|
ESP-IDF [2] ąĖčüą┐ąŠą╗čīąĘčāąĄčé ą╝ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮčāčÄ ą▓ąĄčĆčüąĖčÄ FreeRTOS v10.4.3, čüąŠą┤ąĄčƹȹ░čēčāčÄ ąĘąĮą░čćąĖč鹥ą╗čīąĮčŗąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą┤ą╗čÅ SMP-čüąŠą▓ą╝ąĄčüčéąĖą╝ąŠčüčéąĖ (čüą╝. [3]). ą×ą┤ąĮą░ą║ąŠ, ą▓ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ ESP-IDF FreeRTOS, čüąĖčüč鹥ą╝ą░ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ESP-IDF ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čĆą░ąĘą╗ąĖčćąĮčŗąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ ą▓ ą┤ąŠą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ čäčāąĮą║čåąĖčÅą╝, ą┐čĆąĄą┤ą╗ą░ą│ą░ąĄą╝čŗą╝ čéčĆą░ą┤ąĖčåąĖąŠąĮąĮąŠą╣ FreeRTOS.
ąŁč鹊čé ą┤ąŠą║čāą╝ąĄąĮčé ąŠą┐ąĖčüčŗą▓ą░ąĄčé čéą░ą║ąĖąĄ čäčāąĮą║čåąĖąĖ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ FreeRTOS, ą┤ąŠą▒ą░ą▓ą╗čÅąĄą╝čŗąĄ čüąĖčüč鹥ą╝ąŠą╣ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ESP-IDF (ą┐ąĄčĆąĄą▓ąŠą┤ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ [1]). ąØąĄąĘąĮą░ą║ąŠą╝čŗąĄ č鹥čĆą╝ąĖąĮčŗ ąĖ čüąŠą║čĆą░čēąĄąĮąĖčÅ čüą╝. ą▓ čĆą░ąĘą┤ąĄą╗ąĄ ąĪą╗ąŠą▓ą░čĆąĖą║, ą▓ ą║ąŠąĮčåąĄ čüčéą░čéčīąĖ.
ą£ąŠą┤ąĖčäąĖčåąĖčĆąŠą▓ą░ąĮąĮą░čÅ ą▓ąĄčĆčüąĖčÅ ESP-IDF FreeRTOS ąŠčüąĮąŠą▓ą░ąĮą░ ąĮą░ ą┐ąŠčĆč鹥 Xtensa FreeRTOS v10.4.3, ą▓ ą║ąŠč鹊čĆčŗą╣ ą▒čŗą╗ąĖ ą▓ą▓ąĄą┤ąĄąĮčŗ ąĘąĮą░čćąĖč鹥ą╗čīąĮčŗąĄ ąĖąĘą╝ąĄąĮąĄąĮąĖčÅ ą┤ą╗čÅ ąŠą▒ąĄčüą┐ąĄč湥ąĮąĖčÅ SMP-čüąŠą▓ą╝ąĄčüčéąĖą╝ąŠčüčéąĖ. ąöąŠą▒ą░ą▓ą╗ąĄąĮčŗ čüą╗ąĄą┤čāčÄčēąĖąĄ ąĮąŠą▓čŗąĄ čäčāąĮą║čåąĖąĖ, čüą┐ąĄčåąĖčäąĖčćąĮčŗąĄ ą┤ą╗čÅ ESP-IDF FreeRTOS:
ąÜąŠą╗čīčåąĄą▓čŗąĄ ą▒čāč乥čĆčŗ (ring buffer). ąŁčéą░ čäčāąĮą║čåąĖčÅ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą▒čāč乥čĆ FIFO, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ą┐čĆąĖąĮąĖą╝ą░čéčī ą▓ čüąĄą▒čÅ čŹą╗ąĄą╝ąĄąĮčéčŗ ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮąŠą╣ ą┤ą╗ąĖąĮčŗ.
ą×ą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ čéąĖą║ąŠą▓ ąĖ čüąŠčüč鹊čÅąĮąĖčÅ ąŠąČąĖą┤ą░ąĮąĖčÅ (ESP-IDF Tick ąĖ Idle Hooks). ESP-IDF ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ąĮąĄčüą║ąŠą╗čīą║ąŠ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čīčüą║ąĖčģ ą┐ąĄčĆąĄčģą▓ą░čéčćąĖą║ąŠą▓ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖą╣ čéąĖą║ą░ (tick interrupt hooks) ąĖ ą┐ąĄčĆąĄčģą▓ą░čéčćąĖą║ąŠą▓ ąĘą░ą┤ą░čćąĖ ąŠąČąĖą┤ą░ąĮąĖčÅ (idle task hooks), ą║ąŠč鹊čĆčŗąĄ ąĮą░ą╝ąĮąŠą│ąŠ ą▒ąŠą│ą░č湥 ą┐ąŠ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčÅą╝ ąĖ ą│ąĖą▒ą║ąŠčüčéąĖ ą▓ čüčĆą░ą▓ąĮąĄąĮąĖąĖ čü čéčĆą░ą┤ąĖčåąĖąŠąĮąĮčŗą╝ąĖ ą┤ą╗čÅ FreeRTOS ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ą╝ąĖ čéąĖą║ą░ ąĖ čüąŠčüč鹊čÅąĮąĖčÅ idle.
Callback-čäčāąĮą║čåąĖąĖ čāą┤ą░ą╗ąĄąĮąĖčÅ TLSP (Thread Local Storage Pointer). ąŁč鹊 čäčāąĮą║čåąĖąĖ ąŠą▒čĆą░čéąĮąŠą│ąŠ ą▓čŗąĘąŠą▓ą░, ą║ąŠč鹊čĆčŗąĄ ąĘą░ą┐čāčüčéčÅčéčüčÅ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą┐čĆąĖ čāą┤ą░ą╗ąĄąĮąĖąĖ ąĘą░ą┤ą░čćąĖ, čćč鹊 ą┐ąŠąĘą▓ąŠą╗ąĖčé čĆąĄą░ą╗ąĖąĘąŠą▓ą░čéčī ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║čāčÄ ąŠčćąĖčüčéą║čā ą┐ą░ą╝čÅčéąĖ (ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗčģ čĆąĄčüčāčĆčüąŠą▓).
ą¤ąŠą┤ą┤ąĄčƹȹ║ą░ čüą▓ąŠą╣čüčéą▓ ą║ąŠą╝ą┐ąŠąĮąĄąĮčéą░. ą¤čĆąĄą┤čāčüą╝ąŠčéčĆąĄąĮą░ ą┐ąŠą┤ą┤ąĄčƹȹ║ą░ čüą▓ąŠą╣čüčéą▓, čüą┐ąĄčåąĖčäąĖčćąĮčŗčģ ą┤ą╗čÅ ą║ąŠą╝ą┐ąŠąĮąĄąĮčéą░. ąÆ ąĮą░čüč鹊čÅčēąĄąĄ ą▓čĆąĄą╝čÅ čŹč鹊 ą┐ąŠą║ą░ č鹊ą╗čīą║ąŠ ORIG_INCLUDE_PATH.
[ąÜąŠą╗čīčåąĄą▓čŗąĄ ą▒čāč乥čĆčŗ]
ąÜąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ ESP-IDF FreeRTOS, čüčéčĆąŠą│ąŠ čĆą░ą▒ąŠčéą░čÄčēąĖą╣ ą┐ąŠ ą┐čĆąĖąĮčåąĖą┐čā FIFO, ą┐ąŠą┤ą┤ąĄčƹȹĖą▓ą░ąĄčé 菹╗ąĄą╝ąĄąĮčéčŗ (čÅč湥ą╣ą║ąĖ) ą▒čāč乥čĆą░ ą┐čĆąŠąĖąĘą▓ąŠą╗čīąĮąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░. ąóą░ą║ąŠą╣ ą▒čāč乥čĆ ą┤ą░ąĄčé ą┐čĆą░ą║čéąĖč湥čüą║ąĖ č鹊čé ąČąĄ čäčāąĮą║čåąĖąŠąĮą░ą╗, čćč鹊 ąĖ čéčĆą░ą┤ąĖčåąĖąŠąĮąĮčŗąĄ ąŠč湥čĆąĄą┤ąĖ FreeRTOS, ąŠą┤ąĮą░ą║ąŠ ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ ESP-IDF ą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĄąĮ, č湥ą╝ ąŠč湥čĆąĄą┤ąĖ FreeRTOS, ą▓ č鹥čģ čüą╗čāčćą░čÅčģ, ą║ąŠą│ą┤ą░ čĆą░ąĘą╝ąĄčĆ čŹą╗ąĄą╝ąĄąĮč鹊ą▓ ą▒čāč乥čĆą░ ąĖąĘą╝ąĄąĮčÅąĄą╝čŗą╣. ąĢą╝ą║ąŠčüčéčī ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ ąĮąĄ ąĖąĘą╝ąĄčĆčÅąĄčéčüčÅ ą▓ ą║ąŠą╗ąĖč湥čüčéą▓ąĄ 菹╗ąĄą╝ąĄąĮč鹊ą▓, ą║ąŠč鹊čĆčŗą╣ ąŠąĮ ą╝ąŠąČąĄčé čģčĆą░ąĮąĖčéčī, ą░ ą▓ ą║ąŠą╗ąĖč湥čüčéą▓ąĄ ą┐ą░ą╝čÅčéąĖ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝ąŠą╣ ą┤ą╗čÅ čģčĆą░ąĮąĄąĮąĖčÅ čŹą╗ąĄą╝ąĄąĮč鹊ą▓. ąÜąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé API-čäčāąĮą║čåąĖąĖ ą┤ą╗čÅ ąŠčéą┐čĆą░ą▓ą║ąĖ 菹╗ąĄą╝ąĄąĮčéą░ ą▓ ą▒čāč乥čĆ, ąĖą╗ąĖ ą┤ą╗čÅ ą▓čŗą┤ąĄą╗ąĄąĮąĖčÅ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ą┤ą╗čÅ čŹą╗ąĄą╝ąĄąĮčéą░ ą▓ ą║ąŠą╗čīčåąĄą▓ąŠą╝ ą▒čāč乥čĆąĄ, ą║ąŠč鹊čĆąŠąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ąĘą░ą┐ąŠą╗ąĮąĄąĮąŠ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝ ą▓čĆčāčćąĮčāčÄ. ą¤ąŠ čüąŠąŠą▒čĆą░ąČąĄąĮąĖčÅą╝ čŹčäč乥ą║čéąĖą▓ąĮąŠčüčéąĖ 菹╗ąĄą╝ąĄąĮčéčŗ ą▒čāč乥čĆą░ ą▓čüąĄą│ą┤ą░ ąĖąĘą▓ą╗ąĄą║ą░čÄčéčüčÅ ąĖąĘ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ ą┐ąŠ čāą║ą░ąĘą░č鹥ą╗čÄ. ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 ą▓čüąĄ ąĖąĘą╗ąĄč湥ąĮąĮčŗąĄ 菹╗ąĄą╝ąĄąĮčéčŗ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čéą░ą║ąČąĄ ą▓ąŠąĘą▓čĆą░čēąĄąĮčŗ ą▓ ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ čü ą┐ąŠą╝ąŠčēčīčÄ vRingbufferReturnItem() ąĖą╗ąĖ vRingbufferReturnItemFromISR(), čćč鹊ą▒čŗ ąŠąĮąĖ ą▒čŗą╗ąĖ ą┐ąŠą╗ąĮąŠčüčéčīčÄ čāą┤ą░ą╗ąĄąĮčŗ ąĖąĘ ą▒čāč乥čĆą░. ąÜąŠą╗čīčåąĄą▓čŗąĄ ą▒čāč乥čĆčŗ ą┤ąĄą╗čÅčéčüčÅ ąĮą░ čüą╗ąĄą┤čāčÄčēąĖąĄ 3 čéąĖą┐ą░:
No-Split. ąŁčéąĖ ą▒čāč乥čĆčŗ ą│ą░čĆą░ąĮčéąĖčĆčāčÄčé, čćč鹊 菹╗ąĄą╝ąĄąĮčé čüąŠčģčĆą░ąĮąĄąĮ ą▓ ąĮąĄą┐čĆąĄčĆčŗą▓ąĮąŠą╣ ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ, čé. ąĄ. ą▓ ą╗čÄą▒čŗčģ čāčüą╗ąŠą▓ąĖčÅčģ ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą▒čāą┤ąĄčé ą┐ąŠą┐čŗč鹊ą║ čüąŠčģčĆą░ąĮąĖčéčī 菹╗ąĄą╝ąĄąĮčé ą║čāčüą║ą░ą╝ąĖ. ąóąŠą╗čīą║ąŠ čŹč鹊čé čéąĖą┐ ą▒čāč乥čĆą░ ą┐ąŠąĘą▓ąŠą╗ąĖčé ąÆą░ą╝ ą┐ąŠą╗čāčćąĖčéčī ą░ą┤čĆąĄčü 菹╗ąĄą╝ąĄąĮčéą░ ą▒čāč乥čĆą░ ąĖ ą▓čŗą┐ąŠą╗ąĮąĖčéčī ąĘą░ą┐ąĖčüčī ą▓ 菹╗ąĄą╝ąĄąĮčé čüą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮąŠ. ą¤ąŠą┤čĆąŠą▒ąĮąĄąĄ čüą╝. xRingbufferSendAcquire() ąĖ xRingbufferSendComplete().
Allow-Split. ąŁč鹊čé čéąĖą┐ ą▒čāč乥čĆąŠą▓ ą┤ąŠą┐čāčüą║ą░ąĄčé čĆą░ąĘą┤ąĄą╗ąĖčéčī 菹╗ąĄą╝ąĄąĮčé ą▒čāč乥čĆą░ ąĮą░ 2 čćą░čüčéąĖ, ą║ąŠą│ą┤ą░ ą▒čŗą╗ ą┤ąŠčüčéąĖą│ąĮčāčé ą║ąŠąĮąĄčå ąŠą▒ą╗ą░čüčéąĖ ą┐ą░ą╝čÅčéąĖ ą▒čāč乥čĆą░ (čüą╗čāčćą░ą╣, ą║ąŠą│ą┤ą░ ą┐ą░ą╝čÅčéąĖ ą▒čāč乥čĆą░ ąĮąĄ čģą▓ą░čéąĖą╗ąŠ, ąĖ ąĮą░čćą░ą╗ąŠ 菹╗ąĄą╝ąĄąĮčéą░ ą▒čāą┤ąĄčé ąĘą░ą┐ąĖčüą░ąĮąŠ ą▓ ą║ąŠąĮąĄčå ą▒čāč乥čĆą░, ą░ čģą▓ąŠčüčé 菹╗ąĄą╝ąĄąĮčéą░ ą▓ ąĮą░čćą░ą╗ąŠ ą▒čāč乥čĆą░). ąæčāč乥čĆčŗ Allow-Split ą▒ąŠą╗ąĄąĄ čŹčäč乥ą║čéąĖą▓ąĮčŗ, č湥ą╝ ą▒čāč乥čĆčŗ No-Split, ąŠą┤ąĮą░ą║ąŠ ą┐čĆąĖ ąĖąĘą▓ą╗ąĄč湥ąĮąĖąĖ 菹╗ąĄą╝ąĄąĮčéą░ ą╝ąŠą│čāčé ą▓ąŠąĘą▓čĆą░čéąĖčéčī ąĄą│ąŠ ą┤ą▓čāą╝čÅ ą║čāčüą║ą░ą╝ąĖ.
ąæą░ą╣č鹊ą▓čŗą╣ ą▒čāč乥čĆ. ąÆčüąĄ ą┤ą░ąĮąĮčŗąĄ čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ ą▓ ą┐ą░ą╝čÅčéąĖ ą║ą░ą║ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ą▒ą░ą╣čé, ąĖ ą║ą░ąČą┤čŗą╣ čĆą░ąĘ ą▓ ą▒čāč乥čĆ ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠčéą┐čĆą░ą▓ą╗ąĄąĮąŠ ą╗čÄą▒ąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ 菹╗ąĄą╝ąĄąĮč鹊ą▓, ąĖ ąĖąĘą▓ą╗ąĄč湥ąĮąŠ ą╗čÄą▒ąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ 菹╗ąĄą╝ąĄąĮč鹊ą▓. ąśčüą┐ąŠą╗čīąĘčāą╣č鹥 ą▒ą░ą╣č鹊ą▓čŗąĄ ą▒čāč乥čĆčŗ, ą║ąŠą│ą┤ą░ ąĮąĄ čéčĆąĄą▒čāąĄčéčüčÅ ą┐ąŠą┤ą┤ąĄčƹȹ║ą░ ąŠčéą┤ąĄą╗čīąĮčŗčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓ čĆą░ąĘąĮąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░ (ąĮą░ą┐čĆąĖą╝ąĄčĆ ą┐ąŠč鹊ą║ ą▒ą░ą╣čé, byte stream).
ąÆą░ąČąĮčŗąĄ ąĘą░ą╝ąĄčćą░ąĮąĖčÅ:
1. ąæčāč乥čĆčŗ No-Split ąĖ Allow-Split ą▒čāą┤čāčé ą▓čüąĄą│ą┤ą░ čüąŠčģčĆą░ąĮčÅčéčī 菹╗ąĄą╝ąĄąĮčéčŗ ą┐ąŠ ą▒ą░ą╣č鹊ą▓ąŠą╝čā ą░ą┤čĆąĄčüčā, ą▓čŗčĆąŠą▓ąĮąĄąĮąĮąŠą╝čā ąĮą░ 32 ą▒ąĖčéą░ (ą░ą┤čĆąĄčü ąĮą░čåąĄą╗ąŠ ą┤ąĄą╗ąĖčéčüčÅ ąĮą░ 4). ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ą┤ą╗čÅ ąĖąĘą▓ą╗ąĄč湥ąĮąĖčÅ čŹą╗ąĄą╝ąĄąĮčéą░ ąĖąĘ ą▒čāč乥čĆą░, ą▒čāą┤ąĄčé ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮ čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ 32-ą▒ąĖčéąĮąŠąĄ čüą╗ąŠą▓ąŠ. ąŁč鹊 ąŠčüąŠą▒ąĄąĮąĮąŠ ą┐ąŠą╗ąĄąĘąĮąŠ, ą║ąŠą│ą┤ą░ ąĮčāąČąĮąŠ ąŠčéą┐čĆą░ą▓ąĖčéčī ąĮąĄą║ąŠč鹊čĆčŗąĄ ą┤ą░ąĮąĮčŗąĄ č湥čĆąĄąĘ DMA.
2. ąÜą░ąČą┤čŗą╣ 菹╗ąĄą╝ąĄąĮčé, čüąŠčģčĆą░ąĮąĄąĮąĮčŗą╣ ą▓ ą▒čāč乥čĆą░čģ No-Split ąĖą╗ąĖ Allow-Split, ą┐ąŠčéčĆąĄą▒čāąĄčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗąĄ 8 ą▒ą░ą╣čé ą┤ą╗čÅ ąĘą░ą│ąŠą╗ąŠą▓ą║ą░. ąĀą░ąĘą╝ąĄčĆčŗ 菹╗ąĄą╝ąĄąĮčéą░ čéą░ą║ąČąĄ ąŠą║čĆčāą│ą╗čÅčÄčéčüčÅ ą▓ą▓ąĄčĆčģ ą┤ą╗čÅ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖčÅ ąĮą░ 32 ą▒ąĖčéą░ (čĆą░ąĘą╝ąĄčĆ čŹą╗ąĄą╝ąĄąĮčéą░ ą▓ ą▒ą░ą╣čéą░čģ ą┤ąĄą╗ąĖčéčüčÅ ąĮą░čåąĄą╗ąŠ ąĮą░ 4), ąŠą┤ąĮą░ą║ąŠ čĆąĄą░ą╗čīąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ čŹą╗ąĄą╝ąĄąĮčéą░ ąĘą░ą┐ąĖčüčŗą▓ą░ąĄčéčüčÅ ą▓ ąĘą░ą│ąŠą╗ąŠą▓ą║ąĄ. ąĀą░ąĘą╝ąĄčĆčŗ čüą░ą╝ąĖčģ ą▒čāč乥čĆąŠą▓ No-Split ąĖ Allow-Split ą┐čĆąĖ čüąŠąĘą┤ą░ąĮąĖąĖ čéą░ą║ąČąĄ ąŠą║čĆčāą│ą╗čÅčÄčéčüčÅ ą▓ą▓ąĄčĆčģ.
ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ xRingbufferCreate() ąĖ xRingbufferSend() ą┤ą╗čÅ čüąŠąĘą┤ą░ąĮąĖčÅ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ ąĖ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĄą╣ ąŠčéą┐čĆą░ą▓ą║ąĖ ą▓ ąĮąĄą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░.
#include "freertos/ringbuf.h"
static char tx_item[] = "test_item";
...
// ąĪąŠąĘą┤ą░ąĮąĖąĄ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░:
RingbufHandle_t buf_handle;
buf_handle = xRingbufferCreate(1028, RINGBUF_TYPE_NOSPLIT);
if (buf_handle == NULL)
{
printf("Failed to create ring buffer\n");
}
// ą×čéą┐čĆą░ą▓ą║ą░ 菹╗ąĄą╝ąĄąĮčéą░:
UBaseType_t res = xRingbufferSend(buf_handle,
tx_item,
sizeof(tx_item),
pdMS_TO_TICKS(1000));
if (res != pdTRUE)
{
printf("Failed to send item\n");
}
ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ xRingbufferSendAcquire() ąĖ xRingbufferSendComplete() ą▓ą╝ąĄčüč鹊 xRingbufferSend(), čćč鹊ą▒čŗ ą▓čŗą┤ąĄą╗ąĖčéčī ą┐ą░ą╝čÅčéčī ąĮą░ ą║ąŠą╗čīčåąĄą▓ąŠą╝ ą▒čāč乥čĆąĄ (čéąĖą┐ą░ RINGBUF_TYPE_NOSPLIT), ąĖ ąĘą░č鹥ą╝ ąŠčéą┐čĆą░ą▓ąĖčéčī ą▓ ąĮąĄą│ąŠ 菹╗ąĄą╝ąĄąĮčé. ąŁčéą░ ą┐čĆąŠčåąĄą┤čāčĆą░ ą▓ą║ą╗čÄčćą░ąĄčé ąŠą┤ąĖąĮ ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčŗą╣ čłą░ą│, ąŠą┤ąĮą░ą║ąŠ ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐ąŠą╗čāčćąĖčéčī ą░ą┤čĆąĄčü ą┐ą░ą╝čÅčéąĖ, čćč鹊ą▒čŗ ą╝ąŠąČąĮąŠ ą▒čŗą╗ąŠ ą▓ čŹčéčā ą┐ą░ą╝čÅčéčī čüą┤ąĄą╗ą░čéčī ąĘą░ą┐ąĖčüčī čüą░ą╝ąŠčüč鹊čÅč鹥ą╗čīąĮąŠ.
#include "freertos/ringbuf.h"
#include "soc/lldesc.h"
typedef struct
{
lldesc_t dma_desc;
uint8_t buf[1];
}dma_item_t;
#define DMA_ITEM_SIZE(N) (sizeof(lldesc_t)+(((N)+3)&(~3)))
...
// ą¤ąŠą╗čāč湥ąĮąĖąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ą┤ą╗čÅ ą┤ąĄčüą║čĆąĖą┐č鹊čĆą░ DMA ąĖ čüąŠąŠčéą▓ąĄčéčüčéą▓čāčÄčēąĄą│ąŠ
// ą▒čāč乥čĆą░ ą┤ą░ąĮąĮčŗčģ. ąŁč鹊 ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī čüą┤ąĄą╗ą░ąĮąŠ č湥čĆąĄąĘ SendAcquire,
// ąĖą╗ąĖ ą░ą┤čĆąĄčü ą╝ąŠąČąĄčé ąŠčéą╗ąĖčćą░čéčīčüčÅ, ą║ąŠą│ą┤ą░ ą╝čŗ ą┤ąĄą╗ą░ąĄą╝ ą║ąŠą┐ąĖčĆąŠą▓ą░ąĮąĖąĄ.
dma_item_t item;
UBaseType_t res = xRingbufferSendAcquire(buf_handle,
&item,
DMA_ITEM_SIZE(buffer_size),
pdMS_TO_TICKS(1000));
if (res != pdTRUE)
{
printf("Failed to acquire memory for item\n");
}
item->dma_desc = (lldesc_t)
{
.size = buffer_size,
.length = buffer_size,
.eof = 0,
.owner = 1,
.buf = &item->buf,
};
// ąŚą┤ąĄčüčī ą┐čĆąŠąĖčüčģąŠą┤ąĖčé čĆąĄą░ą╗čīąĮą░čÅ ąŠčéą┐čĆą░ą▓ą║ą░ ą▓ ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ:
res = xRingbufferSendComplete(buf_handle, &item);
if (res != pdTRUE)
{
printf("Failed to send item\n");
}
ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄčé ąĘą░ą┐čĆąŠčü ąĖ ą┐ąŠą╗čāč湥ąĮąĖąĄ 菹╗ąĄą╝ąĄąĮčéą░ ąĖąĘ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ čéąĖą┐ą░ No-Split čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ xRingbufferReceive() ąĖ vRingbufferReturnItem().
...
// ą¤ąŠą╗čāč湥ąĮąĖąĄ 菹╗ąĄą╝ąĄąĮčéą░:
size_t item_size;
char *item = (char *)xRingbufferReceive(buf_handle,
&item_size,
pdMS_TO_TICKS(1000));
// ą¤čĆąŠą▓ąĄčĆą║ą░, ą┐ąŠą╗čāč湥ąĮ ą╗ąĖ 菹╗ąĄą╝ąĄąĮčé:
if (item != NULL)
{
// ą¤ąĄčćą░čéčī 菹╗ąĄą╝ąĄąĮčéą░:
for (int i = 0; i < item_size; i++)
{
printf("%c", item[i]);
}
printf("\n");
// ąÆąŠąĘą▓čĆą░čé 菹╗ąĄą╝ąĄąĮčéą░:
vRingbufferReturnItem(buf_handle, (void *)item);
}
else
{
// ąØąĄ ą┐ąŠą╗čāčćąĖą╗ąŠčüčī ą┐ąŠą╗čāčćąĖčéčī 菹╗ąĄą╝ąĄąĮčé
printf("Failed to receive item\n");
}
ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄčé ą┐ąŠą╗čāč湥ąĮąĖąĄ ąĖ ą▓ąŠąĘą▓čĆą░čé 菹╗ąĄą╝ąĄąĮčéą░ ąĖąĘ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ Allow-Split čü ą┐ąŠą╝ąŠčēčīčÄ xRingbufferReceiveSplit() ąĖ vRingbufferReturnItem().
...
// ą¤ąŠą╗čāč湥ąĮąĖąĄ 菹╗ąĄą╝ąĄąĮčéą░:
size_t item_size1, item_size2;
char *item1, *item2;
BaseType_t ret = xRingbufferReceiveSplit(buf_handle,
(void **)&item1,
(void **)&item2,
&item_size1,
&item_size2,
pdMS_TO_TICKS(1000));
// ą¤čĆąŠą▓ąĄčĆą║ą░, ą┐ąŠą╗čāč湥ąĮ ą╗ąĖ 菹╗ąĄą╝ąĄąĮčé:
if (ret == pdTRUE && item1 != NULL)
{
for (int i = 0; i < item_size1; i++)
{
printf("%c", item1[i]);
}
vRingbufferReturnItem(buf_handle, (void *)item1);
// ą¤čĆąŠą▓ąĄčĆą║ą░, ą┐ąŠą╗čāč湥ąĮ ą╗ąĖ 菹╗ąĄą╝ąĄąĮčé čåąĄą╗ąĖą║ąŠą╝, ąĖą╗ąĖ ą▒čŗą╗ ą┐ąŠą┤ąĄą╗ąĄąĮ ąĮą░ čćą░čüčéąĖ:
if (item2 != NULL)
{
// ąśą╝ąĄąĄčéčüčÅ čéą░ą║ąČąĄ ąĖ ą▓č鹊čĆą░čÅ čćą░čüčéčī:
for (int i = 0; i < item_size2; i++)
{
printf("%c", item2[i]);
}
vRingbufferReturnItem(buf_handle, (void *)item2);
}
printf("\n");
}
else
{
// ąØąĄ ą┐ąŠą╗čāčćąĖą╗ąŠčüčī ą┐ąŠą╗čāčćąĖčéčī 菹╗ąĄą╝ąĄąĮčé
printf("Failed to receive item\n");
}
ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄčé ą┐ąŠą╗čāč湥ąĮąĖąĄ ąĖ ą▓ąŠąĘą▓čĆą░čéčī ą▒ą░ą╣č鹊ą▓ąŠą│ąŠ ą▒čāč乥čĆą░ čü ą┐ąŠą╝ąŠčēčīčÄ xRingbufferReceiveUpTo() ąĖ vRingbufferReturnItem().
...
// ą¤čĆąĖąĄą╝ ą┤ą░ąĮąĮčŗčģ ąĖąĘ ą▒ą░ą╣č鹊ą▓ąŠą│ąŠ ą▒čāč乥čĆą░:
size_t item_size;
char *item = (char *)xRingbufferReceiveUpTo(buf_handle,
&item_size,
pdMS_TO_TICKS(1000),
sizeof(tx_item));
// ą¤čĆąŠą▓ąĄčĆą║ą░ ą┐čĆąĖąĮčÅčéčŗčģ ą┤ą░ąĮąĮčŗčģ:
if (item != NULL)
{
// ą¤ąĄčćą░čéčī ą┐čĆąĖąĮčÅč鹊ą╣ ą┐ąŠčĆčåąĖąĖ ą┤ą░ąĮąĮčŗčģ:
for (int i = 0; i < item_size; i++)
{
printf("%c", item[i]);
}
printf("\n");
// ąÆąŠąĘą▓čĆą░čé ą┤ą░ąĮąĮčŗčģ:
vRingbufferReturnItem(buf_handle, (void *)item);
}
else
{
// ąØąĄ ą┐ąŠą╗čāčćąĖą╗ąŠčüčī ą┐ąŠą╗čāčćąĖčéčī ą┤ą░ąĮąĮčŗąĄ ąĖąĘ ą▒čāč乥čĆą░
printf("Failed to receive item\n");
}
ąöą╗čÅ ą▒ąĄąĘąŠą┐ą░čüąĮąŠą│ąŠ ą▓čŗąĘąŠą▓ą░ ąĖąĘ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ (ISR safe čäčāąĮą║čåąĖąĖ) ąĖčüą┐ąŠą╗čīąĘčāą╣č鹥 ą░ąĮą░ą╗ąŠą│ąĖčćąĮčŗąĄ čäčāąĮą║čåąĖąĖ čü čüčāčäčäąĖą║čüąŠą╝ ISR: xRingbufferSendFromISR(), xRingbufferReceiveFromISR(), xRingbufferReceiveSplitFromISR(), xRingbufferReceiveUpToFromISR() ąĖ vRingbufferReturnItemFromISR().
ąĢčüą╗ąĖ ą▒ą░ą╣čéčŗ 菹╗ąĄą╝ąĄąĮčéą░ ą┐ąĄčĆąĄčģąŠą┤čÅčé ąĖąĘ ą║ąŠąĮčåą░ ą▓ ąĮą░čćą░ą╗ąŠ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░, č鹊 čéčĆąĄą▒čāąĄčéčüčÅ 2 ą▓čŗąĘąŠą▓ą░ RingbufferReceive[UpTo][FromISR]().
ą×čéą┐čĆą░ą▓ą║ą░ ą▓ ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ. ąĪą╗ąĄą┤čāčÄčēąĖąĄ ą┤ąĖą░ą│čĆą░ą╝ą╝čŗ ąĮą░ čĆąĖčü. 1 ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé čĆą░ąĘą╗ąĖčćąĖčÅ ą╝ąĄąČą┤čā ą▒čāč乥čĆą░ą╝ąĖ No-Split ąĖ Allow-Split ą▓ čüčĆą░ą▓ąĮąĄąĮąĖąĖ čü ą▒ą░ą╣č鹊ą▓čŗą╝ąĖ ą▒čāč乥čĆą░ą╝ąĖ ą▓ ą║ąŠąĮč鹥ą║čüč鹥 ąŠčéą┐čĆą░ą▓ą║ąĖ ą▓ ą▒čāč乥čĆ čŹą╗ąĄą╝ąĄąĮč鹊ą▓/ą┤ą░ąĮąĮčŗčģ. ąöąĖą░ą│čĆą░ą╝ą╝čŗ ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░čÄčé, čćč鹊 ą▒čŗą╗ąĖ ąŠčéą┐čĆą░ą▓ą╗ąĄąĮčŗ 3 菹╗ąĄą╝ąĄąĮčéą░ ą┐ąŠ 18, 3 ąĖ 27 ą▒ą░ą╣čé čüąŠąŠčéą▓ąĄčéčüčéą▓ąĄąĮąĮąŠ ą▓ ą▒čāč乥čĆ čĆą░ąĘą╝ąĄčĆąŠą╝ 128 ą▒ą░ą╣čé.

ąĀąĖčü. 1. ą×čéą┐čĆą░ą▓ą║ą░ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą▓ ą▓ ą║ąŠą╗čīčåąĄą▓čŗąĄ ą▒čāč乥čĆčŗ No-Split ąĖą╗ąĖ Allow-Split.
ąÜą░ą║ ą▓ąĖą┤ąĮąŠ ąĖąĘ ą┤ąĖą░ą│čĆą░ą╝ą╝čŗ čĆąĖčü. 1, ą┤ą╗čÅ ą▒čāč乥čĆąŠą▓ No-Split ąĖ Allow-Split ą║ą░ąČą┤ąŠą╝čā 菹╗ąĄą╝ąĄąĮčéčā ą┐čĆąĄą┤čłąĄčüčéą▓čāąĄčé ąĘą░ą│ąŠą╗ąŠą▓ąŠą║ ąĖąĘ 8 ą▒ą░ą╣čé. ąÜčĆąŠą╝ąĄ č鹊ą│ąŠ, ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░ ą▓čŗą┤ąĄą╗čÅąĄčéčüčÅ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ą░ą╣čé, ąŠą║čĆčāą│ą╗ąĄąĮąĮąŠąĄ ą▓ą▓ąĄčĆčģ čéą░ą║, čćč鹊ą▒čŗ ąŠąĮąŠ ą┤ąĄą╗ąĖą╗ąŠčüčī ąĮą░čåąĄą╗ąŠ ąĮą░ 4 (32-bit aligned, čé. ąĄ. čĆą░ąĘą╝ąĄčĆčŗ 18, 3 ąĖ 27 ą▒ą░ą╣čé ąŠą║čĆčāą│ą╗čÅčÄčéčüčÅ ąĮą░ 20, 4 ąĖ 28). ąŁč鹊 ąŠą▒ąĄčüą┐ąĄčćąĖą▓ą░ąĄčé 32-ą▒ąĖčéąĮąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ ą▓ ą┐ą░ą╝čÅčéąĖ. ą×ą┤ąĮą░ą║ąŠ ą▓ ąĘą░ą│ąŠą╗ąŠą▓ąŠą║ ą▒čāą┤ąĄčé ąĘą░ą┐ąĖčüą░ąĮ čĆąĄą░ą╗čīąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ čŹą╗ąĄą╝ąĄąĮč鹊ą▓ ą┤ą░ąĮąĮčŗčģ, čćč鹊ą▒čŗ čŹč鹊čé čĆą░ąĘą╝ąĄčĆ ą╝ąŠą│ ą▒čŗčéčī ą┐ąŠą╗čāč湥ąĮ ą┐čĆąĖ ą▓čŗąĄą╝ą║ąĄ ą┤ą░ąĮąĮčŗčģ ąĖąĘ ą▒čāč乥čĆą░.
ąæą░ą╣č鹊ą▓čŗąĄ ą▒čāč乥čĆčŗ ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčé ą┤ą░ąĮąĮčŗąĄ ą║ą░ą║ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠčüčéčī ą▒ą░ą╣čé, ąĖ ą┐čĆąĖ čŹč鹊ą╝ ąĮąĄčé ą╗ąĖčłąĮąĖčģ čĆą░čüčģąŠą┤ąŠą▓ ąĮą░ ąĘą░ą│ąŠą╗ąŠą▓ąŠą║ ąĖ 32-ą▒ąĖčéąĮąŠąĄ ą▓čŗčĆą░ą▓ąĮąĖą▓ą░ąĮąĖąĄ ą┤ą░ąĮąĮčŗčģ ą▓ ą┐ą░ą╝čÅčéąĖ. ąÆ čĆąĄąĘčāą╗čīčéą░č鹥 ą▓čüąĄ 菹╗ąĄą╝ąĄąĮčéčŗ ą┤ą░ąĮąĮčŗčģ, ąŠčéą┐čĆą░ą▓ą╗ąĄąĮąĮčŗąĄ ą▓ ą▒ą░ą╣č鹊ą▓čŗą╣ ą▒čāč乥čĆ, ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ ą┐čĆąĖą╝čŗą║ą░čÄčé ą┤čĆčāą│ ą║ ą┤čĆčāą│čā, č乊čĆą╝ąĖčĆčāčÅ ąŠą┤ąĖąĮ 菹╗ąĄą╝ąĄąĮčé ą┤ą░ąĮąĮčŗčģ (čüą╝. čĆąĖčü. 2).

ąĀąĖčü. 2. ą×čéą┐čĆą░ą▓ą║ą░ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą▓ ą▒ą░ą╣č鹊ą▓čŗą╣ ą▒čāč乥čĆ.
ąØą░ ą┤ąĖą░ą│čĆą░ą╝ą╝ąĄ čĆąĖčü. 2 ą▓ąĖą┤ąĮąŠ, čćč鹊 ąŠčéą┐čĆą░ą▓ą╗ąĄąĮąĮčŗąĄ 菹╗ąĄą╝ąĄąĮčéčŗ ąĖąĘ 18, 3 ąĖ 27 ą▒ą░ą╣čé ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ ą▓ ą┐ą░ą╝čÅčéčī ą▒ą░ą╣č鹊ą▓ąŠą│ąŠ ą▒čāč乥čĆą░, ąŠą▒čŖąĄą┤ąĖąĮčÅčÅčüčī ą▓ ąŠą┤ąĖąĮ 菹╗ąĄą╝ąĄąĮčé ąĖąĘ 48 ą▒ą░ą╣čé.
ąśčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ SendAcquire ąĖ SendComplete. ąŁą╗ąĄą╝ąĄąĮčéčŗ ą▓ ą▒čāč乥čĆą░čģ No-Split ąĖąĘą▓ą╗ąĄą║ą░čÄčéčüčÅ (ą▓čŗąĘąŠą▓ąŠą╝ SendAcquire) ą▓ čüčéčĆąŠą│ąŠą╝ ą┐ąŠčĆčÅą┤ą║ąĄ FIFO, ąĖ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąŠčéą┐čĆą░ą▓ą╗ąĄąĮčŗ ą▓ ą▒čāč乥čĆ ą▓čŗąĘąŠą▓ąŠą╝ SendComplete, čćč鹊ą▒čŗ ą┤ą░ąĮąĮčŗąĄ čüčéą░ą╗ąĖ ą┤ąŠčüčéčāą┐ąĮčŗ ąĖčģ ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗čÄ. ą£ąŠą│čāčé ą▒čŗčéčī ąŠčéą┐čĆą░ą▓ą╗ąĄąĮčŗ ąĖą╗ąĖ ąĖąĘą▓ą╗ąĄč湥ąĮčŗ ąĮąĄčüą║ąŠą╗čīą║ąŠ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą▒ąĄąĘ ą▓čŗąĘąŠą▓ą░ SendComplete, ąĖ 菹╗ąĄą╝ąĄąĮčéčŗ ąĮąĄ ąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąĘą░ą┐ąŠą╗ąĮąĄąĮčŗ ą▓ č鹊ą╝ ąČąĄ ą┐ąŠčĆčÅą┤ą║ąĄ, ą▓ ą║ąŠč鹊čĆąŠą╝ ą▒čŗą╗ąĖ ąĖąĘą▓ą╗ąĄč湥ąĮčŗ. ą×ą┤ąĮą░ą║ąŠ ą┐ąŠą╗čāč湥ąĮąĖąĄ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą┤ą░ąĮąĮčŗčģ ą┤ąŠą╗ąČąĮąŠ ąŠčüčāčēąĄčüčéą▓ą╗čÅčéčīčüčÅ ą▓ ą┐ąŠčĆčÅą┤ą║ąĄ FIFO, ą┐ąŠčŹč鹊ą╝čā ąĮąĄ ą▓čŗąĘčŗą▓ą░ą╣č鹥 SendComplete ą┤ą╗čÅ čüą░ą╝ąŠą│ąŠ čĆą░ąĮąĮąĄą│ąŠ ąĖąĘą▓ą╗ąĄč湥ąĮąĮąŠą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░, čćč鹊 ą┐čĆąĄą┤ąŠčéą▓čĆą░čéąĖą╗ąŠ ą▒čŗ ą┐ąŠą╗čāč湥ąĮąĖąĄ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓.
ąĪą╗ąĄą┤čāčÄčēą░čÅ ą┤ąĖą░ą│čĆą░ą╝ą╝ą░ ąĮą░ čĆąĖčü. 3. ą┐ąŠą║ą░ąĘčŗą▓ą░ąĄčé, čćč鹊 ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé, ą║ąŠą│ą┤ą░ SendAcquire ąĖ SendComplete ą▓čŗąĘčŗą▓ą░čÄčéčüčÅ ą▓ ąŠą┤ąĮąŠą╝ ąĖ č鹊ą╝ ąČąĄ ą┐ąŠčĆčÅą┤ą║ąĄ. ąÆ čüą░ą╝ąŠą╝ ąĮą░čćą░ą╗ąĄ ą▓ ą▒čāč乥čĆąĄ čāąČąĄ ąĖą╝ąĄčÄčéčüčÅ ąŠčéą┐čĆą░ą▓ą╗ąĄąĮąĮčŗą╣ 菹╗ąĄą╝ąĄąĮčé ą┤ą░ąĮąĮčŗčģ ąĖąĘ 16 ą▒ą░ą╣čé. ąŚą░č鹥ą╝ ą▓čŗąĘčŗą▓ą░ąĄčéčüčÅ SendAcquire, čćč鹊ą▒čŗ ą▓čŗą┤ąĄą╗ąĖčéčī ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ąĖąĘ 20, 8, 24 ą▒ą░ą╣čé ą▓ ą║ąŠą╗čīčåąĄą▓ąŠą╝ ą▒čāč乥čĆąĄ.
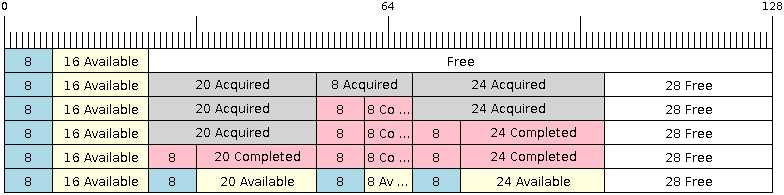
ąĀąĖčü. 3. SendAcquire/SendComplete ą┤ą╗čÅ čŹą╗ąĄą╝ąĄąĮč鹊ą▓ ą▓ ą║ąŠą╗čīčåąĄą▓ąŠą╝ ą▒čāč乥čĆąĄ čéąĖą┐ą░ No-Split.
ą¤ąŠčüą╗ąĄ čŹč鹊ą│ąŠ ą╝čŗ ąĘą░ą┐ąŠą╗ąĮąĖą╝ (ąĖčüą┐ąŠą╗čīąĘčāąĄą╝) ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗąĄ ąŠą▒ą╗ą░čüčéąĖ, ąĖ ąŠčéą┐čĆą░ą▓ąĖą╝ ąĖčģ ą▓ ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ ą▓čŗąĘąŠą▓ąŠą╝ ą▓ ą┐ąŠčĆčÅą┤ą║ąĄ 8, 24, 20. ąÜąŠą│ą┤ą░ ą▒čāą┤čāčé ąŠčéą┐čĆą░ą▓ą╗ąĄąĮčŗ 8 ą▒ą░ą╣čé ąĖ 24 ą▒ą░ą╣čéą░ ą┤ą░ąĮąĮčŗčģ, ą┐ąŠą╗čāčćą░č鹥ą╗čī ą▓čüąĄ ąĄčēąĄ ą╝ąŠąČąĄčé ą┐ąŠą╗čāčćąĖčéčī 16 ą▒ą░ą╣čé ą┐čĆąĄą┤čŗą┤čāčēąĄą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░ ą┤ą░ąĮąĮčŗčģ. ąĪą╗ąĄą┤ąŠą▓ą░č鹥ą╗čīąĮąŠ, ąĄčüą╗ąĖ SendComplete ąĮąĄ ą▒čāą┤ąĄčé ą▓čŗąĘą▓ą░ąĮą░ ą┤ą╗čÅ 20 ą▒ą░ą╣čé, čŹčéąĖ 16 ą▒ą░ą╣čé ąĮąĄ ą▒čāą┤čāčé ą┤ąŠčüčéčāą┐ąĮčŗ, ą║ą░ą║ ąĖ ą┤ą░ąĮąĮčŗąĄ 菹╗ąĄą╝ąĄąĮč鹊ą▓, čüą╗ąĄą┤čāčÄčēąĖčģ ąĘą░ 菹╗ąĄą╝ąĄąĮč鹊ą╝ ąĖąĘ 20 ą▒ą░ą╣čé.
ąÜąŠą│ą┤ą░ 菹╗ąĄą╝ąĄąĮčé 20 ą▒ą░ą╣čé ąĘą░ą▓ąĄčĆčłąĄąĮ ąŠą║ąŠąĮčćą░č鹥ą╗čīąĮąŠ (č湥čĆąĄąĘ SendComplete), č鹊ą│ą┤ą░ ą╝ąŠą│čāčé ą▒čŗčéčī ą┐ąŠą╗čāč湥ąĮčŗ ą▓čüąĄ 3 菹╗ąĄą╝ąĄąĮčéą░ ą┤ą░ąĮąĮčŗčģ ą▓ ą┐ąŠčĆčÅą┤ą║ąĄ 20, 8, 24, čüčĆą░ąĘčā ą┐ąŠčüą╗ąĄ 菹╗ąĄą╝ąĄąĮčéą░ 16 ą▒ą░ą╣čé, ą║ąŠč鹊čĆčŗą╣ ąĮą░čģąŠą┤ąĖčéčüčÅ ą▓ ąĮą░čćą░ą╗ąĄ ą▒čāč乥čĆą░.
ąæčāč乥čĆčŗ Allow-Split ąĖ ą▒ą░ą╣č鹊ą▓čŗąĄ ą▒čāč乥čĆą░ ąĮąĄ ą┐ąŠą╗čīąĘą▓ąŠą╗čÅčÄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčī SendAcquire ąĖą╗ąĖ SendComplete, ą┐ąŠčüą║ąŠą╗čīą║čā ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗąĄ ąŠą▒ą╗ą░čüčéąĖ ą▓ ą▒čāč乥čĆąĄ čéčĆąĄą▒čāčÄčé ąĘą░ą▓ąĄčĆčłąĄąĮąĖčÅ (ą▒ąĄąĘ ą┐ąĄčĆąĄčģąŠą┤ą░ ą▓ ąĮą░čćą░ą╗ąŠ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░).
ą¤ąĄčĆąĄčģąŠą┤ ąĖąĘ ą║ąŠąĮčåą░ ą▓ ąĮą░čćą░ą╗ąŠ. ąĪą╗ąĄą┤čāčÄčēąĖąĄ ą┤ąĖą░ą│čĆą░ą╝ą╝čŗ ąĮą░ čĆąĖčü. 4, 5 ąĖ 6 ą┐ąŠą║ą░ąĘčŗą▓ą░čÄčé čĆą░ąĘą╗ąĖčćąĖčÅ ą╝ąĄąČą┤čā ą▒čāč乥čĆą░ą╝ąĖ No-Split, Allow-Split ąĖ ą▒ą░ą╣č鹊ą▓čŗą╝ąĖ ą▒čāč乥čĆą░ą╝ąĖ, ą║ąŠą│ą┤ą░ ąŠčéą┐čĆą░ą▓ą╗ąĄąĮąĮčŗąĄ 菹╗ąĄą╝ąĄąĮčéčŗ ą┤ą░ąĮąĮčŗčģ čéčĆąĄą▒čāčÄčé ą┐ąĄčĆąĄčüą║ąŠą║ą░ ąĖąĘ ą║ąŠąĮčåą░ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ ą▓ ąĄą│ąŠ ąĮą░čćą░ą╗ąŠ. ą¤ąŠą║ą░ąĘą░ąĮąĮčŗąĄ ą┤ąĖą░ą│čĆą░ą╝ą╝čŗ ą┐ąŠą┤čĆą░ąĘčāą╝ąĄą▓ą░čÄčé, čćč鹊 ą▒čāč乥čĆ ąĖą╝ąĄąĄčé čĆą░ąĘą╝ąĄčĆ 128 čüąŠ čüą▓ąŠą▒ąŠą┤ąĮčŗą╝ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠą╝ ąĖąĘ 56 ą▒ą░ą╣čé, ą┐ąĄčĆąĄč鹥ą║ą░čēąĖą╝ ąĖąĘ ą║ąŠąĮčåą░ ą▓ ąĮą░čćą░ą╗ąŠ, ąĖ ąŠčéą┐čĆą░ą▓ą╗čÅąĄą╝čŗą╣ 菹╗ąĄą╝ąĄąĮčé ąĖą╝ąĄąĄčé čĆą░ąĘą╝ąĄčĆ 28 ą▒ą░ą╣čé.

ąĀąĖčü. 4. ą¤ąĄčĆąĄčüą║ąŠą║ ą▓ ąĮą░čćą░ą╗ąŠ ą┤ą╗čÅ ą▒čāč乥čĆą░ No-Split.
ąæčāč乥čĆčŗ čéąĖą┐ą░ No-Split ą╝ąŠą│čāčé čüąŠčģčĆą░ąĮčÅčéčī 菹╗ąĄą╝ąĄąĮčéčŗ č鹊ą╗čīą║ąŠ ą▓ ąĮąĄą┐čĆąĄčĆčŗą▓ąĮčŗčģ ąŠą▒ą╗ą░čüčéčÅčģ ą┐ą░ą╝čÅčéąĖ, ąĖ ąĮąĖ ą┐čĆąĖ ą║ą░ą║ąĖčģ ąŠą▒čüč鹊čÅč鹥ą╗čīčüčéą▓ą░čģ čüąŠčģčĆą░ąĮčÅąĄą╝čŗąĄ 菹╗ąĄą╝ąĄąĮčéčŗ ą┤ą░ąĮąĮčŗčģ ąĮąĄ ą▒čāą┤čāčé ą┐ąŠą┤ąĄą╗ąĄąĮčŗ ąĮą░ ą║čāčüą║ąĖ. ąÜąŠą│ą┤ą░ čüą▓ąŠą▒ąŠą┤ąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ą▓ ą║ąŠąĮčåąĄ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ ąĮąĄą┤ąŠčüčéą░č鹊čćąĮąŠ, čćč鹊ą▒čŗ ą┐ąŠą╗ąĮąŠčüčéčīčÄ čüąŠčģčĆą░ąĮąĖčéčī 菹╗ąĄą╝ąĄąĮčé ąĖ ąĄą│ąŠ ąĘą░ą│ąŠą╗ąŠą▓ąŠą║, č鹊 čŹč鹊 čüą▓ąŠą▒ąŠą┤ąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ą▓ ą║ąŠąĮčåąĄ ą┐ąŠą╝ąĄčćą░ąĄčéčüčÅ ą║ą░ą║ ą┐čāčüčéčŗąĄ ą┤ą░ąĮąĮčŗčģ (dummy data). ąóąŠą│ą┤ą░ ą┐čĆąŠąĖčüčģąŠą┤ąĖčé ą┐ąĄčĆąĄčüą║ąŠą║ ą▓ ąĮą░čćą░ą╗ąŠ, ąĖ ą┤ą╗čÅ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ čŹą╗ąĄą╝ąĄąĮčéą░ ą▒čāą┤ąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ čüą▓ąŠą▒ąŠą┤ąĮą░čÅ ąŠą▒ą╗ą░čüčéčī ąŠčé ąĮą░čćą░ą╗ą░ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░.
ąÜą░ą║ ą▓ąĖą┤ąĮąŠ ąĖąĘ čĆąĖčü. 4, čüą▓ąŠą▒ąŠą┤ąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ąĖąĘ 16 ą▒ą░ą╣čé ą▓ čģą▓ąŠčüč鹥 ą▒čāč乥čĆą░ ąĮąĄą┤ąŠčüčéą░č鹊čćąĮąŠ, čćč鹊ą▒čŗ čüąŠčģčĆą░ąĮąĖčéčī 28 菹╗ąĄą╝ąĄąĮčé čĆą░ąĘą╝ąĄčĆąŠą╝ 28 ą▒ą░ą╣čé. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ čŹčéąĖ 16 ą▒ą░ą╣čé ą┐ąŠą╝ąĄčćą░čÄčéčüčÅ ą║ą░ą║ dummy data, ąĖ 菹╗ąĄą╝ąĄąĮčé čü ąĘą░ą│ąŠą╗ąŠą▓ą║ąŠą╝ ąĘą░ą┐ąĖčłąĄčéčüčÅ ą▓ čüą▓ąŠą▒ąŠą┤ąĮčāčÄ ąŠą▒ą╗ą░čüčéčī ą▓ ąĮą░čćą░ą╗ąĄ ą▒čāč乥čĆą░.

ąĀąĖčü. 5. ą¤ąĄčĆąĄčüą║ąŠą║ ą▓ ąĮą░čćą░ą╗ąŠ ą┤ą╗čÅ ą▒čāč乥čĆą░ Allow-Split.
ąæčāč乥čĆčŗ čéąĖą┐ą░ Allow-Split ą▒čāą┤čāčé ą┐čŗčéą░čéčīčüčÅ ą┐ąŠą┤ąĄą╗ąĖčéčī 菹╗ąĄą╝ąĄąĮčé ąĮą░ 2 ą║čāčüą║ą░, ąĄčüą╗ąĖ čüą▓ąŠą▒ąŠą┤ąĮąŠąĄ ą╝ąĄčüč鹊 ą▓ ą║ąŠąĮčåąĄ ą▒čāč乥čĆą░ ąĮąĄ čģą▓ą░čéąĖčé ą╝ąĄčüčéą░ ą┤ą╗čÅ čĆą░ąĘą╝ąĄčēąĄąĮąĖčÅ čŹą╗ąĄą╝ąĄąĮčéą░ ąĖ ąĄą│ąŠ ąĘą░ą│ąŠą╗ąŠą▓ą║ą░. ą×ą▒ą░ ą║čāčüą║ą░ čĆą░ąĘą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░ ą▓ čŹč鹊ą╝ čüą╗čāčćą░ąĄ ą┐ąŠą╗čāčćą░čé čüą▓ąŠą╣ ąĘą░ą│ąŠą╗ąŠą▓ąŠą║ (čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ąĮą░ ąĘą░ą│ąŠą╗ąŠą▓ą║ąĖ ą▒čāą┤ąĄčé ą┐ąŠčéčĆą░č湥ąĮąŠ 16 ą▒ą░ą╣čé ą▓ą╝ąĄčüč鹊 8 ą▒ą░ą╣čé, ą║ąŠą│ą┤ą░ 菹╗ąĄą╝ąĄąĮčé ąĮąĄ ą┤ąĄą╗ąĖčéčüčÅ ąĮą░ ą║čāčüą║ąĖ).
ąśąĘ ą┤ąĖą░ą│čĆą░ą╝ą╝čŗ ąĮą░ čĆąĖčü. 5 ą▓ąĖą┤ąĮąŠ, čćč鹊 čüą▓ąŠą▒ąŠą┤ąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ 16 ą▒ą░ą╣čé ą▓ čģą▓ąŠčüč鹥 ą▒čāč乥čĆą░ ąĮąĄą┤ąŠčüčéą░č鹊čćąĮąŠ, čćč鹊ą▒čŗ čüąŠčģčĆą░ąĮąĖčéčī 菹╗ąĄą╝ąĄąĮčé ąĖąĘ 28 ą▒ą░ą╣čé. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, 菹╗ąĄą╝ąĄąĮčé ą┤ąĄą╗ąĖčéčüčÅ ąĮą░ 2 ą║čāčüą║ą░ (ą┐ąŠ 8 ąĖ 20 ą▒ą░ą╣čé), ąĖ čŹčéąĖ ą║čāčüą║ąĖ ąĘą░ą┐ąĖčüčŗą▓ą░čÄčéčüčÅ ą▓ ą▒čāč乥čĆ.
ąÆą░ąČąĮąŠąĄ ąĘą░ą╝ąĄčćą░ąĮąĖąĄ: ą▒čāč乥čĆčŗ Allow-Split ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čÄčé ąŠą▒ą░ čŹčéąĖčģ ą║čāčüą║ą░ ą║ą░ą║ ą┤ą▓ą░ ąŠčéą┤ąĄą╗čīąĮčŗąĄ 菹╗ąĄą╝ąĄčéą░, čéą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝ ą▓čŗąĘčŗą▓ą░ą╣č鹥 xRingbufferReceiveSplit() ą▓ą╝ąĄčüč鹊 xRingbufferReceive(), čćč鹊ą▒čŗ ą▒ąĄąĘąŠą┐ą░čüąĮąŠ (thread safe) ąĖąĘą▓ą╗ąĄčćčī ąŠą▒ą░ ą║čāčüą║ą░ čĆą░ąĘą┤ąĄą╗ąĄąĮąĮąŠą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░.

ąĀąĖčü. 6. ą¤ąĄčĆąĄčüą║ąŠą║ ą▓ ąĮą░čćą░ą╗ąŠ ą┤ą╗čÅ ą▒ą░ą╣č鹊ą▓ąŠą│ąŠ ą▒čāč乥čĆą░.
ąæą░ą╣č鹊ą▓čŗąĄ ą▒čāč乥čĆčŗ ą▒čāą┤čāčé čüąŠčģčĆą░ąĮčÅčéčī ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą▓ąŠąĘą╝ąŠąČąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ ą▒ą░ą╣čé ą┤ą░ąĮąĮčŗčģ ą▓ čüą▓ąŠą▒ąŠą┤ąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ čģą▓ąŠčüčéą░ ą▒čāč乥čĆą░. ą×čüčéą░ą╗čīąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ ą▒čāą┤čāčé ąĘą░ą┐ąĖčüą░ąĮčŗ ą▓ čüą▓ąŠą▒ąŠą┤ąĮčāčÄ ąŠą▒ą╗ą░čüčéčī, ąĮą░čģąŠą┤čÅčēčāčÄčüčÅ ą▓ ąĮą░čćą░ą╗ąĄ ą▒čāč乥čĆą░. ą¤čĆąĖ čŹč鹊ą╝ ąĮąĄ ą▒čāą┤ąĄčé ąĮąĖą║ą░ą║ąĖčģ ą╗ąĖčłąĮąĖčģ čĆą░čüčģąŠą┤ąŠą▓ ą┐čĆąĖ ą┐ąĄčĆąĄčüą║ąŠą║ąĄ ąĖąĘ ą║ąŠąĮčåą░ ą▓ ąĮą░čćą░ą╗ąŠ ą▒ą░ą╣č鹊ą▓ąŠą│ąŠ ą▒čāč乥čĆą░.
ąÜą░ą║ ą▓ąĖą┤ąĮąŠ ąĖąĘ čĆąĖčü. 6, ąĘą┤ąĄčüčī 16 ą▒ą░ą╣čé čģą▓ąŠčüčéą░ ą▒čāč乥čĆą░ ąĮąĄ čģą▓ą░čéąĖčé, čćč鹊ą▒čŗ ą┐ąŠą╗ąĮąŠčüčéčīčÄ čĆą░ąĘą╝ąĄčüčéąĖčéčī 菹╗ąĄą╝ąĄąĮčé ąĖąĘ 28 ą▒ą░ą╣čé. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, čŹčéąĖ 16 ą▒ą░ą╣čé čüą▓ąŠą▒ąŠą┤ąĮąŠą│ąŠ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ą▒čāą┤čāčé ą┐ąŠą╗ąĮąŠčüčéčīčÄ ąĘą░ą┐ąŠą╗ąĮąĄąĮąĮčŗ ą┤ą░ąĮąĮčŗą╝ąĖ 菹╗ąĄą╝ąĄąĮčéą░, ąĖ ąŠčüčéą░ą╗čīąĮčŗąĄ 12 ą▒čāą┤čāčé ąĘą░ą┐ąĖčüą░ąĮčŗ ą▓ čüą▓ąŠą▒ąŠą┤ąĮąŠąĄ ą╝ąĄčüč鹊, ąĮą░čģąŠą┤čÅčēąĄąĄčüčÅ ą▓ ąĮą░čćą░ą╗ąĄ ą▒čāč乥čĆą░. ąóąĄą┐ąĄčĆčī ą▒čāč乥čĆ čüąŠą┤ąĄčƹȹĖčé ą┤ą░ąĮąĮčŗąĄ 菹╗ąĄą╝ąĄąĮčéą░ ą▓ ą┤ą▓čāčģ ąŠčéą┤ąĄą╗čīąĮčŗčģ ąĮąĄą┐čĆąĄčĆčŗą▓ąĮčŗčģ ą║čāčüą║ą░čģ, ą║ą░ąČą┤čŗą╣ ąĖąĘ ą║čāčüą║ąŠą▓ ą▒čāą┤čāčé ąŠą▒čĆą░ą▒ą░čéčŗą▓ą░čéčīčüčÅ ą▒ą░ą╣č鹊ą▓čŗą╝ ą▒čāč乥čĆąŠą╝ ą║ą░ą║ ąŠą┤ąĄą╗čīąĮčŗą╣ 菹╗ąĄą╝ąĄąĮčé ą┤ą░ąĮąĮčŗčģ.
ą¤ąŠą╗čāč湥ąĮąĖąĄ/ą▓ąŠąĘą▓čĆą░čé 菹╗ąĄą╝ąĄąĮč鹊ą▓. ąöąĖą░ą│čĆą░ą╝ą╝čŗ ąĮąĖąČąĄ ą┐ąŠą║ą░ąČčāčé čĆą░ą╗ąĖčćąĖčÅ ą▒čāč乥čĆąŠą▓ No-Split ąĖ Allow-Split ą▓ čüčĆą░ą▓ąĮąĄąĮąĖąĖ čü ą▒ą░ą╣č鹊ą▓čŗą╝ąĖ ą▒čāč乥čĆą░ą╝ąĖ, ą║ąŠą│ą┤ą░ ą┤ą░ąĮąĮčŗąĄ ąĘą░ą┐čĆą░čłąĖą▓ą░čÄčéčüčÅ ąĖ ą▓ąŠąĘą▓čĆą░čēą░čÄčéčüčÅ ą┤ą╗čÅ ą┐ąŠčéčĆąĄą▒ąĖč鹥ą╗čÅ.

ąĀąĖčü. 7. ąŚą░ą┐čĆąŠčü/ą▓ąŠąĘą▓čĆą░čé 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą┤ą╗čÅ ą║ąŠą╗čīčåąĄą▓čŗčģ ą▒čāč乥čĆąŠą▓ No-Split ąĖ Allow-Split.
ąŁą╗ąĄą╝ąĄąĮčéčŗ ąĖąĘ ą▒čāč乥čĆąŠą▓ No-Split ąĖ Allow-Split ąĖąĘą▓ą╗ąĄą║ą░čÄčéčüčÅ ą▓ čüčéčĆąŠą│ąŠą╝ ą┐ąŠčĆčÅą┤ą║ąĄ FIFO, ąĖ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą▓ąŠąĘą▓čĆą░čēąĄąĮčŗ ą┤ą╗čÅ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░, ąĘą░ąĮąĖą╝ą░ąĄą╝ąŠą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░ą╝ąĖ. ąØąĄčüą║ąŠą╗čīą║ąŠ 菹╗ąĄą╝ąĄąĮč鹊ą▓ ą╝ąŠą│čāčé ą▒čŗčéčī ąĘą░ą┐čĆąŠčłąĄąĮčŗ ą┐ąĄčĆąĄą┤ ąĖčģ ą▓ąŠąĘą▓čĆą░č鹊ą╝, ąĖ 菹╗ąĄą╝ąĄąĮčéčŗ ąĮąĄąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą▓ąŠąĘą▓čĆą░čēąĄąĮčŗ ą▓ č鹊ą╝ ąČąĄ ą┐ąŠčĆčÅą┤ą║ąĄ, ą▓ ą║ąŠč鹊čĆąŠą╝ ą▒čŗą╗ąĖ ąĘą░ą┐čĆąŠčłąĄąĮčŗ. ą×ą┤ąĮą░ą║ąŠ ą▓ąŠąĘą▓čĆą░čēąĄąĮąĖąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ą┤ąŠą╗ąČąĮąŠ ą┐čĆąŠąĖčüčģąŠą┤ąĖčéčī ą▓ ą┐ąŠčĆčÅą┤ą║ąĄ FIFO, ą┐ąŠčŹč鹊ą╝čā ą▓ąŠąĘą▓čĆą░čé čüą░ą╝ąŠą│ąŠ čĆą░ąĮąĮąĄą│ąŠ ąĘą░ą┐čĆąŠčłąĄąĮąĮąŠą│ąŠ 菹╗ąĄą╝ąĄąĮčéą░ ą┐čĆąĄą┤ąŠčéą▓čĆą░čéąĖčé ąŠčé ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ą░ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĖčģ 菹╗ąĄą╝ąĄąĮč鹊ą▓.
ąØą░ ą┤ąĖą░ą│čĆą░ą╝ą╝ąĄ čĆąĖčü. 7 ą▓ąĖą┤ąĮąŠ, čćč鹊 菹╗ąĄą╝ąĄąĮčéčŗ ąĖąĘ 16, 20 ąĖ 8 ą▒ą░ą╣čé ąĘą░ą┐čĆą░čłąĖą▓ą░čÄčéčüčÅ ą▓ ą┐ąŠčĆčÅą┤ą║ąĄ FIFO. ą×ą┤ąĮą░ą║ąŠ ąĮąĄ ą▓ąŠąĘą▓čĆą░čēą░čÄčéčüčÅ ą▓ č鹊ą╝ ą┐ąŠčĆčÅą┤ą║ąĄ, ą▓ ą║ąŠč鹊čĆąŠą╝ ąŠąĮąĖ ą▒čŗą╗ąĖ ąĘą░ą┐čĆąŠčłąĄąĮčŗ. ąĪąĮą░čćą░ą╗ą░ ą▓ąŠąĘą▓čĆą░čēą░ąĄčéčüčÅ čŹą╗ąĄą╝ąĄąĮčé ąĖąĘ 20 ą▒ą░ą╣čé, ąĘą░ č鹥ą╝ 菹╗ąĄą╝ąĄąĮčé 8 ą▒ą░ą╣čé, ąĖ ąĘą░č鹥ą╝ 菹╗ąĄą╝ąĄąĮčé ąĖąĘ 16 ą▒ą░ą╣čé. ą¤čĆąŠčüčéčĆą░čüčéą▓ąŠ ąĮąĄ ąŠčüą▓ąŠą▒ąŠąČą┤ą░ąĄčéčüčÅ, ą┐ąŠą║ą░ ąĮąĄ ą▒čāą┤ąĄčé ą▓ąŠąĘą▓čĆą░čēąĄąĮ ą┐ąĄčĆą▓čŗą╣ 菹╗ąĄą╝ąĄąĮčé, čé. ąĄ. 菹╗ąĄą╝ąĄąĮčé ąĖąĘ 16 ą▒ą░ą╣čé.

ąĀąĖčü. 8. ąŚą░ą┐čĆąŠčü/ą▓ąŠąĘą▓čĆą░čé ą┤ą░ąĮąĮčŗčģ ą▓ ą▒ą░ą╣č鹊ą▓čŗčģ ą▒čāč乥čĆą░čģ.
ąæą░ą╣č鹊ą▓čŗąĄ ą▒čāč乥čĆčŗ ąĮąĄ ą┐ąŠąĘą▓ąŠą╗čÅčÄčé ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčéčī ąĮąĄčüą║ąŠą╗čīą║ąŠ ąĘą░ą┐čĆąŠčüąŠą▓ ą┐ąĄčĆąĄą┤ ą▓ąŠąĘą▓čĆą░č鹊ą╝ (ąĘą░ ą║ą░ąČą┤čŗą╝ ąĘą░ą┐čĆąŠčüąŠą╝ ąŠą▒čÅąĘą░č鹥ą╗čīąĮąŠ ą┤ąŠą╗ąČąĄąĮ ą┐ąŠčüą╗ąĄą┤ąŠą▓ą░čéčī ą▓ąŠąĘą▓čĆą░čé, ą┐ąĄčĆąĄą┤ č鹥ą╝ ą║ą░ą║ ą╝ąŠąČąĄčé ą▒čŗčéčī čĆą░ąĘčĆąĄčłąĄąĮ ą┤čĆčāą│ąŠą╣ ąĘą░ą┐čĆąŠčü). ąÜąŠą│ą┤ą░ ąĖčüą┐ąŠą╗čīąĘčāčÄčéčüčÅ xRingbufferReceive() ąĖą╗ąĖ xRingbufferReceiveFromISR(), ą▒čāą┤čāčé ąĘą░ą┐čĆąŠčłąĄąĮčŗ ą▓čüąĄ ąĮąĄą┐čĆąĄčĆčŗą▓ąĮąŠ čüąŠčģčĆą░ąĮąĄąĮąĮčŗąĄ ą┤ą░ąĮąĮčŗąĄ. xRingbufferReceiveUpTo() ąĖą╗ąĖ xRingbufferReceiveUpToFromISR() ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ ą┤ą╗čÅ ąŠą│čĆą░ąĮąĖč湥ąĮąĖčÅ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ąĘą░ą┐čĆą░čłąĖą▓ą░ąĄą╝čŗčģ ą▒ą░ą╣čé. ą¤ąŠčüą║ąŠą╗čīą║čā ą║ą░ąČą┤čŗą╣ ąĘą░ą┐čĆąŠčü ą┤ąŠą╗ąČąĄąĮ čüąŠą┐čĆąŠą▓ąŠąČą┤ą░čéčīčüčÅ ą▓ąŠąĘą▓čĆą░č鹊ą╝, ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ą▒čāą┤ąĄčé ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąŠ, ą║ą░ą║ č鹊ą╗čīą║ąŠ ą┤ą░ąĮąĮčŗąĄ ą▒čŗą╗ąĖ ą▓ąŠąĘą▓čĆą░čēąĄąĮčŗ.
ąÜą░ą║ ą▓ąĖą┤ąĮąŠ ąĖąĘ ą┤ąĖą░ą│čĆą░ą╝ą╝čŗ čĆąĖčü. 8, ąĮąĄą┐čĆąĄčĆčŗą▓ąĮąŠ čüąŠčģčĆą░ąĮąĄąĮąĮčŗąĄ 38 ą▒ą░ą╣čé ą▓ čģą▓ąŠčüč鹥 ą▒čāč乥čĆą░ ąĘą░ą┐čĆą░čłąĖą▓ą░čÄčéčüčÅ, ą▓ąŠąĘą▓čĆą░čēą░čÄčéčüčÅ ąĖ ąŠčüą▓ąŠą▒ąŠąČą┤ą░čÄčéčüčÅ. ą¤ąŠčüą╗ąĄą┤čāčÄčēąĖą╣ ą▓čŗąĘąŠą▓ xRingbufferReceive() ąĖą╗ąĖ xRingbufferReceiveFromISR() ąĘą░č鹥ą╝ ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ ą┐ąĄčĆąĄčüą║ąŠą║čā ą║ ąĮą░čćą░ą╗čā ą▒čāč乥čĆą░ ąĖ ą┤ąĄą╗ą░ąĄčé č鹊 ąČąĄ čüą░ą╝ąŠą│ąŠ čü 30 ą▒ą░ą╣čéą░ą╝ąĖ ąĮąĄą┐čĆąĄčĆčŗą▓ąĮąŠ čüąŠčģčĆą░ąĮąĄąĮąĮčŗčģ ą┤ą░ąĮąĮčŗčģ ą▓ ąĮą░čćą░ą╗ąĄ ą▒čāč乥čĆą░.
ąÜąŠą╗čīčåąĄą▓čŗąĄ ą▒čāč乥čĆčŗ ąĖ ąĮą░ą▒ąŠčĆčŗ ąŠč湥čĆąĄą┤ąĄą╣. ąÜąŠą╗čīčåąĄą▓čŗąĄ ą▒čāč乥čĆčŗ ą╝ąŠą│čāčé ą▒čŗčéčī ą┤ąŠą▒ą░ą▓ą╗ąĄąĮčŗ ą▓ ąĮą░ą▒ąŠčĆčŗ ąŠč湥čĆąĄą┤ąĄą╣ FreeRTOS (queue sets) čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ xRingbufferAddToQueueSetRead(), čéą░ą║ čćč鹊 ą║ą░ąČą┤čŗ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ ą┐čĆąĖąĮąĖą╝ą░ąĄčé 菹╗ąĄą╝ąĄąĮčé ąĖą╗ąĖ ą┤ą░ąĮąĮčŗąĄ, ąŠą▒ čŹč鹊ą╝ čüąŠą▒čŗčéąĖąĖ ą▒čāą┤ąĄčé ąŠą┐ąŠą▓ąĄčēąĄąĮ queue set. ąÜąŠą│ą┤ą░ ą▒čŗą╗ąŠ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ ą║ queue set, ą║ą░ąČą┤ą░čÅ ą┐ąŠą┐čŗčéą║ą░ ą┐ąŠą╗čāčćąĖčéčī 菹╗ąĄą╝ąĄąĮčé ąĖąĘ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ ą┤ąŠą╗ąČąĮą░ čüąŠą┐čĆąŠą▓ąŠąČą┤ą░čéčīčüčÅ ą┐čĆąĄą┤ą▓ą░čĆąĖč鹥ą╗čīąĮčŗą╝ ą▓čŗąĘąŠą▓ąŠą╝ xQueueSelectFromSet(). ąöą╗čÅ ą┐čĆąŠą▓ąĄčĆą║ąĖ, čÅą▓ą╗čÅąĄčéčüčÅ ą╗ąĖ ą▓čŗą▒čĆą░ąĮąĮčŗą╣ čćą╗ąĄąĮ queue set ą║ąŠą╗čīčåąĄą▓čŗą╝ ą▒čāč乥čĆąŠą╝, ą▓čŗąĘąŠą▓ąĖč鹥 xRingbufferCanRead().
ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą┐čĆąĖą╝ąĄčĆ ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄ queue set ą▓ą╝ąĄčüč鹥 čü ą║ąŠą╗čīčåąĄą▓čŗą╝ąĖ ą▒čāč乥čĆą░ą╝ąĖ.
#include "freertos/queue.h"
#include "freertos/ringbuf.h"
...
// ąĪąŠąĘą┤ą░ąĮąĖąĄ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ ąĖ queue set:
RingbufHandle_t buf_handle = xRingbufferCreate(1028, RINGBUF_TYPE_NOSPLIT);
QueueSetHandle_t queue_set = xQueueCreateSet(3);
// ąöąŠą▒ą░ą▓ą╗ąĄąĮąĖąĄ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ ą║ queue set:
if (xRingbufferAddToQueueSetRead(buf_handle, queue_set) != pdTRUE)
{
printf("Failed to add to queue set\n");
}
...
// ąæą╗ąŠą║ąĖčĆąŠą▓ą║ą░ ąĮą░ queue set:
QueueSetMemberHandle_t member = xQueueSelectFromSet(queue_set,
pdMS_TO_TICKS(1000));
// ą¤čĆąŠą▓ąĄčĆą║ą░, čÅą▓ą╗čÅąĄčéčüčÅ ą╗ąĖ 菹╗ąĄą╝ąĄąĮčé ąĖąĘ queue set ą║ąŠą╗čīčåąĄą▓čŗą╝ ą▒čāč乥čĆąŠą╝:
if (member != NULL && xRingbufferCanRead(buf_handle, member) == pdTRUE)
{
// ąŁč鹊 ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ, ąĘą░ą┐čĆąŠčü 菹╗ąĄą╝ąĄąĮčéą░ ąĖąĘ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░:
size_t item_size;
char *item = (char *)xRingbufferReceive(buf_handle, &item_size, 0);
// ą×ą▒čĆą░ą▒ąŠčéą║ą░ 菹╗ąĄą╝ąĄąĮčéą░:
...
}
else
{
...
}
ąÜąŠą╗čīčåąĄą▓čŗąĄ ą▒čāč乥čĆčŗ ąĖ čüčéą░čéąĖč湥čüą║ąŠąĄ ą▓čŗą┤ąĄą╗ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ. ą£ąŠąČąĄčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ xRingbufferCreateStatic() ą┤ą╗čÅ čüąŠąĘą┤ą░ąĮąĖčÅ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ čüąŠ čüą┐ąĄčåąĖčäąĖč湥čüą║ąĖą╝ąĖ čéčĆąĄą▒ąŠą▓ą░ąĮąĖčÅą╝ąĖ ą║ ą┐ą░ą╝čÅčéąĖ, ą║ą░ą║ ąĮą░ą┐čĆąĖą╝ąĄčĆ ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ, ąĮą░čģąŠą┤čÅčēąĖą╣čüčÅ ą▓ąŠ ą▓ąĮąĄčłąĮąĄą╝ ą×ąŚąŻ (external RAM). ąÆčüąĄ ą▒ą╗ąŠą║ąĖ ą┐ą░ą╝čÅčéąĖ, ąĖčüą┐ąŠą╗čīąĘčāąĄą╝čŗąĄ ą║ąŠą╗čīčåąĄą▓čŗą╝ ą▒čāč乥čĆąŠą╝, ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ą▓čŗą┤ąĄą╗ąĄąĮčŗ ą▓čĆčāčćąĮčāčÄ ąĘą░čĆą░ąĮąĄąĄ, ąĖ ąĘą░č鹥ą╝ ą┐ąĄčĆąĄą┤ą░ąĮčŗ ą▓ xRingbufferCreateStatic(), čćč鹊ą▒čŗ ą▒čŗčéčī ąĖąĮąĖčåąĖą░ą╗ąĖąĘąĖčĆąŠą▓ą░ąĮąĮčŗą╝ąĖ ą║ą░ą║ ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ. ąŁčéąĖ ą▒ą╗ąŠą║ąĖ ą▓ą║ą╗čÄčćą░čÄčé čüą╗ąĄą┤čāčÄčēąĄąĄ:
ŌĆó ąĪčéčĆčāą║čéčāčĆą░ ą┤ą░ąĮąĮčŗčģ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ čéąĖą┐ą░ StaticRingbuffer_t.
ŌĆó ą×ą▒ą╗ą░čüčéčī čģčĆą░ąĮąĄąĮąĖčÅ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ čĆą░ąĘą╝ąĄčĆą░ xBufferSize. ą×ą▒čĆą░čéąĖč鹥 ą▓ąĮąĖą╝ą░ąĮąĖąĄ, čćč鹊 ąĘąĮą░č湥ąĮąĖąĄ xBufferSize čāą║ą░ąĘčŗą▓ą░ąĄčéčüčÅ ą▓ ą▒ą░ą╣čéą░čģ, ąĖ ąŠąĮąŠ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą▓čŗčĆąŠą▓ąĮąĄąĮąŠ ąĮą░ 32-ą▒ąĖčéą░ ą┤ą╗čÅ ą▒čāč乥čĆąŠą▓ No-Split ąĖ Allow-Split.
ąĪą┐ąŠčüąŠą▒, ą║ąŠč鹊čĆčŗą╝ ą▓čŗą┤ąĄą╗čÅčÄčéčüčÅ čŹčéąĖ ą▒ą╗ąŠą║ąĖ, ą▒čāą┤ąĄčé ąĘą░ą▓ąĖčüąĄčéčī ąŠčé čéčĆąĄą▒ąŠą▓ą░ąĮąĖą╣ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅ (ąĮą░ą┐čĆąĖą╝ąĄčĆ ą▓čüąĄ ą▒ą╗ąŠą║ąĖ ą┤ąĄą║ą╗ą░čĆąĖčĆčāčÄčéčüčÅ čüčéą░čéąĖč湥čüą║ąĖ, ąĖą╗ąĖ ą▓čŗą┤ąĄą╗čÅčÄčéčüčÅ ą┤ąĖąĮą░ą╝ąĖč湥čüą║ąĖ, čü čāč湥č鹊ą╝ čüą┐ąĄčåąĖą░ą╗čīąĮčŗčģ ąŠčüąŠą▒ąĄąĮąĮąŠčüč鹥ą╣, čéą░ą║ąĖčģ ą║ą░ą║ external RAM).
ąÆą░ąČąĮąŠąĄ ąĘą░ą╝ąĄčćą░ąĮąĖąĄ: ą║ąŠą│ą┤ą░ čāą┤ąĄą╗čÅąĄčéčüčÅ ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ, čüąŠąĘą┤ą░ąĮąĮčŗą╣ č湥čĆąĄąĘ xRingbufferCreateStatic(), čäčāąĮą║čåąĖčÅ vRingbufferDelete() ąĮąĄ ąŠčüą▓ąŠą▒ąŠą┤ąĖčé ąĮąĖą║ą░ą║ąĖąĄ ą▒ą╗ąŠą║ąĖ ą┐ą░ą╝čÅčéąĖ. ąŁč鹊 ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮąŠ ą▒čŗčéčī ą▓čŗą┐ąŠą╗ąĮąĄąĮąŠ ą▓čĆčāčćąĮčāčÄ ą┐ąŠčüą╗ąĄ ą▓čŗąĘąŠą▓ą░ vRingbufferDelete().
ąĪą╗ąĄą┤čāčÄčēąĖą╣ ą║čāčüąŠą║ ą║ąŠą┤ą░ ą┤ąĄą╝ąŠąĮčüčéčĆąĖčĆčāąĄčé ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ, ą┐ąŠą╗ąĮąŠčüčéčīčÄ čĆą░ąĘą╝ąĄčēąĄąĮąĮčŗą╣ ą▓ external RAM.
#include "freertos/ringbuf.h"
#include "freertos/semphr.h"
#include "esp_heap_caps.h"
#define BUFFER_SIZE 400 // čĆą░ąĘą╝ąĄčĆ, ą▓čŗčĆąŠą▓ąĮąĄąĮąĮčŗą╣ ąĮą░ 32 ą▒ąĖčéą░
#define BUFFER_TYPE RINGBUF_TYPE_NOSPLIT
...
// ąÆčŗą┤ąĄą╗ąĄąĮąĖąĄ čüčéčĆčāą║čéčāčĆčŗ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ ąĖ ąŠą▒ą╗ą░čüčéąĖ čģčĆą░ąĮąĄąĮąĖčÅ ą▓ external RAM:
StaticRingbuffer_t *buffer_struct = (StaticRingbuffer_t*)heap_caps_malloc(sizeof(StaticRingbuffer_t),
MALLOC_CAP_SPIRAM);
uint8_t *buffer_storage = (uint8_t*)heap_caps_malloc(sizeof(uint8_t)*BUFFER_SIZE, MALLOC_CAP_SPIRAM);
// ąĪąŠąĘą┤ą░ąĮąĖąĄ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ čü ą▓čĆčāčćąĮčāčÄ ą▓čŗą┤ąĄą╗ąĄąĮąĮąŠą╣ ą┐ą░ą╝čÅčéčīčÄ:
RingbufHandle_t handle = xRingbufferCreateStatic(BUFFER_SIZE,
BUFFER_TYPE,
buffer_storage,
buffer_struct);
...
// ąŻą┤ą░ą╗ąĄąĮąĖąĄ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ ą┐ąŠčüą╗ąĄ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ:
vRingbufferDelete(handle);
// ą×čüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ą▓čüąĄčģ ą▒ą╗ąŠą║ąŠą▓ ą┐ą░ą╝čÅčéąĖ ą▓čĆčāčćąĮčāčÄ:
free(buffer_struct);
free(buffer_storage);
ąśąĮą▓ąĄčĆčüąĖčÅ ą┐čĆąĖąŠčĆąĖč鹥čéą░. ąÆ ąĖą┤ąĄą░ą╗ąĄ ą║ąŠą╗čīčåąĄą▓čŗąĄ ą▒čāč乥čĆčŗ ą╝ąŠą│čāčé ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░čéčīčüčÅ čü ąĮąĄčüą║ąŠą╗čīą║ąĖą╝ąĖ ąĘą░ą┤ą░čćą░ą╝ąĖ ą▓ čüčĆąĄą┤ąĄ SMP, ą║ąŠą│ą┤ą░ ąĘą░ą┤ą░čćą░ čü čüą░ą╝čŗą╝ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ ą▒čāą┤ąĄčé ą▓čüąĄą│ą┤ą░ ąŠą▒čüą╗čāąČąĖą▓ą░čéčīčüčÅ ą┐ąĄčĆą▓ąŠą╣. ą×ą┤ąĮą░ą║ąŠ ąĖąĘ-ąĘą░ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖčÅ ą▒ąĖąĮą░čĆąĮčŗčģ čüąĄą╝ą░č乊čĆąŠą▓ ą▓ ąĮąĖąČąĄą╗ąĄąČą░čēąĄą╣ čĆąĄą░ą╗ąĖąĘą░čåąĖąĖ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ ąĖąĮą▓ąĄčĆčüąĖčÅ ą┐čĆąĖąŠčĆąĖč鹥čéą░ ą╝ąŠąČąĄčé ą┐čĆąŠąĖąĘąŠą╣čéąĖ ą┐čĆąĖ ąŠč湥ąĮčī čüą┐ąĄčåąĖčäąĖč湥čüą║ąĖčģ ąŠą▒čüč鹊čÅč鹥ą╗čīčüčéą▓ą░čģ.
ąÜąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ čāą┐čĆą░ą▓ą╗čÅąĄčé ąŠčéą┐čĆą░ą▓ą║ąŠą╣ čü ą┐ąŠą╝ąŠčēčīčÄ ą┤ą▓ąŠąĖčćąĮąŠą│ąŠ čüąĄą╝ą░č乊čĆą░, ą║ąŠč鹊čĆčŗą╣ ą▓čŗą┤ą░ąĄčéčüčÅ ą▓čüčÅą║ąĖą╣ čĆą░ąĘ, ą║ąŠą│ą┤ą░ ąŠčüą▓ąŠą▒ąŠąČą┤ą░ąĄčéčüčÅ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ą▓ ą║ąŠą╗čīčåąĄą▓ąŠą╝ ą▒čāč乥čĆąĄ. ąŚą░ą┤ą░čćą░ čü ąĮą░ąĖą▓čŗčüčłąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝, ąŠąČąĖą┤ą░čÄčēą░čÅ ąŠčéą┐čĆą░ą▓ą║ąĖ, ą▒čāą┤ąĄčé ąĮąĄąŠą┤ąĮąŠą║čĆą░čéąĮąŠ ą▒čĆą░čéčī čüąĄą╝ą░č乊čĆ ą┤ąŠ č鹥čģ ą┐ąŠčĆ, ą┐ąŠą║ą░ ąĮąĄ čüčéą░ąĮąĄčé ą┤ąŠčüčéčāą┐ąĮąŠ ą┤ąŠčüčéą░č鹊čćąĮąŠąĄ ą║ąŠą╗ąĖč湥čüčéą▓ąŠ čüą▓ąŠą▒ąŠą┤ąĮąŠą│ąŠ ą╝ąĄčüčéą░, ąĖą╗ąĖ ą┐ąŠą║ą░ ąĮąĄ ąĖčüč鹥č湥čé čéą░ą╣ą╝ą░čāčé. ąÆ ąĖą┤ąĄą░ą╗ąĄ čŹč鹊 ą┤ąŠą╗ąČąĮąŠ ą┐čĆąĄą┤ąŠčéą▓čĆą░čéąĖčéčī ąŠą▒čüą╗čāąČąĖą▓ą░ąĮąĖąĄ ą╗čÄą▒čŗčģ ąĘą░ą┤ą░čć ąĮąĖąĘą║ąŠą│ąŠ ą┐čĆąĖąŠčĆąĖč鹥čéą░, ą┐ąŠčüą║ąŠą╗čīą║čā čüąĄą╝ą░č乊čĆ ą▓čüąĄą│ą┤ą░ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ąŠčéą┤ą░ąĮ ąĘą░ą┤ą░č湥 čü čüą░ą╝čŗą╝ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝.
ą×ą┤ąĮą░ą║ąŠ ą▓ ą┐čĆąŠą╝ąĄąČčāčéą║ą░čģ ą╝ąĄąČą┤čā ąĖč鹥čĆą░čåąĖčÅą╝ąĖ ą┐ąŠą╗čāč湥ąĮąĖčÅ čüąĄą╝ą░č乊čĆą░ ąĄčüčéčī ąĘą░ąĘąŠčĆ ą▓ ą║čĆąĖčéąĖč湥čüą║ąŠą╣ čüąĄą║čåąĖąĖ, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ą┐ąŠąĘą▓ąŠą╗ąĖčéčī ą┤čĆčāą│ąŠą╣ ąĘą░ą┤ą░č湥 (ąĮą░ ą┤čĆčāą│ąŠą╝ čÅą┤čĆąĄ, ąĖą╗ąĖ čü ąĄčēąĄ ą▒ąŠą╗ąĄąĄ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝) ąŠčüą▓ąŠą▒ąŠą┤ąĖčéčī ąĮąĄą║ąŠč鹊čĆąŠąĄ ą╝ąĄčüč鹊 ą▓ ą║ąŠą╗čīčåąĄą▓ąŠą╝ ą▒čāč乥čĆąĄ, ąĖ ą▓ čĆąĄąĘčāą╗čīčéą░č鹥 ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗą┤ą░ąĮ čüąĄą╝ą░č乊čĆ. ą¤ąŠčŹč鹊ą╝čā čüąĄą╝ą░č乊čĆ ą▒čāą┤ąĄčé ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗ąĄąĮ ą┤ąŠ č鹊ą│ąŠ, ą║ą░ą║ ąĘą░ą┤ą░čćą░ čü čüą░ą╝čŗą╝ ą▓čŗčüąŠą║ąĖą╝ ą┐čĆąĖąŠčĆąĖč鹥č鹊ą╝ čüą╝ąŠąČąĄčé ą┐ąŠą▓č鹊čĆąĮąŠ ą┐ąŠą╗čāčćąĖčéčī čüąĄą╝ą░č乊čĆ. ąŁč鹊 ą┐čĆąĖą▓ąĄą┤ąĄčé ą║ č鹊ą╝čā, čćč鹊 čüąĄą╝ą░č乊čĆ ą▒čāą┤ąĄčé ąĘą░čģą▓ą░č湥ąĮ ąĘą░ą┤ą░č湥ą╣ ą▓č鹊čĆąŠą│ąŠ čāčĆąŠą▓ąĮčÅ ą┐ąŠ ą┐čĆąĖąŠčĆąĖč鹥čéčā, ą║ąŠč鹊čĆą░čÅ ąŠąČąĖą┤ą░ąĄčé ąŠčéą┐čĆą░ą▓ą║ąĖ, ąĖ čŹč鹊 ą▓čŗąĘąŠą▓ąĄčé ąĖąĮą▓ąĄčĆčüąĖčÄ ą┐čĆąĖąŠčĆąĖč鹥čéą░.
ąŁč鹊čé ą┐ąŠą▒ąŠčćąĮčŗą╣ čŹčäč乥ą║čé ąĮąĄ ą┐čĆąĖą▓ąĄą┤ąĄčé ąĘąĮą░čćąĖč鹥ą╗čīąĮąŠ ąĮą░ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖč鹥ą╗čīąĮąŠčüčéčī ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░, ąĄčüą╗ąĖ čćąĖčüą╗ąŠ ąĘą░ą┤ą░čć, ąŠą┤ąĮąŠą▓čĆąĄą╝ąĄąĮąĮąŠ ąĖčüą┐ąŠą╗čīąĘčāčÄčēąĖčģ ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ, ąĮąĄą▓ąĄą╗ąĖą║ąŠ, ąĖ ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ ąĮąĄ čĆą░ą▒ąŠčéą░ąĄčé ą▓ą▒ą╗ąĖąĘąĖ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą╣ ąĄą╝ą║ąŠčüčéąĖ.
[ą¤ąĄčĆąĄčģą▓ą░čéčćąĖą║ąĖ ESP-IDF ą┤ą╗čÅ čéąĖą║ą░ ąĖ ą┤ą╗čÅ čüąŠčüč鹊čÅąĮąĖčÅ ąŠąČąĖą┤ą░ąĮąĖčÅ]
FreeRTOS ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅą╝ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ čéąĖą║ą░ (tick hook) ąĖ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ čüąŠčüč鹊čÅąĮąĖčÅ ąŠąČąĖą┤ą░ąĮąĖčÅ (idle hook) ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ:
ŌĆó FreeRTOS tick hook ą╝ąŠąČąĄčé ą▒čŗčéčī čĆą░ąĘčĆąĄčłąĄąĮ ąŠą┐čåąĖąĄą╣ CONFIG_FREERTOS_USE_TICK_HOOK. ą¤čĆąĖą╗ąŠąČąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮąŠ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ callback-čäčāąĮą║čåąĖčÄ void vApplicationTickHook (void).
ŌĆó FreeRTOS idle hook ą╝ąŠąČąĄčé ą▒čŗčéčī čĆą░ąĘčĆąĄčłąĄąĮ ąŠą┐čåąĖąĄą╣ CONFIG_FREERTOS_USE_IDLE_HOOK. ą¤čĆąĖą╗ąŠąČąĄąĮąĖąĄ ą┤ąŠą╗ąČąĮąŠ ą┐čĆąĄą┤ąŠčüčéą░ą▓ąĖčéčī ą┤ą╗čÅ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░ callback-čäčāąĮą║čåąĖčÄ void vApplicationIdleHook (void).
ą×ą┤ąĮą░ą║ąŠ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ FreeRTOS ąĖą╝ąĄčÄčé čüą╗ąĄą┤čāčÄčēąĖąĄ ąĮąĄą┤ąŠčüčéą░čéą║ąĖ:
ŌĆó ą×ą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ FreeRTOS čĆąĄą│ąĖčüčéčĆąĖčĆčāčÄčéčüčÅ ą▓ąŠ ą▓čĆąĄą╝čÅ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ.
ŌĆó ą£ąŠąČąĄčé ą▒čŗčéčī ąĘą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮ č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ą║ą░ąČą┤ąŠą│ąŠ čéąĖą┐ą░.
ŌĆó ąöą╗čÅ ą╝ąĮąŠą│ąŠčÅą┤ąĄčĆąĮčŗčģ čåąĄą╗ąĄą╣ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ FreeRTOS čüąĖą╝ą╝ąĄčéčĆąĖčćąĮčŗąĄ. ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ą║ą░ąČą┤ąŠąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ čéąĖą║ą░ CPU ąĖ ą║ą░ąČą┤ąŠąĄ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ ąĘą░ą▓ąĄčĆčłą░ąĄčéčüčÅ ą▓čŗąĘąŠą▓ąŠą╝ ąŠą┤ąĮąŠą│ąŠ ąĖ č鹊ą│ąŠ ąČąĄ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ą░.
ESP-IDF ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čüą▓ąŠąĖ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ čéąĖą║ą░ ąĖ idle ą┤ą╗čÅ ą┐ąŠą┤ą┤ąĄčƹȹ║ąĖ FreeRTOS-čäčāąĮą║čåąĖą╣ ą┐ąĄčĆąĄčģą▓ą░čéą░ čéąĖą║ą░ ąĖ idle. ą×ą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ ESP-IDF ąĖą╝ąĄčÄčé čüą╗ąĄą┤čāčÄčēąĖąĄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéąĖ:
ŌĆó ą×ą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ ą╝ąŠą│čāčé čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░čéčīčüčÅ ąĖ ą╝ąŠąČąĄčé ąŠčéą╝ąĄąĮčÅčéčīčüčÅ ąĖčģ čĆąĄą│ąĖčüčéčĆą░čåąĖčÅ ą▓ąŠ ą▓čĆąĄą╝čÅ čĆą░ą▒ąŠčéčŗ ą┐čĆąĖą╗ąŠąČąĄąĮąĖčÅ (run-time).
ŌĆó ą£ąŠąČąĄčé ą▒čŗčéčī ąĘą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮąŠ ąĮąĄčüą║ąŠą╗čīą║ąŠ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąŠą▓ (ą╝ą░ą║čüąĖą╝čāą╝ ą┤ąŠ 8 ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąŠą▓ ą║ą░ąČą┤ąŠą│ąŠ čéąĖą┐ą░ ąĮą░ ąŠą┤ąĖąĮ CPU).
ŌĆó ąöą╗čÅ ą╝ąĮąŠą│ąŠčÅą┤ąĄčĆąĮčŗčģ čåąĄą╗ąĄą╣ ą║ąŠą╝ą┐ąĖą╗čÅčåąĖąĖ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ ą╝ąŠą│čāčé ą▒čŗčéčī ą░čüąĖą╝ą╝ąĄčéčĆąĖčćąĮčŗą╝ąĖ. ąŁč鹊 ąŠąĘąĮą░čćą░ąĄčé, čćč鹊 ąĮą░ ą┤ą╗čÅ ą║ą░ąČą┤ąŠą│ąŠ CPU ą╝ąŠą│čāčé ą▒čŗčéčī ąĘą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮčŗ čĆą░ąĘąĮčŗąĄ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ.
ą×ą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ ESP-IDF ą╝ąŠą│čāčé ą▒čŗčéčī ąĘą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮčŗ ąĖ ą┤ąĄčĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮčŗ čüą╗ąĄą┤čāčÄčēąĖą╝ąĖ ą▓čŗąĘąŠą▓ą░ą╝ąĖ API-čäčāąĮą║čåąĖą╣:
Tick hook. ą×ą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ čĆąĄą│ąĖčüčĆąĖčĆčāčÄčéčüčÅ ą▓čŗąĘąŠą▓ąŠą╝ esp_register_freertos_tick_hook() ąĖą╗ąĖ esp_register_freertos_tick_hook_for_cpu(). ąöąĄčĆąĄą│ąĖčüčéčĆą░čåąĖčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčéčüčÅ ą▓čŗąĘąŠą▓ąŠą╝ esp_deregister_freertos_tick_hook() ąĖą╗ąĖ esp_deregister_freertos_tick_hook_for_cpu().
Idle hook. ą×ą▒čĆą░ą▒ąŠčéčćąĖą║ąĖ čĆąĄą│ąĖčüčĆąĖčĆčāčÄčéčüčÅ ą▓čŗąĘąŠą▓ąŠą╝ esp_register_freertos_idle_hook() ąĖą╗ąĖ esp_register_freertos_idle_hook_for_cpu(). ąöąĄčĆąĄą│ąĖčüčéčĆą░čåąĖčÅ ą┐čĆąŠąĖąĘą▓ąŠą┤ąĖčéčüčÅ ą▓čŗąĘąŠą▓ąŠą╝ esp_deregister_freertos_idle_hook() ąĖą╗ąĖ esp_deregister_freertos_idle_hook_for_cpu().
ąÆą░ąČąĮąŠąĄ ąĘą░ą╝ąĄčćą░ąĮąĖąĄ: ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ čéąĖą║ą░ ąŠčüčéą░ąĄčéčüčÅ ą░ą║čéąĖą▓ąĮčŗą╝, ą║ąŠą│ą┤ą░ ą║čŹčł ąŠčéą║ą╗čÄč湥ąĮ, ą┐ąŠčŹč鹊ą╝čā ą╗čÄą▒čŗąĄ čäčāąĮą║čåąĖąĖ tick hook (FreeRTOS ąĖą╗ąĖ ESP-IDF) ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī čĆą░ąĘą╝ąĄčēąĄąĮčŗ ą▓ąŠ ą▓ąĮčāčéčĆąĄąĮąĮąĄą╝ ą×ąŚąŻ (internal RAM). ą¤ąŠą┤čĆąŠą▒ąĮąŠčüčéąĖ čüą╝. ą▓ ą┤ąŠą║čāą╝ąĄąĮčéą░čåąĖąĖ ą┐ąŠ SPI flash API [4], čĆą░ąĘą┤ąĄą╗ "IRAM-Safe Interrupt Handlers".
[Callback-čäčāąĮą║čåąĖąĖ čāą┤ą░ą╗ąĄąĮąĖčÅ TLSP]
Vanilla FreeRTOS ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé čäčāąĮą║čåąĖčÄ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ąĮą░ čģčĆą░ąĮąĖą╗ąĖčēąĄ ąĘą░ą┤ą░čćąĖ (Thread Local Storage Pointers, TLSP). ąŁčéąĖ čāą║ą░ąĘą░č鹥ą╗ąĖ čüąŠčģčĆą░ąĮčÅčÄčéčüčÅ ąĮąĄą┐ąŠčüčĆąĄą┤čüčéą▓ąĄąĮąĮąŠ ą▓ ą▒ą╗ąŠą║ąĄ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąĘą░ą┤ą░č湥ą╣ (Task Control Block, TCB) ą┤ą╗čÅ ą║ą░ąČą┤ąŠą╣ ąŠčéą┤ąĄą╗čīąĮąŠą╣ ąĘą░ą┤ą░čćąĖ. TLSP ą┐ąŠąĘą▓ąŠą╗čÅąĄčé ą║ą░ąČą┤ąŠą╣ ąĘą░ą┤ą░č湥 ąĖą╝ąĄčéčī čüą▓ąŠą╣ čüąŠą▒čüčéą▓ąĄąĮąĮčŗą╣ čāąĮąĖą║ą░ą╗čīąĮčŗą╣ ąĮą░ą▒ąŠčĆ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ąĮą░ čüčéčĆčāą║čéčāčĆčŗ ą┤ą░ąĮąĮčŗčģ. Vanilla FreeRTOS ąŠąČąĖą┤ą░ąĄčé ąŠčé ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╣ čüą╗ąĄą┤čāčÄčēąĄąĄ:
ŌĆó ąŻčüčéą░ąĮąŠą▓ą║čā TLSP čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ą┤ą╗čÅ ąĘą░ą┤ą░čćąĖ ą┐čāč鹥ą╝ ą▓čŗąĘąŠą▓ą░ vTaskSetThreadLocalStoragePointer() ą┐ąŠčüą╗ąĄ č鹊ą│ąŠ, ą║ą░ą║ ąĘą░ą┤ą░čćą░ ą▒čŗą╗ą░ čüąŠąĘą┤ą░ąĮą░.
ŌĆó ą¤ąŠą╗čāč湥ąĮąĖąĄ TLSP čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ą┤ą╗čÅ ąĘą░ą┤ą░čćąĖ ą▓čŗąĘąŠą▓ąŠą╝ pvTaskGetThreadLocalStoragePointer() ą▓ č鹥č湥ąĮąĖąĄ ą▓čüąĄą│ąŠ ą▓čĆąĄą╝ąĄąĮąĖ ąČąĖąĘąĮąĖ ąĘą░ą┤ą░čćąĖ.
ŌĆó ą×čüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ, ąĮą░ ą║ąŠč鹊čĆčāčÄ čāą║ą░ąĘčŗą▓ą░čÄčé TLSP ą┐ąĄčĆąĄą┤ č鹥ą╝, ą║ą░ą║ ąĘą░ą┤ą░čćą░ čāą┤ą░ą╗čÅąĄčéčüčÅ.
ą×ą┤ąĮą░ą║ąŠ ą╝ąŠą│čāčé ą▒čŗčéčī čüąĖčéčāą░čåąĖąĖ, ą║ąŠą│ą┤ą░ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗čÅą╝ ąĮčāąČąĮąŠ ą┐ąŠą╗čāčćąĖčéčī ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąŠąĄ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ TLSP. ą¤ąŠčŹč鹊ą╝čā ESP-IDF FreeRTOS ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮčāčÄ ą▓ąŠąĘą╝ąŠąČąĮąŠčüčéčī ą▓ ą▓ąĖą┤ąĄ callback-čäčāąĮą║čåąĖą╣ čāą┤ą░ą╗ąĄąĮąĖčÅ TLSP. ąŁčéąĖ callback-čäčāąĮą║čåąĖąĖ ą┐ąŠą┤ą│ąŠčéą░ą▓ą╗ąĖą▓ą░čÄčéčüčÅ ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĄą╝, ąĖ ąŠąĮąĖ ą▓čŗąĘčŗą▓ą░čÄčéčüčÅ ą░ą▓č鹊ą╝ą░čéąĖč湥čüą║ąĖ ą▓ ą╝ąŠą╝ąĄąĮčé čāą┤ą░ą╗ąĄąĮąĖčÅ ąĘą░ą┤ą░čćąĖ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą┐ą░ą╝čÅčéčī TLSP ą╝ąŠąČąĄčé ą▒čŗčéčī ąŠčćąĖčēąĄąĮą░ ą▒ąĄąĘ ąĮąĄąŠą▒čģąŠą┤ąĖą╝ąŠčüčéąĖ ą┤ąŠą▒ą░ą▓ą╗ąĄąĮąĖčÅ ą▓ ą║ą░ąČą┤čāčÄ ąĘą░ą┤ą░čćčā ą║ąŠą┤ą░ ą╗ąŠą│ąĖą║ąĖ ąŠčćąĖčüčéą║ąĖ ą┐ą░ą╝čÅčéčī.
Callback-čäčāąĮą║čåąĖąĖ čāą┤ą░ą╗ąĄąĮąĖčÅ TLSP čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░čÄčéčüčÅ ą░ąĮą░ą╗ąŠą│ąĖčćąĮąŠ čüą░ą╝ąĖą╝ąĖ TLSP.
ŌĆó vTaskSetThreadLocalStoragePointerAndDelCallback() čāčüčéą░ąĮą░ą▓ą╗ąĖą▓ą░ąĄčé ąŠą▒ą░ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĮčŗą╣ TLSP ąĖ čüą▓čÅąĘą░ąĮąĮčŗą╣ čü ąĮąĖą╝ callback.
ŌĆó ąÆčŗąĘąŠą▓ Vanilla FreeRTOS čäčāąĮą║čåąĖąĖ vTaskSetThreadLocalStoragePointer() ą┐čĆąŠčüč鹊 čāčüčéą░ąĮąŠą▓ąĖčé ą┤ą╗čÅ čüą▓čÅąĘą░ąĮąĮąŠą╣ čü TLSP čäčāąĮą║čåąĖąĖ ąŠą▒čĆą░čéąĮąŠą│ąŠ ą▓čŗąĘąŠą▓ą░ čāą┤ą░ą╗ąĄąĮąĖčÅ (Deletion Callback) ą▓ NULL. ąŁč鹊 ąĘąĮą░čćąĖčé, čćč鹊 ą┐čĆąĖ čāą┤ą░ą╗ąĄąĮąĖąĖ ąĘą░ą┤ą░čćąĖ ą┤ą╗čÅ čŹč鹊ą│ąŠ TLSP callback ą▓čŗąĘčŗą▓ą░čéčīčüčÅ ąĮąĄ ą▒čāą┤ąĄčé.
ąÜąŠą│ą┤ą░ čĆąĄą░ą╗ąĖąĘčāčÄčéčüčÅ callback-čäčāąĮą║čåąĖąĖ TLSP, ą┐ąŠą╗čīąĘąŠą▓ą░č鹥ą╗ąĖ ą┤ąŠą╗ąČąĮčŗ ąĖą╝ąĄčéčī ą▓ ą▓ąĖą┤čā čüą╗ąĄą┤čāčÄčēąĄąĄ:
ŌĆó Callback ąĮąĖą║ąŠą│ą┤ą░ ąĮąĄ ą┤ąŠą╗ąČąĄąĮ ą┐čŗčéą░čéčīčüčÅ ą┤ąĄą╗ą░čéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ąĖą╗ąĖ ą▓čŗą┐ąŠą╗ąĮčÅčéčī čāčüčéčāą┐ą░čéčī ą║ąŠąĮč鹥ą║čüčé (yield), ąĖ ą║čĆąĖčéąĖč湥čüą║ąĖąĄ čüąĄą║čåąĖąĖ ą┤ąŠą╗ąČąĮčŗ ą▒čŗčéčī ąĮą░čüč鹊ą╗čīą║ąŠ ą║ąŠčĆąŠčéą║ąĖą╝ąĖ, ąĮą░čüą║ąŠą╗čīą║ąŠ čŹč鹊 ą▓ąŠąĘą╝ąŠąČąĮąŠ.
ŌĆó Callback ą▓čŗąĘčŗą▓ą░ąĄčéčüčÅ ąĮąĄąĘą░ą┤ąŠą╗ą│ąŠ ą┤ąŠ ąŠčüą▓ąŠą▒ąŠąČą┤ąĄąĮąĖčÅ ą┐ą░ą╝čÅčéąĖ čāą┤ą░ą╗ąĄąĮąĮąŠą╣ ąĘą░ą┤ą░čćąĖ. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, callback ą╝ąŠąČąĄčé ą▒čŗčéčī ą▓čŗąĘą▓ą░ąĮ ą╗ąĖą▒ąŠ ąĖąĘ čüą░ą╝ąŠą╣ čäčāąĮą║čåąĖąĖ vTaskDelete(), ąĖą╗ąĖ ąĖąĘ ąĘą░ą┤ą░čćąĖ ąŠąČąĖą┤ą░ąĮąĖčÅ (idle task).
[ąĪą▓ąŠą╣čüčéą▓ą░, čüą┐ąĄčåąĖčäąĖčćąĮčŗąĄ ą┤ą╗čÅ ą║ąŠą╝ą┐ąŠąĮąĄąĮčéą░]
ą¤ąŠą╝ąĖą╝ąŠ čüčéą░ąĮą┤ą░čĆčéąĮčŗčģ ą┐ąĄčĆąĄą╝ąĄąĮąĮčŗčģ ą║ąŠą╝ą┐ąŠąĮąĄąĮčéą░, ą║ąŠč鹊čĆčŗąĄ ą┤ąŠčüčéčāą┐ąĮčŗ čü ą▒ą░ąĘąŠą▓čŗą╝ąĖ čüą▓ąŠą╣čüčéą▓ą░ą╝ąĖ čüą▒ąŠčĆą║ąĖ cmake, ą║ąŠą╝ą┐ąŠąĮąĄąĮčé FreeRTOS čéą░ą║ąČąĄ ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčé ą░čĆą│čāą╝ąĄąĮčéčŗ (ą┐ąŠą║ą░ č鹊ą╗čīą║ąŠ ąŠą┤ąĖąĮ) ą┤ą╗čÅ čāą┐čĆąŠčēąĄąĮąĖčÅ ąĖąĮč鹥ą│čĆą░čåąĖąĖ čü ą┤čĆčāą│ąĖą╝ąĖ ą╝ąŠą┤čāą╗čÅą╝ąĖ:
ORIG_INCLUDE_PATH - čüąŠą┤ąĄčƹȹĖčé ą░ą▒čüąŠą╗čÄčéąĮčŗą╣ ą┐čāčéčī ą┤ąŠ ą║ąŠčĆąĮčÅ ą┐ą░ą┐ą║ąĖ ą┐ąŠą┤ą║ą╗čÄčćą░ąĄą╝čŗčģ ąĘą░ą│ąŠą╗ąŠą▓ą║ąŠą▓ FreeRTOS. ąóą░ą║ąĖą╝ ąŠą▒čĆą░ąĘąŠą╝, ą▓ą╝ąĄčüč鹊 #include "freertos/FreeRTOS.h" ą╝ąŠąČąĮąŠ ą┐čĆąŠčüč鹊 ą┐ąŠą┤ą║ą╗čÄčćą░čéčī ąĘą░ą│ąŠą╗ąŠą▓ą║ąĖ ąĮą░ą┐čĆčÅą╝čāčÄ: #include "FreeRTOS.h".
[ąĪą┐čĆą░ą▓ąŠčćąĮąĖą║ API]
ą¤ąŠą┤čĆąŠą▒ąĮąŠąĄ ąŠą┐ąĖčüą░ąĮąĖąĄ čäčāąĮą║čåąĖą╣, čüčéčĆčāą║čéčāčĆ ąĖ ąŠą┐čĆąĄą┤ąĄą╗ąĄąĮąĖą╣ čéąĖą┐ą░ čüą╝. ą▓ [1].
| ążčāąĮą║čåąĖčÅ |
ą×ą┐ąĖčüą░ąĮąĖąĄ |
| ążčāąĮą║čåąĖąĖ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ ą┐ąŠą┤ą║ą╗čÄčćą░čÄčéčüčÅ ąĘą░ą│ąŠą╗ąŠą▓ą║ąŠą╝ components/esp_ringbuf/include/freertos/ringbuf.h. |
| xRingbufferCreate |
ąĪąŠąĘą┤ą░ąĄčé ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ. |
| xRingbufferCreateNoSplit |
ąĪąŠąĘą┤ą░ąĄčé ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ čéąĖą┐ą░ RINGBUF_TYPE_NOSPLIT ą┤ą╗čÅ čäąĖą║čüąĖčĆąŠą▓ą░ąĮąĮąŠą│ąŠ čĆą░ąĘą╝ąĄčĆą░ 菹╗ąĄą╝ąĄąĮčéą░ ą▒čāč乥čĆą░ item_size. ąŁčéą░ API ą┐ąŠą┤ąŠą▒ąĮą░ xRingbufferCreate(), ąŠą┤ąĮą░ą║ąŠ ą▒čāą┤ąĄčé ą▓ąĮčāčéčĆąĖ čüąĄą▒čÅ ą▓čŗą┤ąĄą╗čÅčéčī ą┤ąŠą┐ąŠą╗ąĮąĖč鹥ą╗čīąĮąŠąĄ ą┐čĆąŠčüčéčĆą░ąĮčüčéą▓ąŠ ą┤ą╗čÅ ąĘą░ą│ąŠą╗ąŠą▓ą║ąŠą▓ 菹╗ąĄą╝ąĄąĮčéą░. |
| xRingbufferCreateStatic |
ąĪąŠąĘą┤ą░ąĄčé ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ, ąĮąŠ čéčĆąĄą▒čāąĄą╝ą░čÅ ą┐ą░ą╝čÅčéčī ą┐čĆąĄą┤ąŠčüčéą░ą▓ą╗čÅąĄčéčüčÅ ą▓čĆčāčćąĮčāčÄ. |
| xRingbufferSend |
ą¤čŗčéą░ąĄčéčüčÅ ąŠčéą┐čĆą░ą▓ąĖčéčī 菹╗ąĄą╝ąĄąĮčé ą▓ ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ. ąŁčéą░ čäčāąĮą║čåąĖčÅ ą▒čāą┤ąĄčé ą┤ąĄą╗ą░čéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ą┤ąŠ č鹥čģ ą┐ąŠčĆ, ą┐ąŠą║ą░ ą▓ ą▒čāč乥čĆąĄ ąĮąĄ ą┐ąŠčÅą▓ąĖčéčüčÅ ą┤ąŠčüčéą░č鹊čćąĮąŠ ą╝ąĄčüčéą░ ą┤ą╗čÅ čŹą╗ąĄą╝ąĄąĮčéą░, ąĖą╗ąĖ ą┐ąŠą║ą░ ąĮąĄ ąĖčüč鹥č湥čé čéą░ą╣ą╝ą░čāčé. |
| xRingbufferSendFromISR |
ISR-ą▓ąĄčĆčüąĖčÅ xRingbufferSend. ąÆčŗą┐ąŠą╗ąĮąĖčé ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮčŗą╣ ą▓ąŠąĘą▓čĆą░čé, ąĄčüą╗ąĖ ą▓ ą▒čāč乥čĆąĄ ąĮąĄą┤ąŠčüčéą░č鹊čćąĮąŠ ą╝ąĄčüčéą░ ą┤ą╗čÅ čŹą╗ąĄą╝ąĄąĮčéą░. |
| xRingbufferSendAcquire |
ą¤ąŠą╗čāč湥ąĮąĖąĄ ą┐ą░ą╝čÅčéąĖ ąĖąĘ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ ą┤ą╗čÅ ąĘą░ą┐ąĖčüąĖ ą▓ąŠ ą▓ąĮąĄčłąĮąĖą╣ ąĖčüč鹊čćąĮąĖą║ ąĖ ą┐ąŠčüą╗ąĄą┤čāčÄčēąĄą╣ ąŠčéą┐čĆą░ą▓ą║ąĖ. ą¤čŗčéą░ąĄčéčüčÅ ą▓čŗą┤ąĄą╗ąĖčéčī ą▒čāč乥čĆ ą┤ą╗čÅ čŹą╗ąĄą╝ąĄąĮčéą░, ąŠčéą┐čĆą░ą▓ą╗čÅąĄą╝ąŠą│ąŠ ą▓ ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ. ąŁčéą░ čäčāąĮą║čåąĖčÅ ą▒čāą┤ąĄčé ą┤ąĄą╗ą░čéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ą┤ąŠ č鹥čģ ą┐ąŠčĆ, ą┐ąŠą║ą░ ą▓ ą▒čāč乥čĆąĄ ąĮąĄ ą┐ąŠčÅą▓ąĖčéčüčÅ ą┤ąŠčüčéą░č鹊čćąĮąŠ ą╝ąĄčüčéą░ ą┤ą╗čÅ čŹą╗ąĄą╝ąĄąĮčéą░, ąĖą╗ąĖ ą┐ąŠą║ą░ ąĮąĄ ąĖčüč鹥č湥čé čéą░ą╣ą╝ą░čāčé. |
| xRingbufferSendComplete |
ąöąĄą╗ą░ąĄčé čäą░ą║čéąĖč湥čüą║čāčÄ ąŠčéą┐čĆą░ą▓ą║čā 菹╗ąĄą╝ąĄąĮčéą░ ą▓ ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ, ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗą╣ čĆą░ąĮąĄąĄ ą▓čŗąĘąŠą▓ąŠą╝ xRingbufferSendAcquire. ą¤čĆąĖą╝ąĄąĮąĖą╝ąŠ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ ą║ąŠą╗čīčåąĄą▓čŗčģ ą▒čāč乥čĆąŠą▓ čéąĖą┐ą░ No-Split. ąÆčŗąĘčŗą▓ą░ąĄčéčüčÅ č鹊ą╗čīą║ąŠ ą┤ą╗čÅ čŹą╗ąĄą╝ąĄąĮč鹊ą▓, ą▓čŗą┤ąĄą╗ąĄąĮąĮčŗčģ č湥čĆąĄąĘ xRingbufferSendAcquire. |
| xRingbufferReceive |
ą¤čŗčéą░ąĄčéčüčÅ ąĖąĘą▓ą╗ąĄčćčī 菹╗ąĄą╝ąĄąĮčé ąĖąĘ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░. ąŁčéą░ čäčāąĮą║čåąĖčÅ ą▒čāą┤ąĄčé ą┤ąĄą╗ą░čéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ą┤ąŠ č鹥čģ ą┐ąŠčĆ, ą┐ąŠą║ą░ ą▓ ą▒čāč乥čĆąĄ ąĮąĄ ą┐ąŠčÅą▓ąĖčéčüčÅ ą┤ąŠčüčéčāą┐ąĮčŗą╣ 菹╗ąĄą╝ąĄąĮčé, ąĖą╗ąĖ ą┐ąŠą║ą░ ąĮąĄ ąĖčüč鹥č湥čé čéą░ą╣ą╝ą░čāčé. |
| xRingbufferReceiveFromISR |
ISR-ą▓ąĄčĆčüąĖčÅ xRingbufferReceive. ąŁčéą░ čäčāąĮą║čåąĖčÅ ą┤ąĄą╗ą░ąĄčé ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮčŗą╣ ą▓ąŠąĘą▓čĆą░čé, ąĄčüą╗ąĖ ą▓ ą▒čāč乥čĆąĄ ą┐ąŠą║ą░ ąĮąĄčé 菹╗ąĄą╝ąĄąĮčéą░ ą┤ą╗čÅ ąĖąĘą▓ą╗ąĄč湥ąĮąĖčÅ. |
| xRingbufferReceiveSplit |
ą¤čŗčéą░ąĄčéčüčÅ ąĖąĘą▓ą╗ąĄčćčī čĆą░ąĘą┤ąĄą╗ąĄąĮąĮčŗą╣ ąĮą░ čćą░čüčéąĖ 菹╗ąĄą╝ąĄąĮčé ąĖąĘ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░. ąĢčüą╗ąĖ 菹╗ąĄą╝ąĄąĮčé ąĮąĄ ą┐ąŠą┤ąĄą╗ąĄąĮ ąĮą░ čćą░čüčéąĖ, č鹊 ąĖąĘą▓ą╗ąĄą║ą░ąĄčéčüčÅ čüčĆą░ąĘčā 菹╗ąĄą╝ąĄąĮčé čåąĄą╗ąĖą║ąŠą╝, ąĖąĮą░č湥 ąĖąĘą▓ą╗ąĄą║ą░čÄčéčüčÅ čćą░čüčéąĖ 菹╗ąĄą╝ąĄąĮčéą░ ą║ą░ą║ 2 ąŠčéą┤ąĄą╗čīąĮčŗčģ 菹╗ąĄą╝ąĄąĮčéą░. ąŁčéą░ čäčāąĮą║čåąĖčÅ ą▒čāą┤ąĄčé ą┤ąĄą╗ą░čéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā ą┤ąŠ č鹥čģ ą┐ąŠčĆ, ą┐ąŠą║ą░ ą▓ ą▒čāč乥čĆąĄ ąĮąĄ ą┐ąŠčÅą▓ąĖčéčüčÅ ą┤ąŠčüčéčāą┐ąĮčŗą╣ 菹╗ąĄą╝ąĄąĮčé, ąĖą╗ąĖ ą┐ąŠą║ą░ ąĮąĄ ąĖčüč鹥č湥čé čéą░ą╣ą╝ą░čāčé. |
| xRingbufferReceiveSplitFromISR |
ISR-ą▓ąĄčĆčüąĖčÅ xRingbufferReceiveSplit. ąŁčéą░ čäčāąĮą║čåąĖčÅ ą┤ąĄą╗ą░ąĄčé ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮčŗą╣ ą▓ąŠąĘą▓čĆą░čé, ąĄčüą╗ąĖ ą▓ ą▒čāč乥čĆąĄ ą┐ąŠą║ą░ ąĮąĄčé 菹╗ąĄą╝ąĄąĮčéą░ ą┤ą╗čÅ ąĖąĘą▓ą╗ąĄč湥ąĮąĖčÅ. |
| xRingbufferReceiveUpTo |
ą¤čŗčéą░ąĄčéčüčÅ ąĖąĘą▓ą╗ąĄčćčī ą┤ą░ąĮąĮčŗąĄ ąĖąĘ ą▒ą░ą╣č鹊ą▓ąŠą│ąŠ ą▒čāč乥čĆą░ čü čāą║ą░ąĘą░ąĮąĖąĄą╝ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠą│ąŠ ą║ąŠą╗ąĖč湥čüčéą▓ą░ ą▒ą░ą╣čé ą┤ą╗čÅ ąĖąĘą▓ą╗ąĄč湥ąĮąĖčÅ. ąŁčéą░ čäčāąĮą║čåąĖčÅ ą▒čāą┤ąĄčé ą┤ąĄą╗ą░čéčī ą▒ą╗ąŠą║ąĖčĆąŠą▓ą║čā, ą┐ąŠą║ą░ ąĮąĄ ą┐ąŠčÅą▓čÅčéčüčÅ ą┤ą░ąĮąĮčŗąĄ ą┤ą╗čÅ ąĖąĘą▓ą╗ąĄč湥ąĮąĖčÅ, ąĖą╗ąĖ ą┐ąŠą║ą░ ąĮąĄ ą┐čĆąŠąĖąĘąŠą╣ą┤ąĄčé čéą░ą╣ą╝ą░čāčé. |
| xRingbufferReceiveUpToFromISR |
ISR-ą▓ąĄčĆčüąĖčÅ xRingbufferReceiveUpTo. ąŁčéą░ čäčāąĮą║čåąĖčÅ ą┤ąĄą╗ą░ąĄčé ąĮąĄą╝ąĄą┤ą╗ąĄąĮąĮčŗą╣ ą▓ąŠąĘą▓čĆą░čé, ąĄčüą╗ąĖ ą▓ ą▒čāč乥čĆąĄ ą┐ąŠą║ą░ ą┤ą░ąĮąĮčŗčģ ą┤ą╗čÅ ąĖąĘą▓ą╗ąĄč湥ąĮąĖčÅ. |
| vRingbufferReturnItem |
ąÆąŠąĘą▓čĆą░čéąĖčé čĆą░ąĮąĄąĄ ąĘą░ą┐čĆąŠčłąĄąĮąĮčŗą╣ 菹╗ąĄą╝ąĄąĮčé ąĖąĘ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░. |
| vRingbufferReturnItemFromISR |
ISR-ą▓ąĄčĆčüąĖčÅ vRingbufferReturnItem. |
| vRingbufferDelete |
ąŻą┤ą░ą╗ąĖčé ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ. |
| xRingbufferGetMaxItemSize |
ąÆąŠąĘą▓čĆą░čéąĖčé ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮčŗą╣ čĆą░ąĘą╝ąĄčĆ čŹą╗ąĄą╝ąĄąĮčéą░, ą║ąŠč鹊čĆčŗą╣ ą╝ąŠąČąĄčé ą▒čŗčéčī ą┐ąŠą╝ąĄčēąĄąĮ ą▓ ą║ąŠą╗čīčåąĄą▓ąŠą╣ ą▒čāč乥čĆ. |
| xRingbufferGetCurFreeSize |
ąÆąŠąĘą▓čĆą░čéąĖčé čĆą░ąĘą╝ąĄčĆ čüą▓ąŠą▒ąŠą┤ąĮąŠą│ąŠ ą╝ąĄčüčéą░ ą▓ ą║ąŠą╗čīčåąĄą▓ąŠą╝ ą▒čāč乥čĆąĄ, ą┤ąŠčüčéčāą┐ąĮąŠą│ąŠ ą▓ ąĮą░čüč鹊čÅčēąĖą╣ ą╝ąŠą╝ąĄąĮčé ą┤ą╗čÅ čŹą╗ąĄą╝ąĄąĮčéą░/ą┤ą░ąĮąĮčŗčģ. |
| xRingbufferAddToQueueSetRead |
ąöąŠą▒ą░ą▓ąĖčé čüąĄą╝ą░č乊čĆ čćč鹥ąĮąĖčÅ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ ą▓ ąĮą░ą▒ąŠčĆ ąŠč湥čĆąĄą┤ąĄą╣. |
| xRingbufferCanRead |
ą¤čĆąŠą▓ąĄčĆčÅąĄčé, čÅą▓ą╗čÅąĄčéčüčÅ ą╗ąĖ ą▓čŗą▒čĆą░ąĮąĮčŗą╣ čćą╗ąĄąĮ ąŠč湥čĆąĄą┤ąĖ čüąĄą╝ą░č乊čĆąŠą╝ čćč鹥ąĮąĖčÅ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░. |
| xRingbufferRemoveFromQueueSetRead |
ąŻą┤ą░ą╗ąĖčé čüąĄą╝ą░č乊čĆ čćč鹥ąĮąĖčÅ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░ ąĖąĘ ąĮą░ą▒ąŠčĆą░ ąŠč湥čĆąĄą┤ąĄą╣. |
| vRingbufferGetInfo |
ąÆąŠąĘą▓čĆą░čéąĖčé ąĖąĮč乊čĆą╝ą░čåąĖčÄ ąŠ čüąŠčüč鹊čÅąĮąĖąĖ ą║ąŠą╗čīčåąĄą▓ąŠą│ąŠ ą▒čāč乥čĆą░. |
| xRingbufferPrintInfo |
ą×čéą╗ą░ą┤ąŠčćąĮą░čÅ čäčāąĮą║čåąĖčÅ ą┤ą╗čÅ ą┐ąĄčćą░čéąĖ ą▓ąĮčāčéčĆąĄąĮąĮąĖčģ čāą║ą░ąĘą░č鹥ą╗ąĄą╣ ą▓ ą║ąŠą╗čīčåąĄą▓ąŠą╝ ą▒čāč乥čĆąĄ. |
| ążčāąĮą║čåąĖąĖ čāčüčéą░ąĮąŠą▓ą║ąĖ ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ąŠą▓ čéąĖą║ą░ ąĖ idle (Hook API) ą┐ąŠą┤ą║ą╗čÄčćą░čÄčéčüčÅ ąĘą░ą│ąŠą╗ąŠą▓ą║ąŠą╝ components/esp_system/include/esp_freertos_hooks.h. |
| esp_register_freertos_idle_hook |
ąĀąĄą│ąĖčüčéčĆąĖčĆčāąĄčé callback-čäčāąĮą║čåąĖčÄ ą┤ą╗čÅ ą▓čŗąĘąŠą▓ą░ ąĖąĘ idle hook. ąŁč鹊čé callback ą┤ąŠą╗ąČąĄąĮ ą▓ąĄčĆąĮčāčéčī true, ąĄčüą╗ąĖ ąŠąĮ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓čŗąĘą▓ą░ąĮ ąĖąĘ idle hook ąŠą┤ąĖąĮ čĆą░ąĘ ąĮą░ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖąĄ (ąĖą╗ąĖ ąĮą░ čéąĖą║ FreeRTOS), ąĖ ą┤ąŠą╗ąČąĄąĮ ą▓ąĄčĆąĮčāčéčī false, ąĄčüą╗ąĖ ąŠąĮ ą┤ąŠą╗ąČąĄąĮ ą▒čŗčéčī ą▓čŗąĘą▓ą░ąĮ ąĖąĘ idle hook ą┐ąŠą▓č鹊čĆąĮąŠ ą╝ą░ą║čüąĖą╝ą░ą╗čīąĮąŠ ą▒čŗčüčéčĆąŠ, ąĮą░čüą║ąŠą╗čīą║ąŠ čŹč鹊 ą▓ąŠąĘą╝ąŠąČąĮąŠ. ąŻ čäčāąĮą║čåąĖąĖ esp_register_freertos_idle_hook ąĄčüčéčī 2 ą▓ą░čĆąĖą░ąĮčéą░, ą▒ąĄąĘ čāą║ą░ąĘą░ąĮąĖčÅ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆą░ CPU ąĖ čü čāą║ą░ąĘą░ąĮąĖąĄą╝ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆą░ CPU. |
| esp_register_freertos_tick_hook |
ąĀąĄą│ąĖčüčéčĆąĖčĆčāąĄčé callback-čäčāąĮą║čåąĖčÄ ą┤ą╗čÅ ą▓čŗąĘąŠą▓ą░ ąĖąĘ tick hook. ąŻ čäčāąĮą║čåąĖąĖ esp_register_freertos_tick_hook ąĄčüčéčī 2 ą▓ą░čĆąĖą░ąĮčéą░, ą▒ąĄąĘ čāą║ą░ąĘą░ąĮąĖčÅ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆą░ CPU ąĖ čü čāą║ą░ąĘą░ąĮąĖąĄą╝ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆą░ CPU. |
| esp_deregister_freertos_idle_hook |
ą×čéą╝ąĄąĮčÅąĄčé čĆąĄą│ąĖčüčéčĆą░čåąĖčÄ callback-čäčāąĮą║čåąĖąĖ idle hook. ąŻ čäčāąĮą║čåąĖąĖ ąĄčüčéčī 2 ą▓ą░čĆąĖą░ąĮčéą░, ą▒ąĄąĘ čāą║ą░ąĘą░ąĮąĖčÅ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆą░ CPU ąĖ čü čāą║ą░ąĘą░ąĮąĖąĄą╝ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆą░ CPU. ąĢčüą╗ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ą░čüčī čäčāąĮą║čåąĖčÅ ą▒ąĄąĘ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆą░ CPU, ąĖ callback-čäčāąĮą║čåąĖčÅ ą▒čŗą╗ą░ ąĘą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮą░ ą┤ą╗čÅ ąŠą▒ąŠąĖčģ čÅą┤ąĄčĆ CPU, č鹊 ąŠąĮą░ ą┤ąĄčĆąĄą│ąĖčüčéčĆąĖčĆčāąĄčéčüčÅ ąĮą░ ąŠą▒ąŠąĖčģ čÅą┤čĆą░čģ. |
| esp_deregister_freertos_tick_hook |
ą×čéą╝ąĄąĮčÅąĄčé čĆąĄą│ąĖčüčéčĆą░čåąĖčÄ callback-čäčāąĮą║čåąĖąĖ tick hook. ąŻ čäčāąĮą║čåąĖąĖ ąĄčüčéčī 2 ą▓ą░čĆąĖą░ąĮčéą░, ą▒ąĄąĘ čāą║ą░ąĘą░ąĮąĖčÅ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆą░ CPU ąĖ čü čāą║ą░ąĘą░ąĮąĖąĄą╝ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆą░ CPU. ąĢčüą╗ąĖ ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ą╗ą░čüčī čäčāąĮą║čåąĖčÅ ą▒ąĄąĘ ąĖą┤ąĄąĮčéąĖčäąĖą║ą░č鹊čĆą░ CPU, ąĖ callback-čäčāąĮą║čåąĖčÅ ą▒čŗą╗ą░ ąĘą░čĆąĄą│ąĖčüčéčĆąĖčĆąŠą▓ą░ąĮą░ ą┤ą╗čÅ ąŠą▒ąŠąĖčģ čÅą┤ąĄčĆ CPU, č鹊 ąŠąĮą░ ą┤ąĄčĆąĄą│ąĖčüčéčĆąĖčĆčāąĄčéčüčÅ ąĮą░ ąŠą▒ąŠąĖčģ čÅą┤čĆą░čģ. |
[ąĪą╗ąŠą▓ą░čĆąĖą║]
FIFO First Input First Output, ą┐čĆąĖąĮčåąĖą┐ čüąŠčģčĆą░ąĮąĄąĮąĖčÅ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą▓ ą▒čāč乥čĆ ąĖ ąĖąĘą▓ą╗ąĄč湥ąĮąĖčÅ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ąĖąĘ ąĮąĄą│ąŠ - ą┐ąĄčĆą▓čŗą╝ ą┐čĆąĖčłąĄą╗, ą┐ąĄčĆą▓čŗą╝ ą▓čŗčłąĄą╗.
ISR Interrupt Service Routine, ąŠą▒čĆą░ą▒ąŠčéčćąĖą║ ą┐čĆąĄčĆčŗą▓ą░ąĮąĖčÅ.
SMP Symmetric MultiProcessing, čüąĖą╝ą╝ąĄčéčĆąĖčćąĮąŠąĄ ą▓čŗą┐ąŠą╗ąĮąĄąĮąĖąĄ ą║ąŠą┤ą░ čü ąĖčüą┐ąŠą╗čīąĘąŠą▓ą░ąĮąĖąĄą╝ ąĮąĄčüą║ąŠą╗čīą║ąĖčģ ą┐čĆąŠčåąĄčüčüąŠčĆąĮčŗčģ čÅą┤ąĄčĆ.
TCB Task Control Block, ą▒ą╗ąŠą║ čāą┐čĆą░ą▓ą╗ąĄąĮąĖčÅ ąĘą░ą┤ą░č湥ą╣.
TLSP Thread Local Storage Pointer, čāą║ą░ąĘą░č鹥ą╗čī ąĮą░ ą╗ąŠą║ą░ą╗čīąĮąŠąĄ čģčĆą░ąĮąĖą╗ąĖčēąĄ ąĖąĮč乊čĆą╝ą░čåąĖąĖ ą┐ąŠč鹊ą║ą░.
[ąĪčüčŗą╗ą║ąĖ]
1. FreeRTOS Supplemental Features site:docs.espressif.com.
2. ąŻčüčéą░ąĮąŠą▓ą║ą░ čüčĆąĄą┤čŗ čĆą░ąĘčĆą░ą▒ąŠčéą║ąĖ ESP-IDF ą┤ą╗čÅ ESP32.
3. ESP-IDF FreeRTOS SMP.
4. Concurrency Constraints for flash on SPI1 site:docs.espressif.com.
5. ESP-IDF FreeRTOS Task API.
6. ESP32 Inter-Processor Call. |



