|
ąÆ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ (ą┐ąĄčĆąĄą▓ąŠą┤ ą│ą╗ą░ą▓čŗ "21 SYSTEM DESIGN" ą┤ą░čéą░čłąĖčéą░ [1]) ą┤ą░ąĮą░ ąĖąĮč乊čĆą╝ą░čåąĖčÅ ą┐ąŠ ą░ą┐ą┐ą░čĆą░čéąĮčŗą╝, ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗą╝ ąĖ čüąĖčüč鹥ą╝ąĮčŗą╝ ą░čüą┐ąĄą║čéą░ą╝ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ, ą║ąŠč鹊čĆčŗąĄ ą┤ąŠą╗ąČąĮčŗ ą┐ąŠą╝ąŠčćčī ąĖąĮąČąĄąĮąĄčĆą░ą╝ čüąŠąĘą┤ą░ą▓ą░čéčī čüąĖčüč鹥ą╝čŗ ąĮą░ ąŠčüąĮąŠą▓ąĄ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin. ą×ą┐čåąĖąĖ ą┤ąĖąĘą░ą╣ąĮą░, ą▓čŗą▒čĆą░ąĮąĮčŗąĄ ą┐čĆąĖ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĄ, ą▓ą╗ąĖčÅčÄčé ąĮą░ čüč鹊ąĖą╝ąŠčüčéčī, ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī (čüąŠąŠčéąĮąŠčłąĄąĮąĖąĄ čüą║ąŠčĆąŠčüčéąĖ čĆą░ą▒ąŠčéčŗ ąĖ 菹ĮąĄčĆą│ąŠą┐ąŠčéčĆąĄą▒ą╗ąĄąĮąĖčÅ) ąĖ čüąĖčüč鹥ą╝ąĮčŗąĄ čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅ. ąÆąŠ ą╝ąĮąŠą│ąĖčģ čüą╗čāčćą░čÅčģ čĆąĄčłąĄąĮąĖčÅ ą┐čĆąŠą▒ą╗ąĄą╝ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ, čāą┐ąŠą╝čÅąĮčāčéčŗąĄ ąĘą┤ąĄčüčī, ą▓ ą┐ąŠą┤čĆąŠą▒ąĮąŠą╝ čĆą░čüčüą╝ąŠčéčĆąĄąĮąĖąĖ ą╝ąŠąČąĮąŠ ąĮą░ą╣čéąĖ ą▓ ą┤čĆčāą│ąĖčģ čĆą░ąĘą┤ąĄą╗ą░čģ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ą░ [1]. ąÆ ą┐ąŠą┤ąŠą▒ąĮčŗčģ čüą╗čāčćą░čÅčģ ą▒čāą┤ąĄčé ą┤ą░ąĮą░ čüčüčŗą╗ą║ą░ ąĮą░ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖąĄ čüąĄą║čåąĖąĖ č鹥ą║čüčéą░ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮąŠą│ąŠ čĆčāą║ąŠą▓ąŠą┤čüčéą▓ą░ ąĖą╗ąĖ ą┤čĆčāą│ąĖąĄ čüčüčŗą╗ą║ąĖ, ą▓ą╝ąĄčüč鹊 ą┐ąŠą▓č鹊čĆąĄąĮąĖčÅ ąŠą┤ąĮąŠą│ąŠ ąĖ č鹊ą│ąŠ ąČąĄ ą╝ą░č鹥čĆąĖą░ą╗ą░.
ą×ą┐ąĖčüą░ąĮąĖąĄ ą▓čŗą▓ąŠą┤ąŠą▓. ą×ą▒čĆą░čéąĖč鹥čüčī ą║ ą┤ąŠą║čāą╝ąĄąĮčéčā "ADSP-BF538/ADSP-BF538F Embedded Processor Data Sheet", ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĮąŠ ąĮą░ą╣čéąĖ ąĮą░ čüą░ą╣č鹥 analog.com, ąĖą╗ąĖ čéą░ą║ąČąĄ čüą╝. [2].
ąĀąĄą║ąŠą╝ąĄąĮą┤ą░čåąĖąĖ ą┐ąŠ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗą╝ ą▓čŗą▓ąŠą┤ą░ą╝. ąśąĮąŠą│ą┤ą░ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ ą▓čŗą▓ąŠą┤čŗ čéčĆąĄą▒čāčÄčé čüą┐ąĄčåąĖą░ą╗čīąĮąŠą│ąŠ č鹥čĆą╝ąĖąĮąĖčĆąŠą▓ą░ąĮąĖčÅ. ąĪąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēčāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ čüą╝. "ADSP-BF538/ADSP-BF538F Embedded Processor Data Sheet", čéą░ą║ąČąĄ čüą╝. [2].
[ąĪą▒čĆąŠčü ą┐čĆąŠčåąĄčüčüąŠčĆą░]
ąÆ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ čĆąĄąČąĖą╝čā ą░ą┐ą┐ą░čĆą░čéąĮąŠą│ąŠ čüą▒čĆąŠčüą░, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄą╝ąŠą│ąŠ ą▓čŗą▓ąŠą┤ąŠą╝ ~RESET, ą┐čĆąŠčåąĄčüčüąŠčĆ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮčŗčģ čĆąĄąČąĖą╝ąŠą▓ čüą▒čĆąŠčüą░ (software reset). ą¤ąŠą┤čĆąŠą▒ąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ čŹčéąĖčģ ą▓ąŠąĘą╝ąŠąČąĮąŠčüč鹥ą╣ čüą╝. ą▓ čüąĄą║čåąĖąĖ "System Reset and Power-up", čüąŠčüč鹊čÅąĮąĖąĄ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą┐ąŠčüą╗ąĄ čüą▒čĆąŠčüą░ ąŠą┐ąĖčüą░ąĮąŠ ą▓ čüąĄą║čåąĖąĖ "Reset State" [1] (čéą░ą║ąČąĄ čüą╝. ą▓čĆąĄąĘą║čā "ąĪąŠčüč鹊čÅąĮąĖąĄ čüą▒čĆąŠčüą░" čüčéą░čéčīąĖ [3]).
[ąŚą░ą│čĆčāąĘą║ą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░ (boot)]
ą¤čĆąŠą│čĆą░ą╝ą╝ą░ (ąĖ ą┤ą░ąĮąĮčŗąĄ) ą╝ąŠą│čāčé ą▒čŗčéčī ąĘą░ą│čĆčāąČąĄąĮčŗ ą┤ą╗čÅ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą▓ ą┐ą░ą╝čÅčéčī čüąĖčüč鹥ą╝čŗ čü ą┐ąŠą╝ąŠčēčīčÄ čĆą░ąĘą╗ąĖčćąĮčŗčģ ą╝ąĄč鹊ą┤ąŠą▓ ąĘą░ą│čĆčāąĘą║ąĖ [4]. ąŁčéąĖ ą╝ąĄč鹊ą┤čŗ ą▓ą║ą╗čÄčćą░čÄčé ąĘą░ą│čĆčāąĘą║čā ąĖąĘ ą▓ąĮąĄčłąĮąĄą╣ 16-ą▒ąĖčéąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ, ąĖąĘ ROM (ą¤ąŚąŻ čü ą║ąŠą┤ąŠą╝ ąĘą░ą│čĆčāąĘą║ąĖ, ą▓čüčéčĆąŠąĄąĮąĮąŠąĄ ą▓ čÅą┤čĆąŠ), čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ ą┤ą╗čÅ ąĘą░ą│čĆčāąĘą║ąĖ ą║ąŠą┤ą░ ąĖąĘ 8-ą▒ąĖčéąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ flash, ąĖą╗ąĖ ąĘą░ą│čĆčāąĘą║ąĖ ąĖąĘ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠą╣ ą╝ąĖą║čĆąŠčüčģąĄą╝čŗ ROM (čü 8-ą▒ąĖčéąĮčŗą╝, 16-ą▒ąĖčéąĮčŗą╝ ąĖą╗ąĖ 24-ą▒ąĖčéąĮčŗą╝ ą┤ąĖą░ą┐ą░ąĘąŠąĮąŠą╝ ą░ą┤čĆąĄčüąŠą▓). ą¤ąŠą┤čĆąŠą▒ąĮąŠ ą┐čĆąŠ čĆąĄąČąĖą╝čŗ ąĘą░ą│čĆčāąĘą║ąĖ (boot modes), čüą╝. čĆą░ąĘą┤ąĄą╗ "Booting Methods" [1], čéą░ą║ąČąĄ čüą╝. čüčéą░čéčīčÄ [4].
ąØą░ čĆąĖčü. 21-1 ąĖ 21-2 ą┐ąŠą║ą░ąĘą░ąĮčŗ čüąŠąĄą┤ąĖąĮąĄąĮąĖčÅ, čéčĆąĄą▒čāąĄą╝čŗąĄ ą┤ą╗čÅ 8-ą▒ąĖčéąĮąŠą╣ ąĖ 16-ą▒ąĖčéąĮąŠą╣ ąĘą░ą│čĆčāąĘą║ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖąĄ ą░ą┤čĆąĄčüąŠą▓ čüą┤ąĄą╗ą░ąĮąŠ ąŠą┤ąĖąĮą░ą║ąŠą▓čŗą╝ čüą┐ąŠčüąŠą▒ąŠą╝ ą║ą░ą║ ą┤ą╗čÅ 8-ą▒ąĖčéąĮąŠą│ąŠ, čéą░ą║ ąĖ 16-ą▒ąĖčéąĮąŠą│ąŠ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓. ąśčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ č鹊ą╗čīą║ąŠ ą╝ą╗ą░ą┤čłąĖą╣ ą▒ą░ą╣čé ą║ą░ąČą┤ąŠą│ąŠ 16-ą▒ąĖčéąĮąŠą│ąŠ čüą╗ąŠą▓ą░, ą║ąŠą│ą┤ą░ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ ą║ ą┐ą░ą╝čÅčéąĖ čü čłąĖčĆąĖąĮąŠą╣ čüą╗ąŠą▓ą░ ą▓ 1 ą▒ą░ą╣čé.
ąØą░ą┐čĆąĖą╝ąĄčĆ, ą┐čĆąĖ čćč鹥ąĮąĖčÅčģ čÅą┤čĆą░ ą▓ č乊čĆą╝ąĄ:
R0 = W[P0] (Z); //P0 čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ ą▓čŗčĆąŠą▓ąĮąĄąĮąĮčāčÄ ą┐ąŠ 16 ą▒ąĖčéą░ą╝ čÅč湥ą╣ą║čā
// ą░čüąĖąĮčģčĆąŠąĮąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ
ąóąŠą╗čīą║ąŠ ą╝ą╗ą░ą┤čłąĖąĄ 8 ą▒ąĖčé R0 čüąŠą┤ąĄčƹȹ░čé ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, ą┐čĆąŠčćąĖčéą░ąĮąĮąŠąĄ ąĖąĘ 8-ą▒ąĖčéąĮąŠą│ąŠ čāčüčéčĆąŠą╣čüčéą▓ą░ ą┐ą░ą╝čÅčéąĖ.
ąöą╗čÅ ąĘą░ą┐ąĖčüąĄą╣ čÅą┤čĆą░ ą▓ č乊čĆą╝ąĄ:
W[P0] = R0.L; //P0 čāą║ą░ąĘčŗą▓ą░ąĄčé ąĮą░ ą▓čŗčĆąŠą▓ąĮąĄąĮąĮčāčÄ ą┐ąŠ 16 ą▒ąĖčéą░ą╝ čÅč湥ą╣ą║čā
// ą░čüąĖąĮčģčĆąŠąĮąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ
8-ą▒ąĖčéąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ, ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĮąŠąĄ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ ą▓ 8-ą▒ąĖčéąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ą┐ą░ą╝čÅčéąĖ, ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čüąĮą░čćą░ą╗ą░ ąĘą░ą│čĆčāąČąĄąĮąŠ ą▓ ą╝ą╗ą░ą┤čłąĖą╣ ą▒ą░ą╣čé čĆąĄą│ąĖčüčéčĆą░ R0.
ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ ą┐čĆąŠ čüąĖčüč鹥ą╝čā ą║ąŠą╝ą░ąĮą┤ ą░čüčüąĄą╝ą▒ą╗ąĄčĆą░ Blackfin ą╝ąŠąČąĮąŠ ą┐ąŠčćąĖčéą░čéčī ą▓ [5].
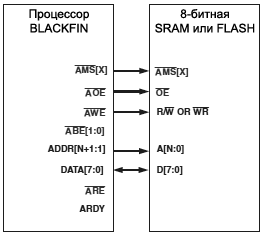
ąĀąĖčü. 21-1. ą¤ąŠą┤ą║ą╗čÄč湥ąĮąĖąĄ ąĘą░ą│čĆčāąĘąŠčćąĮąŠą╣ 8-ą▒ąĖčéąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ SRAM ąĖą╗ąĖ FLASH.
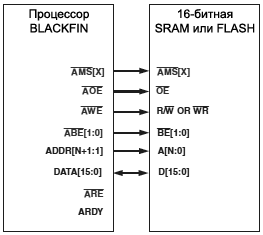
ąĀąĖčü. 21-2. ą¤ąŠą┤ą║ą╗čÄč湥ąĮąĖąĄ ąĘą░ą│čĆčāąĘąŠčćąĮąŠą╣ 16-ą▒ąĖčéąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ SRAM ąĖą╗ąĖ FLASH.
[ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čéą░ą║čéąĖčĆąŠą▓ą░ąĮąĖąĄą╝]
ąĪąĖčüč鹥ą╝čŗ ą╝ąŠą│čāčé ą┐ąŠą┤ą░ą▓ą░čéčī čéą░ą║č鹊ą▓čāčÄ čćą░čüč鹊čéą░ ąĮą░ čéą░ą║č鹊ą▓čŗąĄ ą▓čģąŠą┤čŗ čü ą┐ąŠą╝ąŠčēčīčÄ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖčÅ ą║ą▓ą░čĆčåąĄą▓ąŠą│ąŠ čĆąĄąĘąŠąĮą░č鹊čĆą░ (ą║ą▓ą░čĆčå ą┐ąŠą┤ą║ą╗čÄčćą░ąĄčéčüčÅ ą║ ą▓čŗą▓ąŠą┤ą░ą╝ CLKIN ąĖ XTAL), ą╗ąĖą▒ąŠ ąĮą░ ą▓čģąŠą┤ CLKIN ą╝ąŠąČąĄčé ą┐ąŠą┤ą░ą▓ą░čéčīčüčÅ čćą░čüč鹊čéą░ čü ą▓čŗčģąŠą┤ą░ ą▒čāč乥čĆą░ ą▓ąĮąĄčłąĮąĄą│ąŠ čéą░ą║č鹊ą▓ąŠą│ąŠ ą│ąĄąĮąĄčĆą░č鹊čĆą░. ąÆąŠ ą▓čĆąĄą╝čÅ ąĮąŠčĆą╝ą░ą╗čīąĮąŠą│ąŠ čäčāąĮą║čåąĖąŠąĮąĖčĆąŠą▓ą░ąĮąĖčÅ ąĮąĄą╗čīąĘčÅ ą┐čĆąĖąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čéčī, ą╝ąĄąĮčÅčéčī, ąĖą╗ąĖ ą╝ą░ąĮąĖą┐čāą╗ąĖčĆąŠą▓ą░čéčī čüąĖą│ąĮą░ą╗ąŠą╝ ąĮą░ CLKIN ąĮąĖąČąĄ čāą║ą░ąĘą░ąĮąĮąŠą╣ čćą░čüč鹊čéčŗ. ą¤čĆąŠčåąĄčüčüąŠčĆ ąĖčüą┐ąŠą╗čīąĘčāąĄčé čéą░ą║č鹊ą▓čŗą╣ ą▓čģąŠą┤ CLKIN, čćč鹊ą▒čŗ ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ą▓ąĮčāčéčĆąĄąĮąĮąĖąĄ čüąĖą│ąĮą░ą╗čŗ čéą░ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ. ąŁč鹊 čüąĖą│ąĮą░ą╗čŗ čéą░ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ čÅą┤čĆą░ (CCLK) ąĖ čéą░ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ąĖ ą▓ąĮąĄčłąĮąĄą╣ čüąĖąĮčģčĆąŠąĮąĮąŠą╣ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą╣ ą┐ą░ą╝čÅčéąĖ (SCLK).
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: čéą░ą║ąČąĄ ąĖąĮąŠą│ą┤ą░ ą┐čĆąĖą╝ąĄąĮčÅąĄčéčüčÅ ąĄčēąĄ ąŠą┤ąĖąĮ ą║ą▓ą░čĆčå ąĮą░ čćą░čüč鹊čéčā 32768 ąōčå, ą┐čĆąĄą┤ąĮą░ąĘąĮą░č湥ąĮąĮčŗą╣ ą┤ą╗čÅ čćą░čüąŠą▓ čĆąĄą░ą╗čīąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ (RTC).
ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ čćą░čüč鹊čéą░ą╝ąĖ CCLK ąĖ SCLK. ą¤čĆąŠčåąĄčüčüąŠčĆ ą┤ąĄą╗ą░ąĄčé čāą╝ąĮąŠąČąĄąĮąĖąĄ (ąĮą░ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ ą▓čŗą▒čĆą░ąĮąĮčŗą╣ ą║ąŠčŹčäčäąĖčåąĖąĄąĮčé) čćą░čüč鹊čéčŗ ąĮą░ ą▓čģąŠą┤ąĄ CLKIN, ąĖ ą│ąĄąĮąĄčĆąĖčĆčāąĄčé ąĖąĘ ąĮąĄčæ čü ą┐ąŠą╝ąŠčēčīčÄ ą┐ąĄčéą╗ąĖ PLL ą▓ąĮčāčéčĆąĄąĮąĮčÄčÄ čćą░čüč鹊čéčā VCO, ą║ąŠč鹊čĆą░čÅ ąĮą░ą┐čĆčÅą╝čāčÄ ąĮąĖą│ą┤ąĄ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ. ąŁčéą░ čćą░čüč鹊čéą░ VCO ą┤ąĄą╗ąĖčéčüčÅ (ąĮą░ ą┤čĆčāą│ąŠą╣ ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠ ą▓čŗą▒čĆą░ąĮąĮčŗą╣ ą║ąŠčŹčäčäąĖčåąĖąĄąĮčé), čćč鹊ą▒čŗ ą┐ąŠą╗čāčćąĖčéčī čéą░ą║č鹊ą▓čāčÄ čćą░čüč鹊čéčā čÅą┤čĆą░ (core clock, CCLK) ąĖ čéą░ą║č鹊ą▓čāčÄ čćą░čüč鹊čéčā čüąĖčüč鹥ą╝ąĮąŠą╣ čłąĖąĮčŗ (system clock, SCLK). ą¦ą░čüč鹊čéą░ čÅą┤čĆą░ ą▒ą░ąĘąĖčĆčāąĄčéčüčÅ ąĮą░ ą║ąŠčŹčäčäąĖčåąĖąĄąĮč鹥 ą┤ąĄą╗ąĄąĮąĖčÅ, ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆčāąĄą╝ąŠą╝ ą┐ąŠą╗ąĄą╝ ą▒ąĖčé CSEL čĆąĄą│ąĖčüčéčĆą░ PLL_DIV. ą¦ą░čüč鹊čéą░ čüąĖčüč鹥ą╝ąĮąŠą╣ čłąĖąĮčŗ ą▒ą░ąĘąĖčĆčāąĄčéčüčÅ ąĮą░ ą║ąŠčŹčäčäąĖčåąĖąĄąĮč鹥 ą┤ąĄą╗ąĄąĮąĖčÅ, ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆčāąĄą╝ąŠą╝ ą┐ąŠą╗ąĄą╝ ą▒ąĖčé SSEL čĆąĄą│ąĖčüčéčĆą░ PLL_DIV. ą¤ąŠą┤čĆąŠą▒ąĮčāčÄ ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠ č鹊ą╝, ą║ą░ą║ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čéčī ąĖ ą╝ąĄąĮčÅčéčī čćą░čüč鹊čéčŗ CCLK ąĖ SCLK, čüą╝. ąōą╗ą░ą▓čā 8 "Dynamic Power Management" ą┤ą░čéą░čłąĖčéą░ [1]. ąóą░ą║ąČąĄ čüą╝. ą┐ąĄčĆąĄą▓ąŠą┤ čŹč鹊ą╣ ą│ą╗ą░ą▓čŗ ąĖ ąŠąĮą╗ą░ą╣ąĮ-ą║ą░ą╗čīą║čāą╗čÅč鹊čĆ čćą░čüč鹊čé ą▓ čüčéą░čéčīąĄ [6]. ąśą╝ąĄąĄčéčüčÅ čéą░ą║ąČąĄ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ą░ ADI (Analog Devices) adi_pwr, ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčēą░čÅ čäčāąĮą║čåąĖąĖ ą┐ąŠ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÄ ą┐ąĖčéą░ąĮąĖąĄą╝, ąĄčüčéčī ąŠą┐ąĖčüą░ąĮąĖąĄ čŹč鹊ą╣ ą▒ąĖą▒ą╗ąĖąŠč鹥ą║ąĖ ąĖ ą┐čĆąĖą╝ąĄčĆčŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą▓ čüąŠčüčéą░ą▓ąĄ IDE VisualDSP++ (čüą╝. [7]).
[ąÜąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖ ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣]
ąśą╝ąĄąĄčéčüčÅ ą╝ąĮąŠąČąĄčüčéą▓ąŠ ą░ą┐ą┐ą░čĆą░čéąĮčŗčģ ąĖčüč鹊čćąĮąĖą║ąŠą▓, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░čéčī ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ. ąŁč鹊 ą▓ą║ą╗čÄčćą░ąĄčé ą║ą░ą║ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąŠčé čÅą┤čĆą░, čéą░ą║ ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ ąŠčé ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓. ą¤čĆąŠčåąĄčüčüąŠčĆ ąĮą░ąĘąĮą░čćą░ąĄčé ą┐čĆąĖąŠčĆąĖč鹥čéčŗ čÅą┤čĆą░ ą┐ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ (core priorities) ą┤ą╗čÅ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ čüąĖčüč鹥ą╝ąĮąŠą│ąŠ čāčĆąŠą▓ąĮčÅ (system-level interrupts). ą×ą┤ąĮą░ą║ąŠ ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčüčé ą╝ąŠąČąĄčé ą┐ąĄčĆąĄąĮą░ąĘąĮą░čćąĖčéčī čŹčéąĖ čüąĖčüč鹥ą╝ąĮčŗąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ (ą┐čĆąĖąŠčĆąĖč鹥čéčŗ) č湥čĆąĄąĘ čüą┐ąĄčåąĖą░ą╗čīąĮčŗąĄ čĆąĄą│ąĖčüčéčĆčŗ ąĮą░ąĘąĮą░č湥ąĮąĖčÅ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ (System interrupt Assignment registers, SIC_IARx). ąöą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ čüą╝. "System Interrupt Assignment (SIC_IARx) Registers" [1], čéą░ą║ąČąĄ čüą╝. ą┐ąĄčĆąĄą▓ąŠą┤ čŹč鹊ą╣ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ ą▓ čüčéą░čéčīąĄ [3].
ą»ą┤čĆąŠ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé ą▓ą╗ąŠąČąĄąĮąĮčŗąĄ ą┤čĆčāą│ ą▓ ą┤čĆčāą│ą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ (nested interrupts) ąĖ ąĮąĄ ą▓ą╗ąŠąČąĄąĮąĮčŗąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ (non-nested interrupts), ą║ą░ą║ ąĖ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé ą▒čŗčéčī ą▓ą╗ąŠąČąĄąĮčŗ čüą░ą╝ąĖ ą▓ čüąĄą▒čÅ. ą¤ąŠ čāą╝ąŠą╗čćą░ąĮąĖčÄ ą▓ą╗ąŠąČąĄąĮąĮąŠčüčéčī ąŠčéą║ą╗čÄč湥ąĮą░, ąĮąŠ ąĄčæ ą╝ąŠąČąĮąŠ ą▓ą║ą╗čÄčćąĖčéčī. ąÜą░ą║ čŹč鹊 ą┤ąĄą╗ą░ąĄčéčüčÅ ąĖ ą┤čĆčāą│ąĖąĄ ą┐ąŠą┤čĆąŠą▒ąĮąŠčüčéąĖ čüą╝. ą▓ čüąĄą║čåąĖąĖ "Nesting of Interrupts" [1], čéą░ą║ąČąĄ čüą╝. ą┐ąĄčĆąĄą▓ąŠą┤ čŹč鹊ą╣ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ ą▓ čüčéą░čéčīąĄ [3].
[ąĪąĄą╝ą░č乊čĆčŗ]
ąĪąĄą╝ą░č乊čĆčŗ (Semaphores) ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅčÄčé ą╝ąĄčģą░ąĮąĖąĘą╝ ą║ąŠą╝ą╝čāąĮąĖą║ą░čåąĖą╣ ą╝ąĄąČą┤čā ąŠčéą┤ąĄą╗čīąĮčŗą╝ąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ą╝ąĖ (čÅą┤čĆą░ą╝ąĖ) ąĖą╗ąĖ ą┐čĆąŠčåąĄčüčüą░ą╝ąĖ/ą┐ąŠč鹊ą║ą░ą╝ąĖ (processes/threads), čĆą░ą▒ąŠčéą░čÄčēąĖą╝ąĖ ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ą▓ ąŠą┤ąĮąŠą╣ čüąĖčüč鹥ą╝ąĄ. ąĪąĄą╝ą░č乊čĆčŗ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ ą┤ą╗čÅ ą║ąŠąŠčĆą┤ąĖąĮą░čåąĖąĖ ą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ąŠą▒čēąĖą╝ąĖ čĆąĄčüčāčĆčüą░ą╝ąĖ ąĖ čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖąĖ ą▓čŗčćąĖčüą╗ąĄąĮąĖą╣. ąØą░ą┐čĆąĖą╝ąĄčĆ, ąĄčüą╗ąĖ ą┐čĆąŠčåąĄčüčü ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą║ą░ą║ąŠą╣-č鹊 ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╣ čĆąĄčüčāčĆčü (ąĮą░ą┐čĆąĖą╝ąĄčĆ, UART ąĖą╗ąĖ ą┤čĆčāą│ąŠąĄ ą┐ąĄčĆąĖč乥čĆąĖą╣ąĮąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ, ąĖą╗ąĖ ąŠą▒čŖąĄą║čé ą▓ ą┐ą░ą╝čÅčéąĖ), ąĖ ą┤čĆčāą│ąŠą╣ ą┐ą░čĆą░ą╗ą╗ąĄą╗čīąĮąŠ čĆą░ą▒ąŠčéą░čÄčēąĖą╣ ą┐čĆąŠčåąĄčüčü čéčĆąĄą▒čāąĄčé č鹊ą│ąŠ ąČąĄ čüą░ą╝ąŠą│ąŠ čĆąĄčüčāčĆčüą░, č鹊 čŹč鹊čé ą┤čĆčāą│ąŠą╣ ą┐čĆąŠčåąĄčüčü ą┤ąŠą╗ąČąĄąĮ ąŠąČąĖą┤ą░čéčī, ą┐ąŠą║ą░ ą┐ąĄčĆą▓čŗą╣ ą┐čĆąŠčåąĄčüčü ąŠčéą┐čĆą░ą▓ąĖčé č湥čĆąĄąĘ čüąĄą╝ą░č乊čĆ čüąĖą│ąĮą░ą╗, čćč鹊 čĆąĄčüčāčĆčü čüą▓ąŠą▒ąŠą┤ąĄąĮ, ąĖ ąĄą│ąŠ ą╝ąŠąČąĮąŠ ąĘą░ąĮčÅčéčī. ąóą░ą║ą░čÅ čüąĖą│ąĮą░ą╗ąĖąĘą░čåąĖčÅ ą╝ąĄąČą┤čā ą┐ąŠč鹊ą║ą░ą╝ąĖ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ čüąĄą╝ą░č乊čĆąŠą▓ - ąŠą┤ąĖąĮ ą┐ąŠč鹊ą║ ąČą┤ąĄčé ąĮą░ čüąĄą╝ą░č乊čĆąĄ (ą┐čāč鹥ą╝ ą▓čŗąĘąŠą▓ą░ PendSemafore), ąĖ ą┤čĆčāą│ąŠą╣ ą┐ąŠč鹊ą║ ą┐ąŠčüčŗą╗ą░ąĄčé čüąĖą│ąĮą░ą╗ ą┤čĆčāą│ąŠą╝čā ą┐ąŠč鹊ą║čā ą┐čāą▒ą╗ąĖą║ą░čåąĖąĄą╣ čüąĄą╝ą░č乊čĆą░ (ą▓čŗąĘąŠą▓ąŠą╝ PostSemafore), ą┐ąŠčüą╗ąĄ č湥ą│ąŠ ąŠąČąĖą┤ą░čÄčēąĖą╣ ą┐ąŠč鹊ą║ ą▓ąŠąĘąŠą▒ąĮąŠą▓ą╗čÅąĄčé čüą▓ąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ.
ąÜąŠą│ąĄčĆąĄąĮčéąĮąŠčüčéčī čĆą░ą▒ąŠčéčŗ čüąĄą╝ą░č乊čĆąŠą▓ ą│ą░čĆą░ąĮčéąĖčĆčāąĄčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ ą░č鹊ą╝ą░čĆąĮąŠą╣ (atomic) ąĖąĮčüčéčĆčāą║čåąĖąĖ ą┐čĆąŠą▓ąĄčĆą║ąĖ ąĖ čāčüčéą░ąĮąŠą▓ą║ąĖ ą▒ą░ą╣čéą░ (TESTSET). ąśąĮčüčéčĆčāą║čåąĖčÅ TESTSET ą▓čŗą┐ąŠą╗ąĮčÅąĄčé čüą╗ąĄą┤čāčÄčēąĖąĄ čäčāąĮą║čåąĖąĖ:
ŌĆó ąŚą░ą│čĆčāąČą░ąĄčé ą┐ąŠą╗ąŠą▓ąĖąĮčā čüą╗ąŠą▓ą░ ąĖąĘ čāą║ą░ąĘą░ąĮąĮąŠą╣ čÅč湥ą╣ą║ąĖ ą┐ą░ą╝čÅčéąĖ (čÅč湥ą╣ą║ą░ čāą║ą░ąĘčŗą▓ą░ąĄčéčüčÅ čü ą┐ąŠą╝ąŠčēčīčÄ P-čĆąĄą│ąĖčüčéčĆą░). ąĪąŠą┤ąĄčƹȹĖą╝ąŠąĄ P-čĆąĄą│ąĖčüčéčĆą░ (ą░ą┤čĆąĄčü čÅč湥ą╣ą║ąĖ) ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓čŗčĆąŠą▓ąĮąĄąĮ ąĮą░ ą┐ąŠą╗ąŠą▓ąĖąĮčā čüą╗ąŠą▓ą░ (čé. ąĄ. ą▒ą░ą╣č鹊ą▓čŗą╣ ą░ą┤čĆąĄčü ą┤ąŠą╗ąČąĄąĮ ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░ 2).
ŌĆó ąŻčüčéą░ąĮąŠą▓ąĖčé CC, ąĄčüą╗ąĖ ąĘą░ą│čĆčāąČąĄąĮąĮąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ čĆą░ą▓ąĮąŠ 0.
ŌĆó ąĪąŠčģčĆą░ąĮąĖčé ąĘąĮą░č湥ąĮąĖąĄ ąŠą▒čĆą░čéąĮąŠ ą▓ čüą▓ąŠąĄ ąŠčĆąĖą│ąĖąĮą░ą╗čīąĮąŠąĄ ą╝ąĄčüč鹊 čĆą░čüą┐ąŠą╗ąŠąČąĄąĮąĖčÅ, ąĮąŠ ą┐čĆąĖ čŹč鹊ą╝ čüą░ą╝čŗą╣ ąĘąĮą░čćą░čēąĖą╣ ą▒ąĖčé (MSB) ą╝ą╗ą░ą┤čłąĄą│ąŠ ą▒ą░ą╣čéą░ čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčéčüčÅ ą▓ 1.
ąÆčüąĄ čŹčéąĖ čüąŠą▒čŗčéąĖčÅ, ą┐čĆąŠąĖčüčģąŠą┤čÅčēąĖąĄ ą▓ ąĖąĮčüčéčĆčāą║čåąĖąĖ TESTSET, čÅą▓ą╗čÅčÄčéčüčÅ ą░č鹊ą╝ą░čĆąĮčŗą╝ąĖ ąŠą┐ąĄčĆą░čåąĖčÅą╝ąĖ. ą©ąĖąĮą░ ą┐ą░ą╝čÅčéąĖ, čü ą║ąŠč鹊čĆąŠą╣ čüą▓čÅąĘą░ąĮą░ čÅč湥ą╣ą║ą░ ą┐ą░ą╝čÅčéąĖ ąĖąĮčüčéčĆčāą║čåąĖąĖ TESTSET, ąĮąĄ ą▒čāą┤ąĄčé ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮą░ ą┤ą╗čÅ ą┤čĆčāą│ąĖčģ ą┤ąĄą╣čüčéą▓ąĖą╣ ą┐čĆąŠčåąĄčüčüąŠčĆą░, ą┐ąŠą║ą░ ąĮąĄ ąĘą░ą▓ąĄčĆčłąĖčéčüčÅ ą▓čüčÅ ą░č鹊ą╝ą░čĆąĮą░čÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī čäčāąĮą║čåąĖą╣ ąĖąĮčüčéčĆčāą║čåąĖąĖ TESTSET. ąÆ ą╝ąĮąŠą│ąŠą┐ąŠč鹊čćąĮčŗčģ čüąĖčüč鹥ą╝ą░čģ ąĖąĮčüčéčĆčāą║čåąĖčÅ TESTSET čéčĆąĄą▒čāąĄčéčüčÅ, čćč鹊ą▒čŗ ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░čéčī ą║ąŠą│ąĄčĆąĄąĮčéąĮąŠčüčéčī čĆą░ą▒ąŠčéčŗ čüąĄą╝ą░č乊čĆą░.
ą¦č鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ąŠą┐ąĄčĆą░čåąĖčÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ą▒čŗą╗ą░ čüą▒čĆąŠčłąĄąĮą░ ąĖąĘ ą║čŹčłą░ (ą▒čāč乥čĆą░) ą▓ ą┤ąĄą╣čüčéą▓ąĖč鹥ą╗čīąĮąŠąĄ ą╝ąĄčüč鹊 čģčĆą░ąĮąĄąĮąĖčÅ, ą▓čŗą┐ąŠą╗ąĮąĖč鹥 ąĖąĮčüčéčĆčāą║čåąĖčÄ SSYNC čüčĆą░ąĘčā ą┐ąŠčüą╗ąĄ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ čüąĄą╝ą░č乊čĆą░ (ą┐čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ą┐čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ ą▒ąĖą▒ą╗ąĖąŠč鹥čćąĮčŗčģ čäčāąĮą║čåąĖą╣ ADI ą┤ą╗čÅ čĆą░ą▒ąŠčéčŗ čü čüąĄą╝ą░č乊čĆą░ą╝ąĖ [8] čŹč鹊 ą┤ąĄą╗ą░ąĄčéčüčÅ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ). ąśąĮčüčéčĆčāą║čåąĖčÅ TESTSET ą╝ąŠąČąĄčé ą▒čŗčéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮą░ ą┤ą╗čÅ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą┤ą▓ąŠąĖčćąĮčŗčģ čüąĄą╝ą░č乊čĆąŠą▓ ąĖą╗ąĖ ą╗čÄą▒ąŠą│ąŠ ą┤čĆčāą│ąŠą│ąŠ čéąĖą┐ą░ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą╝ąĄč鹊ą┤ą░ ą▓ąĘą░ąĖą╝ąĮąŠą│ąŠ ąĖčüą║ą╗čÄč湥ąĮąĖčÅ (mutual exclusion). ąśąĮčüčéčĆčāą║čåąĖčÅ TESTSET ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅ ąĮą░ čāčĆąŠą▓ąĮąĄ čüąĖčüč鹥ą╝čŗ ą┤ą╗čÅ ą╝ąĄčģą░ąĮąĖąĘą╝ą░ ą╝ąĮąŠą│ąŠčåąĖą║ą╗ąŠą▓ąŠą╣ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ čłąĖąĮčŗ. ą¤čĆąŠčåąĄčüčüąŠčĆ ąŠą│čĆą░ąĮąĖčćąĖą▓ą░ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ TESTSET č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ąŠą▒ą╗ą░čüčéąĖ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąĖąĮčüčéčĆčāą║čåąĖąĖ TESTSET ą┤ą╗čÅ ą░ą┤čĆąĄčüą░ ą╗čÄą▒ąŠą╣ ą┤čĆčāą│ąŠą╣ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ ąĖą╗ąĖ čĆąĄą│ąĖčüčéčĆąŠą▓, ą┐čĆąĖą▓čÅąĘą░ąĮąĮčŗčģ ą║ ą░ą┤čĆąĄčüąĮąŠą╝čā ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓čā ą┐čĆąŠčåąĄčüčüąŠčĆą░, ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ąĮąĄą┐čĆąĄą┤čüą║ą░ąĘčāąĄą╝ąŠą╝čā ą┐ąŠą▓ąĄą┤ąĄąĮąĖčÄ ą║ąŠą┤ą░.
ą¤čĆąĖą╝ąĄčĆ ąŠą┐čĆąŠčüą░ čüąĄą╝ą░č乊čĆą░. ąøąĖčüčéąĖąĮą│ 21-1 ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┐čĆąĖą╝ąĄčĆ ąŠą┐čĆąŠčüą░ čüąĄą╝ą░č乊čĆą░, č湥ą╝ ą┐čĆąŠą▓ąĄčĆčÅąĄčéčüčÅ ą┤ąŠčüčéčāą┐ąĮąŠčüčéčī ąŠą▒čēąĄą│ąŠ čĆąĄčüčāčĆčüą░.
// ąøąĖčüčéąĖąĮą│ 21-1. Query Semaphore (ąŠą┐čĆąŠčü čüąĄą╝ą░č乊čĆą░).
/* ą¤čĆąĖ ąŠą┐čĆąŠčüąĄ čüąĄą╝ą░č乊čĆą░ ąŠąĮ čüčćąĖčéą░ąĄčéčüčÅ ąĘą░ąĮčÅčéčŗą╝ ("Busy"), ąĄčüą╗ąĖ ąĄą│ąŠ ąĘąĮą░č湥ąĮąĖąĄ
ąĮąĄ čĆą░ą▓ąĮąŠ 0. ą¤čĆąŠąĖčüčģąŠą┤ąĖčé ąŠąČąĖą┤ą░ąĮąĖąĄ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ čüąĄą╝ą░č乊čĆą░ (ąĖą╗ąĖ ą┐čĆąŠą┤ąŠą╗ąČąĄąĮąĖąĄ
ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖčÅ ą┐ąŠč鹊ą║ą░ ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ąŠą╝, čüą╝. ą┐čĆąĖą╝ąĄčćą░ąĮąĖąĄ ąĮąĖąČąĄ). ąĀąĄą│ąĖčüčéčĆ
čāą║ą░ąĘą░č鹥ą╗čÅ P0 čģčĆą░ąĮąĖčé ą░ą┤čĆąĄčü čüąĄą╝ą░č乊čĆą░. */
QUERY:
TESTSET ( P0 );
IF !CC JUMP QUERY;
/* ąÆ čŹč鹊ą╣ č鹊čćą║ąĄ ą║ąŠą┤ą░ čüąĄą╝ą░č乊čĆ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮ č鹥ą║čāčēąĄą╝čā ą┐ąŠč鹊ą║čā, ąĖ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ
ą▓čüąĄčģ ą┤čĆčāą│ąĖąĄ ą║ąŠąĮą║čāčĆąĖčĆčāčÄčēąĖčģ ą┐ąŠč鹊ą║ąŠą▓ (ąŠąČąĖą┤ą░čÄčēąĖčģ čüąĄą╝ą░č乊čĆą░) ą▒čāą┤ąĄčé ą┐čĆąĖąŠčüčéą░ąĮąŠą▓ą╗ąĄąĮąŠ
(ąŠčéą╗ąŠąČąĄąĮąŠ), ą┐ąŠč鹊ą╝čā čćč鹊 čüąĄą╝ą░č乊čĆ, čé. ąĄ. ąĘąĮą░č湥ąĮąĖąĄ, ąĮą░ ą║ąŠč鹊čĆąŠąĄ čāą║ą░ąĘčŗą▓ą░ąĄčé P0,
čüčéą░ąĮąĄčé ąĮąĄąĮčāą╗ąĄą▓čŗą╝. ąóąĄą║čāčēąĖą╣ ą┐ąŠč鹊ą║ ą╝ąŠąČąĄčé ąĘą░ą┐ąĖčüą░čéčī ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆ ą┐ąŠč鹊ą║ą░ ą▓
čÅč湥ą╣ą║čā čüąĄą╝ą░č乊čĆą░, čćč鹊ą▒čŗ ą┐ąŠą║ą░ąĘą░čéčī, ą║ą░ą║ąŠą╣ ą┐ąŠč鹊ą║ ą▓ ąĮą░čüč鹊čÅčēąĖą╣ ą╝ąŠą╝ąĄąĮčé čÅą▓ą╗čÅąĄčéčüčÅ
č鹥ą║čāčēąĄą╝ ą▓ą╗ą░ą┤ąĄą╗čīčåąĄą╝ čüąĄą╝ą░č乊čĆą░ (čĆąĄčüčāčĆčüą░). */
R0.L = THREAD_ID;
B[P0] = R0;
/* ąÜąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ąŠą▒čēąĄą│ąŠ čĆąĄčüčāčĆčüą░ ąĘą░ą▓ąĄčĆčłąĄąĮąŠ, ą▓ čÅč湥ą╣ą║čā [P0]
ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ąĮčāą╗ąĄą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ */
R0 = 0;
B[P0] = R0;
SSYNC;
/* ąÆąØąśą£ąÉąØąśąĢ: ą▓ą╝ąĄčüč鹊 č鹊ą│ąŠ, čćč鹊ą▒čŗ ą▓ čŹč鹊ą╝ ą╝ąĄčüč鹥 ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąŠąČąĖą┤ą░ąĮąĖąĄ čü ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄą╝
čåąĖą║ą╗ąŠą▓ ą┐ąŠ ą╝ąĄčéą║ąĄ QUERY, ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą▓čŗąĘąŠą▓ ąŠą┐ąĄčĆą░čåąĖąŠąĮąĮąŠą╣ čüąĖčüč鹥ą╝čŗ
ą┤ą╗čÅ ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║ąĖ č鹥ą║čāčēąĄą│ąŠ ą┐ąŠč鹊ą║ą░ ąĮą░ čüąĄą╝ą░č乊čĆąĄ, čćč鹊ą▒čŗ ą┐ąŠą┤ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄą╝
ą┐ą╗ą░ąĮąĖčĆąŠą▓čēąĖą║ą░ ąĘą░ą┤ą░čéčī ąĄą│ąŠ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖą╣ ąĘą░ą┐čāčüą║. */
[ąŚą░ą┤ąĄčƹȹ║ąĖ ą┤ą░ąĮąĮčŗčģ, ą╗ą░č鹥ąĮčéąĮąŠčüčéčī ąĖ ą┐ąŠą╗ąŠčüą░ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ]
ąöą╗čÅ ą┐ąŠą╗čāč湥ąĮąĖčÅ ą┐ąŠą┤čĆąŠą▒ąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ąŠ ą╗ą░č鹥ąĮčéąĮąŠčüčéąĖ (ąĘą░ą┤ąĄčƹȹ║ą░čģ) ą┐čĆąĖ ą┤ąŠčüčéčāą┐ąĄ ą║ ą┤ą░ąĮąĮčŗą╝, čćč鹊 ą▓ą╗ąĖčÅąĄčé ąĮą░ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąĖ DMA ą┐čĆąĖ ąŠą▒ą╝ąĄąĮąĄ ą┤ą░ąĮąĮčŗą╝ąĖ ą┐ąŠ ą▓ąĮąĄčłąĮąĖą╝ čłąĖąĮą░ą╝, čüą╝. ąōą╗ą░ą▓čā 7 "Chip Bus Hierarchy" [1]. ąÆ čŹč鹊ą╣ ąČąĄ ą│ą╗ą░ą▓ąĄ ąŠą▒čŖčÅčüąĮčÅąĄčéčüčÅ ą┐čĆąĖąĮčåąĖą┐ čĆą░ą▒ąŠčéčŗ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą▓ ą┤ą╗čÅ čĆą░ąĘą╗ąĖčćąĮčŗčģ ą▓ąĮčāčéčĆąĄąĮąĮąĖčģ čłąĖąĮ.
[ą¤čĆąŠą▒ą╗ąĄą╝čŗ ą┤ąĖąĘą░ą╣ąĮą░, čüą▓čÅąĘą░ąĮąĮčŗąĄ čü ą▓ąĮąĄčłąĮąĄą╣ čłąĖąĮąŠą╣]
ąÆ čŹč鹊ą╝ čĆą░ąĘą┤ąĄą╗ąĄ ąŠą▒čüčāąČą┤ą░čÄčéčüčÅ ą▓ąŠą┐čĆąŠčüčŗ, čüą▓čÅąĘą░ąĮąĮčŗąĄ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ (SRAM, SDRAM, FLASH).
ą¤čĆąĖą╝ąĄčĆ ą░čüąĖąĮčģčĆąŠąĮąĮčŗčģ ąĖąĮč鹥čĆč乥ą╣čüąŠą▓ ą┐ą░ą╝čÅčéąĖ. ąŚą┤ąĄčüčī ą┐ąŠą║ą░ąĘą░ąĮąŠ ą┐čĆąŠąĘčĆą░čćąĮąŠąĄ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖąĄ ą┐čĆąŠčåąĄčüčüąŠčĆą░ Blackfin ą║ 16-ą▒ąĖčéąĮąŠą╝čā ą×ąŚąŻ (SRAM). ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čŹč鹊čé ąĖąĮč鹥čĆč乥ą╣čü ąĮąĄ čéčĆąĄą▒čāąĄčé ą▓čŗčüčéą░ą▓ą╗ąĄąĮąĖčÅ čüąĖą│ąĮą░ą╗ą░ ARDY, ą┐ąŠčüą║ąŠą╗čīą║čā ą▓ąĮčāčéčĆąĄąĮąĮąĖą╣ čüč湥čéčćąĖą║ čüąŠčüč鹊čÅąĮąĖčÅ ąŠąČąĖą┤ą░ąĮąĖčÅ ąĮąĄ čéčĆąĄą▒čāąĄčé ąĘą░ą┤ąĄčƹȹ║ąĖ ą┤ą╗čÅ ąĘą░čĆą░ąĮąĄąĄ ą┐čĆąĄą┤ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ ą┤ąŠčüčéčāą┐ą░ ą║ ą┐ą░ą╝čÅčéąĖ čéą░ą║ąŠą│ąŠ čéąĖą┐ą░. ąĀąĖčü. 21-3 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖčÅ čüąĖčüč鹥ą╝čŗ, čéčĆąĄą▒čāąĄą╝ąŠąĄ ą┤ą╗čÅ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ 16-ą▒ąĖčéąĮčŗčģ čāčüčéčĆąŠą╣čüčéą▓ ą░čüąĖąĮčģčĆąŠąĮąĮąŠą╣ ą┐ą░ą╝čÅčéąĖ. ą£ąŠą┤ąĄą╗čī ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ ą┤ąŠą╗ąČąĮą░ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ą┤ą░ąĮąĮčŗą╝ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ čüčéčĆąŠą│ąŠ ą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗą╣ ą┤ąŠčüčéčāą┐ ą┐ąŠ 16 ą▒ąĖčéą░ą╝ (ą▒ą░ą╣č鹊ą▓čŗą╣ ą░ą┤čĆąĄčü ą┤ąŠą╗ąČąĄąĮ ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖčéčīčüčÅ ąĮą░ 2).
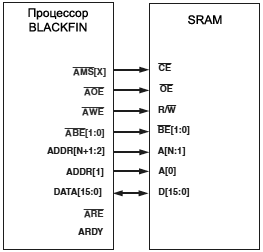
ąĀąĖčü. 21-3. ąśąĮč鹥čĆč乥ą╣čü ą║ 16-ą▒ąĖčéąĮąŠą╣ SRAM.
ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ SDRAM ą╝ąĄąĮčīčłąĄ 16 ą╝ąĄą│ą░ą▒ą░ą╣čé. ąöą╗čÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ADSP-BF538 ą╝ąŠąČąĮąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą┐ą░ą╝čÅčéčī SDRAM čĆą░ąĘą╝ąĄčĆąŠą╝ ą╝ąĄąĮčīčłąĄ 16M ą▒ą░ą╣čé, ąĄčüą╗ąĖ ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░ąĄčéčüčÅ č湥čéą║ąŠąĄ čĆąĄąĘčāą╗čīčéąĖčĆčāčÄčēąĄąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖąĄ ą║ą░čĆčéčŗ ą┐ą░ą╝čÅčéąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░. ąĀąĖčü. 21-4 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ą┐čĆąĖą╝ąĄčĆ, ą│ą┤ąĄ SDRAM ąĮą░ 2 ą╝ąĄą│ą░ą▒ą░ą╣čéą░ (ąŠčĆą│ą░ąĮąĖąĘą░čåąĖčÅ 2 ą▒ą░ąĮą║ą░, ą║ą░ąČą┤čŗą╣ 512K čÅč湥ąĄą║ ą┐ąŠ 16 ą▒ąĖčé) ąŠč鹊ą▒čĆą░ąČąĄąĮą░ ąĮą░ ą░ą┤čĆąĄčüąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ č湥čĆąĄąĘ ąĖąĮč鹥čĆč乥ą╣čü ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ.
ąÆ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ ą║ ą▒ą░ąĮą║čā ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąŠą▒čĆą░čēąĄąĮąĖąĄ ą┐ąŠ ą░ą┤čĆąĄčüčā ąĖąĘ 11 čüčéčĆąŠą║ (row address) ąĖ 8 čüč鹊ą╗ą▒čåąŠą▓ (column address). ąĢčüą╗ąĖ ą┐ąŠčüą╝ąŠčéčĆąĄčéčī ą▓ čéą░ą▒ą╗ąĖčåčā 18-5, čüą░ą╝čŗą╣ ą╝ą░ą╗čŗą╣ ą┤ąŠčüčéčāą┐ąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ ą▒ą░ąĮą║ą░ (16 ą╝ąĄą│ą░ą▒ą░ą╣čé) ą┤ą╗čÅ čāčüčéčĆąŠą╣čüčéą▓ą░ čü ą░ą┤čĆąĄčüąŠą╝ ąĖąĘ 8 čüč鹊ą╗ą▒čåąŠą▓ ąĖą╝ąĄąĄčé 2 čüąĖą│ąĮą░ą╗ą░ ą░ą┤čĆąĄčüą░ ą▒ą░ąĮą║ą░ (IA[23:22]) ąĖ 13 ą░ą┤čĆąĄčüąŠą▓ čüčéčĆąŠą║ąĖ (IA[21:9]). ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, 1 čüąĖą│ąĮą░ą╗ ą░ą┤čĆąĄčüą░ ą▒ą░ąĮą║ą░ ąĖ 2 čüąĖą│ąĮą░ą╗ą░ ą░ą┤čĆąĄčüą░ čüčéčĆąŠą║ąĖ ąĮąĄ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ, čćč鹊 ą╝čŗ ą▓ąĖą┤ąĖą╝ ą▓ čŹč鹊ą╝ ą┐čĆąĖą╝ąĄčĆąĄ. ąŁč鹊 ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ č鹊ą╝čā, ą▓ ą║ą░čĆč鹥 ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ąŠą▒čĆą░ąĘčāčÄčéčüčÅ "ą┤čŗčĆą║ąĖ", ą┐ąŠč鹊ą╝čā čćč鹊 SDRAM ąŠč鹊ą▒čĆą░ąČą░ąĄčéčüčÅ ąĮą░ ą┐čĆąĄčĆčŗą▓ą░čÄčēąĖąĄčüčÅ čĆąĄą│ąĖąŠąĮčŗ ą▓ ą░ą┤čĆąĄčüąĮąŠą╝ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąĄ ą┐čĆąŠčåąĄčüčüąŠčĆą░.

ąĀąĖčü. 21-4. ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ SDRAM ą╝ą░ą╗ąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░.
ąóą░ą▒ą╗ąĖčåą░ 18-5. ą¤čĆąĖą▓čÅąĘą║ą░ ą▓ąĮčāčéčĆąĄąĮąĮąĖčģ ą░ą┤čĆąĄčüąŠą▓.
ąĀą░ąĘą╝ąĄčĆ ą▒ą░ąĮą║ą░, ą╝ąĄą│ą░ą▒ą░ą╣čé (ą▒ąĖčéčŗ EBSZ)
|
ą©ąĖčĆąĖąĮą░ ą░ą┤čĆąĄčüą░ čüč鹊ą╗ą▒čåą░ (ą▒ąĖčéčŗ EBCAW)
|
ąĀą░ąĘą╝ąĄčĆ čüčéčĆą░ąĮąĖčåčŗ, ą║ą▒ą░ą╣čé
|
ąÉą┤čĆąĄčü ą▒ą░ąĮą║ą░
|
ąÉą┤čĆąĄčü čüčéčĆąŠą║ąĖ |
ąĪčéčĆą░ąĮąĖčåą░
|
| ąÉą┤čĆąĄčü čüč鹊ą╗ą▒čåą░ |
ąÉą┤čĆąĄčü ą▒ą░ą╣čéą░ |
128
|
11 |
4 |
IA[26:25] |
IA[24:12] |
IA[11:1] |
IA[0] |
| 10 |
2 |
IA[24:11] |
IA[10:1] |
IA[0] |
| 9 |
1 |
IA[24:10] |
IA[9:1] |
IA[0] |
| 8 |
0.5 |
IA[24:9] |
IA[8:1] |
IA[0] |
64
|
11 |
4 |
IA[25:24] |
IA[23:12] |
IA[11:1] |
IA[0] |
| 10 |
2 |
IA[23:11] |
IA[10:1] |
IA[0] |
| 9 |
1 |
IA[23:10] |
IA[9:1] |
IA[0] |
| 8 |
0.5 |
IA[23:9] |
IA[8:1] |
IA[0] |
32
|
11 |
4 |
IA[24:23] |
IA[22:12] |
IA[11:1] |
IA[0] |
| 10 |
2 |
IA[22:11] |
IA[10:1] |
IA[0] |
| 9 |
1 |
IA[22:10] |
IA[9:1] |
IA[0] |
| 8 |
0.5 |
IA[22:9] |
IA[8:1] |
IA[0] |
16
|
11 |
4 |
IA[23:22] |
IA[21:12] |
IA[11:1] |
IA[0] |
| 10 |
2 |
IA[21:11] |
IA[10:1] |
IA[0] |
| 9 |
1 |
IA[21:10] |
IA[9:1] |
IA[0] |
| 8 |
0.5 |
IA[21:9] |
IA[8:1] |
IA[0] |
ąÆ čüąŠąŠčéą▓ąĄčéčüčéą▓ąĖąĖ čü čéą░ą▒ą╗ąĖčåąĄą╣ čĆąĖčüčāąĮą║ą░ 21-4, ą║ą░ąČą┤ą░čÅ čüčéčĆąŠą║ą░ ą▓ čéą░ą▒ą╗ąĖčåąĄ čüąŠąŠčéą▓ąĄčéčüčéą▓čāąĄčé 2^19 ą▒ą░ą╣čéą░ą╝, ąĖą╗ąĖ 512 ą║ąĖą╗ąŠą▒ą░ą╣čéą░ą╝. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą┐čĆąĖą▓čÅąĘą║ą░ SDRAM ąĮą░ 2 ą╝ąĄą│ą░ą▒ą░ą╣čéą░ ą║ ą░ą┤čĆąĄčüąĮąŠą╝čā ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓čā Blackfin ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ ąŠčéčüčāčéčüčéą▓ąĖčÄ ąĮąĄą┐čĆąĄčĆčŗą▓ąĮąŠčüčéąĖ ą×ąŚąŻ, čćč鹊 ą┐ąŠą║ą░ąĘą░ąĮąŠ ą▓ ą╗ąĄą▓ąŠą╣ čćą░čüčéąĖ čĆąĖčüčāąĮą║ą░. ąĪą░ą╝ąŠ čüąŠą▒ąŠą╣, čŹč鹊 ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čāčćč鹥ąĮąŠ ą┐čĆąĖ ąĮą░ą┐ąĖčüą░ąĮąĖąĖ ą┐čĆąŠą│čĆą░ą╝ą╝čŗ (ąŠč鹊ą▒čĆą░ąČąĄąĮąŠ ą▓ ąŠą┐ąĖčüą░ąĮąĖąĖ čĆąĄą│ąĖąŠąĮąŠą▓ ą┐ą░ą╝čÅčéąĖ čäą░ą╣ą╗ą░ LDF ą┐čĆąŠąĄą║čéą░ VisualDSP++).
[ąŻą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖąĄą╝ SDRAM ą┐čĆąĖ ą┐ąĄčĆąĄąĮą░čüčéčĆąŠą╣ą║ą░čģ PLL]
ą¤ąŠčüą║ąŠą╗čīą║čā čćą░čüč鹊čéą░ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ SDRAM (refresh rate) ą┐čĆąĖą▓čÅąĘą░ąĮą░ ą║ čćą░čüč鹊č鹥 SCLK, č鹊 čüąĮąĖąČąĄąĮąĖąĄ SCLK ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ SDRAM čüą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮą░, ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ąĮąĄą┤ąŠčüčéą░č鹊čćąĮąŠą╣ čćą░čüč鹊č鹥 ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ, čćč鹊 ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą╝ąŠąČąĄčé ą┐ąŠą▓čĆąĄą┤ąĖčéčī ą┤ą░ąĮąĮčŗąĄ, ąĮą░čģąŠą┤čÅčēąĖąĄčüčÅ ą▓ SDRAM. ąĪ ą┤čĆčāą│ąŠą╣ čüč鹊čĆąŠąĮčŗ, ą┐ąŠą▓čŗčłąĄąĮąĖąĄ SCLK ą┐ąŠčüą╗ąĄ ą║ąŠąĮčäąĖą│čāčĆąĖčĆąŠą▓ą░ąĮąĖčÅ SDRAM ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ čüąĮąĖąČąĄąĮąĖčÄ čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéąĖ SDRAM, ą┐ąŠčüą║ąŠą╗čīą║čā ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖąĄ ą┐čĆąĖąŠčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé ąŠą▒čĆą░čēąĄąĮąĖčÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą║ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą╝čā ą×ąŚąŻ, ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 čüą╗ąĖčłą║ąŠą╝ čćą░čüčéčŗąĄ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ ą┐čĆąĖą▓ąŠą┤čÅčé ą║ ąĮąĄąČąĄą╗ą░č鹥ą╗čīąĮčŗą╝ ąĘą░ą┤ąĄčƹȹ║ą░ą╝ ąĖ ą╗ąĖčłąĮąĖą╝ ąĘą░čéčĆą░čéą░ą╝ ą┐čĆąŠčåąĄčüčüąŠčĆąĮąŠą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ.
ąÆ čüąĖčüč鹥ą╝ą░čģ, ą│ą┤ąĄ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ SDRAM čĆąĄą║ąŠą╝ąĄąĮą┤čāąĄčéčüčÅ čüą╗ąĄą┤čāčÄčēą░čÅ ą┐čĆąŠčåąĄą┤čāčĆą░ ą┤ą╗čÅ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ VCO ą┐čĆąĖ ą┐ąĄčĆąĄčüčéčĆąŠą╣ą║ąĄ PLL:
1. ąÆčŗą┤ą░ą╣č鹥 ąĖąĮčüčéčĆčāą║čåąĖčÄ SSYNC, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ąĘą░ą▓ąĄčĆčłąĄąĮčŗ ą▓čüąĄ č鹥ą║čāčēąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ, ąŠąČąĖą┤ą░čÄčēąĖąĄ ą┤ąŠčüčéčāą┐ąĮąŠčüčéąĖ ą┐ą░ą╝čÅčéąĖ.
2. ąŻčüčéą░ąĮąŠą▓ąĖč鹥 čĆąĄąČąĖą╝ čüą░ą╝ąŠąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ SDRAM (self-refresh mode) ą┐čāč鹥ą╝ ąĘą░ą┐ąĖčüąĖ 1 ą▓ ą▒ąĖčé SRFS čĆąĄą│ąĖčüčéčĆą░ EBIU_SDGCTL.
3. ąÆčŗą┐ąŠą╗ąĮąĖč鹥 ąĮąĄąŠą▒čģąŠą┤ąĖą╝čāčÄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆąŠą▓ą░ąĮąĖčÅ PLL (čüą╝. ąōą╗ą░ą▓čā 8 "Dynamic Power Management" [1], ąĖą╗ąĖ ą┐ąĄčĆąĄą▓ąŠą┤ ą▓ čüčéą░čéčīąĄ [6]).
4. ą¤ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ą┐čĆąŠąĖąĘąŠčłą╗ąŠ ą┐čĆąŠą▒čāąČą┤ąĄąĮąĖąĄ (wake-up), čćč鹊 ąŠą▒ąŠąĘąĮą░čćą░ąĄčé ą║ąŠčĆčĆąĄą║čéąĮčāčÄ ą┐ąĄčĆąĄąĮą░čüčéčĆąŠą╣ą║čā PLL ąĮą░ ąĮąŠą▓čāčÄ čćą░čüč鹊čéčā VCO, ą┐ąĄčĆąĄą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆčāą╣č鹥 čćą░čüč鹊čéčā ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ SDRAM (refresh rate) čü ą┐ąŠą╝ąŠčēčīčÄ čĆąĄą│ąĖčüčéčĆą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ EBIU_SDRRC. ąÆ ąĮąĄą│ąŠ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ąĘą░ą┐ąĖčüą░ąĮąŠ ąĮąŠą▓ąŠąĄ ąĘąĮą░č湥ąĮąĖąĄ ą┤ą╗čÅ čüč湥čéčćąĖą║ą░ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄąĄ ąĮąŠą▓ąŠą╣ čćą░čüč鹊č鹥 SCLK.
5. ąÆčŗą▓ąĄą┤ąĖč鹥 SDRAM ąĖąĘ čĆąĄąČąĖą╝ą░ čüą░ą╝ąŠąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ (self-refresh) ąŠčćąĖčüčéą║ąŠą╣ ą▒ąĖčéą░ SRFS čĆąĄą│ąĖčüčéčĆą░ EBIU_SDGCTL. ąĢčüą╗ąĖ čŹč鹊 čéčĆąĄą▒čāąĄčé ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ čĆąĄą│ąĖčüčéčĆą░ čĆąĄąČąĖą╝ą░ SDRAM, ąĘą░ą┐ąĖčłąĖč鹥 čéą░ą║ąČąĄ čŹčéąĖ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą▓ čĆąĄą│ąĖčüčéčĆ EBIU_SDGCTL ąĖ čāą▒ąĄą┤ąĖč鹥čüčī, čćč鹊 čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą▒ąĖčé PSSE.
ąśąĘą╝ąĄąĮąĄąĮąĖąĄ čćą░čüč鹊čéčŗ SCLK čü ą┐ąŠą╝ąŠčēčīčÄ ą▒ąĖč鹊ą▓ SSEL ą▓ čĆąĄą│ąĖčüčéčĆąĄ PLL_DIV, ą▓ ąŠčéą╗ąĖčćąĖąĄ ąŠčé ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ čćą░čüč鹊čéčŗ VCO, ą┤ąŠą╗ąČąĮąŠ ąŠčüčāčēąĄčüčéą▓ą╗čÅčéčīčüčÅ čüą╗ąĄą┤čāčÄčēąĖą╝ąĖ čłą░ą│ą░ą╝ąĖ:
1. ąÆčŗą┤ą░ą╣č鹥 ąĖąĮčüčéčĆčāą║čåąĖčÄ SSYNC, čćč鹊ą▒čŗ ą│ą░čĆą░ąĮčéąĖčĆąŠą▓ą░čéčī, čćč鹊 ąĘą░ą▓ąĄčĆčłąĄąĮčŗ ą▓čüąĄ č鹥ą║čāčēąĖąĄ ąŠą┐ąĄčĆą░čåąĖąĖ, ąŠąČąĖą┤ą░čÄčēąĖąĄ ą┤ąŠčüčéčāą┐ąĮąŠčüčéąĖ ą┐ą░ą╝čÅčéąĖ.
2. ąŻčüčéą░ąĮąŠą▓ąĖč鹥 čĆąĄąČąĖą╝ čüą░ą╝ąŠąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ SDRAM (self-refresh mode) ą┐čāč鹥ą╝ ąĘą░ą┐ąĖčüąĖ 1 ą▓ ą▒ąĖčé SRFS čĆąĄą│ąĖčüčéčĆą░ EBIU_SDGCTL.
3. ąÆčŗą┐ąŠą╗ąĮąĖč鹥 ąĮčāąČąĮčāčÄ ąĘą░ą┐ąĖčüčī ą▓ ą▒ąĖčéčŗ SSEL.
4. ą¤ąĄčĆąĄą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆčāą╣č鹥 čćą░čüč鹊čéčā ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ SDRAM č湥čĆąĄąĘ čĆąĄą│ąĖčüčéčĆ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ EBIU_SDRRC ąĮąŠą▓čŗą╝ ąĘąĮą░č湥ąĮąĖąĄą╝ čüč湥čéčćąĖą║ą░, čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĖą╝ ąĮąŠą▓ąŠą╣ čćą░čüč鹊č鹥 SCLK.
5. ąÆčŗą▓ąĄą┤ąĖč鹥 SDRAM ąĖąĘ čĆąĄąČąĖą╝ą░ čüą░ą╝ąŠąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÅ (self-refresh) ąŠčćąĖčüčéą║ąŠą╣ ą▒ąĖčéą░ SRFS čĆąĄą│ąĖčüčéčĆą░ EBIU_SDGCTL. ąĢčüą╗ąĖ čŹč鹊 čéčĆąĄą▒čāąĄčé ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ čĆąĄą│ąĖčüčéčĆą░ čĆąĄąČąĖą╝ą░ SDRAM, ąĘą░ą┐ąĖčłąĖč鹥 čéą░ą║ąČąĄ čŹčéąĖ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą▓ čĆąĄą│ąĖčüčéčĆ EBIU_SDGCTL ąĖ čāą▒ąĄą┤ąĖč鹥čüčī, čćč鹊 čāčüčéą░ąĮąŠą▓ą╗ąĄąĮ ą▒ąĖčé PSSE.
ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 čłą░ą│ąĖ 2 ąĖ 4 ąĮąĄ ąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ ąĮčāąČąĮąŠ ą▓čŗą┐ąŠą╗ąĮčÅčéčī, ąĄčüą╗ąĖ SCLK ą╝ąĄąĮčÅąĄčéčüčÅ ą▓ čüč鹊čĆąŠąĮčā ą┐ąŠą▓čŗčłąĄąĮąĖčÅ, ąŠą┤ąĮą░ą║ąŠ ą┤ąŠą╗ąČąĮčŗ ą▓čüąĄą│ą┤ą░ ą▓čŗą┐ąŠą╗ąĮčÅčéčīčüčÅ, ą║ąŠą│ą┤ą░ čüąĮąĖąČą░ąĄčéčüčÅ čćą░čüč鹊čéą░ SCLK.
ąöą╗čÅ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą┐ąŠ ąŠą▒ąĮąŠą▓ą╗ąĄąĮąĖčÄ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą│ąŠ ą×ąŚąŻ (SDRAM refresh), čüą╝. čĆą░ąĘą┤ąĄą╗ "SDRAM Controller (SDC)" [1] (čüą╝. čéą░ą║ąČąĄ ą┐ąĄčĆąĄą▓ąŠą┤ ą▓ čüčéą░čéčīąĄ [9]).
[ąÜą░ą║ ąĖąĘą▒ąĄąČą░čéčī ą║ąŠąĮčäą╗ąĖą║č鹊ą▓ ąĮą░ čłąĖąĮąĄ]
ąśąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 čłąĖąĮą░ ą┤ą░ąĮąĮčŗčģ čü čéčĆąĄą╝čÅ čüąŠčüč鹊čÅąĮąĖčÅą╝ąĖ ąĖčüą┐ąŠą╗čīąĘčāąĄčéčüčÅ čüąŠą▓ą╝ąĄčüčéąĮąŠ ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝ąĖ ą▓ čüąĖčüč鹥ą╝ąĄ, ąĖąĘą▒ąĄą│ą░ą╣č鹥 ą║ąŠąĮčäą╗ąĖą║č鹊ą▓ ąĮą░ čłąĖąĮąĄ. ąÜąŠąĮčäą╗ąĖą║čé ą┐čĆąĖą▓ąŠą┤ąĖčé ą║ čćčĆąĄąĘą╝ąĄčĆąĮąŠą╣ čĆą░čüčüąĄąĖą▓ą░ąĄą╝ąŠą╣ ą╝ąŠčēąĮąŠčüčéąĖ, ąĖ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐čĆąĖčćąĖąĮąŠą╣ ąŠčéą║ą░ąĘąŠą▓ čāčüčéčĆąŠą╣čüčéą▓ą░. ąÜąŠąĮčäą╗ąĖą║čé ą┐čĆąŠąĖčüčģąŠą┤ąĖčé, ą║ąŠą│ą┤ą░ ąŠą┤ąĮąŠ čāčüčéčĆąŠą╣čüčéą▓ąŠ ąŠčéą║ą╗čÄčćą░ąĄčéčüčÅ ąŠčé čłąĖąĮčŗ, ąĖ ą┤čĆčāą│ąŠąĄ ąĮą░ąŠą▒ąŠčĆąŠčé, ą┐ąŠą┤ą║ą╗čÄčćą░ąĄčéčüčÅ ą║ ąĮąĄą╣. ąĢčüą╗ąĖ ą┐ąĄčĆą▓ąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ą╝ąĄą┤ą╗ąĄąĮąĮąŠ ą┐ąĄčĆąĄą▓ąŠą┤ąĖčé čüą▓ąŠąĖ čüąĖą│ąĮą░ą╗čŗ čłąĖąĮčŗ ą▓ čéčĆąĄčéčīąĄ čüąŠčüč鹊čÅąĮąĖąĄ, ąĖ ą▓č鹊čĆąŠąĄ čāčüčéčĆąŠą╣čüčéą▓ąŠ ą┐ąŠą┤ą║ą╗čÄčćą░ąĄčé čüą▓ąŠąĖ ą▓čŗčģąŠą┤čŗ ą║ čłąĖąĮąĄ čüą╗ąĖčłą║ąŠą╝ ą▒čŗčüčéčĆąŠ, č鹊 ą▓ąŠąĘąĮąĖą║ą░čÄčé čüą║ą▓ąŠąĘąĮčŗąĄ č鹊ą║ąĖ ą╝ąĄąČą┤čā ą▓čŗčģąŠą┤ą░ą╝ąĖ čāčüčéčĆąŠą╣čüčéą▓, čćč鹊 ąĖ čÅą▓ą╗čÅąĄčéčüčÅ ą║ąŠąĮčäą╗ąĖą║č鹊ą╝.
ąĢčüčéčī 2 čüą╗čāčćą░čÅ, ą║ąŠą│ą┤ą░ ą╝ąŠąČąĄčé ą▓ąŠąĘąĮąĖą║ąĮčāčéčī ą║ąŠąĮčäą╗ąĖą║čé. ą¤ąĄčĆą▓čŗą╣ čüą╗čāčćą░ą╣ - čćč鹥ąĮąĖąĄ, ąĘą░ ą║ąŠč鹊čĆčŗą╝ ąĖą┤ąĄčé ąĘą░ą┐ąĖčüčī ą▓ čéčā ąČąĄ čüą░ą╝čāčÄ ąŠą▒ą╗ą░čüčéčī ą┐ą░ą╝čÅčéąĖ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą┤čĆą░ą╣ą▓ąĄčĆčŗ čłąĖąĮčŗ ą┤ą░ąĮąĮčŗčģ ą╝ąŠą│čāčé ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ ą║ąŠąĮčäą╗ąĖą║č鹊ą▓ą░čéčī čü ą┤čĆą░ą╣ą▓ąĄčĆą░ą╝ąĖ čāčüčéčĆąŠą╣čüčéą▓ą░ ą┐ą░ą╝čÅčéąĖ, ą║ąŠą│ą┤ą░ čāčüčéčĆąŠą╣čüčéą▓ąŠ ą▒čŗą╗ąŠ ą░ą┤čĆąĄčüąŠą▓ą░ąĮąŠ ąĮą░ čćč鹥ąĮąĖąĄ. ąÆč鹊čĆąŠą╣ čüą╗čāčćą░ą╣ čŹč鹊 čćč鹥ąĮąĖąĄ čéąĖą┐ą░ back-to-back ąĖąĘ ą┤ą▓čāčģ čĆą░ąĘąĮčŗčģ ąŠą▒ą╗ą░čüč鹥ą╣ ą┐ą░ą╝čÅčéąĖ. ąÆ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą┤ą▓ą░ čāčüčéčĆąŠą╣čüčéą▓ą░ ą┐ą░ą╝čÅčéąĖ ą┐ąŠąŠč湥čĆąĄą┤ąĮąŠ ą┐ąŠą┤ą║ą╗čÄčćą░čÄčé čüą▓ąŠąĖ ą▓čŗčģąŠą┤čŗ ą║ čłąĖąĮąĄ ą┤ą░ąĮąĮčŗčģ, ą║ąŠą│ą┤ą░ ąŠą┤ąĮąŠ čćč鹥ąĮąĖąĄ ąĖą┤ąĄčé ąĘą░ ą┤čĆčāą│ąĖą╝, čćč鹊 ą┐ąŠč鹥ąĮčåąĖą░ą╗čīąĮąŠ ą╝ąŠąČąĄčé ą┐čĆąĖą▓ąĄčüčéąĖ ą║ ą║ąŠąĮčäą╗ąĖą║čéą░ą╝ ą╝ąĄąČą┤čā ą┤ą▓čāą╝čÅ ąŠą┐ąĄčĆą░čåąĖčÅą╝ąĖ čćč鹥ąĮąĖčÅ.
ą¦č鹊ą▒čŗ ąĖąĘą▒ąĄąČą░čéčī ą║ąŠąĮčäą╗ąĖą║čéą░, ąĘą░ą┐čĆąŠą│čĆą░ą╝ą╝ąĖčĆčāą╣č鹥 čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄąĄ ą▓čĆąĄą╝čÅ "ą┐ąŠą╗ąĮąŠą│ąŠ čĆąĄą╣čüą░" (turnaround time, ąĖą╗ąĖ ą▓čĆąĄą╝čÅ ą┐ąĄčĆąĄčģąŠą┤ą░ ą╝ąĄąČą┤čā ą▒ą░ąĮą║ą░ą╝ąĖ, bank transition time) ą▓ čĆąĄą│ąĖčüčéčĆą░čģ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą░čüąĖąĮčģčĆąŠąĮąĮčŗą╝ąĖ ą▒ą░ąĮą║ą░ą╝ąĖ ą┐ą░ą╝čÅčéąĖ. ąŁčéą░ čäčāąĮą║čåąĖčÅ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐čĆąŠą│čĆą░ą╝ą╝ąĮąŠą╝čā ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖčÄ čāčüčéą░ąĮąŠą▓ąĖčéčī ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čéą░ą║č鹊ą▓ ą╝ąĄąČą┤čā čŹčéąĖą╝ąĖ čéąĖą┐ą░ą╝ąĖ ą┤ąŠčüčéčāą┐ą░ ąĮą░ ą▒ą░ąĘąĄ ą┐ąĄčĆąĄčģąŠą┤ą░ ąŠčé ą▒ą░ąĮą║ą░ ą║ ą▒ą░ąĮą║čā. ą£ąĖąĮąĖą╝ą░ą╗čīąĮąŠ ąĖąĮč鹥čĆč乥ą╣čü ą▓ąĮąĄčłąĮąĄą╣ čłąĖąĮčŗ (external bus interface unit, EBIU) ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ąŠą┤ąĖąĮ čéą░ą║čé ą┤ą╗čÅ ąŠčüčāčēąĄčüčéą▓ą╗ąĄąĮąĖčÅ ą┐ąĄčĆąĄčģąŠą┤ą░.
[ą¤čĆąŠą▒ą╗ąĄą╝čŗ ą▓čŗčüąŠą║ąŠčćą░čüč鹊čéąĮąŠą│ąŠ ą┤ąĖąĘą░ą╣ąĮą░]
ąśąĘ-ąĘą░ č鹊ą│ąŠ, čćč鹊 ą┐čĆąŠčåąĄčüčüąŠčĆ ą╝ąŠąČąĄčé čĆą░ą▒ąŠčéą░čéčī ąĮą░ ąŠč湥ąĮčī ą▓čŗčüąŠą║ąĖčģ čéą░ą║č鹊ą▓čŗčģ čćą░čüč鹊čéą░čģ, ą▓ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĄ čĆą░ąĘą▓ąŠą┤ą║ąĖ ą┐ąĄčćą░čéąĮąŠą╣ ą┐ą╗ą░čéčŗ ą┤ąŠą╗ąČąĮąŠ čāčćąĖčéčŗą▓ą░čéčīčüčÅ ą║ą░č湥čüčéą▓ąŠ ą┐ąĄčĆąĄą┤ą░čćąĖ čüąĖą│ąĮą░ą╗ąŠą▓ (signal integrity) ąĖ čāčüčéčĆą░ąĮąĄąĮąĖąĄ ą┐čĆąŠą▒ą╗ąĄą╝ čłčāą╝ą░ ąĖ ą┐ąŠą╝ąĄčģ. ąÆ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖčģ čüąĄą║čåąĖčÅčģ ąŠą▒čüčāąČą┤ą░čÄčéčüčÅ čŹčéąĖ ą▓ąŠą┐čĆąŠčüčŗ, ąĖ ą┤ą░čÄčéčüčÅ čüąŠą▓ąĄčéčŗ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖčÅ čĆą░ąĘą╗ąĖčćąĮčŗčģ č鹥čģąĮąĖą║ ą▓ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĄ ąĖ ąŠčéą╗ą░ą┤ą║ąĄ čüąĖčüč鹥ą╝ ąŠą▒čĆą░ą▒ąŠčéą║ąĖ čüąĖą│ąĮą░ą╗ąŠą▓ (DSP).
ąĪąŠąĄą┤ąĖąĮąĄąĮąĖąĄ č鹊čćą║ą░-č鹊čćą║ą░ ą┤ą╗čÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗčģ ą┐ąŠčĆč鹊ą▓. ąźąŠčéčÅ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗąĄ ą┐ąŠčĆčéčŗ ą╝ąŠą│čāčé čĆą░ą▒ąŠčéą░čéčī ąĮą░ ąĮąĖąĘą║ąŠą╣ čüą║ąŠčĆąŠčüčéąĖ, ąĖčģ ą▓čŗčģąŠą┤ąĮčŗąĄ ą┤čĆą░ą╣ą▓ąĄčĆčŗ ą▓čüąĄ ąĄčēąĄ ąĖą╝ąĄčÄčé ą▒čŗčüčéčĆčŗąĄ čäčĆąŠąĮčéčŗ ą┐ąĄčĆąĄą║ą╗čÄč湥ąĮąĖčÅ ą╗ąŠą│ąĖč湥čüą║ąĖčģ čāčĆąŠą▓ąĮąĄą╣, ąĖ ąĄčüą╗ąĖ ą┤ą╗ąĖąĮą░ čüąŠąĄą┤ąĖąĮąĖč鹥ą╗čīąĮąŠą╣ ą╗ąĖąĮąĖąĖ ą▓ąĄą╗ąĖą║ą░, č鹊 ą┤ą╗čÅ ą┤čĆą░ą╣ą▓ąĄčĆąŠą▓ ą╝ąŠąČąĄčé ą┐ąŠčéčĆąĄą▒ąŠą▓ą░čéčīčüčÅ ą║ąŠčĆčĆąĄą║čéąĮąŠąĄ č鹥čĆą╝ąĖąĮąĖčĆąŠą▓ą░ąĮąĖąĄ ąĖčüč鹊čćąĮąĖą║ą░.
ąöą╗čÅ čüą│ą╗ą░ąČąĖą▓ą░ąĮąĖčÅ čäčĆąŠąĮč鹊ą▓ ąĖ čüąĮąĖąČąĄąĮąĖčÅ ą┐ąŠą╝ąĄčģ ąÆčŗ ą╝ąŠąČąĄč鹥 ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ ą┐ąŠą┤ą║ą╗čÄčćąĖčéčī čĆąĄąĘąĖčüč鹊čĆ čĆčÅą┤ąŠą╝ čü ą▓čŗą▓ąŠą┤ąŠą╝, ąĮą░ ą║ąŠč鹊čĆąŠą╝ ąŠčüčāčēąĄčüčéą▓ą╗čÅąĄčéčüčÅ čüąŠąĄą┤ąĖąĮąĄąĮąĖąĄ č鹊čćą║ą░-č鹊čćą║ą░. ą×ą▒čŗčćąĮąŠ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ, ąĖčüą┐ąŠą╗čīąĘčāčÄčēąĖąĄ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮčŗą╣ ą┐ąŠčĆčé, ąĖčüą┐ąŠą╗čīąĘčāčÄčé čéą░ą║ąŠą╣ čéąĖą┐ č鹥čĆą╝ąĖąĮąĖčĆąŠą▓ą░ąĮąĖčÅ, ą║ąŠą│ą┤ą░ čĆą░čüčüč鹊čÅąĮąĖąĄ čüąŠąĄą┤ąĖąĮąĖč鹥ą╗čīąĮąŠą╣ ą╗ąĖąĮąĖąĖ čüąĖą│ąĮą░ą╗ą░ ą┐čĆąĄą▓čŗčłą░ąĄčé 6 ą┤čÄą╣ą╝ąŠą▓ (152 ą╝ą╝). ą¤ąŠą┤čĆąŠą▒ąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ čĆąĄčłąĄąĮąĖčÅ ą┐čĆąŠą▒ą╗ąĄą╝ č鹥čĆą╝ąĖąĮąĖčĆąŠą▓ą░ąĮąĖčÅ ą╗ąĖąĮąĖą╣ ą┐ąĄčĆąĄą┤ą░čćąĖ ąĖčēąĖč鹥 ą▓ čüą┐ąĄčåąĖą░ą╗čīąĮąŠą╣ ą╗ąĖč鹥čĆą░čéčāčĆąĄ (ą┐čĆąĖą╝ąĄčĆ čüą╝. ą▓ąŠ ą▓čĆąĄąĘą║ąĄ). ąóą░ą║ąČąĄ čüą╝. ą┤ą░čéą░čłąĖčé ąĮą░ ą┐čĆąŠčåąĄčüčüąŠčĆ ADSP-BF538/ADSP-BF538F, ą│ą┤ąĄ ą┤ą░ąĮčŗ ą┐ą░čĆą░ą╝ąĄčéčĆčŗ ą▓čĆąĄą╝ąĄąĮąĖ ąĮą░čĆą░čüčéą░ąĮąĖčÅ ąĖ čüą┐ą░ą┤ą░ ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ ą▓čŗčģąŠą┤ąĮčŗčģ ą┤čĆą░ą╣ą▓ąĄčĆąŠą▓.
ąŁčéą░ ą║ąĮąĖą│ą░ - č鹥čģąĮąĖč湥čüą║ąĖą╣ čüą┐čĆą░ą▓ąŠčćąĮąĖą║, ą║ąŠč鹊čĆčŗą╣ ą║ą░čüą░ąĄčéčüčÅ ą┐čĆąŠą▒ą╗ąĄą╝, čü ą║ąŠč鹊čĆčŗą╝ąĖ ą▓čüčéčĆąĄčćą░čÄčéčüčÅ čĆą░ąĘčĆą░ą▒ąŠčéčćąĖą║ąĖ ą┐čĆąĖ ą┐čĆąŠąĄą║čéąĖčĆąŠą▓ą░ąĮąĖąĖ ą▓čŗčüąŠą║ąŠčćą░čüč鹊čéąĮčŗčģ čåąĖčäčĆąŠą▓čŗčģ čüčģąĄą╝. ąŁč鹊 ąŠčéą╗ąĖčćąĮčŗą╣ ąĖčüč鹊čćąĮąĖą║ ą┐ąŠą╗ąĄąĘąĮąŠą╣ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ąĖ ą┐čĆą░ą║čéąĖč湥čüą║ąĖčģ ąĖą┤ąĄą╣. ąÆ ą║ąĮąĖą│ąĄ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░čÄčéčüčÅ čüą╗ąĄą┤čāčÄčēąĖąĄ č鹥ą╝čŗ:
ŌĆó ąÆčŗčüąŠą║ąŠčćą░čüč鹊čéąĮčŗąĄ čüą▓ąŠą╣čüčéą▓ą░ ą╗ąŠą│ąĖč湥čüą║ąĖčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓
ŌĆó ąóąĄčģąĮąĖą║ąĖ ąĖąĘą╝ąĄčĆąĄąĮąĖčÅ
ŌĆó ąøąĖąĮąĖąĖ ą┐ąĄčĆąĄą┤ą░čćąĖ
ŌĆó ąŚą░ą╗ąĖą▓ą║ąĖ ą╝ąĄą┤čīčÄ, ą╝ąĮąŠą│ąŠčüą╗ąŠą╣ąĮčŗąĄ ą┐ąĄčćą░čéąĮčŗąĄ ą┐ą╗ą░čéčŗ
ŌĆó ąóąĄčĆą╝ąĖąĮąĖčĆąŠą▓ą░ąĮąĖąĄ čüąĖą│ąĮą░ą╗ąŠą▓
ŌĆó ą¤ąĄčĆąĄčģąŠą┤ąĮčŗąĄ ąŠčéą▓ąĄčĆčüčéąĖčÅ ą▓ ą┐ąĄčćą░čéąĮąŠą╣ ą┐ą╗ą░č鹥 (via)
ŌĆó ąĪąĖčüč鹥ą╝čŗ ą┐ąĖčéą░ąĮąĖčÅ
ŌĆó ąÜąŠąĮąĮąĄą║č鹊čĆčŗ (čüąŠąĄą┤ąĖąĮąĖč鹥ą╗ąĖ)
ŌĆó ąøąĄąĮč鹊čćąĮčŗąĄ ą║ą░ą▒ąĄą╗ąĖ
ŌĆó ąØą░čĆčāčłąĄąĮąĖčÅ čéą░ą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ
ŌĆó ąóą░ą║č鹊ą▓čŗąĄ ą│ąĄąĮąĄčĆą░č鹊čĆčŗ
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: ąĘą┤ąĄčüčī ąĮąĄ čĆą░čüčüą╝ą░čéčĆąĖą▓ą░čÄčéčüčÅ ą▓ąŠą┐čĆąŠčüčŗ ą┐čĆąŠąĄą║čéąĖčĆąŠą▓ą░ąĮąĖčÅ ą░ąĮą░ą╗ąŠą│ąŠą▓čŗčģ čćą░čüč鹥ą╣ čüčģąĄą╝čŗ (čāčüąĖą╗ąĖč鹥ą╗ąĖ, čäąĖą╗čīčéčĆčŗ, ą▓čģąŠą┤ąĮčŗąĄ čåąĄą┐ąĖ ąÉą”ą¤), ą║ąŠč鹊čĆčŗąĄ čéą░ą║ąČąĄ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čāč湥ąĮčŗ ą┤ą╗čÅ ą┐ąŠčüčéčĆąŠąĄąĮąĖčÅ čüąĖčüč鹥ą╝čŗ čü ą╝ąĖąĮąĖą╝ą░ą╗čīąĮčŗą╝ čāčĆąŠą▓ąĮąĄą╝ ą┐ąŠą╝ąĄčģ.
ąÜą░č湥čüčéą▓ąŠ ą┐ąĄčĆąĄą┤ą░čćąĖ čüąĖą│ąĮą░ą╗ąŠą▓ (Signal Integrity). ąĢą╝ą║ąŠčüčéąĮą░čÅ ą┐ą░čĆą░ąĘąĖčéąĮą░čÅ ąĮą░ą│čĆčāąĘą║ą░ ąĮą░ ą▓čŗčüąŠą║ąŠčüą║ąŠčĆąŠčüčéąĮčŗčģ čüąĖą│ąĮą░ą╗ą░čģ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ čāą╝ąĄąĮčīčłąĄąĮą░, ąĮą░čüą║ąŠą╗čīą║ąŠ čŹč鹊 ą▓ąŠąĘą╝ąŠąČąĮąŠ. ąØą░ą│čĆčāąĘą║ą░ čłąĖąĮ ą╝ąŠąČąĄčé ą▒čŗčéčī čāą╝ąĄąĮčīčłąĄąĮą░ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ą▒čāč乥čĆąŠą▓ ą┤ą╗čÅ čāčüčéčĆąŠą╣čüčéą▓, ą║ąŠč鹊čĆčŗąĄ ą╝ąŠą│čāčé čĆą░ą▒ąŠčéą░čéčī čü čéą░ą║čéą░ą╝ąĖ ąŠąČąĖą┤ą░ąĮąĖčÅ (ąĮą░ą┐čĆąĖą╝ąĄčĆ, ą╝ąĖą║čĆąŠčüčģąĄą╝čŗ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠą╣ ą┐ą░ą╝čÅčéąĖ, DRAM). ąŁč鹊 čüąĮąĖąČą░ąĄčé ąĄą╝ą║ąŠčüčéčī čüąĖą│ąĮą░ą╗ąŠą▓, ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĮčŗčģ ą║ čāčüčéčĆąŠą╣čüčéą▓ą░ą╝, ą║ąŠč鹊čĆčŗąĄ ą┐ąĄčĆąĄą║ą╗čÄčćą░čÄčé čüą▓ąŠąĖ ą▓čŗčģąŠą┤čŗ ą▓ čéčĆąĄčéčīąĄ čüąŠčüč鹊čÅąĮąĖąĄ, čćč鹊 ą┐ąŠąĘą▓ąŠą╗čÅąĄčé čéą░ą║ąĖą╝ čüąĖą│ąĮą░ą╗ą░ą╝ ą▒čŗčüčéčĆąĄąĄ ą┐ąĄčĆąĄą║ą╗čÄčćą░čéčīčüčÅ, ąĖ čüąĮąĖąČą░ąĄčé ą│ąĄąĮąĄčĆąĖčĆąŠą▓ą░ąĮąĖąĄ ą┐ąŠą╝ąĄčģ ą┐ąŠ ą┐ąĖčéą░ąĮąĖčÄ ąĖąĘ-ąĘą░ ąĖą╝ą┐čāą╗čīčüąĮčŗčģ č鹊ą║ąŠą▓ ą┐ąĄčĆąĄąĘą░čĆčÅą┤ą║ąĖ ą┐ą░čĆą░ąĘąĖčéąĮčŗčģ ąĄą╝ą║ąŠčüč鹥ą╣.
ąöą╗ąĖąĮą░ ą┐čĆąŠčģąŠąČą┤ąĄąĮąĖčÅ čüąĖą│ąĮą░ą╗ąŠą▓ (ą▓ą╗ąĖčÅąĄčé ąĮą░ ą┐ą░čĆą░ąĘąĖčéąĮčāčÄ ąĖąĮą┤čāą║čéąĖą▓ąĮąŠčüčéčī ą╗ąĖąĮąĖąĖ) čéą░ą║ąČąĄ ą┤ąŠą╗ąČąĮą░ ą▒čŗčéčī čāą╝ąĄąĮčīčłąĄąĮą░ ą┤ą╗čÅ čüąĮąĖąČąĄąĮąĖčÅ ą┐ą░čĆą░ąĘąĖčéąĮčŗčģ ą║ąŠą╗ąĄą▒ą░ąĮąĖą╣ (čéą░ą║ ąĮą░ąĘčŗą▓ą░ąĄą╝čŗą╣ "ąĘą▓ąŠąĮ"). ą×čüąŠą▒ąŠąĄ ą▓ąĮąĖą╝ą░ąĮąĖąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čāą┤ąĄą╗ąĄąĮąŠ čüąĖą│ąĮą░ą╗ą░ą╝ ą▓ąĮąĄčłąĮąĄą╣ ą┐ą░ą╝čÅčéąĖ ąĖ čüčéčĆąŠą▒ą░ą╝ čćč鹥ąĮąĖčÅ, ąĘą░ą┐ąĖčüąĖ ąĖ ą┐ąŠą┤čéą▓ąĄčƹȹ┤ąĄąĮąĖčÅ ąŠą┐ąĄčĆą░čåąĖąĖ.
ąöčĆčāą│ąĖąĄ čĆąĄą║ąŠą╝ąĄąĮą┤ą░čåąĖąĖ ąĖ ą┐čĆąĄą┤ą╗ąŠąČąĄąĮąĖčÅ, čüą┐ąŠčüąŠą▒čüčéą▓čāčÄčēąĖąĄ čåąĄą╗ąŠčüčéąĮąŠčüčéąĖ čüąĖą│ąĮą░ą╗ąŠą▓:
ŌĆó ąśčüą┐ąŠą╗čīąĘčāą╣č鹥 ą╝ąĮąŠą│ąŠčüą╗ąŠą╣ąĮčāčÄ ą┐ą╗ą░čéčā čü ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ (ąČąĄą╗ą░č鹥ą╗čīąĮąŠ ąĮąĄ ą╝ąĄąĮčīčłąĄ ą┤ą▓čāčģ) čüą┐ą╗ąŠčłąĮčŗą╝ąĖ ą╝ąĄą┤ąĮčŗą╝ąĖ ąĘą░ą╗ąĖą▓ą║ą░ą╝ąĖ ą╝ąĄą┤čīčÄ ą┤ą╗čÅ čłąĖąĮčŗ ąĘąĄą╝ą╗ąĖ (ground plane), čćč鹊ą▒čŗ čāą╝ąĄąĮčīčłąĖčéčī ą┐ąĄčĆąĄą║čĆąĄčüčéąĮčŗąĄ ą┐ąŠą╝ąĄčģąĖ ą╝ąĄąČą┤čā čüąĖą│ąĮą░ą╗ą░ą╝ąĖ, čé. ąĄ. ą▓ą╗ąĖčÅąĮąĖąĄ čüąĖą│ąĮą░ą╗ąŠą▓ ą┤čĆčāą│ ąĮą░ ą┤čĆčāą│ą░ ąĖąĘ-ąĘą░ ą┐ą░čĆą░ąĘąĖčéąĮčŗčģ ąĄą╝ą║ąŠčüč鹥ą╣ (crosstalk). ąŻą▒ąĄą┤ąĖč鹥čüčī, čćč鹊 ąĖčüą┐ąŠą╗čīąĘčāąĄč鹥 ą┤ąŠčüčéą░č鹊čćąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą┐ąĄčĆąĄą╝čŗč湥ą║ (ą┐ąĄčĆąĄčģąŠą┤ąŠą▓) ą╝ąĄąČą┤čā čŹčéąĖą╝ąĖ čüą╗ąŠčÅą╝ąĖ. ąŁčéąĖ ąĘą░ą╗ąĖą▓ą║ąĖ ą┤ąŠą╗ąČąĮčŗ ąĮą░čģąŠą┤ąĖčéčīčüčÅ ą▓ čüąĄčĆąĄą┤ąĖąĮąĄ ą┐ąĄčćą░čéąĮąŠą╣ ą┐ą╗ą░čéčŗ.
ŌĆó ąĪčéą░čĆą░ą╣č鹥čüčī čĆą░ąĘą▓ąŠą┤ąĖčéčī ą║čĆąĖčéąĖč湥čüą║ąĖąĄ čüąĖą│ąĮą░ą╗čŗ, čéą░ą║ąĖąĄ ą║ą░ą║ čéą░ą║čéčŗ, čüčéčĆąŠą▒čŗ, ąĘą░ą┐čĆąŠčüčŗ ąĮą░ ą┤ąŠčüčéčāą┐ ą║ čłąĖąĮąĄ, ąĮą░ čüąĖą│ąĮą░ą╗čīąĮąŠą╝ čüą╗ąŠąĄ, ą║ąŠč鹊čĆčŗą╣ čÅą▓ą╗čÅąĄčéčüčÅ čüąŠčüąĄą┤ąĮąĖą╝ čüąŠ čüą╗ąŠąĄą╝ ąĘąĄą╝ą╗ąĖ. ąĪčéą░čĆą░ą╣č鹥čüčī čĆą░ąĘą▓ąŠą┤ąĖčéčī čŹčéąĖ čüąĖą│ąĮą░ą╗čŗ ą┐ąĄčĆą┐ąĄąĮą┤ąĖą║čāą╗čÅčĆąĮąŠ ą║ ą┤čĆčāą│ąĖą╝ čüąĖą│ąĮą░ą╗ą░ą╝ ąĖ ą┐ąŠą┤ą░ą╗čīčłąĄ ąŠčé ąĮąĖčģ, čćč鹊ą▒čŗ čāą╝ąĄąĮčīčłąĖčéčī ąĖąĮą┤čāą║čéąĖą▓ąĮčŗąĄ ąĖ ąĄą╝ą║ąŠčüčéąĮčŗąĄ ą┐ąŠą╝ąĄčģąĖ ąĖ ąĮą░ą▓ąŠą┤ą║ąĖ.
ŌĆó ąĪčéą░čĆą░ą╣č鹥čüčī ą┐čĆąŠąĄą║čéąĖčĆąŠą▓ą░čéčī ą┐ą╗ą░čéčā čü čāč湥č鹊ą╝ čüąĮąĖąČąĄąĮąĖčÅ čüąŠą┐čĆąŠčéąĖą▓ą╗ąĄąĮąĖčÅ ą╗ąĖąĮąĖąĖ ą┐ąĄčĆąĄą┤ą░čćąĖ, čćč鹊ą▒čŗ čüąĮąĖąĘąĖčéčī ą┐ąĄčĆąĄą║čĆąĄčüčéąĮčŗąĄ ą┐ąŠą╝ąĄčģąĖ, ąĖ ą┐ąŠą╗čāčćąĖčéčī ą╗čāčćčłąĄąĄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ąĮą░ą┤ čüąŠą┐čĆąŠčéąĖą▓ą╗ąĄąĮąĖąĄą╝ ą╗ąĖąĮąĖąĖ ąĖ ąĘą░ą┤ąĄčƹȹ║ąŠą╣ čĆą░čüą┐čĆąŠčüčéčĆą░ąĮąĄąĮąĖčÅ čüąĖą│ąĮą░ą╗ą░.
ŌĆó ą¤čĆąŠą▓ąŠą┤ąĖč鹥 菹║čüą┐ąĄčĆąĖą╝ąĄąĮčéčŗ čü ą┐ąĄčćą░čéąĮąŠą╣ ą┐ą╗ą░č鹊ą╣, čćč鹊ą▒čŗ ąĮą░ą╣čéąĖ ą┐čĆąĖčćąĖąĮčā ą┐čĆąŠą▒ą╗ąĄą╝ čü ą┐ąĄčĆąĄą║čĆąĄčüčéąĮčŗą╝ąĖ ą┐ąŠą╝ąĄčģą░ą╝ąĖ ą╝ąĄąČą┤čā ąĖąĘąŠą╗ąĖčĆąŠą▓ą░ąĮąĮčŗą╝ąĖ čåąĄą┐čÅą╝ąĖ ąĖ ą┐čĆąŠą▒ą╗ąĄą╝ čü ą┐ąŠą╝ąĄčģą░ą╝ąĖ ąĖąĘ-ąĘą░ ąŠčéčĆą░ąČąĄąĮąĖą╣ čüąĖą│ąĮą░ą╗ą░. ą¤ąŠą┤ąŠą▒ąĮčŗąĄ 菹║čüą┐ąĄčĆąĖą╝ąĄąĮčéčŗ ą╝ąŠąČąĮąŠ ą┐čĆąŠą▓ąĄčüčéąĖ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄą╝ čüąĖą│ąĮą░ą╗čīąĮčŗą╝ ą┐čĆąŠą▓ąŠą┤ąĮąĖą║ąŠą╝ ąŠčé ą│ąĄąĮąĄčĆą░č鹊čĆą░ ąĖą╝ą┐čāą╗čīčüąŠą▓, ą░ąĮą░ą╗ąĖąĘąĖčĆčāčÅ ą┐ąŠą╝ąĄčģąĖ ąĖ ąŠčéčĆą░ąČąĄąĮąĖčÅ, ą▓ č鹊 ą▓čĆąĄą╝čÅ ą║ą░ą║ ą┤čĆčāą│ąĖąĄ ą║ąŠą╝ą┐ąŠąĮąĄąĮčéčŗ ąĖ čüąĖą│ąĮą░ą╗čŗ čüąĖčüč鹥ą╝čŗ ąĮą░čģąŠą┤čÅčéčüčÅ ą▓ ąĮąĄą░ą║čéąĖą▓ąĮąŠą╝ čüąŠčüč鹊čÅąĮąĖąĖ.
ąæą╗ąŠą║ąĖčĆčāčÄčēąĖąĄ ą║ąŠąĮą┤ąĄąĮčüą░č鹊čĆčŗ ąĖ ąĘą░ą╗ąĖą▓ą║ąĖ ą╝ąĄą┤čīčÄ. ąöą╗čÅ čłąĖąĮ ąĘąĄą╝ą╗ąĖ ąĖ ą┐ąĖčéą░ąĮąĖčÅ ą┤ąŠą╗ąČąĮčŗ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ąĘą░ą╗ąĖą▓ą║ąĖ ą╝ąĄą┤čīčÄ (ground plane), ą▓čŗą┐ąŠą╗ąĮąĄąĮąĮčŗąĄ ą║ą░ą║ ąĮą░ čüąĖą│ąĮą░ą╗čīąĮčŗčģ, čéą░ą║ ąĖ ąĮą░ ąŠčéą┤ąĄą╗čīąĮčŗčģ ą▓ąĮčāčéčĆąĄąĮąĮąĖčģ čüą╗ąŠčÅčģ ą┐ąĄčćą░čéąĮąŠą╣ ą┐ą╗ą░čéčŗ. ąĀą░ąĘą▓čÅąĘčŗą▓ą░čÄčēąĖąĄ (ą▒ą╗ąŠą║ąĖčĆčāčÄčēąĖąĄ ą┐ąŠą╝ąĄčģąĖ ą┐ąŠ ą┐ąĖčéą░ąĮąĖčÄ) ą║ąŠąĮą┤ąĄąĮčüą░č鹊čĆčŗ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čĆą░ąĘą╝ąĄčēąĄąĮčŗ ą▓ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ ą▒ą╗ąĖąĘąŠčüčéąĖ ą║ ą▓čŗą▓ąŠą┤ą░ą╝ VDDEXT ąĖ VDDINT ą║ąŠčĆą┐čāčüą░ ą┐čĆąŠčåąĄčüčüąŠčĆą░, ą║ą░ą║ ą┐ąŠą║ą░ąĘą░ąĮąŠ ąĮą░ čĆąĖčü. 21-5. ąśčüą┐ąŠą╗čīąĘčāą╣č鹥 ą║ąŠčĆąŠčéą║ąĖąĄ ąĖ č鹊ą╗čüčéčŗąĄ ą┐čĆąŠą▓ąŠą┤ąĮąĖą║ąĖ ą┤ą╗čÅ čłąĖąĮ ą┐ąĖčéą░ąĮąĖčÅ. ąÆčŗą▓ąŠą┤ ąĘąĄą╝ą╗ąĖ ą║ąŠąĮą┤ąĄąĮčüą░č鹊čĆąŠą▓ ą┤ąŠą╗ąČąĄąĮ ą┐ąŠą┤ą║ą╗čÄčćą░čéčīčüčÅ ąĮą░ą┐čĆčÅą╝čāčÄ ą║ ąĘą░ą╗ąĖą▓ą║ąĄ ą╝ąĄą┤čīčÄ, ą║ąŠąĮą┤ąĄąĮčüą░č鹊čĆčŗ ą┤ąŠą╗ąČąĮčŗ ąĮą░čģąŠą┤ąĖčéčīčüčÅ ą╗ąĖą▒ąŠ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą▒ą╗ąĖąĘą║ąŠ ą║ ą║ąŠčĆą┐čāčüčā ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą┐čĆąĖ čĆą░ąĘą╝ąĄčēąĄąĮąĖąĖ ą║ąŠąĮą┤ąĄąĮčüą░č鹊čĆąŠą▓ ąĮą░ ą▓ąĄčĆčģąĮąĄą╝ čüą╗ąŠąĄ ą┐ą╗ą░čéčŗ, ą╗ąĖą▒ąŠ ąĮą░čģąŠą┤ąĖčéčīčüčÅ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ ą┐ąŠą┤ ą║ąŠčĆą┐čāčüąŠą╝ ą┐čĆąŠčåąĄčüčüąŠčĆą░, ą║ąŠą│ą┤ą░ ą║ąŠąĮą┤ąĄąĮčüą░č鹊čĆčŗ čĆą░ąĘą╝ąĄčēąĄąĮčŗ ąĮą░ ąŠą▒čĆą░čéąĮąŠą╣ čüč鹊čĆąŠąĮąĄ ą┐ąĄčćą░čéąĮąŠą╣ ą┐ą╗ą░čéčŗ.
ąĀąĖčü. 21-5. ąĀą░ąĘą╝ąĄčēąĄąĮąĖąĄ ąĮą░ ą┐ąĄčćą░čéąĮąŠą╣ ą┐ą╗ą░č鹥 ą▒ą╗ąŠą║ąĖčĆąŠą▓ąŠčćąĮčŗčģ ą║ąŠąĮą┤ąĄąĮčüą░č鹊čĆąŠą▓ ą┐ąŠ ą┐ąĖčéą░ąĮąĖčÄ.
ąĪąŠąĄą┤ąĖąĮčÅą╣č鹥 ąĘą░ą╗ąĖą▓ą║ąĖ ą╝ąĄą┤čīčÄ čü ą▓čŗą▓ąŠą┤ą░ą╝ąĖ ą┐ąĖčéą░ąĮąĖčÅ ą┐čĆąŠčåąĄčüčüąŠčĆą░ ą┐čĆąŠą▓ąŠą┤ąĮąĖą║ą░ą╝ąĖ ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠą╣ ą┤ą╗ąĖąĮčŗ. ąŚą░ą╗ąĖą▓ą║ąĖ ą╝ąĄą┤čīčÄ ąĮąĄ ą┤ąŠą╗ąČąĮčŗ ąĖą╝ąĄčéčī ą╝ąĮąŠą│ąŠ ą┐čāčüč鹊čé, ąĖ ą┤ąŠą╗ąČąĮčŗ ąĖą╝ąĄčéčī ą╝ąĮąŠą│ąŠčćąĖčüą╗ąĄąĮąĮčŗąĄ ą┐ąĄčĆąĄčģąŠą┤čŗ ą╝ąĄąČą┤čā čüą╗ąŠčÅą╝ąĖ ąĖ/ąĖą╗ąĖ ą┐čĆąŠą▓ąŠą┤ąĮąĖą║ą░ą╝ąĖ, čćč鹊ą▒čŗ ą┐ąŠą▓čŗčüąĖčéčī čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéčī čłąĖąĮ ąĘąĄą╝ą╗ąĖ ąĖ ą┐ąĖčéą░ąĮąĖčÅ. ąöąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠ ą║ ą║ąĄčĆą░ą╝ąĖč湥čüą║ąĖą╝ ą║ąŠąĮą┤ąĄąĮčüą░č鹊čĆą░ą╝ (0.1 - 0.22 ą╝ą║čä) ąĮą░ ą┐ą╗ą░č鹥 ą┤ąŠą╗ąČąĮčŗ ą┐čĆąĖčüčāčéčüčéą▓ąŠą▓ą░čéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ą▒ąŠą╗čīčłąĖčģ čéą░ąĮčéą░ą╗ąŠą▓čŗčģ ą║ąŠąĮą┤ąĄąĮčüą░č鹊čĆąŠą▓ (10 - 22 ą╝ą║čä).
ą¤čĆąĖą╝ąĄčćą░ąĮąĖąĄ: čĆą░ąĘą▓ąŠą┤ą║ą░ ą┐ą╗ą░čéčŗ ą╝ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ąŠą┤ąĖąĮ ąĖąĘ ą▓ą░čĆąĖą░ąĮč鹊ą▓ čĆą░ąĘą╝ąĄčēąĄąĮąĖčÅ ą║ąŠąĮą┤ąĄąĮčüą░č鹊čĆąŠą▓ - čüą▓ąĄčĆčģčā ąĖą╗ąĖ čüąĮąĖąĘčā ą┐ą╗ą░čéčŗ, čüą╝. čĆąĖčü. 21-5 - ą╗ąĖą▒ąŠ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī ą║ąŠą╝ą▒ąĖąĮą░čåąĖčÄ čŹčéąĖčģ ą▓ą░čĆąĖą░ąĮč鹊ą▓. ąĀą░ąĘčĆą░ą▒ąŠčéčćąĖą║ ą┐ą╗ą░čéčŗ ą┤ąŠą╗ąČąĄąĮ čüčéą░čĆą░čéčīčüčÅ ą╝ąĖąĮąĖą╝ąĖąĘąĖčĆąŠą▓ą░čéčī ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ ą▓ąĮčāčéčĆąĄąĮąĮąĖčģ ąĘą░ą╗ąĖą▓ąŠą║ ą╝ąĄą┤čīčÄ ą┤ą╗čÅ ą┐ąĄčĆąĄą┤ą░čćąĖ čüąĖą│ąĮą░ą╗ąŠą▓, čćč鹊ą▒čŗ ąĖąĘą▒ąĄąČą░čéčī ą┐ąŠčÅą▓ą╗ąĄąĮąĖčÅ ąŠą║ąŠąĮ ą▓ ąĘą░ą╗ąĖą▓ą║ą░čģ.
ą×čüčåąĖą╗ą╗ąŠą│čĆą░čä ąĖ ąĄą│ąŠ čēčāą┐čŗ. ą¤čĆąĖ ą┐čĆąŠą▓ąĄą┤ąĄąĮąĖąĖ ą▓čŗčüąŠą║ąŠčćą░čüč鹊čéąĮčŗčģ 菹║čüą┐ąĄčĆąĖą╝ąĄąĮč鹊ą▓ ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 "ą▒ą░ą╣ąŠąĮąĄčéąĮčŗą╣" čéąĖą┐ ą┐ąŠą┤ą║ą╗čÄč湥ąĮąĖčÅ ąĘąĄą╝ą╗čÅąĮąŠą│ąŠ ą┐čĆąŠą▓ąŠą┤ąĮąĖą║ą░ čēčāą┐ą░, čćč鹊ą▒čŗ ąĄą│ąŠ ą┐ąĄčéą╗čÅ ą▒čŗą╗ą░ ą╝ąĖąĮąĖą╝ą░ą╗čīąĮąŠą╣ ą┤ą╗ąĖąĮčŗ (< 0.5 ą┤čÄą╣ą╝ą░).

ą¦č鹊ą▒čŗ čüąĮąĖąĘąĖčéčī ąĮą░ą│čĆčāąĘą║čā č鹥čüčéąĖčĆčāąĄą╝čŗčģ čüąĖą│ąĮą░ą╗ąŠą▓, čēčāą┐ ą┤ąŠą╗ąČąĄąĮ ąĖą╝ąĄčéčī ąĮąĖąĘą║čāčÄ ą▓čģąŠą┤ąĮčāčÄ ąĄą╝ą║ąŠčüčéčī ą┐ąŠčĆčÅą┤ą║ą░ 3 ą┐ąĖą║ąŠčäą░čĆą░ą┤, čćč鹊 ąŠą▒čŗčćąĮąŠ ą┤ąŠčüčéąĖą│ą░ąĄčéčüčÅ č鹊ą╗čīą║ąŠ ą┐čĆąĖą╝ąĄąĮąĄąĮąĖąĄą╝ čüą┐ąĄčåąĖą░ą╗čīąĮčŗčģ ą░ą║čéąĖą▓ąĮčŗčģ čēčāą┐ąŠą▓. ą¤čĆąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĖ čüčéą░ąĮą┤ą░čĆčéąĮąŠą│ąŠ ąĘąĄą╝ą╗čÅąĮąŠą│ąŠ ą║ąŠąĮąĮąĄą║č鹊čĆą░ čü "ą║čĆąŠą║ąŠą┤ąĖą╗ąŠą╝" (ą┤ą╗ąĖąĮąŠą╣ ą┐ąŠčĆčÅą┤ą║ą░ 4 ą┤čÄą╣ą╝ą░) ą▓ ąĖčüčüą╗ąĄą┤čāąĄą╝ąŠą╝ ą▓čŗčüąŠą║ąŠčćą░čüč鹊čéąĮąŠą╝ čüąĖą│ąĮą░ą╗ąĄ ą▒čāą┤čāčé ą▓ąĖą┤ąĮčŗ ą┐ą░čĆą░ąĘąĖčéąĮčŗąĄ ą║ąŠą╗ąĄą▒ą░ąĮąĖčÅ ("ąĘą▓ąŠąĮ"). ą¦č鹊ą▒čŗ ą║ąŠčĆčĆąĄą║čéąĮąŠ ąĮą░ą▒ą╗čÄą┤ą░čéčī ą┐ąĄčĆąĄčģąŠą┤čŗ čāčĆąŠą▓ąĮąĄą╣ čüąĖą│ąĮą░ą╗ąŠą▓, čéčĆąĄą▒čāąĄčéčüčÅ ąŠčüčåąĖą╗ą╗ąŠą│čĆą░čä čü ą┐ąŠą╗ąŠčüąŠą╣ ą┐čĆąŠą┐čāčüą║ą░ąĮąĖčÅ ąĮąĄ ą╝ąĄąĮčīčłąĄ 1 ąōąōčå ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą╣ čćą░čüč鹊č鹊ą╣ ą▓čŗą▒ąŠčĆąŠą║ čüąĖą│ąĮą░ą╗ą░ (sample rate).
[ąĪčüčŗą╗ą║ąĖ]
1. ADSP-BF538/ADSP-BF538F Blackfin® Processor Hardware Reference site:analog.com.
2. Blackfin ADSP-BF538.
3. ADSP-BF538: ąŠą▒čĆą░ą▒ąŠčéą║ą░ čüąŠą▒čŗčéąĖą╣ (ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ, ąĖčüą║ą╗čÄč湥ąĮąĖčÅ).
4. ąÜą░ą║ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ąĘą░ą│čĆčāąĘą║ą░ ADSP-BF533 Blackfin.
5. Blackfin: čüąĖčüč鹥ą╝ą░ ą║ąŠą╝ą░ąĮą┤ (ą░čüčüąĄą╝ą▒ą╗ąĄčĆ).
6. ADSP-BF538: ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąŠąĄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖąĄ ą┐ąĖčéą░ąĮąĖąĄą╝.
7. ąĪą╗čāąČą▒ą░ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ą┐ąĖčéą░ąĮąĖąĄą╝ ą┐čĆąŠčåąĄčüčüąŠčĆąŠą▓ Blackfin.
8. VDK: čüąĖą│ąĮą░ą╗čŗ, ą▓ąĘą░ąĖą╝ąŠą┤ąĄą╣čüčéą▓ąĖąĄ ą┐ąŠč鹊ą║ąŠą▓ ąĖ ISR (čüąĖąĮčģčĆąŠąĮąĖąĘą░čåąĖčÅ).
9. ADSP-BF538: ą▒ą╗ąŠą║ ąĖąĮč鹥čĆč乥ą╣čüą░ ą▓ąĮąĄčłąĮąĄą╣ čłąĖąĮčŗ. |



