляторов, // где из A0 вычитается A1 См. также инструкции Add, Subtract (в разделе "Арифметические операции"). Общая форма: dest_reg = src_reg >>> shift_magnitude (V) dest_reg = ASHIFT src_reg BY shift_magnitude (V) Синтаксис с магнитудой сдвига в виде константы: Dreg = Dreg >>> uimm4 (V); // арифм. сдвиг вправо, с непосредственной константой (b)1 Синтаксис с магнитудой сдвига в регистре: Dreg = ASHIFT Dreg BY Dreg_lo (V); // арифм. сдвиг (b) Нет специального синтаксиса инструкции для векторного арифметического сдвига влево с непосредственной константой (vector arithmetic left shift immediate). Используйте инструкцию Vector Logical Shift для сдвига вектора влево, которая выполняет ту же самую функцию для чисел, расширенных знаком в подпрограммах нормализации чисел. См. примечания к синтаксису >>> для тонкостей использования. Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: R0, ..., R7. Dreg_lo: R0.L, ..., R7.L. uimm4: 4-битное поле без знака, с диапазоном от 0 до 15. [Функциональное описание] Инструкция Vector Arithmetic Shift делает арифметические сдвиги пар чисел, расположенных в половинках регистра на указанное количество бит и в указанном направлении. Хотя две половинки регистра сдвигаются одновременно, они обрабатываются независимо, как два отдельных числа. Арифметические сдвиги вправо сохраняют знак сдвигаемой величины. Бит знака восстанавливается в крайней левой позиции, когда она освобождается при сдвиге вправо. Для положительных чисел это поведение эквивалентно логическому сдвигу вправо для беззнаковых чисел. Поддерживается только арифметические сдвиги вправо. Сдвиги влево выполняются как логические сдвиги влево, которые могут не сохранять сдвиг оригинального числа. В случае по умолчанию (без указанной опции насыщения) числа могут быть сдвинуты влево так далеко, что бит знака уйдет из регистра и будет потерян. Однако, когда разрешена опция насыщения, сдвиг a влево вместо этого насыщает значение к максимальной положительной или отрицательной величине. Таким образом, если насыщение разрешено, то результат всегда сохранит тот же знак, что был у оригинального числа. Подробнее про насыщение см. секцию "Saturation (насыщение)". Синтаксис >>> и <<< . Две половинки регистра в регистре назначения dest_reg сдвигаются вправо на количество бит, указанное в shift_magnitude, и результат сохраняется в dest_reg. Данные всегда находятся в паре 16-битных половинок регистра. Допустимая величина сдвига shift_magnitude находится в пределах 0 .. 15. Синтаксис ASHIFT. Обе половинки регистра в src_reg сдвигаются на количество бит, описанное в shift_magnitude, и результат помещается в dest_reg. Знак магнитуды сдвига определяет направление сдвига для версий ASHIFT следующим образом: • Положительное значение магнитуды делает сдвиг без флага насыщения ( – , S) производит ЛОГИЧЕСКИЕ сдвиги ВЛЕВО. В сущности магнитуда это степень числа 2, умноженная на значение в src_reg. Положительные магнитуды дают умножение ( N x 2n ), тогда как отрицательные магнитуды производят деление ( N x 2-n или N / 2n ). Оба регистра dest_reg и src_reg являются парами 16-битных половинок регистра. Опционально может быть применено насыщение результата. Для 16-битного src_reg допустимы магнитуды сдвига –16 .. +15, включая 0. Если магнитуда сдвига больше поддерживаемой, то инструкция маскирует и игнорирует дополнительные не значащие биты магнитуды. Эта инструкция не делает неявную модификацию значений src_reg. Однако опционально dest_reg может быть тем же самым D-регистром, что и src_reg. В случае, когда используется тот же D-регистр и для dest_reg, и для src_reg, делается явная модификация исходного регистра. Опции. Инструкция ASHIFT поддерживает опцию ( – , S), которая делает насыщение результата. [Флаги] Инструкция влияет на следующие флаги: • AZ установится, если любой из результатов равен 0, иначе очистится. Все другие флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] r4=r5>>>3 (v); // арифм. сдвиг вправо R5.H и R5.L на 3 бита, // магнитуда сдвига указана непосредственной // константой (сдвиг делит каждое полуслово // на 8). Если r5 = 0x8004 000F, то результат // будет r4 = 0xF000 0001 r4=r5>>>3 (v, s); // то же самое, что в предыдущем примере, // но с насыщением результата r2=ashift r7 by r5.l (v); // арифм. сдвиг (вправо или влево, в зависимости // от знака r5.l) R7.H и R7.L на магнитуду сдвига, // указанную в R5.L r2=ashift r7 by r5.l (v, s); // то же самое, что и в предыдущем примере, // но с насыщением результата r2 = r5 << 7 (v,s); // логический сдвиг влево R5.H и R5.L на 7 бит // (магнитуда сдвига указана в непосредственной // константе команды), с насыщением См. также инструкции Vector Logical Shift, Arithmetic Shift, Logical Shift (последние две команды в разделе "Shift / Rotate", т. е. сдвиг / циклический сдвиг). Общая форма: dest_reg = src_reg >> shift_magnitude (V) dest_reg = src_reg << shift_magnitude (V) dest_reg = LSHIFT src_reg BY shift_magnitude (V) Синтаксис с магнитудой сдвига в виде константы: Dreg = Dreg >> uimm4 (V); // лог. сдвиг вправо, с непосредственной константой (b)1 Синтаксис с магнитудой сдвига в регистре: Dreg = LSHIFT Dreg BY Dreg_lo (V); // логический сдвиг (b) Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: R0, ..., R7. Dreg_lo: R0.L, ..., R7.L. uimm4: 4-битное поле без знака, с диапазоном от 0 до 15. [Функциональное описание] Инструкция Vector Logical Shift делает логические сдвиги пар чисел, расположенных в половинках регистра на указанное количество бит и в указанном направлении. Хотя две половинки регистра сдвигаются одновременно, они обрабатываются независимо, как два отдельных числа. Логические сдвиги отбрасывают выдвигаемые наружу биты, и заполняют нулями освобождающиеся места бит. Синтаксис >> и << . Две половинки регистра в регистре назначения dest_reg сдвигаются на количество бит, указанное в shift_magnitude, и результат сохраняется в dest_reg. Данные всегда находятся в паре 16-битных половинок регистра. Допустимая величина сдвига shift_magnitude находится в пределах 0 .. 15. Синтаксис LSHIFT. Обе половинки регистра в src_reg сдвигаются на количество бит, описанное в shift_magnitude, и результат помещается в dest_reg. Знак магнитуды сдвига определяет направление сдвига для версий LSHIFT следующим образом: • Положительное значение магнитуды производит ЛОГИЧЕСКИЕ сдвиги ВЛЕВО. Оба регистра dest_reg и src_reg являются парами 16-битных половинок регистра. Для 16-битного src_reg допустимы магнитуды сдвига –16 .. +15, включая 0. Если магнитуда сдвига больше поддерживаемой, то инструкция маскирует и игнорирует дополнительные не значащие биты магнитуды. Эта инструкция не делает неявную модификацию значений src_reg. Однако опционально dest_reg может быть тем же самым D-регистром, что и src_reg. В случае, когда используется тот же D-регистр и для dest_reg, и для src_reg, делается явная модификация исходного регистра. [Флаги] Инструкция влияет на следующие флаги: • AZ установится, если любой из результатов равен 0, иначе очистится. Все другие флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] r4 = r5 >> 3 (v); // логический сдвиг вправо R5.H и R5.L на 3 бита // (это указано в виде непосредственной константы) r4 = r5 << 3 (v); // логический сдвиг влево R5.H и R5.L на 3 бита // (это указано в виде непосредственной константы) r2 = lshift r7 by r5.l (v); // логический сдвиг R7.H и R7.L на количество // бит, указанное в R5.L (направление вправо или // влево зависит также от знака числа в r5.l) См. также инструкции Vector Arithmetic Shift, Arithmetic Shift, Logical Shift (последние две команды в разделе "Shift / Rotate", т. е. сдвиг / циклический сдвиг). Общая форма: dest_reg = MAX ( src_reg_0, src_reg_1 ) (V) Синтаксис: Dreg = MAX (Dreg, Dreg) (V); // двойные 16-битные операции (b)1 Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: R0, ..., R7. [Функциональное описание] Инструкция Vector Maximum возвращает максимальное значение (имеется в виду максимальное положительное значение, максимально близкое к 0x7FFF) из 16-битных полуслов регистров, и помещает это максимальное значение в dest_reg. Инструкция сравнивает старшие полуслова регистров src_reg_0 и src_reg_1 возвратит максимум в старшей половине регистра dest_reg. Инструкция также сравнивает младшие полуслова src_reg_0 и src_reg_1, и возвратит максимум в младшей половине регистра dest_reg. Результат будет конкатенацией этих двух максимальных 16-битных величин. Инструкция Vector Maximum не делает неявное модифицирование входных значений. Однако dest_reg может быть тем же самым D-регистром, что и исходные регистры. В таком случае инструкция явно произведет модификацию исходного регистра. [Флаги] Инструкция влияет на следующие флаги: • AZ установится, если любой из результатов равен 0, иначе очистится. Все другие флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Пример] r7 = max (r1, r0) (v); Предположим: R1 = 0x0007 0000 и R0 = 0x0000 000F, тогда R7 = 0x0007 000F. R1 = 0xFFF7 8000 и R0 = 0x000A 7FFF, тогда R7 = 0x000A 7FFF. R1 = 0x1234 5678 и R0 = 0x0000 000F, тогда R7 = 0x1234 5678. См. также инструкции Vector Search, Vector Minimum, или Maximum и Minimum в разделе "Арифметические операции". Общая форма: dest_reg = MIN ( src_reg_0, src_reg_1 ) (V) Синтаксис: Dreg = MIN (Dreg, Dreg) (V); // двойные 16-битные операции (b)1 Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: R0, ..., R7. [Функциональное описание] Инструкция Vector Minimum возвращает минимальное значение (имеется в виду минимальное положительное значение, максимально близкое к 0x8000) из 16-битных полуслов регистров, и помещает это минимальное значение в dest_reg. Инструкция сравнивает старшие полуслова регистров src_reg_0 и src_reg_1 возвратит минимум в старшей половине регистра dest_reg. Инструкция также сравнивает младшие полуслова src_reg_0 и src_reg_1, и возвратит минимум в младшей половине регистра dest_reg. Результат будет конкатенацией этих двух минимальных 16-битных величин. Инструкция Vector Minimum не делает неявное модифицирование входных значений. Однако dest_reg может быть тем же самым D-регистром, что и исходные регистры. В таком случае инструкция явно произведет модификацию исходного регистра. [Флаги] Инструкция влияет на следующие флаги: • AZ установится, если любой из результатов равен 0, иначе очистится. Все другие флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Пример] r7 = min (r1, r0) (v);
Предположим: R1 = 0x0007 0000 и R0 = 0x0000 000F, тогда R7 = 0x0000 0000. R1 = 0xFFF7 8000 и R0 = 0x000A 7FFF, тогда R7 = 0xFFF7 8000. R1 = 0x1234 5678 и R0 = 0x0000 000F, тогда R7 = 0x0000 000F. См. также инструкции Vector Search, Vector Maximum, или Maximum и Minimum в разделе "Арифметические операции". [Проблемы одновременного выполнения инструкций] Пара совместимых, скалярных (индивидуально) инструкций Multiply из секции "Арифметические операции" может быть скомбинирована с одной инструкцией Vector Multiply. Векторная инструкция выполняет одновременно две скалярные операции и сохраняет результаты как векторный куплет. Любая скалярная инструкция MAC0 Multiply может быть скомбинирована с совместимой скалярной инструкцией MAC1 Multiply с соблюдением следующих условий: 1. Обе скалярные инструкции должны разделять одну и ту же опцию режима (например: по умолчанию, IS, IU, T, и т. п.). Исключение: инструкция MAC1 может опционально использовать смешанный режим (mixed mode, (M)), который не применим к MAC0. 2. Обе скалярные инструкции должны разделять ту же самую пару регистров источников данных, но могут обращаться к разным половинкам этих регистров. 3. Обе скалярные операции должны записывать в регистры назначения одинакового размера, либо 16-, либо 32-битные. 4. Регистры назначения для обоих скалярных операций должны формировать векторный куплет, как описано ниже. a. 16-бит: сохранение результатов в старшую и младшую половины одного и того же 32-битного Dreg. MAC0 записывает в младшую половину, и MAC1 записывает в старшую половину. [Синтаксис] Отделите запятой друг от друга две совместимых скалярных инструкции, чтобы получилась векторная инструкция. В конец такой комбинированной инструкции добавьте точку с запятой, как обычно. Порядок следования друг за другом операций MAC в одной строке команды может быть произвольным. [Длина инструкции] Эта инструкция имеет длину 32 бита. [Флаги] Инструкция влияет на следующие флаги: • V установится, если в любом из результатов было насыщение; очистится, если ни в одном из результатов насыщения не было. Все другие флаги не поменяют свое значение. [Примеры] r2.h=r7.l*r6.h, r2.l=r7.h*r6.h; // Одновременное выполнение MAC0 и MAC1, // 16-битные результаты. Оба результата // это дробные числа со знаком. r4.l=r1.l*r0.l, r4.h=r1.h*r0.h; // То же самое, что и предыдущий пример. // Порядок следования MAC произвольный. r0.h=r3.h*r2.l(m), r0.l=r3.l*r2.l; // MAC1 умножает дробное число со знаком // на дробное число без знака. MAC0 умножает // два дробных числа со знаком. r5.h=r3.h*r2.h(m), r5.l=r3.l*r2.l(fu); // MAC1 умножает дробное число со знаком // на дробное число без знака. MAC0 умножает // два дробных числа без знака. r0.h=r3.h*r2.h, r0.l=r3.l*r2.l(is); // Обе операции MAC выполняют умножение // целых чисел со знаком. r3.h=r0.h*r1.h, r3.l=r0.l*r1.l(s2rnd); // MAC1 и MAC0 умножают дробные числа со // знаком. Обе операции масштабируют результат // для регистра назначения. r0.l=r7.l*r6.l, r0.h=r7.h*r6.h (iss2); // Обе операции MAC обрабатывают целые операнды // со знаком, масштабируют и округляют результат // для половинки регистра назначения. r7=r2.l*r5.l, r6=r2.h*r5.h; // Обе операции дают 32-битные результаты, // и сохраняют их в паре регистров Dreg. r0=r4.l*r7.l, r1=r4.h*r7.h (s2rnd); // То же самое, что и в предыдущем примере, // но в режиме масштабирования дробного числа // со знаком. Порядок следования инструкций MAC // может быть произвольным. [Проблемы одновременного выполнения инструкций] Пару совместимых, скалярных (по отдельности) инструкций ... • Multiply and Multiply-Accumulate to Accumulator ... (см. раздел "Арифметические операции" для получения подробностей по скалярным операциям) можно скомбинировать в одну векторную инструкцию. Эта векторная инструкция одновременно выполняет две скалярные операции и сохраняет результат как векторный куплет. Любая скалярная инструкция MAC0 из приведенного выше списка может быть скомбинирована с совместимой скалярной инструкцией MAC1 Multiply с соблюдением следующих условий: 1. Обе скалярные инструкции должны разделять одну и ту же опцию режима (например: по умолчанию, IS, IU, T, и т. п.). Исключение: инструкция MAC1 может опционально использовать смешанный режим (mixed mode, (M)), который не применим к MAC0. 2. Обе скалярные инструкции должны разделять ту же самую пару регистров источников данных, но могут обращаться к разным половинкам этих регистров. 3. Если обе скалярные операции записывают результат в регистр данных назначения (Dreg), то они должны записывать в регистры назначения одинакового размера, либо 16-, либо 32-битные. 4. Регистры назначения (если это применимо) для обоих скалярных операций должны формировать векторный куплет, как описано ниже. a. 16-бит: сохранение результатов в старшую и младшую половины одного и того же 32-битного Dreg. MAC0 записывает в младшую половину, и MAC1 записывает в старшую половину. [Синтаксис] Отделите запятой друг от друга две совместимых скалярных инструкции, чтобы получилась векторная инструкция. В конец такой комбинированной инструкции добавьте точку с запятой, как обычно. Порядок следования друг за другом операций MAC в одной строке команды может быть произвольным. [Длина инструкции] Эта инструкция имеет длину 32 бита. [Флаги] Инструкция влияет на следующие флаги: • V установится, если в любом из результатов, распакованном в Dreg, было насыщение; очистится, если ни в одном из результатов насыщения не было. Все другие флаги не поменяют свое значение. [Примеры] Результат в 40-битном аккумуляторе. a1=r2.l*r3.h, a0=r2.h*r3.h; // Оба умножаемых дробные числа попадают // в отдельные аккумуляторы. a0=r1.l*r0.l, a1+=r1.h*r0.h; // То же самое, что в предыдущем примере, // но результат суммируется в A1. Порядок // операций MAC может быть произвольным. a1+=r3.h*r3.l, a0=r3.h*r3.h; // Суммирование происходит в A1, вычитание // из A0. a1=r3.h*r2.l (m), a0+=r3.l*r2.l; // MAC1 умножает дробные числа со знаком в r3.h // на дробное число без знака в r2.l. MAC0 // умножает два дробных числа со знаком. a1=r7.h*r4.h (m), a0+=r7.l*r4.l (fu); // MAC1 умножает дробное число со знаком на // дробное число без знака. MAC0 умножает // и накапливает 2 дробных числа без знака. a1+=r3.h*r2.h, a0=r3.l*r2.l (is); // Оба MAC-а выполняют умножение целых чисел // со знаком. a1=r6.h*r7.h, a0+=r6.l*r7.l (w32); // Оба MAC-а умножают два дробных числа со знаком, // происходит расширение бит знака и насыщение // в обоих аккумуляторах на позиции бита 31. Результат в 16-битной половинке D-регистра. r2.h=(a1=r7.l*r6.h), r2.l=(a0=r7.h*r6.h); // Одновременное выполнение операций с MAC0 и MAC1, // обе обрабатывают дробные числа со знаком, // оба результата загружаются в аккумуляторы, // MAC1 загружает в половинку регистров. r4.l=(a0=r1.l*r0.l), r4.h=(a1+=r1.h*r0.h); // То же самое, что и в предыдущем примере, но // результат суммы помещается в A1. Порядок // операций MAC может быть произвольным. r7.h=(a1+=r6.h*r5.l), r7.l=(a0=r6.h*r5.h); // Сумма в A1, вычитание в A0. r0.h=(a1=r7.h*r4.l) (m), r0.l=(a0+=r7.l*r4.l); // MAC1 умножает дробное число со знаком на // дробное число без знака. MAC0 умножает два // дробных числа со знаком. r5.h=(a1=r3.h*r2.h) (m), r5.l=(a0+=r3.l*r2.l) (fu); // MAC1 умножает дробное число со знаком на // дробное число без знака. MAC0 умножает два // дробных числа без знака. r0.h=(a1+=r3.h*r2.h), r0.l=(a0=r3.l*r2.l) (is); // Оба MAC-а выполняют умножение целых чисел // со знаком. r5.h=(a1=r2.h*r1.h), a0+=r2.l*r1.l; // Оба MAC-а умножают дробные числа со знаком. // MAC0 не делает копию результата в аккумуляторе. r3.h=(a1=r2.h*r1.h) (m), a0=r2.l*r1.l; // MAC1 умножает дробное число со знаком на // дробное число без знака и использует при этом // все 40 бит аккумулятора A1. // MAC0 умножает два дробных числа со знаком. r3.h=a1, r3.l=(a0+=r0.l*r1.l) (s2rnd); // MAC1 копирует аккумулятор в половинку регистра. // MAC0 умножает дробные числа со знаком. Оба // масштабируют и округляют результат на пути // в регистр назначения. r0.l=(a0+=r7.l*r6.l), r0.h=(a1+=r7.h*r6.h) (iss2); // Оба MAC-а обрабатывают целые числа со знаком // и помещают результаты в половинки регистров. Результат в 32-битном D-регистре. r3=(a1=r6.h*r7.h), r2=(a0=r6.l*r7.l); // Одновременное выполнение операций с MAC0 и MAC1, // оба работают с дробными числами со знаком, оба // результата загружаются в аккумуляторы. r4=(a0=r6.l*r7.l), r5=(a1+=r6.h*r7.h); // То же самое, что и в предыдущем примере, но // результат суммы помещается в A1. Порядок // операций MAC может быть произвольным. r7=(a1+=r3.h*r5.h), r6=(a0-=r3.l*r5.l); // Сумма помещается в A1, вычитание в A0. r1=(a1=r7.l*r4.l) (m), r0=(a0+=r7.h*r4.h); // MAC1 умножает дробное число со знаком на // дробное число без знака. MAC0 умножает два дробных // числа со знаком. r5=(a1=r3.h*r7.h) (m), r4=(a0+=r3.l*r7.l) (fu); // MAC1 умножает дробное число со знаком на // дробное число без знака. MAC0 умножает два дробных // числа без знака. r1=(a1+=r3.h*r2.h), r0=(a0=r3.l*r2.l) (is); // Оба MAC-а выполняют умножение целых чисел // со знаком. r5=(a1-=r6.h*r7.h), a0+=r6.l*r7.l; // Оба MAC-а умножают дробные числа со знаком. MAC0 // не делает копию результата в аккумуляторе. r3=(a1=r6.h*r7.h) (m), a0-=r6.l*r7.l; // MAC1 умножает дробное число со знаком на дробное // число без знака и использует при этом все 40 бит A1. // MAC0 умножает два дробных числа со знаком. r3=a1, r2=(a0+=r0.l*r1.l) (s2rnd); // MAC1 перемещает значение аккумулятора в регистр. // MAC0 умножает дробные числа со знаком. Обе операции // делают масштабирование и округление результата // на пути в регистр назначения. r0=(a0+=r7.l*r6.l), r1=(a1+=r7.h*r6.h) (iss2); // Оба MAC-а обрабатывают операнды как целые // числа со знаком, и масштабируют результат на пути // в регистры назначения. Общая форма: dest_reg = – source_reg (V) Синтаксис: Dreg = – Dreg (V); // двойная 16-битная операция (b)1 Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: R0, ..., R7. [Функциональное описание] Инструкция Vector Negate возвращает ту же самую магнитуду числа, но с противоположным арифметическим знаком, с применением насыщения каждого 16-битного полуслова в регистре-источнике. Инструкция делает такое вычисление путем вычитания исходного регистра из нуля. Подробнее про насыщение см. секцию "Saturation (насыщение)". [Флаги] Инструкция влияет на следующие флаги: • AZ установится, если любой из результатов (или оба результата) равен 0, иначе очистится. Все другие флаги не поменяют свое значение. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Пример] r5 = -r3 (v); // R5.H получит результат, равный и противоположный // по знаку R3.H, и R5.L получит результат, равный // и противоположный по знаку R3.L. // Если r3 = 0x0004 7FFF, то результат r5 = 0xFFFC 8001. См. также инструкцию Negate (Two’s Complement) в разделе "Арифметические операции". Общая форма: Dest_reg = PACK ( src_half_0, src_half_1 ) Синтаксис: Dreg = PACK (Dreg_lo_hi, Dreg_lo_hi); // (b)1 Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: R0, ..., R7. Dreg_lo_hi: R0.L, ..., R7.L, R0.H, ..., R7.H. [Функциональное описание] Инструкция Vector Pack упаковывает две 16-битные половинки регистров в один 32-битный регистр данных.
[Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] 32-битные версии инструкции могут быть выполнены параллельно с некоторыми другими 16-битными инструкциями. Подробнее см. раздел "Параллельная обработка инструкций". [Примеры] r3=pack(r4.l, r5.l); r1=pack(r6.l, r4.h); r0=pack(r2.h, r4.l); r5=pack(r7.h, r2.h); // Если r4.l = 0xDEAD и r5.l = 0xBEEF, то ... r3 = pack (r4.l, r5.l); // ... приведет к результату r3 = 0xDEAD BEEF.
См. также инструкцию Quad 8-Bit Pack (в разделе "Операции обработки видео (Video Pixel Operations)"). Общая форма: (dest_pointer_hi, dest_pointer_lo) = SEARCH src_reg (searchmode) Синтаксис: (Dreg, Dreg) = SEARCH Dreg (searchmode); // (b)1 Примечание 1: в синтаксисе комментарий (b) показывает длину инструкции 32 бита. [Терминология синтаксиса] Dreg: R0, ..., R7. searchmode: (GT), (GE), (LE) или (LT). [Функциональное описание] Эта инструкция используется в цикле, чтобы найти максимум или минимум в массиве 16-битно упакованных данных. За один раз проверяется сразу 2 значения. Инструкция Vector Search сравнивает два 16-битных полуслова как числа со знаком со значениями, сохраненными в аккумуляторах. Затем она по заданному условию обновляет каждый аккумулятор и результирующий указатель, основываясь на результатах сравнения. Указатель в регистре P0 всегда подразумевается как указатель на элементы массива, по которым ведется поиск. Если рассмотреть подробнее, старшее полуслово как число со знаком в src_reg сравнивается с 16 младшими битами в A1. Если src_reg_hi удовлетворяет критерию сравнения, то A1 обновляется значением src_reg_hi, и значение в регистре указателя P0 сохраняется в регистре dest_pointer_hi. Та же самая операция одновременно производится для src_reg_low и A0. Базируясь на указанном режиме поиска, инструкция проверяет значения массива на максимальные или минимальные значения (как числа со знаком). Значения знака расширяются остальные биты, когда число копируется в аккумулятор (аккумуляторы). Пример использования инструкции в цикле см. в секции "Пример". После завершения цикла поиска вектора аккумуляторы A1 и A0 содержат два оставшихся (найденных?) элемента, и dest_pointer_hi и dest_pointer_lo содержат их соответствующие адреса. Следующим шагом в программе будет выбор конечного значения из этих двух оставшихся элементов. [Режимы поиска] Поддерживается 4 режима сравнения, которые указываются обязательным флагом режима поиска searchmode. Они перечислены в таблице ниже. Таблица 14-2. Compare Modes.
Подразумевается для указателя P0: src_reg_hi сравнивается с младшими 16 битами A1. Если условие сравнения выполнено, то будут перезаписаны младшие 16 бит A1, и значение P0 будет скопировано в dest_pointer_hi. src_reg_lo сравнивается с младшими 16 битами A0. Если условие сравнения выполнено, то будут перезаписаны младшие 16 бит A0, и значение P0 будет скопировано в dest_pointer_ho. Специальное применение: эта инструкция используется для нахождения элемента в векторе по значению (с помощью цикла). [Флаги] Инструкция не влияет ни на какие флаги. [Требуемый режим] Режим пользователя (User mode) и режим супервизора (Supervisor mode). [Параллельное выполнение] Эта инструкция может быть выполнена параллельно с одной 32-битной инструкцией, при которой загрузка основывается на значении регистра указателя P0. Это условие - единственный случай, который поддерживает параллельное выполнение инструкций вместе с инструкцией Vector Search. [Пример] /* Инициализация аккумуляторов соответствующим значением
для нужного типа поиска. */ r0.l=0x7fff; r0.h=0; a0=r0; // максимальное положительное 16-битное значение a1=r0; // максимальное положительное 16-битное значение /* Инициализация R2. */ r2=[p0++]; lsetup (search_loop, search_loop) lc0=p1>>1; // настройка цикла search_loop: (r1,r0) = search r2 (le) || r2=[p0++]; // поиск последнего минимума в массиве (r1,r0) = search r2 (le); // по завершении поиск последнего элемента /* В этом примере младшие 16 бит аккумуляторов A1 и A0 содержат последние минимумы,
найденные в массиве. R1 содержит значение P0, соответствующее значению в A1.
R0 содержит значение P0, соответствующее значению в A0. После этого сравниваются
друг с другом A1 и A0, чтобы найти один последний минимум в массиве. Это
выбирается соответствующим указателем из R1 или R0.
Примечание: в этом примере результирующие указатели указывают на адрес ячейки,
находящейся на 4 байта после действительного (найденного?) элемента массива.
Это по той причине, что применяется операция пост-инкремента. Отнимите 4
перед использованием полученного конечного значения указателя. */
См. также инструкции Vector Maximum, Vector Minimum, или Maximum and Minimum. [Параллельная обработка инструкций] Процессор Blackfin не является суперскалярным; он не поддерживает произвольное параллельное выполнение инструкций. Однако с некоторыми ограничениями можно выполнить параллельно до 3 инструкций. Инструкция с возможностью параллельности будет длиной 64 бита, и будет состоять из одной 32-битной инструкции и двух 16-битных инструкций. Все 3 инструкции выполняются в один и тот же интервал времени, как самая медленная из этих трех инструкций. Поддерживаемые комбинации параллельного выполнения. Ниже на диаграмме показаны комбинации инструкций, которые поддерживает Blackfin.
Синтаксис параллельного выполнения инструкций. Синтаксис параллельного выполнения следующий. 32-bit ALU/MAC instruction || A 16-bit instructions || A 16-bit instruction; Вертикальные палки (||) показывают, что последующие инструкции выполняются параллельно с предыдущей. Обратите внимание, что завершающая точка с запятой появляется только в конце инструкции с использованием параллелизма. Можно запускать инструкцию, основанную на инструкции 32-bit ALU/MAC, параллельно с другой 16-битной инструкцией по следующему синтаксису. В результате все так же получится 64-битная инструкция, где будет автоматически вставлена 16-битная инструкция пустой операции (no-op) в не используемом 16-битном слоте. 32-bit ALU/MAC instruction || A 16-bit instruction; Альтернативно также можно выполнять две 16-битные инструкции параллельно с одной другой без активной инструкции 32-bit ALU/MAC, путем использования инструкции MNOP, как это показано ниже. И опять получается 64-битная инструкция. MNOP || A 16-bit instructions || A 16-bit instruction; Описание инструкции MNOP (32-битный NOP) см. во врезке, описывающей команду "No Op". Инструкция не будет явно использоваться программистом; инструментарий программирования добавляет её автоматически. Инструкция MNOP будет видна в листинге дизассемблера вместе с параллельно выполняющимися 16-битными инструкциями. 32-битные инструкции ALU/MAC. Список 32-битных инструкций, которые можно запускать параллельно, показан ниже в таблице. Таблица 15-1. 32-битные инструкции DSP.
16-битные инструкции. Имеются две 16-битные инструкции, распределенные по группам 1 и 2, что показано в таблицах. Таблица 15-2. Группа 1 совместимых 16-битных инструкций.
Таблица 15-3. Группа 2 совместимых 16-битных инструкций.
Есть дополнительные ограничения, связанные с 16-битными инструкциями, запускаемыми параллельно: • Только одна из 16-битных инструкций может быть инструкцией сохранения (store instruction). [Примеры] Инструкции двух параллельных обращений к памяти. /* Subtract-Absolute-Accumulate выдается параллельно вместе с инструкциями
доступа к памяти, которые выбирают данные для следующей инструкции SAA.
Эта последовательность выполняется в цикле для переключения назад и вперед
между данными в R1 и R3, после чего данные появятся в R0 и R2. */ saa (r1:0, r3:2) || r0=[i0++] || r2=[i1++]; saa (r1:0, r3:2)(r) || r1=[i0++] || r3=[i1++]; mnop || r1 = [i0++] || r3 = [i1++]; Инструкция с доступом к Ireg и одним доступом к памяти. /* Add on Sign при инкрементировании Ireg, и загрузка регистра данных,
базируясь на предыдущем значении Ireg. */ r7.h=r7.l=sign(r2.h)*r3.h + sign(r2.l)*r3.l || i0+=m3 || r0=[i0]; /* Add/subtract два значения вектора при инкрементировании Ireg,
и загрузка регистра данных. */ R2 = R2 +|+ R4, R4 = R2 -|- R4 (ASR) || I0 += M0 (BREV) || R1 = [I0]; /* Умножение и накопление в аккумуляторе при загрузке регистра данных,
и сохранении регистра данных, используя указатель в Ireg. */ A1=R2.L*R1.L, A0=R2.H*R1.H || R2.H=W[I2++] || [I3++]=R3; /* Умножение и накопление при загрузке двух регистров данных.
Одна загрузка использует указатель Ireg. */ A1+=R0.L*R2.H,A0+=R0.L*R2.L || R2.L=W[I2++] || R0=[I1--]; R3.H=(A1+=R0.L*R1.H), R3.L=(A0+=R0.L*R1.L) || R0=[P0++] || R1=[I0]; /* Упаковка двух значений вектора при сохранении регистра данных
с использованием указателя Ireg и загрузкой другого регистра данных. */ R1=PACK(R1.H,R0.H) || [I0++]=R0 || R2.L=W[I2++]; Одна инструкция с Ireg. // Операция Multiply-Accumulate с регистром данных, при которой инкрементируется Ireg. r6=(a0+=r3.h*r2.h)(fu) || i2-=m0; [Ссылки] 1. Blackfin Instruction Set Reference site:analog.com. |